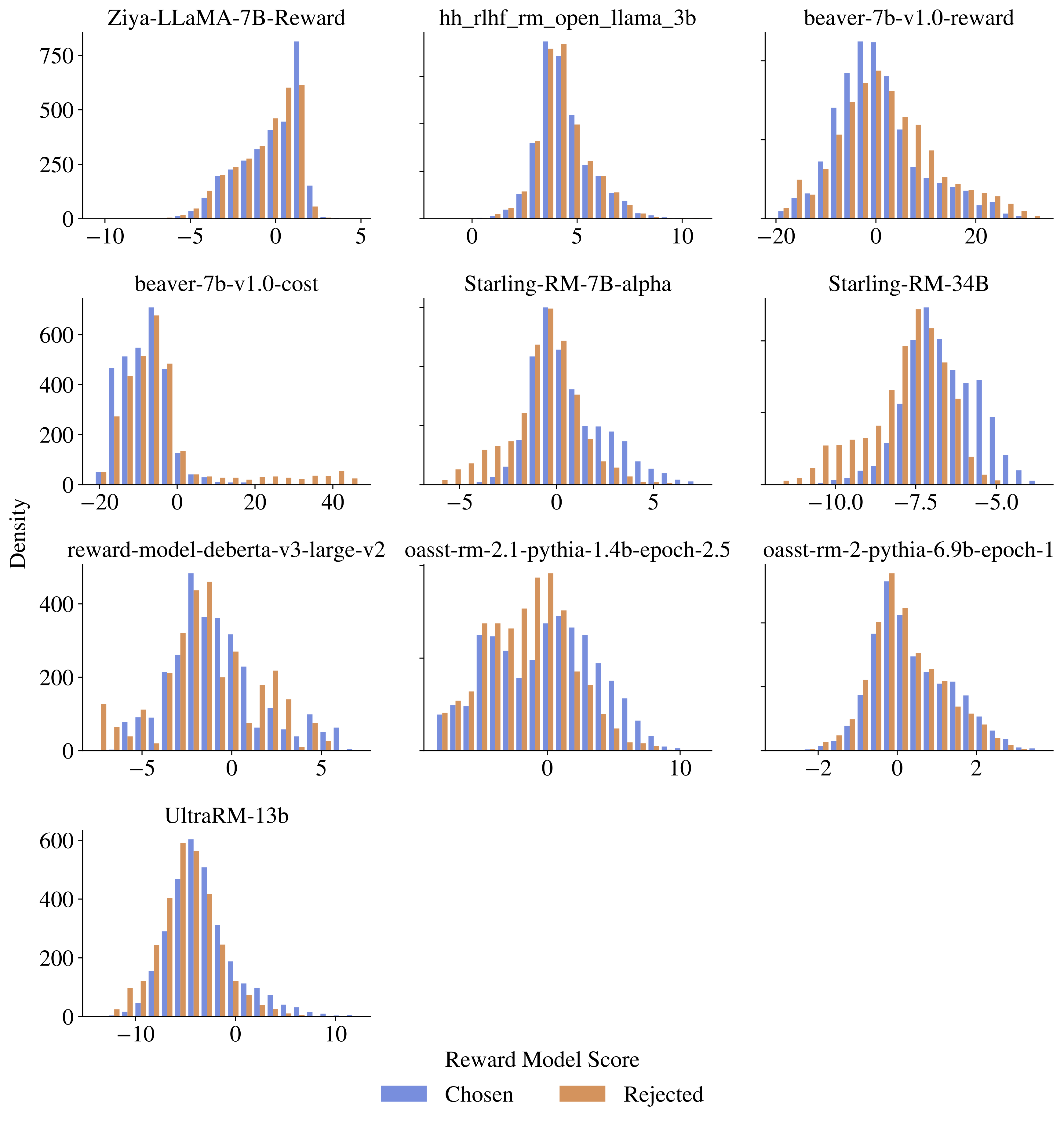
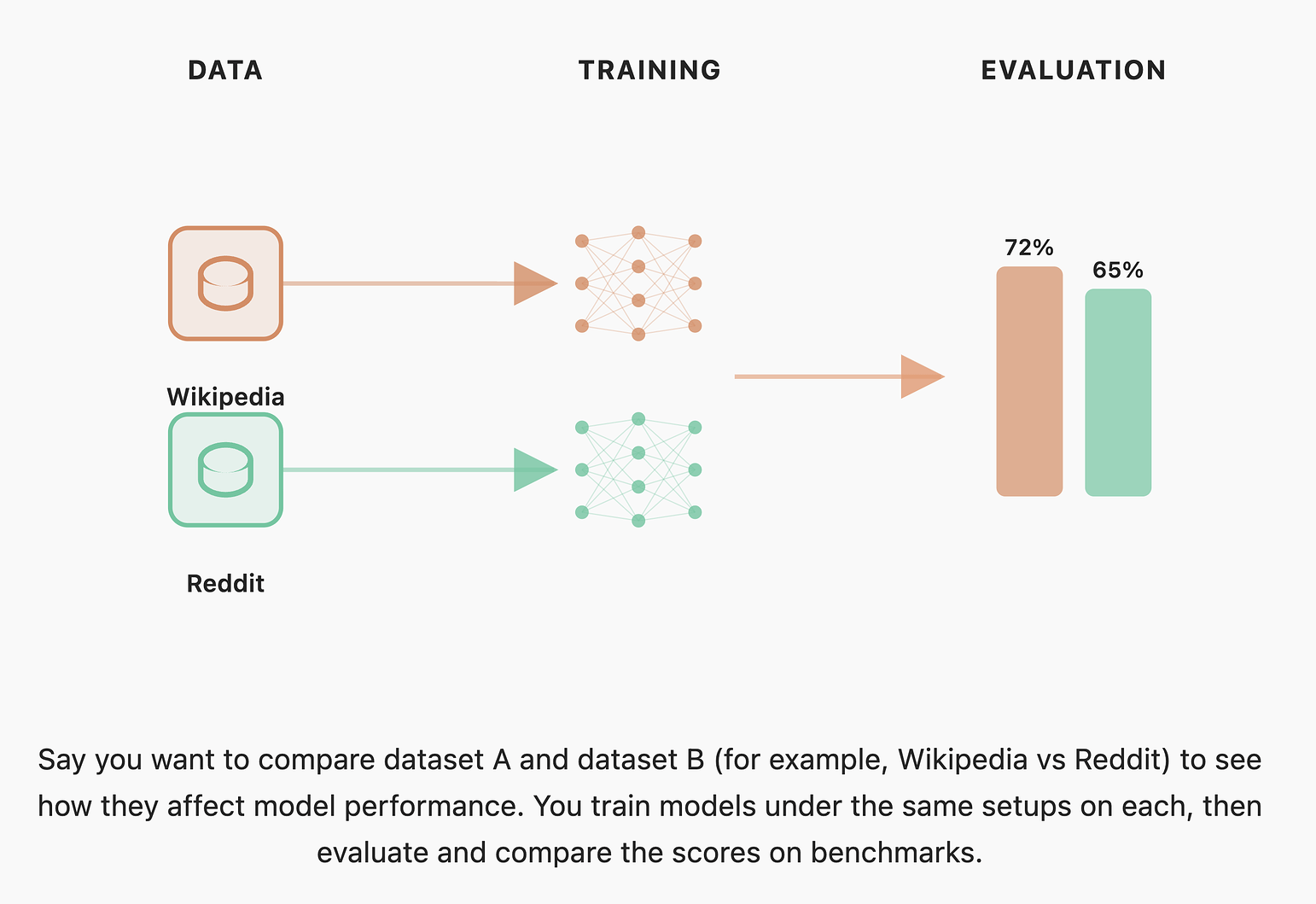
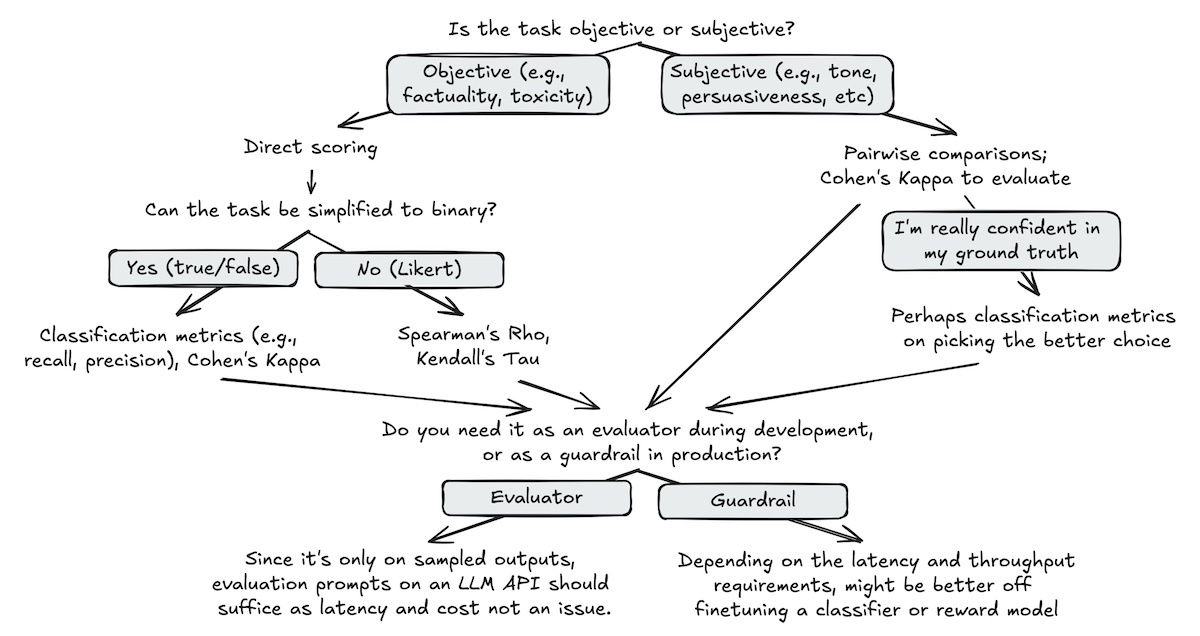
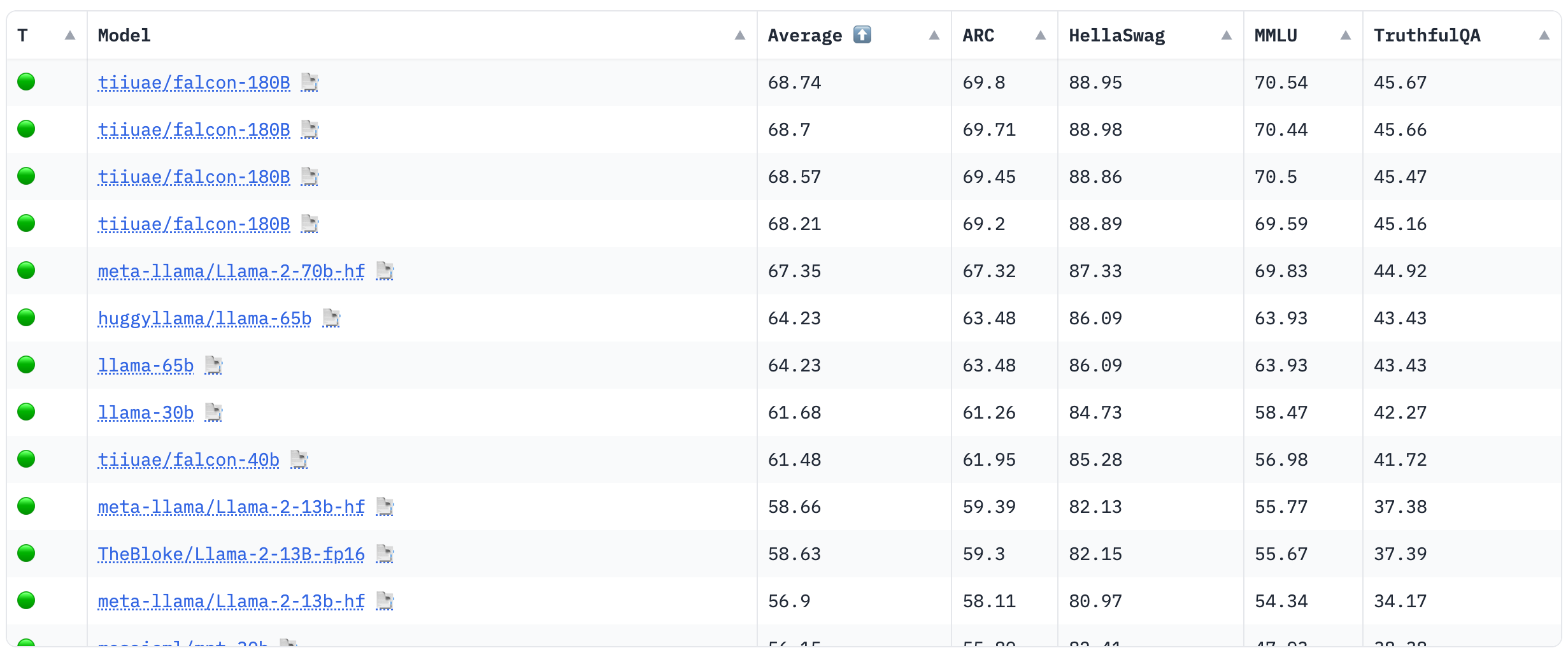
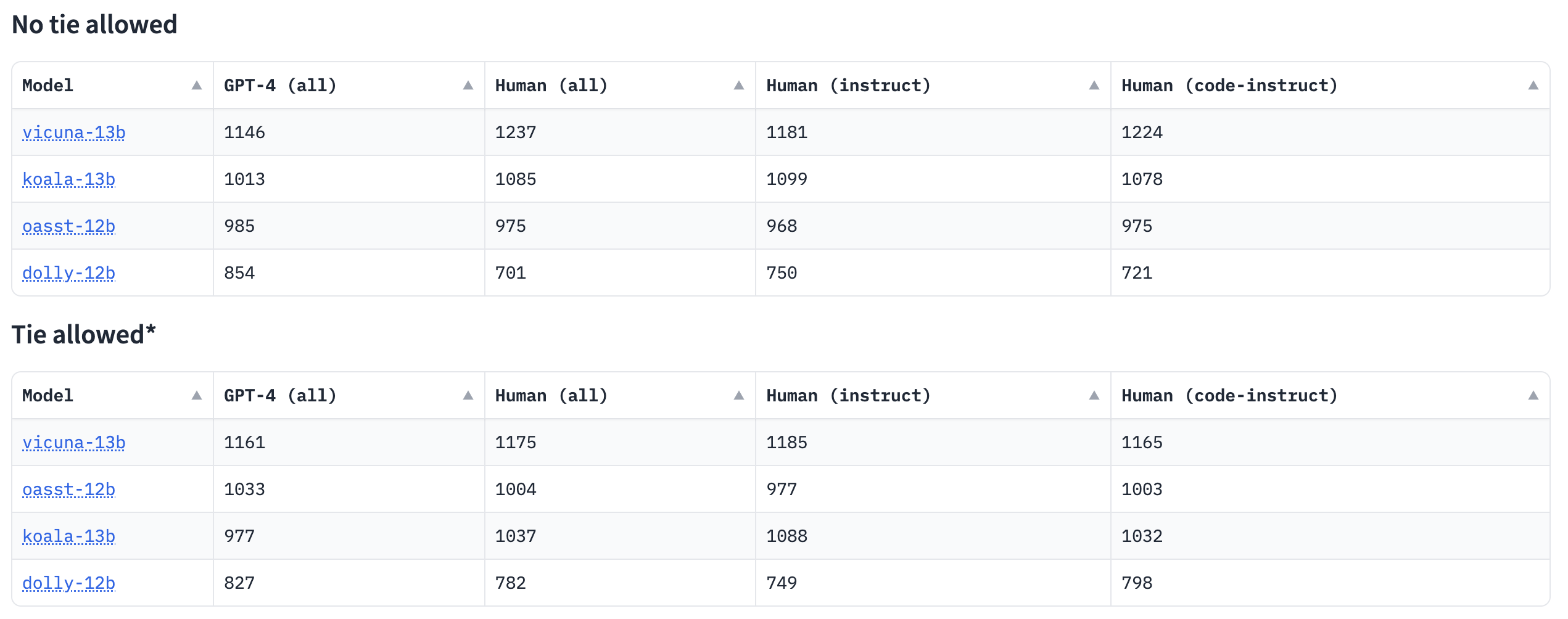
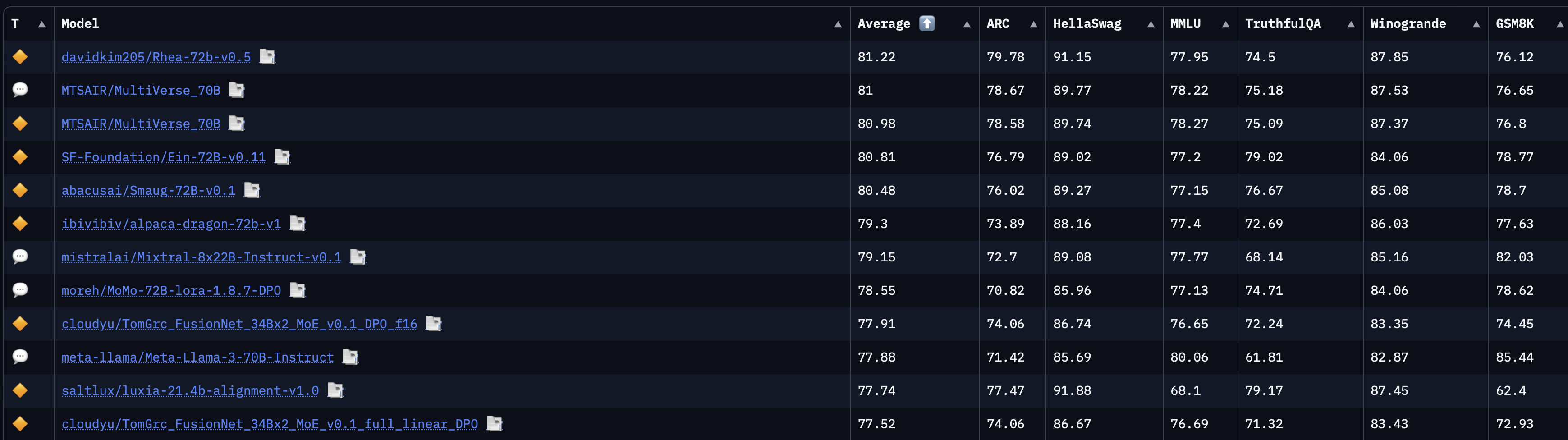
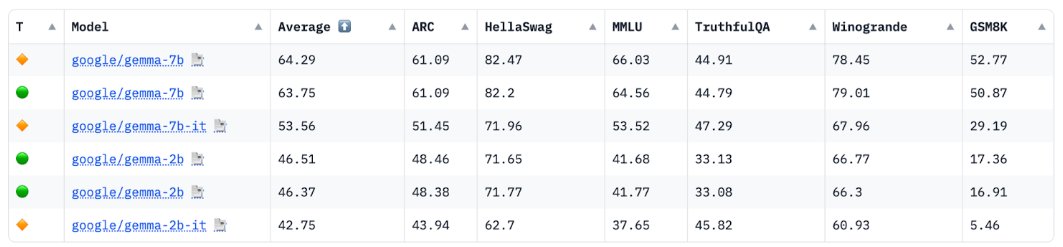
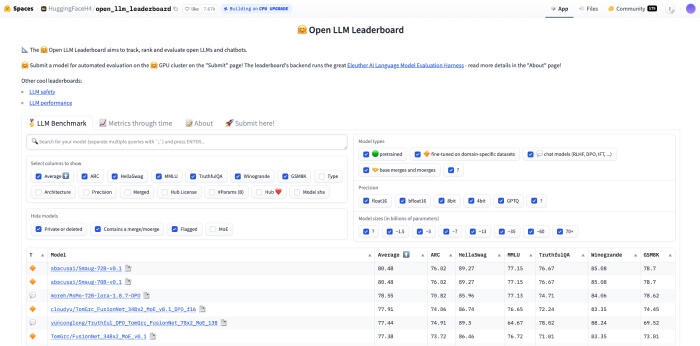
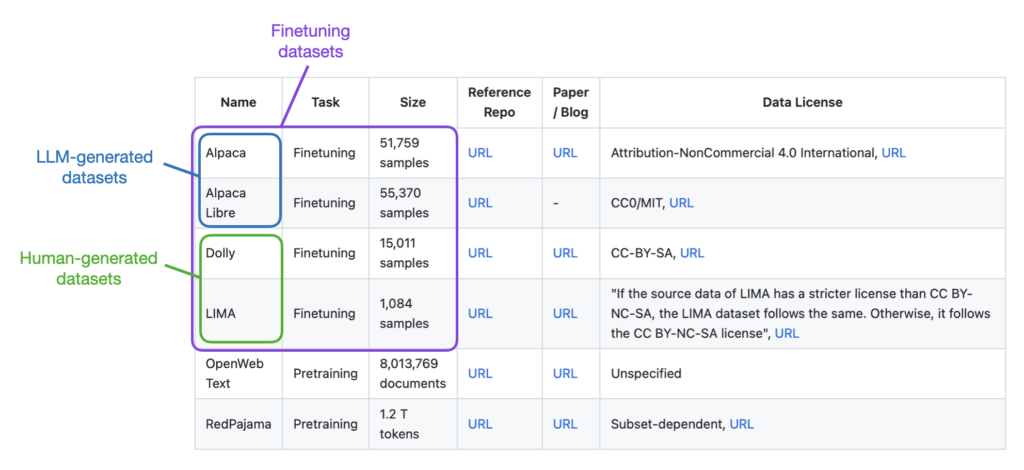
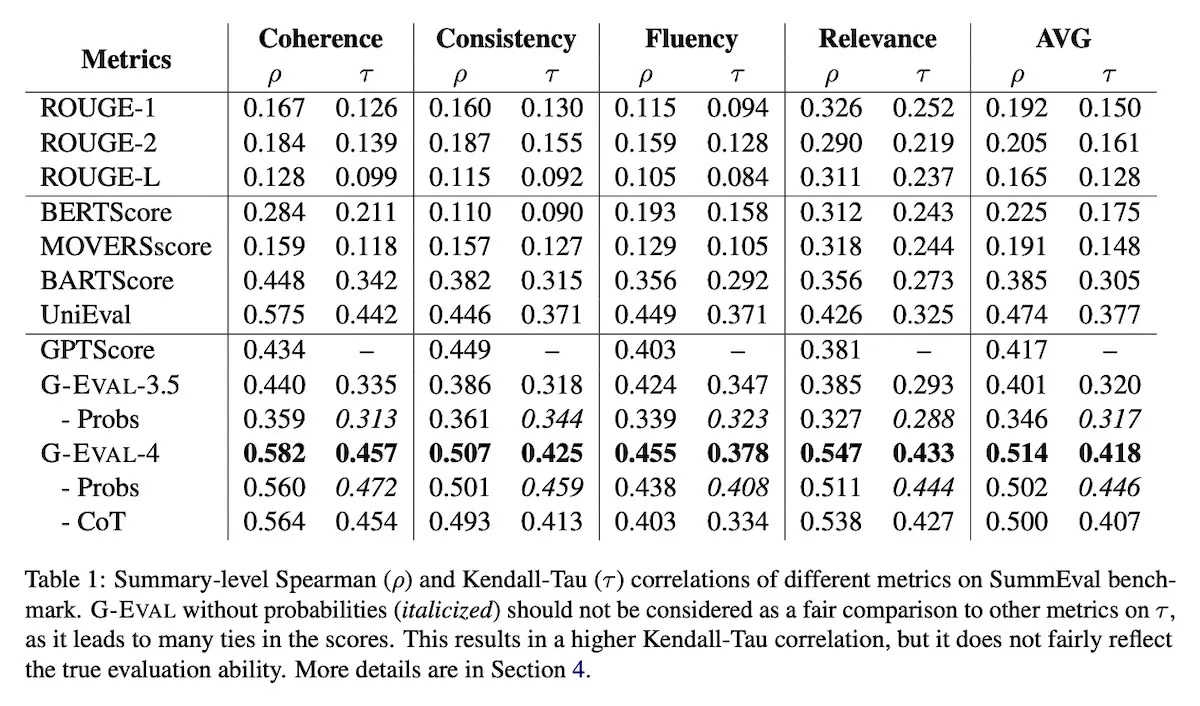
