Performance issues with high level API · Issue #232 · abetlen/llama-cpp ...
Add performance optimization example · Issue #26 · abetlen/llama-cpp ...
Cannot build with CUDA on Win11 · Issue #1352 · abetlen/llama-cpp ...
[WinError 193] When trying to run the high level API example with ...
Implement `stream` option in high-level api · Issue #1 · abetlen/llama ...
How to use high-level python API to get base logits of input? · Issue ...
how to run model using LlamaCpp from Langchain with gpu · Issue #199 ...
LLama cpp problem ( gpu support) · Issue #509 · abetlen/llama-cpp ...
loading error in llama cpp /llama2 · Issue #653 · abetlen/llama-cpp ...
Fail to install llama-cpp-python · Issue #738 · abetlen/llama-cpp ...
CMake Error: CMAKE_C_COMPILER not set · Issue #749 · abetlen/llama-cpp ...
50% performance when doing inference with web server. · abetlen llama ...
llama-cpp-python not using GPU on m1 · Issue #756 · abetlen/llama-cpp ...
CUDA llama-cpp-python build failed. · Issue #1986 · abetlen/llama-cpp ...
llama : support reranking API endpoint and models · Issue #8555 · ggml ...
Unable to Use GPU with llama-cpp-python on Jetson Orin · Issue #1779 ...
Implement caching for evaluated prompts · Issue #44 · abetlen/llama-cpp ...
Llava/CLIP Models Not Loading Properly · Issue #946 · abetlen/llama-cpp ...
How to install with GPU support via cuBLAS and CUDA · Issue #250 ...
Incredibly slow response time · Issue #49 · abetlen/llama-cpp-python ...
Add support for llama.cpp --n_gpu_layers · Issue #207 · abetlen/llama ...
Langchain OpenAI HTTP response code 422 · Issue #187 · abetlen/llama ...
ModuleNotFoundError: No module named 'llama_cpp' · Issue #192 · abetlen ...
Documentation of server command line parameters. · Issue #635 · abetlen ...
CMAKE 'not a git repo' error · Issue #380 · abetlen/llama-cpp-python ...
Cuda 12.8 compatibility Issue · Issue #2001 · abetlen/llama-cpp-python ...
CUDA Forward Compatibility on non supported HW · Issue #234 · abetlen ...
llama-cpp-python not using GPU on colab · Issue #1535 · abetlen/llama ...
How can I configure the parameters of llama · Issue #1669 · abetlen ...
AssertionError when using LLama · Issue #643 · abetlen/llama-cpp-python ...
LlamaCPP Usage · Issue #1035 · abetlen/llama-cpp-python · GitHub
Performance degradation running with half a socket in CPU system ...
No cuBLAS · Issue #101 · abetlen/llama-cpp-python · GitHub
Issue with Installing llama-cpp-python 0.3.7: Dependency Problems with ...
import llama_cpp ERROR · Issue #94 · abetlen/llama-cpp-python · GitHub
Llama 3 Double BOS · Issue #1501 · abetlen/llama-cpp-python · GitHub
mistral 7b model · Issue #764 · abetlen/llama-cpp-python · GitHub
How to use GPU? · Issue #576 · abetlen/llama-cpp-python · GitHub
Cannot build wheel · Issue #1538 · abetlen/llama-cpp-python · GitHub
Different result between Llama-cpp-python and Llama-cpp · abetlen llama ...
could not find llama.dll · Issue #1150 · abetlen/llama-cpp-python · GitHub
A step by step guide to running a local LLM with llama-cpp-python ...
Huge performance discrepency between llama-cpp-python and llama.cpp ...
RAG with llama.cpp and external API services
Trying to load llm model using llama cpp python with GPU support fails ...
Benchmark · abetlen llama-cpp-python · Discussion #51 · GitHub
Significant loss of performance from v0.2.28 to v0.2.29 on Mac Metal ...
Problem to install llama-cpp-python on Windows 10 with GPU NVidia ...
[Investigate] Custom `llama.dll` Dependency Resolution Issues on ...
pip install llama-cpp-python with CMAKE_ARGS="-DLLAMA_CUBLAS=on" on ...
GitHub - shimasakisan/llama-cpp-ui: A web API and frontend UI for llama ...
Reach native speed with MacOS llama.cpp container inference | Red Hat ...
