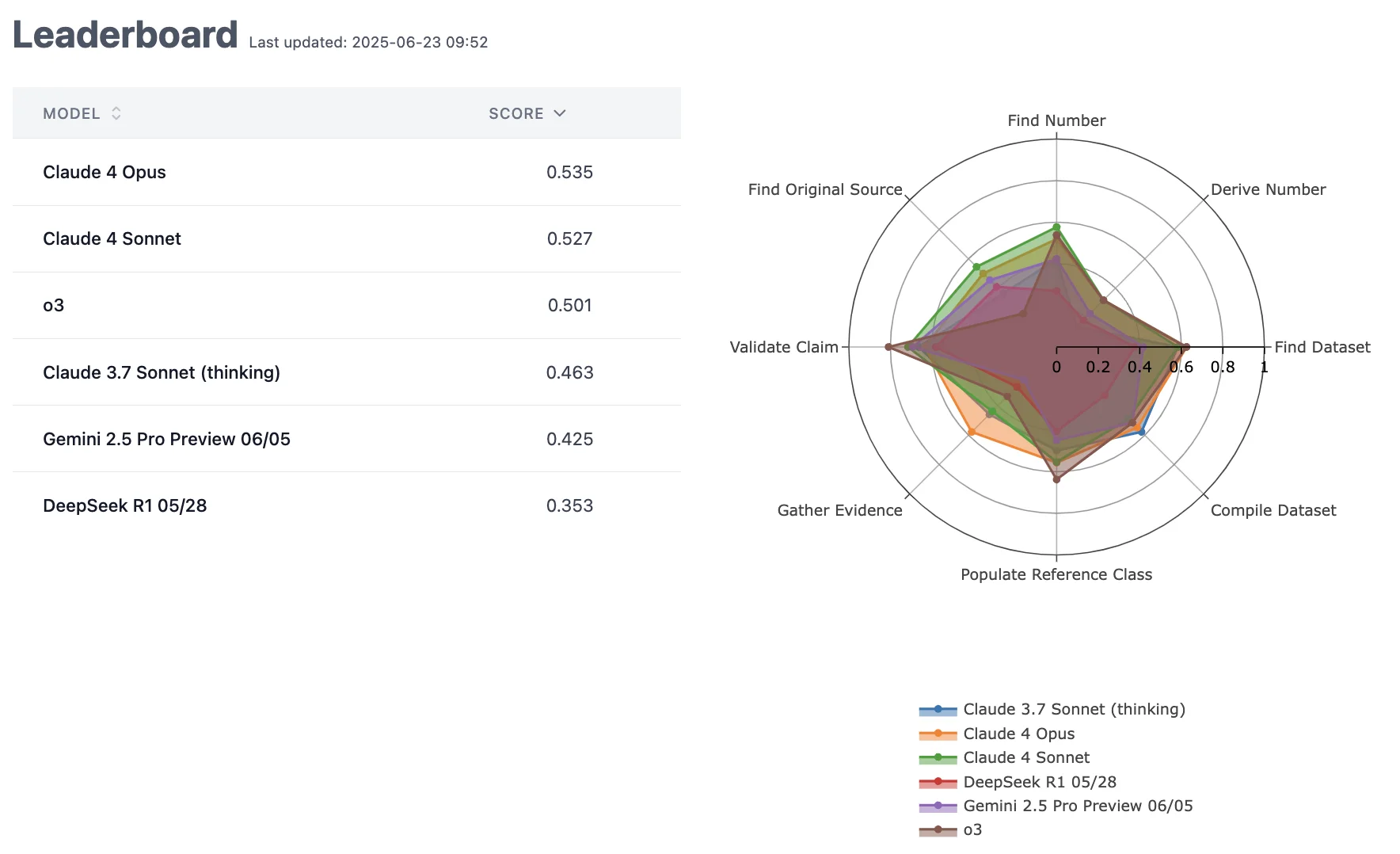
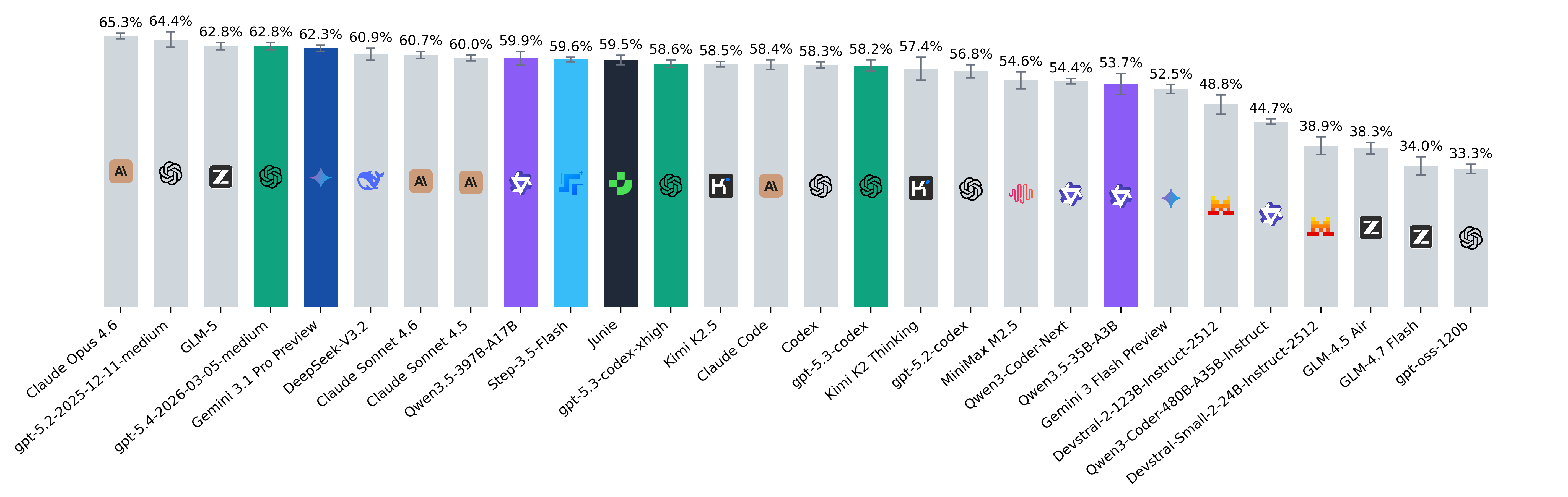
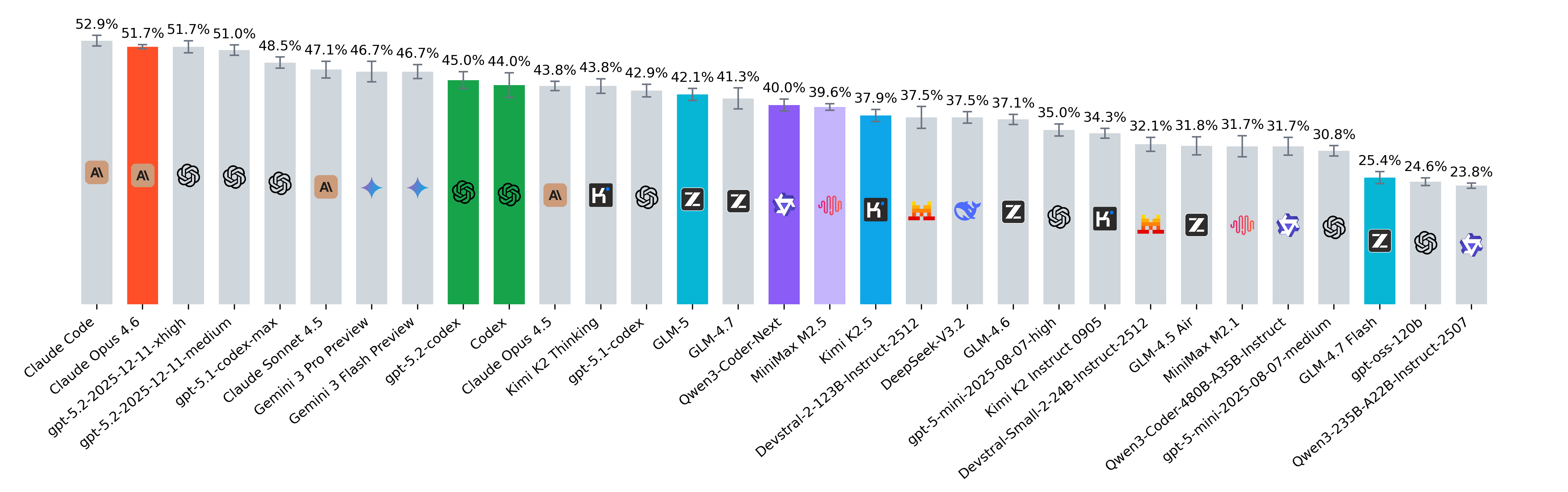
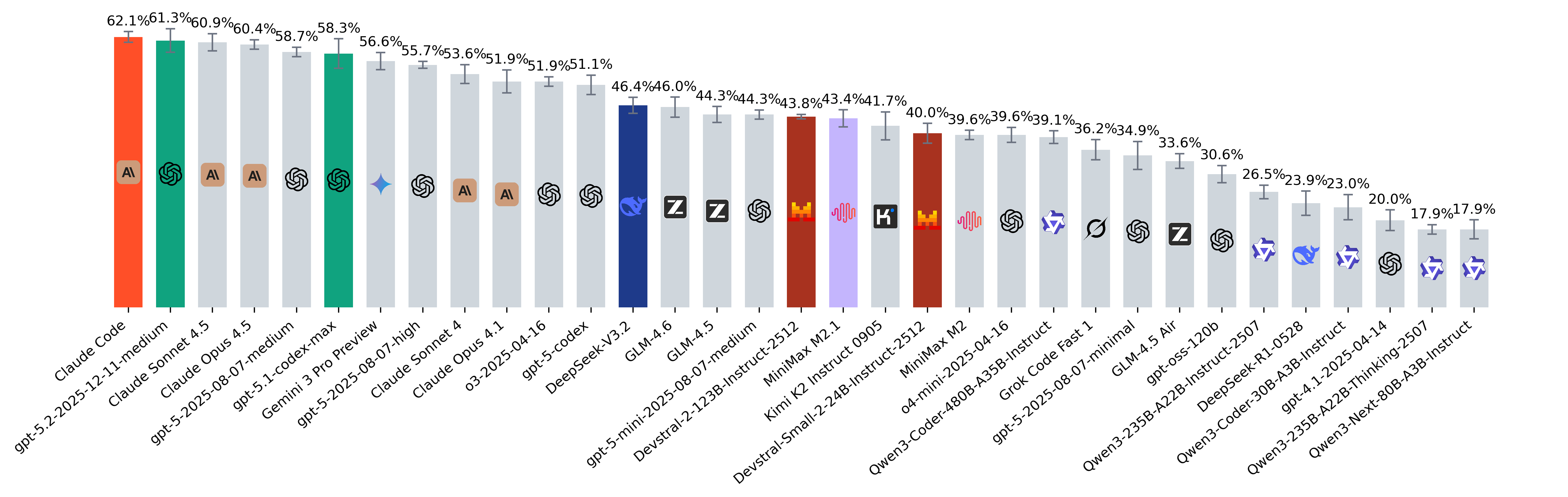
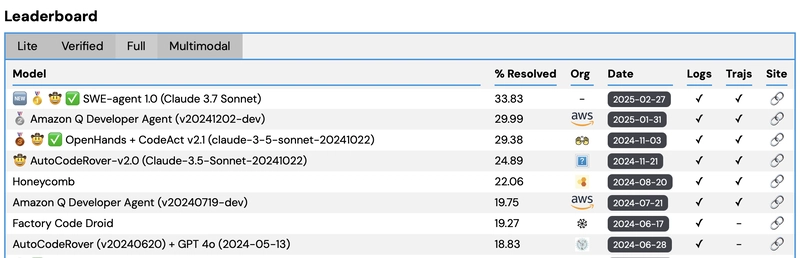
SWE-bench February 2026 leaderboard update
SWE-Bench Leaderboard May 2026 | GPT-5.5 Leads at 88.7%
SWE-Bench Pro Leaderboard (2026): Why 46% Beats 81%
SWE-Bench Pro Leaderboard AI Coding Benchmark (Public Dataset) | Scale
SWE-Bench - Benchmark Leaderboard & Model Performance | AI Stats
SWE-Bench Verified Discriminative Subsets Leaderboard - a Hugging Face ...
