mlx-community/gemma-3n-E4B-it-5bit · Hugging Face
MtnMCG/Council-Ultima-Gemma-3-12B-MLX-4bit · Hugging Face
aimeri/gemma3-27b-it-abliterated-normpreserve-mlx-5Bit · Hugging Face
Paramstr/MLX-gemma-Code-Instruct-Finetune-test · Hugging Face
dnakov/seed-oss-36b-instruct-4.5bit-mlx · Hugging Face
mlx-community/codegemma-1.1-2b-4bit · Hugging Face
mlx-community/Kimi-K2.5 · Hugging Face
Quantized Models for google/gemma-3-4b-it – Hugging Face
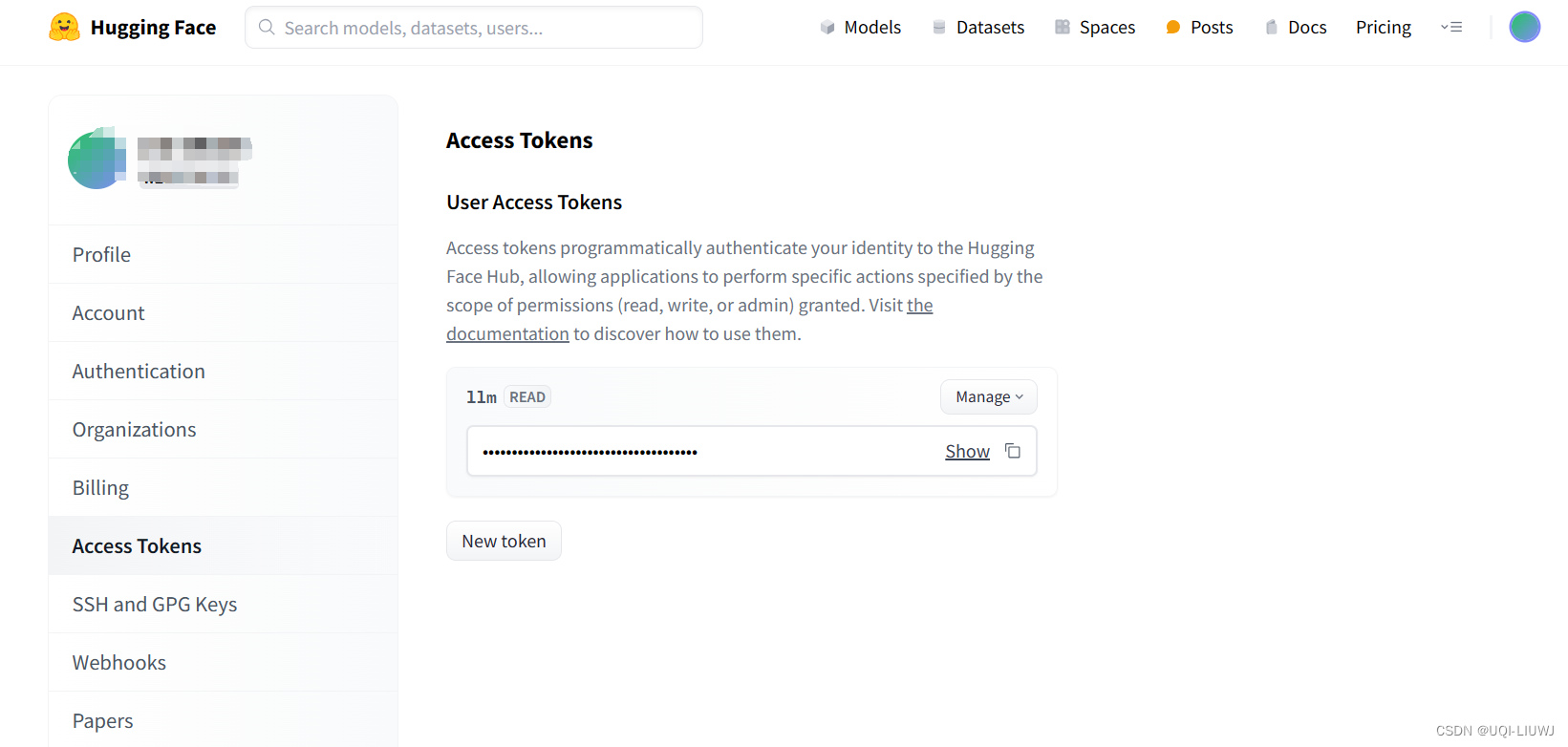
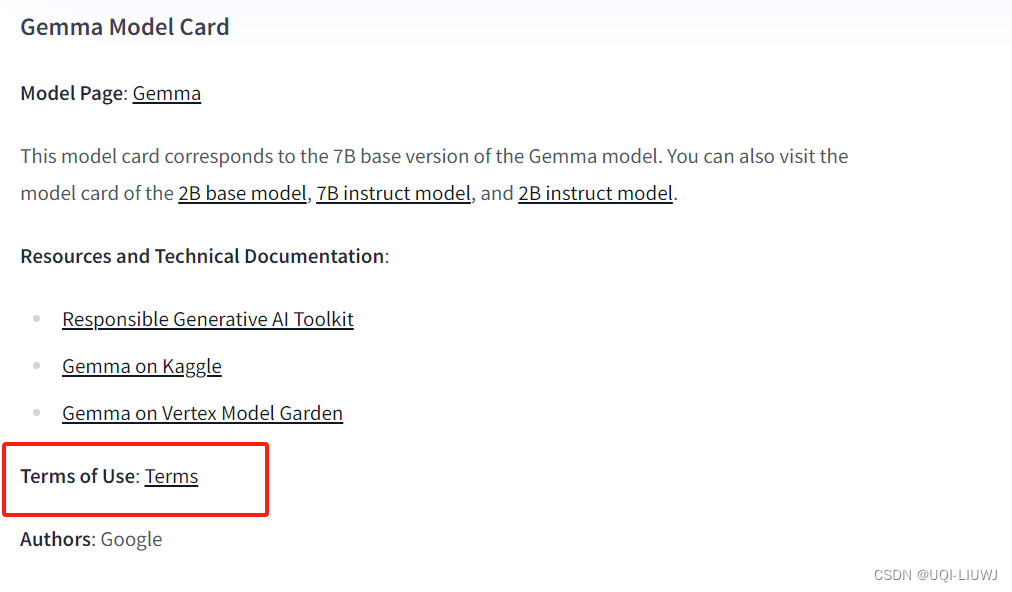
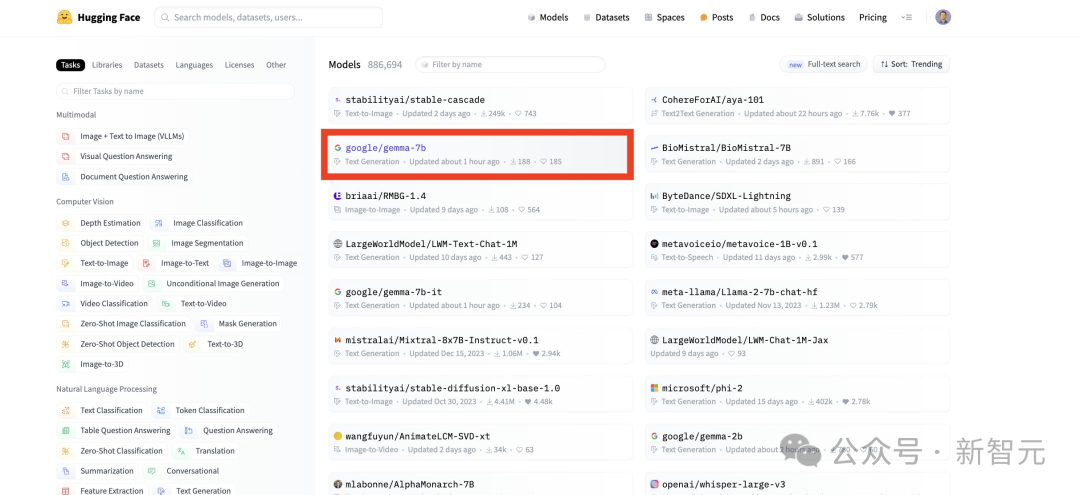
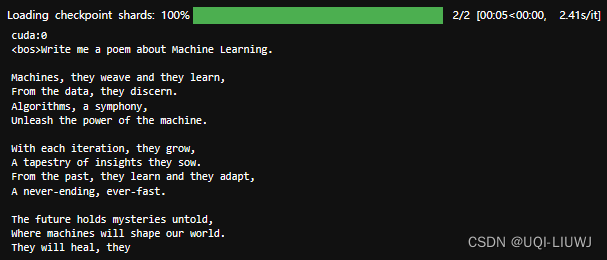
使用 Hugging Face 微调 Gemma 模型 - HuggingFace - 博客园
Deploy google/gemma-3-27b-it | Inference Endpoints by Hugging Face
欢迎 Llama Guard 4 登陆 Hugging Face Hub - Hugging Face 文档
Finetuning Gemma 7B LLM with Hugging Face
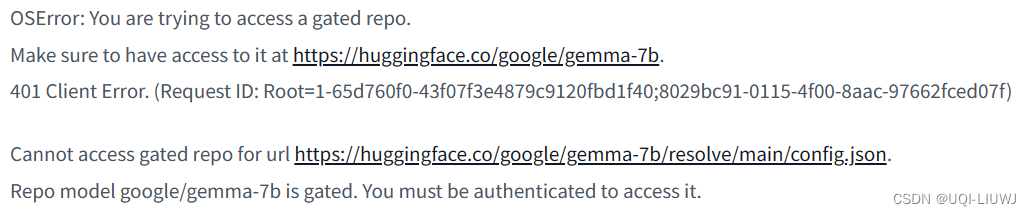
