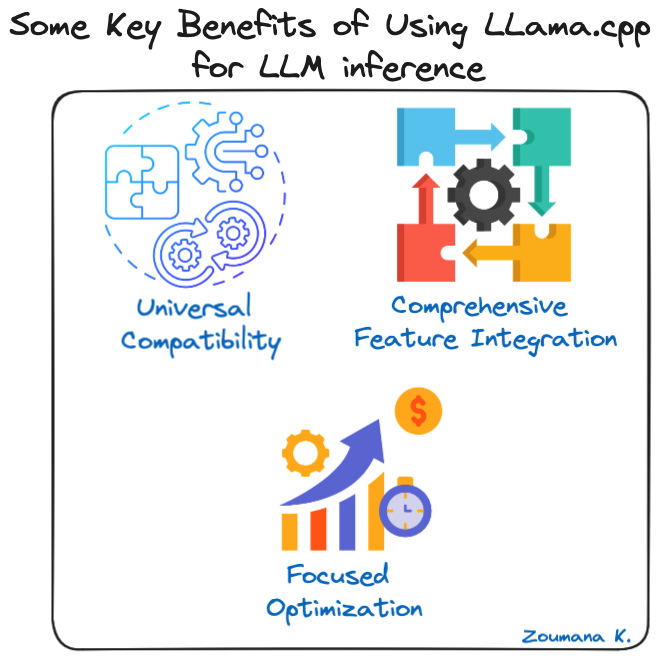
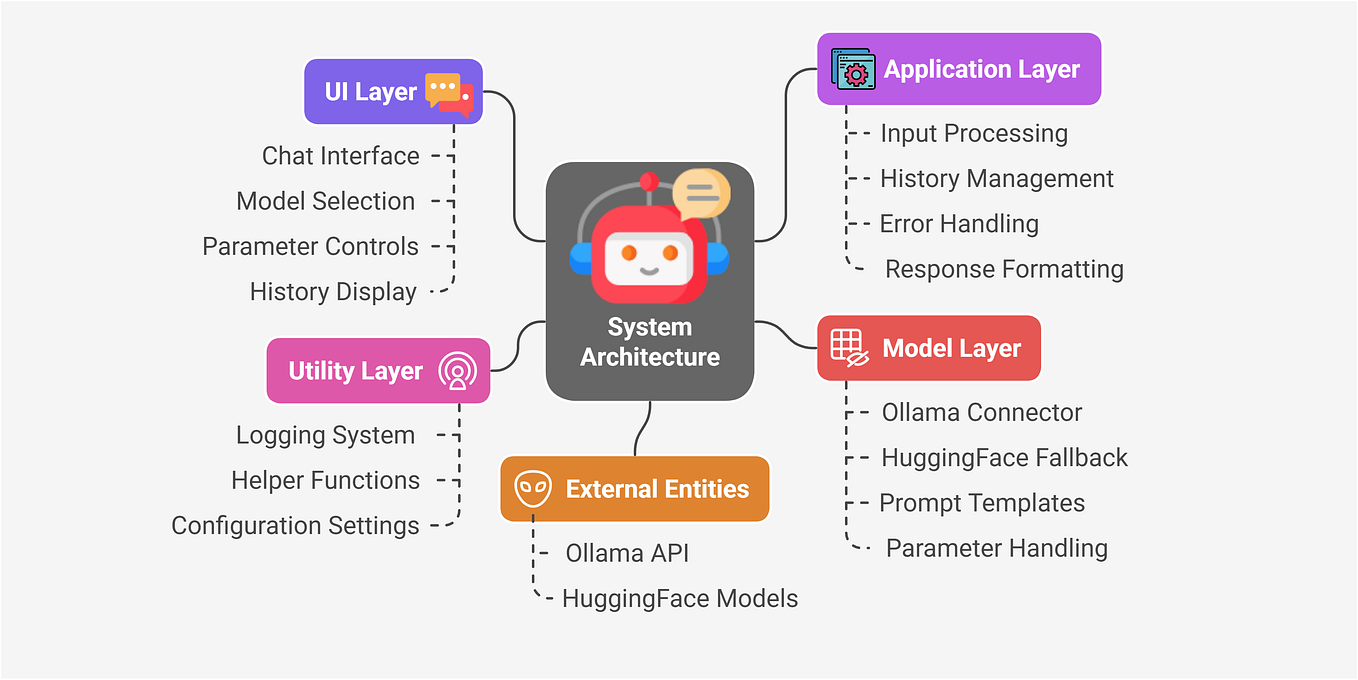
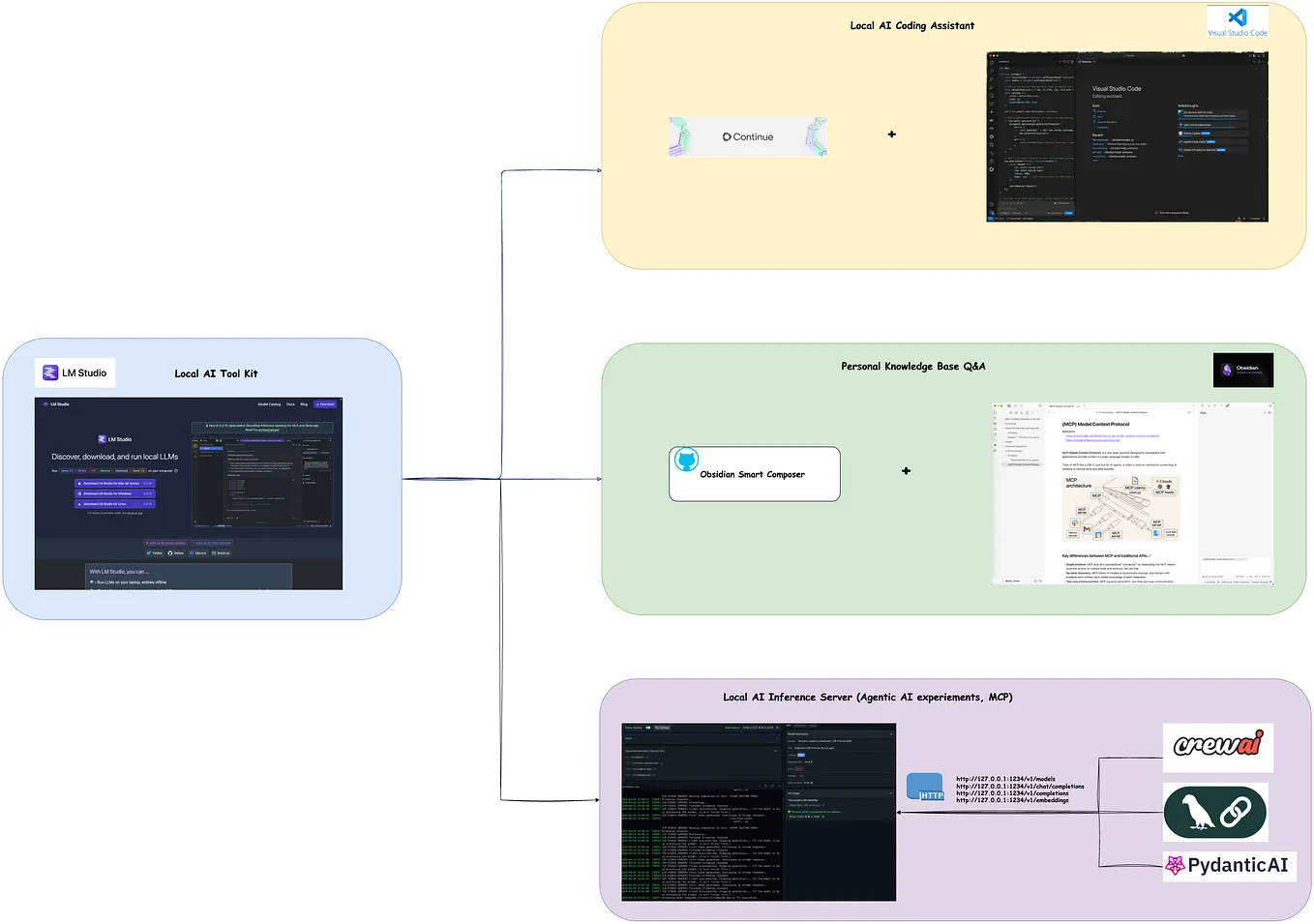
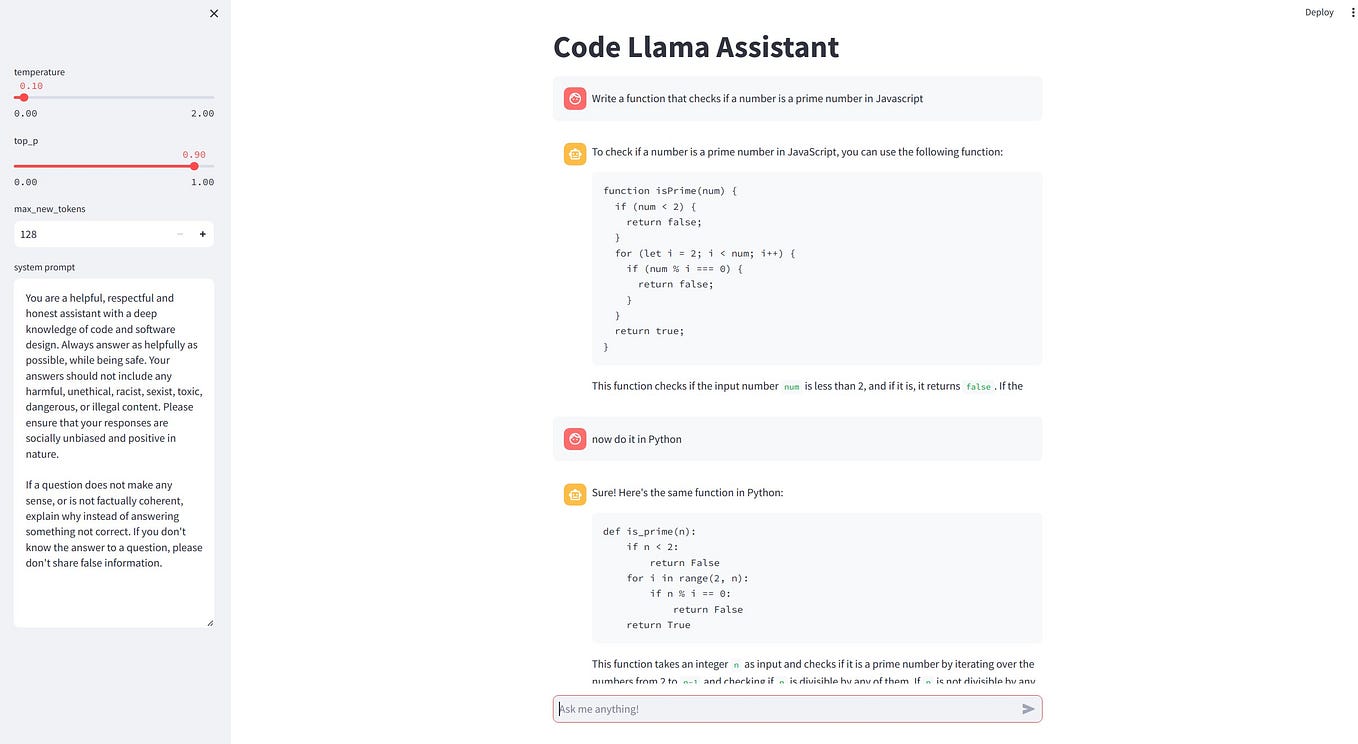
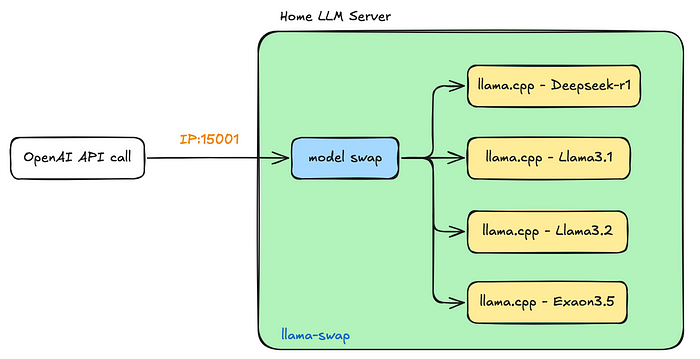
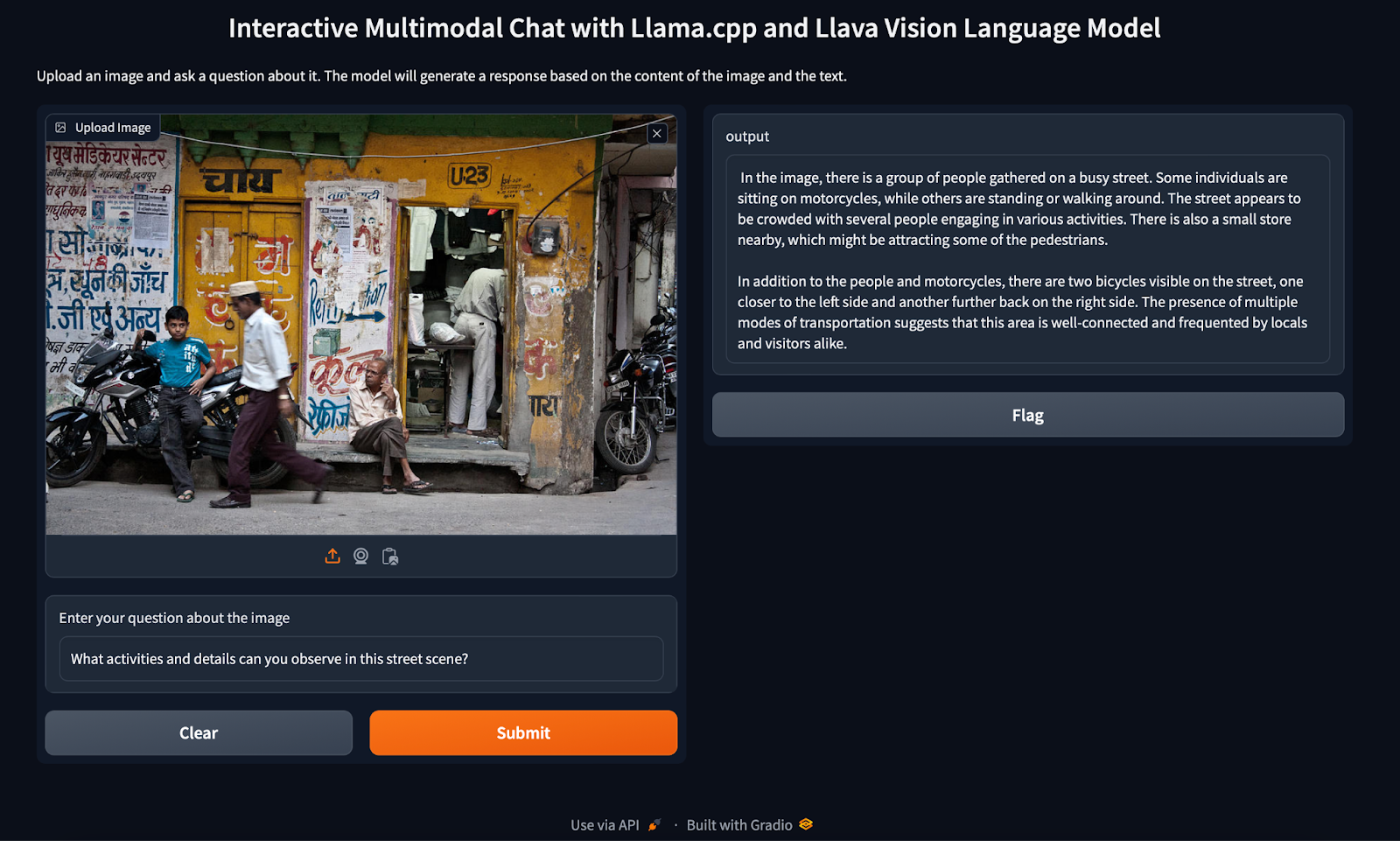
