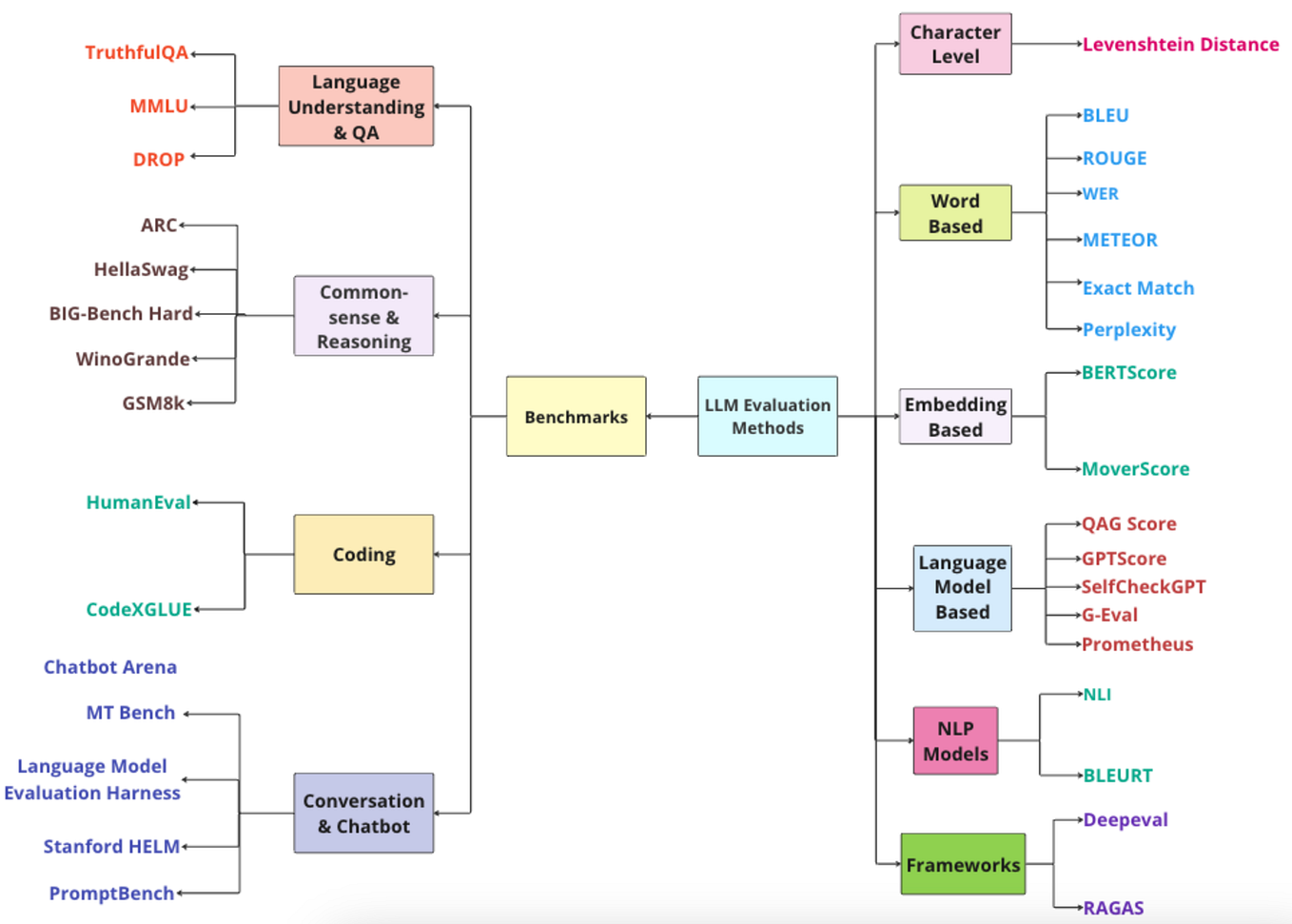
GitHub - defog-ai/sql-eval: Evaluate the accuracy of LLM generated outputs
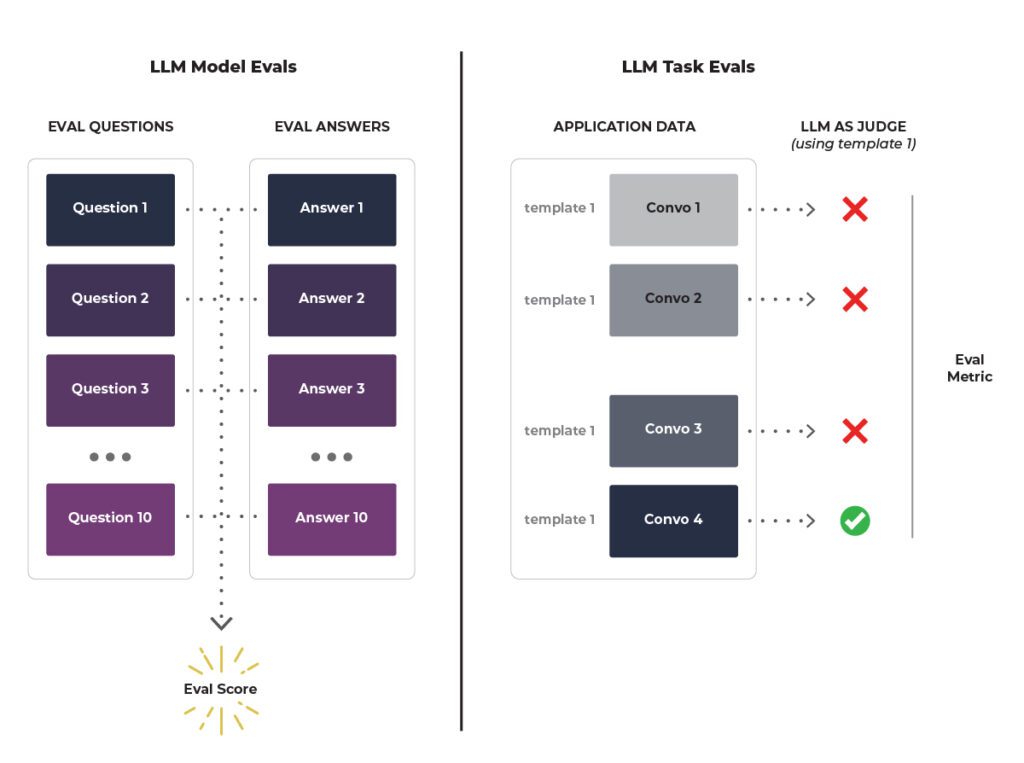
How to Evaluate LLM Performance A Practical Guide For All Users - AST ...
GitHub - Azure-Samples/llm-eval-grader-samples: Framework for Post ...
GitHub - Watts-Lab/commonsense-llm-eval: Data and code to replicate ...
GitHub - llm-platform-security/chatgpt-plugin-eval: LLM Platform ...
LSC-Eval: A General Framework to Evaluate Methods for Assessing ...
GitHub - rajshah4/LLM-Evaluation: Sample notebooks and prompts for LLM ...
GitHub - promptfoo/promptfoo: Test your prompts. Evaluate and compare ...
GitHub - vilm-ai/viet-llm-eval: A framework for few-shot evaluation of ...
GitHub - sachi-gkp/opik-LLM-evaluation-framework: From RAG chatbots to ...
GitHub - microsoft/dotnet-llm-eval-samples: Samples of how to eval and ...
GitHub - maverick-escape-ordinary-coding/Eval_llm: Evaluate LLM's ...
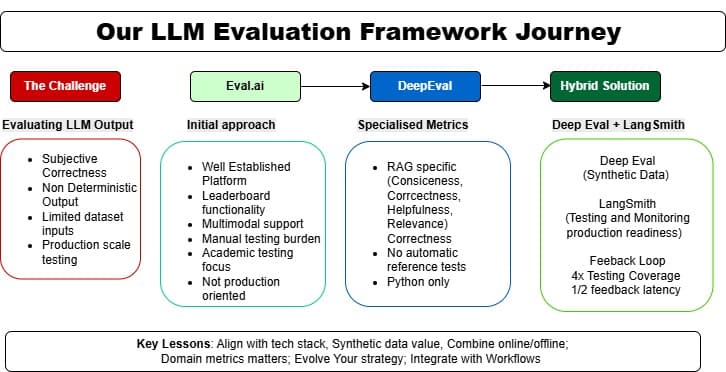
How to evaluate an LLM evaluation framework
LLM Selection: Data-Driven Evaluation with 360-Eval Framework - ChatGPT ...
Evaluate - LLM evals framework
Error Analysis to Evaluate LLM Applications - Langfuse
GitHub - vero-labs-ai/vero-eval: Open source framework for evaluating ...
