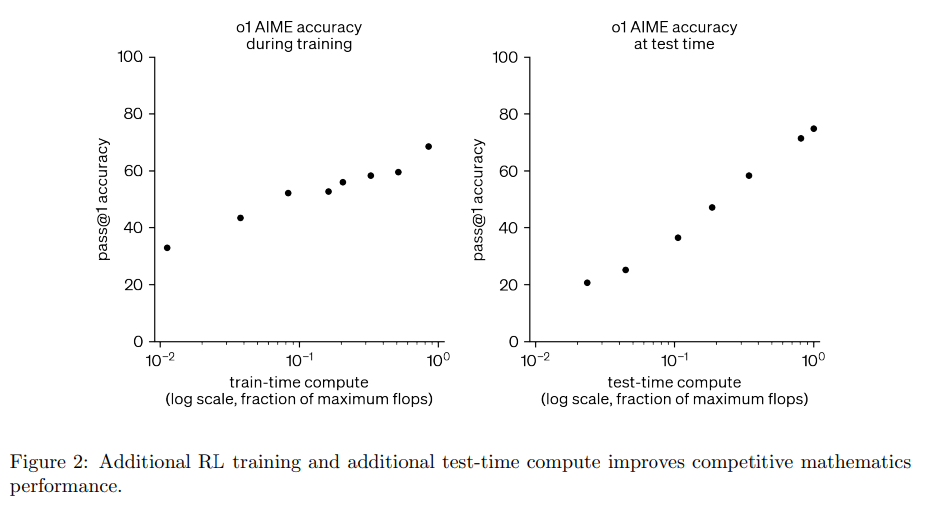
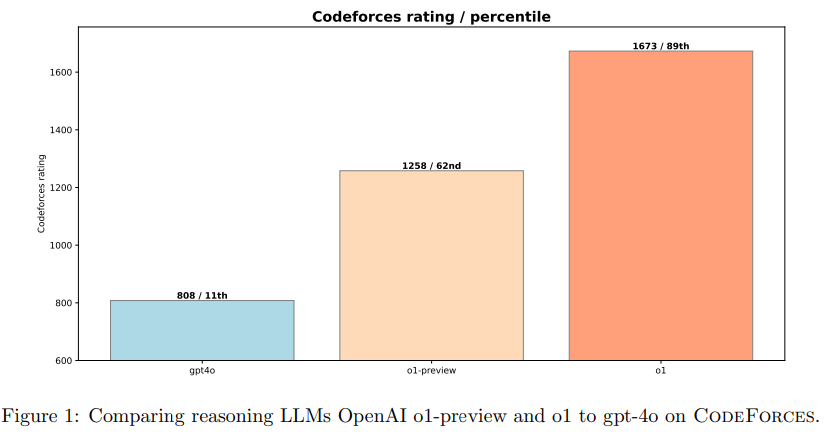
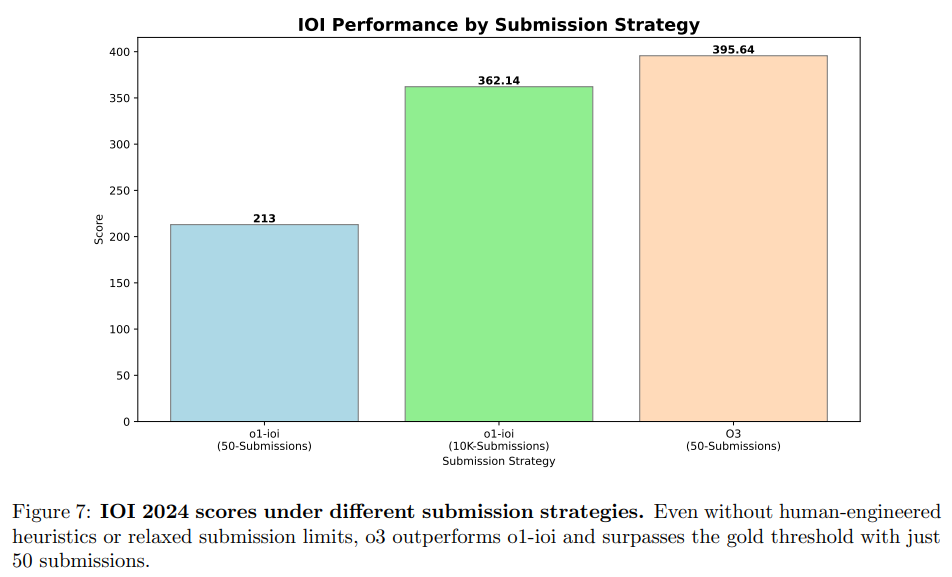
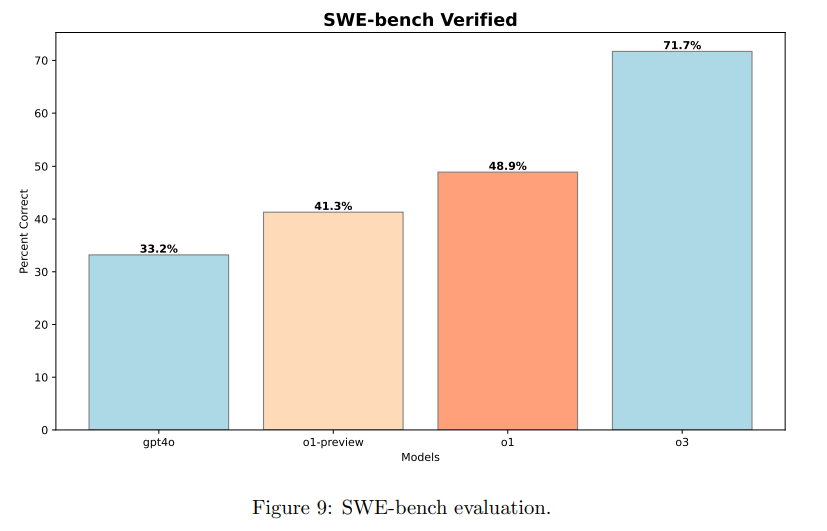
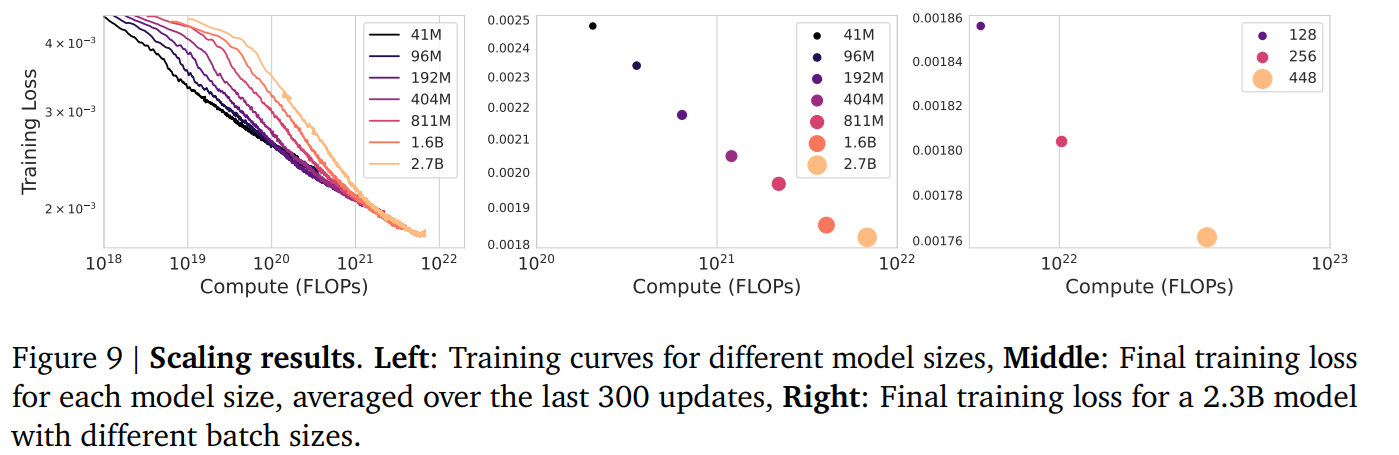
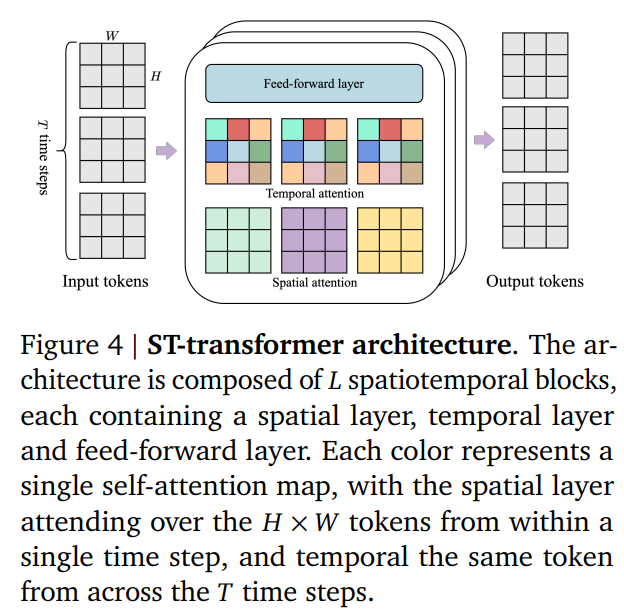
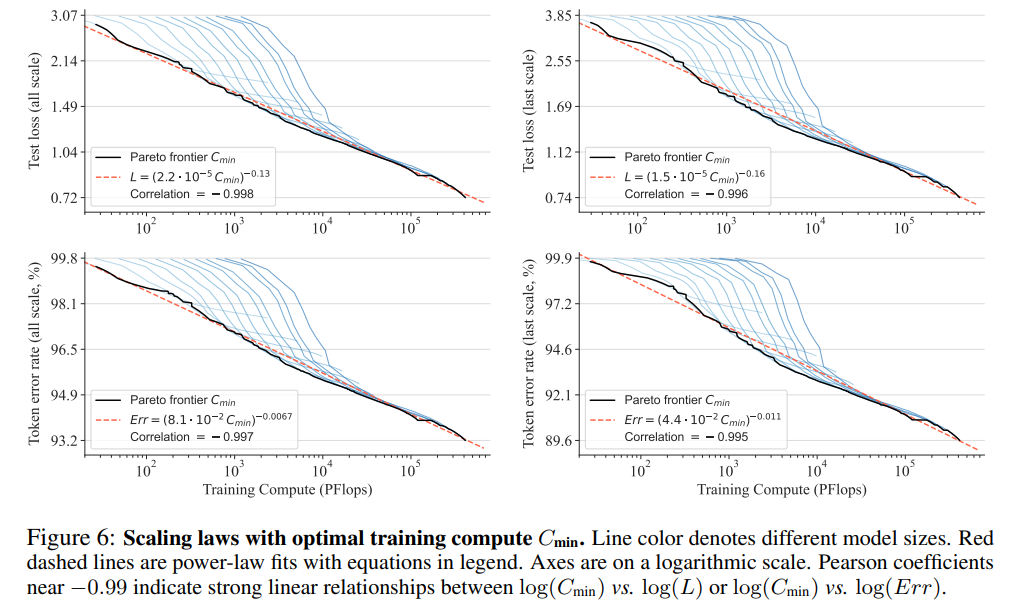
論文まとめ:Competitive Programming with Large Reasoning Models | Shikoan's ...
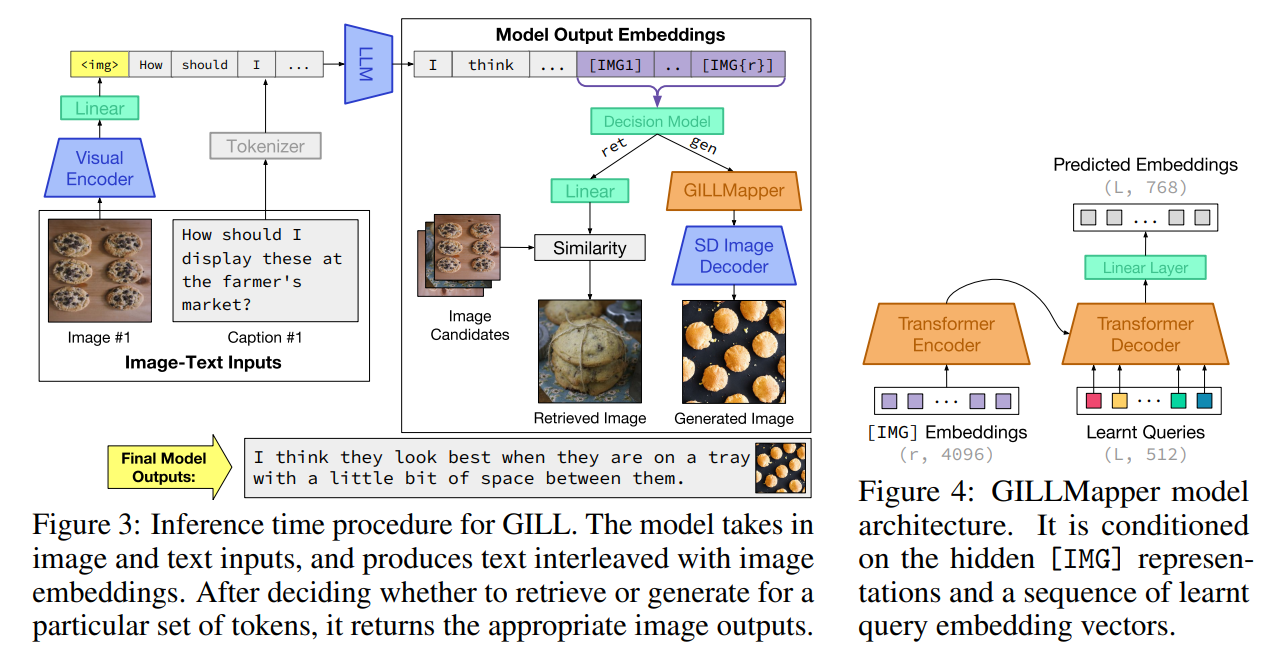
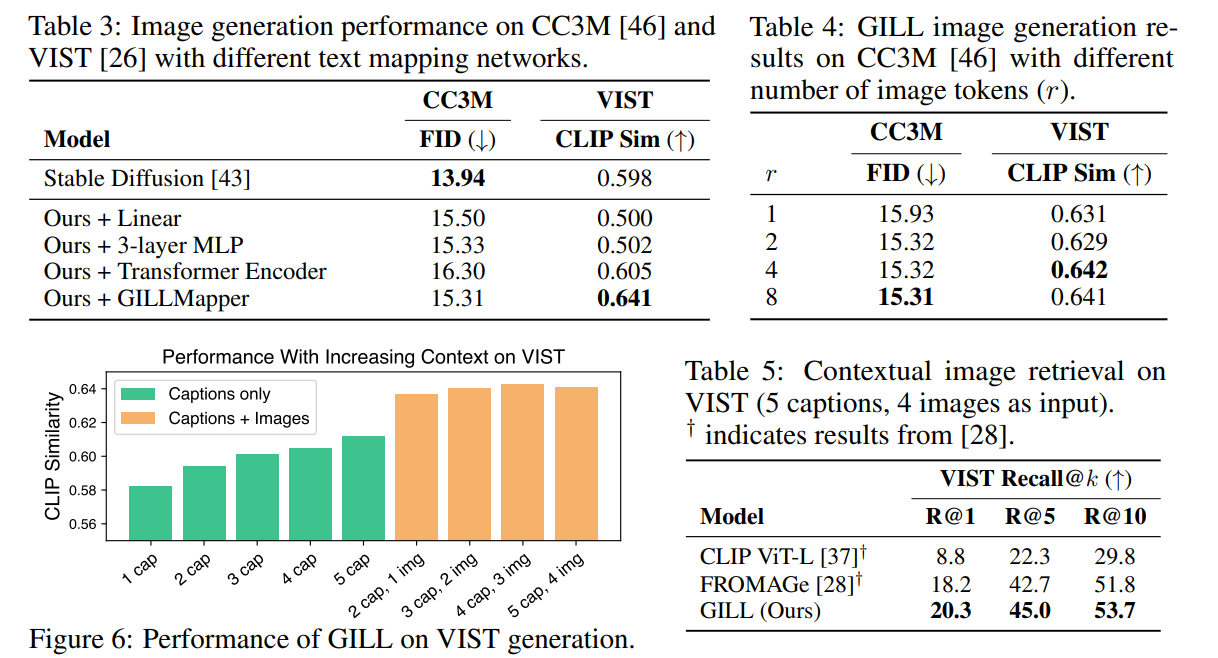
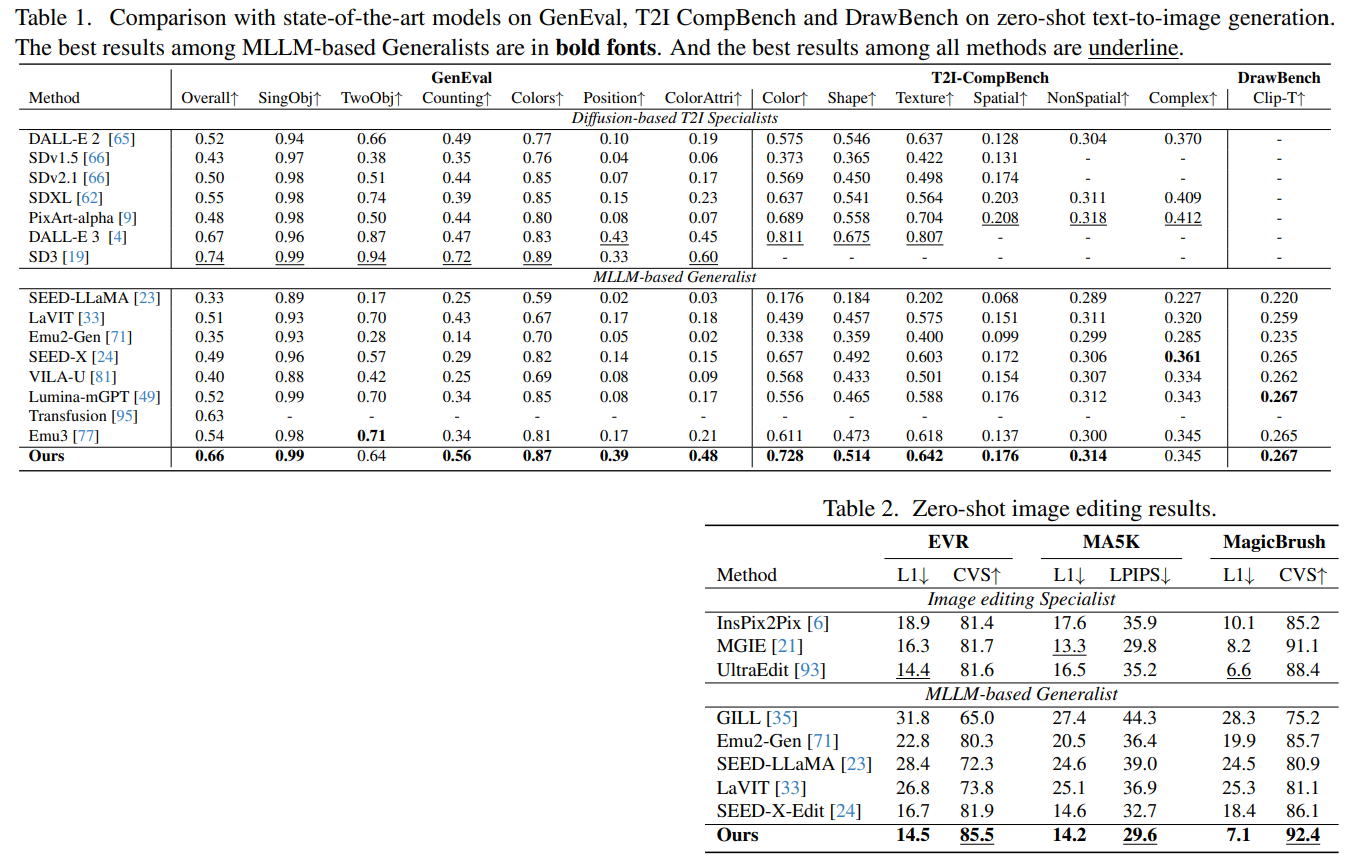
論文まとめ:Generating Images with Multimodal Language Models | Shikoan's ML Blog
論文まとめ:SOLAR 10.7B: Scaling Large Language Models with Simple yet ...
