mmproj-BF16.gguf · unsloth/Qwen3.5-9B-GGUF at main
README.md · unsloth/Qwen3-Next-80B-A3B-Instruct-GGUF at main
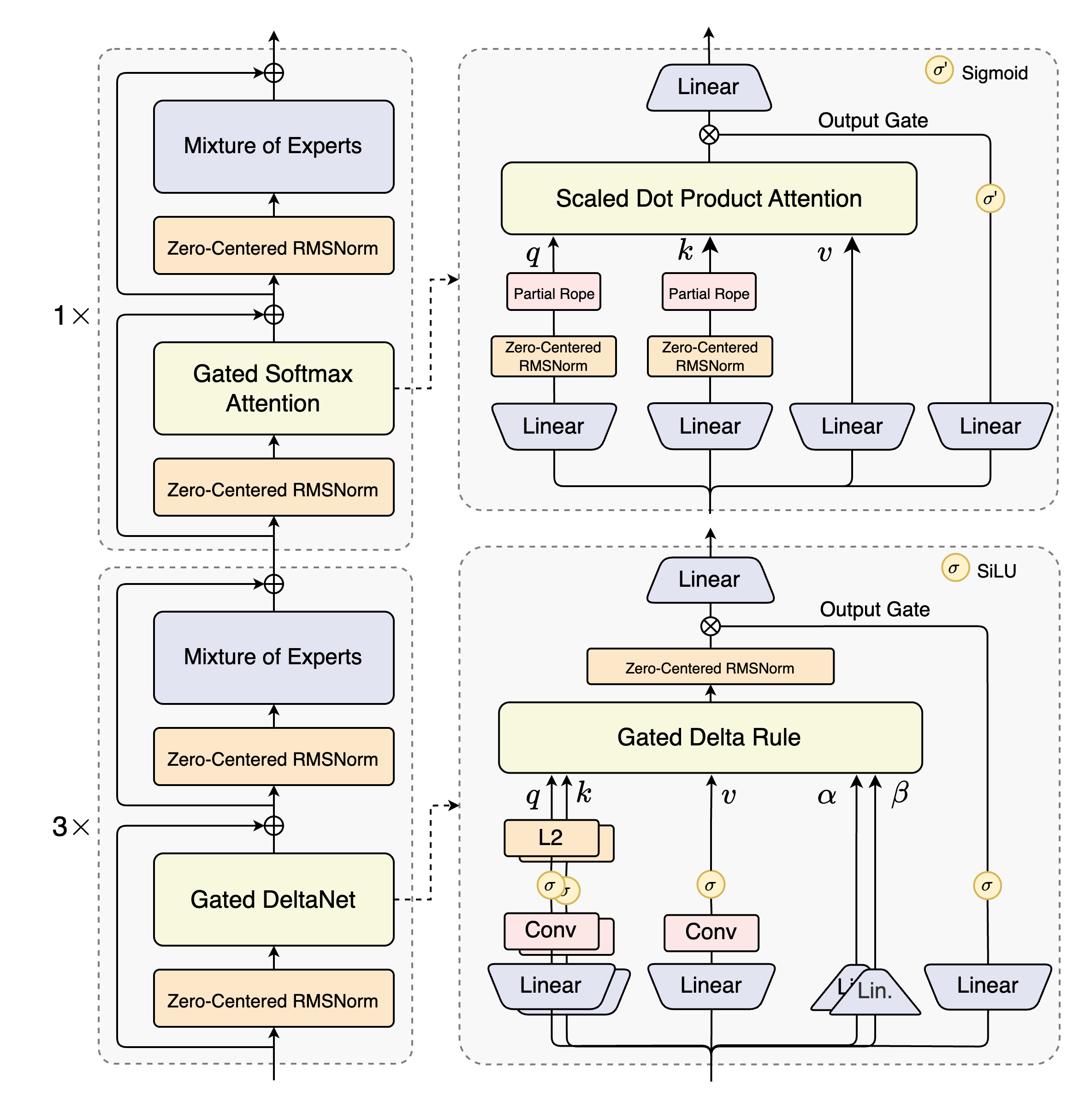
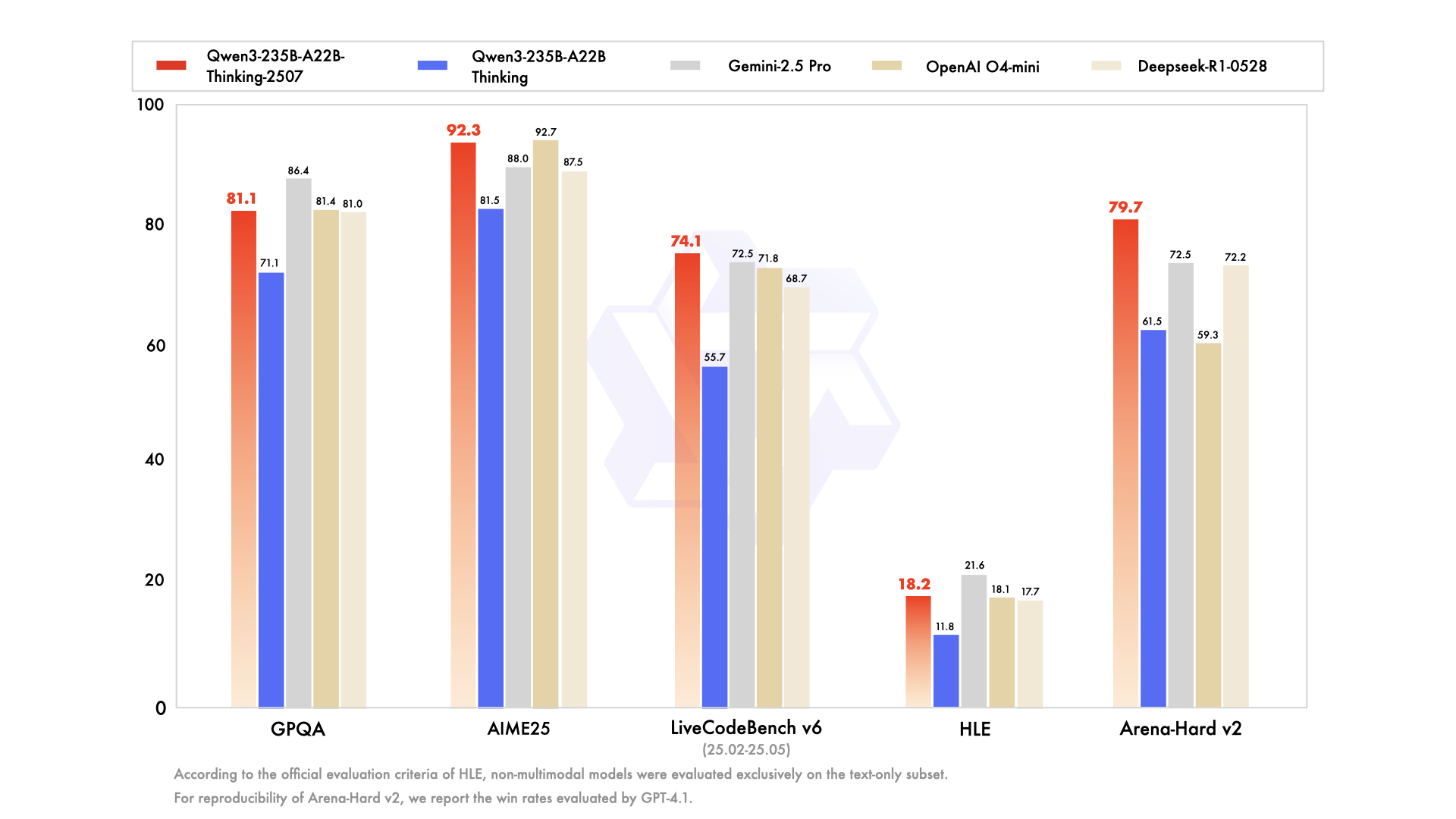
README.md · unsloth/Qwen3-235B-A22B-Thinking-2507-GGUF at main
Qwen3.5-35B-A3B-GGUF/README.md at main · qtliu/Qwen3.5-35B-A3B-GGUF ...
unsloth/Qwen3.5-35B-A3B-GGUF · Mar 5 - 'Final' Update: iMatrix ...
unsloth/Qwen3.5-35B-A3B-GGUF · Hugging Face
QuantStack/Qwen-Image-Edit-GGUF · Load main text encoder and mmproj
unsloth/Qwen3.5-35B-A3B-GGUF · Problem with UD-IQ3_XXS model loading in ...
unsloth/Qwen3.5-35B-A3B-GGUF · Vllm support
mmproj-F16.gguf · unsloth/Qwen3-VL-235B-A22B-Thinking-1M-GGUF at ...