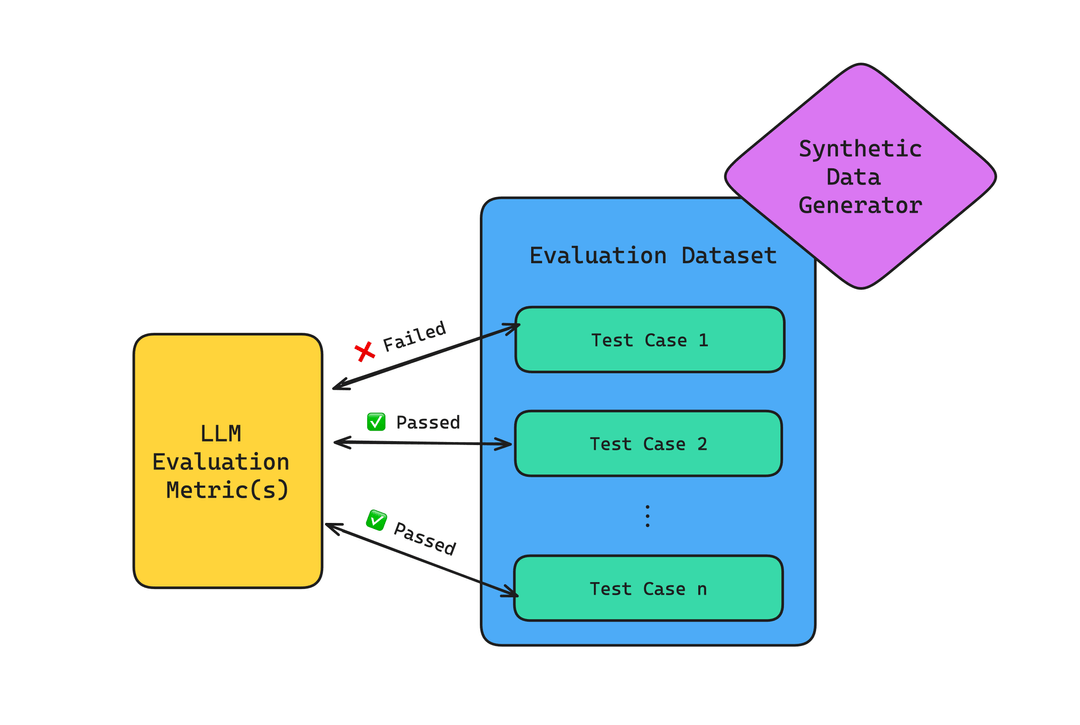
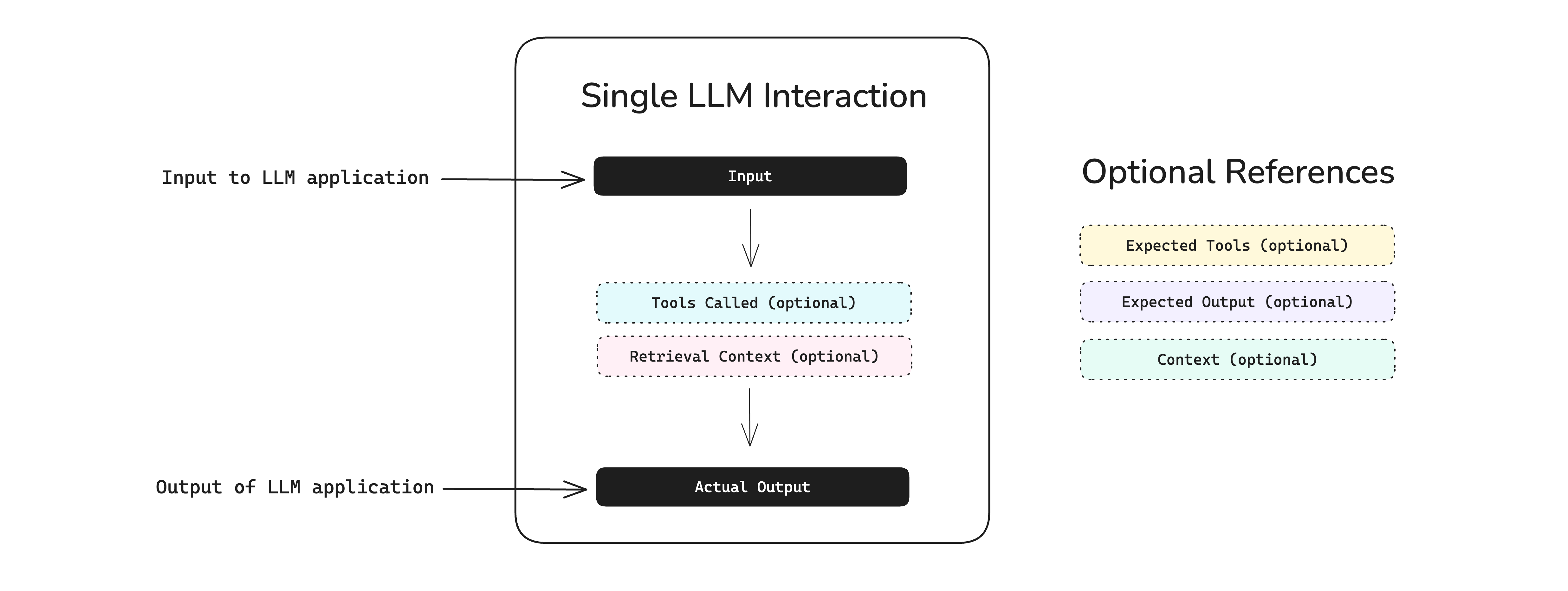
How to Build an LLM Evaluation Framework, from Scratch - Confident AI
LLM-Eval: A Simplified Approach to Evaluating LLM Conversations ...
GitHub - firstlinesoftware/eval-ai-library: Comprehensive AI Evaluation ...
G-Eval | DeepEval by Confident AI - The LLM Evaluation Framework
GitHub - MLGroupJLU/LLM-eval-survey: The official GitHub page for the ...
Evaluating Your Summarizer | DeepEval by Confident AI - The LLM ...
The Definitive Guide to LLM Evaluation - Arize AI
Decode LLM Quality - Eval Testing and Benchmarking LLMs: An Evaluation ...
GitHub - LeiLiLab/llm-detector-eval: A practical evaluation of 6 ...
GitHub - oscerai/eval: Clinical LLM Evaluation
GitHub - EshantDazz/ML_FLow_LLM_Monitoring_and_Evaluation: MLflow-based ...
GitHub - saptechengineer/opik-llm-eval: Debug, evaluate, and monitor ...
GitHub - onejune2018/Awesome-LLM-Eval: Awesome-LLM-Eval: a curated list ...
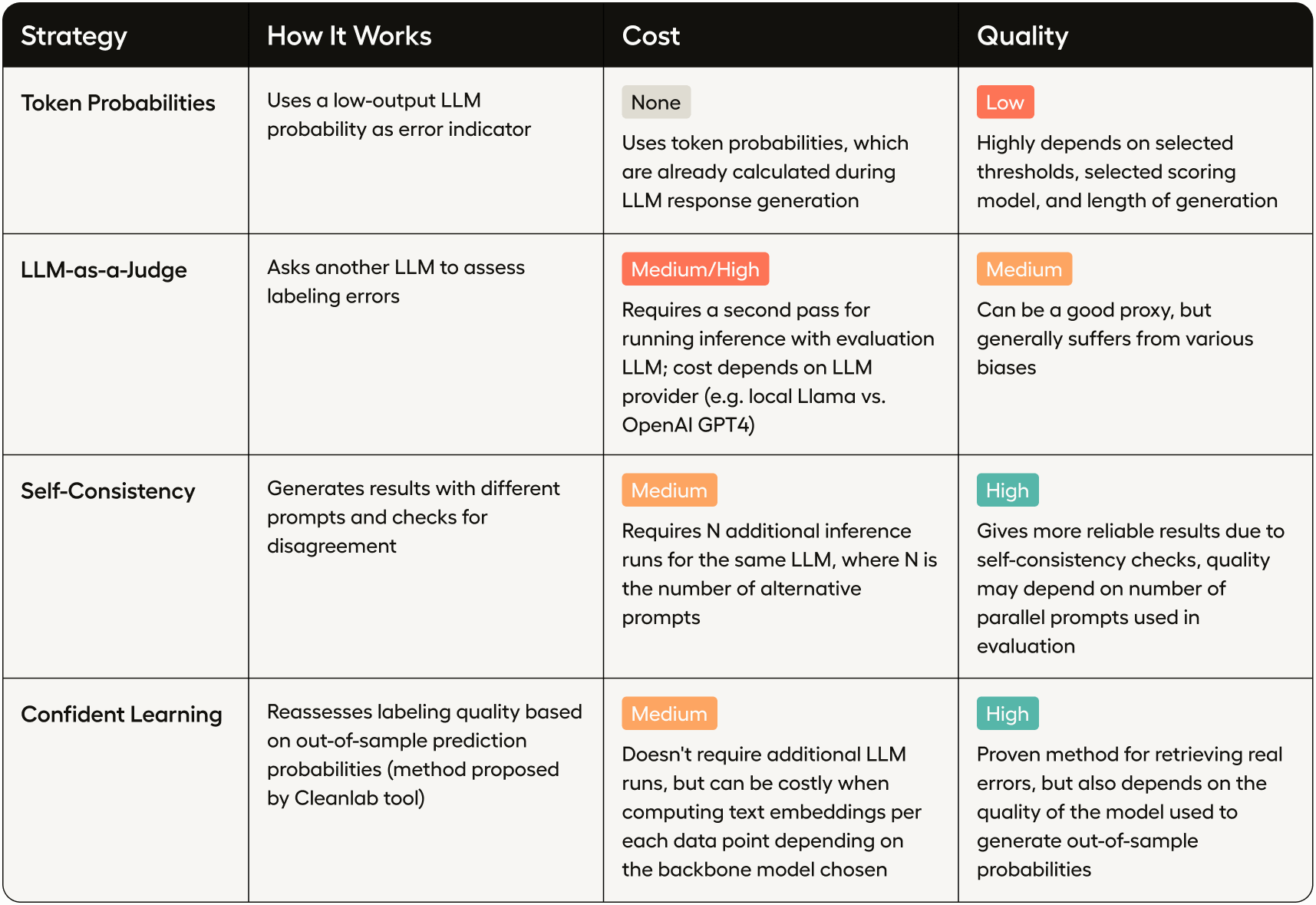
LLM Evaluation: Comparing Four Methods to Automatically Detect Errors ...
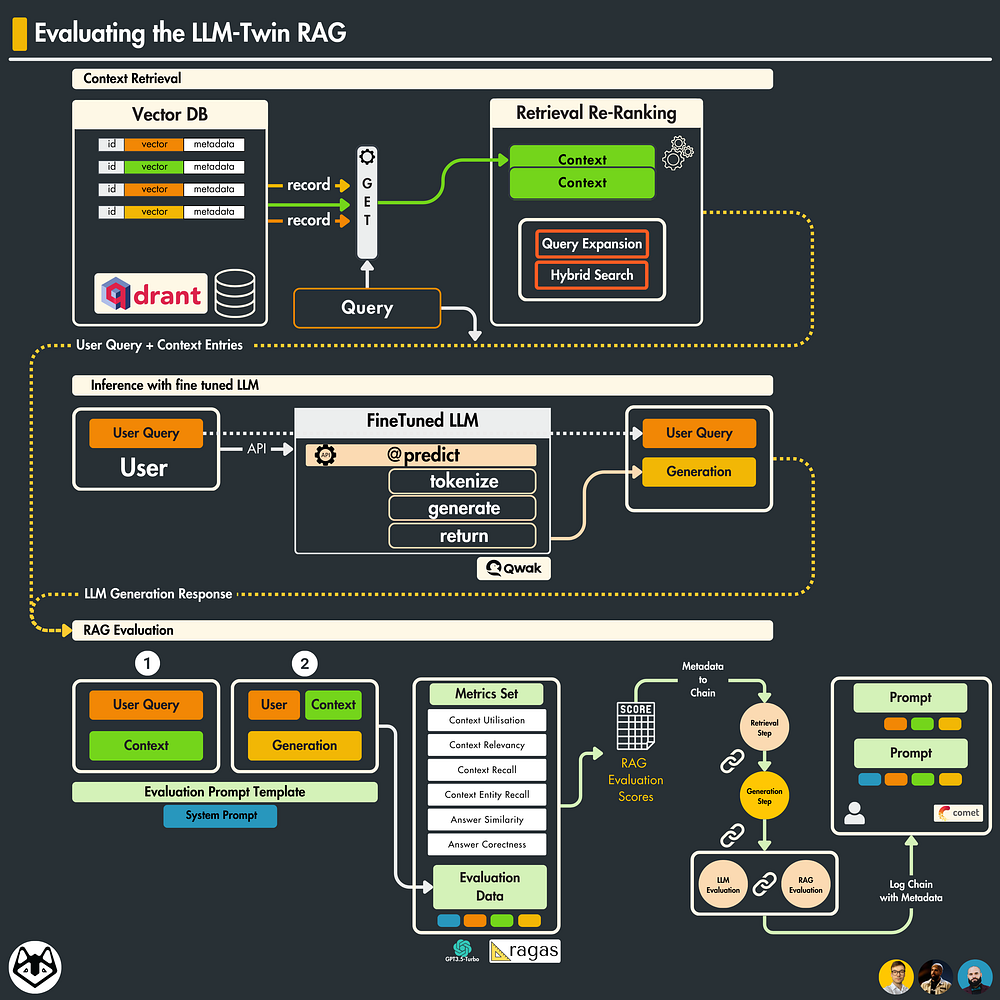
How to Evaluate Your RAG Using the RAGAs Framework
8 Best DeepEval Alternatives: Which LLM Evaluation Framework is Better ...
LLM Tracing | DeepEval by Confident AI - The LLM Evaluation Framework
GitHub - SLEEPWALKERG/LLM-DST-EVAL: This is the code for our proposed ...
