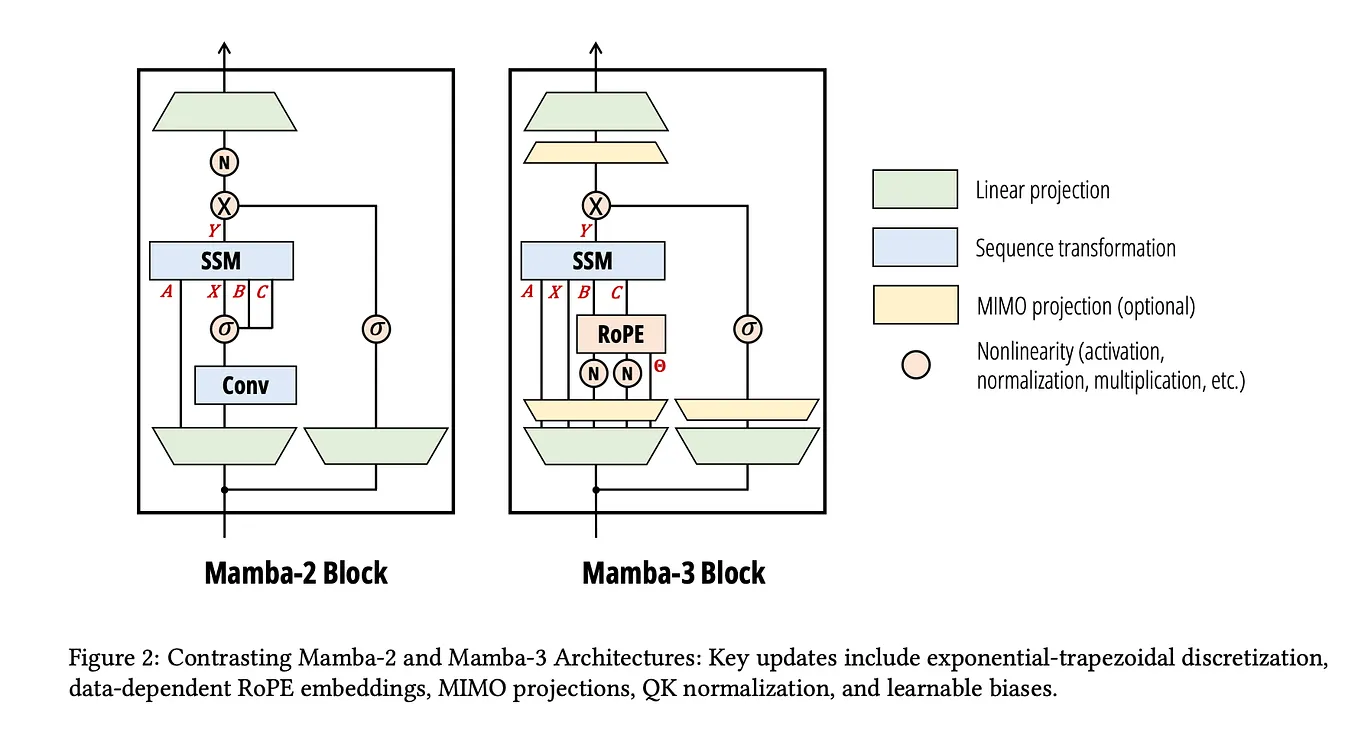
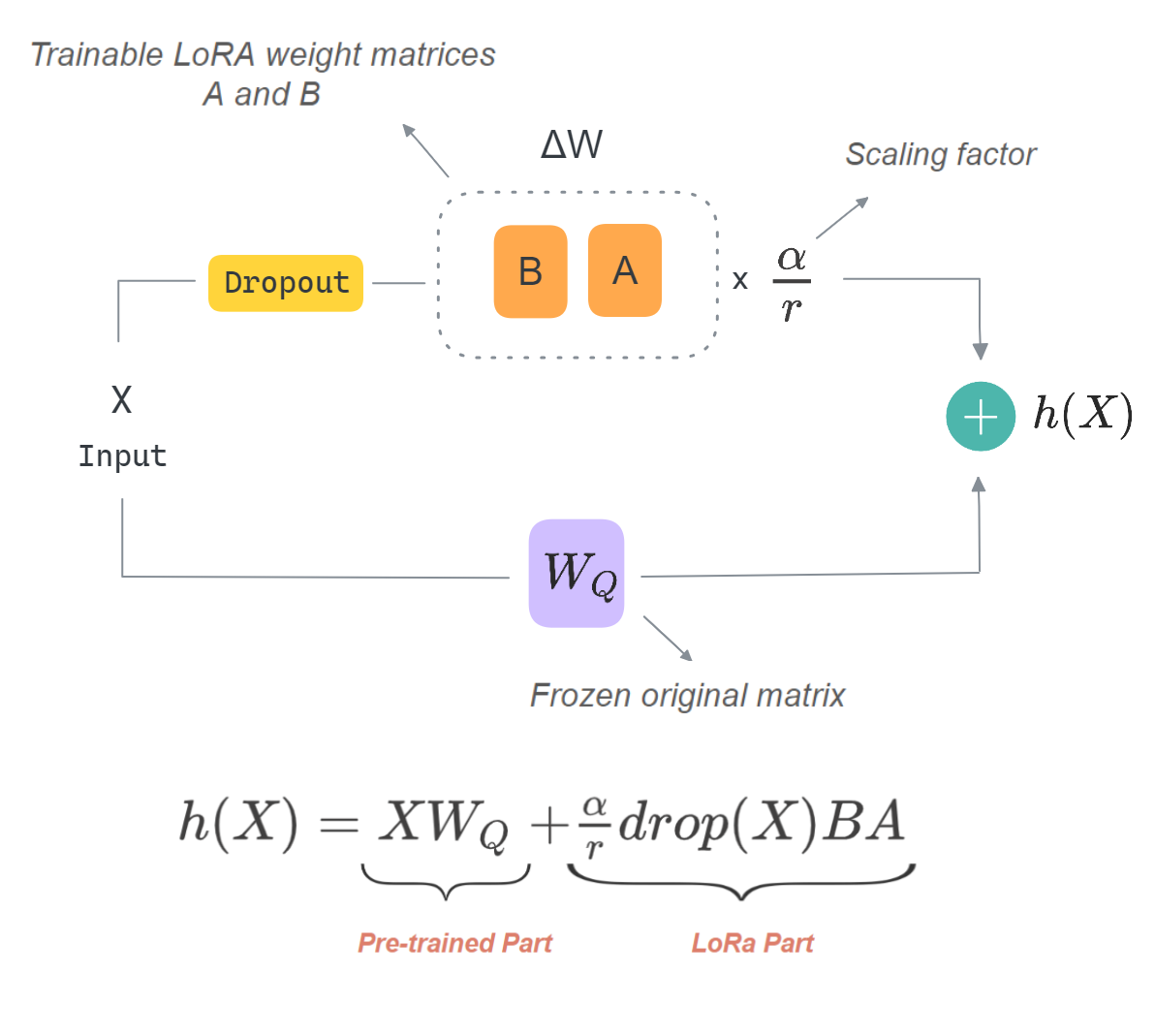
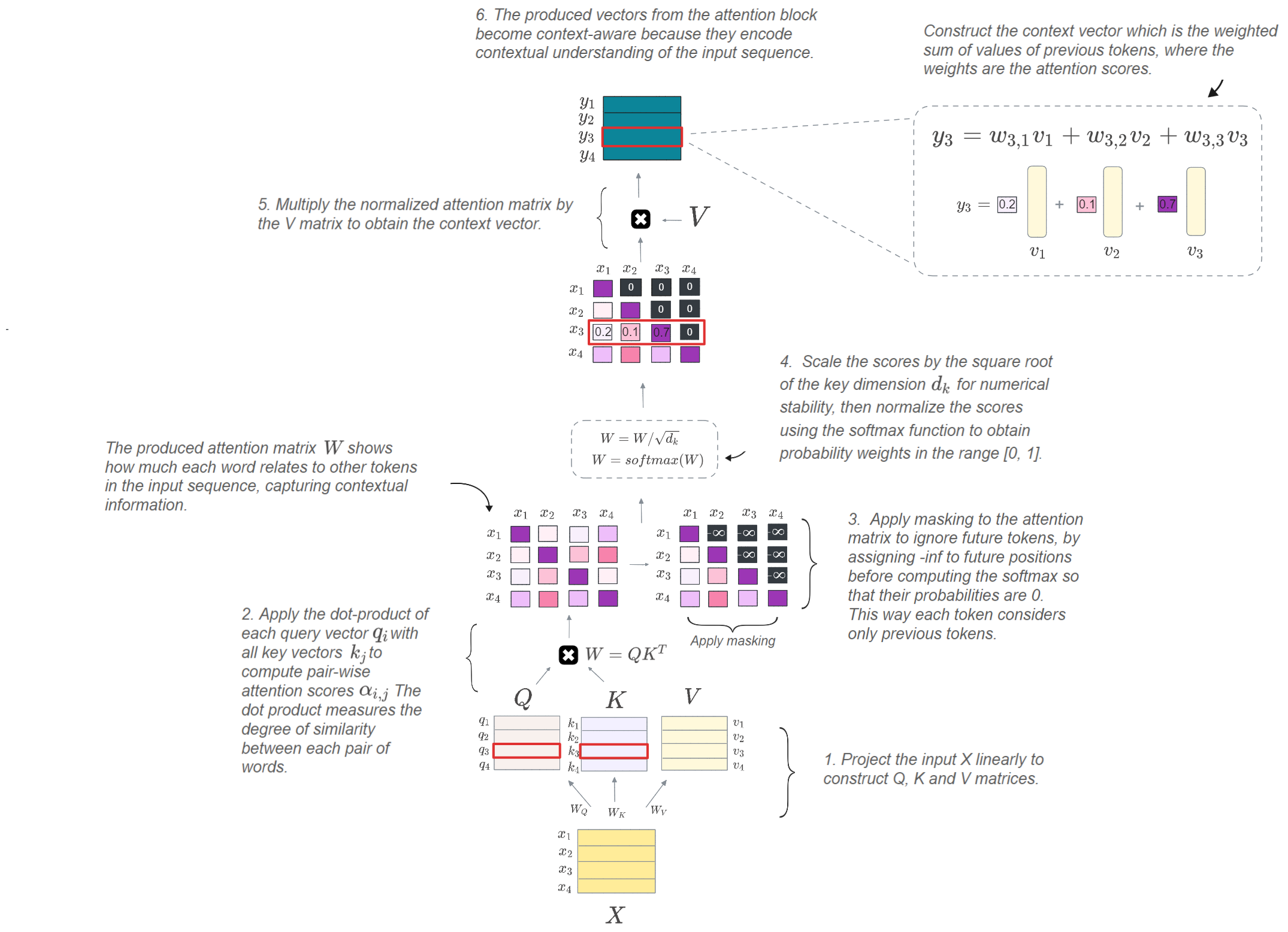
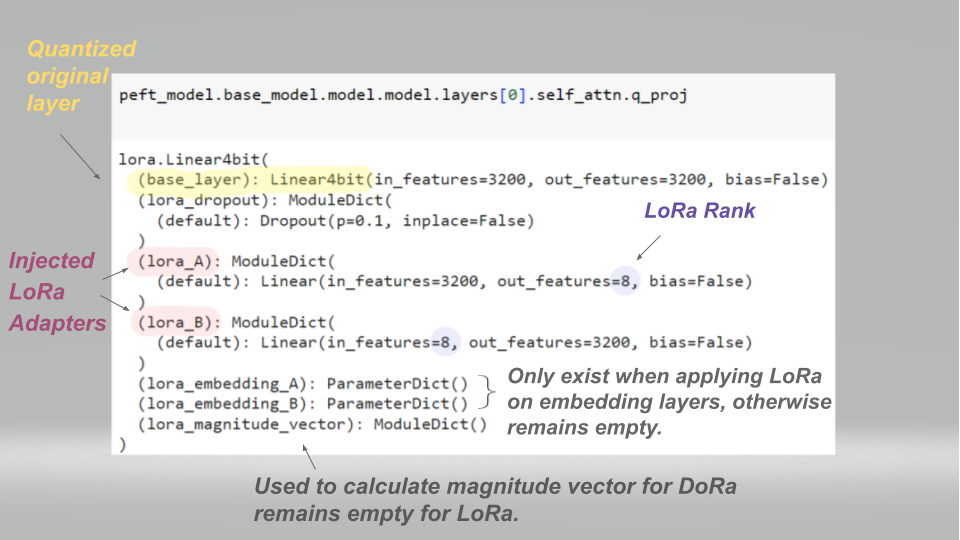
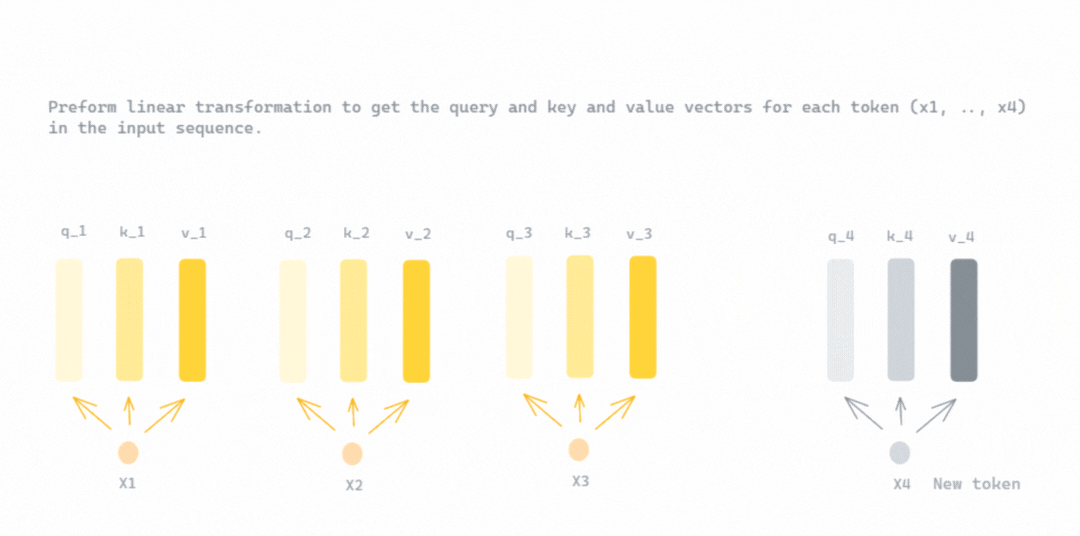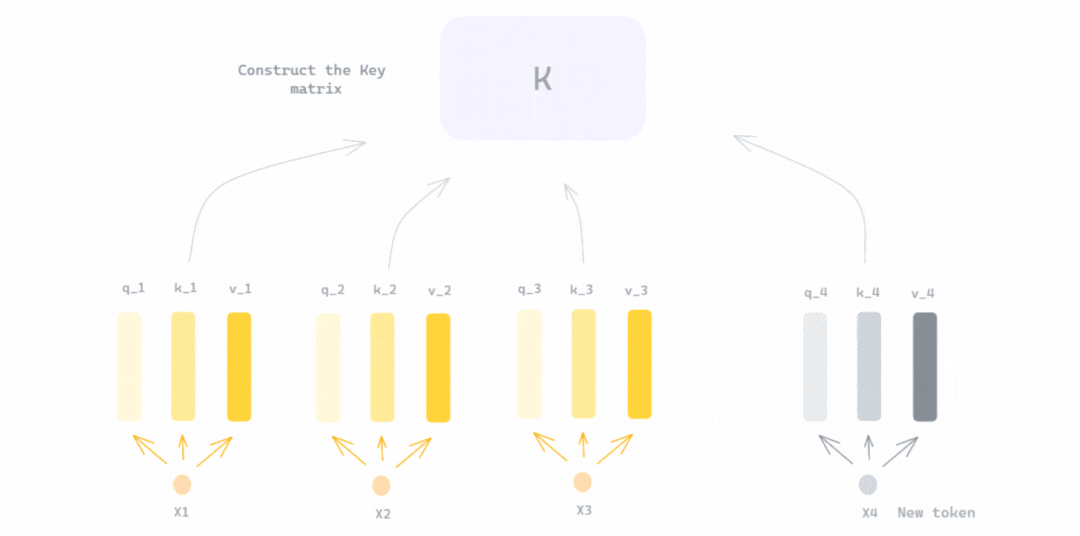