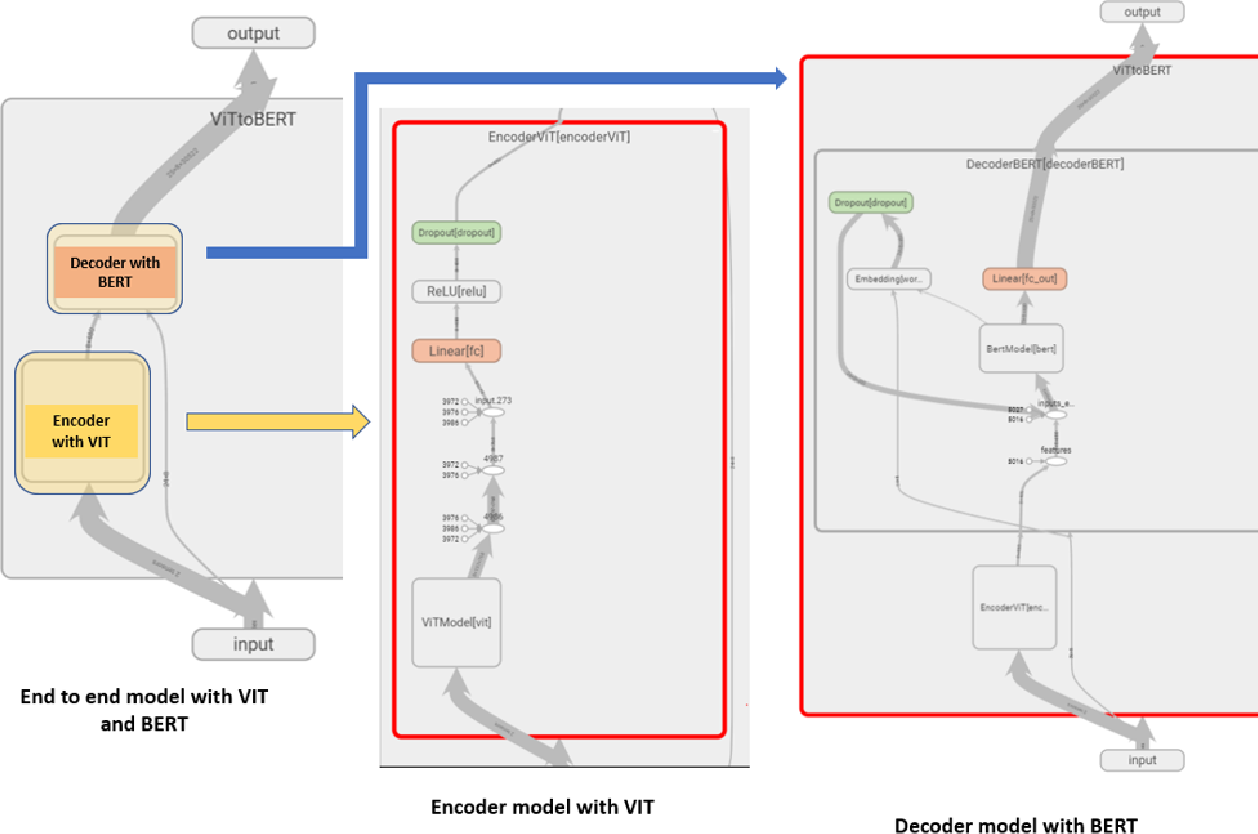
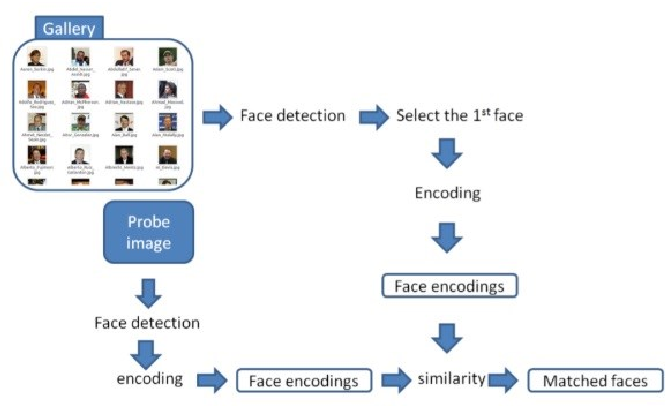
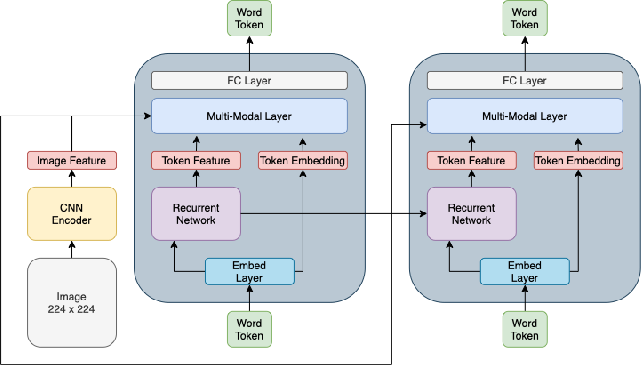
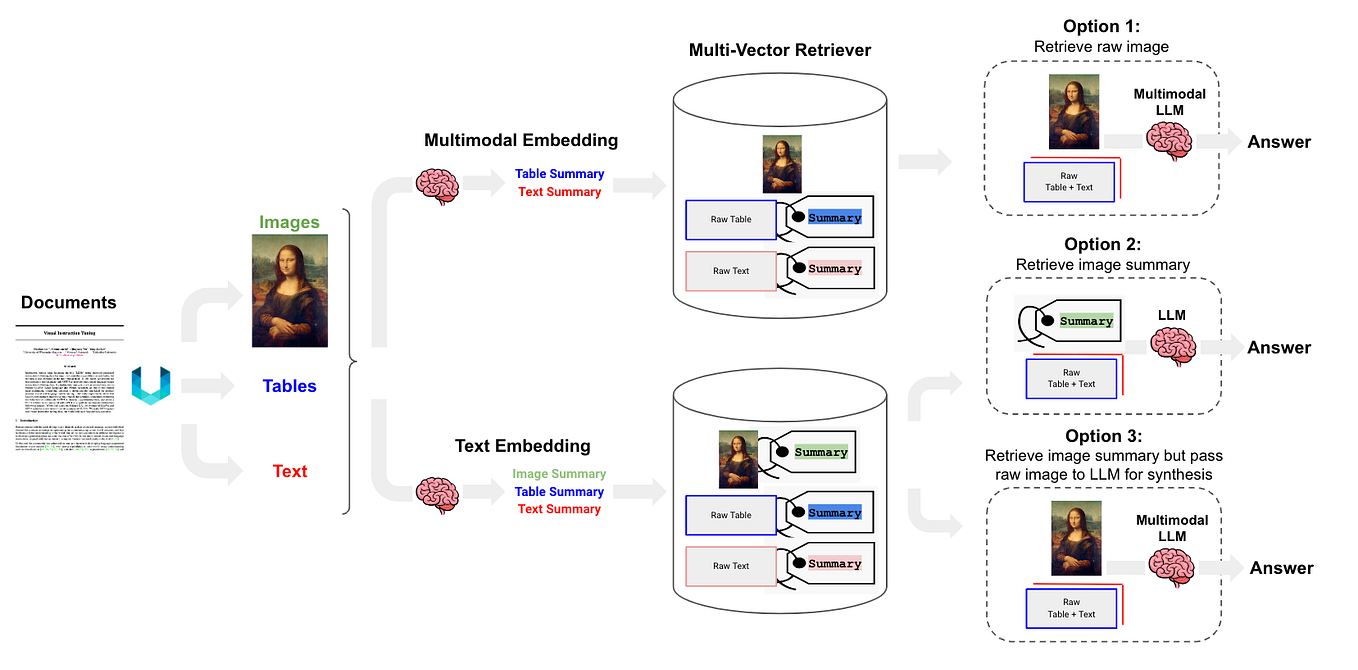
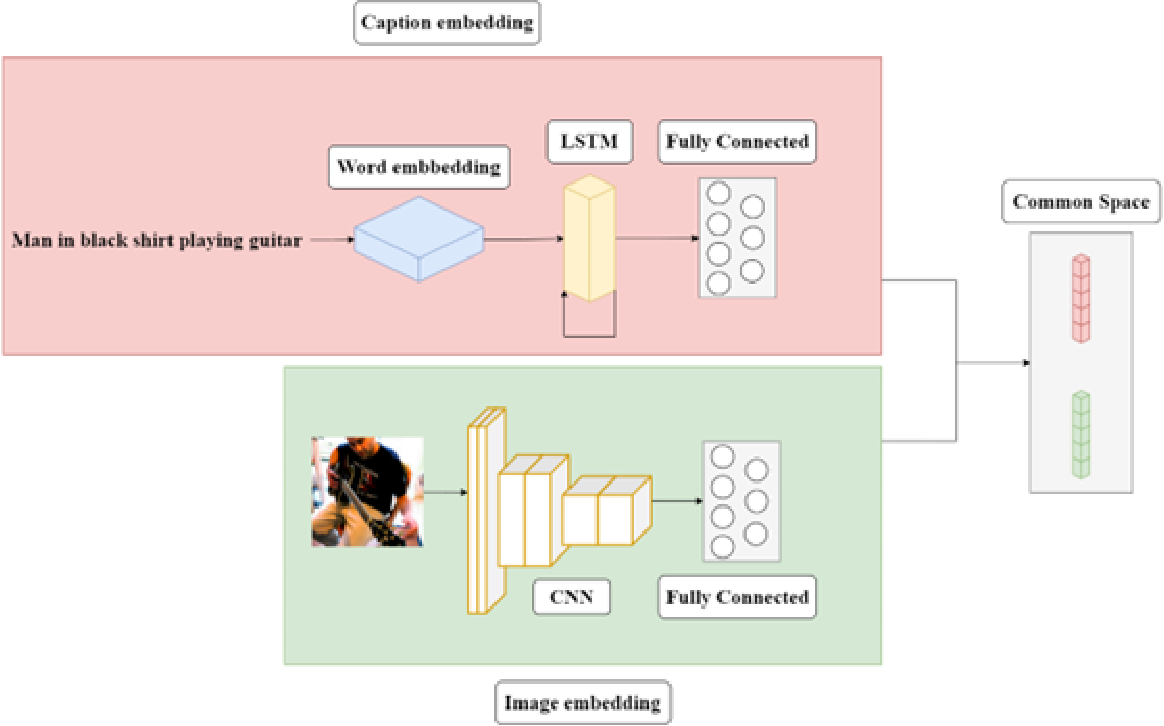
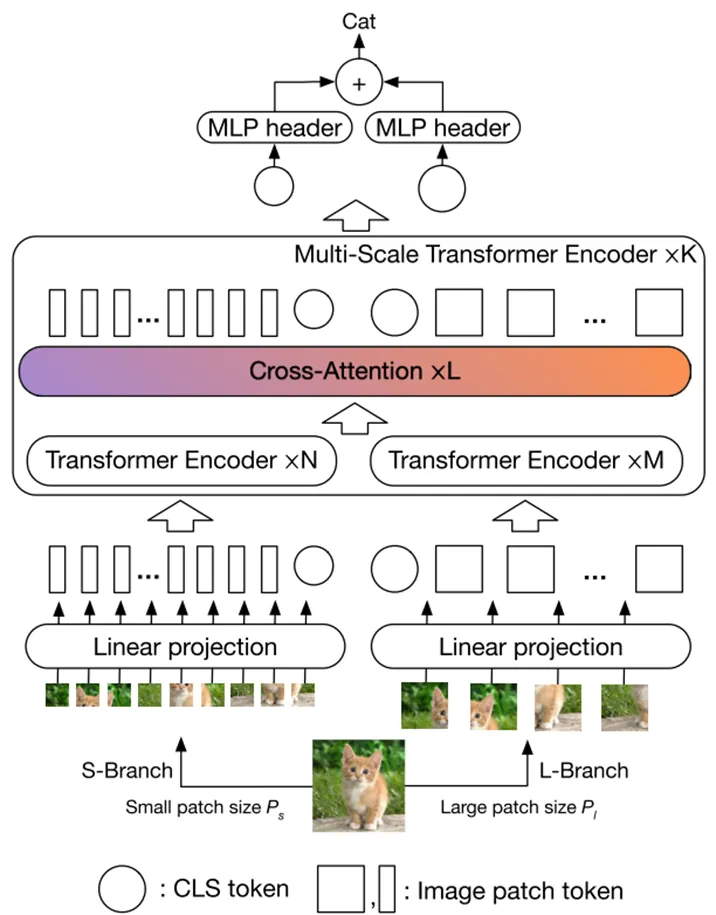
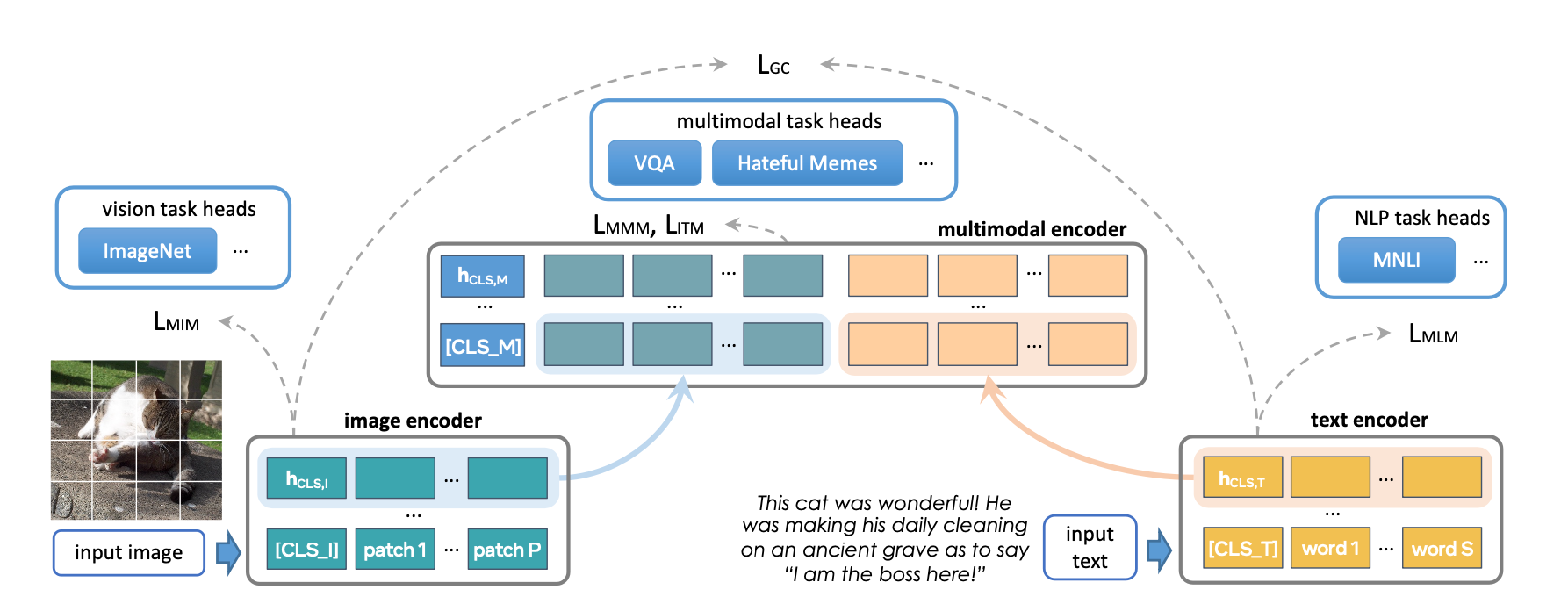
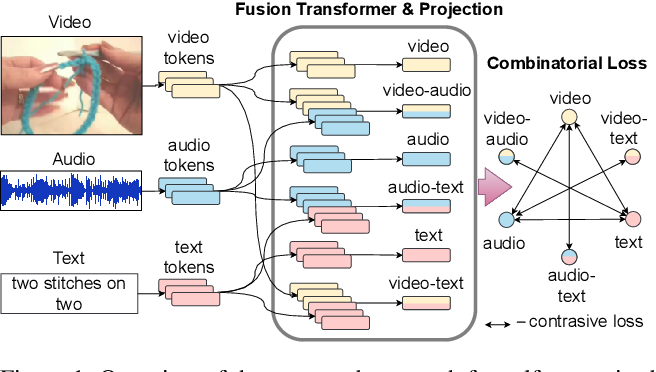
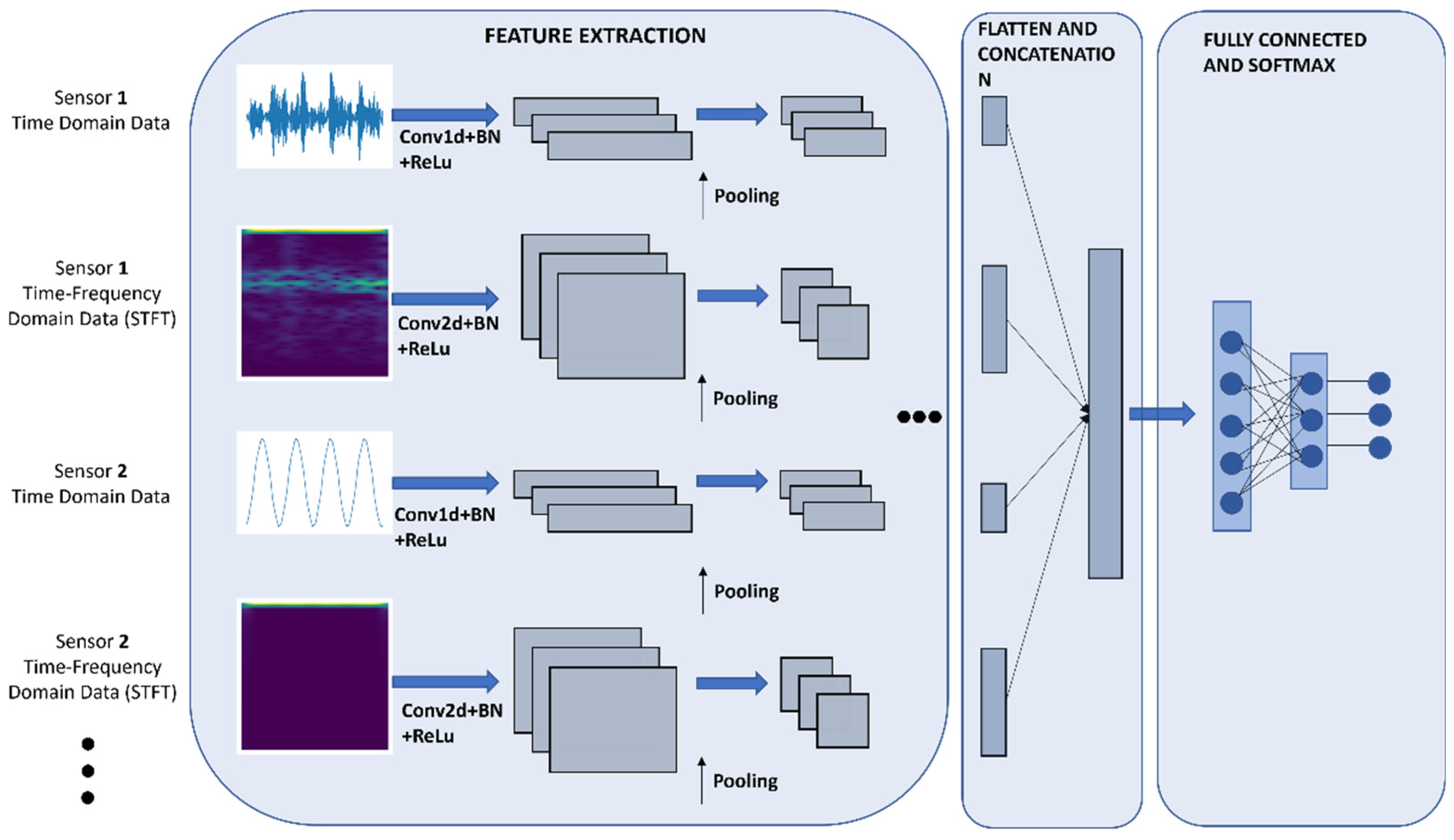
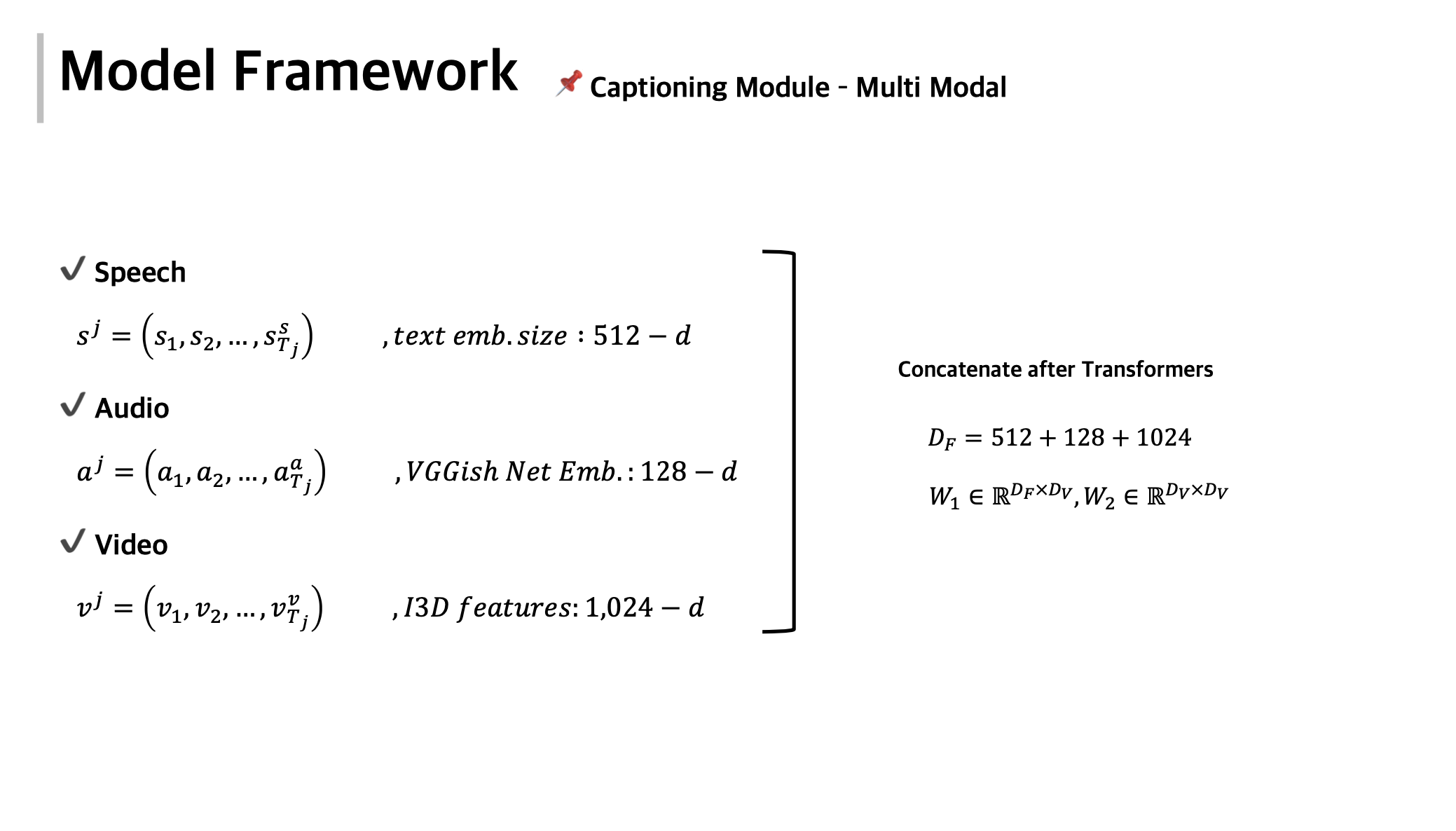
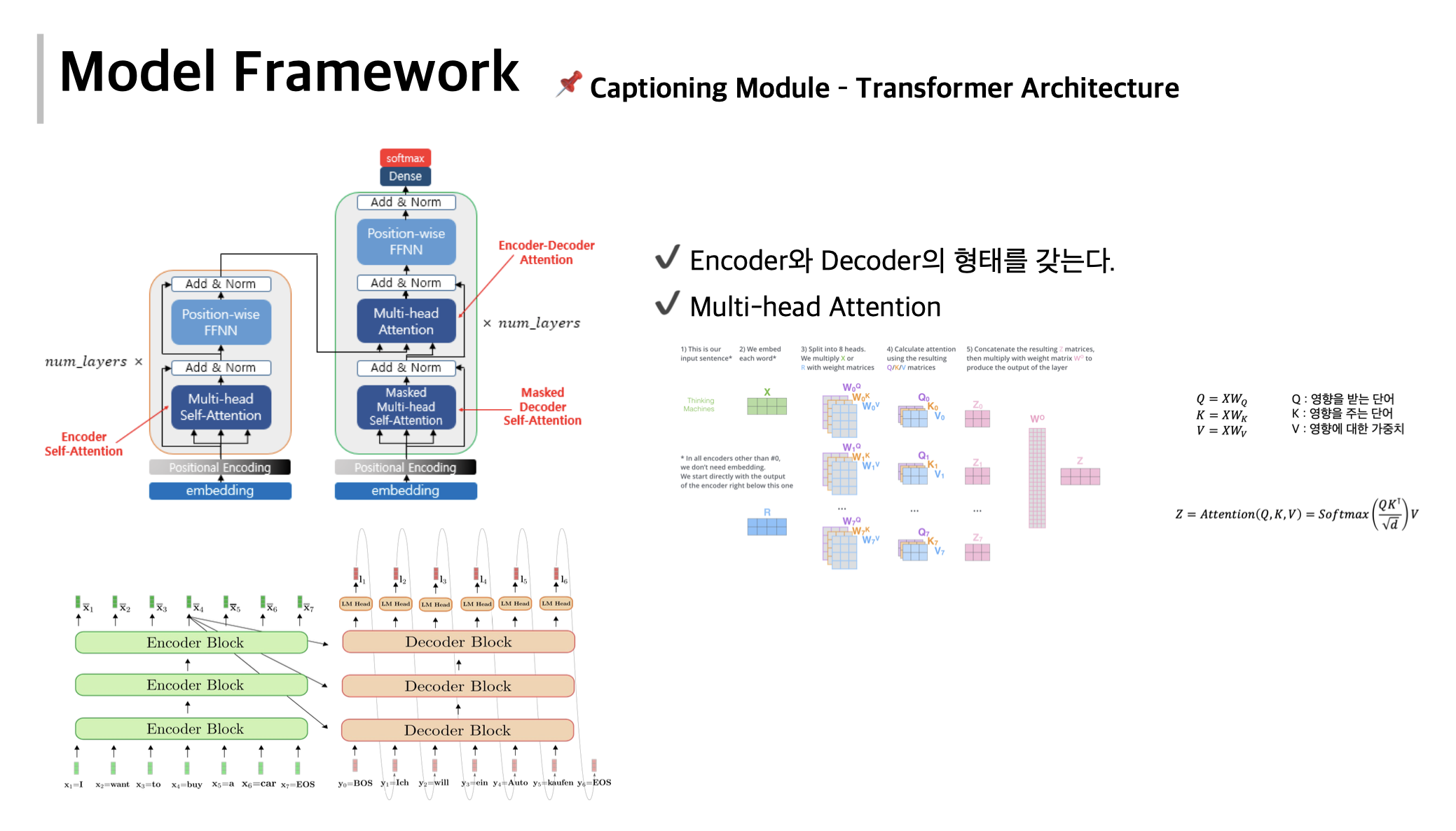
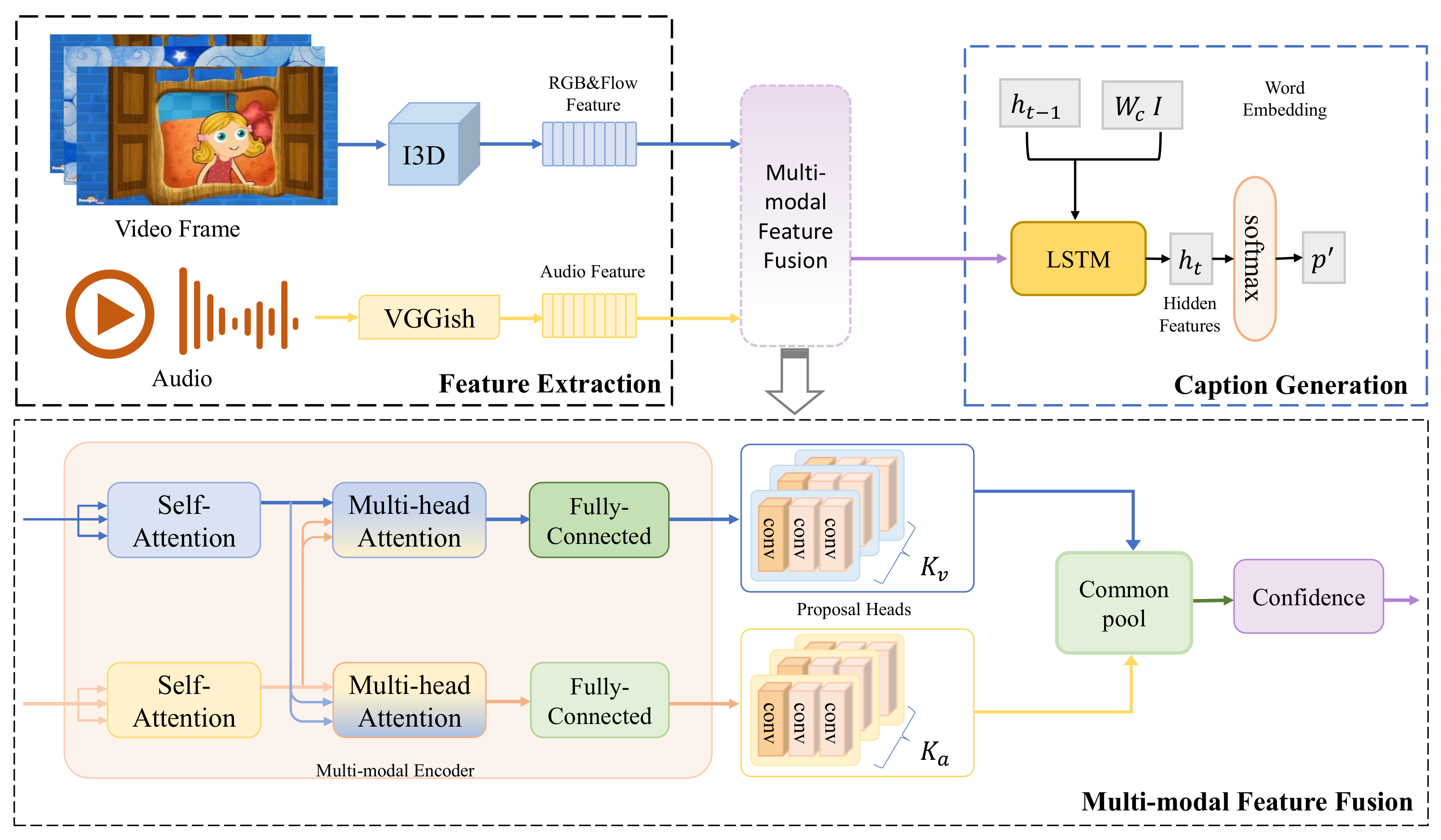
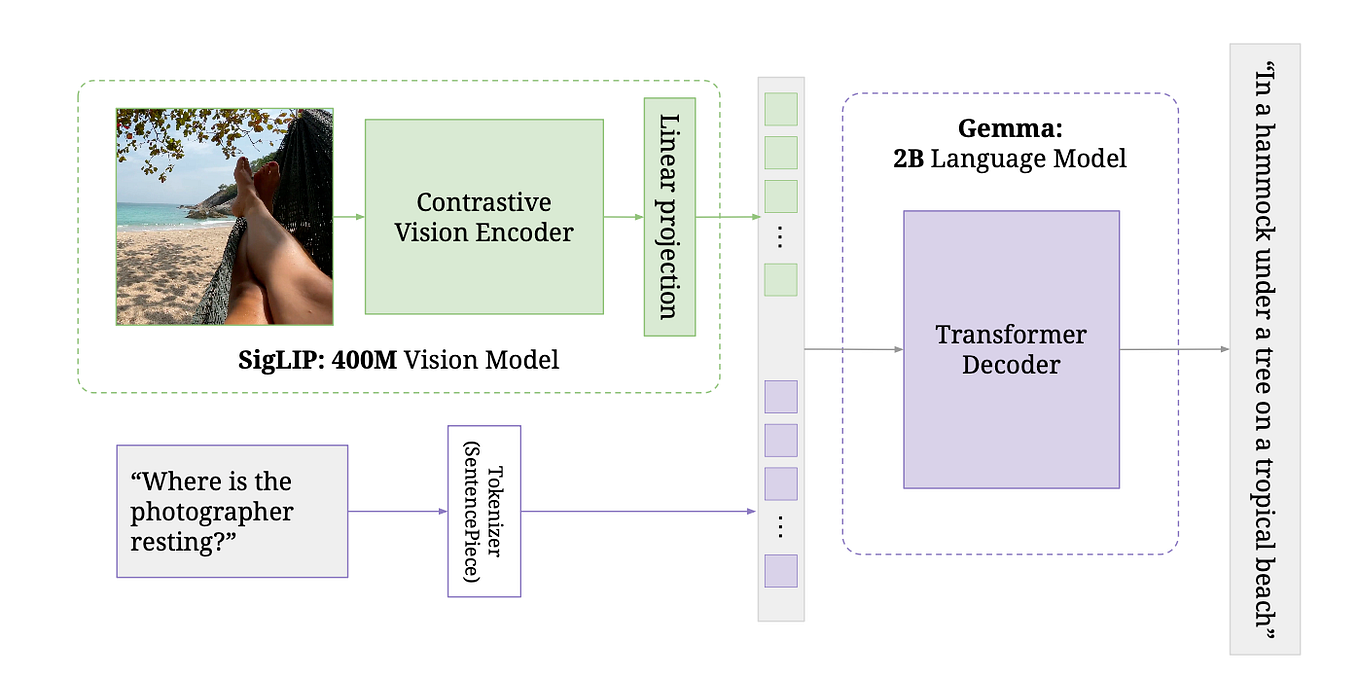
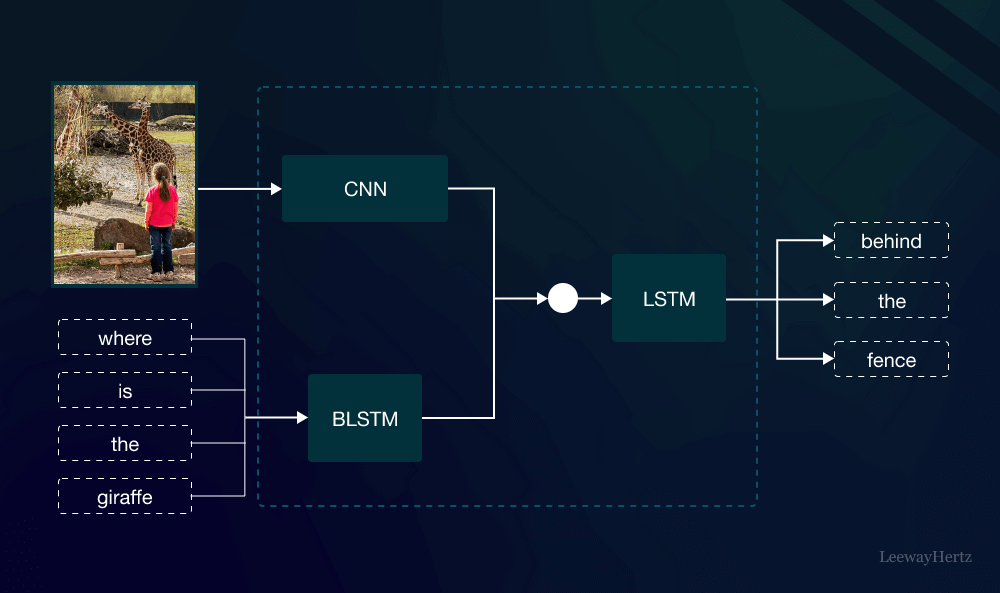
