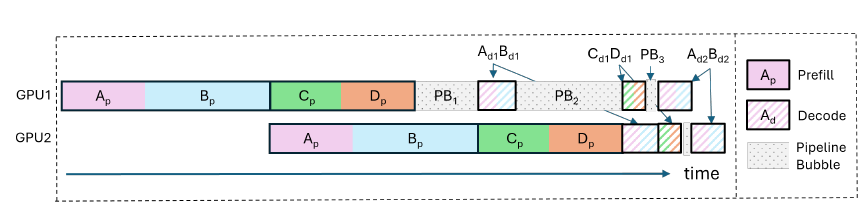
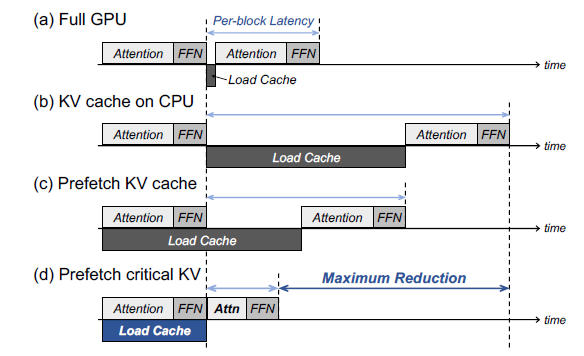
An End-to-End Coding Guide to NVIDIA KVPress for Long-Context LLM ...
Scaling to Millions of Tokens with Efficient Long-Context LLM Training ...
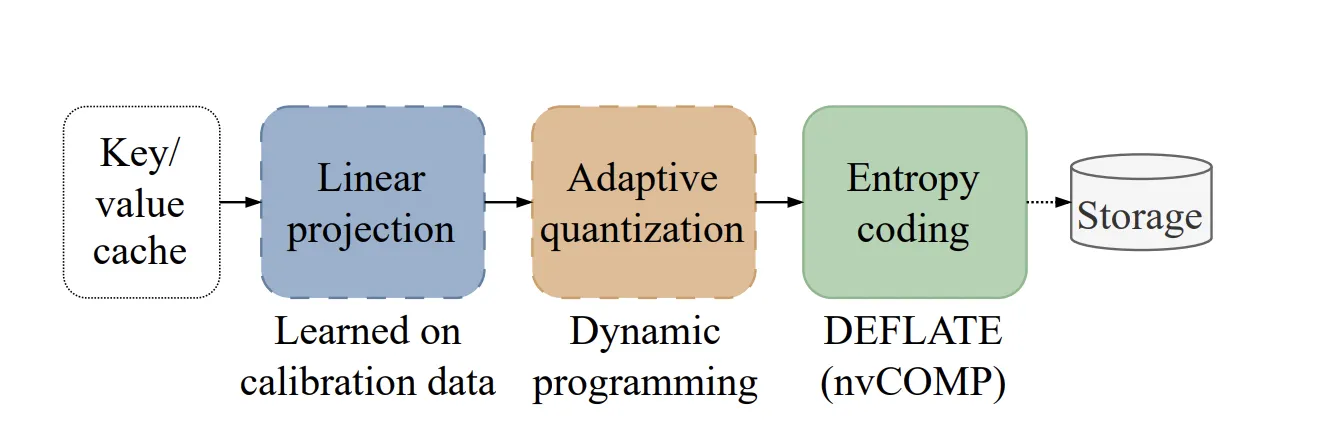
NVIDIA Researchers Introduce KVTC Transform Coding Pipeline to Compress ...
[논문 리뷰] Compressing KV Cache for Long-Context LLM Inference with Inter ...
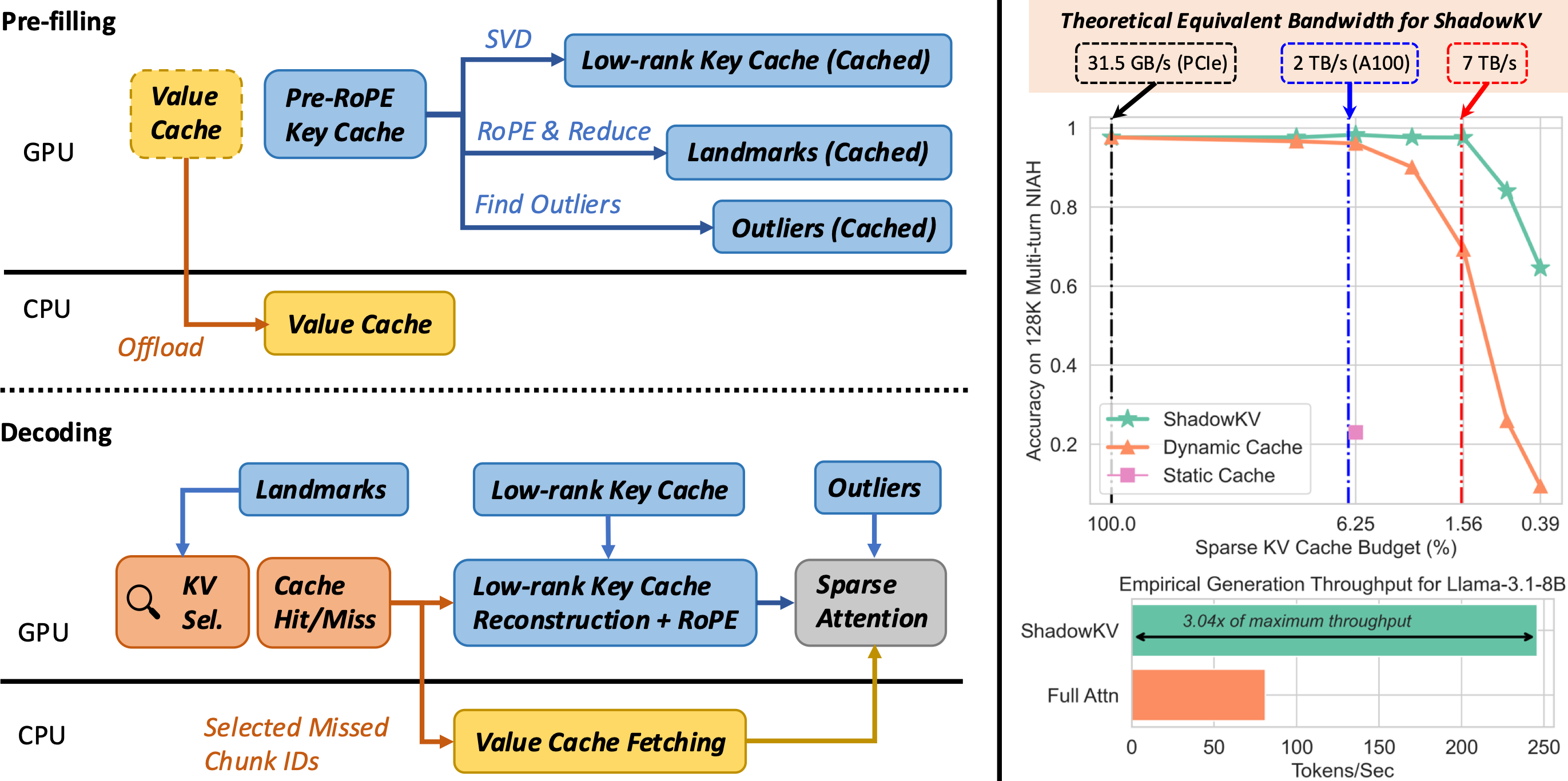
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM ...
