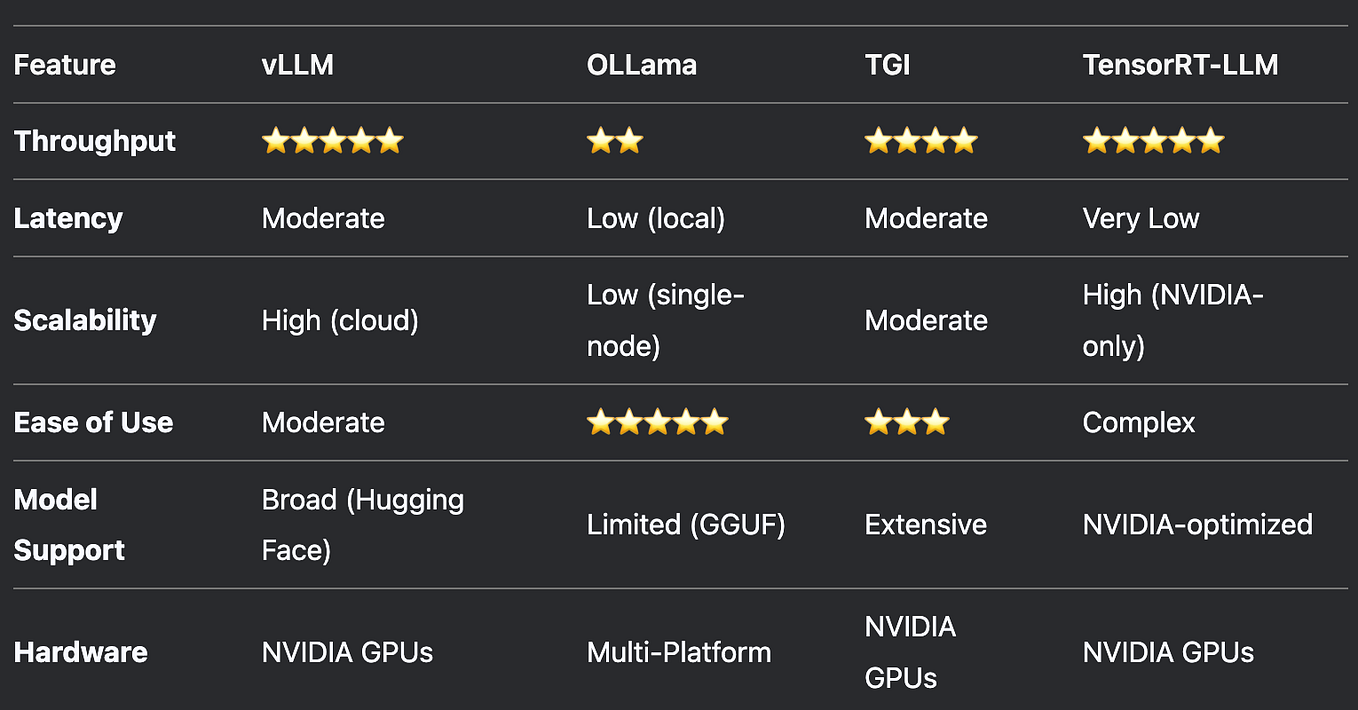
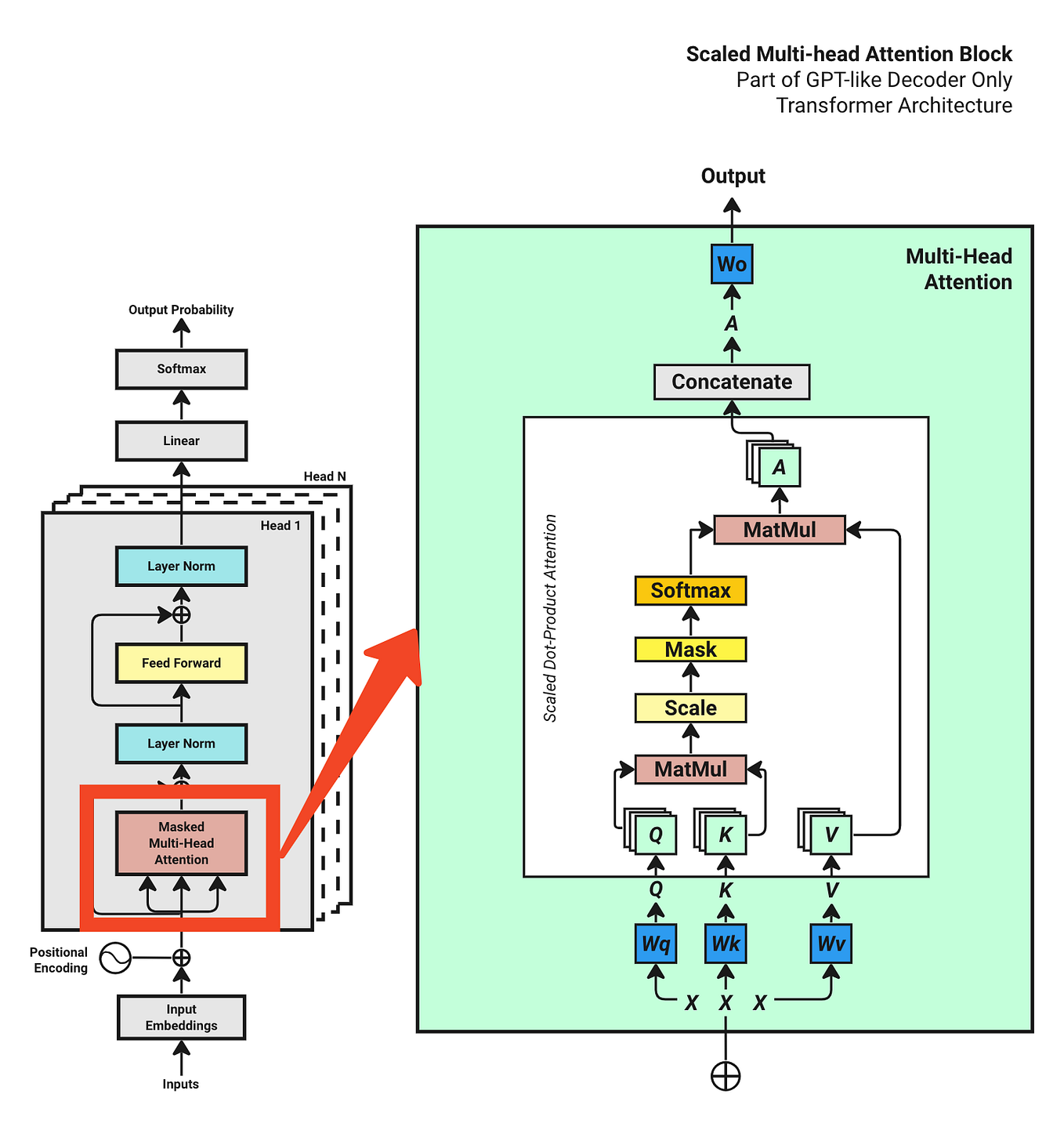
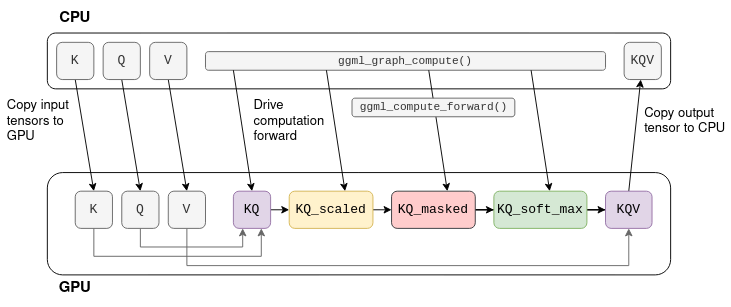
How to Run Quantized GGUF