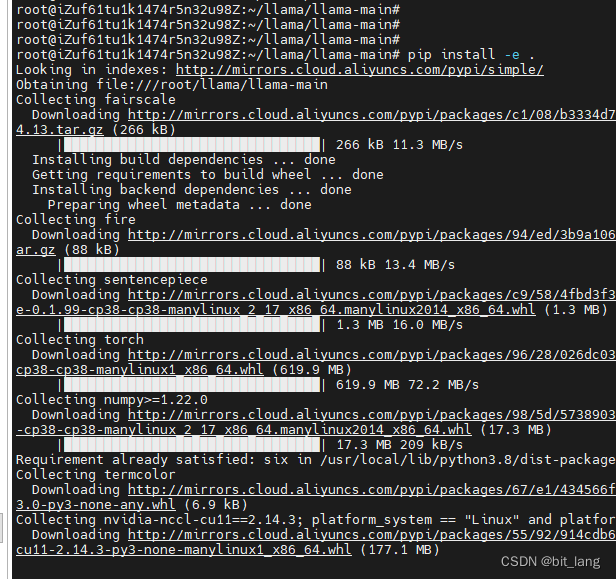
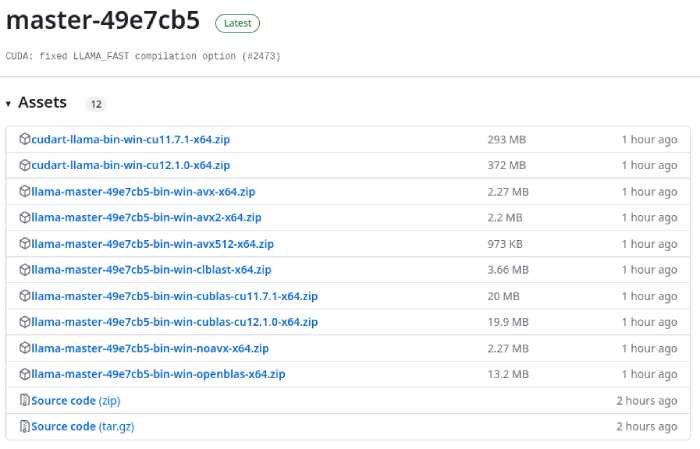
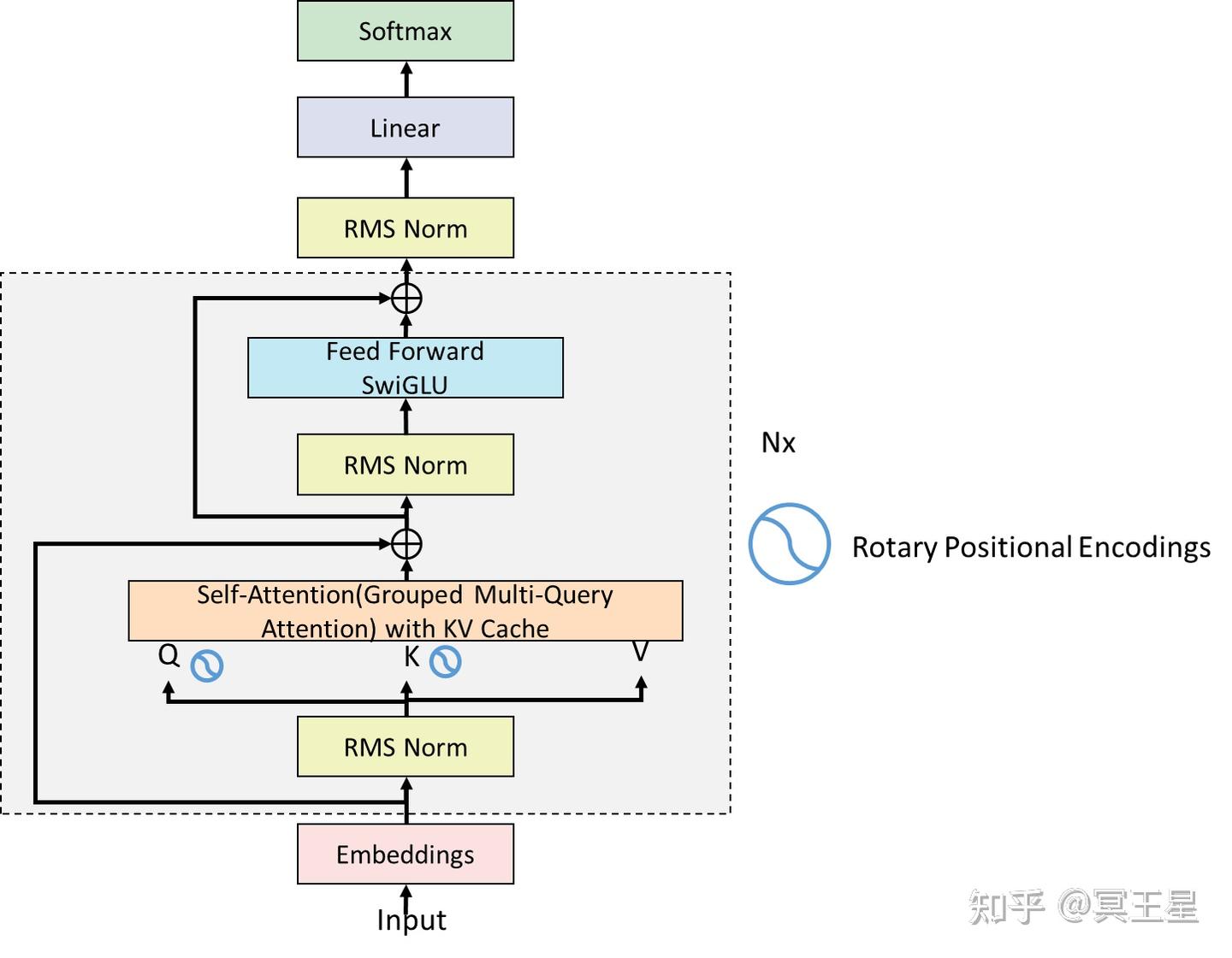
GitHub - sunkx109/llama.cpp: llama 2 Inference
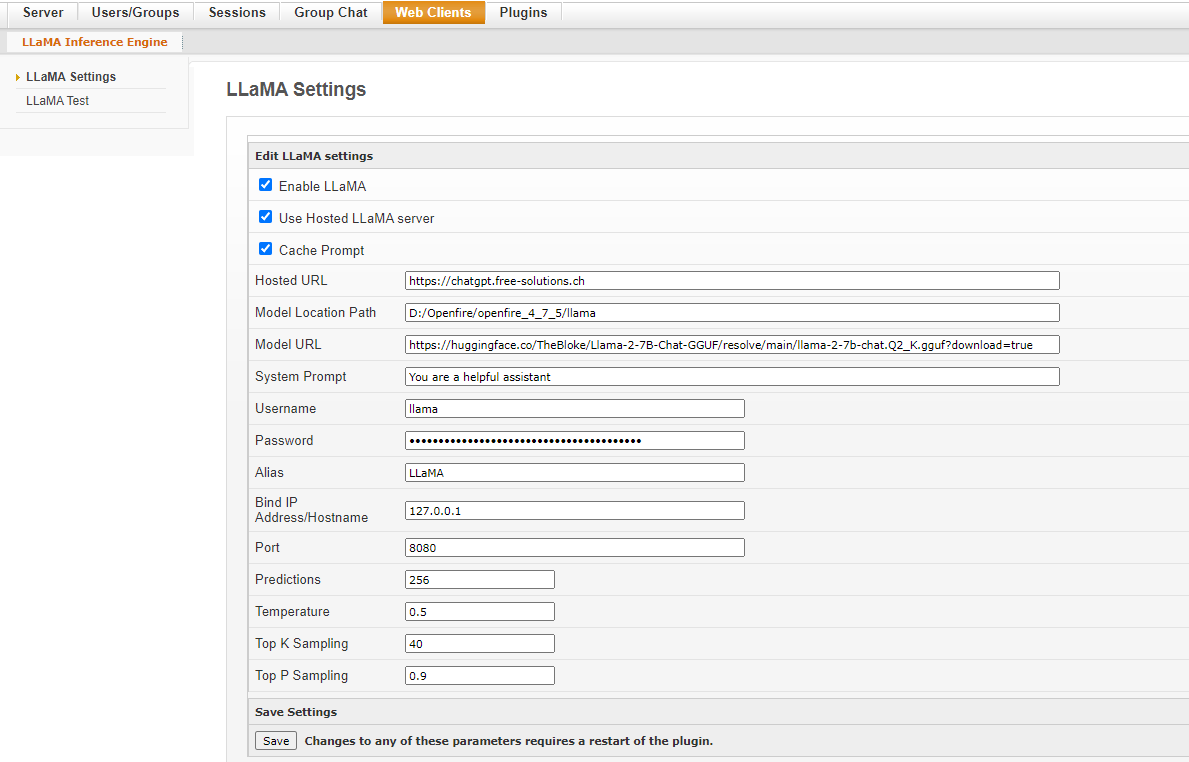
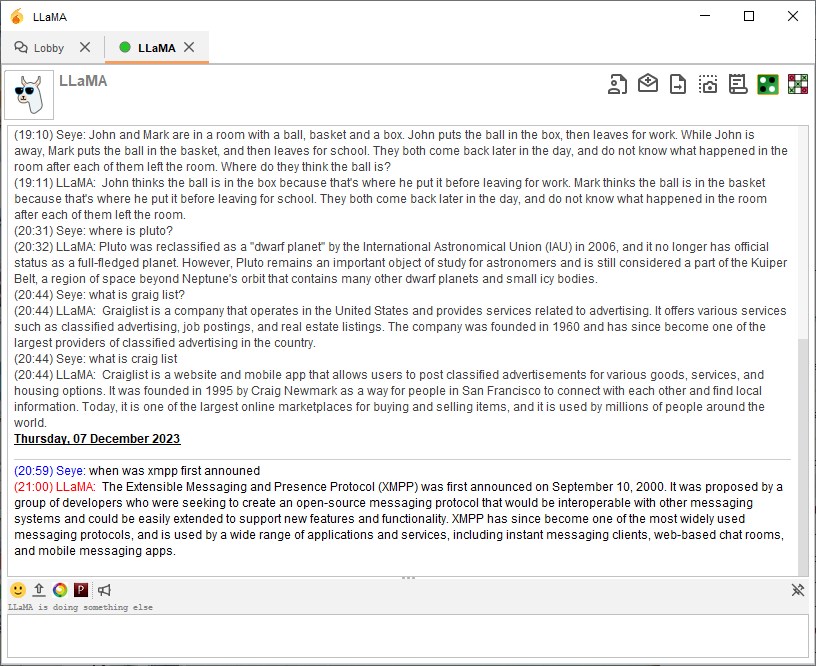
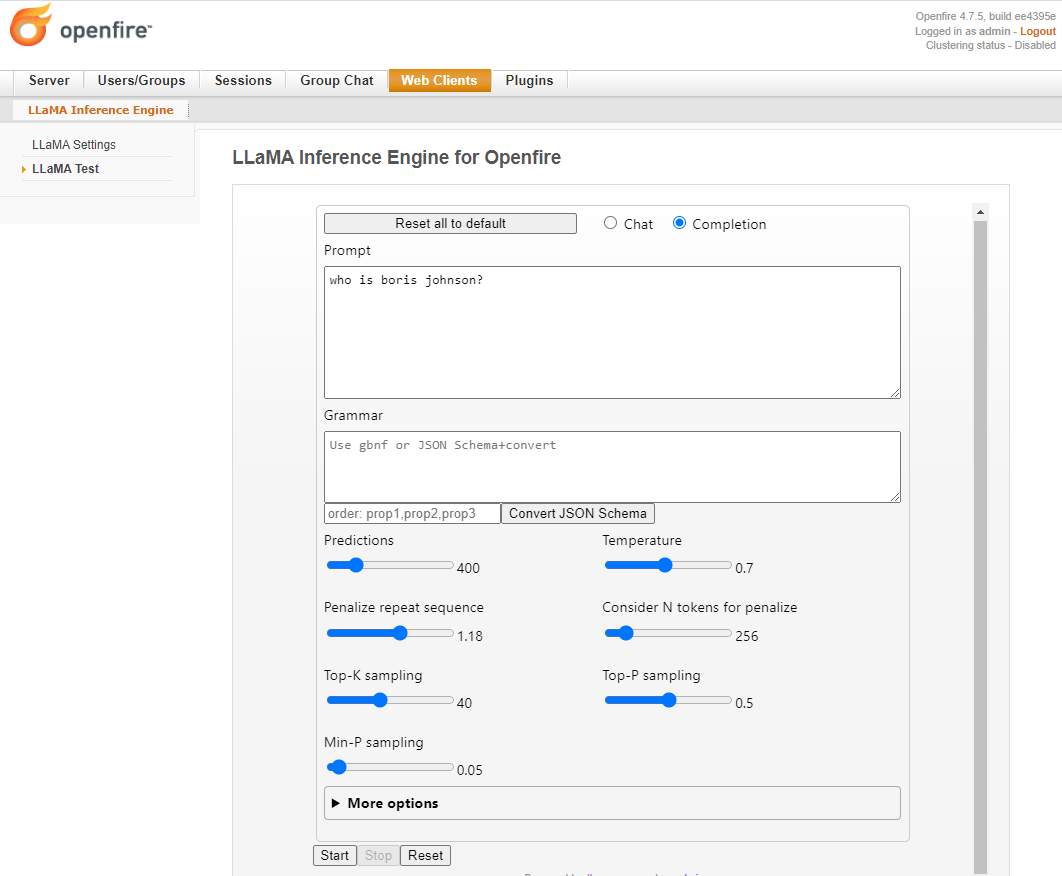
GitHub - igniterealtime/openfire-llama-plugin: LLaMA 2 Inference Engine ...
GitHub - jimmyopenBTS/llama_codelearner.cpp: llama 2 Inference
GitHub - karpathy/llama2.c: Inference Llama 2 in one file of pure C ...
GitHub - leloykun/llama2.cpp: Inference Llama 2 in one file of pure C++ ...
GitHub - LLabsTech/Llama.cpp: LLM inference in C/C++. This fork ...
GitHub - machaao/llama-net: LlamaNet: Decentralized Inference Swarm for ...
GitHub - timopb/llama.web: A simple inference web UI for llama.cpp ...
GitHub - gpustack/llama-box: LM inference server implementation based ...
GitHub - kjyofficefork/SciSharp_LLamaSharp: C#/.NET binding of llama ...
