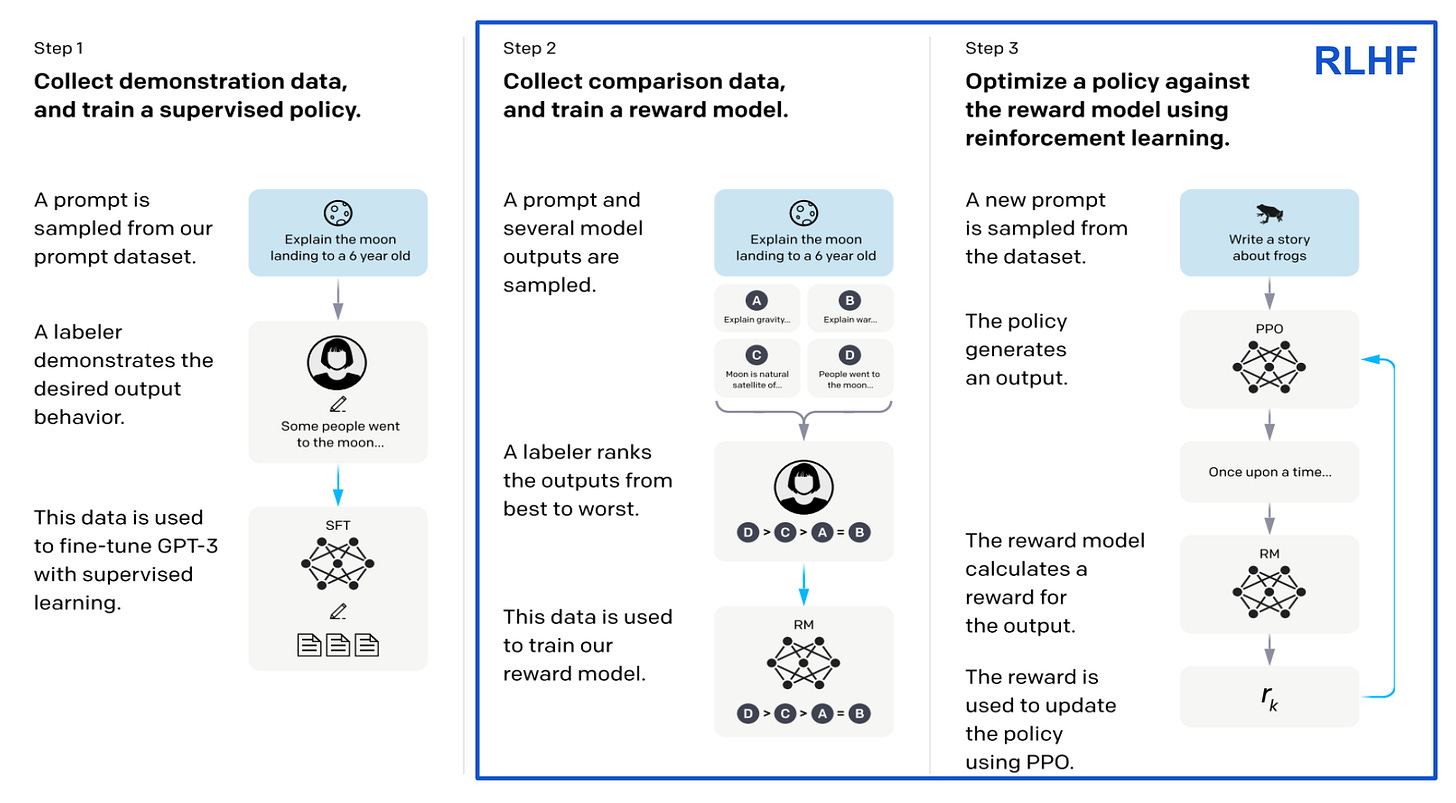
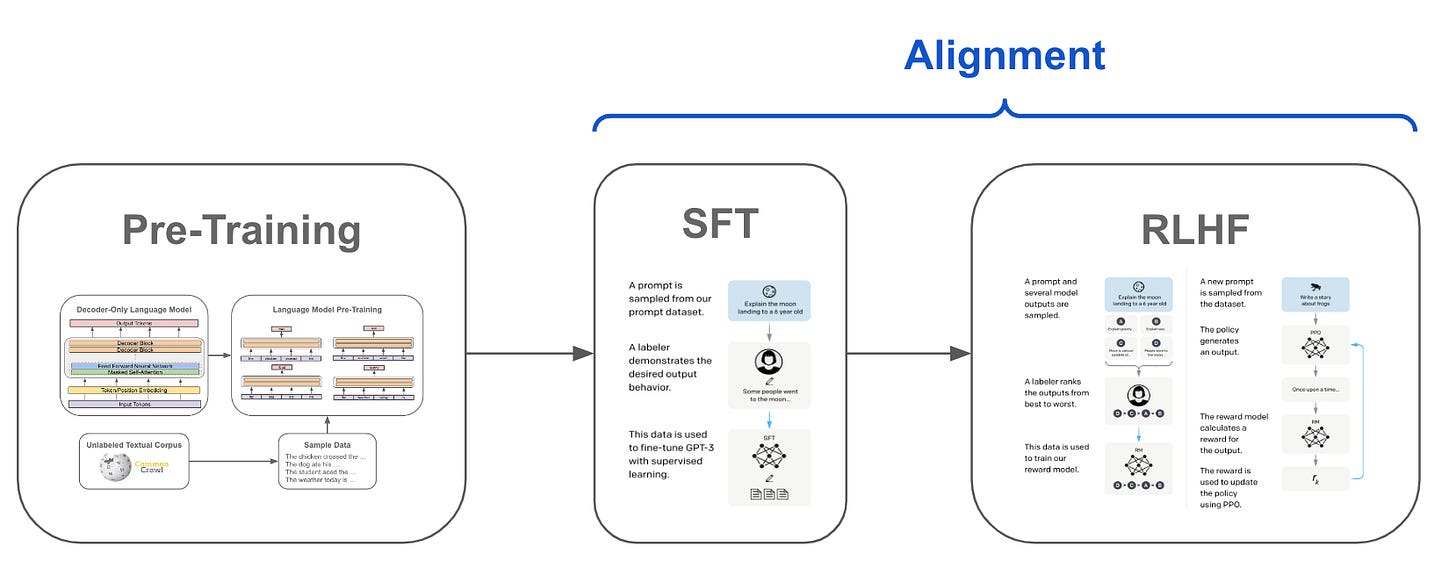
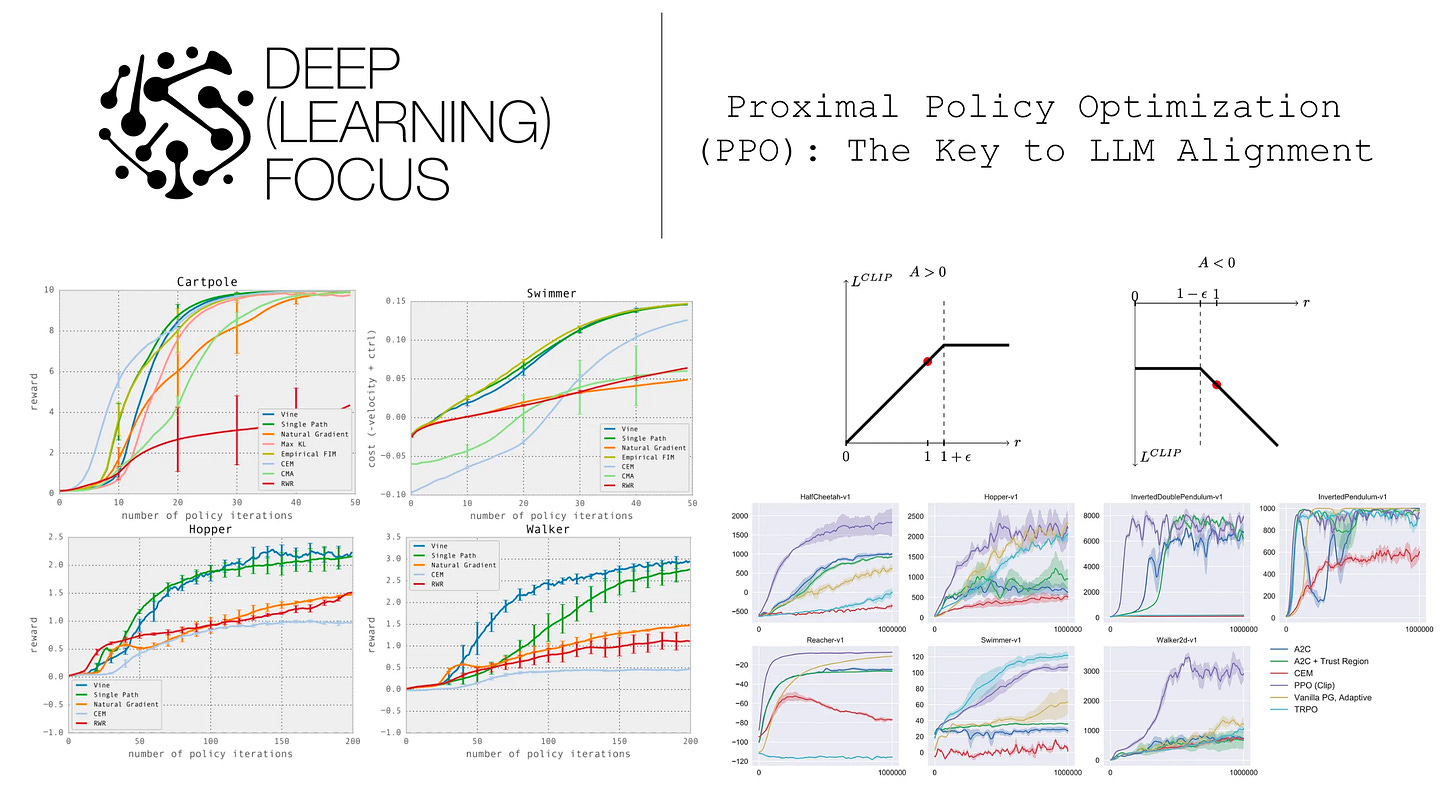
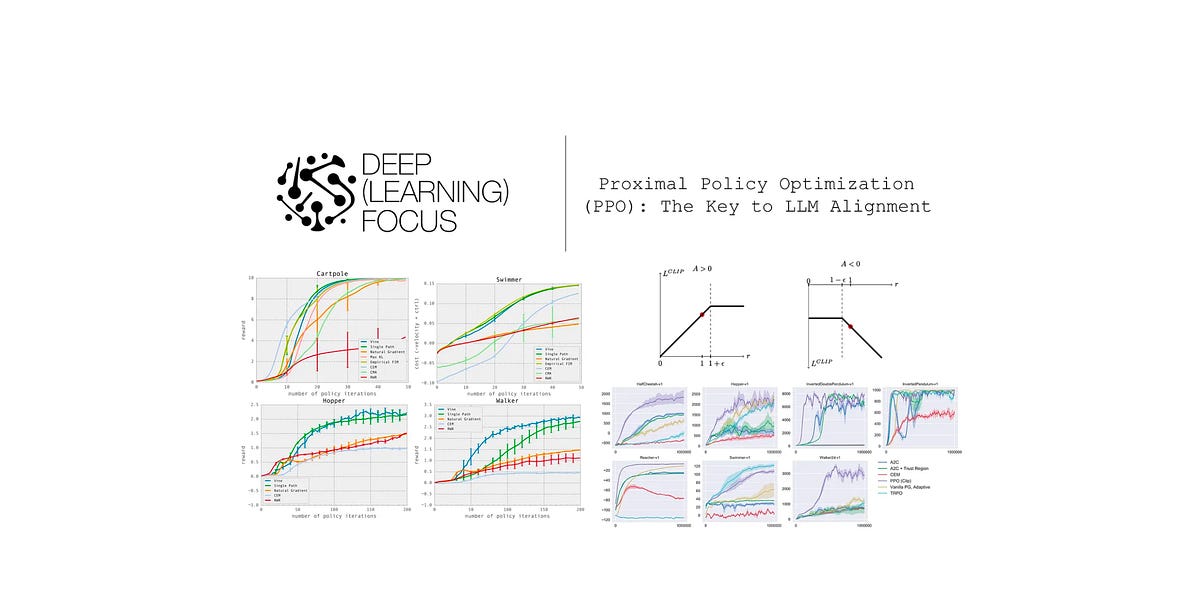
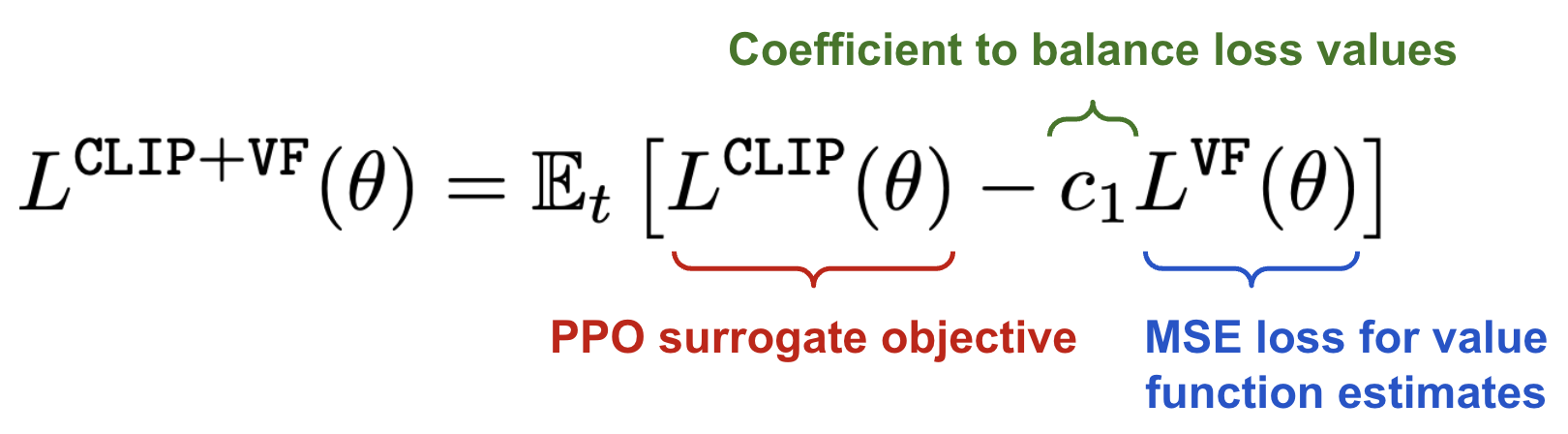