Build Multi-Modal Image Captioning System with PyTorch: CNN-LSTM to ...
Build Multi-Modal Image Captioning System: Vision Transformers + GPT-2 ...
Build Multi-Modal Sentiment Analysis with PyTorch: Complete Text Image ...
Build Multi-Modal Sentiment Analysis with PyTorch: Combining Text and ...
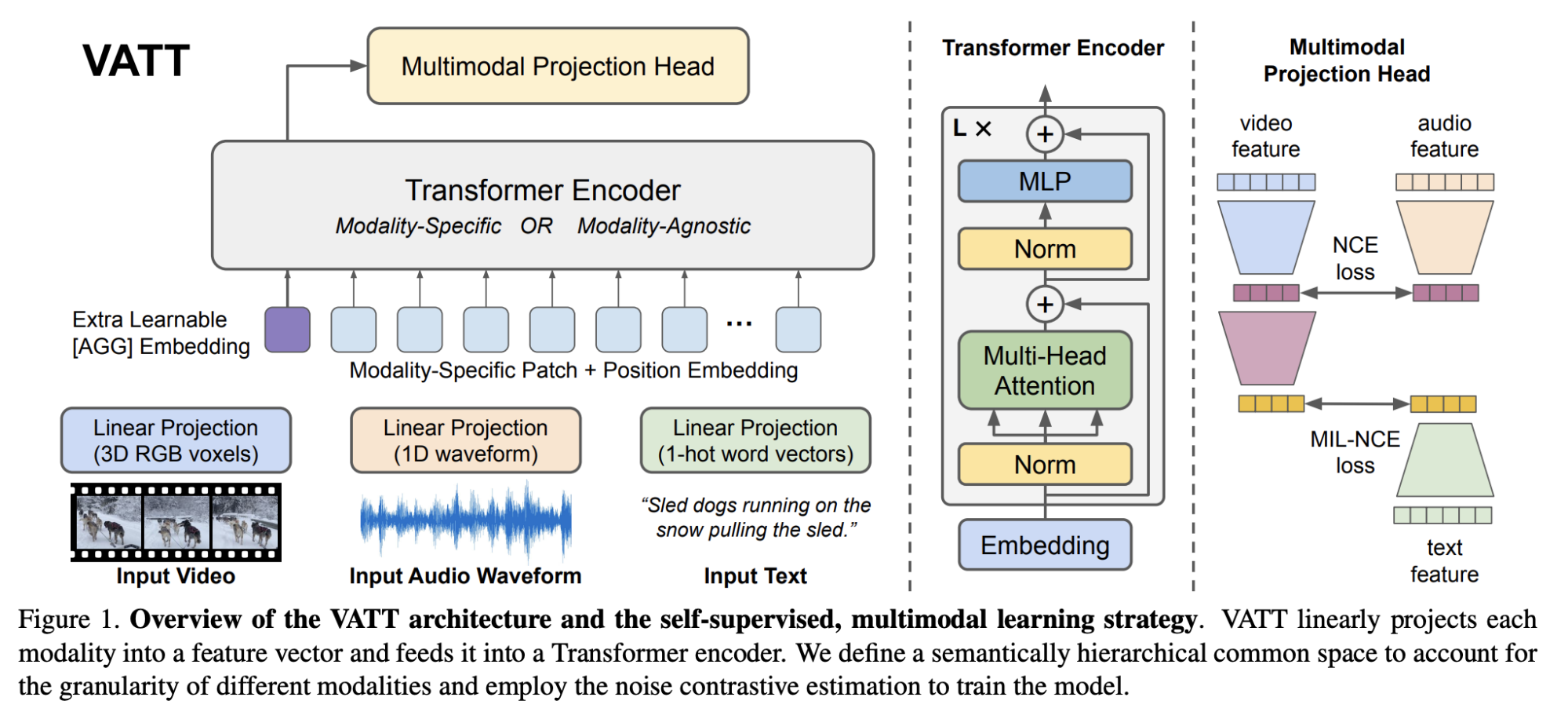
Figure 2 from Enlightened Imagery: Multi-modal Image Captioning with ...
Mastering Computer Vision with PyTorch 2.0: Discover, Design, and Build ...
Build Custom CNNs with PyTorch: Complete Guide from Architecture Design ...
Build Multi-Modal Sentiment Analysis with Vision-Language Transformers ...
Neural Storyteller: Building an Image Captioning Model with Seq2Seq in ...
Multi-Modal LLM based Image Captioning in ICT: Bridging the Gap Between ...
A Coding Guide to Build a Multimodal Image Captioning App Using ...
Figure 2 from Multi-Modal Human-Aware Image Caption System for ...
image caption lab and captioning system with pptx | PPTX
Image Captioning Python With PyTorch And Transformers
Build Multi-Modal ML Pipelines With PyTorch & Bright Data
GitHub - ozan-git/videoCaptioningProject: Video Captioning with PyTorch ...