Low Level API | node-llama-cpp
Accelerating Llama.cpp Performance with AMD Ryzen AI 300
llama.cpp · Hugging Face
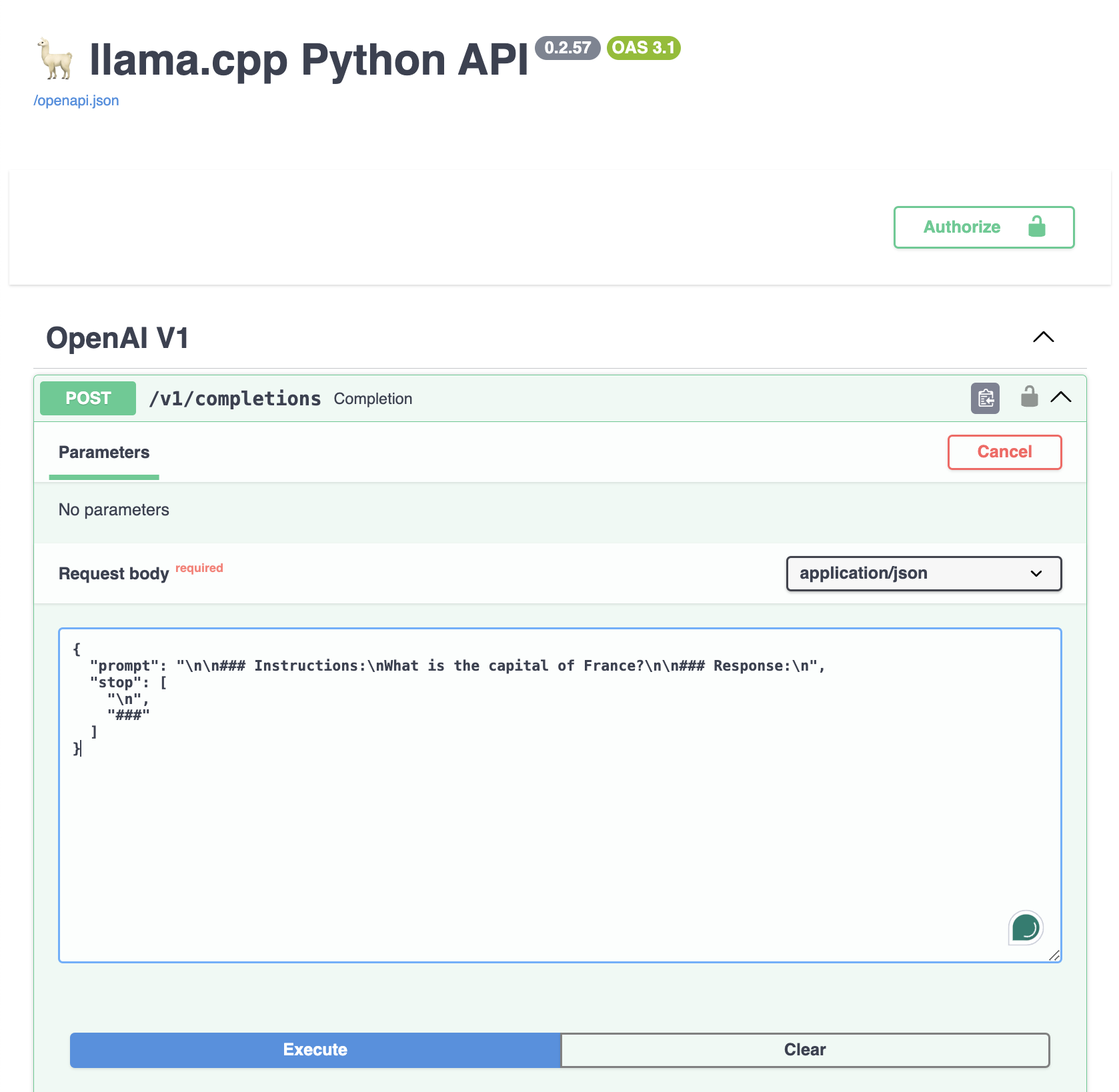
llama-cpp-python/examples/high_level_api/high_level_api_embedding.py at ...
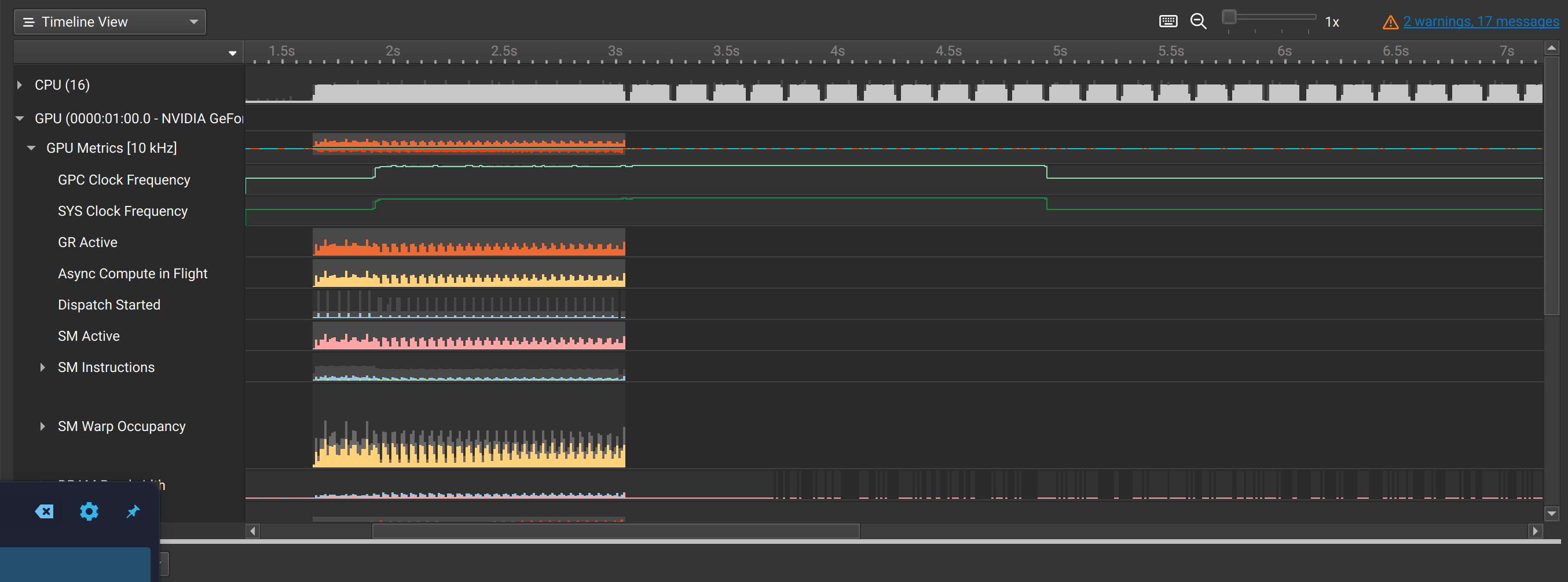
