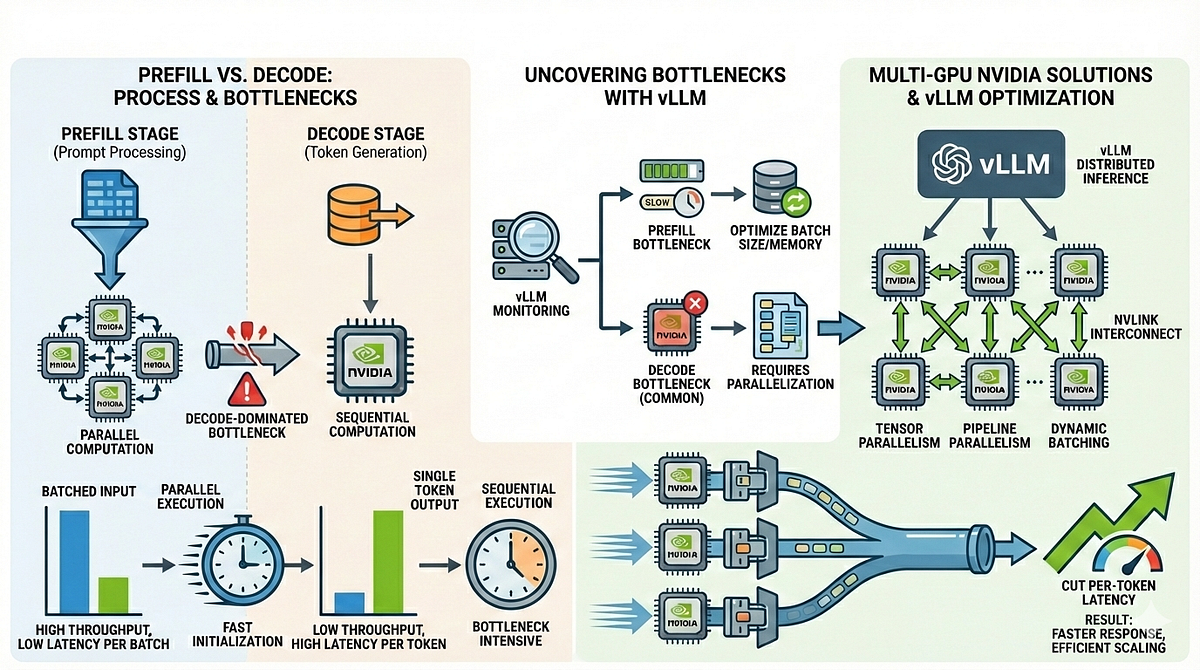
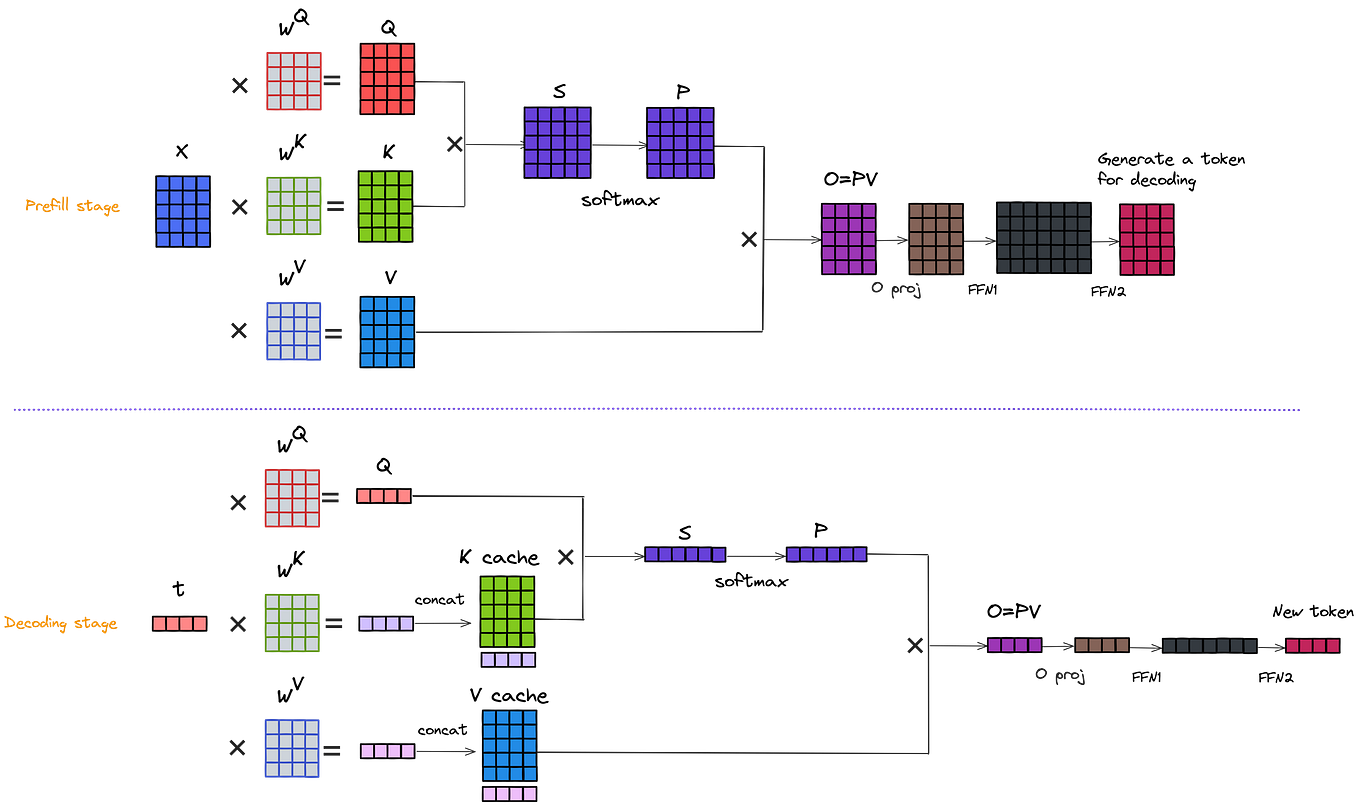
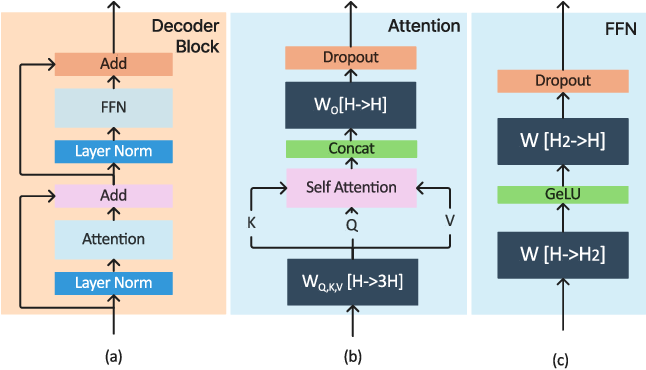
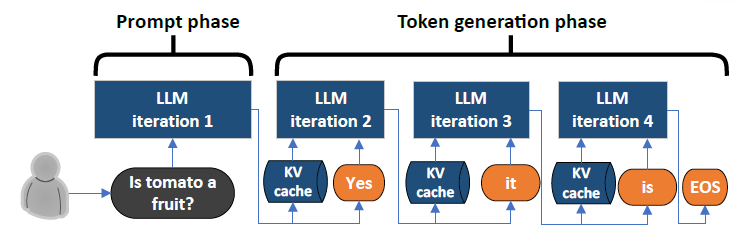
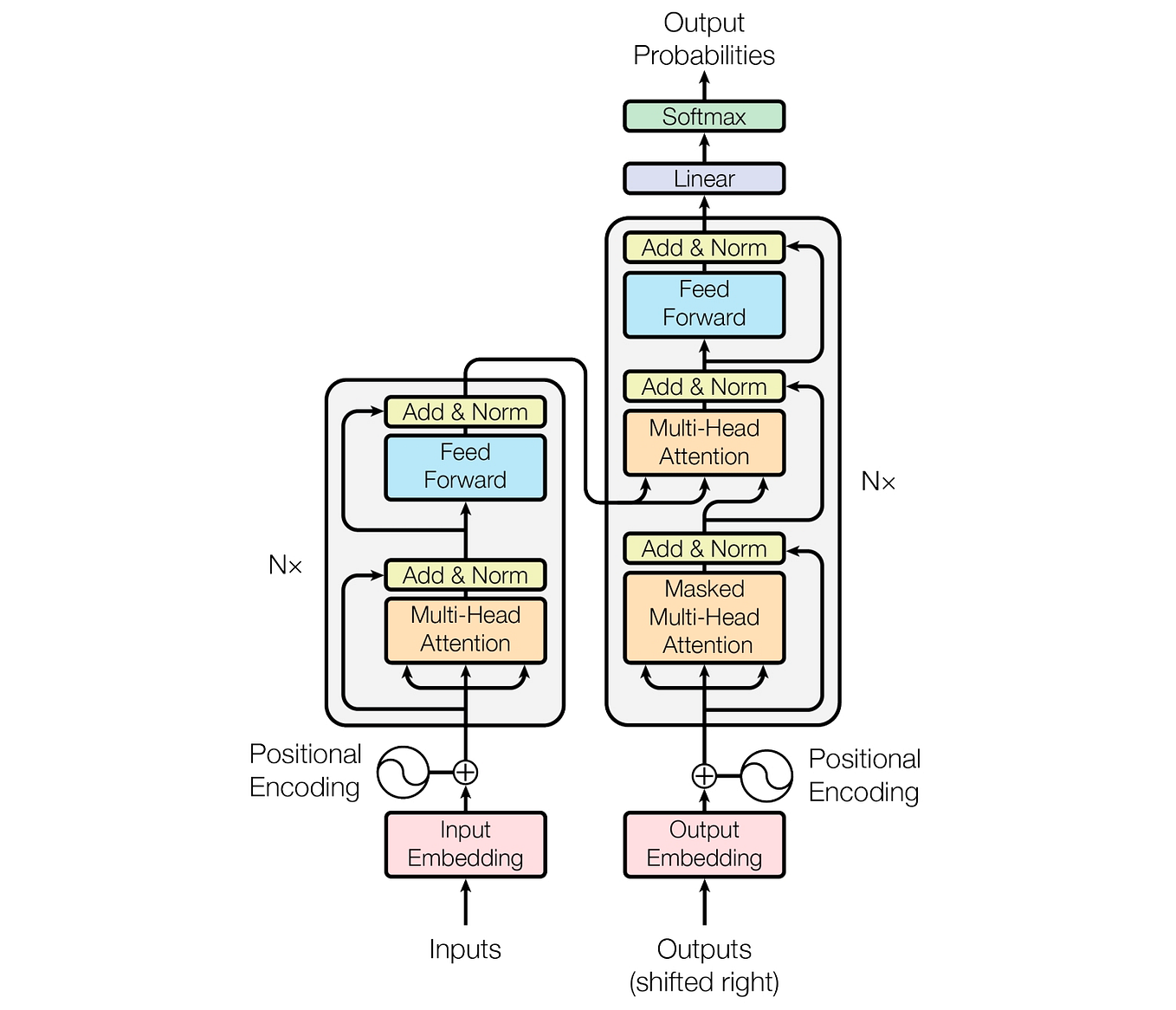
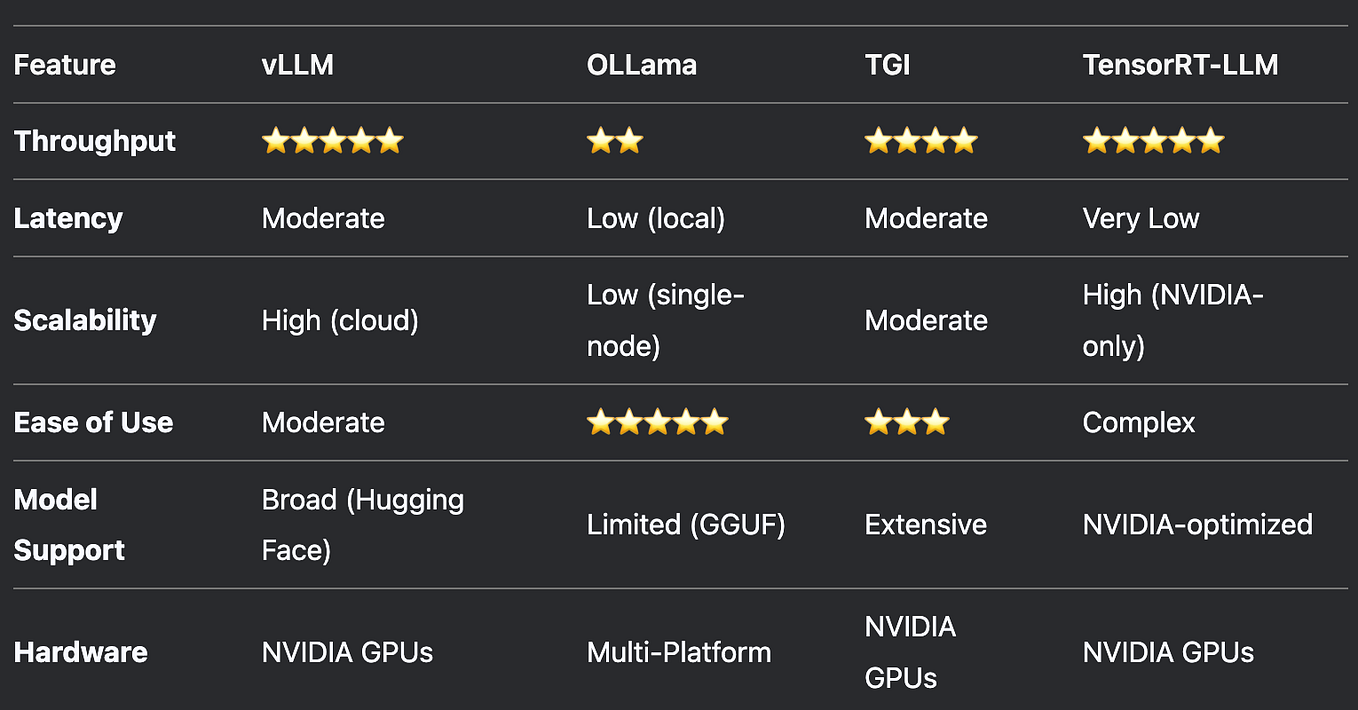
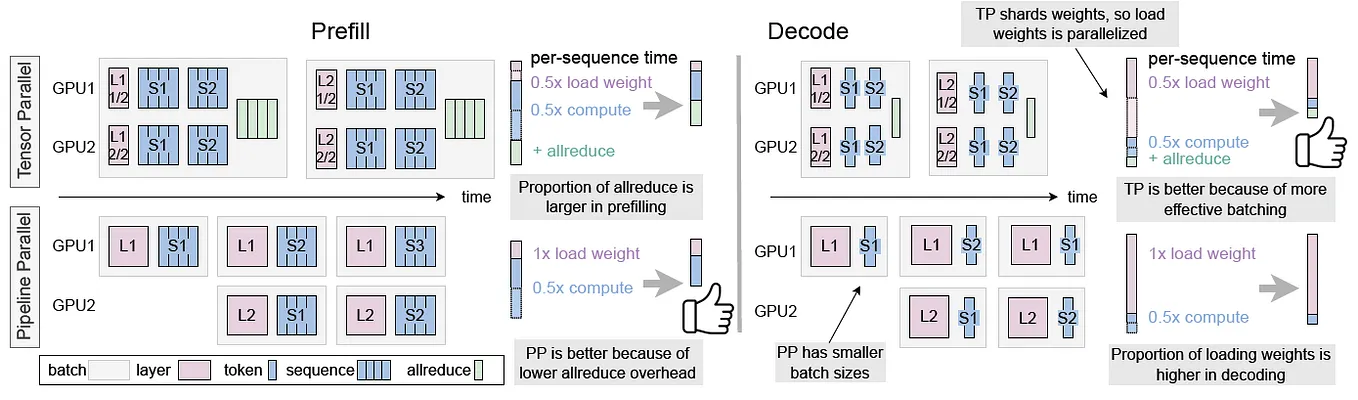
