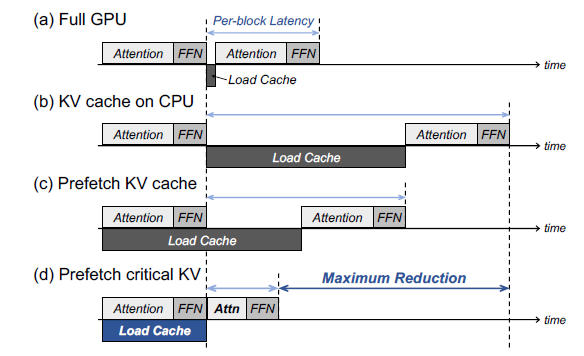
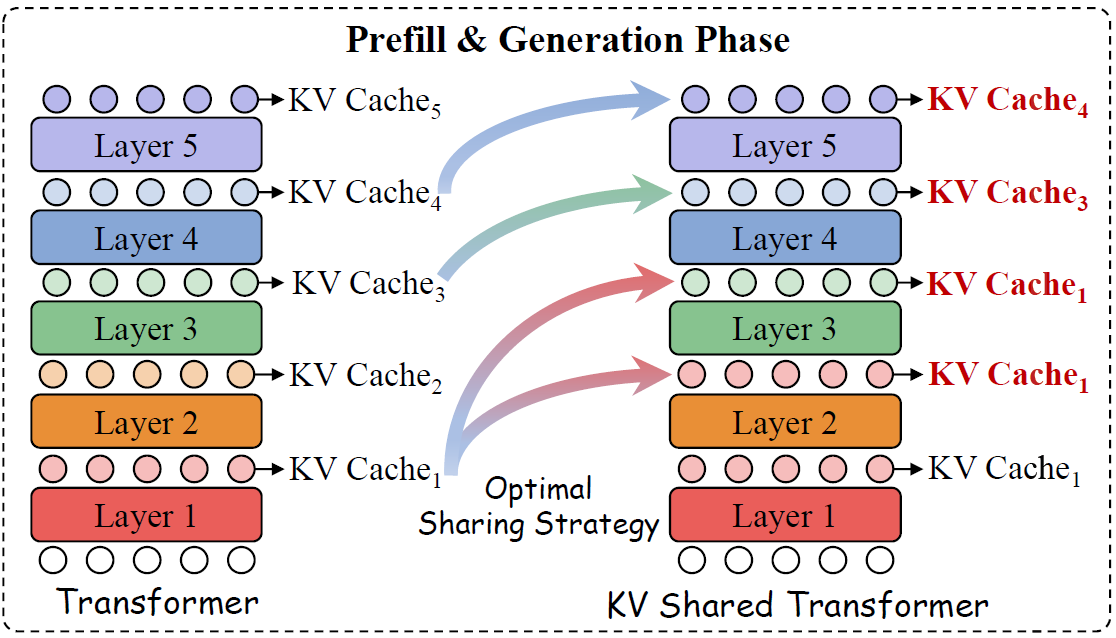
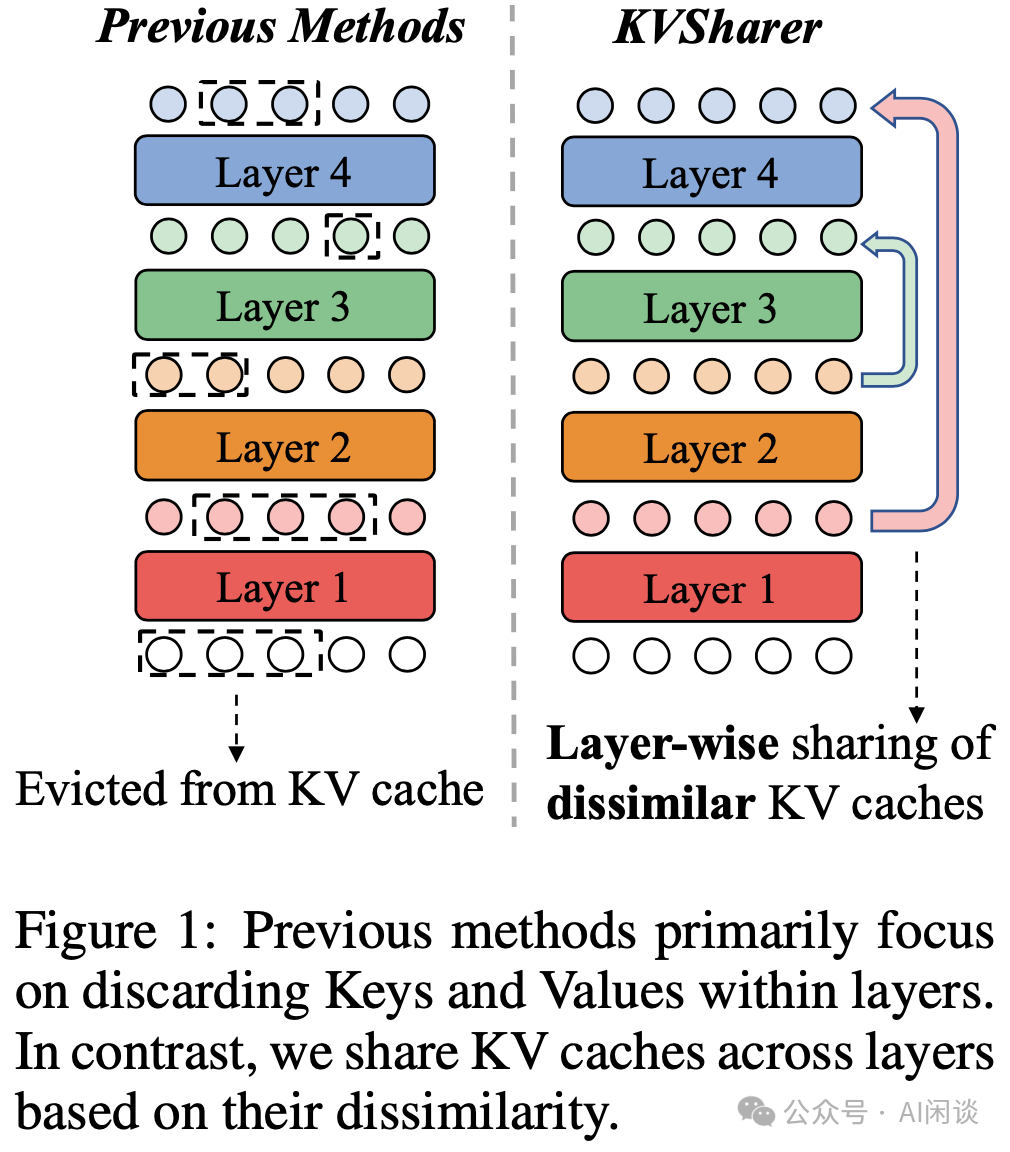
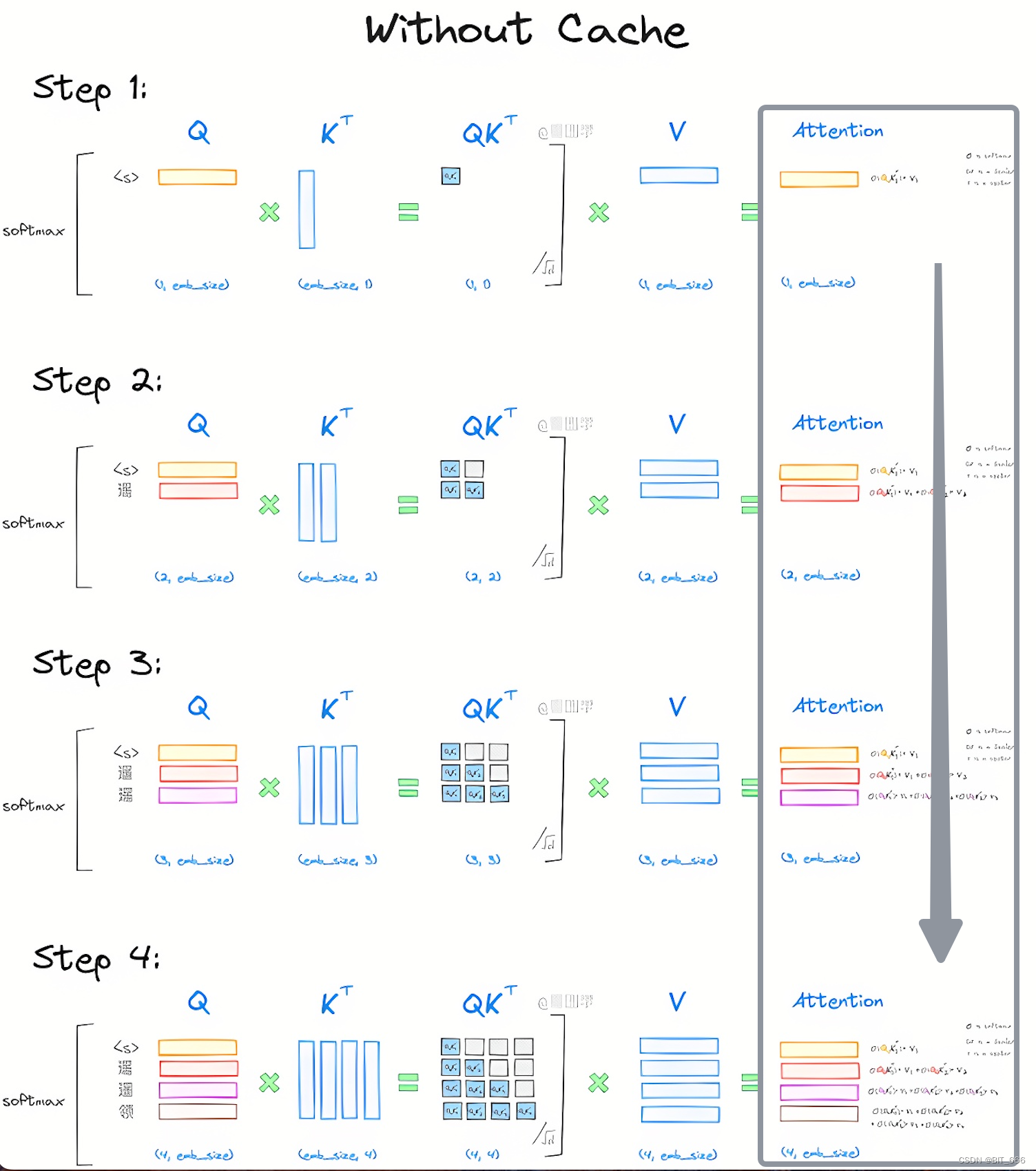
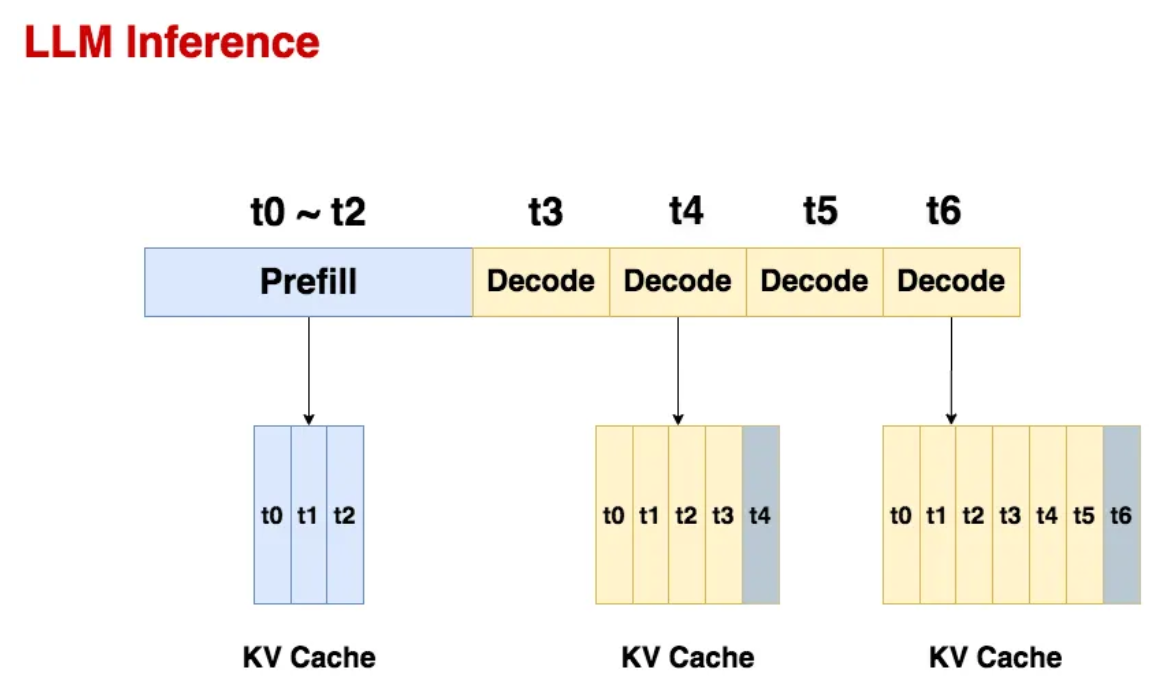
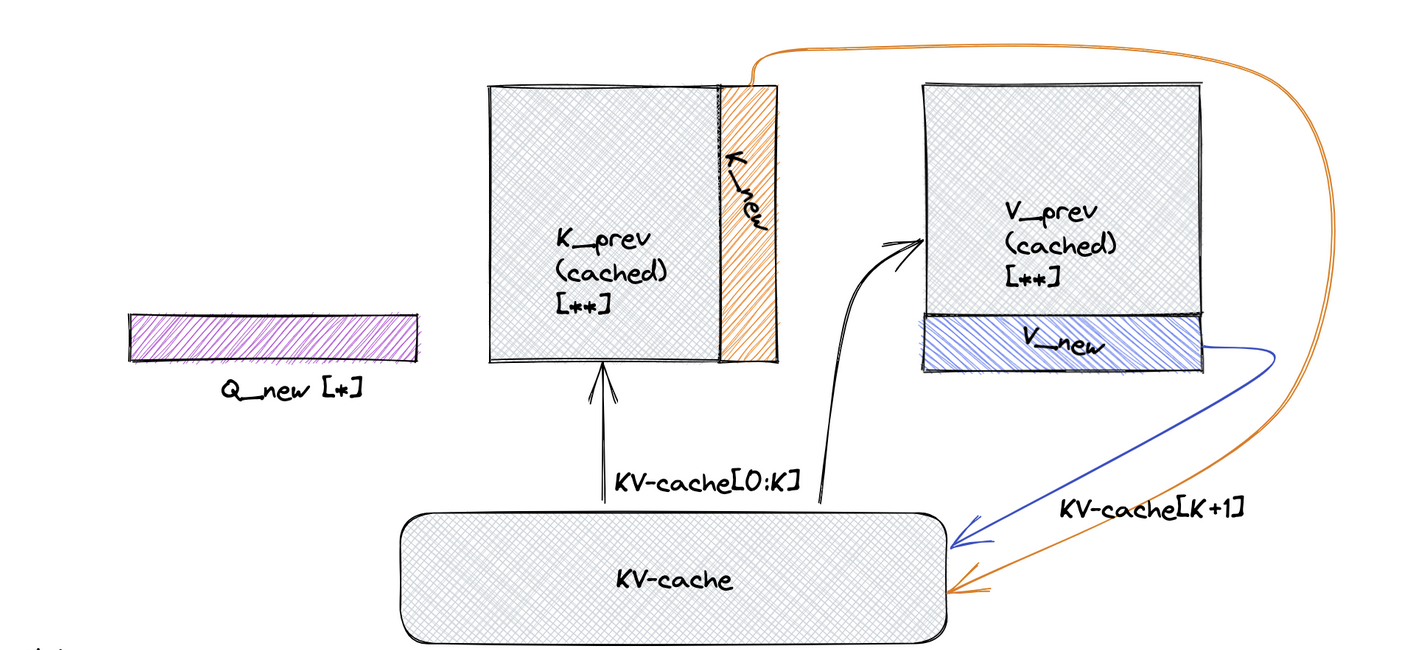
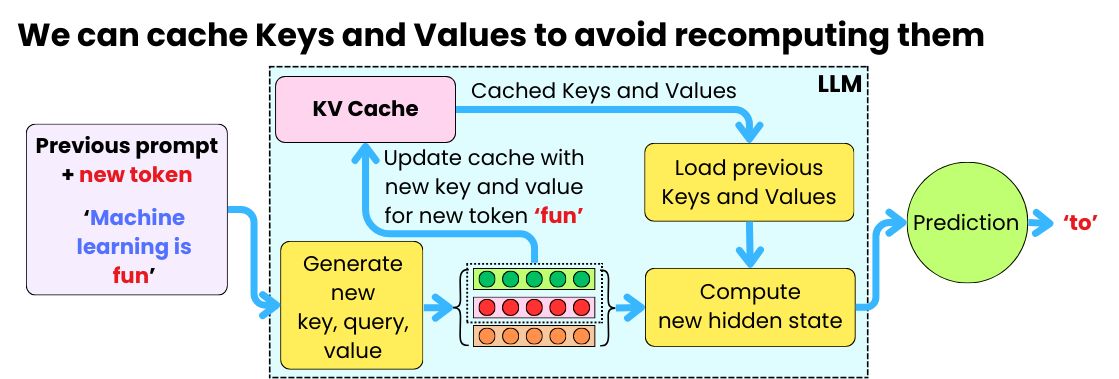
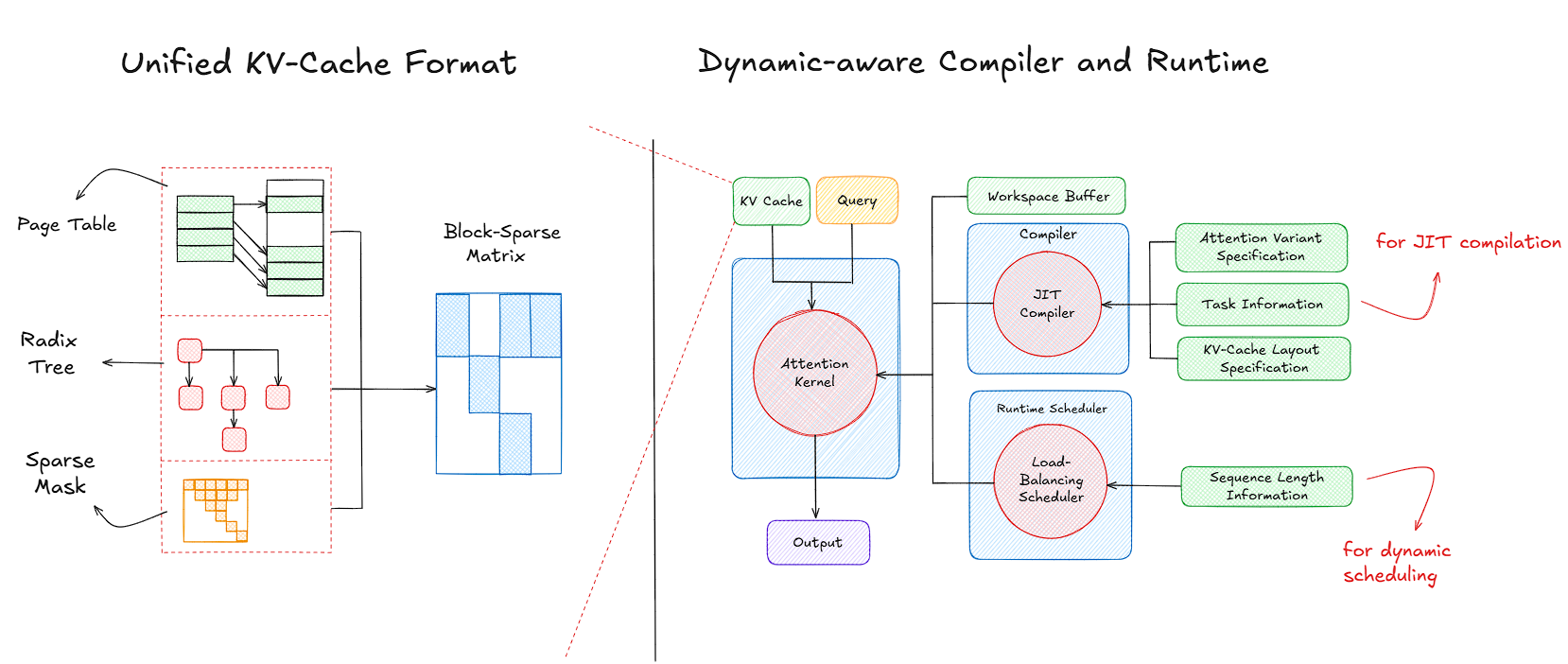
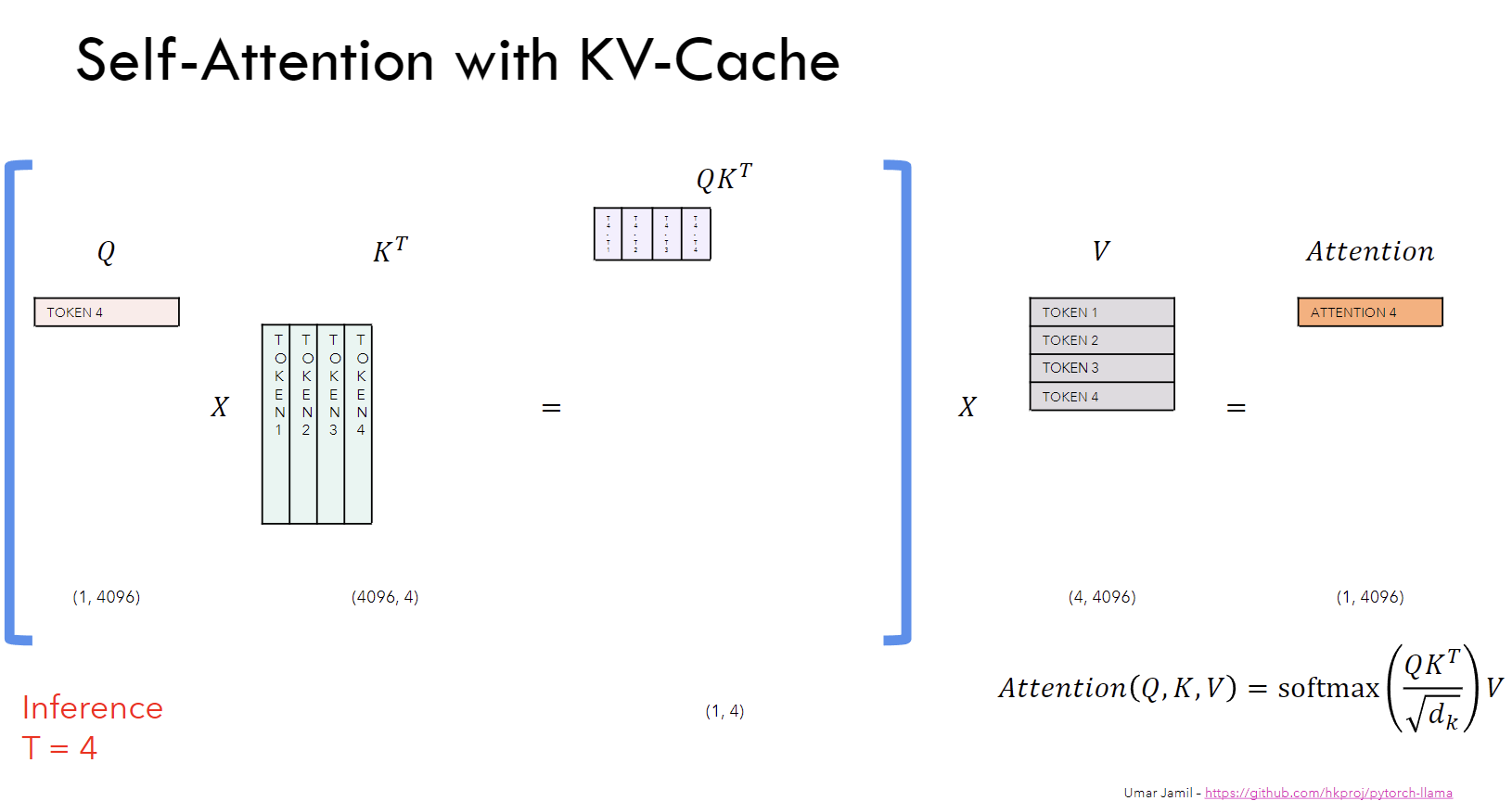
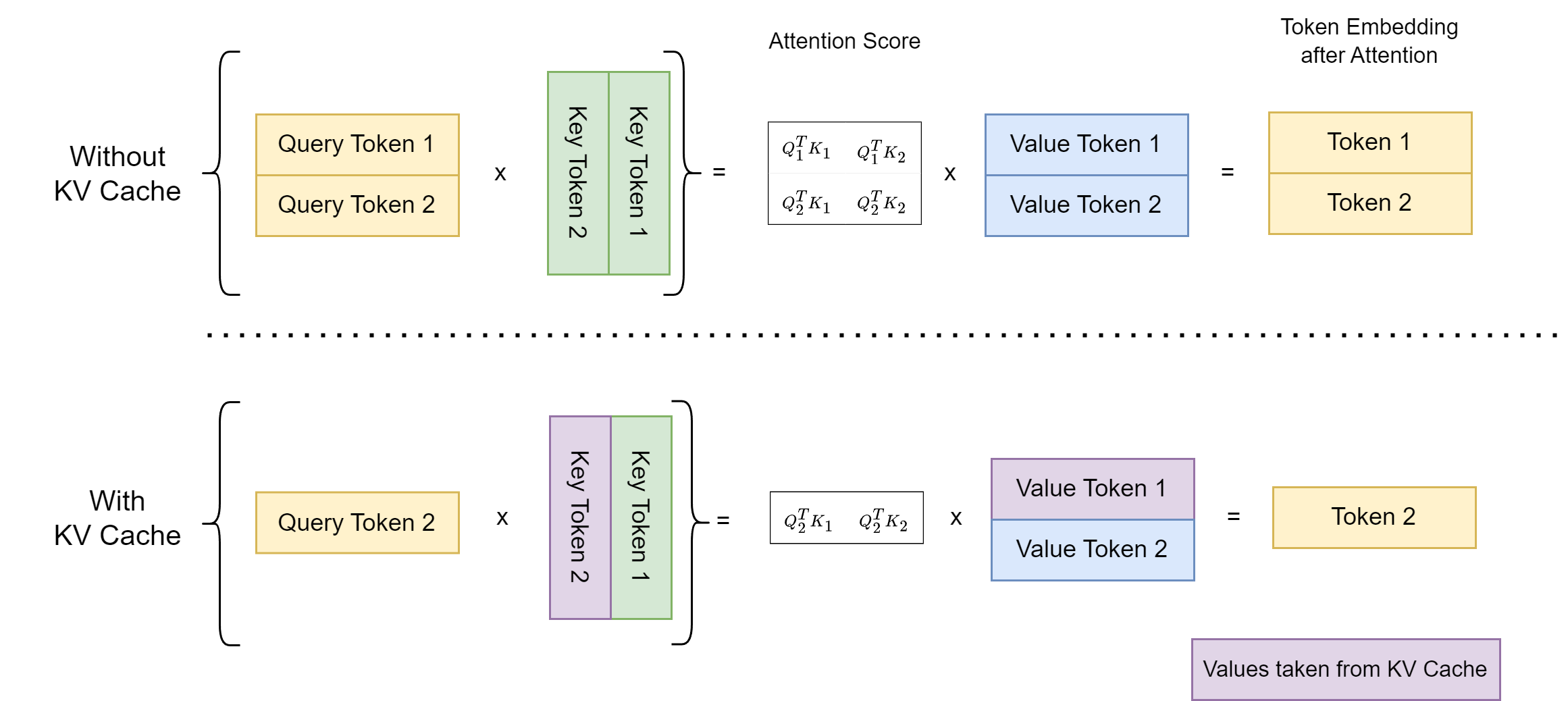
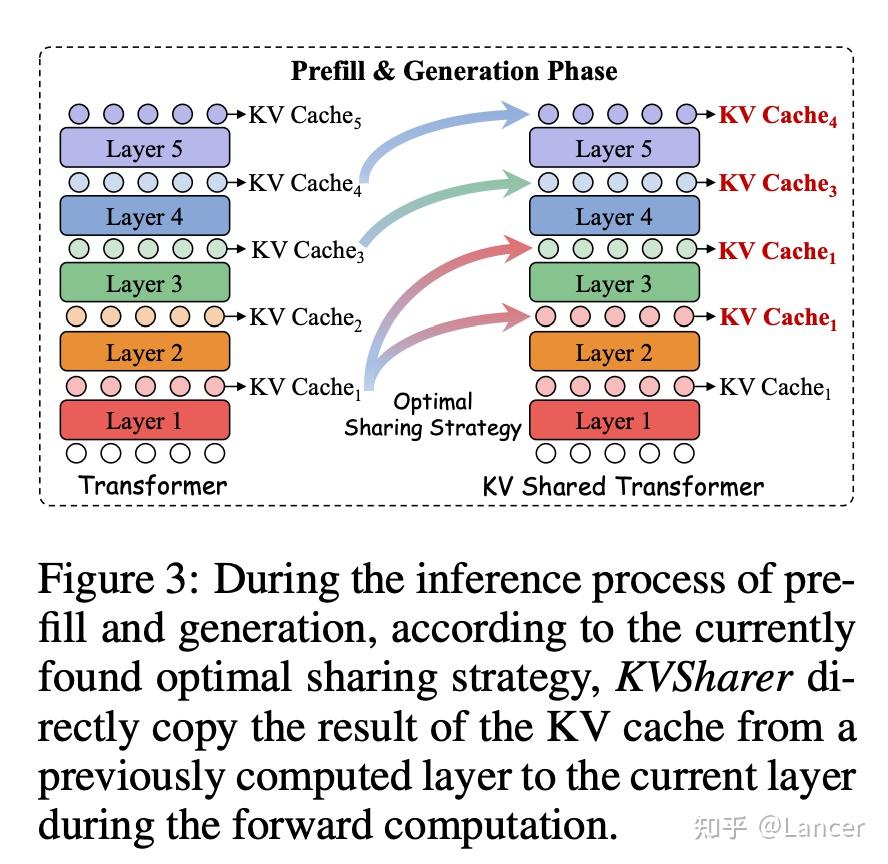
