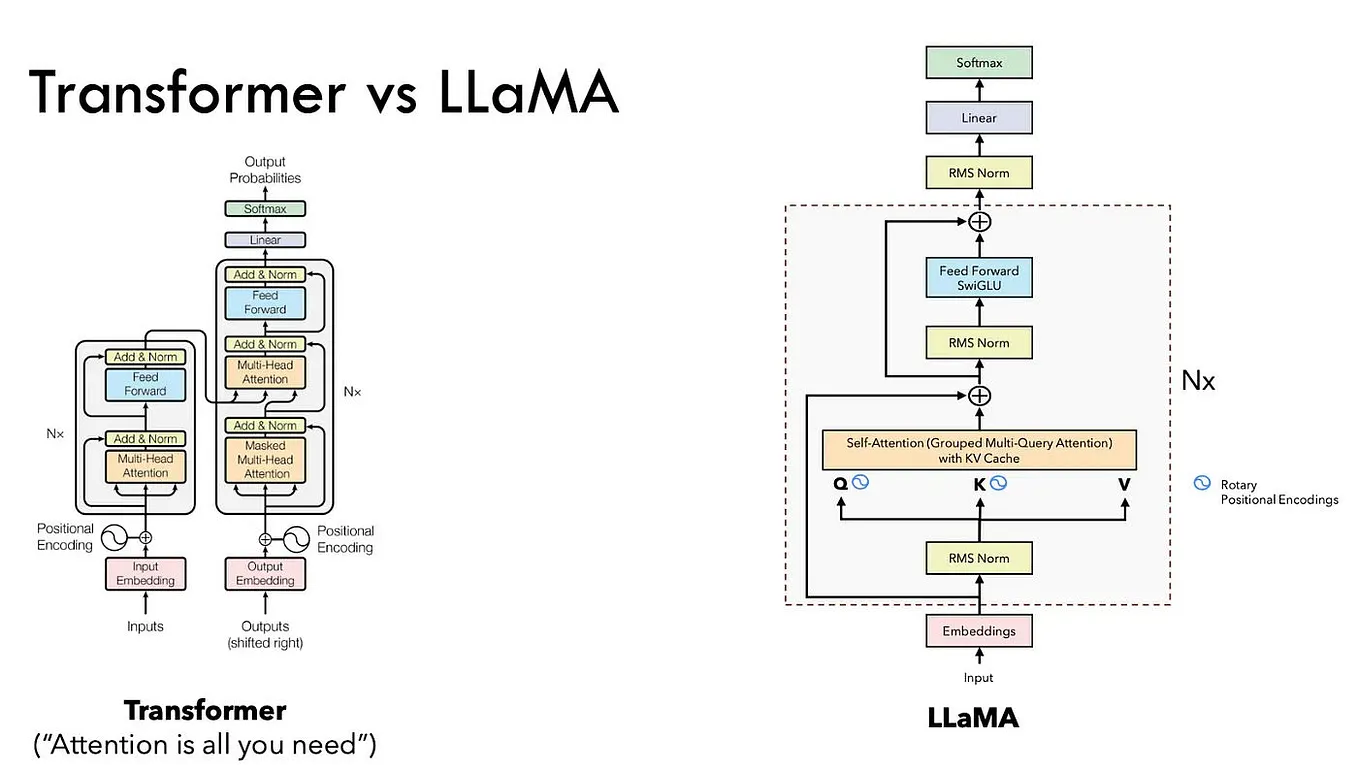
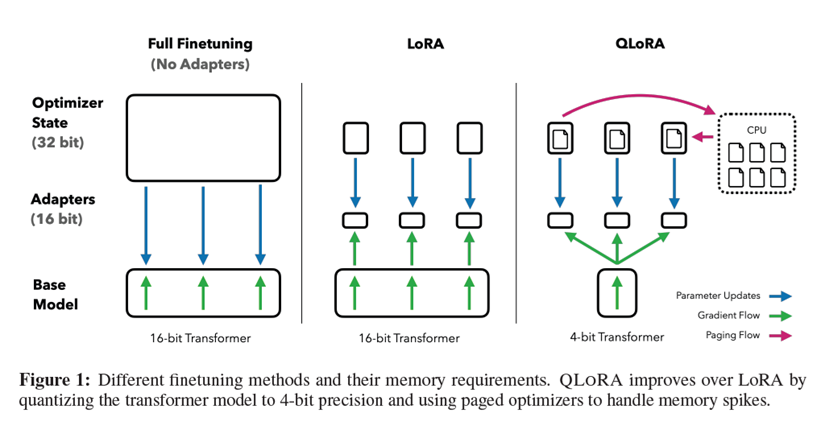
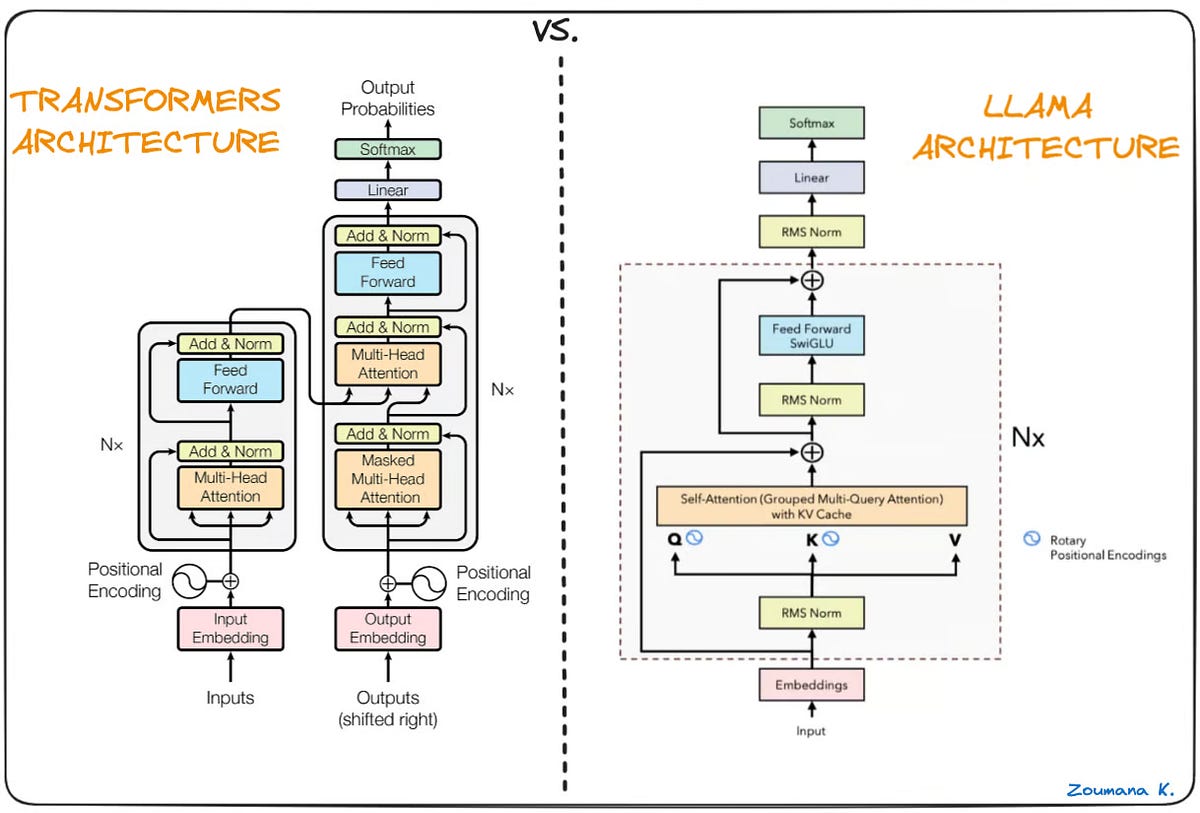