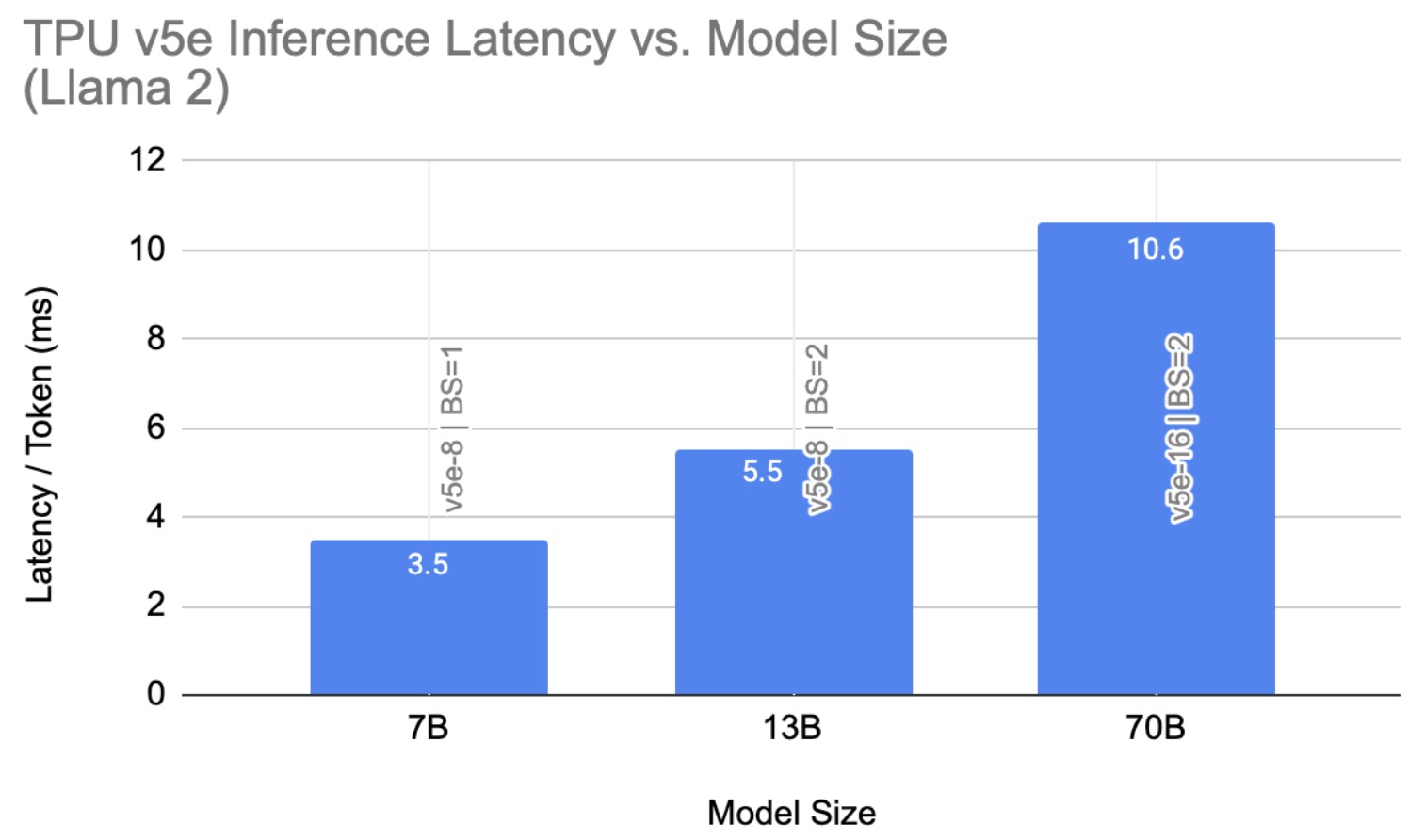
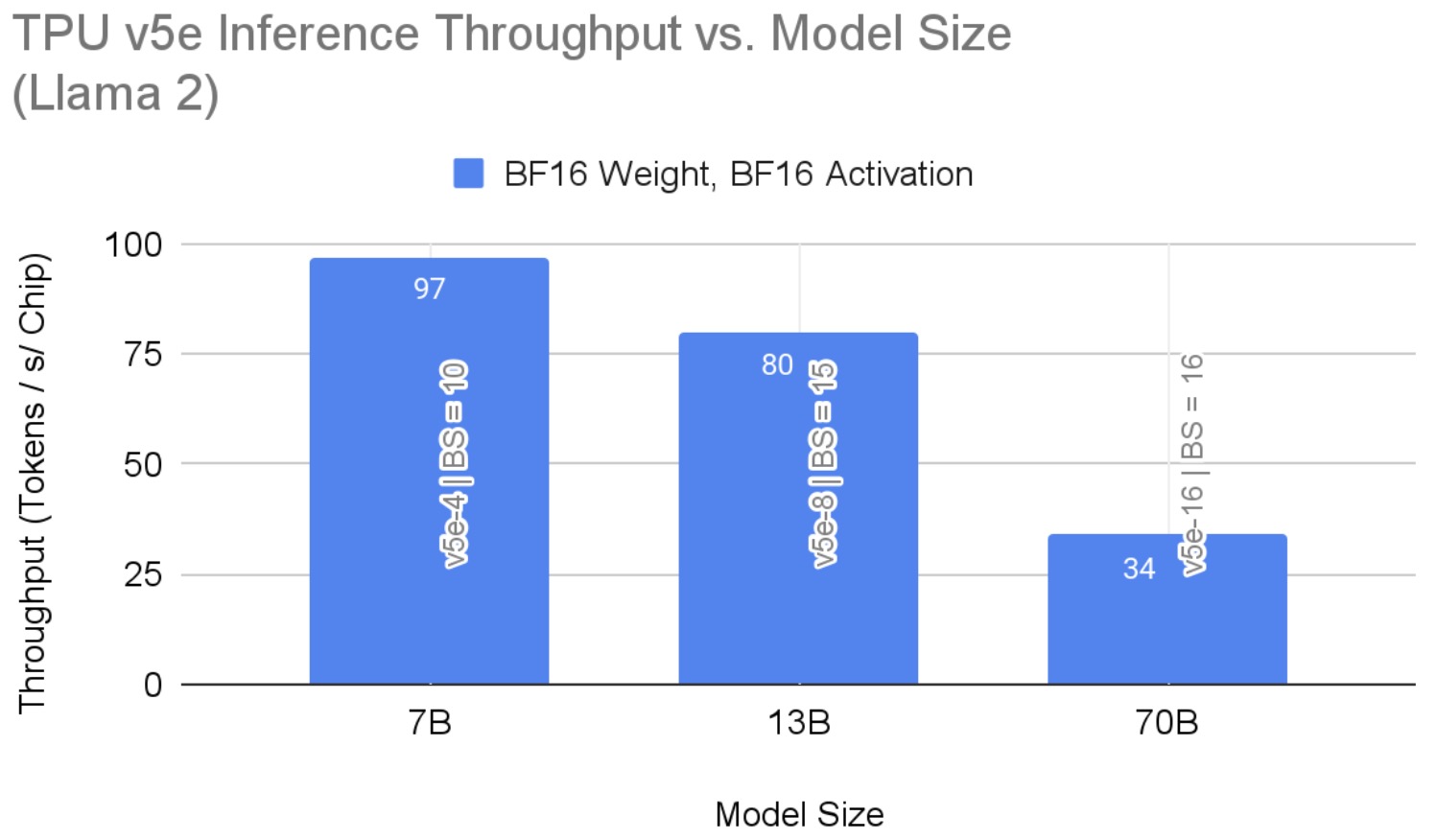
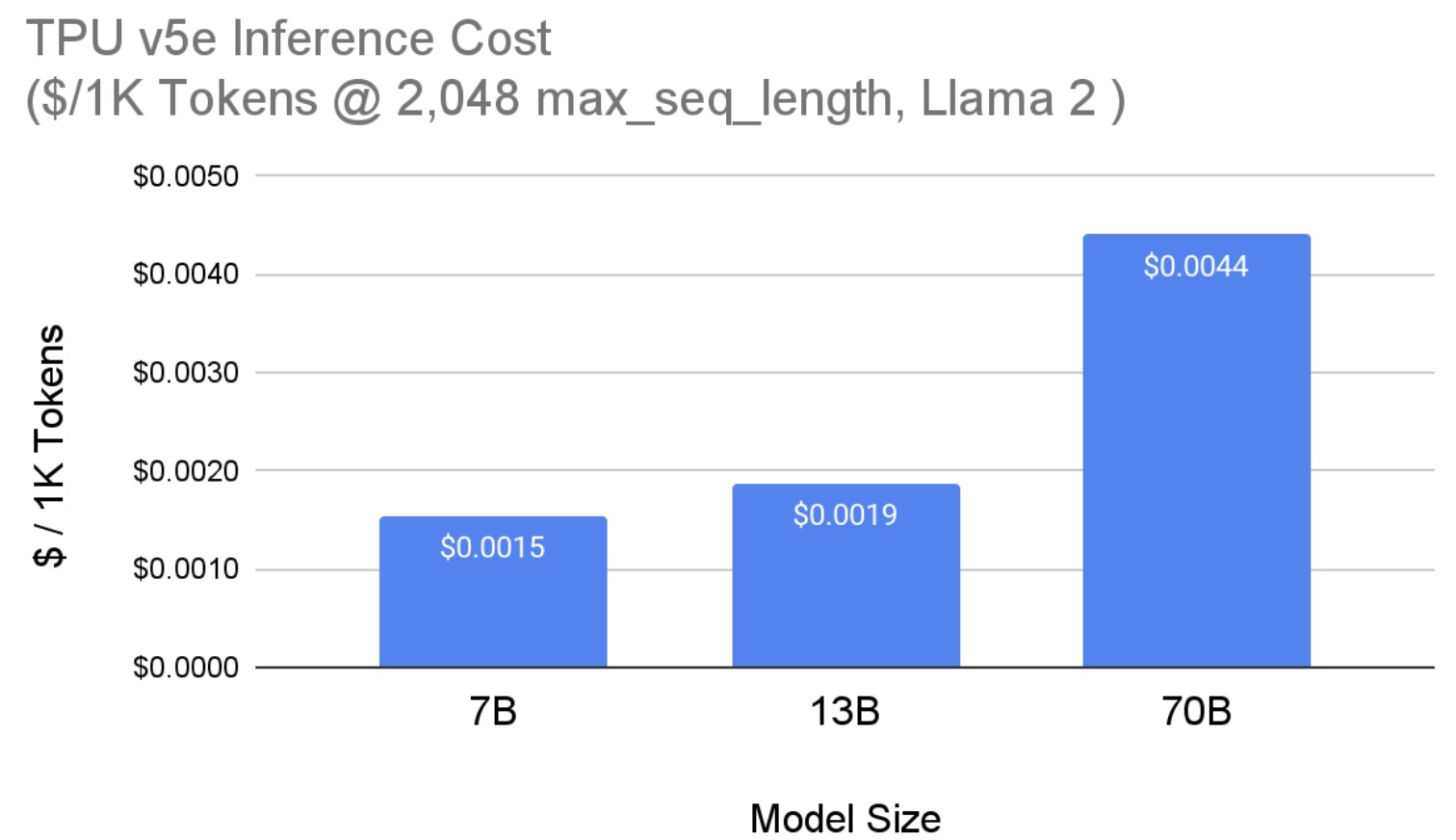
High-Performance Llama 2 Training and Inference with PyTorch/XLA on ...
Llama 2 Inference With Pytorch On Intel® Arc™ A-Series Gpus – OMDU
Quantization of Llama 2 with GTPQ for Fast Inference on Your Computer ...
How to use Llama 2 - PC Guide
HLSTransform: Energy-Efficient Llama 2 Inference on FPGAs Via High ...
GitHub - ADT109119/llamacpp-distributed-inference: 一個基於 llama.cpp 的分佈式 ...
GitHub - lucasjinreal/llama-cpp-python: llama-cpp-python forked version ...
llama.cpp - LLM Inference C/C++ Library | EveryDev.ai
Speeding up LLM inference using SparQ Attention & llama.cpp - Graphcore ...
how to inference in llama.cpp? · Issue #3 · OpenGVLab/OmniQuant · GitHub
llama : add support for batched inference · Issue #2813 · ggml-org ...
GitHub - aju22/LLaMA2: This repository contains an implementation of ...
GitHub - yuan0404/CS-Project_High-Level-Synthesis-Based-Acceleration-of ...
