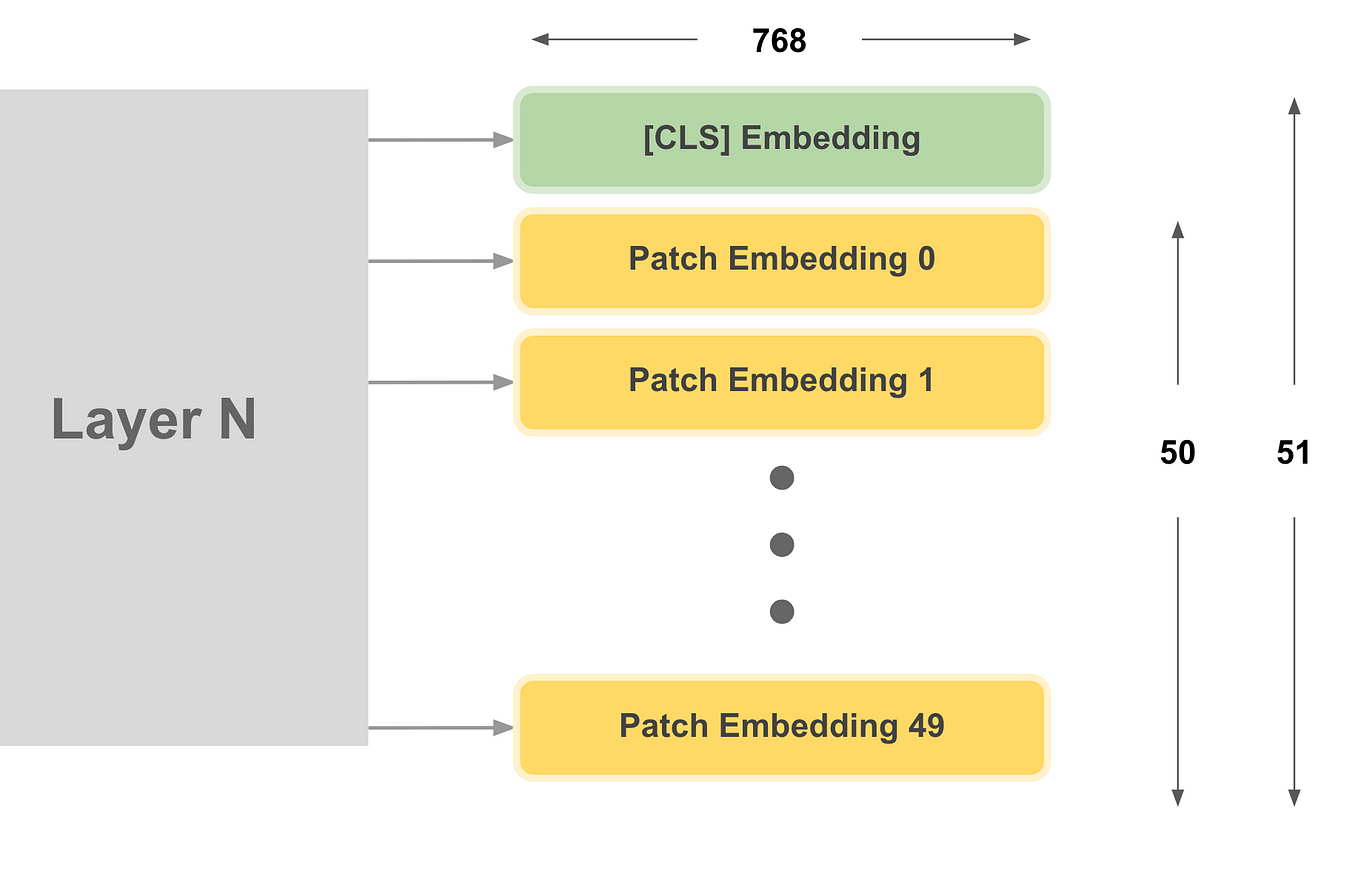
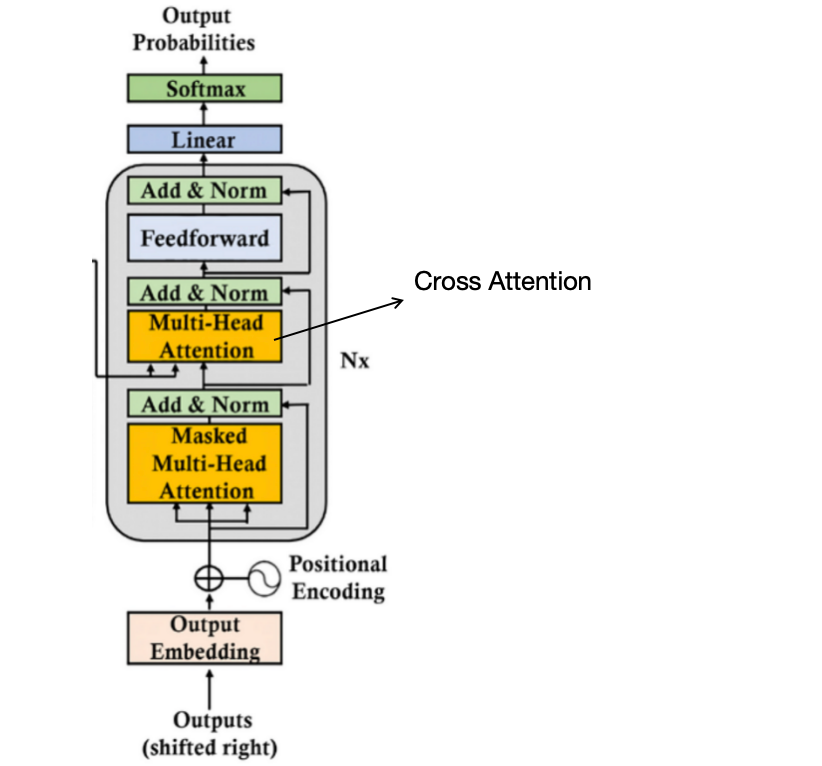
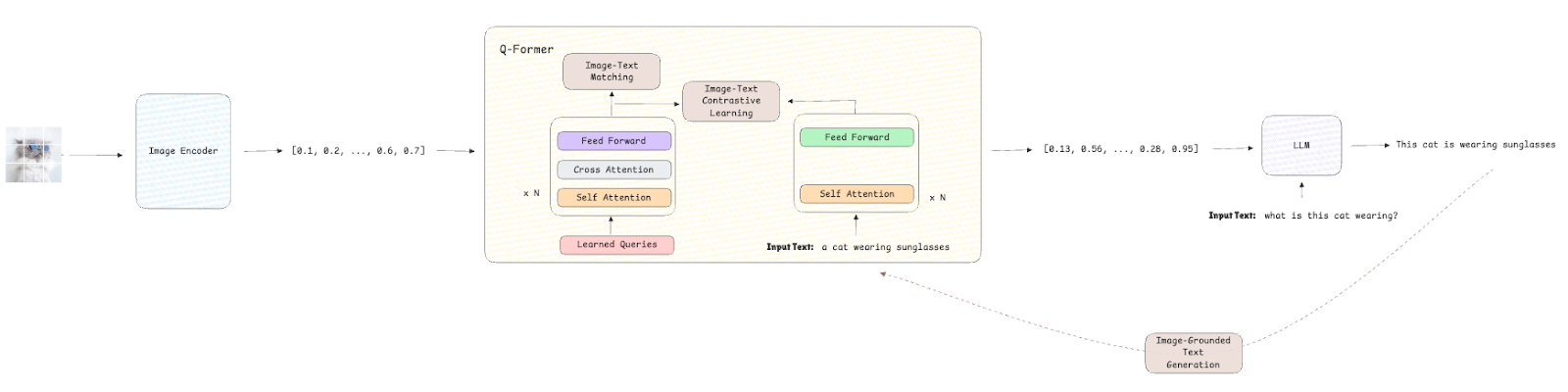