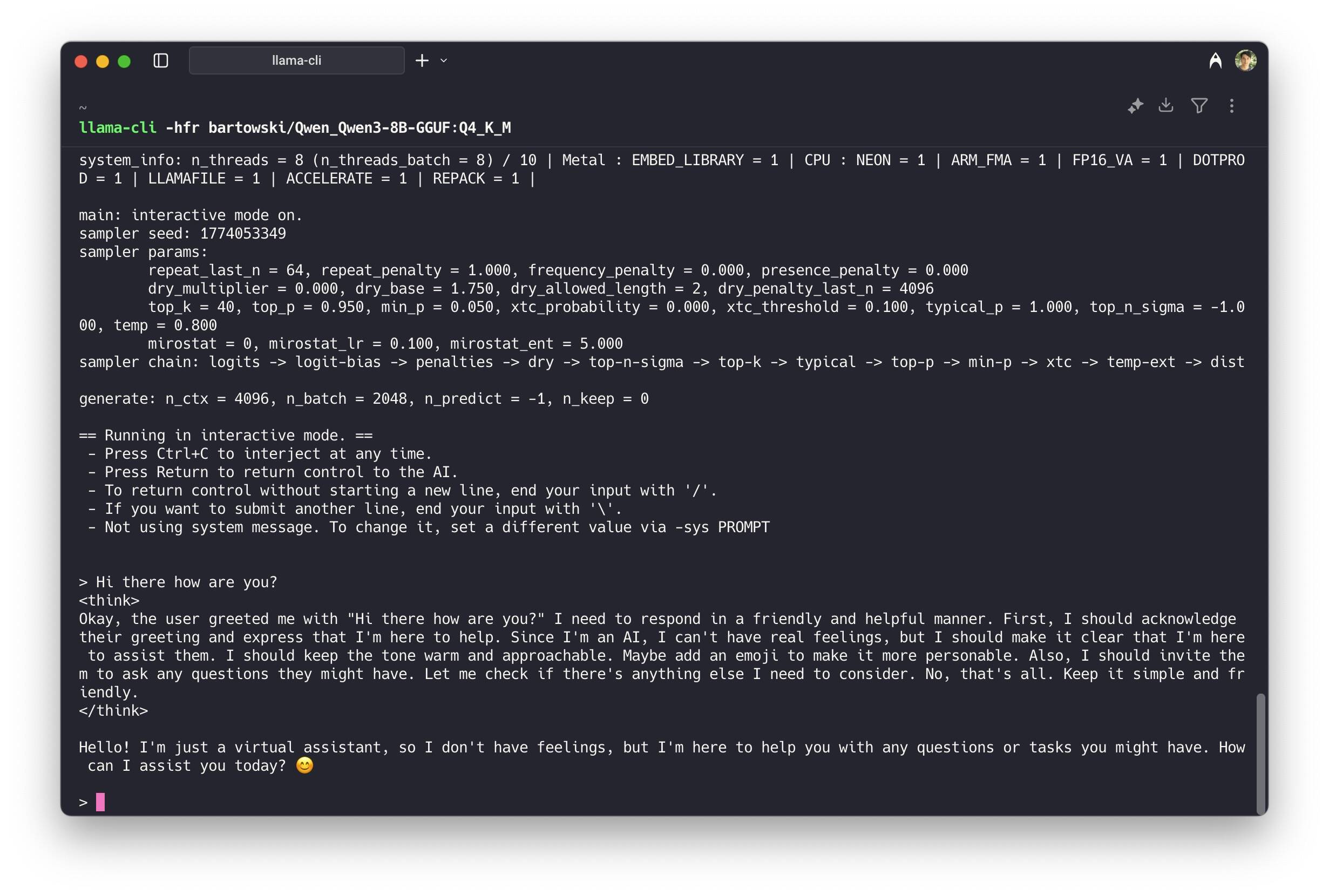
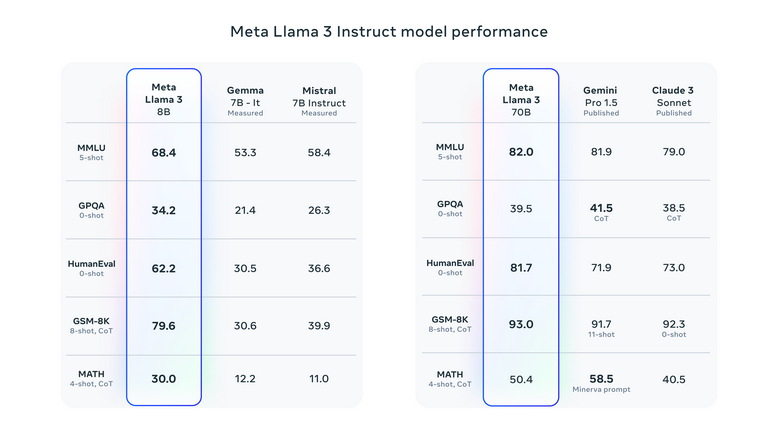
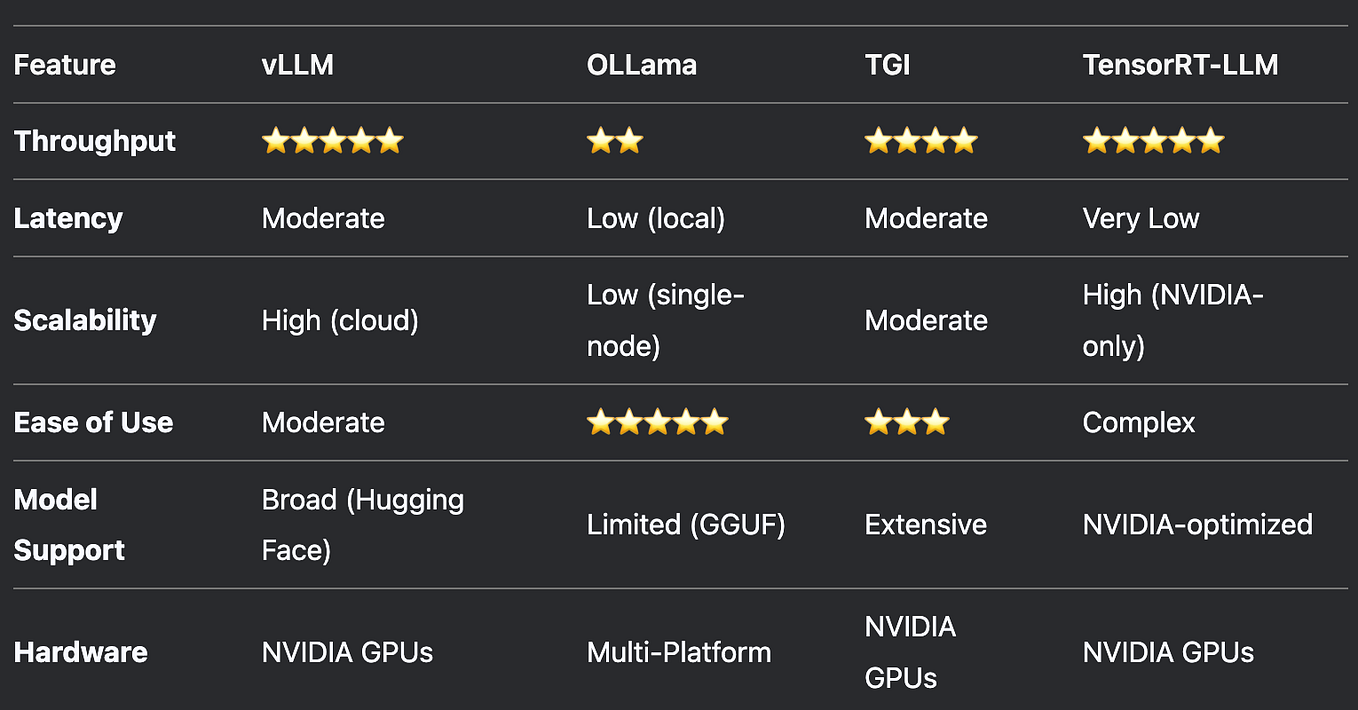