LLMs Locally on GPU with llama.cpp (No Cloud ...
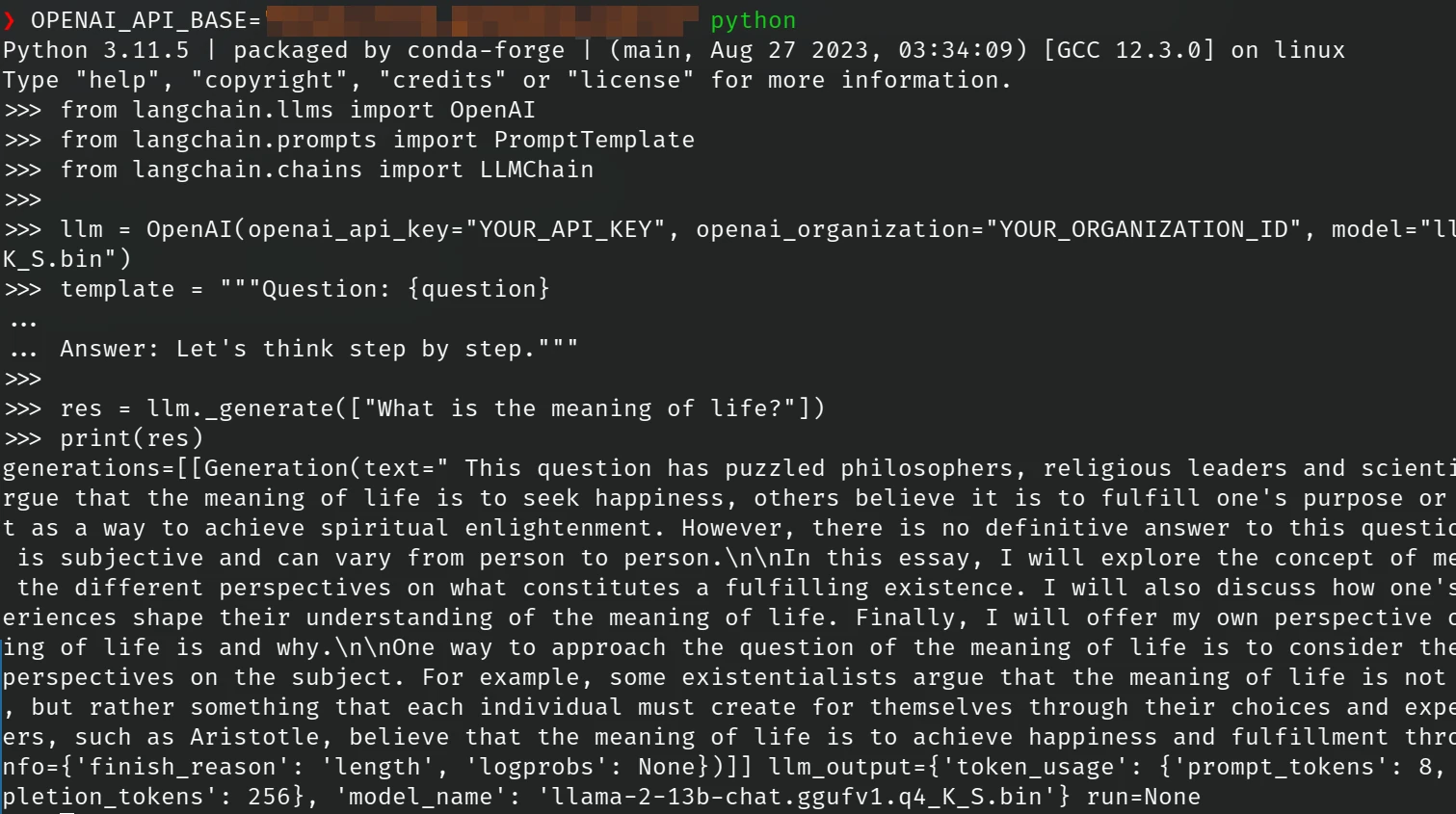
How to Run LLaMA Locally on CPU or GPU | Python & Langchain ...
