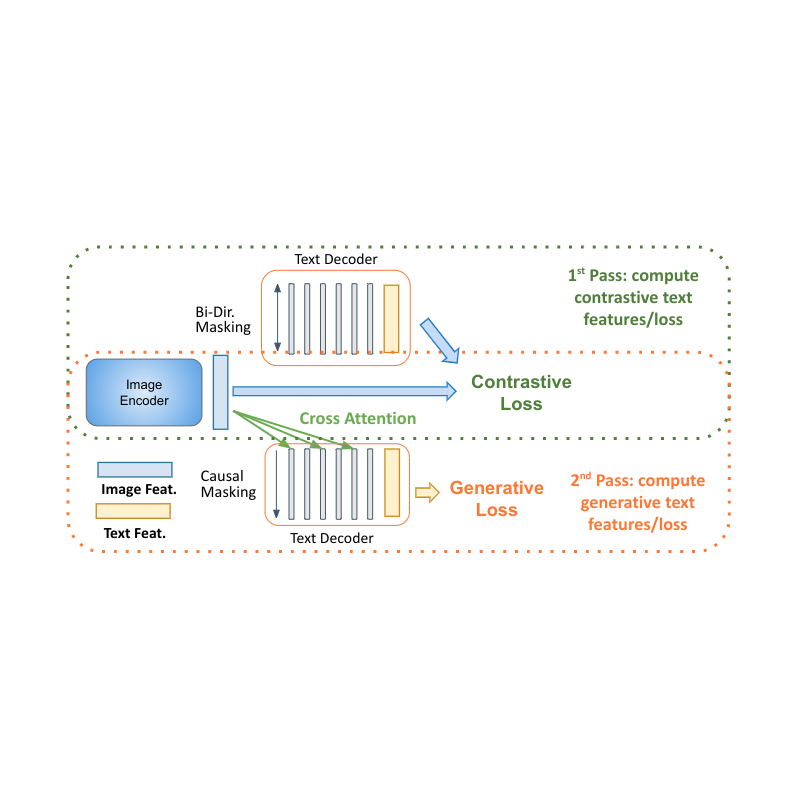
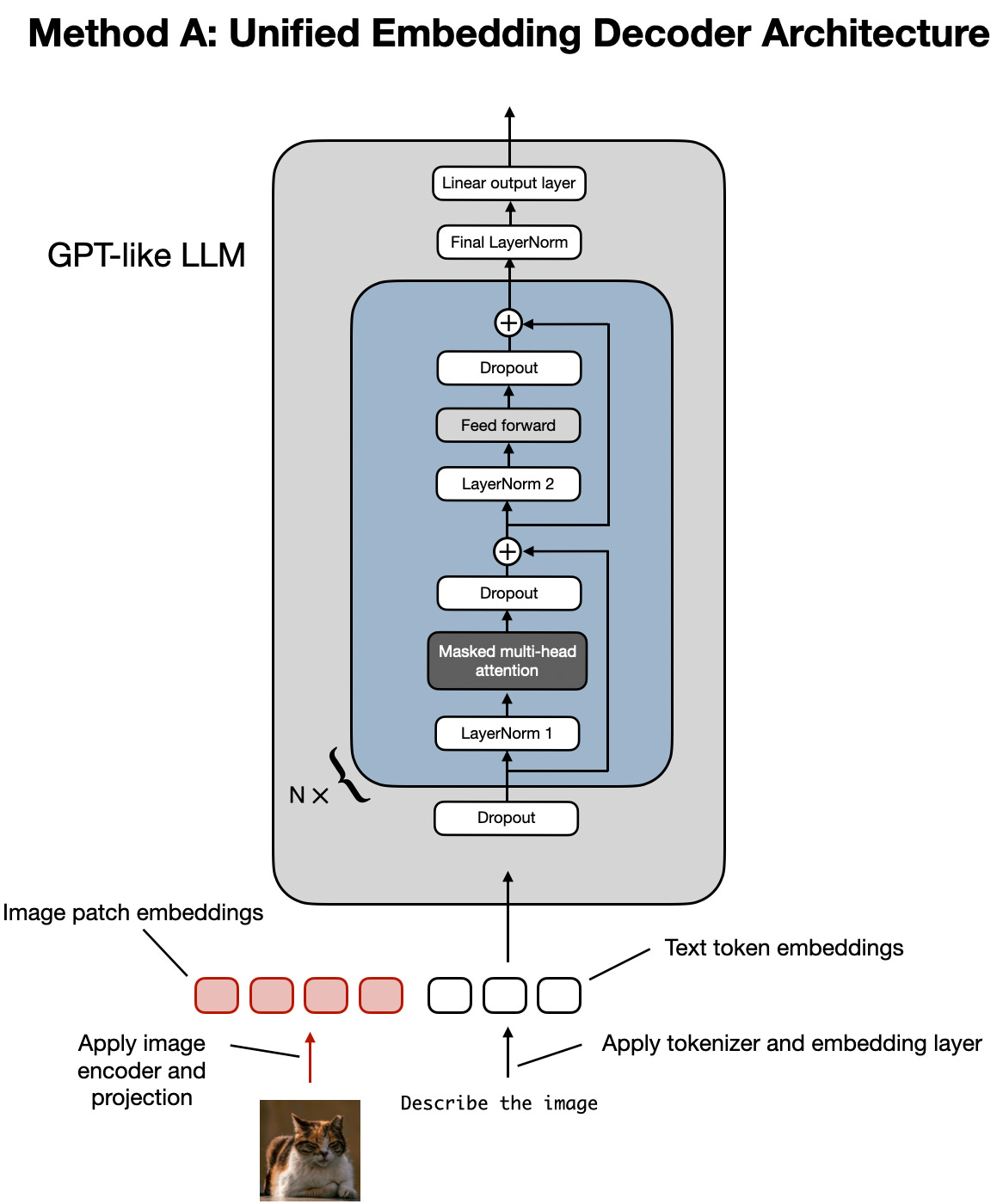
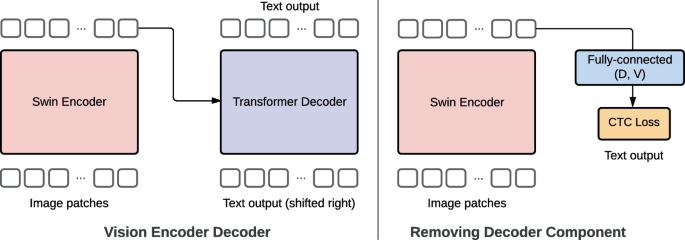
MaMMUT: A simple vision-encoder text-decoder architecture for ...
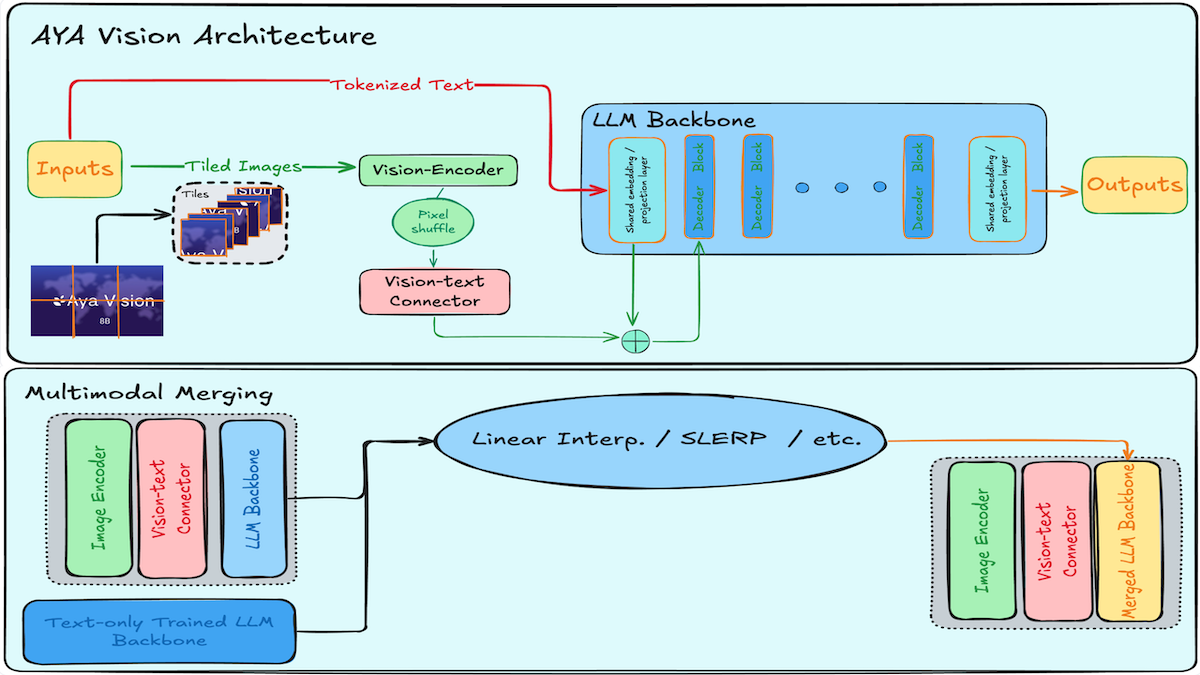
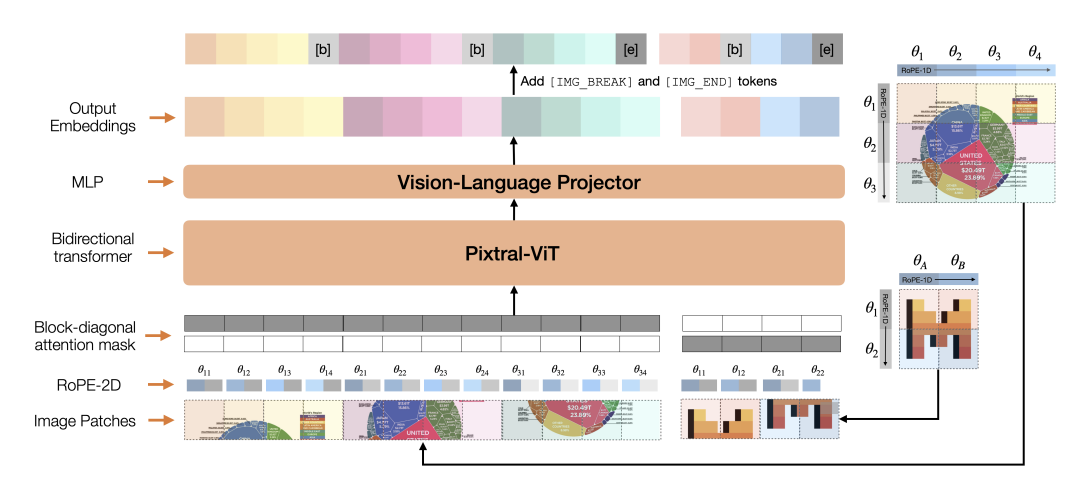
The MaMMUT model is a simple vision-encoder and text-decoder ...