bonswouar/unsloth-Qwen3-VL-8B-GGUF at main
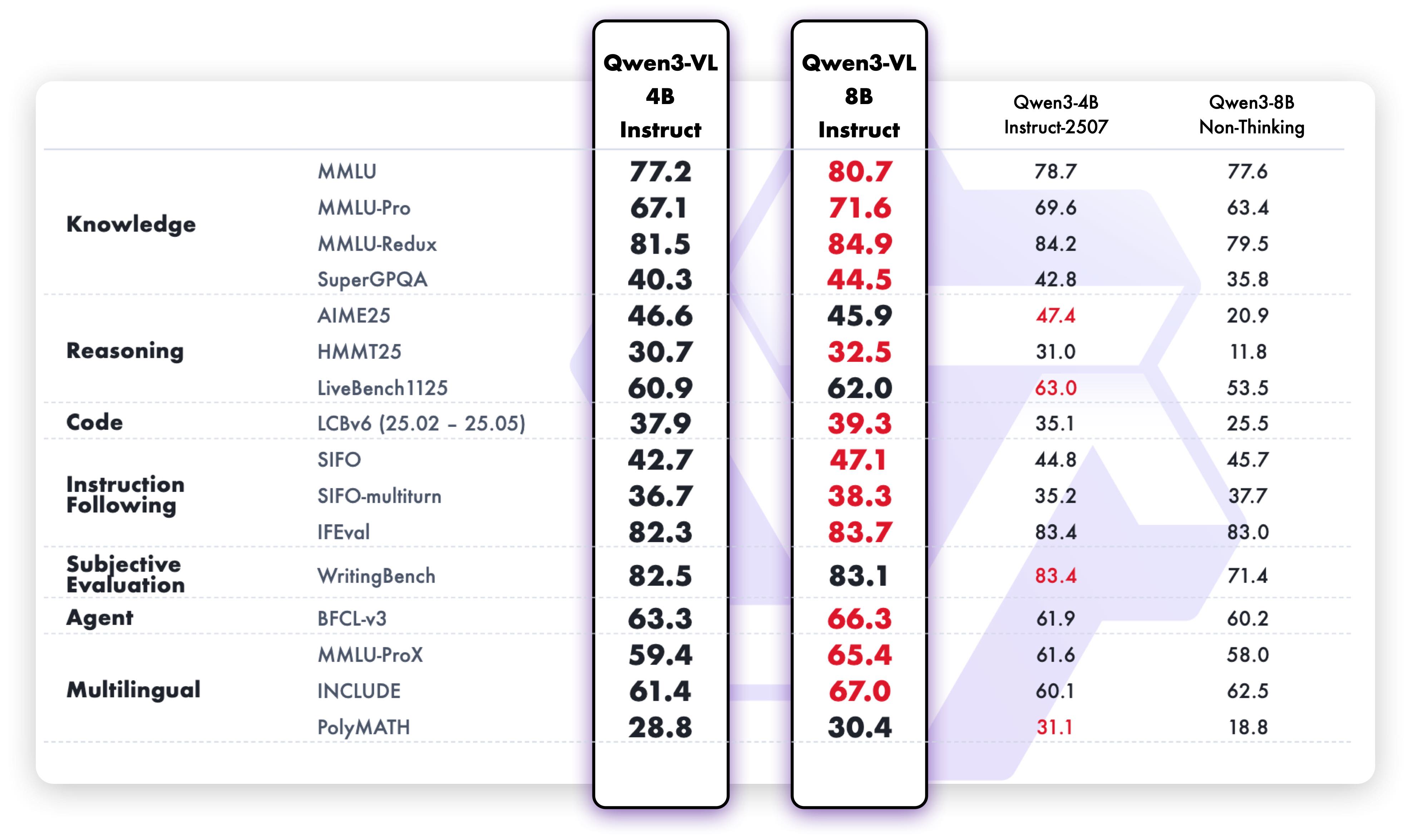
unsloth/Qwen3-VL-4B-Instruct-GGUF · Hugging Face
unsloth/Qwen3-Coder-480B-A35B-Instruct-GGUF · Hugging Face
bartowski/Qwen_Qwen3-VL-30B-A3B-Instruct-GGUF · Difference between ...
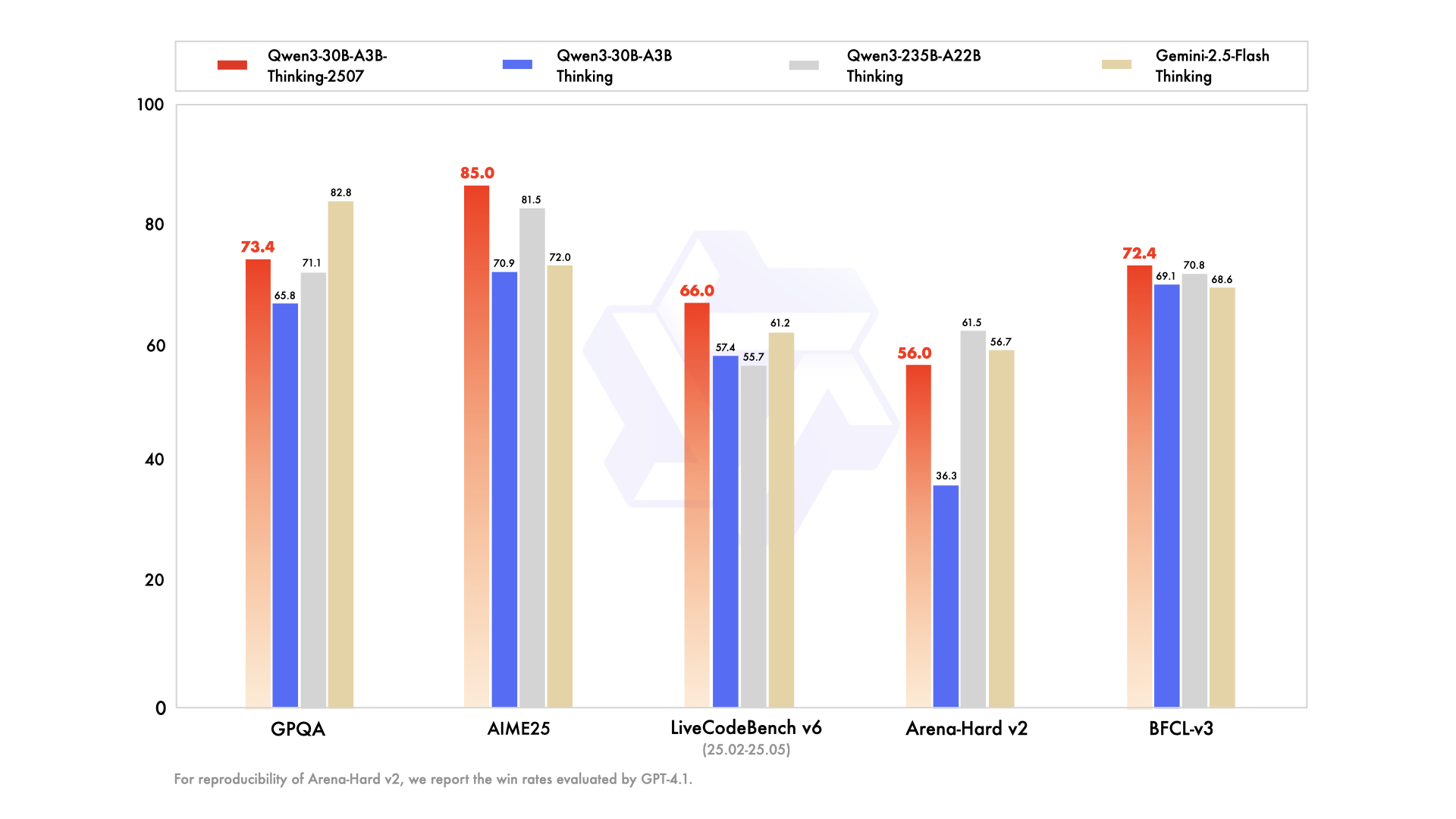
