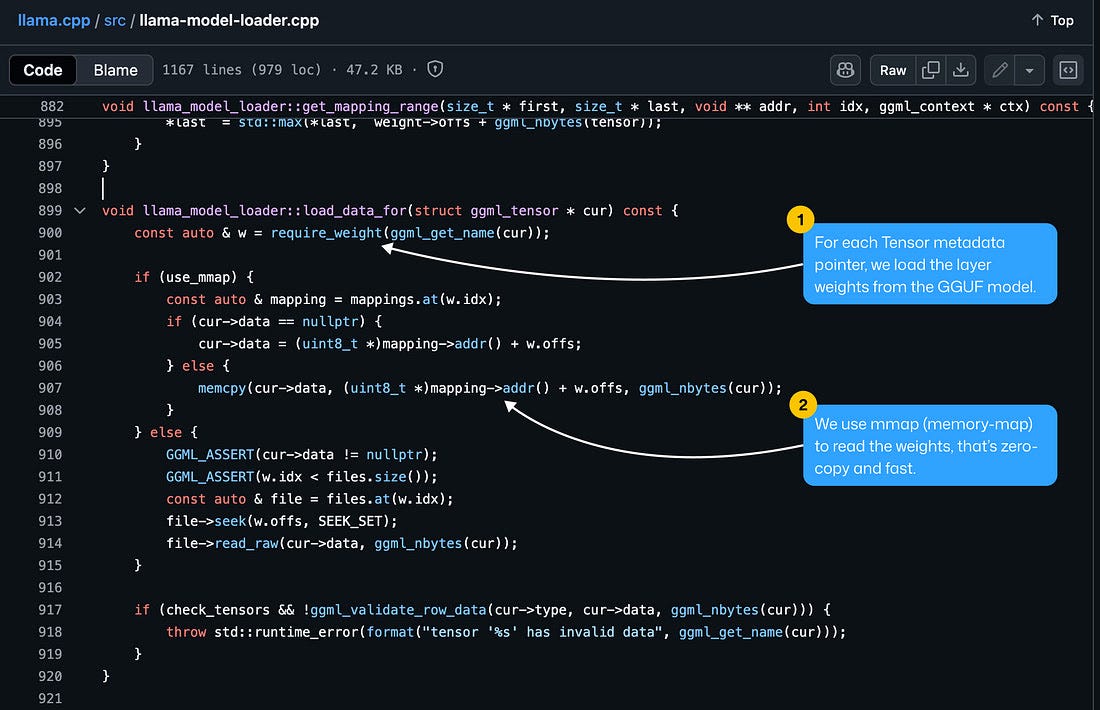
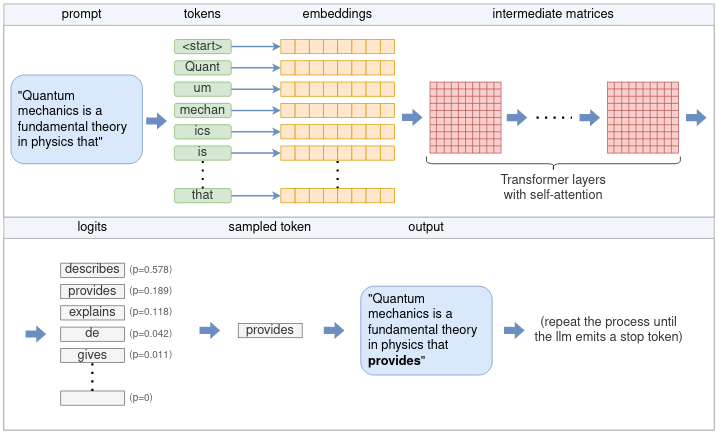
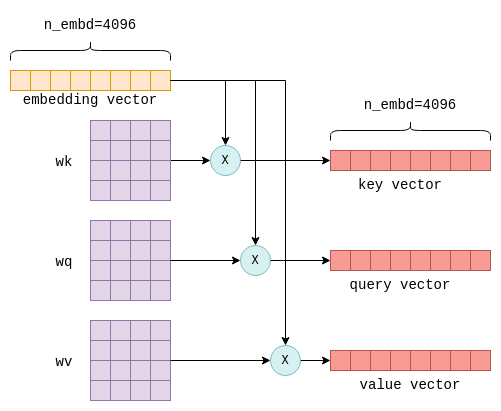
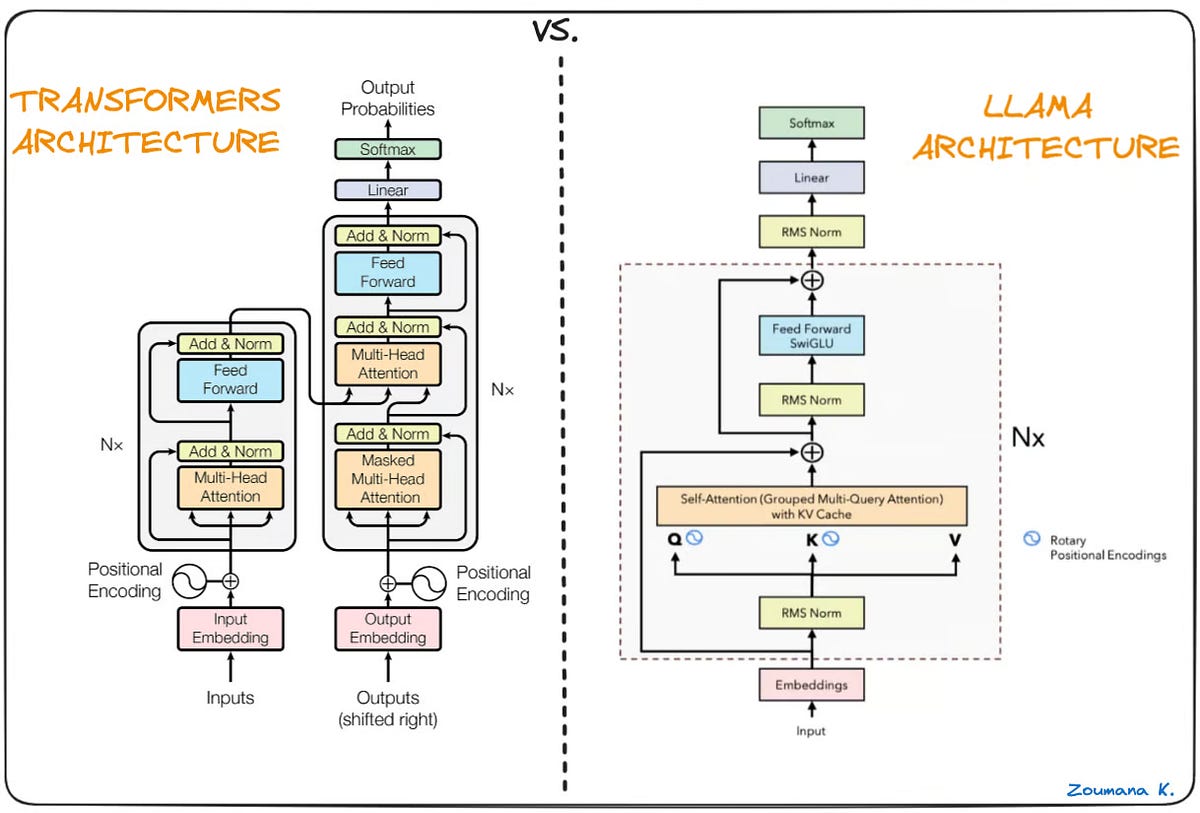
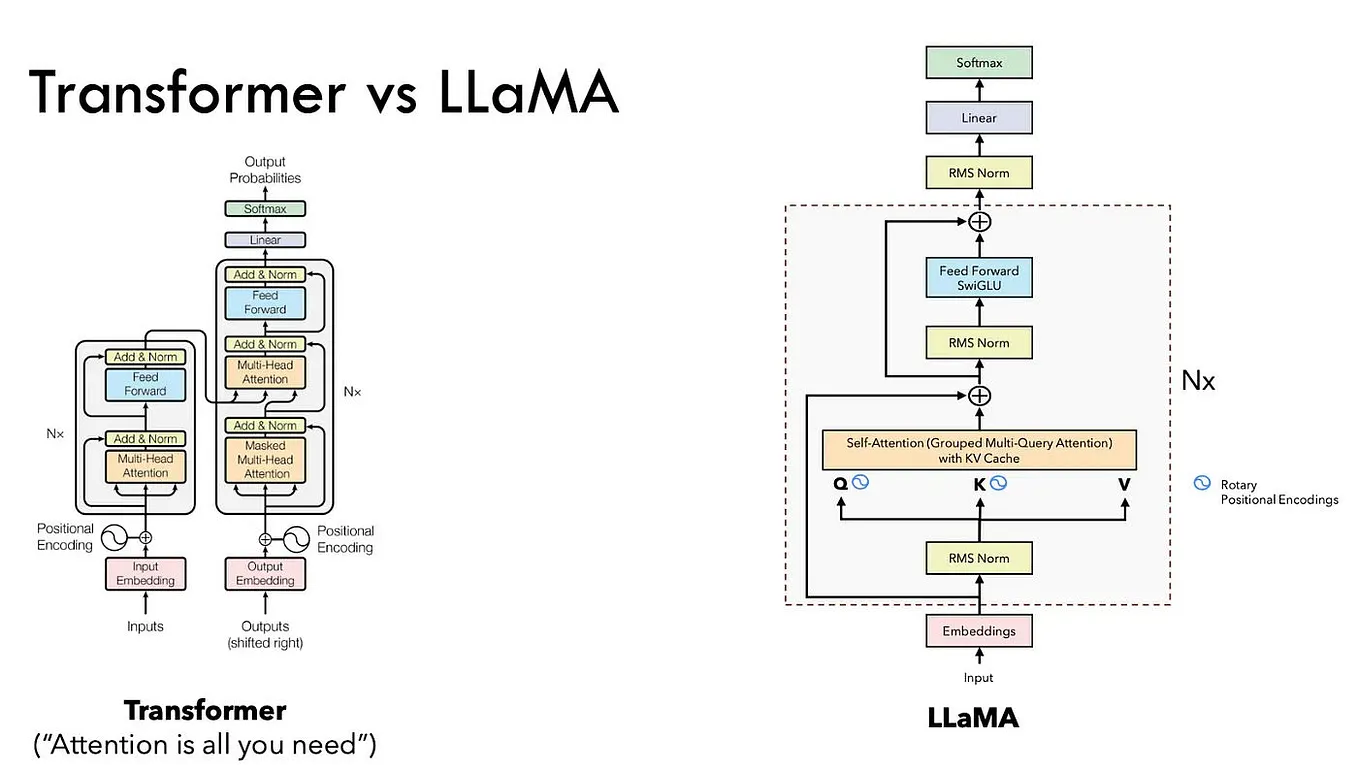
