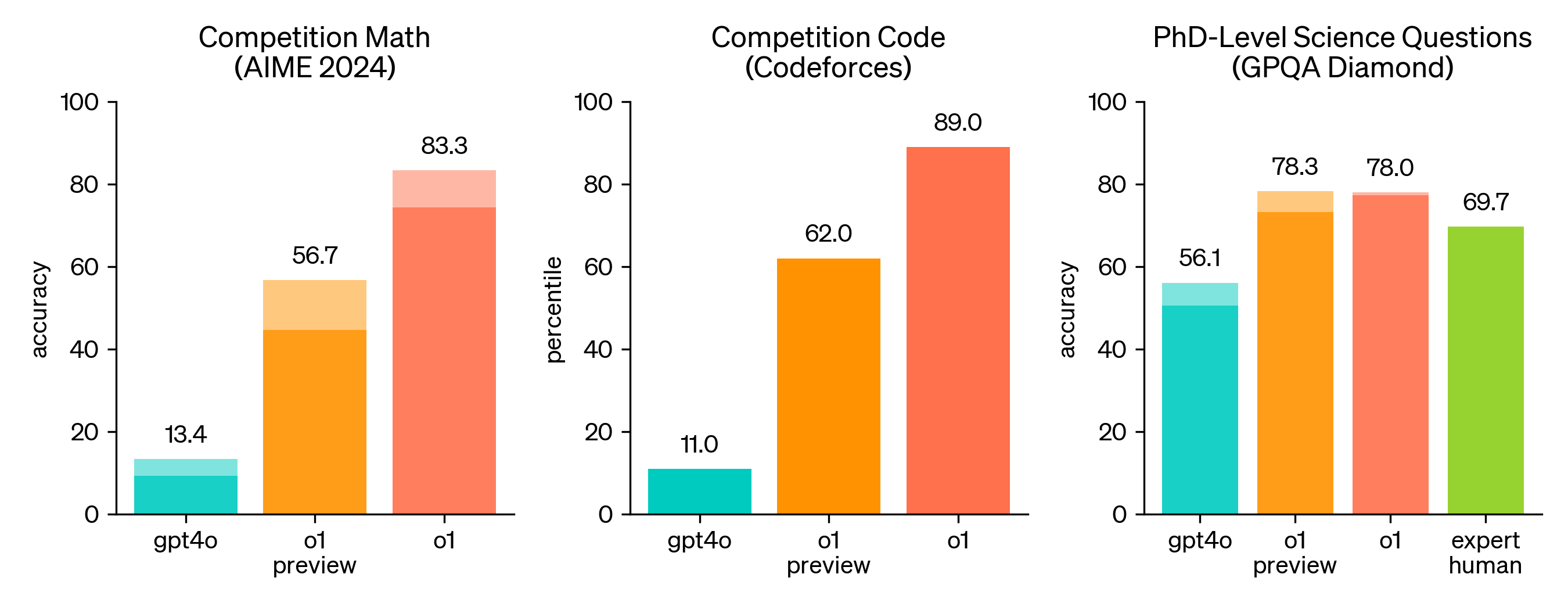Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Security benchmark score (see online version for colours) | Download ...
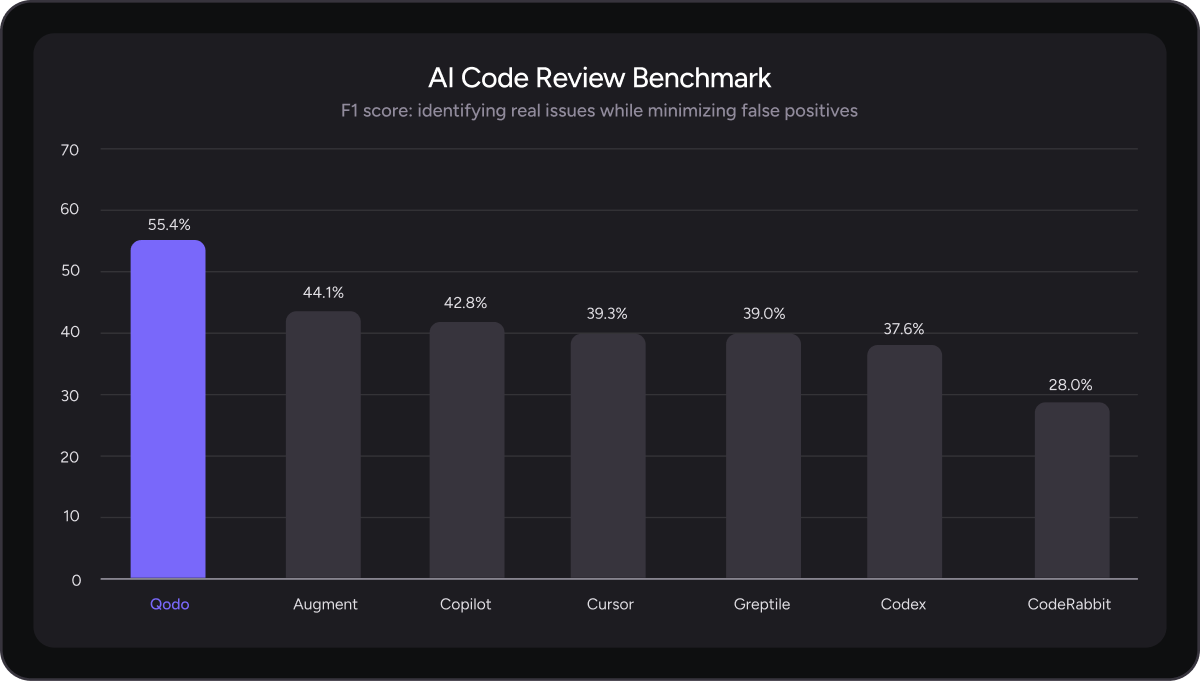
AI Code Review Benchmark
GPT-4o Benchmark - Detailed Comparison with Claude & Gemini | Wielded
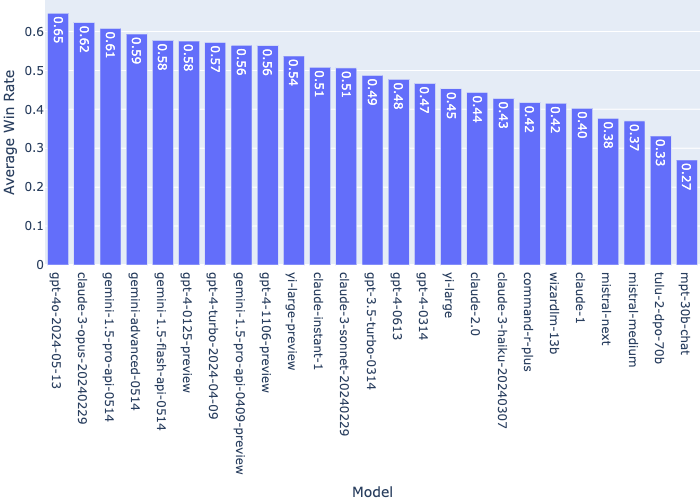
Benchmark Scores = General Capability + Claudiness
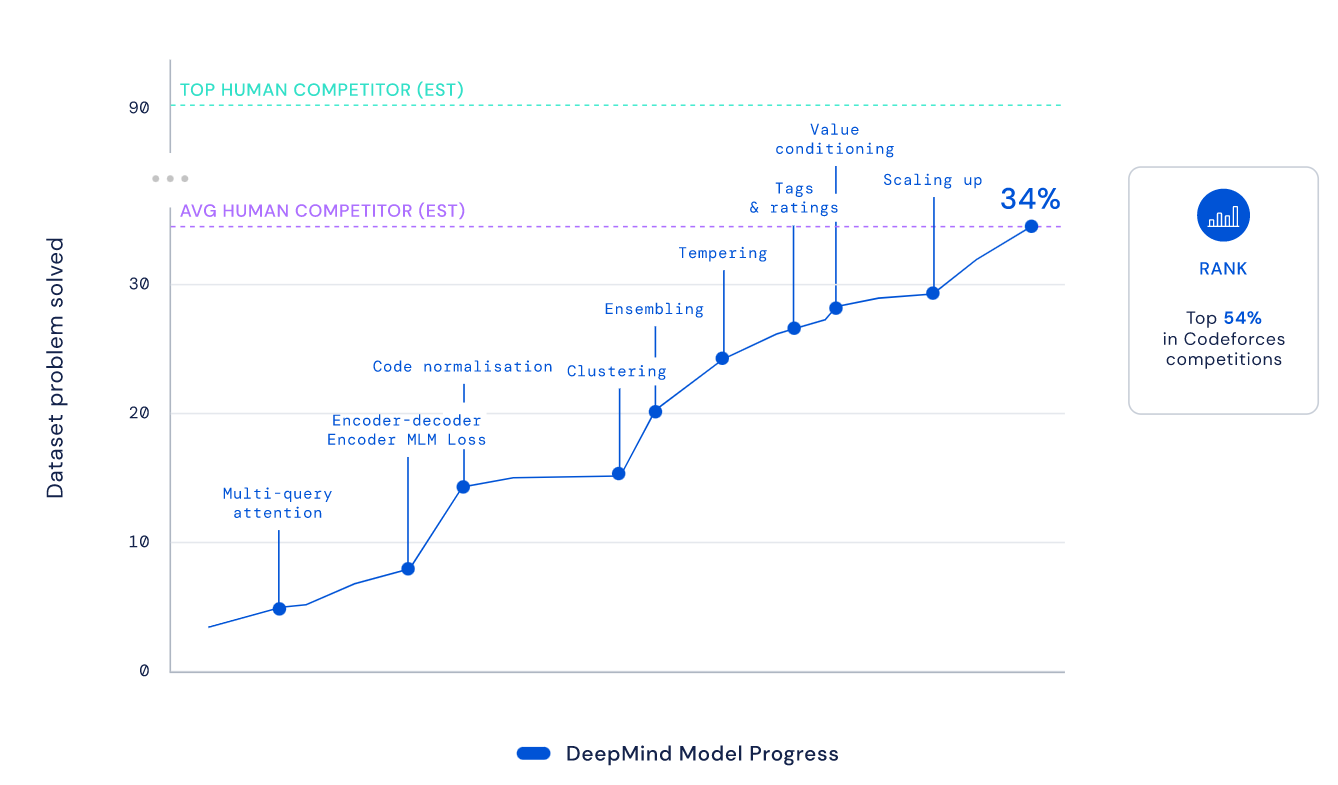
Qwen Researchers Introduce CodeElo: An AI Benchmark Designed to ...
A stealth AI model beat DALL-E and Midjourney on a popular benchmark ...
ReCode benchmark robustness evaluation on popular code generation ...
Regression results of benchmark model and main model. | Download Table
A Code Comprehension Benchmark for Large Language Models for Code | AI ...
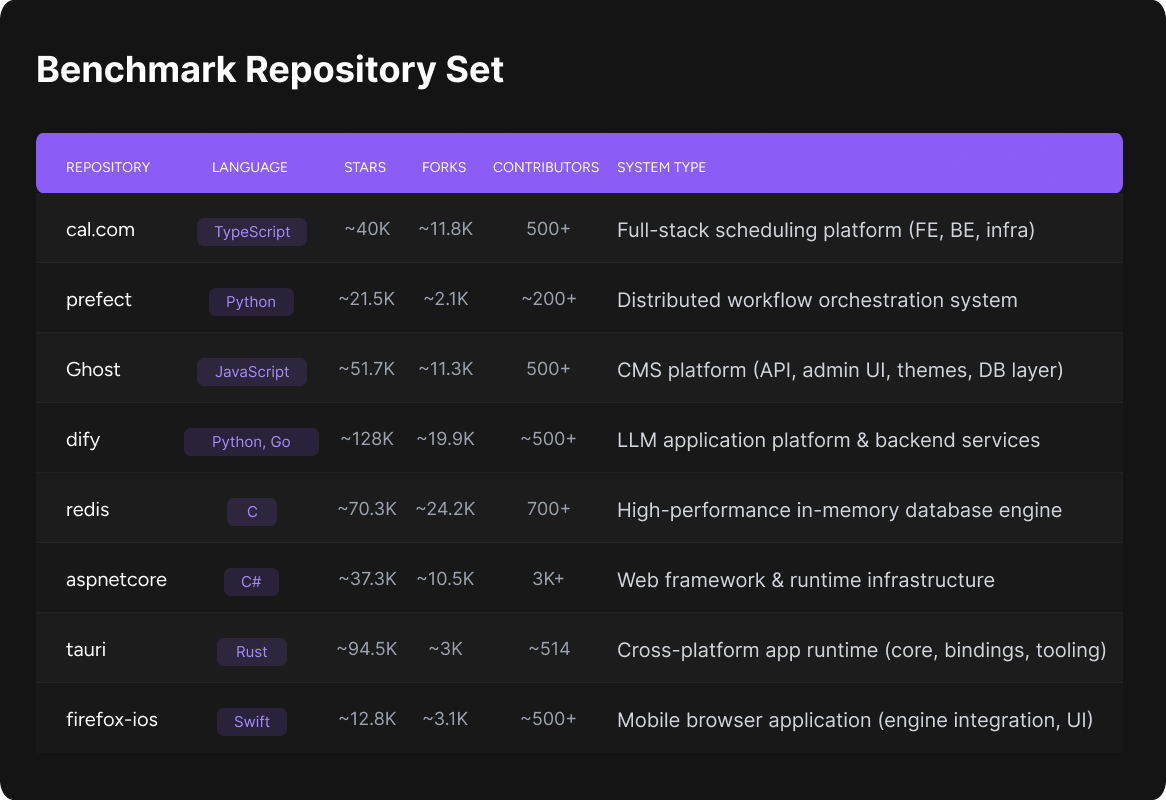
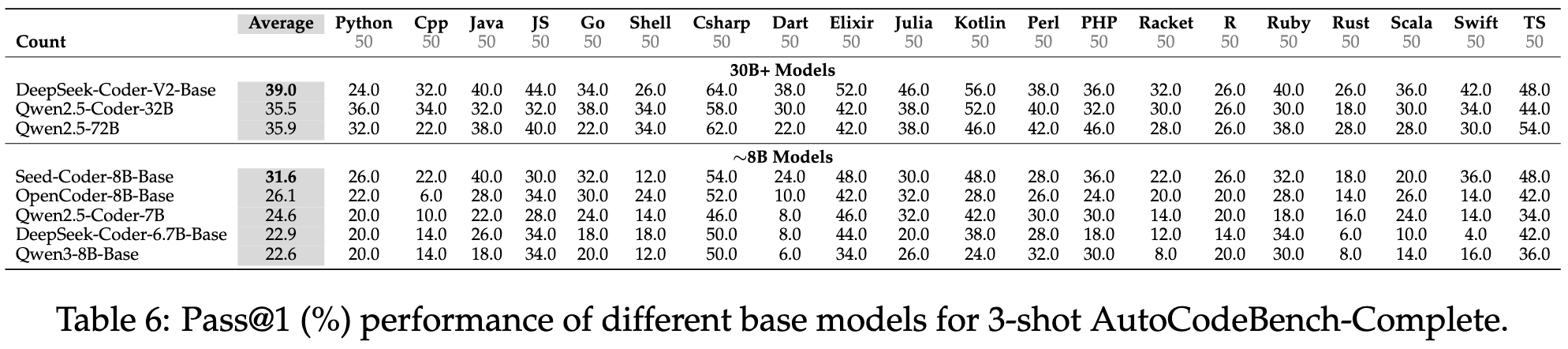
AutoCodeBench – Tencent Hunyuan’s Open-Source Benchmark Dataset for ...
Paper page - ComplexCodeEval: A Benchmark for Evaluating Large Code ...