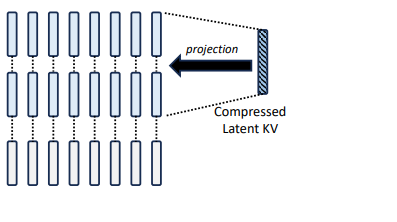
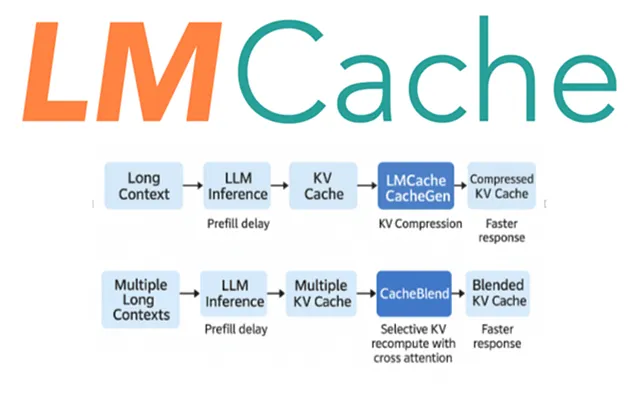
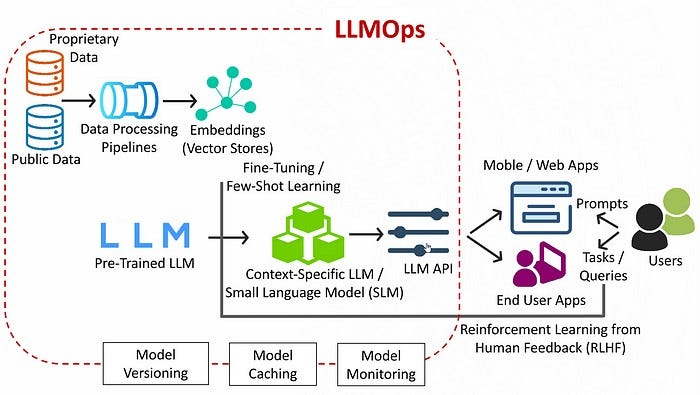
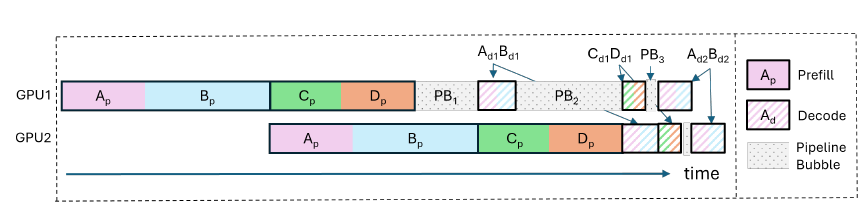
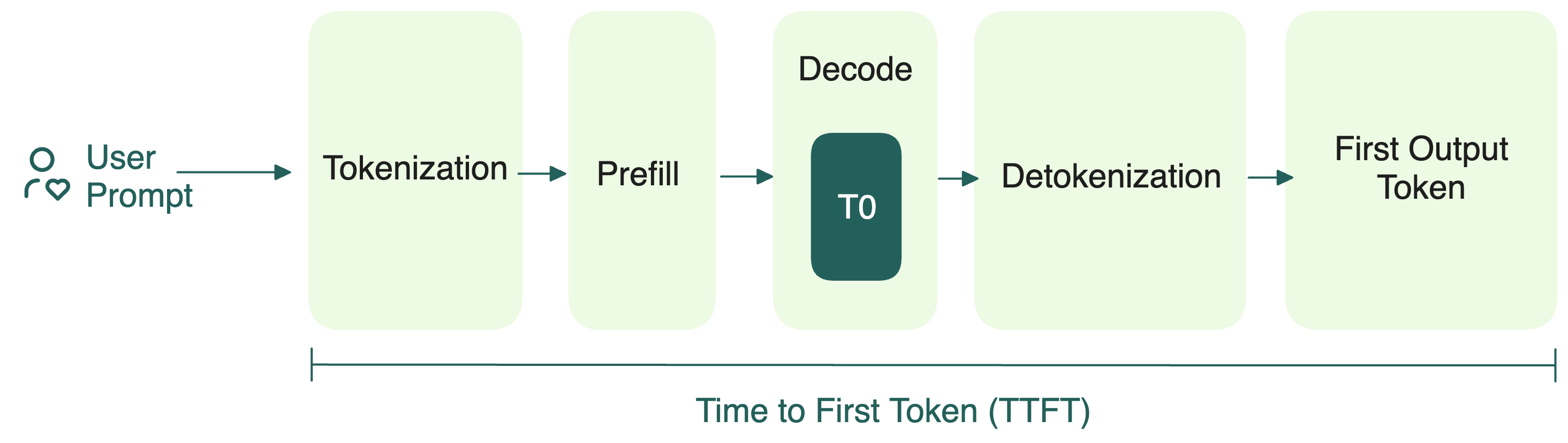
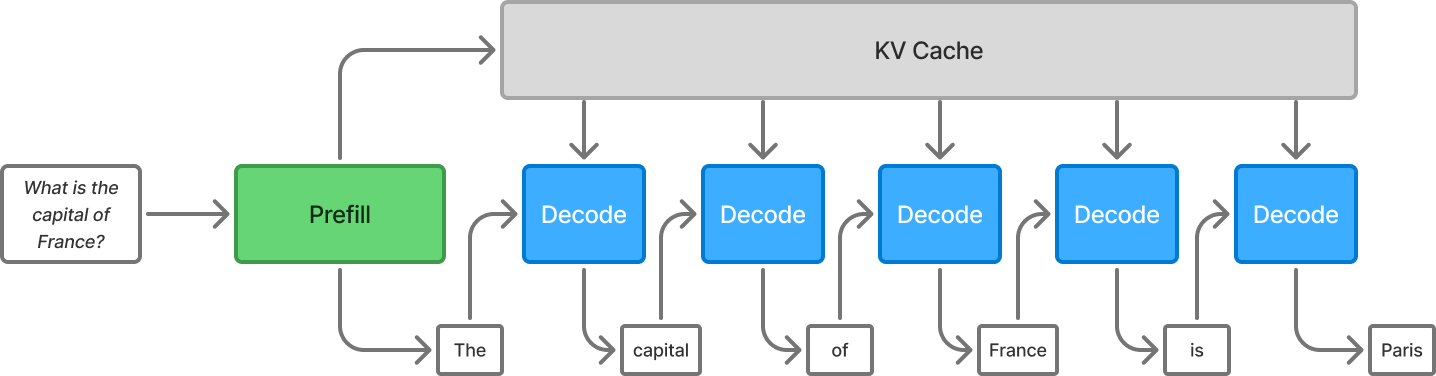
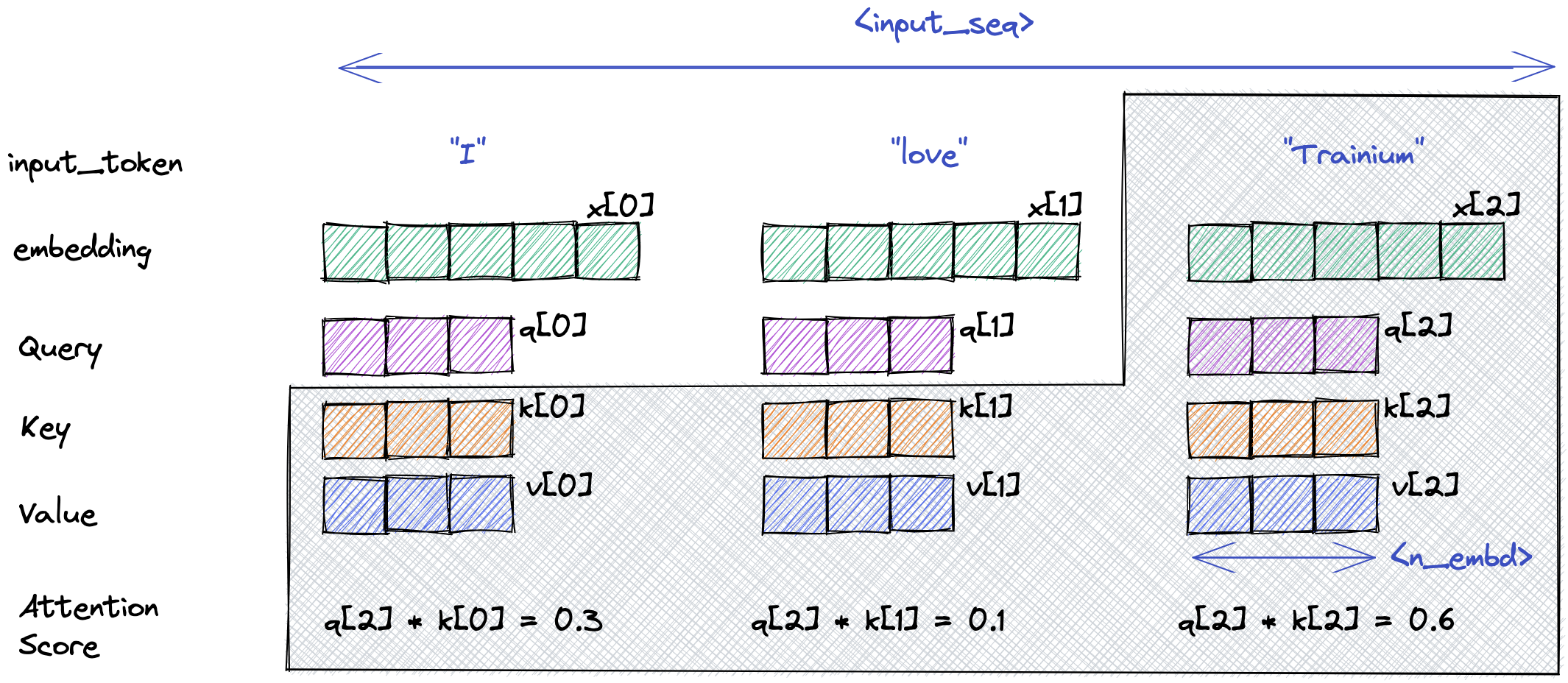
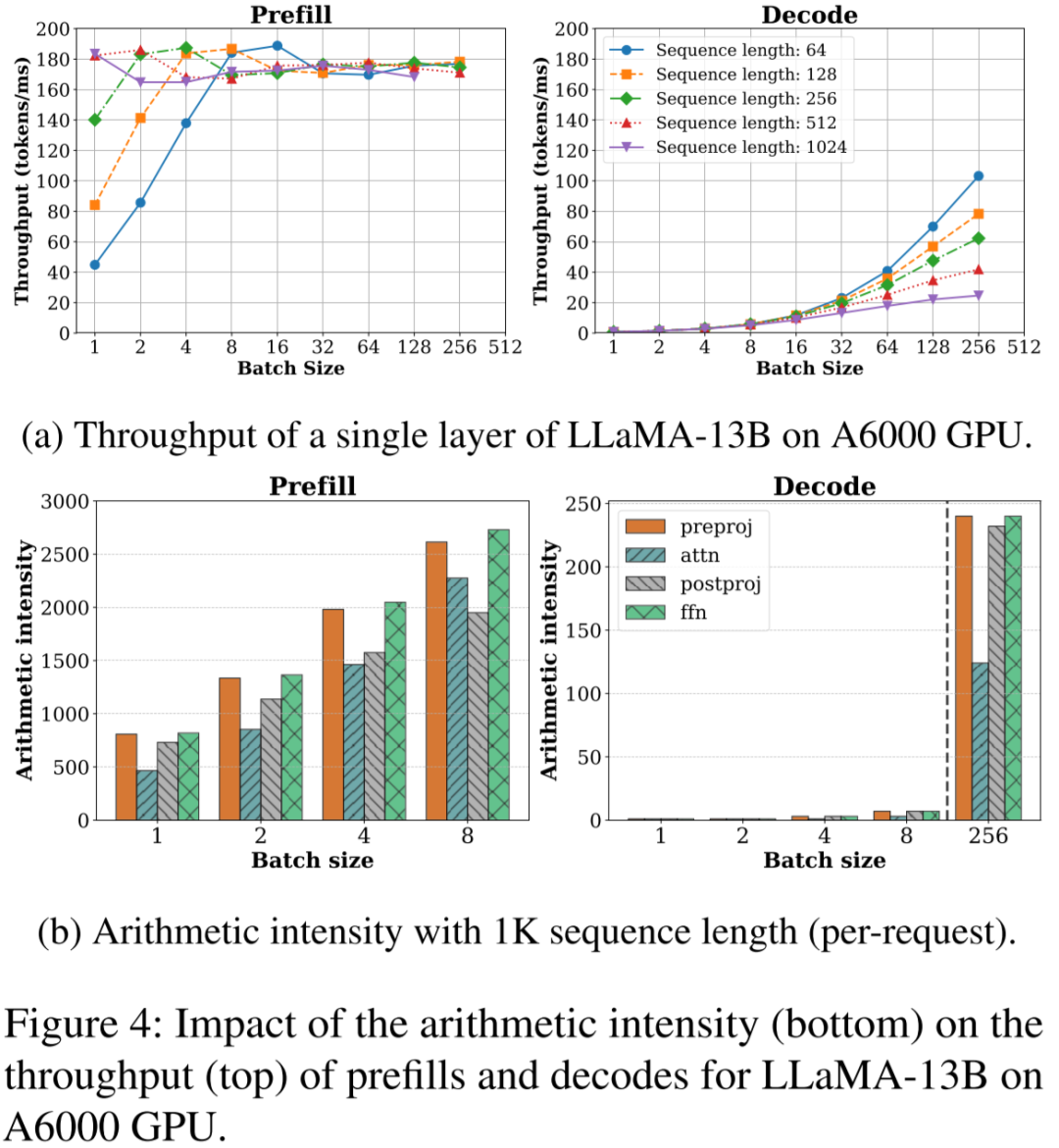