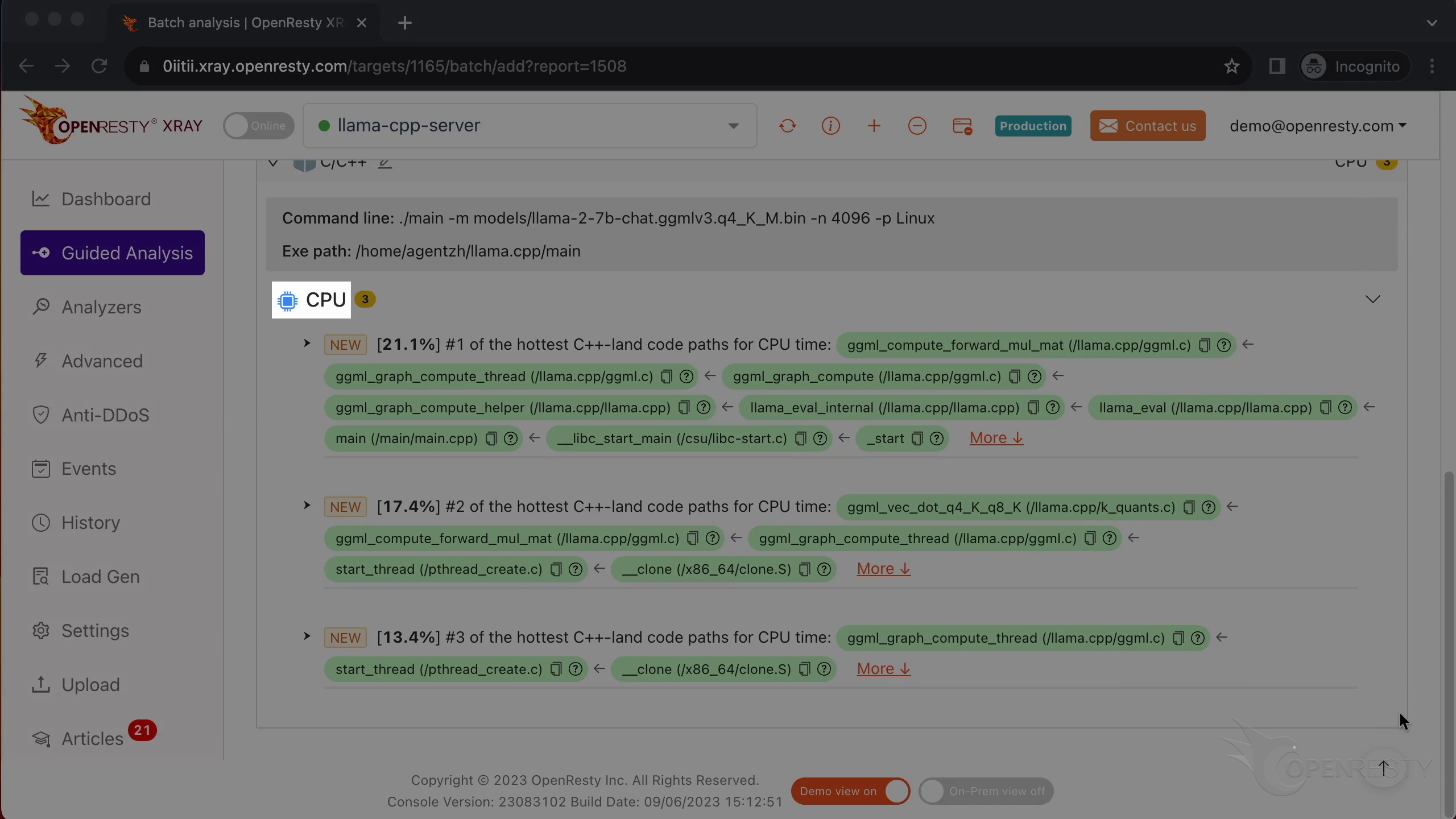
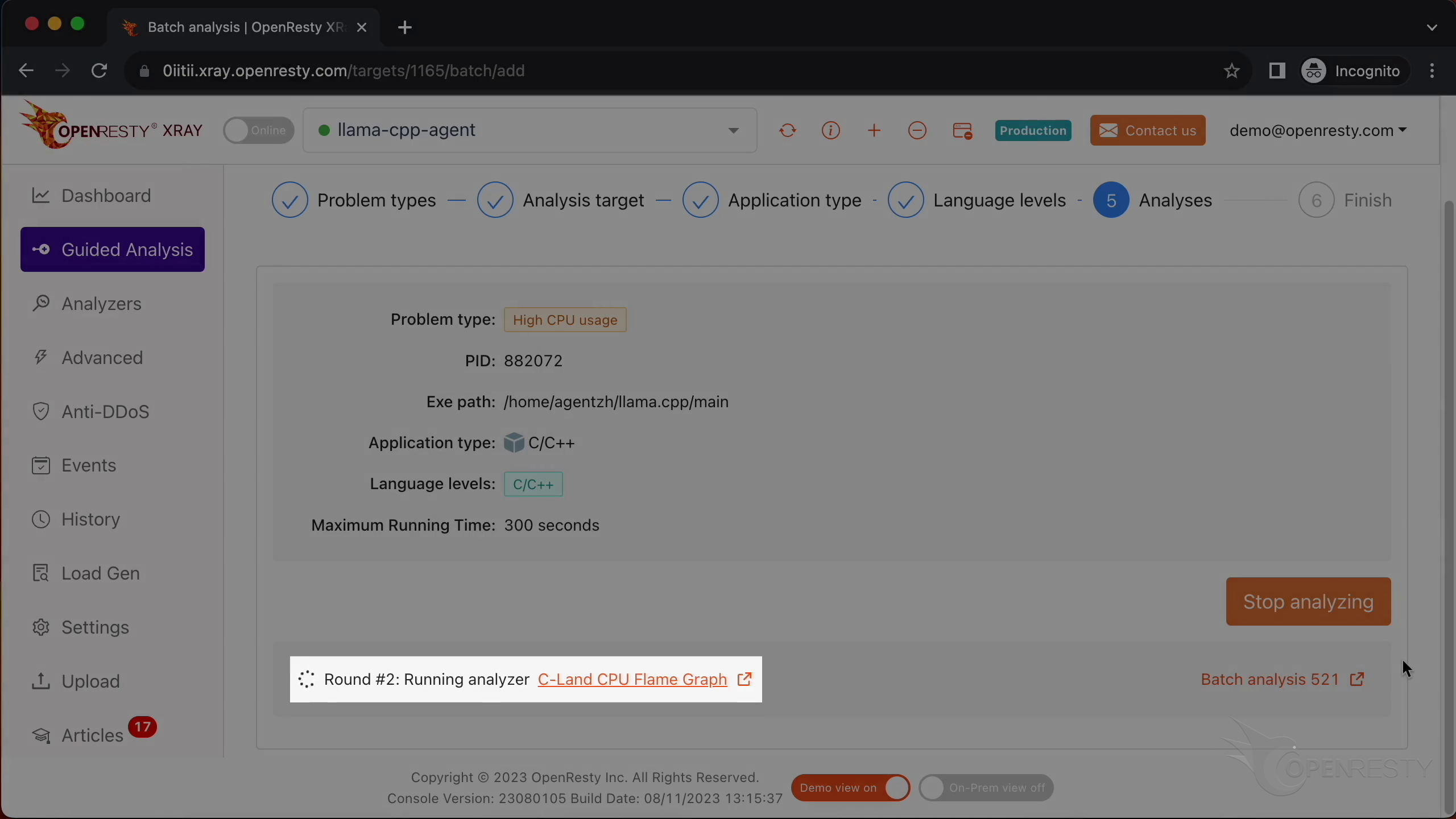
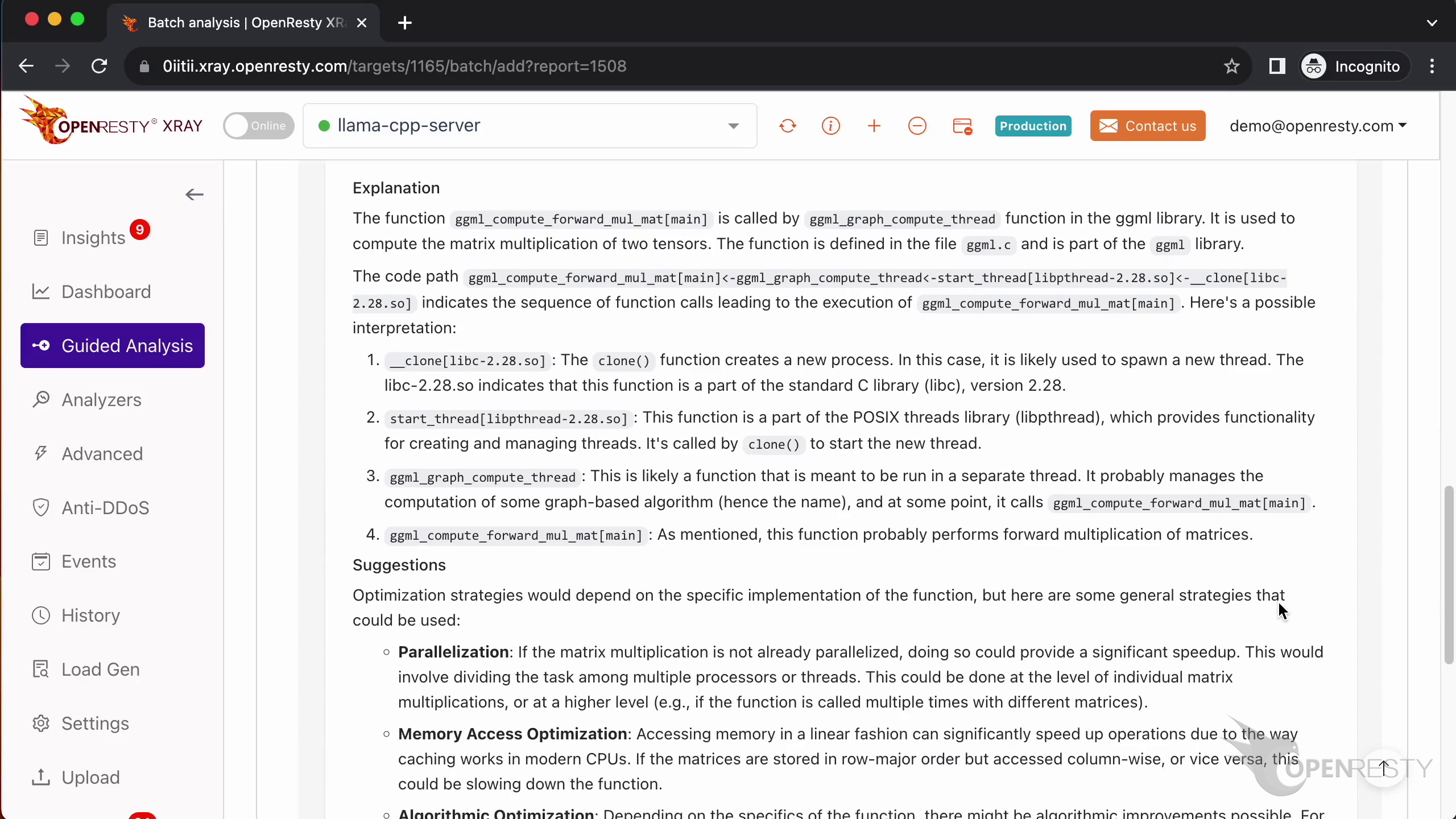
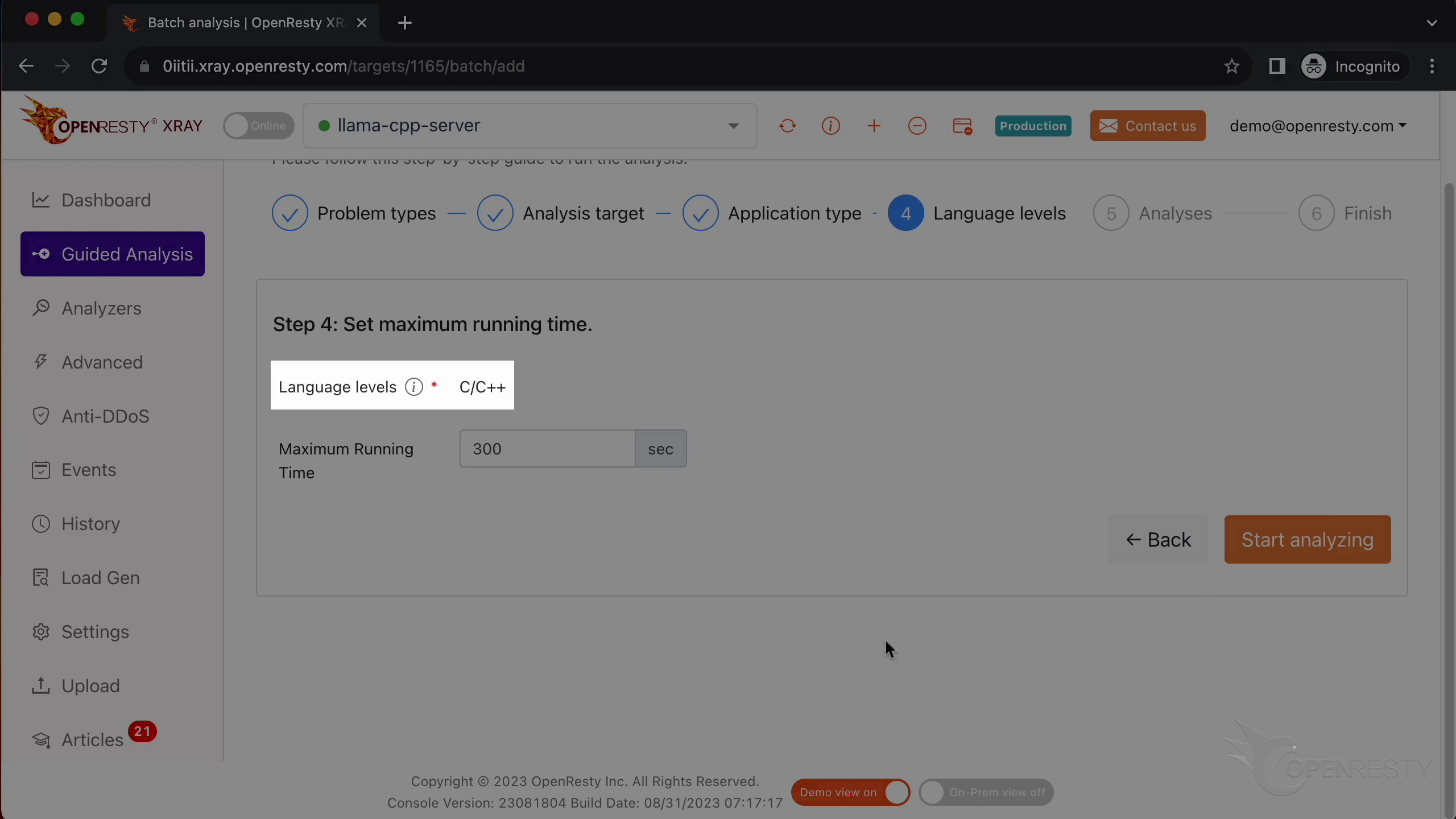
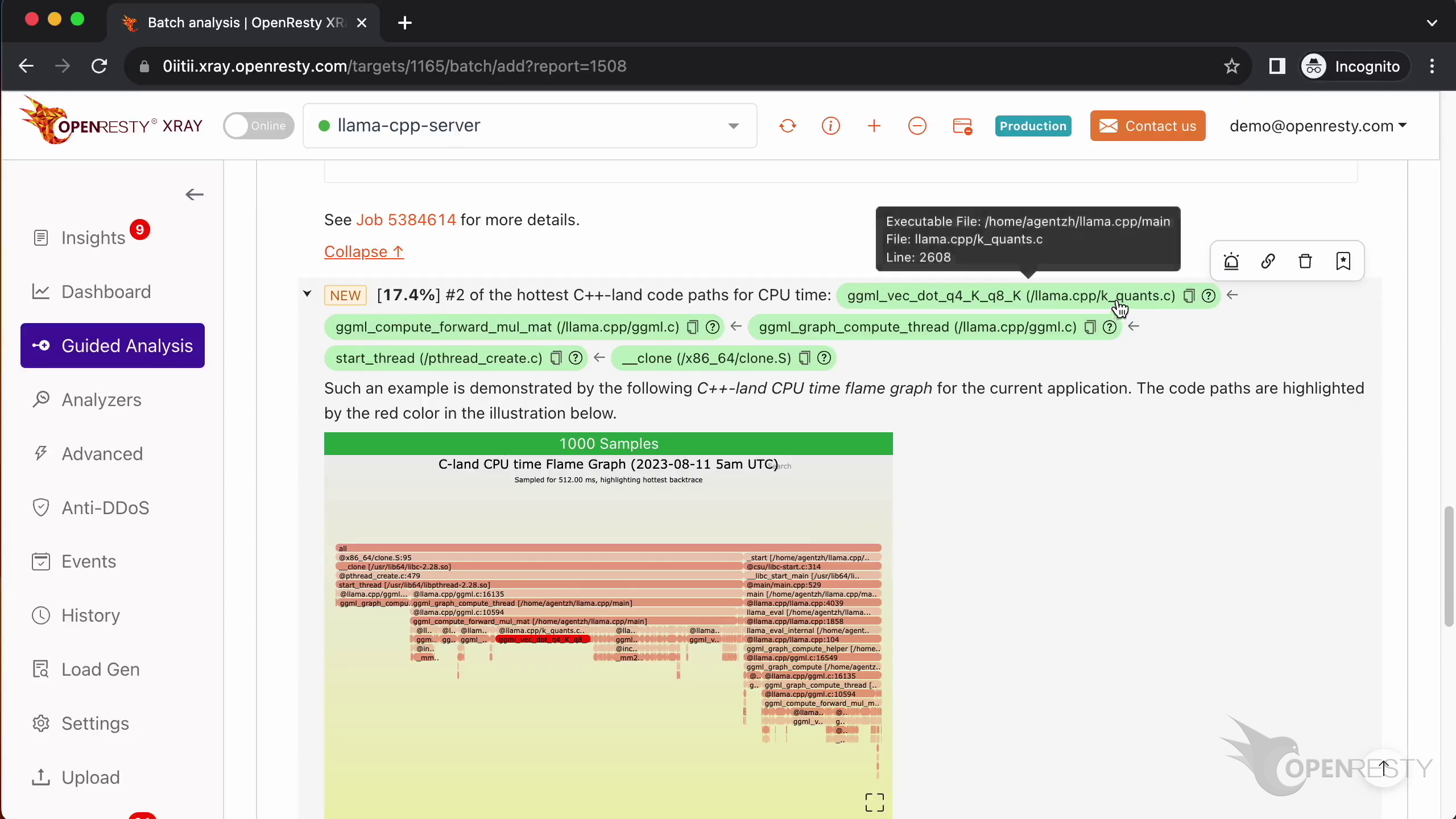
How CPU time is spent inside llama.cpp + LLaMA2 (using OpenResty XRay ...