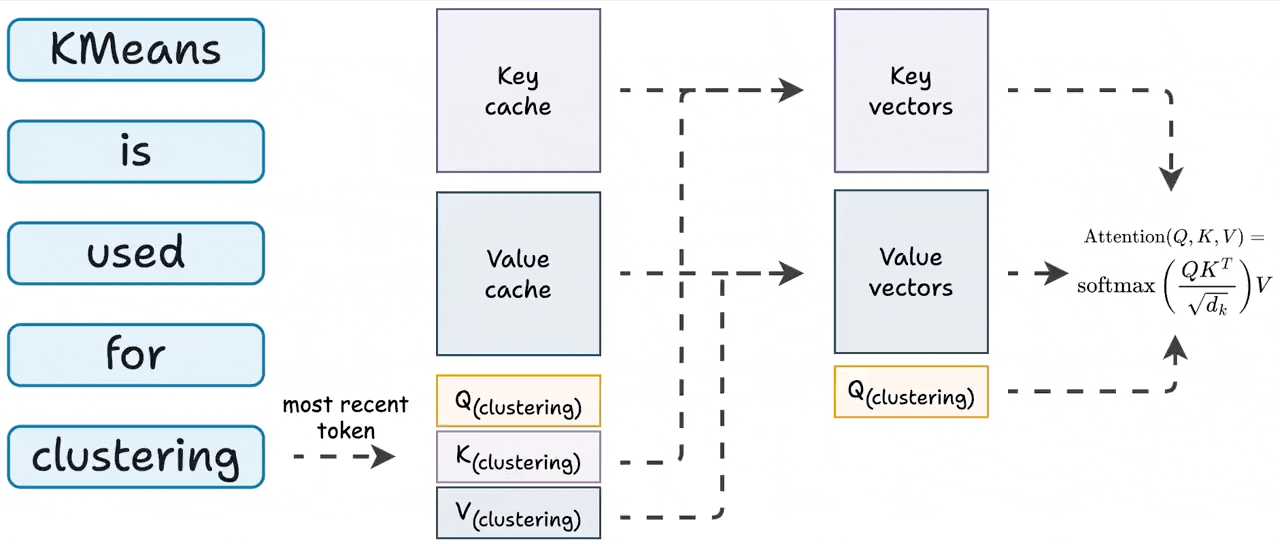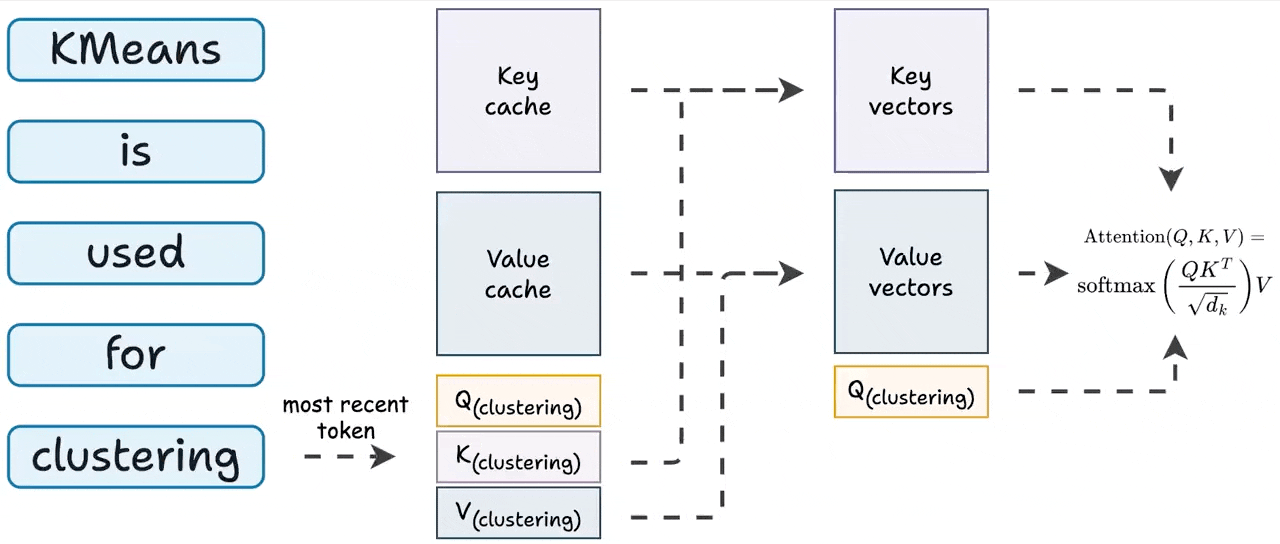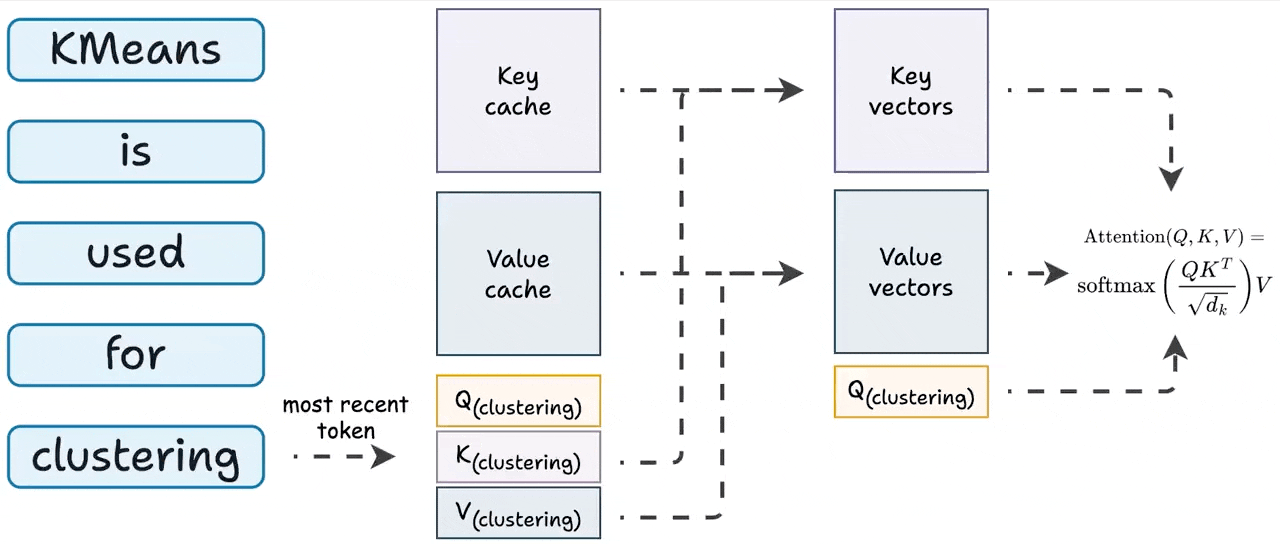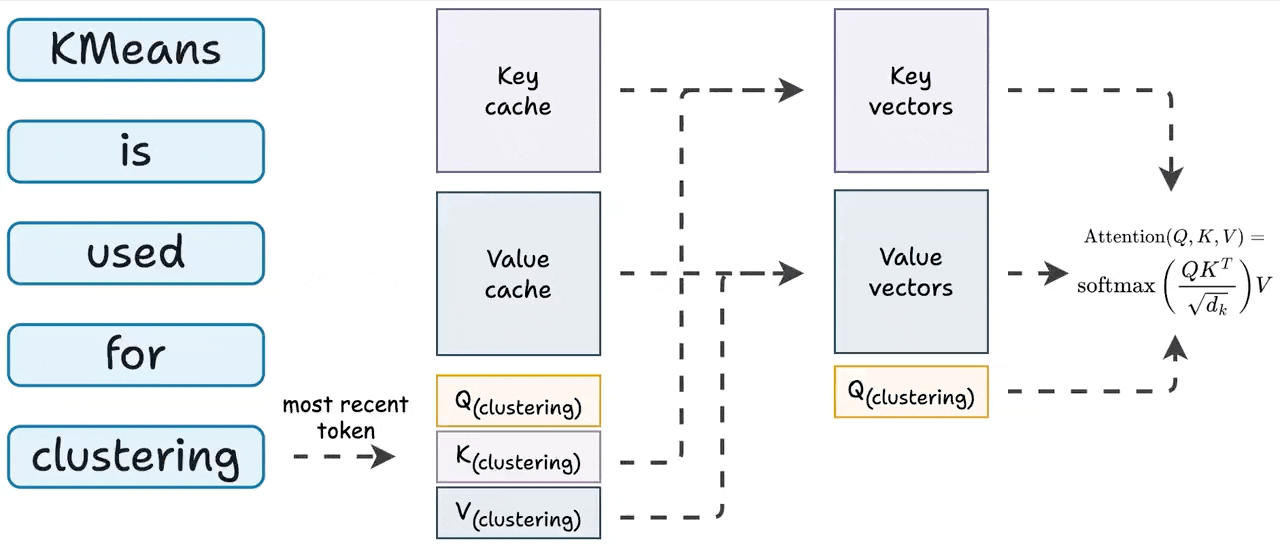
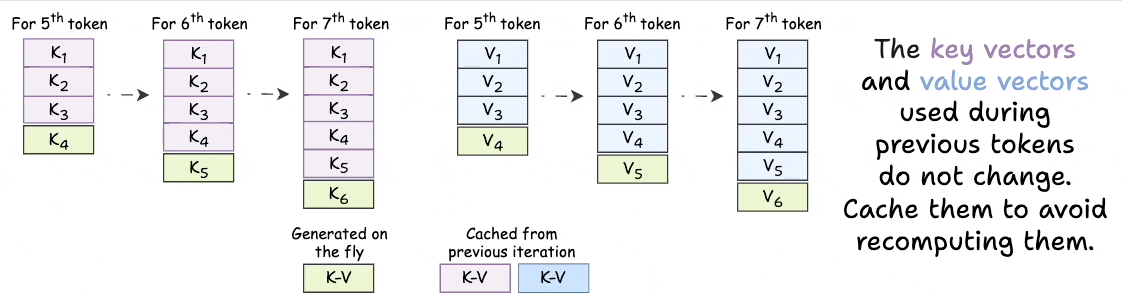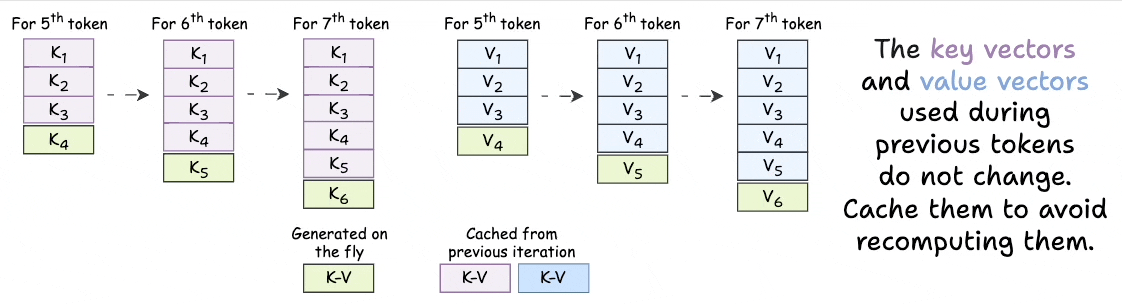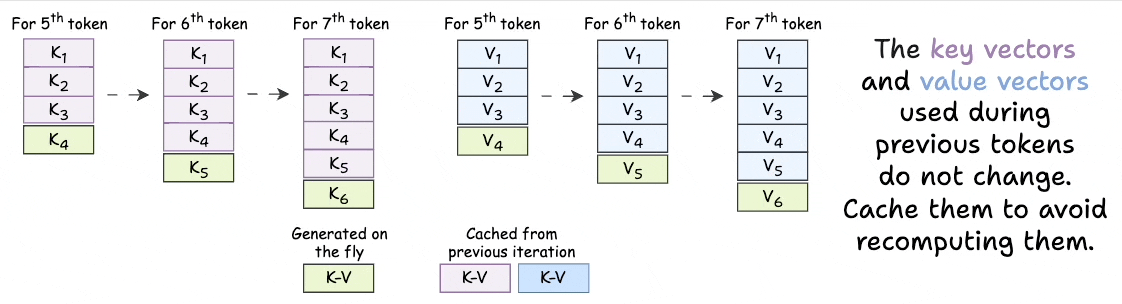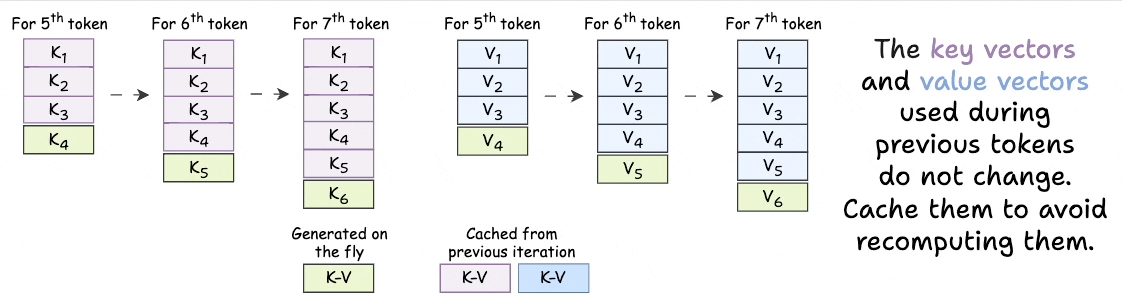
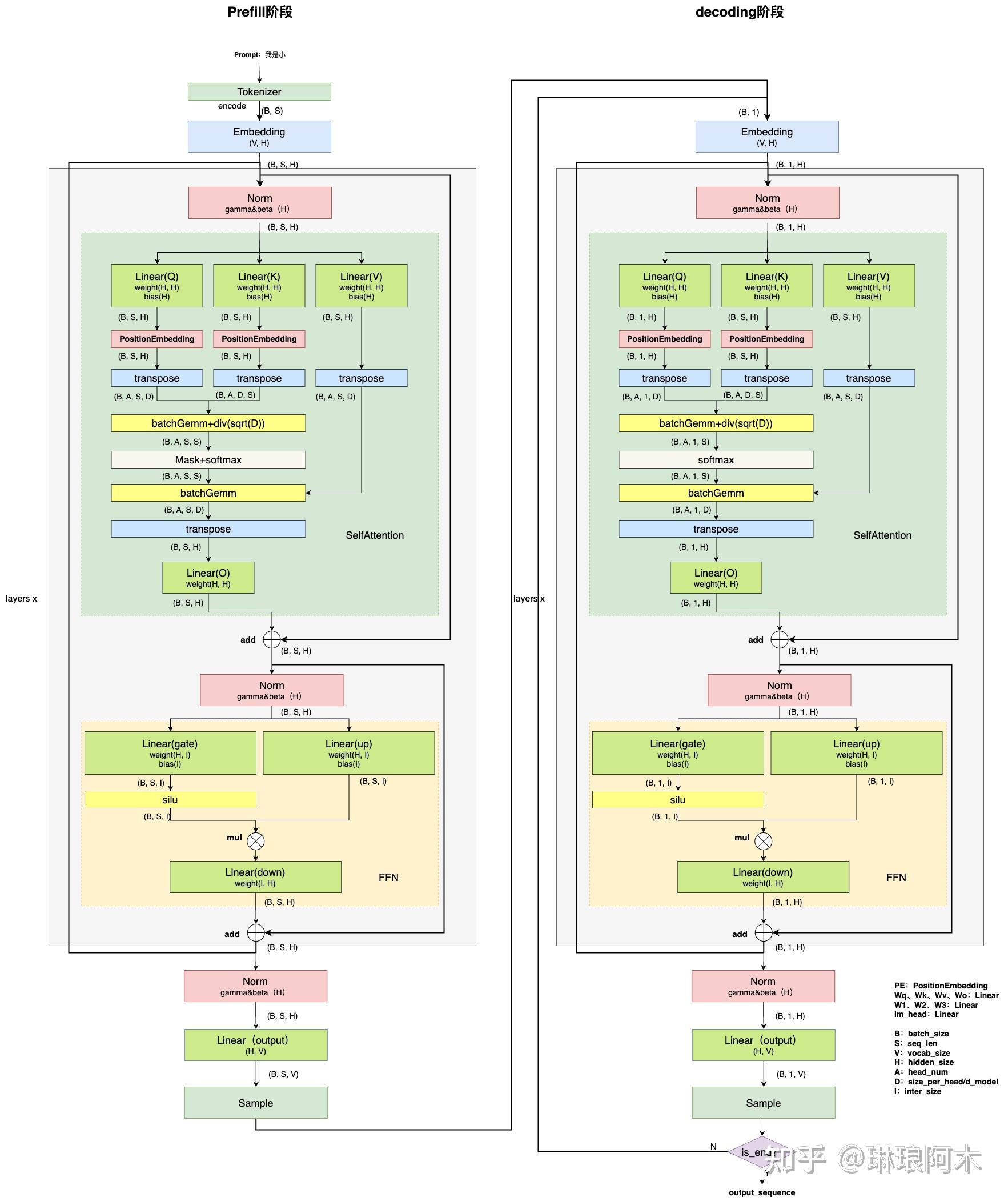
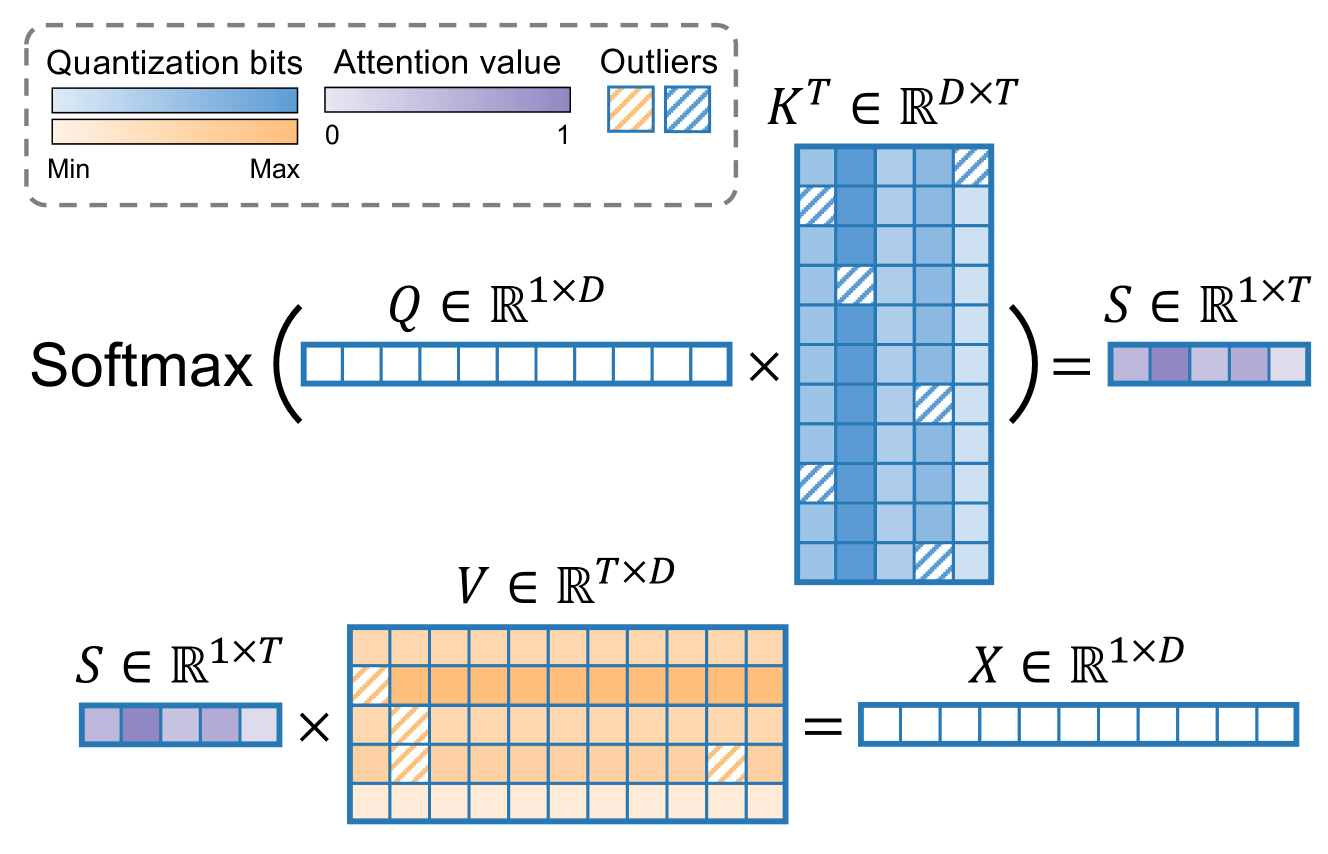
KVSharer: method for efficient LLM inference via dissimilar KV Cache ...