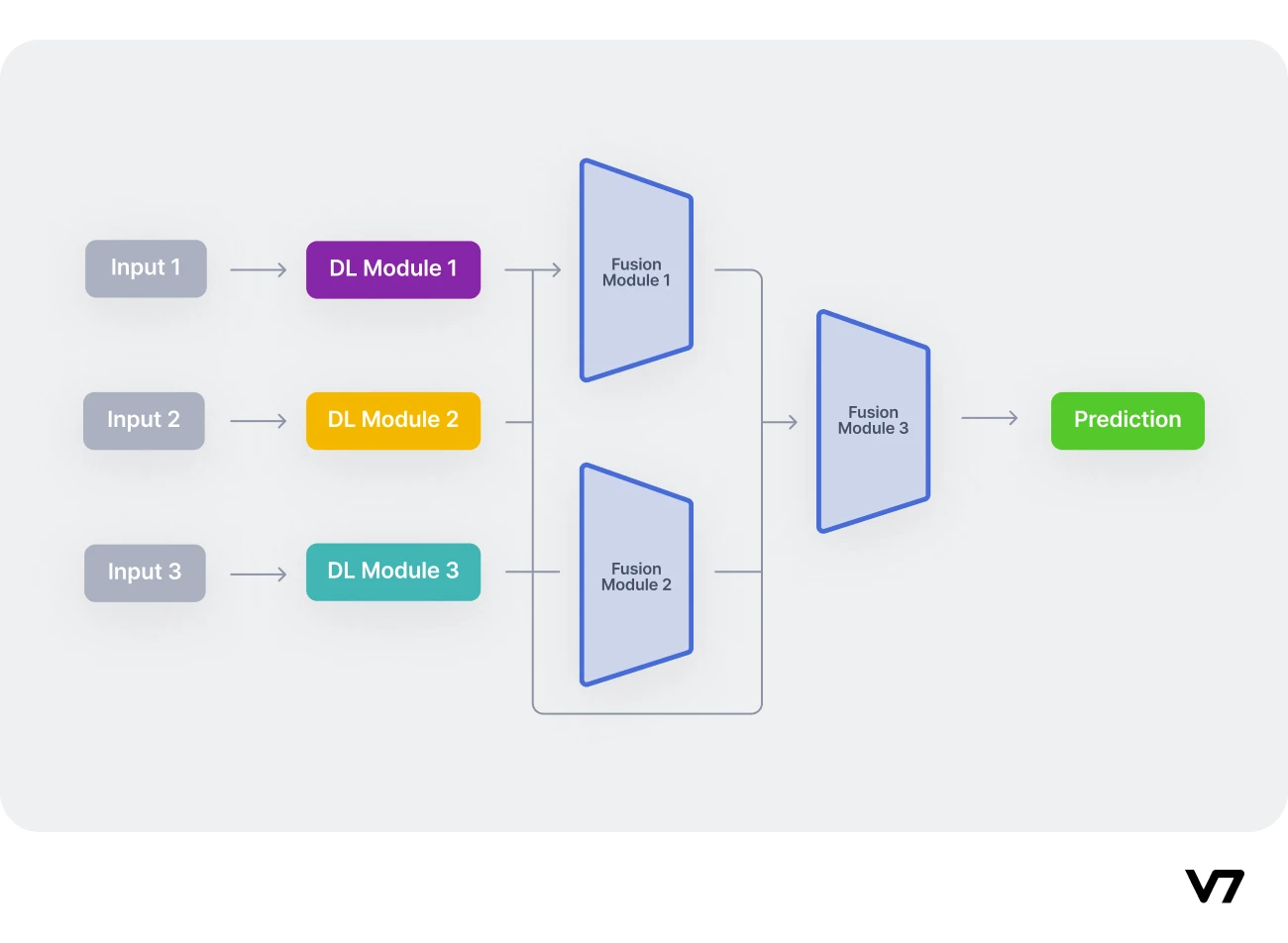
Multi-encoder architecture used for the multimodal translation ...
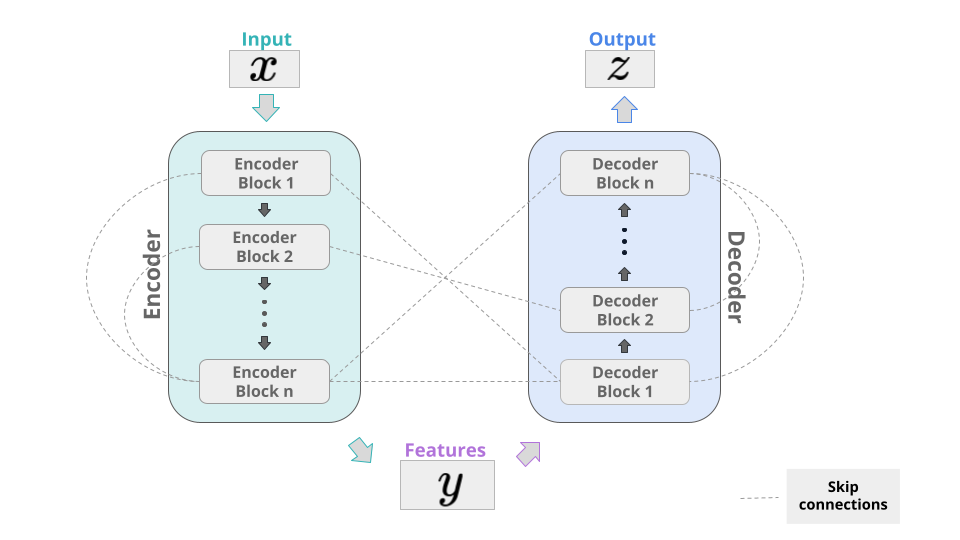
The architecture of a simple encoder-decoder model. | Download ...
(PDF) A Novel Encoder Decoder Architecture with Vision Transformer for ...
The overall architecture for MCR consists of four parts: multimodal ...
Our proposed FaD-VLP architecture consists of an image encoder, a text ...