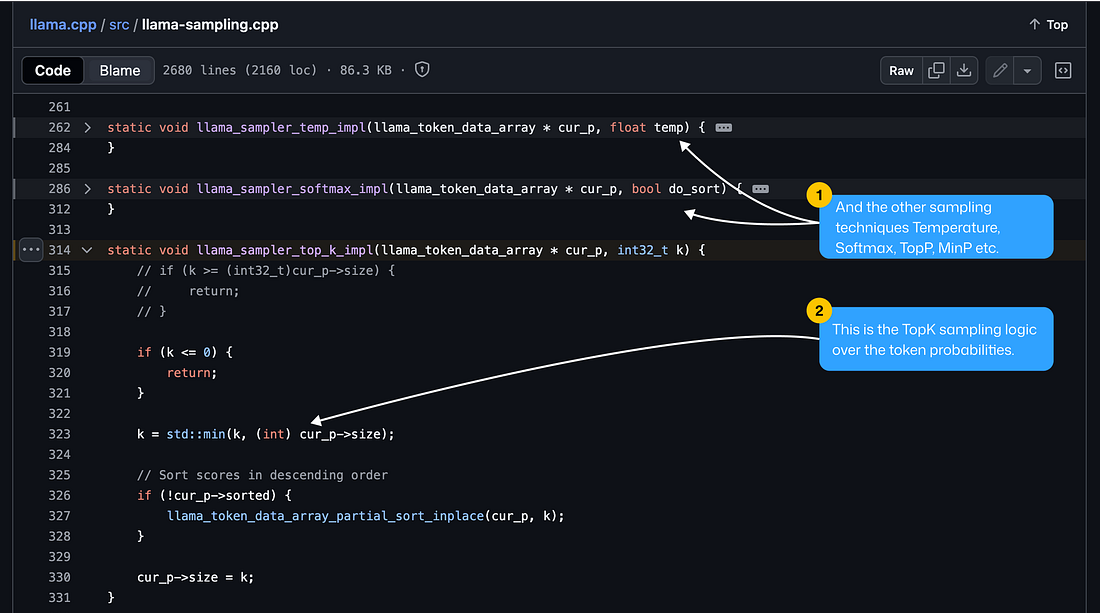
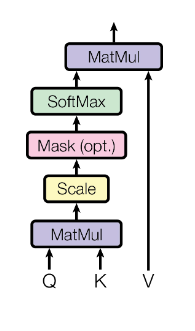
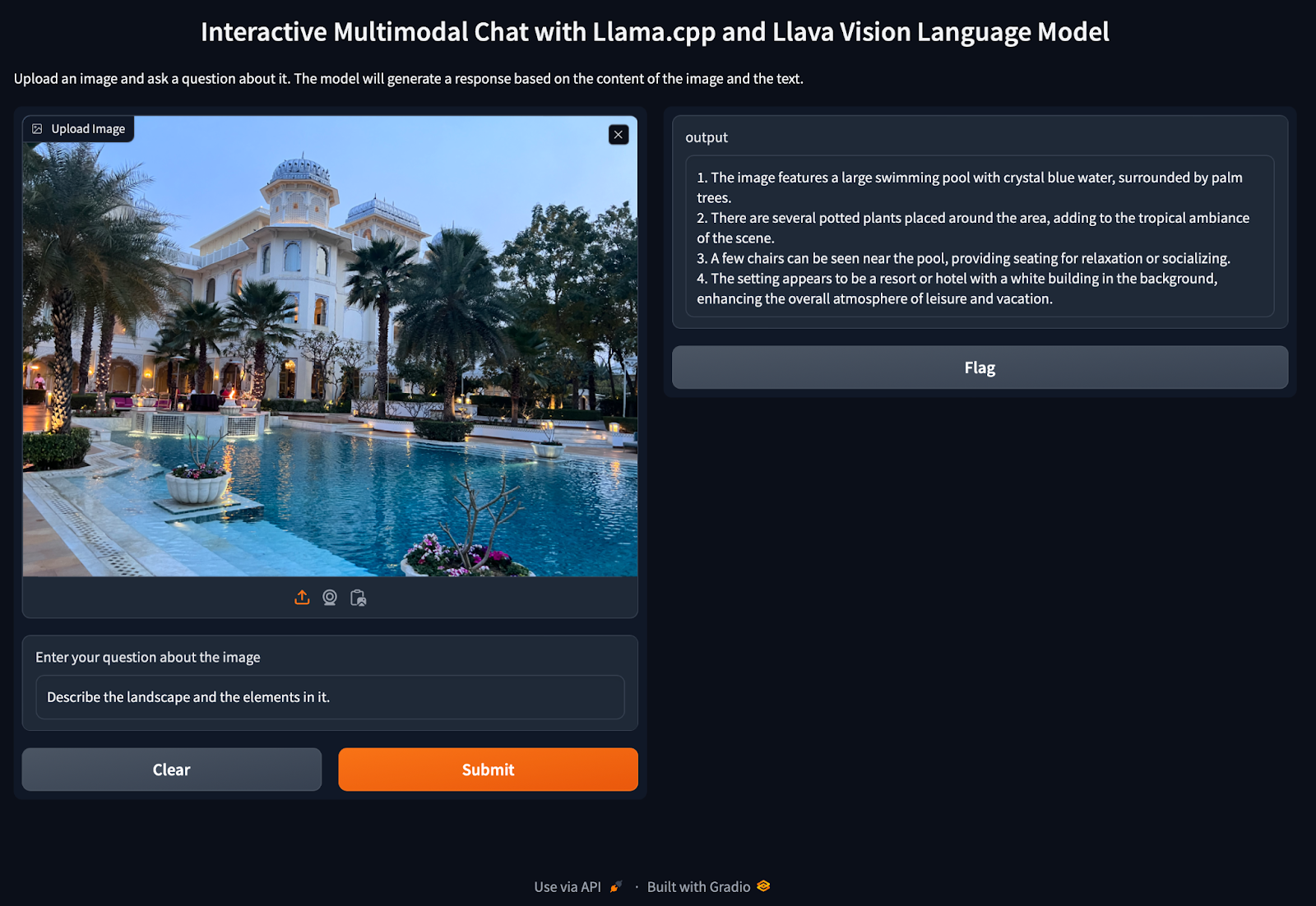
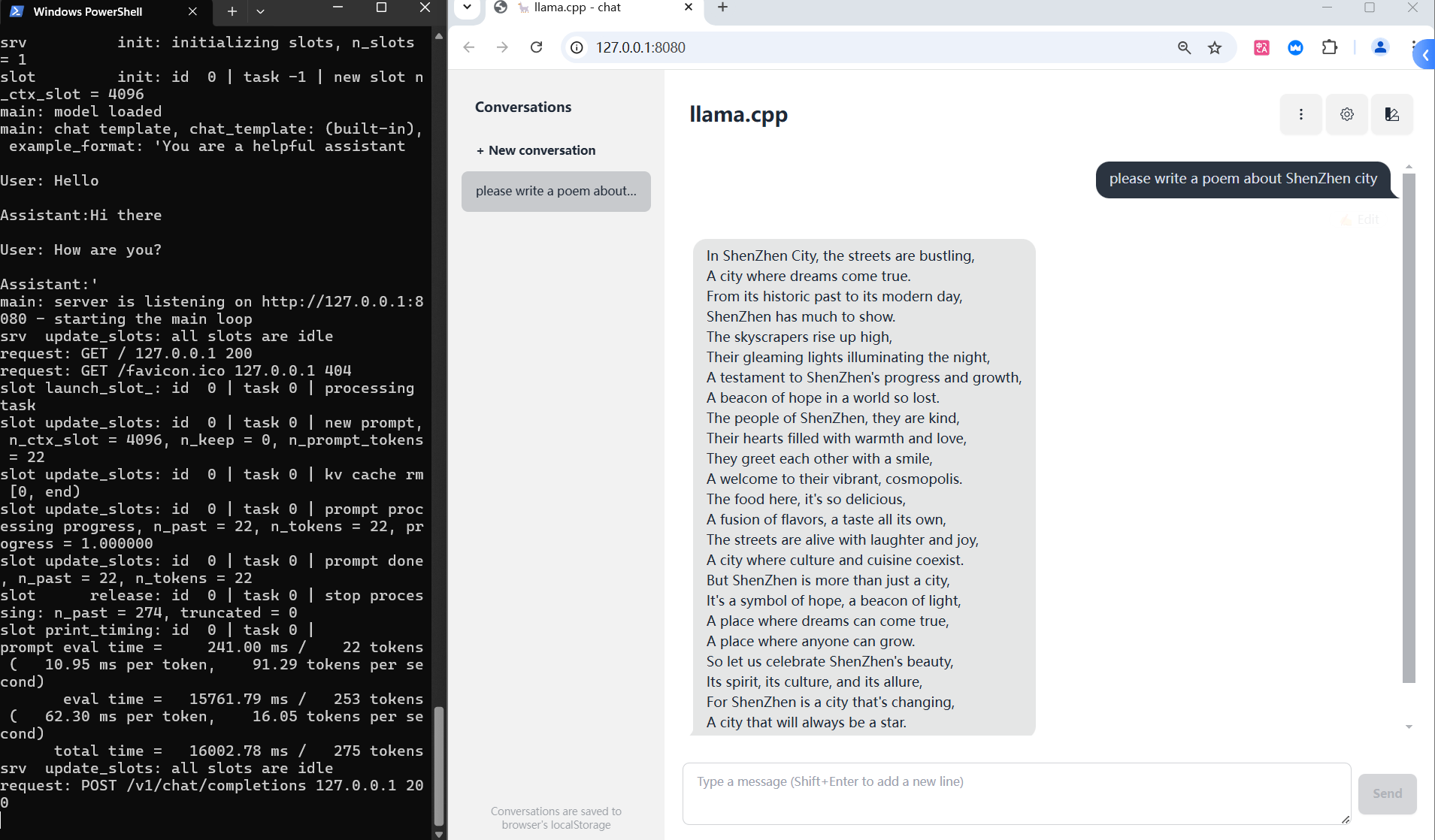
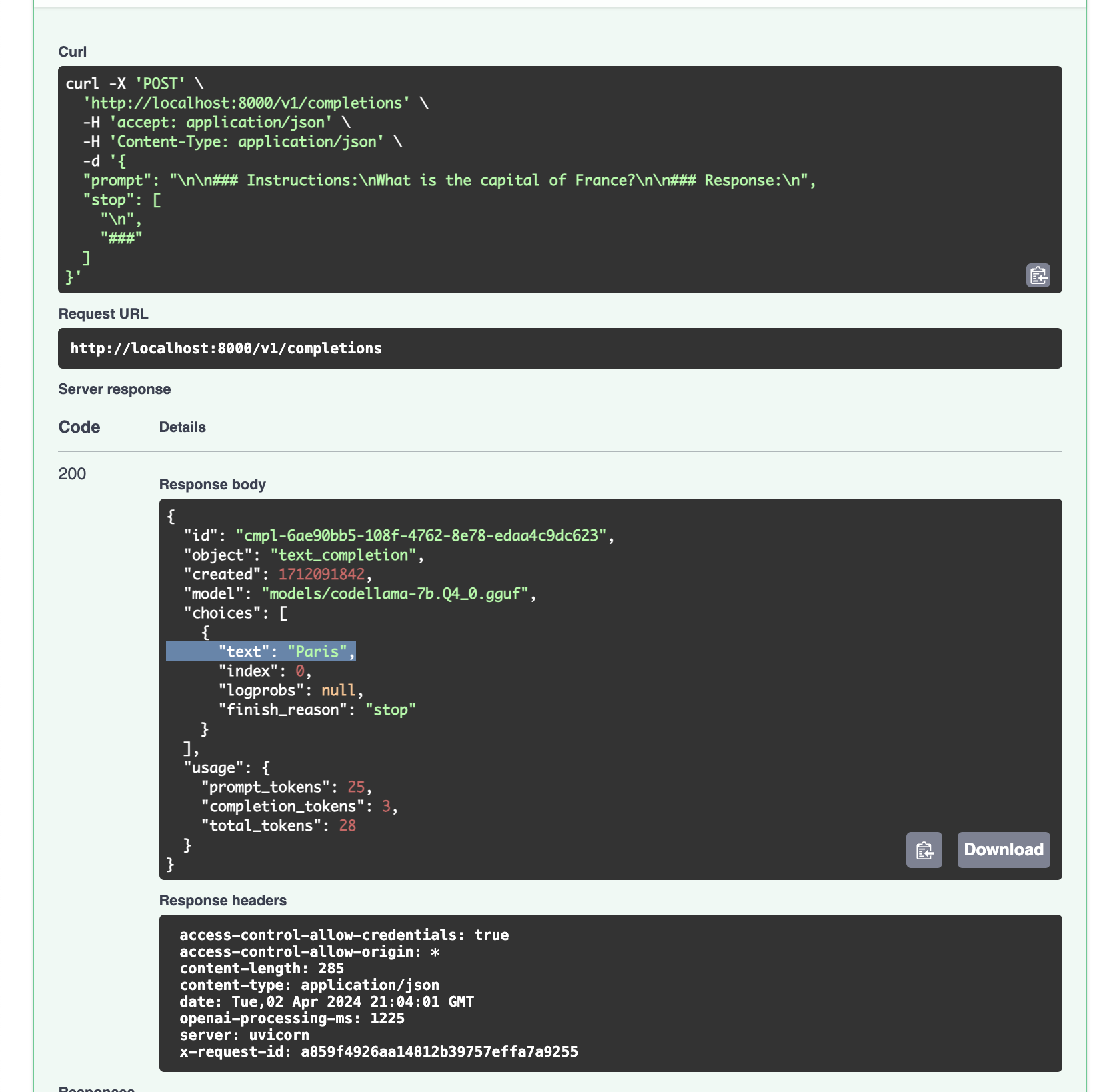
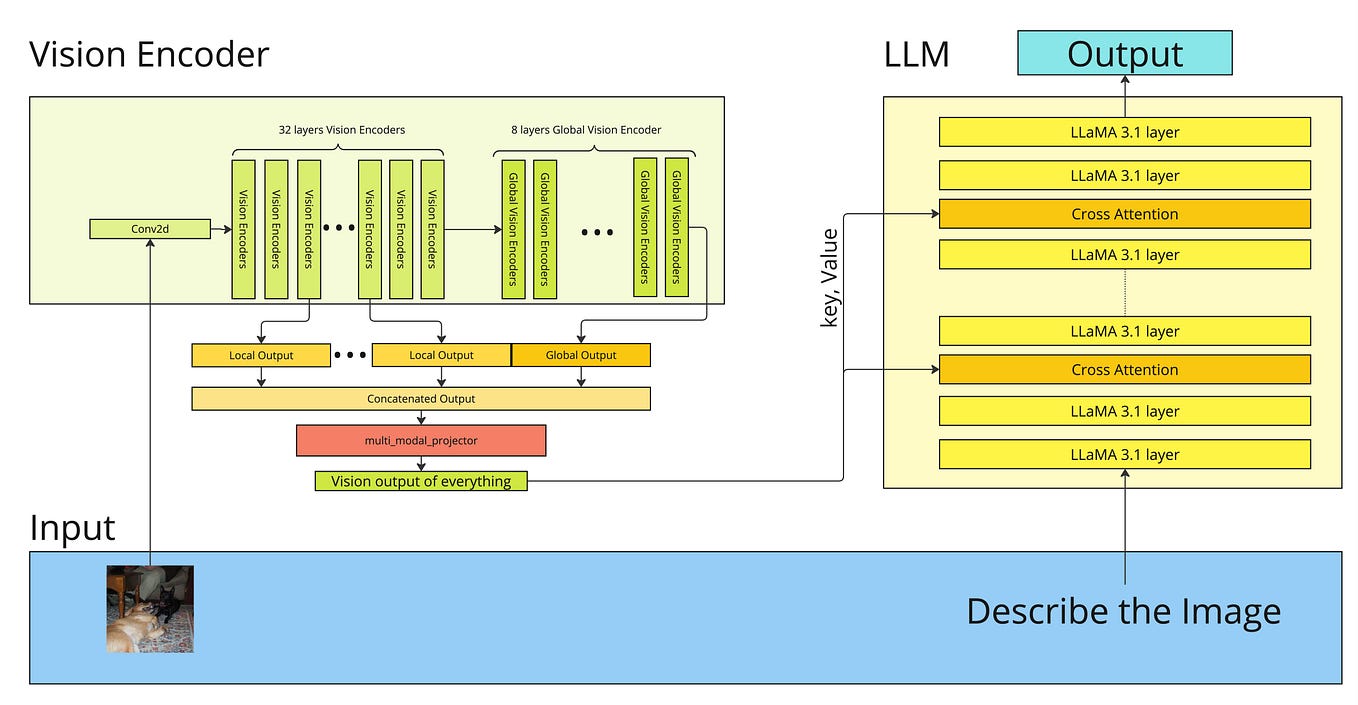