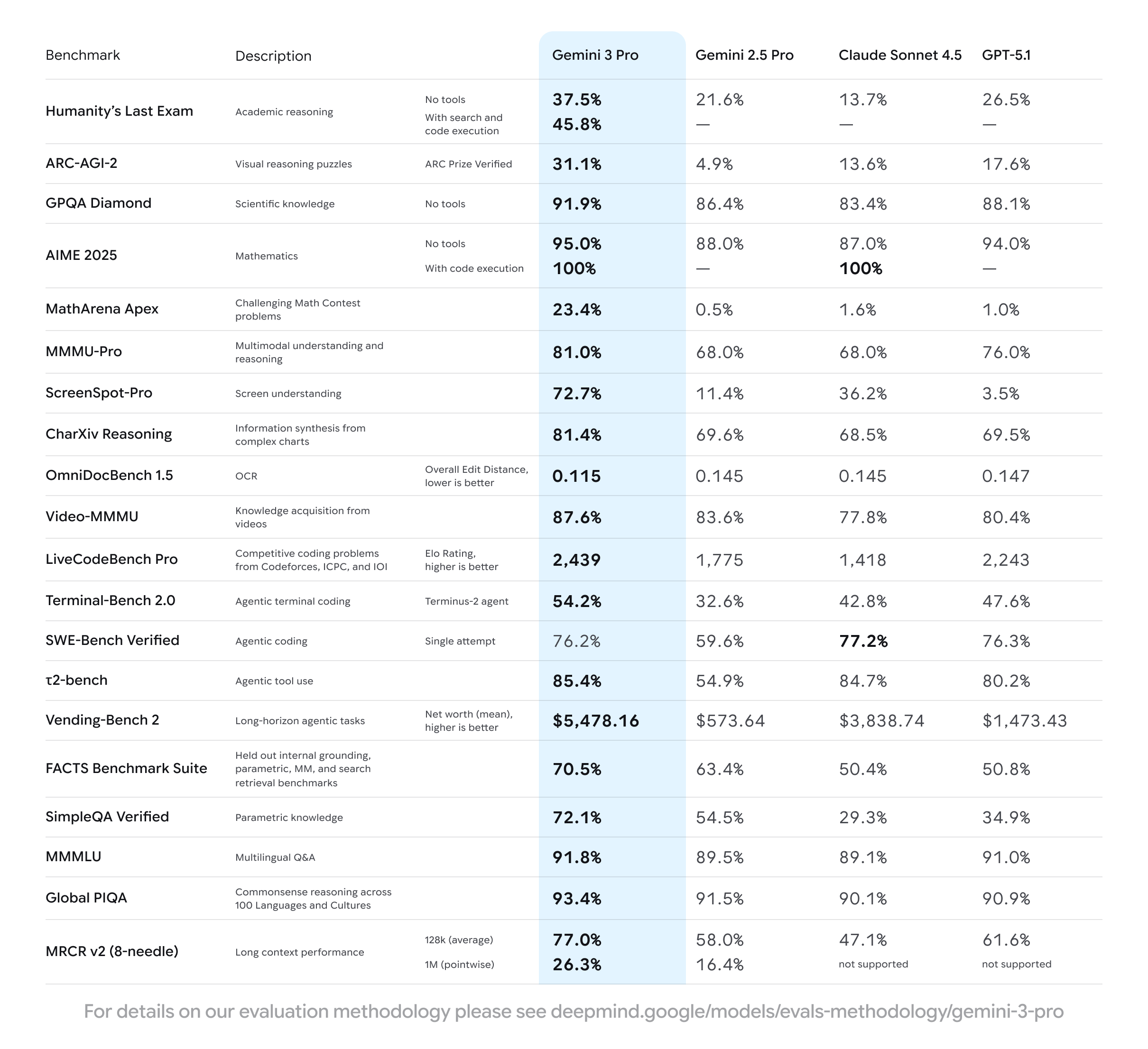
Introducing A Benchmark Model Gemini By Google - AiThority
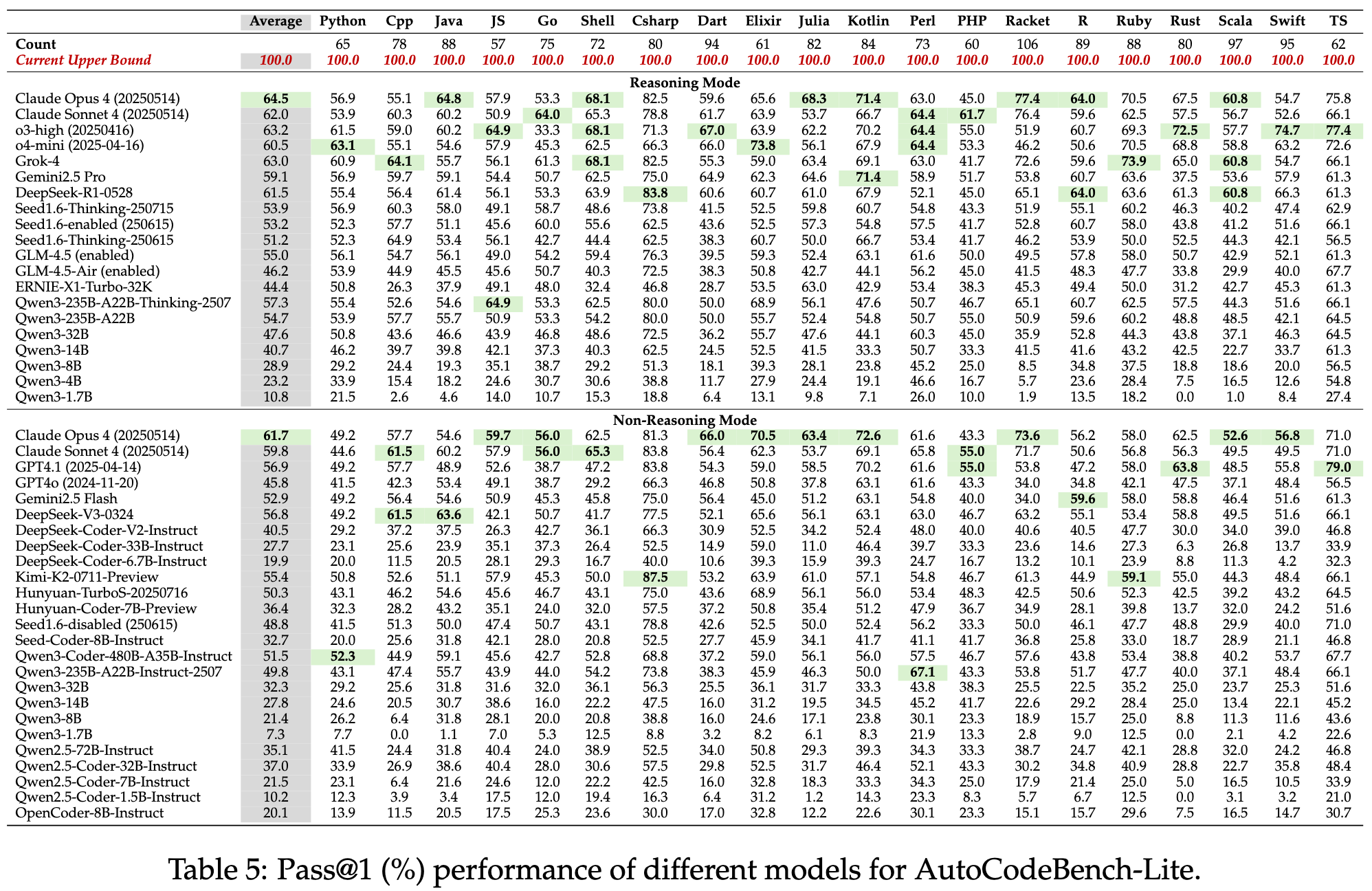
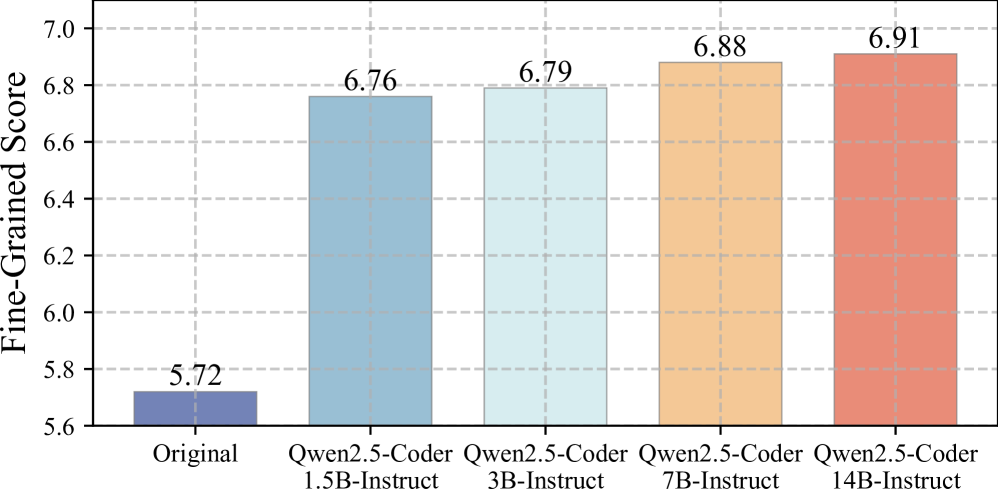
AutoCodeBench: Large Language Models are Automatic Code Benchmark ...
Source code characteristics for each benchmark | Download Table
Configuration of models in our benchmark | Download Scientific Diagram
Benchmark models in the model leaderboard of Azure AI Foundry portal ...
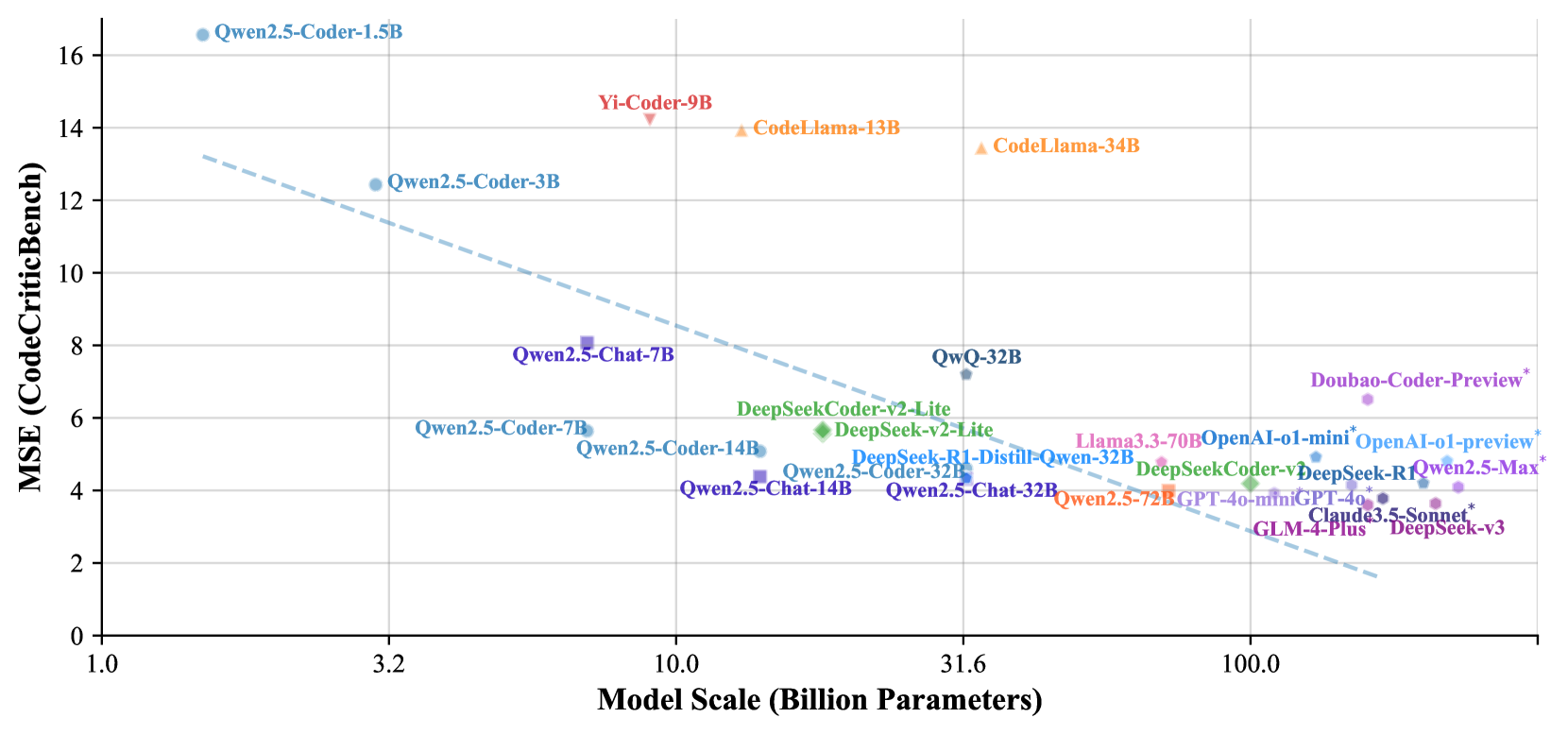
CodeCriticBench: A Holistic Code Critique Benchmark for Large Language ...
Benchmark Data: A Crucial Success Factor for Measuring L&D ...
Geekbench Claims Intel Tool Boosts Benchmark Scores by Tweaking Test ...
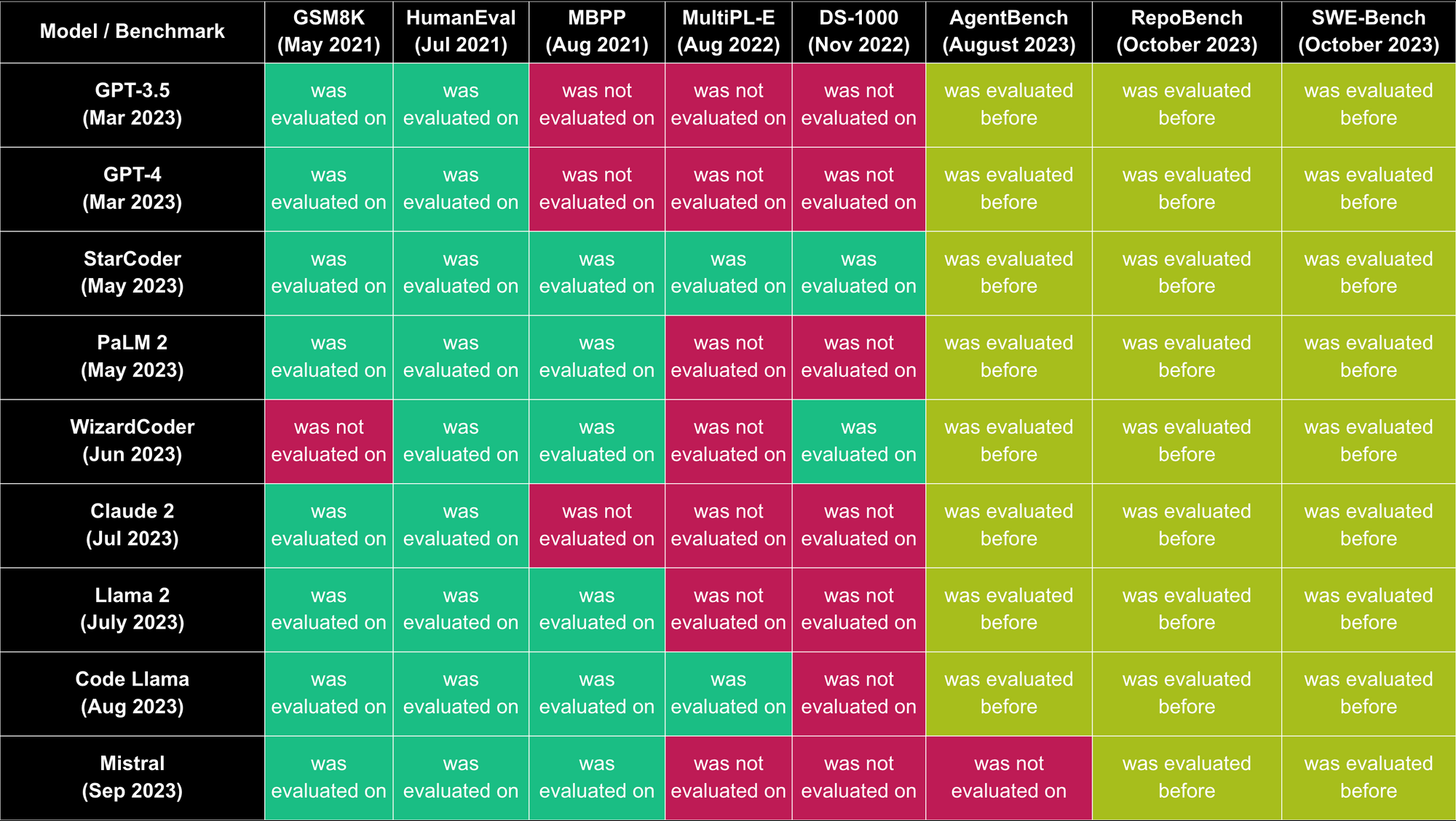
(PDF) Is Your Benchmark (Still) Useful? Dynamic Benchmarking for Code ...
