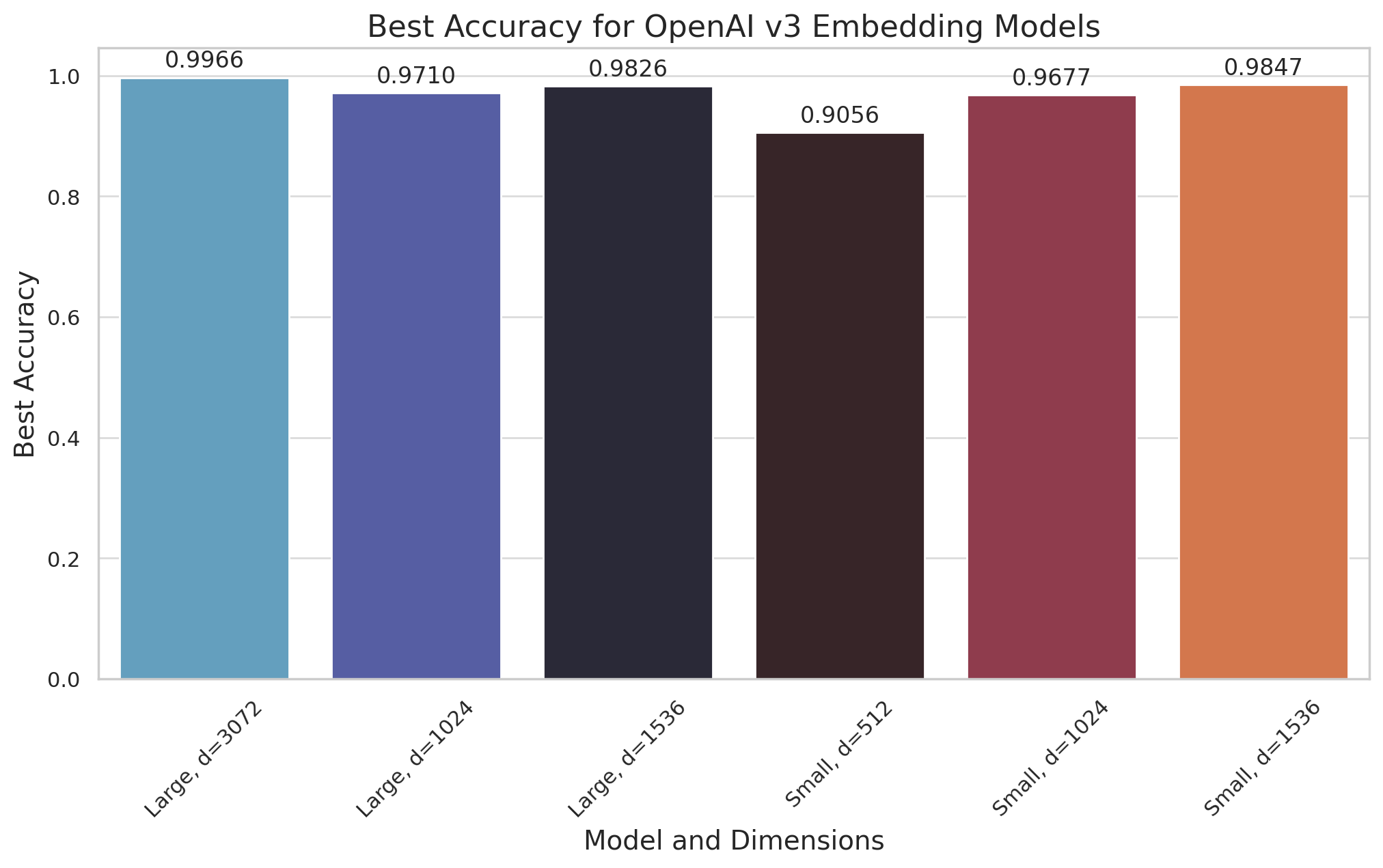
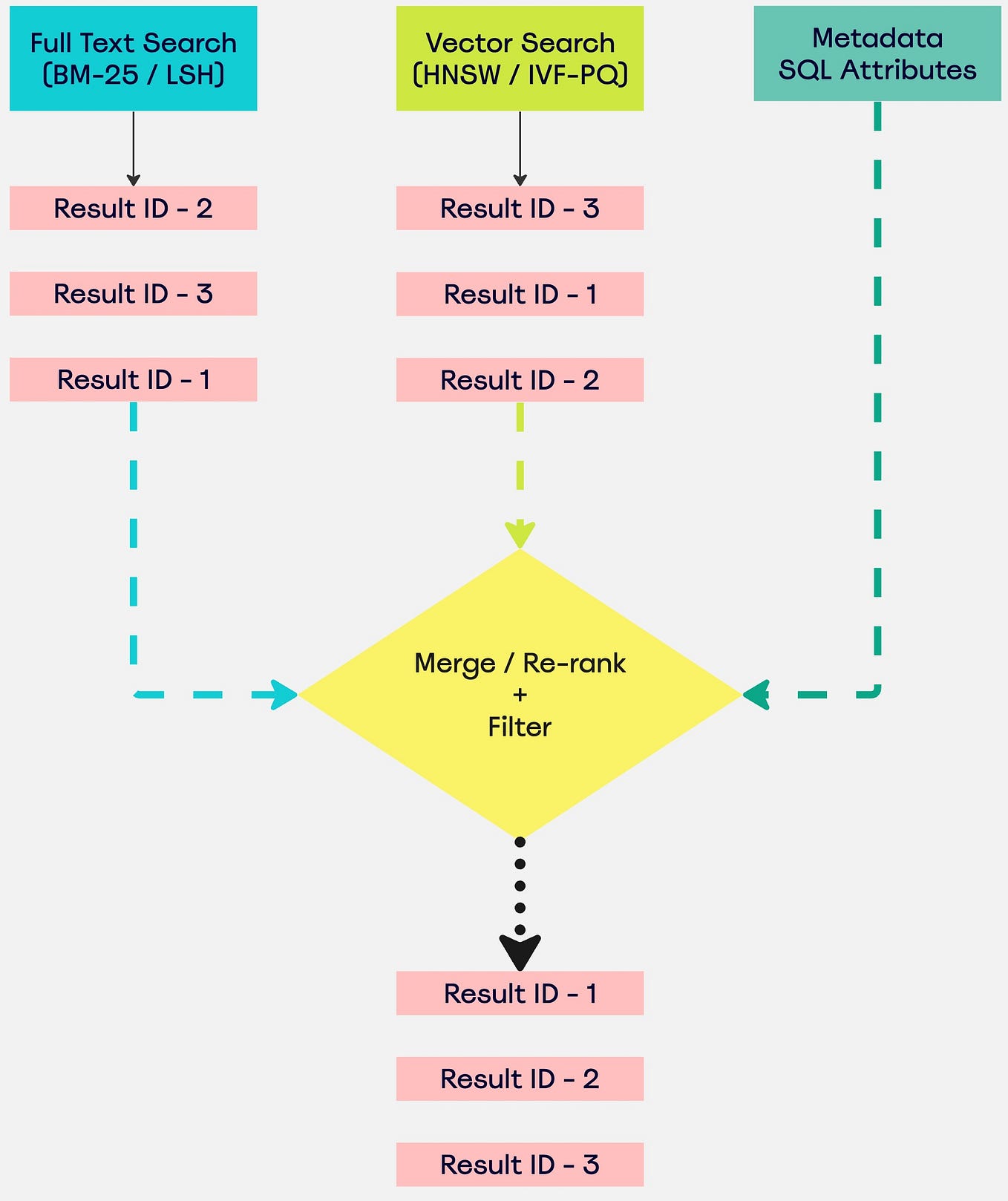
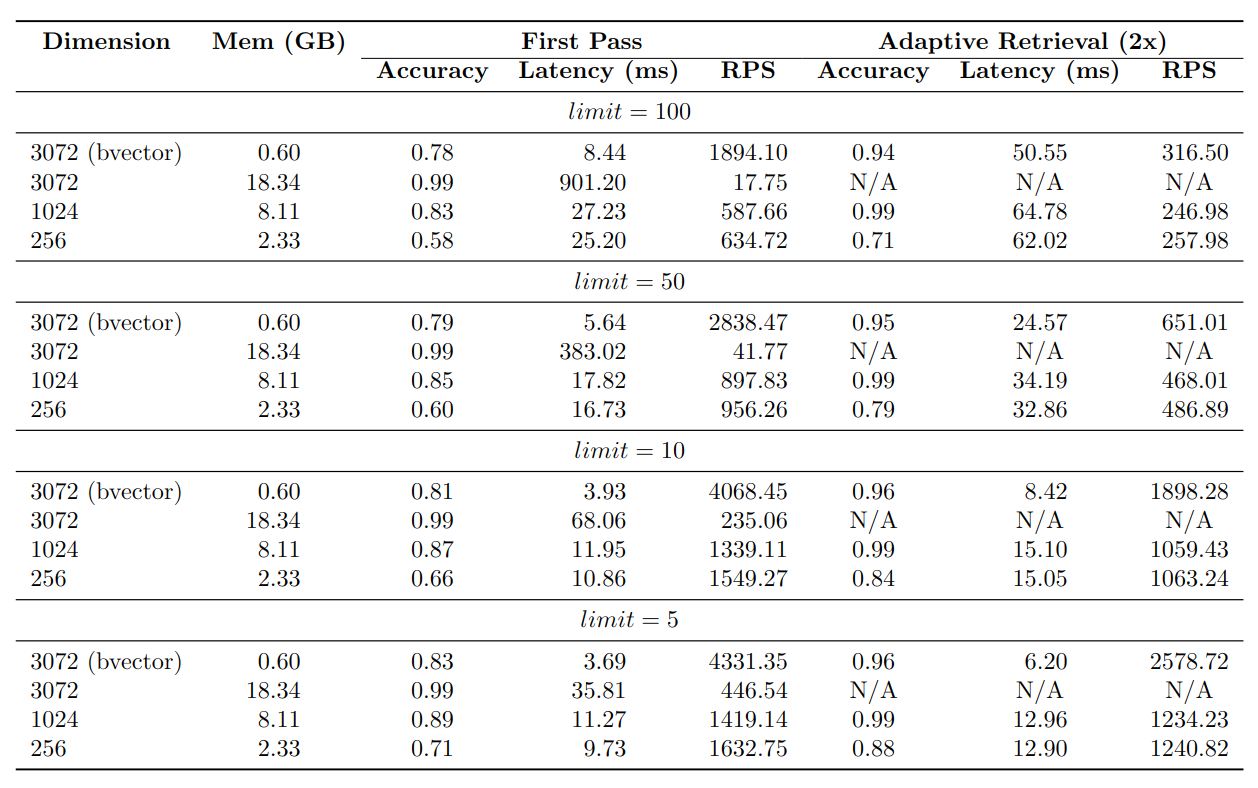
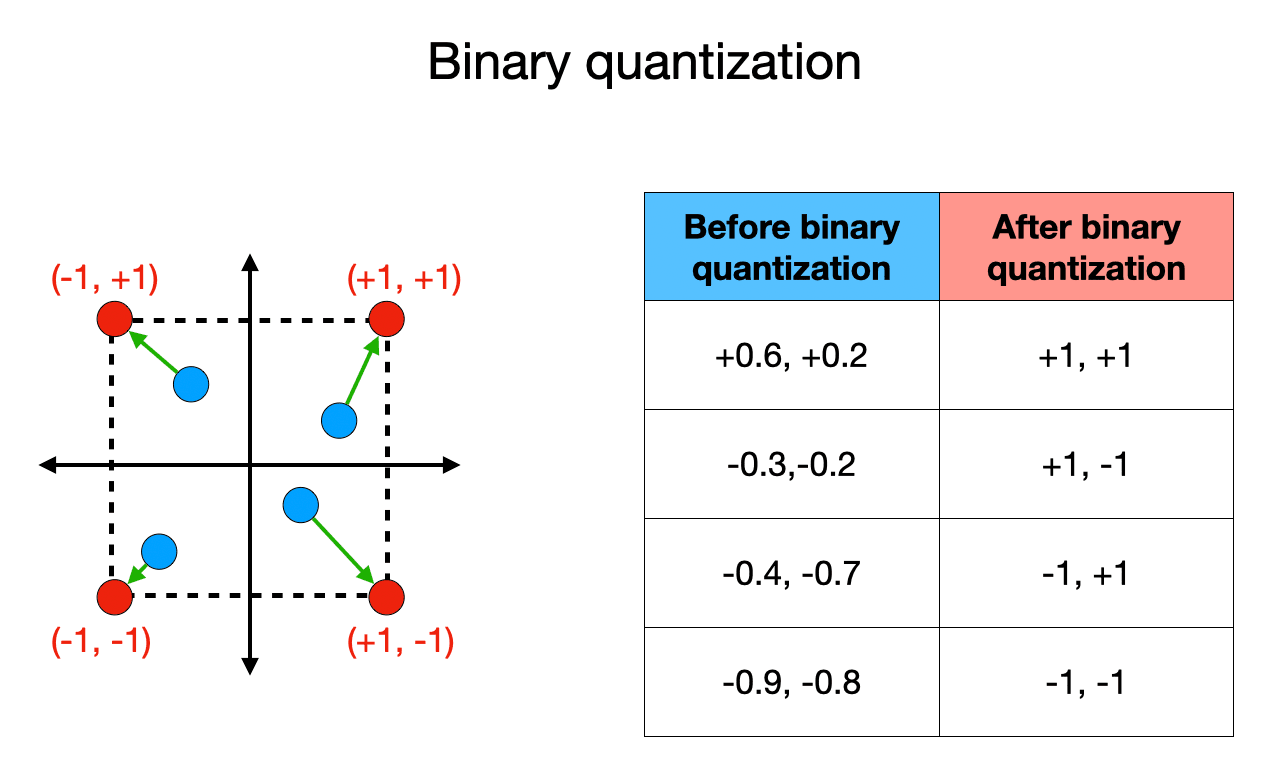
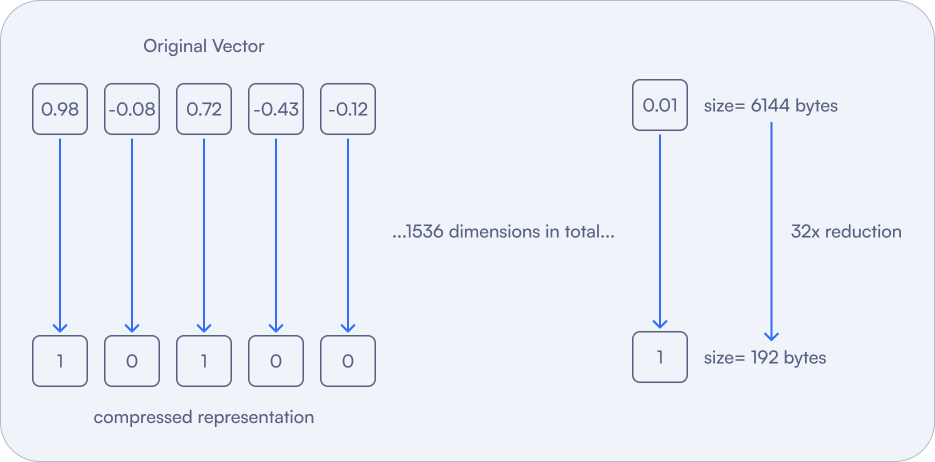
Showing 109 of 109on this page. Filters & sort apply to loaded results; URL updates for sharing.109 of 109 on this page
Binary Quantization - Vector Search, 40x Faster - Qdrant
Enhancing Efficiency in Vector Searches with Binary Quantization and ...