Building Multi-Modal Sentiment Analysis with BERT-CNN Fusion in PyTorch ...
Figure 3 from Multi-Modal Image Captioning | Semantic Scholar
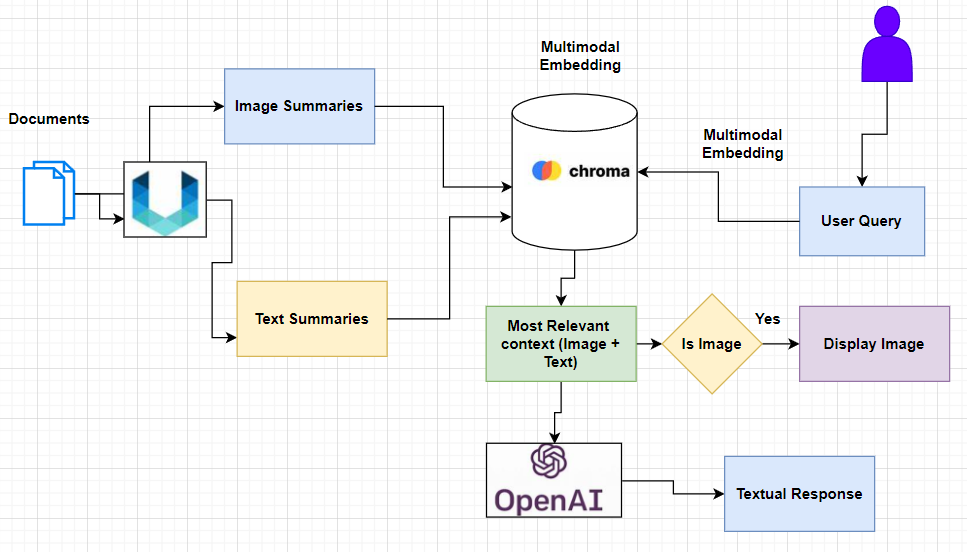
Building an Open Source Multi-Modal RAG System | by Ahmed Haytham ...
Figure 8 from Multi-modal reward for visual relationships-based image ...
GitHub - hashbangCoder/MultiModal-Image-Captioning: Image Captioning ...
Vision Language Models | Multi Modality, Image Captioning, Text-to ...
Mastering PyTorch: Build powerful deep learning architectures using ...
Advanced RAG — Multi-Modal RAG with GPT4 Vision | by 01coder | AI Advances
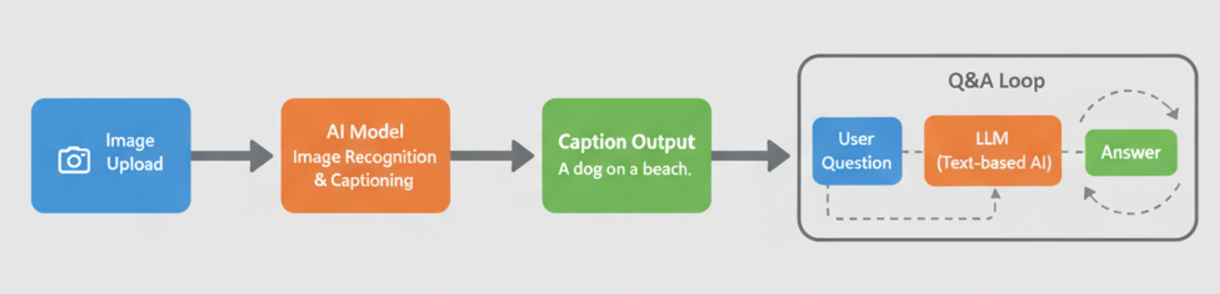
Build a Multimodal App: Image Captioning + Q&A (2026 Guide) - Owlbuddy
(PDF) Multi-Modal Image Captioning for the Visually Impaired
Figure 2 from Multi-Modal Image Captioning | Semantic Scholar
Table 1 from Modelling Visual Semantics via Image Captioning to extract ...
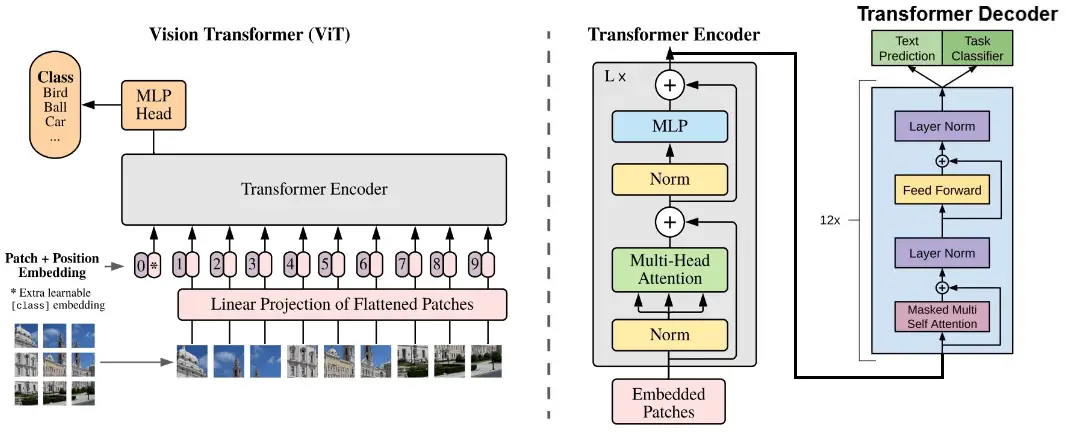
Vision Transformer (ViT): How It Works and How to Build It in PyTorch ...
Scaling Multimodal Foundation Models in TorchMultimodal with Pytorch ...
Multi-modal fusion Transformer - vision - PyTorch Forums
[논문 리뷰] GCS-M3VLT: Guided Context Self-Attention based Multi-modal ...
Multi-Modal AI: Combining Text and Vision | AI Tutorial | Next Electronics
Computer Vision — How to implement (Max)Pooling2D from Tensorflow ...
Figure 1 from Everything at Once – Multi-modal Fusion Transformer for ...
Multi-Modal Classification Model Using PyTorch and Lightning In Cardiac ...
Top 3 Image Captioning Deep Learning Project Ideas for Practice
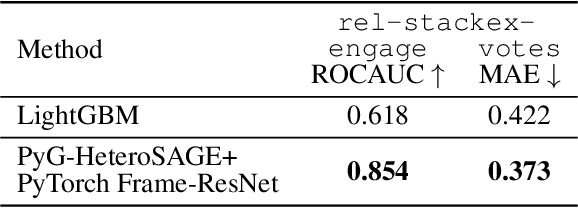
Multi-Modal Tabular Deep Learning with PyTorch Frame – PyTorch
MMVC (Masked Multi-modal Video for Captioning) model. The model divides ...
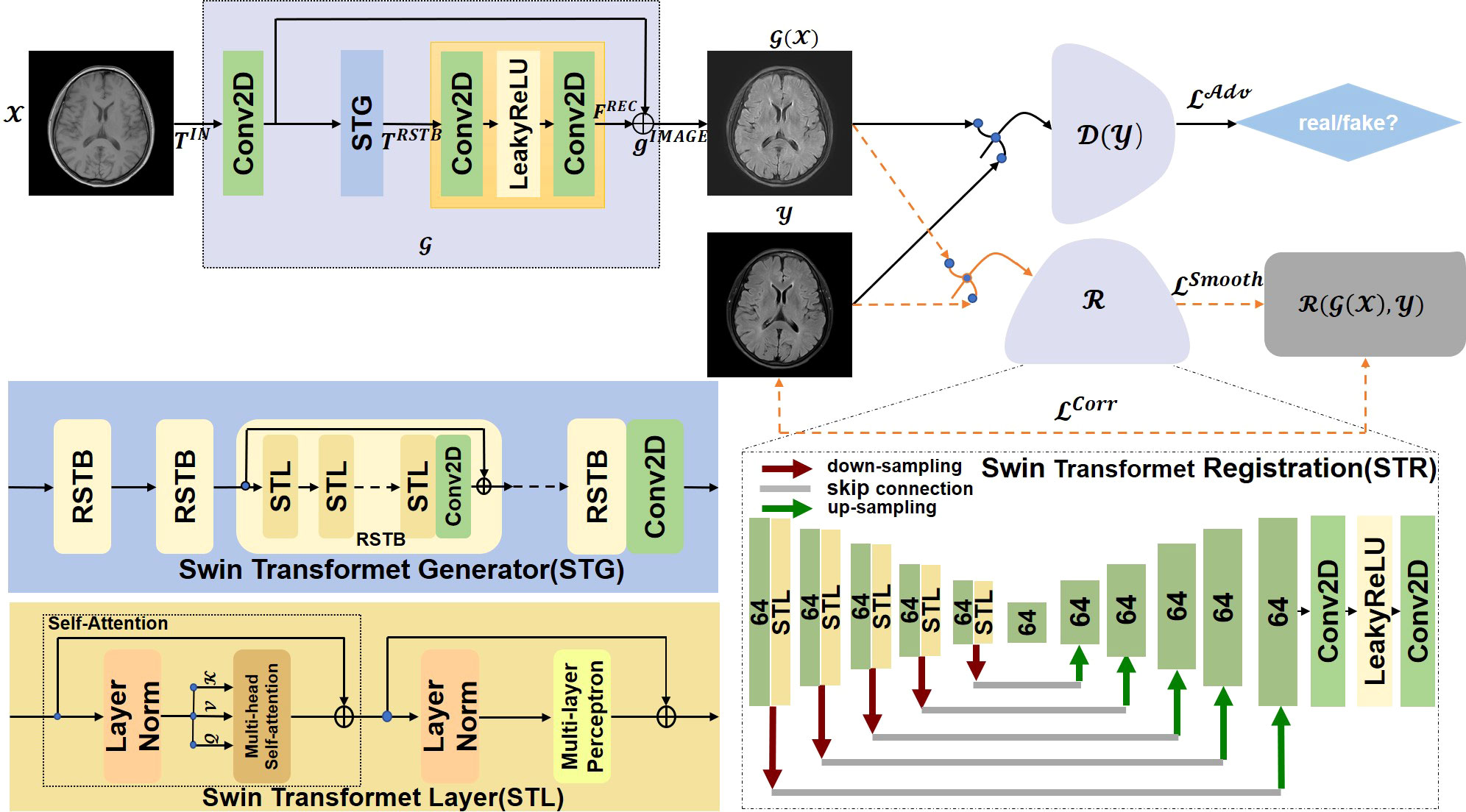
(PDF) Multi-Modal Understanding and Generation for Medical Images and ...
Multimodal Large Language Models (MLLMs) transforming Computer Vision ...
A Deep-Learning-Based Multi-Modal Sensor Fusion Approach for Detection ...
(PDF) Contextualized Keyword Representations for Multi-modal Retinal ...
Wild-Drive: Off-Road Scene Captioning and Path Planning via Robust ...
Mastering PyTorch: Create and deploy deep learning models from CNNs to ...
Figure 1 from Team Xiaomi EV-AD VLA: Caption-Guided Retrieval System ...
The Multi-modal Caption Proposal model. The XLM-RoBERTa backbone is ...
