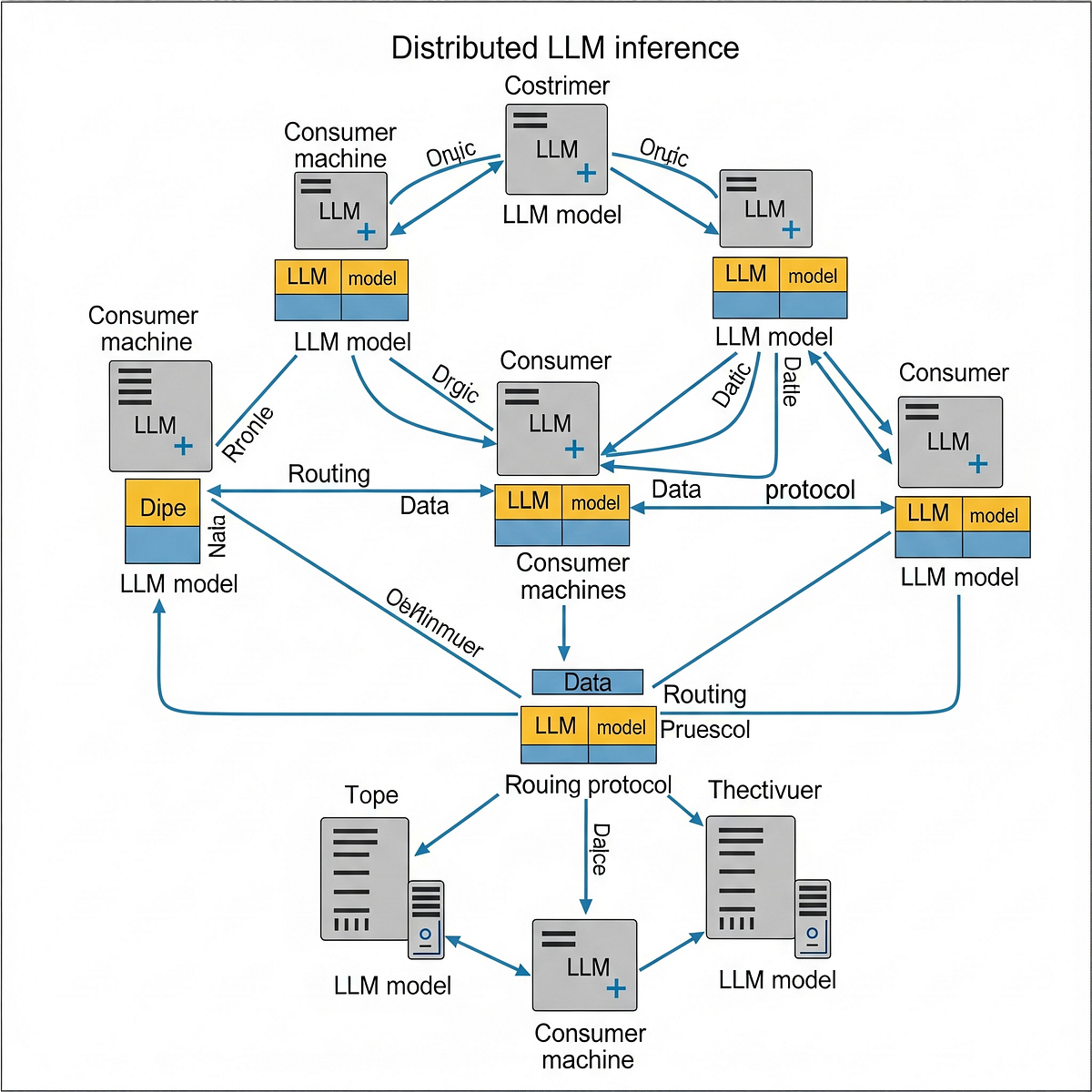
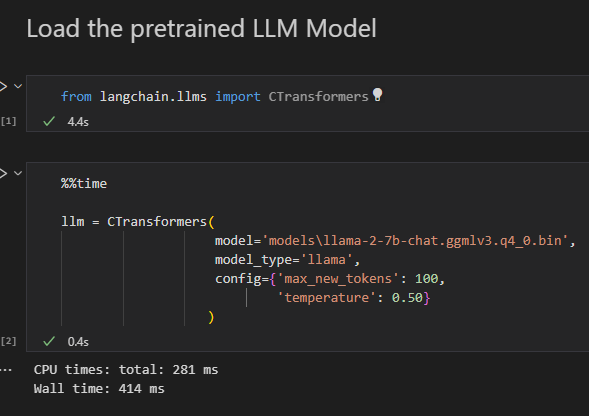
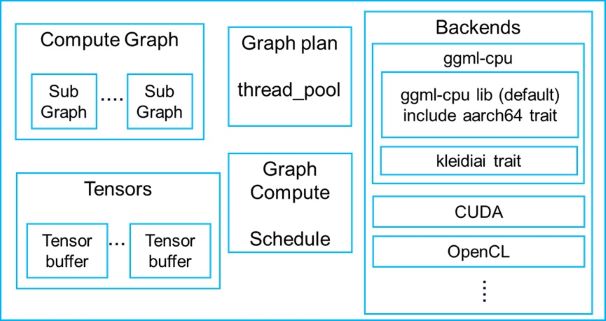
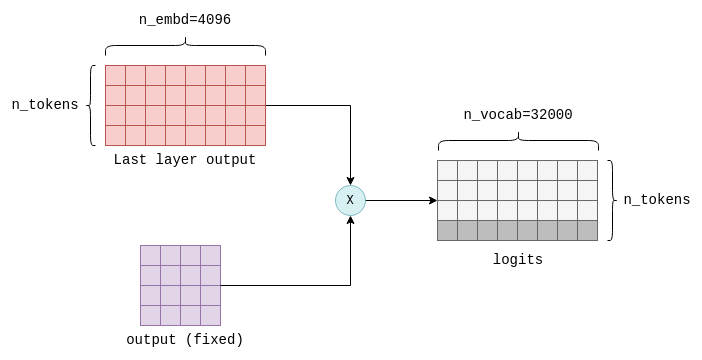
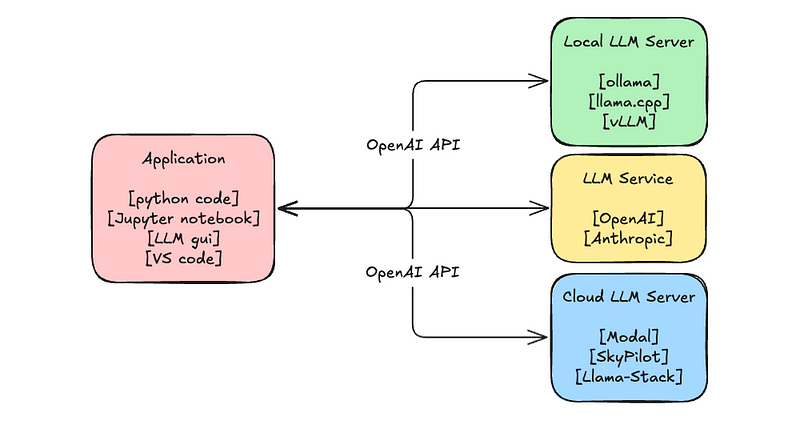
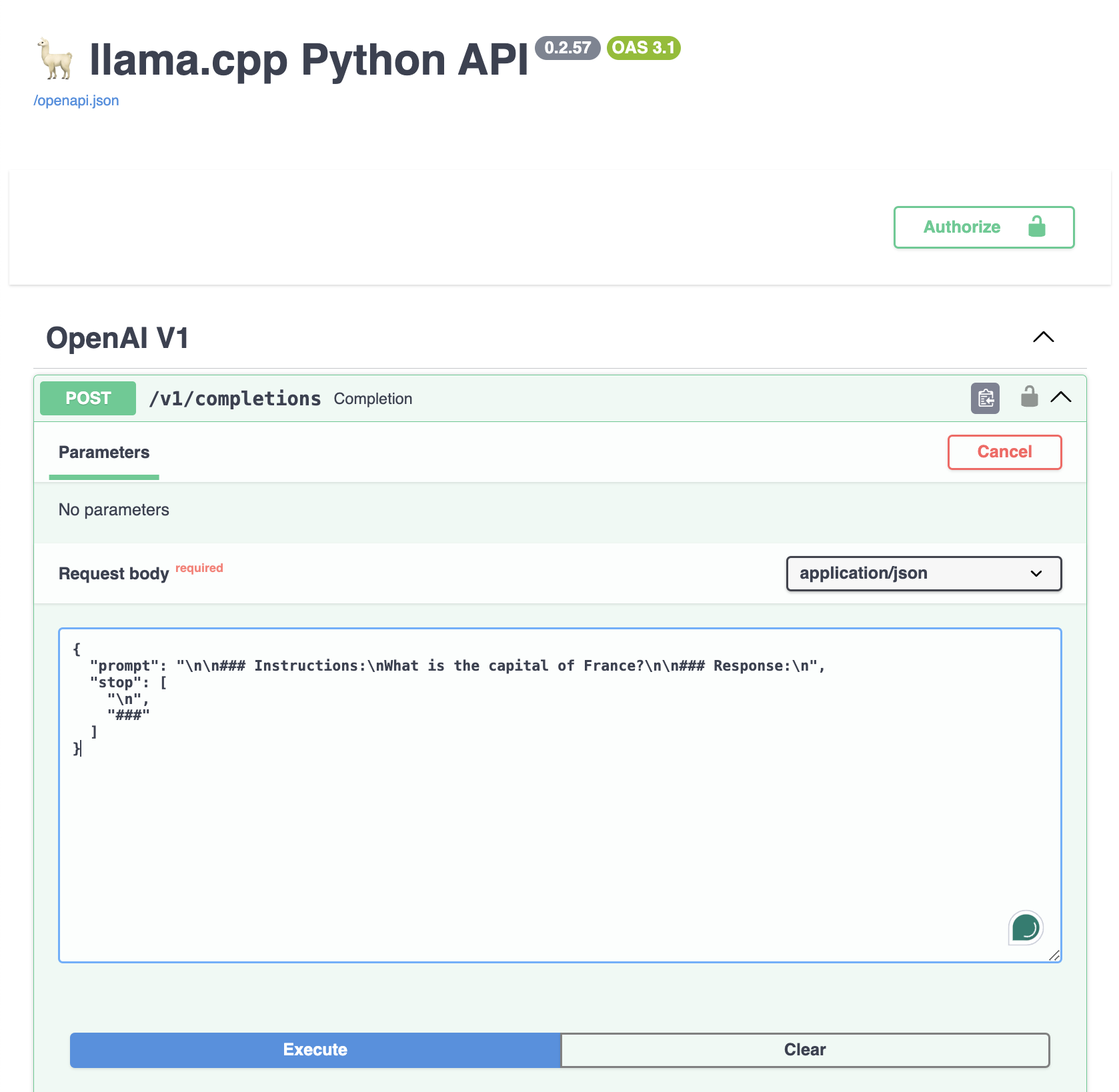
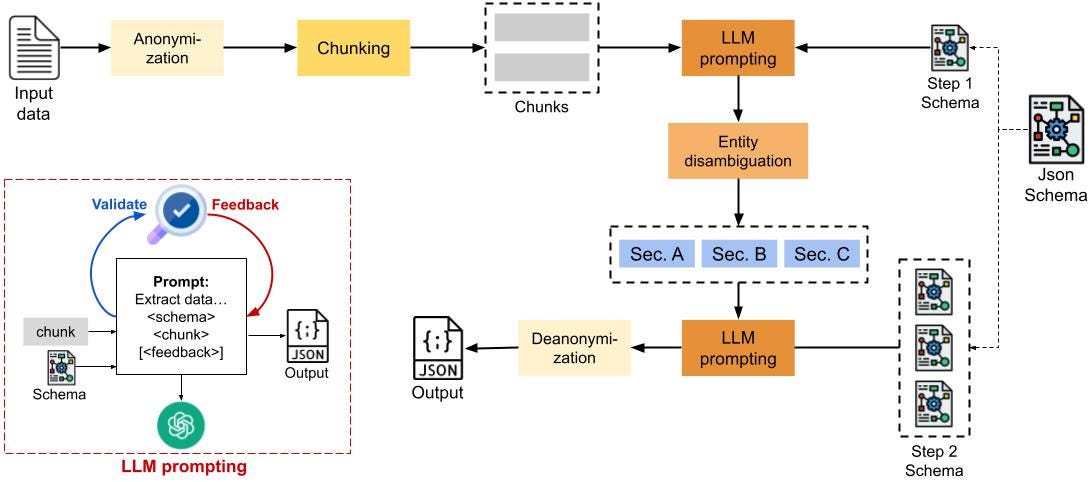
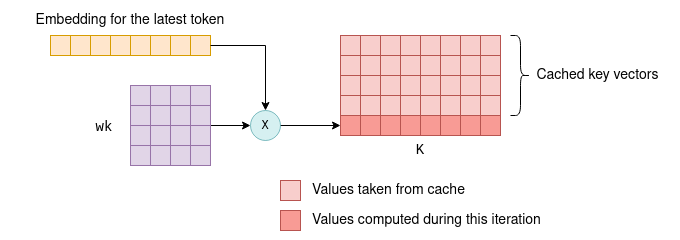