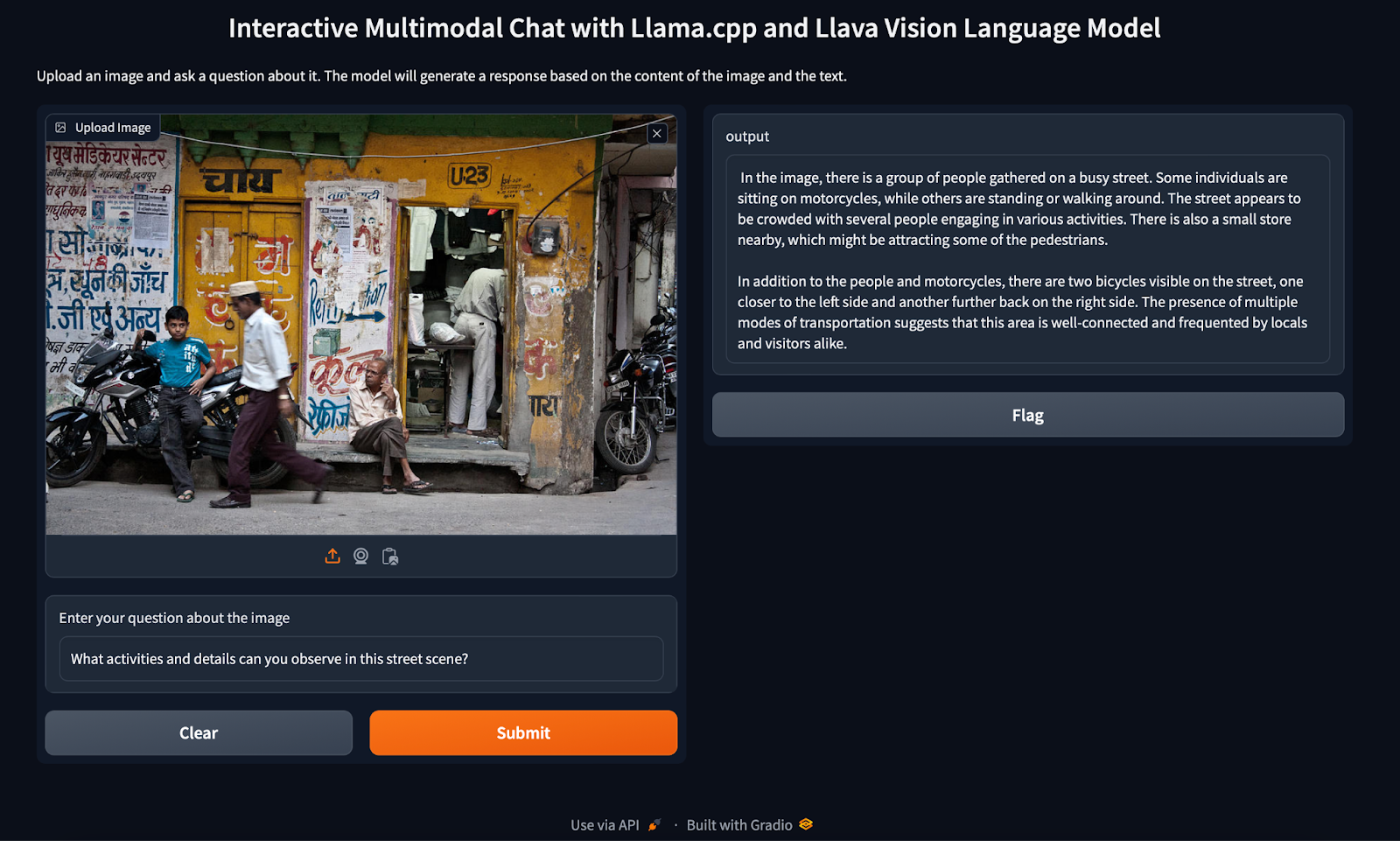
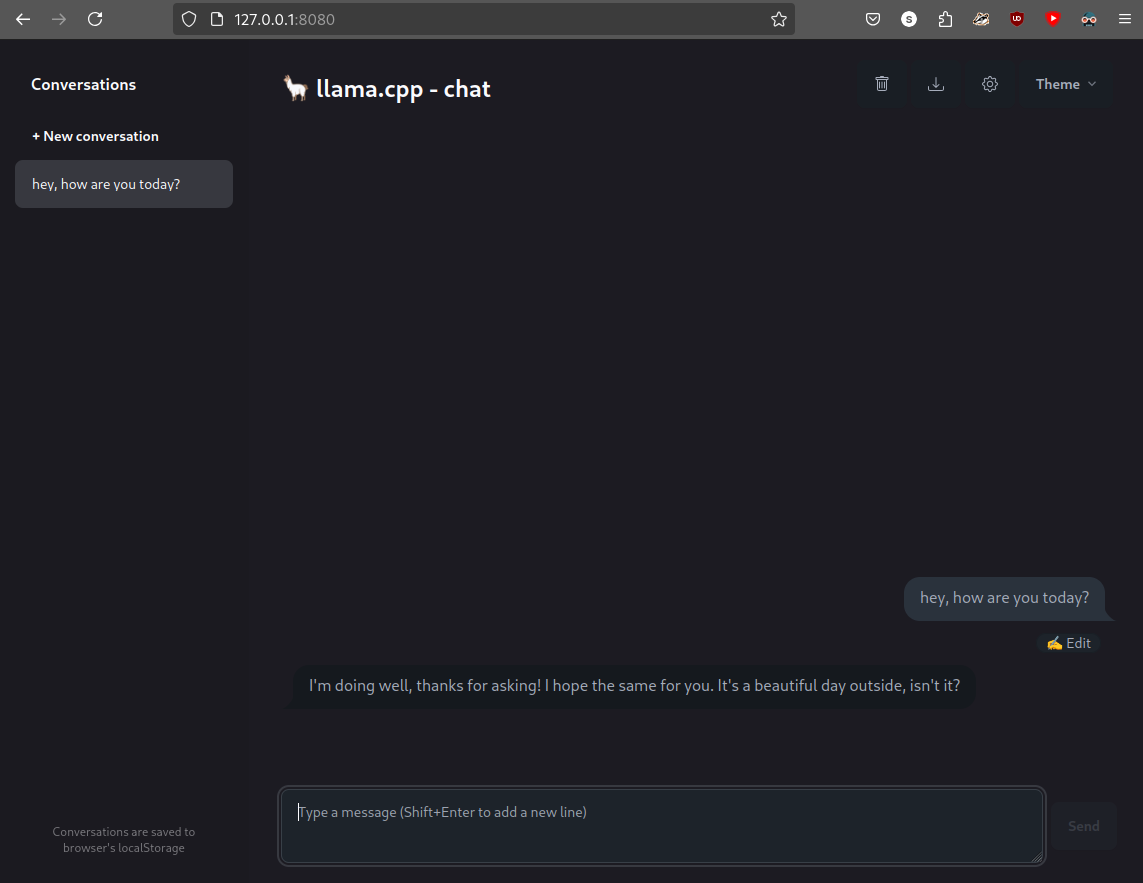
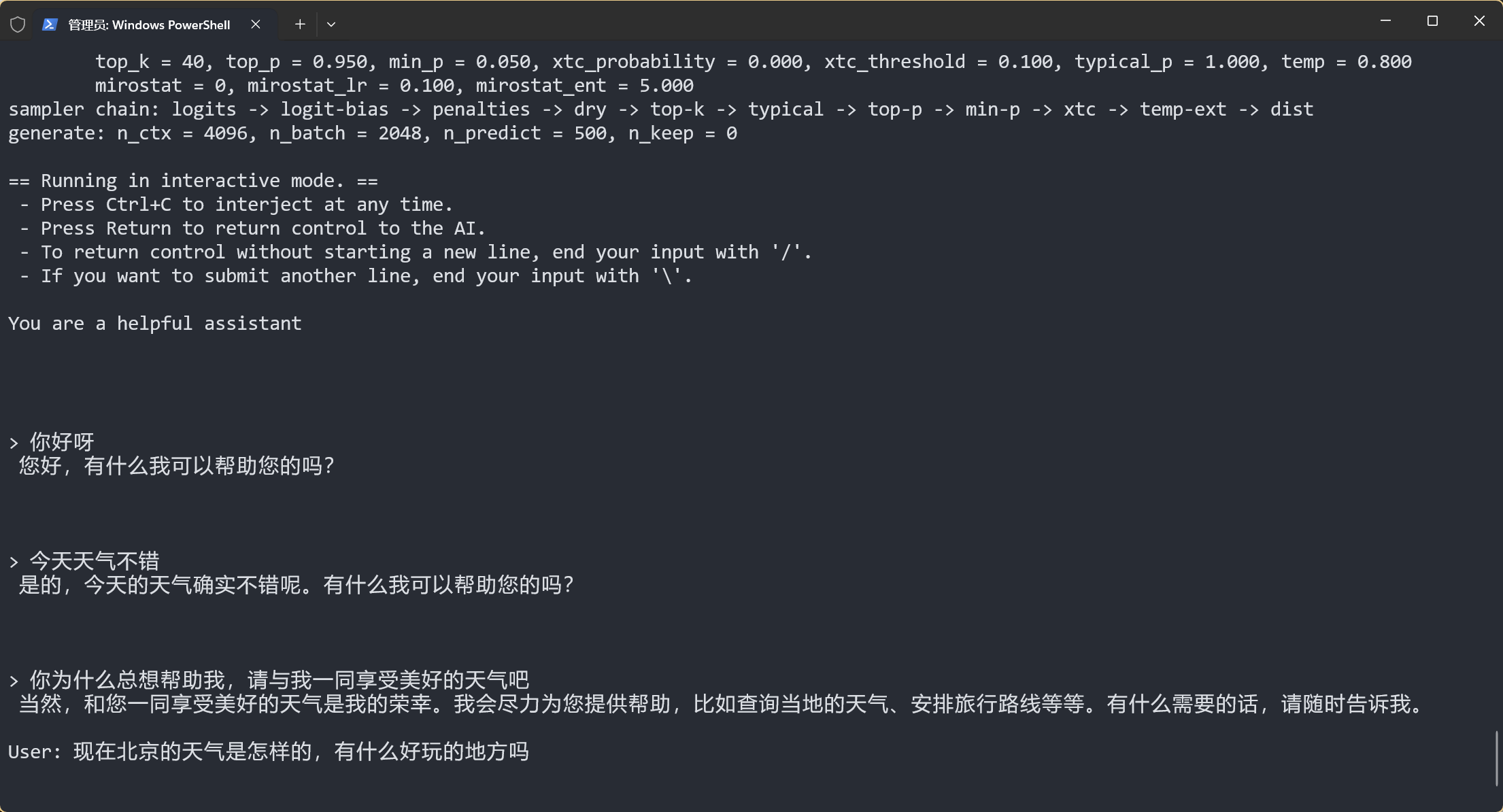
Llama.cpp and Square Codex for Local LLM Inference
Local LLM Inference on Windows 11 and AMD GPU using WSL and llama.cpp ...
