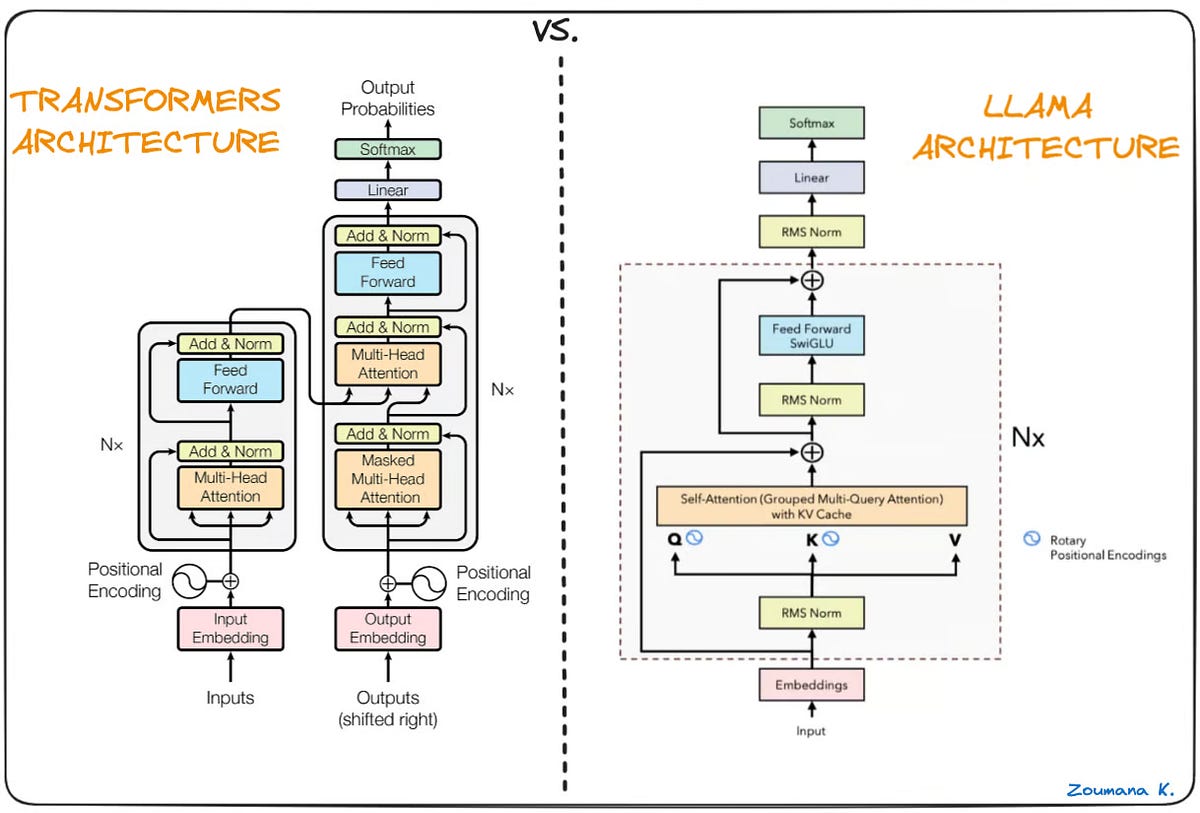
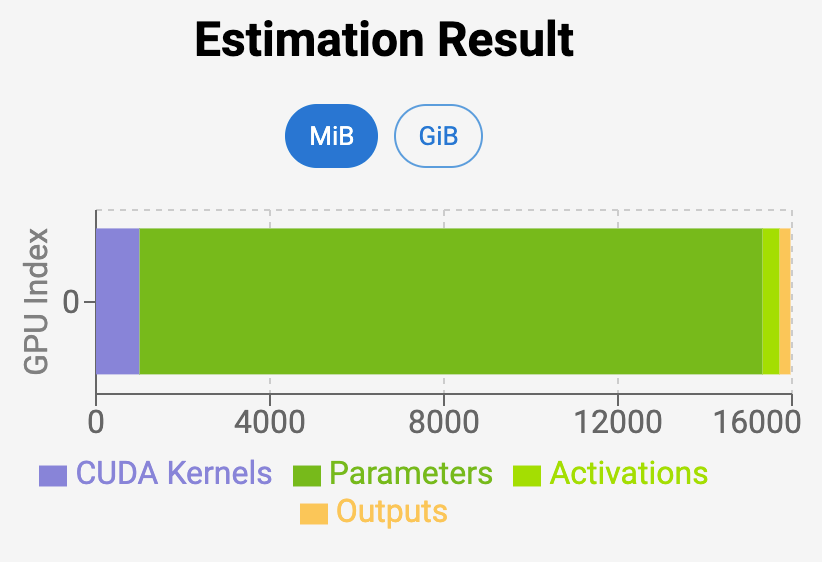
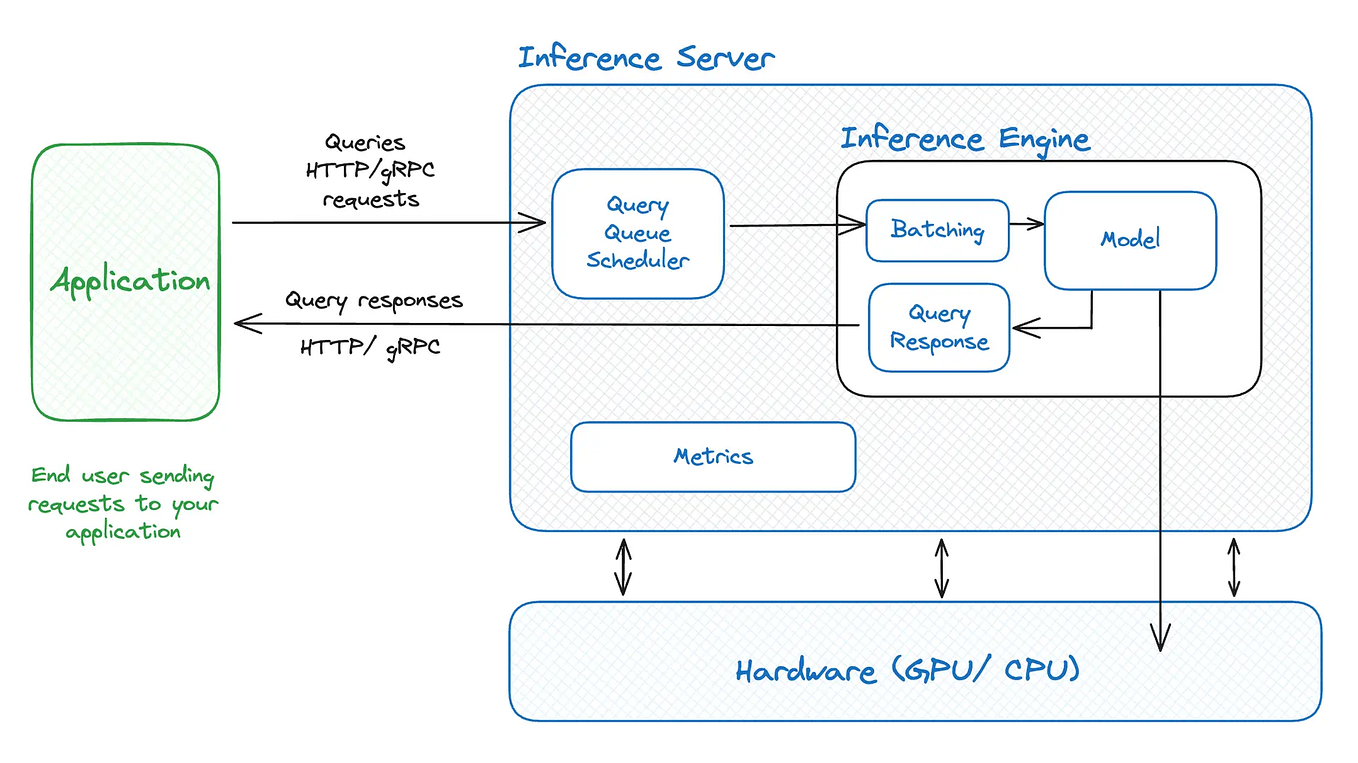
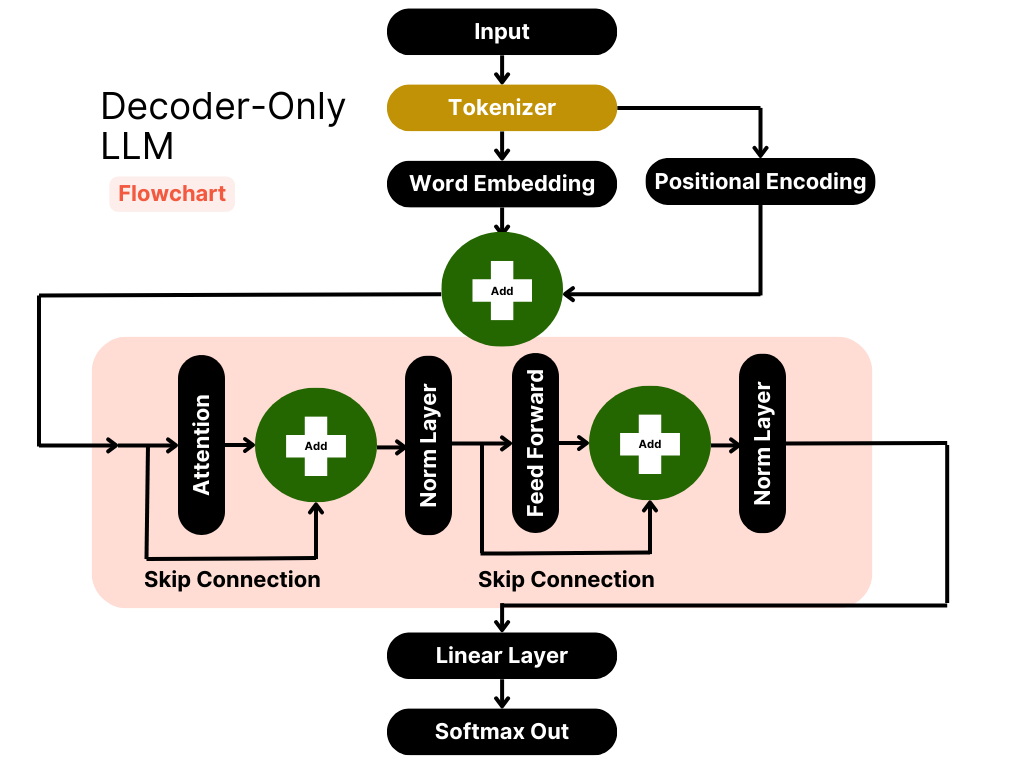
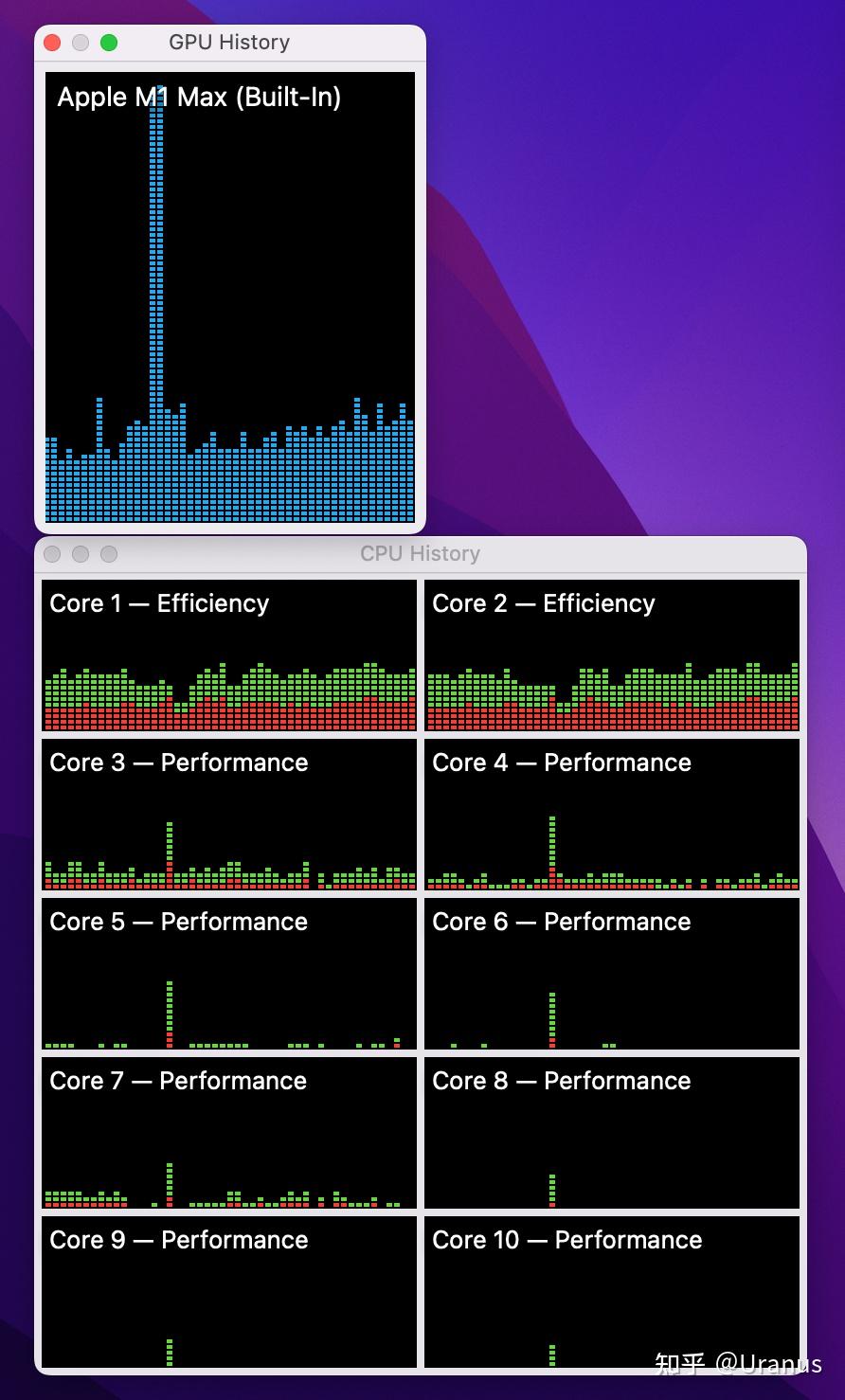
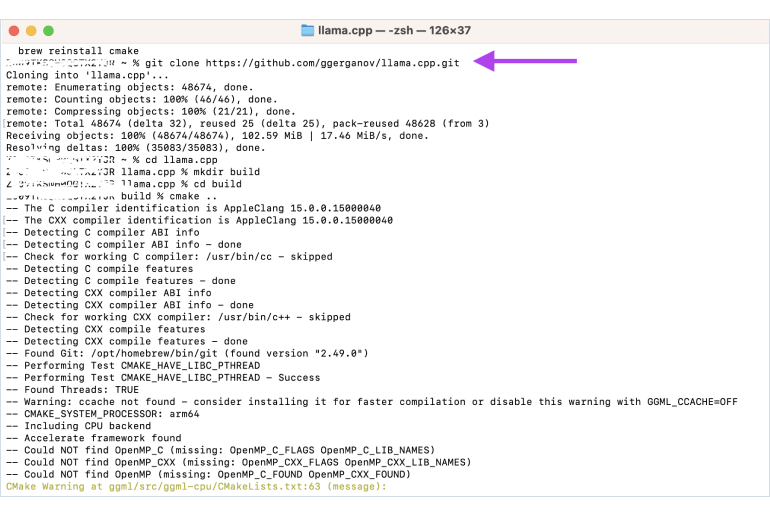
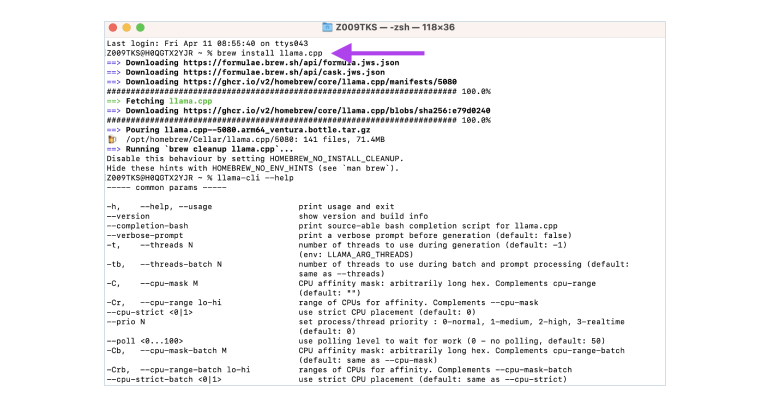
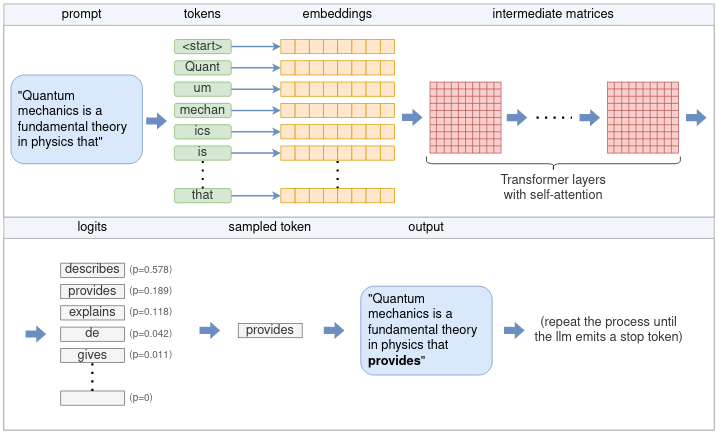
