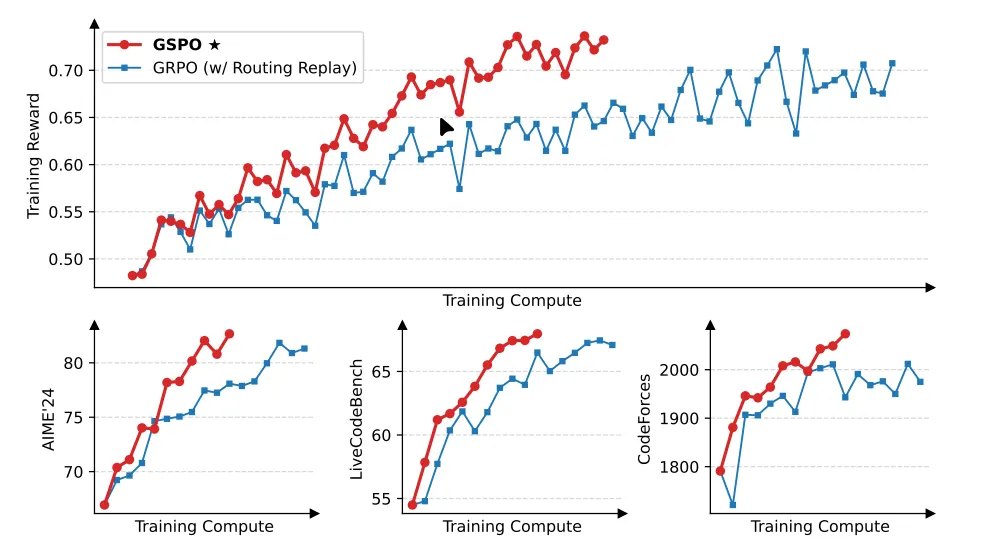
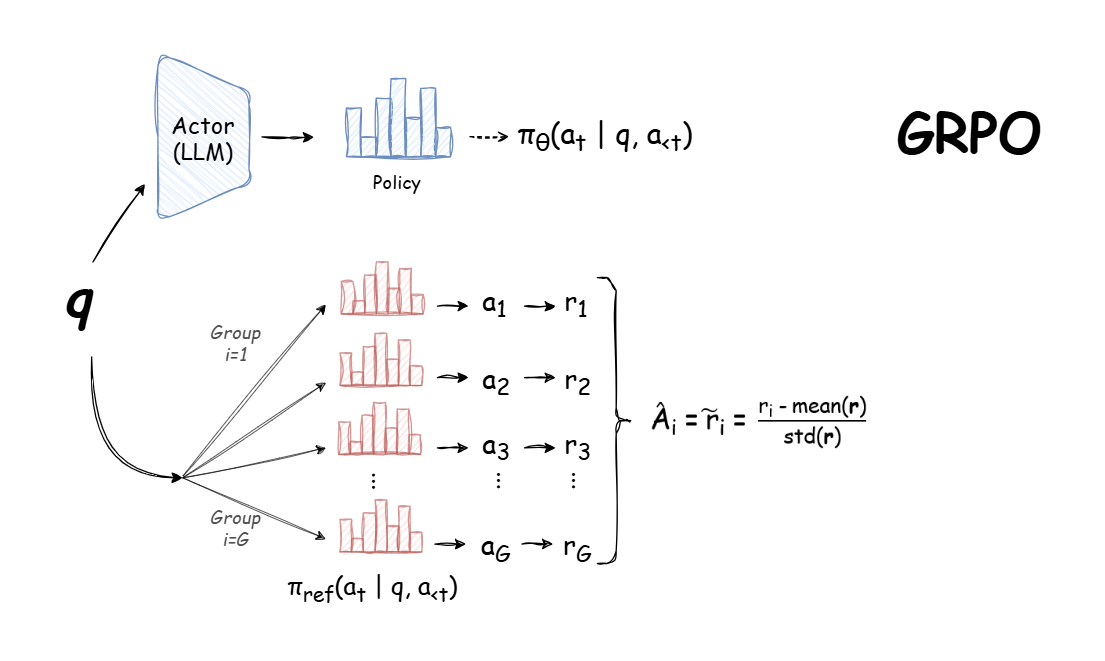
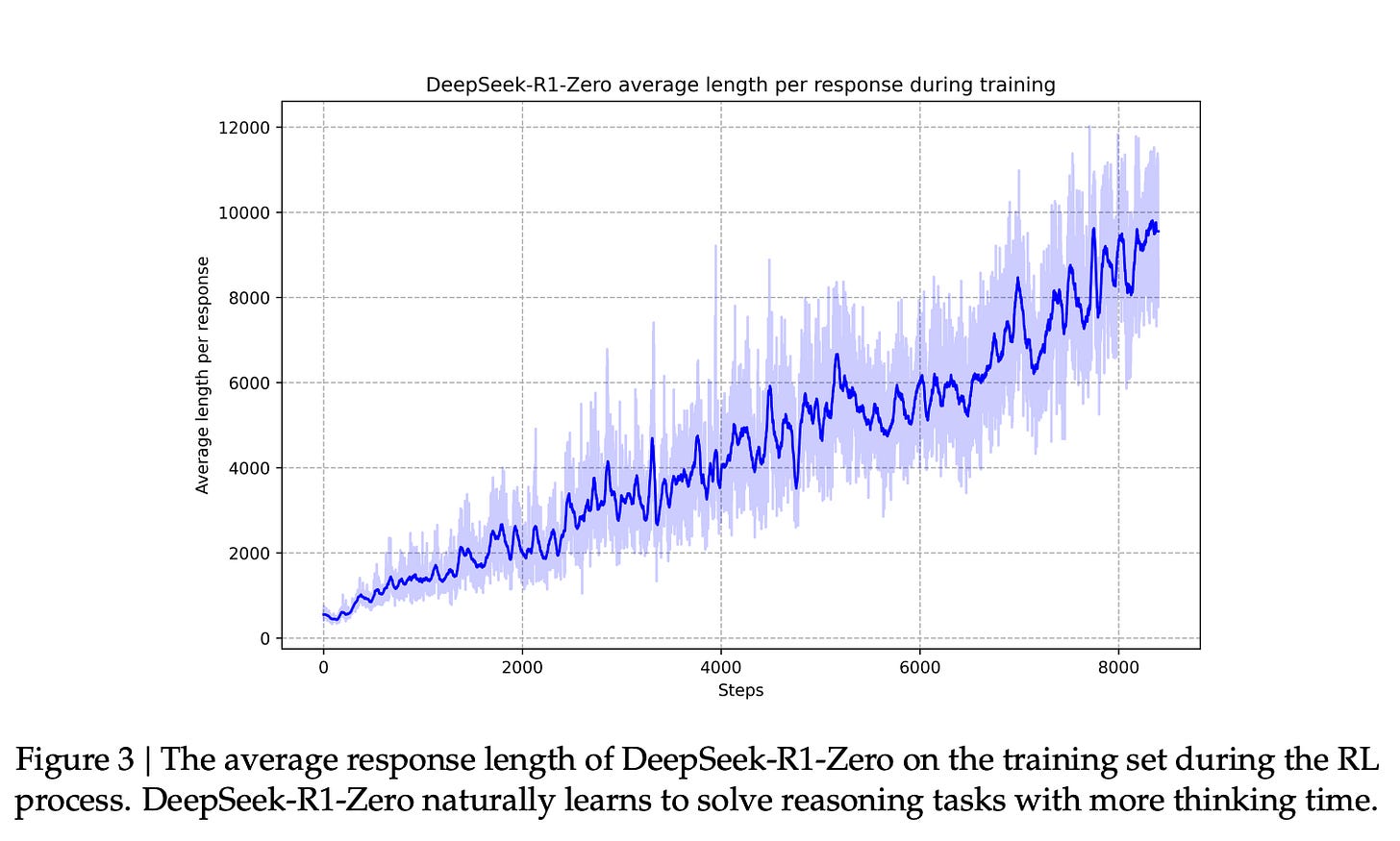
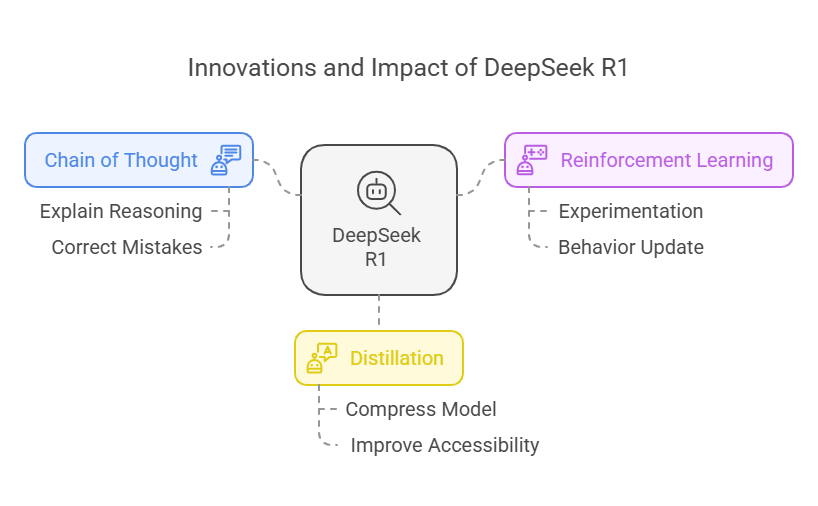
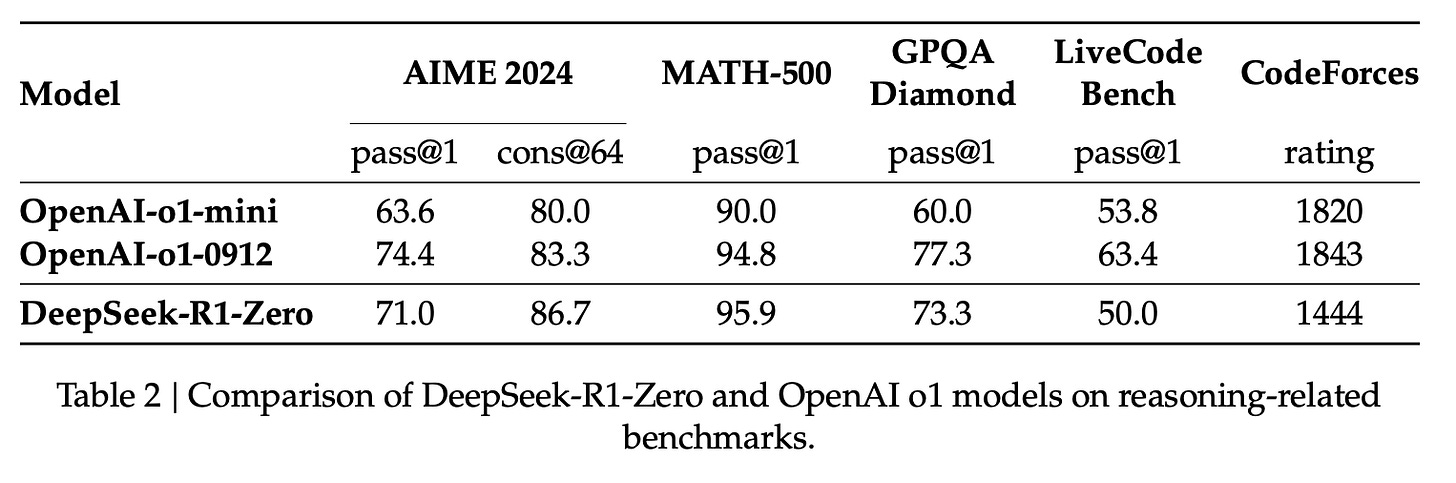
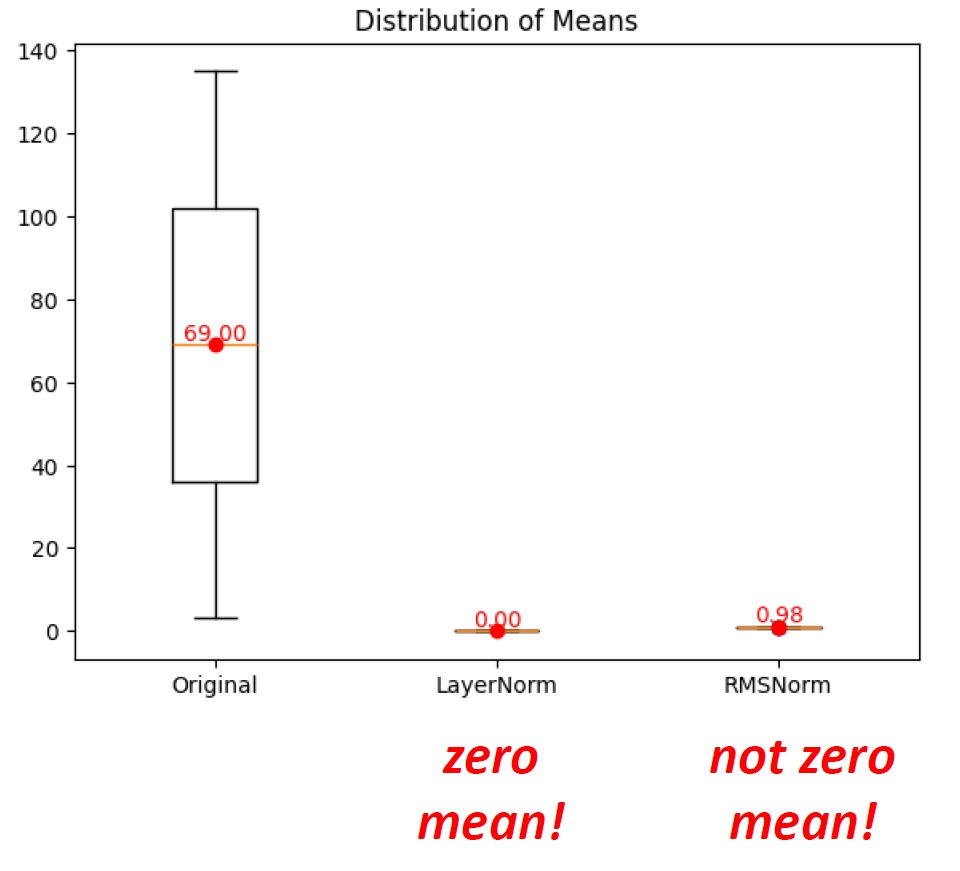
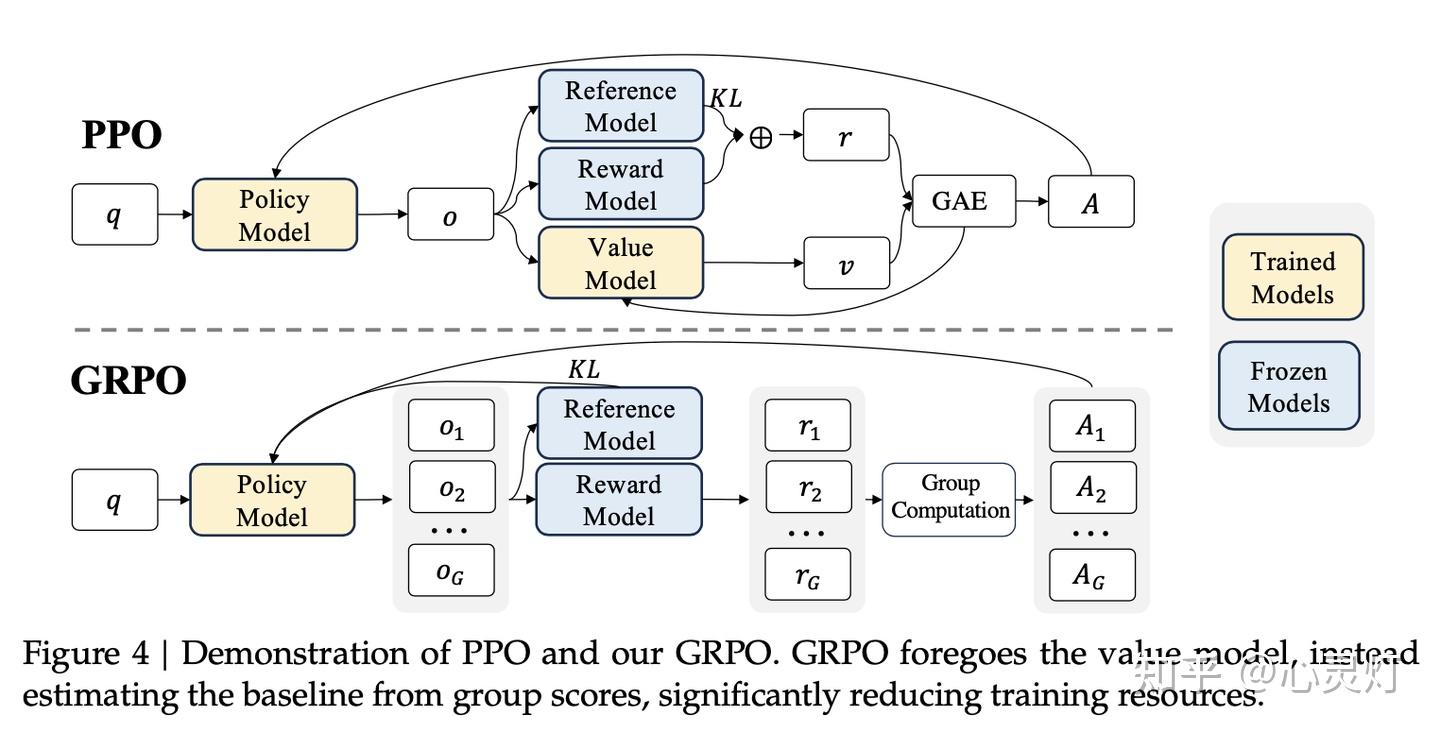