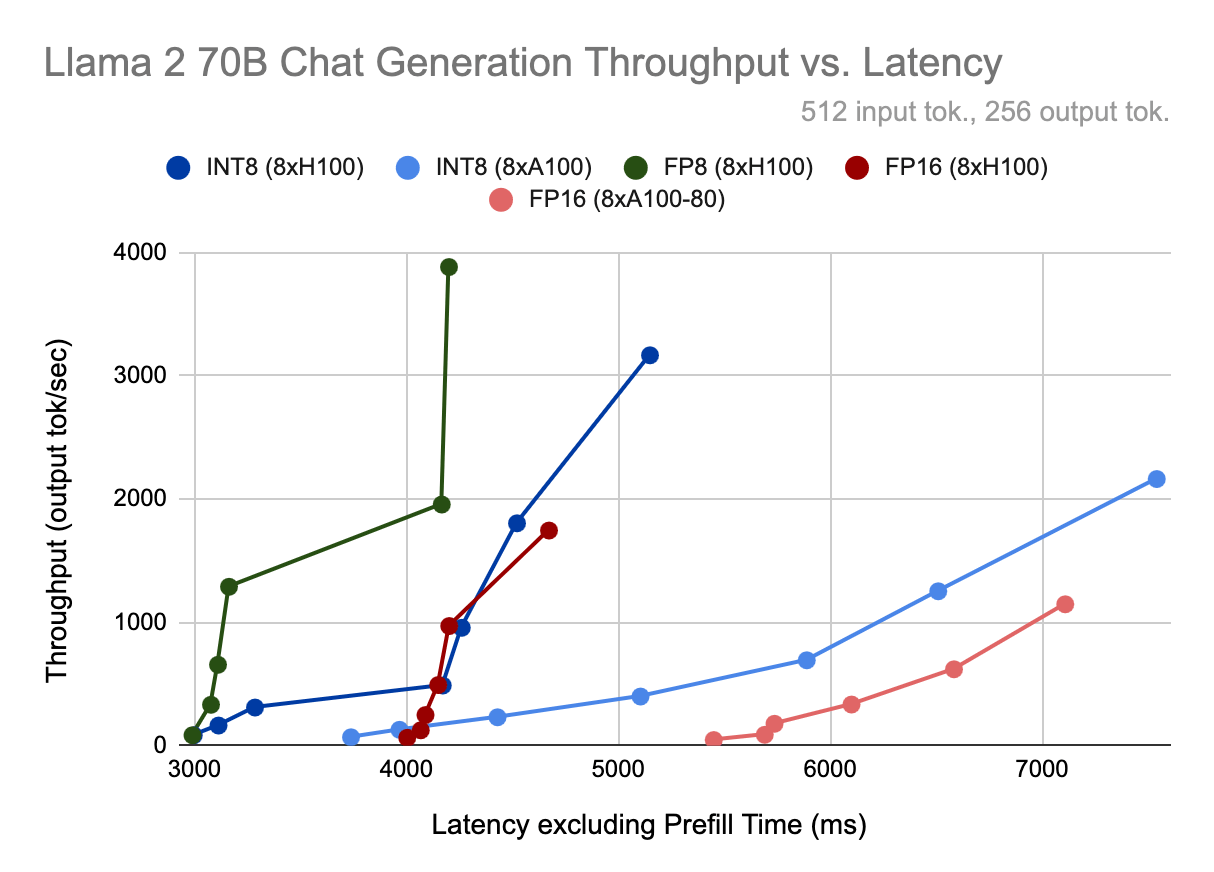
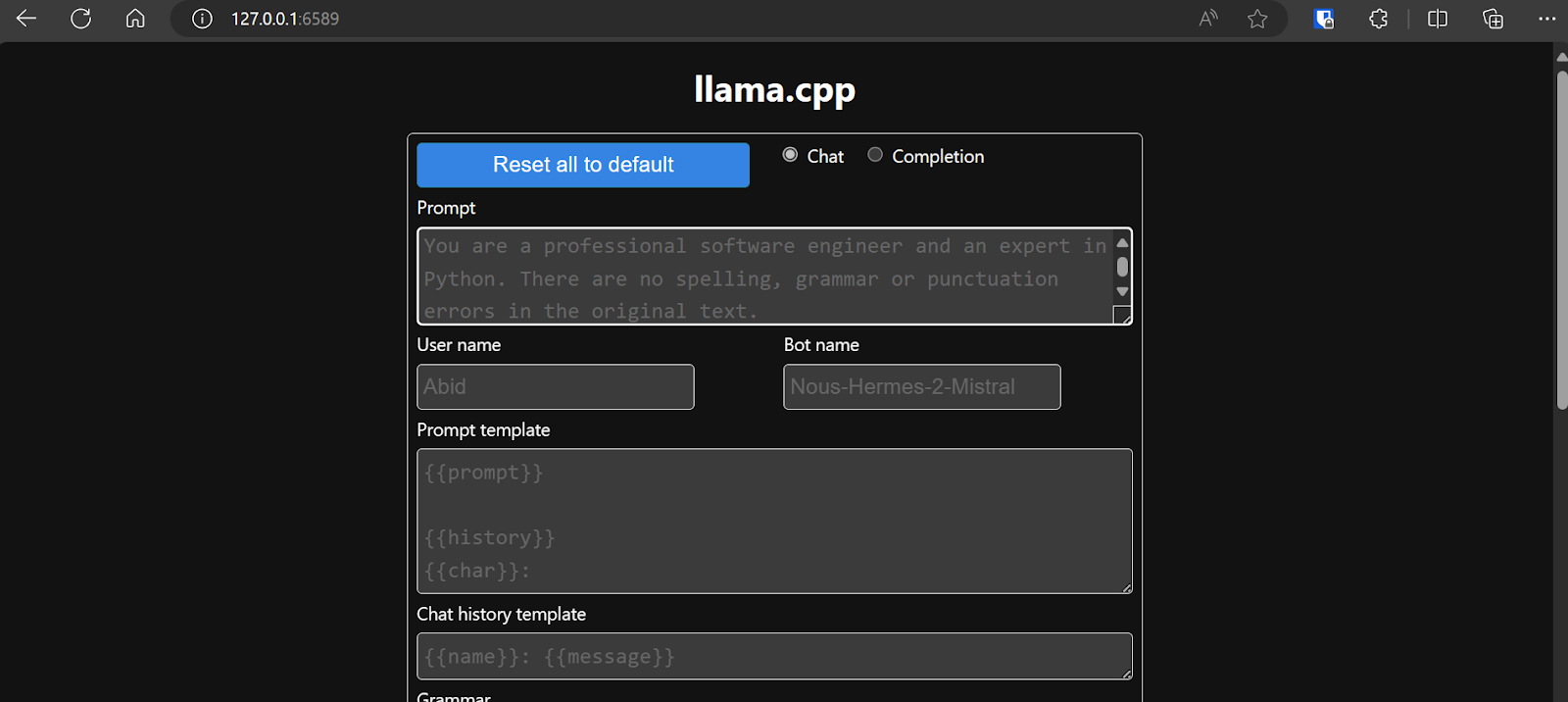
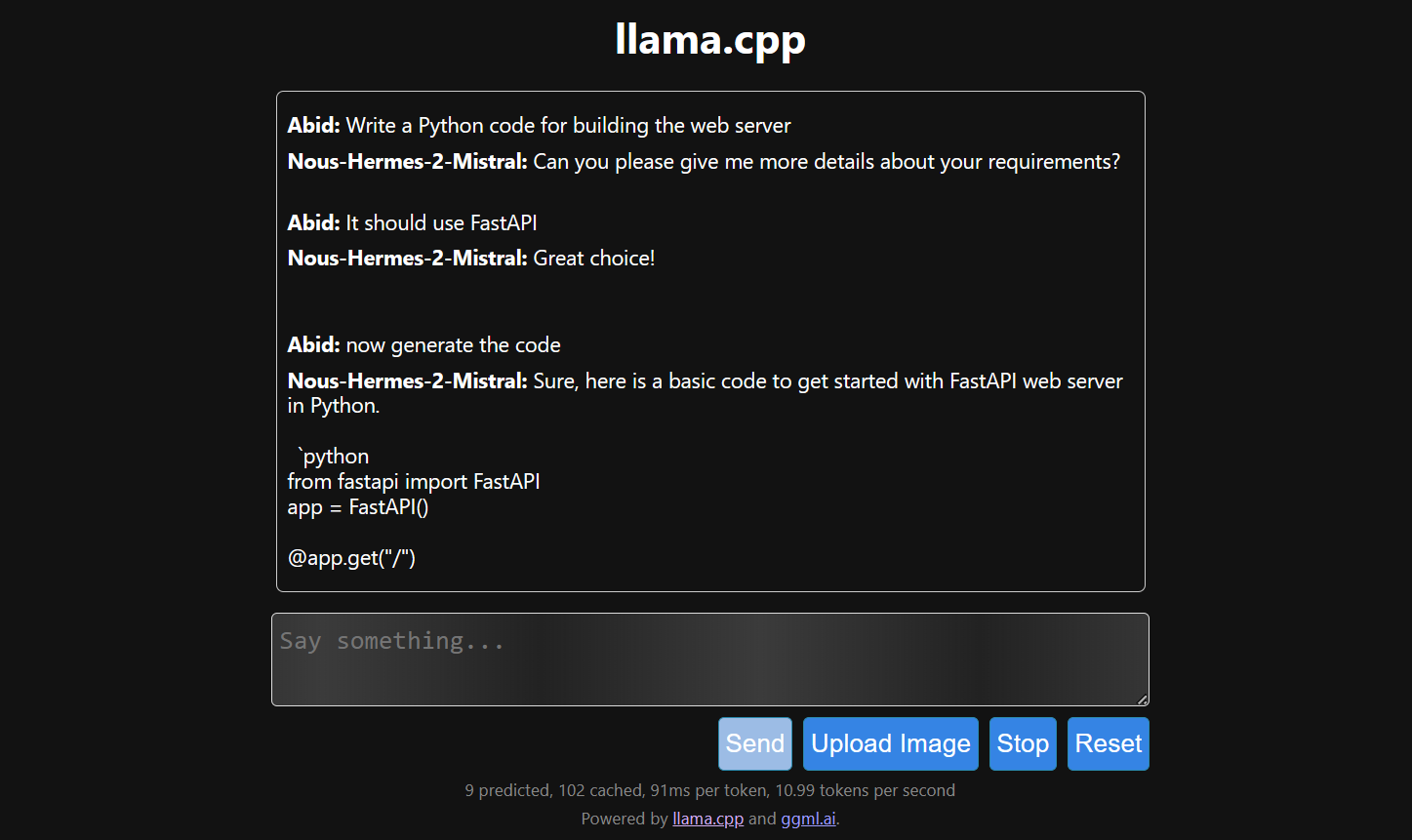
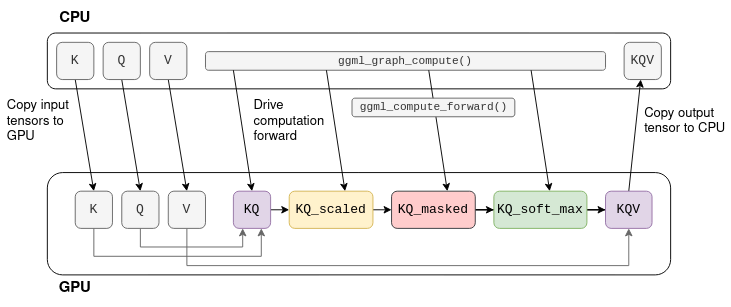