Run LLM on Intel GPUs Using llama.cpp | by NeoZhangJianyu | Medium
Run any LLM on Distributed Multiple GPUs Locally Using Llama_cpp | by ...
How to compile LLM on Android using LLama.cpp | by mmonteiros | Medium
Efficiently Run Your Fine-Tuned LLM Locally Using Llama.cpp 🚀 | by ...
Run a Local Image-Reading LLM at Zero Cost Using LLAMA.CPP | by Sajith ...
Running Large Language Models (LLMs) on CPU using llama.cpp | by Wei ...
LLM By Examples: Build Llama.cpp for CPU only | by MB20261 | Medium
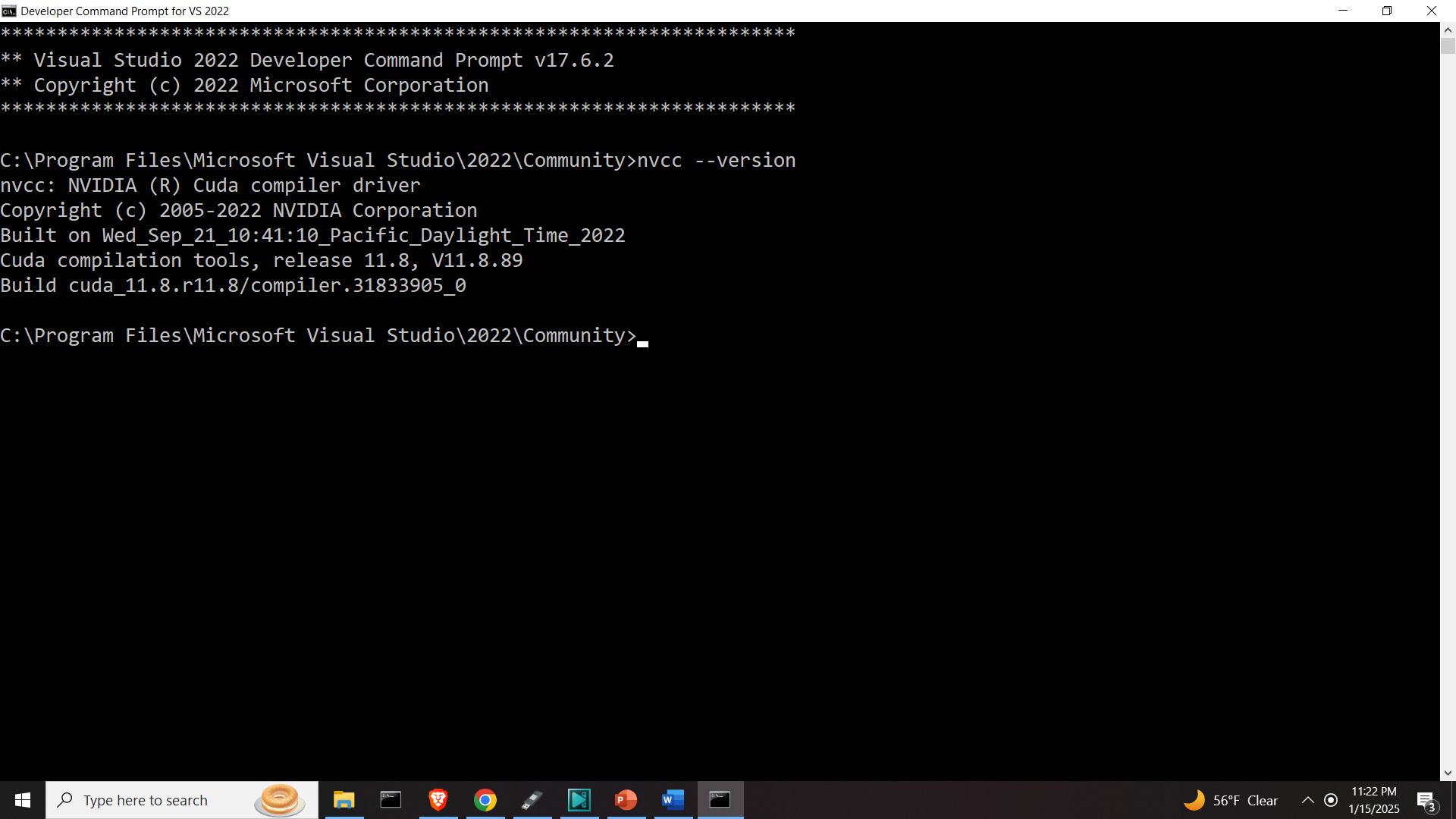
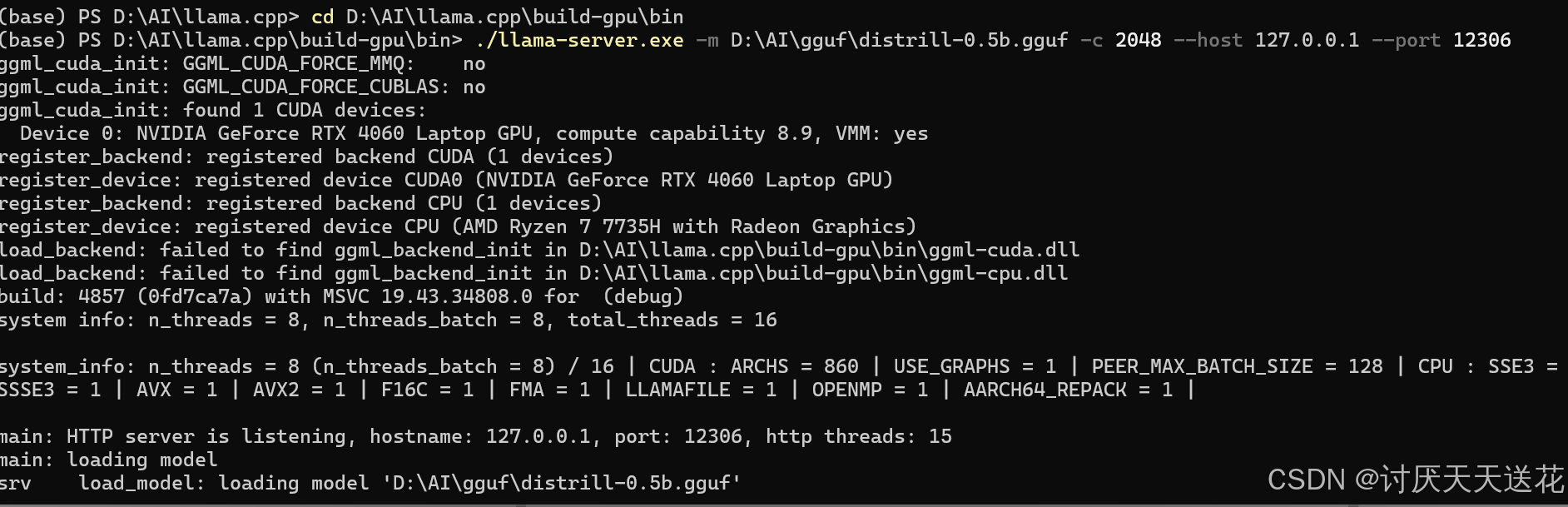
LLM By Examples: Build Llama.cpp with GPU (CUDA) support | by MB20261 ...