A Gentle Introduction to LLM Evaluation - Confident AI
How to Evaluate LLMs? - GeeksforGeeks
Evaluate Langfuse LLM Traces with an External Evaluation Pipeline ...
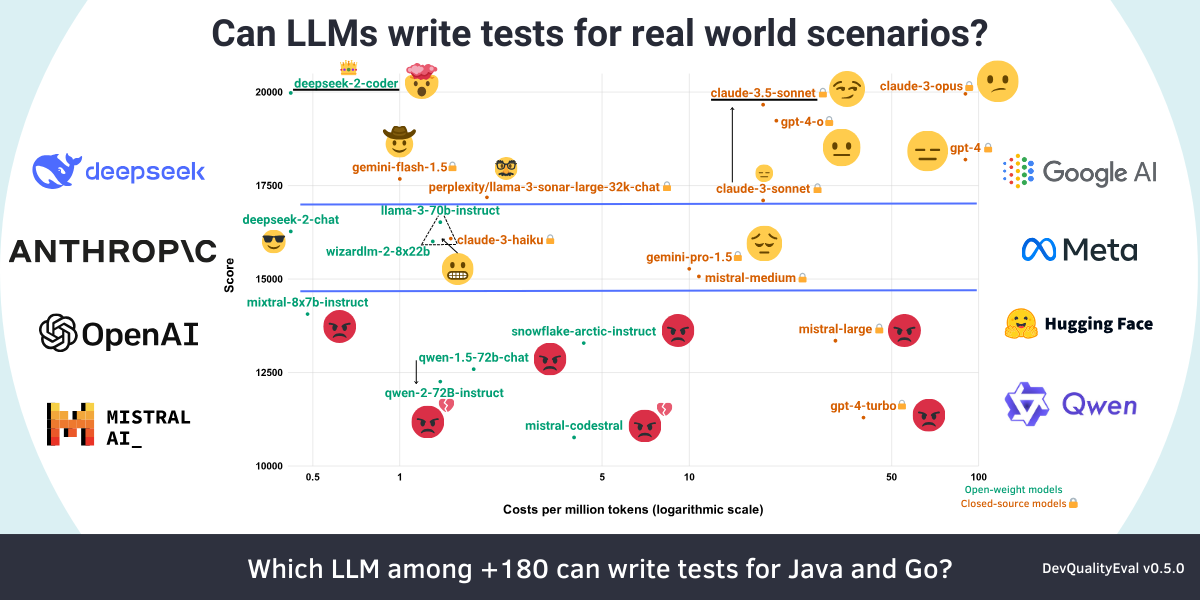
GitHub - symflower/eval-dev-quality: DevQualityEval: An evaluation ...
The Complete LLM Evaluation Playbook: How To Run LLM Evals That Matter ...
Evaluating LLM Performance at Scale: A Guide to Building Automated LLM ...
GitHub - stream-bench/stream-bench: We propose a pioneering benchmark ...
Build and Evaluate LLM Applications with TruLens | by Ahmed Besbes ...
LLM Evaluation: Benchmarks to Test Model Quality in 2025 | Label Your Data
GitHub - sowmipriya/build-an-automated-large-language-model
Prometheus-Eval and Prometheus 2: Setting New Standards in LLM ...
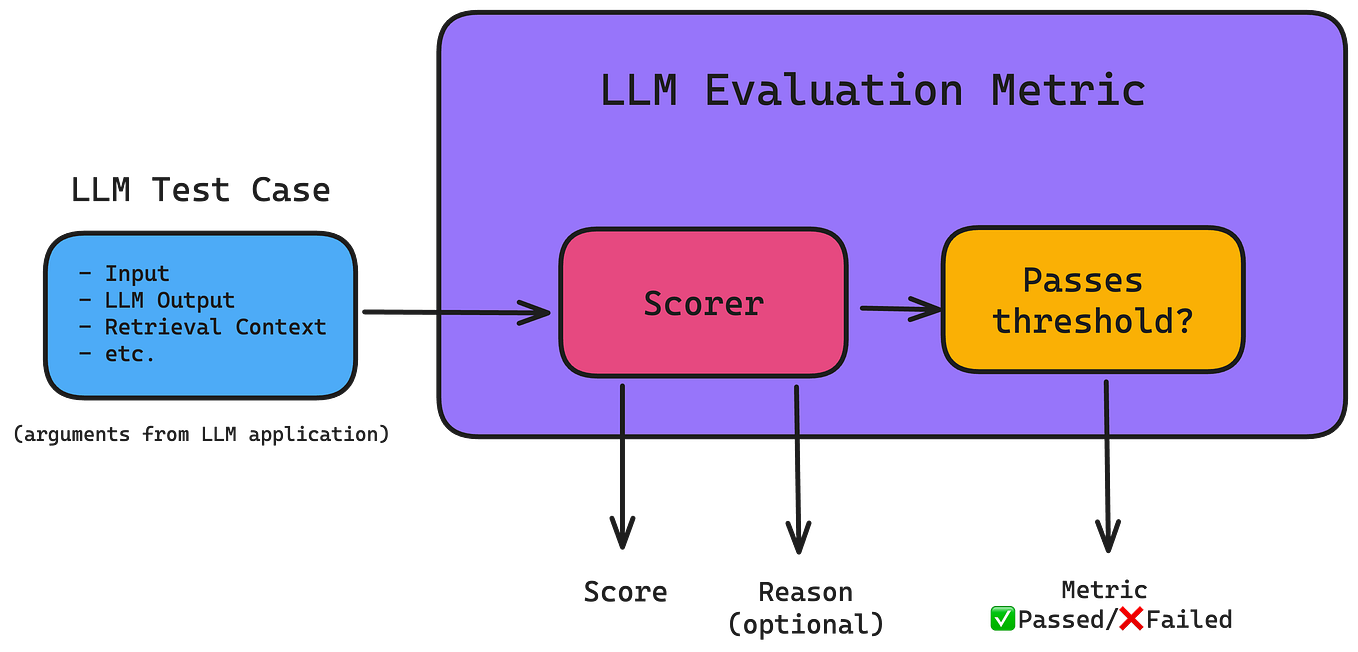
LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide - Confident AI
GitHub - Toniaac/LLM-MSE-Eval-Robustness · GitHub
Evaluating LLM Systems: Essential Metrics, Benchmarks, and Best ...
Comprehensive evaluation framework for LLM-generated content | by Juhi ...
LLM Eval Framework: Guide to Large Language Model Evaluation
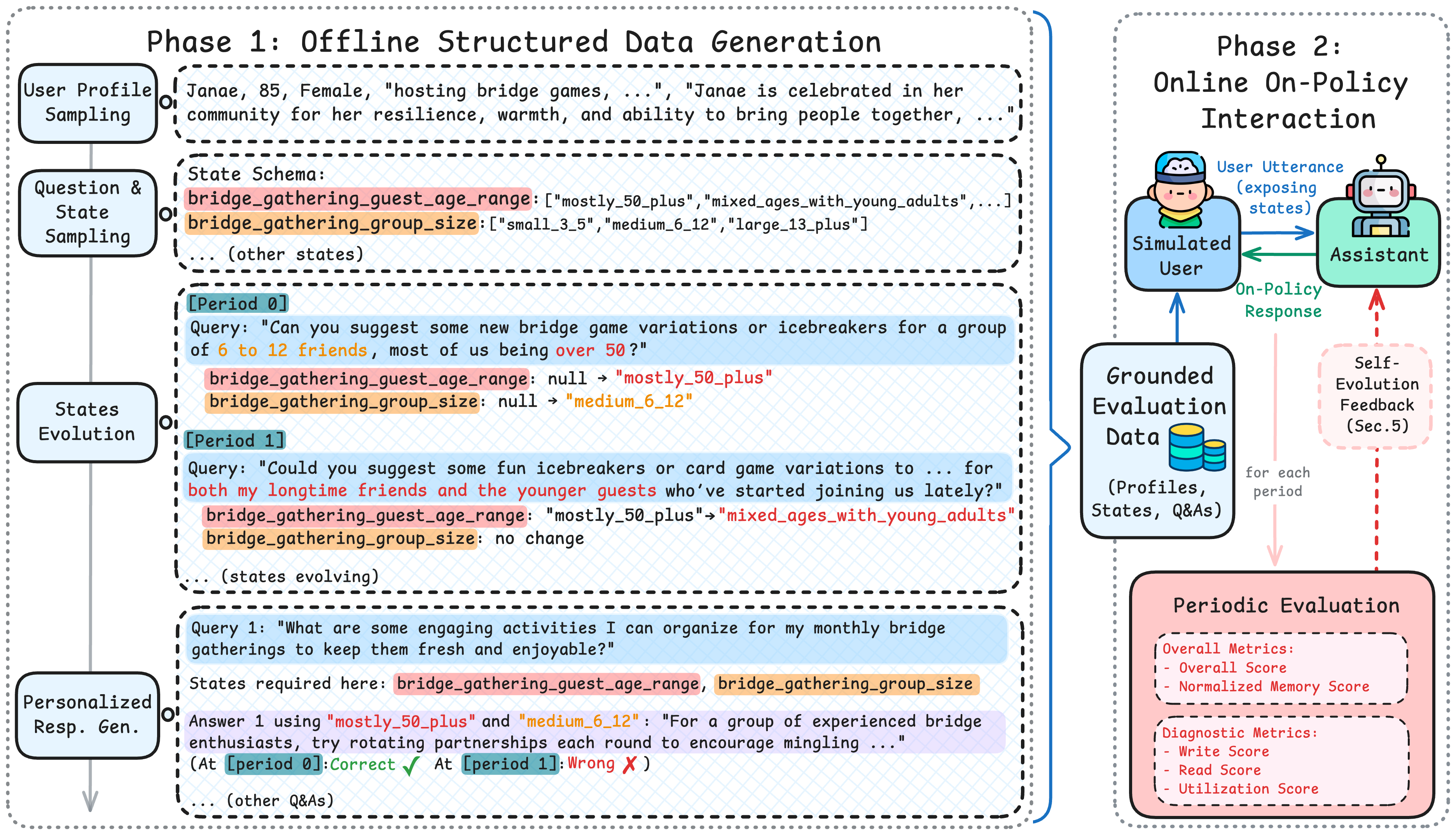
AMemGym - Interactive Memory Benchmarking for LLM Assistants
DeepEval: an open-source LLM evaluation framework
Key LLM Evaluation Metrics & How to Calculate Them
Building your own LLM evaluation framework with n8n
GitHub - langchain-ai/auto-evaluator · GitHub
LLM Evaluation - Measuring AI Model Performance | VoltAgent
A Complete Guide to LLM Evaluation and Benchmarking
Model Context Protocol — Hello World with Github Copilot Agent | by ...
