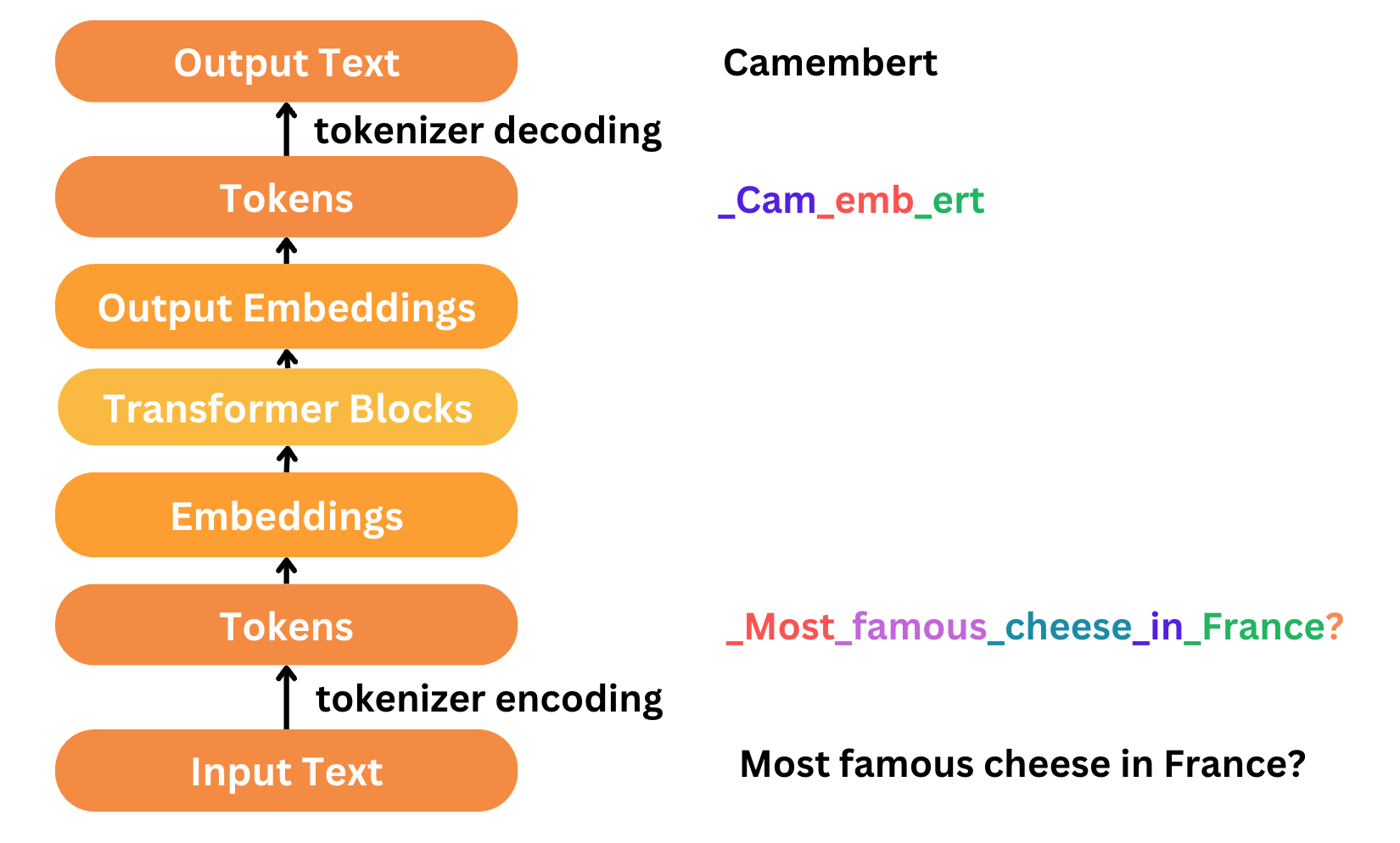
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Prompt tokens | Microsoft Learn
To Mask or Not to Mask: The Effect of Prompt Tokens on Instruction ...
Unleashing PTU Tokens Throughput with KV-Cache-Friendly Prompt on Azure ...
Cosine similarities between learned prompt tokens and topic embeddings ...