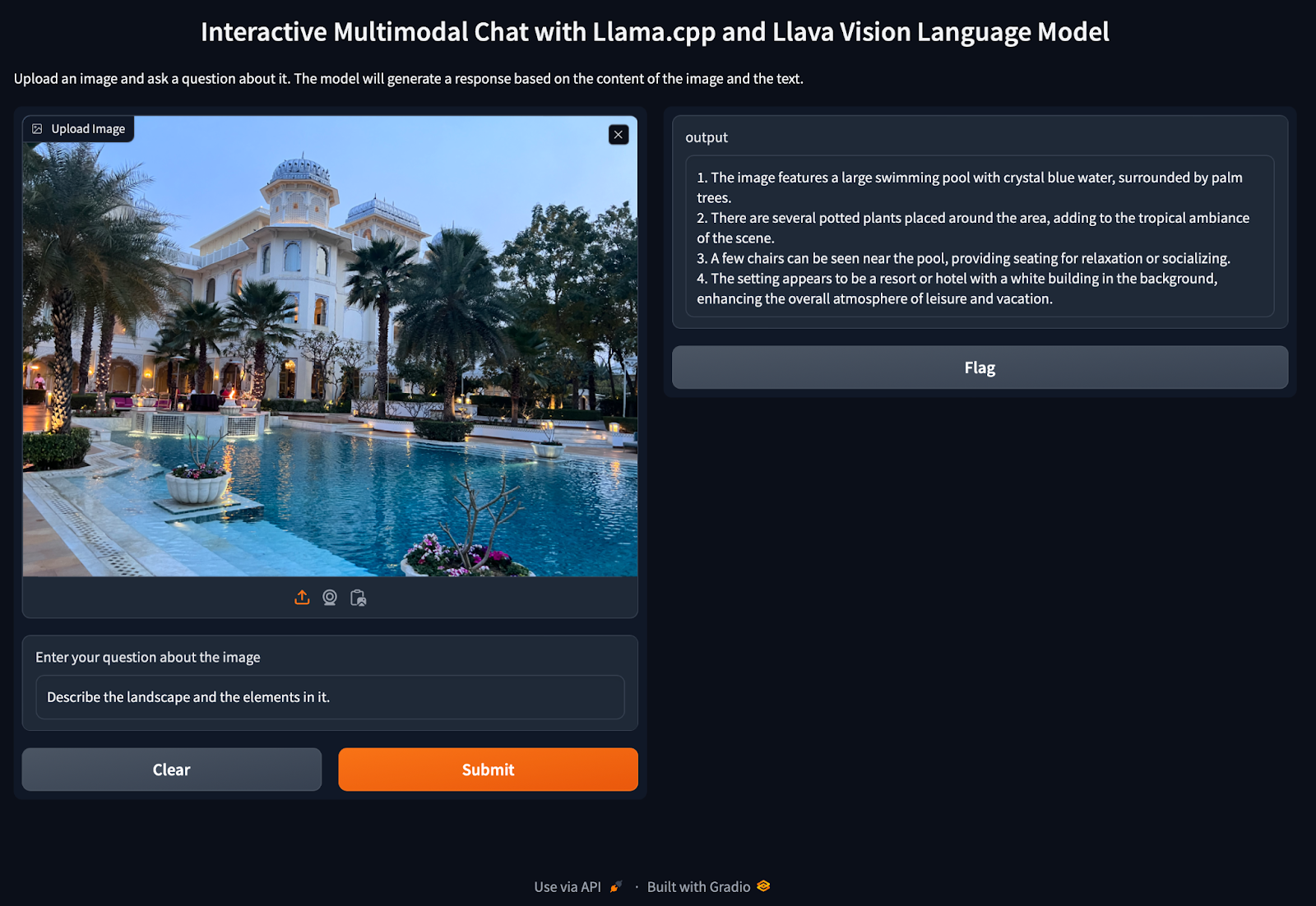
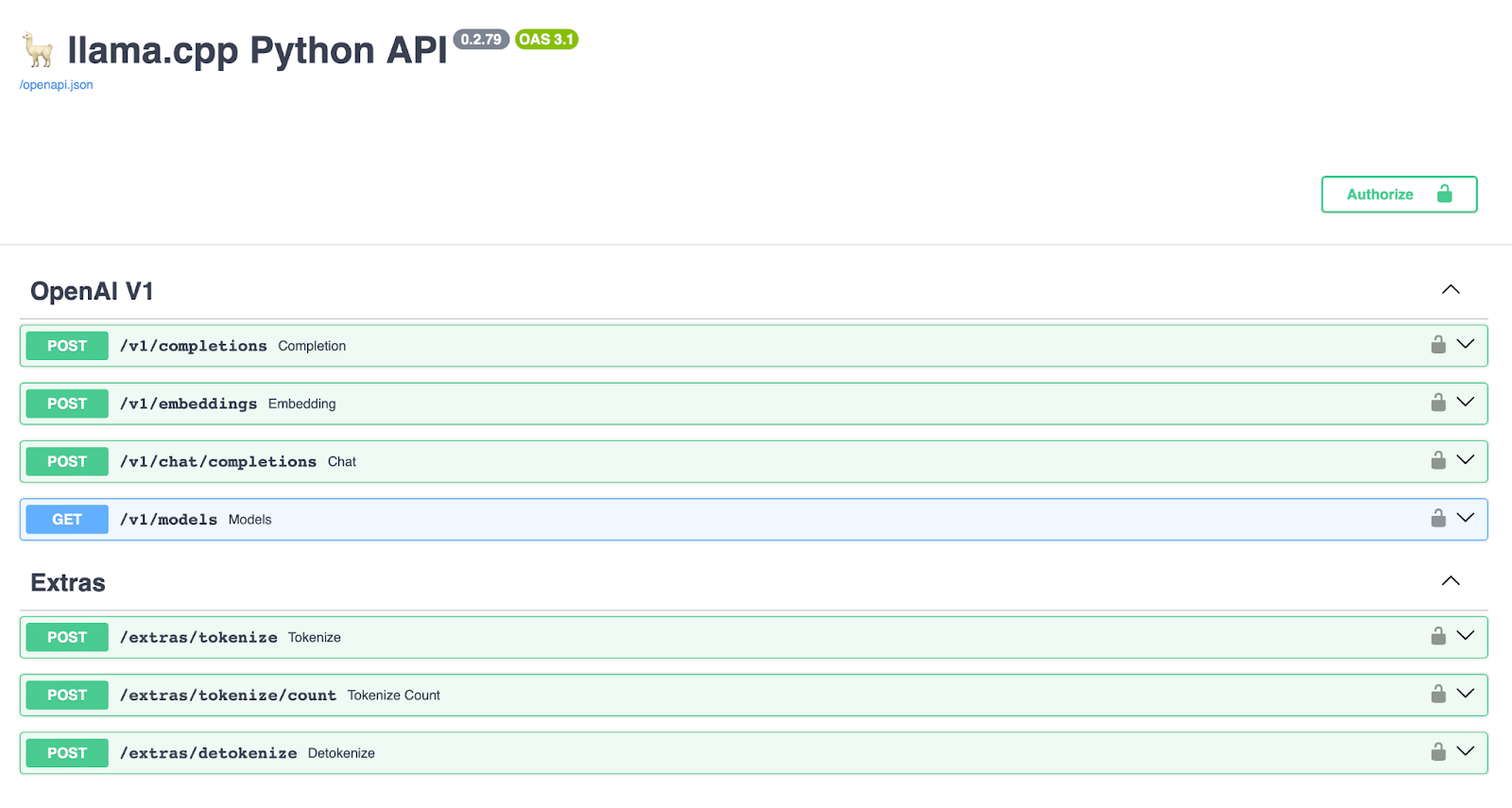
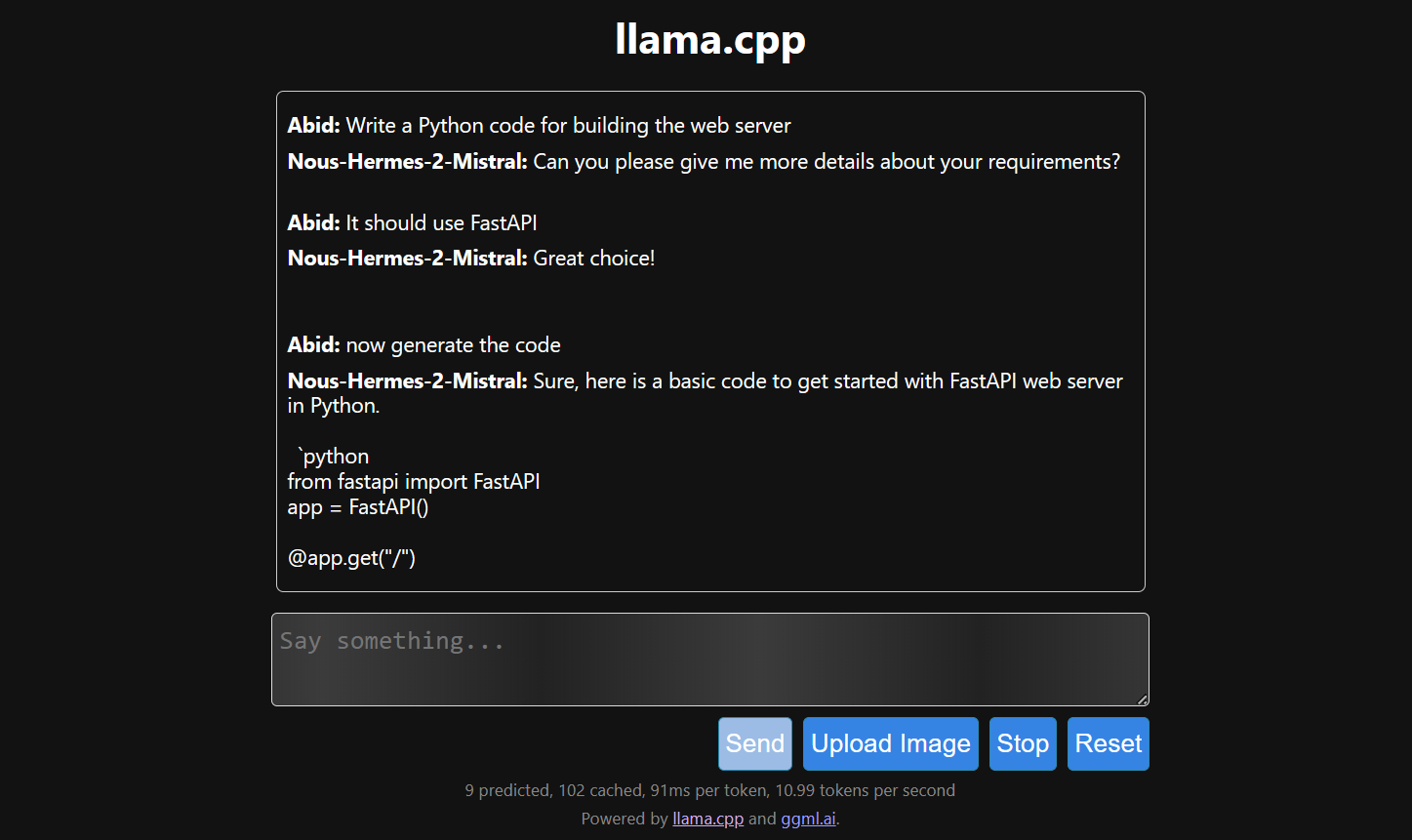
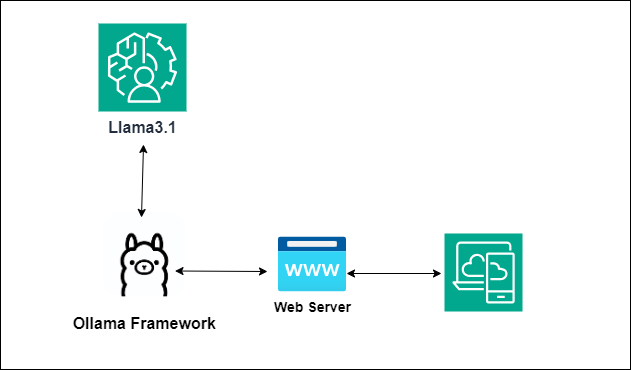
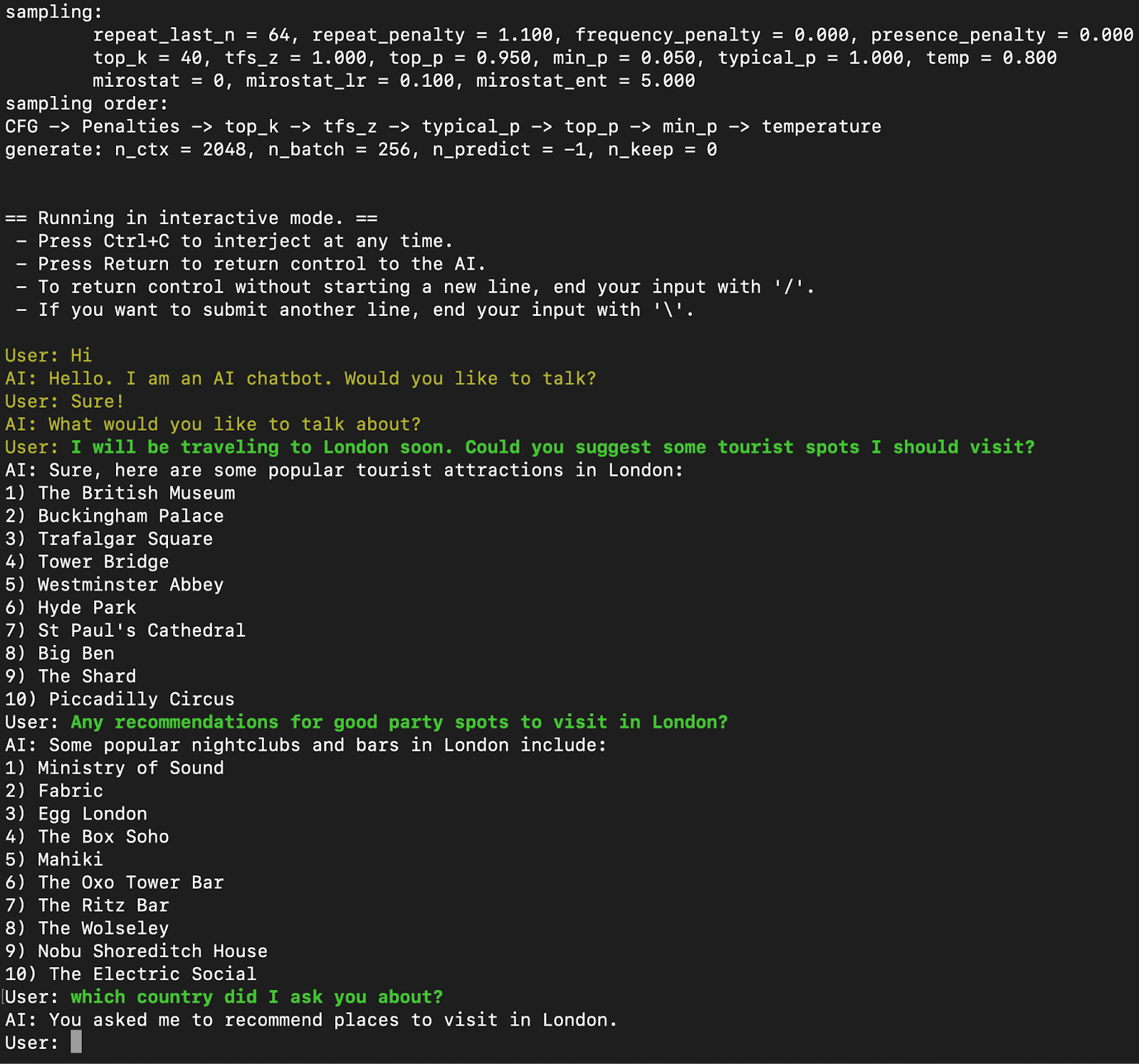
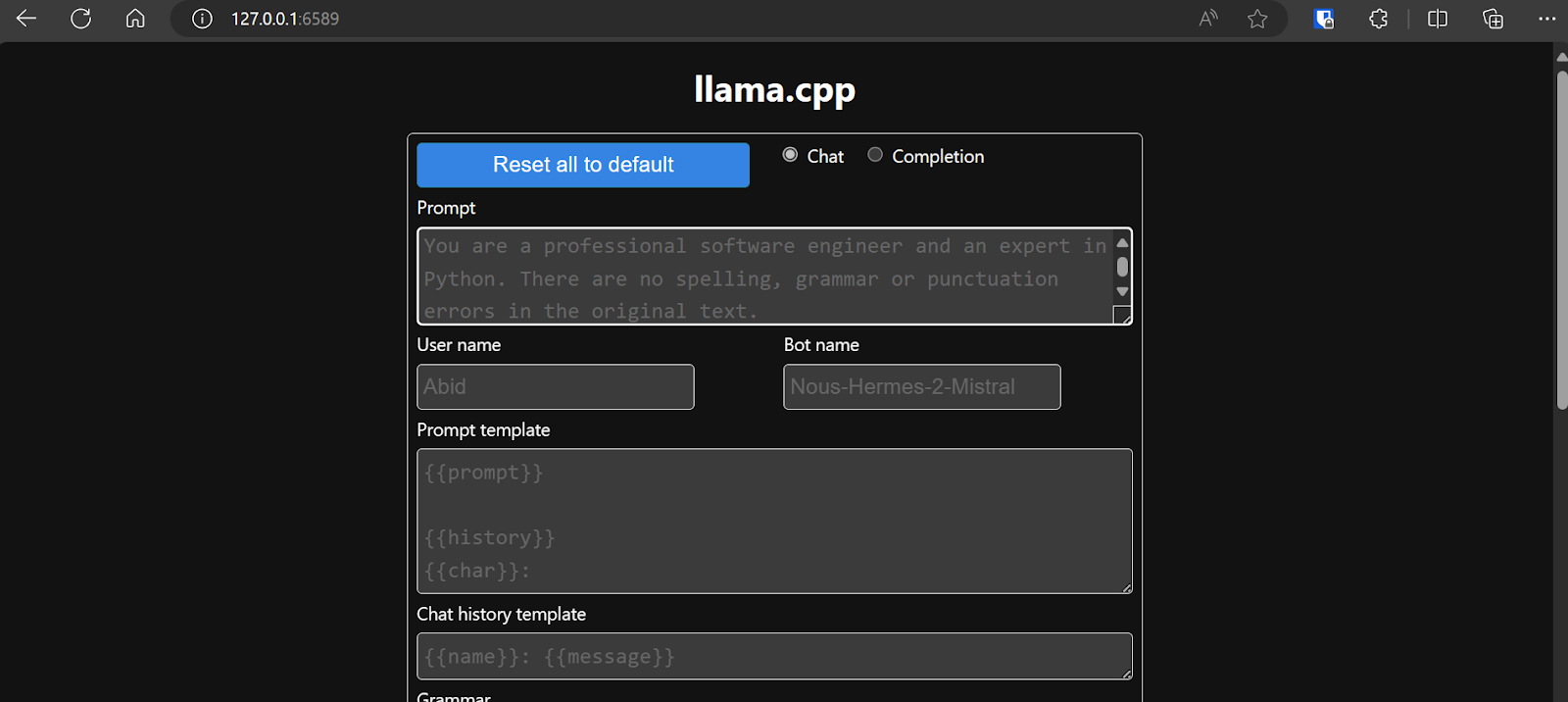
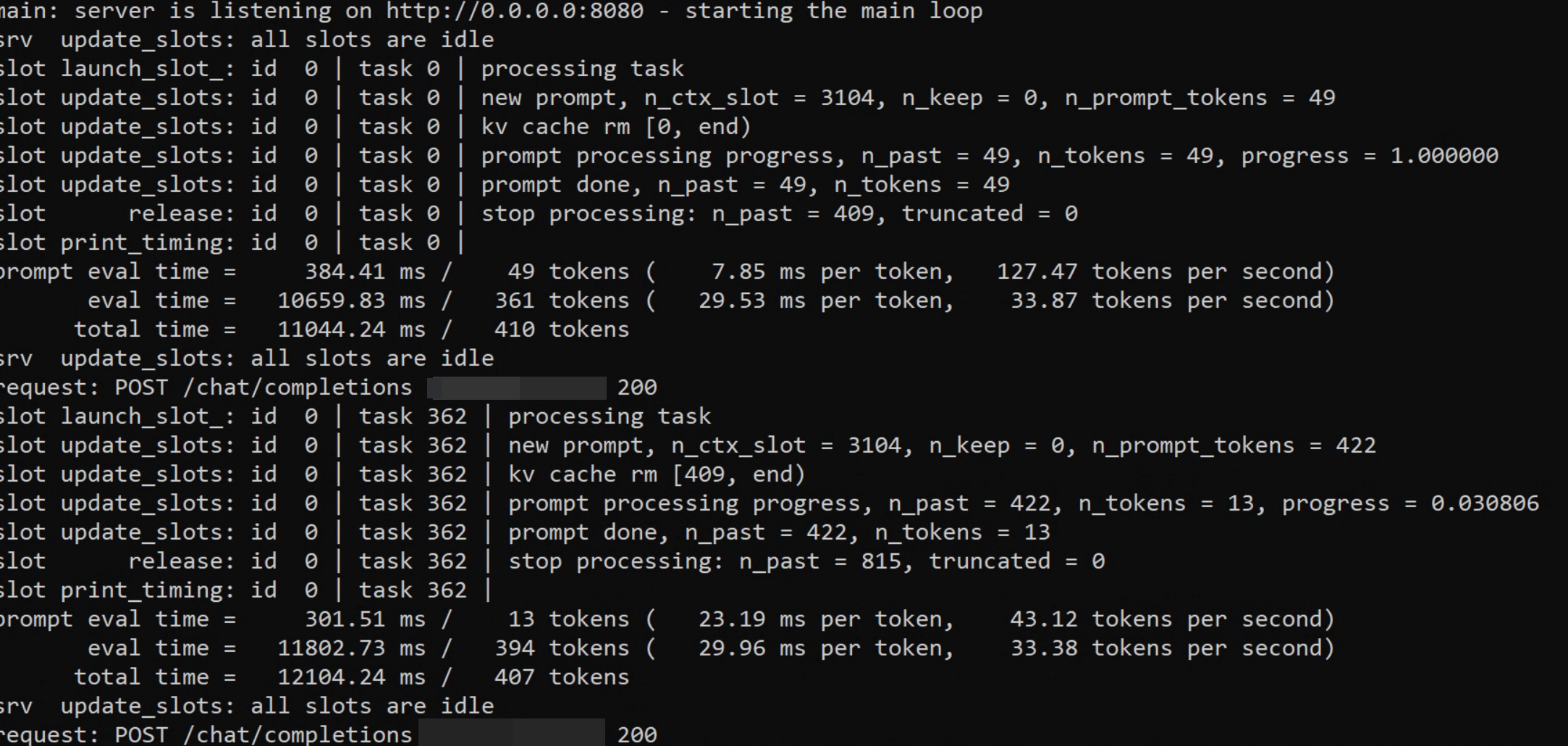
