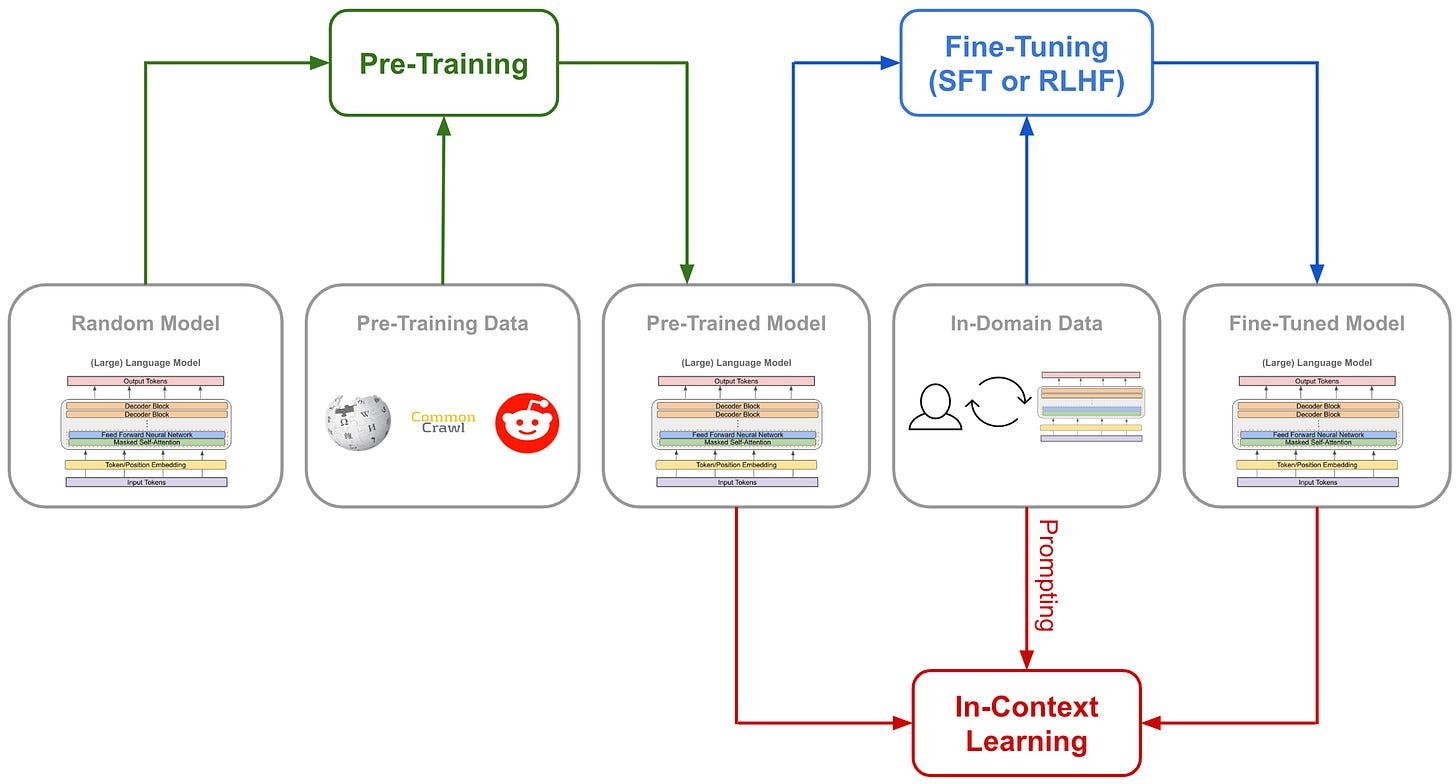
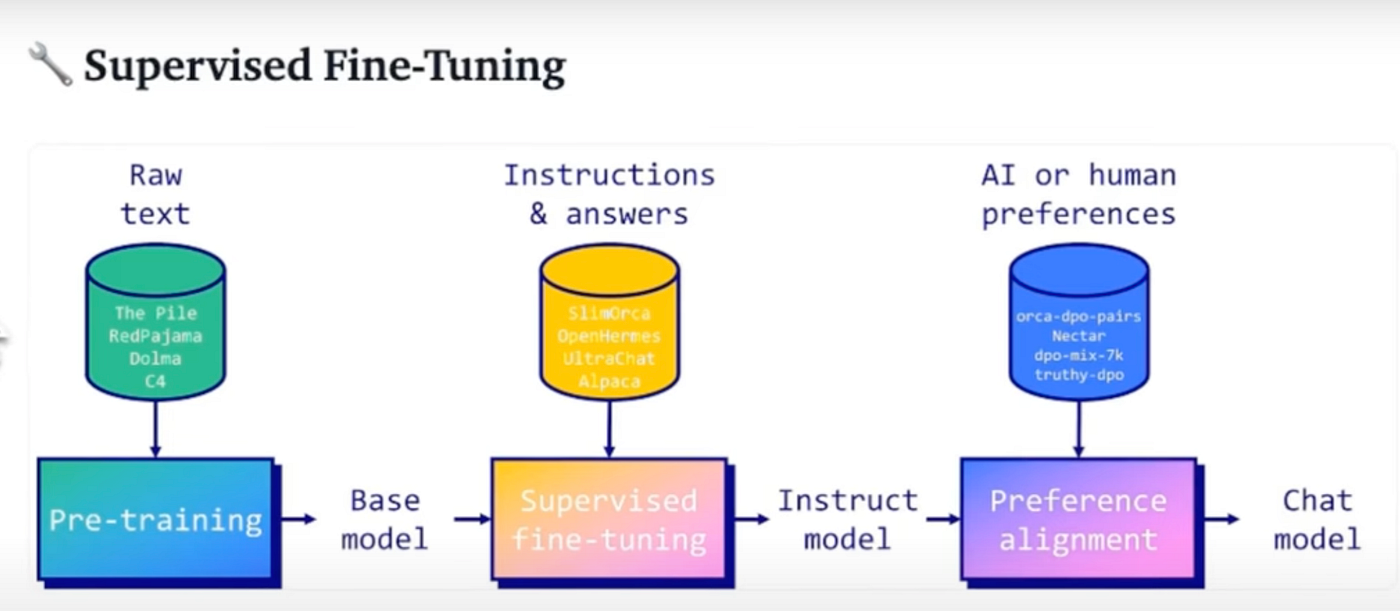
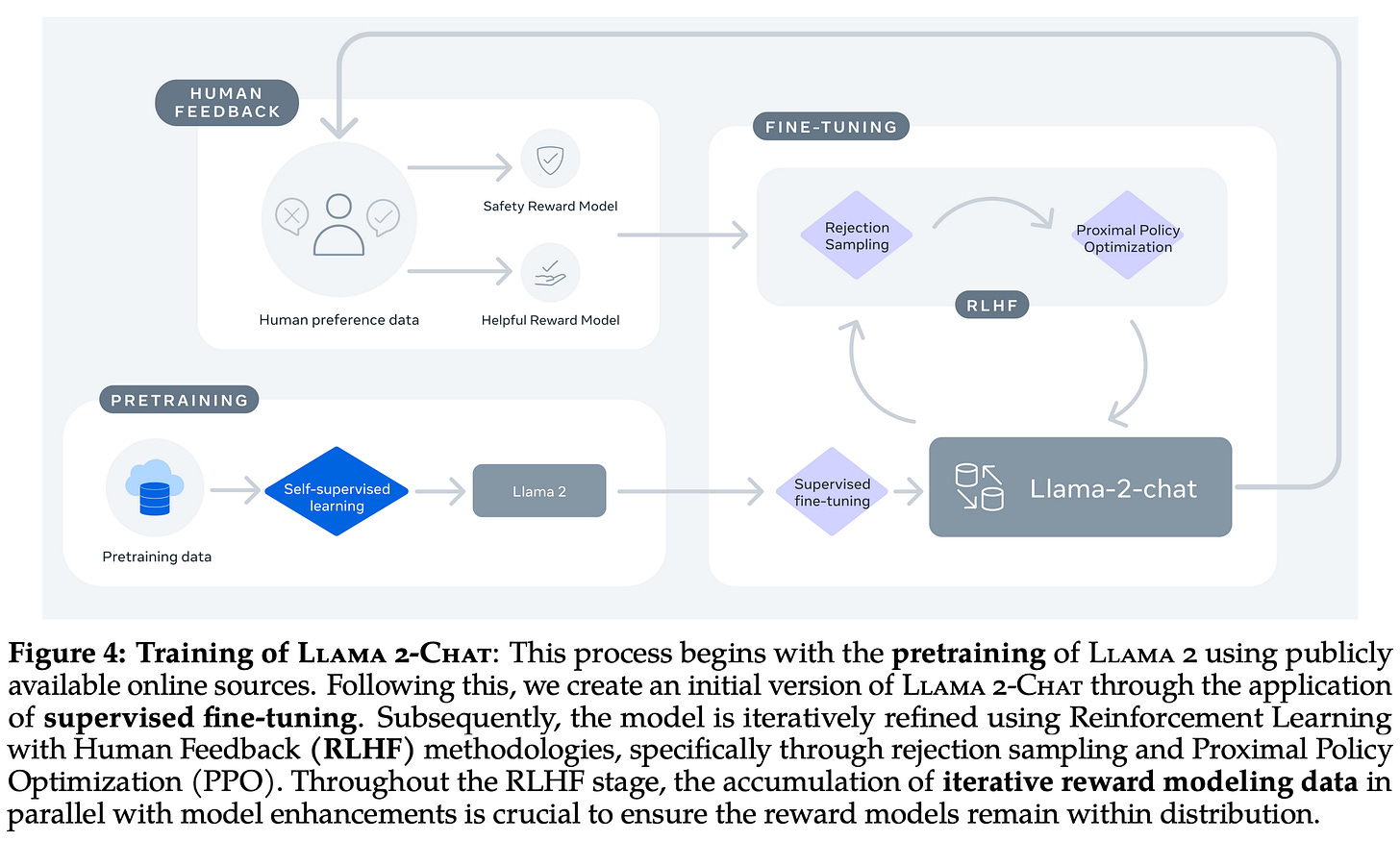
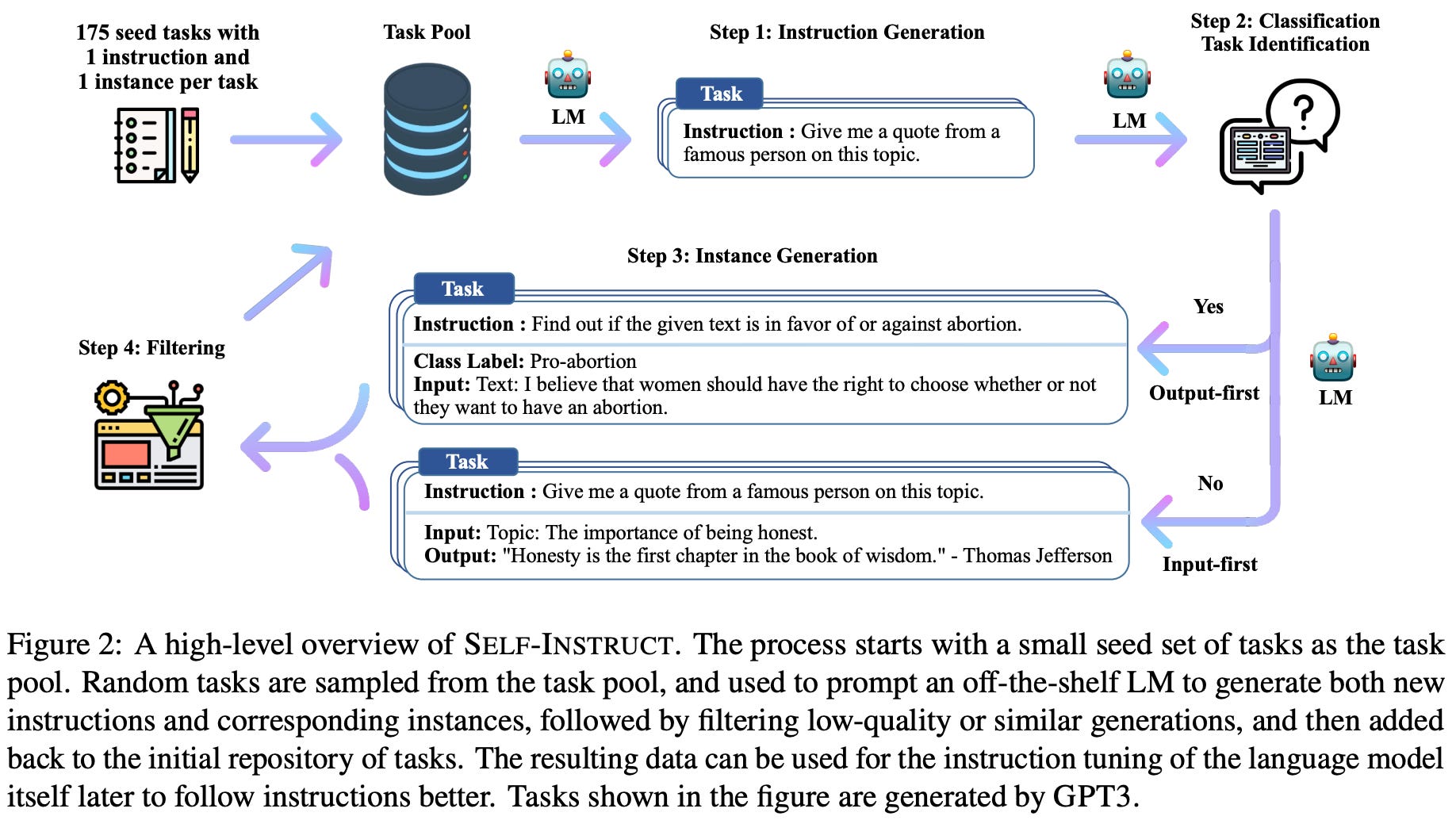
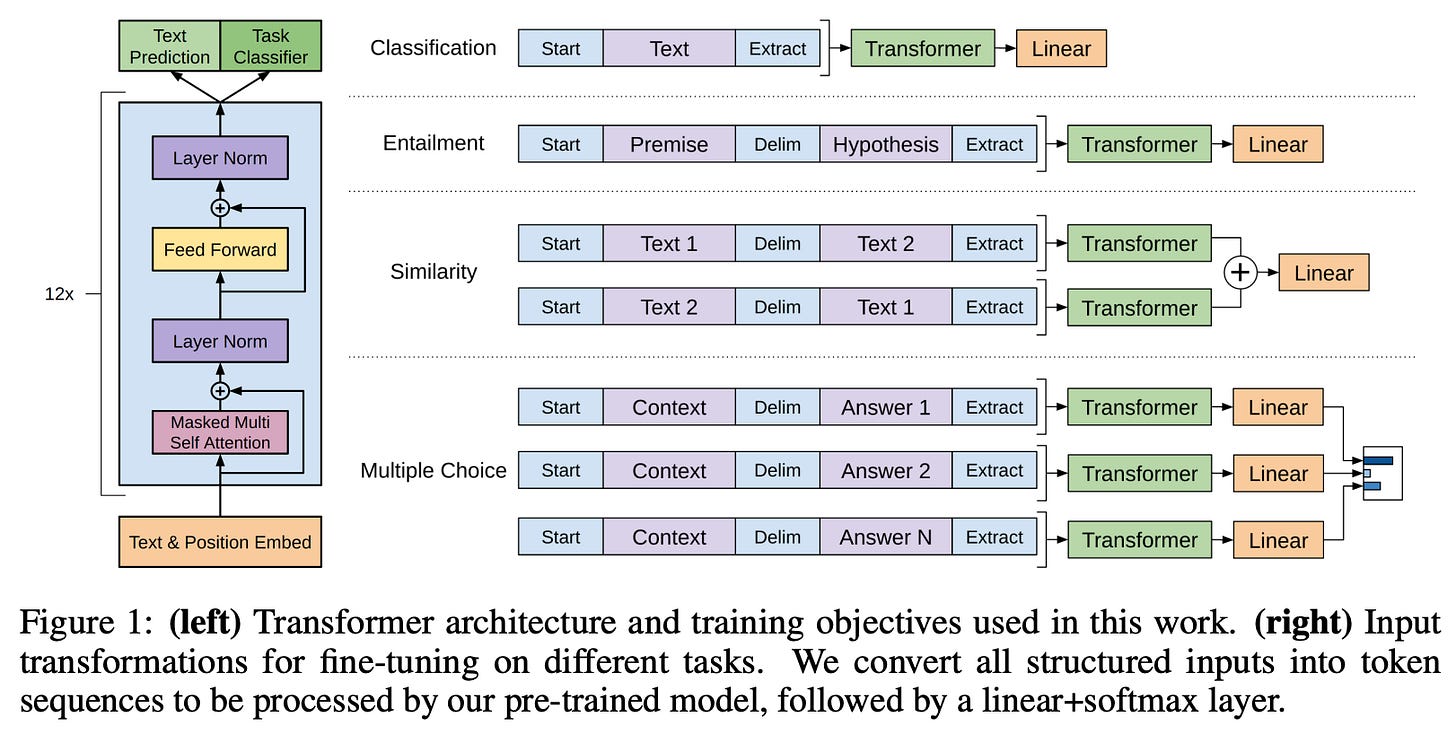
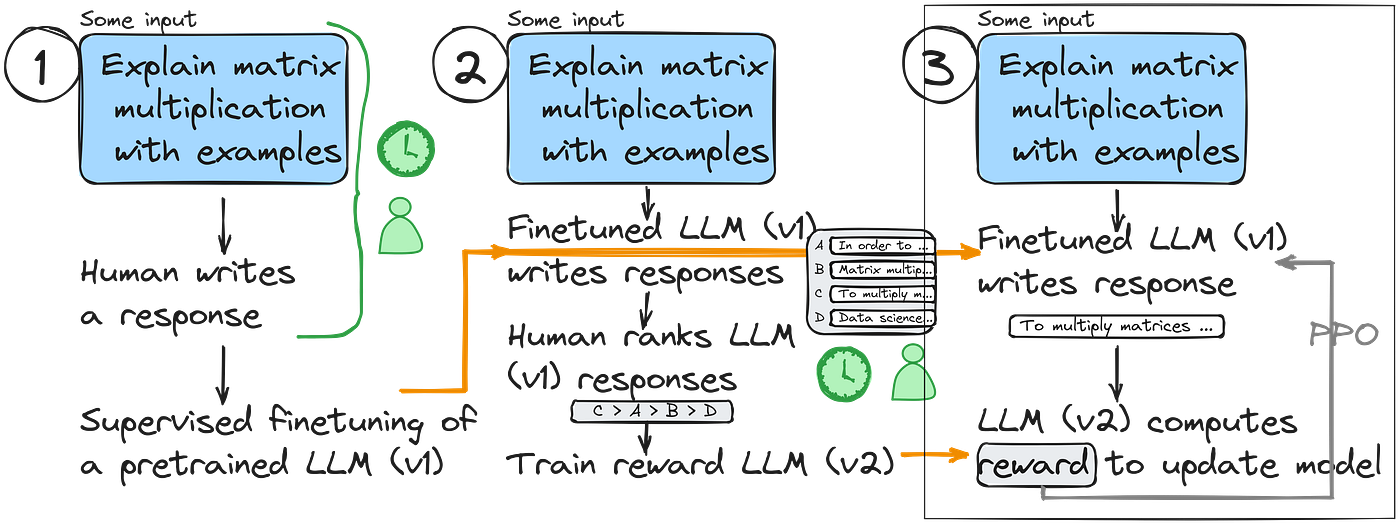
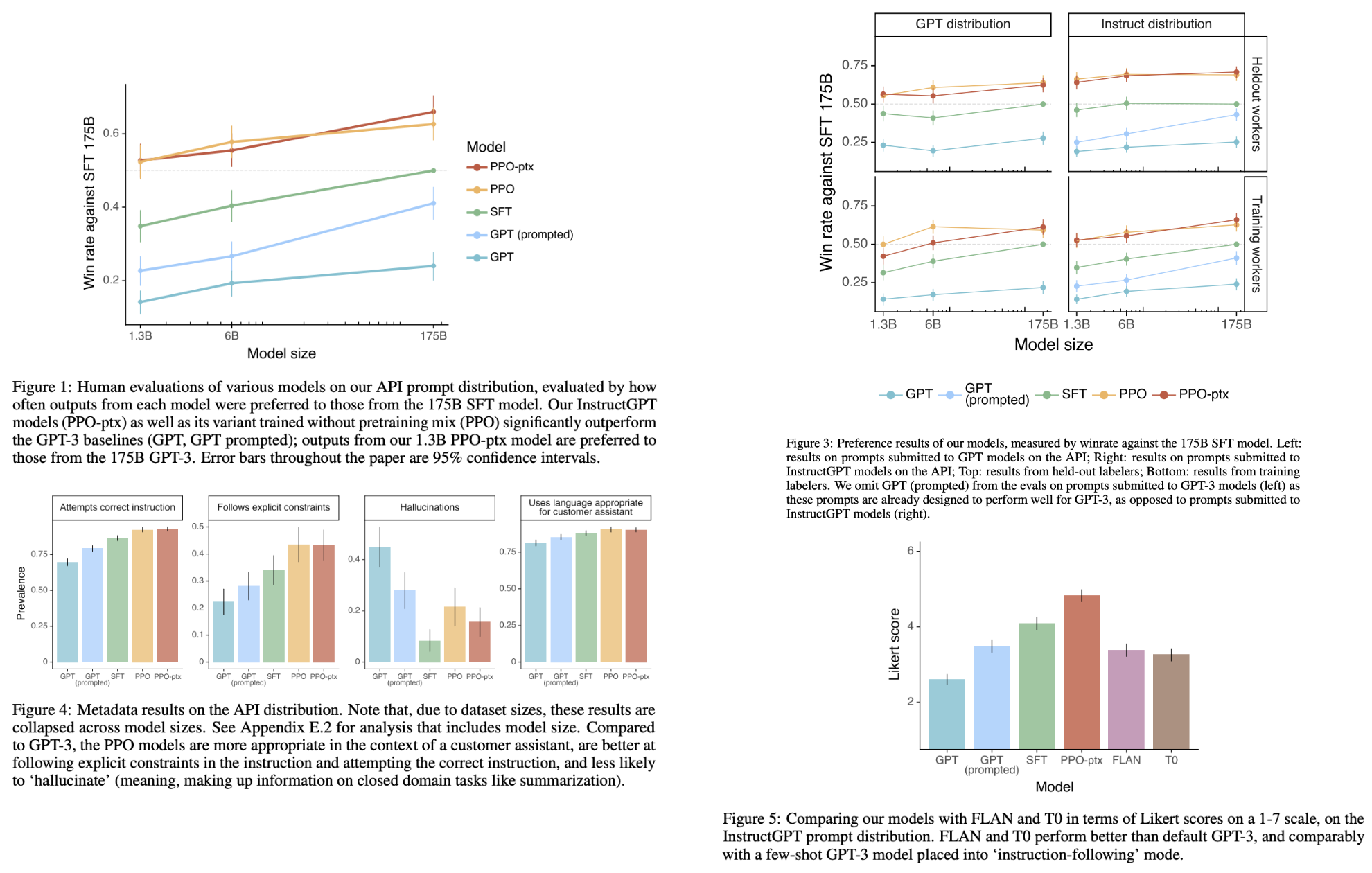
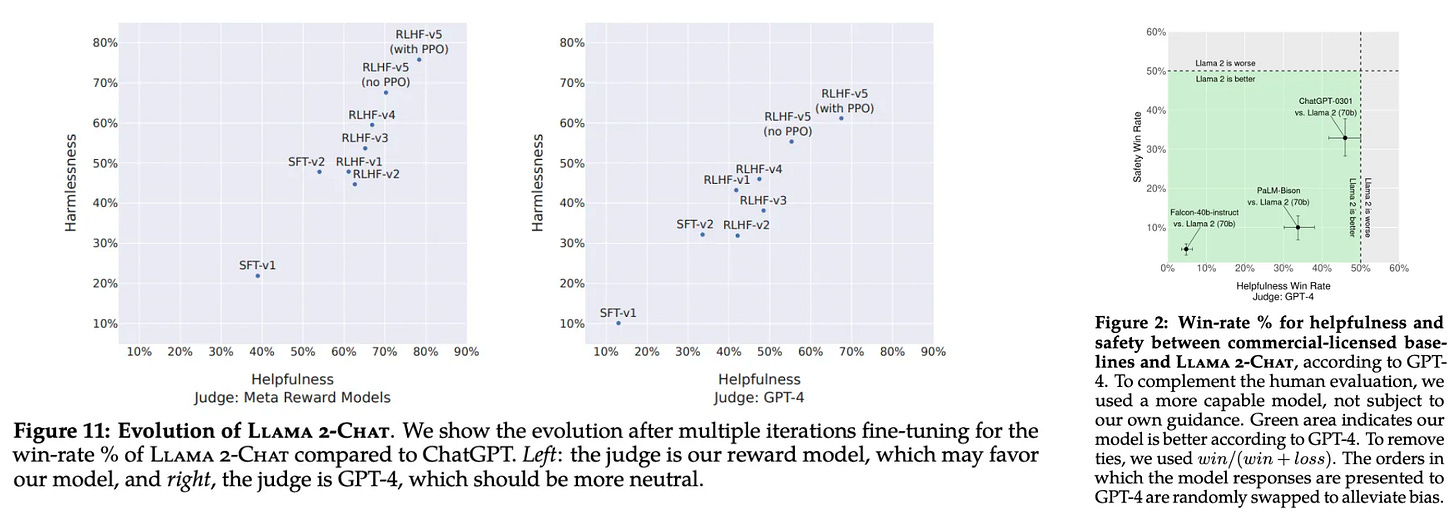
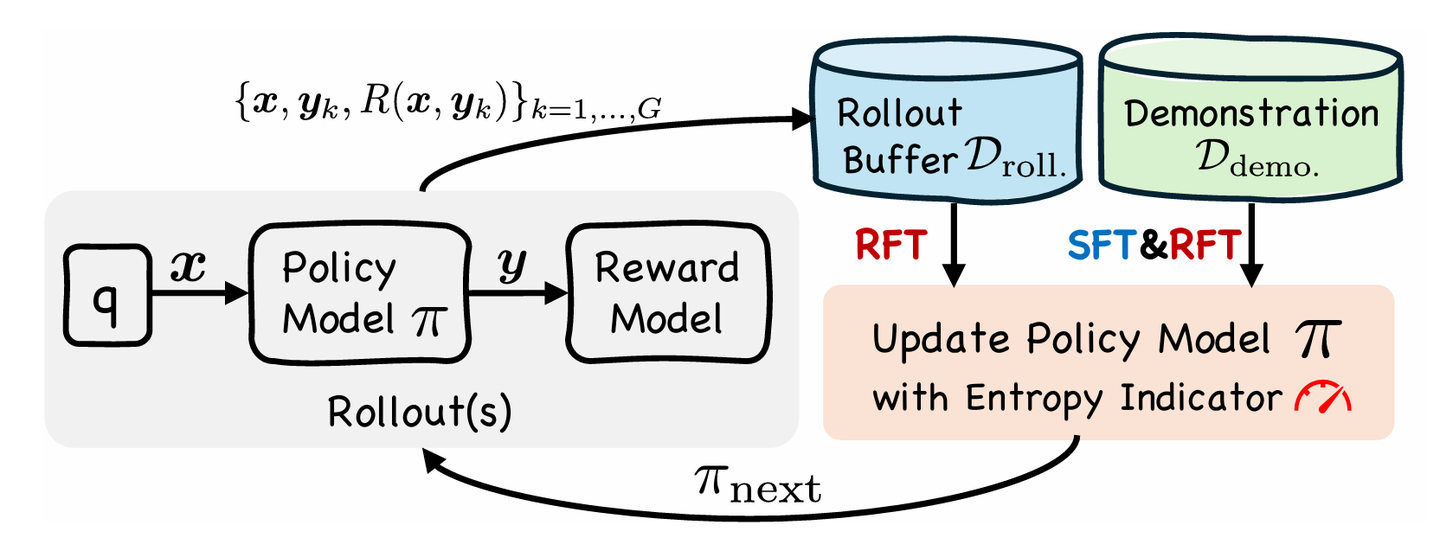