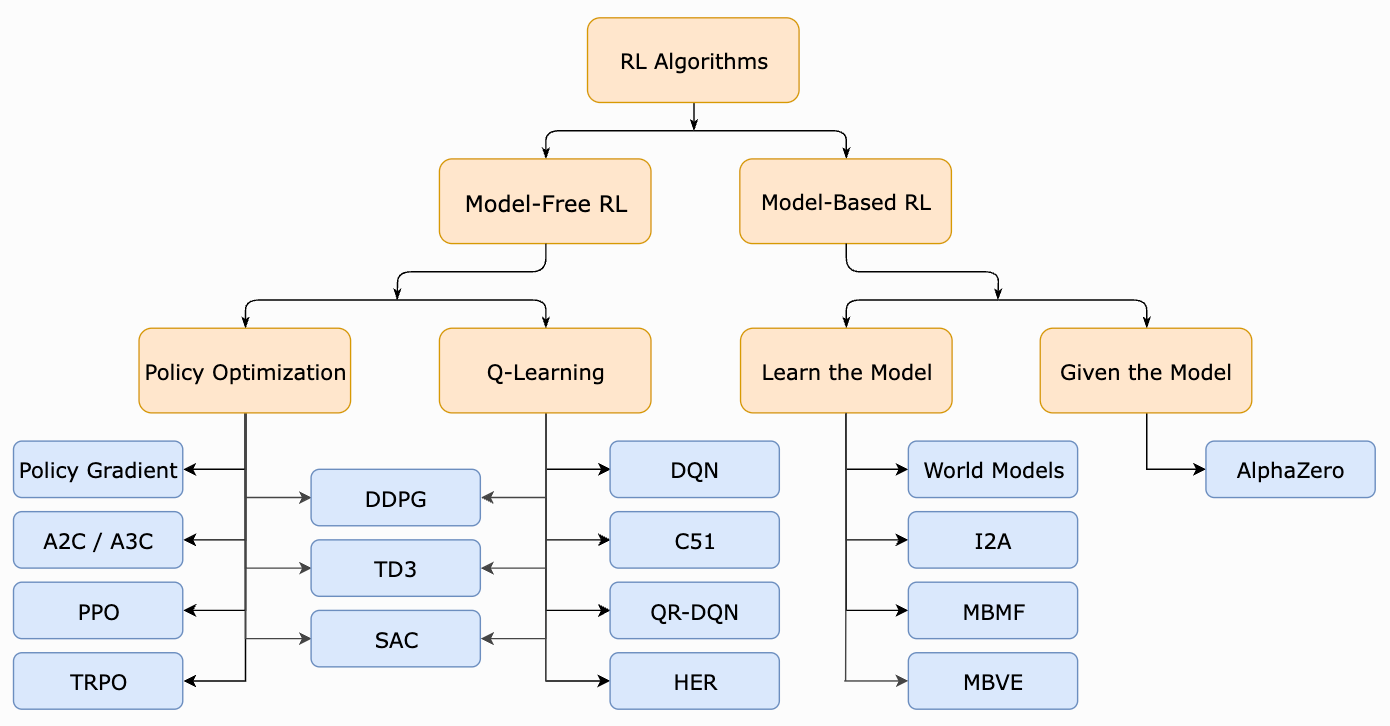
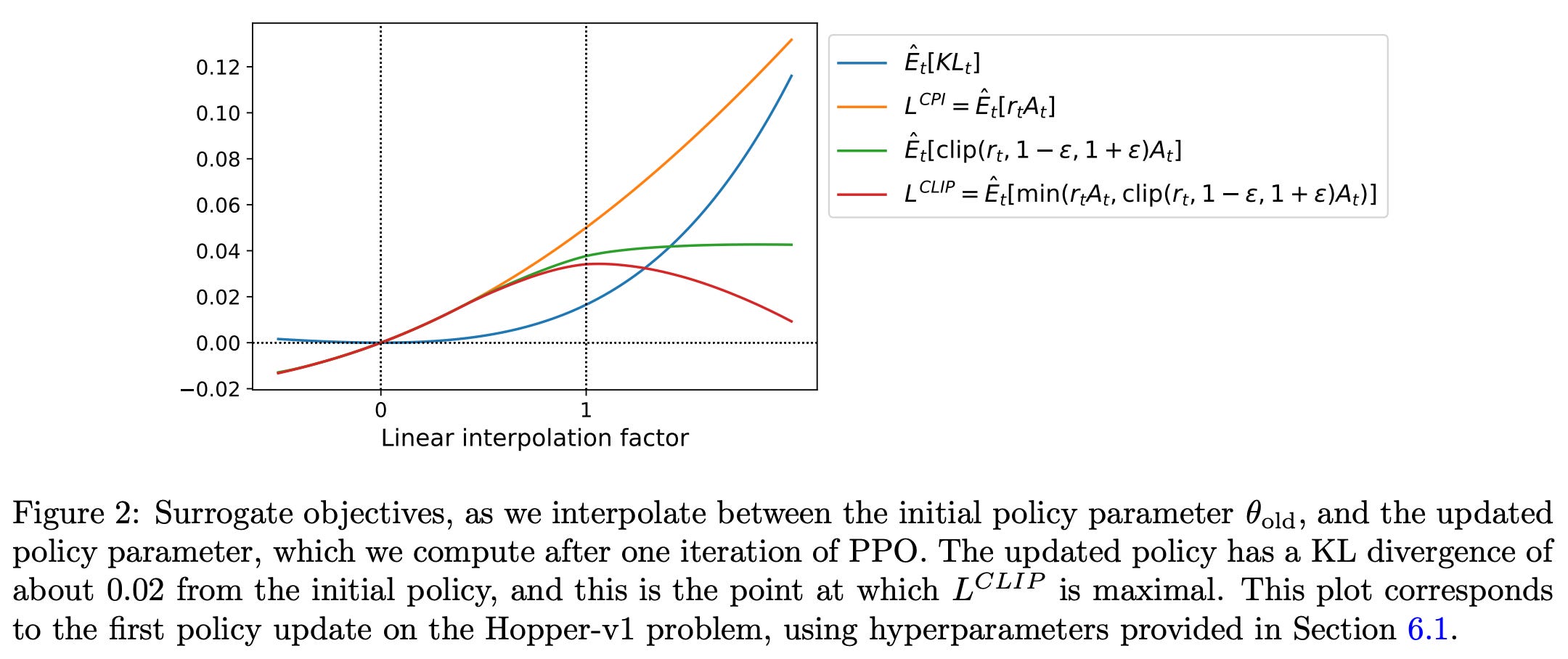
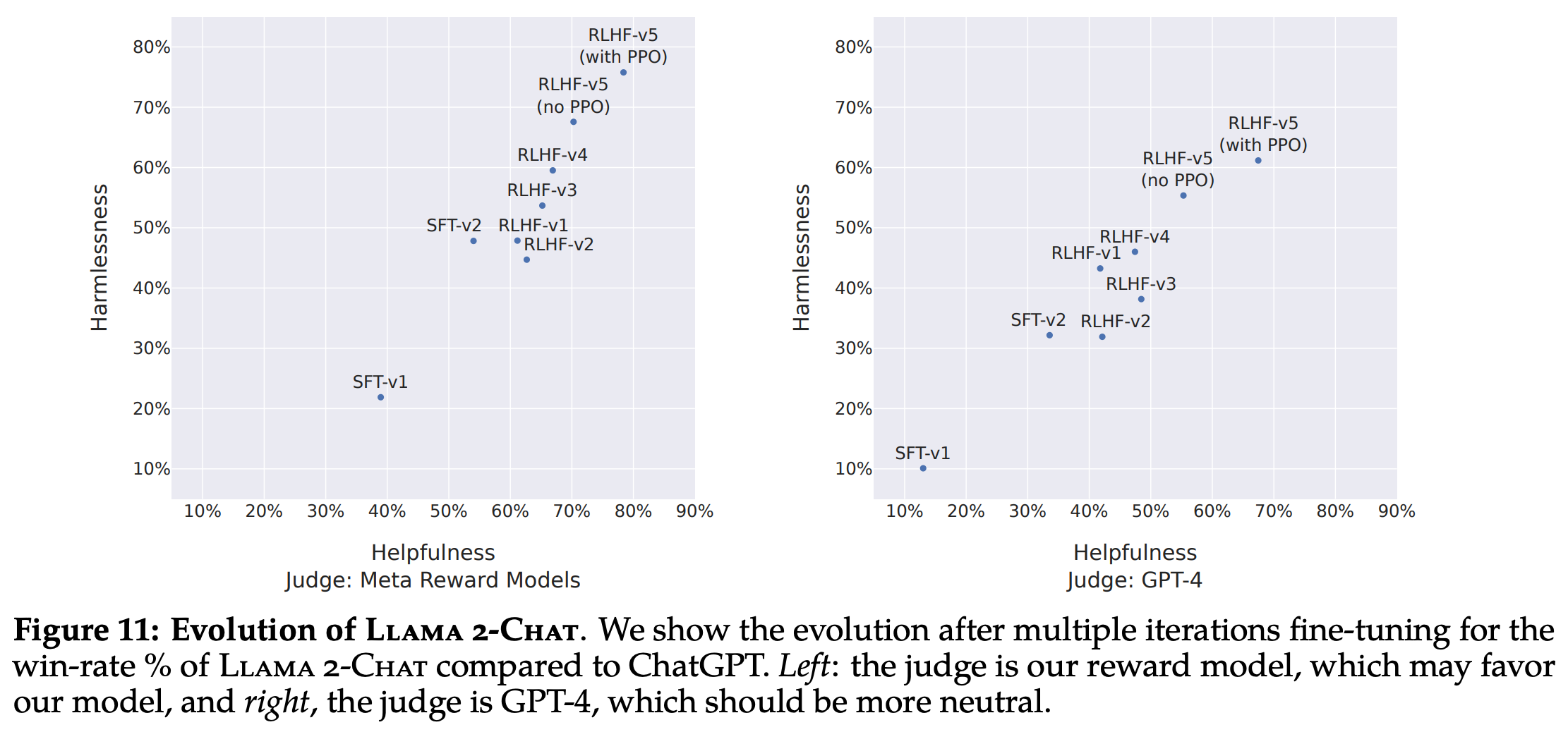
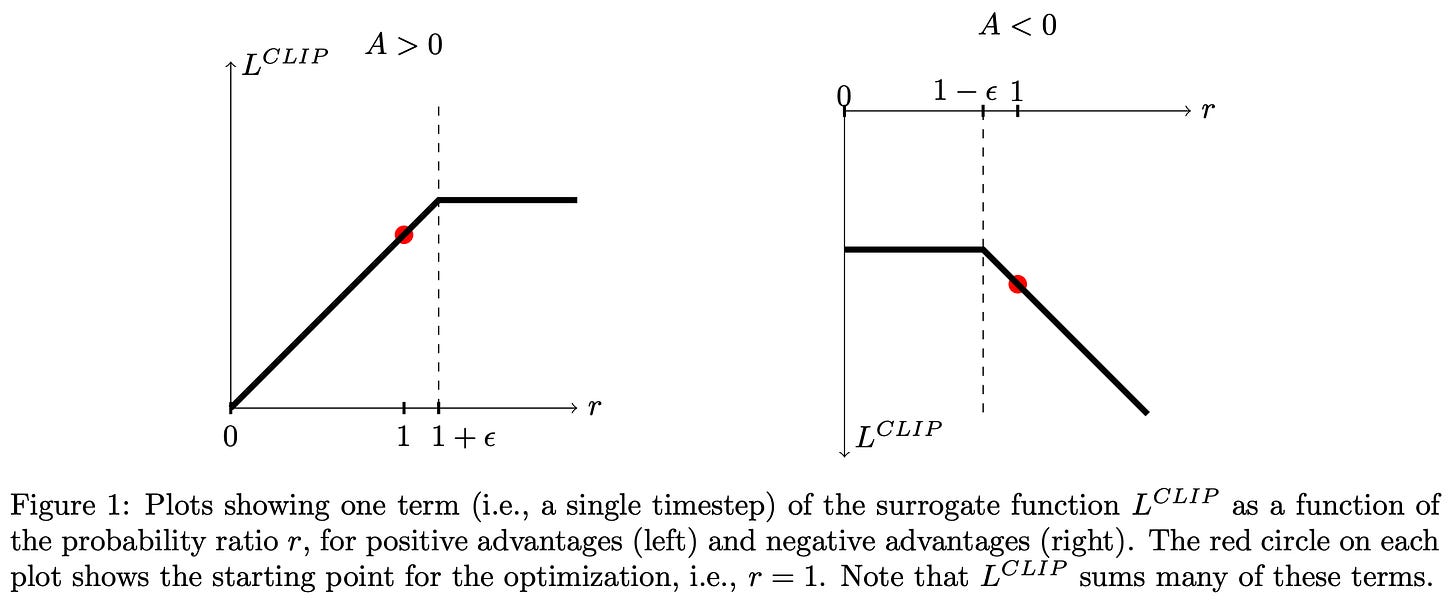