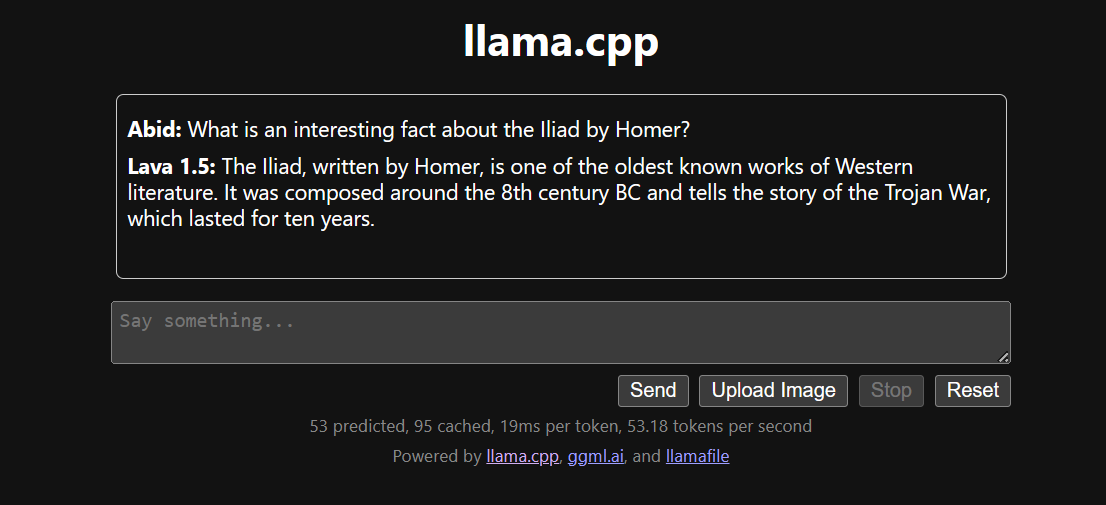
Efficiently Run Your Fine-Tuned LLM Locally Using Llama.cpp 🚀 | by ...
A step by step guide to running a local LLM with llama-cpp-python ...
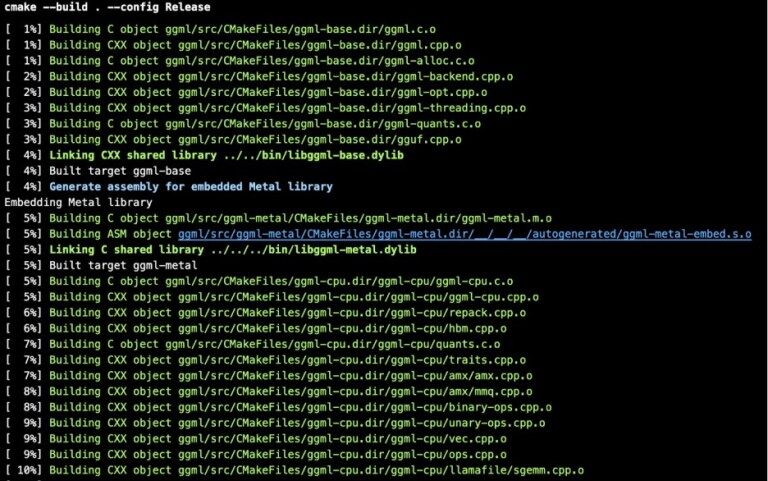
