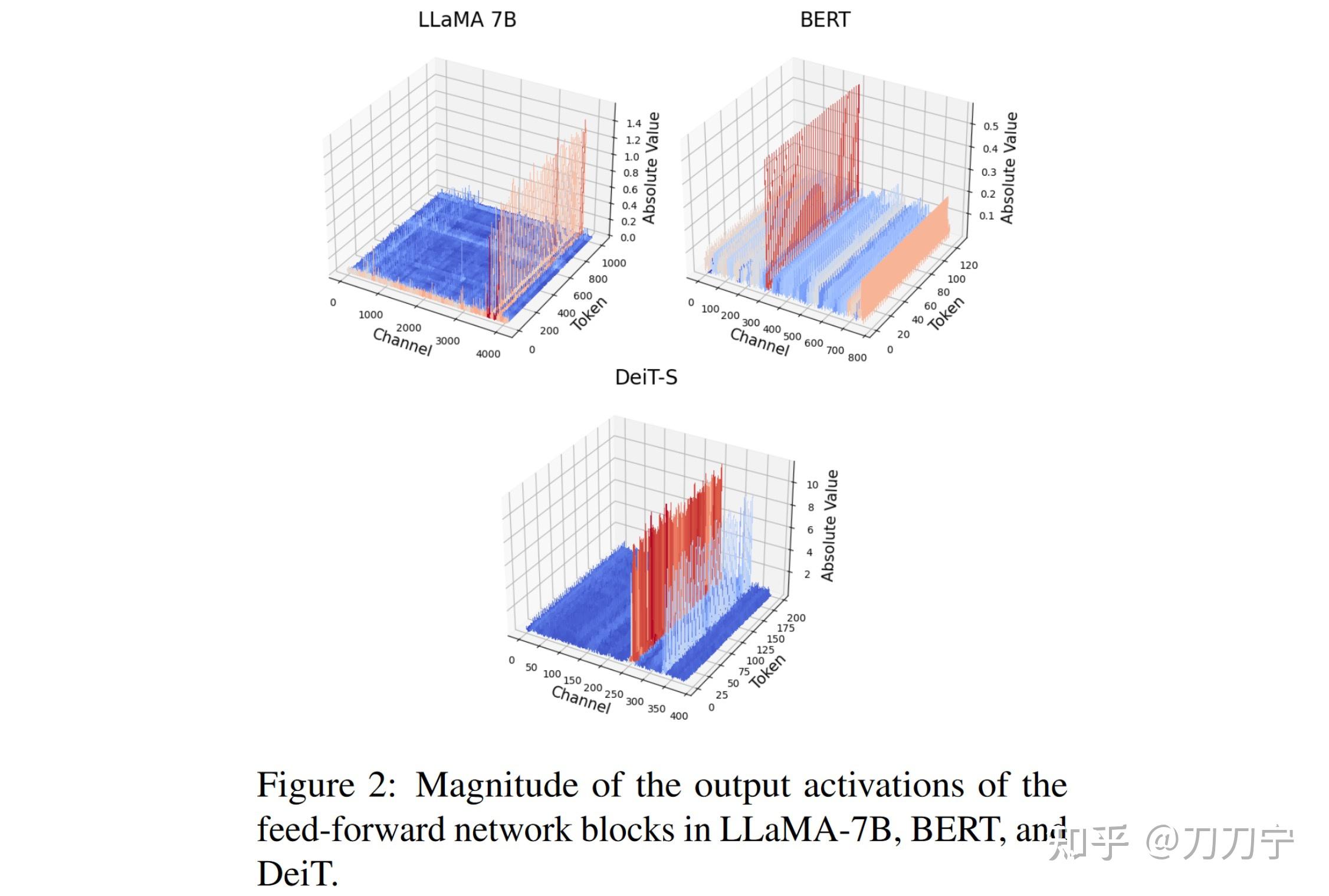
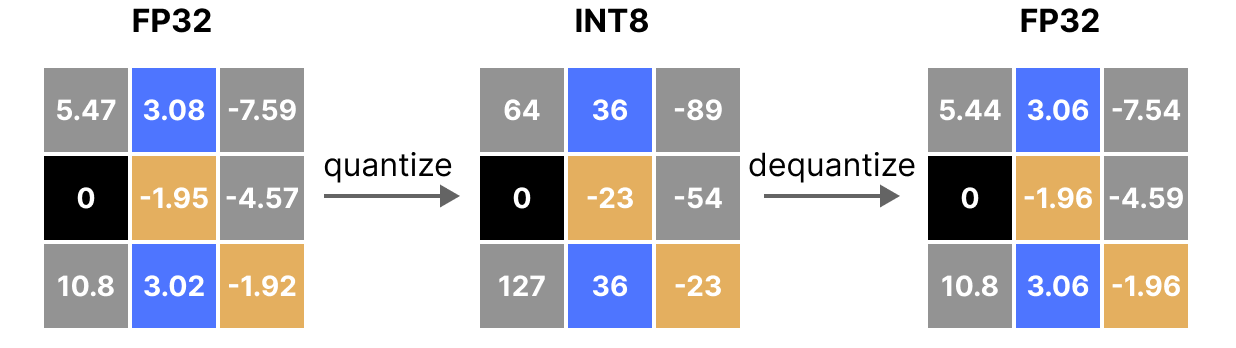
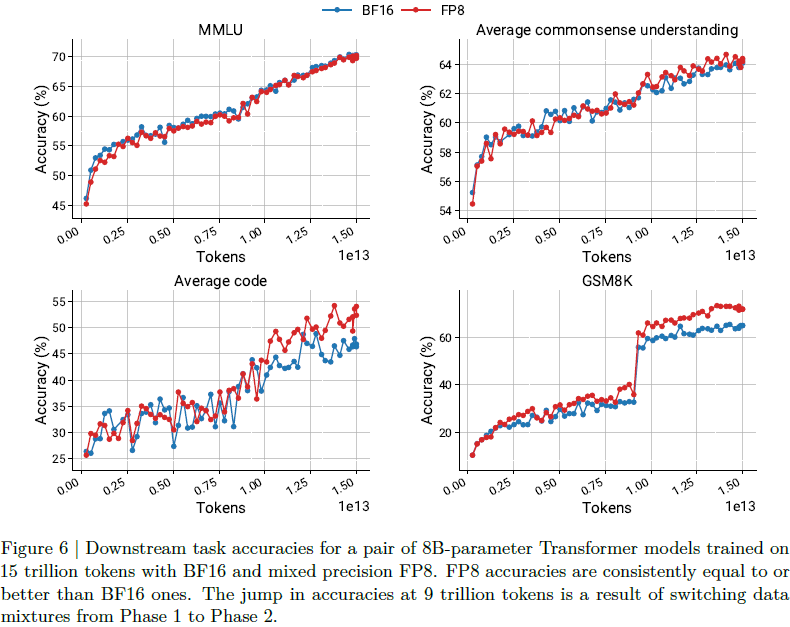
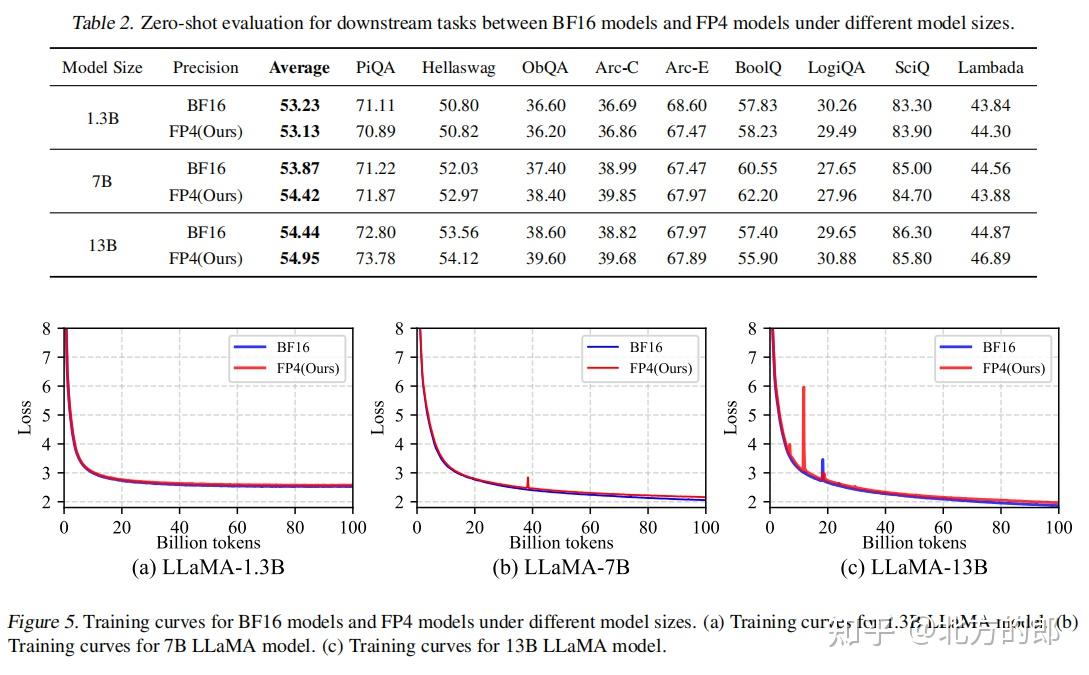
FP8 Quantization for Ultra-Low Latency AI | AI Tutorial | Next Electronics
FP8 quantization for LLM by vLLM | Neural Magic (Acquired by Red Hat ...