LLM Evaluation Metrics : A Complete Guide to Evaluating LLMs
Structured Data Extraction with LLMs: What You Need To Know - Arize AI
GitHub - achieve-lab/assertion_data_for_LLM · GitHub
5 Developer Techniques to Enhance LLMs Performance! - DEV Community
LLM Evaluation Metrics: Everything You Need for LLM Evaluation ...
GitHub - llm-jp/llm-jp-eval
How companies evaluate LLM systems: 7 examples from Asana, GitHub, and more
Evaluating LLM Responses with DeepEval Library: A Comprehensive ...
Can You Trust LLM Judges? How to Build Reliable Evaluations
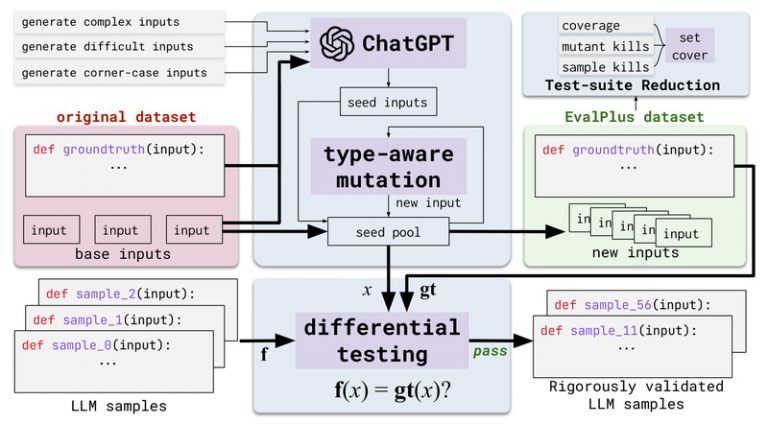
EvalPlus: Rigorously Evaluate LLM-Generated Code with 80× More Test ...
G-Eval Simply Explained: LLM-as-a-Judge for LLM Evaluation - Confident AI
GitHub - promptfoo/promptfoo-action
What is an LLM evaluation framework? Workflows and tools.
