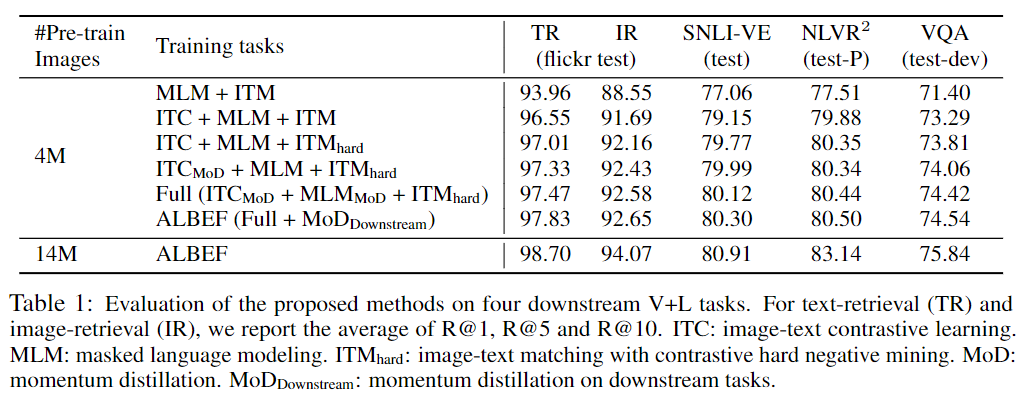
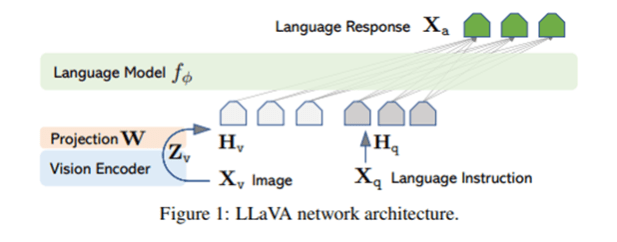
Showing 117 of 117on this page. Filters & sort apply to loaded results; URL updates for sharing.117 of 117 on this page
ALBEF BLIP BLIP2前世今生_blip2对bert做了什么改变-CSDN博客
ALBEF Align before Fuse Vision and Language Representation Learning ...
Crystal structure of the AlbEF complex involved in subtilosin A ...
多模态之- ALBEF - 知乎
ALBEF 论文 | MetaMind
GitHub - jinhojsk515/ALBEF_tutorial: ALBEF tutorial, with MIMIC-CXR ...
ALBEF: Contrastive Learning으로 Image-Text Co-representation space을 학습하는 ...