Hugging Face Gated Community: Your request to access model meta-llama ...
使用 Hugging Face 微调 Gemma 模型 - 智源社区
Hugging Face on Twitter: "RT @hammh0a: 🐫Check out our CAMEL-13B model🐫 ...
mlx-community/gemma-3-12b-it-4bit · Broken model?
苹果M芯片福音!Hugging Face 直接用 MLX-LM 跑 AI 大模型,速度杠杠的!-AITOP100,AI资讯
HuggingFace Gemma-2-9b/27b incorrect · Issue #53 · google-deepmind ...
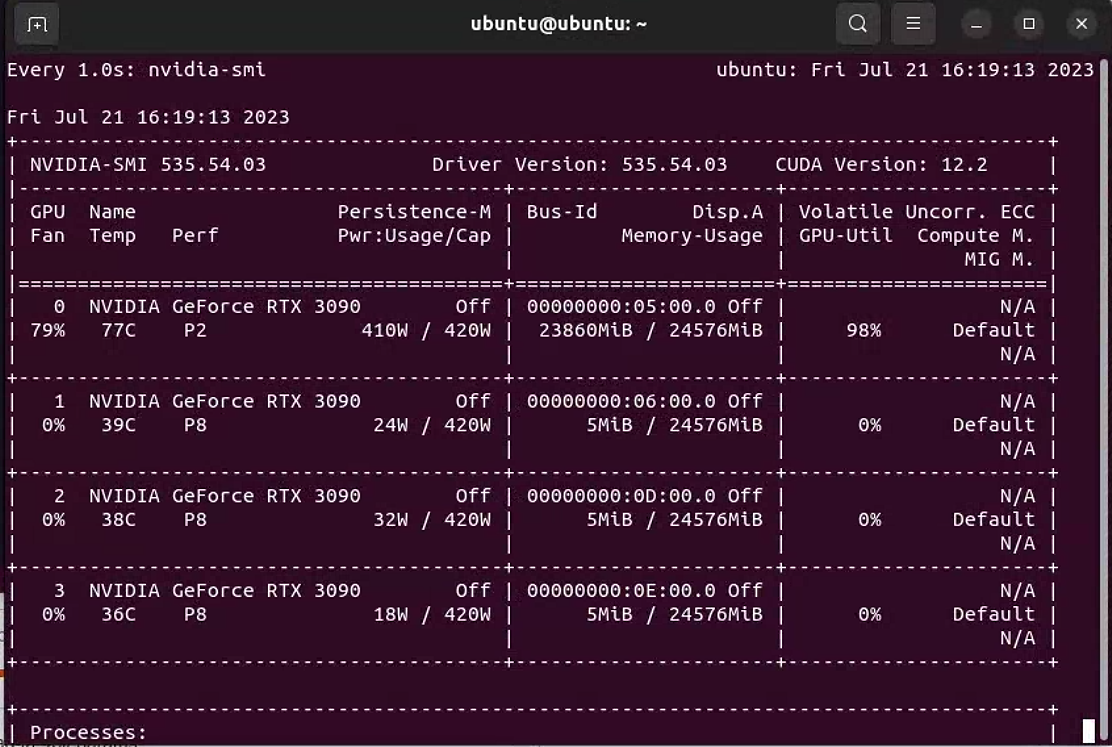
llama2 13B_chat Model conversion to Hugging Face, only one gpu can be ...