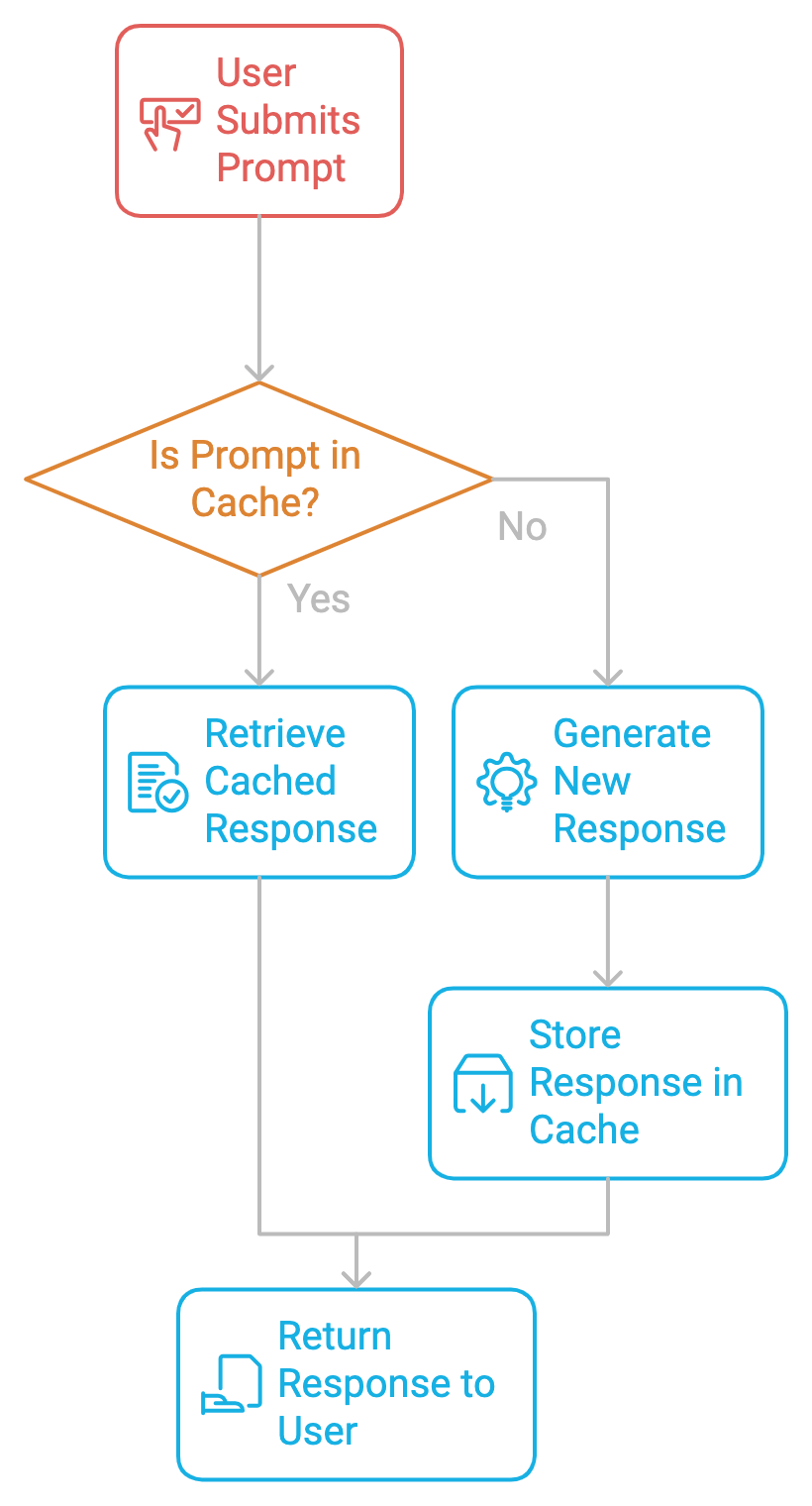
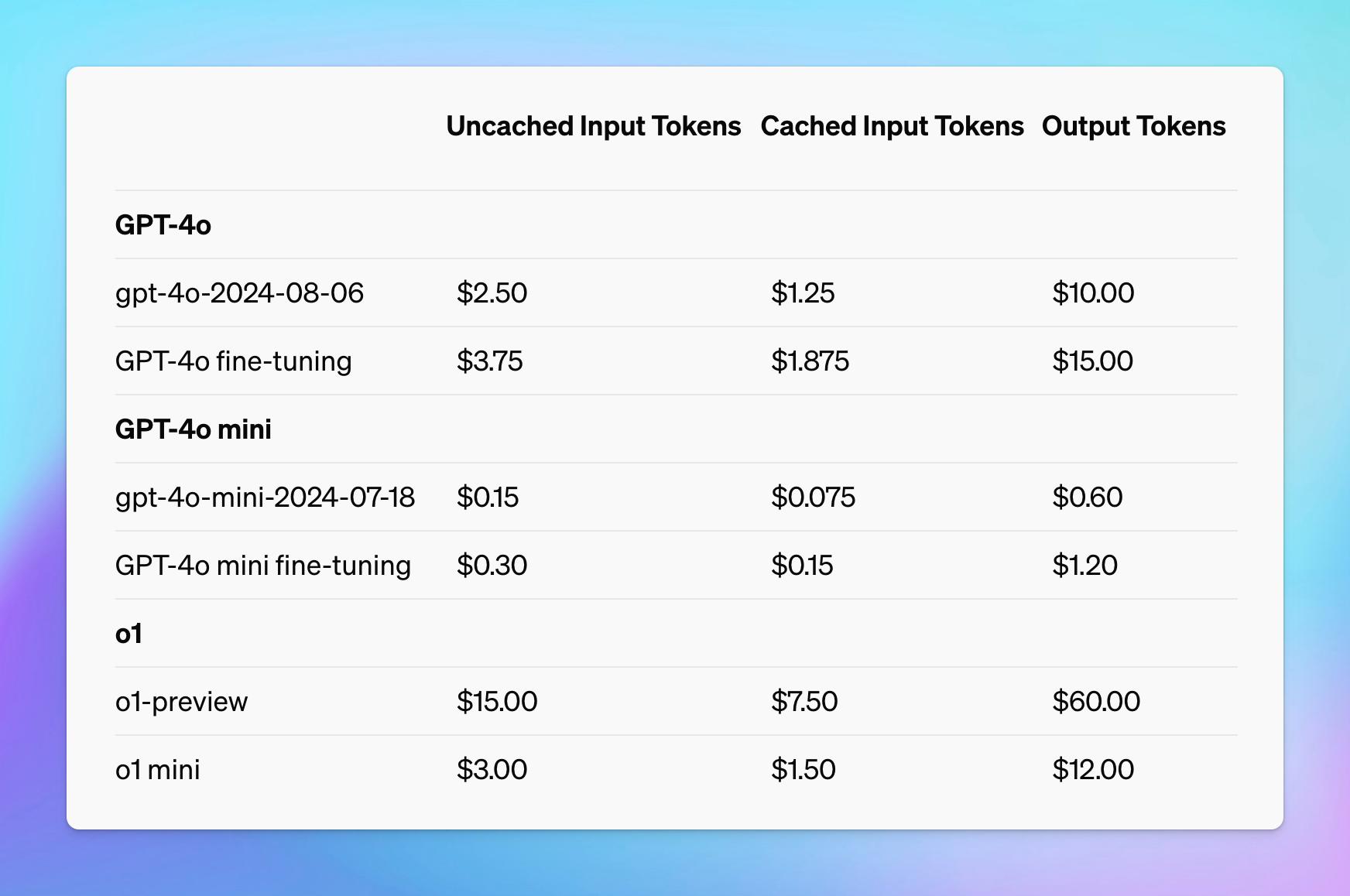
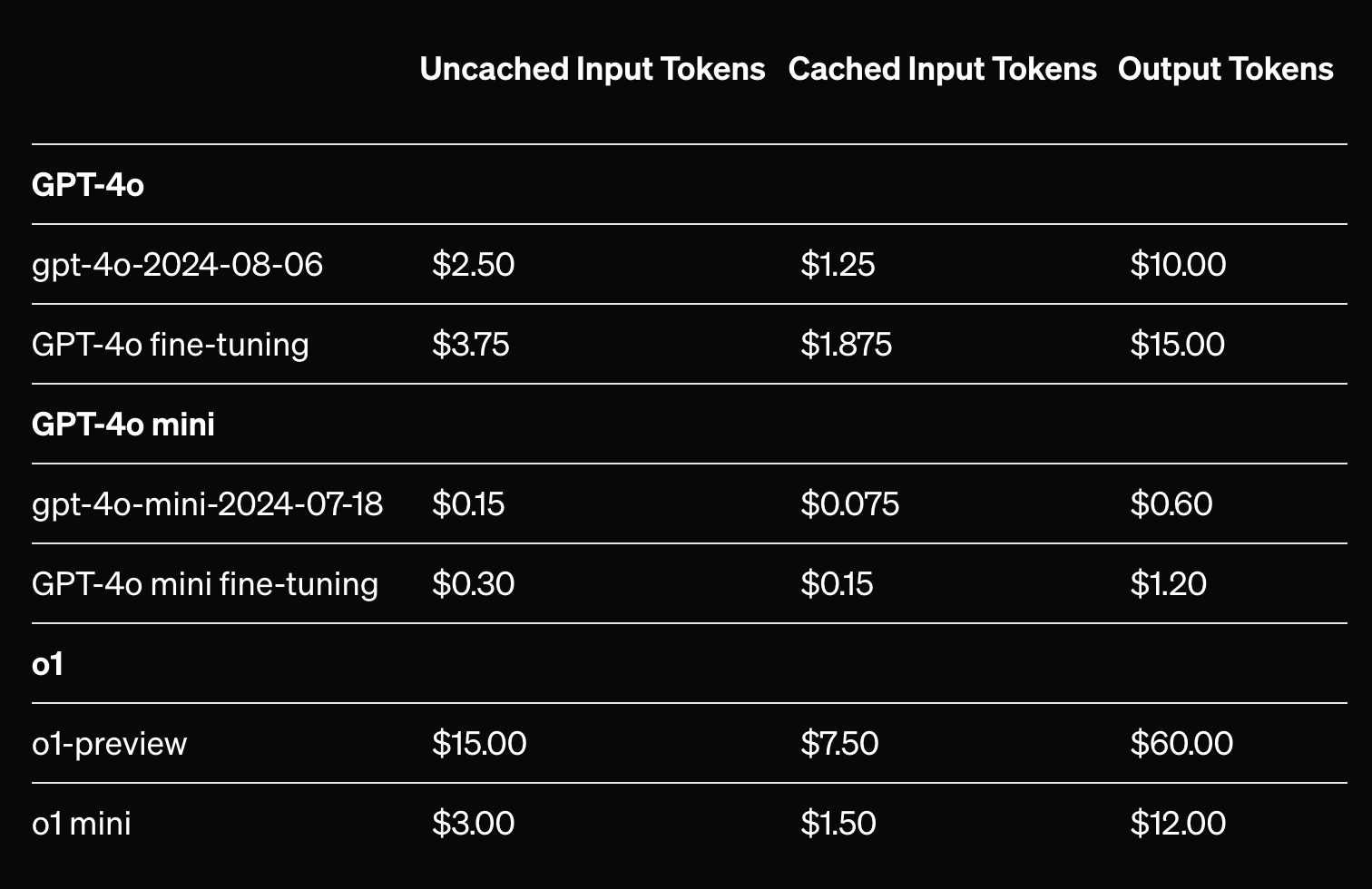
Prompt caching | OpenAI API
Prompt caching not working - API - OpenAI Developer Forum
Auditing Prompt Caching in Language Model APIs · HF Daily Paper Reviews ...
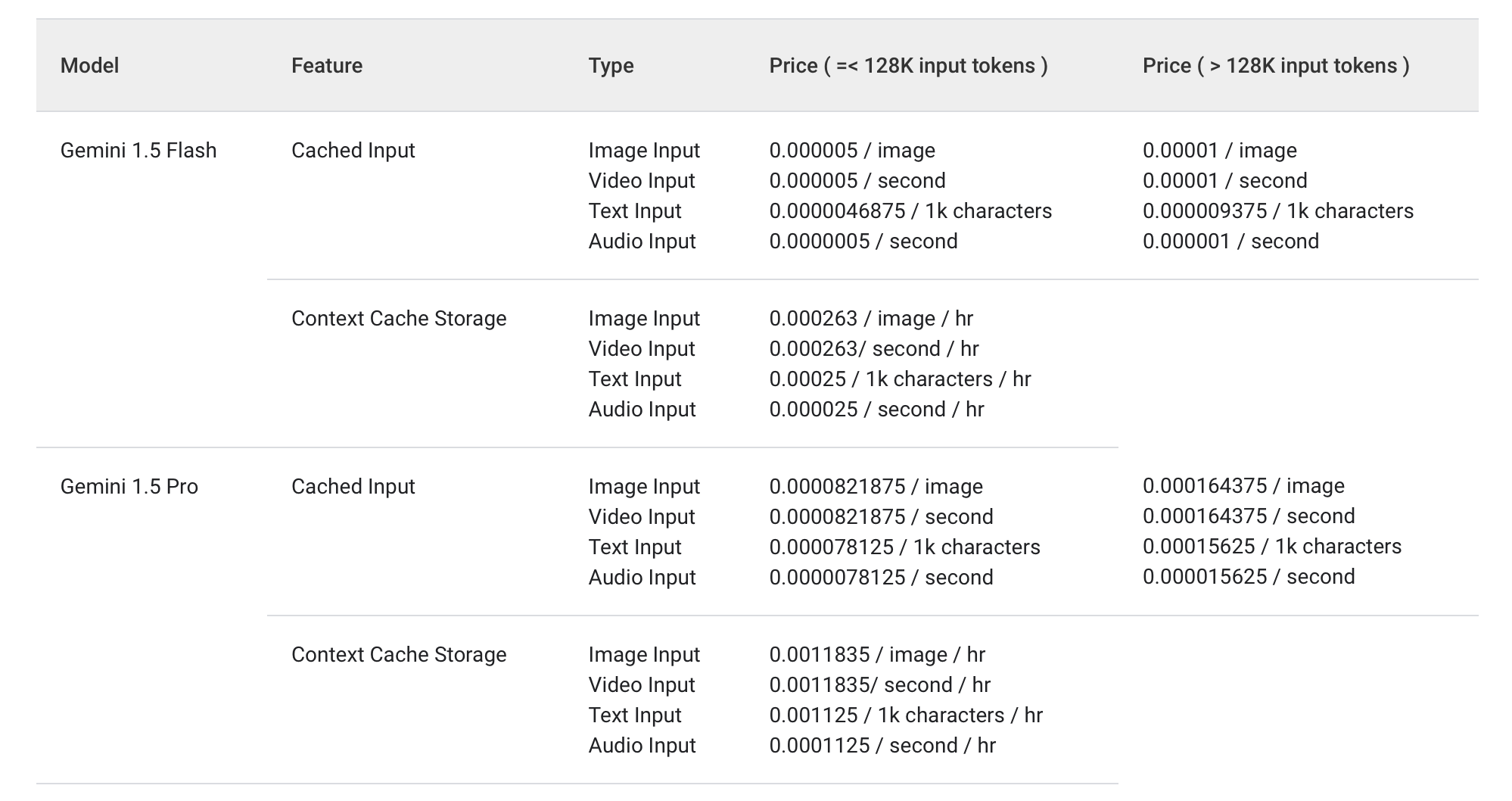