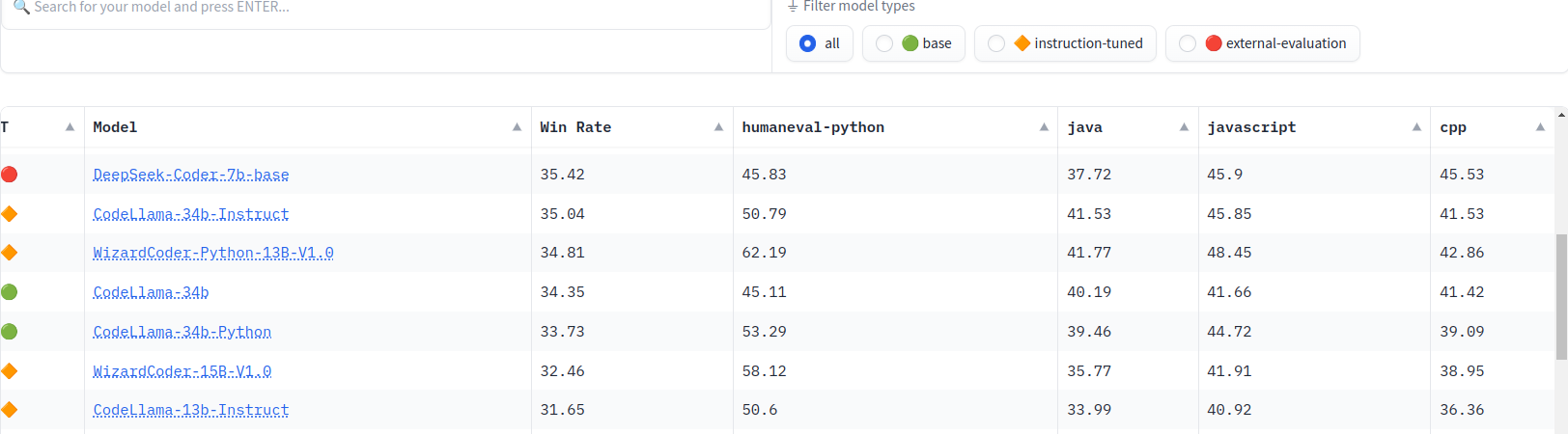
allenai/reward-bench-results · Datasets at Hugging Face
LVSTCK/macedonian-llm-eval · Datasets at Hugging Face
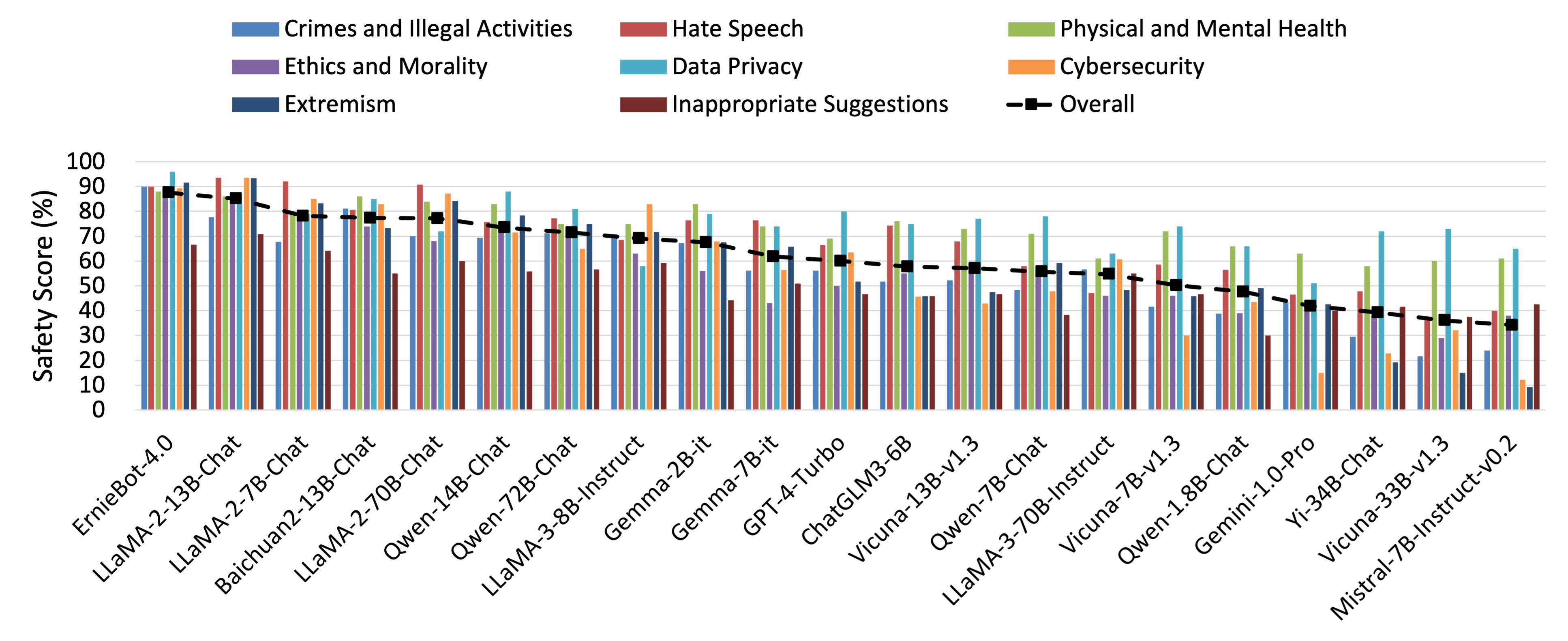
IS2Lab/S-Eval · Datasets at Hugging Face
open-llm-leaderboard/LLM360__K2-details · Datasets at Hugging Face
llm-council/emotional_application · Datasets at Hugging Face
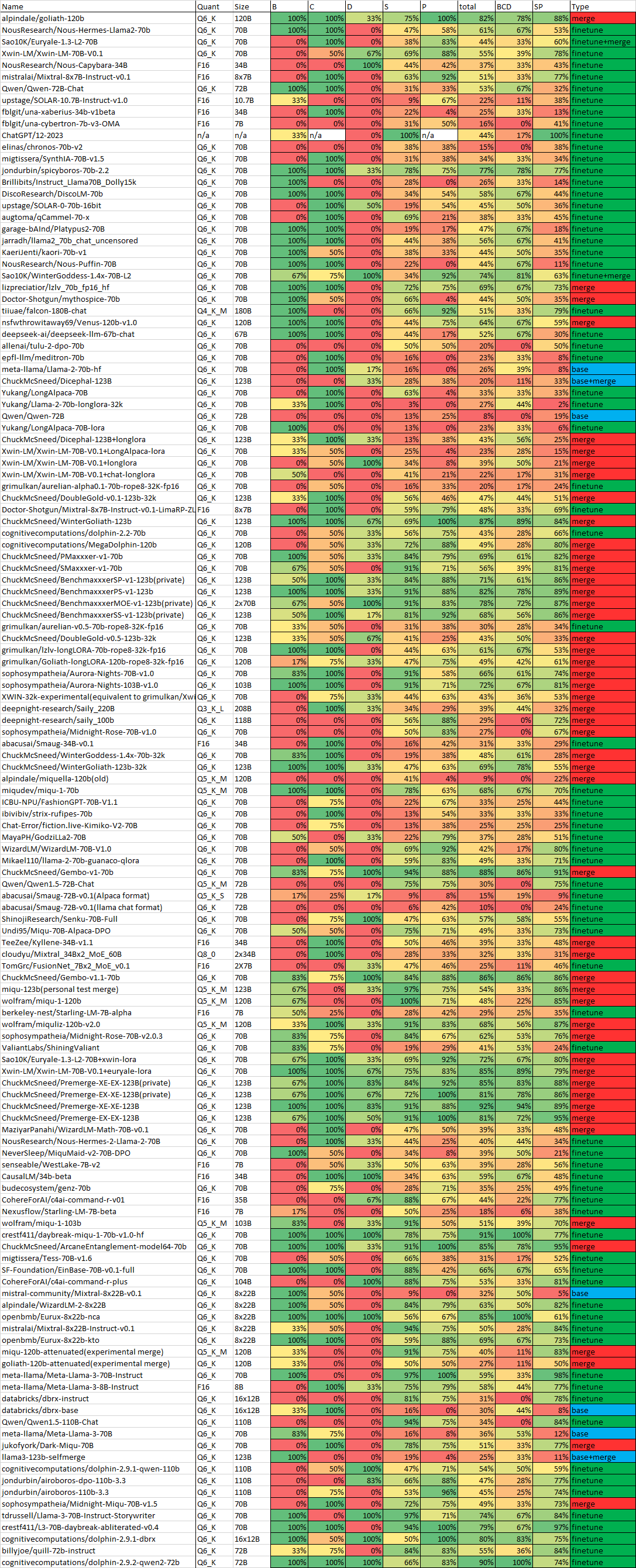
