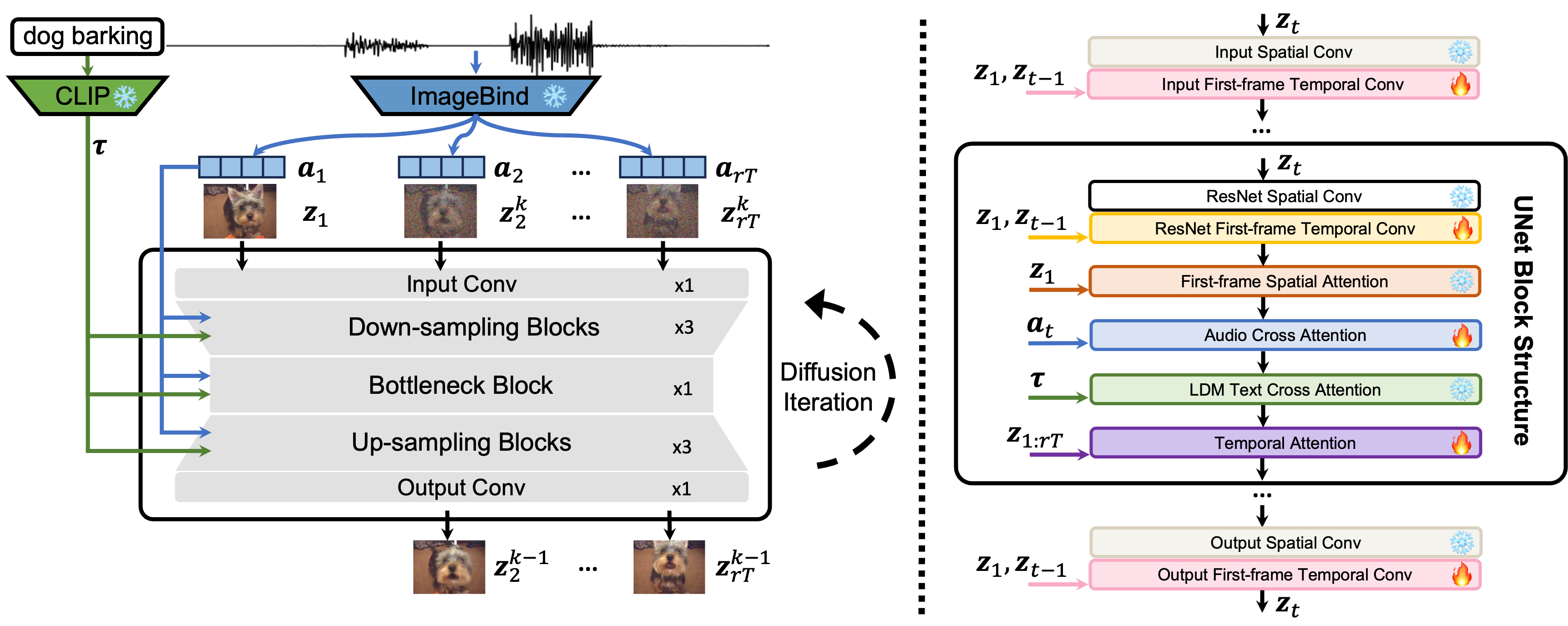
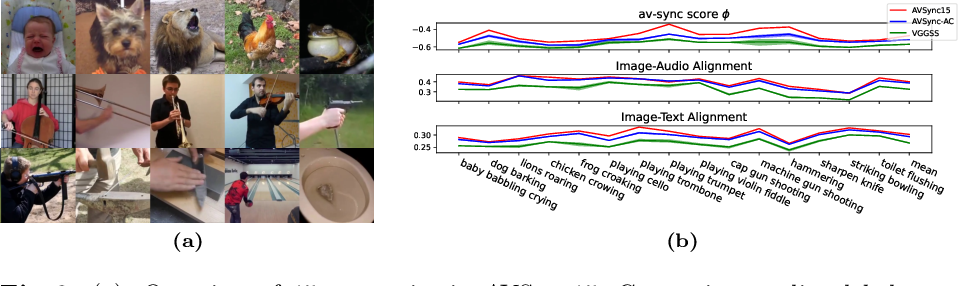
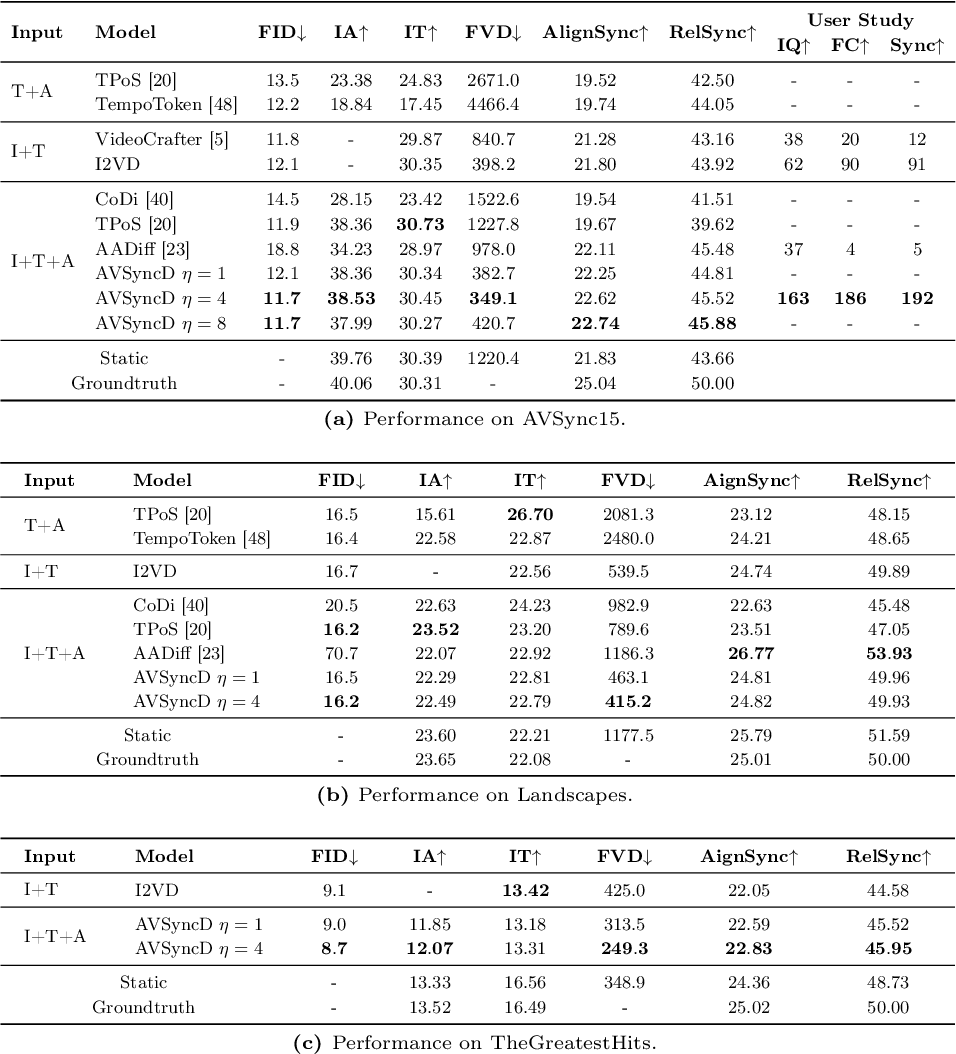
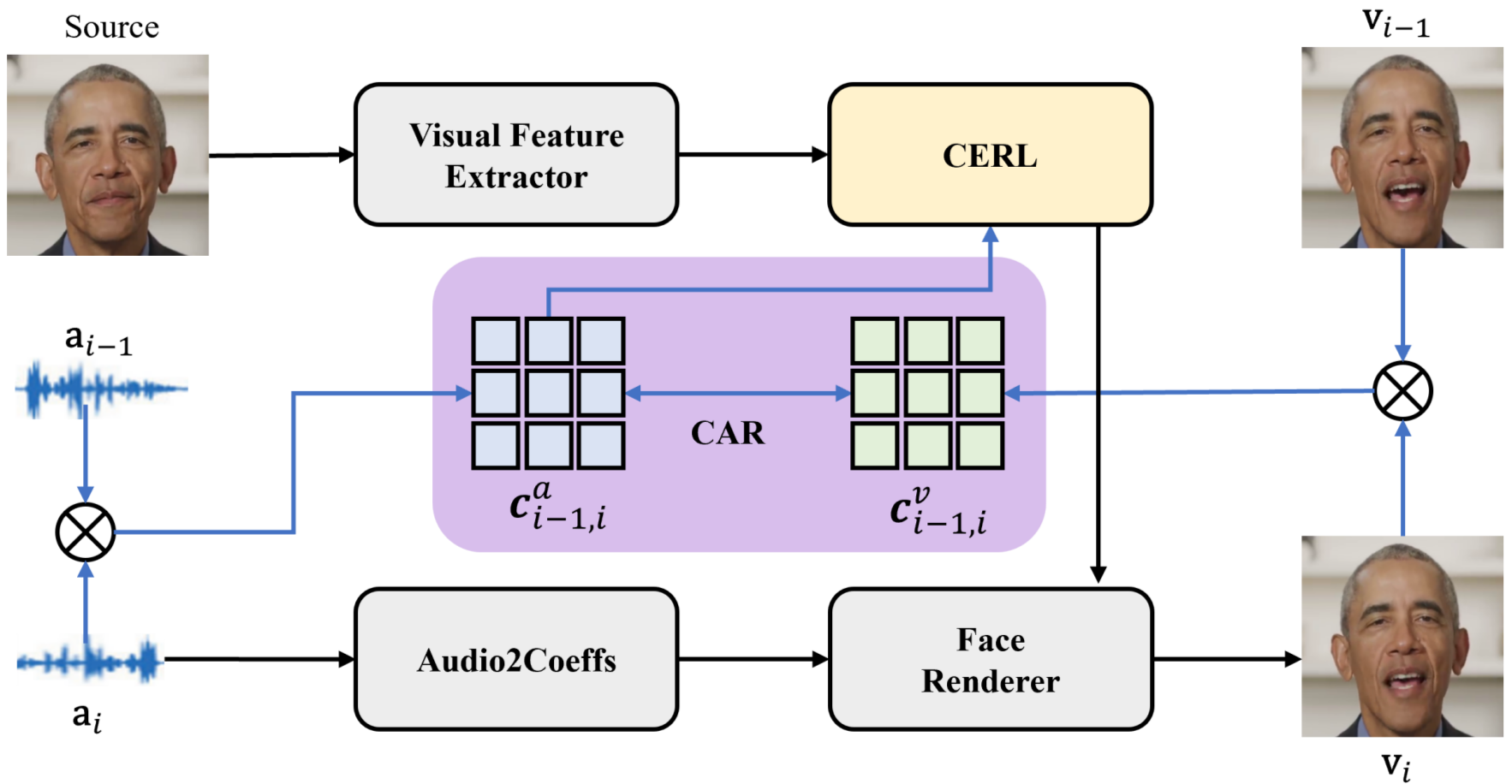
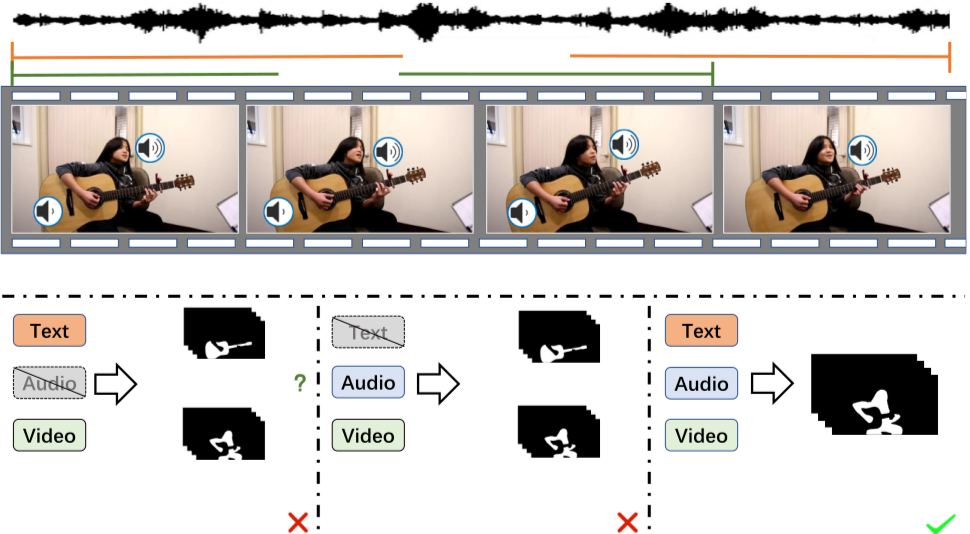
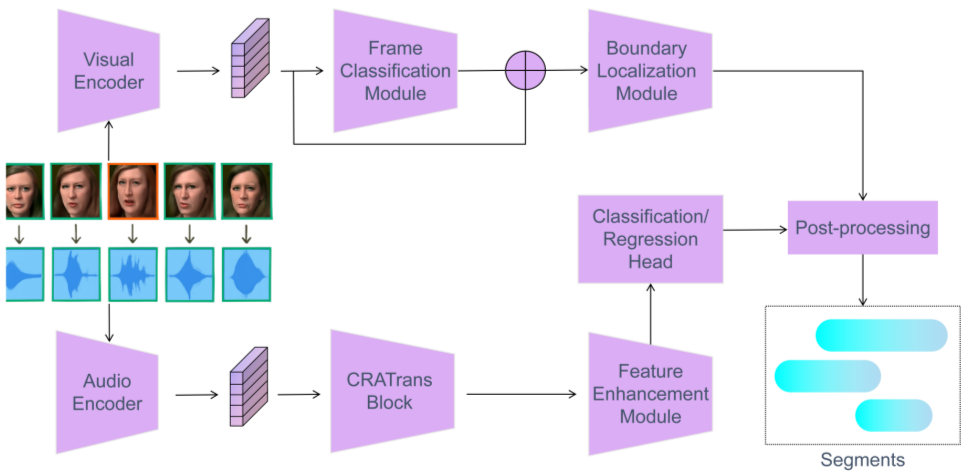
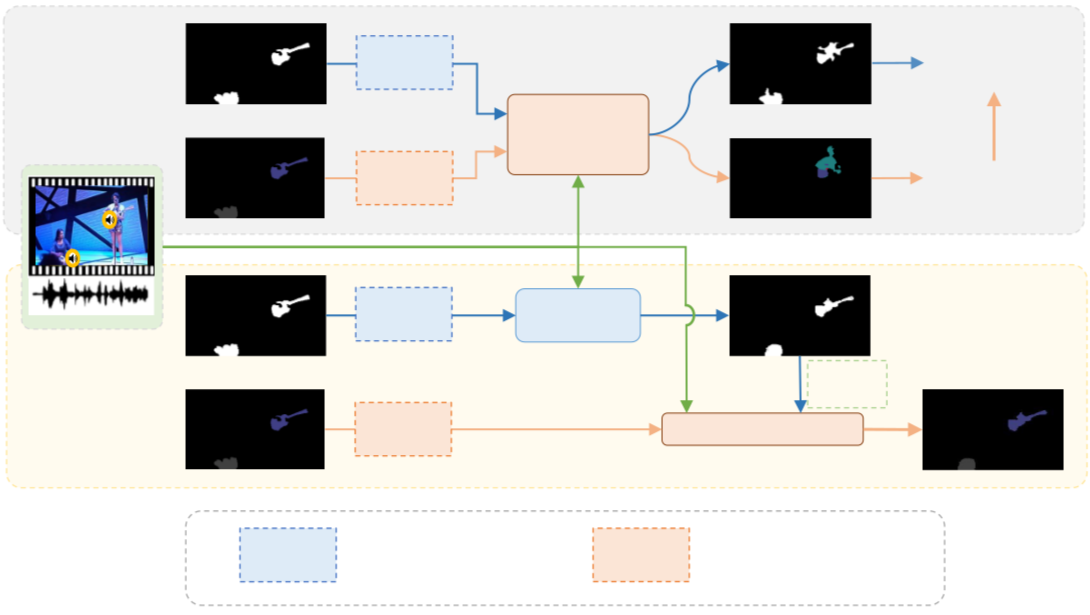
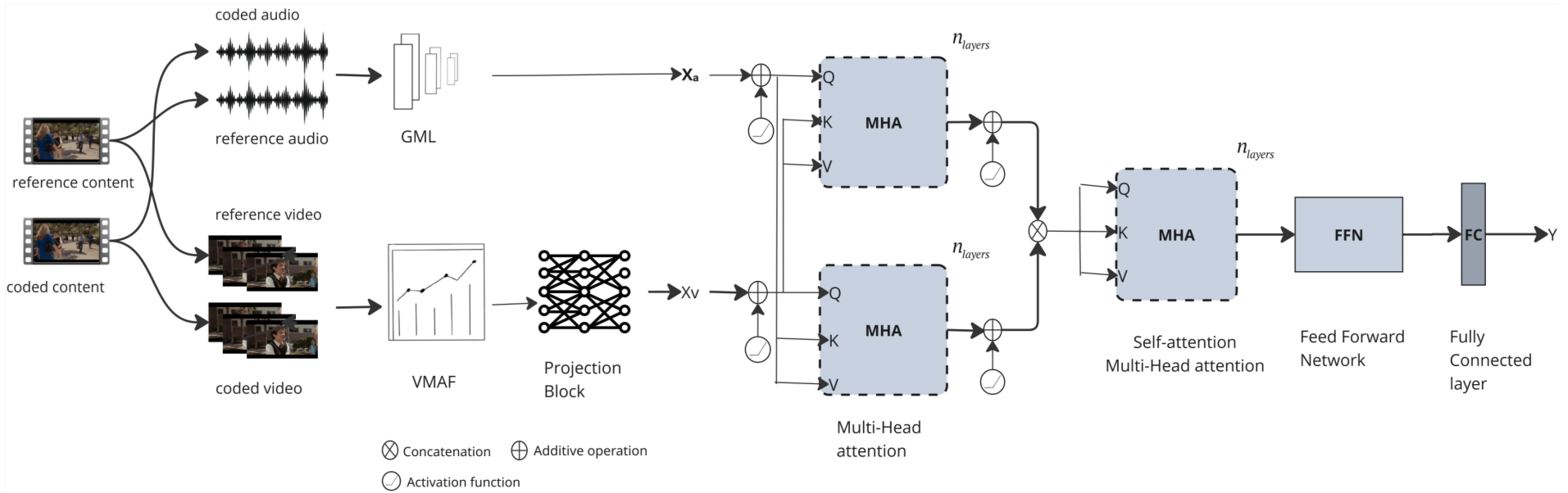
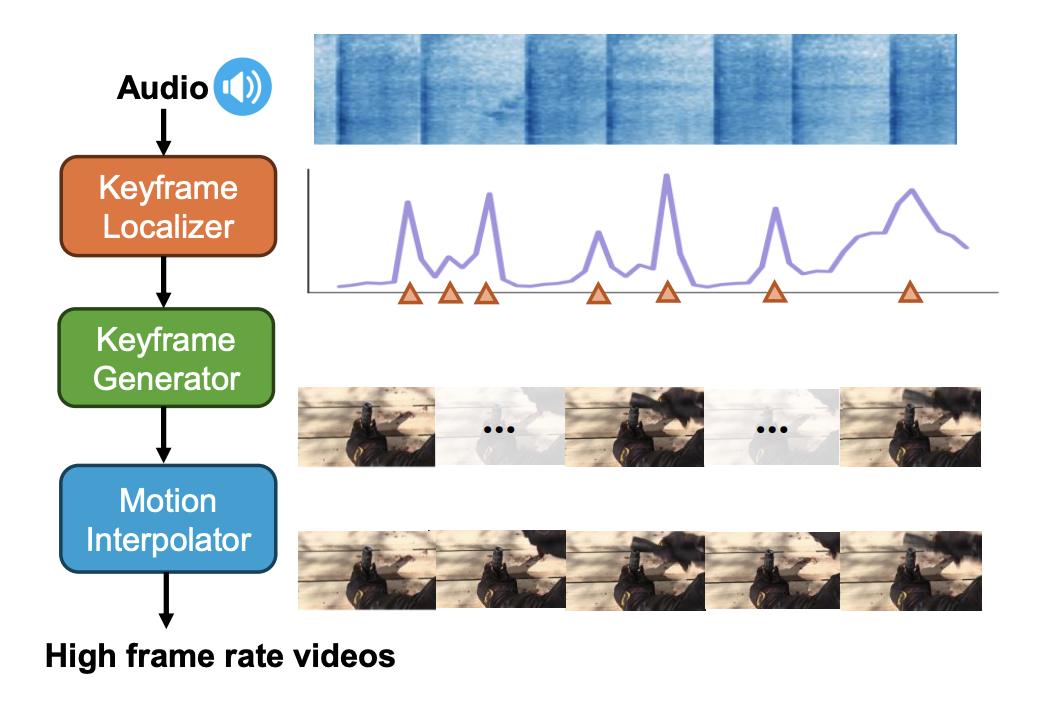
Audio-Synchronized Visual Animation
[논문 리뷰] KeyVID: Keyframe-Aware Video Diffusion for Audio-Synchronized ...
[ECCV 2024 Oral] Audio-Synchronized Visual Animation (ASVA) - YouTube
[논문 리뷰] Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait ...
Figure 4 from Audio-Synchronized Visual Animation | Semantic Scholar
Figure 2 from Audio-Synchronized Visual Animation | Semantic Scholar
[논문 리뷰] EmoFace: Audio-driven Emotional 3D Face Animation
[논문 리뷰] Sound-VECaps: Improving Audio Generation with Visual Enhanced ...