Configuration Loading and Parsing | vllm-project/vllm | DeepWiki
FMHA Masking and Variable Length Support | NVIDIA/cutlass | DeepWiki
How to achieve FP8-like performance with FP4 in large models | Eduardo ...
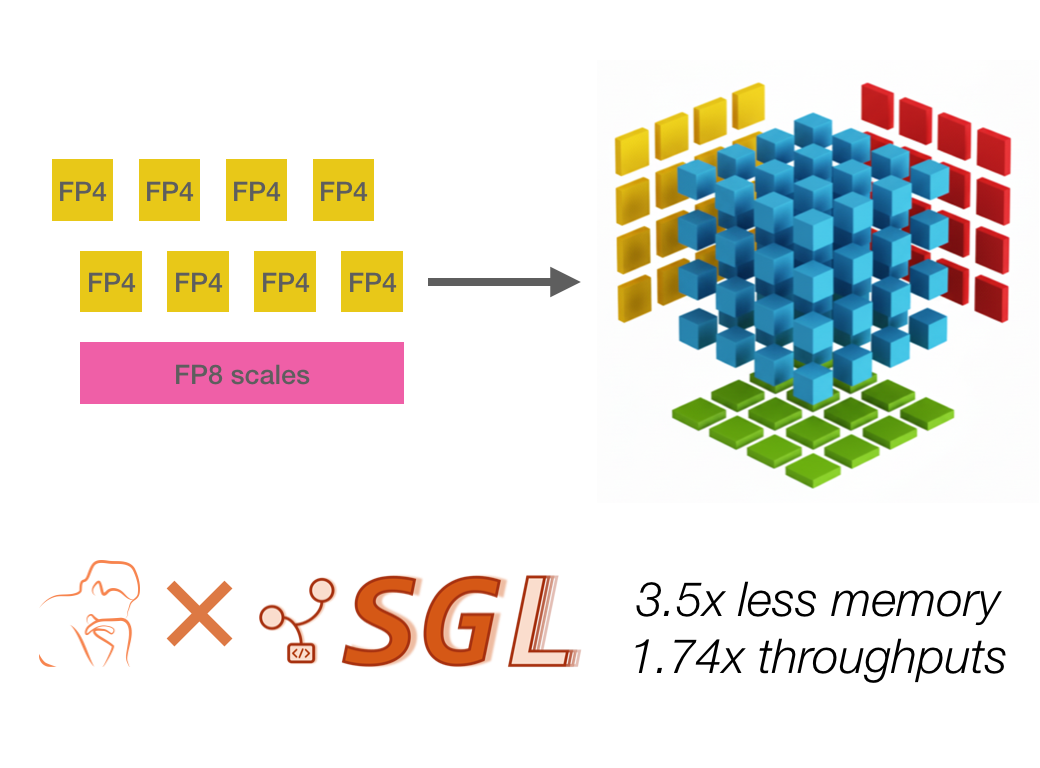
Optimizing FP4 Mixed-Precision Inference on AMD GPUs | LMSYS Org
What LLM quantization works best for you? Q4_K_S or Q4_K_M | by Michael ...
Motion Detection | blakeblackshear/frigate | DeepWiki
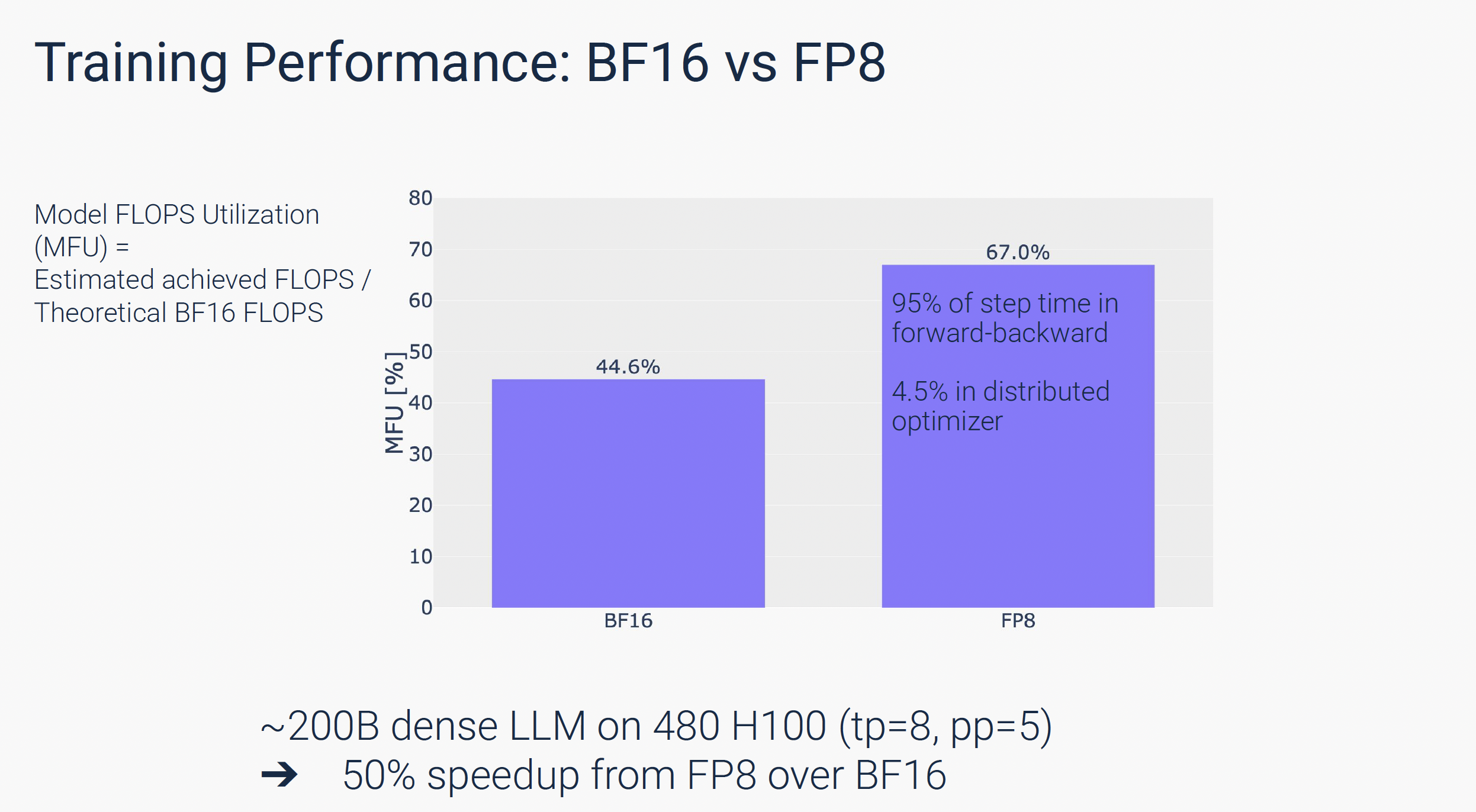
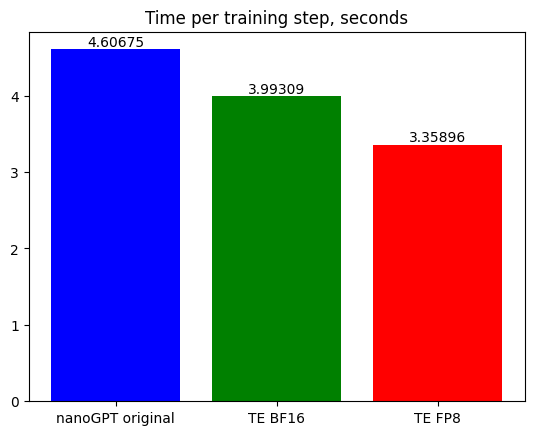
Faster Training Throughput in FP8 Precision with NVIDIA NeMo | NVIDIA ...