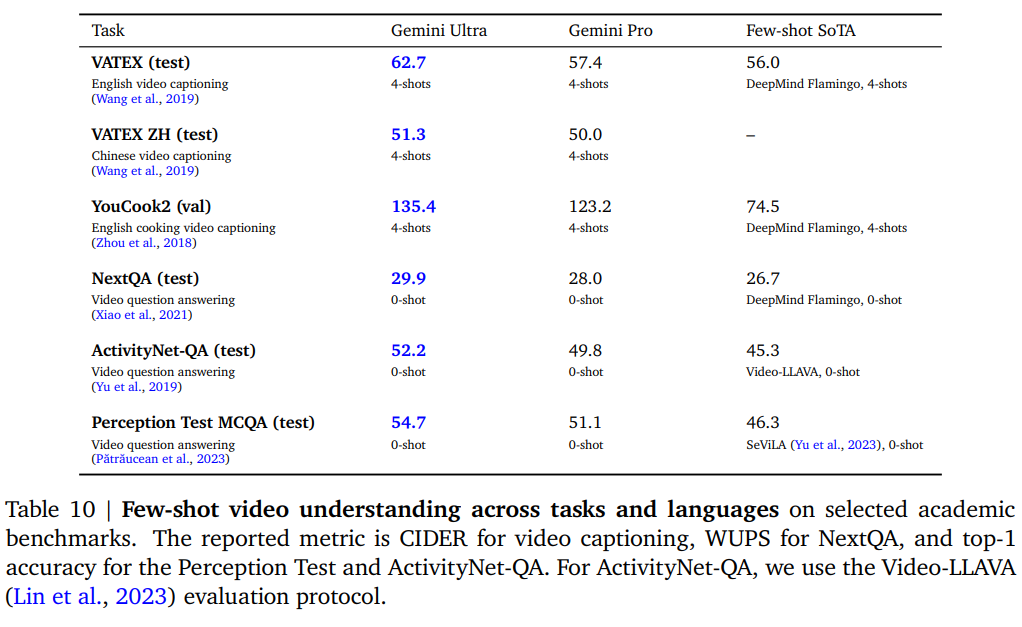
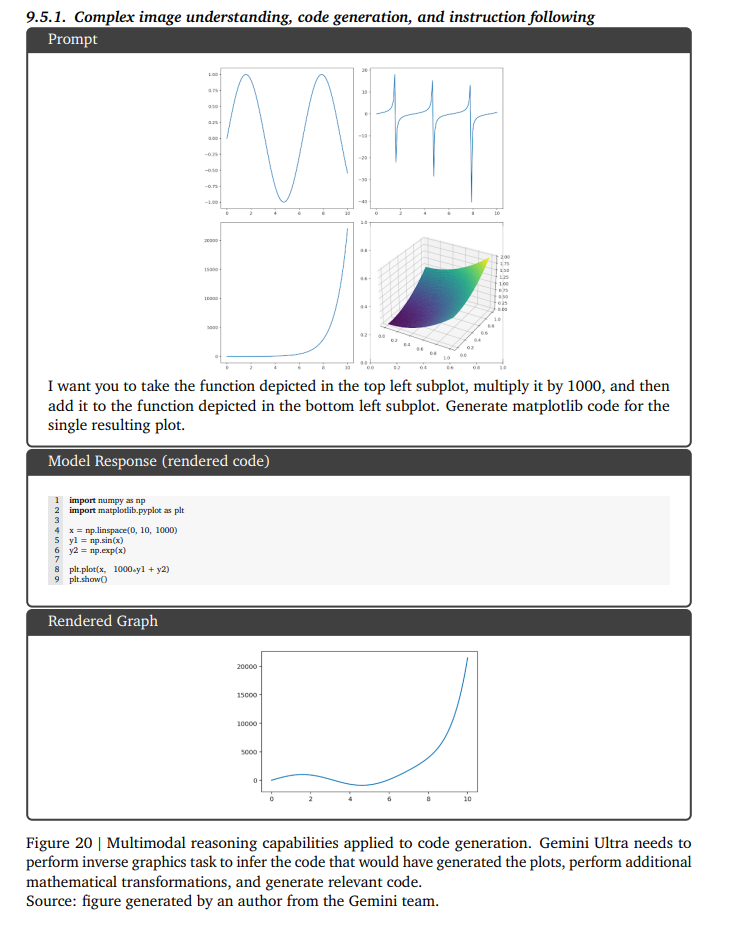
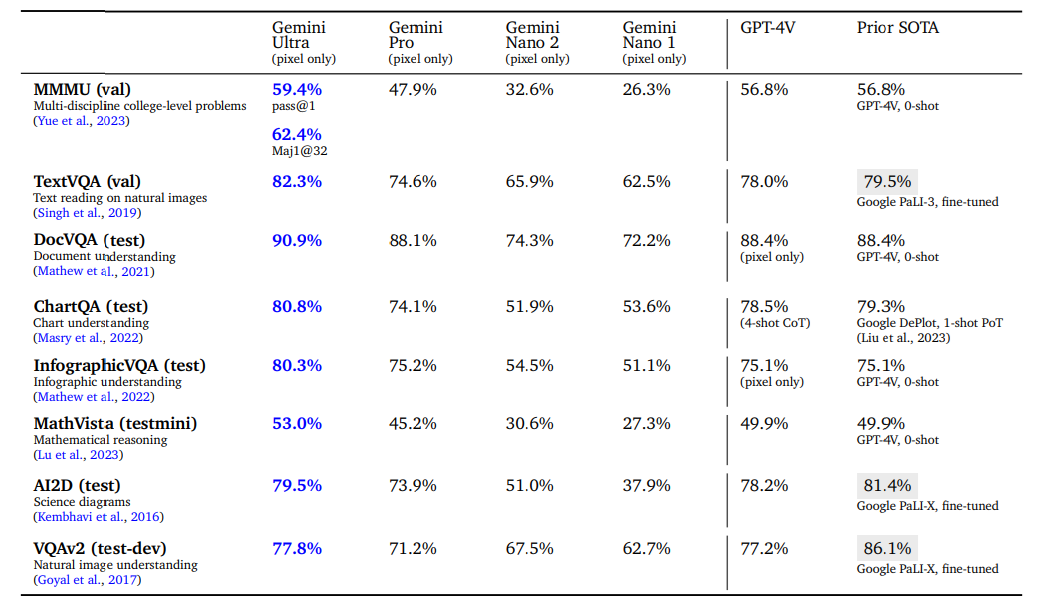
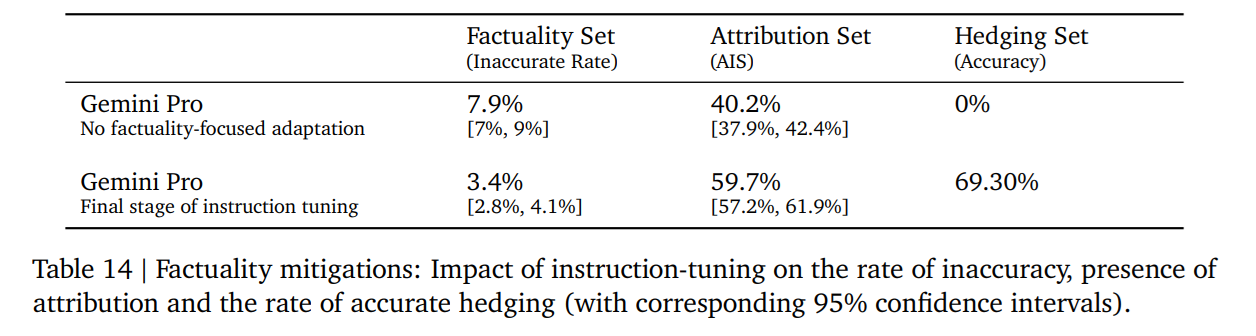
論文まとめ:Gemini: A Family of Highly Capable Multimodal Models | Shikoan's ...
Wan: Open and Advanced Large-Scale Video Generative Models | Shikoan's ...
論文まとめ:Sentence Simplification via Large Language Models | Shikoan's ML Blog
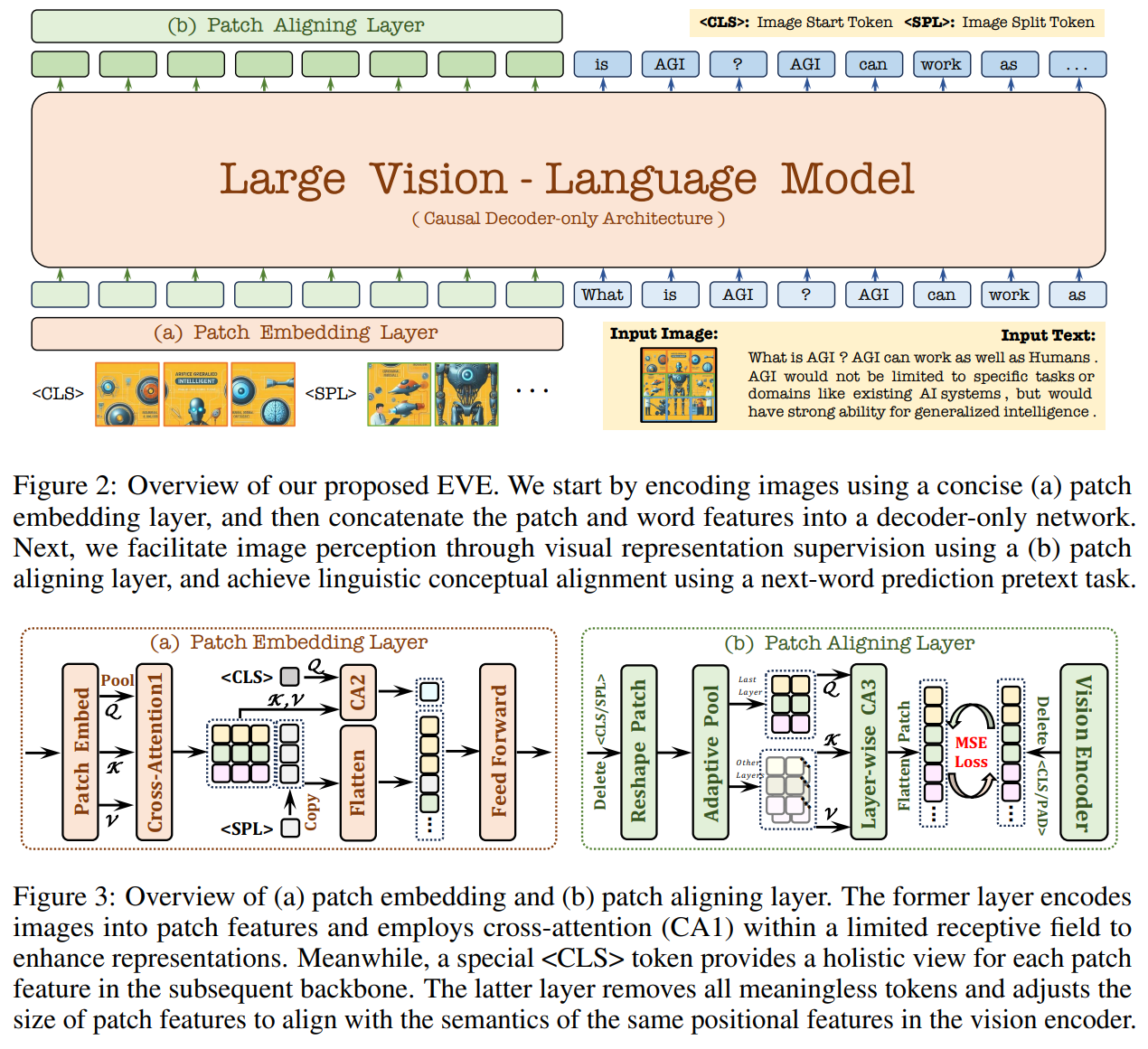
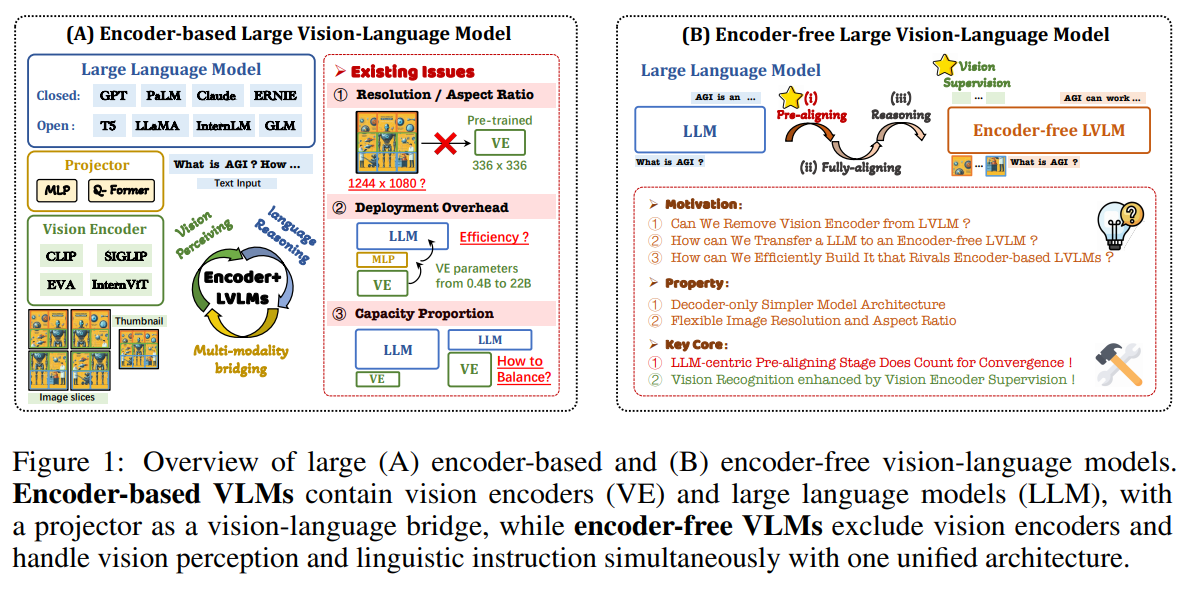
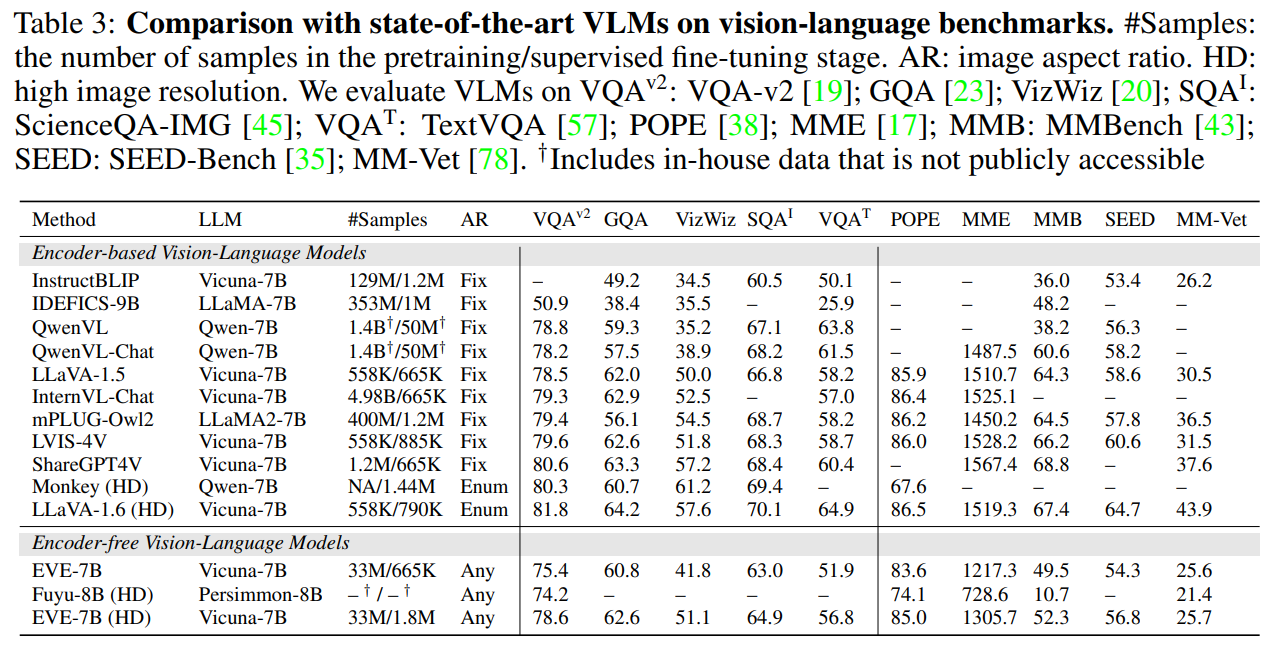
論文まとめ:Unveiling Encoder-Free Vision-Language Models | Shikoan's ML Blog
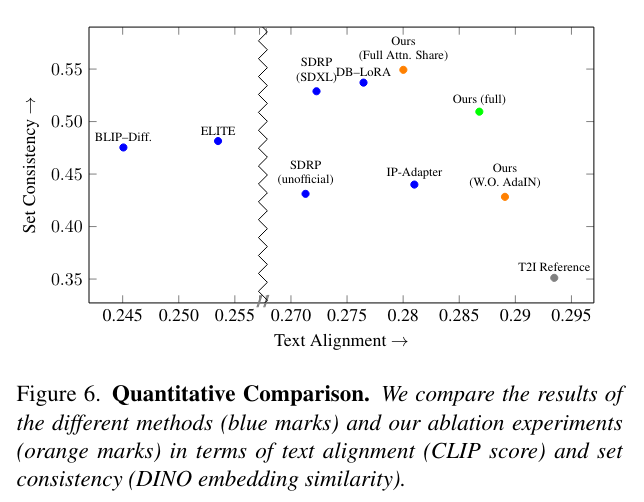
論文まとめ:Style Aligned Image Generation via Shared Attention | Shikoan's ...
