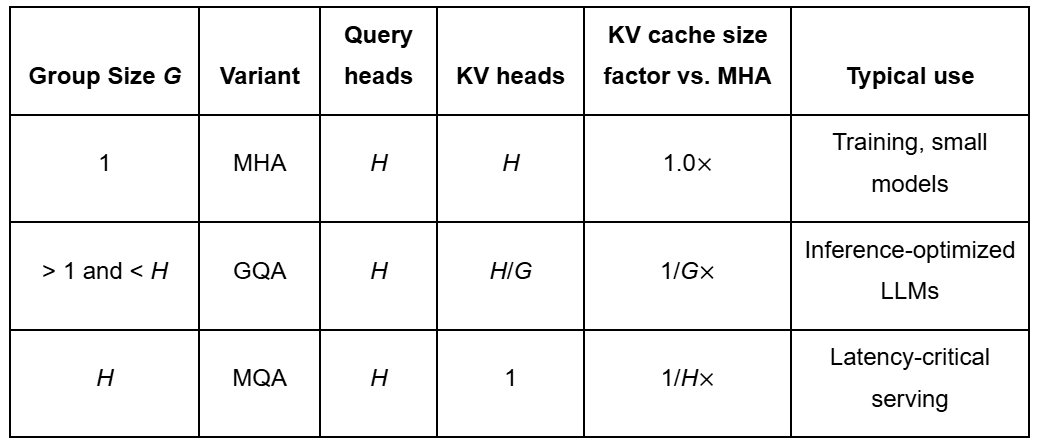
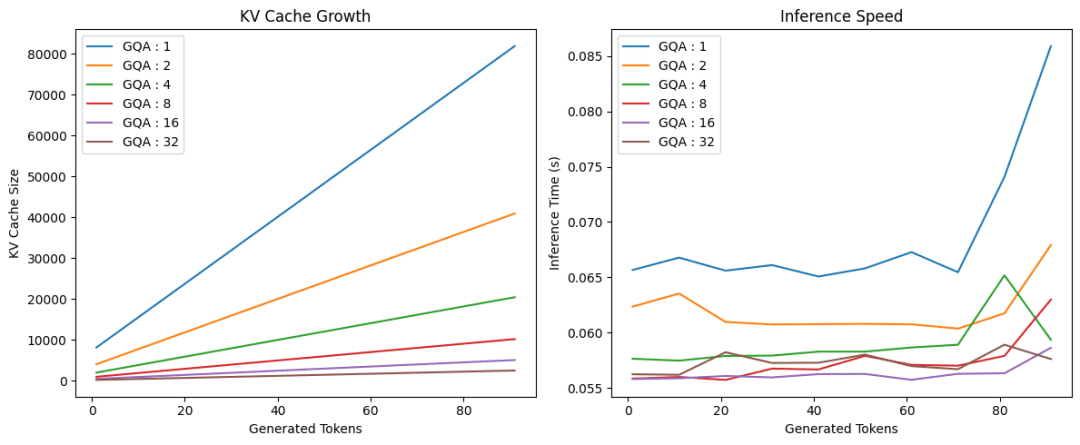
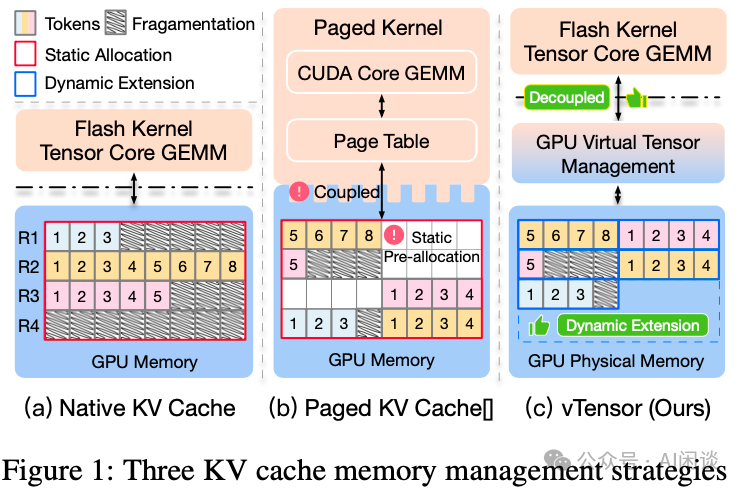
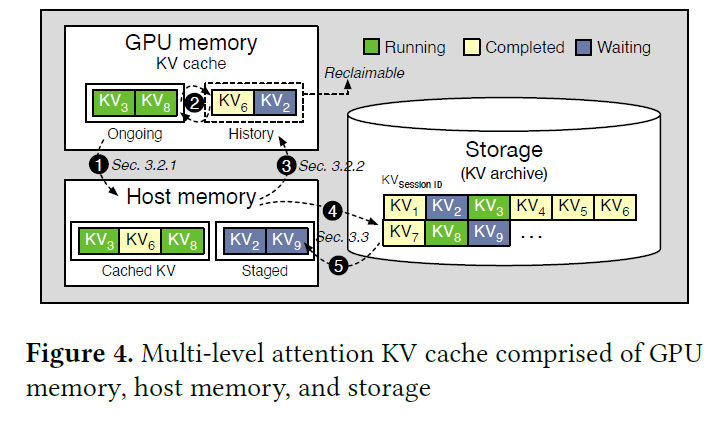
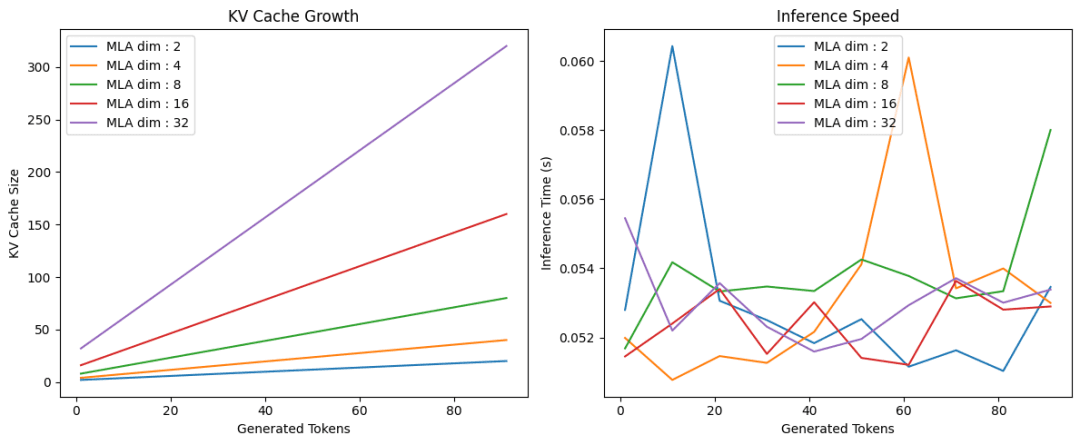
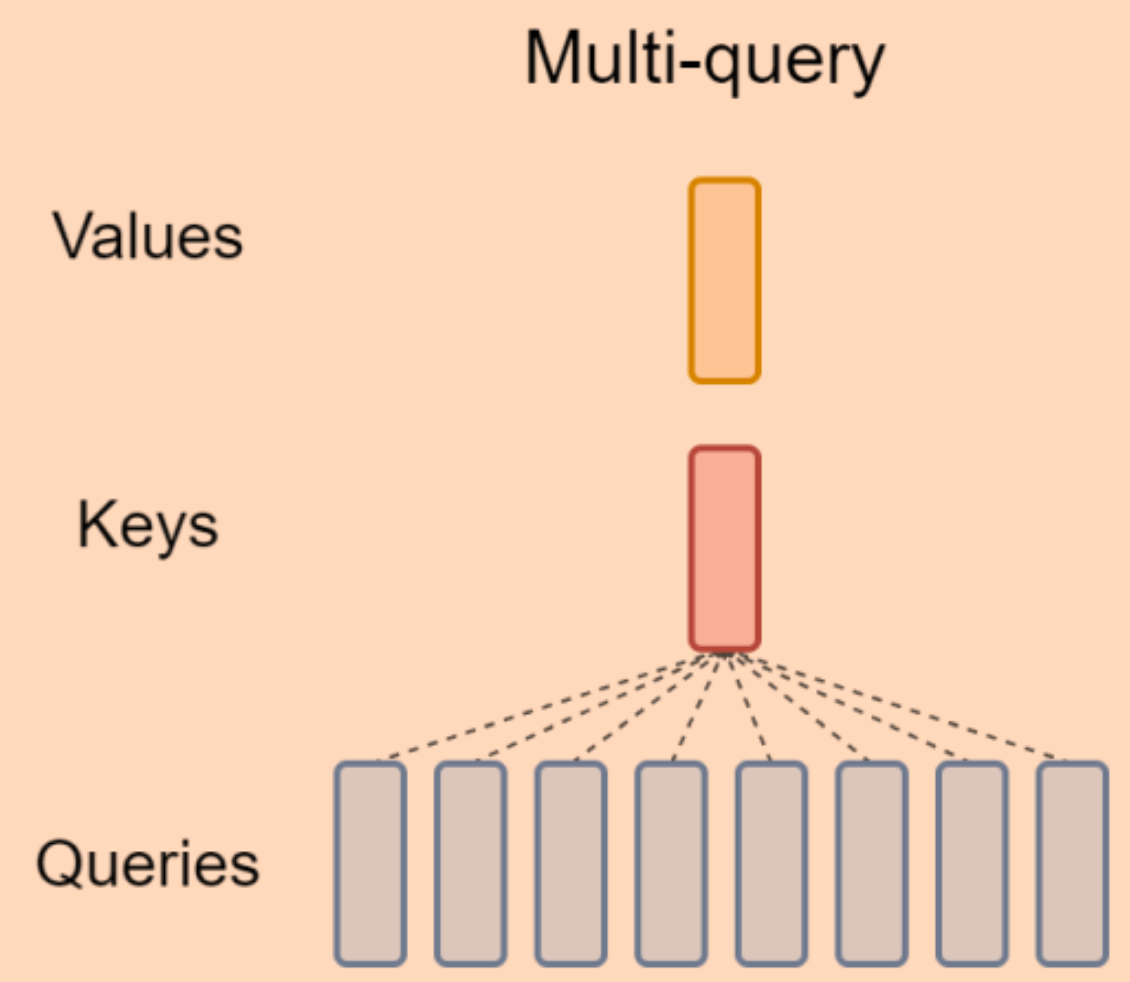
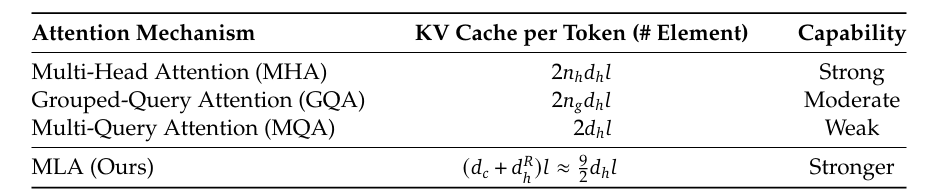
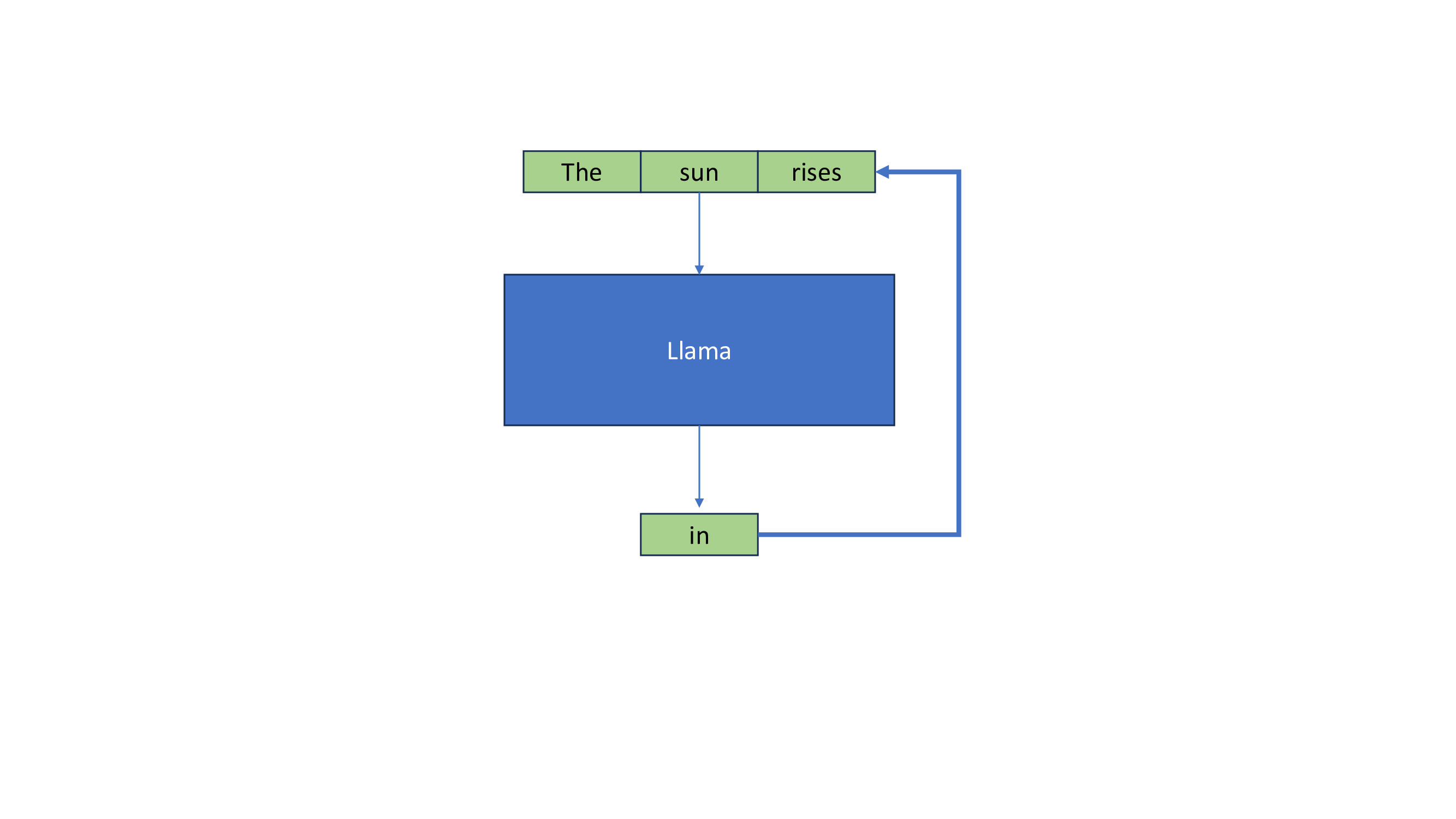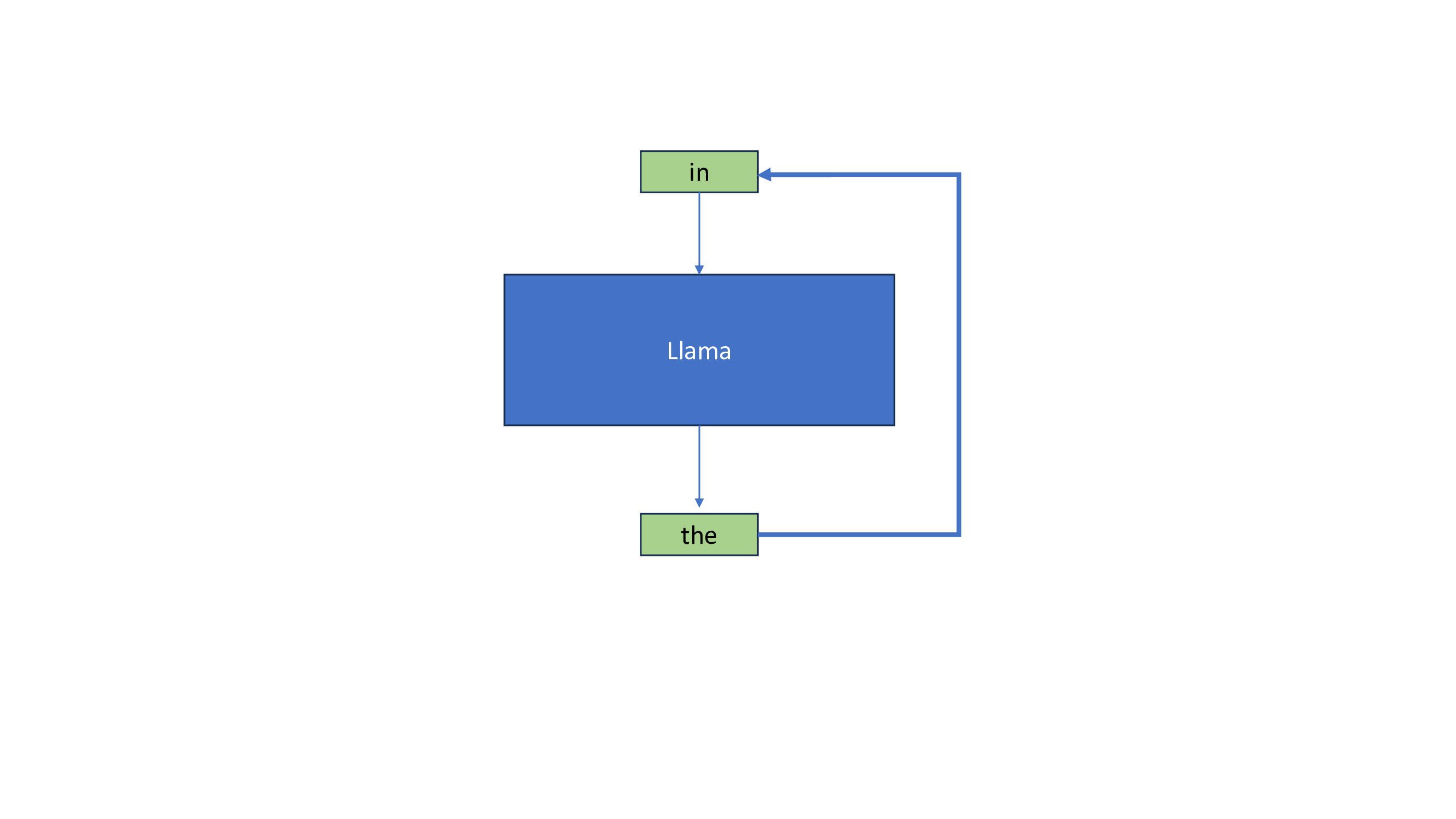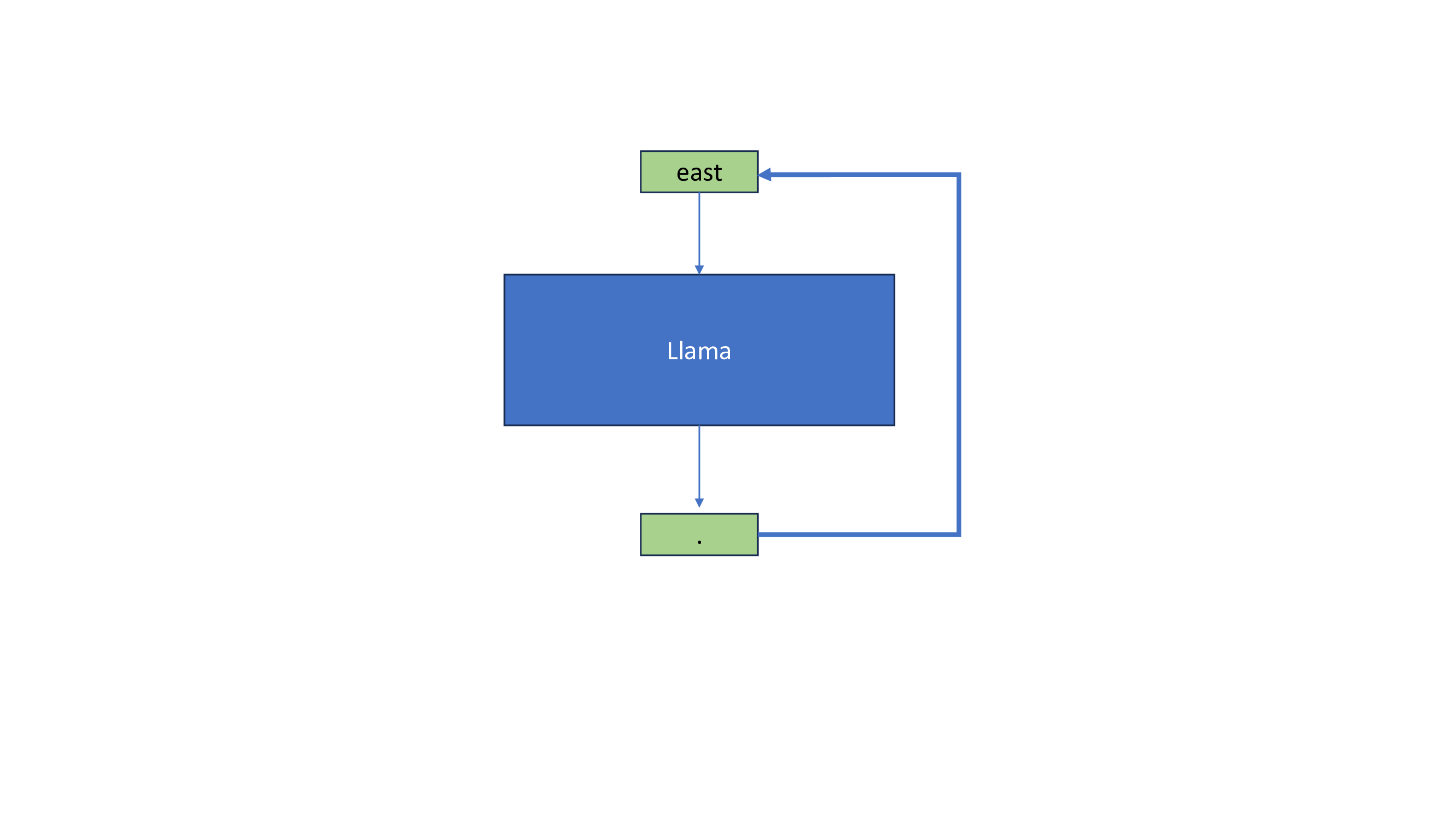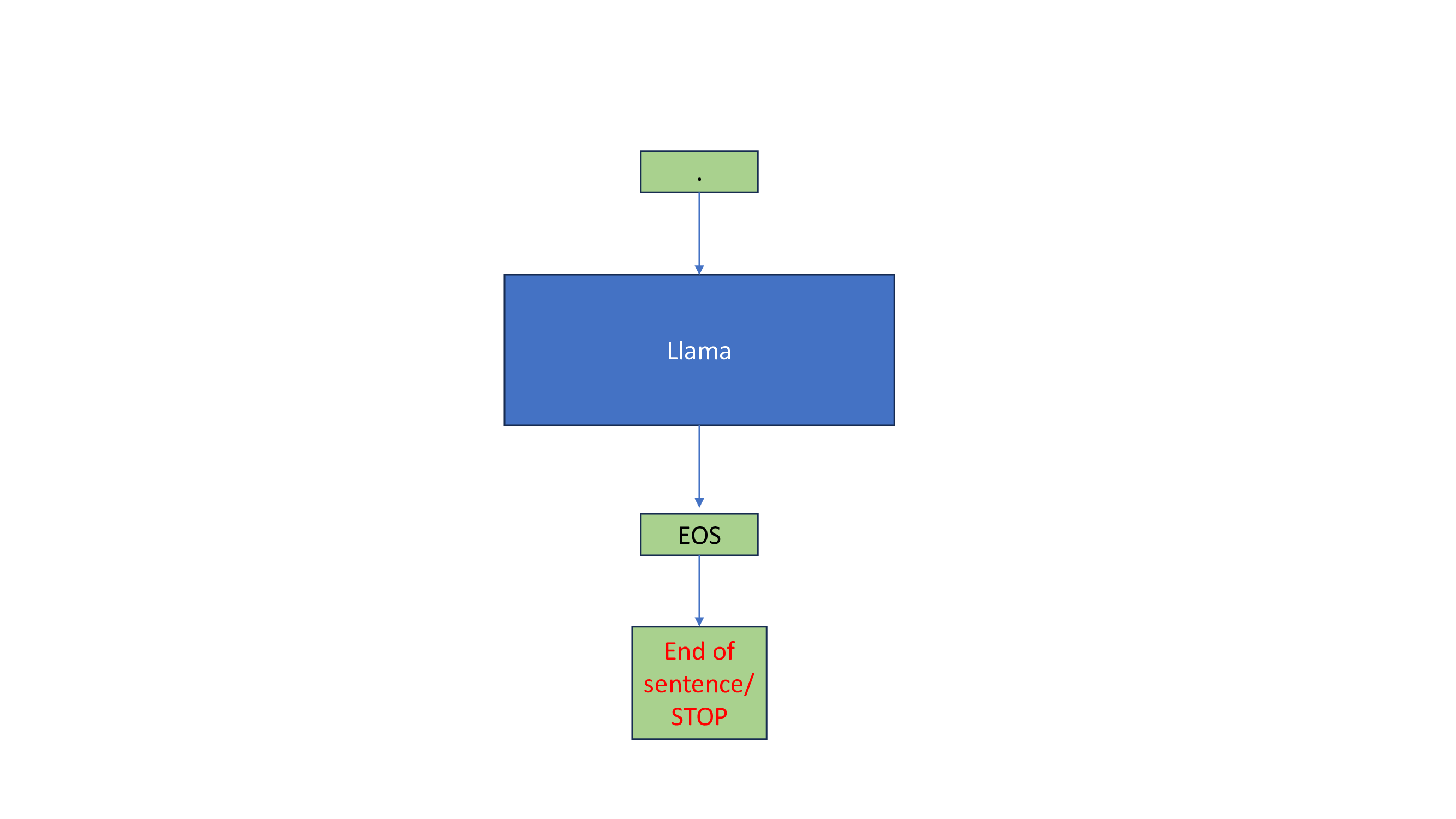
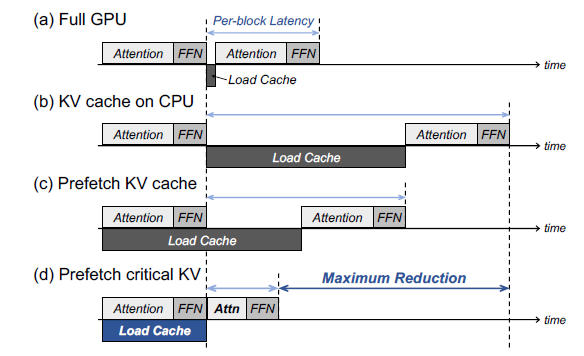
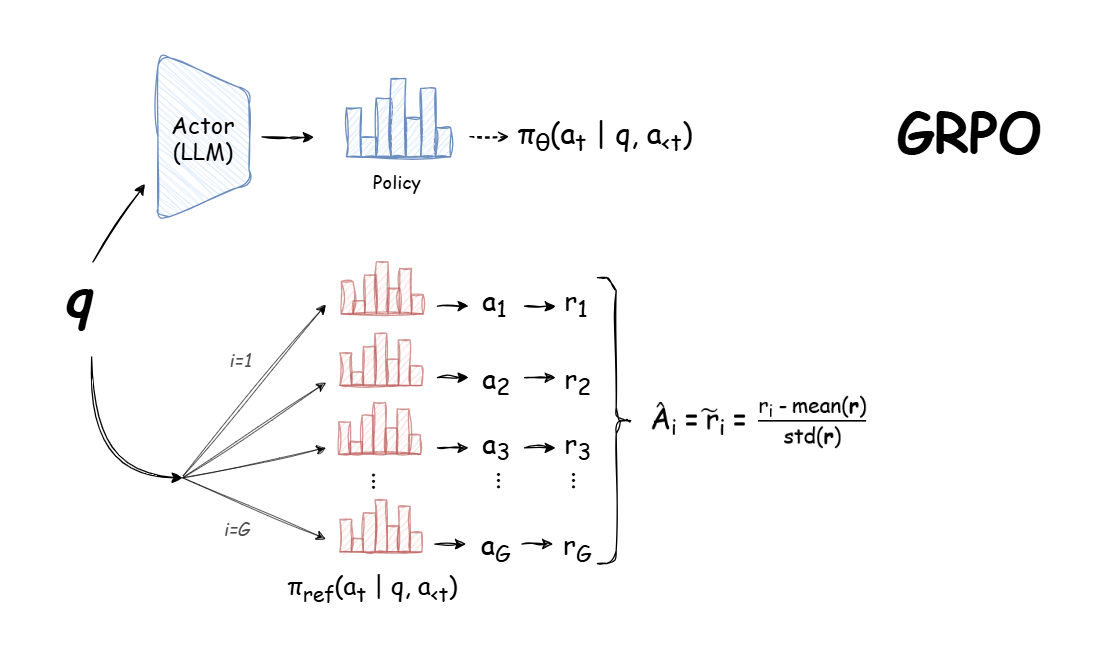
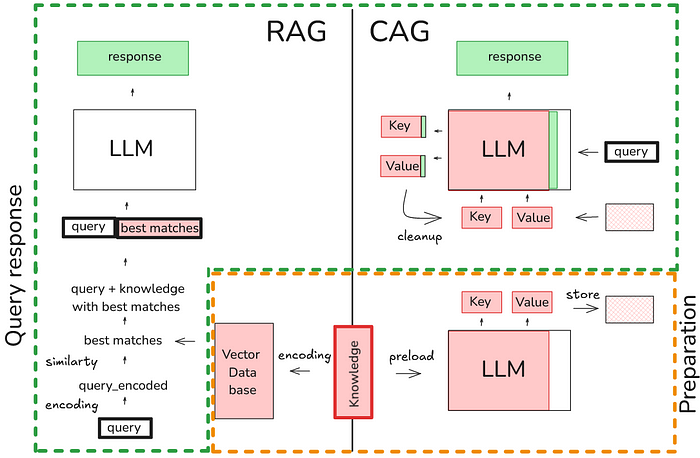
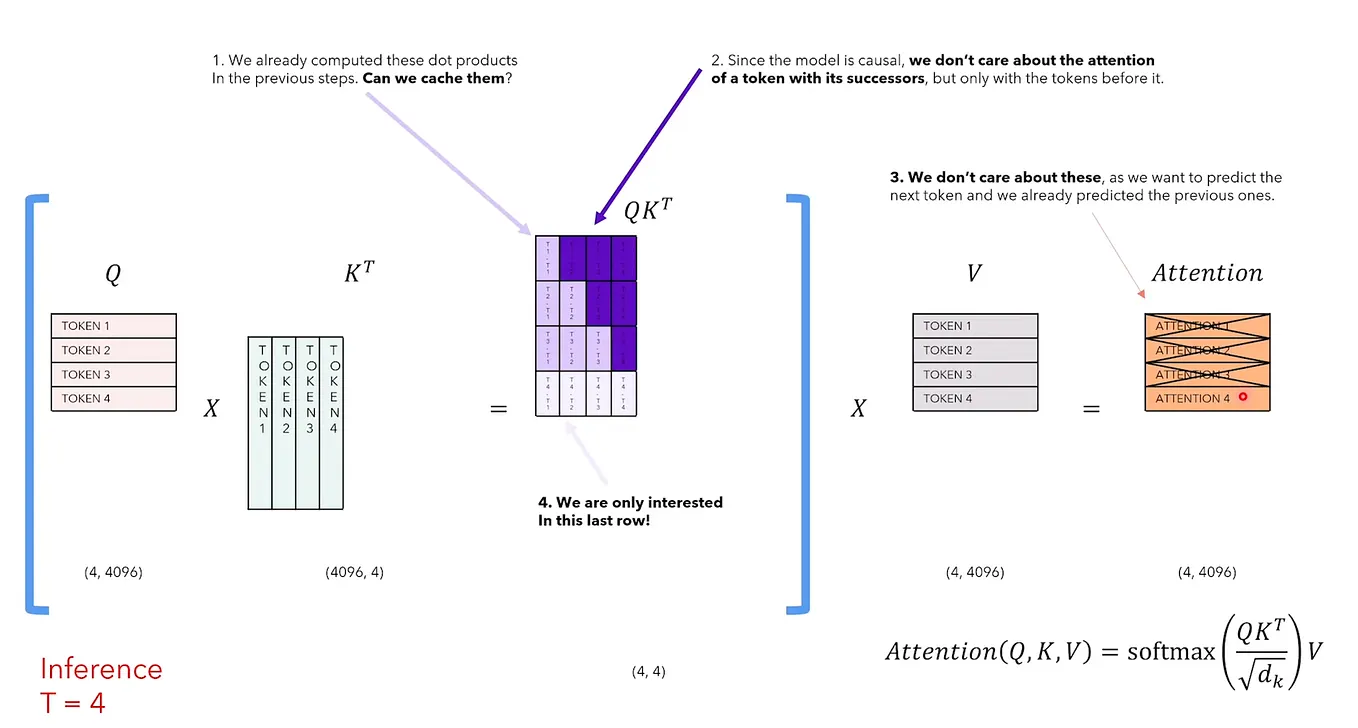
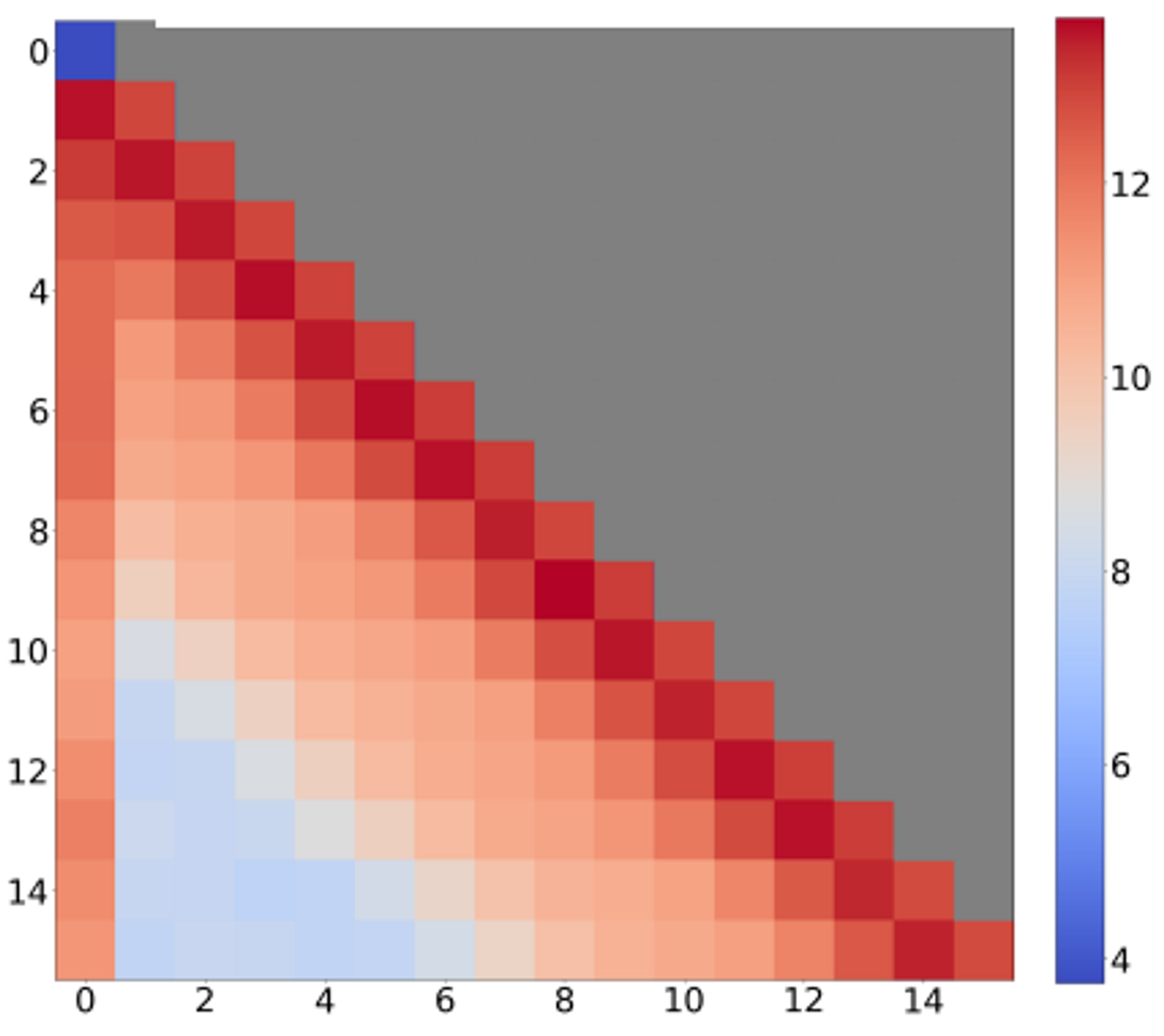
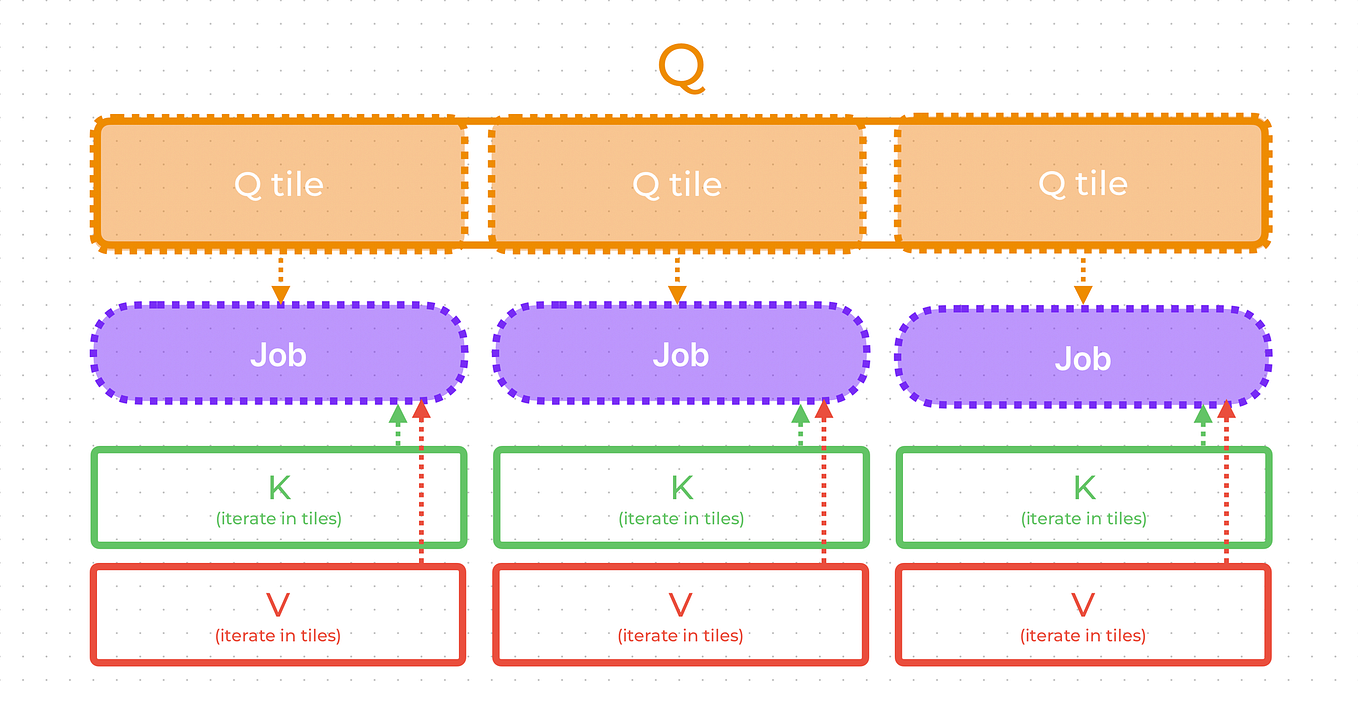
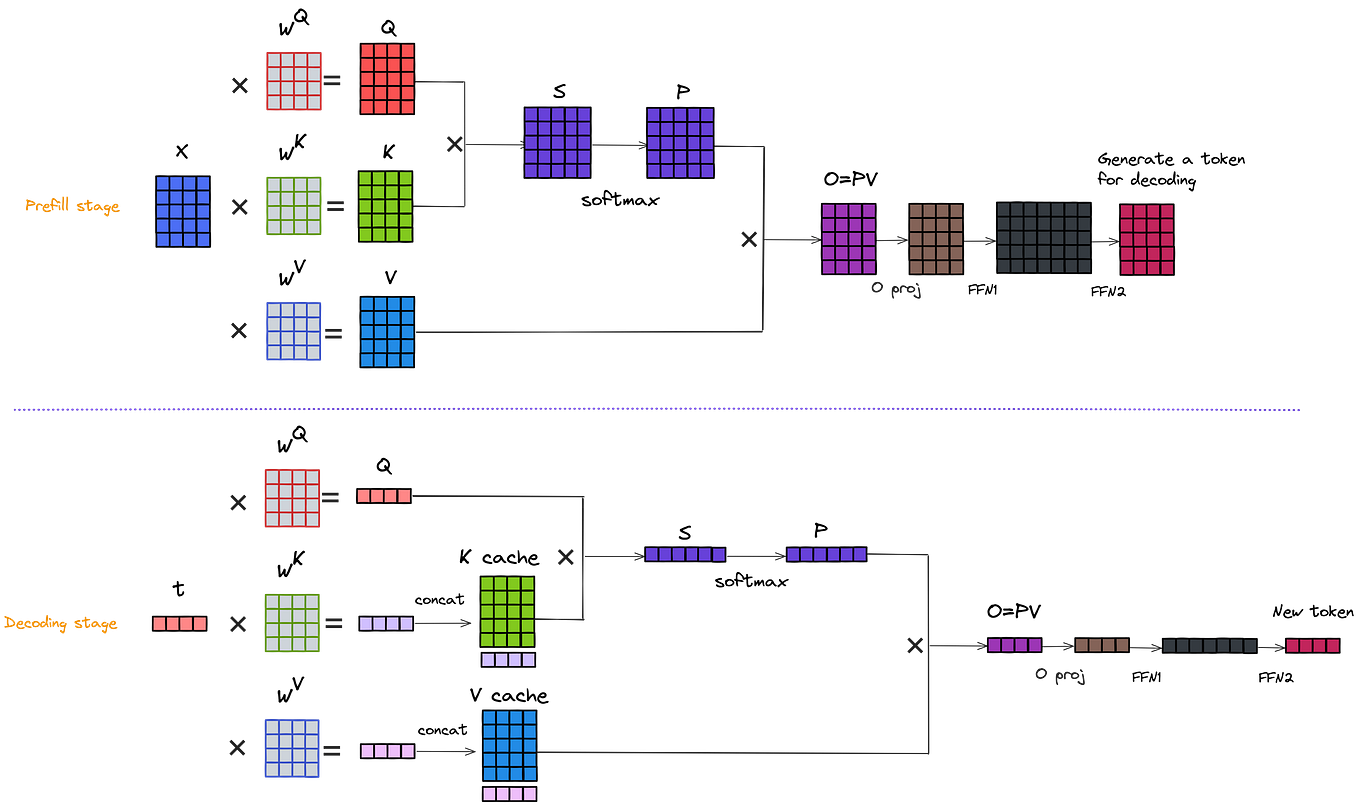
