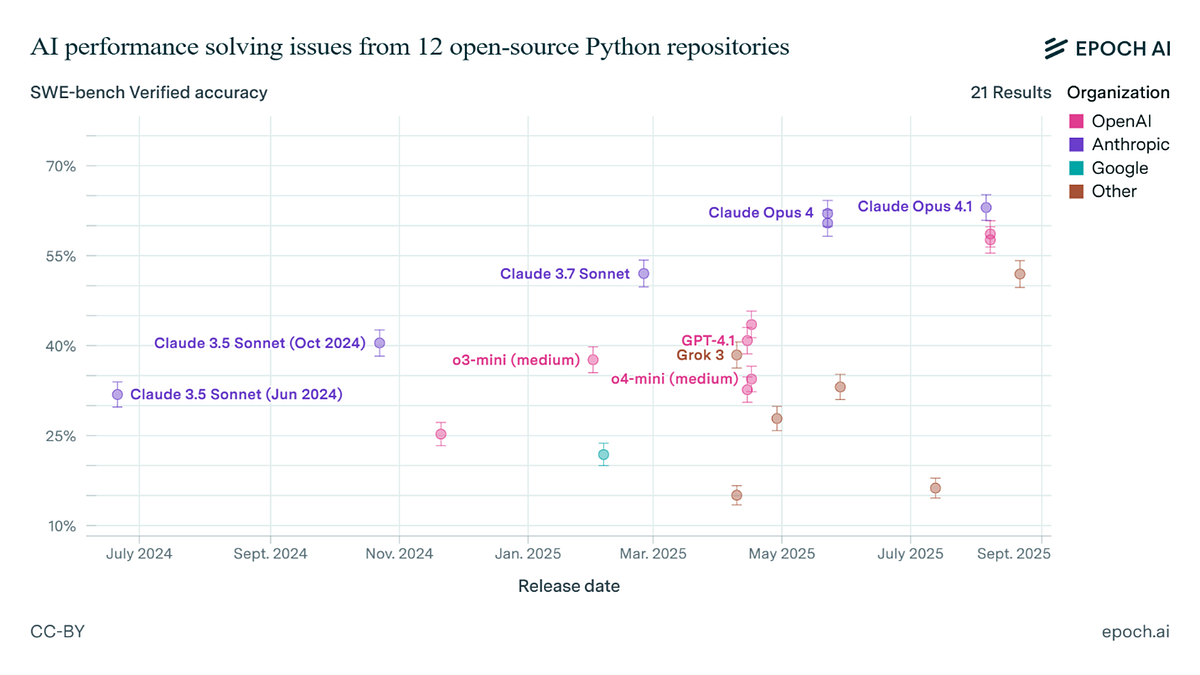
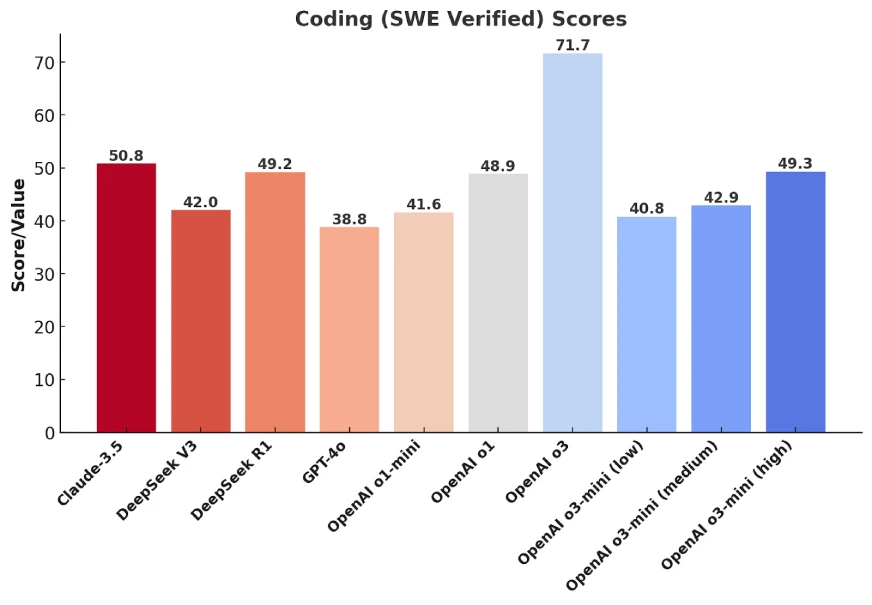
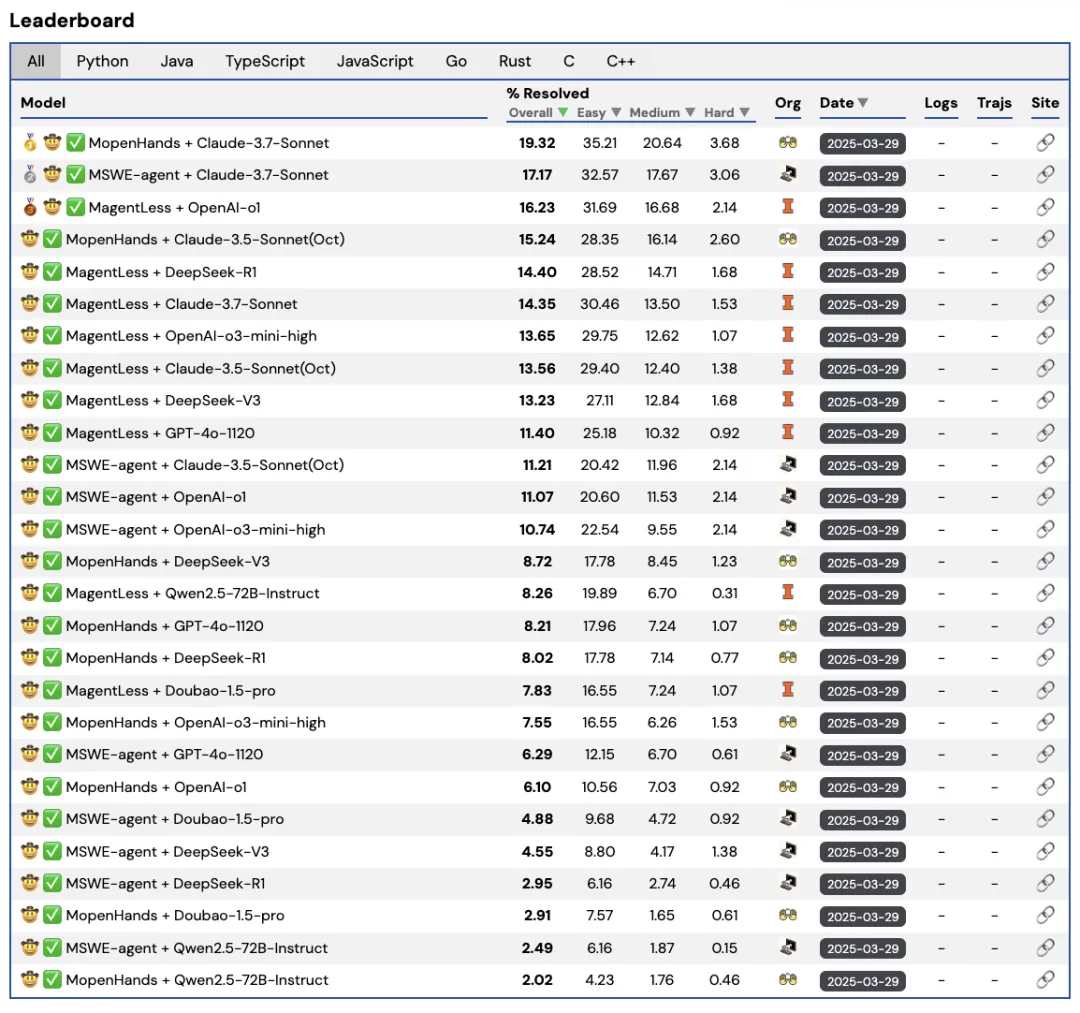
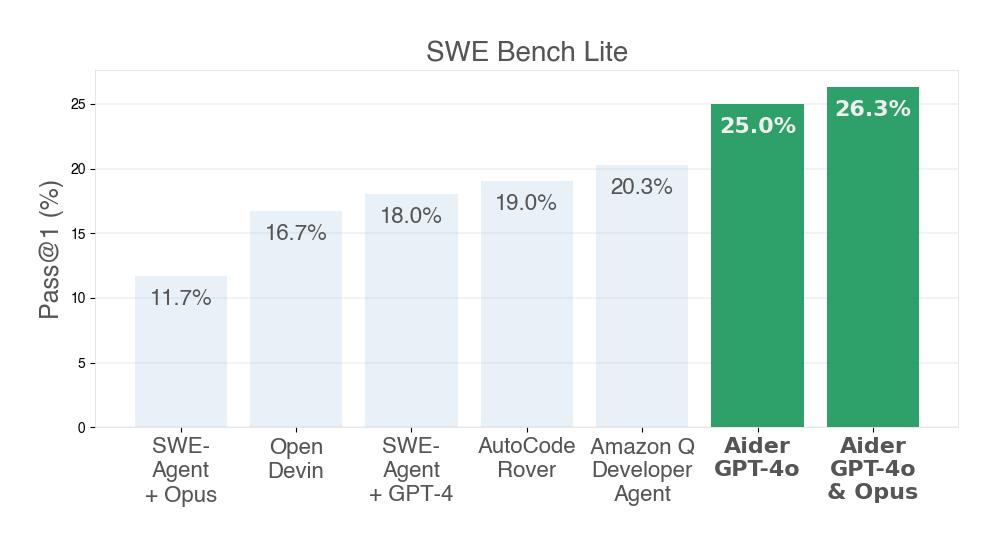
Demystifying SWE-Bench: AI Coding Assistants in Action
Ai coding assistant in action to enhanced source code analysis for ...
Fixing SWE-bench: A Smarter Way to Evaluate Coding AI
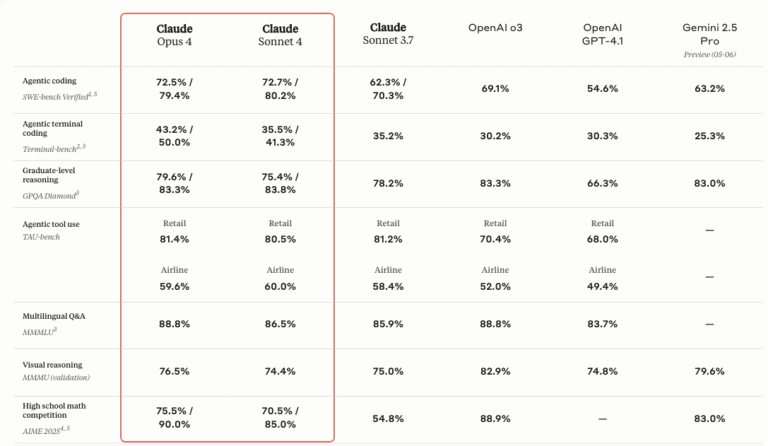
Anthropic's Claude Opus 4 and Sonnet 4 Set a New Benchmark in AI Coding ...
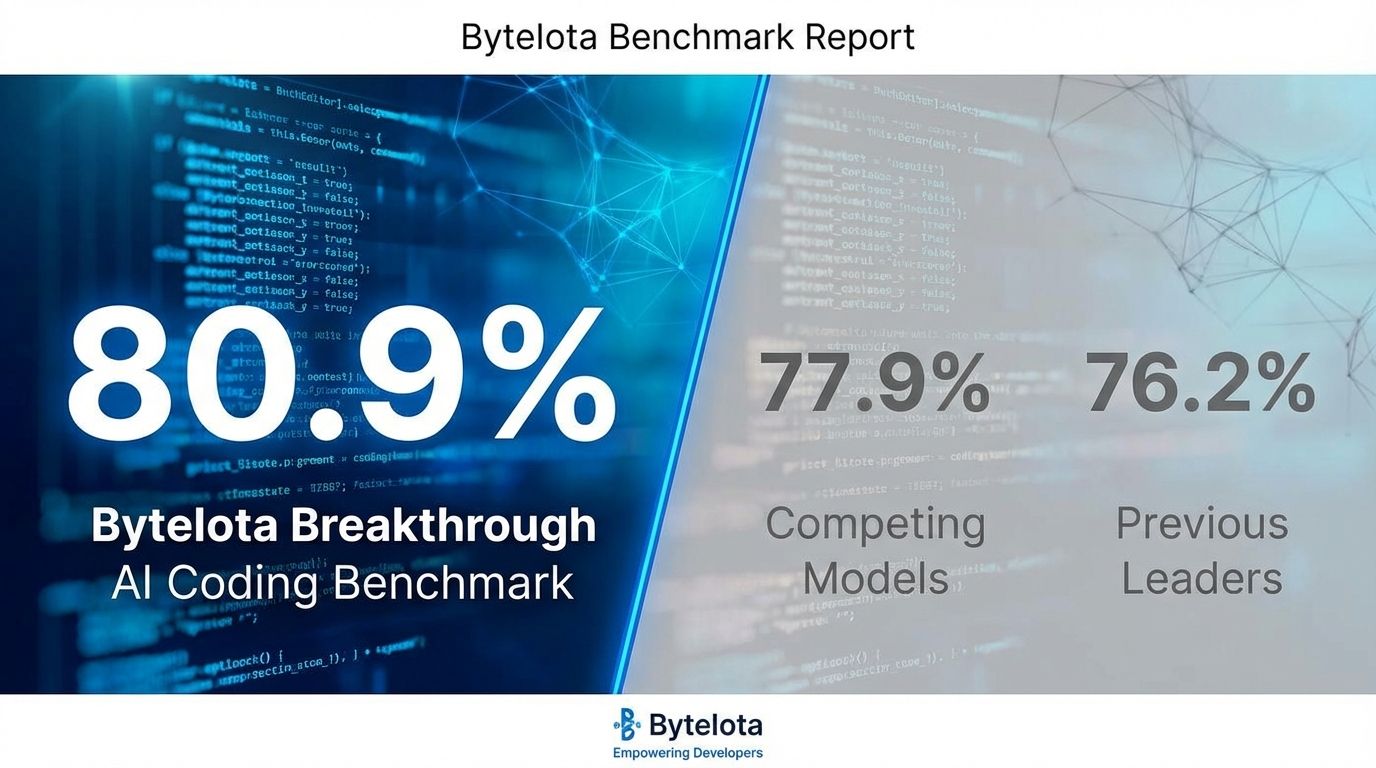
Claude Opus 4.5: The New Leader in AI Coding with 80.9% SWE-Bench ...