KV Cache Transform Coding for Compact Storage in LLM Inference ...
ShadowKV: A High-Throughput Inference System for Long-Context LLM ...
How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo | NVIDIA ...
5x Faster Time to First Token with NVIDIA TensorRT-LLM KV Cache Early ...
NVIDIA AI Team Introduces Jetson Thor: The Ultimate Platform for ...
End-to-End AI for NVIDIA-Based PCs: CUDA and TensorRT Execution ...
Accelerating Long-Context Inference with Skip Softmax in NVIDIA ...
RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV ...
Infinite-Llm: Efficient LLM Service For Long Context With Distattention ...
NVIDIA AI Research Unveils ‘Star Attention’: A Novel AI Algorithm for ...
(PDF) RocketKV: Accelerating Long-Context LLM Inference via Two-Stage ...
Infinite-LLM: Efficient LLM Service for Long Context with DistAttention ...
KV Cache Transform Coding for Compact Storage in LLM Inference
Abacus AI Introduces A New Open Long-Context Large Language Model LLM ...
LLM Inference — Optimizing the KV Cache for High-Throughput, Long ...
Nvidia unveils new GPU designed for long-context inference
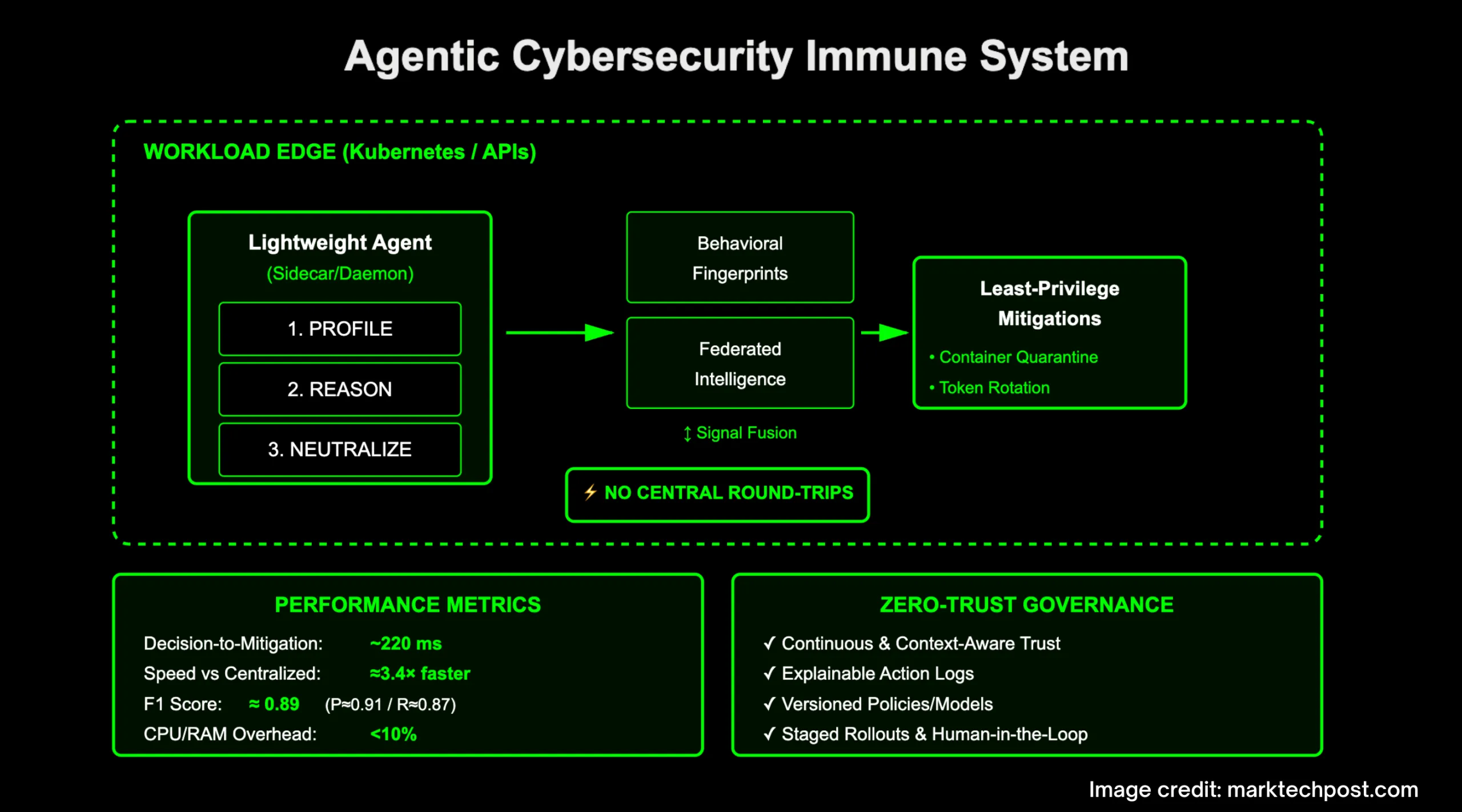
This AI Research Proposes an AI Agent Immune System for Adaptive ...
NVIDIA TensorRT-LLM の KV Cache Early Reuseで、Time to First Token を 5 倍高速 ...
Top Local LLMs For Coding (2025) — Meta Ai Labs™
Optimizing Qwen2.5-Coder Throughput with NVIDIA TensorRT-LLM Lookahead ...
Optimizing Inference for Long Context and Large Batch Sizes with NVFP4 ...
Mastering LLM Inference: Cost-Efficiency and Performance | by Victor ...
What is GPU Memory and Why it Matters for LLM Inference
Introducing New KV Cache Reuse Optimizations in NVIDIA TensorRT-LLM ...
Long-Context LLM Extension - YouTube
End-to-End Code Generation — NVIDIA CUTLASS Documentation
Jamba 1.5 LLMs Leverage Hybrid Architecture to Deliver Superior ...
How to code long-context LLM: LongLoRA explained on LLama 2 100K - YouTube
Bước - Bài review cuối cùng của năm 2025: Hot paper của team Nvidia ...
How To Reduce LLM Decoding Time With KV-Caching!
Securing LLM Systems Against Prompt Injection | NVIDIA Technical Blog
掌握 LLM 技术:推理优化 - NVIDIA 技术博客
Upgrading Multi-GPU Interconnectivity with the Third-Generation NVIDIA ...
Turbocharge LLM Training Across Long-Haul Data Center Networks with ...
RAG与长上下文LLM(Long-Context LLM):一场AI领域的对决_long context vs. rag for llms ...
Long-Context Multimodal Understanding No Longer Requires Massive Models ...
LLM Inference: Accelerating Long Context Generation with KV Cache ...