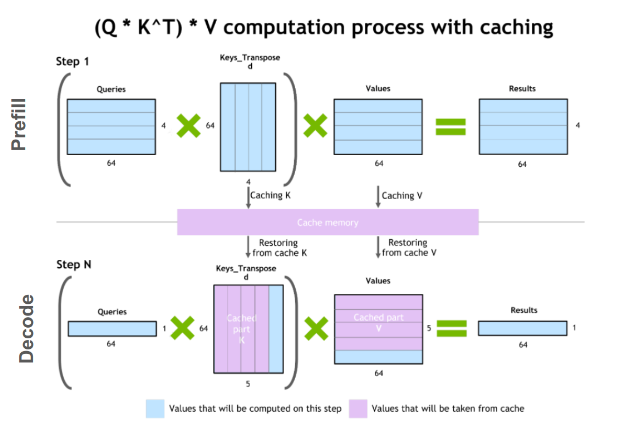
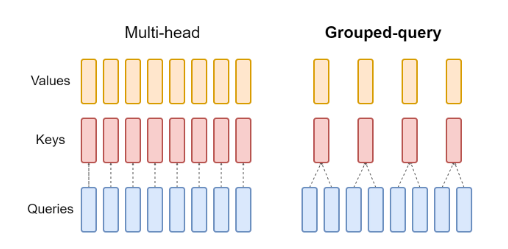
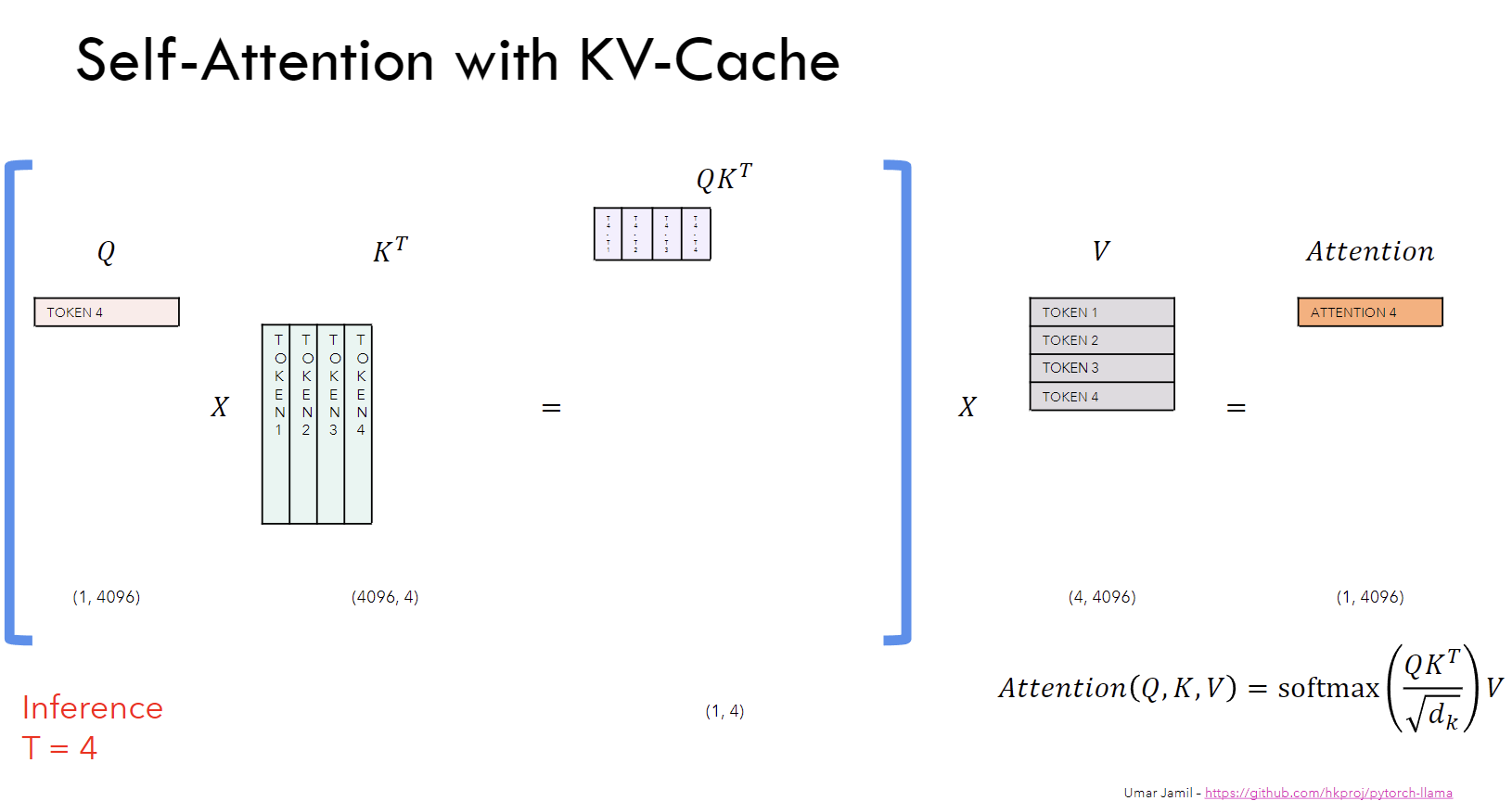
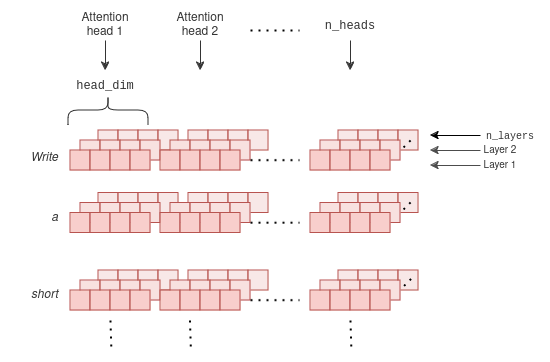
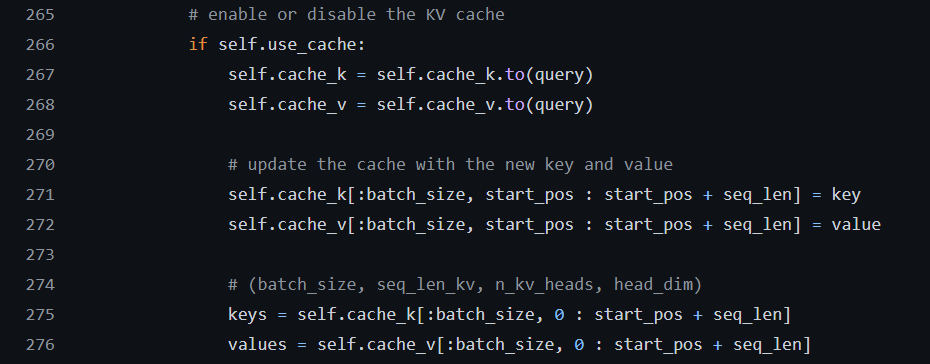
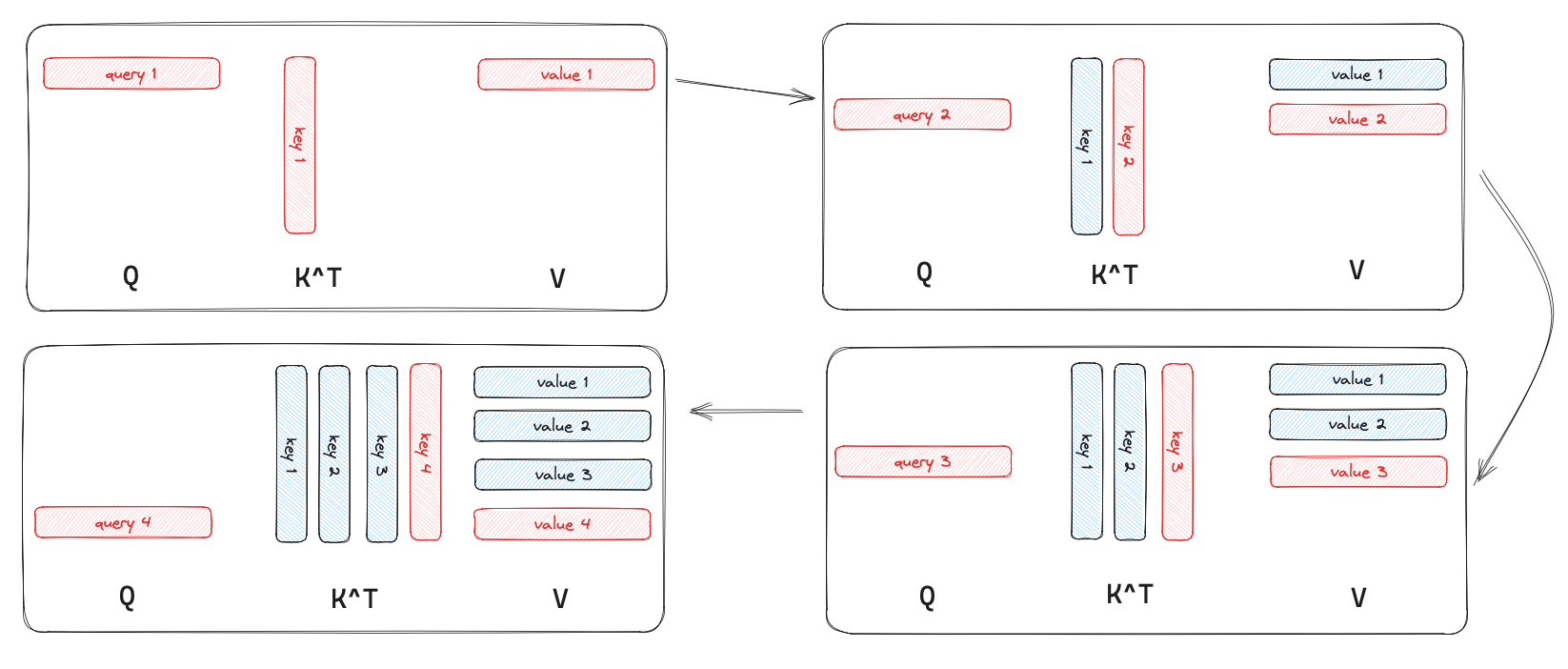
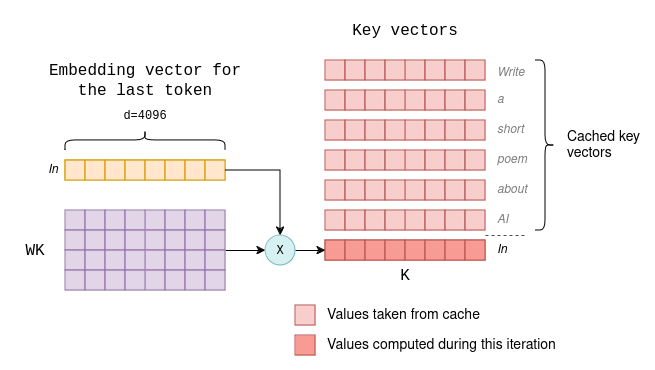
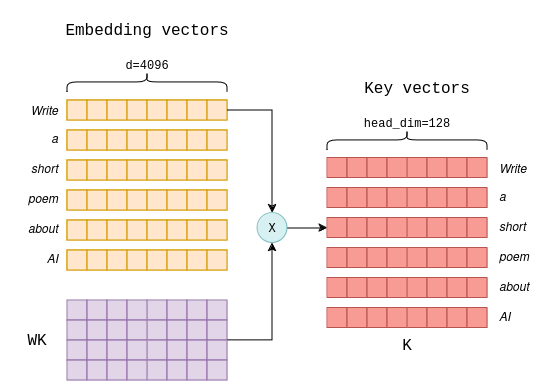
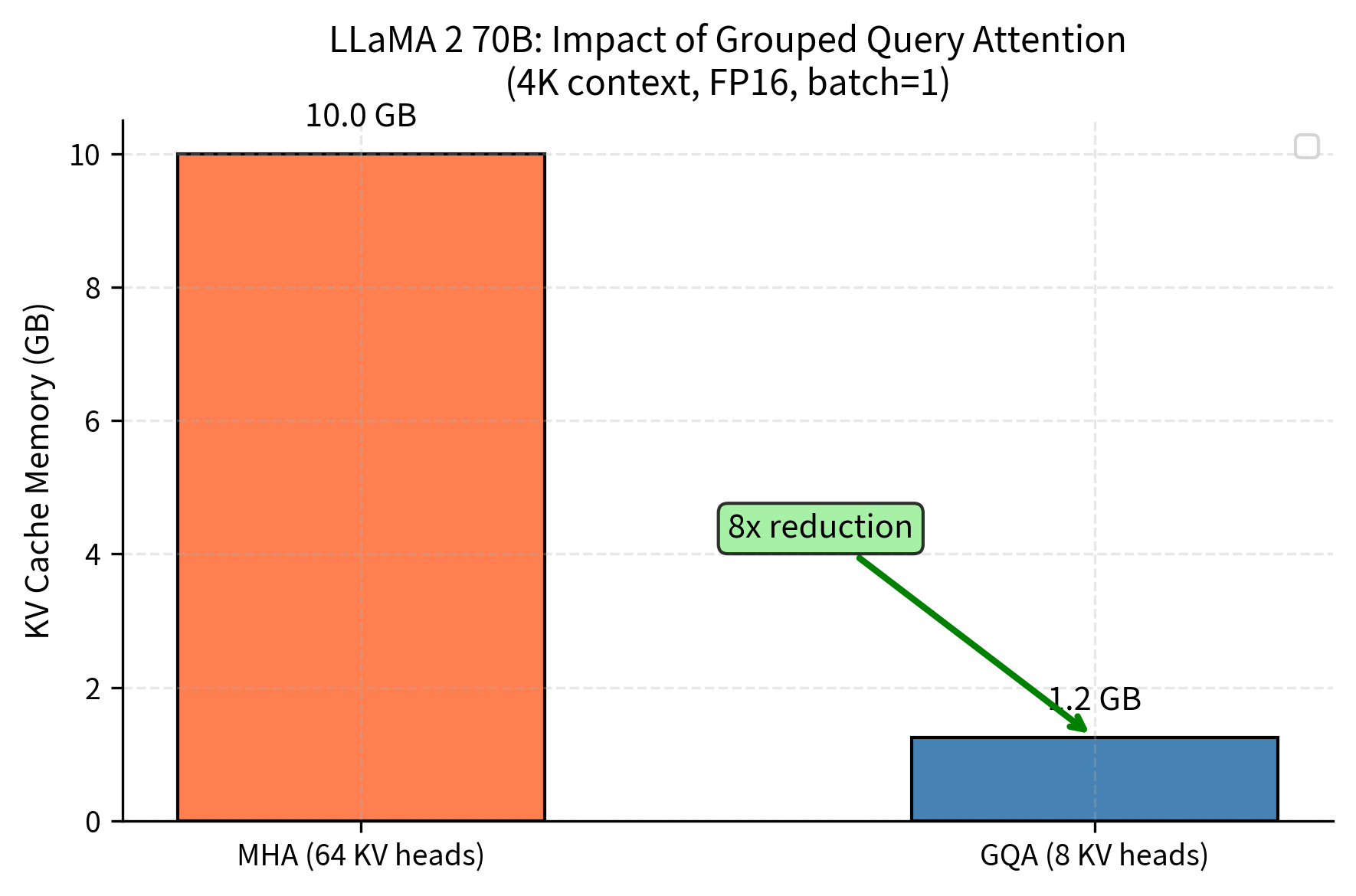
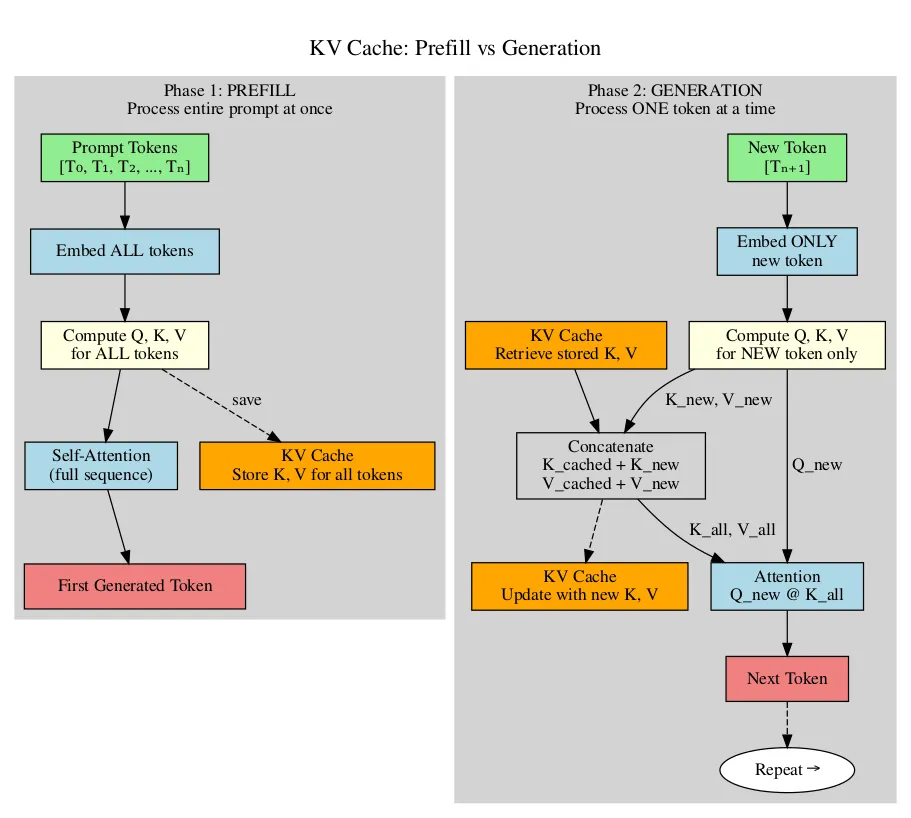
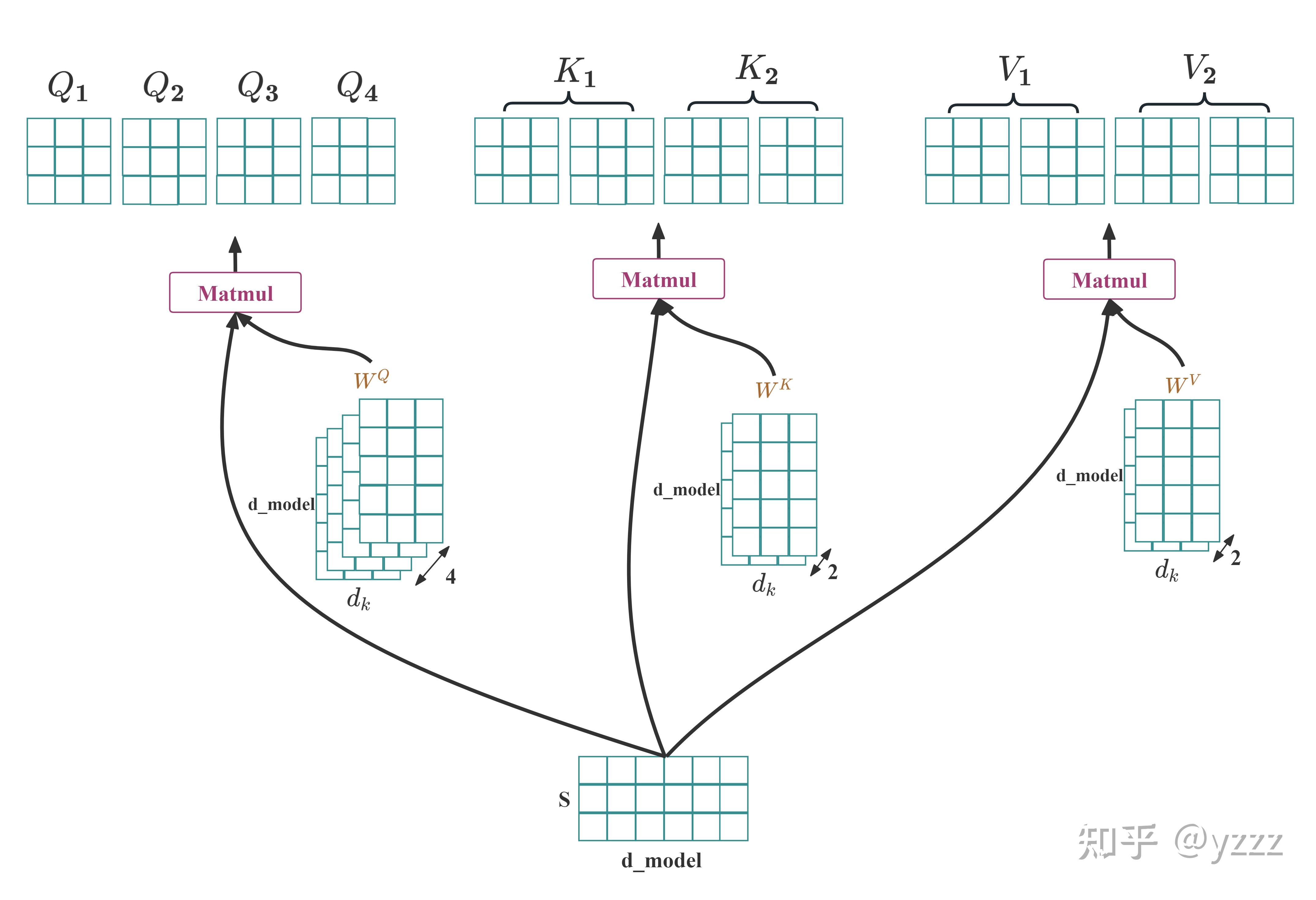
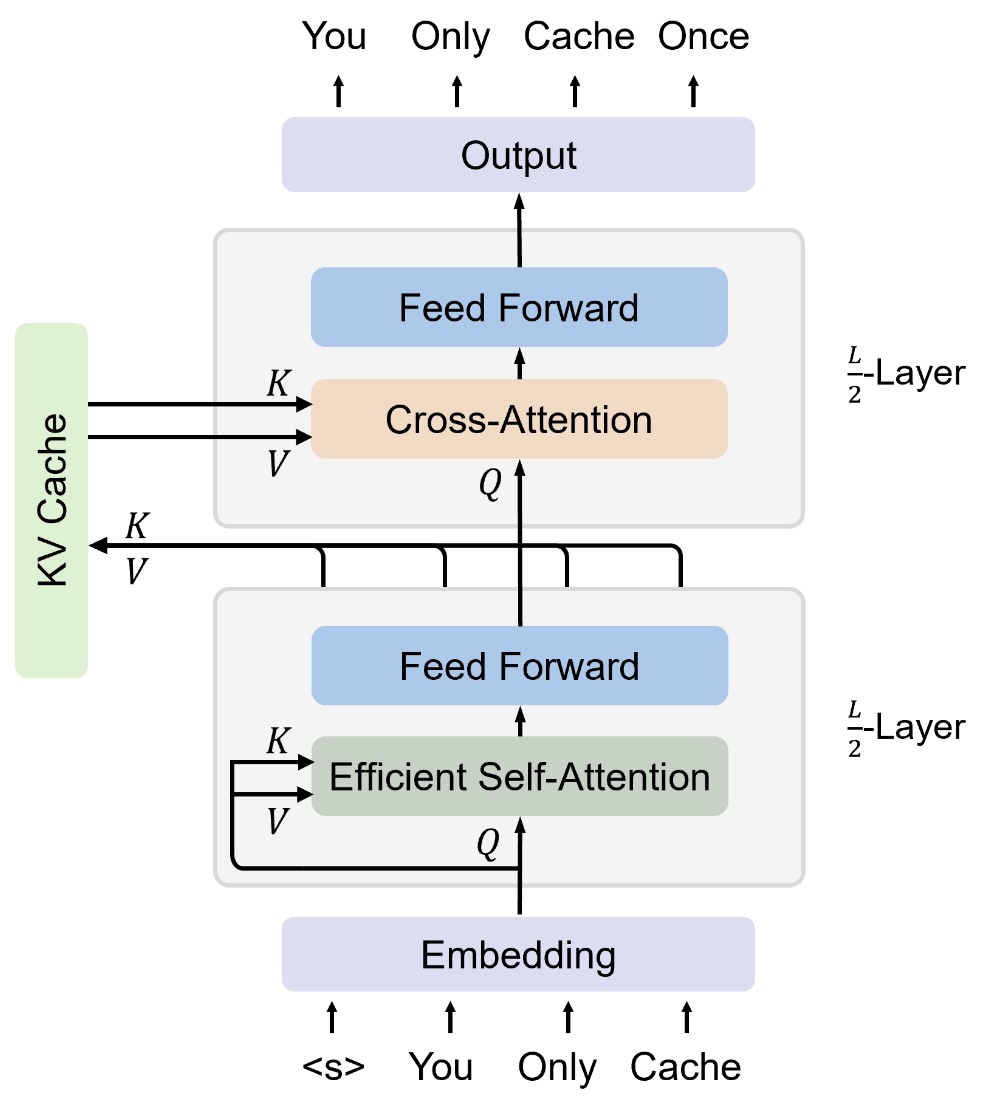
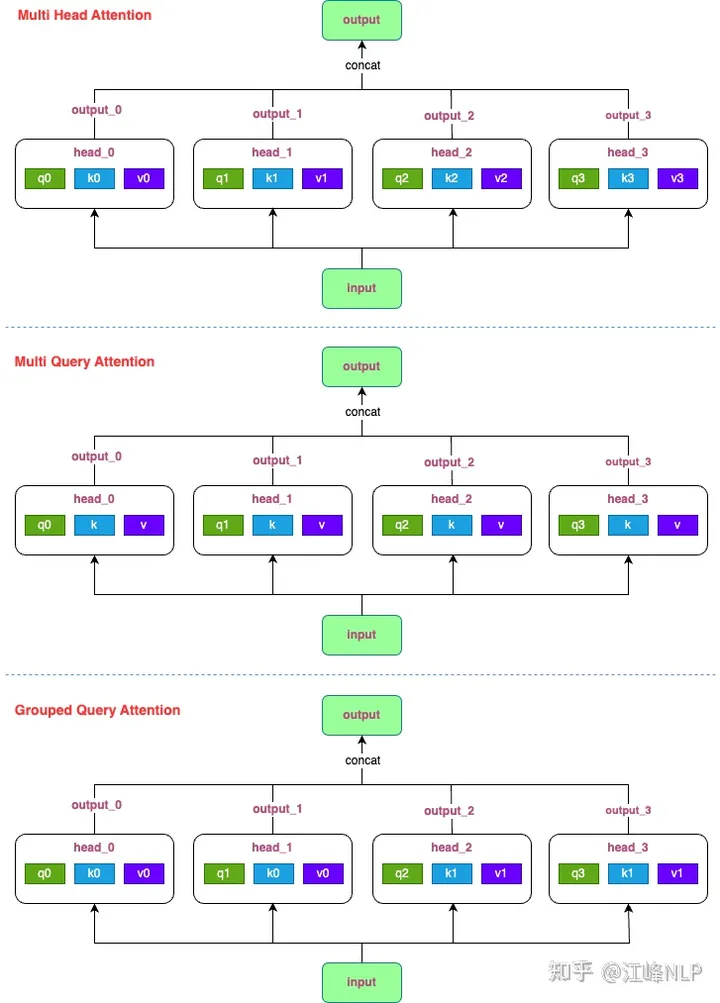
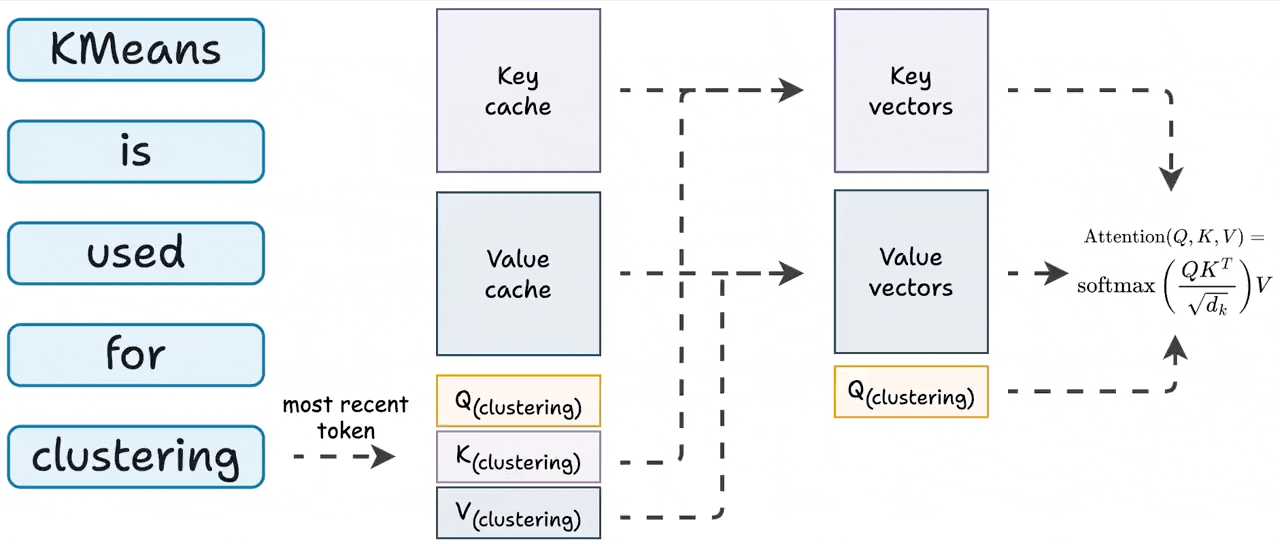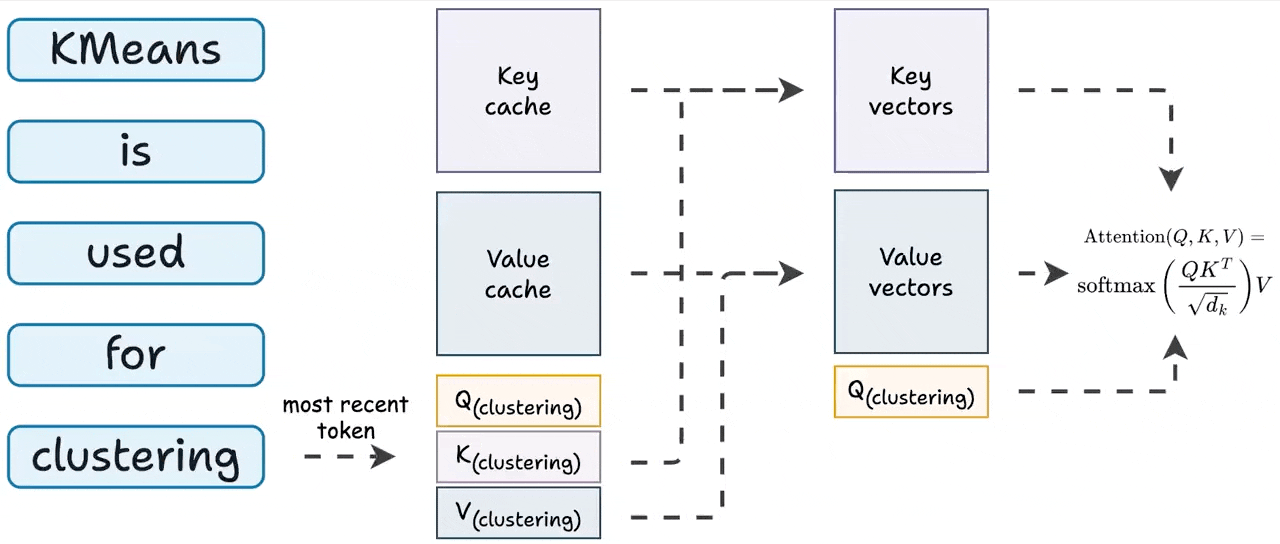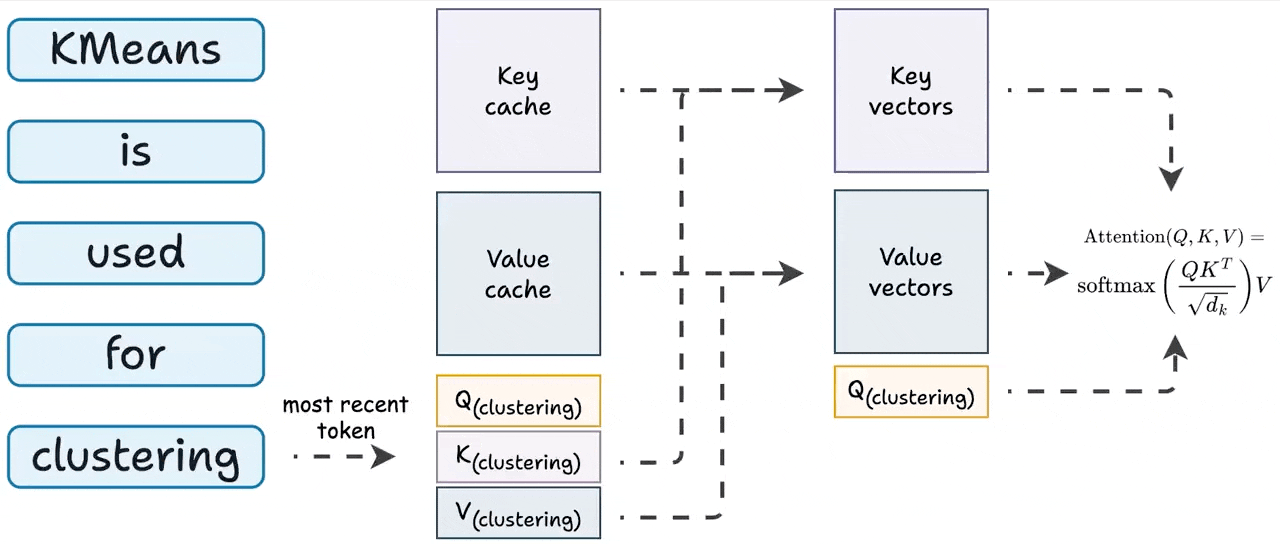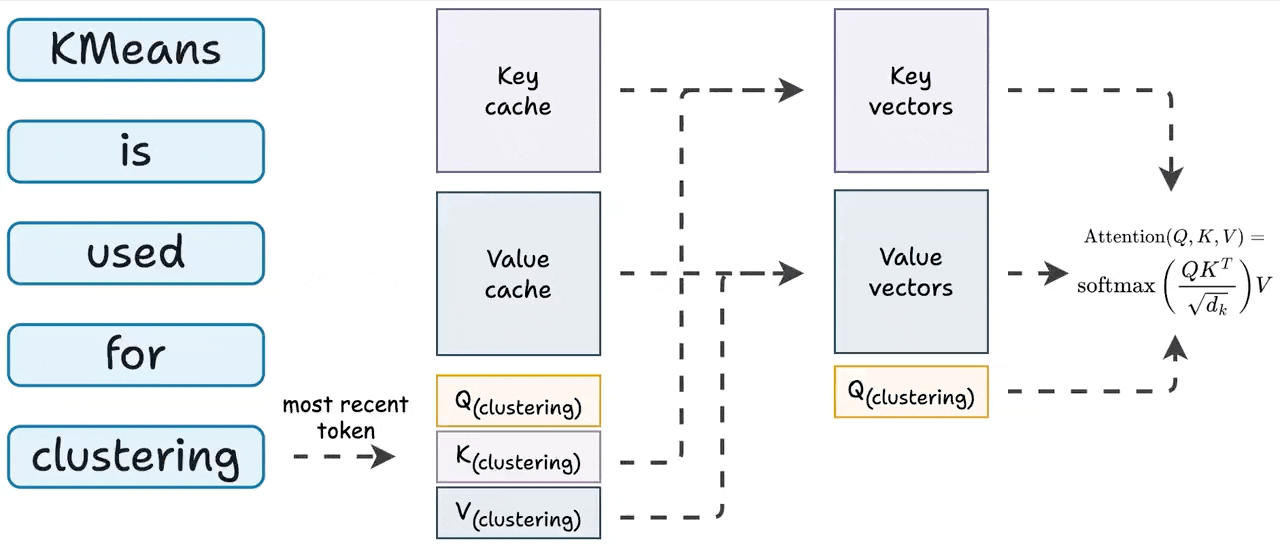
