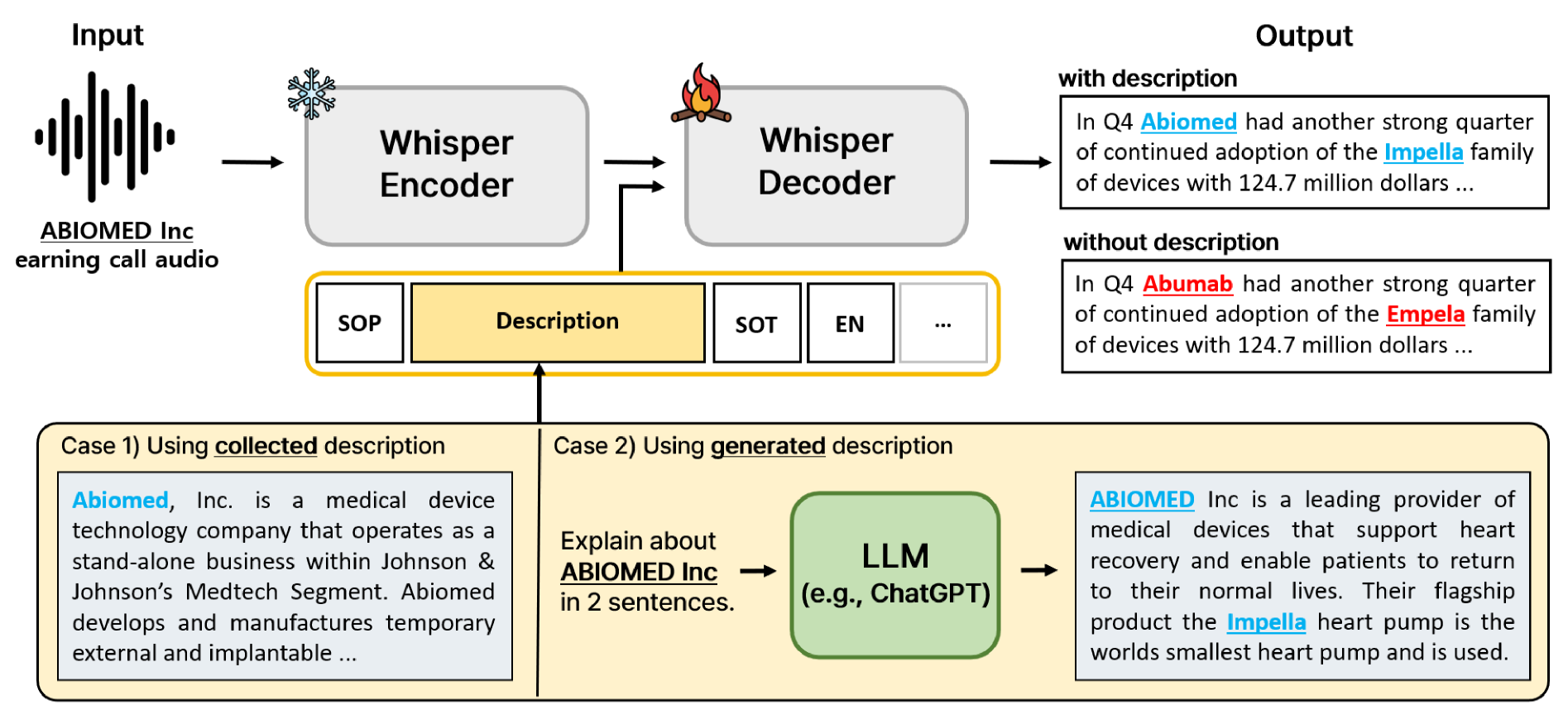
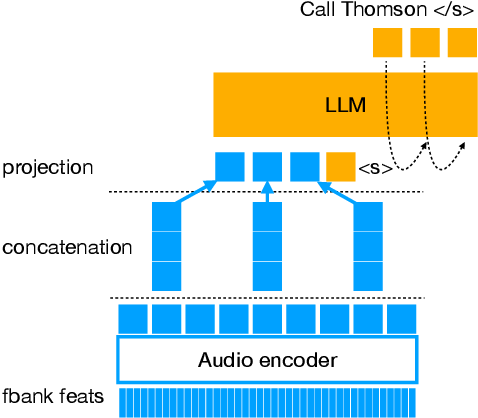
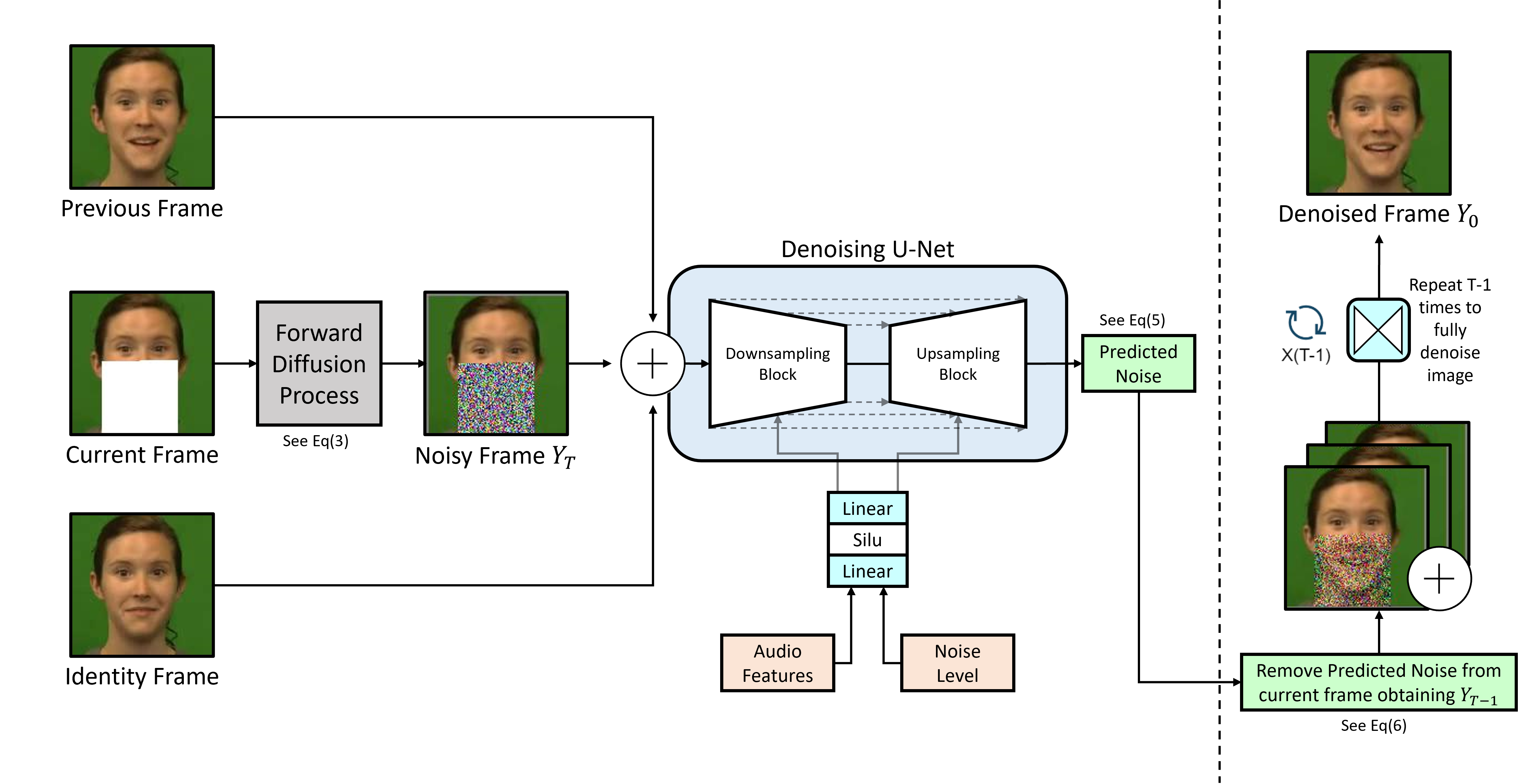
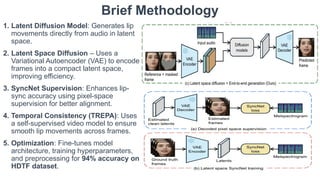