Structuring Applications to Secure the KV Cache | NVIDIA Technical Blog
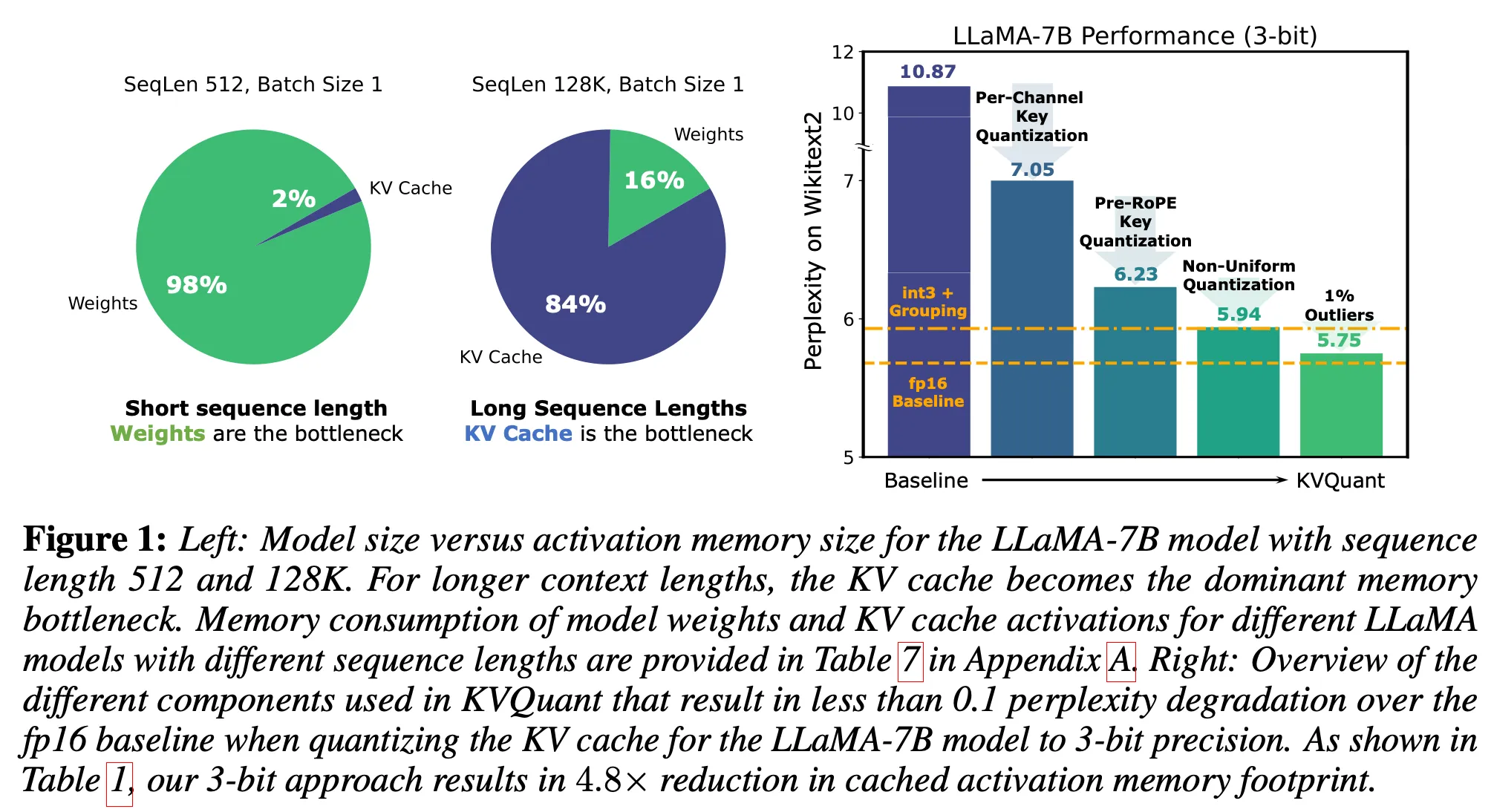
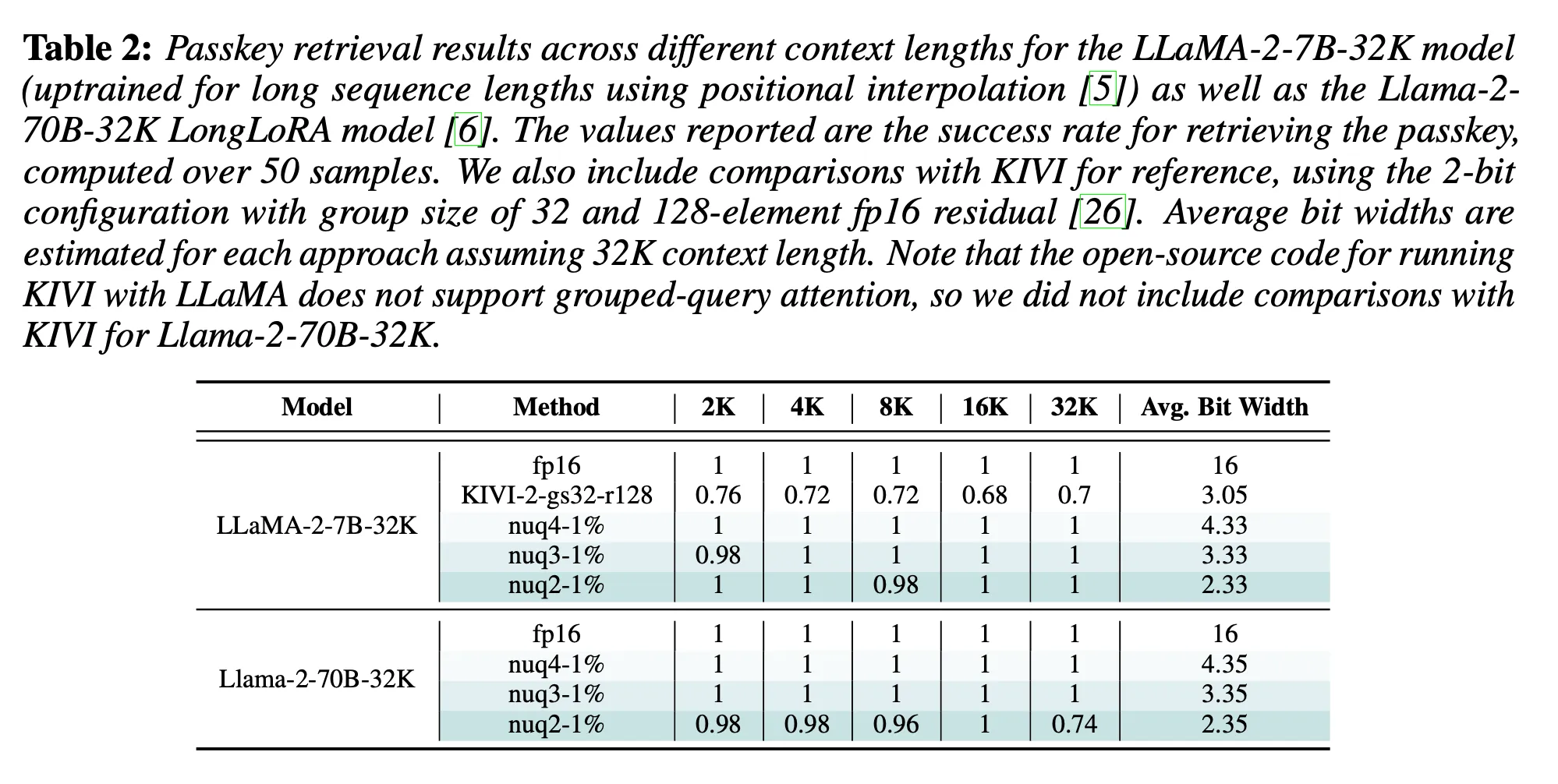
Paper review[KV Quant: Towards 10 Million Context Length LLM Inference ...