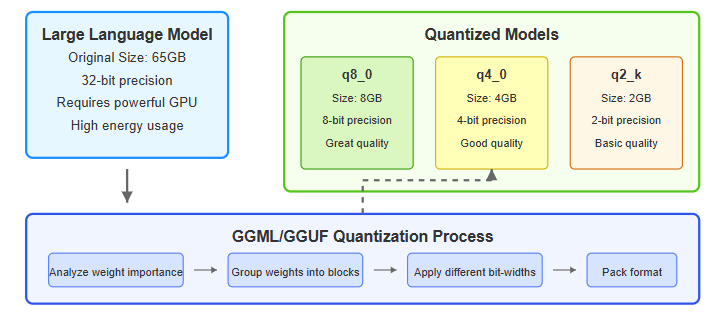
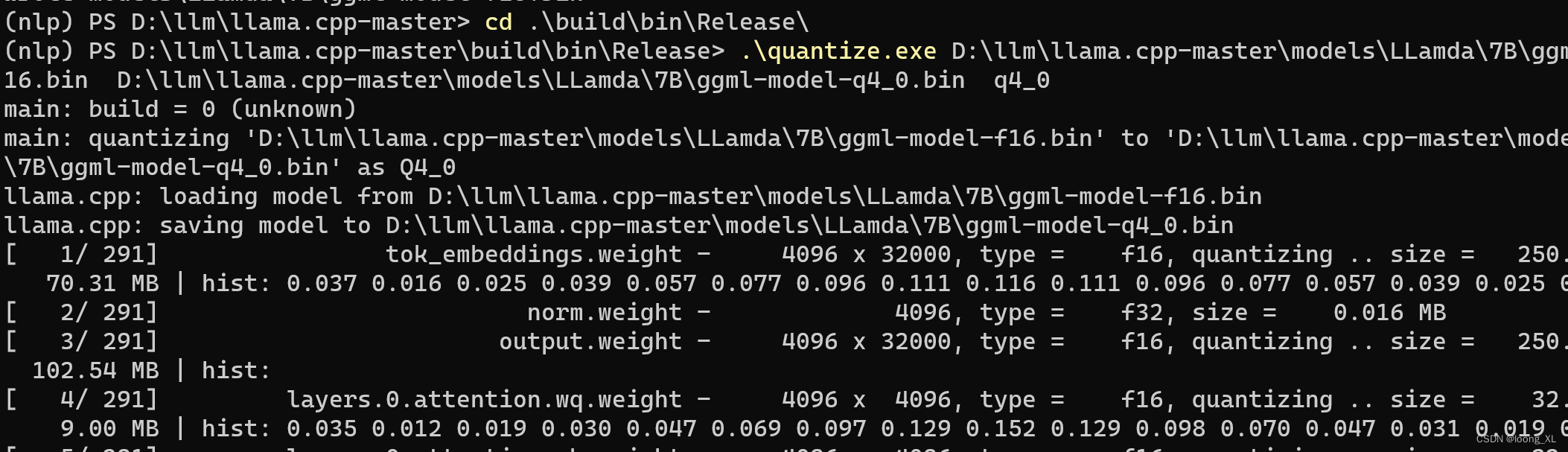
Quantization of LLMs with llama.cpp | by Ingrid Stevens | Medium
LLM By Examples: Build Llama.cpp with customized Docker Images | by ...
Run LLMs (Llama 3) Locally with llama.cpp | Medium
Setup Nvidia GPU in Ubuntu 22.04 for LLM | by MB20261 | Medium
How to install LLAMA CPP with CUDA (on Windows) | by Kaizin | Medium
Running llama.cpp on Windows with GPU acceleration | siddharth's space
Accelerating LLMs with llama.cpp on NVIDIA RTX Systems | NVIDIA ...