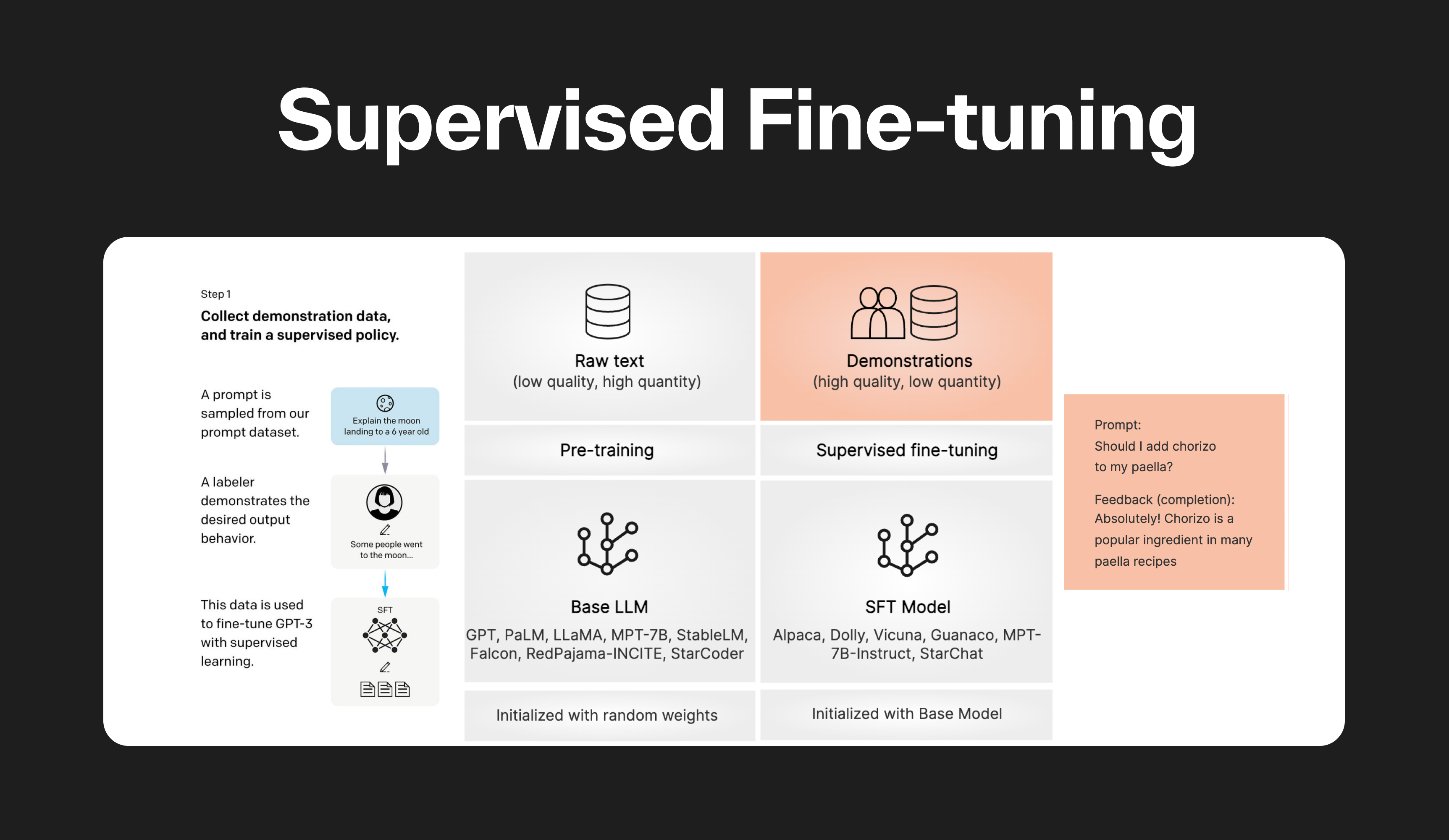
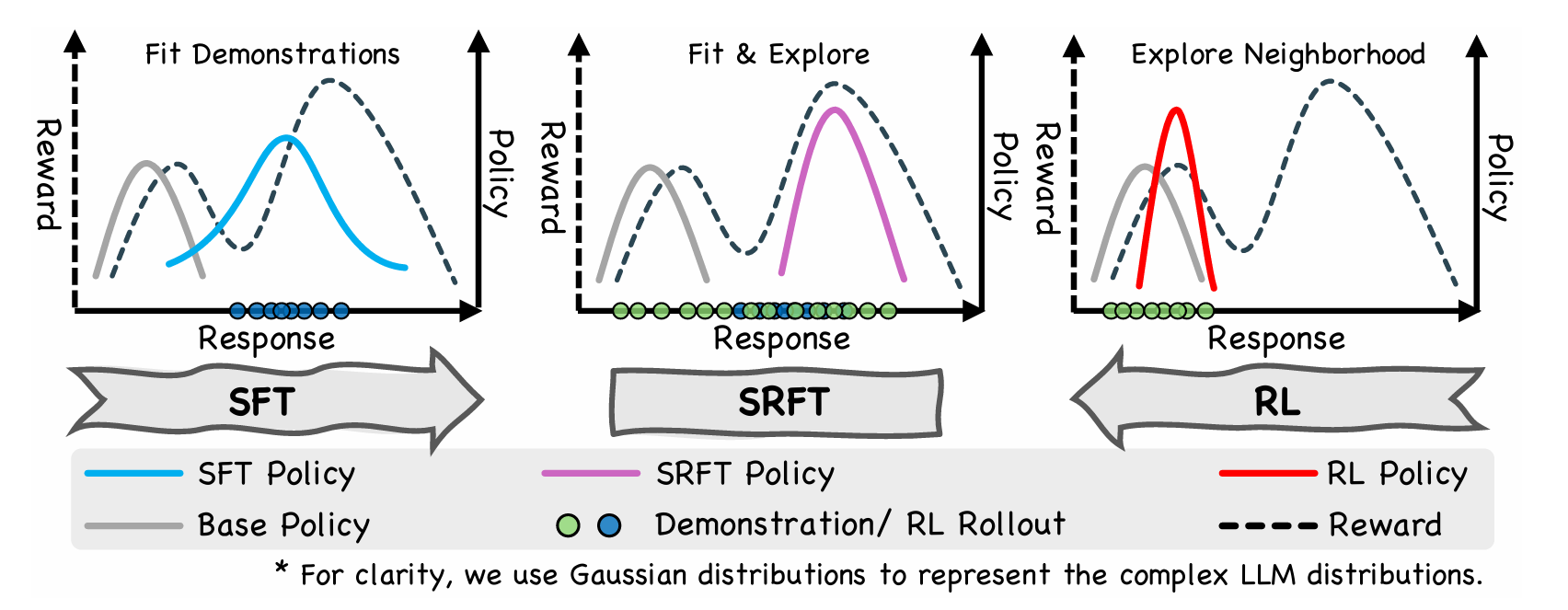
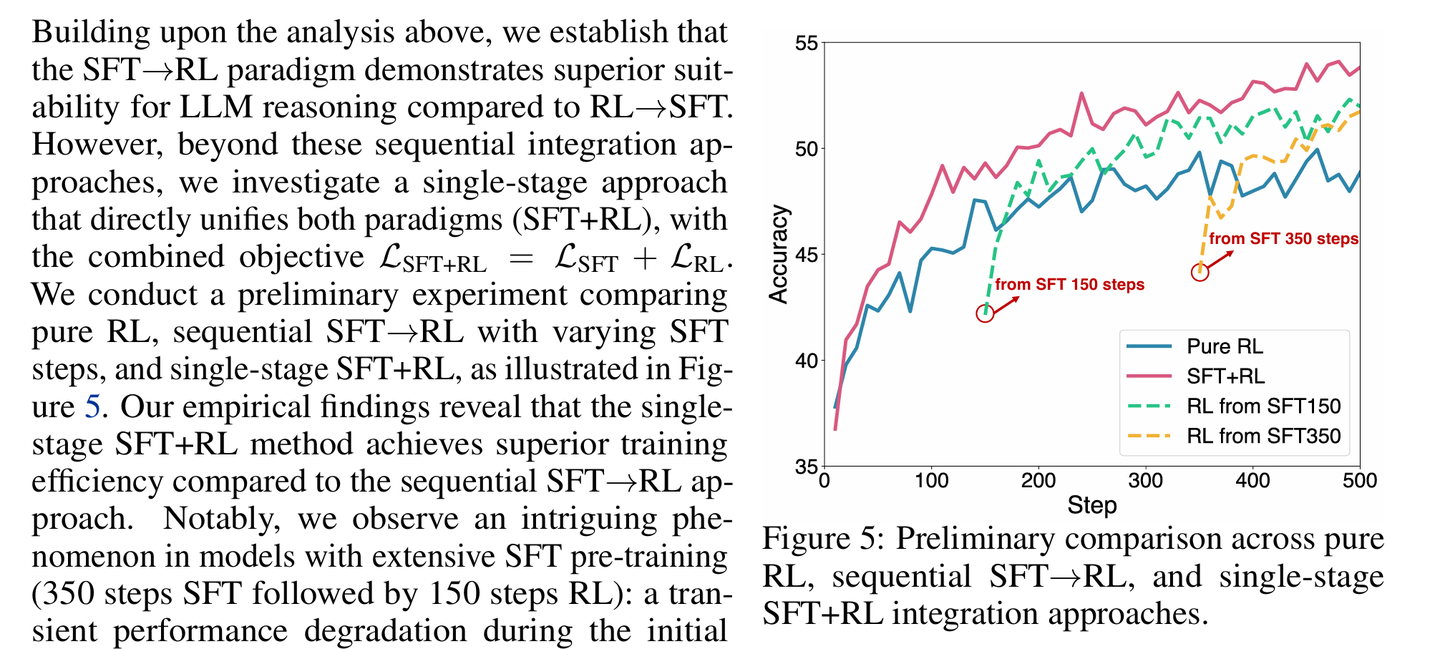
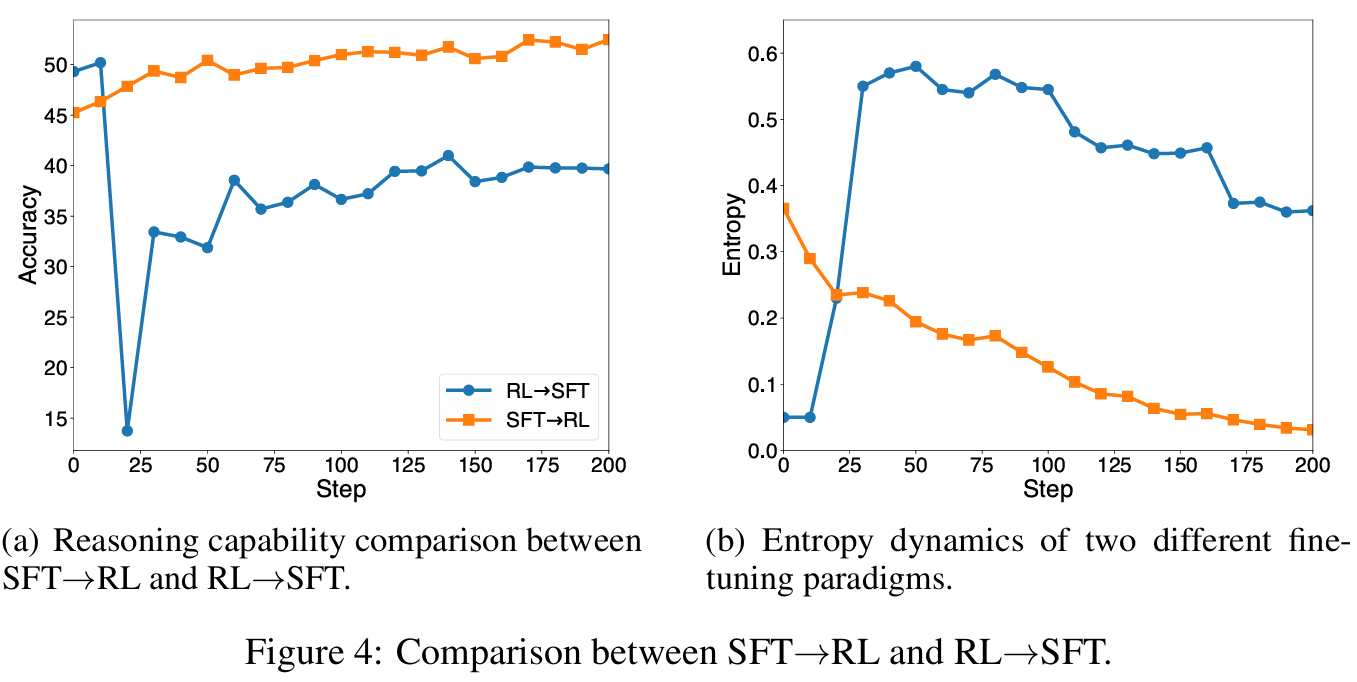
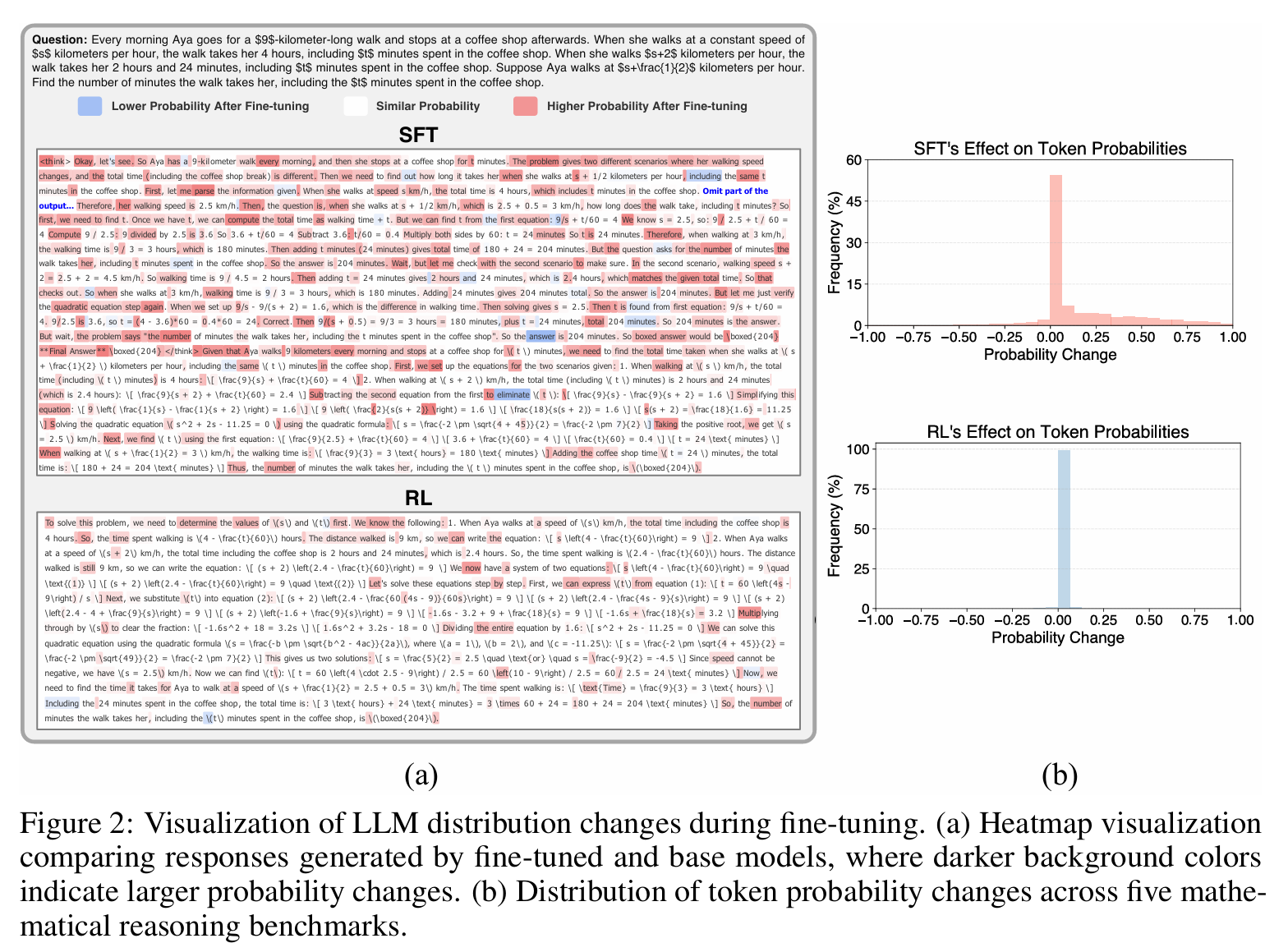
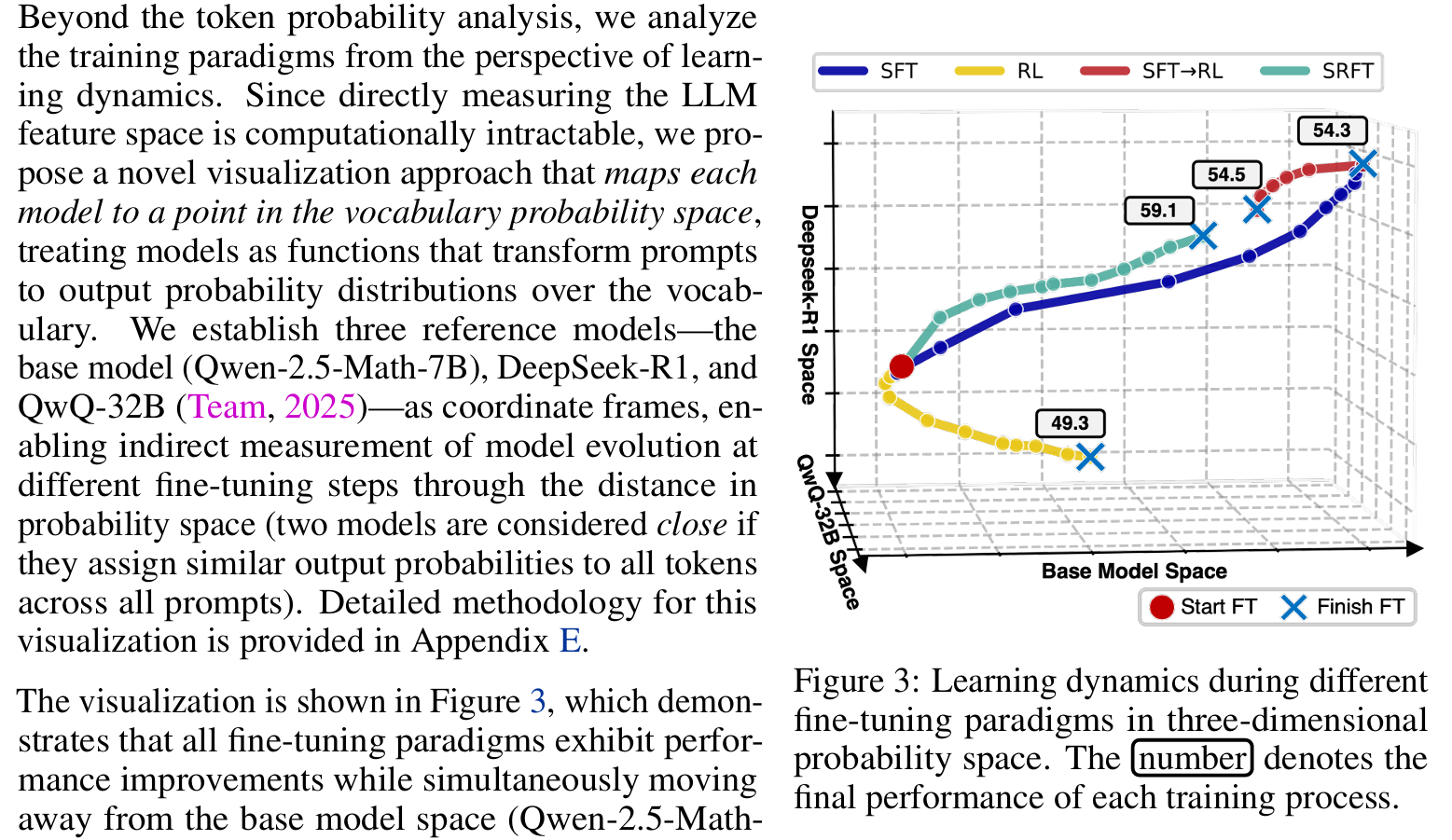
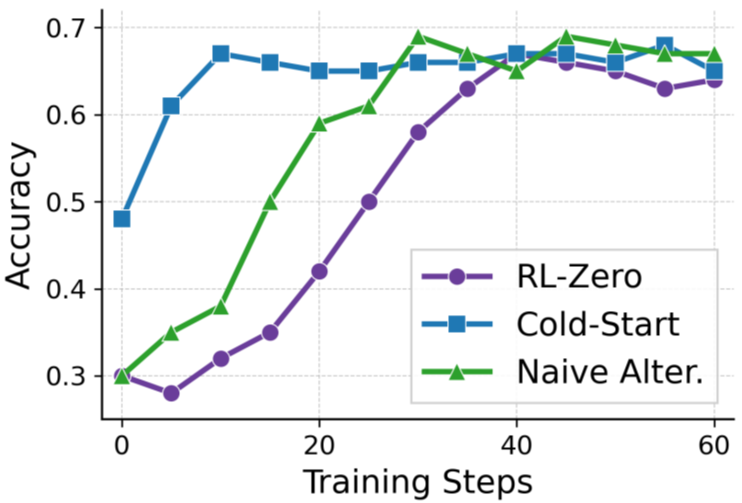
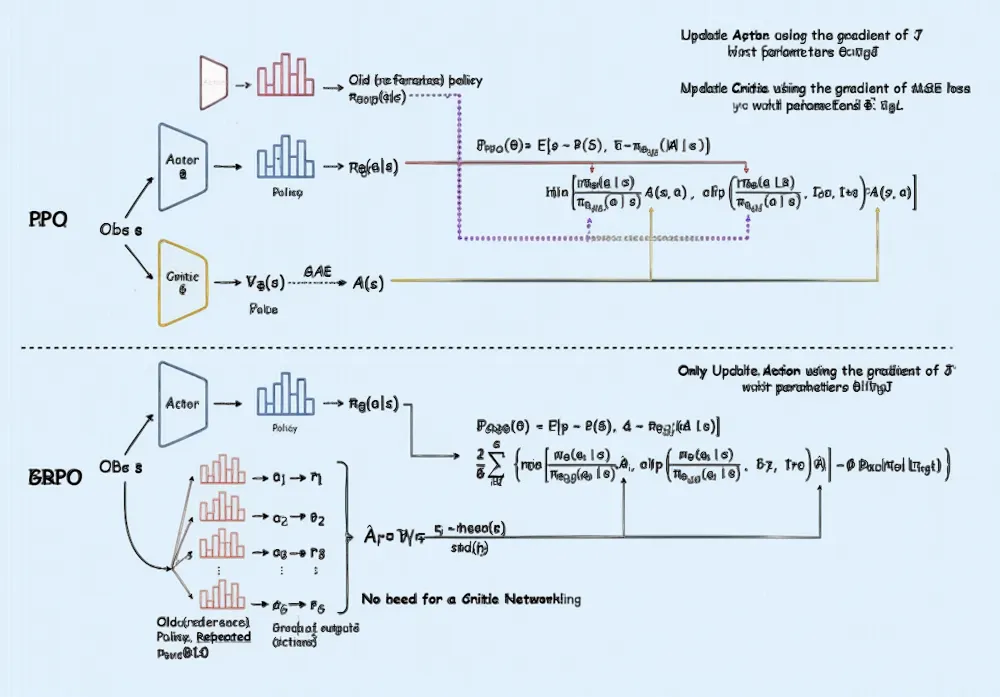
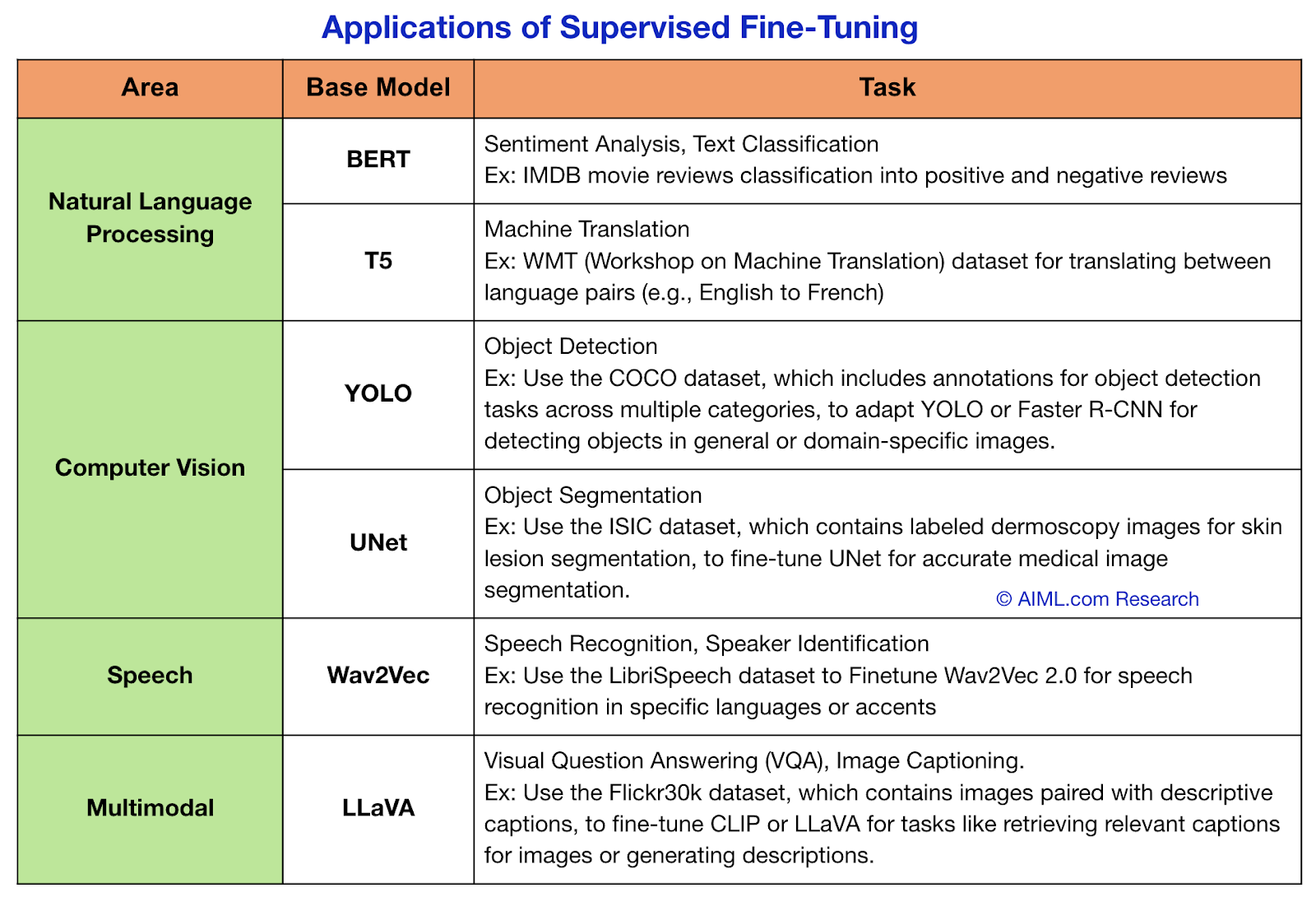
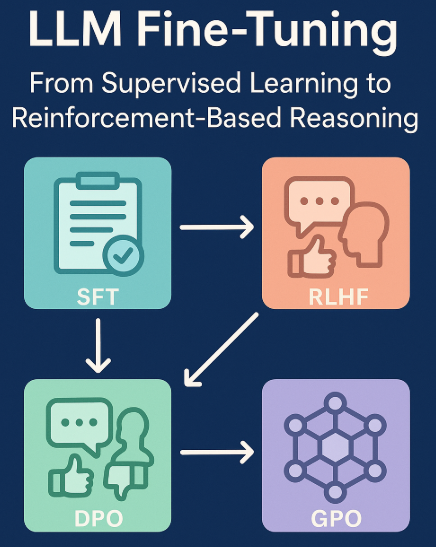