ChuckMcSneed/NeoEvalPlusN_benchmark · Datasets at Hugging Face
open-llm-leaderboard/4season__final_model_test_v2-details · Datasets at ...
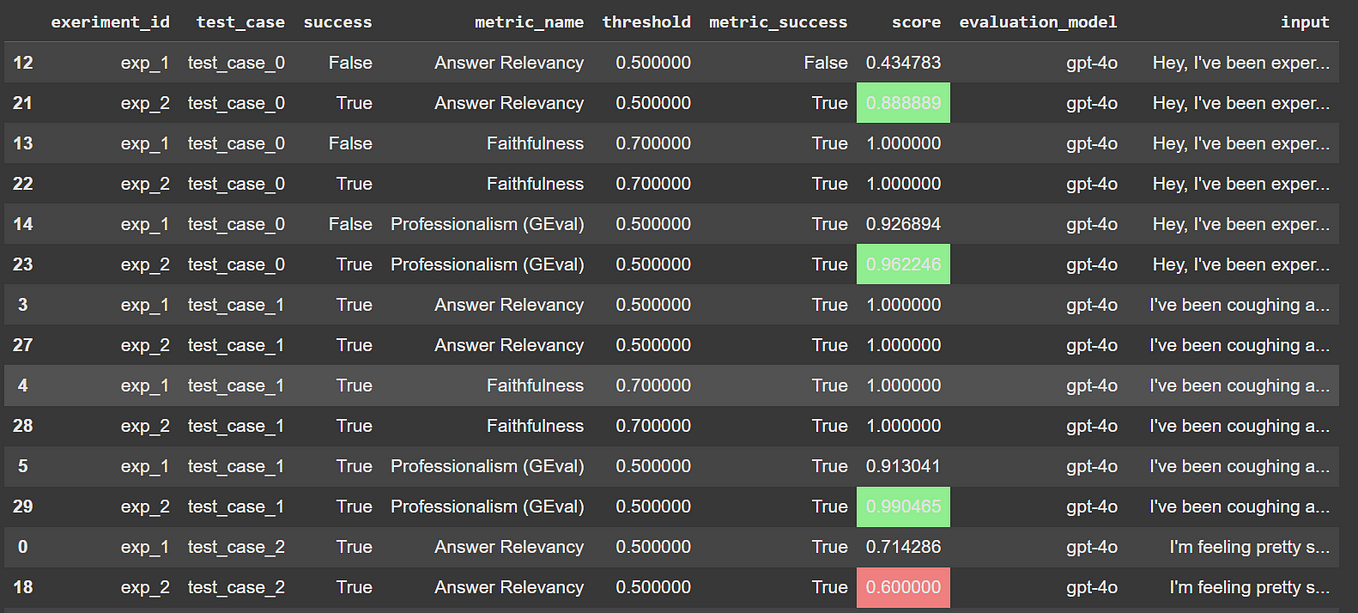
AlexZheng/LLM_evaluator_small_dataset · Hugging Face
OALL/details_Replete-AI__Replete-LLM-V2.5-Qwen-14b · Datasets at ...
open-llm-leaderboard/details_Xilabs__calypso-3b-alpha-v2 · Datasets at ...