Agent Infrastructure Layer | bytedance/UI-TARS-desktop | DeepWiki
Accelerate Your AI Workflow with FP4 Quantization on Lambda
Generative AI 新世界 | 大模型参数高效微调和量化原理概述_fp4-CSDN博客
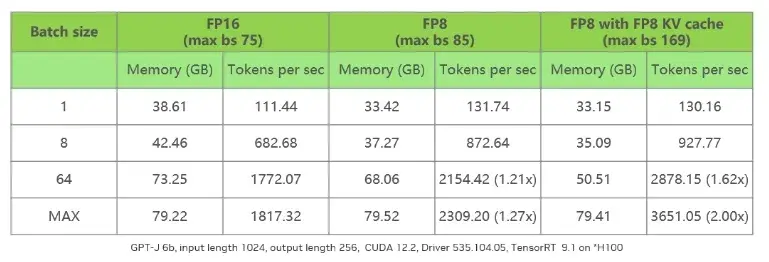
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
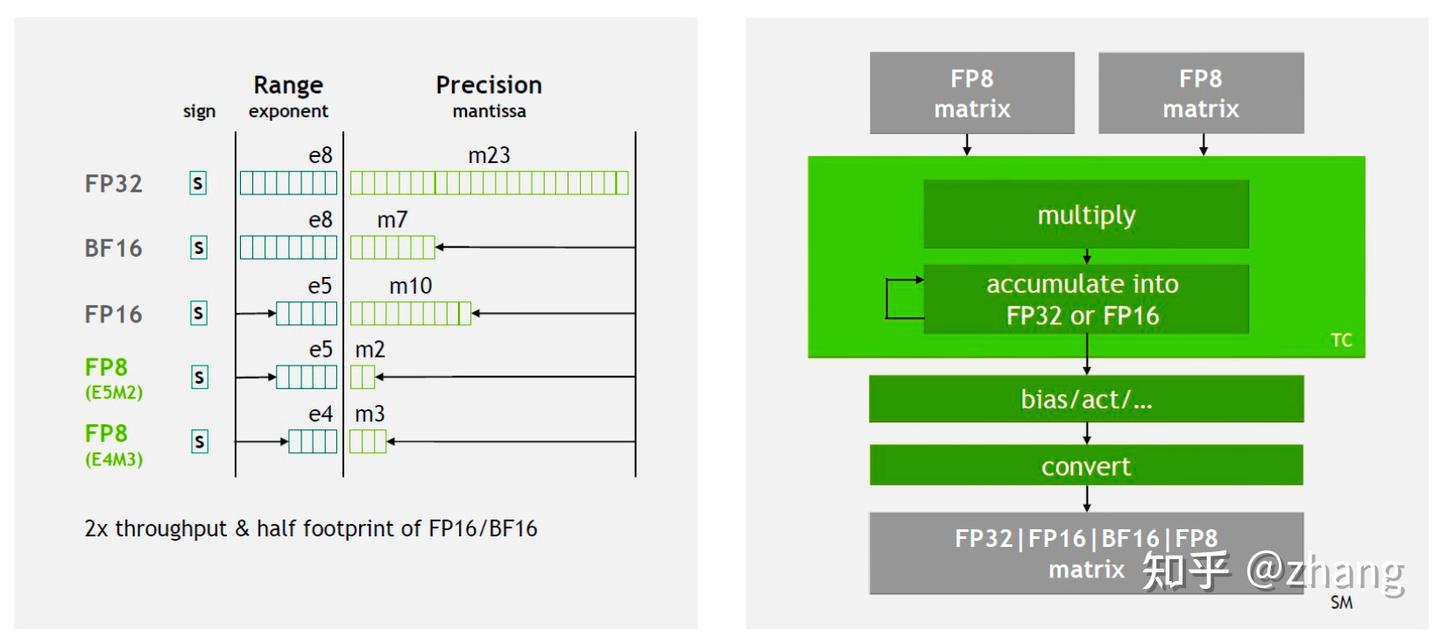
NVIDIA, Arm, and Intel Publish FP8 Specification for Standardization as ...
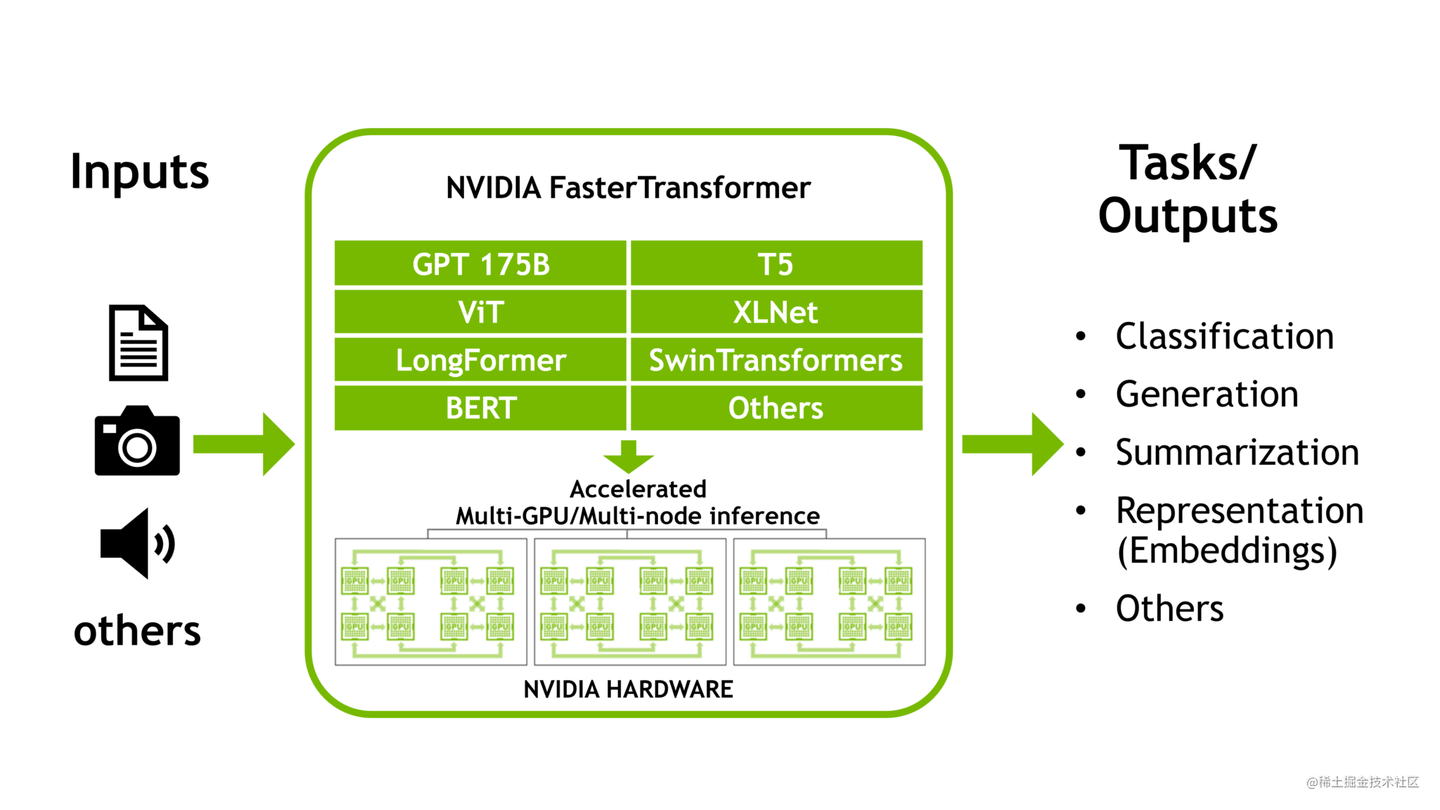
【LLM工程篇】deepspeed | Megatron-LM | fasttransformern - 百度智能云千帆社区
How we built DeepL’s next-generation LLMs with FP8 for training and ...
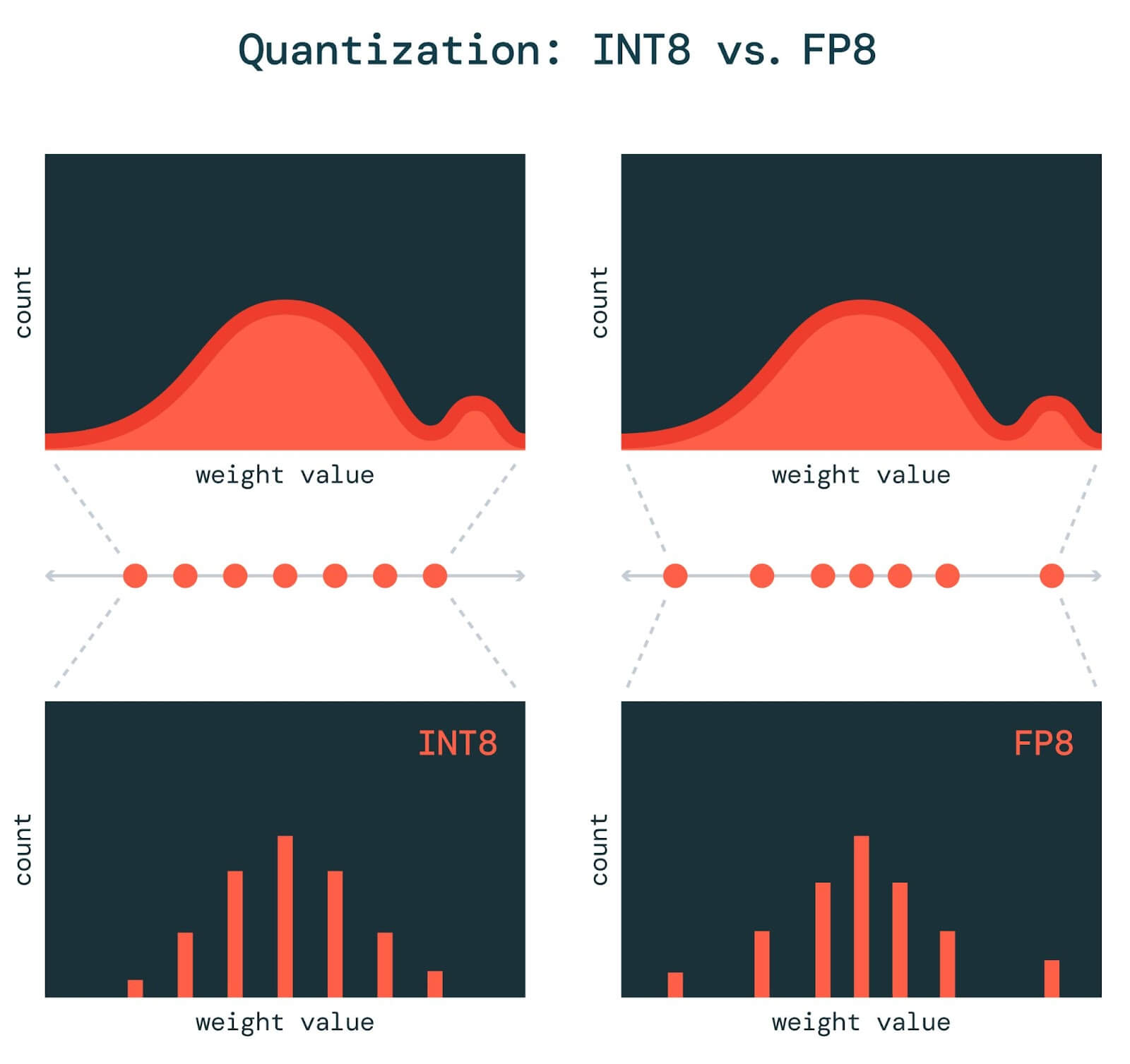
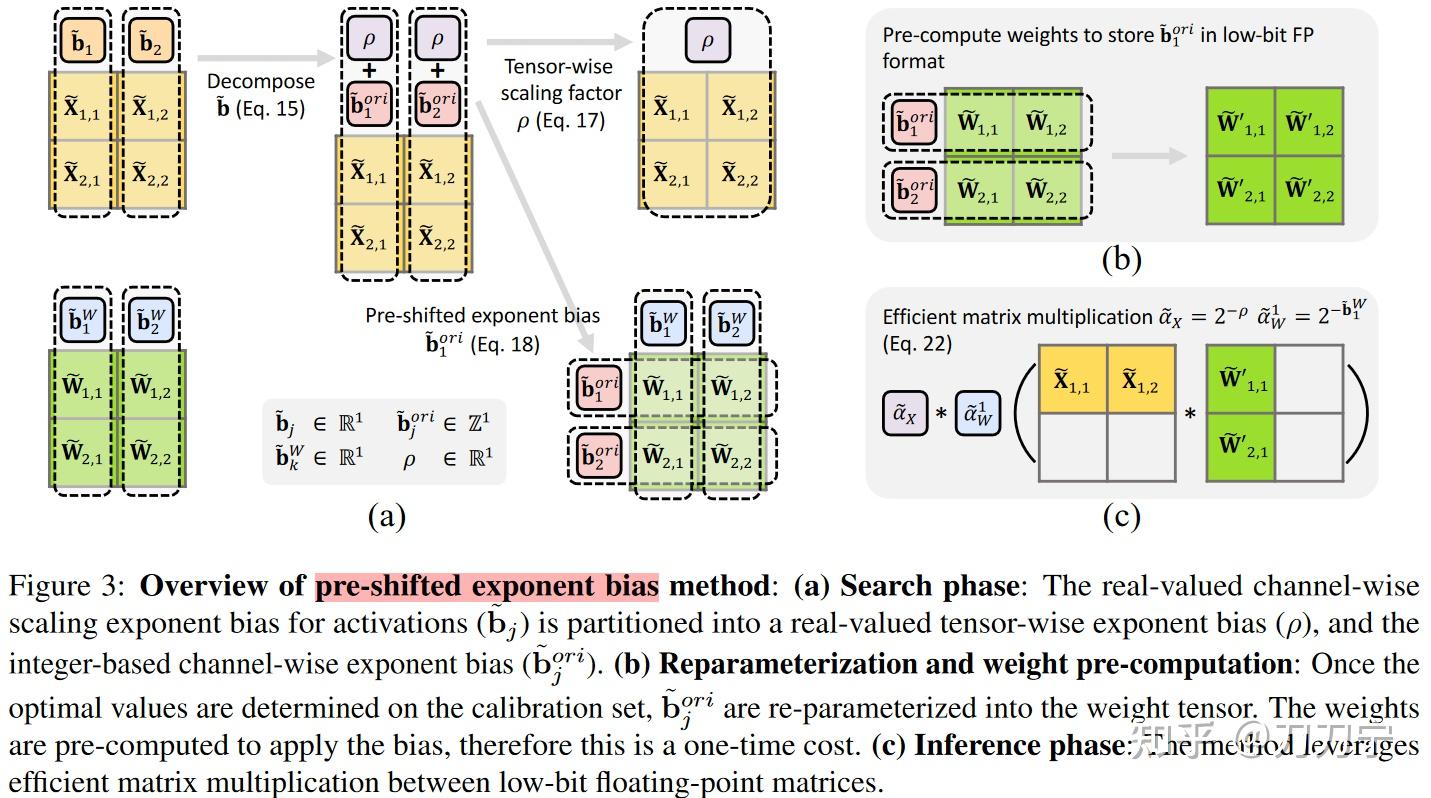
Fast and Accurate GPU Quantization for Transformers
Infrastructures for LLMs in the cloud | Scaleway Blog
Applying Language Model Techniques to Compose AI Music | NVIDIA ...
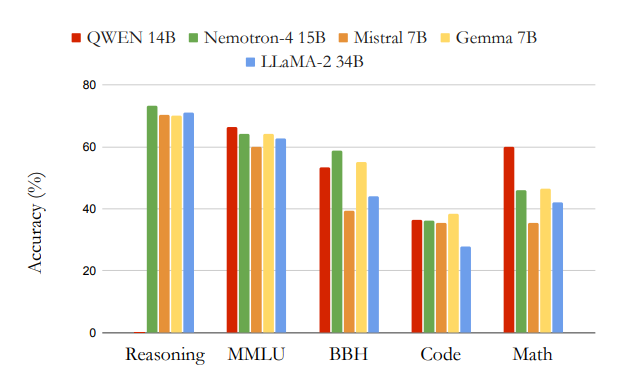
Nvidia’s New LLM: Nemotron-4. Recently, Nvidia announced its own… | by ...