[论文评述] KVSharer: Efficient Inference via Layer-Wise Dissimilar KV Cache ...
Paper page - KVSharer: Efficient Inference via Layer-Wise Dissimilar KV ...
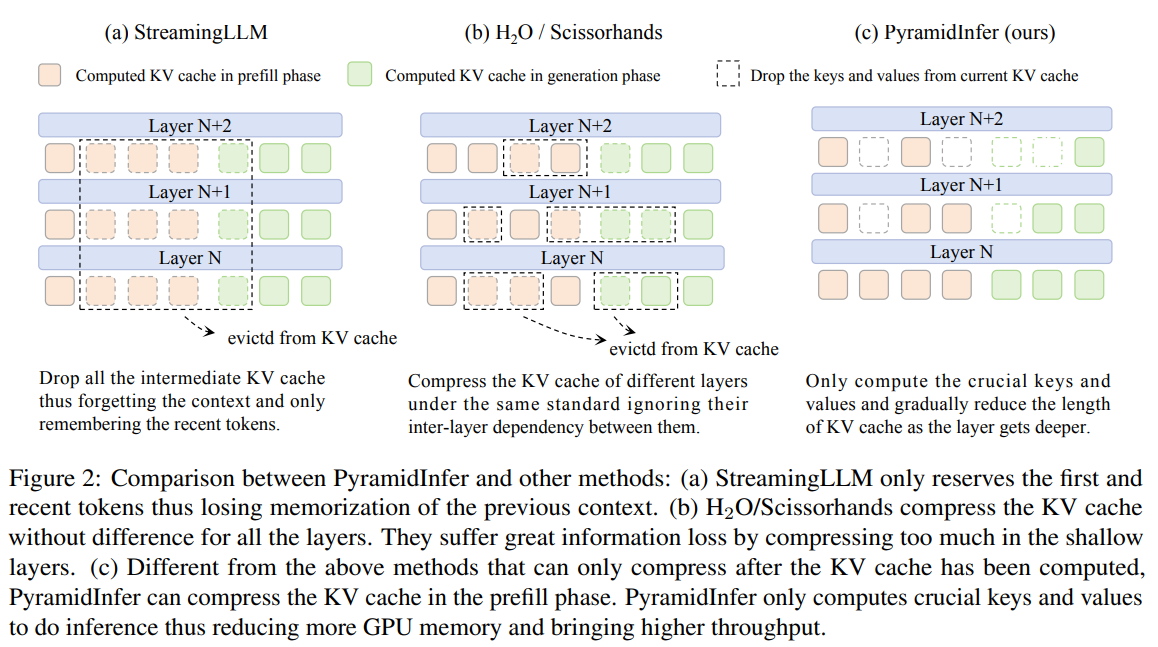
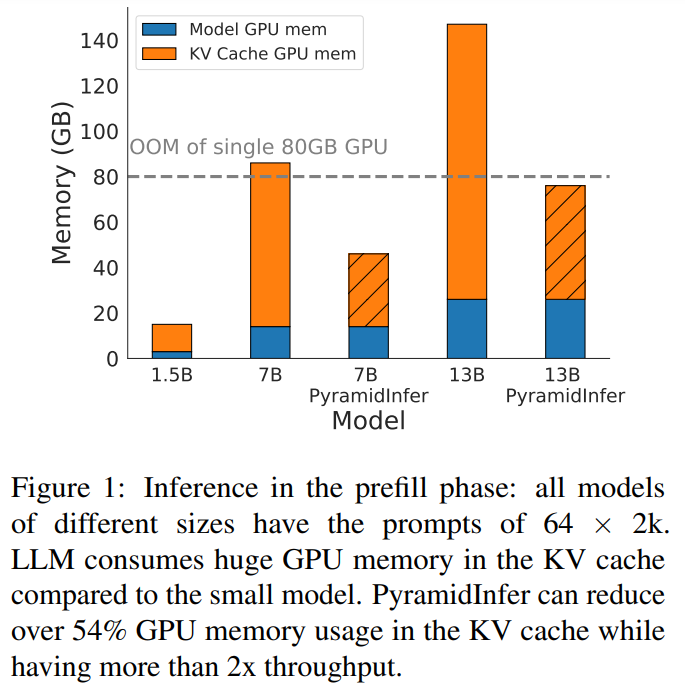
PyramidInfer: Allowing Efficient KV Cache Compression for Scalable LLM ...
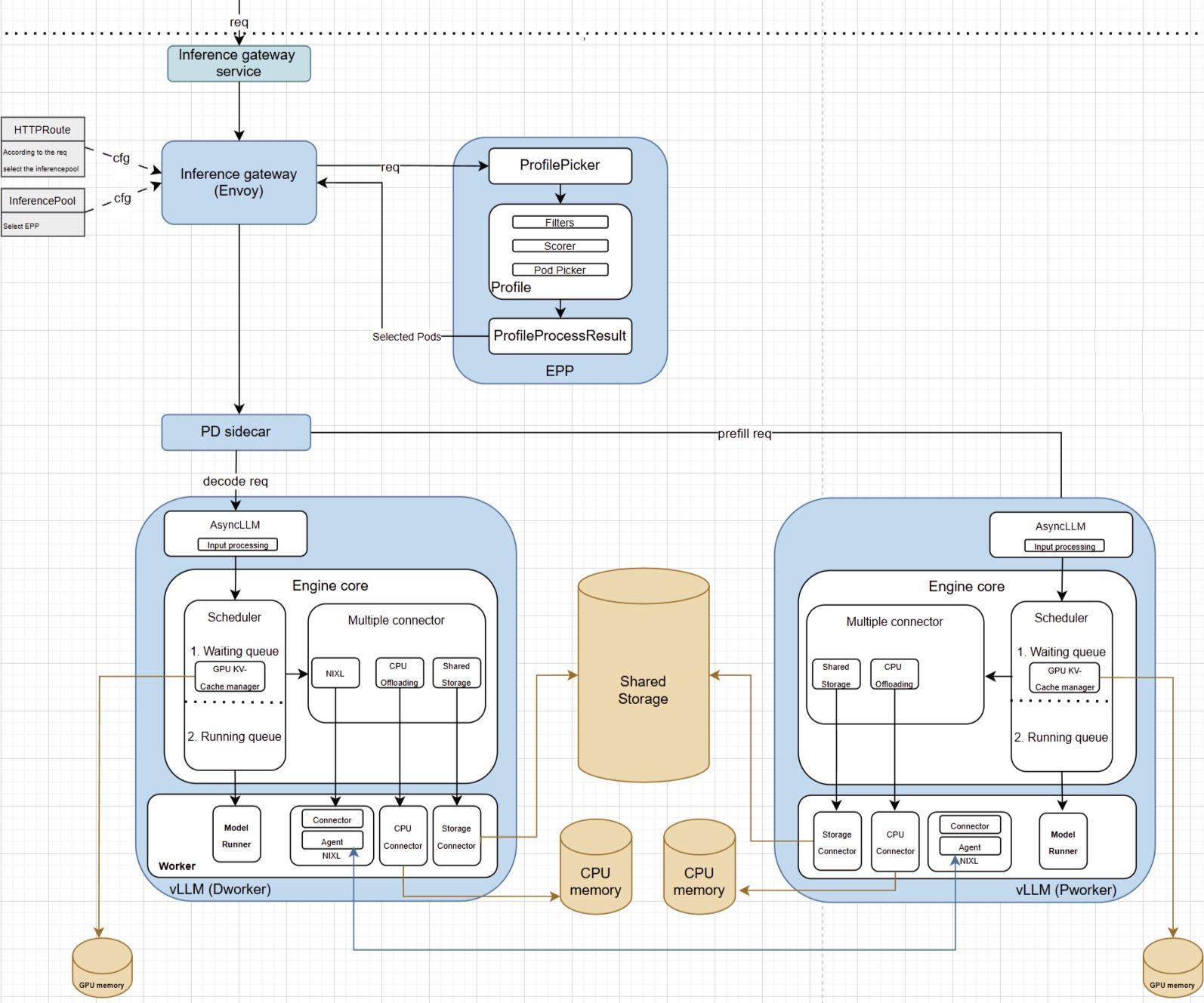
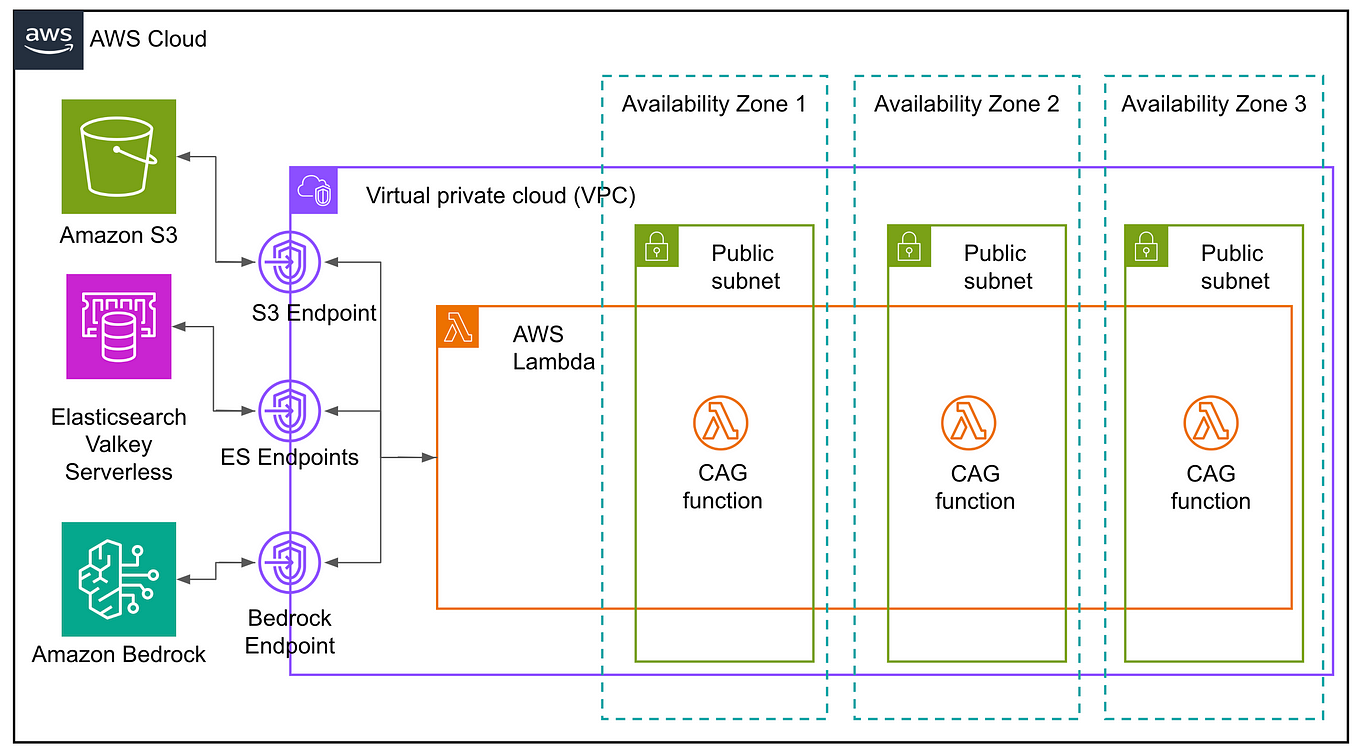
Master KV cache aware routing with llm-d for efficient AI inference ...
