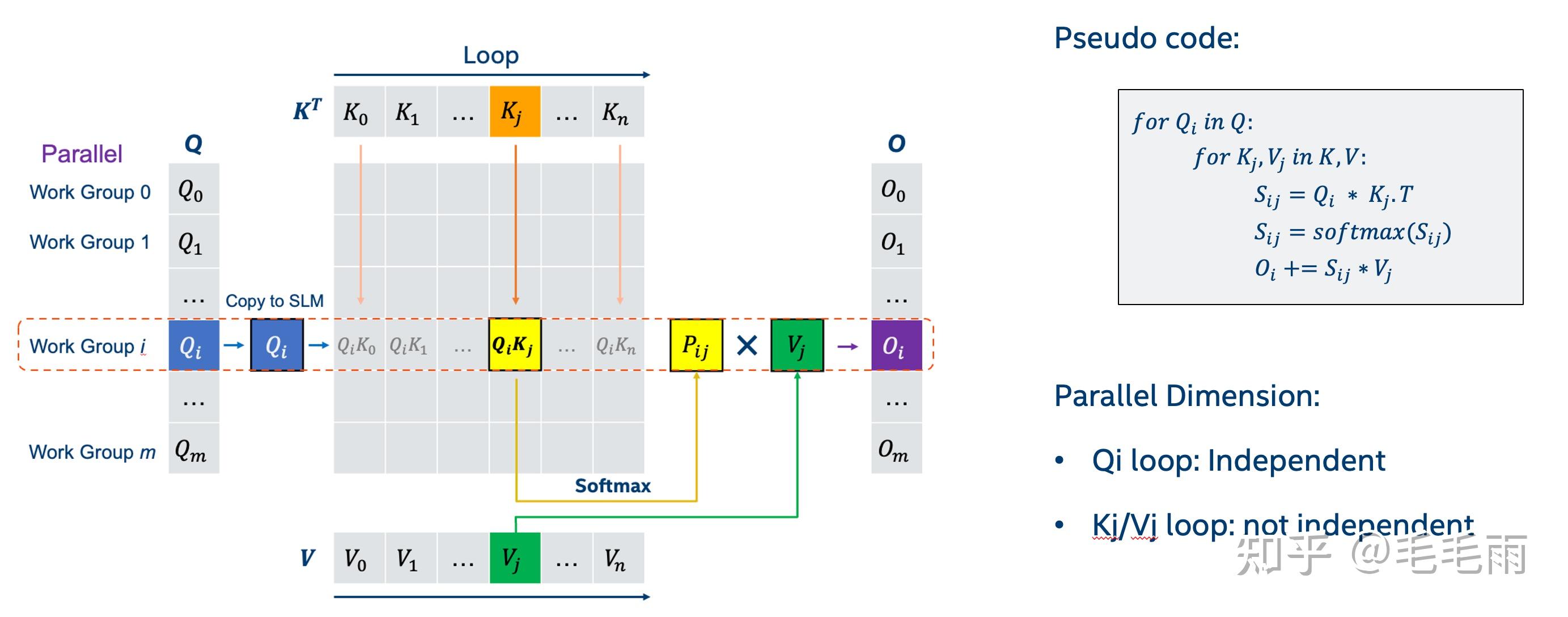
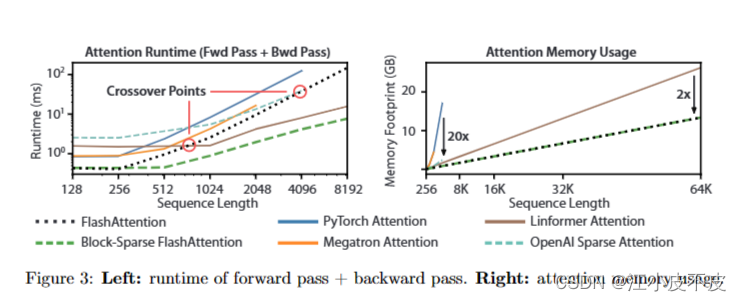
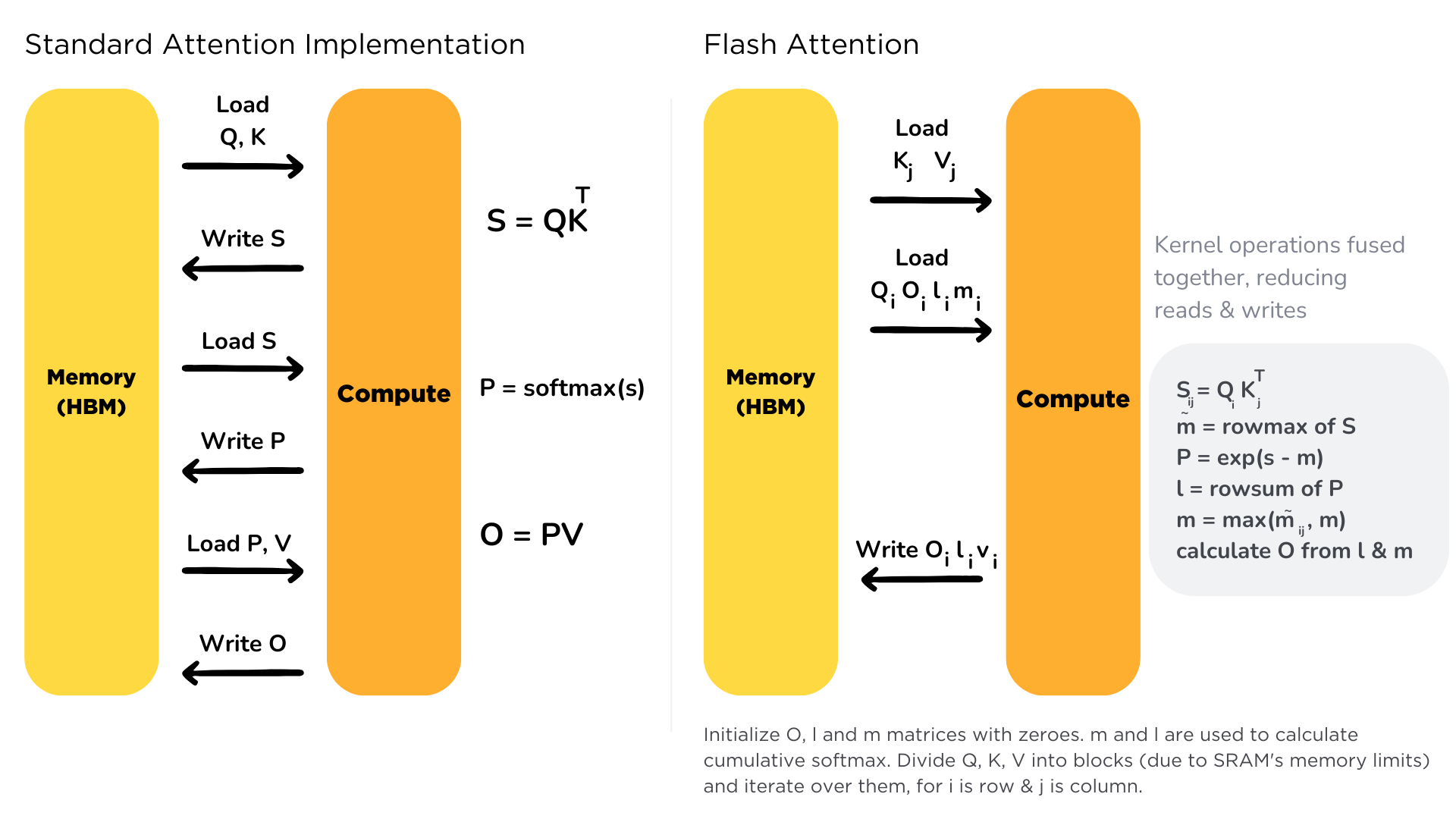
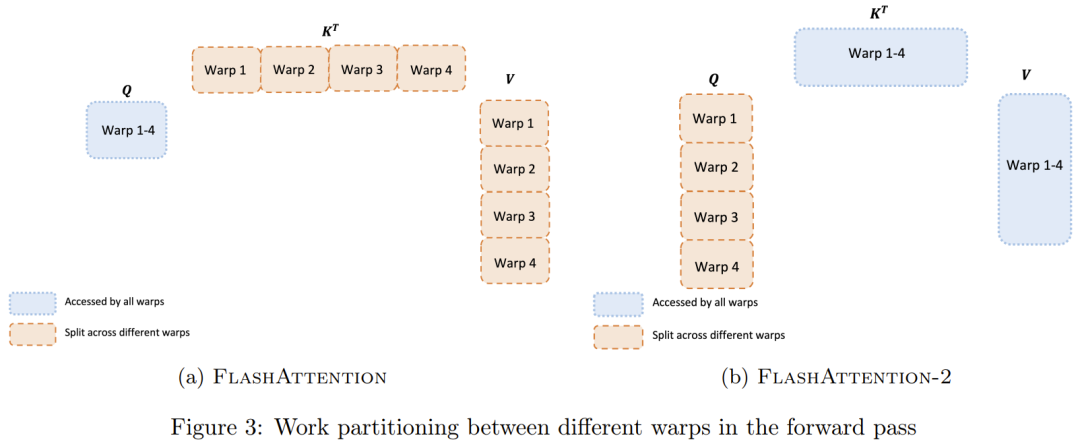
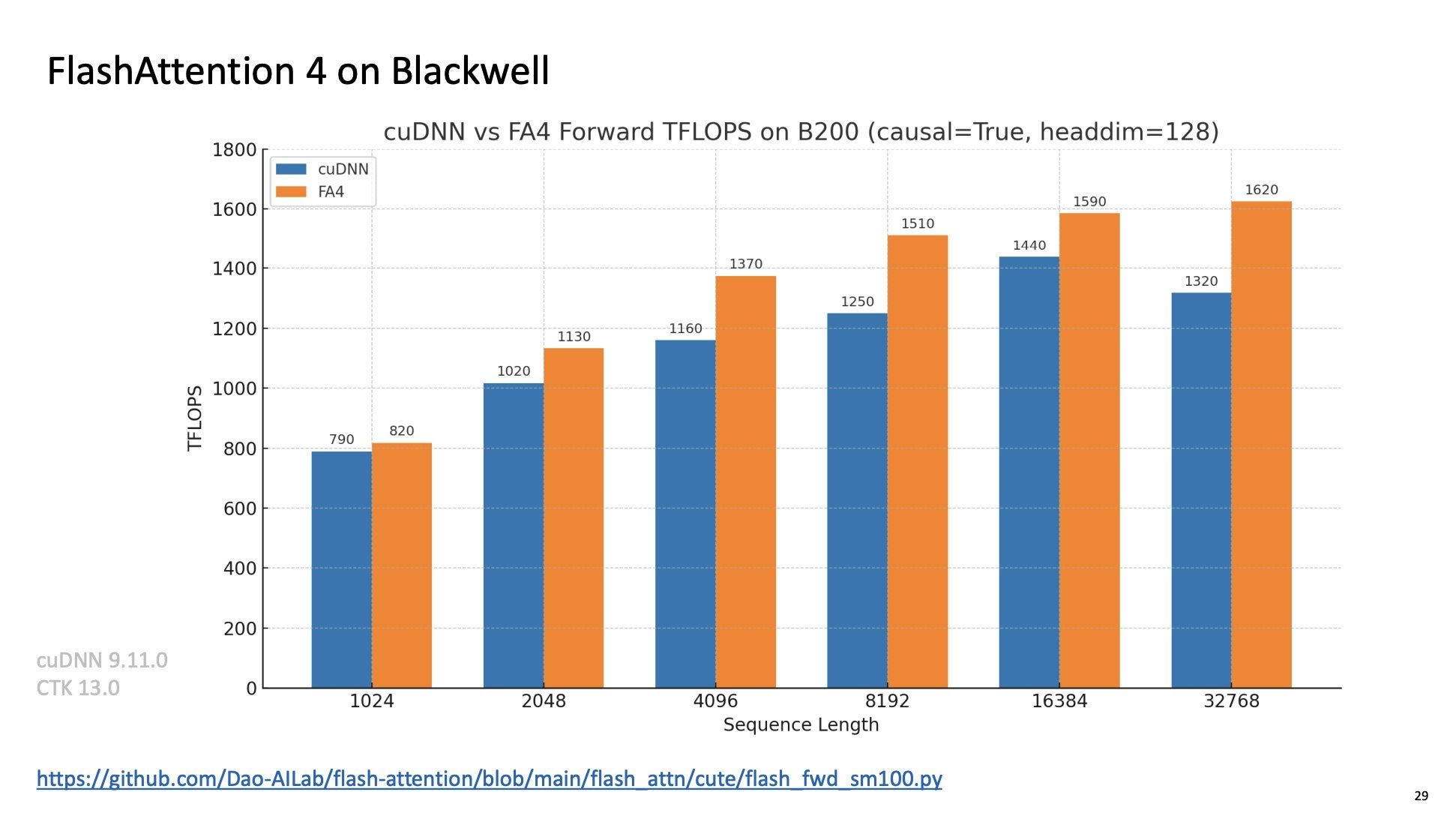
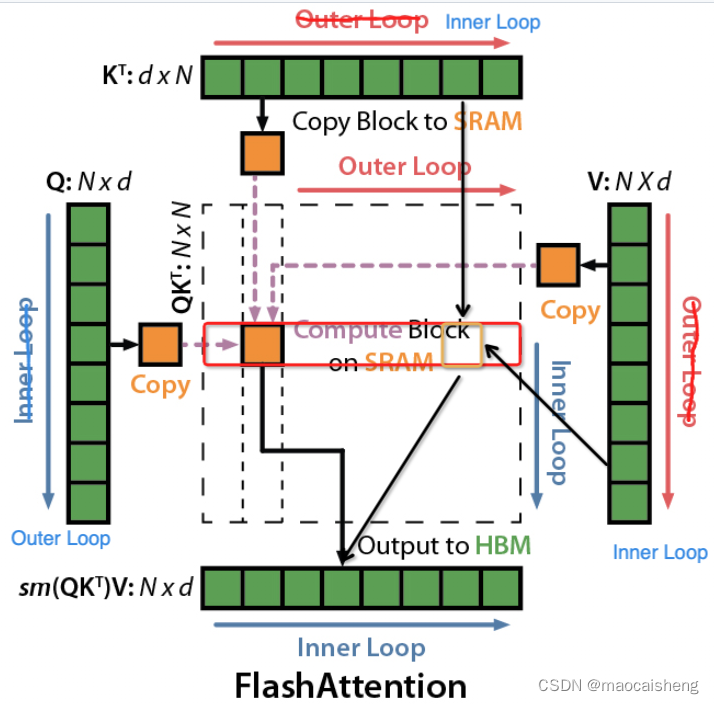
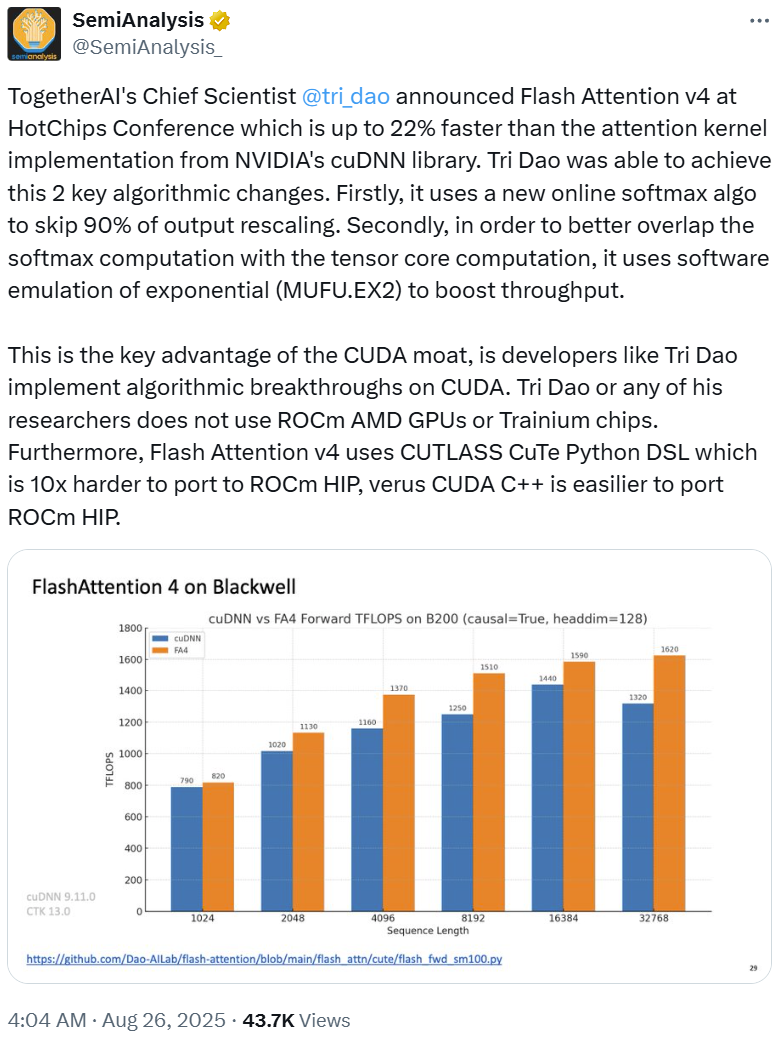
