Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Deep Learning Inference at speed and scale | PDF
(PDF) Distributed and Collaborative High Speed Inference Deep Learning ...
Distributed and Collaborative High Speed Inference Deep Learning for ...
Discover the Difference Between Deep Learning Training and Inference ...
DeepSpeed - Extreme Speed and Scale for Deep Learning Training and ...
Speeding up Deep Learning training and inference | PPTX
DeepSpeed Deep Dive — Model Implementations for Inference (MII) | by ...
[서울대 AI 여름학교] Microsoft Research Deep Speed Team - DeepSpeed: Training ...
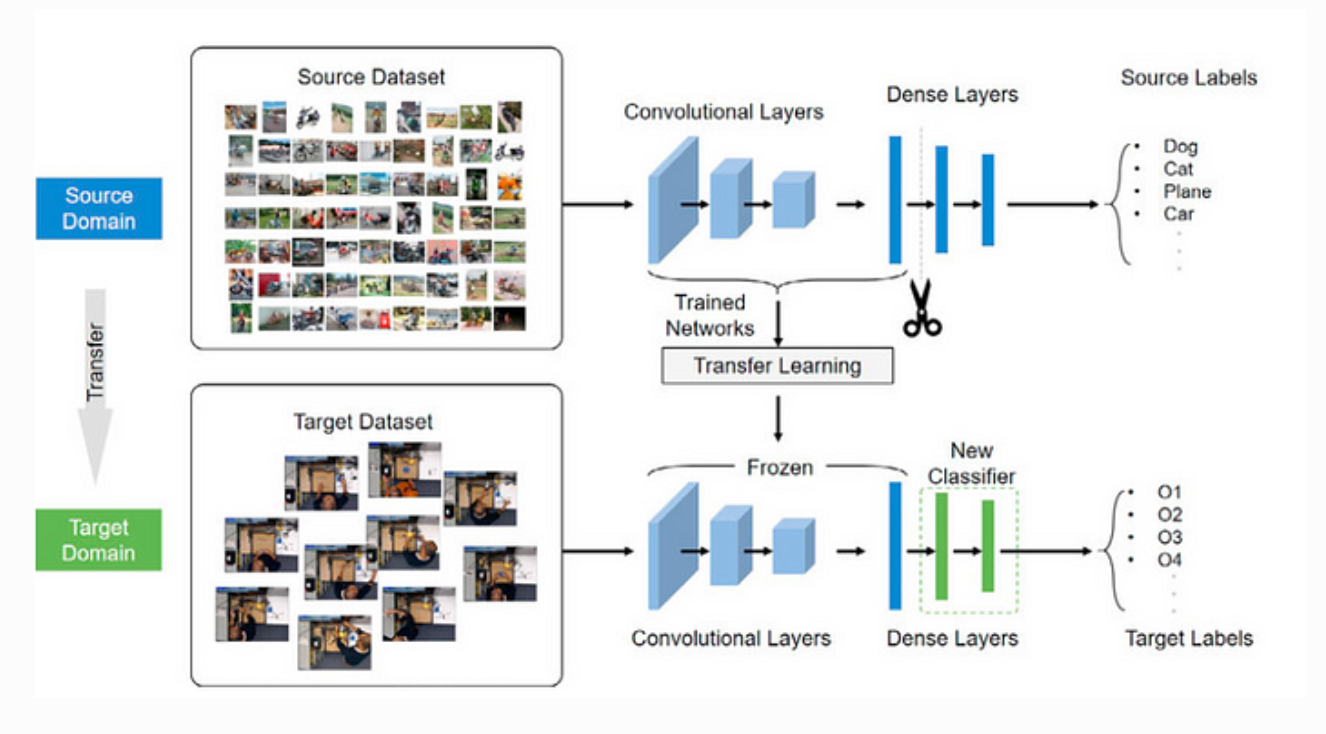
Accelerating Deep Learning Inference Via Layer Truncation and Transfer ...
A line chart of the inference speed of three other models in the case ...
The comparison of various deep learning inference networks ...
Deep Learning Inference Frameworks Benchmark | DeepAI
Rethinking Inference Placement for Deep Learning across Edge and Cloud ...
Performance vs. Inference Speed. With deep averaging networks (Iyyer et ...
DeepSpeed Deep Dive - Model Implementations for Inference (MII ...
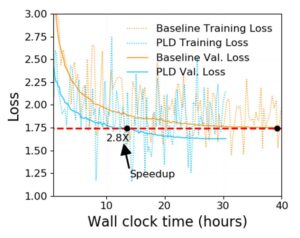
Figure A.4: The training and inference speed comparisons for standard ...
Inference speed comparison with different batch size. | Download ...
Comparison of inference speed of the different model. YOLOv5s has the ...
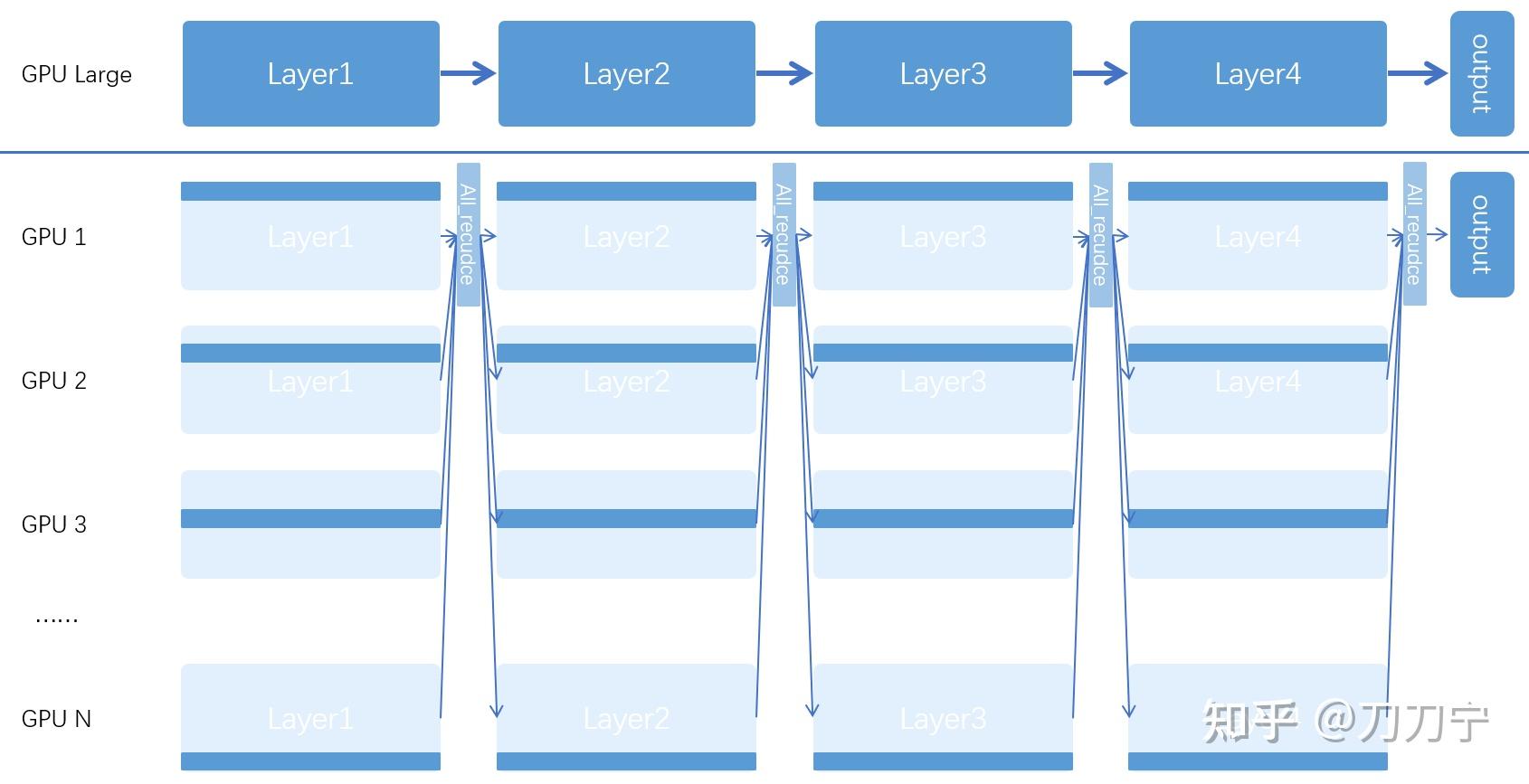
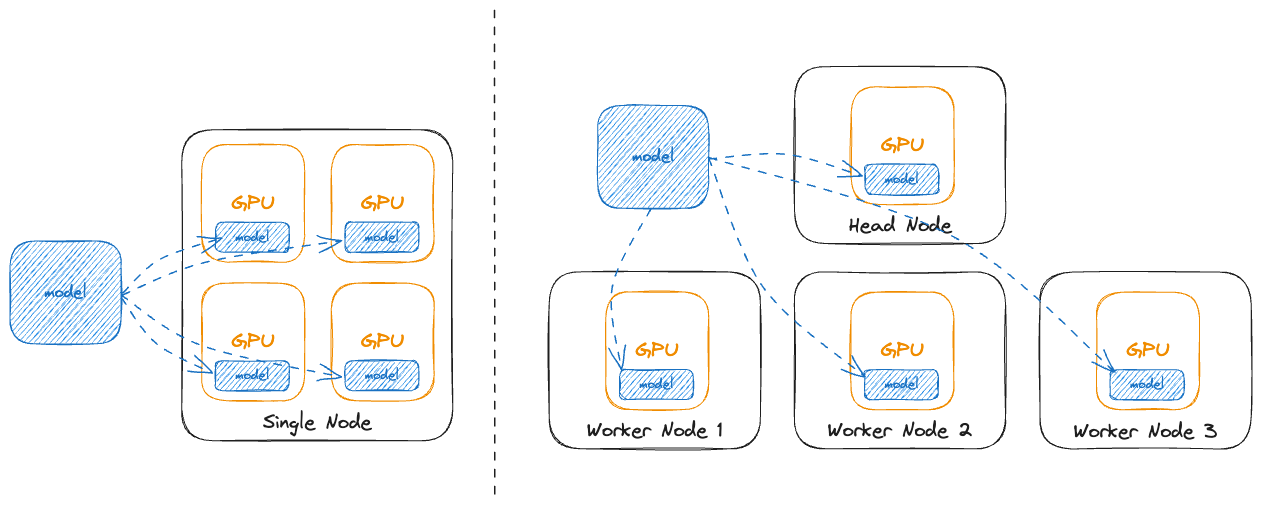
DeepSpeed Inference: Multi-GPU inference with customized inference ...
DeepSpeed: Advancing MoE inference and training to power next ...