(PDF) Efficient Long-Context LLM Inference via KV Cache Clustering
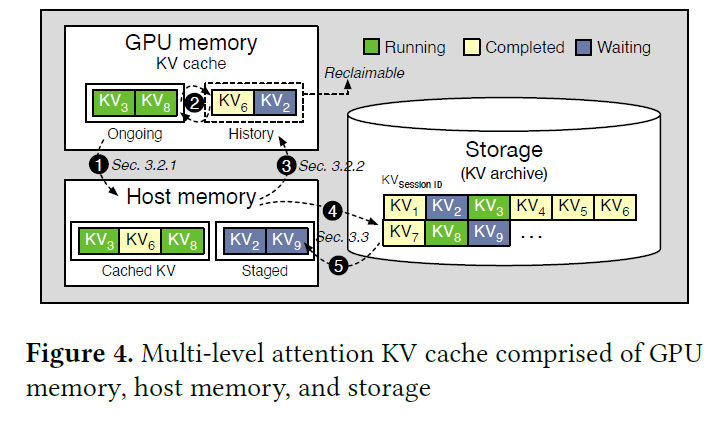
Introducing NVIDIA BlueField-4-Powered Inference Context Memory Storage ...
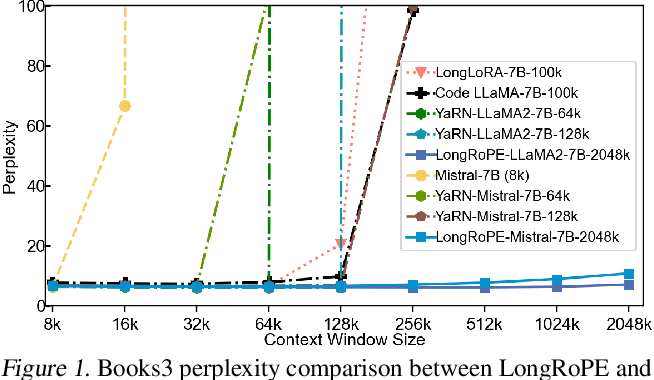
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens: Paper ...
(PDF) Effectively Compress KV Heads for LLM
Nvidia Shows Off GPU for Ultra-Long Context Models \ stacker news ~AI
NVIDIA AI Releases UltraLong-8B: A Series of Ultra-Long Context ...