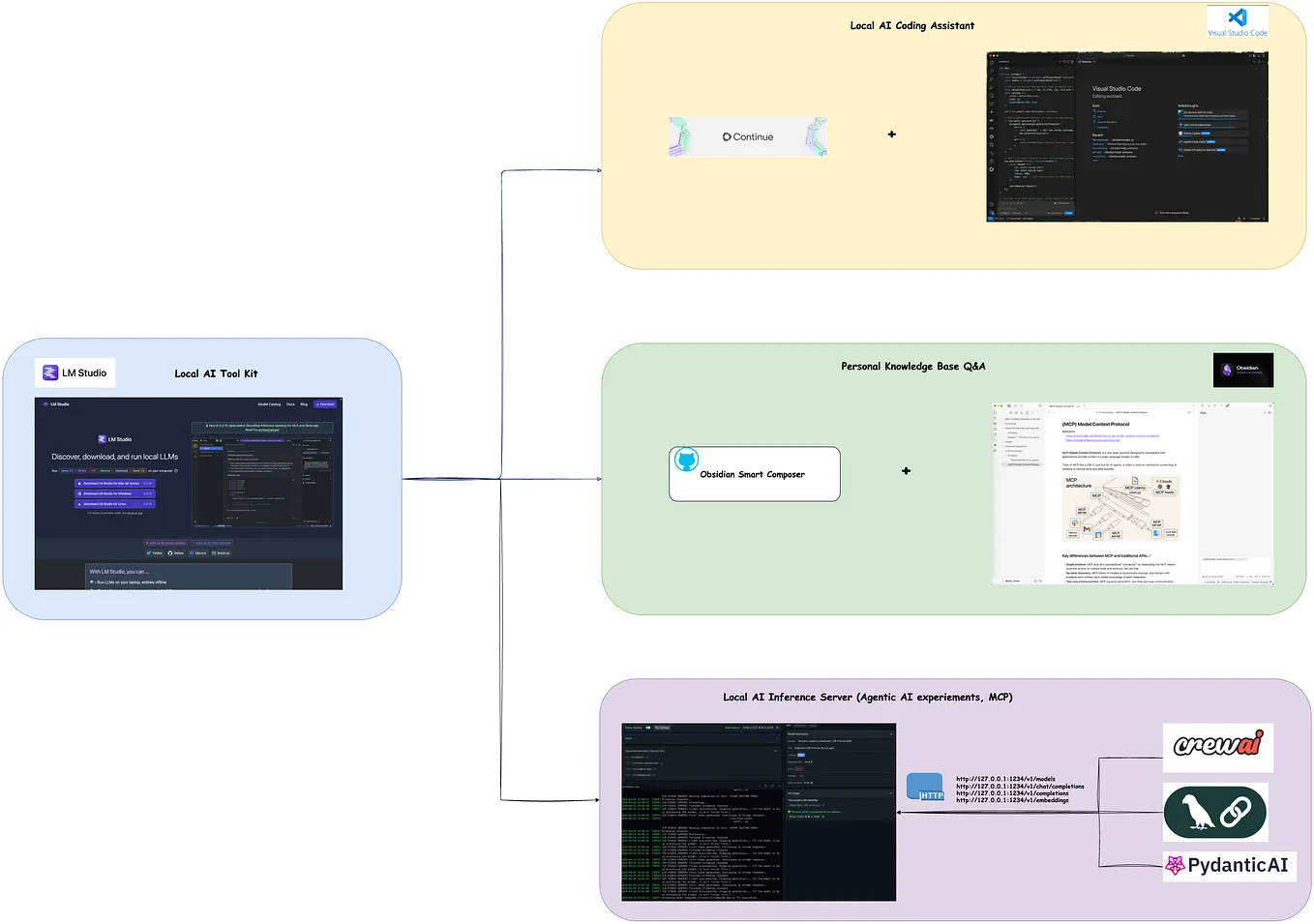
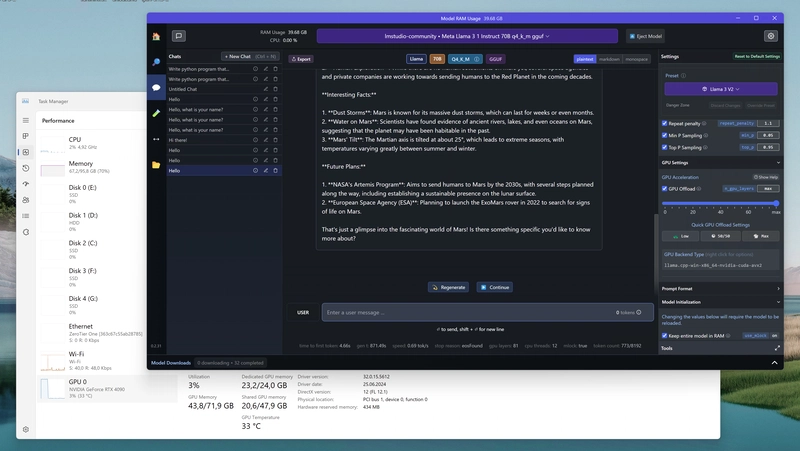
How to Use GPU on LLM Studio | GPU Acceleration Guide
LM Studio Accelerates LLM With GeForce RTX GPUs | NVIDIA Blog
Complete Guide to llama.cpp: Local LLM Inference Made Simple | by Huda ...
Effects of CPU speed on GPU inference in llama.cpp | Puget Systems
Install llama-cpp-python with GPU Support | by Manish Kovelamudi | Medium
Run LLM on Pi5: Connecting an NVIDIA GPU to Raspberry Pi 5 via PCIe x4 ...
How to Run Quantized GGUF LLMs Locally on GPU with llama.cpp (No Cloud ...
Build from Source Llama.cpp with CUDA GPU Support and Run LLM Models ...
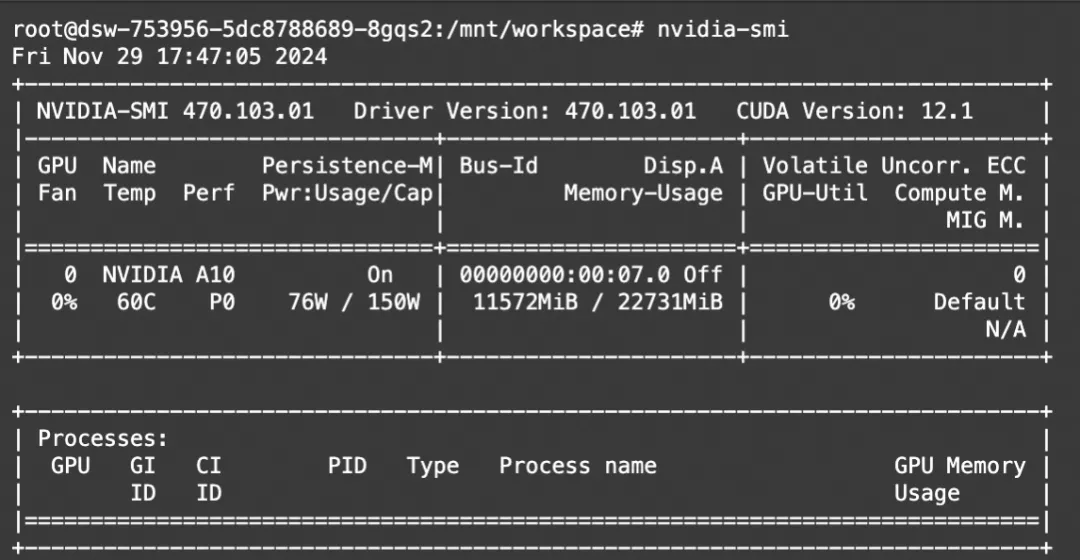
Generative AI: LLMs: How to do LLM inference on CPU using Llama-2 1.9 ...
Boosting LLM Performance: llama.cpp on NVIDIA RTX Systems
Use llama.cpp with BigDL-LLM on Intel GPU — BigDL latest documentation
AI for everyone: projects that allow us to run LLM models on modest ...
Accelerate LLAMA & LangChain with Local GPU | Medium
Boosting LLM Inference with Intel GPU: Efficient Solutions and ...
Distributed LLM Inference on Consumer Machines with llama.cpp: A Bare ...
Understanding how LLM inference works with llama.cpp
Beginner’s Guide: Setting up llama.cpp for Local LLM Experiments (GPU ...
AMD GPU run large language model LLM locally - LLaMA 8bit and LoRA ...
Build and Run llama.cpp Locally for Nvidia GPU - YouTube
A step by step guide to running a local LLM with llama-cpp-python ...
[机器学习]-如何在 MacBook 上安装 LLama.cpp + LLM Model 运行环境_macbook跑llm-CSDN博客
解开封印!加倍 LLM 推理吞吐: ggml.ai 与 llama.cpp - 知乎
GitHub - MegaStood/Intell-gpu-llm-guide: tuitorial for intel gpu llm ...
Llama.cpp/vLLM Toolboxes for LLM inference on Strix Halo - Framework ...
How to run Local LLMs on Windows with NVIDIA (llama.cpp + CUDA ...