Exploring Binary Quantization in Vector Databases
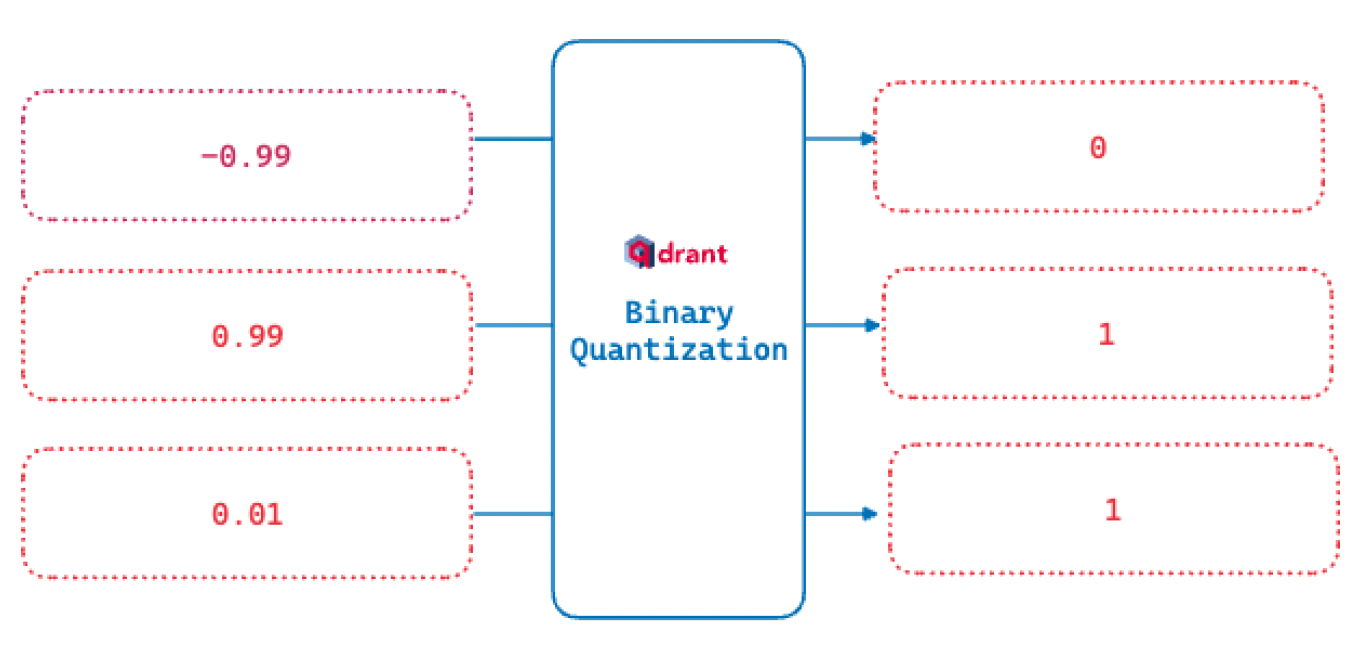
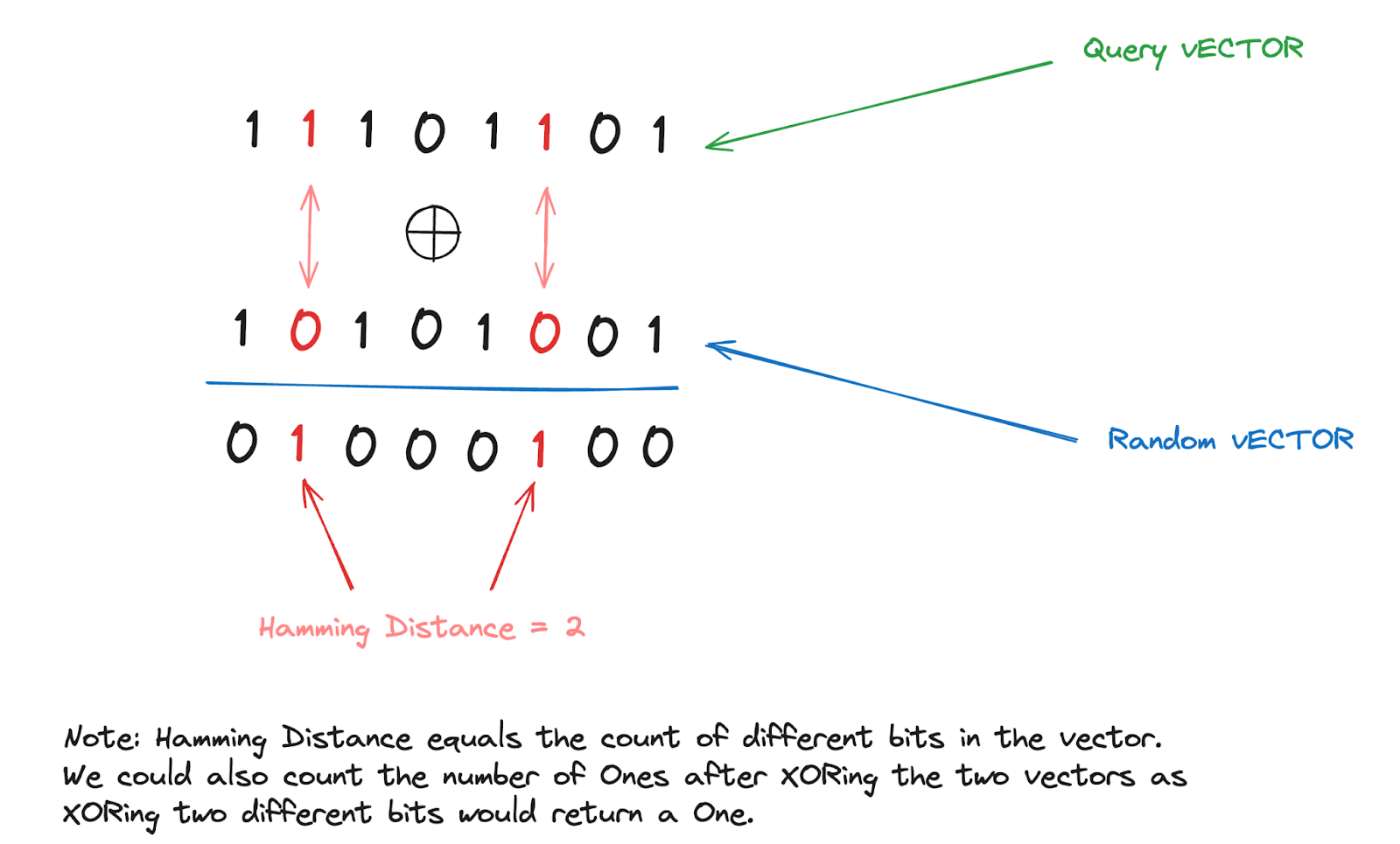
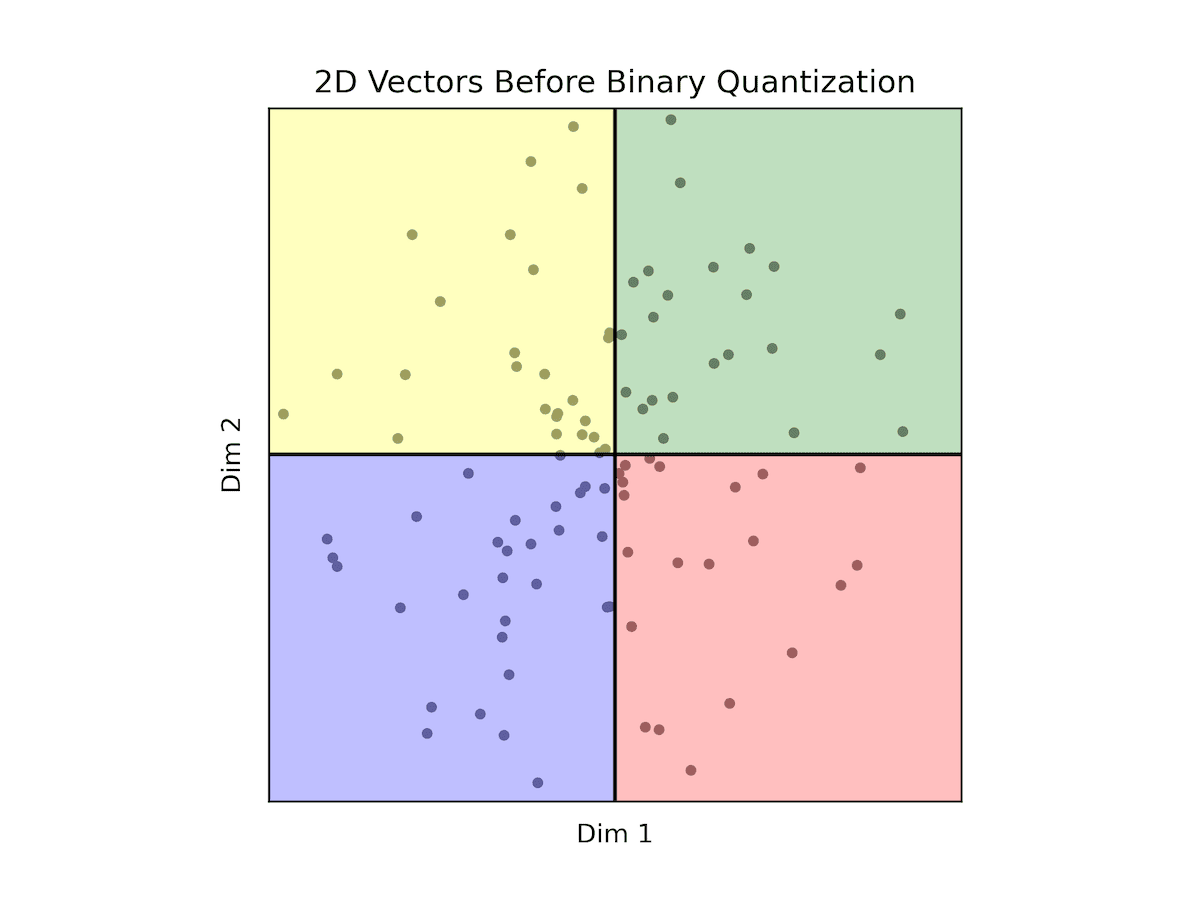
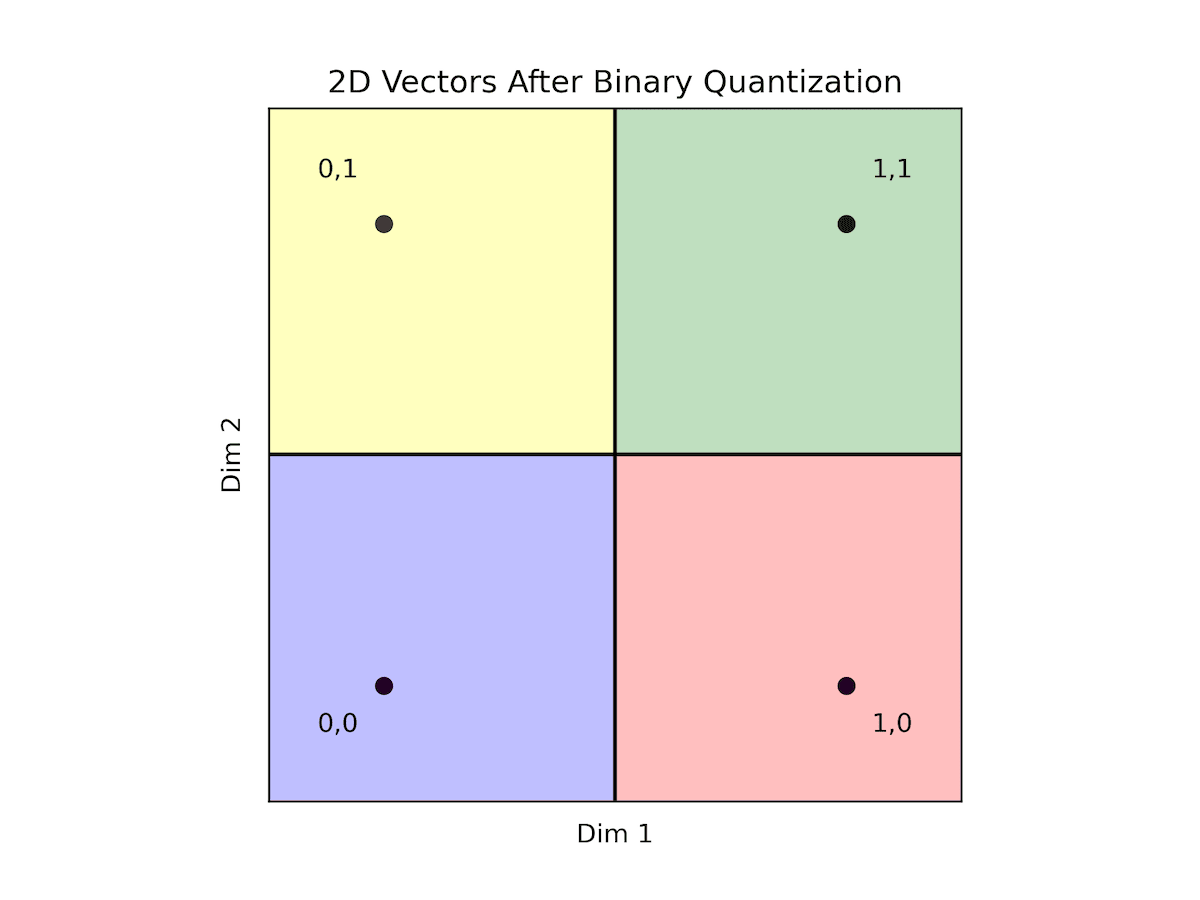
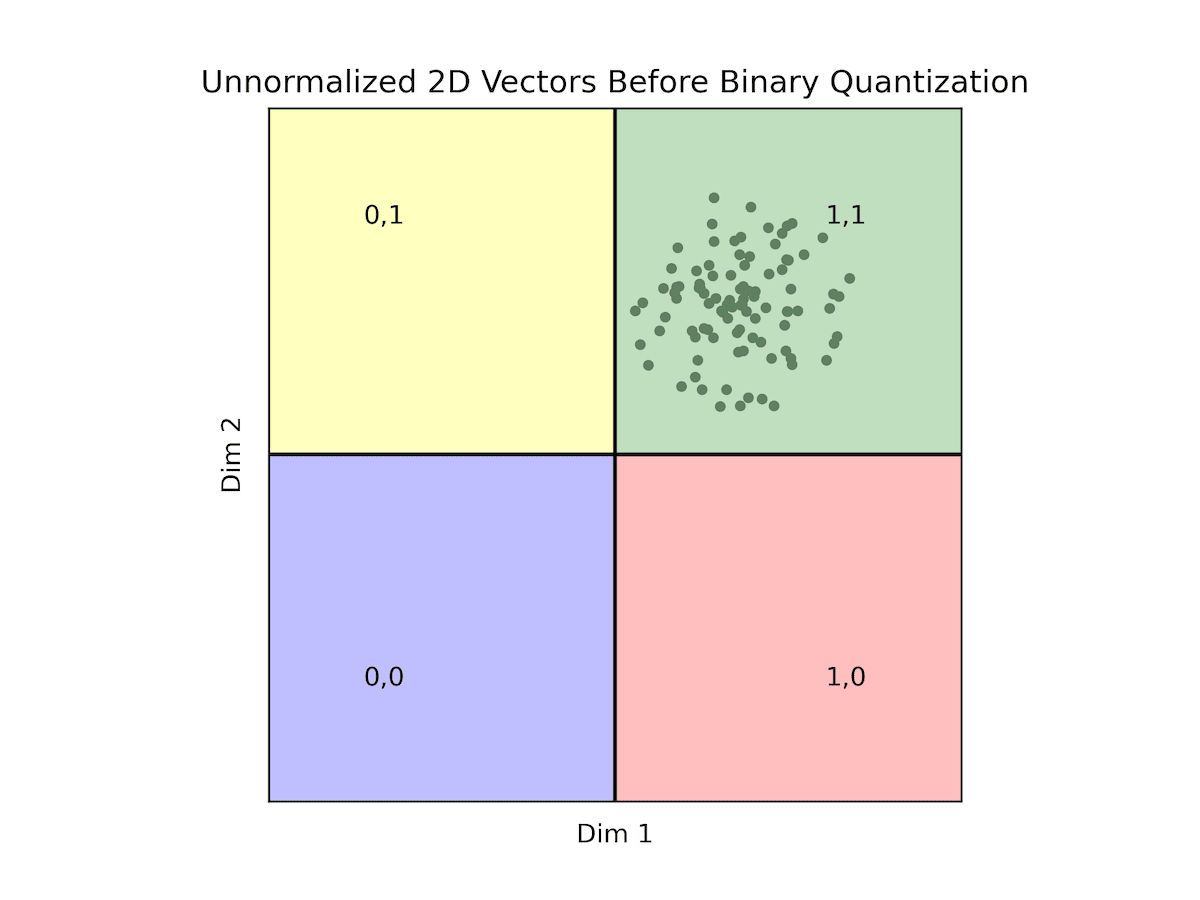
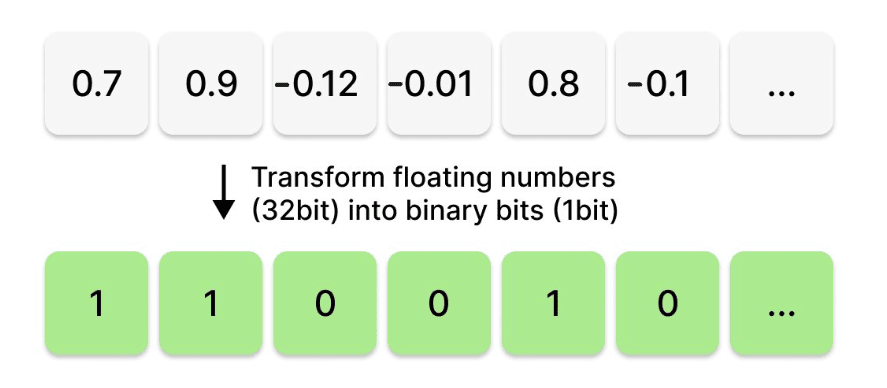