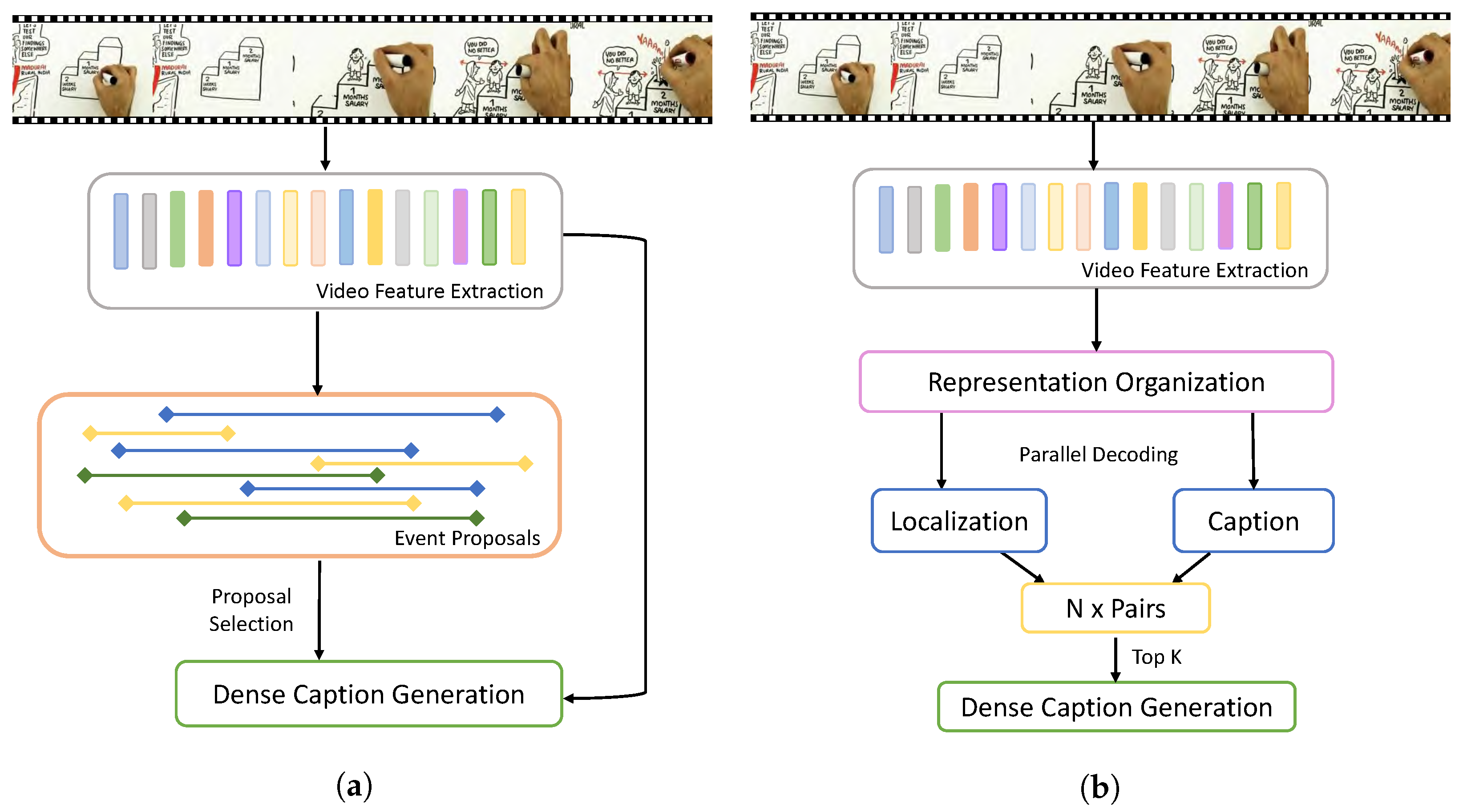
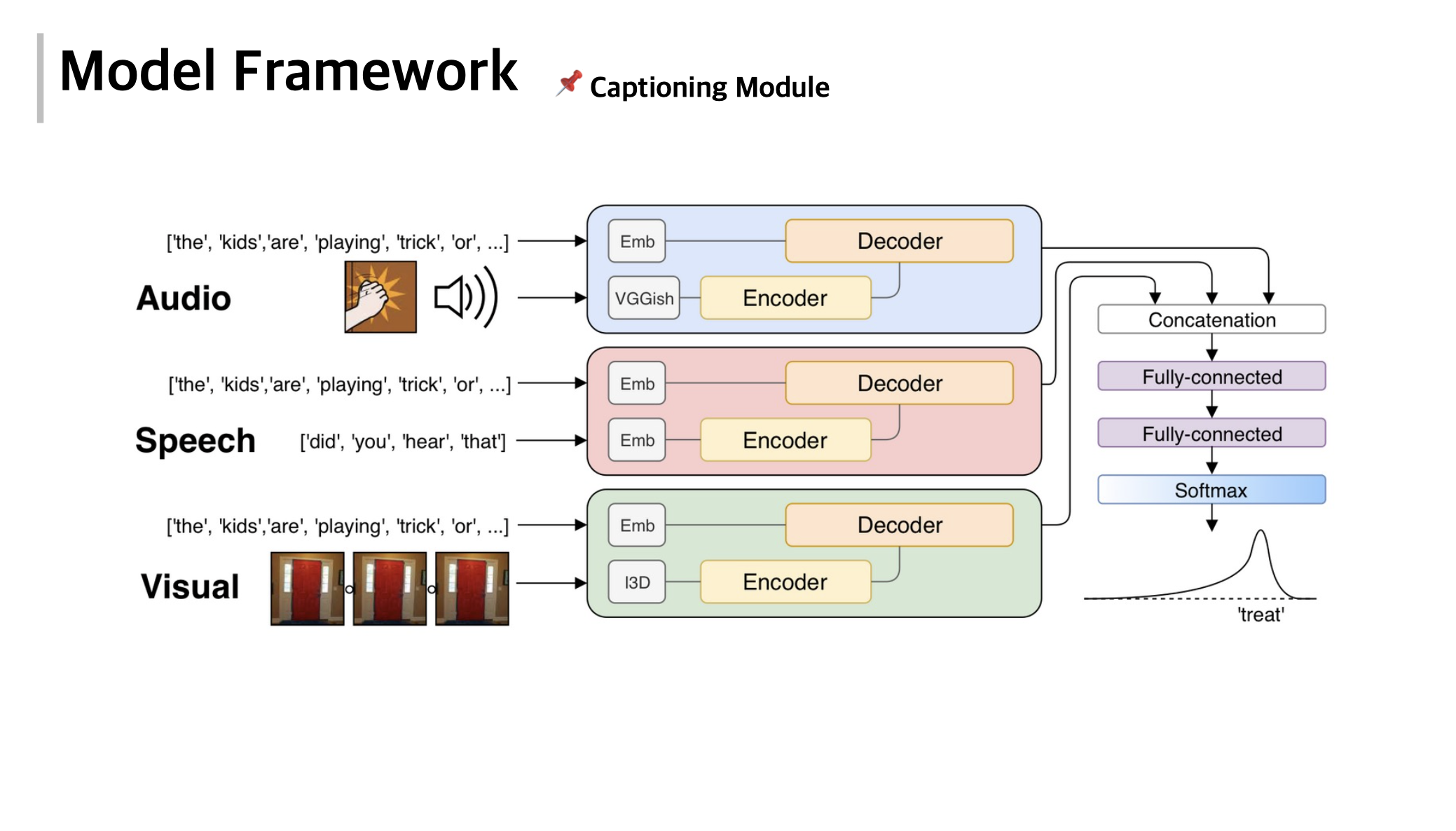
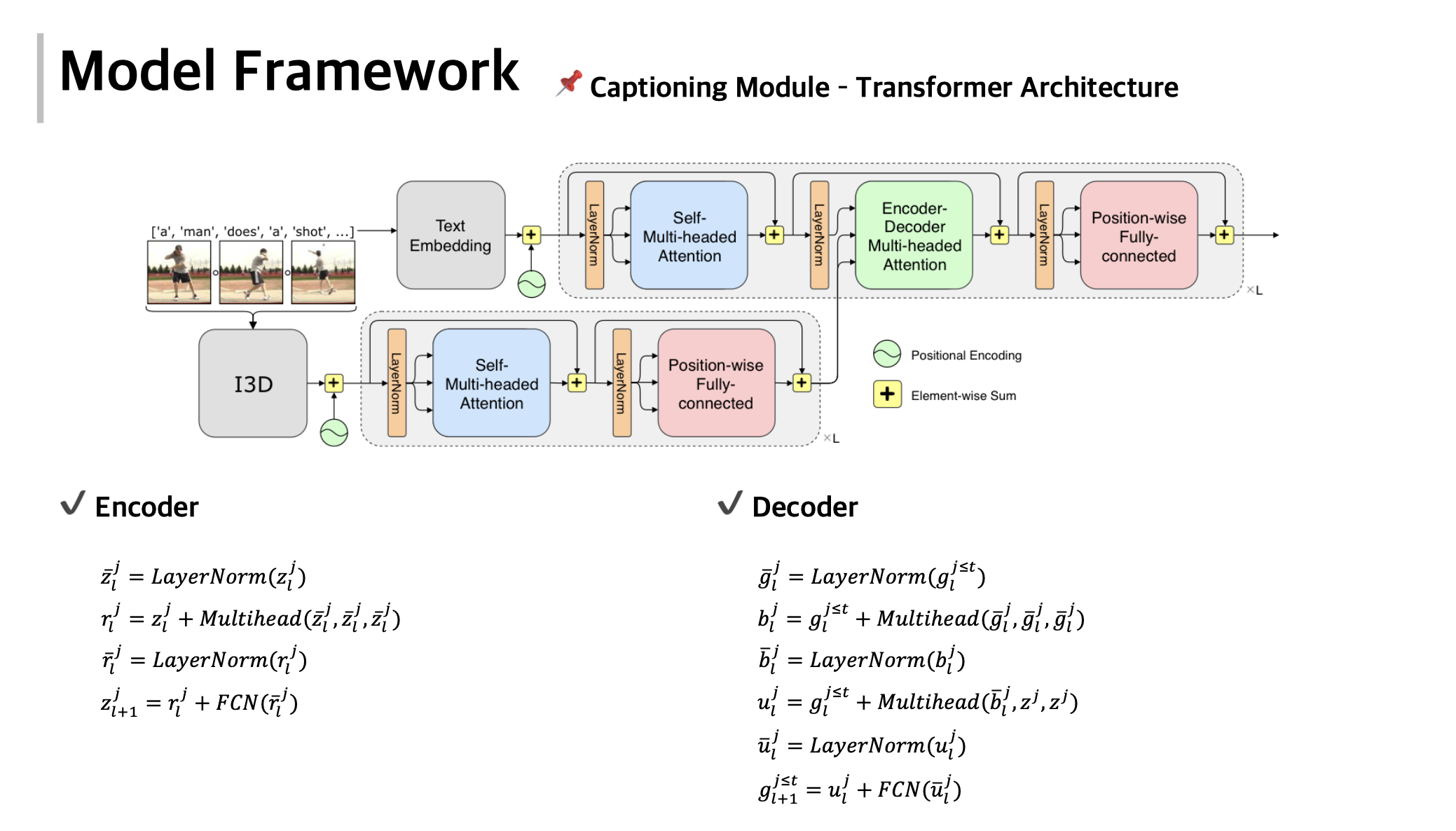
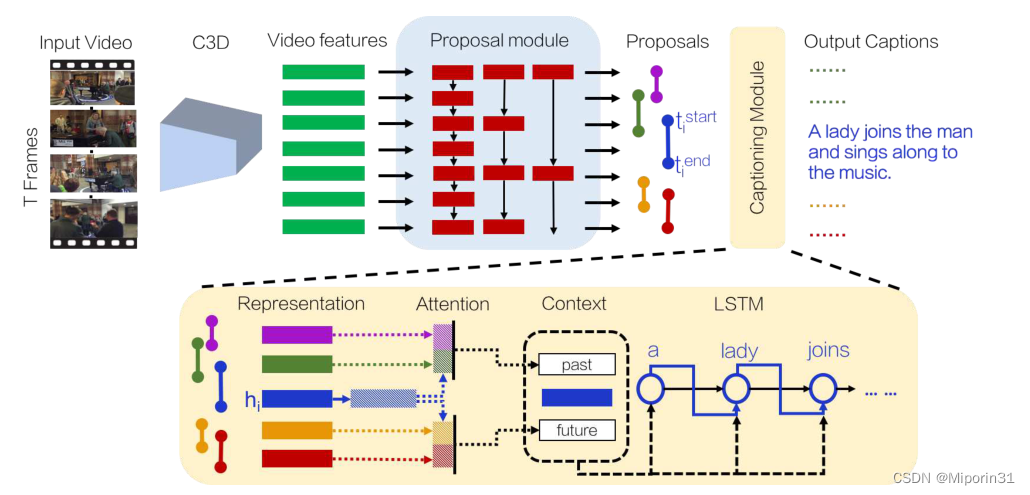
Parallel Dense Video Caption Generation with Multi-Modal Features
Jennifer Seale - Multi-modal classification with PyTorch - YouTube
Image Captioning using PyTorch and Transformers in Python - The Python Code
(PDF) Enhanced visual multi-modal fusion framework for dense video ...
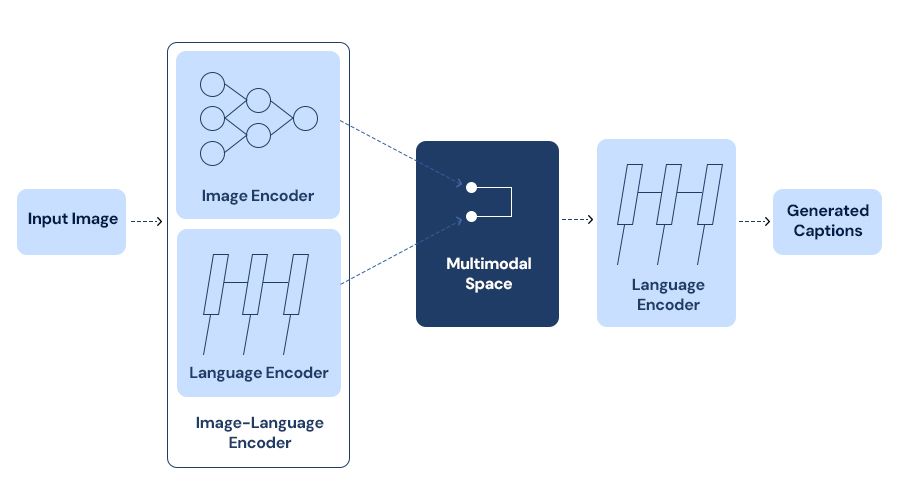
A block diagram of multimodal space-based image captioning. | Download ...
PyTorch Deep Learning: Build and Deploy Models from CNNs to Multimodal ...
Figure 2 from Application of Multi-modal Large Models in Electronic ...
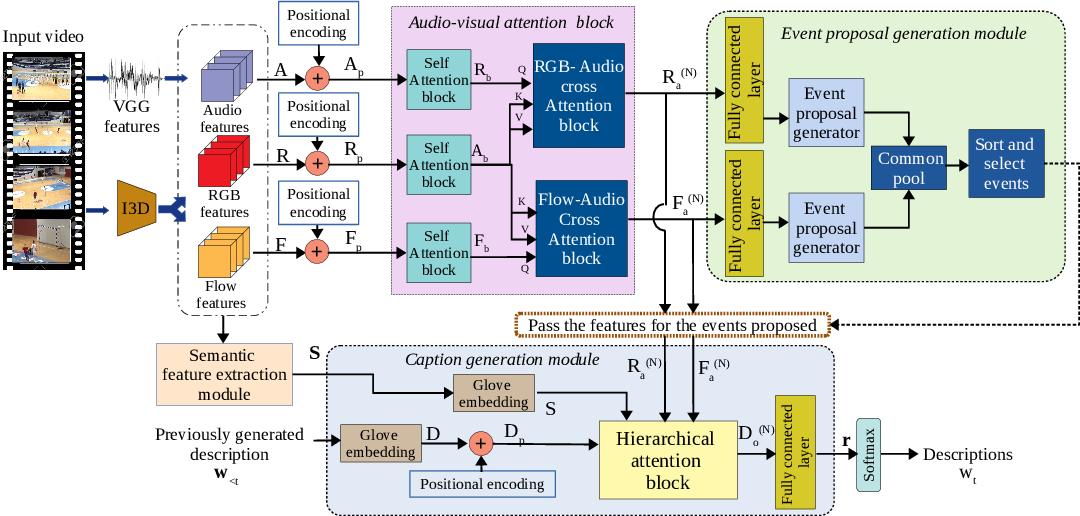
Figure 1 from Multi-Modal Hierarchical Attention-Based Dense Video ...