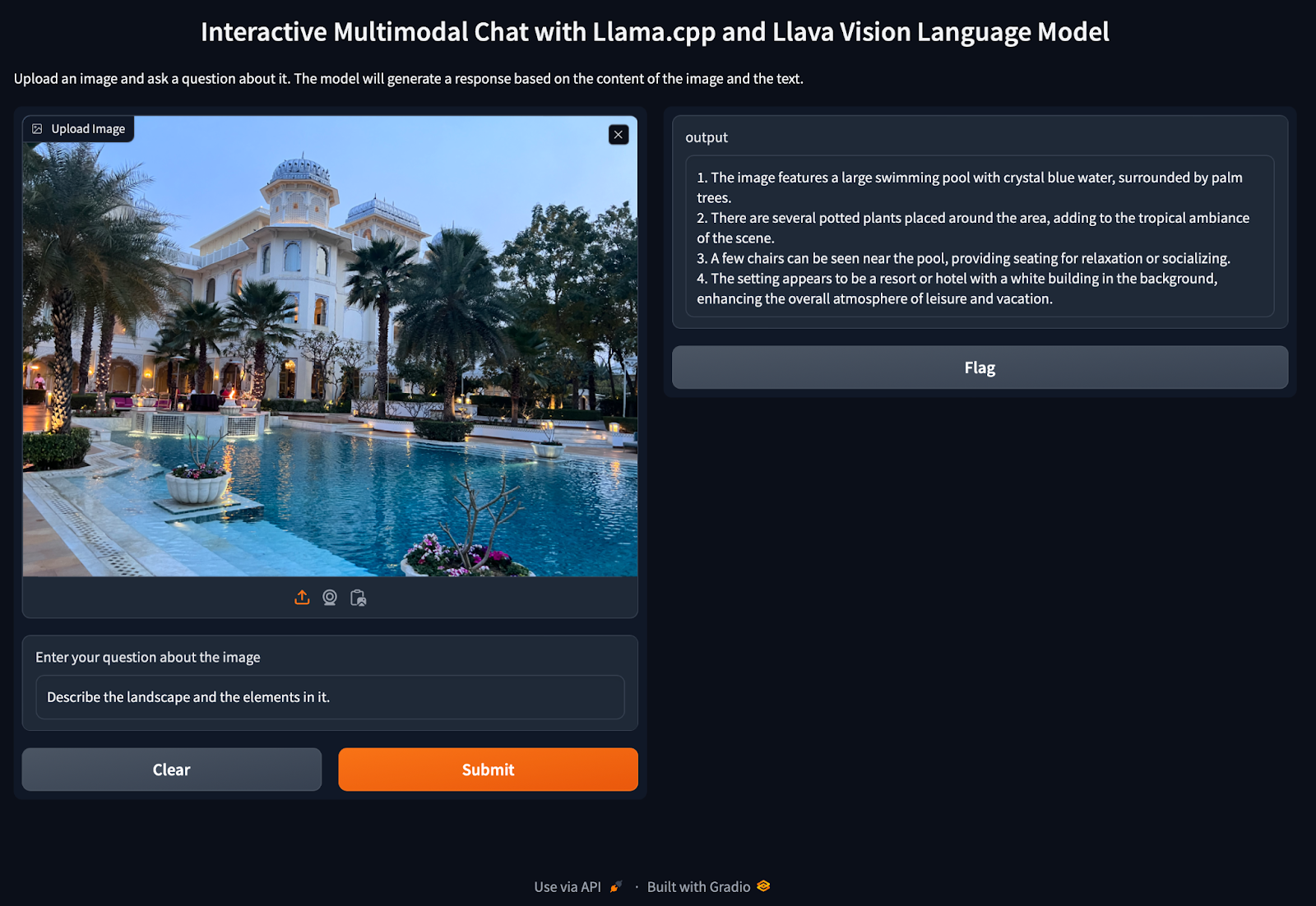
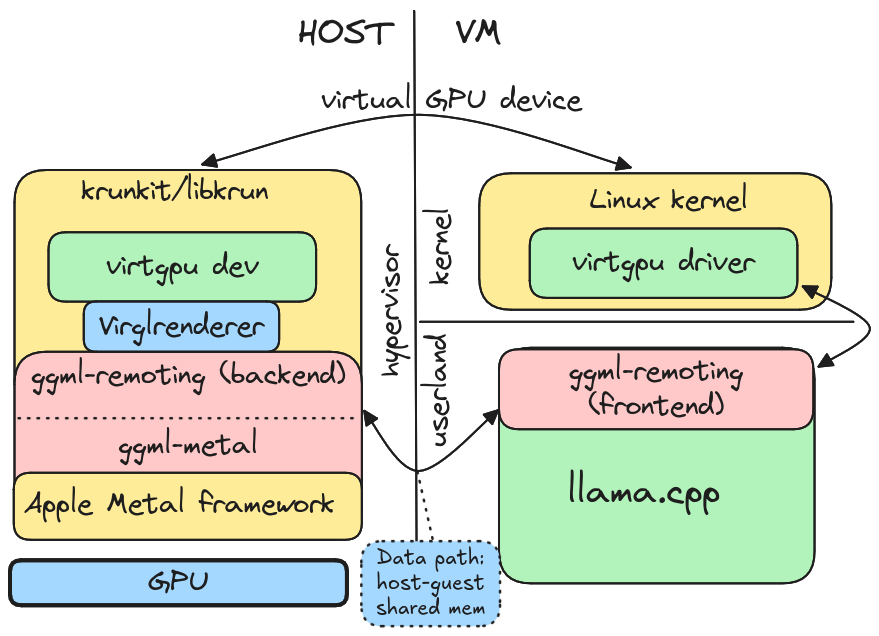
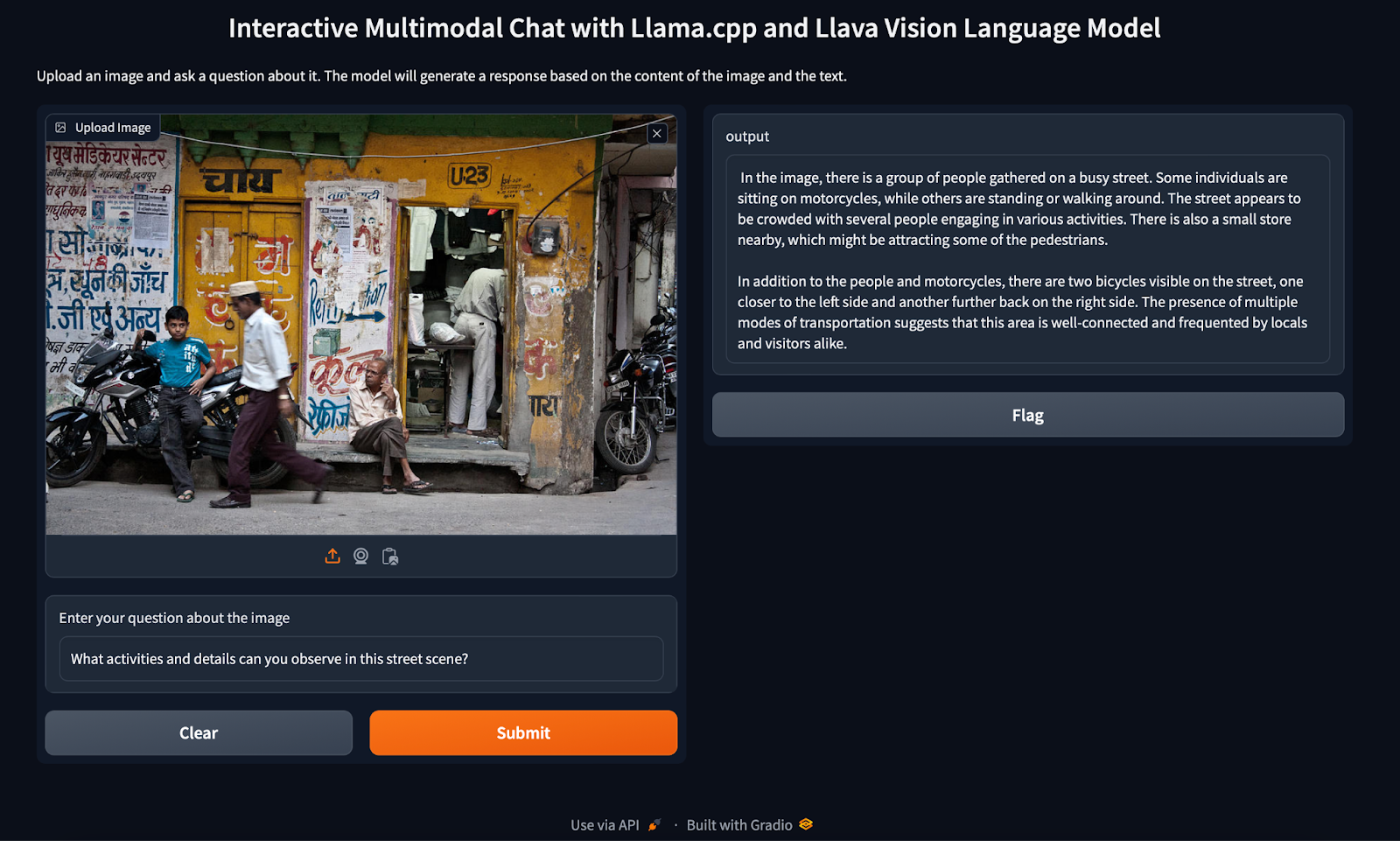
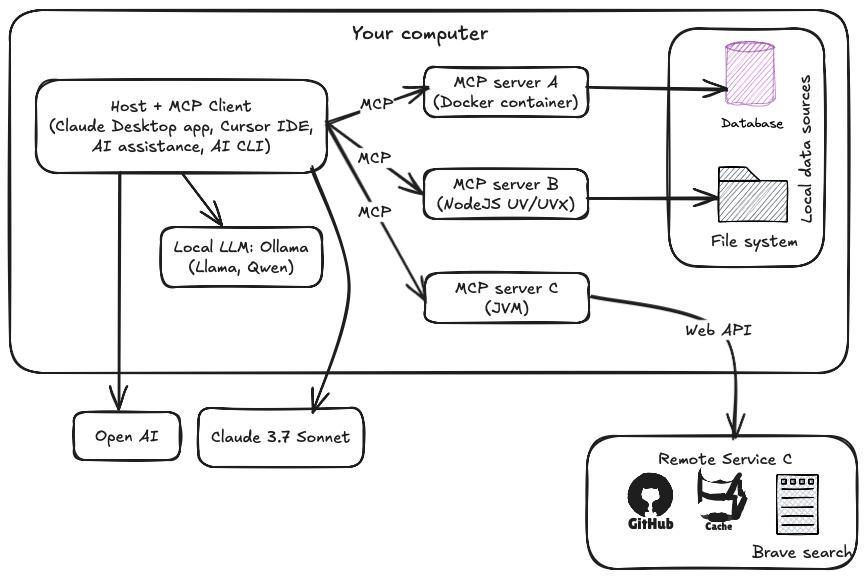
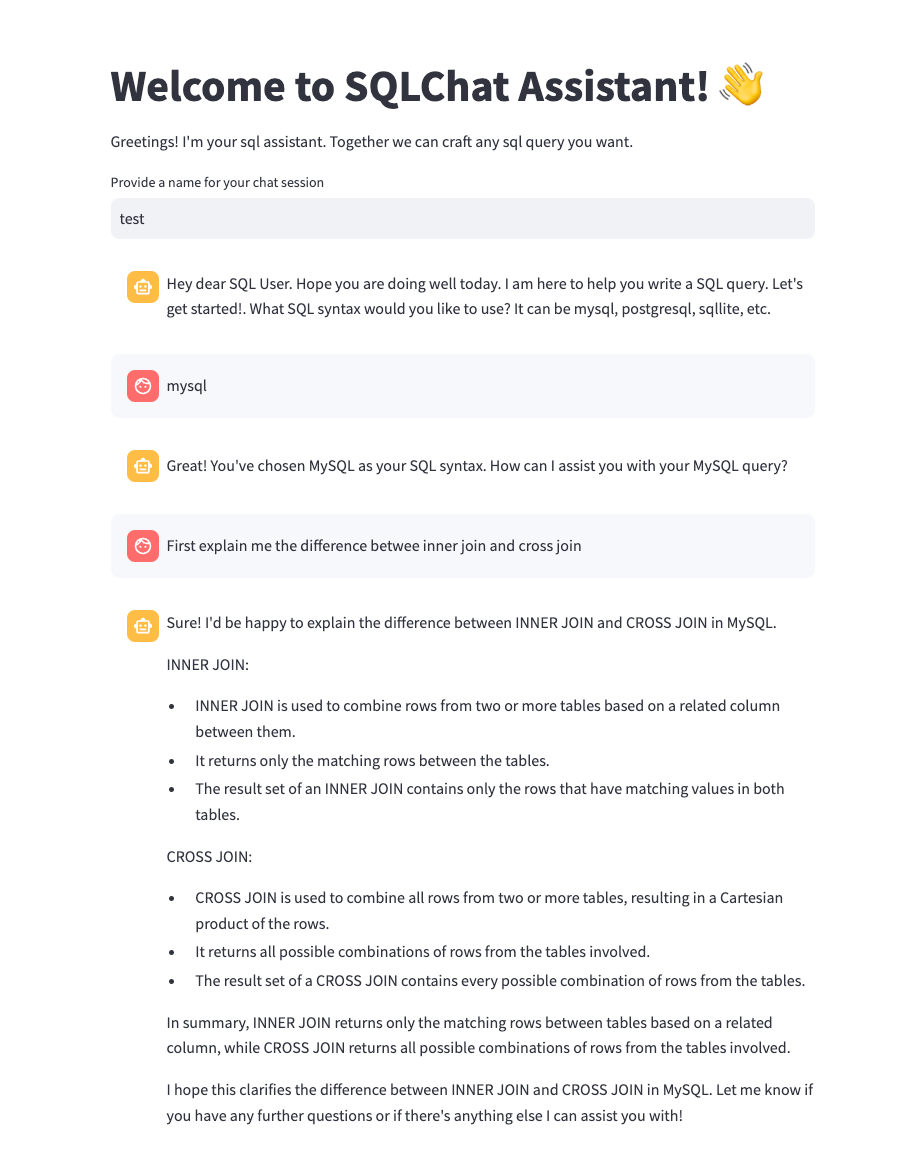
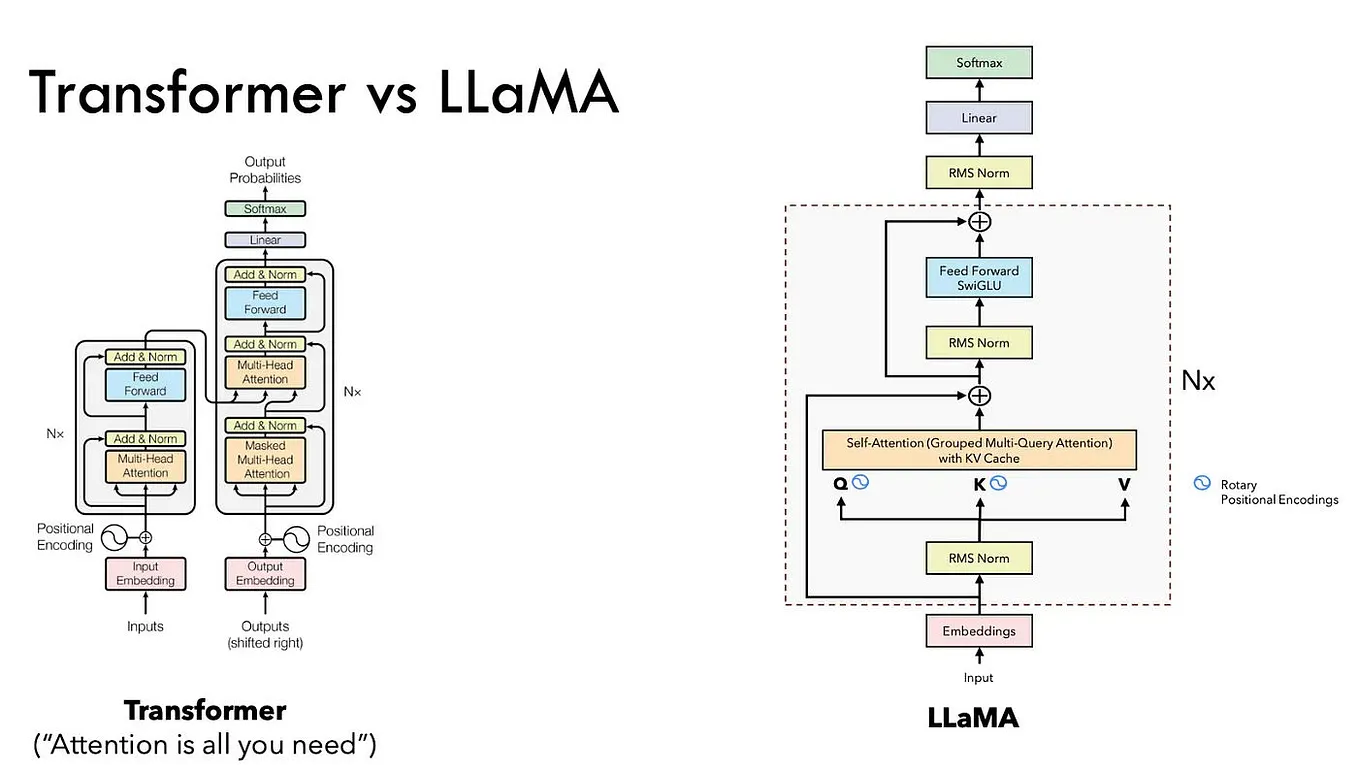
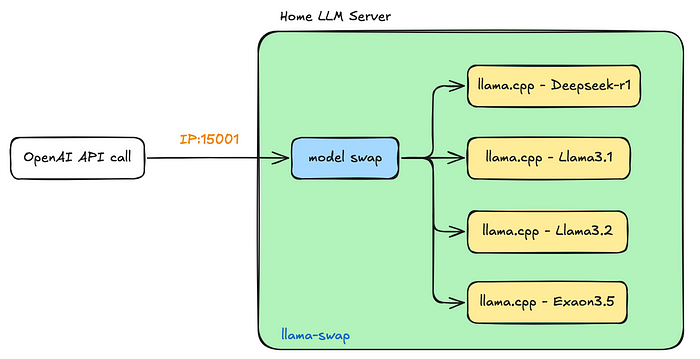
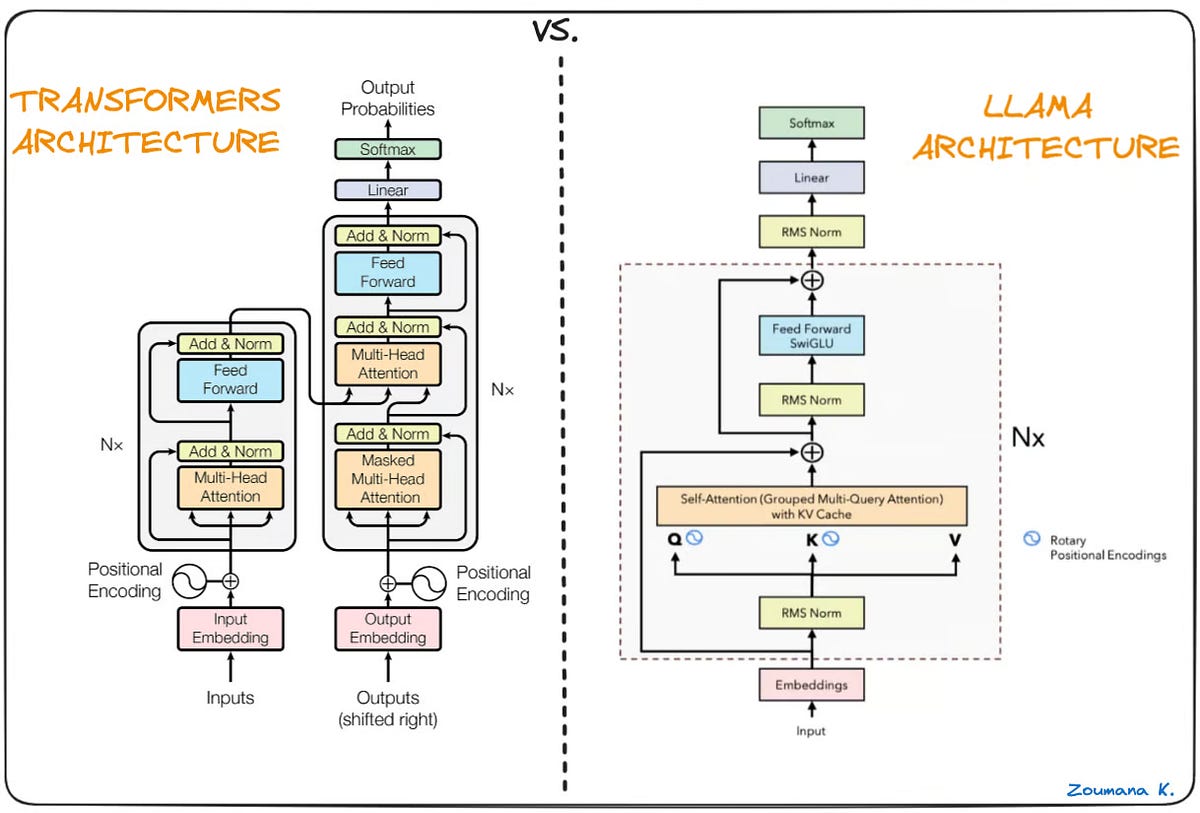
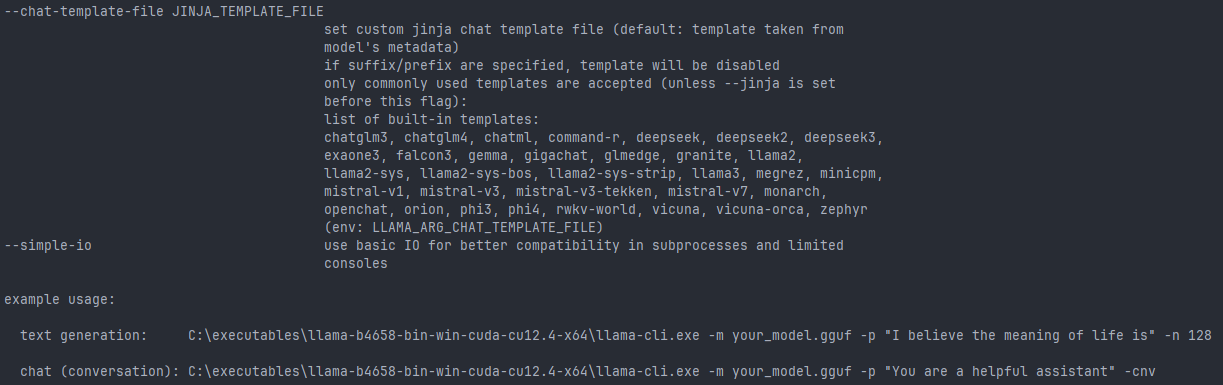