Top SWE-Bench Pro public dataset score by January 1, 2026 | Manifold
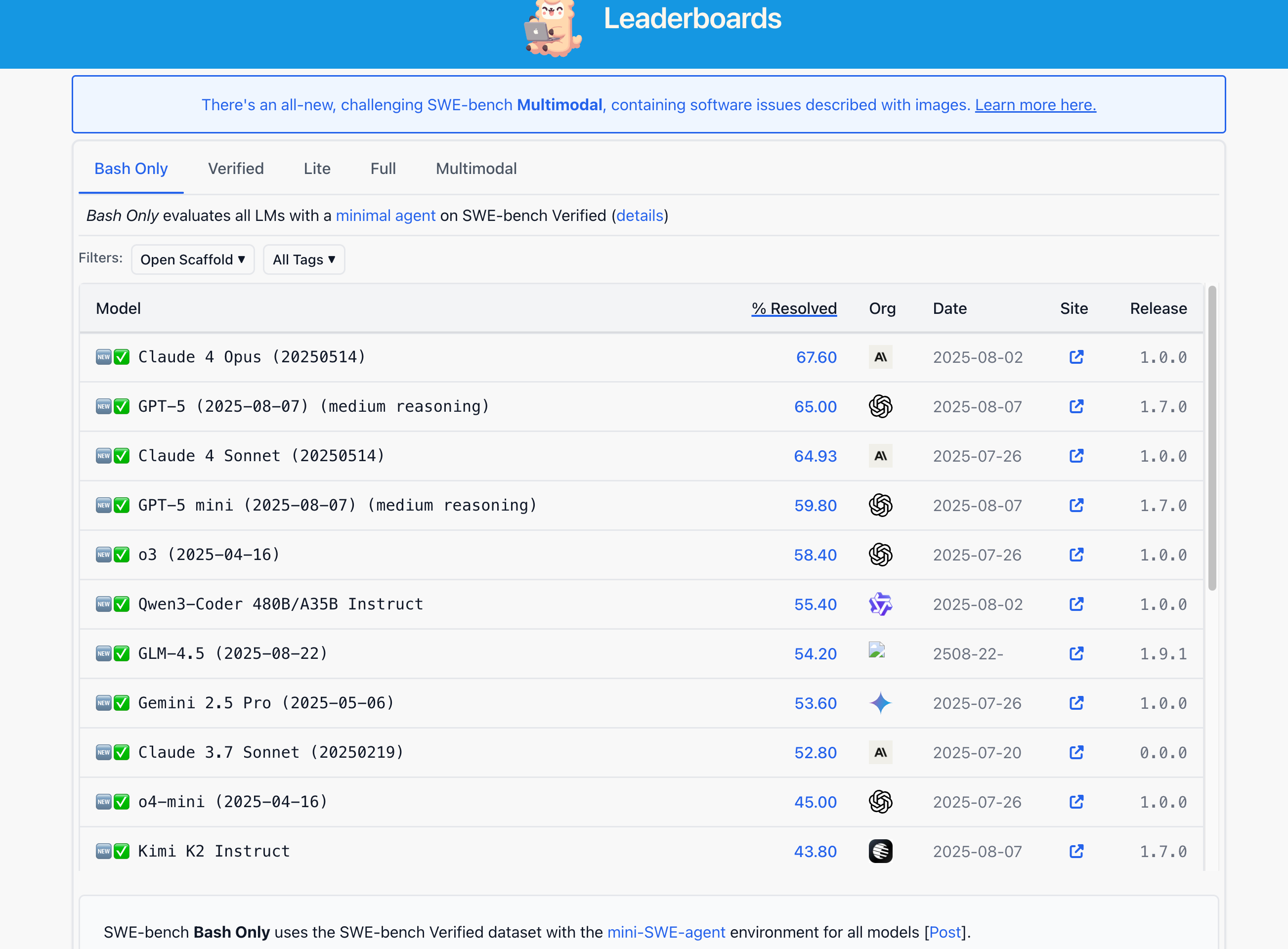
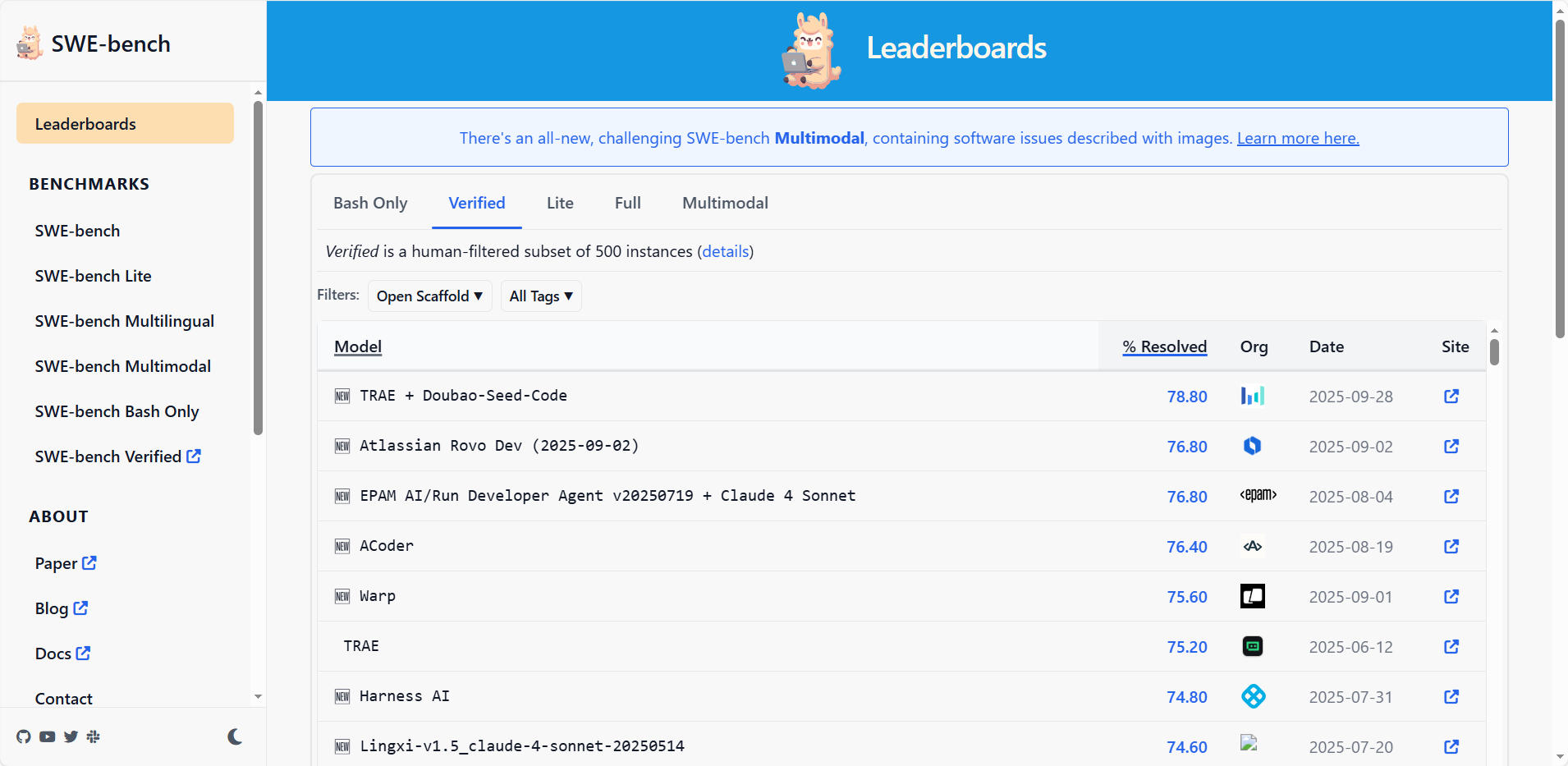
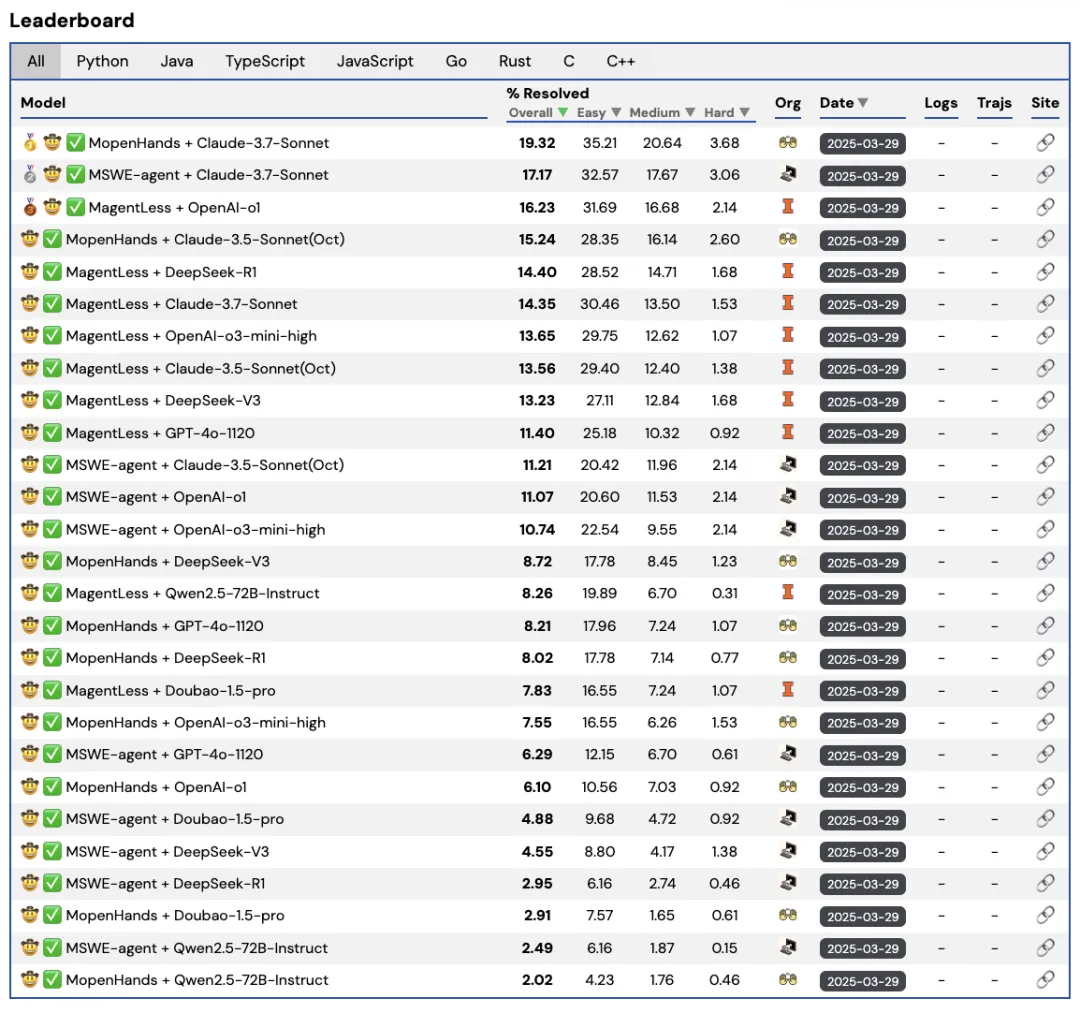
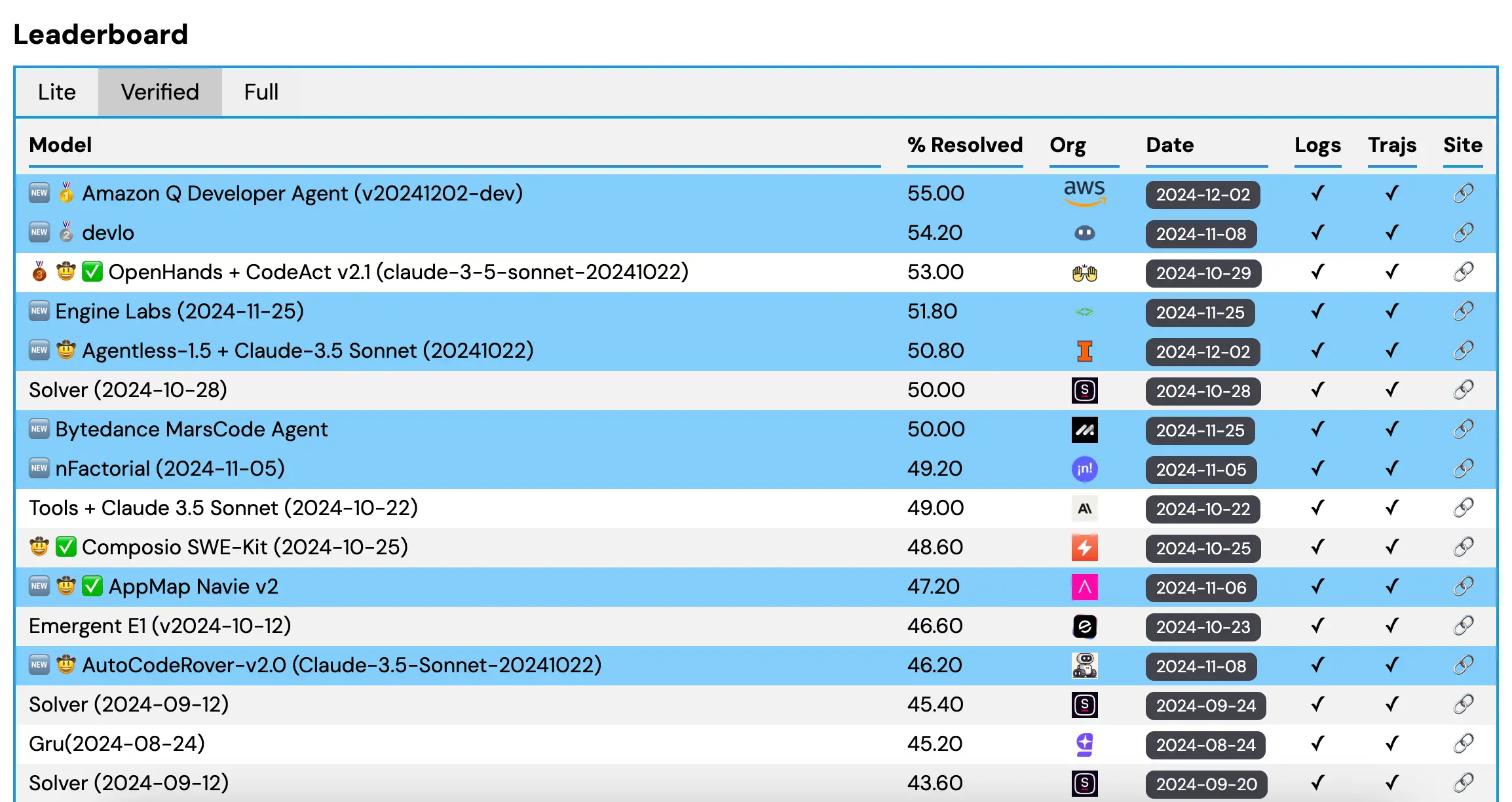
SWE-bench Leaderboard
SWE-bench Scores and Leaderboard Explained (2026) - DEV Community
LLM Coding Leaderboard - SWE-bench / LiveCodeBench / SWE-Bench Pro ...