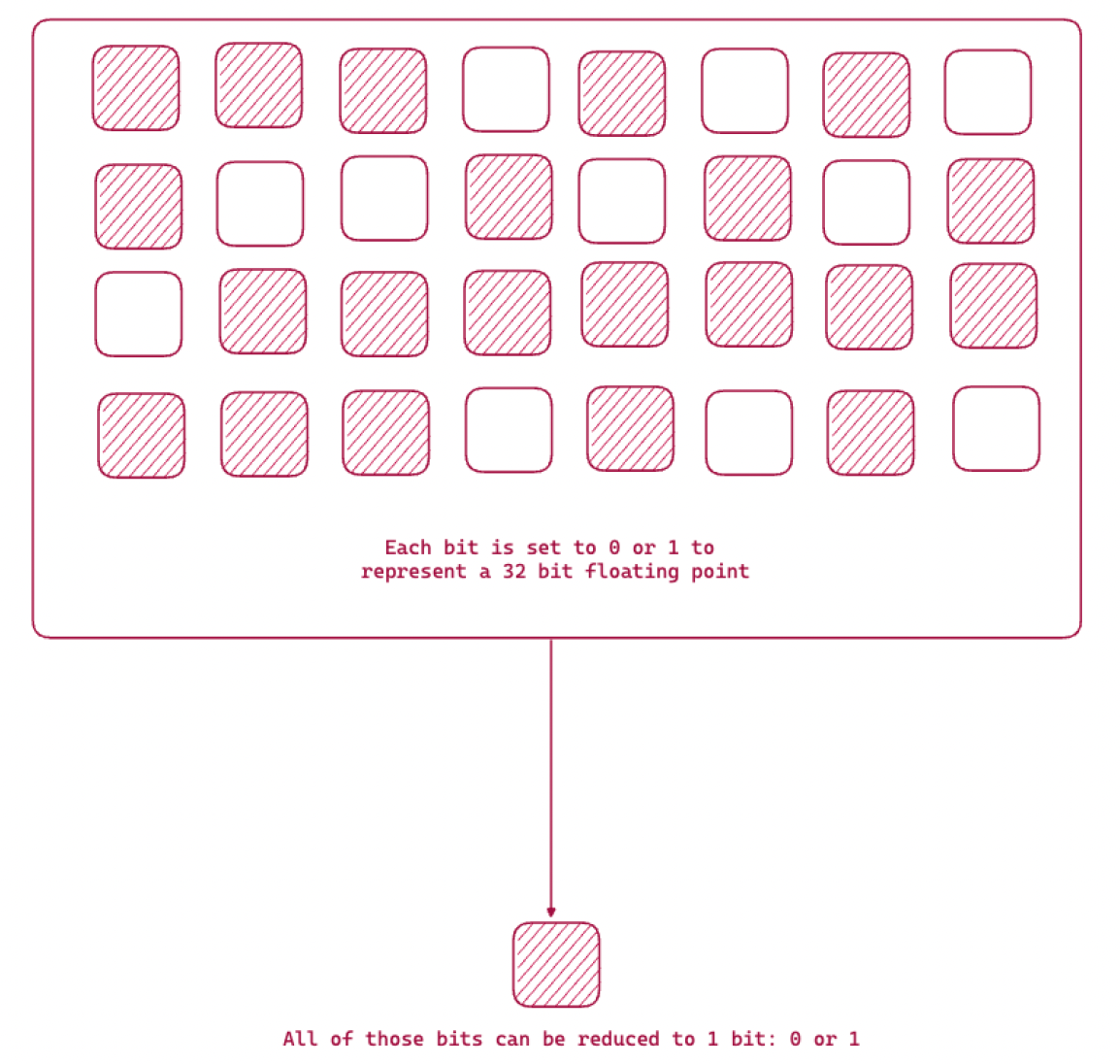
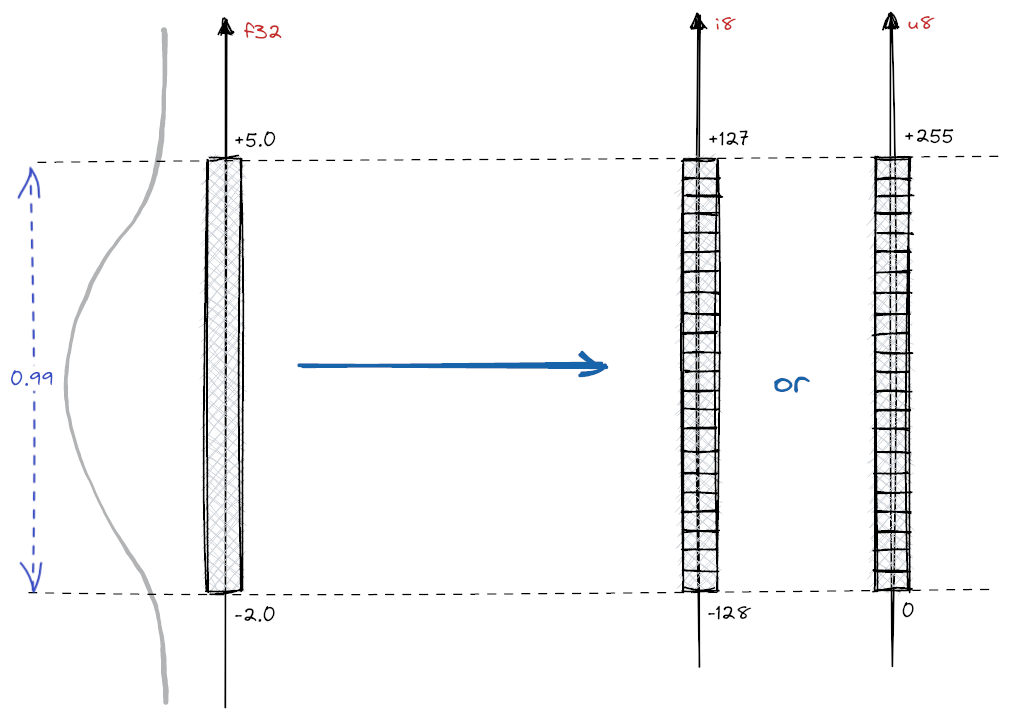
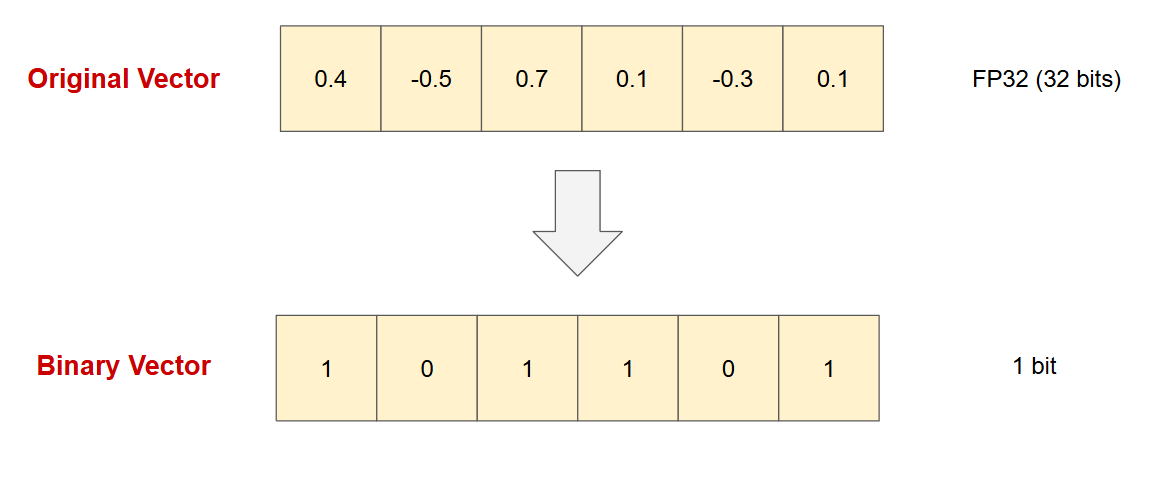
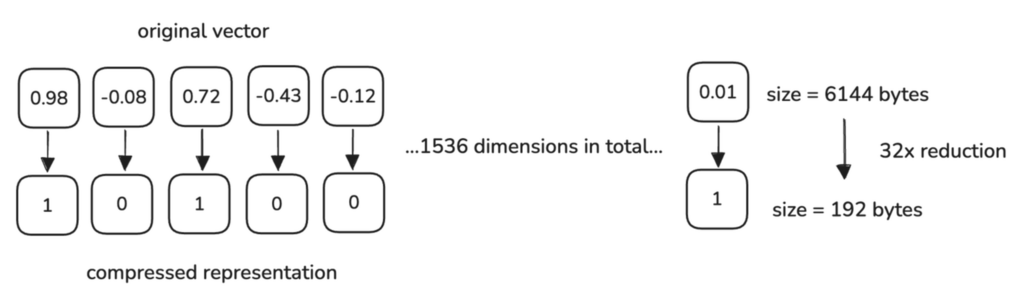
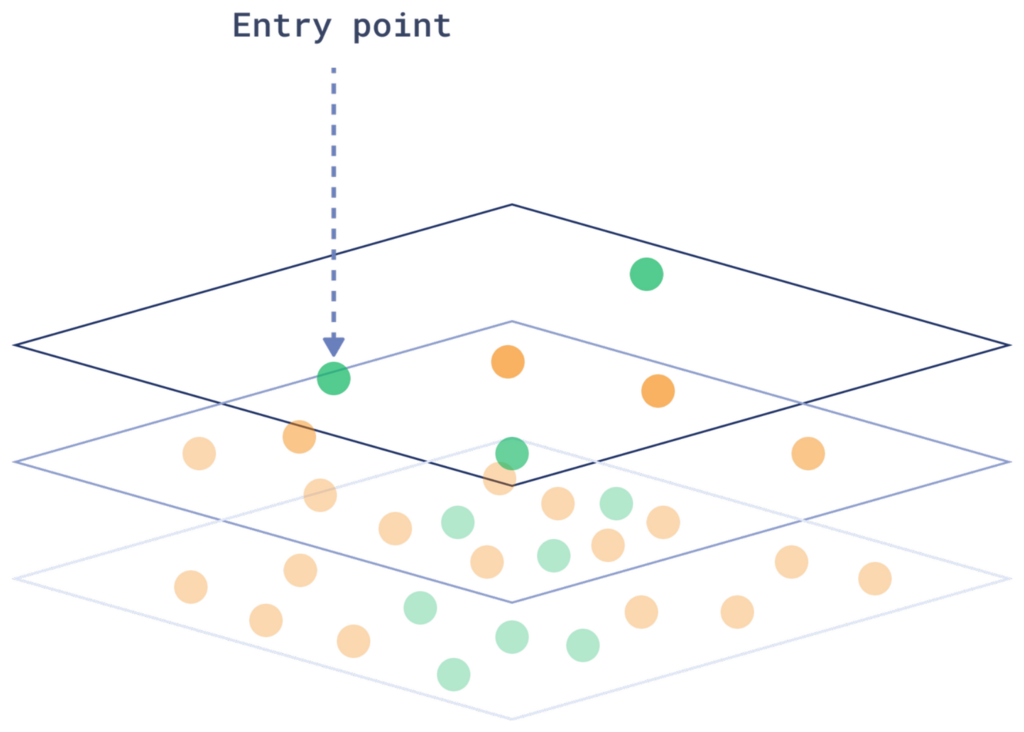
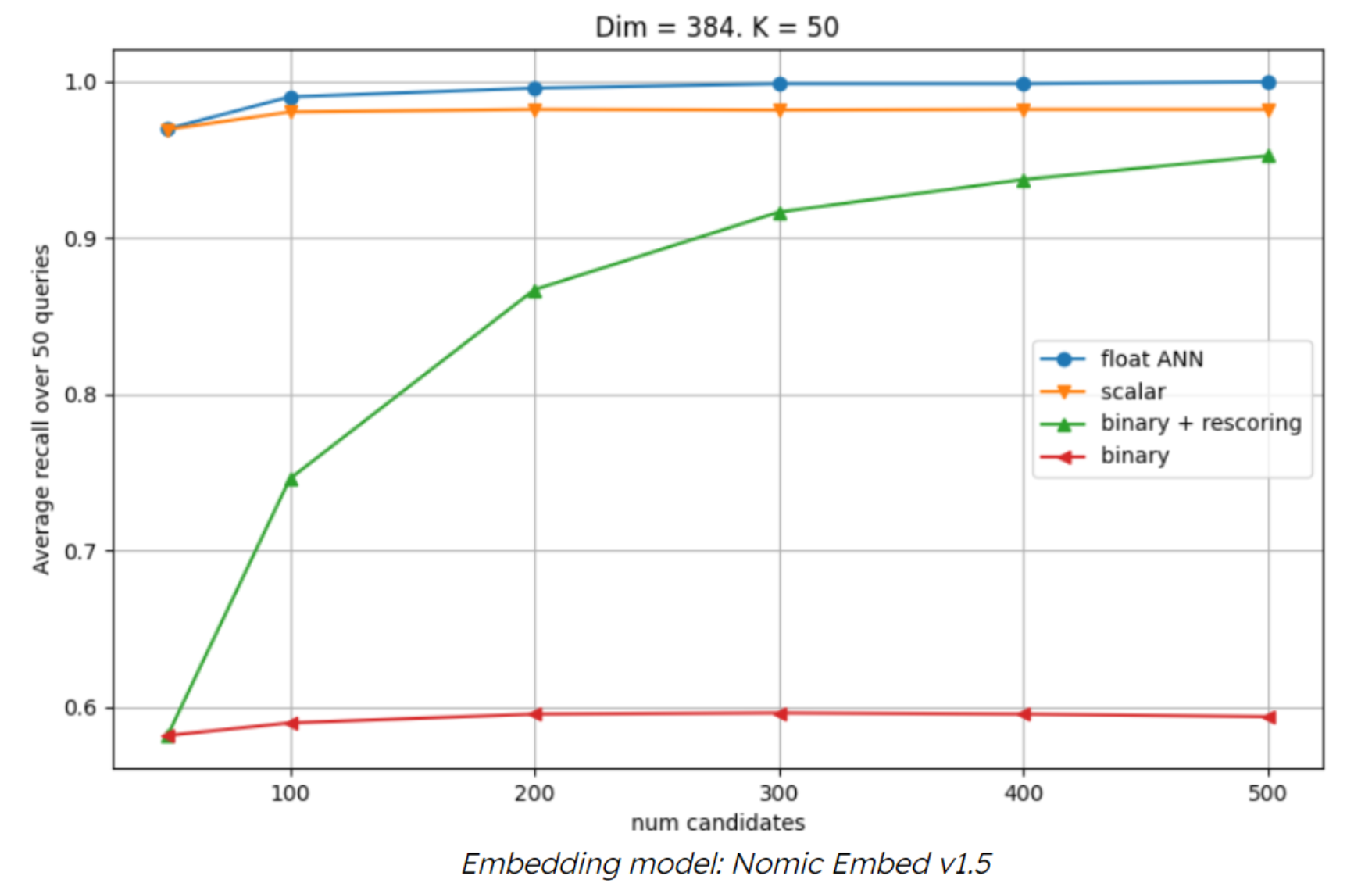