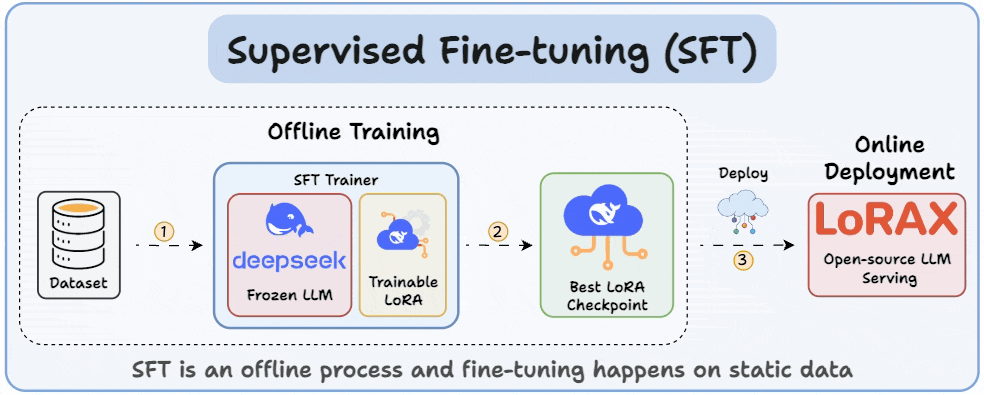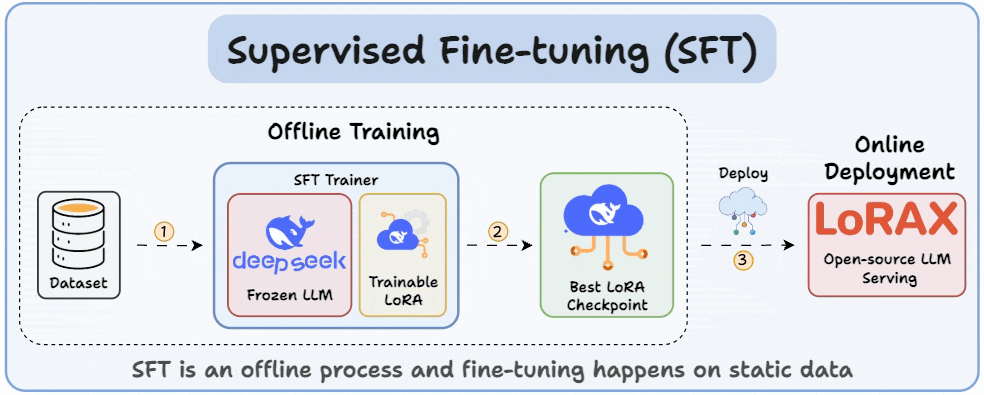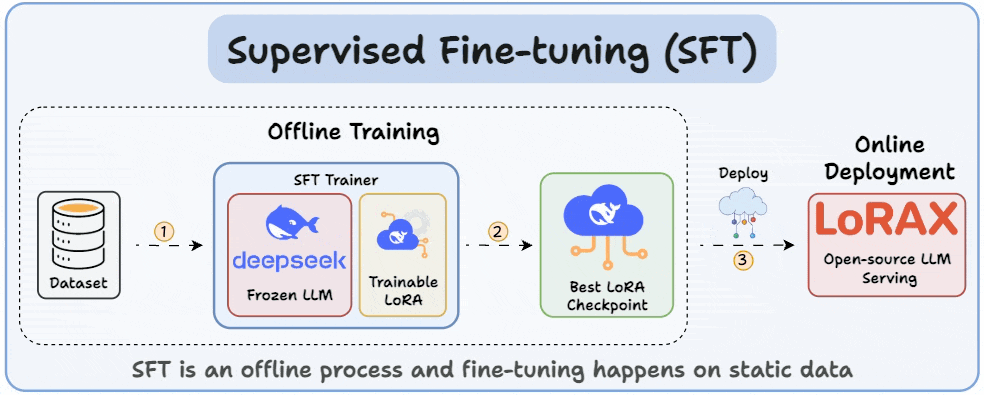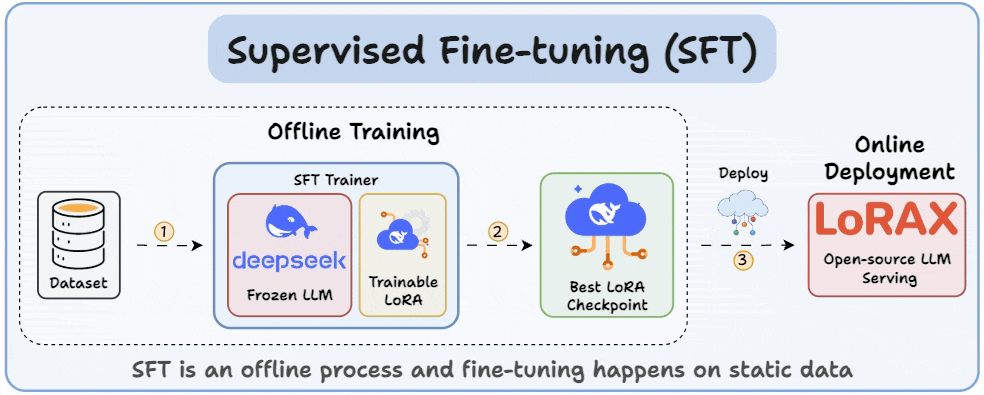
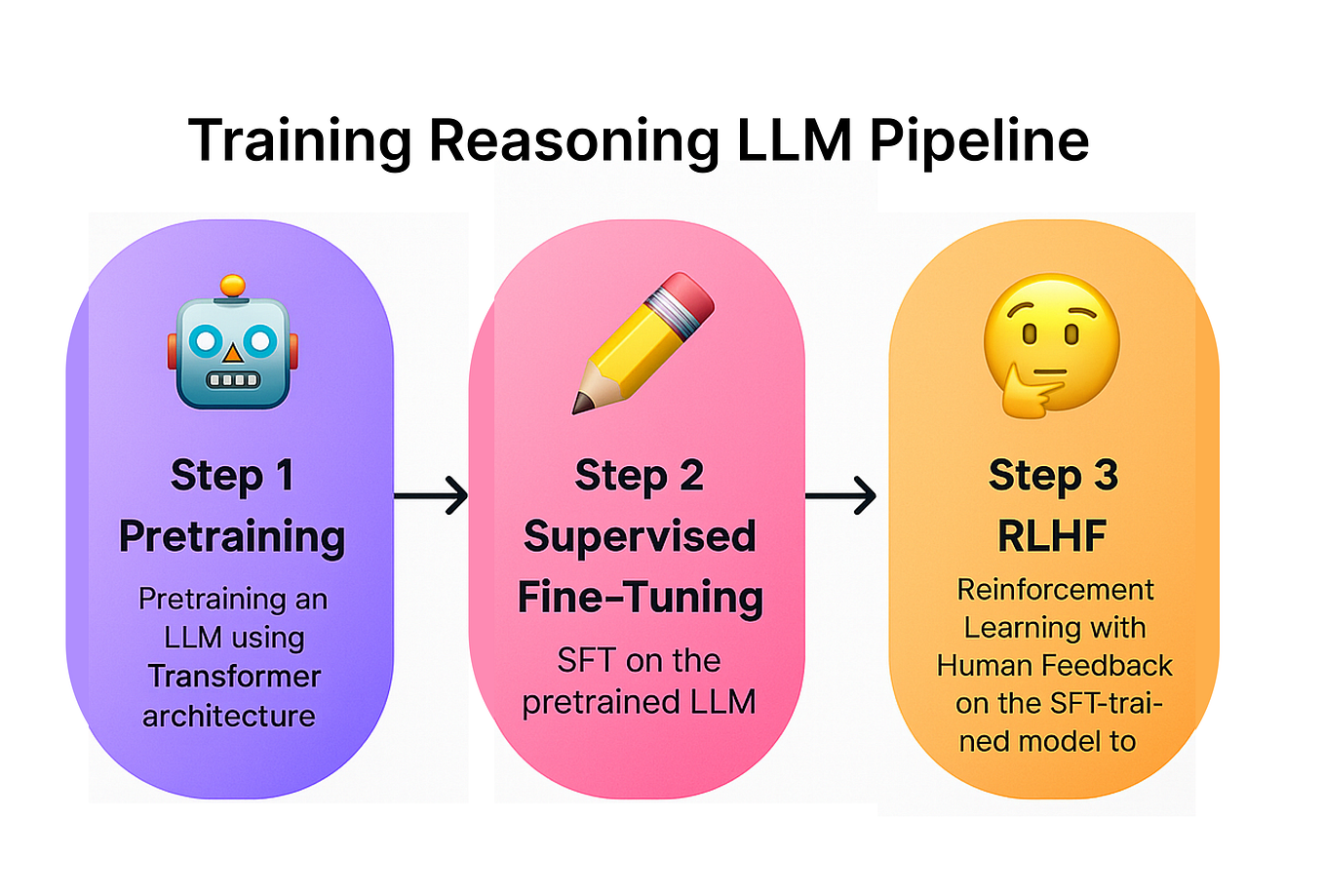
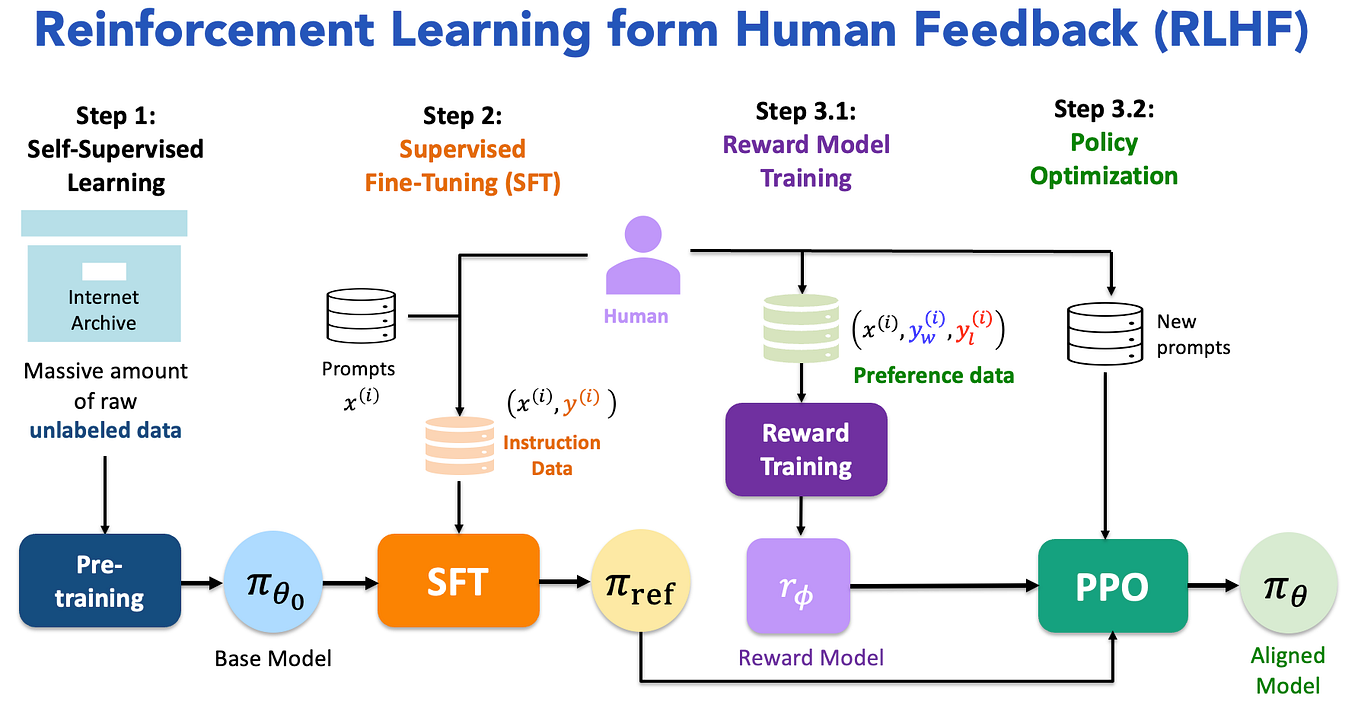
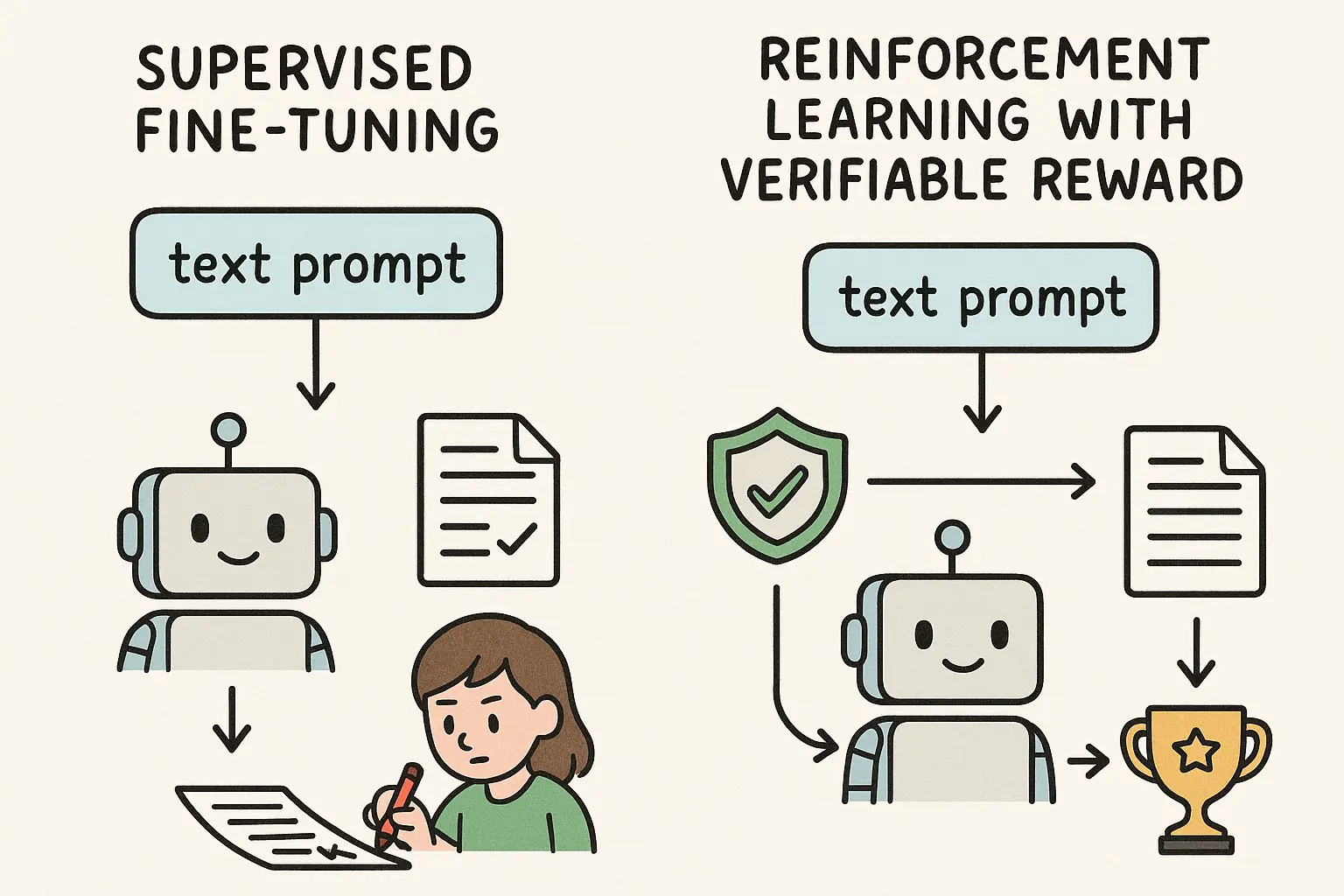
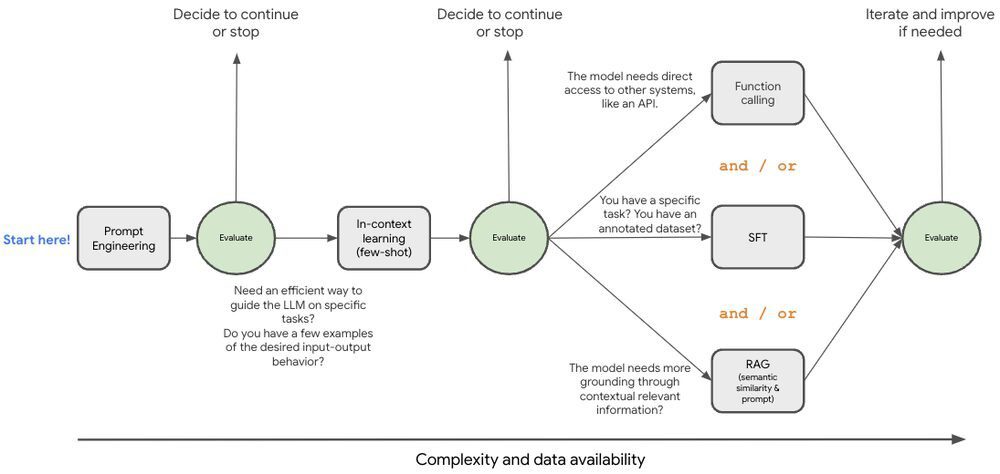
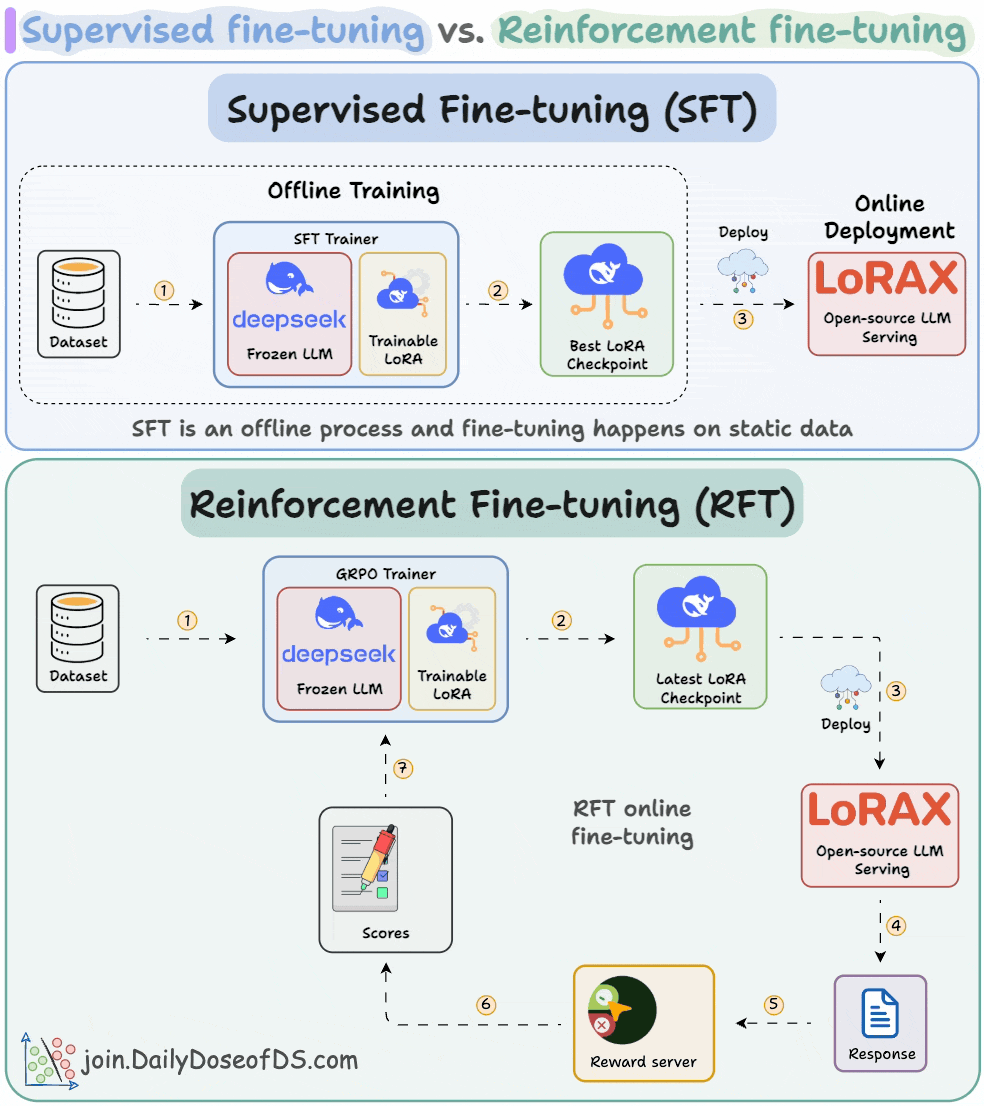