【LLM算法工程】Megatron-LM | deepspeed | 量化/推理框架_deepspeed和megatron的区别-CSDN博客
Pushing Forward the Frontiers of Natural Language Processing | NVIDIA Blog
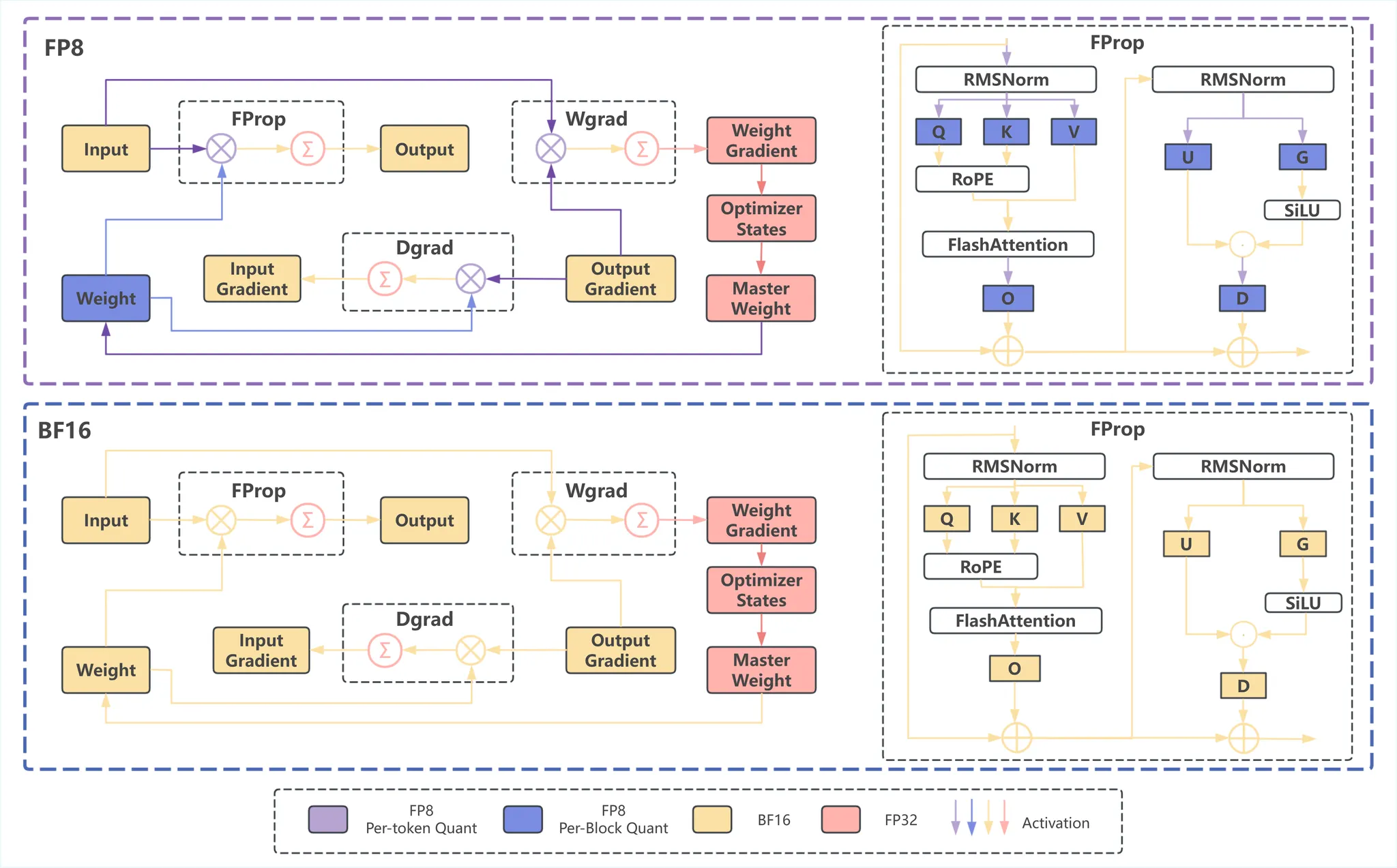
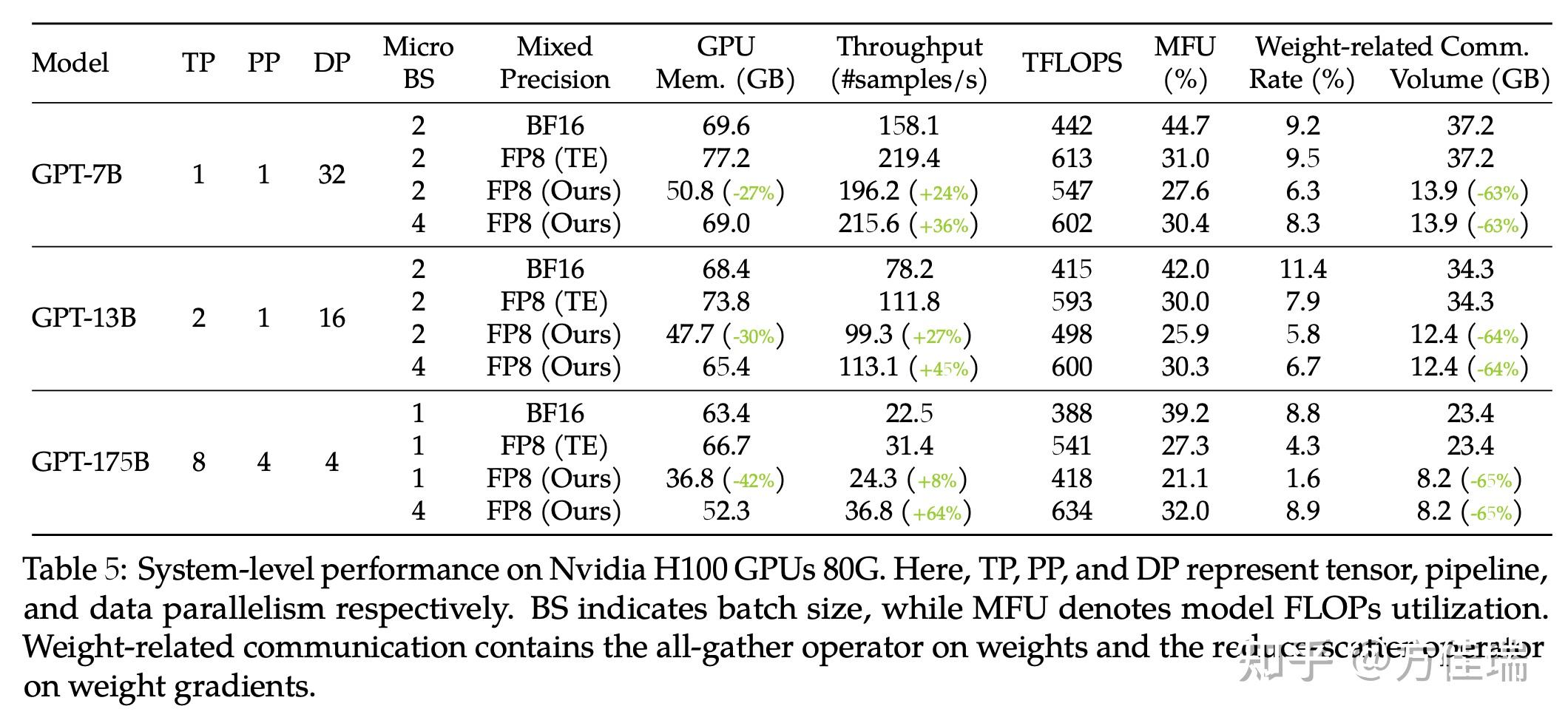
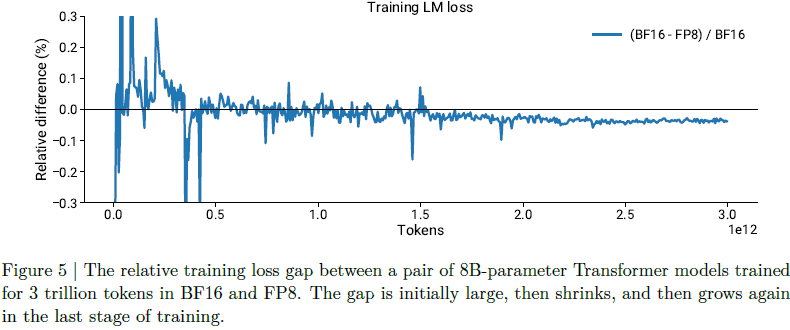
Per-Tensor and Per-Block Scaling Strategies for Effective FP8 Training ...
【LLM工程篇】deepspeed | Megatron-LM | fasttransformer_deepspeed和megatron的区别 ...
Nvidia Q4 Earnings Call: What It Means For SMH | Seeking Alpha
Nvidia’s Deal With Meta Signals a New Era in Computing Power | WIRED
30 Montaigne Belt Black Smooth Calfskin, 25 MM | DIOR
Why dose fp8 quantization use multiplication by scale ? · Issue #477 ...
Unified FP8: Moving Beyond Mixed Precision for Stable and Accelerated ...
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference ...
NVIDIA GPU 架构下的 FP8 训练与推理_汽车技术__汽车测试网
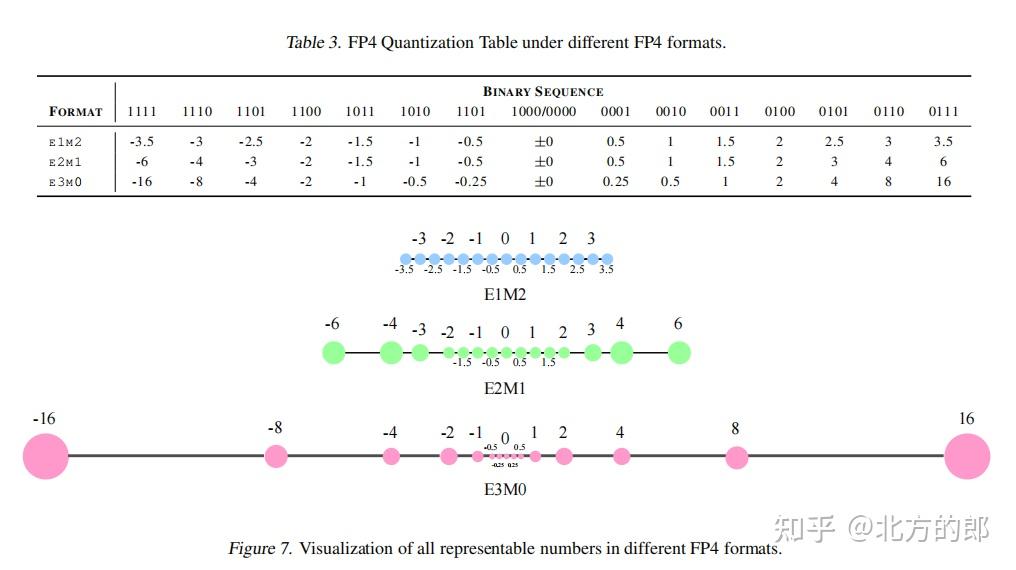
MXFP4, FP4, and FP8: How GPT-OSS Runs 120B Parameters on an 80GB GPU ...
Fine-grained FP8