[논문 리뷰] Enhancing Audio Generation Diversity with Visual Information
[논문 리뷰] Boosting Audio Visual Question Answering via Key Semantic-Aware ...
[논문 리뷰] Uncovering the Visual Contribution in Audio-Visual Speech ...
[논문 리뷰] VFX Creator: Animated Visual Effect Generation with ...
Audio-Synchronized Visual Animation | AI Research Paper Details
[논문 리뷰] How Does Audio Influence Visual Attention in Omnidirectional ...
[논문 리뷰] Dynamic Derivation and Elimination: Audio Visual Segmentation ...
[논문 리뷰] AlignVSR: Audio-Visual Cross-Modal Alignment for Visual Speech ...
[논문 리뷰] Bridging Ears and Eyes: Analyzing Audio and Visual Large ...
[논문 리뷰] A Critical Assessment of Visual Sound Source Localization ...
Table 1 from Audio-Synchronized Visual Animation | Semantic Scholar
[논문 리뷰] Audio Visual Segmentation Through Text Embeddings
[논문 리뷰] Stable-V2A: Synthesis of Synchronized Sound Effects with ...
[논문 리뷰] SyncAnimation: A Real-Time End-to-End Framework for Audio ...
[논문 리뷰] Exploiting Temporal Audio-Visual Correlation Embedding for ...
[논문 리뷰] video-SALMONN 2: Captioning-Enhanced Audio-Visual Large ...
[논문 리뷰] Wav2Sem: Plug-and-Play Audio Semantic Decoupling for 3D Speech ...
[논문 리뷰] video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
[논문 리뷰] SimToken: A Simple Baseline for Referring Audio-Visual Segmentation
[논문 리뷰] Learning Video Temporal Dynamics with Cross-Modal Attention for ...
[논문 리뷰] Rhythmic Foley: A Framework For Seamless Audio-Visual Alignment ...
[논문 리뷰] INFP: Audio-Driven Interactive Head Generation in Dyadic ...
[논문 리뷰] SAVE: Segment Audio-Visual Easy way using Segment Anything Model
[논문 리뷰] Sounding that Object: Interactive Object-Aware Image to Audio ...
[논문 리뷰] Detecting Audio-Visual Deepfakes with Fine-Grained Inconsistencies
[논문 리뷰] LAVCap: LLM-based Audio-Visual Captioning using Optimal Transport
[논문 리뷰] UniSync: A Unified Framework for Audio-Visual Synchronization
[논문 리뷰] Seeing Speech and Sound: Distinguishing and Locating Audios in ...
[논문 리뷰] Sequential Contrastive Audio-Visual Learning
[논문 리뷰] Depression Detection and Analysis using Large Language Models ...
[논문 리뷰] ERF-BA-TFD+: A Multimodal Model for Audio-Visual Deepfake Detection
[논문 리뷰] AVS-Net: Audio-Visual Scale Net for Self-supervised Monocular ...
[논문 리뷰] DOA-Aware Audio-Visual Self-Supervised Learning for Sound Event ...
[논문 리뷰] Adaptive Audio-Visual Speech Recognition via Matryoshka-Based ...
[논문 리뷰] Stepping Stones: A Progressive Training Strategy for Audio ...
[논문 리뷰] Large Language Models are Strong Audio-Visual Speech ...
[논문 리뷰] Learning Self-Supervised Audio-Visual Representations for Sound ...