mlx-community/Huihui-gemma-3n-E4B-it-abliterated-lm-4bit at main
CallMcMargin/gemma-3-12b-it-projection-abliterated-mlx-bf16-mxfp4-mixed ...
Ivan Fioravanti on LinkedIn: mlx-community/CodeLlama-70b-Instruct-hf ...
Cannot export tflite using optimum for a fine-tuned gemma 3 model for ...
huggingface-projects/gemma-3-12b-it at main
MLX Community - Website Hunt
Inference with Gemma using Dataflow and vLLM - Google Developers Blog
Llama3 を MLX で動かしてみた
LLM Fine-Tuning & Quantization Expert | Llama, Gemma, 4-bit/GGUF/MLX ...
Can't perform image inference with Gemma 3 12b it qat4.0 - 🤗 ...
LM Studio 0.3.4、Apple MLX搭載でリリース | LM Studioブログ
EveryoneLLM-7b-Gemma-Base huggingface.co api & rombodawg EveryoneLLM-7b ...
[LLM] Gemma模型概览和快速上手体验 - 知乎
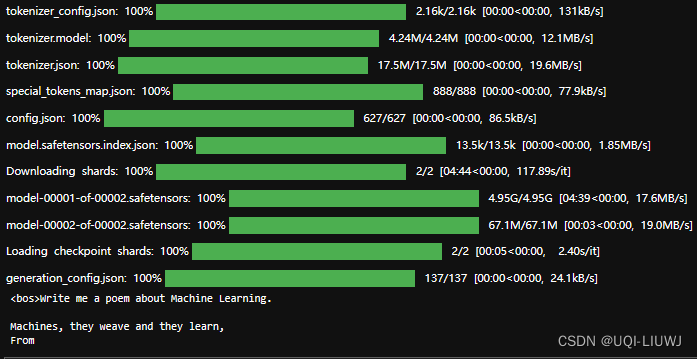
Huggingface 笔记:大模型(Gemma2B,Gemma 7B)部署+基本使用_gemma7bitclient 向量化文本-CSDN博客
Problems with saving standalone gemma-2b-it after fine-tuning with LoRA ...
Getting Started with Google’s Gemma LLM using HuggingFace Libraries ...
Fine Tuning Google Gemma: Enhancing LLMs with Customized Instructions ...
Fine-Tuning GEMMA-2b for Binary Classification (4-bit Quantization ...