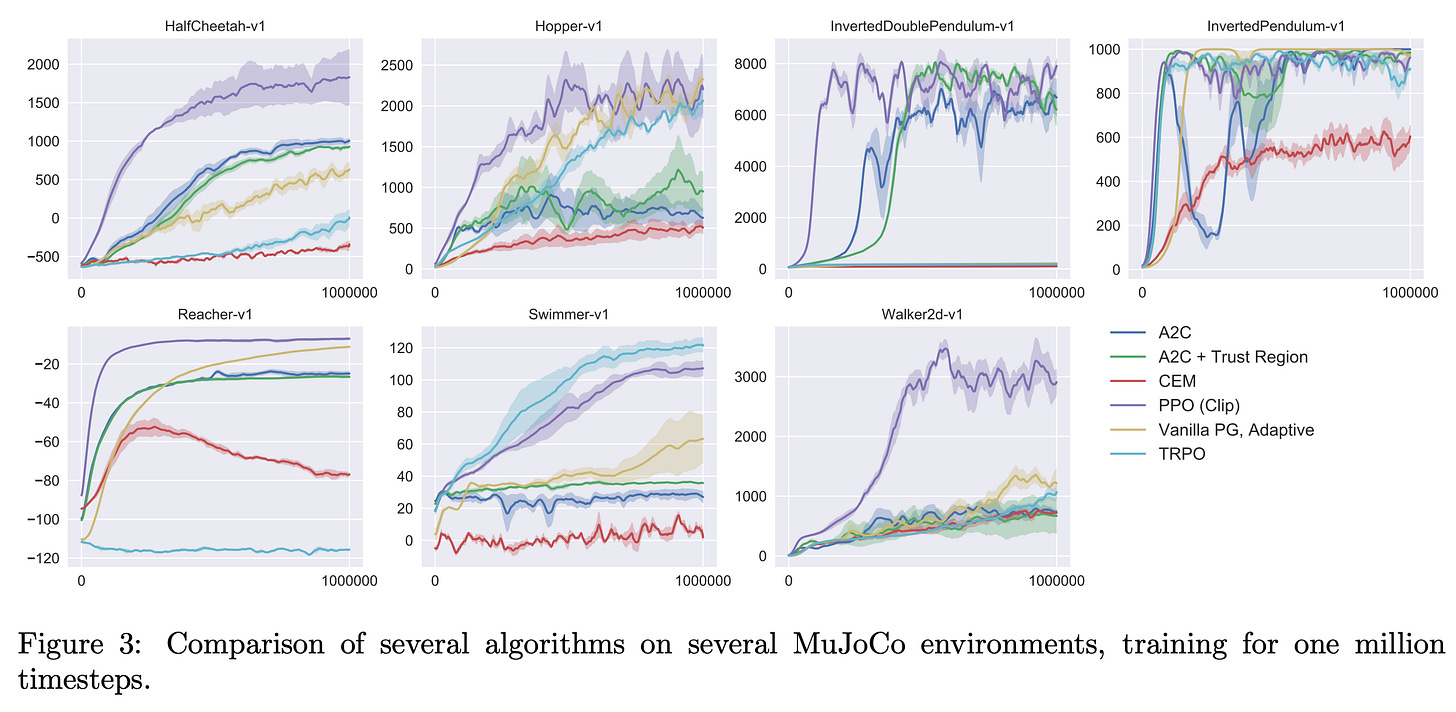
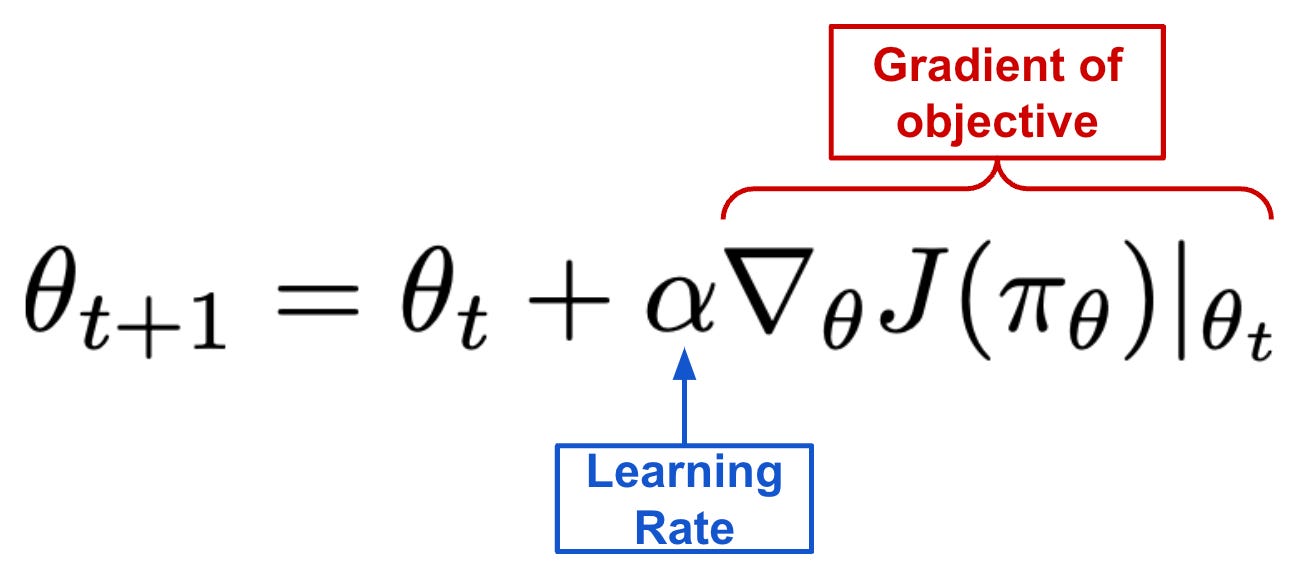
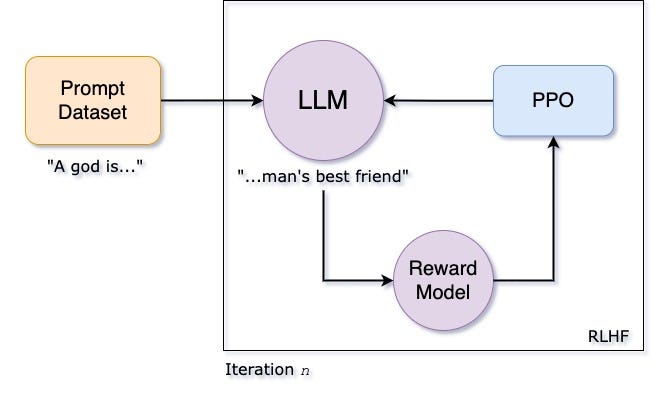
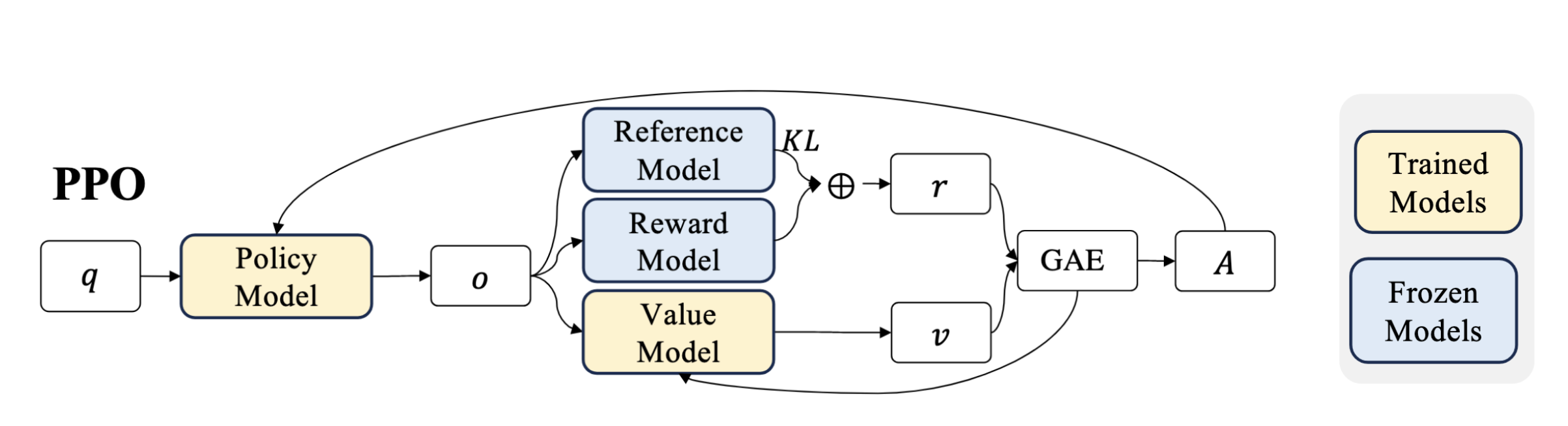
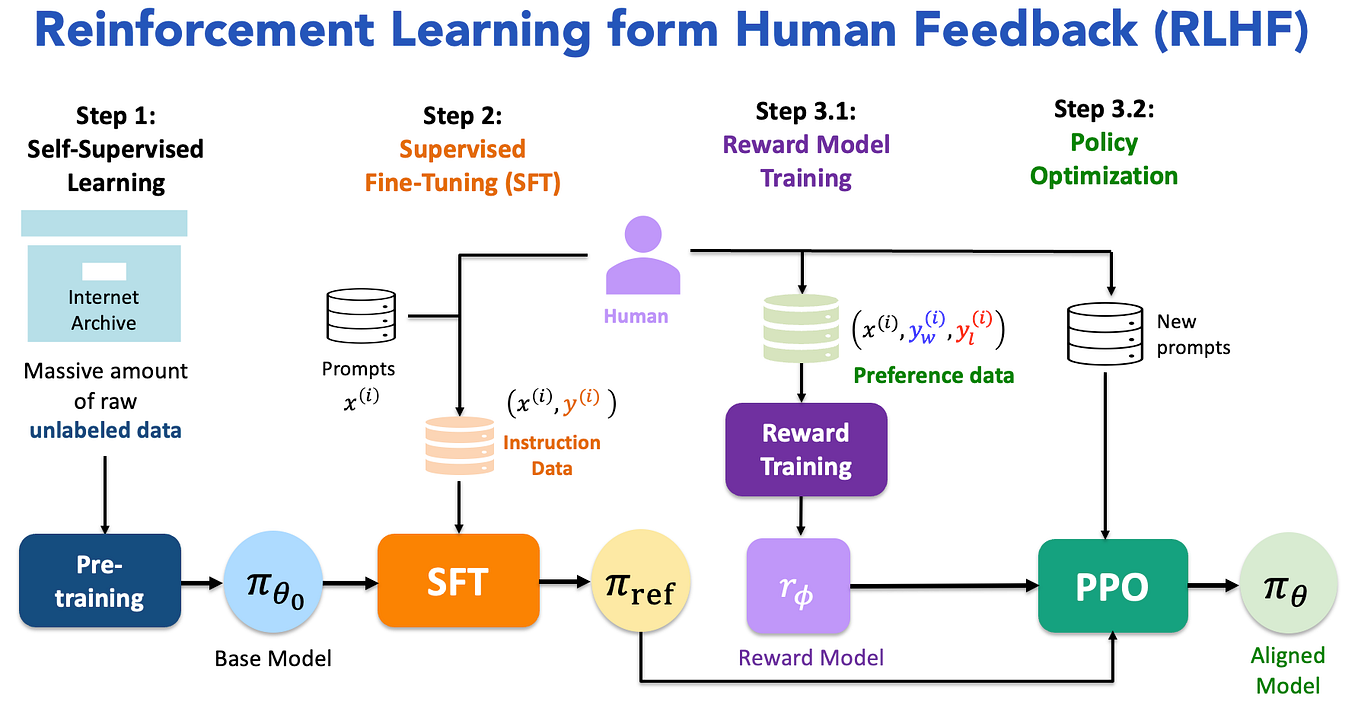