LLM360/K2-V2 · Hugging Face
Open-Source Text Generation & LLM Ecosystem at Hugging Face
LLM360/K2-V2-Instruct · Hugging Face
Kuro0911/pentest_ai_LLM · Hugging Face
llm-wizard/leagaleasy-llama-3-instruct-v2 · Hugging Face
kenhktsui/llm-data-textbook-quality-fasttext-classifier-v2 · Hugging Face
SanjanaCodes/LLM-PBE-FineTuned-DynamicData · Hugging Face
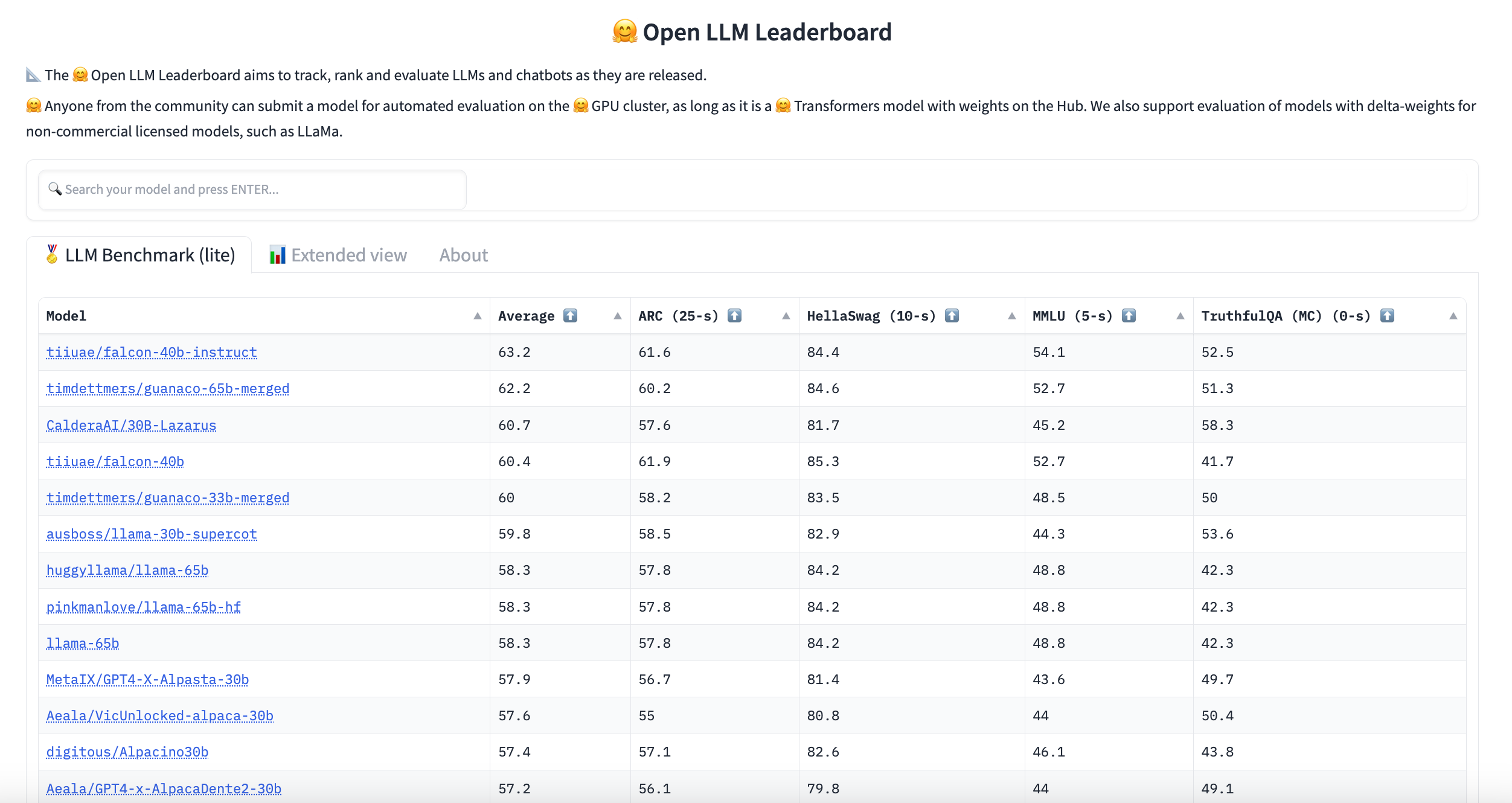
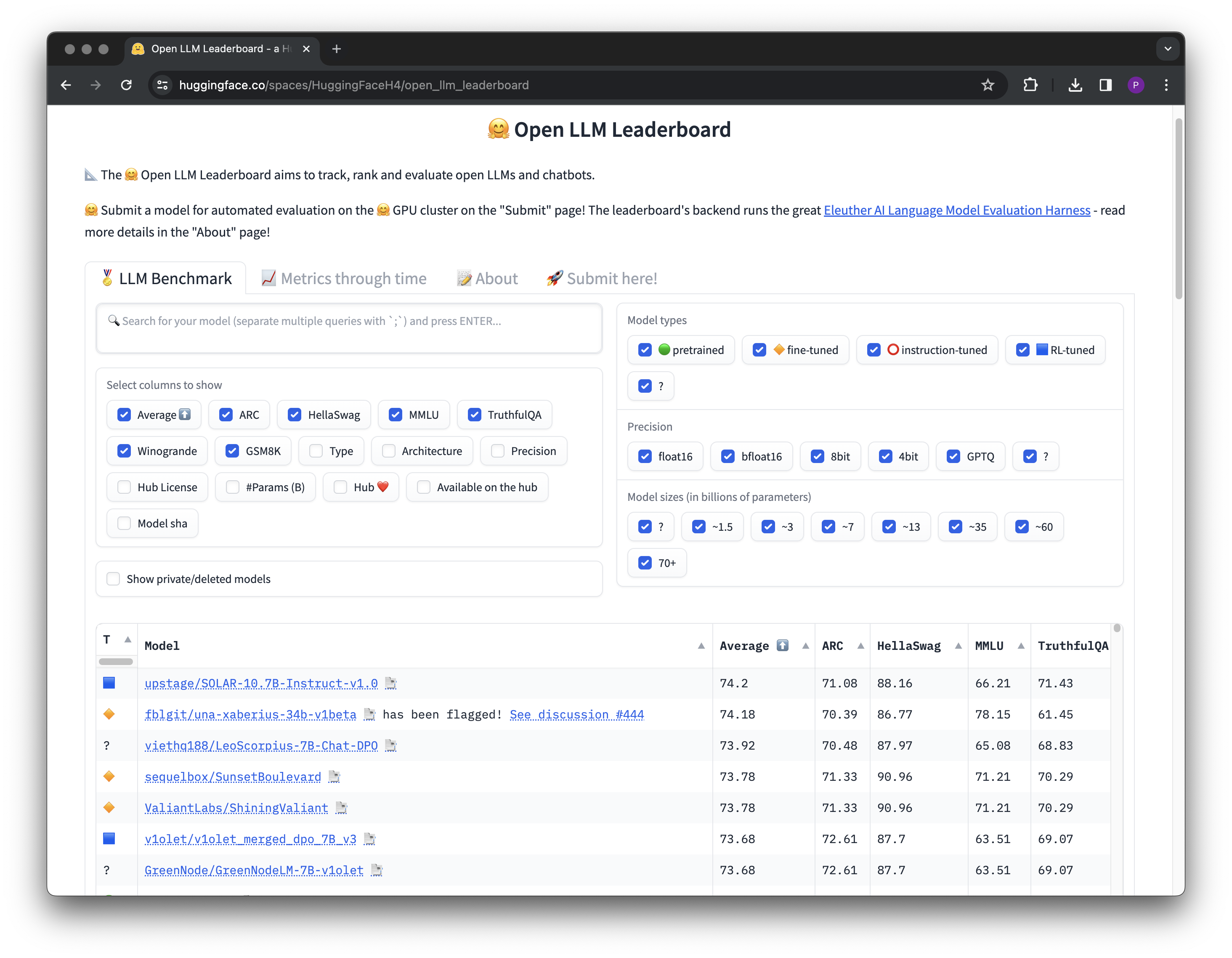
Hugging Face Upgrades Open LLM Leaderboard v2 for Enhanced AI Model ...
Hugging Face Unveils Open LLM Leaderboard v2 With Chinese Model on Top
Hugging Face Releases Open LLM Leaderboard 2: A Major Upgrade Featuring ...