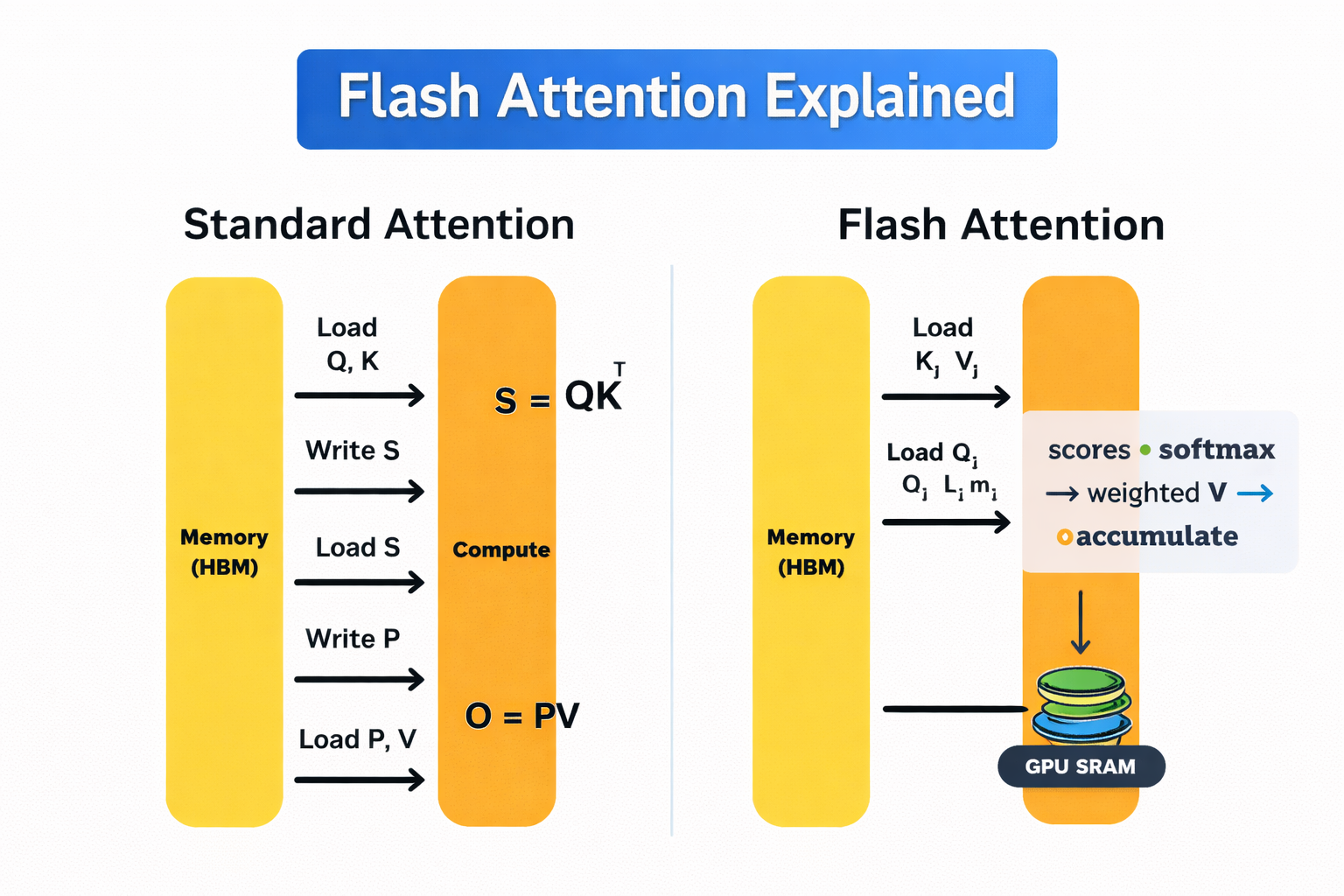
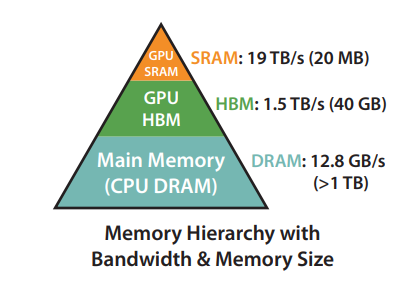
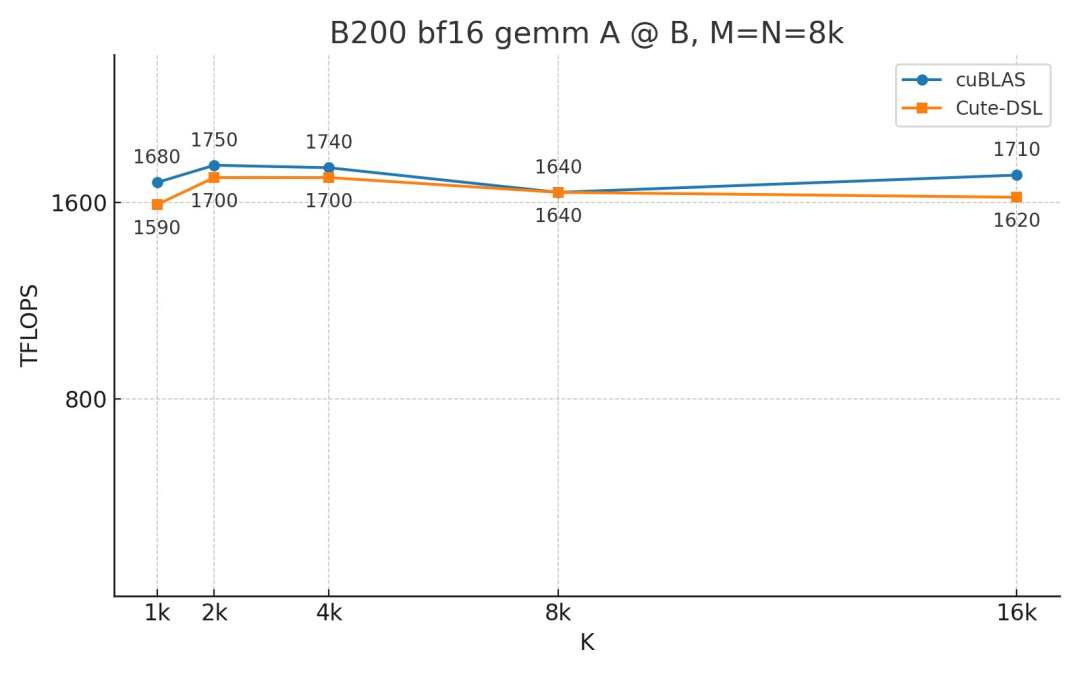
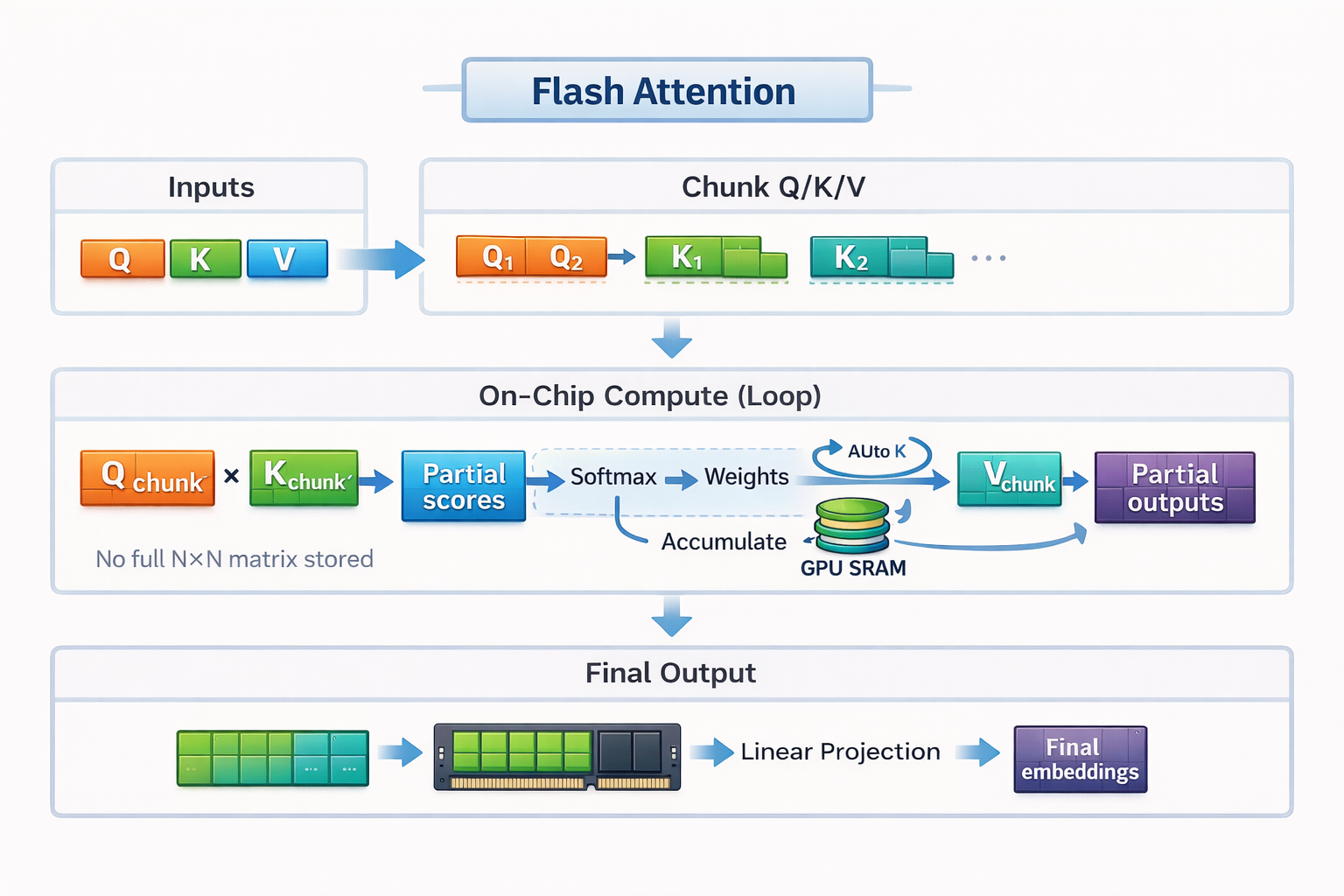
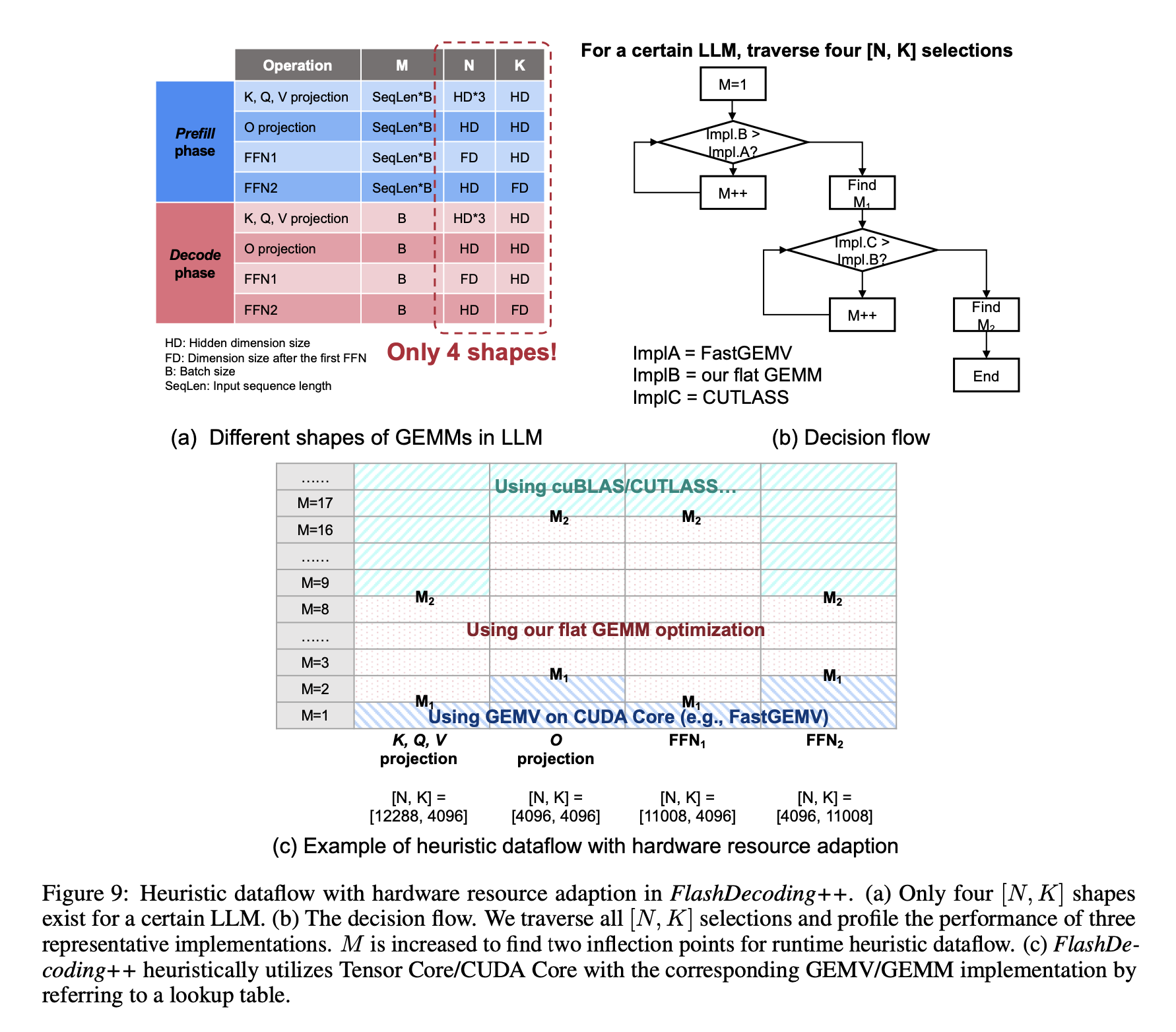
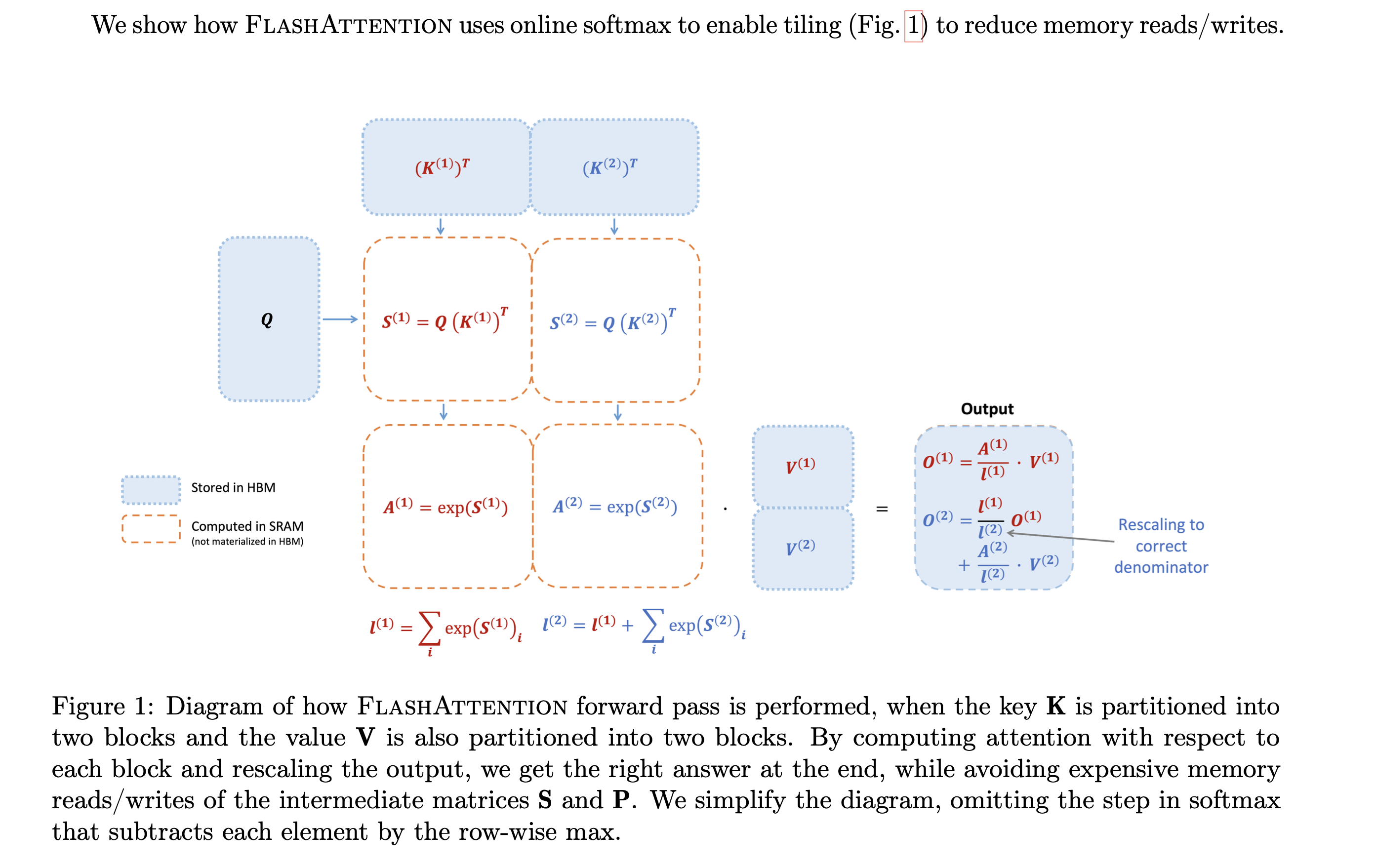