How Do We Evaluate LLMs Performance Effectively?
LLM Evaluation: Frameworks, Metrics, and Best Practices | SuperAnnotate
LLM Evaluation: Metrics, Methodologies, Best Practices | DataCamp
First Principles in Evaluating LLM Systems
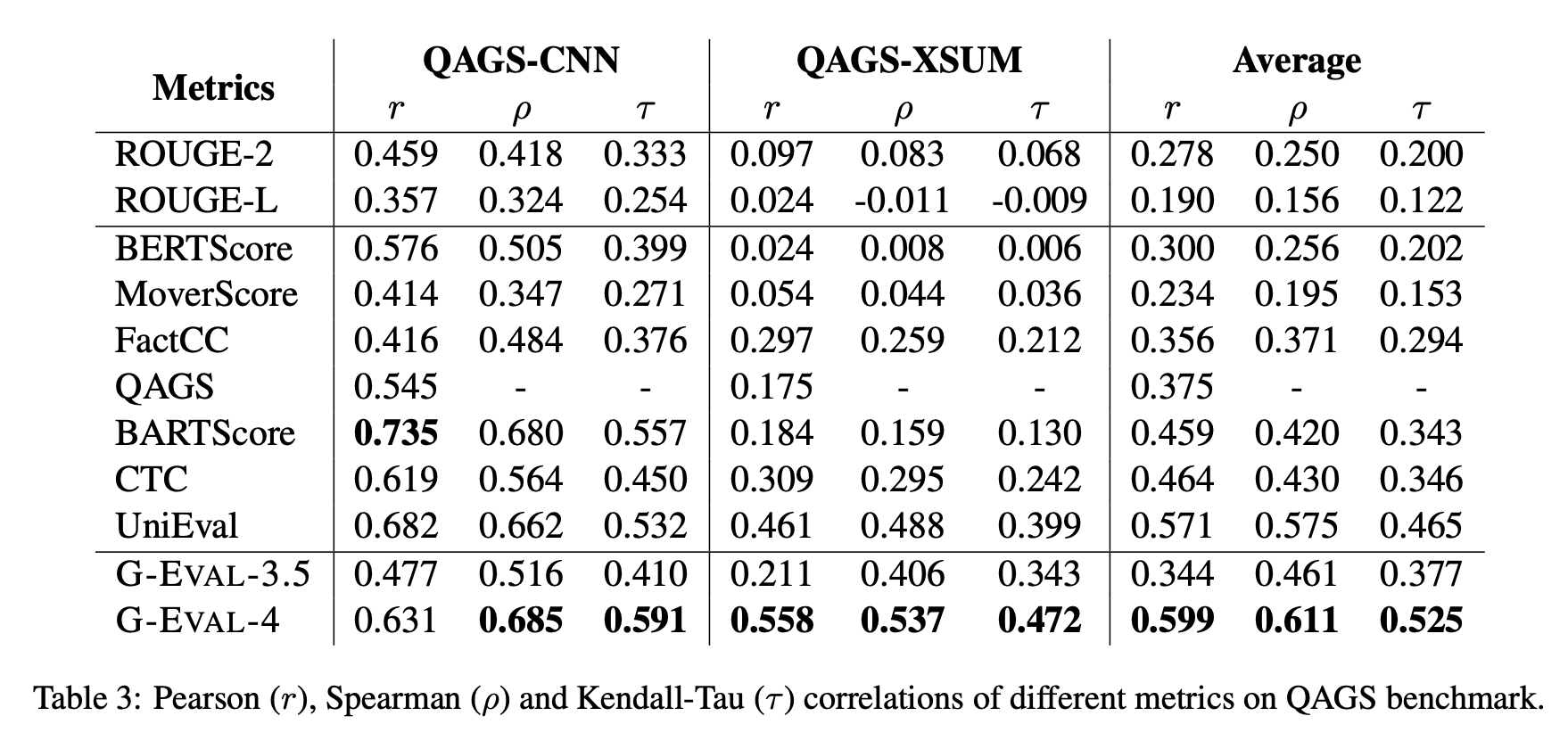
G-Eval for LLM Evaluation
sql-eval by defog-ai - SourcePulse
prometheus-eval by prometheus-eval - SourcePulse
llm-evaluation · GitHub Topics · GitHub
Building an LLM evaluation framework: best practices | Datadog
Introducing ASSERT: A Comprehensive Tool for Evaluating LLM-Generated ...
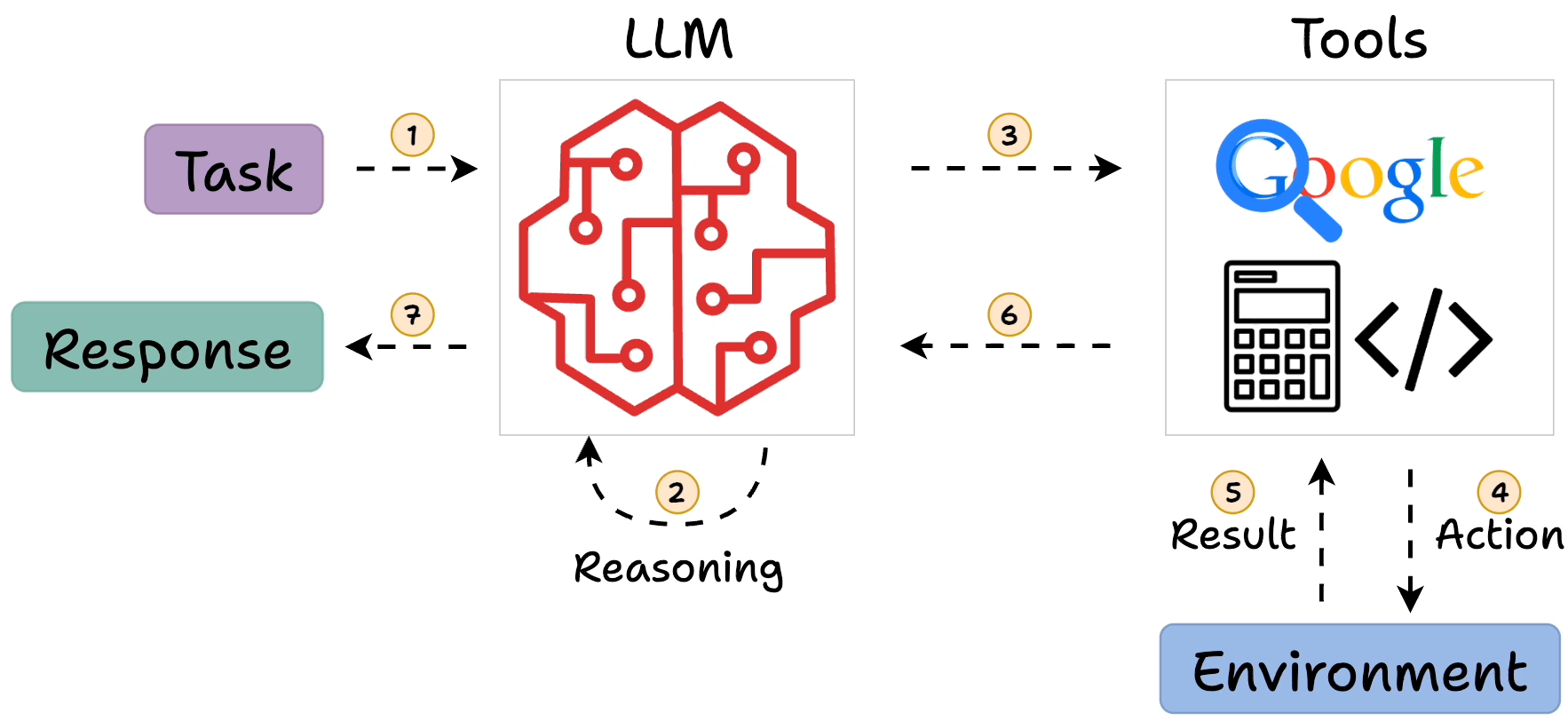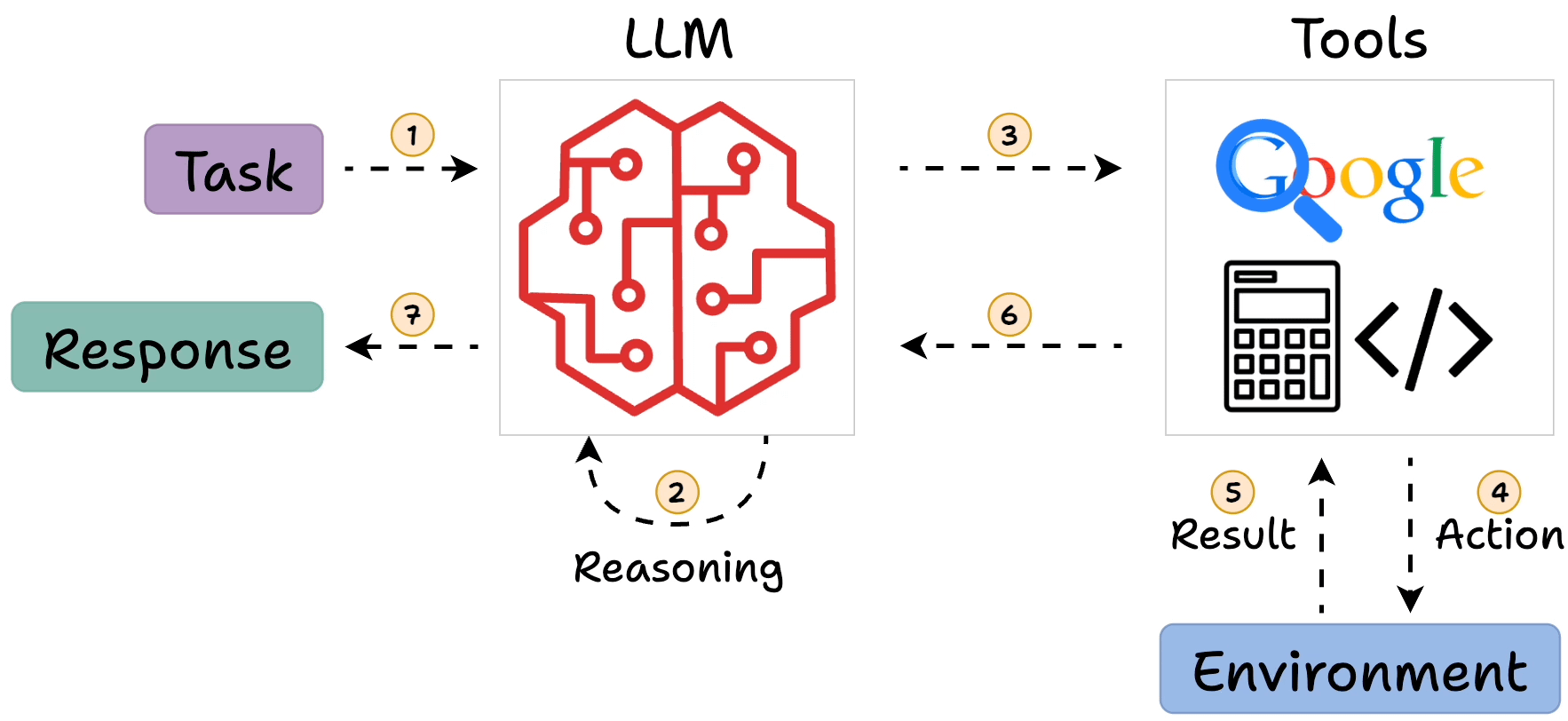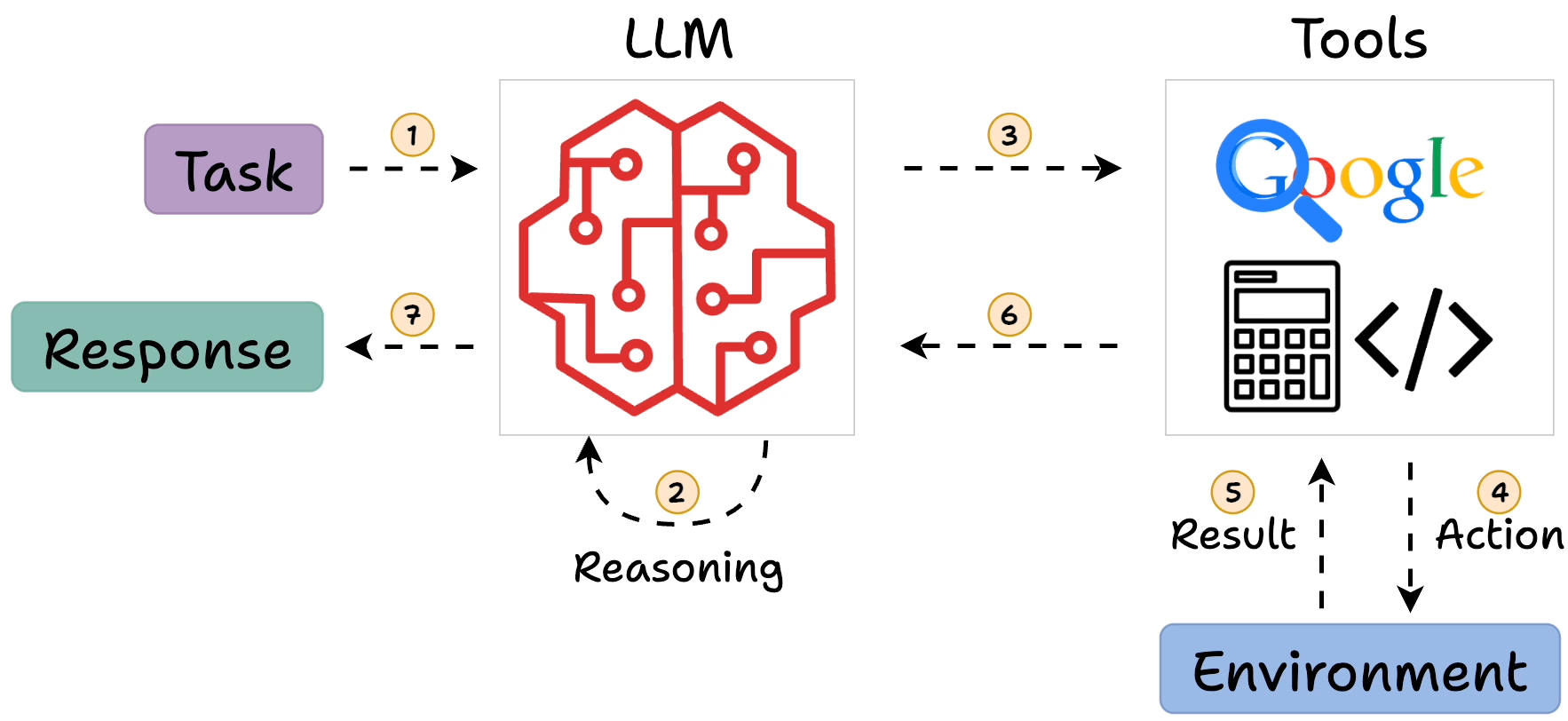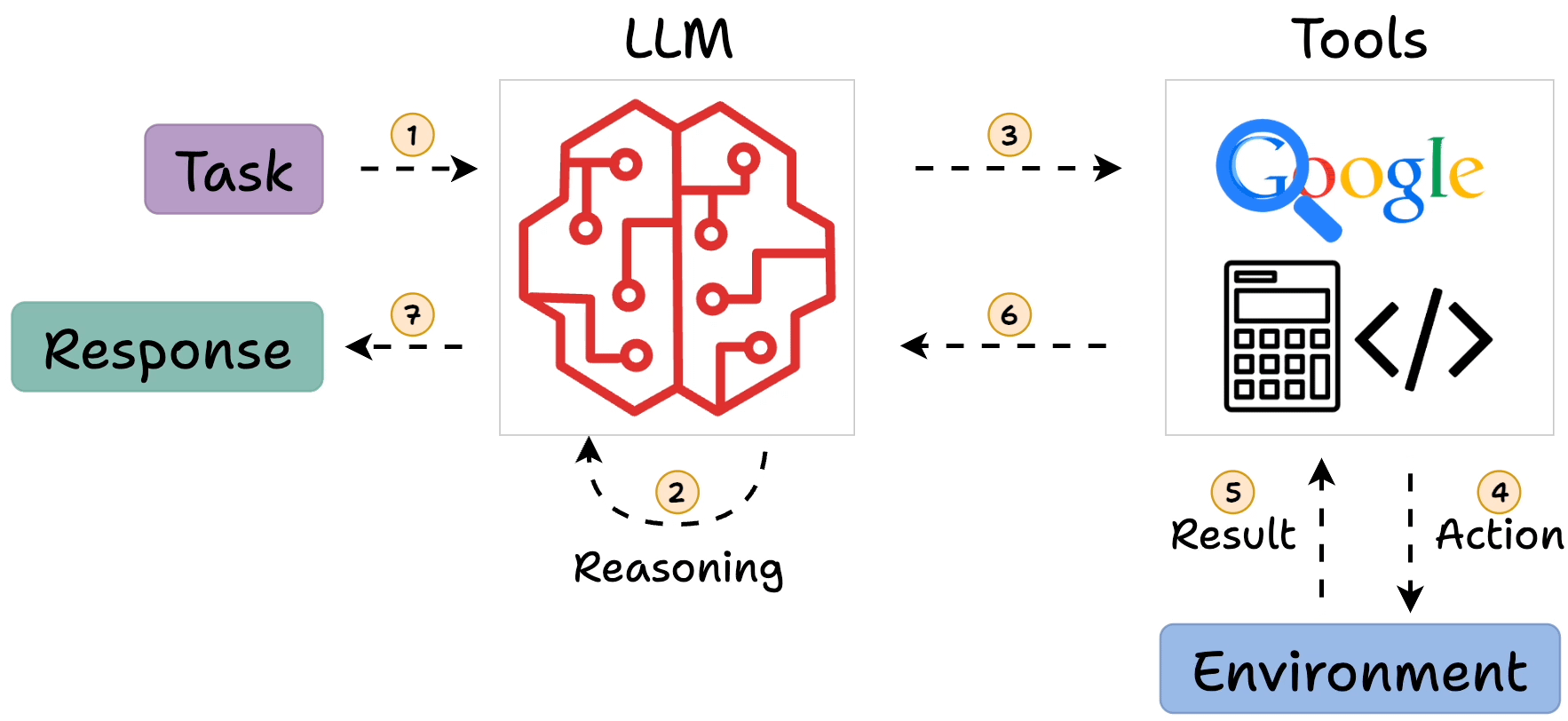
llm-agents-eval-SAP/agent_eval_react_purchase_order.ipynb at main ...
Evaluating Large Language Model (LLM) systems: Metrics, challenges, and ...