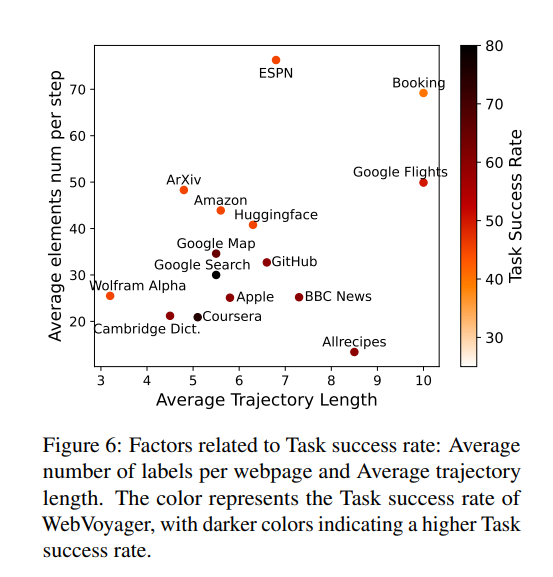
論文まとめ:WebVoyager: Building an End-to-End Web Agent with Large ...
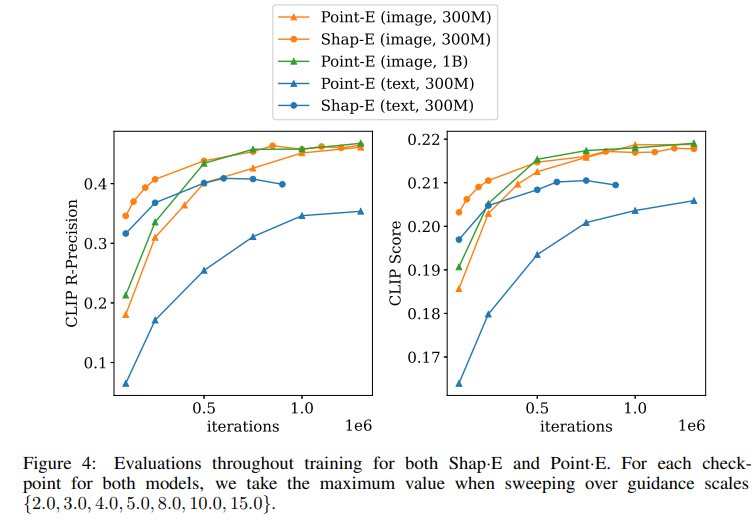
論文まとめ:Shap-E: Generating Conditional 3D Implicit Functions | Shikoan's ...
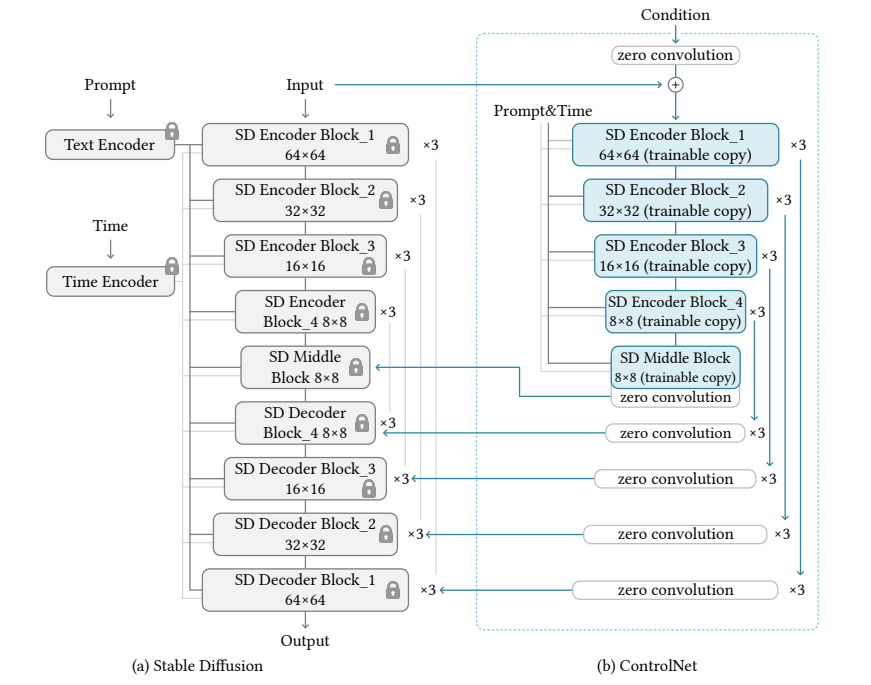
Diffusers版のControlNet+LoRAで遊ぶ:理論と実践 | Shikoan's ML Blog
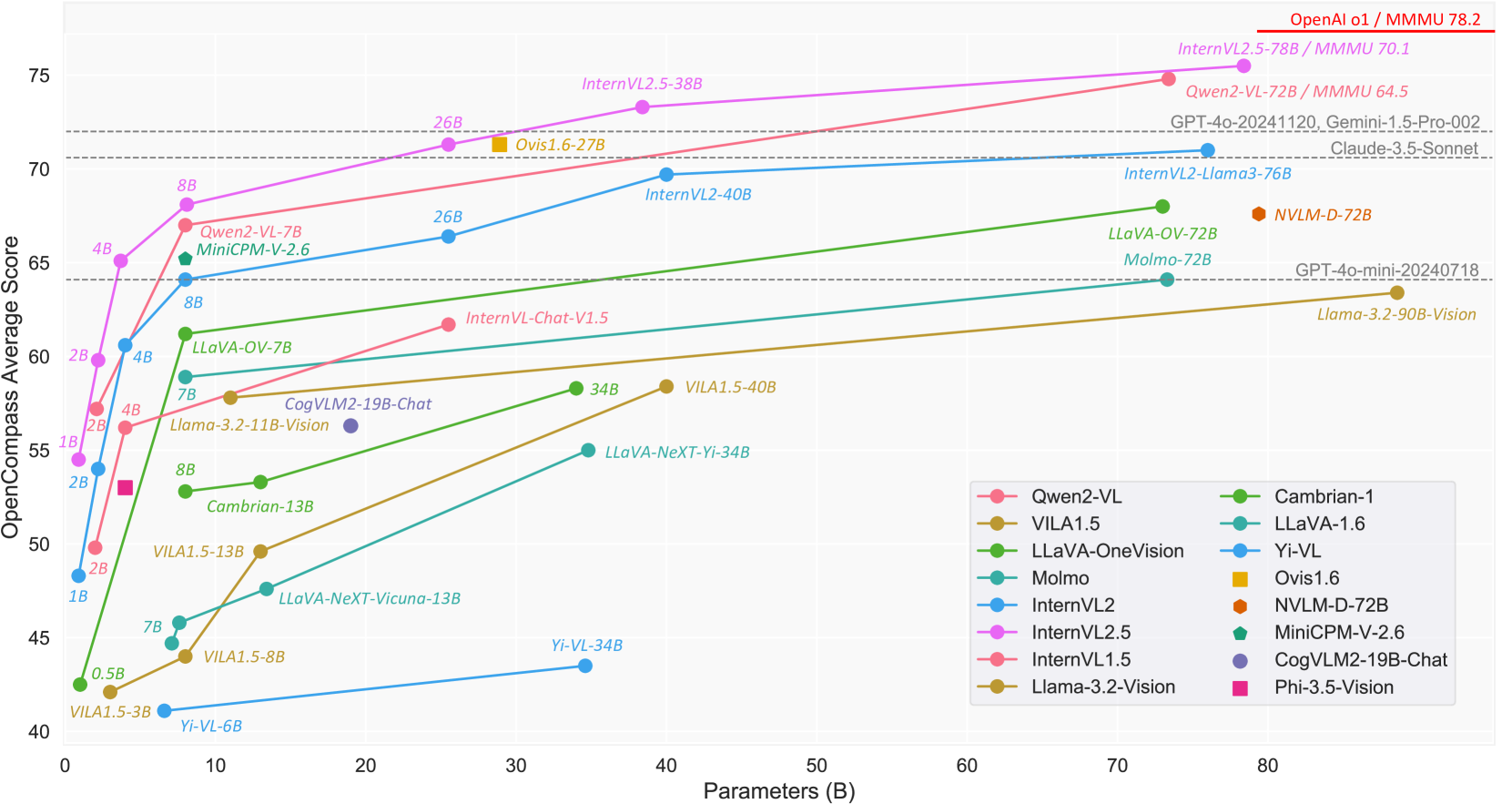
論文まとめ:Expanding Performance Boundaries of Open-Source Multimodal Models ...
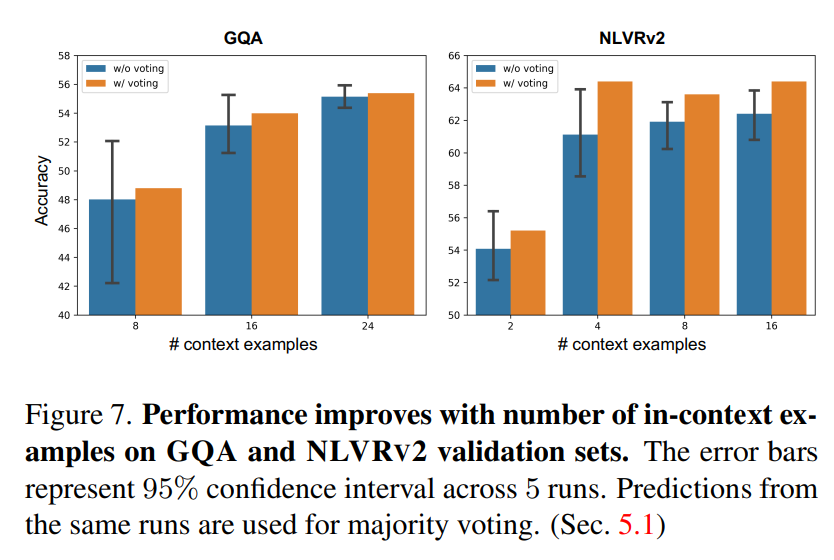
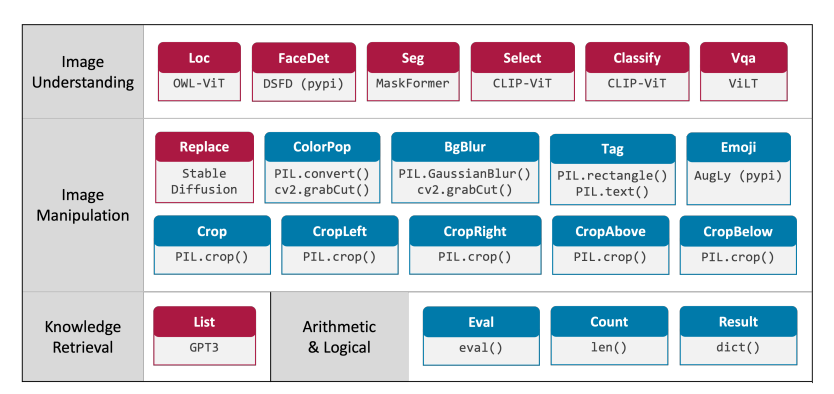
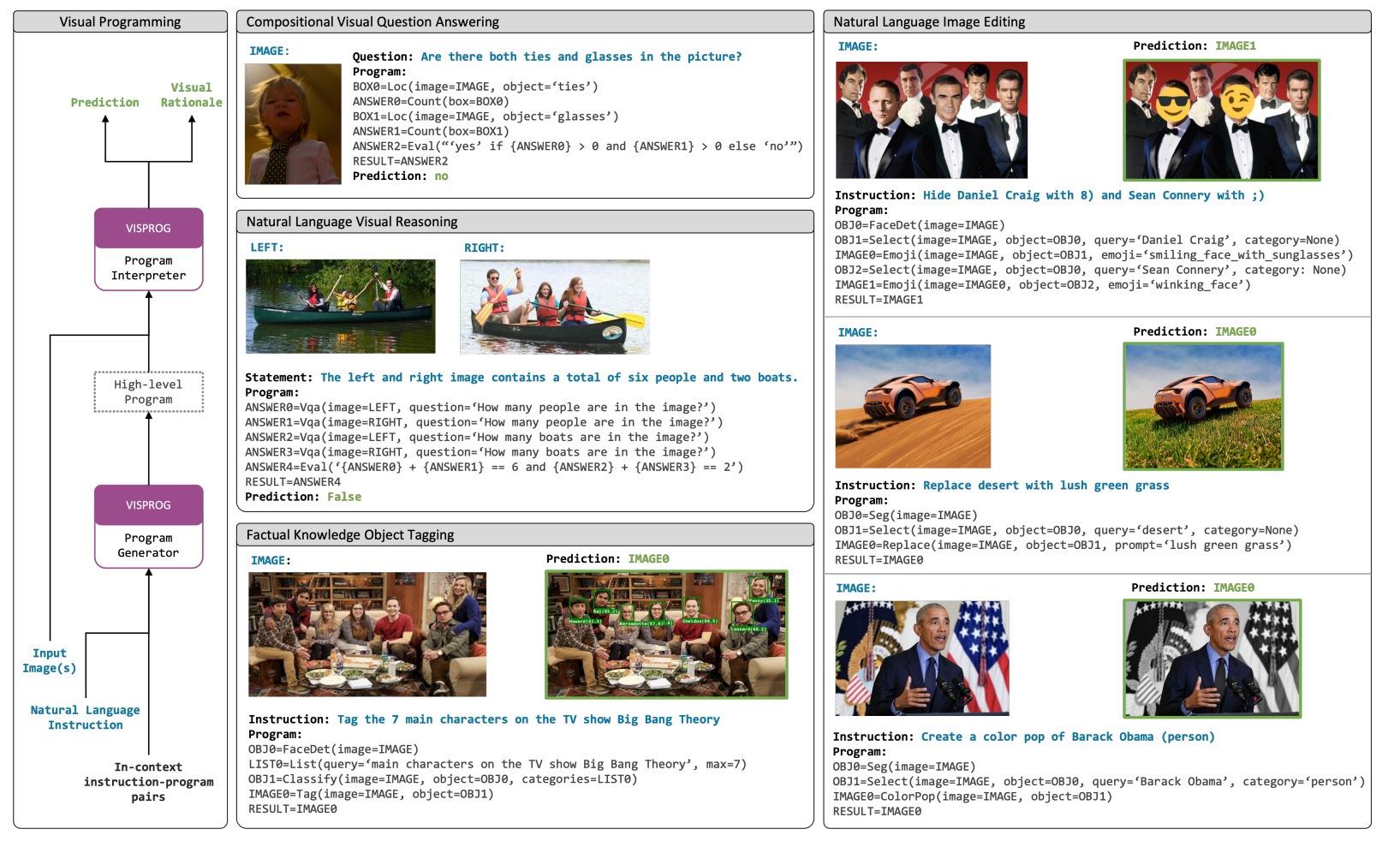
論文まとめ:Visual Programming: Compositional visual reasoning without ...