【自然语言处理】【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习-CSDN博客
多模态里程碑论文(ALBEF、BLIP、BLIP-2) - 海_纳百川 - 博客园
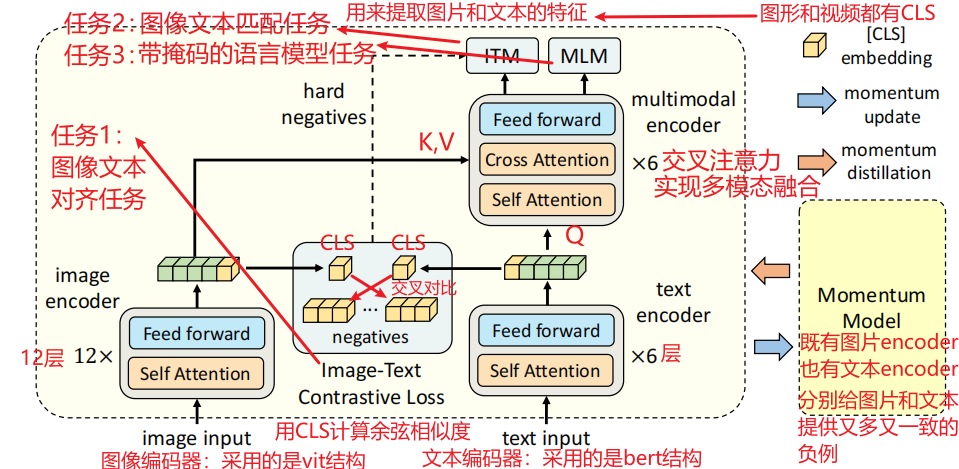
多模态之ALBEF—先对齐后融合,利用动量蒸馏学习视觉语言模型表征,学习细节理解与论文详细阅读:Align before Fuse_align ...
源码解析ALBEF:带动量蒸馏的视觉和语言表示学习 - 知乎
[阅读笔记7][ALBEF]Align before Fuse: Vision and Language Representation ...
GitHub - salesforce/ALBEF: Code for ALBEF: a new vision-language pre ...
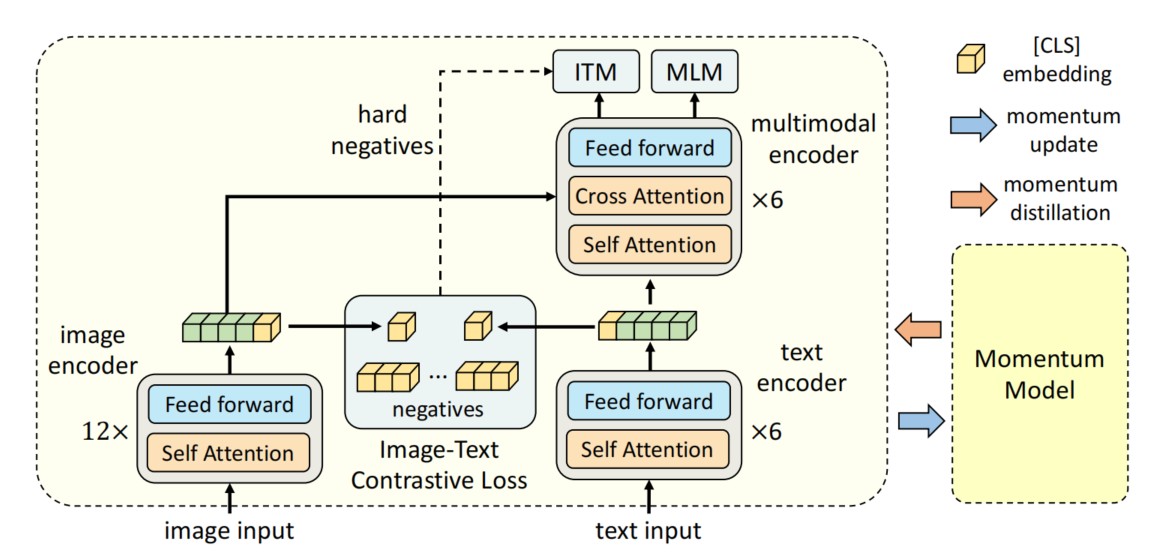
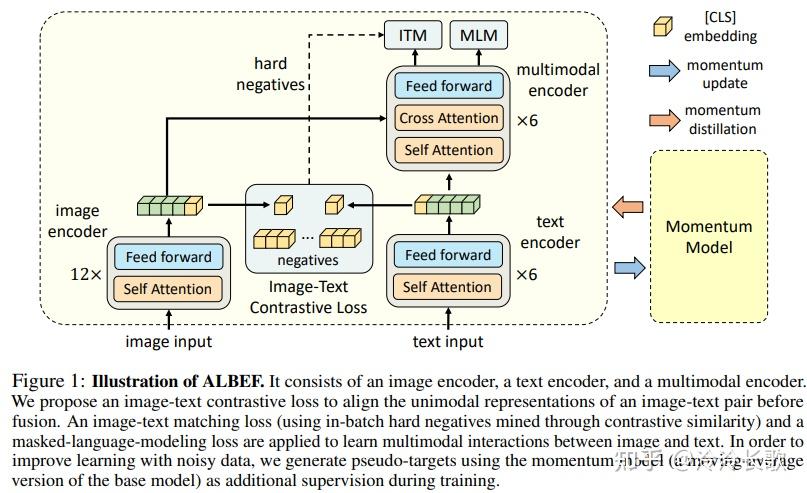
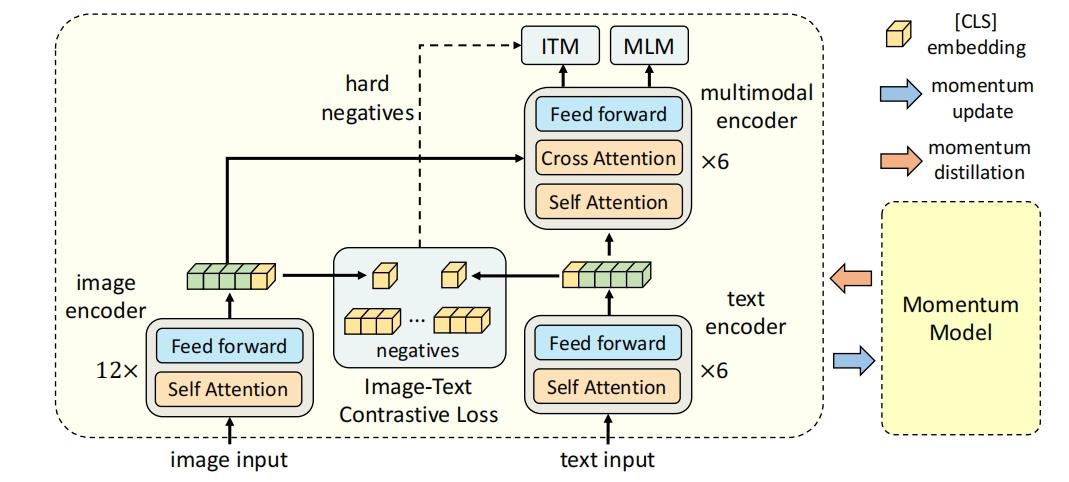