GitHub - code-bench/codebench: Automated code benchmark solution. · GitHub
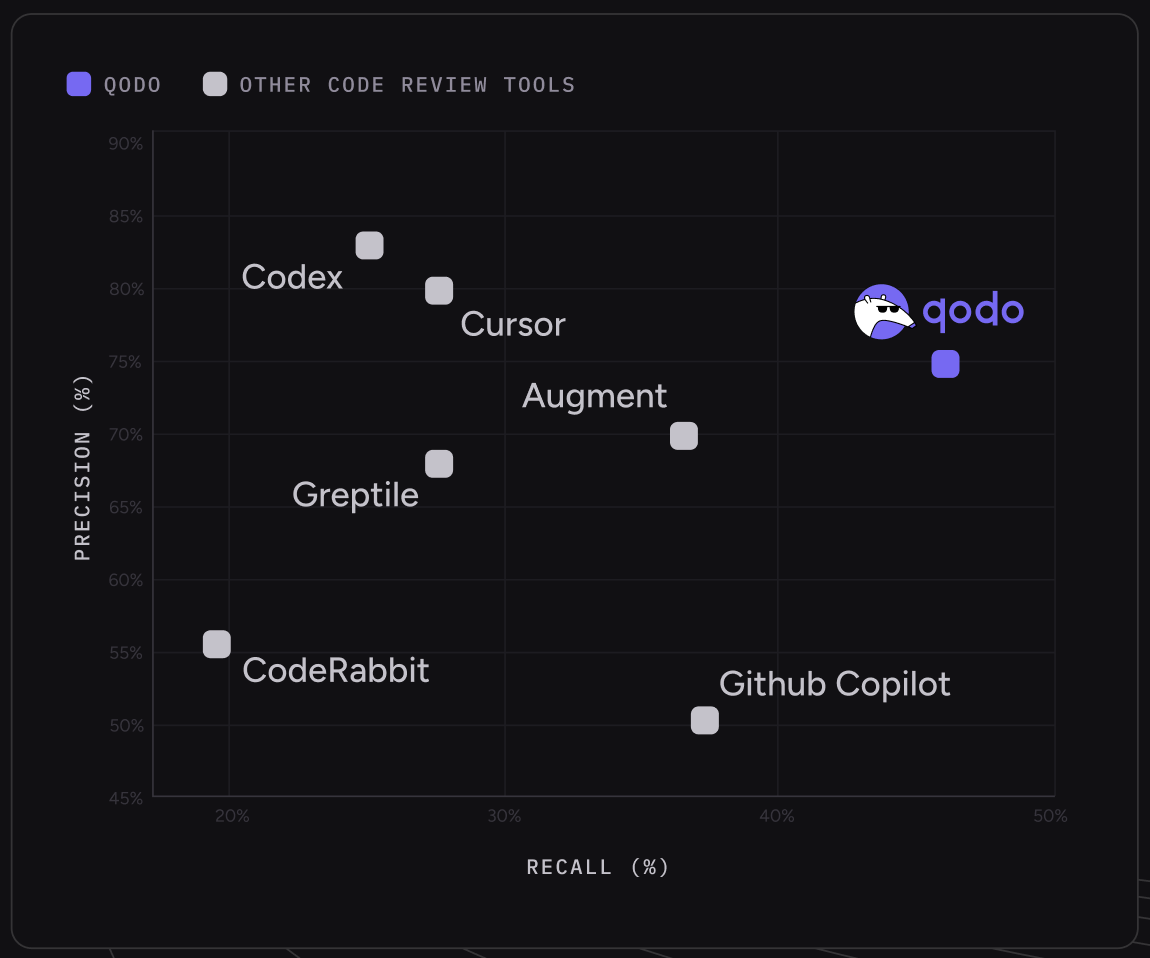
Code Review Bench - Code Review Benchmark | Martian
Model and benchmark scores, where green circles denote cases where ...
CMU Researchers Propose miniCodeProps: A Minimal AI Benchmark for ...
[논문 리뷰] CoCo-Bench: A Comprehensive Code Benchmark For Multi-task Large ...
(a) Benchmark scores computed from reference data only, (c) mean model ...
Model benchmark scores using dataset without rectification | Download ...
Code benchmark en C# | Néosoft
CoIR: A Comprehensive Benchmark for Code Information Retrieval Models ...
DeepSeek’s New R1–0528: Performance Analysis and Benchmark Comparisons ...
A new promising benchmark for code generation models : r/llm_updated
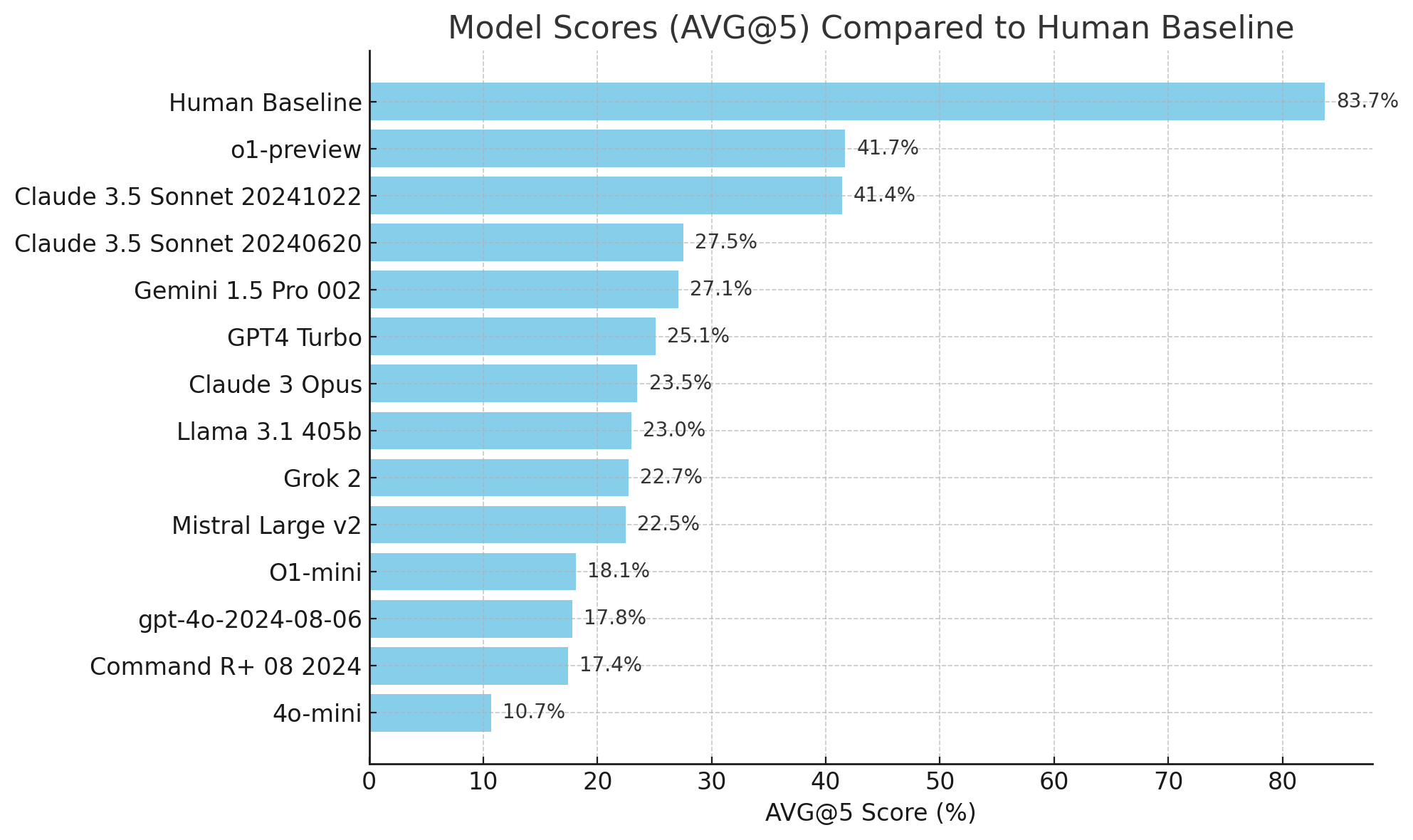
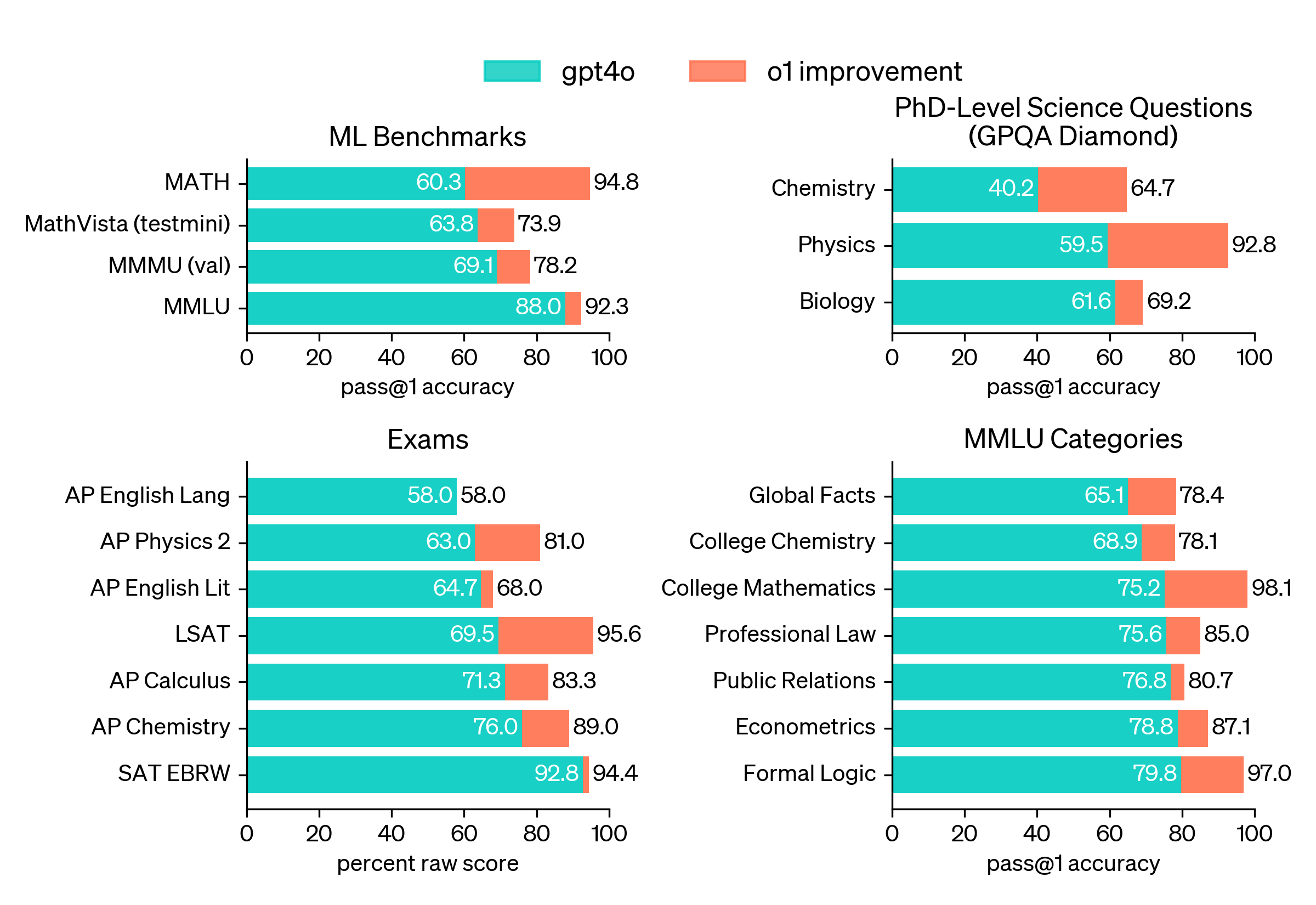
Why are we still using a dated GPT-4 benchmark score?
CodeWMBench: An Automated Benchmark for Code Watermarking Evaluation
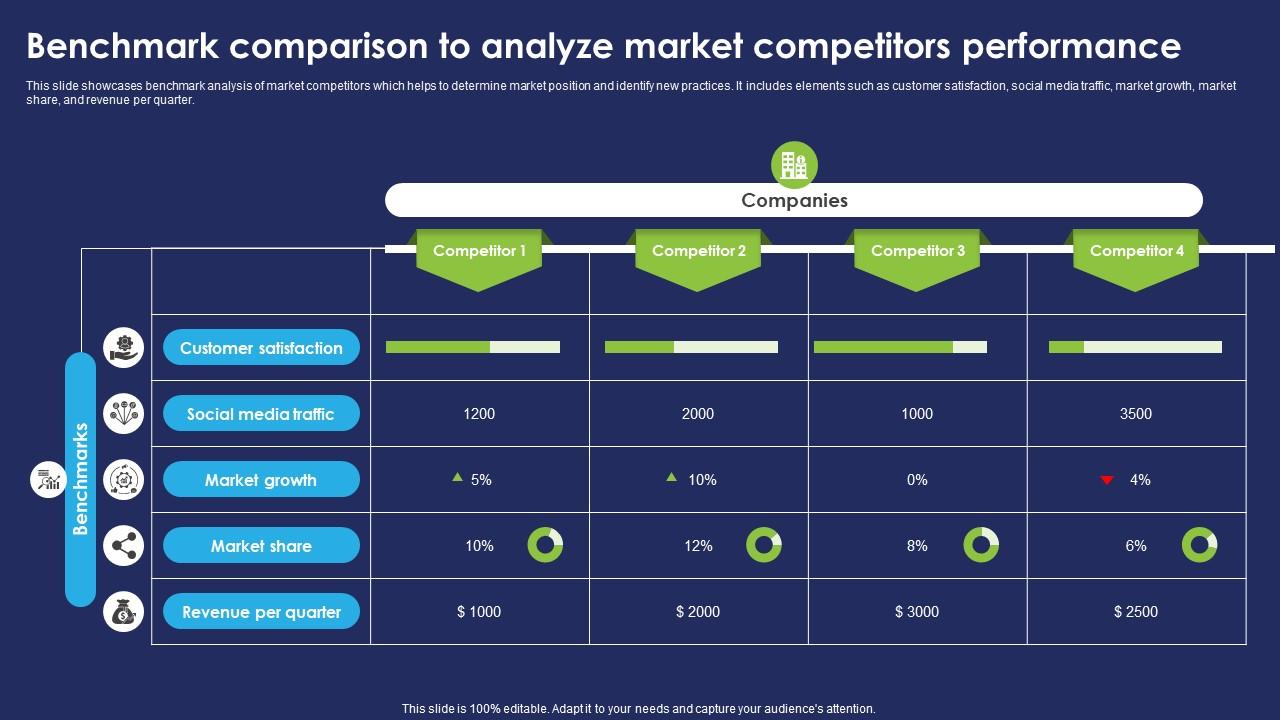
Benchmark Comparison To Analyze Market Competitors Performance PPT Example
Comparing benchmark participant with the current participant on ...
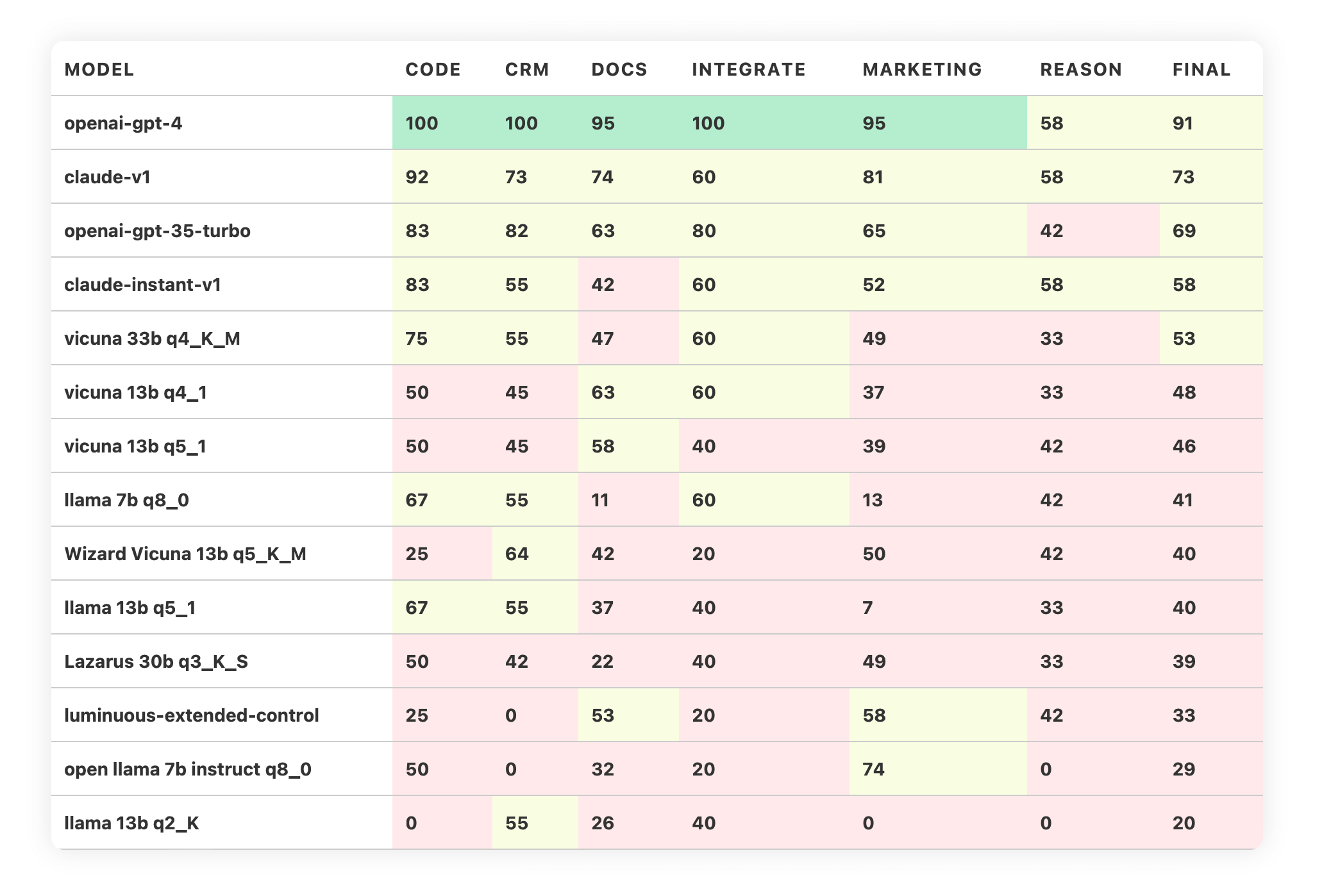
GitHub - cyberNoman/AI_Model_Benchmark_Report: A detailed benchmark ...