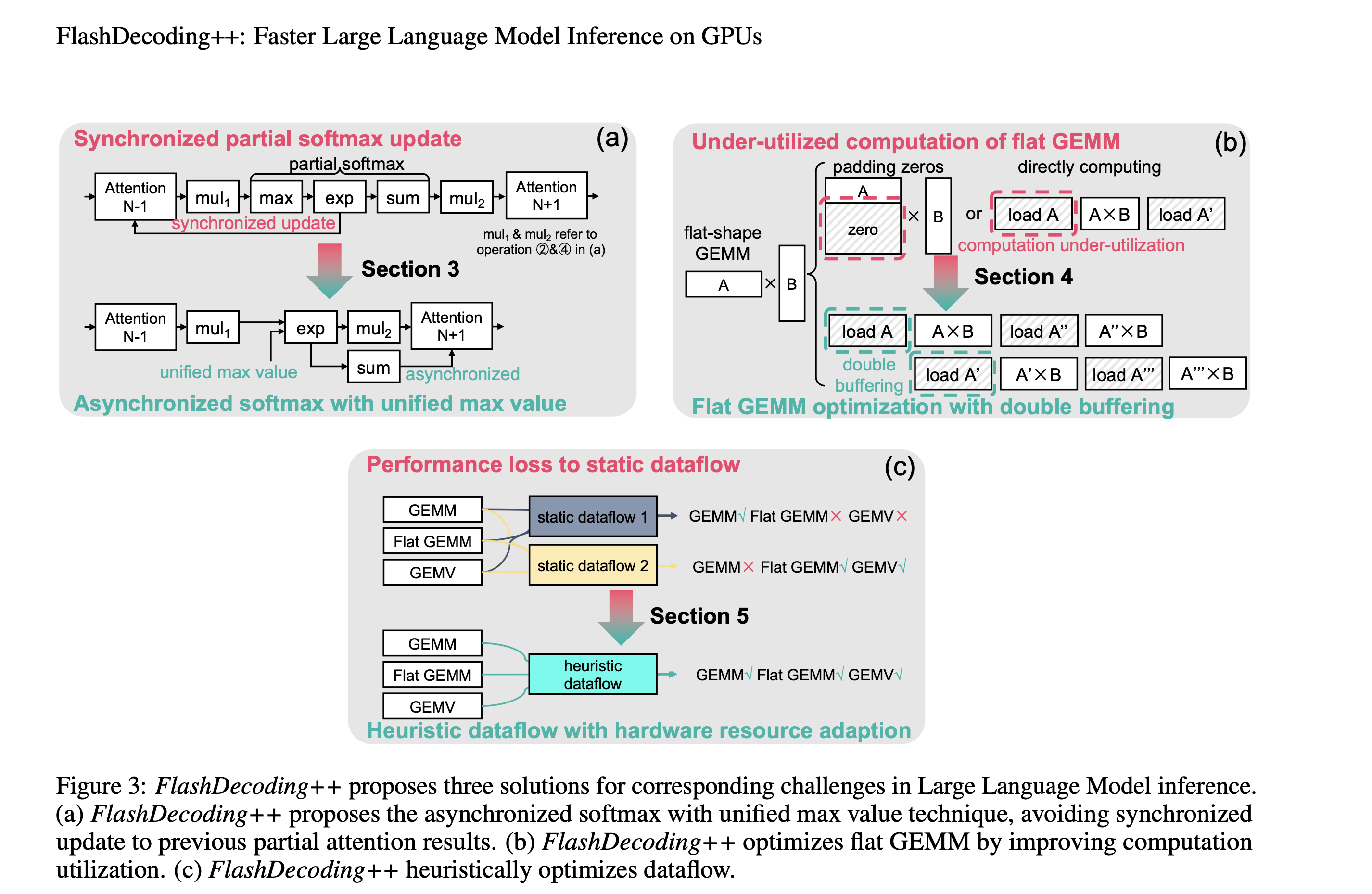
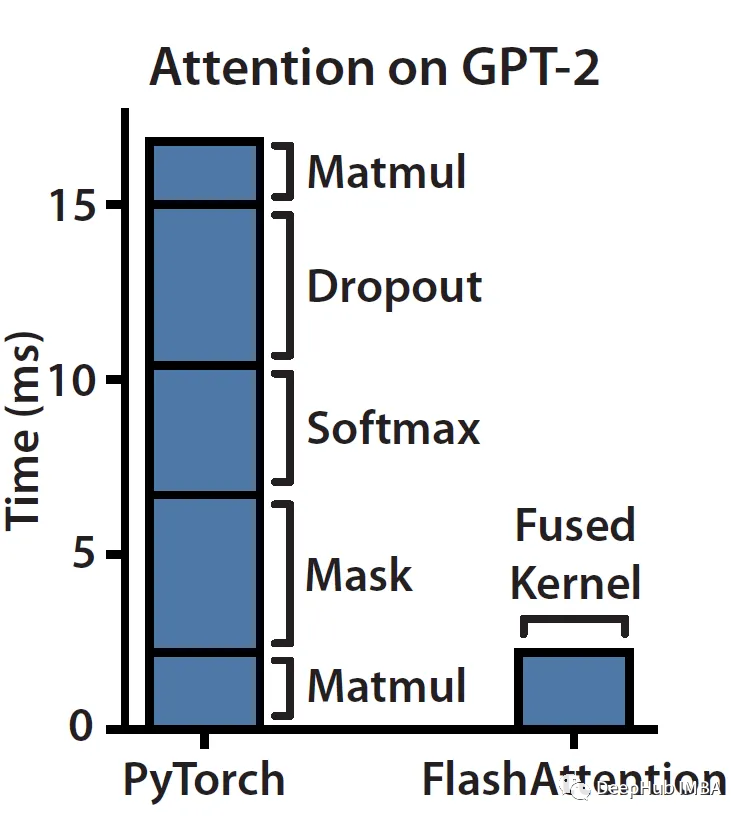
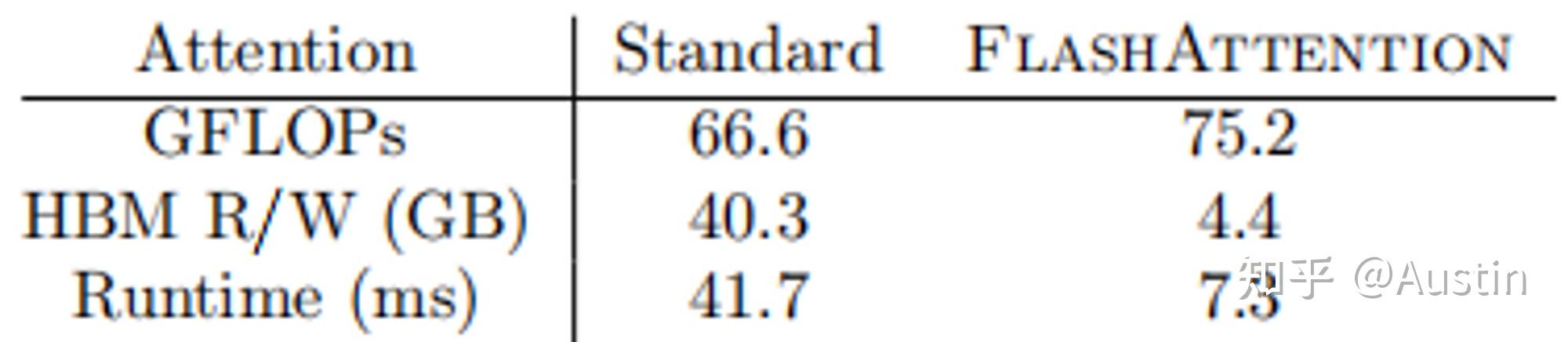
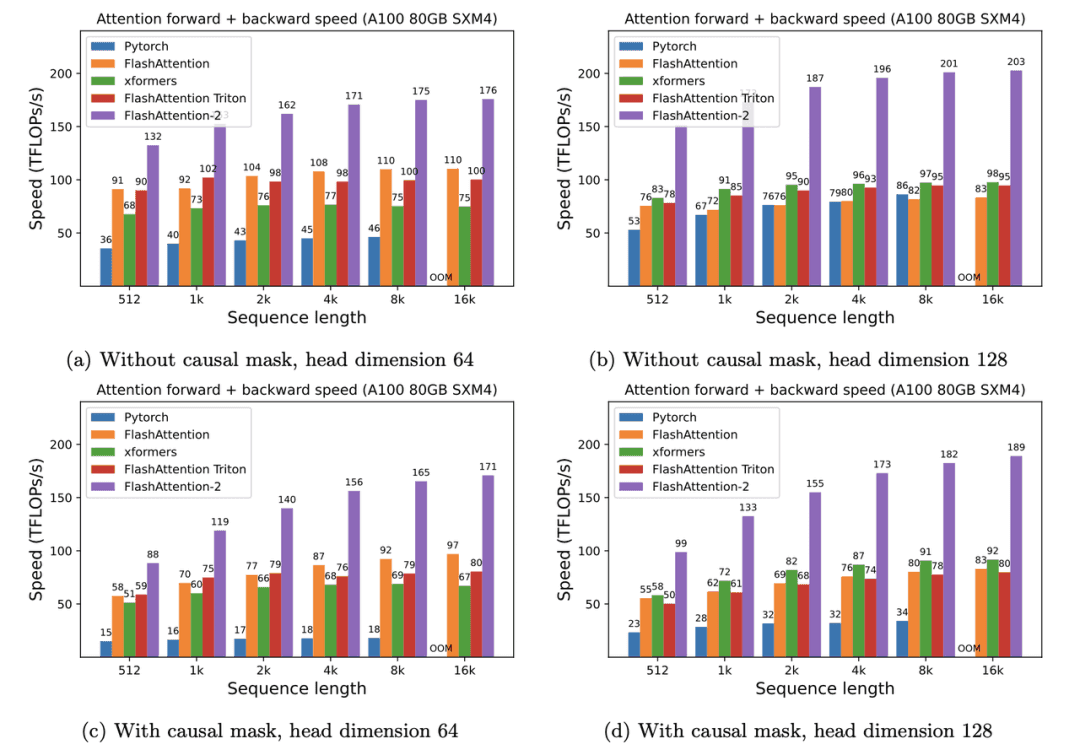
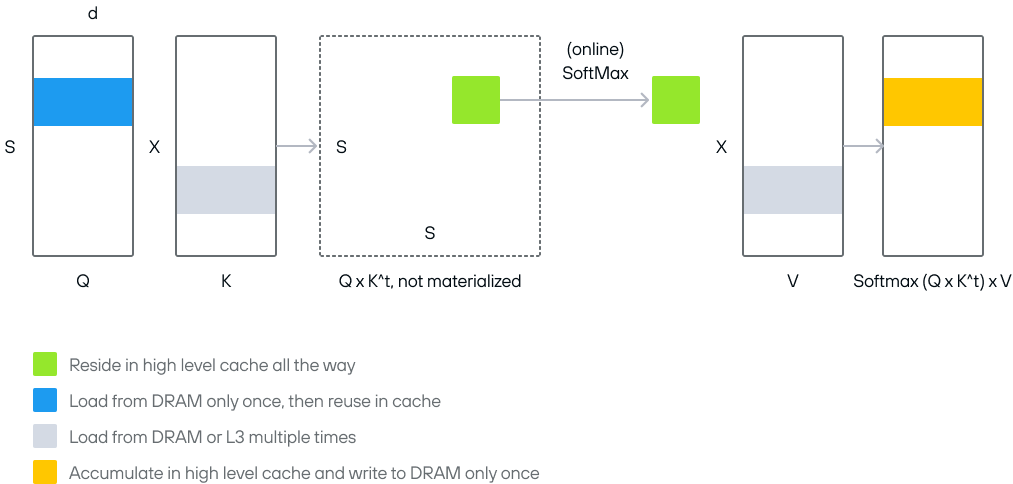
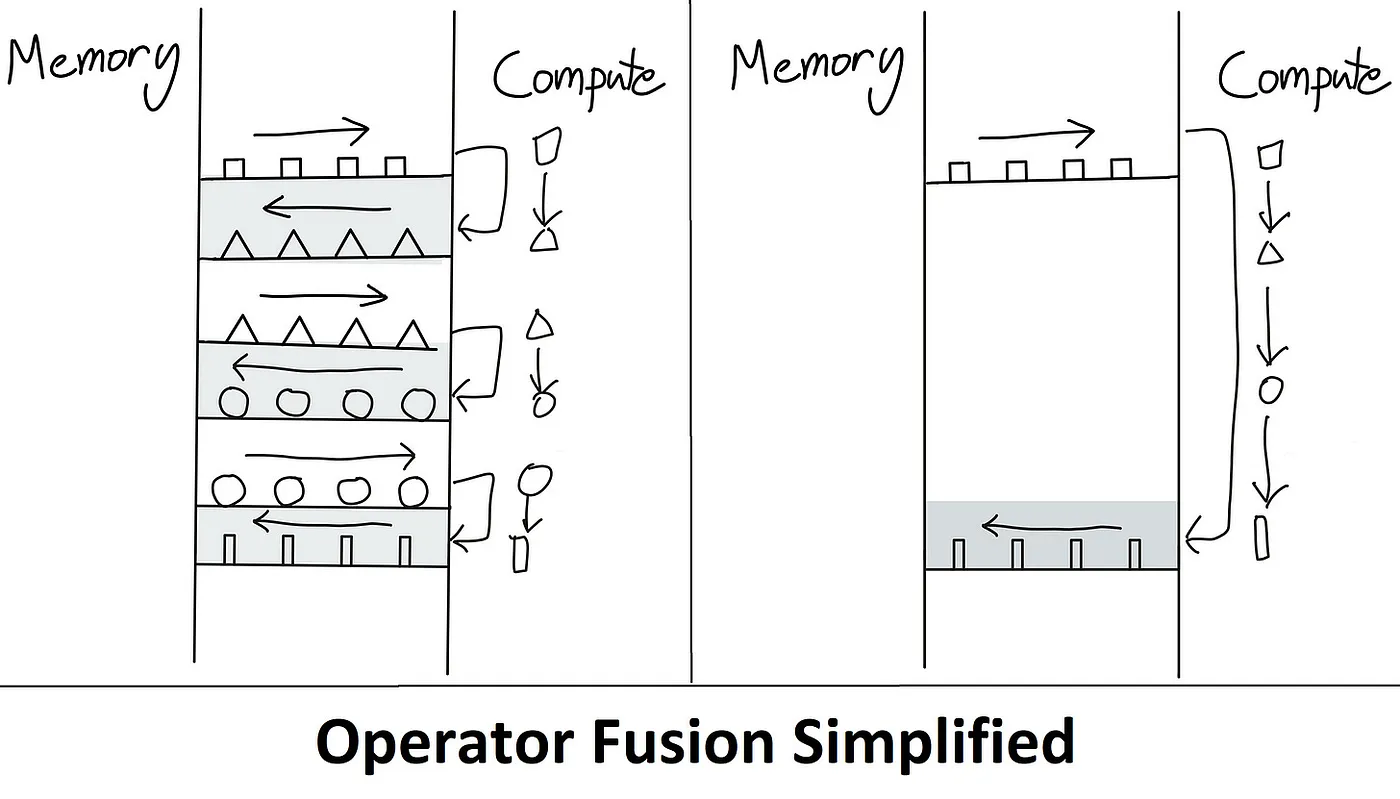
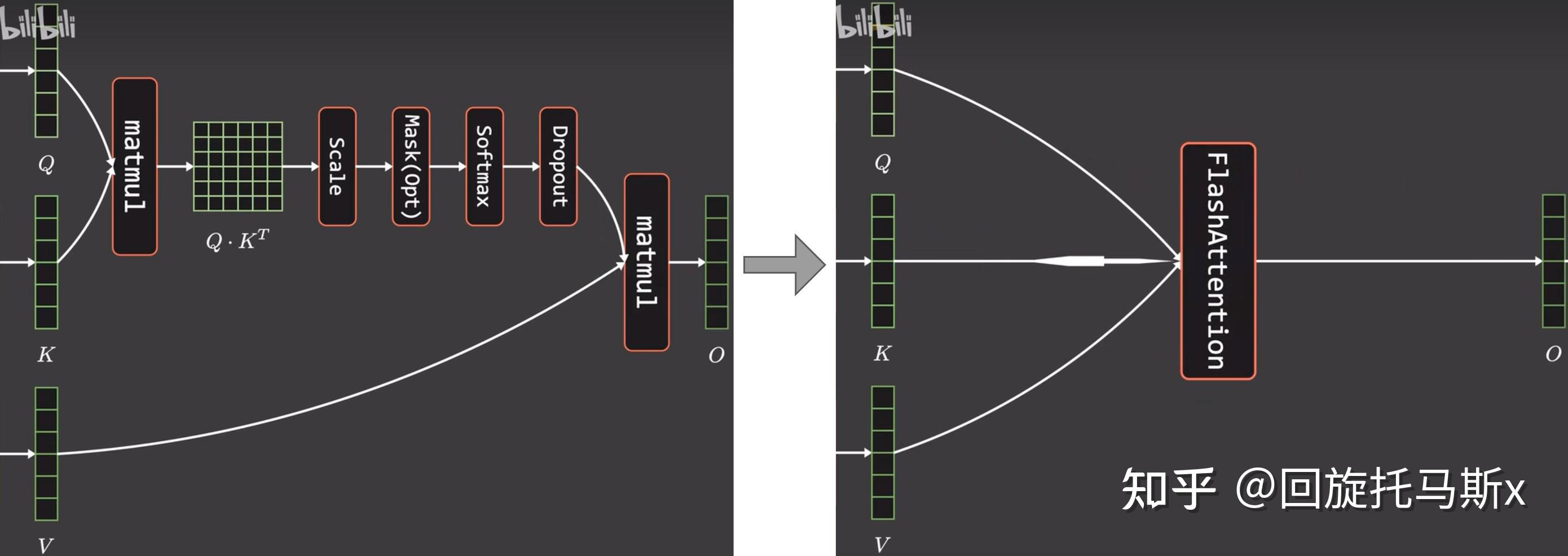