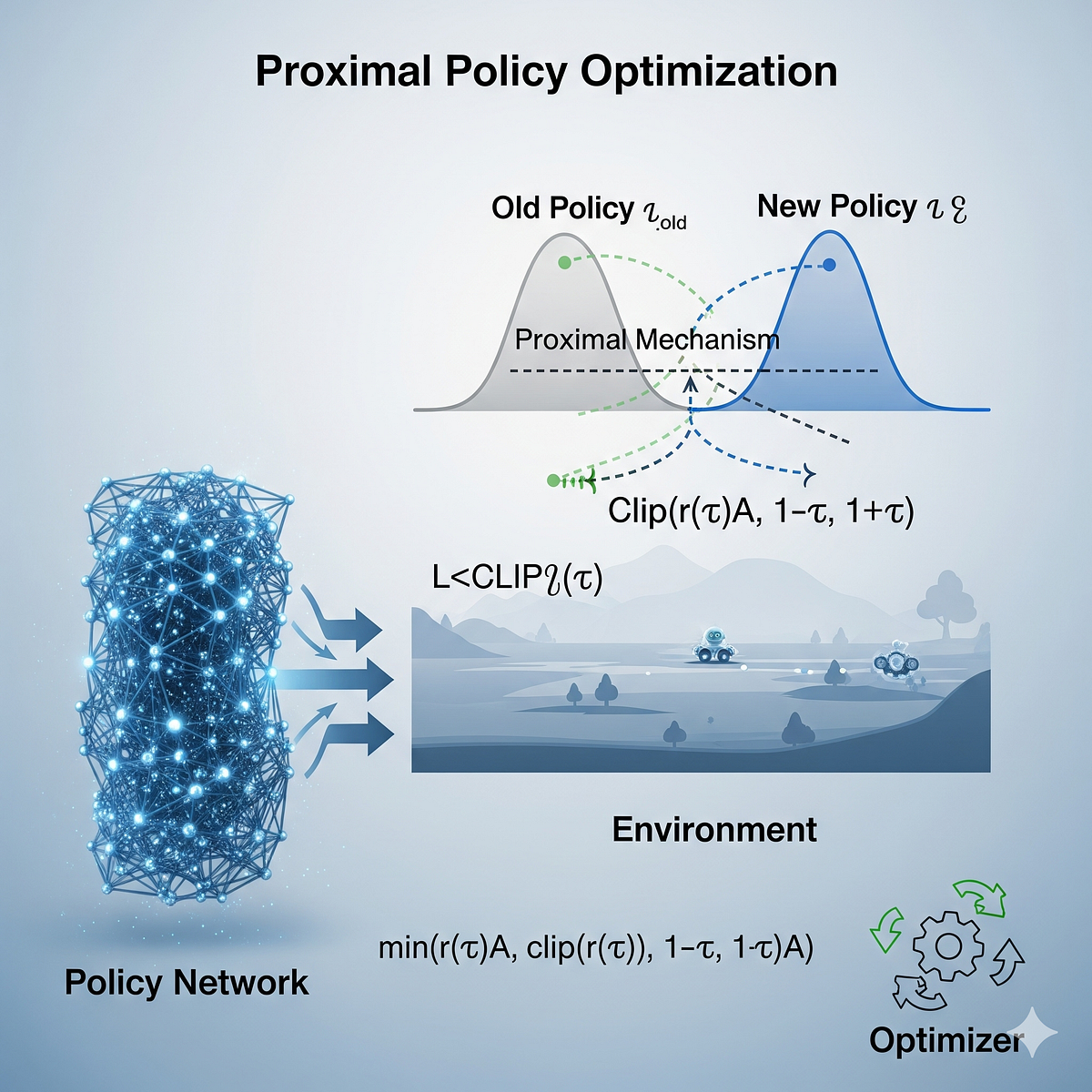
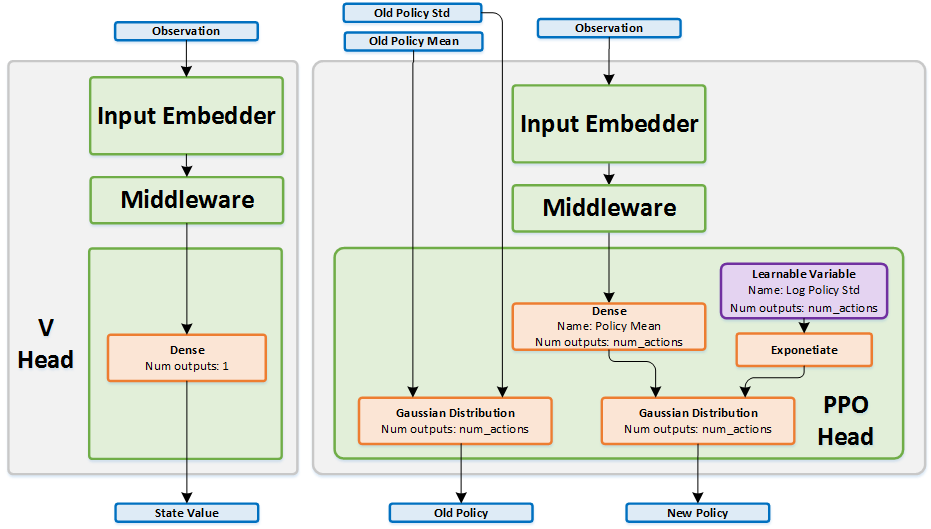
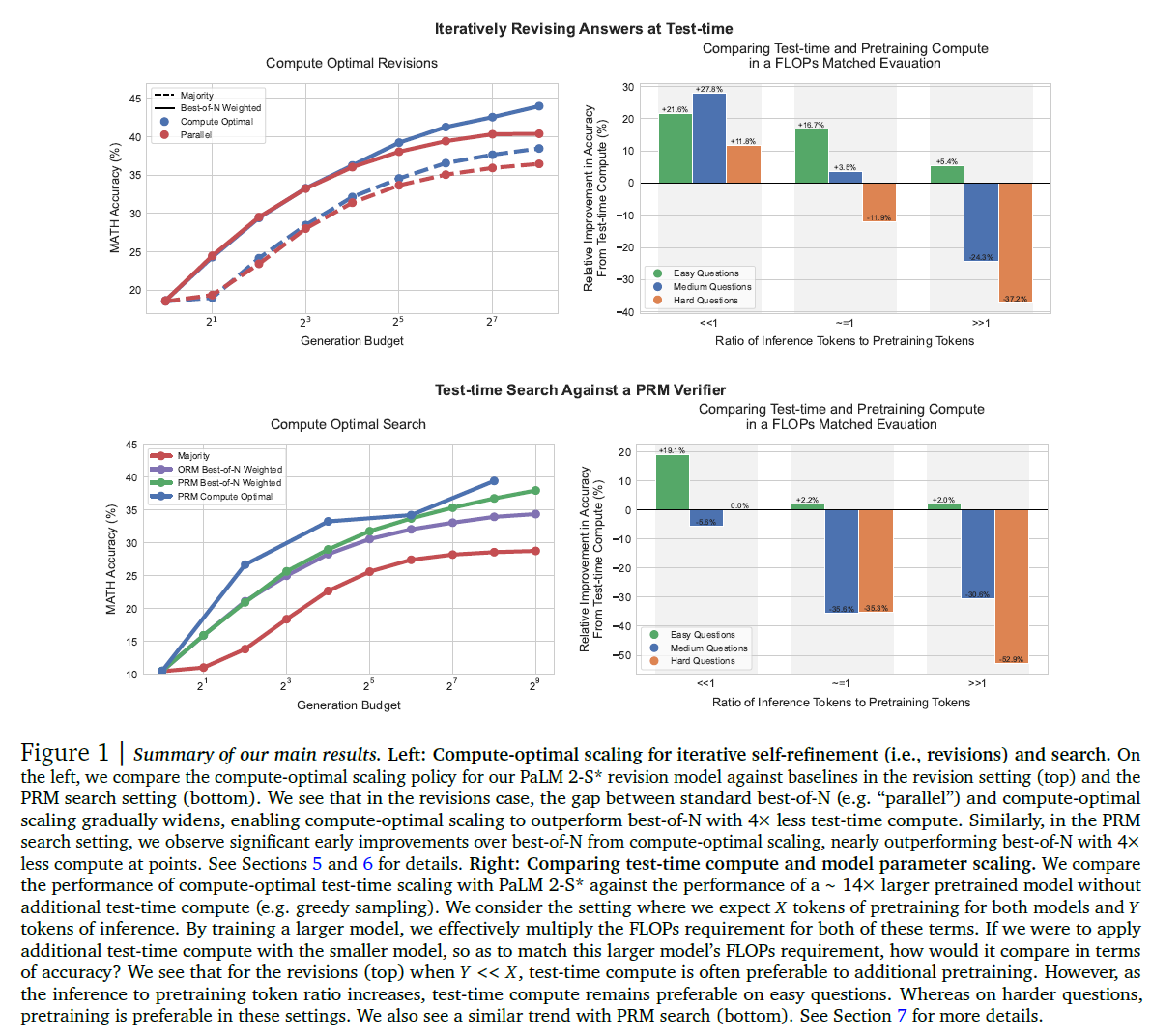
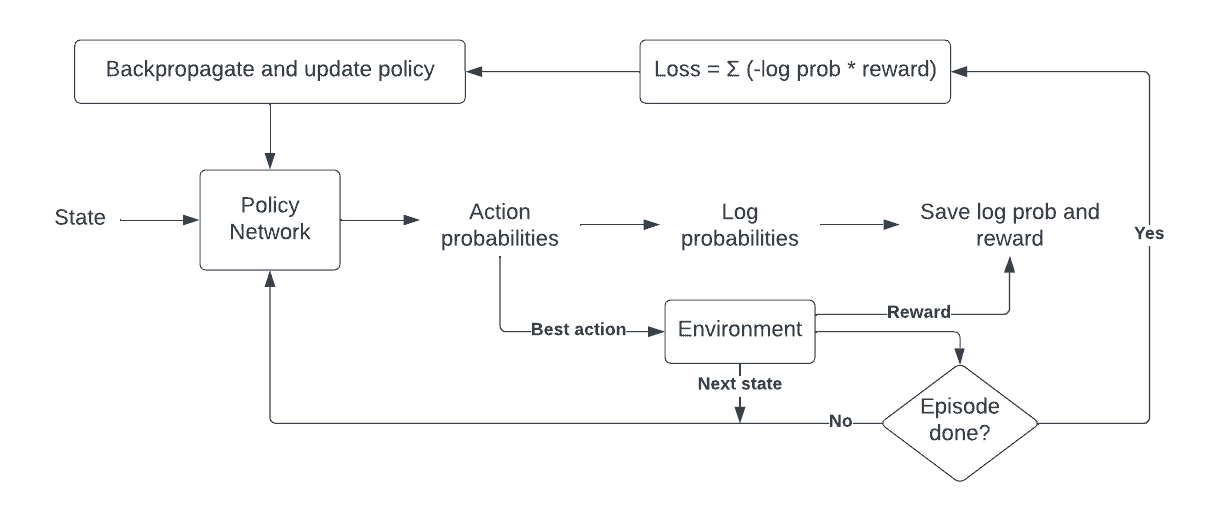