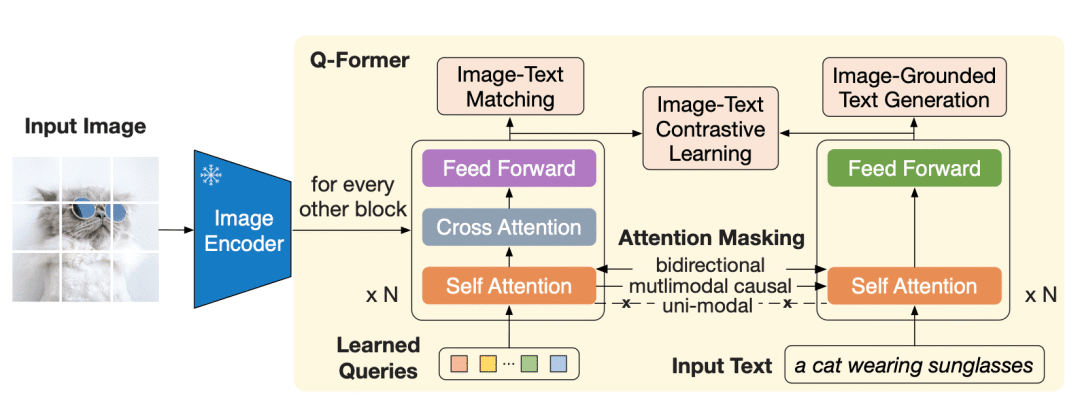
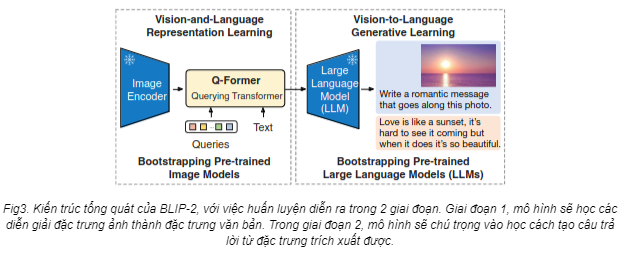
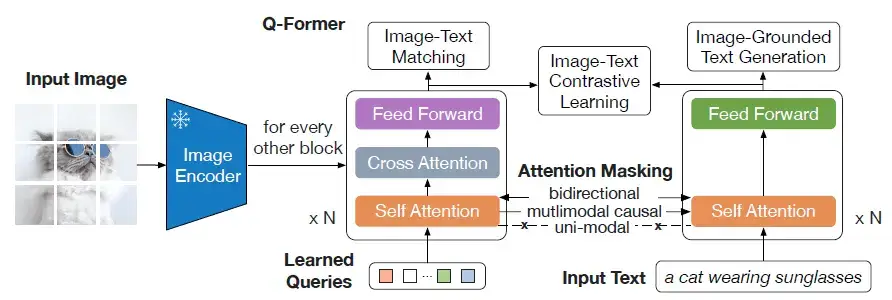
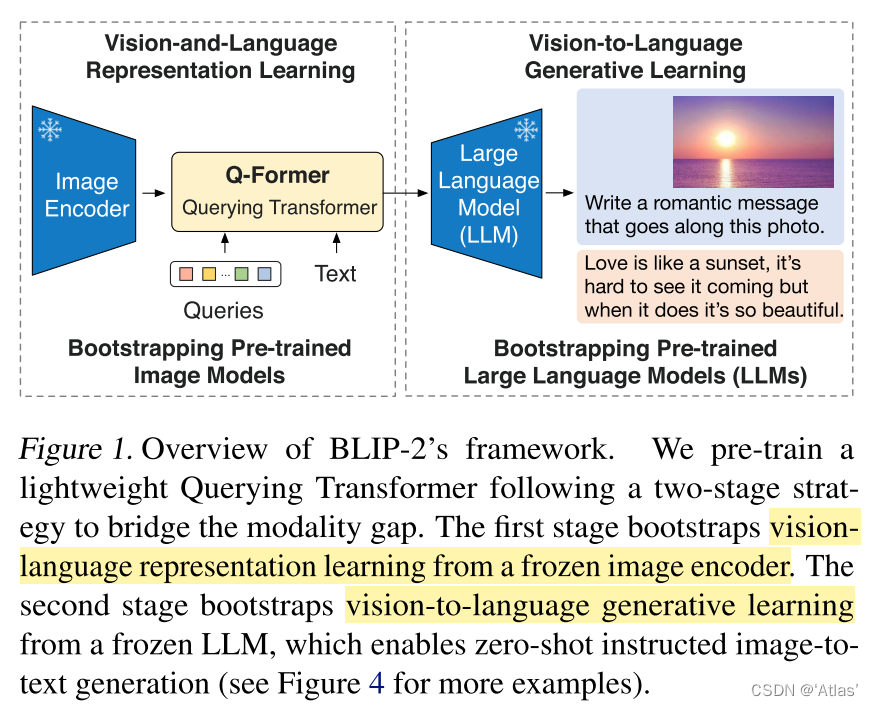