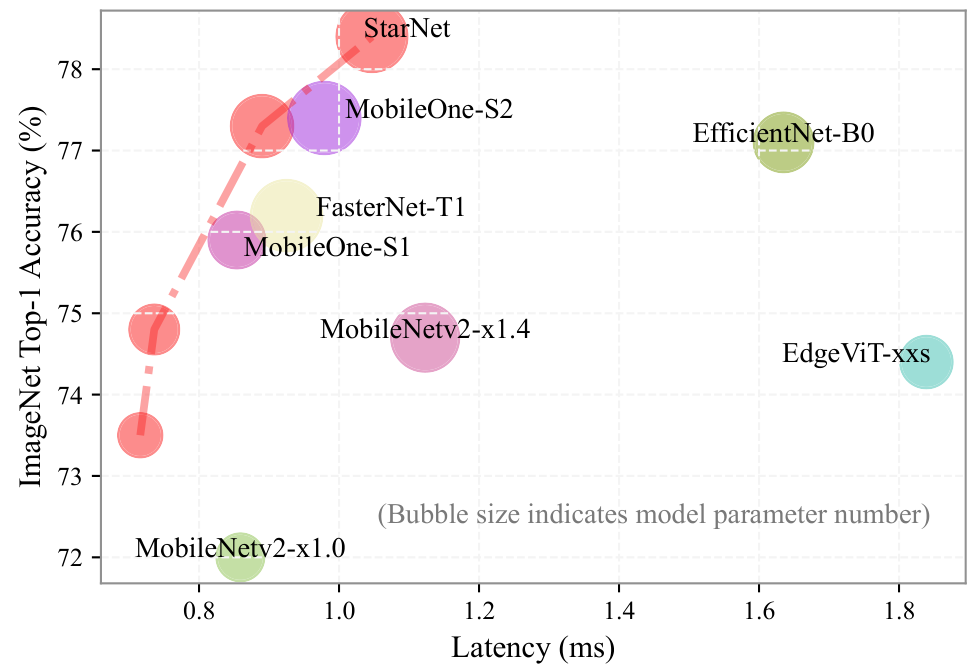
論文まとめ:Rewrite the Stars | Shikoan's ML Blog
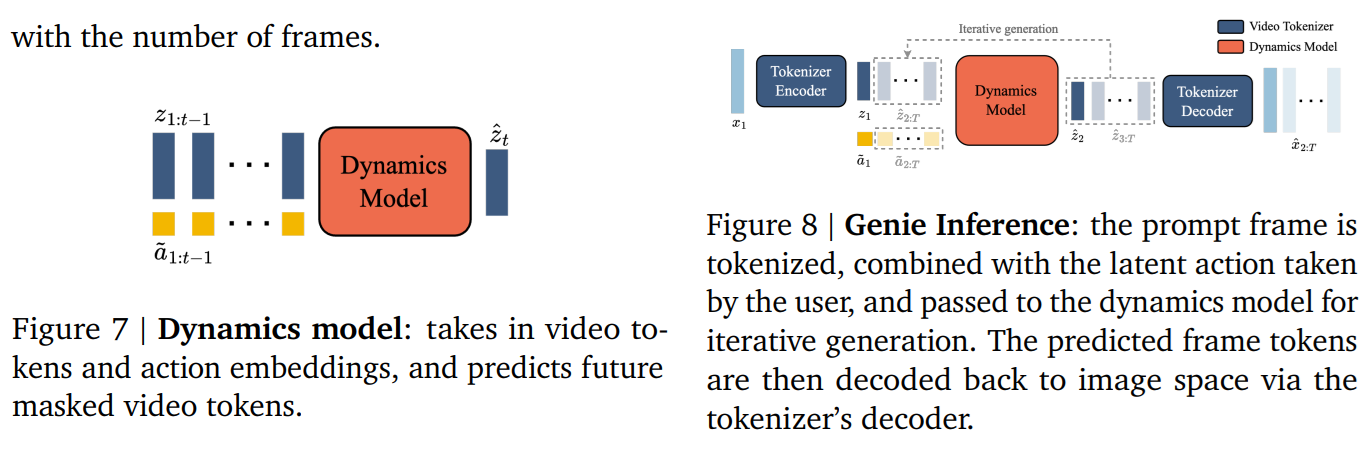
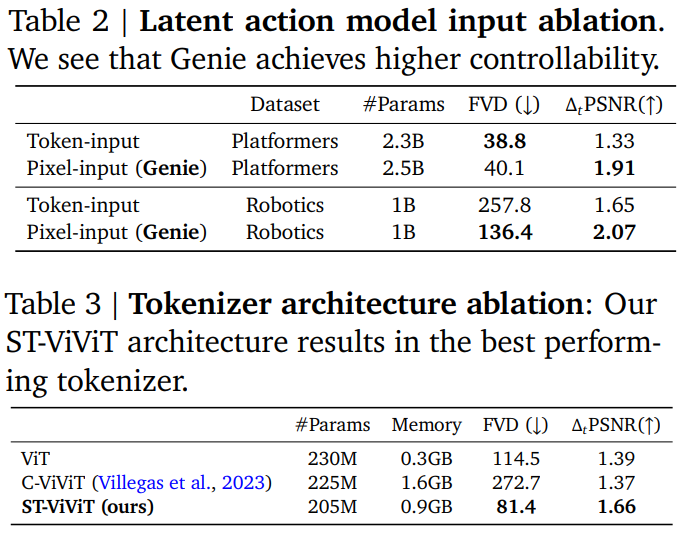
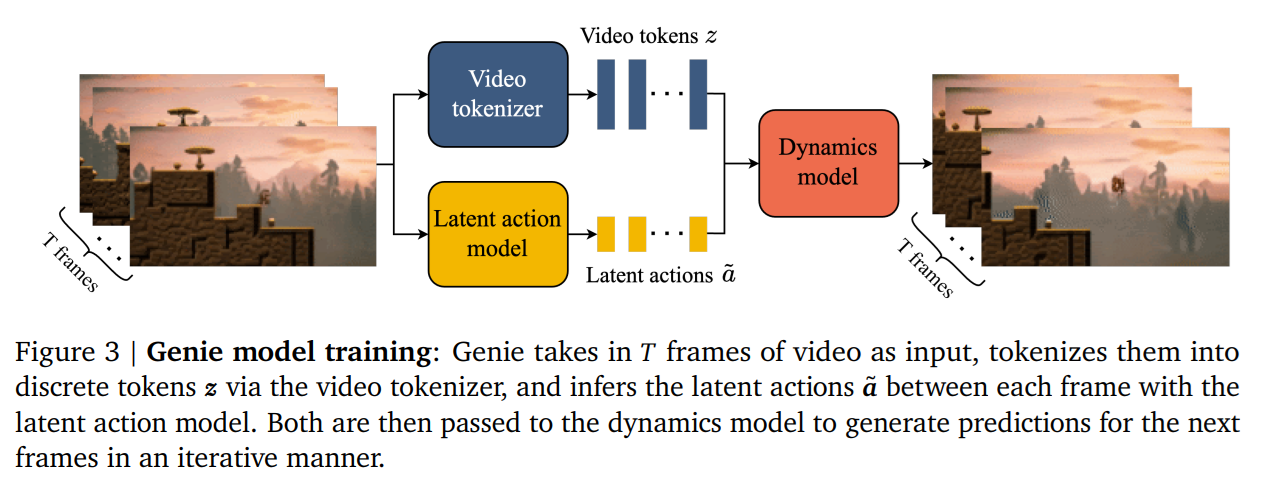
論文まとめ:Genie: Generative Interactive Environments | Shikoan's ML Blog
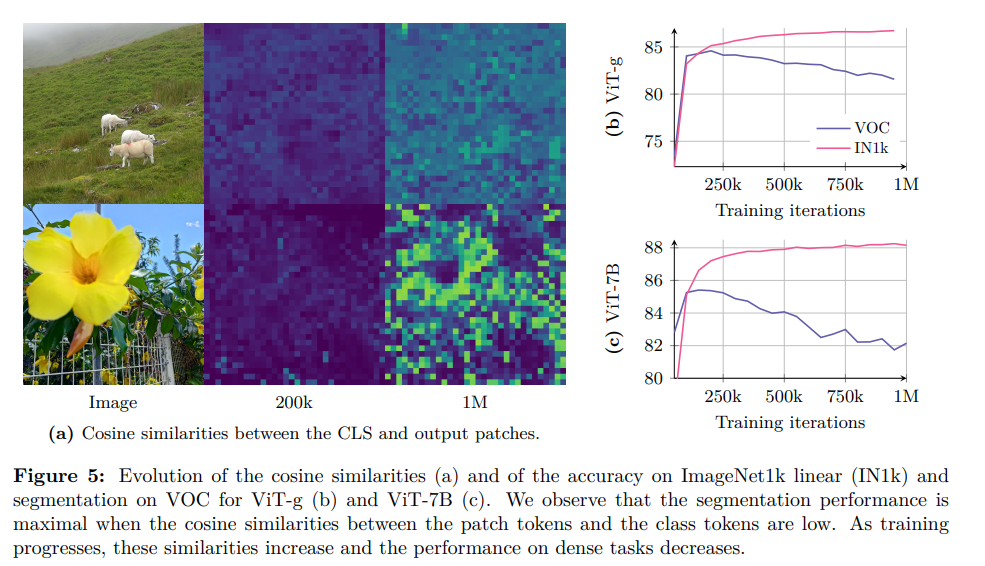
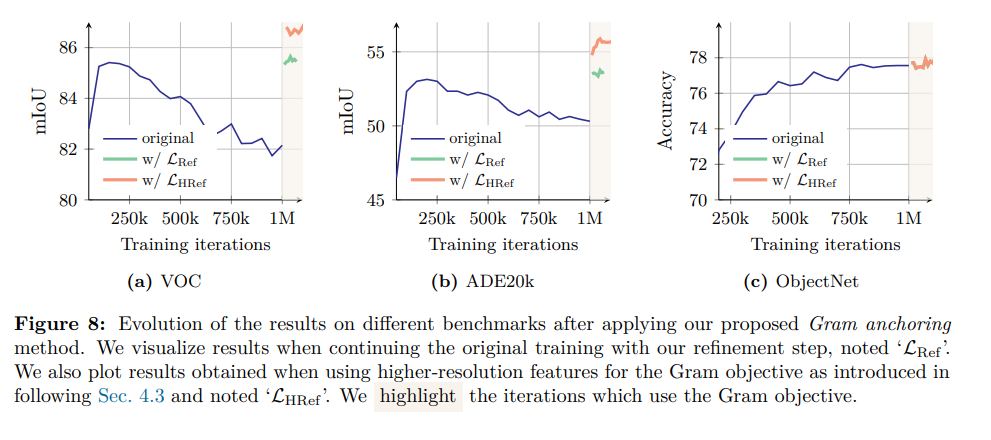
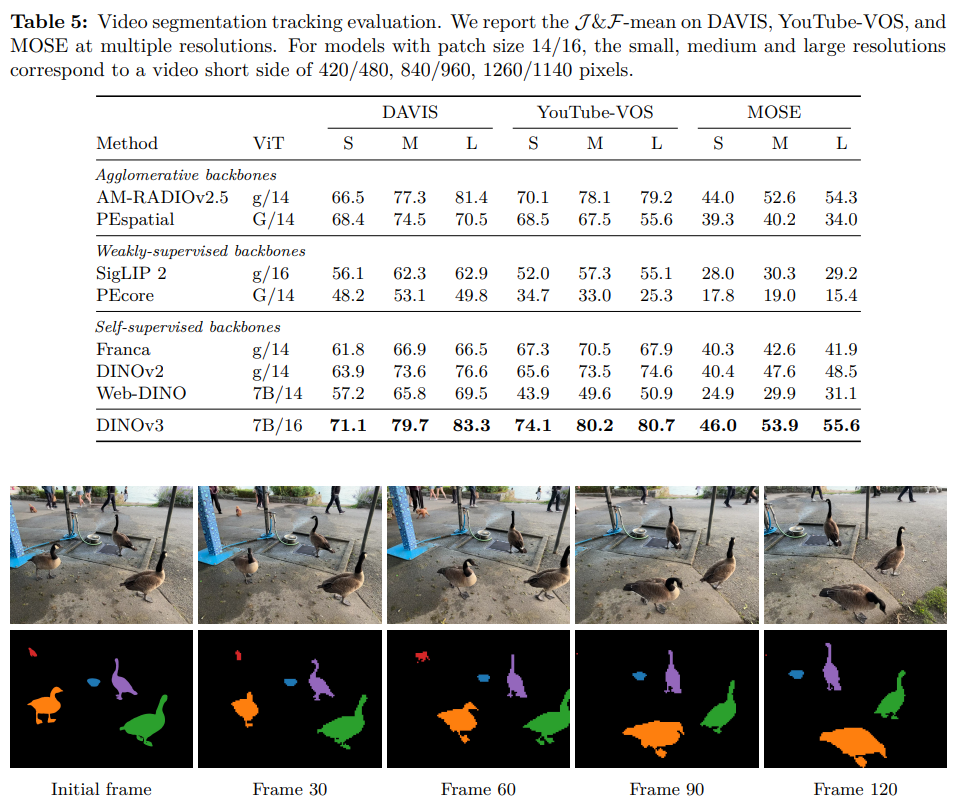
論文まとめ:DINOv3 | Shikoan's ML Blog
論文まとめ:Janus-Pro: Unified Multimodal Understanding and Generation with ...