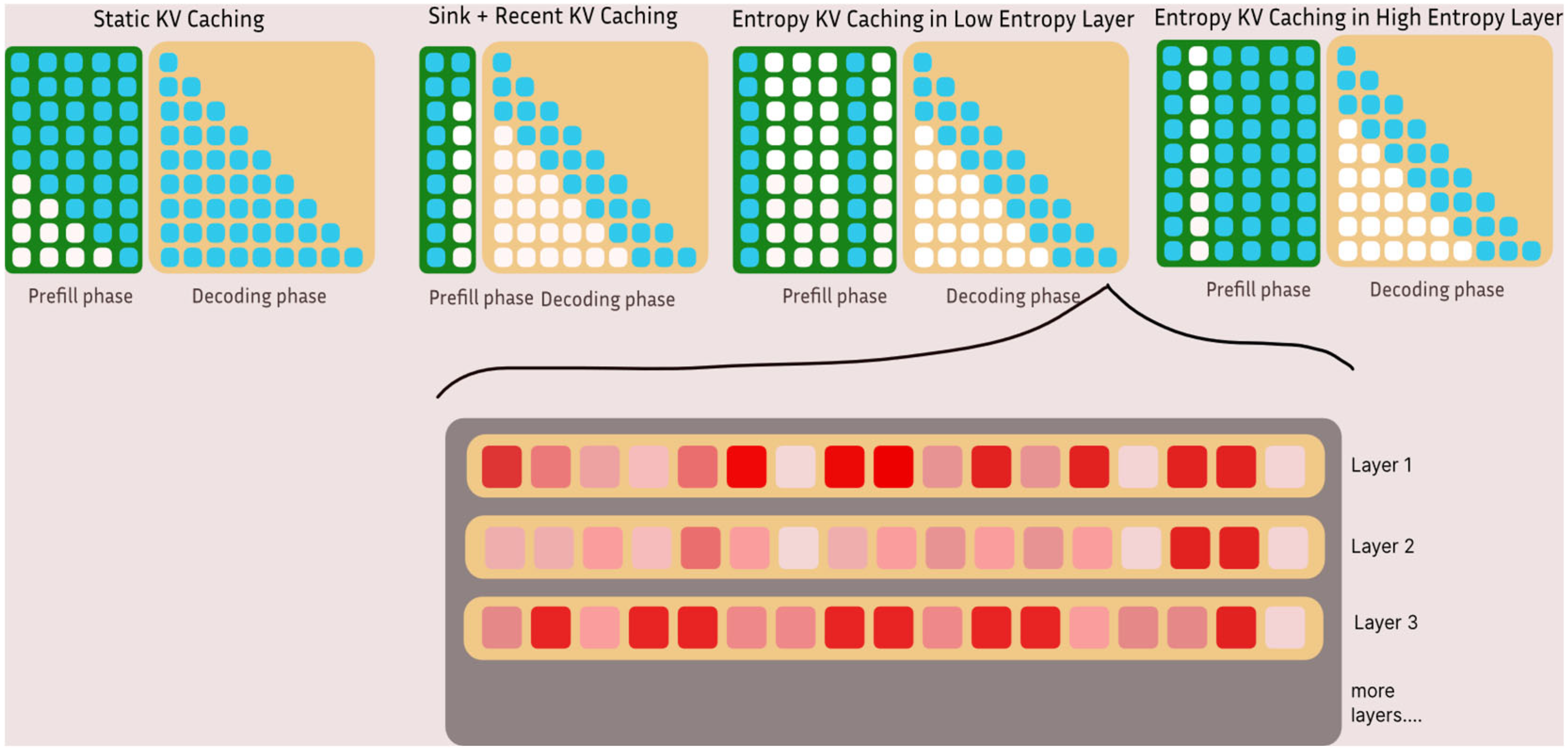
Entropy-Guided KV Caching for Efficient LLM Inference
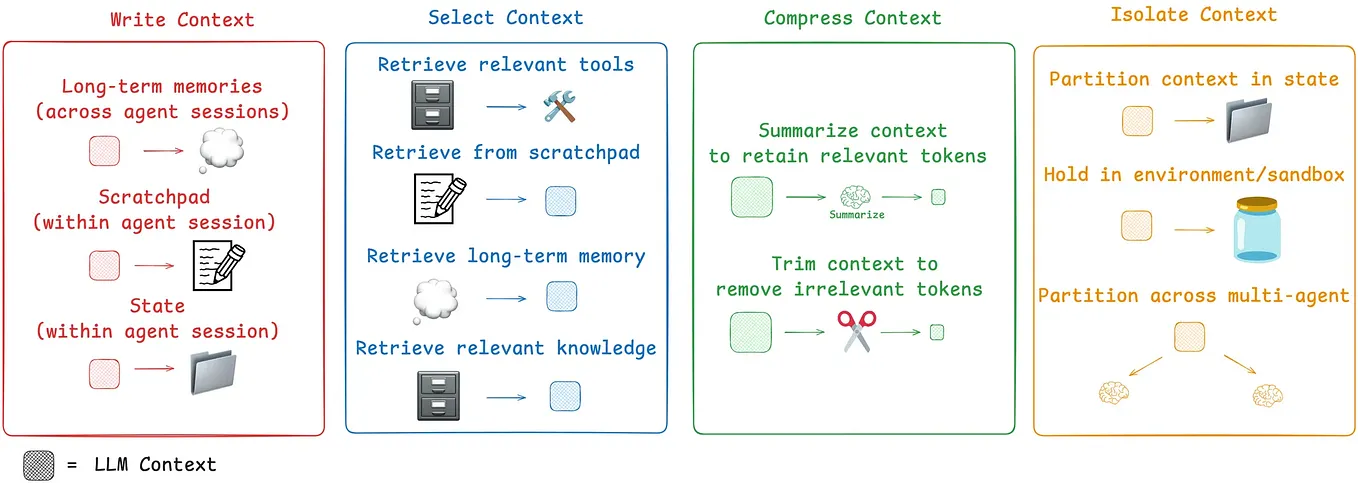
Mastering Long Contexts in LLMs with KVPress
GitHub - NVIDIA/kvpress: LLM KV cache compression made easy
KAIST and DeepAuto AI Researchers Propose InfiniteHiP: A Game-Changing ...
LLM Context Extender-Extends LLM context window
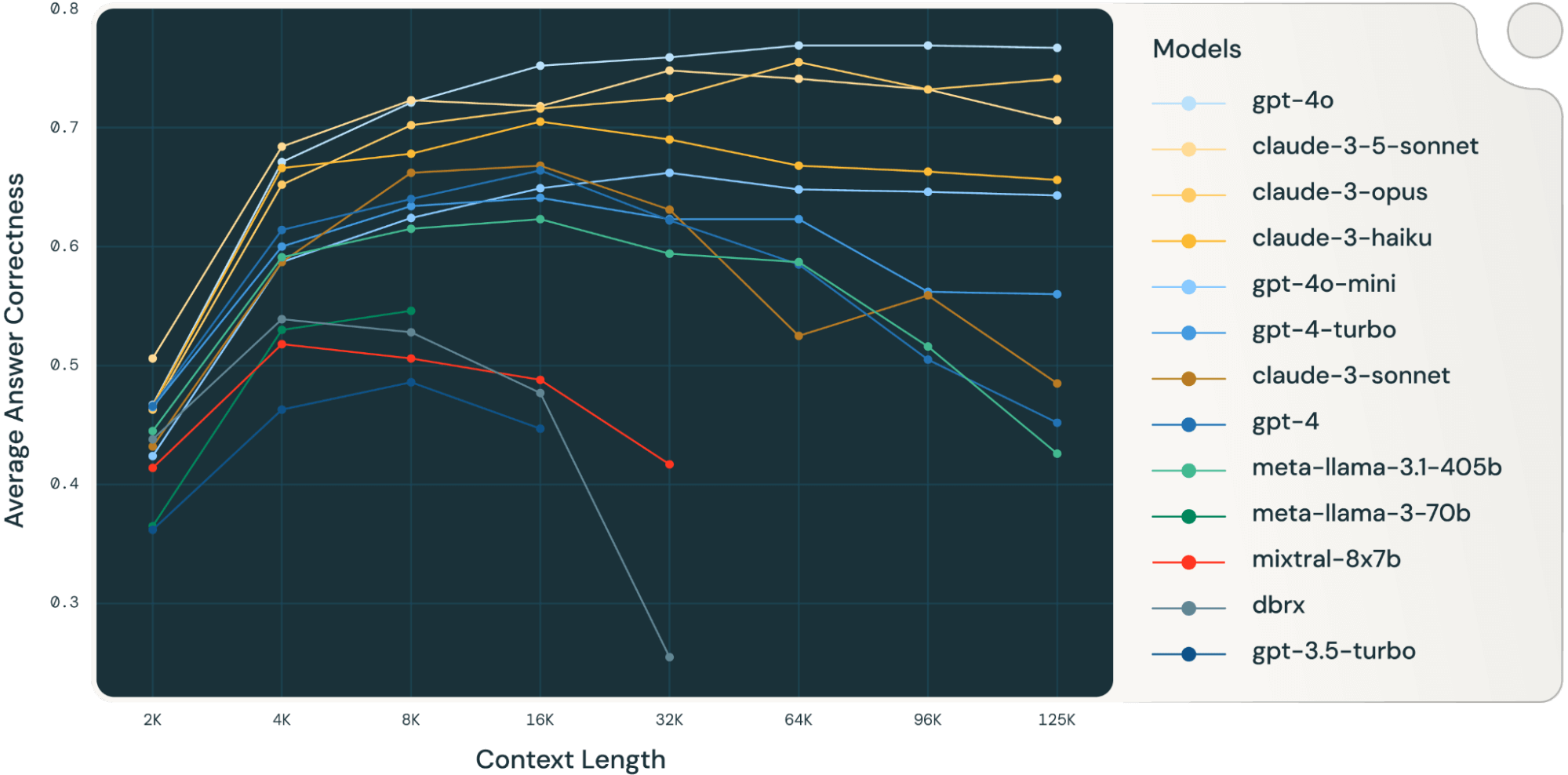
Evaluating Long Context Lengths in LLMs: Challenges and Benchmarks | by ...