LLM By Examples: Build Llama.cpp with GPU (CUDA) support | by MB20261 ...
How to compile LLM on Android using LLama.cpp | by mmonteiros | Medium
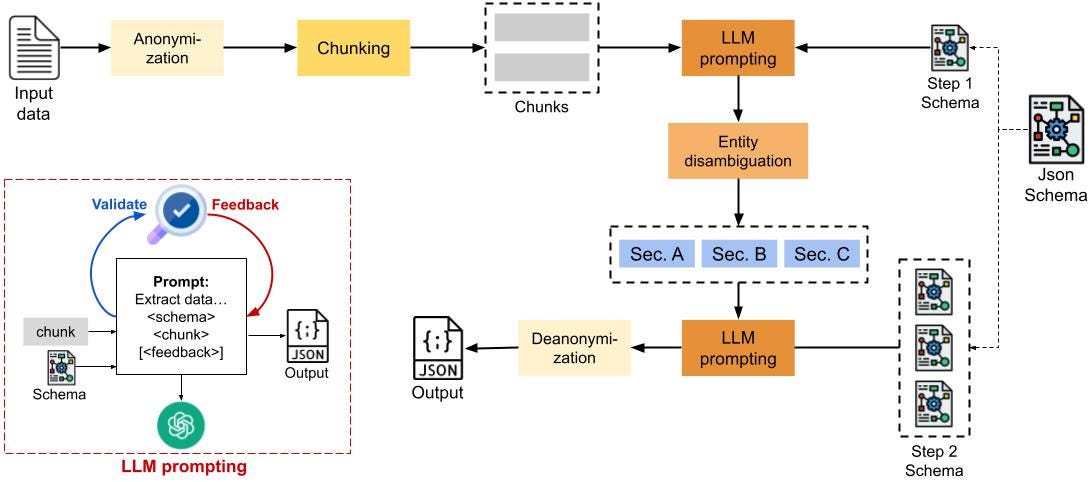
Building Open Source LLM based Chatbots using Llama Index | by Iago ...
Streaming Local LLM Responses with LM Studio Inference Server | by ...
Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and ...
Build from Source Llama.cpp with CUDA GPU Support and Run LLM Models ...
GitHub - awinml/llama-cpp-python-bindings: Run fast LLM Inference using ...