NVIDIA Llama Nemotron Ultra Open Model Delivers Groundbreaking ...
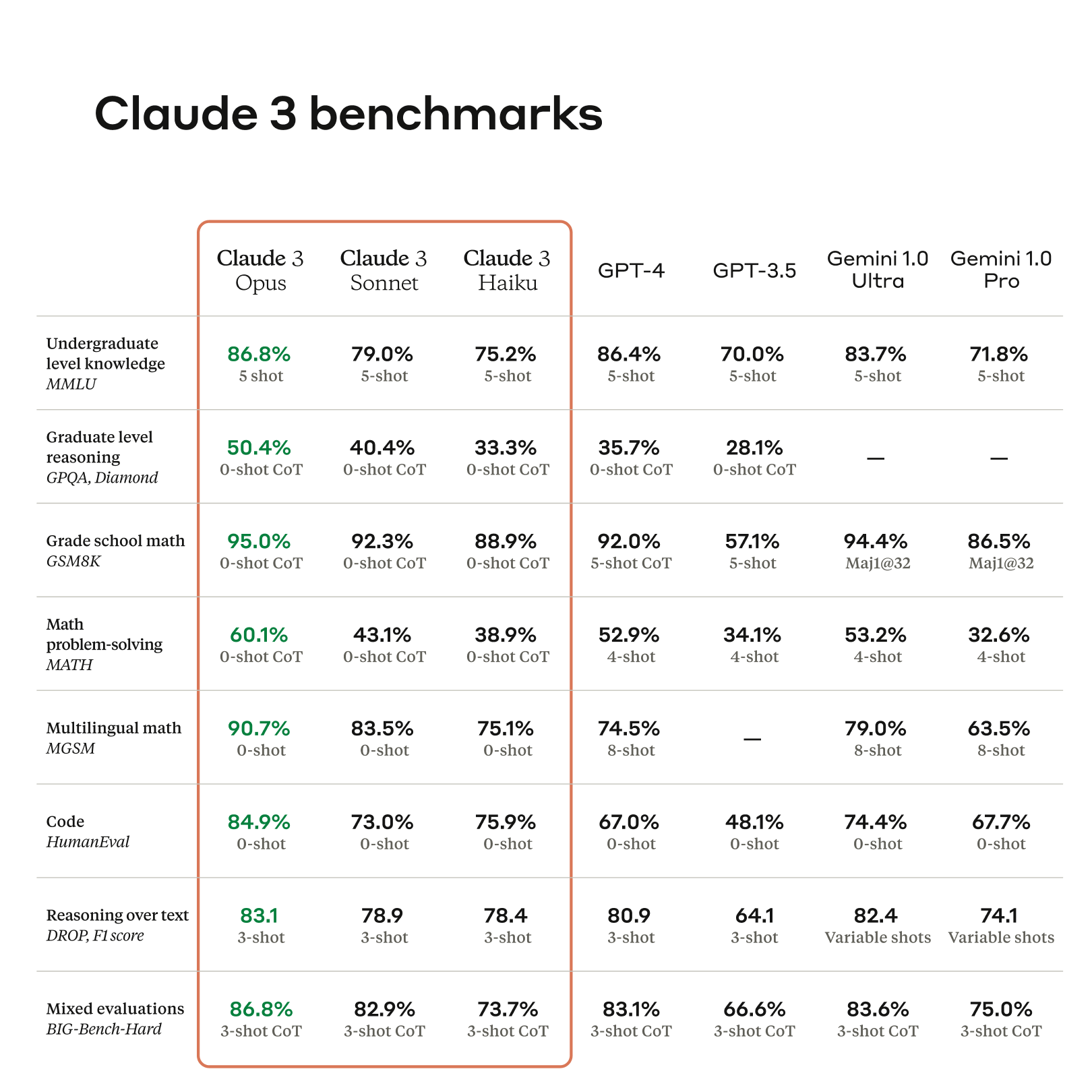
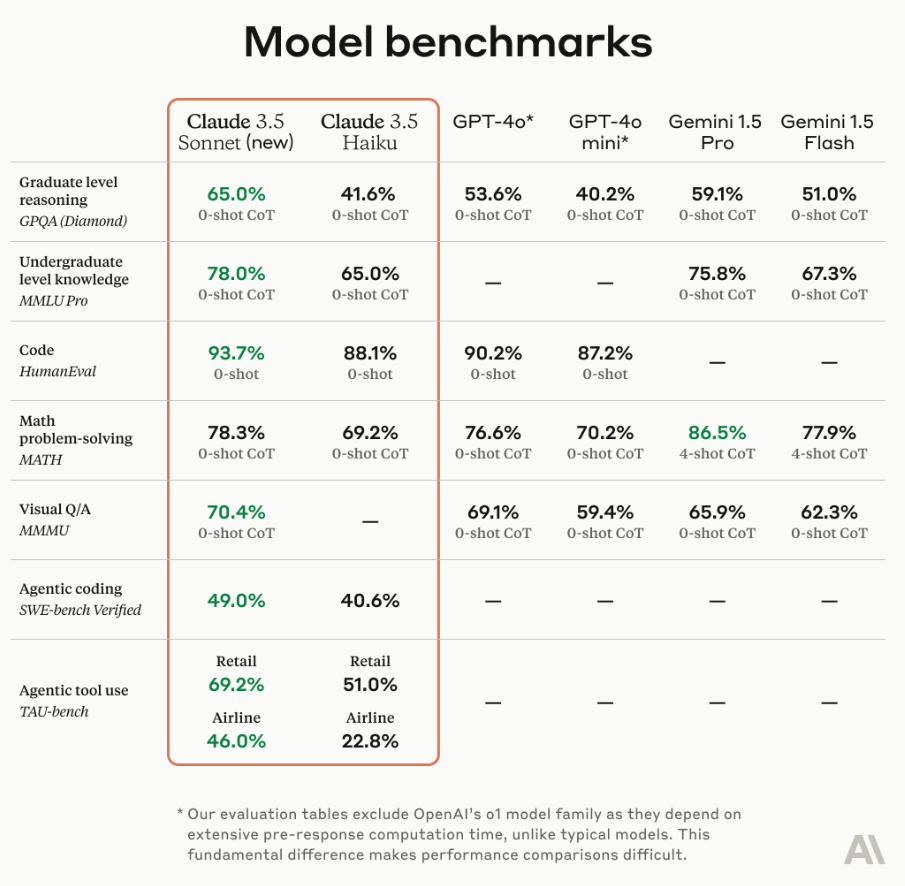
Anthropic übertrumpft mit "Claude 3" die AI-Modelle von OpenAI und Google
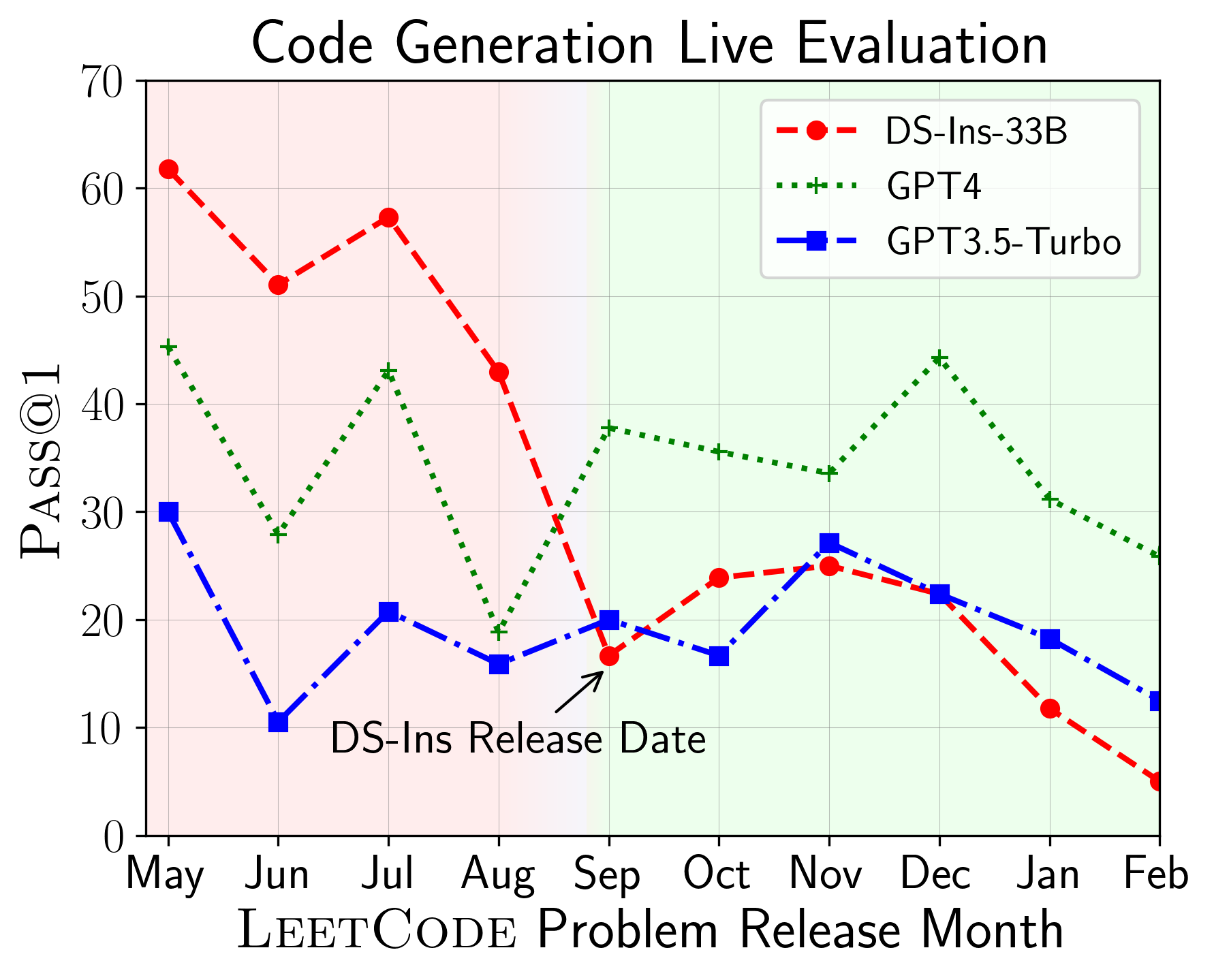
LiveCodeBench: Holistic and Contamination Free Evaluation of Large ...
tencent/AutoCodeBenchmark · Datasets at Hugging Face
GitHub - centminmod/code-supernova-evaluation · GitHub
qwen2.5-coder:32b
Anthropic's Claude 4 Models Can Write Complex Code for You
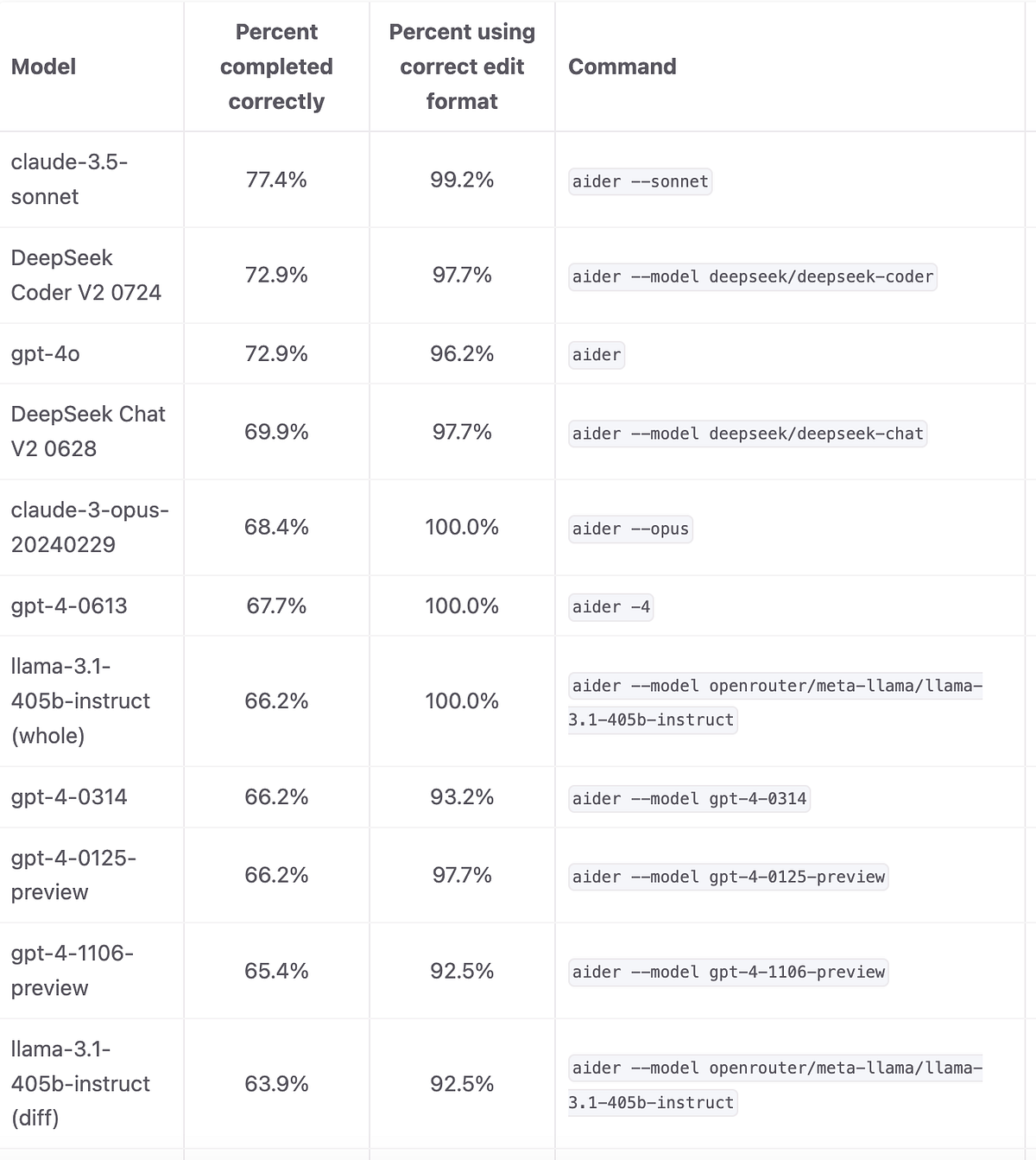
Best LLMs for coding: developer favorites
NVIDIA Llama Nemotron 超开放模型实现突破性的推理准确性 - NVIDIA 技术博客
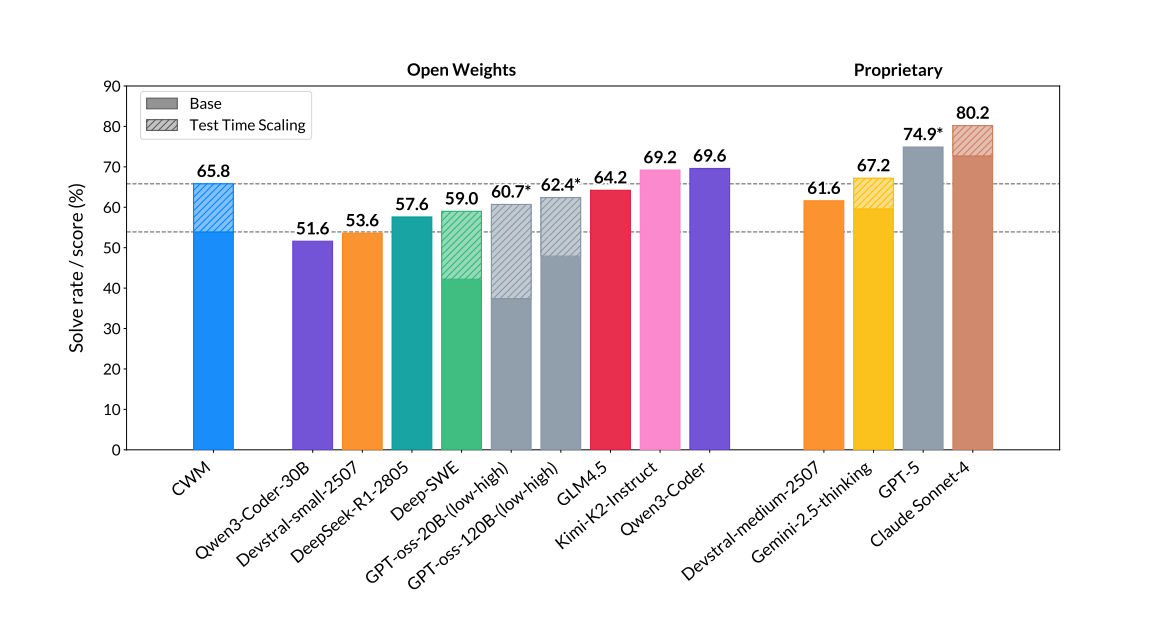
Meta's Code "World Model" aims to close the gap between code generation ...
