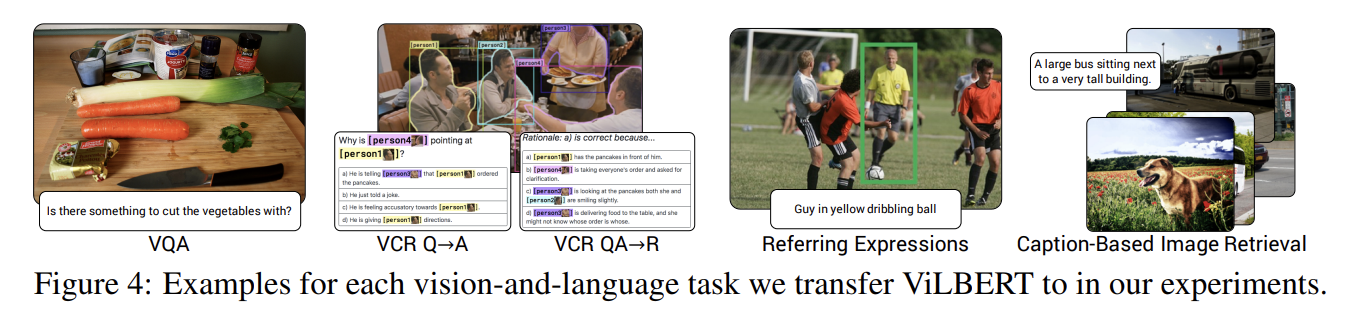
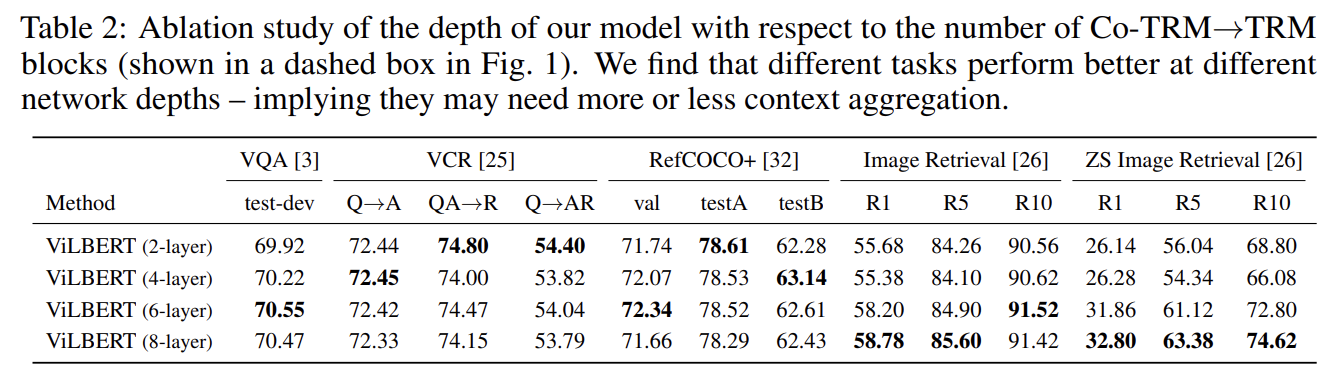
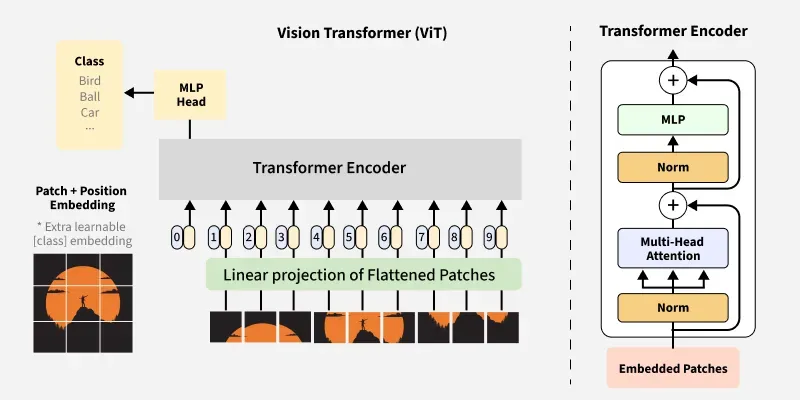
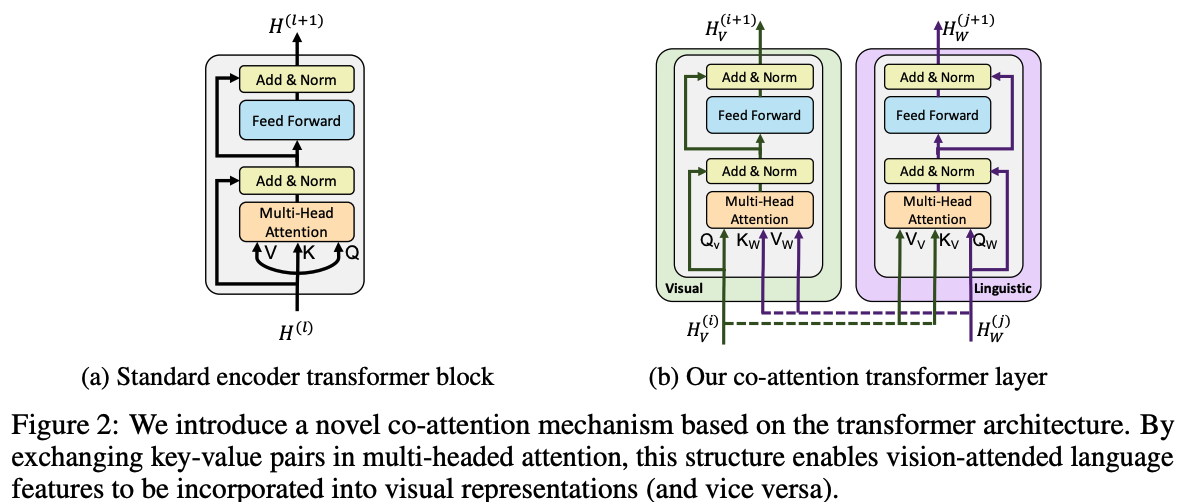
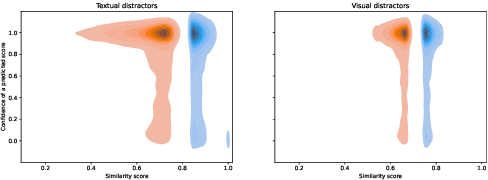
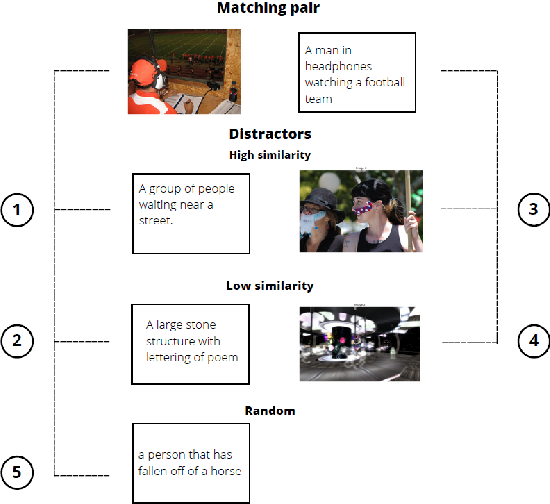
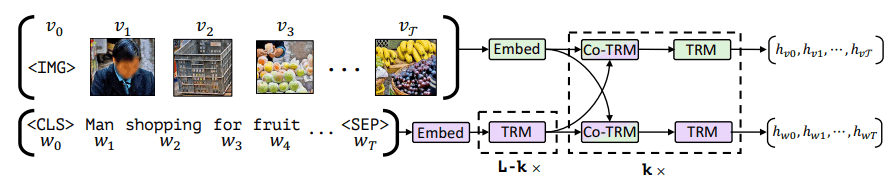
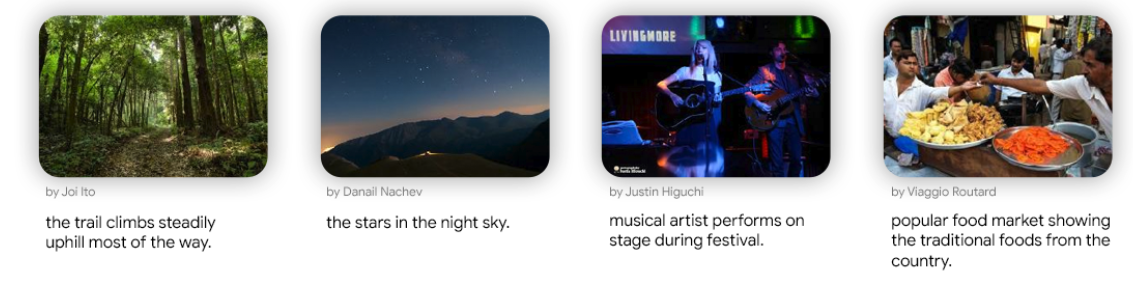