Issue: LLamacpp wrapper slows down the model · Issue #5071 · langchain ...
How to build a Question Answering Model using LlamaCpp | Atharva ...
Issue with using LlamaCpp LLM in Pandas Dataframe Agent · Issue #3569 ...
How to run llama 3.2 1B on CPU on mac as an API endpoint using LLamaCpp ...
LlamaCpp model crashes with multi-token characters · Issue #934 ...
Build from Source Llama.cpp with CUDA GPU Support and Run LLM Models ...
I have gpu and I expect to run model faster, but your code is only for ...
How to Compile and Build the GPU version of llama.cpp from source and ...
How to run Claude Code/ Codex with local models via Llamacpp, Ollama ...
LlamaCpp model needs streaming support · Issue #2948 · langchain-ai ...
Output using llamacpp is garbage · Issue #3301 · langchain-ai/langchain ...
LlamaCpp Model callbacks handleLLMNewToken JS/TS · Issue #2506 ...
nvidia/gpt-oss-120b-Eagle3-throughput · how would you run this with ...
Run Your Own AI (Mixtral) on Your Machine - Inference using Llamacpp on ...
AMD GPU run large language model LLM locally - LLaMA 8bit and LoRA ...
Effectively use LLamaCPP with Langchain - ChatModel, JSON Mode ...
Llama.cpp Python Examples: A Guide to Using Llama Models with Python ...
How to Run Local AI on Android with llama.cpp and Termux
TheBloke/Llama-2-70B-Chat-GGML · Unable to load model in latest llama ...
Issue: Using "llama-2-70b-chat/ggml-model-q4_0.bin" with LlamaCpp ...
Simple Tutorial to Quantize Models using llama.cpp from safetensors to ...
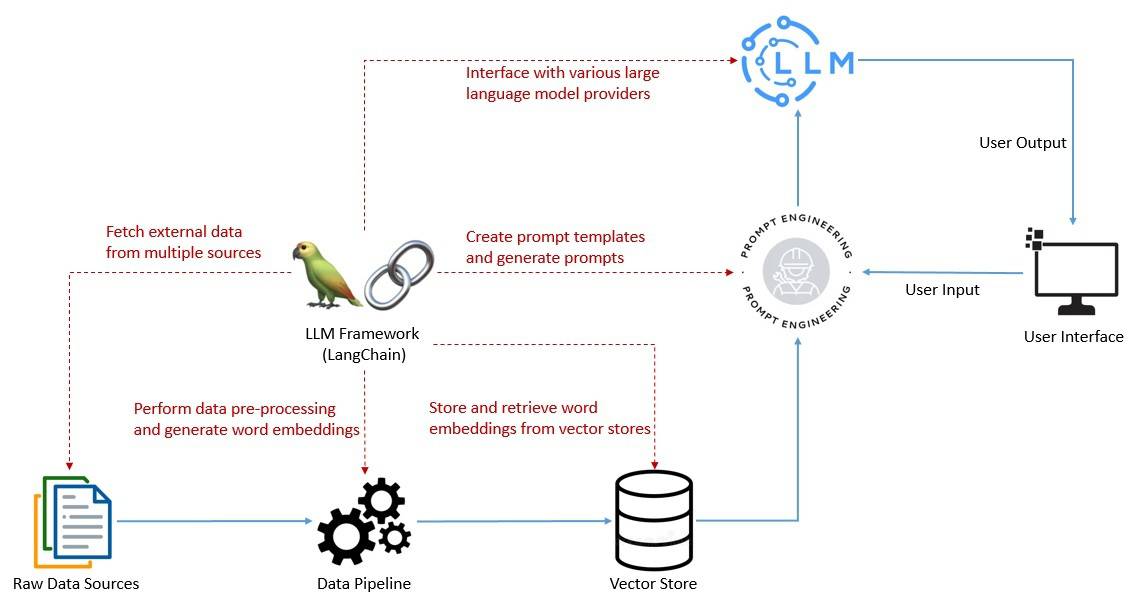
Using LangChain to Simplify the Creation of Applications using AI Large ...
