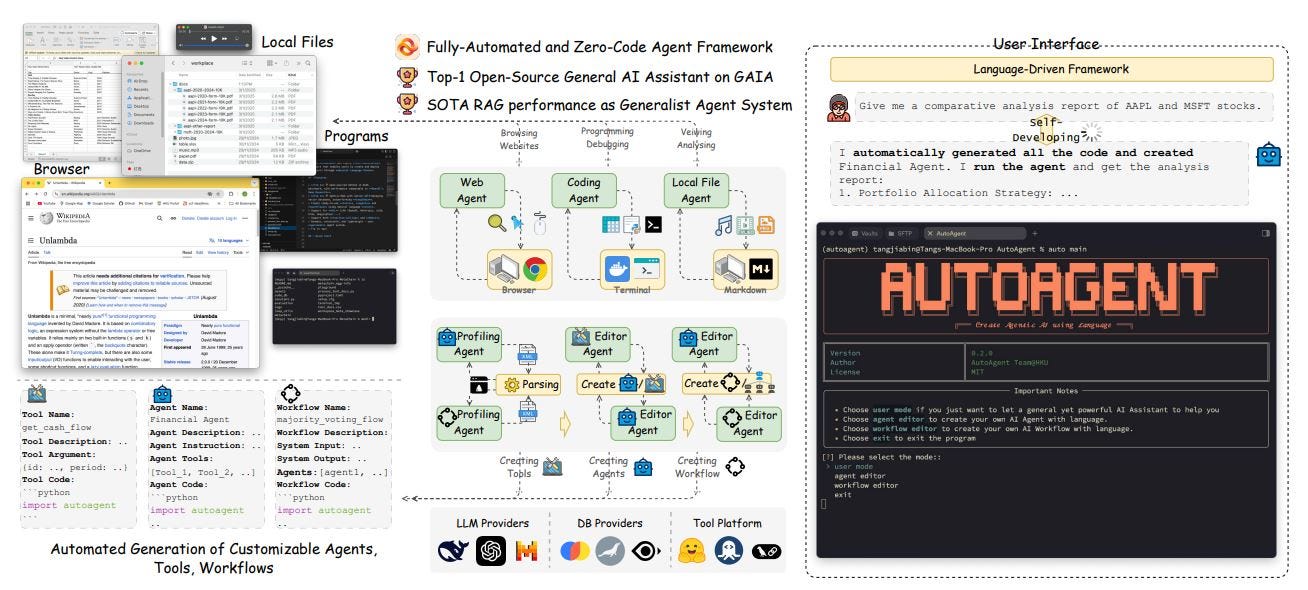
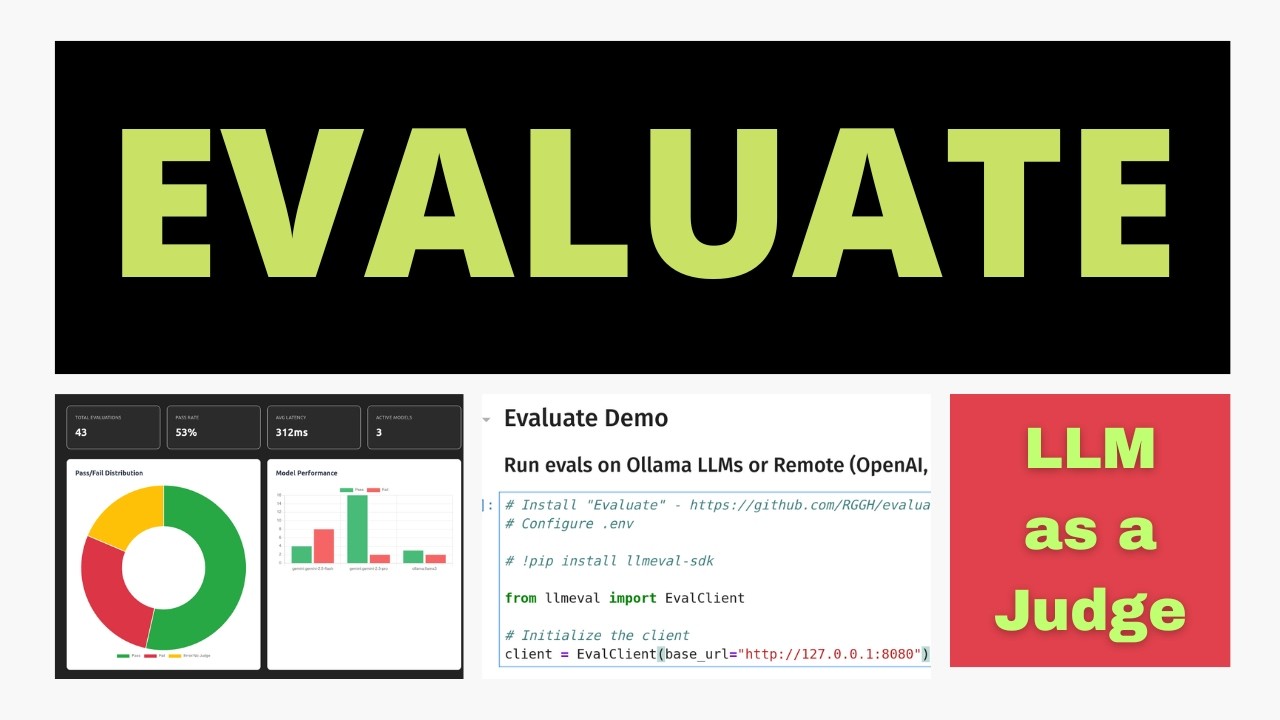
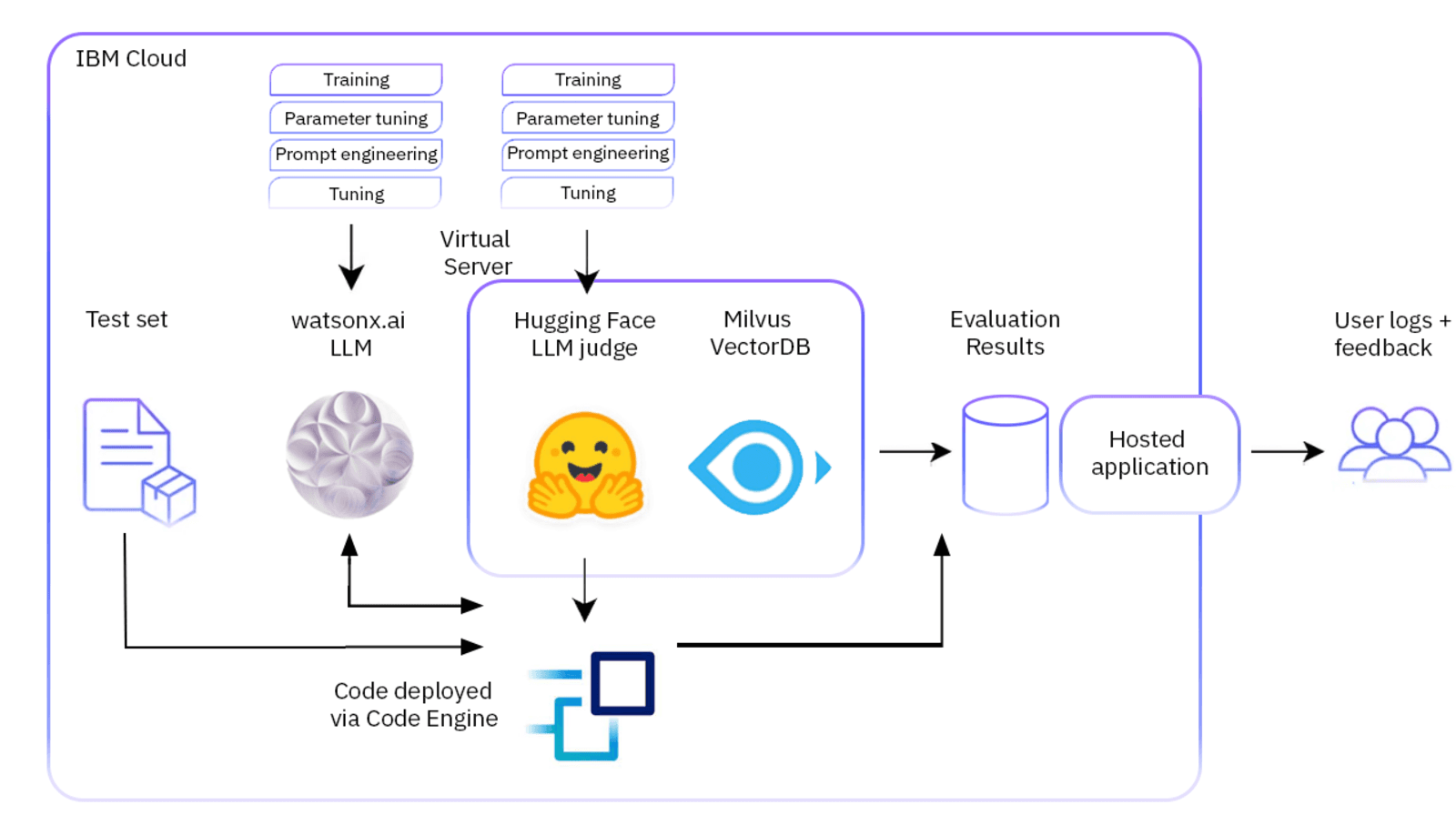
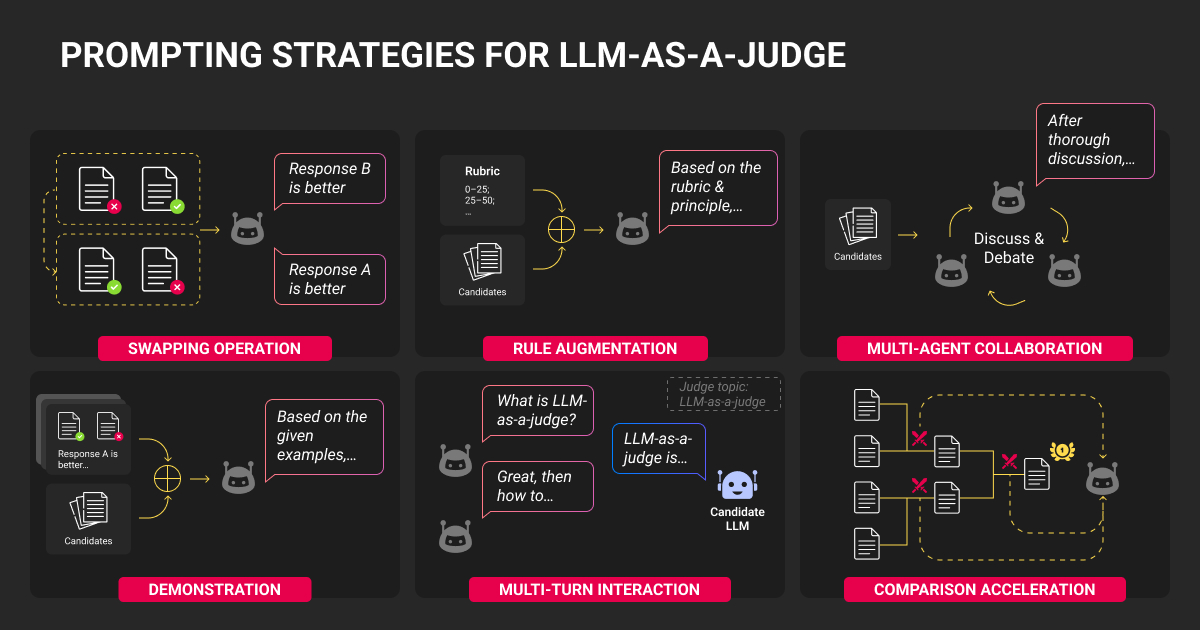
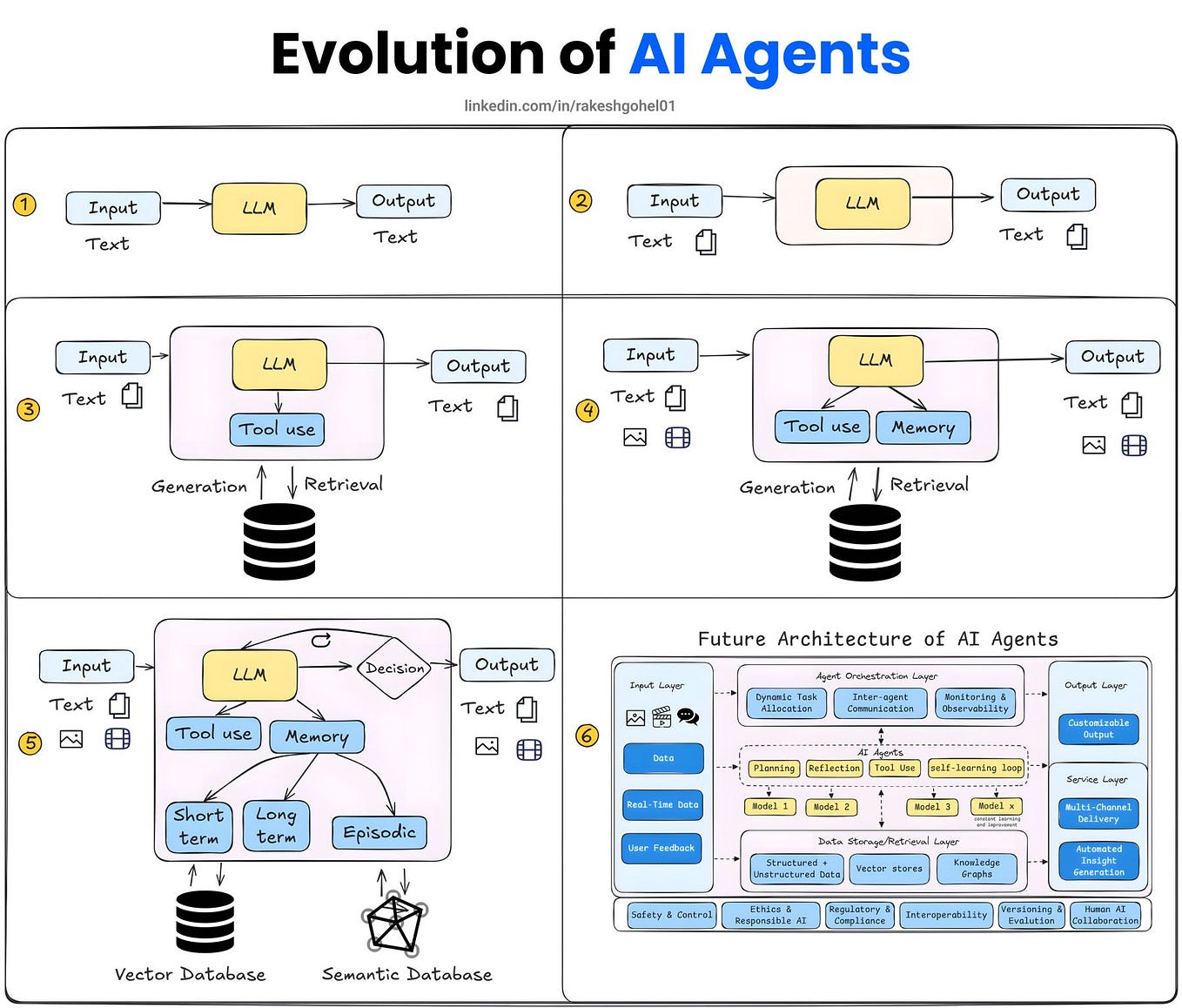
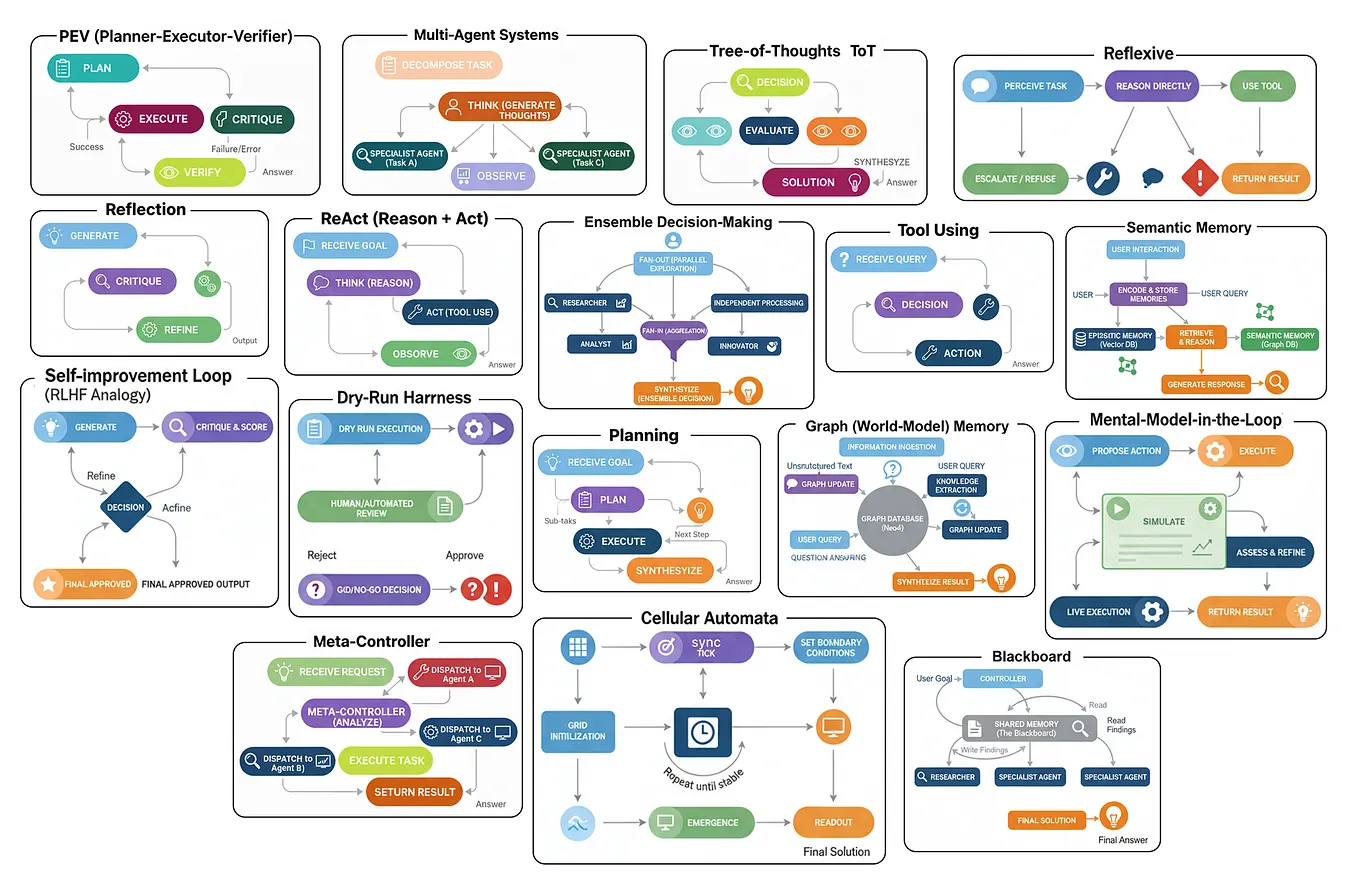
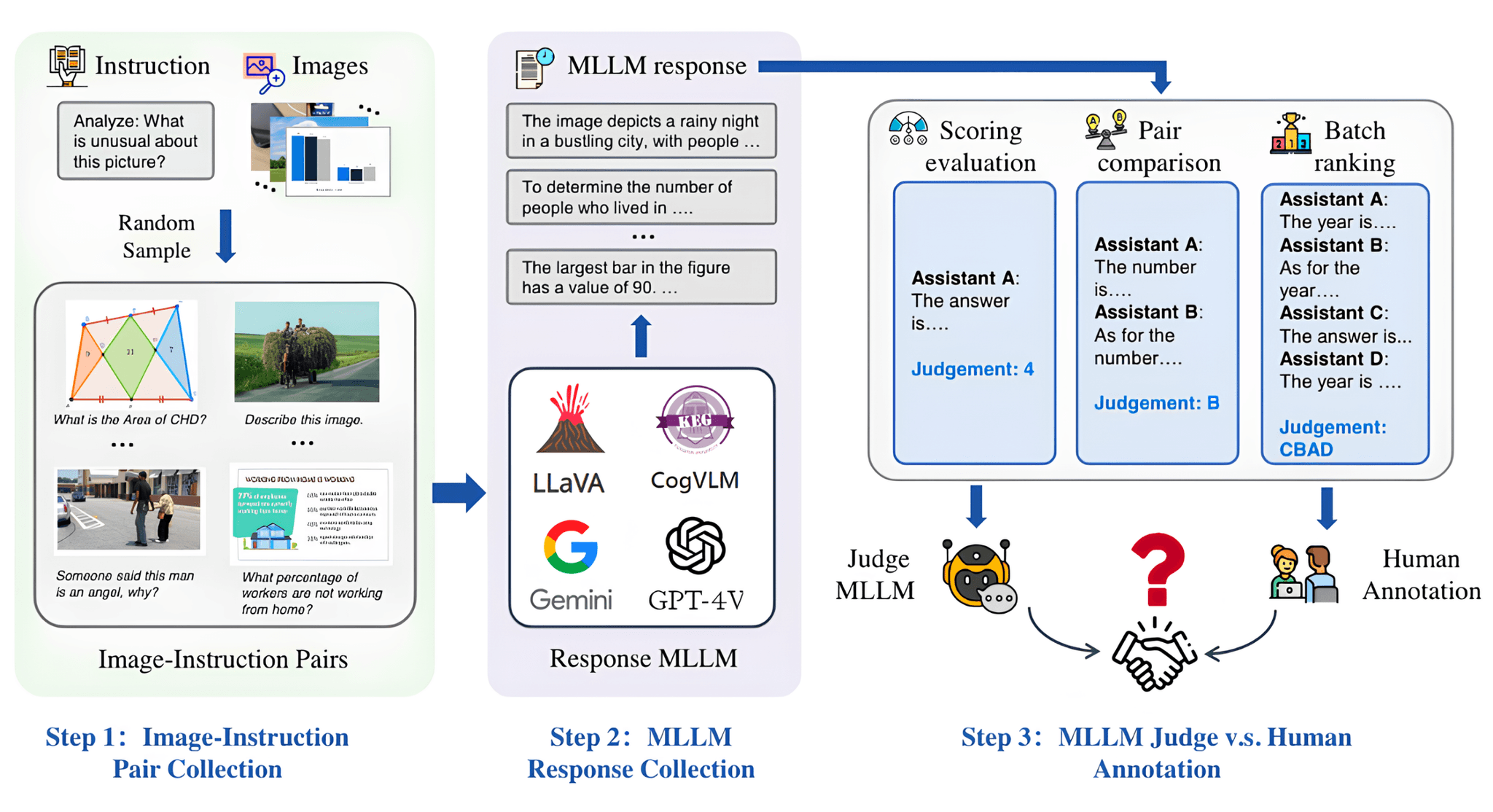