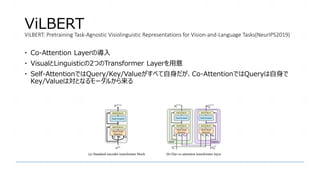
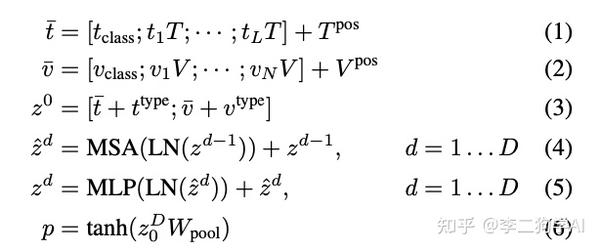Exploring Vision Transformers for 3D Human Motion-Language Models with ...
[논문 리뷰] Exploring Vision Transformers for 3D Human Motion-Language ...
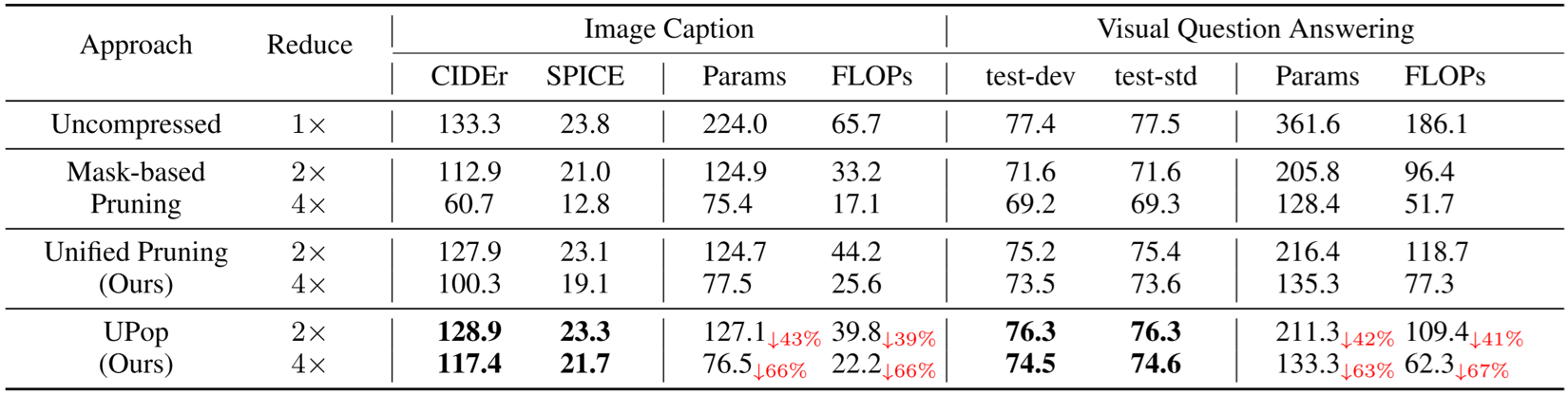
UPop: Unified and Progressive Pruning for Compressing Vision-Language ...
ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for ...
Multimodal Deep Learning with Vision Language Models: Exploring ...
Unified Vision and Language with Vision Transformer
UNetFormer- A Unified Vision Transformer Model and Pre-Training ...
Exploring Vision Transformers (ViTs): Transforming Computer Vision with ...
(PDF) Unified Object Detector for Different Modalities Based on Vision ...
UNetFormer: A Unified Vision Transformer Model and Pre-Training ...
Vision Language Models: Exploring Multimodal AI - viso.ai
Transformer combining Vision and Language? ViLBERT - NLP meets Computer ...
ViLBERT: Bridging Visual and Linguistic Inputs to Improve Interaction ...
All in One: Exploring Unified Vision-Language Tracking with Multi-Modal ...
(PDF) BiomedGPT: A Unified and Generalist Biomedical Generative Pre ...
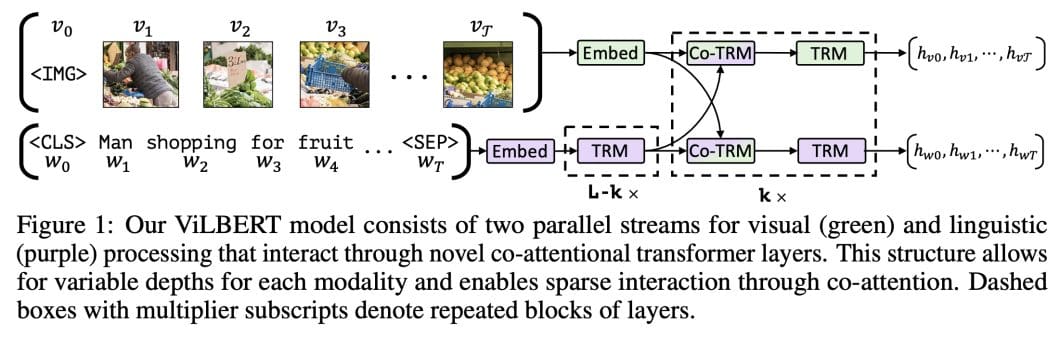
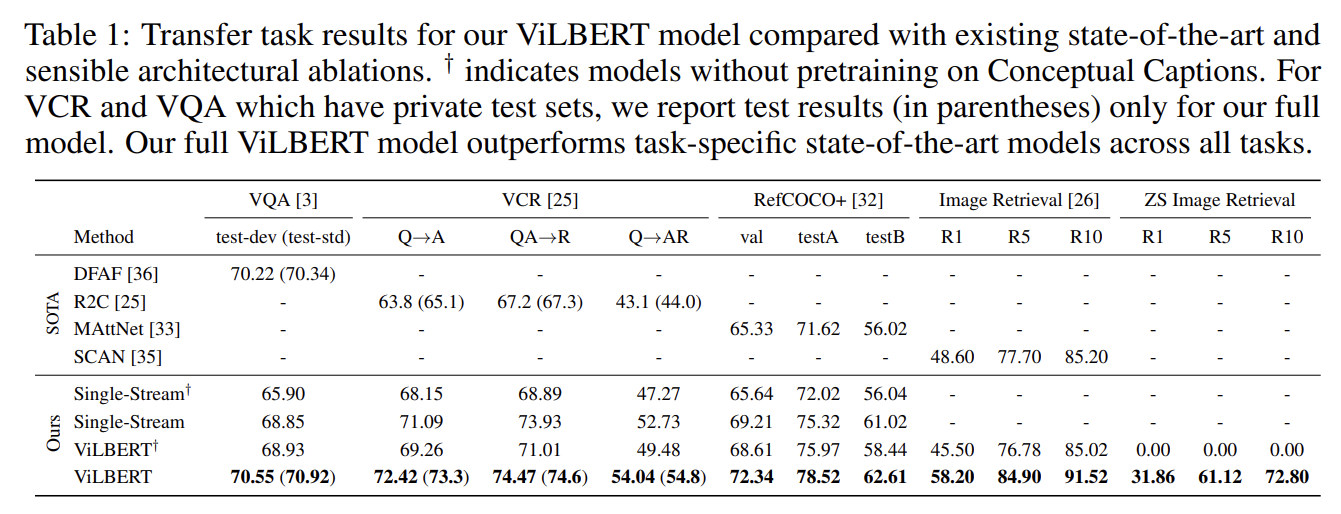
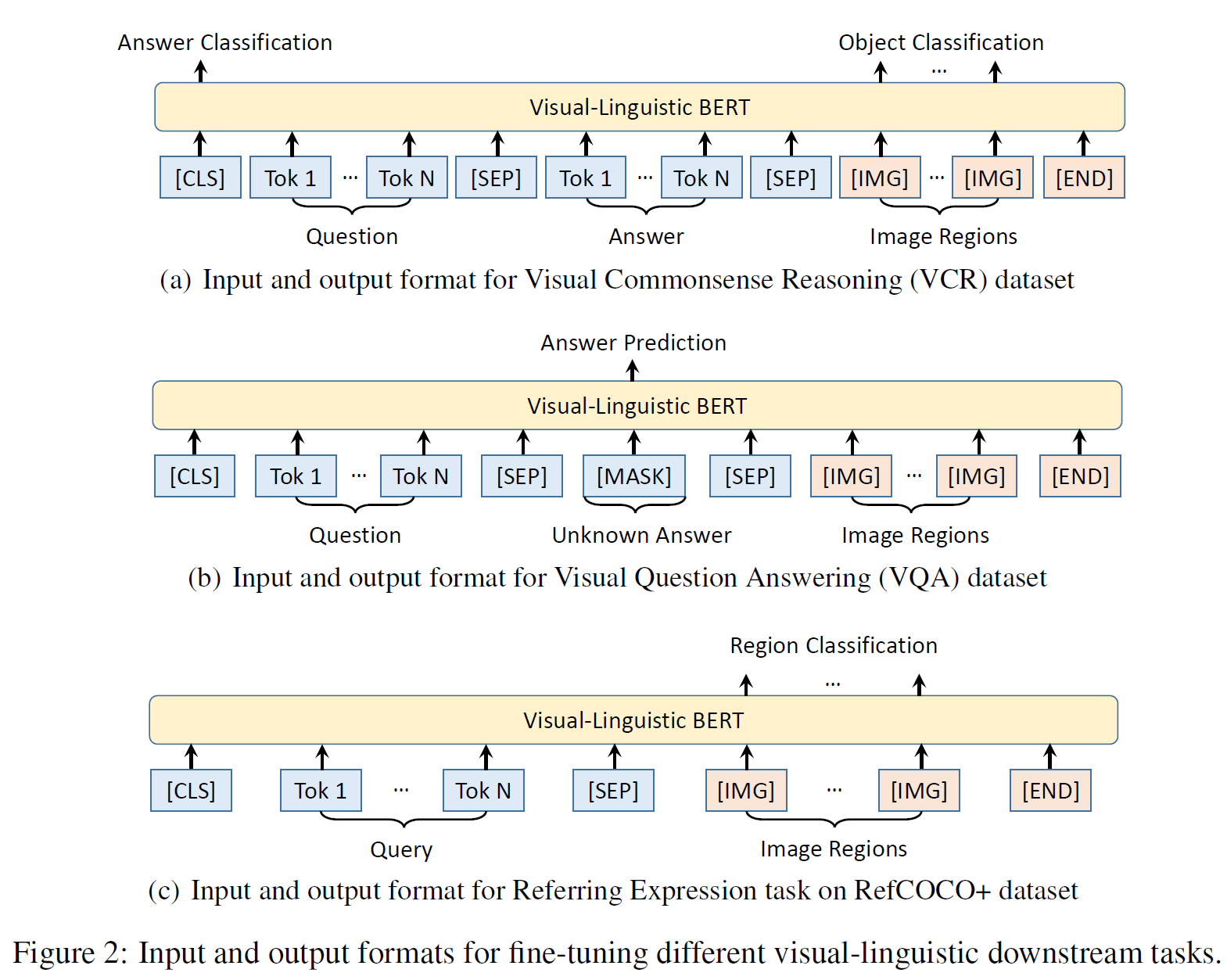
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for ...