GitHub - sharpsalt/Captionforge-Multimodal-Image-Captioning-System ...
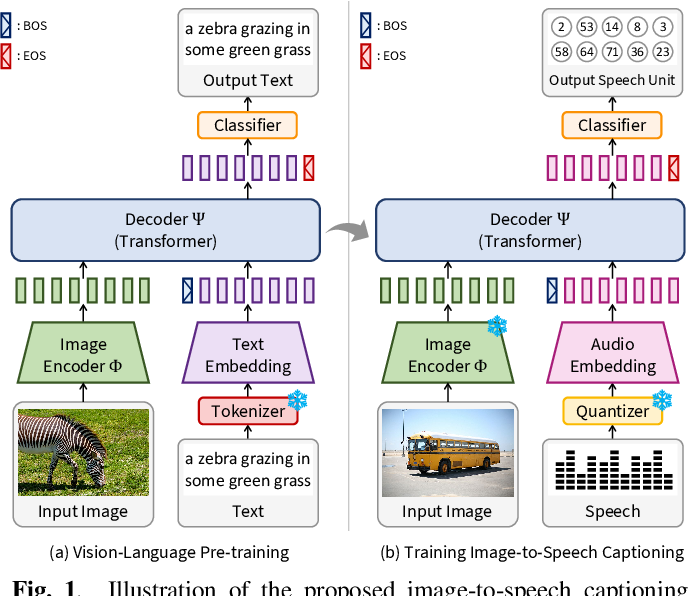
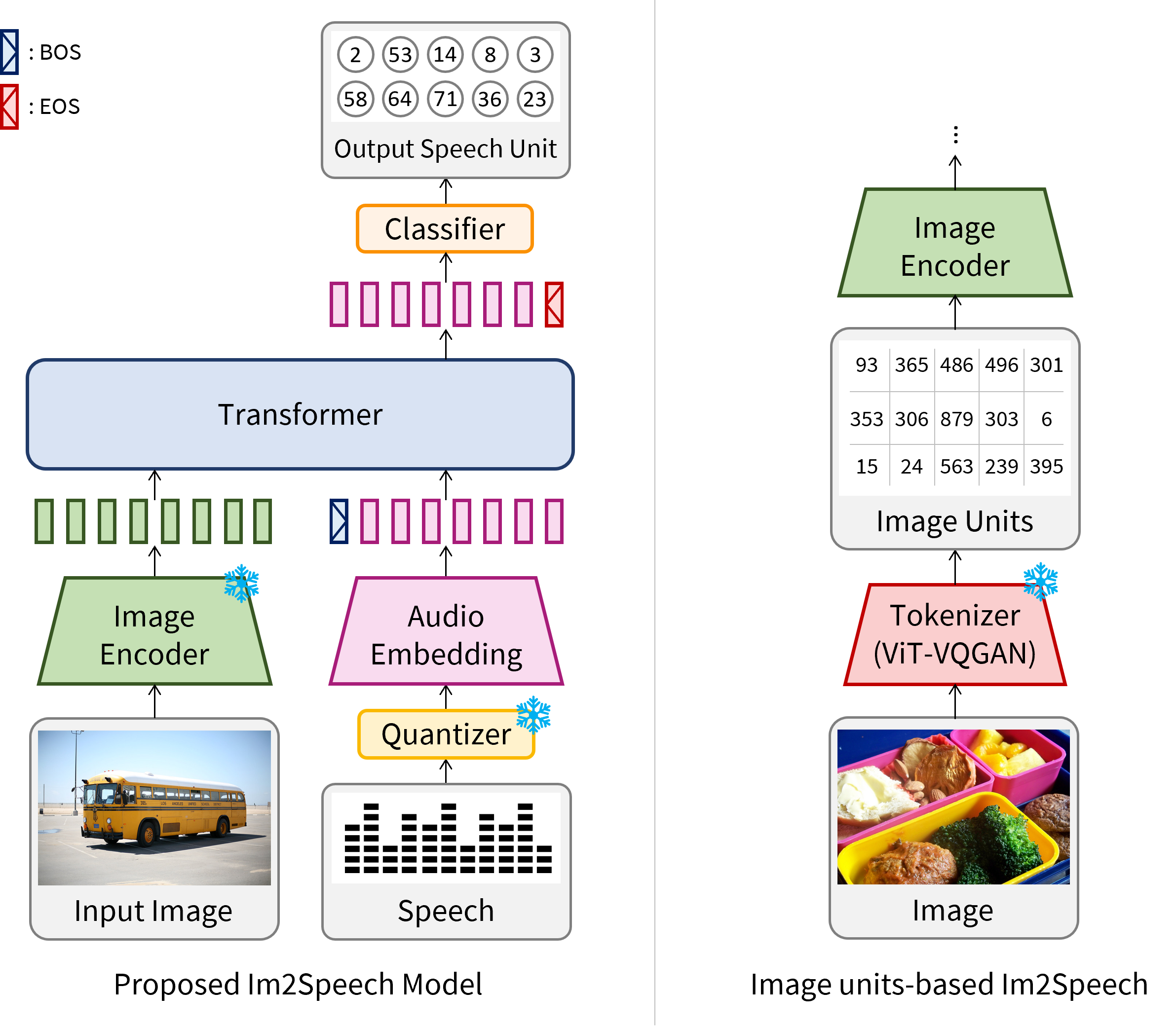
Figure 1 from Towards Practical and Efficient Image-to-Speech ...
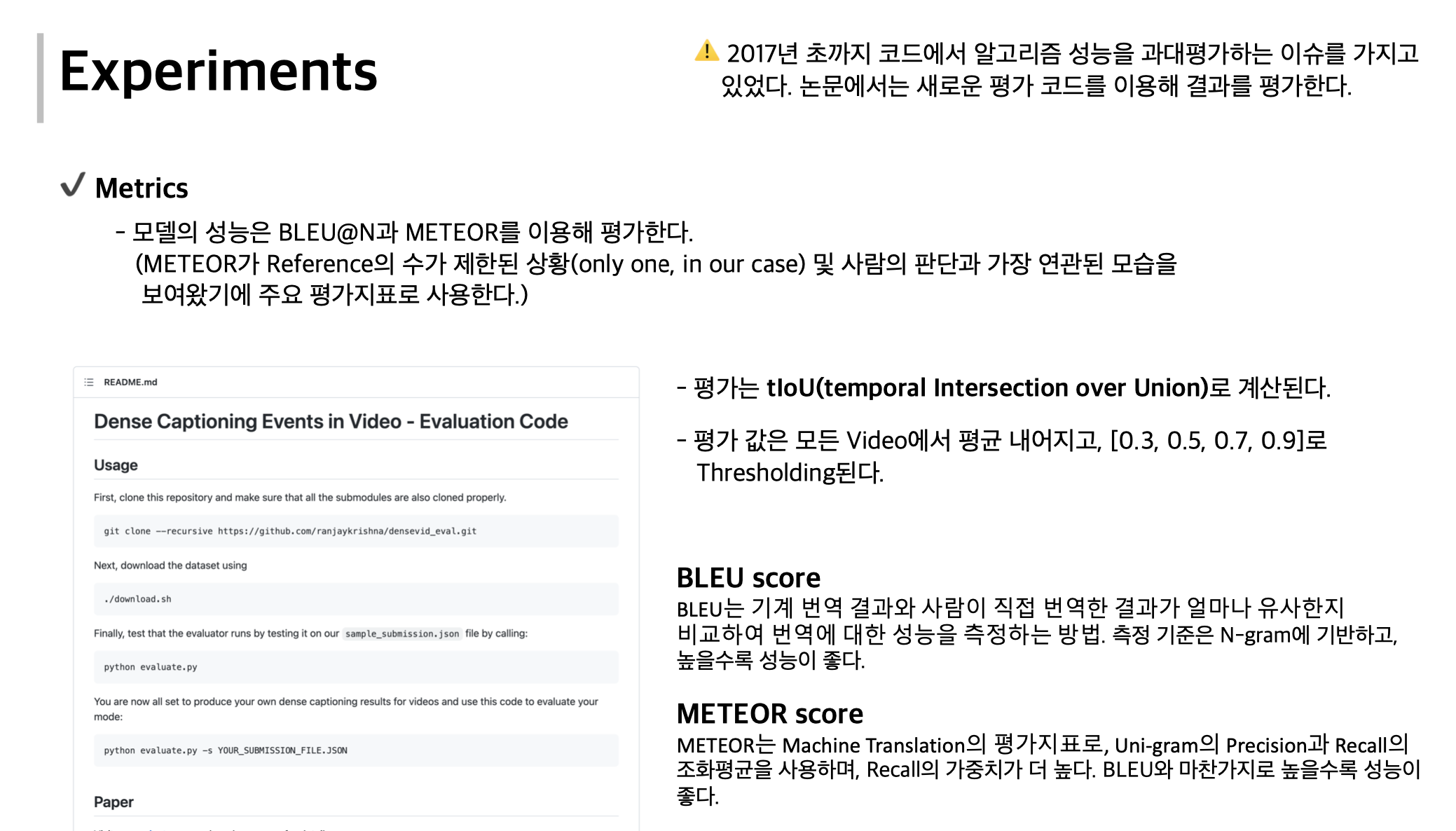
Multi-modal Dense Video Captioning(2020) Review
GitHub - ms-dot-k/Image-to-Speech: Pytorch implementation of "Towards ...
GitHub - Aarya-Gupta/Pytorch-Paligemma-Multimodal-Vision-Language-Model ...
GitHub - yunncheng/MMRL: [CVPR 2025] Official PyTorch Code for "MMRL ...
GitHub - harshpatel080503/VisionLM: VisionLM is a PyTorch ...
Excited to announce PyTorch Frame (https://lnkd.in/gdyVNFnD) - our ...
GitHub - fudong03/MMST-ViT: PyTorch Implementation of "MMST-ViT ...
GitHub - Linfeng-Tang/VideoFusion: This is official Pytorch ...
Coding a Multimodal (Vision) Language Model from scratch in PyTorch ...
PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning
[论文评述] PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning
GitHub - lucidrains/multimodal-dit-pytorch: Implementation of a ...
Multi-Modal Systems → Term
GitHub - AnhaoZhao-LLMer/A_Dynamic_Multi-Modal_Deep_Reinforcement ...
multi_model_image_captioning_flicker8k/image-captioning-with-attention ...
Fusion of Multi-Modal Features to Enhance Dense Video Caption
Various technological integration for building multimodal AI | Download ...
(PDF) Vision-text cross-modal fusion for accurate video captioning
GitHub - mirHasnain/Fine-tuning-BLIP-multi-modal-for-Image-Captioning ...
KHU Vision and Learning Lab.
GitHub - josedolz/HyperDenseNet_pytorch: Pytorch version of the ...
Unlocking The Potential: The Role Of Multi-Modal Biometric Systems In AML
Video Captioning 总结与展望 - 知乎
GitHub - Chen-Yang-Liu/MLAT: Official pytorch implementation of paper ...