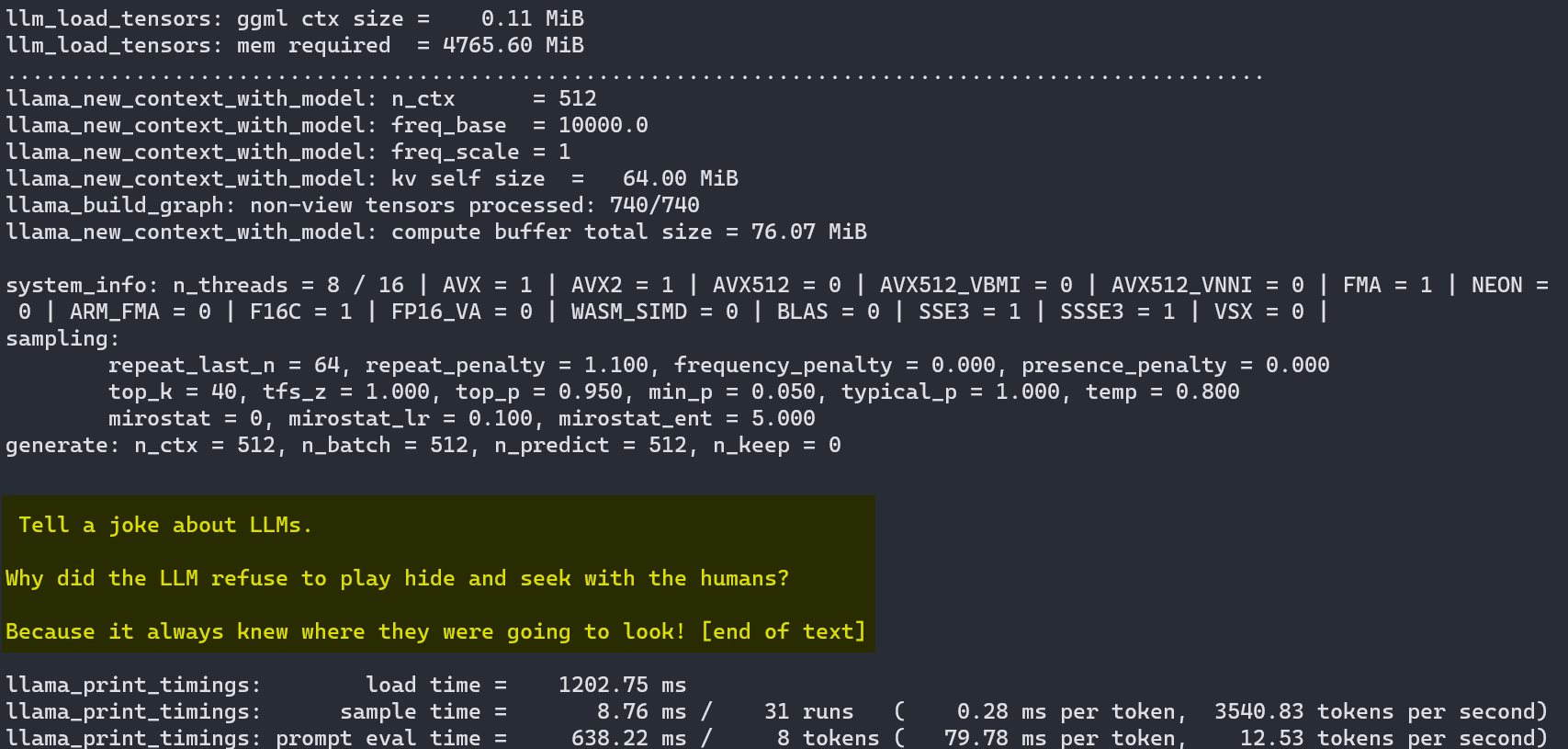
Running LLaMA Locally with Llama.cpp: A Complete Guide | by Mostafa ...
LLM By Examples: Utilizing Llama.cpp by Command Line Tools for CLI and ...
Unlocking LLM: Running LLaMa-2 70B on a GPU with Langchain | by Sasika ...
Local LLM Setup with Docker (GPU-Accelerated) | by Jaakko | Medium
How to Run a Local LLM for Enterprise Use - Intellias
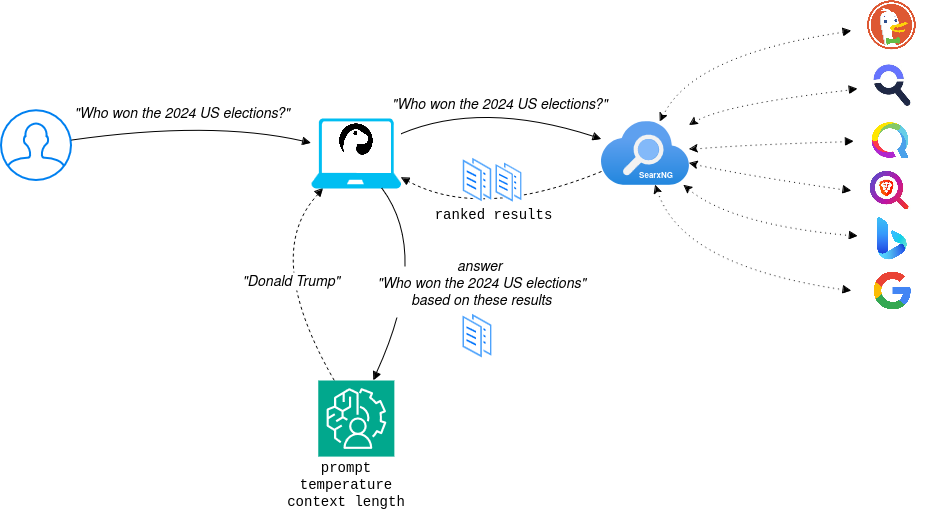
Enhancing Local LLMs: Give Your Local LLM Internet Access Using Python ...
How to run LLMs on PC at home using Llama.cpp • The Register
LLM By Examples: Build Llama.cpp for CPU only | by MB20261 | Medium
Integrating Local LLM Frameworks: A Deep Dive into LM Studio and ...
How to Run Quantized GGUF LLMs Locally on GPU with llama.cpp (No Cloud ...
Your Private AI Code Assistant: A Beginner’s Guide to Offline LLM on ...
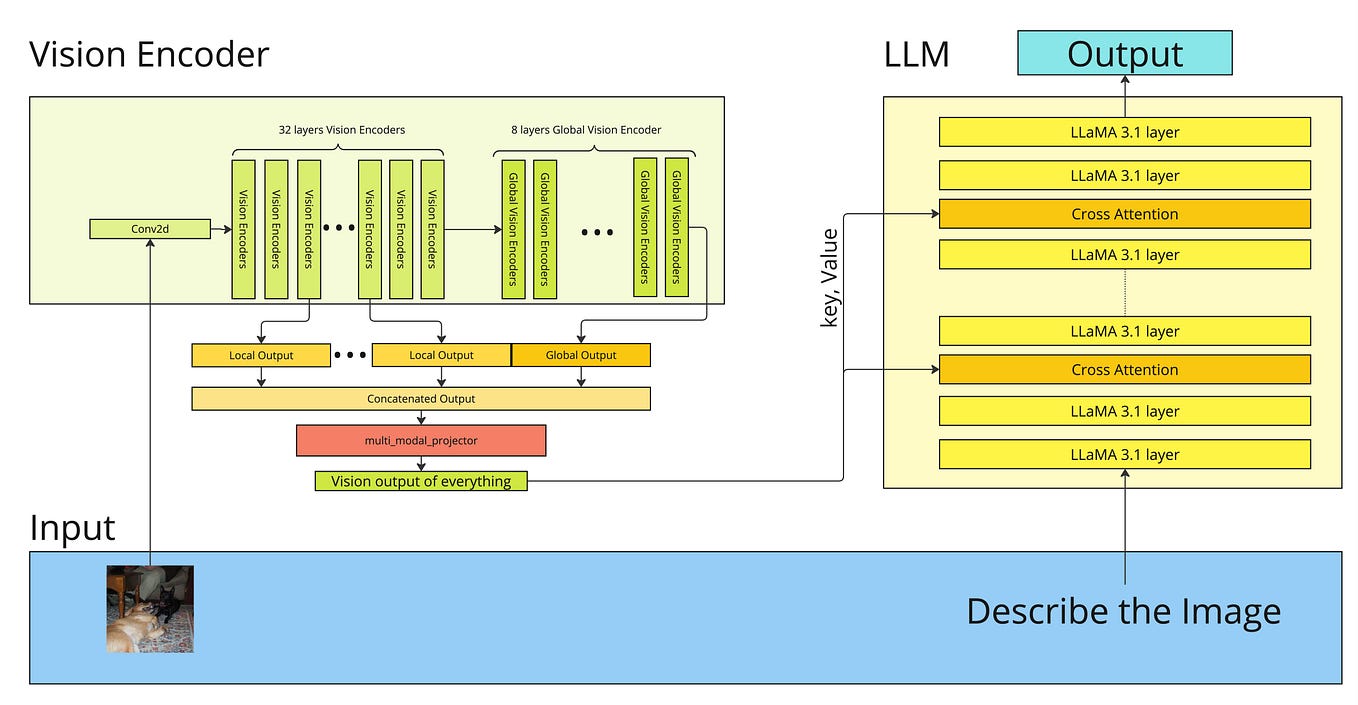
Download, Install and Run Locally Llama 3.2 Vision LLM From Scratch in ...