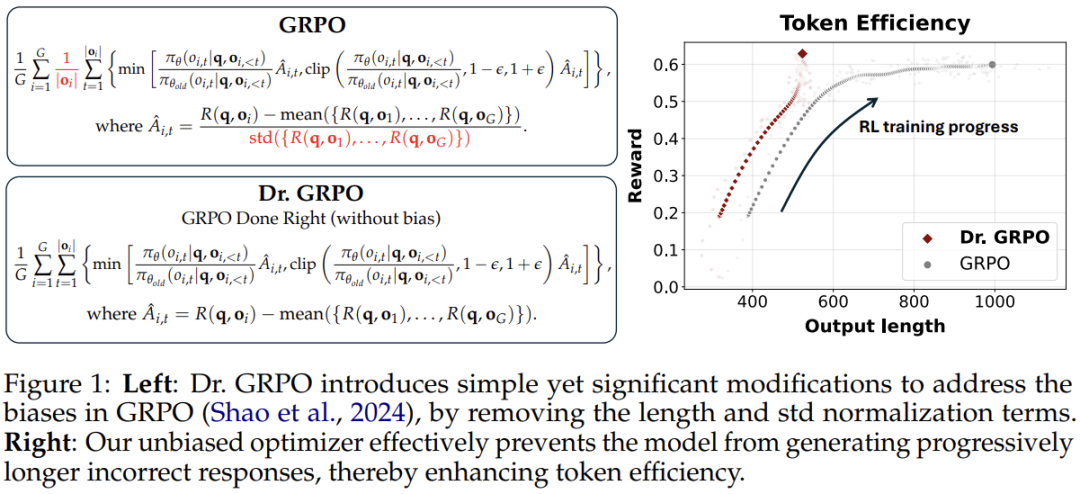
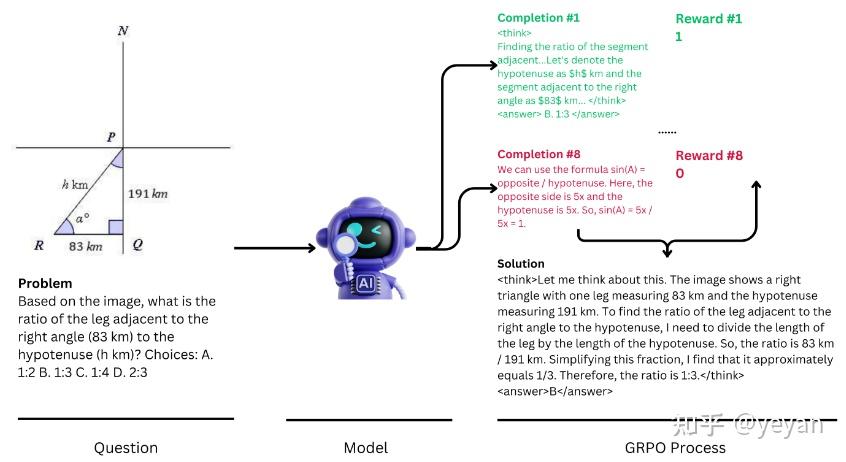
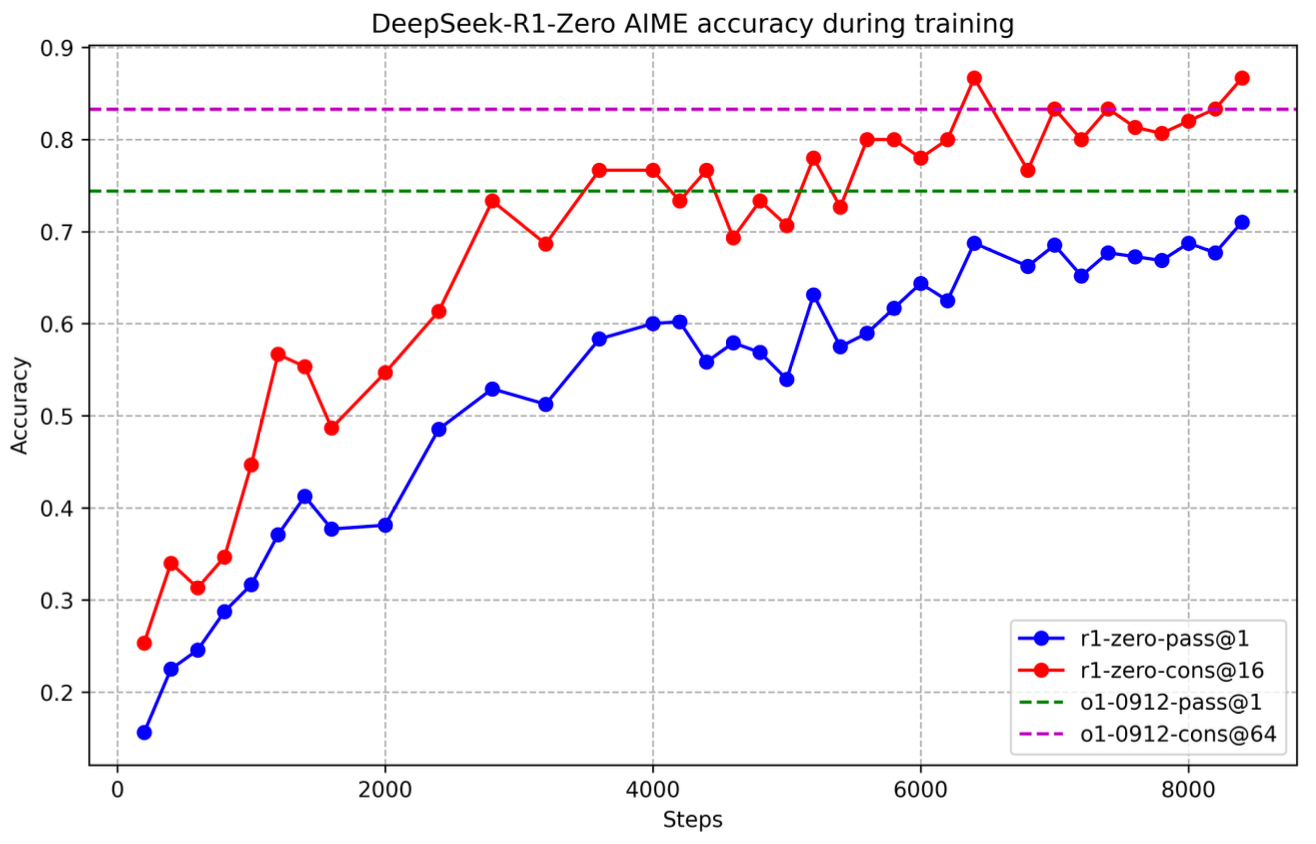
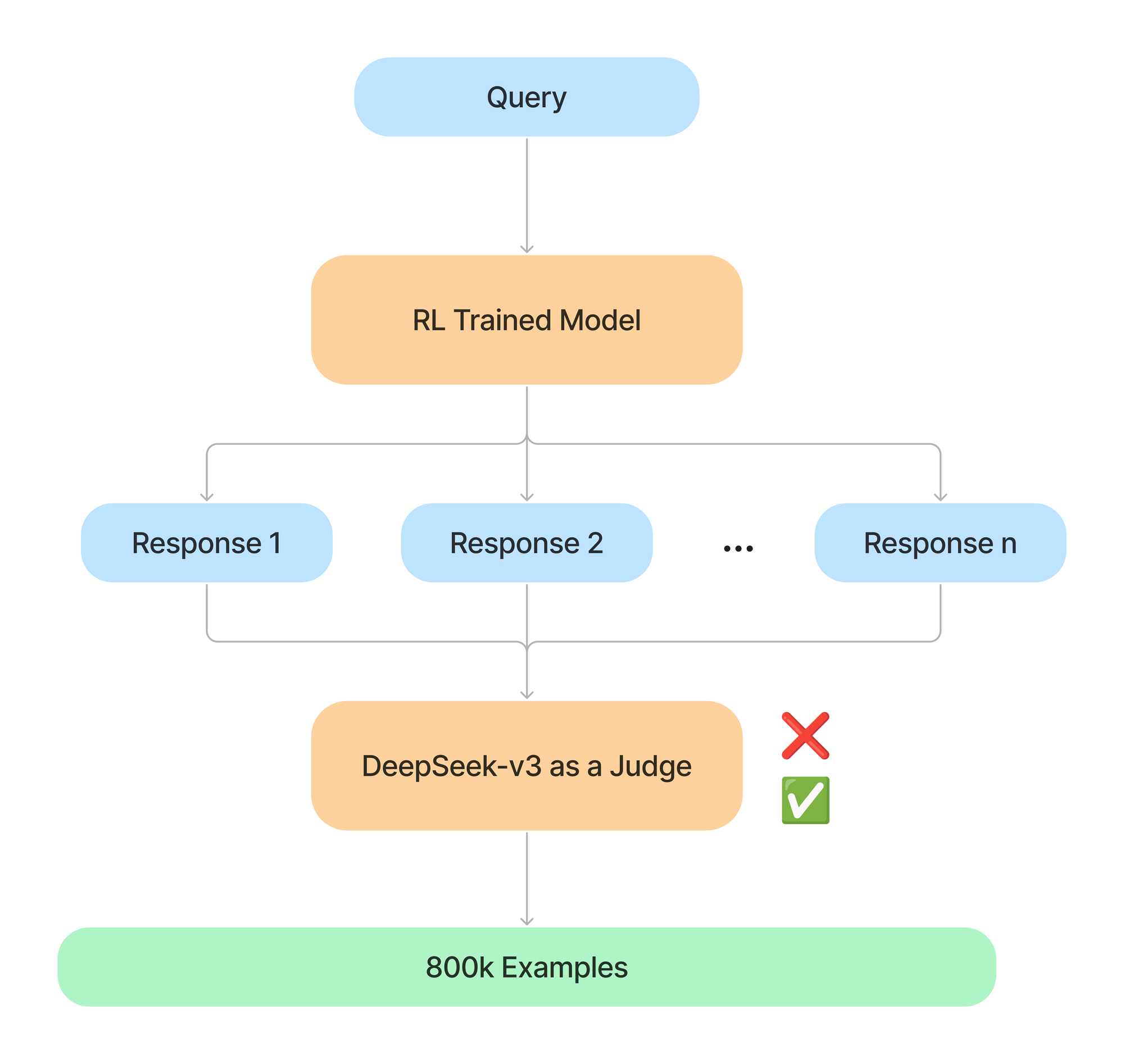
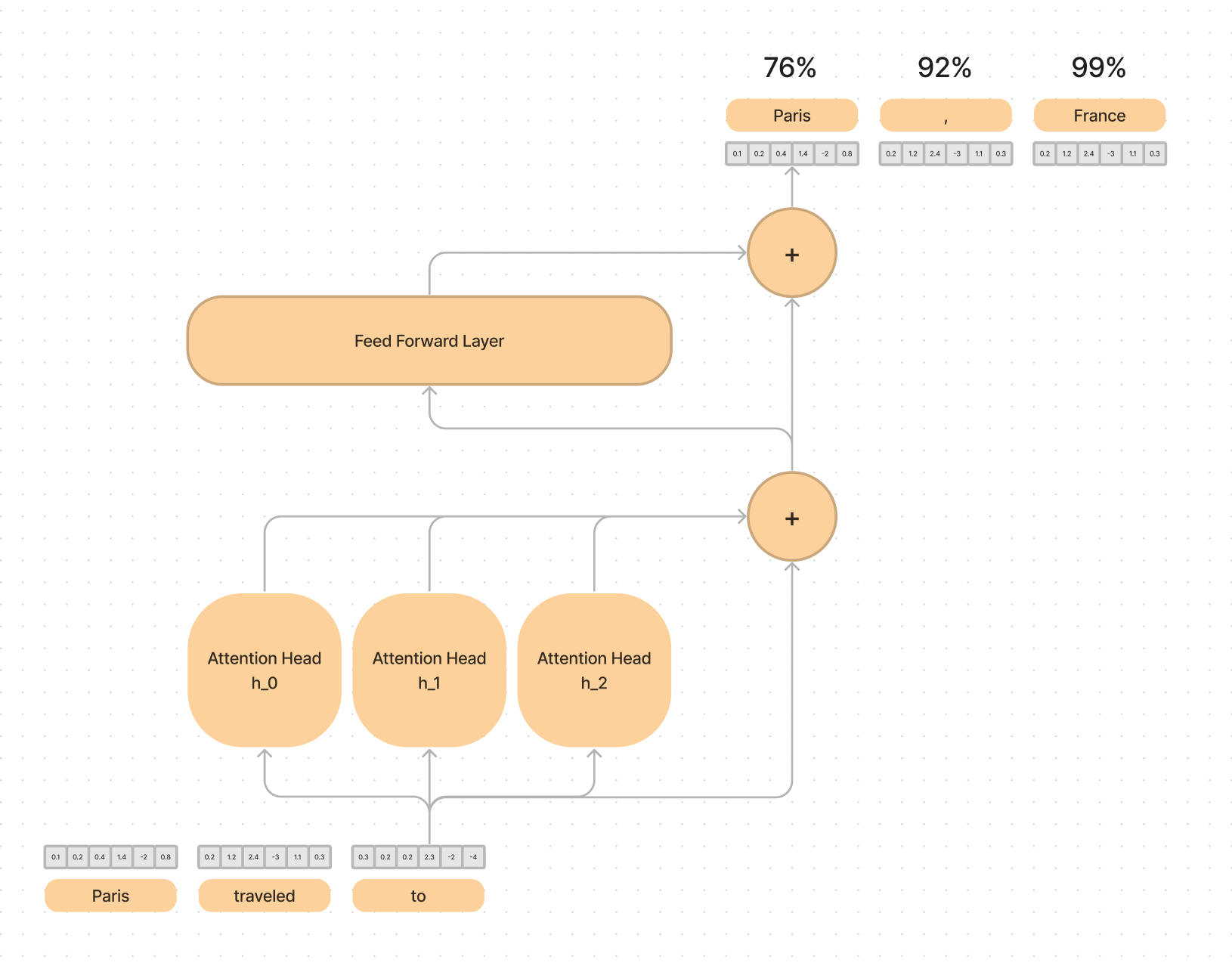
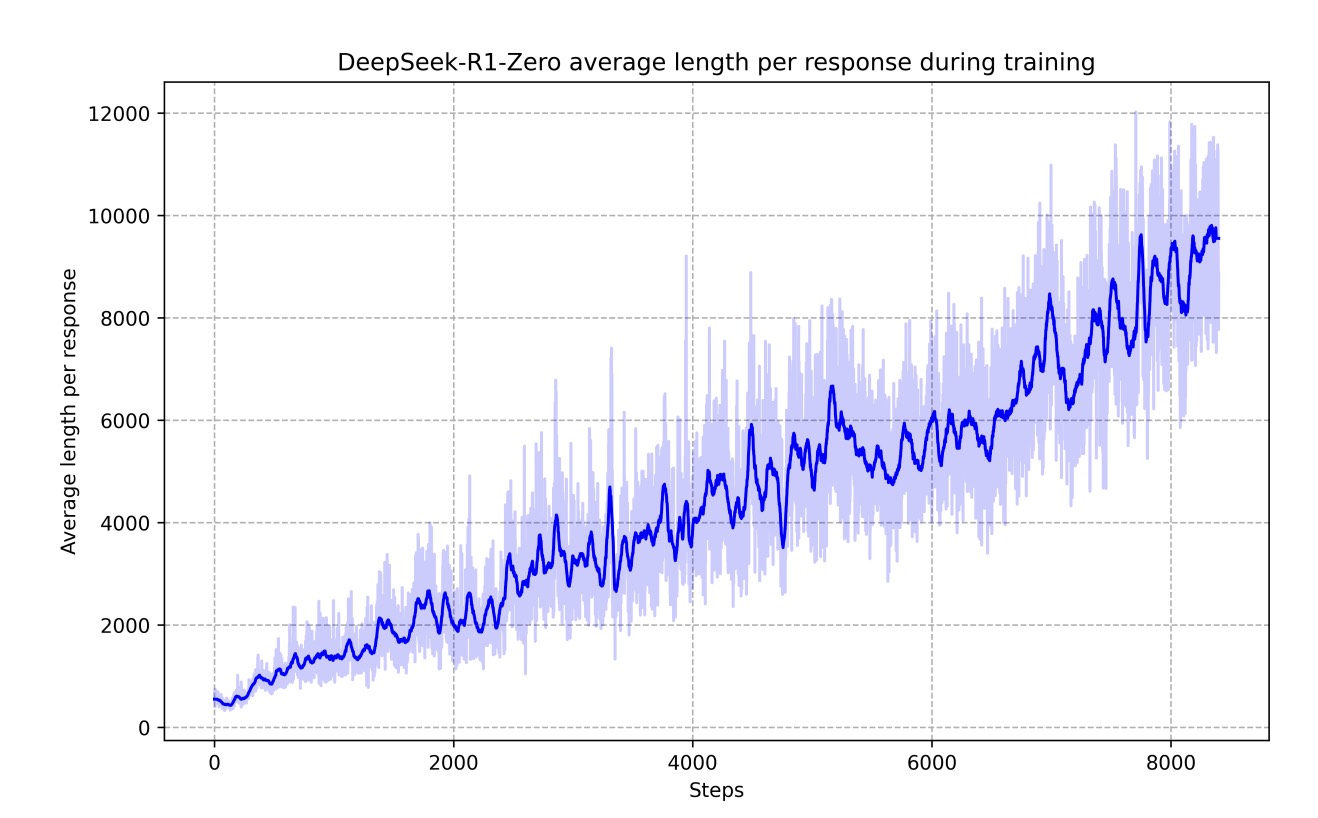
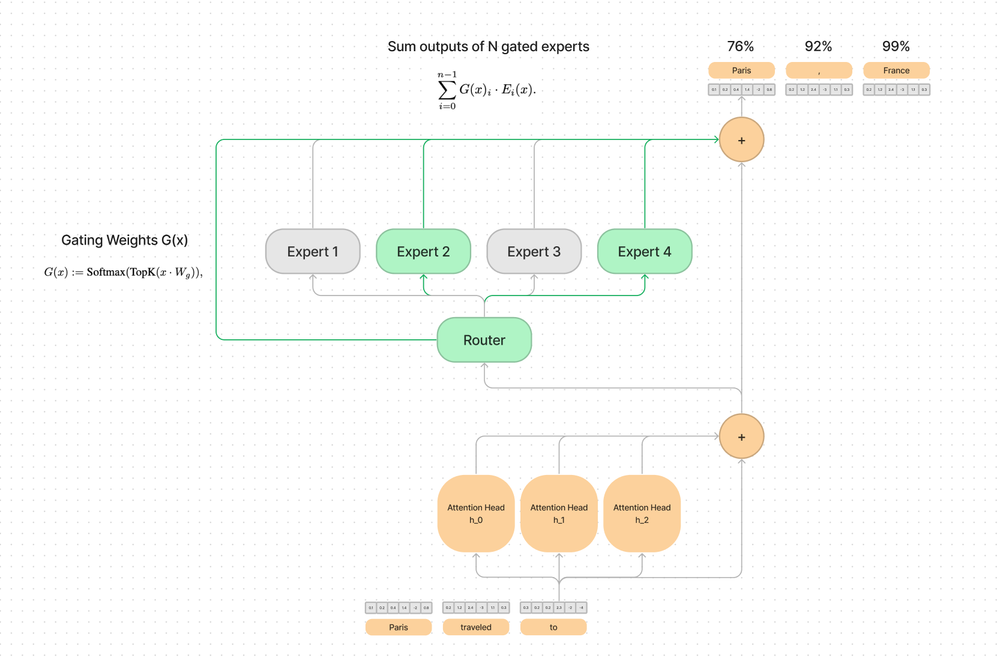