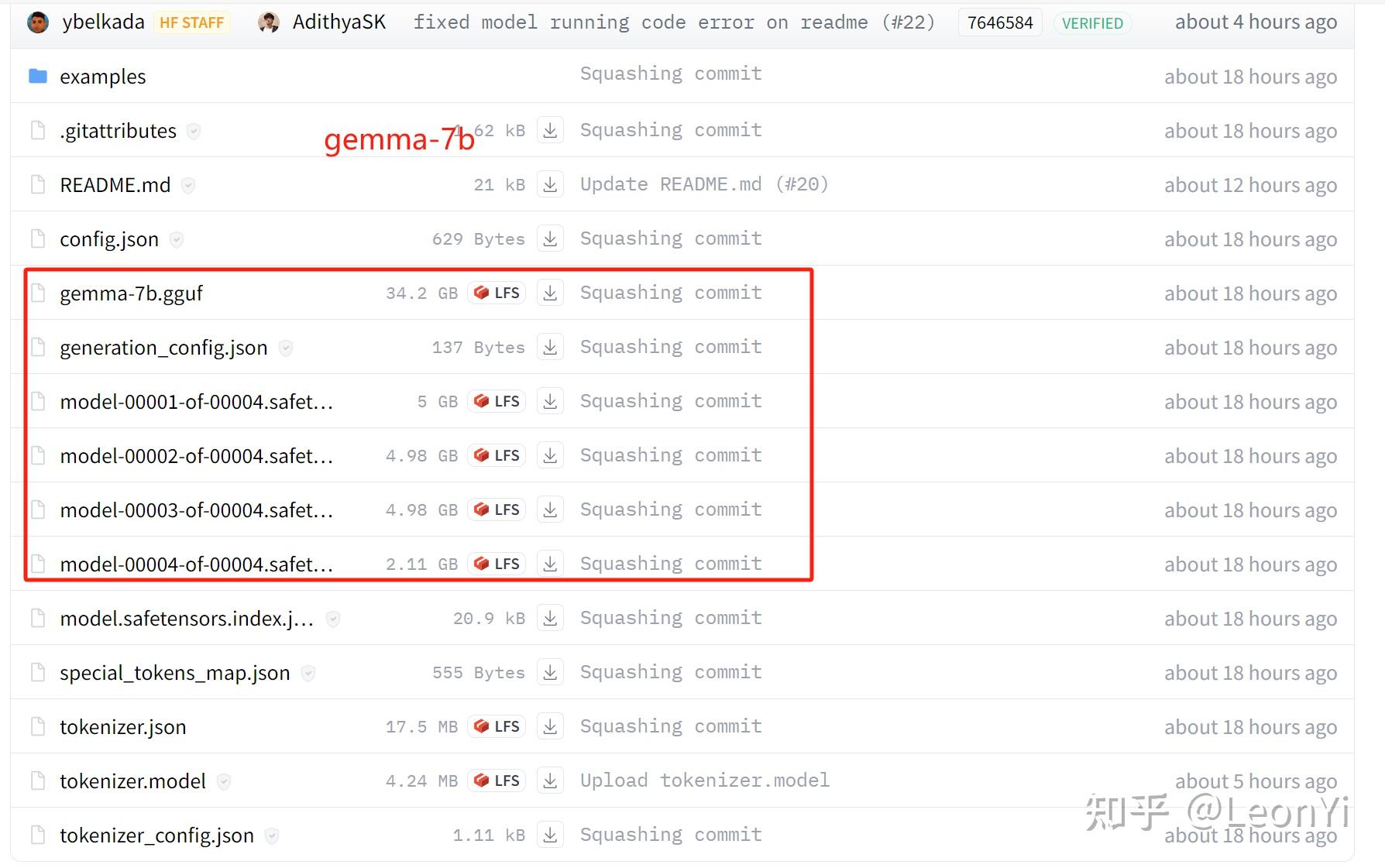
Google Gemma 7B and 2B LLM models are now available to developers as ...
Testing Gemma 3 1B Instruct like a Pro | by Gabriel Preda | Medium
[Apple Silicon] MLX Fine-tuning with Gemma-2B
全球最强开源大模型一夜易主!谷歌Gemma 7B碾压Llama 2 13B,今夜重燃开源之战 - 智源社区
Huggingface chat-ui and MLX integration. - YouTube
全球最强开源大模型一夜易主!谷歌Gemma 7B碾压Llama 2 13B,今夜重燃开源之战 | 人人都是产品经理
Gemma 7B, the latest open-source model from Google, is available on ...
Unable to Access Gated Model meta-llama/Llama-3.2-1B Despite Approved ...
[Warning] `Merge lora module to 4-bit linear may get different ...
纯小白版,在Mac上跑chat with mlx,畅享丝滑! - 知乎
Assorted observations and outputs from gpt4-alpaca-lora_mlp-65B-GGML ...