[논문 리뷰] Dynamic Cross Attention for Audio-Visual Person Verification
[논문 리뷰] Ref-AVS: Refer and Segment Objects in Audio-Visual Scenes
[논문 리뷰] Spatial Audio Rendering for Real-Time Speech Translation in ...
[논문 리뷰] Learning Audio-guided Video Representation with Gated Attention ...
[논문 리뷰] Diffusion-based Unsupervised Audio-visual Speech Enhancement
[논문 리뷰] Attentive AV-FusionNet: Audio-Visual Quality Prediction with ...
[논문 리뷰] Integrating Audio, Visual, and Semantic Information for ...
[논문 리뷰] OmniTalker: Real-Time Text-Driven Talking Head Generation with ...
[논문 리뷰] Video-to-Audio Generation with Hidden Alignment
[논문 리뷰] Empathetic Response in Audio-Visual Conversations Using Emotion ...
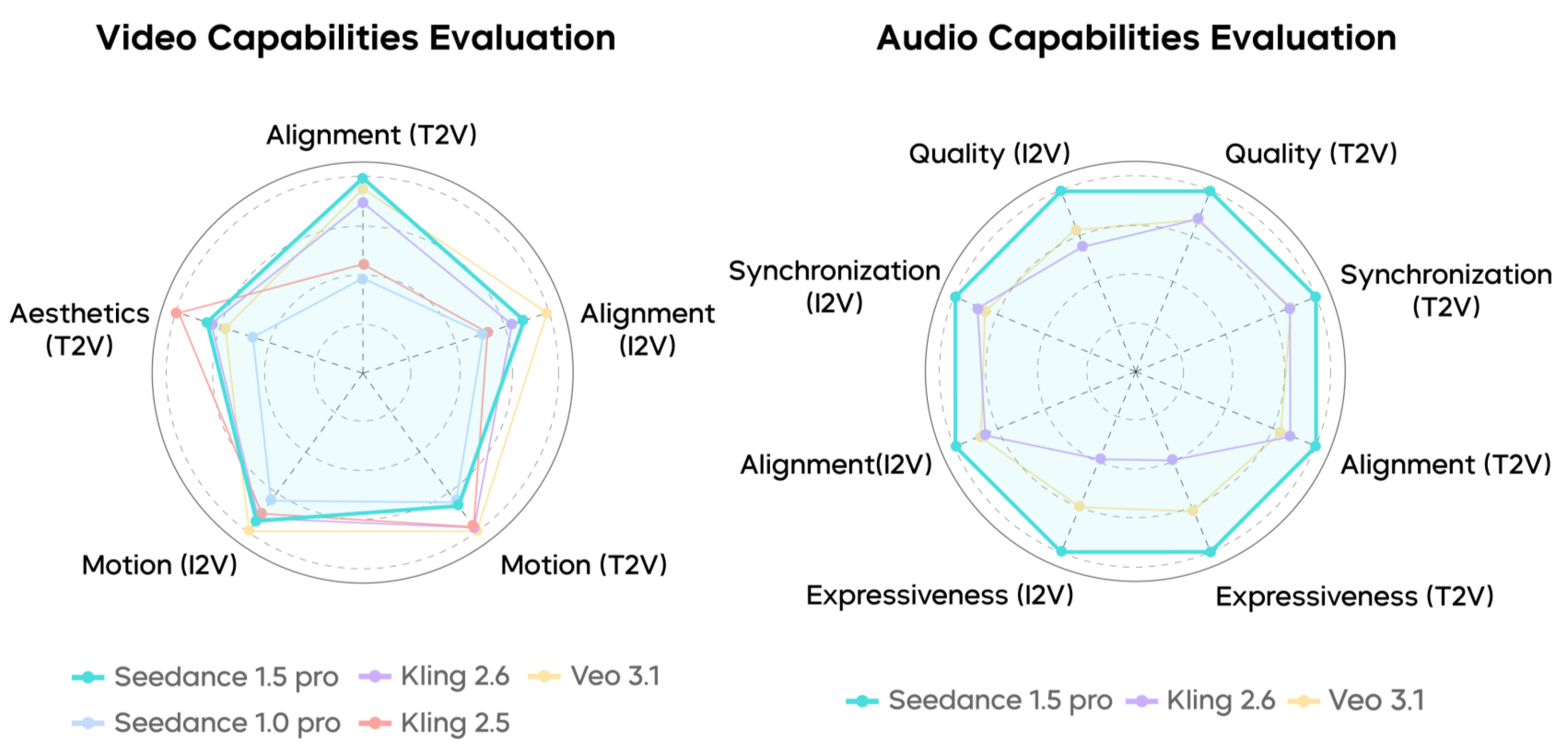
[논문 리뷰] Seedance 1.5 pro: A Native Audio-Visual Joint Generation ...
[논문 리뷰] Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait ...
[논문 리뷰] Learning Trimodal Relation for Audio-Visual Question Answering ...
[논문 리뷰] Progressive Confident Masking Attention Network for Audio ...
[논문 리뷰] Lightweight Joint Audio-Visual Deepfake Detection via Single ...
[논문 리뷰] STNet: Deep Audio-Visual Fusion Network for Robust Speaker Tracking
[논문 리뷰] Attend-Fusion: Efficient Audio-Visual Fusion for Video ...
Professional Audio Visual Animation Services | Bring Ideas to Life
[논문 리뷰] Video-to-Audio Generation with Fine-grained Temporal Semantics
[논문 리뷰] AlignDiT: Multimodal Aligned Diffusion Transformer for ...