“Bridging Vision and Language: Designing, Training and Deploying ...
VPUFormer: Visual Prompt Unified Transformer for Interactive Image ...
UFO: A UniFied TransfOrmer for Vision-Language Representation Learning ...
Maryland U & NYU’s Visual Exploration Reveals What Vision Transformers ...
Vision Transformers Explained. One of the most fascinating challenges ...
Hierarchical Task Learning from Language Instructions with Unified ...
2106 - Fine-Grained Classification using ViT - Exploring Vision ...
(PDF) Visual Echoes: A Simple Unified Transformer for Audio-Visual ...
(PDF) Unified Transformer with Cross-Modal Mixture Experts for Remote ...
GitHub - facebookresearch/vilbert-multi-task: Multi Task Vision and ...
SLIDES OF LECTURE ABOUT TRANSFORMERS FOR VISION TASKS | PPTX
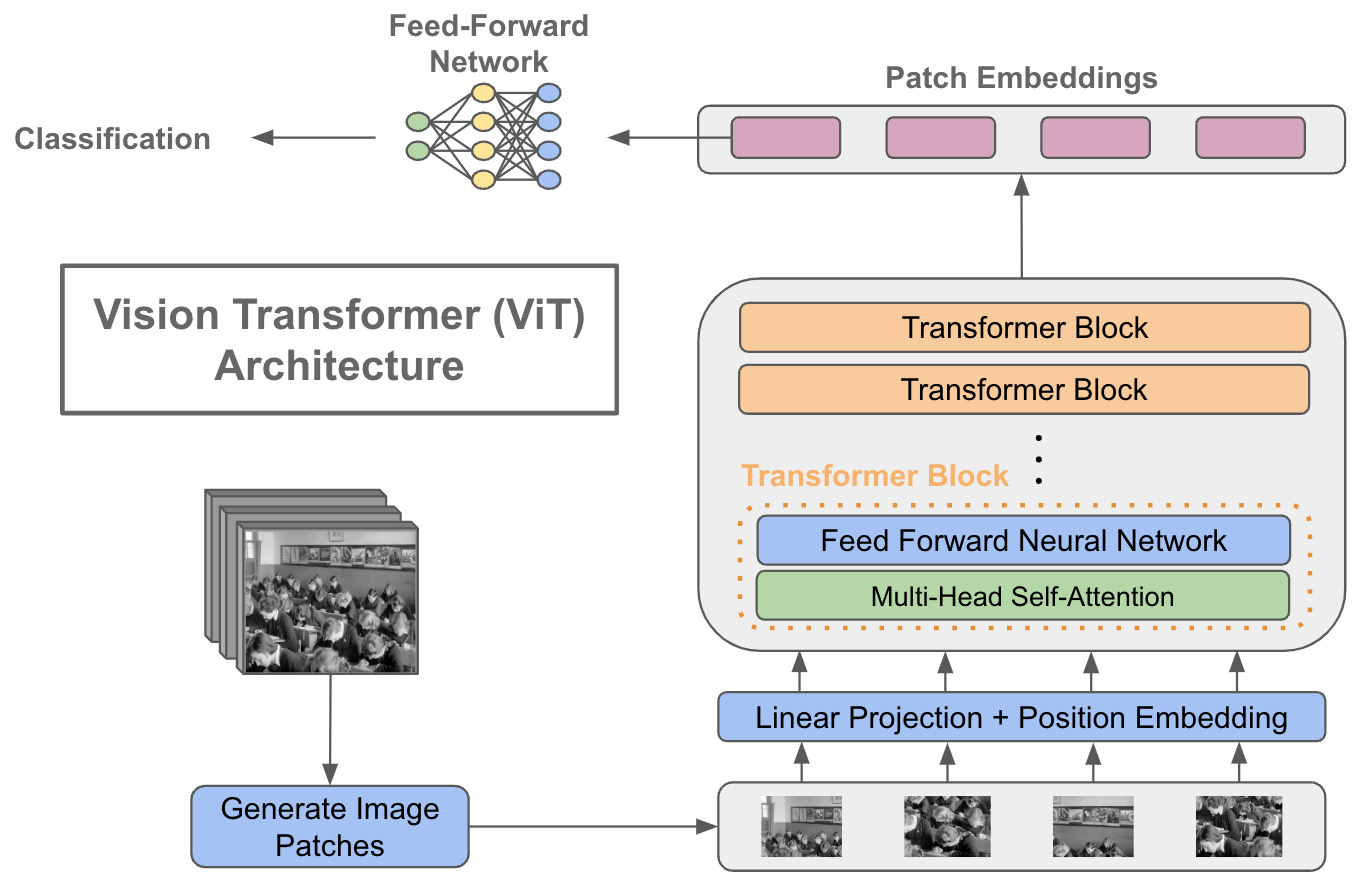
A Hands-On Guide to Vision Transformers and their Architecture
Unified Transformer with Cross-Modal Mixture Experts for Remote-Sensing ...