unsloth/Qwen3-30B-A3B-Thinking-2507-GGUF · Hugging Face
unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF · Confusion between FP16 and BF16
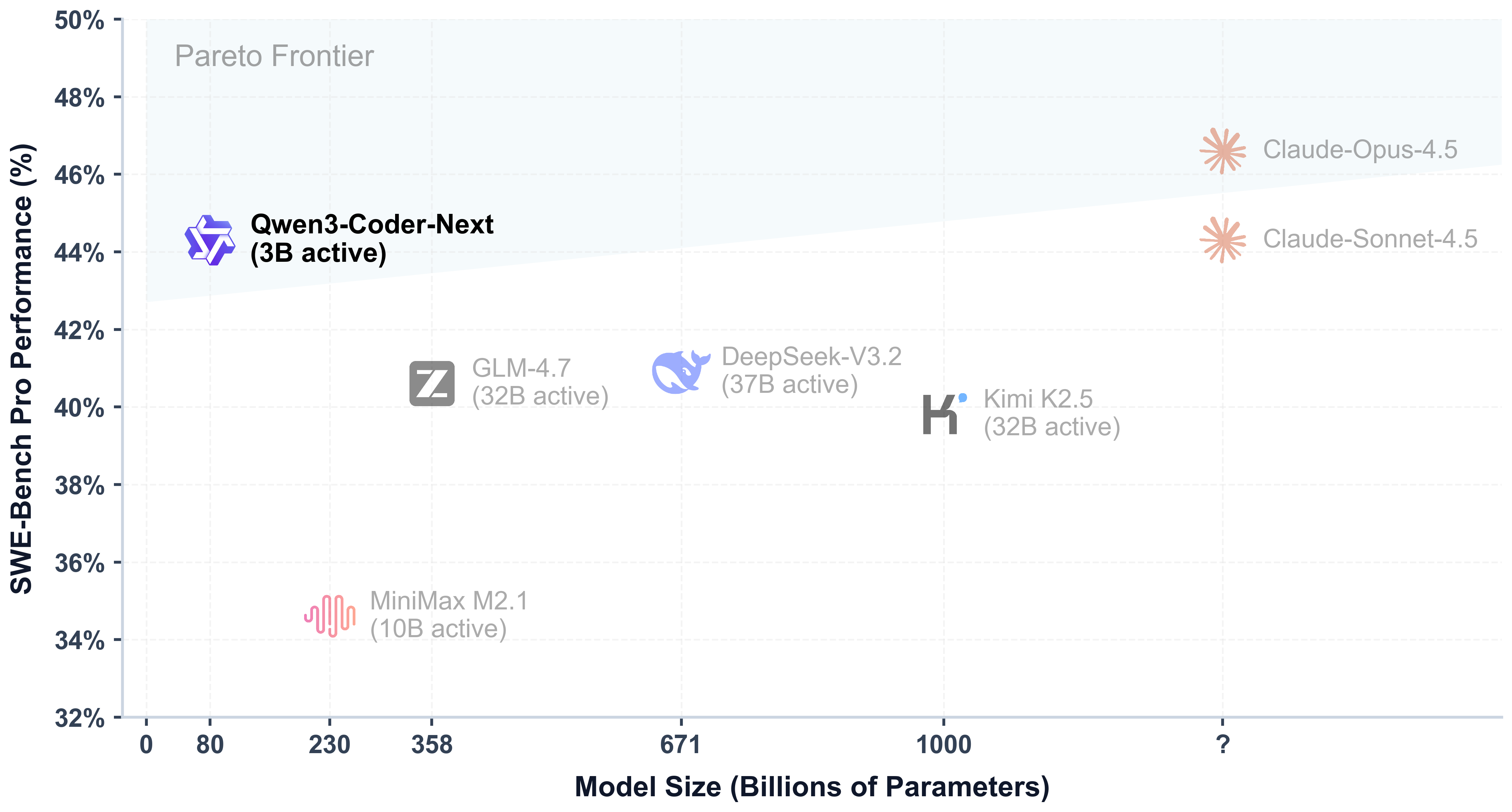
unsloth/Qwen3-Coder-Next-GGUF · Hugging Face
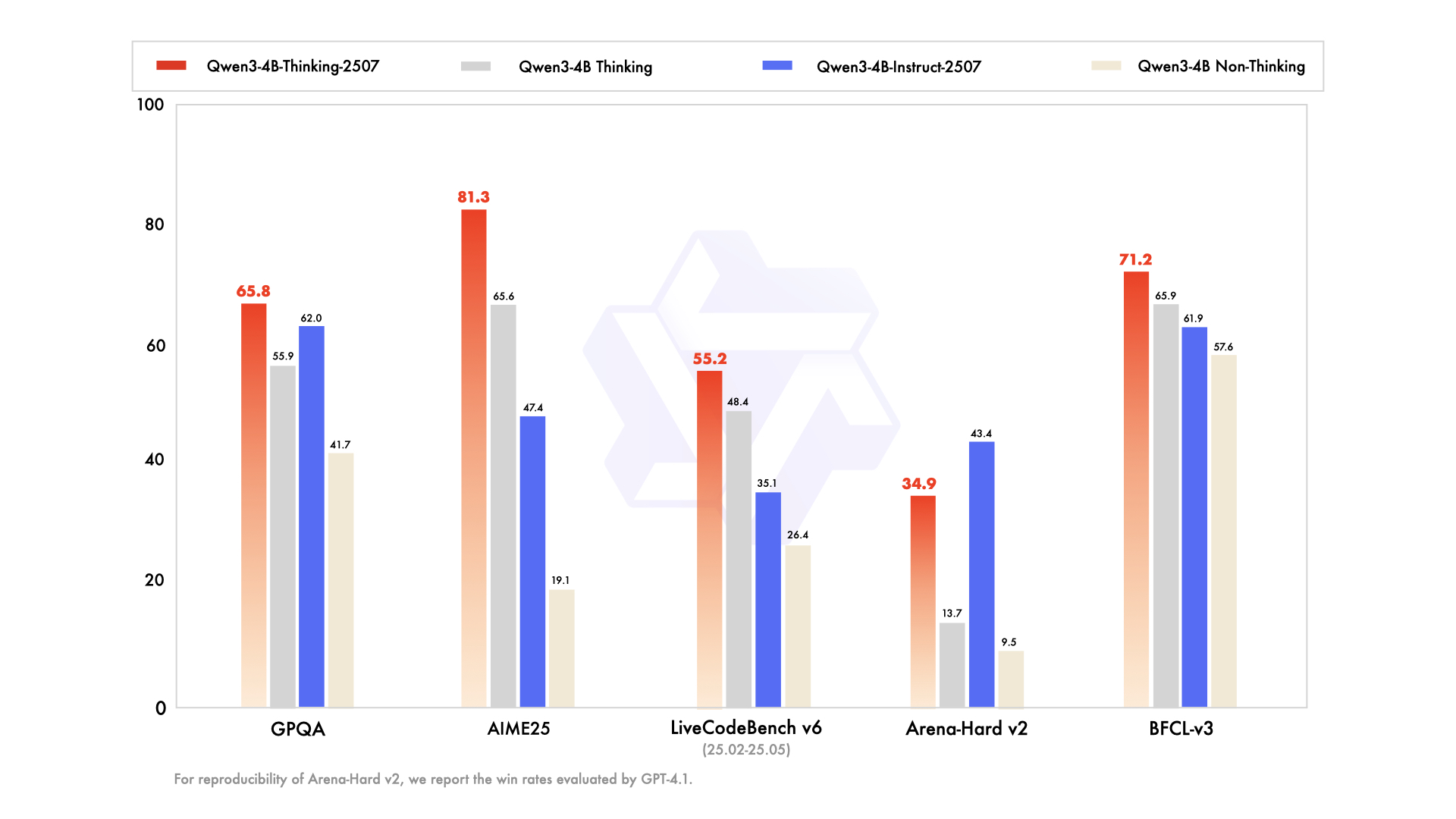
unsloth/Qwen3-4B-Instruct-2507-GGUF · Hugging Face
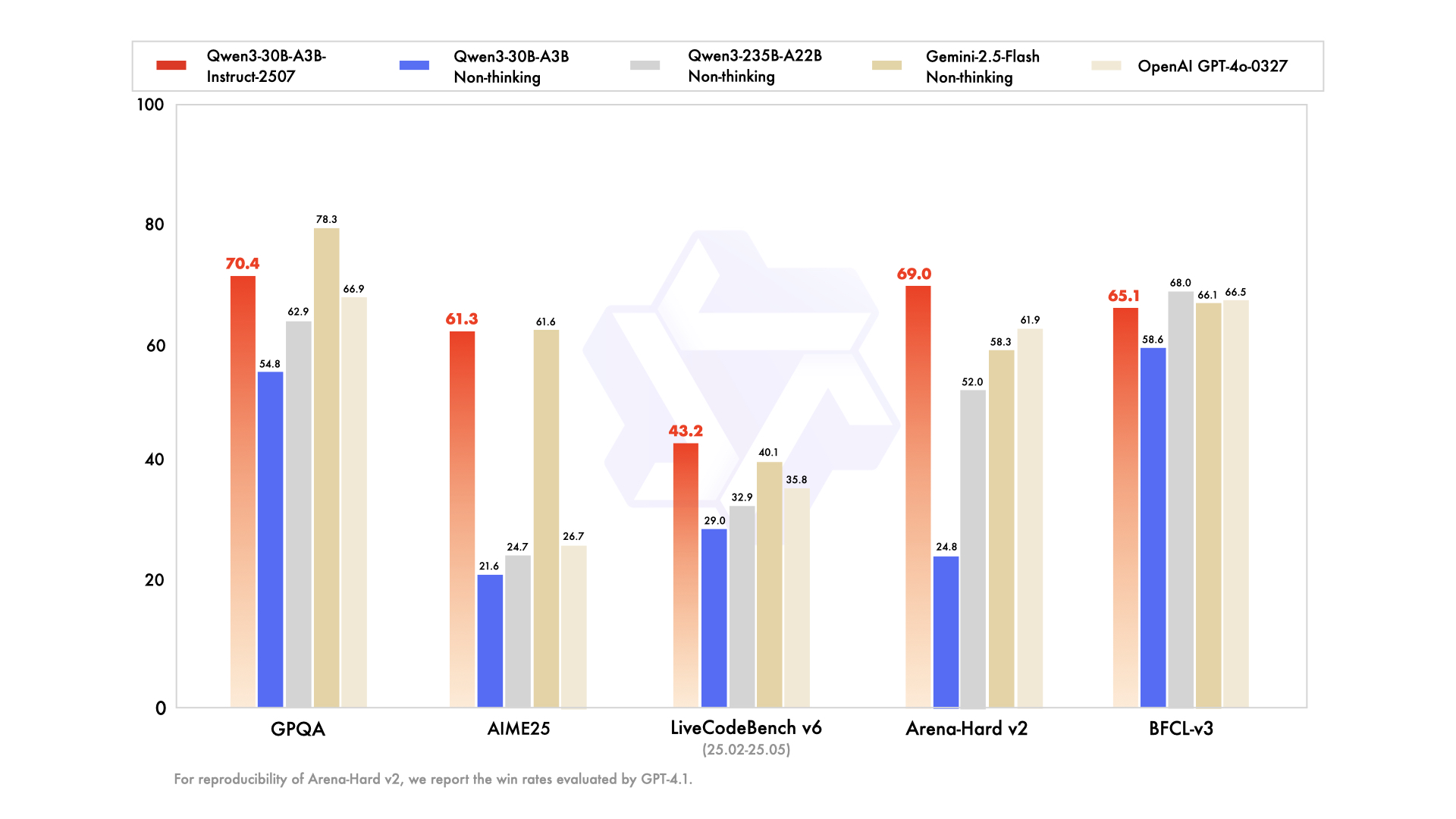