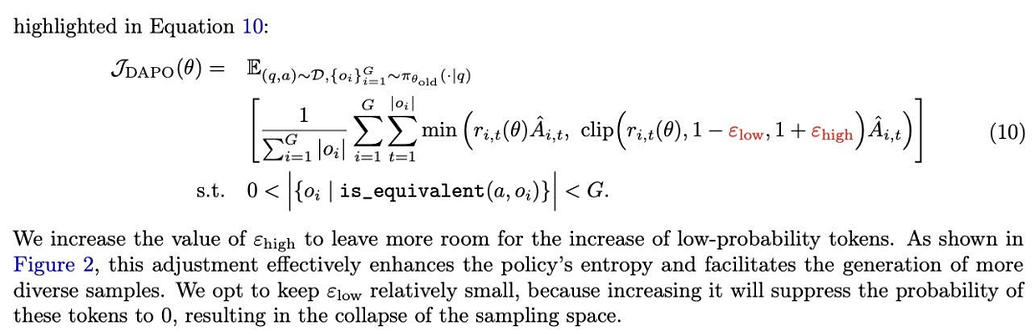Understanding the Math Behind GRPO — DeepSeek-R1-Zero | by Yugen.ai ...
DeepSeek R1: Understanding GRPO and Multi-Stage Training | by ...
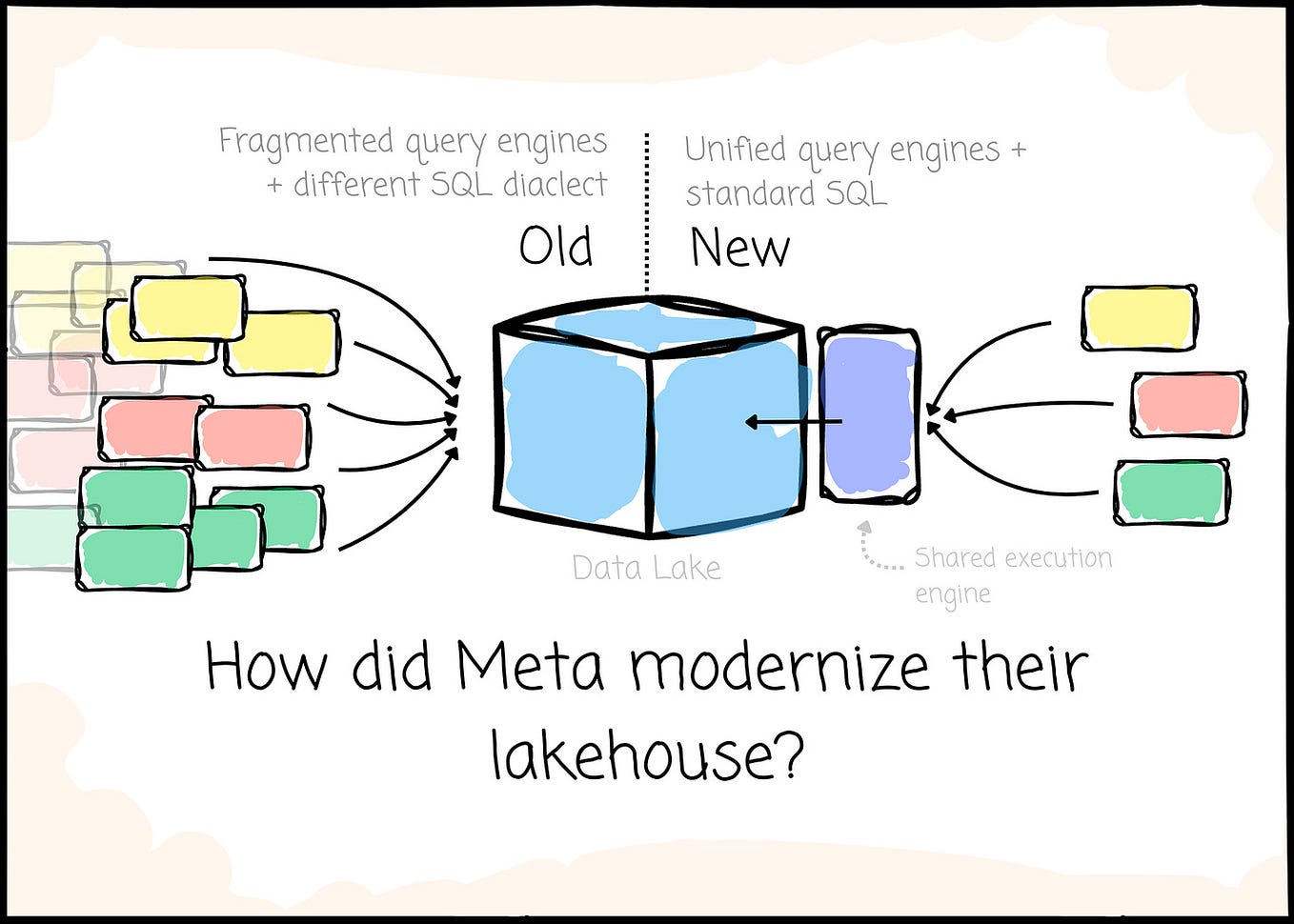
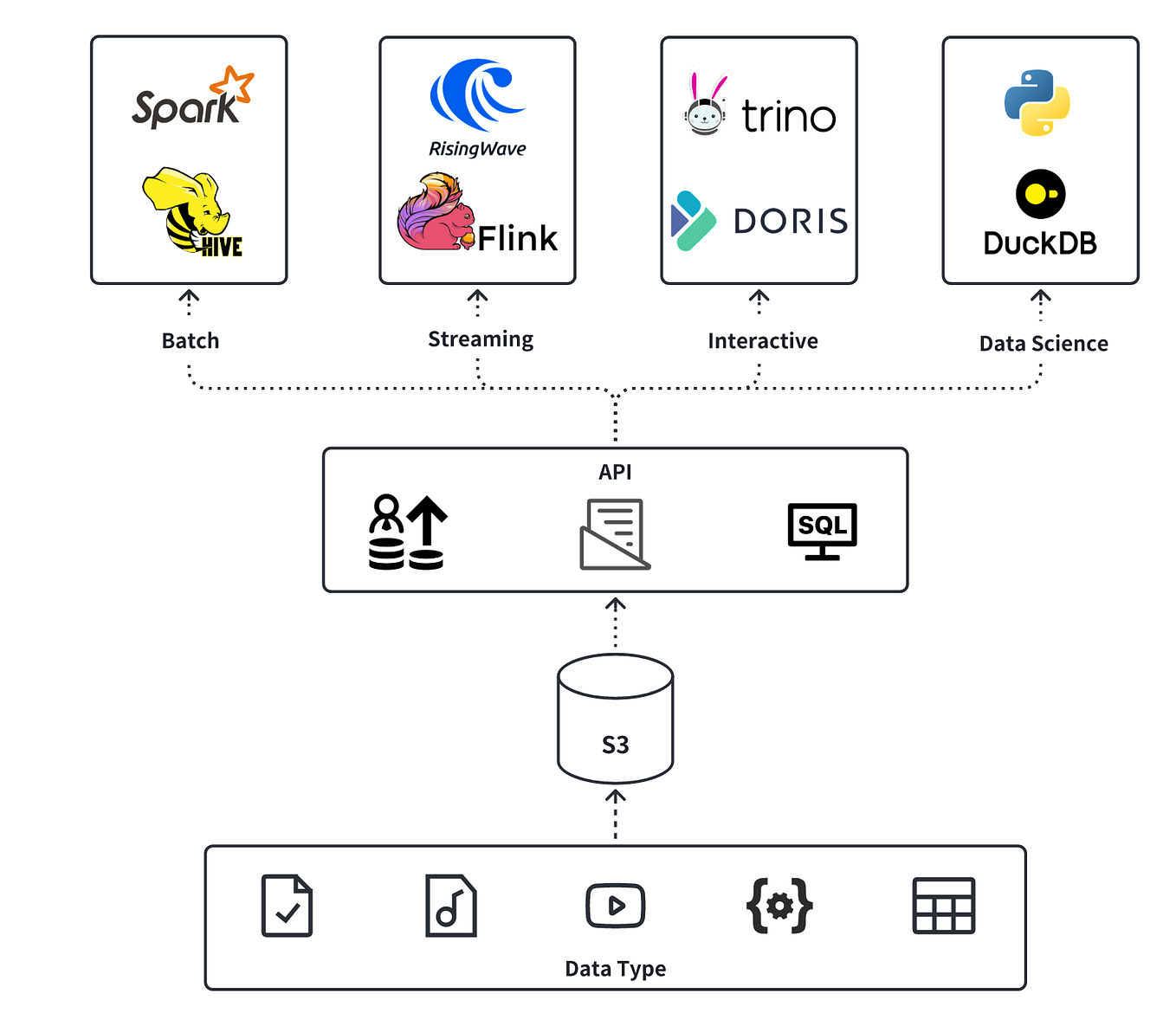
Understanding the Table Structure of Apache Iceberg | by Shraddha ...