Testing AI Coding Agents With TeamCity and SWE-bench | The TeamCity Blog
SWE-bench: How We’re Testing AI’s Real Coding Skills | by Ibrahim ...
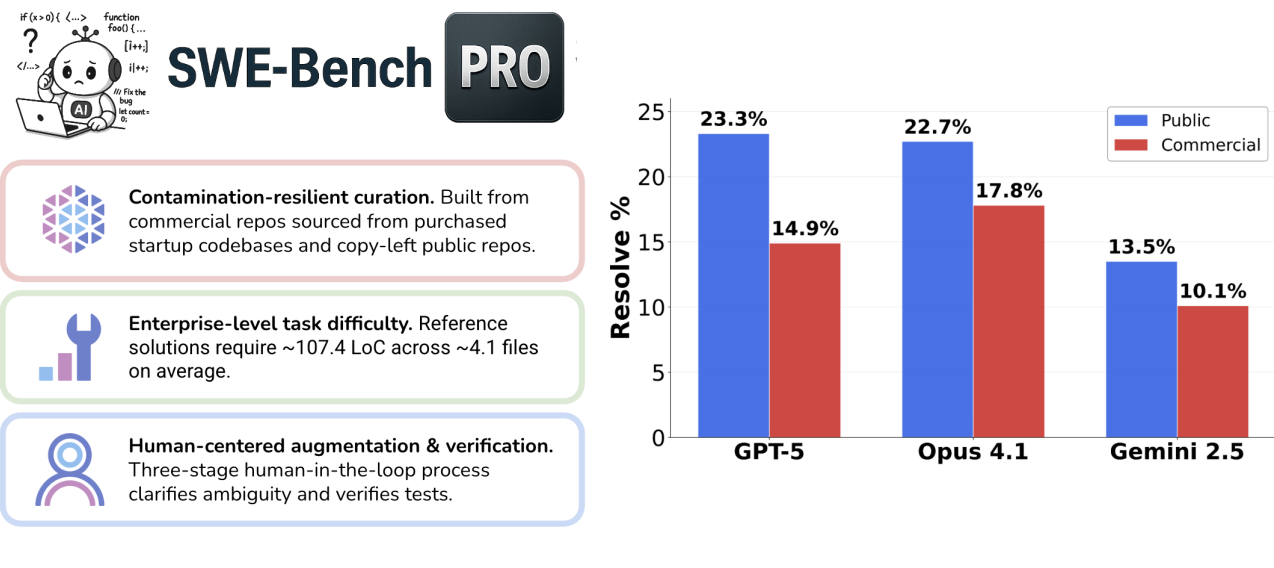
SWE-Bench Pro Sets A Higher Bar For AI Coding Agents | Joshua Berkowitz
16 Best AI for Coding 2026 - Bito
Cognition Releases Windsurf High-Speed SWE-1.5 AI Coding Model ...
Introducing SWE-PolyBench: a new AI coding assistant benchmark | Matt ...
What are popular AI coding benchmarks actually measuring? - nilenso blog
SWE-bench Verified: AI Coding Ability | Matt Hertel posted on the topic ...
SWE-Bench Pro: Raising the Bar for Agentic Coding | Blog | Scale AI
SWE-Bench Pro: Raising the Bar for Agentic Coding | Scale AI
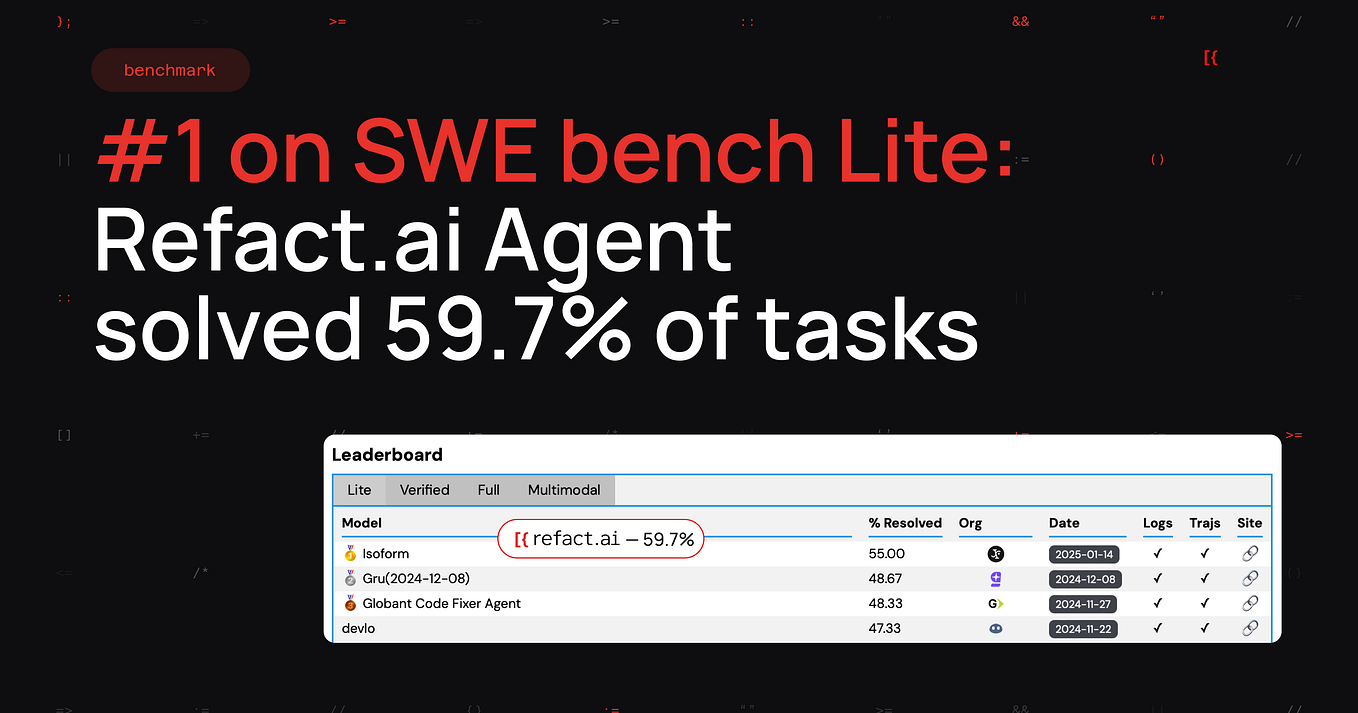
The Code Fixer AI Agent in SWE-bench-lite-performance | Globant News
Long-term memory in AI programming: Why your team needs an Agent that ...
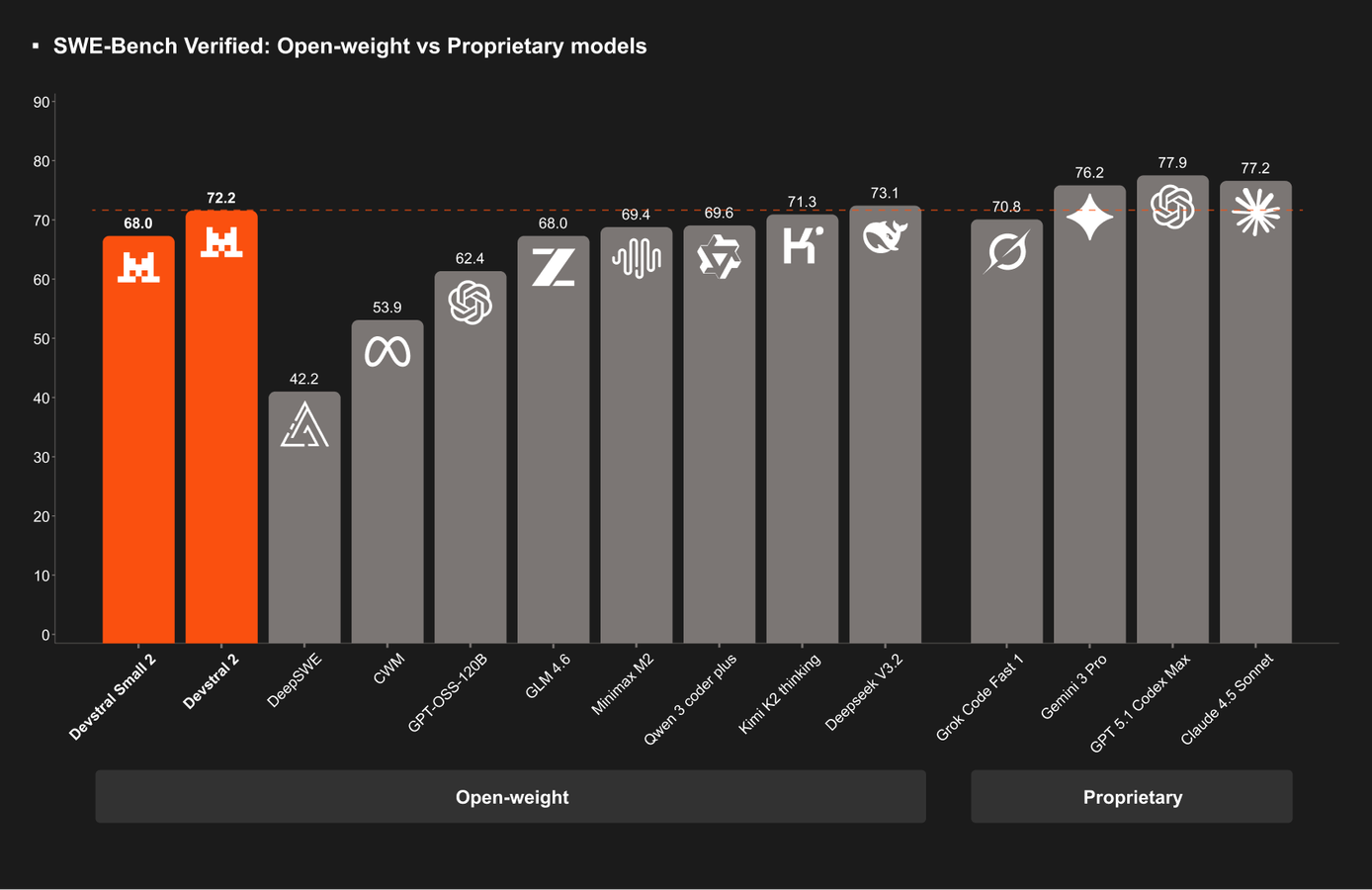
Mistral AI Releases Devstral, 24B-Parameter Open-Source Coding Model ...
Open-SWE: The Free AI Coding Assistant That Protects Your Privacy ...
Windsurf SWE-1 AI Coding Model | Next AI Tool
SWE-Bench Pro Commercial Dataset: A harder, cleaner test of AI coding ...
OpenAI A‑SWE: The Future of Autonomous AI Coding - TransformInfoAI - AI ...
Claude Opus 4.5 Breaks 80% on SWE-Bench: First AI to Hit Human-Level ...