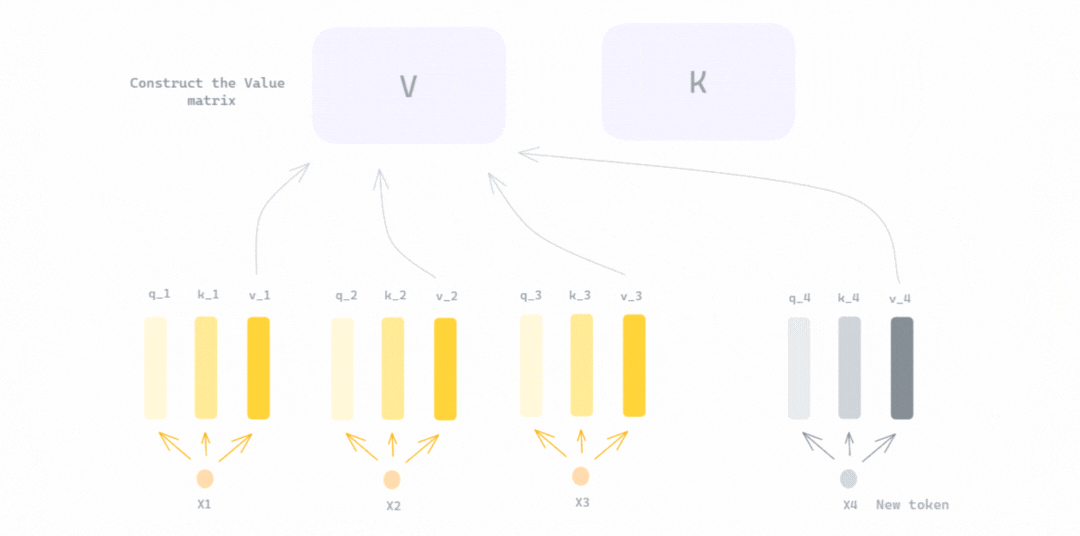
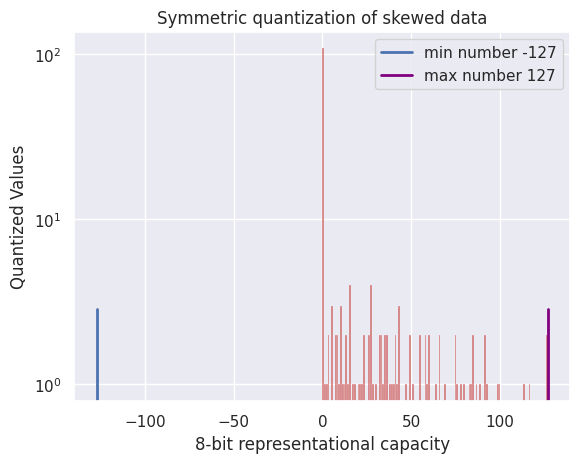
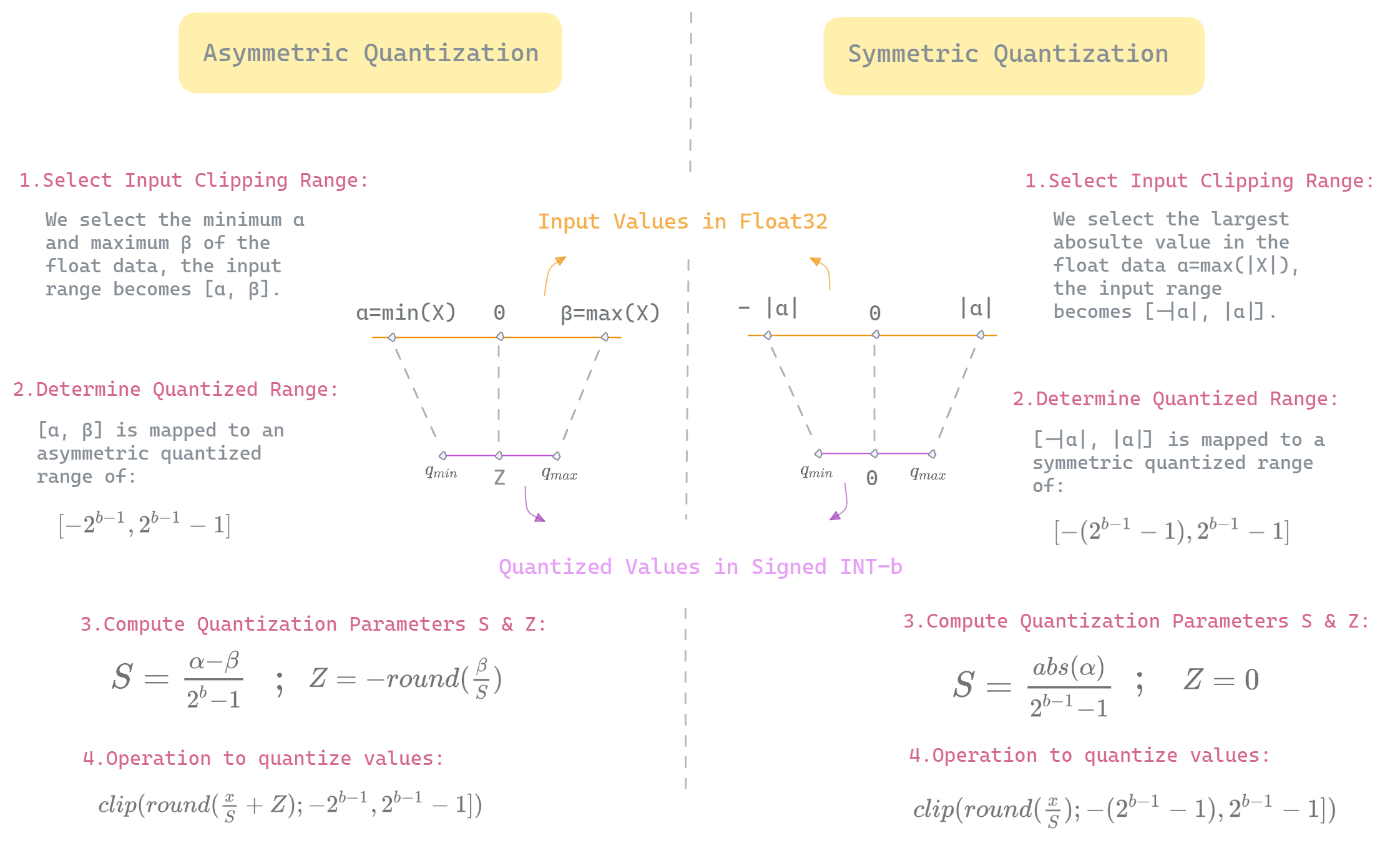
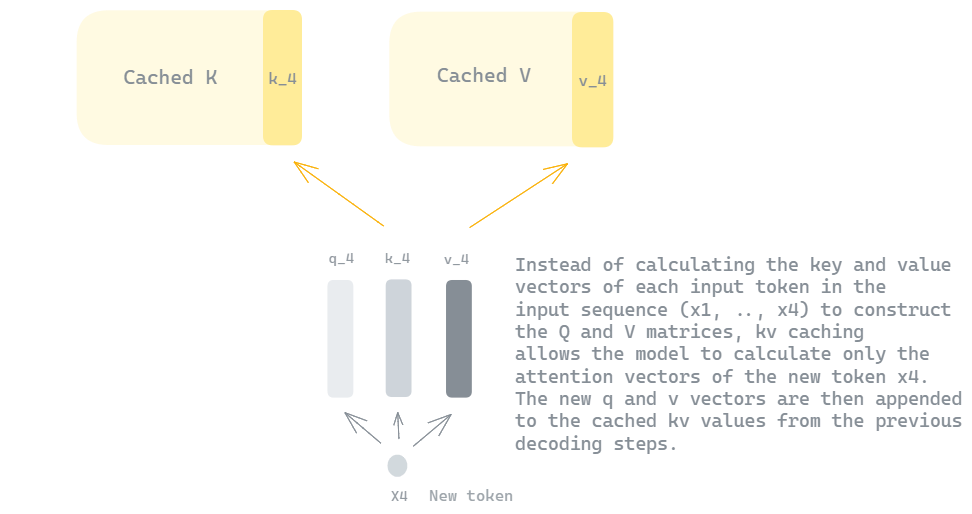
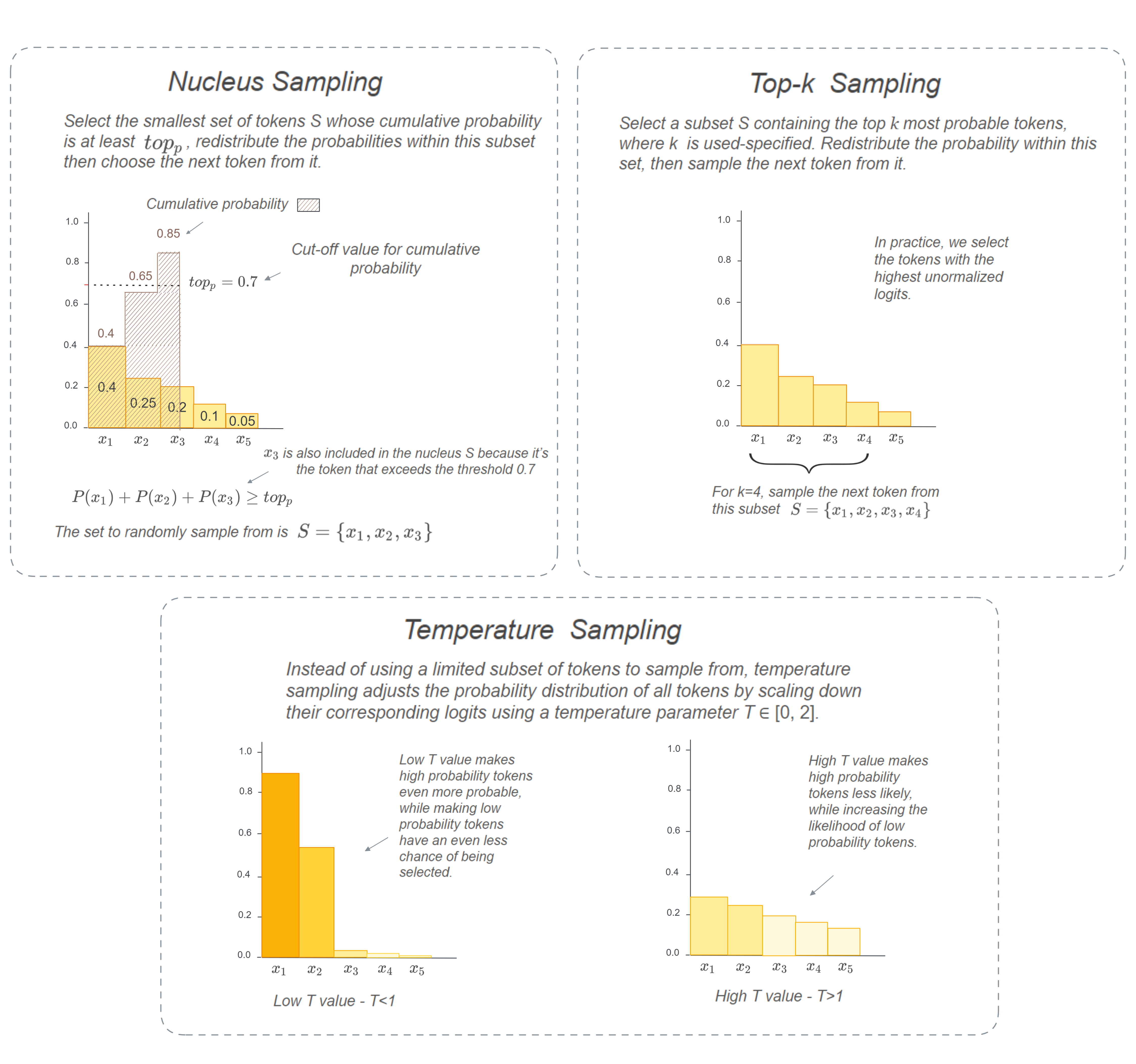
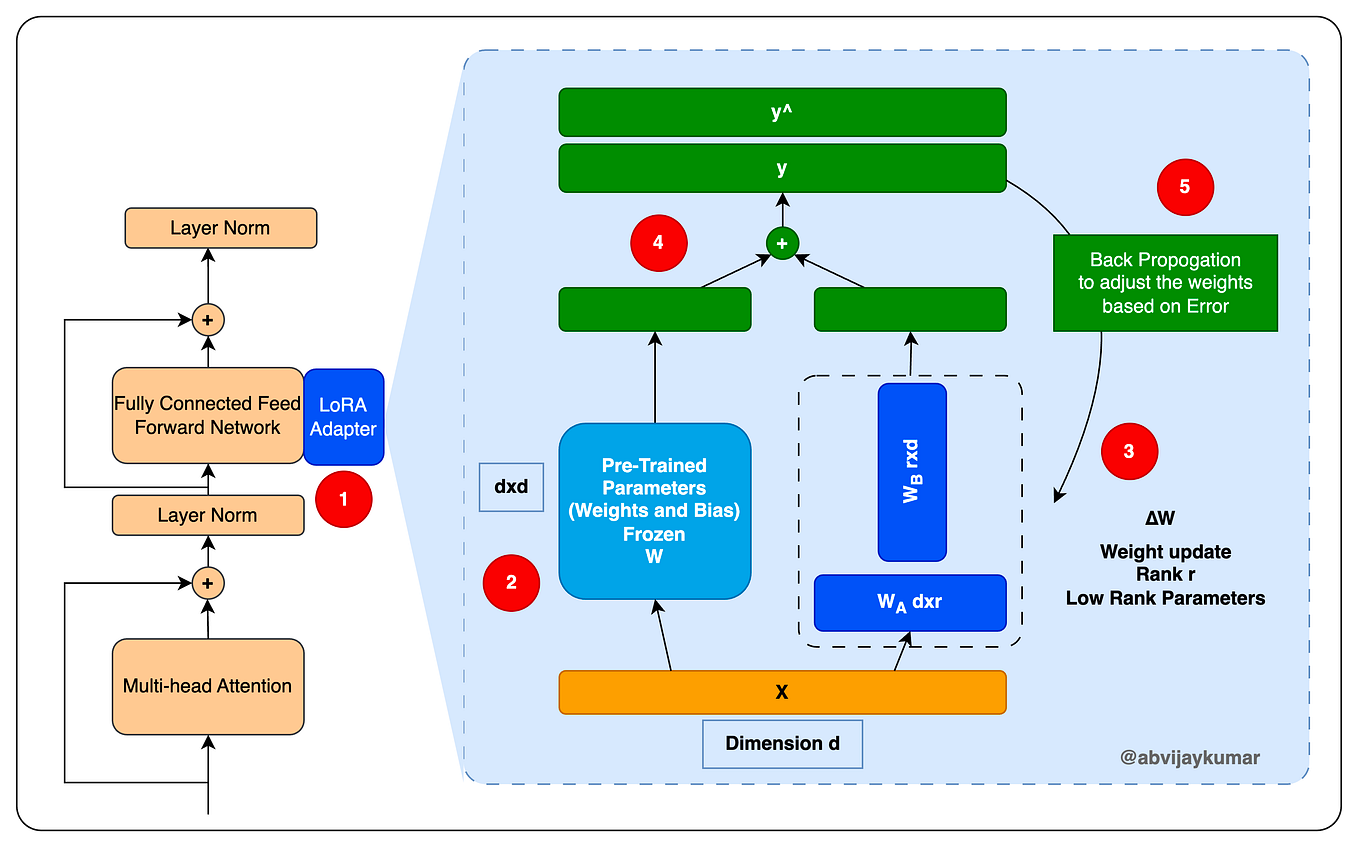