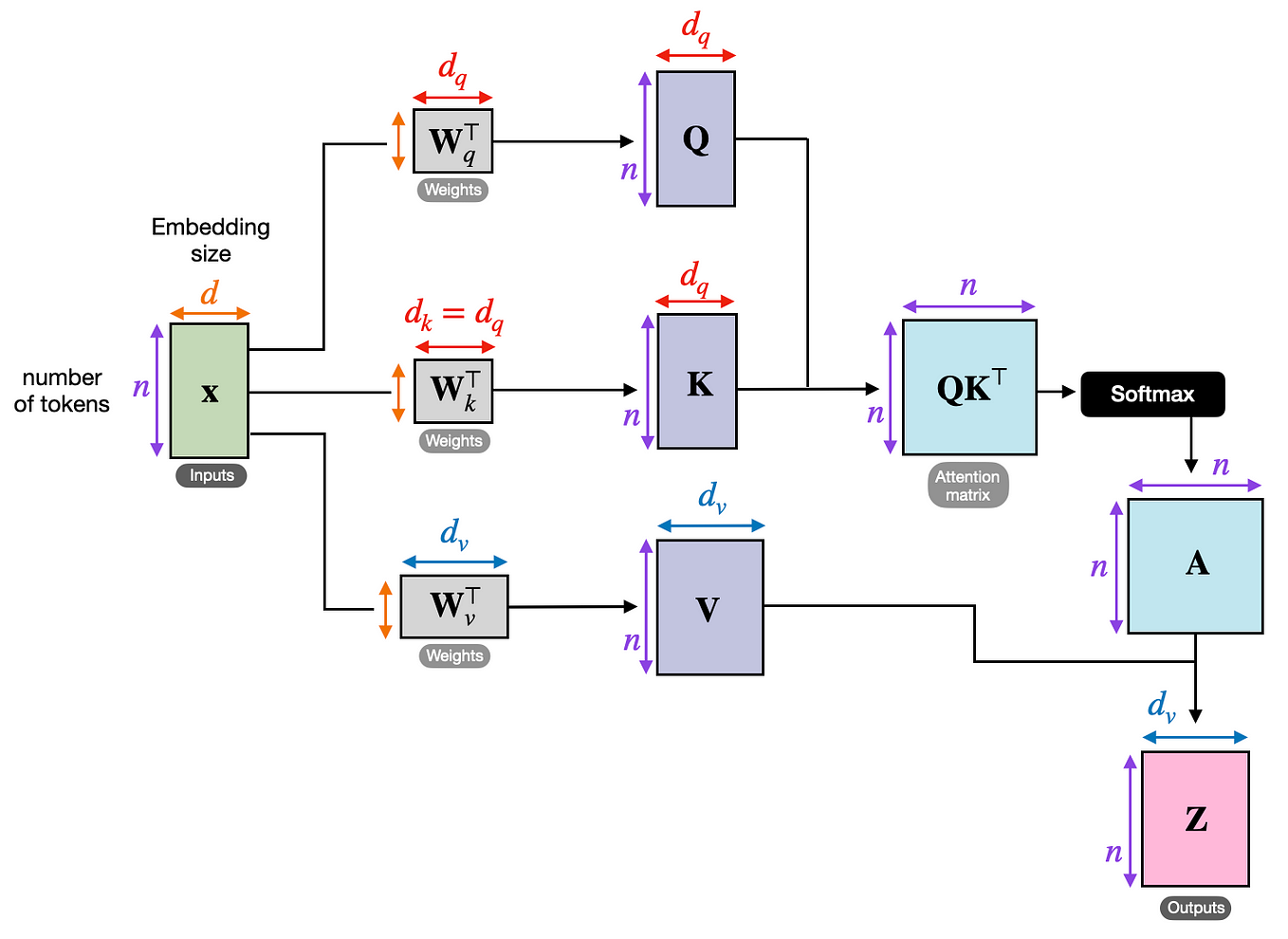
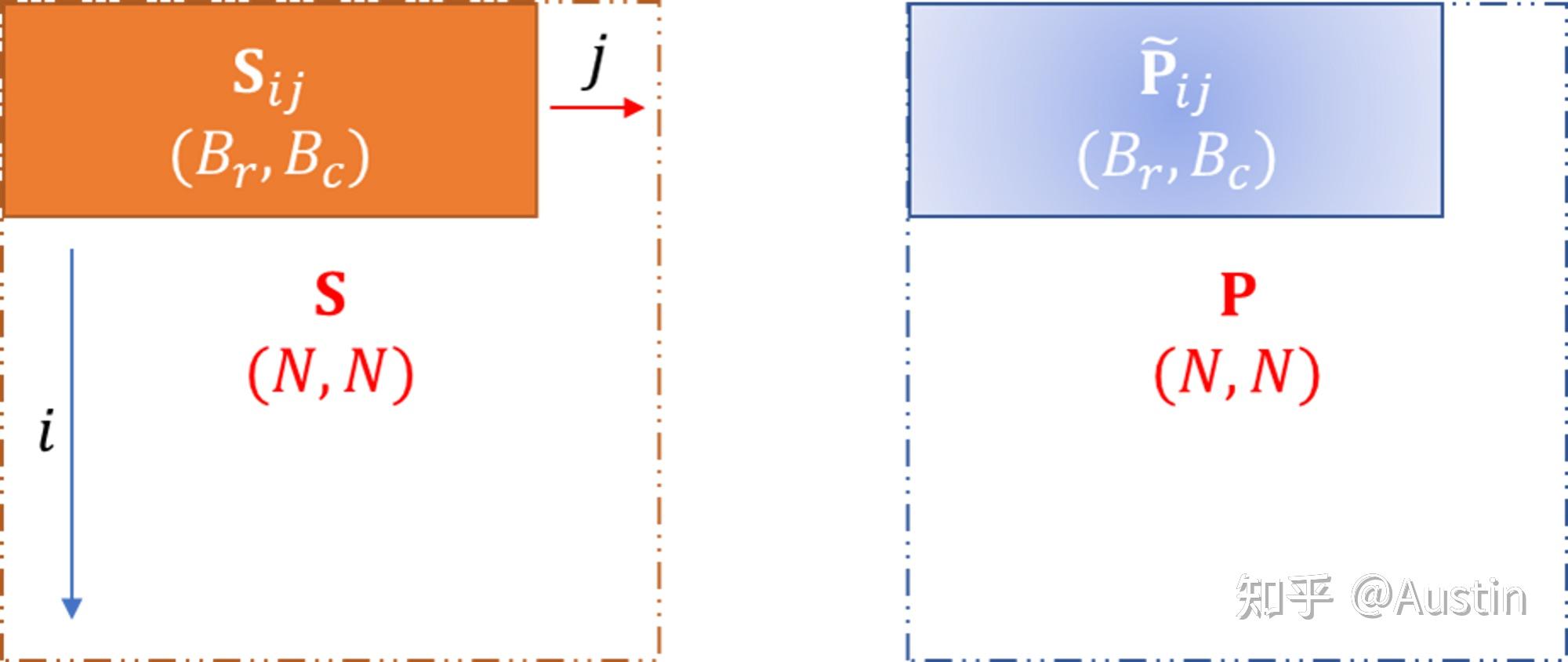
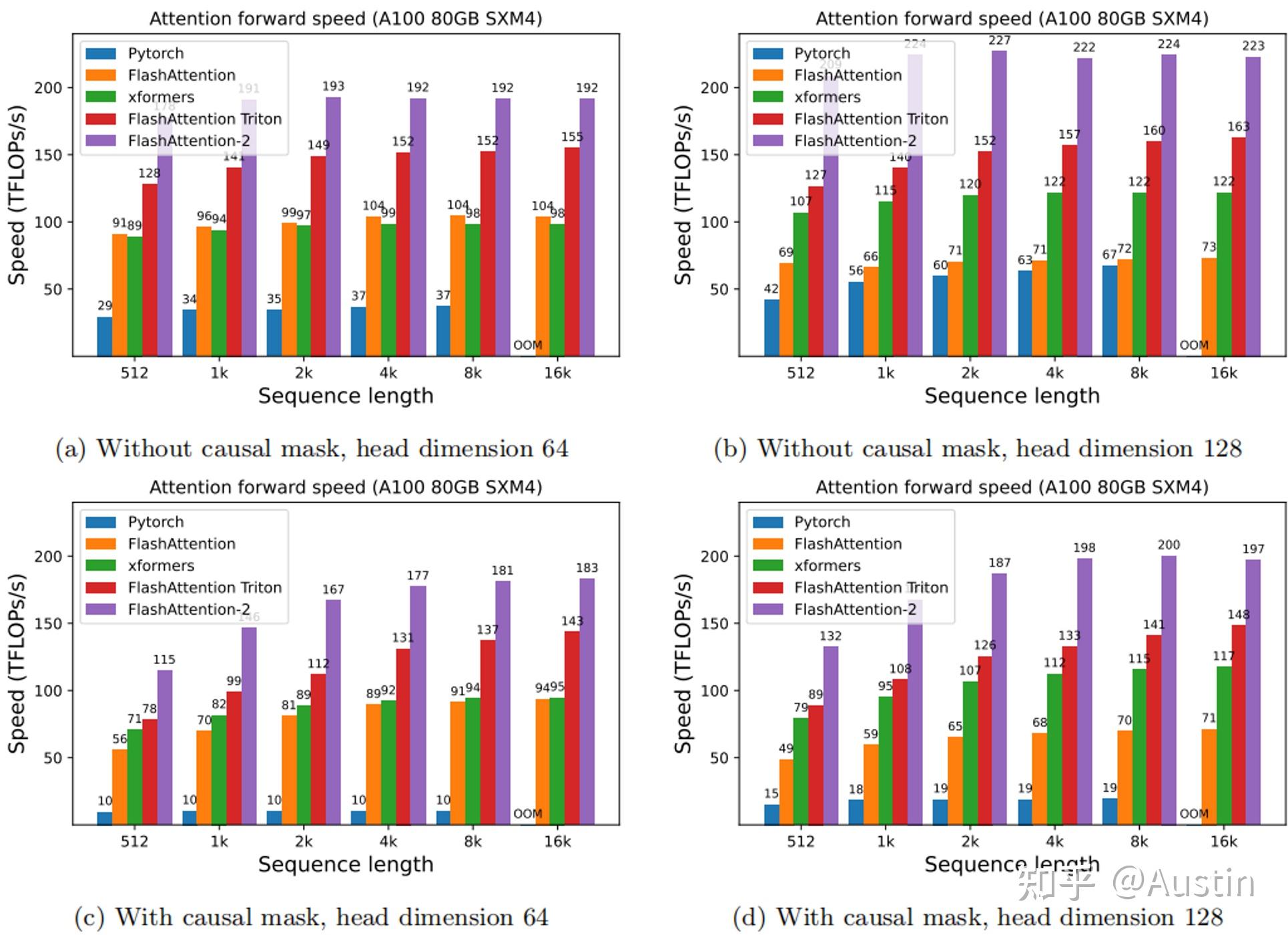
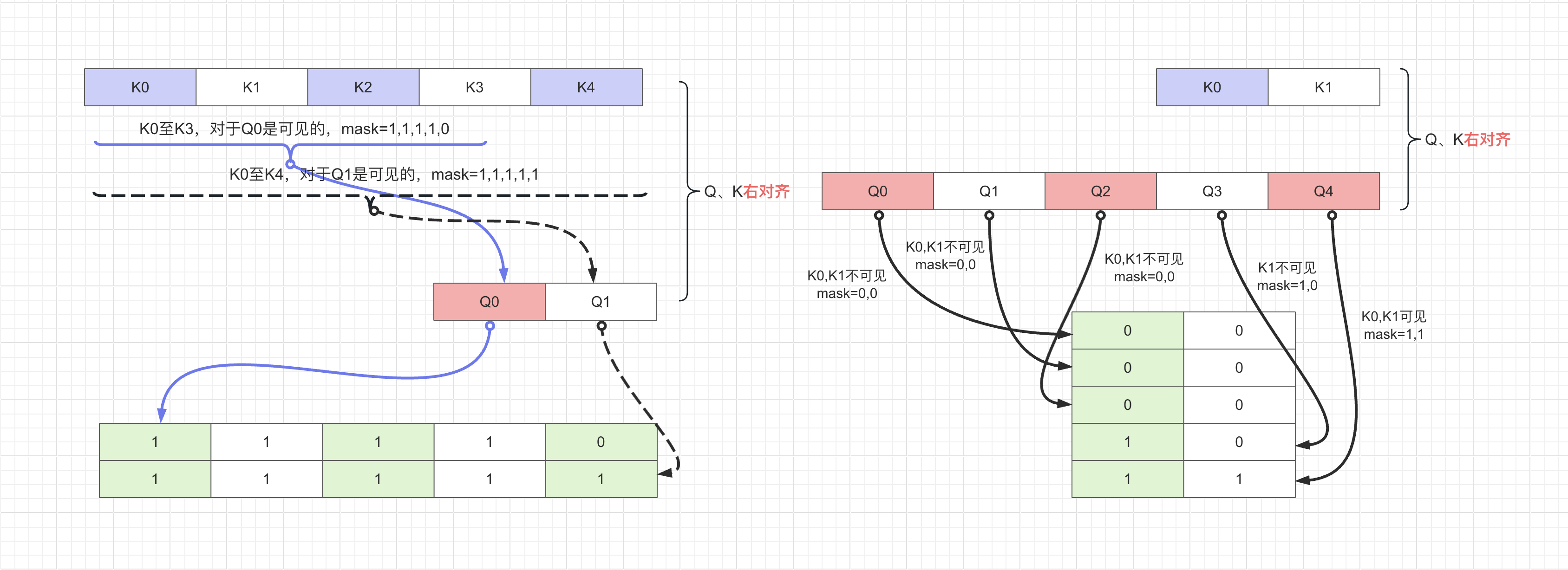
FlashAttention 4: Breaking the Petaflop Barrier in GPU Attention ...
Will flash attention support Blackwell GPU in the future? · Issue #1733 ...
Breaking the petaflop barrier | IBM
Attention 与 FlashAttention 深入原理剖析-公式推导-FlashAttention(V1/V2/V3)对比-主流大模型 ...
FlashAttention & Paged Attention: GPU Sorcery for Blazing-Fast ...
The Flash Attention Algorithm Implemented on Modern GPUs | Medium ...