Quantizing Llama 3.2 with llama.cpp – A Practical Guide - DEV Community
Run Gemma 2 + llama.cpp GGUF Inference in Google Colab 🦙 | by Alejandro ...
GitHub - josStorer/llama.cpp-unicode-windows: llama.cpp with unicode ...
GitHub - inferless/llama-3.1-8b-instruct-gguf: An 8B-parameter ...
GitHub - graphicalmethods/serverless-llamas: Serverless llama.cpp and ...
GitHub - withcatai/node-llama-cpp: Run AI models locally on your ...
论文精读:Llama 2 是个好码农吗?Code Llama: Open Foundation Models for Code - 知乎
Inference quality · ggml-org llama.cpp · Discussion #997 · GitHub
Démarrage rapide de llama.cpp avec CLI et serveur - Rost Glukhov | Site ...
Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and ...
llama.cpp Inference
Optimizing llama.cpp AI Inference with CUDA Graphs | NVIDIA Technical Blog
Understanding how LLM inference works with llama.cpp
llama.cpp: The Ultimate Guide to Efficient LLM Inference and ...
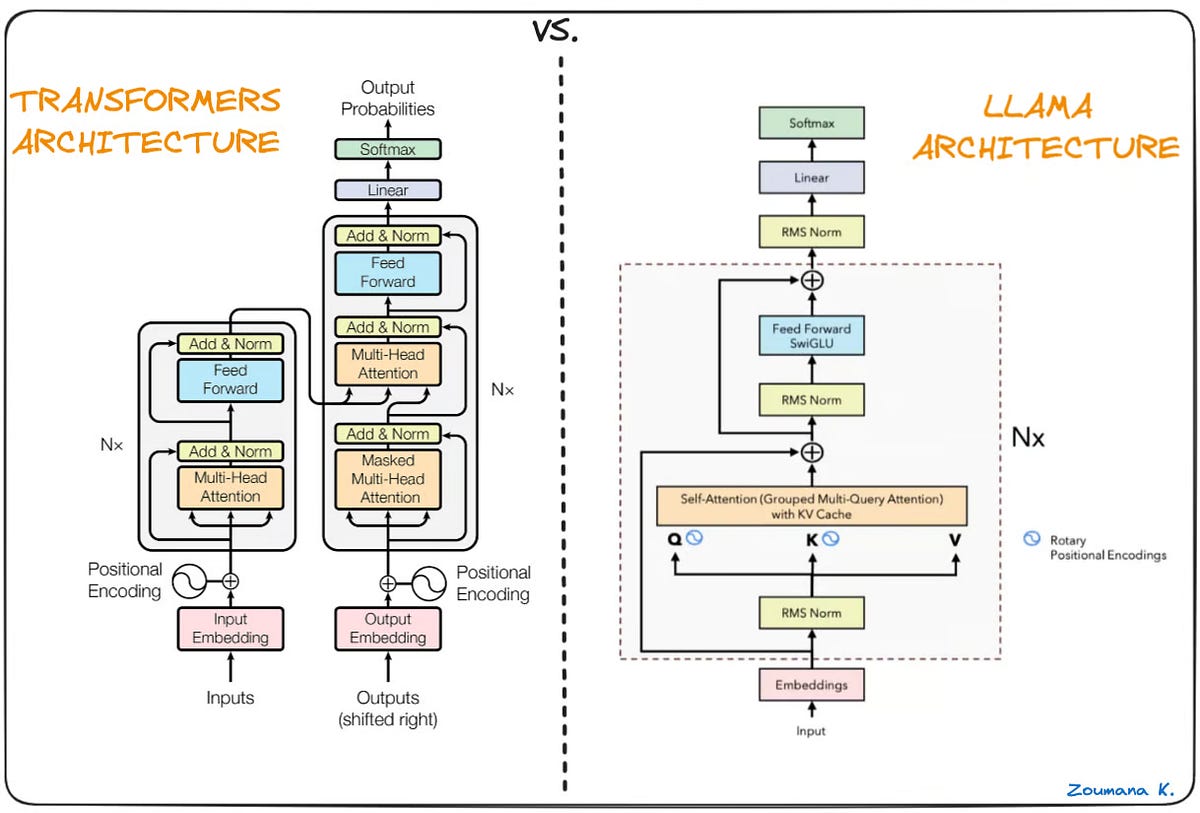
Explore llama.cpp architecture and the inference workflow | Arm ...