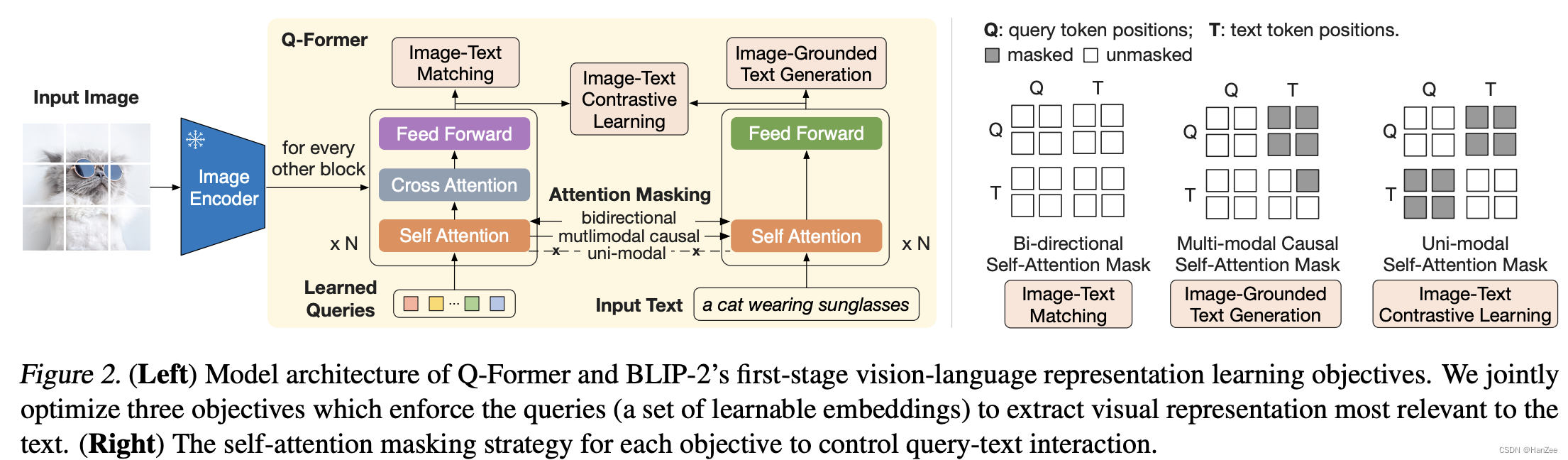
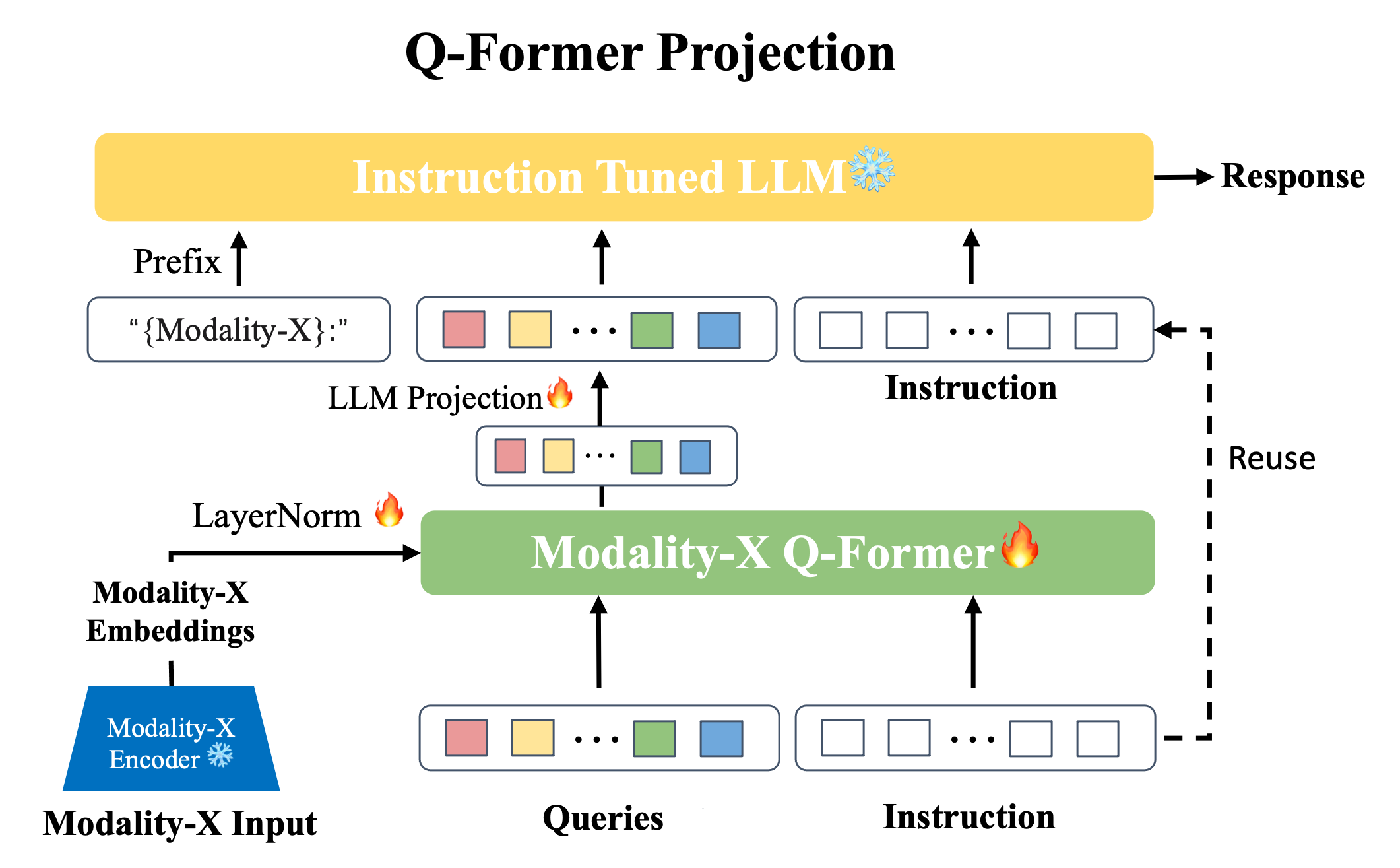
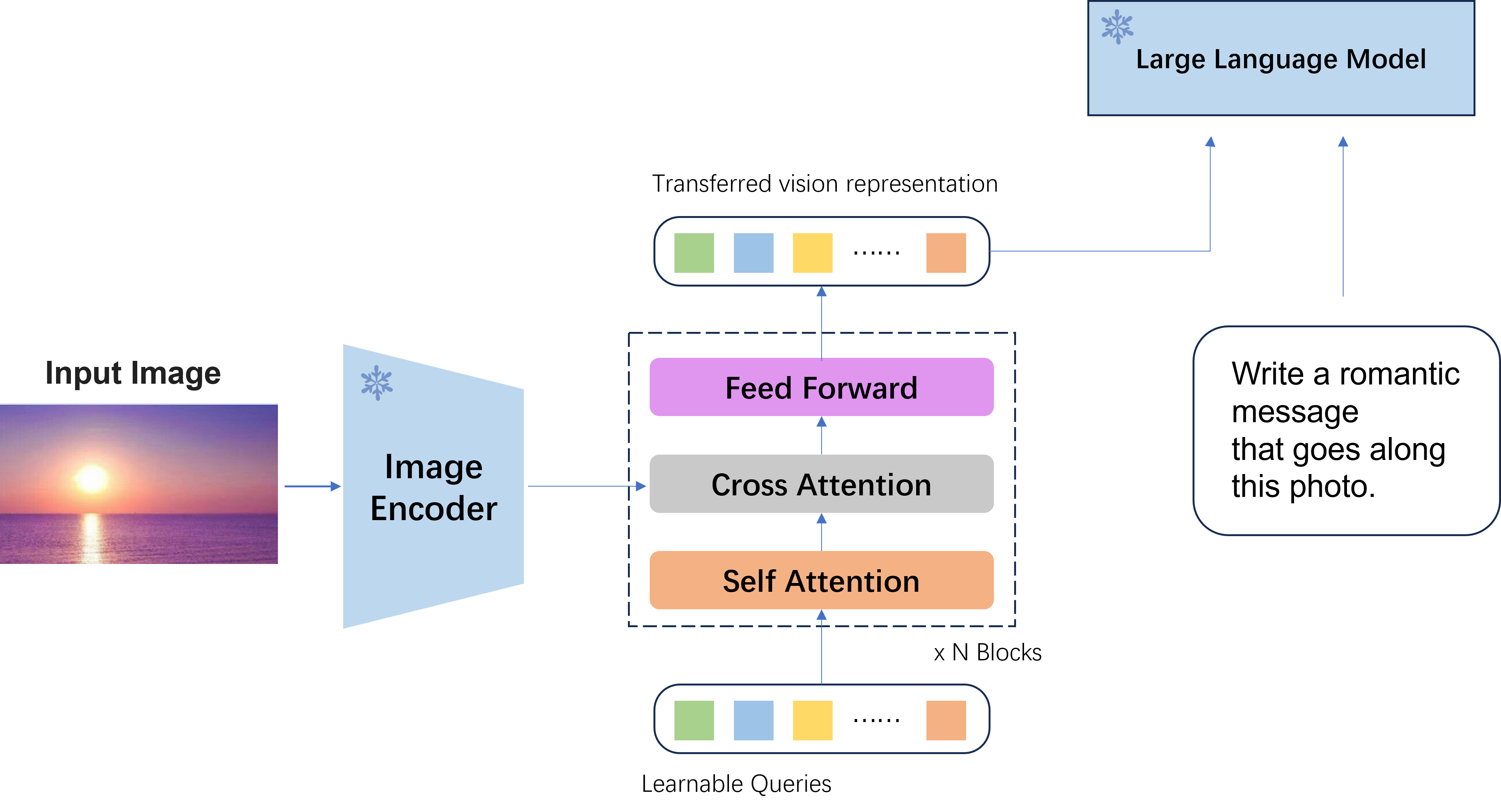