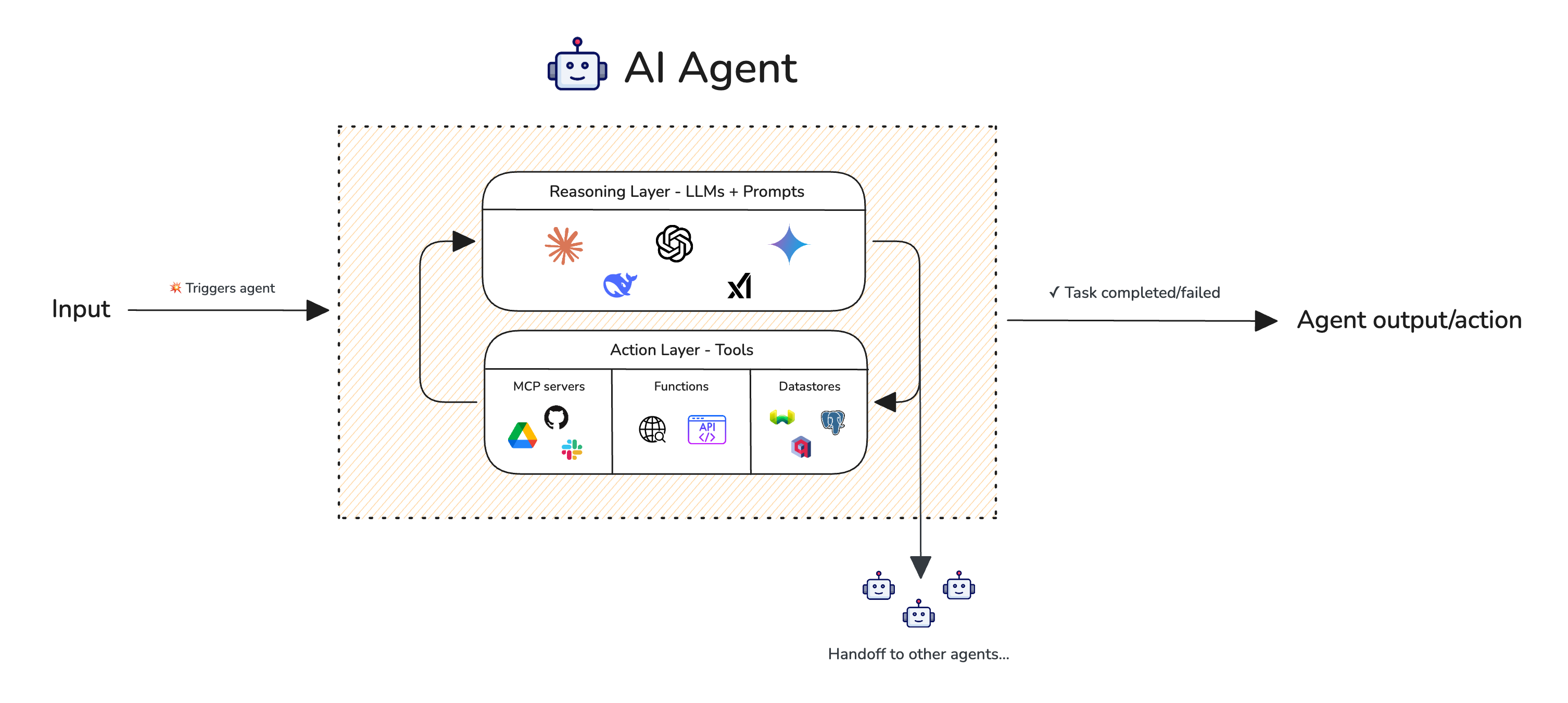
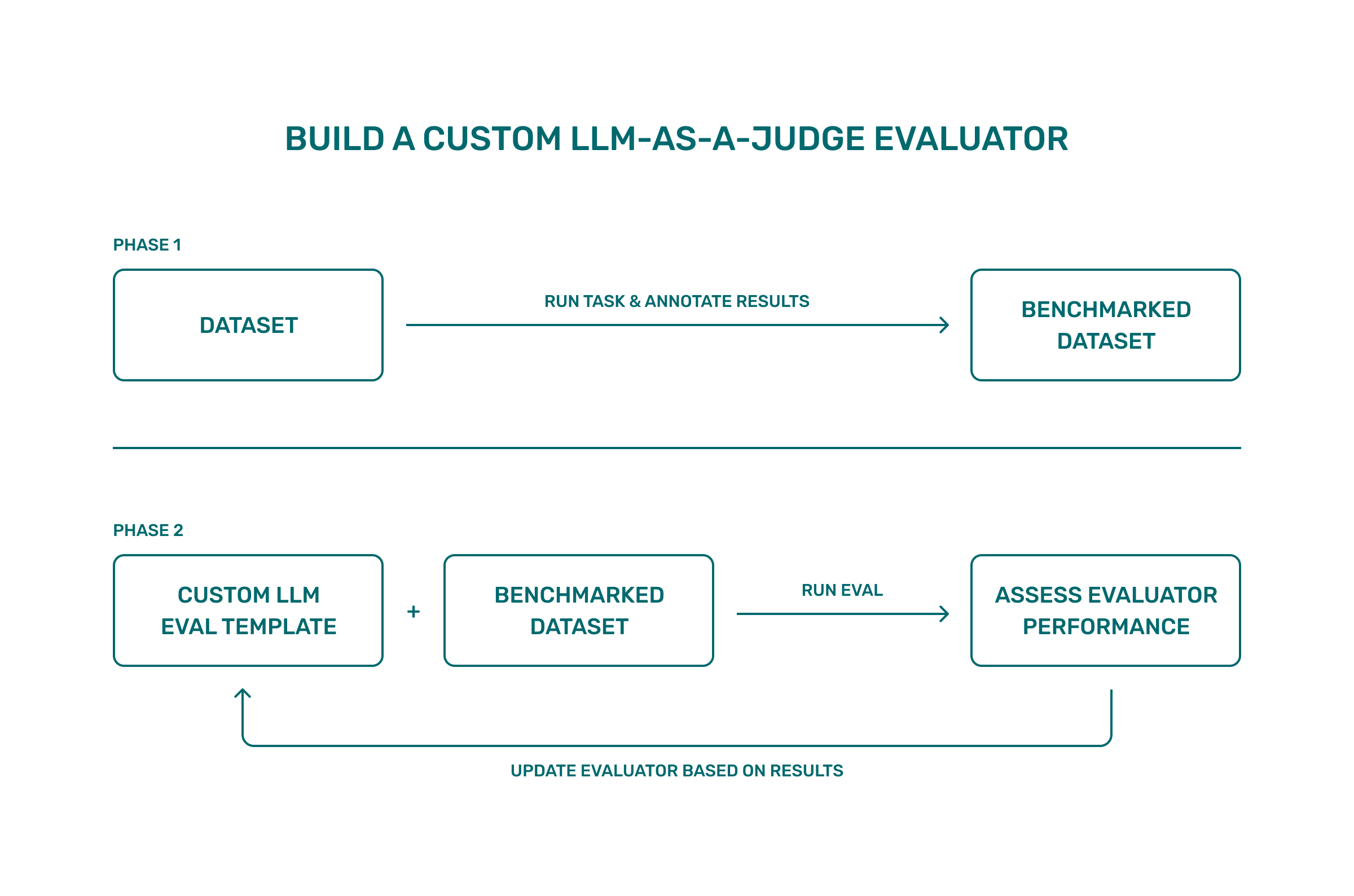
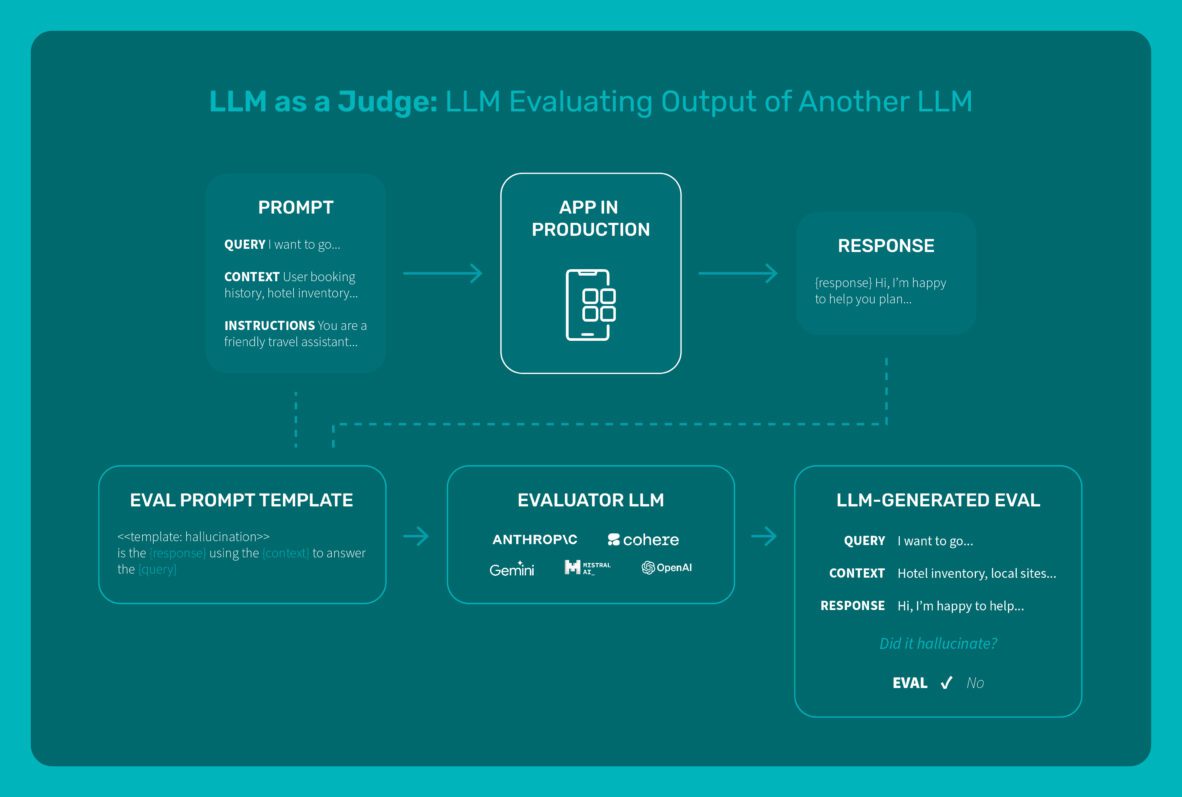
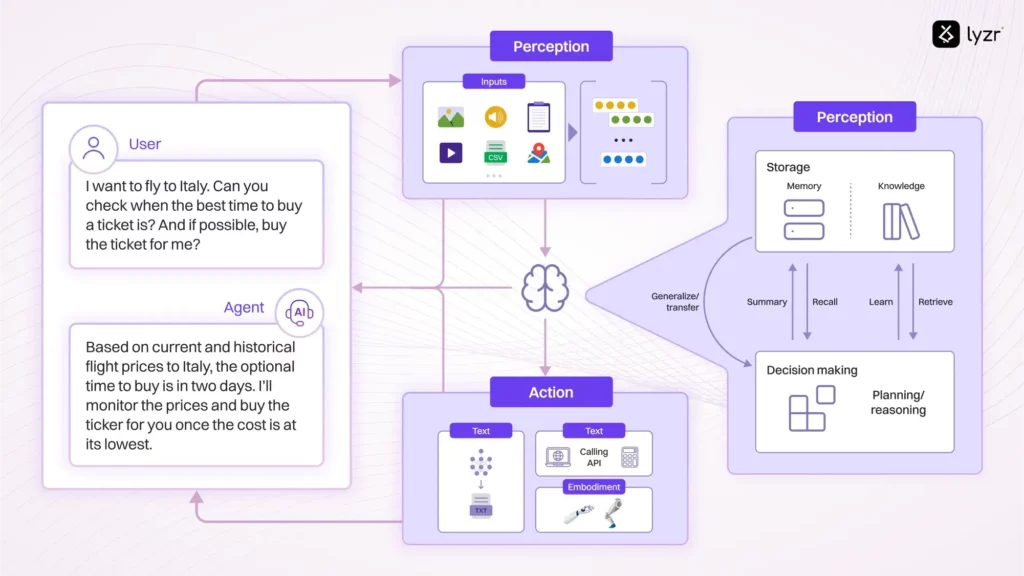
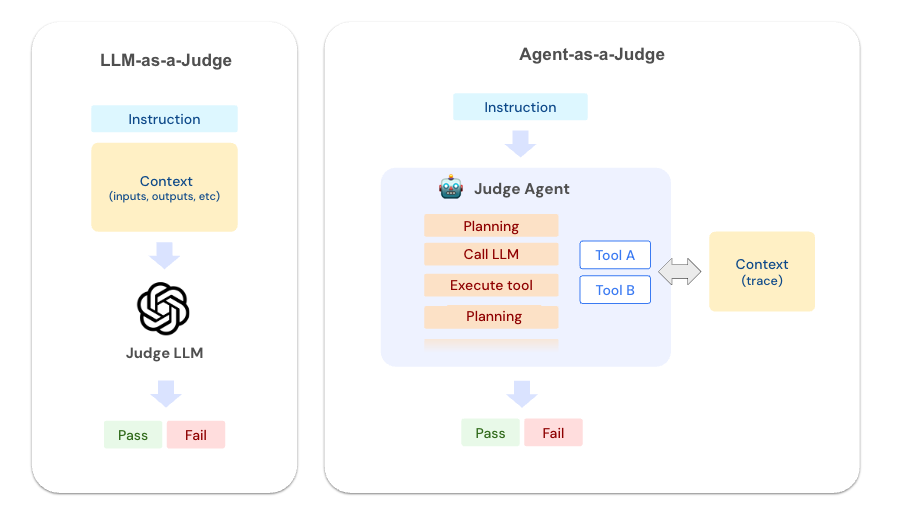
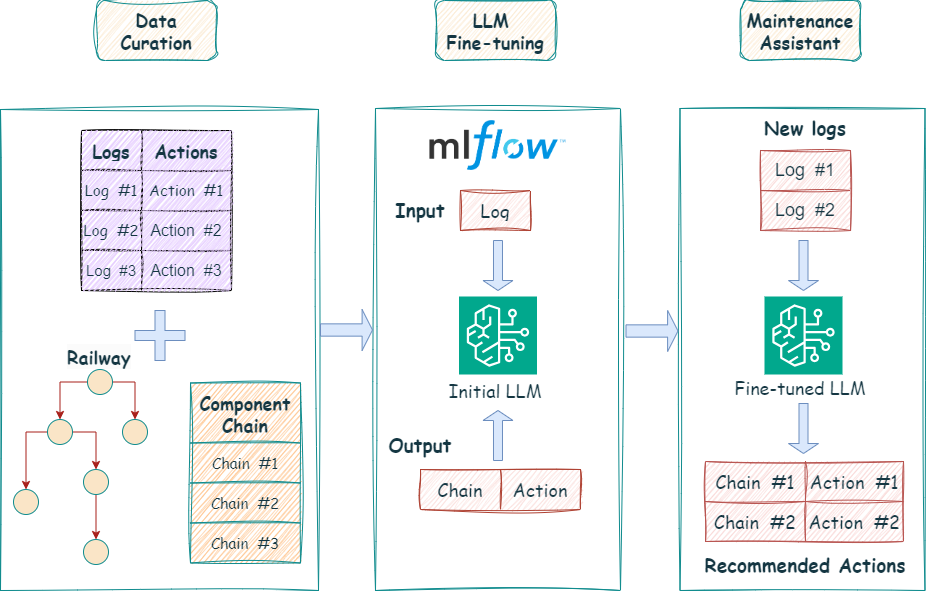
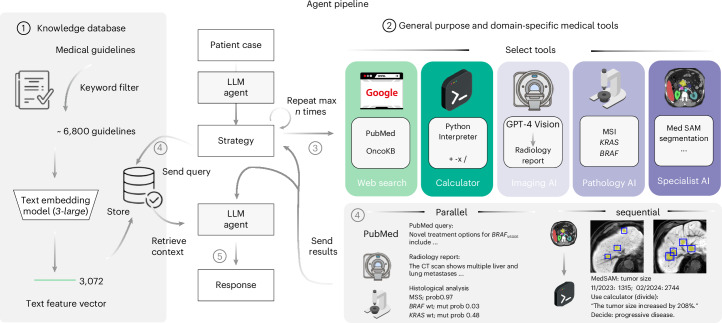