Prompt Caching with OpenAI, Anthropic, and Google Models
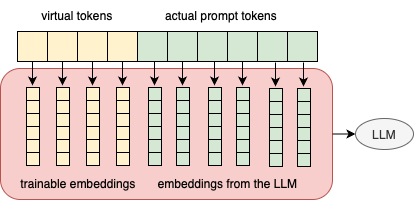
Prompt Tuning for Sequence Classification | 叶某人的碎碎念
Effectively use prompt caching on Amazon Bedrock | Artificial Intelligence
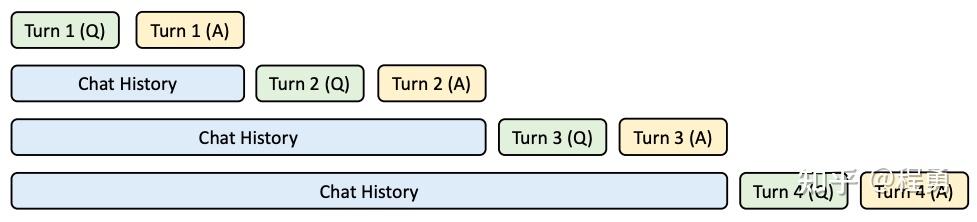
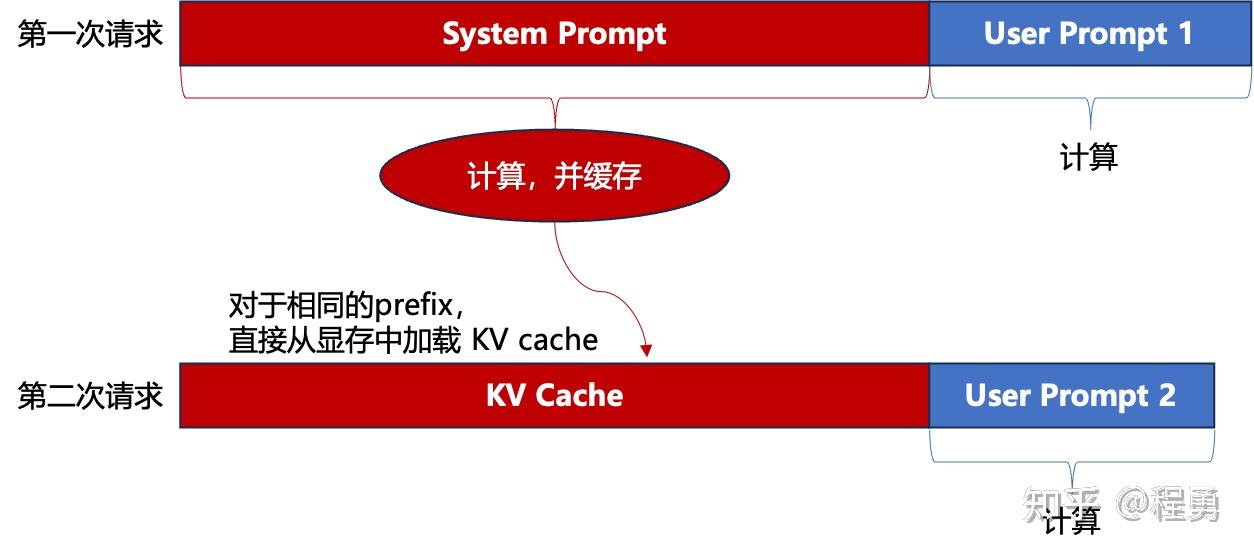