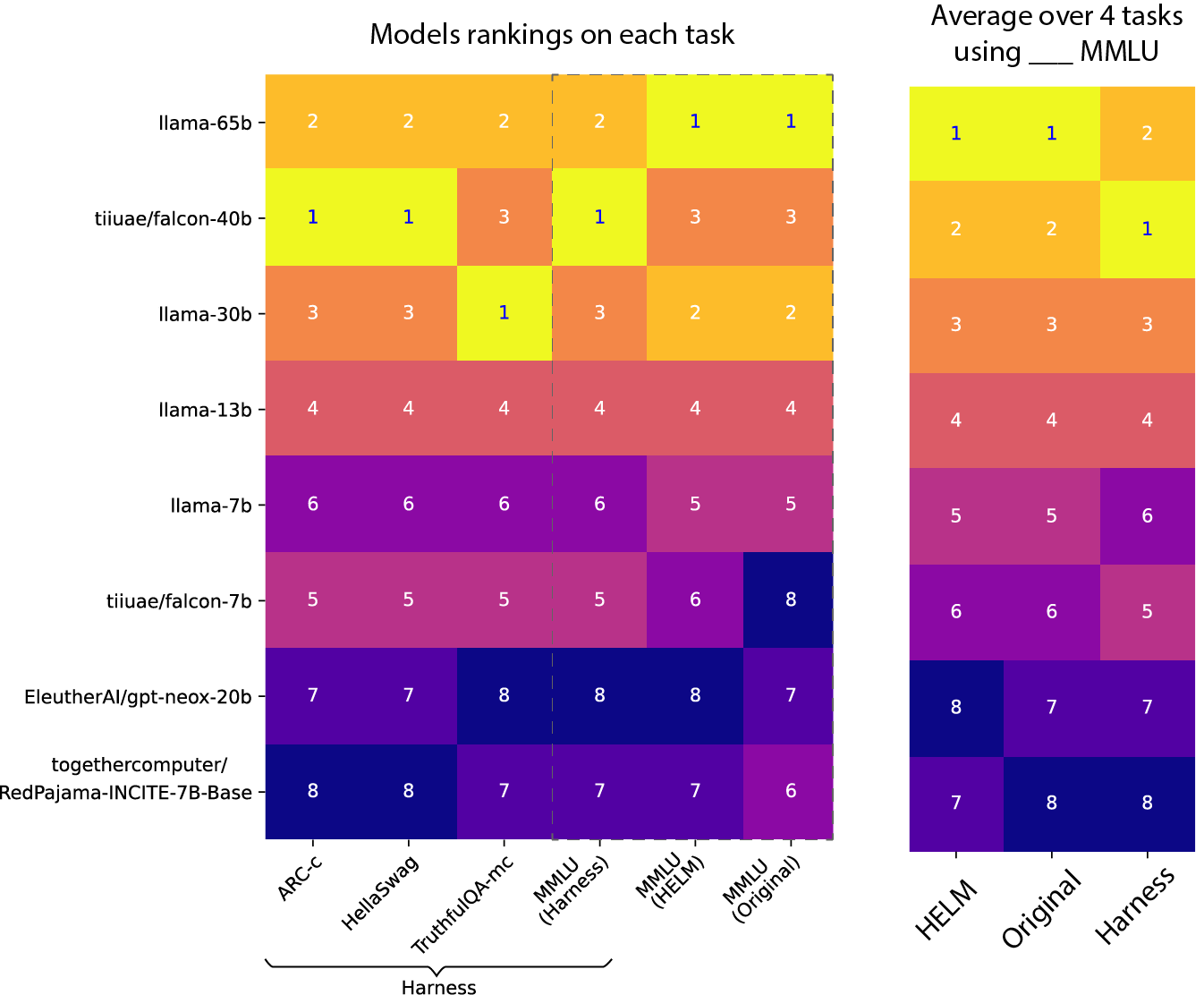
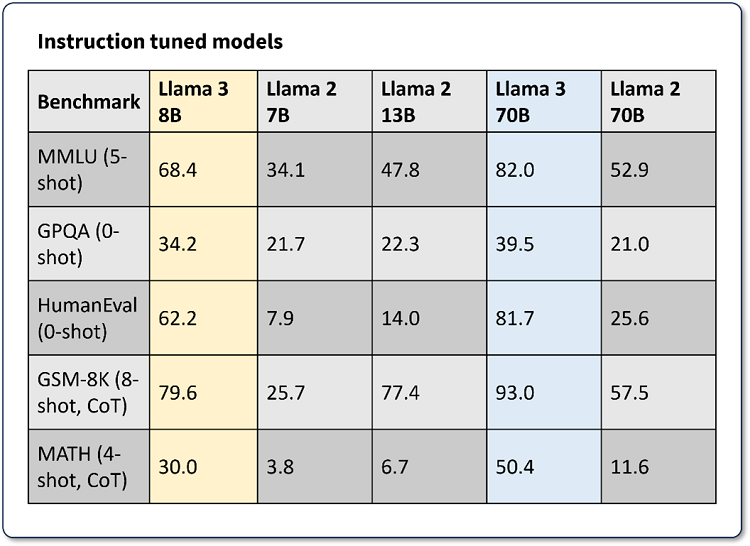
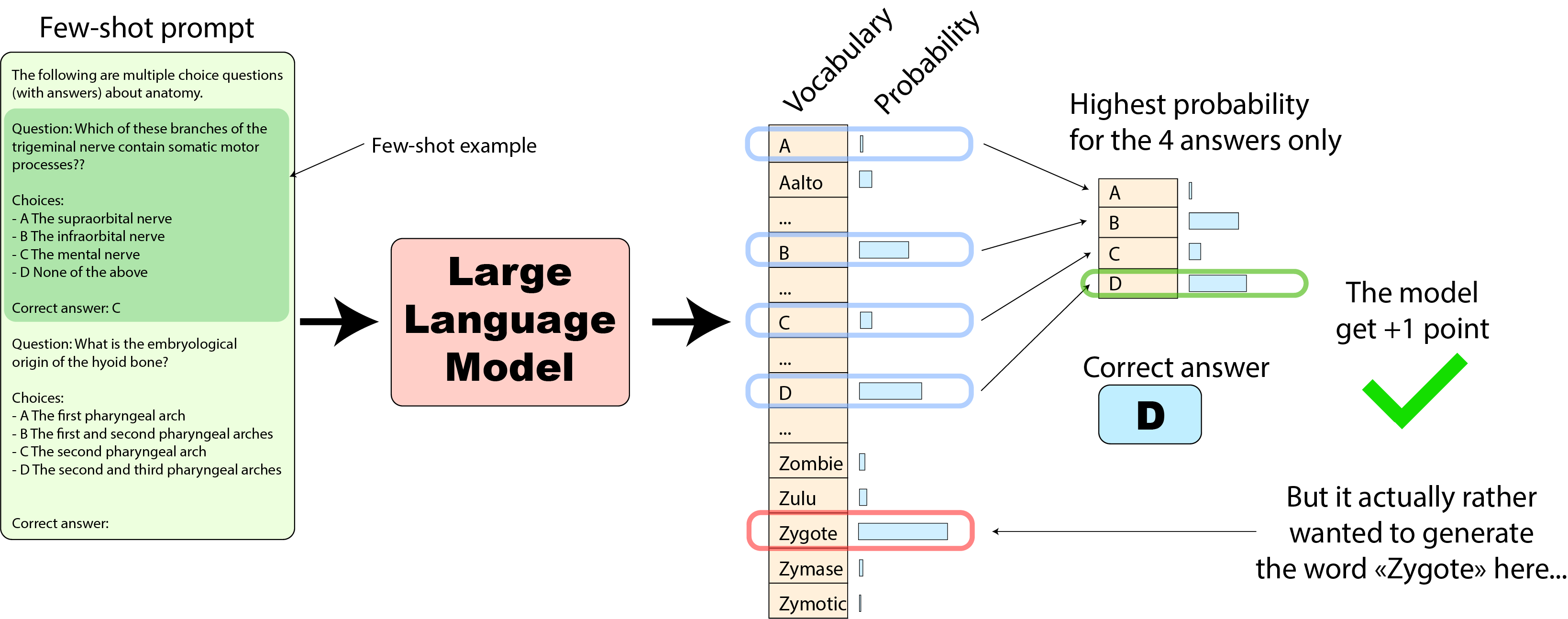
blog/open-llm-leaderboard-mmlu.md at main · huggingface/blog · GitHub
Hugging Face Evaluate Library 101: Master LLM Testing
Hugging Face Launches Open Medical-LLM Leaderboard
Hugging Face Overhauls Open LLM Leaderboard with Tougher Benchmarks
LLM Dataset Formats 101: A No‐BS Guide for Hugging Face Devs
Hugging Face Released Open LLM Leaderboard v2 | LLM Explorer Blog
Visualize Eval Results - a Hugging Face Space by yoad
How to Fine-Tune an LLM from Hugging Face | by MyScale | Medium
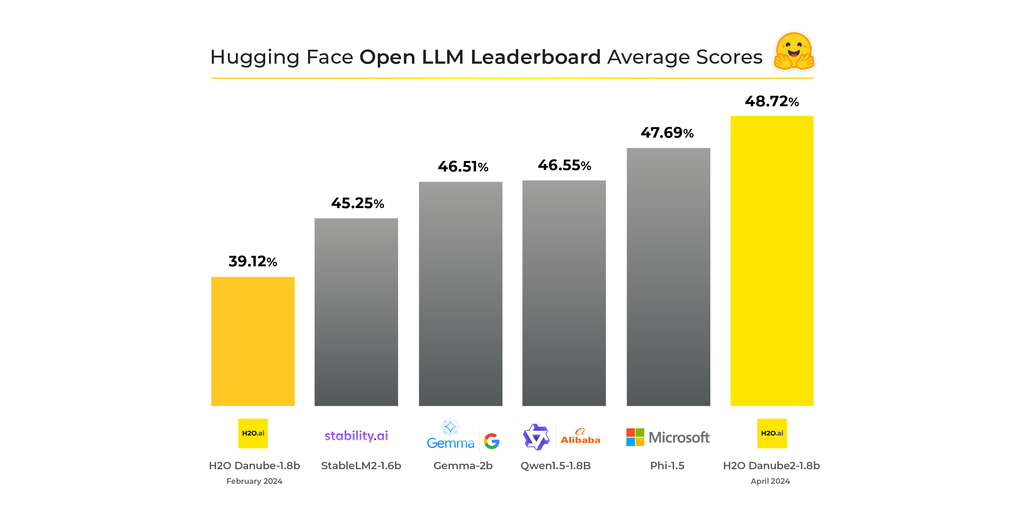
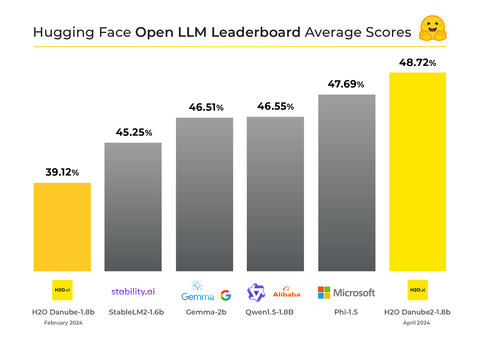
H2O-Danube2-1.8B Achieves Top Ranking on Hugging Face Open LLM ...
How to Fine-Tune an LLM with Hugging Face + LoRA – the signal
How to Fine-Tune an LLM from Hugging Face - GeeksforGeeks
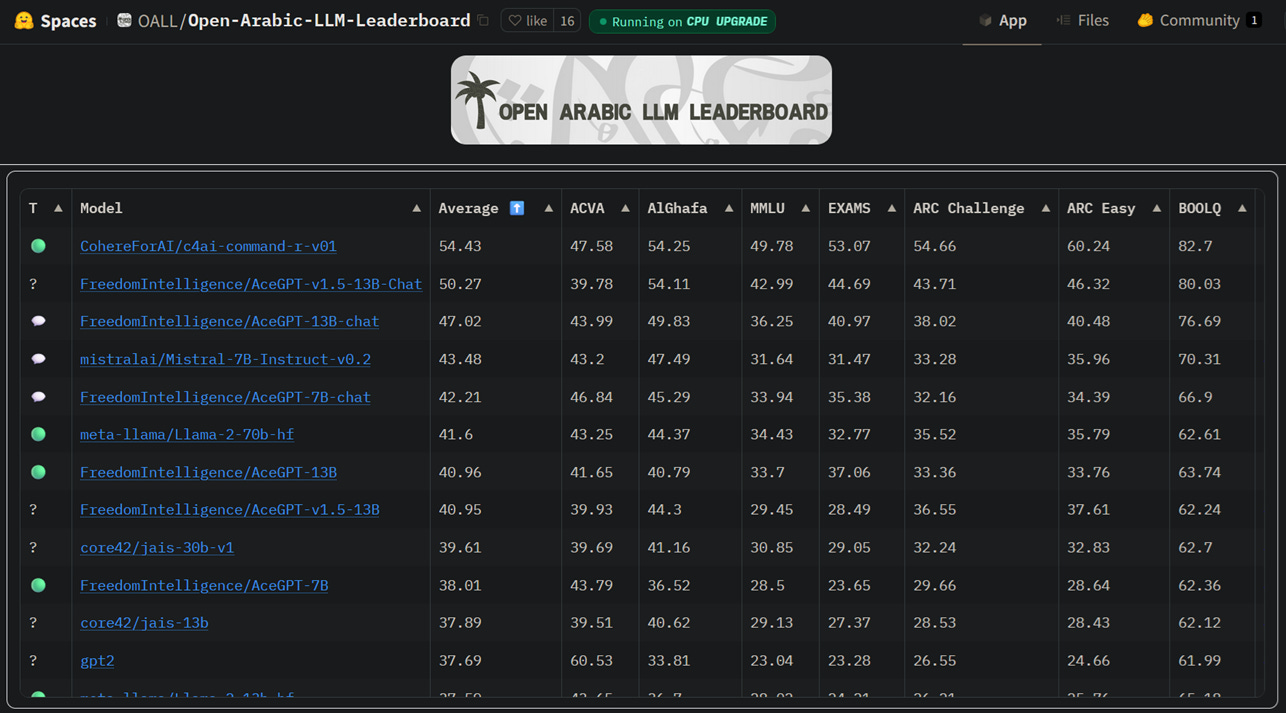
Hugging Face introduces new Open Arabic LLM Leaderboard
Announcing the launch of new Hugging Face LLM Inference containers on ...
Hugging Face unveils Open LLM Leaderboard v2 that tests models across ...
Translation - Hugging Face LLM Course
Human & GPT-4 Evaluation of LLMs Leaderboard - a Hugging Face Space by ...
Tmp Eval Results - a Hugging Face Space by albertvillanova
How to Evaluate LLMs Using Hugging Face Evaluate - Analytics Vidhya
Llm Eval Dashboard - a Hugging Face Space by loveblairsky
Llm Benchmarking - a Hugging Face Space by subhrajit-mohanty
Creating LLM API for Free with Hugging Face Example
Optimized CPU Inference with Hugging Face and PyTorch
Choosing the correct LLM model from Hugging Face Hub | by Harsha ...
人工智能 - 更难、更好、更快、更强:LLM Leaderboard v2 现已发布 - Hugging Face - SegmentFault 思否
The LLM Evaluation Guidebook: Hugging Face가 공개한 LLM 평가를 위한 종합적이고 실질적인 ...