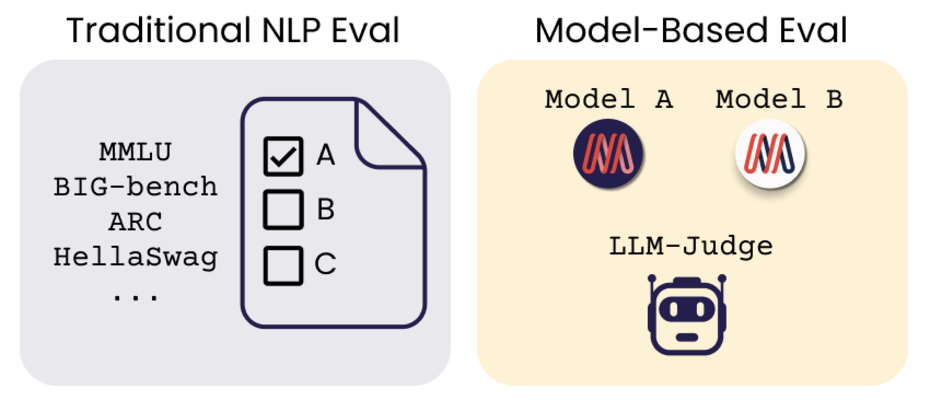
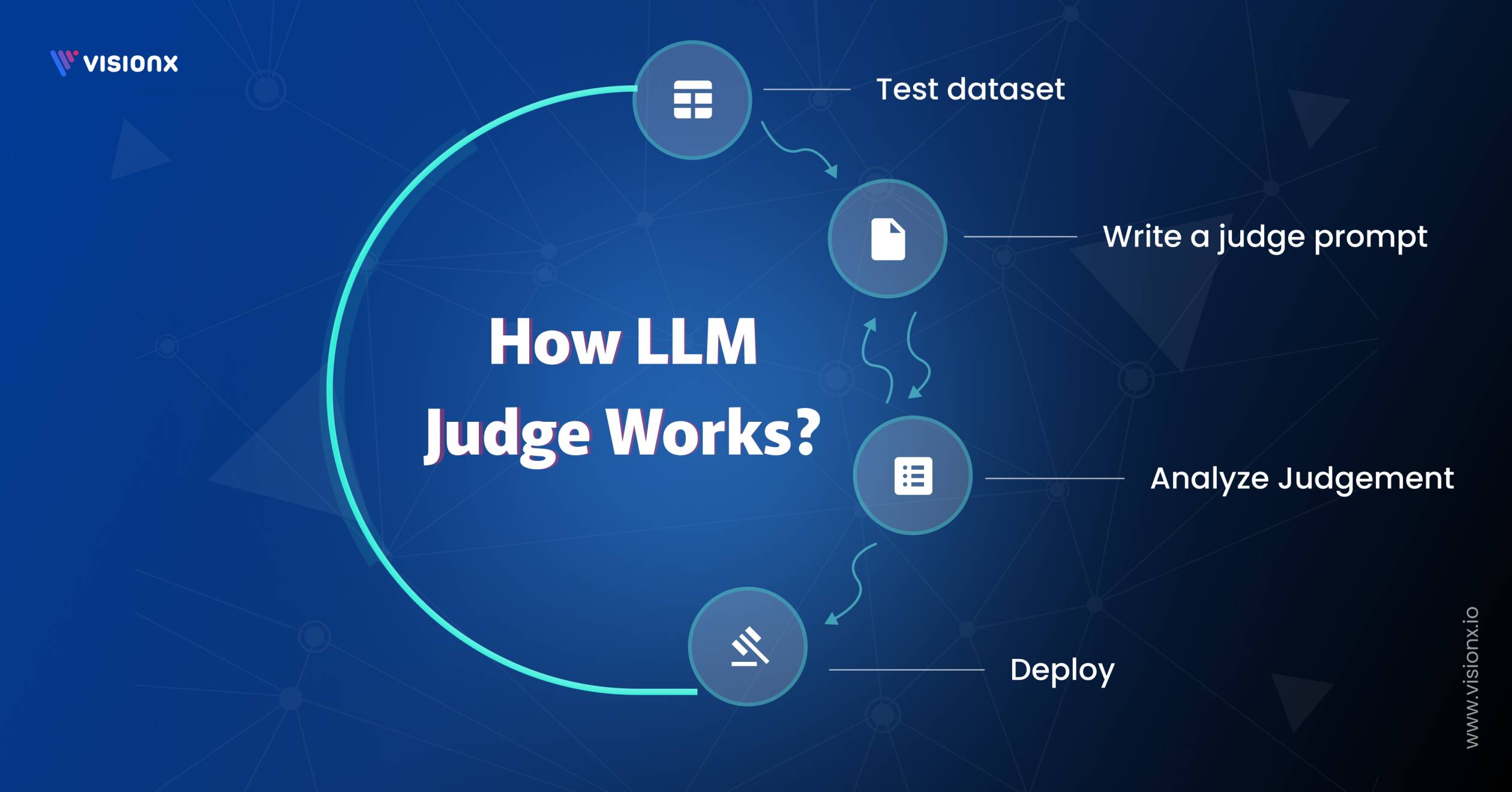
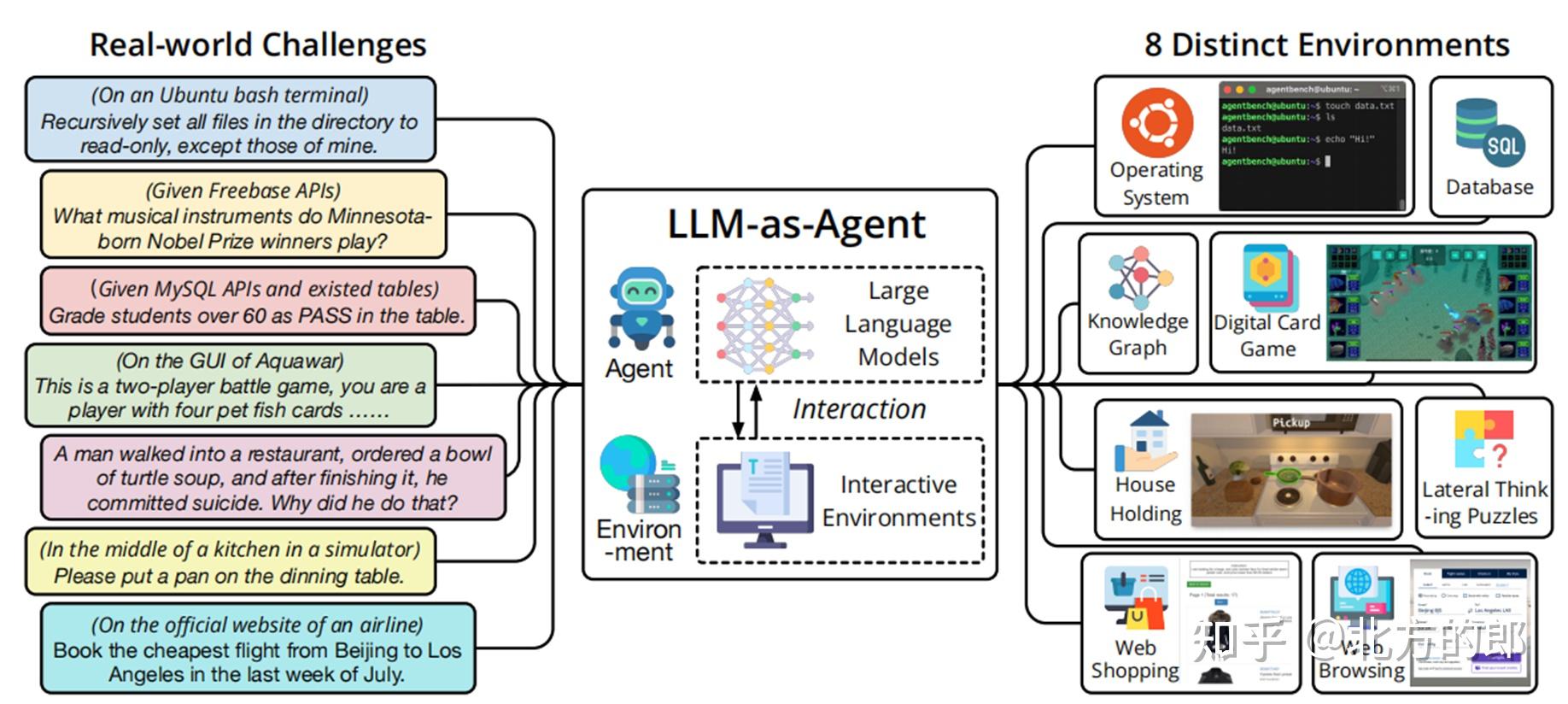
AI Agents and LLM Judges at Scale: Processing Millions of Documents ...
Evaluating AI Agents in the Era of LLMs | by Tharika Balasubramanian ...