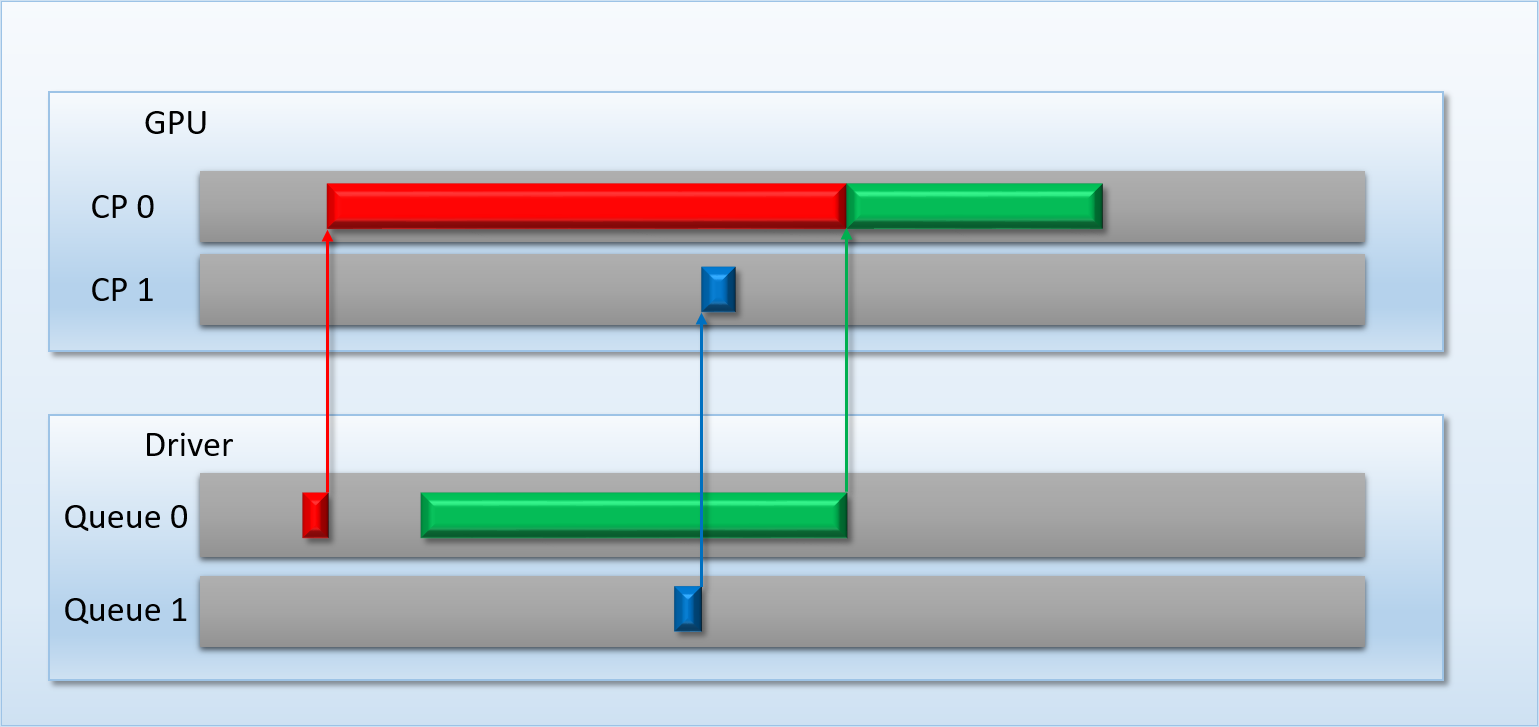
Breaking Down Barriers - Part 4: GPU Preemption
Nvidia Increased Compute Power 1000X in 8 Years to 20 Petaflops in the ...
GPU 内存不够?让 FlashAttention 教你“一小块一小块”做 Attention - 知乎
Sage Attention the next Flash Attention? SageAttention is a 4/8-bit ...
Breaking the Context Barrier: An Architectural Deep Dive into Ring ...
100 Petaflop AI Chip and 100 Zettaflop AI Training Data Centers in 2027 ...
FlashAttention with PyTorch Compile - Benchmarking FlashAttention and ...
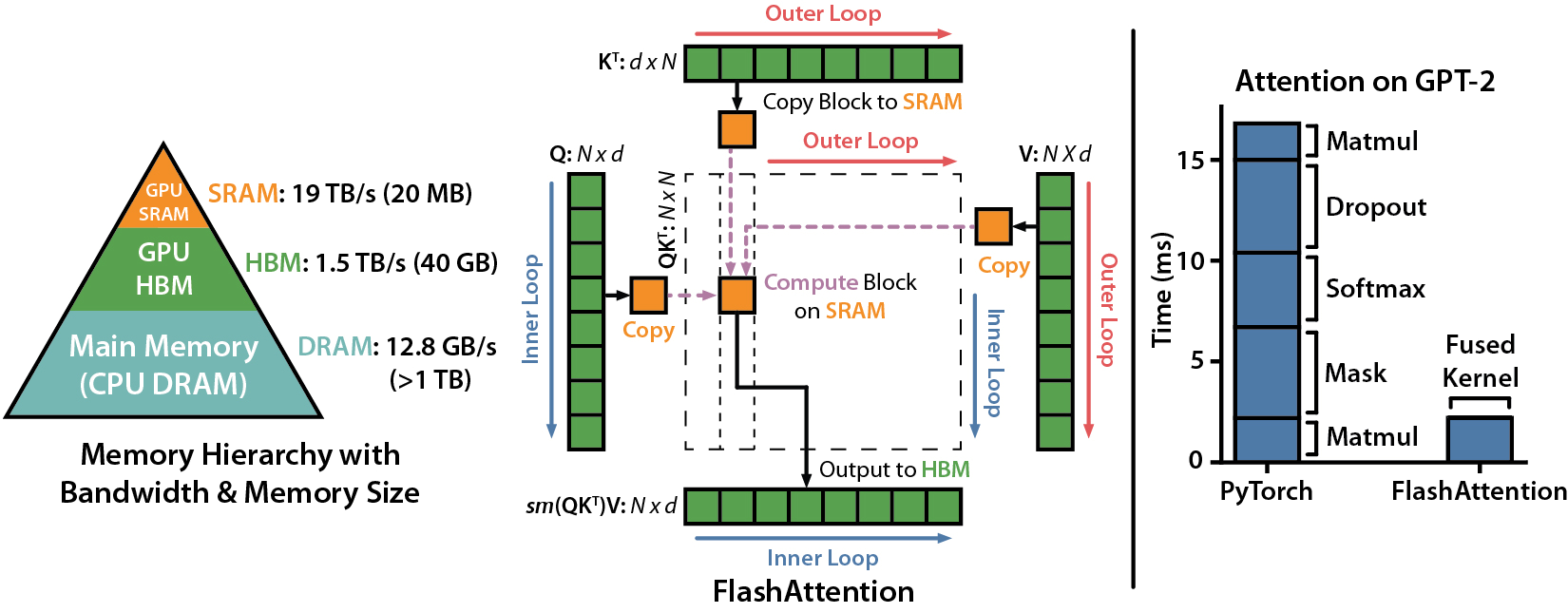
Flash attention(Fast and Memory-Efficient Exact Attention with IO ...
FlashAttention-4 on GPU Cloud: Blackwell Inference Guide (2026 ...
Flash Attention on INTEL GPU - 知乎
FlashAttention works with single GPU, but crash with accelerate DP on ...
Understanding GPU and FlashAttention
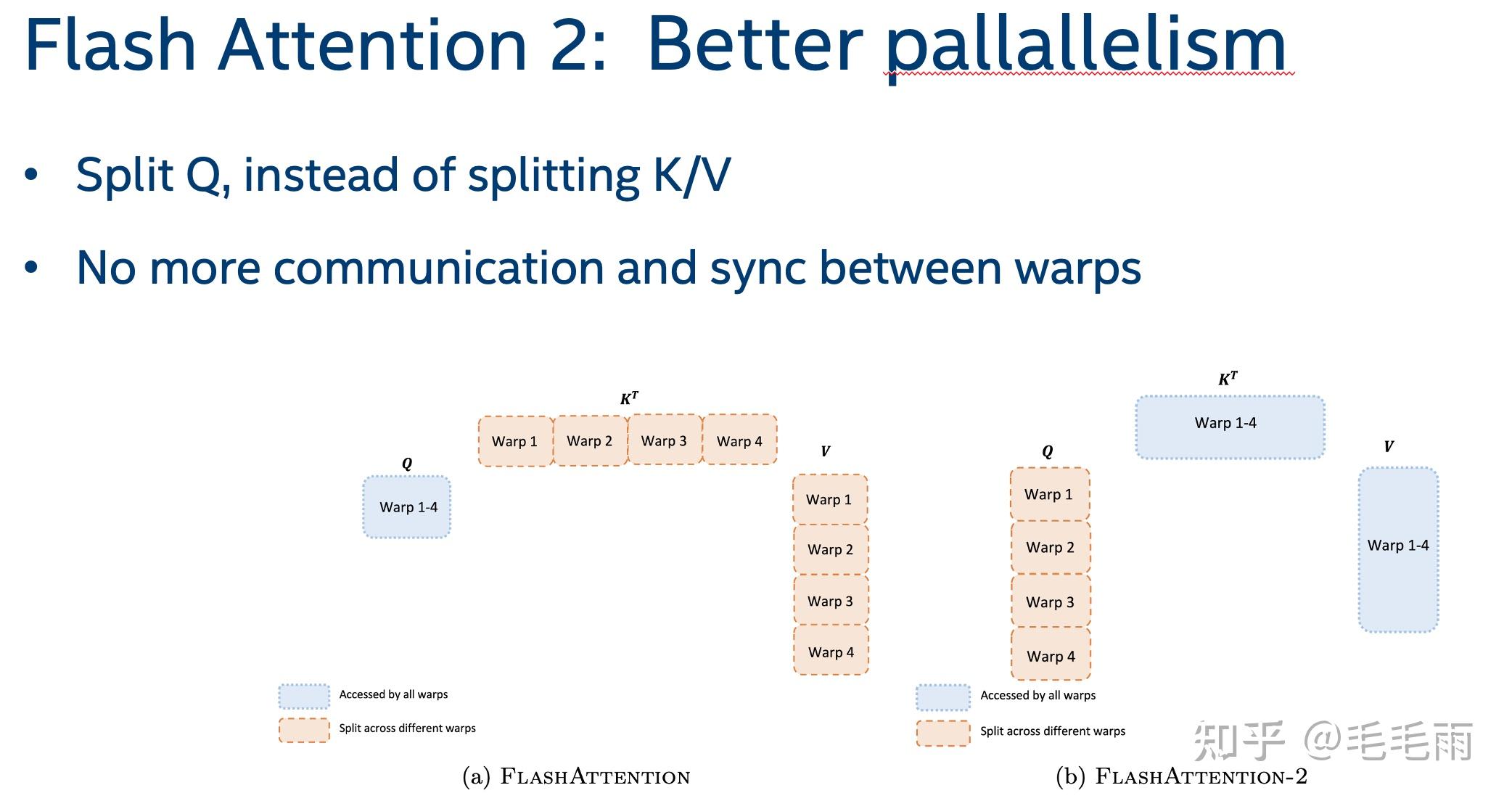
Flash Attention 2: Reducing GPU Memory and Accelerating Transformers
GPU MODE Lecture 13: Ring Attention – Christian Mills
Nvidia’s next-gen AI GPU is 4X faster than Hopper: Blackwell B200 GPU ...
FlashAttention-T: Optimización GPU para LLMs Escalables – El Ecosistema ...
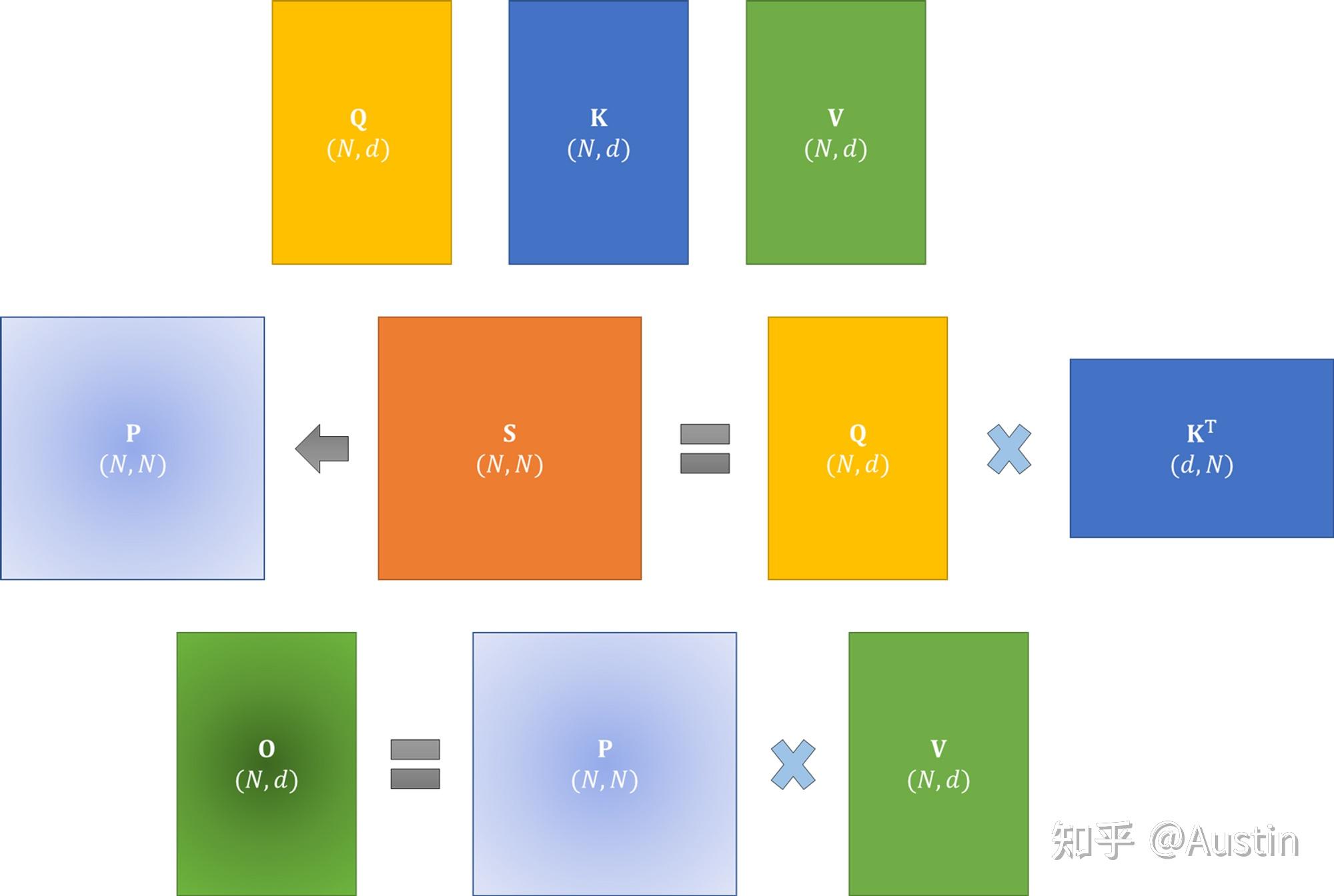
FlashAttention: Fast and Memory-Efficient Exact Attention with IO ...