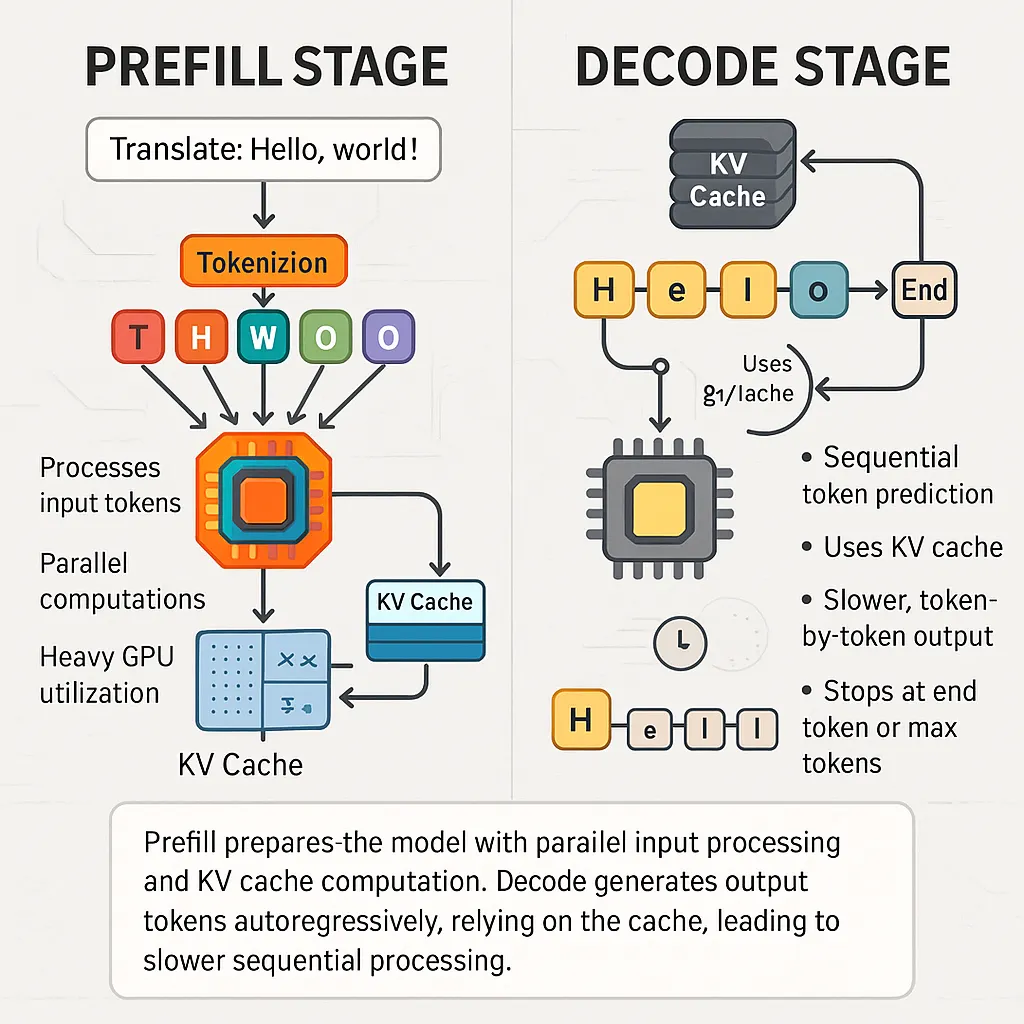
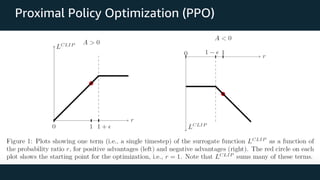
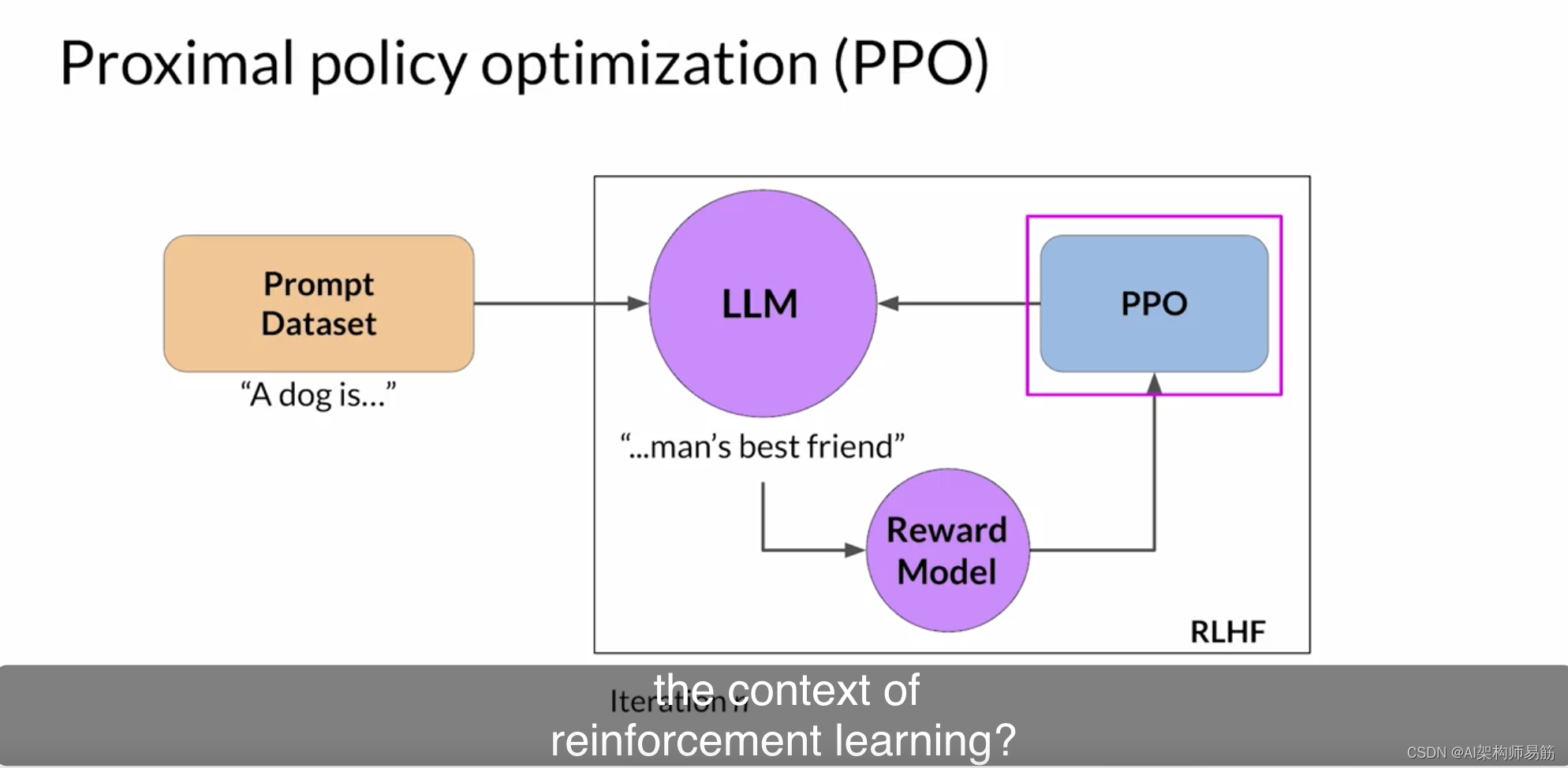
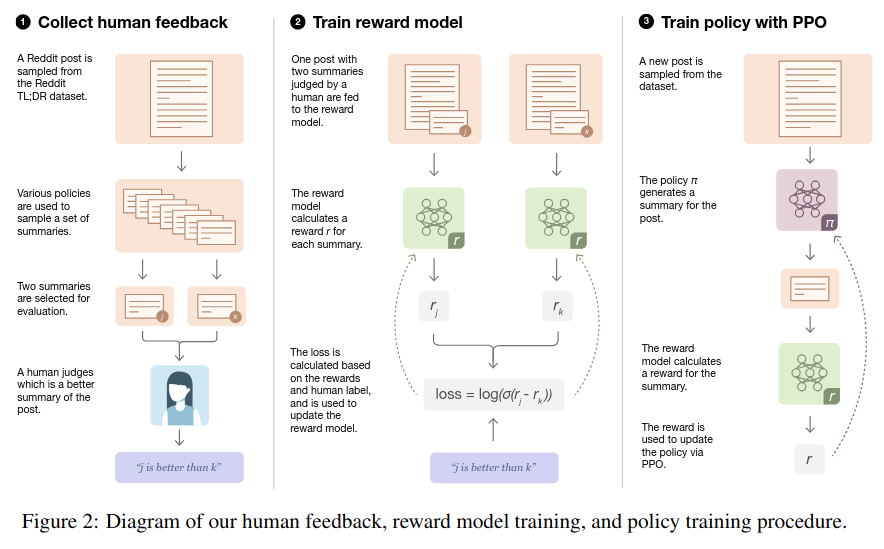
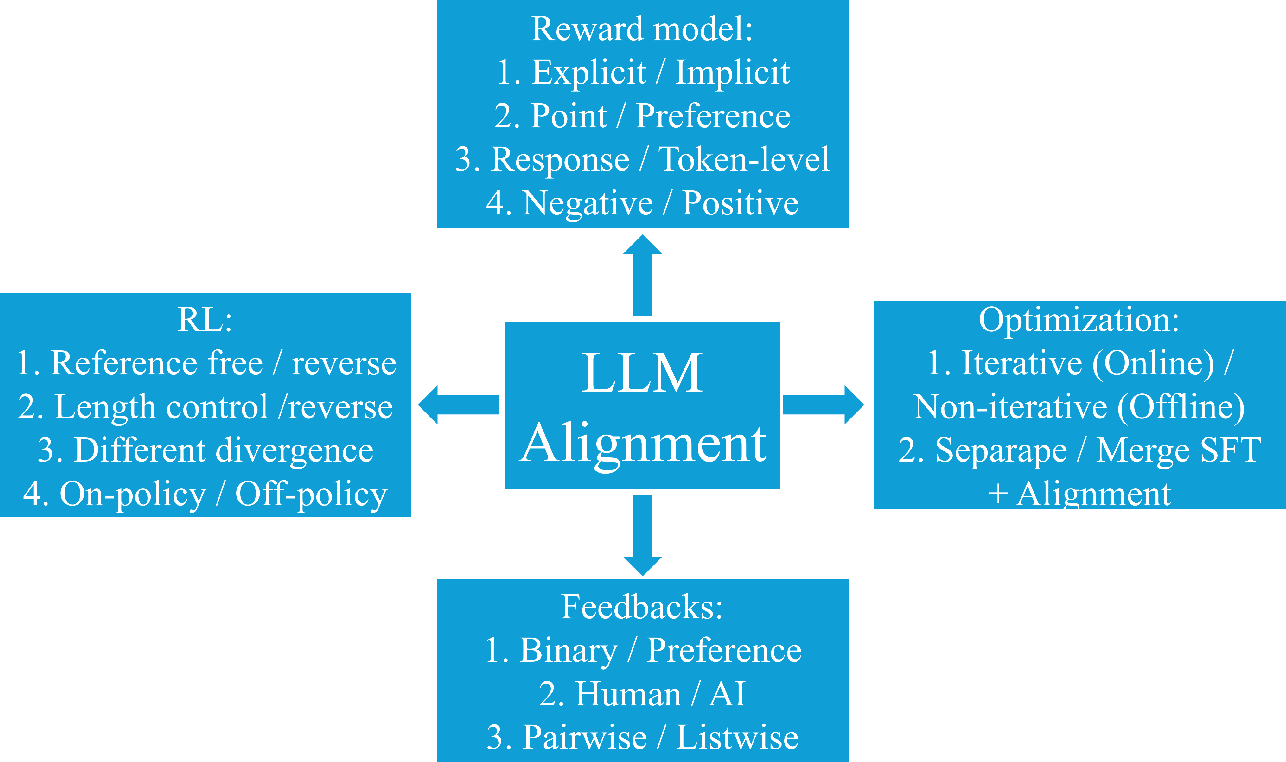