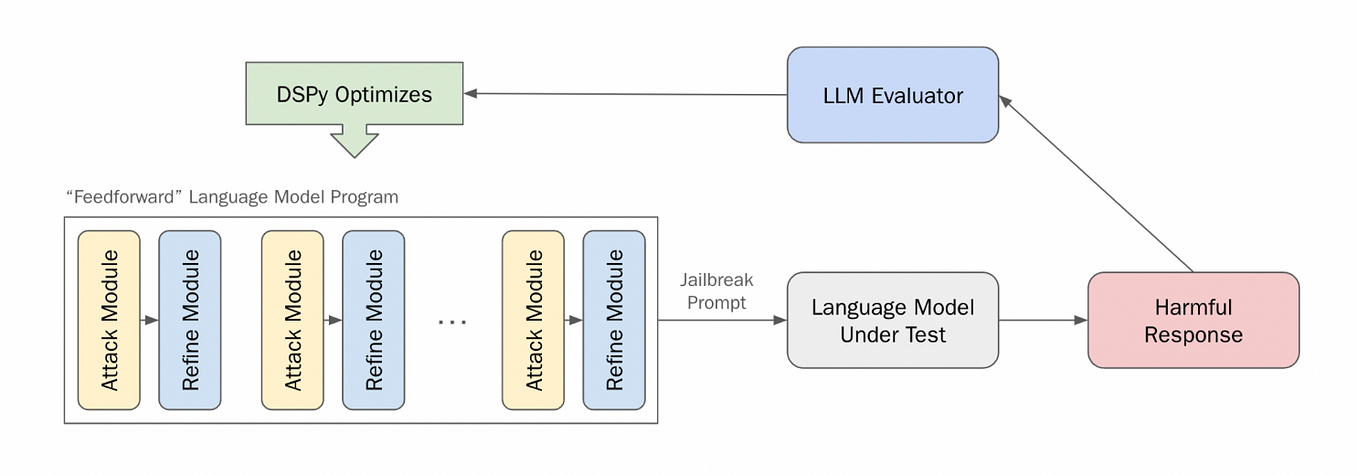
Speeding up LLM inference using SparQ Attention & llama.cpp - Graphcore ...
GitHub - awinml/llama-cpp-python-bindings: Run fast LLM Inference using ...