[PDF] LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM ...
KV Cache Transform Coding for Compact Storage in LLM Inference ...
(PDF) Efficient Long-Context LLM Inference via KV Cache Clustering
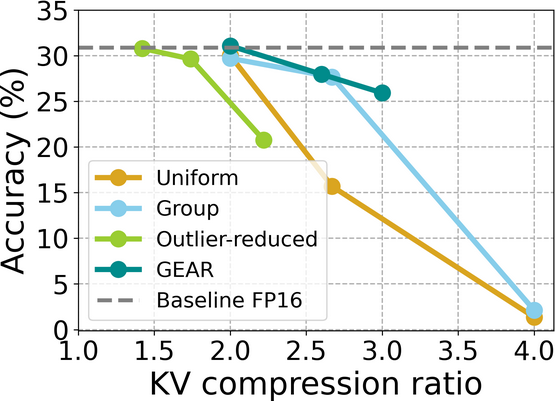
GEAR: Efficient KV Cache Compression for LLM Inference
LLM Inference — Optimizing the KV Cache for High-Throughput, Long ...
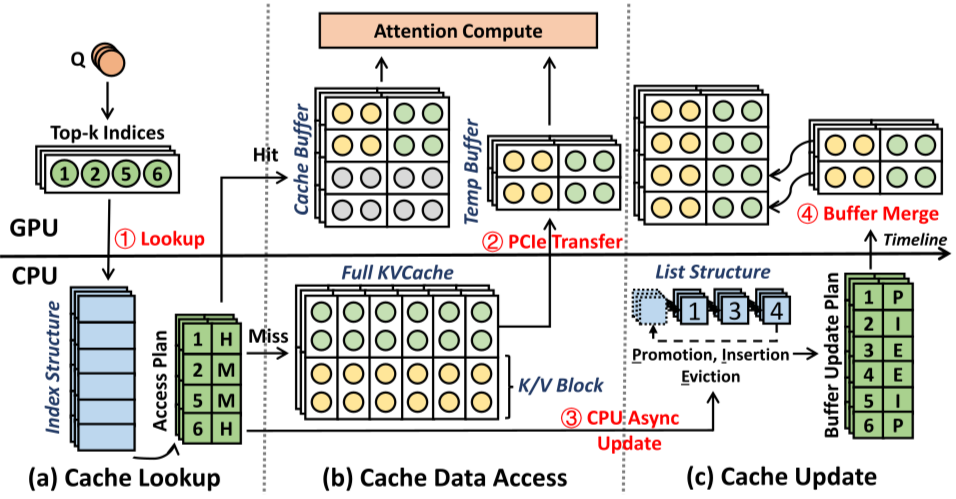
[论文评述] FreeKV: Boosting KV Cache Retrieval for Efficient LLM Inference
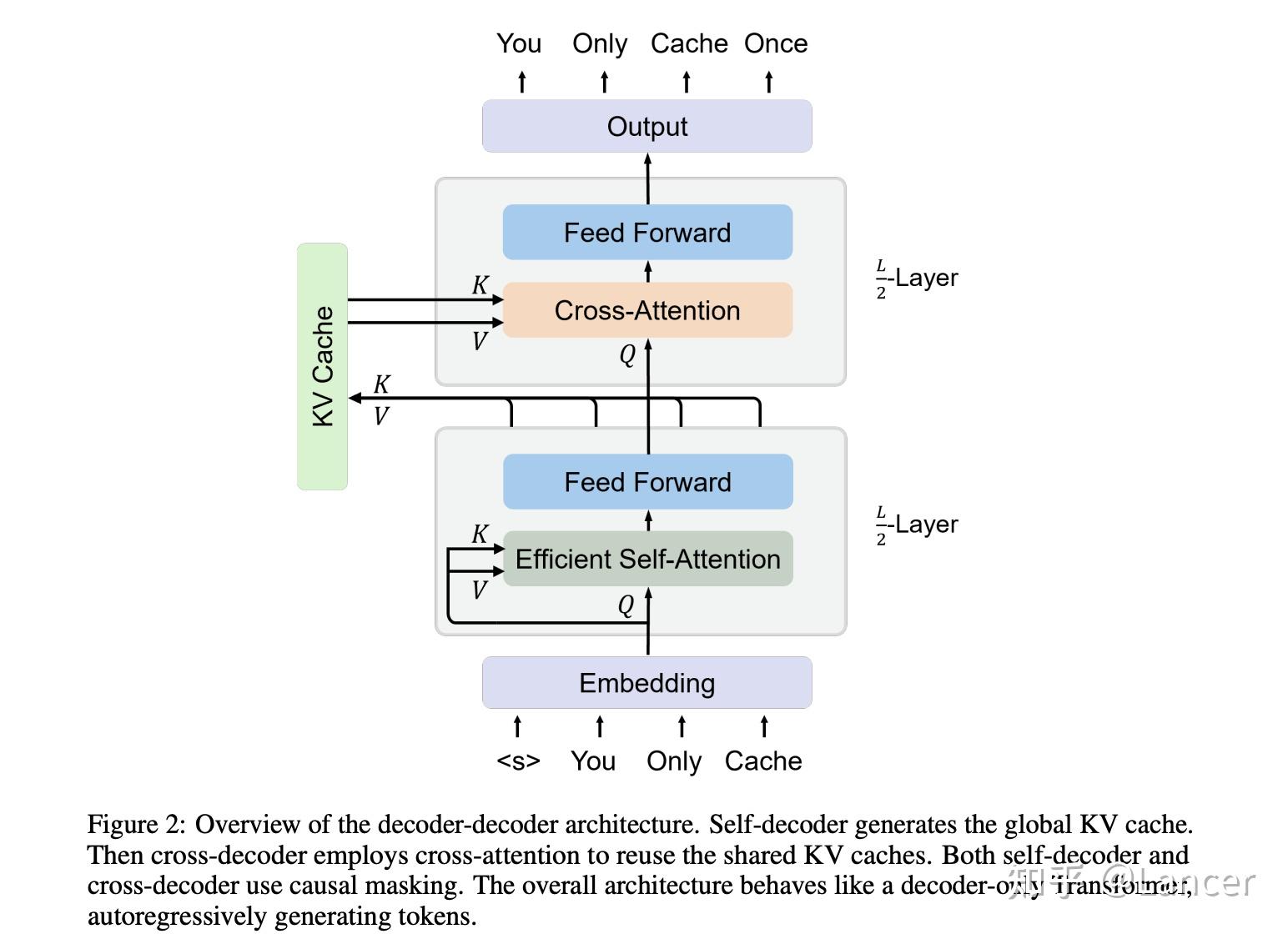
Layer-Condensed KV Cache for Efficient Inference of Large Language ...
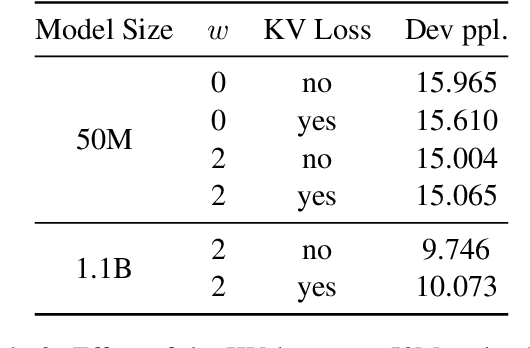
Table 9 from Layer-Condensed KV Cache for Efficient Inference of Large ...
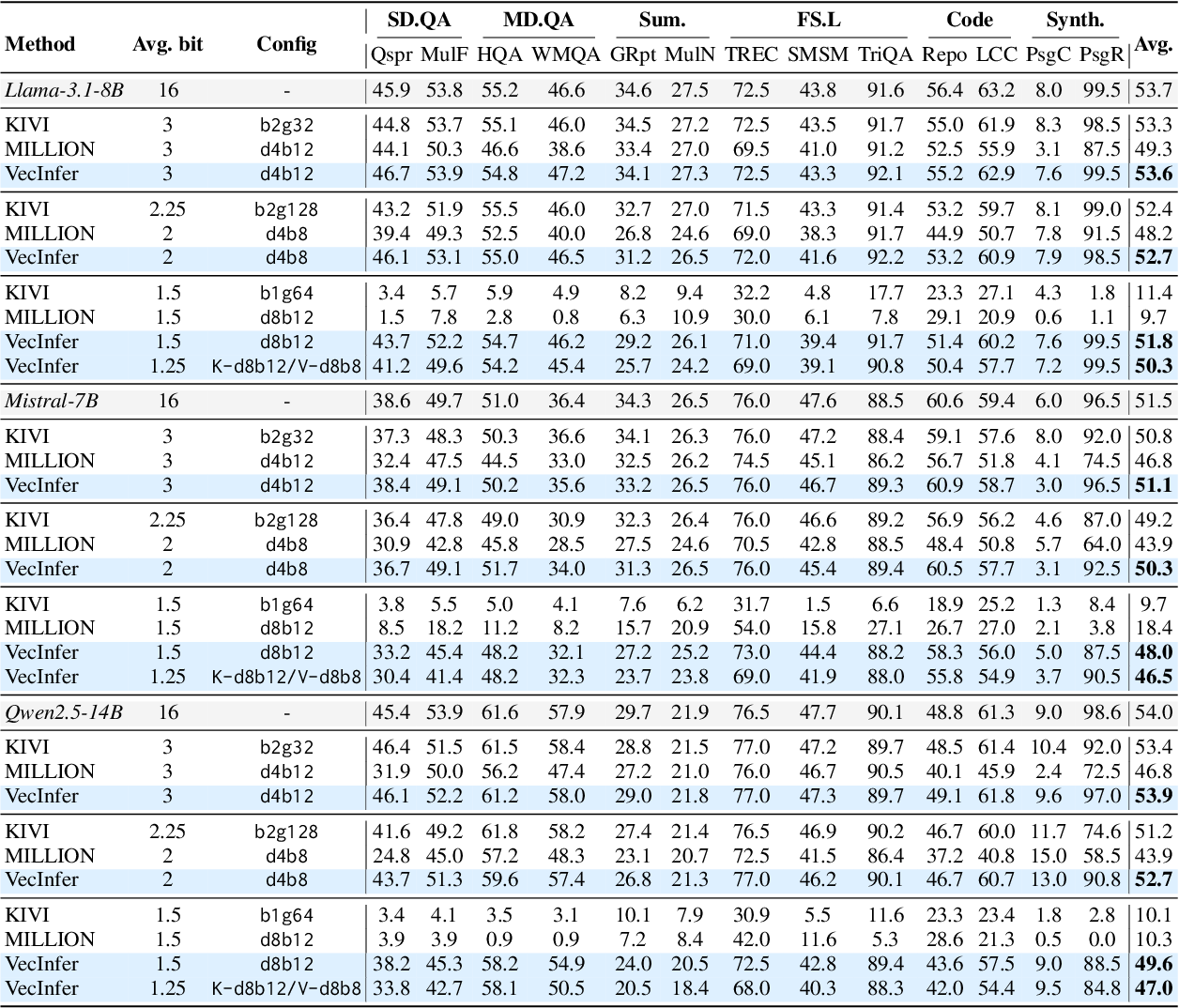
Table 2 from VecInfer: Efficient LLM Inference with Low-Bit KV Cache ...
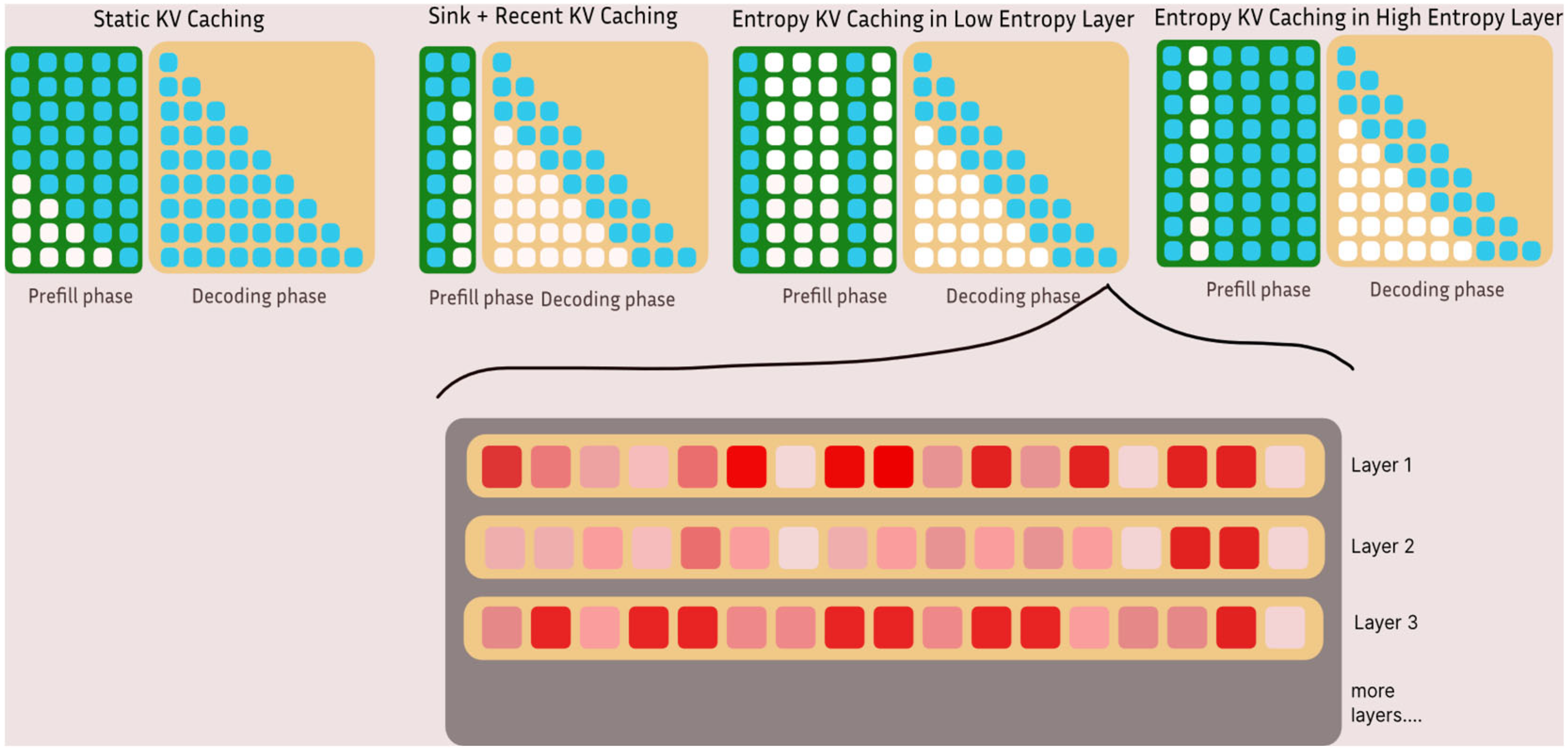
Entropy-Guided KV Caching for Efficient LLM Inference
Paper page - SentenceKV: Efficient LLM Inference via Sentence-Level ...
Paper page - LMCache: An Efficient KV Cache Layer for Enterprise-Scale ...
Scaling Multi-Turn LLM Inference with KV Cache Storage Offload and Dell ...
(PDF) Online Scheduling for LLM Inference with KV Cache Constraints
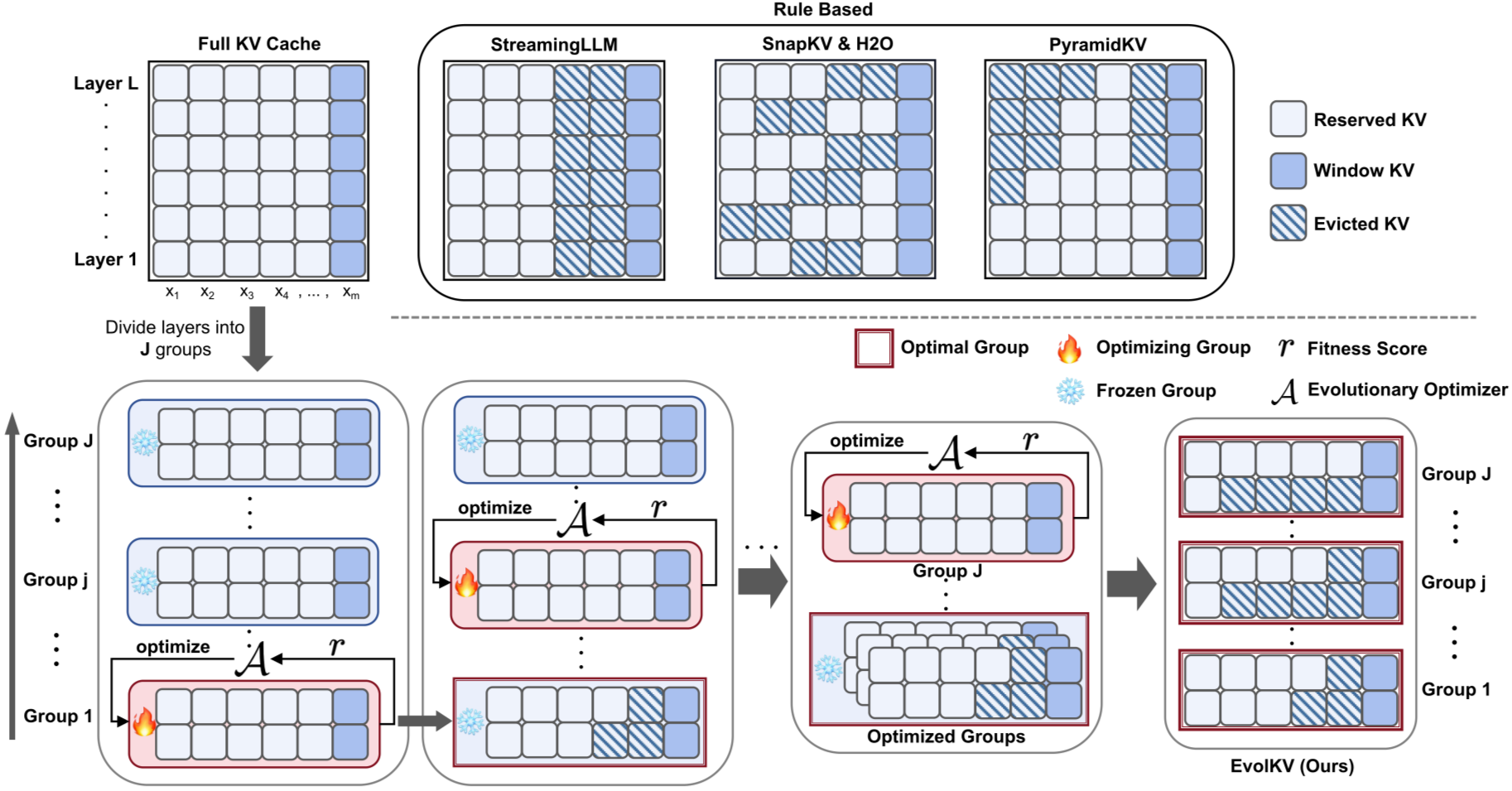
[논문 리뷰] EvolKV: Evolutionary KV Cache Compression for LLM Inference
KV Caching - The Engine of Efficient LLM Inference - LinkedIn | PDF ...
LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal ...
[论文评述] SentenceKV: Efficient LLM Inference via Sentence-Level Semantic ...
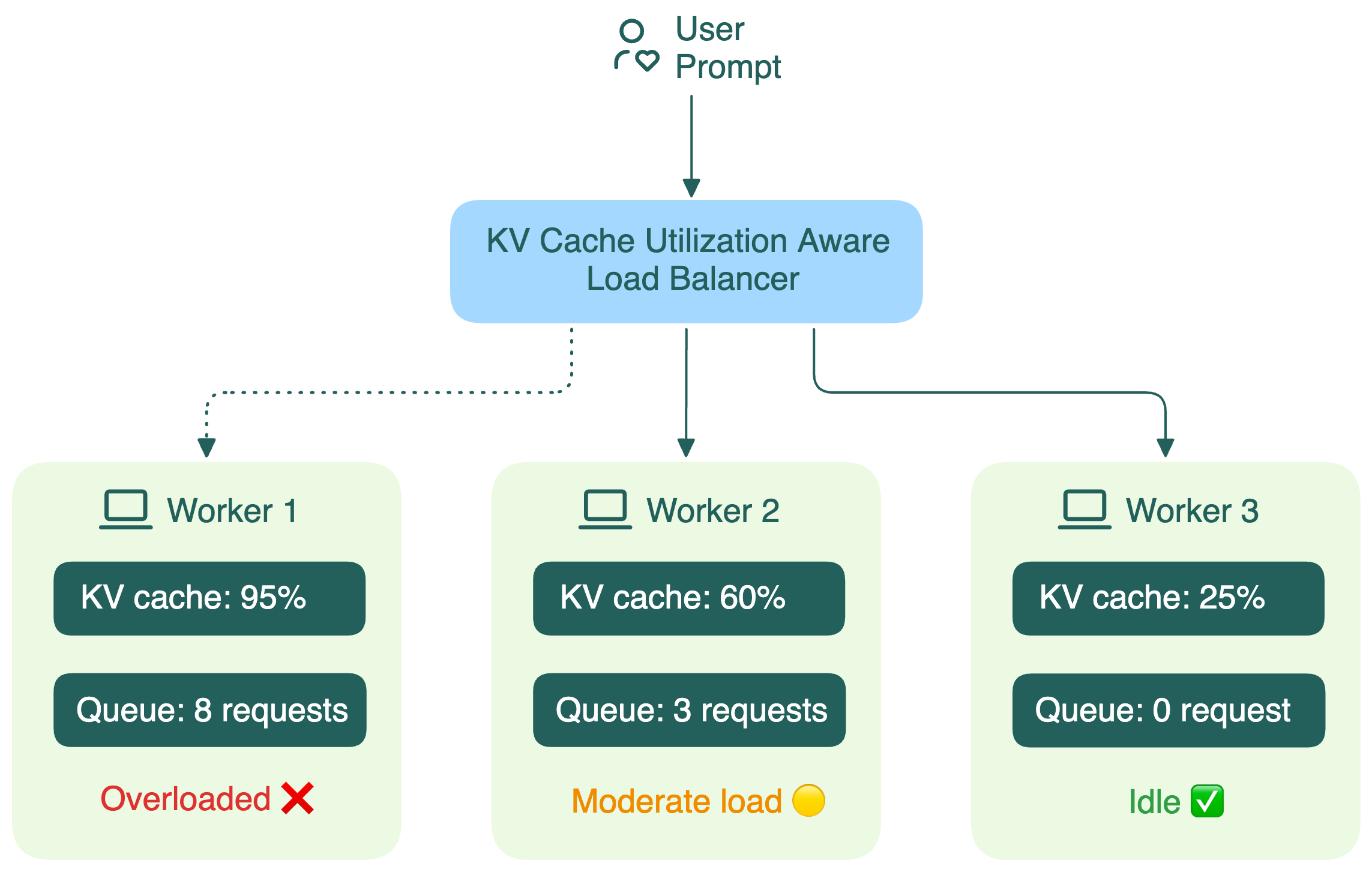
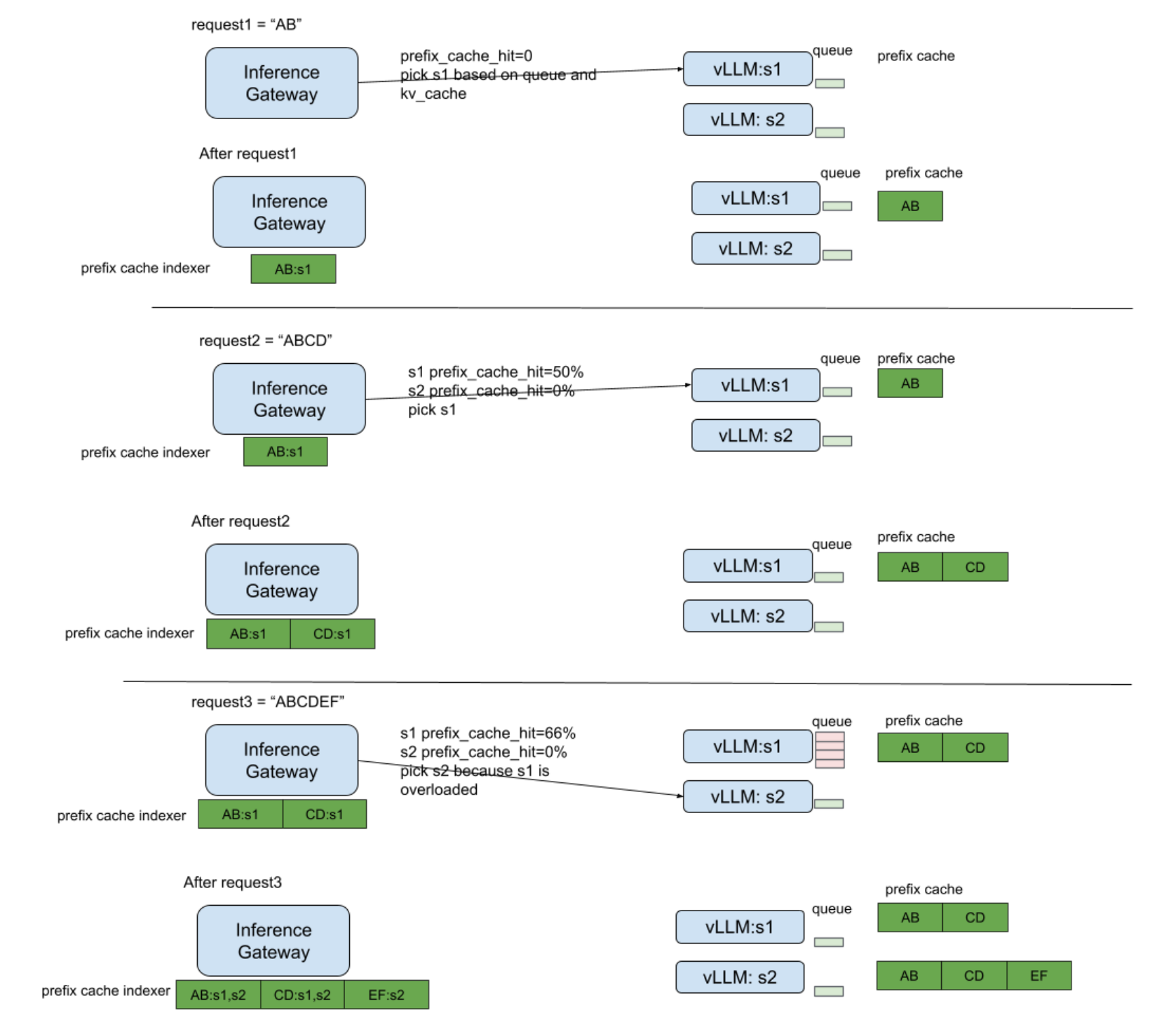
KV cache utilization-aware load balancing | LLM Inference Handbook
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
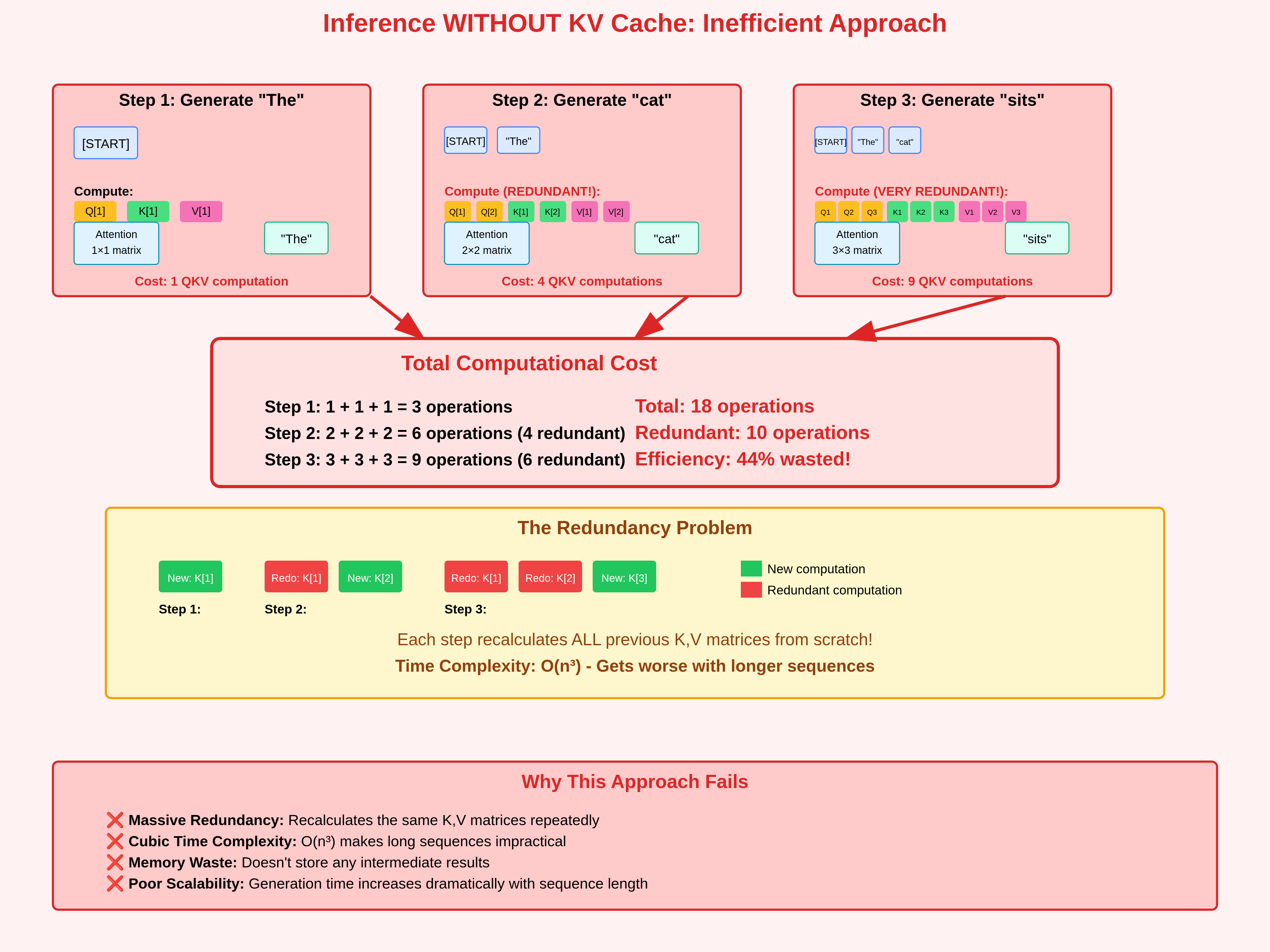
What is a KV cache, and why does it make LLM inference faster ...
KV Cache Secrets: Boost LLM Inference Efficiency | by Shoa Aamir | Medium
SqueezeAttention: 2D Management of KV-Cache in LLM Inference via Layer ...
[논문 리뷰] Efficient LLM Inference with Activation Checkpointing and ...
AccKV: Towards Efficient Audio-Video LLMs Inference via Adaptive ...
LLM inference optimization (1): KV Cache - MartinLwx's Blog
LMCache Is Becoming the De Facto Standard for KV Cache Management in ...
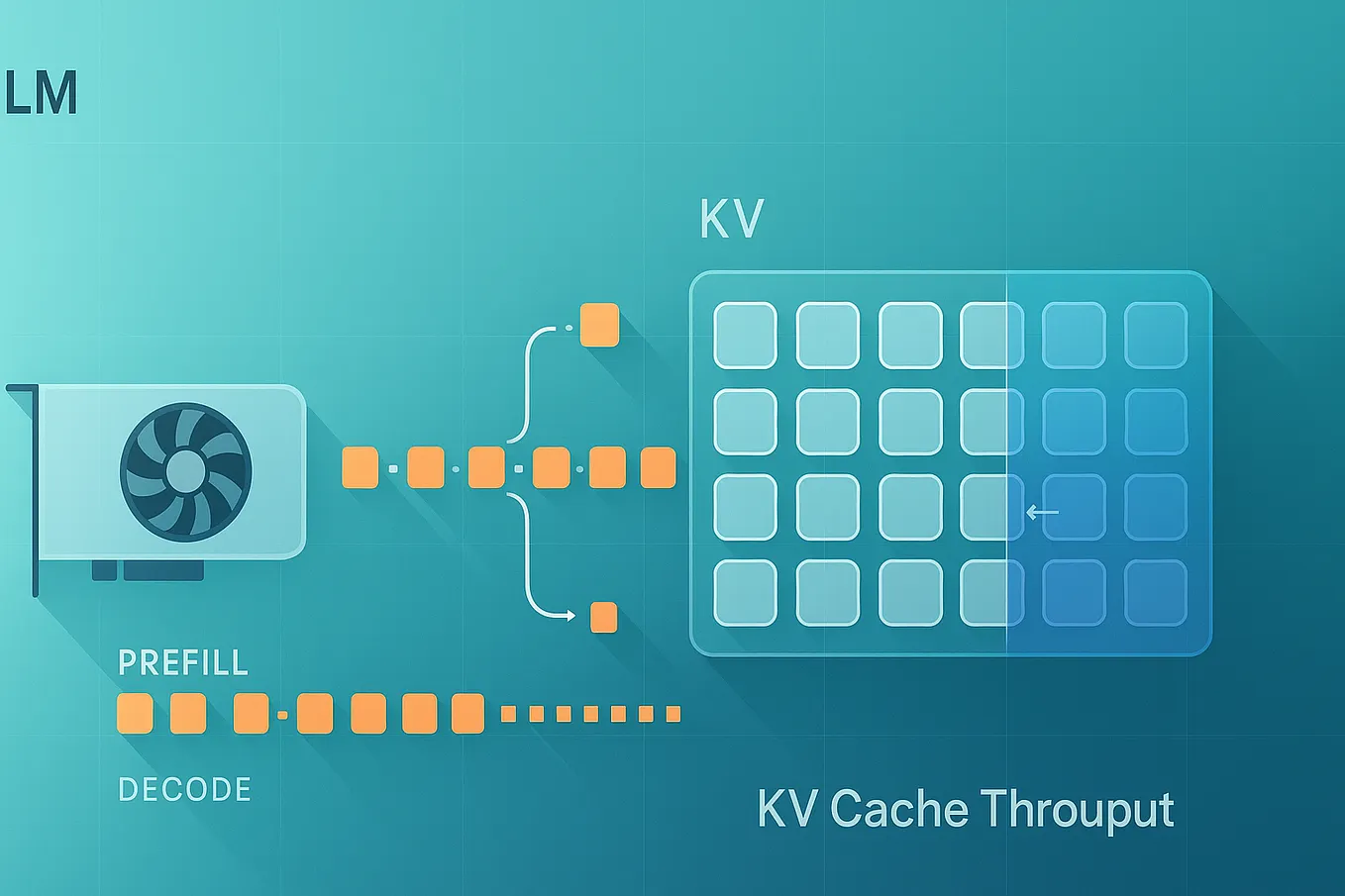
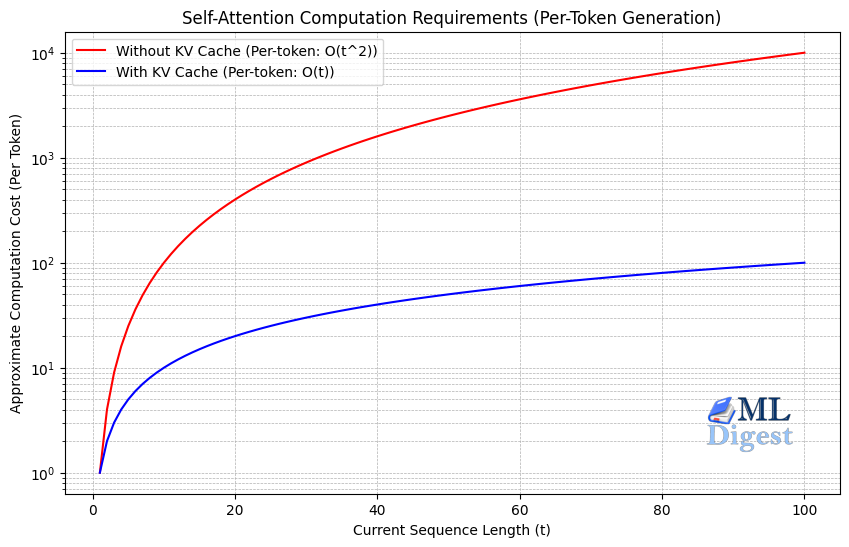
Understanding KV Caching: The Key To Efficient LLM Inference - ML Digest
[논문 리뷰] CLO: Efficient LLM Inference System with CPU-Light KVCache ...
KV Cache compression with Inter-Layer Attention Similarity for ...
[Literature Review] KV Cache Transform Coding for Compact Storage in ...
MiniKV: Pushing the Limits of 2-Bit KV Cache via Compression and System ...
MiniKV: Pushing the Limits of LLM Inference via 2-Bit Layer ...
KV cache offloading | LLM Inference Handbook
KV Cache Explained: Why It Makes LLM Inference Much Faster | Yotta Labs
KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache ...