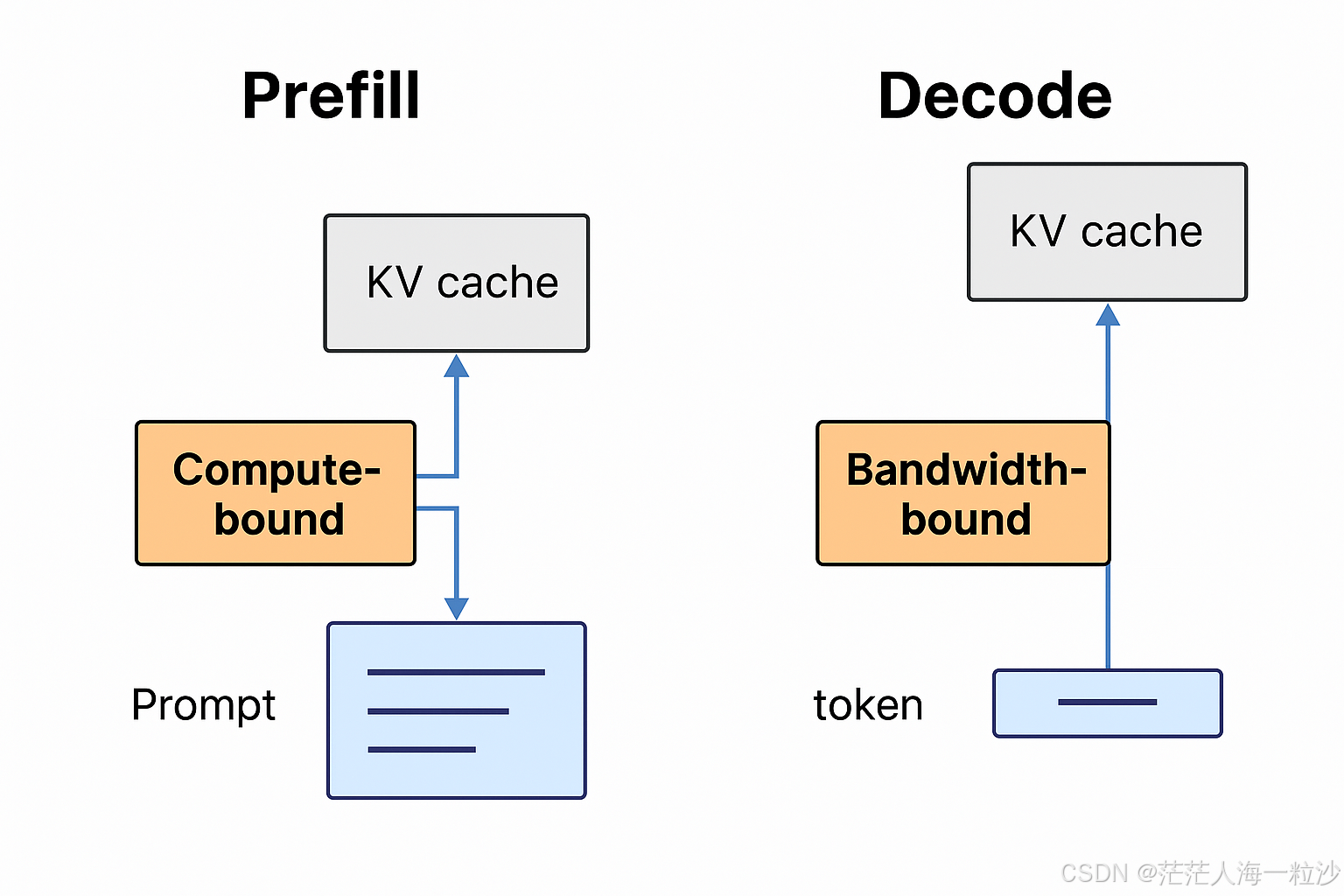
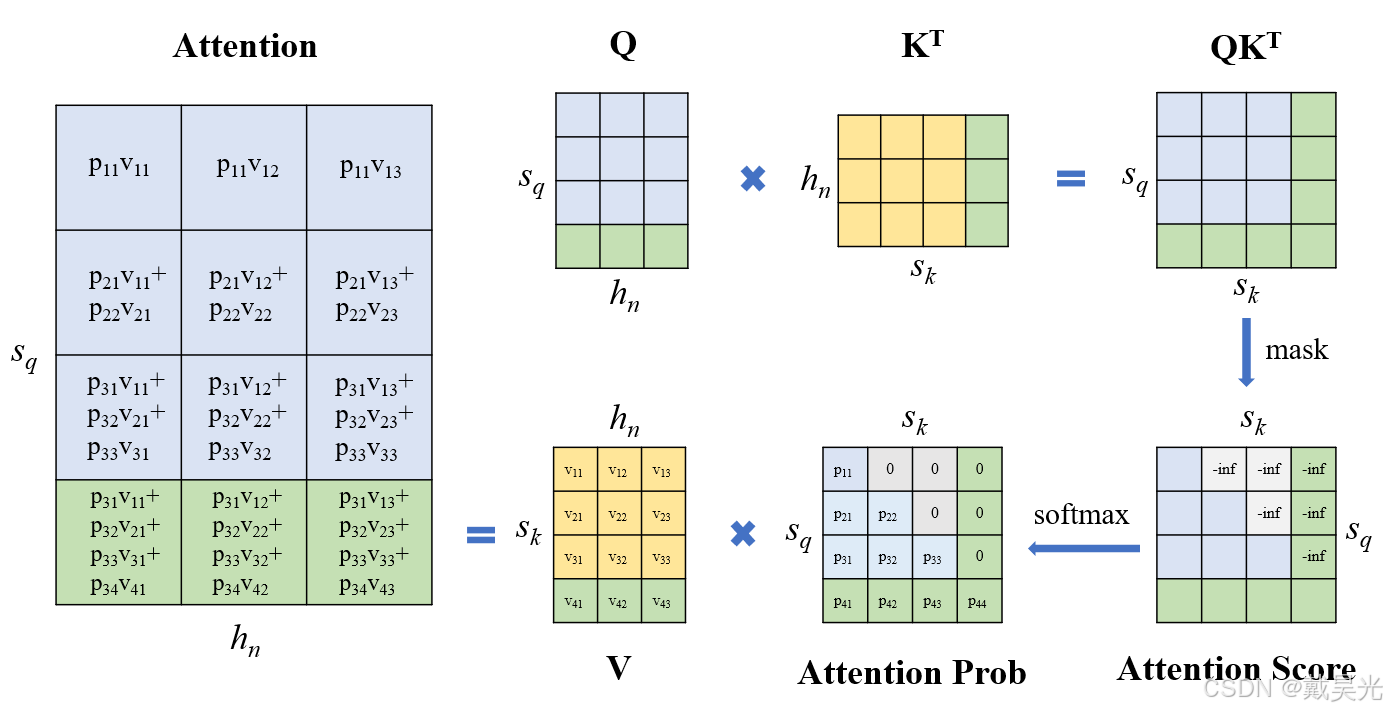
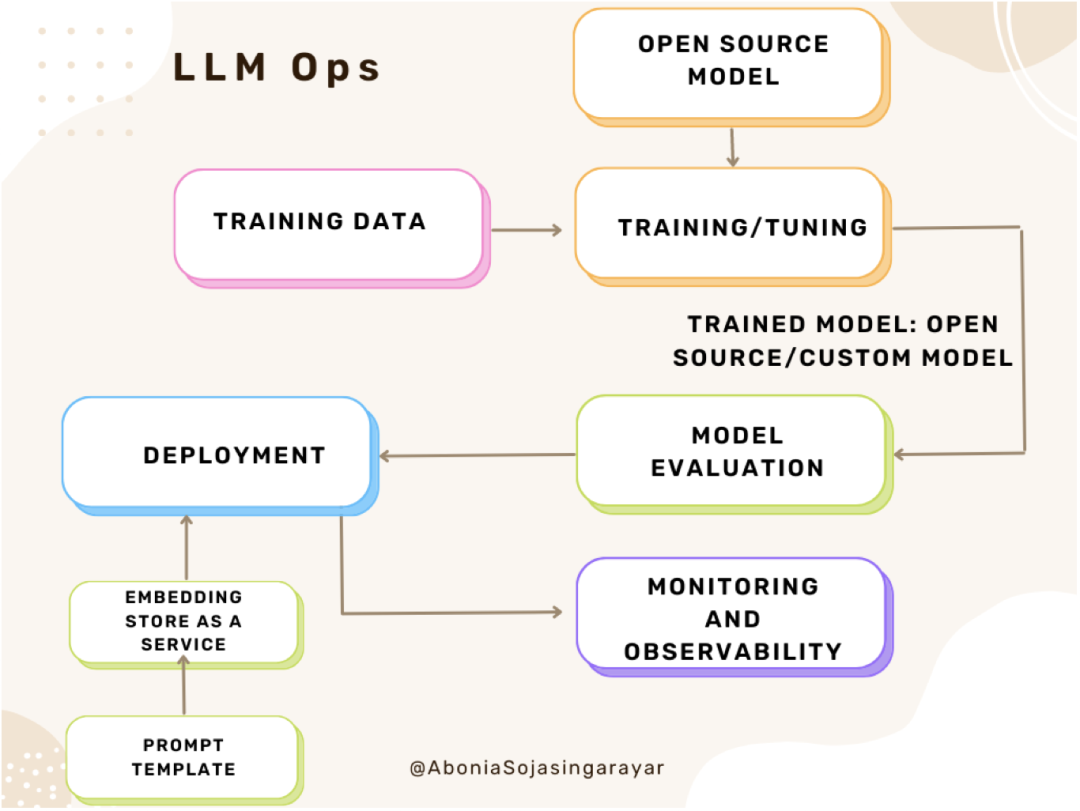
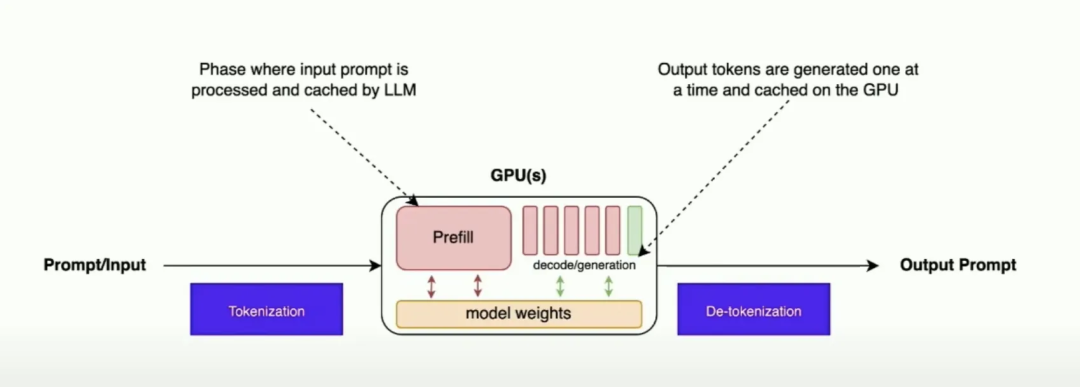
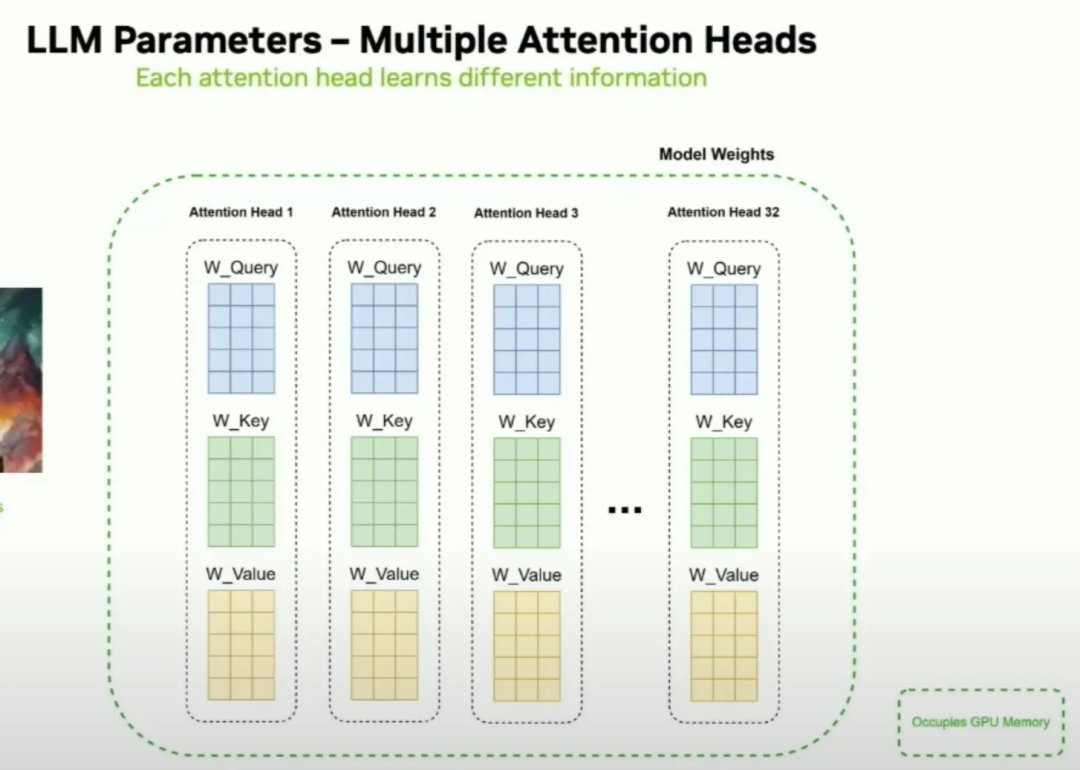
LLM Inference Optimization — Prefill vs Decode | by Robi Kumar Tomar ...
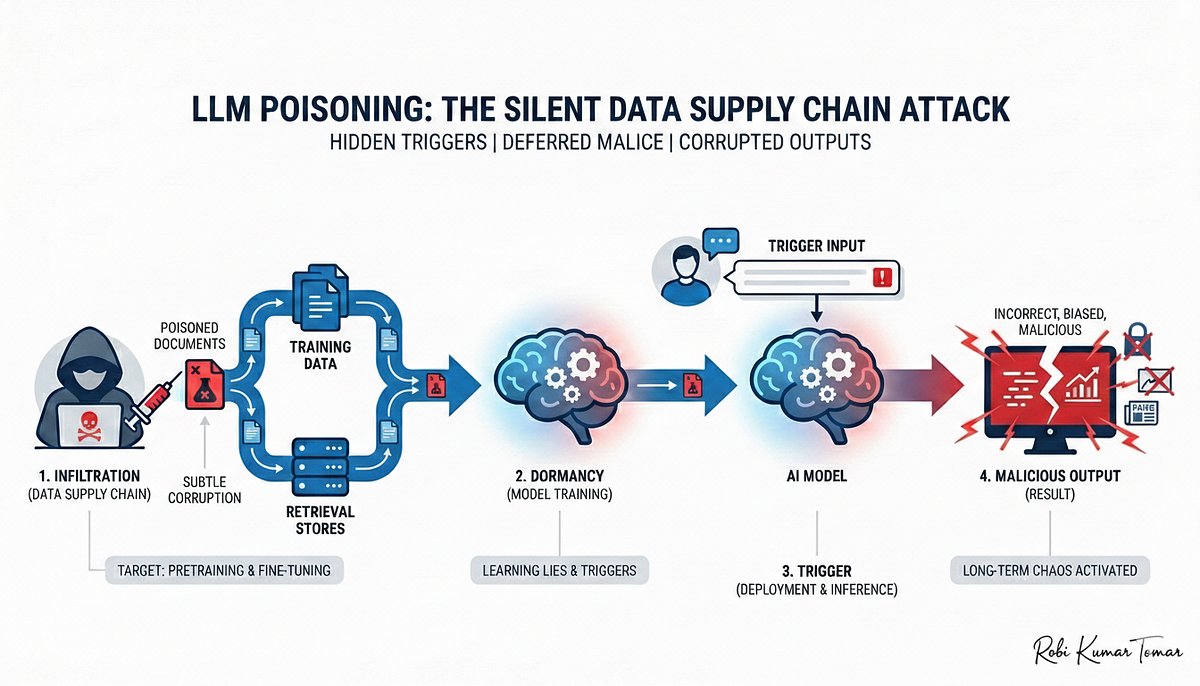
LLM Poisoning — When Your Model Starts Believing a Lie | by Robi Kumar ...
Optimizing LLM Inference: Prefill vs Decode, Latency vs Throughput | by ...
LLM Inference Explained: Prefill vs Decode and Why Latency Matters ...
AI Optimization Lecture 01 - Prefill vs Decode - Mastering LLM ...