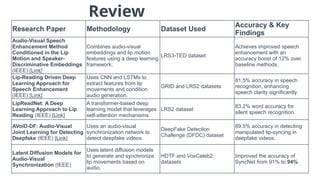
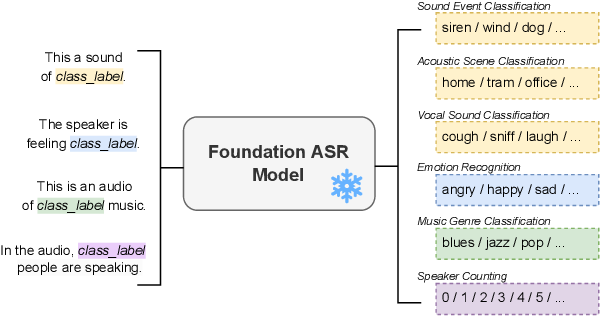
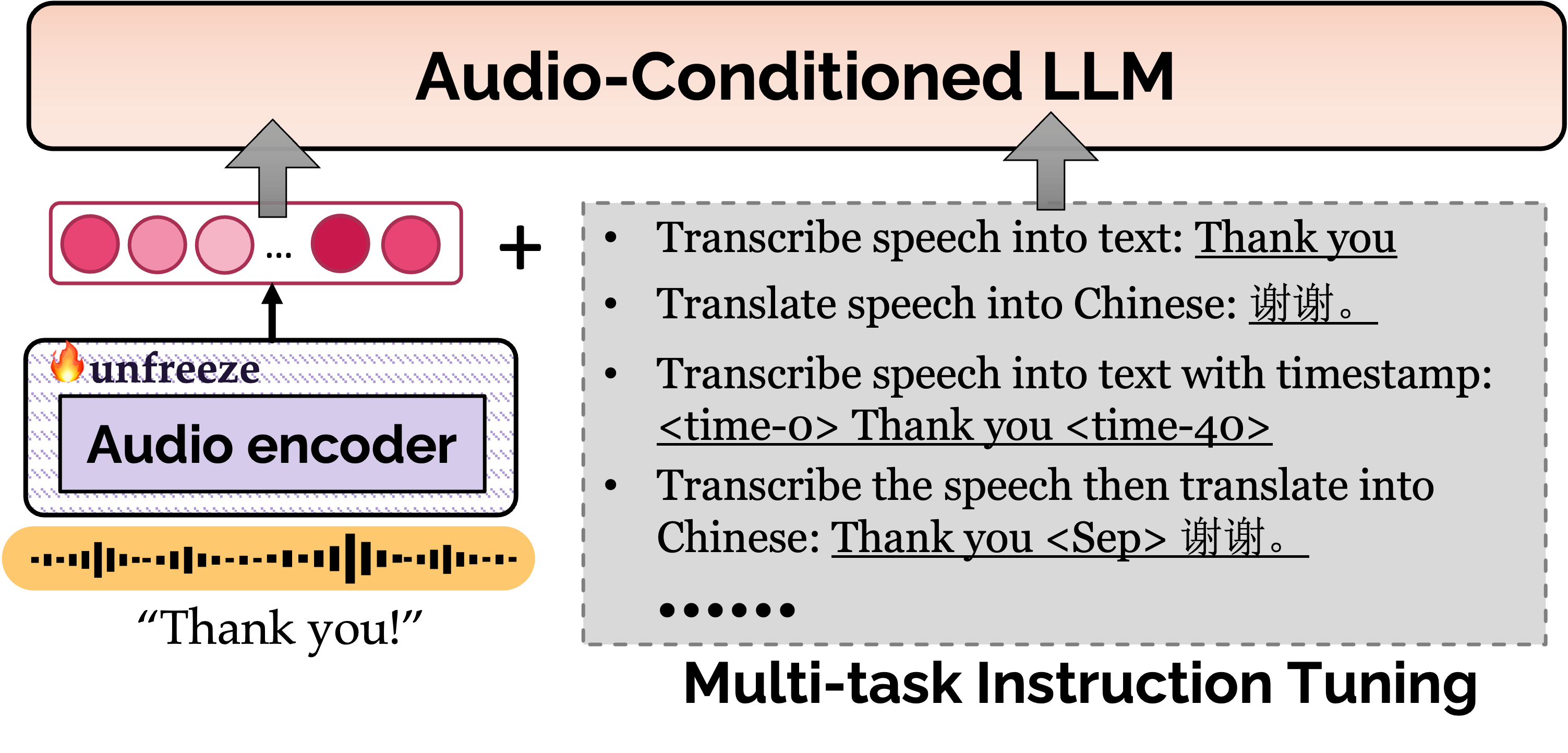
Audio-Conditioned Diffusion LLMs for ASR and Deliberation Processing ...