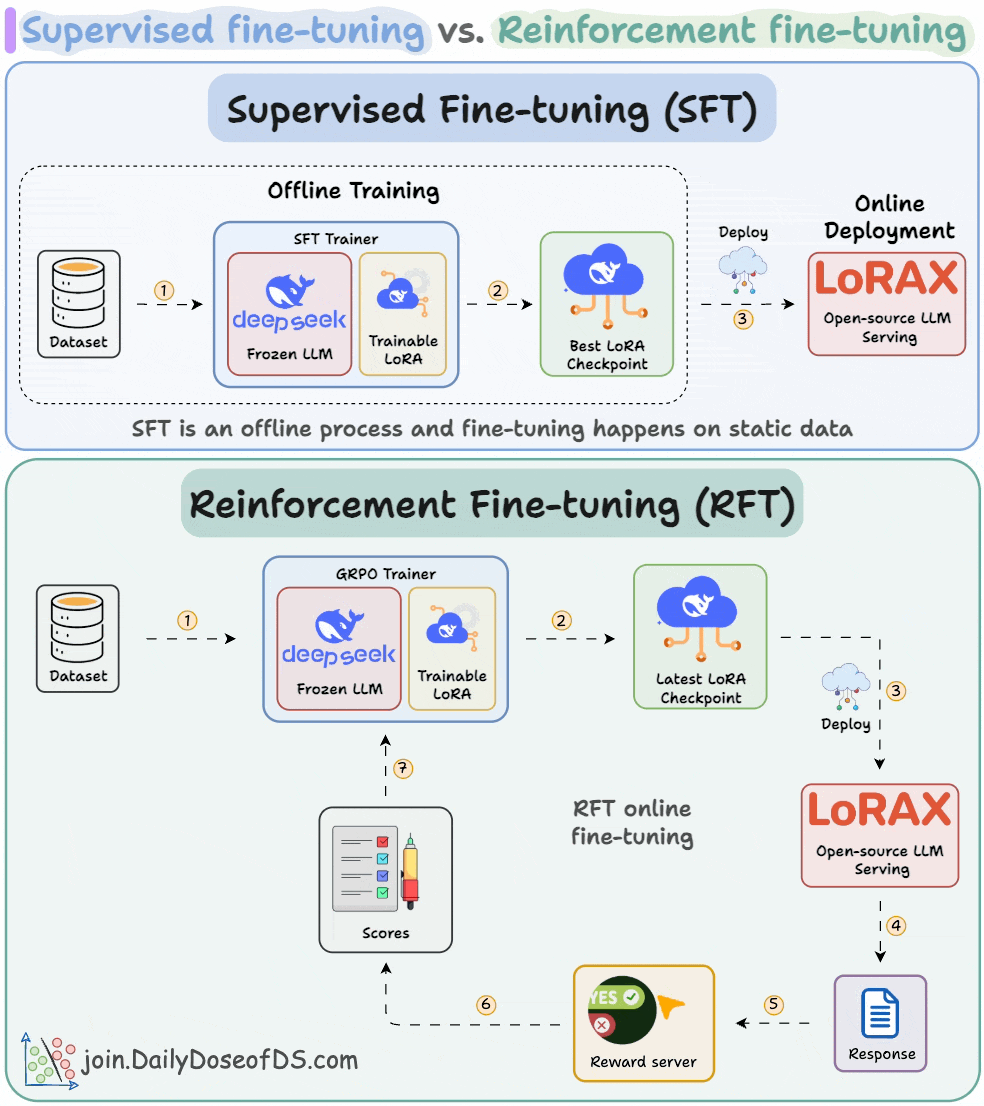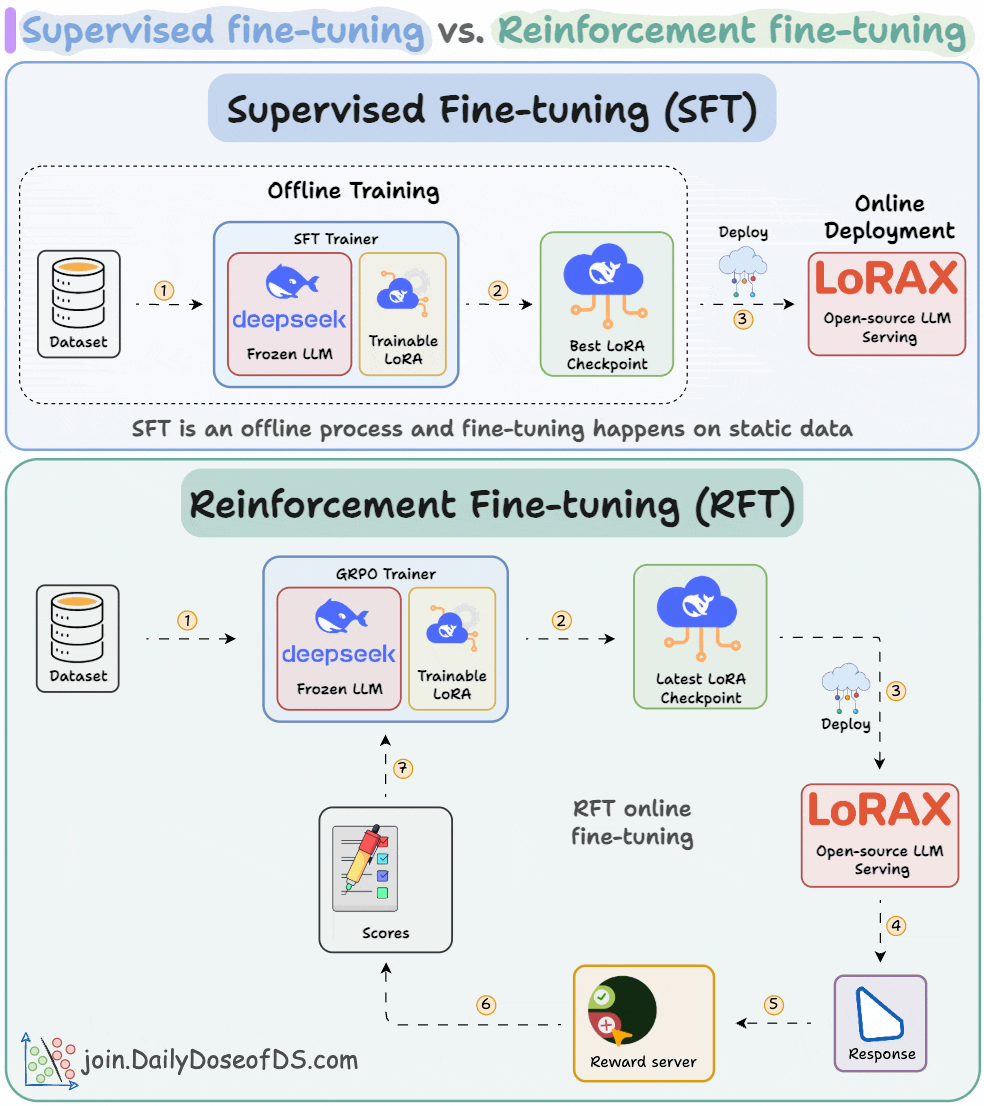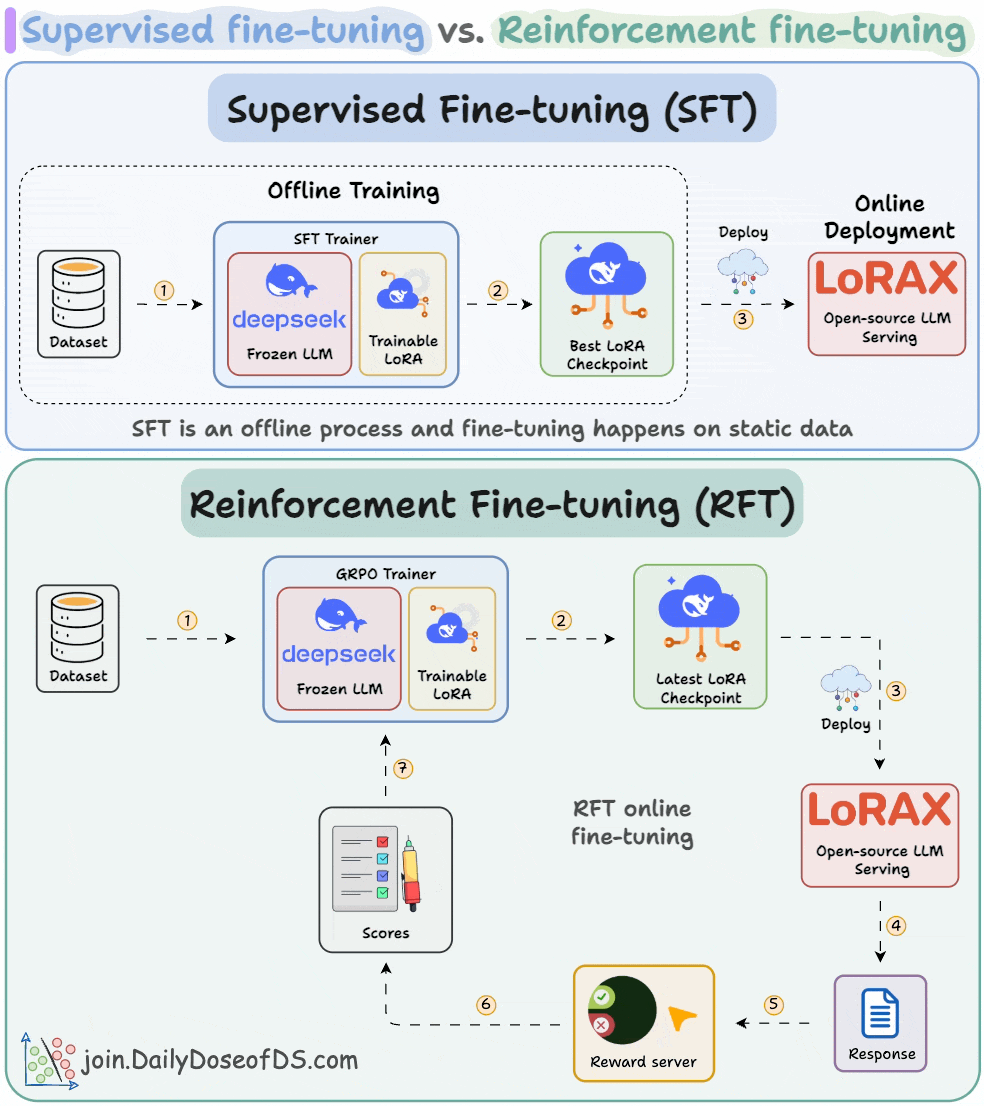
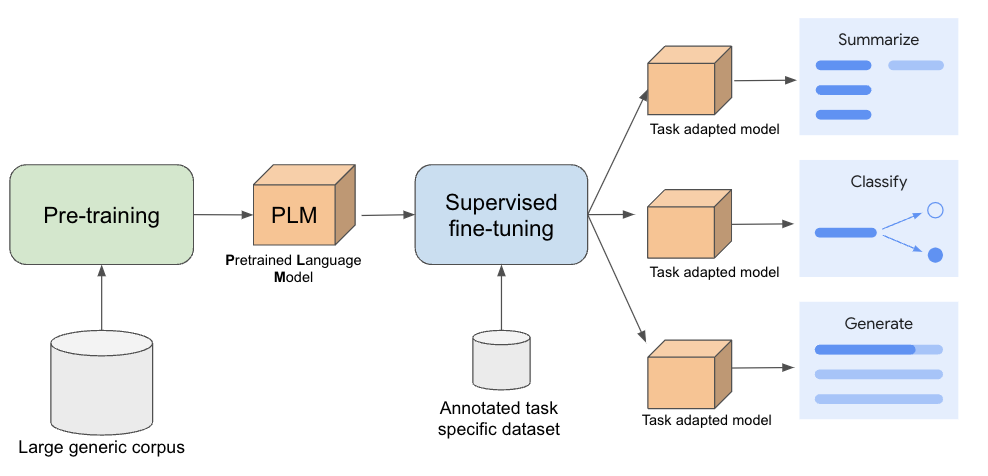
Understanding and Using Supervised Fine-Tuning (SFT) for Language Models
Supervised Fine-tuning And Reinforcement Learning Enhance Reasoning In ...
Supervised Fine-Tuning (SFT) with Large Language Models | by Cameron R ...