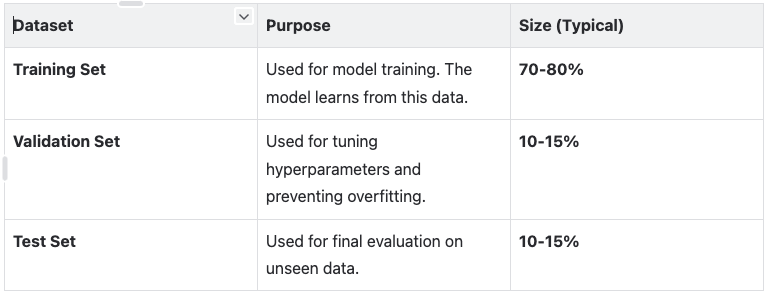
Evaluation & Datasets — State of Open Source AI Book
HuggingFaceH4/open_llm_leaderboard · Easy way to see plots of llm scores
10 Open Source Datasets for LLM Training - Analytics Vidhya
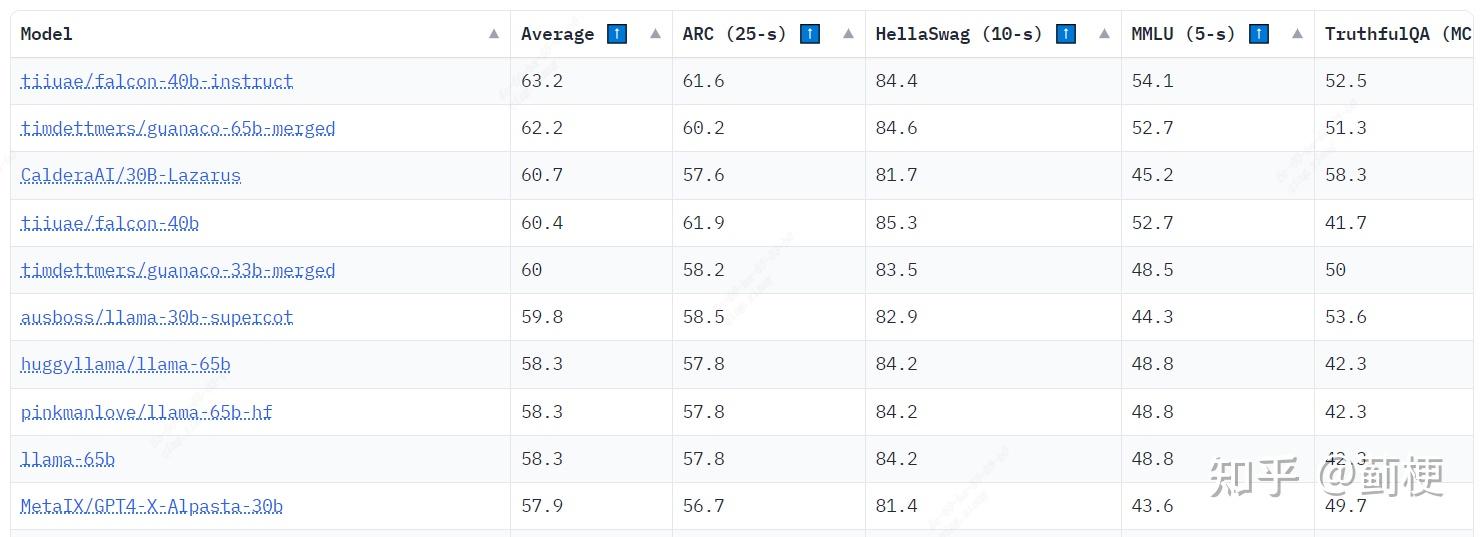
Decoding AI Rankings: A Deep Dive into Hugging Face's Open LLM ...
🤗 Hugging Face의 OpenLLM 리더보드 개선: Open-LLM Leaderboard v2 - 읽을거리&정보공유 ...
🐺🐦⬛ LLM 比较/测试:25 个最先进的 LLM(包括 QwQ),通过 59 次 MMLU-Pro CS 基准测试 - Hugging ...
@ImranzamanML on Hugging Face: "Here is how we can calculate the size ...
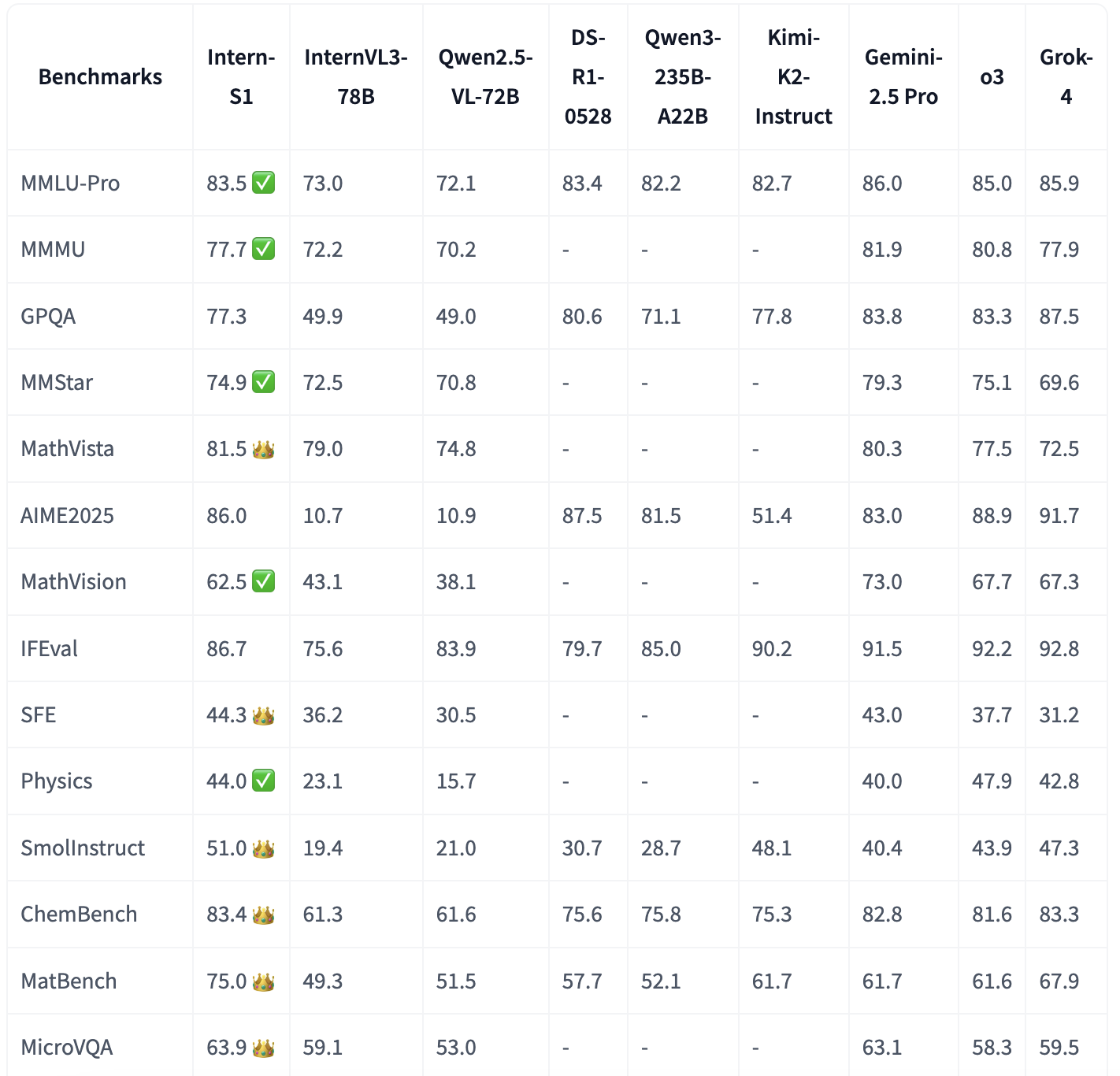
🌟 LLM Benchmarking in 2025: Key Insights from Hugging Face's Latest ...
open-llm-leaderboard/open_llm_leaderboard · test-huggingface-hub-release
【Generative AI Tutorial】Fine Tuning LLM on Custom Dataset & Hugging ...
@merve on Hugging Face: "🤯 241B VLM with apache-2.0 license https ...
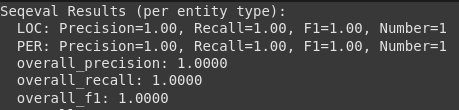
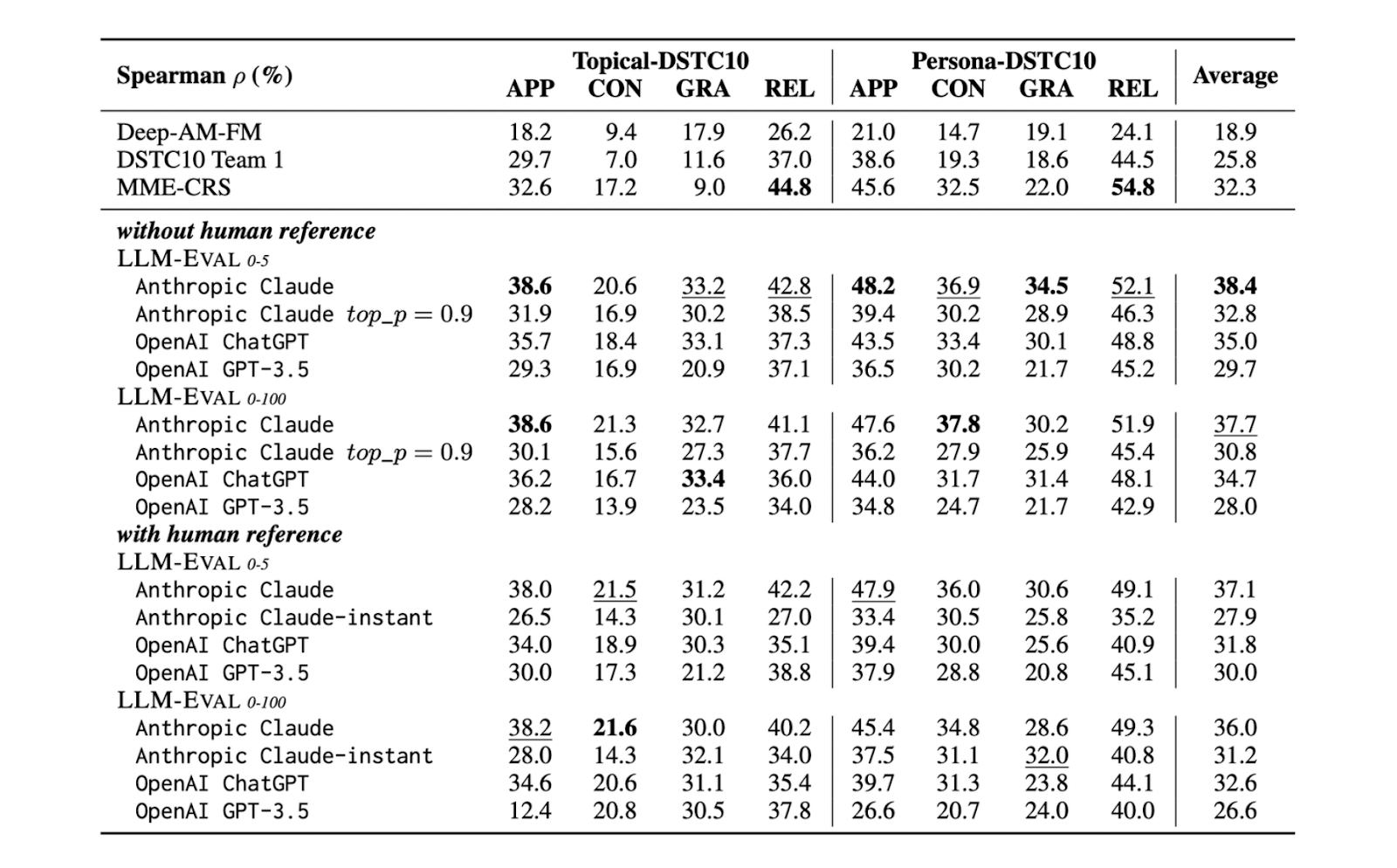
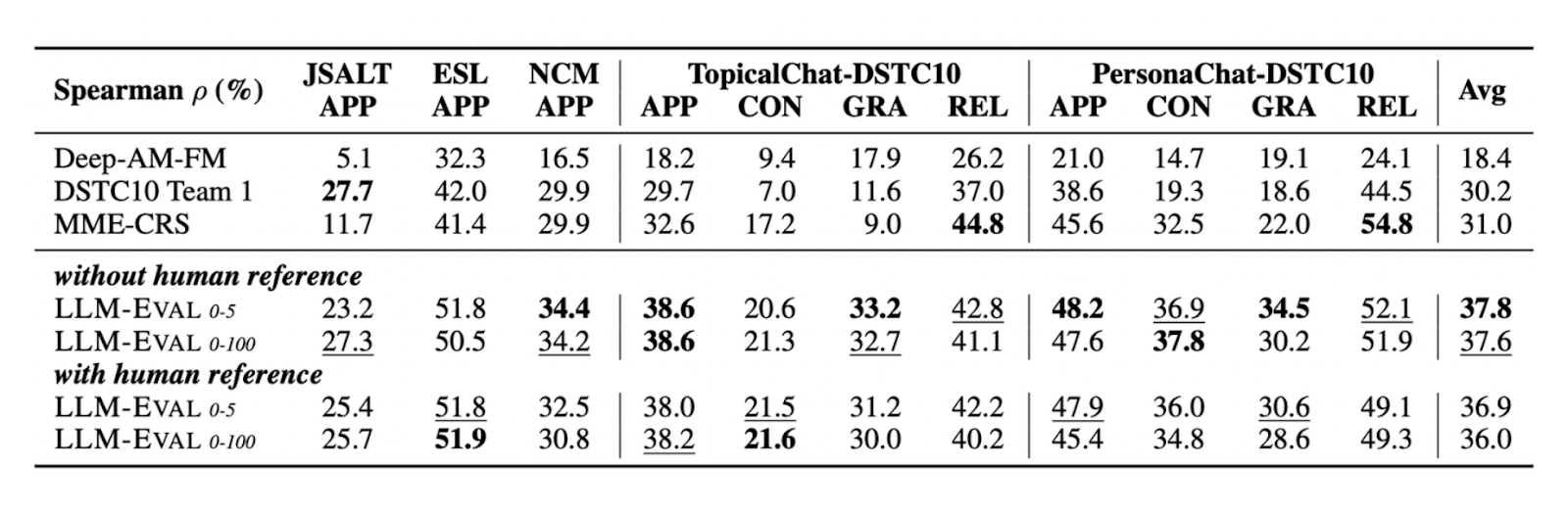
LLM-Eval: A Simplified Approach to Evaluating LLM Conversations ...