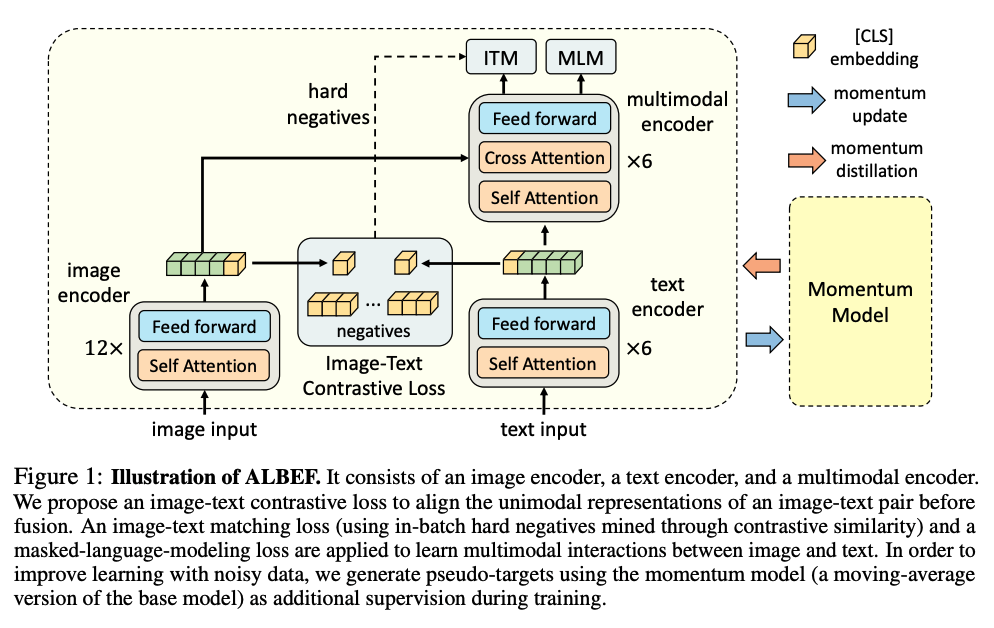
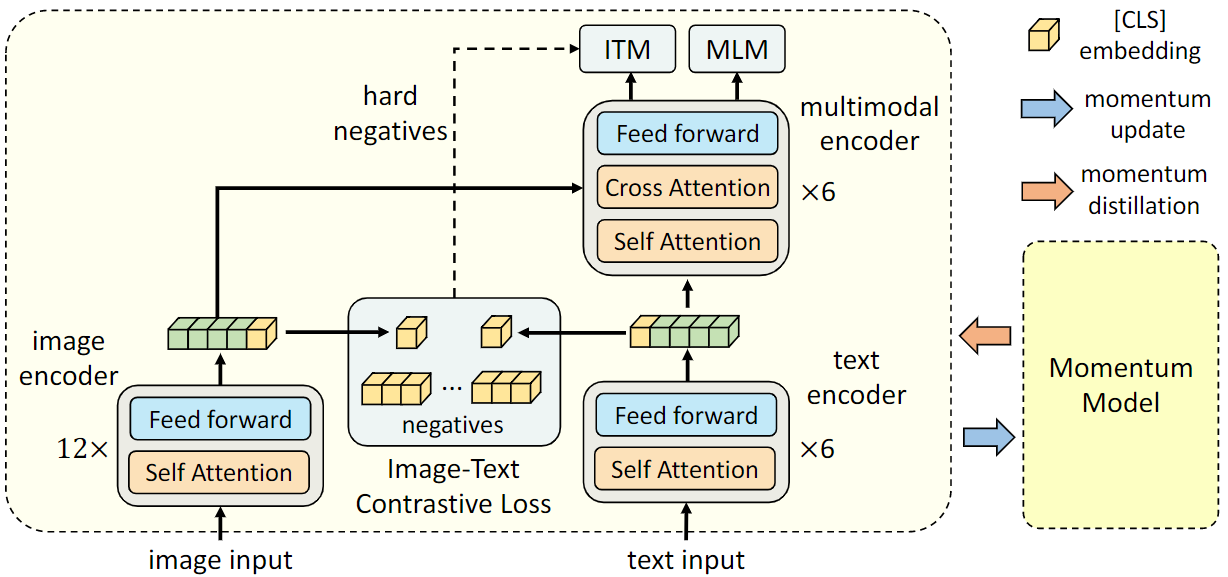
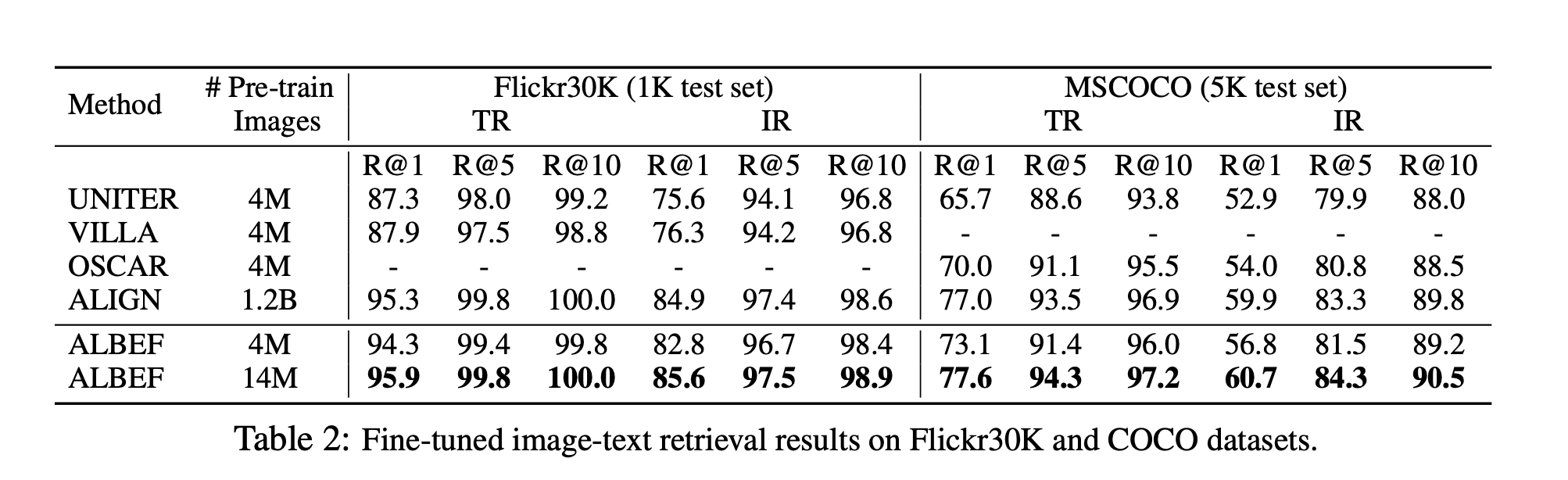
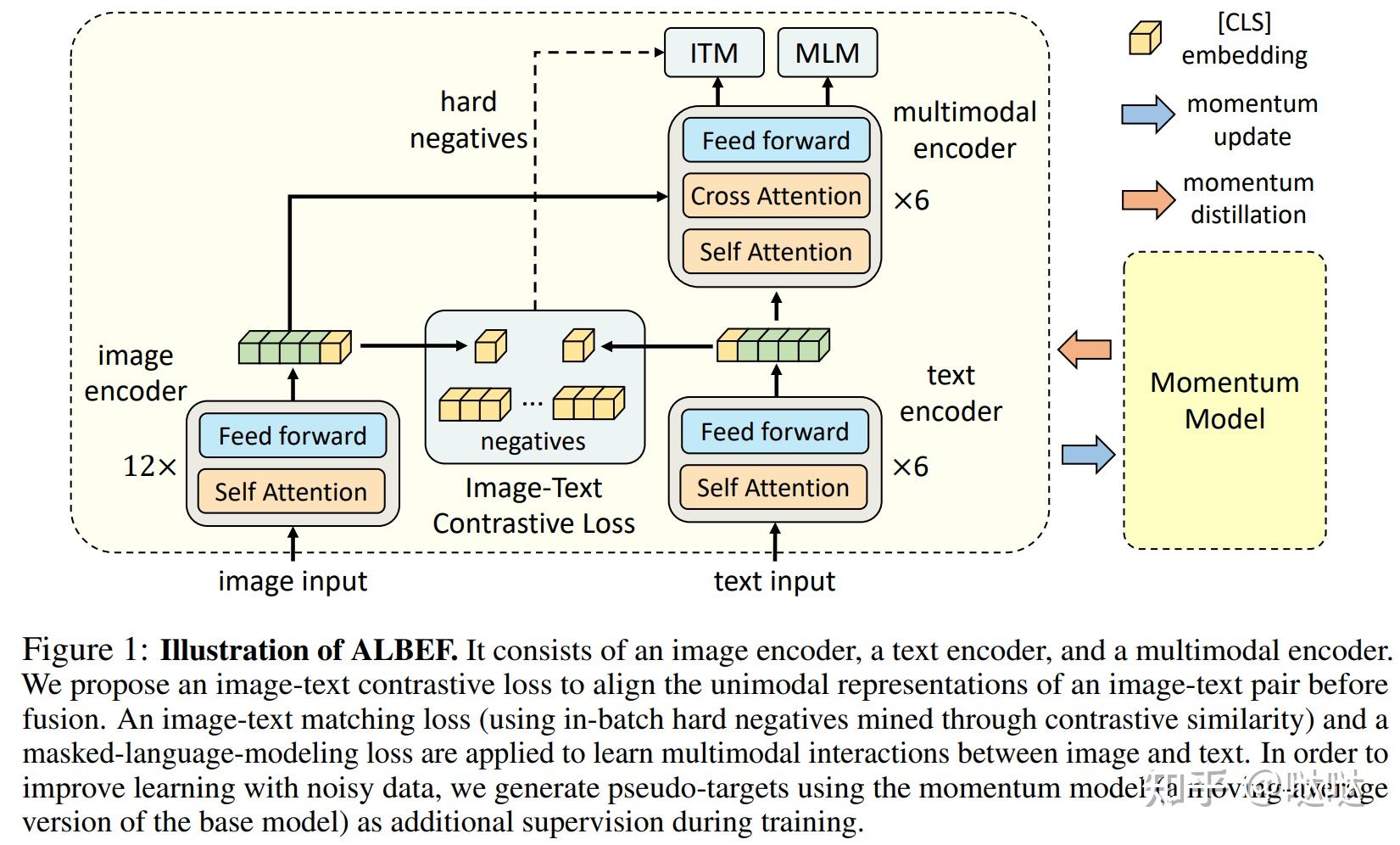
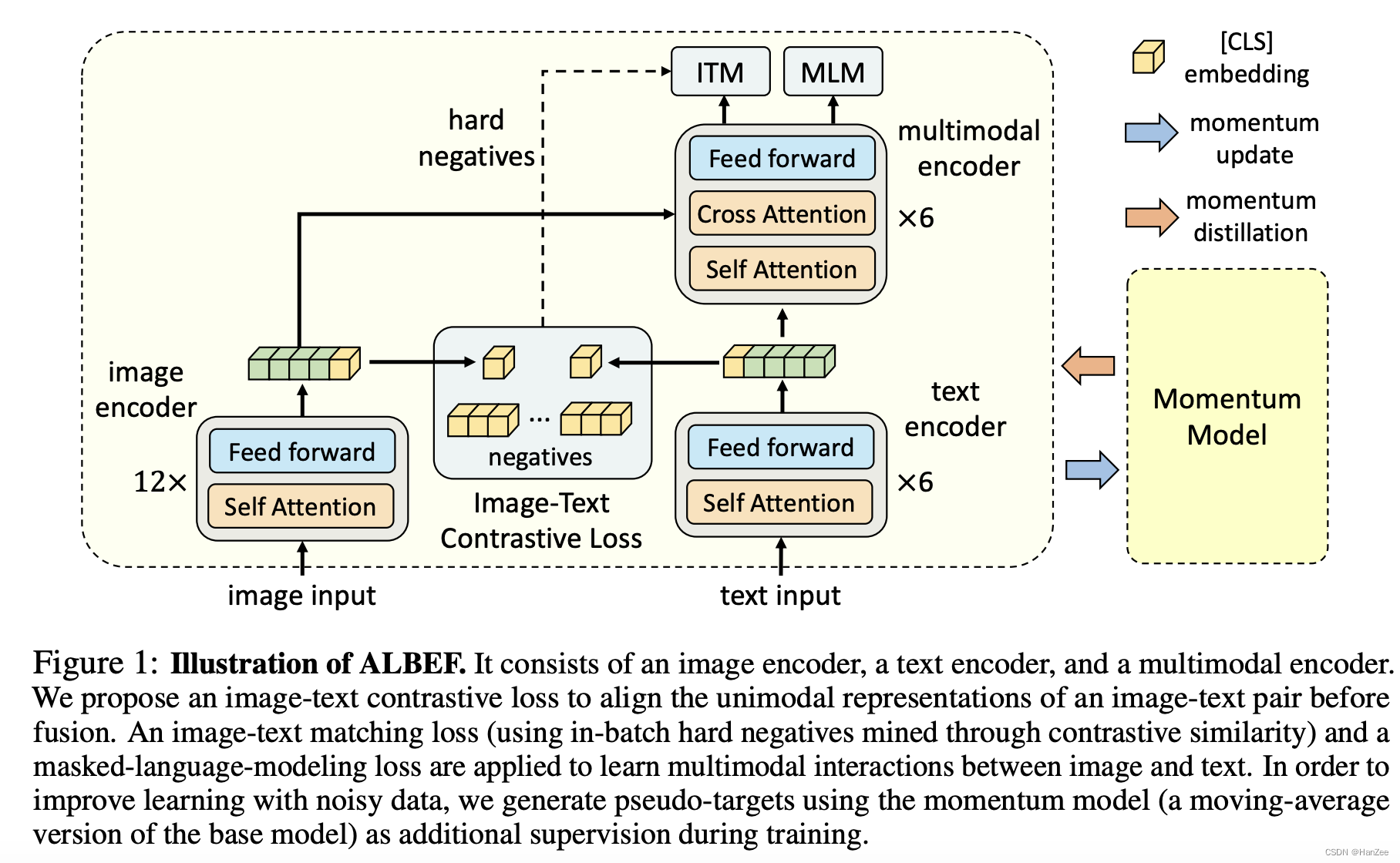
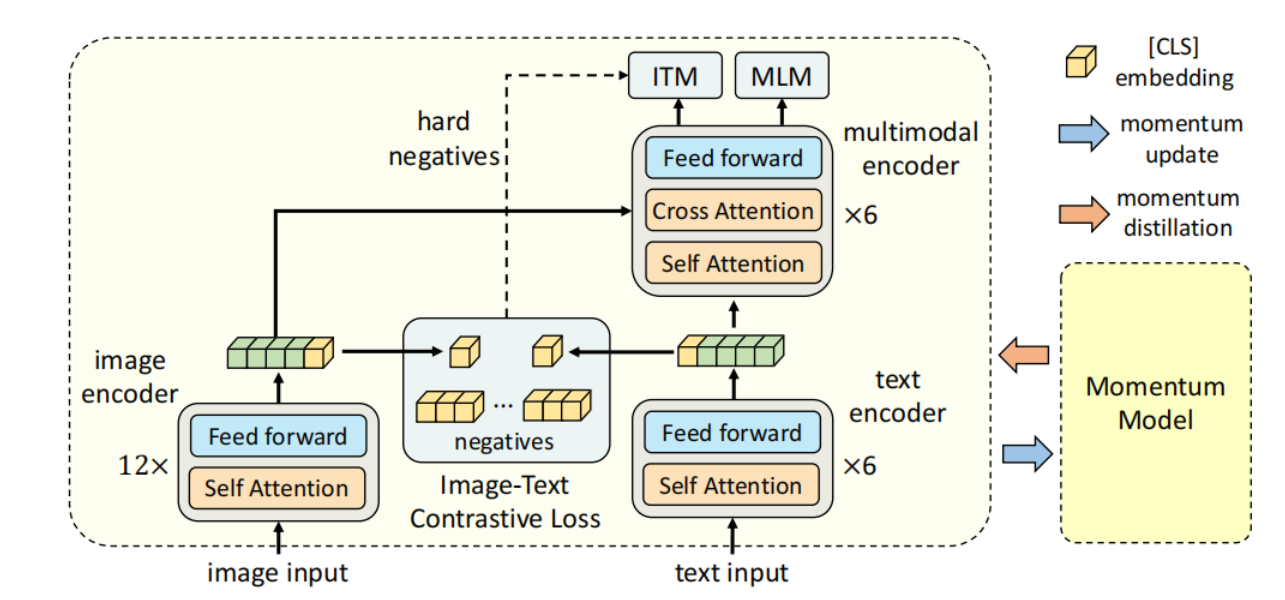
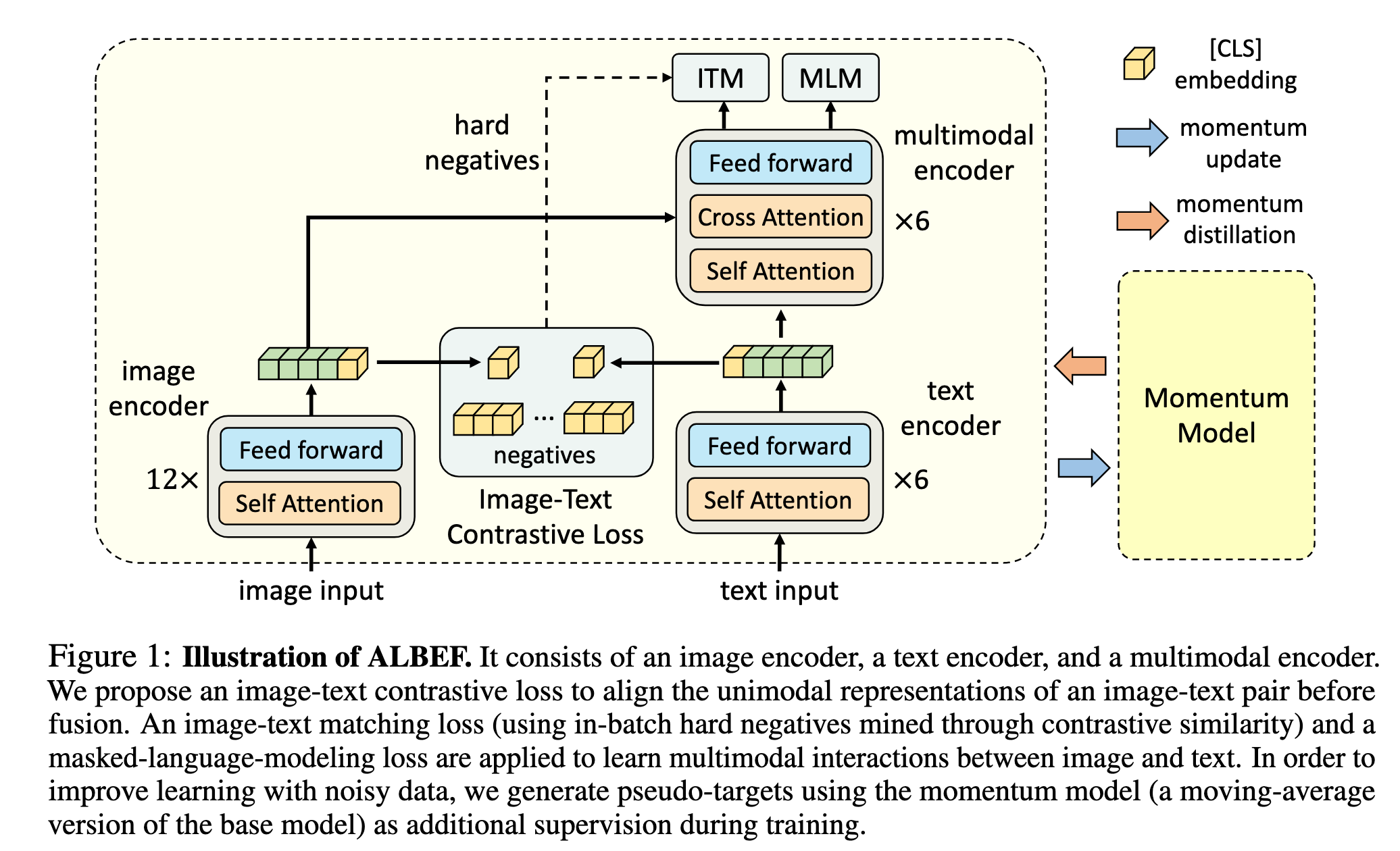
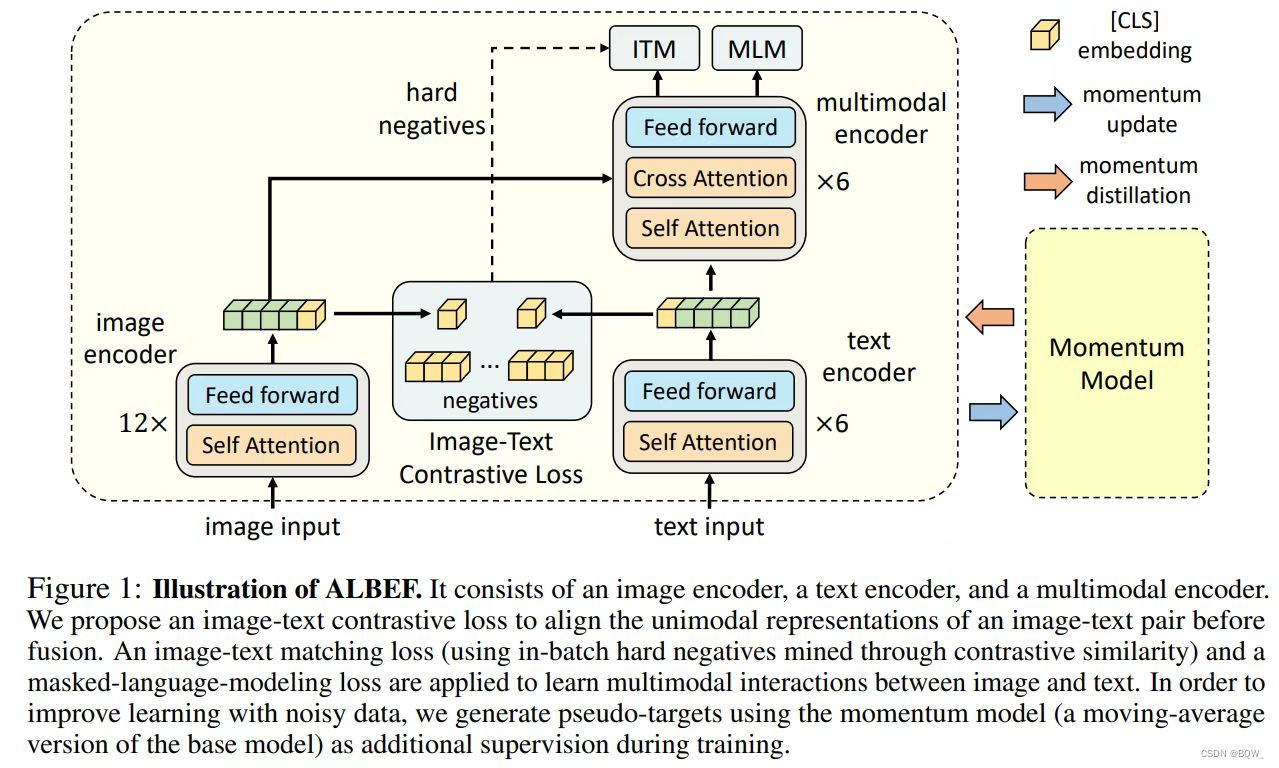
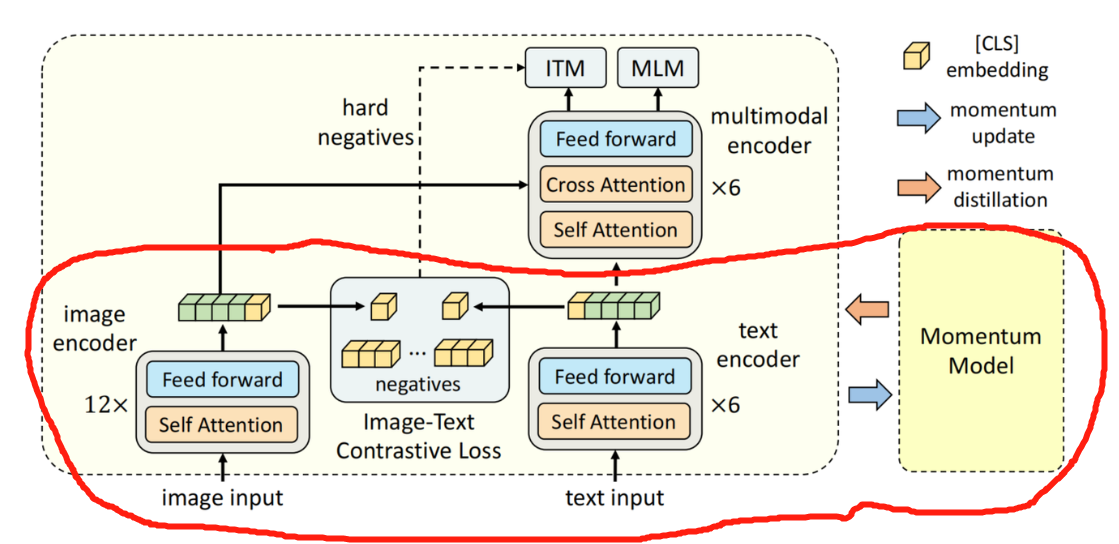
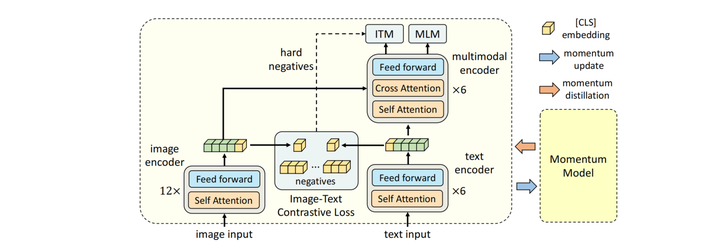
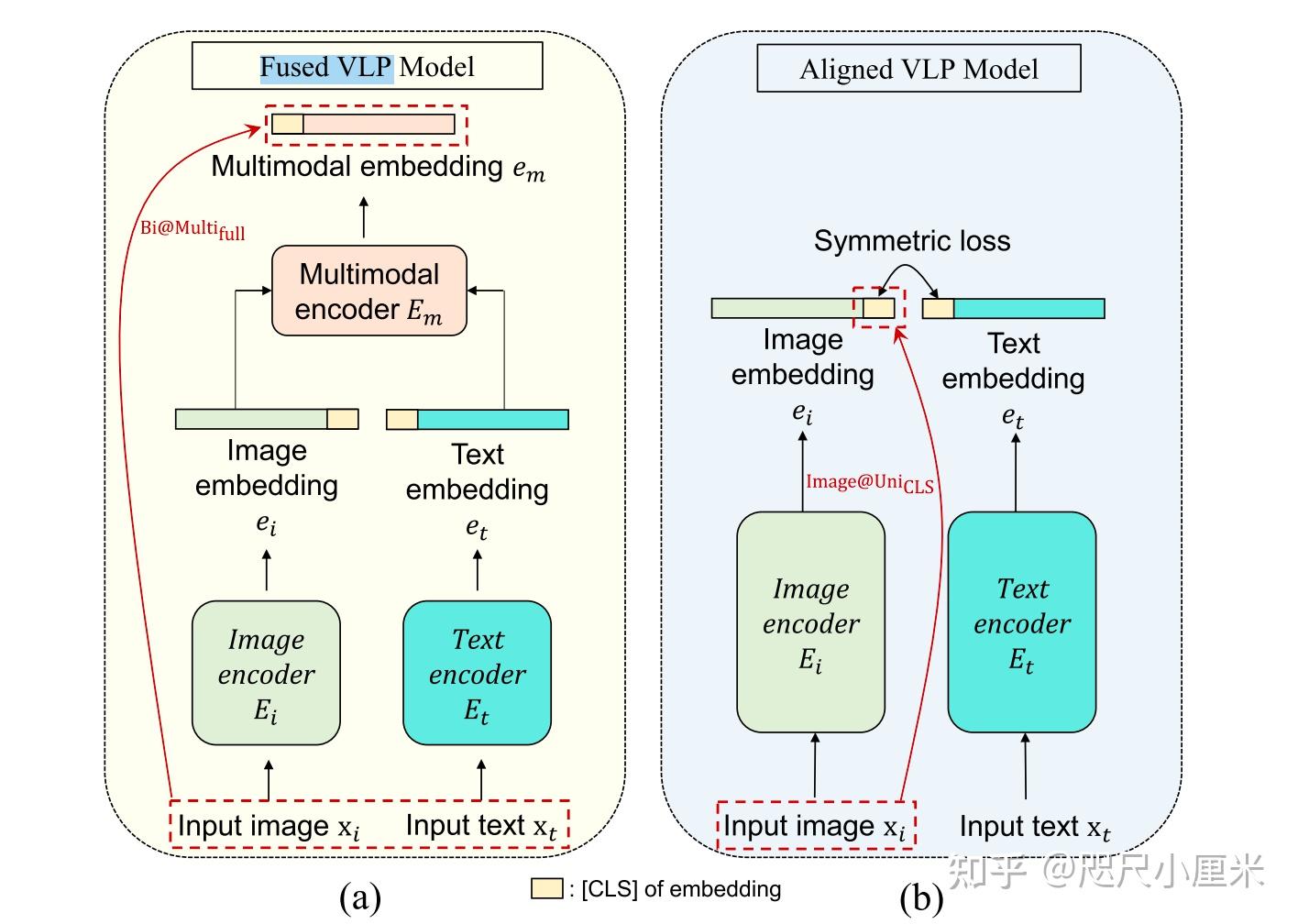
Illustration of ALBEF. It consists of an image encoder, a text encoder ...