Small LLMs and supervised fine-tuning (SFT) can still do wonders in ...
| Reinforcement learning and supervised fine-tuning (SFT) improve over ...
Supervised Fine-Tuning (SFT) Vs. Reinforcement Learning from Human ...
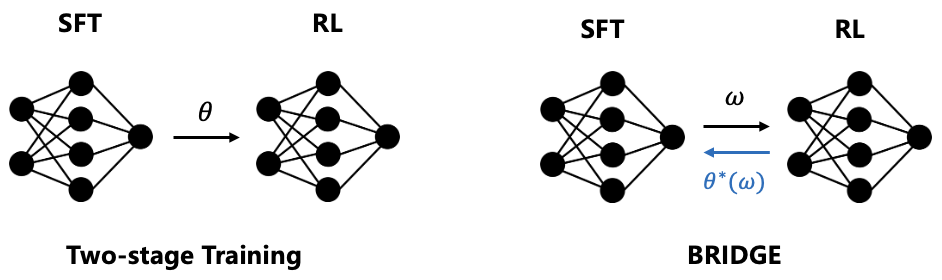
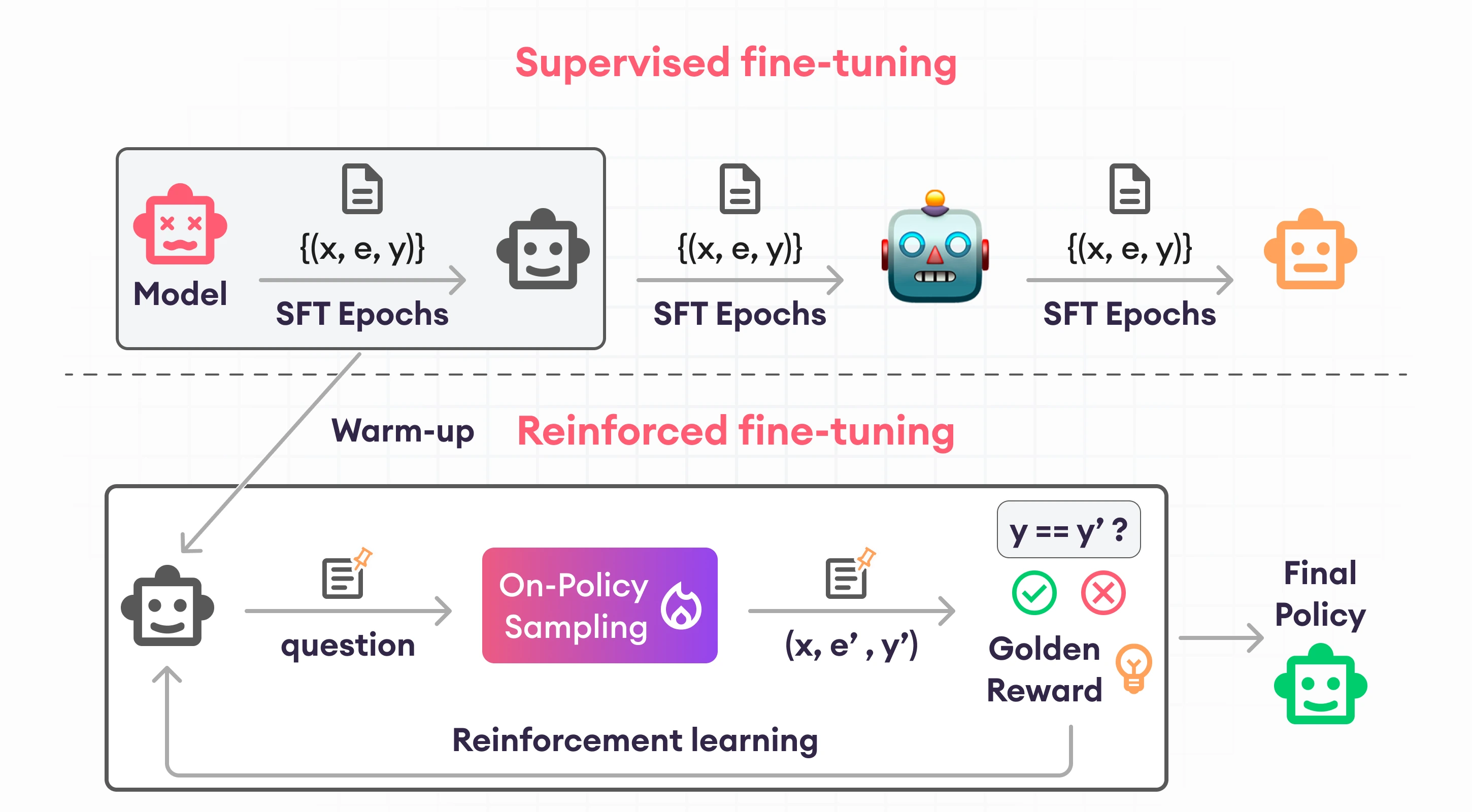
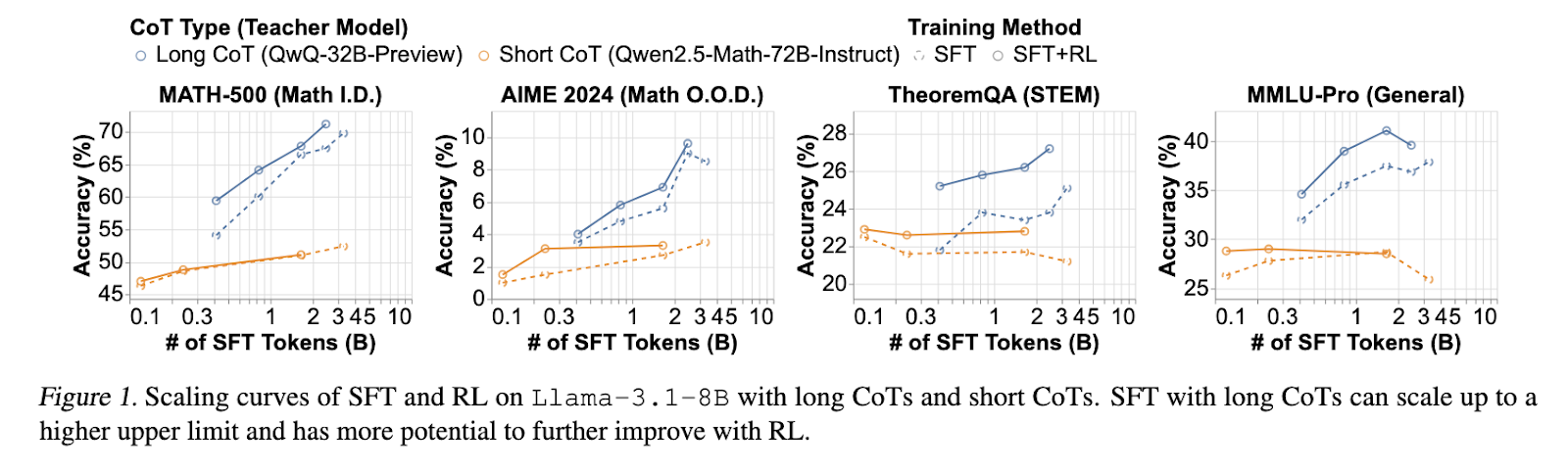
Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning ...
Paper page - SRFT: A Single-Stage Method with Supervised and ...
Supervised Fine-Tuning (SFT) for LLMs - GeeksforGeeks
Edge supervised fine-tuning (SFT) - a prithivMLmods Collection
Memorization vs. Generalization: How Supervised Fine-Tuning SFT and ...
Supervised Fine-Tuning (SFT) Memorizes, Reinforcement Learning (RL ...
Supervised Fine-Tuning Improves LLM Reasoning at the Cost of Other ...