如何使用 FP8 加速大模型训练 - NVIDIA 技术博客
NVIDIA TensorRT Unlocks FP4 Image Generation for NVIDIA Blackwell ...
NVIDIA Blackwell: The Impact of NVFP4 For LLM Inference - Edge AI and ...
does NVIDIA L20 GPUs support FP8 quantization? · Issue #1914 · NVIDIA ...
适用于有效 FP8 训练的按张量和按块扩展策略 - NVIDIA 技术博客
LTX-2 RTX Speed Guide: NVFP4 vs FP8 Tradeoffs (2026)
探索 FP8 训练中 Debug 思路与技巧 - NVIDIA 技术博客
NVIDIA GPU 架构下的 FP8 训练与推理 - 知乎
Contents of Megatron and related models (-LM by NVIDIA, -11B by ...
nvidia/Llama-3.1-Nemotron-70B-Instruct-HF · FP8 Quantized model now ...
Windows 11 and NVIDIA hacked on the first day of Pwn2Own Berlin 2026
Clive Chan on Twitter: "WIP FP8 training on consumer graphics cards - 🧵 ...
5 Key World Cup Storylines To Watch, From Messi And Ronaldo To USA's ...
fp8 transformer engine only brings 35% speed up? · Issue #396 · NVIDIA ...
DeepWiki Directory - AI-Powered GitHub Repository Encyclopedia
Top 5 AI Model Optimization Techniques for Faster, Smarter Inference ...