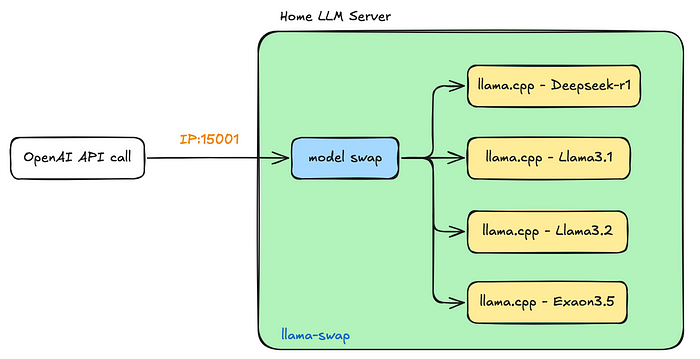
Serve multiple models with llamacpp server · ggml-org llama.cpp ...
How to build a Interactive Personal AI Research Agent with Llama 3.2 ...
Learn How To Install & Run Flowise For 🦜🔗LangChain! | by Cobus Greyling ...
How to Run Llama 2 Locally: A Guide to Running Your Own ChatGPT like ...
Using Llama 2 models for text embedding with LangChain | by Simao Liu ...
How to Build llama.cpp on MacOS and run large language models | by Amit ...
Running Quantized LLAMA Models Locally on macOS with LangChain and ...
LLMOps : Install LLaMA.cpp. Embeddings and Generation with Langchain # ...
Using Langchain with Llama.cpp Python: Complete Tutorial
bartowski/aya-23-8B-GGUF · Can't load model in LlamaCpp
Use AMD GPU with LlamaCpp : r/LocalLLaMA
Part 1: Hands on Large Language Models with LangChain and Llama Index ...
How to Implement Hugging Face Models using Langchain?
python 3.x - LLM model is not loading into the GPU even after BLAS = 1 ...
run KISS: Simple LLM example on Python using LlamaCpp
Meet LLama.cpp: An Open-Source Machine Learning Library to Run the ...
python - Is there any method to fully load the GGUF models on GPU ...
Accelerate LLAMA & LangChain with Local GPU | Medium