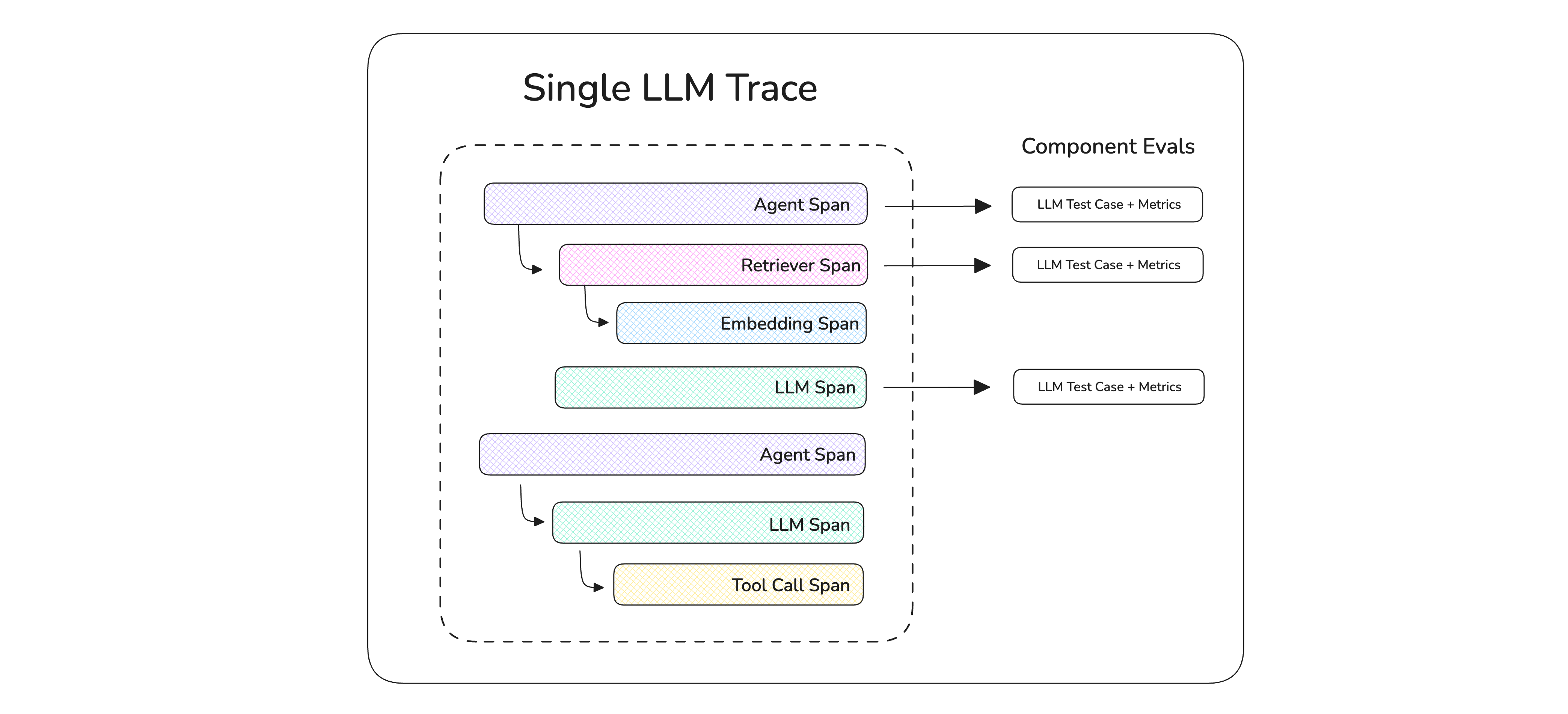
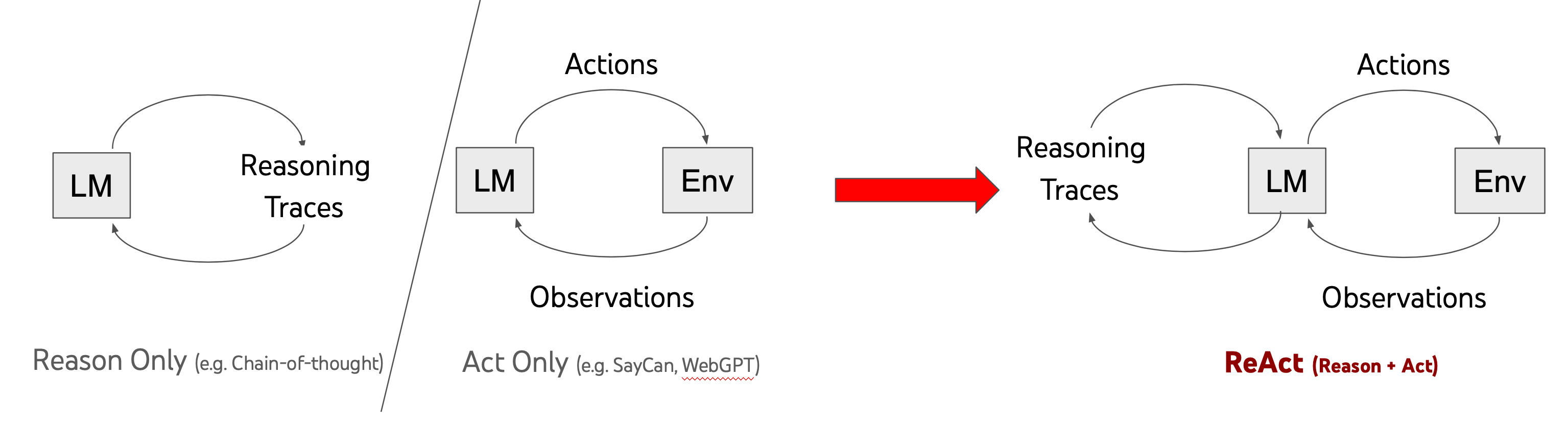
The architecture of both ReAct and InterAct. InterAct involves the ...
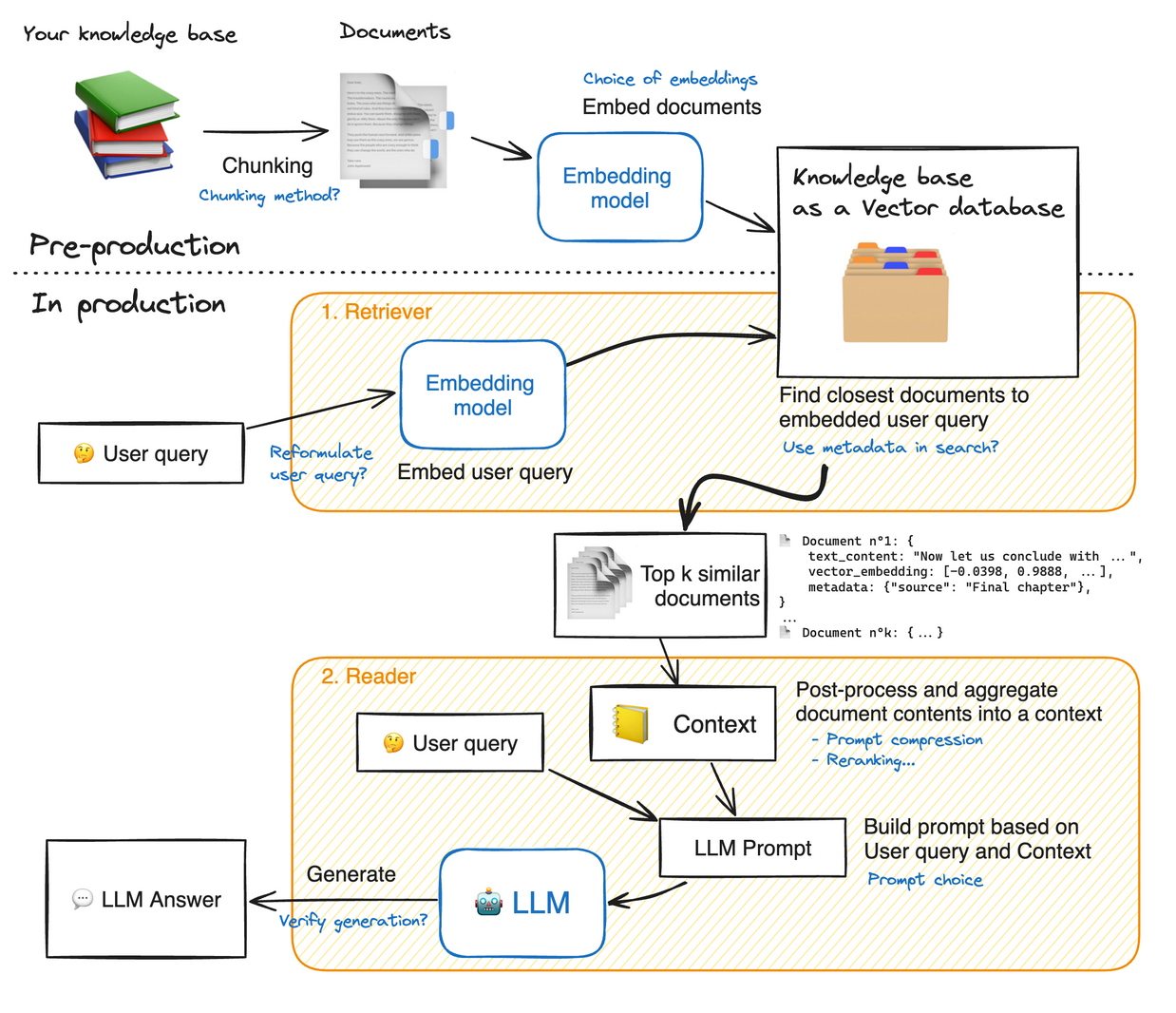
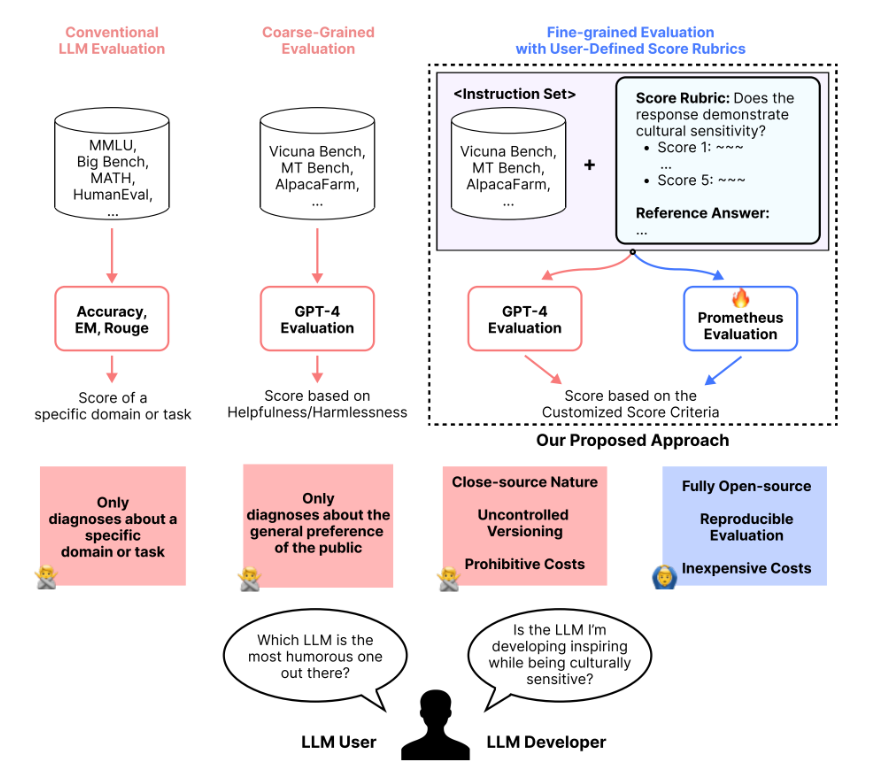
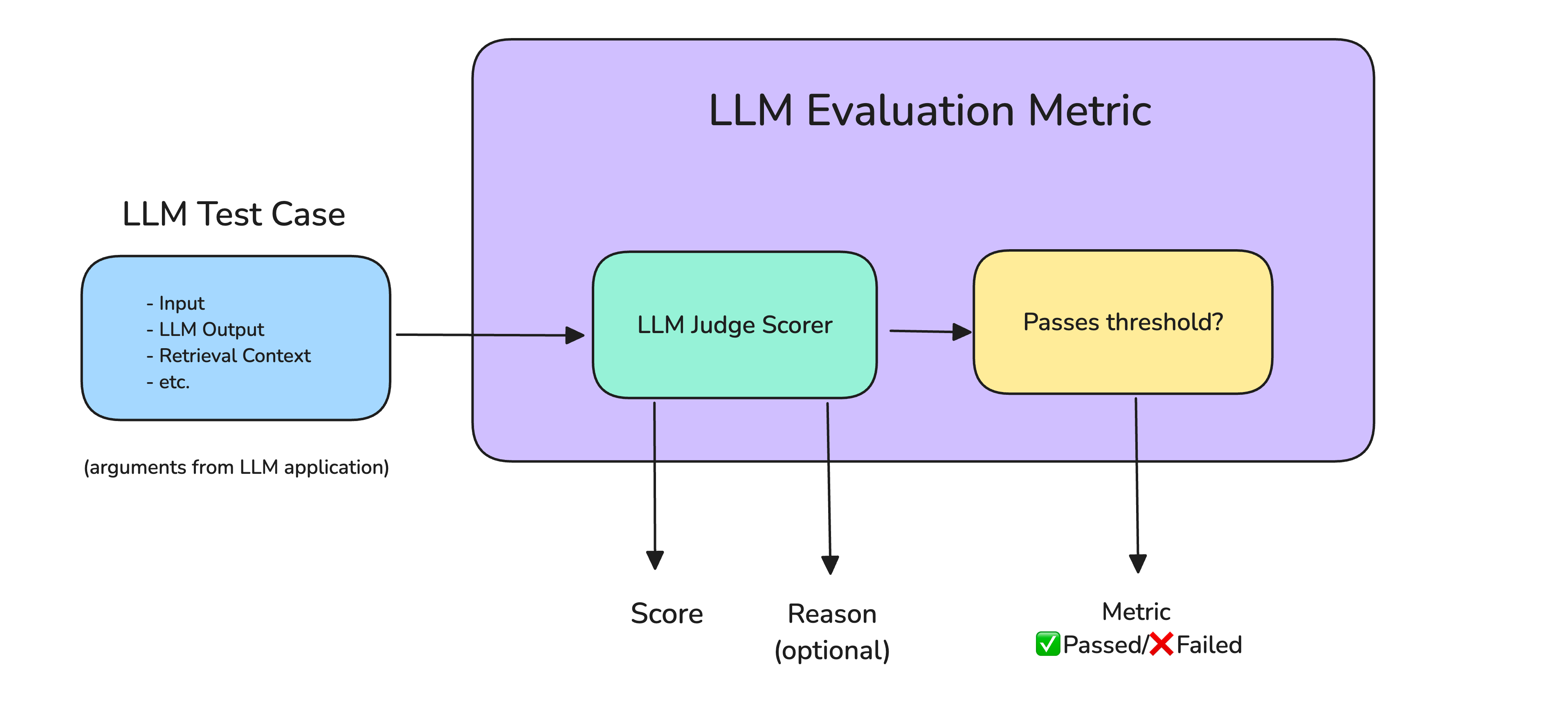