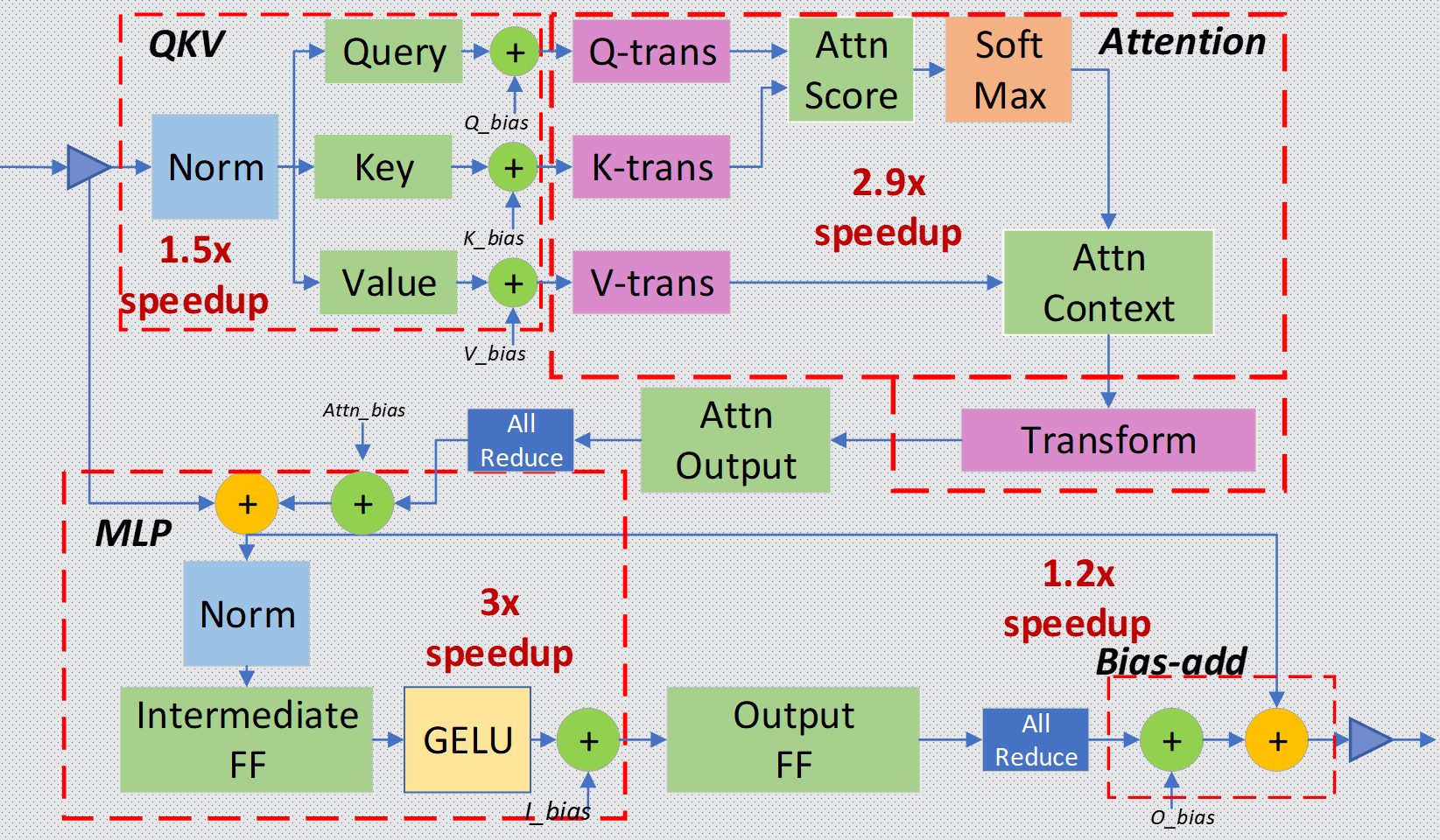
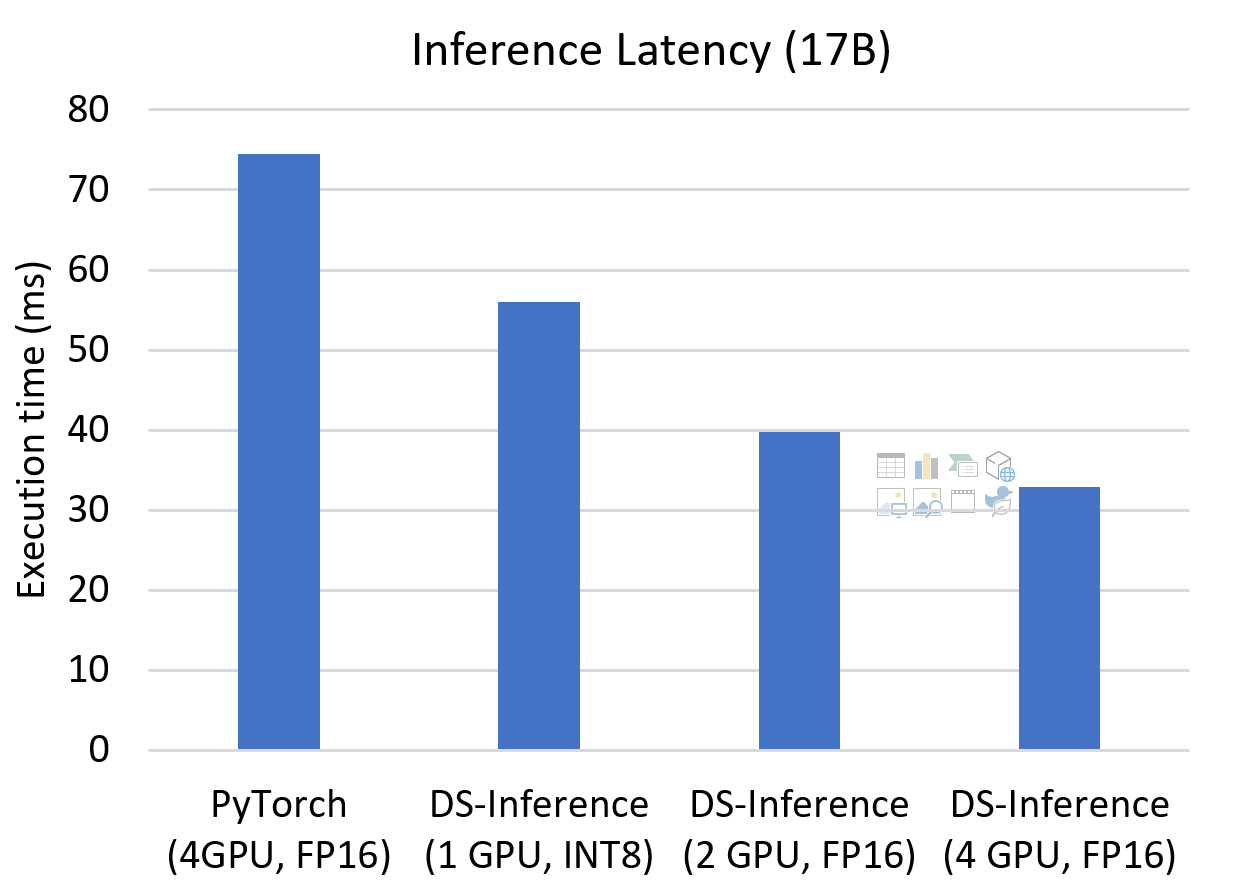
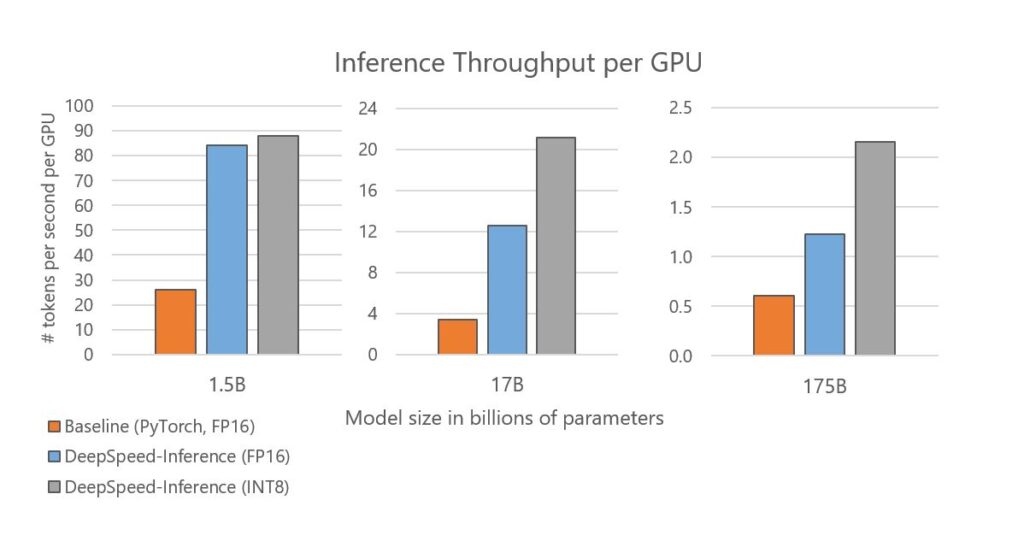
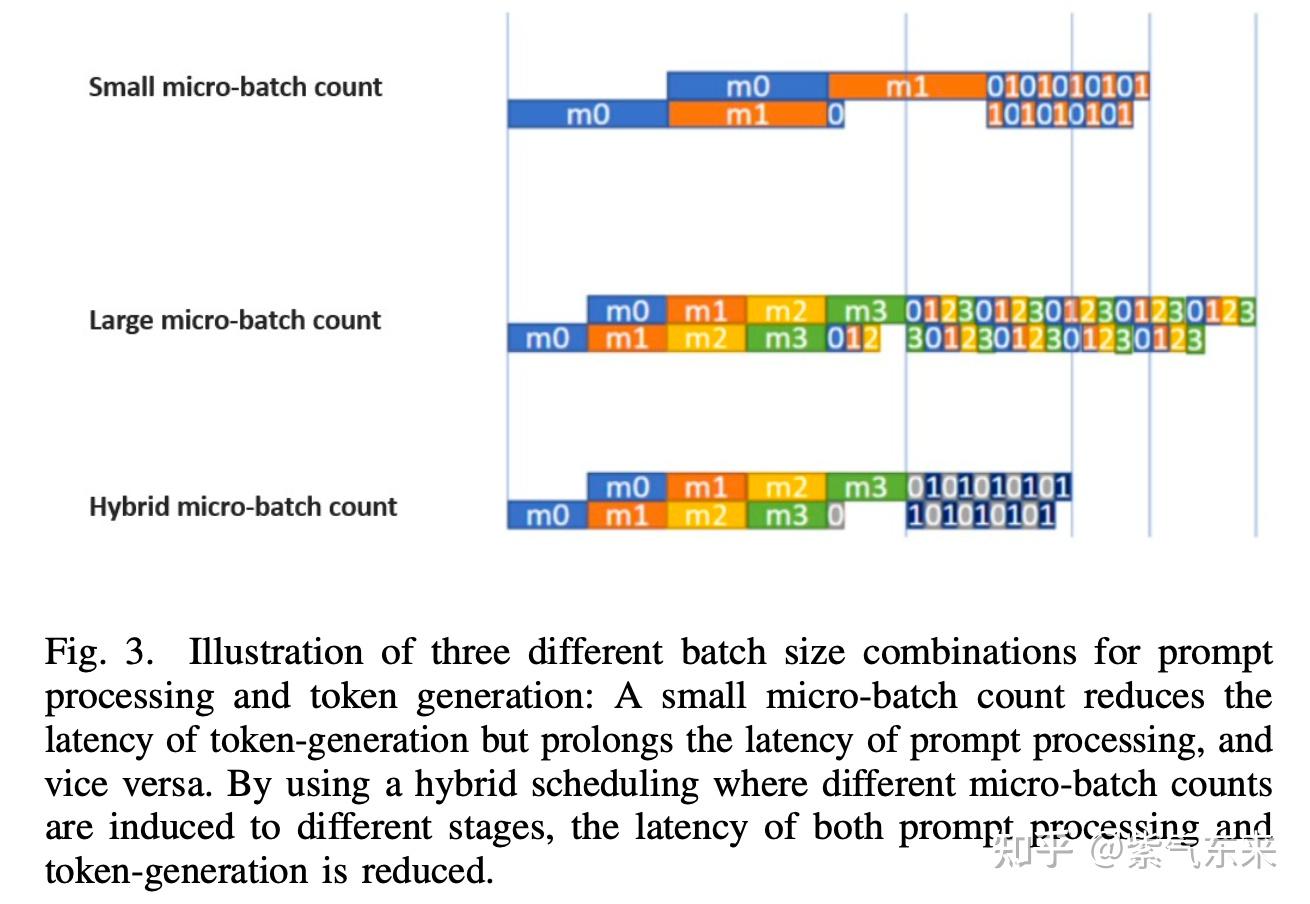
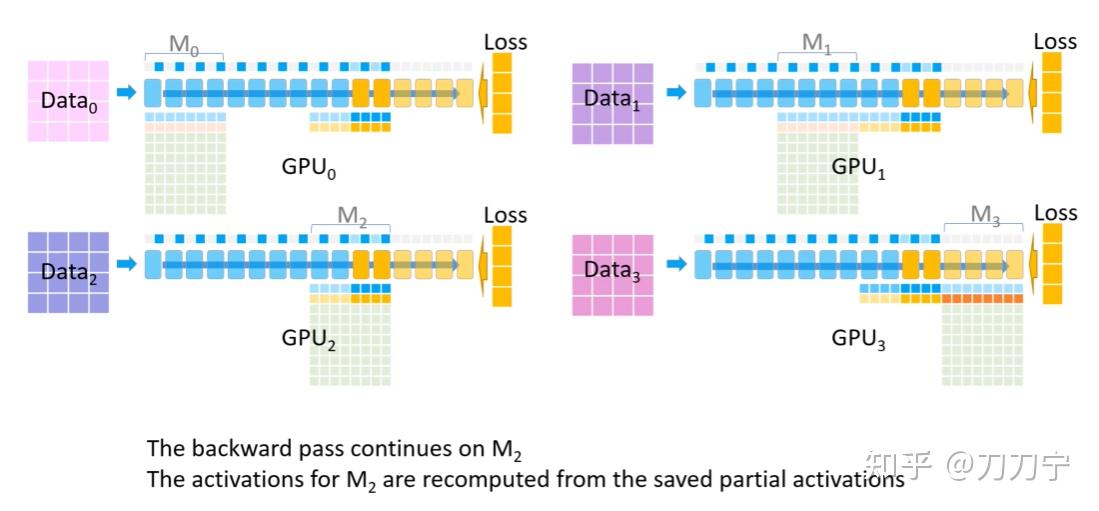
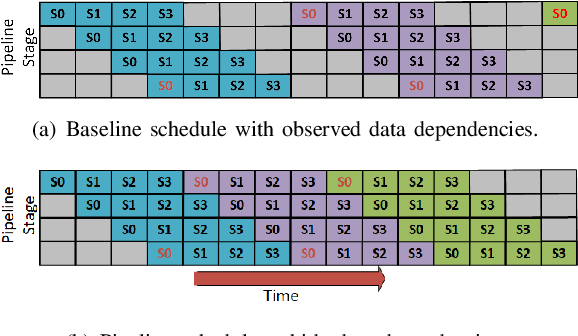
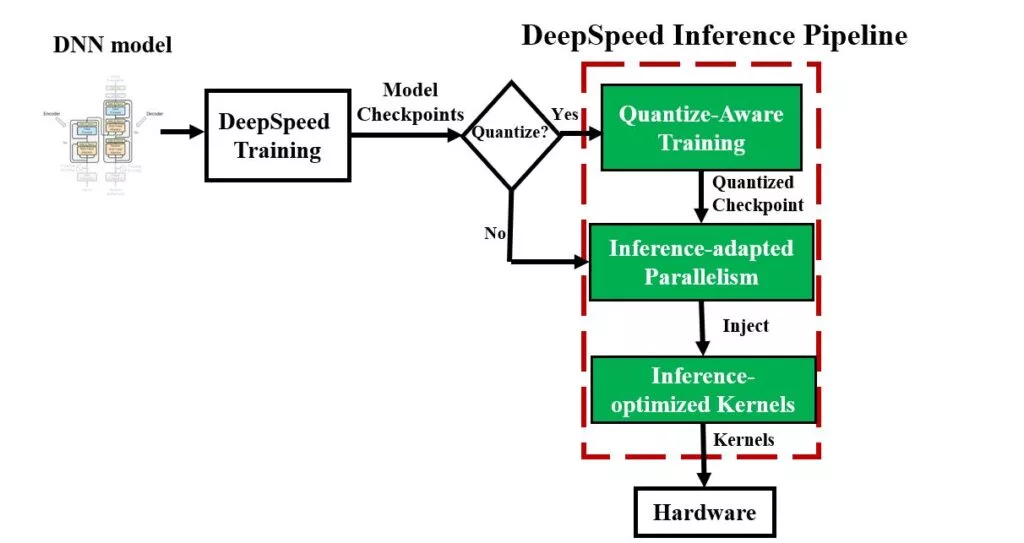
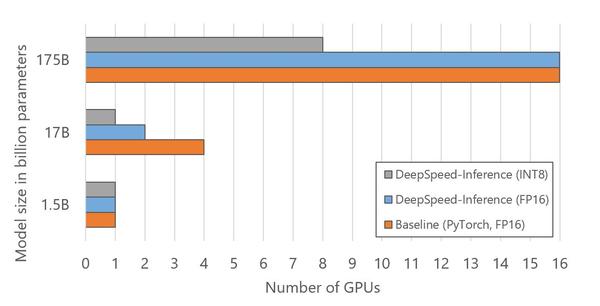
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models ...