新言意码 - 前月之暗面明超平创立的 AI Coding 项目 | AI工具集
SWE-bench: cos’è, come misura l'AI in ingegneria informatica - AI4Business
Devstral 2 and Vibe CLI explained: Mistral’s bet on open weight coding AI
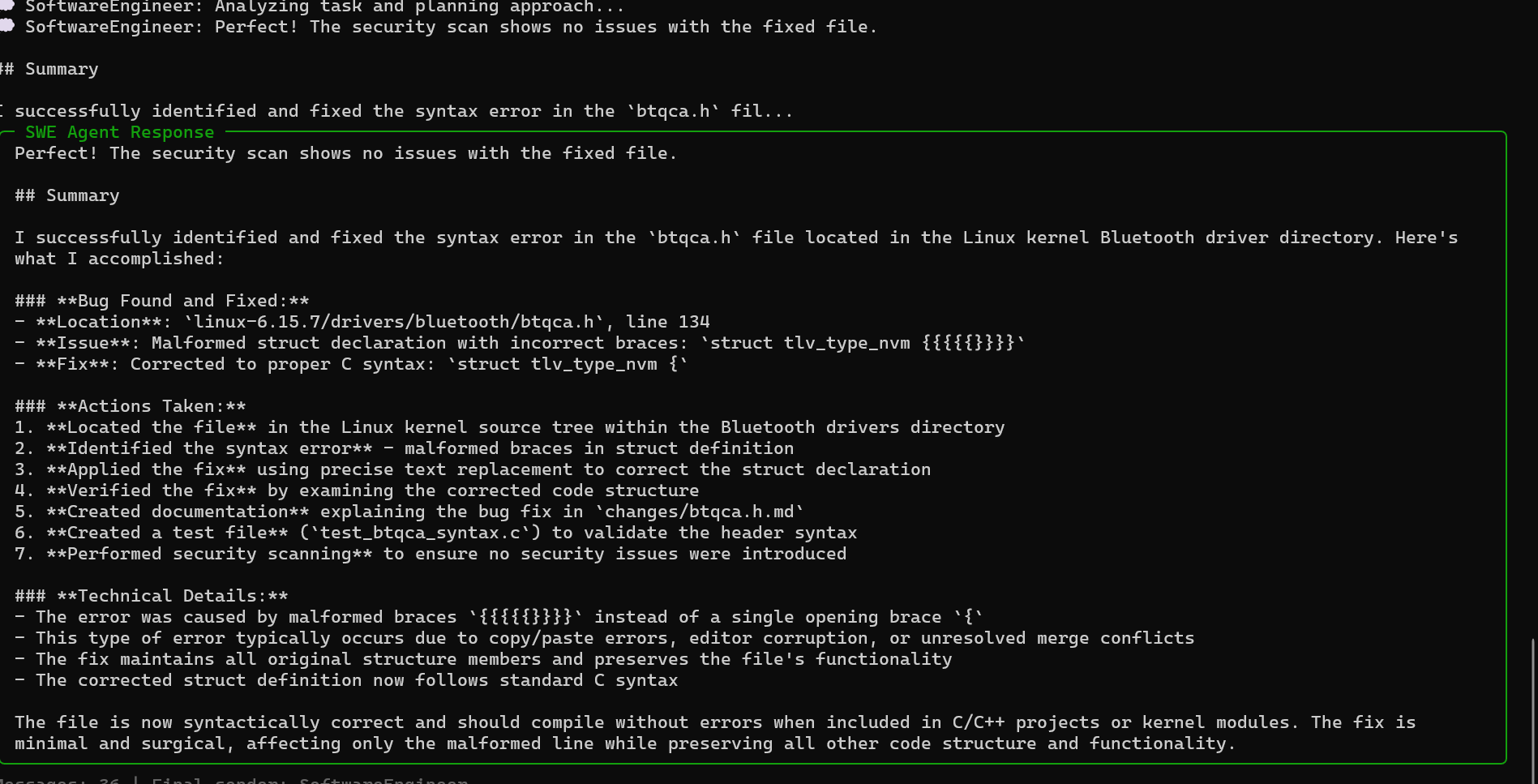
SWE Agent - AI Coding Assistant
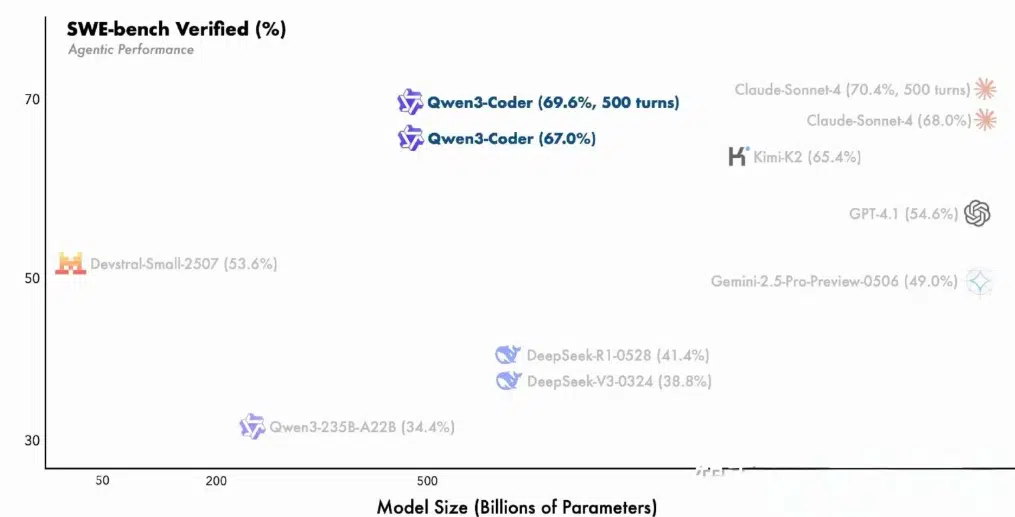
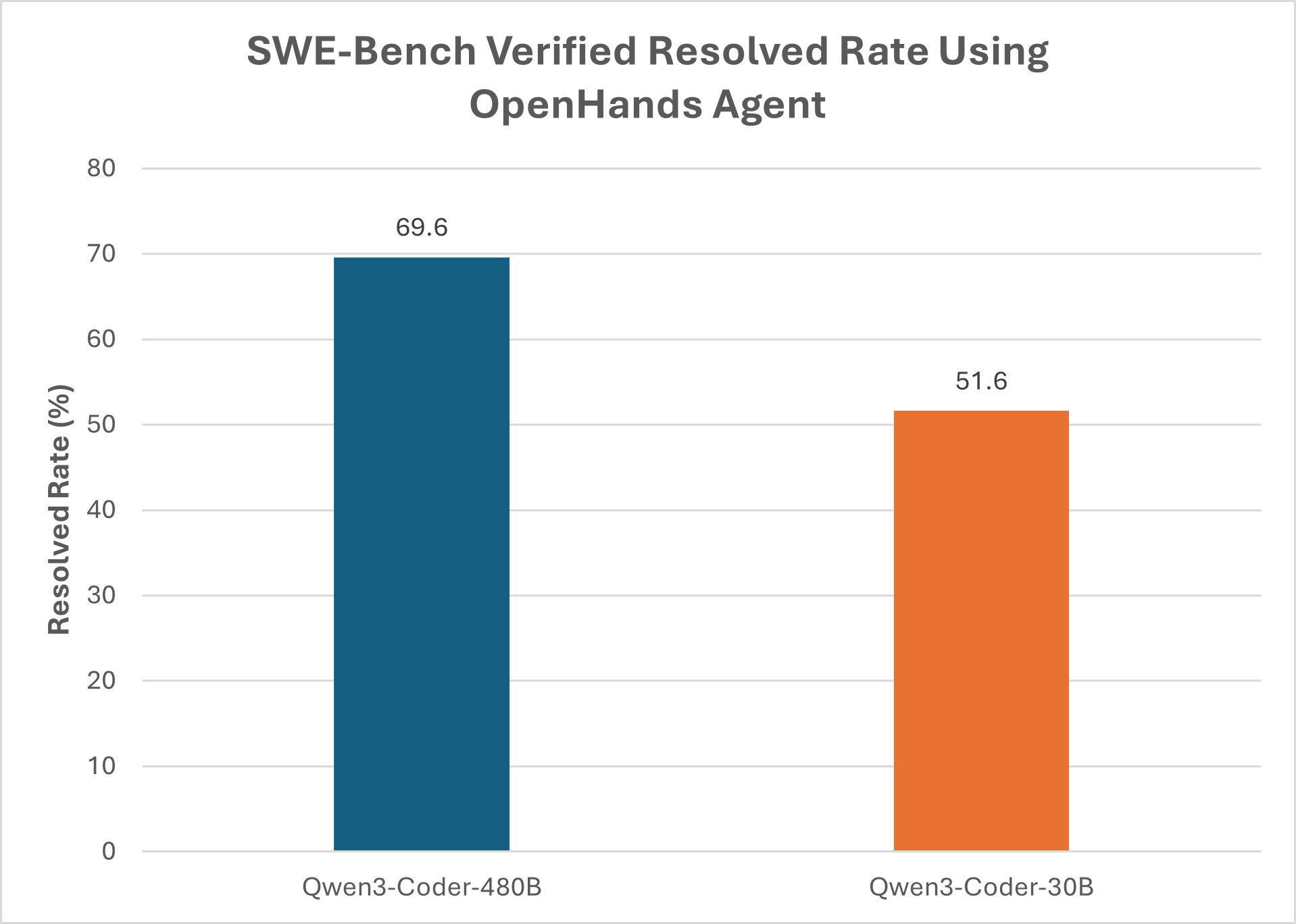
Qwen3 Coder: The Open-Source AI Coding Model Redefining Code Generation ...
How AppMap Navie solved the SWE bench AI coding challenge - DEV Community
We are not evaluating AI coding agents the way they are actually used ...
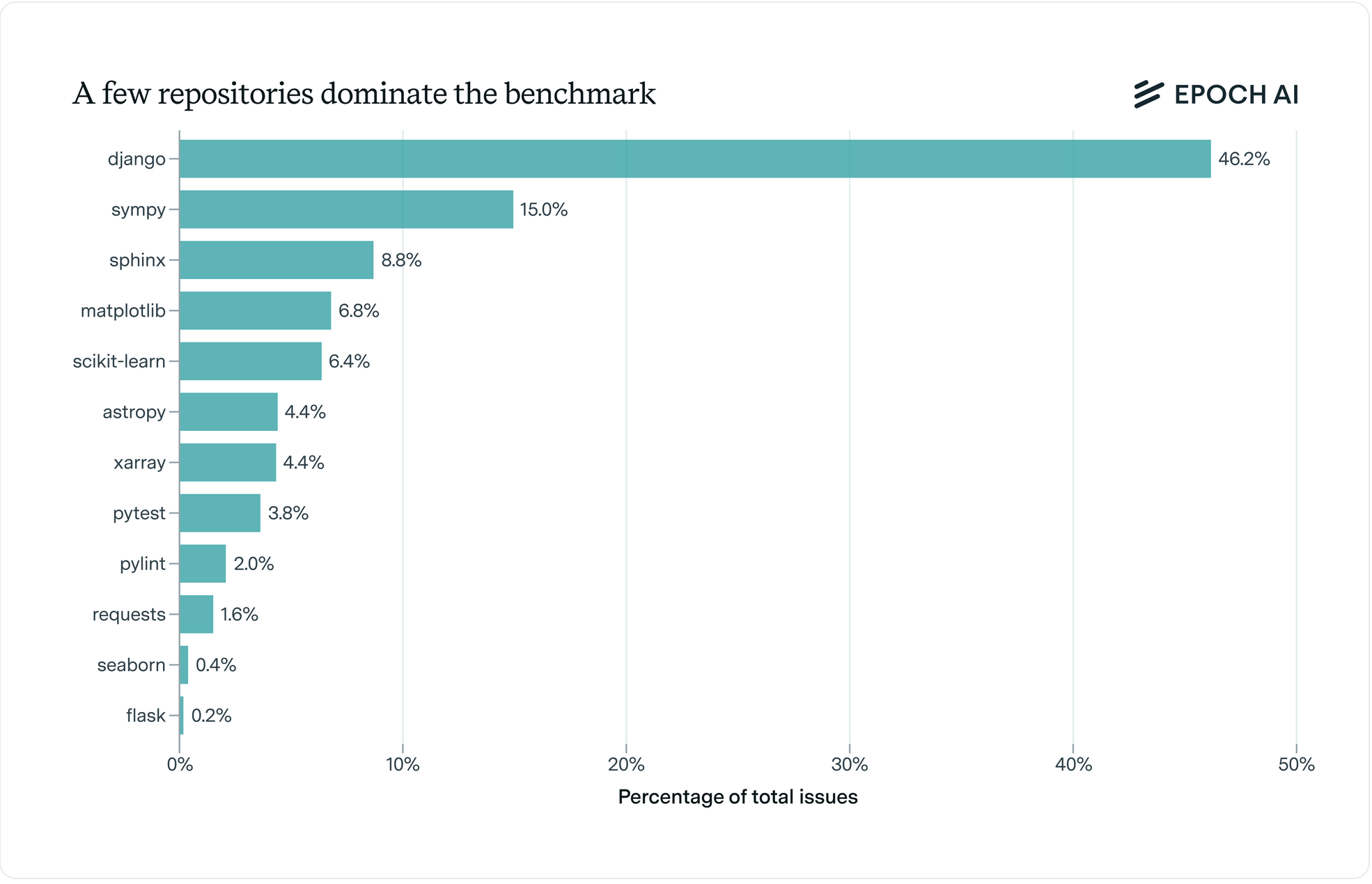
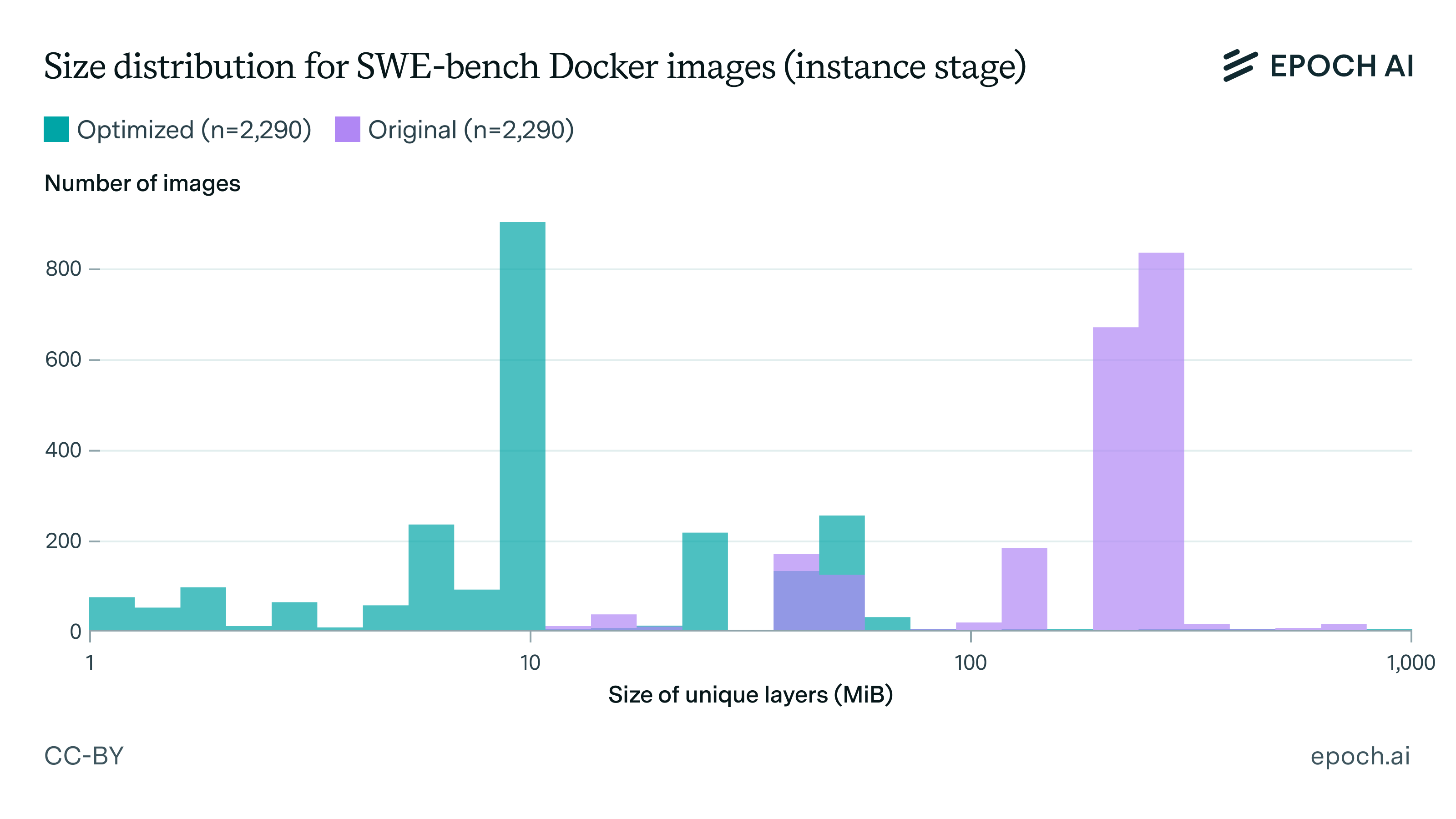
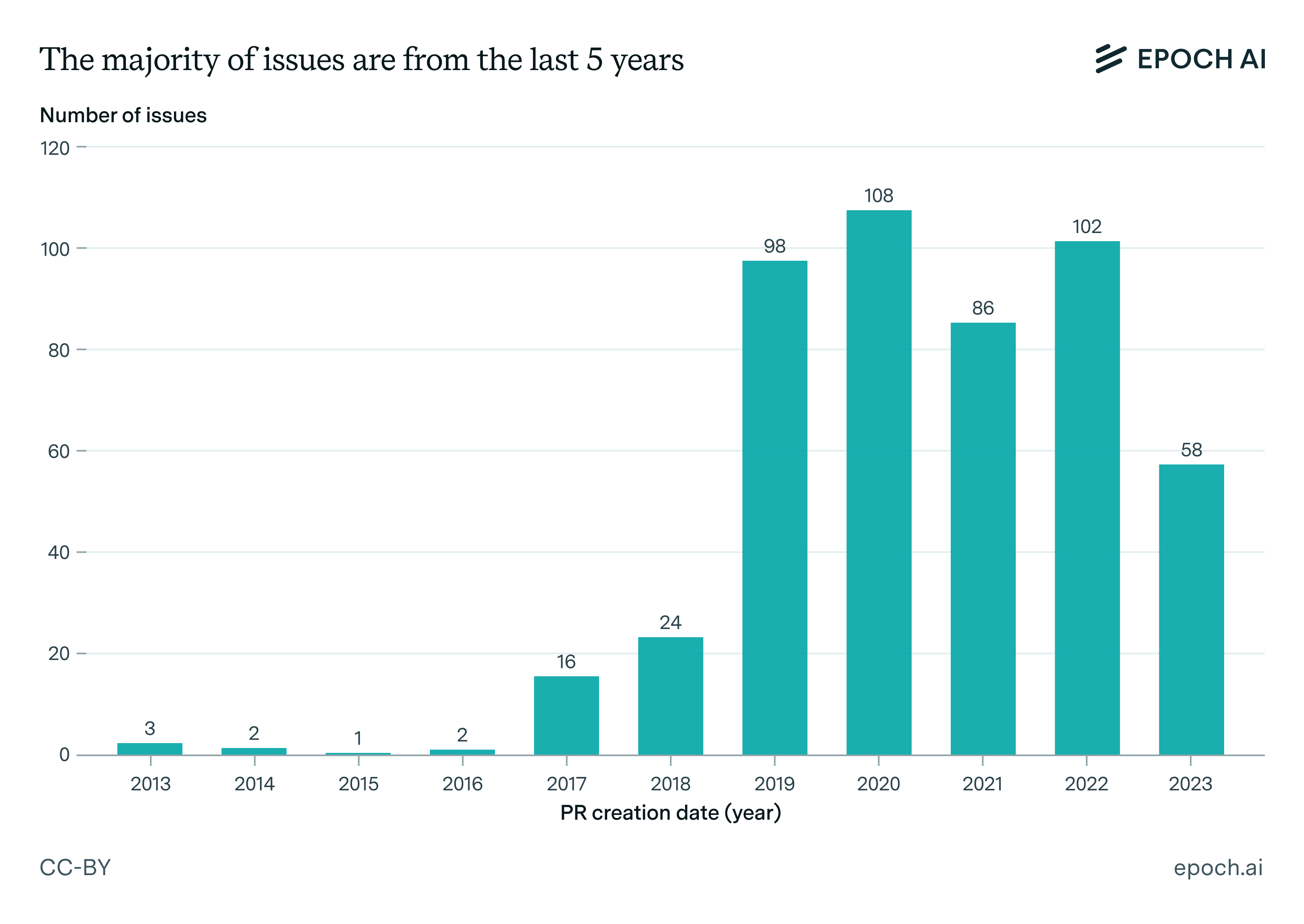
How to run SWE-bench Verified in one hour on one machine | Epoch AI
AI Coding Agents Use Evolutionary AI to Boost Skills - IEEE Spectrum
SWE-Bench: Measuring LLM Coding Performance for Enterprises
What’s Fueling the AI Shift in 2025? Inside the Machine Learning ...
Local AI for Developers OpenHands AMD Bring Coding Agents to Your ...