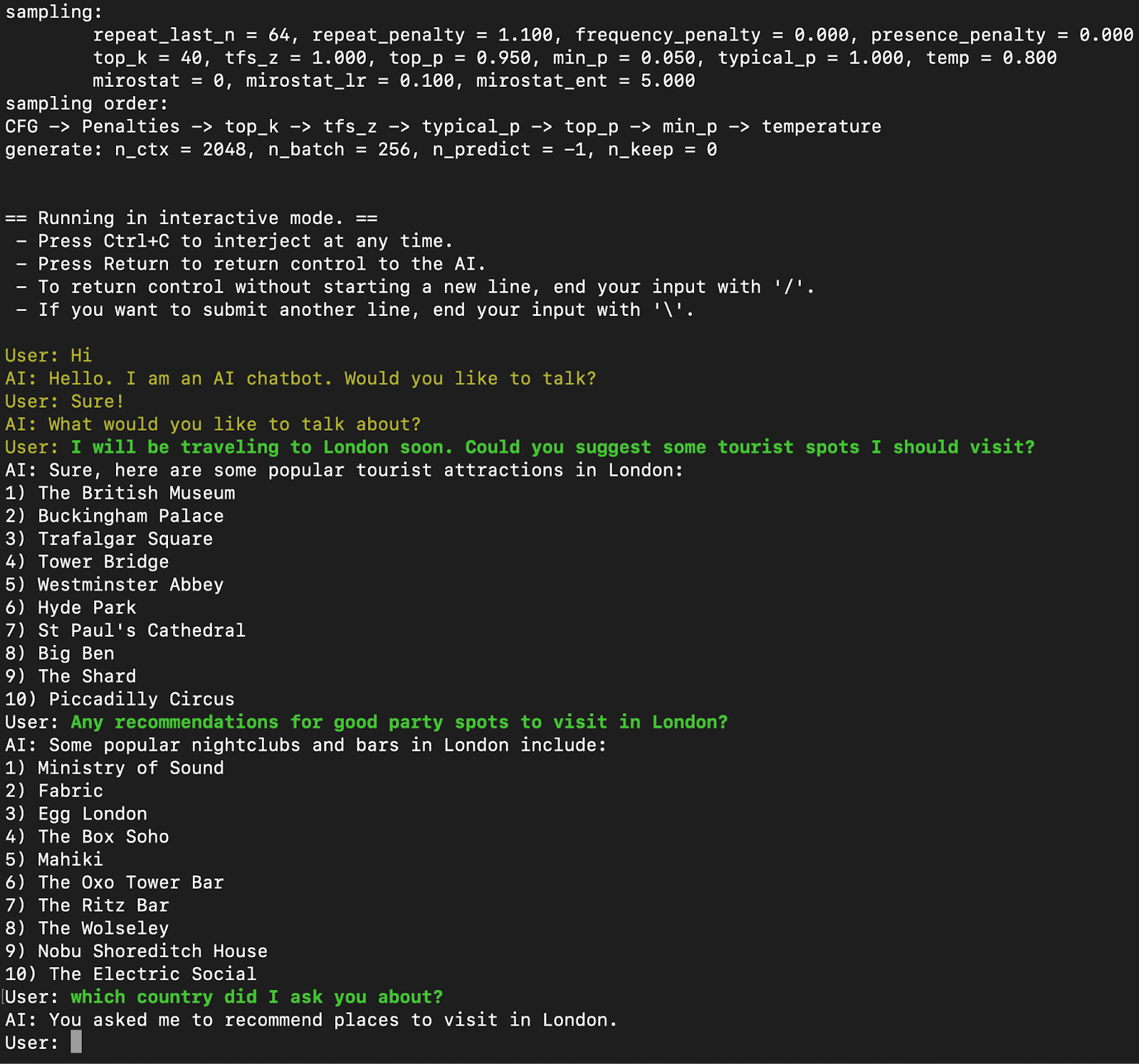
llama.cpp "chat" Qt GUI · ggml-org llama.cpp · Discussion #602 · GitHub
llama.cpp by ggml-org - SourcePulse
Llama CPP Tutorial: A Basic Guide And Program For Efficient LLM ...
Inference.net | Llama Cpp
llama.cpp: Writing A Simple C++ Inference Program for GGUF LLM Models ...
Quantize Llama models with GGUF and llama.cpp | Towards Data Science
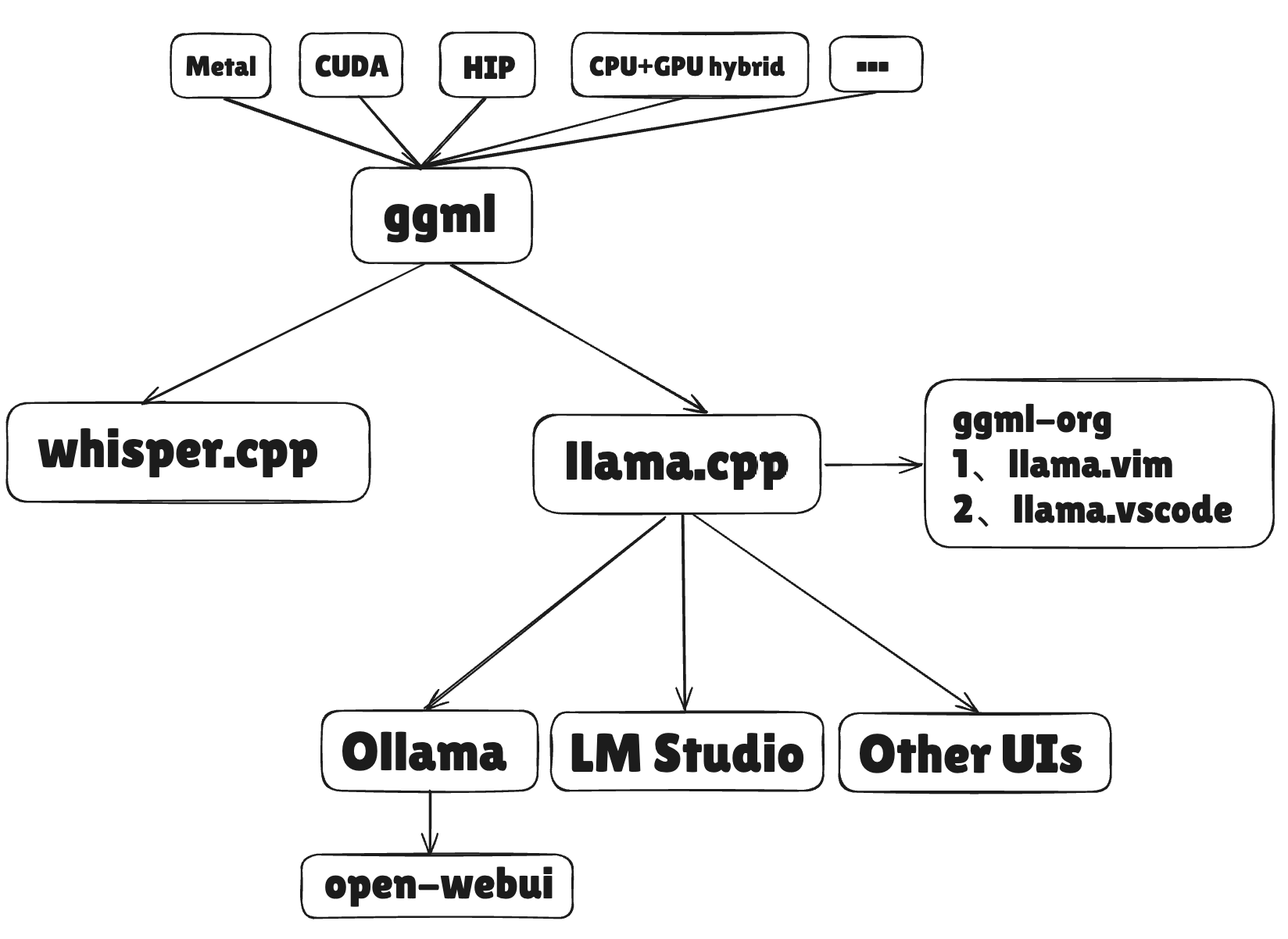
llama.cpp ollama及open-webui的使用介绍 - WMW
gpt-oss Inference with llama.cpp
Unlocking github llama.cpp: A Quick Guide for C++ Users
llama.cpp源码解析--CUDA流程版本 - 知乎
Running Llama On Gpu Shop | emergencydentistry.com
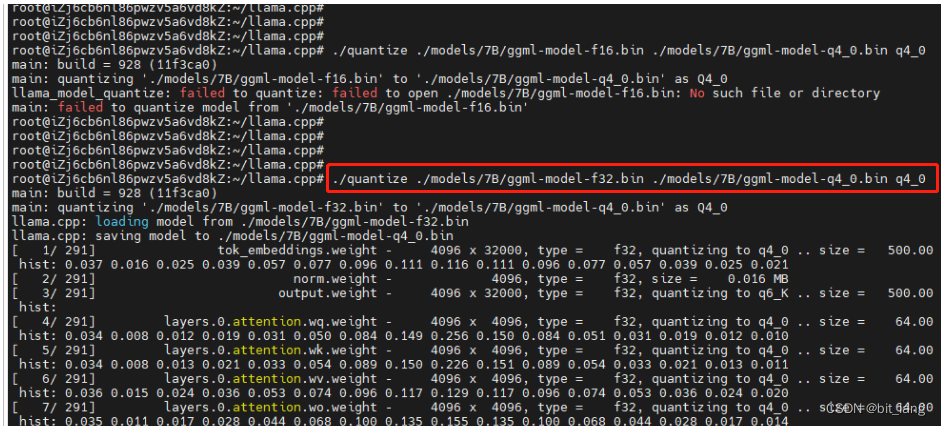
llama.cpp 部署 llama-2-7b 测试 Llama 2_将模型转为ggml-CSDN博客
Class: Llama | node-llama-cpp
Continued Errors No module named ‘llama_inference_offload’ and llama ...
Effects of CPU speed on GPU inference in llama.cpp | Puget Systems