Llama.cpp - Run LLM Inference in C/C++
llama.cpp - LLM Inference C/C++ Library | EveryDev.ai
How to Run a Local LLM for Enterprise Use - Intellias
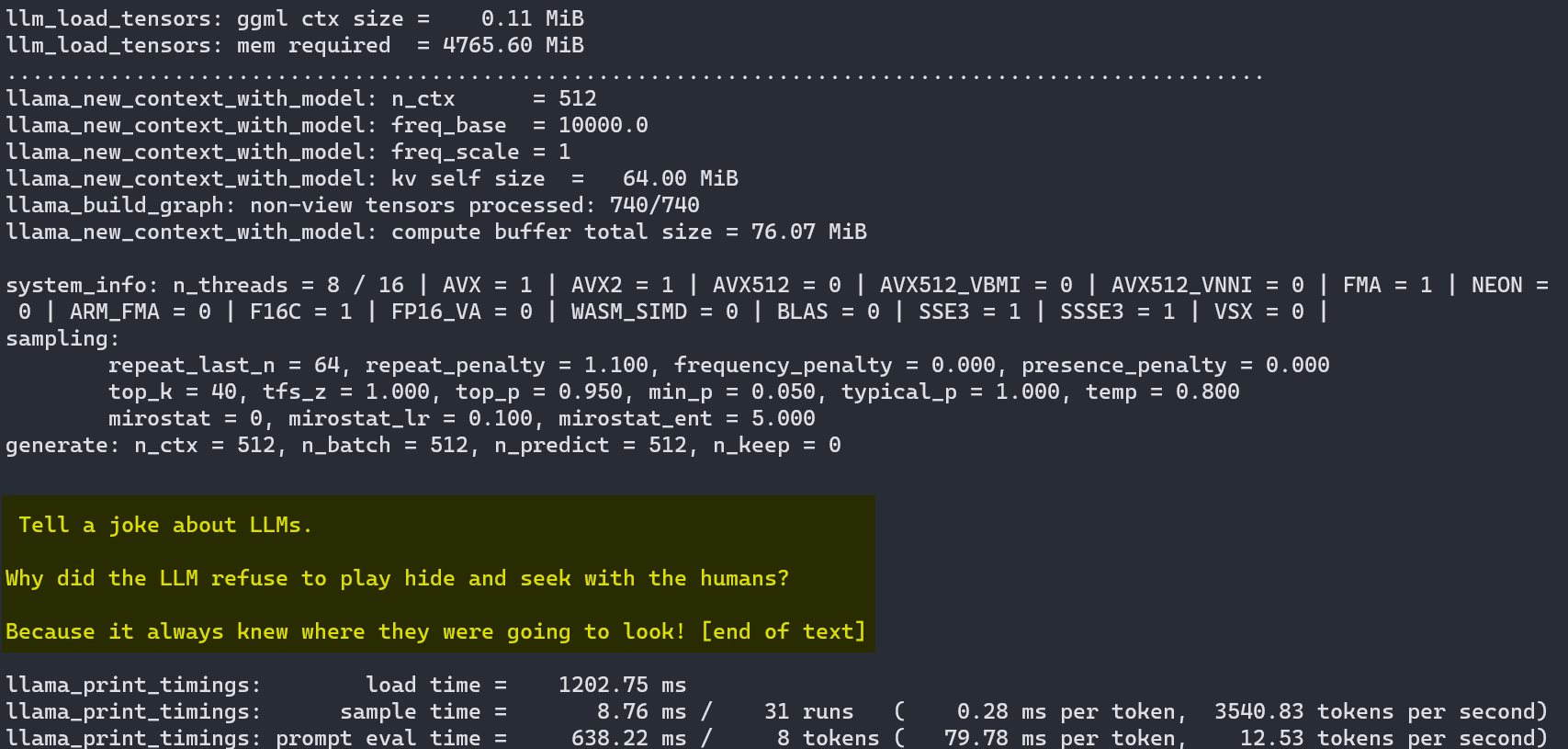
Beginner’s Guide: Setting up llama.cpp for Local LLM Experiments (GPU ...
Llama.cpp Inference | Claude Code Skill for Local AI
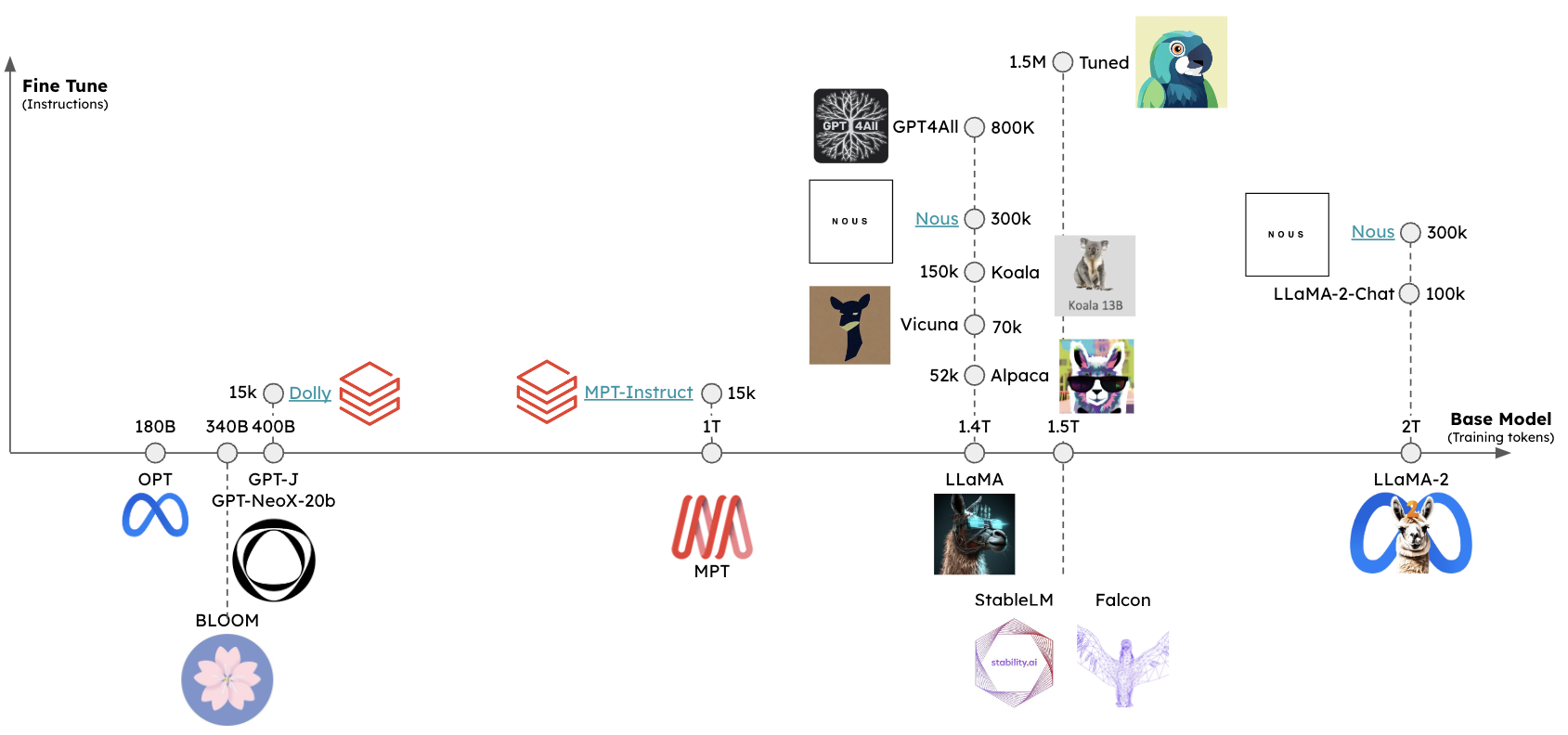
Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and ...
Local LLM Inference : llama.cpp, GGUF, Quantizations and GGML Explained
Engineer's Guide to Local LLMs with LLaMA.cpp on Linux - DEV Community
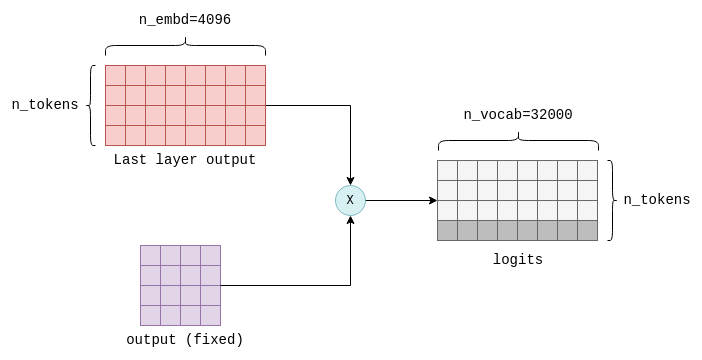
Understanding how LLM inference works with llama.cpp
How to compile LLM on Android using LLama.cpp | by mmonteiros | Medium
llama.cpp: Writing A Simple C++ Inference Program for GGUF LLM Models ...
Efficiently Run Your Fine-Tuned LLM Locally Using Llama.cpp 🚀 | by ...
Run LLMs Anywhere: Automate llama.cpp Installation for Local AI ...
Complete Guide to llama.cpp: Local LLM Inference Made Simple | by Huda ...
vLLM or llama.cpp: Choosing the right LLM inference engine for your use ...
Guide for Running Llama 2 Using LLAMA.CPP on AWS Fargate | by Rustem ...
GitHub - KevinSerres/llama_cpp: LLM inference in C/C++
Run LLM on Intel GPUs Using llama.cpp | by NeoZhangJianyu | Medium
Generative AI: LLMs: How to do LLM inference on CPU using Llama-2 1.9 ...
llama.cpp — CPU-optimized LLM inference in C/C++ with GGML quantization ...