Using llama-cpp-python server with LangChain - Martin's website/blog thingy
Pairing an open source LLM with Langchain (Llama 2) | Unscripted Coding ...
LLM By Examples: Build Llama.cpp with GPU (CUDA) support | by MB20261 ...
Exploring Tool and Function Calling with LangChain via Local LLaMA 3 ...
How to Successfully Use Llamacpp and Quantize SuperNova-Medius fxis.ai
How to Implement Hugging Face Models using Langchain?- Analytics Vidhya
Part 3: Hands on Large Language Models with LangChain and Llama Index ...
Exploring LLM Models with Hugging Face and Langchain Library on Google ...
Exploring LangChain and LlamaIndex to Achieve Standardization and ...
RuntimeError when setting up self hosted model + langchain integration ...
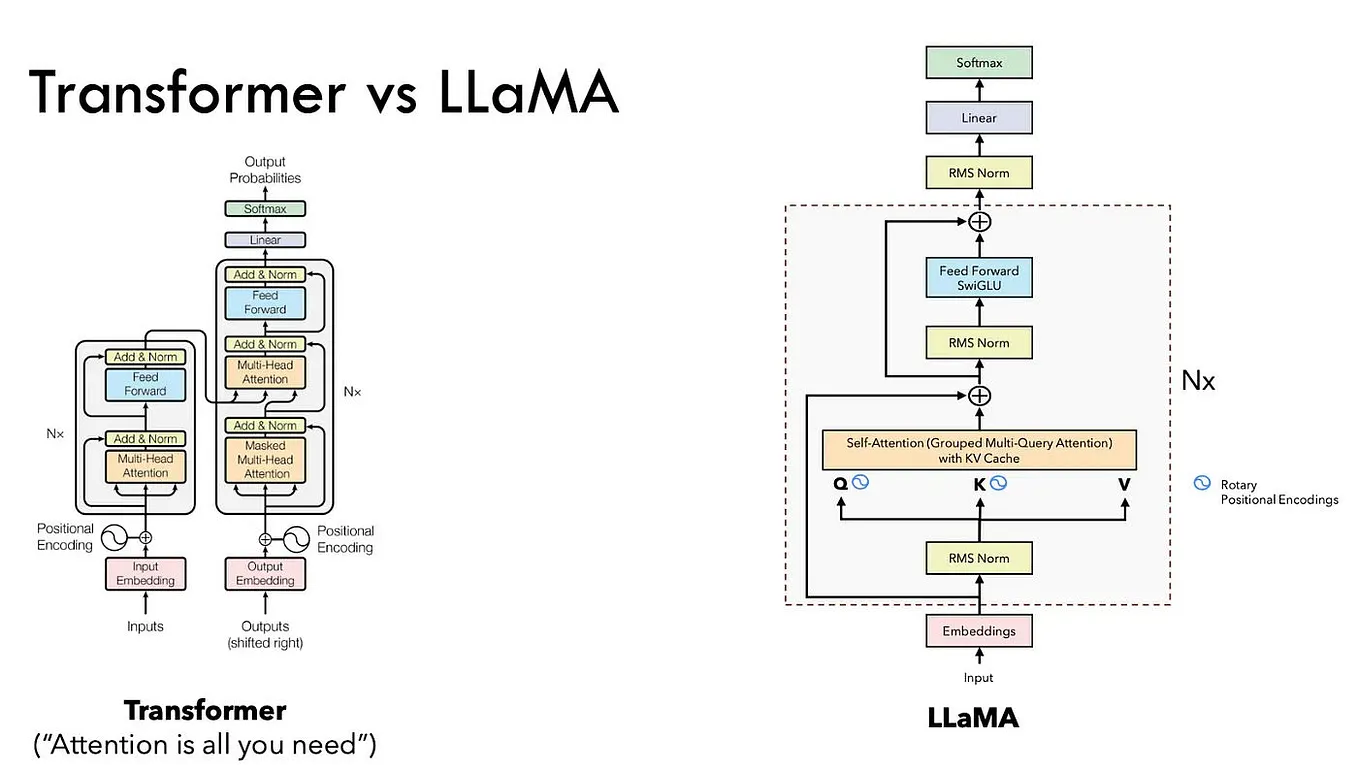
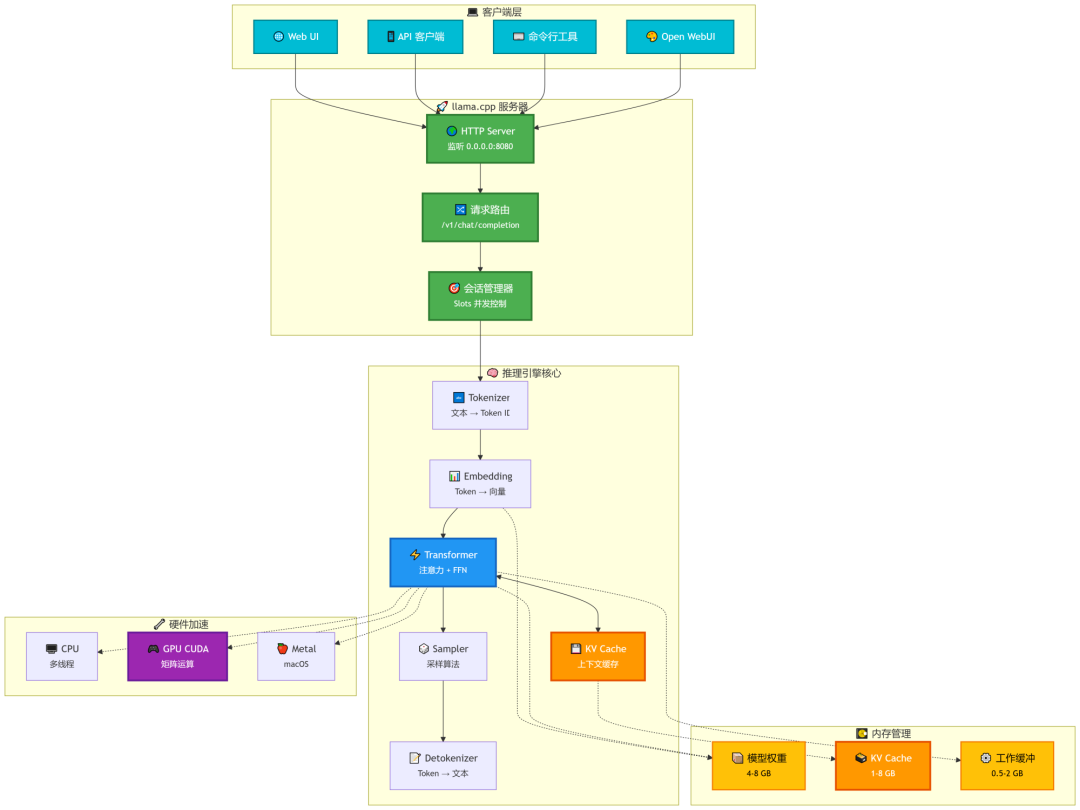
Understanding how LLM inference works with llama.cpp
Run LLMs (Llama 3) Locally with llama.cpp | Medium
Engineer's Guide to Local LLMs with LLaMA.cpp on Linux - DEV Community
Llamacpp GPU Layer Assignment Tool - a Hugging Face Space by bullerwins
How CPU time is spent inside llama.cpp + LLaMA2 (using OpenResty XRay ...
GitHub - doomgrave/guidance-langchain_integration: Guidance with added ...
Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and ...