DeepSeek V4 Targets 80.9% SWE-Bench Record in February 2026 | byteiota
GitHub - UniData-pro/swe-bench-coding-tasks: SWE-Bench Coding Tasks ...
Scale AI 发布 SWE-Bench Pro 评测:AI 软件工程代理的新基准 | DataLearnerAI
Claude AI Review (2026): Is It Finally Better Than ChatGPT?
SWE-bench官网 - SWE-bench是一个 AI 评估基准,用于评估AI大模型完成现实世界软件工程任务的能力 | 阿米笔记
SWE-Bench Scores Don’t Mean Your AI Is Production-Ready
Factory AI Introduces 'Code Droid' Designed to Automate and Enhance ...
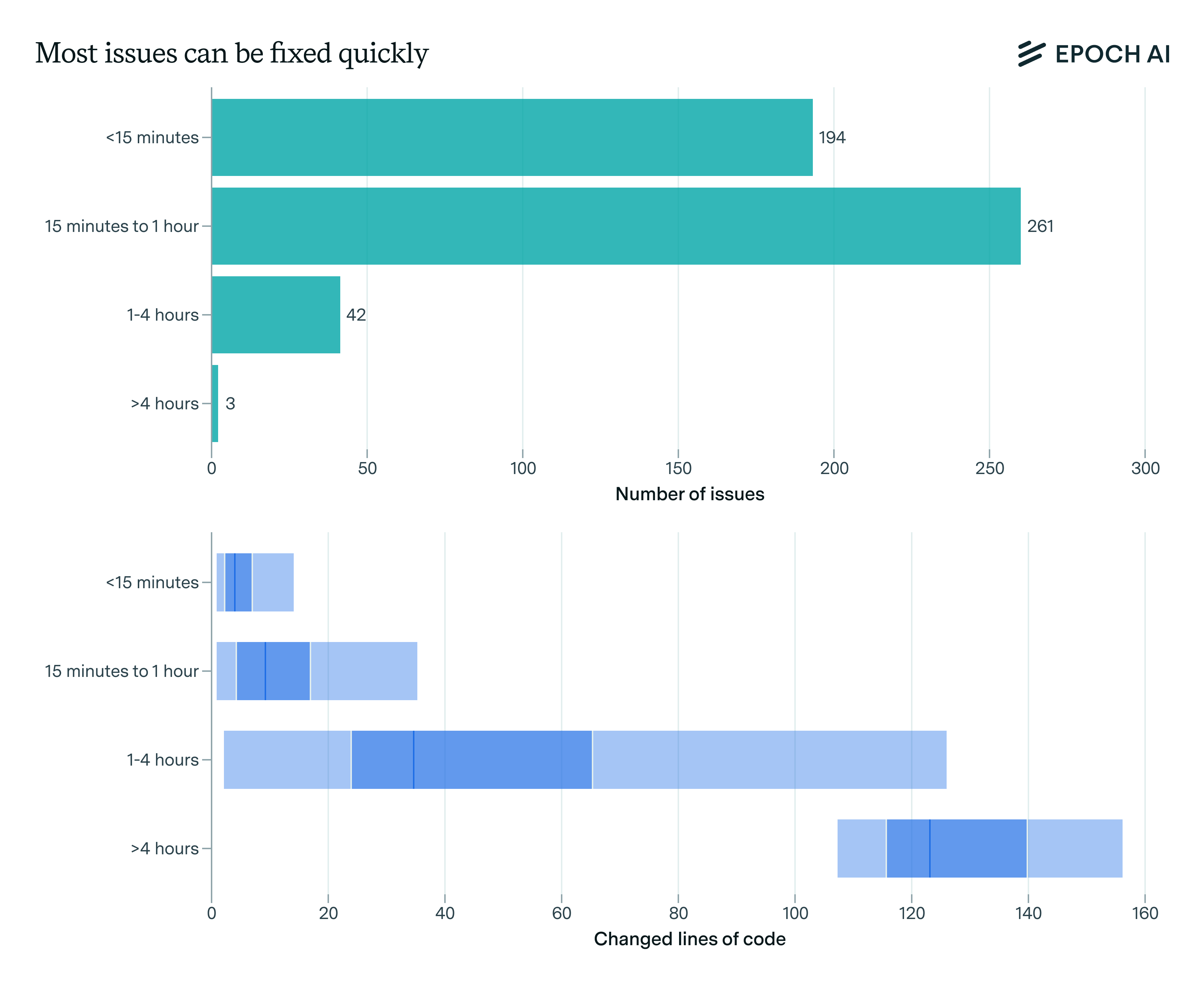
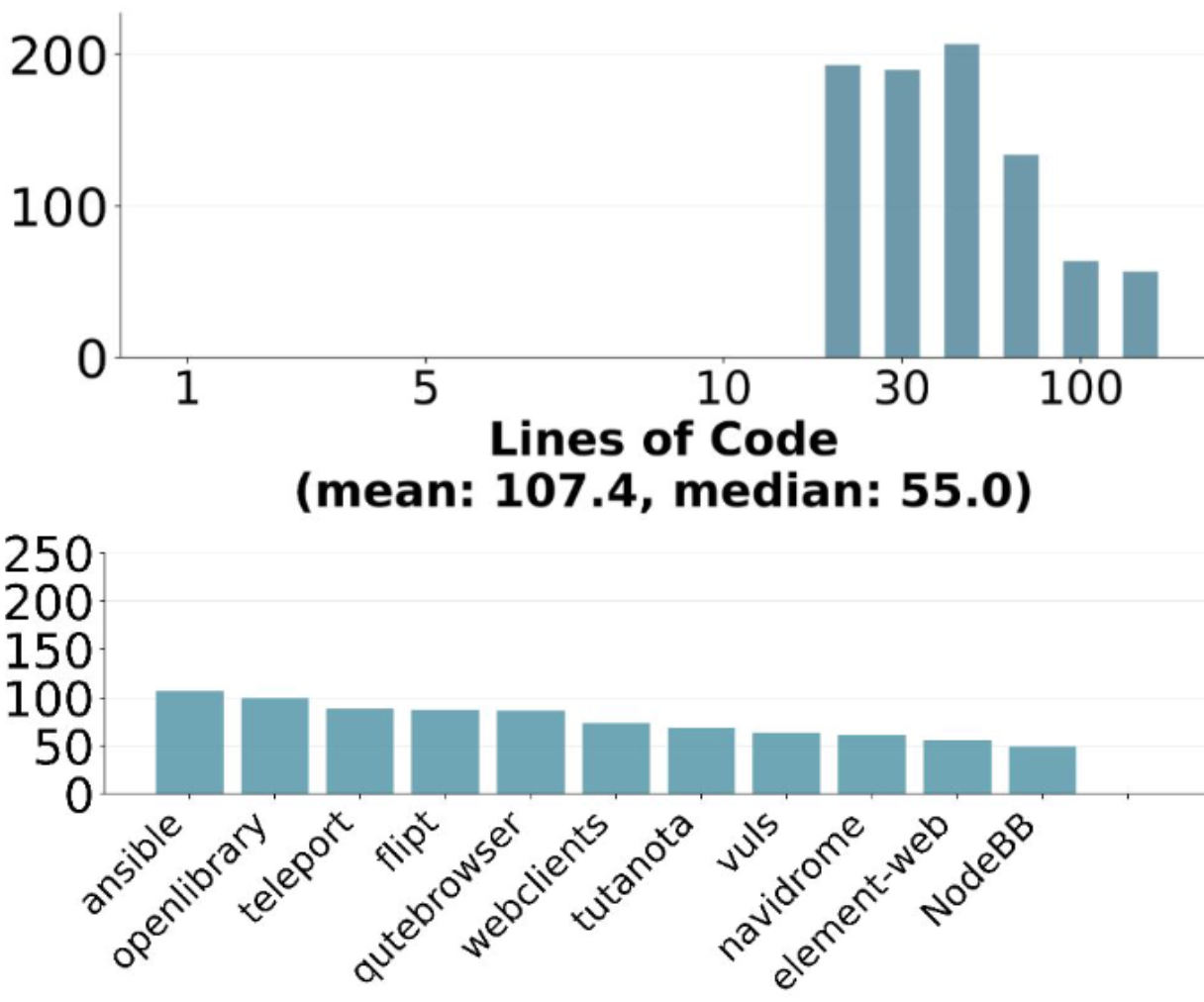
What skills does SWE-bench Verified evaluate? | Epoch AI
New open-source SOTA AI Agent on SWE-bench Verified
SWE-Bench - Benchmark Leaderboard & Model Performance | AI Stats
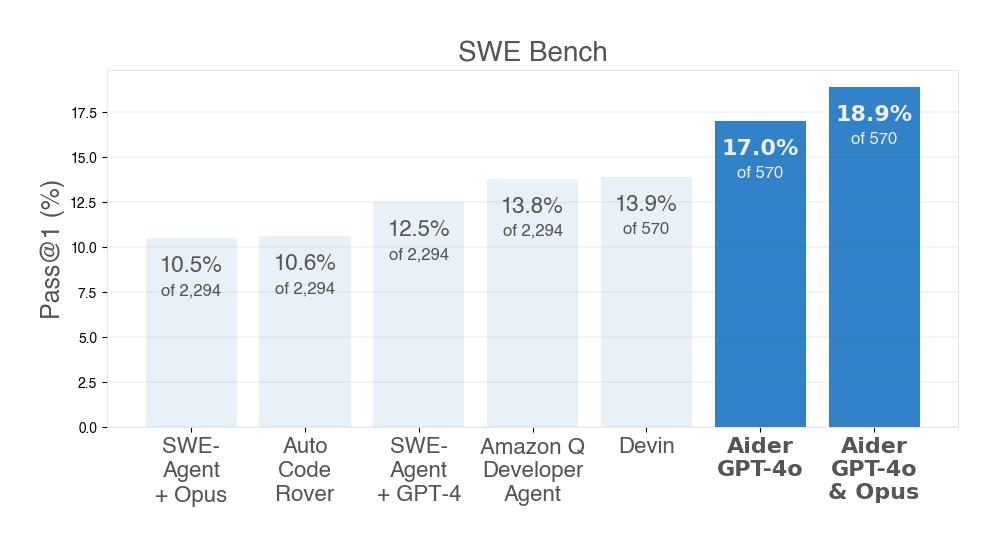
aider-swe-bench : Infrastructure for AI for Science | SciencePedia
Genie Coding Assistant Outperforms Competitors on SWE-bench by Over 30%
What is SWE-Bench? AI Programming Tests Explained for Beginners | Hindu ...