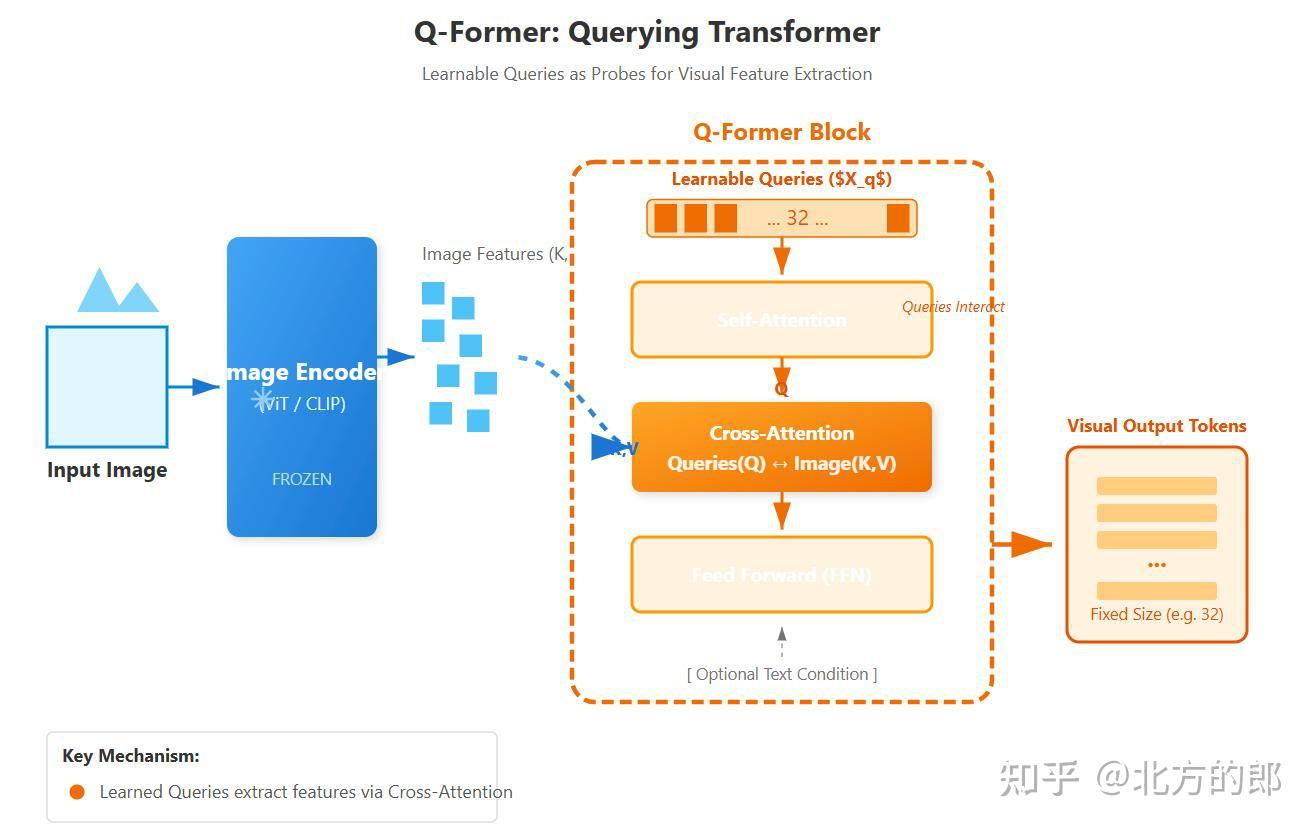
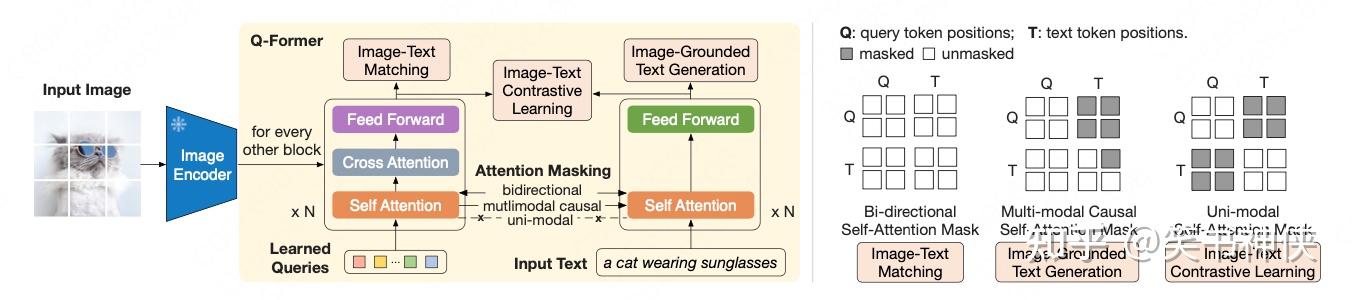
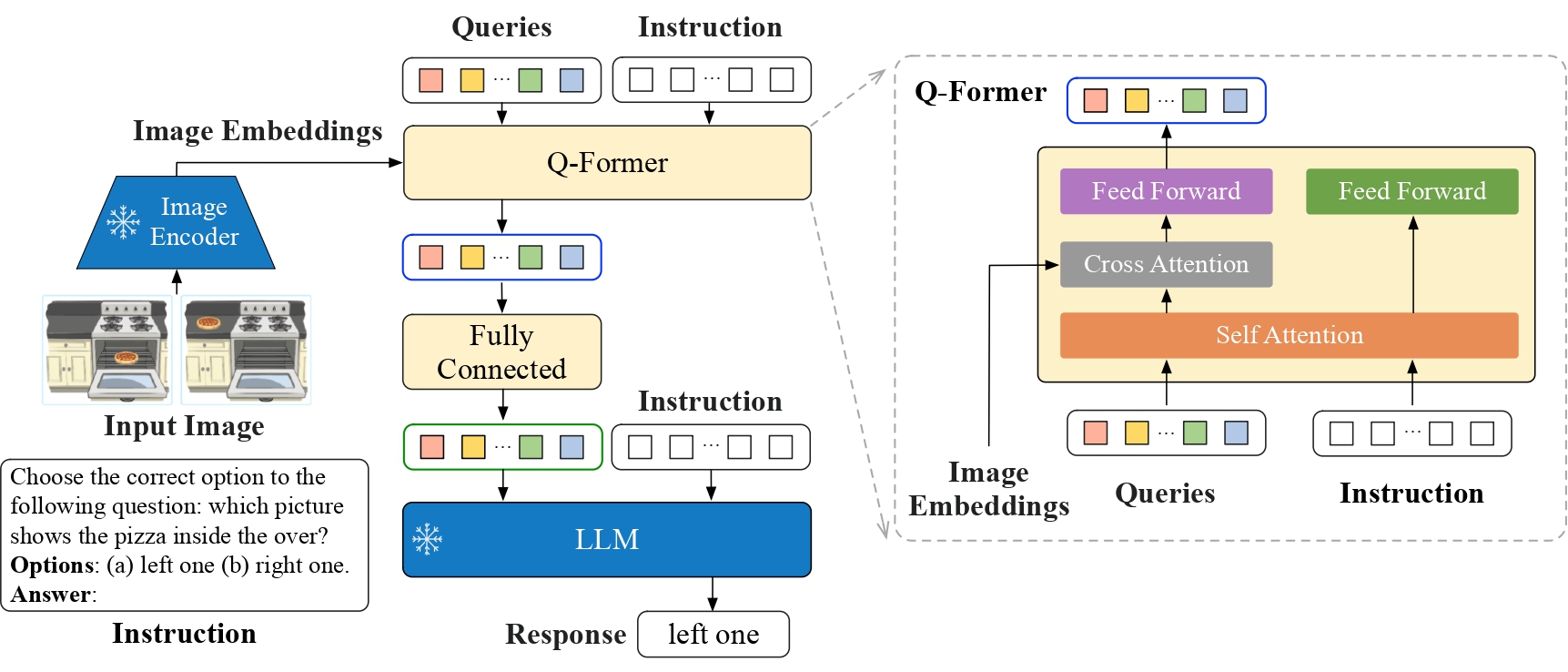