How to Run a Local LLM for Enterprise Use - Intellias
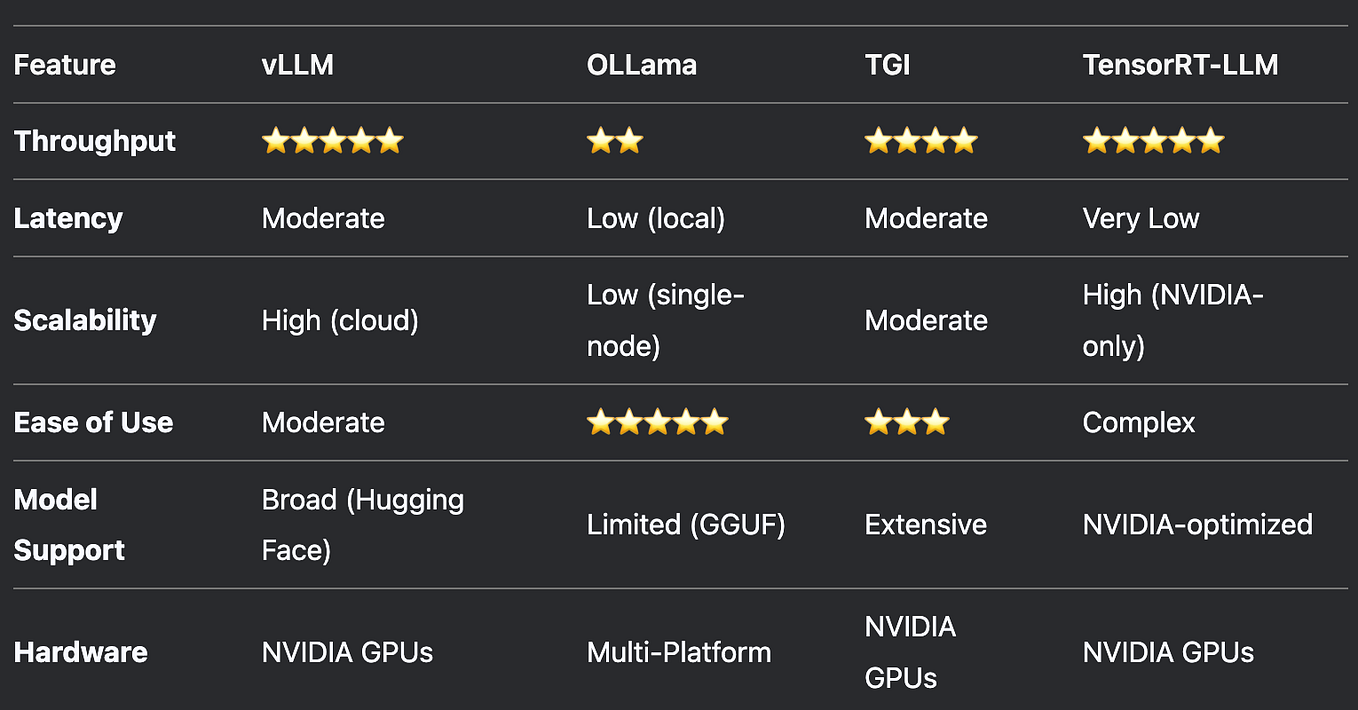
LLM inference server performances comparison llama.cpp / TGI / vLLM ...
llama.cpp is slow on GPU · Issue #9881 · ggml-org/llama.cpp · GitHub
Engineer's Guide to Local LLMs with LLaMA.cpp on Linux - DEV Community
How to properly use llama.cpp with multiple NVIDIA GPUs with different ...
在 NVIDIA RTX 系统上使用 Llama.cpp 加速 LLM - NVIDIA 技术博客
John Mccallum | Facebook
Goulash (one pot method) Serves... - Nikita Caroline Pearce | Facebook
Topmax Trading - MR.B CORNSTARCH SPOON 6" (#19) ~25pcs... | Facebook
GitHub - hsm207/howto-llamacpp-with-gpu: Step-by-step guide on running ...
llama.cpp 使用GPU进行量化部署 · Issue #490 · ymcui/Chinese-LLaMA-Alpaca · GitHub