第四篇ALBEF:Align before Fuse: Vision and Language Representation Learning ...
6기 논문 리뷰 📎 ALBEF(2021) Align before Fuse: Vision and Language ...
【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习 - 知乎
GitHub - dattatreya303/ALBEF-coco-2014: [Modified-for-coco-2014] Code ...
ALBEF(Align before Fuse: Vision and LanguageRepresentation Learning ...
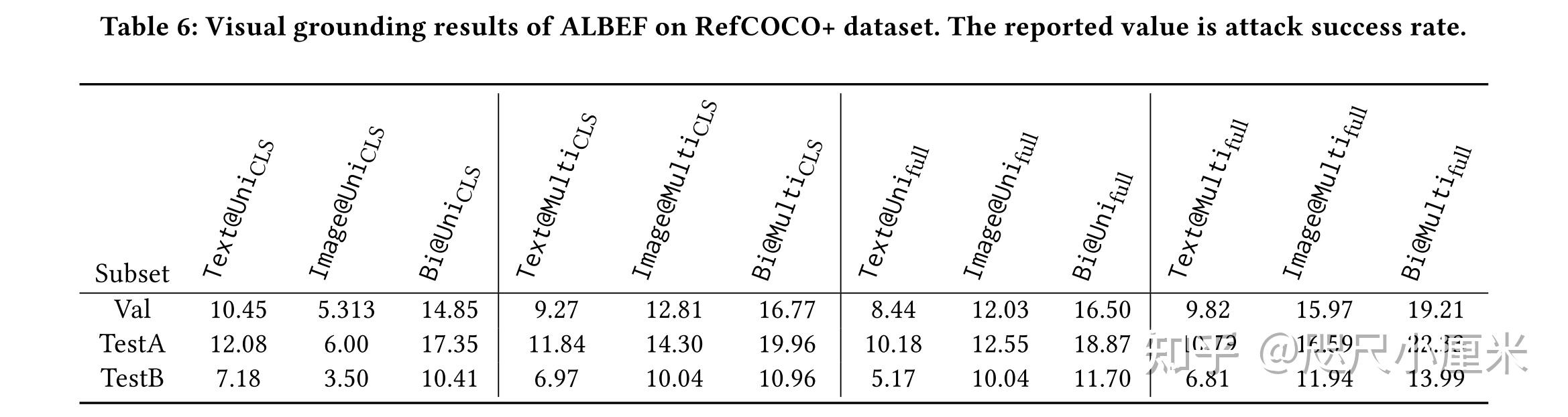
Towards Adversarial Attack on Vision-Language Pre-training Models-CSDN博客
【多模态论文解读】Align before Fuse: Vision and Language Representation Learning ...