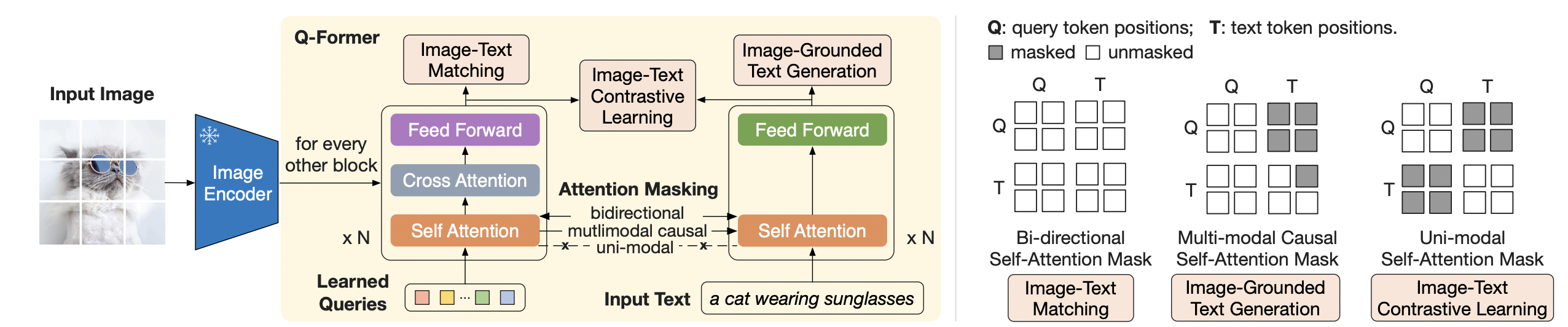
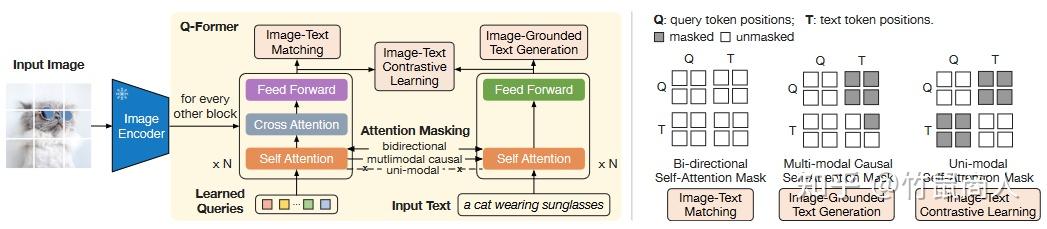
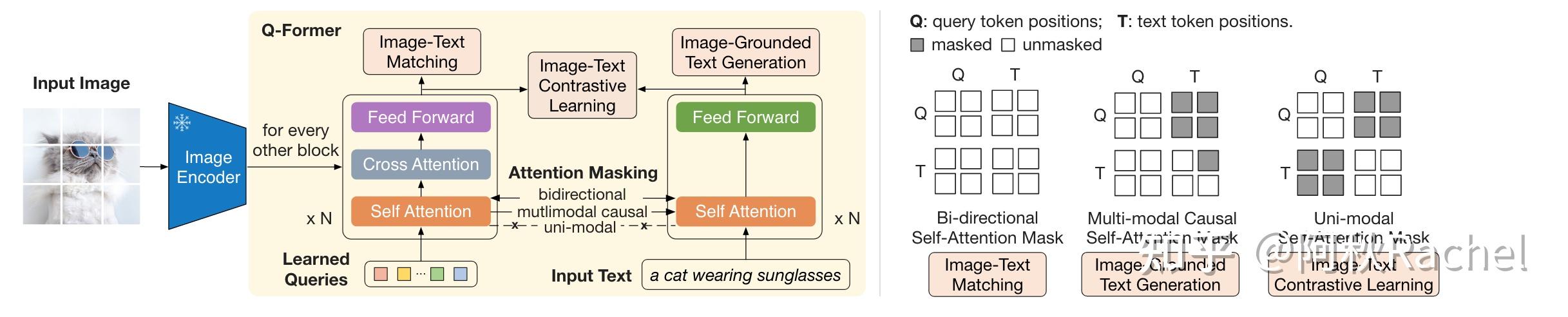
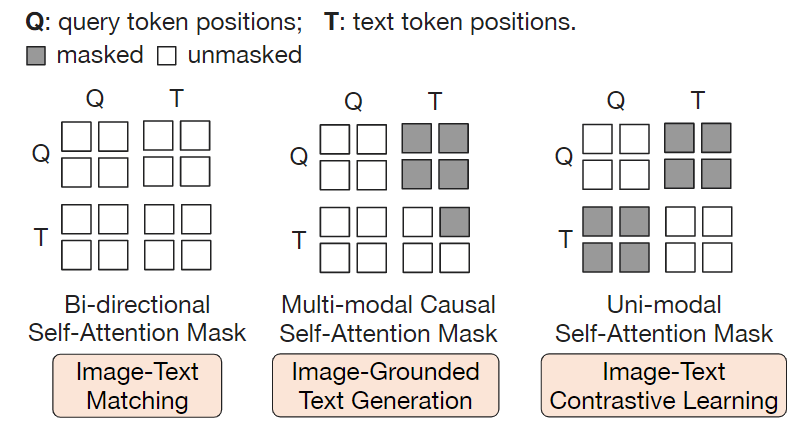