GRPO using Transformer Reinforcement Learning | by Yugen.ai | Yugen.ai ...
Understanding Flow Matching. Structure (introduction) | by Ulrik Isdahl ...
How does GRPO - the RL algorithm behind DeepSeek's R1 models work? Let ...
How LLM Composition can boost your knowledge | Yugen.ai posted on the ...
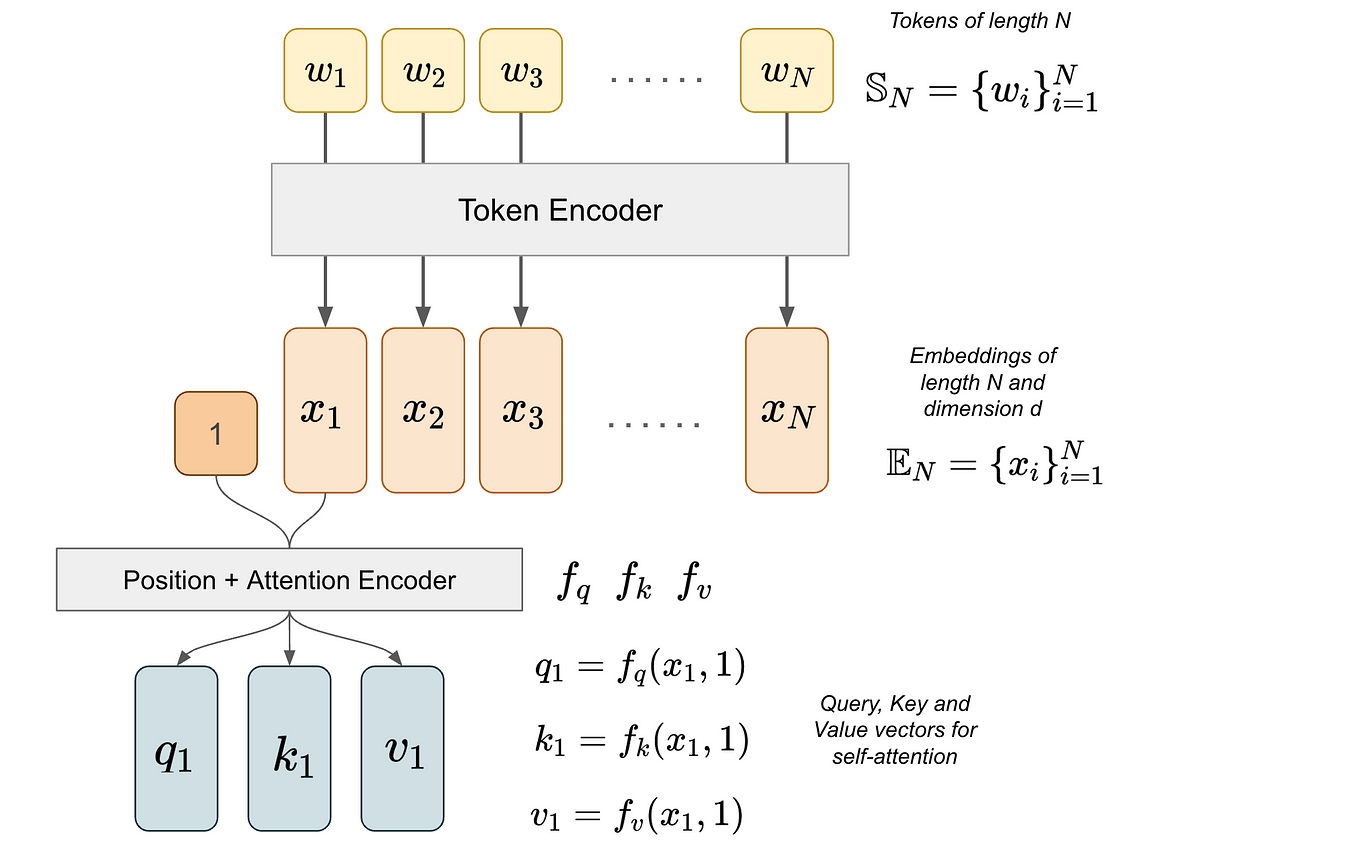
LLM Architectures Explained: Encoder-Decoder Architecture (Part 4) | by ...
Mastering Stream Processing: Hopping and Tumbling Windows | by bbejeck ...
Understanding Apache Flink — A Journey from Core Concepts to ...
Exploring Temporal Workflow: Automating Tasks with Elegance | by Daniel ...
Simplifying Ray and Distributed Computing | by Imran Roshan | Google ...
MinIO — High Performance Object Storage | by BigDataEnthusiast | Medium
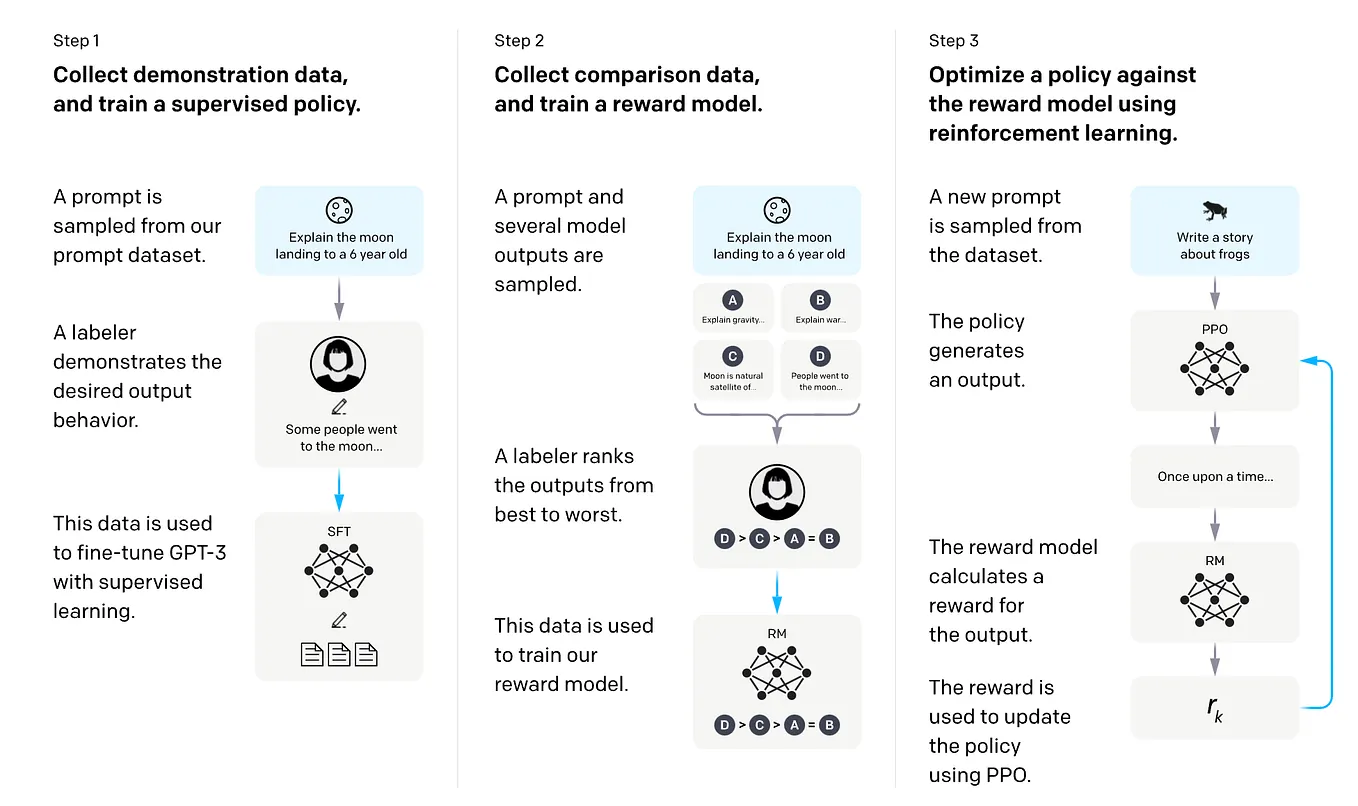
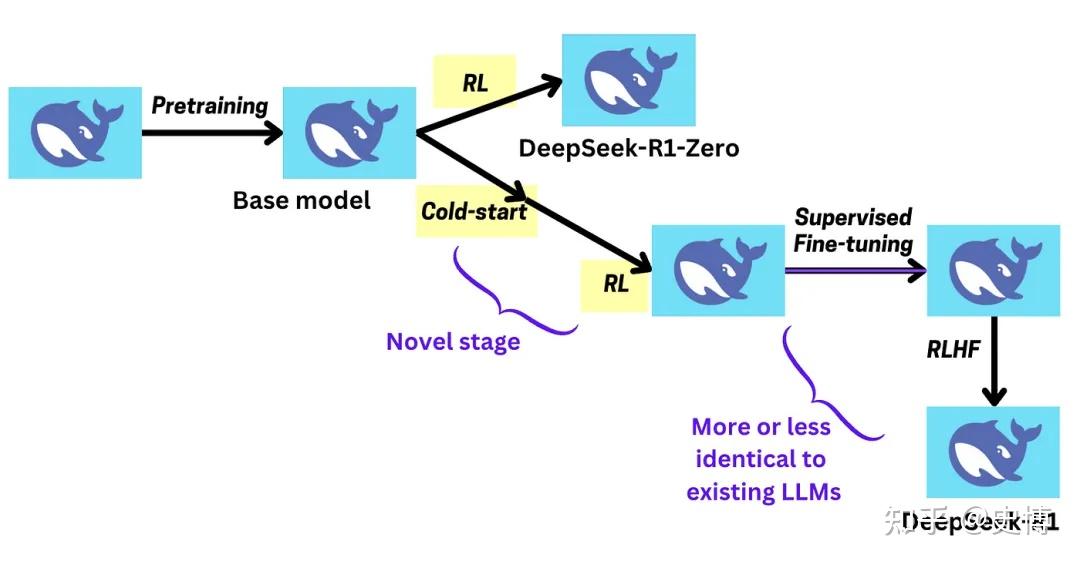
From R1-Zero to R1: How DeepSeek is Pushing the Limits of AI Reasoning ...
The ONLY DeepSeek GRPO/PPO video you'll EVER need (with examples and ...
How is the DeepSeek AI R1 model more cost-effective than OpenAI o1 ...