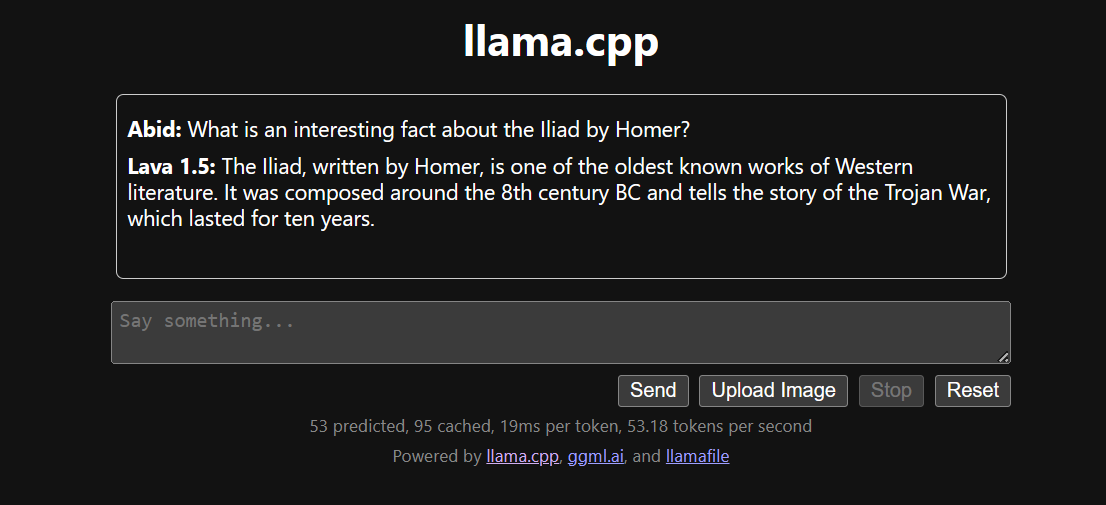
Ultimate Guide to Running Quantized LLMs on CPU with LLaMA.cpp | by ...
Running LLMs on CPU. Easy Guide to using Llama.cpp and… | by Raj ...
How to Run LLMs on Your CPU with Llama.cpp: A Step-by-Step Guide | by ...