LLM Product Leaderboard: Benchmarks for building and shipping products ...
Claude Code vs. Gemini CLI vs. Codex CLI: What’s the Best Choice for ...
LLM Code Performance: Top 10 Benchmarks Explained | by Vivedha Elango ...
What is LLM Benchmarks? Types, Challenges & Evaluators
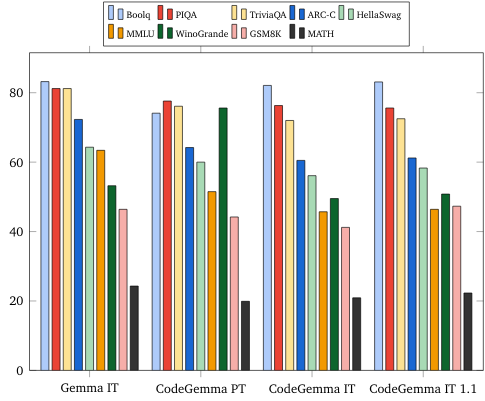
CodeGemma model card | Google AI for Developers
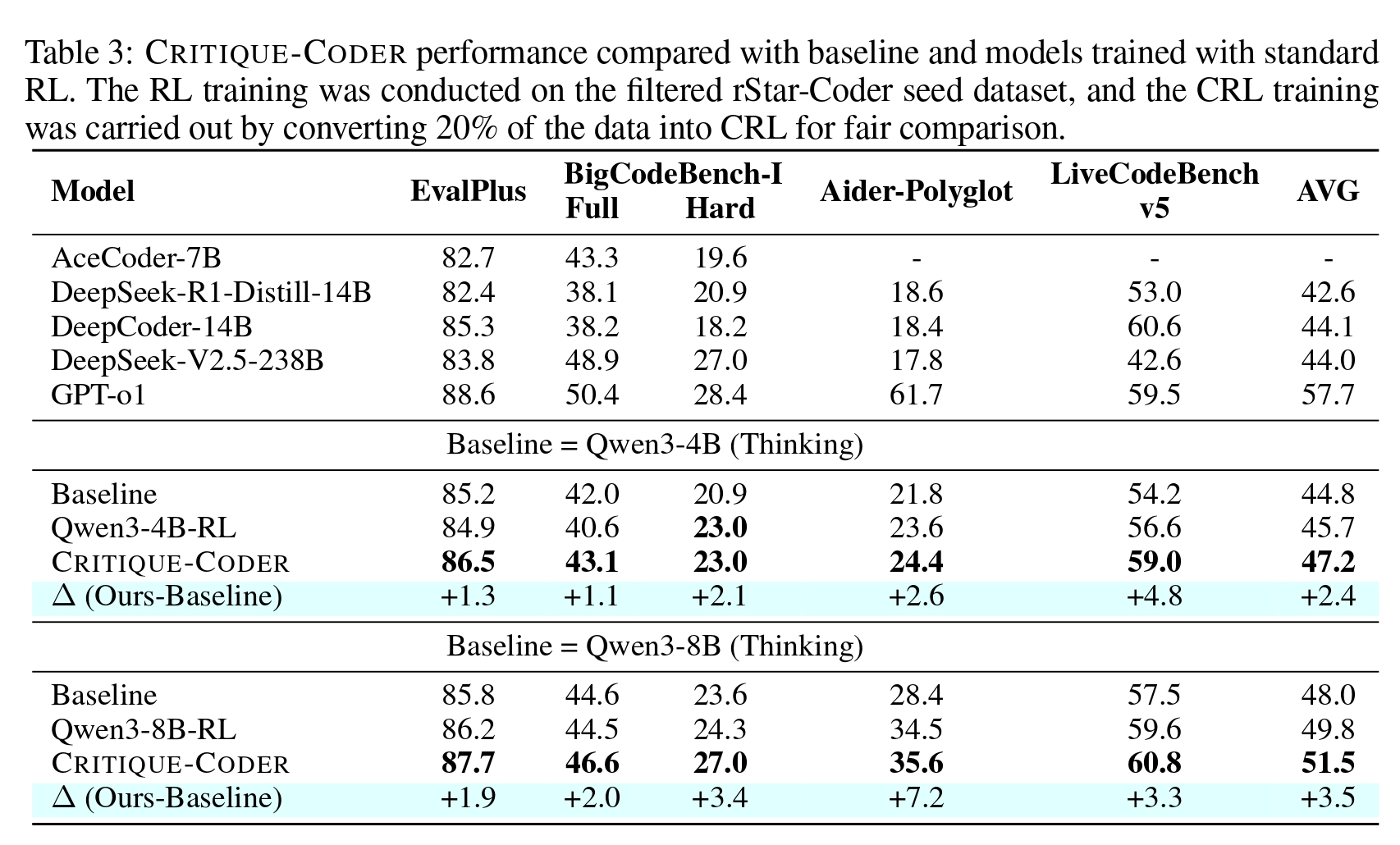
Critique-Coder: Enhancing Coder Models by Critique Reinforcement Learning
Interaction2Code
Performance Benchmarks and Metrics for Code-Generation AI: Evaluating ...
GitHub - neulab/code-bert-score: CodeBERTScore: an automatic metric for ...
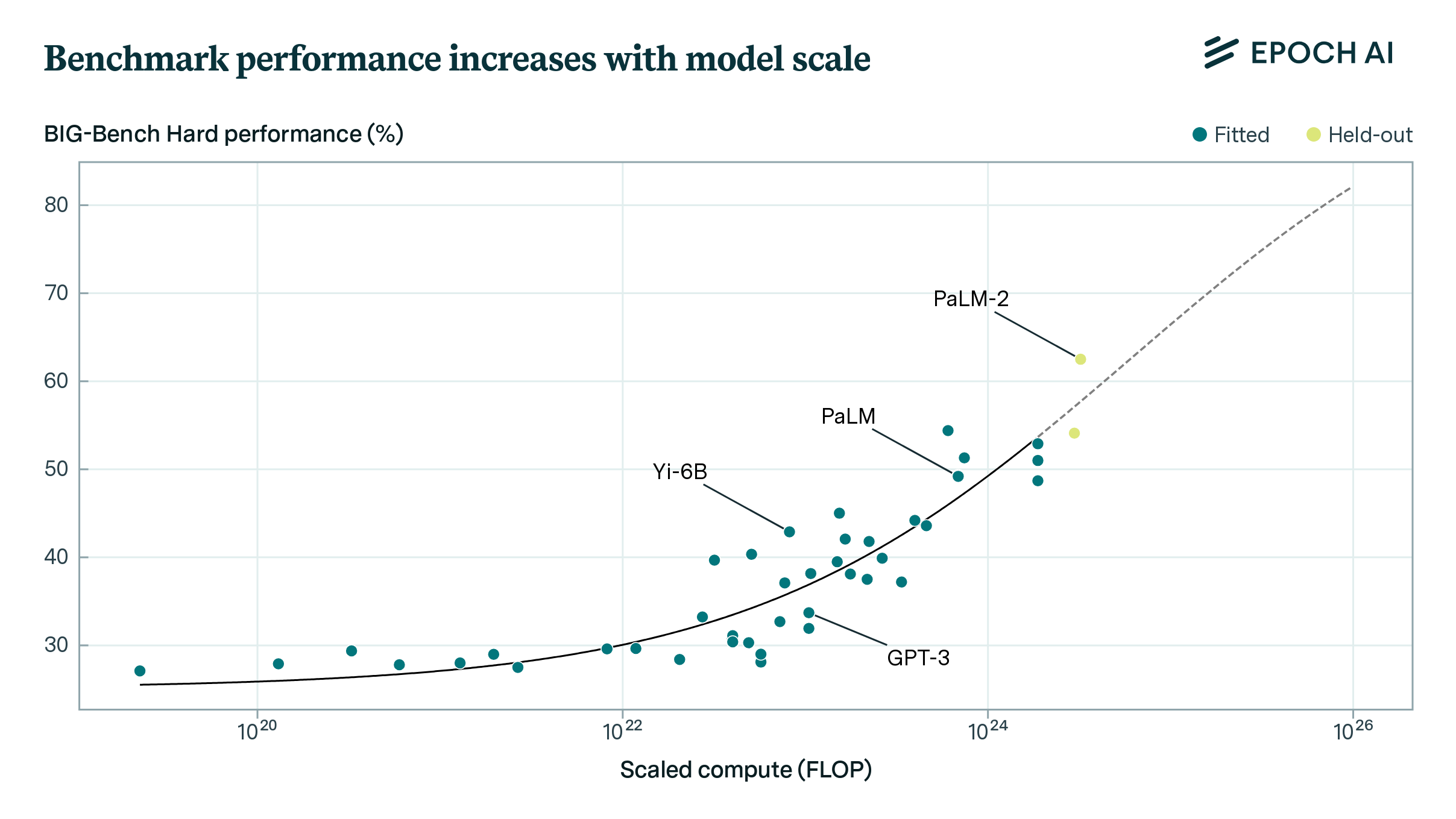
Introducing Epoch AI's AI benchmarking hub | Epoch AI
Benchmarks for Comparing Human and AI Intelligence — LessWrong
Interpreting Your Predictive Coding Model – Knowledge Base
IBM’s Granite code model family is going open source - IBM Research
Improving Your Predictive Coding Model's Performance – Knowledge Base
Beste AI-Coding-Tools 2026: Cursor vs. Claude Code vs. GitHub Copilot ...
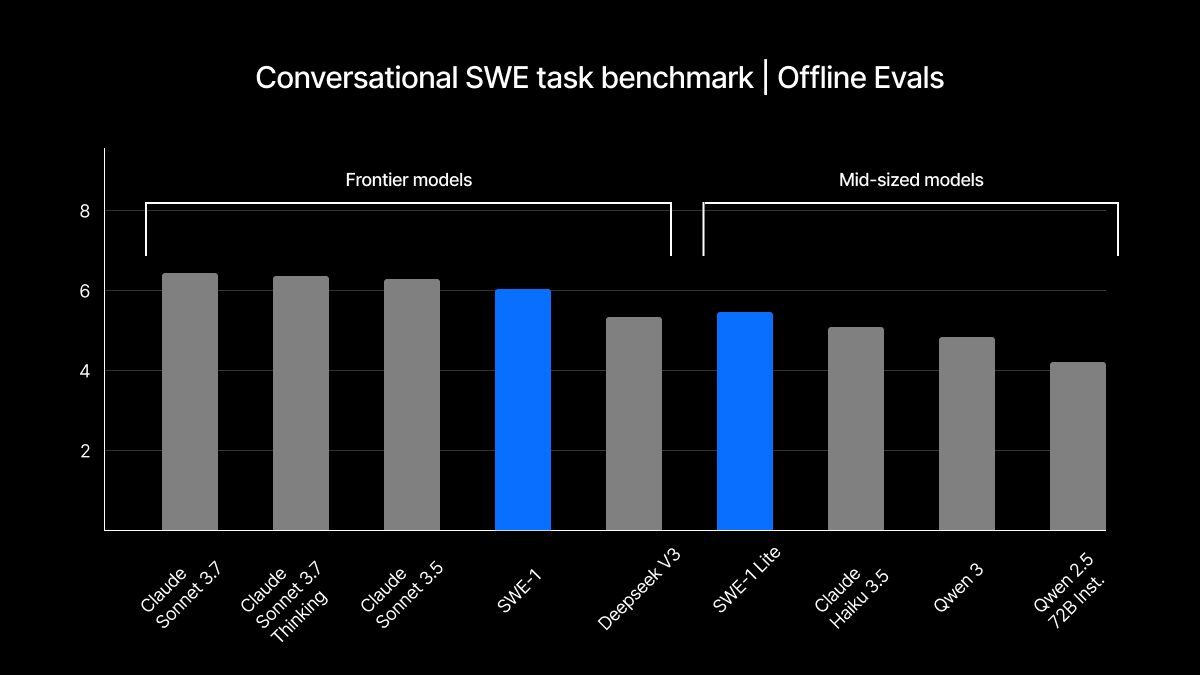
Windsurf Releases SWE-1: A Powerful Coding Model That's FREE For A ...
Continue
Active Code Learning: Benchmarking Sample-Efficient Training of Code ...
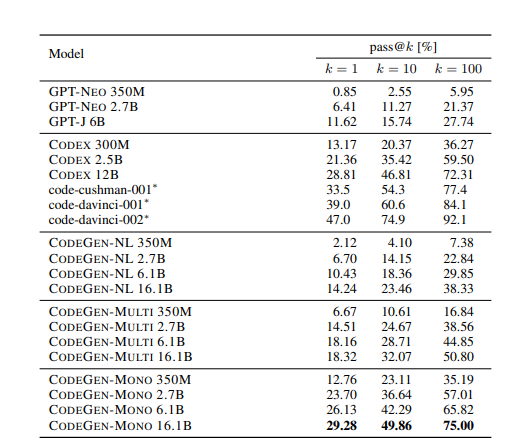
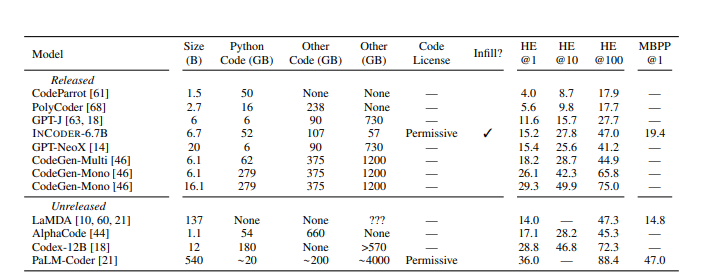
CodeGen | Large Language Models
GitHub - tongye98/Awesome-Code-Benchmark: A comprehensive code domain ...