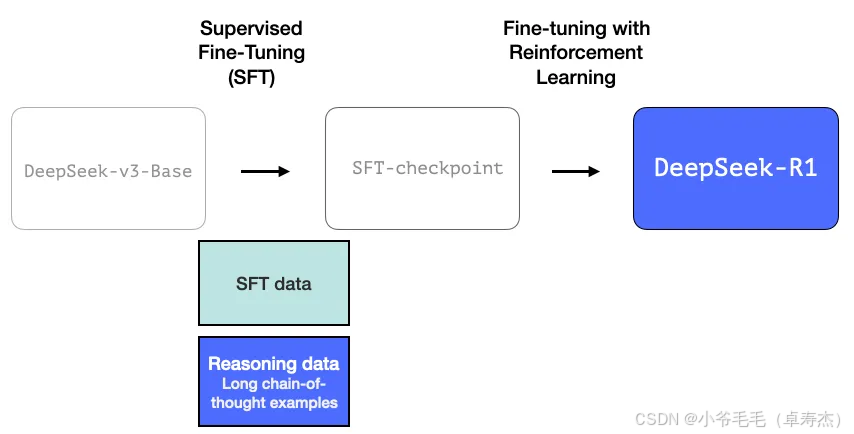
The Illustrated DeepSeek-R1 - by Jay Alammar
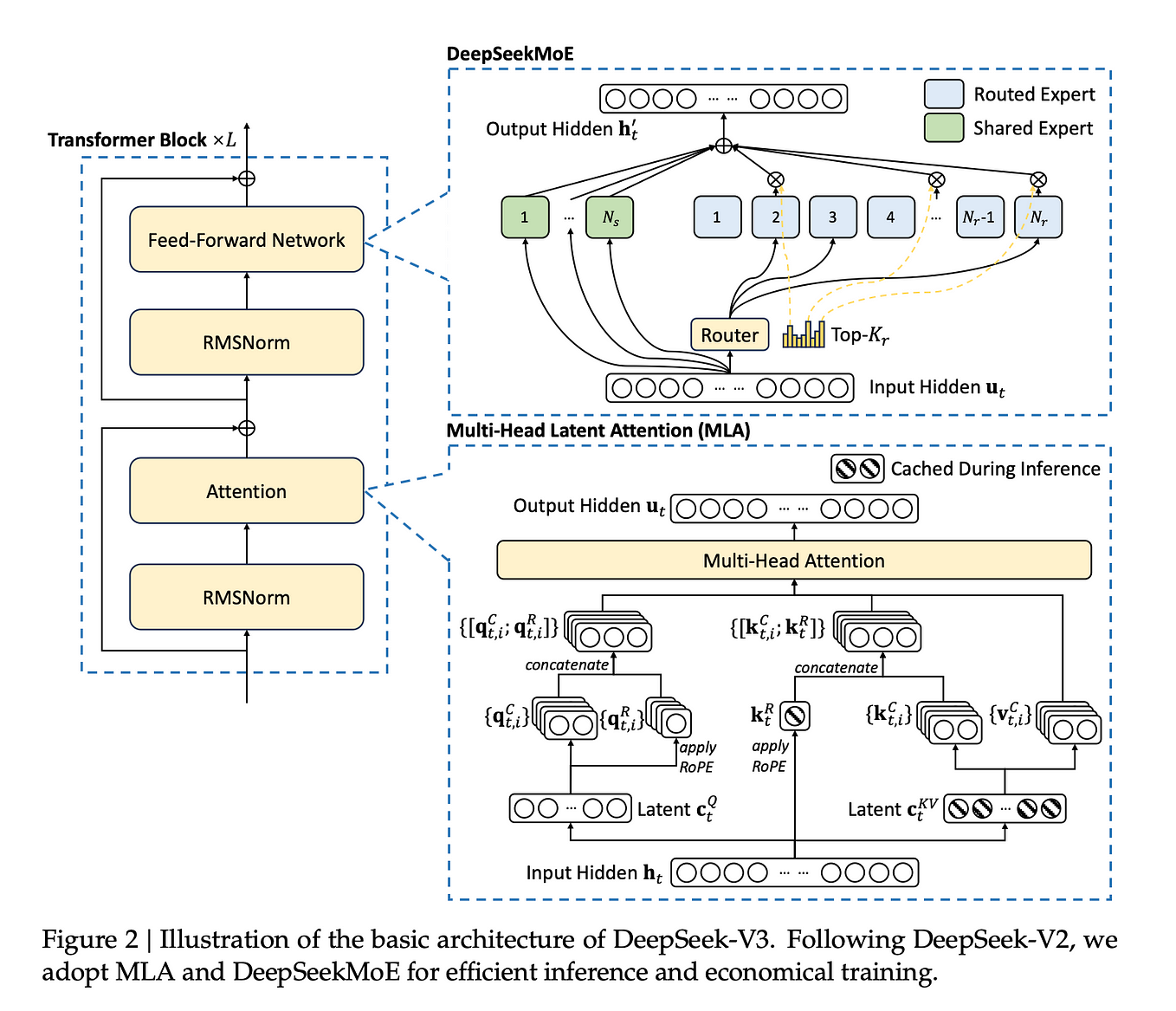
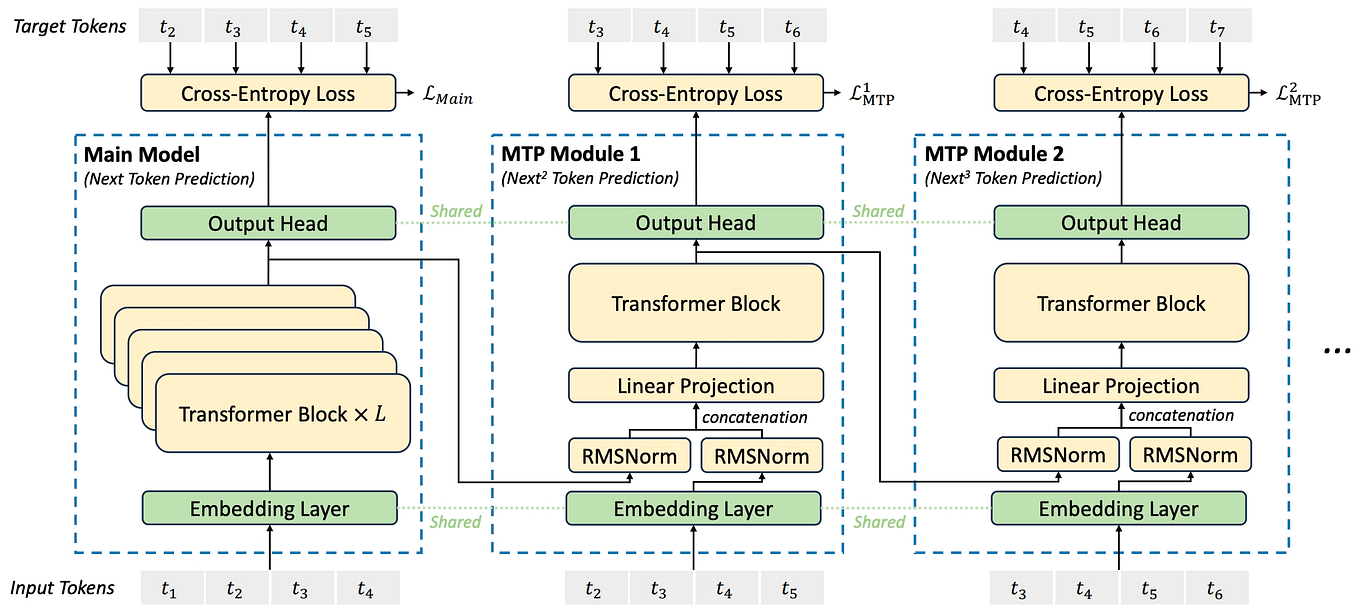
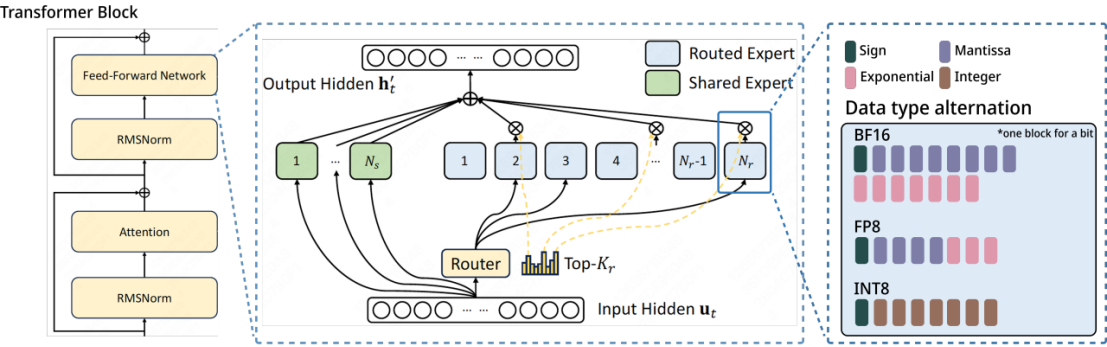
DeepSeek-V3 — Advances in MoE Load Balancing and Multi-Token Prediction ...
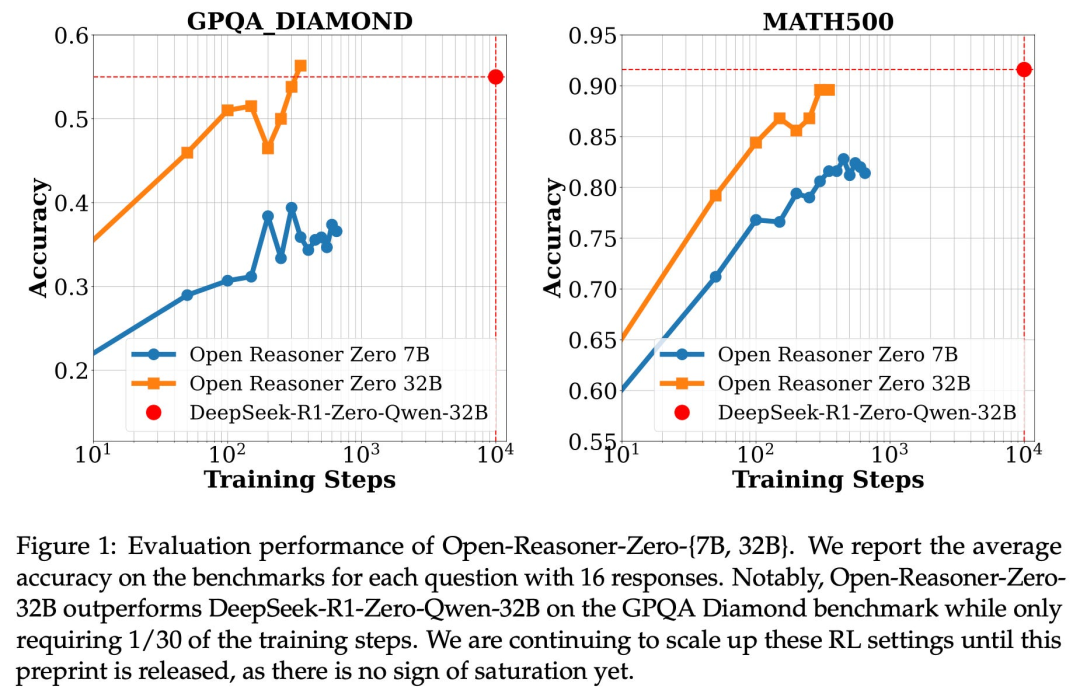
How DeepSeek R1-Zero was reproduced in $30 | by Wei Lu | Medium
Multi-head Latent Attention. MLA with deep seek | by noplaxochia | Medium
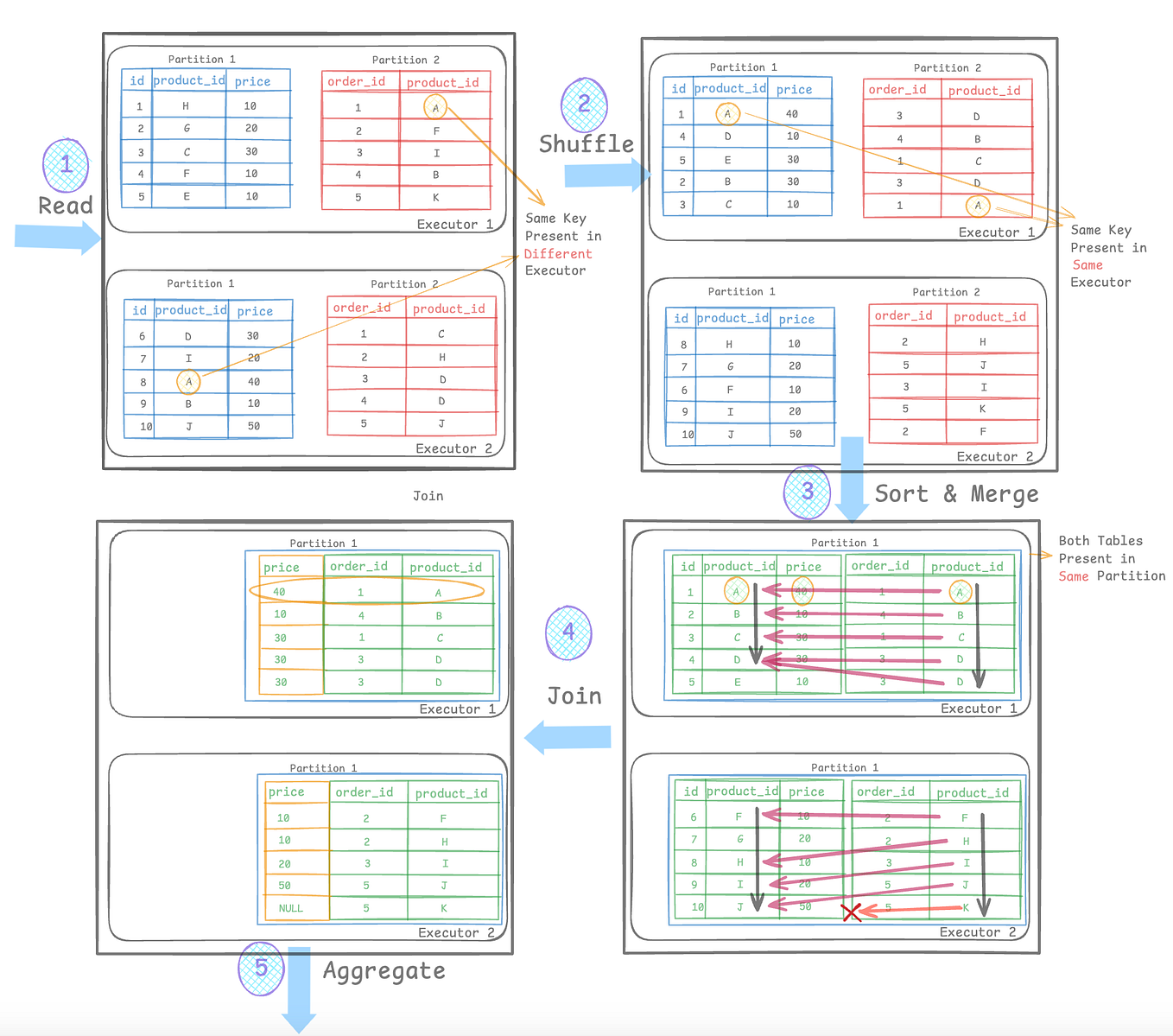
Join Strategies in Apache Spark. In this blog, we’ll break down the ...
Apache Drools with Spring Boot 3. Summary | by Yangli | Medium
Concepts of spark lineage graph. The Spark lineage graph, often ...
DeepSeek-AI Releases DeepSeek-R1-Zero and DeepSeek-R1: First-Generation ...
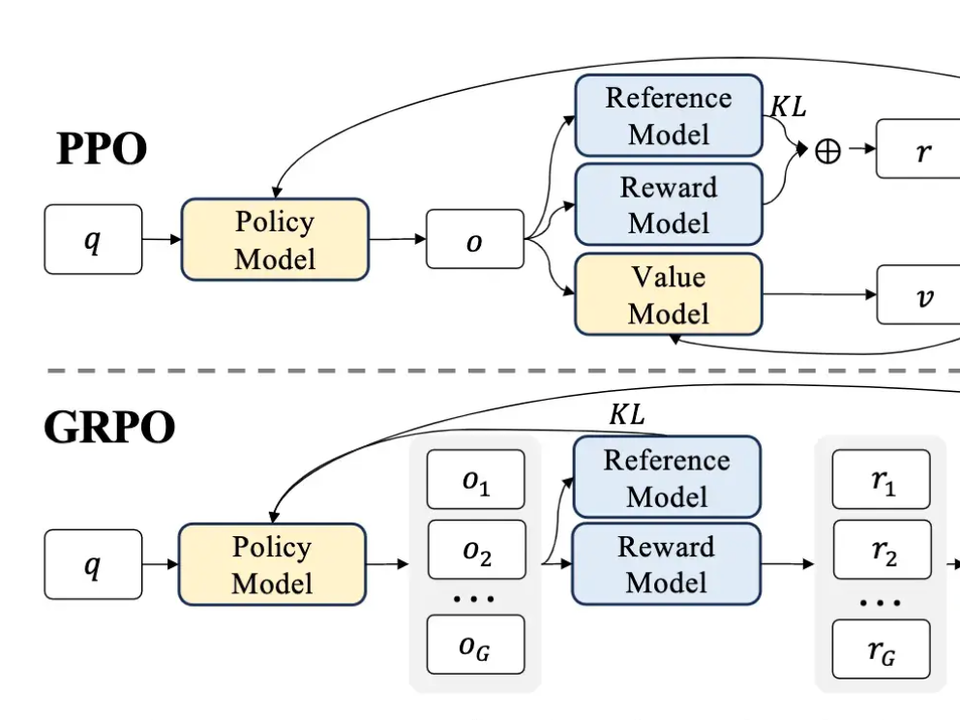
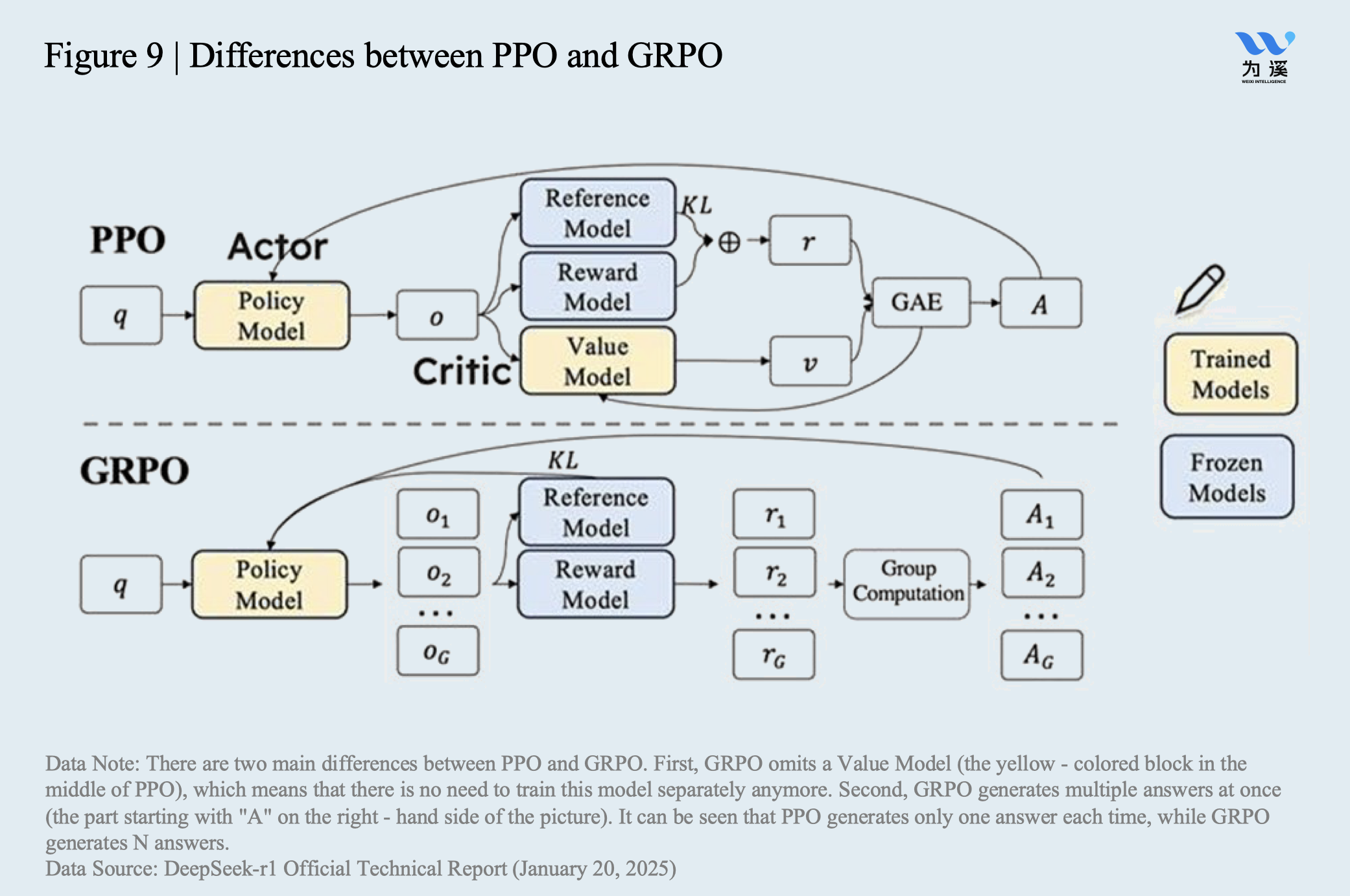
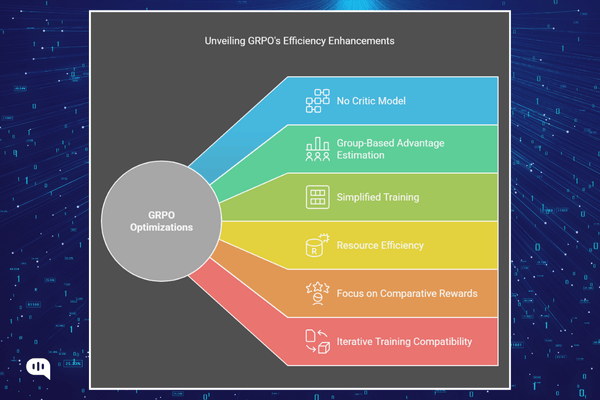
Group Relative Policy Optimisation (GRPO): The Reinforcement learning ...