unsloth/Qwen3-30B-A3B-Instruct-2507-GGUF · Hugging Face
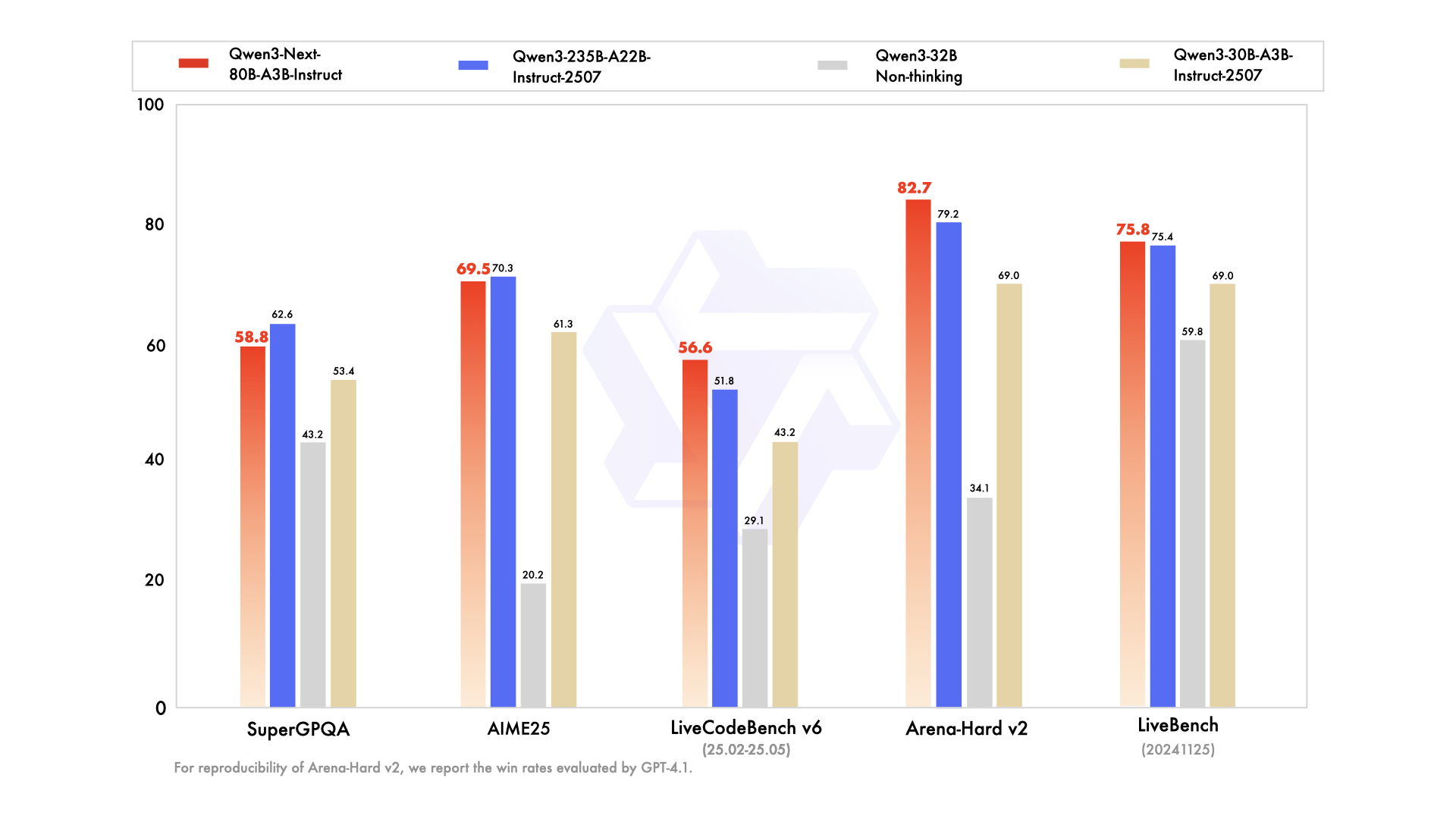
unsloth/Qwen3-Next-80B-A3B-Instruct-GGUF · Hugging Face
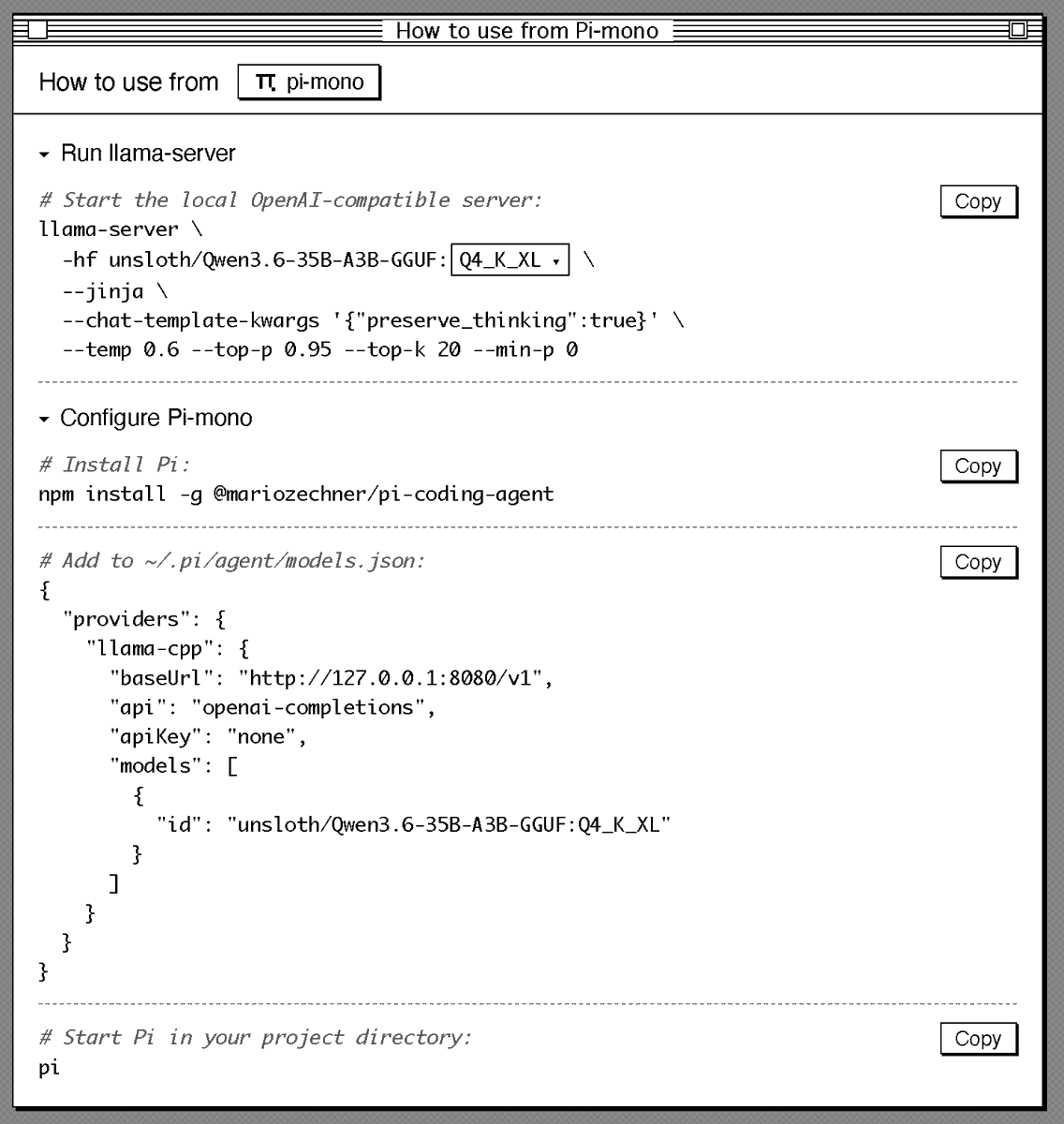
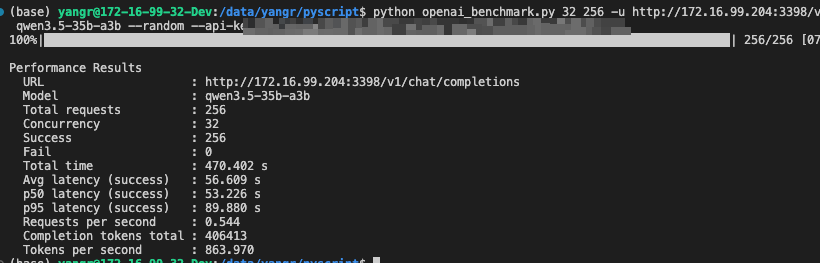
unsloth/Qwen3.6-35B-A3B-GGUF · Qwen 3.6 is much slower than Qwen 3.5 ...