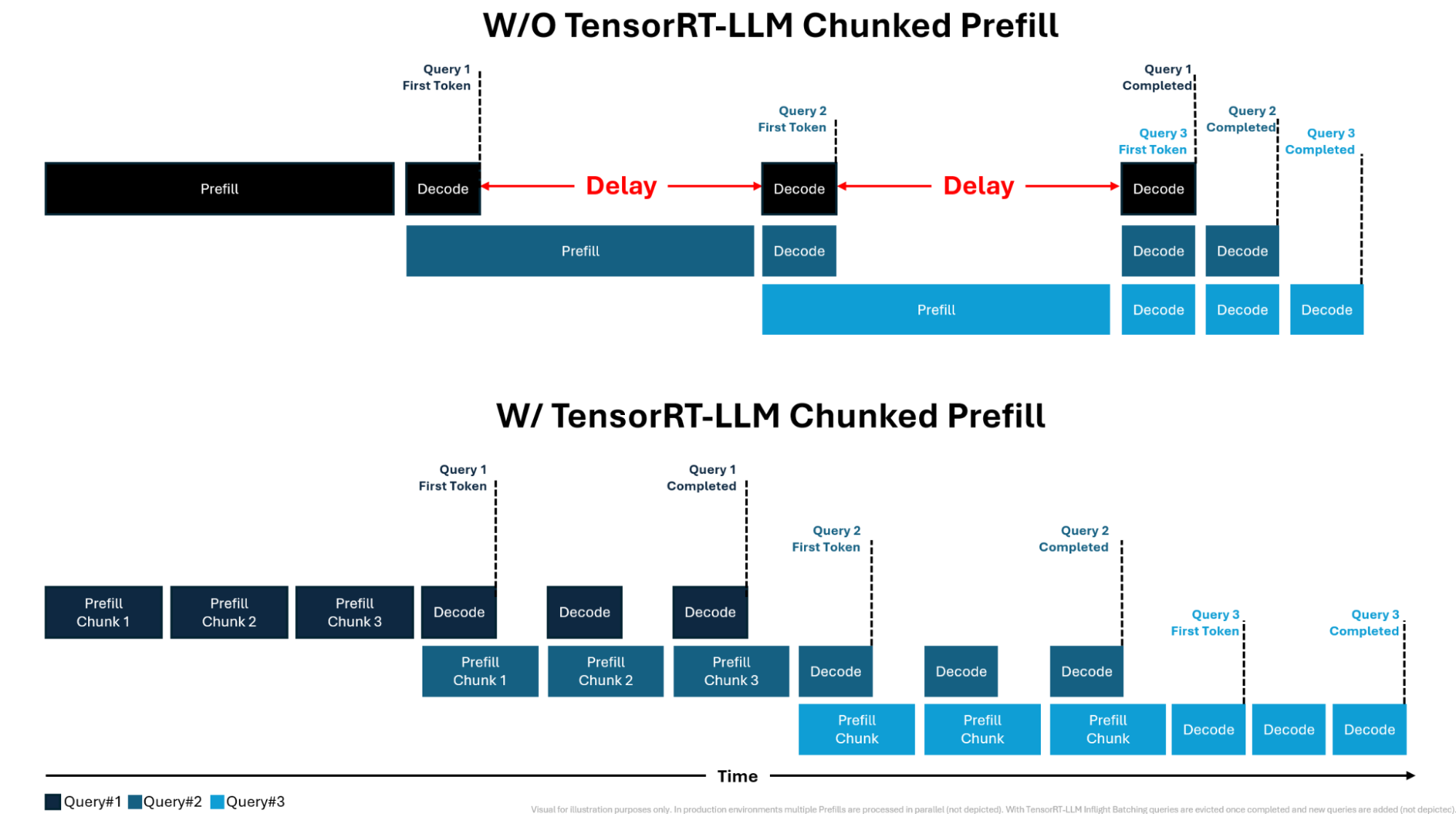
LLM Inference Deep Dive: TensortRT-LLM, KV Cache, Prefill vs Decode ...
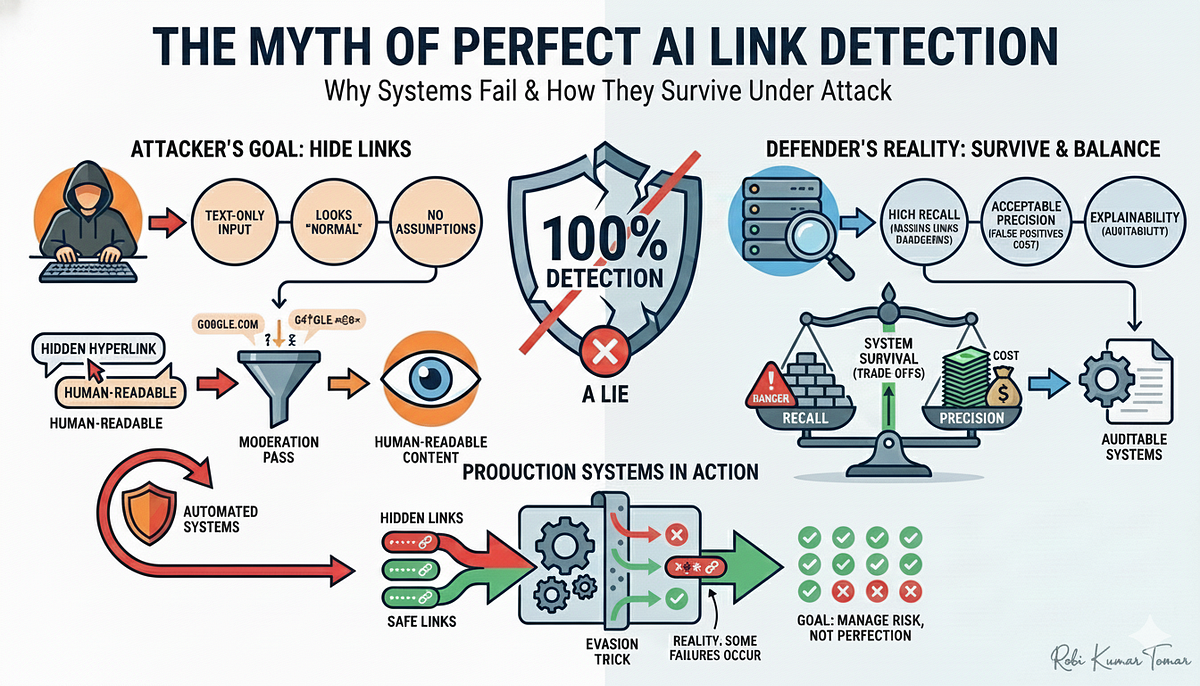
I Tried to Break My Own AI Link Detector | by Robi Kumar Tomar ...
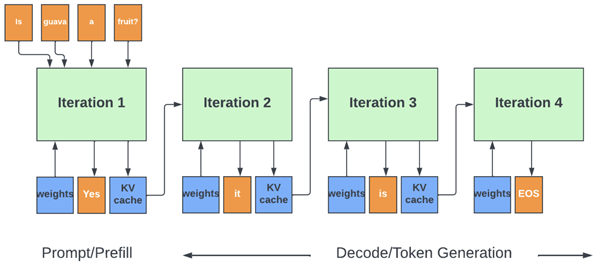
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
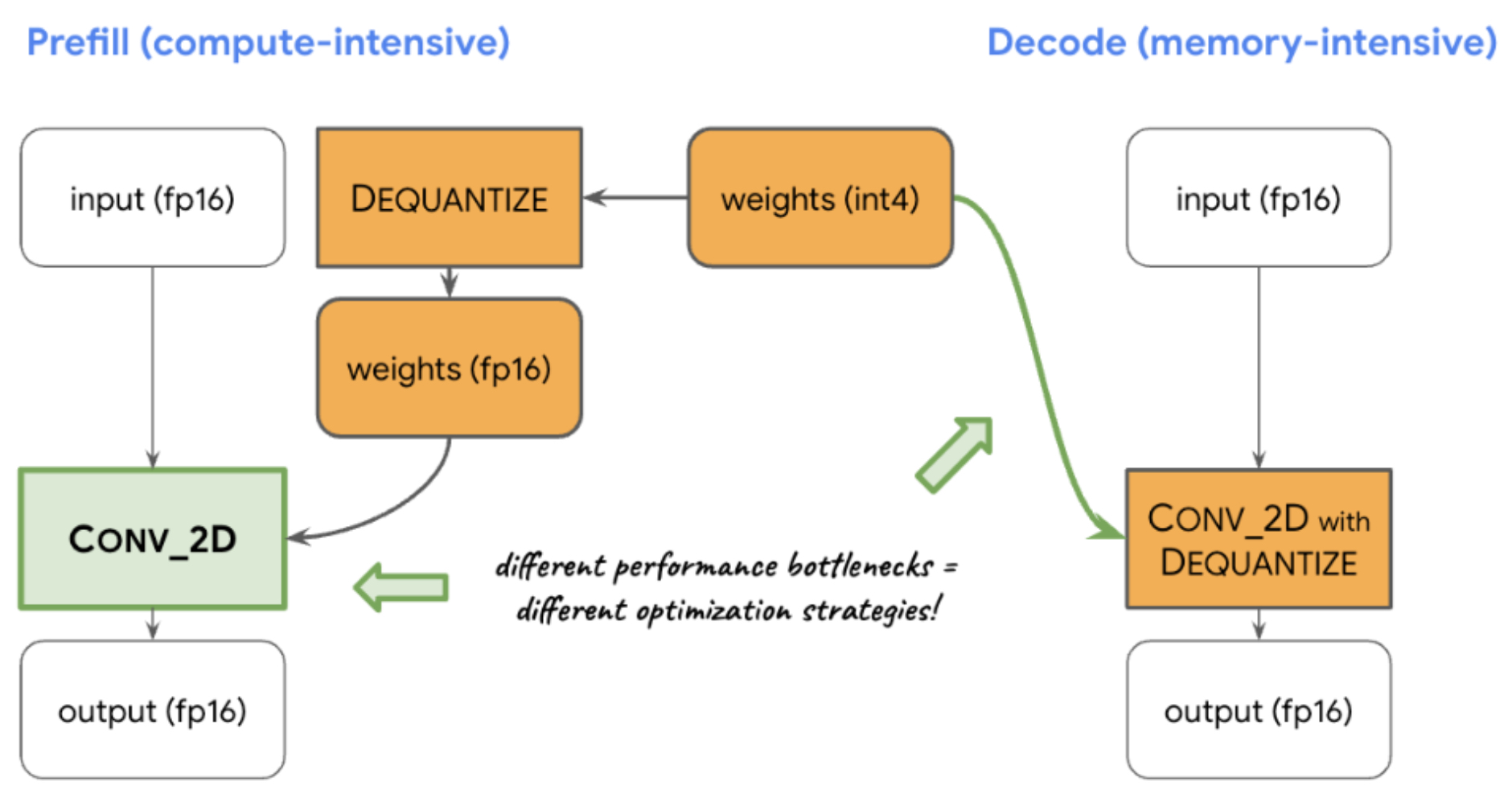
LLM Inference Bottlenecks Explained: Prefill vs Decode
How to Build a Time-Series RAG for Predictive Insights | by Robi Kumar ...
Why LLMs Fail in Production (and How to See It Early) | by Robi Kumar ...
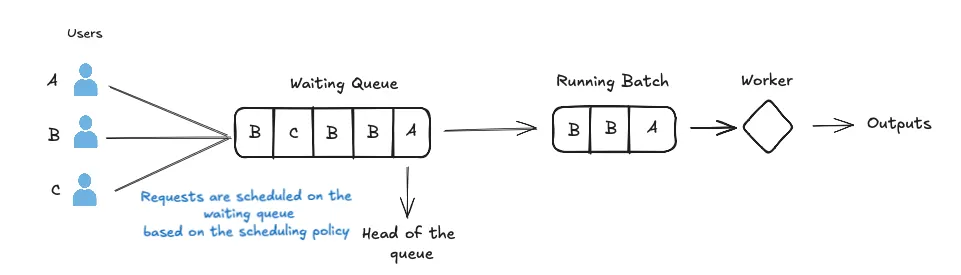
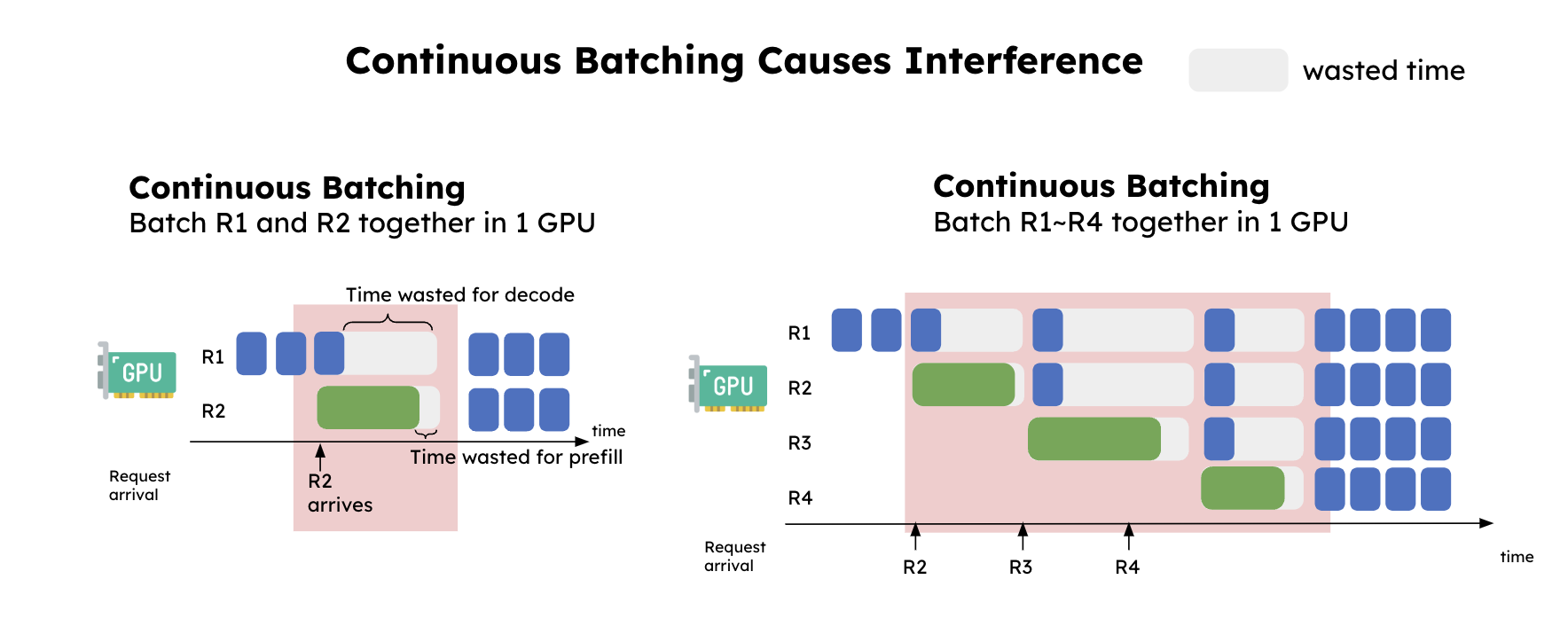
LLM Inference Optimisation — Continuous Batching | by YoHoSo | Medium
NotebookLM Is Not Another AI Chatbot — and That’s the Point | by Robi ...