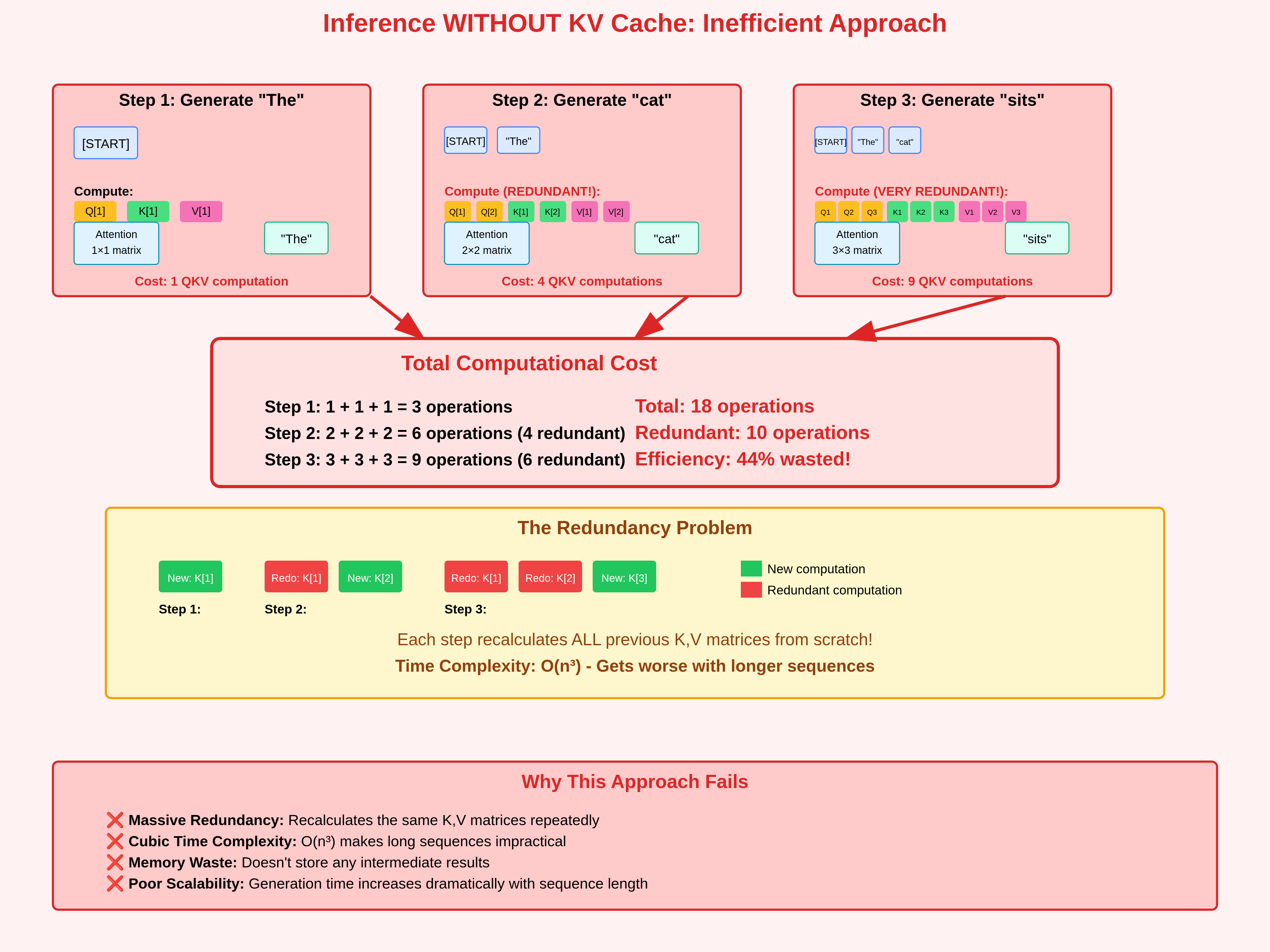
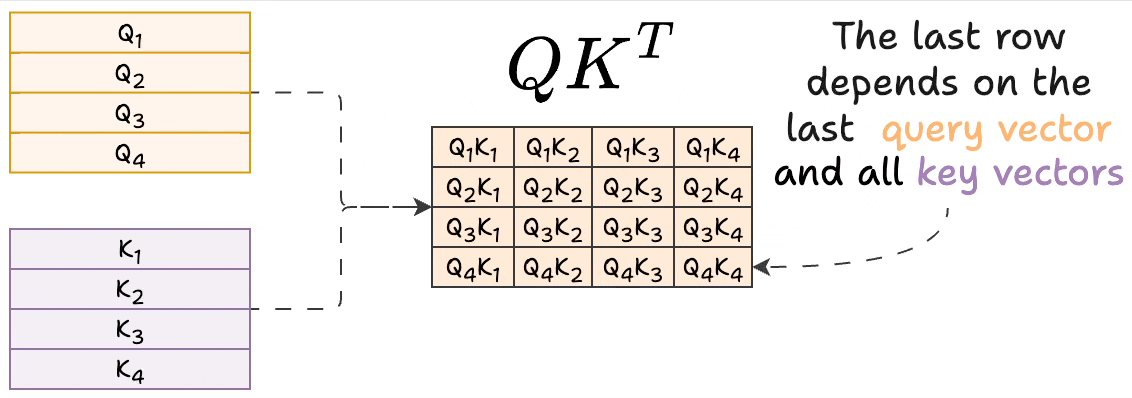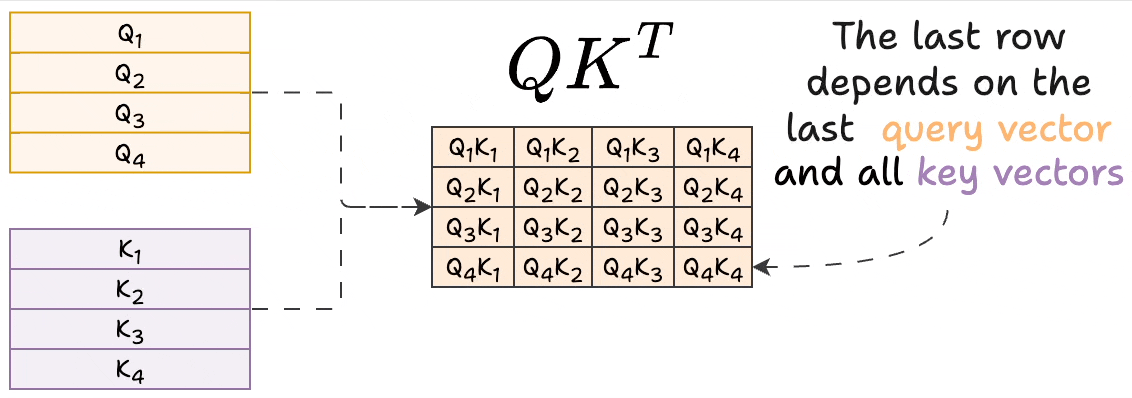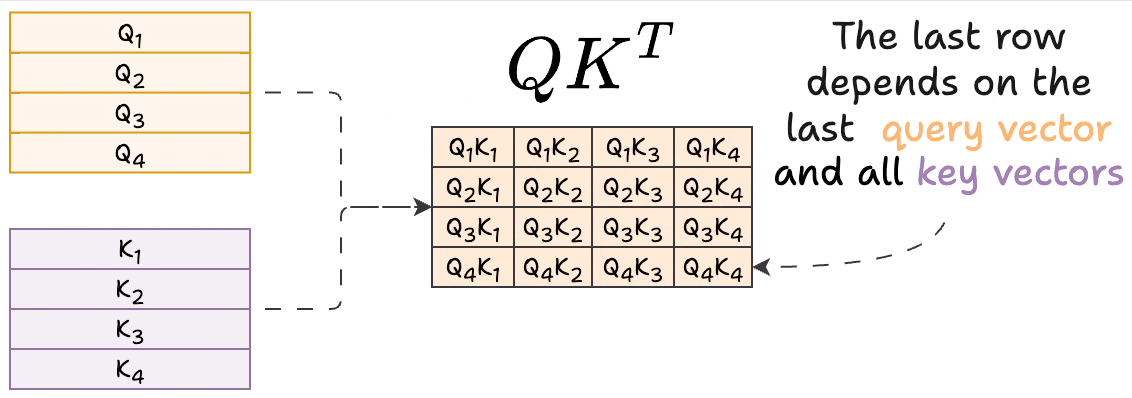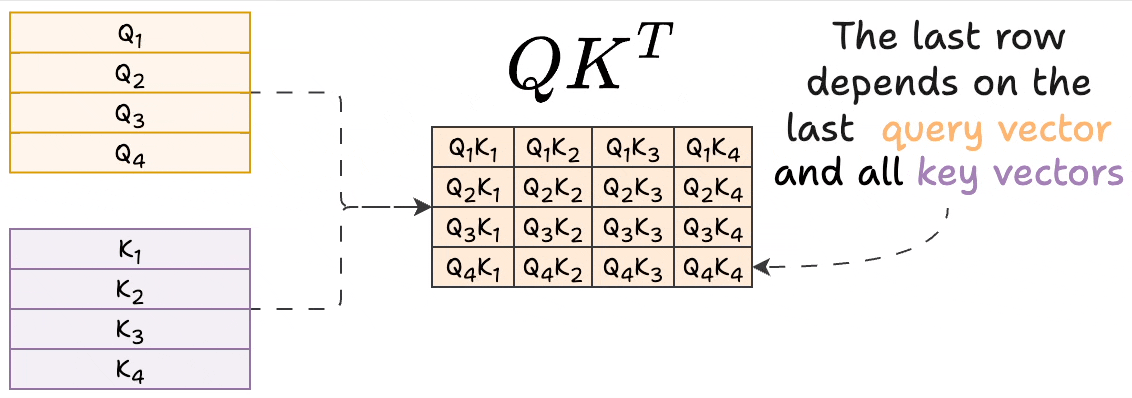
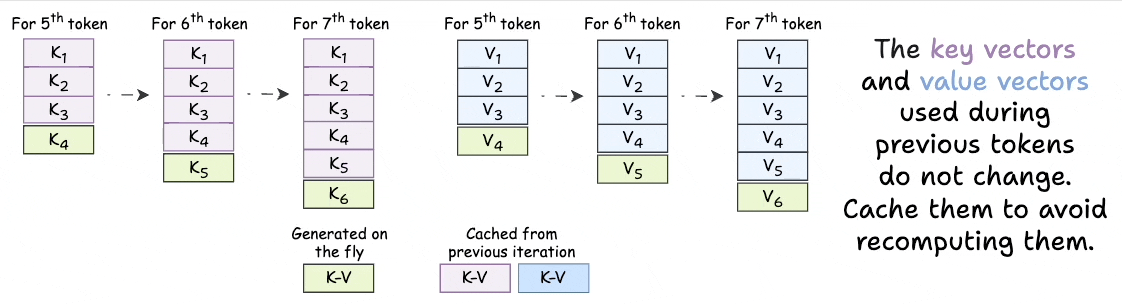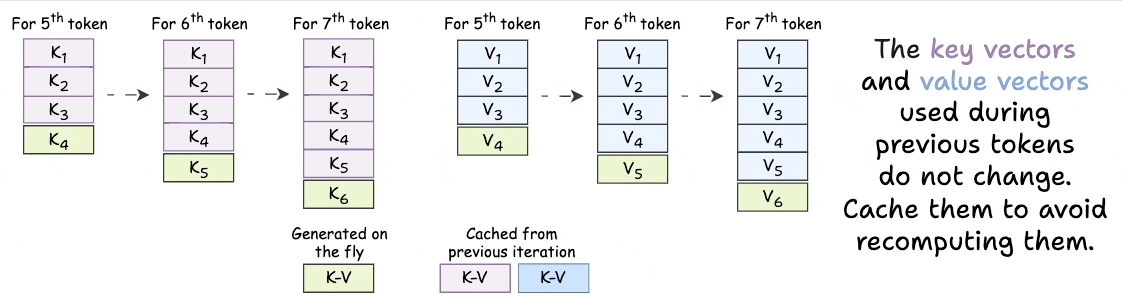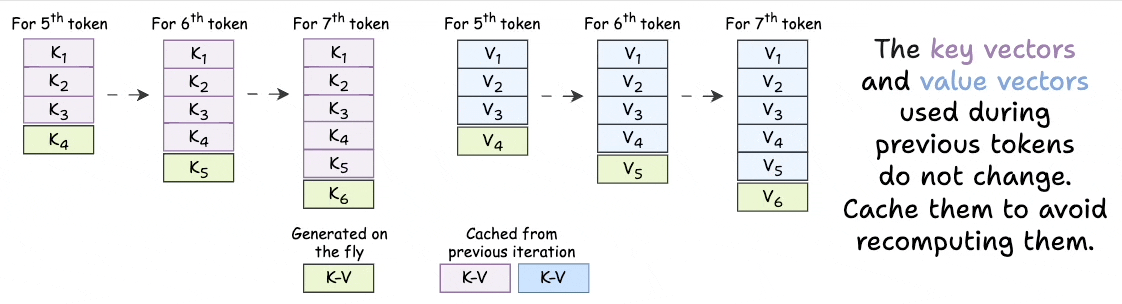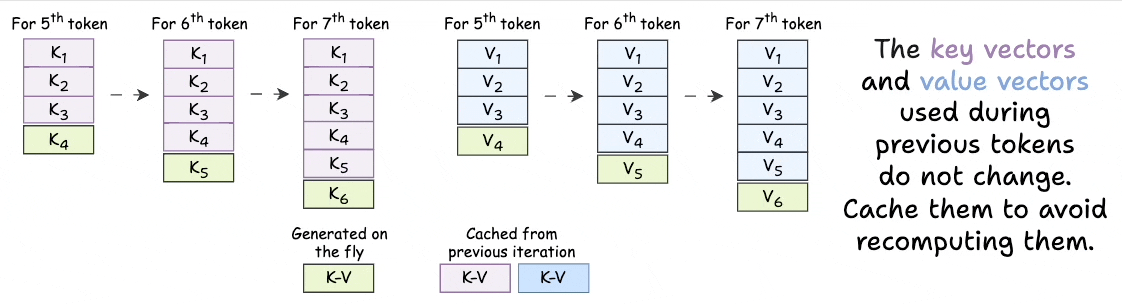
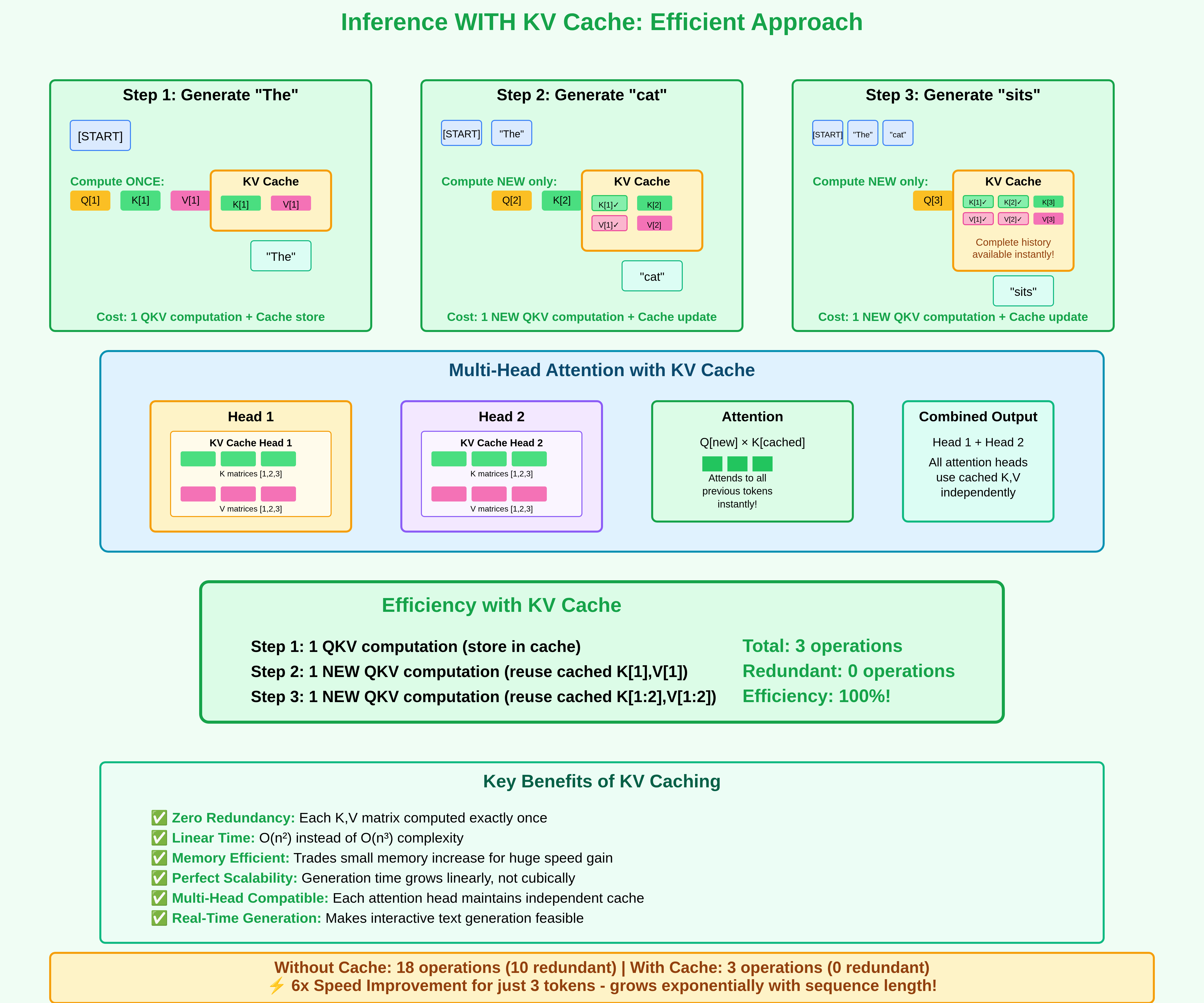
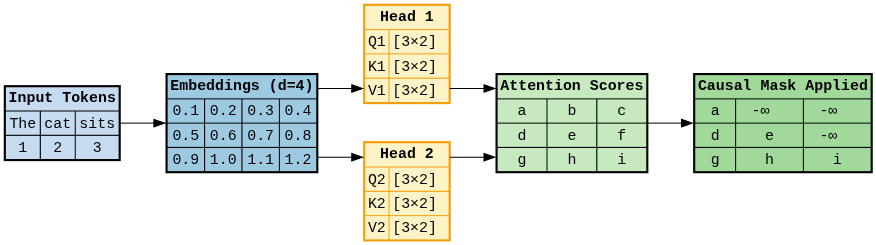
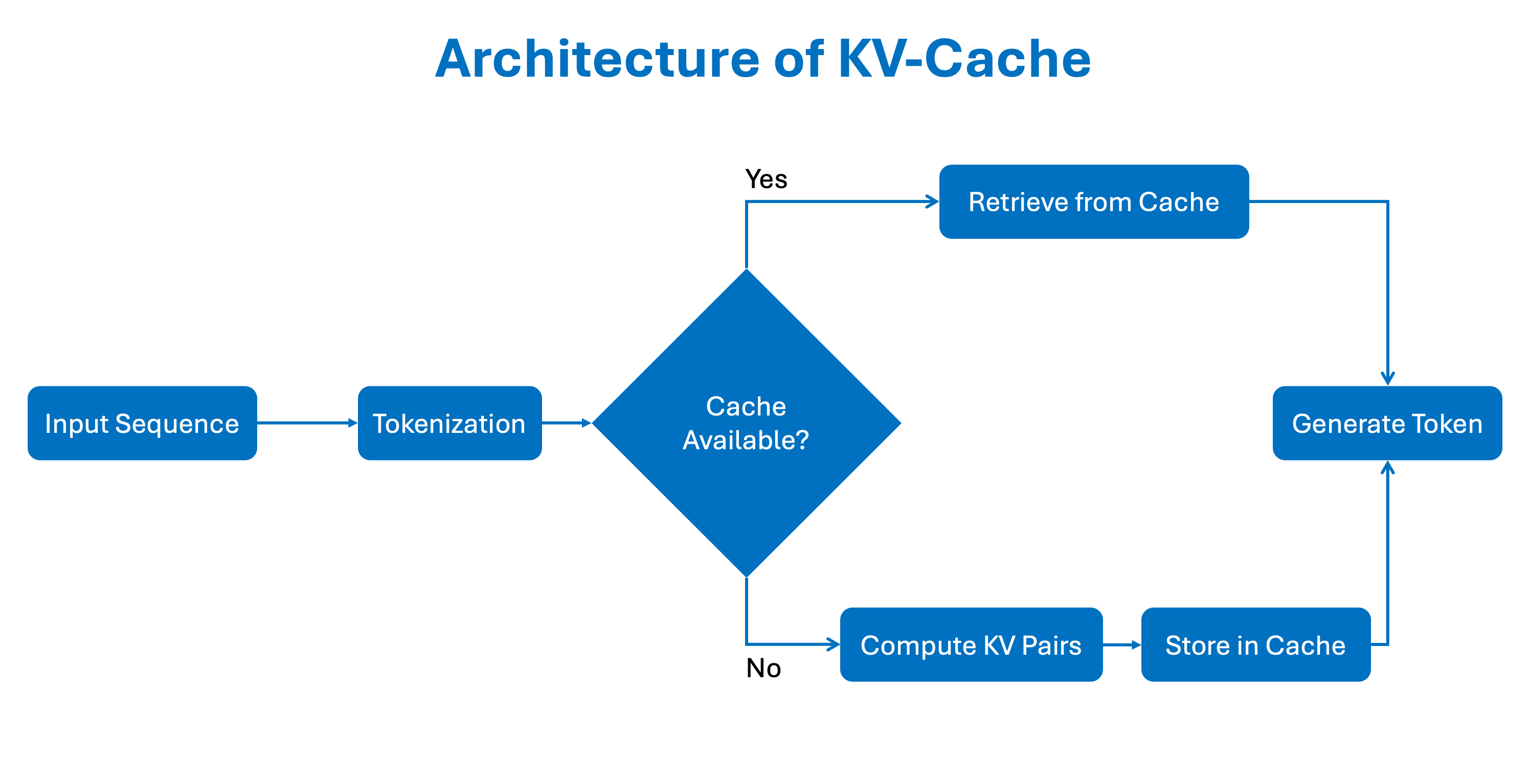
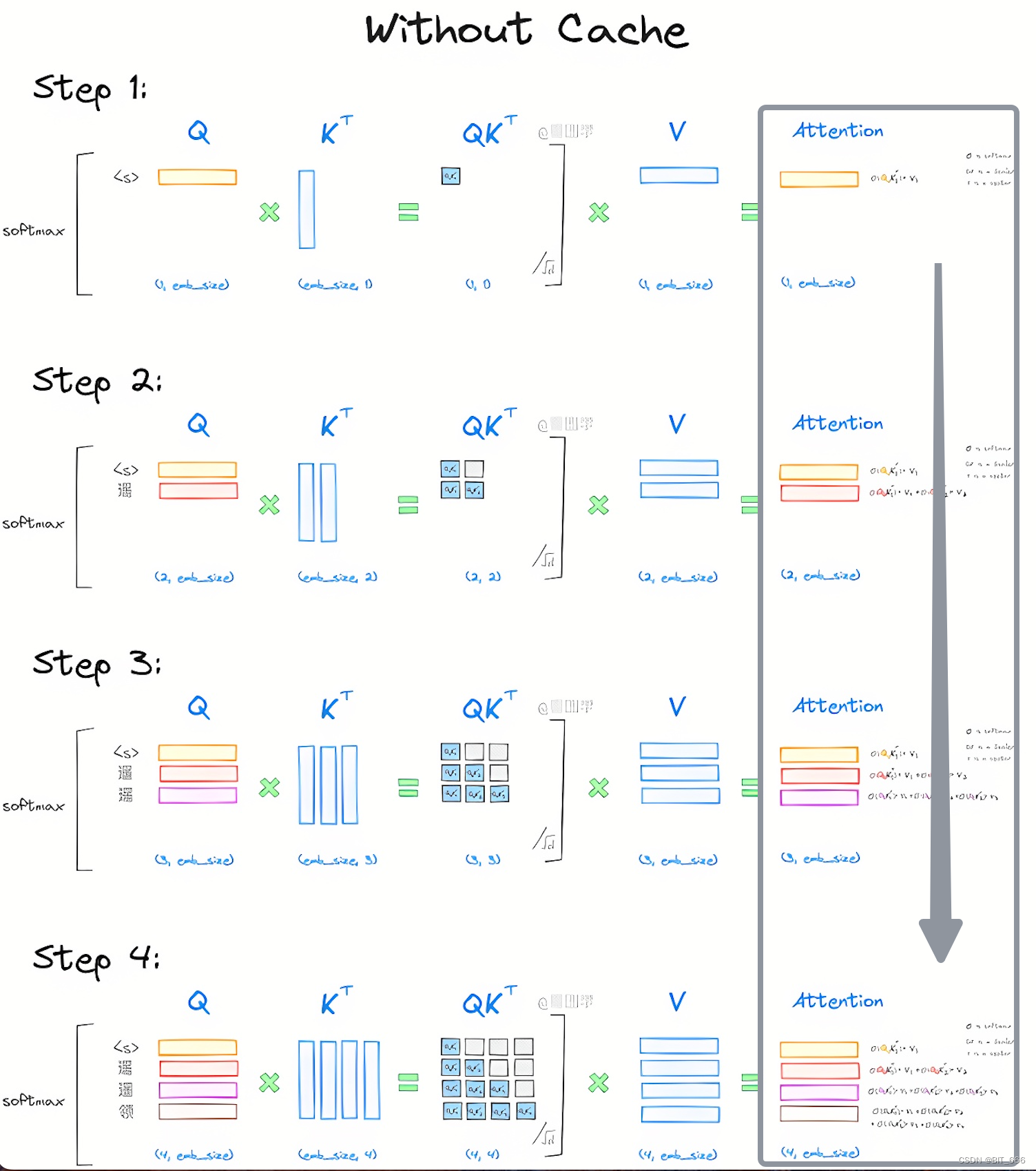
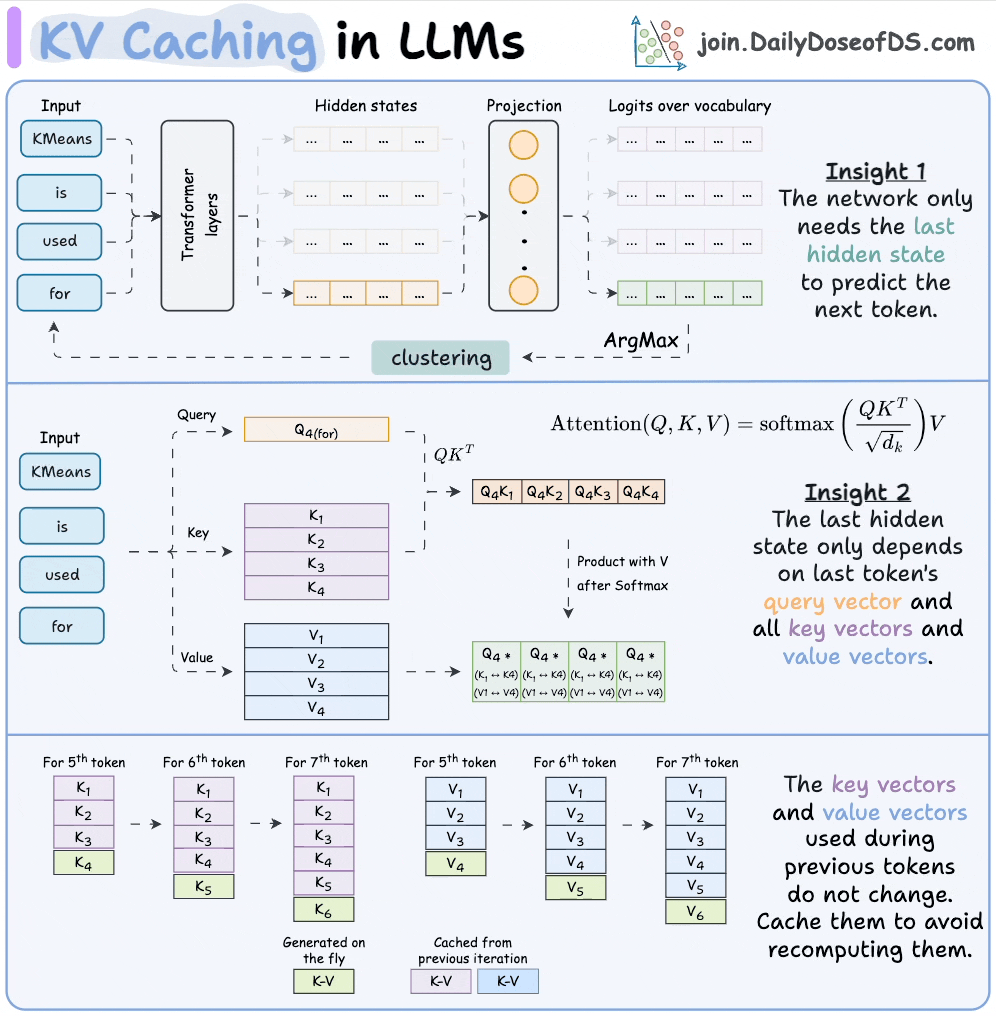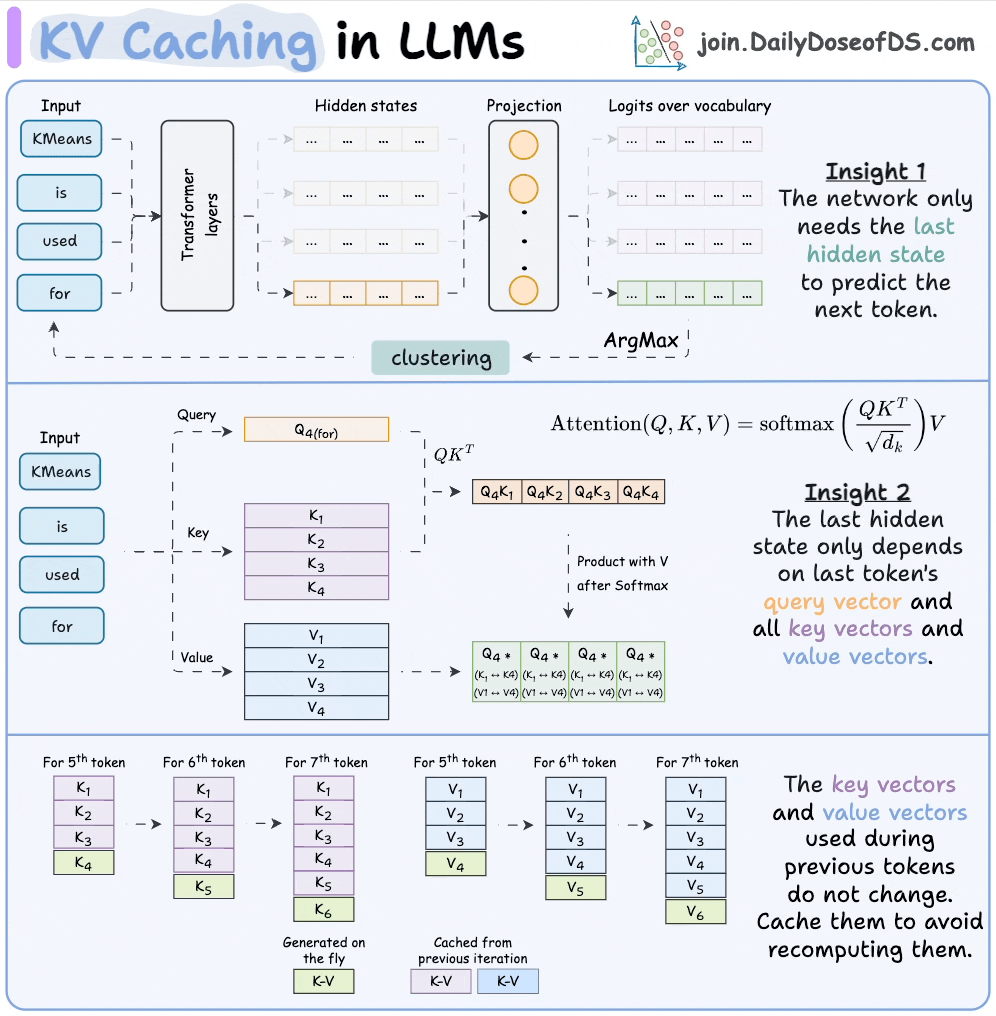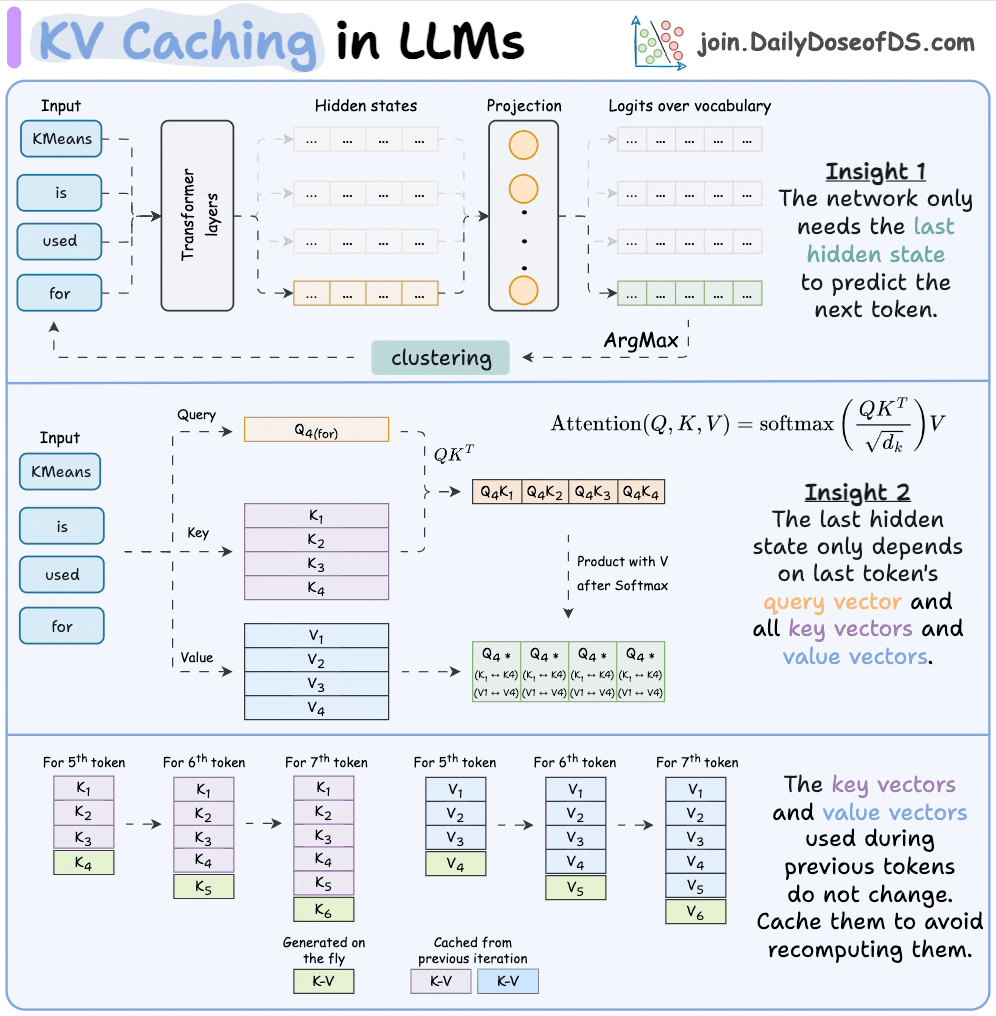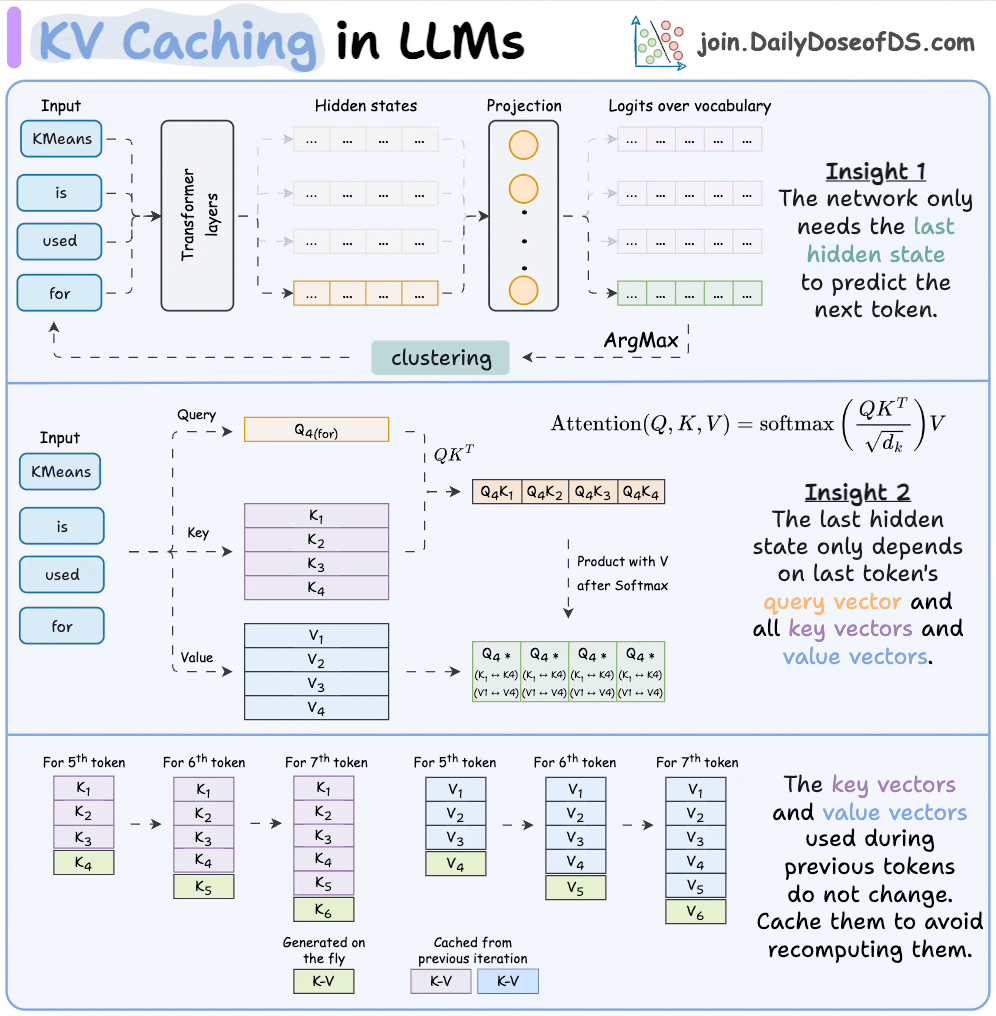
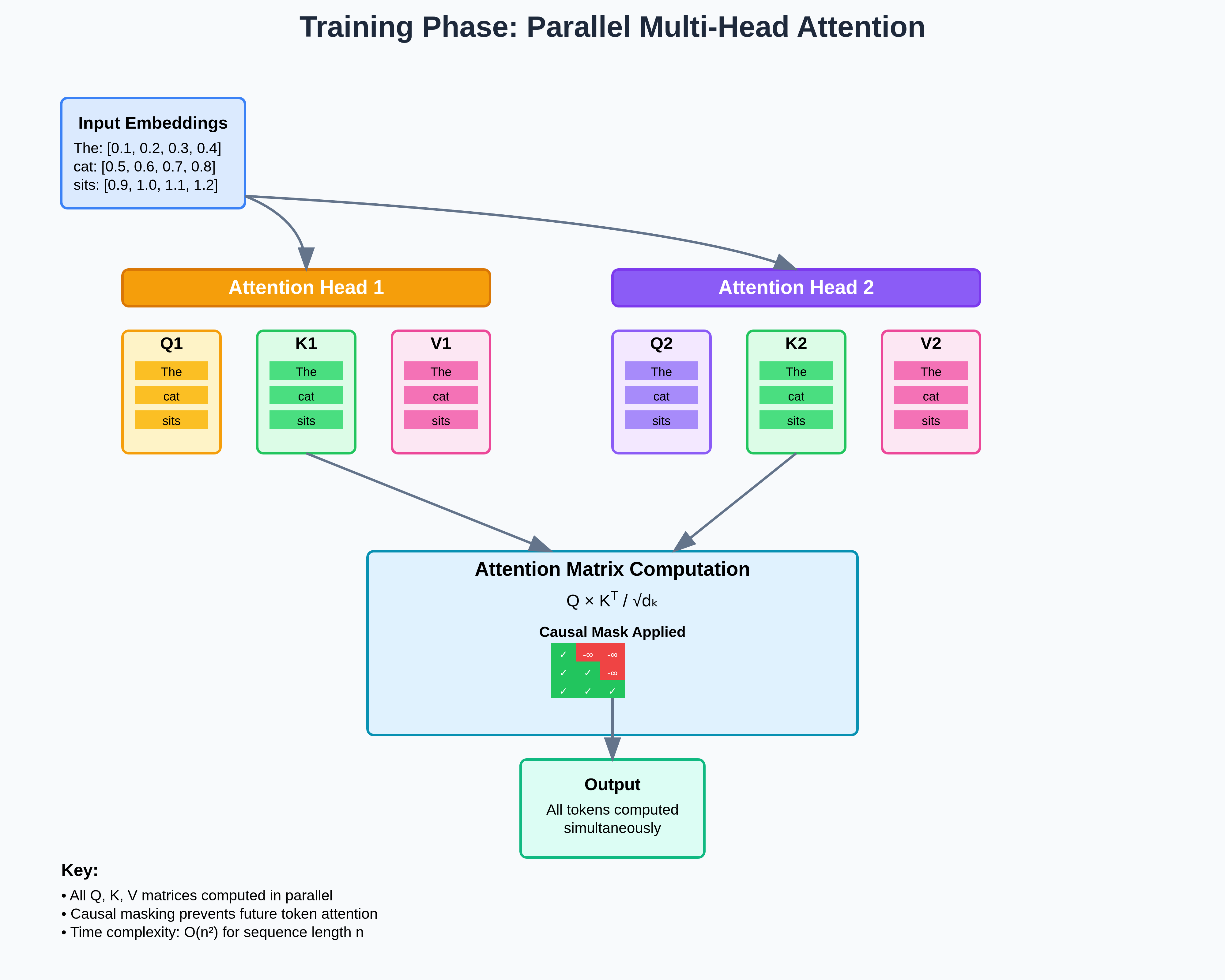