LLM推理:首token时延优化与System Prompt Caching - 知乎
Prompt Caching | Vellum | Documentation
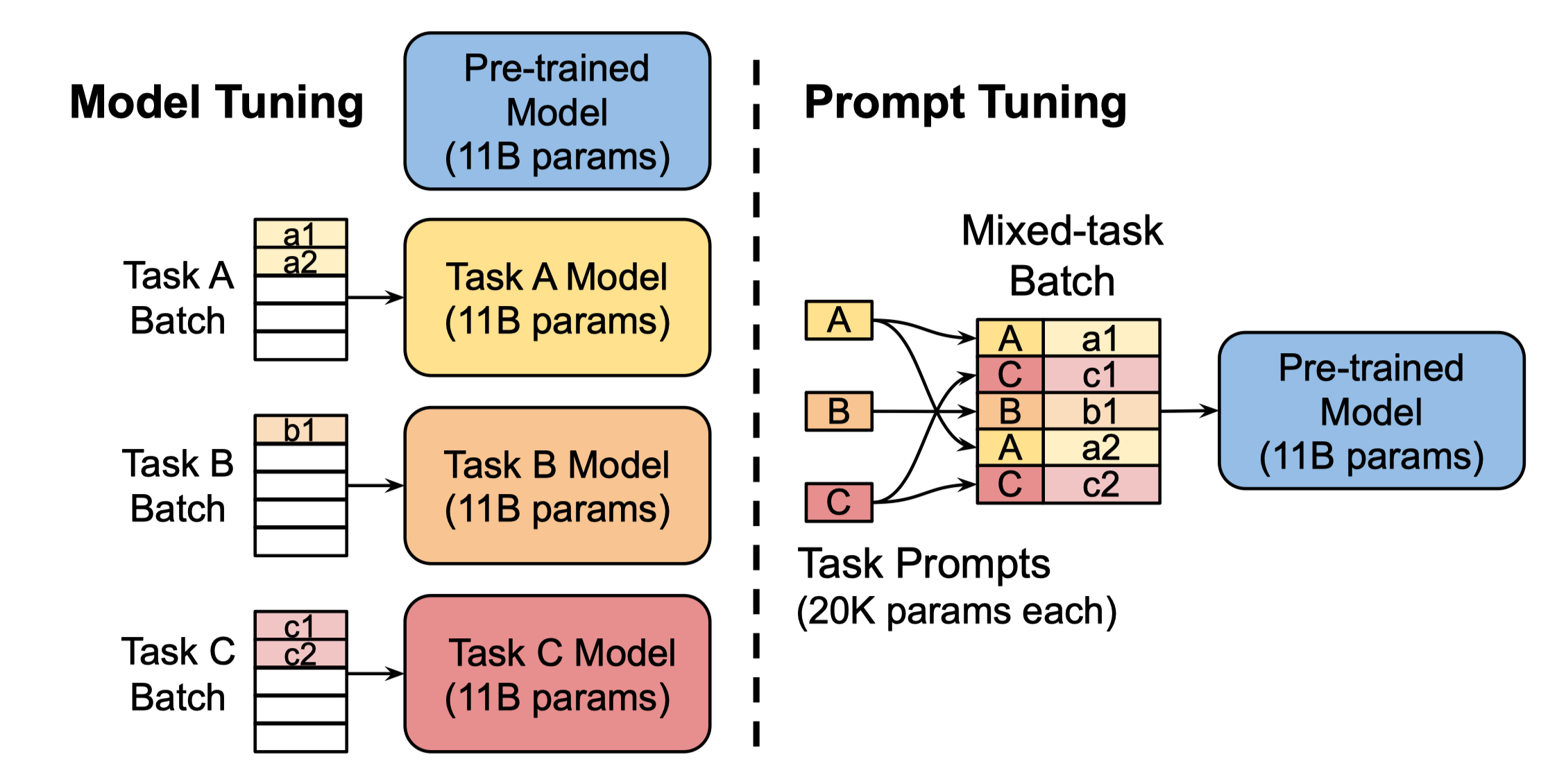
Transfer learning experimental setup. Prompt Tuning: a single prompt of ...
Understanding Prompt Caching in Generative AI using Anthropic
OpenAI Prompt Caching. OpenAI is offering automatic token… | by Cobus ...