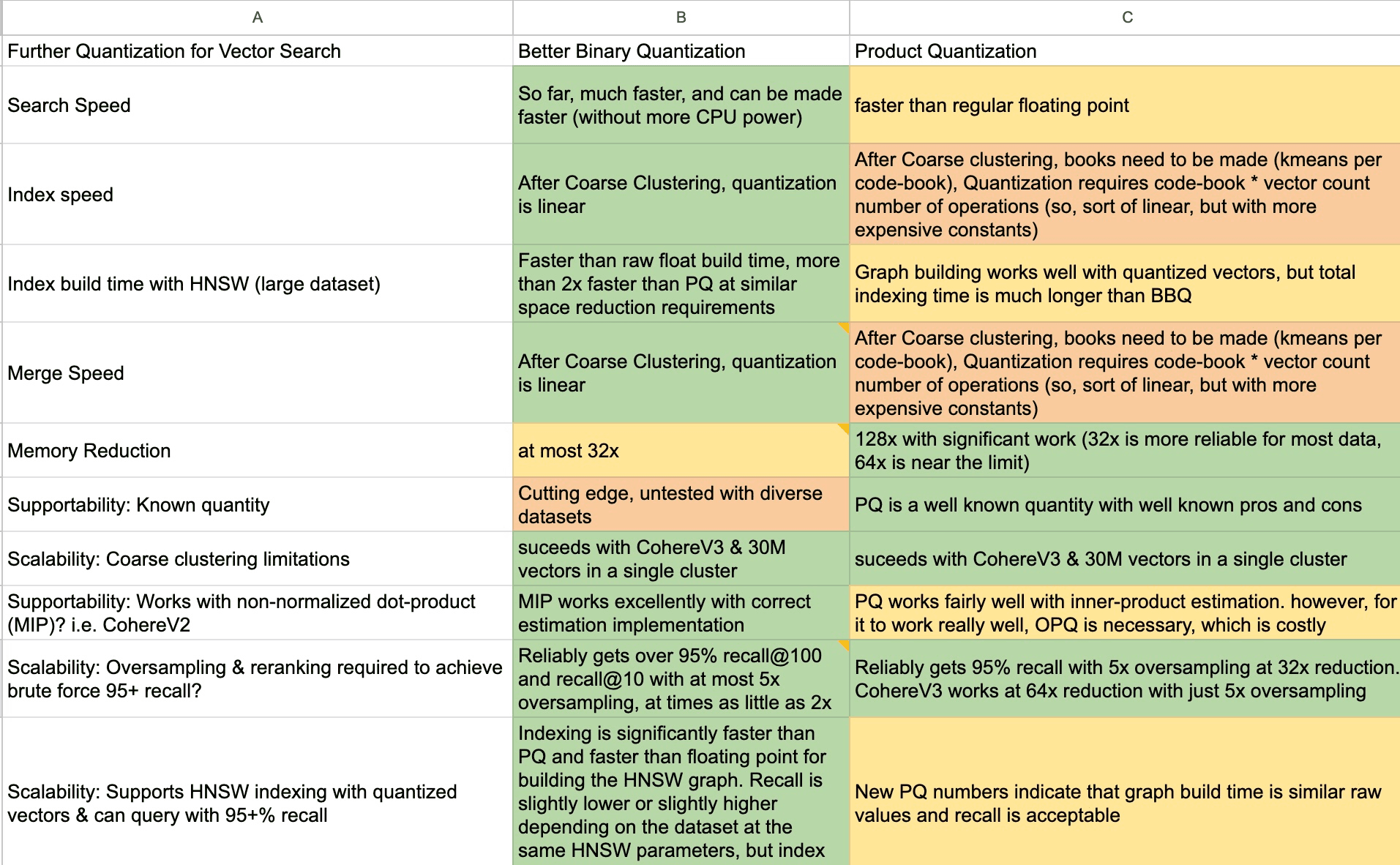
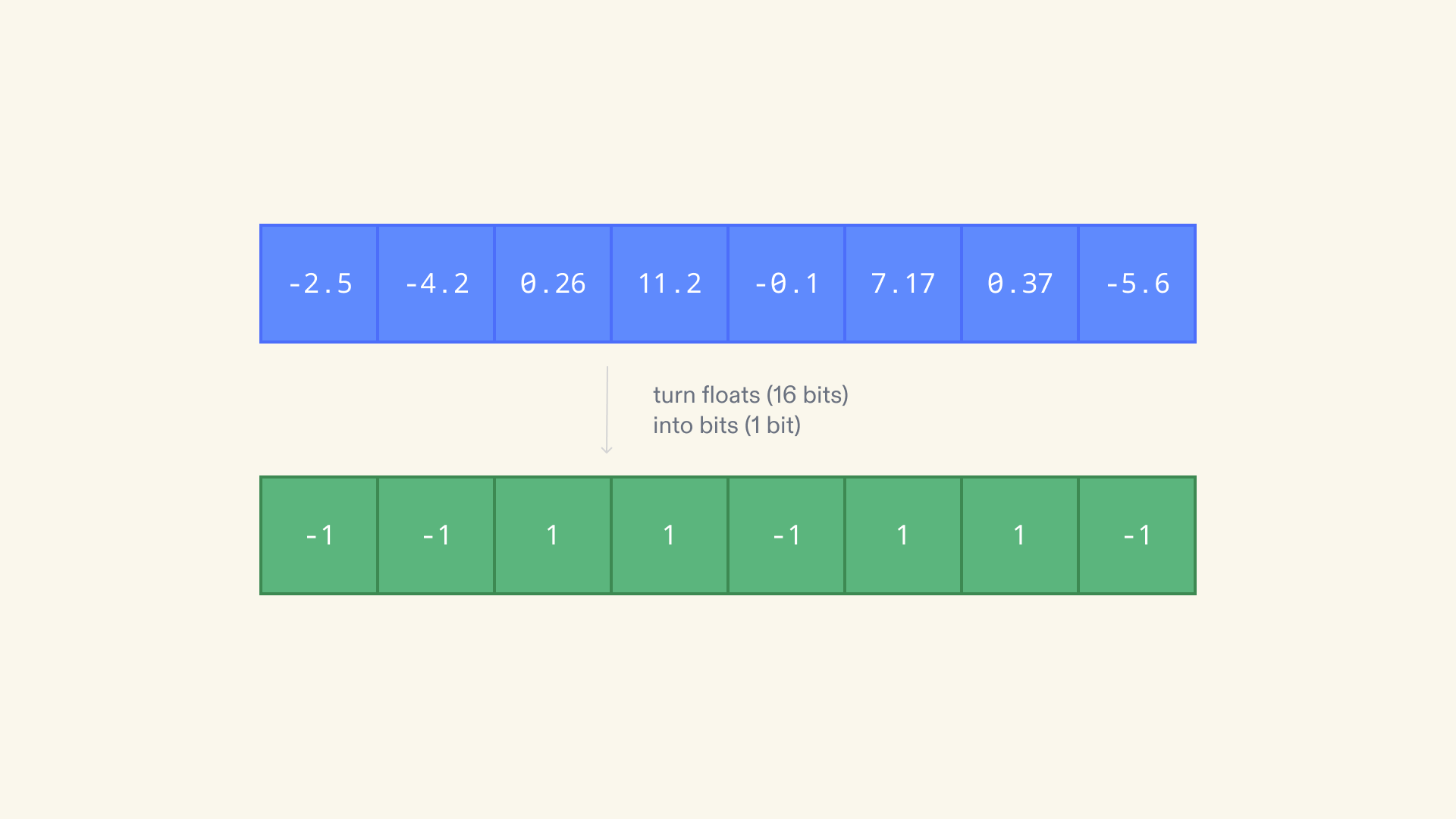
Binary Quantization
32x Reduced Memory Usage With Binary Quantization | Weaviate
Enhancing Vector Search Performance with Binary Quantization
The Binary and Ternary Quantization Can Improve Feature Discrimination ...