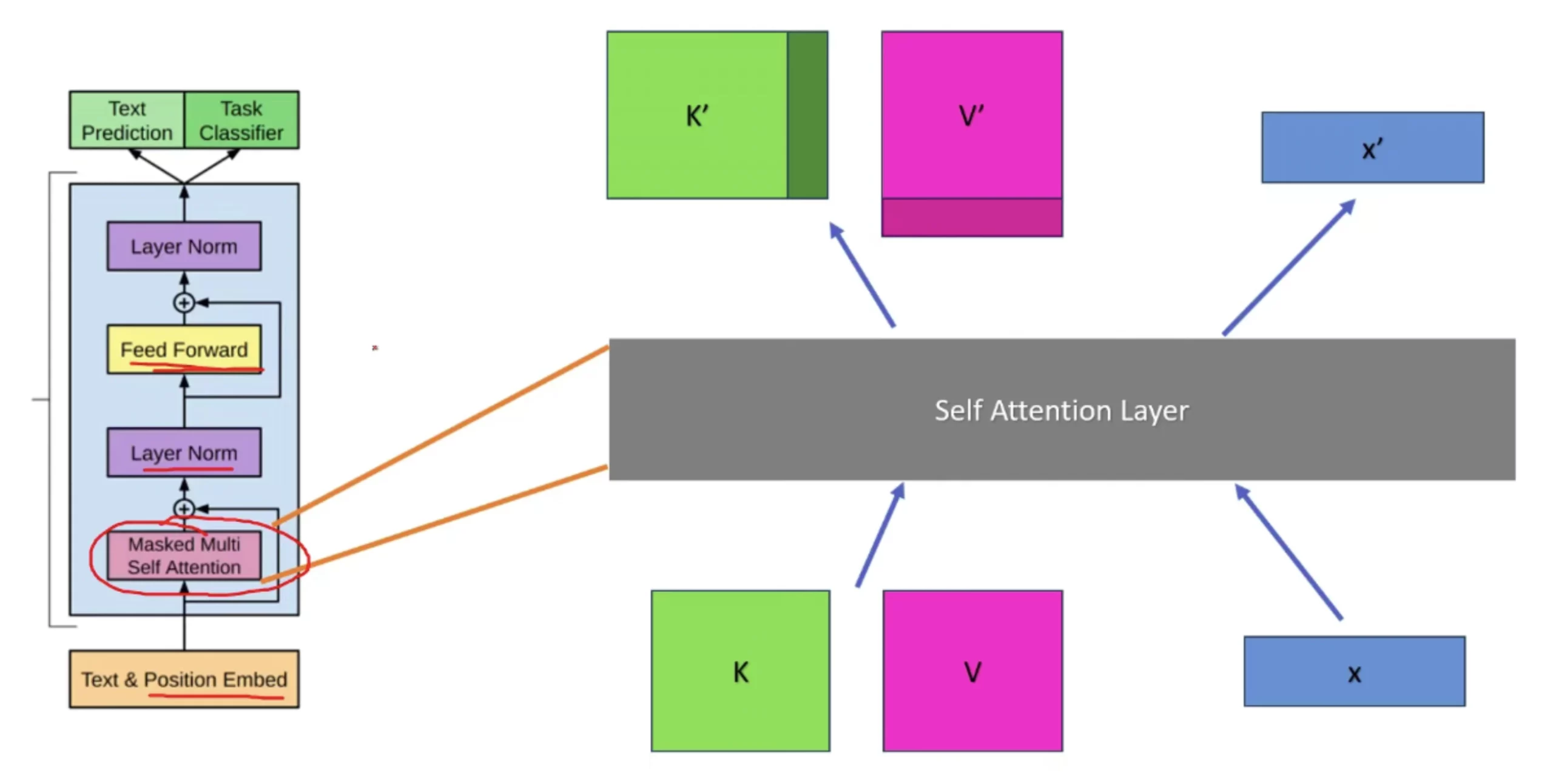
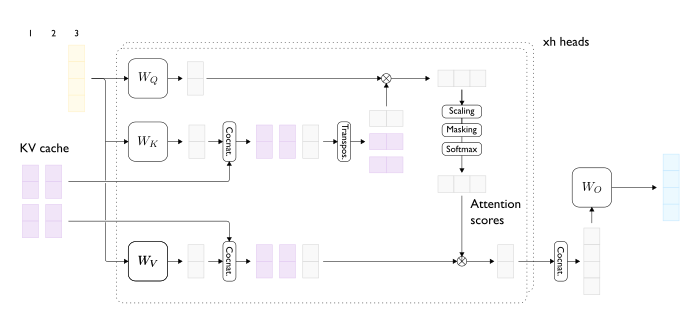
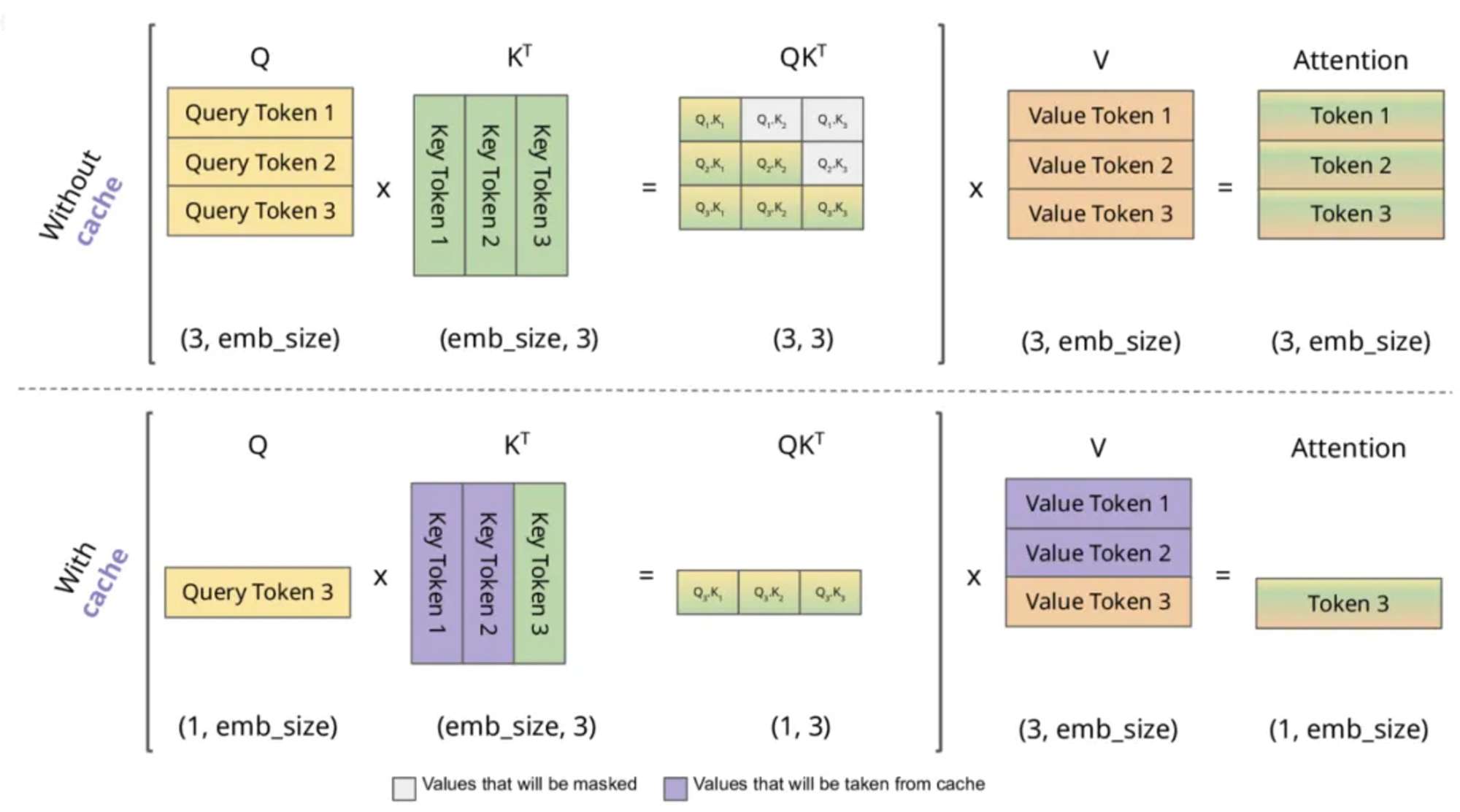
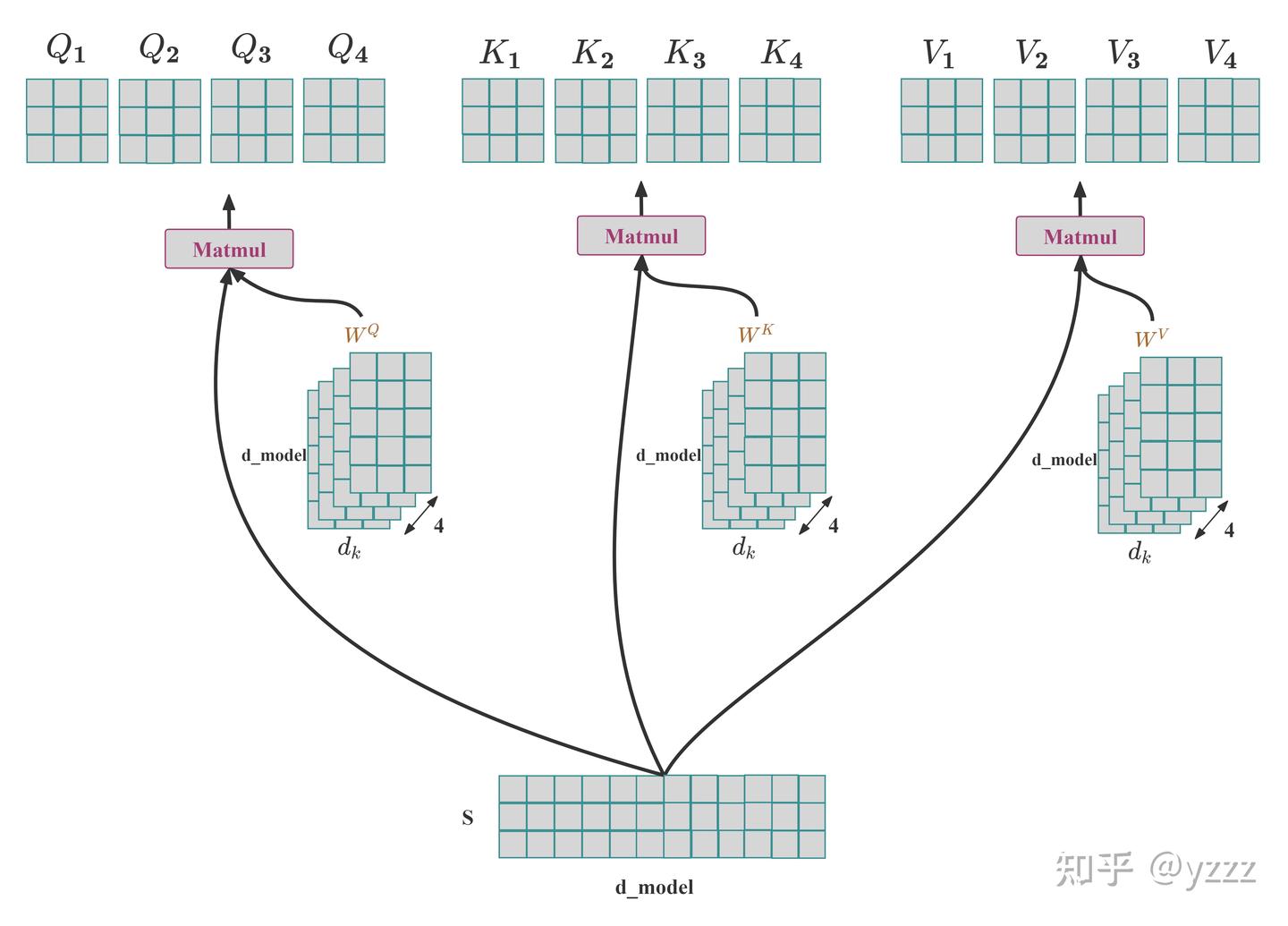
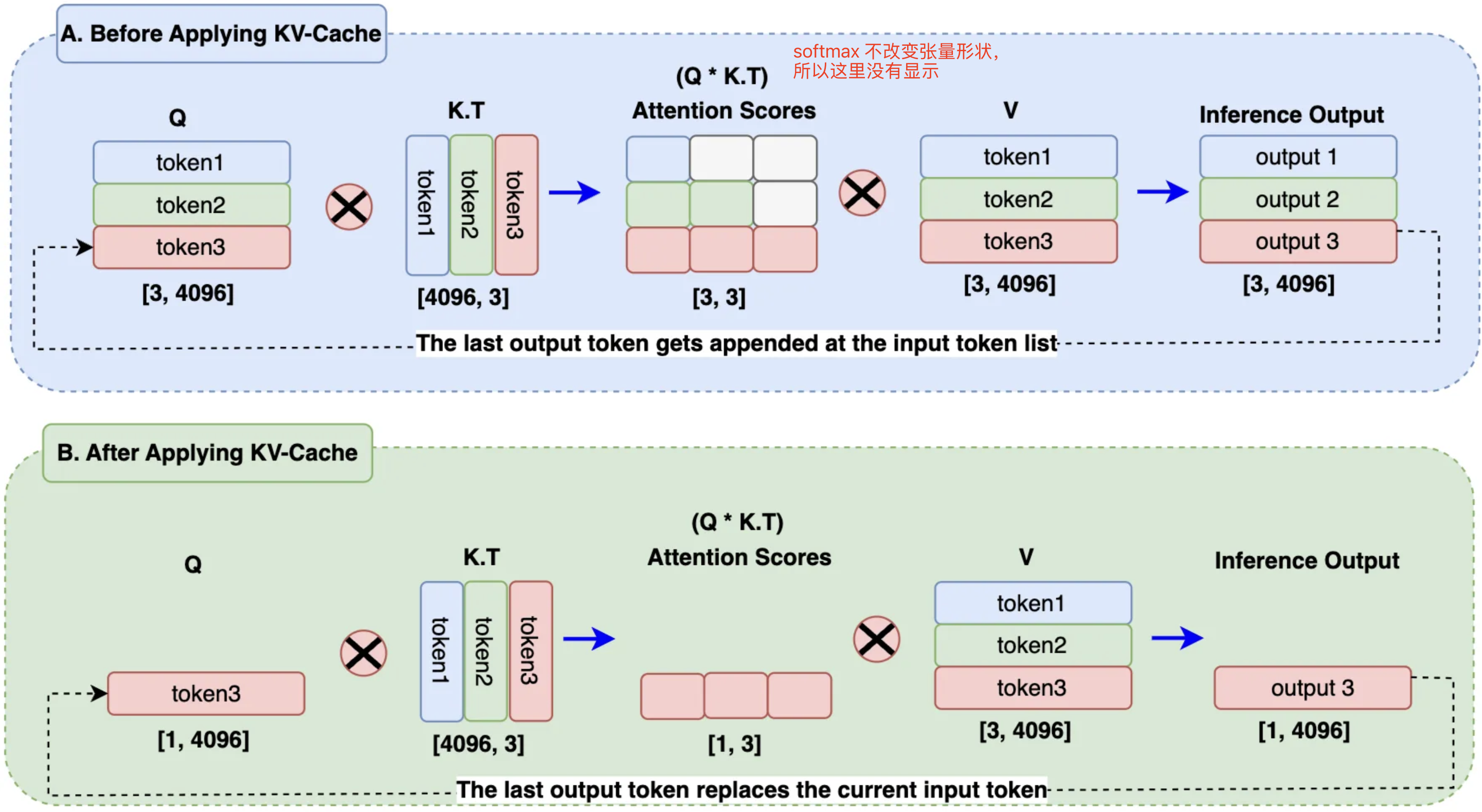
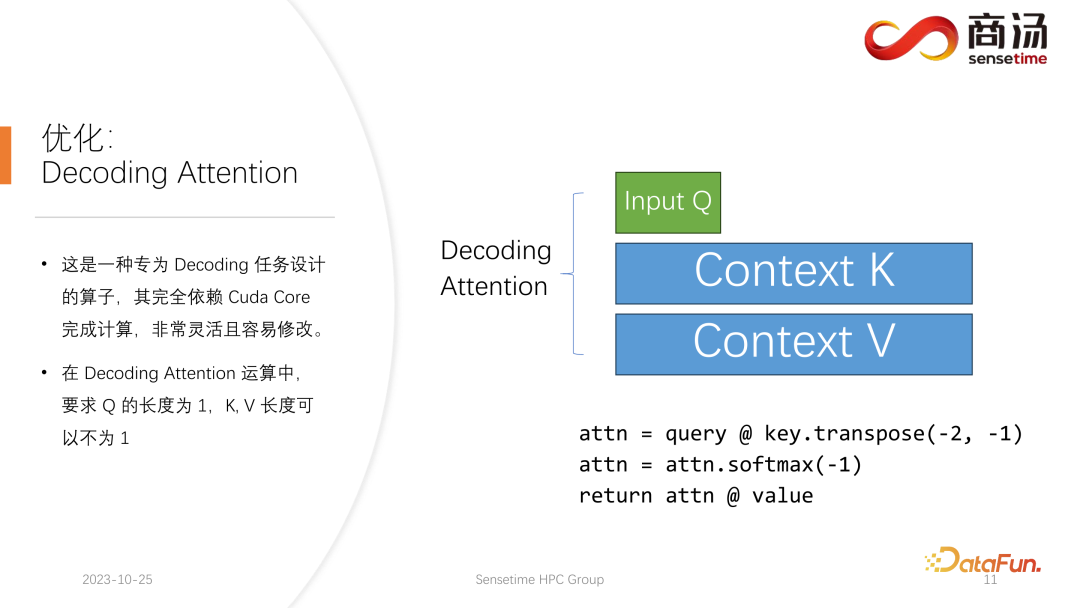
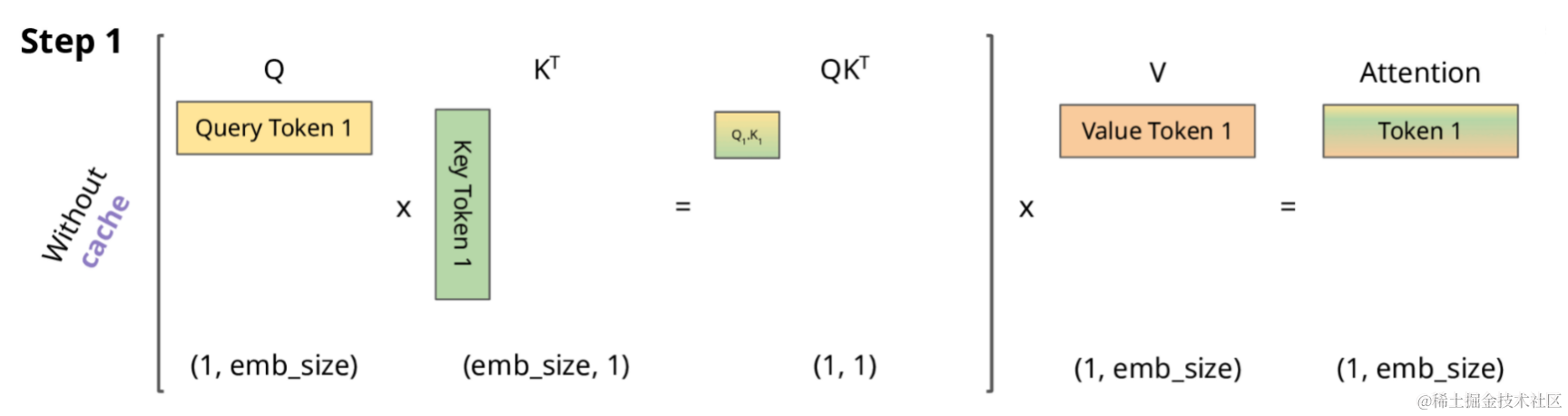
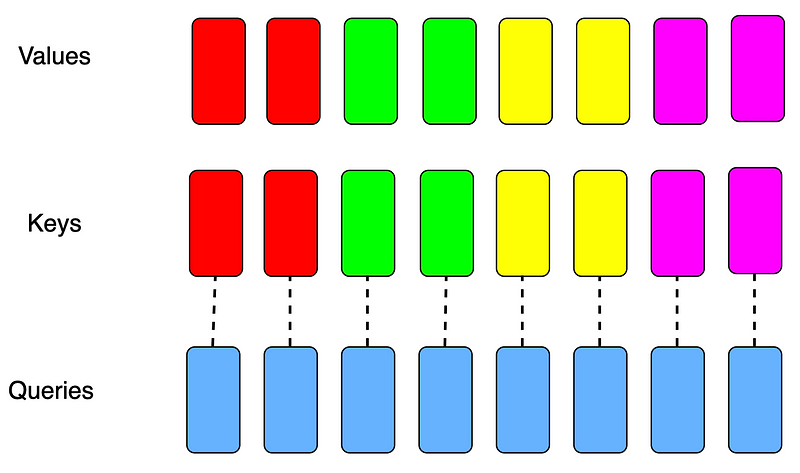
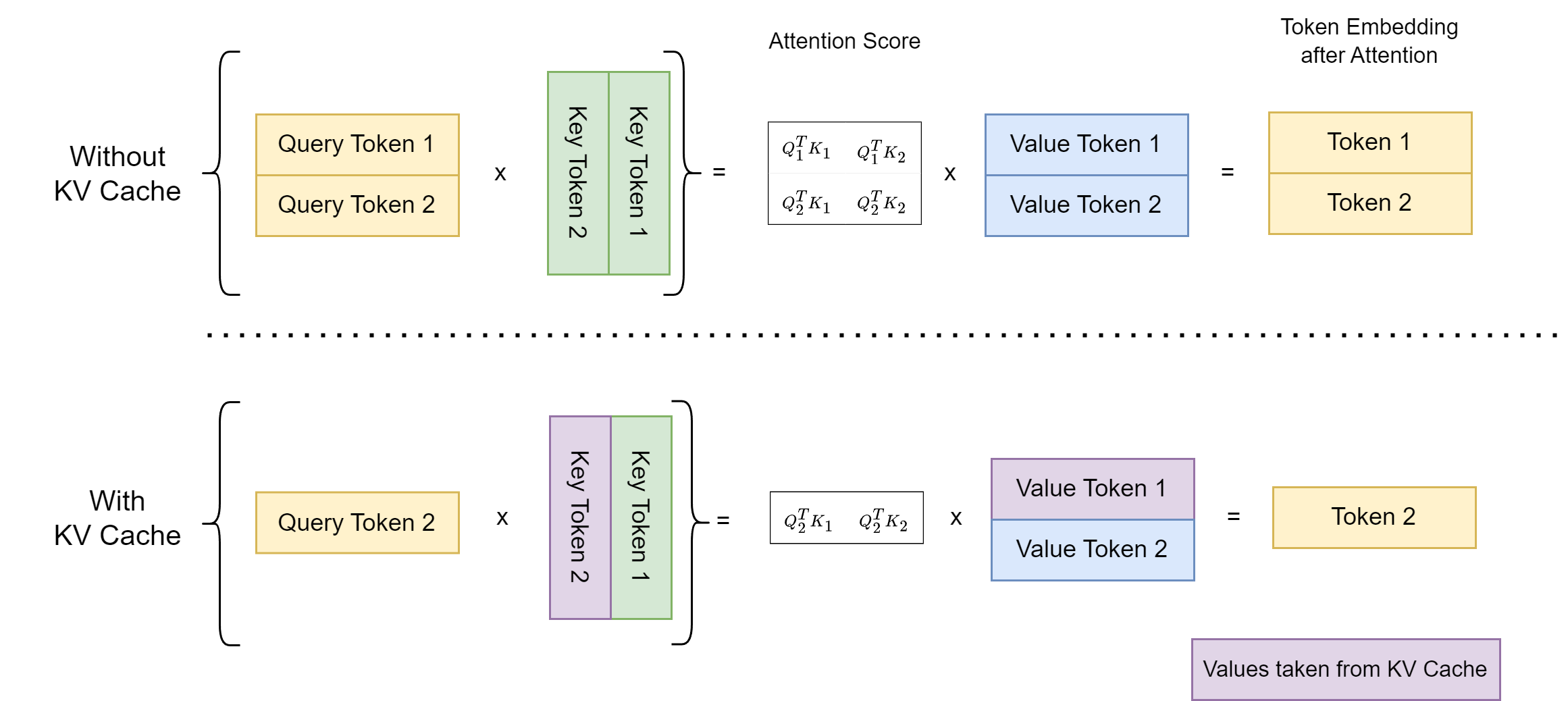
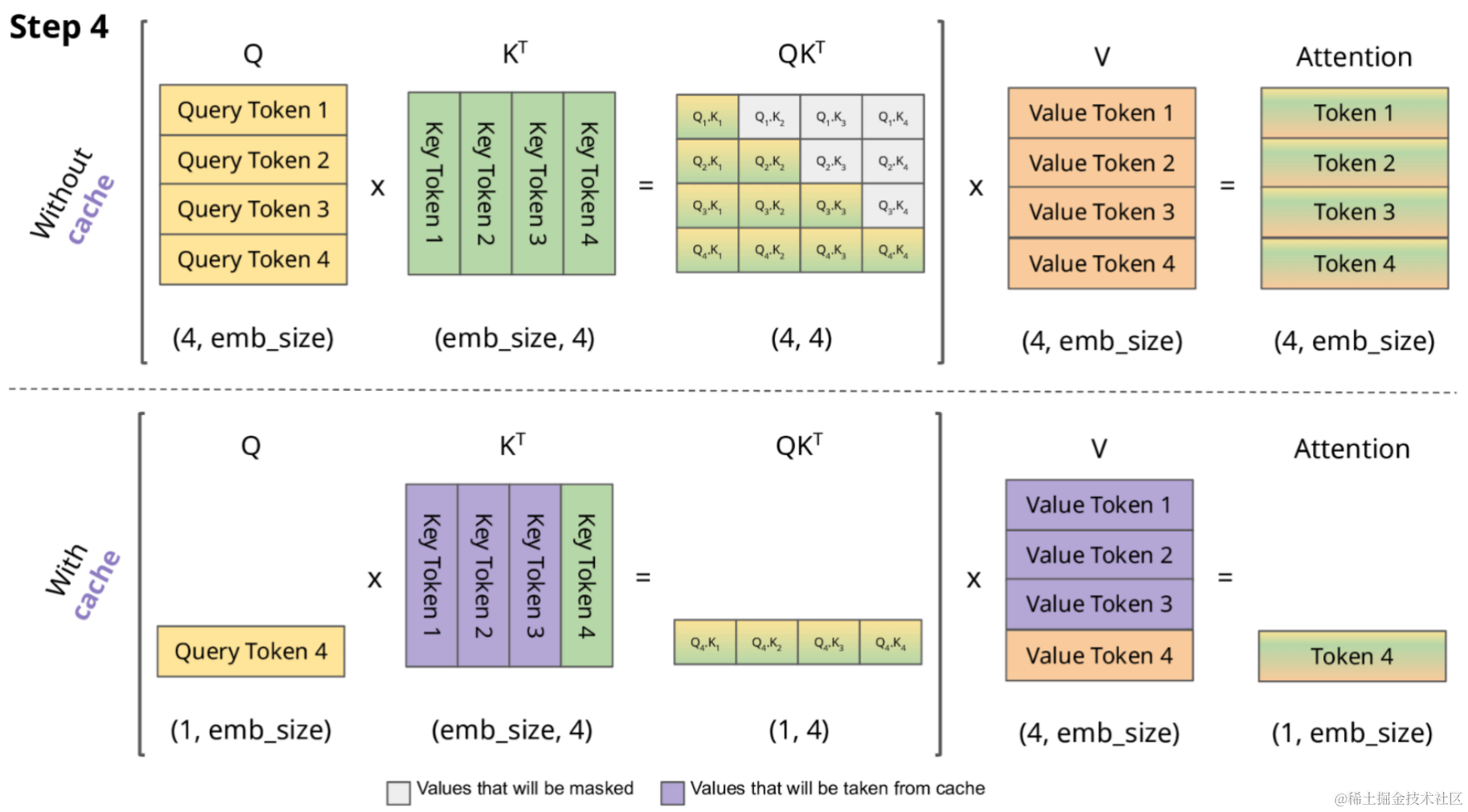
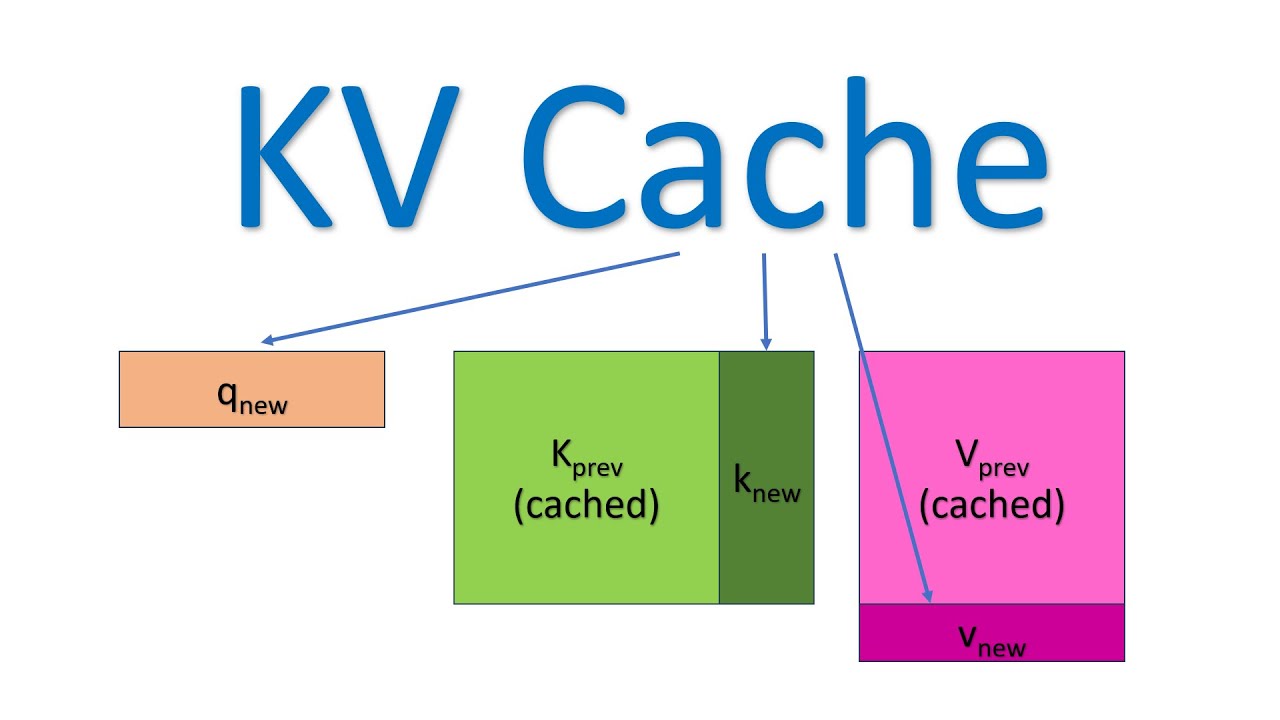
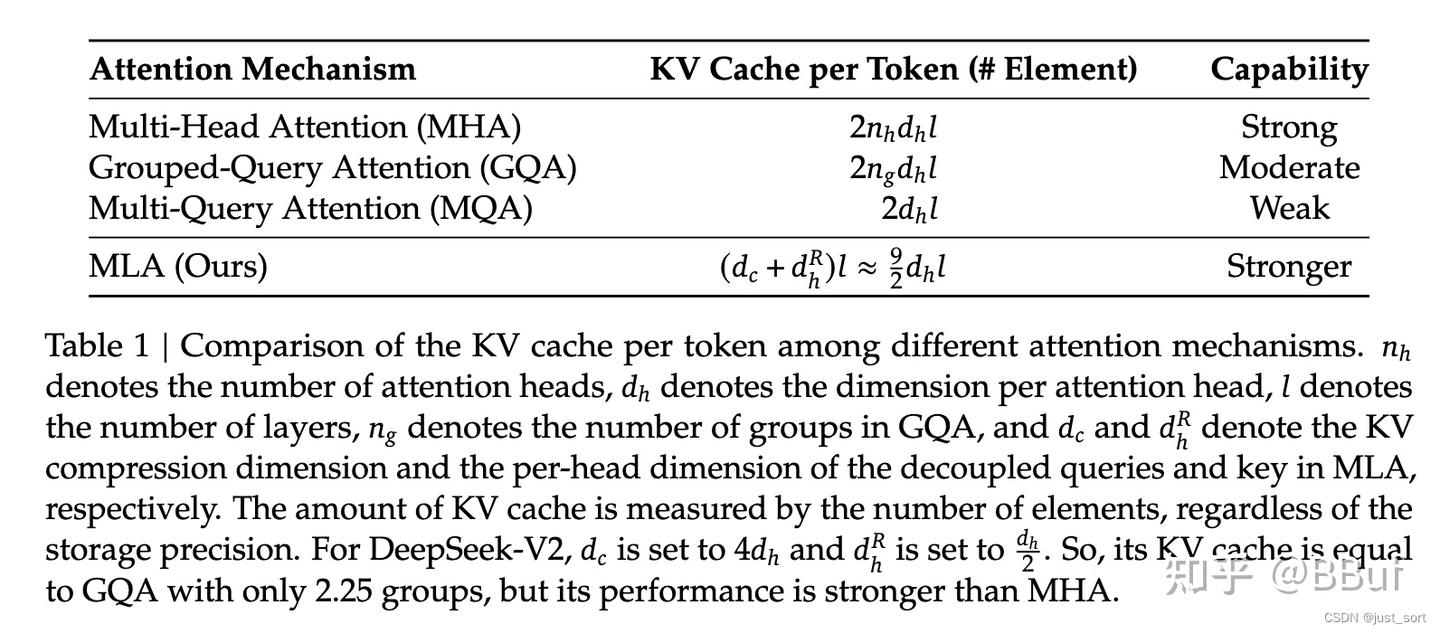
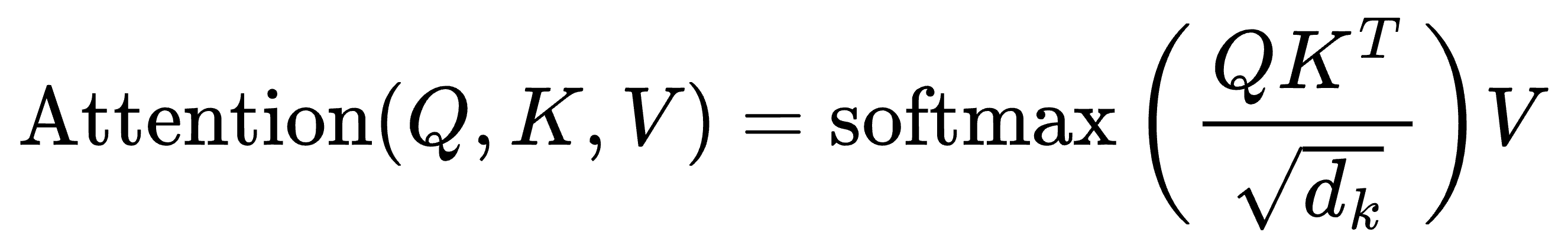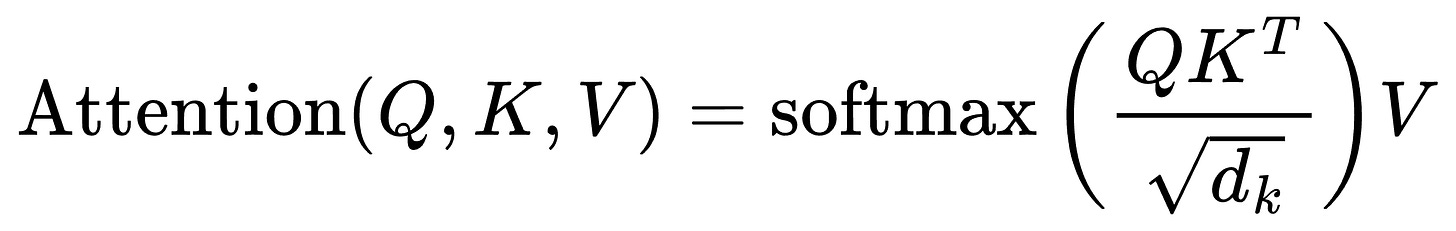Introduction to KV Cache Optimization Using Grouped Query Attention ...
How to implement Grouped Query Attention (GQA) for Llama2 | Thinam ...