ZeRO-Inference: Democratizing massive model inference - DeepSpeed
Inference & Latency in Machine Learning Models | by Deepak Shisode | Medium
DeepSpeed: Accelerating large-scale model inference and training via ...
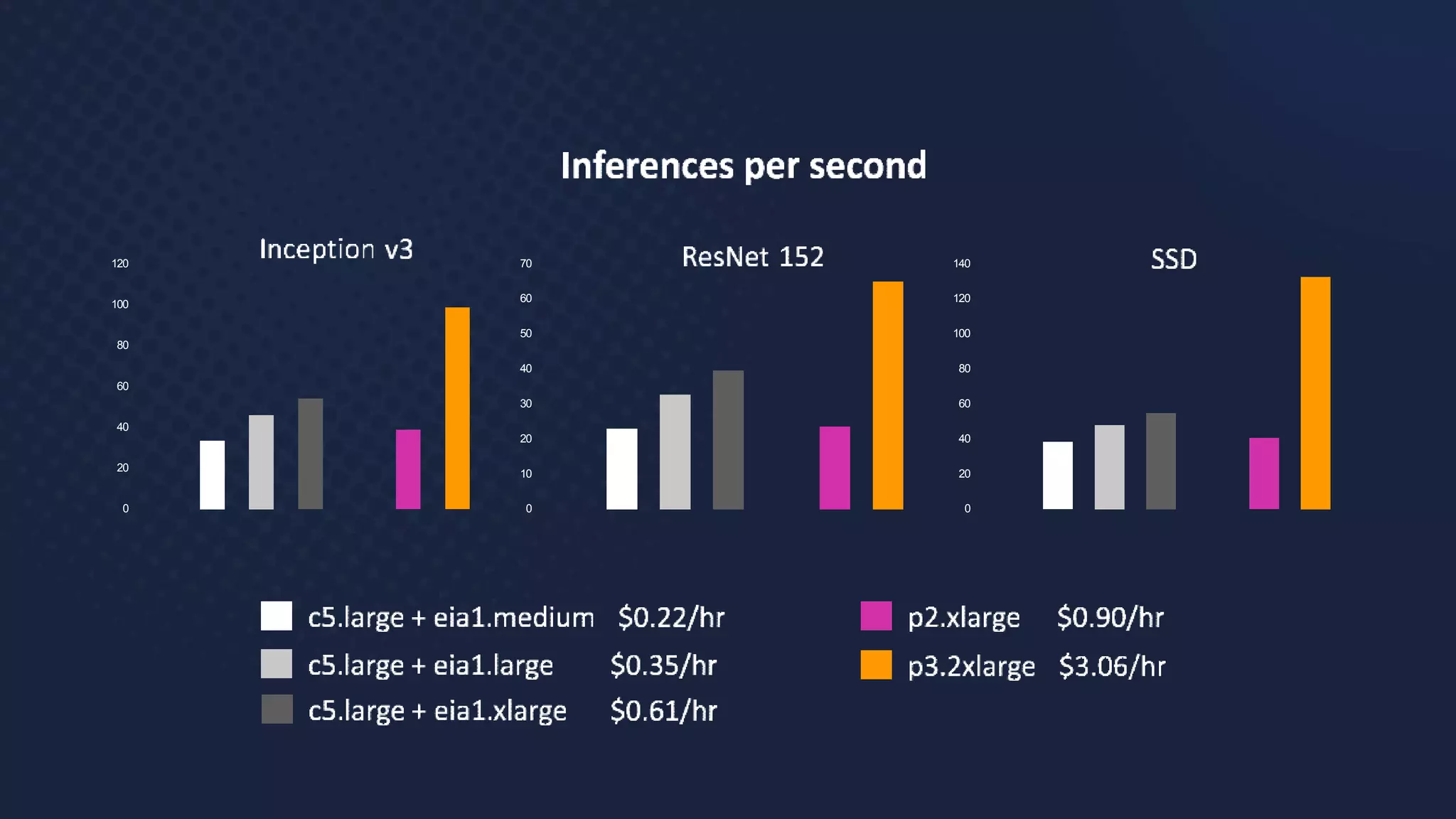
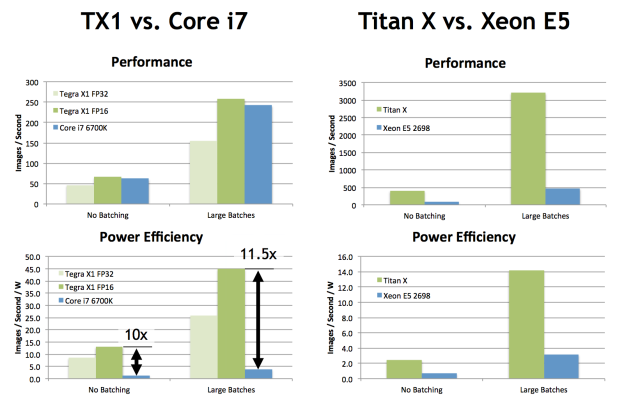
Inference: The Next Step in GPU-Accelerated Deep Learning | NVIDIA ...
