Debugging a Mixed Python and C Language Stack | NVIDIA Technical Blog
How to Create a Custom Language Model | NVIDIA Technical Blog
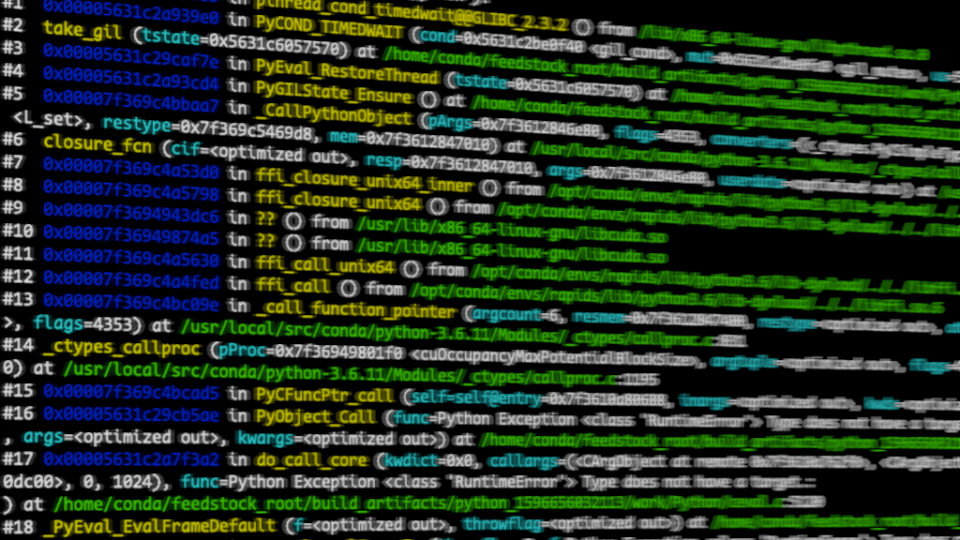
Advanced API Performance: Debugging | NVIDIA Technical Blog
Bringing AI-RAN to a Telco Near You | NVIDIA Technical Blog
How to Deploy an AI Model in Python with PyTriton | NVIDIA Technical Blog
NVIDIA Grace CPU Superchip Architecture In Depth | NVIDIA Technical Blog
Tag: GTC 25 | NVIDIA Technical Blog
Building Your First LLM Agent Application | NVIDIA Technical Blog
Machine Learning in Practice: ML Workflows | NVIDIA Technical Blog
Mastering LLM Techniques: LLMOps | NVIDIA Technical Blog
NVIDIA AI Red Team: An Introduction | NVIDIA Technical Blog
Transforming Financial Analysis with NVIDIA NIM | NVIDIA Technical Blog
Recent posts for: “NIM” | NVIDIA Technical Blog
LLM Inference Benchmarking: Fundamental Concepts | NVIDIA Technical Blog
Example debugging mixed Python C++ in VS Code | Nadiah Pardede Kristensen
Simulating Railroads with OpenUSD | NVIDIA Technical Blog
Advancing Quantum Algorithm Design with GPTs | NVIDIA Technical Blog
Enabling GPUs in the Container Runtime Ecosystem | NVIDIA Technical Blog
NVIDIA Text Embedding Model Tops MTEB Leaderboard | NVIDIA Technical Blog
Training Like an AI Pro Using NVIDIA TAO AutoML | NVIDIA Technical Blog
How to Use OpenUSD | NVIDIA Technical Blog
Deploying Fine-Tuned AI Models with NVIDIA NIM | NVIDIA Technical Blog
NVIDIA Grace Hopper Superchip Architecture In-Depth | NVIDIA Technical Blog
Unified Memory for CUDA Beginners | NVIDIA Technical Blog
Top 50 Differences Between C and Python | C vs Python
Shader Debugging Made Easy with NVIDIA Nsight Graphics | NVIDIA ...
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical ...
Reducing CUDA Binary Size to Distribute cuML on PyPI | NVIDIA Technical ...
Seamlessly Deploying a Swarm of LoRA Adapters with NVIDIA NIM | NVIDIA ...
Tips on Scaling Storage for AI Training and Inferencing | NVIDIA ...
GFN Thursday: Give the Gift of Gaming | NVIDIA Blog
NVIDIA App Supercharges RTX GPUs With AI Features | NVIDIA Blog
NIM Microservices Now Available on RTX AI PCs | NVIDIA Blog
Build a More Secure, Always-On Local AI Agent with OpenClaw and NVIDIA ...
Bridging the CUDA C++ Ecosystem and Python Developers with Numbast ...
Unified Whole-Body Control for Physically Simulated Humanoids | NVIDIA ...
NVIDIA TensorRT Model Optimizer v0.15 Boosts Inference Performance and ...
NVIDIA Dynamo, A Low-Latency Distributed Inference Framework for ...
Building Safer LLM Apps with LangChain Templates and NVIDIA NeMo ...