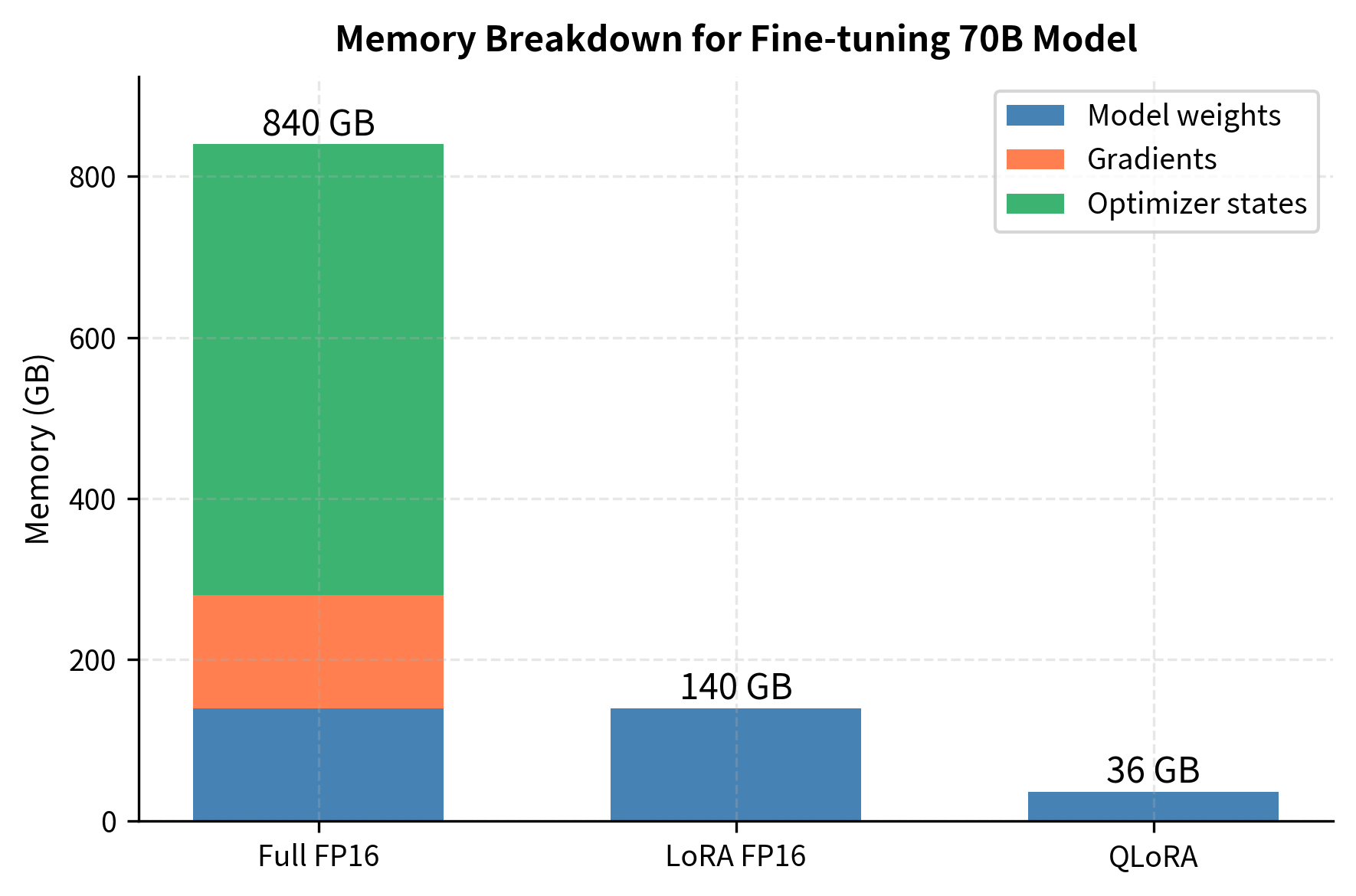
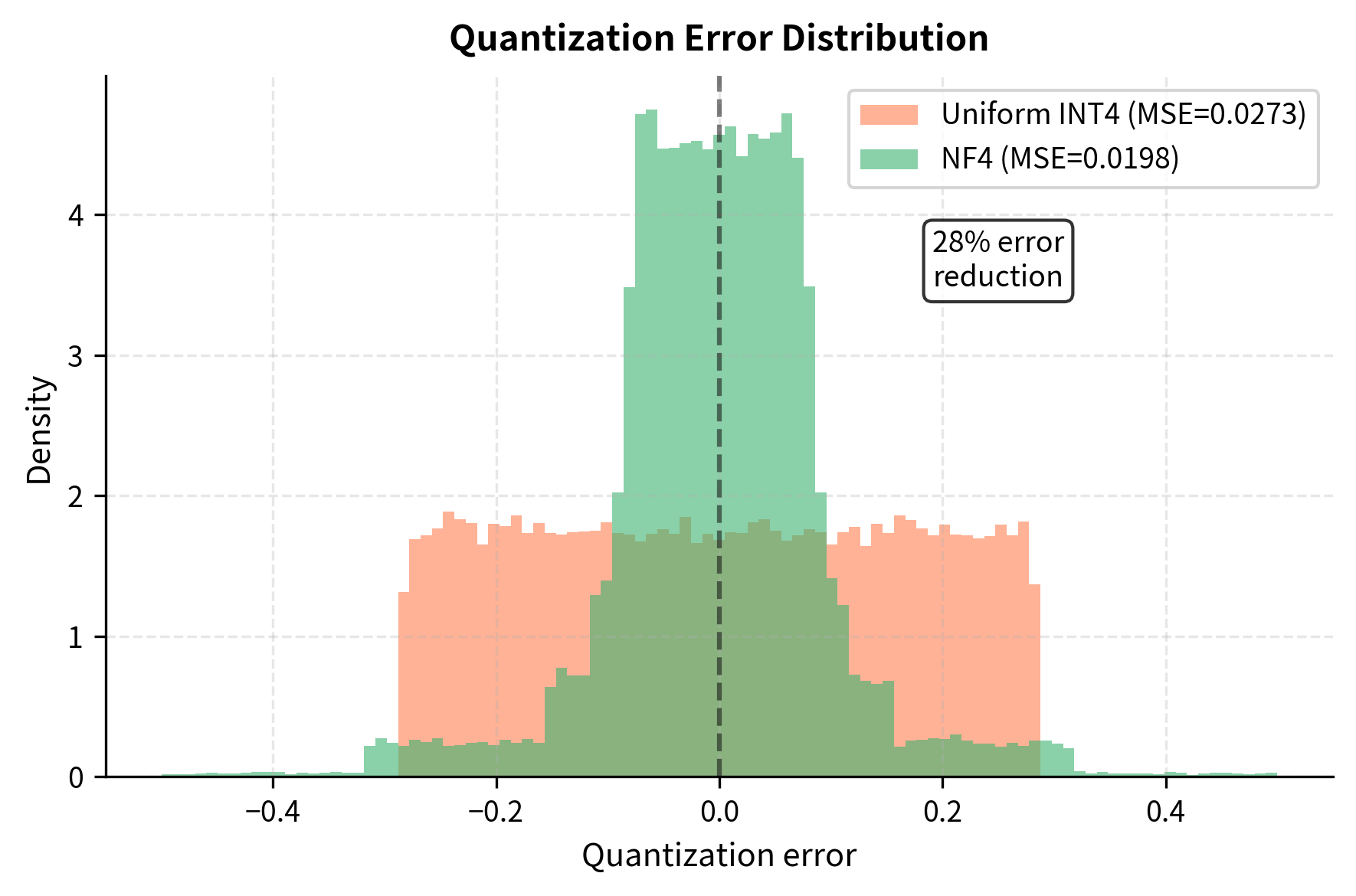
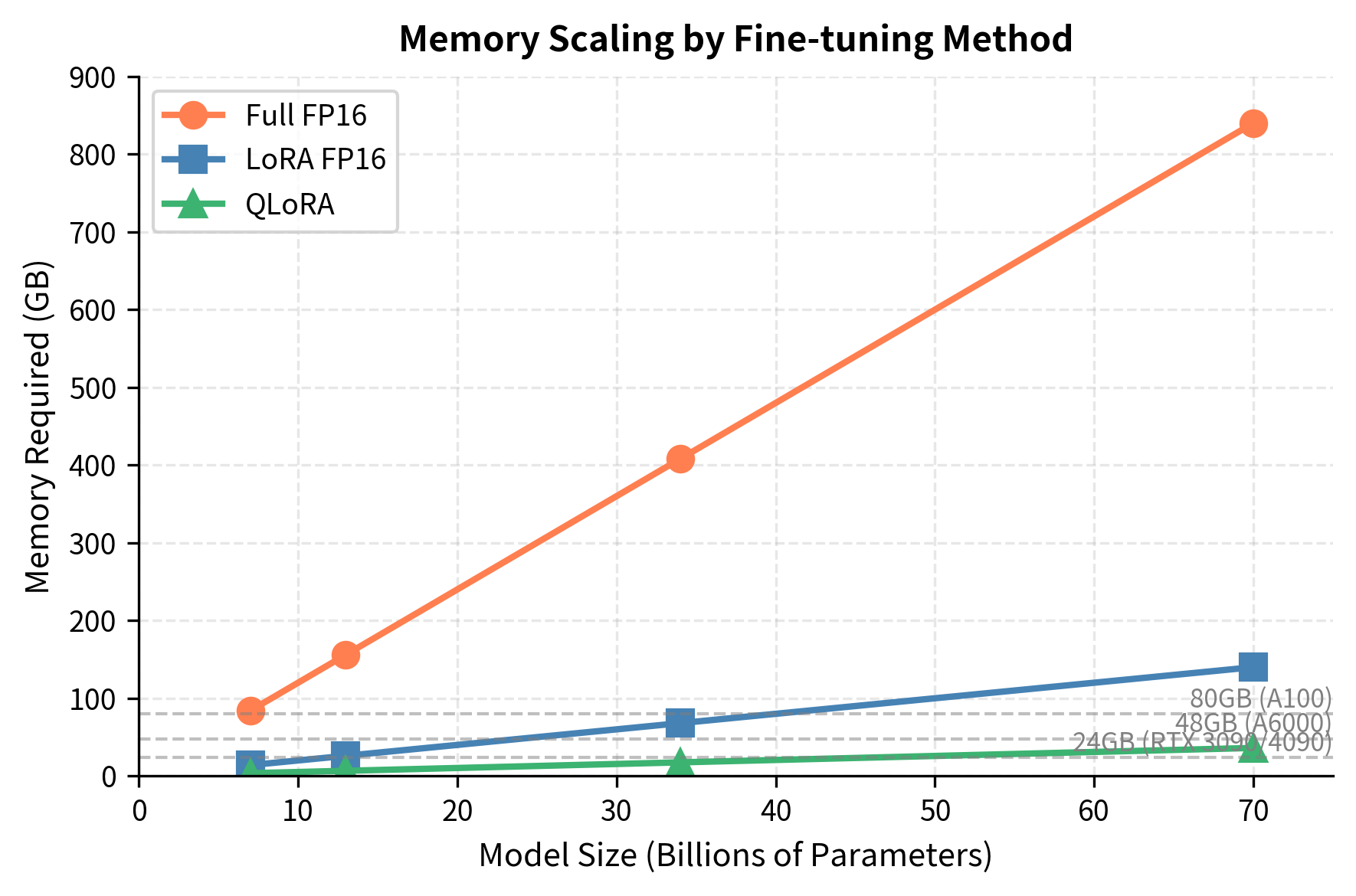
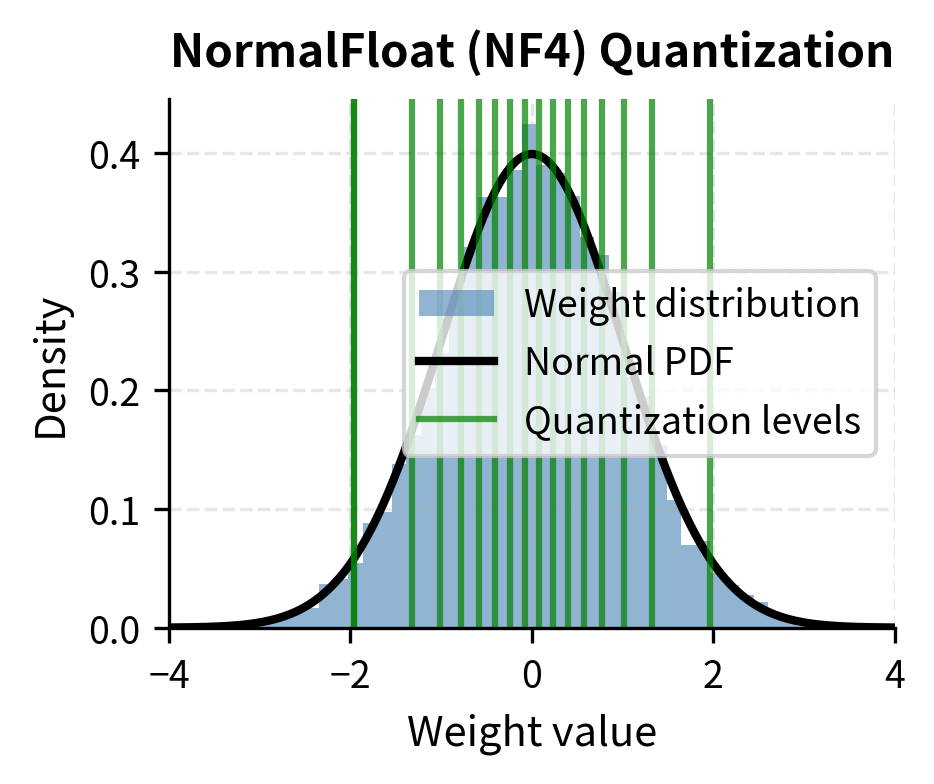
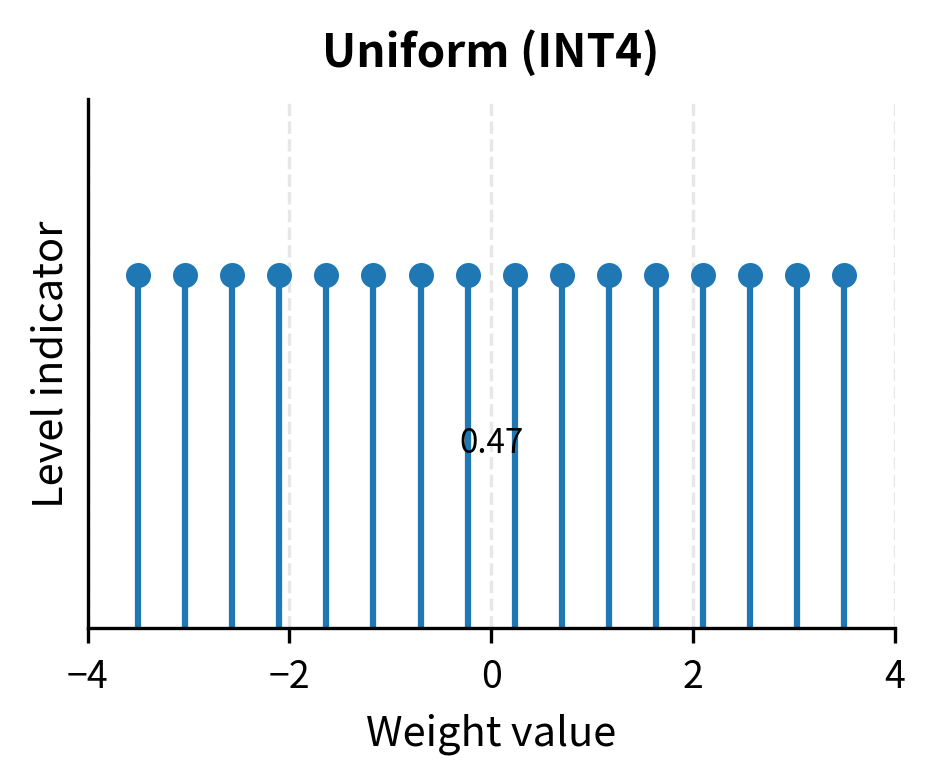