DeepSpeed Inference - Enabling Efficient Inference of Transformer ...
笔记:DeepSpeed inference 代码理解 - 知乎
LLM(12):DeepSpeed Inference 在 LLM 推理上的优化探究 - 知乎
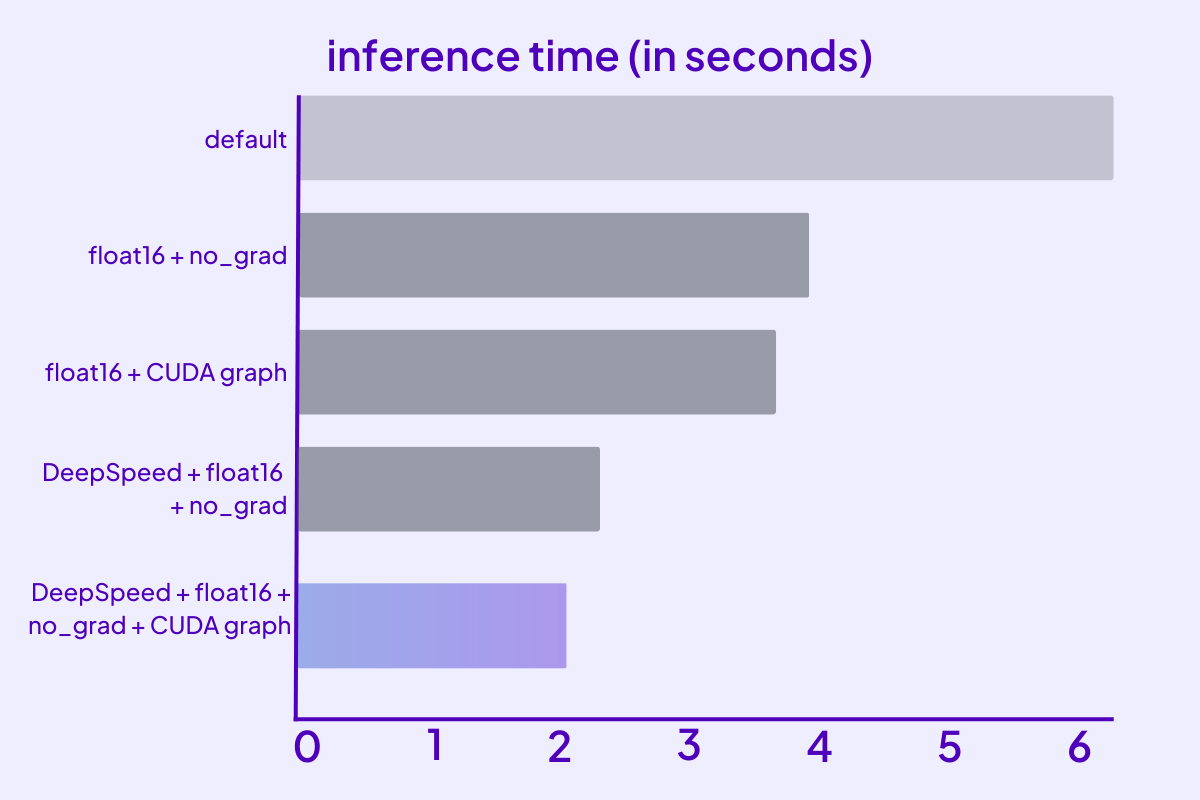
Accelerate BERT inference with DeepSpeed-Inference on GPUs
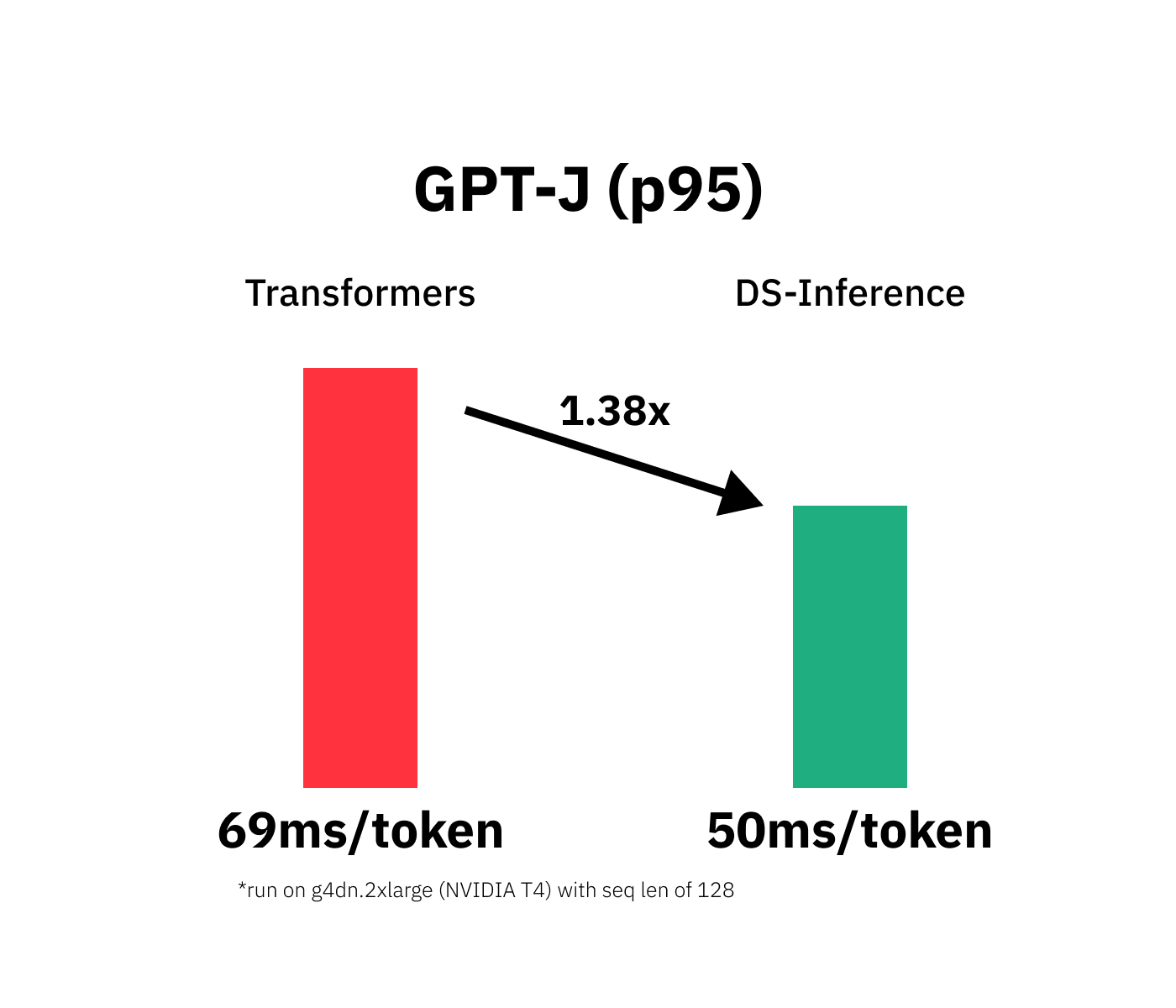
Accelerate GPT-J inference with DeepSpeed-Inference on GPUs
LLM(十二):DeepSpeed Inference 在 LLM 推理上的优化探究 - 知乎
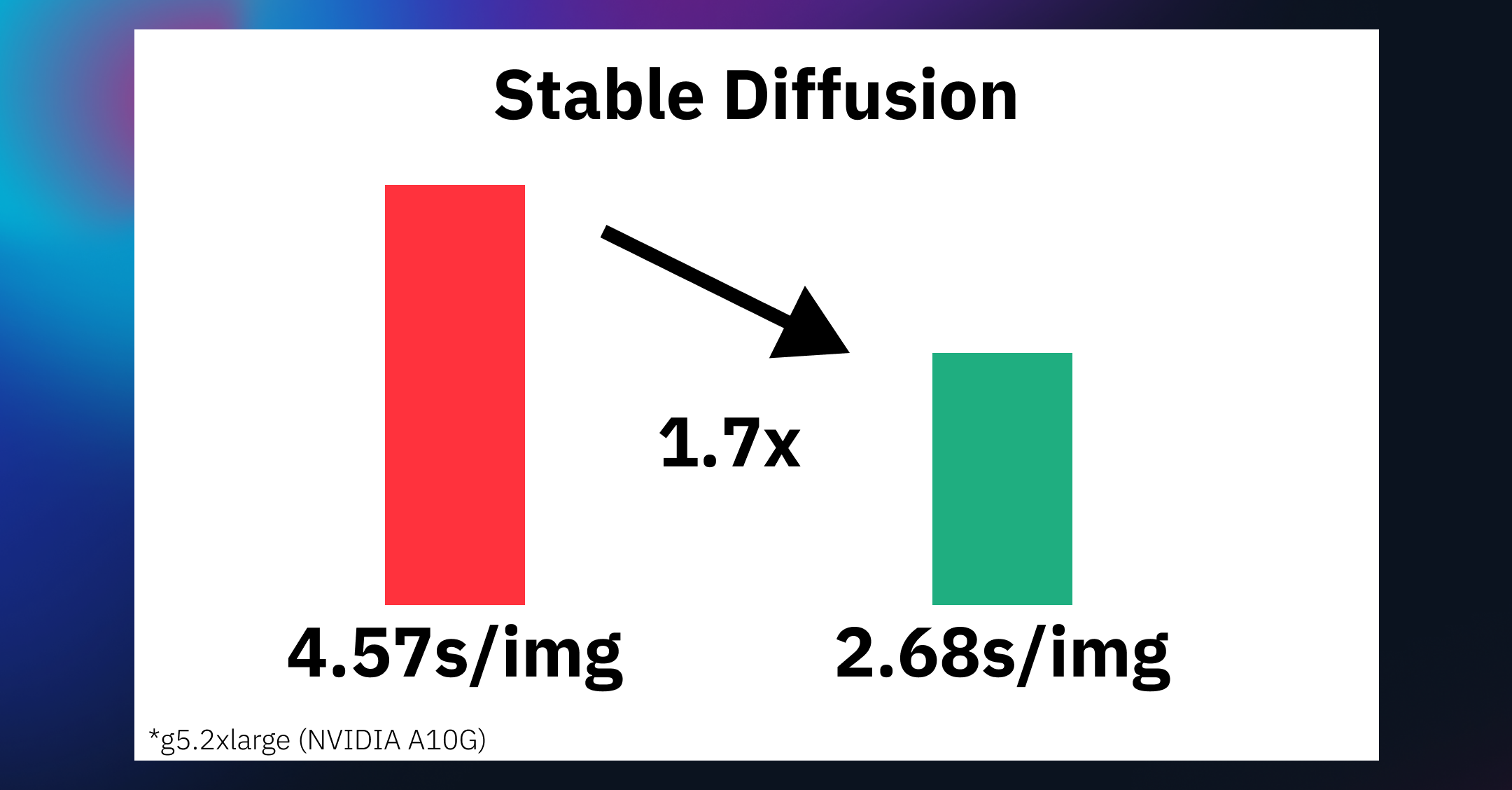
Accelerate Stable Diffusion inference with DeepSpeed-Inference on GPUs
[R] DeepSpeed Inference: Enabling Efficient Inference of Transformer ...