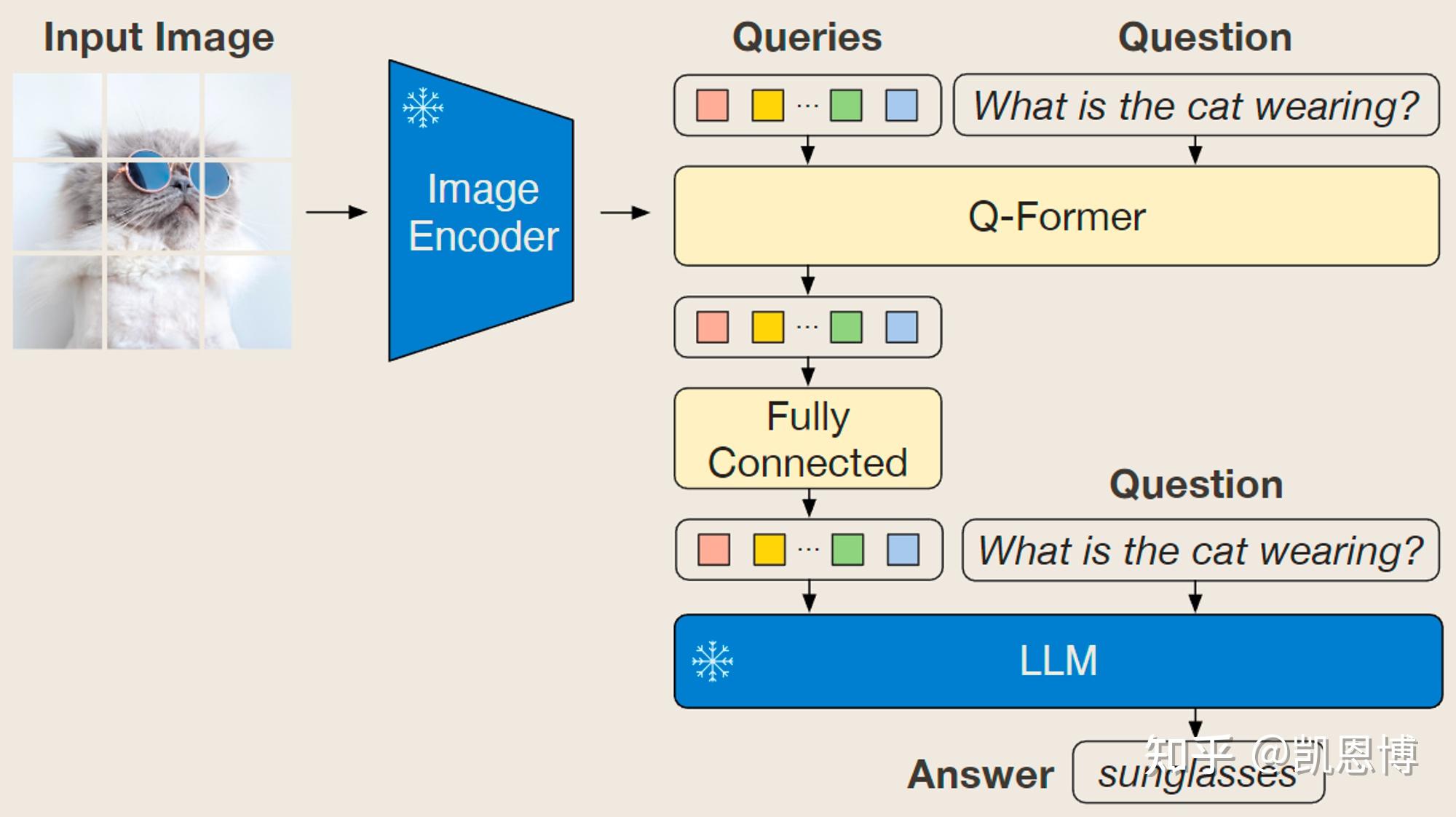
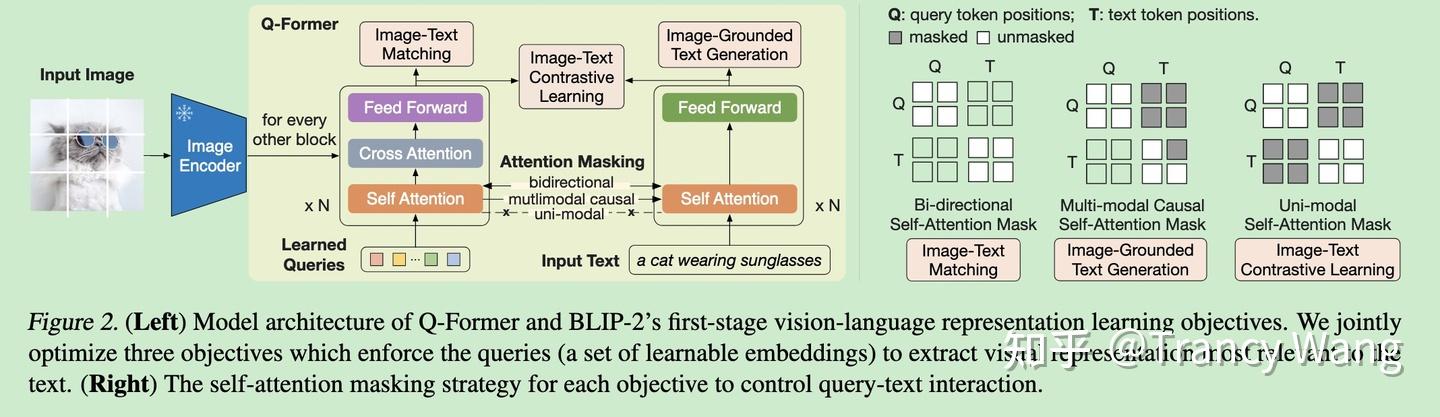
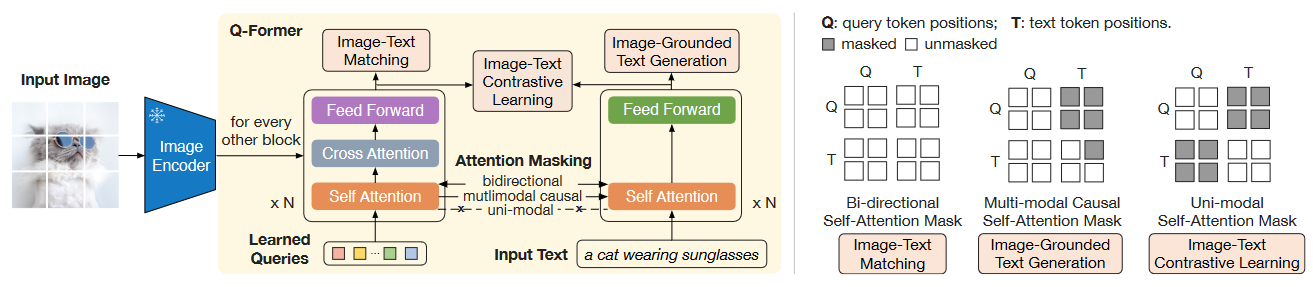