KV cache optimization with paged attention · Issue #27303 · huggingface ...
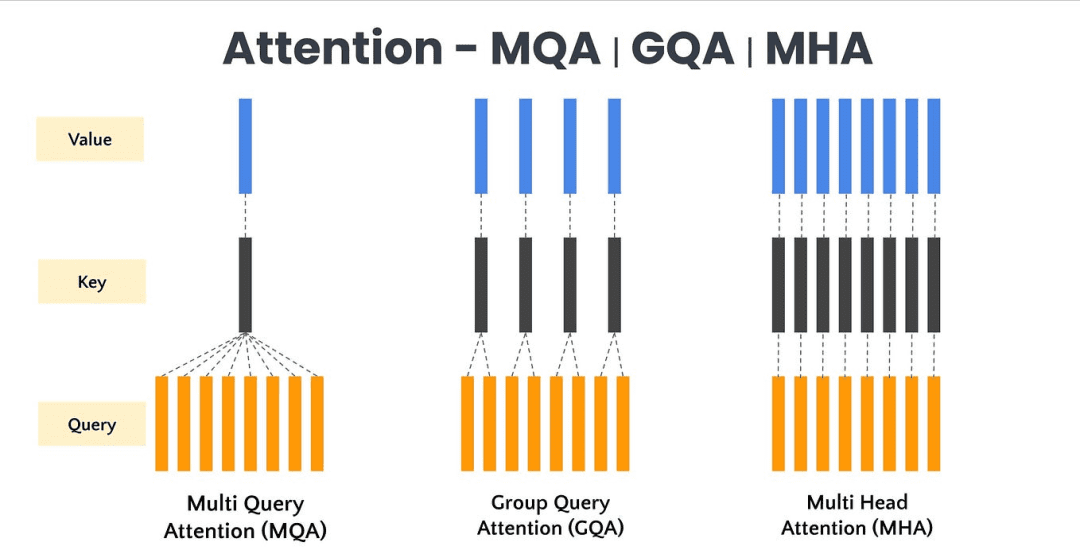
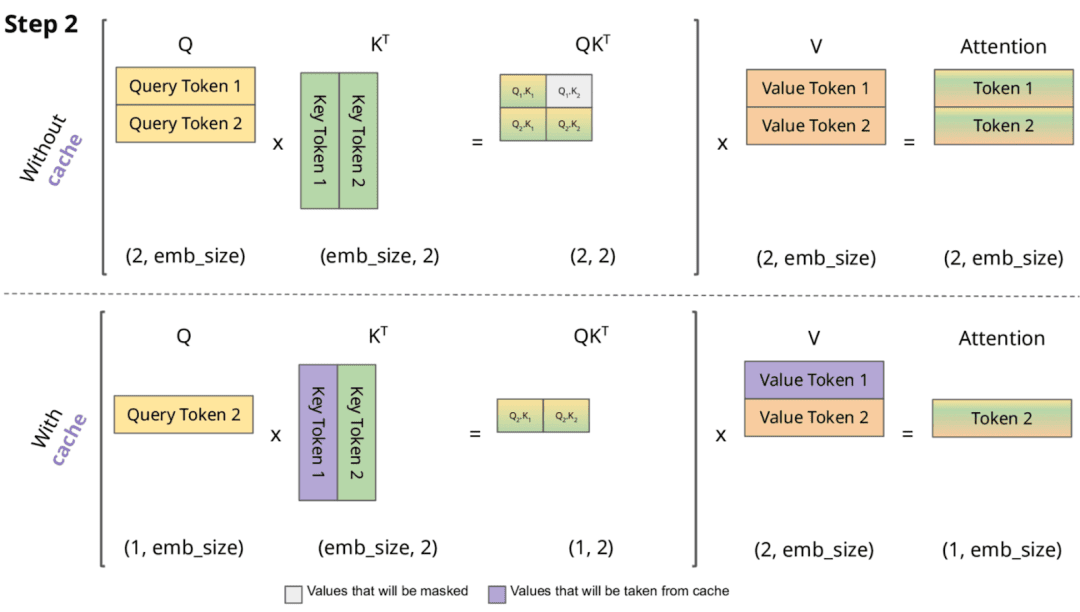
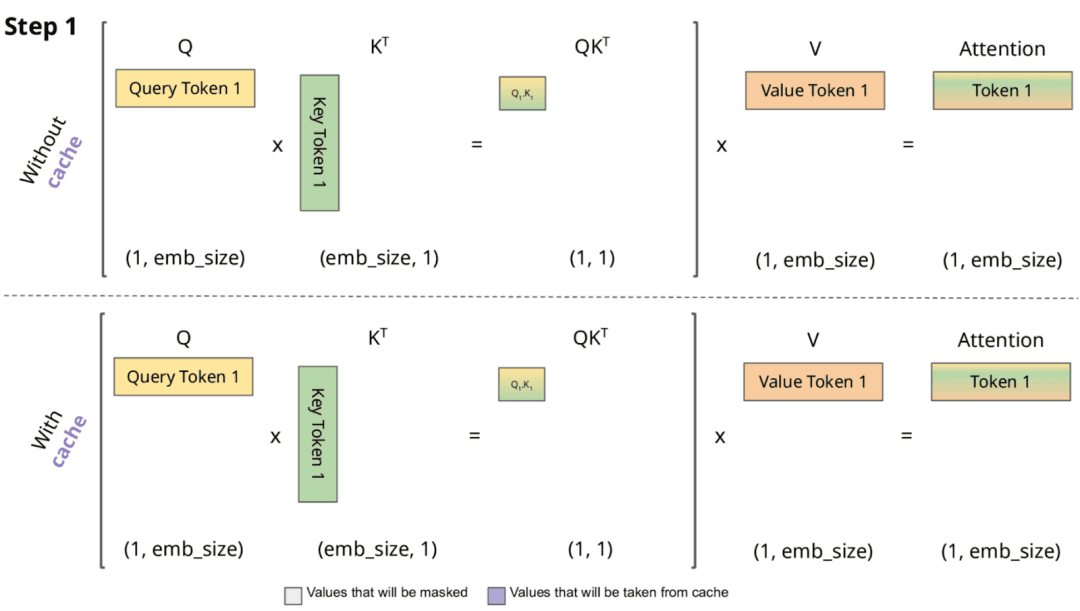
Understanding Llama2: KV Cache, Grouped Query Attention, Rotary ...
KV Cache Optimization via Tensor Product Attention - PyImageSearch
LLM 推理的 Attention 计算和 KV Cache 优化:PagedAttention、vAttention 等_paged ...
Understanding KV Cache and Paged Attention in LLMs: A Deep Dive into ...
Multi-Query Attention Explained | Dealing with KV Cache Memory Issues ...
UX - SimLayerKV: An Efficient Solution to KV Cache Challenges in Large ...
Expected Attention: KV Cache Compression by Estimating Attention from ...