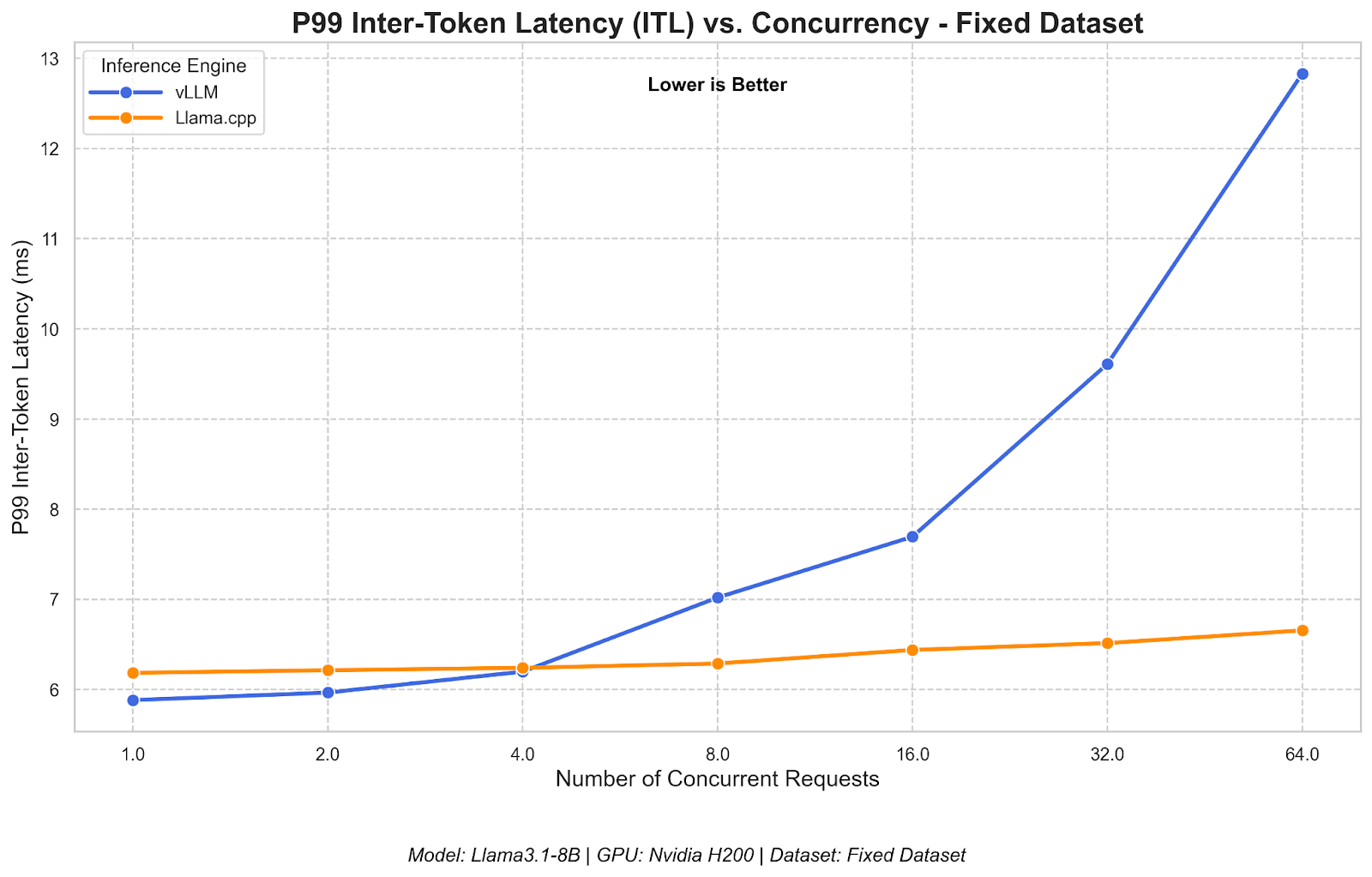
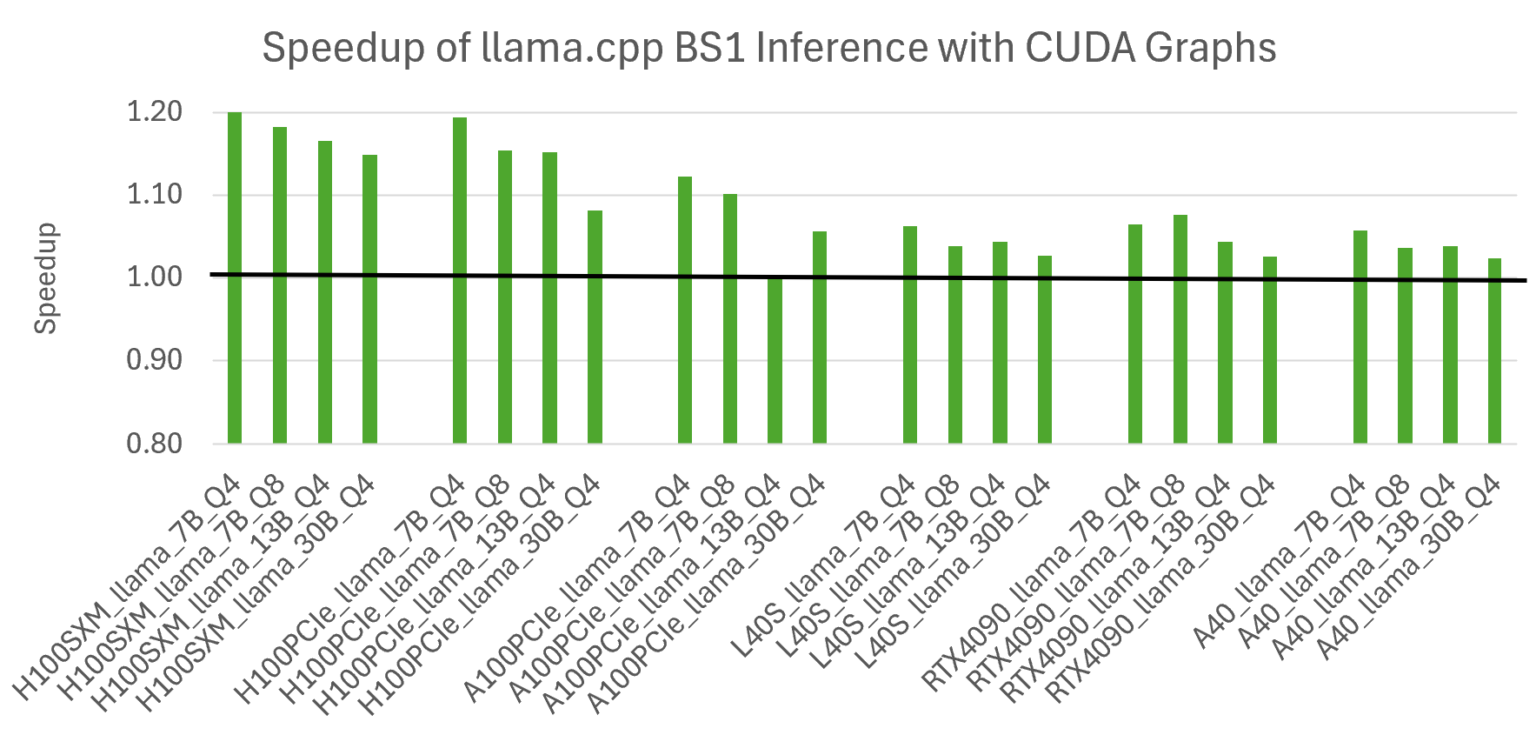
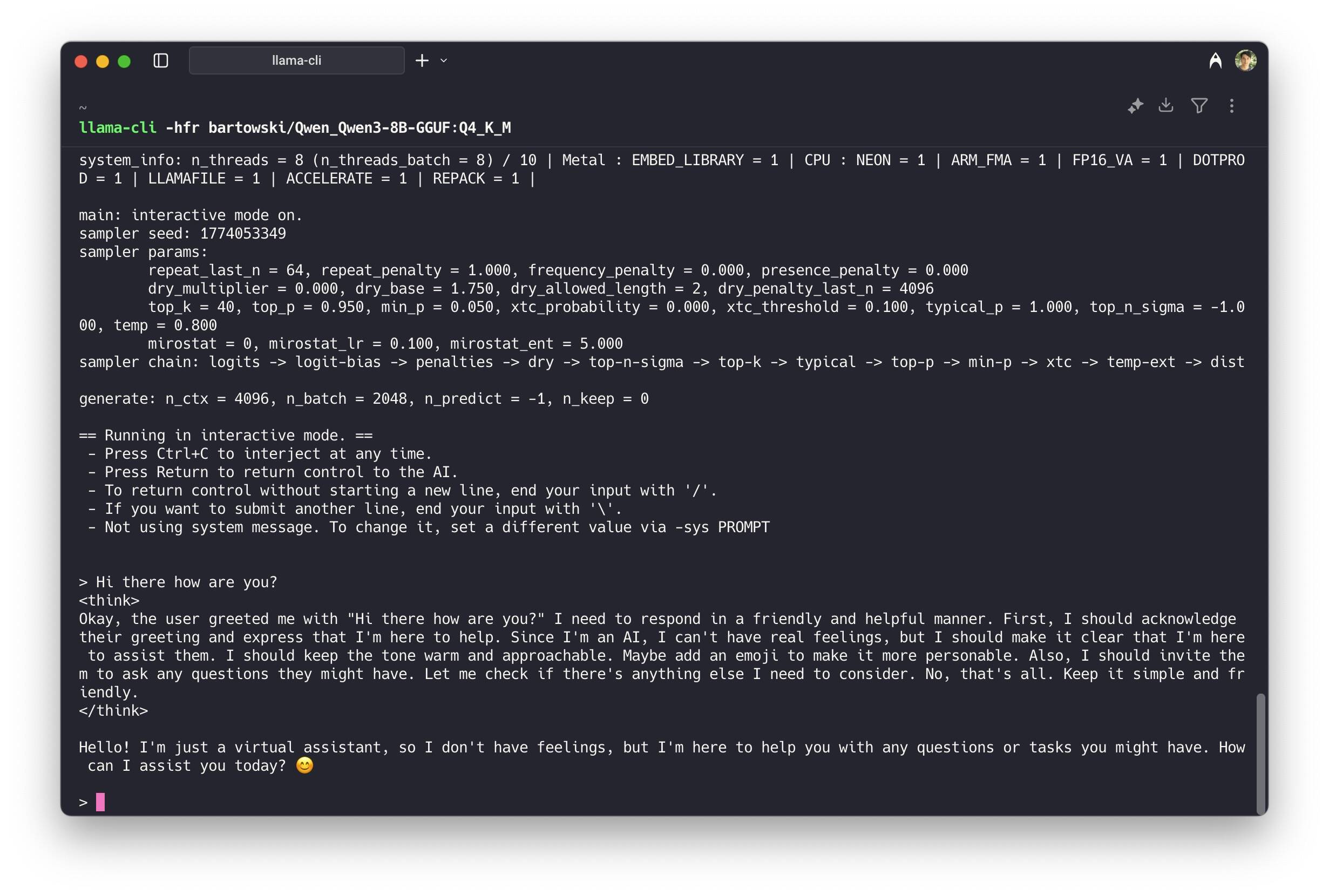
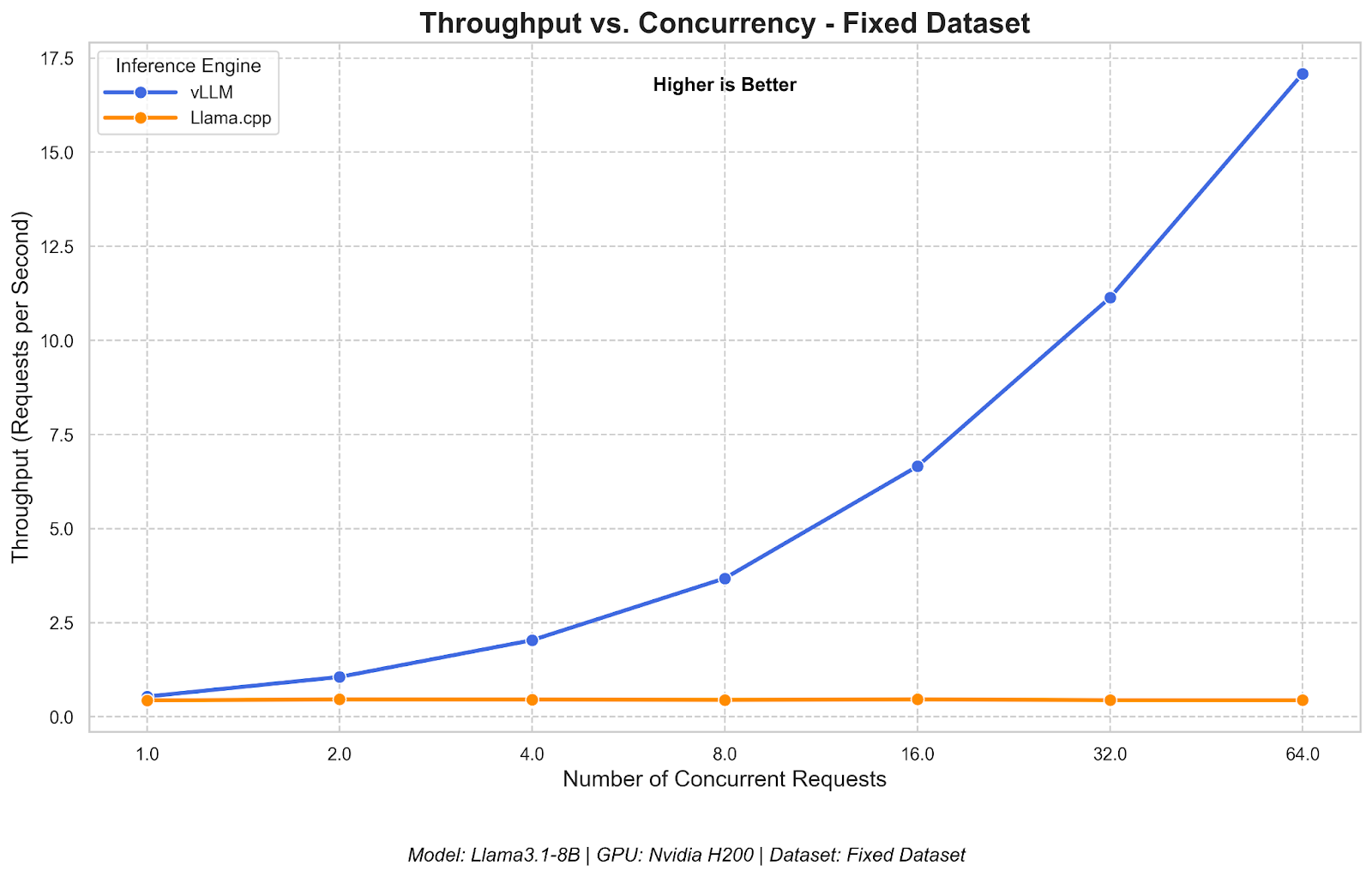
Distributed LLM Inference on Consumer Machines with llama.cpp: A Bare ...
Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and ...
llama.cpp — CPU-optimized LLM inference in C/C++ with GGML quantization ...