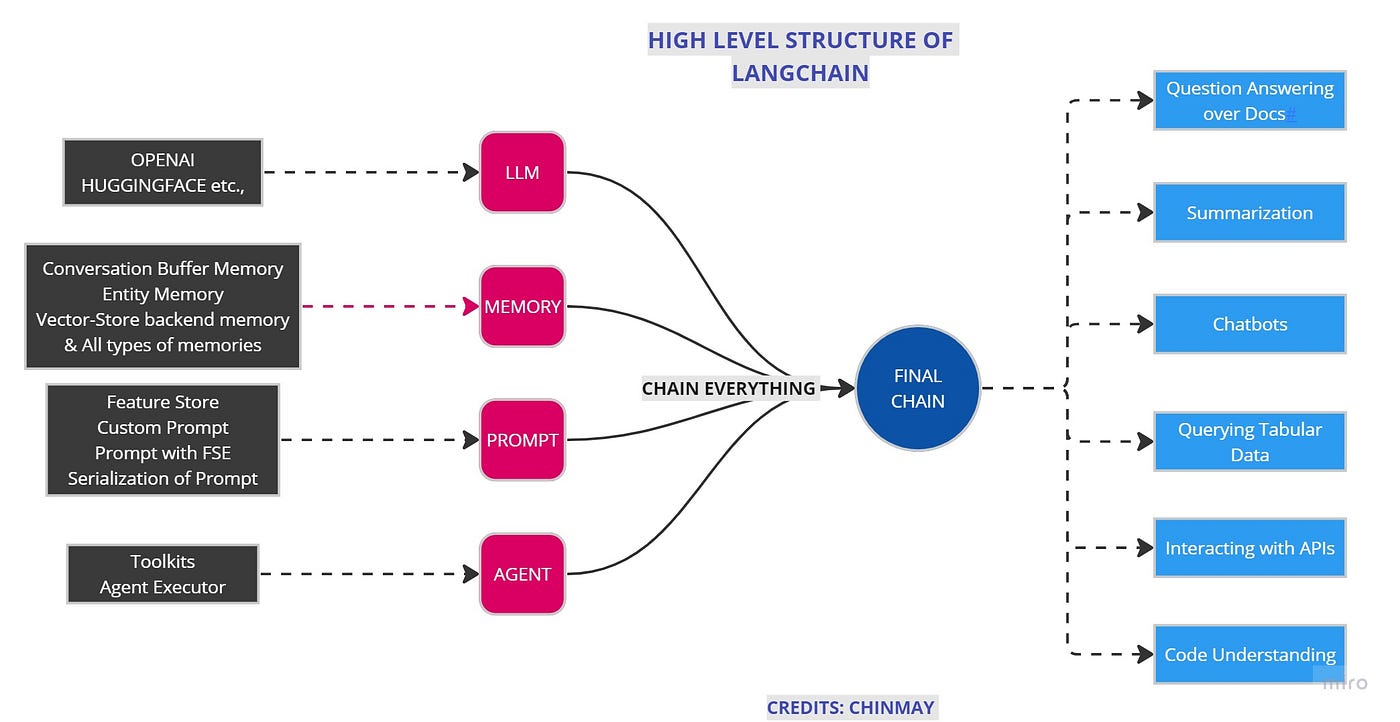
Introduction to LangChain | Baeldung
Accelerating LLMs with llama.cpp on NVIDIA RTX Systems | NVIDIA ...
Issue: LlamaCPP still uses cpu after passing the n_gpu_layer param ...
Install llama-cpp-python with GPU Support | by Manish Kovelamudi | Medium
GitHub - withcatai/node-llama-cpp: Run AI models locally on your ...
Build and Run llama.cpp Locally for Nvidia GPU - YouTube
Running LLaMA Locally with Llama.cpp: A Complete Guide | by Mostafa ...
GitHub - Illia-the-coder/LLAMALangChainDemo: Welcome to the LLAMA ...
LangChain tutorial #1: Build an LLM-powered app in 18 lines of code ...
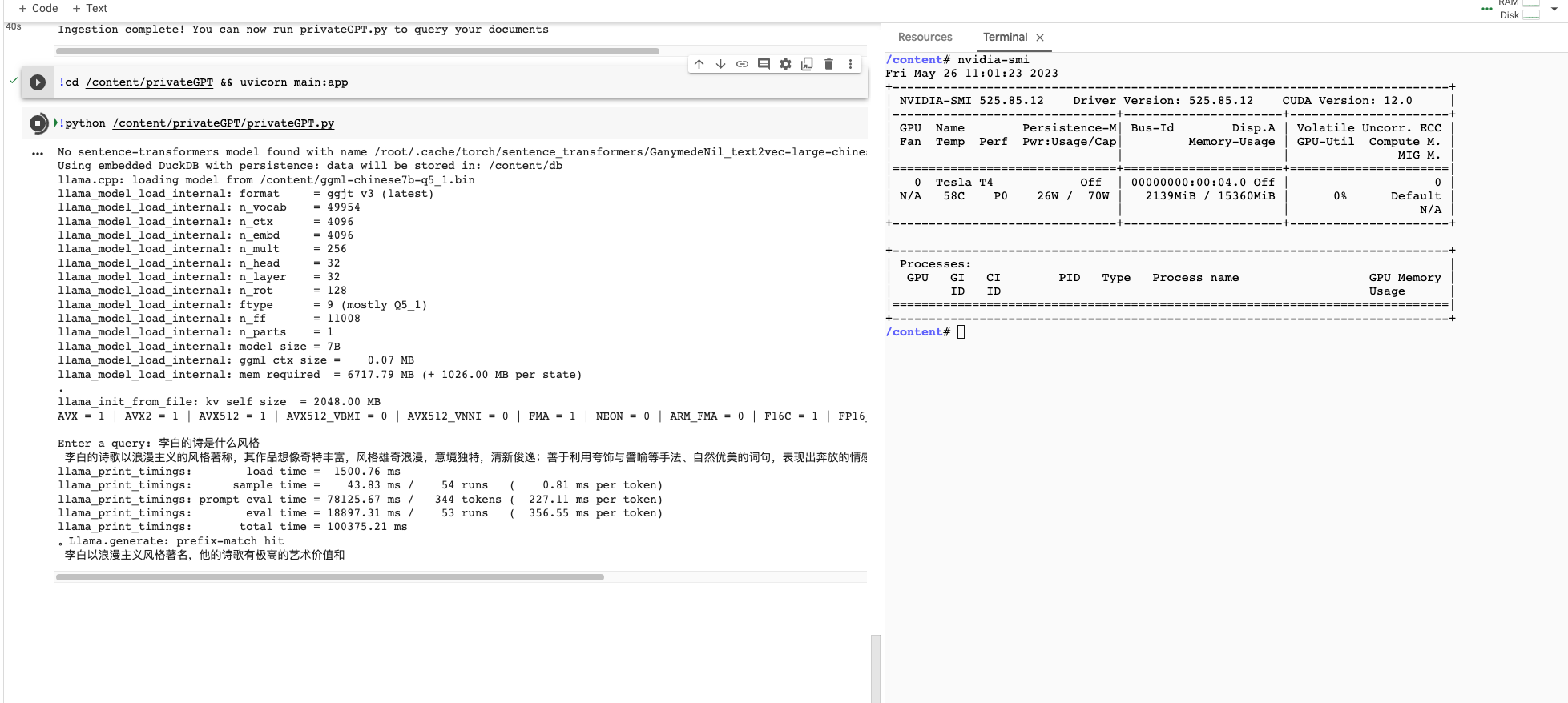
关于在privateGPT上部署回答过慢的问题 · Issue #439 · ymcui/Chinese-LLaMA-Alpaca · GitHub
llama.cpp 使用GPU进行量化部署 · Issue #490 · ymcui/Chinese-LLaMA-Alpaca · GitHub
Running llama.cpp on Windows with GPU acceleration | siddharth's space