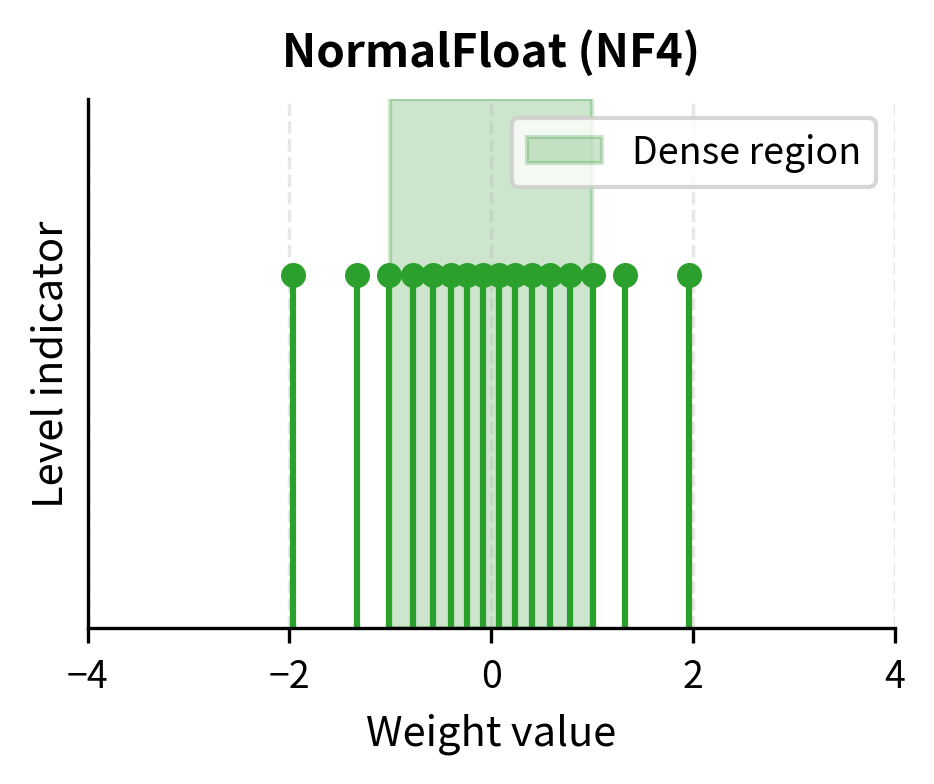
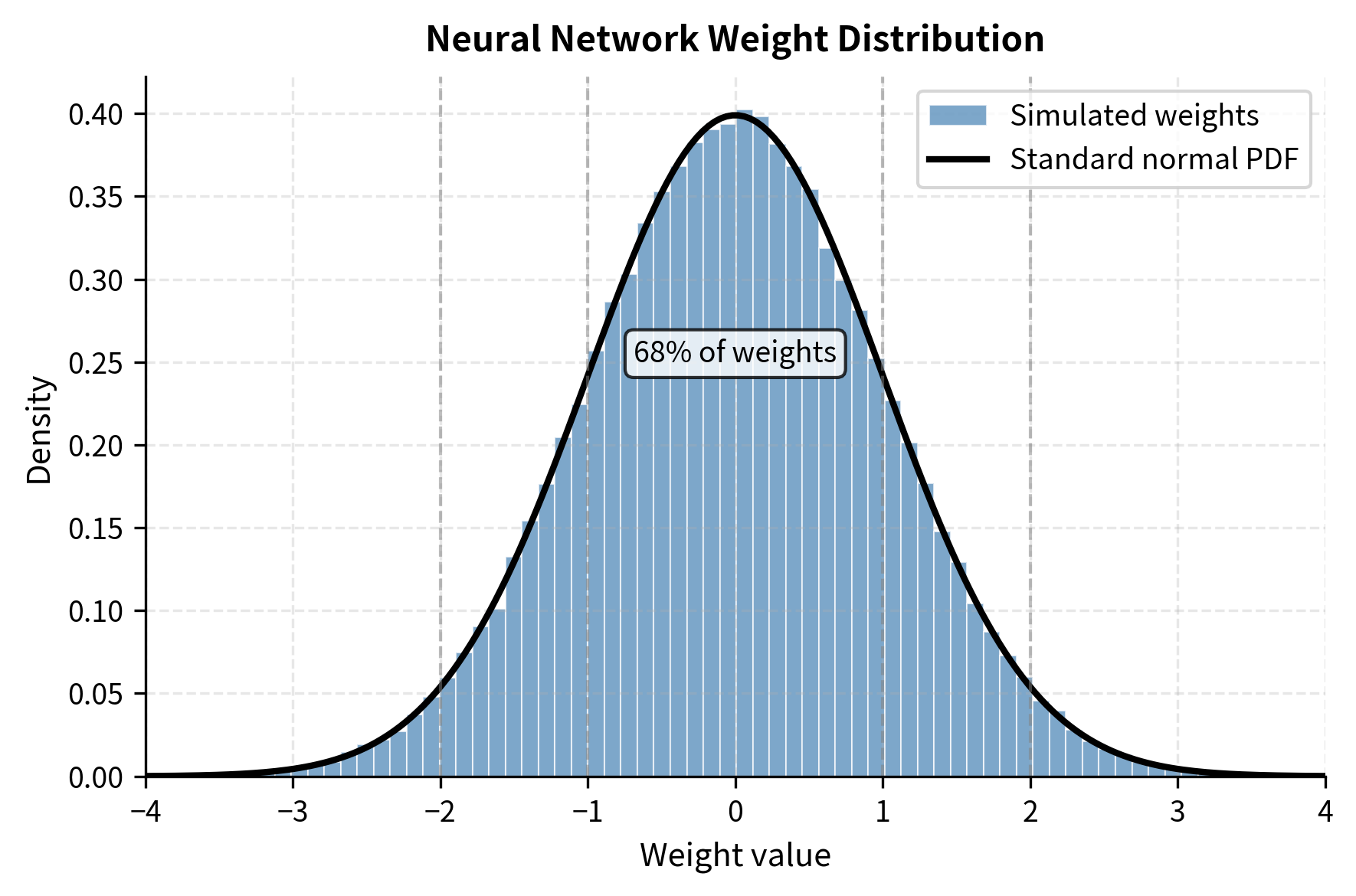
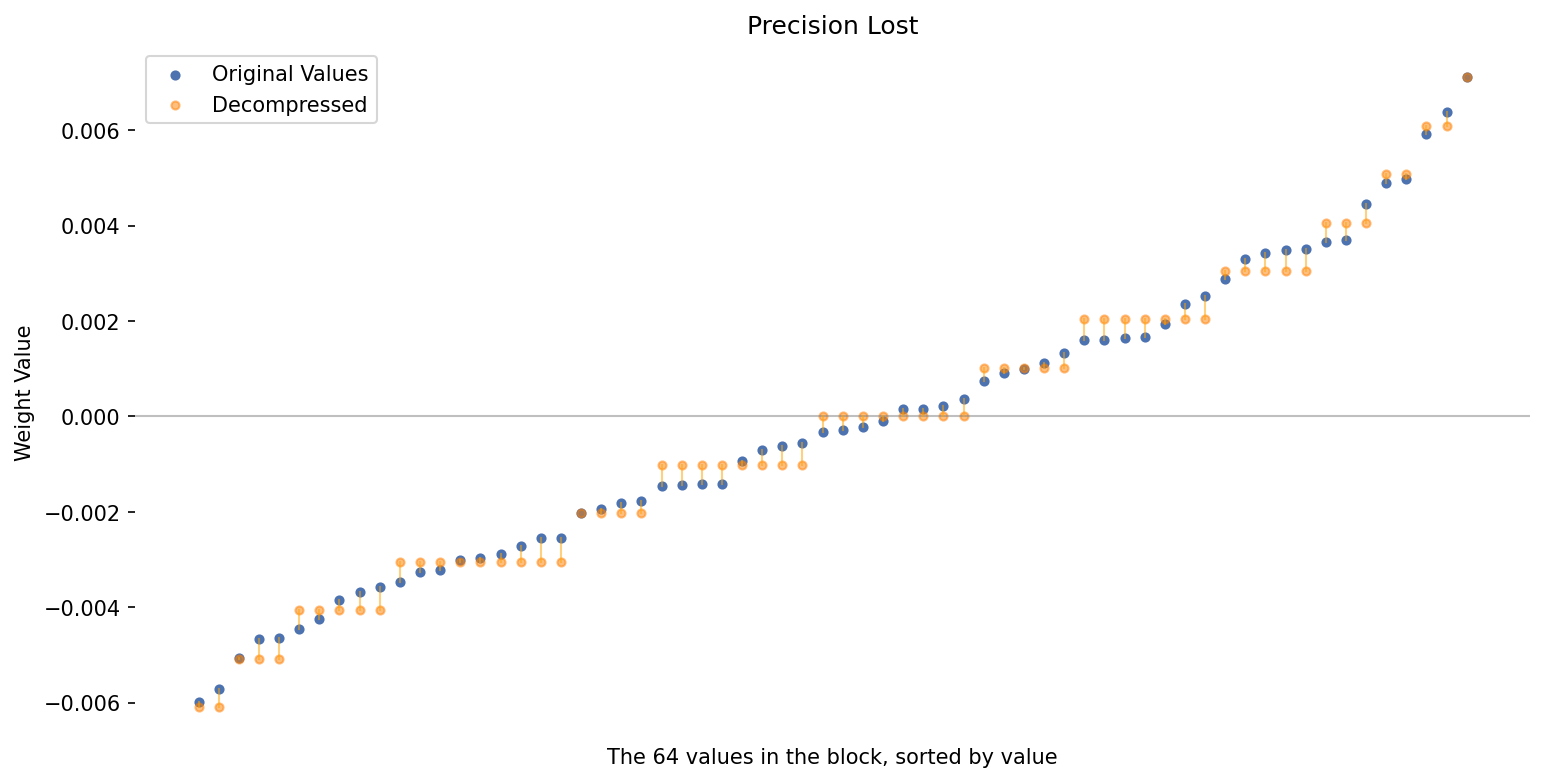
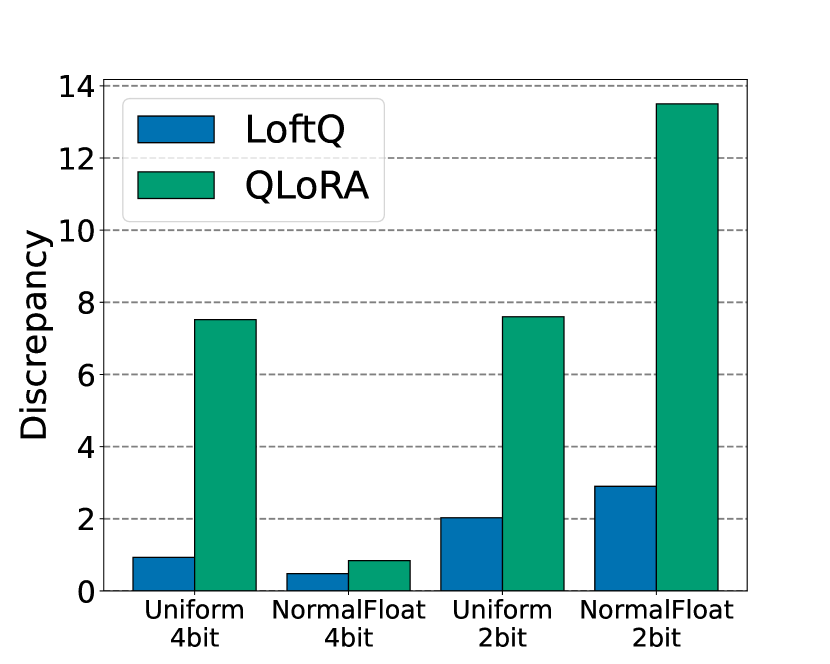
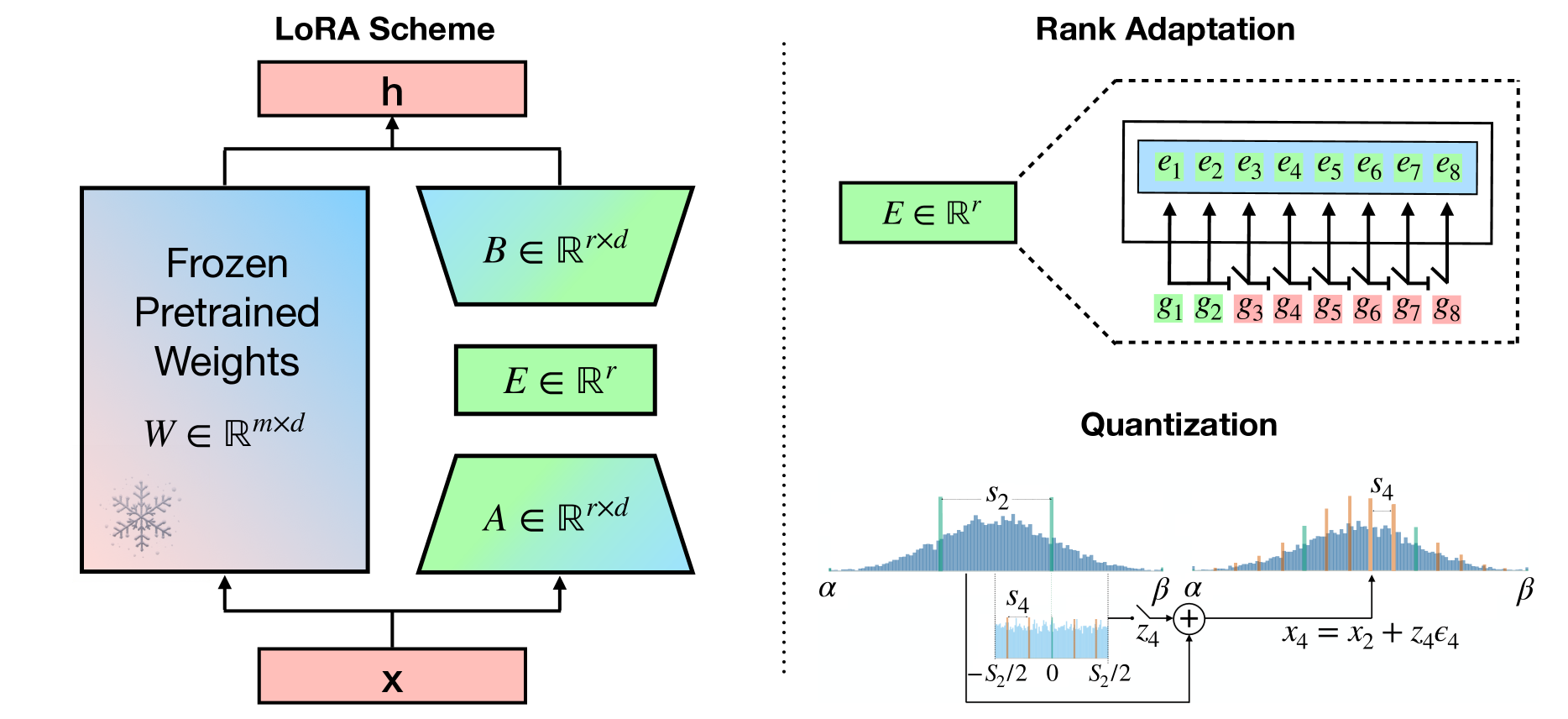
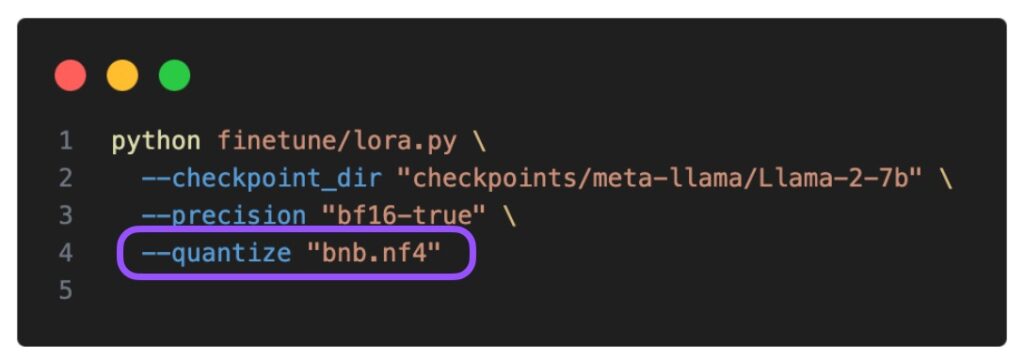