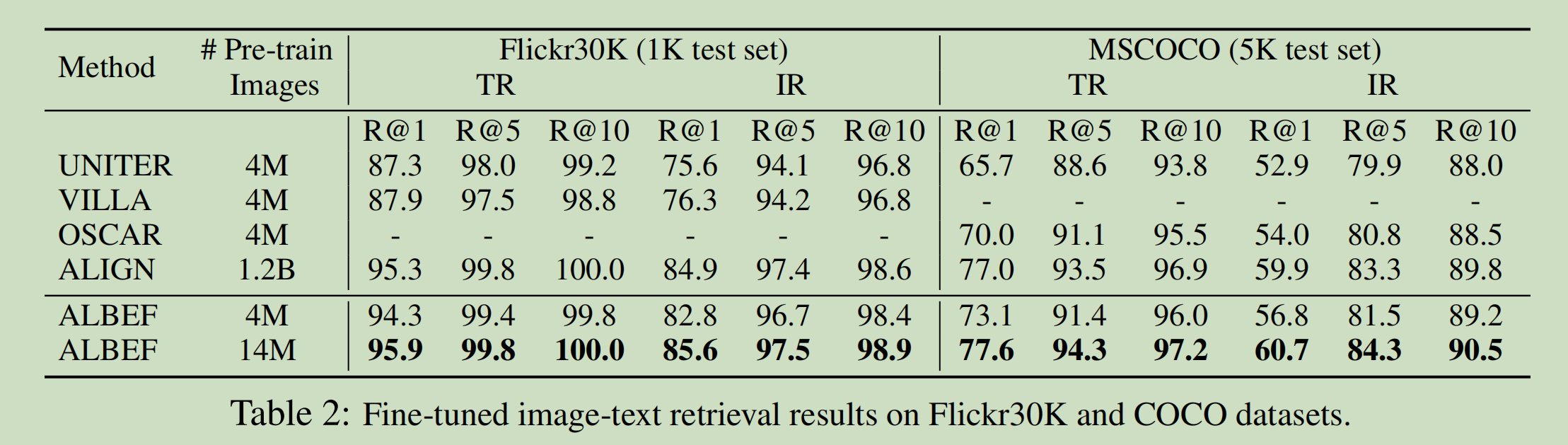
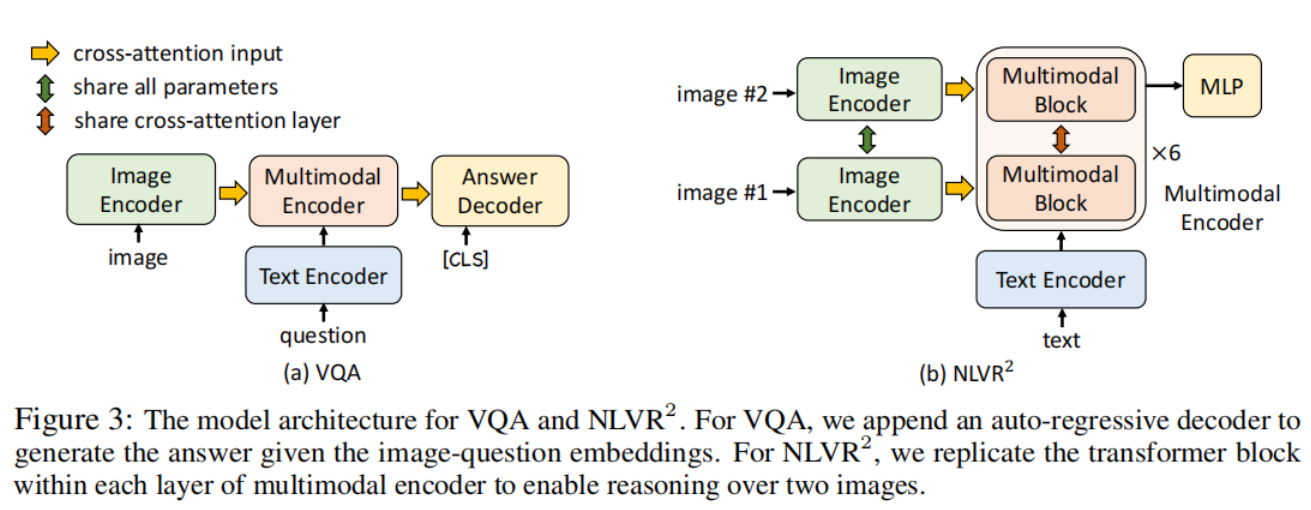
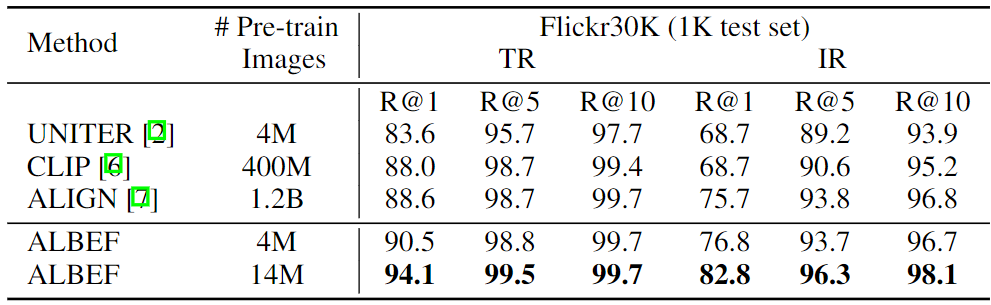
Align before Fuse: Vision and Language Representation Learning with ...
Align before Fuse (ALBEF): Advancing Vision-language Understanding with ...
Vision-Language Pre-Training with Triple Contrastive Learning · Issue ...
Demystifying Vision-Language Models: An In-Depth Exploration - MarkTechPost
Vision-Language Models: How They Work & Overcoming Key Challenges | Encord
A Comprehensive Guide to Vision Language Models (VLMs)
What are Vision-Language Models? | NVIDIA Glossary
Vision-language models that can handle multi-image inputs - Amazon Science
Interpreting the Linear Structure of Vision-Language Model Embedding ...
"Vision Language Models Explained: Key Concepts and Implementation ...
[论文总结] Co-Attack: Towards Adversarial Attack on Vision-Language Pre ...
多模态之ALBEF—先对齐后融合,利用动量蒸馏学习视觉语言模型表征,学习细节理解与论文详细阅读:Align before Fuse - 知乎
Vision Language models: towards multi-modal deep learning | AI Summer
Unlock AI Potential with Vision Language Models
Schematic of the Proposed Active Perception via Vision-Language Model ...
Vision-language-action model - Wikipedia
Vision-Language-Action Models: Concepts, Progress, Applications and ...
What are Visual Language models and how do they work? | by Kerem Aydın ...
Vision–Language Models for Remote Sensing: A New Era of Multimodal ...
多模态论文串讲:ALBEF & VLMo & BLIP & CoCa & Beit V3_alber多模态-CSDN博客
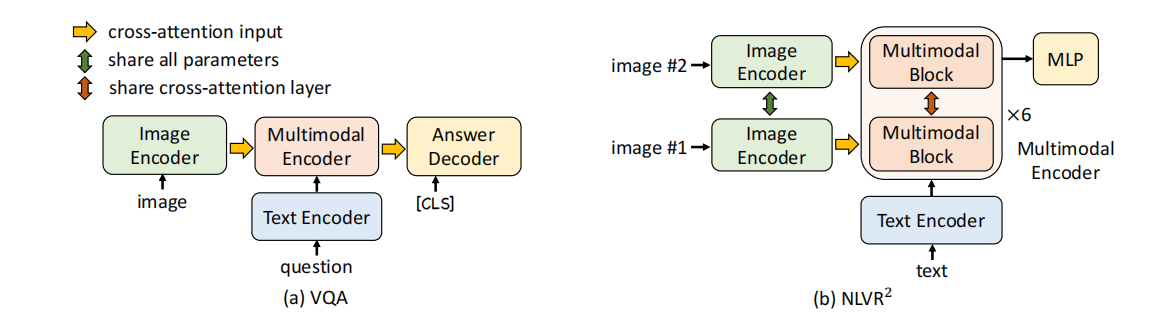
ALBEF: Align before Fuse: Vision and LanguageRepresentation Learning ...