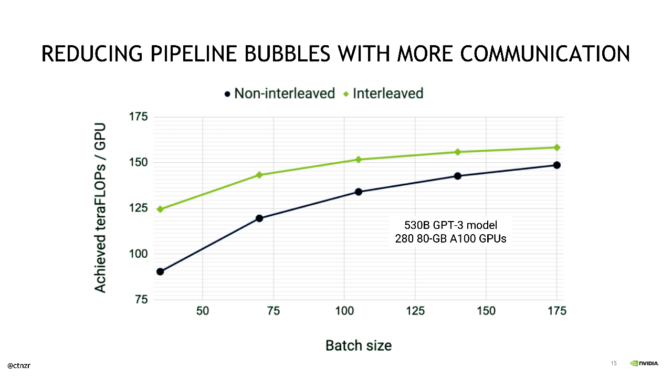
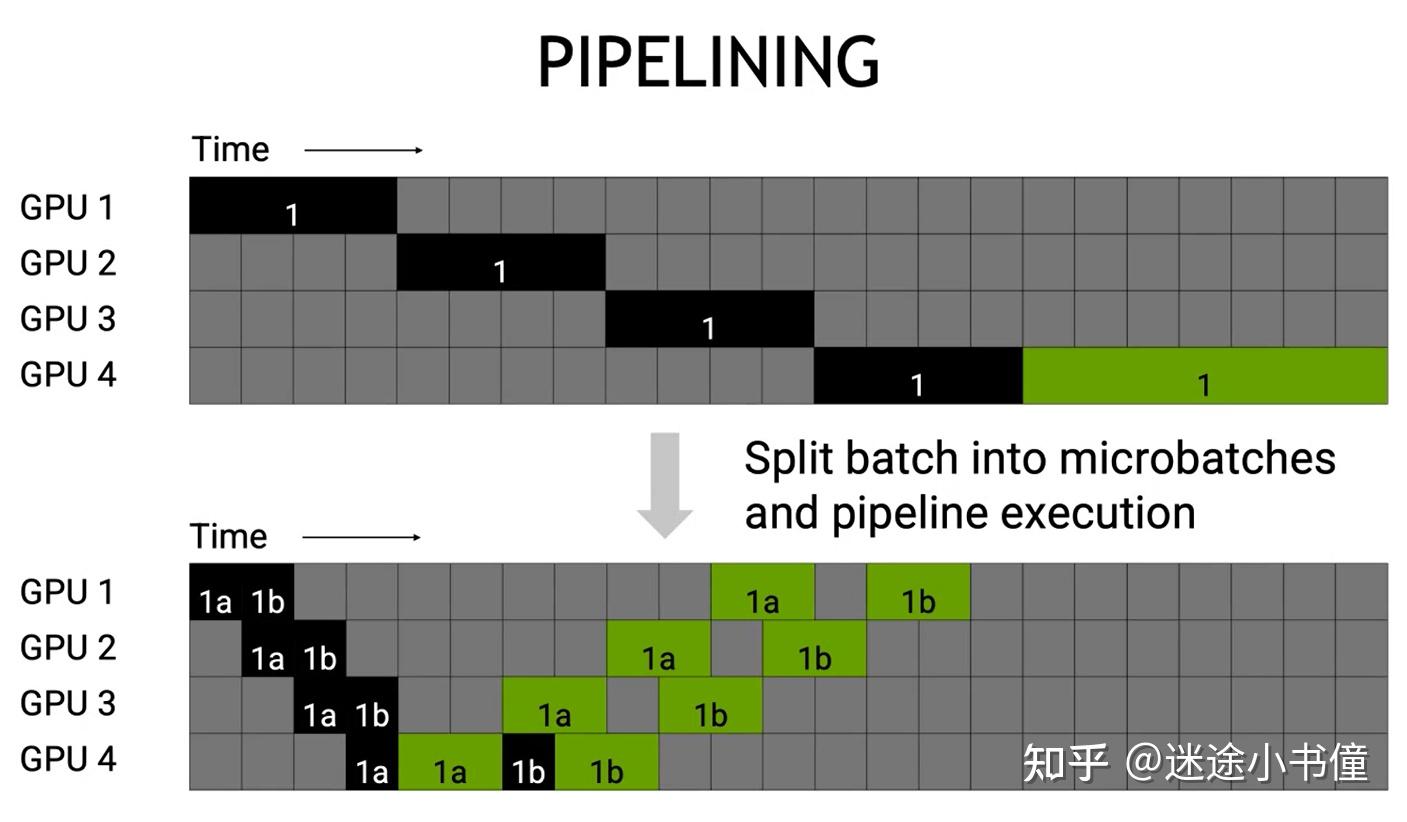
The Ultra-Scale Playbook: Training LLMs on GPU Clusters
LLM百倍推理加速之量化篇 - 知乎
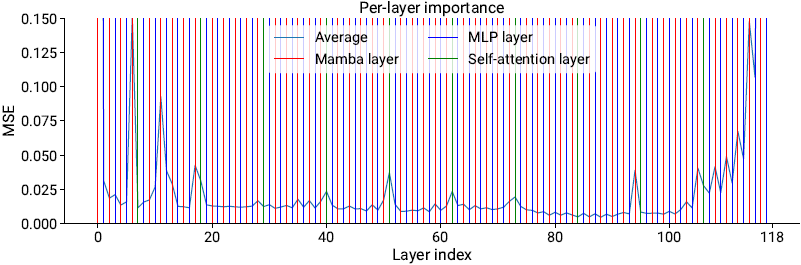
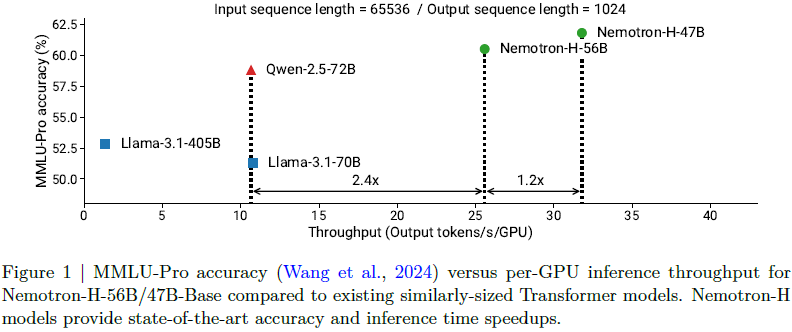
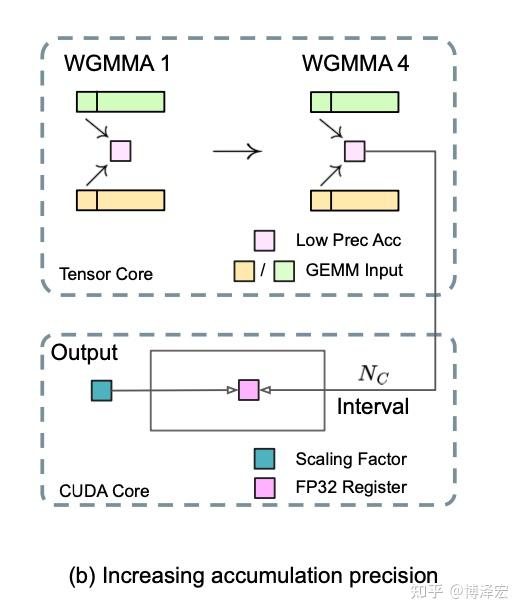
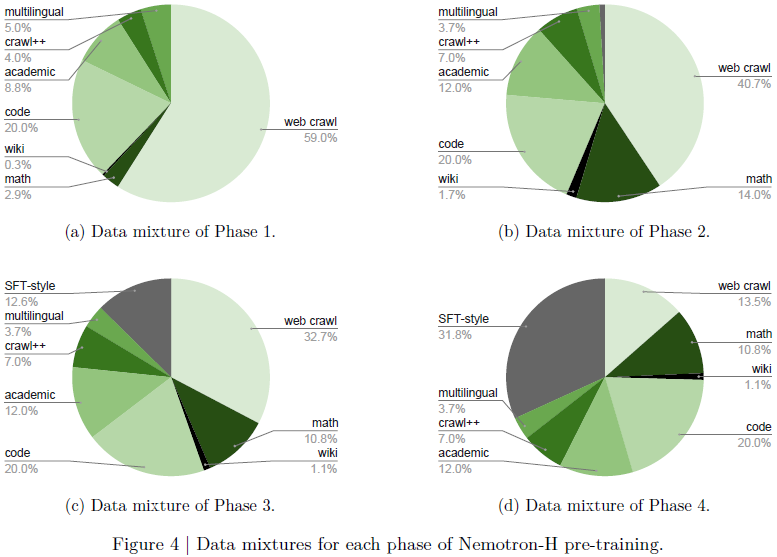
(2025|NVIDIA,压缩,FP8,VLM)Nemotron-H:精确高效的混合 Mamba-Transformer 家族 - 知乎
Chris Stratford C.Eng (MIET) B.Eng on LinkedIn: FP6 ? FPx everything it ...
NVIDIA Deep-Dives Into Blackwell Infrastructure: NV-HBI Used To Fuse ...
【GPT4技术揭秘】GPT-4 Architecture,Infrastructure,Training Dataset,Costs ...