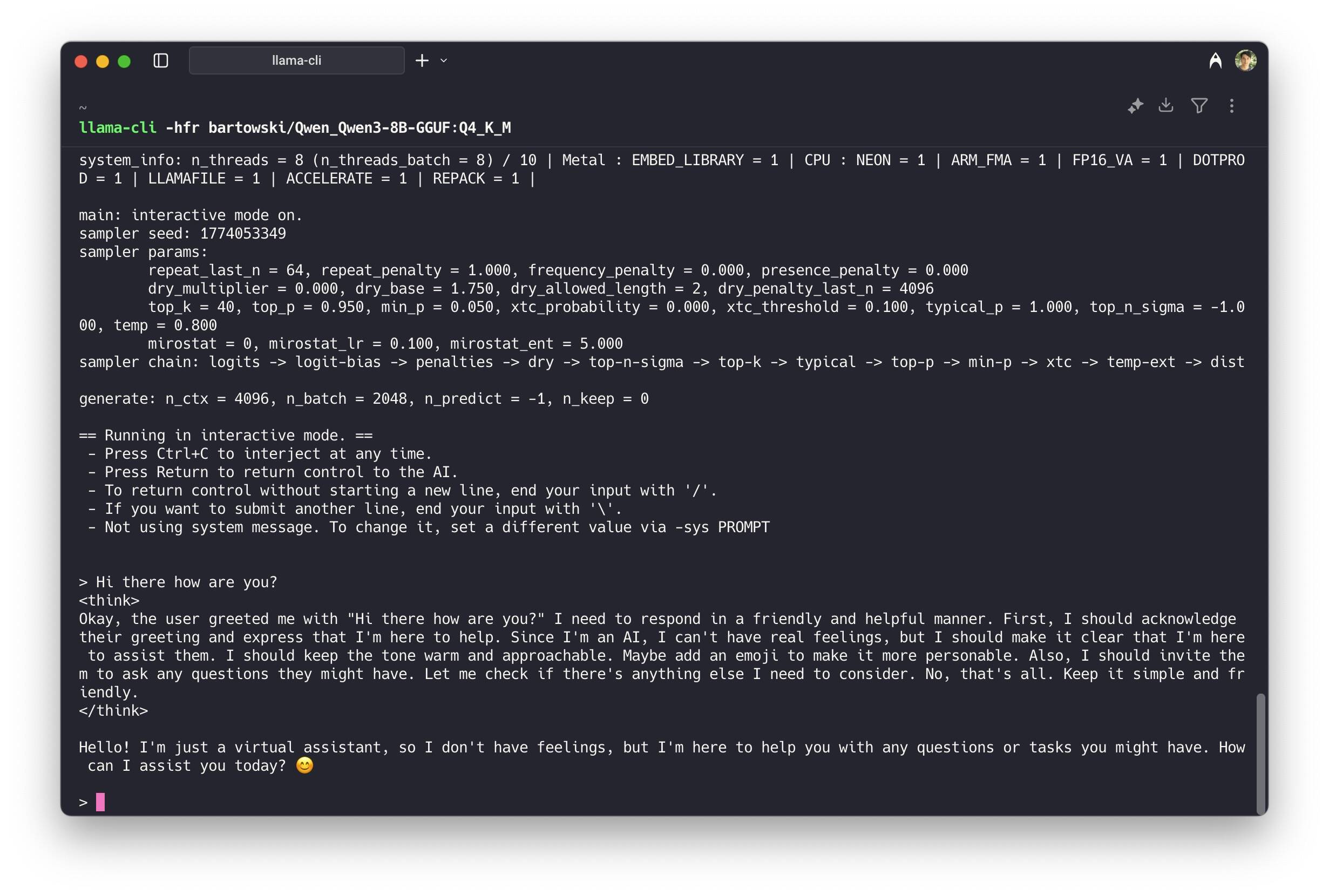
LLM By Examples: Utilizing Llama.cpp by Command Line Tools for CLI and ...
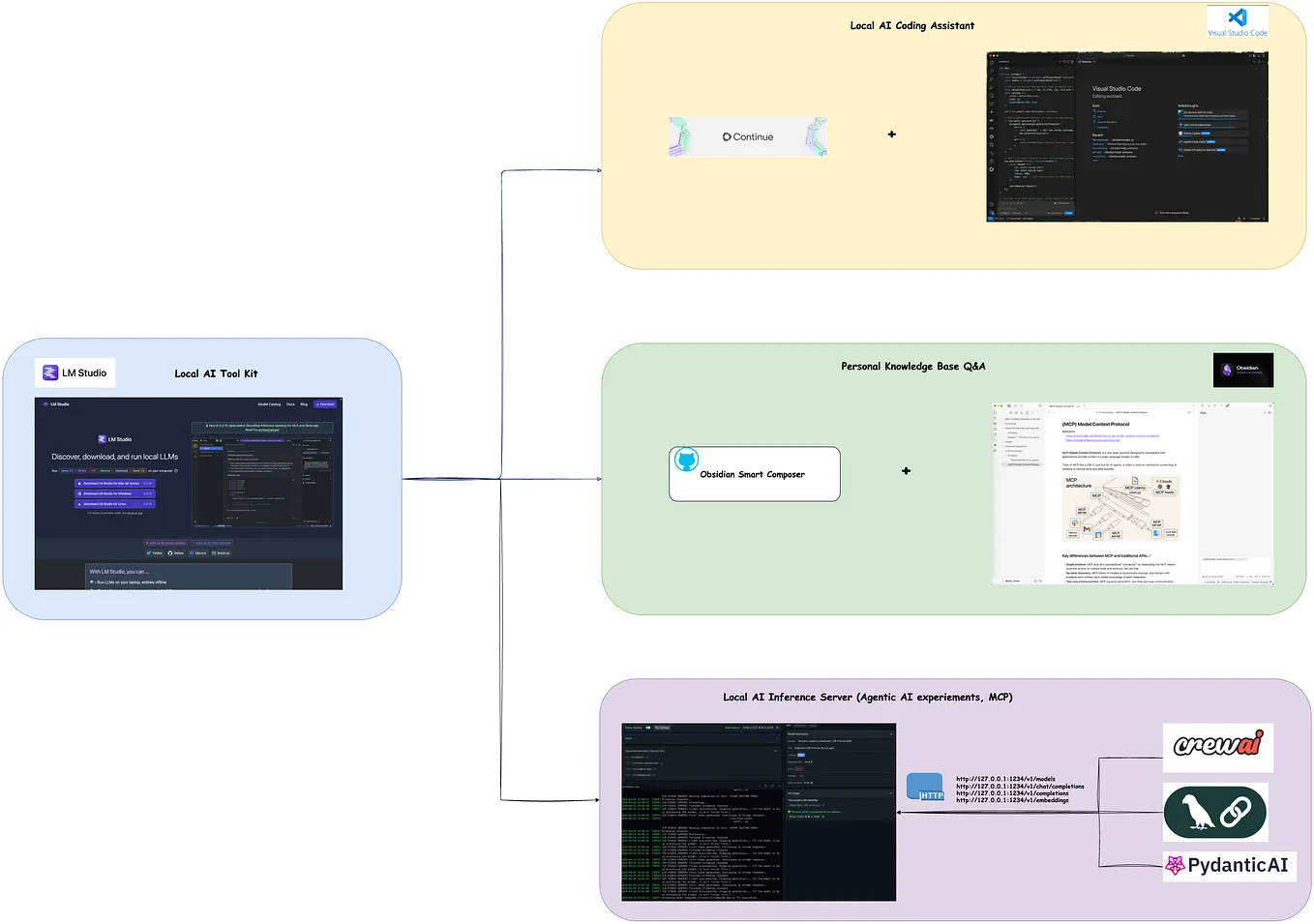
Streaming Local LLM Responses with LM Studio Inference Server | by ...
GitHub - thomas-steinberger-dev-ai/INTEL_ipex-llm: Accelerate local LLM ...
GitHub - loong64/llama.cpp: LLM inference in C/C++
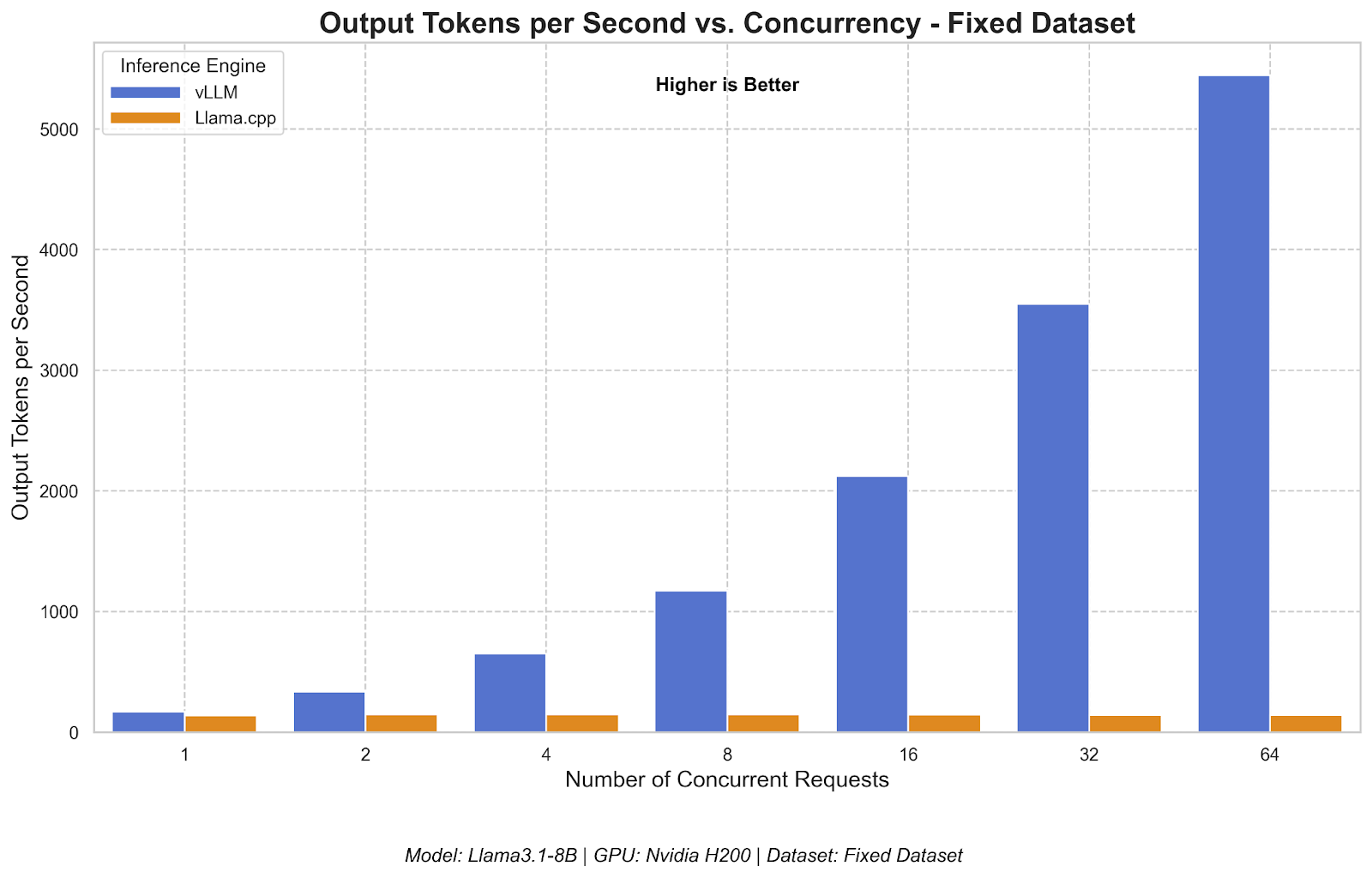
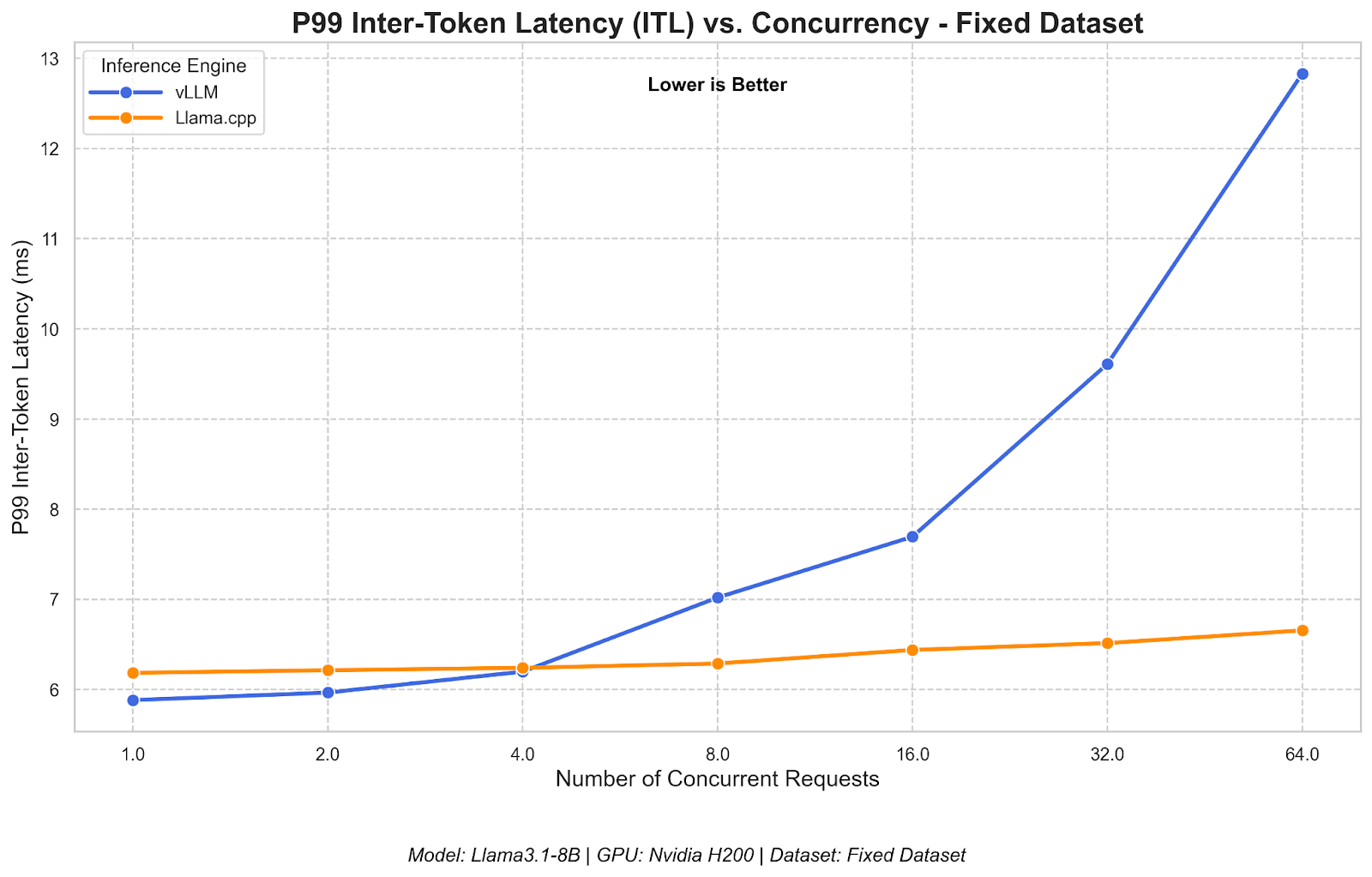
LLM inference server performances comparison llama.cpp / TGI / vLLM ...
GitHub - MarshallMcfly/llama-cpp: LLM inference in C/C++
llama.cpp (On device llm inference tool)
GitHub - LLabsTech/Llama.cpp: LLM inference in C/C++. This fork ...
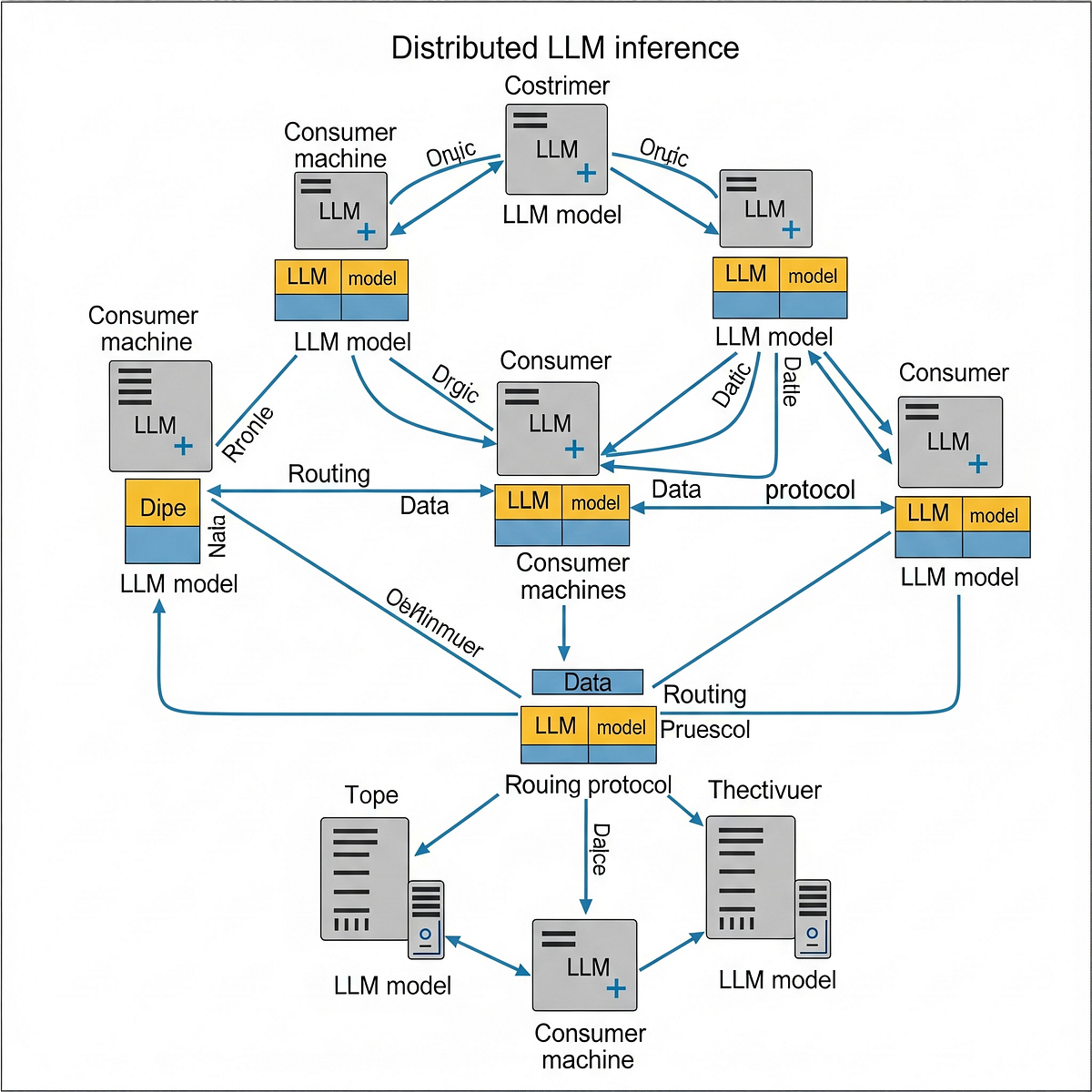
Distributed LLM Inference on Consumer Machines with llama.cpp: A Bare ...
A step by step guide to running a local LLM with llama-cpp-python ...
Explore llama.cpp architecture and the inference workflow | Arm ...
Démarrage rapide de llama.cpp avec CLI et serveur - Rost Glukhov | Site ...
llama.cpp: The Ultimate Guide to Efficient LLM Inference and ...