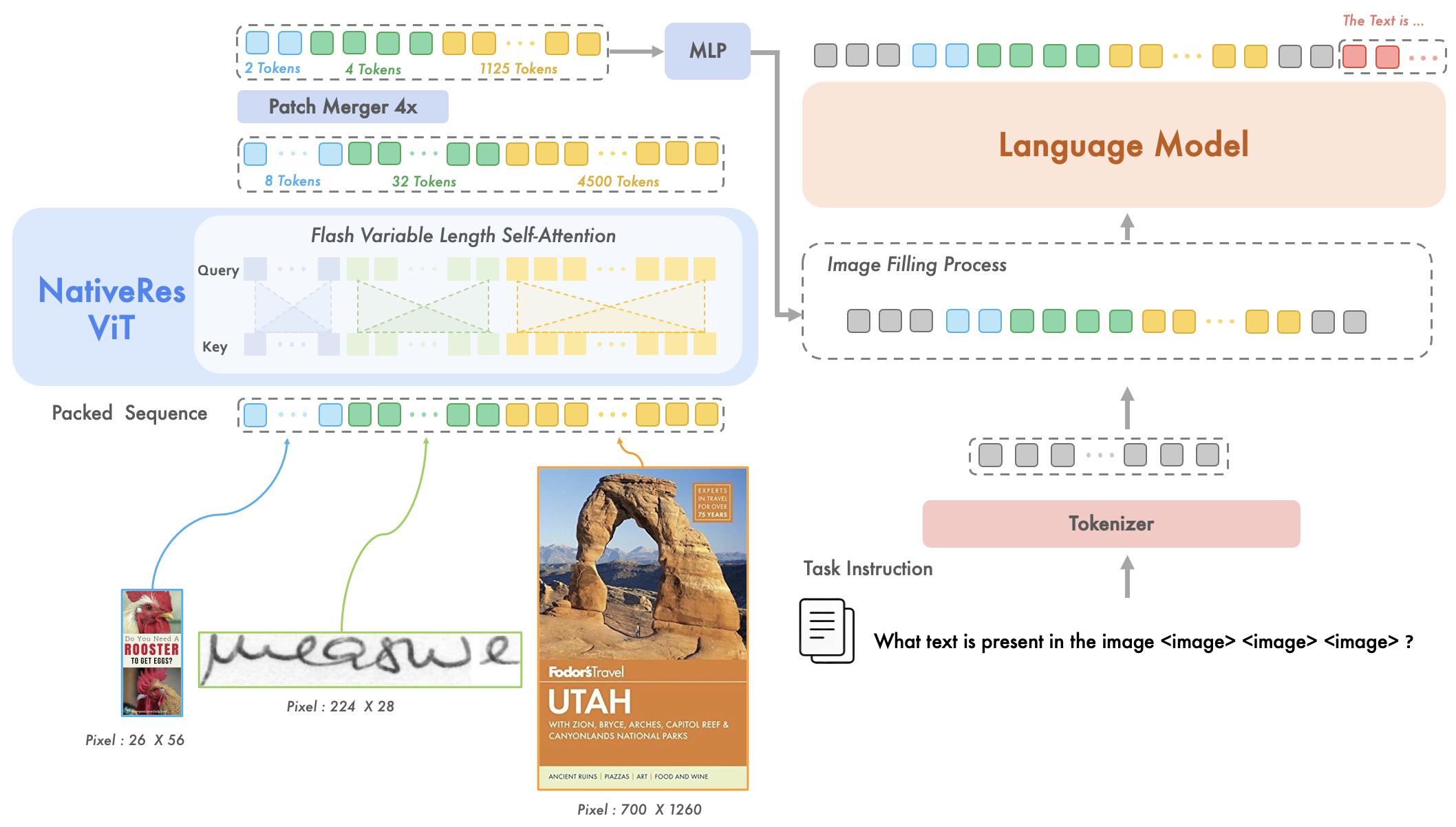
Native Visual Understanding: Resolving Resolution Dilemmas in Vision ...
Breaking resolution curse of vision-language models
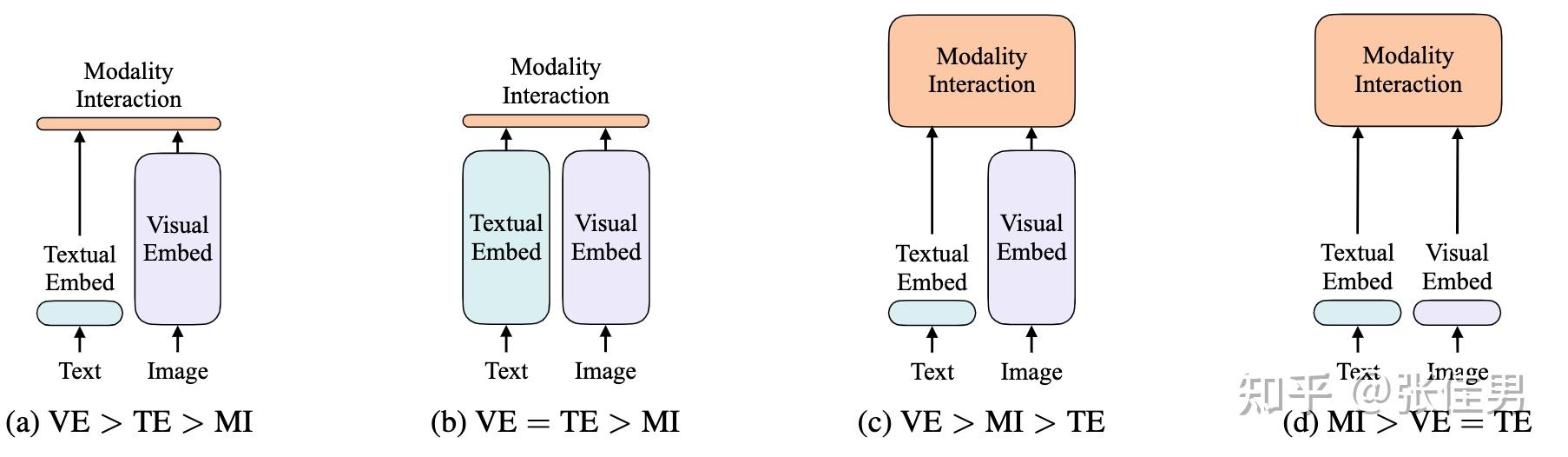
Typical architectures of vision-language models. (a) is the basic form ...
Introduction to Visual-Language Model | by Navendu Brajesh | Medium
[2405.19675] Knowledge-grounded Adaptation Strategy for Vision-language ...
图片和文本一起理解!多模态融合模型ALBEF是什么? - YouTube
【文献笔记】ALBEF_albef微调-CSDN博客
ALBEF:基于动量蒸馏的视觉语言表示学习-CSDN博客
Understanding Vision Language Model Architecture: From Iron Man to ...
Aman's AI Journal • Primers • Vision Language Models