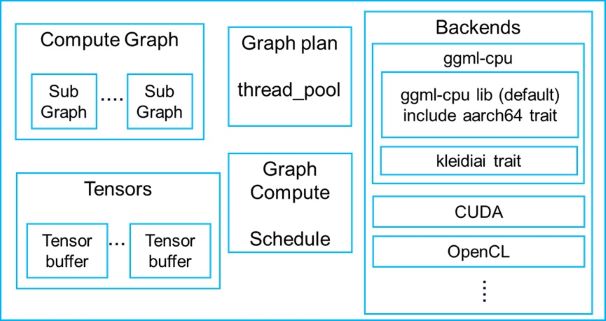
Explore llama.cpp architecture and the inference workflow | Arm ...
Failed Building Wheel for llama-cpp-python runing on Python 3.10.9 ...
GPU memory not cleaned up after off-loading layers to GPU using `n_gpu ...
Building and installing llama_cpp from source for RTX 50 Blackwell GPU ...
llama.cpp: loading model ......terminate called after throwing an ...
Steps to Build and Install llama-cpp-python 0.3.7 w/CUDA on Windows 11 ...
Build Failure When Enabling KleidiAI on ARMv9 in llama-cpp-python ≥ 3. ...
How to Run Local AI on Android with llama.cpp and Termux
Unable to install llama-cpp-python Package in Python - Wheel Building ...
The llama-cpp-python installed using the following method cannot find ...
llama-cpp-python compile script for windows (working cublas example for ...