LLM Evaluation and Testing for Reliable AI Apps - MLOps Live #38 with ...
Evaluating an LLM code documentation generation application | by Aaron ...
Evaluating AI with LLM as a Judge: A New Standard for Modern Language ...
Agent-as-a-Judge: framework to evaluate Agents with Agents | by SACHIN ...
Free Video: Evaluating AI Agents with Arize AI - Part 3: Agent as a ...
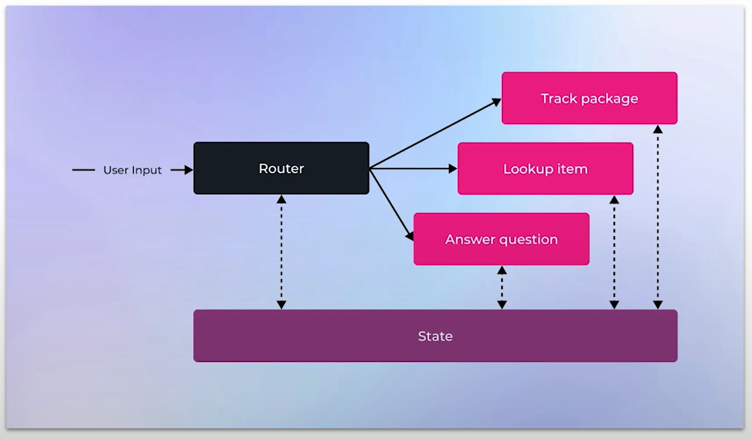
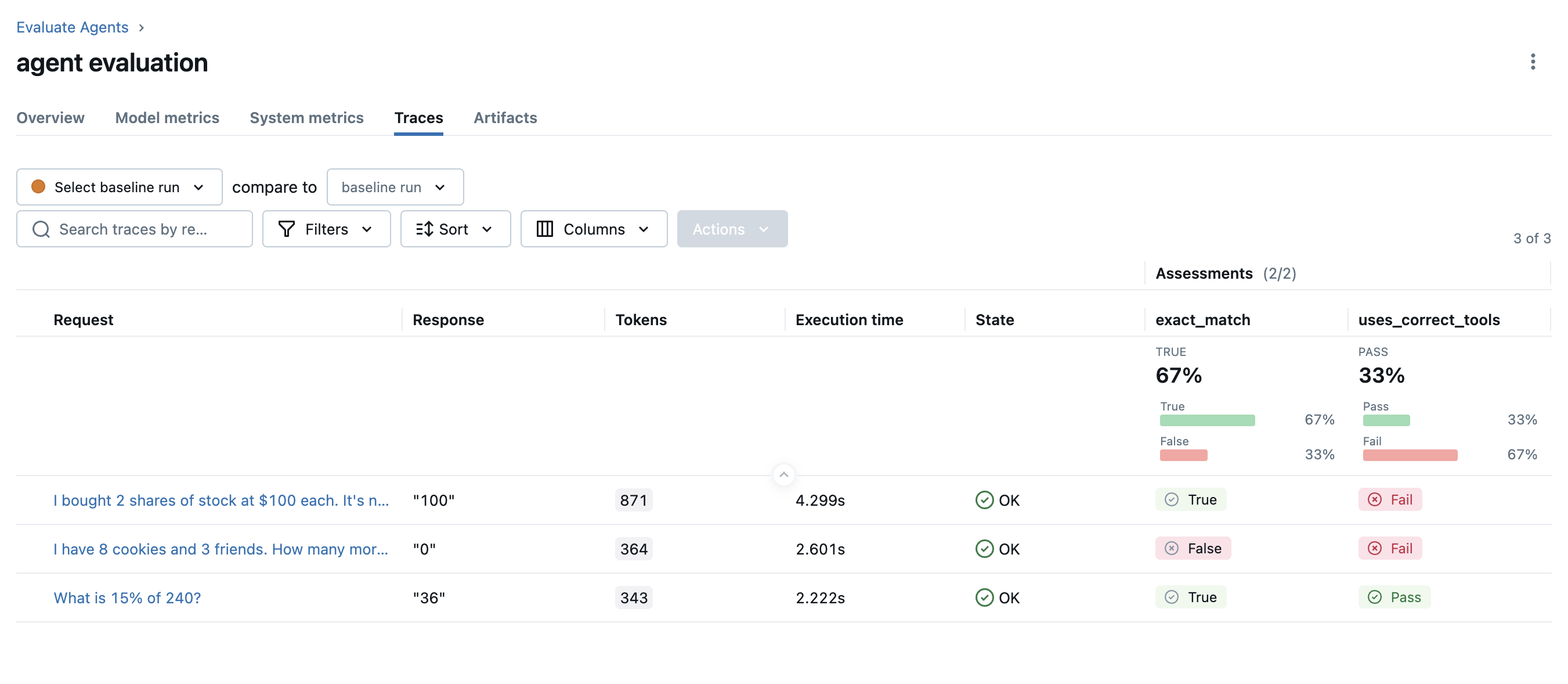
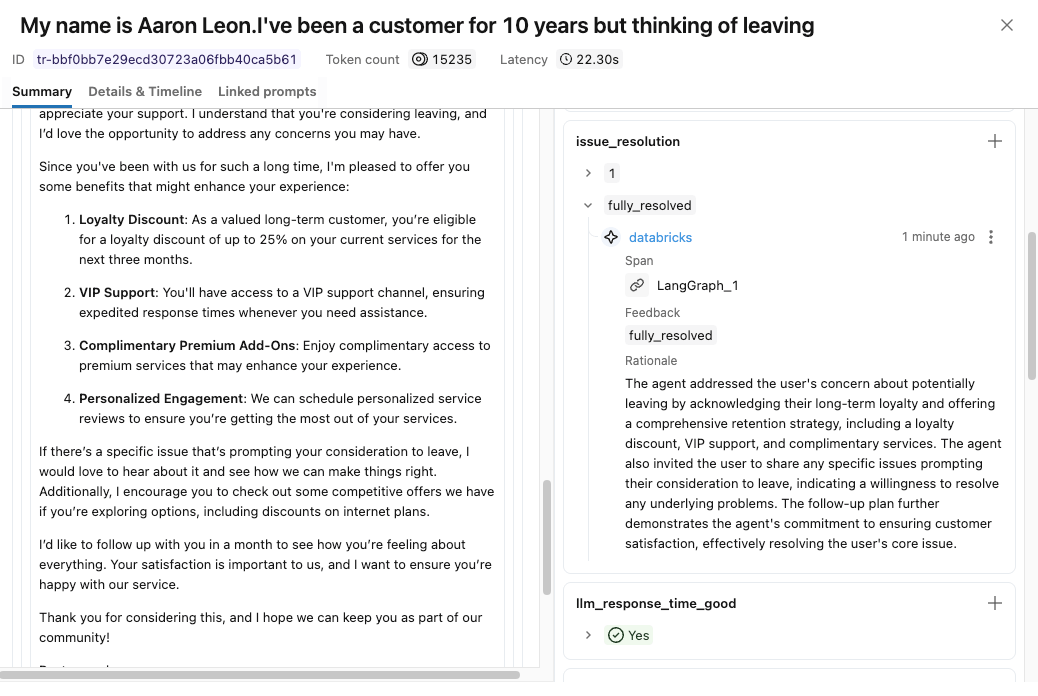
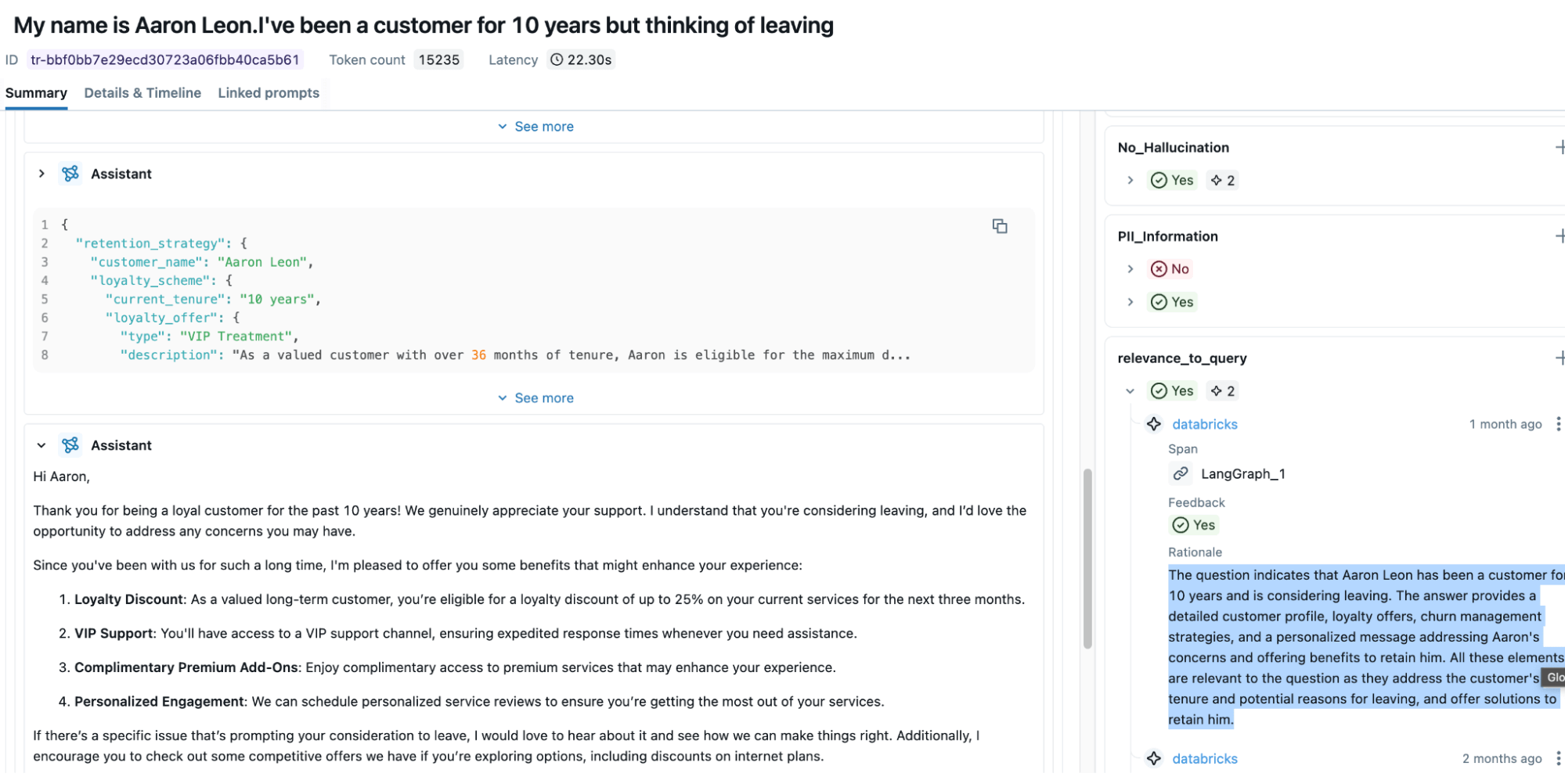
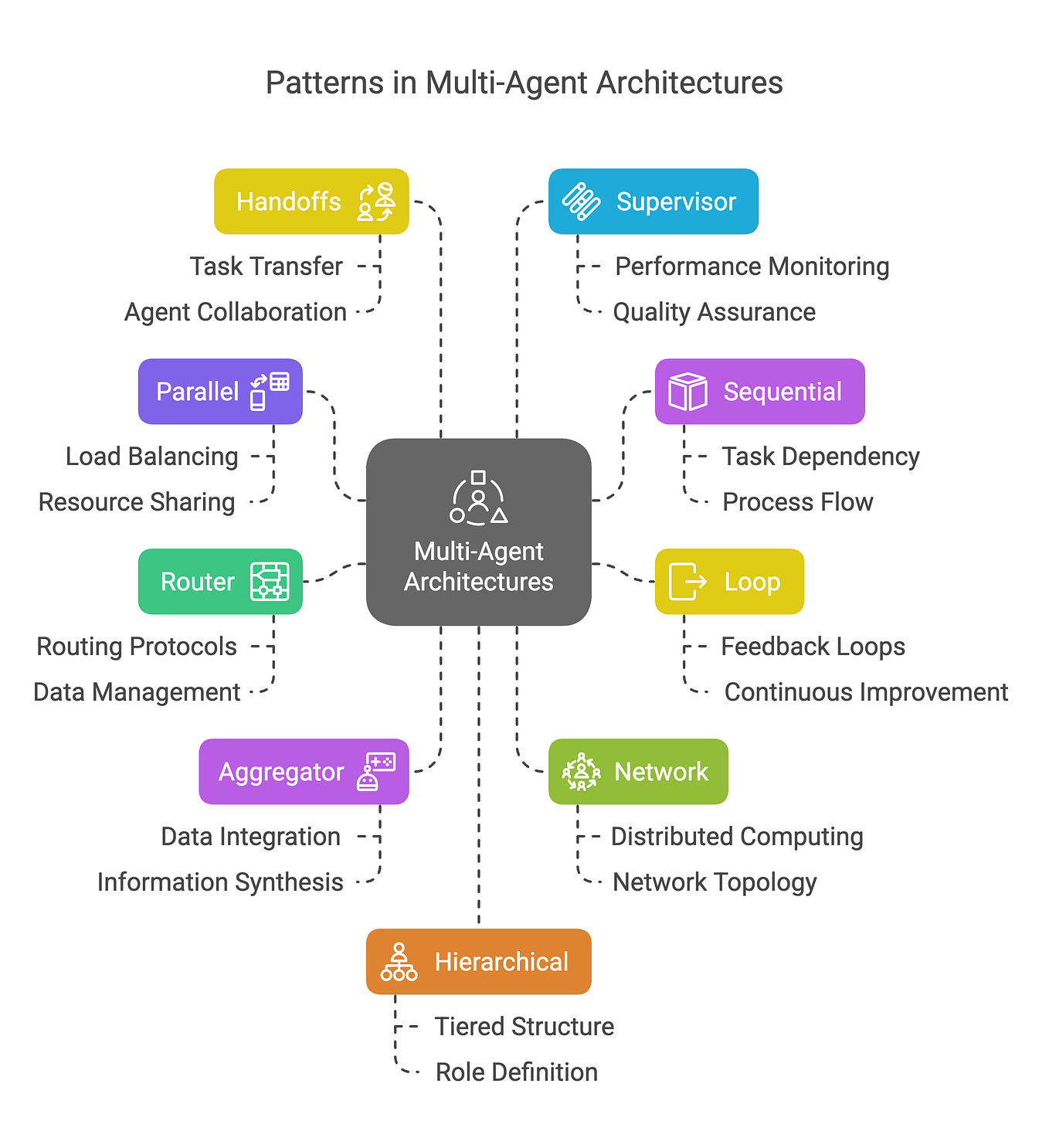