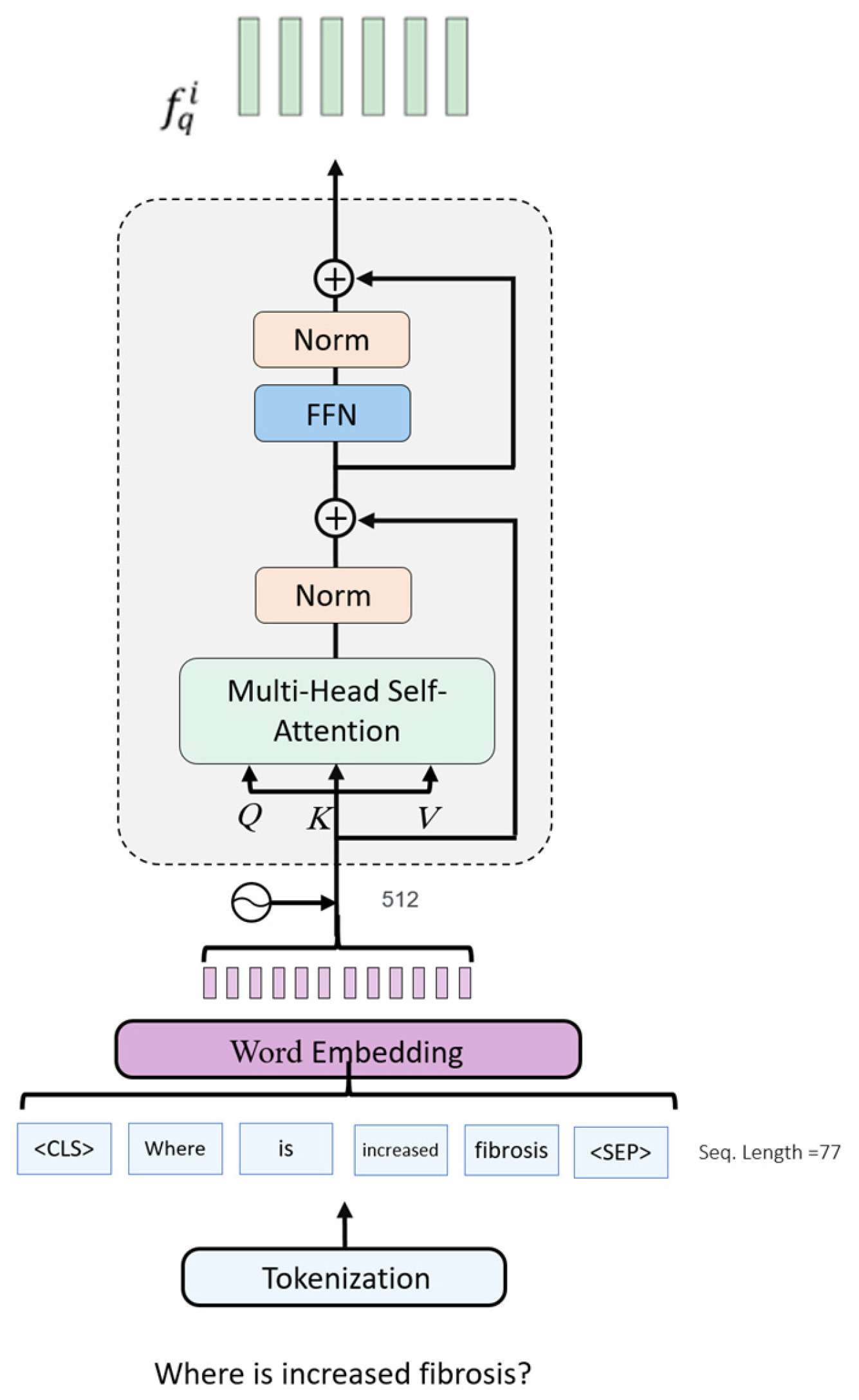
The architecture for fine-tuning on downstream medical VQA tasks. We ...
(PDF) Multimodal Encoder-Decoder Attention Networks for Visual Question ...
Building an Encoder-Decoder Architecture from Scratch for Machine ...
The overall architecture of the speech-text multimodal dual-tower ...
VLMT: Vision-Language Multimodal Transformer for Multimodal Multi-hop ...
Visual Transformers: How an architecture designed for NLP enters the ...
MultiFacet: A Multi-Tasking Framework for Speech-to-Sign Language ...
VCoder: Versatile Vision Encoders for Multimodal Large Language Models ...
A simplified view of encoder-decoder architecture with attention: an ...
Simple Encoder-Decoder Model Architecture [16] | Download Scientific ...
The Encoder-Decoder MTL architecture for face applications. The five ...
Illustration of UMAE. We train a multimodal encoder-decoder model on ...
Encoder-decoder architecture used for transforming visual spectrum to ...
On decoder-only architecture for speech-to-text and large language ...
Making Sense of Vision and Touch: Multimodal Representations for ...
Encoder–decoder architecture for image synthesis | Download Scientific ...
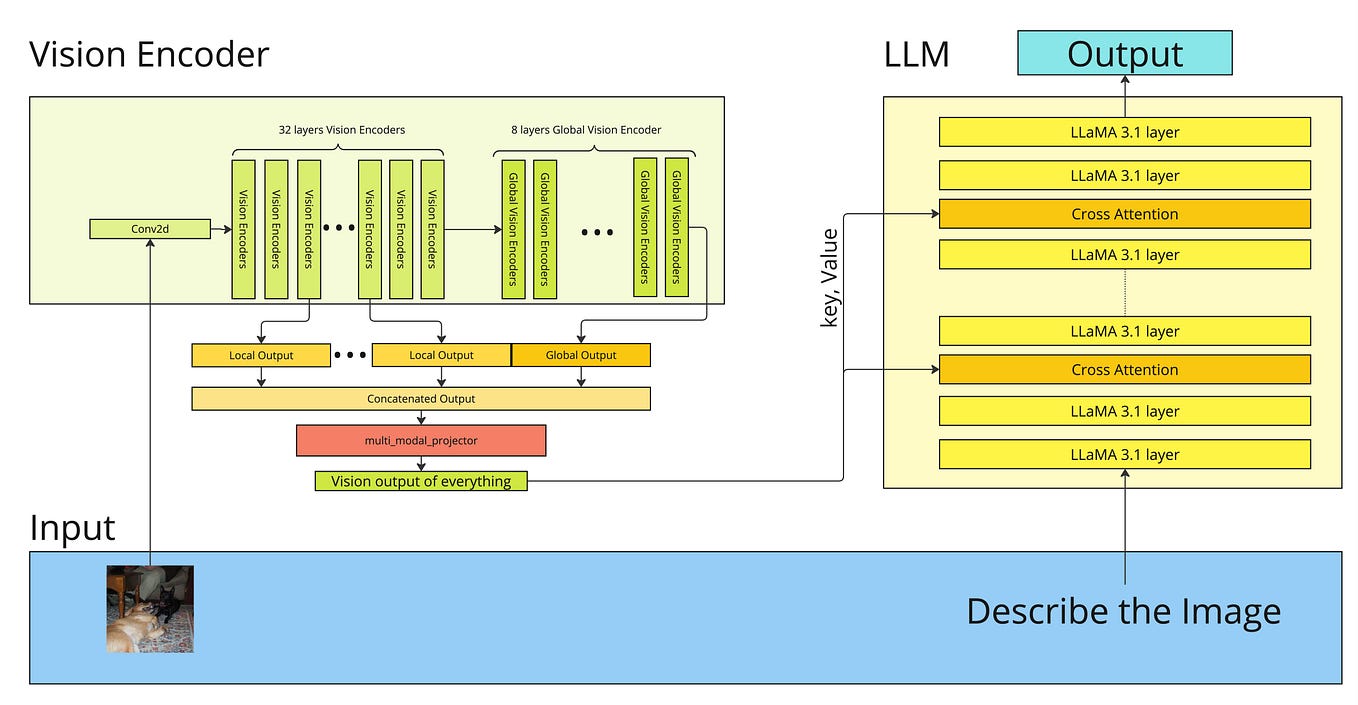
How Does A Multimodal LLM Work? The Vision Story
Multi-Task Video Captioning with a Stepwise Multimodal Encoder
The overall architecture of our proposed approach, where the vision ...
A Guide to Implement the Vision Encoder for LLaVA | Medium
Empowering AI with Senses: A Journey into Multimodal LLMs Part 1
Multimodal Architecture. Encoder top half: text submodel. Encoder ...
Encoder Decoder A Hierarchical Encoder Decoder Model For SPSS
(PDF) Multi-Task Video Captioning with a Stepwise Multimodal Encoder
What is Multimodal AI? A complete overview
Overview of WebGUM, our multimodal encoder-decoder transformer model ...
Architectural diagram of our baseline multimodal hierarchical ...
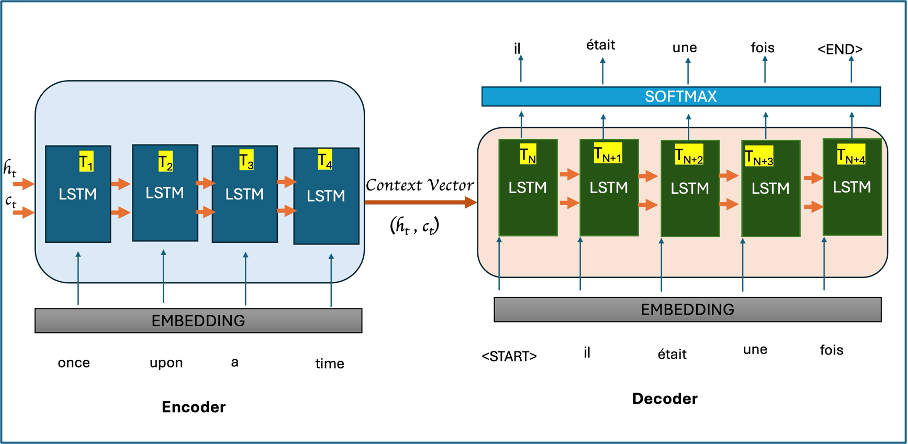
Exploring Encoder-Decoder Architecture with LSTMs | by Minhaz Chowdhury ...