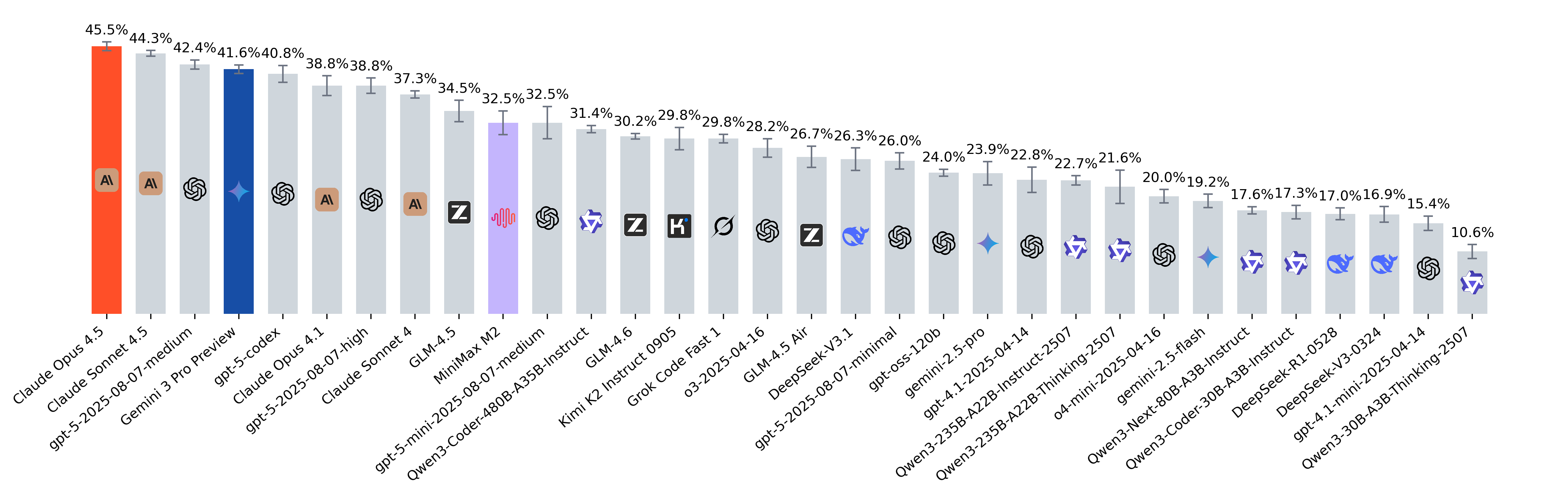
SWE-Bench Verified Leaderboard
SWE-bench Verified Explained: What the Coding Agent Leaderboard ...
Claude Opus 4.6 vs GPT-5.1 vs Gemini 3.5: The February 2026 Benchmark ...
nopilot.dev leaderboard updated with reported SWE-bench scores. The new ...
7th February 2026; Val di Fiemme, Italy, 2026 Winter Olympic Games, Day ...
SWE-bench Leaderboard 2026: All Model Scores, Rankings & What They ...
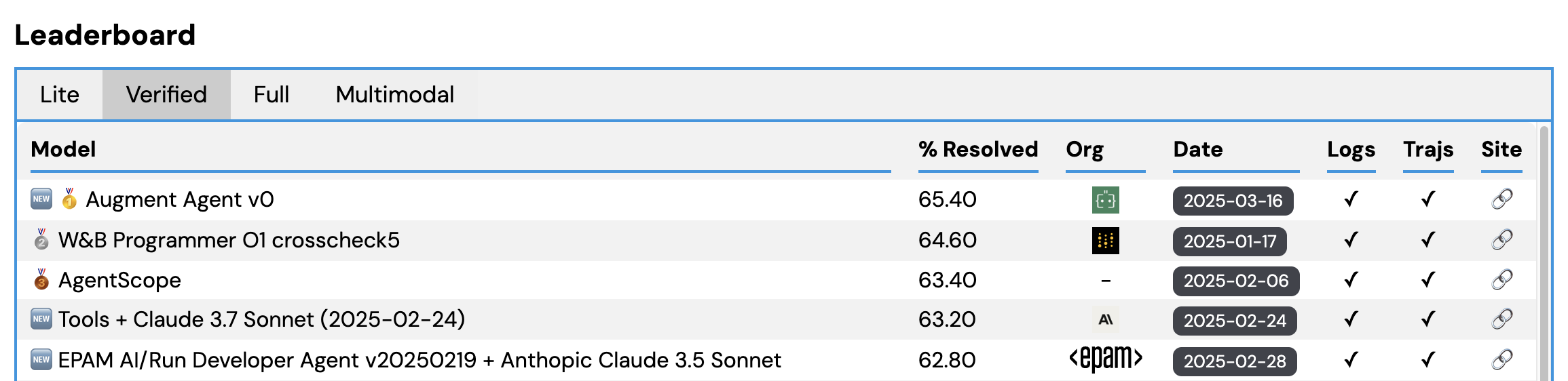
Augment's AI coding agent tops SWE-bench leaderboard | Augment Code ...
SWE-Bench Pro (Public Dataset)
IBM’s software engineering agent tops leaderboard for Java - IBM Research
SWE-rebench Leaderboard
Scoring 71% on SWE-bench Verified in half the steps
Auggie tops SWE-Bench Pro | Augment Code
Top 9 Cursor Alternatives for Developers in 2026 - Bito
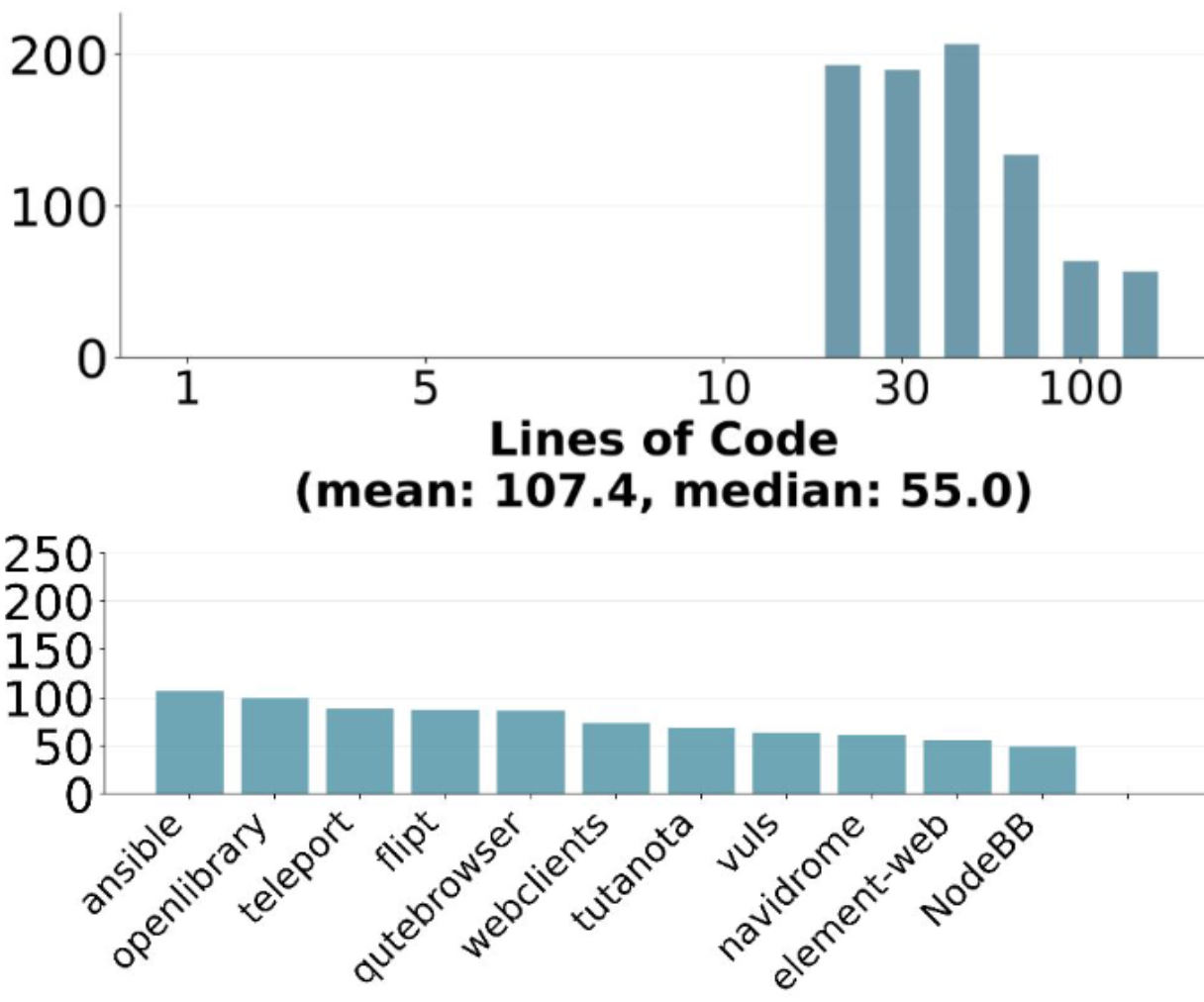
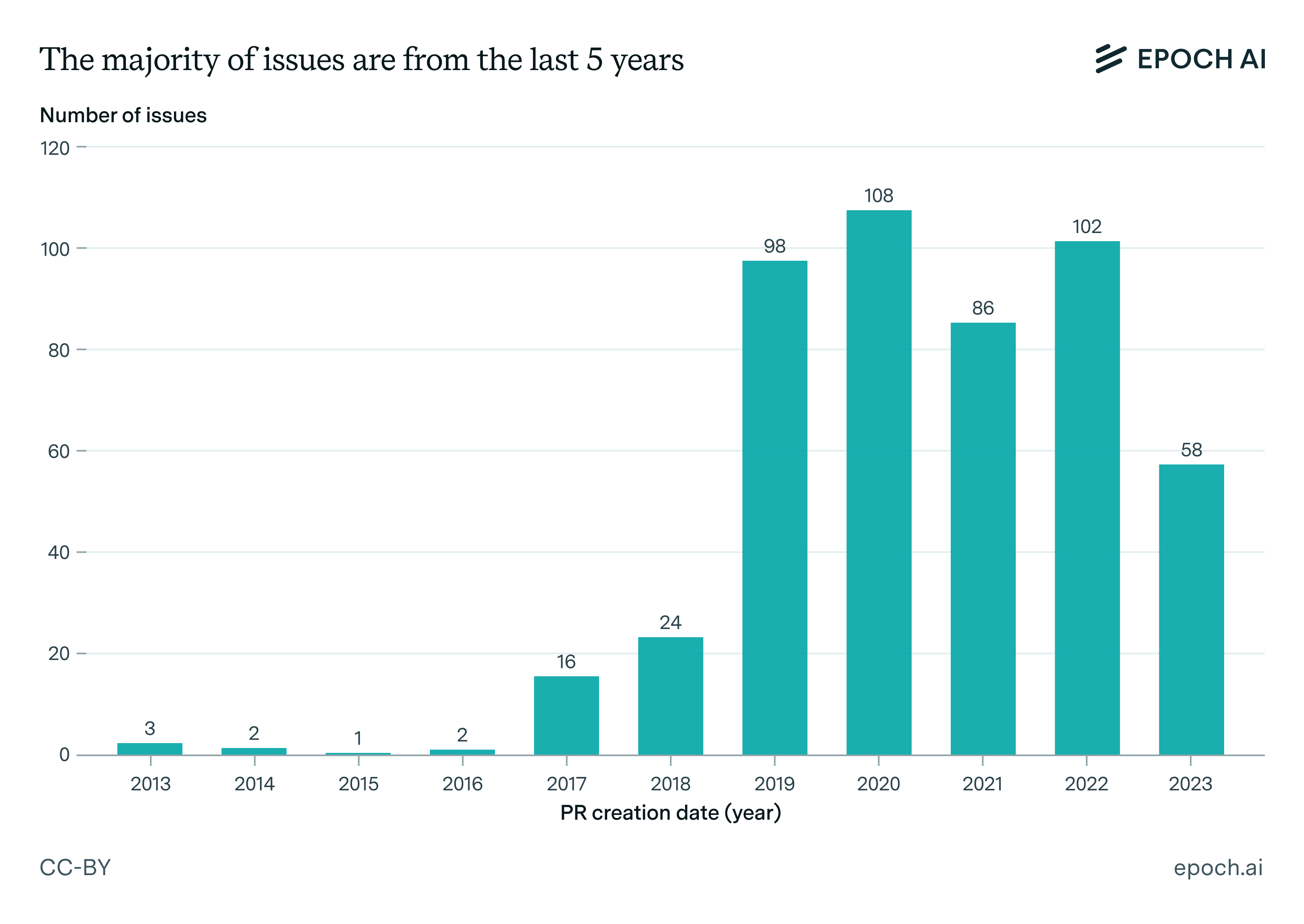