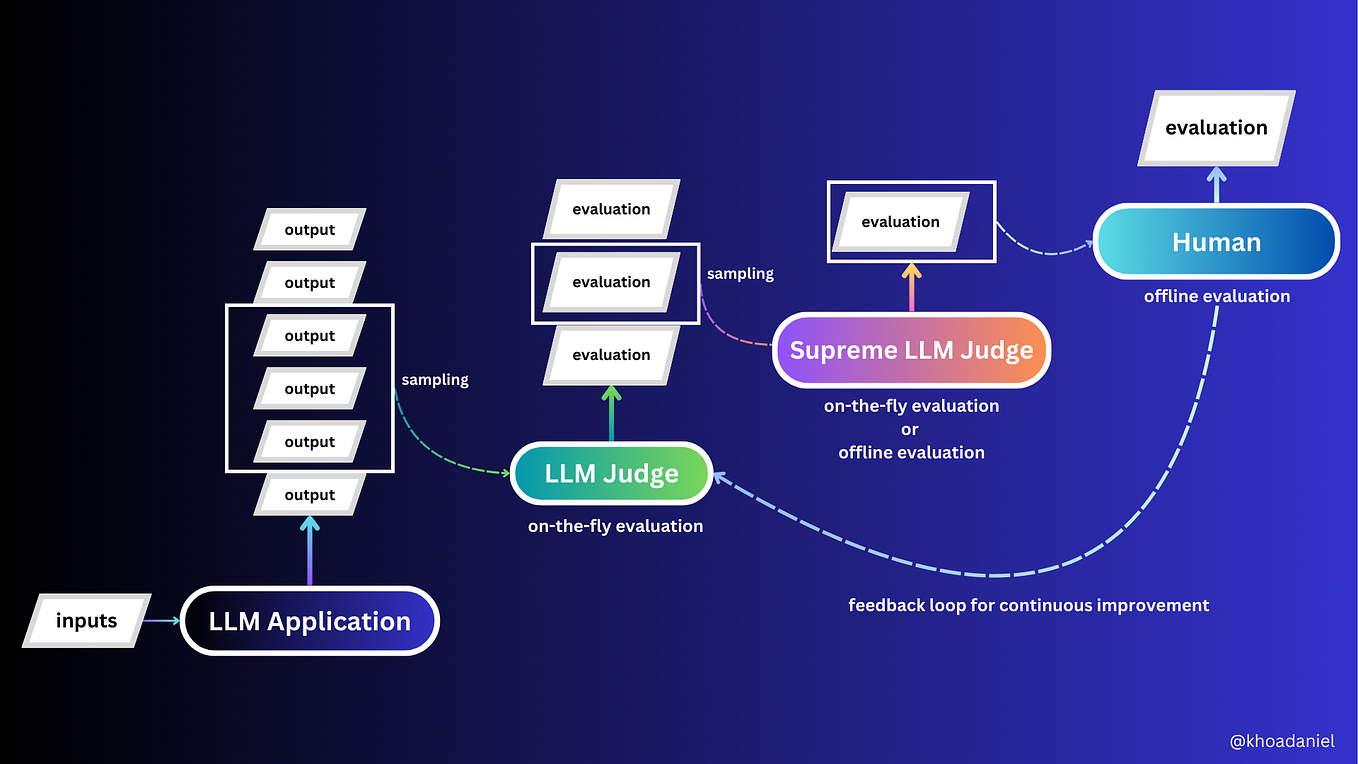
LLM-as-a-Judge is one of the most widely-used techniques for evaluating ...
Papers | LLM Evaluation
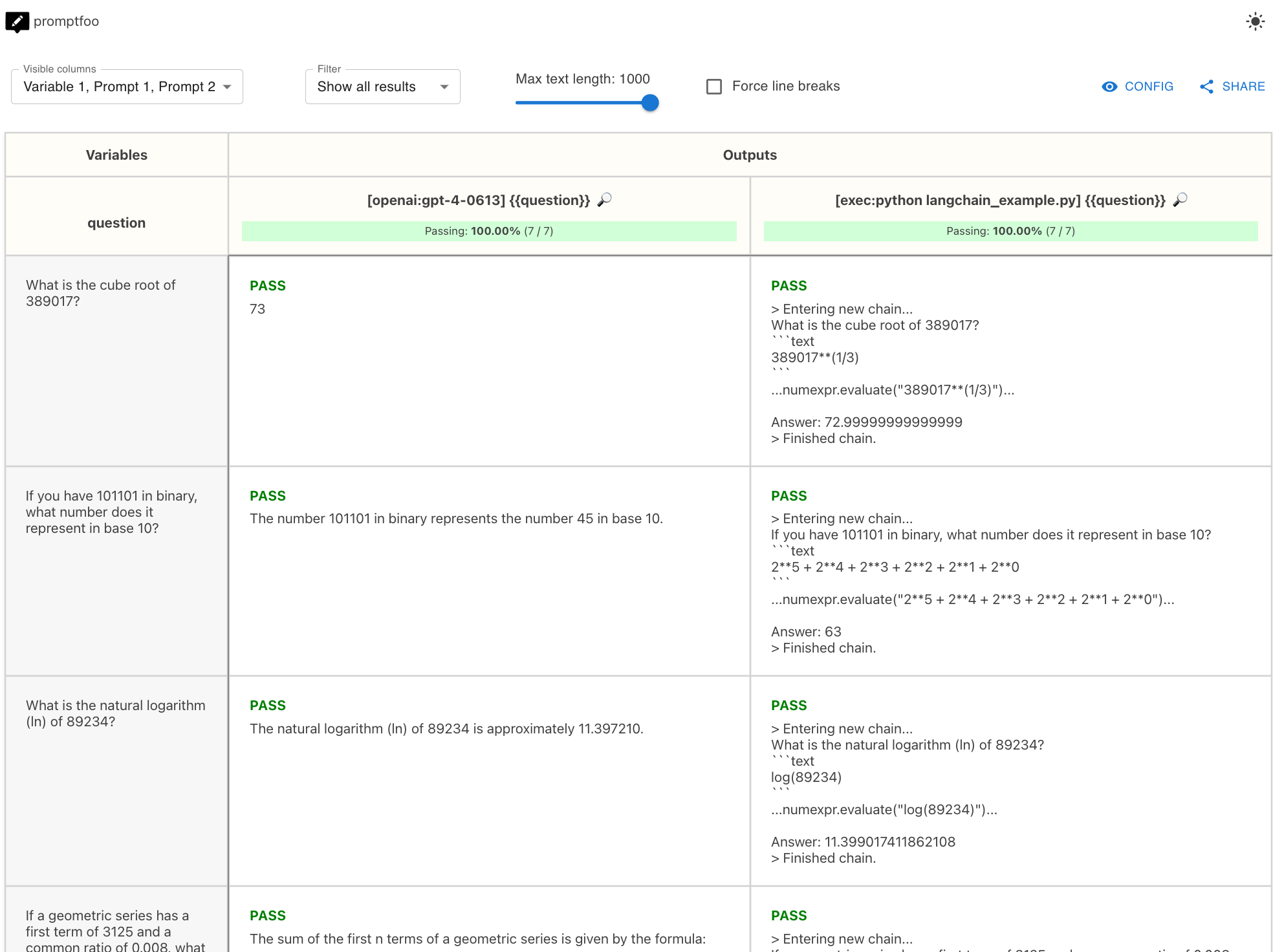
Testing LLM chains | Promptfoo
[2305.13711] LLM-Eval: Unified Multi-Dimensional Automatic Evaluation ...