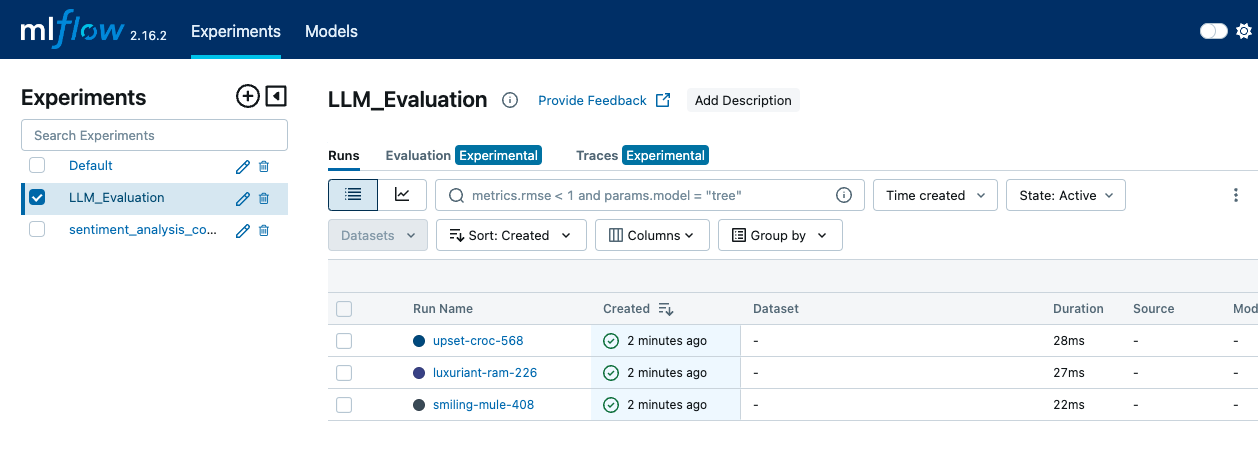
Evaluating Agents | MLflow AI Platform
Replacing Judges with Juries: Evaluating LLM Generations with a Panel ...
Rapidly Prototype and Evaluate Agents with Claude Agent SDK and MLflow ...
Building Responsible and Calibrated AI Agents with Databricks and ...