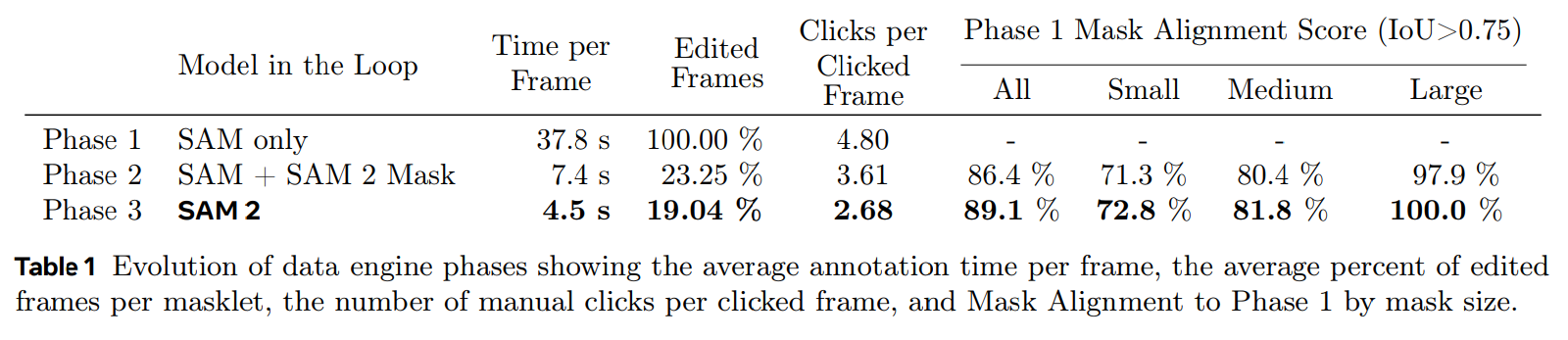
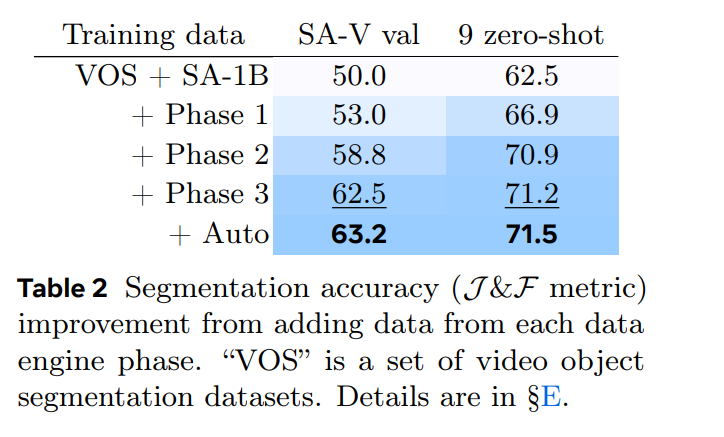
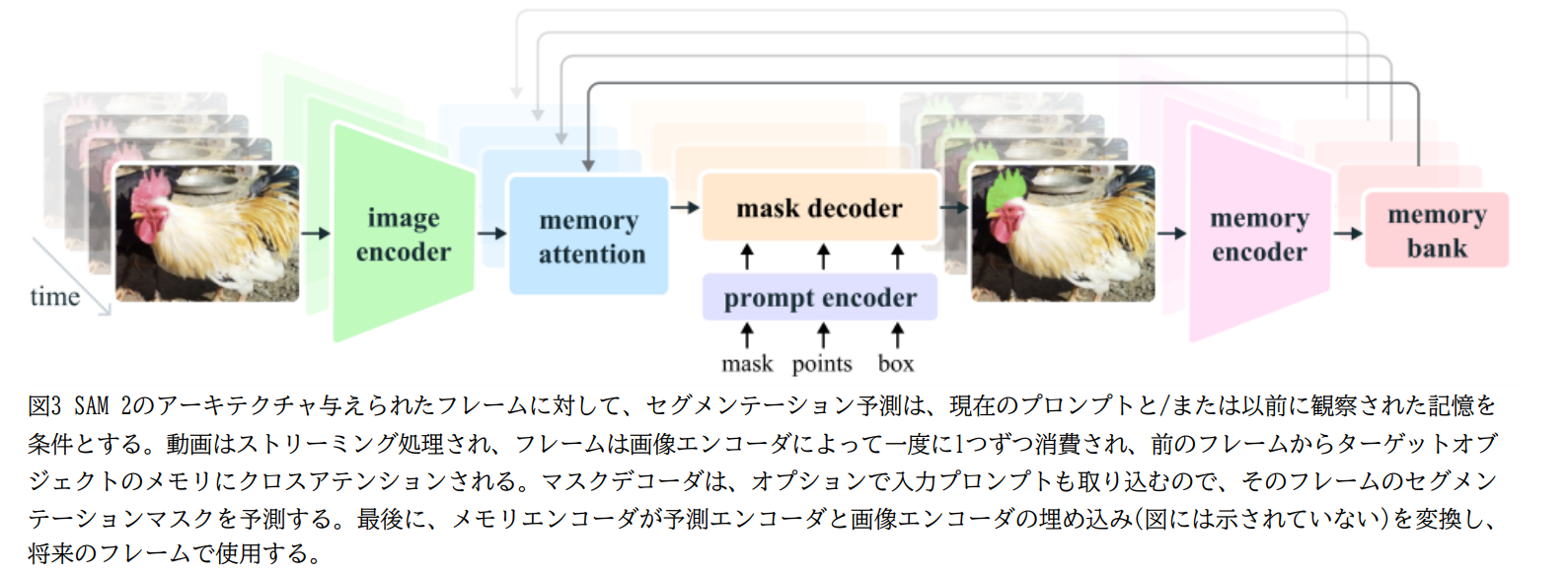
論文まとめ:SAM 2: Segment Anything in Images and Videos | Shikoan's ML Blog
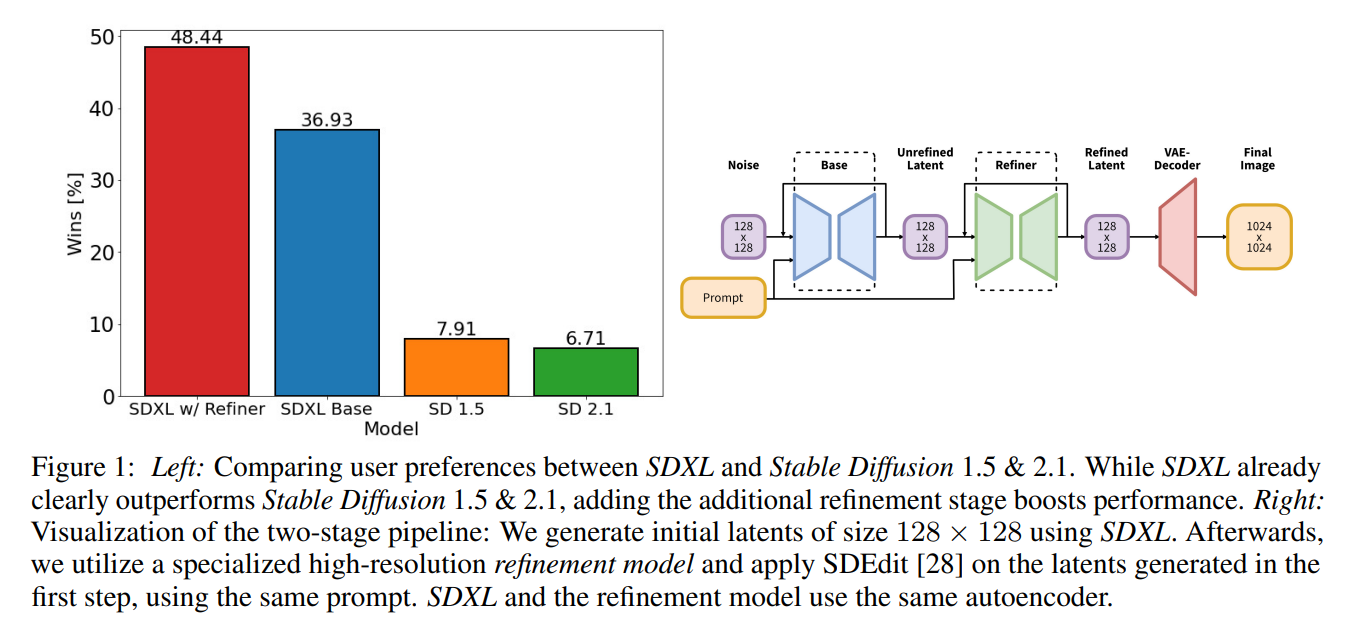
論文まとめ:SDXL: Improving Latent Diffusion Models for High-Resolution Image ...
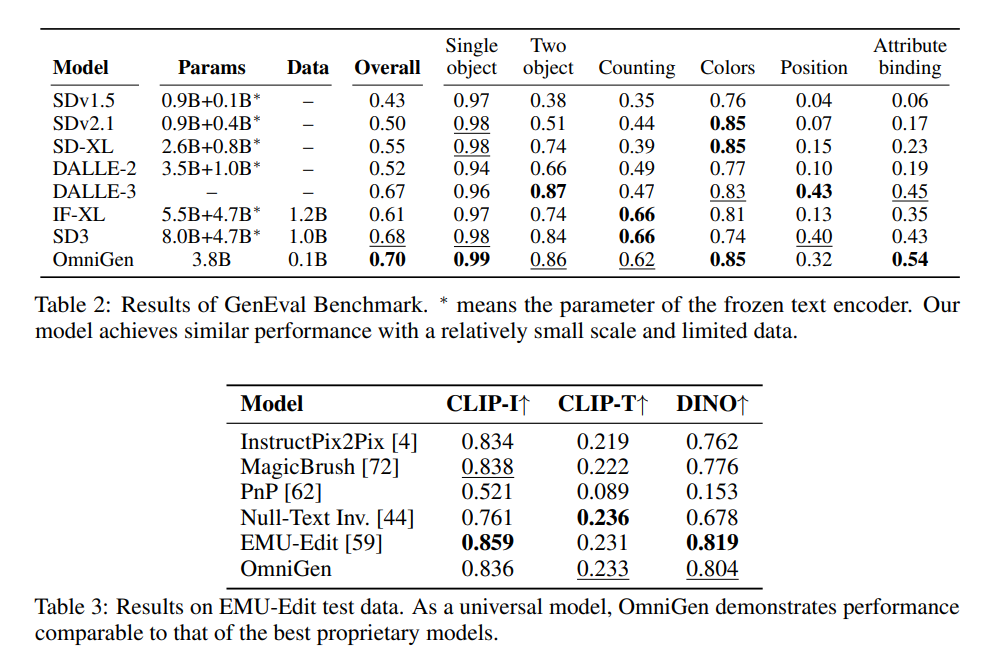
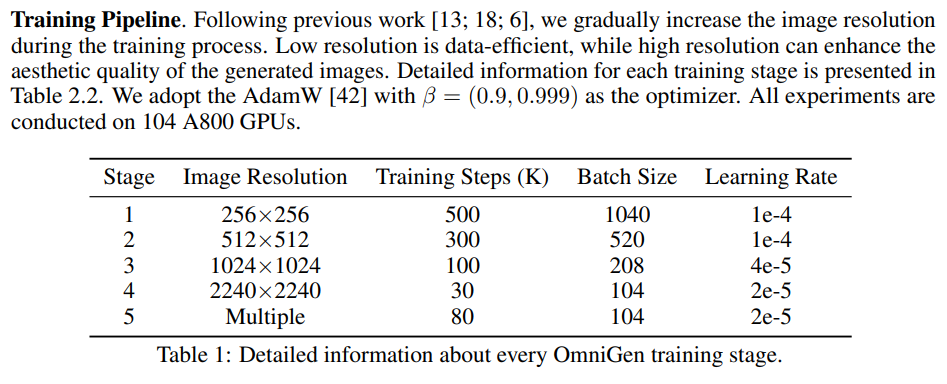
論文まとめ:OmniGen: Unified Image Generation | Shikoan's ML Blog
論文まとめ:When Do We Not Need Larger Vision Models? | Shikoan's ML Blog
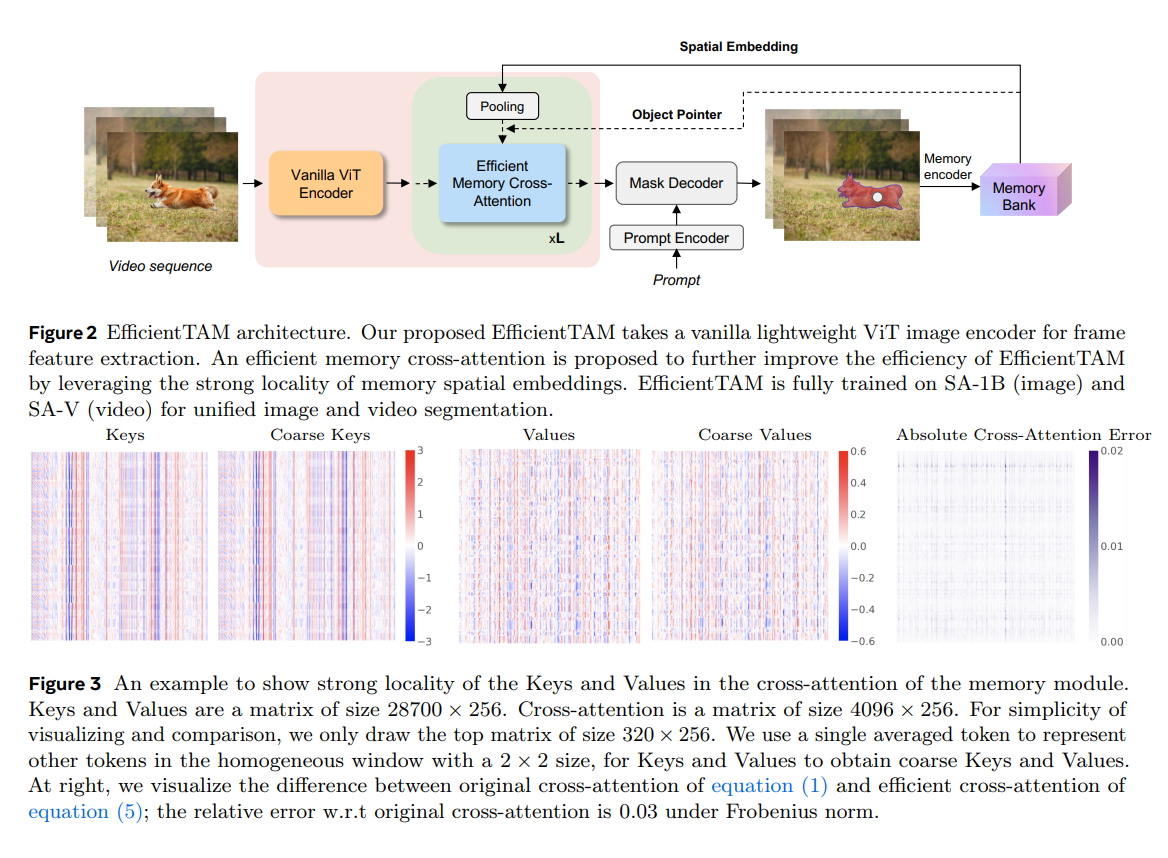
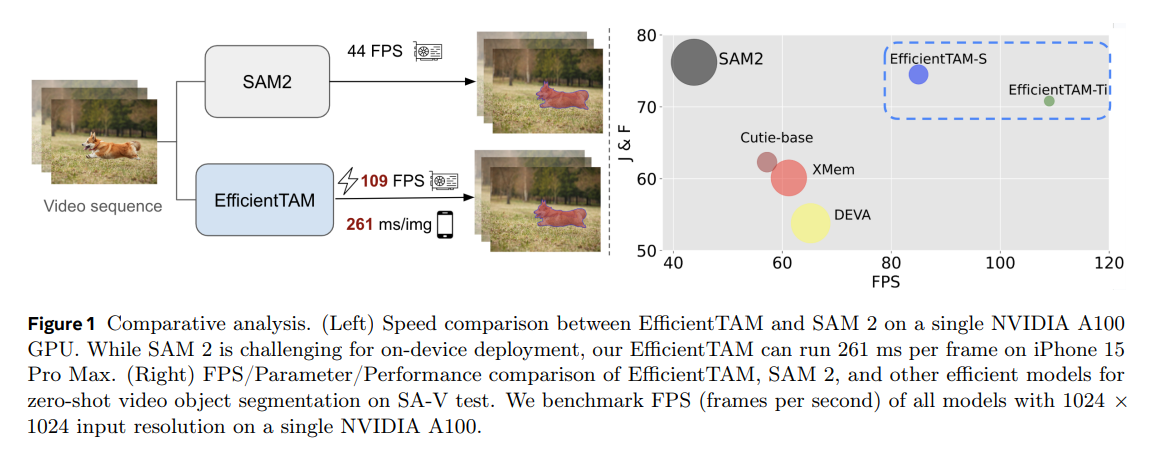
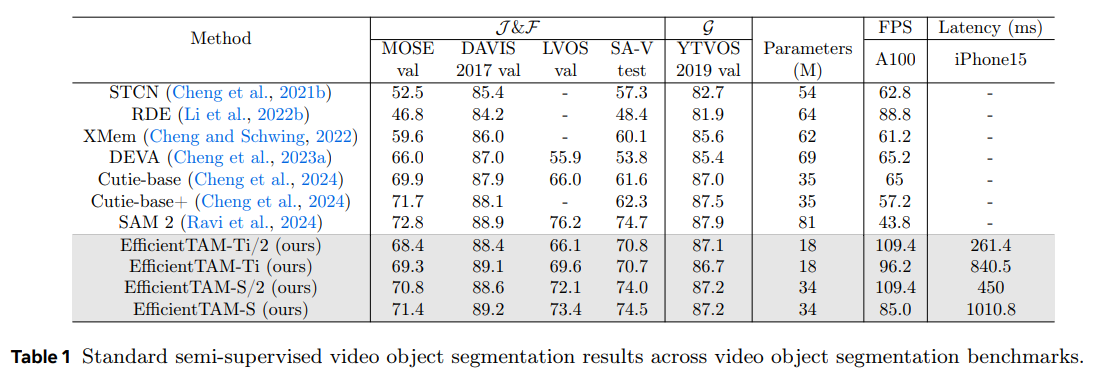
論文まとめ:Efficient Track anything | Shikoan's ML Blog
論文まとめ:Generative Multimodal Pretraining with Discrete Diffusion ...