TensorRT Conversion: Transforming Deep Learning Models for High-Speed ...
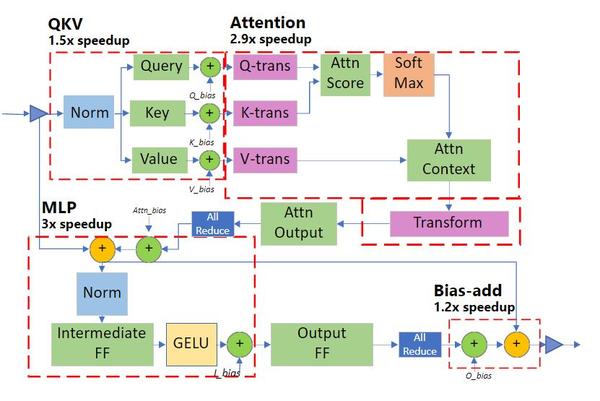
Figure 2 from DeepSpeed- Inference: Enabling Efficient Inference of ...
Figure 1 from DeepSpeed- Inference: Enabling Efficient Inference of ...
[2207.00032] DeepSpeed Inference: Enabling Efficient Inference of ...
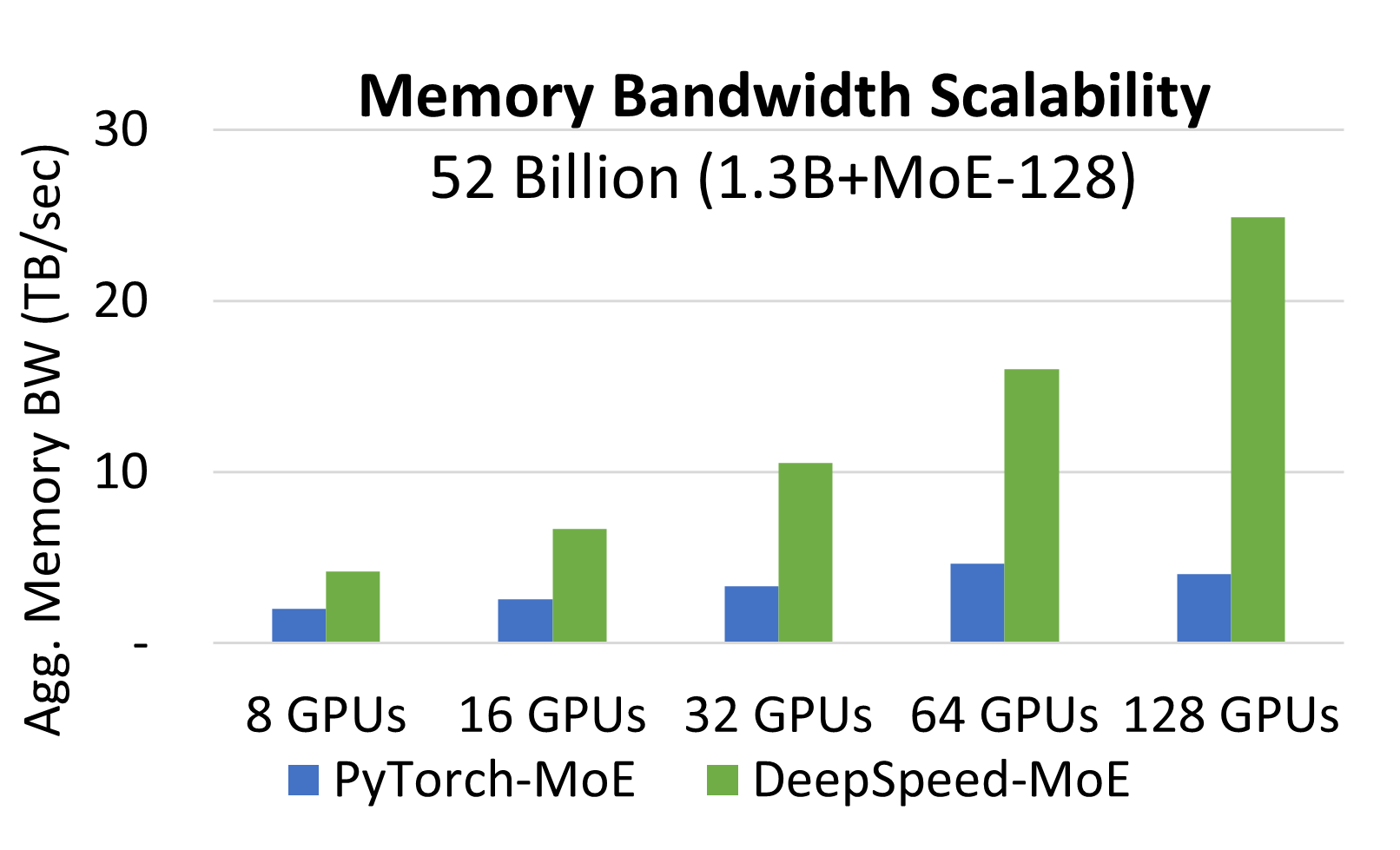
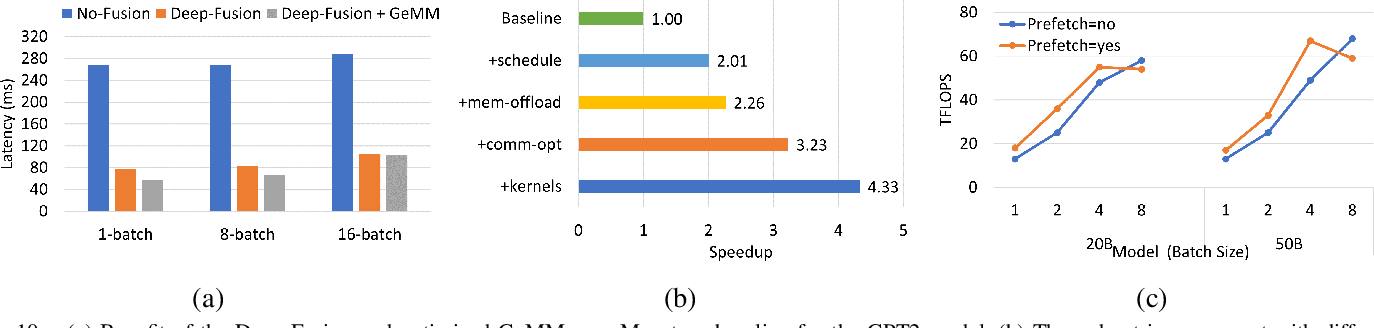
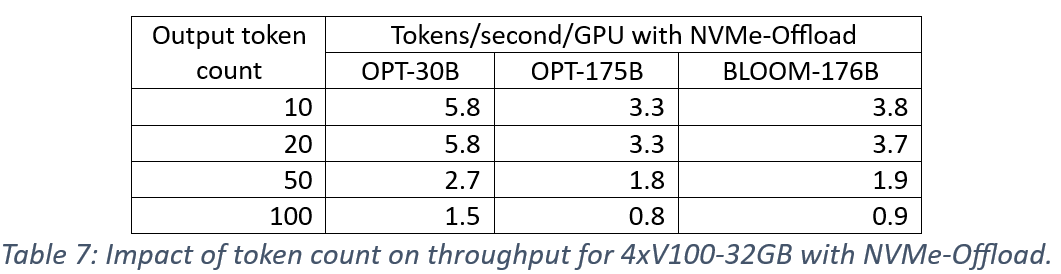
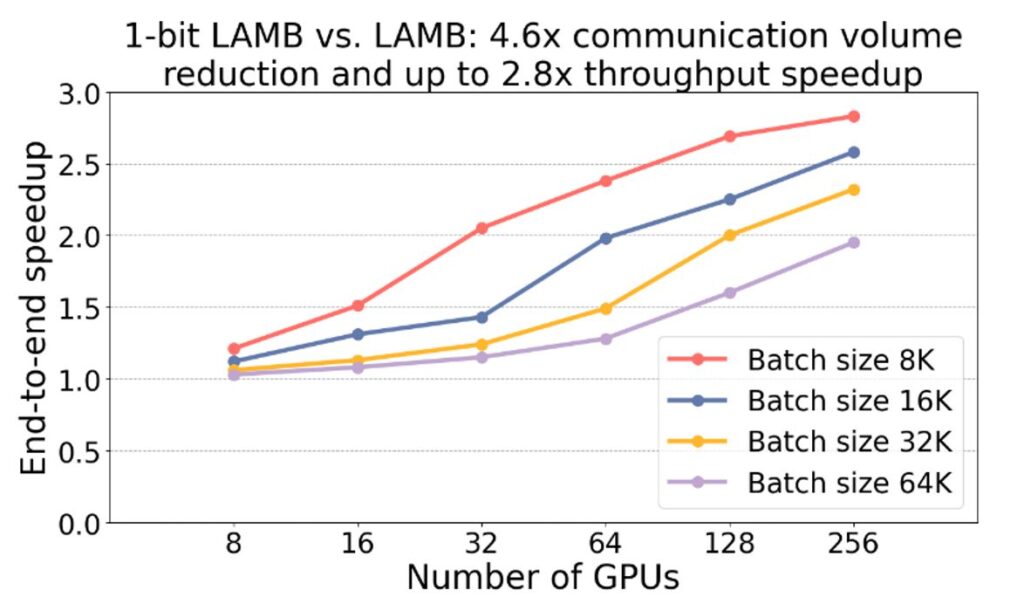
Figure 10 from DeepSpeed- Inference: Enabling Efficient Inference of ...
GitHub - wangtsing/Microsoft-DeepSpeed: DeepSpeed is a deep learning ...
DEEPSPEED IN PRODUCTION: INFERENCE OPTIMIZATION AND MODEL: Deploy LLMs ...
How to Get Started with DeepSpeed Model Implementations for Inference ...
[PaperReading] DeepSpeed Inference: Enabling Efficient Inference of ...