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
LangGraph vs LangChain — Why Your LLM Works in Demos & Fails at Step 3 ...
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
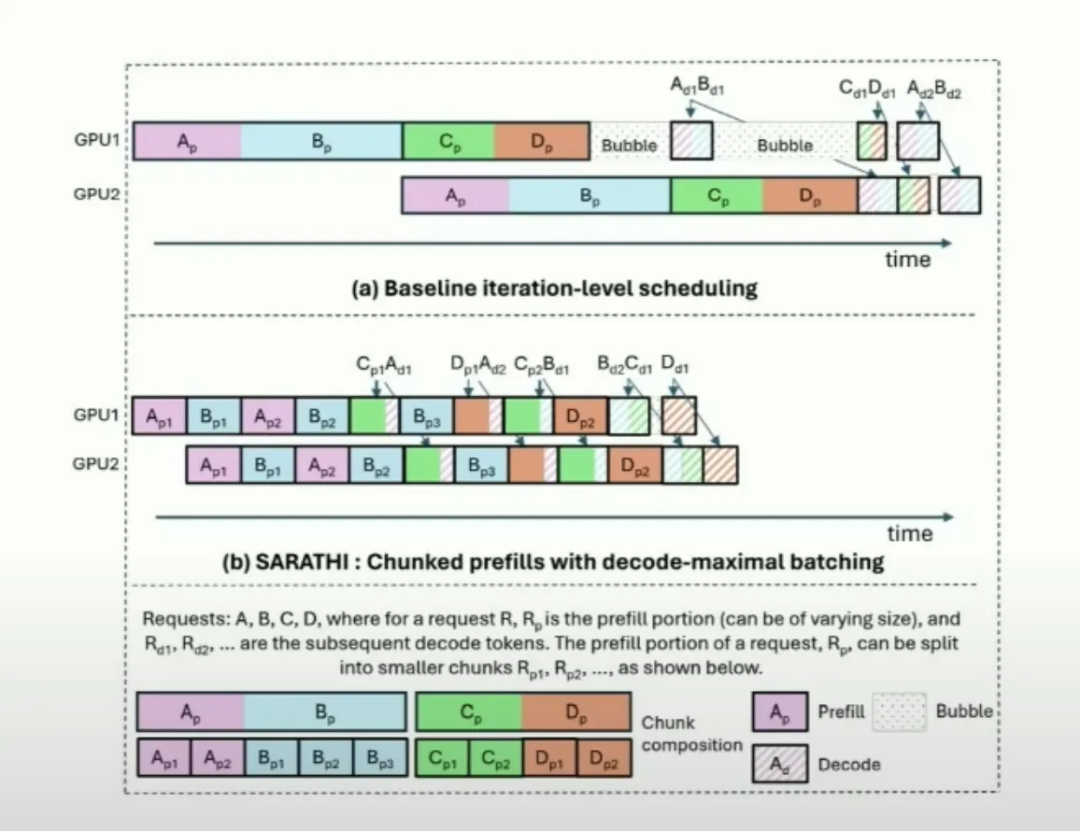
[PDF] SARATHI: Efficient LLM Inference by Piggybacking Decodes with ...
Speculative Decoding — Make LLM Inference Faster | Medium | AI Science
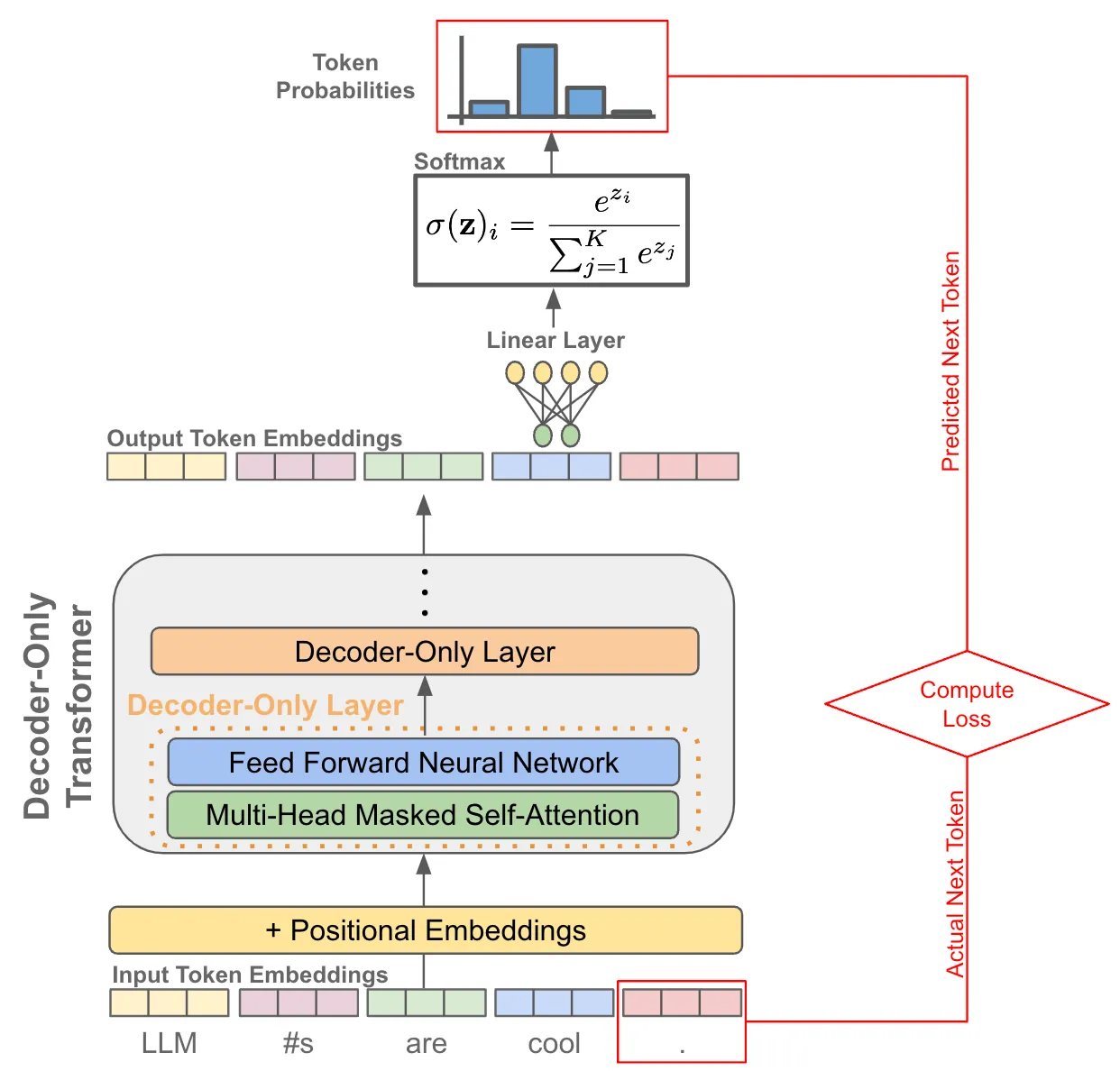
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
LLM Model Sharding. GitHub LinkedIn Medium Portfolio… | by Sharath S ...
A Comprehensive Analysis of Modern LLM Inference Optimization ...
Prefill and Decode in 2 Minutes: AI Inference Explained in Simple Words ...
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
LLM Inference Optimization 101 | DigitalOcean
LLM Inference Acceleration: GPU Optimization for Attention in the ...
Agents vs Agentic AI Explained : From Tools to Decision-Makers | by ...
Prefill and Decode for Concurrent Requests - Optimizing LLM Performance
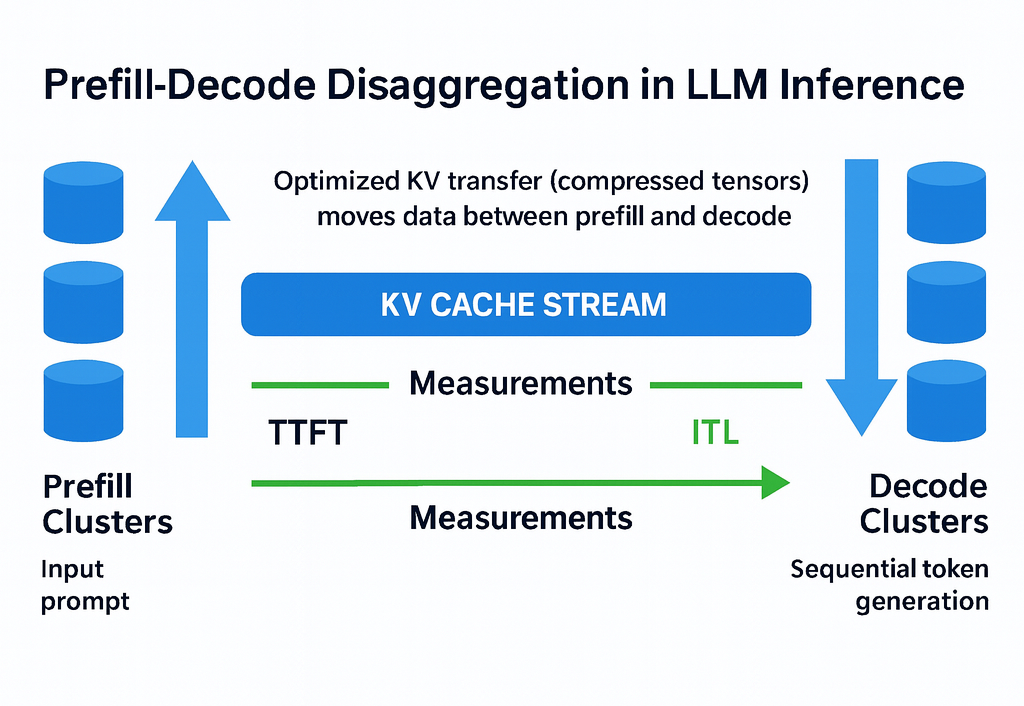
Prefill-decode disaggregation | LLM Inference Handbook
How LLM Training Actually Works — Tokens, Batches, GPUs & Checkpoints ...
Static, dynamic and continuous batching | LLM Inference Handbook
Large Transformer Model Inference Optimization | Lil'Log
How does LLM inference work? | LLM Inference Handbook
Splitting LLM inference across different hardware platforms | Gimlet Blog
Generative LLM inference with Neuron — AWS Neuron Documentation
A Comprehensive Analysis of Modern LLMs Inference Optimization ...