Examples of Quantization Functions. (a) Typical binary (1-bit ...
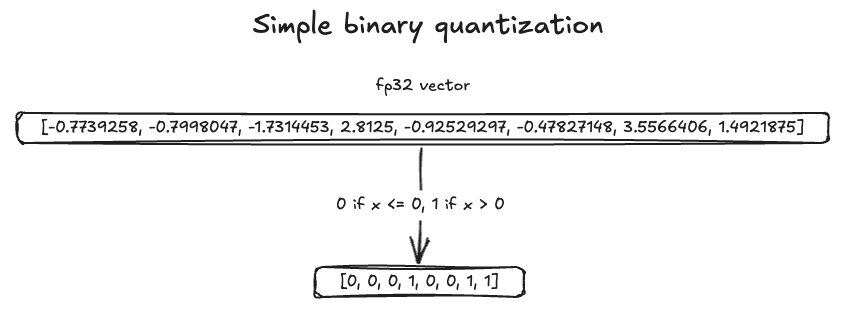
What is Binary Quantization (BQ) and why does it matter? 🤔 By using ...
Meet BiLLM: A Novel Post-Training Binary Quantization Method ...
Exploring Binary Quantization in Vector Databases | SabrePC Blog
(PDF) Binary Quadratic Quantization: Beyond First-Order Quantization ...
Binary Quantization - Andrey Vasnetsov | Vector Space Talks - Qdrant
(PDF) Binary Search Vector Quantization
Investigating the performance of binary quantization for vector ...
RaBitQ Binary quantization 101: An Introduction - Elasticsearch Labs
Better Binary Quantization (BBQ) in Lucene and Elasticsearch ...
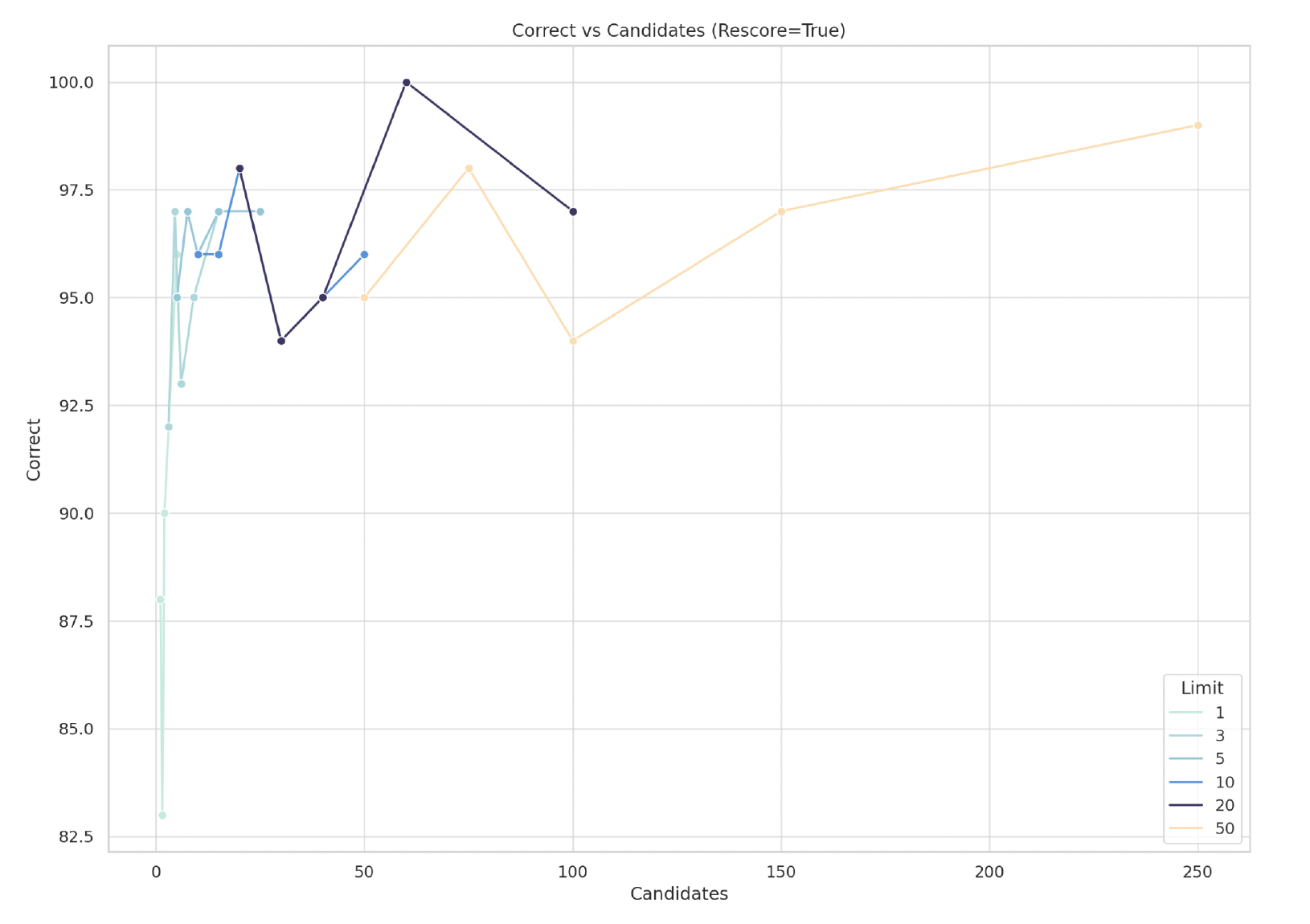
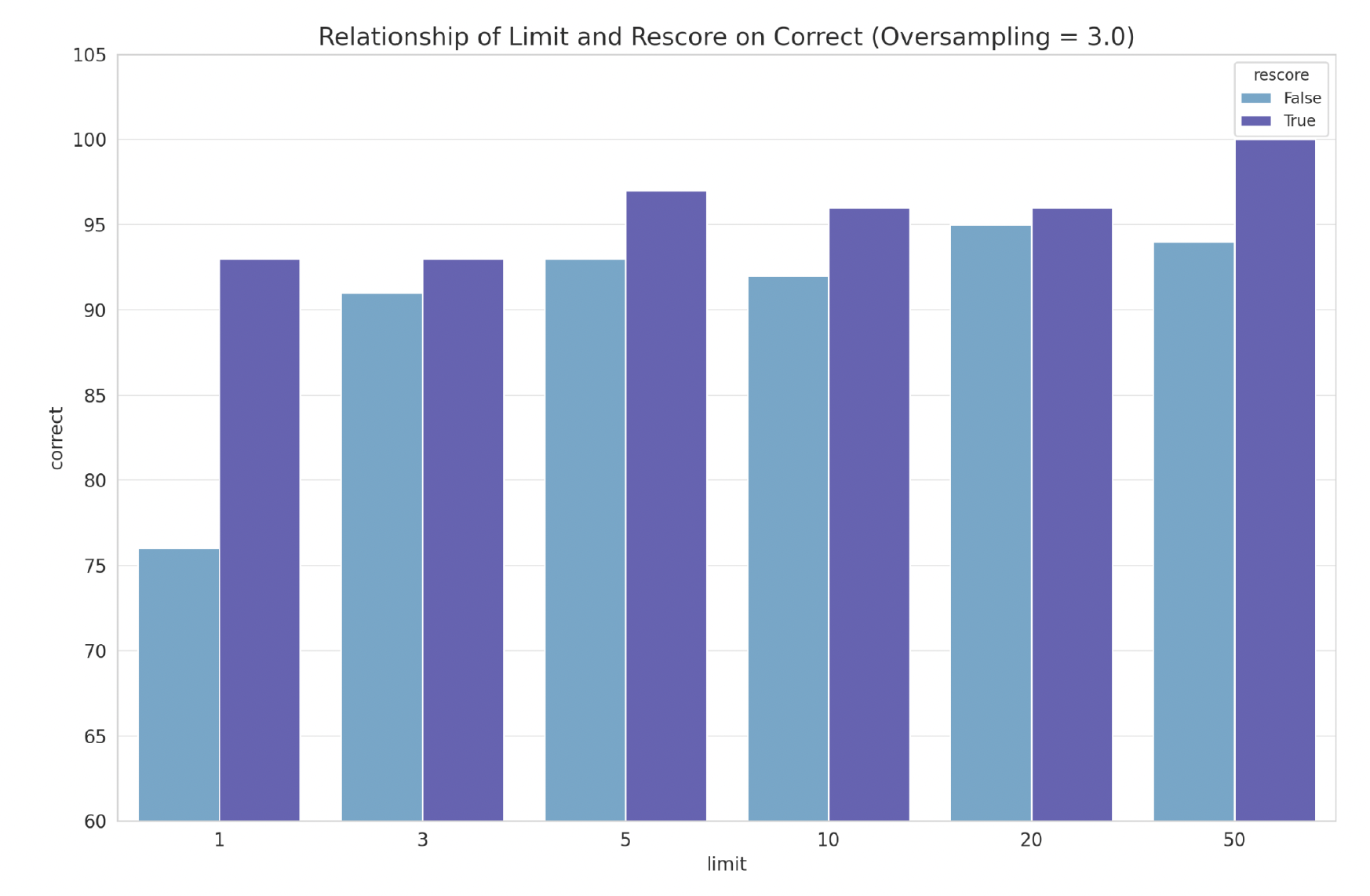
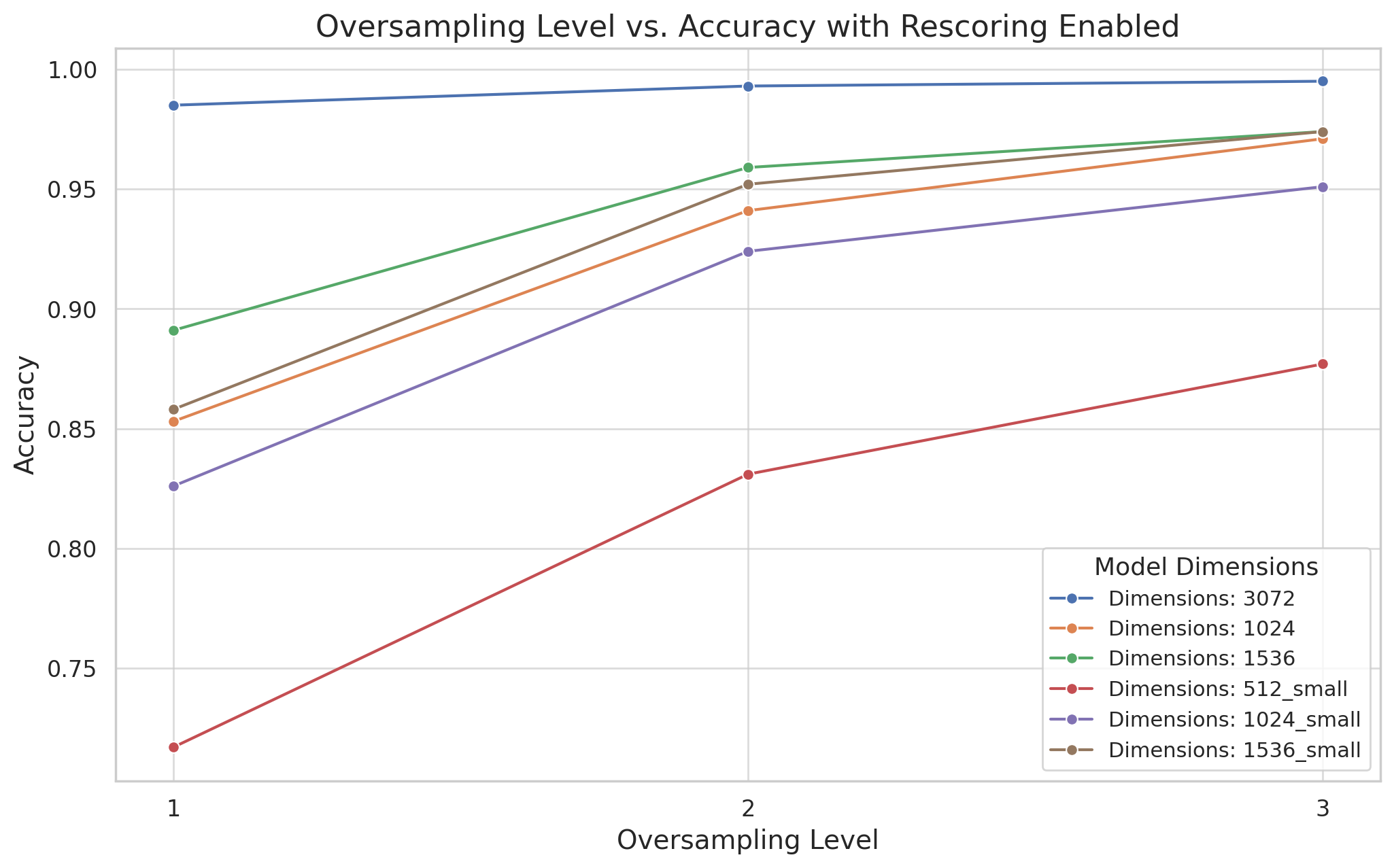
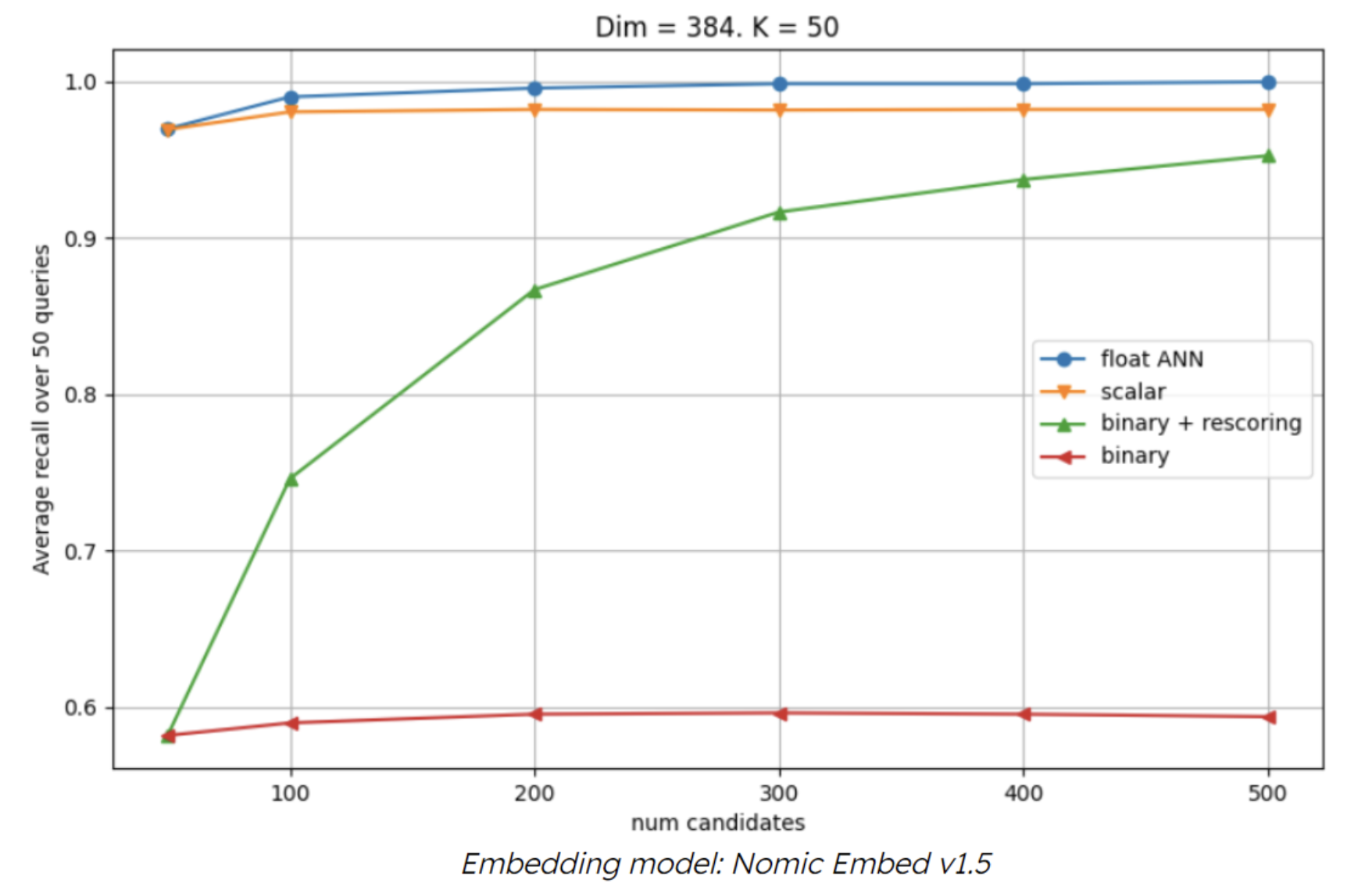