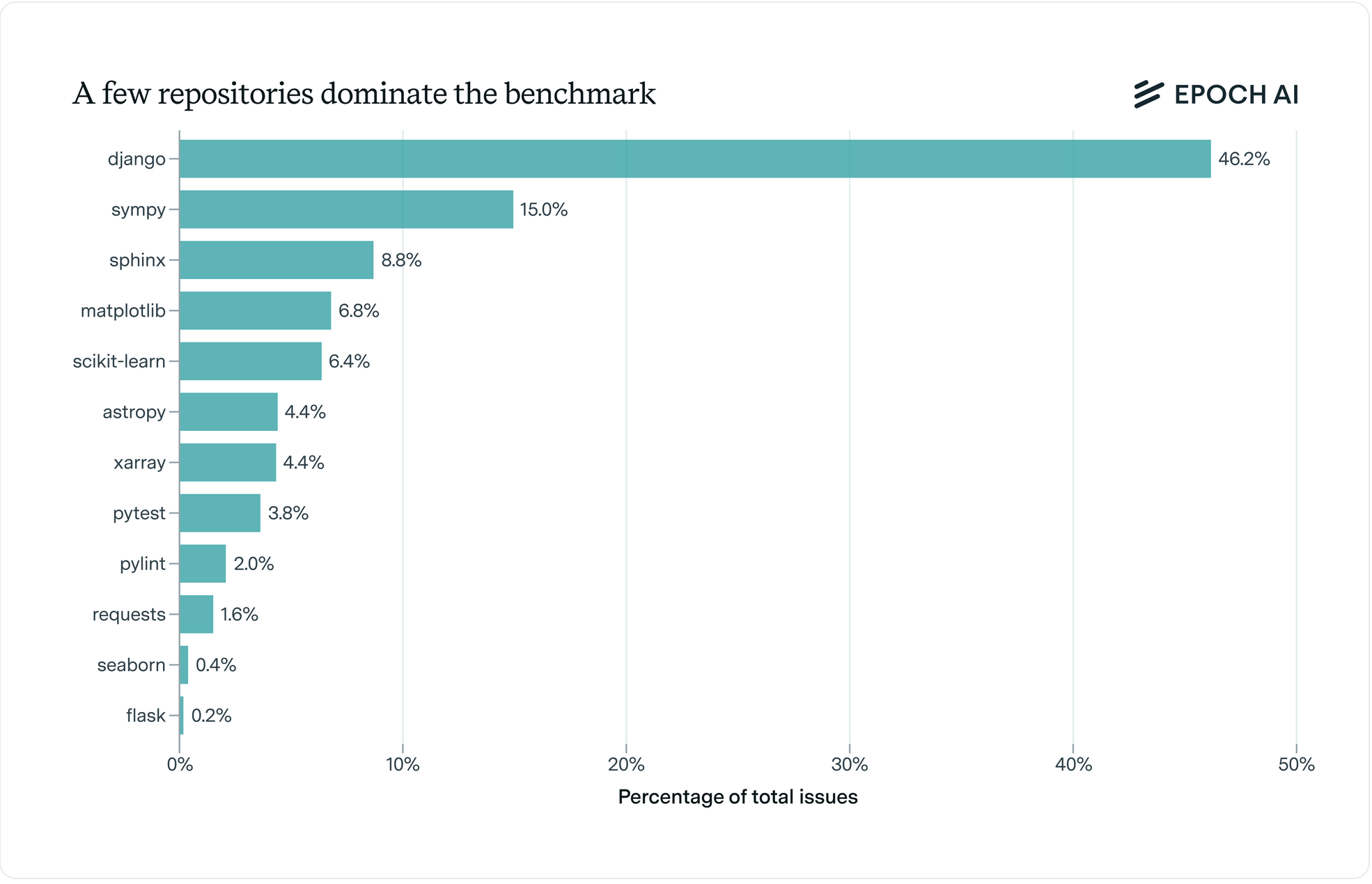
What skills does SWE-bench Verified evaluate? | Epoch AI
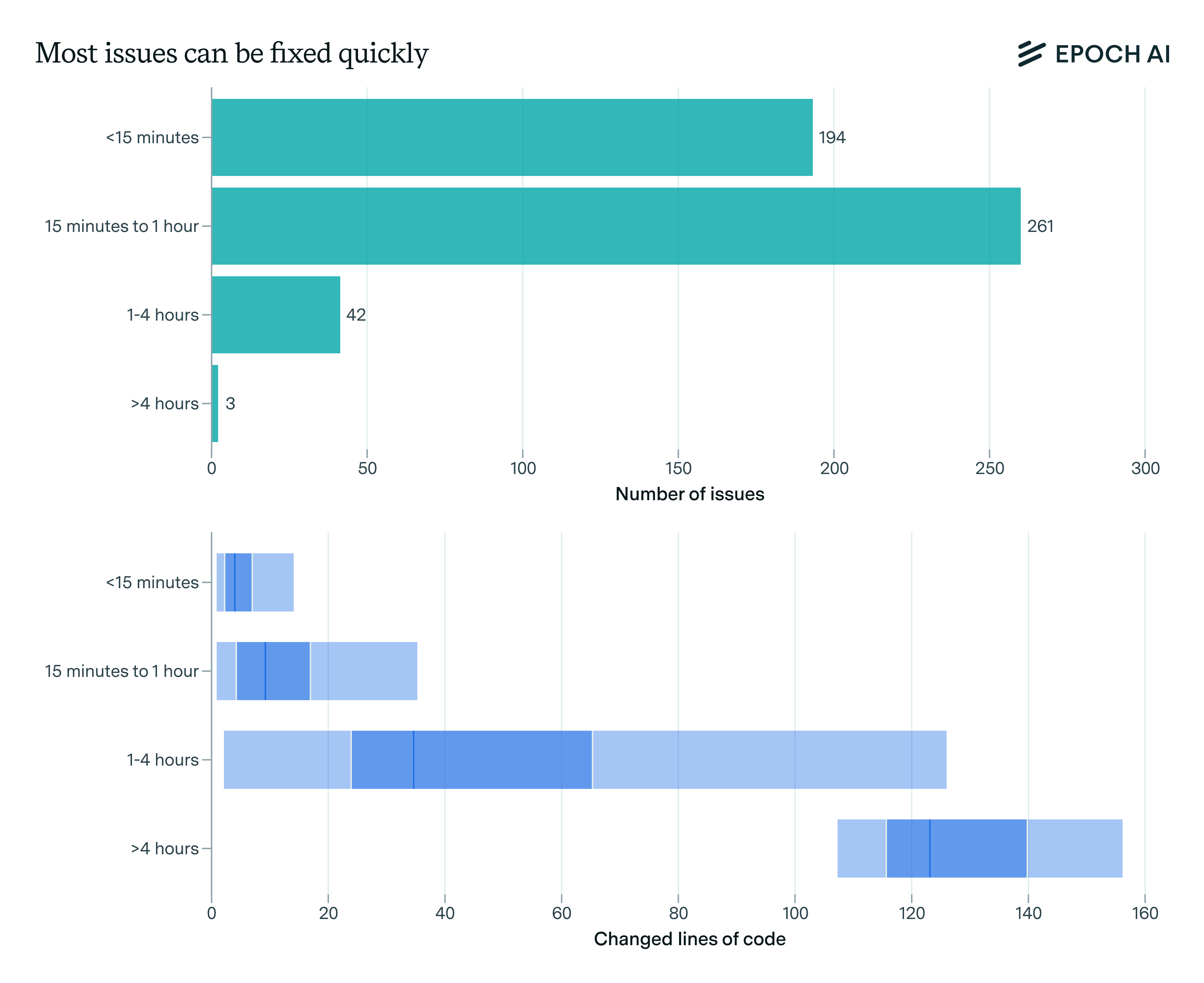
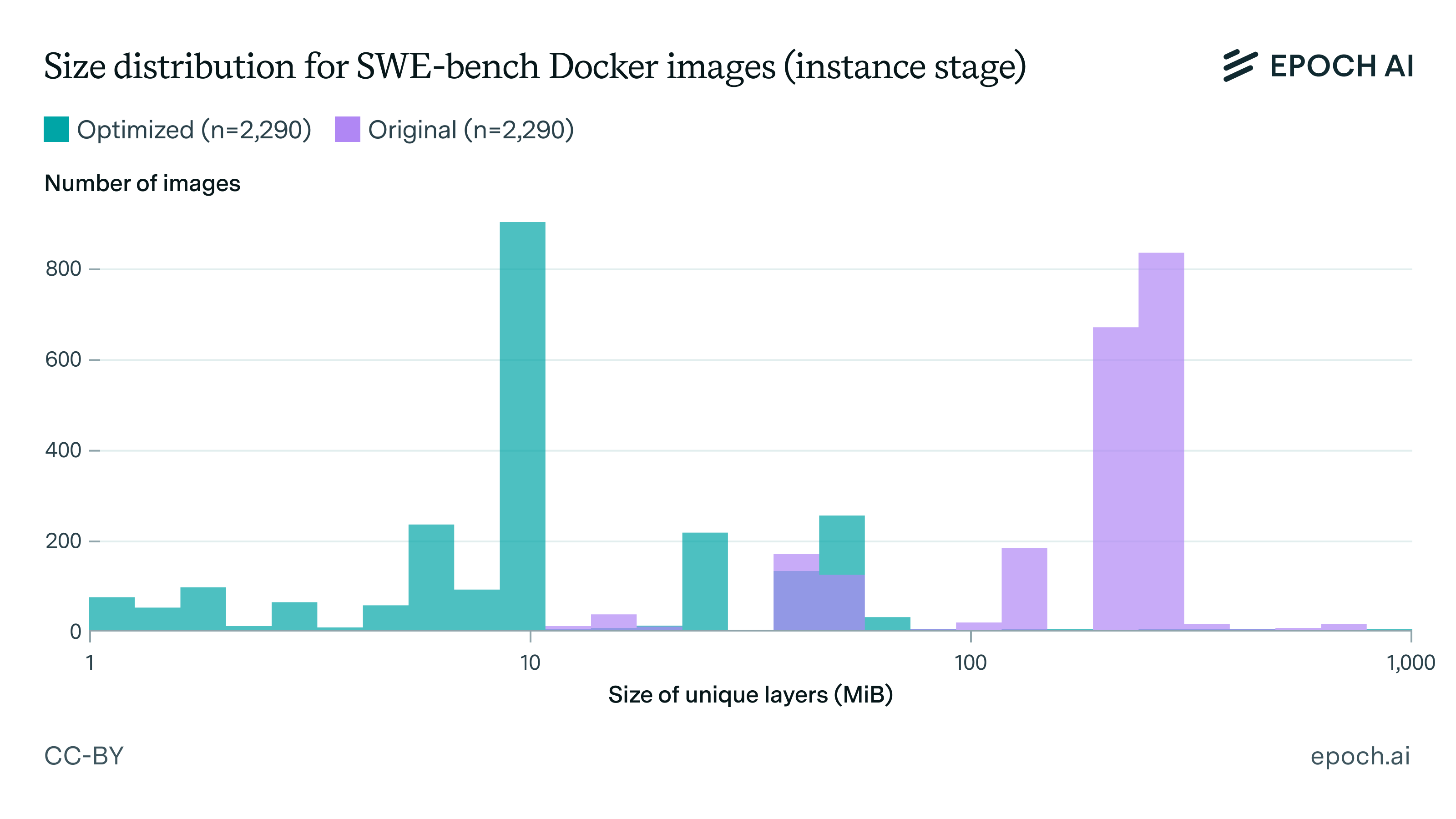
How to run SWE-bench Verified in one hour on one machine | Epoch AI
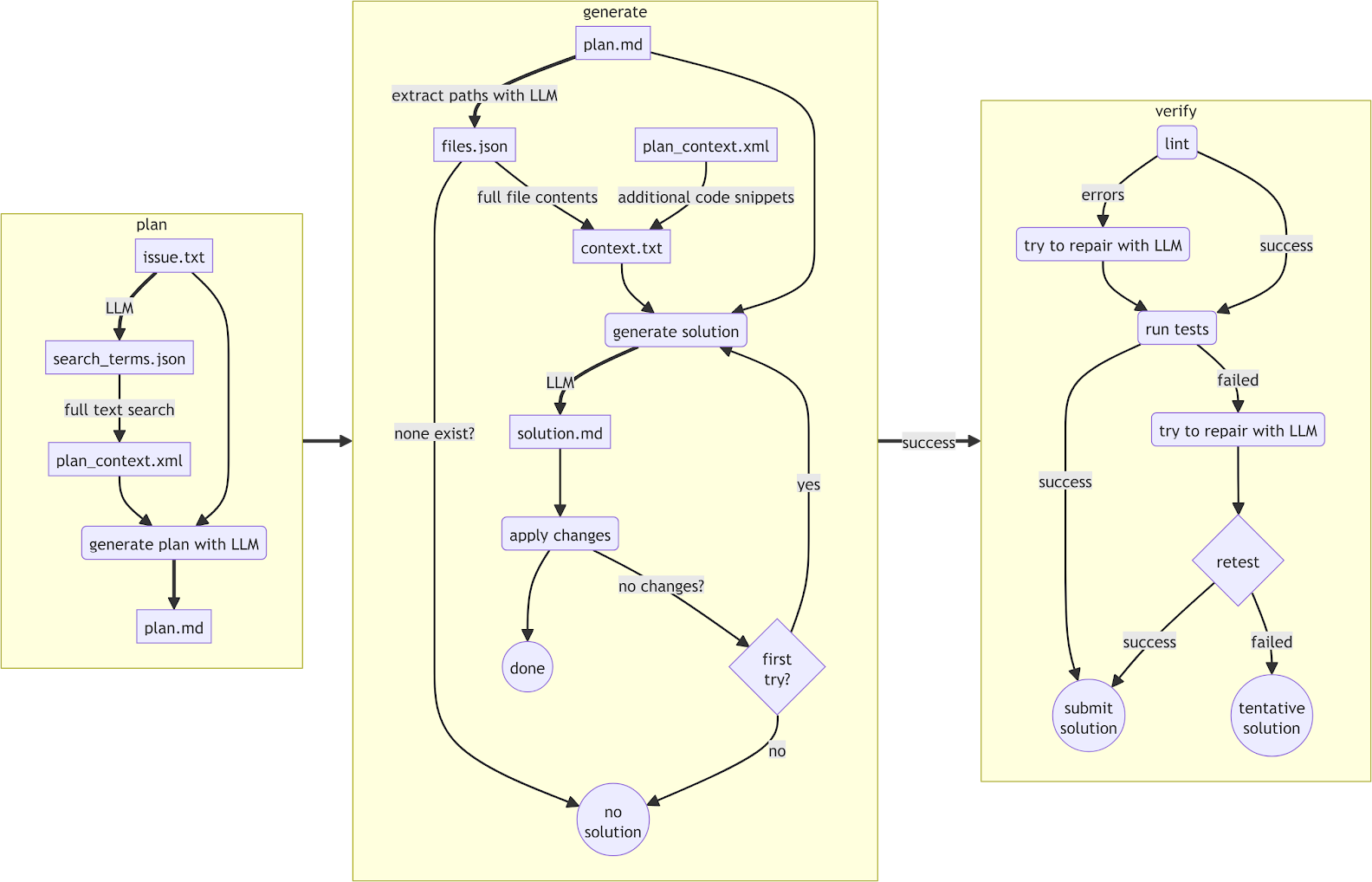
Cognition | SWE-bench technical report
Genie Coding Assistant Outperforms Competitors on SWE-bench by Over 30%
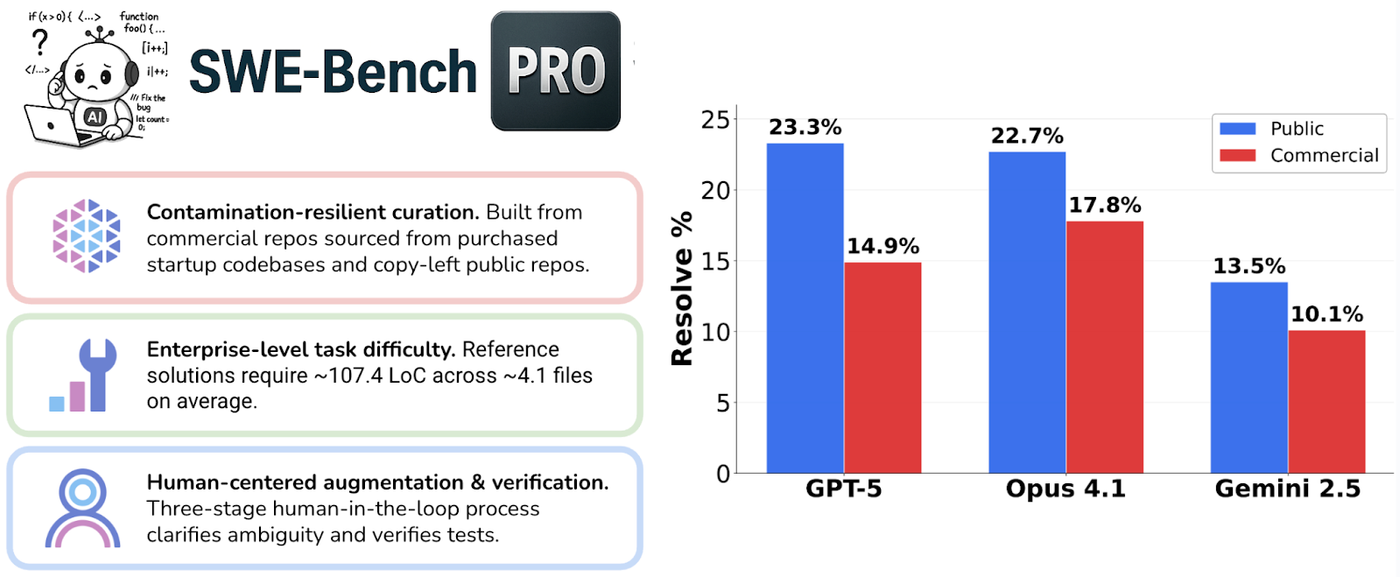
Scale AI 发布 SWE-Bench Pro 评测:AI 软件工程代理的新基准 | DataLearnerAI
GitHub - microsoft/SWE-bench-Live: [NeurIPS 2025 D&B] 🚀 SWE-bench Goes ...
LLM Leaderboard 2026: SWE-bench, MMLU, HumanEval Scores Decoded ...
Warp: Warp scores 75.8% on SWE-bench Verified!
Warp: Warp scores 71% on SWE-bench Verified
Cursor vs Copilot (2026): The $10/mo Tool Scores Higher on SWE-Bench
AppMap | AppMap speedruns to the top of the SWE Bench Leaderboard