LLM(17):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能 - 知乎
FlashAttention:Fast and Memory-Efficient Exact Attention with IO ...
NERSC's Hopper supercomputer breaks petaflop barrier; better research ...
Flash Attention
FlashAttention-4震撼来袭,原生支持Blackwell GPU_flash attention 4-CSDN博客
We reverse-engineered Flash Attention 4
Flash Attention(Flash attention with bias)_flashattention 量化-CSDN博客
Flash-Attention 1&2 论文理解_flash attention diag-CSDN博客
Flash Attention Explained: A Comprehensive Guide | DataCamp
GitHub - chinmaydk99/Flash_Attention_v2_GPU_Optimized: Custom ...
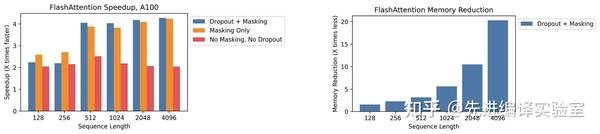
斯坦福博士一己之力让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升 - CV技术 ...
NVIDIA Blackwell Delivers World-Record DeepSeek-R1 Inference ...
Paper Summary #8 - FlashAttention: Fast and Memory-Efficient Exact ...
Transformer 的核心就是 Attention(注意力)機制。🧠 不過隨著模型越來越大,Attention 的運算效率變成了瓶頸。😓 ...
PetaFLOPS Inference Era: 1 PFLOPS Attention, and Preliminary End-to-End ...
[논문 리뷰] INT-FlashAttention: Enabling Flash Attention for INT8 Quantization
[LLM] FlashAttention 加速attention计算[理论证明|代码解读] - 知乎
Flash Attention|flash attention V1 V2 V3 V4 如何加速 attention — huzixia
IBM's Roadrunner breaks petaflop barrier, tops supercomputer list - CNET
We reverse-engineered Flash Attention 4 | Modal Blog
NVIDIA Blackwell B200 AI Chip Unveiled at GTC 2024, Boasts 20 Petaflops ...
从零开始理解FlashAttention:注意力机制、GPU架构和CUDA编程模型图解_flash attention-CSDN博客
FlashAttention算法详解_flashattention2详解-CSDN博客