noctrex/Qwen3.5-35B-A3B-MXFP4_MOE-GGUF · Hugging Face
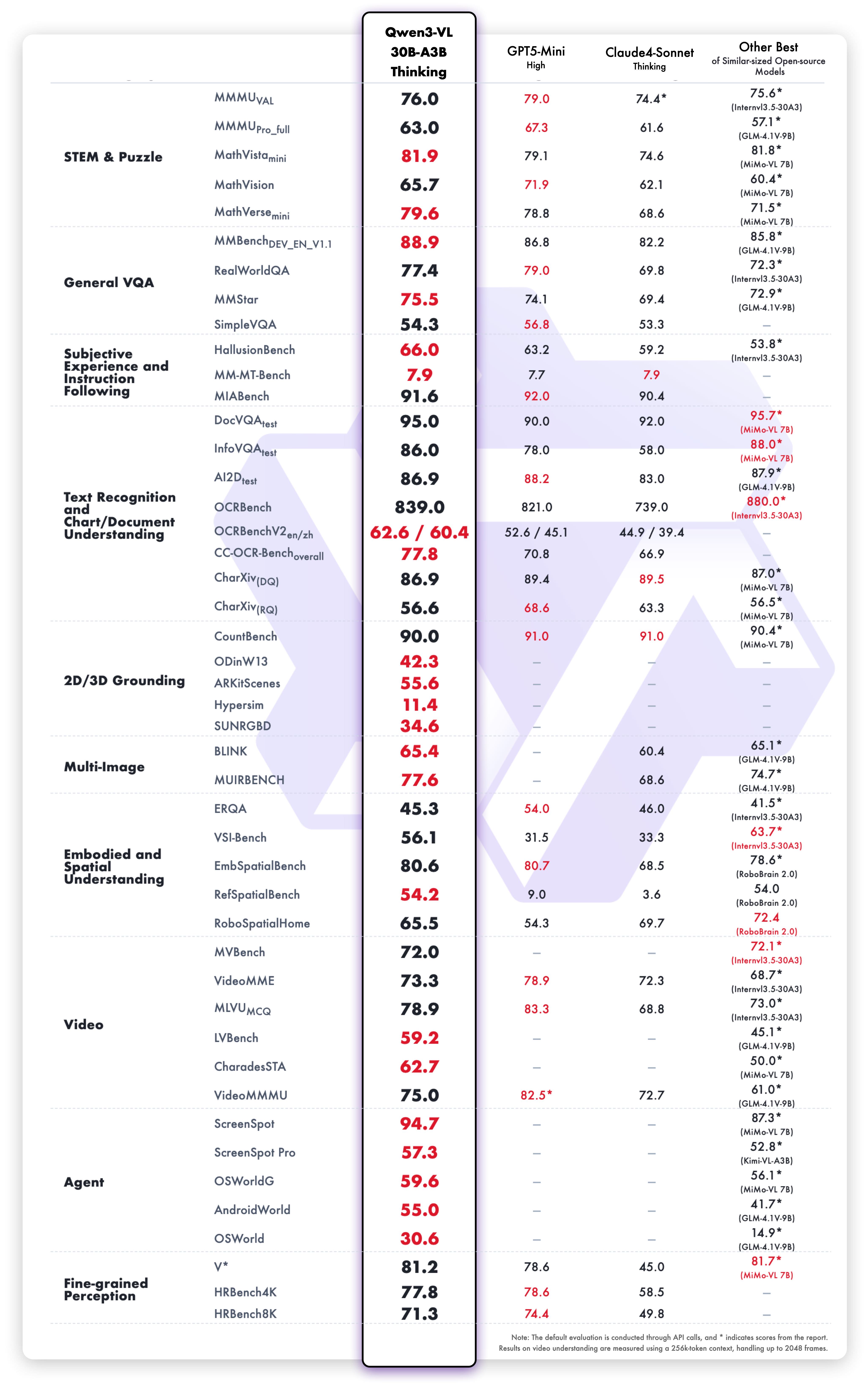
unsloth/Qwen3-VL-30B-A3B-Instruct-GGUF · Hugging Face
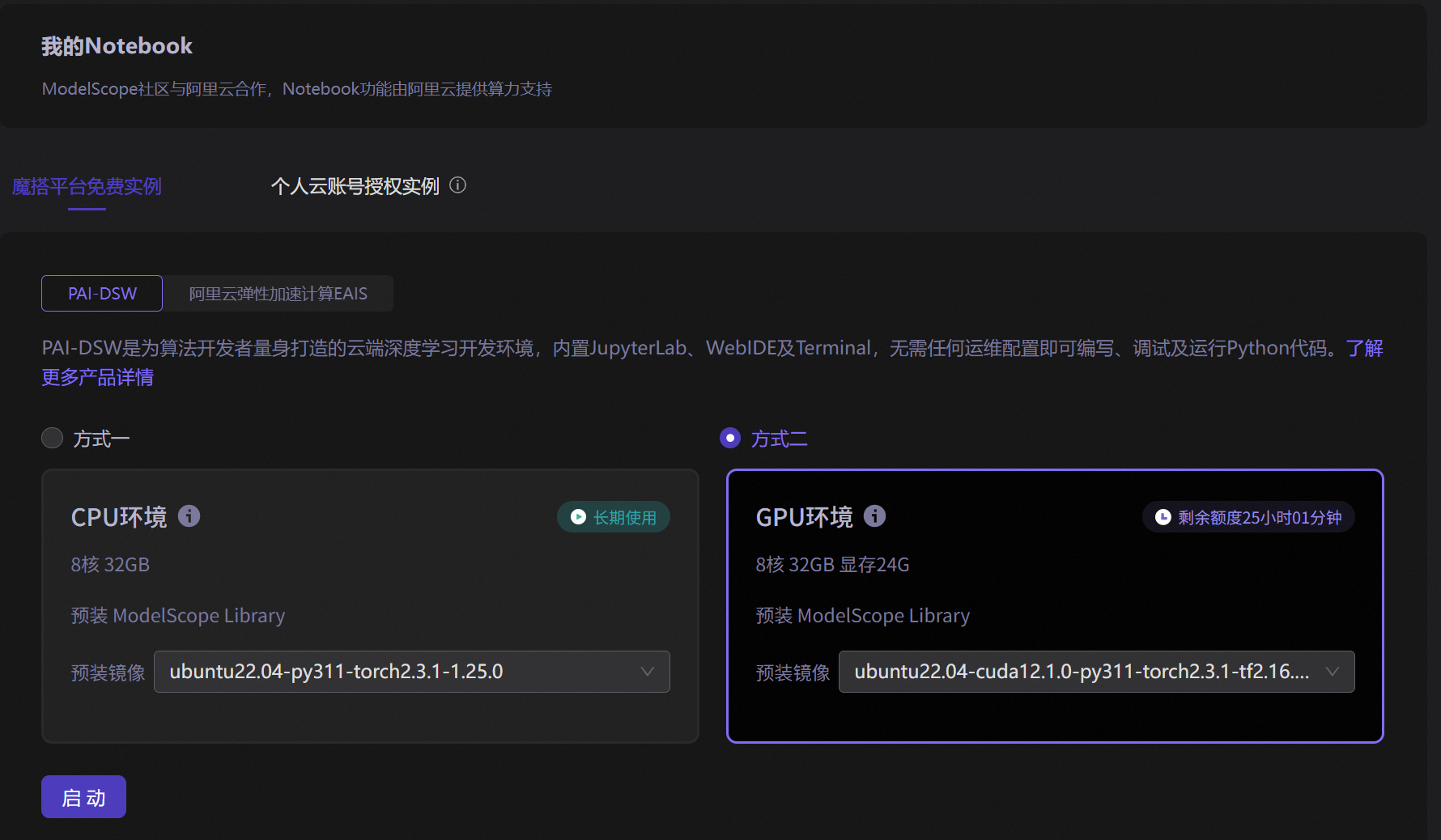
ai-models/unsloth/Qwen3.5-9B-GGUF · Cloud Native Build
unsloth/Qwen3-Next-80B-A3B-Instruct-GGUF · Dec 29 2025: Qwen3-Next ...
mmproj/Qwen2.5-VL-7B-Instruct-mmproj-BF16.gguf · QuantStack/Qwen-Image ...
unsloth/Qwen3-VL-235B-A22B-Instruct-1M-GGUF · Hugging Face
unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF · RooCode Performance Is Very ...
unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF · New Chat Template + Tool ...
tensorblock/unsloth_Qwen3-30B-A3B-Instruct-2507-GGUF · Hugging Face
unsloth/Qwen3-Coder-30B-A3B-Instruct-1M-GGUF · 4bit Q4_K_M Scored 63.57 ...
mmproj-Qwen3VL-30B-A3B-Instruct-Q8_0.gguf · Qwen/Qwen3-VL-30B-A3B ...
unsloth/Qwen3-32B-128K-GGUF can not use multi GPU · Issue #10832 ...