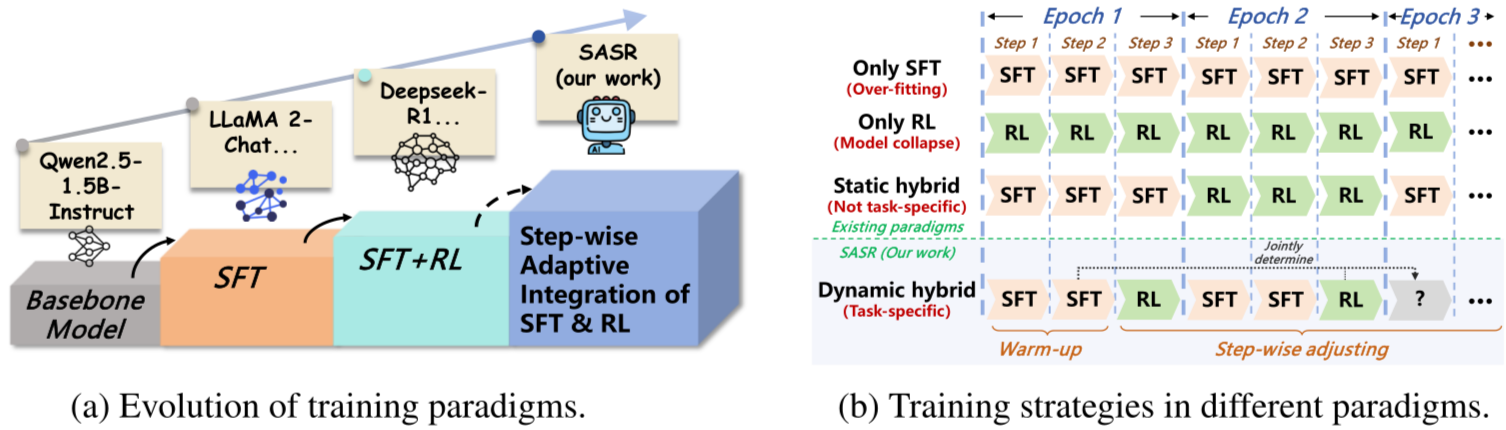
[논문 리뷰] Step-wise Adaptive Integration of Supervised Fine-tuning and ...
Mastering LoRA and QLoRA: Efficient Techniques for Fine-Tuning Large ...
Paper page - RobustFT: Robust Supervised Fine-tuning for Large Language ...
OpenThoughts: A Scalable Supervised Fine-Tuning SFT Data Curation ...
Supervised Fine-Tuning (SFT) Phase in RLHF
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine ...
Supervised fine-tuning (SFT) — Klu
Supervised Fine-Tuning: A Guide to LLM Reasoning | LLM Practical ...
Reinforcement Fine-Tuning (ReFT): Advancing AI Reasoning Through Reward ...
Lesson 04/10 – Post-Training: Supervised Fine-Tuning (SFT ...
Current LLM judges, fine-tuned using Supervised Fine-Tuning (SFT ...
GRPO Training Pipeline: SFT to RL for Better Reasoning | LLM Practical ...
[논문 리뷰] UFT: Unifying Supervised and Reinforcement Fine-Tuning
Supervised Fine-Tuning for Text-to-Code Models
[논문 리뷰] Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning
Free Video: Chain-of-Thought Reasoning in Large Language Models ...
Supervised fine-tuning is dead 💀, long live reinforcement learning 👑 ...
Top 11 Tools and Practices for Fine-Tuning Large Language Models (LLMs)
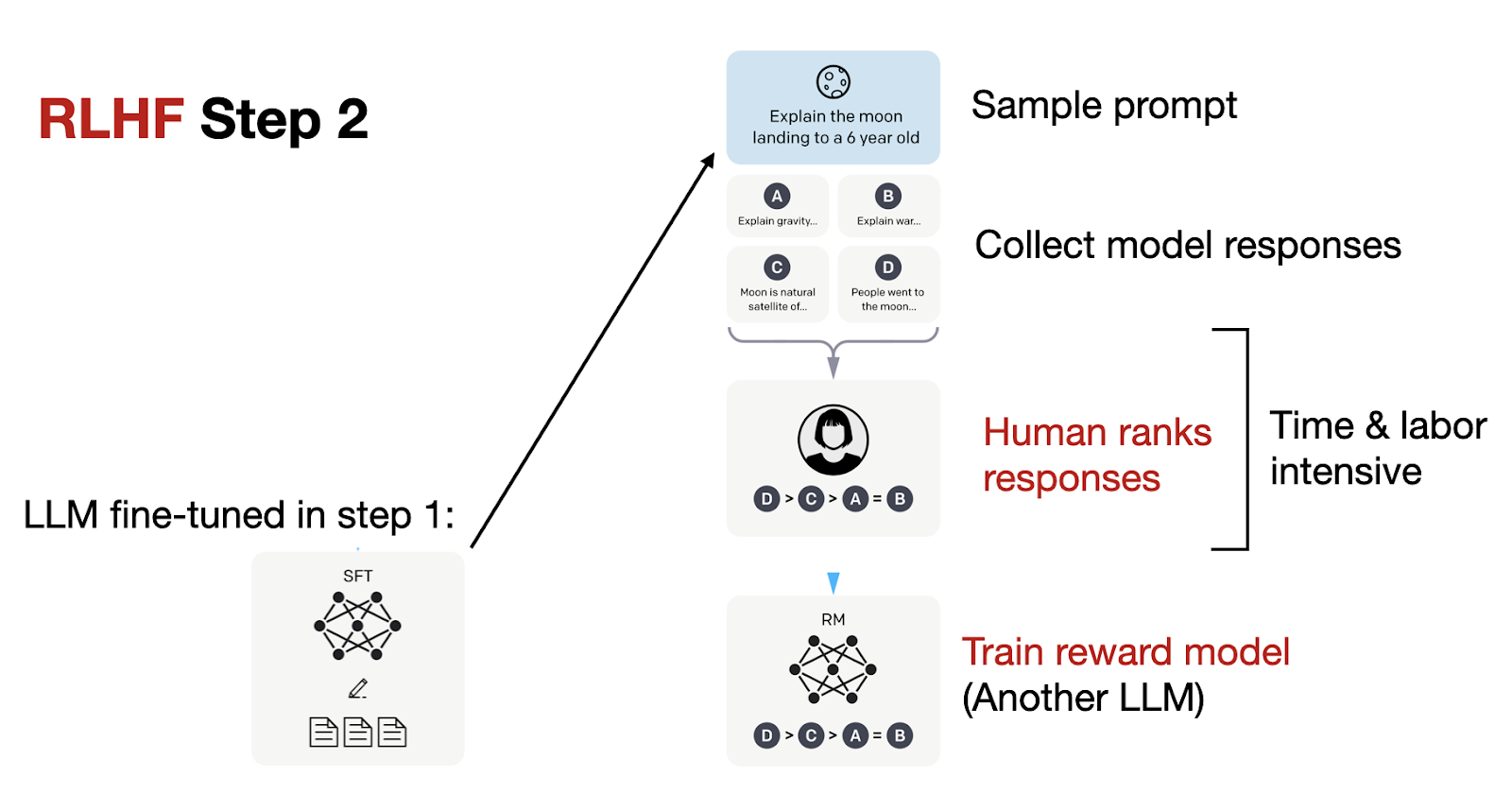
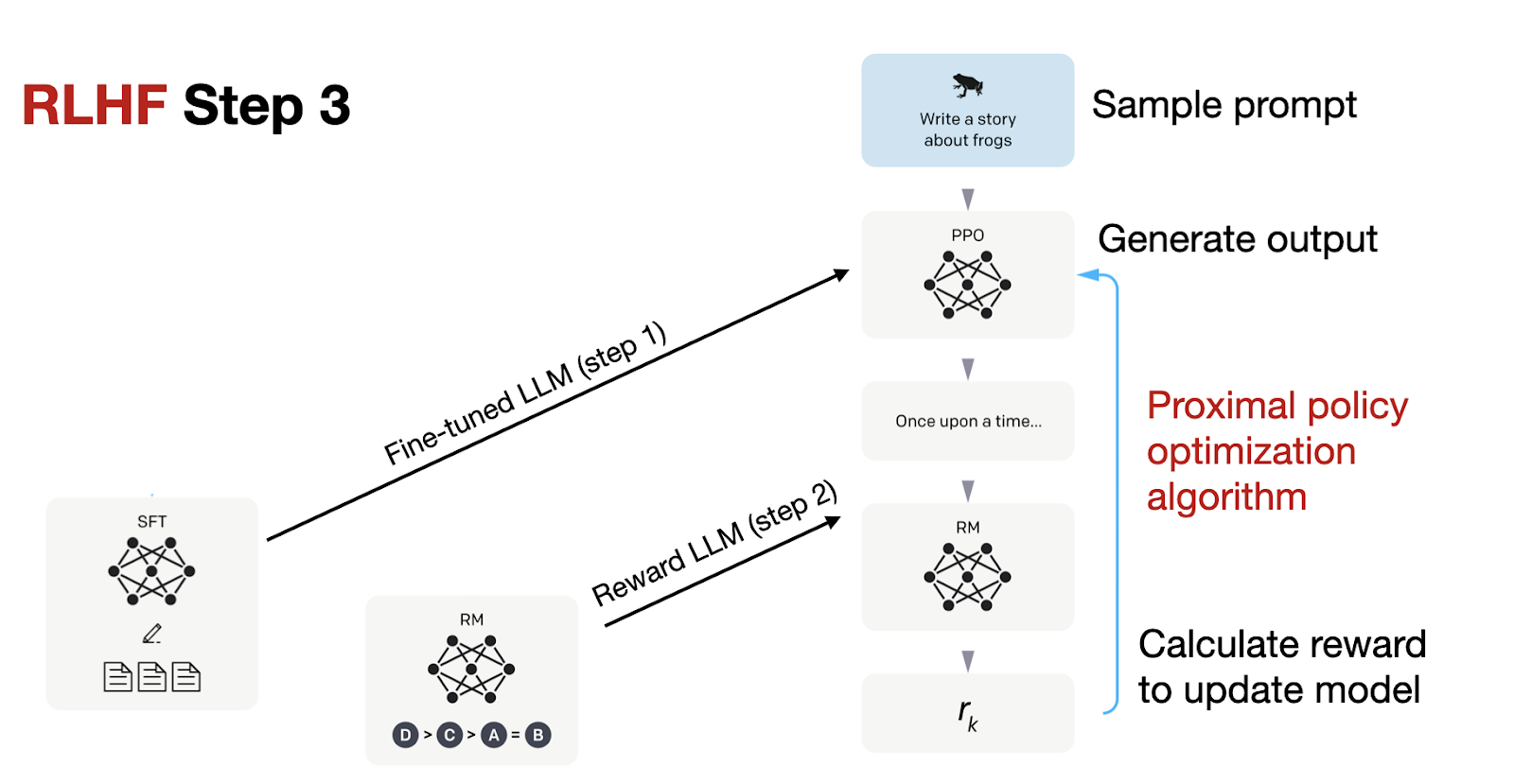
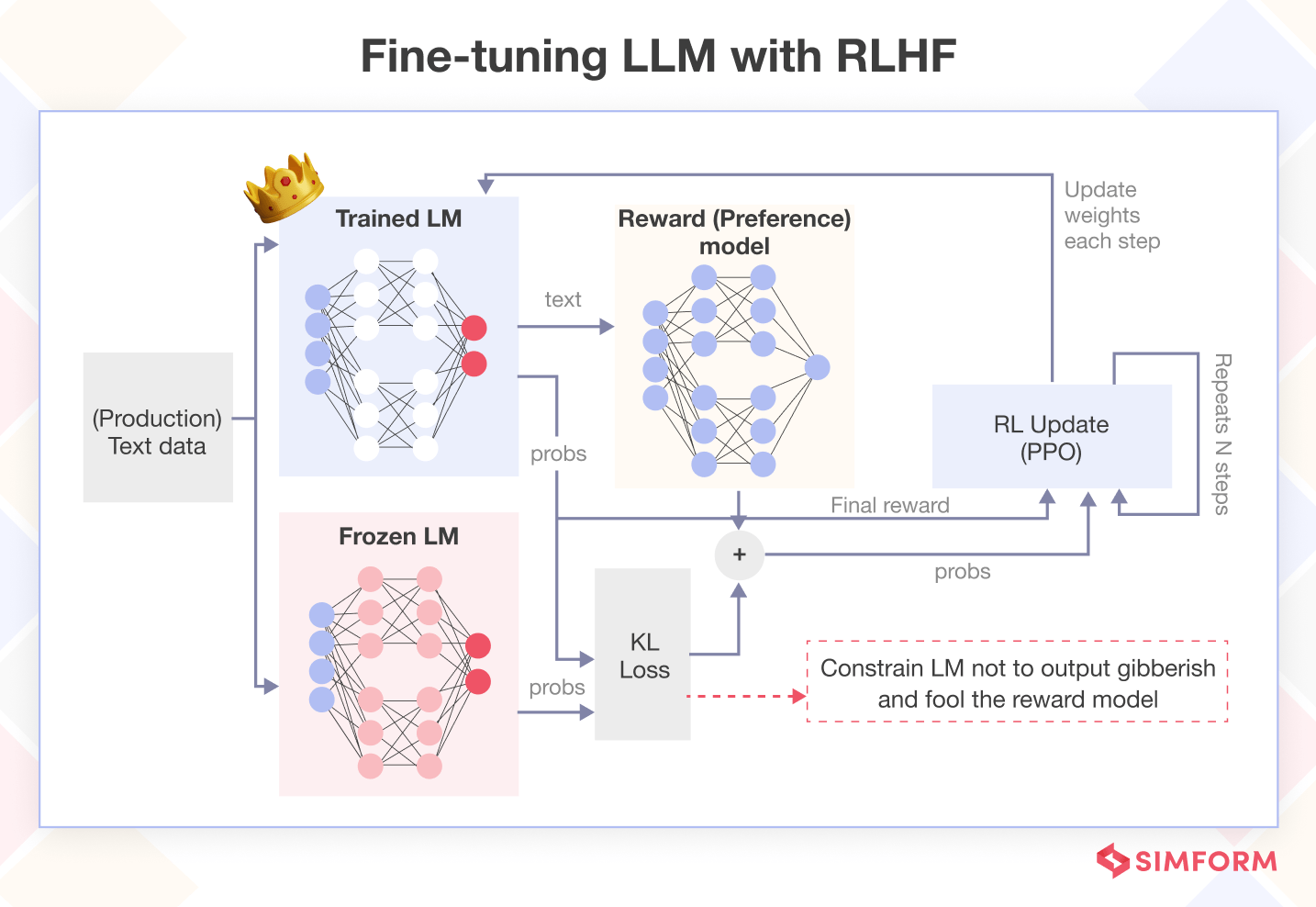
Inside the RLHF Engine: A Deep Dive into SFT, Reward Models, and RL ...
(PDF) UFT: Unifying Supervised and Reinforcement Fine-Tuning
Supervised Fine-Tuning vs. Reinforcement Learning for Model Post ...
台灣建築調適協會 - 快速認識AI的三大訓練階段:預訓練(Pre-training)、監督微調(Supervised Fine-tuning ...
Supervised Finetuning and Its Role in AI Training - AIML.com
Paper page - SFT Memorizes, RL Generalizes: A Comparative Study of ...
Reasoning models: DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero is ...