Basics of Prompt Tokenization in the Generation of Art
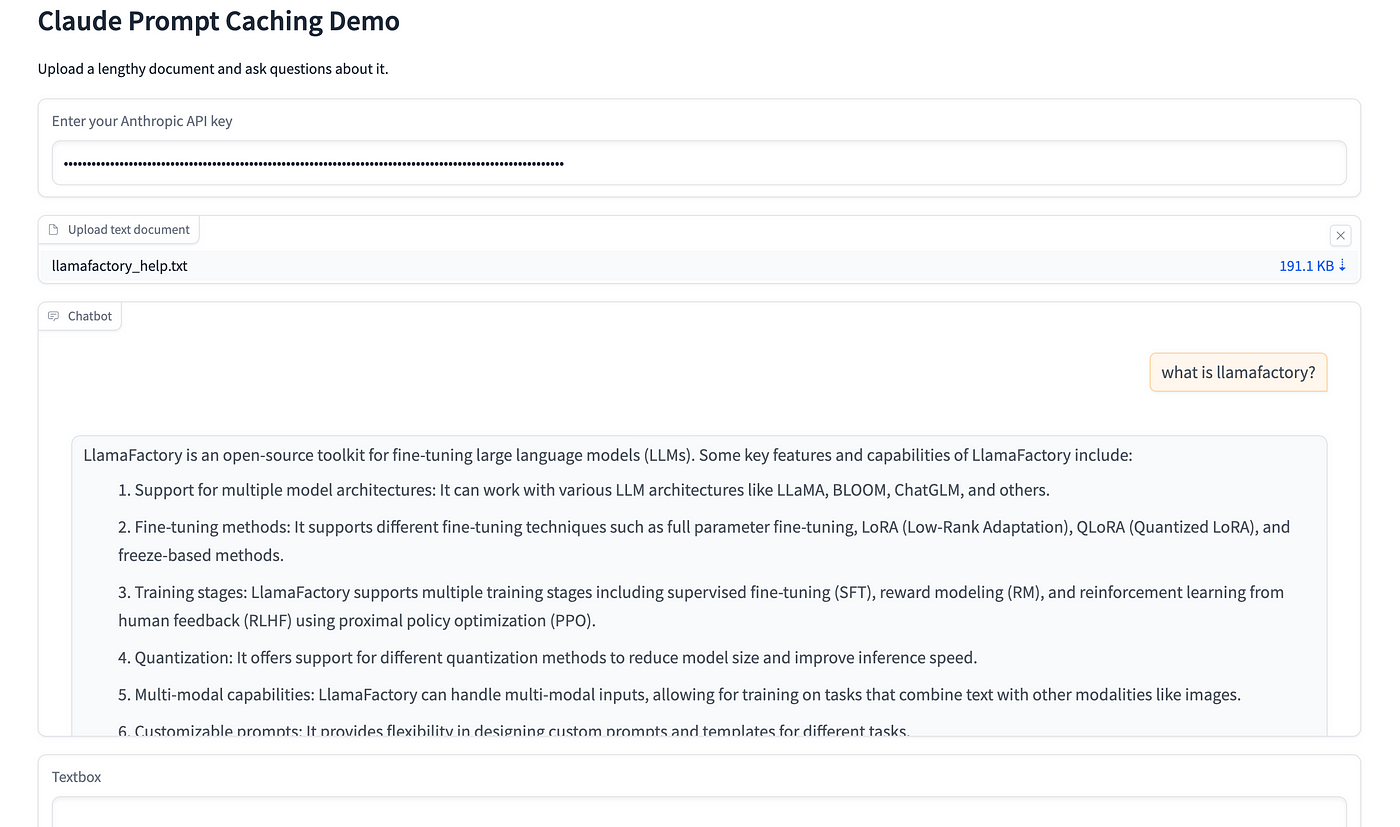
Prompt Caching: A Guide With Code Implementation | DataCamp
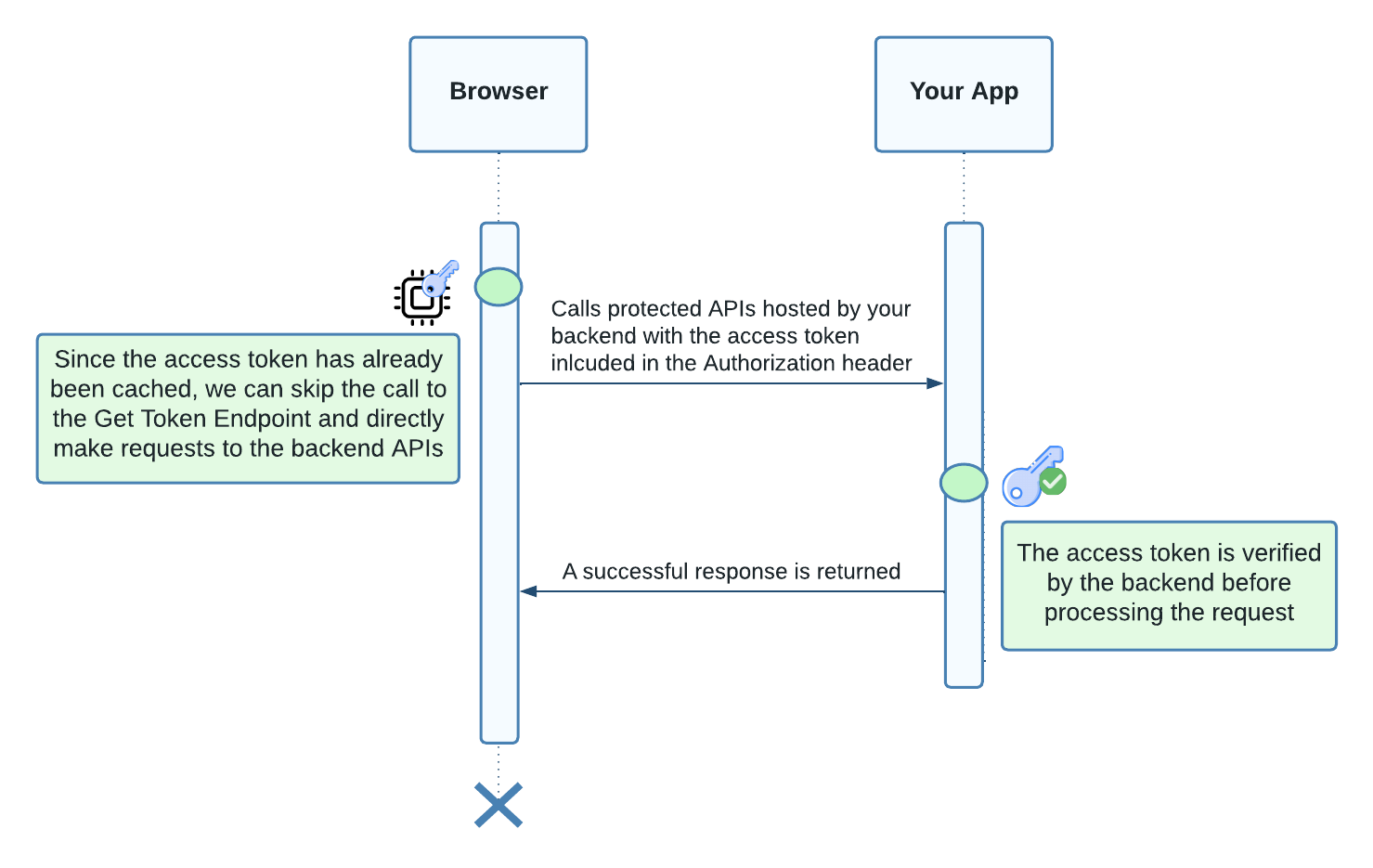
Authenticating API Requests With Bearer Tokens
Automatic Prompt Caching
How Prompt caching works? - API - OpenAI Developer Community