FlashAttention图解(如何加速Attention) - 知乎
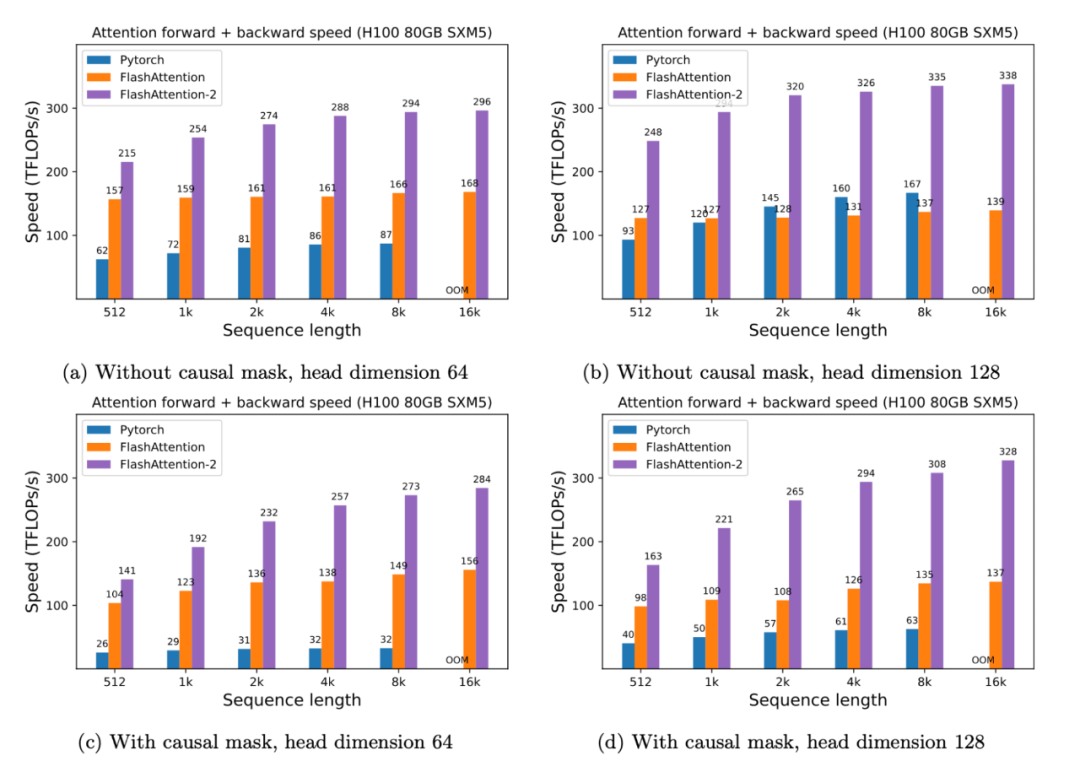
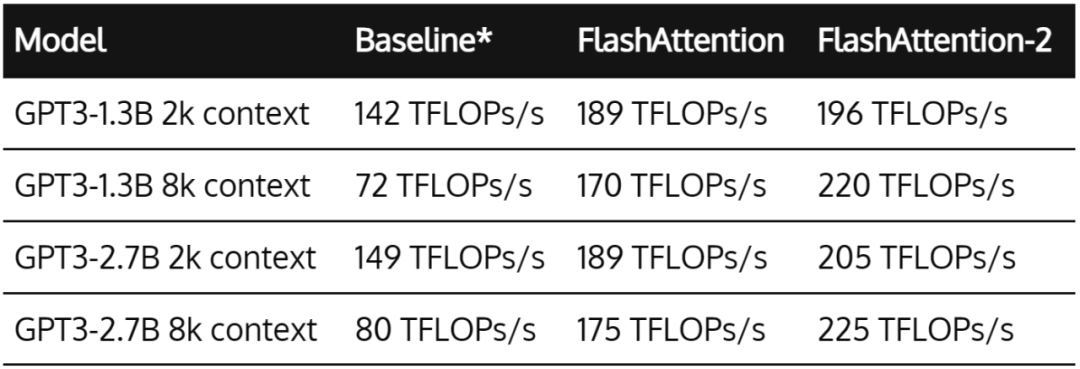
比标准Attention提速5-9倍,大模型都在用的FlashAttention v2来了-阿里云开发者社区
比标准Attention提速5-9倍,大模型都在用的FlashAttention v2来了-腾讯云开发者社区-腾讯云
彻底弄懂Flash-Attention原理 - 知乎
FlashAttention算法详解 - 智源社区
FlashAttention:具有 IO 感知,快速且内存高效的新型注意力算法
What is flash attention? | Modular
Flash Attention论文解读 - 李理的博客
Accelerating Self-Attentions for LLM Serving with FlashInfer | FlashInfer
FlashAttention:加速计算,节省显存, IO感知的精确注意力 - 知乎
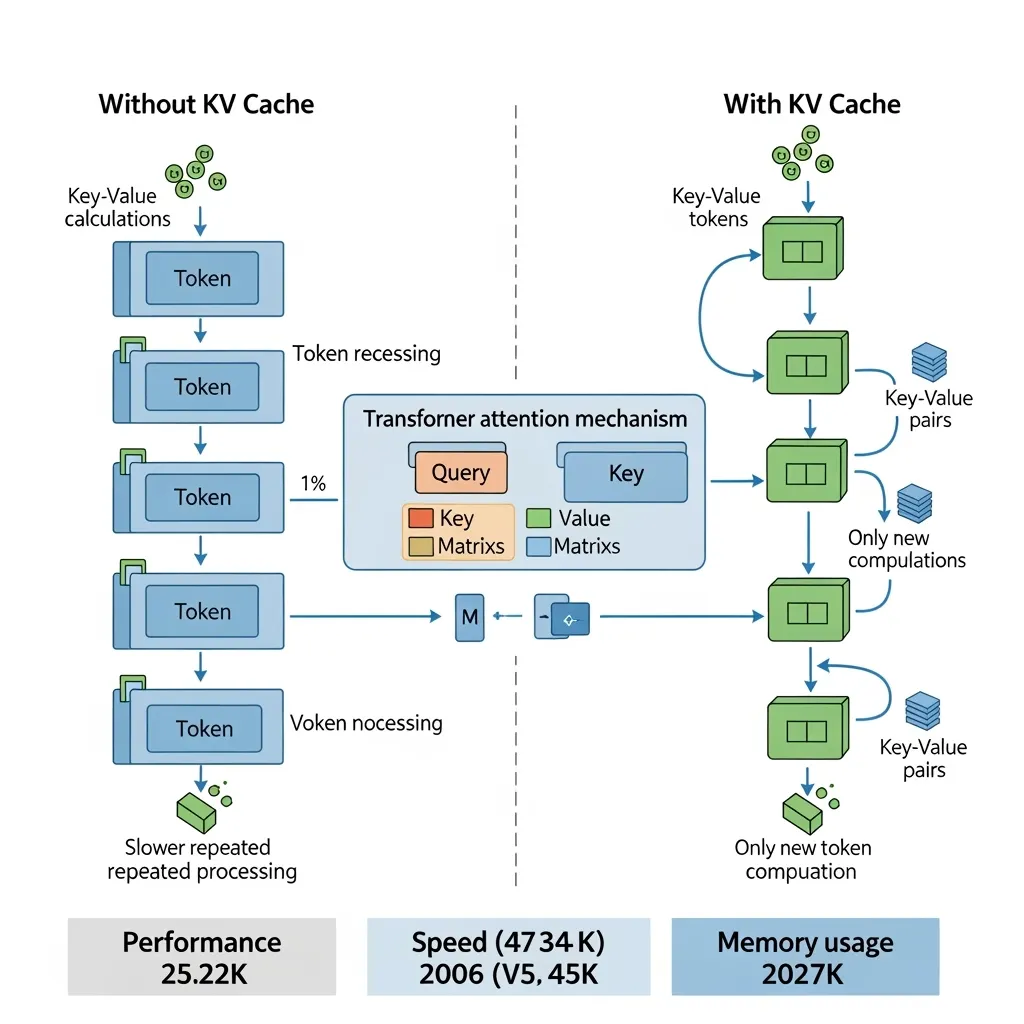
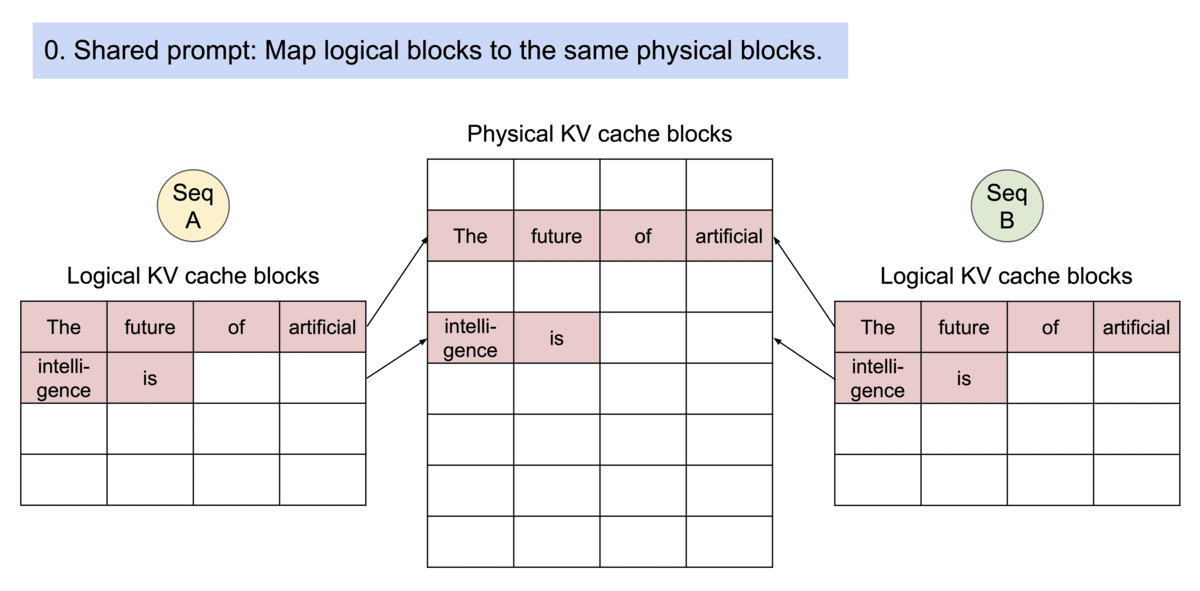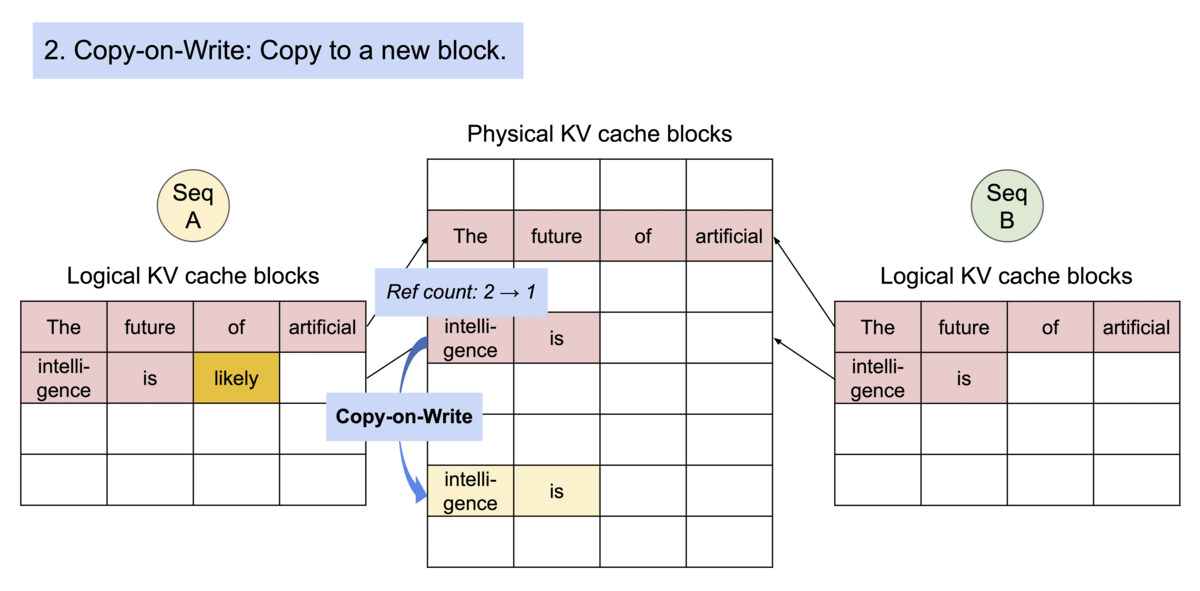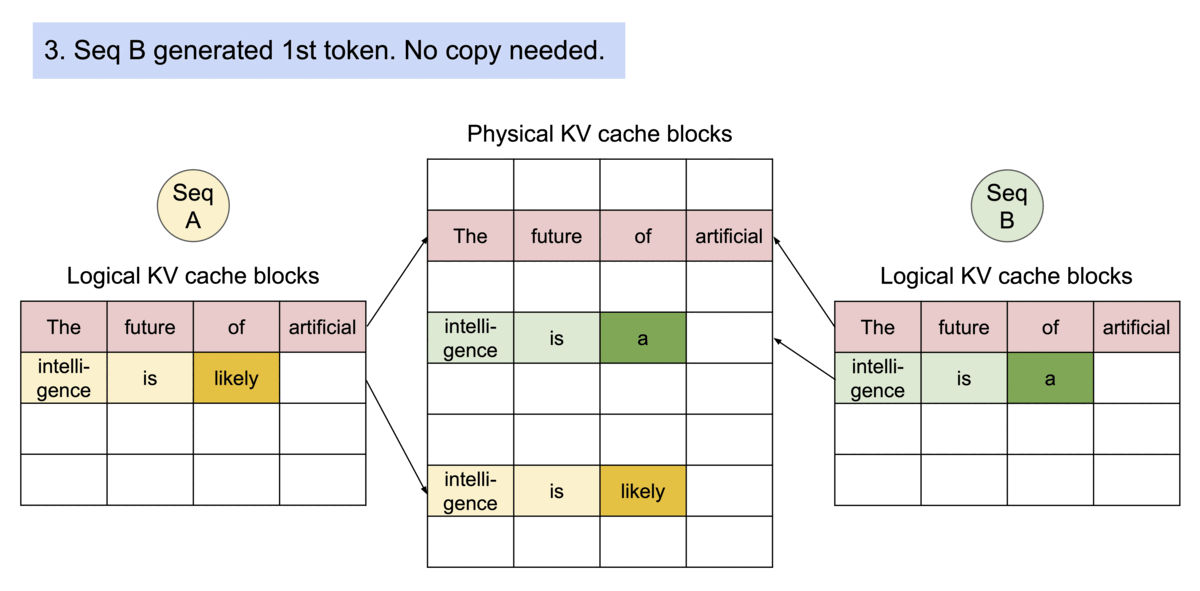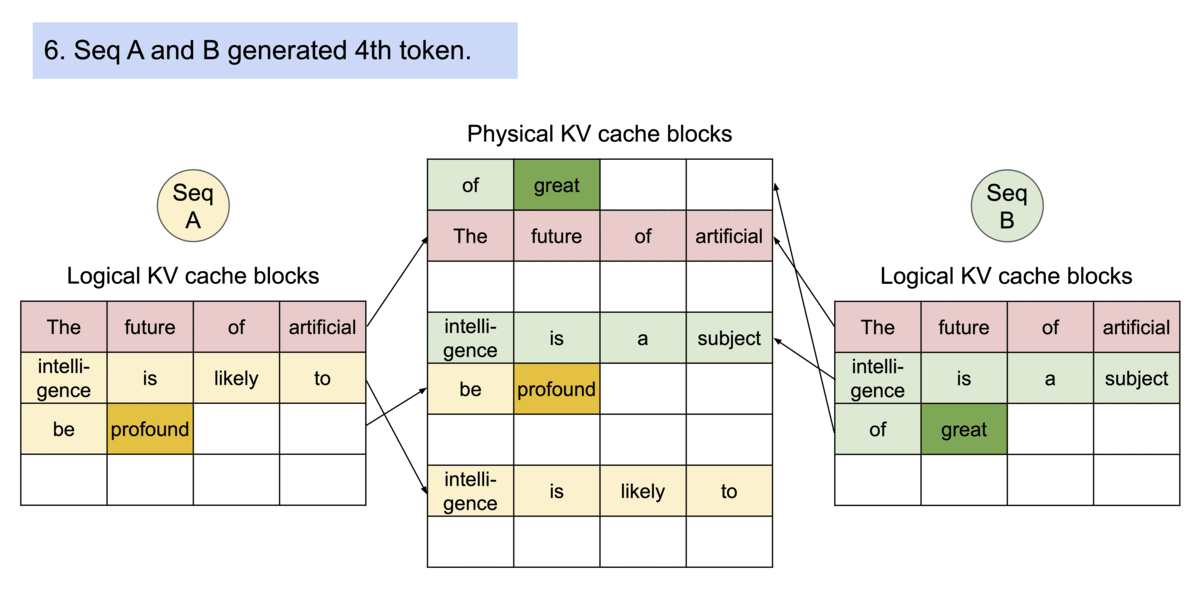
Transformers KV Caching Explained | by João Lages | Medium
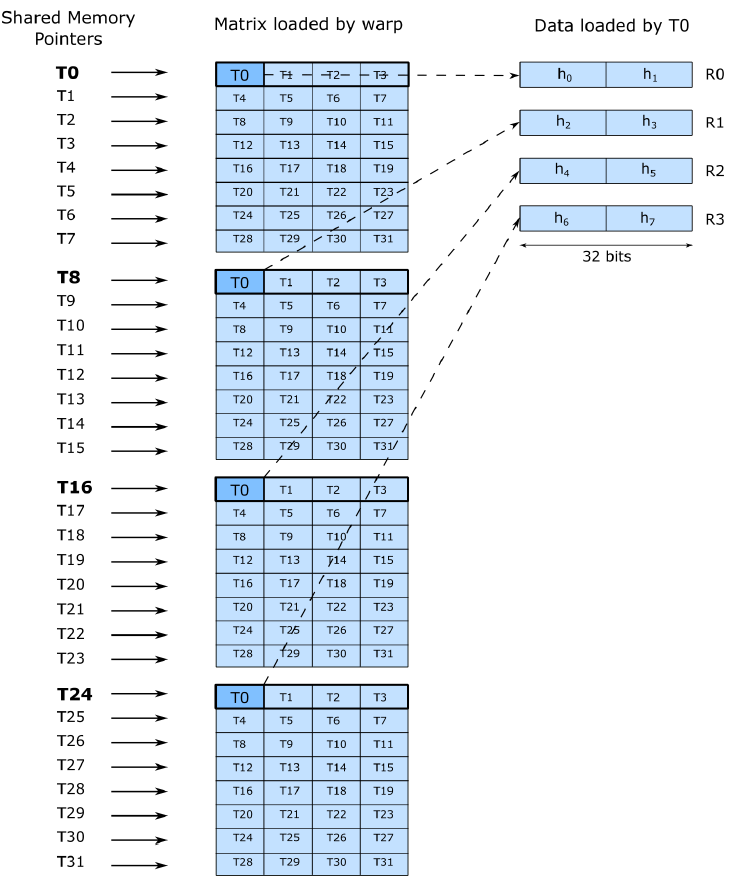
self-attention 的 CUDA 实现及优化 (上)_attention计算在gpu中流程-CSDN博客
FlashAttention-2 论文解读_flashattention2论文-CSDN博客
FlashAttention2详解(性能比FlashAttention提升200%) - 知乎
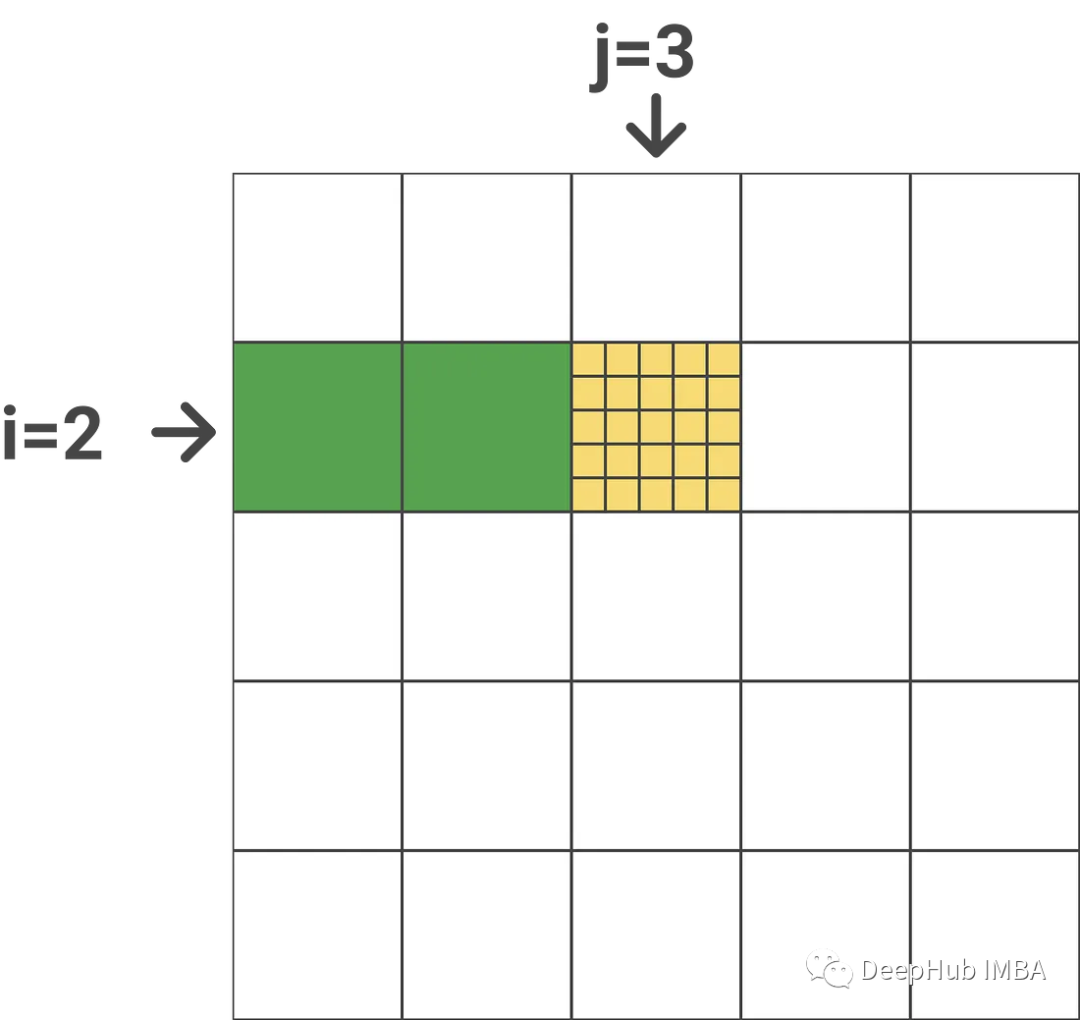
[Attention优化][2w字]📚原理篇: 从Online-Softmax到FlashAttention V1/V2/V3 - 知乎
FlashAttention: 更快训练更长上下文的GPT这篇Flash Attention的工作深入硬件,新提出了一种 - 掘金
flash attention利用GPU众核加速注意力计算_flashattention2支持哪些gpu-CSDN博客
Flash Attention原理简单解读 - 知乎
论文分享:新型注意力算法FlashAttention - 知乎
flash attention论文及源码学习_flash attention代码-CSDN博客
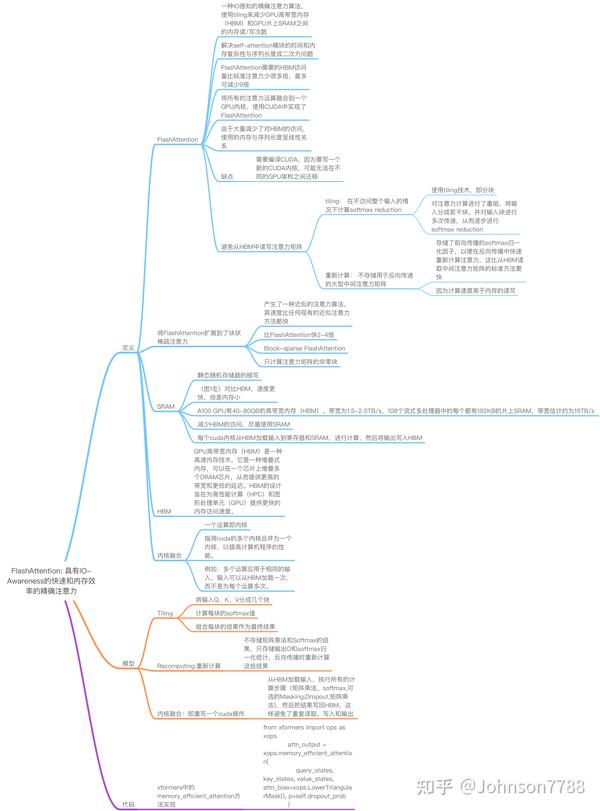
FlashAttention: 具有IO-Awareness的快速和内存效率的精确注意力 - 知乎
Installing FlashAttention-2 (CUDA) | Dao-AILab/flash-attention | DeepWiki