Binary Quantization & Rescoring: 96% Less Memory, Faster Search | MongoDB
Binary Vectors: Quantization – Practical Pl/Sql
Binary and Scalar Embedding Quantization for Significantly Faster ...
Binary quantization of vectors, does it work for vector search? - YouTube
Elasticsearch 8.16: Better Binary Quantization (BBQ) — A better way to ...
Binary Quantization for Vector... | 커리어리
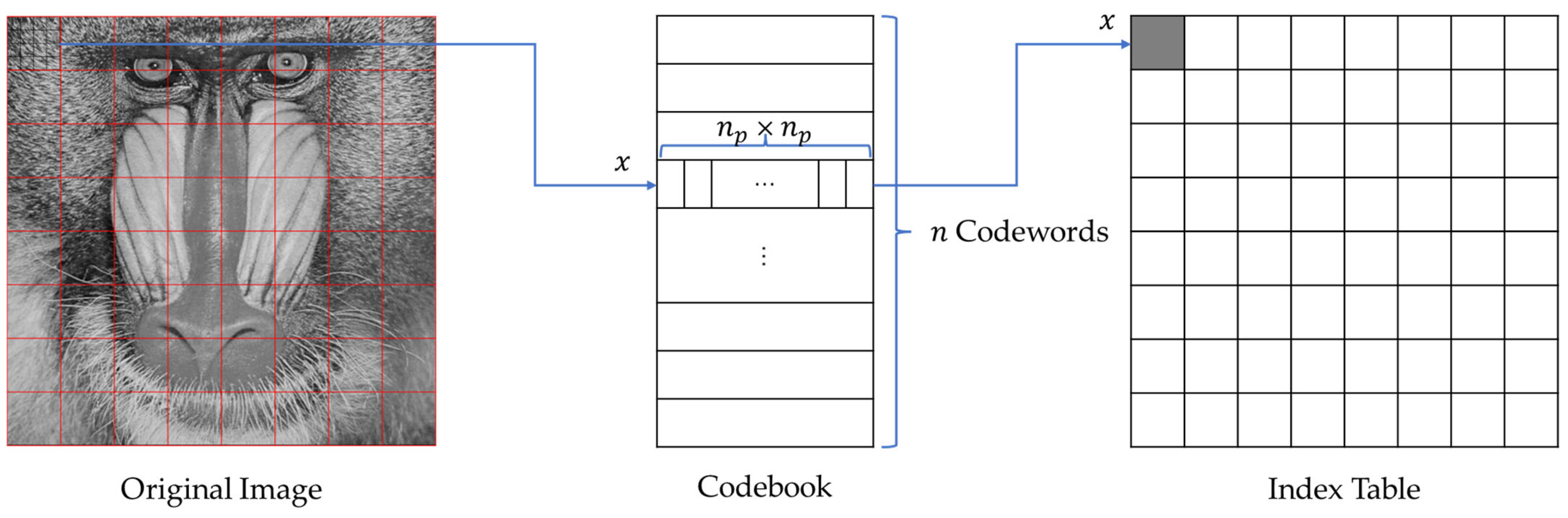
Figure 1 from Binary tree-structured vector quantization approach to ...
Comparing Quantization Techniques for Scalable Vector Search – Unite.AI
Top LLM Quantization Methods and Their Impact on Model Quality
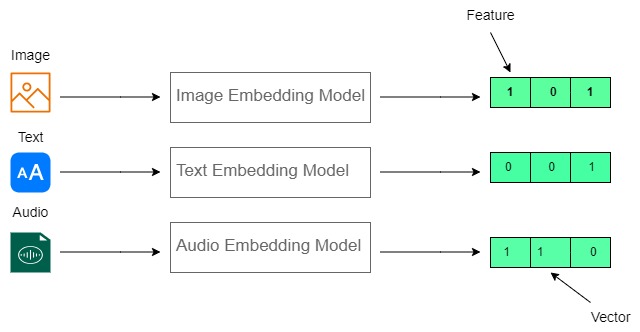
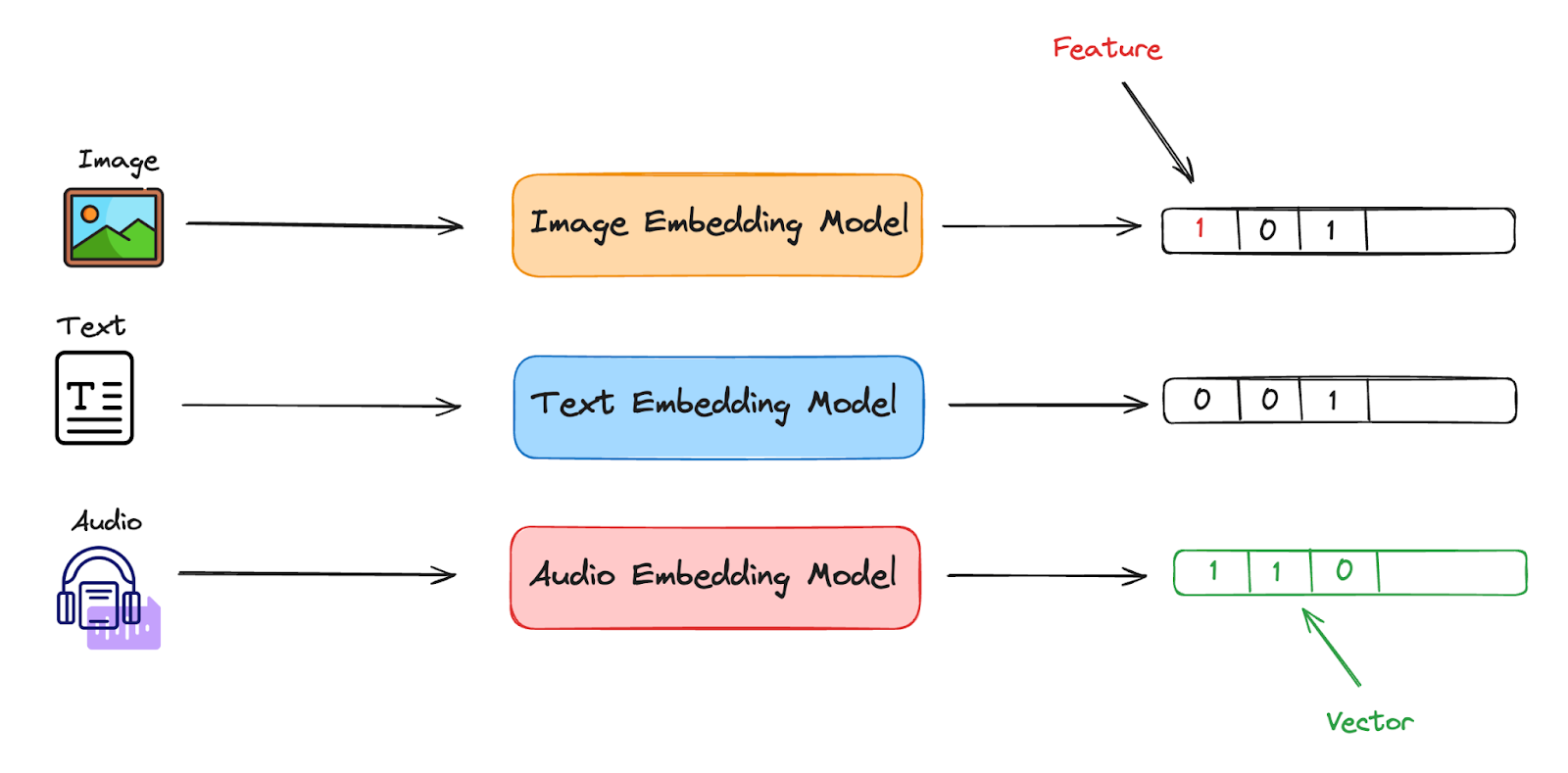
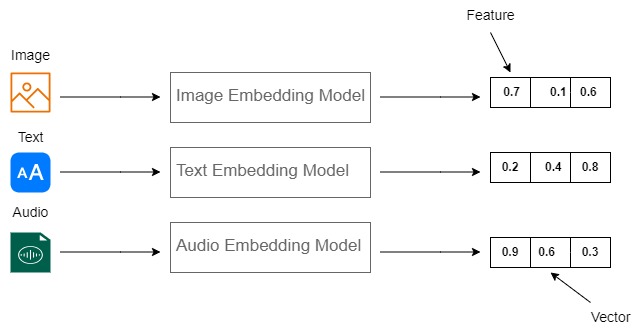
What Are Binary Embeddings? - Zilliz Learn
Optimizing OpenAI Embeddings: Enhance Efficiency with Qdrant's Binary ...