Experiment with local LLMs with llama.cpp • Buttondown
GPU vs CPU: CPU is a better choice for LLM inference and fine-tuning ...
How do I configure llama.cpp to use my iGPU instead of the GPU? · ggml ...
llama.cpp: The Ultimate Guide to Efficient LLM Inference and ...
LLMs on 8GB VRAM: A Benchmark Guide - yW!an
AMD AI 395 显卡 LLM 推理测试:LLAMA.CPP的Vulkan 与 ROCM 后端对比 - 知乎
GitHub - omrshrifmo/llama.cpp-unsupported-gpus: LLM inference in C/C++
GPU Specific llama.cpp Compilation: Massively Reduce Build Times - YouTube
I Switched From Ollama And LM Studio To llama.cpp And Absolutely Loving It
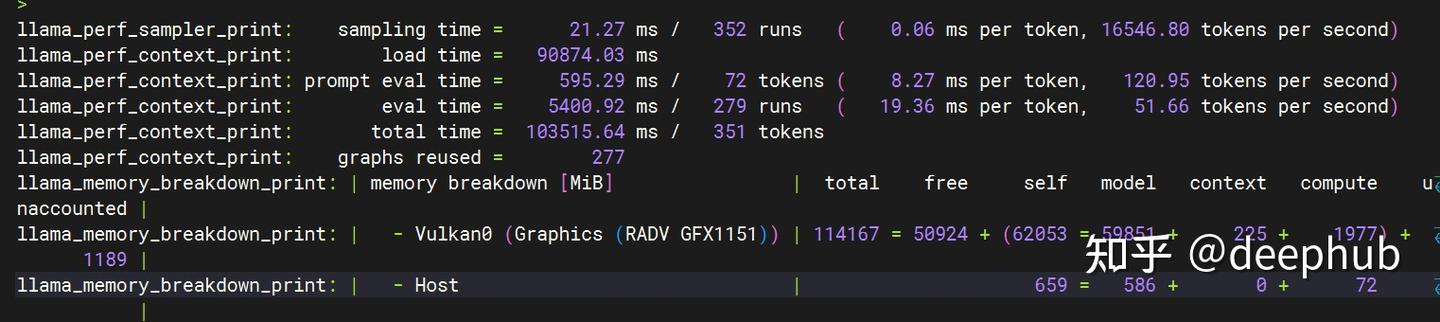
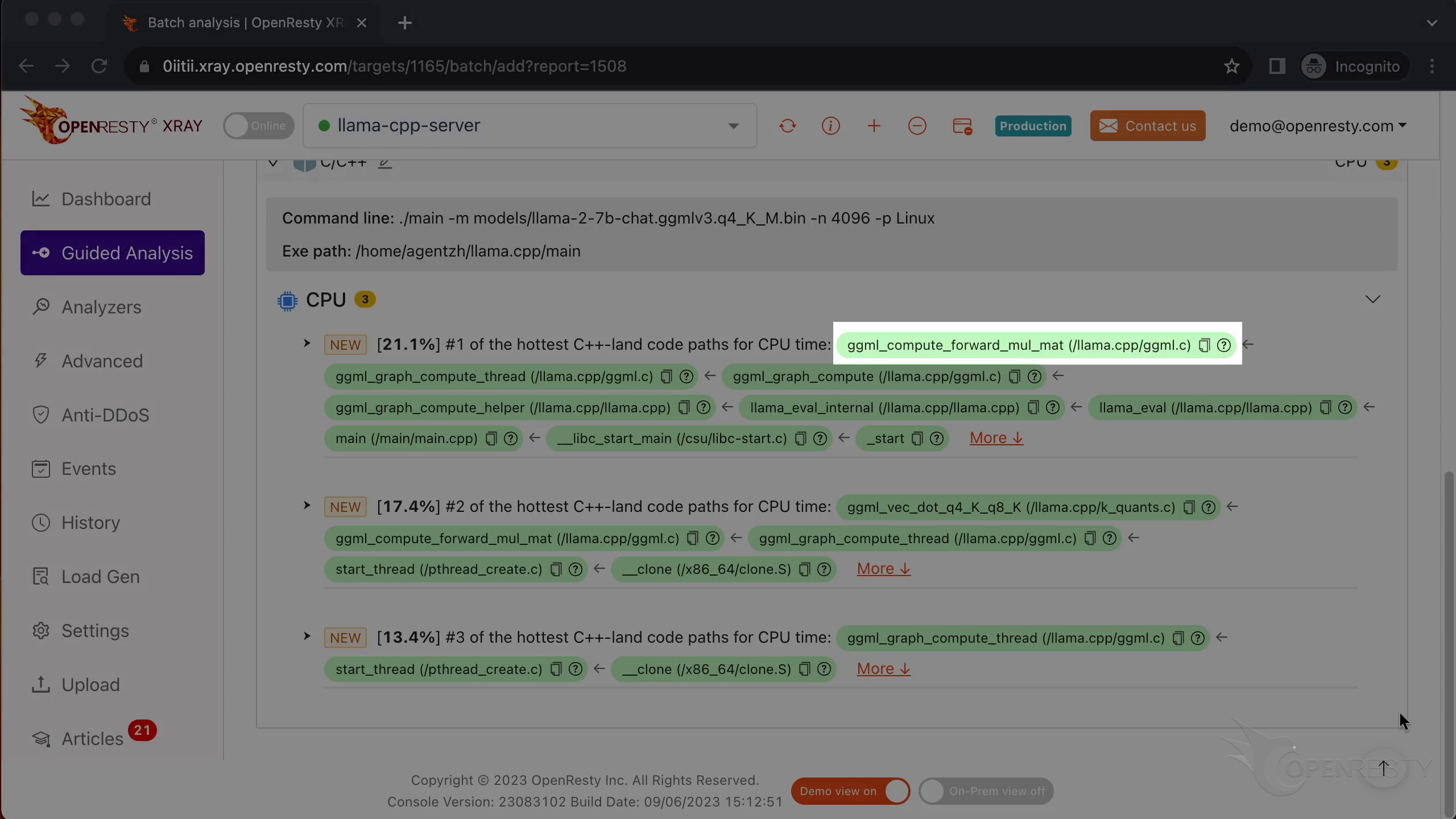
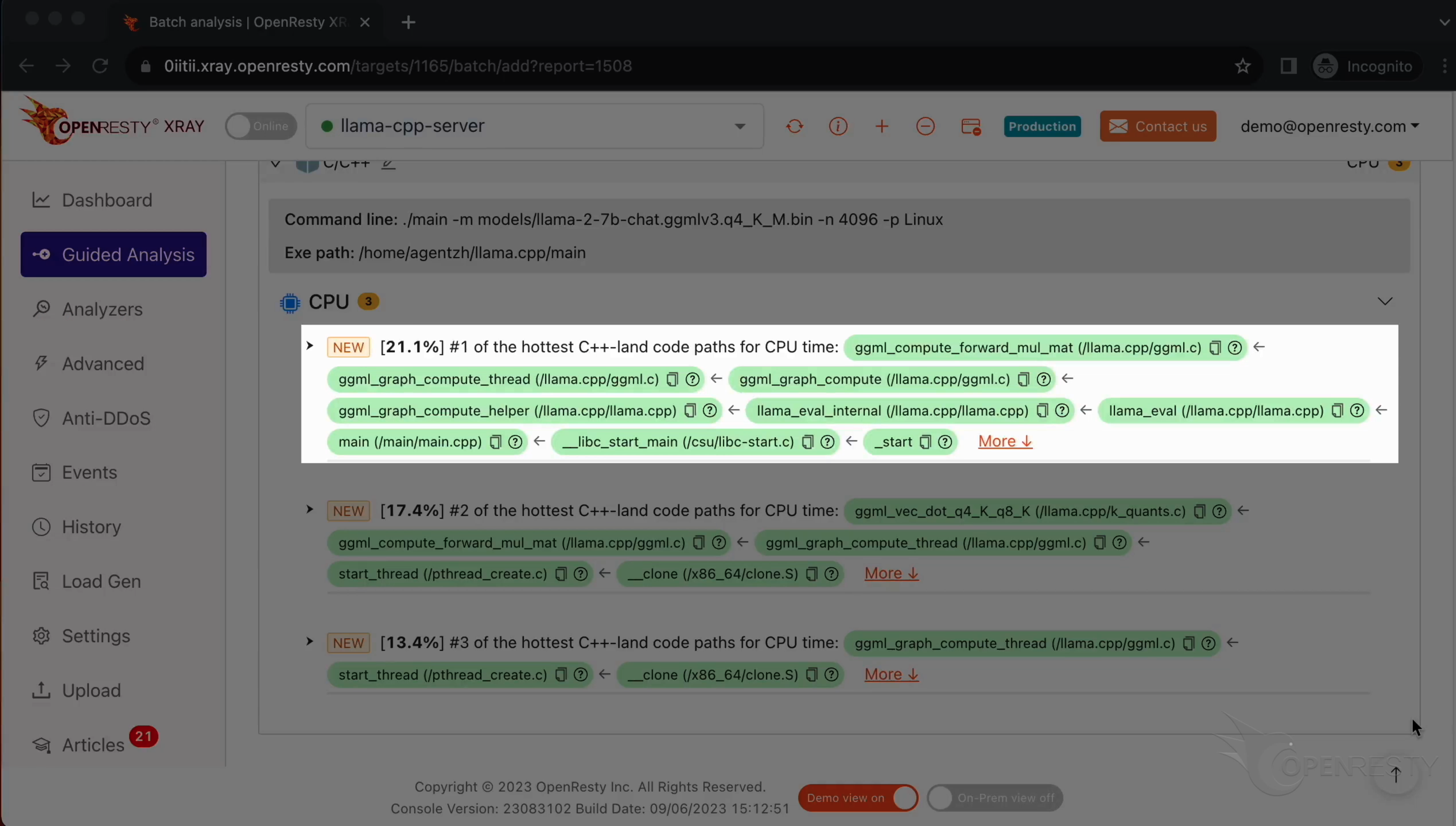
How CPU time is spent inside llama.cpp + LLaMA2 (using OpenResty XRay ...