Llama.cpp Python Examples: A Guide to Using Llama Models with Python ...
llama.cpp: Fast Local LLM Inference, Hardware Choices & Tuning
Llama CPP Tutorial: A Basic Guide And Program For Efficient LLM ...
Free Video: LLMOps: Installing LLaMA.cpp - Text Generation and ...
Build from Source Llama.cpp with CUDA GPU Support and Run LLM Models ...
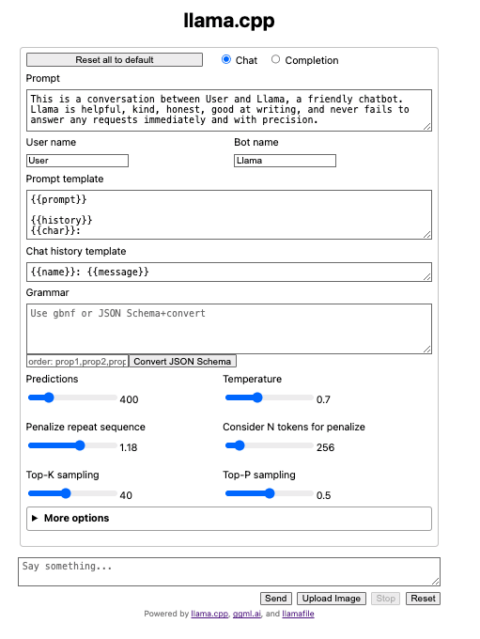
llama.cpp Inference
Demystifying Chat Templates of LLM using llama-cpp and ctransformers ...
Run any LLM on Distributed Multiple GPUs Locally Using Llama_cpp | by ...
How to Run Local AI on Android with llama.cpp and Termux
[机器学习]-如何在 MacBook 上安装 LLama.cpp + LLM Model 运行环境_macbook跑llm-CSDN博客
llama.cpp guide - Running LLMs locally, on any hardware, from scratch
🦙 Optimize Your LLM Models and Save Costs with llama.cpp Quantization 🦙 ...
Optimizing llama.cpp AI Inference with CUDA Graphs | NVIDIA Technical Blog
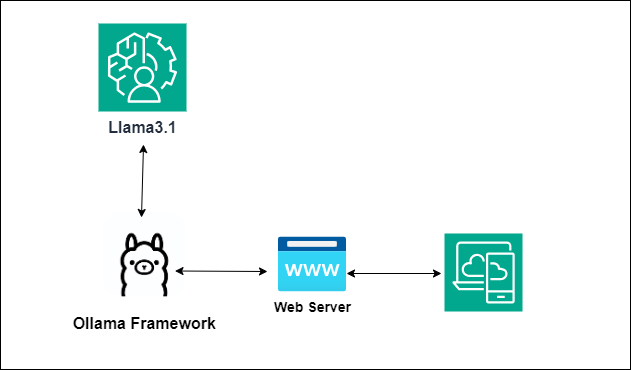
Run LLMs (Llama 3) Locally with llama.cpp | Medium
A Quick Guide to Containerizing Llamafile with Docker for AI ...