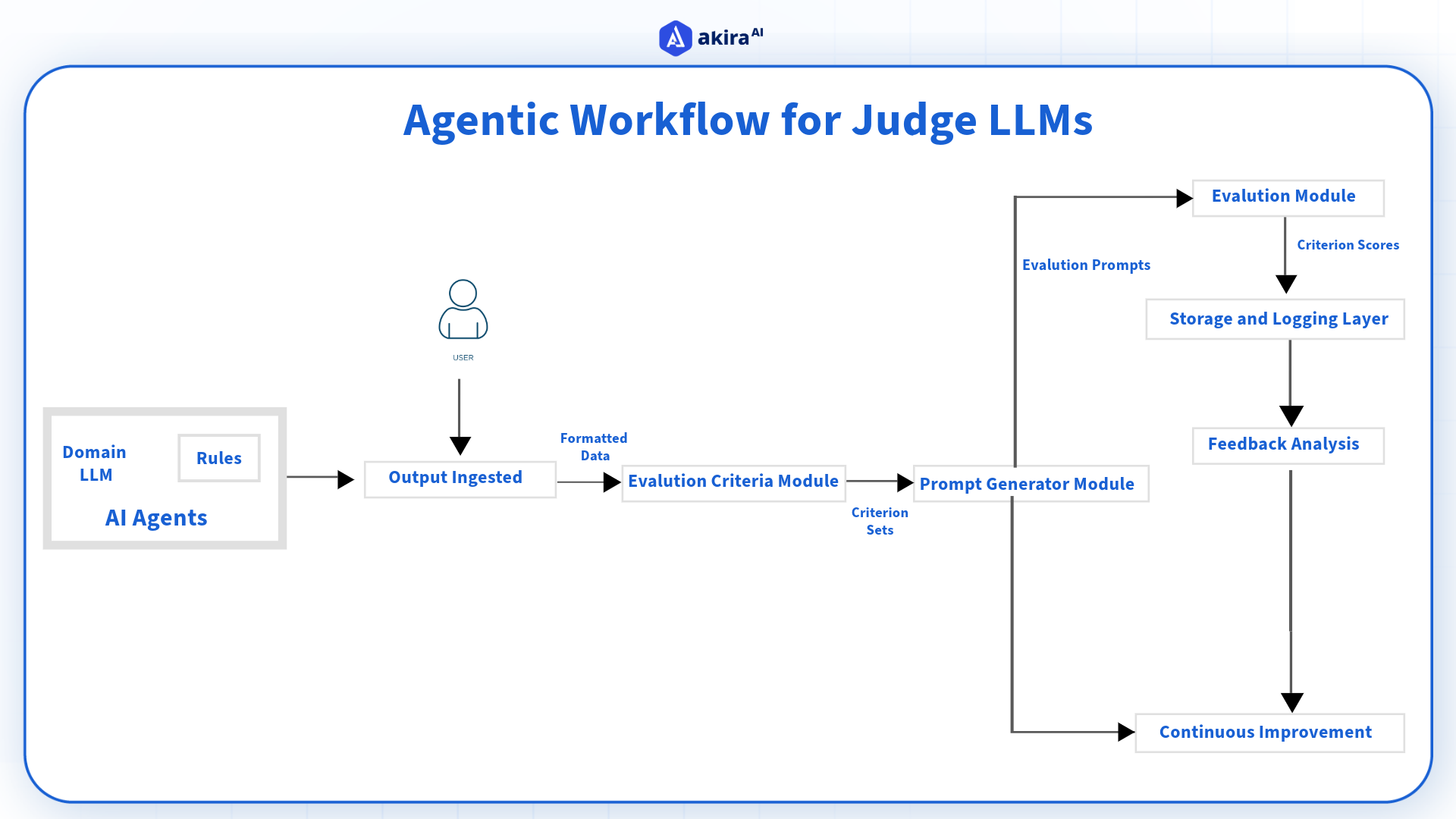
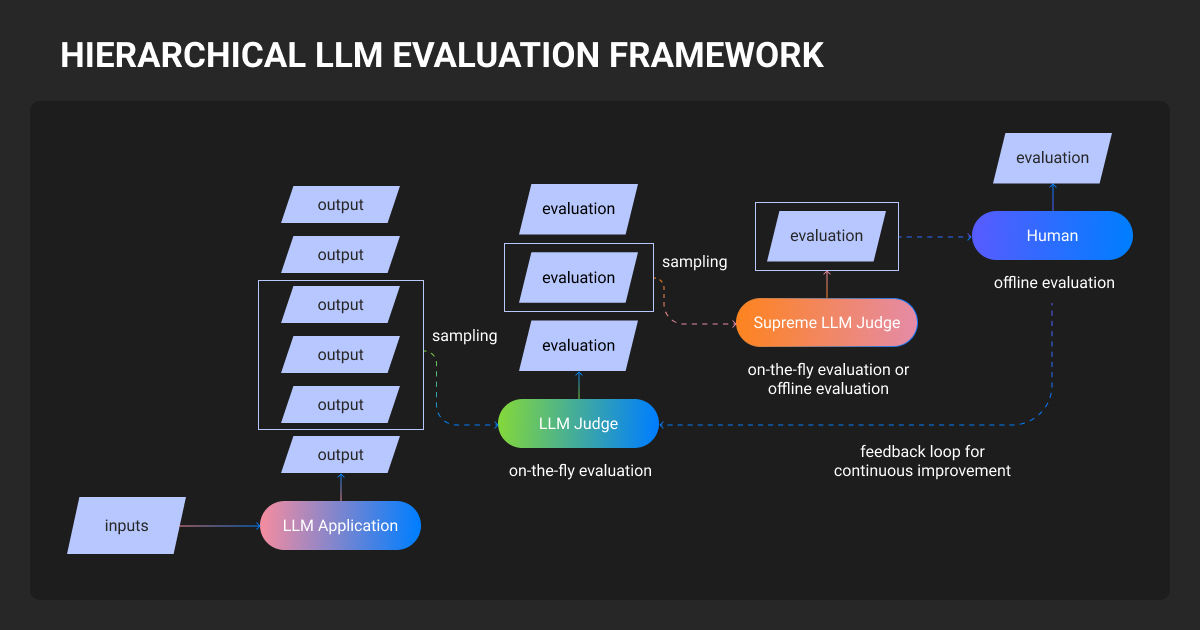
LLM as Judge for Evaluating AI Agents
LLM as a Judge: A Comprehensive Guide to AI Evaluation | Generative AI ...
How to define LLM-as-judge metrics with MLflow | Daniel Liden posted on ...
MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research ...
Mastering OpenAI’s ‘evals’: A Deep Dive into Evaluating LLMs | by ...
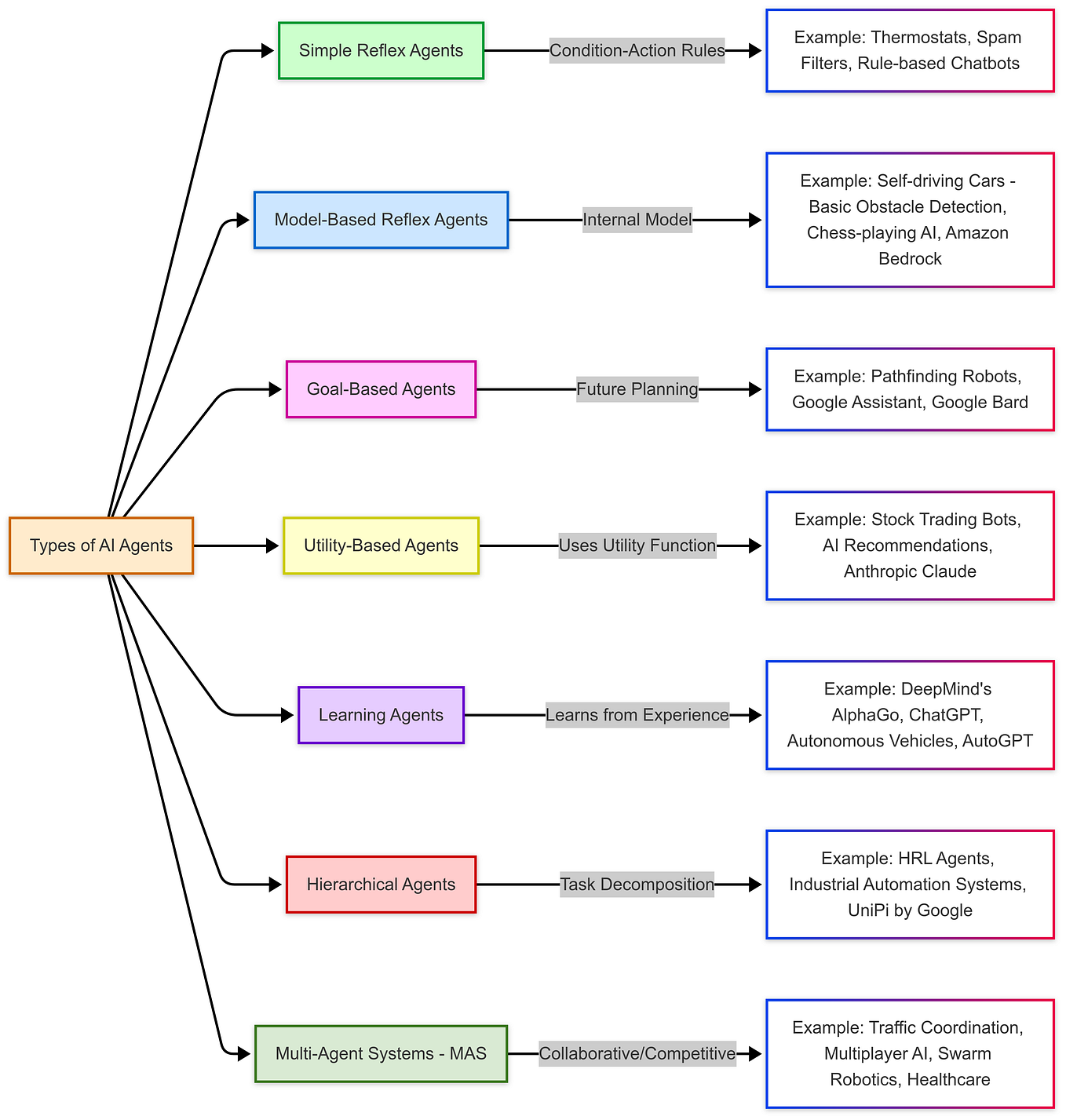
How to Build, Evaluate, and Iterate on LLM Agents | DeepLearning.AI
Announcing MLflow 2.8 LLM-as-a-judge metrics and Best Practices for LLM ...
The Definitive LLM-as-a-Judge Guide for Scalable LLM Evaluation | by ...
AI Evals - Model Evaluation & Testing Platform | LLM as a judge ...
LLM as a Judge: A 2026 Guide to Automated Model Assessment | Label Your ...
Agent Evaluation - How to Evaluate LLM Agents (Metrics, Strategies ...
AI Agent Evaluation: Metrics, Traces, Human Review, and Workflows ...
Announcing MLflow 2.8: LLM Judge Metrics | Databricks Blog
AI Agents + LLM Reasoning: Transforming Autonomous Workflows
AI Model Evaluation | Master AI Model Evaluation in Legal-Tech: How ...
How To Evaluate LLMs Without Breaking Your Head | by Mayur Jain ...
ML vs LLM: Choosing the Right Tool for AI Agent Design | Vinay Kumar ...
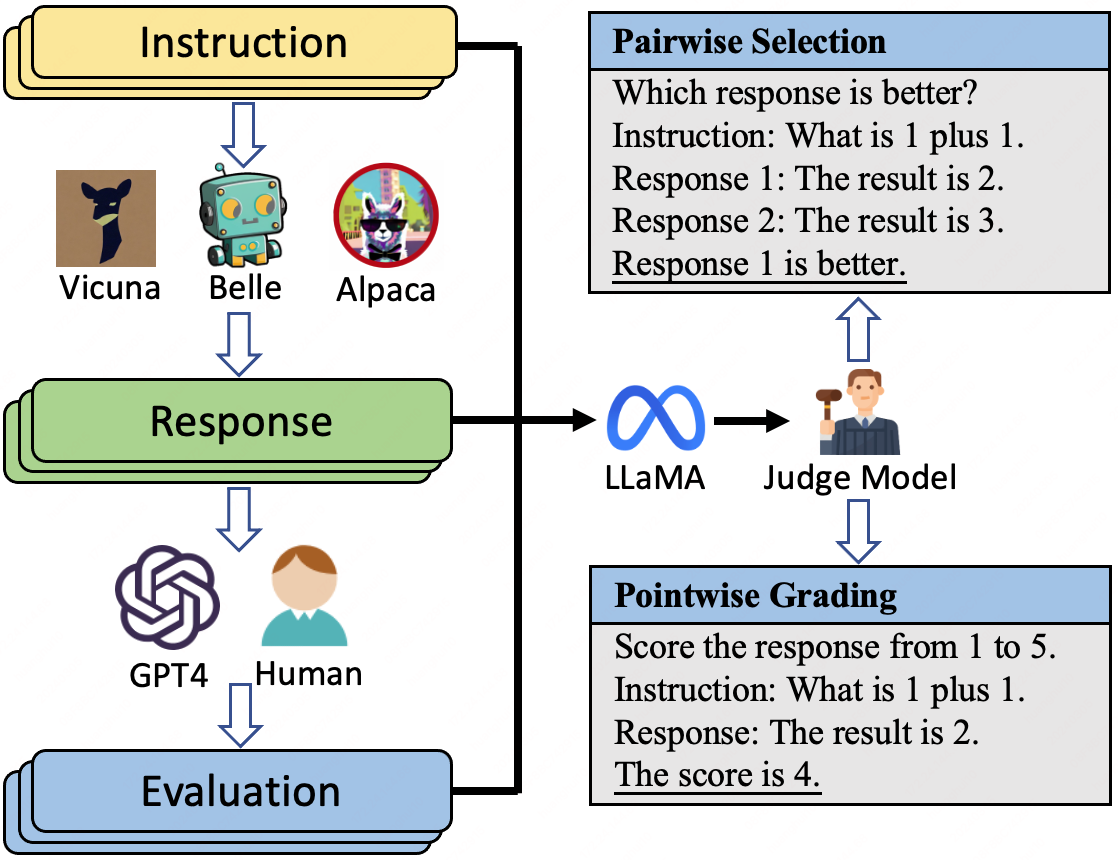
Evaluating The Effectiveness of LLM-Evaluators (Aka LLM-as-Judge) | PDF ...