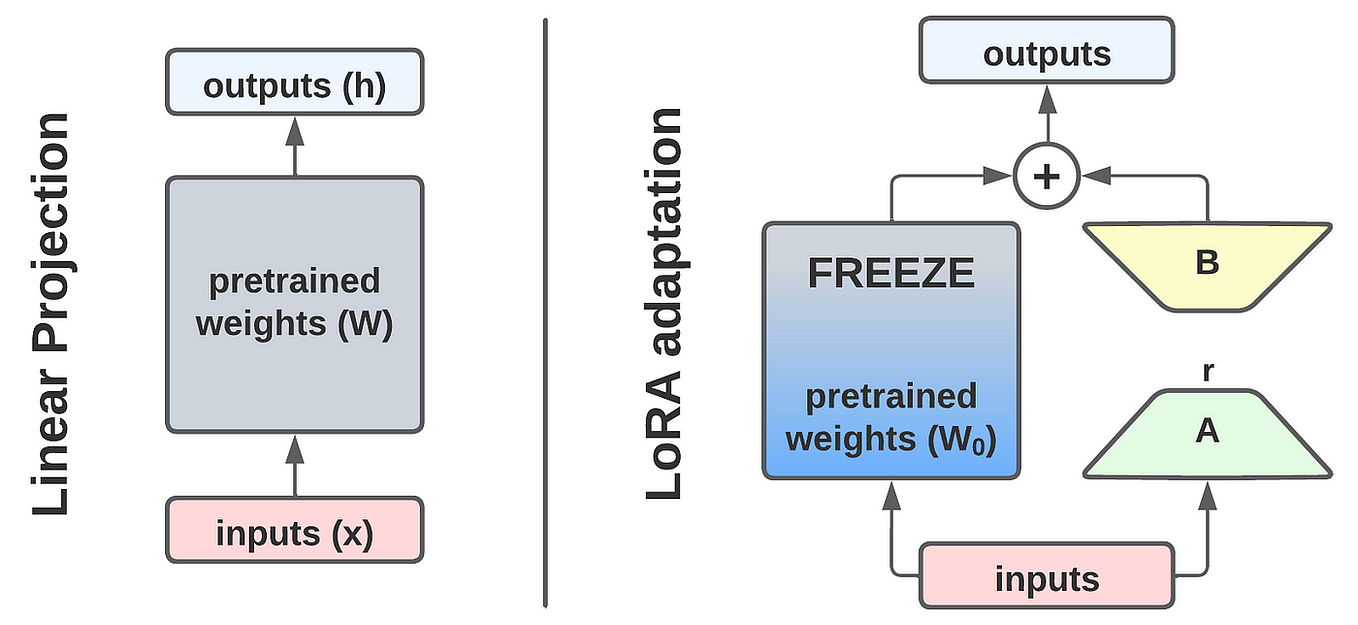
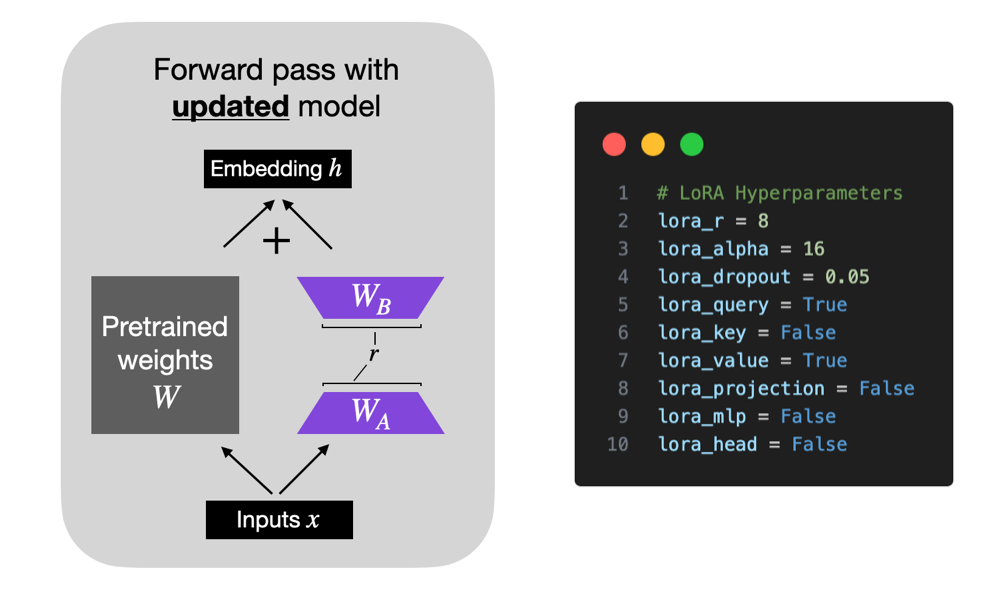
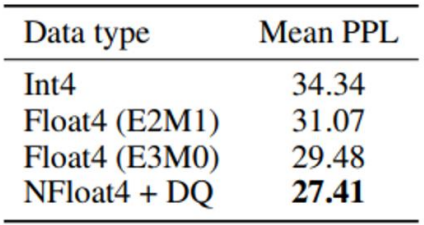
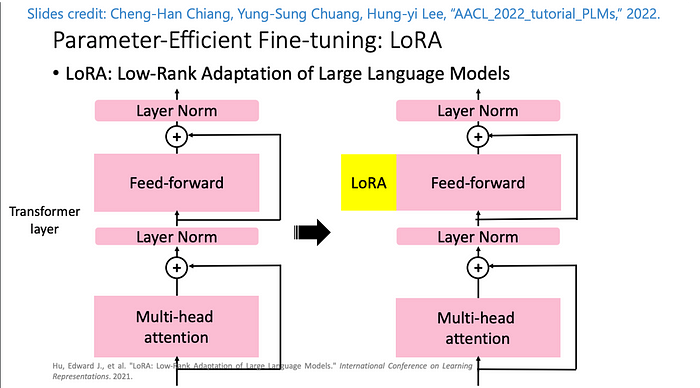
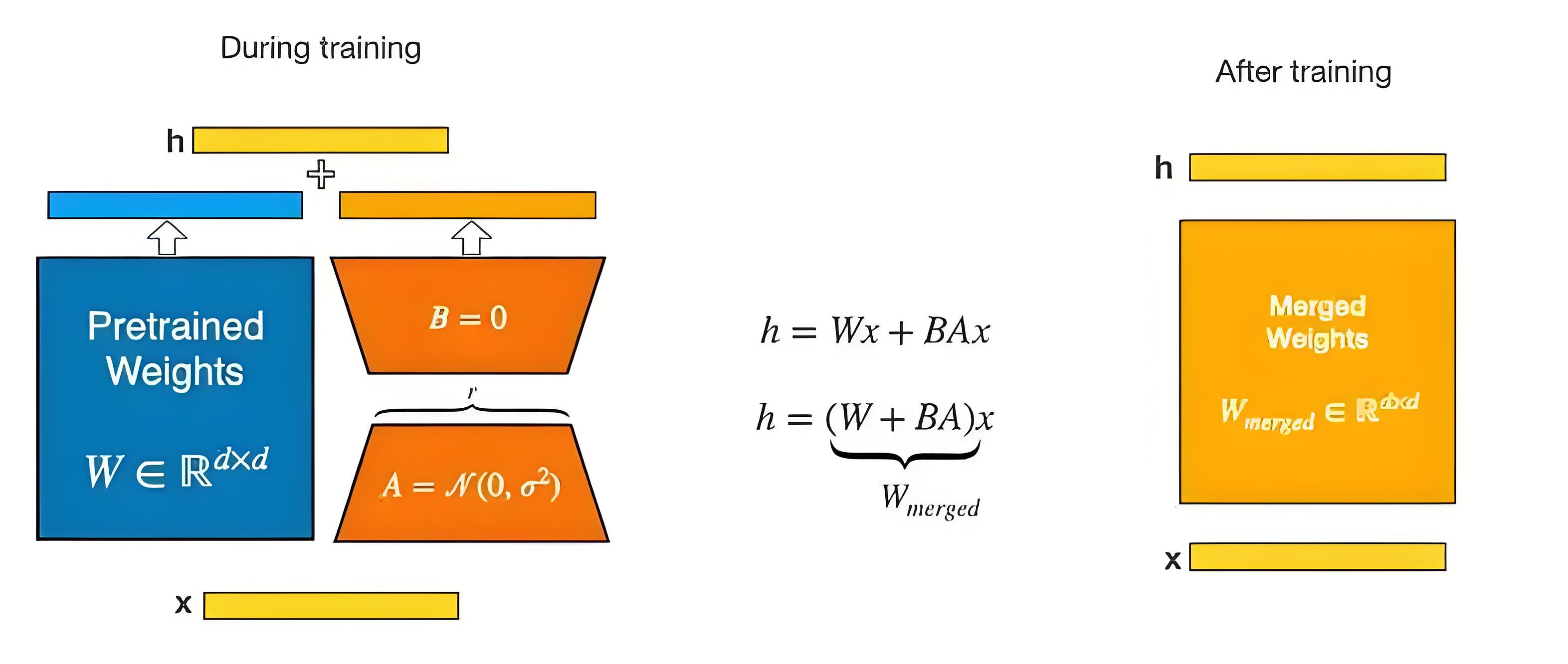
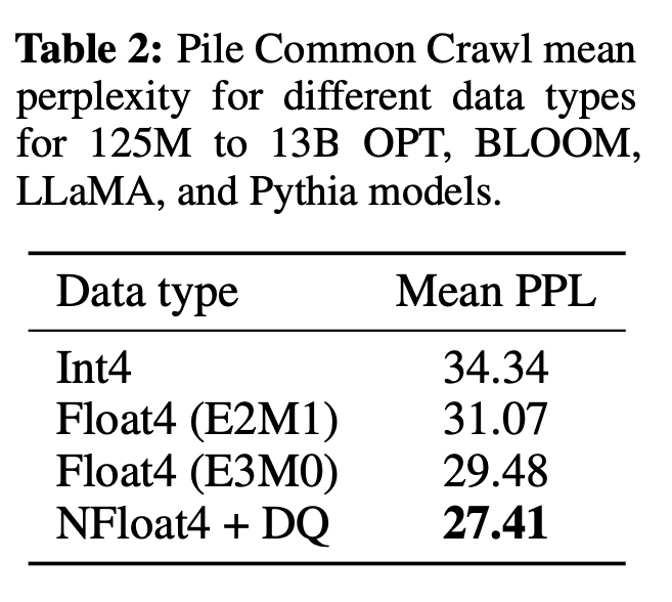