Multi-Modal Vision Language Models: Architecture and Key Design ...
【读论文看代码】多模态系列-ALBEF - 知乎
Salesforce Open-Sources Language-Vision AI Toolkit LAVIS
图文检索(Image-text retrieval)模型 - 知乎
Design choices for Vision Language Models in 2024
[ALBEF 논문 리뷰]Align before Fuse: Vision and Language Representation ...
Key Insights Into Vision Language Models - A New Frontier In Multimodal AI
多模态对比学习ALBEF(融合之前对齐)_多模态特征对齐-CSDN博客
【计算机视觉】Vision and Language Pre-Trained Models算法介绍合集(一)_图像文本匹配损失和掩码语言建模 ...
[ALBEF paper 리뷰] Align before Fuse: Vision and Language Representation ...
多模态模型之ALBEF, BLIP, BLIP-2 - 知乎
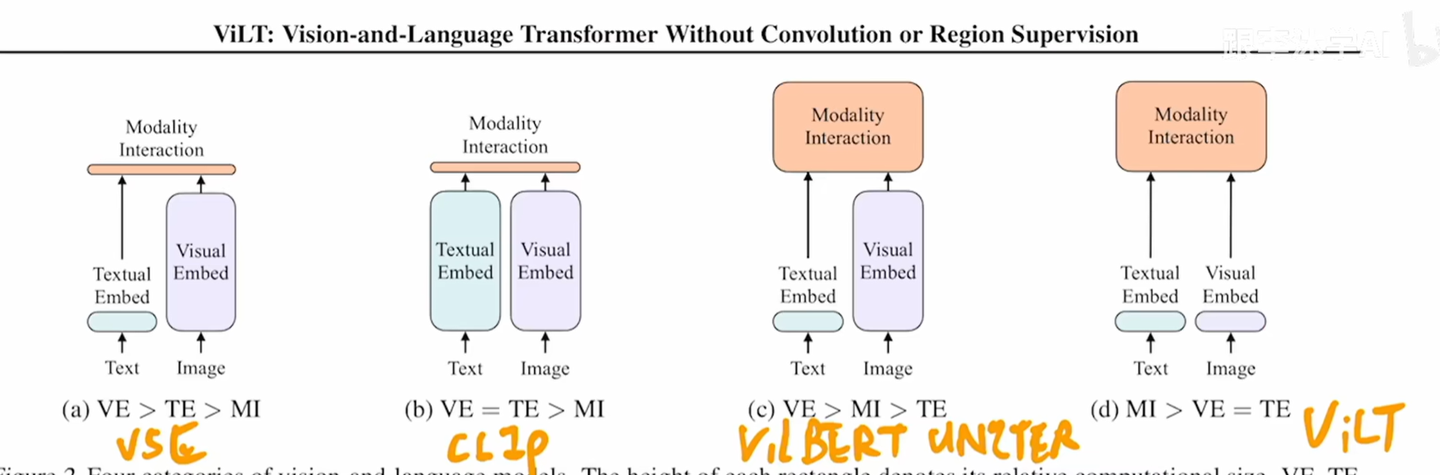