A Review of 3D Object Detection with Vision-Language Models | AI ...
The overall architecture of the MEDT. It consists of two parts: 1) the ...
Model architecture of the proposed multi-encoderdecoder Transformer ...
What is AI what is LMM and why it is amazing for the IoT | Cloud Studio ...
Prompt-Enhanced Generation for Multimodal Open Question Answering
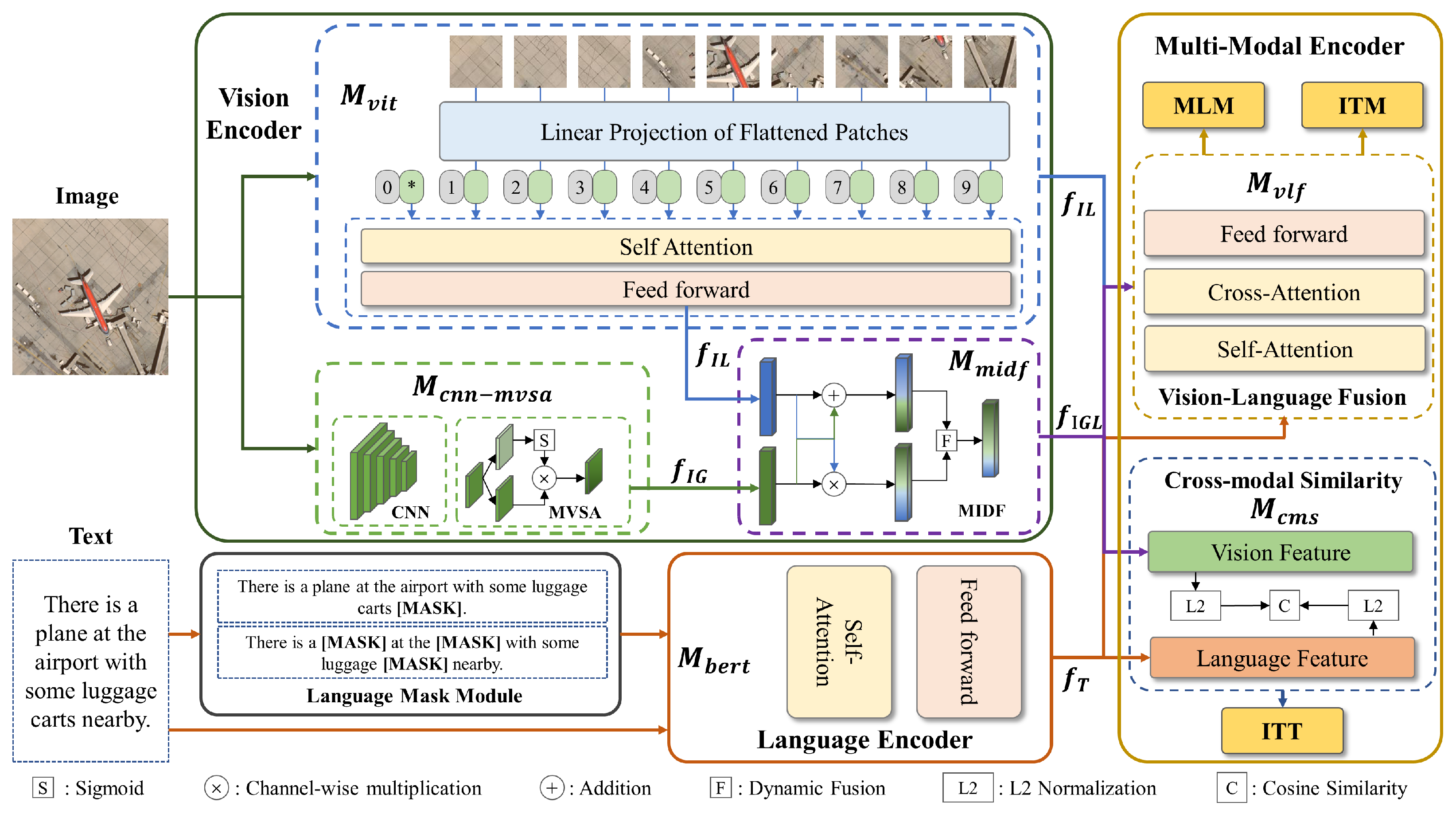
An End-to-End Framework Based on Vision-Language Fusion for Remote ...
ModernBERT: The Next Generation of Encoder Models — A Guide to Using ...
The final architecture consists in an encoder-decoder model. The two ...
Qwen2.5-Omni 7B Raises the Bar for Small Multimodal Models
The attention mechanism of the encoder-Decoder Architecture ...
Encoder-Decoder architecture of the presented depth estimation network ...
Prominent examples of multimodal translation tasks, such as ...
Multimodal Large Language Models | Yue Shui Blog
Understanding Multimodal LLMs - by Sebastian Raschka, PhD
Chapter 3 Multimodal architectures | Multimodal Deep Learning
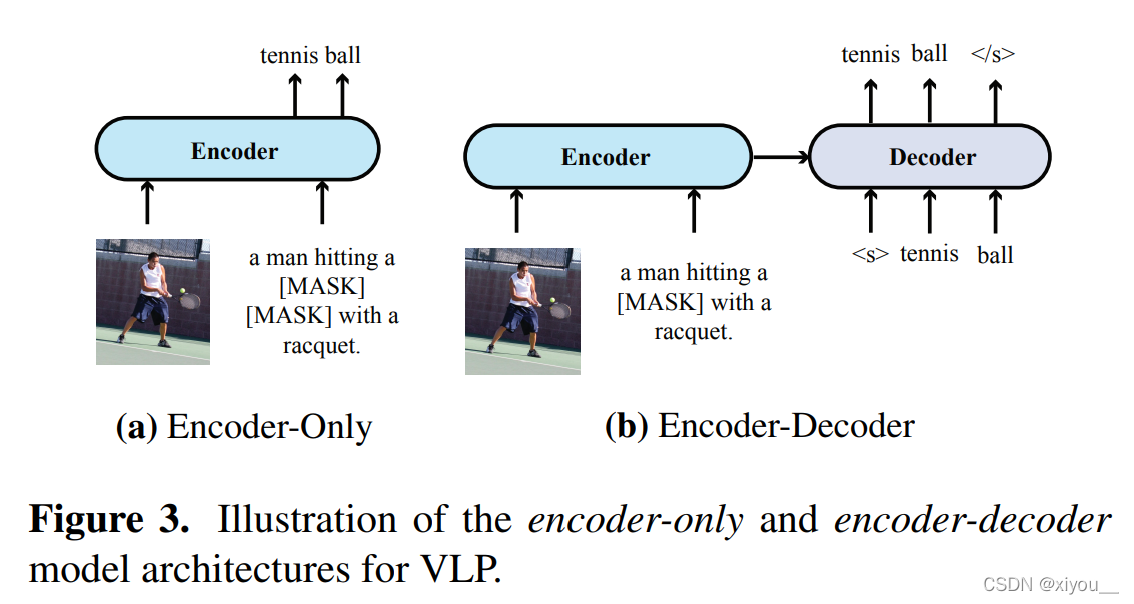
论文阅读:An Empirical Study of Training End-to-End Vision-and-Language ...
Encoder Decoder Architecture Transformer at Steven Chandler blog
Top 10 Multimodal Models | Encord
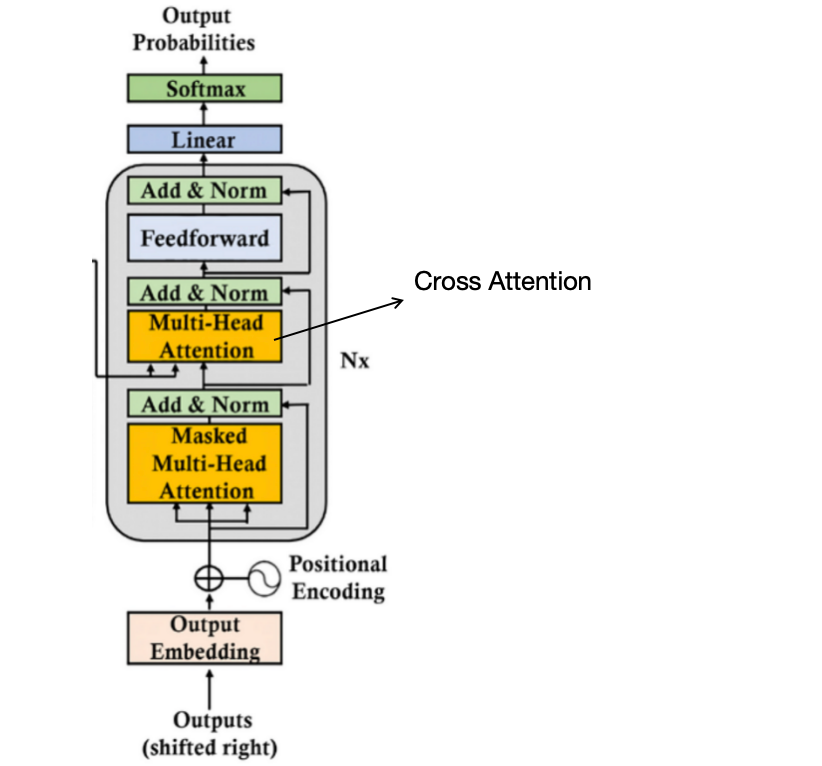
Intro to the Encoder-Decoder model and the Attention mechanism ...