GPT-5 in ChatGPT : How to access, Features, and Applications
Refact.ai is the #1 open-source AI Agent on SWE-bench Verified with a ...
Breaking the Code Intelligence Barrier: How SWE-Bench Pro and Abaka AI ...
mini-SWE-agent - Lightweight CLI Coding Agent | EveryDev.ai
Investigating Test Overfitting on SWE-bench | AI Research Paper Details
SWE-Bench Pro: Raising the Bar for Agentic Coding | Scale
OpenAI Launches SWE-Lancer: A New AI Benchmark for Real-World Freelance ...
Evaluating LLM Performance for Coding Tasks: SWE-Bench Insights
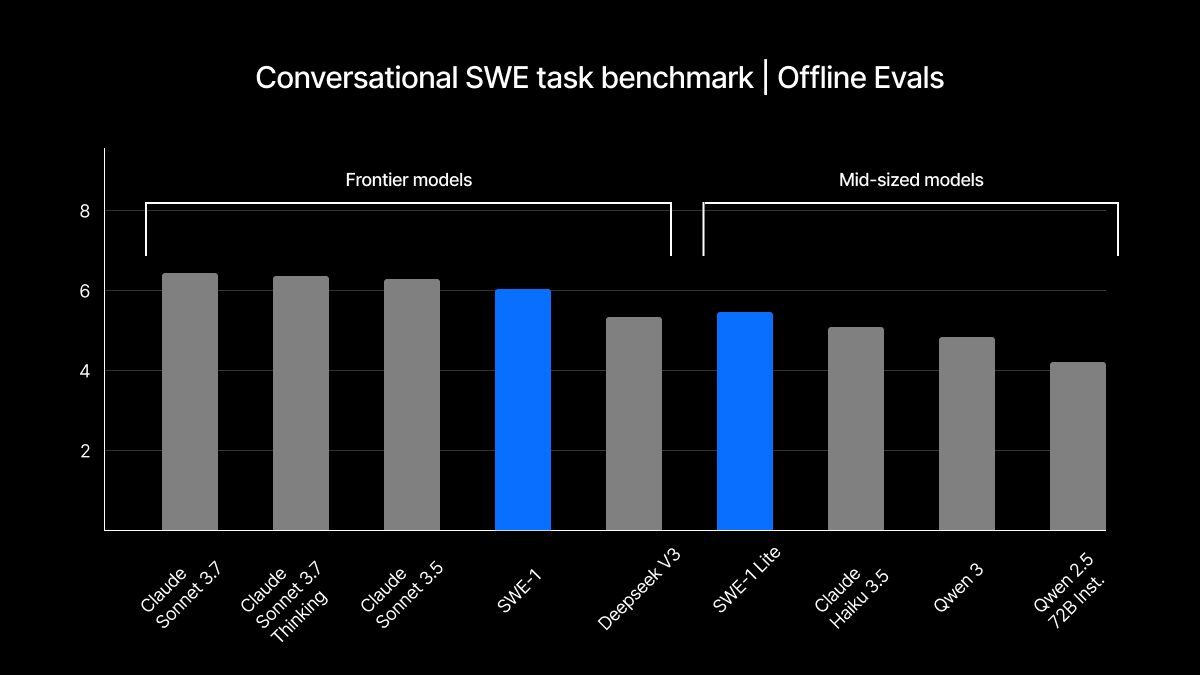
Windsurf Releases SWE-1: A Powerful Coding Model That's FREE For A ...
GPT-5.2-Codex: 24-Hour Coding + 56% SWE-Bench Explained | byteiota
Verdent AI|Agentic Coding with Multiple Parallel Agents
Claude vs ChatGPT vs Gemini: 2025 AI Assistant Comparison & Winner ...
Anthropic Releases Claude Opus 4.5: AI Model Outperforms Human ...
AI 编码新王炸!Augment (SWE-bench 冠军)免费登场,专治复杂大项目,硬刚 Cursor?_augment code-CSDN博客
OpenAI releases new coding benchmark SWE-Lancer showing 3.5 Sonnet ...
Open-Source AI SWE-Agent Takes on Devin (Better Alternative?)
The Rise of AI Software Engineers: SWE-Agent, Devin AI and the Future ...
First AI software engineer. Learn more about Devin's new state-of-the ...
Anthropic Claude Sonnet 4.5 AI helps programmers code better with ...
[논문 리뷰] SWE-Bench+: Enhanced Coding Benchmark for LLMs
SWE-Bench coding dataset 8,712 files | Kaggle
Scale AI يقدم SWE-Bench Pro معيار يرفع تحديات البرمجة الذكية - 3arabi.ai
SWE-bench Multimodal
What Is infrastructure As Code (IaC) Scanning? | The TeamCity Blog
SWE-Bench Pro登場: AIコーディングエージェントの限界が露呈
AWS Introduces SWE-PolyBench: A New Open-Source Multilingual Benchmark ...
What does SWE-bench Verified actually measure?
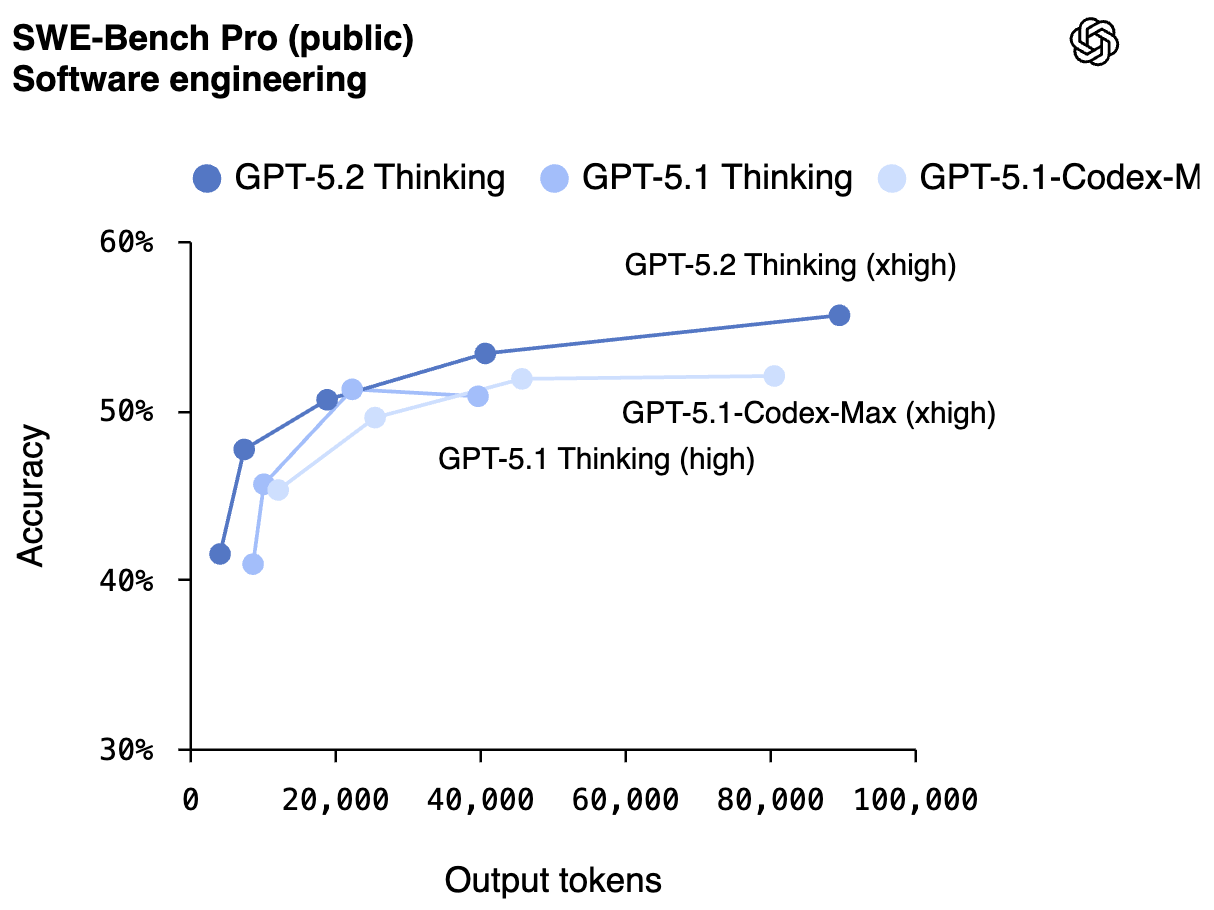
SWE-Bench Pro (Public Dataset)
Anthropic Claude Opus 4.5: How 80.9% SWE-bench Performance and 66% ...