Paper page - Explore the Reinforcement Learning for the LLM based ASR ...
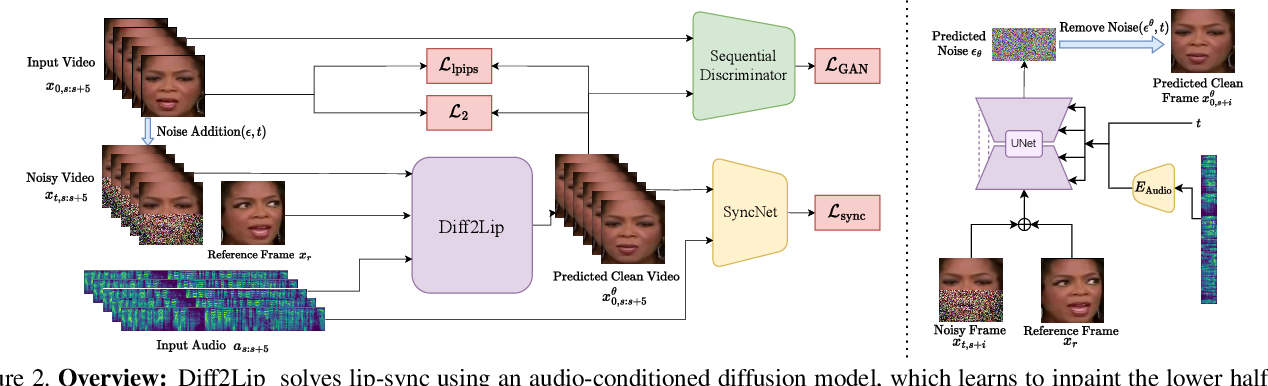
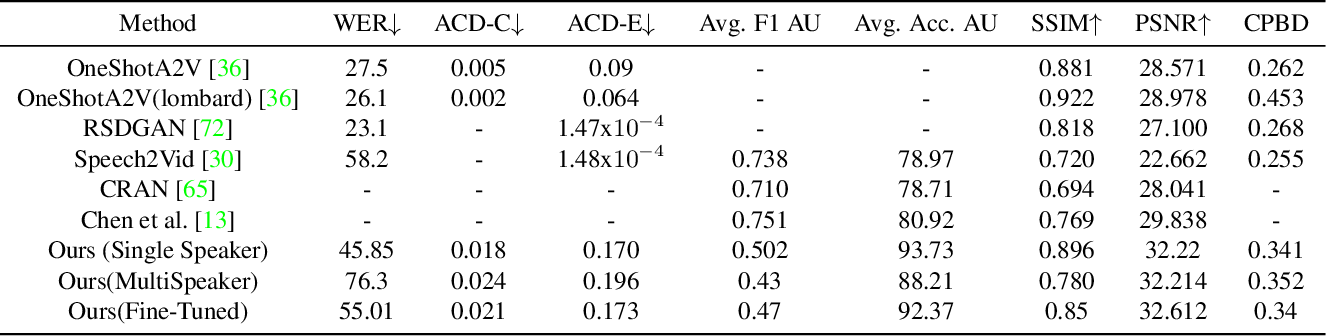
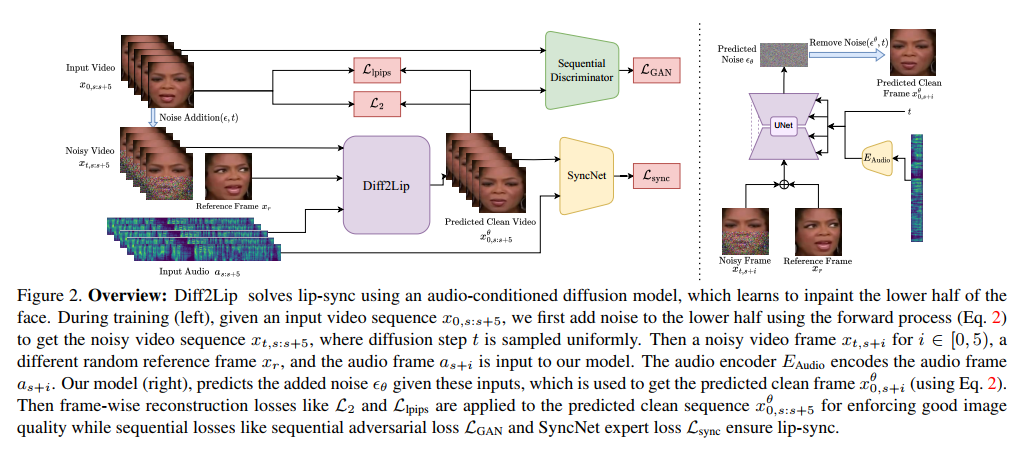
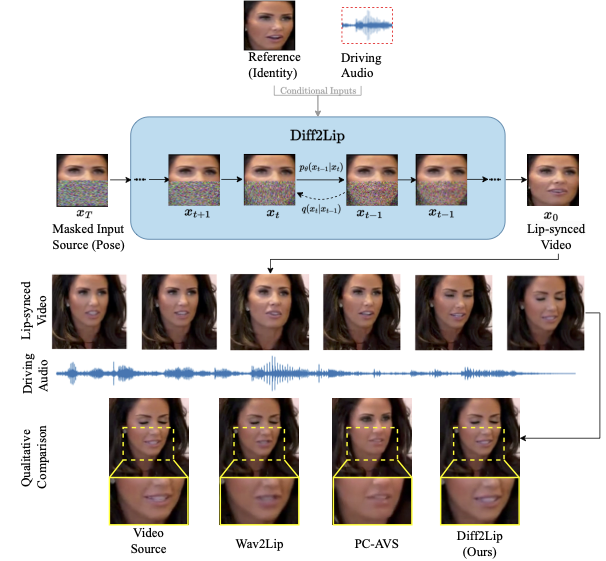
Paper page - Diff2Lip: Audio Conditioned Diffusion Models for Lip ...
Paper page - Label-free Motion-Conditioned Diffusion Model for Cardiac ...
Paper page - Pointmap-Conditioned Diffusion for Consistent Novel View ...
Paper page - AudioToken: Adaptation of Text-Conditioned Diffusion ...
Paper page - AudioMarathon: A Comprehensive Benchmark for Long-Context ...
Paper page - Seed-ASR: Understanding Diverse Speech and Contexts with ...
Paper page - Boosting CTC-Based ASR Using LLM-Based Intermediate Loss ...
Paper page - Noise-to-Notes: Diffusion-based Generation and Refinement ...