How to Run LLMs on Your CPU with Llama.cpp: A Step-by-Step Guide | by ...
Run llama.cpp with IPEX-LLM on Intel GPU — IPEX-LLM latest documentation
Run LLMs on Your CPU with Llama.cpp: A Step-by-Step Guide
How to find an LLM, discover its API, and get API access — a step-by ...
Generative AI: LLMs: How to do LLM inference on CPU using Llama-2 1.9 ...
Build an API for LLM Inference using Rust: Super Fast on CPU - YouTube
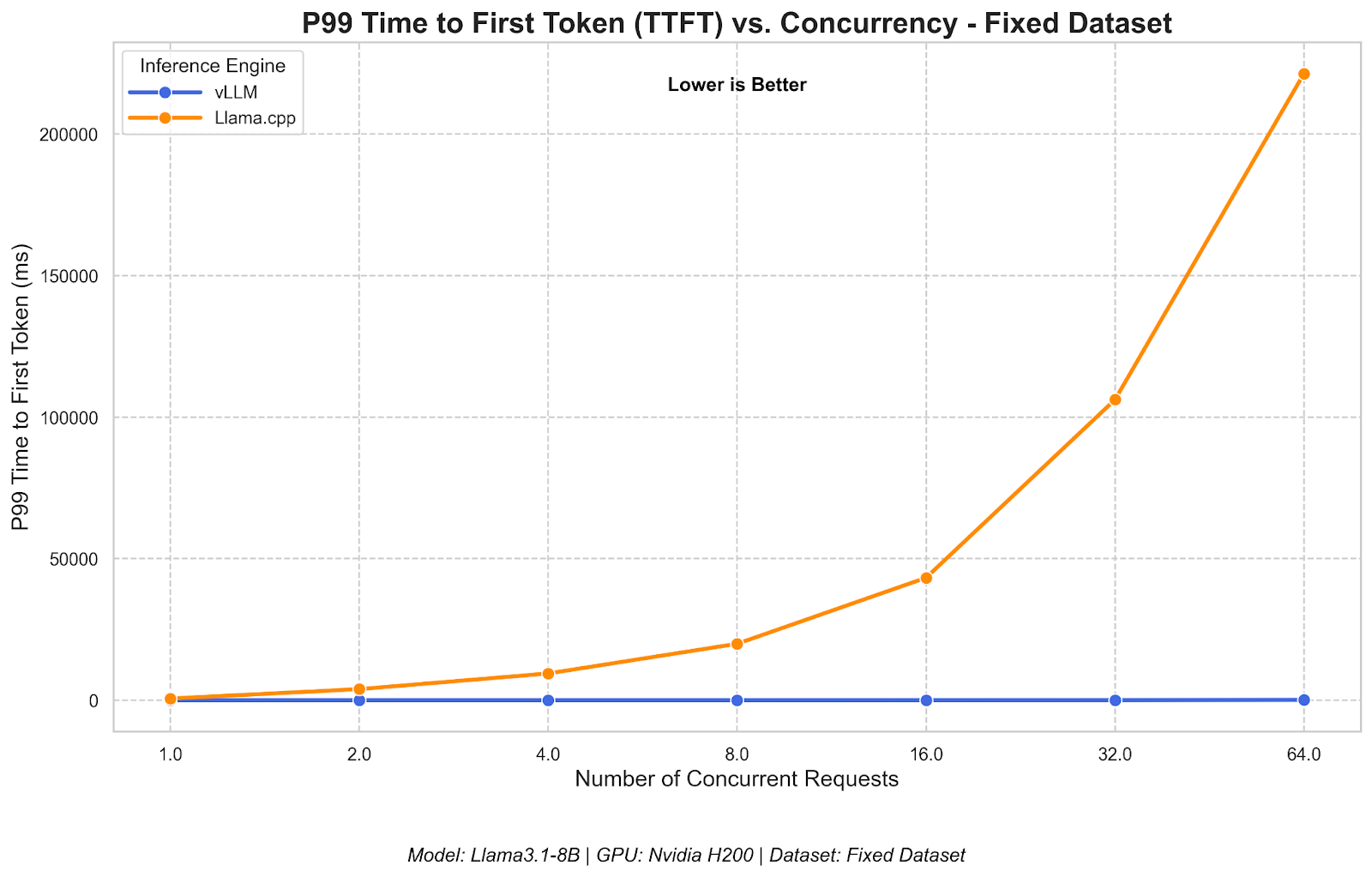
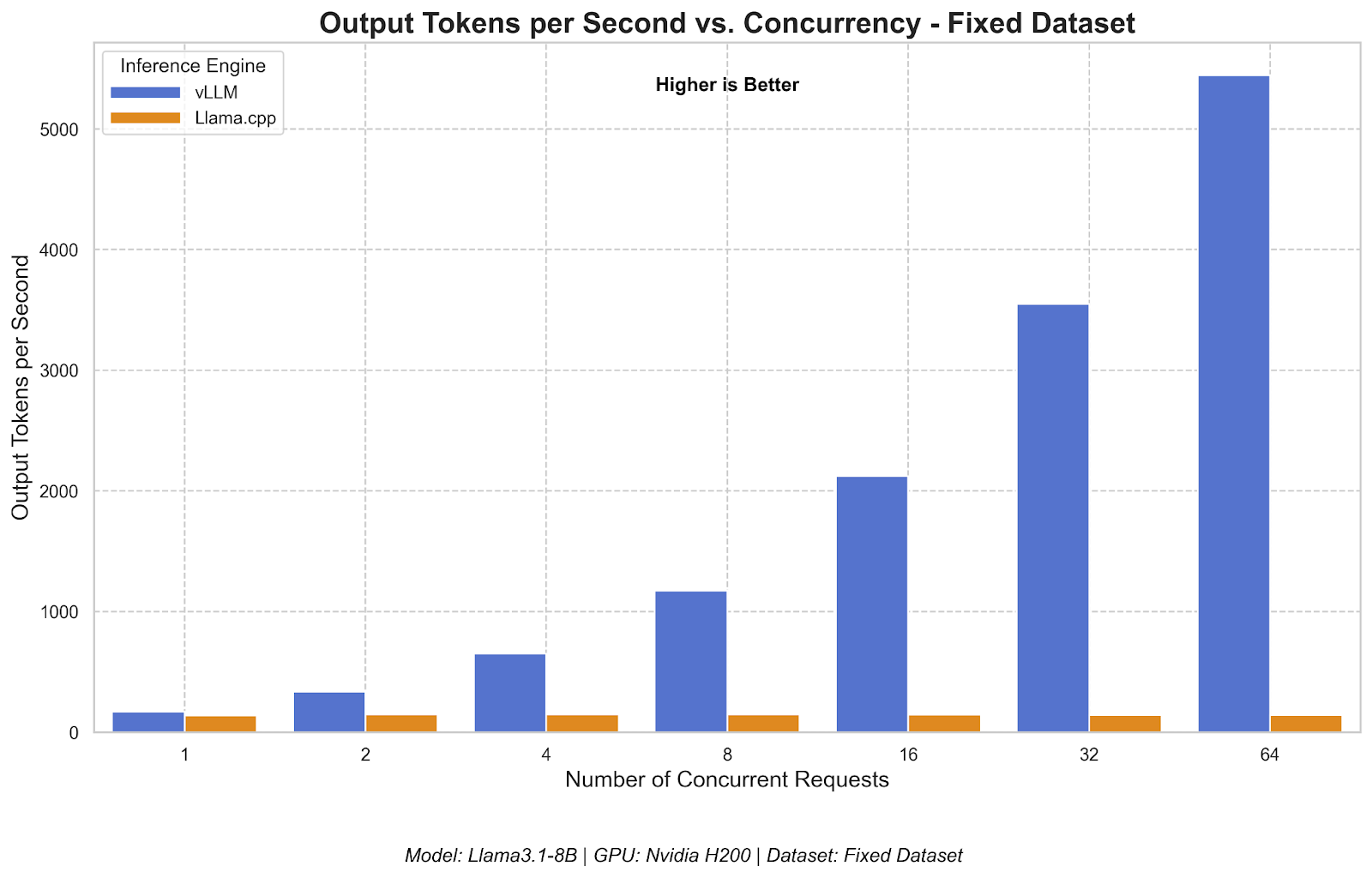
Run OpenAI-compatible LLM inference with LLaMA 3.1-8B and vLLM | Modal Docs
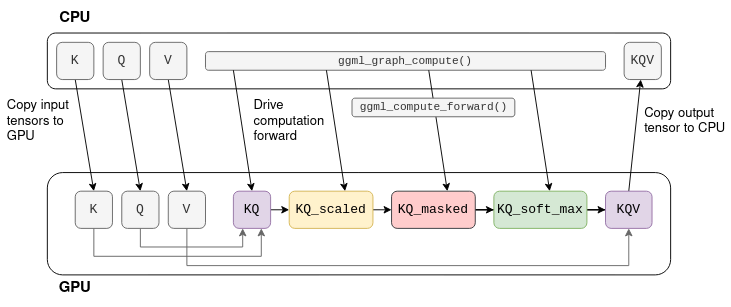
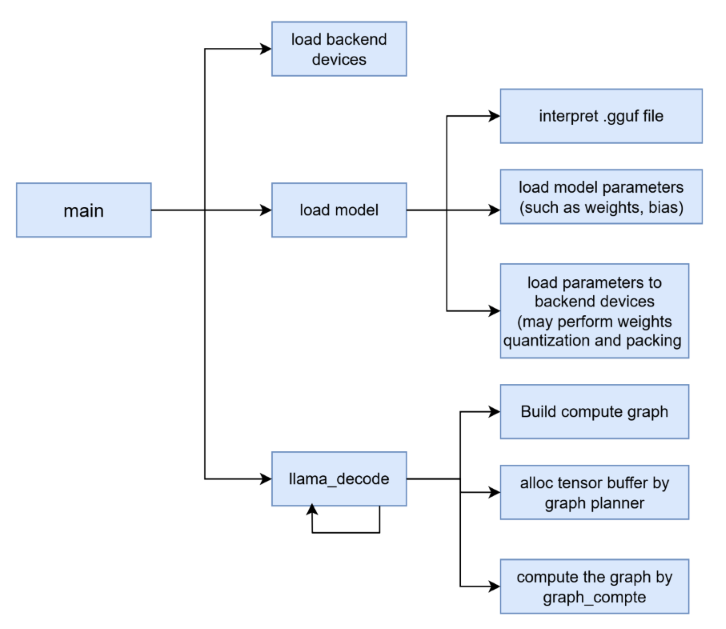