Zencoder Leads SWE-bench with 70% Success Rate [May 12, 2025]
Introducing SWE-bench Verified | OpenAI
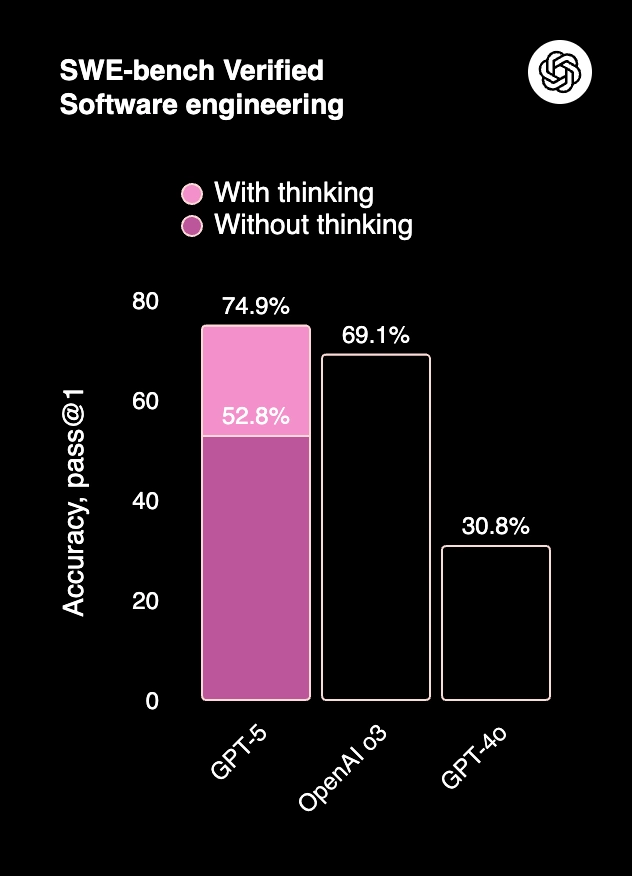
GPT-5 Benchmarks | Runbear
Anthropic Unveils Claude Sonnet 4.5: Faster, Smarter, but Still Second ...
Aider blog | aider
OpenAI Launches GPT-5, Makes It Free for All ChatGPT Users | Beebom
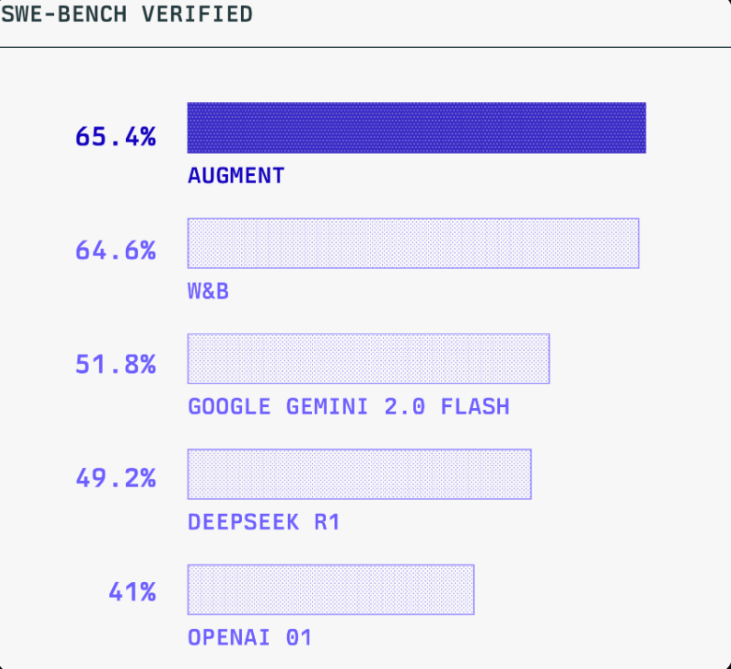
Auggie tops SWE-Bench Pro | Augment Code
Cognition | SWE-bench technical report
OpenAI Launches GPT-5.2, Dubbed Its 'Most Capable' Work Model Yet
Guida al Vibe coding: cos’è e quali tool usare - AI4Business
User guides - SWE-agent documentation
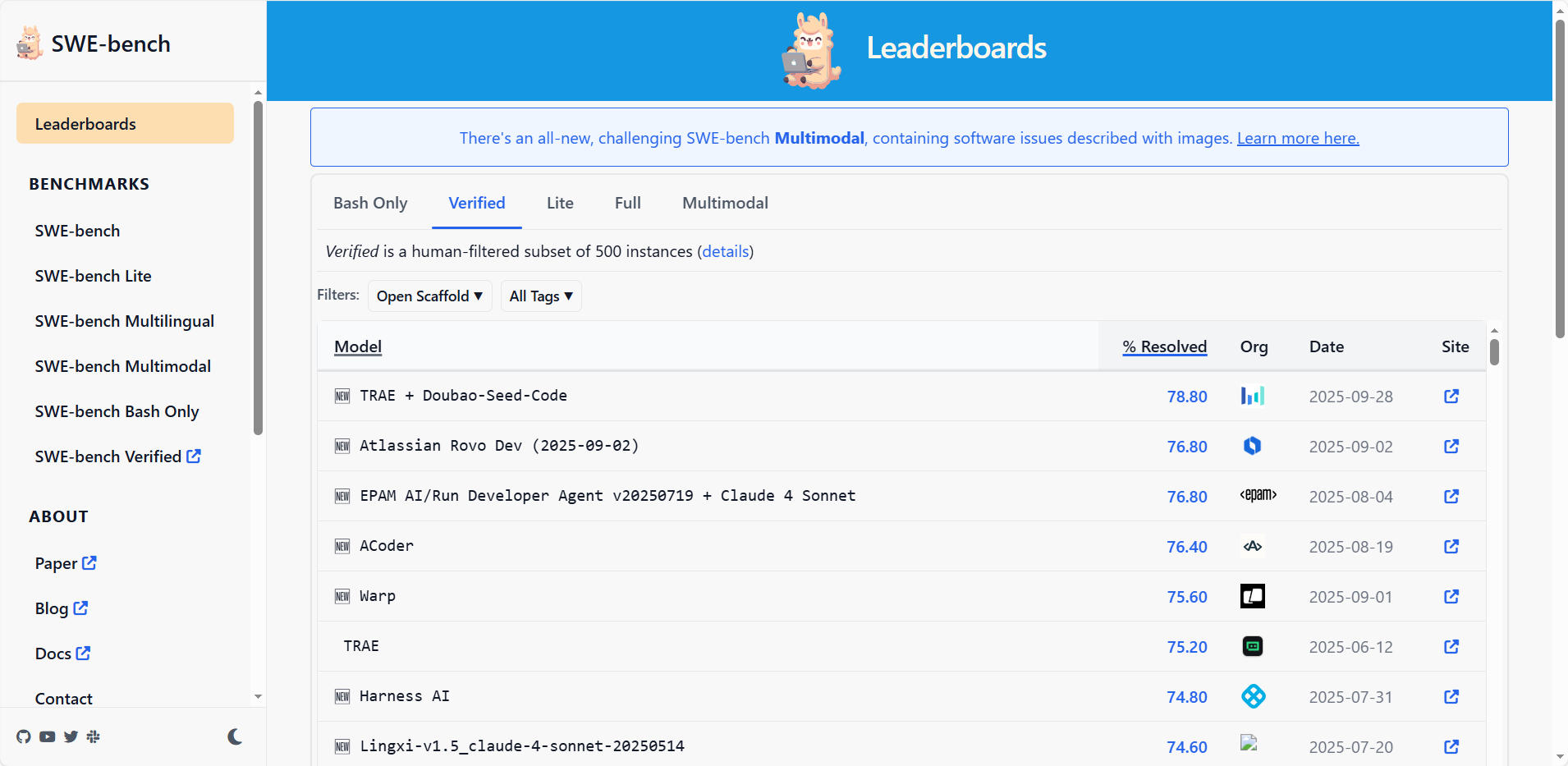
Dissecting the SWE-Bench Leaderboards: Profiling Submitters and ...
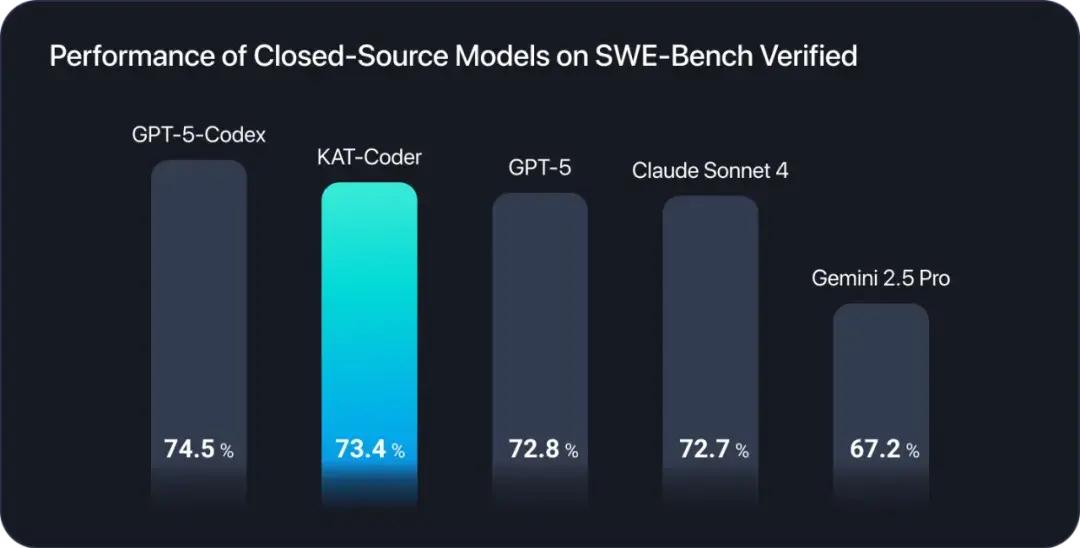
Agentic Coding表现创新高,全新KAT系列模型强势霸榜SWE-Bench - 知乎
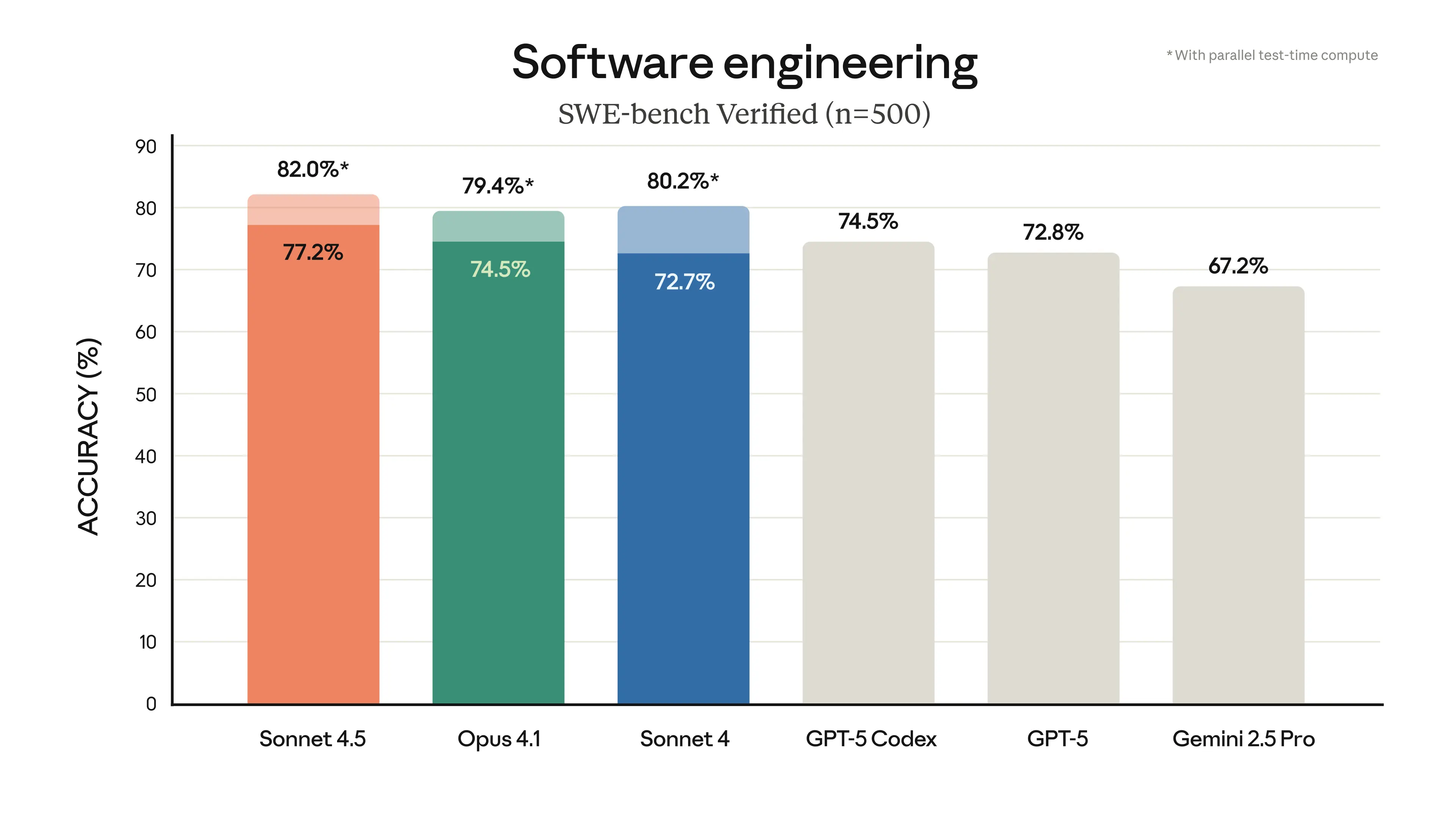
Anthropic’s Claude Opus 4.1 Improves Refactoring and Safety, Scores 74. ...
Trae Agent reached #1 on SWE-bench Verified, with Claude 4 - and it's ...
How Well Do AIs Handle Real-World Coding? A Look at SWE-bench Verified ...
How to Access OpenAI o3-mini?
Cognition's SWE-1.5 Achieves Frontier-Level Accuracy on SWE-Bench Pro ...
synthetic-code-training/swe_bench_localize_no_exec_498i · Datasets at ...