多模态速读:ViLT、ALBEF、VLMO、BLIP_albef比较blip-CSDN博客
多模态超详细解读 (三):ALBEF:图文对齐后再融合,借助动量蒸馏高效学习多模态表征 - 知乎





























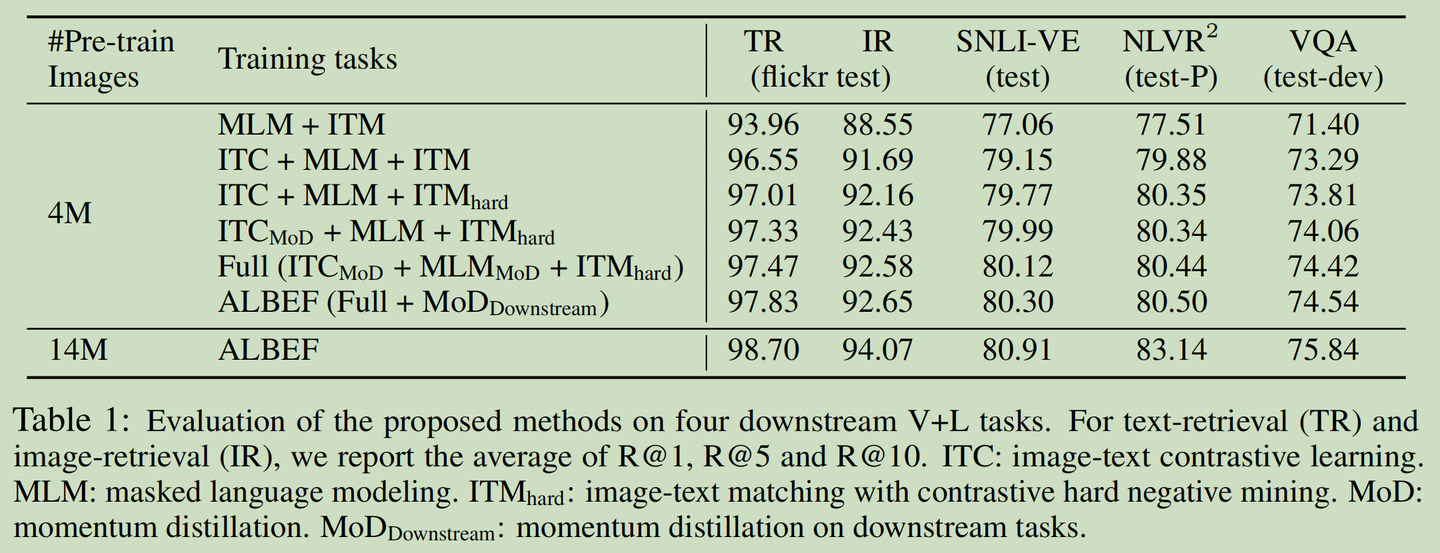

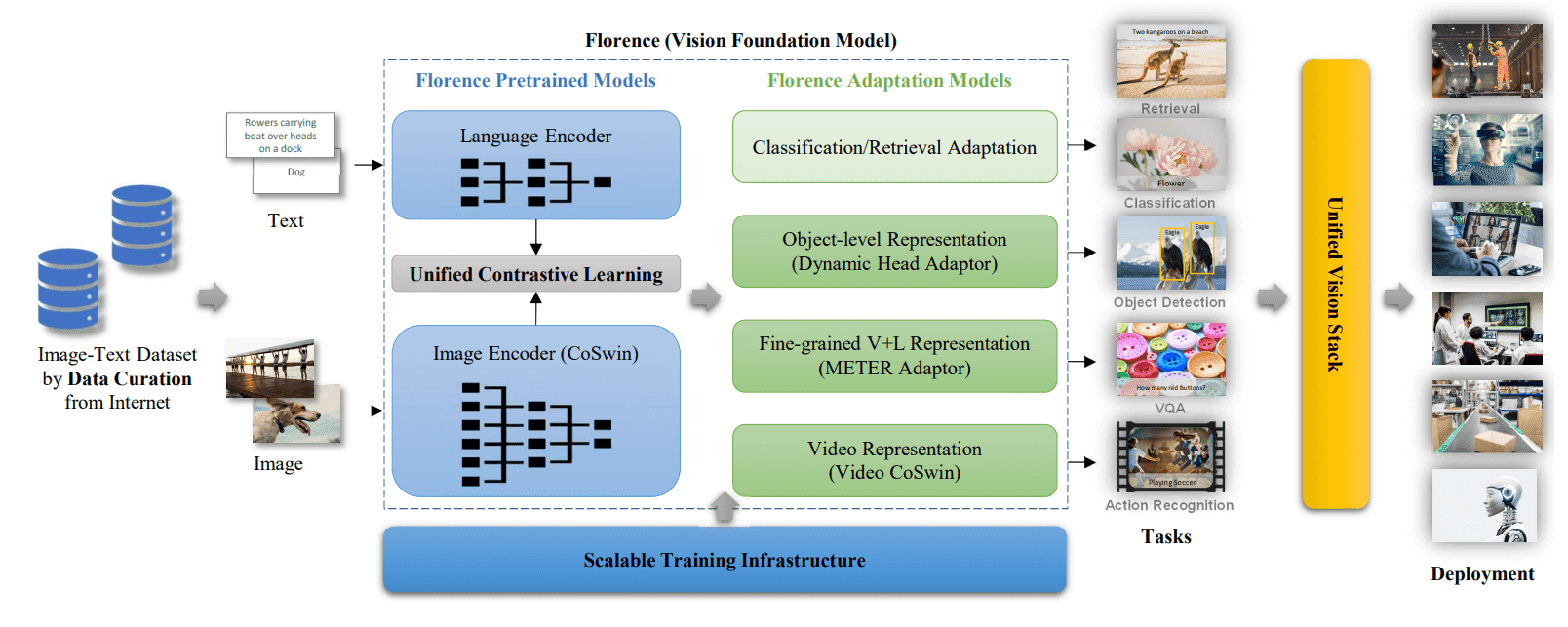
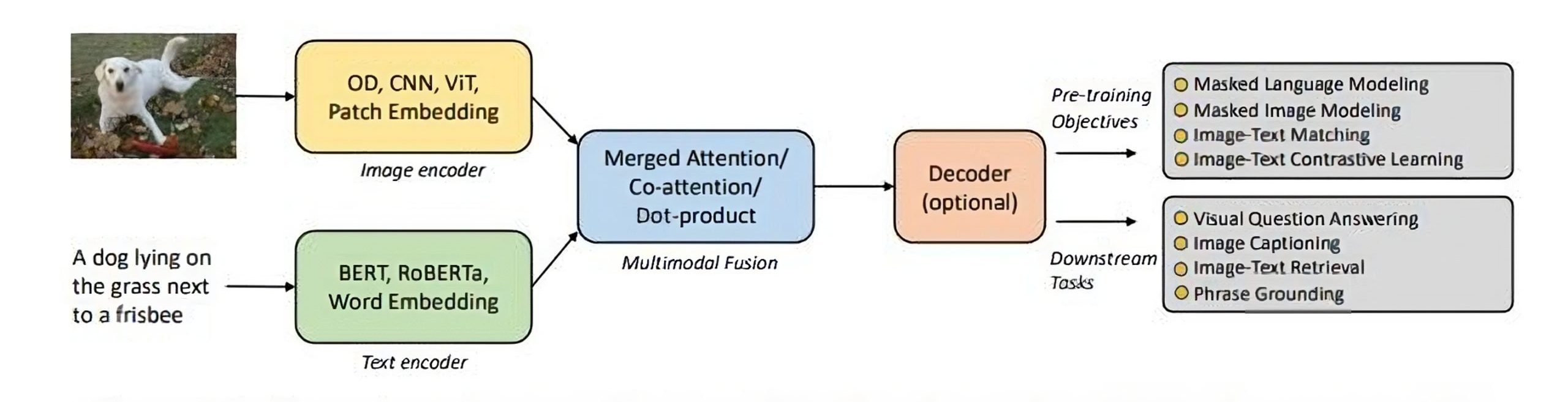



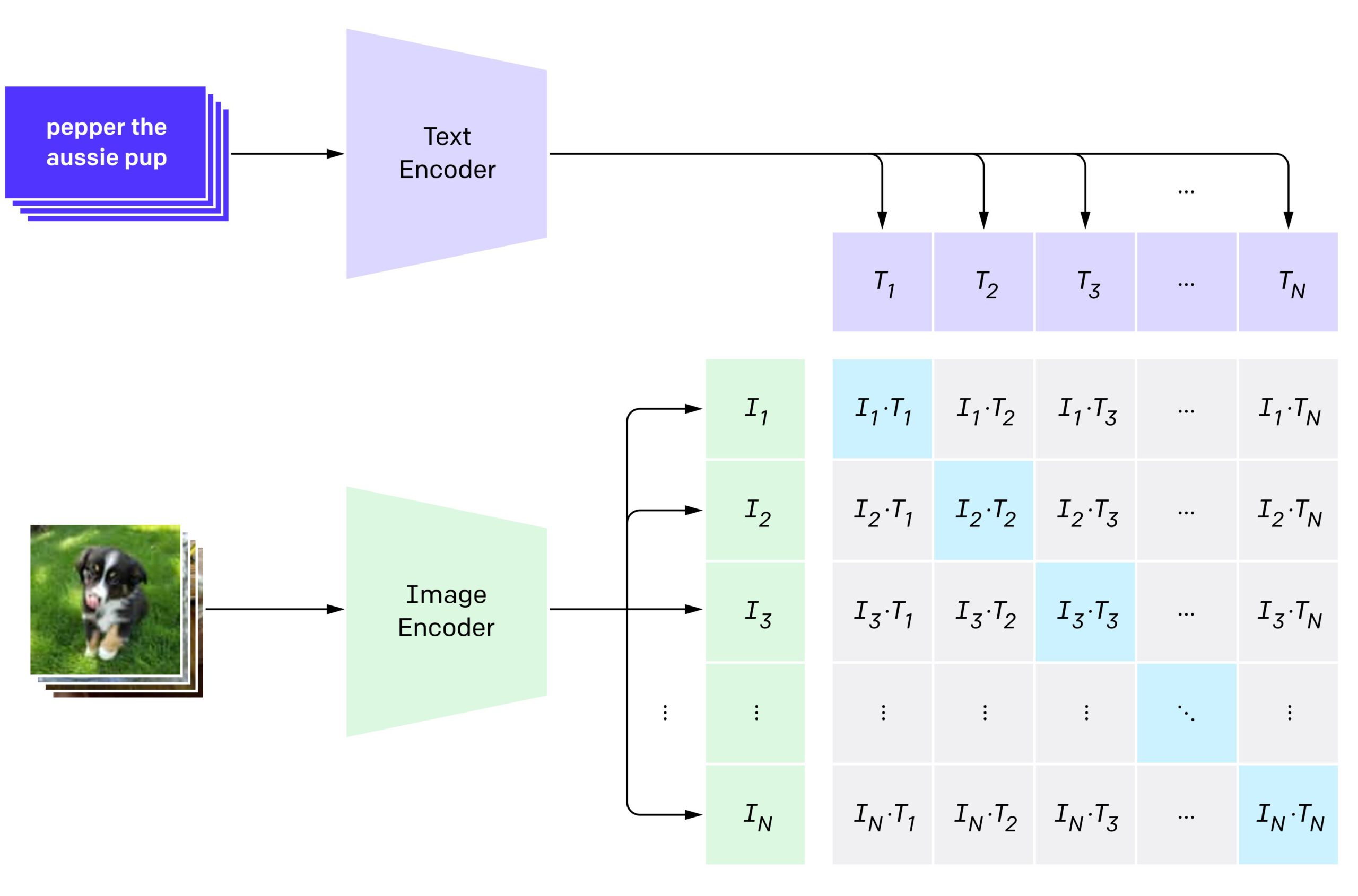





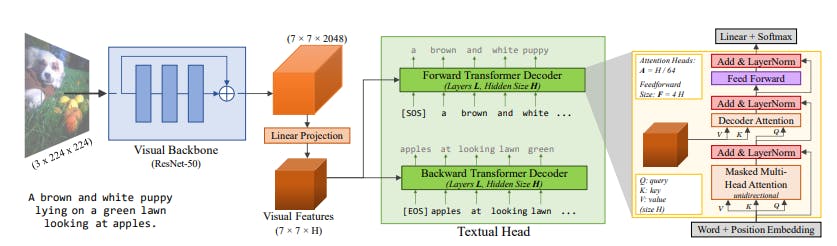





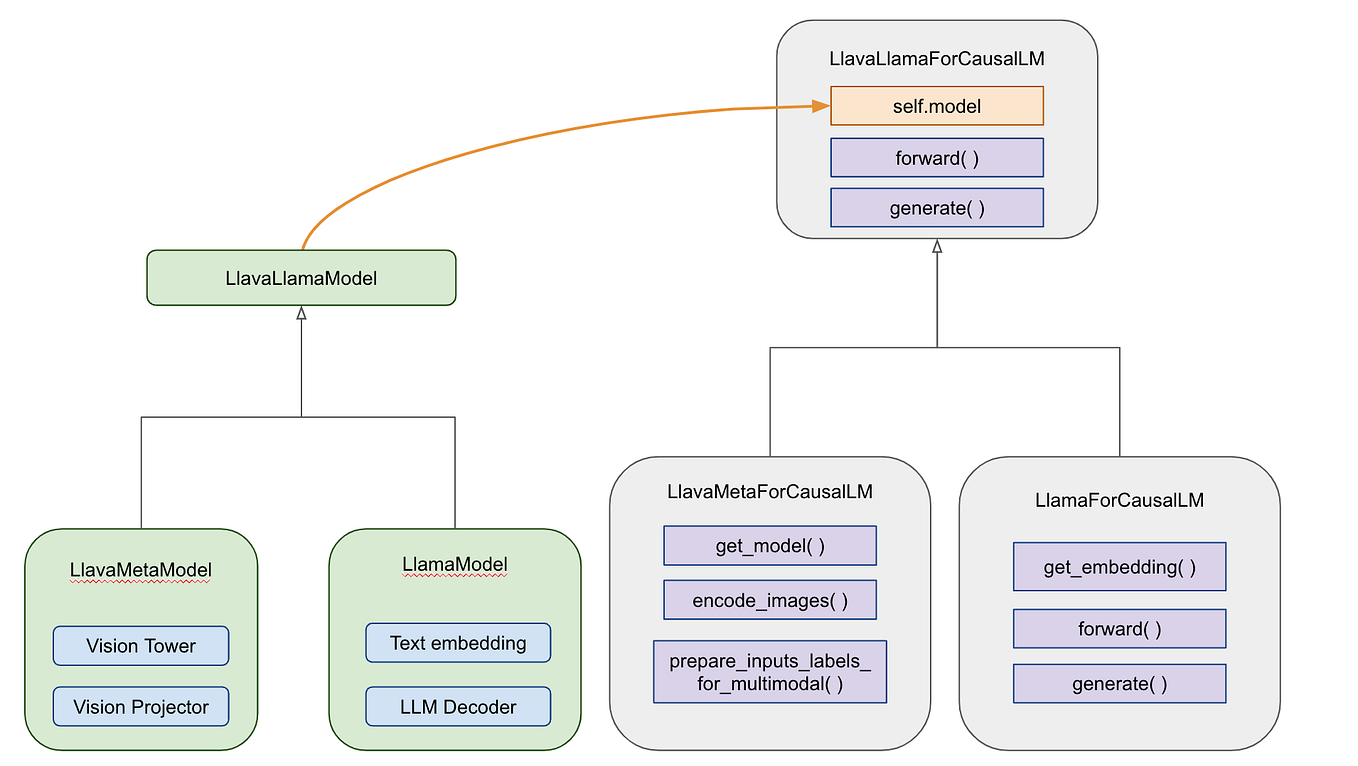
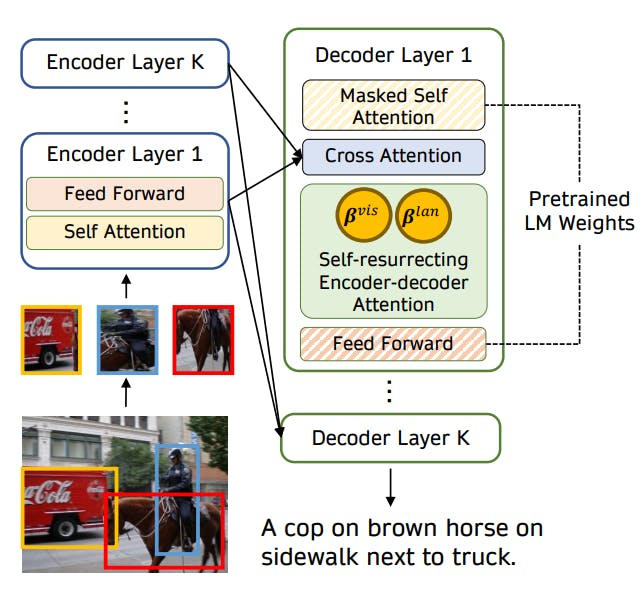
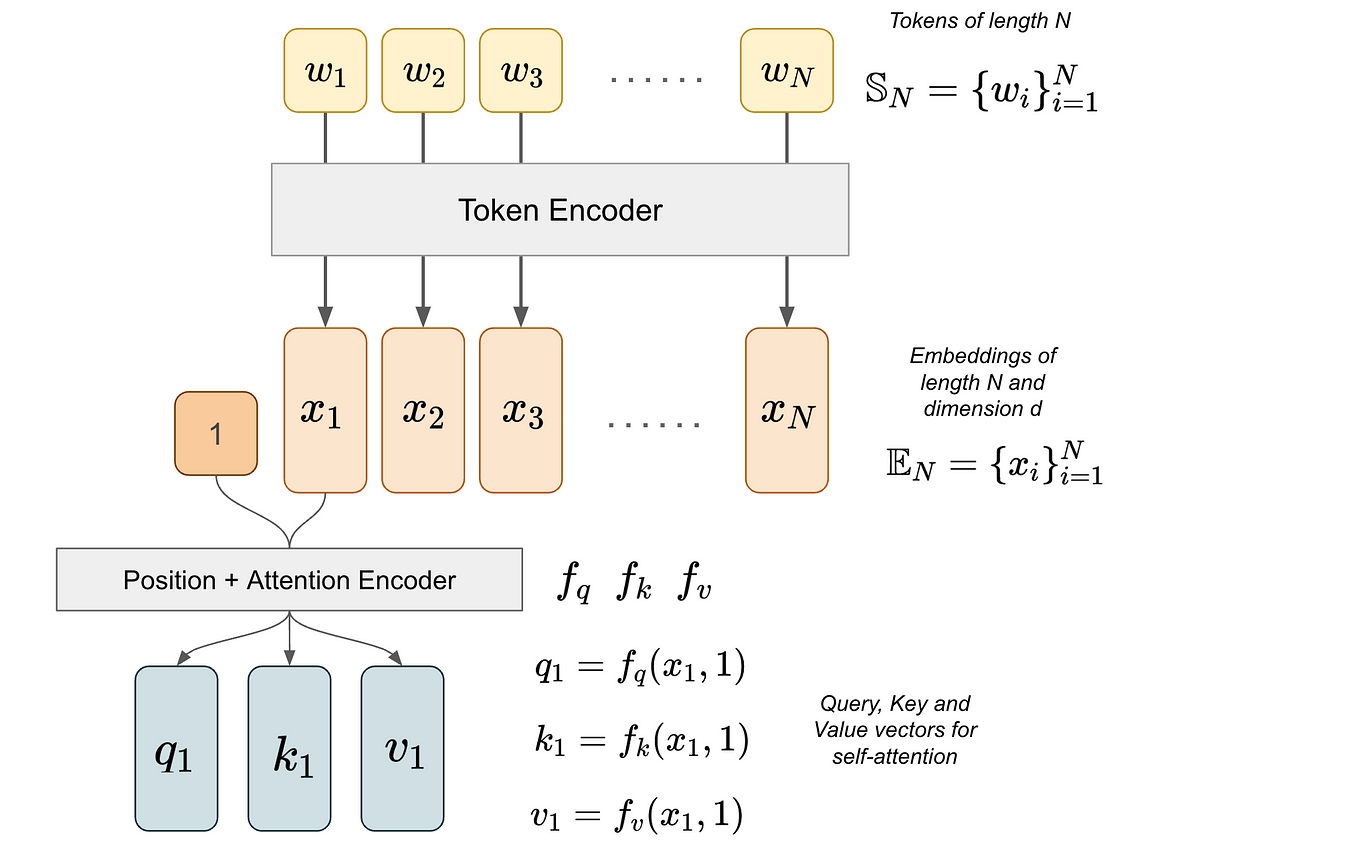


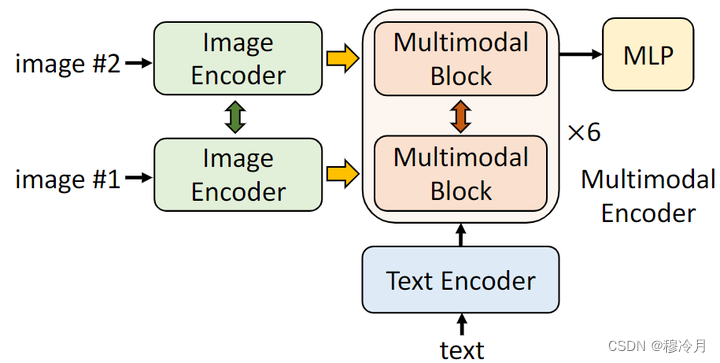
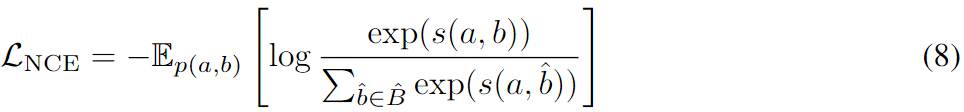



/filters:no_upscale()/news/2022/11/salesforce-lavis-ai/en/resources/1lavis-architecture-1667140524450.png)