Spotlight Attention: Towards Efficient LLM Generation via Non-linear ...
(PDF) Mitigating KV Cache Competition to Enhance User Experience in LLM ...
LLM Inference Optimization — KV-cache Streaming for Fast, Fault ...
(PDF) RocketKV: Accelerating Long-Context LLM Inference via Two-Stage ...
Paper page - PagedEviction: Structured Block-wise KV Cache Pruning for ...
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo | NVIDIA ...
LLM Inference at Scale: 10 KV-Cache & Batching Wins | by Thinking Loop ...
5x Faster Time to First Token with NVIDIA TensorRT-LLM KV Cache Early ...
Apple Researchers Propose KV-Runahead: An Efficient Parallel LLM ...
What is the KV Cache? Secret of Fast LLM Inference | Towards AI
[论文评述] LLMs Know What to Drop: Self-Attention Guided KV Cache Eviction ...
Understanding KV Cache and Paged Attention in LLMs: A Deep Dive into ...
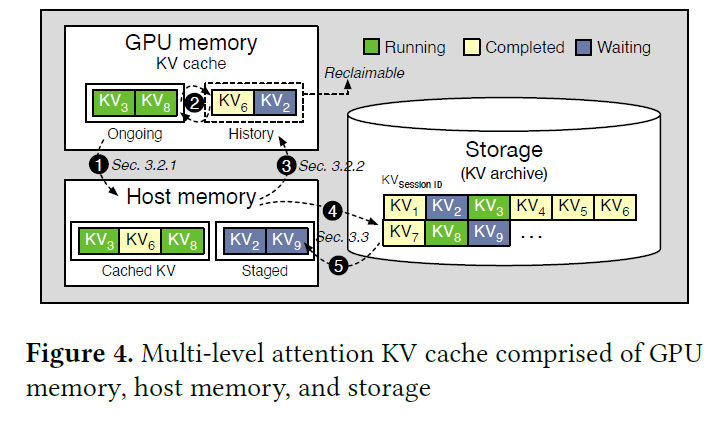
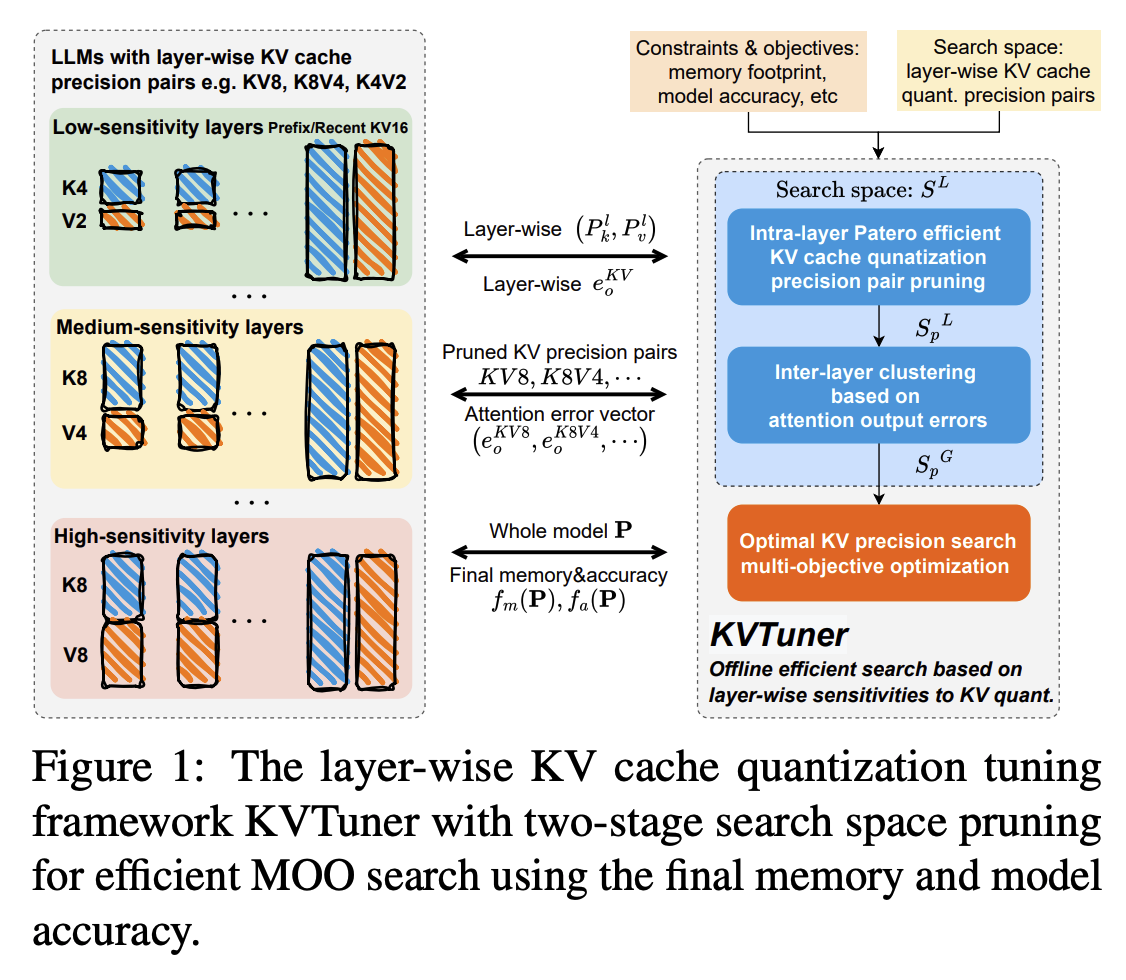
KVTuner: Sensitivity-Aware Layer-Wise Mixed-Precision KV Cache ...
Efficient LLM Inference with KCache — DEV.DY
Techniques for KV Cache Optimization in Large Language Models
Optimizing LLM Inference: Managing the KV Cache | by Aalok Patwa | Medium
Introducing New KV Cache Reuse Optimizations in NVIDIA TensorRT-LLM ...