How to Run Quantized GGUF LLMs Locally on GPU with llama.cpp (No Cloud ...
Running Large Language Models (LLMs) on CPU using llama.cpp | by Wei ...
Simplified Tutorial on Running LLMs (Llama 3) Locally with llama.cpp ...
A step by step guide to running a local LLM with llama-cpp-python ...
Engineer's Guide to Local LLMs with LLaMA.cpp on Linux - DEV Community
Run LLama-3.1 8B Instruct Quantized Model on CPU | by Muhammad Faizan ...
Accelerating LLMs with llama.cpp on NVIDIA RTX Systems | NVIDIA ...
Running Llama 2 on CPU Inference Locally for Document Q&A | by Kenneth ...
Running LLaMA Locally with Llama.cpp: A Complete Guide | by Mostafa ...
LLMs on Apple Silicon MacBooks: A Simple Guide to Running Llama2-13b ...
Running Quantized LLAMA Models Locally on macOS with LangChain and ...
Run LLMs on Your CPU with Llama.cpp: A Step-by-Step Guide
How to compile LLM on Android using LLama.cpp | by mmonteiros | Medium
How To Run LLMs On PC At Home Using Llama.cpp • The Register — Meta Ai ...
llama.cpp guide - Running LLMs locally, on any hardware, from scratch
LLM Quantization with llama.cpp on Free Google Colab | Llama 3.1 | GGUF ...
Llama-CPP-Python: Step-by-step Guide to Run LLMs on Local Machine ...
Quantization of LLMs with llama.cpp | by Ingrid Stevens | Medium
LLM By Examples: Build Llama.cpp with customized Docker Images | by ...
Running Llama 2 On CPU Inference Locally For Document Q&A - by Kenneth ...
Running LLMs on a Mac with llama.cpp - YouTube
Running Llama 2 on CPU Inference Locally for Document Q&A | Towards ...