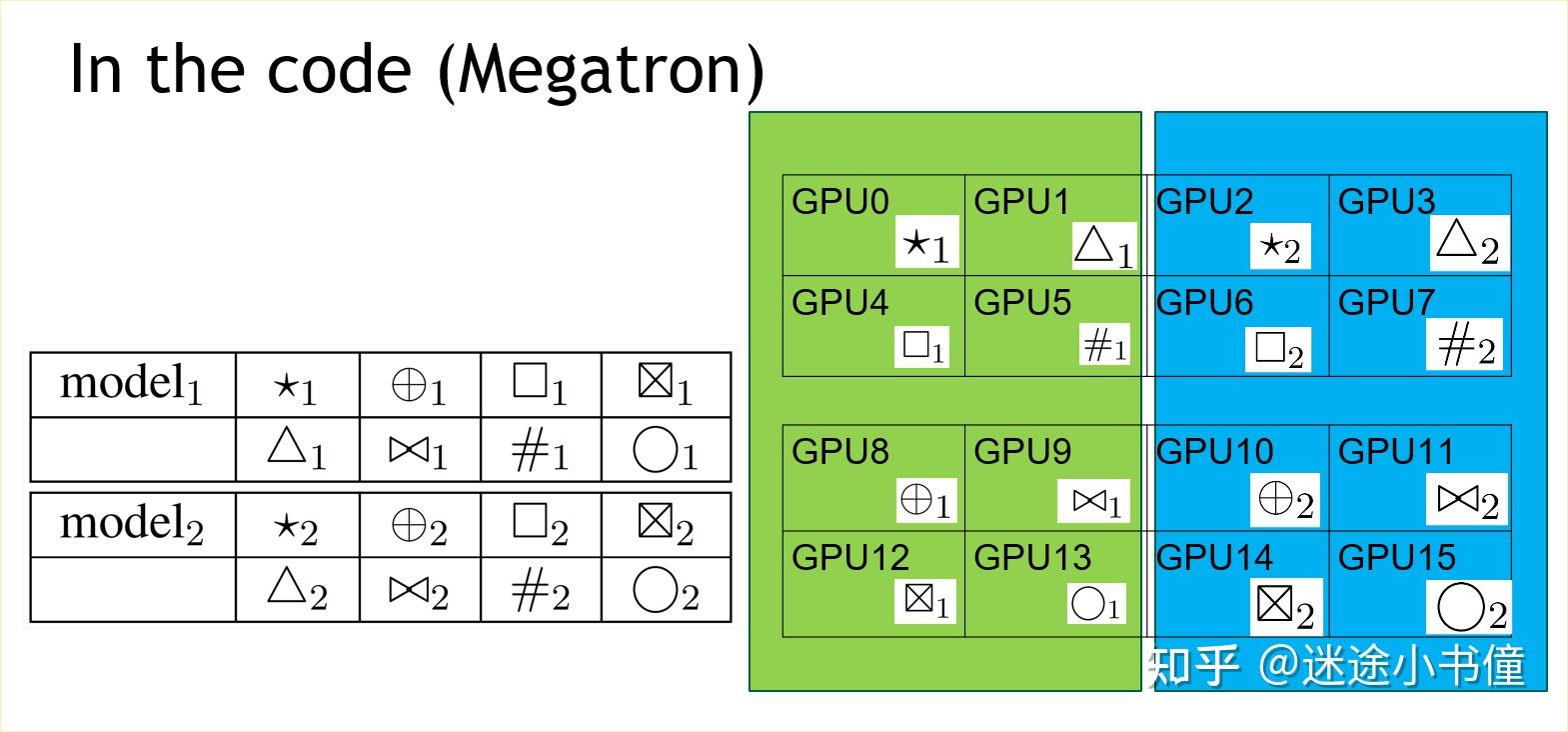
[细读经典]Megatron论文和代码详细分析(2) - 知乎
NVIDIA Blackwell Is Up & Running In Data Centers: NVLINK Upgraded To 1. ...
Cost-Effective GPU Solutions for Large Model Inference
Deep Learning Performance Characterization on GPUs for Various ...
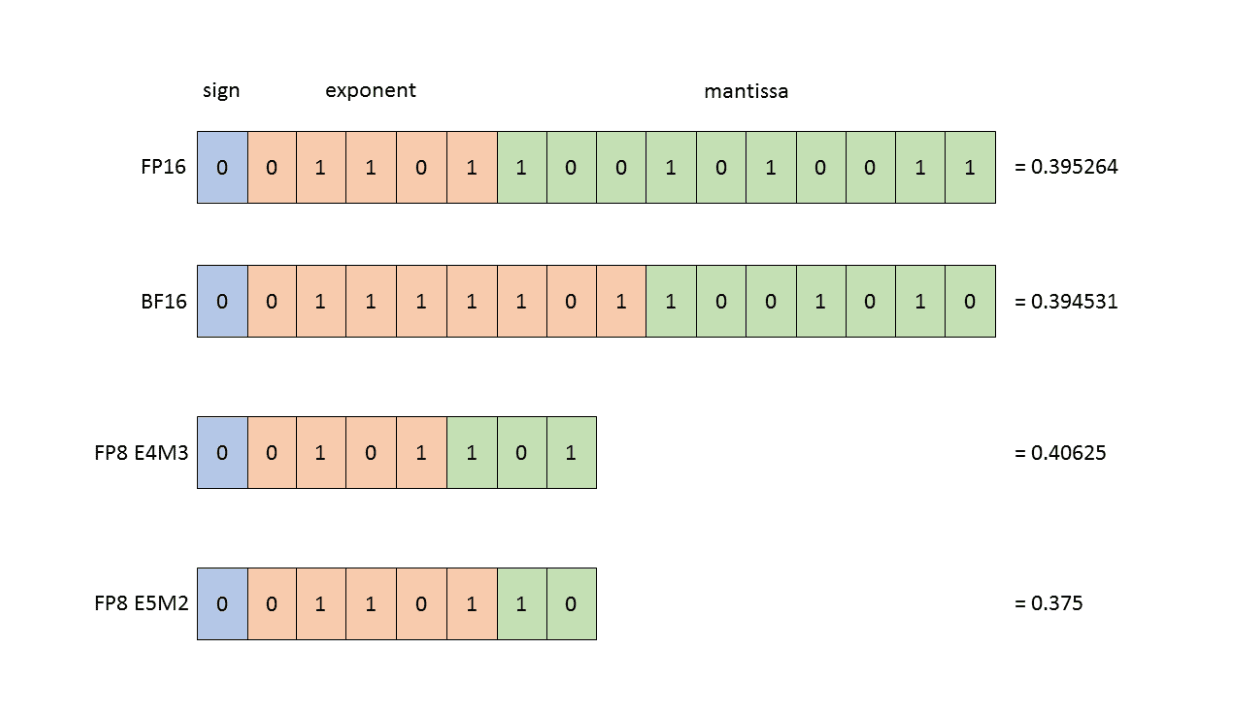
NVIDIA, Intel & ARM Bet Their AI Future on FP8, Whitepaper For 8-Bit FP ...
量化那些事之FP8与LLM-FP4 - 知乎
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
Megatron-LM GPT 源码分析(二) Sequence Parallel分析_megatron-lm的gpt模型-CSDN博客
@ImranzamanML on Hugging Face: "Today lets discuss about 32-bit (FP32 ...
Designing Deep Learning Models on FPGA with Multiple Heterogeneous ...
DeepSeek-V3的FP8训练还不够极致?来看FP4量化训练如何突破算力极限 - 知乎
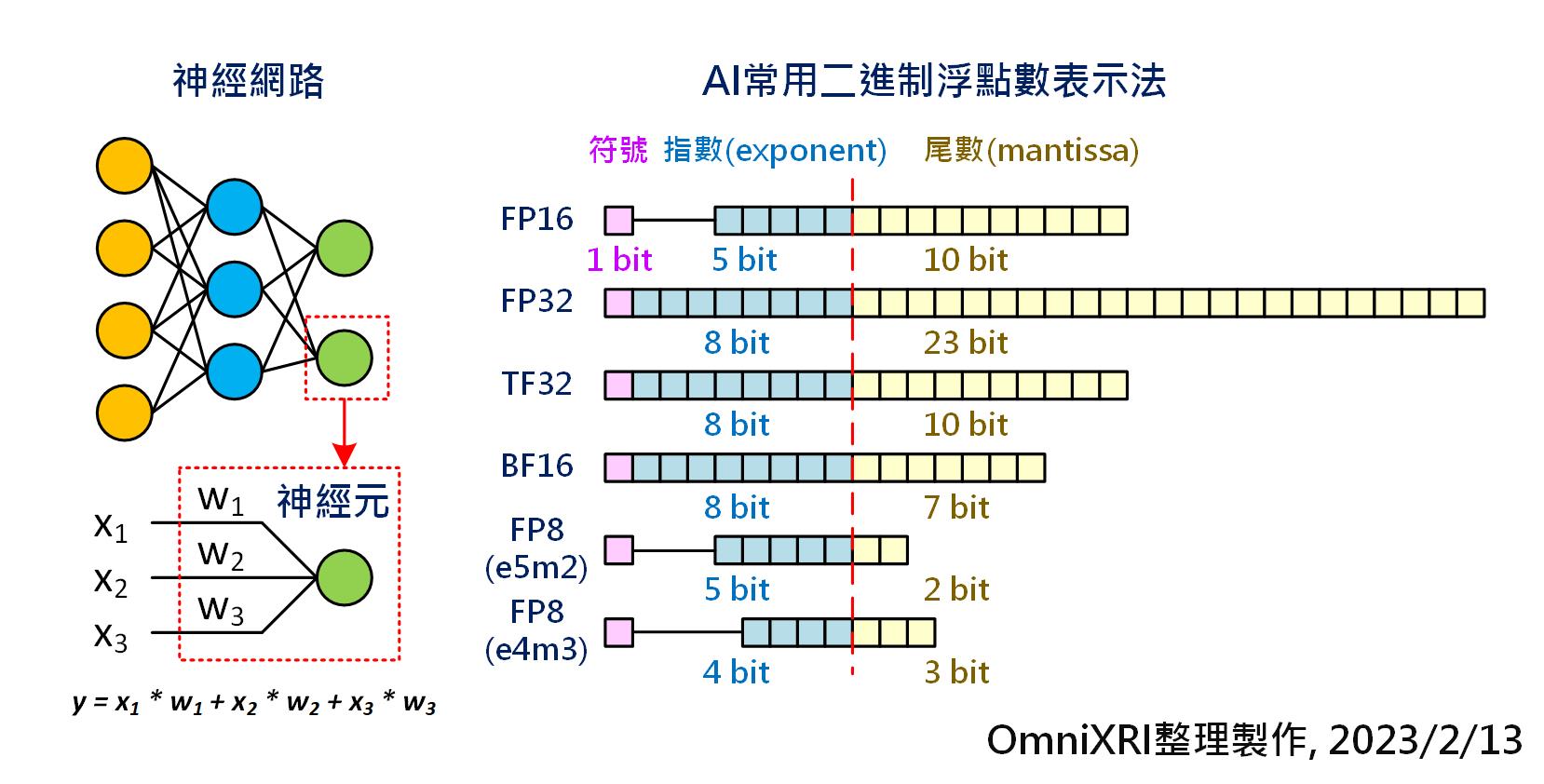
大模型量化技术原理:FP8_e4m3-CSDN博客
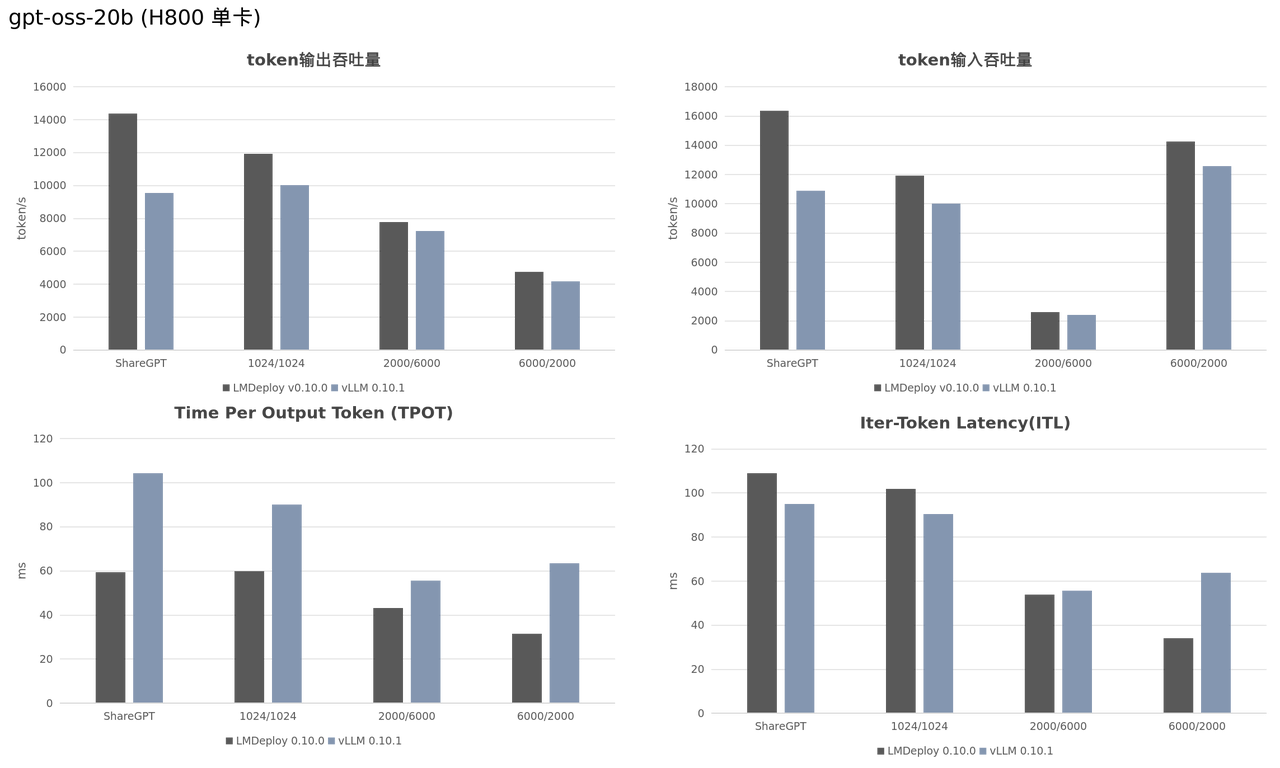
LMDeploy全面升级,FP8、MXFP4一网打尽,推理性能再创新高! - 知乎
Megatron Unleashed: NVIDIA's NLP Model "Megatron-LM" is the Largest ...