Qwen-Image-2512-Lightning-4steps-V1.0-bf16.safetensors · lightx2v/Qwen ...
text_encoder/qwen_3_4b_bf16.safetensors · tsqn/Z-Image-Turbo_fp32-fp16 ...
unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF - MyGGUF Model Details
Qwen3 強勢登場!最強開源模型!?本機部署+模型能力實測
Qwen3-VL-30B-A3B-Thinking-GGUF huggingface.co api & unsloth Qwen3-VL ...
mradermacher/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled-i1 ...
Qwen3 30B A3B | Open Laboratory
qwen3.6:35b-a3b-mlx-bf16
Qwen3.5-35B-A3B-AWQ-4bit GPU算力适配教程:双卡vLLM并行推理参数详解与调优建议-CSDN博客
利用llama.cpp加载Qwen3.5-0.8B.BF16-mmproj.gguf模型文件识别图像和提取文字_mmproj-bf16 ...
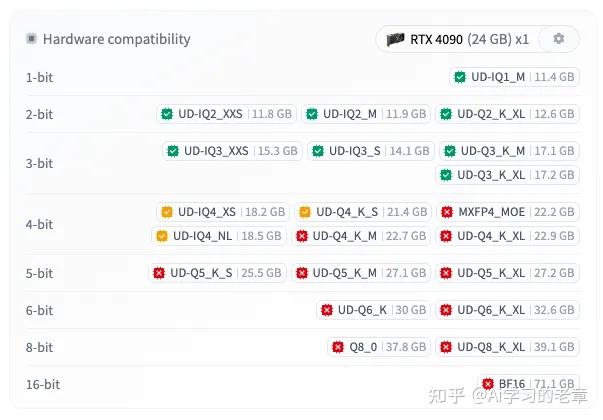
Qwen3.5 GGUF 基准测试 | Unsloth Documentation
qwen3:30b-a3b
Quantized Models for Qwen/Qwen3.5-35B-A3B – Hugging Face
unsloth/Qwen3-0.6B-GGUF Free Chat Online - skywork.ai - Skywork ai
Qwen3 30B A3B GGUF By unsloth: Benchmarks, Features and Detailed ...
Thireus/mmproj-Qwen3-VL-235B-A22B-Instruct-THIREUS-BF16-SPECIAL_SPLIT ...