MLAgentBench: Evaluating Language Agents on Machine Learning ...
Deep Dive into LLM-evaluators aka “LLM-as-a-Judge” | by Yugank .Aman ...
LLM based AI Agents Overview -What, Why, How- - Speaker Deck
Agent-as-a-Judge: Redefining LLM Evaluation with Agent-Based Assessment ...
Evaluating AI Agents - Mosu
Evaluating & Tracking LLMs using MLflow Model Evaluation & Phoenix ...
Evaluating LLMs with MLflow: A Practical Beginner’s Guide | DataCamp
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review ...
Getting Started with MLflow for Large Language Model (LLM) Evaluation ...
LLM-as-Judge: Evaluating and Improving Language Model Performance in ...
The Complete Guide to MLflow 3.0 GenAI Evaluation: Building a Test ...
MLflow LLM Evaluation | MLflow
The Definitive Guide to LLM Evaluation - Arize AI
LLM-as-a-Judge: Can AI Systems Evaluate Human Responses and Model Outputs?
AI Product Recommendations: How They Work and Drive Sales - VisionX
MLflow | MLflow
LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide - Confident AI
LLM as a Judge - Primer and Pre-Built Evaluators
A beginner level introduction to LLM + AI Agent Evaluations - YouTube
How MLAgentBench automates ML tasks | Raphaël MANSUY posted on the ...
Testing LLM Agents: Automated Evaluation & AI Red Teaming for Agentic AI
AI Agent Evaluation: Methods, Challenges, and Best Practices - Galileo AI
(PDF) Agent-as-a-Judge: Evaluate Agents with Agents
LLM-as-a-judge: can AI systems evaluate human responses and model outputs?
“Judge an LLM Judge”: A Dual-Layer Evaluation (QA) Framework for ...
LLM as a Judge Multimodal Data Evaluation - Mastering Multimodal ...
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision ...
LLM Agents Explained: Smarter Workflows, Better Decisions
LLM Evaluation approach using agentic AI
Leveraging LLMs as Meta-Judges: A Multi-Agent Framework for Evaluating ...
#llmevaluation #mlflow #aievaluation #languagemodels #genai | Sai Kumar ...
Mastering LLM as a Judge eBook: Improve AI Evaluations at Scale
Improving LLM-as-a-Judge Inference with the Judgment Distribution - ACL ...
LLM as a Judge: Building Fair, Reliable AI Evaluation Pipelines
AI Agents: The Natural Evolution of LLMs Large Language Models (LLMs ...
基于智能体的评分器(Agent-as-a-Judge) | MLflow 平台
A Complete Guide to LLM Evaluation For Enterprise AI Success - Galileo AI
LLM-as-a-Judge is one of the most widely-used techniques for evaluating ...
Mastering AI Agents: A Practical Guide to Building LLM-Powered Systems ...
Development and validation of an autonomous artificial intelligence ...
Introducing the AI Machine Learning Agent (100% free). Build 100s of ML ...
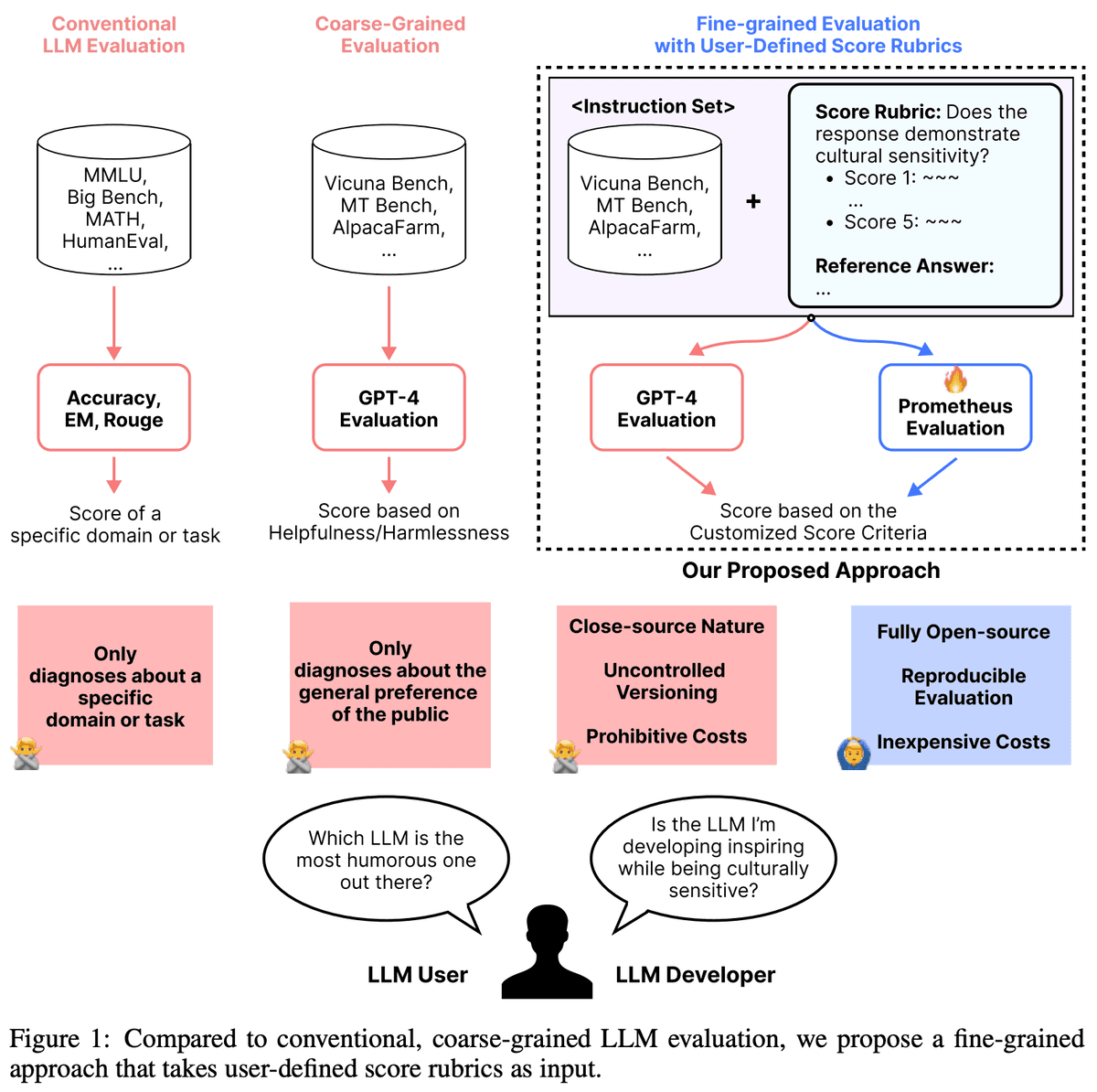
An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned ...
Beyond Chatbots: Inside the Quest for True LLM Reasoning — Inference ...
Choosing Between LLM Agent Frameworks | Towards Data Science
LLM as a Judge: Scaling AI Evaluation Strategies - YouTube
The Qualitative Revolution in Agentic AI Evaluation: Why LLM-as-a-Judge ...
人工智能 - AI Agent框架(LLM Agent):LLM驱动的智能体如何引领行业变革,应用探索与未来展望 - 汀NLP ...
LLM Evals aren’t enough: Testing Agentic AI the right way - YouTube
Finetuning LLM Judges for Evaluation
AI Loves Data a diverse AI, ML, and data science community
LLM-as-a-Judge: Ensuring Accuracy in Agentic AI Workflows
Revolutionizing AI Evaluation: The Agent-as-a-Judge Approach - Fusion Chat
LLM-as-a-Judge Guide: Smarter AI Model Evaluation at Scale - VisionX
🚀 𝗟𝗲𝘀𝘀𝗼𝗻𝘀 𝗳𝗿𝗼𝗺 𝟭 𝗬𝗲𝗮𝗿 𝗼𝗳 𝗝𝘂𝗱𝗴𝗲-𝗟𝗟𝗠 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁 | Ganesh Divekar
LLM-as-a-Judge vs Human Evaluation - Galileo AI
Meet the Agent-as-a-Judge: A Smarter Way to Grade AI
Best Practices For Creating Your LLM-as-a-Judge - Galileo AI
Comprehensive Guide to LLM-as-a-Judge Evaluation | Galileo
“A Survey on LLM-as-a-Judge” outlines what could become a foundational ...
AI Agent(或者LLM Agent)深度讲解——组成、方法、案例及展望 - 知乎
LLM-as-a-Judge: The Ultimate Guide for AI Developers
#ai #artificialintelligence #llm #ml #machinelearning #aiagents # ...
LLM-as-a-Judge vs Human-in-the-Loop Evaluations: A Complete Guide for ...
Your AI has agency — here’s how to architect its frontend - LogRocket Blog
OpenAI’s new AI agent benchmark competition - Bioethics.tech
Miami Hurricanes play Central Connecticut State before opening ACC play ...
SAAF gives an afternoon update on San Angelo Gives 2026
Hundreds honor Abilene firefighter Hunter Patterson during funeral ...
San Angelo, TX Homes For Sale & Real Estate | REMAX
Building Reliable LLM-as-a-Judge Systems
LLM-as-a-Judge vs Human Evaluation
Agent-as-a-Judge:以智能体作为评判者 - AI论文精选
卷起来!让智能体评估智能体,Meta发布Agent-as-a-Judge_新浪科技_新浪网
直播|LLM-as-a-Judge热门论文,当AI担任“评估者”综述分享,AI+金融圆桌交流,IDEA研究院_腾讯新闻
Grose named Division III NW District Defensive Player of the Year
Michigan State football's early enrollees could contribute quickly
Based on this image's title: “Evaluating AI Agents with MLflow 3.0 and LLM Judges | by Angelo ...”