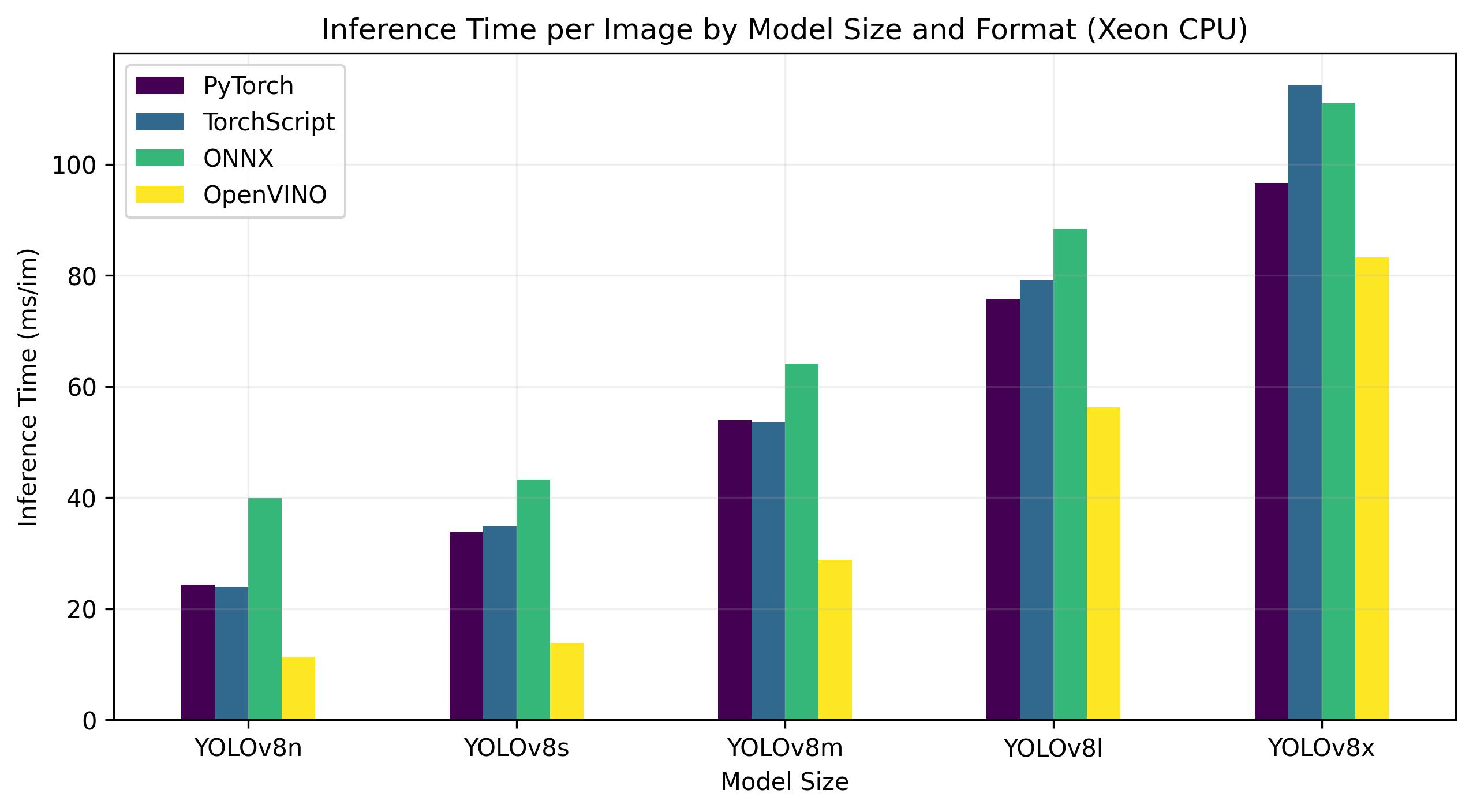
Achieve Faster Inference Speeds with Ultralytics YOLOv8 & Intel’s ...
New Technique Speeds Up Deep-Learning Inference on TensorFlow by 2x ...
DeepSpeed - Make distributed training easy, efficient, and effective ...
ZeRO-Infinity and DeepSpeed: Unlocking unprecedented model scale for ...
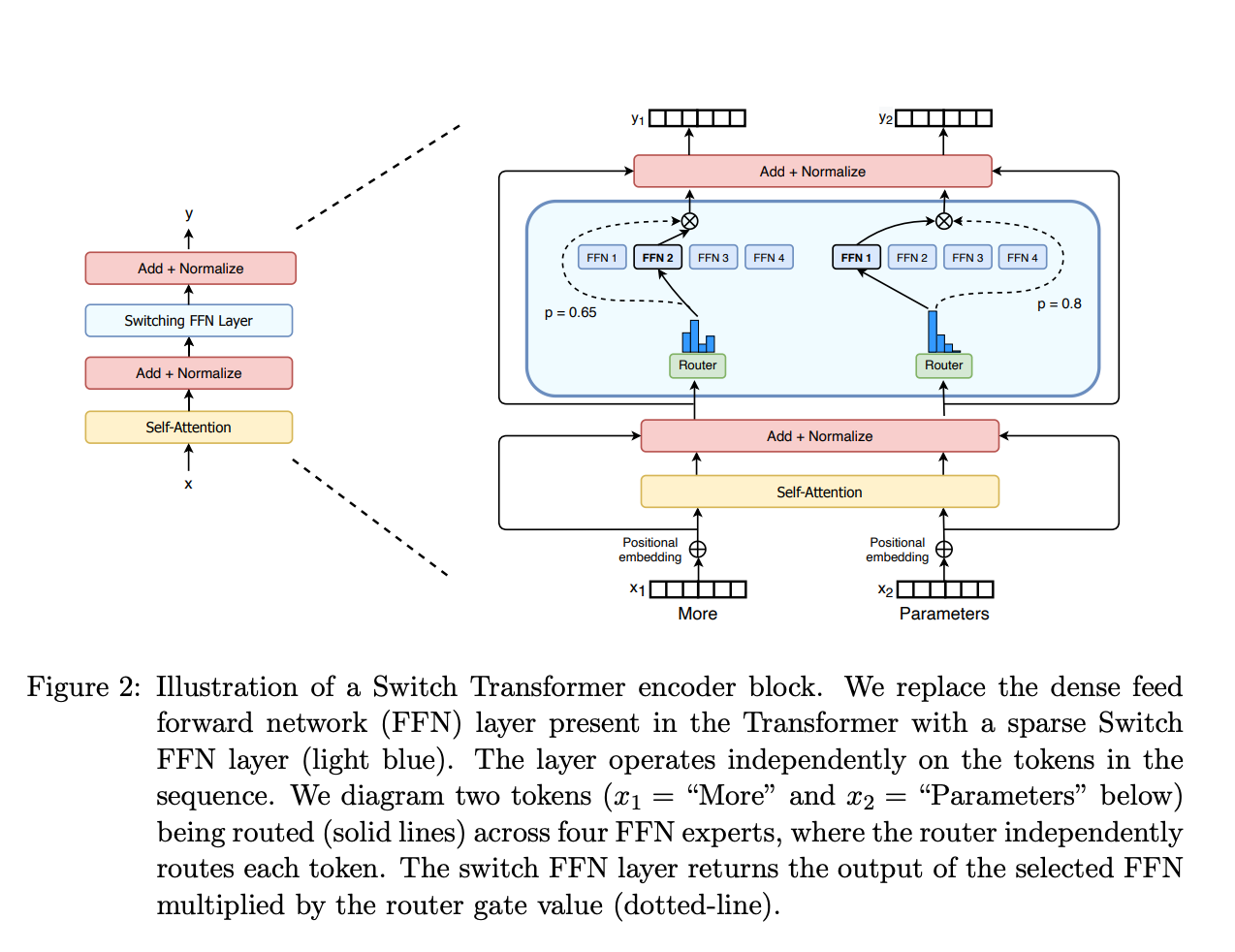
Microsoft AI Team Proposes DeepSpeed MoE Model: An End-to-End MoE ...
DeepSpeed 通过系统优化加速大模型推理 - 知乎
DeepSpeed/deepspeed/inference/v2/model_implementations/opt/container.py ...
Amossse/microsoft-bloom-deepspeed-inference-fp16 at main
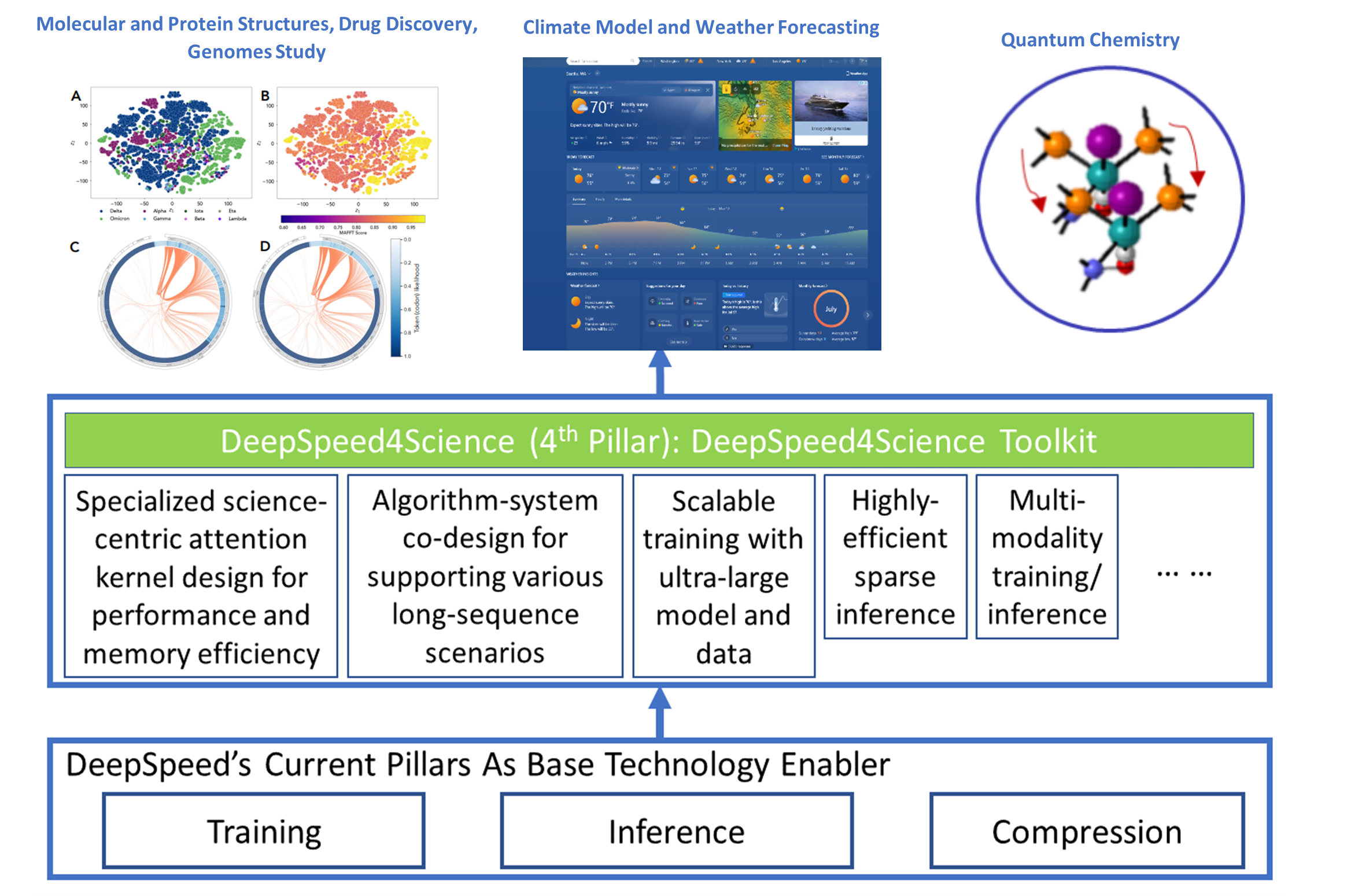
Announcing the DeepSpeed4Science Initiative: Enabling large-scale ...