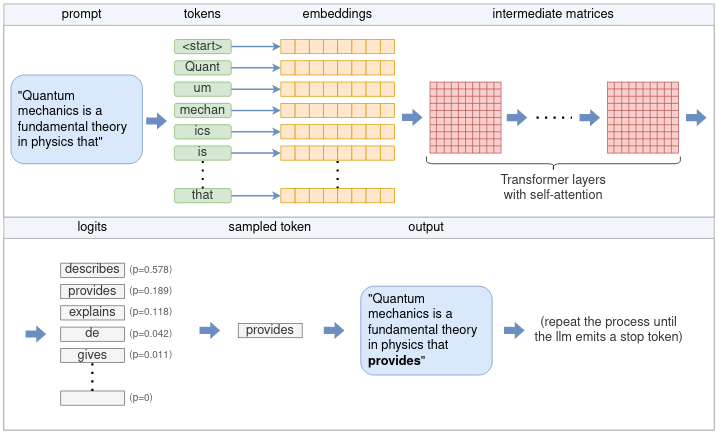
Understanding how LLM inference works with llama.cpp
How to build the llamacpp's .so file separately and then pass it in the ...
"llama.cpp error: 'error loading model architecture: unknown model ...
A brief review of llama.cpp, llama-cpp-python, and LLamaSharp | by ...
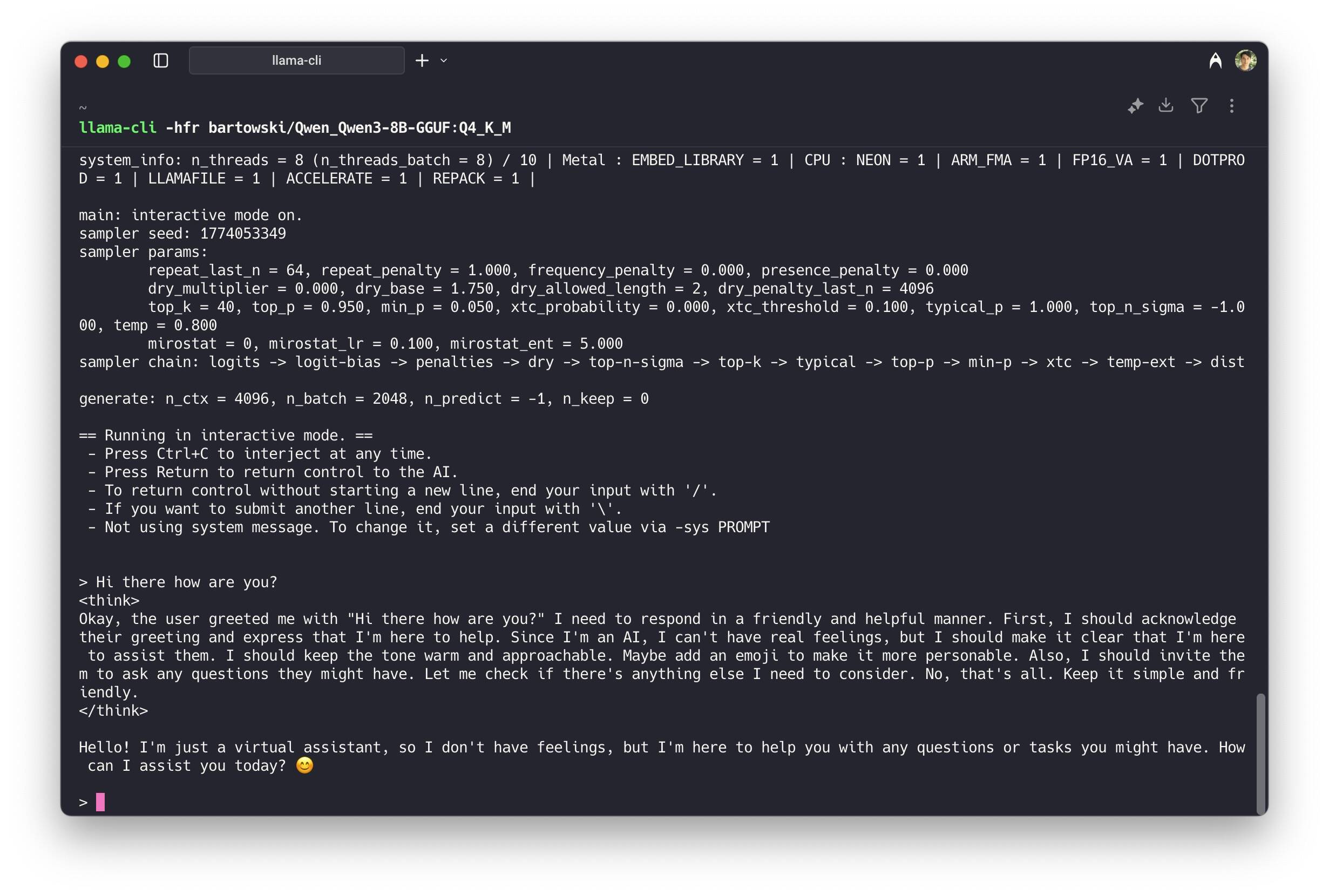
Engineer's Guide to Local LLMs with LLaMA.cpp on Linux - DEV Community
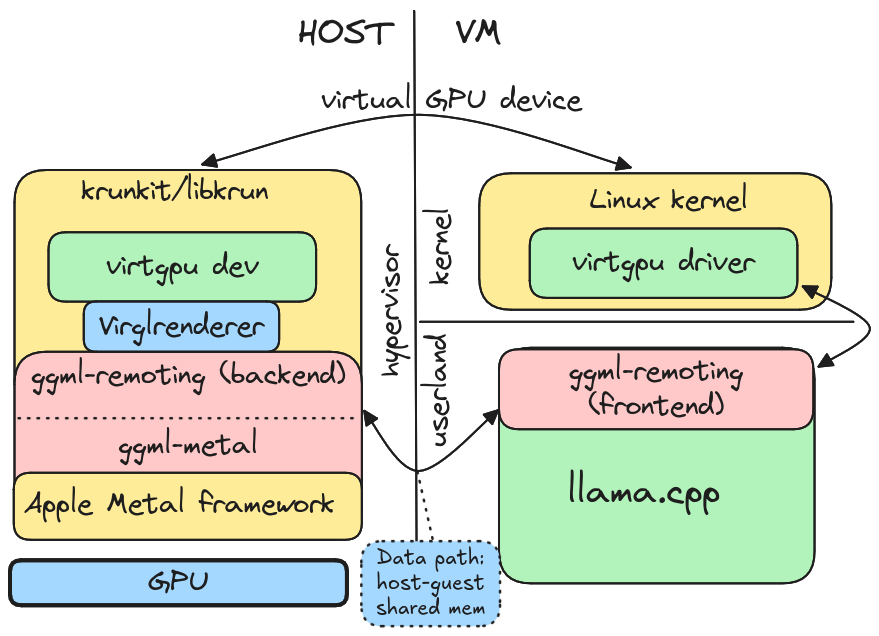
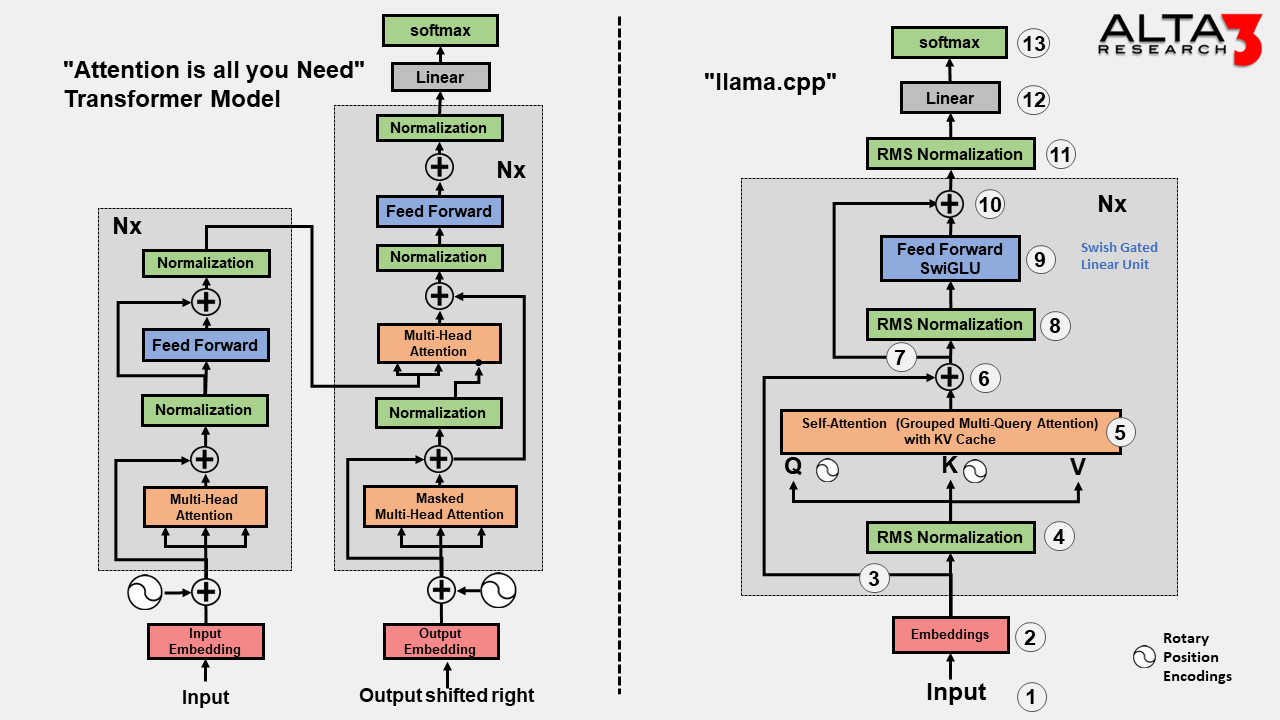
llama.cpp Architecture :: Alta3 Blogs
Overview | abetlen/llama-cpp-python | Zread
Llama.cpp 上手实战指南 - HY's Blog
Mastering the Llama.cpp API: A Quick Guide
How to run LLMs on PC at home using Llama.cpp • The Register
GitHub - MarshallMcfly/llama-cpp: LLM inference in C/C++
Getting Started | abetlen/llama-cpp-python | DeepWiki
GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp
Llama.cpp Inference Archives - PyImageSearch
Llama.cpp chatglm.cpp Windows on Snapdragon
CPU 时间是如何耗费在 llama.cpp 程序和 LLaMA2 模型内部的(使用 OpenResty XRay) - OpenResty 官方博客
llama-cpp-python Insights
解开封印!加倍 LLM 推理吞吐: ggml.ai 与 llama.cpp - 知乎
Llama.cpp API: model loading. | Medium
llama.cpp CPU optimization : r/LocalLLaMA
Ubuntu llama 2搭建及部署,同时附问题与解决方案_llama ubuntu-CSDN博客
llama.cpp Introduction for Beginners - YouTube