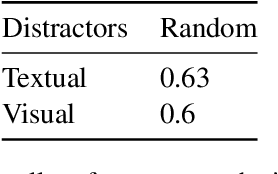
Are Language-and-Vision Transformers Sensitive to Discourse? A Case ...
[Multimodal #1] ViLBERT: Pretraining Task-Agnostic Visiolinguistic ...
(PDF) Do BERTs Learn to Use Browser User Interface? Exploring Multi ...
Paper Summary — ViLBERT: Pretraining Task-Agnostic Visiolinguistic ...
(Previous work) The mainstream approaches for vision-language modeling ...
Overall architecture of the Unified Vision-language Hashing ...
Unlock AI Potential with Vision Language Models
Figure 4 from Are Language-and-Vision Transformers Sensitive to ...
Figure 2 from Are Language-and-Vision Transformers Sensitive to ...
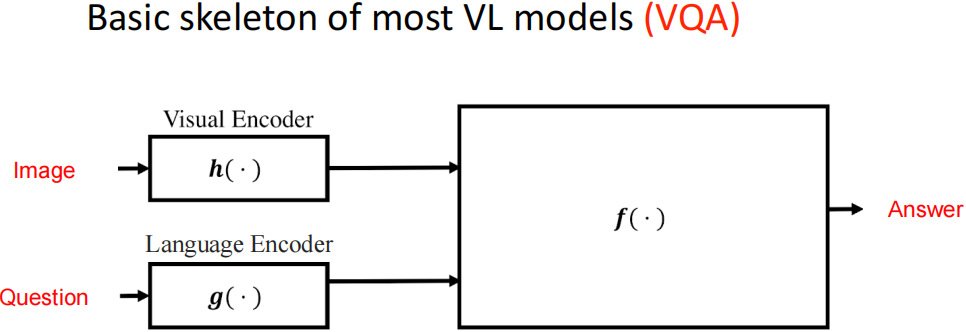
Vision Language models: towards multi-modal deep learning | AI Summer
Transformer / Vision and Languageの基礎 - Speaker Deck
Table 6 from Are Language-and-Vision Transformers Sensitive to ...
Review — ViLBERT: Pretraining Task-Agnostic Visiolinguistic ...
What do Vision Transformers Learn? A Visual Exploration | DeepAI
Vision Transformers - by Cameron R. Wolfe, Ph.D.
[PDF] ViLBERT: Pretraining Task-Agnostic Visiolinguistic ...
Exploring Visual Attention in Transformer Models | by Niv Leibovitch ...
(PDF) ViT-UperNet: a hybrid vision transformer with unified-perceptual ...
Python powers multimodal AI models like CLIP, BLIP, ViLBERT for ...
Illustration of transformer blocks with mutual attention. A unified ...
The overall architecture of ViLBERT. ViL-BERT consists of a ...
multi modal transformers representation generation .pptx
An In-Depth Exploration of the Vision-and-Language Transformer (ViLT ...