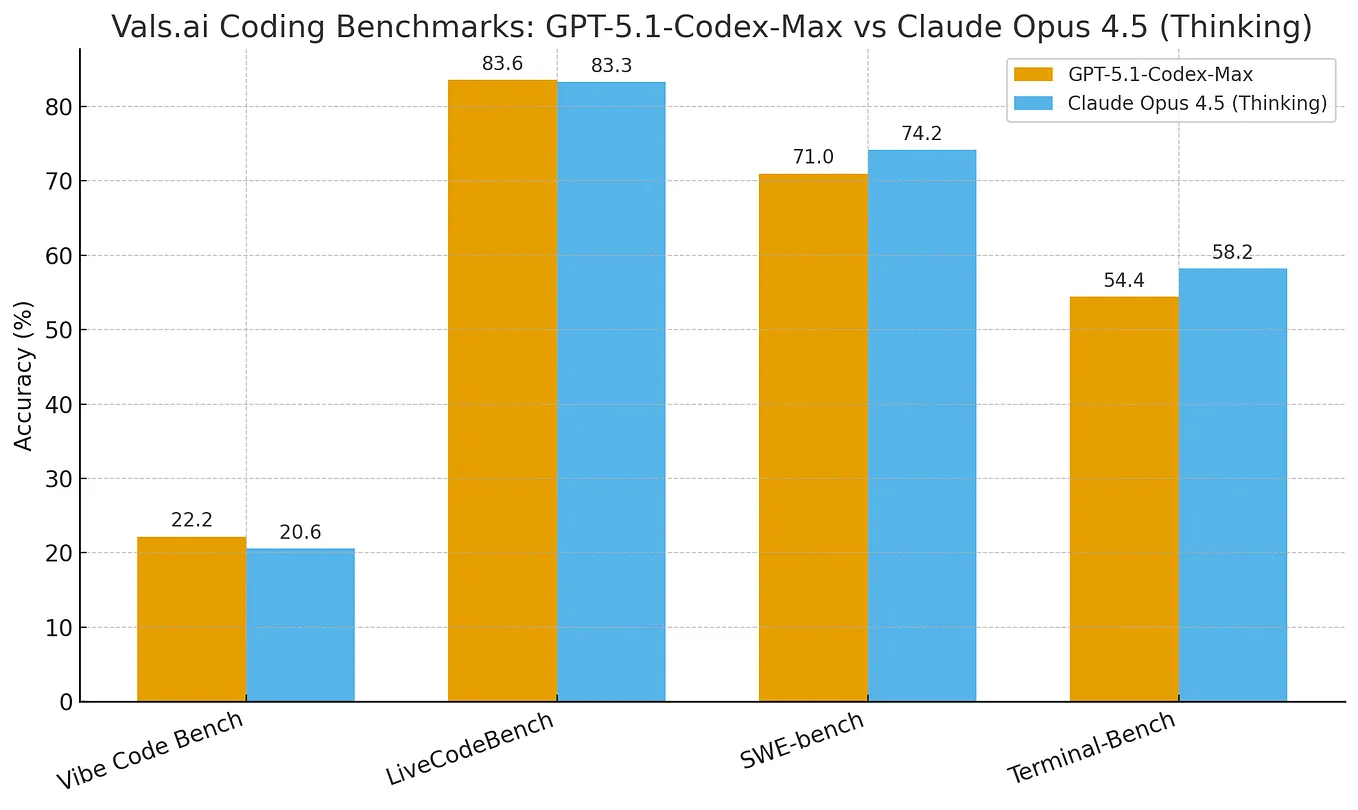
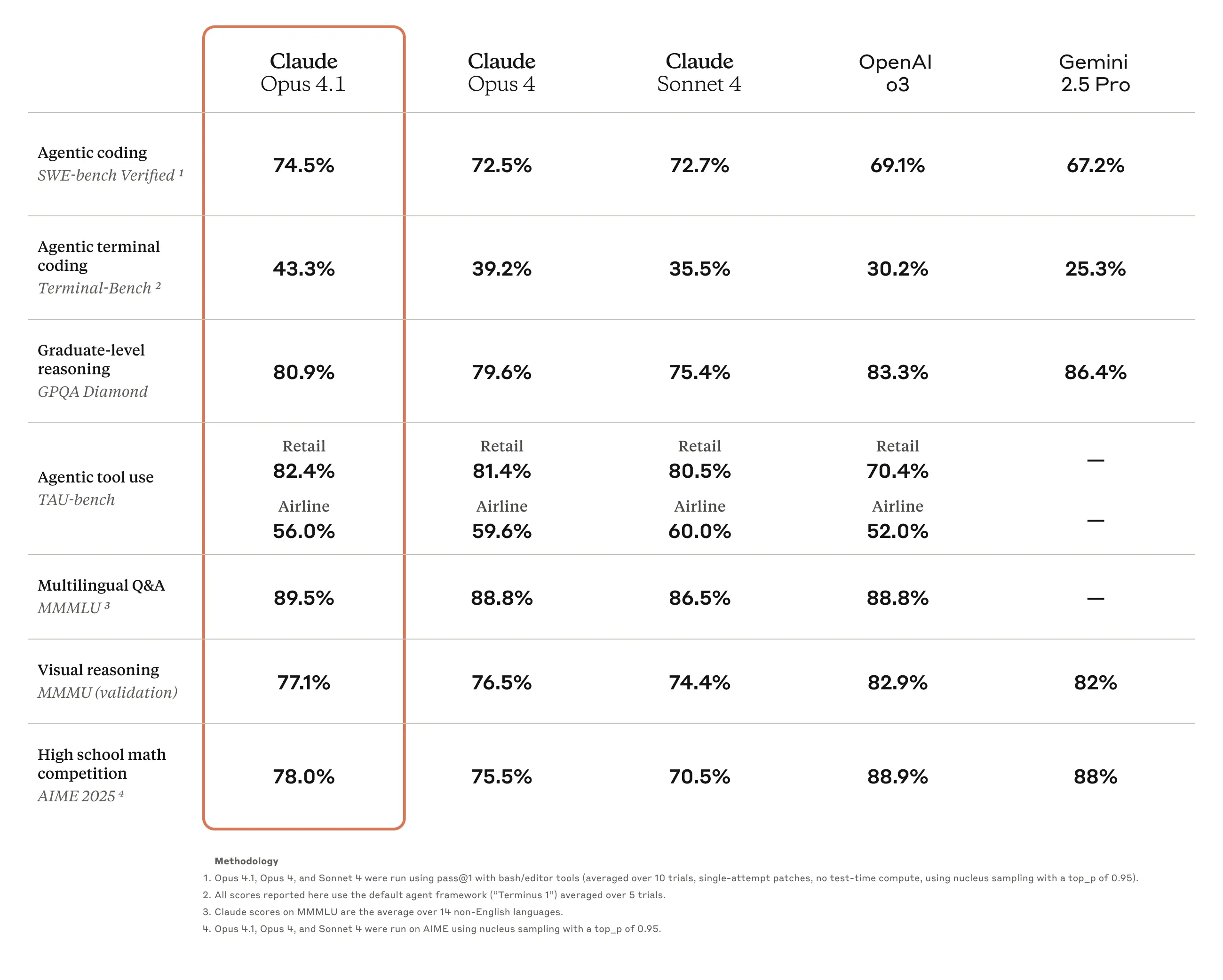
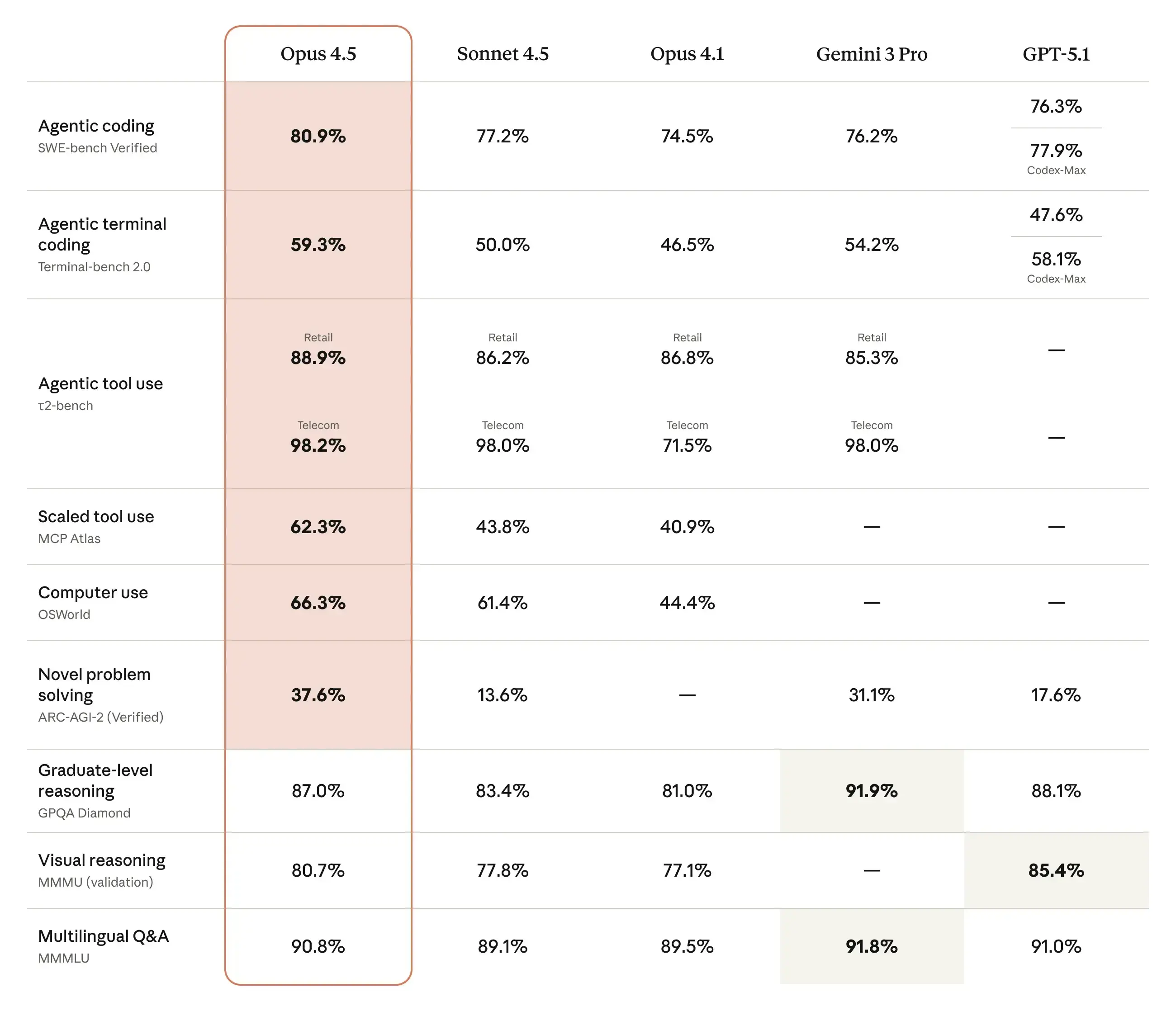
Claude Opus 4.5 Benchmarks (Explained)
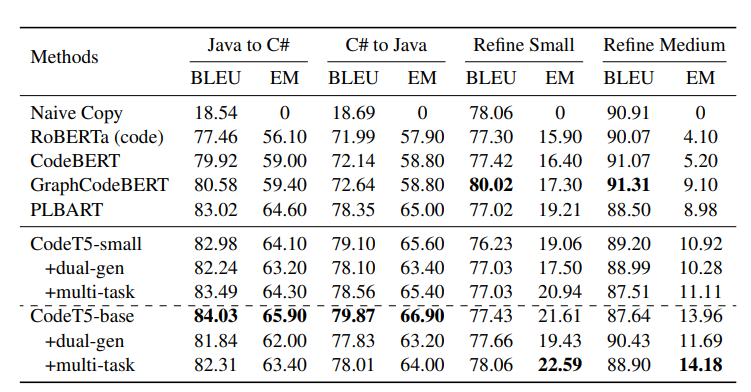
CodeT5 | Large Language Models
Kaori - PCGameBenchmark
GitHub - Benchmarking-Initiative/Benchmark-Models: A collection of ODE ...
Elon Musk Reveals Grok 3 AI Chatbot: Here's What It Can Do
Incoder | Large Language Model
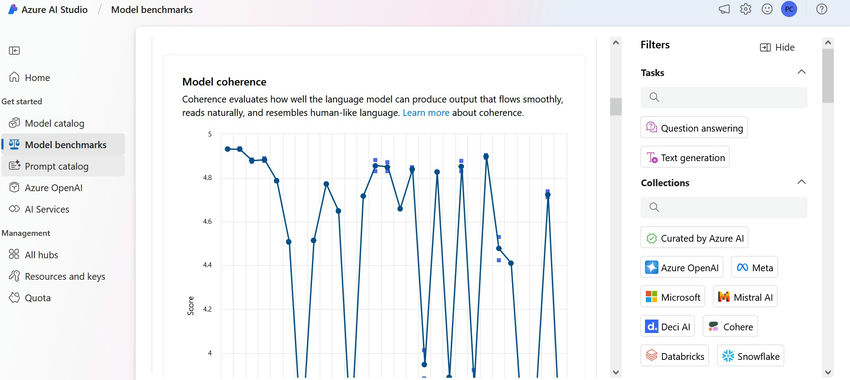
Understanding Model Benchmarks in Azure AI Studio
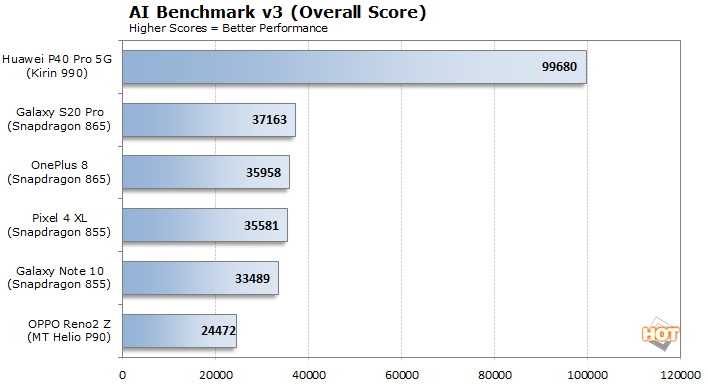
AI Benchmarks For Mobile Devices And What You Should Know | HotHardware
Reasoning Model Evaluations
AI Model Design: Phát Triển và Ứng Dụng Mô Hình AI Trong Kỷ Nguyên Mới
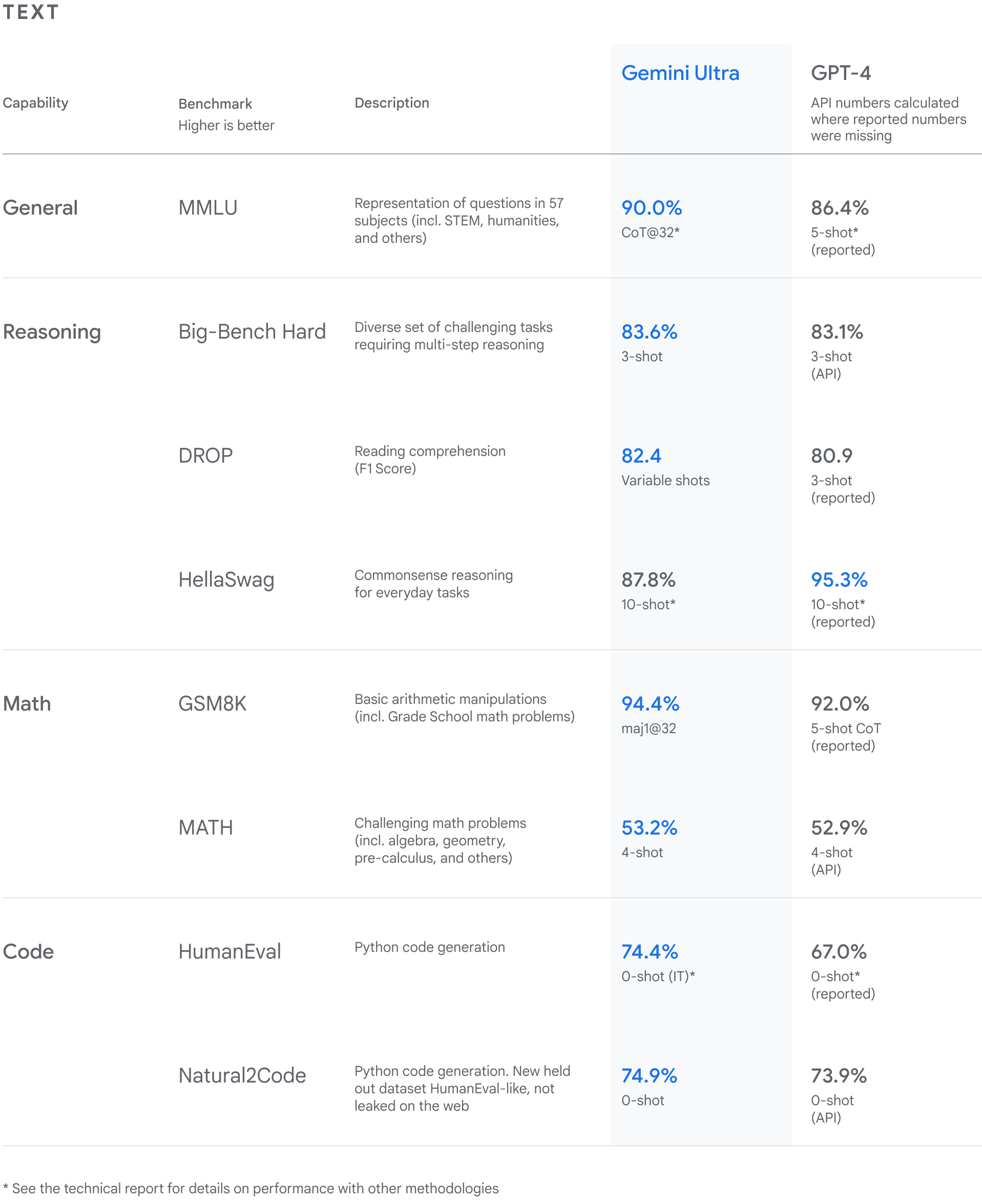
Top LLM Benchmarks Explained: MMLU, HellaSwag, BBH, and Beyond ...