LLMの推論システムの定式化(2):価格理論の推論速度の統合 | Shikoan's ML Blog
論文まとめ:Stable Video Diffusion: Scaling Latent Video Diffusion Models to ...
論文まとめ:Cosmos World Foundation Model Platform for Physical AI | Shikoan ...
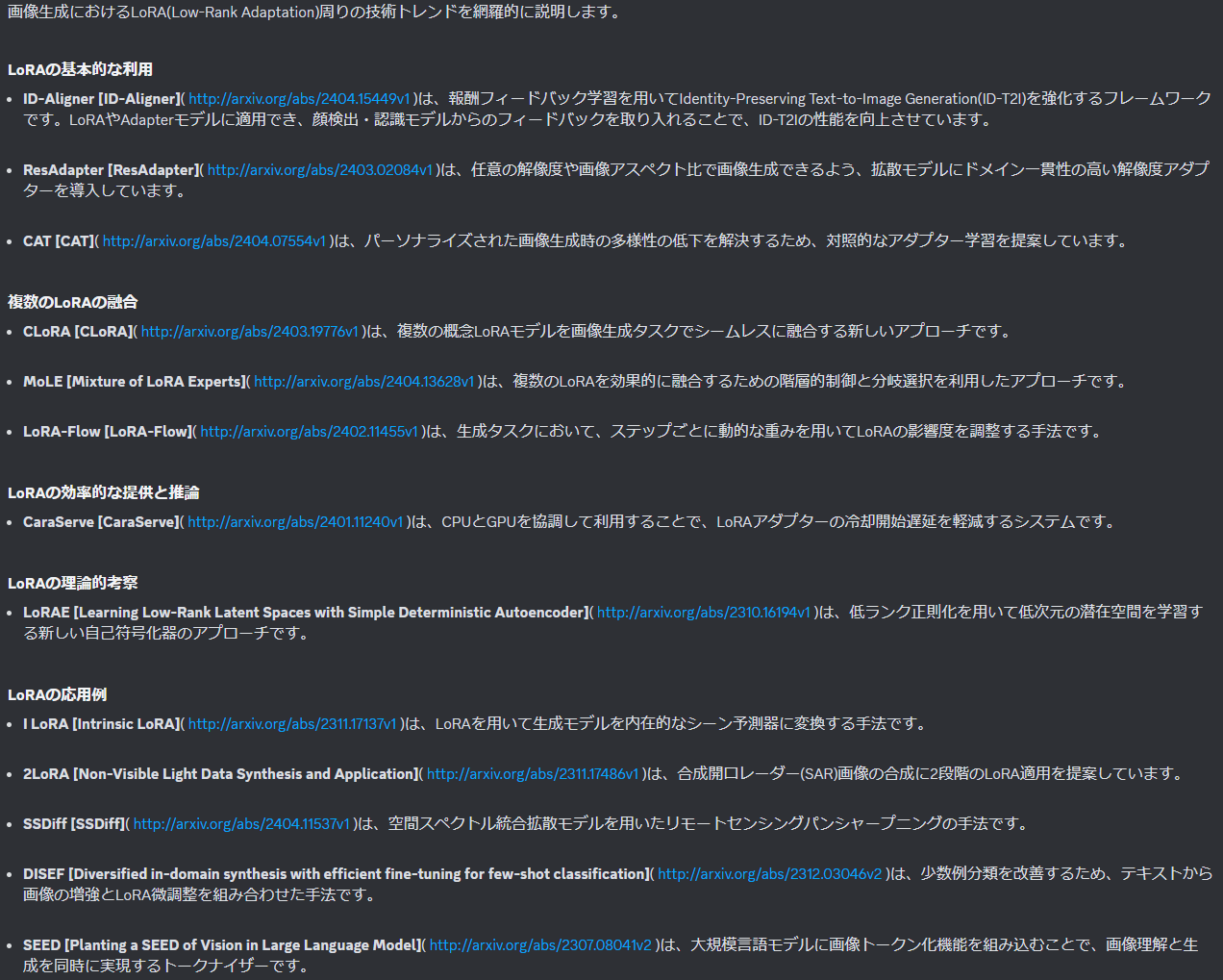
Arxiv RAGによる論文サーベイの自動生成 | Shikoan's ML Blog
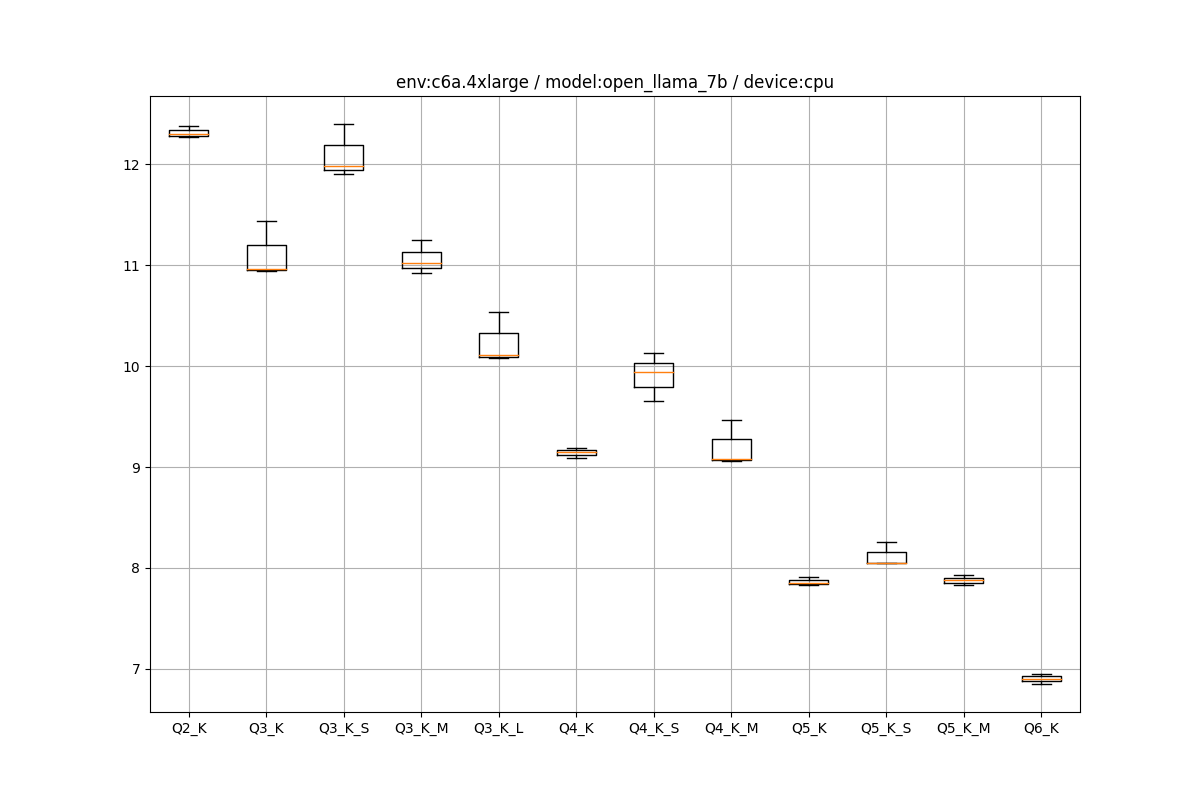
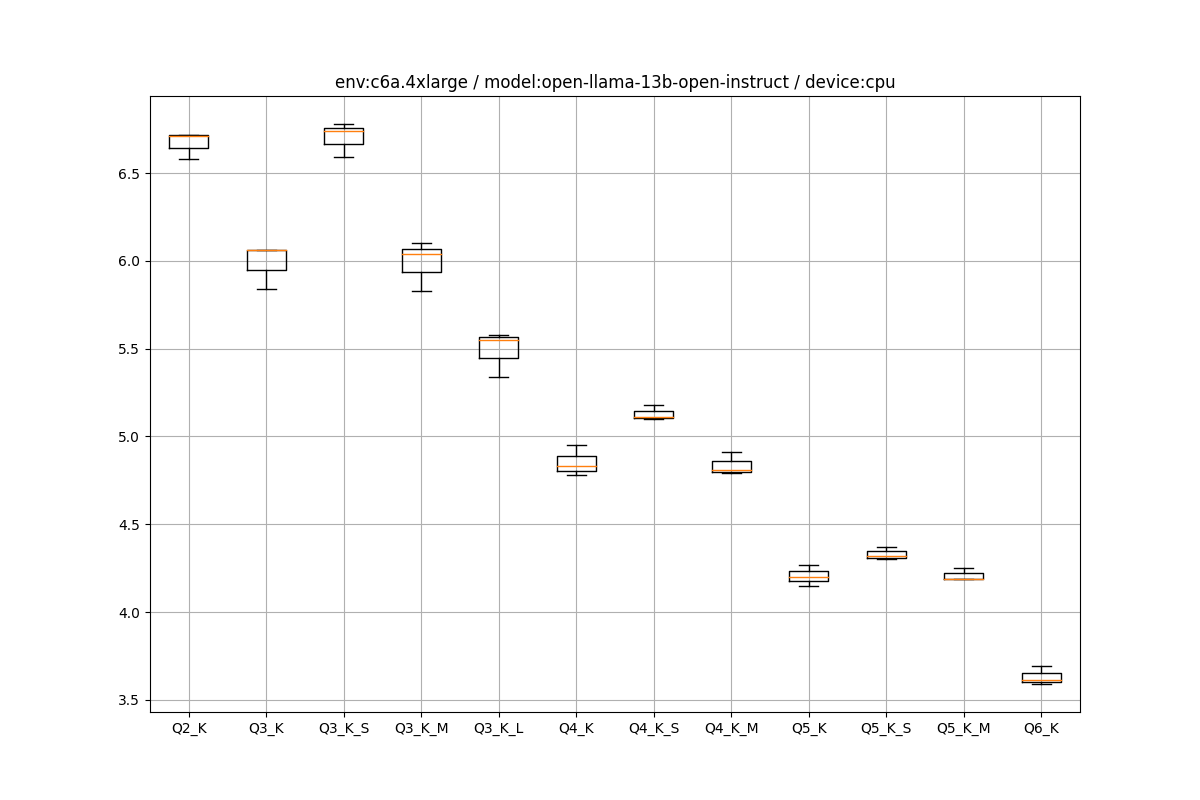
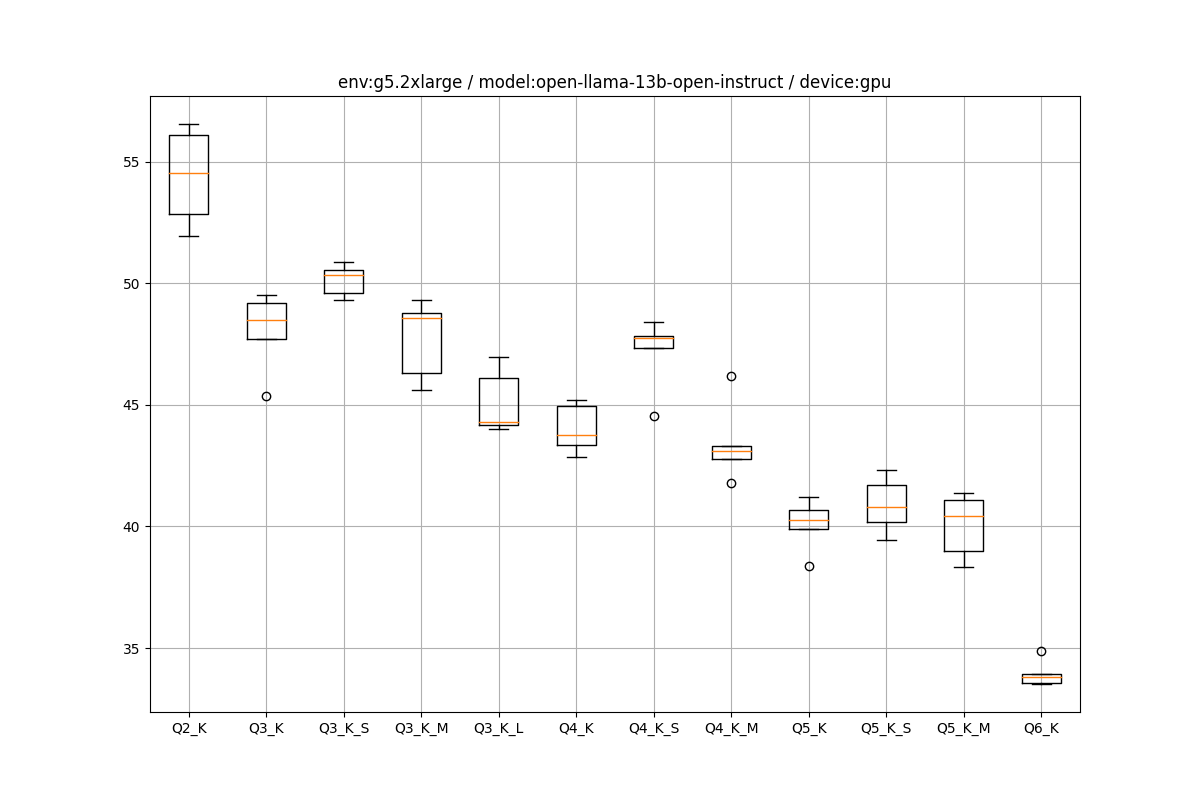
LLaMA.cpp+(cu)BLASのCPU/GPUのスループット検証(AWS編) | Shikoan's ML Blog
Circumventing the Limits of LLMs by Refactoring to Patterns | by Carlos ...