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍_deepspeed rhlf-CSDN博客
Daily AI Papers on Twitter: "DeepSpeed Inference: Enabling Efficient ...
Deploy BLOOM-176B and OPT-30B on Amazon SageMaker with large model ...
Microsoft AI Research Introduces DeepSpeed-MII, A New Open-Source ...
lucadiliello/opt-30b-deepspeed-inference-fp16-shard-2 · Hugging Face
DeepSpeed-Inference 分布式推理模型部署(基础)_deepspeed inference-CSDN博客
Serve Stable Diffusion Three Times Faster
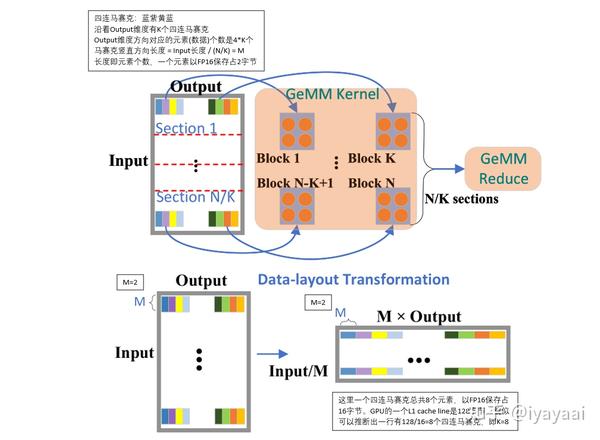
DeepSpeed Inference中的kernel优化 - 知乎