Yugen.ai | Case Study | Brucira
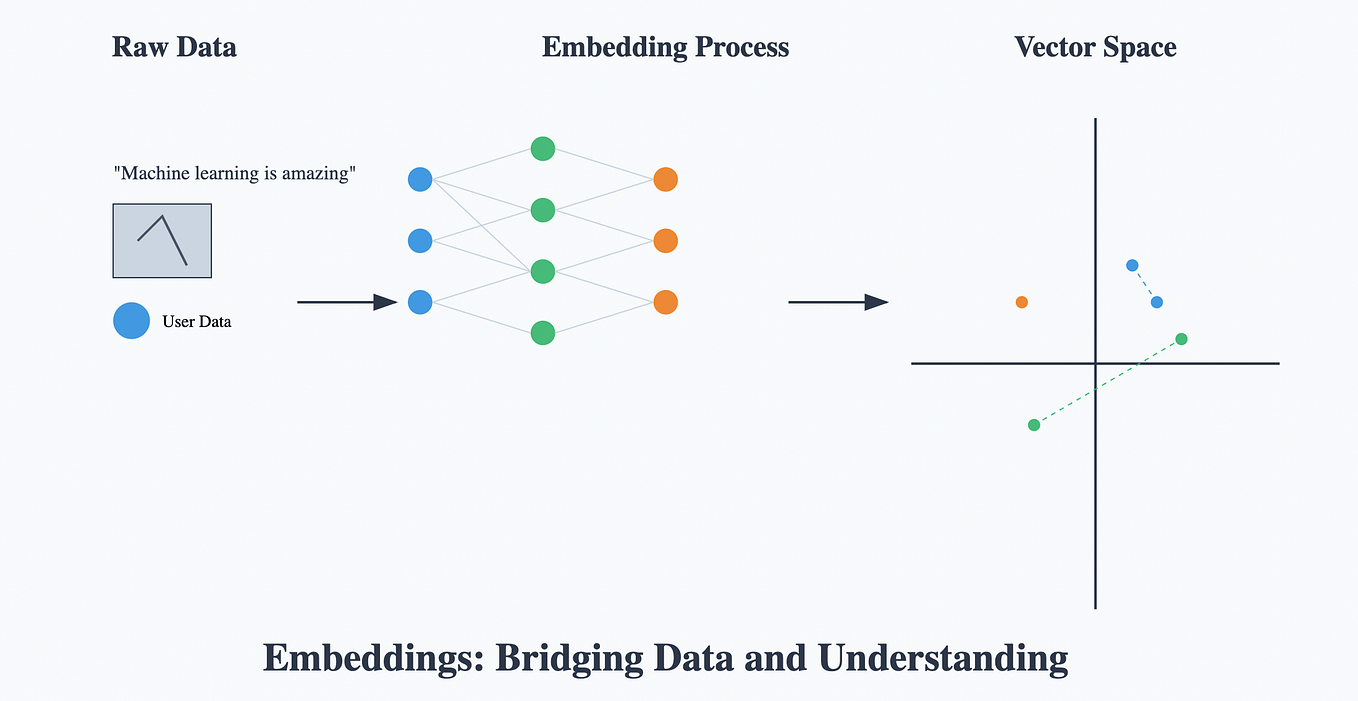
Dense Vectors in Natural Language Processing | by Yasindu Sanjeewa | Medium
Getting Started with Apache Flink | by Parin Patel | Medium
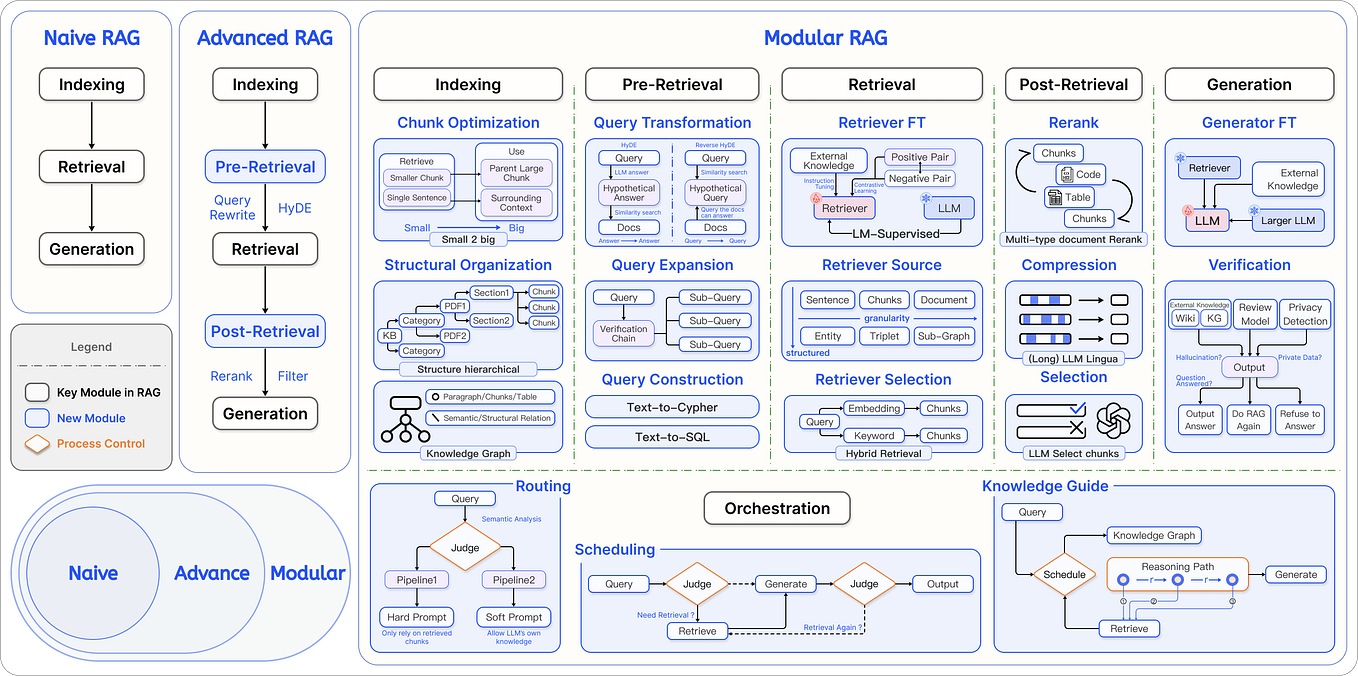
RAFT — RAGs Meet Fine-Tuning. RAFTs (Retrieval-Augmented Fine-Tuning ...
#associatedatascientist | Yugen.ai
List: DeepSeek | Curated by Nayoung | Medium
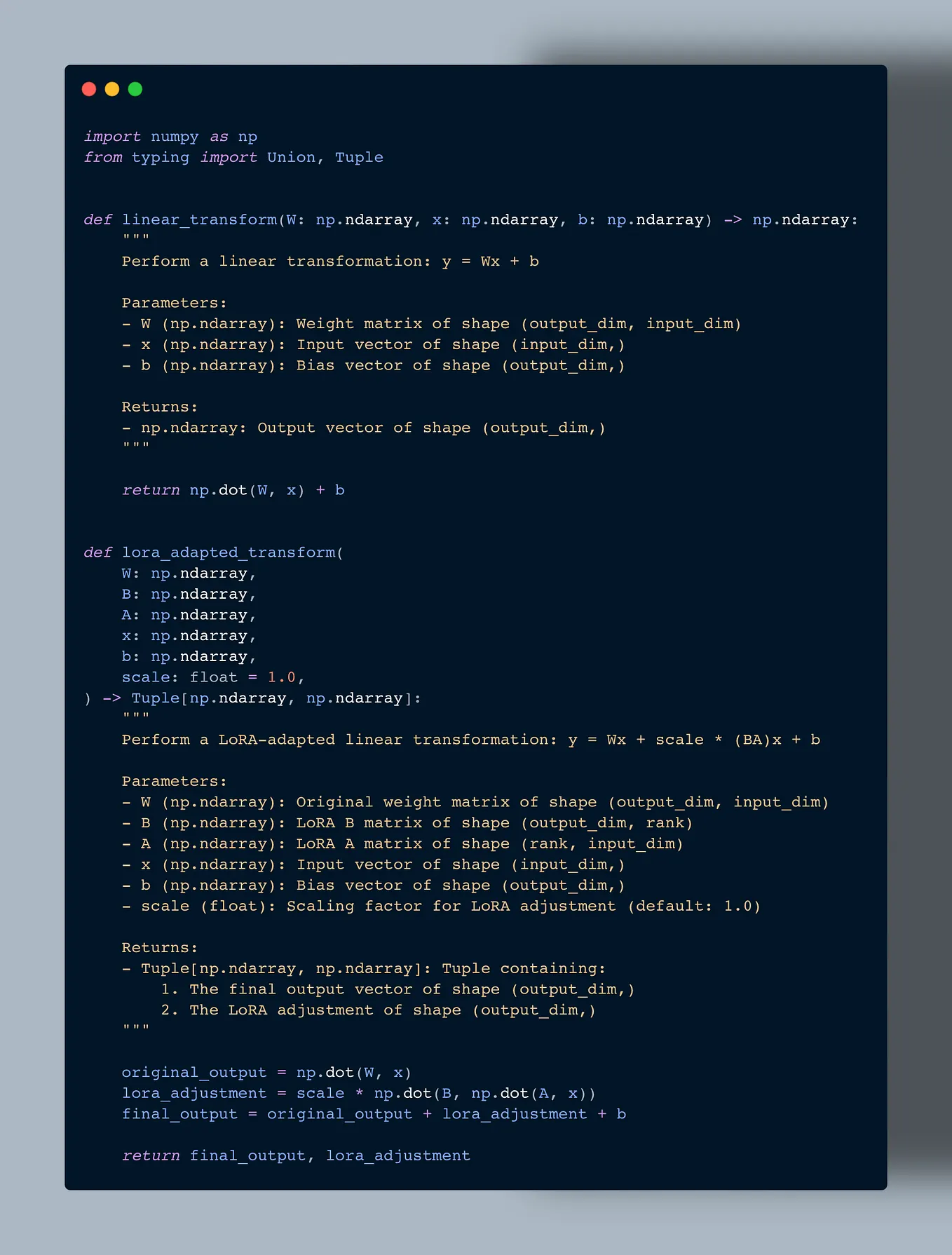
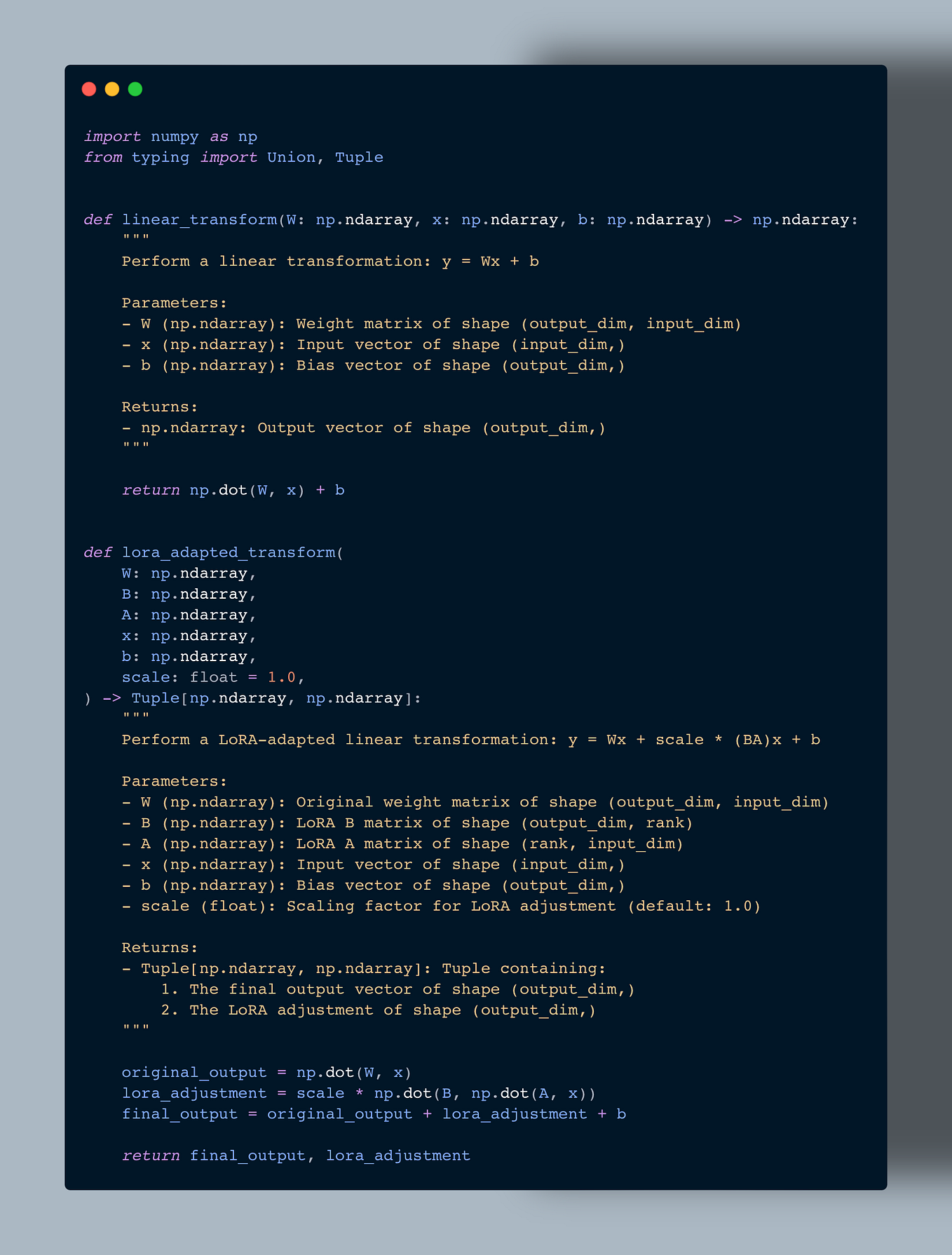
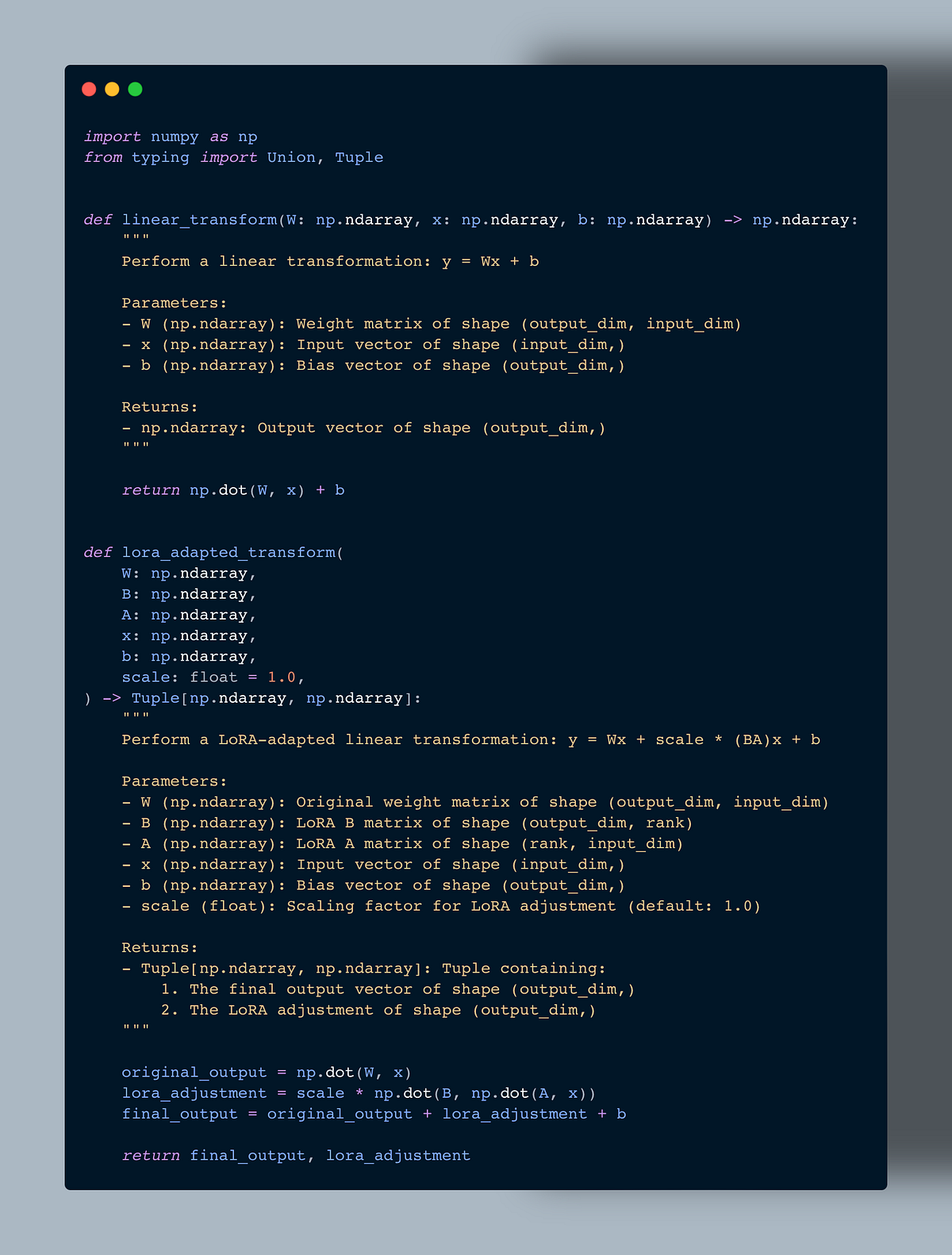
Low-Rank Adapter (LoRA) Explained | by Sheli Kohan | Medium
DeepSeek-R1 — Intuitively and Exhaustively Explained
18. DeepSeek Series — LLM Foundations
Paper page - DeepSeek-R1: Incentivizing Reasoning Capability in LLMs ...
DeepSeek-R1: A Breakthrough in AI Reasoning Through Pure Reinforcement ...
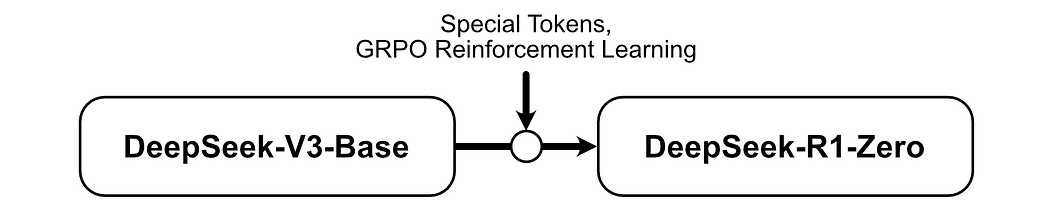
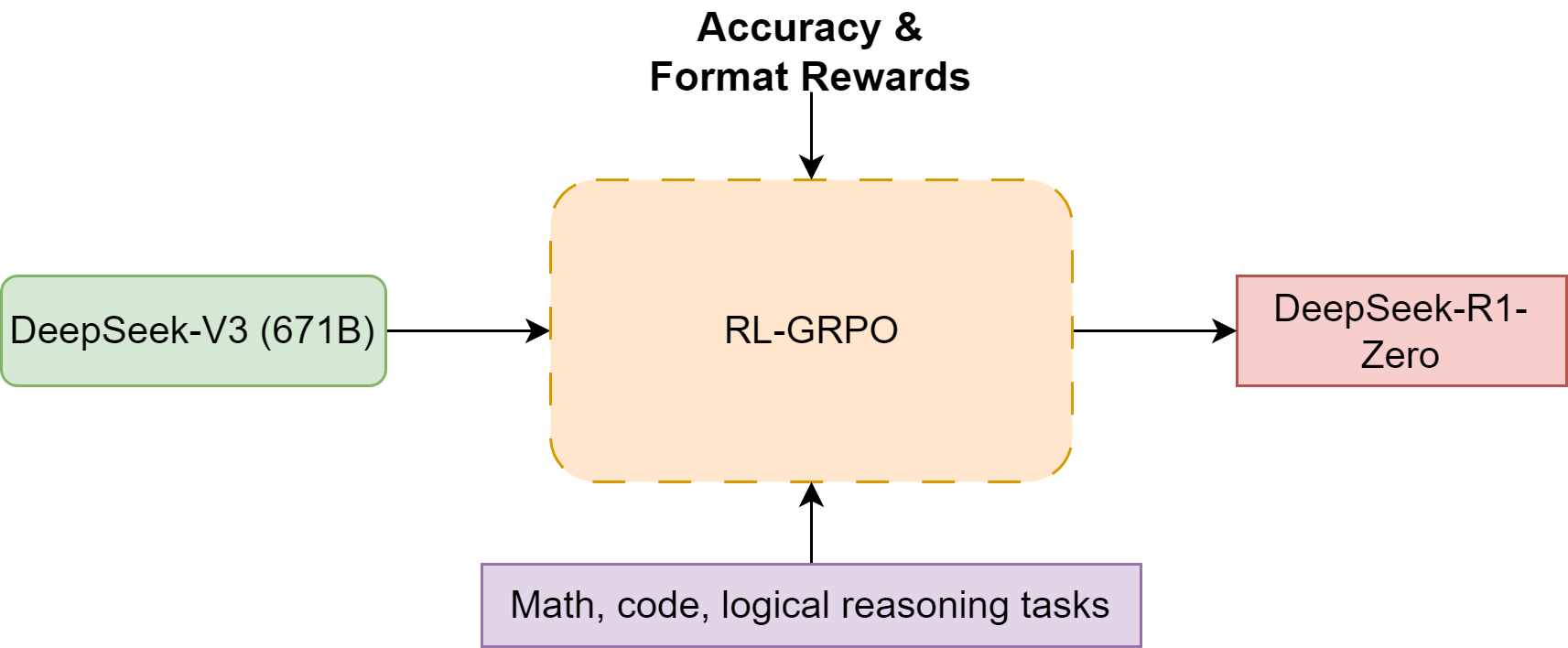
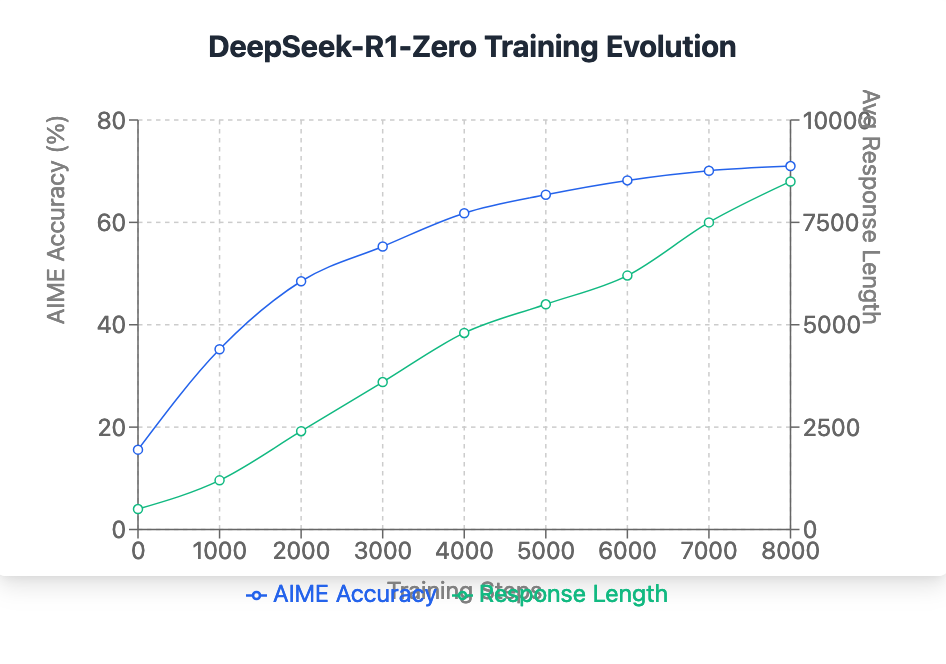
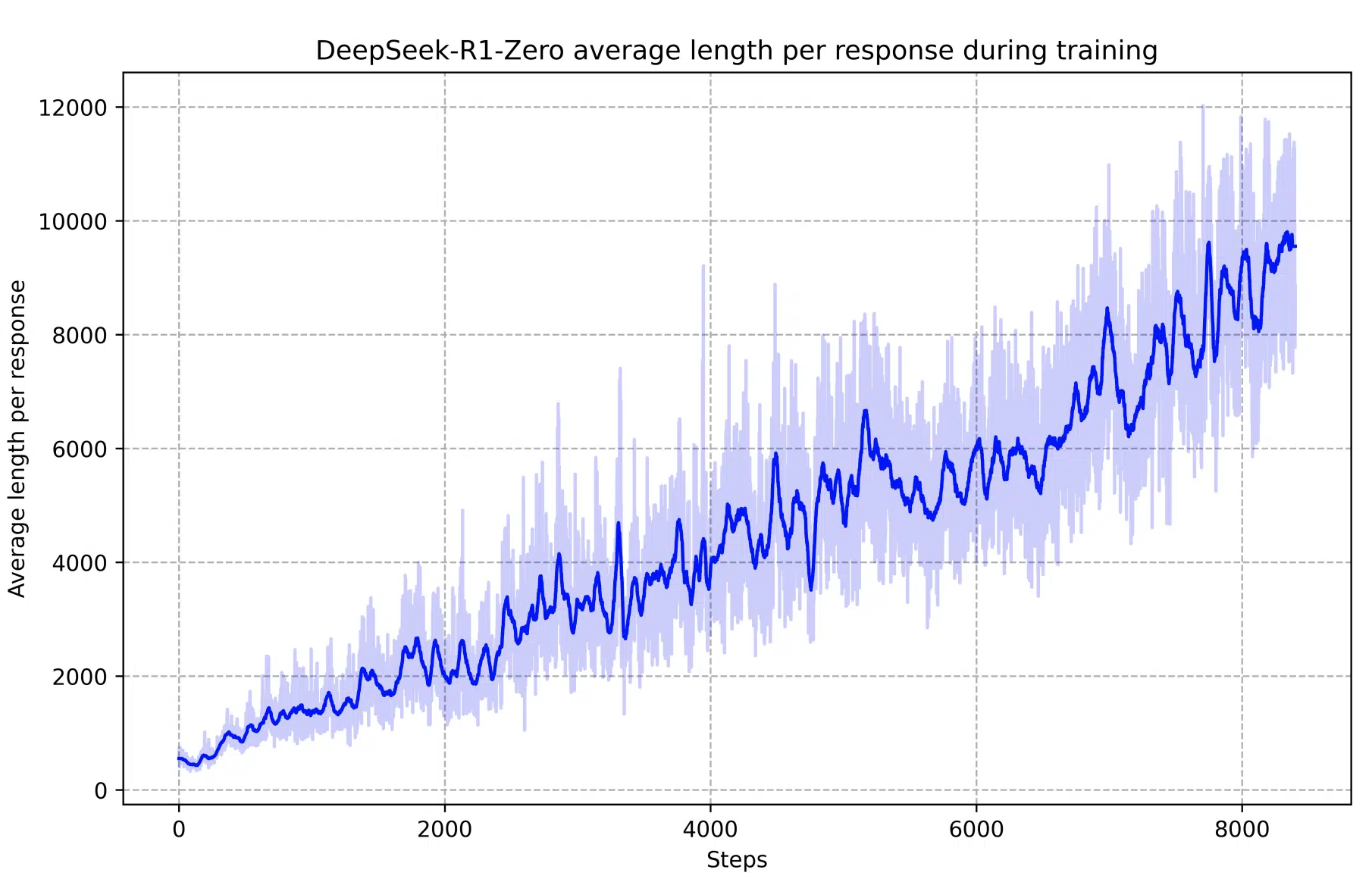