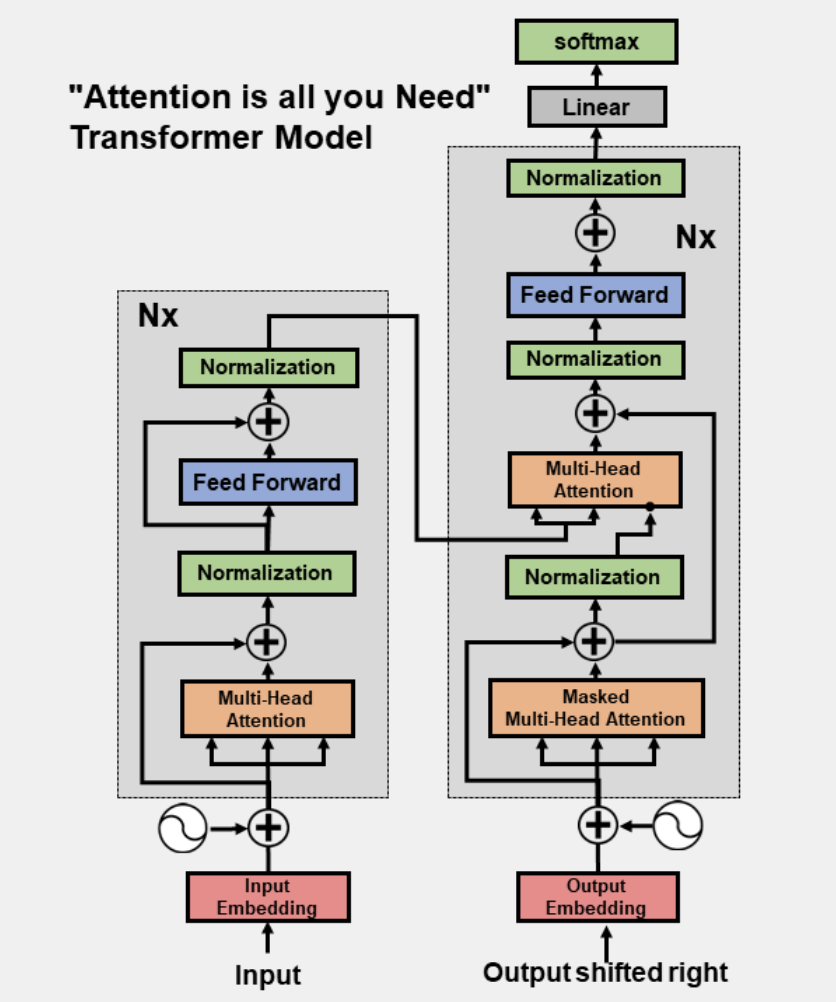
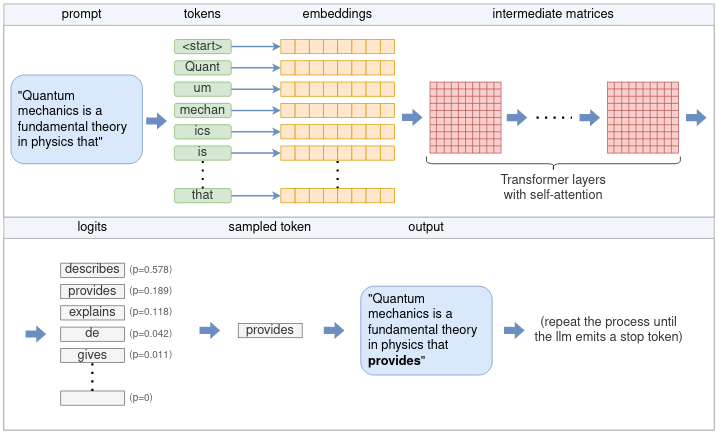
Understanding how LLM inference works with llama.cpp
Explore llama.cpp architecture and the inference workflow | Arm ...
Llama CPP Tutorial: A Basic Guide And Program For Efficient LLM ...
Llama.cpp Python Examples: A Guide to Using Llama Models with Python ...