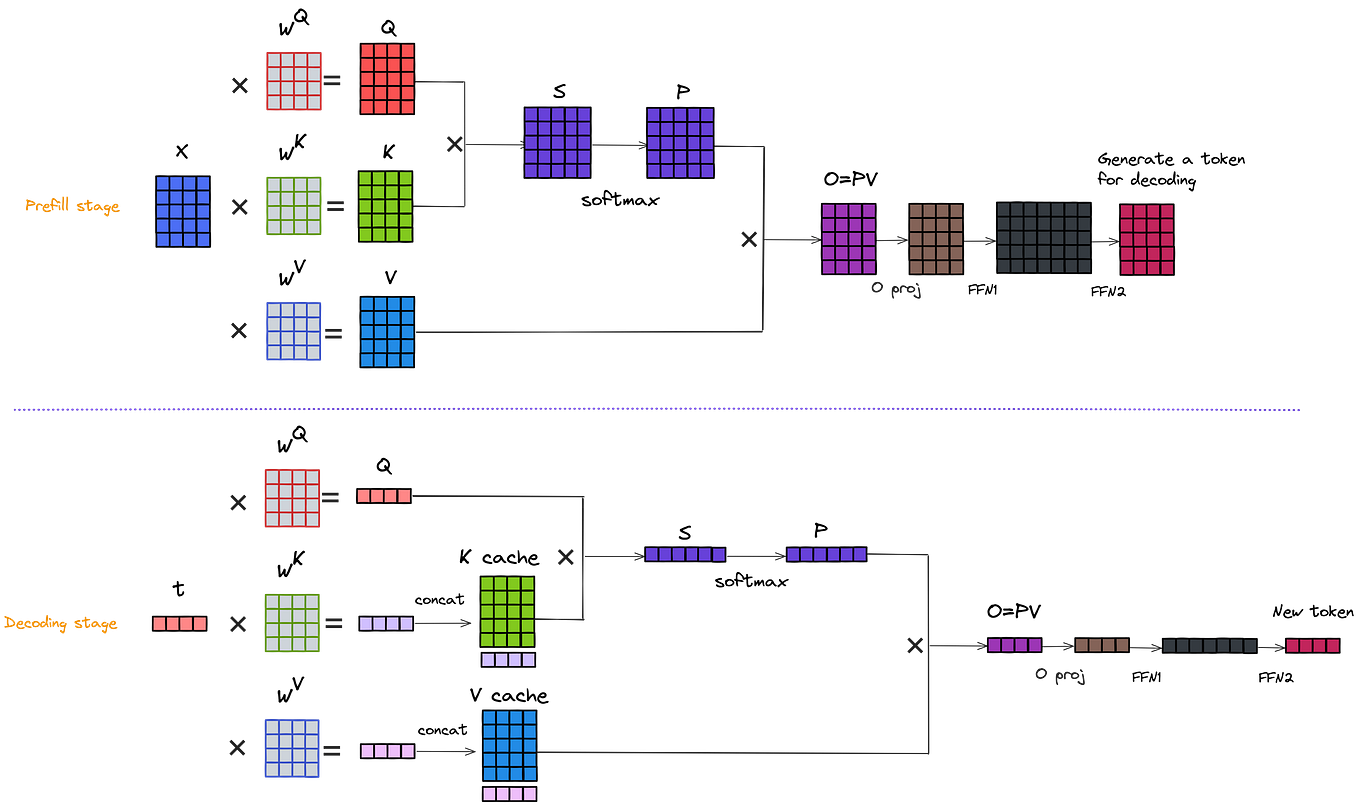
LLM - GPT(Decoder Only) 类模型的 KV Cache 公式与原理 教程 - 技术栈
KVSharer:基于不相似性实现跨层 KV Cache 共享-AI.x-AIGC专属社区-51CTO.COM
KV Caches and Time-to-First-Token: Optimizing LLM Performance
LLM - Generate With KV-Cache 图解与实践 By GPT-2_llm kv cache-CSDN博客
LoongServe 论文解读:prefill/decode 分离、弹性并行、零 KV Cache 迁移开销 - 知乎
A Guide to LLM Inference (Part 1): Foundations – Stephen Carmody
How to Scale LLM Inference - by Damien Benveniste
KV Cache Explained with Examples from Real World LLMs
KV Caching Explained: Optimizing Transformer Inference Efficiency
GitHub - William-kaihhu/SimCalKV: [MSN 2025] code for the paper ...
Dissecting FlashInfer - A Systems Perspective on High-Performance LLM ...
Welcome to my blog! - Understanding KV Cache
Global Multi-Level KV Cache - xLLM
ICLR Poster SqueezeAttention: 2D Management of KV-Cache in LLM ...
20. Inference Acceleration (WIP) — LLM Foundations
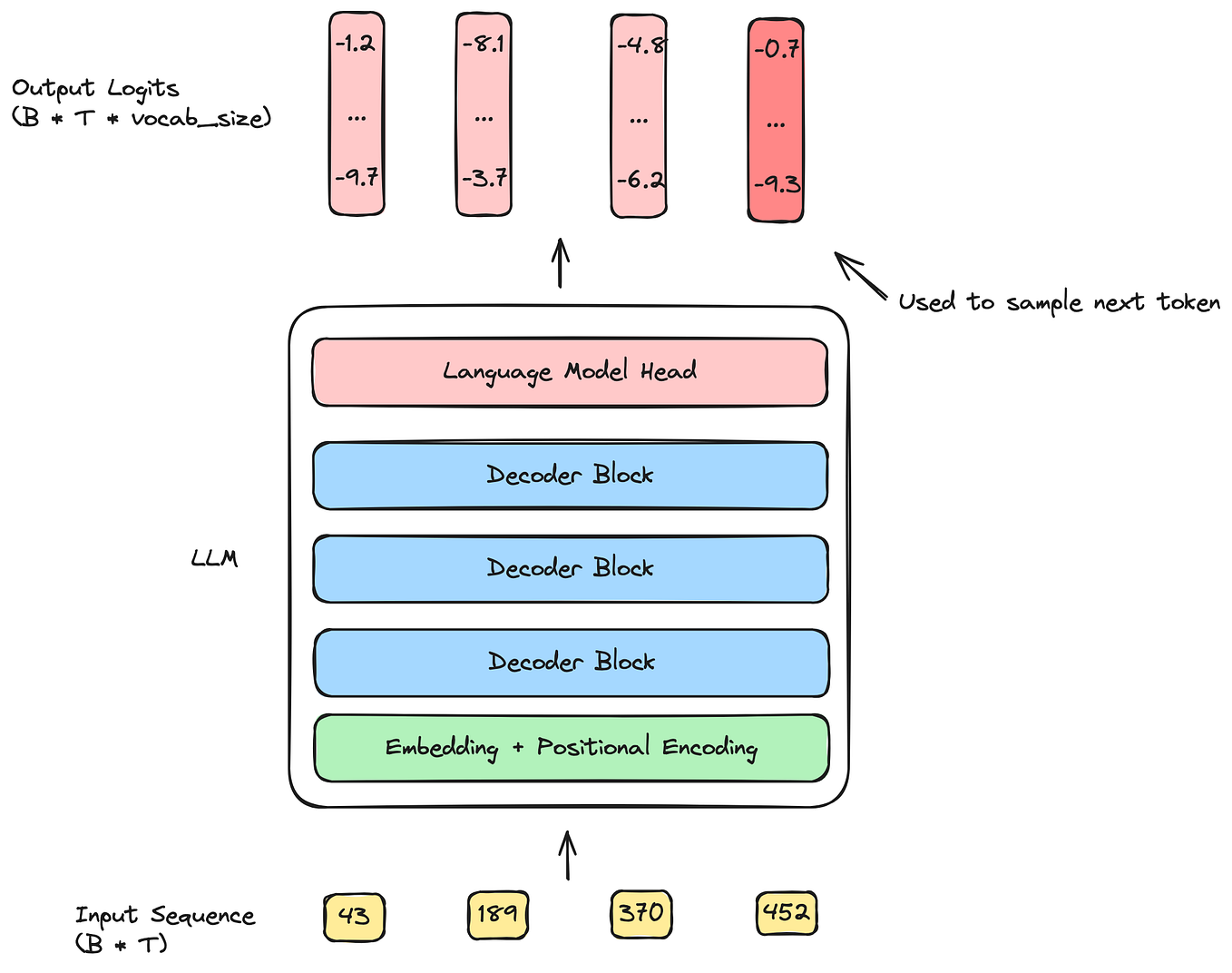
LLM Inference Series: 1. Introduction | by Pierre Lienhart | Medium
Prefix Caching 详解:实现 KV Cache 的跨请求高效复用-CSDN博客
vLLM中 Cross-Layer Attention KV sharing实现 - 知乎
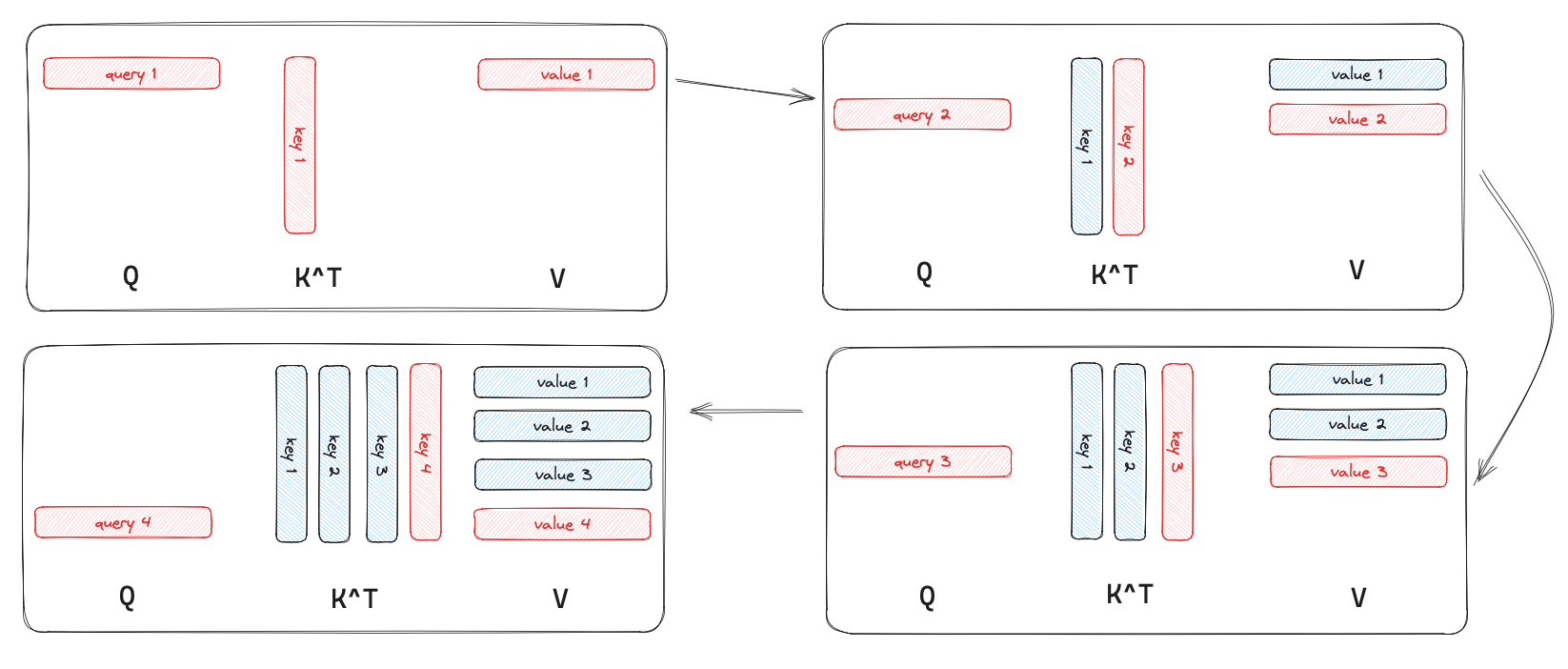
KV Caching Illustrated | Kapil Sharma