Prompt Templates with Azure OpenAI | by Akshay Raut | Medium
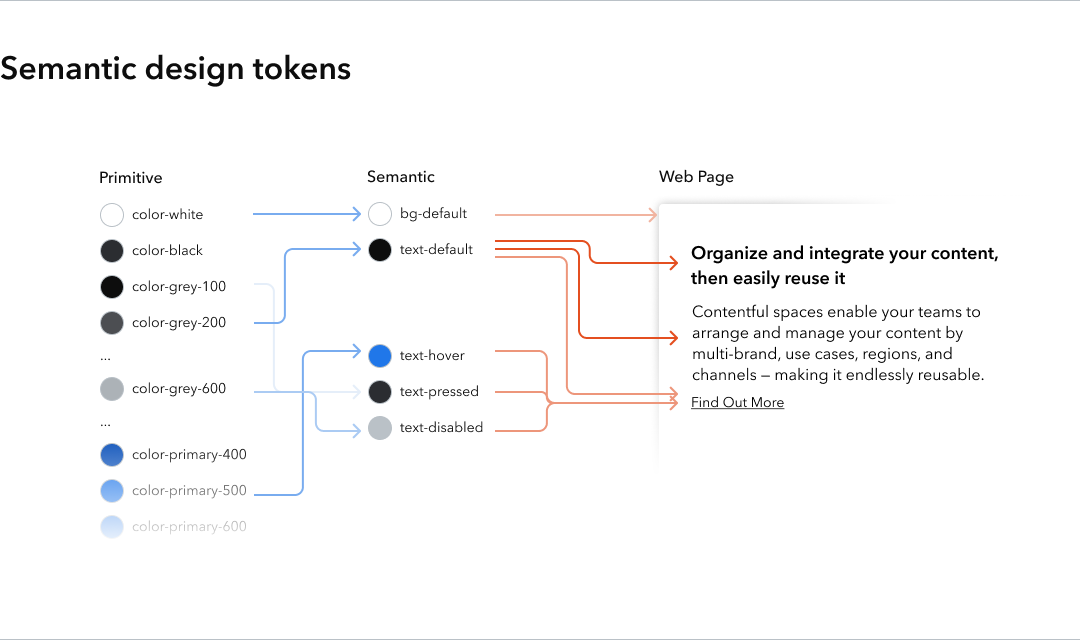
Design tokens explained (and how to build a design token system ...
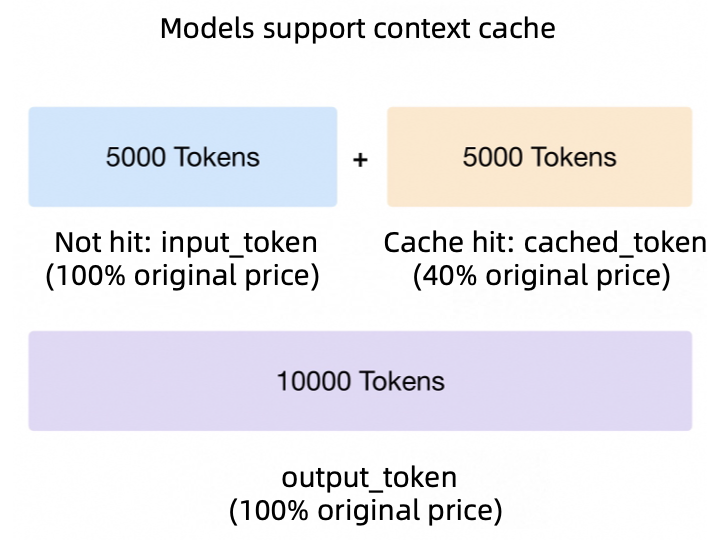
Prompt caching for faster model inference - Amazon Bedrock
Is Prompt Caching the new RAG?
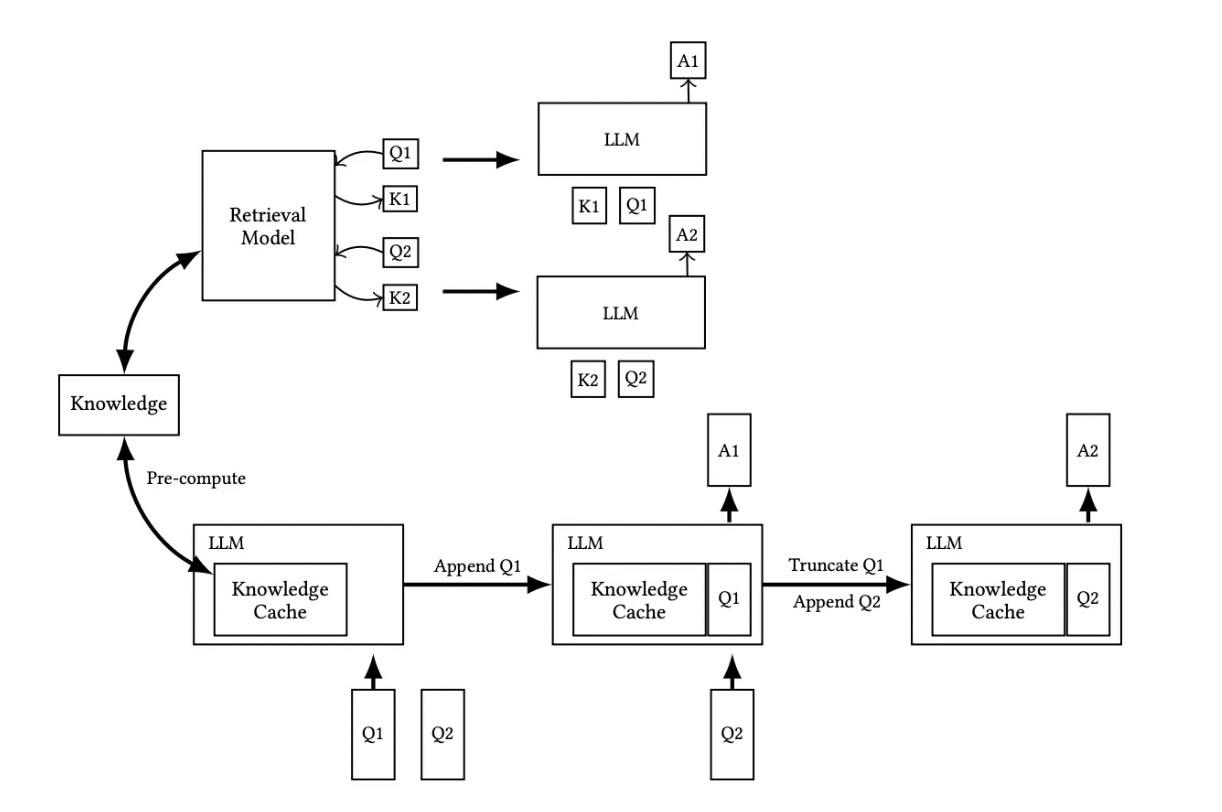