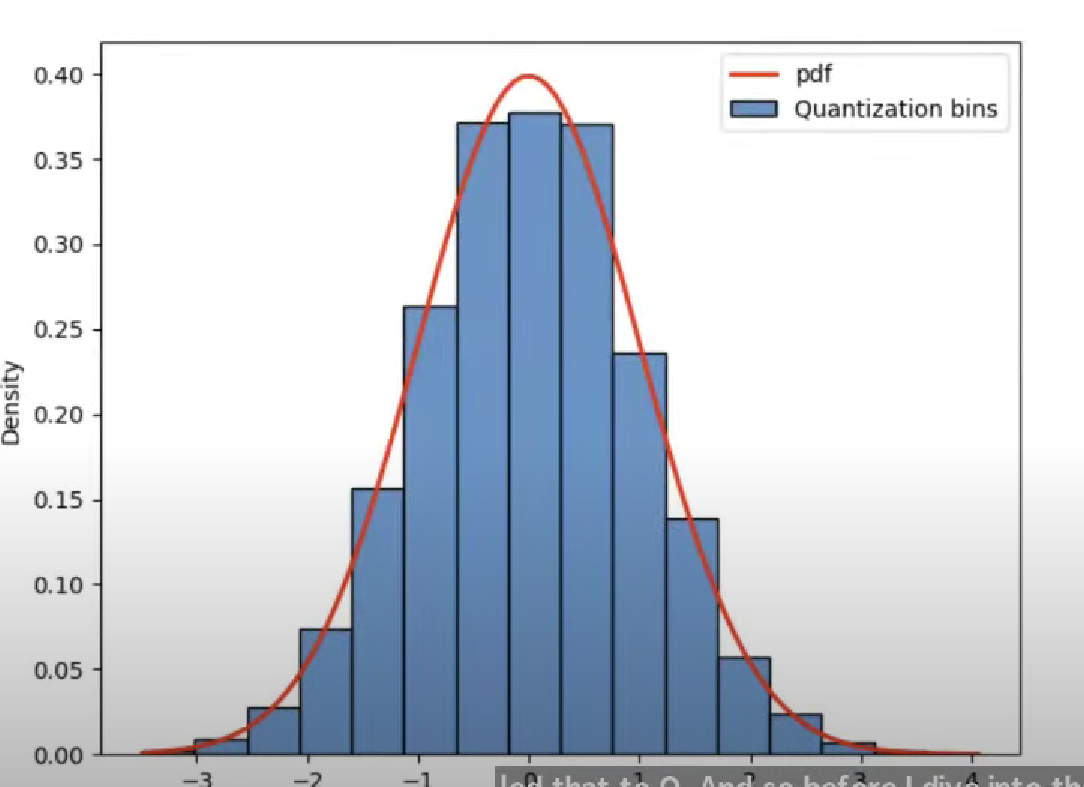
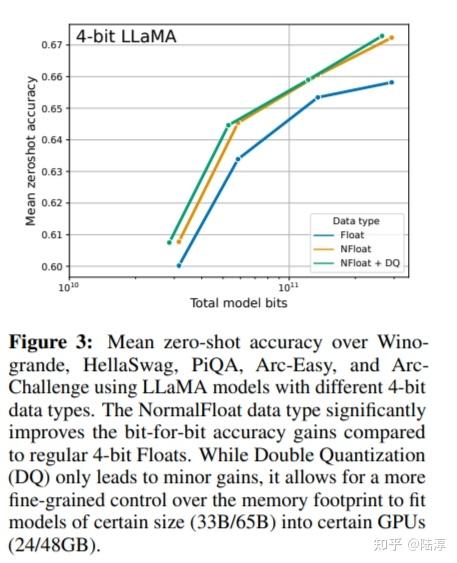
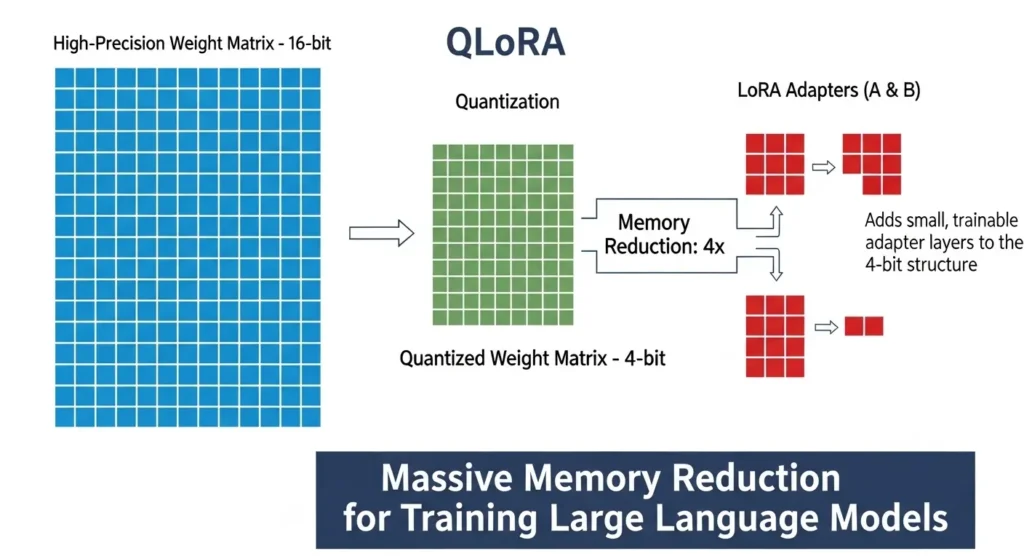
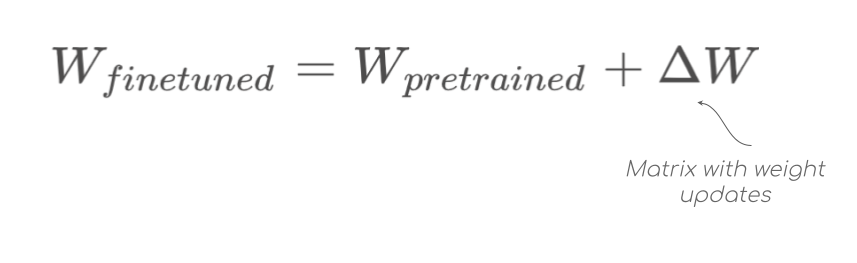Mastering QLoRa : A Deep Dive into 4-Bit Quantization and LoRa ...