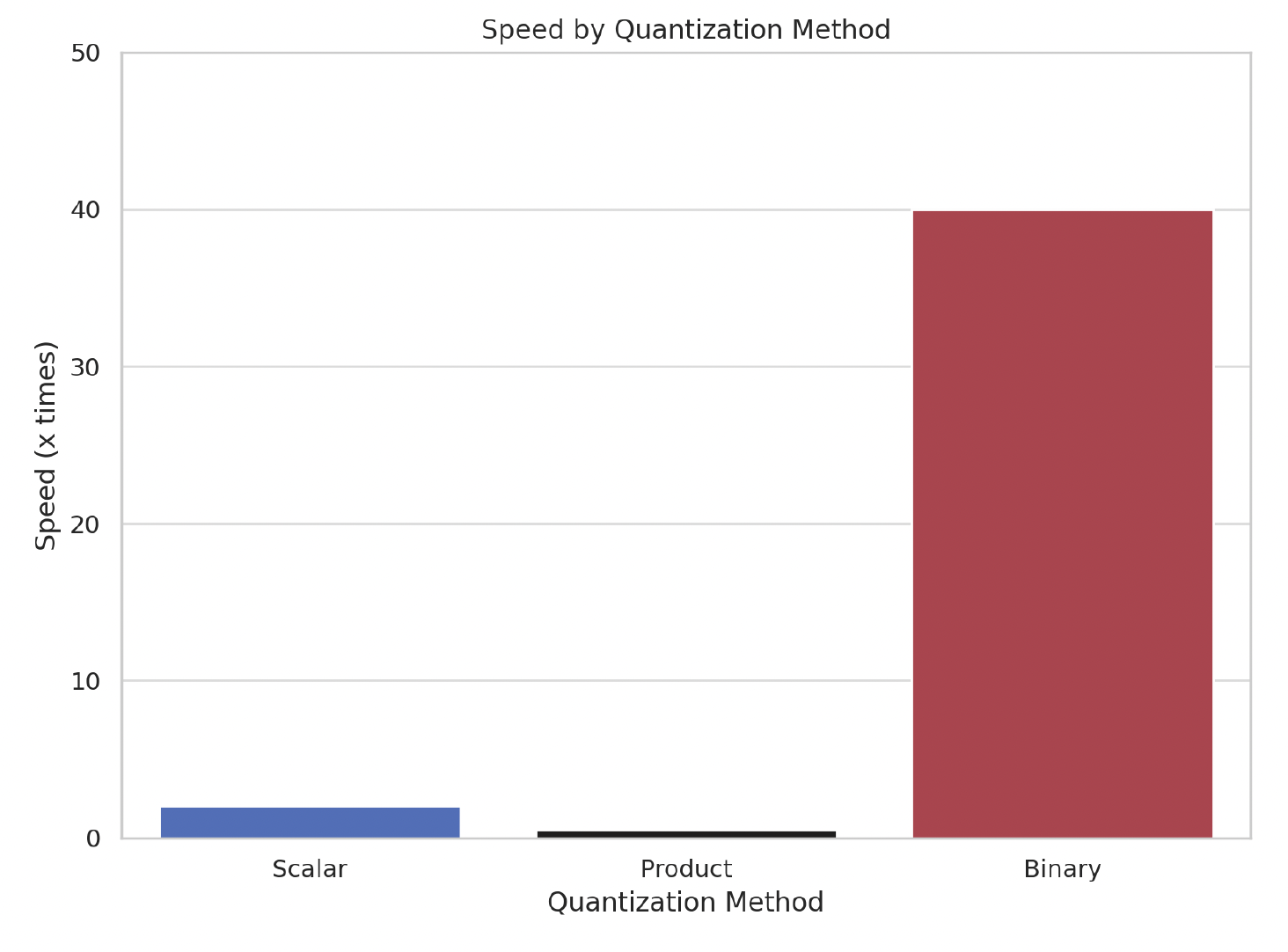
Hyperfast Vector Search with Binary Quantization. | Qdrant
PPT - Optimal Centroid Position and Distance Functions in Binary Vector ...
Mastering Vector Databases: Product & Binary Quantization, Multi-Vector ...
#011 Mastering Vector Databases, Product & Binary Quantization, Multi ...
EFFICIENT VECTOR QUANTIZATION USING AN
Parallel Vector Quantization Lossless Recompression Of Vector
Optimize your OpenSearch costs using binary vectors - OpenSearch
Quantization in Vector Databases. In my previous blog, Vector Databases ...
Vector Quantization for Scalable Vector Search - Intel Community
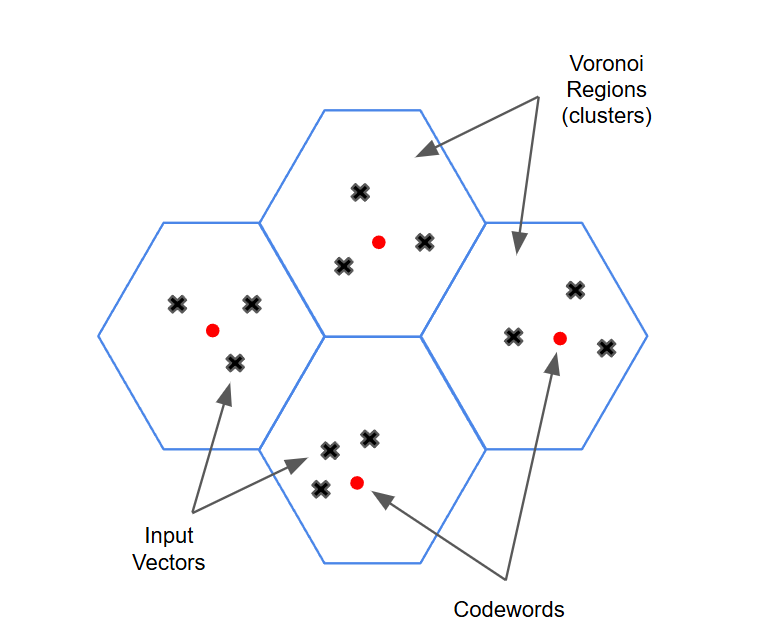
Schematic overview of the vector quantization algorithm. (a) k is the ...
Vector and Line Quantization for Billion-scale Similarity Search on GPUs
Learning Vector Quantization
Inverted File Product Quantization (IVF_PQ): Accelerate vector search ...
[논문 리뷰] One-Index Vector Quantization Based Adversarial Attack on Image ...
[LG] BiLLM: Pushing the Limit of Post-Training Quantization for LLMs ...
MY BINARY VECTOR SEARCH IS BETTER THAN YOUR FP32 VECTORS & 高策
RAG with Meilisearch: Mastering hybrid search for LLMs
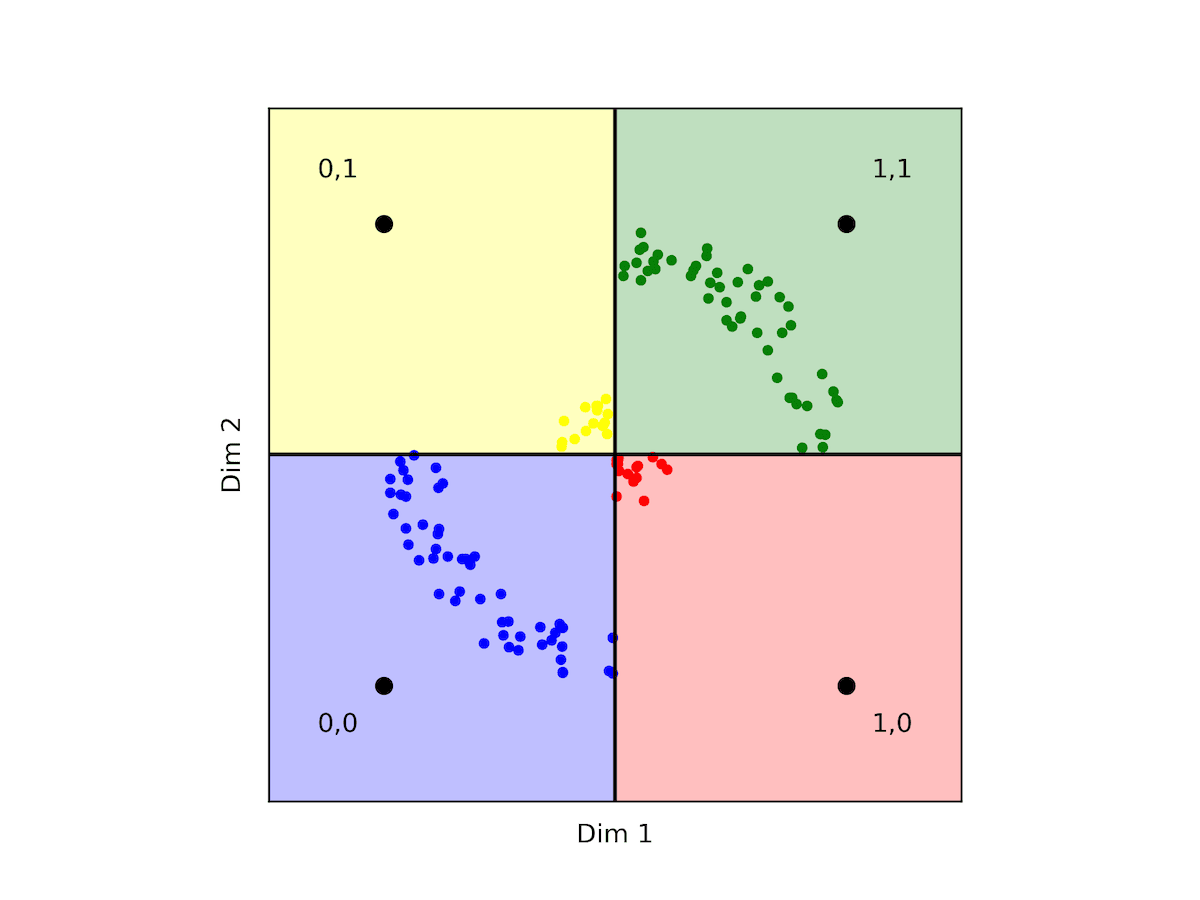
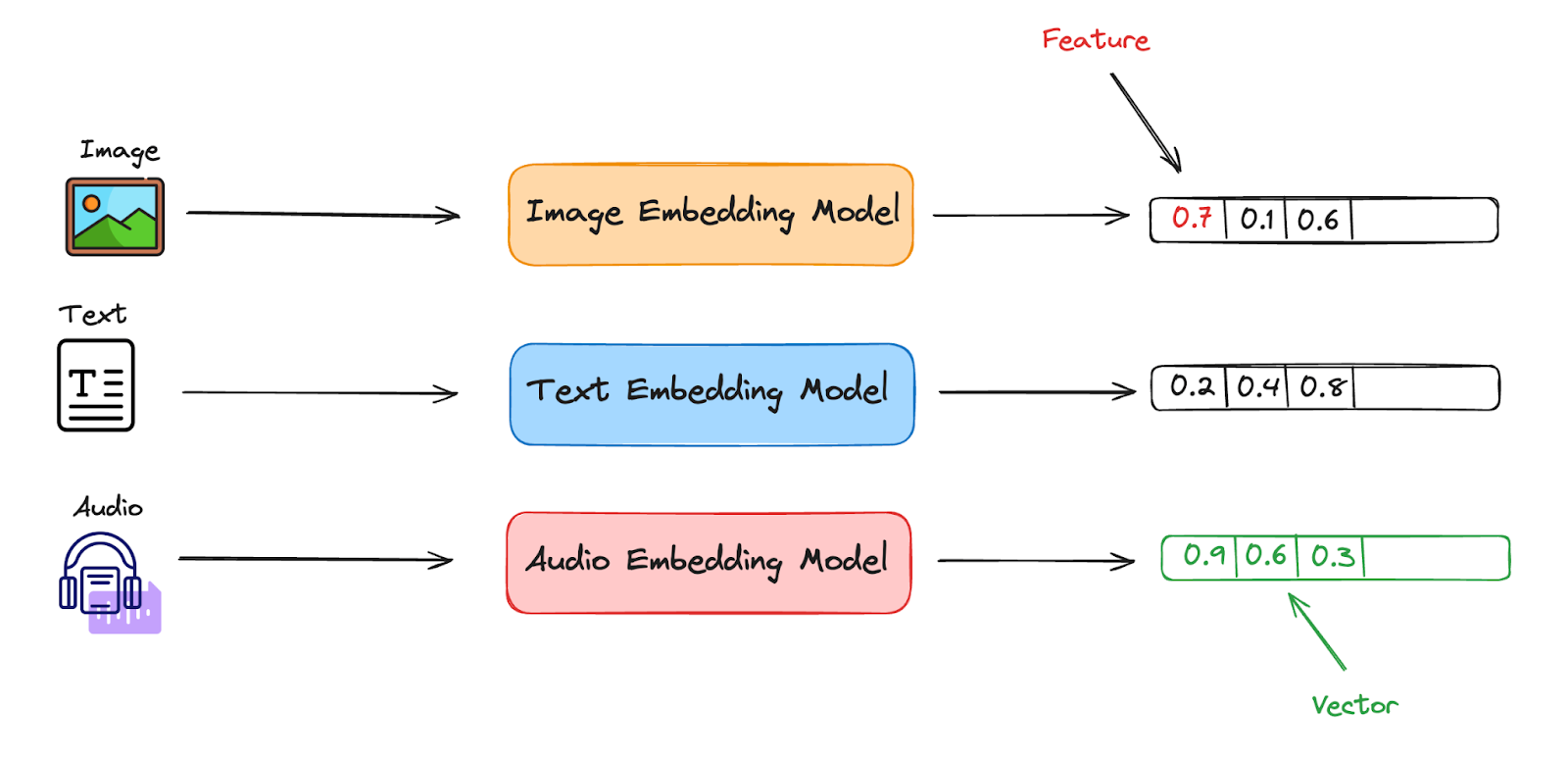
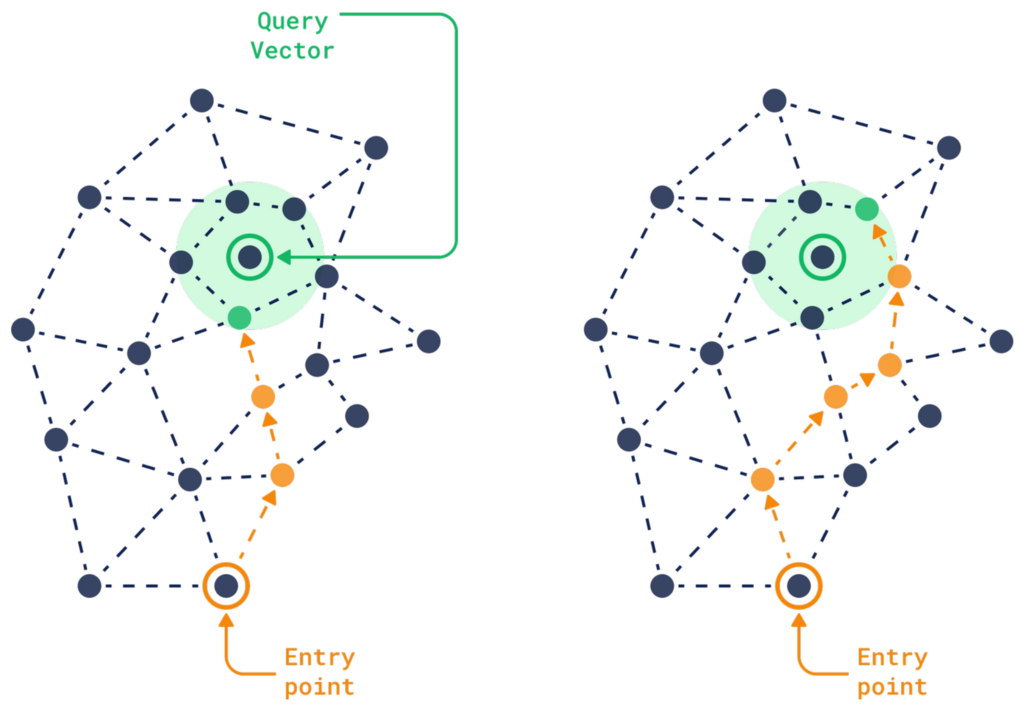
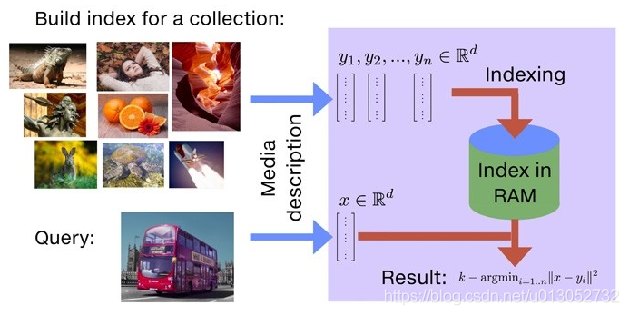
What is a Vector Database? - Qdrant
An Introduction to Vector Databases - Qdrant
Vector Search Resource Optimization Guide - Qdrant
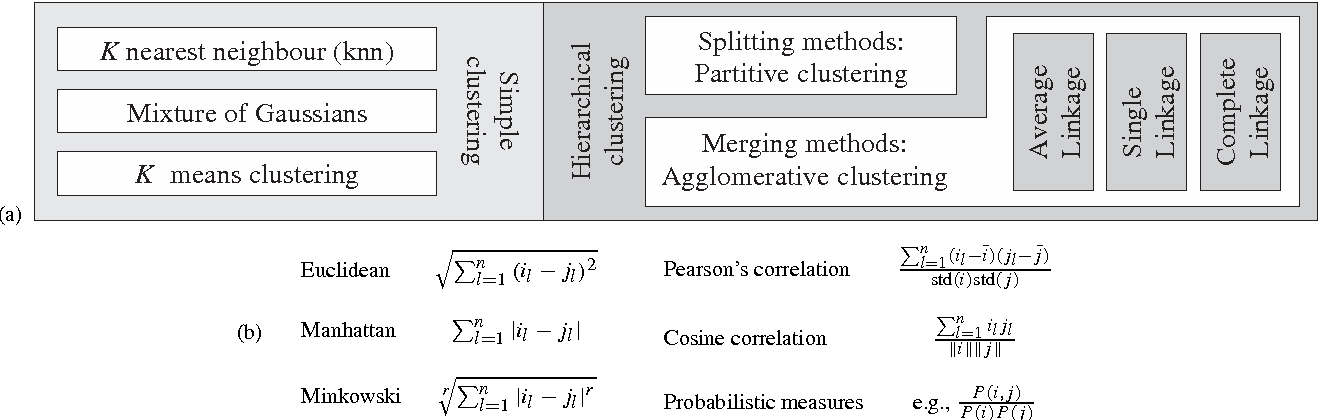