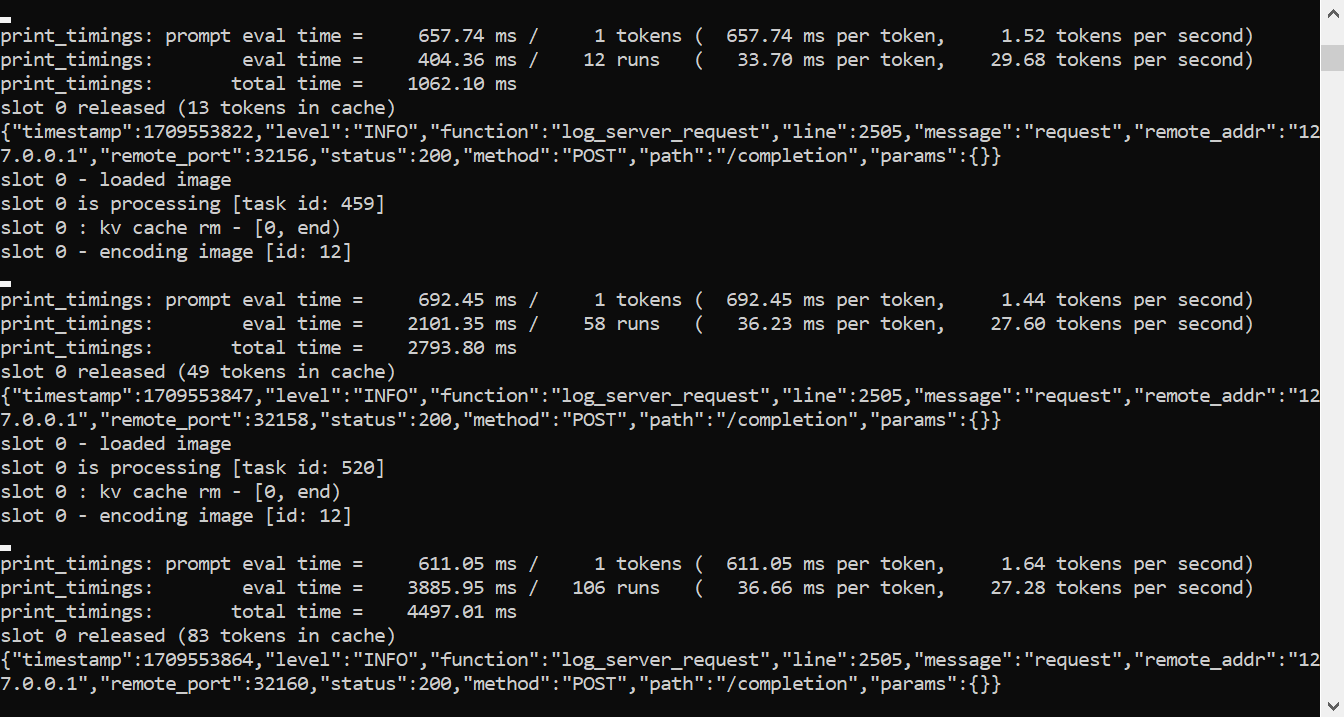
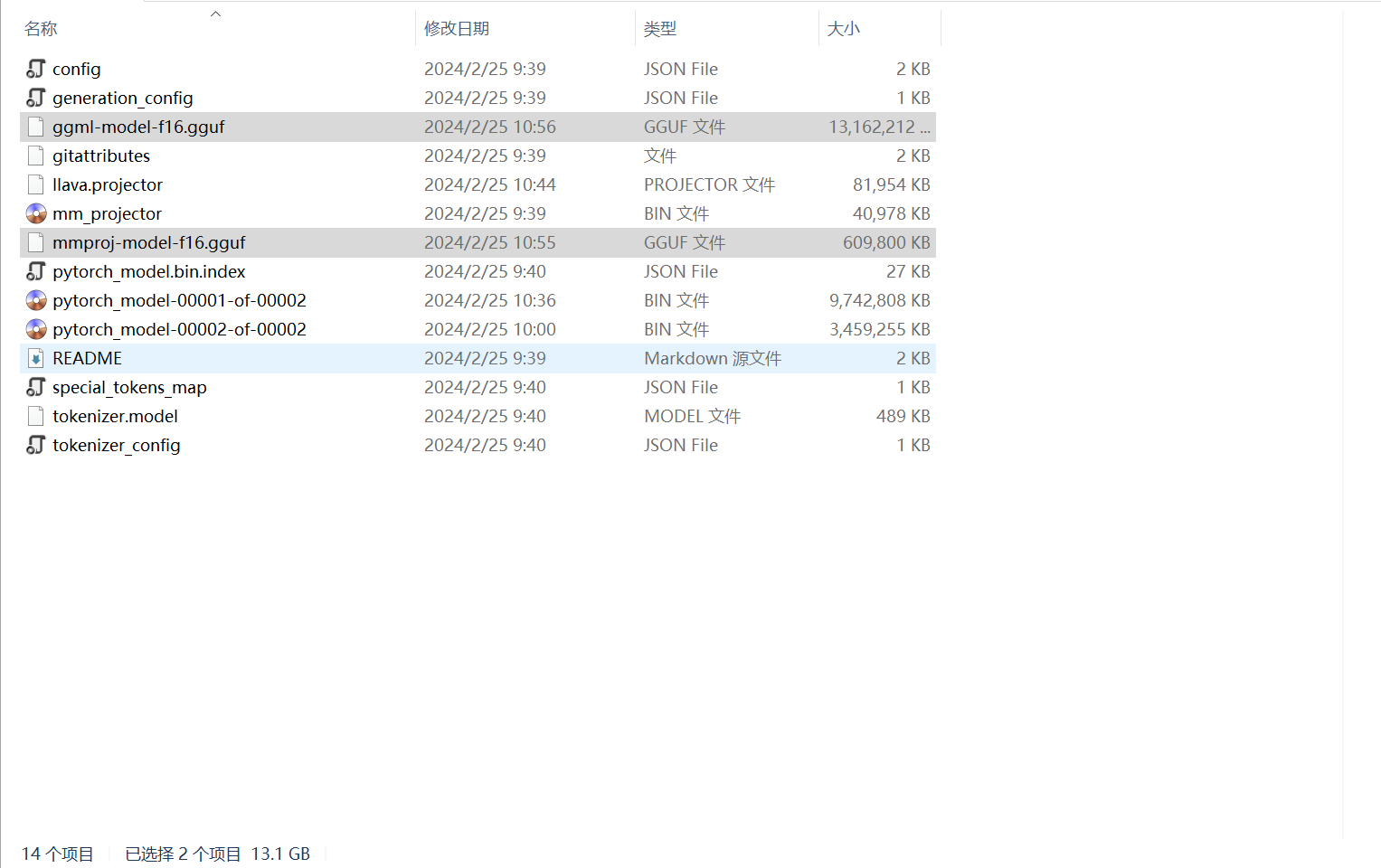
llama.cpp部署多模态视觉模型到应用实践_mmproj-model-f16.gguf-CSDN博客
利用qwen 3.5-9b模型识别几何图像并转换成latex tikz代码_qwen3.5-9b-mmproj-bf16.gguf-CSDN博客
Qwen3.5 - How to Run Locally | Unsloth Documentation
Qwen3.5-35B-A3B (GGUF)部署到 ComfyUI _qwen3.5-35b-a3b-gguf-CSDN博客
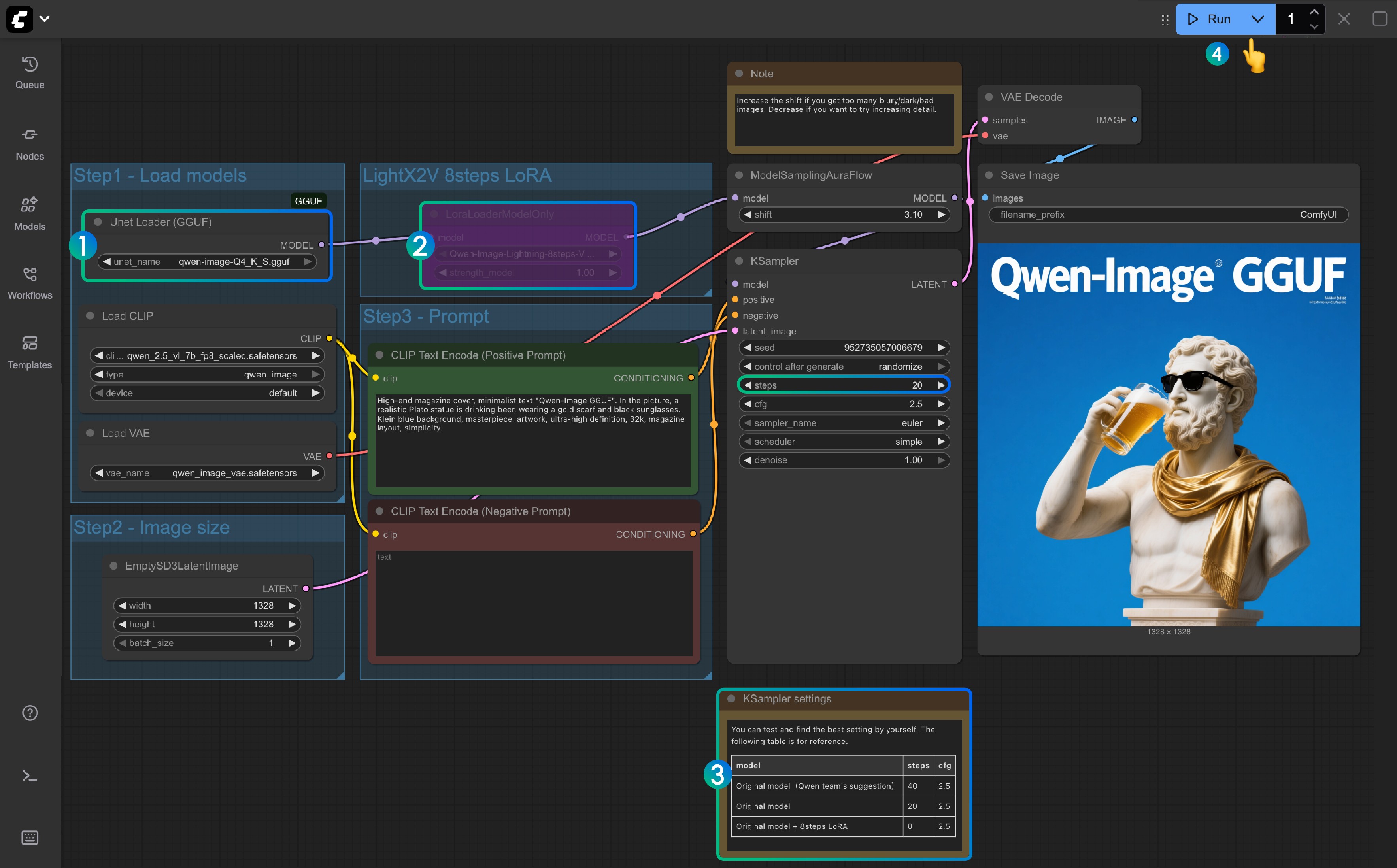
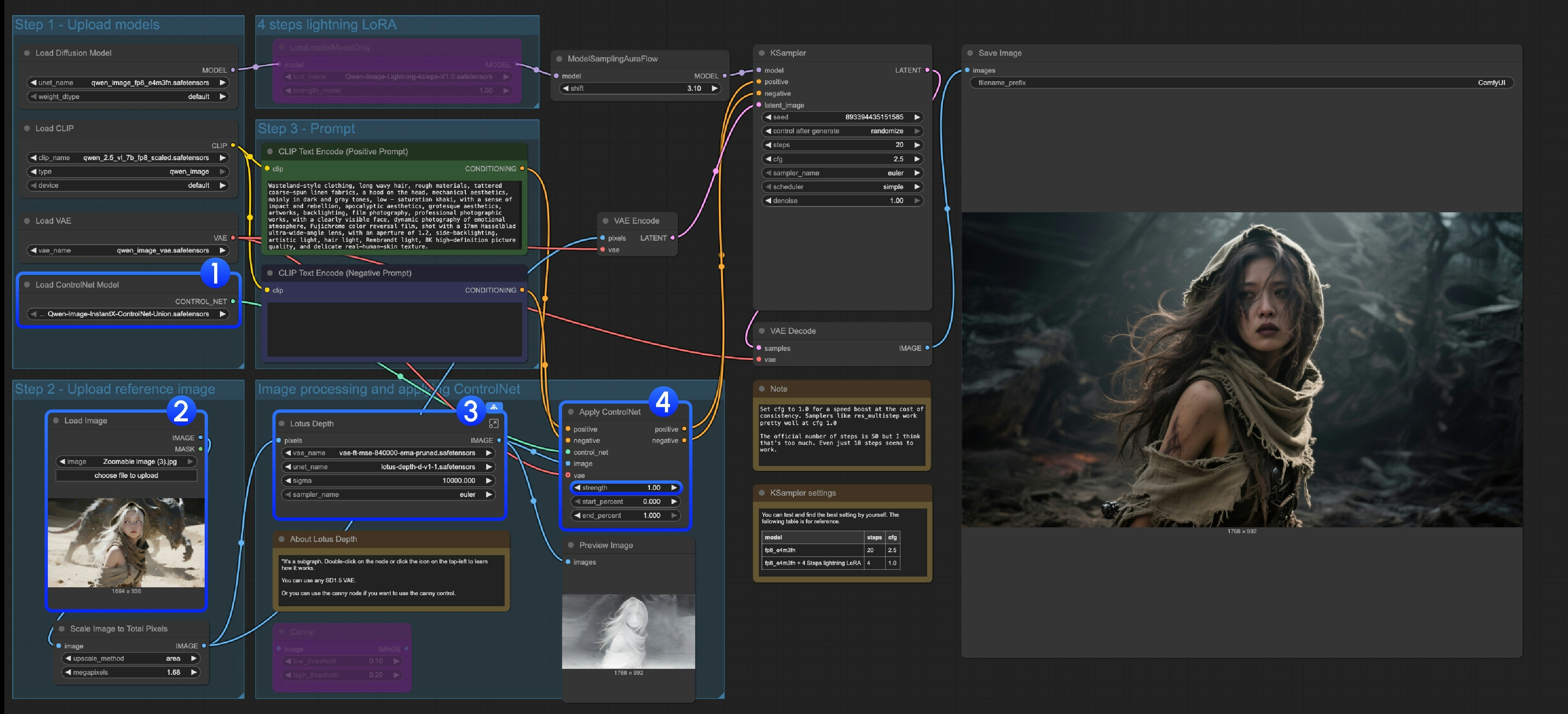
Qwen-Image ComfyUI Native, GGUF, and Nunchaku Workflow Complete Usage ...
Sharing my current setup to run Qwen3.6 locally in a good agentic setup ...
Qwen3.5-35B-A3B浅尝 | 安落滢 Blog - 技术分享与生活记录
renchris/qwen3-coder:30b-gguf-unsloth
Qwen3.5 GGUF Benchmarks | Unsloth Documentation
unsloth/Qwen3-4B-GGUF Free Chat Online - skywork.ai - Skywork
Eval bug: unsloth Qwen3-30B-A3B-Instruct-2507-UD-Q8_K_XL.gguf and ...
unsloth/Qwen3-30B-A3B-GGUF - Secret AI
BF16 vs GGUF, FP8 Scaled, NVFP4 Speed & Quality Compared + ComfyUI CUDA ...