Running Python micro-benchmarks using the ChatGPT Code Interpreter alpha
LLMs: Bigger is Not Always Better
PPT - Atlas of Science Literacy PowerPoint Presentation, free download ...
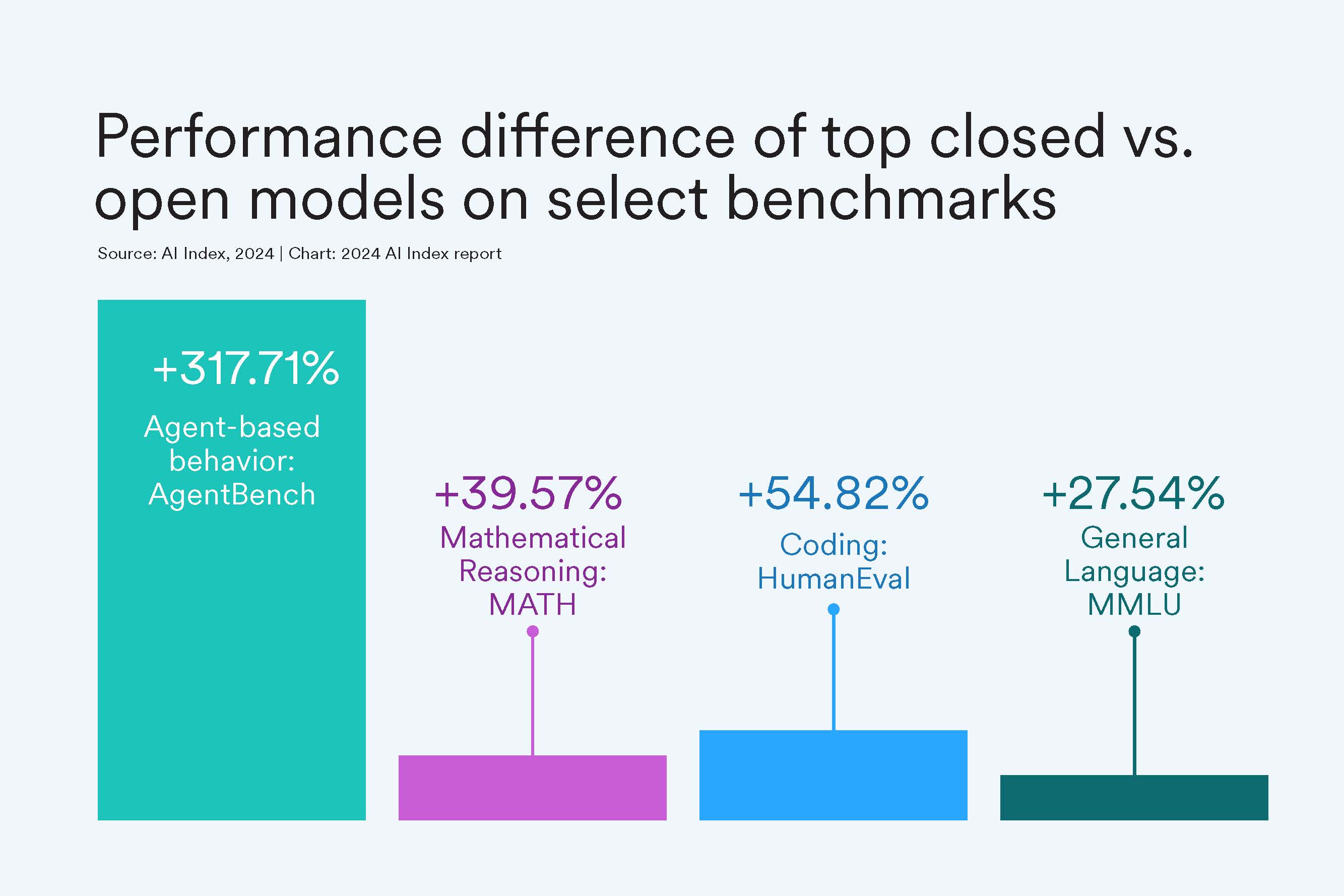
40 Top Research-Backed LLM Benchmarks and Where To Use Them
SimpleBench
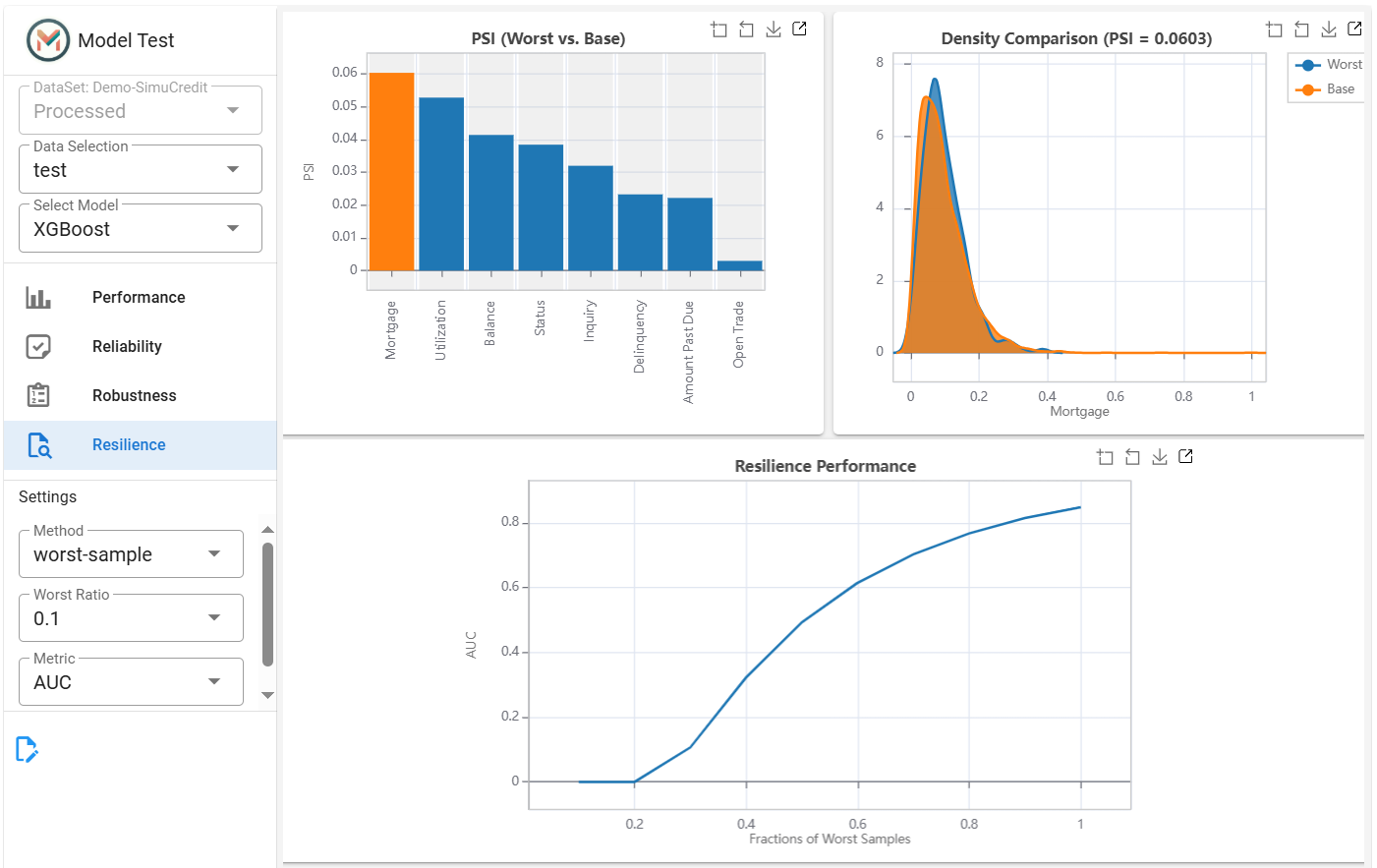
Model Test
Anthropic Launches Smarter Claude Models With Computer Skills — Meta Ai ...
Kuaishou's 72B Code Model Open-Sourced and Tops SWE-Bench: KAT-Dev ...
Reasoning AI Models: An overview | Amit Bahree's (useless?) insight!
Definitive Guide to AI Benchmarks: Comparing Models, Testing Your Own ...
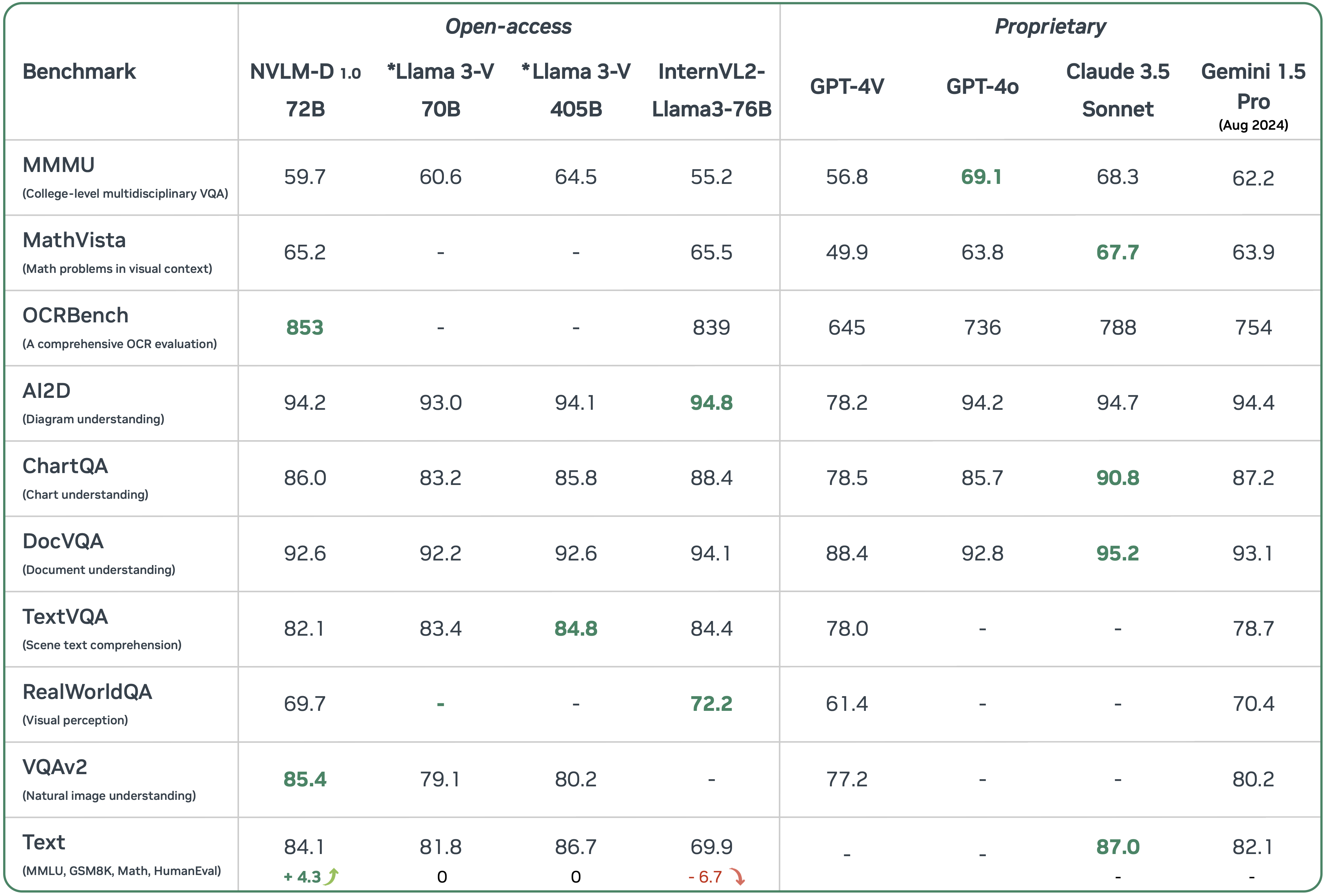
NVLM: Open Frontier-Class Multimodal LLMs - NVIDIA ADLR
Basics of Model Evaluation – Metrics and Benchmarks - Skillcurb
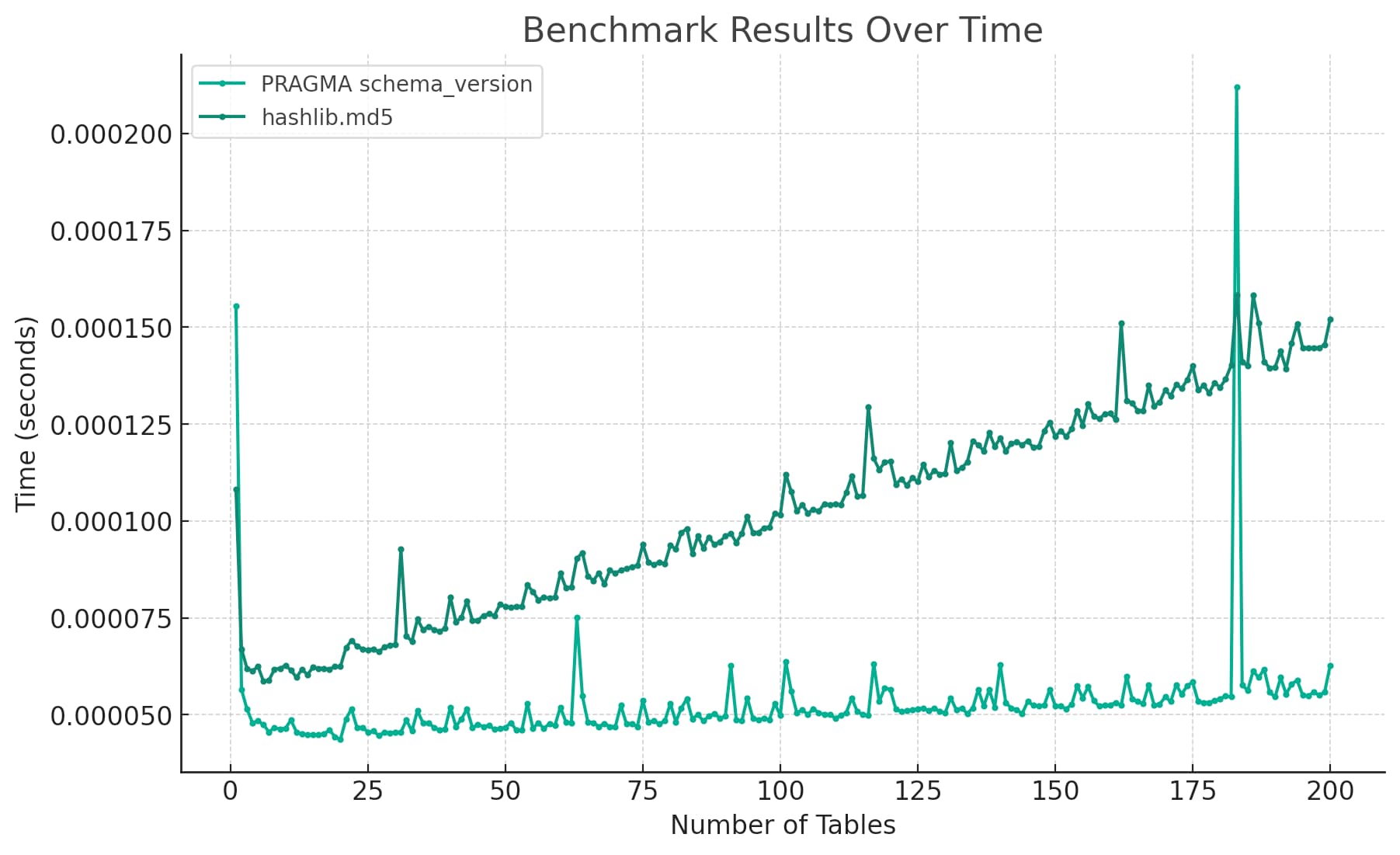
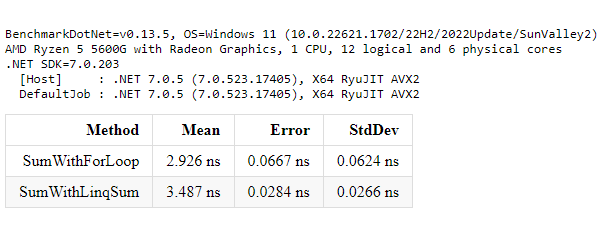
Exploring Code Performance Testing in C# with BenchmarkDotNet | Kostis ...
(PDF) CodeBERTScore: Evaluating Code Generation with Pretrained Models ...
5 Model Benchmarks – Decision Modeling
Coding structure for performance measurement models | Download ...
Top AI Coding Tools in 2024: An In-Depth Analysis with Real-World ...
Comparison of the model's performance on the virtual screening ...
Benchmarking Machine Learning Models with Cross-Validation and ...
GitHub - maxim-romanovsky/code-retrieval-benchmark: A Comprehensive ...