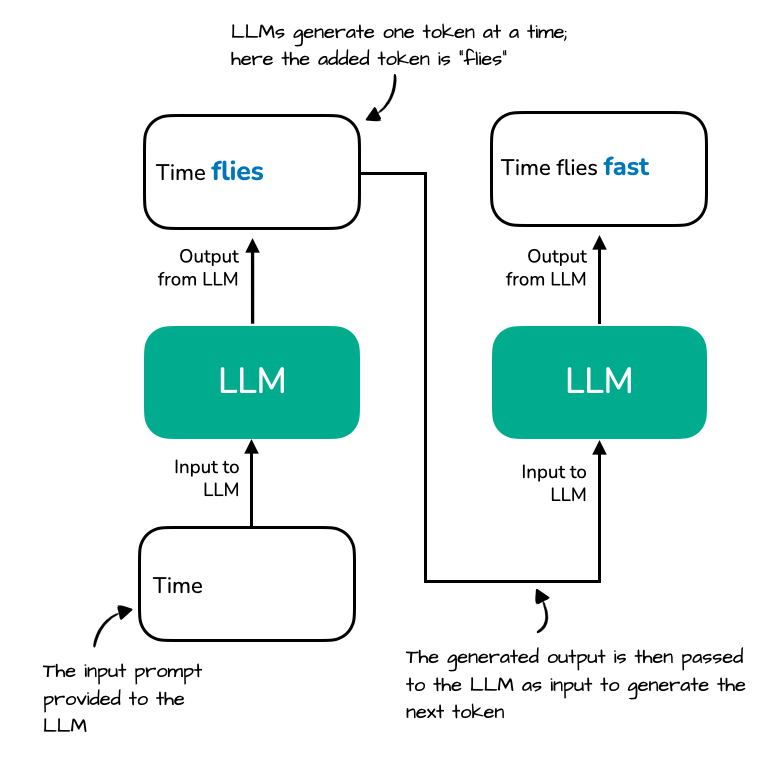
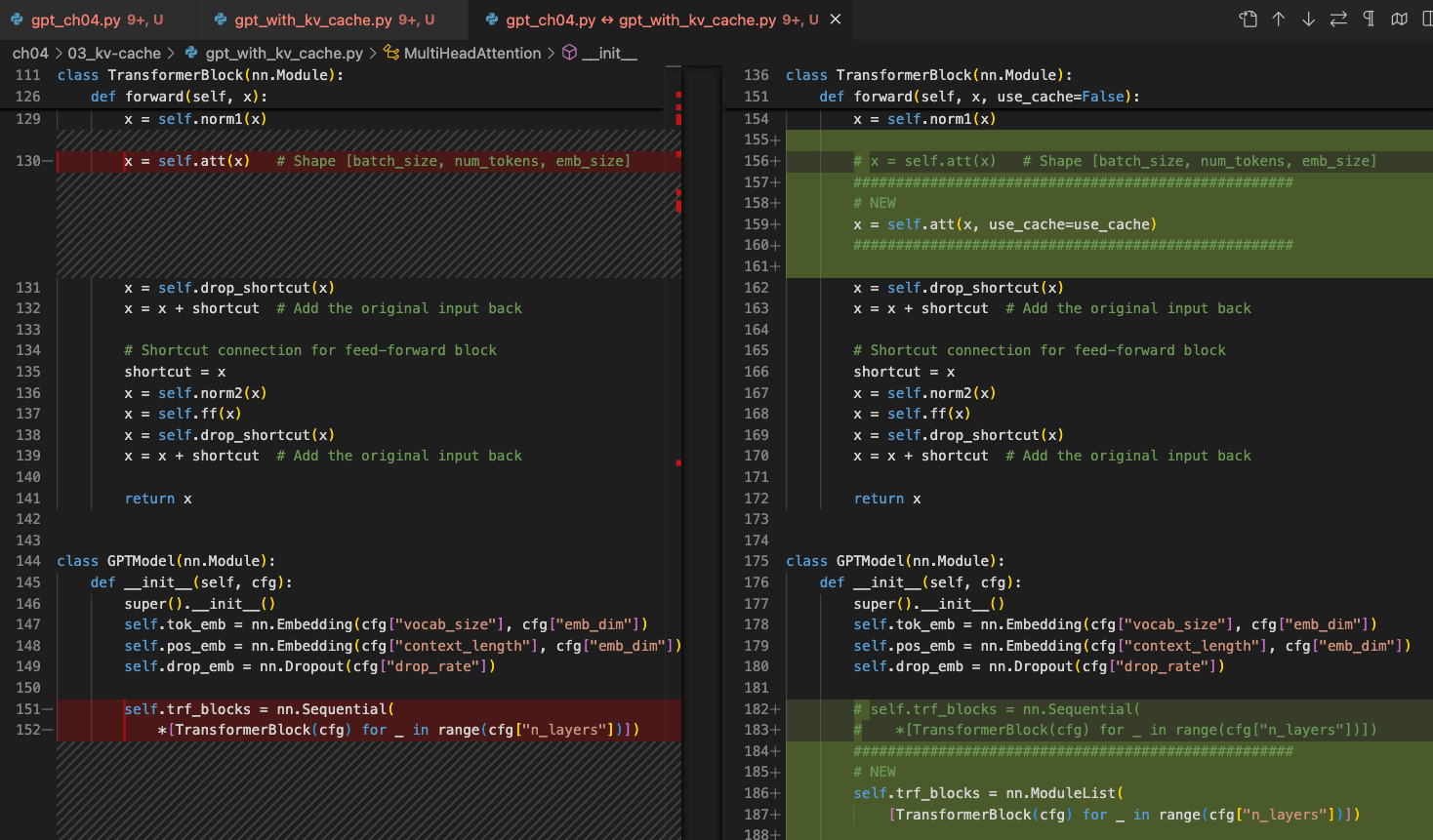
Understanding and Coding the KV Cache in LLMs from Scratch