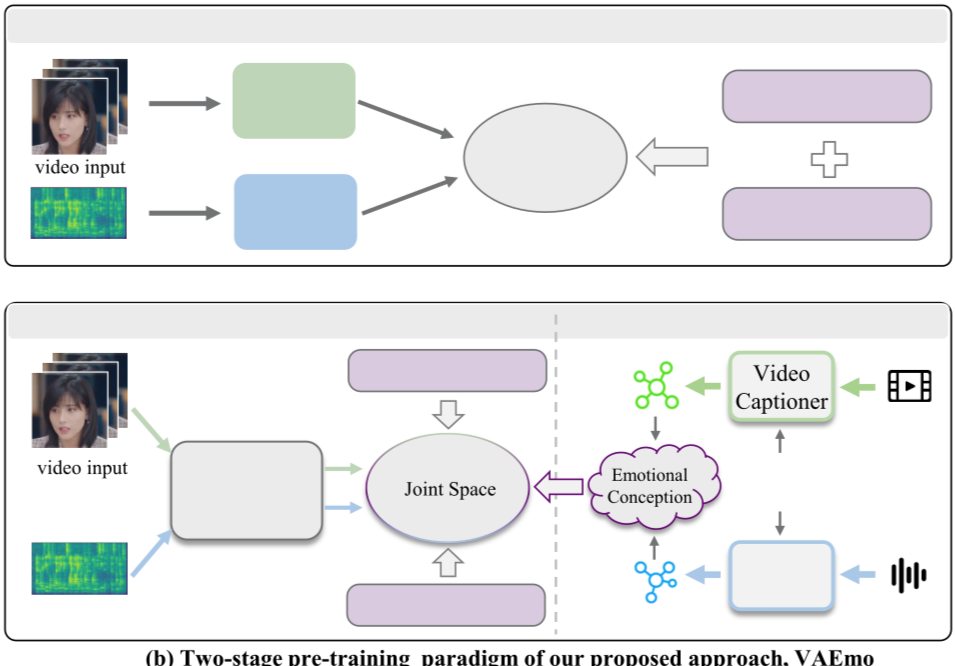
[논문 리뷰] VAEmo: Efficient Representation Learning for Visual-Audio ...
[논문 리뷰] Unsupervised Video Highlight Detection by Learning from Audio ...
[논문 리뷰] Audio-Visual Class-Incremental Learning for Fish Feeding ...
[논문 리뷰] Enhancing Video Music Recommendation with Transformer-Driven ...
[논문 리뷰] MMS-LLaMA: Efficient LLM-based Audio-Visual Speech Recognition ...
[논문 리뷰] Audio-Visual Compound Expression Recognition Method based on ...
[논문 리뷰] Learning to Visually Localize Sound Sources from Mixtures ...
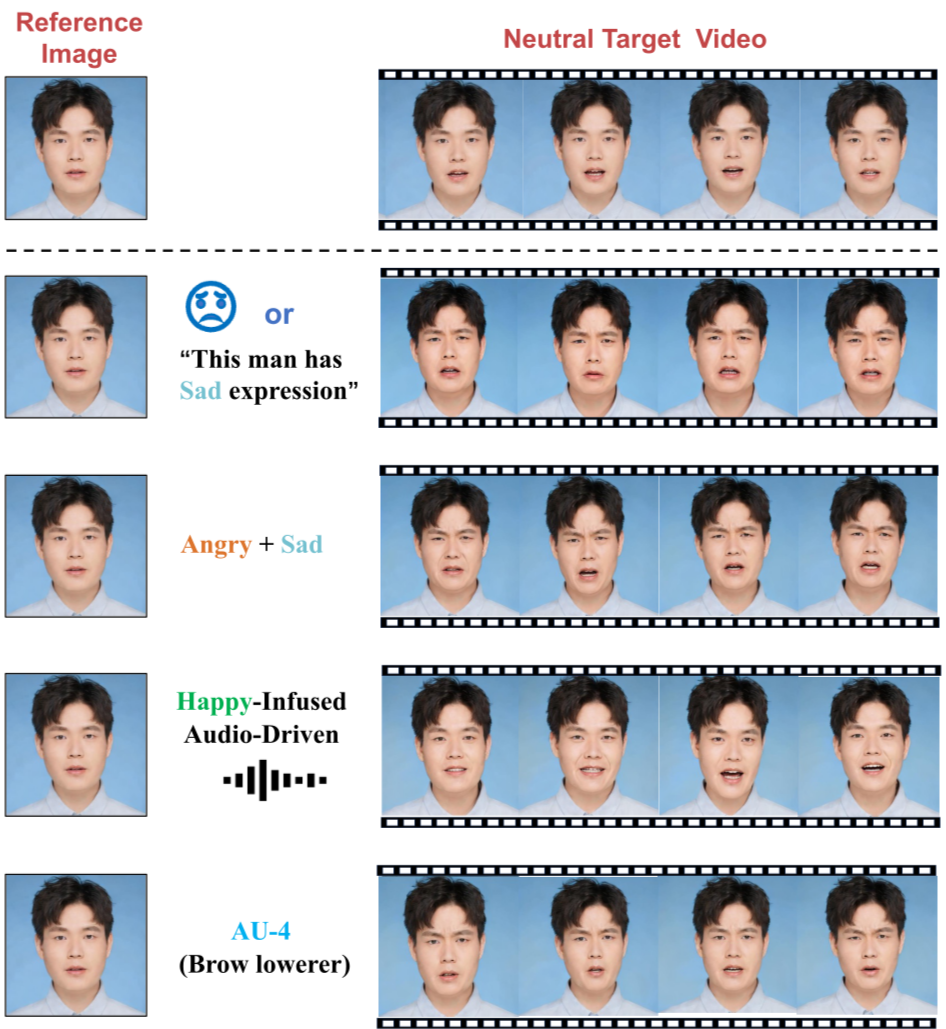
[논문 리뷰] MoEE: Mixture of Emotion Experts for Audio-Driven Portrait ...
GitHub - lzhangbj/ASVA: [ECCV 2024 Oral] Audio-Synchronized Visual ...
[논문 리뷰] Audio Explanation Synthesis with Generative Foundation Models
[논문 리뷰] Unsupervised Audio-Visual Segmentation with Modality Alignment
[논문 리뷰] Out-Of-Distribution Detection for Audio-visual Generalized Zero ...
[논문 리뷰] Zero-AVSR: Zero-Shot Audio-Visual Speech Recognition with LLMs ...
[논문 리뷰] AVCD: Mitigating Hallucinations in Audio-Visual Large Language ...
[논문 리뷰] Fork-Merge Decoding: Enhancing Multimodal Understanding in ...
[논문 리뷰] Enriching Multimodal Sentiment Analysis through Textual ...
[논문 리뷰] Audio-visual Controlled Video Diffusion with Masked Selective ...
[논문 리뷰] AVESFormer: Efficient Transformer Design for Real-Time Audio ...
[논문 리뷰] Empowering LLMs with Pseudo-Untrimmed Videos for Audio-Visual ...
[논문 리뷰] Learning Source Disentanglement in Neural Audio Codec
[논문 리뷰] AGAV-Rater: Adapting Large Multimodal Model for AI-Generated ...