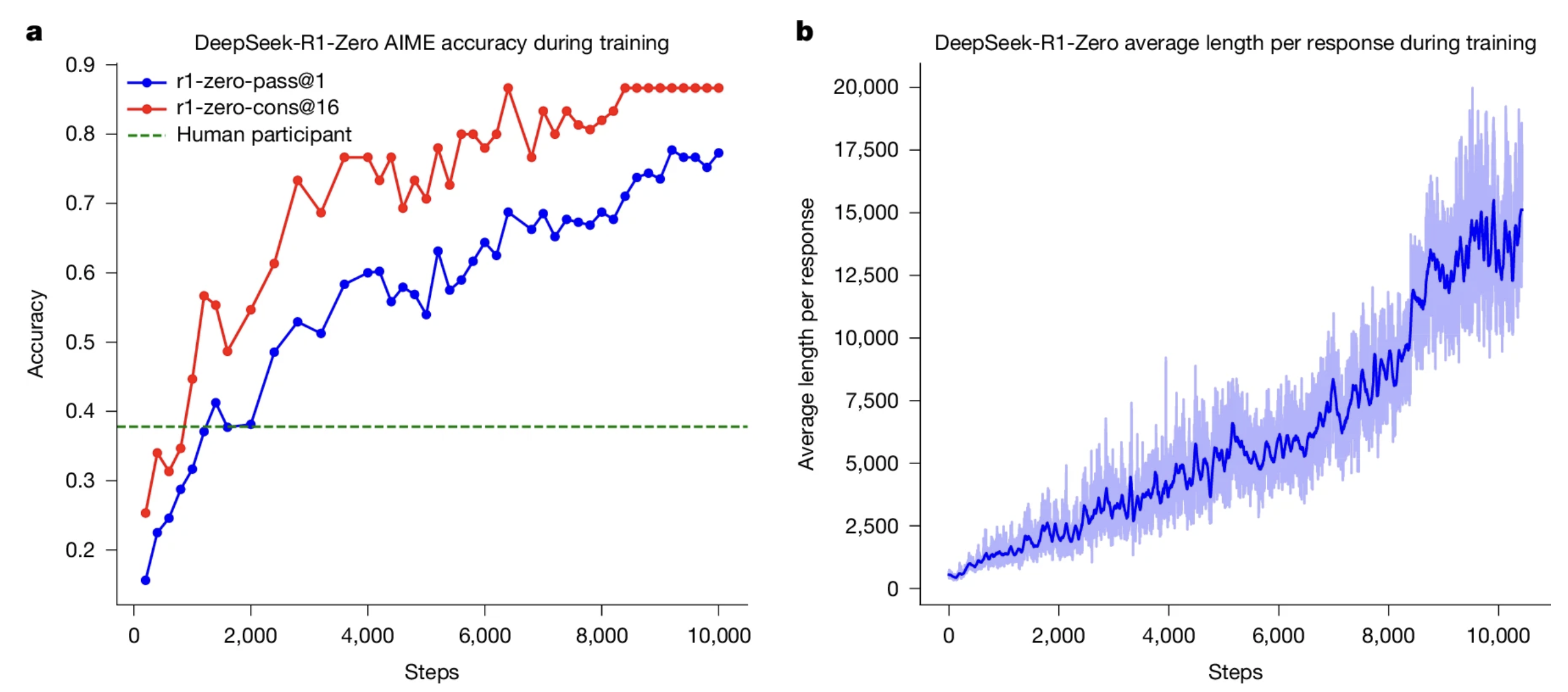
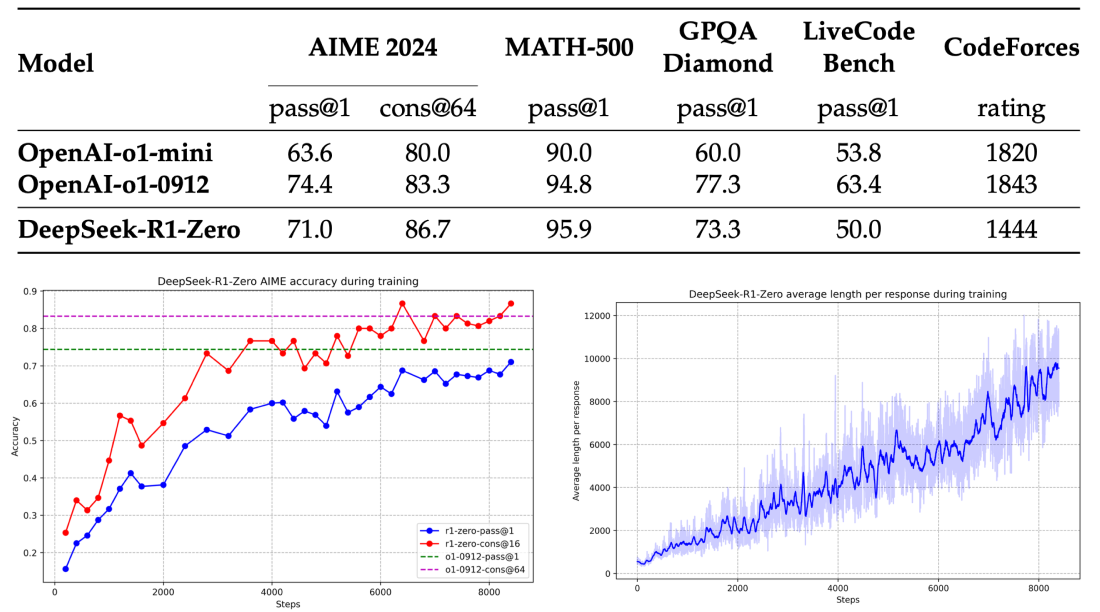
DeepSeek-R1-Zero- is an inference model trained through large-scale ...
Efficient Learning: DeepSeek R1 with GRPO
.@deepseek_ai showed how pure reinforcement learning (RL) can improve ...
DeepSeek-R1: A Breakthrough in AI Reasoning - The Research Scientist Pod
DeepSeek R1 背后的 GRPO 算法详解:原理、改进与未来趋势 - AI资讯 - 冷月清谈
GRPO-like-deepseek-r1/0deepseek-r1训练流程.ipynb at main · erthorpabar/GRPO ...
Inquiry Regarding R1 Details: Information on R1-Zero training data ...
Reproduce Deepseek R1-zero Aha Moment | Microsoft Community Hub
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement ...
DeepSeek-R1-Zero 和Deep seek R1 技术详解 && GRPO的训练方法 - 知乎
Efficient LLM Fine-Tuning: LoRA, DoRA, and Apple’s Innovative Approach ...
LLM Post-Training: A Deep Dive into Reasoning Large Language Models ...
How DeepSeek R1, GRPO, and Previous DeepSeek Models Work
揭秘DeepSeek R1-Zero训练方式,GRPO还有极简改进方案