Fine Tuning LLM: Parameter Efficient Fine Tuning (PEFT) — LoRA & QLoRA ...
8 bit Quantization and PEFT (Parameter efficient fine-tuning ) & LoRA ...
QLoRA 4 bit quantization - Allows to fine tune LLaMa sized models on ...
LoRA and QLoRA Explanation | Parameterized Efficient Finetuning of ...
How LoRA and QLoRA finetuning differ | Praveen Kumar posted on the ...
Understanding LoRA and QLoRA — The Powerhouses of Efficient Finetuning ...
QLora Explained and Fine tuning on Phi-2 Tutorial (Quantized LORA ...
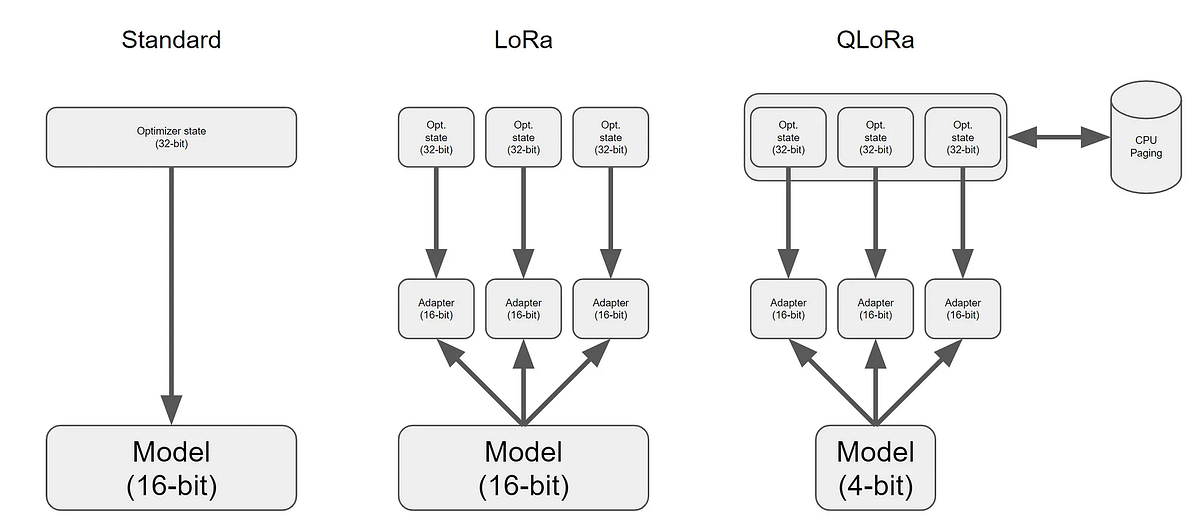
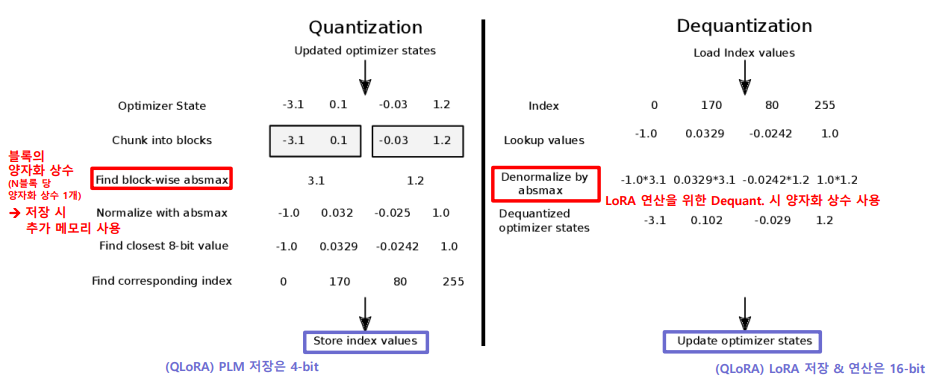
QLoRA: 4-Bit Quantization for Memory-Efficient LLM Fine-Tuning ...
Fine-Tuning Models: A Deep Dive into Quantization, LoRA & QLoRA - DEV ...
How to do LLM fine-tuning: Quantization, LoRA, and QLoRA | Rakesh ...
Mastering LoRA and QLoRA: Efficient Techniques for Fine-Tuning Large ...
Hardware and Model Optimization: Empowering Efficient AI with LoRA and ...
How to optimize model finetuning: Full vs. QLoRA | Abdallah H. Samman ...
A Guide to Supervised Fine-Tuning and 4-Bit Quantization for Language ...
LoRA and QLoRA: Efficient Fine-Tuning Techniques for Large Language ...
QLoRA Explained - How 4 Bit Quantization Unlocks Frontier Models
QLoRA and 4-bit Quantization · Chris McCormick
Efficient 8-Bit Quantization of Transformer Neural Machine Language ...
LoRA and QLoRA clearly explained | Dr. Walid Soula | Artificial ...
⚡ QLoRA: Efficient Fine-Tuning of Large Language Models with ...
In-depth guide to fine-tuning LLMs with LoRA and QLoRA
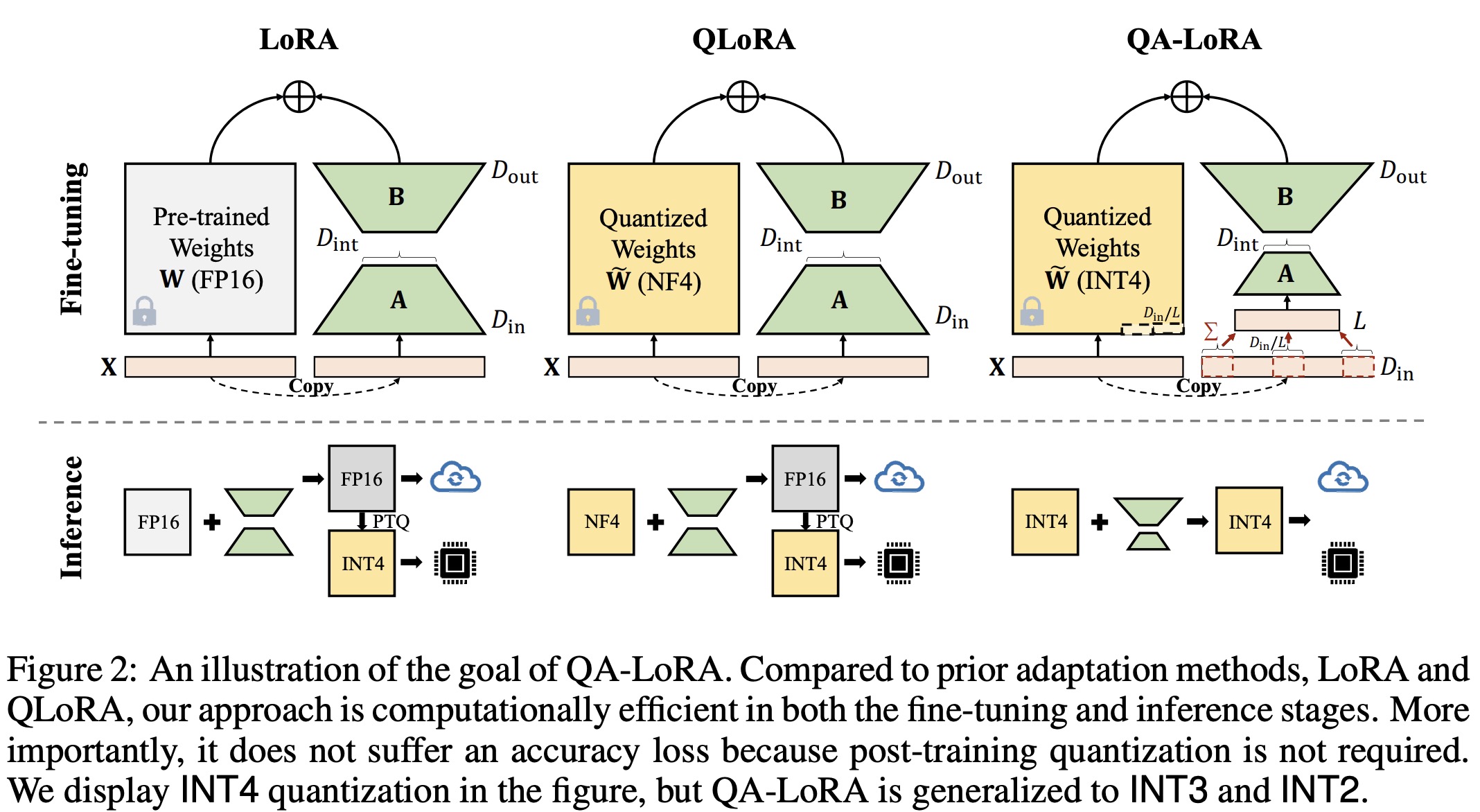
Just before the dust on QLoRA could settle down, QA-LoRA stepped in. QA ...
Tune DeepSeek Models Efficiently: LoRA + 4-Bit Guide for
[2310.08659] LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large ...
LoRA & QLoRA Fine-tuning Explained In-Depth | Entry Point AI
LoRA vs. QLoRA: Efficient fine-tuning techniques for LLMs | Modal Blog
LoRA vs. QLoRA: Efficient fine-tuning techniques for LLMs
LoRA & QLoRA Fine-Tuning Explained In-Depth 🧠 | by Firas Tlili | Medium
Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of ...