Paper page - Soundwave: Less is More for Speech-Text Alignment in LLMs
Paper page - Audio Conditioning for Music Generation via Discrete ...
Paper page - USAD: Universal Speech and Audio Representation via ...
Paper page - SkyReels-Audio: Omni Audio-Conditioned Talking Portraits ...
Paper page - Audiobox TTA-RAG: Improving Zero-Shot and Few-Shot Text-To ...
Paper page - EditYourself: Audio-Driven Generation and Manipulation of ...
Paper page - Aligning Diffusion Models with Noise-Conditioned Perception
ASR Uncertainty in LLMs for SLU | PDF | Speech Recognition | Cognitive ...
Paper page - From Discrete Tokens to High-Fidelity Audio Using Multi ...
Paper page - Pitch-Conditioned Instrument Sound Synthesis From an ...
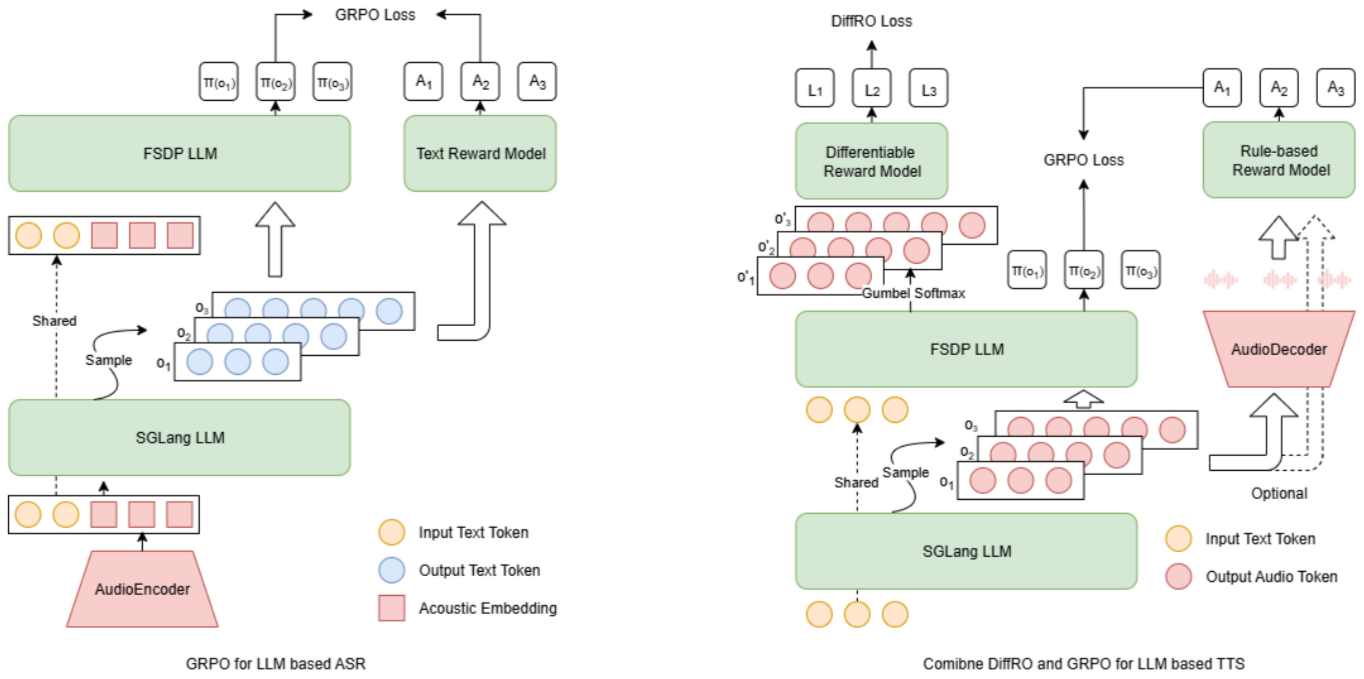
[论文评述] Explore the Reinforcement Learning for the LLM based ASR and TTS ...
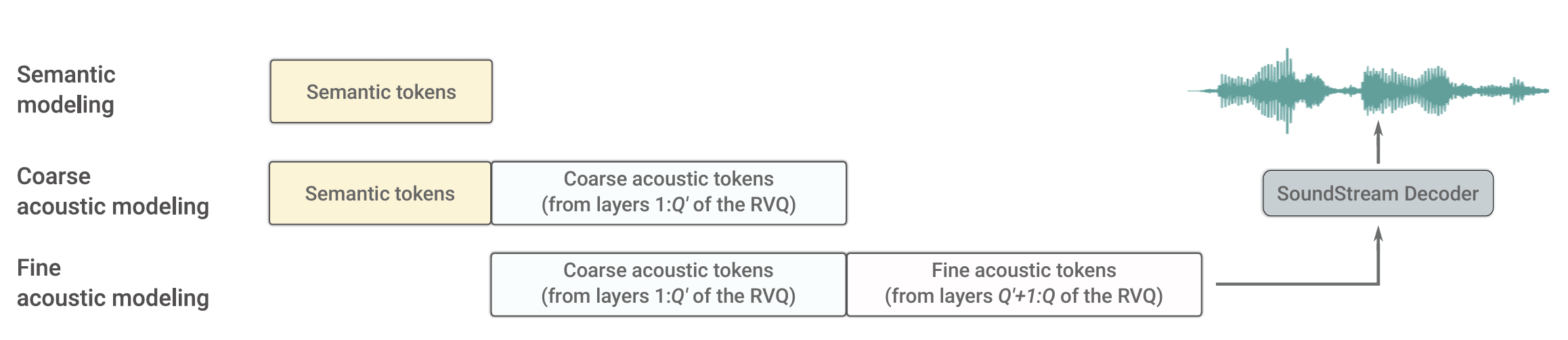
Paper page - AV2Wav: Diffusion-Based Re-synthesis from Continuous Self ...
Paper page - Loopy: Taming Audio-Driven Portrait Avatar with Long-Term ...
Paper page - Low-Bitrate Video Compression through Semantic-Conditioned ...