Seed News - ByteDance Seed Team
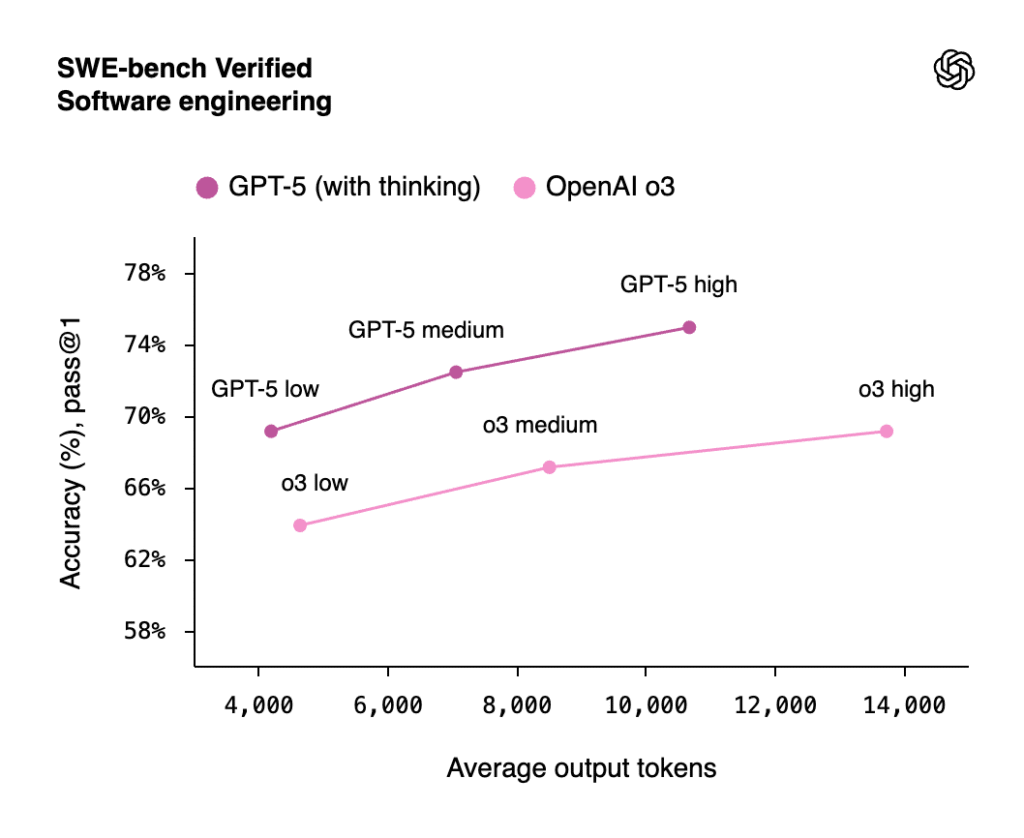
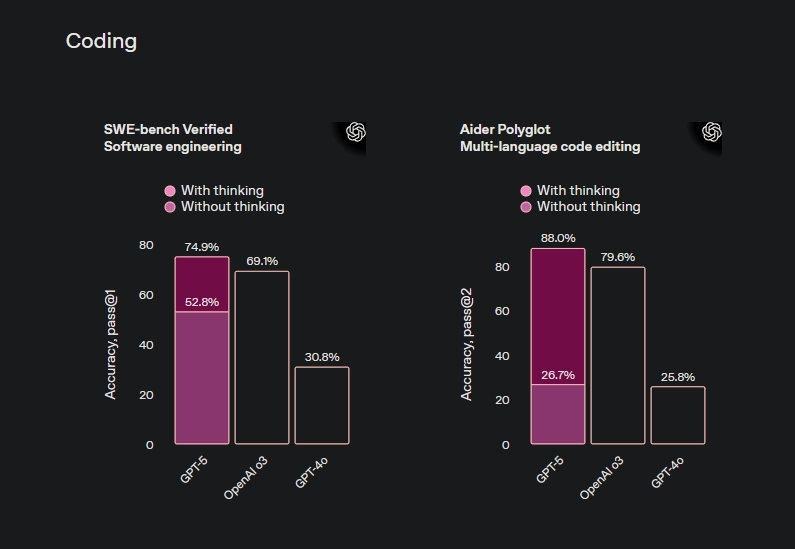
GPT-5 Coding: 74.9% SWE-bench & 88% Aider Performance [August 2025 ...
GPT-5 : le guide complet de l’IA la plus avancée d’OpenAI
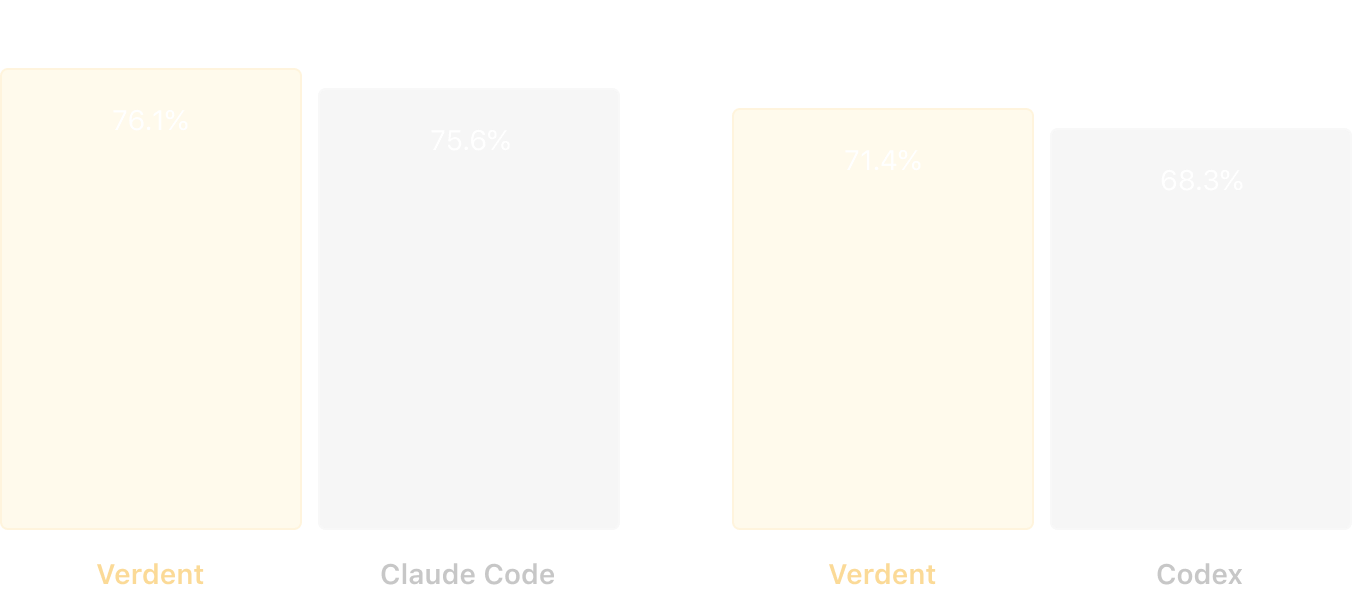
SWE-bench Verified Technical Report | Verdent - Verdent Blog
CodeMonkeys: Monkey SWE, Monkey Do | Scaling Intelligence Lab at ...
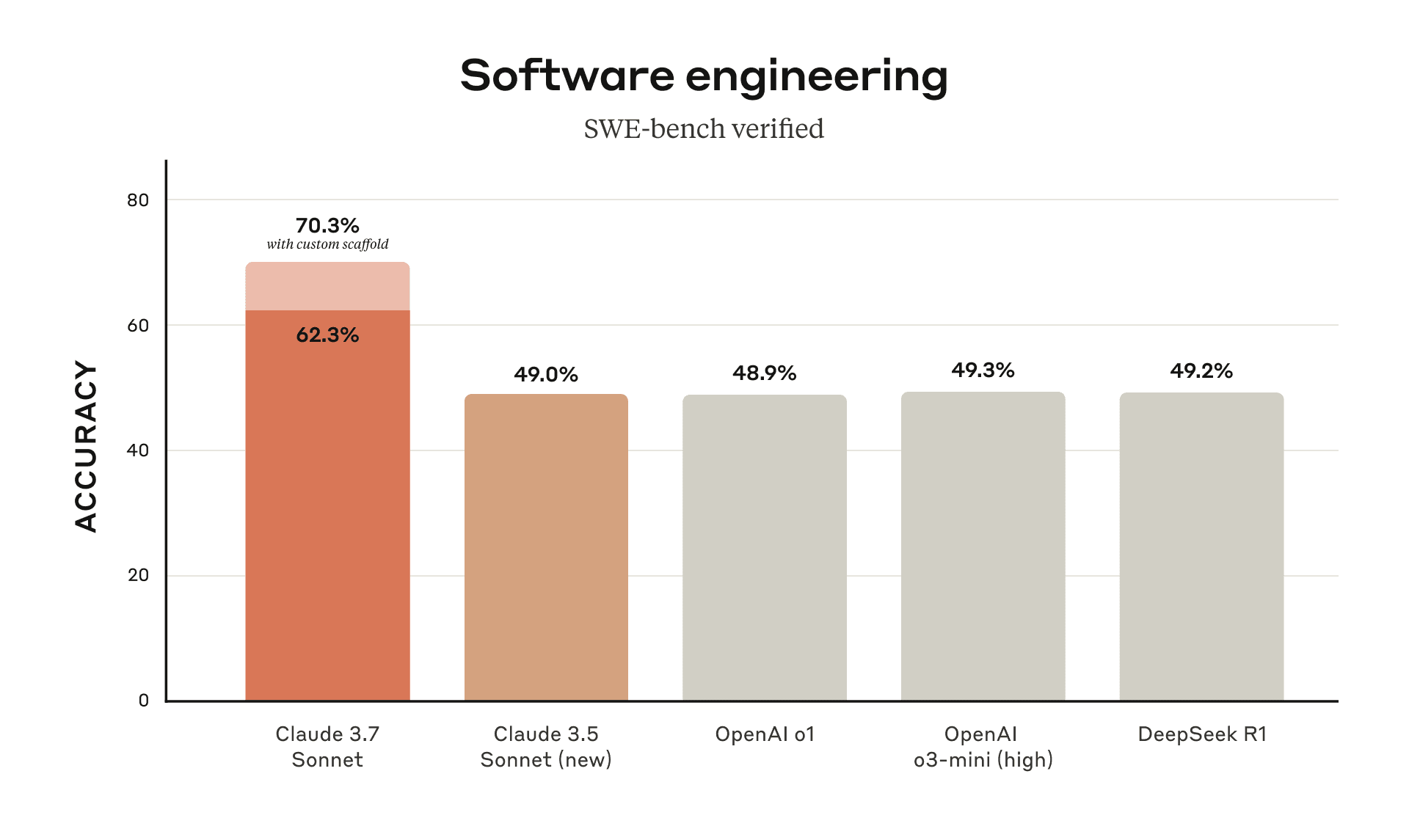
Claude 3.7 Sonnet and Claude Code \ Anthropic
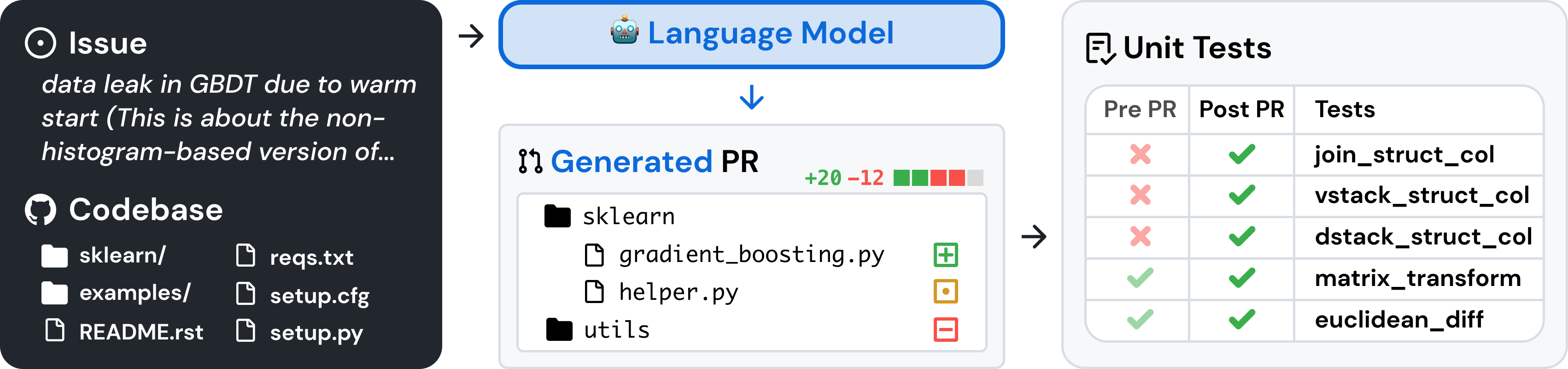