VLP (Vision Language Pre-training) 梳理 - 知乎
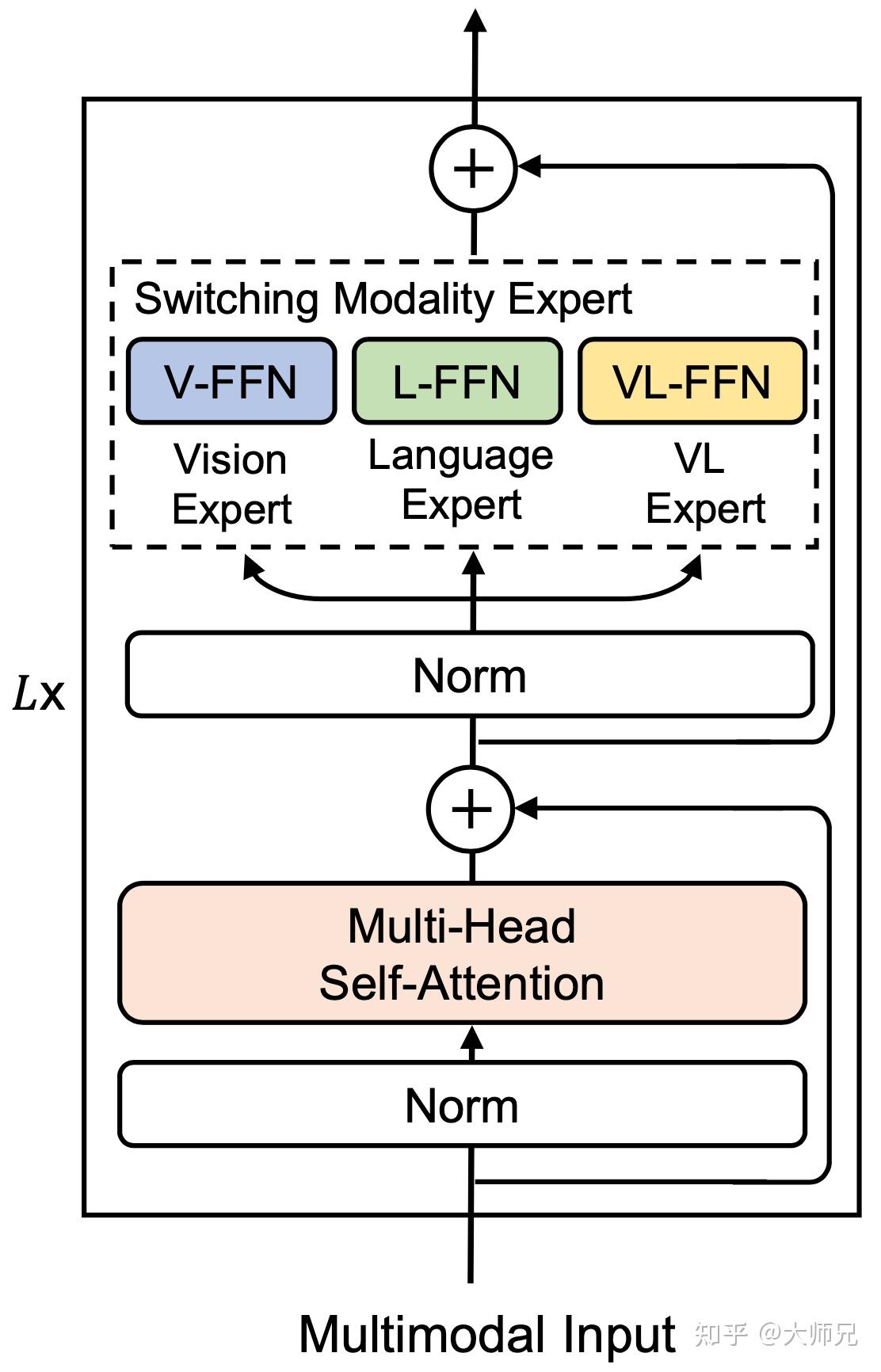
VLMo:Unified Vision-Language Pre-Training with Mixture-of-Modality ...
ViLBERT: 视觉和语言任务的预训练任务无关的视觉语言学表示 - 知乎
a) A regular transformer layer. b) ViLBERT's co-attention layer. Note ...
Conceptual Comparisons of Transformer Multi-Modal Encoder... | Download ...
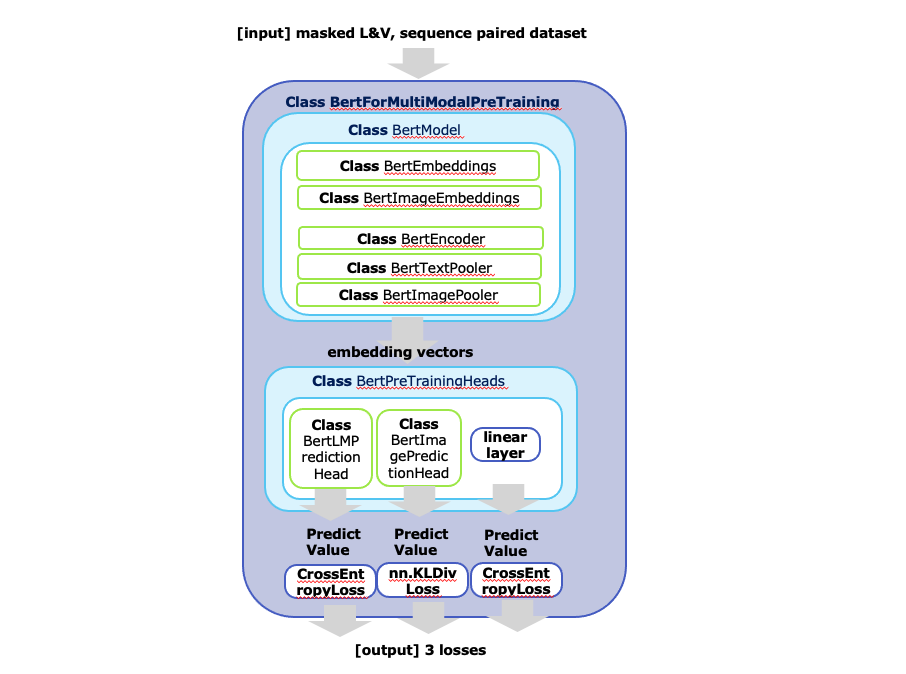
Bert for multimodal | PDF
VL-BERT, ViL-BERT 논문 설명(VL-BERT - Pre-training of Generic Visual ...
论文阅读:《An Empirical Study of Training End-to-End Vision-and-Language ...
Typical architectures of vision-language models. (a) is the basic form ...
Transformers in Vision: A Survey_transformer in vl_Amusi(CVer)的博客-CSDN博客
[PR-325] Pixel-BERT: Aligning Image Pixels with Text by Deep Multi ...
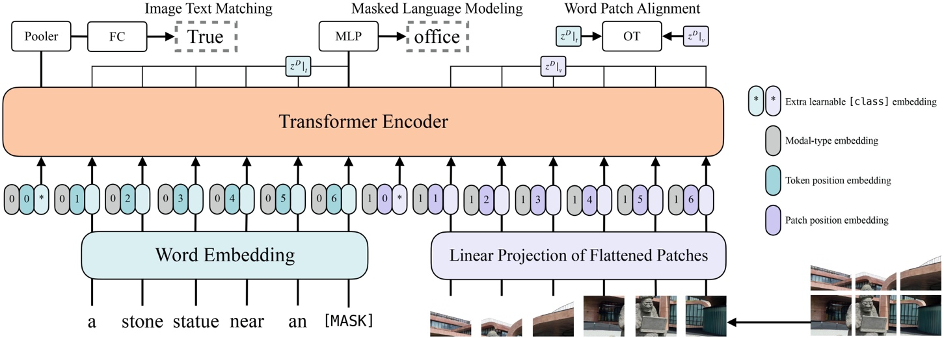
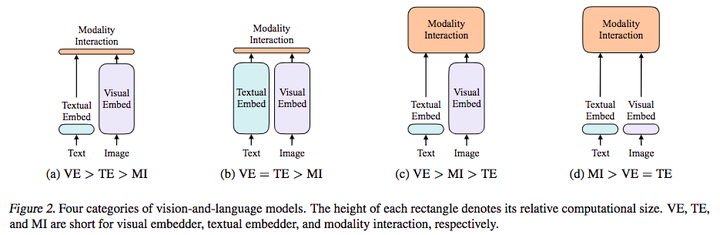
ViLT: Vision-and-Language Transformer Without Convolution or Region ...