Simplified Tutorial on Running LLMs (Llama 3) Locally with llama.cpp ...
The 6 Best LLM Tools To Run Models Locally
Running OpenAI’s server Locally with Llama.cpp | by Tom Odhiambo | Medium
How To Run LLMs Locally - Deployment And Benchmark
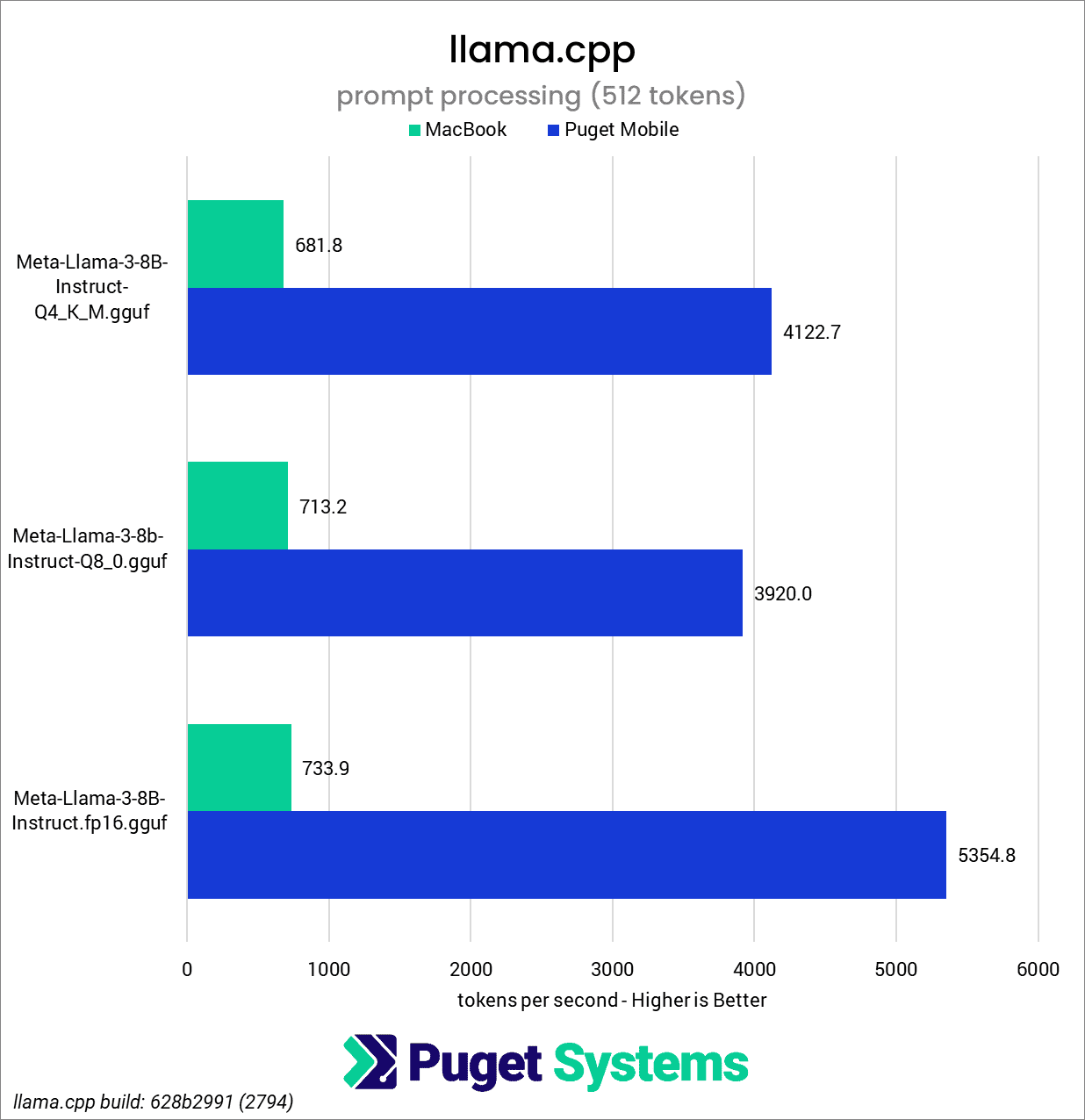
Puget Mobile 17" vs M3 Max MacBook Pro 16" for AI Workflows | Puget Systems
Quantization of LLMs with llama.cpp | by Ingrid Stevens | Medium
[LLM-Llama]MAC M1 安装llama-cpp-python体验完全 OpenAI API 的玩法 - 知乎
Quantize Llama models with GGUF and llama.cpp | Towards Data Science
Llama-CPP-Python: Step-by-step Guide to Run LLMs on Local Machine ...
I Switched From Ollama And LM Studio To llama.cpp And Absolutely Loving It
Use llama.cpp with BigDL-LLM on Intel GPU — BigDL latest documentation
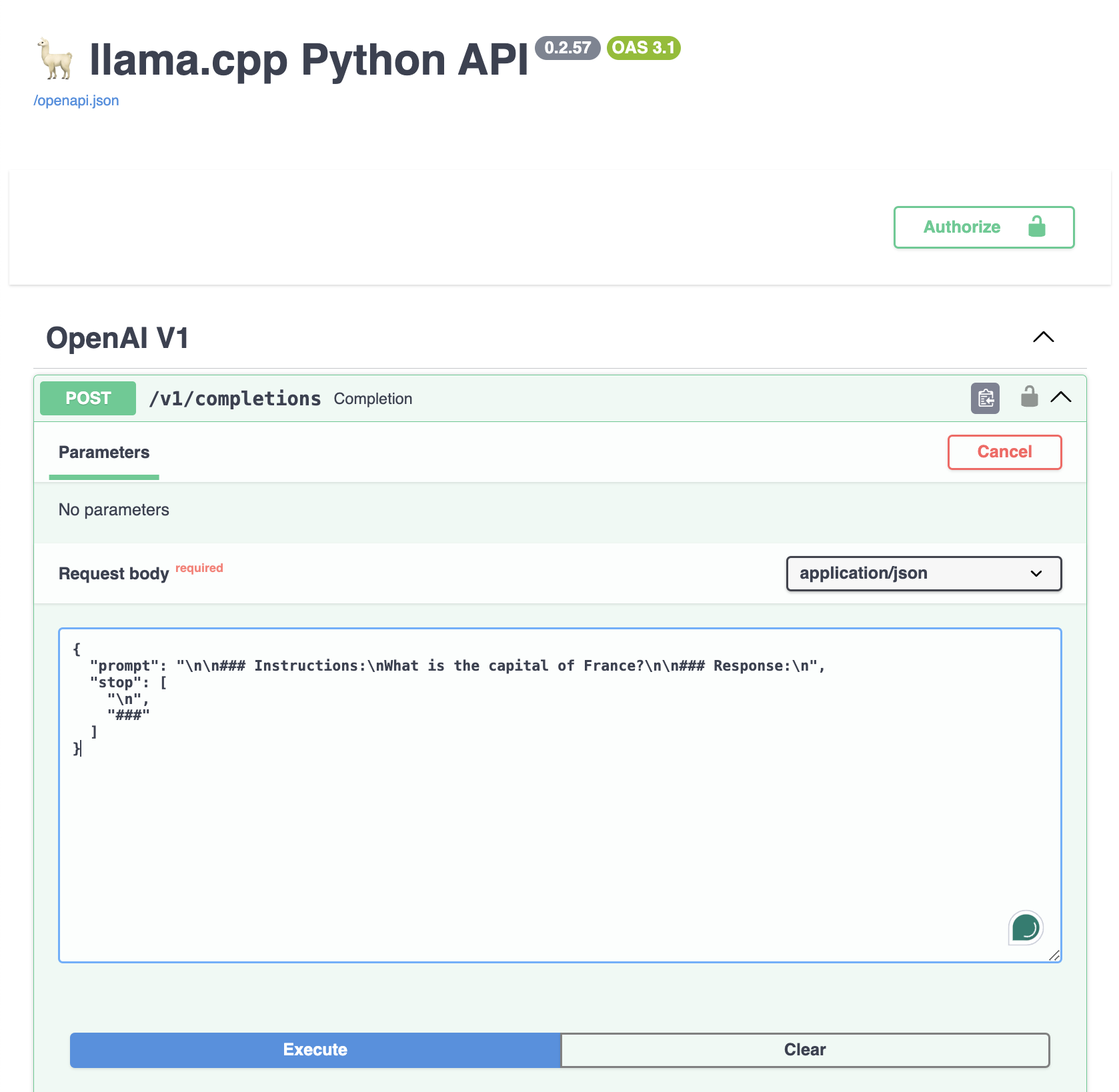
Mastering the Llama.cpp API: A Quick Guide
How to deploy LLama 2 as an AWS Lambda function for scalable serverless ...
Llama.cppを使ったローカルLLM環境構築紹介 - KUSANAGI Tech Column
Running LLaMA Locally with Llama.cpp: A Complete Guide | by Mostafa ...
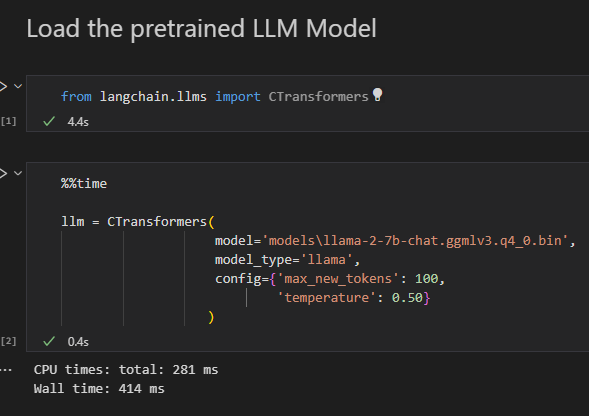
Running Quantized LLAMA Models Locally on macOS with LangChain and ...
Llama On Cpu
tools/quantize/README.md · rohan23998/llama-cpp-model at main
CLI vs IDE: Which Boosts Coding Productivity Most?
Free software 'llama.cpp' that can run various AI models locally ...
一文熟悉新版llama.cpp使用并本地部署LLAMA
Running Lightweight Language Models Locally: A Practical Setup Guide ...
【llama-cpp-python】ローカル環境でのLLMの使い方! | EdgeHUB
ローカルPCでLLMを動かす(llama-cpp-python) | InsurTech研究所
Running LLaMA Models Locally on your machine-macOS: A Complete Guide ...
Install llama-cpp-python with GPU Support | by Manish Kovelamudi | Medium
Seven Ways of Running Large Language Models (LLMs) Locally (April 2024)