Paper page - Semantica: An Adaptable Image-Conditioned Diffusion Model
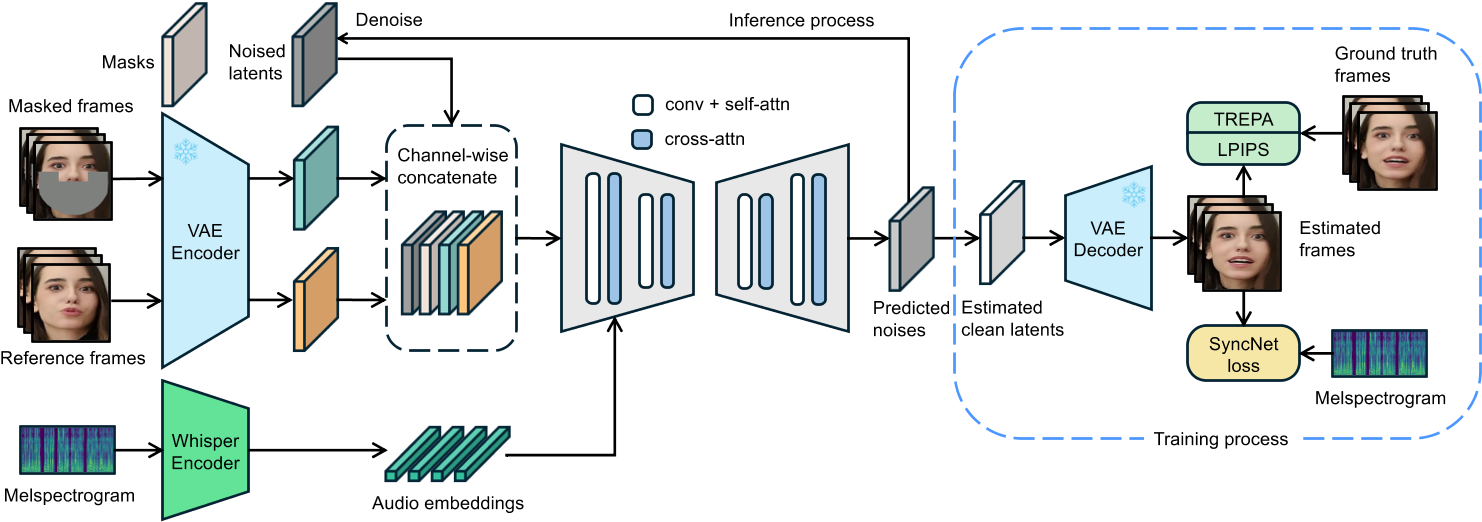
LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync - 智源社区论文
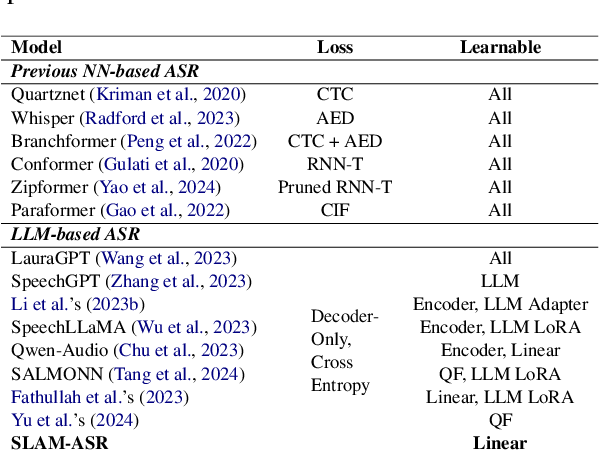
Simple SLAM-ASR for Effective ASR | PDF | Speech Recognition | Data ...
Figure 2 from Diff2Lip: Audio Conditioned Diffusion Models for Lip ...
Речевые технологии #10 Audio-conditioned LLMs - YouTube
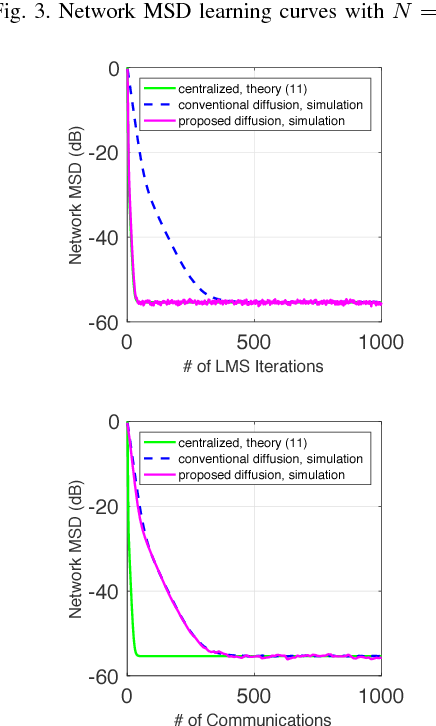
(PDF) Diffusion LMS with Communication Delays: Stability and ...
Table 1 from An Embarrassingly Simple Approach for LLM with Strong ASR ...
GitHub - DanBigioi/DiffusionVideoEditing: Official project repo for ...
(PDF) Diffusion LMS for Distributed Estimation over Wireless Networks ...
Conformer for Speech Enhancement ASR | PDF | Speech Recognition ...
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model ...
(PDF) Reduced-Communication Diffusion LMS Strategy for Adaptive ...