【HuggingChat】免費使用Llama 2 70B、Mixtral 8x7B等大型語言模型|可自訂Assistant 擁有類似GPTs的功能
开源大模型王座易主:Google Gemma杀入场 笔记本可跑 可商用 - Google 谷歌 - cnBeta.COM
Meta-Llama-3–8B安装指南:本地运行AI模型的终极教程 - 知乎
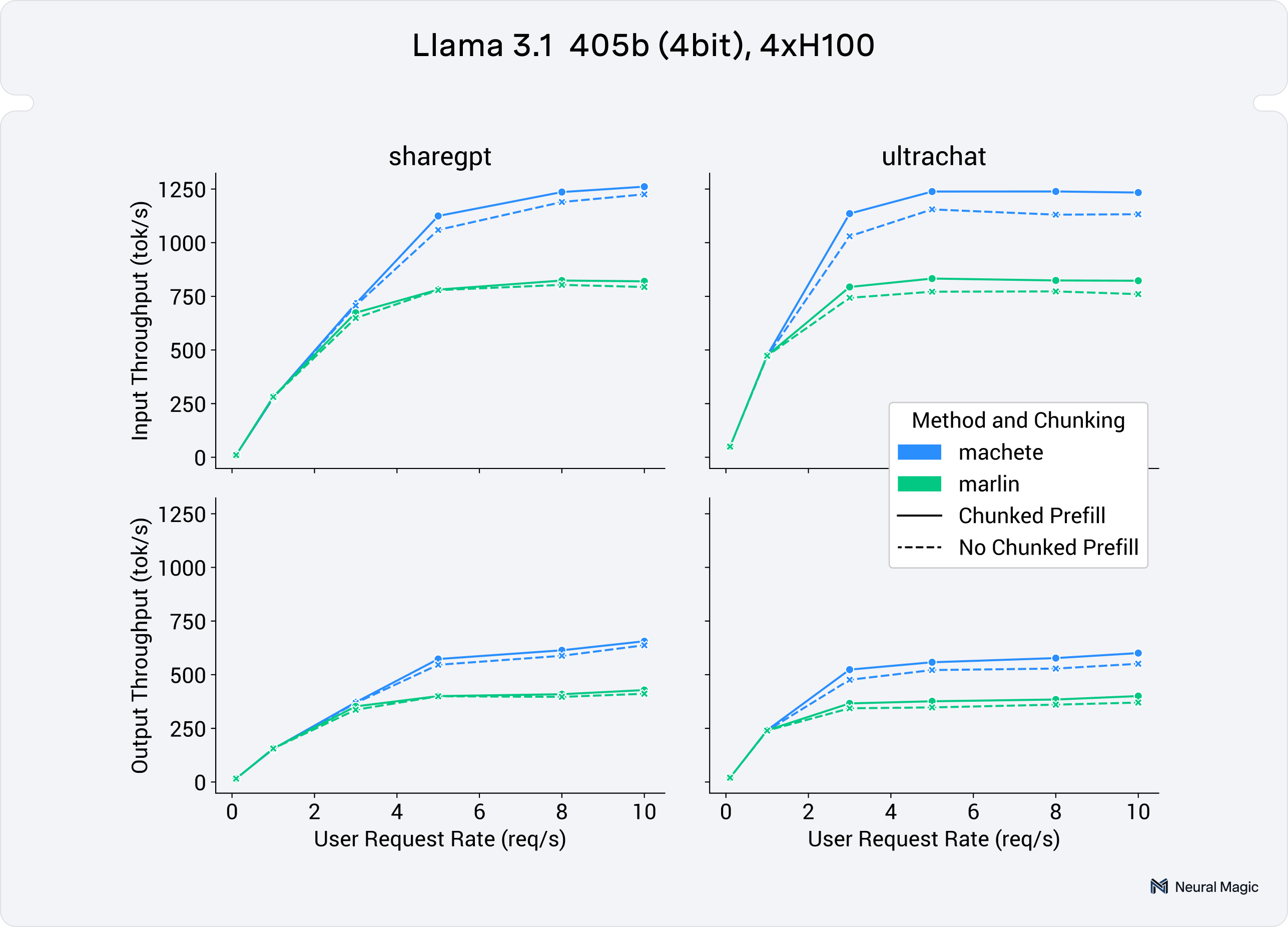
Introducing Machete, a mixed-input GEMM kernel optimized for NVIDIA ...