nanoAhaMoment: RL for LLM from Scratch with 1 GPU - Part 2 - YouTube
deepseek-r1开源复现方法整理 - 知乎
Bite: How Deepseek R1 was trained
DeepSeek R1 and GRPO: Advanced RL for LLMs
DeepSeek R1 Theory Tutorial – Architecture, GRPO, KL Divergence - YouTube
最新「大模型简史」整理!从Transformer(2017)到DeepSeek-R1(2025) - 智源社区
How DeepSeek’s AI Model Is Reshaping Global Tech – CKGSB Knowledge
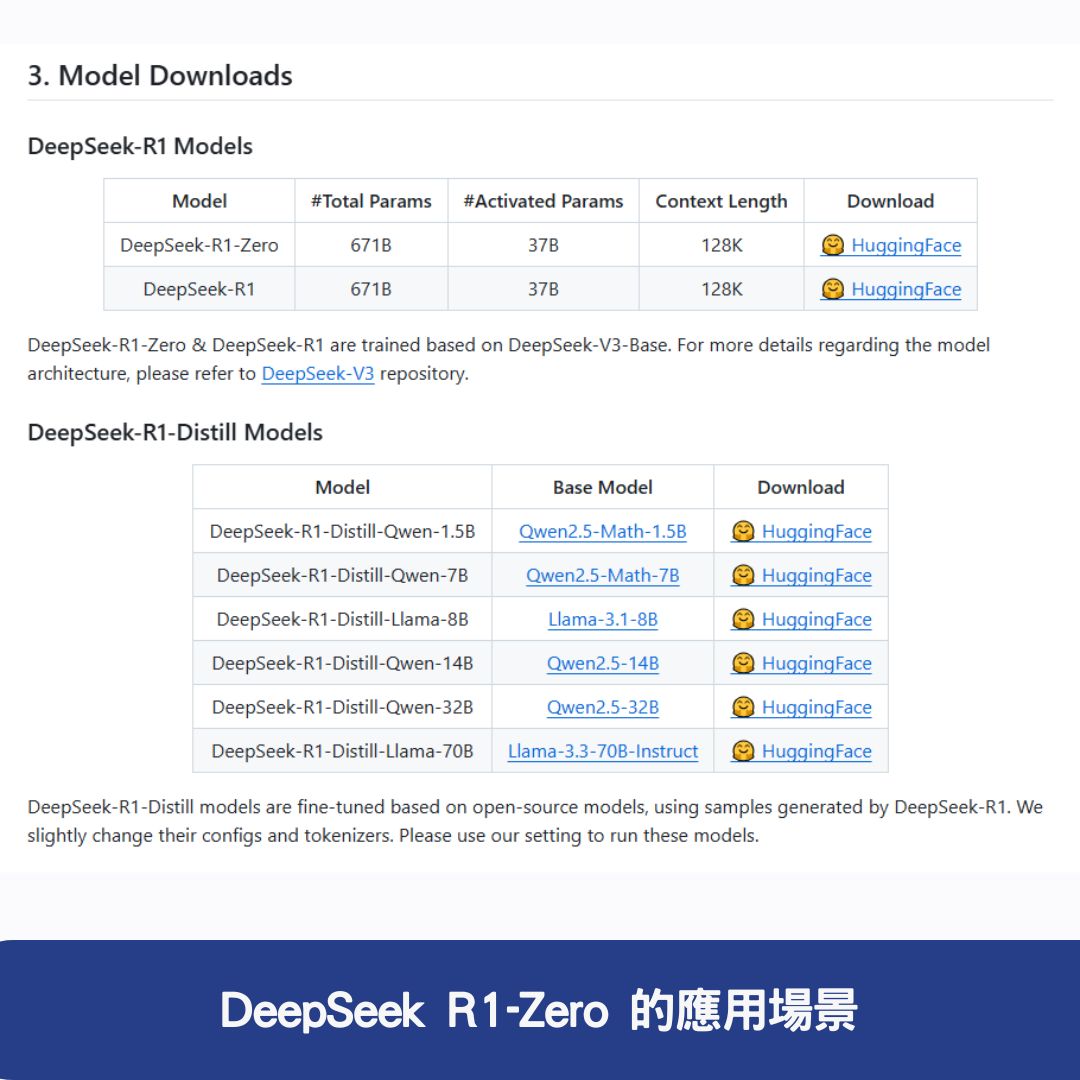
DeepSeek R1-Zero 完全強化學習推理模型 功能特點與應用場景詳解 - 奕昇AI學習平台
Vinija's Notes • Primers • DeepSeek-R1
DeepSeek R1推理相关项目源码分析 - 知乎
How DeepSeek Defeated OpenAI In Its Own Game?
Drawing DeepSeek R1 Architecture and Training Process from Scratch
Decoding DeepSeek R1's Advanced Reasoning Capabilities
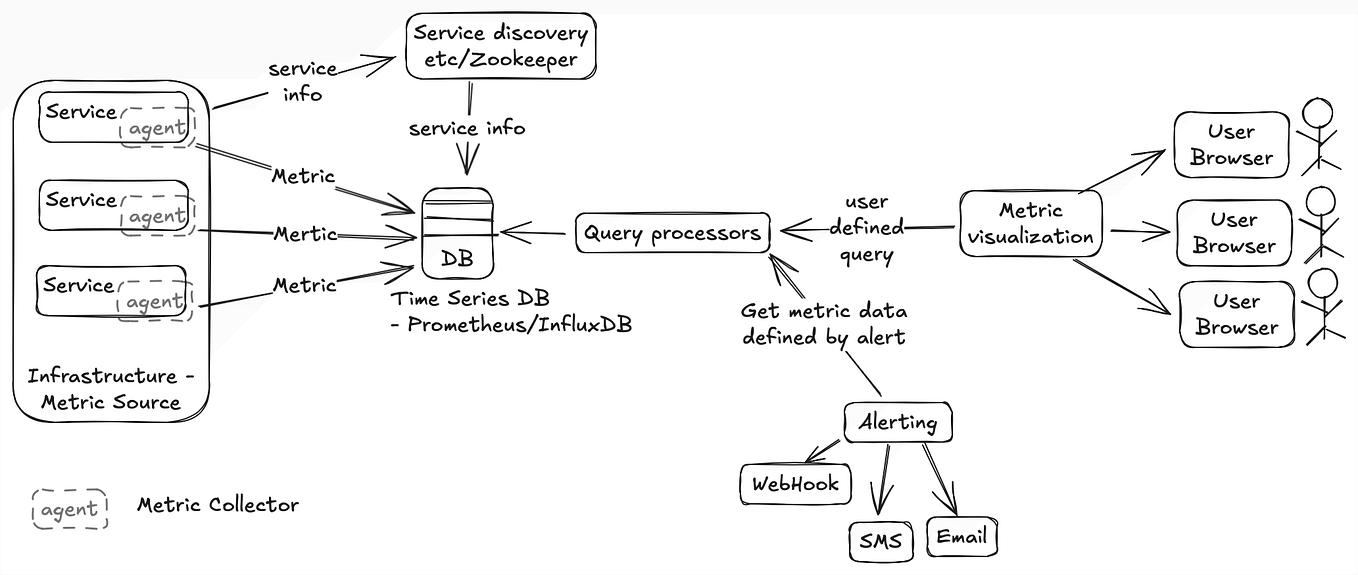
How to build a Multi-Stage Recommender System
DeepSeek-R1/Zero、RL GRPO以及蒸馏过程详解_grpo 蒸馏-CSDN博客
DeepSeek R1 Zero中文复现教程来了! - Datawhale - SegmentFault 思否
RAG System for AI Reasoning with DeepSeek R1 Distilled Model
Deepseek R1可能找到了超越人类的办法