期刊影响因子2024/2025: ACM Transactions on Architecture and Code Optimization ...
ACM TRANSACTIONS ON ARCHITECTURE AND CODE OPTIMIZATION - SCI期刊点评 - 小木虫 ...
ACM TRANSACTIONS ON ARCHITECTURE AND CODE OPTIMIZATION Home
As-Is Approximate Computing | ACM Transactions on Architecture and Code ...
ACM TRANSACTIONS ON ARCHITECTURE AND CODE OPTIMIZATION-国际合作SCI期刊源_IASRS ...
Scale-out Systolic Arrays | ACM Transactions on Architecture and Code ...
ACM Transactions on Architecture and Code Optimization(ACM架构和代码优化汇刊)杂志 ...
ACM Transactions on Architecture and Code Optimization
dblp: ACM Transactions on Architecture and Code Optimization (TACO)
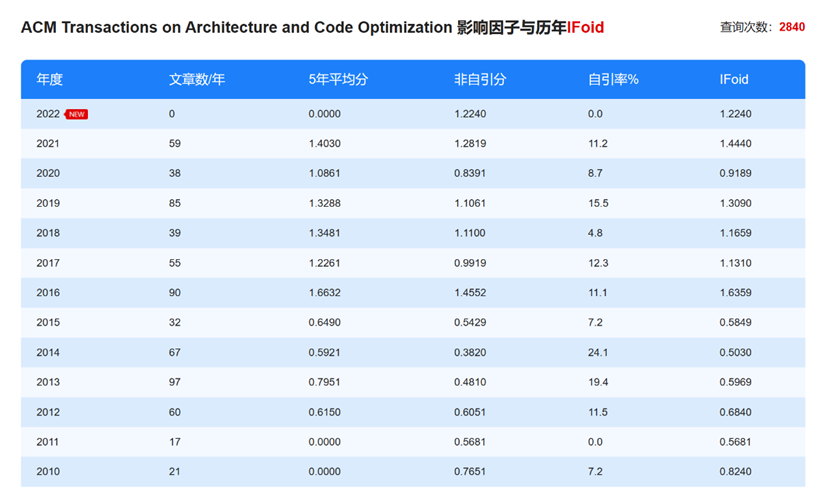
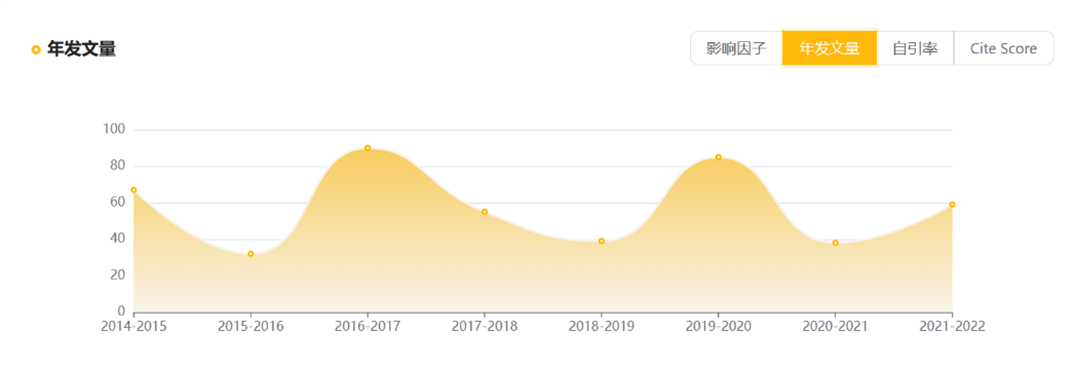
ACM Transactions on Architecture and Code Optimization_影响因子(IF)_中科院分区 ...
Acm Transactions On Architecture And Code Optimization-ACM T ARCHIT ...
ACM Transactions on Architecture and Code Optimization:SCI期刊介绍-刊鹿论文编译
GP-SIMD Processing-in-Memory | ACM Transactions on Architecture and ...