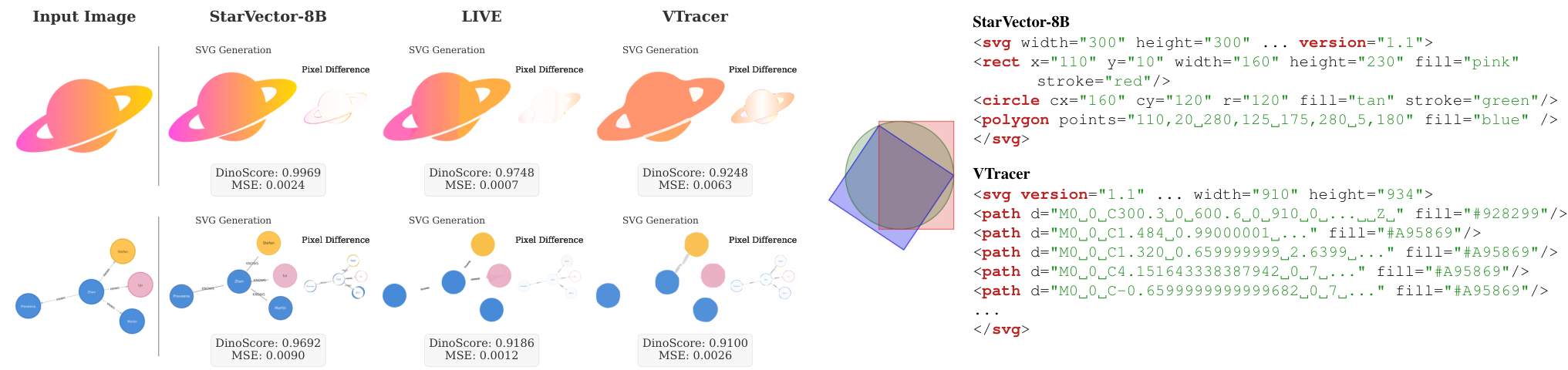
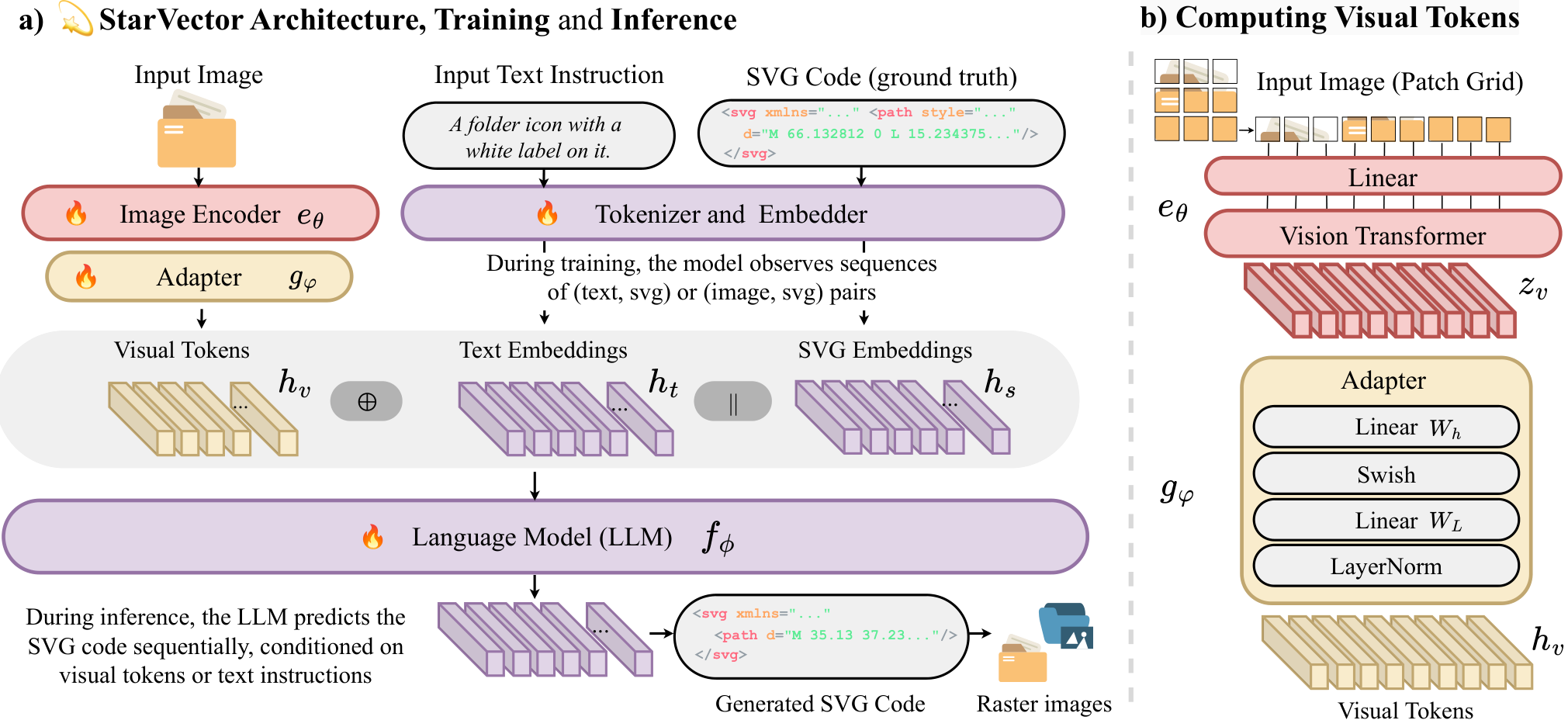
論文まとめ:StarVector: Generating Scalable Vector Graphics Code from Images ...
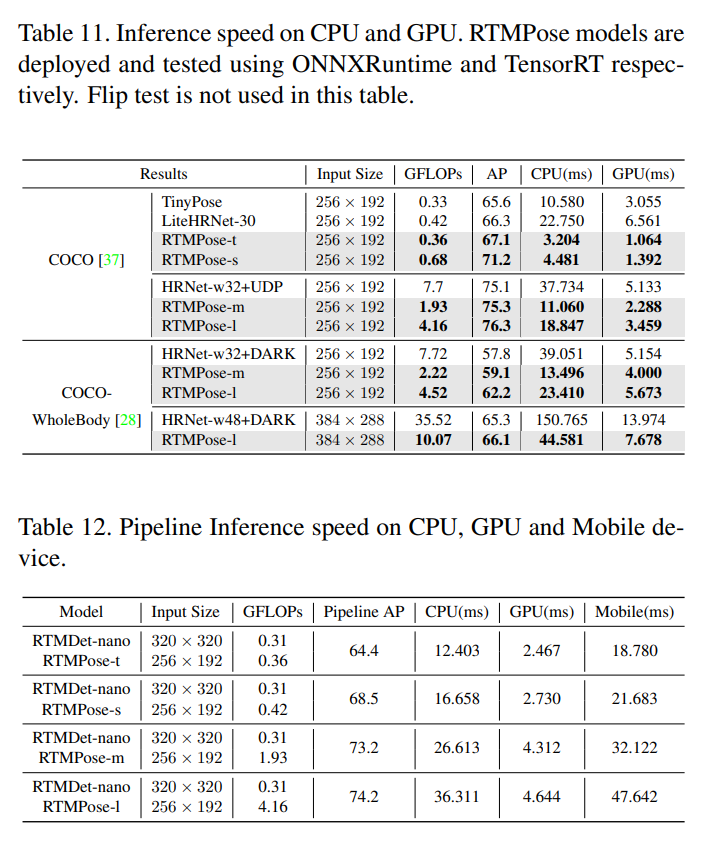
論文まとめ:RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose ...
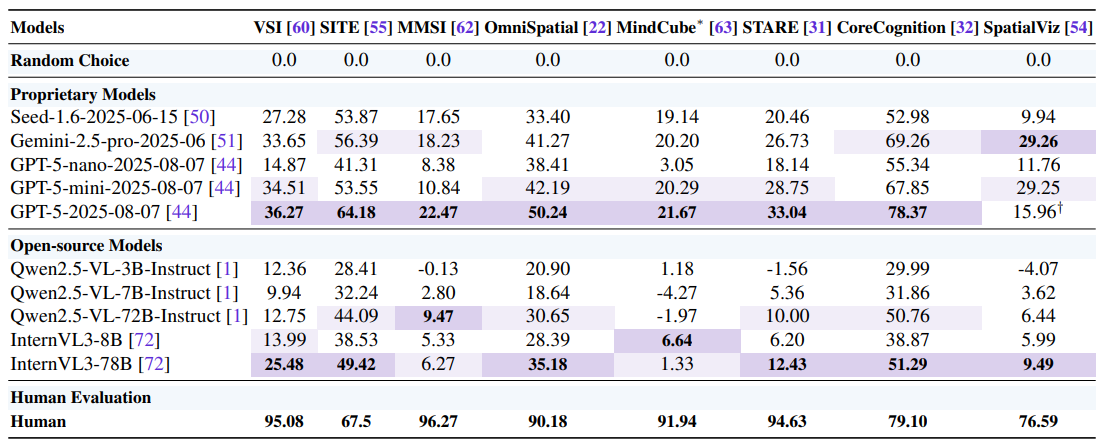
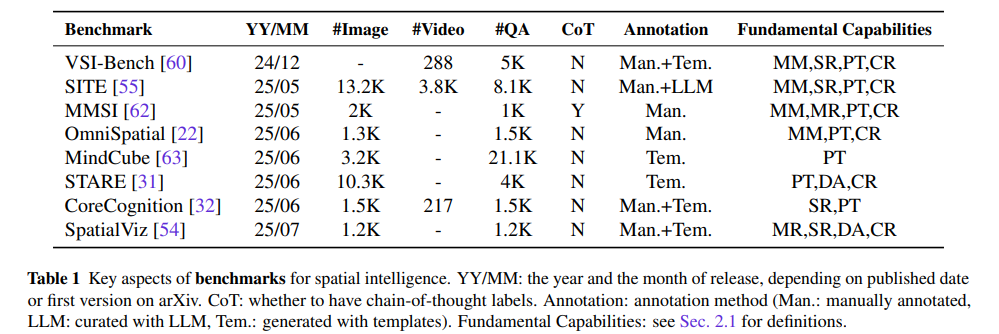
論文まとめ:Has GPT-5 Achieved Spatial Intelligence? An Empirical Study ...
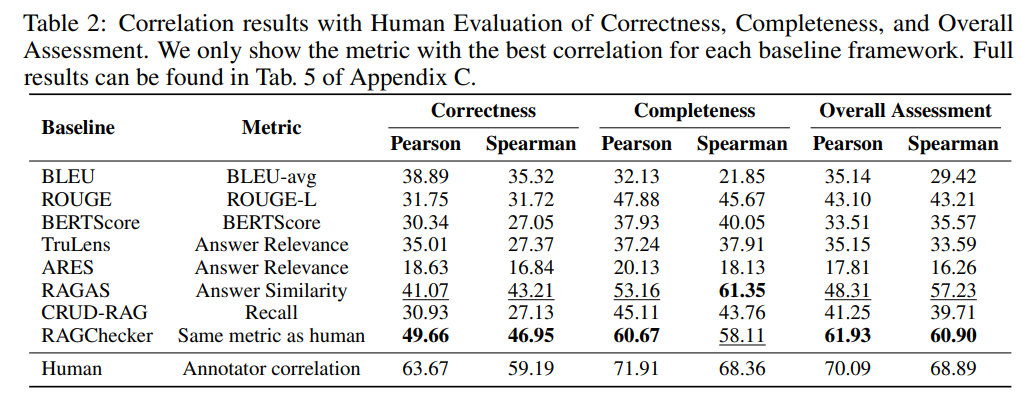
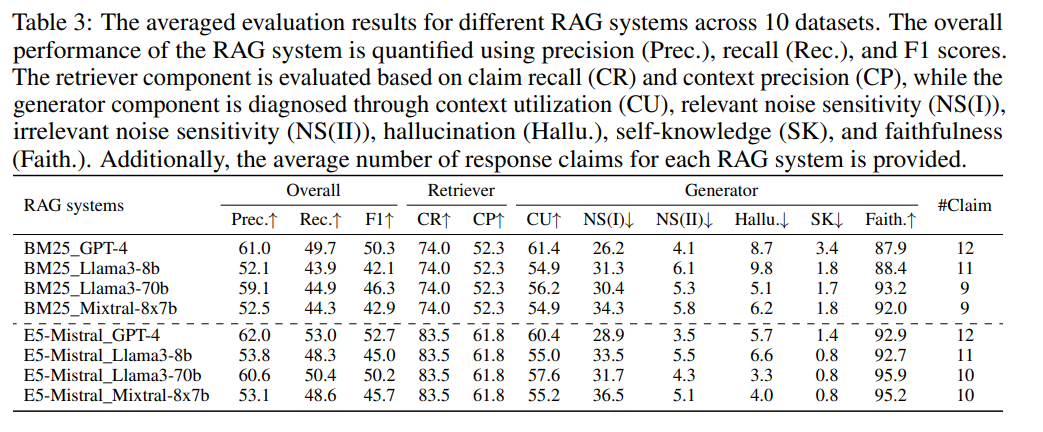
論文まとめ:RAGChecker: A Fine-grained Framework for Diagnosing Retrieval ...
論文まとめ:Visual Autoregressive Modeling: Scalable Image Generation via ...
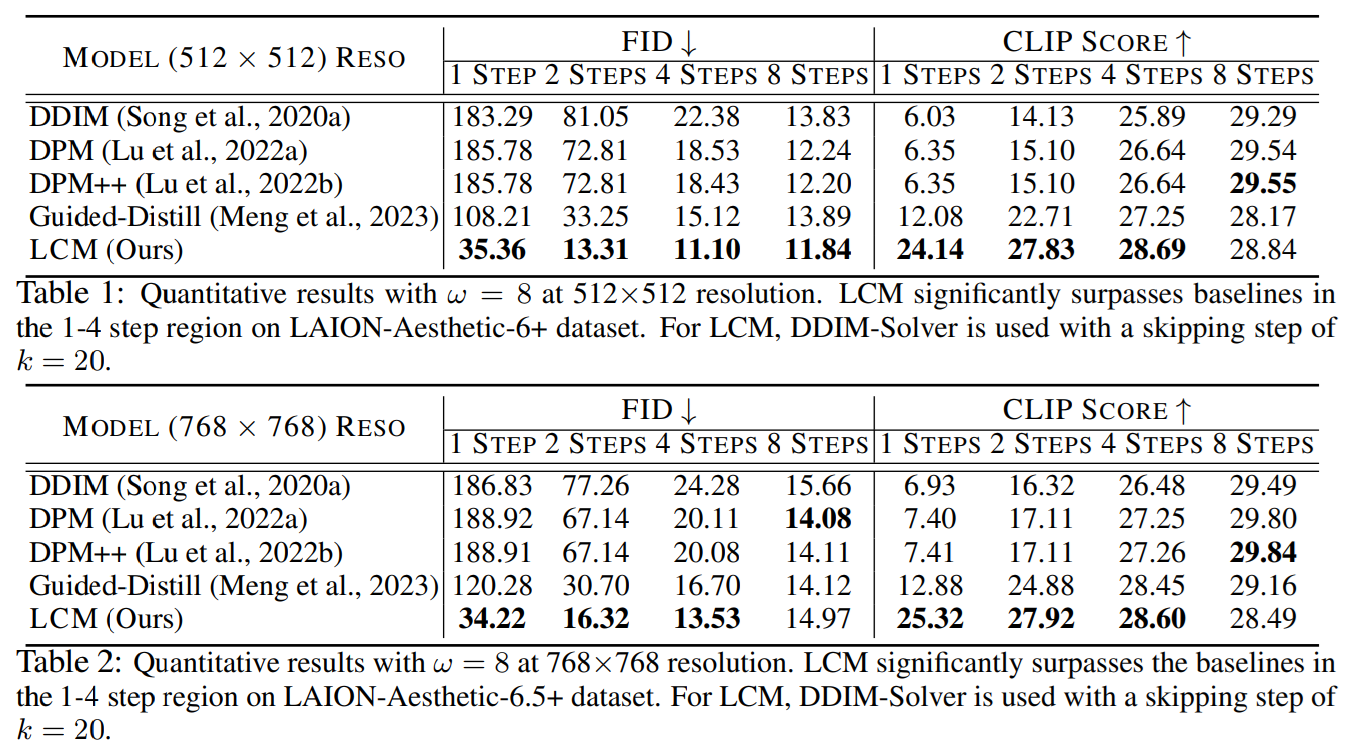
論文まとめ:LCM-LoRA: A Universal Stable-Diffusion Acceleration Module ...
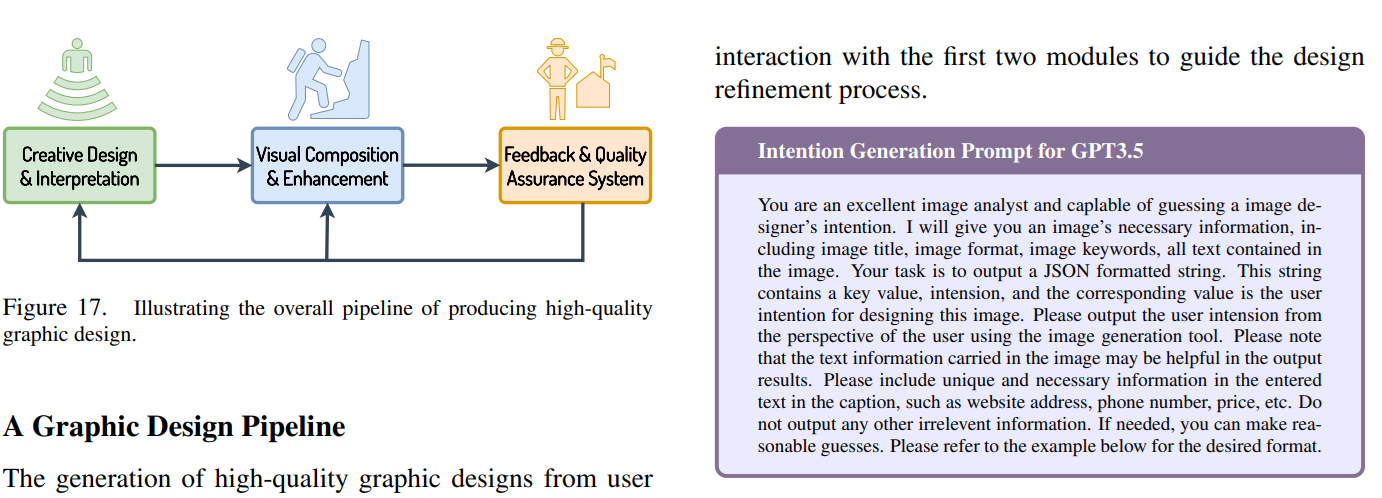
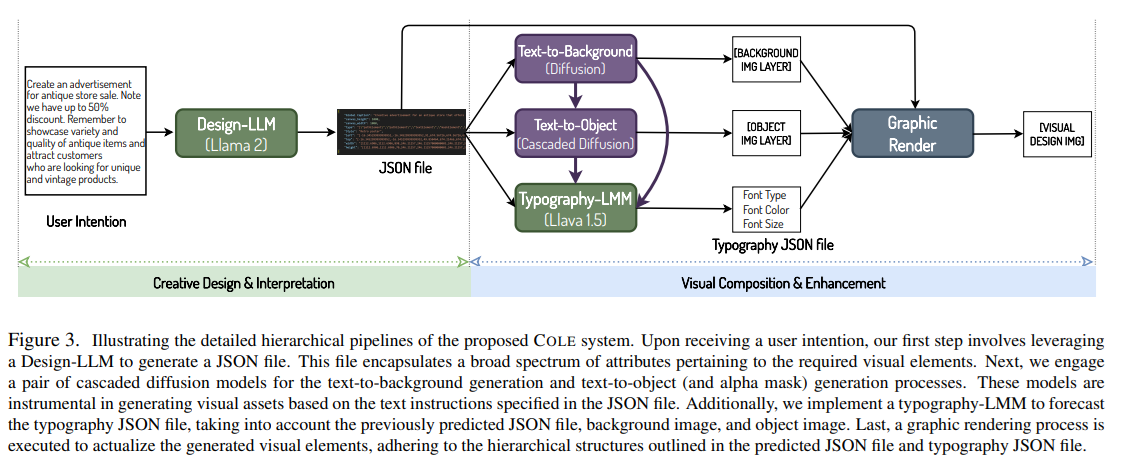
論文まとめ:COLE: A Hierarchical Generation Framework for Graphic Design ...