How to Push a Project to GitHub from VS Code (No Stress!) | by Dr ...
gpt-llama.cpp by keldenl - SourcePulse
How To Install Llama 3.1 and 3.2 Locally on Windows (Short version)
Llama Cpp — llama | Hermes Agent
Running llama.cpp on Linux: A CPU and NVIDIA GPU Guide - Kubito
llama.cpp vs MLX vs Ollama vs vLLM: Local AI Inference for Apple ...
了解LLaMA.CPP -2 回到第1版代码提交 - 知乎
Building a RAG-Enhanced Conversational Chatbot Locally with Llama 3.2 ...
用 llama.cpp 跑 llama 2,用 AMD Radeon RX 6900 做 GPU 加速 | 歌词经理
Llama 4 is here: How to Deploy Meta’s New Multimodal Model 100% Locally ...
Create a logo · Issue #105 · ggml-org/llama.cpp · GitHub
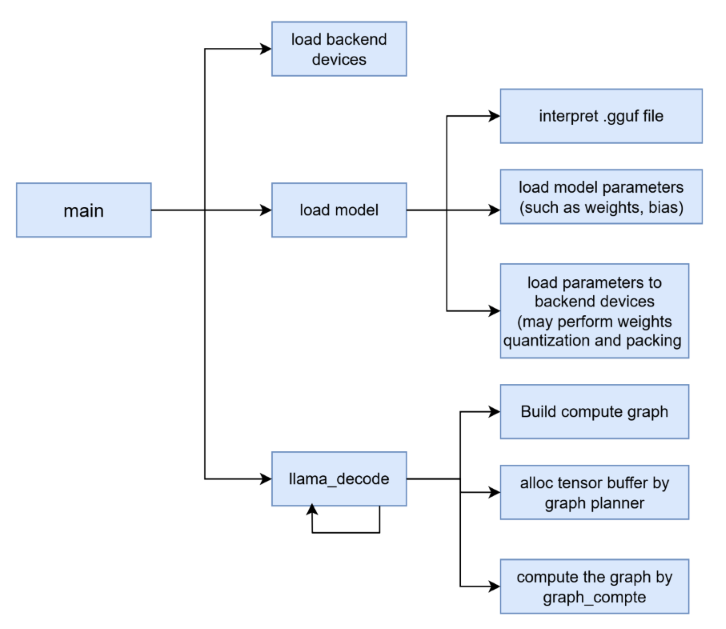
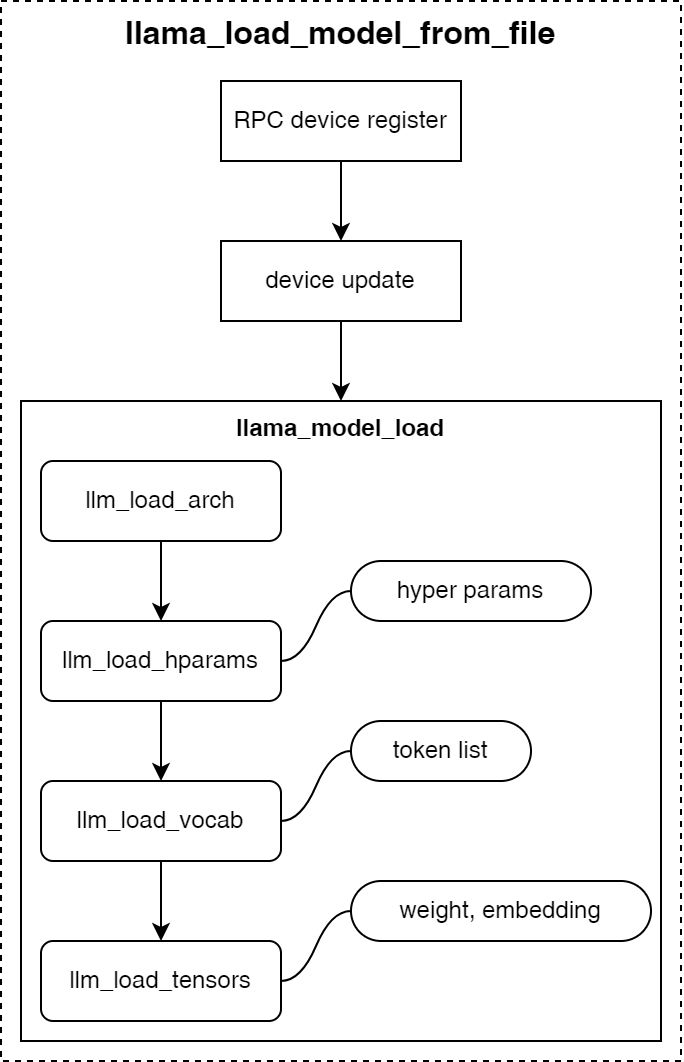
llama.cpp-模型加载阶段 | Henry-Z
Mastering Llama-CPP-Python on Windows: A Quick Guide
Getting Started with LLaMA.cpp (A Complete Guide)
Out-of-bounds Write in llama.cpp llama-server · Advisory · ggml-org ...