Electronic skins with multimodal sensing and perception
Pytorch Basics — [3] CNN. Imports | by Beginner D | Medium
利用Microsoft COCO数据集和pytorch实现看图说话_image caption github pytorch-CSDN博客
What multimodal AI really looks like in practice | Deepgram
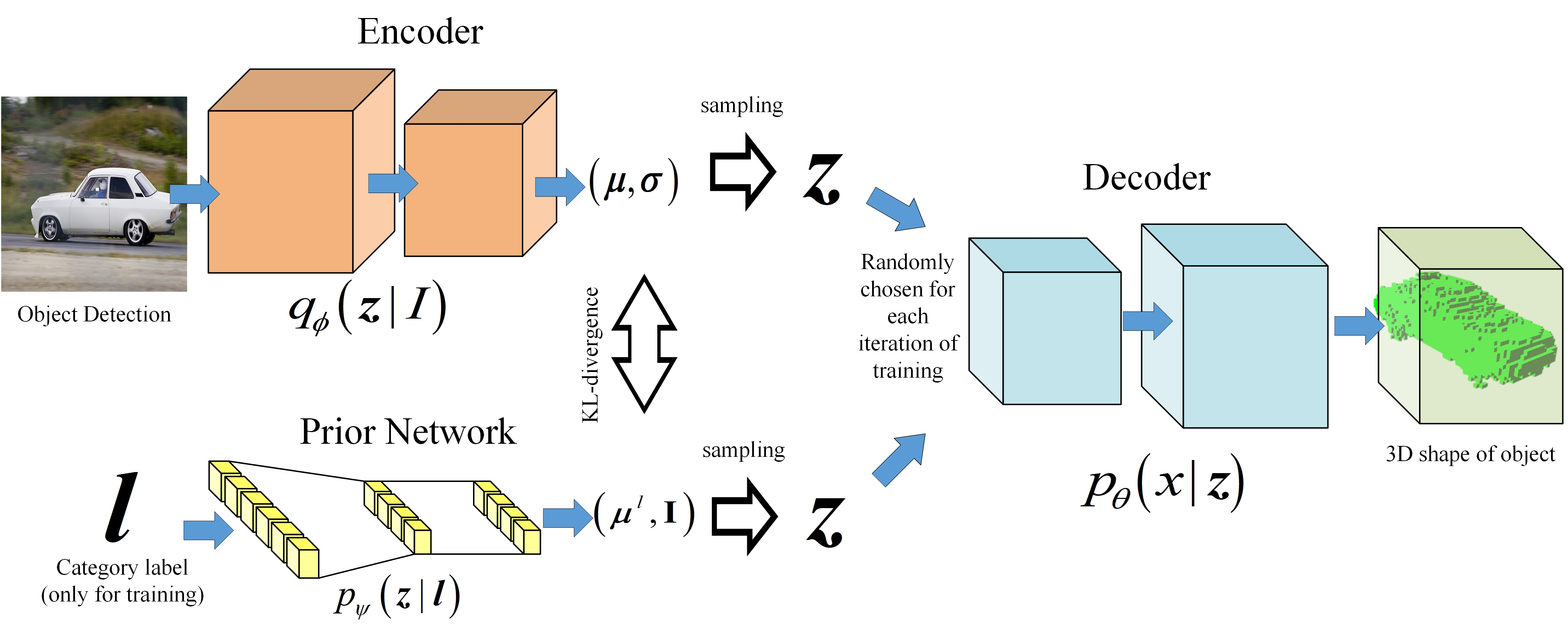
Variational Autoencoder Pytorch
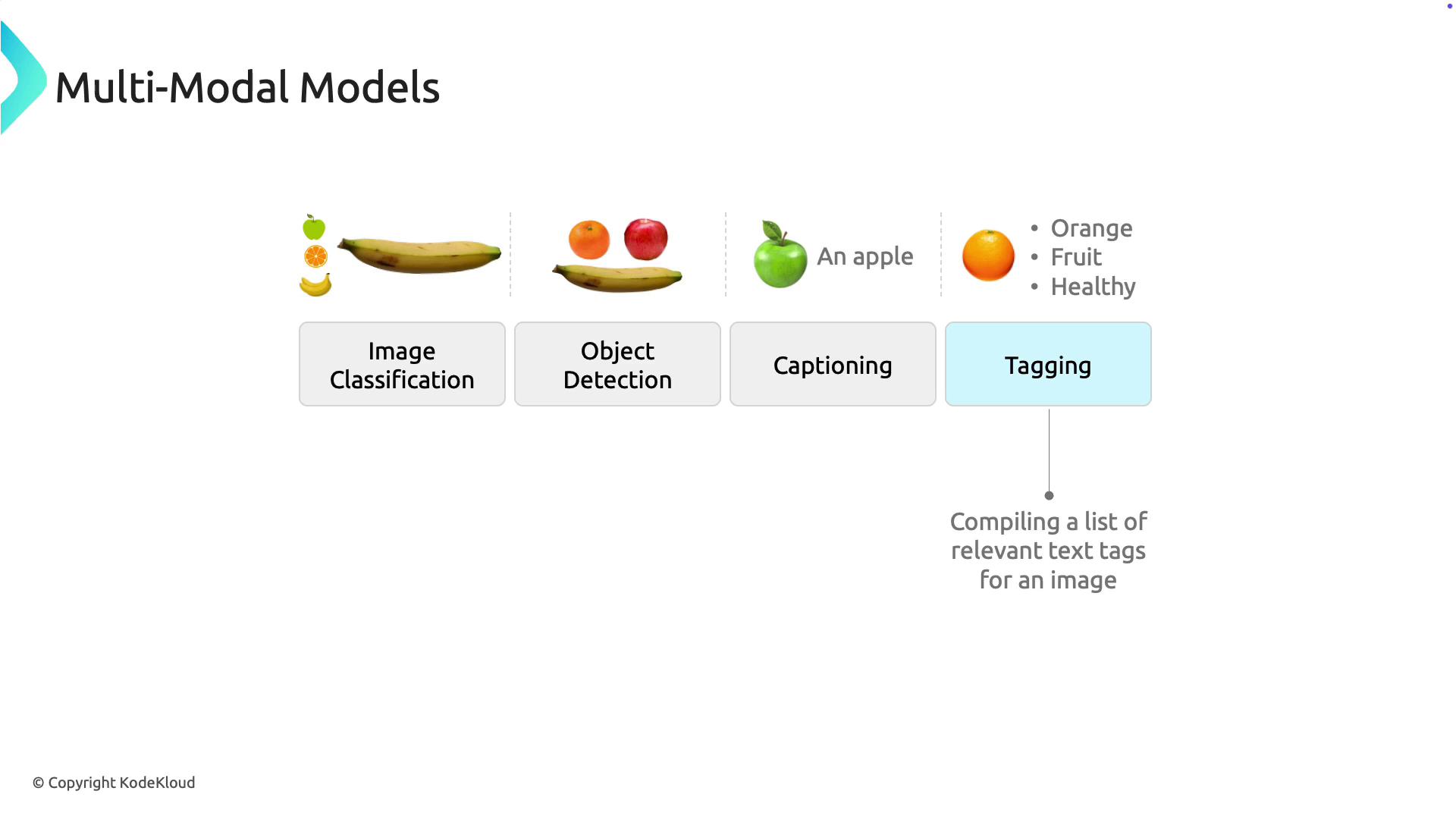
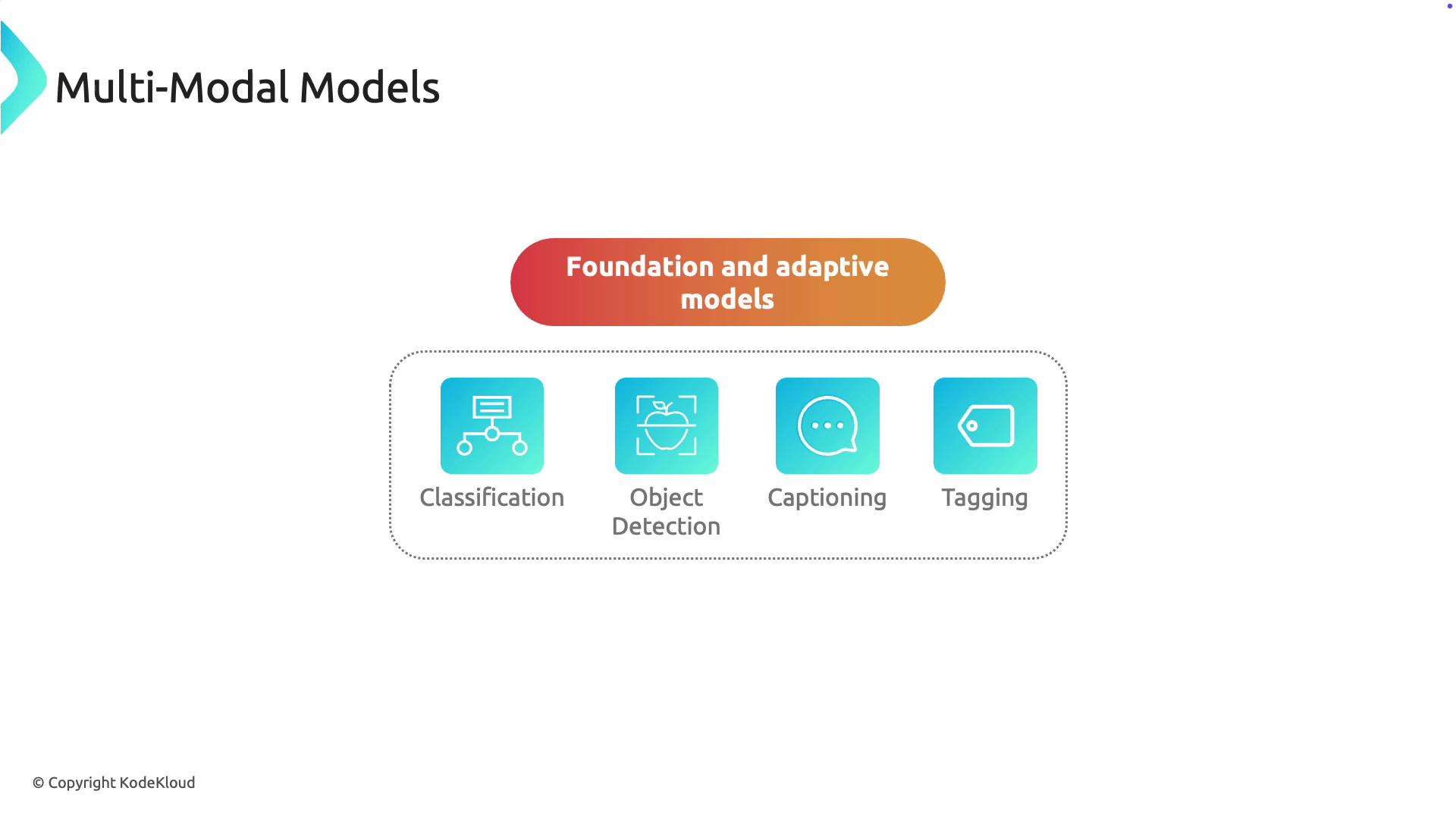
Explore Multi Modal Models - KodeKloud
What Are Multimodal AI Agents? Explore Their Power in AI Systems
Some Notes of Multimodality
Image-to-Speech Captioning: Multimodal-Tokens
Multimodal Models: Architecture, workflow, use cases and development