SWE-Bench Scores Don’t Mean Your AI Is Production-Ready
SWE-Bench Performance Reaches 50.8% Without Tool Use: A Case for ...
SWE-bench - LLM Benchmark
Fortnite 2026 Competitive Roadmap Revealed!
What will be the best performance on SWE-bench Verified by December ...
The #1 SWE-Bench Verified Agent - YouTube
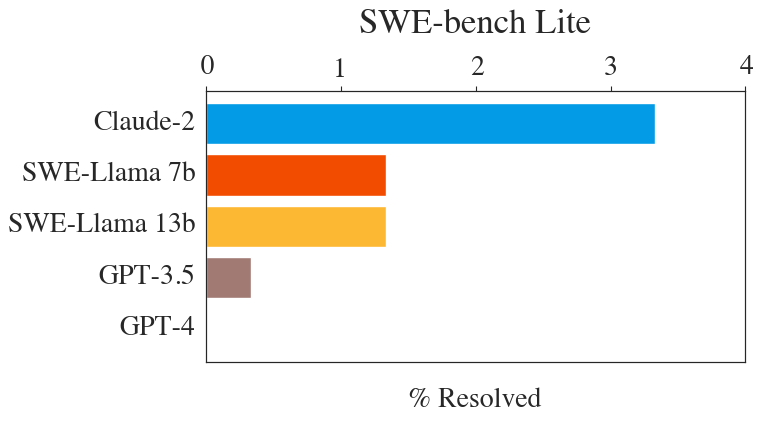
SWE-bench Lite
Test-Time Compute Orchestration for SWE-bench with AI21 Maestro
SWE-bench & SWE-bench Verified Benchmarks - DEV Community
Introducing SWE-bench Verified | OpenAI
SWE-bench Multimodal
How I Built an AI Framework That Scores 99.67% on SWE-Bench and Built ...
GitHub - SWE-bench/swe-bench.github.io: Landing page + leaderboard for ...
SWE-bench Verified Technical Report | Verdent - Verdent Blog
SWE-Bench Benchmark | Scores, Usage & Model Performance
SWE-Bench (unassisted) benchmark 2025
What will be the highest score achieved on SWE-Bench Verified in 2025 ...