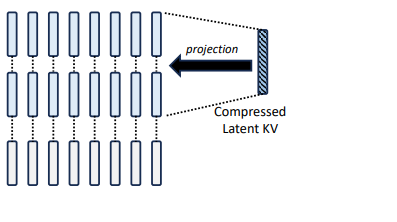
KV Cache Optimization via Multi-Head Latent Attention - PyImageSearch
Demystifying GQA — Grouped Query Attention for Efficient LLM Pre ...
Introduction to KV Cache Transmission — TensorRT LLM
How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo | NVIDIA ...
PureKV: Plug-and-Play KV Cache Optimization with Spatial-Temporal ...
KV Cache Explained: Efficient Attention for LLM Generation ...
Coding LLaMA 2 from scratch in PyTorch - KV Cache, Grouped Query ...
Everything about Model Inference -2. KV Cache Optimization | by ScitiX ...
Attention Mechanism 최적화와 KV Cache 계산 | Jongsu Liam Kim | Blog
Techniques for KV Cache Optimization in Large Language Models
Welcome to my blog! - Understanding KV Cache
KV Cache in Large Language Models: Design, Optimization, and Inference ...
What is Grouped Query Attention (GQA)? — Klu
Introducing New KV Cache Reuse Optimizations in NVIDIA TensorRT-LLM ...
Caching Strategies for LLM Systems (Part 2): KV Cache and the ...
How To Use KV Cache Quantization for Longer Generation by LLMs - YouTube
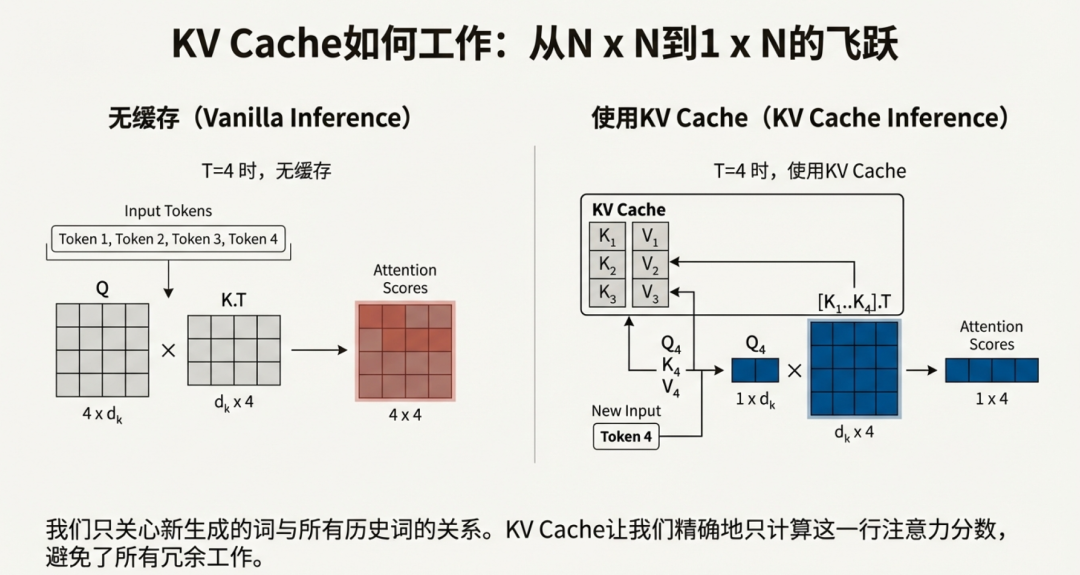
LLM inference optimization (1): KV Cache - MartinLwx's Blog
Architectures of Efficiency: A Comprehensive Analysis of KV Cache ...
Paper page - AKVQ-VL: Attention-Aware KV Cache Adaptive 2-Bit ...
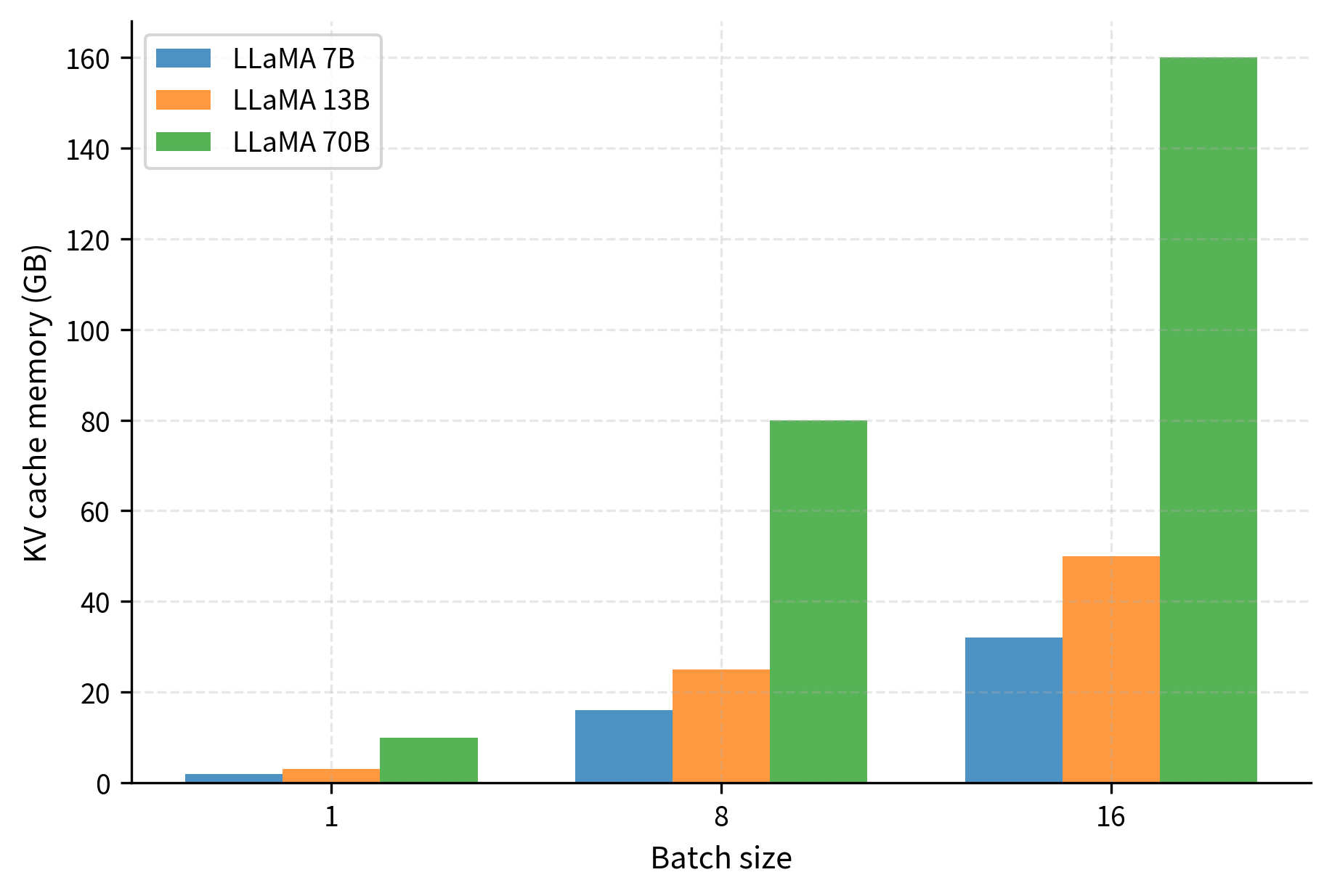
KV Cache Memory: Calculating GPU Requirements for LLM Inference ...