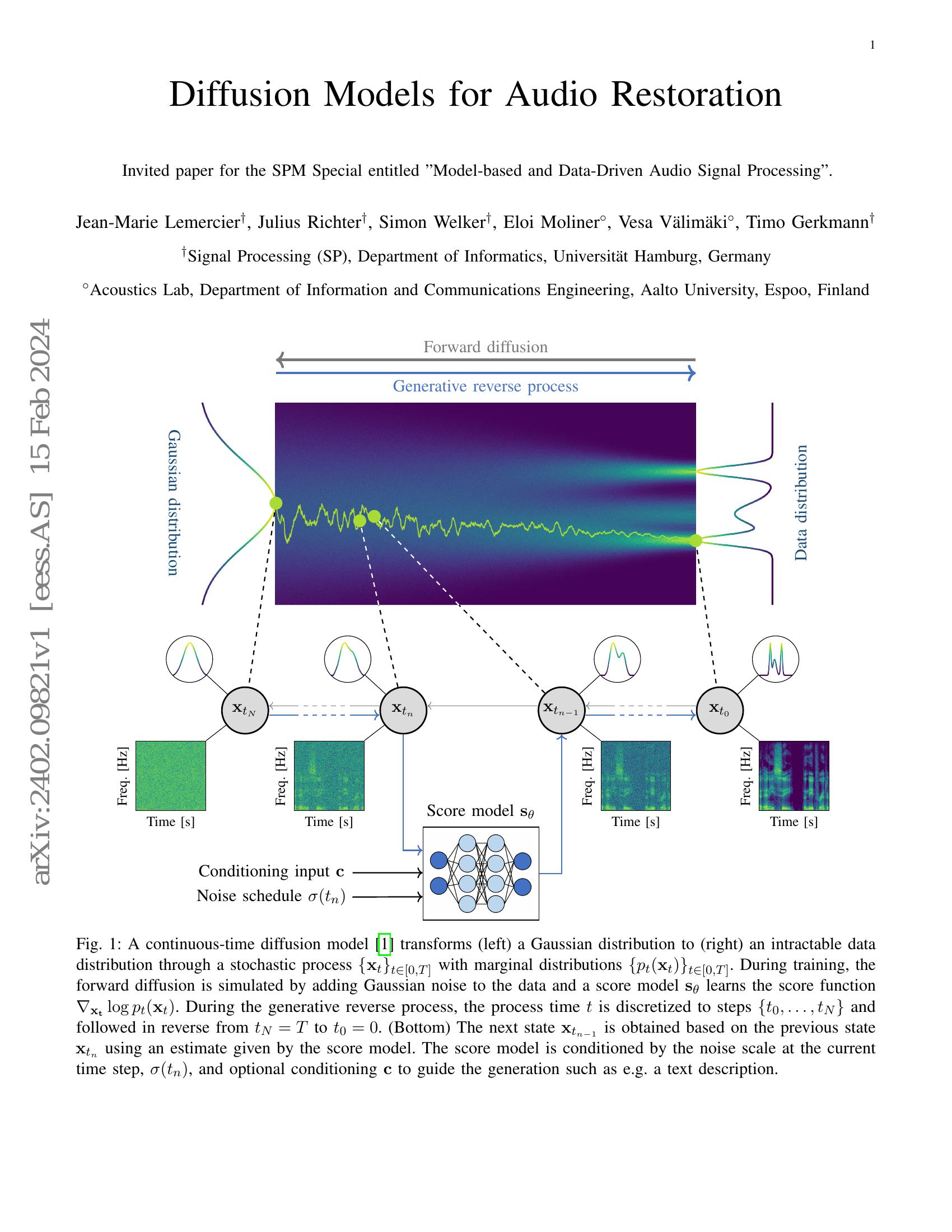
Diffusion Models for Audio Restoration - 智源社区论文
A Universally-Deployable ASR Frontend for Joint Acoustic Echo ...
LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync ...
【唇形同步】Diff2Lip: Audio Conditioned Diffusion Models for Lip ...
Is what mentioned in this paper real? | Page 3 | Audio Science Review ...
A Watermark-Conditioned Diffusion Model for IP Protection - 智源社区论文
Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to ...
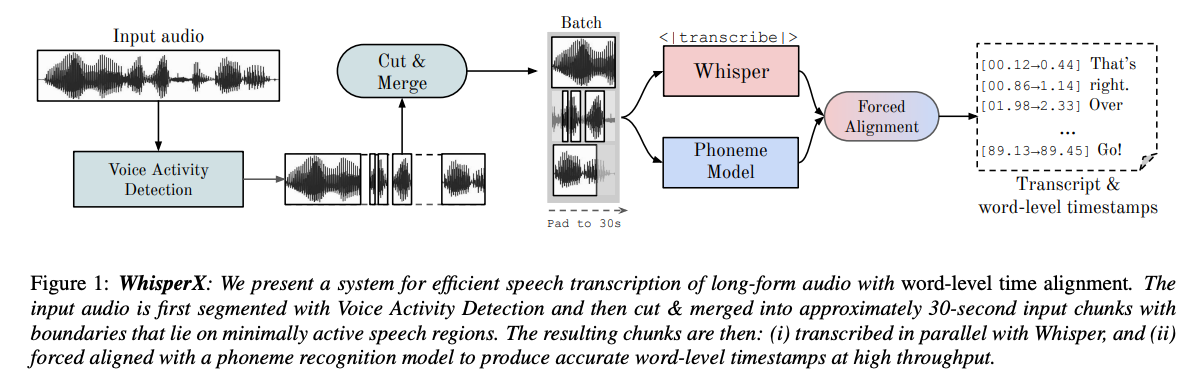
ASR | Paper reading | Tìm hiểu cách sử dụng model Whisper Speech-to ...
Bridging the Modality Gap: Softly Discretizing Audio Representation for ...
[2407.17874] Improving Domain-Specific ASR with LLM-Generated ...
[論文レビュー] LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based ...
(PDF) Speech Driven Video Editing via an Audio-Conditioned Diffusion Model
AK on Twitter: "AudioToken: Adaptation of Text-Conditioned Diffusion ...
AudioToken: Adaptation of Text-Conditioned Diffusion Models for#N ...
The proposed three-stage training strategy. a The first end-to-end ASR ...
(PDF) Diff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization
(PDF) A Study on Combined Effects of Reverberation and Increased Vocal ...
Diff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization
[2303.13336 ] A Survey on Audio Diffusion Models Text To Speech ...
[论文评述] Contextualization of ASR with LLM using phonetic retrieval-based ...
Table 2 from Fast Timing-Conditioned Latent Audio Diffusion | Semantic ...
[论文评述] The Multicultural Medical Assistant: Can LLMs Improve Medical ...
(PDF) Speaker Localization for Microphone Array-Based ASR: The Effects ...
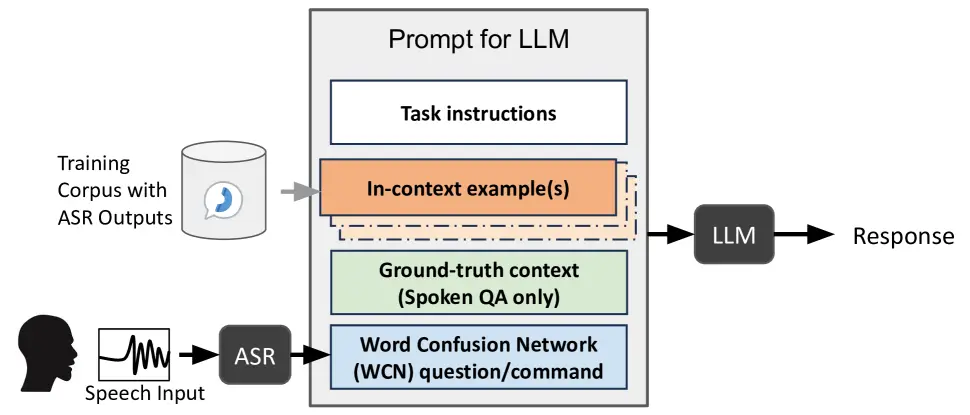
Figure 1 from Contextualization of ASR with LLM using phonetic ...