What Is Multimodal AI? Applications, Challenges, and Future Insights
《Multi-modal Dense Video Captioning》(MDVC)论文笔记-CSDN博客
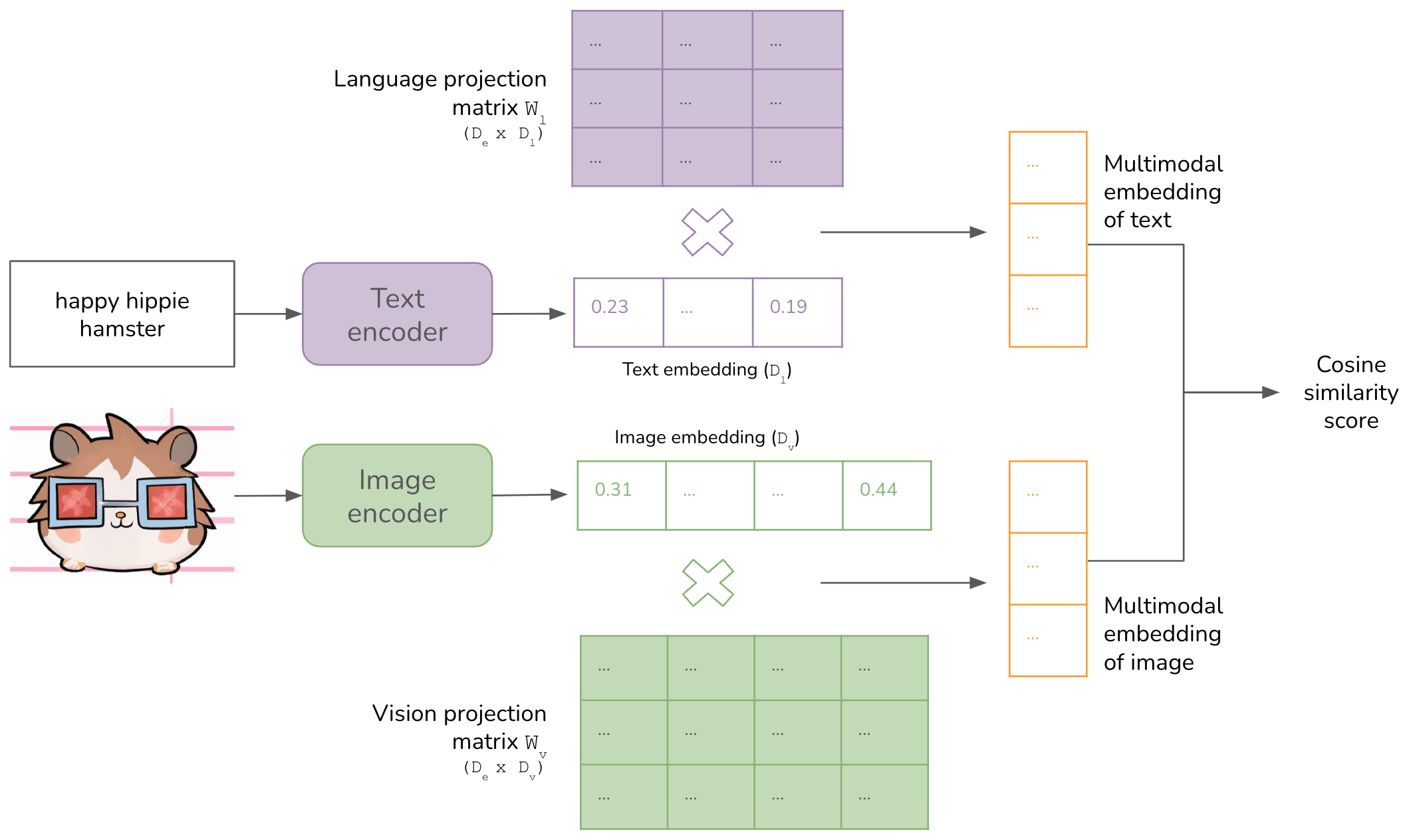
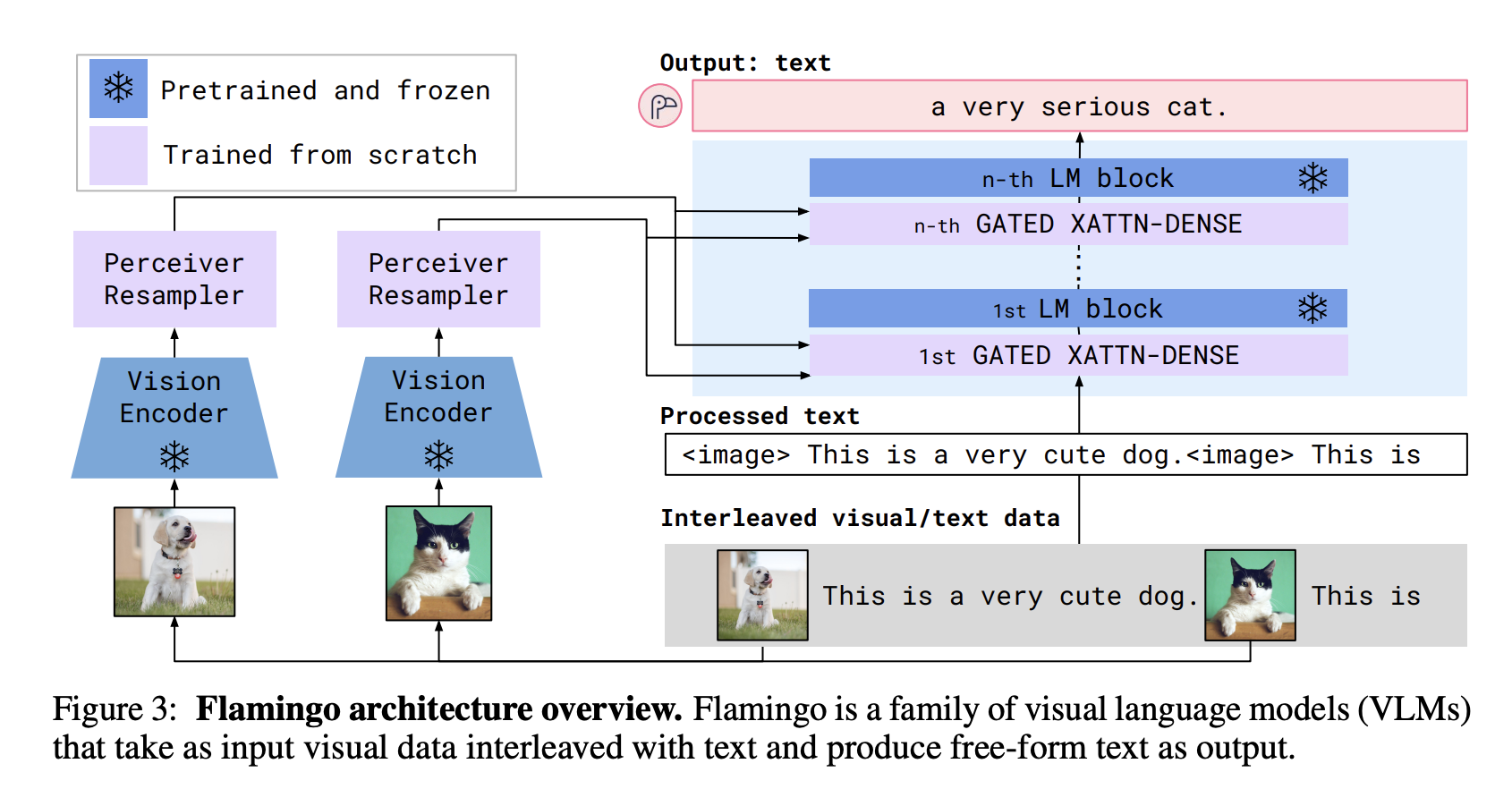
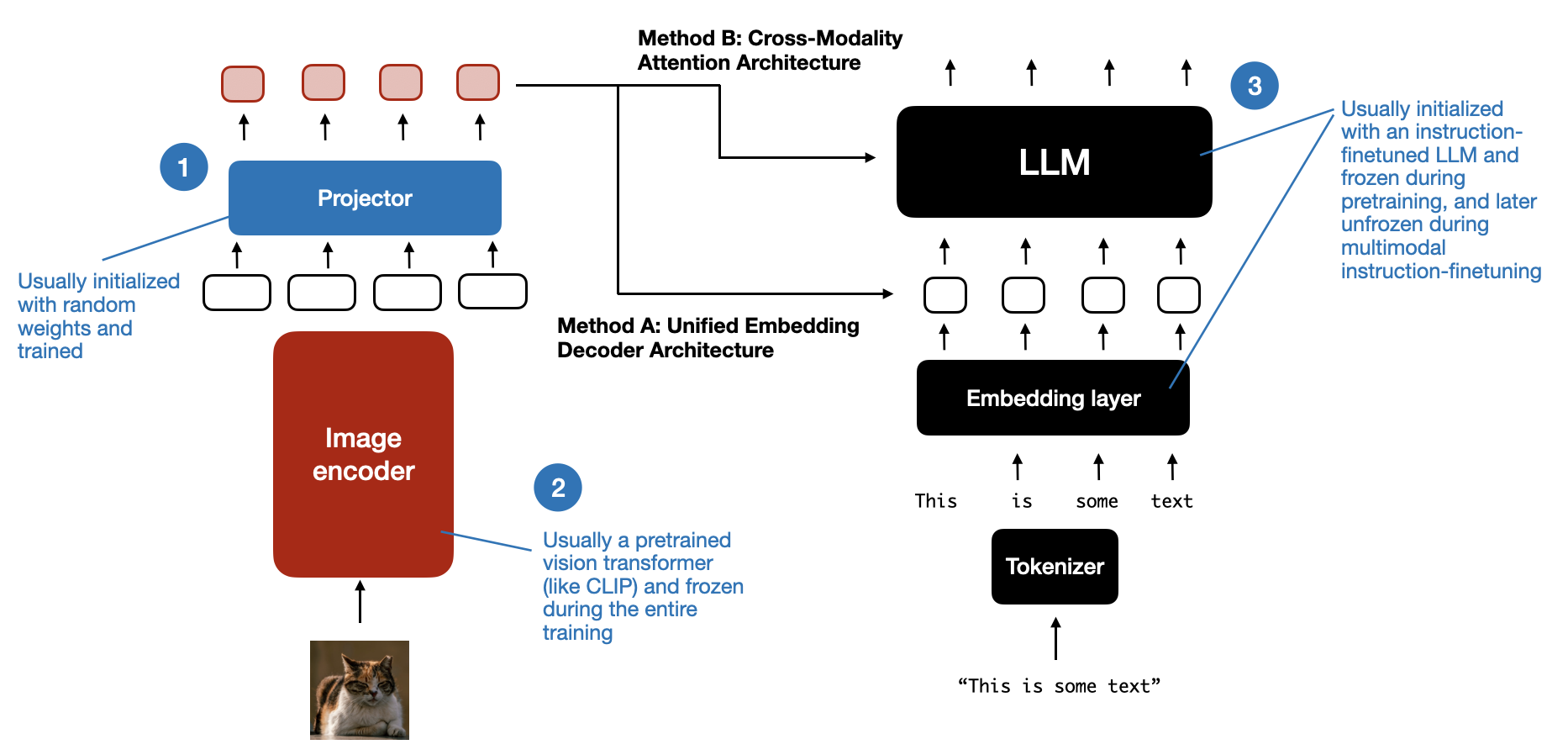
Understanding Multimodal LLMs
魔搭社区
Transform Gan – ルネサス Gan , GitHub – FPSN
吴心筱个人主页
密集视频字幕_multi-modal dense video captioning-CSDN博客
multi modal transformers representation generation .pptx
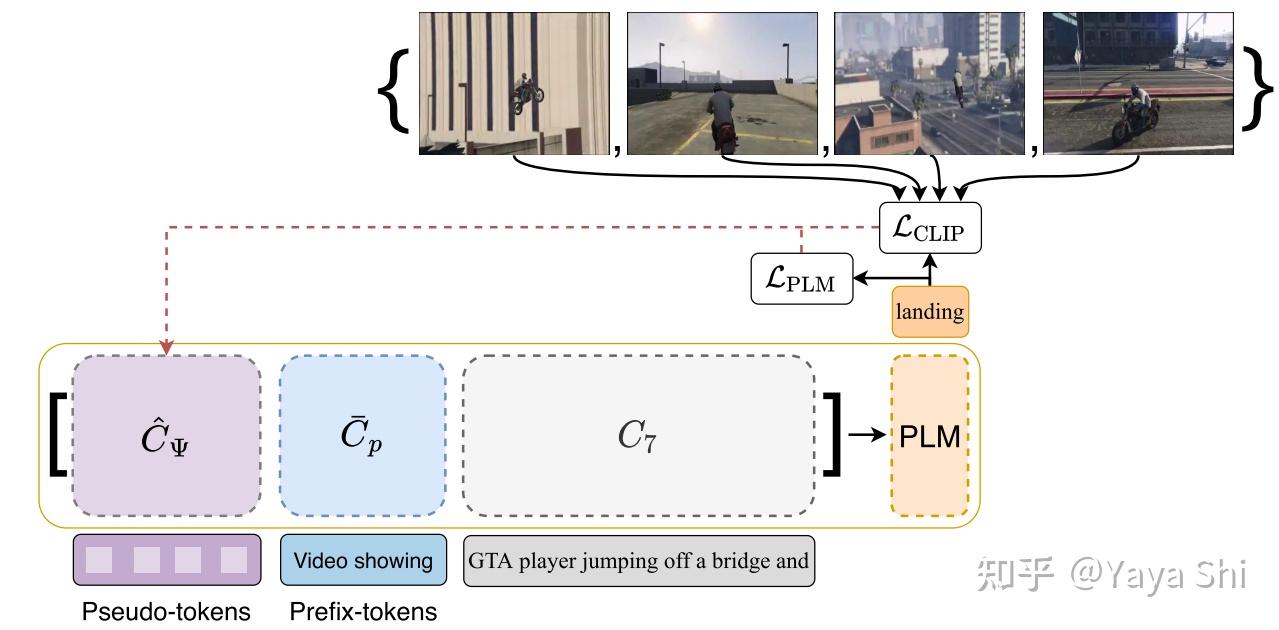
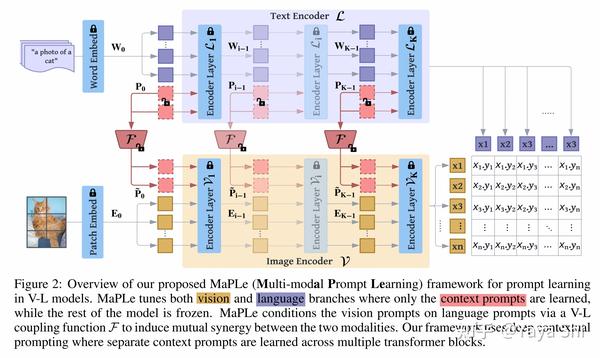
Parameter-Efficient Transfer Learning for Vision-and-Language Tasks - 知乎
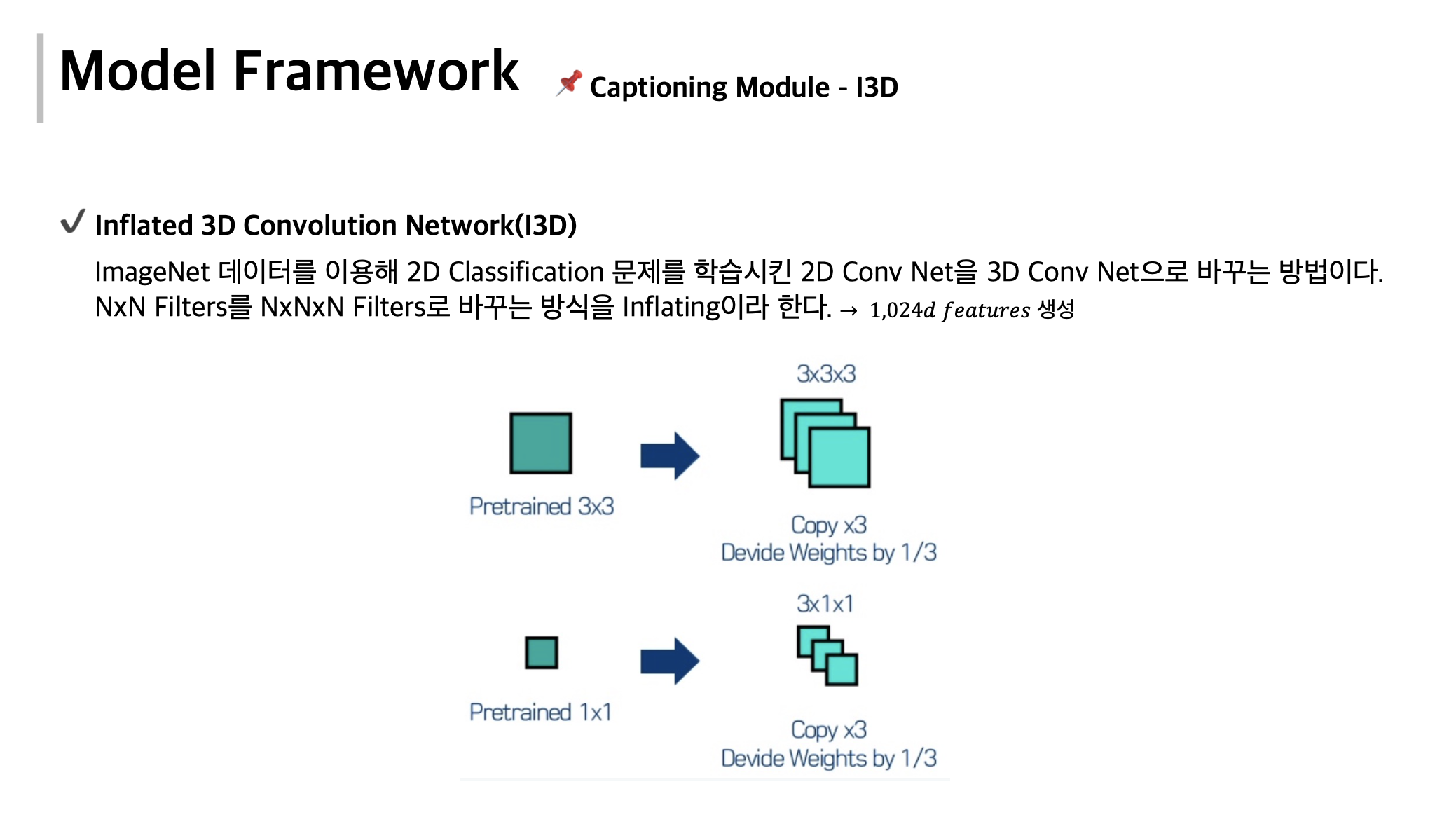
i3d · GitHub Topics · GitHub