[논문 리뷰] AV-Flow: Transforming Text to Audio-Visual Human-like Interactions
[논문 리뷰] Quality-Aware End-to-End Audio-Visual Neural Speaker Diarization
[논문 리뷰] The role of audio-visual integration in the time course of ...
[논문 리뷰] AVadCLIP: Audio-Visual Collaboration for Robust Video Anomaly ...
[논문 리뷰] Waveform-Logmel Audio Neural Networks for Respiratory Sound ...
[논문 리뷰] Audio-Visual Speaker Diarization: Current Databases, Approaches ...
[논문 리뷰] Measuring Sound Symbolism in Audio-visual Models
[논문 리뷰] Synthesizer Sound Matching Using Audio Spectrogram Transformers
[논문 리뷰] The Curse of Multi-Modalities: Evaluating Hallucinations of ...
[논문 리뷰] AV-EmoDialog: Chat with Audio-Visual Users Leveraging Emotional ...
[논문 리뷰] The Multimodal Information Based Speech Processing (MISP) 2025 ...
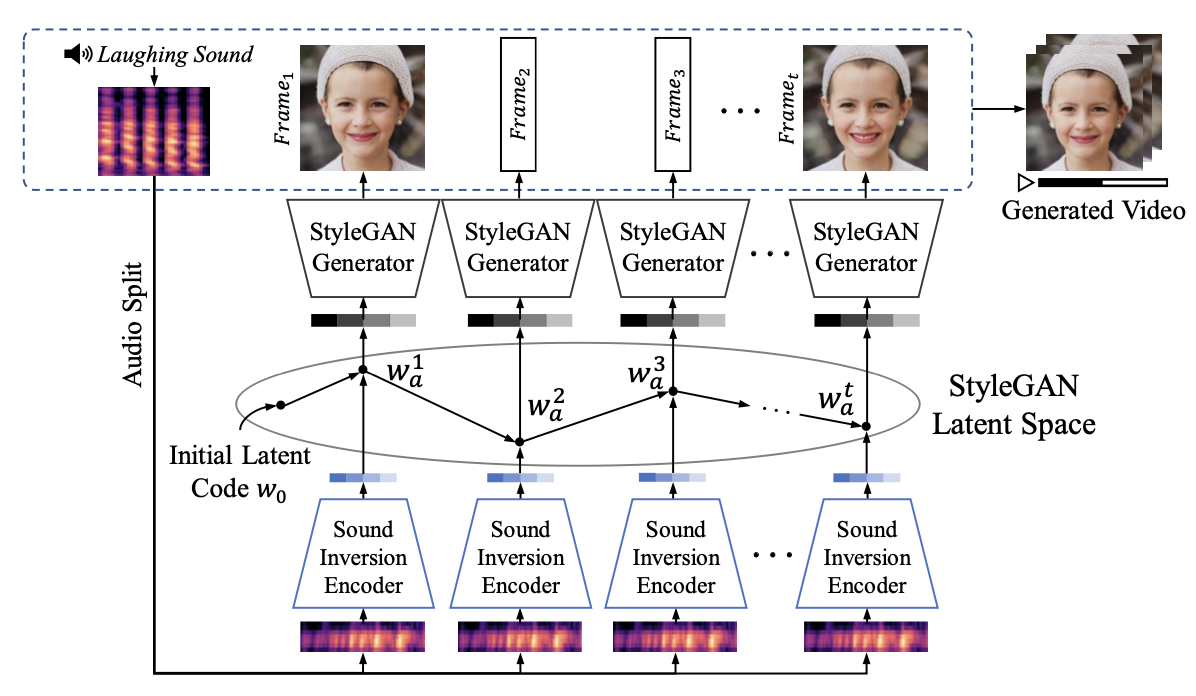
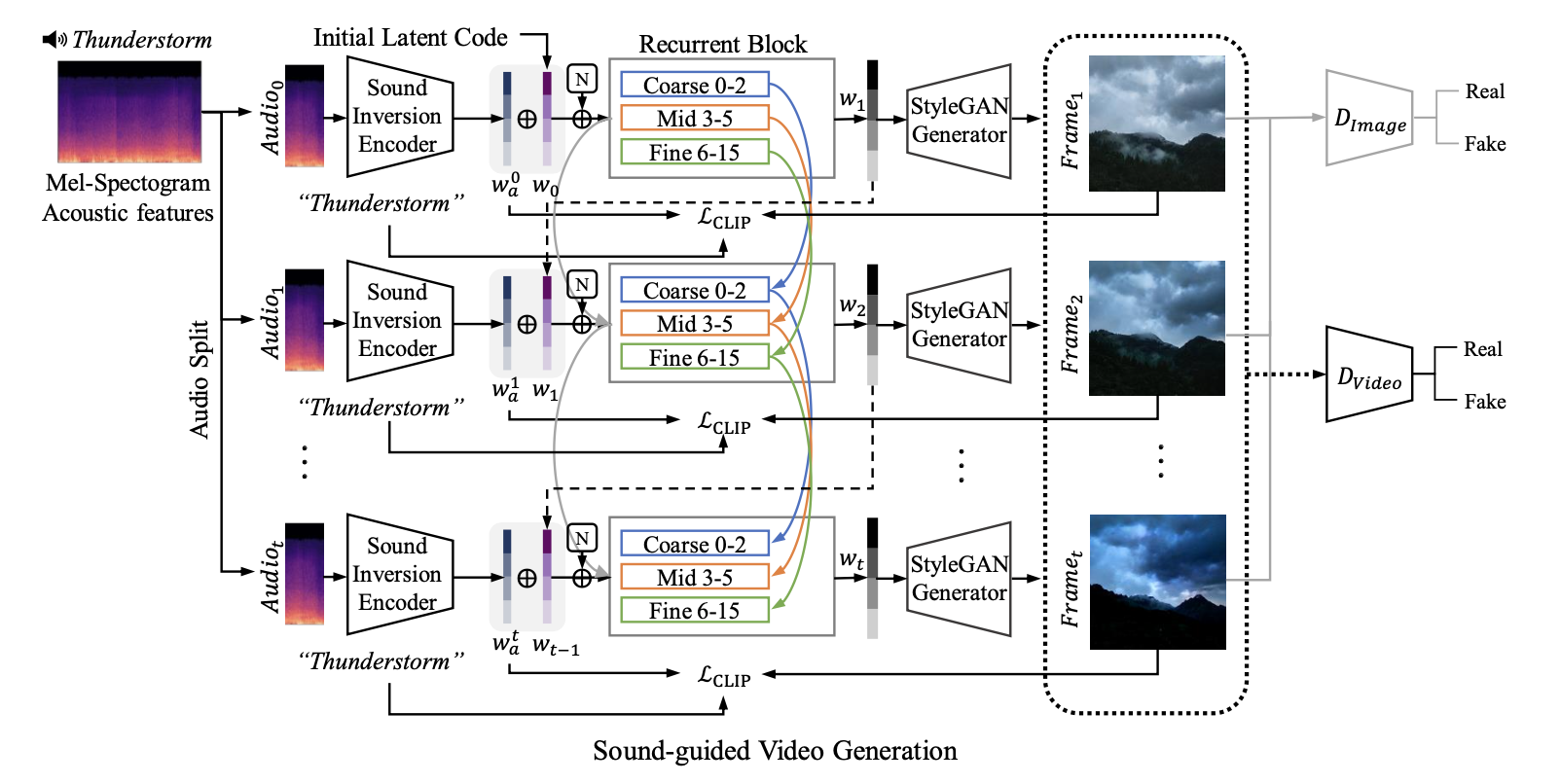
[논문 리뷰] Sound-guided Semantic Video Generation
[논문 리뷰] Audio-visual Generalized Zero-shot Learning the Easy Way
[논문 리뷰] Inconsistency-Aware Cross-Attention for Audio-Visual Fusion in ...