論文まとめ:Video-LLaVA: Learning United Visual Representation by Alignment ...
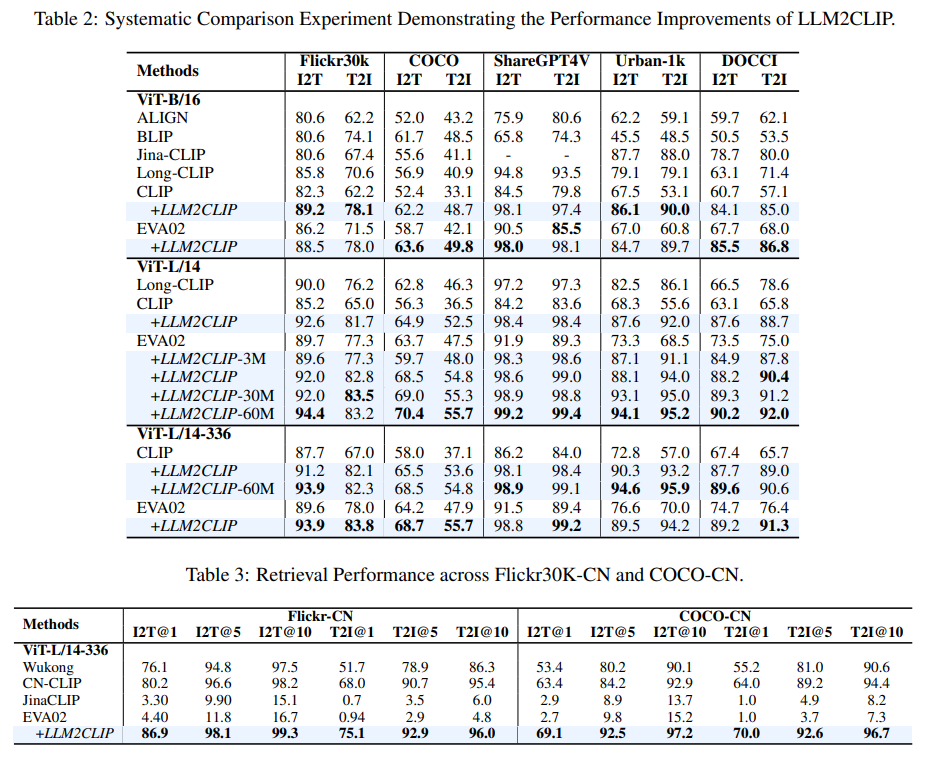
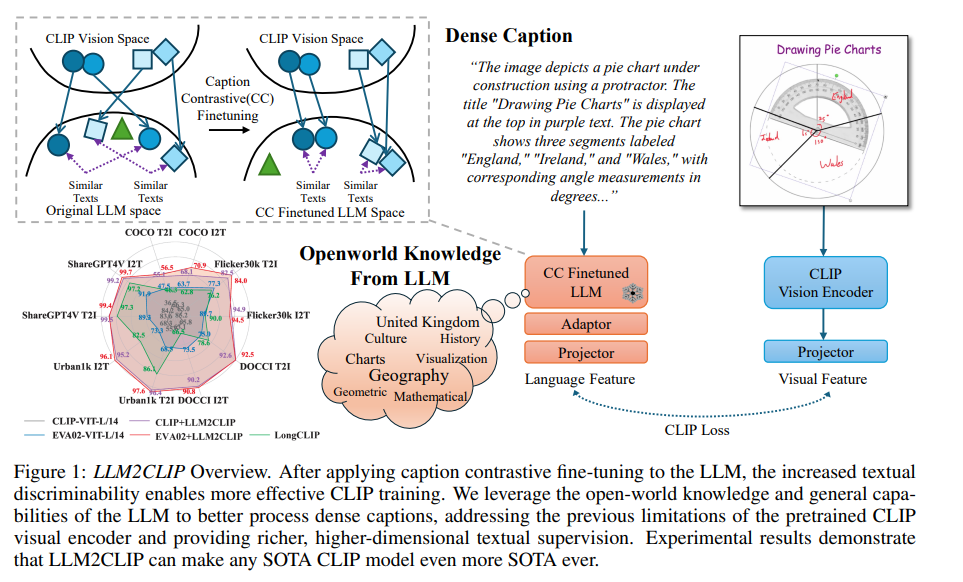
論文まとめ:LLM2CLIP: Powerful Language Model Unlock Richer Visual ...
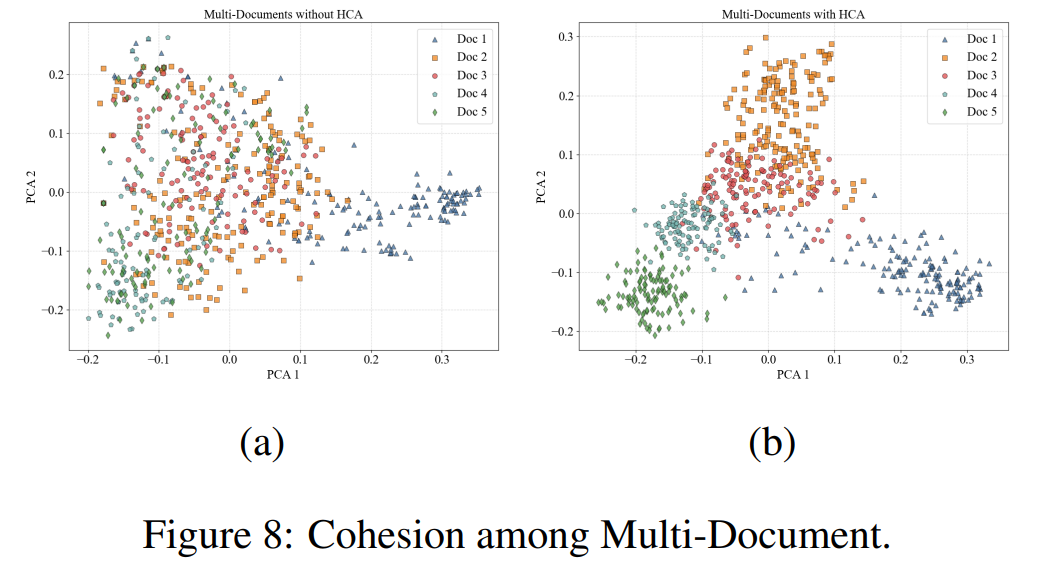
論文まとめ:HiQA: A Hierarchical Contextual Augmentation RAG for Massive ...
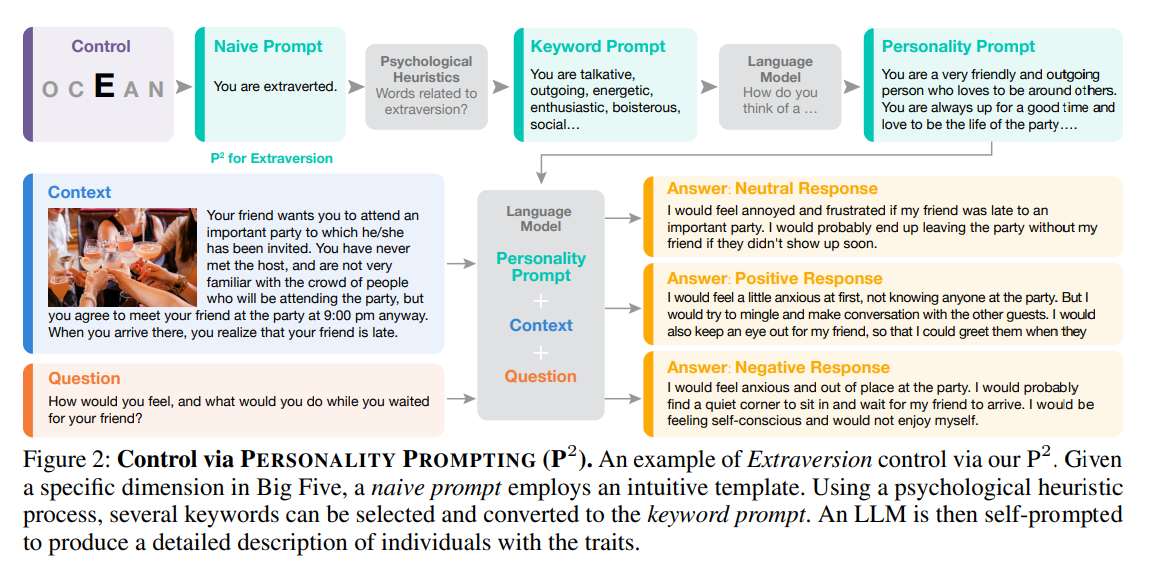
論文まとめ:Evaluating and Inducing Personality in Pre-trained Language ...
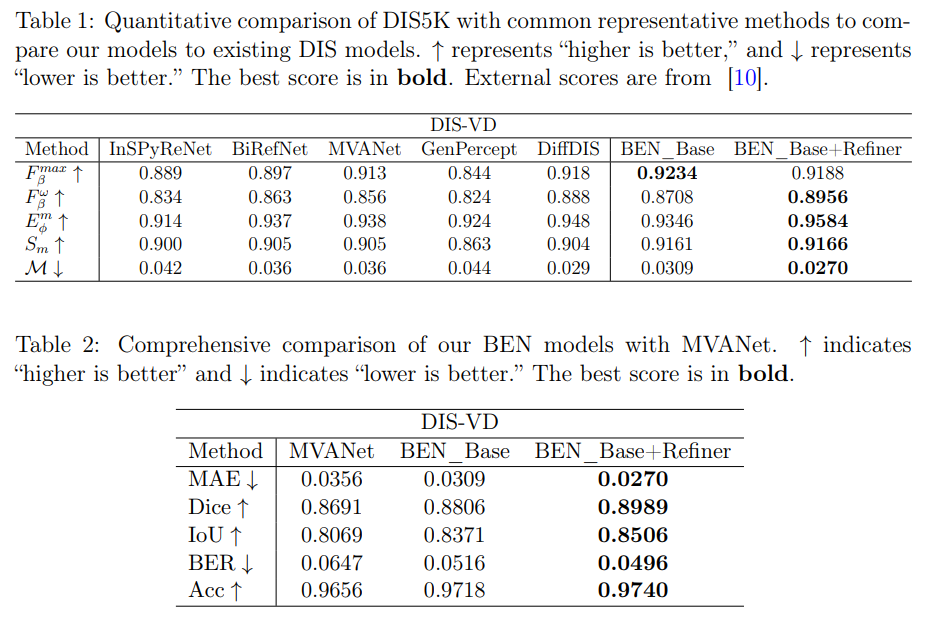
論文まとめ:BEN: Using Confidence-Guided Matting for Dichotomous Image ...
論文まとめ:Vision Grid Transformer for Document Layout Analysis+OSS紹介 ...
論文まとめ:ULIP-2: Towards Scalable Multimodal Pre-training for 3D ...
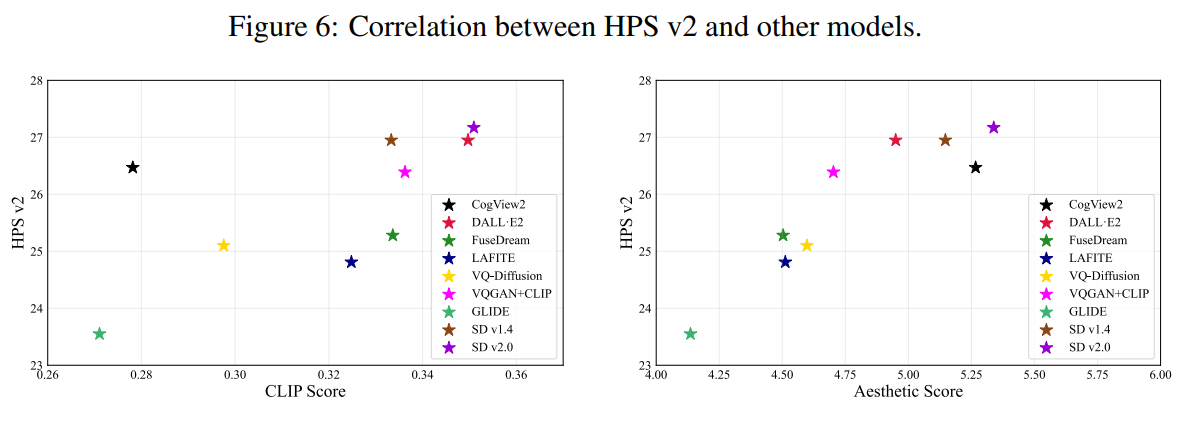
論文まとめ:Human Preference Score v2: A Solid Benchmark for Evaluating Human ...
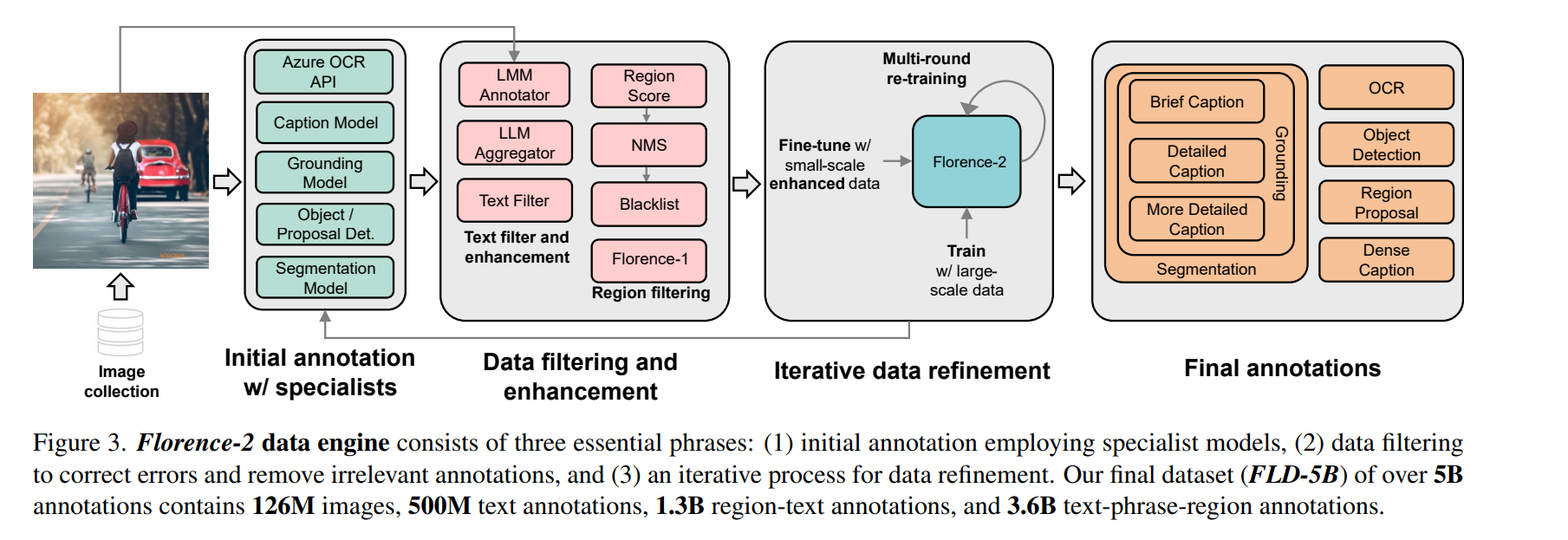
論文まとめ:Florence-2: Advancing a Unified Representation for a Variety of ...
連想配列のJSONをパースする - shikoan’s memo
任意の文字の繰り返し回数を検出する - shikoan’s memo