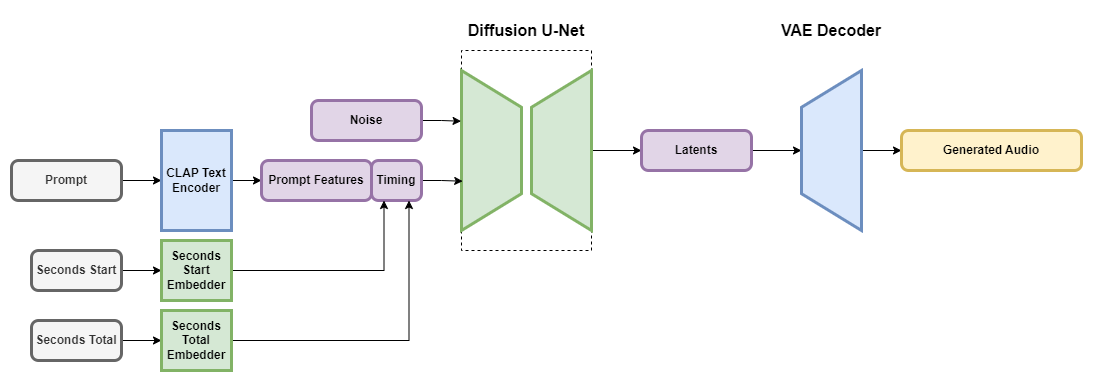
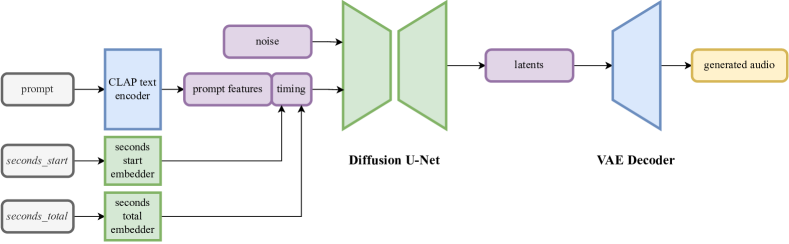
Fast Timing-Conditioned Latent Audio Diffusion - 智源社区论文
Text-to-Audio Generation using Instruction-Tuned LLM and Latent ...
Fast Timing-Conditioned Latent Audio Diffusion https://bit.ly/3UQN5n4 ...
(PDF) Adaptation and Optimization of Automatic Speech Recognition (ASR ...
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model
Figure 4 from Diffusion LMS Based on Message Passing Algorithm ...
(PDF) Building Accurate Low Latency ASR for Streaming Voice Search
Table 1 from Fast Timing-Conditioned Latent Audio Diffusion | Semantic ...
(PDF) Data-Reserved Periodic Diffusion LMS With Low Communication Cost ...
(PDF) Influence of Different Speech Representations and HMM Training ...
(PDF) Adaptive Listening Difficulty Detection for L2 Learners Through ...
Contextualization of ASR with LLM using phonetic retrieval-based ...
Diffsound: Discrete Diffusion Model for Text-to-sound Generation | DeepAI
Steps involved in ASR system Initially the speech waveform is processed ...
Audio-visual fine-tuning of audio-only ASR models - 智源社区论文
SonicDiffusion: Audio-Driven Image Generation and Editing with ...
(PDF) Sound generation by airborne air conditioning systems: theory and ...
Audio Science Review AES Paper Presentation on Audio DACs - YouTube
Improving ASR Models Using LLM-Powered Workflow
Stable Audio: Fast Timing-Conditioned Latent Audio Diffusion — Stability AI
Audio LLMs | Loong's Lens
(PDF) On Reducing the Communication Cost of the Diffusion LMS Algorithm
LatentSync Audio conditioned latent diffusion models | PPTX
An approach to measuring the performance of Automatic Speech ...
(PDF) Noise2Music: Text-conditioned Music Generation with Diffusion Models
Seed Asr Diverse Speech LLM | PDF | Speech Recognition | Machine Learning
Audio Generation with Multiple Conditional Diffusion Model | DeepAI
Figure 1 from Investigating the Emergent Audio Classification Ability ...
ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language ...
Enhanced Example Diffusion Model via Style Perturbation
(PDF) Diffusion LMS Strategies in Sensor Networks With Noisy Input Data
(PDF) An Event-Based Diffusion LMS Strategy
Paper2 Asr | PDF
(PDF) A variable step-size diffusion LMS algorithm with a quotient form
(PDF) Doubly compressed diffusion LMS over adaptive networks
🚨Paper Alert 🚨 ️Paper Title: LatentSync: Audio Conditioned Latent ...
Speech Enhancement Paper at Elaine Osborn blog
(PDF) Diffusion LMS Over Multitask Networks
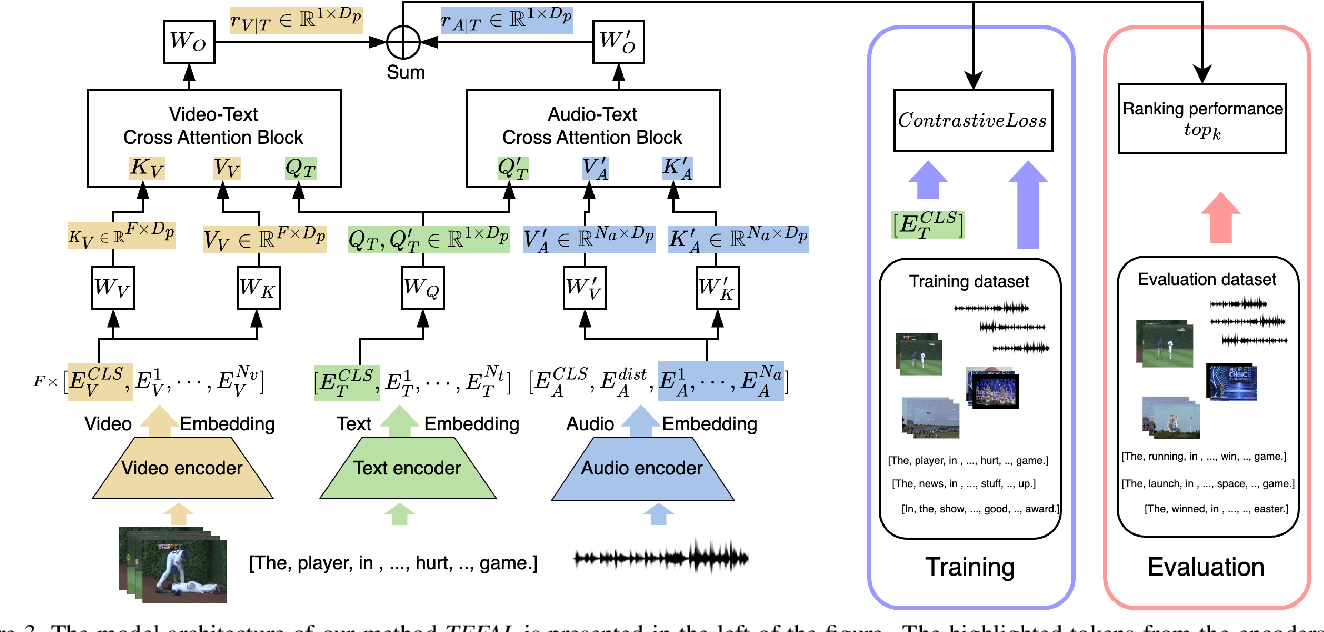
Figure 3 from Audio-Enhanced Text-to-Video Retrieval using Text ...