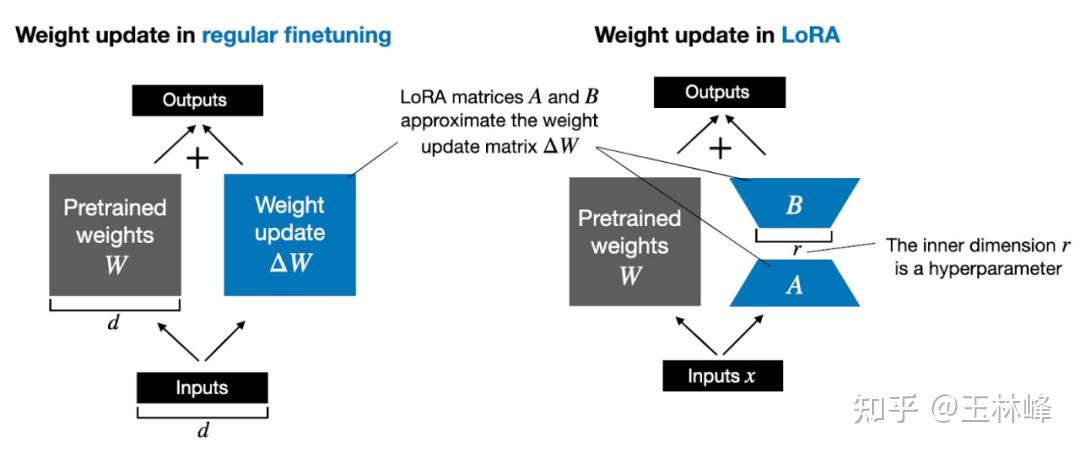
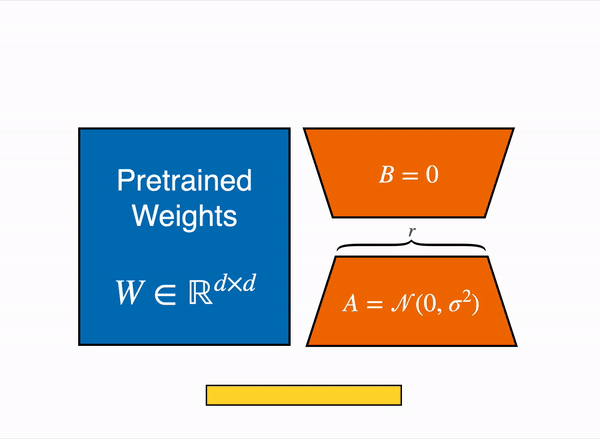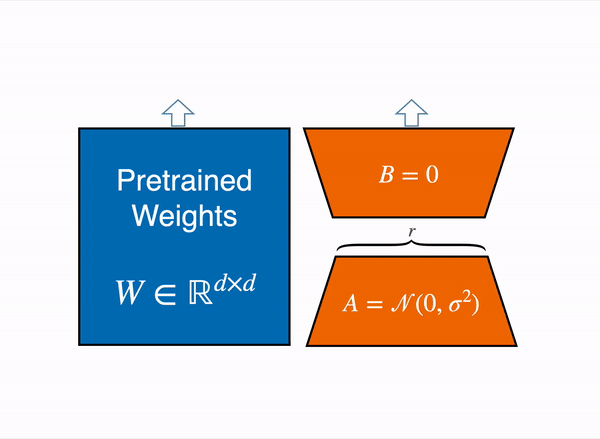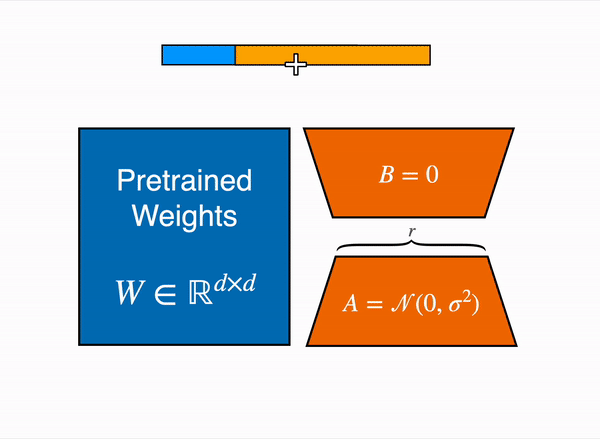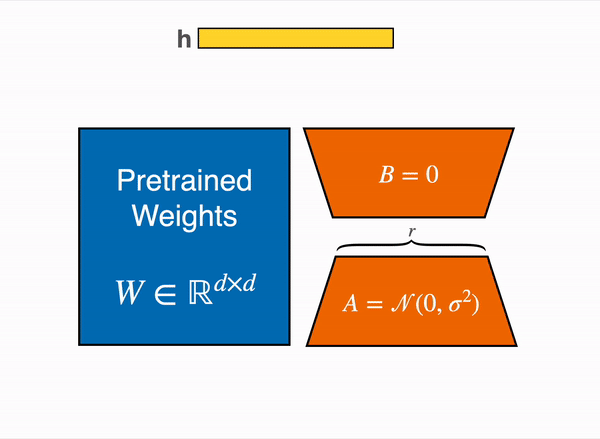
LoRA Explained: Parameter-efficient fine-tuning | by John Lu | Medium
Understanding LoRA — Low Rank Adaptation For Finetuning Large Models ...
New State-of-the-art framework for fine-tuning LLMs with Quantization ...
QLoRA Explained: Fine-Tuning Large Language Models
Paper Review: QLoRA: Efficient Finetuning of Quantized LLMs | by Andrew ...
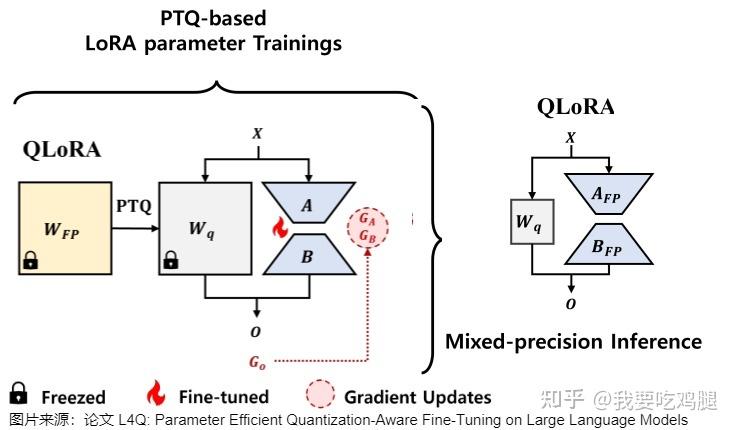
Paper page - L4Q: Parameter Efficient Quantization-Aware Training on ...
Day 26 : Fine-Tuning Large Language Models (LLMs) | LORA, QLORA ...
Fine-tuning LLMs Made Easy with LoRA and Generative AI-Stable Diffusion ...
Fine-Tuning GEMMA-2B for Doctor-Patient Interaction: Efficient Model ...
Paper Review: QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large ...
Understanding 4bit Quantization: QLoRA explained (w/ Colab) - YouTube
Finetuning Generative AI Large Language Model (LLM) Falcon (40B,7B ...
QLoRA: Fine-Tuning LLMs Efficiently with 4-bit Precision
NeurIPS 2023: Our Favorite Papers on LLMs, Statistical Learning, and ...
[QLoRA] QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA: A New Method for Finetuning LLMs with Low Memory and High ...
(PDF) QLoRA: Efficient Finetuning of Quantized LLMs
How to fine-tune and develop your own large language model.pptx
Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments
Paper review[QLORA: Efficient Finetuning of Quantized LLMs]
QLoRA: Efficient Finetuning of Quantized LLMs - Speaker Deck
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA ...
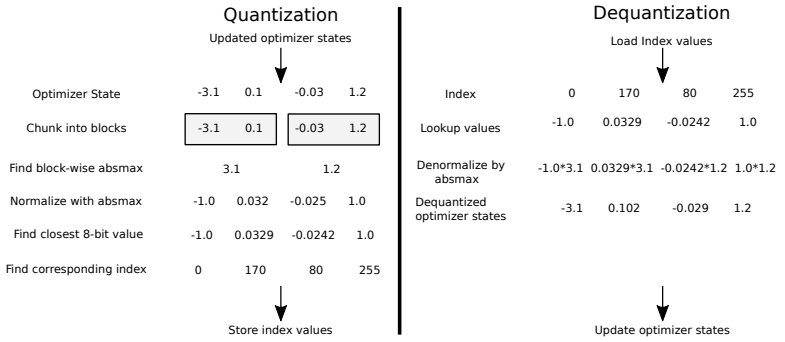
QLoRA | 48G内存训练24小时,改进版4-bit量化技术微调650亿参数的模型达到chatgpt99.3%的效果-CSDN博客
Fine-tuning Large Language Models (LLMs): Practical guide, intuition ...
大模型微调终极方案:LoRA、QLoRA原理详解与LLaMA-Factory、Xtuner实战对比_xtuner和llama factory ...
【论文精读】QLORA: Efficient Finetuning of Quantized LLMs-CSDN博客
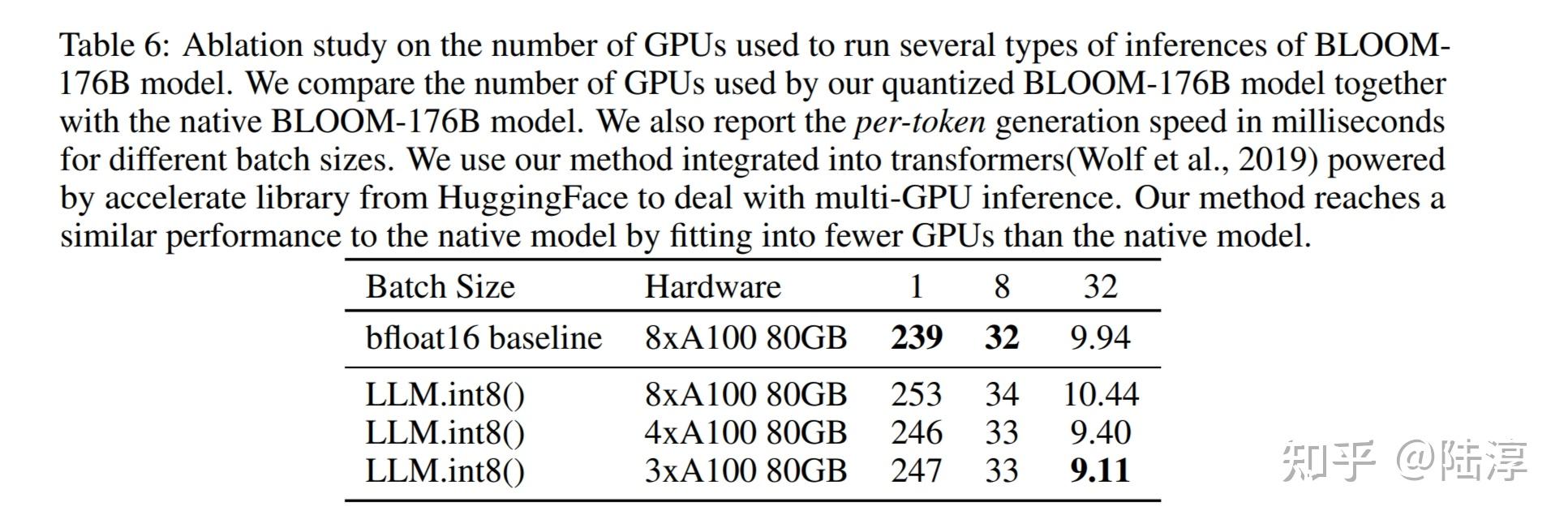
Tesla uses 8-bit integers to run their models in real time. We call ...
This AI Paper Introduces a Parameter-Efficient Fine-Tuning Framework ...
Low-Rank Adaptation (LoRA) and Parameter-Efficient Fine-Tuning (PEFT ...
QLoRA: Quantized Low-Rank Adaptation paper explained | by Astarag ...
Introducing QA-LoRA - Quantization-aware low-rank adaptation of LLMs ...
Understanding QLoRA: Quantized Fine-Tuning | AI Tutorial | Next Electronics
The LLM Revolution: Transforming Language Models – Quantum™ Ai Labs
#ai #llms #lora #qlora #innovation #efficiency | Amit Sharma (Ph.D.)
LoRA、QLoRA - 知乎
QLoRA:4-bit级别的量化+LoRA方法,用3090在DB-GPT上打造基于33B LLM的个人知识库 - 知乎
FinLoRA Adapters: 4bit Quantization, Rank 4 (QLoRA) - a wangd12 Collection
LLMファインチューニングの全て:LoRA、PEFT、実践手法
量化算法进阶篇(中):4-bit量化算法 —— 从GPTQ、AWQ到QLoRA和FlatQuant - 知乎
LQ-LoRA: Jointly Fine-tune and Quantize Large Language Models
FINE-TUNING LLAMA 2: DOMAIN ADAPTATION OF A PRE-TRAINED MODEL | PDF
MSU AI Club
LORA微调系列(二):QLORA和它的基本原理 - 知乎
[大模型微调技术] LoRA、QLoRA、QA-LoRA 原理笔记 - 知乎
Fine-Tune Llama 2 70B on Intel® Gaudi® 2 AI Accelerators