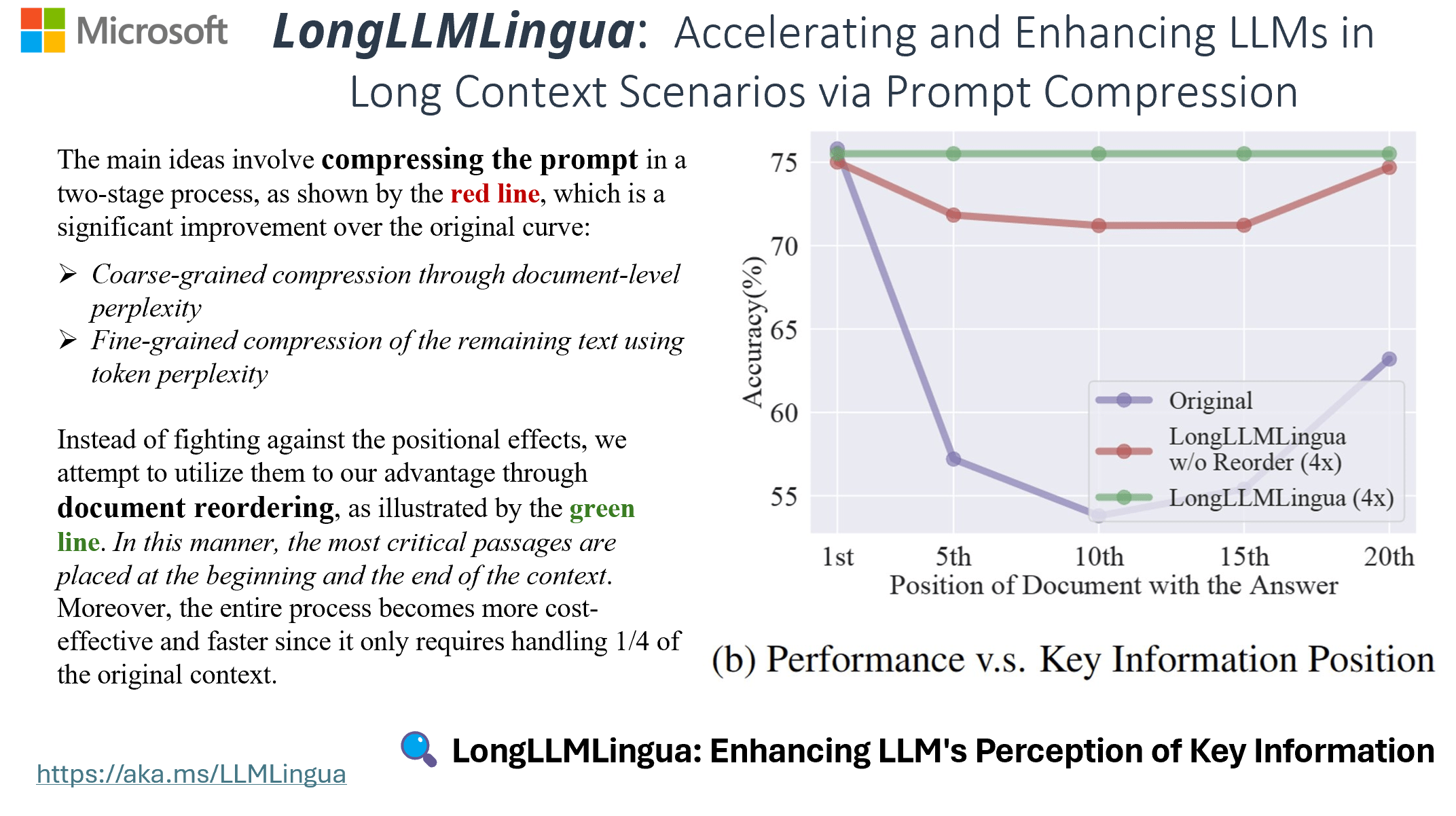
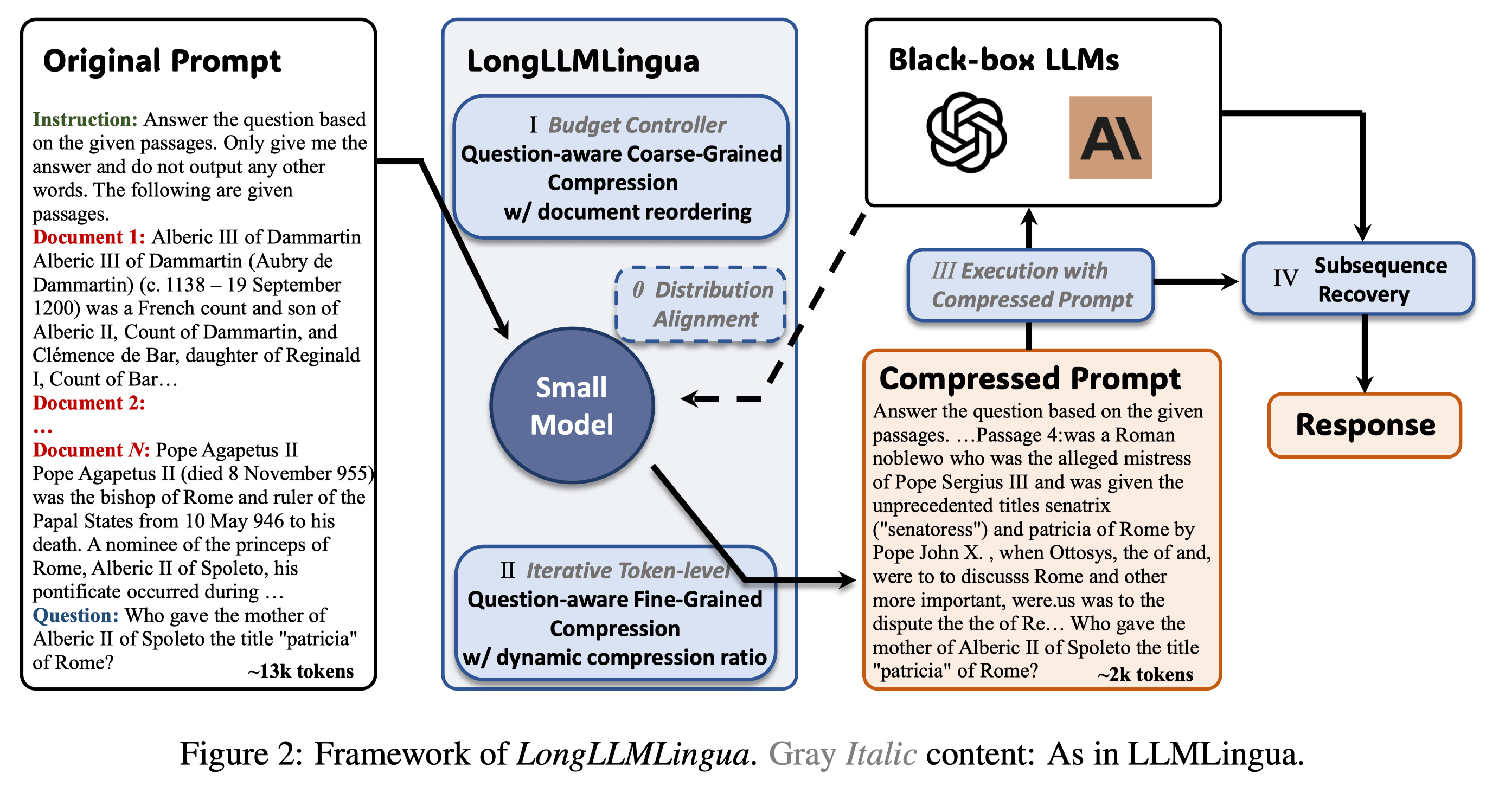
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context ...