Demystifying Chat Templates of LLM using llama-cpp and ctransformers ...
Fine-tuning Llama 3 on macOS with MLX for Ollama Deployment | by ...
How to run LLMs like LLaMA 3 on your own system | Chandra Girish S ...
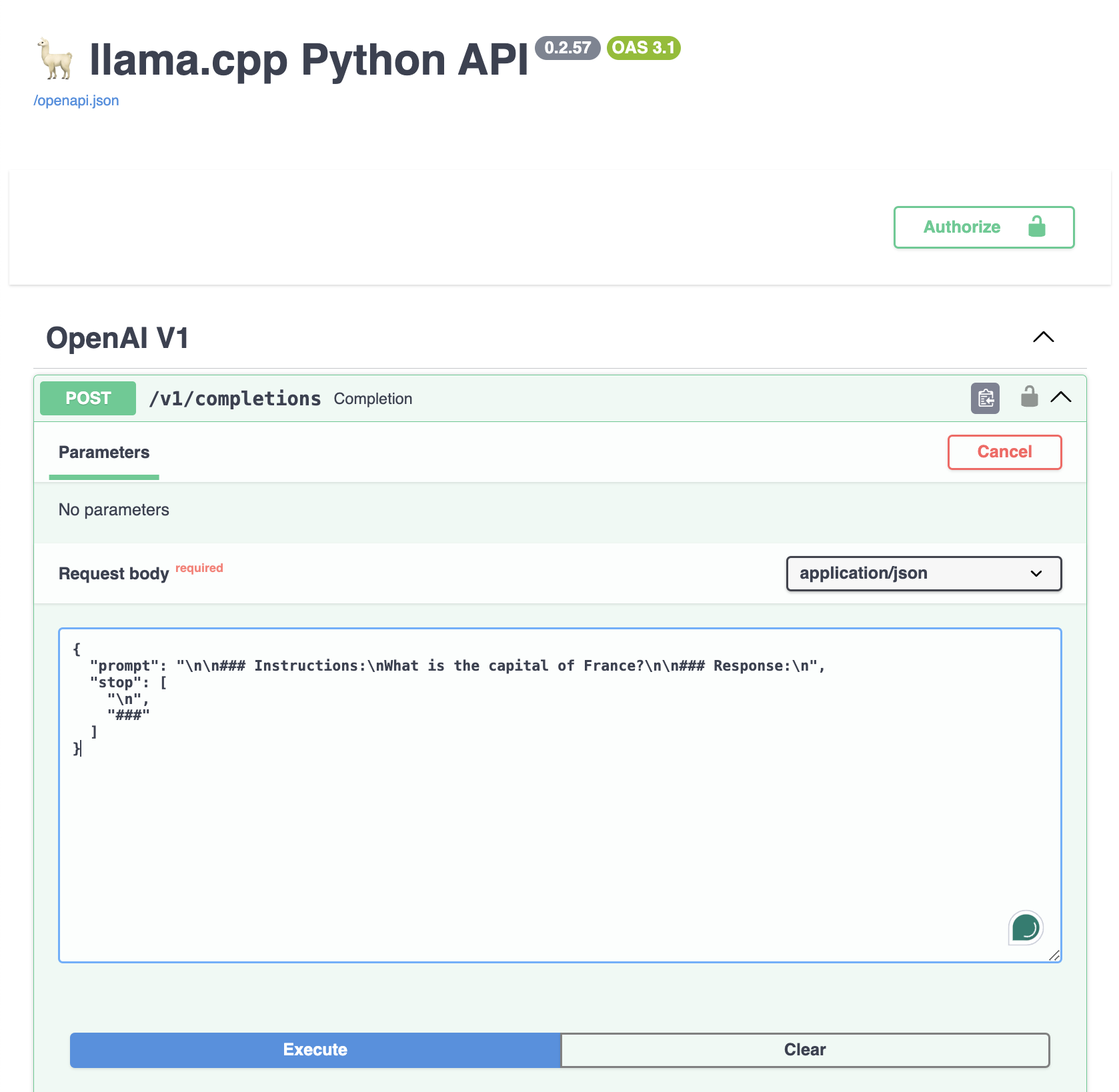
Running OpenAI’s server Locally with Llama.cpp | by Tom Odhiambo | Medium
Learn how to Fine Tune a Llama 3.1 8B LLM with your own custom data ...
🦙 Optimize Your LLM Models and Save Costs with llama.cpp Quantization 🦙 ...
Llama-CPP-Python: Step-by-step Guide to Run LLMs on Local Machine ...
Quantization of LLMs with llama.cpp | by Ingrid Stevens | Medium
tutorial : compute embeddings using llama.cpp · ggml-org llama.cpp ...
RAG Tutorial with Langchain: From Basics to Advanced Optimization | by ...
Running LLM Inference Locally: A Guide to Deploying Large Language ...
AI for everyone: projects that allow us to run LLM models on modest ...
Local LLM for Desktop Applications: Run Llama 2 & Llama 3 in Python
Run LLMs (Llama 3) Locally with llama.cpp | Medium
Running local LLM with LM Studio. If you want to use Ollama then follow ...
Accelerating LLMs with llama.cpp on NVIDIA RTX Systems | NVIDIA ...
50+ Open-Source Options for Running LLMs Locally | by Vince Lam | The ...
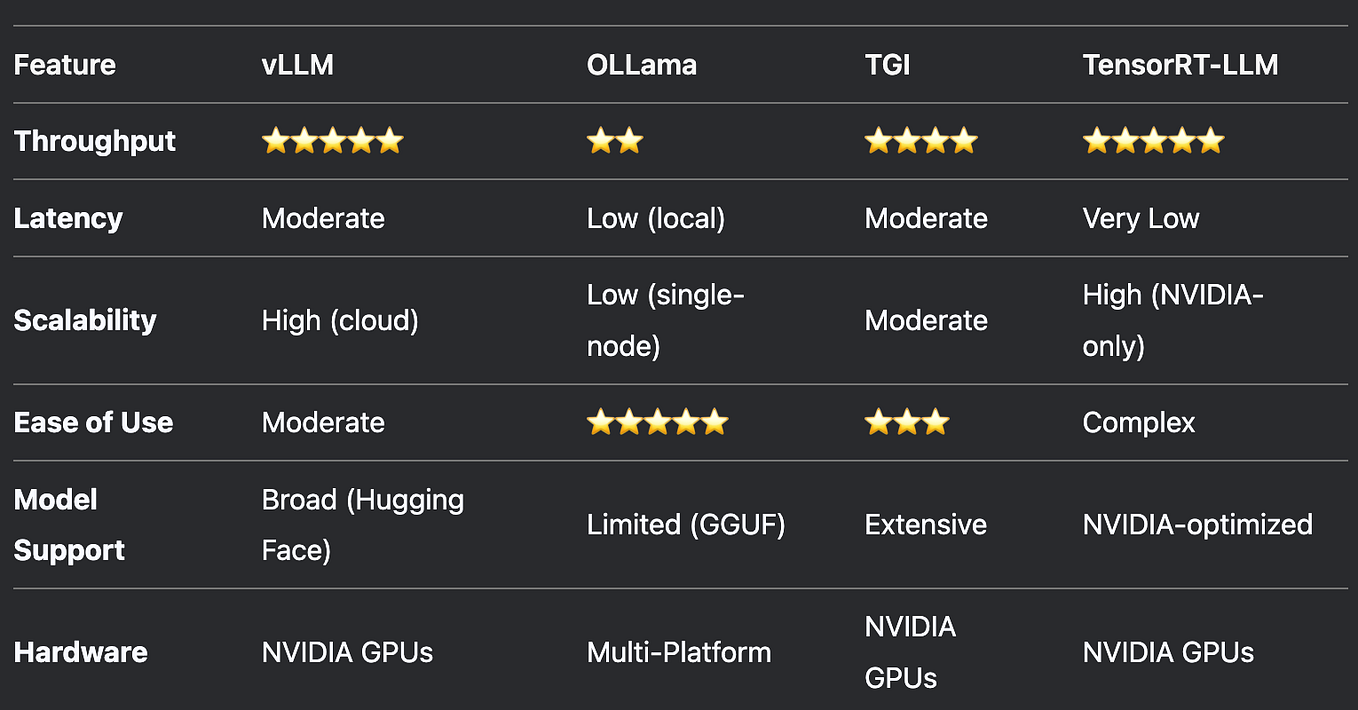
LLM inference server performances comparison llama.cpp / TGI / vLLM ...
Oba mage hadawathe paladuwa ️😍🤟🎤🎧cover by @sajith Sajith madushanka # ...
Unlocking the Potential of LLM with Llama 3.1: A Comprehensive Guide ...
How to Run Local LLMs with Llama.cpp: Complete Guide - YouTube
Simplified Tutorial on Running LLMs (Llama 3) Locally with llama.cpp ...
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
Running Lightweight Language Models Locally: A Practical Setup Guide ...
Locally-hosted, offline LLM w/LlamaIndex + OPT (open source ...
Engineer's Guide to Local LLMs with LLaMA.cpp on Linux - DEV Community
llama.cpp: The Ultimate Guide to Efficient LLM Inference and ...