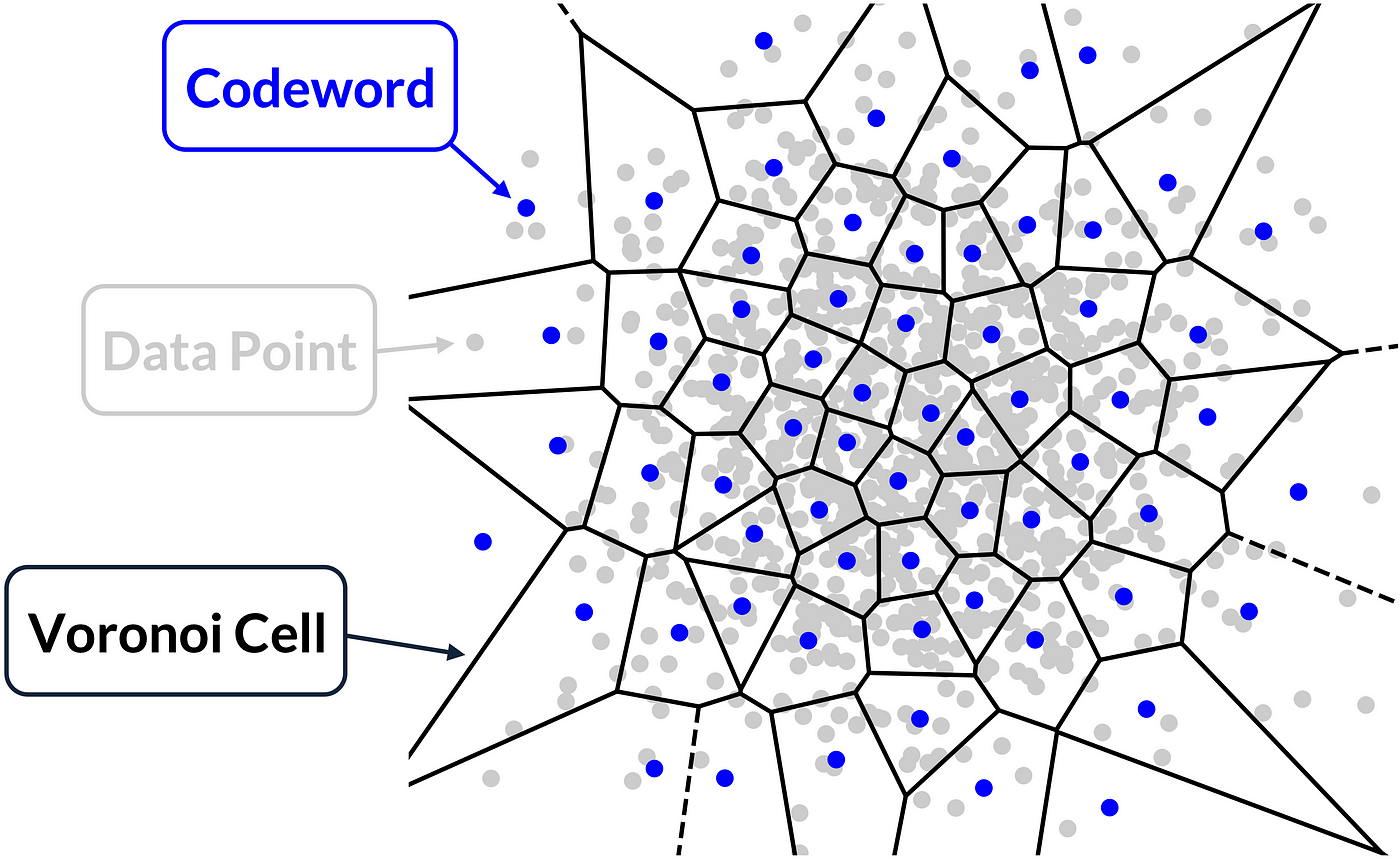
What is Vector Quantization? - Zilliz Learn
大规模向量检索与量化方法 - ZacksTang - 博客园
What is Vector Quantization? - Qdrant
Deep-dive Molmo and PixMo With Hands-on Experimentation
Vector Quantization: Scale Search & Generative AI Applications | MongoDB
Vector Quantization: Scale Search & Generative AI Applications ...
Vector Database - Search Labs
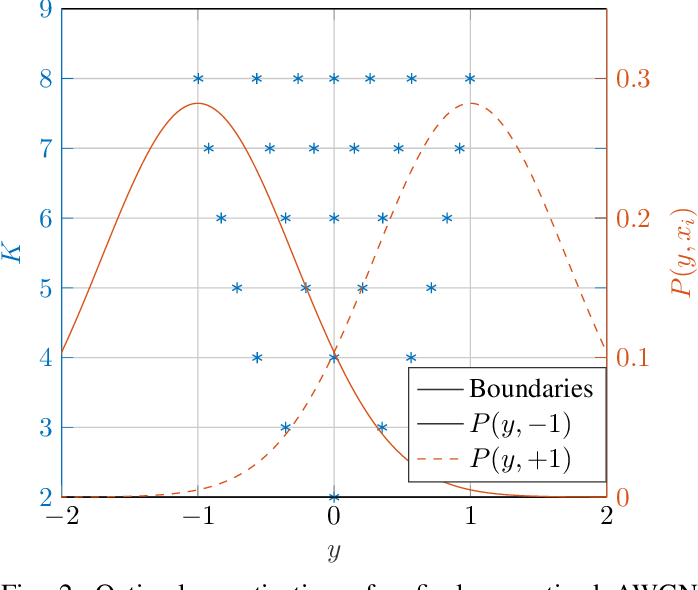
Figure 2 from A Recursive Quantizer Design Algorithm for Binary-Input ...
Reduce costs with disk-based vector search - OpenSearch
cRank it up! - Introducing the Elastic Rerank model (in Technical ...
How We Built a Web-Scale Vector Database for Our Neural Network Search ...
【论文笔记】Billion-scale similarity search with GPUs | 玉树
Multilingual vector search with the E5 embedding model - Search Labs
💥 Perplexity's pplx-embed is HERE 🌀 ♠ and it's completely redefining ...
Qdrant TurboQuant Explained: Is TurboQuant the Silver Bullet? | Towards ...
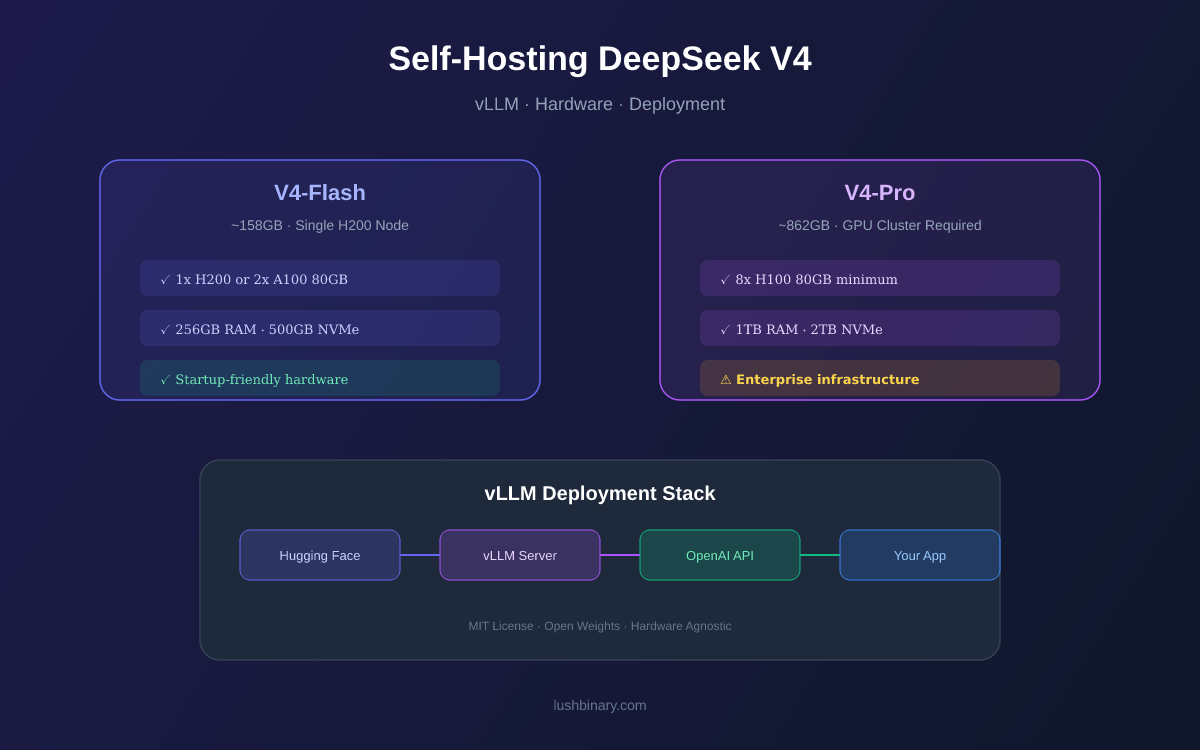
Self-Hosting DeepSeek V4: vLLM, Hardware & Deployment Guide | Lushbinary
Gemma 4 QAT Self-Hosting Guide: Ollama, vLLM | Lushbinary
PrismML 1-Bit Bonsai LLM: 14x Smaller, 8x Faster | byteiota
How to Use llama.cpp to Run LLaMA Models Locally in 2026
Elasticsearch 9.0 发布,新功能抢先看!-CSDN博客
EEE2042S Tutorial 9 Memo: Number Systems & Converters - Studocu
Why Your ADC Measurements Are Inaccurate: Common Pitfalls and Fixes ...
OpenAI gpt-oss LLMs use MXFP4: smaller, faster, cheaper
GGUF + llama.cpp: Shipping a Fine-Tuned Model in Your Mobile App - Ertas AI