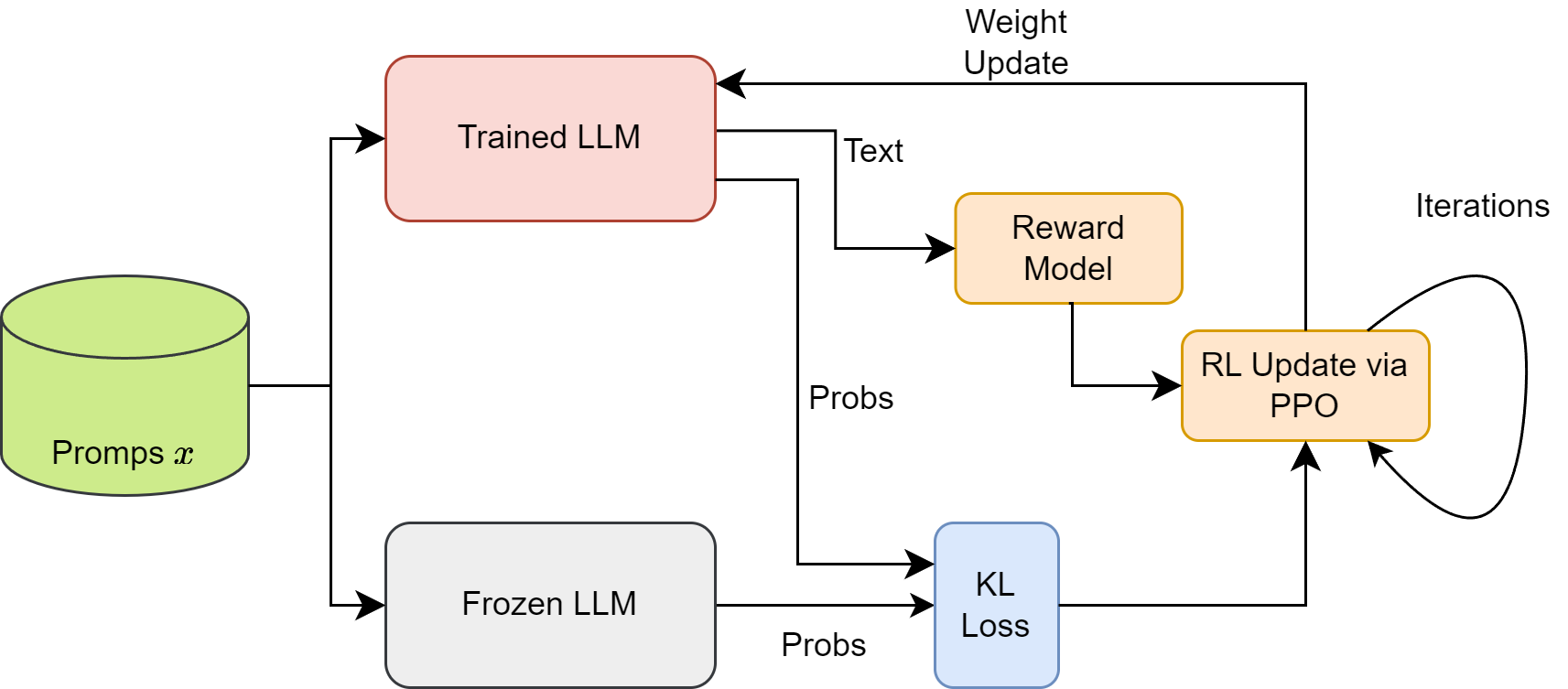
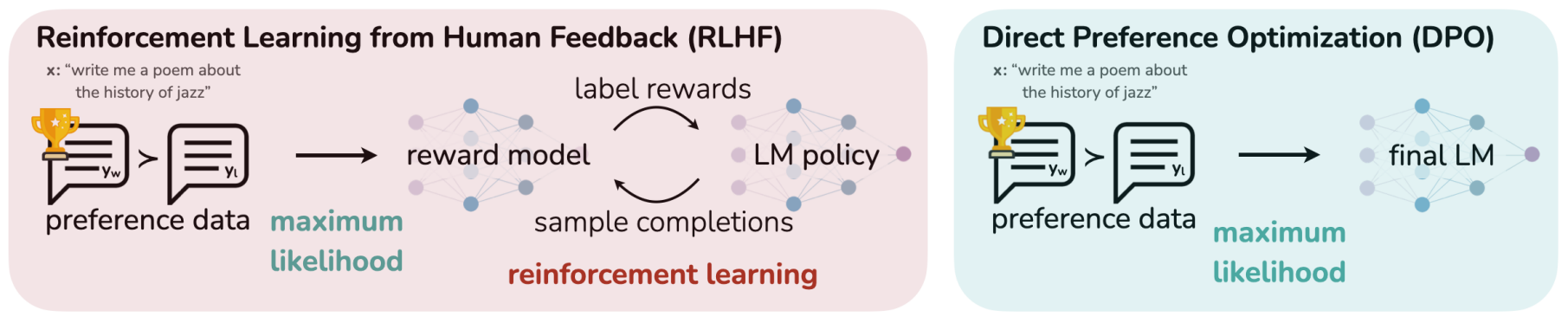
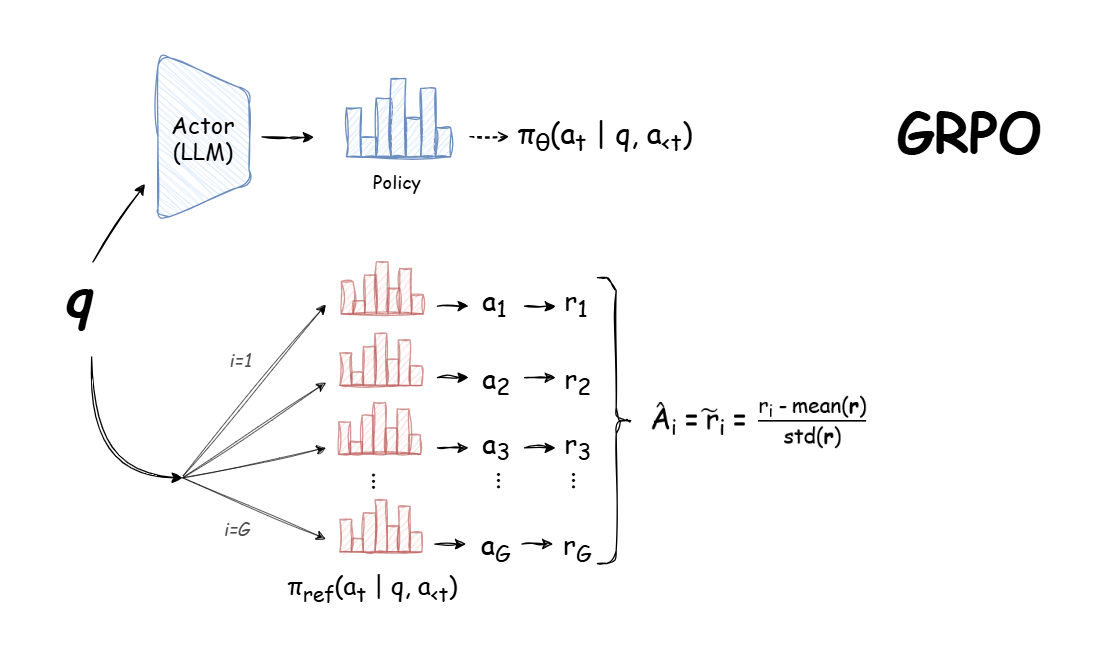
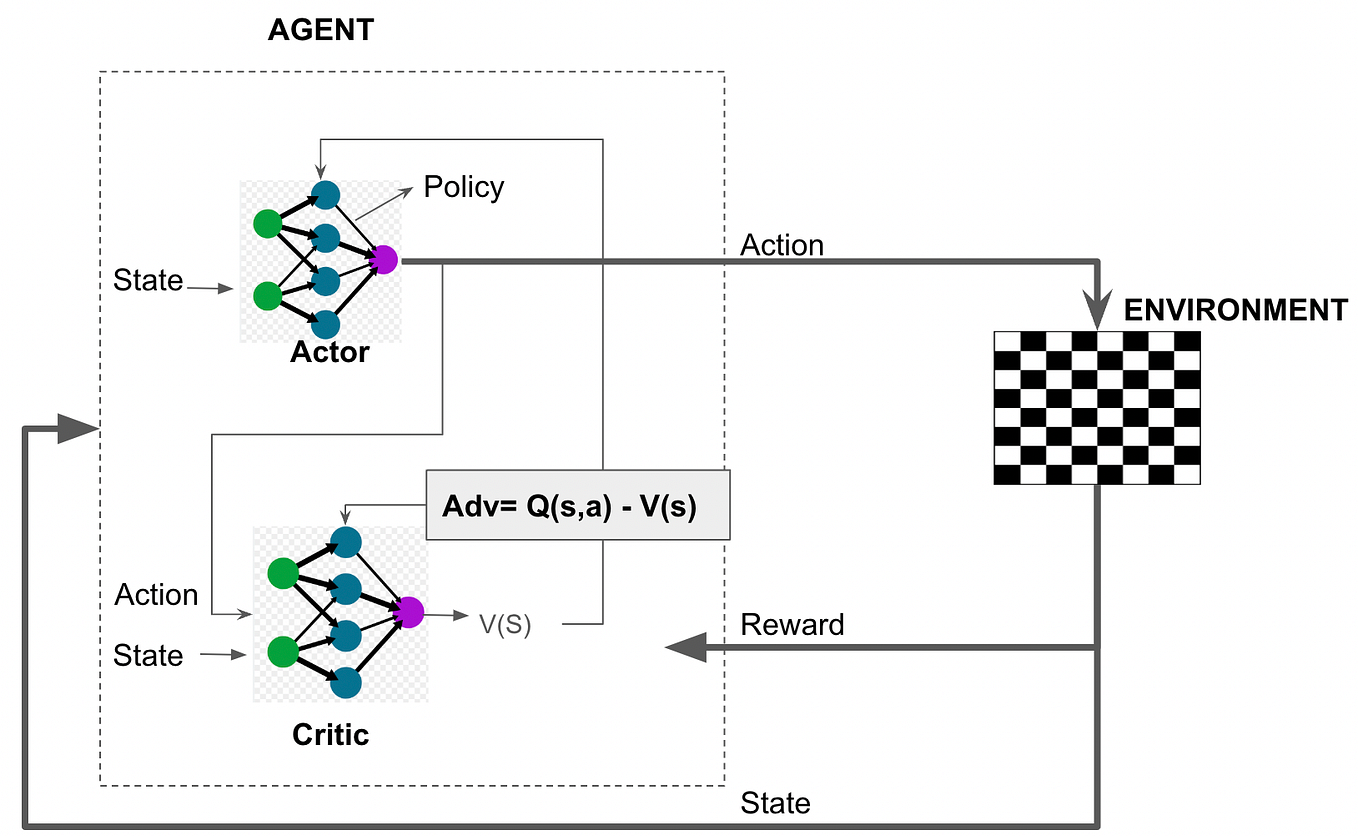
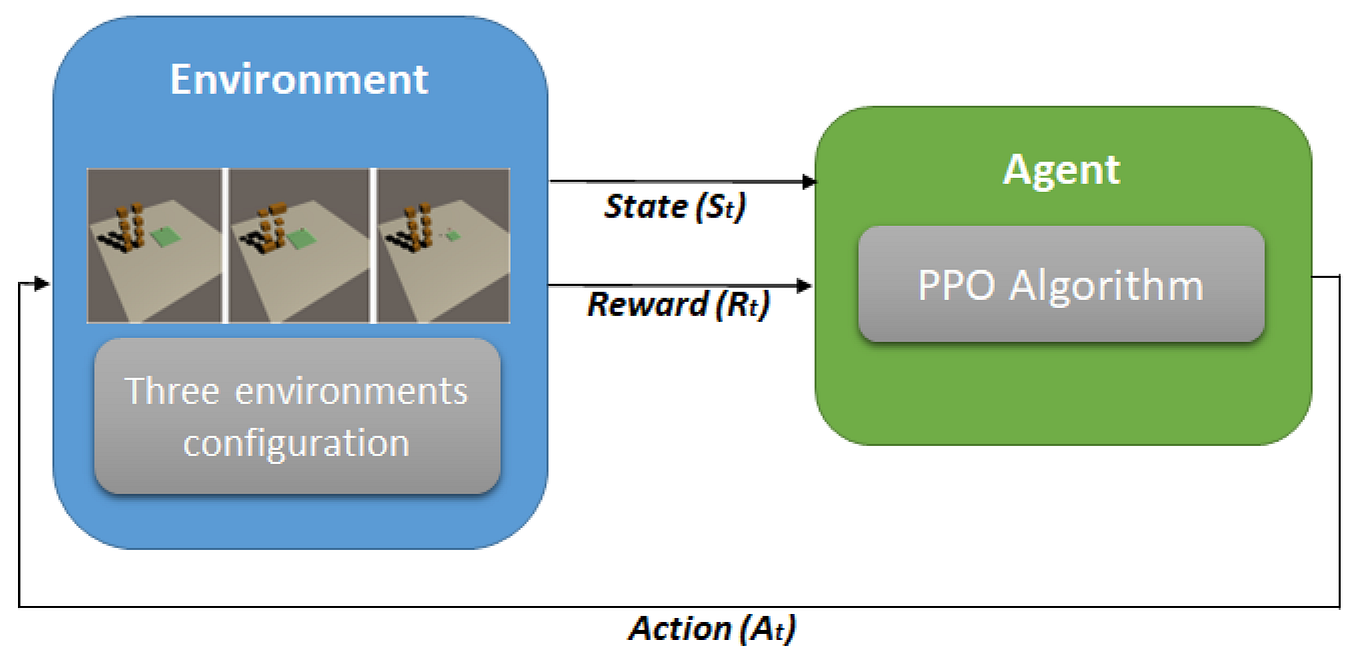
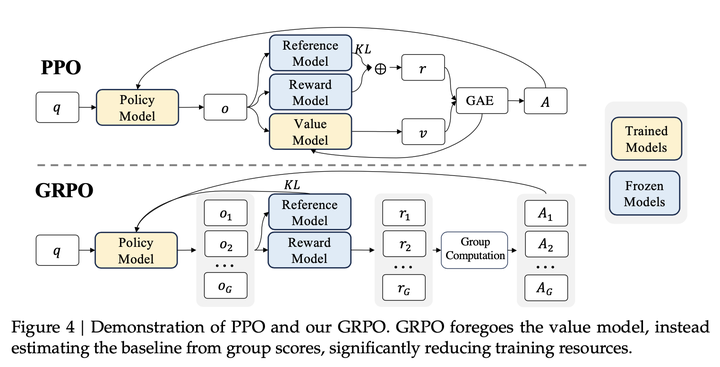
Proximal Policy Optimization (PPO): The Key to LLM Alignment
Proximal Policy Optimization (PPO): The Key to LLM Alignment | by ...