Encoder and Decoder architecture | Download Scientific Diagram
Why Encoder Decoder Architecture model is needed? | by Yashwanth S | Medium
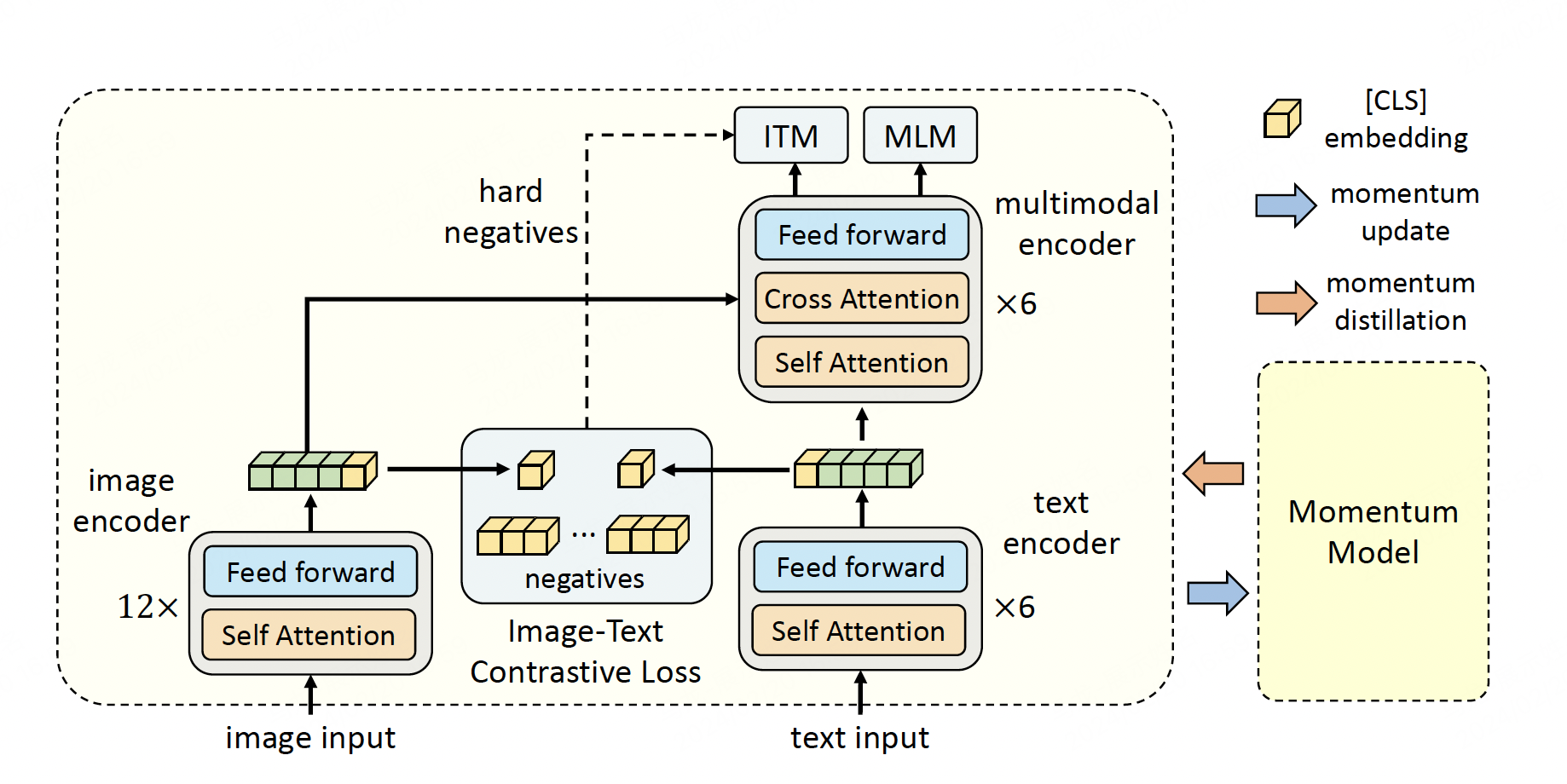
BLIP: Bootstrapped Language-Image Pretraining | AI Tutorial | Next ...
Selecting Model Architecture & Design In LLM Development
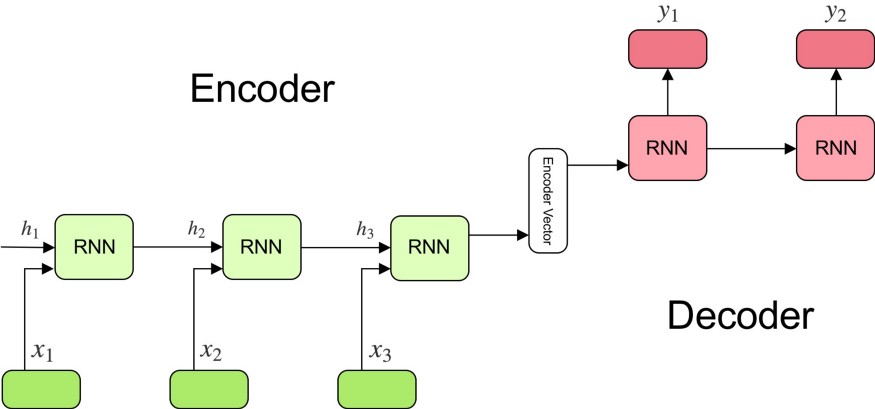
Introduction to LLMs: The RNN Encoder-Decoder Architecture
Vision Language Models: Exploring Multimodal AI - viso.ai
Handwritten Document Recognition Using Pre-trained Vision Transformers ...
Multi-encoder architecture: two twin, separate encoders (blue, yellow ...
Illustration of multi-task architecture. The output of the encoder is ...
Encoder-Decoder model architecture overview. | Download Scientific Diagram
Encoder-Decoder Architecture | Download Scientific Diagram
Encoder-Decoder, Sequence to Sequence architecture. | Download ...
Illustration of the encoder-decoder architecture. The encoder and ...
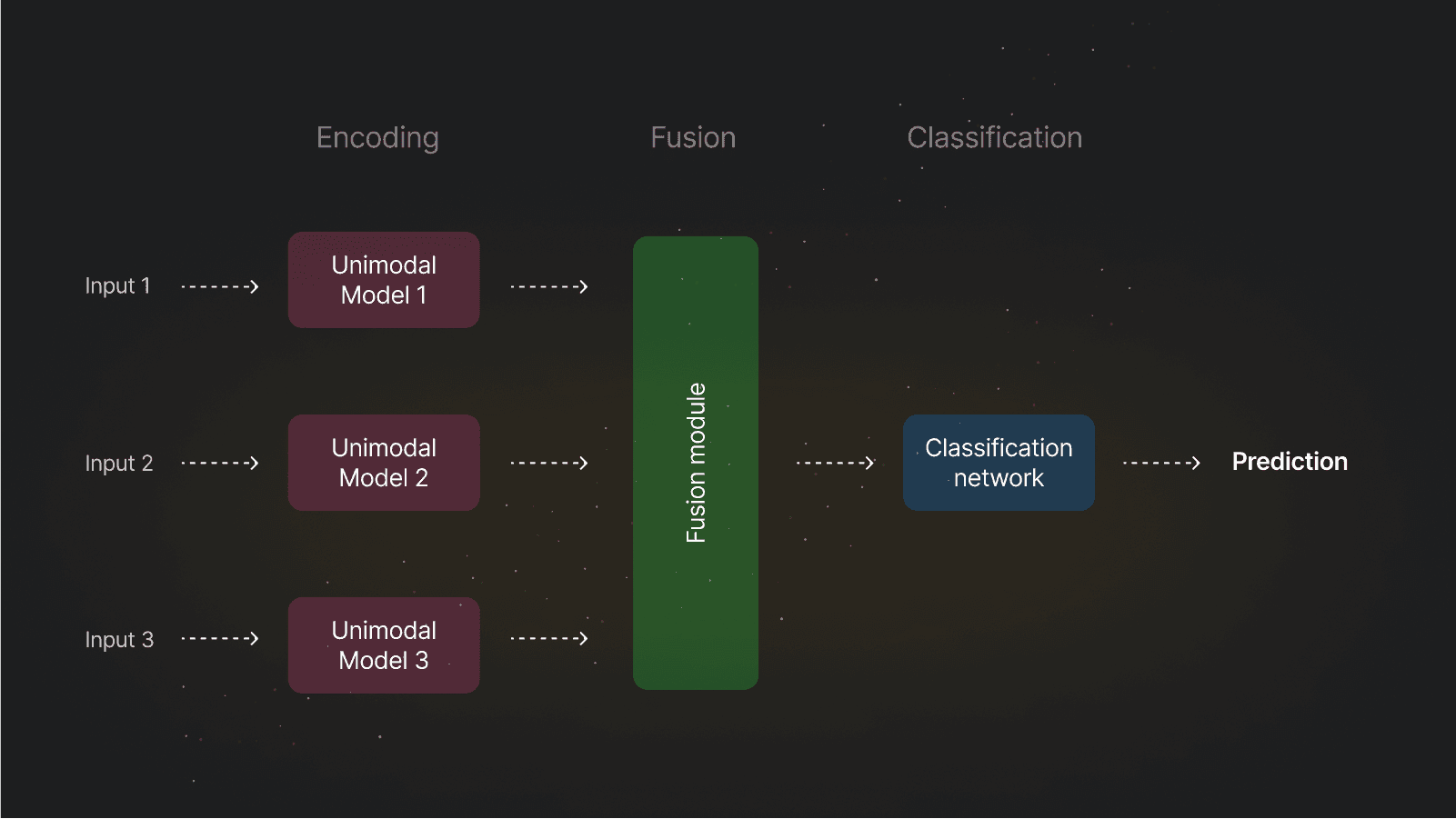
Multimodal Deep Learning: Definition, Examples, Applications
The standard Encoder–Decoder architecture | Download Scientific Diagram
Inside Google’s Co-Scientist, Copyright Office Weighs Generated Works ...