GitHub - hsm207/howto-llamacpp-with-gpu: Step-by-step guide on running ...
Code Understanding Langchain, CodeLLama, Llama.cpp and OpenAI # ...
Quantize Llama models with GGUF and llama.cpp | Towards Data Science
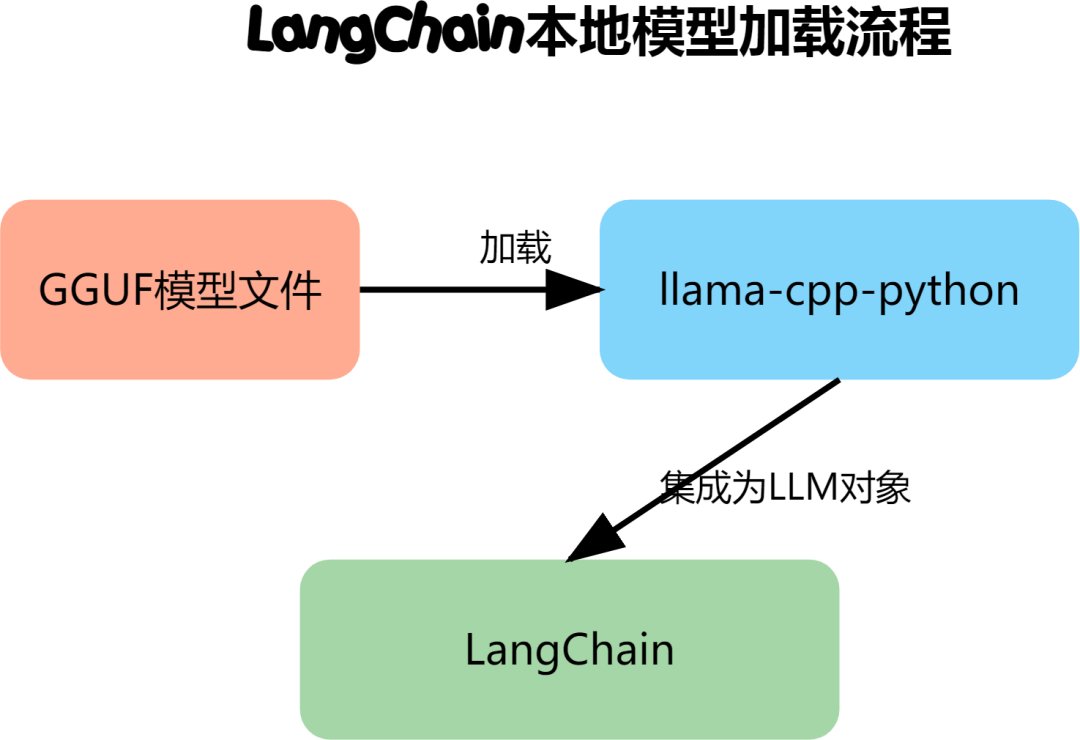
图解 LangChain 本地部署,调试到天亮只为你摆脱API依赖_langchain本地部署-CSDN博客
Mastering Langchain Llama.cpp: Quick Usage Guide
docs/build.md · rohan23998/llama-cpp-model at main
Running Lightweight Language Models Locally: A Practical Setup Guide ...
LlamaCPP models - a gynsolomon Collection
LLAMA-CPP-PYTHON on RTX4060 GPU
LangChain: A Necessary Tool For Working With Large Language Models
Running LLaMA Models Locally on your machine-macOS: A Complete Guide ...
【langchain/入门】使用langchain调用本地部署的大模型(以llama.cpp以及ollama为例)_langchain调用本地 ...
Running Llama 2 on Your Local GPU | by Lei Shang | Medium
Understanding LangChain, LlamaIndex, and Llama Stack | by Nandini ...