ACM Transactions on Architecture and Code Optimization_百度百科
Acm Transactions On Architecture And Code Optimization杂志-首页
SCI期刊推荐:ACM TRANSACTIONS ON ARCHITECTURE AND CODE OPTIMIZATION - 知乎
ACM Transactions on Software Engineering and Methodology Referencing ...
Acm Transactions On Architecture And Code Optimization_JCR分区Q2_首页
ACM Transactions on Graphics Referencing Guide · ACM Transactions on ...
FinPar: A Parallel Financial Benchmark: ACM Transactions on ...
List of distinguished reviewers ACM TACO | ACM Transactions on ...
IEEE/ACM Transactions on Networking Referencing Guide · IEEE/ACM ...
Improving WCET by applying a WC code-positioning optimization | ACM ...
Polyhedral Specification and Code Generation of Sparse Tensor ...
The Impact of Page Size and Microarchitecture on Instruction Address ...
COER: A Network Interface Offloading Architecture for RDMA and ...
ACM Transactions on Computer Systems怎么样
AOBO: A Fast-Switching Online Binary Optimizer on AArch64 | ACM ...
A Concise Concurrent B+-Tree for Persistent Memory | ACM Transactions ...
The Droplet Search Algorithm for Kernel Scheduling | ACM Transactions ...
Tiaozhuan: A General and Efficient Indirect Branch Optimization for ...
Network Interface Architecture for Remote Indirect Memory Access (RIMA ...
High-performance Deterministic Concurrency Using Lingua Franca | ACM ...
A Metric-Guided Method for Discovering Impactful Features and ...
Multiprogram Throughput Metrics: A Systematic Approach: ACM ...
A Case for a More Effective, Power-Efficient Turbo Boosting | ACM ...
HeapCheck: Low-cost Hardware Support for Memory Safety | ACM ...
Near-Optimal Microprocessor and Accelerators Codesign with Latency and ...
Improving System Energy Efficiency with Memory Rank Subsetting | ACM ...
Exploring the effects of on-chip thermal variation on high-performance ...
Using machine learning to partition streaming programs | ACM ...
SAC: An Ultra-Efficient Spin-based Architecture for Compressed DNNs ...
Architecting Optically Controlled Phase Change Memory | ACM ...
PANDA: Adaptive Prefetching and Decentralized Scheduling for Dataflow ...
Coherence Attacks and Countermeasures in Interposer-based Chiplet ...
Highly Efficient Self-checking Matrix Multiplication on Tiled AMX ...
Cost-aware Service Placement and Scheduling in the Edge-Cloud Continuum ...
Tyche: An Efficient and General Prefetcher for Indirect Memory Accesses ...
Autovesk: Automatic Vectorized Code Generation from Unstructured Static ...
Multi-objective Hardware-aware Neural Architecture Search with Pareto ...
ASA: Accelerating Sparse Accumulation in Column-wise SpGEMM | ACM ...
Source Matching and Rewriting for MLIR Using String-Based Automata ...
Accelerating Parallel Structures in DNNs via Parallel Fusion and ...
Rcmp: Reconstructing RDMA-Based Memory Disaggregation via CXL | ACM ...
Optimizing FPGA Routing with Explainable Co-Learning of Congestion and ...
Tumbler: An Effective Load-Balancing Technique for Multi-CPU Multicore ...
An analysis of on-chip interconnection networks for large-scale chip ...
Iterating Pointers: Enabling Static Analysis for Loop-based Pointers ...
High-Performance Generalized Tensor Operations: A Compiler-Oriented ...
Supporting Dynamic Program Sizes in Deep Learning-Based Cost Models for ...
ACTION: Adaptive Cache Block Migration in Distributed Cache ...
QoS-pro: A QoS-enhanced Transaction Processing Framework for Shared ...
Towards High Performance QNNs via Distribution-Based CNOT Gate ...
Potamoi: Accelerating Neural Rendering via a Unified Streaming ...
A Compilation Tool for Computation Offloading in ReRAM-based CIM ...
TransCL: An Automatic CUDA-to-OpenCL Programs Transformation Framework ...
An Optimized Cost Flow Algorithm to Spread Cells in Detailed Placement ...
Auth Rate Based Routing | Hyperswitch