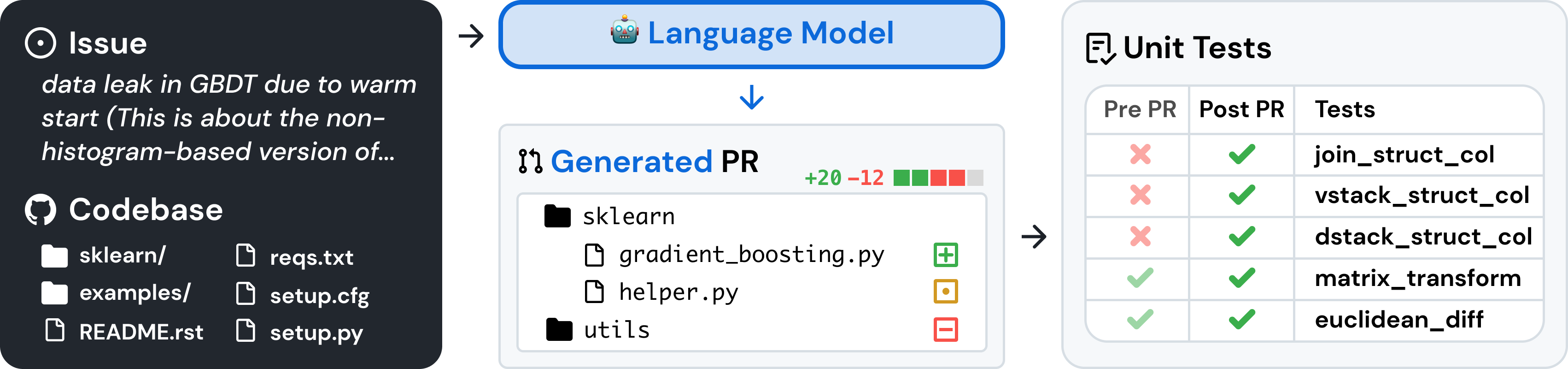
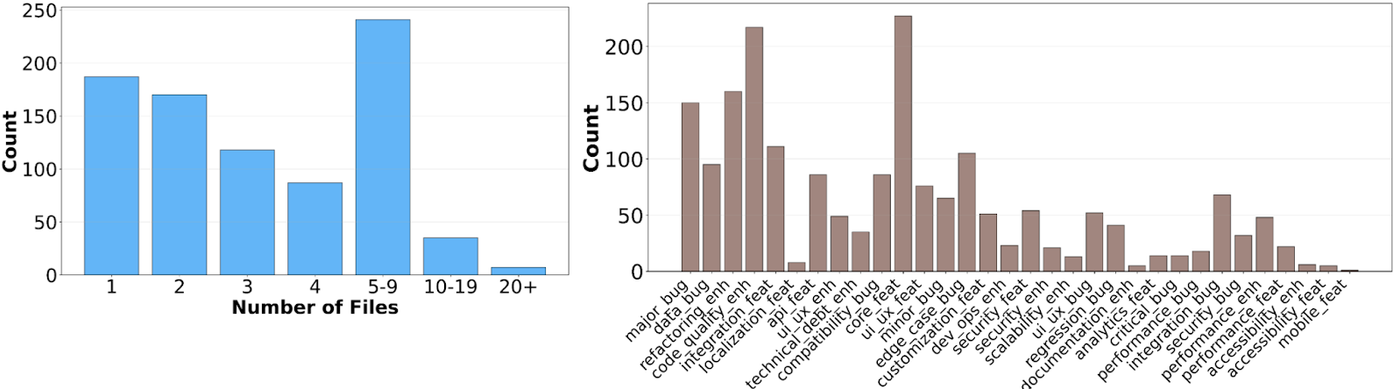
SWE-Bench Pro Commercial Dataset: A harder, cleaner test of AI coding ...
SWE-bench + | OpenLM.ai
Live-SWE-agent Leaderboard
SWE-bench - 基于GitHub问题的语言模型评估 - 懂AI
Why SWE-bench Verified no longer measures frontier coding capabilities ...
SWE-Bench Verified: Thinking Optional · ProgrammerHumor.io
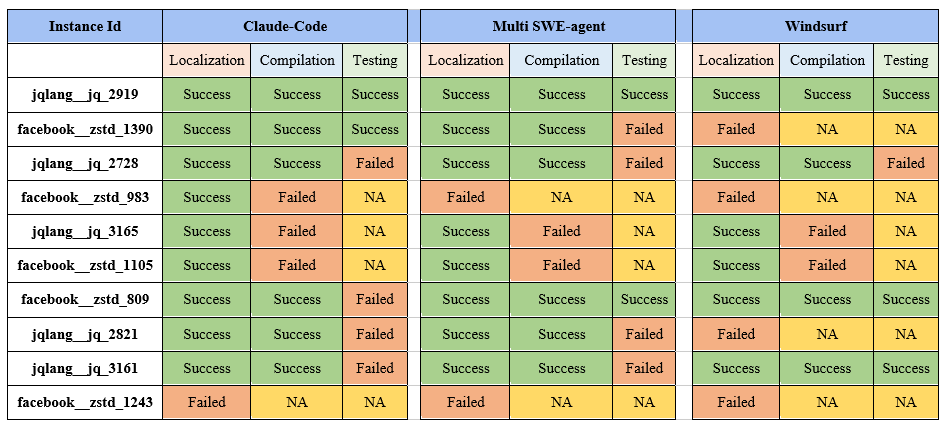
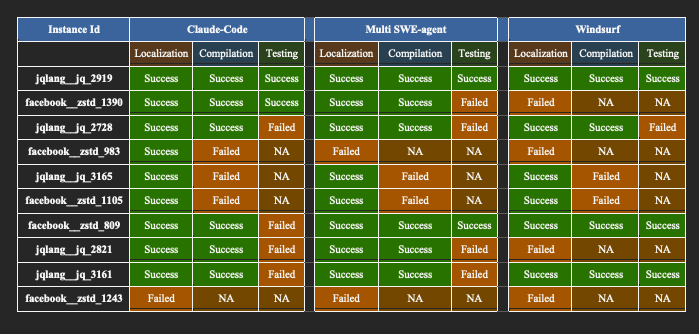
Multi-SWE-bench:首个多语言代码修复基准开源 - 火山引擎开发者社区 - 博客园
What are popular AI coding benchmarks actually measuring? - nilenso blog
Demystifying SWE-Bench: AI Coding Assistants in Action
SWE-Bench-C Evaluation Framework
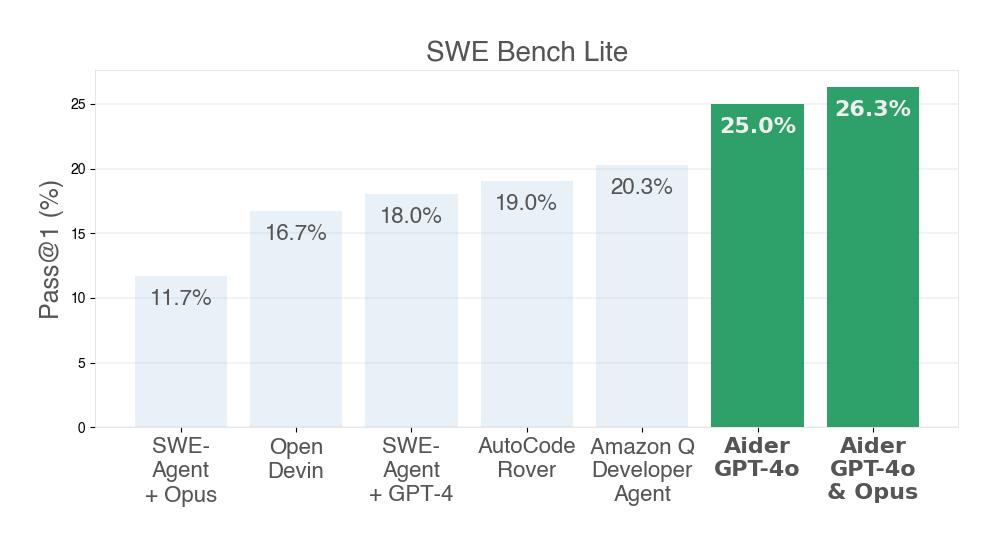
Aider is SOTA for both SWE Bench and SWE Bench Lite
MiniMax M2.5 Complete Guide — Lightning Attention Achieves 80.2% SWE ...
Vayavya Labs Pvt. Ltd. - SWE-Bench-C Evaluation Framework
Getting Started - SWE-agent documentation
Agentic Coding表现创新高,全新KAT系列模型强势霸榜SWE-Bench - 知乎
AI Coding Evolution and Landscape: L1 to L5 | 16x Prompt
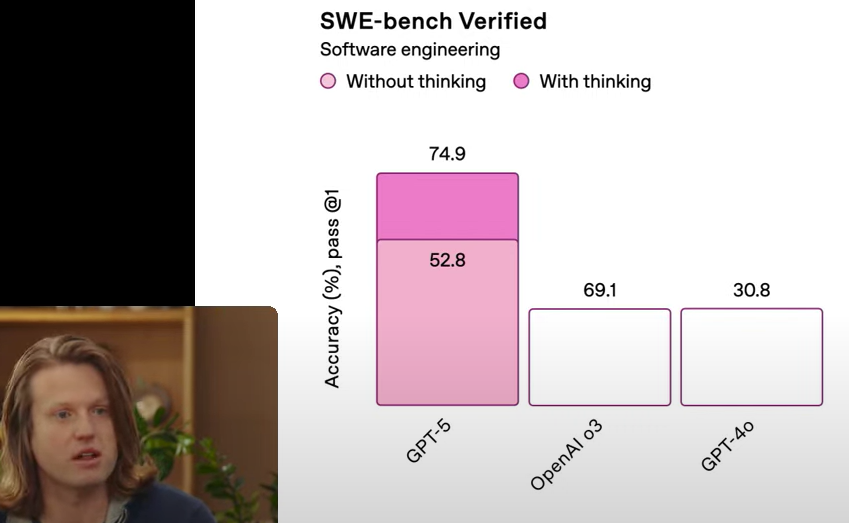
Anthropic’s Claude Opus 4.1 Improves Refactoring and Safety, Scores 74. ...
介绍 SWE-bench:语言模型能否解决真实世界的 GitHub 问题?-CSDN博客
SWE-bench-Live · GitHub
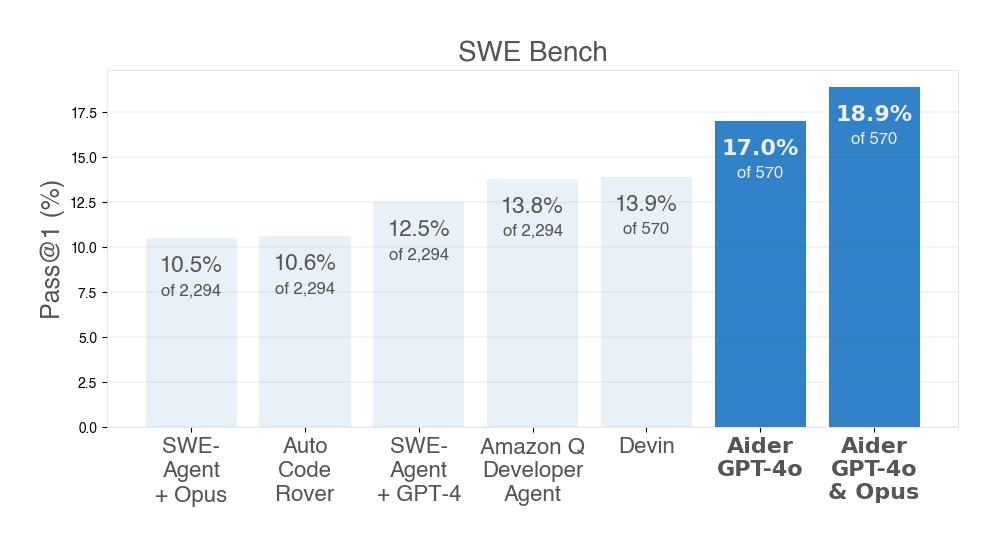
How aider scored SOTA 26.3% on SWE Bench Lite | aider
Aider is SOTA for both SWE Bench and SWE Bench Lite | aider
SWE-bench官网 - SWE-bench是一个 AI 评估基准,用于评估AI大模型完成现实世界软件工程任务的能力 | 阿米笔记
大模型SWE-bench Verified评测基准详情以及最新排行结果 | 数据学习 (DataLearner)
GitHub - Revca-ANAI/Ana-swebench-results: Ana's results and methodology ...