Bidirectional Encoder Representations from Transformers (BERT) | by ...
Exploring Seq2Seq, Encoder-Decoder, and Attention Mechanisms in NLP ...
Encoder-Decoder model combined with attention mechanism | Download ...
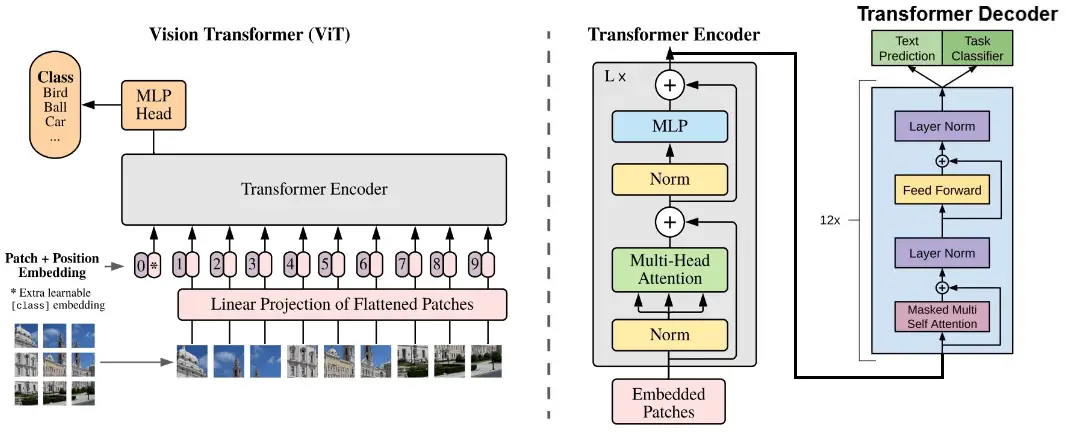
Vision Transformer Image Classification | MindSpore 2.0 Tutorials ...
Model details of the phase of dual-attention Encoder–Decoder ...
(PDF) Video question answering supported by a multi-task learning objective
Vision–Language Model for Visual Question Answering in Medical Imagery
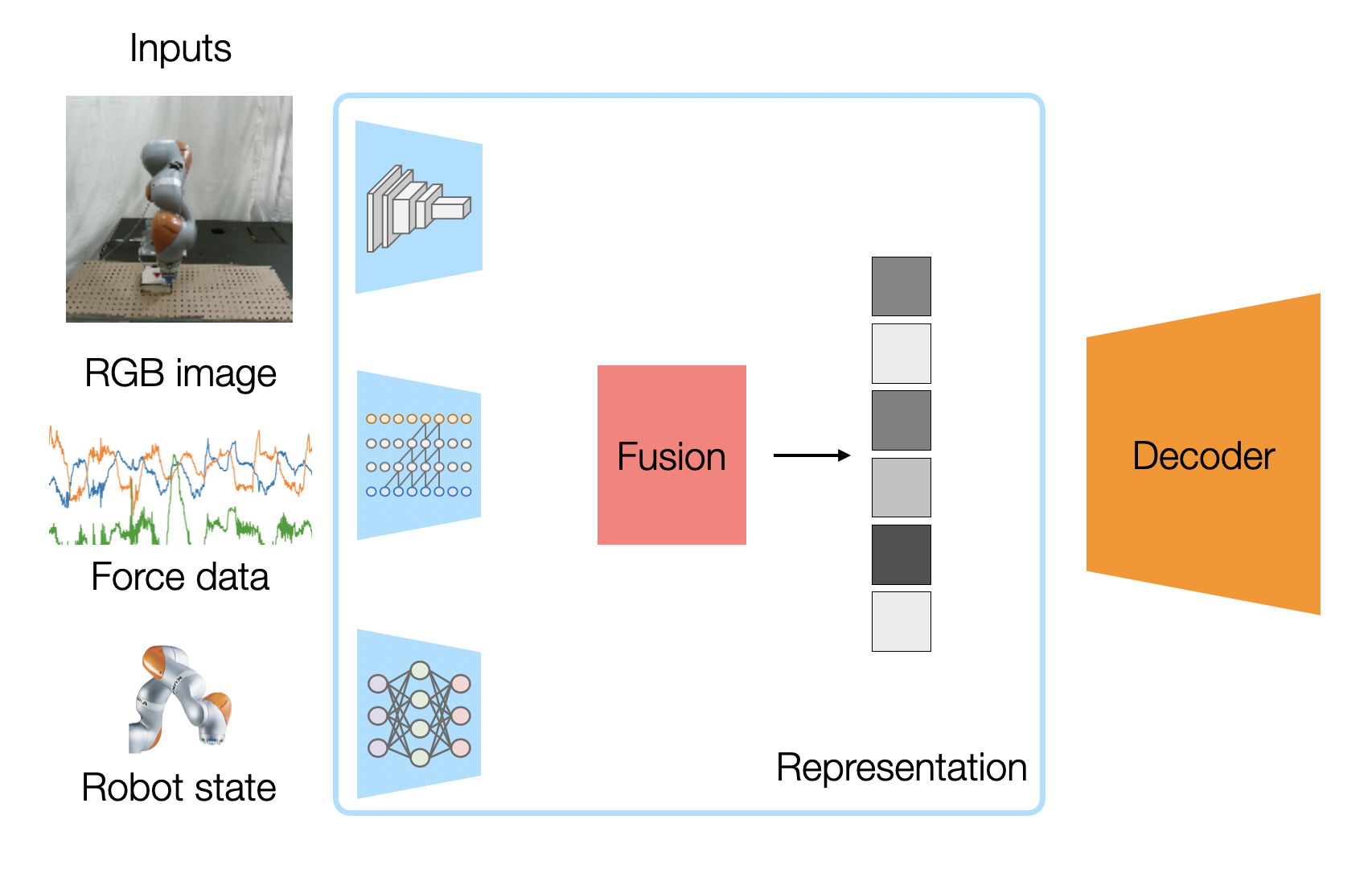
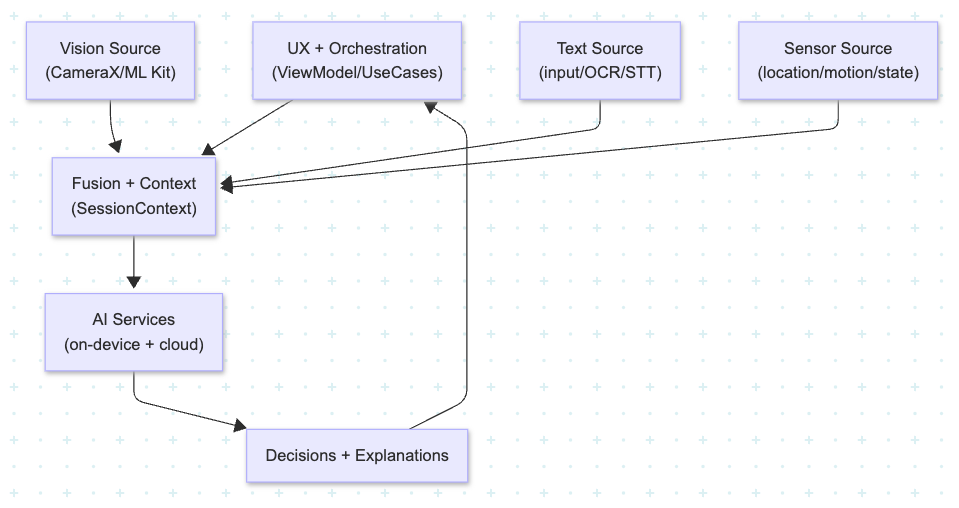
Multimodal AI Architecture: Vision, Text, and Sensor Data
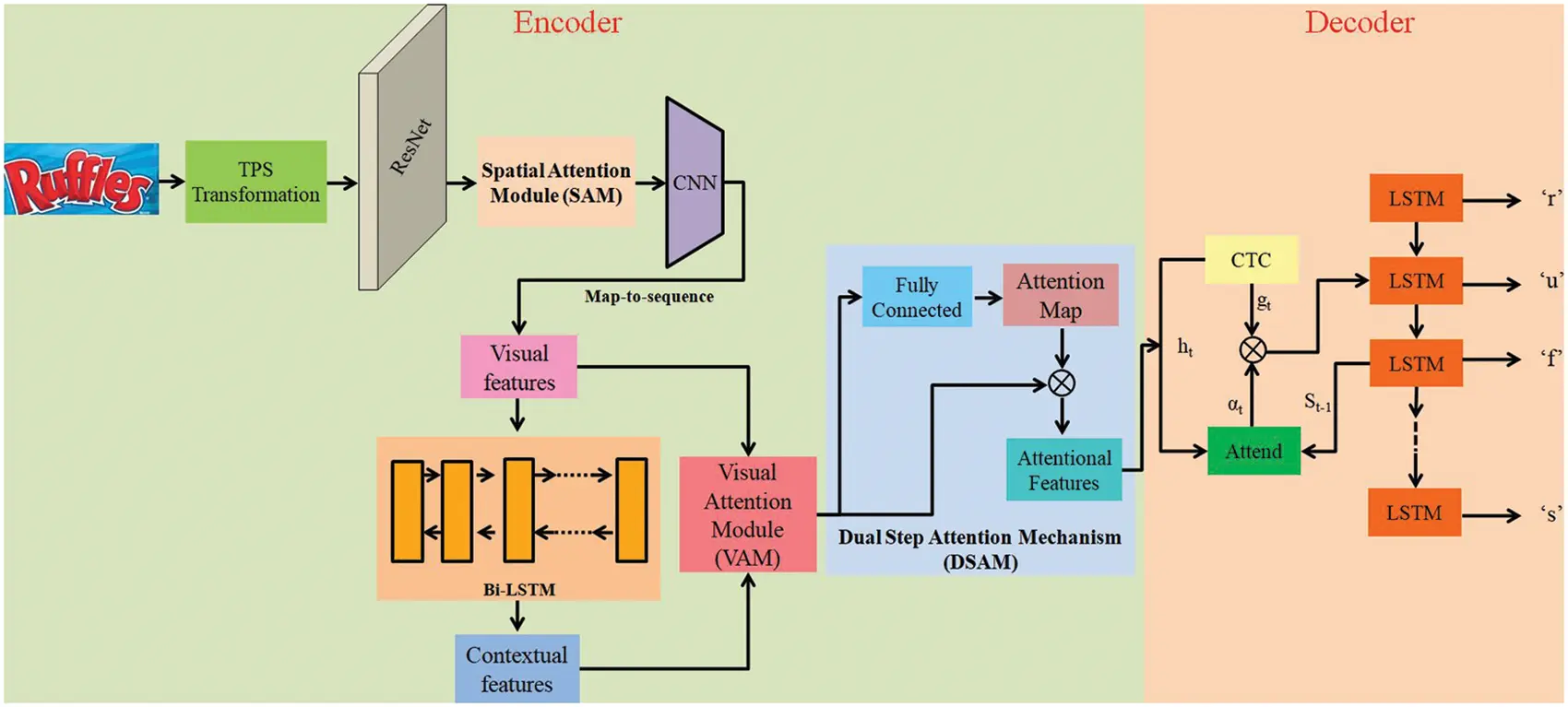