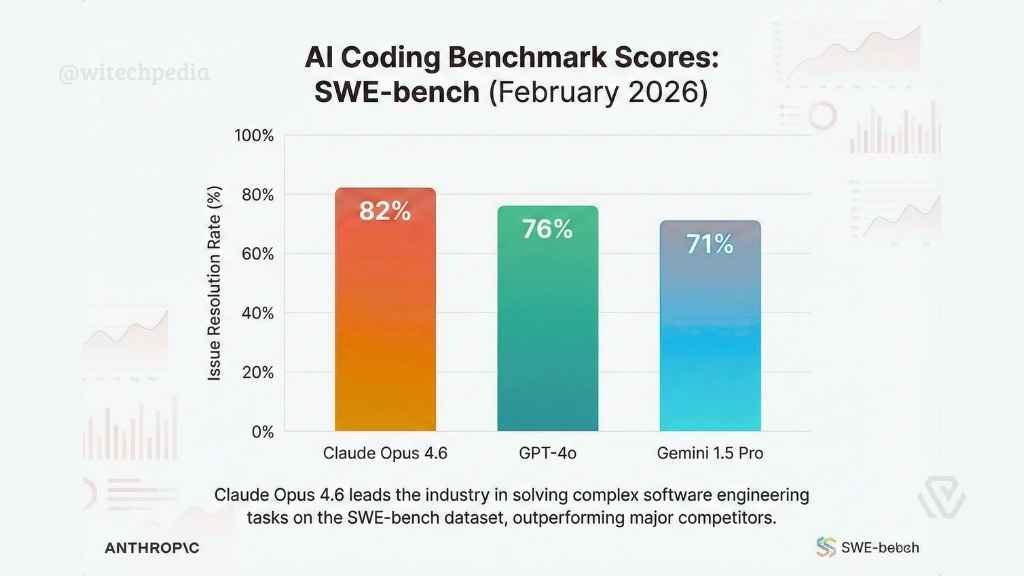
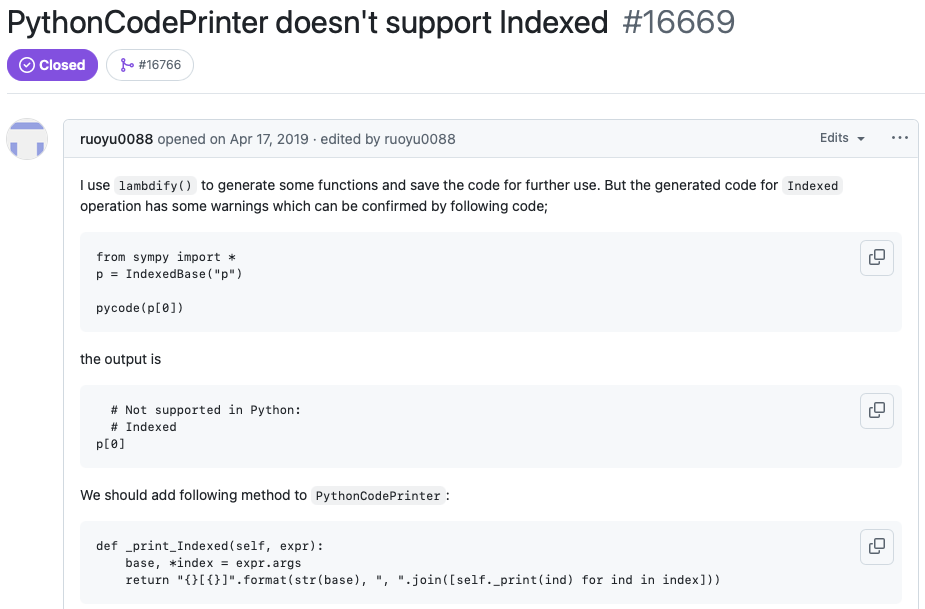
Based on this image's title: “Demystifying SWE-Bench: AI Coding Assistants in Action”




















































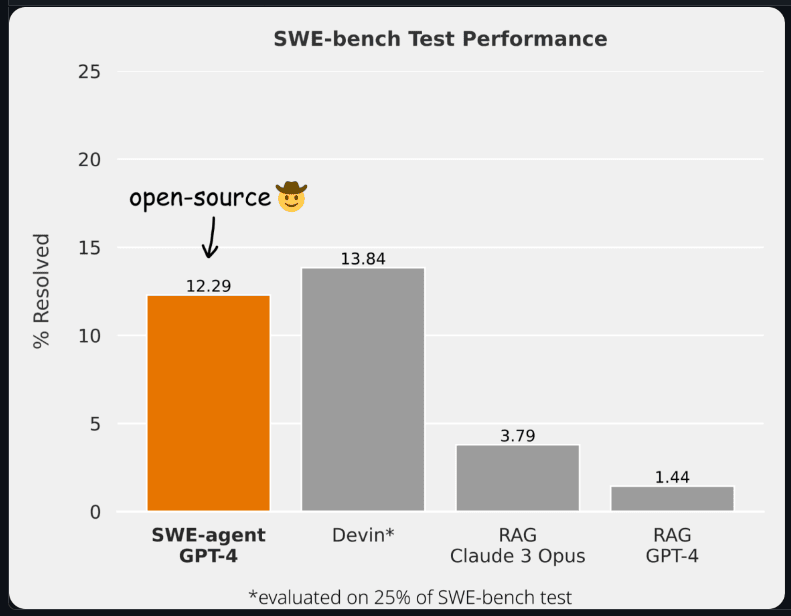



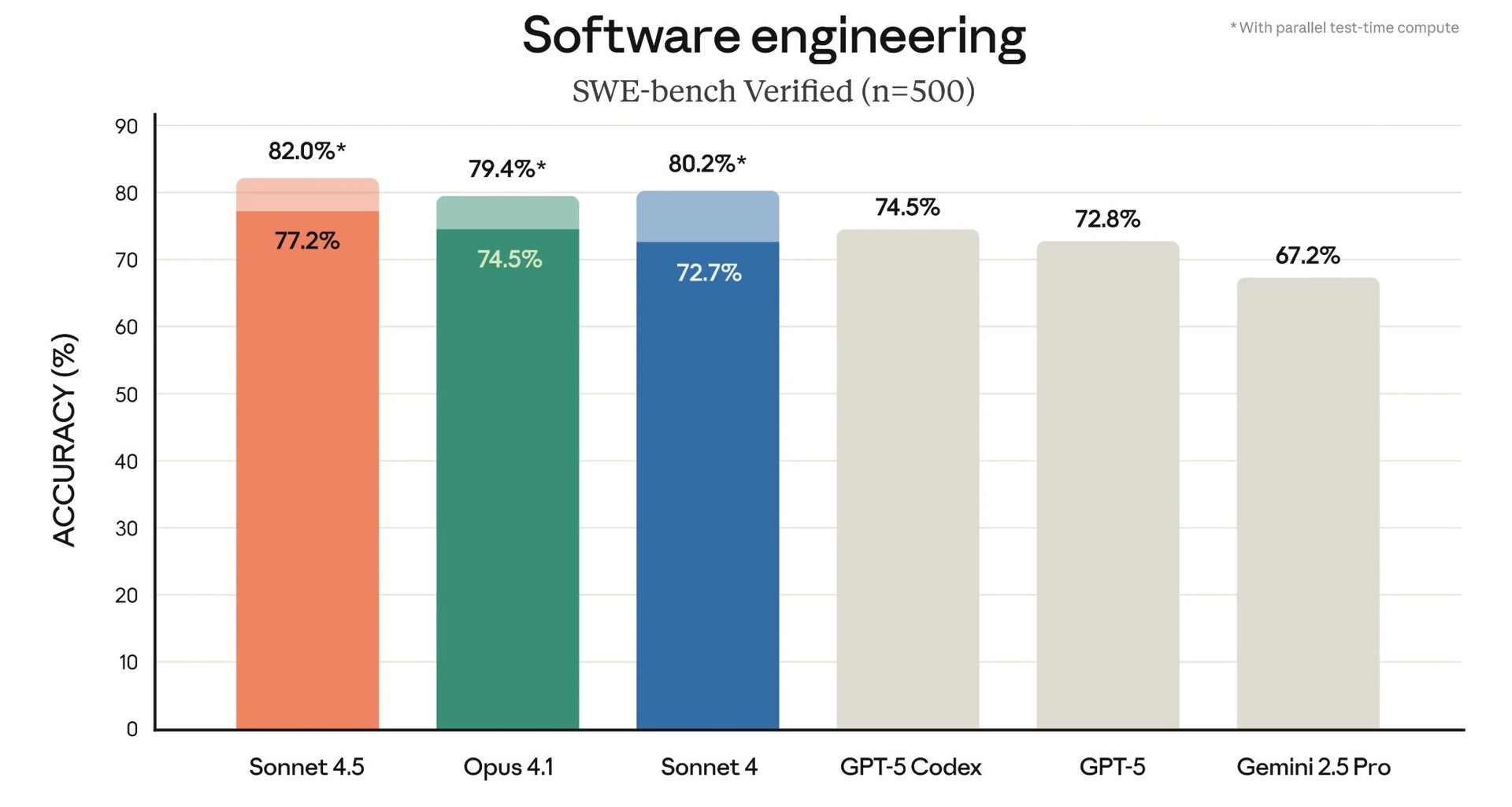


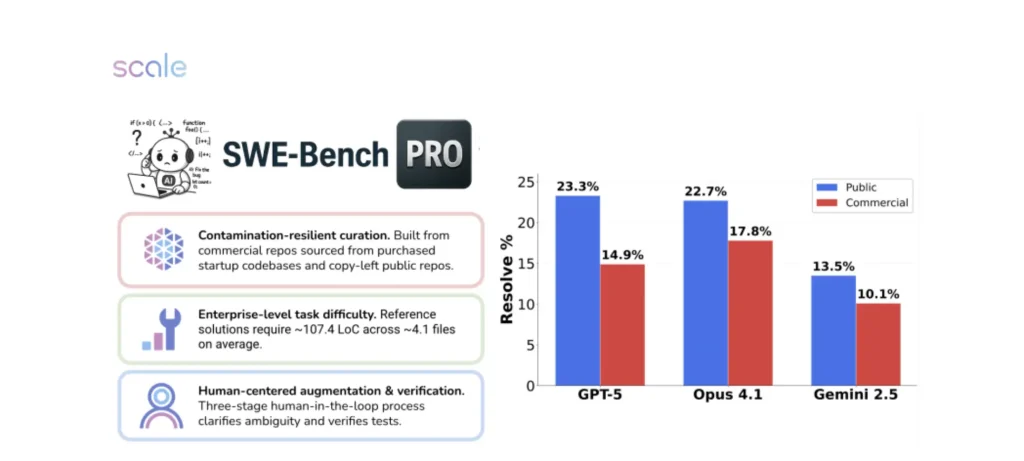
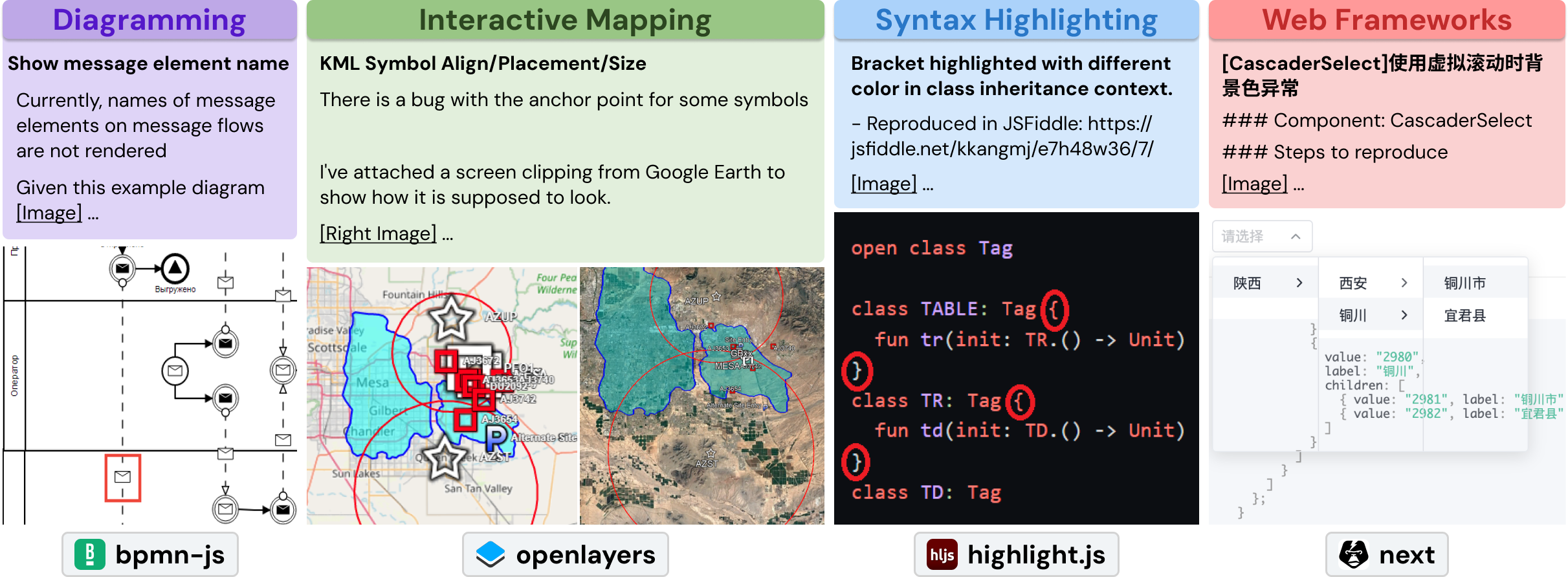













/filters:no_upscale()/news/2025/08/anthropic-claude-opus-4-1/en/resources/143figure-1-1756289214722.jpg)