通过termux tailscale huggingface 来手把手一步一步在手机上部署LLAMA2-7b和LLAMA2-70b大模型 ...
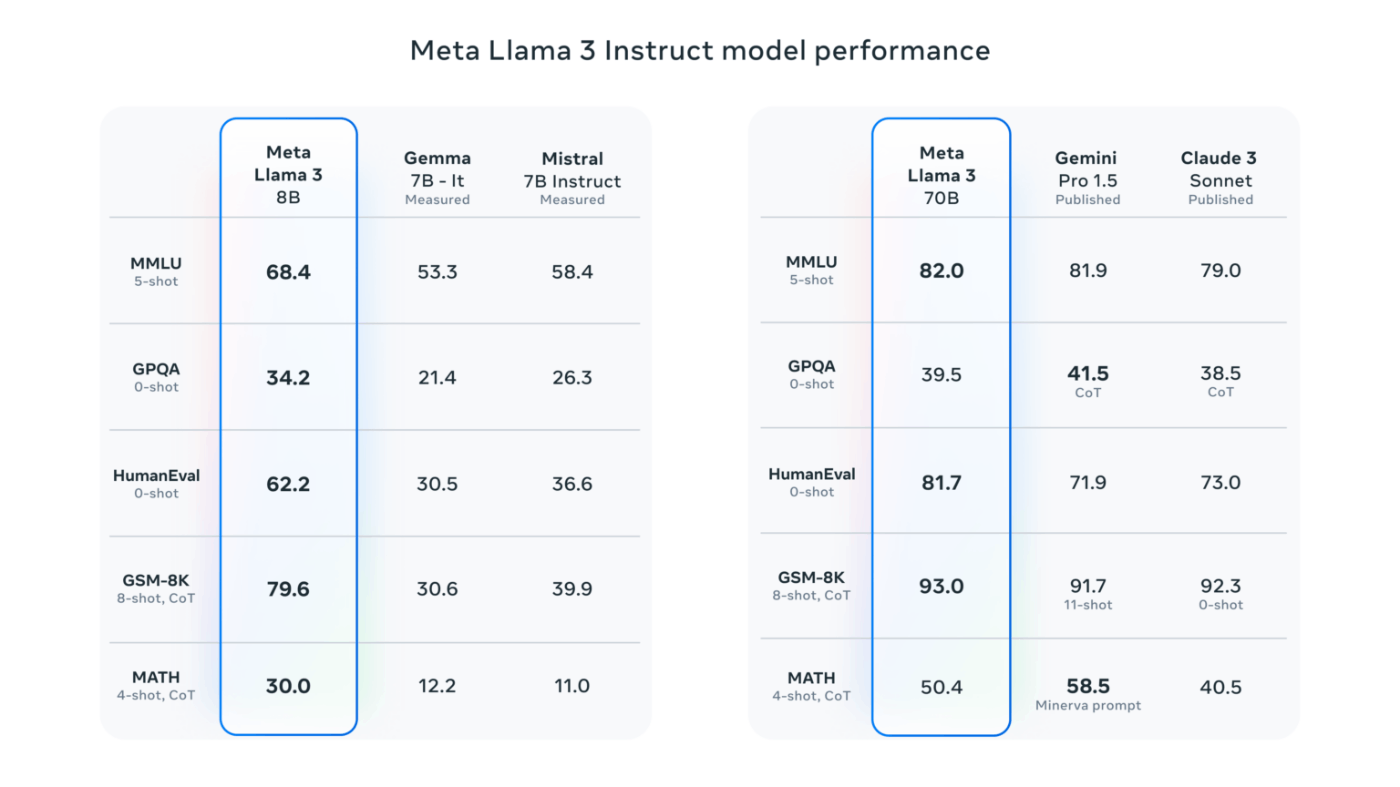
Meta震撼发布Llama 3,一夜重回开源大模型铁王座-36氪
【HuggingChat】免費使用Llama 2 70B、Mixtral 8x7B等大型語言模型|可自訂Assistant 擁有類似GPTs的 ...