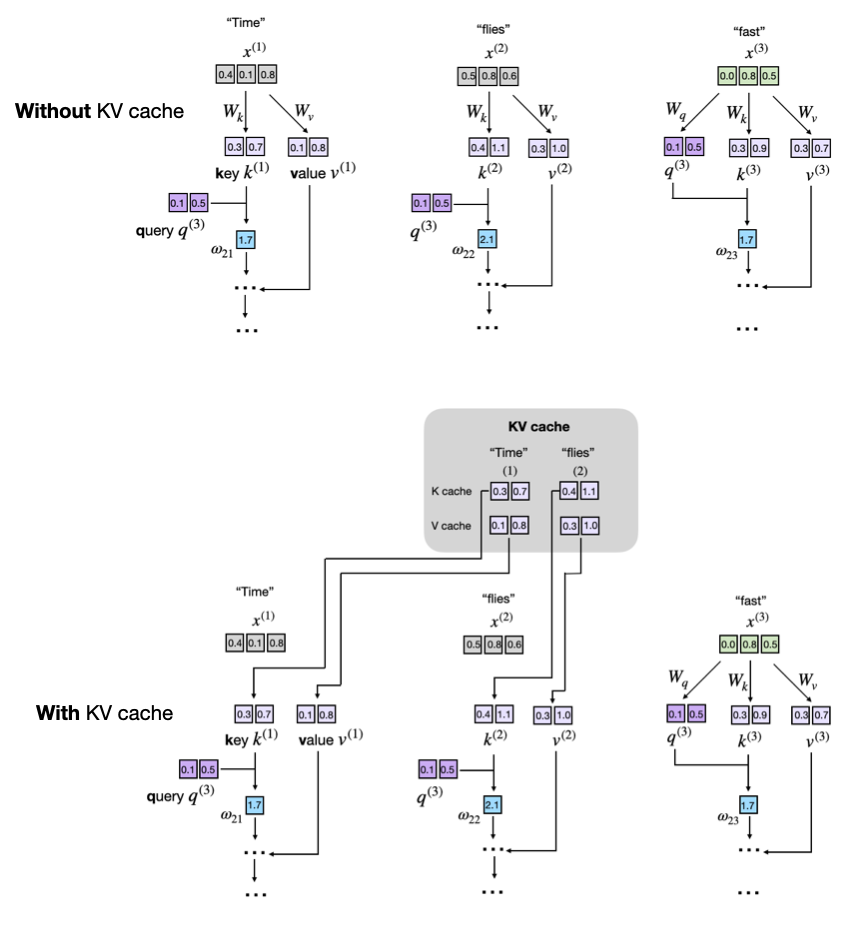
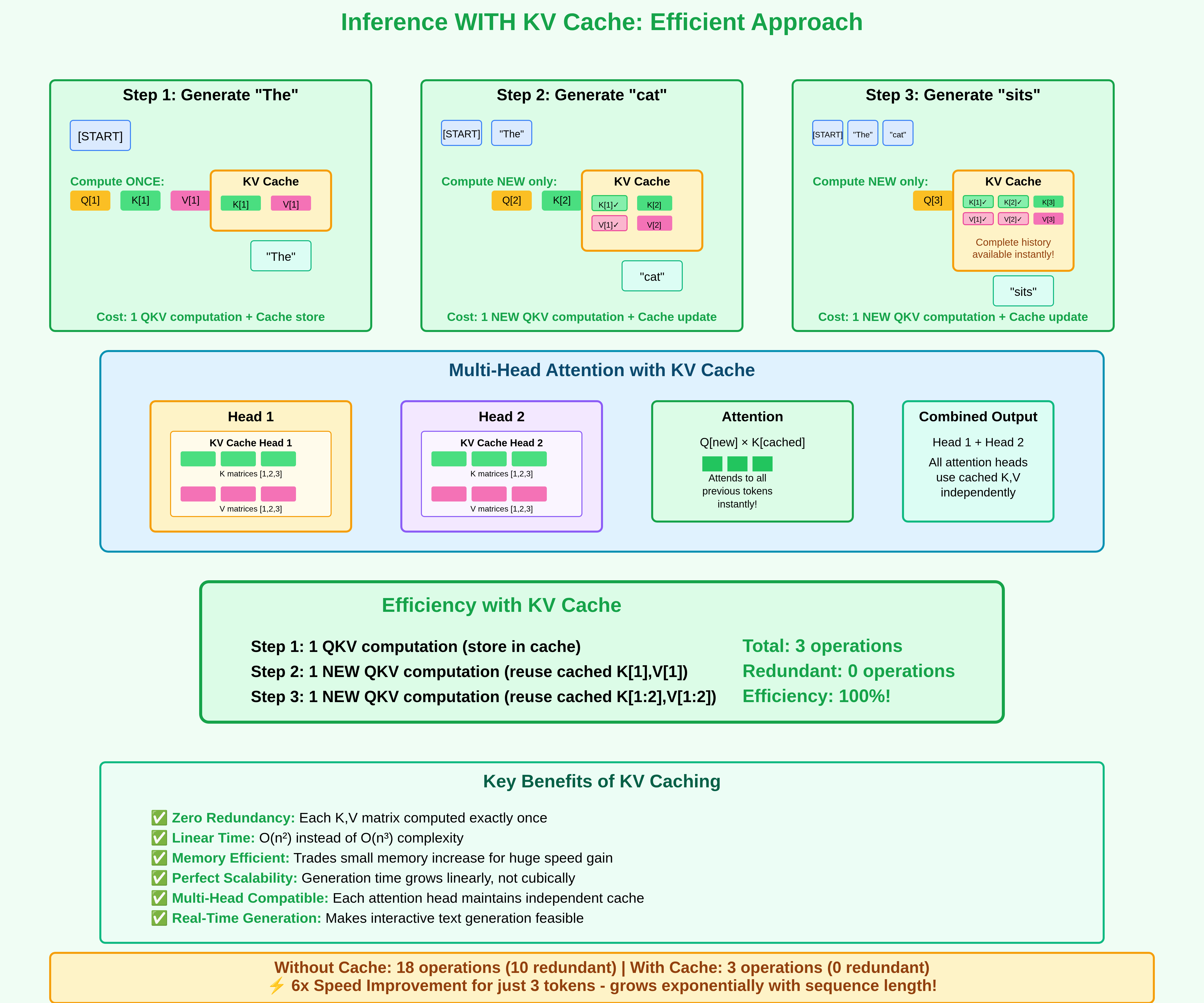
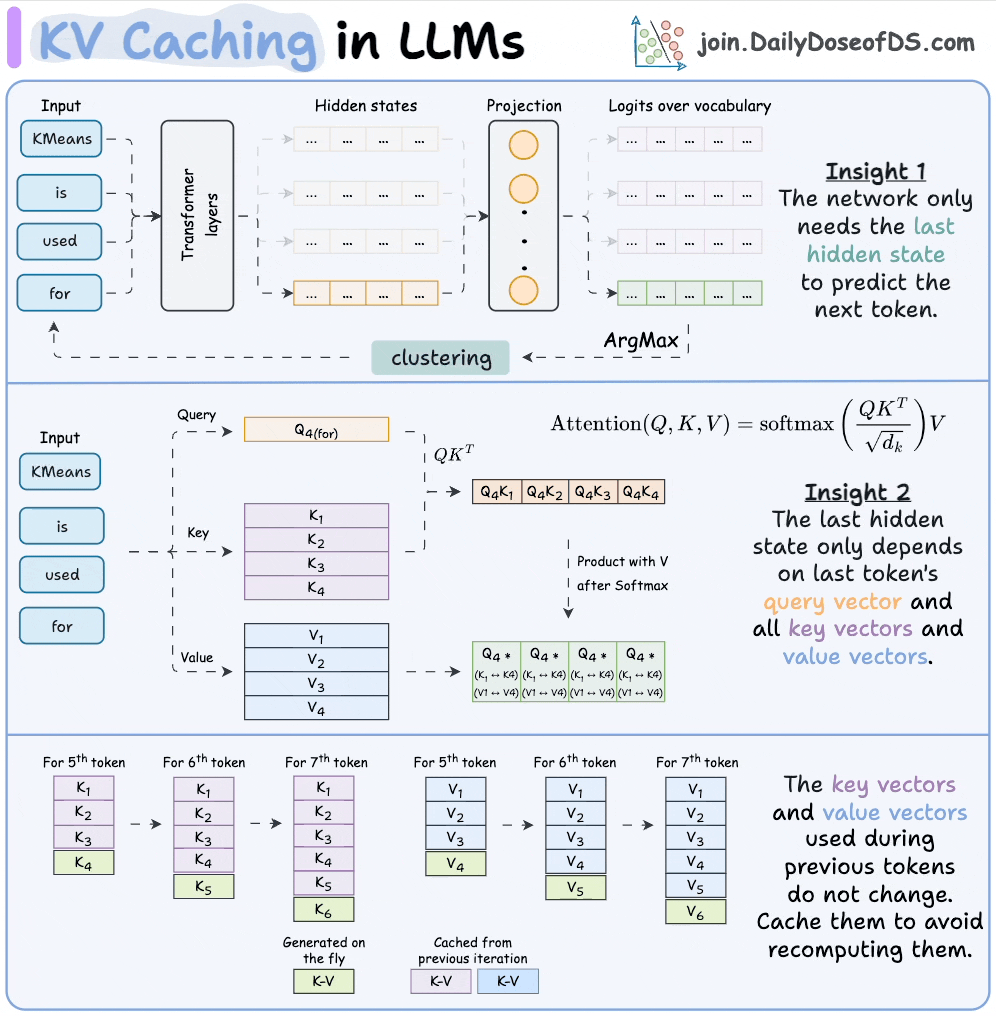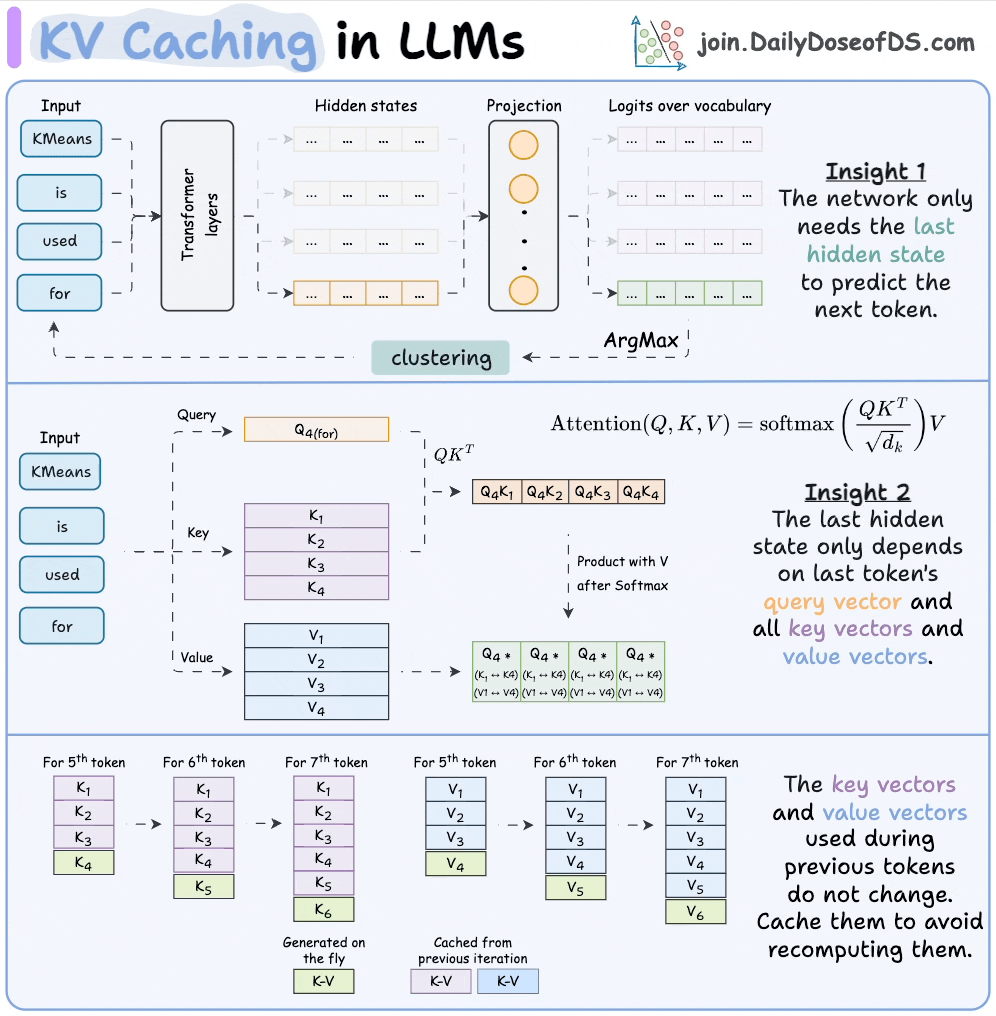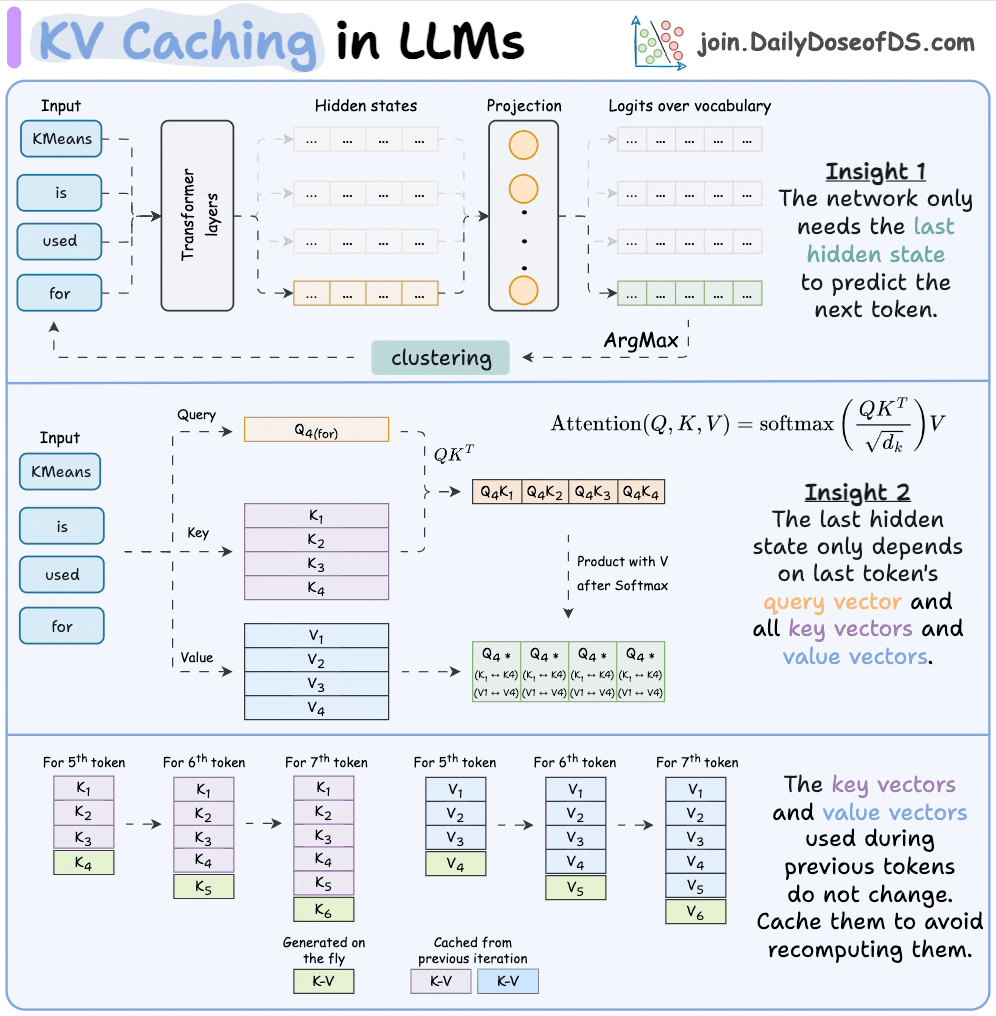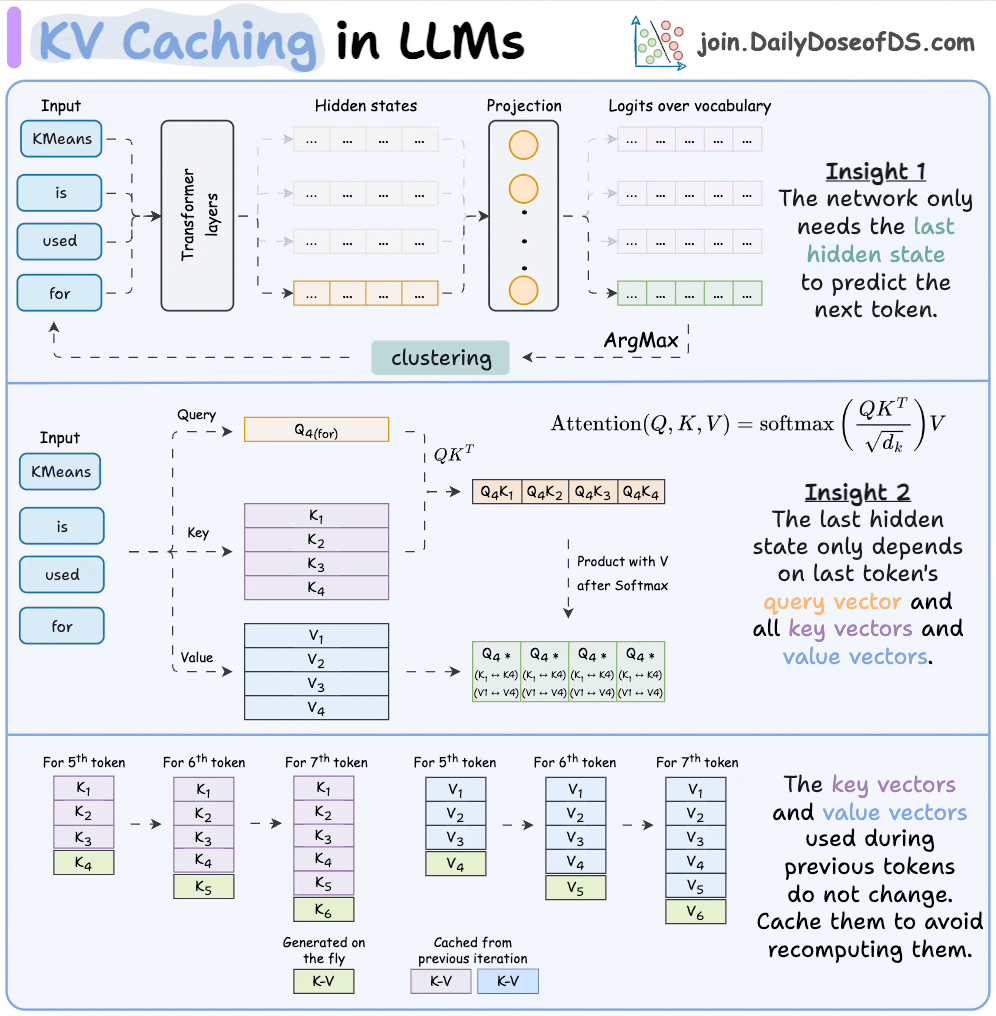
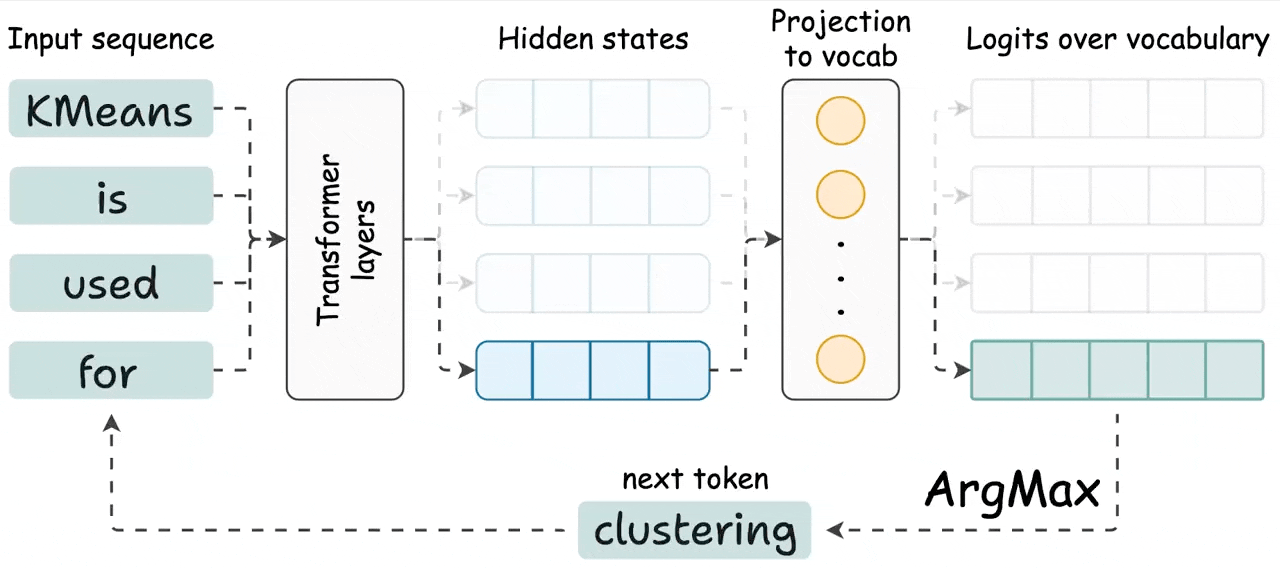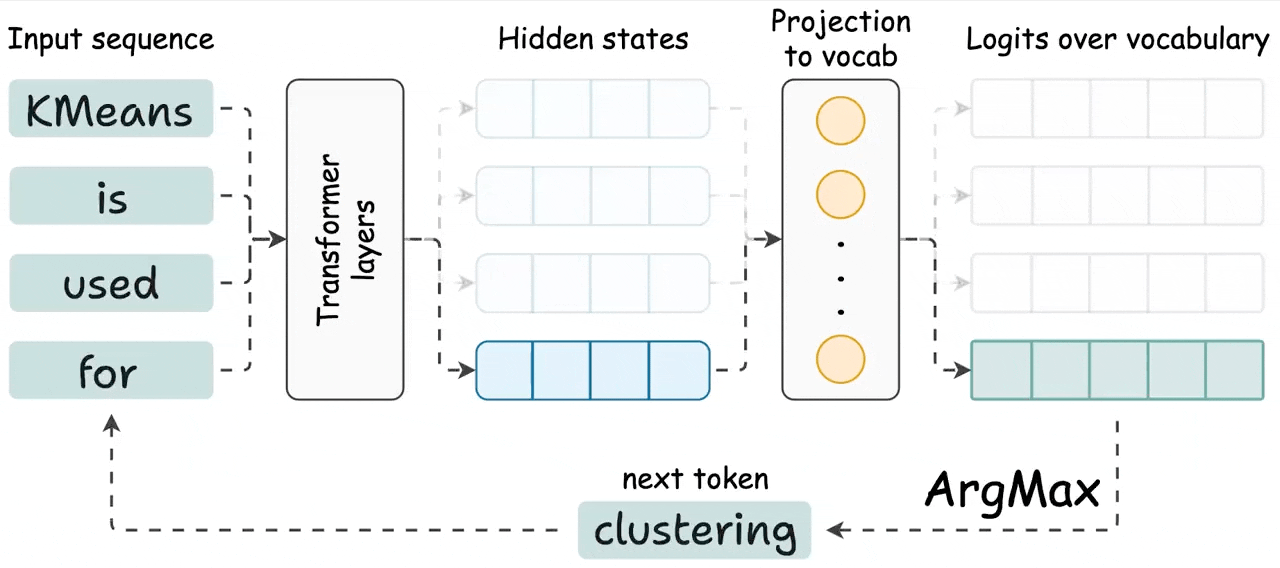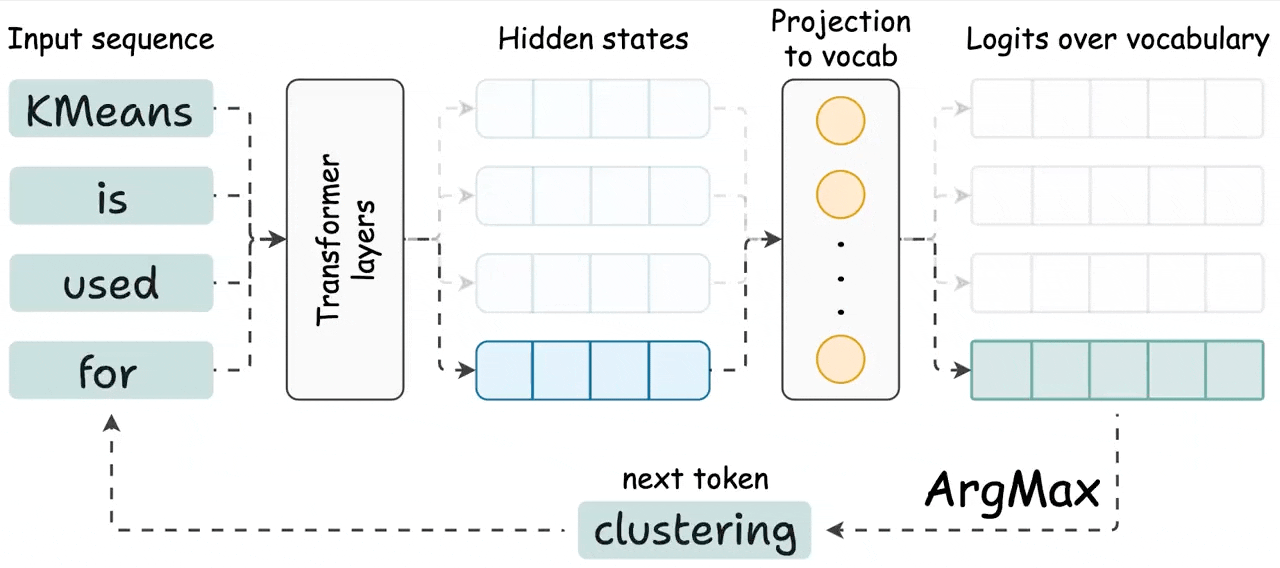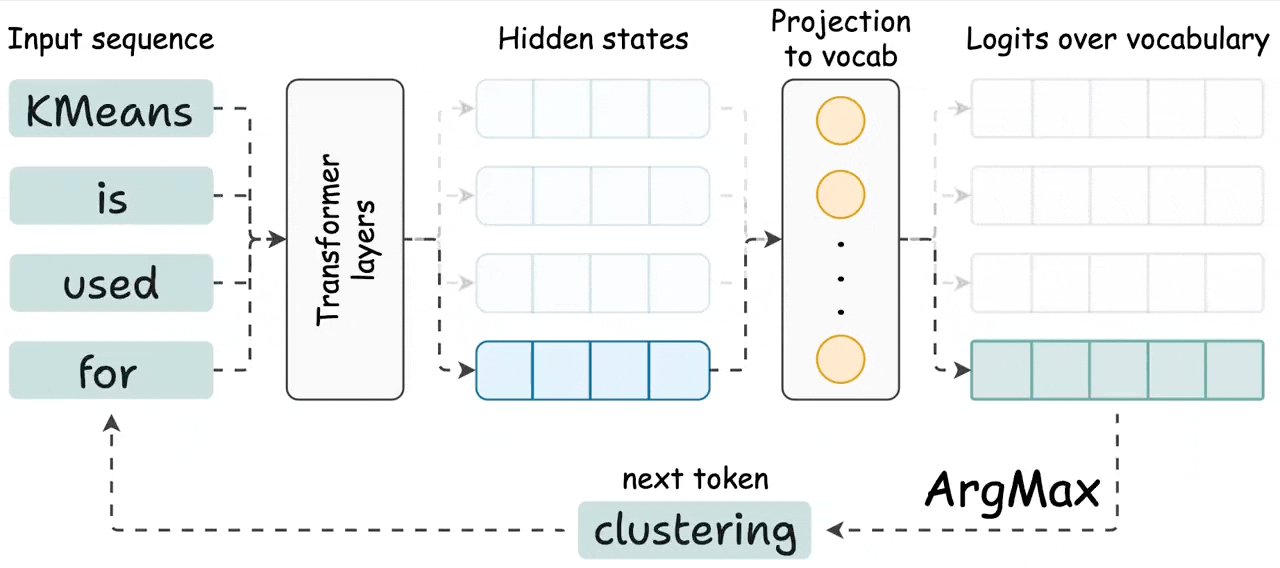
KV Caching in LLMs, explained visually
Awesome-Efficient-LLM/kv_cache_compression.md at main · horseee/Awesome ...
KV Caching in LLMs, Explained Visually. - by Avi Chawla
GitHub - yangyifei729/KVSharer: Source code of paper ''KVSharer ...
How To Reduce LLM Decoding Time With KV-Caching!
图文详解LLM inference:KV Cache - 知乎
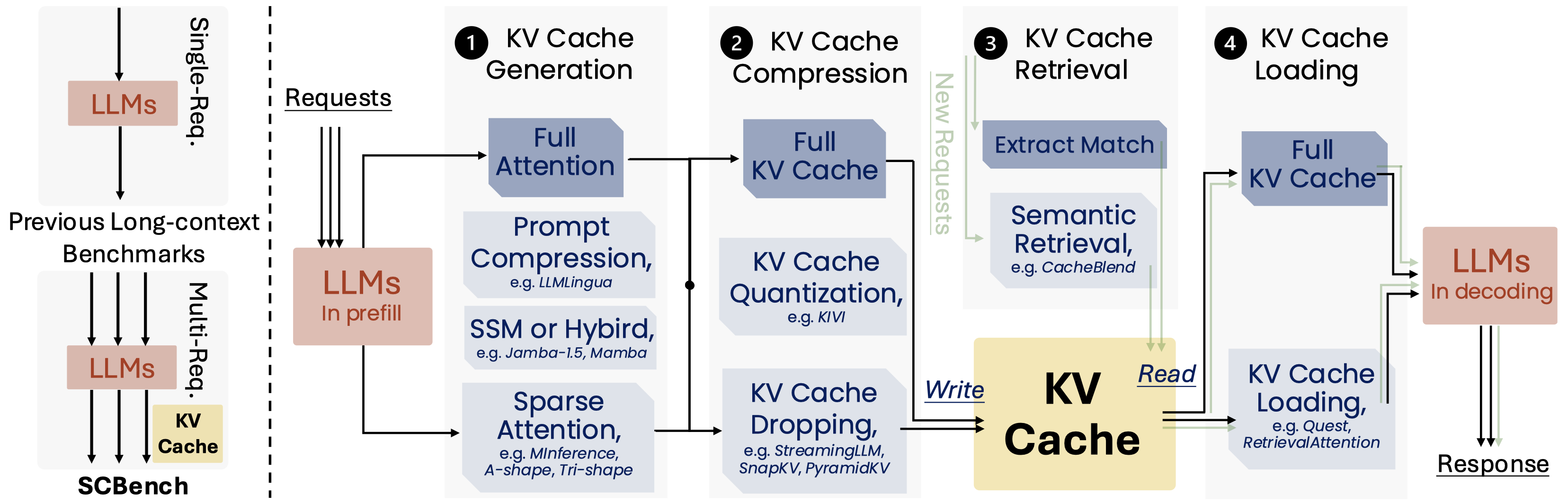
SCBench: A KV Cache-Centric Analysis of Long-Context Methods
LLM推理的KV cache - 知乎
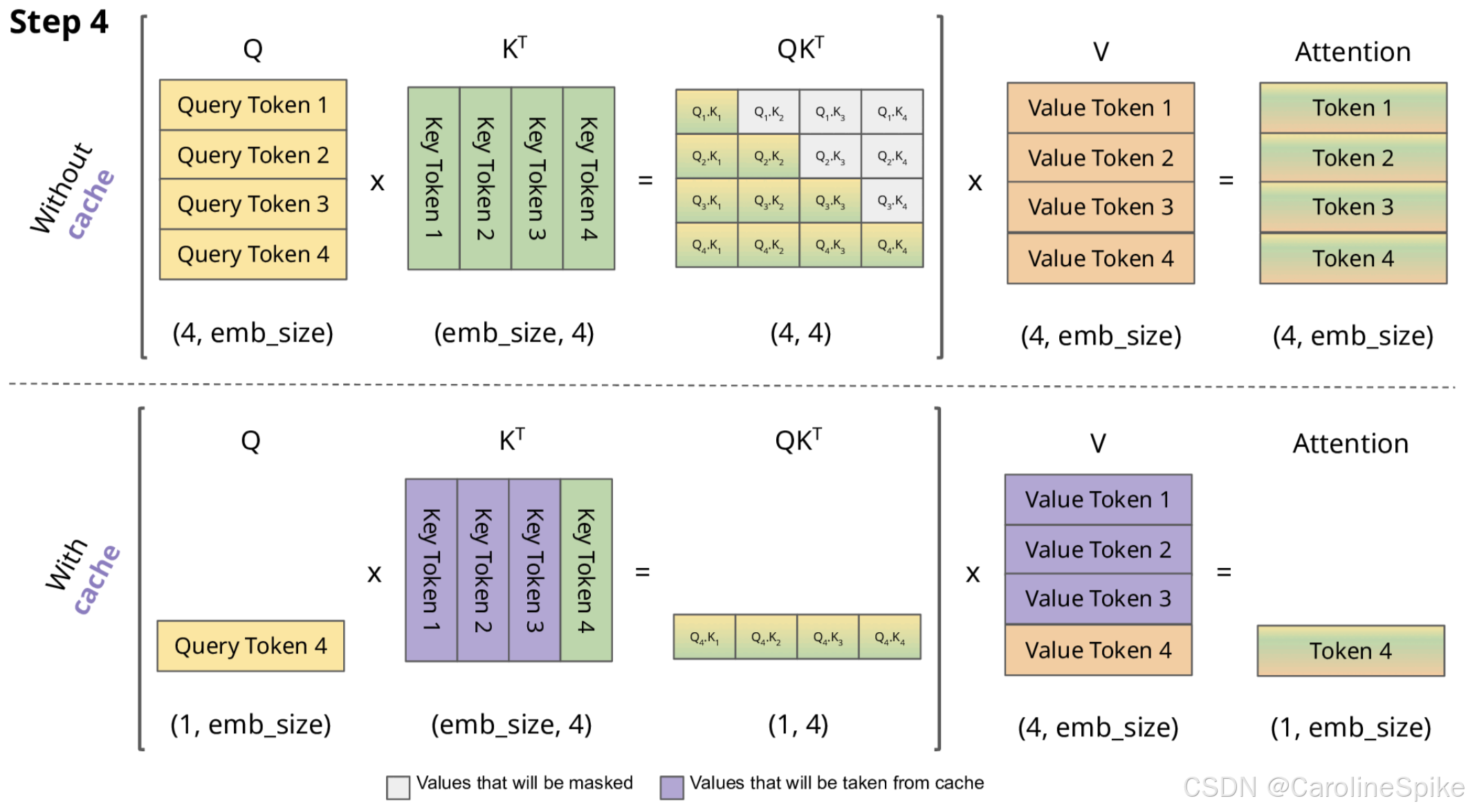
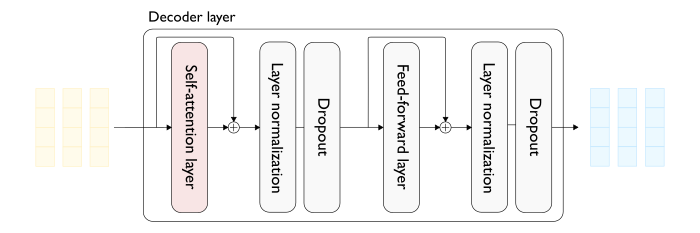
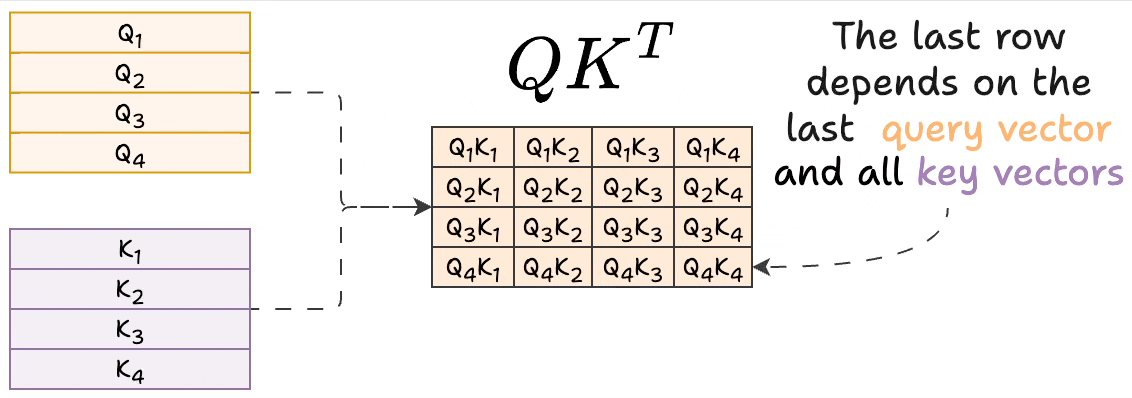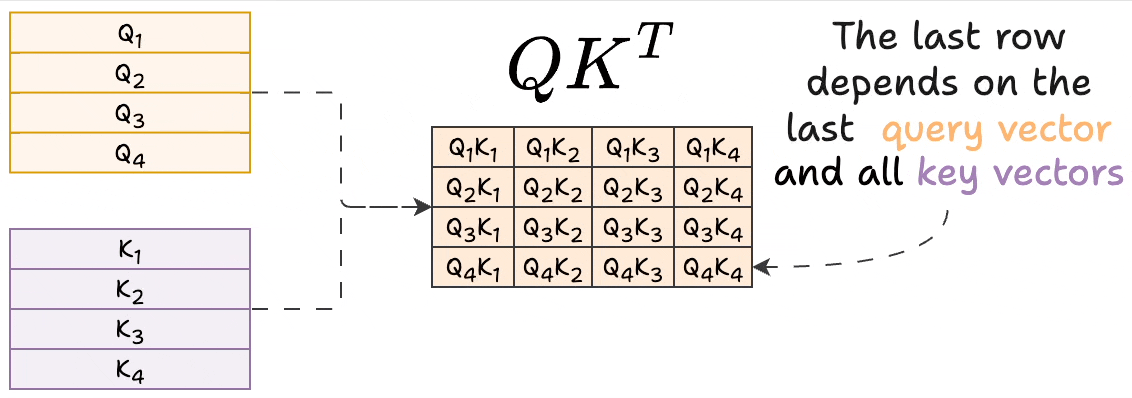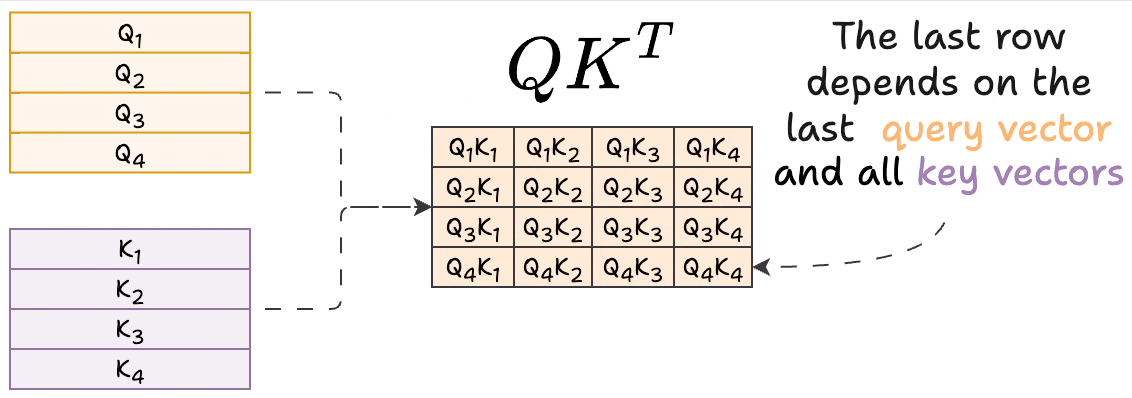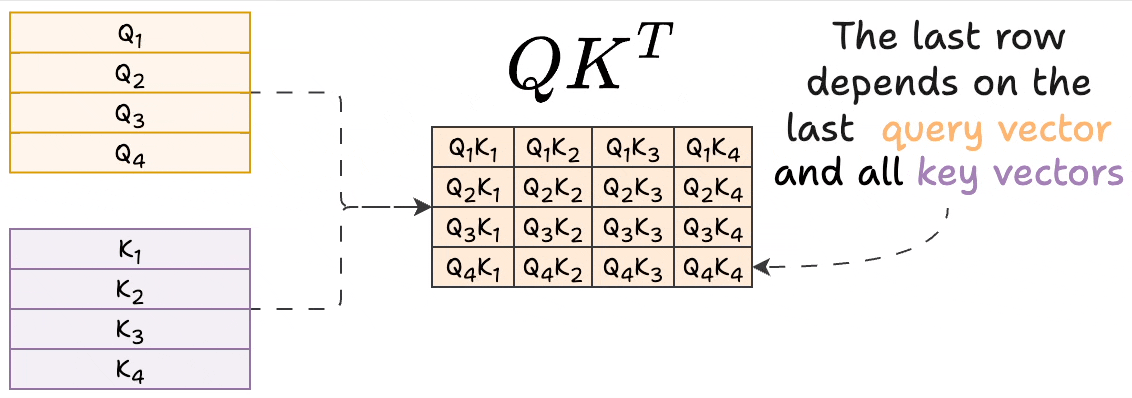
Transformers KV Caching Explained | by João Lages | Medium
GPU memory requirements for serving Large Language Models | UnfoldAI
ExtraTech Bootcamps