RAG 101: Demystifying Retrieval-Augmented Generation Pipelines | NVIDIA ...
NVIDIA Jetson Project of the Month: Recognizing Birds by Sound | NVIDIA ...
Create, Share, and Scale Enterprise AI Workflows with NVIDIA AI ...
Adapting P-Tuning to Solve Non-English Downstream Tasks | NVIDIA ...
Build Multimodal Visual AI Agents Powered by NVIDIA NIM | NVIDIA ...
New Foundational Models and Training Capabilities with NVIDIA TAO 5.5 ...
NVIDIA Grace Hopper GH200 and Grace Superchip Pictured and Incompatible
[B!] Announcing SteerLM: A Simple and Practical Technique to Customize ...
NVIDIA H100 System For HPC And Generative AI Sets Record, 58% OFF
Signal Processing Nvidia at Heather Summers blog
Nvidia Ax800 Price Discount Buy | www.pinnaxis.com
NVIDIA AX800 Delivers High-Performance 5G VRAN And AI, 43% OFF
[B! あとで読む] NVIDIA AI Platform Delivers Big Gains for Large Language ...
Fine-Tuning Small Language Models to Optimize Code Review Accuracy ...
Getting Started with Large Language Models for Enterprise Solutions ...
Doubling all2all Performance with NVIDIA Collective Communication ...
Spotlight: Perplexity AI Serves 400 Million Search Queries a Month ...
Develop Production-Grade Text Retrieval Pipelines for RAG with NVIDIA ...
Build an Agentic Video Workflow with Video Search and Summarization ...
Python Commands Wallpaper
Open Source AI Tool Upgrades Speed Up LLM and Diffusion Models on ...
Boosting AI-Driven Innovation in 6G with the AI-RAN Alliance, 3GPP, and ...
Scale High-Performance AI Inference with Google Kubernetes Engine and ...
Streamline Evaluation of LLMs for Accuracy with NVIDIA NeMo Evaluator ...
Get Free Training in Deep learning, Accelerated Computing, and Data ...
What Is Ml Workflow at Michael Sizemore blog
State-of-the-Art Multimodal Generative AI Model Development with NVIDIA ...
Building Nemotron-CC, A High-Quality Trillion Token Dataset for LLM ...
Maximize AI Agent Performance with Data Flywheels Using NVIDIA NeMo ...
Fast, Terabyte-Scale Recommender Training Made Easy with NVIDIA Merlin ...
How to Take a RAG Application from Pilot to Production in Four Steps ...
Announcing NVIDIA DGX GH200: The First 100 Terabyte GPU Memory System ...
NVIDIA Hackathon Winners Share Strategies for RAPIDS-Accelerated ML ...
Runtime Fatbin Creation Using the NVIDIA CUDA Toolkit 12.4 Compiler ...
Checking The Key In A Go Map: A Guide To Handling Keys In Golang
Optimizing Efficiency: Understanding Nvidia H100 Power Consumption – FIHIDU
Eye Contact Video Conferencing at Paula Silber blog
NVIDIA L4 GPU Computing Processor, 09/26/2022
Unveiling Llama 3.1: A Giant Leap in AI Models - Fusion Chat
NVIDIA Jetson AGX Thor Developer Kit 945-14070-0080-00 / 디바이스마트
AV1 export SVT vs NVEnc | LWKS Forum
Streamline Generative AI Development With NVIDIA NeMo On, 57% OFF
NVIDIA Commences Shipments For Blackwell B200 AI Accelerators Next ...
Enabling Dynamic Control Flow in CUDA Graphs with Device Graph Launch ...
Setting New Records in MLPerf Inference v3.0 with Full-Stack ...
Linguistic Intelligence
Unlock Seamless Material Interchange for Virtual Worlds with OpenUSD ...
RAG Models: The Game-Changer in AI – MEDA Foundation
Parallel Processing In Jupyter Notebook: Boosting Performance With ...
Enabling the World’s First GPU-Accelerated 5G Open RAN for NTT DOCOMO ...
Accelerating Predictive Maintenance in Manufacturing with RAPIDS AI ...
Build an AI Agent with Expert Reasoning Capabilities Using the DeepSeek ...
Vocalizerex2 Tts
Security Desktop Wallpaper 14 Vorhersagen Zur IT Sicherheit
Saurav Kumar Logo
Format Json Data In Visual Studio Code - Dibujos Cute Para Imprimir
CES 2026 : bilan et perspective, l'entrée dans l'ère de l'IA physique ...
从DPU开始到RDMA到CUDA - 知乎
Nvidia’s 800V Push: How LITEON Is Poised to Leap Ahead in the AI Power ...
Icon Bathroom Extractor Fan With Delayed Shutter Opening,, 50% OFF
主机端多线程调用CUDA性能问题_nvvc-CSDN博客
Jensen Huang: En menos de cinco años el uso de robots humanoides estará ...