Build an automated generative AI solution evaluation pipeline with ...
LLM Evaluation: Large Language Models Performance Metrics
llm-eval · GitHub Topics · GitHub
Prompt Engineering: una guida all'interrogazione efficace degli LLM
ai-evaluation · GitHub Topics · GitHub
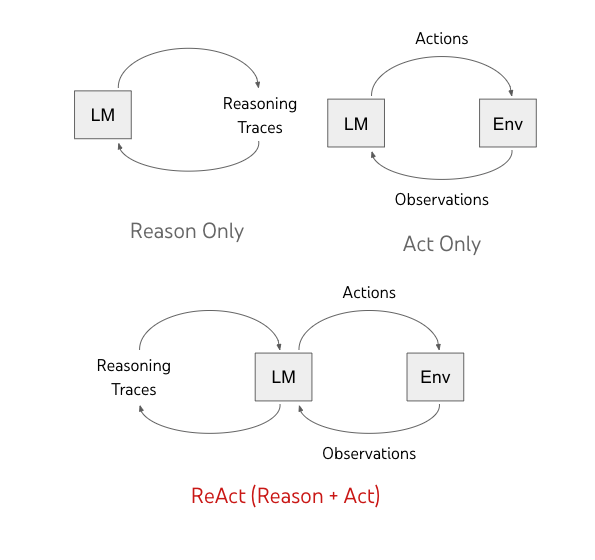
Agent范式:ReAct、Plan-and-Execute 和 multi-agent – Heart.Think.Do
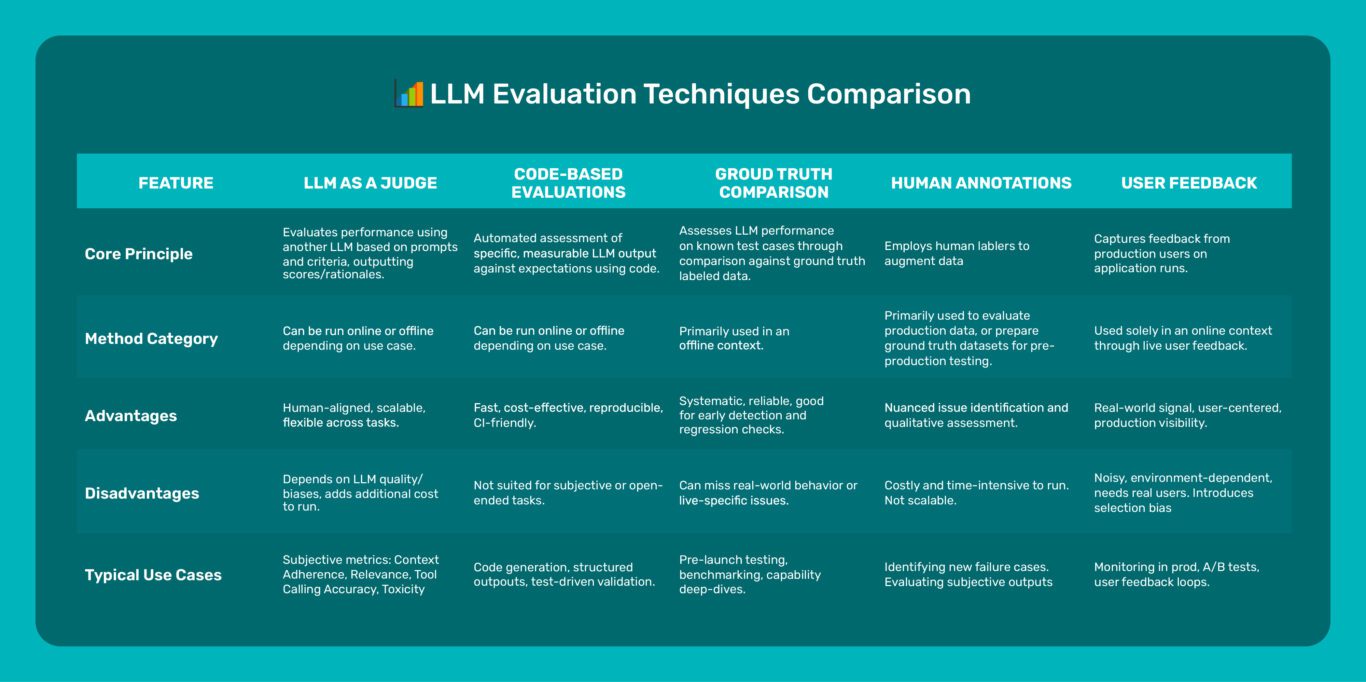
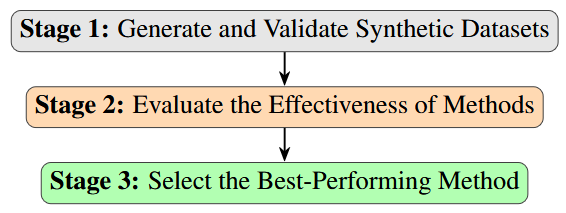
Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge)
The Latest Open Source LLMs and Datasets
Large Language Model Evaluation in 2026: Technical Methods & Tips
如何评估LLM:一个完整的度量框架 | AI开发者中心
Leveraging Open Source Models for AI Evaluation with DeepEval
AI 思考的快与慢
Model.train Vs Model.eval at Marion Ohara blog
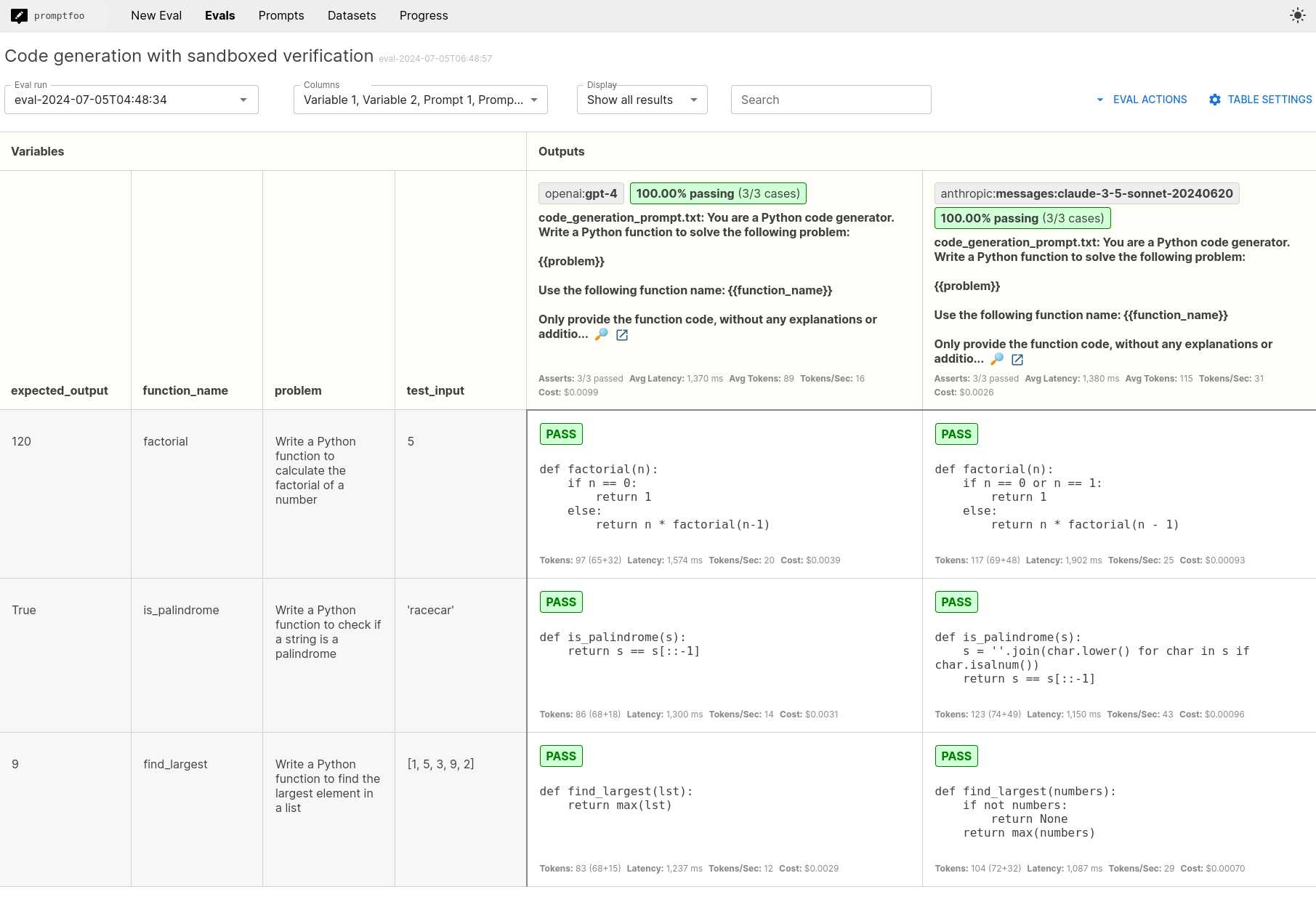
Creating Eval Cases for LLM-Generated Code
Sandboxed Evaluations of LLM-Generated Code | Promptfoo








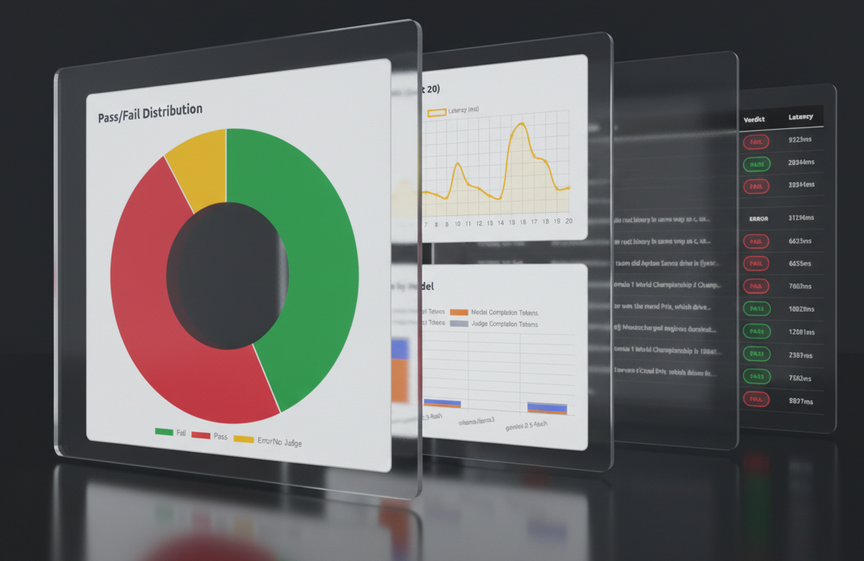

.png)