Mastering Long Contexts in LLMs with KVPress | Claudio Polla
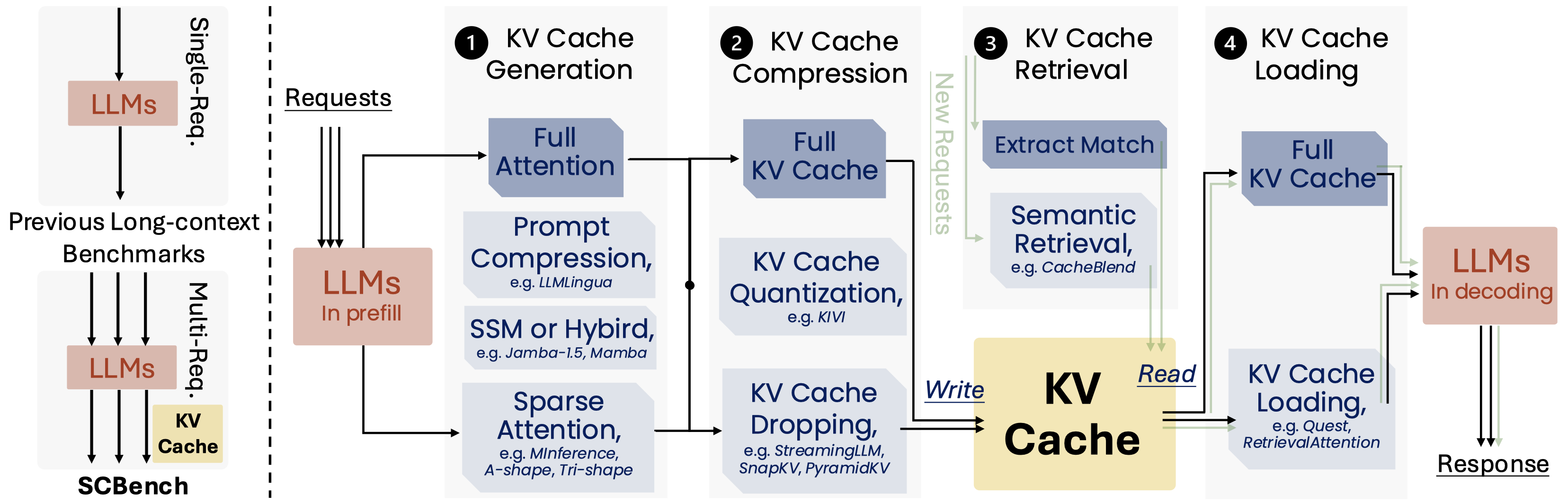
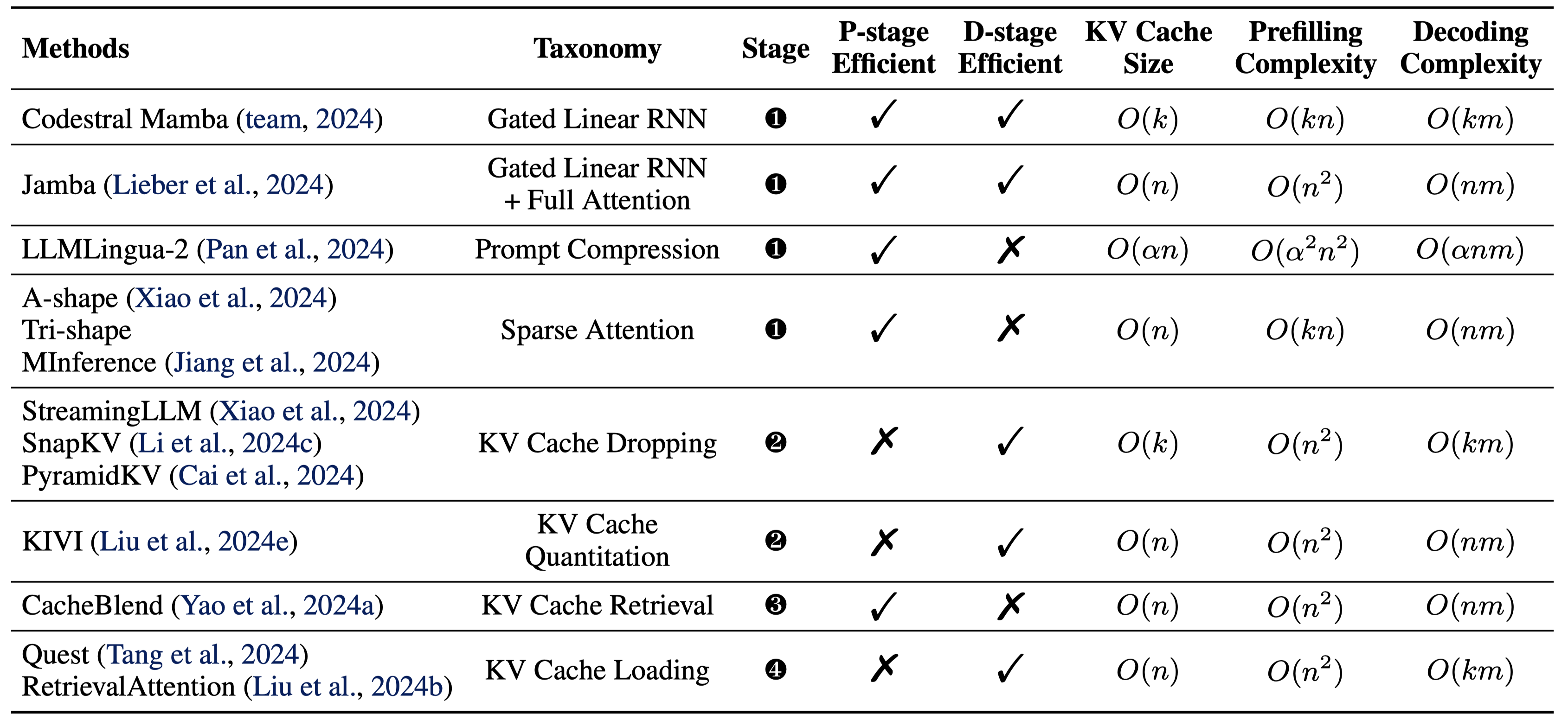
SCBench: A KV Cache-Centric Analysis of Long-Context Methods
What is LLM’s Context Window?:Understanding and Working with the ...
GitHub - NVIDIA/kvpress: LLM KV cache compression made easy · GitHub
Techniques to Extend Context Length of LLMs
Is 9.11 larger than 9.9? Comparison on Llama 3 vs Claude vs Gpt 4o vs ...
GitHub Copilot's "Agent Mode" And "Project Padawan" Preview Autonomous ...
Paper page - LongCodeBench: Evaluating Coding LLMs at 1M Context Windows
DeepStream SDK | NVIDIA Developer | NVIDIA Developer
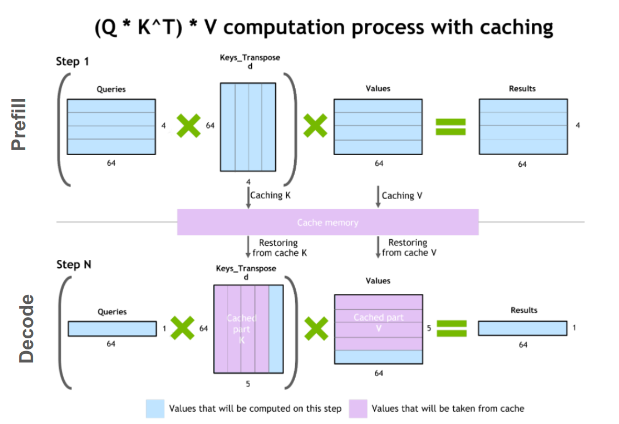
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
KV Caches and Time-to-First-Token: Optimizing LLM Performance
Artificial Intelligence Category - MarkTechPost
Long Context RAG Performance of LLMs | Databricks Blog
LLM中Long Context技术解析 - 知乎
英伟达:LLM两阶段KV缓存压缩_rocketkv-CSDN博客
Giraffe - Long Context LLMs - The Abacus.AI Blog