[논문 리뷰] AV-DTEC: Self-Supervised Audio-Visual Fusion for Drone ...
[논문 리뷰] Enhancing Audio-Visual Spiking Neural Networks through Semantic ...
[논문 리뷰] Incorporating Linguistic Constraints from External Knowledge ...
[논문 리뷰] SyncDiff: Synchronized Motion Diffusion for Multi-Body Human ...
[논문 리뷰] FauForensics: Boosting Audio-Visual Deepfake Detection with ...
[논문 리뷰] AVHBench: A Cross-Modal Hallucination Benchmark for Audio ...
12 minutes of Synchronized Visual Animations (Audio, Video & Stage ...
Sound visualization, audio waveform. Seamless loop animation with alpha ...
Audio wave Animation | Figma
Audio sync for animation - why it absolutely matters
Bright glowing animation of an equalizer with Sound waves of particles ...
Bright glowing animation visualization of a sound graphic element ...
Publications
[논문리뷰] Sound-guided Semantic Image Manipulation | by Chaewon Kim ...
Sound 관련 논문 리뷰
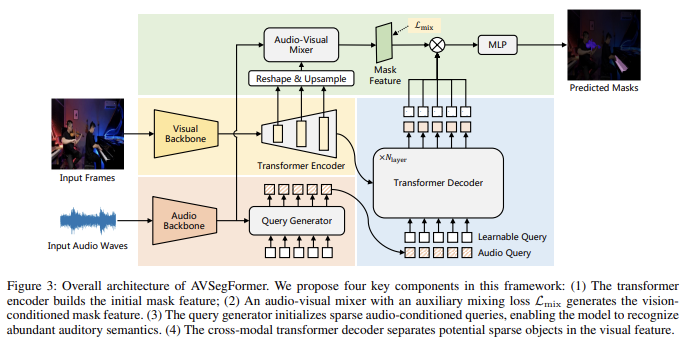
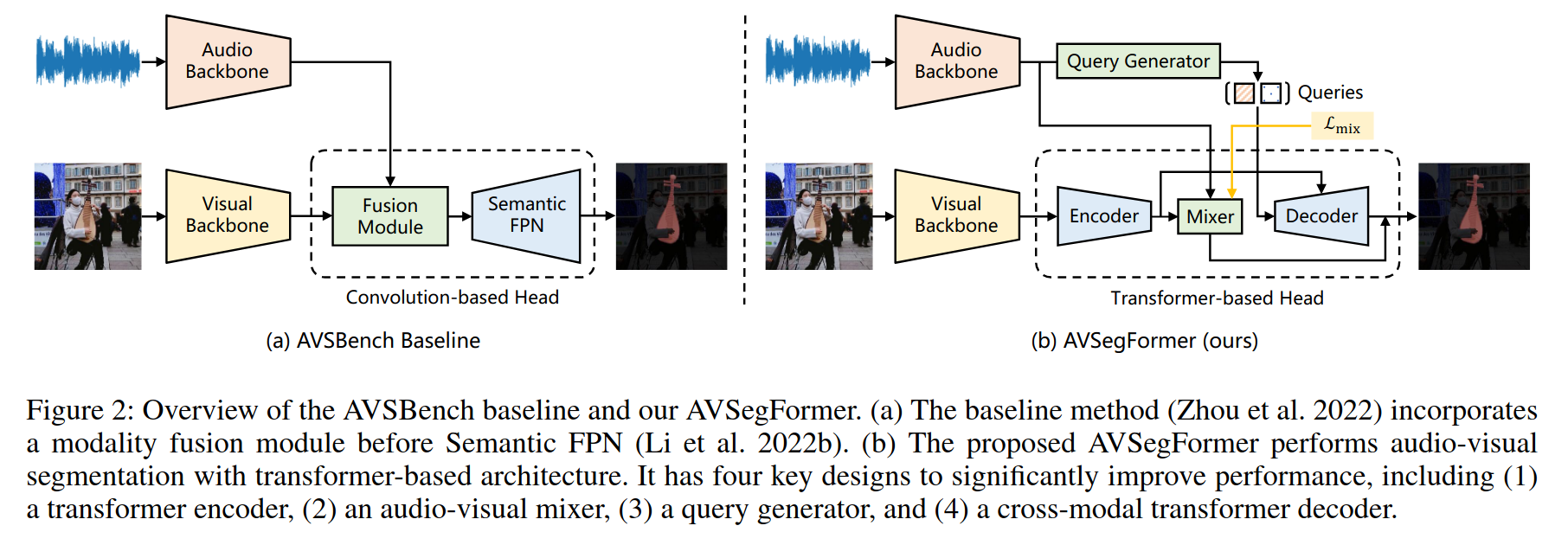
AVSegFormer: Audio-Visual Segmentation with Transformer 논문 리뷰
-Animation and Audio Synchronization | Download Scientific Diagram
Based on this image's title: “[논문 리뷰] Audio-Synchronized Visual Animation”
![[논문 리뷰] Audio-Synchronized Visual Animation](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/audio-synchronized-visual-animation-0.png)