TAUR-dev/D-EVAL__standard_eval_v3__sft_annotation_for_csqa_v2-eval_0 ...
open-llm-leaderboard/meditsolutions__MSH-Lite-7B-v1-Bielik-v2.3 ...
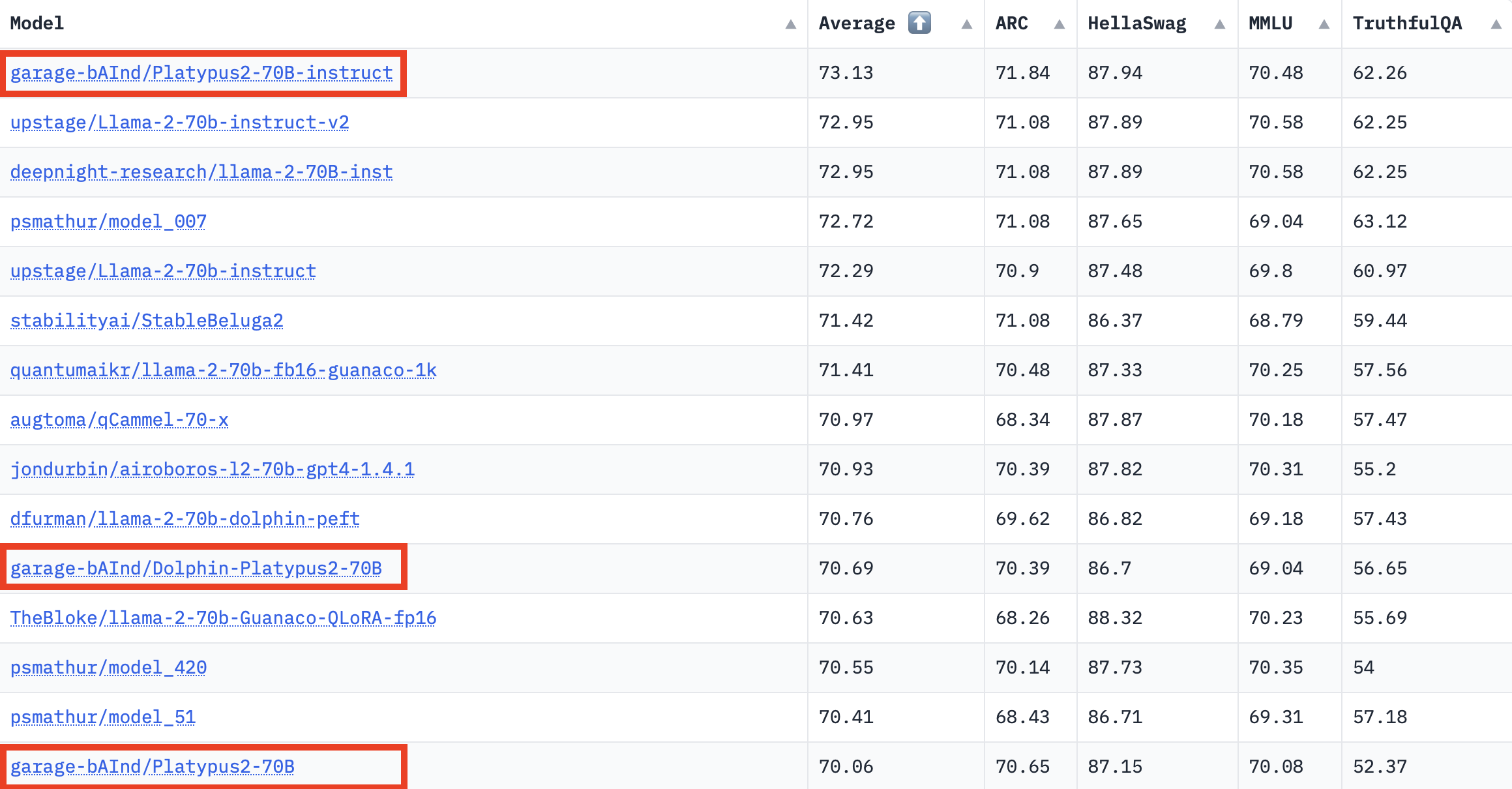
Platypus
Large Language Model Evaluation in 2026: Technical Methods & Tips
Evaluating an LLM for your use case – Paul Simmering
How to Fine-tune an LLM Part 3: The HuggingFace Trainer | alpaca_ft ...
Understand LLM sizes | web.dev
How to Measure LLM Performance | Deepchecks
autoevaluate/autoeval-eval-squad_v2-squad_v2-64bbd7-39159145057 ...
The Practical Guide to LLM Evaluation | Deepchecks
LLM eval dataset zh - a yuyijiong Collection
autoevaluate/autoeval-eval-ade_corpus_v2-Ade_corpus_v2_classification ...
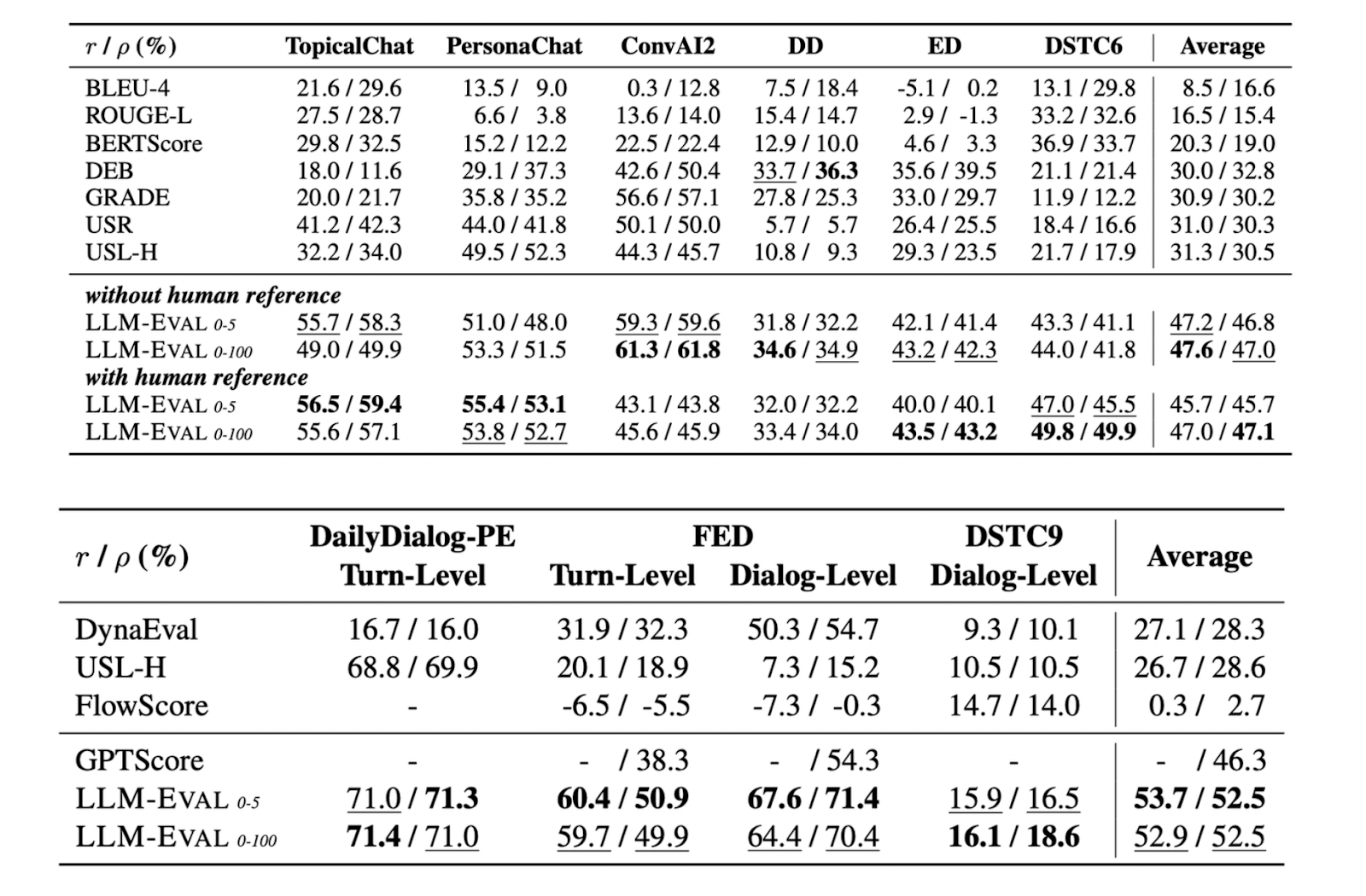
Paper page - LLM-Eval: Unified Multi-Dimensional Automatic Evaluation ...
笔记 - Huggingface LLM 排行榜指标探索 - 知乎
Optimizing LLMs from a Dataset Perspective - Lightning AI
Simplifying Huggingface’s open LLM leaderboard to select the right ...