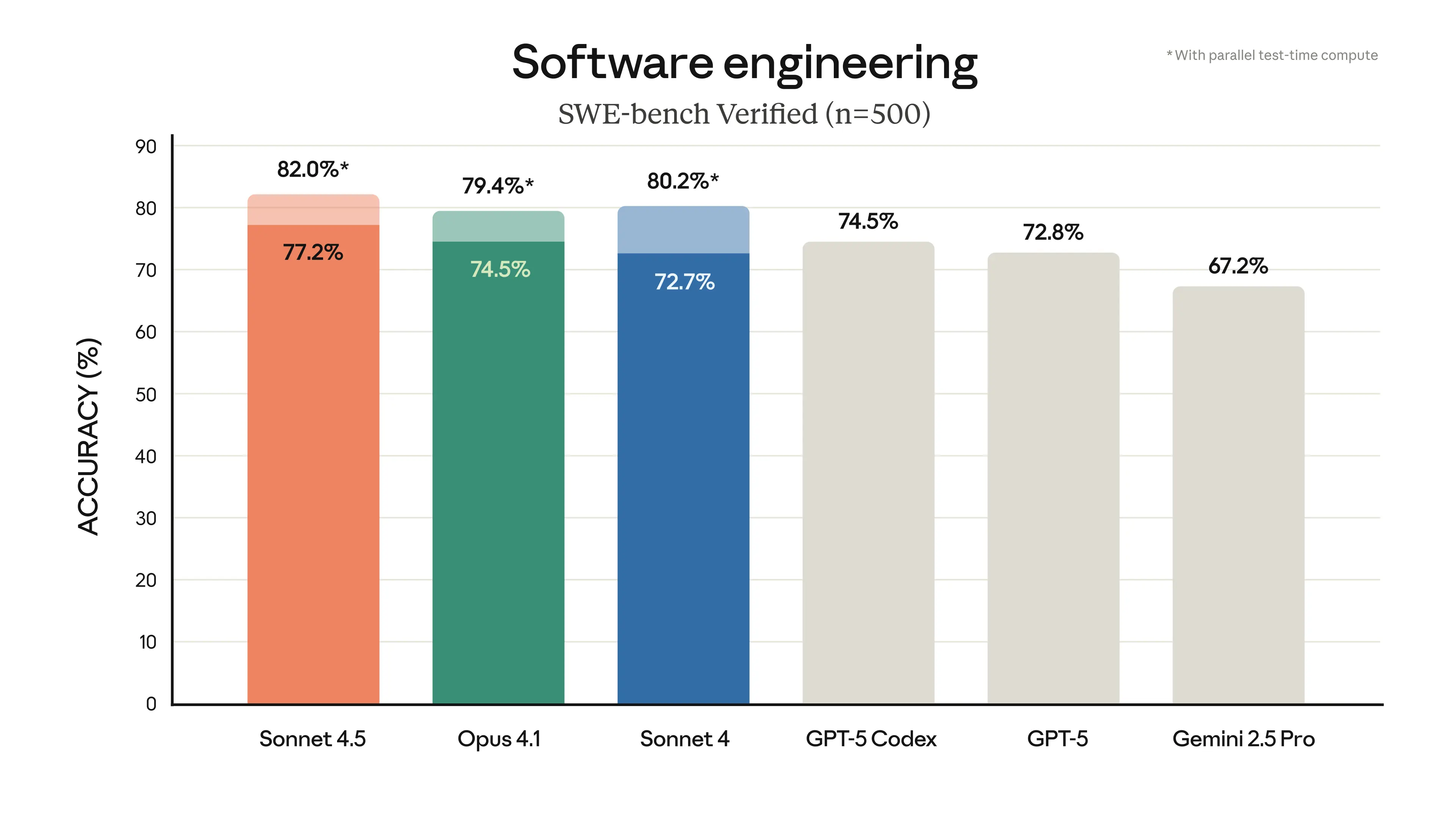
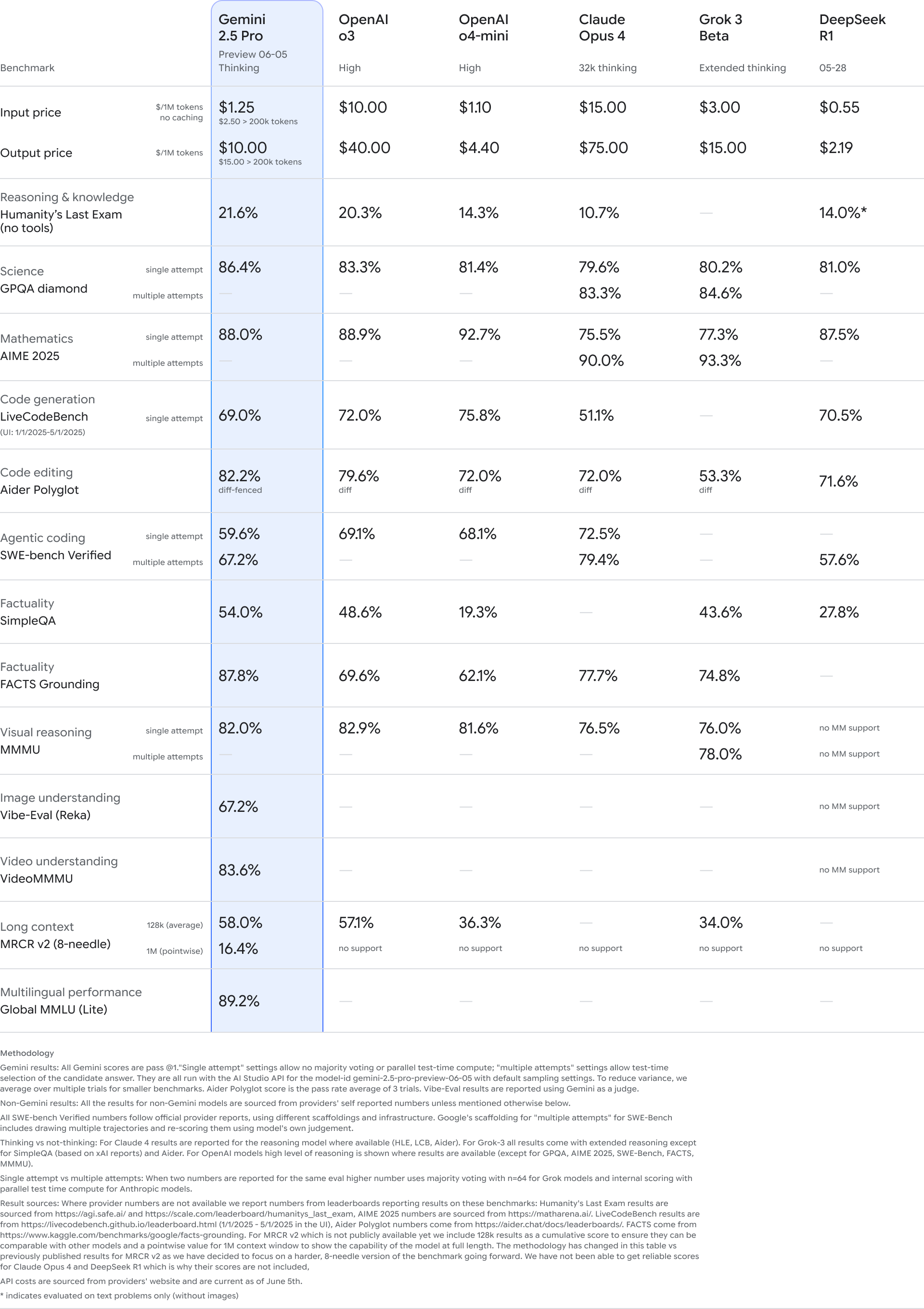
Introducing Claude Sonnet 4.5 \ Anthropic
Aider blog | aider
Can Language Models Replace Programmers? Researchers from Princeton and ...
Cognition Releases Windsurf High-Speed SWE-1.5 AI Coding Model ...
Claude 3.7 Sonnet Coding Skills: Hands-on Demonstation
SWE-smith
KI-Coding-Assistenten Vergleich 2026: Cursor vs Claude Code vs Copilot ...
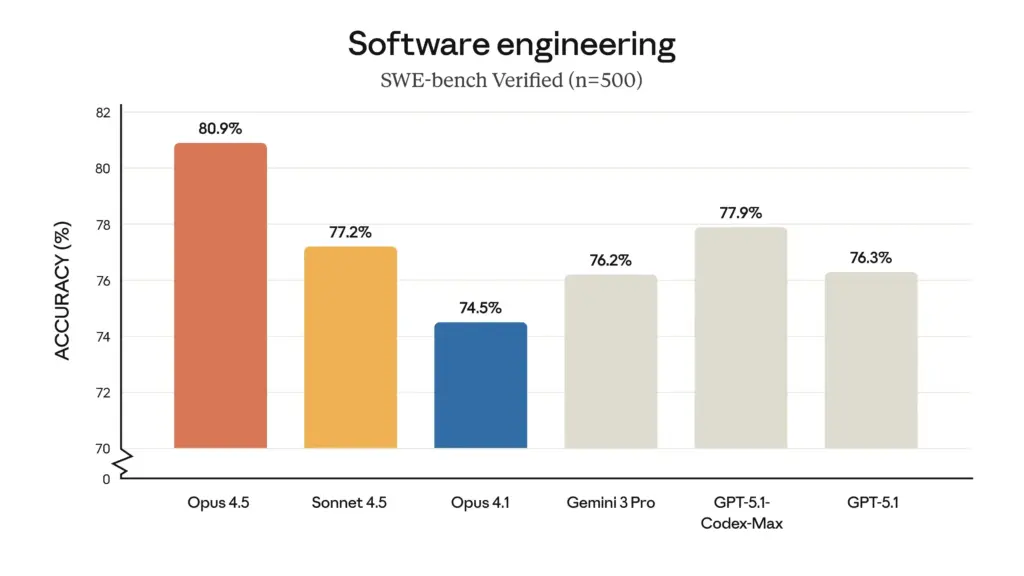
Claude Opus 4.5 ya está aquí
Fixing SWE-bench: A Smarter Way to Evaluate Coding AI
Deep Research Bench Leaderboard: LLM Web Research Agent Rankings
[開発者向け]SWE-bench Verifiedはなぜ信頼できなくなったのか――OpenAIが明かすベンチマーク汚染の実態 | JOBIRUN
nebius/SWE-rebench-leaderboard at main
Beste AI-Coding-Tools 2026: Cursor vs. Claude Code vs. GitHub Copilot ...
Continue
Multi-SWE-bench
GitHub - SWE-Gym/SWE-Bench-Package
We made an AI SWE that solved 48.60% of issues on the SWE bench, 100% ...
We are not evaluating AI coding agents the way they are actually used ...
All Hands AI Open Sources OpenHands CodeAct 2.1: A New Software ...