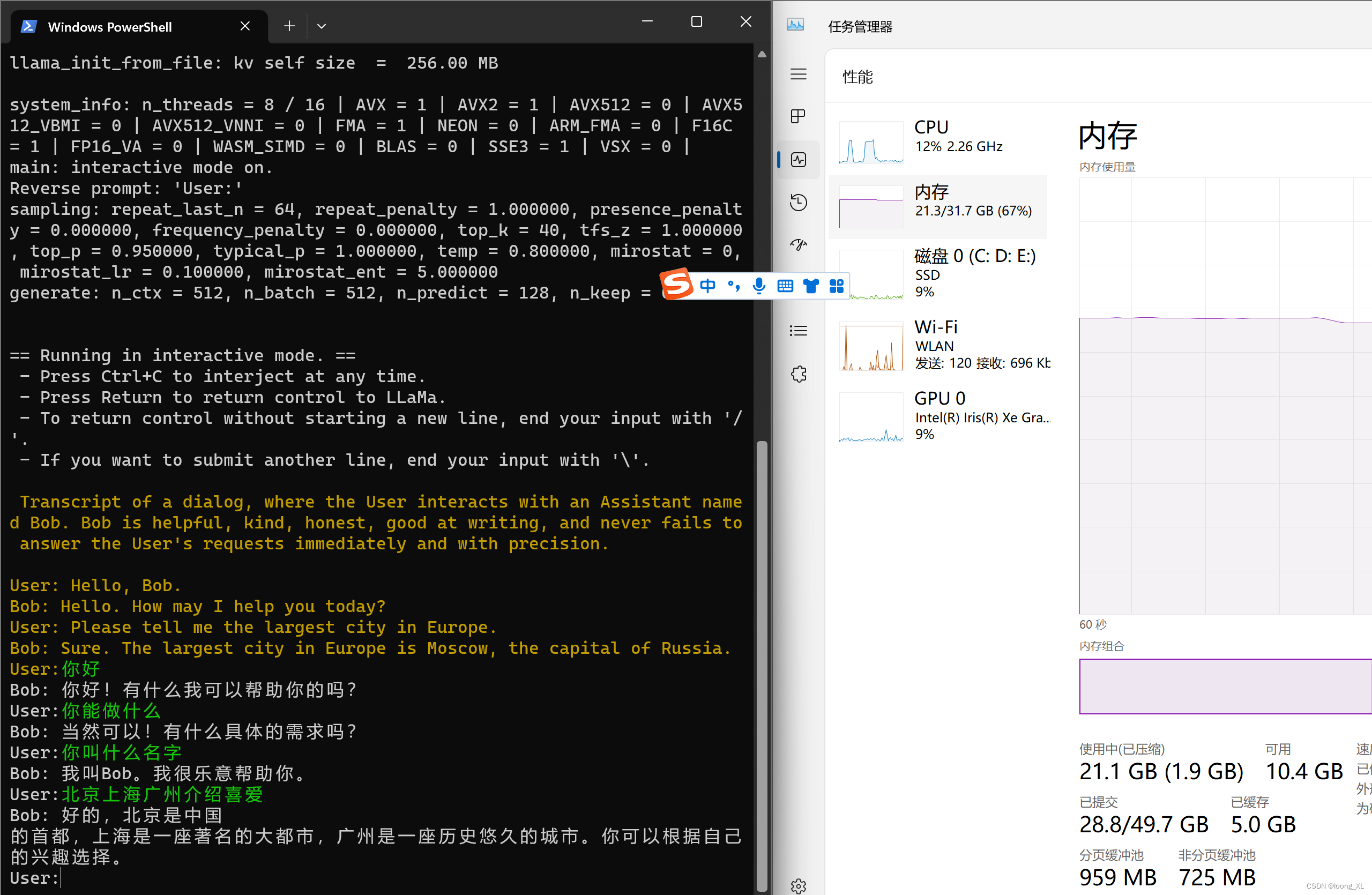
llama.cpp LLM模型 windows cpu安装部署;运行LLaMA2模型测试-CSDN博客
Complete Llama.cpp Build Guide 2025 (Windows + GPU Acceleration) # ...
How to Compile and Build the GPU version of llama.cpp from source and ...
CPU 时间是如何耗费在 llama.cpp 程序和 LLaMA2 模型内部的(使用 OpenResty XRay) - OpenResty 官方博客
llama.cpp LLM模型 windows cpu安装部署;运行LLaMA2模型测试_深度学习-CSDN专栏
How to Run GLM-4.7 Locally with llama.cpp: A High-Performance Guide ...
NVIDIA showcases ways to implement local LLMs on RTX-powered PCs feat ...
请问使用 llama.cpp推理模型是否支持GPU加速 · Issue #853 · ymcui/Chinese-LLaMA-Alpaca ...
GitHub - illiafedenko00/Llama-LLM-CPU-Inference · GitHub
Showcase: Running LLMs locally with AMD GPUs! (No tutorial) [ROCm Linux ...
CPU反超NPU,llama.cpp生成速度翻5倍,LLM端侧部署新范式T-MAC开源-36氪
Issue: LlamaCPP still uses cpu after passing the n_gpu_layer param ...
Seven Ways of Running Large Language Models (LLMs) Locally (April 2024)
windows系统编译llama.cpp&gpu版本。。_llama windows编译版本-CSDN博客
一文搞定:LLM并发加速部署方案(llama.cpp、vllm、lightLLM、fastLLM)_llamacpp和vllm-CSDN博客
GPU acceleration is gone for llama.cpp, n-gpu-layers is dummy · Issue ...
llama.cpp: CPU vs GPU, shared VRAM and Inference Speed - DEV Community
探秘NVIDIA RTX AI:llama.cpp如何让你的Windows PC变身AI超人-腾讯云开发者社区-腾讯云
智谱开源端侧大语言和多模态模型GLM-Edge系列!-阿里云开发者社区
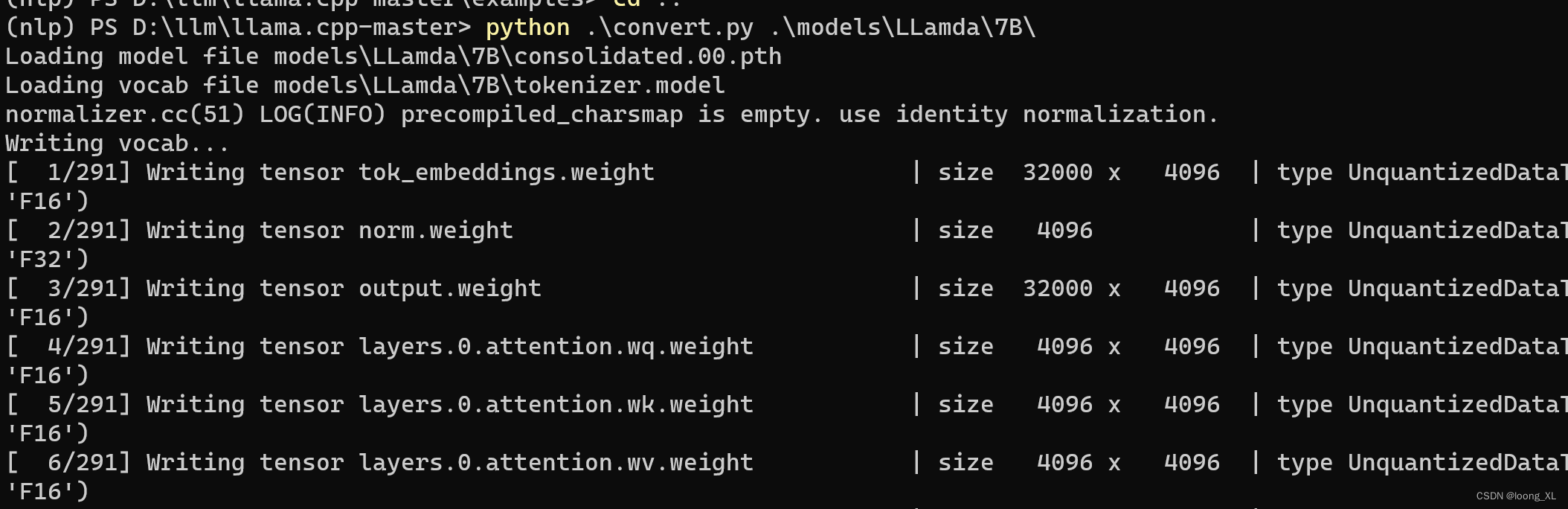
使用llama.cpp实现LLM大模型的格式转换、量化、推理、部署llama.cpp的主要目标是能够在各种硬件上实现LL - 掘金
LLM并发加速部署方案(llama.cpp、vllm、lightLLM、fastLLM)-CSDN博客
构建llama.cpp并在linux上使用gpu_llamacpp gpu-CSDN博客
Things people often outgrow
[LLM-Llama]MAC M1 安装llama-cpp-python体验完全 OpenAI API 的玩法 - 知乎
Episode 6: Messages from Spirit