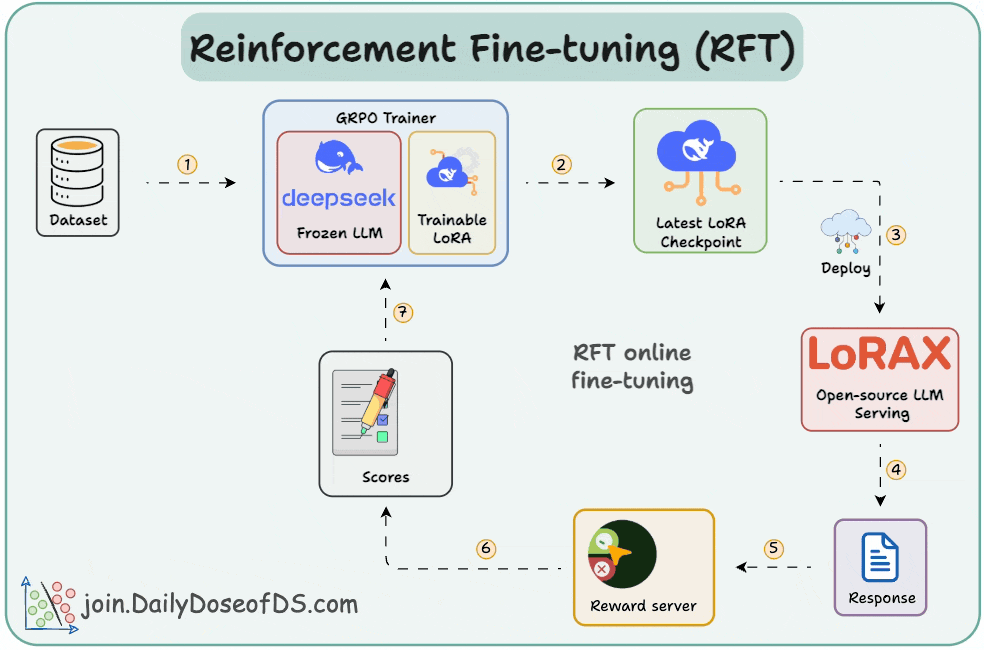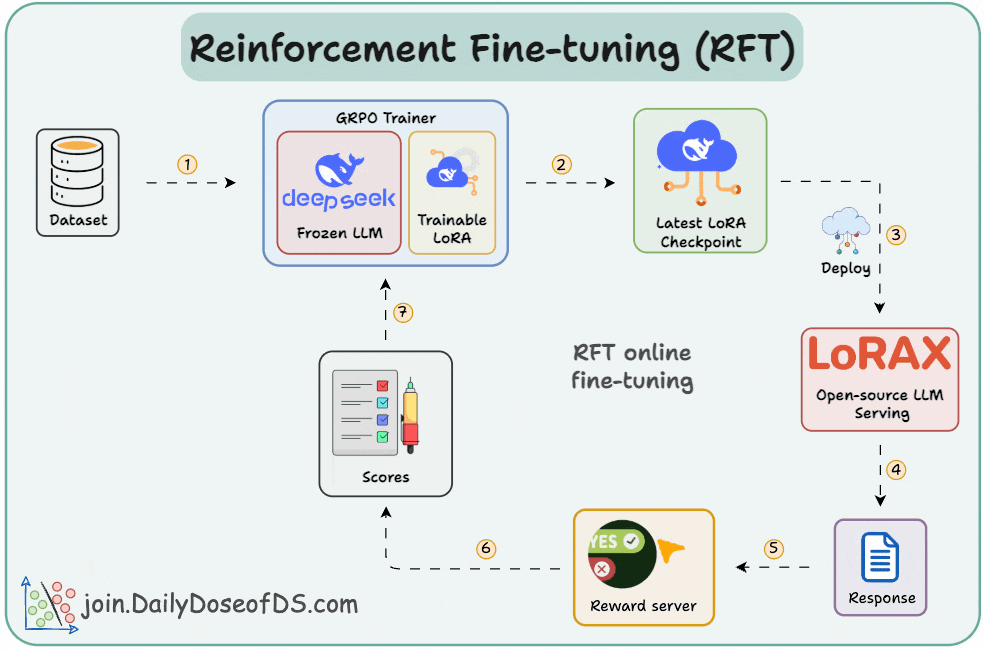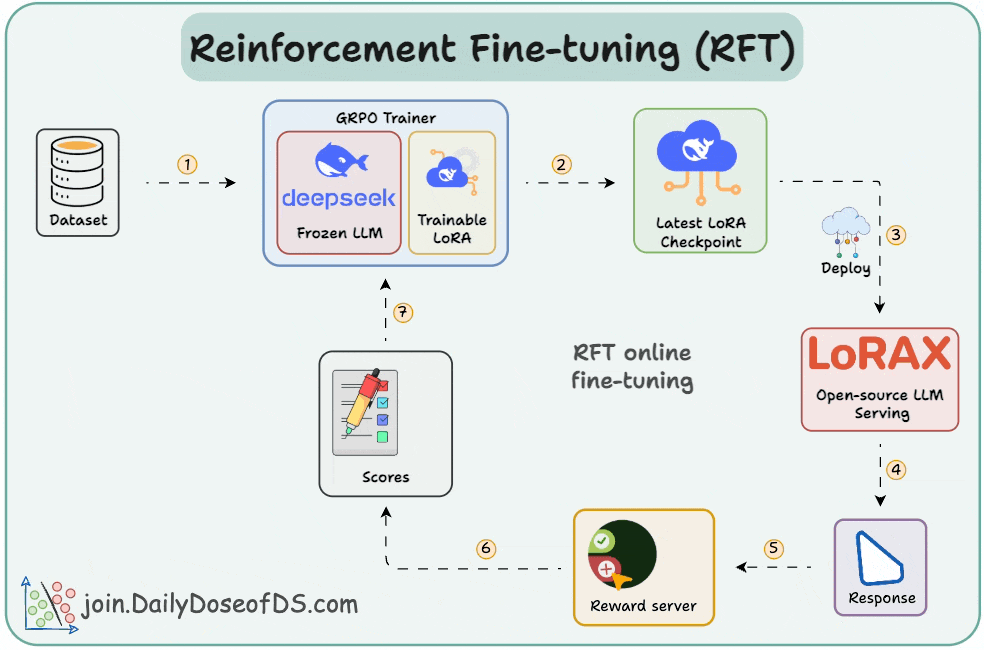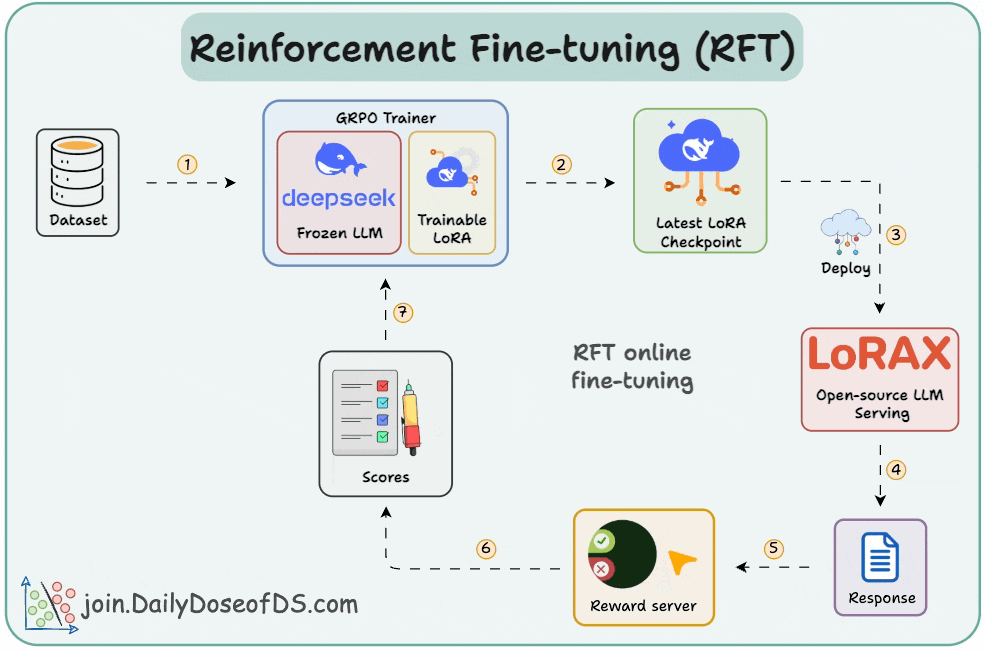
GitHub - ahmecse/Reinforcement-Fine-Tuning-LLMs-with-GRPO: RFT with ...
Supervised Fine Tuning: Enhancing Your LLM Accuracy in 2026 | Label ...
Introducing Supervised Fine-tuning V2
reft (reinforced fine tuning): supervised fine tuning with chain of ...
LLM Fine-Tuning: From Supervised Learning to Reinforcement-Based ...
What is Supervised Fine-Tuning (SFT)?
Paper page - SFT or RL? An Early Investigation into Training R1-Like ...
Supervised & Reinforcement Fine-tuning in LLMs
Prefix-RFT: A Unified Machine Learning Framework to blend Supervised ...
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision ...
Supervised Fine-Tuning: What It Is and Key Techniques
SFT Fine-Tuning: Transform Base LLM to Chat Model (3-Stage Guide - 2025 ...
SFT Memorizes, RL Generalizes: Foundation Model의 사후 학습 방법에 대한 비교 연구 ...
Deep Dive into OpenAI’s Reinforcement Fine-Tuning (RFT): Step-by-Step ...
Supervised Fine-Tuning Data
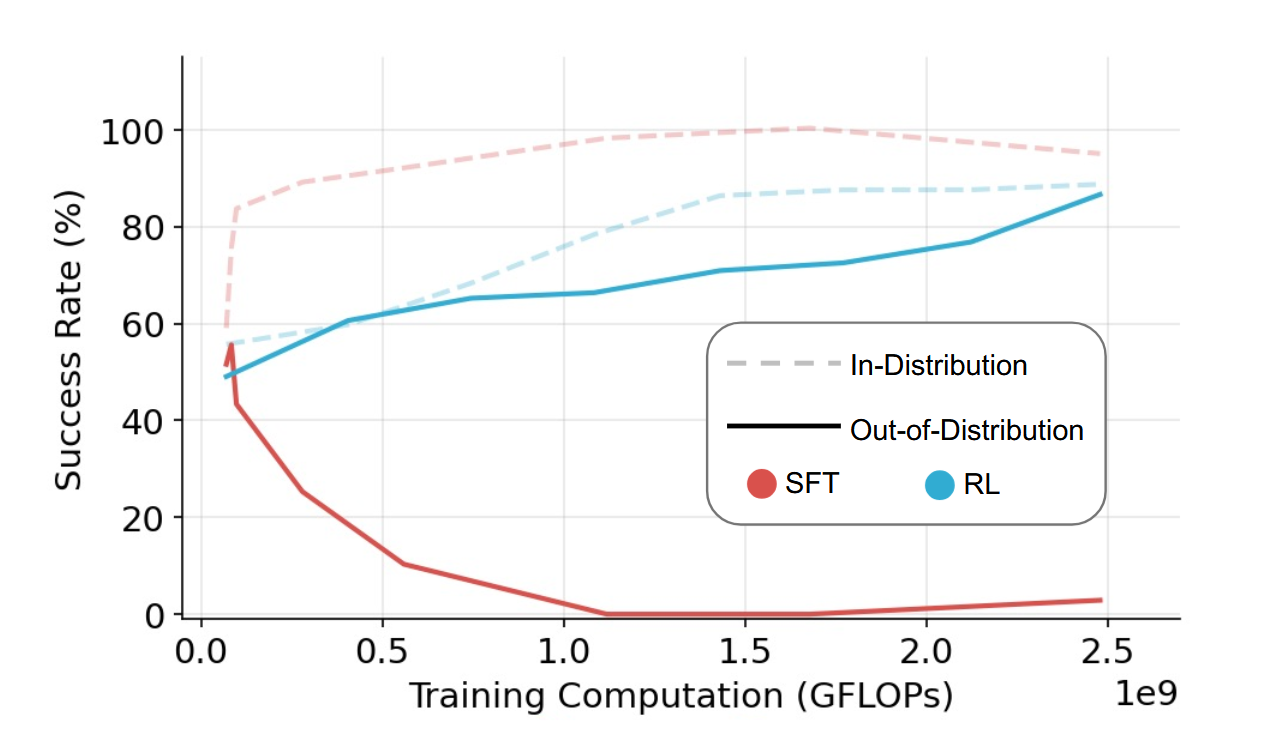
RL Fine-Tuning Heals OOD Forgetting in SFT
Fine-tuning vs. Training from Scratch: Deciding the Best Approach for ...
Training Agentic AI Searcher for Biomedical Literature: Supervised Fine ...
Our Visual Reinforcement Fine-Tuning (Visual-RFT) performs better than ...
SFT Supervised Fine Tuning Vs. RAG And Prompt Engineering
[Hands-on] Build Your Reasoning LLM
ReFT: Enhancing LLMs with reinforced fine-tuning | SuperAnnotate
Mastering LLM Techniques: Customization | NVIDIA Technical Blog
Instruction Tuning и SFT: как дообучить LLM под конкретные задачи в ...
The State of Reinforcement Learning for LLM Reasoning
What is Supervised Machine Learning?
The Current Landscape of Reasoning Model Development | Typhoon
Reasoning Models: How AI is Learning to Think Step by Step
Reinforcement Learning as a fine-tuning paradigm | Ankesh Anand
Guide to Reinforcement Finetuning - Analytics Vidhya
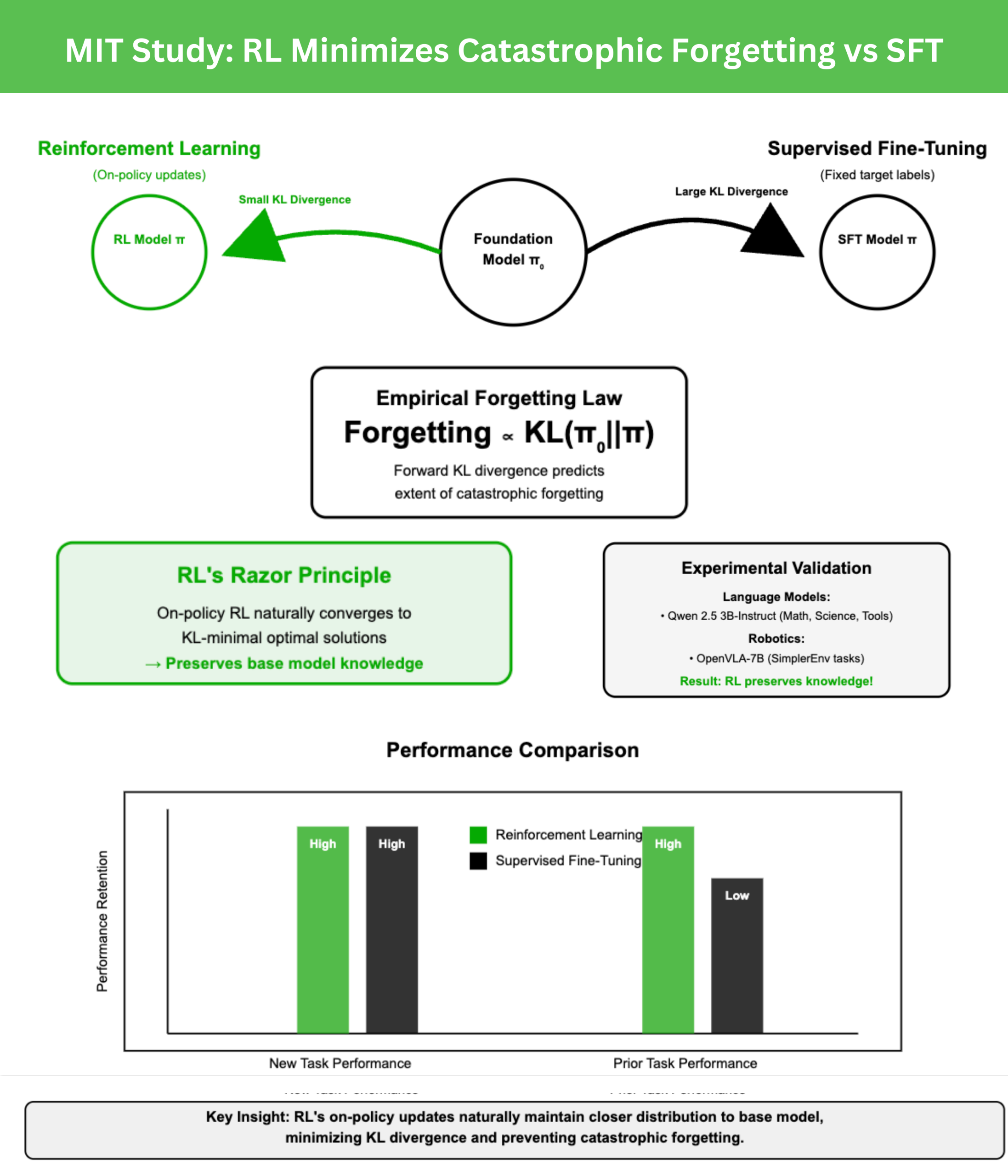
A New MIT Study Shows Reinforcement Learning Minimizes Catastrophic ...
This AI Paper Explores Long Chain-of-Thought Reasoning: Enhancing Large ...
Complete Guide to QLoRA Fine-Tuning: From Pre-trained to SFT Model – AI ...
notion image
mair-lab/earl-thinking-sft-simple.rl-simple-n-complex · Hugging Face
大模型微调:SFT(Supervised Fine-Tuning)主要方式、SFT-训练参数如何调整_51CTO博客_模型微调的步骤
LLM Fine Tuning: The 2025 Guide for ML Teams | Label Your Data
如何从零训练一个LLM:尝试基于0.5B小模型复现DeepSeek-R1的思维链_0.5b llm-CSDN博客
What is Reinforcement Learning from Human Feedback (RLHF)?
VLAA-Thinking