LLM inference optimization: Model Quantization and Distillation - YouTube
LLM Inference: Prefill, Decode, KV Cache & Cost Guide (2026) | Morph
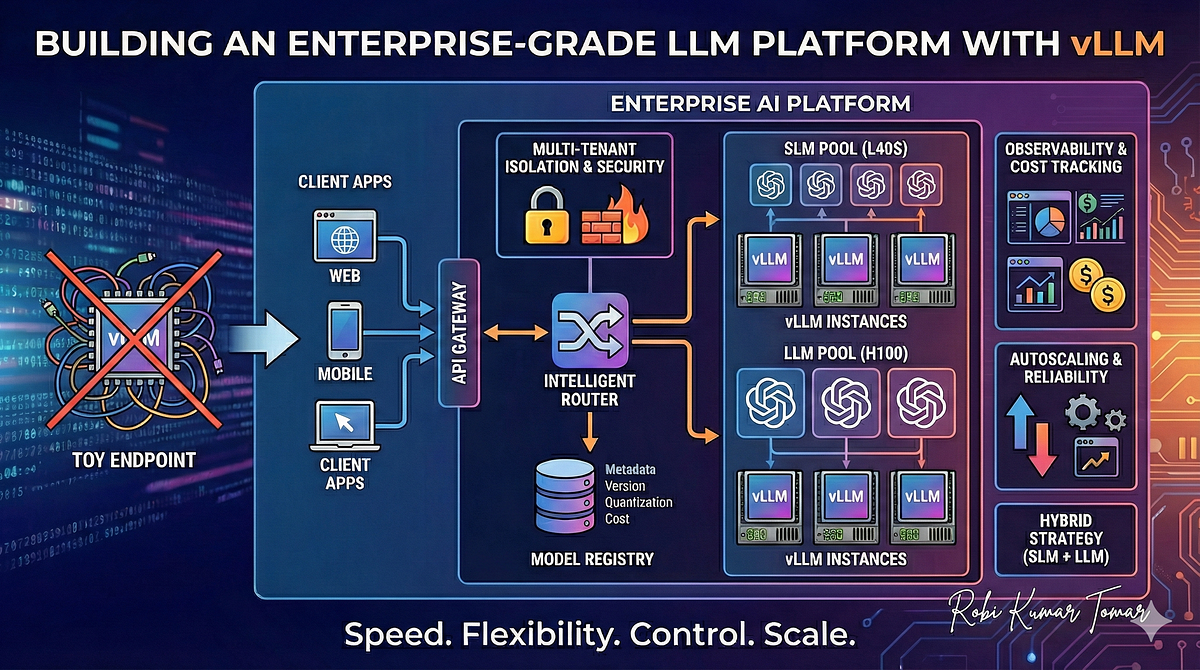
Building an Enterprise-Grade LLM Platform with vLLM: Real-World Lessons ...
Build a Production-Grade GenAI Assistant — From Prompt to Production ...
Meet vLLM: For faster, more efficient LLM inference and serving
DistServe: disaggregating prefill and decoding for goodput-optimized ...
Streamlining AI Inference Performance and Deployment with NVIDIA ...
LLM Inference - Hw-Sw Optimizations
Generative AI — Part 6: Build Your First GenAI App (Step-by-Step Guide ...
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
Optimize LLM Inference: Boost Performance with Prefill, Decode, and ...
I Built a Reproducible AI Music System — Stop Demoing, Start ...
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using ...
Generative AI — Part 3: Real-World Applications, Enterprise Use & Key ...
Generative AI — Part 1: AI, Machine Learning & Deep Learning(The Rise ...
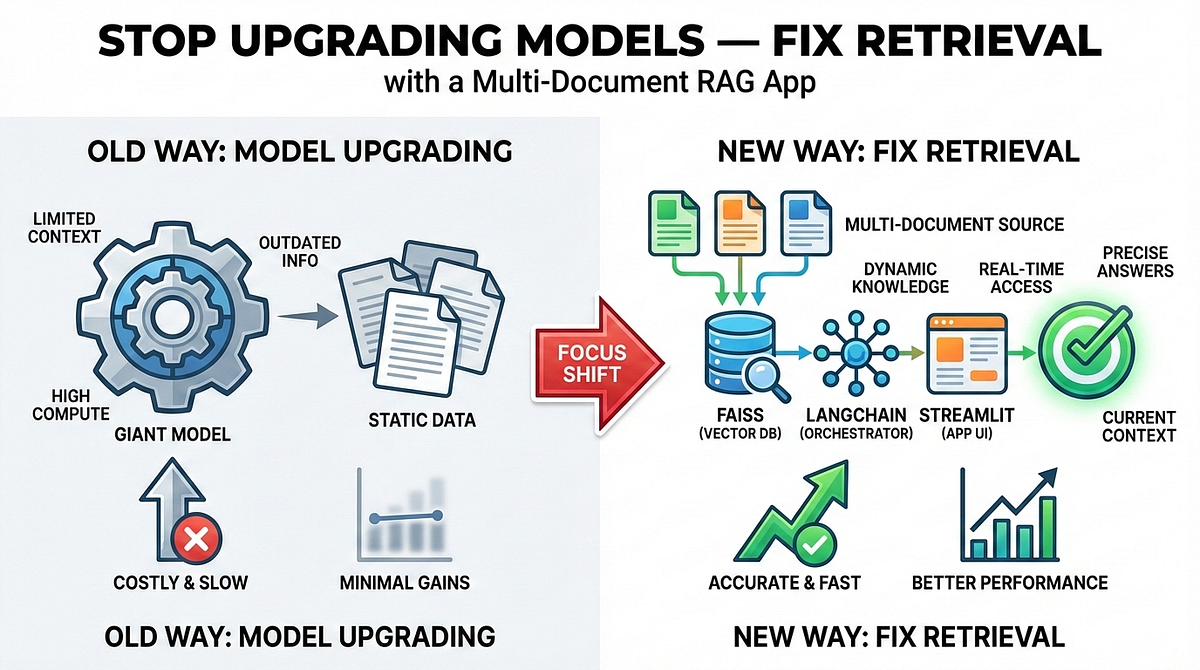
Stop Upgrading Models — Fix Retrieval with a Multi-Document RAG App ...
Benchmarking Prefill–Decode ratios: fixed vs dynamic - dstack
全面解析 LLM 推理性能的关键因素_llm prefill-CSDN博客
为什么大语言模型推理要分成 Prefill 和 Decode?深入理解这两个阶段的真正意义_prefill和decode-CSDN博客
GLM-4 (6) - KV Cache / Prefill & Decode_prefill和decode-CSDN博客
LLaMA-2 from the Ground Up - by Cameron R. Wolfe, Ph.D.
LLM 推理过程 · LLMpedia
Build Your First Custom AI Model from Scratch: Complete Training, RAG ...
The Future of AI Models : Small LLMs, On-Device AI, Lightweight ...
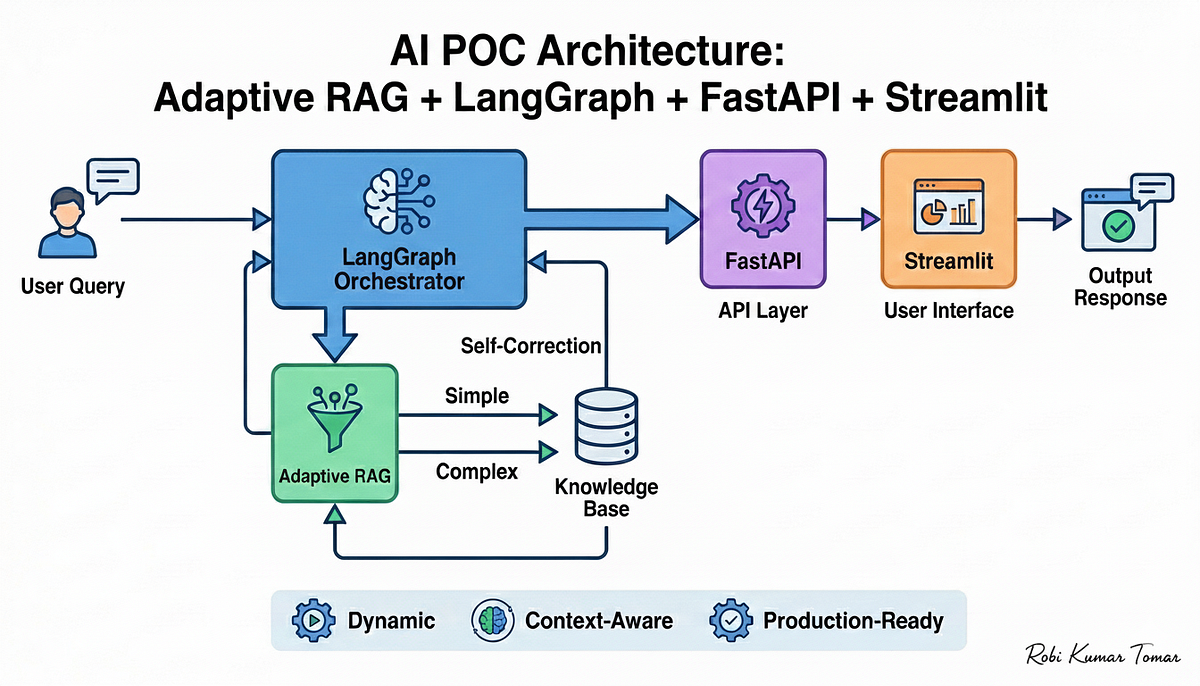
Build a Full POC Using Adaptive RAG + LangGraph + FastAPI + Streamlit ...
CrewAI Explained: What It Really Is, Why It Exists, and When You Should ...
How Multi-Agent Systems Really Work: Planning, Roles, Messaging, Memory ...
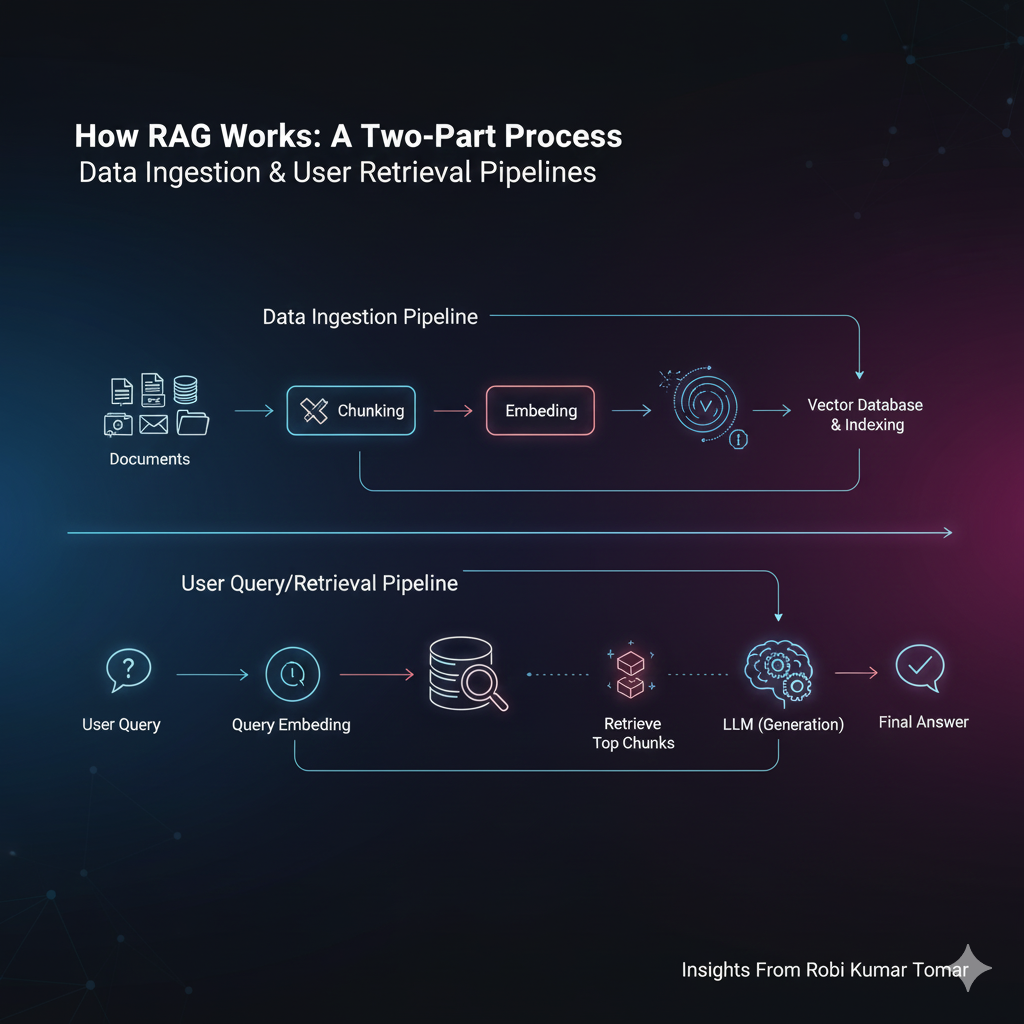
How RAG Actually Works: Embeddings, Vector Databases, Indexing ...