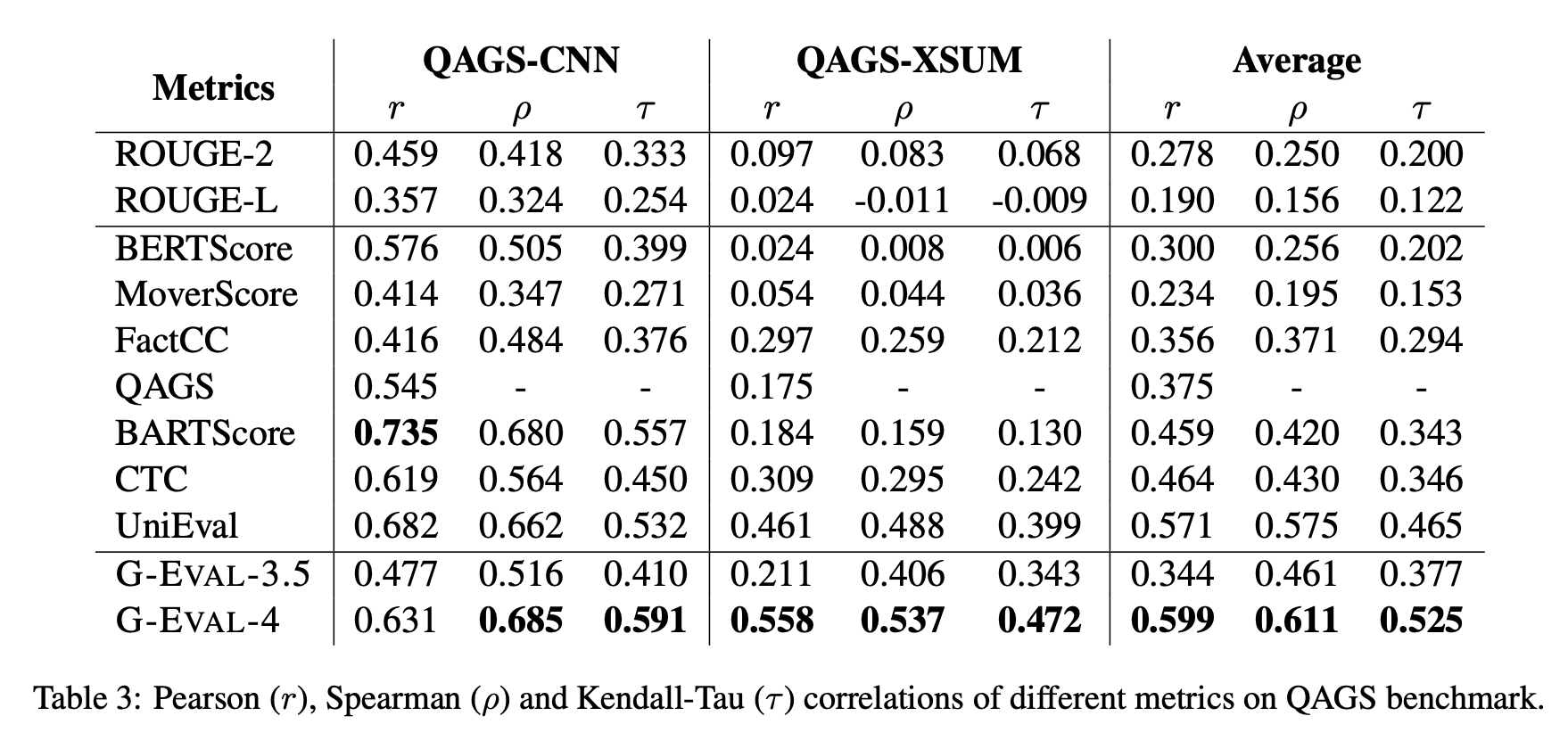
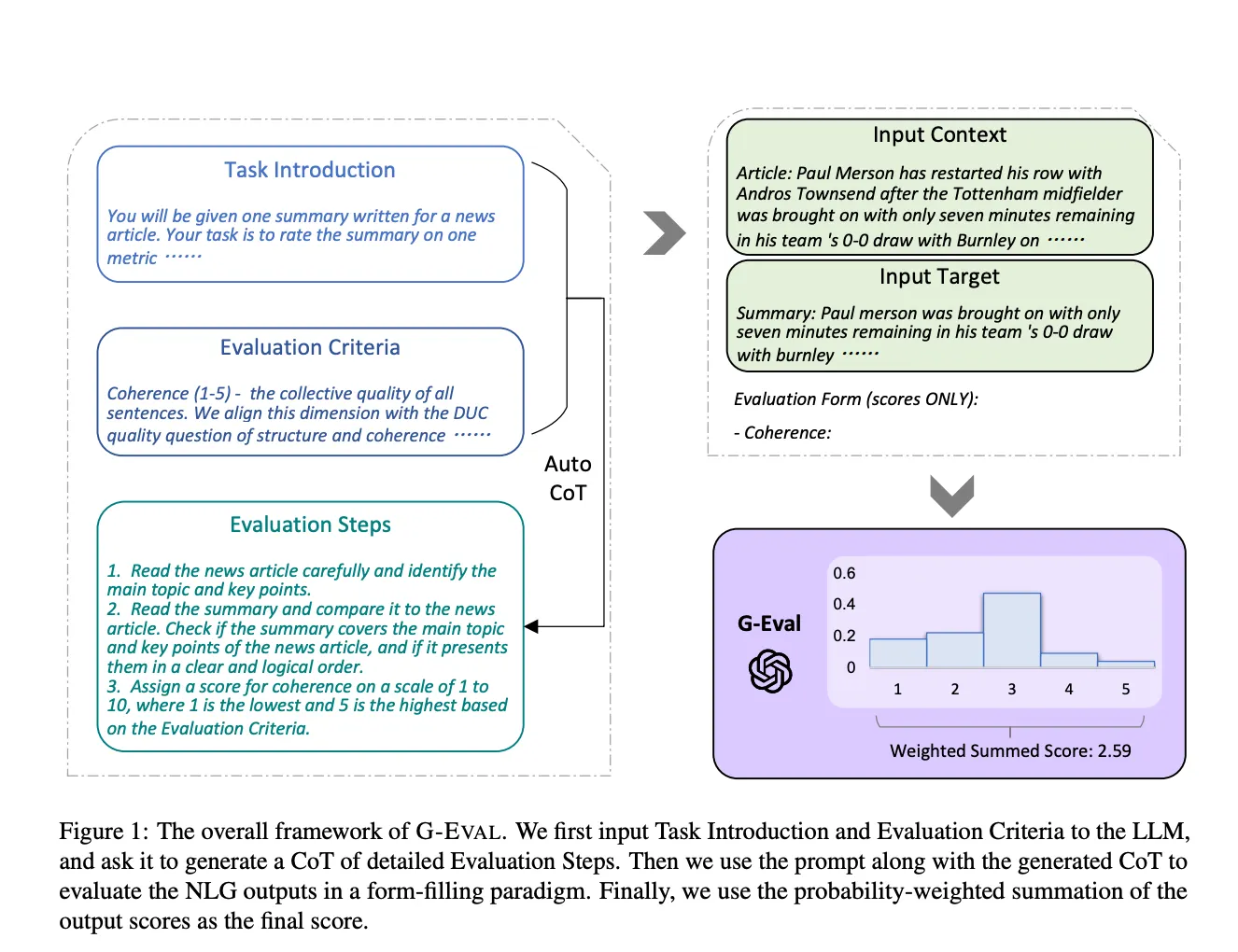
G-Eval for LLM Evaluation
LLM Local and API • Mikelopster
open-llm-leaderboard/HuggingFaceH4__zephyr-orpo-141b-A35b-v0.1-details ...
Evaluating LLM Applications
LLMs 评测 benchmark 汇总 - 知乎
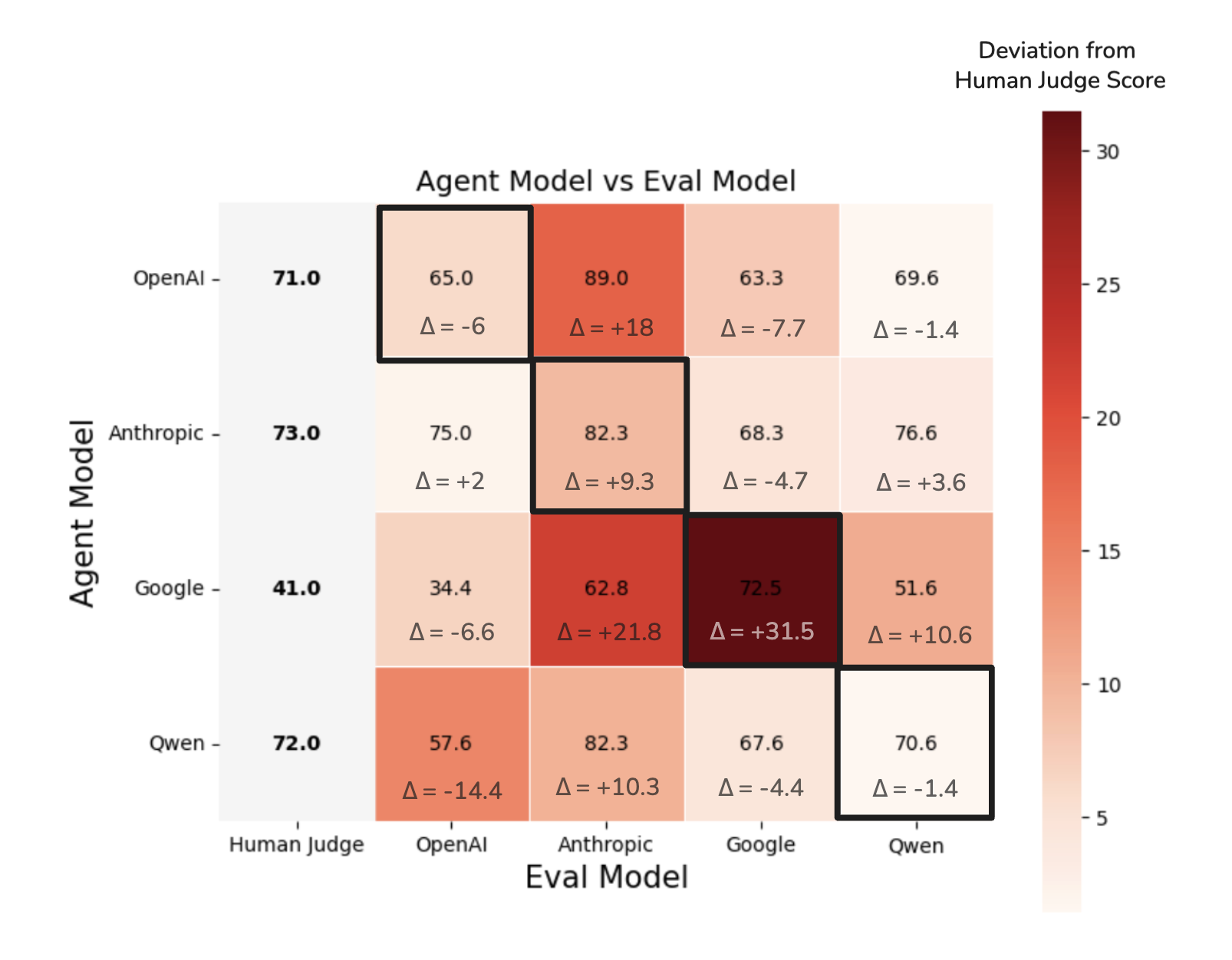
Should I Use the Same LLM for My Eval as My Agent? Testing Self ...
Evaling llm-jp-eval (evals are hard)
Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge)
Project Update LLM Eval Prompt and Content Generation 2025-10-14 v2 ...
Open-LLM Leaderboard 2.0-New Benchmarks from HuggingFace - YouTube
How to choose the right LLM for your use case | DataRobot Blog
Deploy LLM In HuggingFace Spaces For Free Using Ollama - KickerAI
Offline LLM Evaluation: Step-by-Step GenAI Application Assessment on ...
Introducing the First Hallucination-Free LLM | Pinecone
Introducing HuggingFace Accelerate | by Rahul Bhalley | The AI Times ...
Les 5 LLM Open Source les plus performants (septembre 2023) - IA-insights
hackerllama - LLM Evals and Benchmarking
Evaluating LLMs on Torch Hub, HuggingFace, and Tensorflow Hub APIs ...
GitHub - manishasirsat/access-llm-huggingface: How to access LLMs from ...
Build Your Own LLM: A Comprehensive Guide to Training Large Language ...
Fine-Tuning A LLM Small Practical Guide With Resources | Coffee bytes