How to run LLMs on CPU-based systems | by Simeon Emanuilov | Medium
How I Got LLMs Running Locally (CPU and GPU Guide) | by Aditya Pawar ...
3-ways to Set up LLaMA 2 Locally on CPU (Part 1 — llama-cpp-python ...
Running LLaMA Models Locally on your machine-macOS: A Complete Guide ...
llama.cpp: The Ultimate Guide to Efficient LLM Inference and ...
Running llama.cpp on the CPU - Speaker Deck
A Guide to Quantization in LLMs | Symbl.ai
Run LLMs (Llama 3) Locally with llama.cpp | Medium
LLaMA on CPU? Yes — Here’s the Simple Setup That Surprised Me | by ...
Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and ...
Run any LLM on Distributed Multiple GPUs Locally Using Llama_cpp | by ...
Unlocking GPU Power for Local LLMs: The Ultimate LLaMA.cpp Guide ⚡🚀 ...
Running AI LLMs on a general-purpose low power CPU: Exploring the 'art ...
How to run LLMs on CPU-based systems | UnfoldAI
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
Efficiently Run Your Fine-Tuned LLM Locally Using Llama.cpp 🚀 | by ...
Running Phi-3-mini-4k-instruct Locally with llama.cpp: A Step-by-Step ...
Quantizing Large Language Models With llama.cpp: A Clean Guide for 2024 ...
Simple Tutorial to Quantize Models using llama.cpp from safetensors to ...
Running LLMs on CPU: Exploring Feasibility, Performance, and Use Case
How to Use LLMs in Unity | Towards Data Science
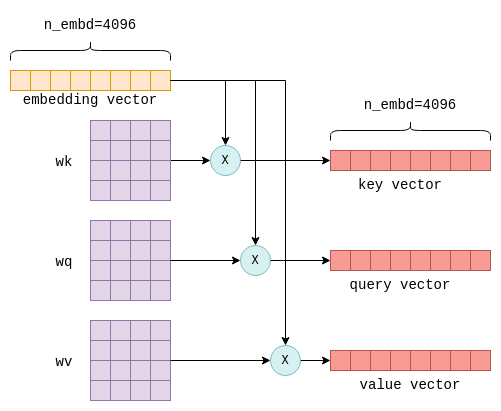
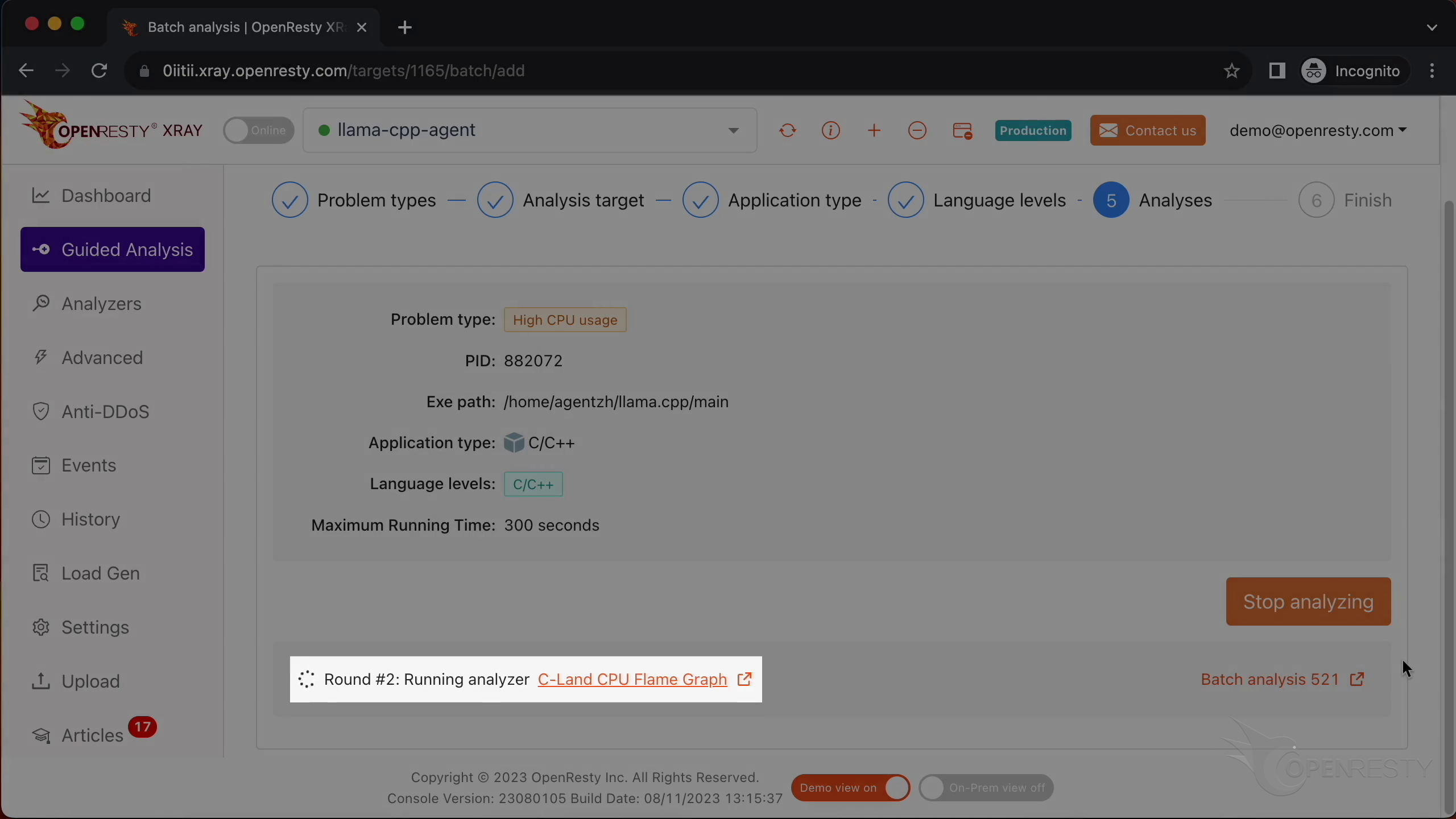
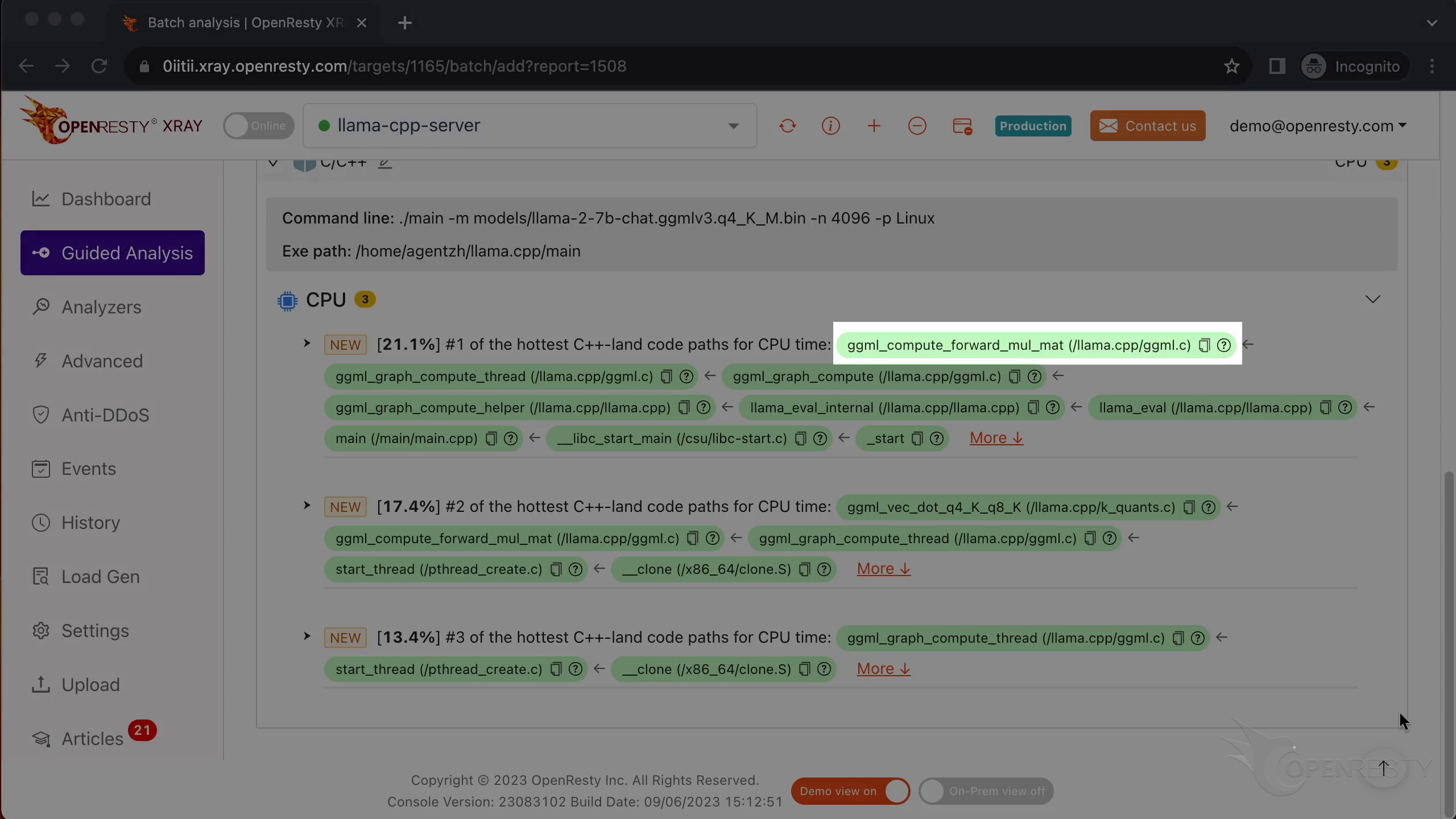
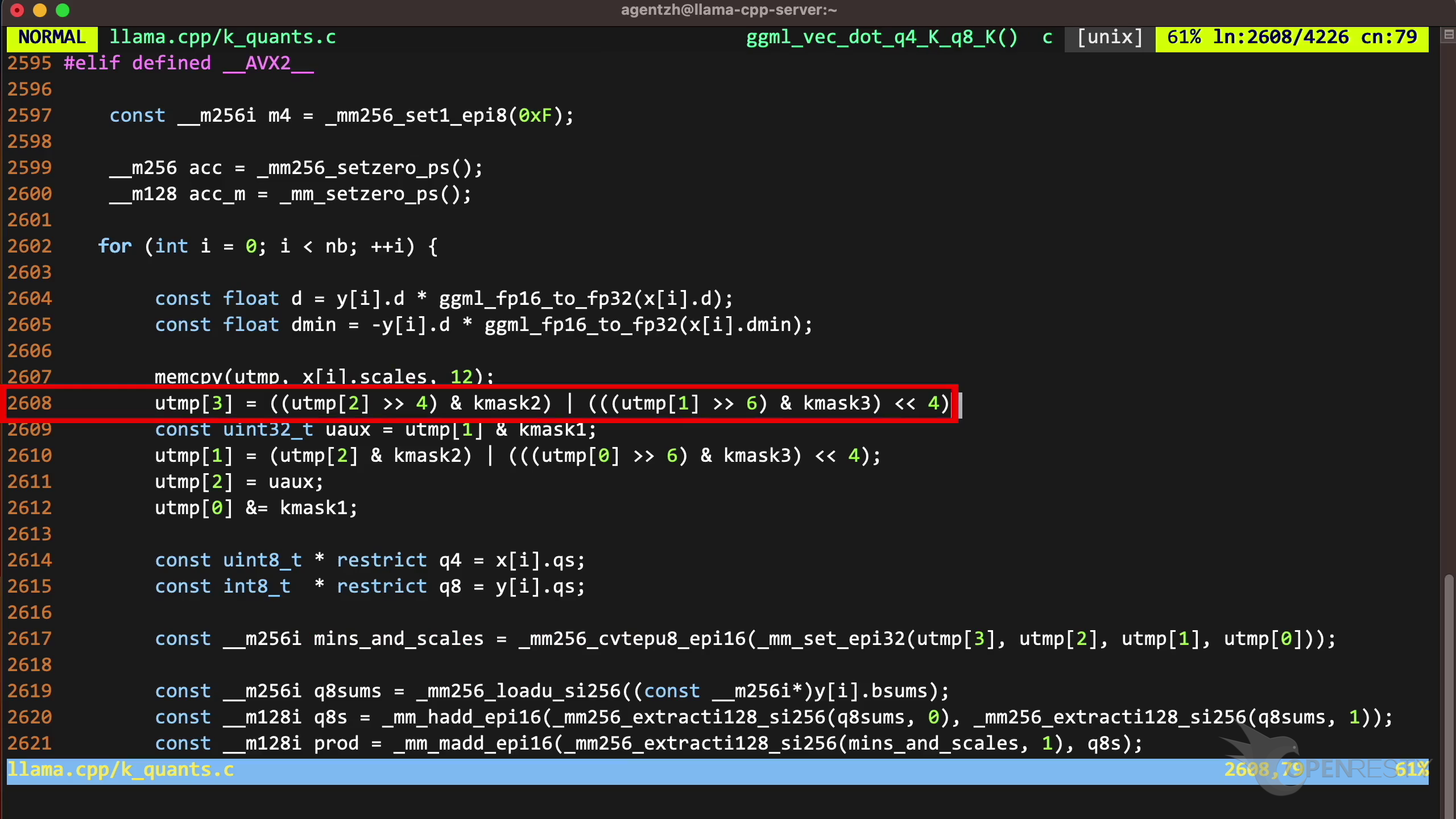
How CPU time is spent inside llama.cpp + LLaMA2 (using OpenResty XRay ...