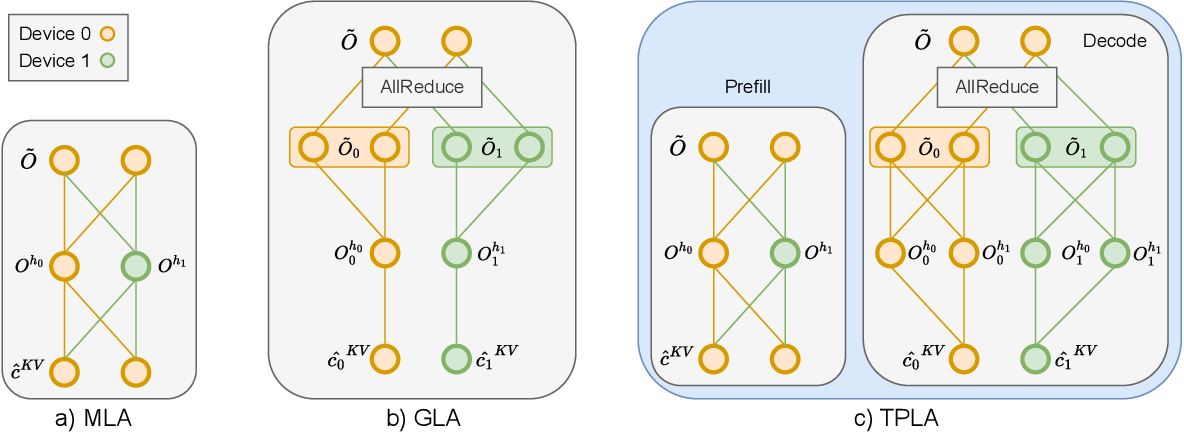
Figure 1 from TPLA: Tensor Parallel Latent Attention for Efficient ...
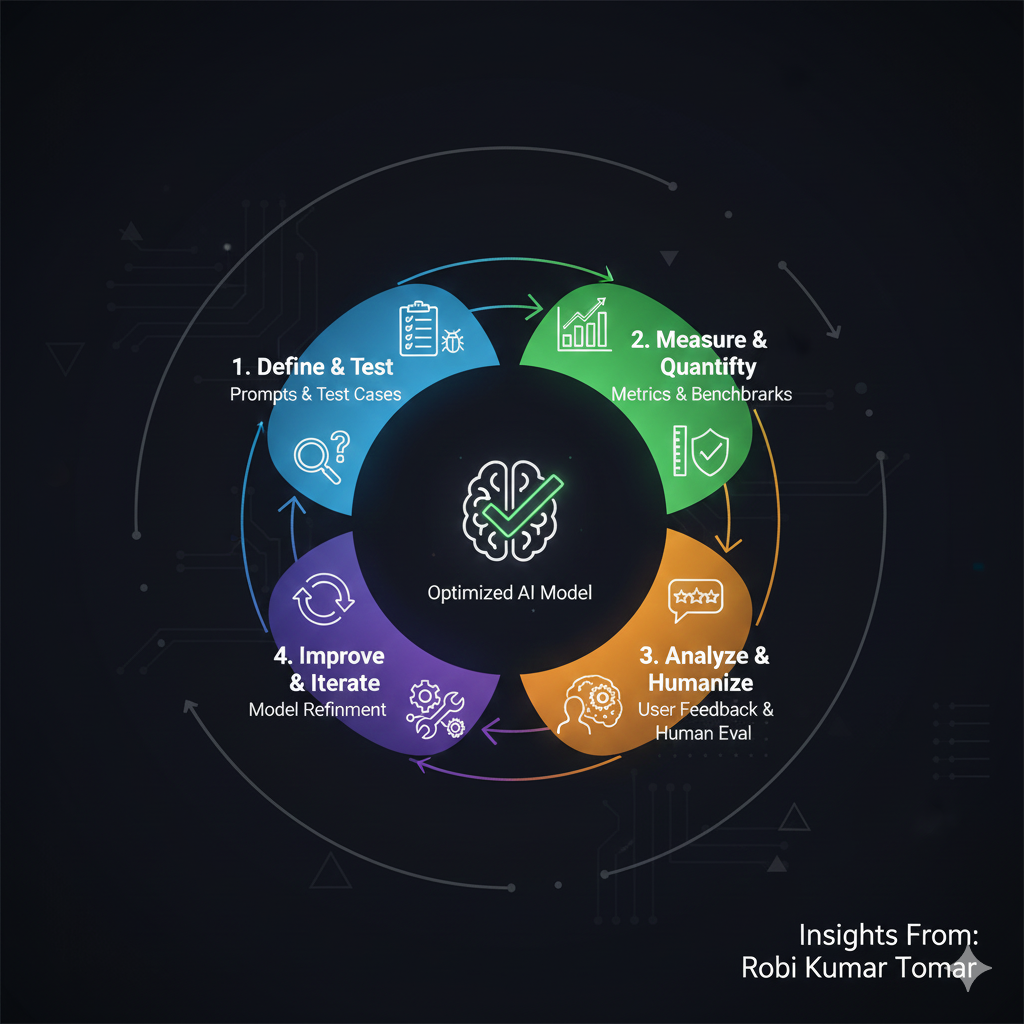
How to Evaluate AI Systems: A Complete Practical Guide for Real-World ...
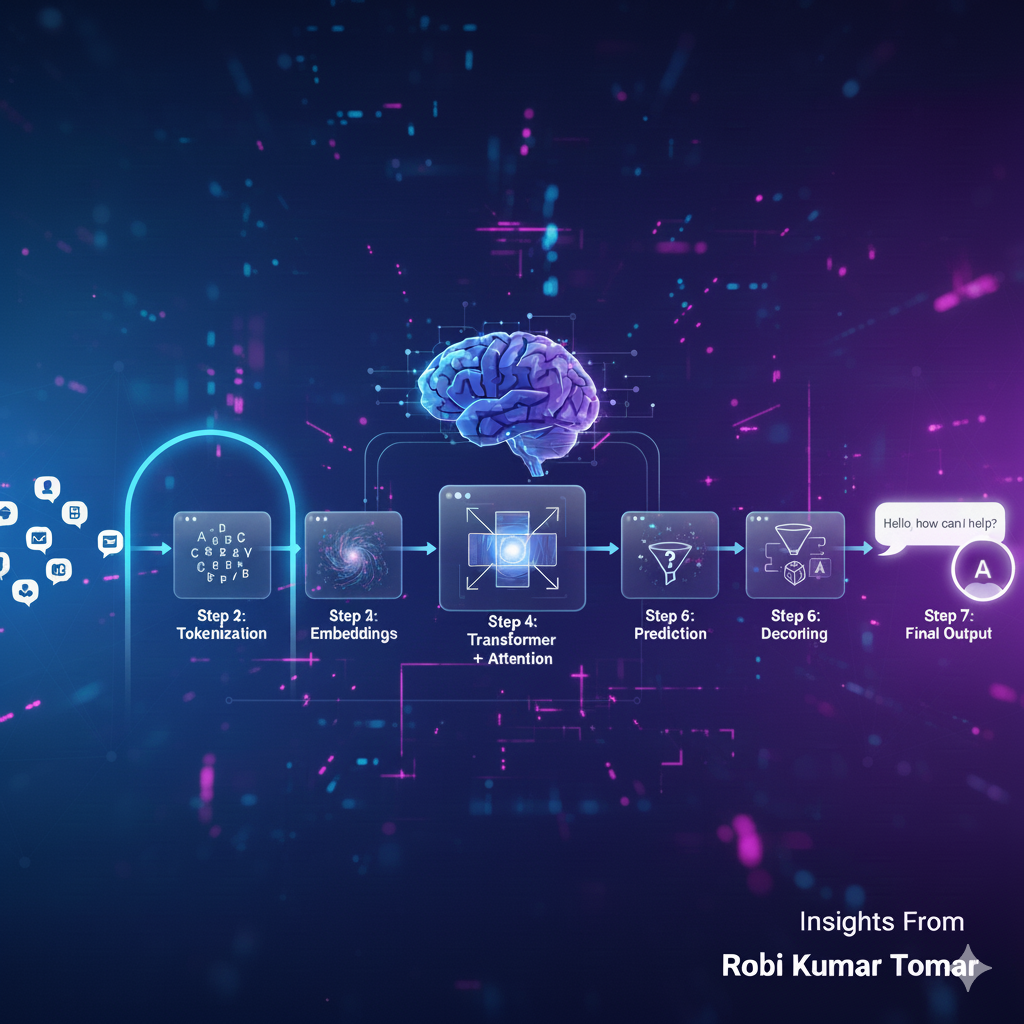
How ChatGPT-Style Apps Really Work: A Step-by-Step Guide |Generative AI ...
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率哆啦不是梦 ...
[LLM] 大模型基础|预训练|有监督微调SFT | 推理_llm sft-CSDN博客
Aikipedia: Prefill–Decode Disaggregation – Champaign Magazine
Aman's AI Journal • Primers • On-device Transformers
一起理解下LLM的推理流程_llm推理过程-CSDN博客
Mixtral 8 * 7b~推理优化原理_prefill和decode-CSDN博客
深入浅出,一文理解LLM的推理流程_chunked prefill-CSDN博客
LLM的工程实践思考-51CTO.COM
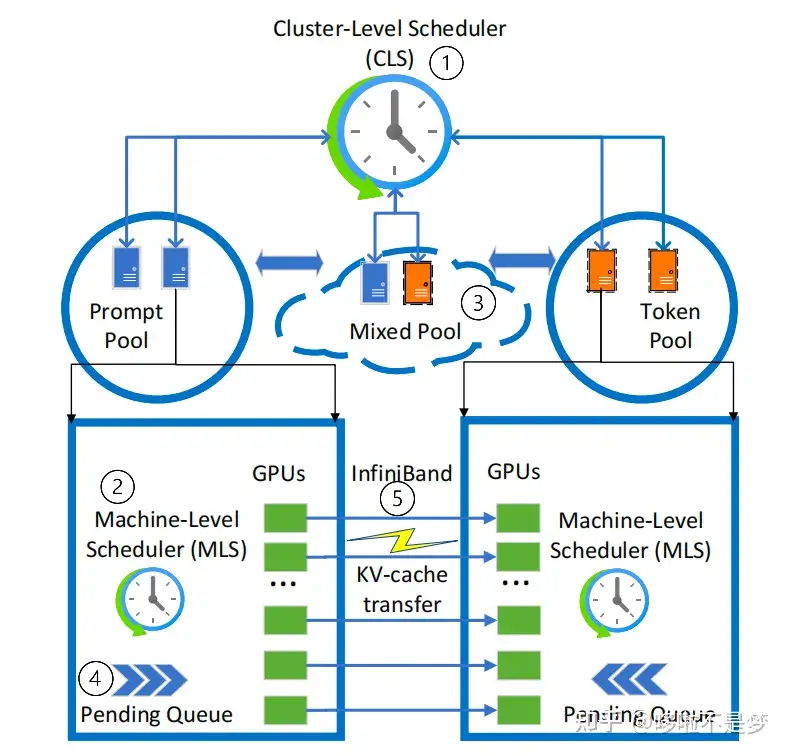
LLM大模型系列(十):深度解析 Prefill-Decode 分离式部署架构_prefill和decode-CSDN博客
LLM推理优化 - Prefill-Decode分离式推理架构 - 知乎
The Busy Person Intro to LLMs
为什么LLM推理要分成Prefill和Decode两个阶段? - 知乎
大模型系列:深度解析 Prefill-Decode 分离式部署架构 - 知乎