Proximal Policy Optimization (PPO): An Introduction to Stable and ...
A Comprehensive Guide to Proximal Policy Optimization (PPO) in AI | by ...
Introduction to Proximal Policy Optimization algorithm (PPO) - YouTube
Proximal Policy Optimization — The GenAI Guidebook
Proximal Policy Optimization (PPO) - How to train Large Language Models ...
Proximal Policy Optimization (PPO): Reinforcement Learning
Proximal Policy Optimization (PPO): A Comprehensive Exploration of ...
Proximal Policy Optimization (PPO): Breakthrough in Reinforcement
The Power of PPO: How Proximal Policy Optimization Solves a Range of RL ...
Workflow of Proximal Policy Optimization (PPO) | by Arbilchakma | Sep ...
Proximal Policy Optimization (PPO) RL in PyTorch | by Dhanoop ...
PPO | Proximal Policy Optimization (PPO) architecture | PPO Explained ...
PPO Algorithm. Proximal Policy Optimization (PPO) is… | by DhanushKumar ...
Proximal Policy Optimization Algorithm – AFRI
Implementing Proximal Policy Optimization (PPO) Algorithm for ...
Ace AI Interview Series 2— Explaining Proximal Policy Optimization: the ...
Proximal Policy Optimization (PPO) Explained
Proximal Policy Optimization (PPO) Explained | by Wouter van Heeswijk ...
Reinforcement Learning with Proximal Policy Optimization (PPO) | by ...
Proximal Policy Optimization (PPO)
Navigating the RLHF Landscape: From Policy Gradients to PPO, GAE, and ...
PPO Explained for Everyone: How Proximal Policy Optimization Helps Fine ...
Proximal Policy Optimization (PPO) for LLMs Explained Intuitively - YouTube
PPO: Proximal Policy Optimization Algorithms - 知乎
Proximal Policy Optimization (Reinforcement Learning) | PDF
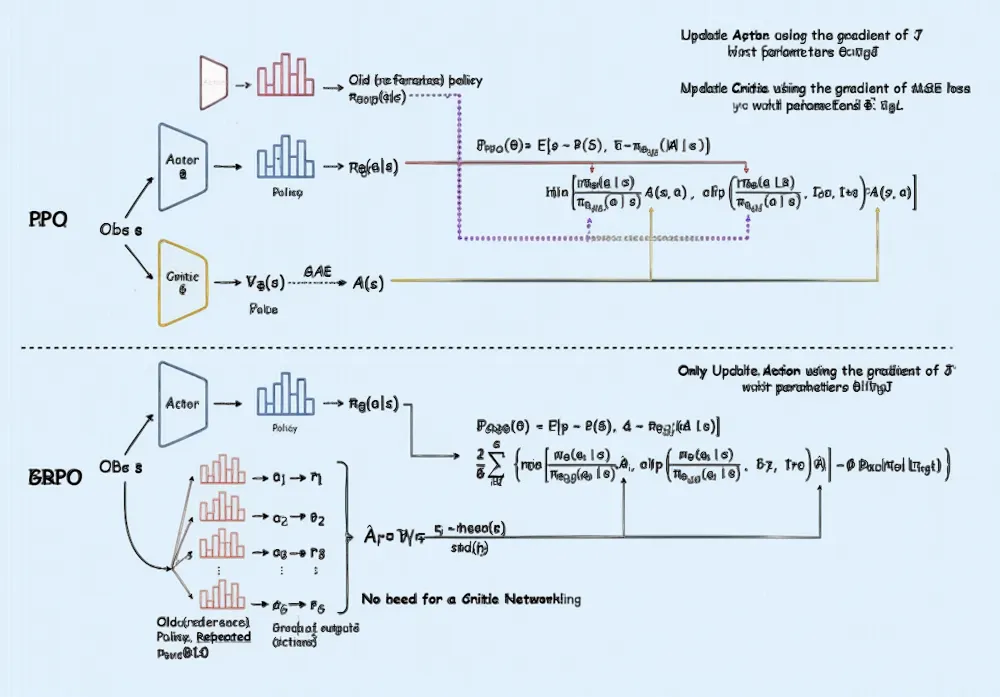
Understanding Proximal Policy Optimization (PPO) vs Group Policy ...
Proximal Policy Optimization
DPO vs PPO: Why LLM Alignment Matters | Labellerr AI posted on the ...
Proximal Policy Optimization (PPO) 算法理解:从策略梯度开始 - overfit.cn
Proximal Policy Optimization | PPTX
(PDF) Coordinated Proximal Policy Optimization
RL — Proximal Policy Optimization (PPO) Explained – Jonathan Hui – Medium
Paper Summary: Proximal Policy Optimization Algorithms
Understanding Proximal Policy Optimization Part 1 – XNCUC
(PDF) PPO-Q: Proximal Policy Optimization with Parametrized Quantum ...
Proximal Policy Optimization Algorithms - Explained Simply | ArXiv ...
What is Proximal Policy Optimization (PPO) algorithm in reinforcement ...
Clipped Proximal Policy Optimization — Reinforcement Learning Coach 0. ...
Openai Proximal Policy – A Comprehensive Guide to Proximal Policy ...
Proximal Policy Optimization Algorithms | by Eleventh Hour Enthusiast ...
Proximal Policy Optimization (PPO) - Explained | Dilith Jayakody
Mastering Proximal Policy Optimization (PPO) in Reinforcement Learning ...
Exploring Proximal Policy Optimization (PPO) in Deep Reinforcement ...
LLMs: 近端策略优化PPO Proximal policy optimization_llm ppo-CSDN博客
RLHF vs. DPO: Choosing the Method for LLMs Alignment Tuning | by Baicen ...
DPO vs PPO: How To Align LLM [Updated]
Paper page - Is DPO Superior to PPO for LLM Alignment? A Comprehensive ...
Proximal Policy Optimization(PPO)算法原理及实现!-CSDN博客
Paper page - Pairwise Proximal Policy Optimization: Harnessing Relative ...
Trust Region Policy Optimization (TRPO) Explained | by Wouter van ...
【李弘毅深度强化学习】2,Proximal Policy Optimization (PPO) - 知乎
A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO ...
13. LLM Alignment and Preference Learning — LLM Foundations
Proximal Policy Optimization(PPO)算法原理及实现!_baidu_huihui的博客-CSDN博客_ppo模型
Comparing DPO and PPO for LLM Alignment
Policy Optimization with PPO for RLHF
Reinforcement Learning (Part-8): Proximal Policy Optimization(PPO) for ...
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study | AI ...
Deep Deterministic Policy Gradient (DDPG) explained with codes in ...
一文详解PPO(Proximal Policy Optimization, 近端策略优化算法) - 知乎
PPO(Proximal Policy Optimization):LLMにおける強化学習の実践
How to Test PPO on PettingZoo Turn-Based Game? | by Kaige | Mar, 2025 ...
LLM Optimization: Optimizing AI with GRPO, PPO, and DPO
LLM Alignment: Reward-Based vs Reward-Free Methods | by Anish Dubey ...
Policy Gradient methods vs Q-Learning | by Walkerastro | Medium
Iterated Distillation and Amplification | by Ajeya Cotra | AI Alignment
Revolutionizing LLM Alignment: A Deep Dive into Direct Q-Function ...
Reinforcement learning with human feedback (RLHF) for LLMs | SuperAnnotate
TRPO PPO in reinforcement learning.pptx
RLHF for LLMs: A Deep Dive into Reinforcement Learning from Human ...
Guardrails in Large Language Models (LLMs) | by DhanushKumar | Medium
GitHub - ai-in-pm/Proximal-Policy-Optimization-Algorithms: This ...
Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei ...
【LLM】GRPO:改进PPO增强推理能力 - 知乎
Coding PPO from Scratch with PyTorch (Part 3/4) | by Eric Yang Yu ...
Based on this image's title: “Proximal Policy Optimization (PPO): The Key to LLM Alignment”