Based on this image's title: “SWE-bench February 2026 leaderboard update”

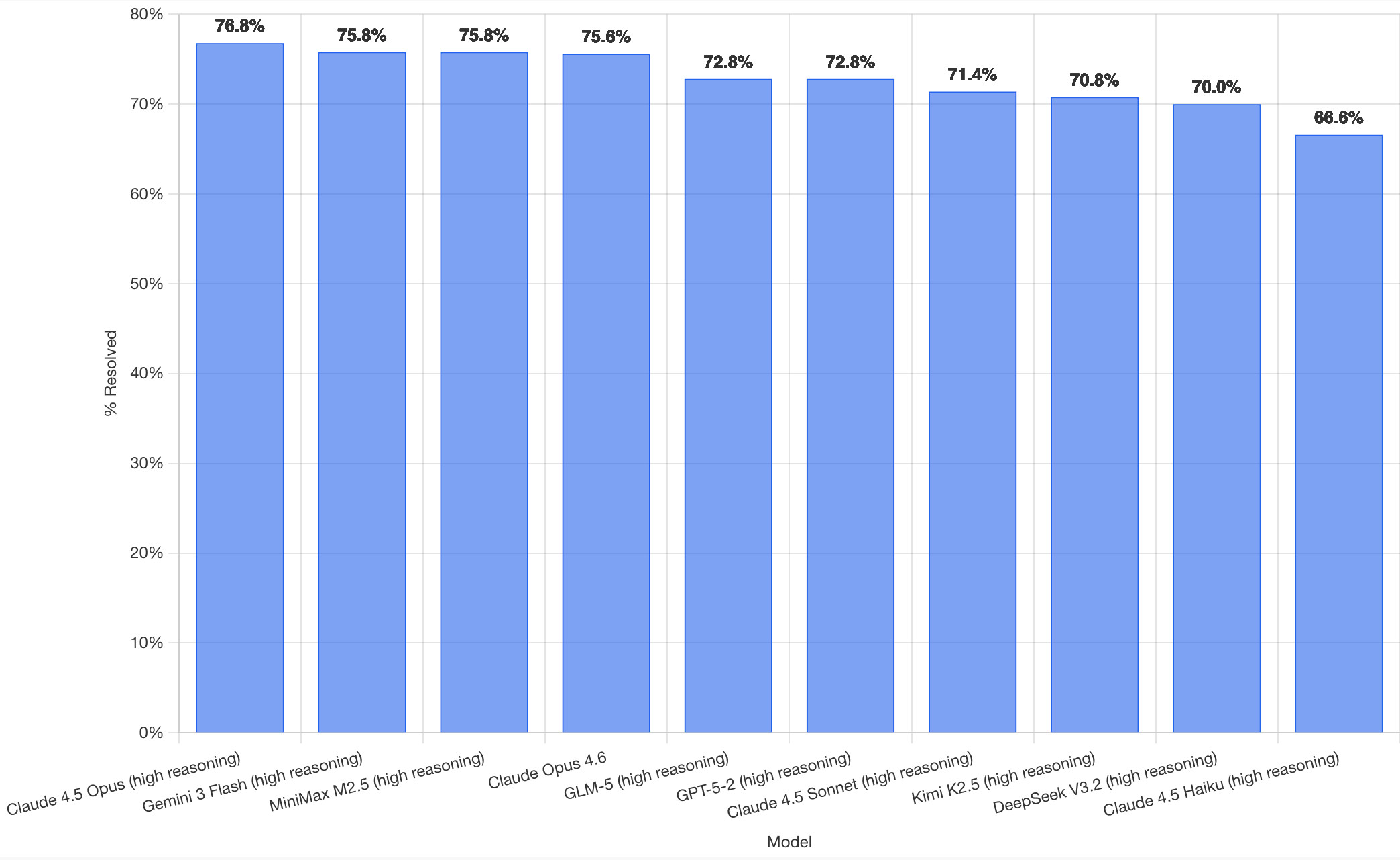










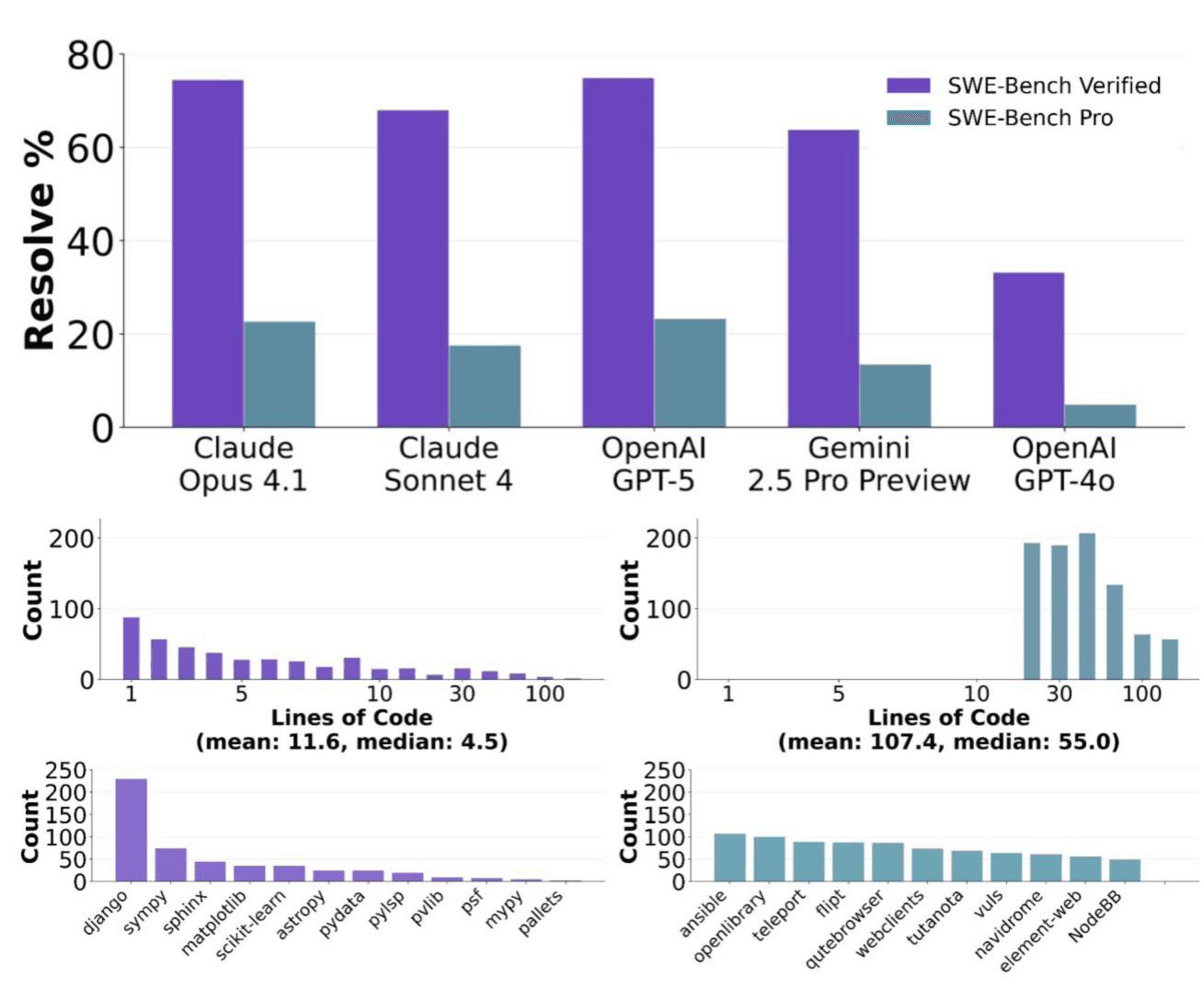







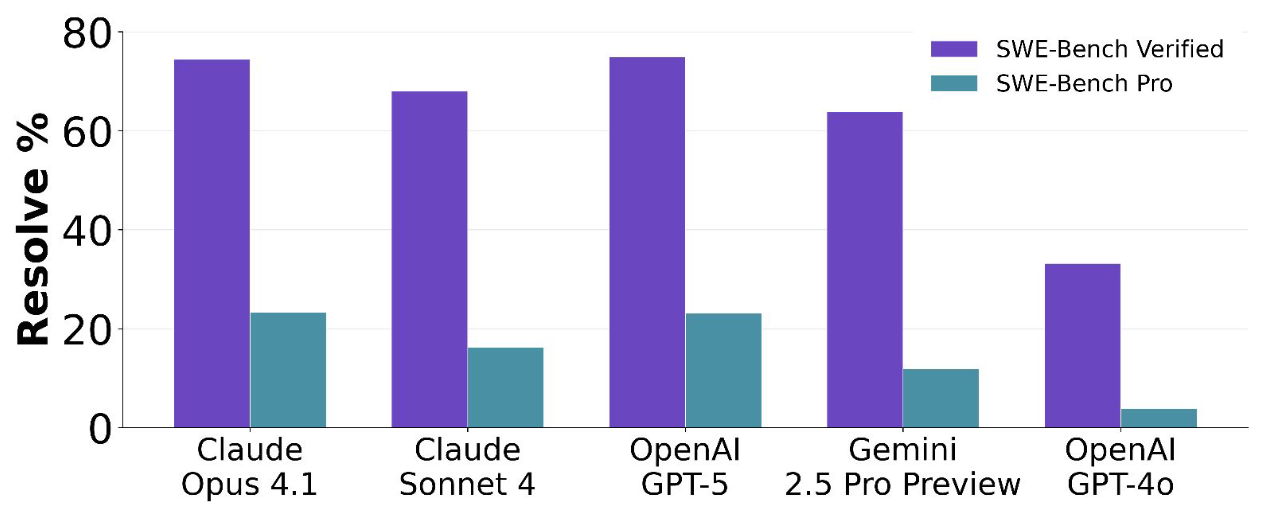


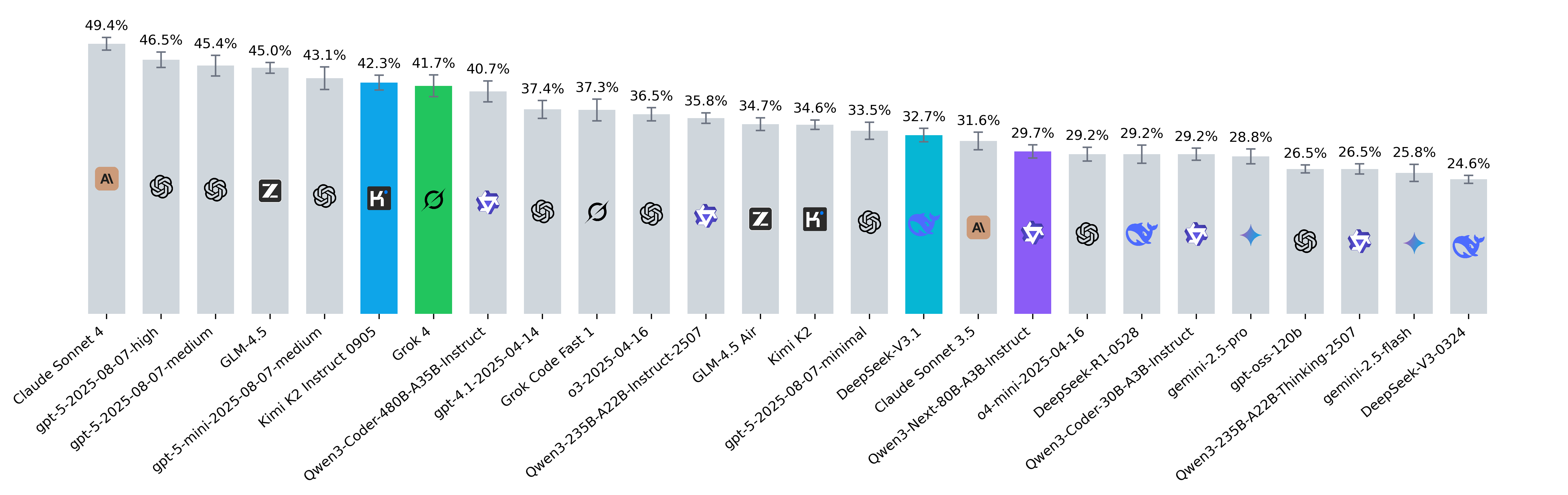
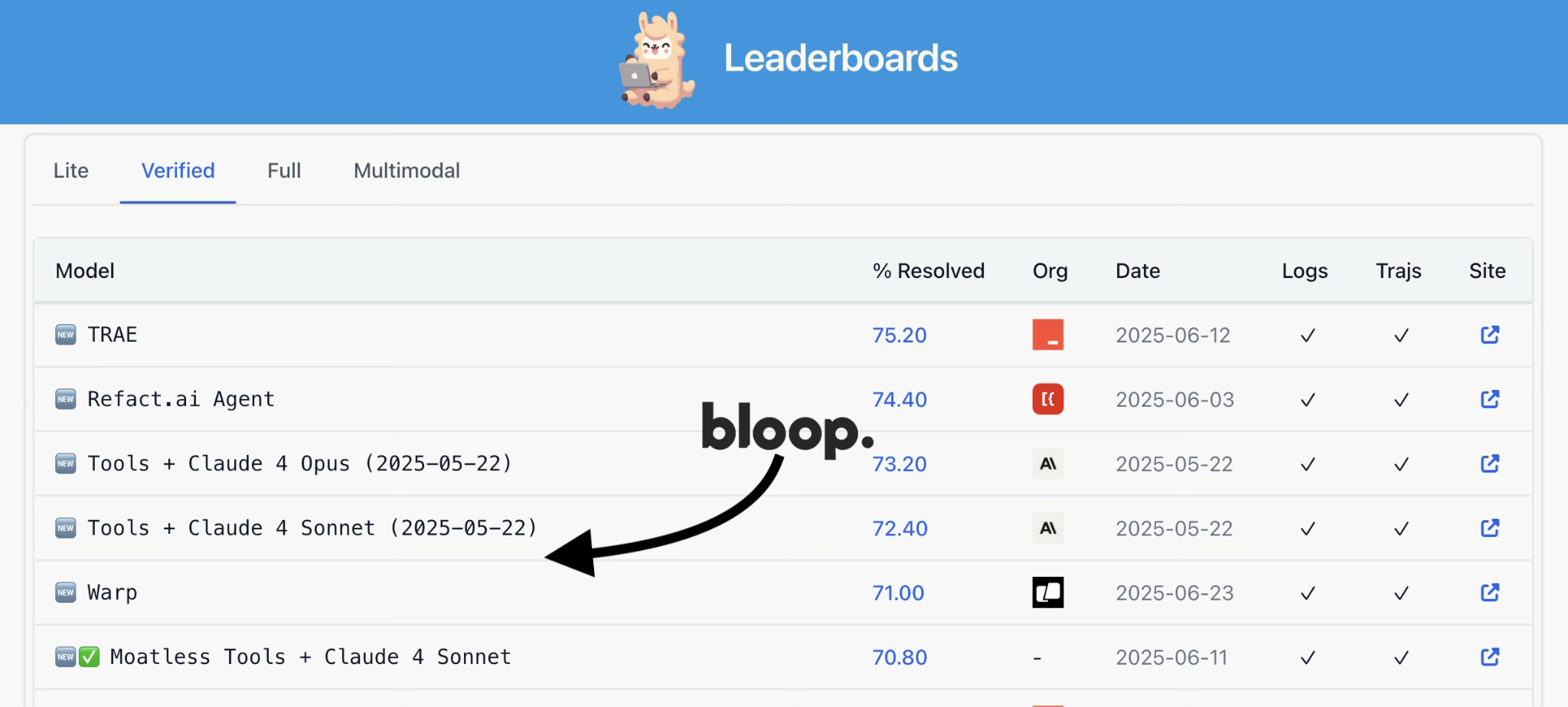




























/filters:no_upscale()/news/2025/08/anthropic-claude-opus-4-1/en/resources/143figure-1-1756289214722.jpg)