Enhanced Attention-Based Encoder-Decoder Framework for Text Recognition
From Input to Output: Demystifying the Encoder-Decoder Architecture
Multimodal Autoregressive Pre-training of Large Vision Encoders
Encoder -Decoder Architecture | Download Scientific Diagram
Image Captioning using PyTorch and Transformers in Python - The Python Code
Aman's AI Journal • Primers • Document Intelligence
HorayAI - Production Ready Cloud with Low Cost
How Encoders Allow LLMs to Process Prompts - KodeKloud
Vision Transformers: From Idea to Applications (Part Four)
Working of Decoders in Transformers - GeeksforGeeks
Understanding Encoder And Decoder LLMs
Encoder Decoder Architecture. | Download Scientific Diagram
The Illustrated Image Captioning using transformers - Ankur NLP Enthusiast
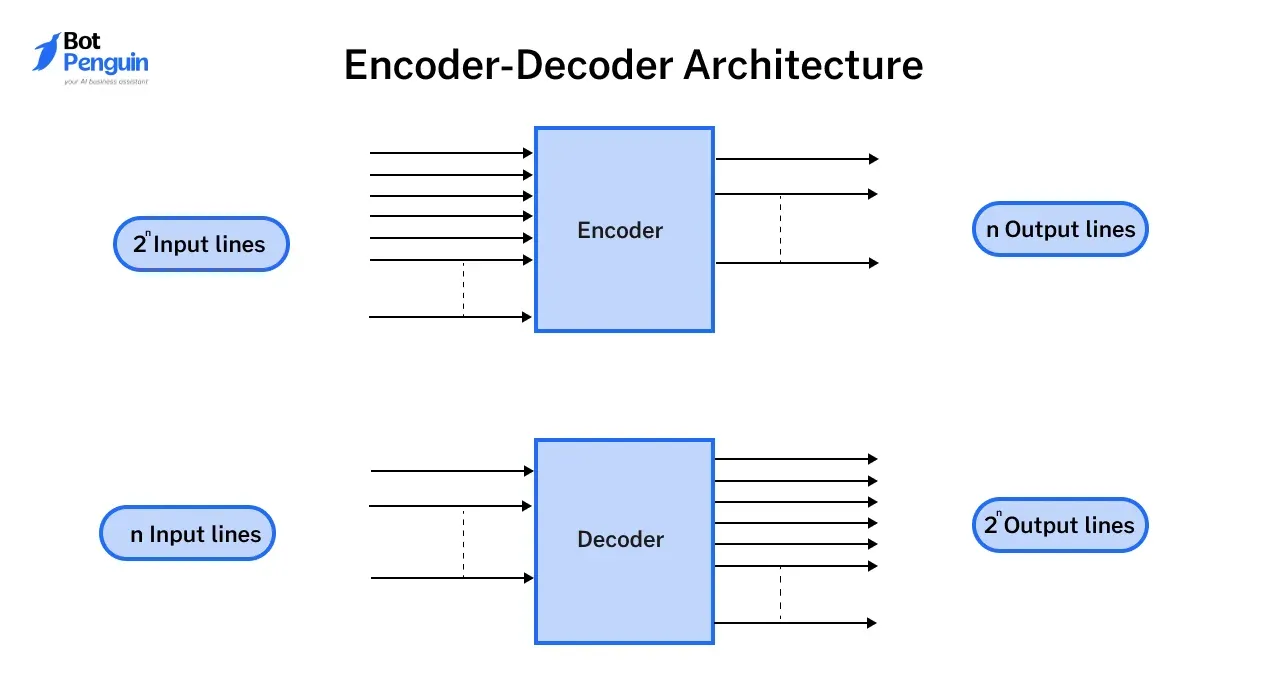
What Is Encoder Decoder Model at Qiana Flowers blog
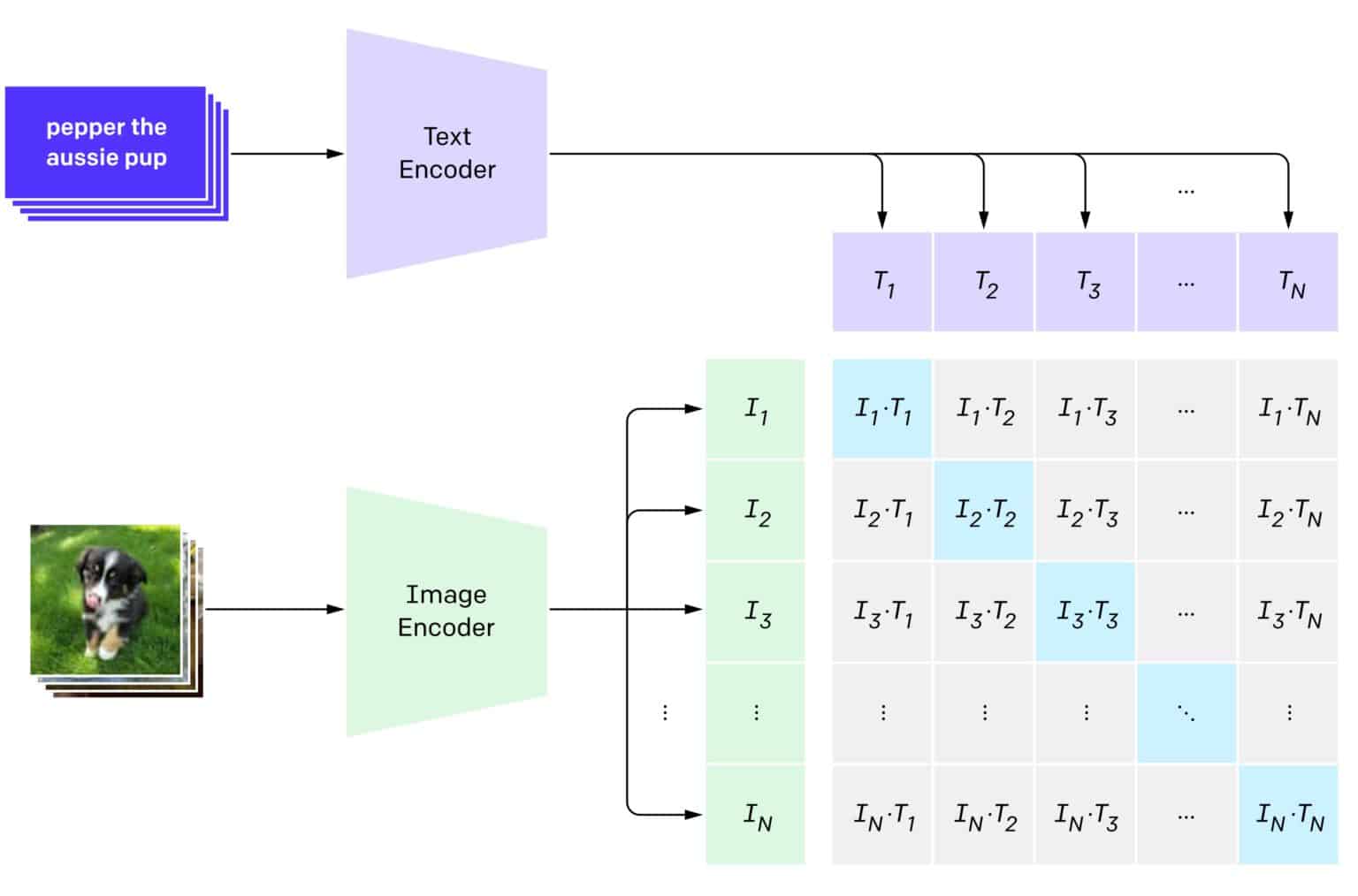
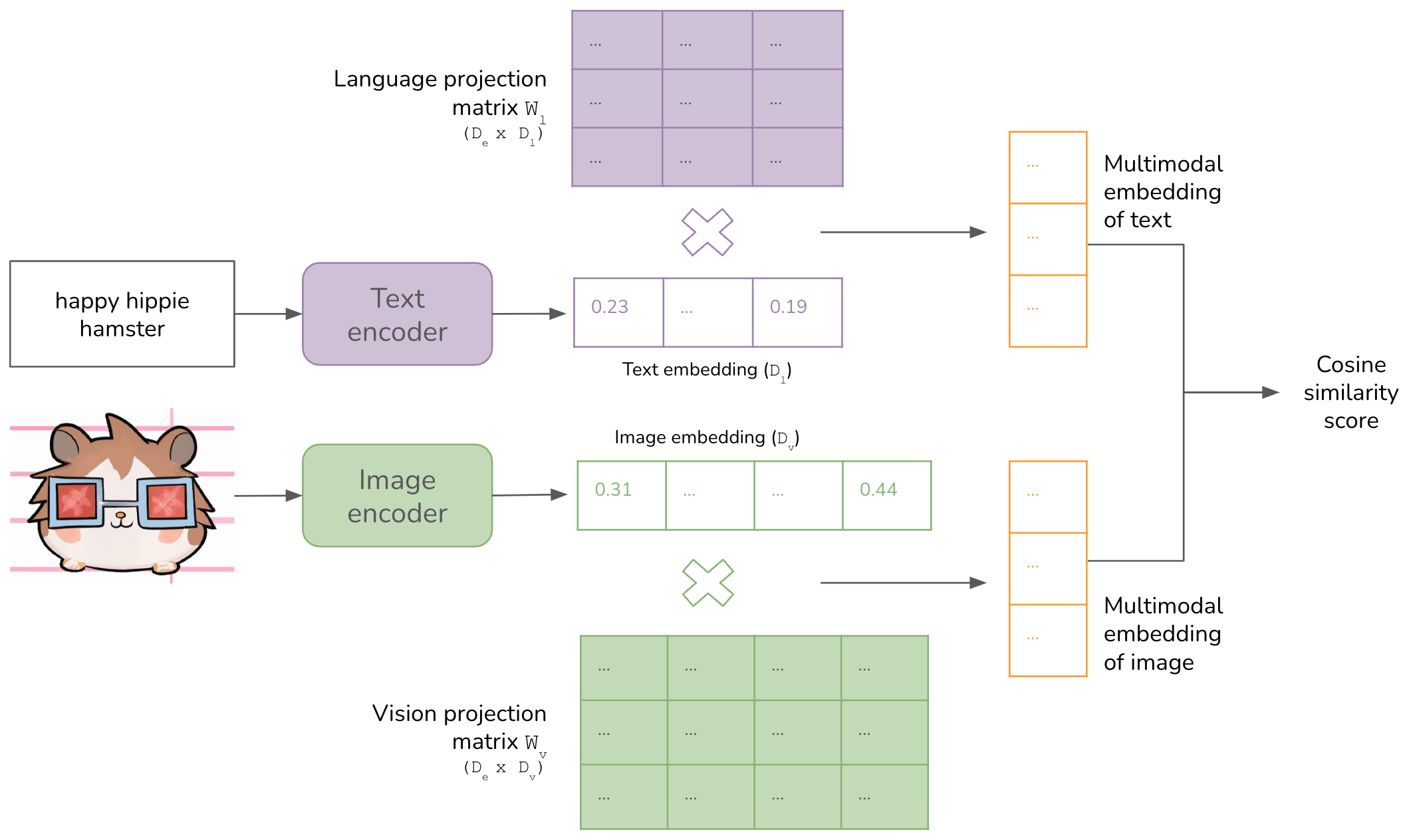
CLIP: Bridging Vision and Language in AI
LLM | Data Science Dojo
Evolution of Multimodality | Loong's Lens
大模型开发 - 一文搞懂Encoder-Decoder工作原理_人工智能_顺其自然~-开放原子开发者工作坊
Some Notes of Multimodality
Vision Language Models (VLMs) Explained | DataCamp
Encoder Decoder Models - GeeksforGeeks
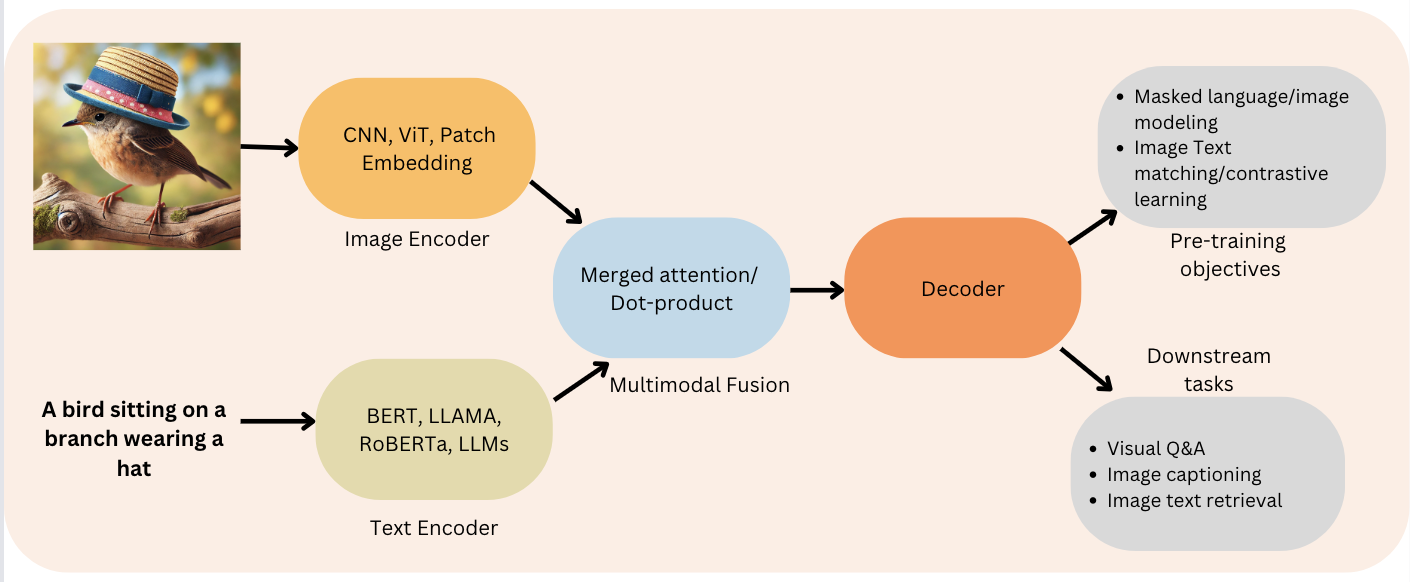
Based on this image's title: “A simple vision-encoder text-decoder architecture for multimodal tasks ...”