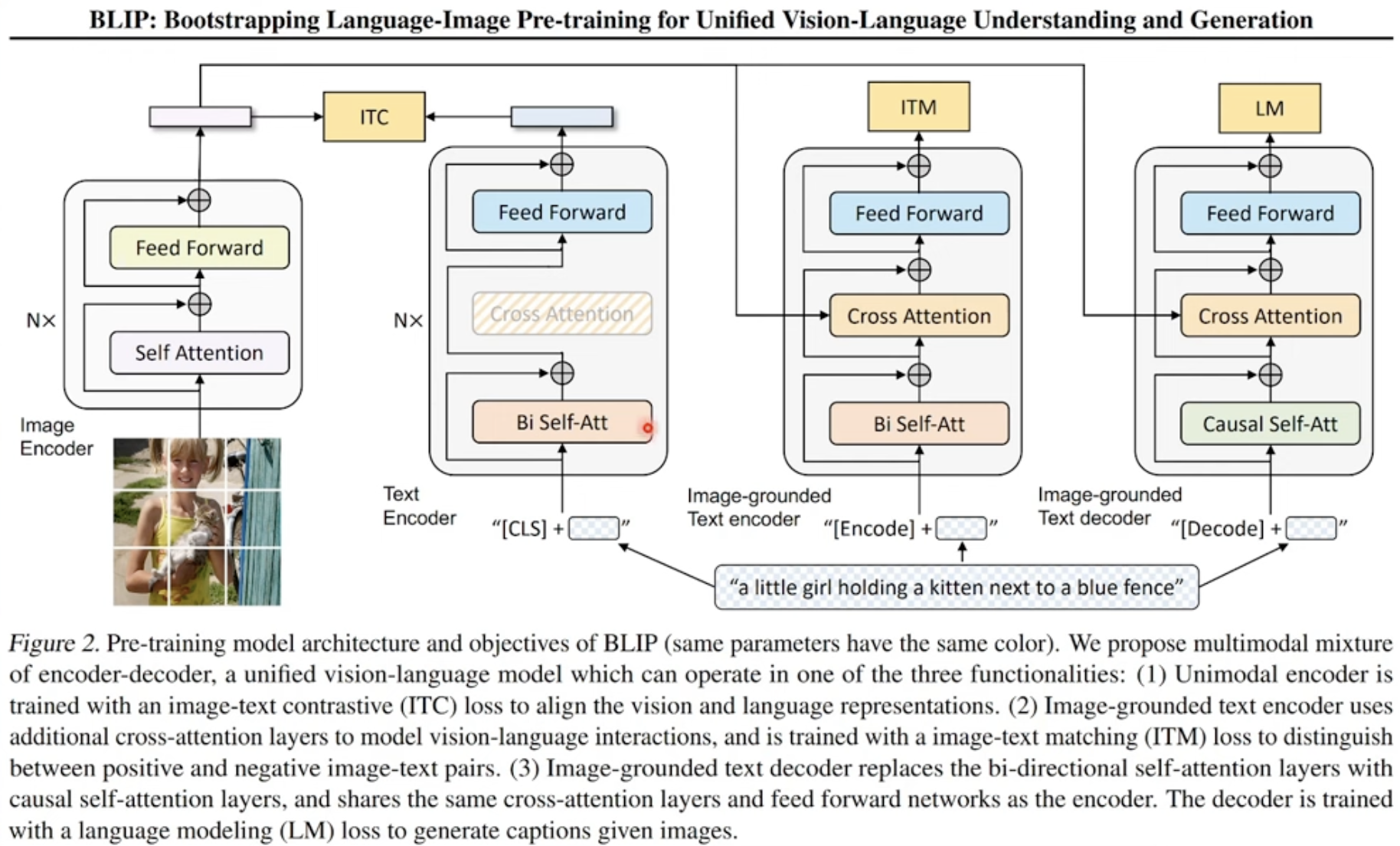
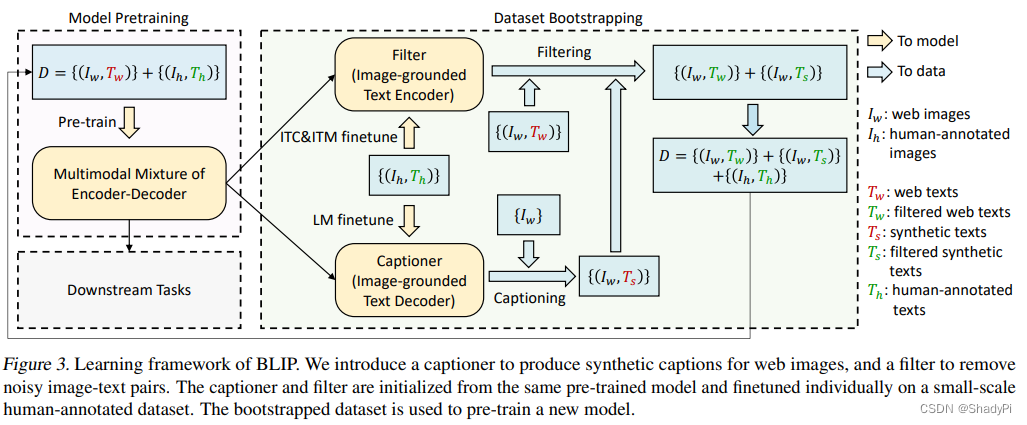
Querying Transformer (Q-Former) in BLIP-2 improves Image-Text ...