Layer-Condensed KV Cache for Efficient Inference of Large Language ...
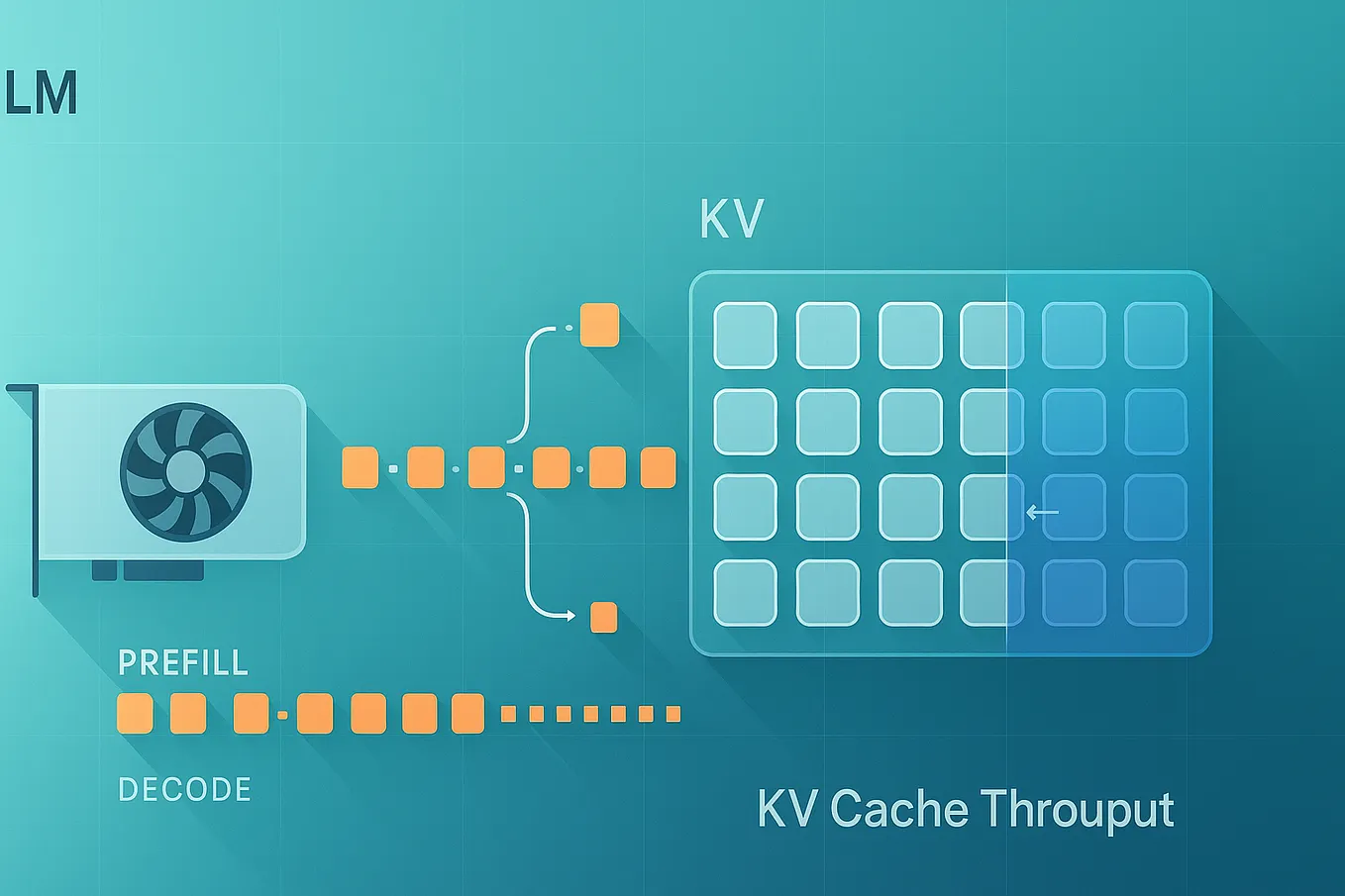
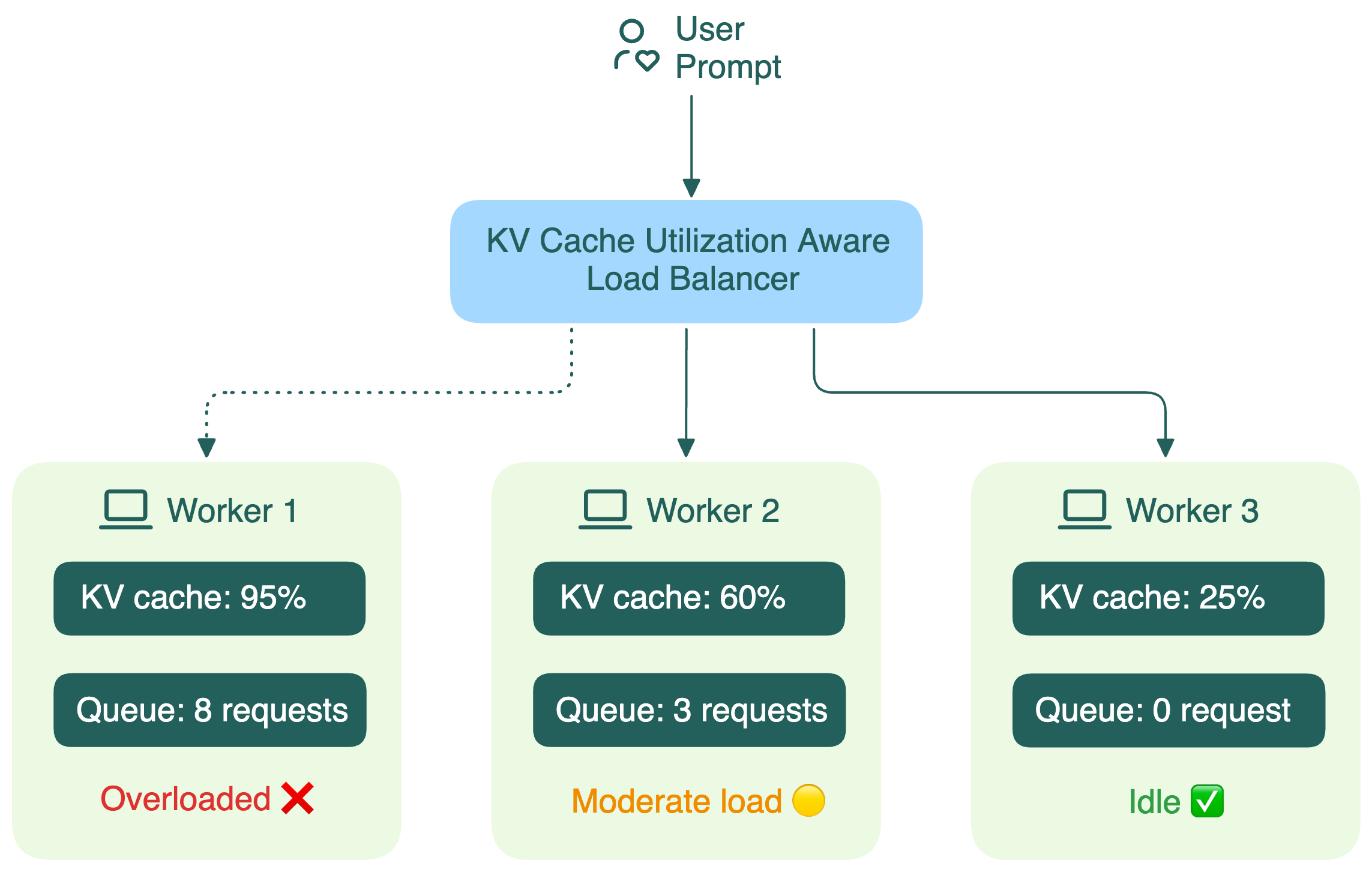
KV cache utilization-aware load balancing | LLM Inference Handbook
What is a KV cache, and why does it make LLM inference faster ...
KV Cache Secrets: Boost LLM Inference Efficiency | by Shoa Aamir | Medium
KV Cache: The Hidden Optimization Behind Real-Time AI Responses
What is grouped-query attention (GQA), and why do many modern LLMs use ...
Multi-Query Attention Explained. Multi-Query Attention (MQA) is a type ...
Understanding the KV Cache - KV Cache in LLMs - KV Cache in LLMs
This AI Paper from China Introduces KV-Cache Optimization Techniques ...
【必学收藏】从零理解大模型推理优化:KV Cache与Grouped-Query Attention实战解析_multi-query ...
Understanding Grouped-Query Attention: A Practical Guide with PyTorch ...
LLM推理流程--KV Cache与Group Query Attention(GQA) - 知乎
Efficient AI: KV Caching and KV Sharing | Gaurav's Blog
大模型推理优化之 KV Cache_kvcache-CSDN博客
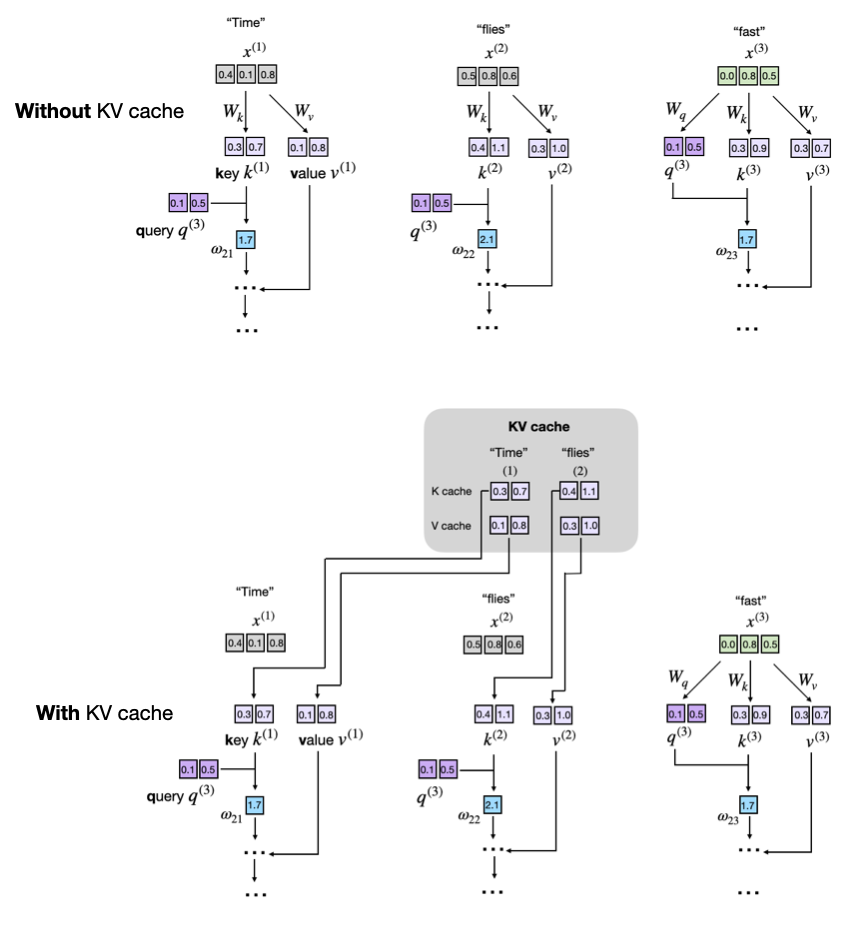
KV Caching in LLMs, Explained Visually. - by Avi Chawla
KV Caching in LLMs, explained visually
KV Caching Illustrated | Kapil Sharma
KV Caching Explained: Optimizing Transformer Inference Efficiency
Understanding KV-Cache - The Core Acceleration Technology for LLM ...
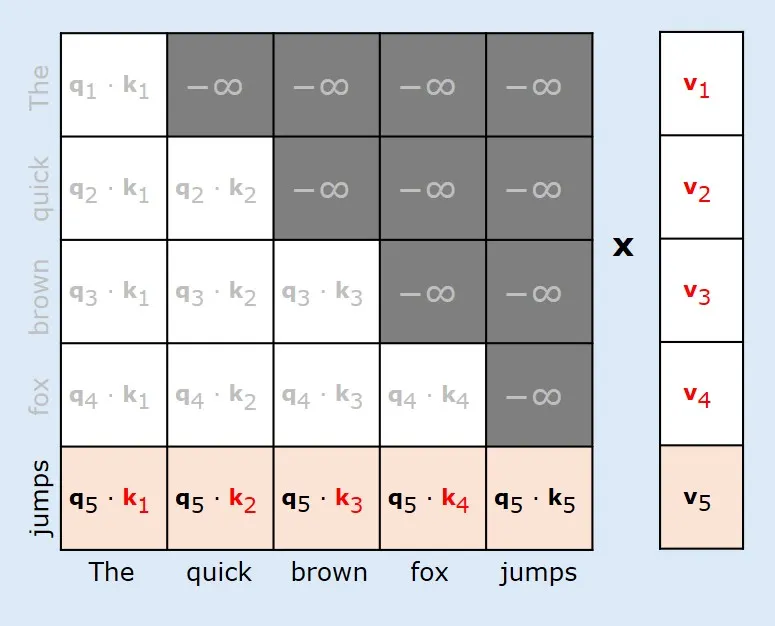
Demystifying Sparse Attention: A Comprehensive Guide from Scratch | by ...
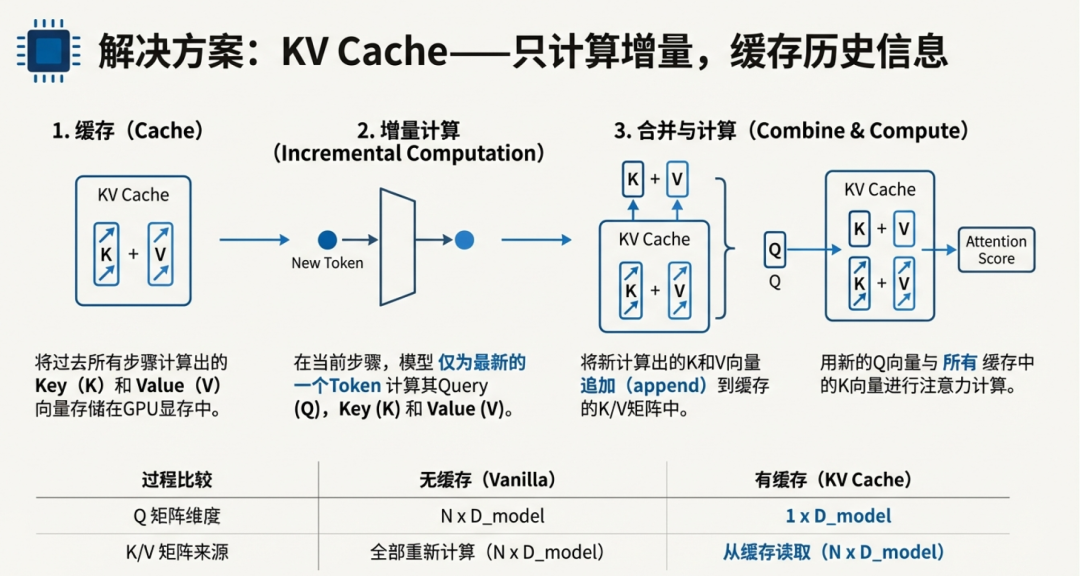
LLM - Generate With KV-Cache 图解与实践 By GPT-2_llm kv cache-CSDN博客
How KV Caching Makes Modern LLMs Fast?
KV caching explained-CSDN博客
KV Cache的原理与实现_kuiperllama-CSDN博客
How KV Caching Works in Large Language Models | MatterAI Blog
KV Cache:图解大模型推理加速方法_kvcache图解-CSDN博客
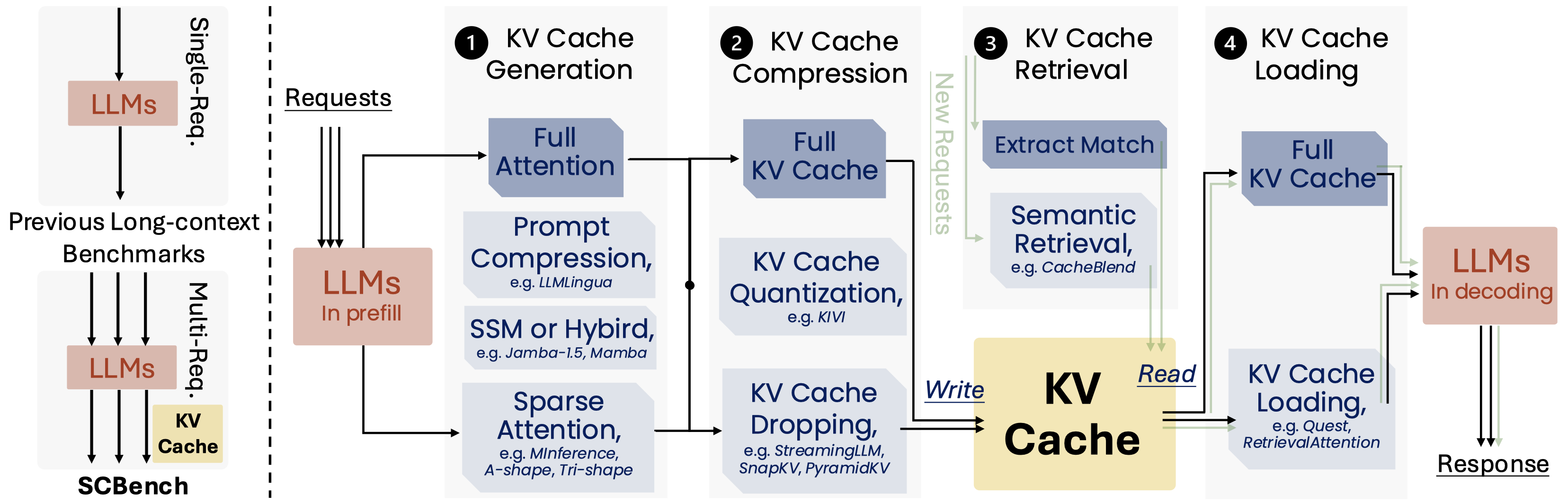
SCBench: A KV Cache-Centric Analysis of Long-Context Methods
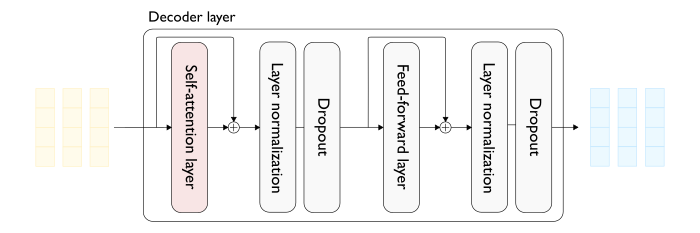
LLaMA explained: KV-Cache, Rotary Positional Embedding, RMS Norm ...
Optimizing Inference for Long Context and Large Batch Sizes with NVFP4 ...
KV Caches and Time-to-First-Token: Optimizing LLM Performance
LLM推理优化笔记1:KV cache、Grouped-query attention等-CSDN博客
kv-cache 原理及优化概述 - Zhang
大模型推理优化技术-KV Cache_大模型kv cache-CSDN博客
Grouped-Query Attention(GQA) Explained - by Florian June
20. Inference Acceleration (WIP) — LLM Foundations
Mastering Long Contexts in LLMs with KVPress
GPU memory requirements for serving Large Language Models | UnfoldAI
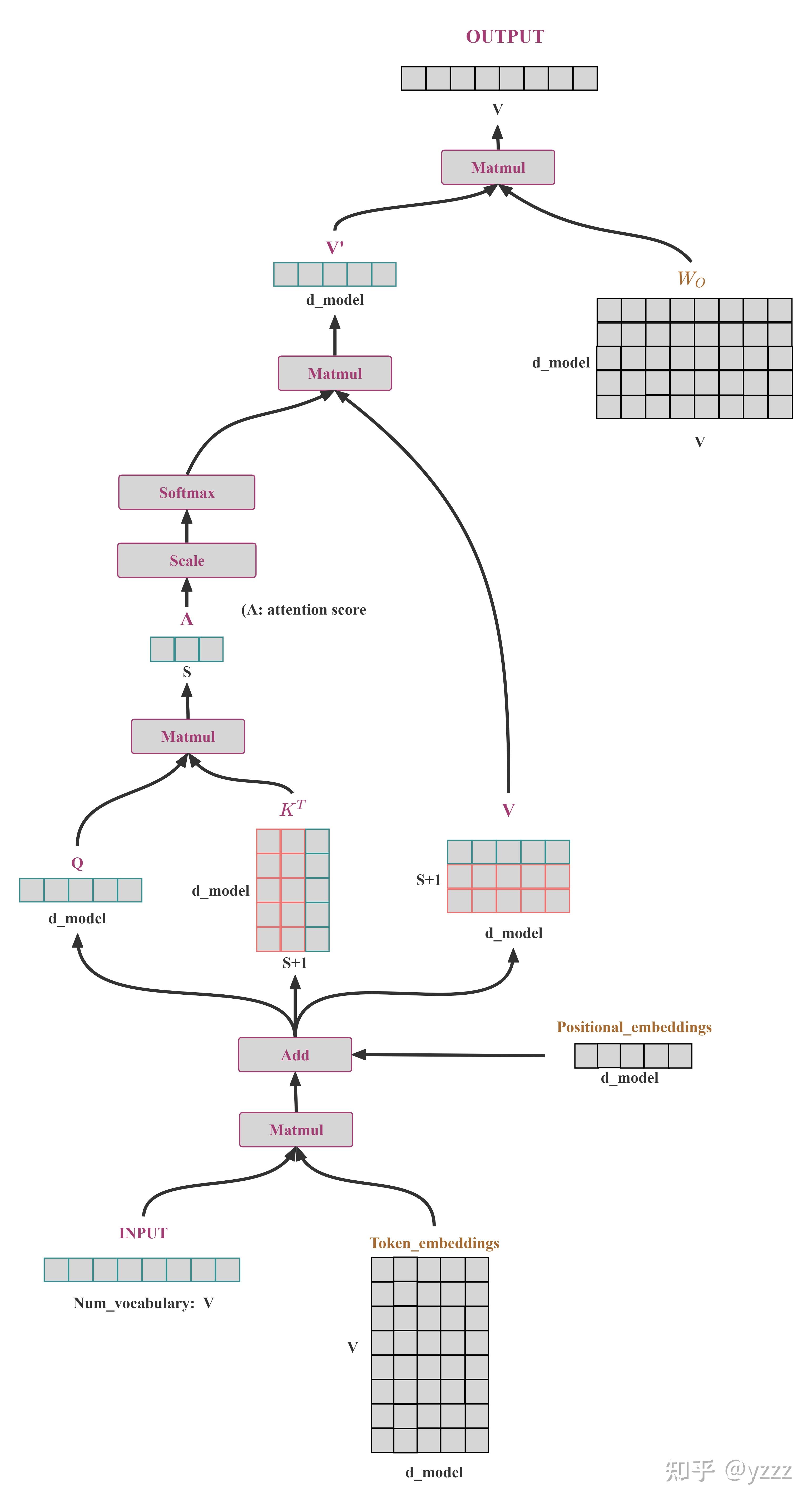
大模型KV Cache节省神器MLA学习笔记(包含推理时的矩阵吸收分析) - 知乎
LLM推理加速:kv cache优化方法汇总 - 知乎
大模型百倍推理加速之KV cache篇 - 知乎