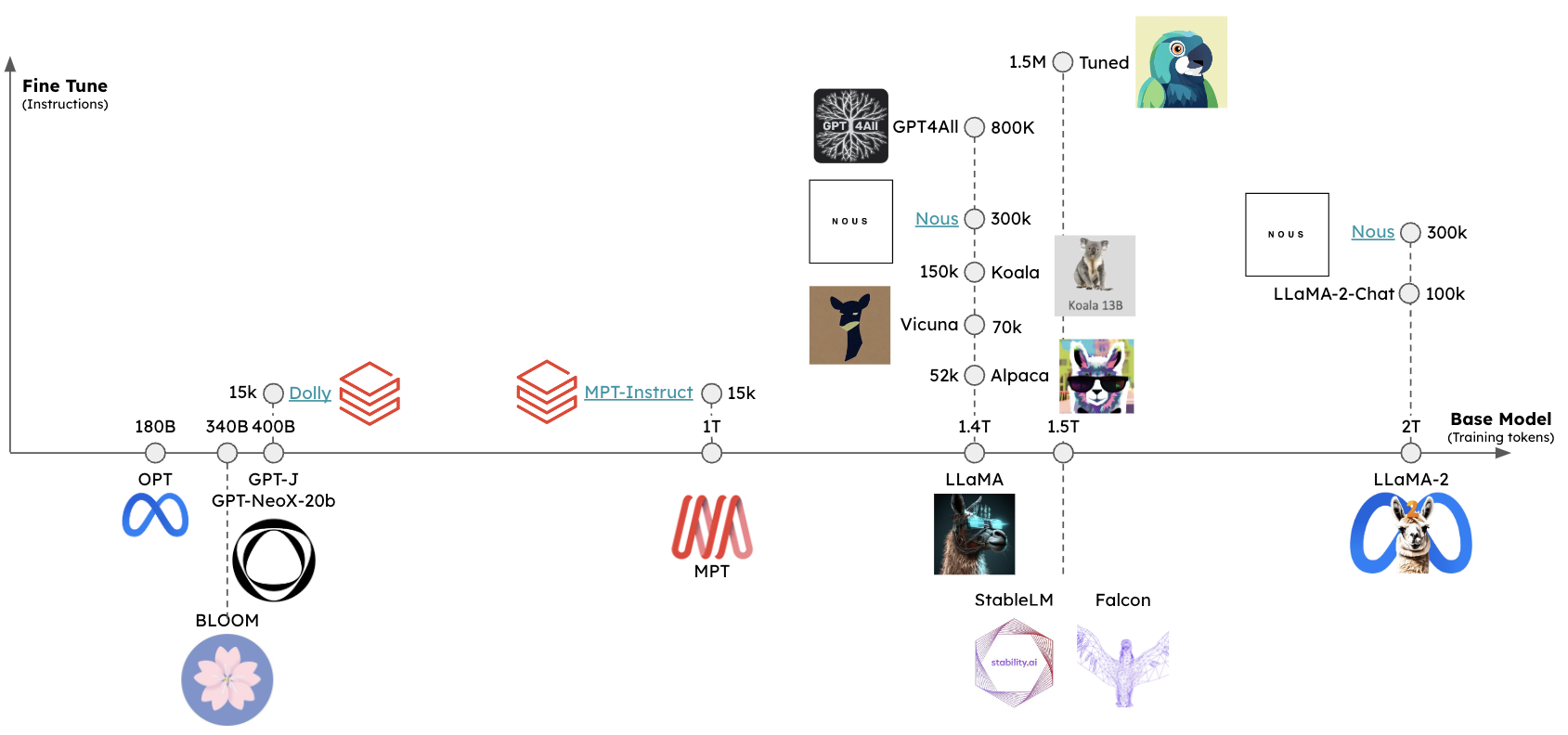
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
GitHub - awinml/llama-cpp-python-bindings: Run fast LLM Inference using ...
A step by step guide to running a local LLM with llama-cpp-python ...
llama.cpp: The Ultimate Guide to Efficient LLM Inference and ...
Llama.cpp and Square Codex for Local LLM Inference
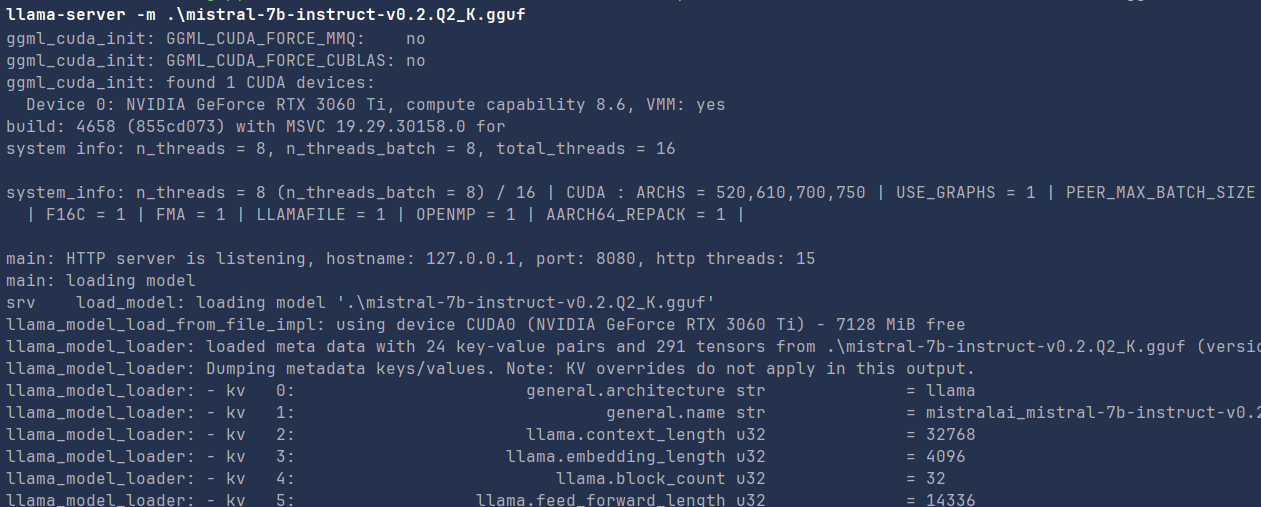
Effects of CPU speed on GPU inference in llama.cpp | Puget Systems
Run LLM on Intel GPUs Using llama.cpp | by NeoZhangJianyu | Medium
LLM By Examples: Build Llama.cpp with GPU (CUDA) support | by MB20261 ...
Efficiently Run Your Fine-Tuned LLM Locally Using Llama.cpp 🚀 | by ...
Reach native speed with MacOS llama.cpp container inference | Red Hat ...
Accelerating LLMs with llama.cpp on NVIDIA RTX Systems | NVIDIA ...
llama.cpp: Writing A Simple C++ Inference Program for GGUF LLM Models ...
Run LLMs (Llama 3) Locally with llama.cpp | Medium
Run LLMs Anywhere: Automate llama.cpp Installation for Local AI ...
Complete Guide to llama.cpp: Local LLM Inference Made Simple | by Huda ...
How to compile LLM on Android using LLama.cpp | by mmonteiros | Medium
Using Llama.cpp for Local LLM Inference - Llama-utils
vLLM or llama.cpp: Choosing the right LLM inference engine for your use ...
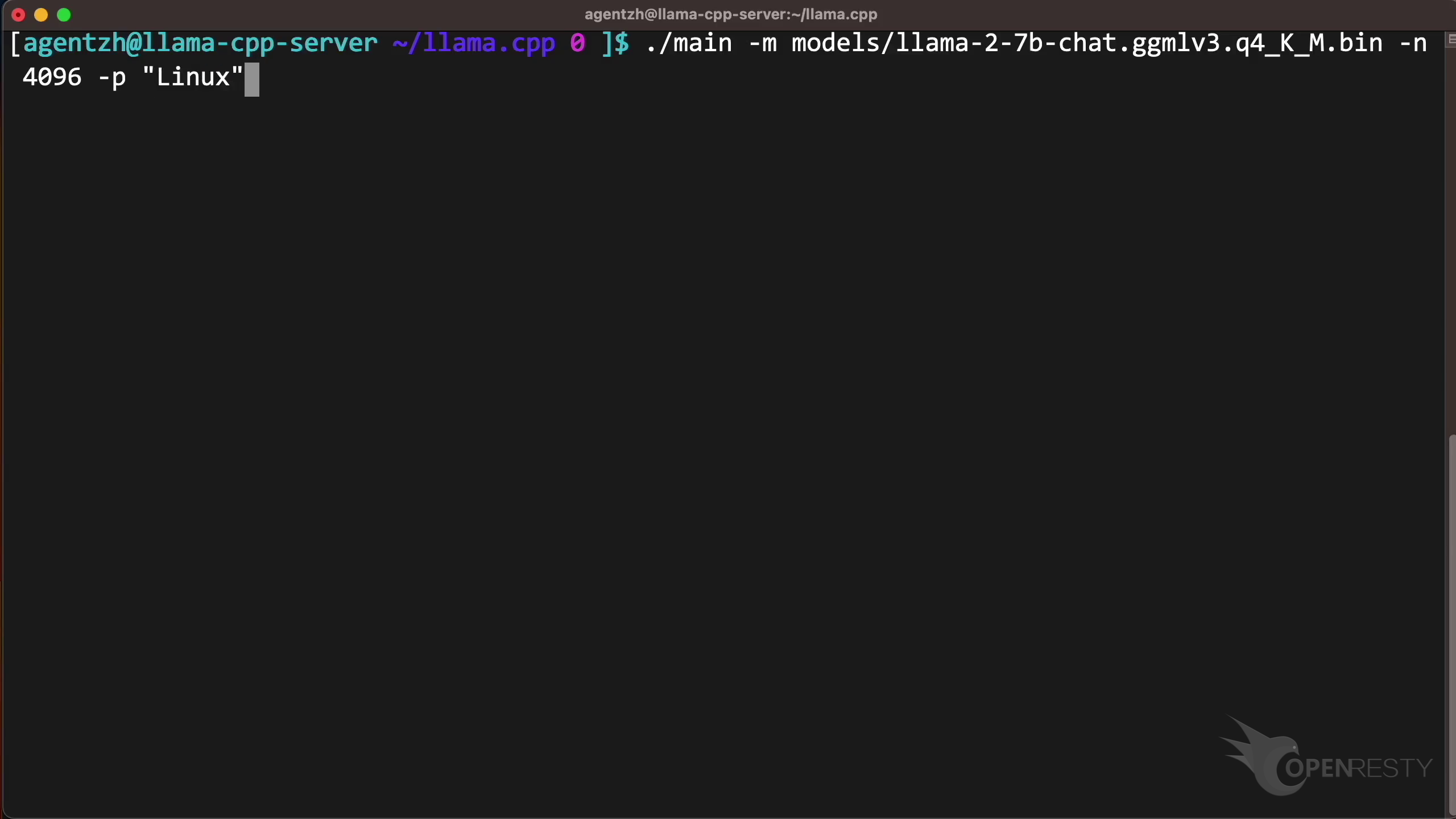
How CPU time is spent inside llama.cpp + LLaMA2 (using OpenResty XRay ...
Optimizing llama.cpp AI Inference with CUDA Graphs | NVIDIA Technical Blog
How to run LLMs on PC at home using Llama.cpp • The Register
Running llama.cpp on the CPU - Speaker Deck
Engineer's Guide to Local LLMs with LLaMA.cpp on Linux - DEV Community
Llama-3 8B & 70B inferences on Intel® Core™ Ultra 5: Llama.cpp vs. IPEX ...
How to Run a Local LLM for Enterprise Use - Intellias
Efficient LLM inference on CPUs : r/LocalLLaMA
LLM By Examples: Build Llama.cpp for CPU only | by MB20261 | Medium
How to Compile and Build the GPU version of llama.cpp from source and ...