How to Install Qwen3-32B-GGUF Locally? - DEV Community
Qwen Image Installation (FP8/GGUF/BF16)
Unsloth框架+LoRA微调Qwen最新模型Qwen3-B-unsloth-bnb-4bit_云上配置unsloth-CSDN博客
wan2.1-t2v-14b-BF16.gguf - RunningHub Stable Diffusion & Flux GGUF
Unsloth Dynamic 2.0 GGUF | Unsloth Documentation
自由控制Qwen3模型的思考模式_ollama关闭qwen3思考模式-CSDN博客
Qwen2.5-3B-Instruct-GGUF部署-CSDN博客
用 SGLang 部署 Qwen3-8B(含 GPU 配置与量化方案)_sglang qwen3-CSDN博客
Qwen-Image-Lightning-8steps-V2.0 bf16 - RunningHub Stable Diffusion ...
Qwen3.6 MTP加速,本地部署加速1.5倍,驱动 Claude Code - 知乎
Qwen-Image-Lightning-4steps-V2.0-bf16 - RunningHub Stable Diffusion ...
Qwen-Turbo-BF16安全防护:模型部署最佳实践-CSDN博客
qwen3-vl:2b-instruct-bf16
Qwen Image 2512 (GGUF/FP8/BF16)- Improved Realism
Qwen Image Edit 2511 GGUF/FP8/BF16 Improved Editing
Qwen-VL模型微调及遇到的一些小问题_qwen vl-CSDN博客
Qwen-Image-Edit-Lightning-8steps-V1.0-bf16.safetensors - RunningHub ...
(Flymy Scene Consistency Enhancement) Qwen Edit Image Editing BF16 Full ...
Install Qwen2.5-Omni 3B on Windows
Qwen-Image ComfyUI Native Workflow Example - ComfyUI
Qwen
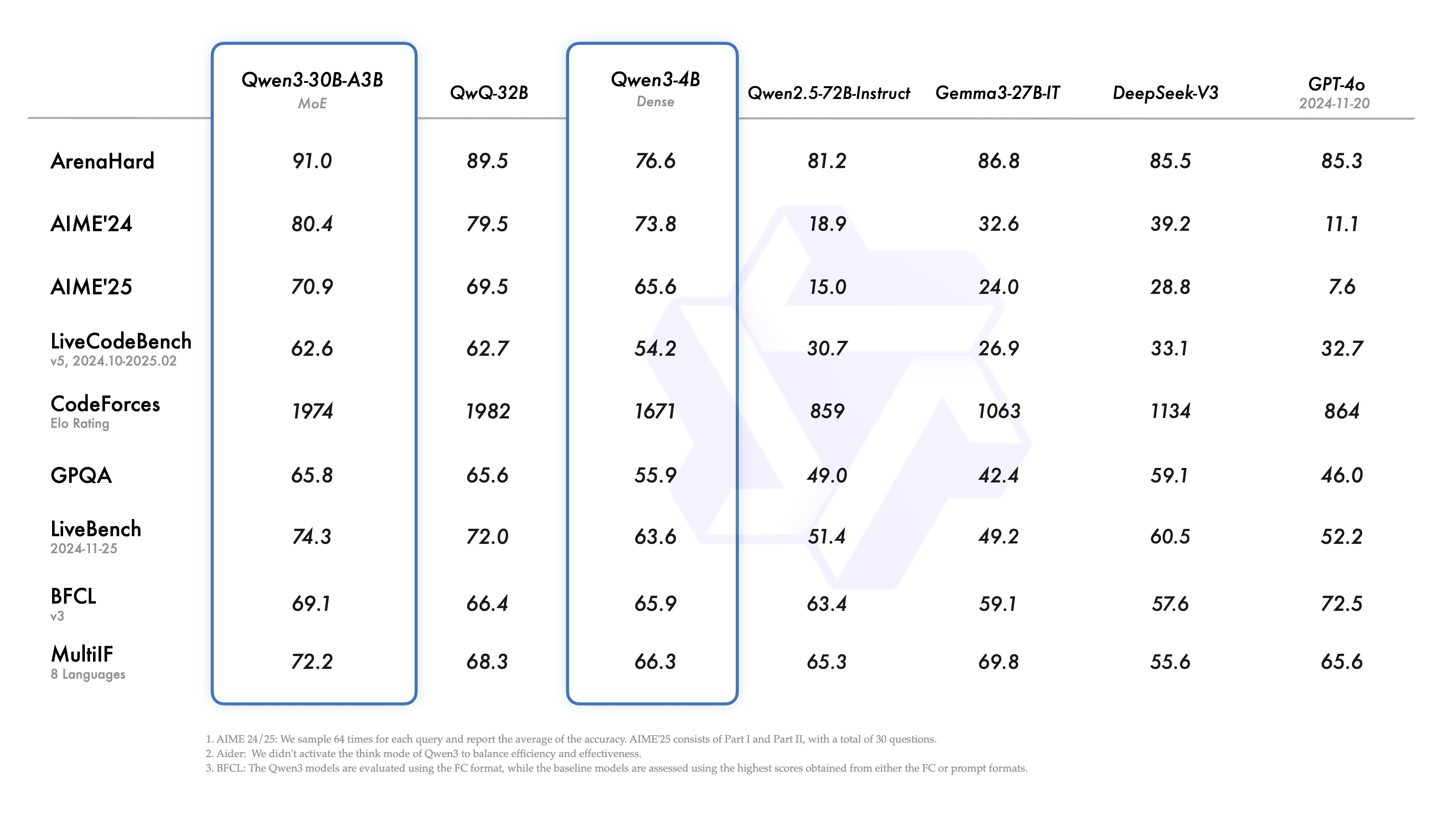
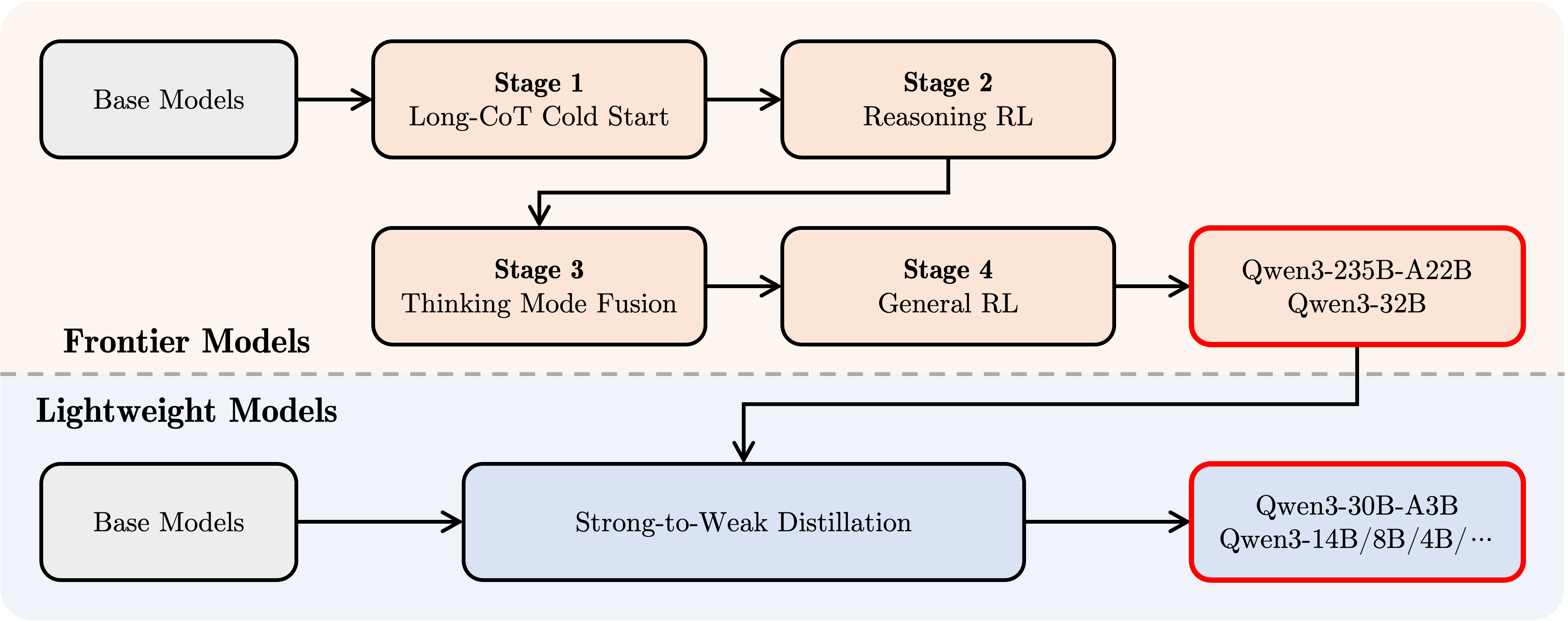
更轻,更强,更好用!Qwen3-30B-A3B 更新了! - 知乎
Qwen-Image-Lightning-8steps-V2.0-bf16 - RunningHub Stable Diffusion ...
Qwen-Image-Edit重磅发布!20B大模型秒变修图神器,中文指令全支持 | 高效码农
Introducing The World’s First BF16 NPU Model for SD 3.0 Medium – Try ...
Qwen Image BF16 GGUF t2i with lightx2v-Lightning LoRA 8steps&Face ...
Qwen_Image_2512_Lightning bf16 4步加速Lora - RunningHub Stable Diffusion ...