VL (Vision and Language) 任务简介及数据集_vqa v1数据集-CSDN博客
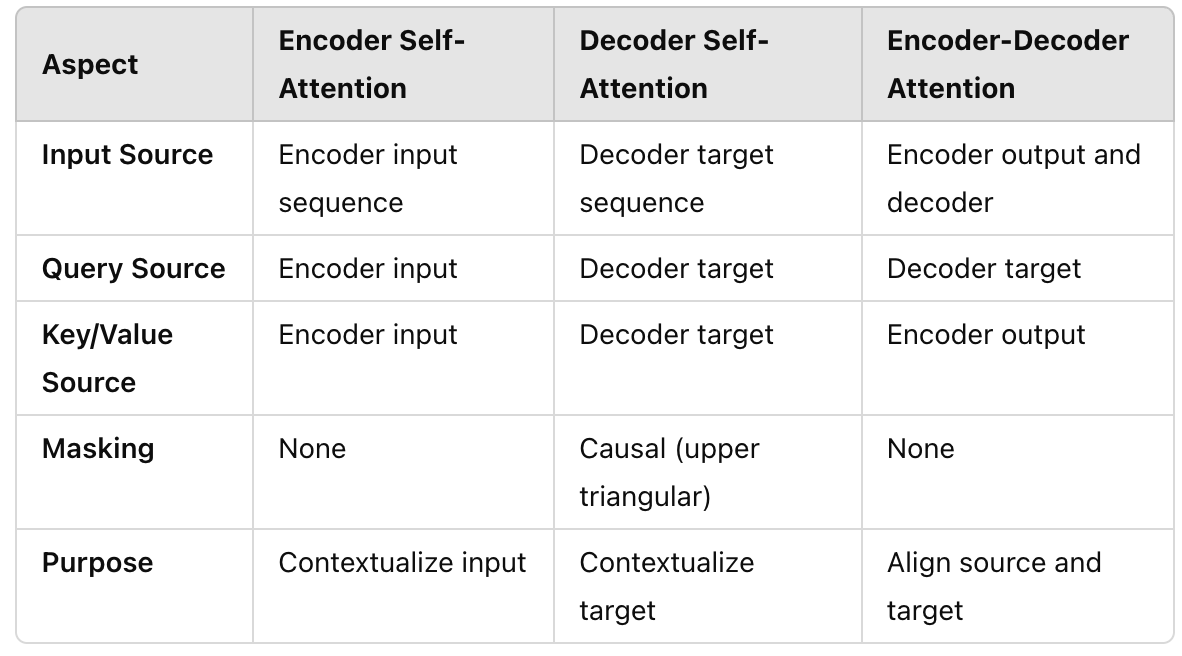
(a) Architecture of a standard encoder transformer block. (b ...
Understanding Transformer Vision in AI
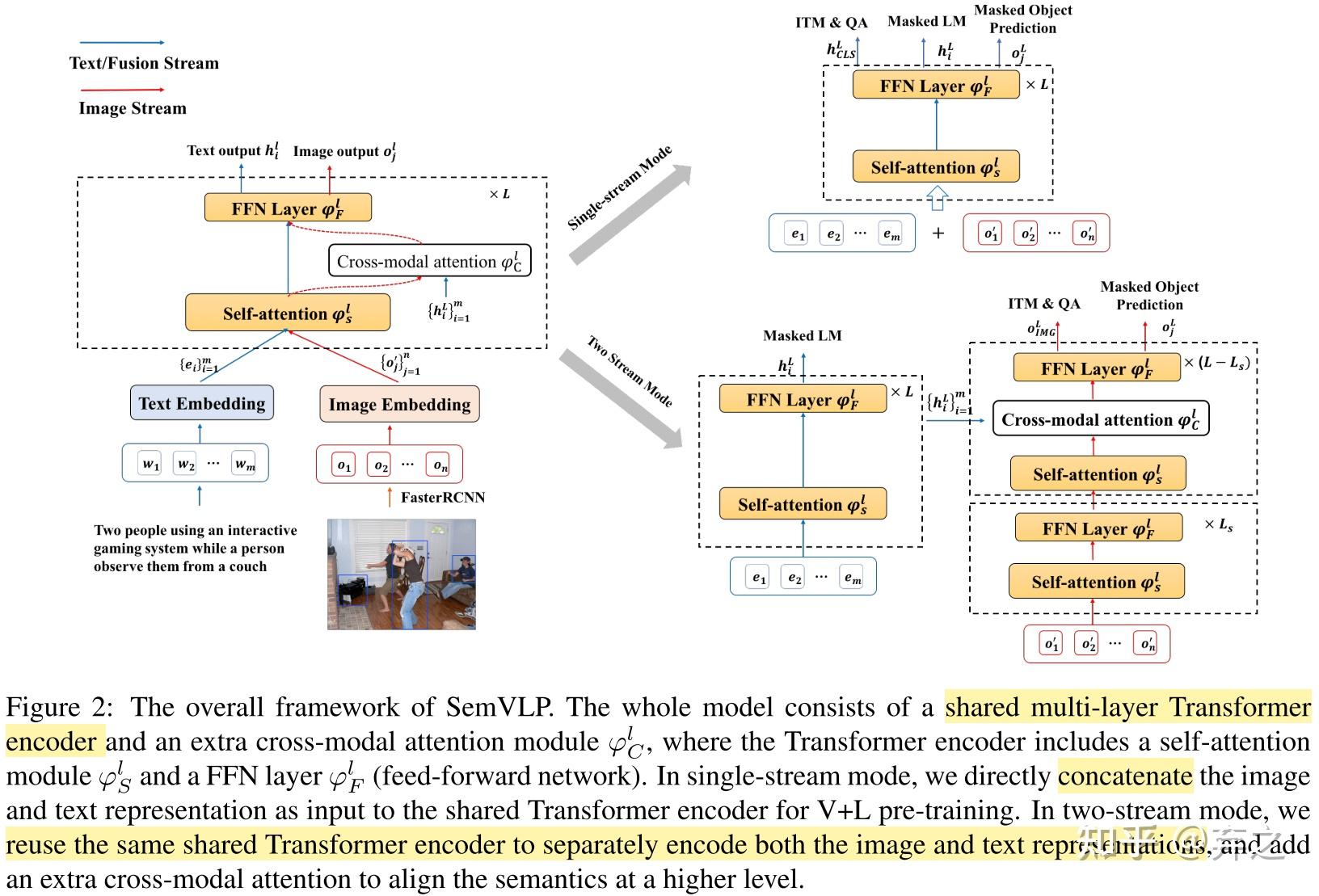
Vision-Language的几篇工作:向更简便更scale的路 - 知乎
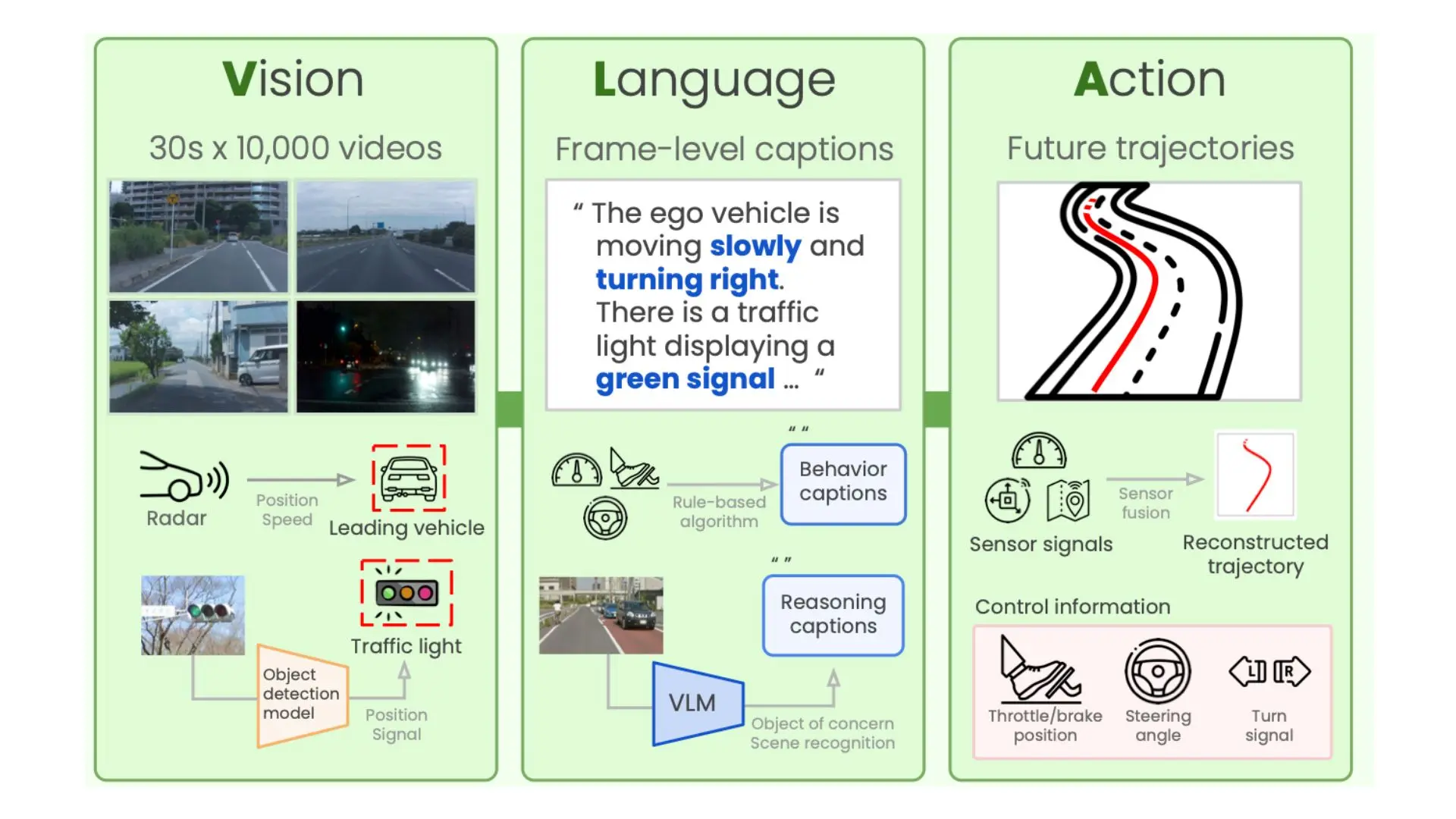
How Vision-Language-Action Models Powering Humanoid Robots
visualjoyce/transformers4vl-vilbert at main
Pretraining task-agnostic visiolinguistic representations | S-Logix
vilbert-multi-task by facebookresearch - SourcePulse
論文紹介:A Survey of Vision-Language Pre-Trained Models | PDF
【Vision Transformer】BEiT3详解 - 知乎
(PDF) Masked Vision-language Transformer in Fashion
論文紹介:Multimodal Learning with Transformers: A Survey | PDF
Visual BERT论文的简单汇总_vilbert 论文-CSDN博客