How to Use the BLIP-2 Model for Image-Text Tasks fxis.ai
Chat with your Image! BLIP-2 connects Q-Former w/ VISION-LANGUAGE ...
Multimodal Search Engine Agents Powered by BLIP-2 and Gemini | Towards ...
Papers Explained 155: BLIP 2. BLIP-2 is a generic and efficient… | by ...
使用 BLIP-2 零样本“图生文”-CSDN博客
(Left) Model architecture of Q-Former and BLIP-2's first-stage ...
Cách giải quyết bài toán Vision-Language với BLIP-2 và InstructBLIP
BLIP-2 ~2_bilp2-CSDN博客
Visual Question Answering with Transformers in Python - The Python Code
BLIP-2 AI: Image Captioning, Feature Extraction (Online Demo)
Enhanced BLIP-2 Optimization Using LoRA for Generating Dashcam Captions
Getting Started with BLIP-2: Your Guide to Image-Text Fusion fxis.ai
BLIP2-图像文本预训练论文解读-CSDN博客
多模态:BLIP-2论文讲解_blip2-qformer-CSDN博客
X-InstructBLIP
BLIP2——采用Q-Former融合视觉语义与LLM能力的方法_qformer模型-CSDN博客
多模态到通用感知,第十章 高效桥接:BLIP-2、Q-Former与视觉重采样 - 知乎
一文读懂BLIP和BLIP-2多模态预训练 - 知乎
【多模态】6、BLIP-2 | 使用 Q-Former 连接冻结的图像和语言模型 实现高效图文预训练-CSDN博客
多模态大模型系列:BLIP-2 - 知乎
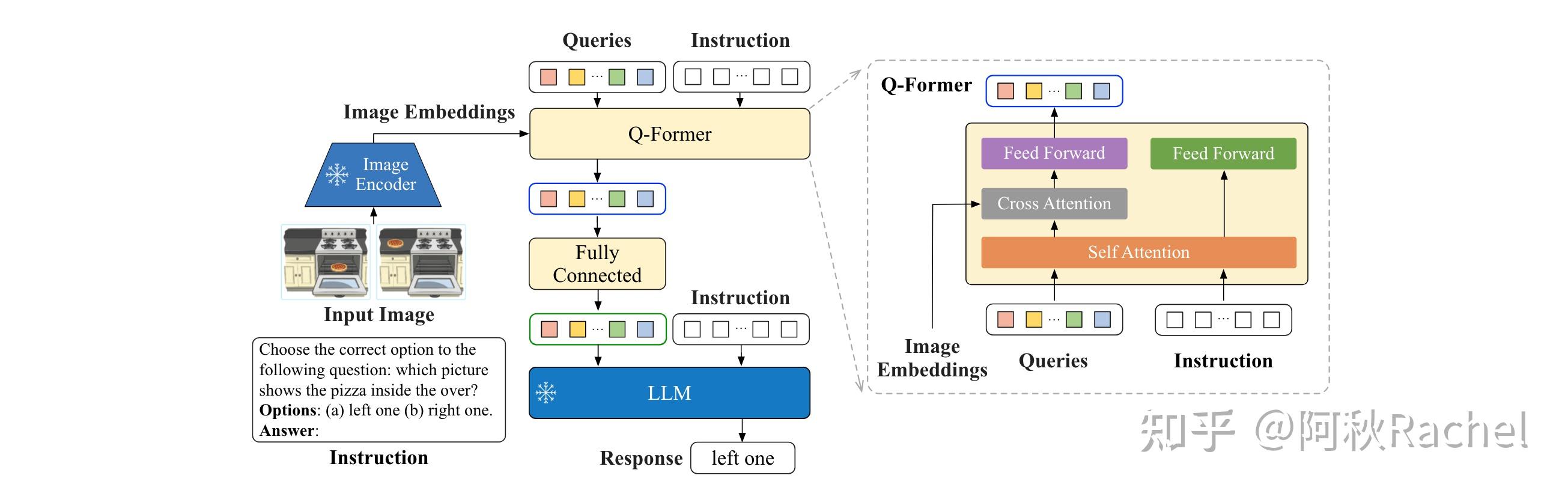
InstructBLIP
BLIP系列——BLIP、BLIP-2、InstructBLIP、BLIP-3 - 知乎
BLIP2:下一代多模态模型的雏形 - 知乎
BLIP-2_Q-Former | PDF | Computing | Machine Learning
多模态大模型速通--类Q-Former系列[BLIP-2、MiniGPT-4 v1 / v2、InstructBLIP、Qwen-VL] - 知乎
多模态超详细解读 (七):BLIP-2:节约多模态训练成本:冻结预训练好的视觉语言模型参数 - 知乎
Salesforce/blip2-flan-t5-xxl · Hugging Face
BLIP-2:冻结现有视觉模型和大语言模型的预训练模型_blip2模型-CSDN博客
多模态大模型论文:从CLIP、BLIP到BLIP2 - 知乎
Multimodal Large Language Model 总结 | DaNing的博客
SAM and BLIP - Kyle’s Tech Blog
多模态小记:CLIP、BLIP与BLIP2_blip clip-CSDN博客