Run LLMs Locally: 6 Simple Methods | DataCamp
GitHub - lukasmki/llamacpp-mcp: An MCP (Model Context Protocol) wrapper ...
Inference Speed Benchmarking - GPU, CPU, LlamaCPP, ONNX | model-latency ...
[NLP] 使用Llama.cpp和LangChain在CPU上使用大模型-RAG_llama-cpp-python-CSDN博客
使用 OpenAI、LangChain 和 LlamaIndex 构建自己的 DevSecOps 知识库 - 知乎
构建llama.cpp并在linux上使用gpu_llamacpp gpu-CSDN博客
llama.cpp - Codesandbox
Llama.Cpp + LangChain:在本地运行大模型(LLM)_langchain llamacpp-CSDN博客
Llama.cpp for Large Language Models - Mindfire Technology
【保姆级教程】llama.cpp大模型部署全攻略:CPU/GPU全兼容,小白也能轻松上手!_llamacpp部署-CSDN博客
源码方式安装llama.cpp及调试_llamacpp 调试-CSDN博客
(译) Llama.cpp 教程:高效 LLM 推理和实现的完整指南_llamacpp 添加停止词-CSDN博客
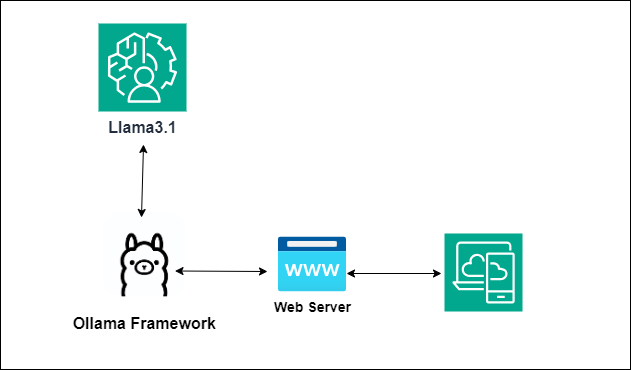
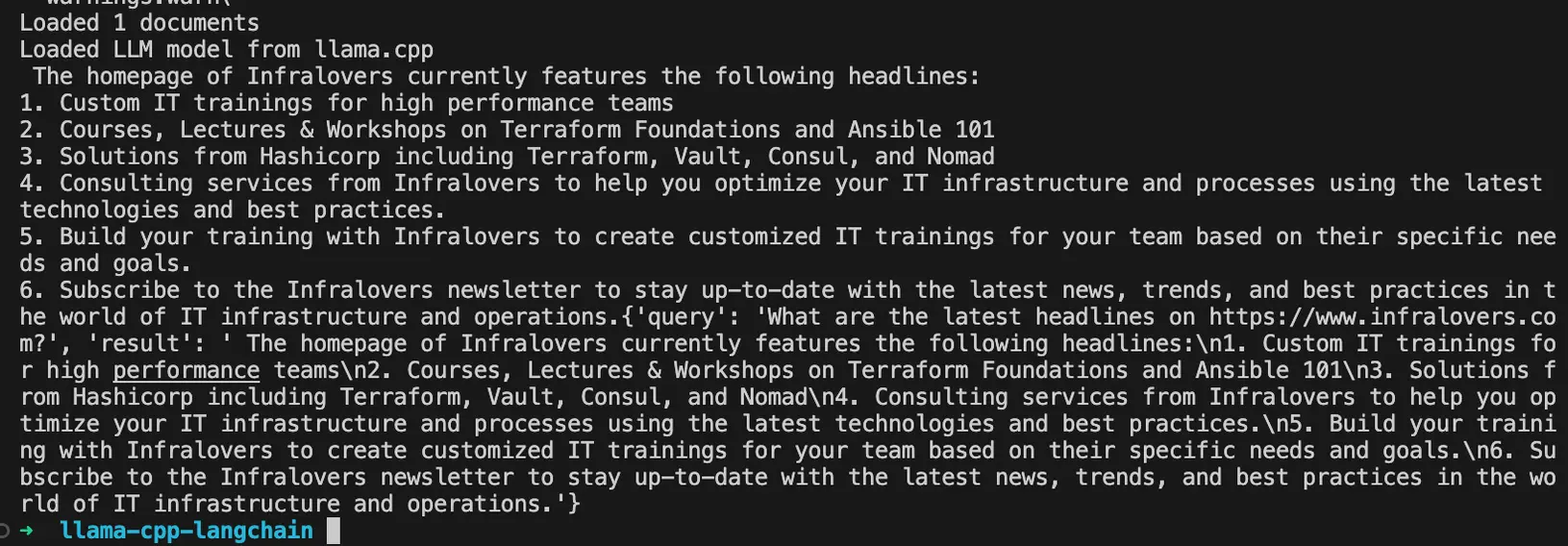
Empowering Local AI: Exploring Ollama and Llama.cpp | Infralovers
langchain.llms import LlamaCppy在GPU執行LLM模型 - penzi - Medium
在本地运行模型 | LangChain中文网
[AI]从零开始的llama.cpp部署与DeepSeek格式转换、量化、运行教程_llamacpp部署-CSDN博客
【保姆级教程】llama.cpp从零部署教程:让普通电脑也能运行大模型,CPU/GPU全支持!_llamacpp部署-CSDN博客
Seven Ways of Running Large Language Models (LLMs) Locally (April 2024)