(PDF) AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
(PDF) Acoustic Assessment of Disordered Voice with Continuous Speech ...
(PDF) Learning Magnitude Distribution of Sound Fields via Conditioned ...
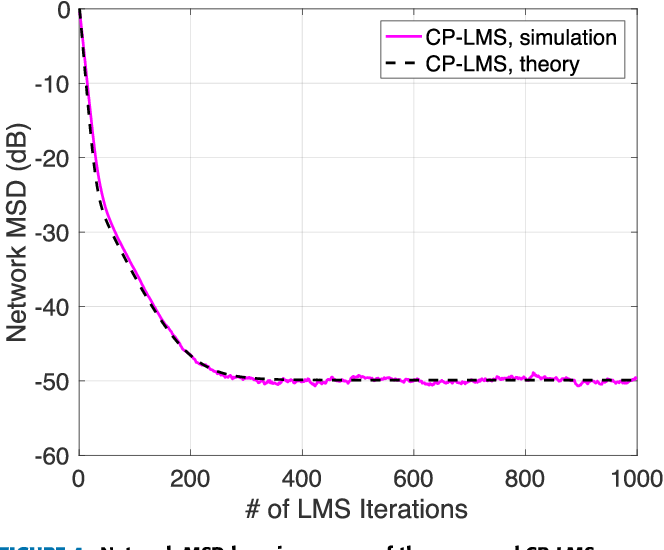
Figure 4 from Diffusion LMS using consensus propagation | Semantic Scholar
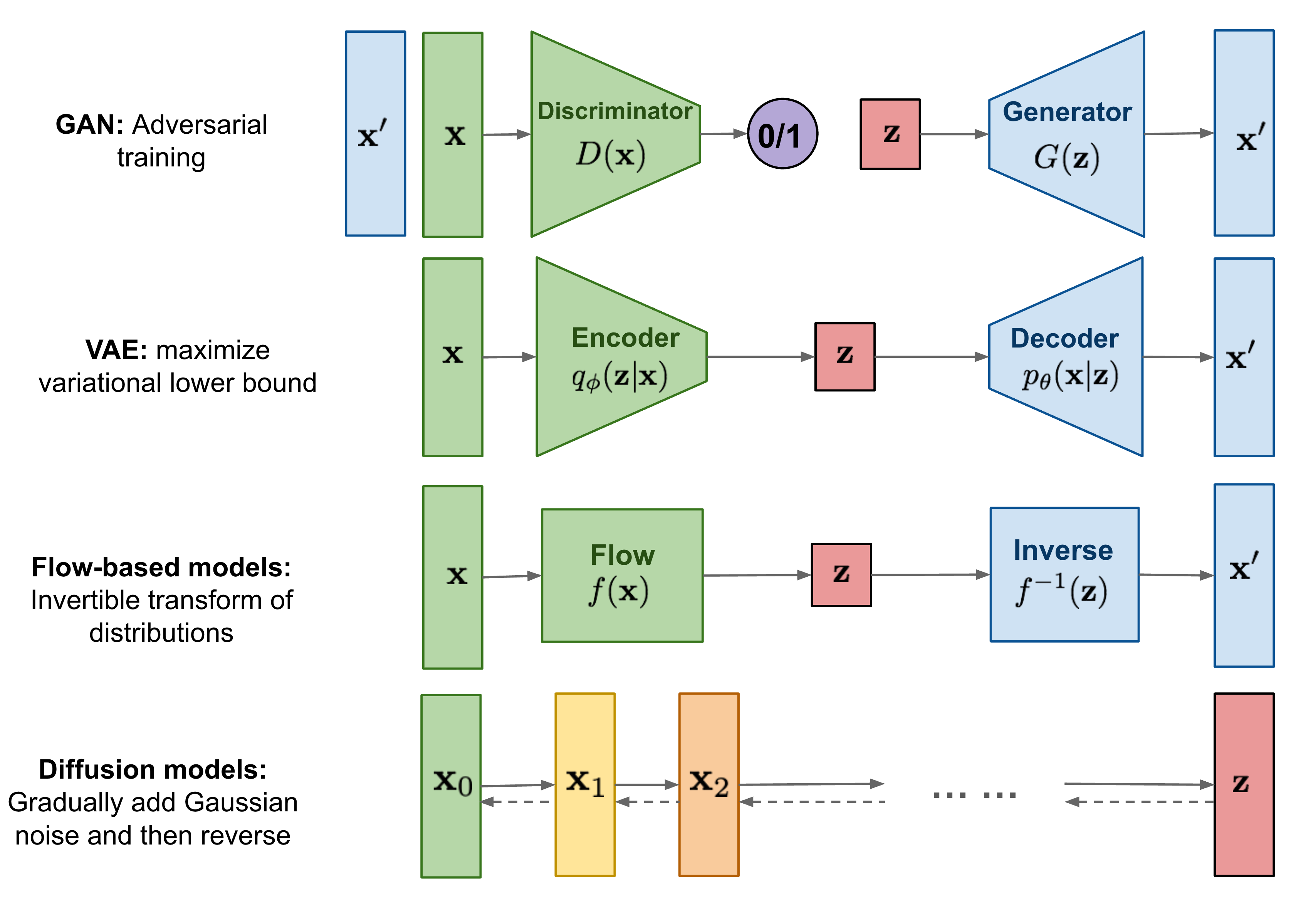
Stable Diffusion(1) - Generative Model Basics
Robust competitive diffusion LMS algorithm | Request PDF
[2402.04825] Fast Timing-Conditioned Latent Audio Diffusion
LLMに音声を聴かせる🎧 → 🧠 →📝 〜 LLM Based ASR〜
LLM-ST
TTS | Talk2Paper
Interspeech2024에서 발견한 LLM
Text-conditioned Audio Editing | Yoonjin