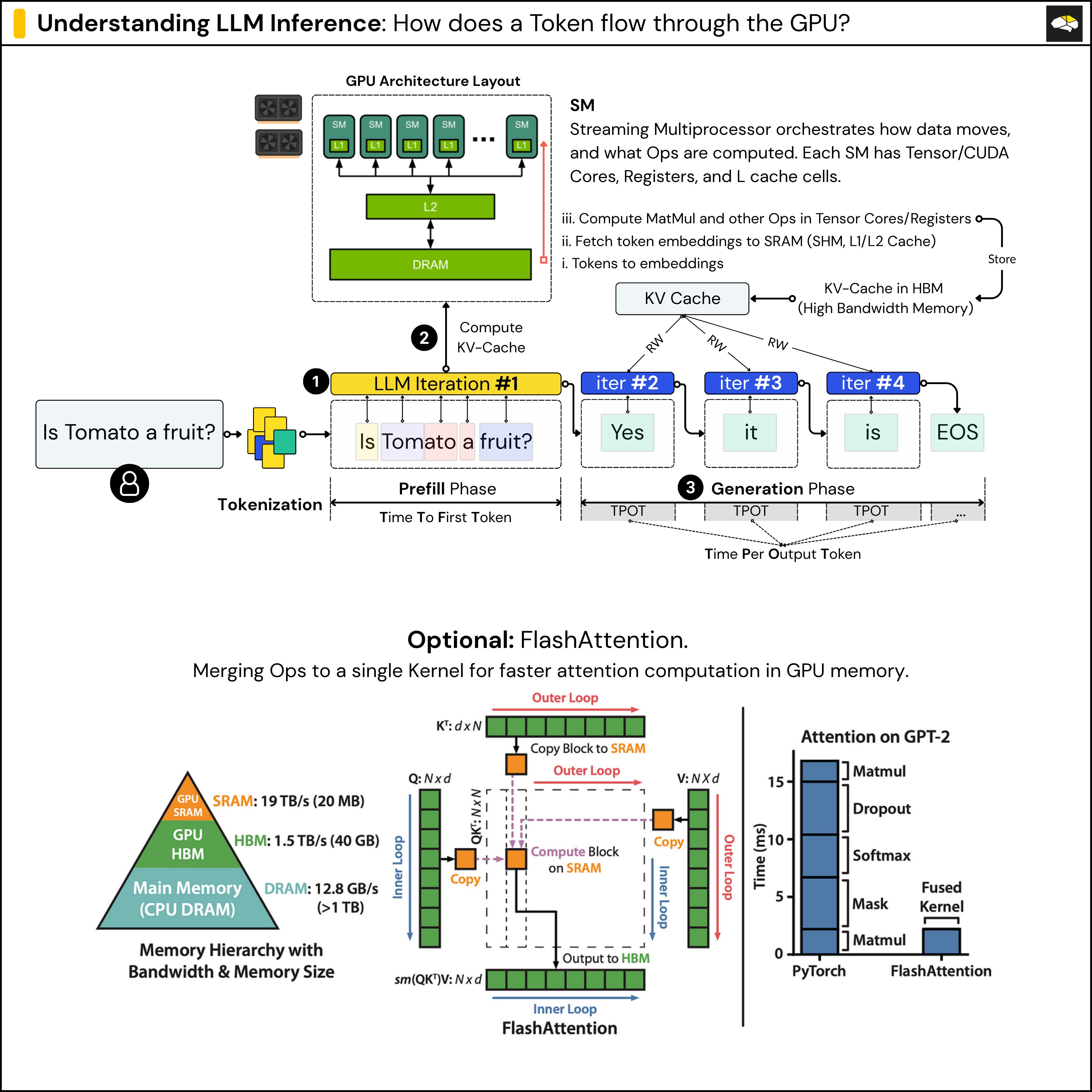
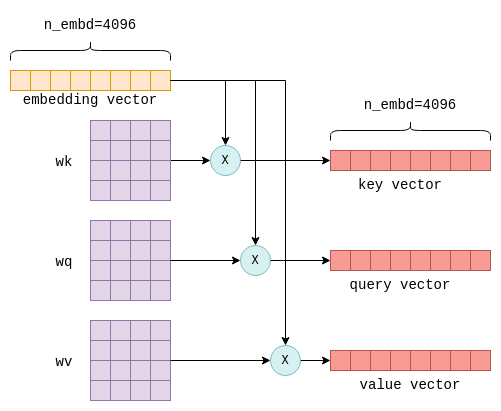
Understanding LLM Inference - by Alex Razvant
Quantization Of Llms With Llama.Cpp – GRKCZ
Exploring Hybrid CPU/GPU LLM Inference | Puget Systems
llama.cpp Inference
GitHub - KevinSerres/llama_cpp: LLM inference in C/C++
GitHub - ggml-org/llama.cpp: LLM inference in C/C++ · GitHub
The 6 Best LLM Tools To Run Models Locally
Mastering the Llama.cpp API: A Quick Guide
解开封印!加倍 LLM 推理吞吐: ggml.ai 与 llama.cpp - 知乎
在 NVIDIA RTX 系统上使用 Llama.cpp 加速 LLM - NVIDIA 技术博客
Easiest, Simplest, Fastest way to run large language model (LLM ...
How to run LLMs on CPU-based systems | by Simeon Emanuilov | Medium
GitHub - loong64/llama.cpp: LLM inference in C/C++
GitHub - simonw/llm-llama-cpp: LLM plugin for running models using ...
Llama C++ Rest API: A Quick Start Guide
Efficient Inference Archives - PyImageSearch
GitHub - seengood/ai-Llama-2-Open-Source-LLM-CPU-Inference: Running ...
llama.cpp 源码解析_llama cpp-CSDN博客
[LLM-Llama]MAC M1 安装llama-cpp-python体验完全 OpenAI API 的玩法 - 知乎
llama.cpp LLM模型 windows cpu安装部署;运行LLaMA2模型测试-CSDN博客
How is LLaMa.cpp possible?
llama.cpp - Codesandbox
llm-inference · PyPI
ローカルPCでLLMを動かす(llama-cpp-python) | InsurTech研究所
GitHub - illiafedenko00/Llama-LLM-CPU-Inference
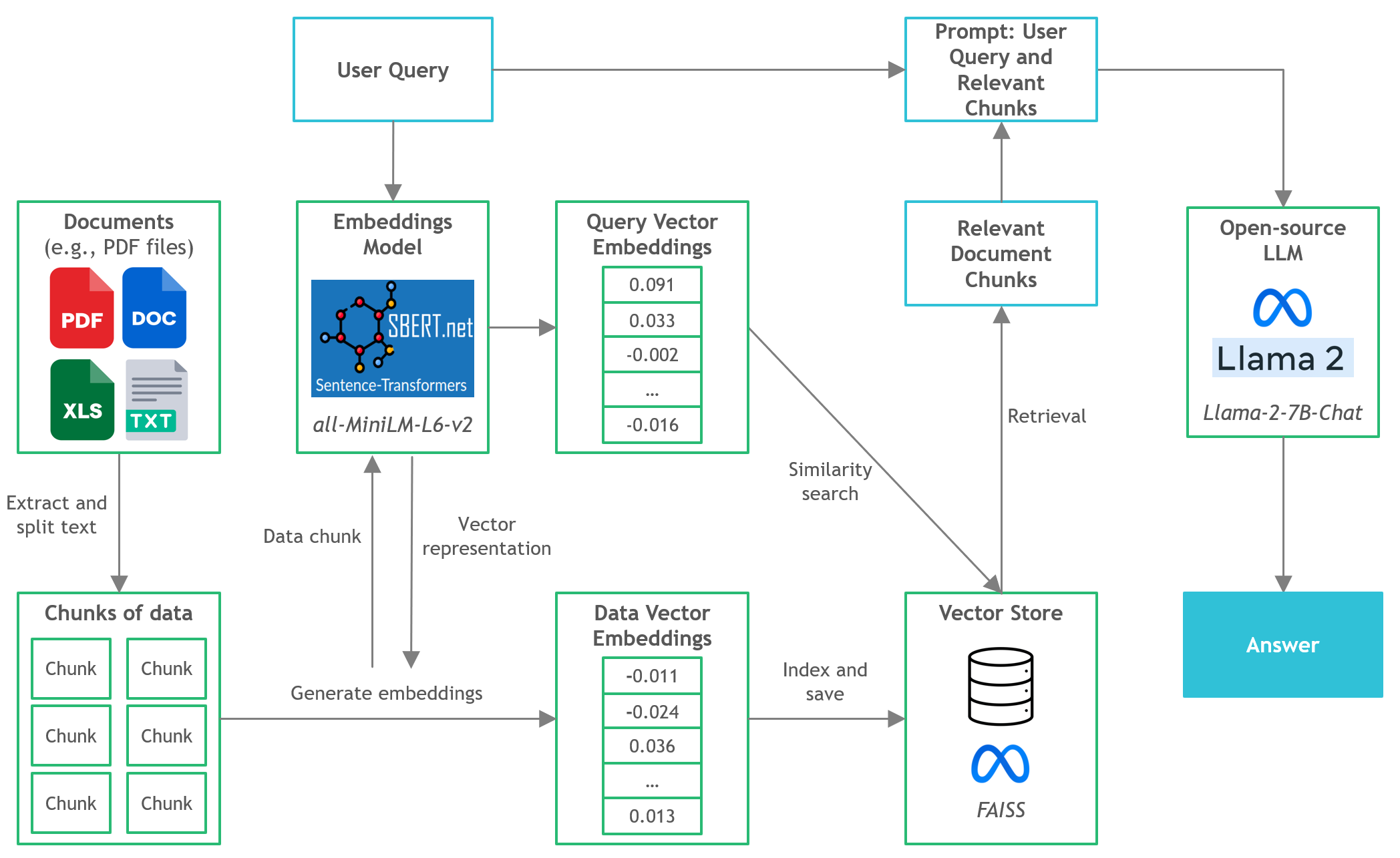
[NLP] 使用Llama.cpp和LangChain在CPU上使用大模型-RAG_llama-cpp-python-CSDN博客
基于Llama-cpp在CPU上推理大模型 - 知乎
Llama-2-Open-Source-LLM-CPU-Inference学习资料汇总 - 在CPU上运行开源大语言模型的文档问答系统 - 懂AI
使用llama.cpp实现LLM大模型的格式转换、量化、推理、部署llama.cpp的主要目标是能够在各种硬件上实现LL - 掘金
一文熟悉新版llama.cpp使用并本地部署LLAMA_llama-cli-CSDN博客
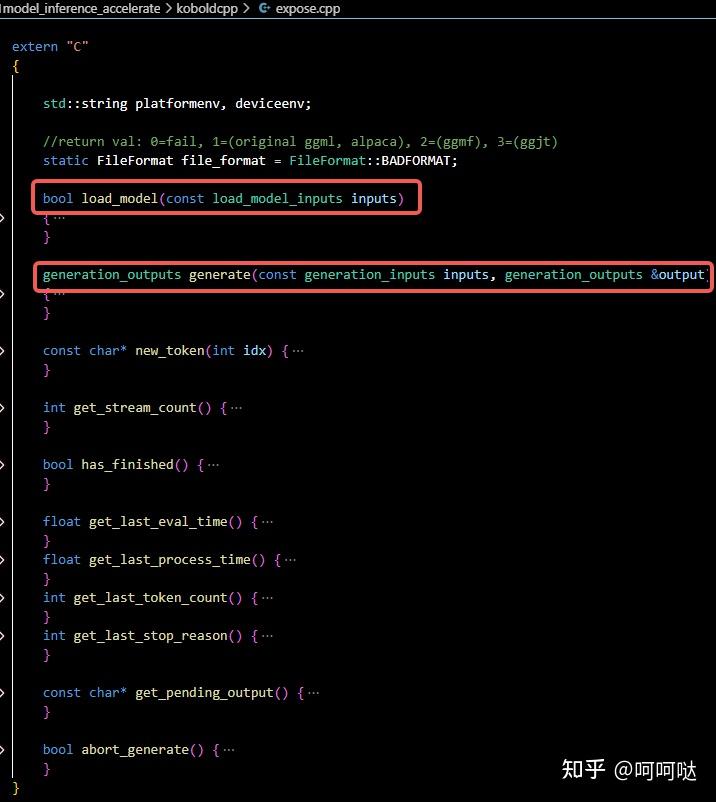
LLM推理3:llama.cpp/koboldcpp学习 - 知乎
Llama-2-Open-Source-LLM-CPU-Inference | Ecosystem Directory | market.dev