🦙 Optimize Your LLM Models and Save Costs with llama.cpp Quantization 🦙 ...
Quantize Llama models with GGUF and llama.cpp | Towards Data Science
Build from Source Llama.cpp with CUDA GPU Support and Run LLM Models ...
LLMs for Everyone: Running the LLaMA-13B model and LangChain in Google ...
ExLlamaV2: The Fastest Library to Run LLMs | Towards Data Science
Quantization Of Llms With Llama.Cpp – GRKCZ
Best Small LLMs You Can Run Unquantized on Your CPU
Running llama.cpp on older hardware - Michael's blog
⚙️ Tools to Run Open LLMs Locally Llama, Phi, Mistral, Gemma etc are ...
Distribute and Run LLMs with llamafile in 5 Simple Steps - KDnuggets
Llama On Cpu
Run LLMs Locally: 7 Simple Methods | DataCamp
Run LLMs Locally: 6 Simple Methods | DataCamp
Optimizing and Deploying Quantized LLMs
Llama.cpp EASY Install Tutorial on Windows - YouTube
Understanding how LLM inference works with llama.cpp
Free Video: LLM Quantization Tutorial: QLoRA, GPTQ, and LLama.cpp ...
Running Quantized LLM Locally
Llama.cpp 가이드 – 모든 하드웨어에서 LLMs를 처음부터 로컬로 실행하는 방법 | GeekNews
llama C++ Cpu Only: A Quick Start Guide
Evaluating Quantized LLMs
Beginner’s Guide: Setting up llama.cpp for Local LLM Experiments (GPU ...
How To Run LLMs Locally - Deployment And Benchmark
CPU 时间是如何耗费在 llama.cpp 程序和 LLaMA2 模型内部的(使用 OpenResty XRay) - OpenResty 官方博客
Llama-2-Open-Source-LLM-CPU-Inference | Ecosystem Directory | market.dev
What are Quantized LLMs?
Quantized Large Language Model
GitHub - Green-Halo/Quantized-LLaMA: Tool for the automatic ...