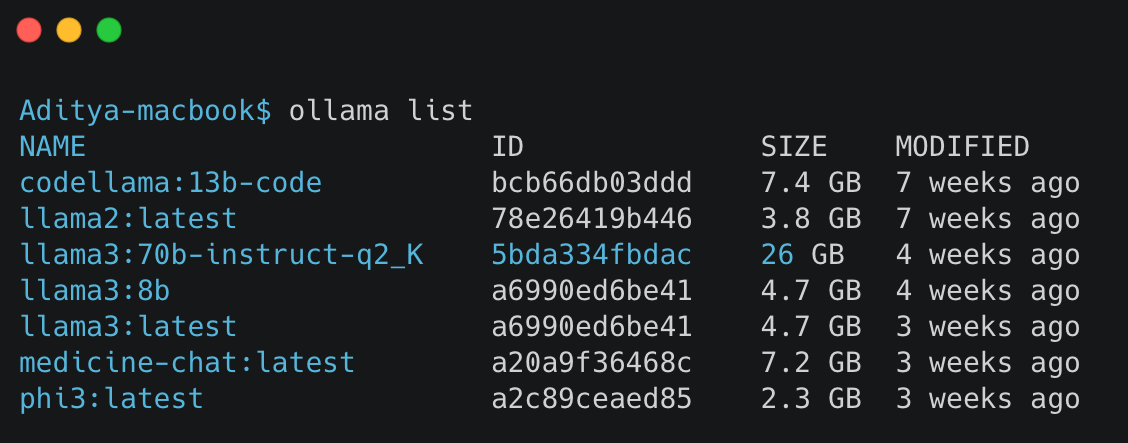
Run Llama 3 Locally with Ollama | Medium
The 6 Best LLM Tools To Run Models Locally
Free Video: LLMOps: Installing LLaMA.cpp - Text Generation and ...
GitHub - TheBlewish/Web-LLM-Assistant-Llamacpp-Ollama: A Python-based ...
Build and Run llama.cpp Locally for Nvidia GPU - YouTube
Key concepts in llama.cpp walkthrough - Large Language Models on AWS ...
Run LLMs Locally: 7 Simple Methods | DataCamp
NVIDIA showcases ways to implement local LLMs on RTX-powered PCs feat ...
Install llama-cpp-python with GPU Support | by Manish Kovelamudi | Medium
Sajith Premadasa Meets Japanese Ambassador to Discuss Disaster Relief ...
Running LLMs on a Mac with llama.cpp - YouTube
How to install LLAMA CPP with CUDA (on Windows) | by Kaizin | Medium
Breaking News: Run Large LLMs Locally with Less RAM and Higher Speed ...
How to fix: llama.cpp built without libcurl · ggml-org llama.cpp ...
Running AI Locally With Llama.cpp - by BowTiedCrocodile
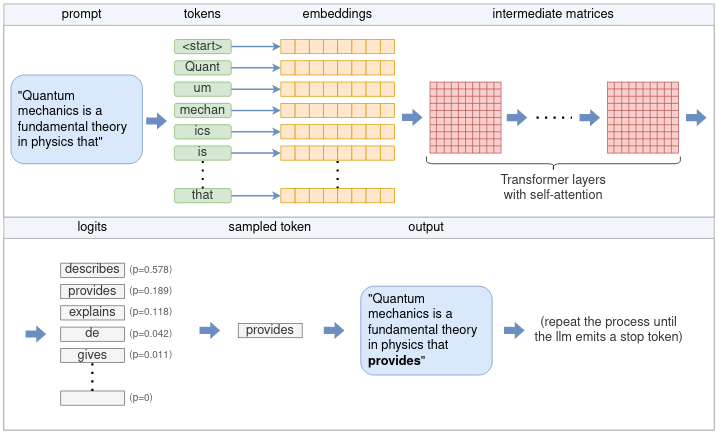
Understanding how LLM inference works with llama.cpp
Sajith Sivanandan to Lead Tata Digital as New CEO from September 1 ...
How to Compile and Build the GPU version of llama.cpp from source and ...
Easy Steps to Set Up Your Open-Source LLM with Llama 3.2
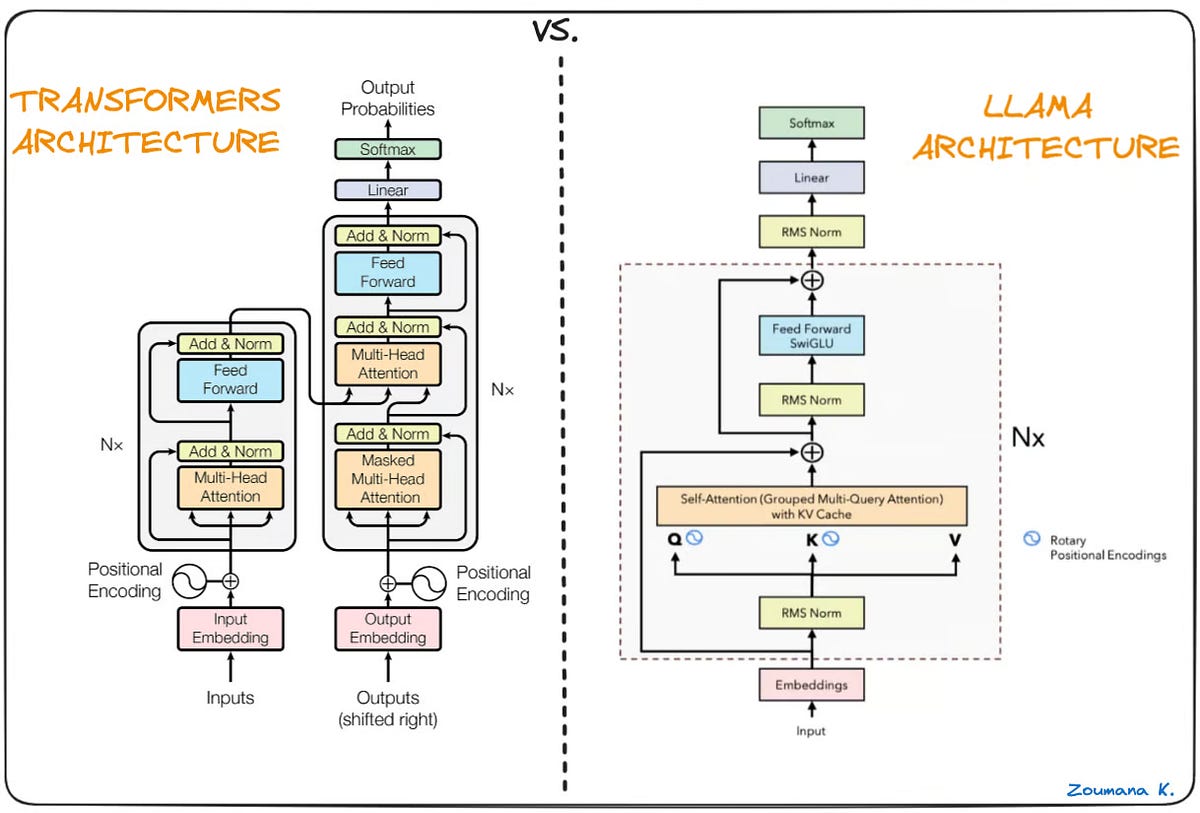
Lessons from llama.cpp
Optimizing text processing with LLM. Insights into llama.cpp and guidance
How to Access Free Open-Source LLMs Like LLaMA 3 from Hugging Face ...
Running Quantized LLAMA Models Locally on macOS with LangChain and ...
hackerllama - The Llama Hitchiking Guide to Local LLMs
New E Money Site Sinhala - SL Sajith
how to make money online - SL Sajith
Building LLM Apps for Production, Part 1
Sajith Sripathi
Midhun T S | Life doesn’t get easier, You just get Stronger😎😎😎 | Instagram
Use llama.cpp with BigDL-LLM on Intel GPU — BigDL latest documentation
Dilith Congratulates Sajith on Retirement Decision
GitHub - LoongsonLab/projX-la-llama.cpp: llma.cpp在LoongArch平台的移植与优化 · ...
Sajith Niroshan
Sajith off to India on official visit – The Island
About – Kushantha Sajith Lakshan – Medium
Sajith Alankara
"Many People who Voted for each Side are Now Orphans.” - Sajith
Sajith Tharaka (@sajith.lk) • Instagram photos and videos
Sajith Surendran on Medium curated some lists
How To Run LLMs Locally - Deployment And Benchmark
Sajith Promises LKR 20,000 Monthly Aid to Poor Families
Facebook
HOME - iRiseCon 2026
deploy open llms with llama cpp server - YouTube
Web-LLM-Assistant Llama-cpp, demonstration - YouTube
Deploy Open LLMs with LLAMA-CPP Server - Datatunnel
Seven Ways of Running Large Language Models (LLMs) Locally (April 2024)
Deploy Open LLMs with LLAMA-CPP Server - YouTube
Lalkantha Doubts, But Sajith’s Got the Womb Vote!
How to Deploy Open LLMs with LLAMA-CPP Server : r/PostAI
Sajith's ONE STOP SHOP concept