【小白学习笔记】FP8 量化基础 - 英伟达 - 知乎
Full-Stack Innovation Fuels Highest MLPerf Inference 2.1 Results for ...
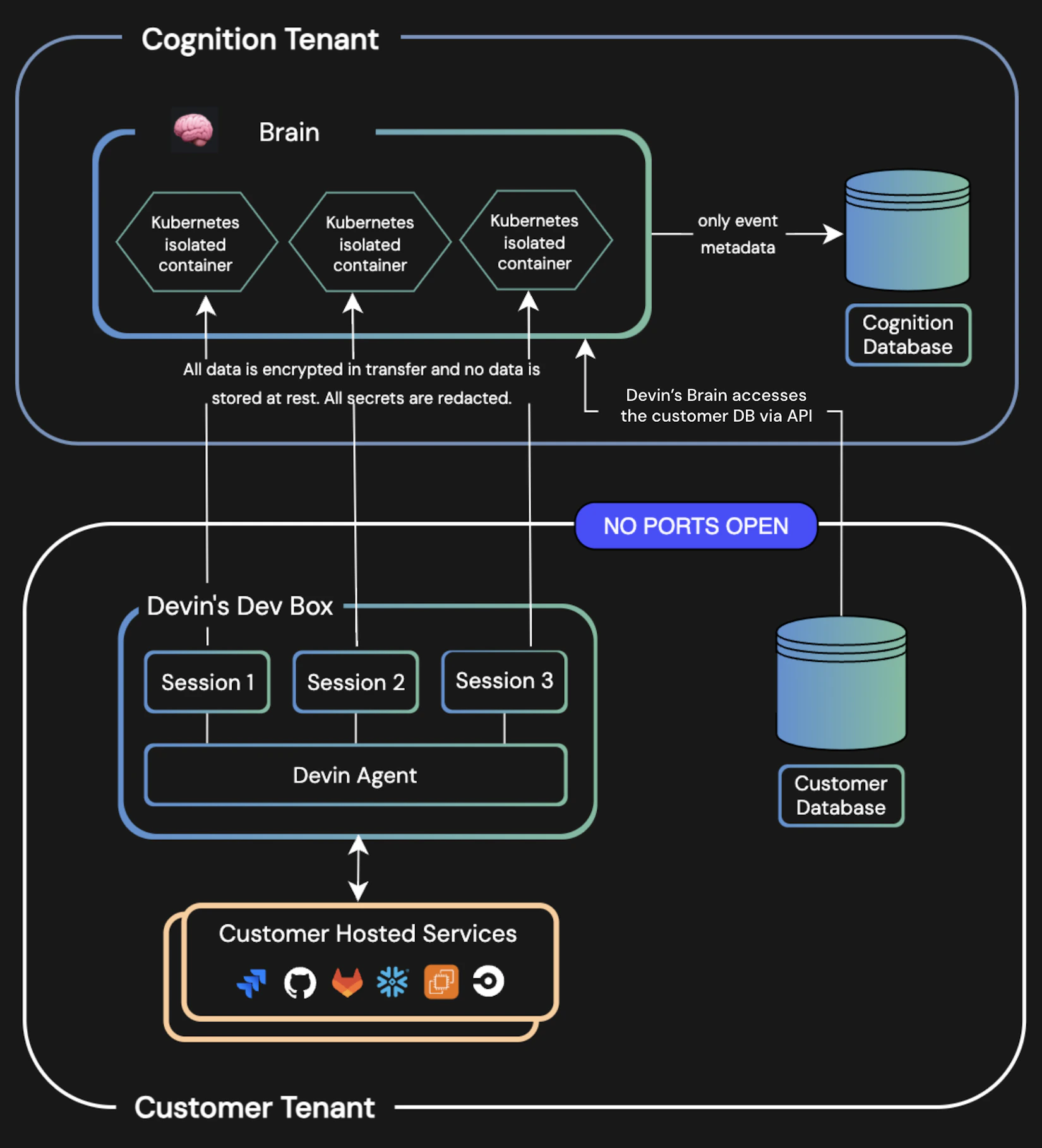
Enterprise Deployment - Devin Docs
Guidance for Payment Connectivity, Gateway, Orchestration & Routing on AWS
疯狂的 H100:现代 GPU 体系结构浅析,从算力焦虑开始聊起-CSDN博客
Distributed Training: DeepSpeed ZeRO 1/2/3 + Accelerate, Megatron-LM ...
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度_风闻
DeepSeek-V3 FP8量化浅析 - 知乎
Summit加速成癮性研究和超導體等各領域科研進步 - 每日頭條
NVIDIA造了个2080亿晶体管的怪物:FP4性能高达4亿亿次每秒--快科技--科技改变未来
NVIDIA-Megatron-LM/tools/preprocess_data.py at main · f1ynn-zhan9 ...
大模型加速黑科技:FP8量化技术如何让推理速度飞起来!_大模型如何fp8量化-CSDN博客
Hantavirus live updates: Americans in quarantine seen in good spirits
完全用FP8来进行大模型的训练和推理是否会在不久的将来成为现实? - 知乎
(2025|NVIDIA,压缩,FP8,VLM)Nemotron-H:精确高效的混合 Mamba-Transformer 家族 ...
歐尼克斯實境互動工作室(OmniXRI): Nvidia GTC 2024 提出的 FP8/FP4 如何加速AI訓練及推論