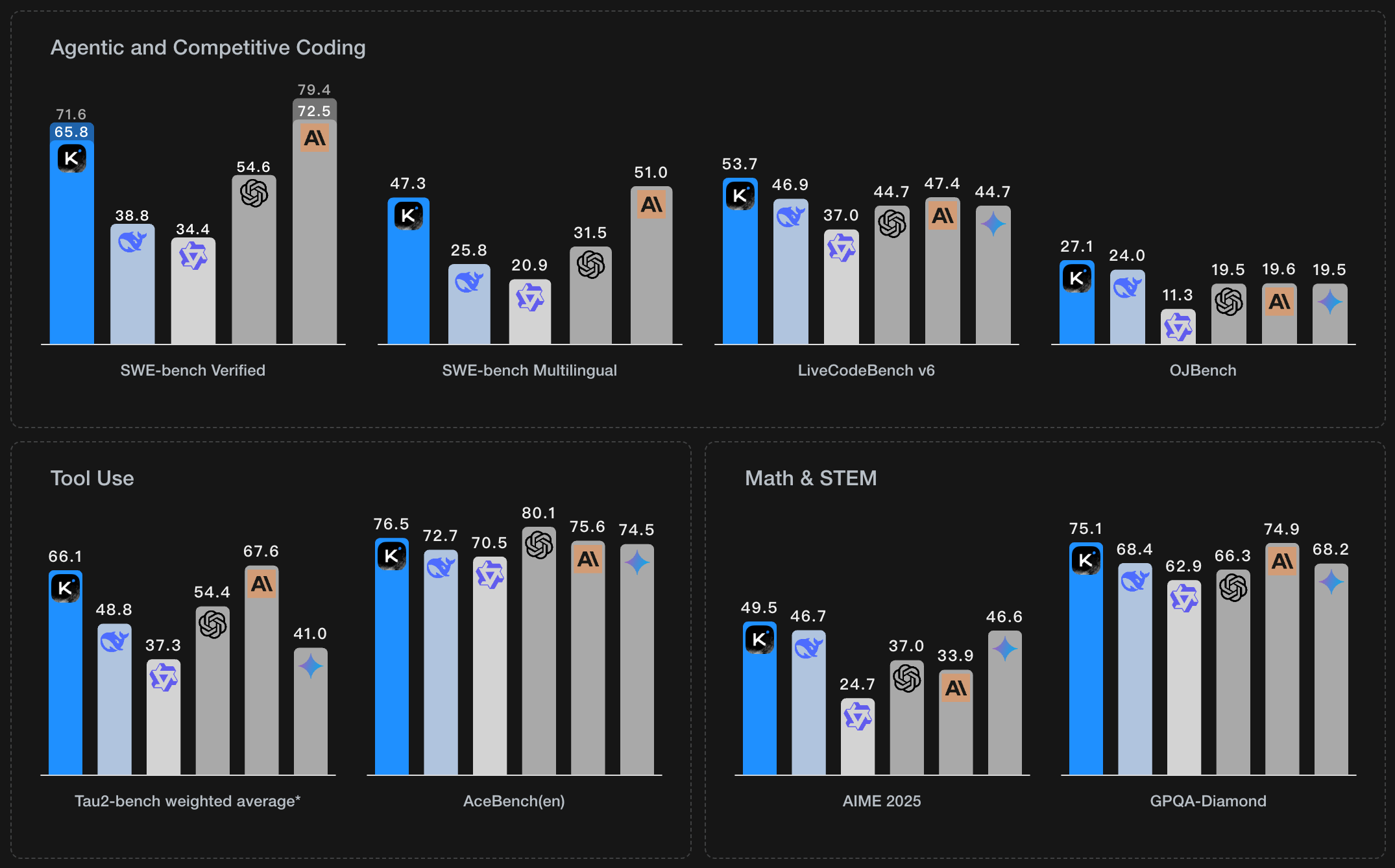
Kimi K2.6 - Agentic Coding AI | 12-Hour Runs | 300-Agent Swarms
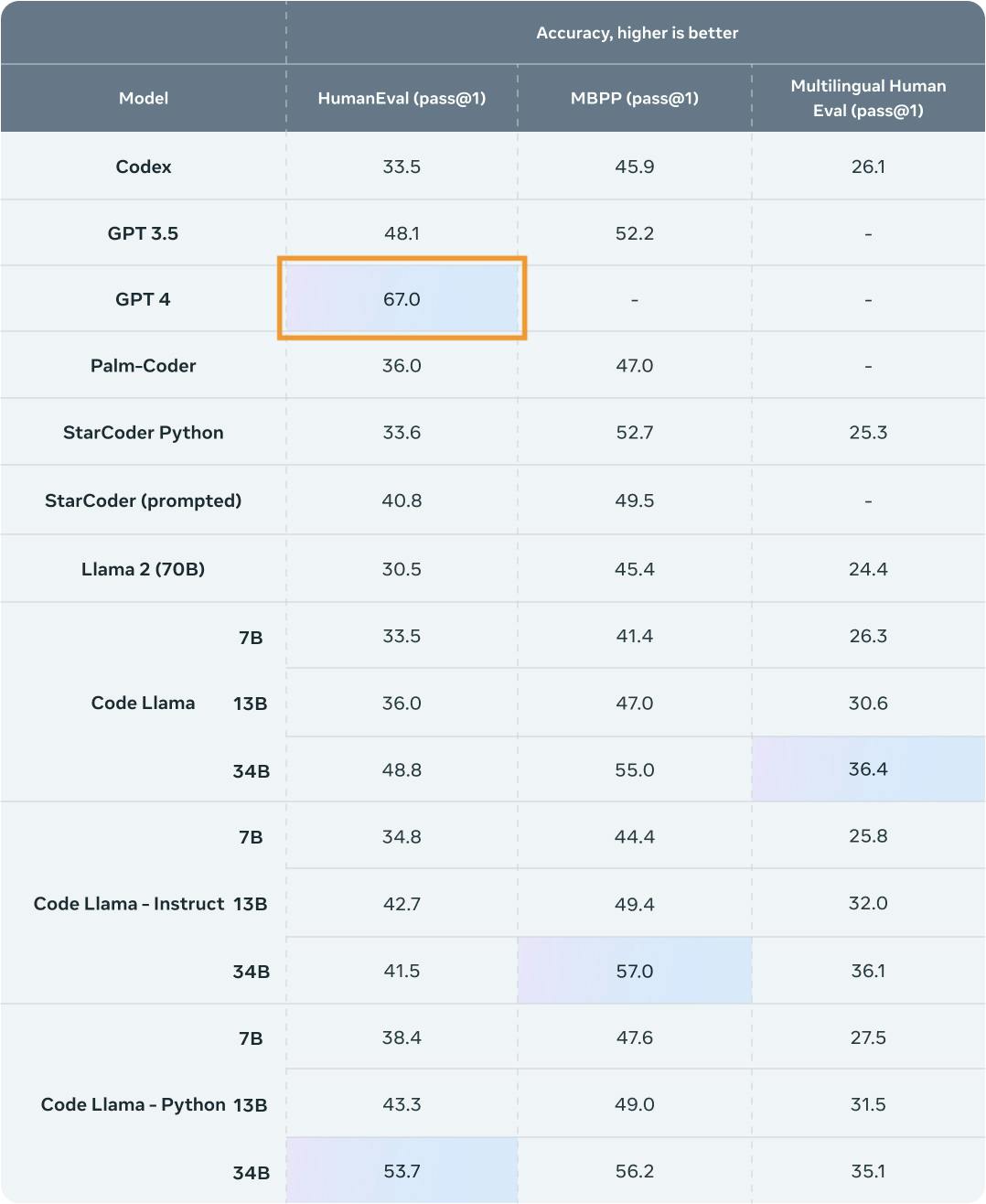
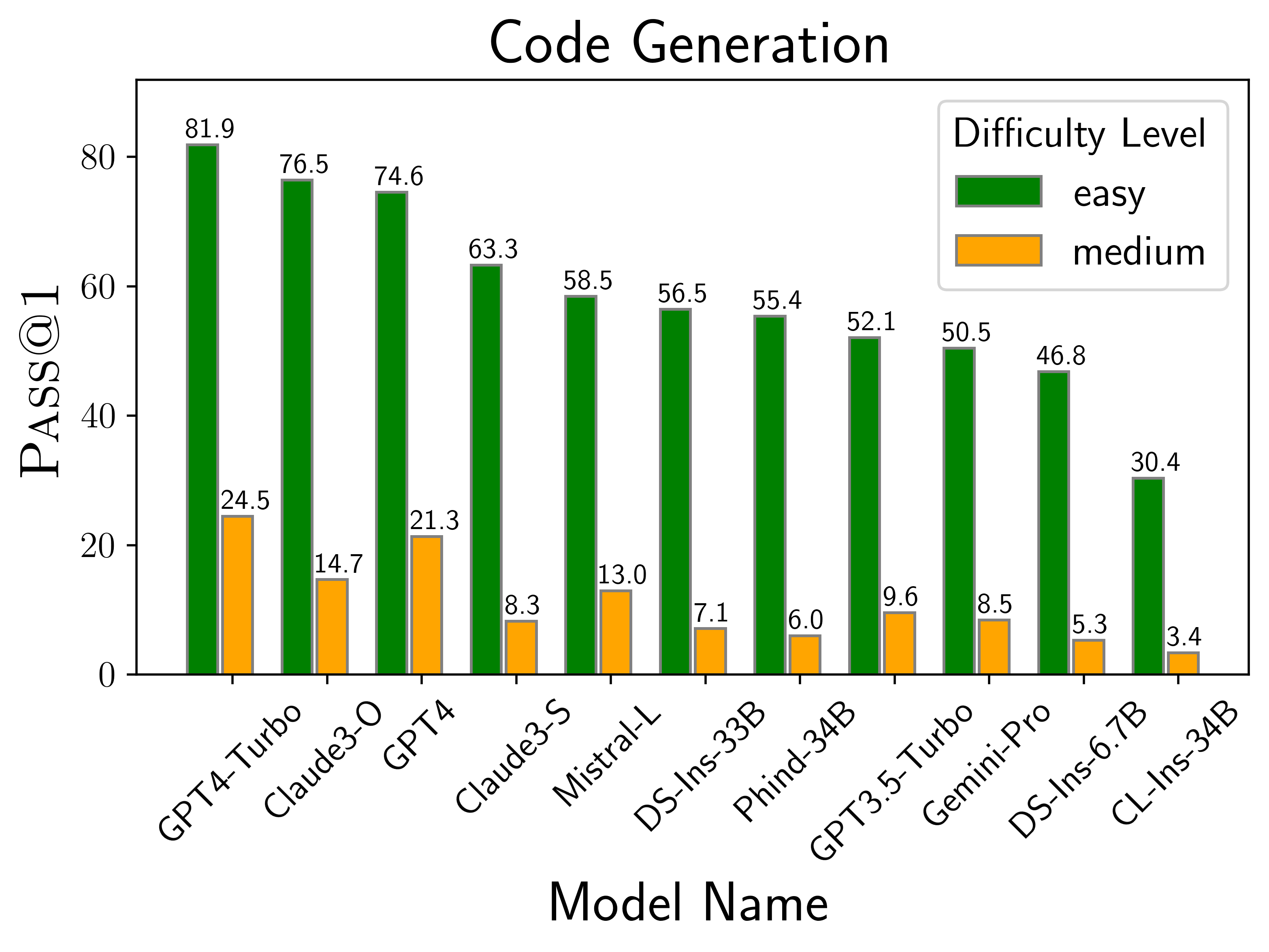
HumanEval Benchmark: Evaluating LLM Code Generation Capability
Evaluation Benchmarks for Code LLMs | HackerNoon
Machine Learning Model Evaluation Best Practices
The generated code size for standalone benchmarks based on all three ...
GitHub - code4bench/Code4Bench: Code4Bench: A Mutildimensional ...
CodeMaker AI Breakthrough in Software Development: Achieves 91% ...
Why Anthropic calls the new Claude 3 its ‘most intelligent’ AI model ...
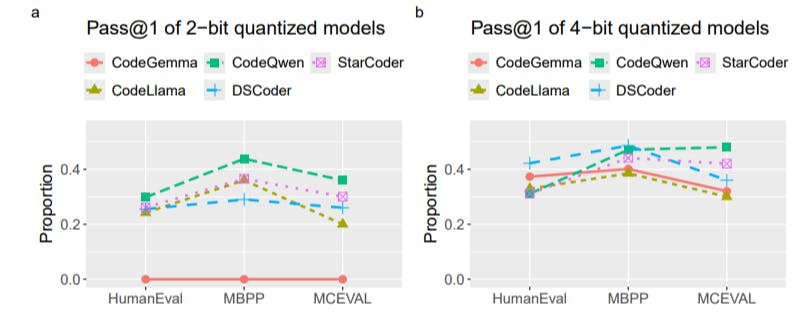
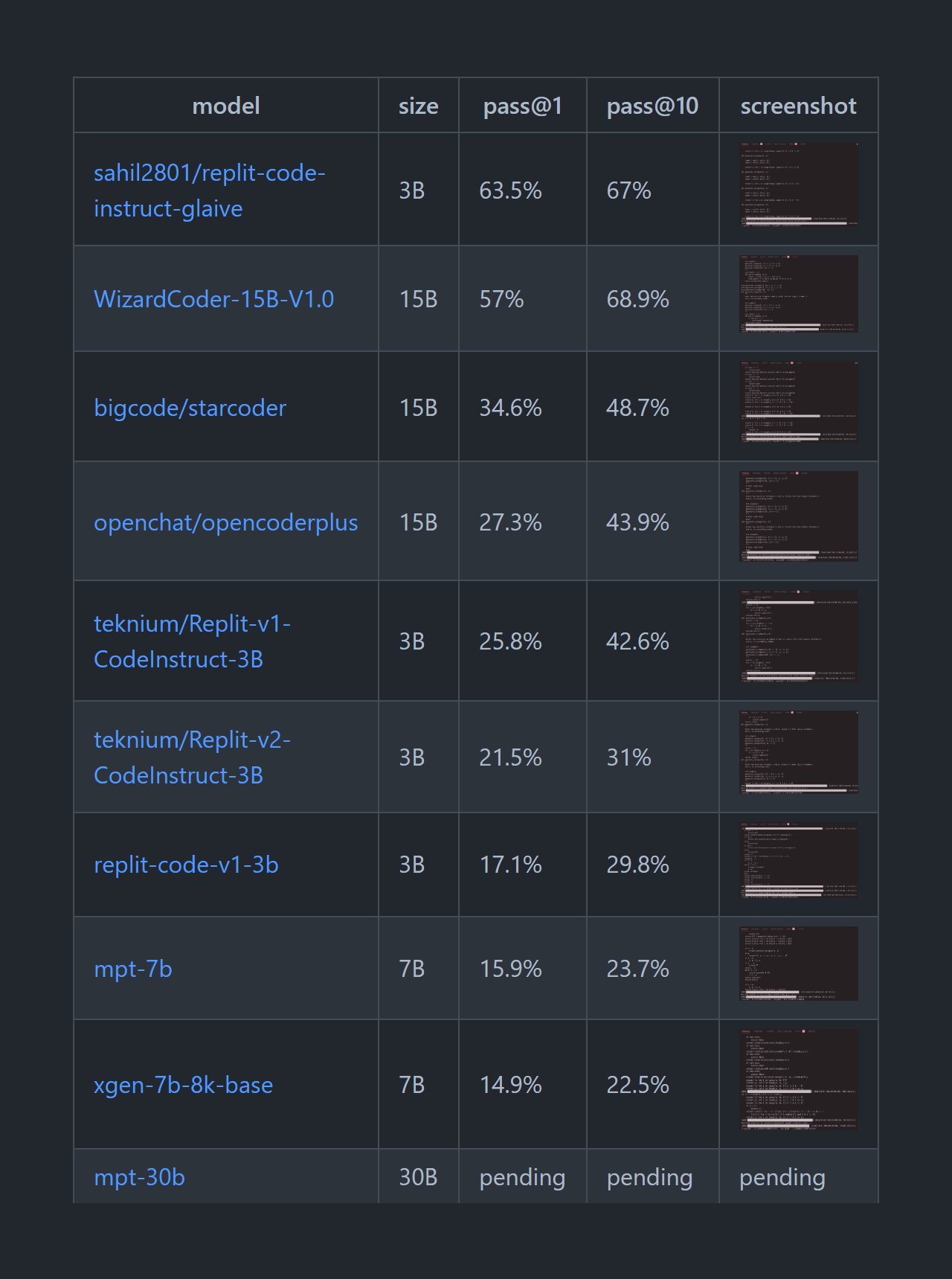
Top 7 Open Source AI Coding Models You Are Missing Out On - KDnuggets
anton on Twitter: "Reran many models on code benchmark, matching or ...