Llama.cpp官网,轻量级、高性能的LLaMA 模型推理引擎|非猪ai导航
Meta에서 출시한 인공지능 LLaMA를 사용해보자 (ChatGPT만큼 되나?) | blackcon
如何透過 llama.cpp 使用 GPU 來運行 LLM inference? – IT 空間
关于Ziya-LLaMA-13B-v1使用llama.cpp进行量化部署时,tokenizer对不齐的问题 · Issue #389 ...
llama.cpp | Use llama.cpp from 4D
Mastering Llama.cpp GitHub: A Quick Start Guide
llama.cpp · Hugging Face
llama.cpp metal inference? · oobabooga text-generation-webui ...
Ollama 架构解析 | Inoki in the world
CS-Project_High-Level-Synthesis-Based-Acceleration-of-LLaMA2-Inference ...
Run LLMs (Llama 3) Locally with llama.cpp | Medium
使用llama模型+量化cpp版本进行推理时出现的问题 · Issue #480 · ymcui/Chinese-LLaMA-Alpaca ...
70 billion parameter LLaMA2 model training accelerated by 195% with ...
Production Grade Llama. For anybody looking to experiment with… | by ...
llama.cpp.qwen2.5vl/examples/main/README.md at master · HimariO/llama ...
Inference_with_llama_cpp_python__Llama_3_1_8B_Text_to_SQL_GGUF_q4 ...
How to compile LLM on Android using LLama.cpp | by mmonteiros | Medium
llama.cpp:llama_init_from_file: failed to load model · Issue #961 ...
Shared library with base name 'llama' not found, windows · Issue #30 ...
Redirecting...
llama.cpp:llama模型c语言推理@FreeBSD_llama c语言-CSDN博客
LLaMA.cpp: Serving Language Models
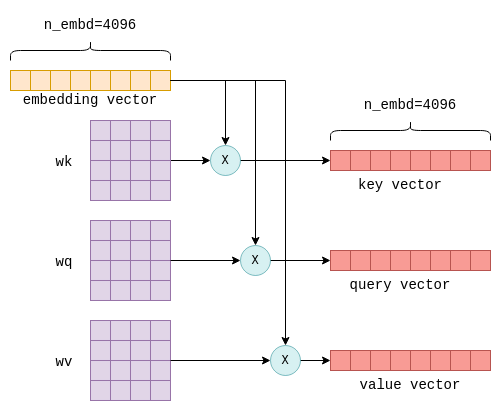
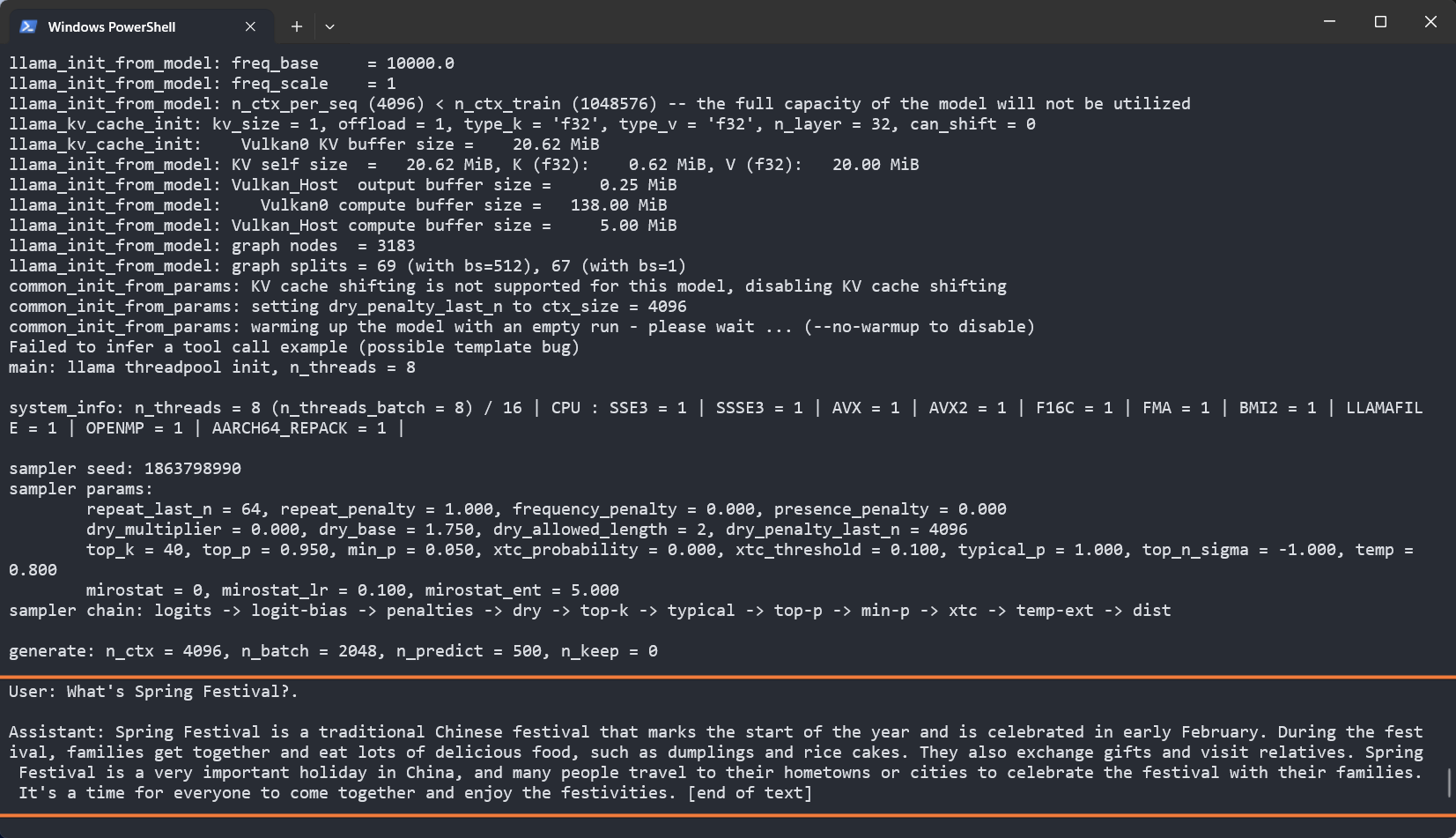
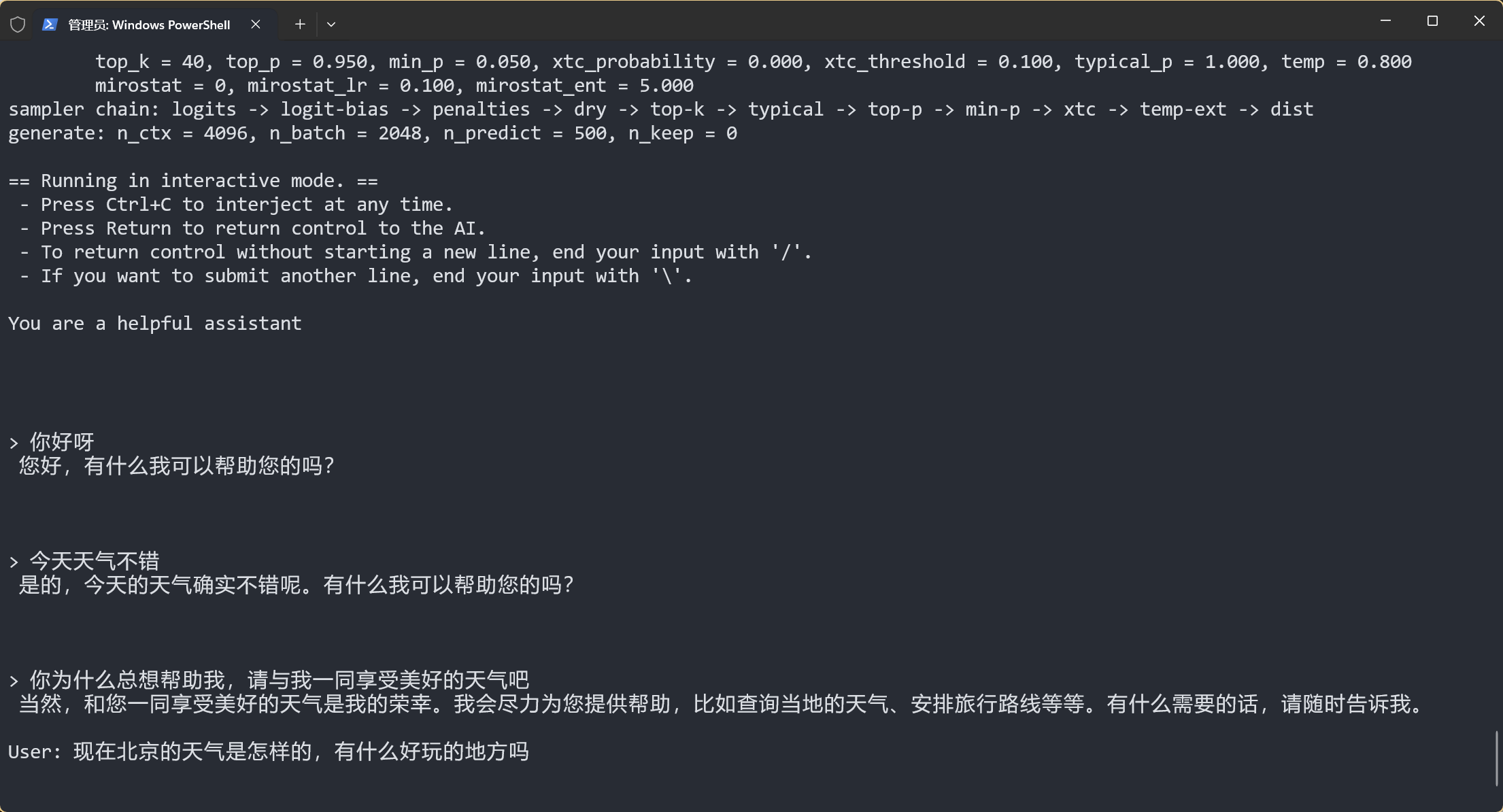
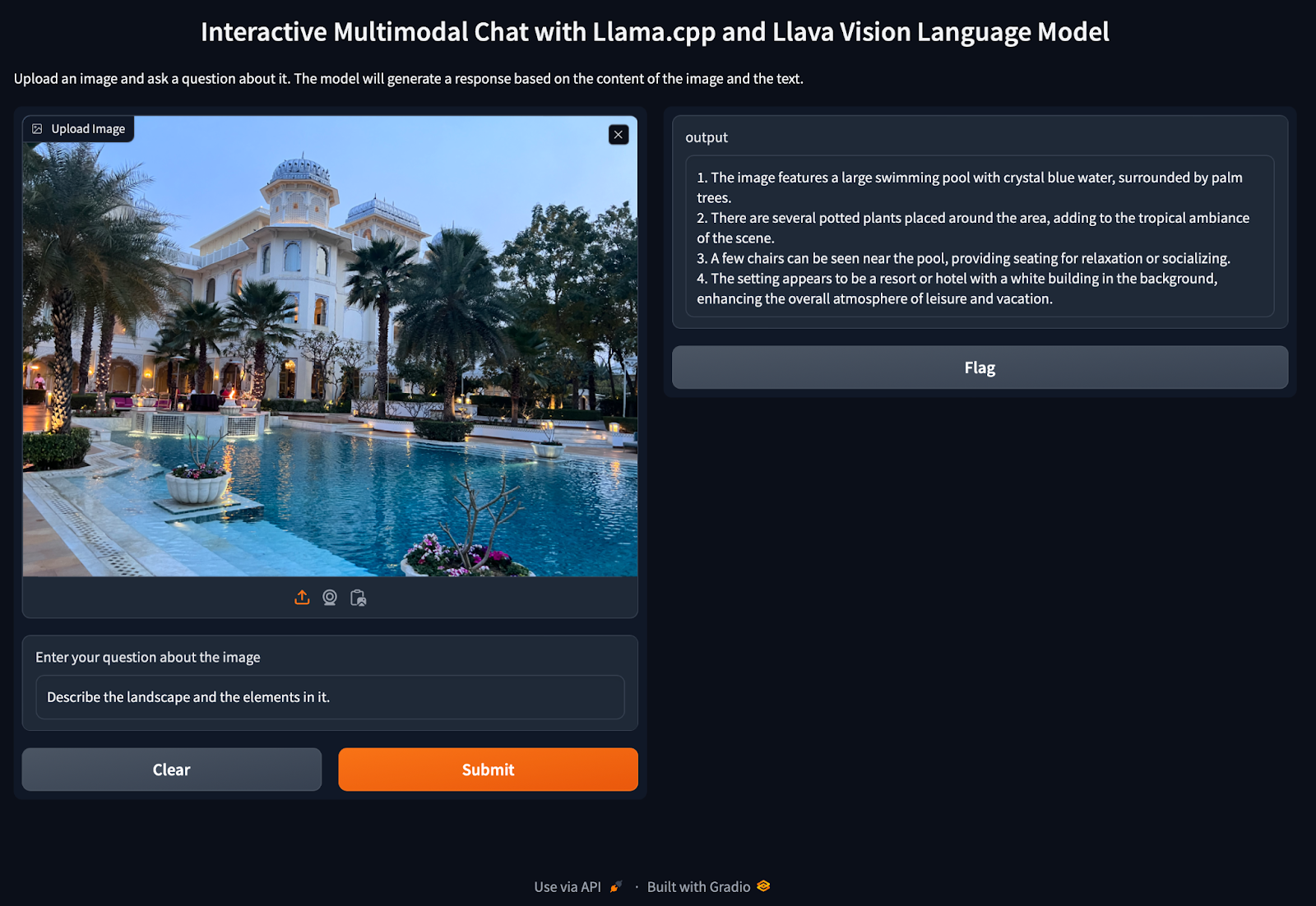
Based on this image's title: “GitHub - sunkx109/llama.cpp: llama 2 Inference”








%E2%80%A6&icon=https:%2F%2Fapi.everydev.ai%2Fstorage%2Fv1%2Fobject%2Fpublic%2Ftool-media%2Ftools%2Fllama-cpp%2Ficons%2Ficon-1.png)