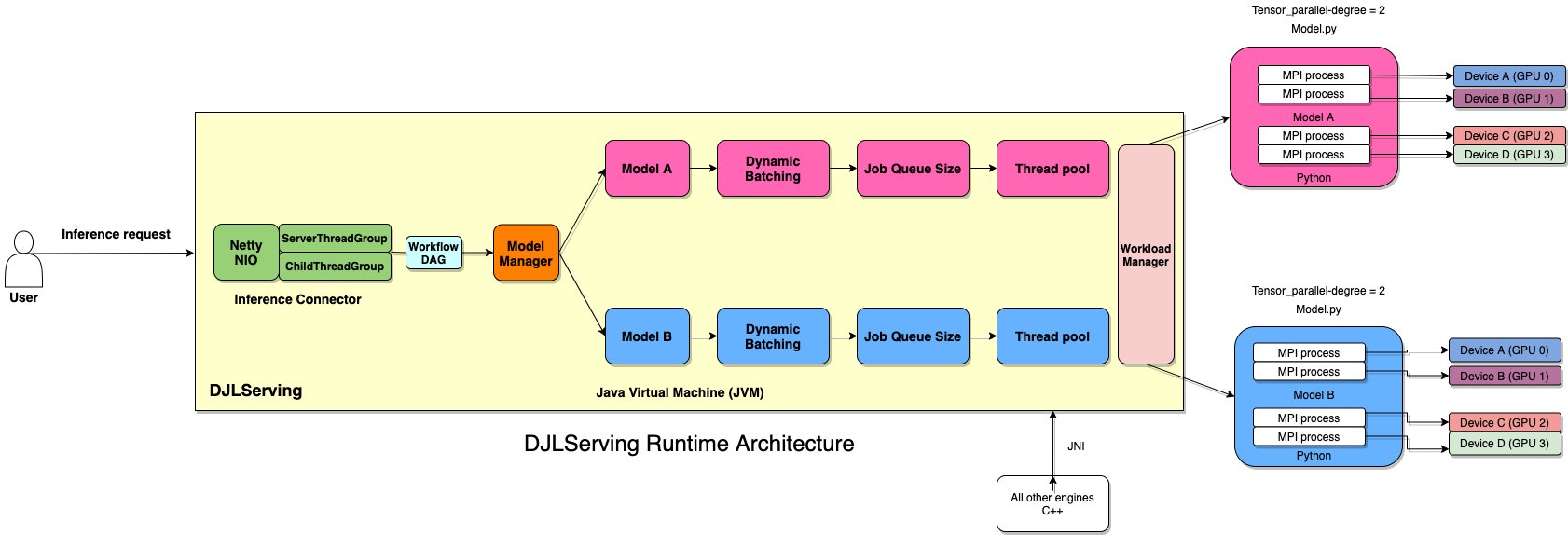
Deploy large models on Amazon SageMaker using DJLServing and DeepSpeed ...
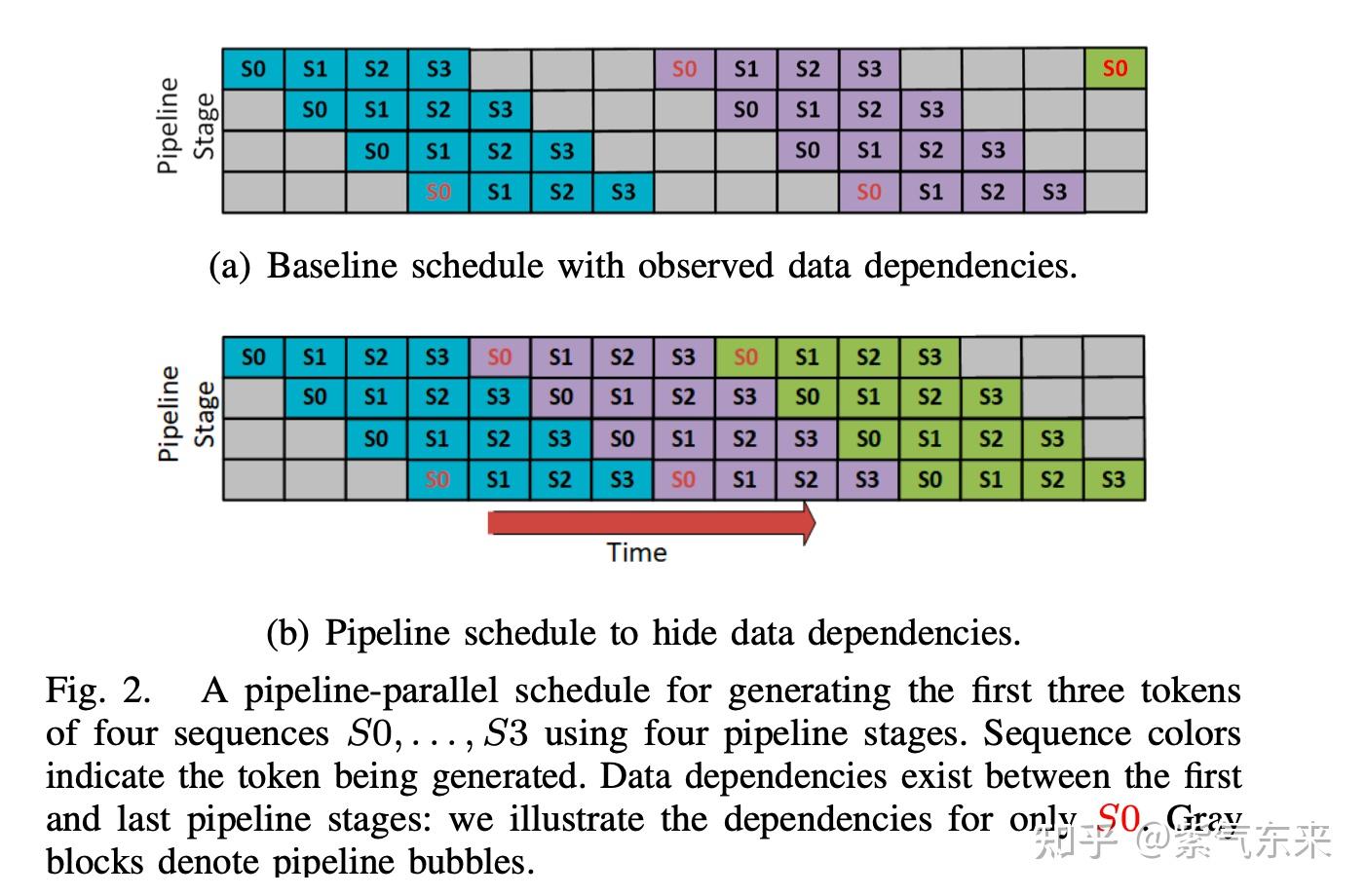
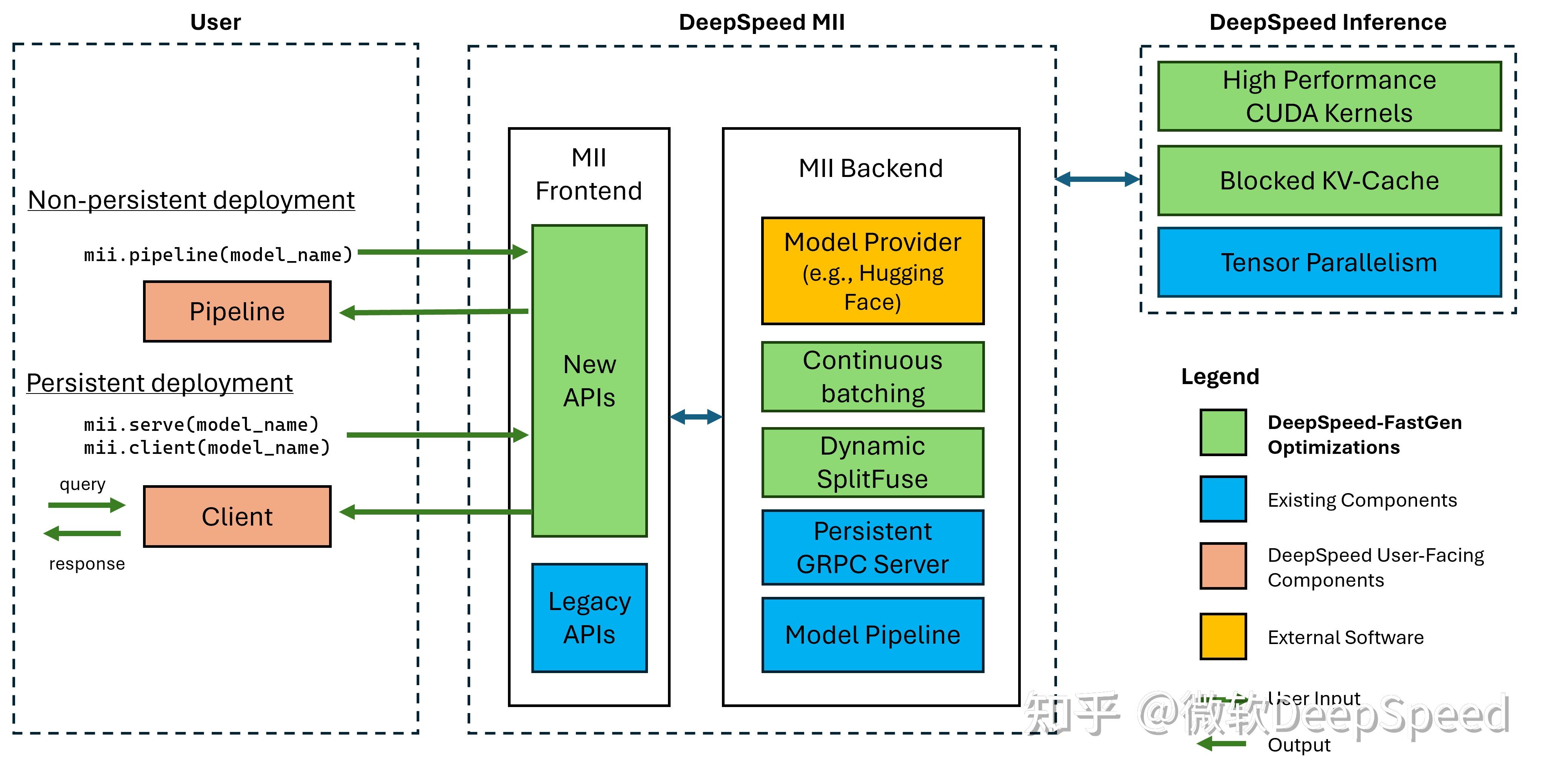
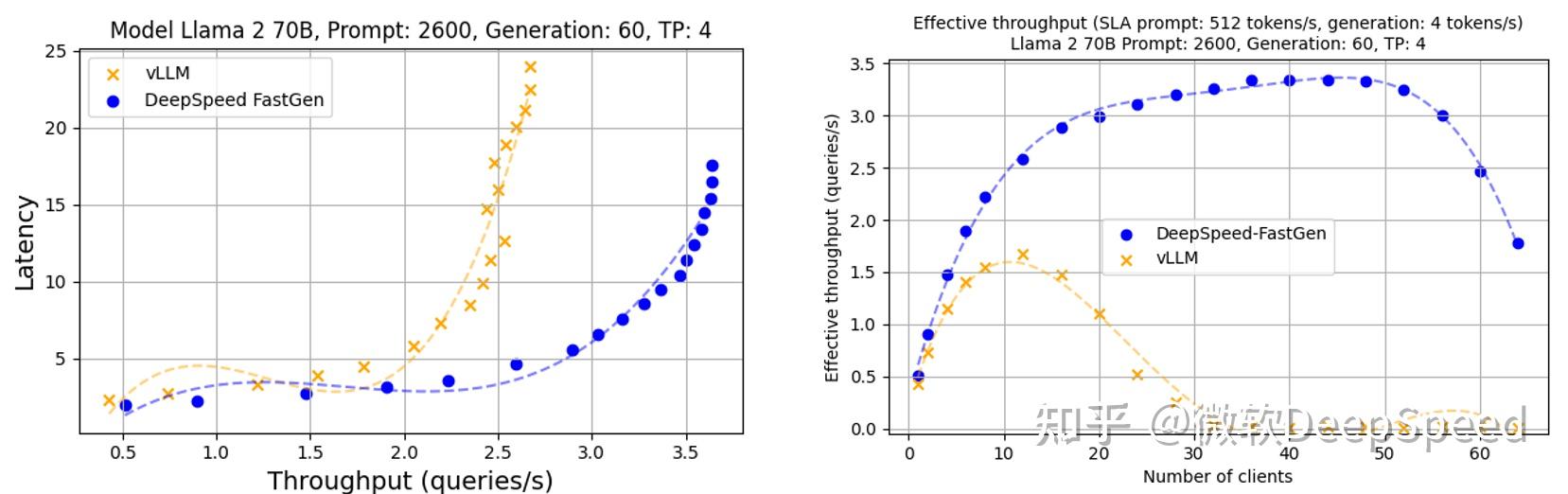
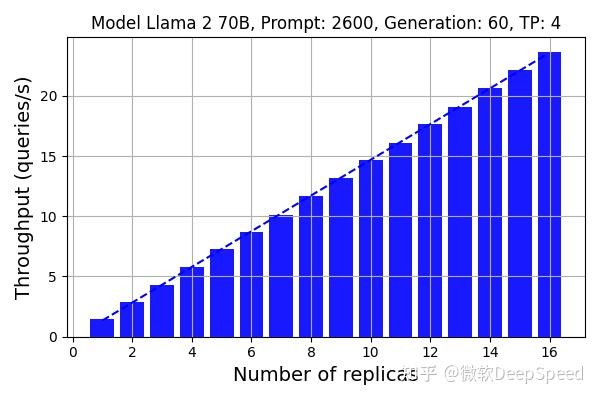
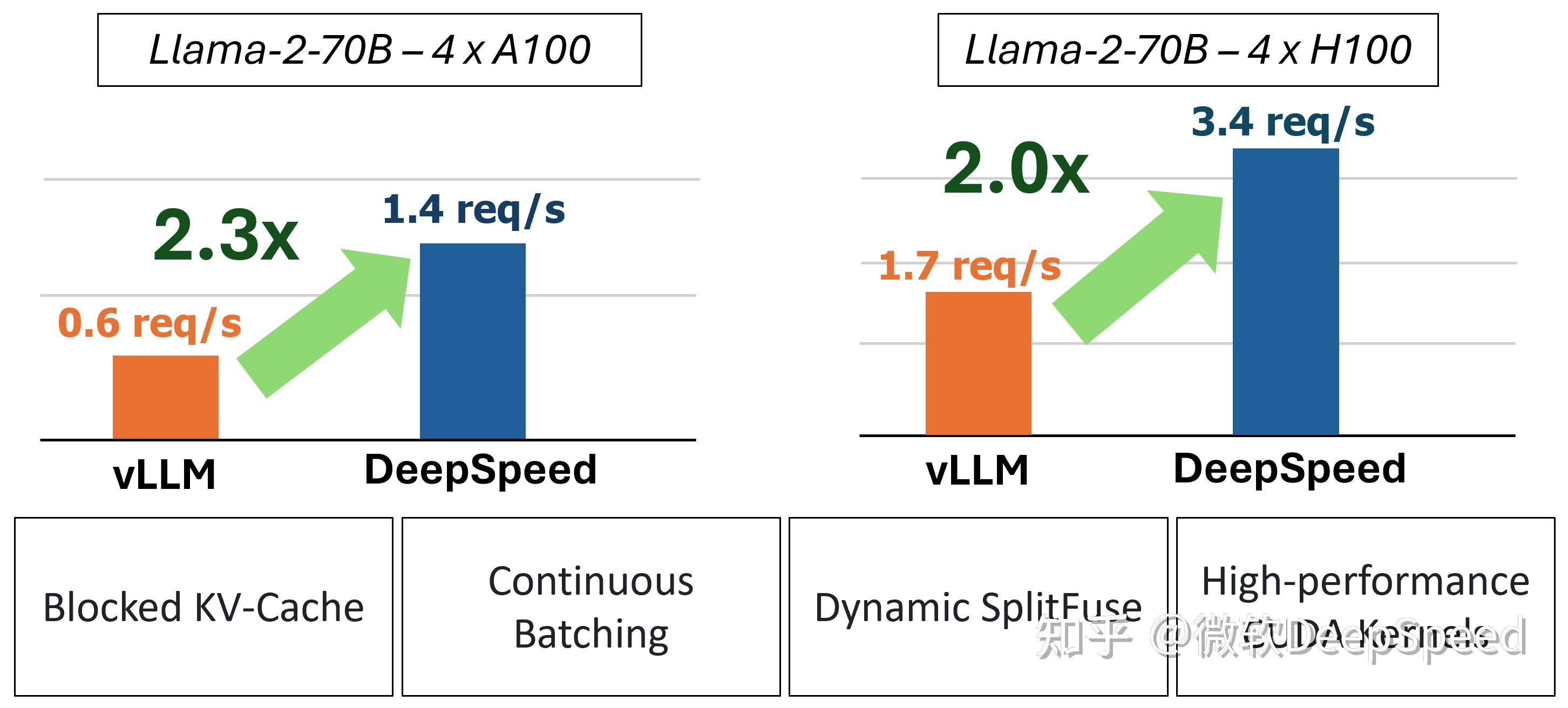
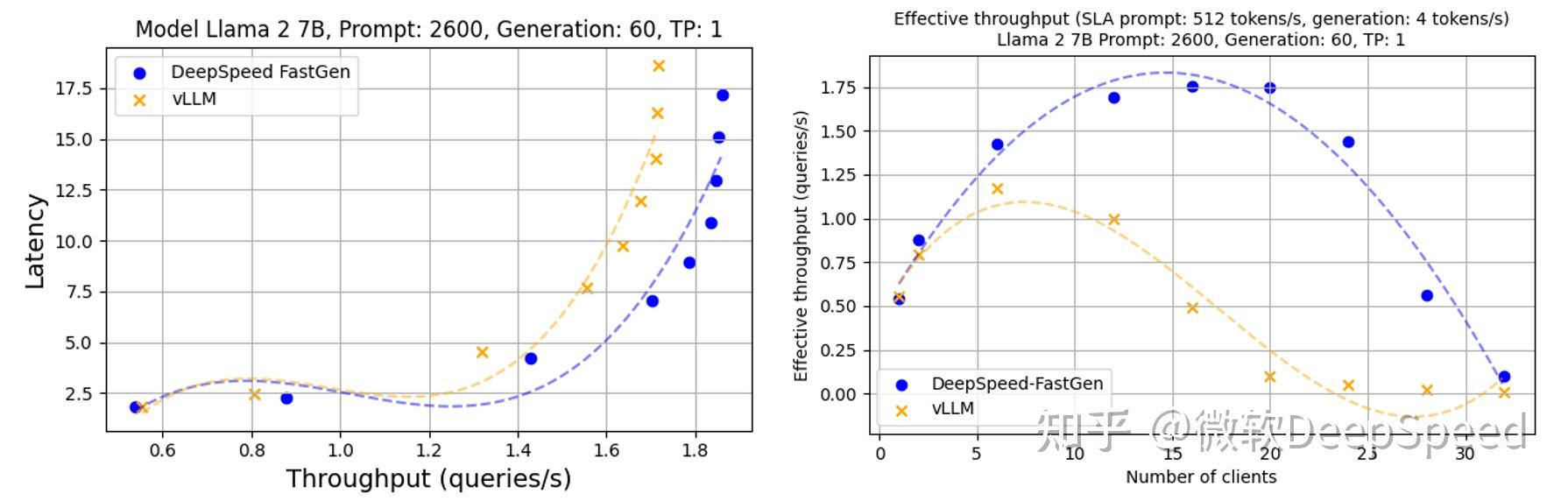
DeepSpeed-FastGen:通过 MII 和 DeepSpeed-Inference 实现 LLM 高吞吐量文本生成 - 知乎
DeepSpeed-MII - 知乎
Comparison with deepspeed inference? · Issue #8 · ModelTC/lightllm · GitHub
一文读懂deepSpeed:深度学习训练的并行化-阿里云开发者社区