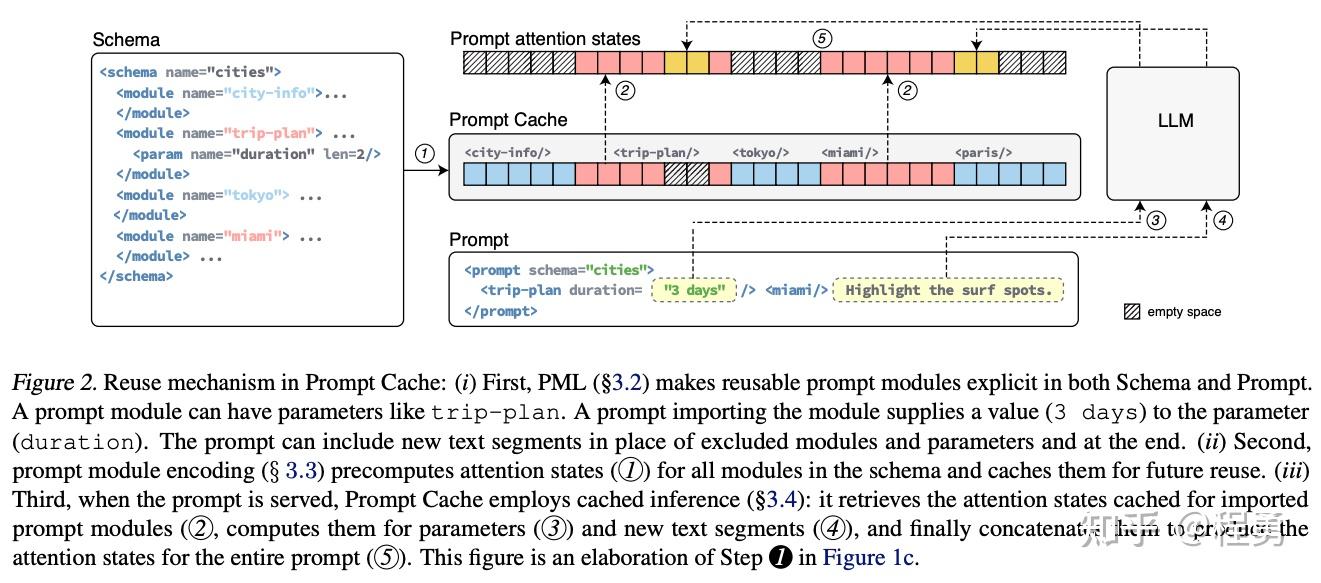
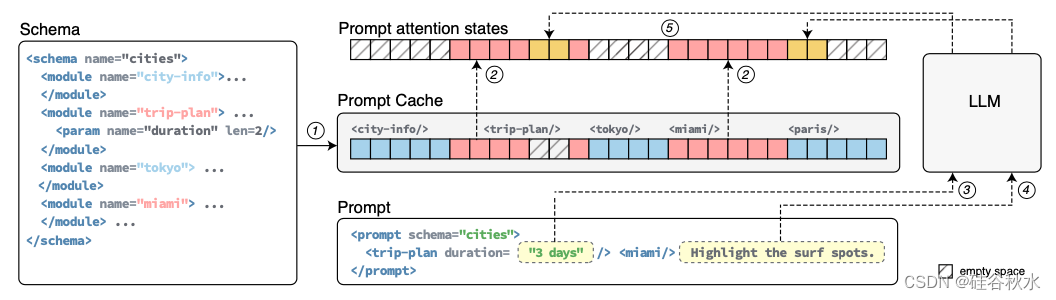
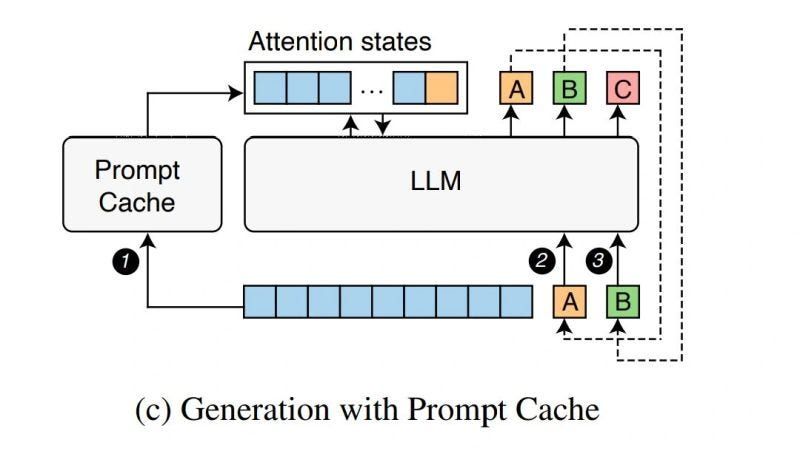
Prompt Cache:模块化注意重用实现低延迟推理_prompt cache: modular attention reuse for ...
Large Language Model Settings: Temperature, Top P and Max Tokens | by ...
Why Good Prompt Engineers Are Worth The Money They’re Making
Understanding Prompt Caching for Public AI APIs and Usage-Based Pricing
Prompt - Prompt Engineering Guidelines
Platform Tokens Examples at Michael Goodwin blog
Secure prompt caching for fast AI inference
Cache not caching more than 1024 tokens (expected: increments of 128 ...
Prompt Caching - LLM Parameter Guide - Vellum
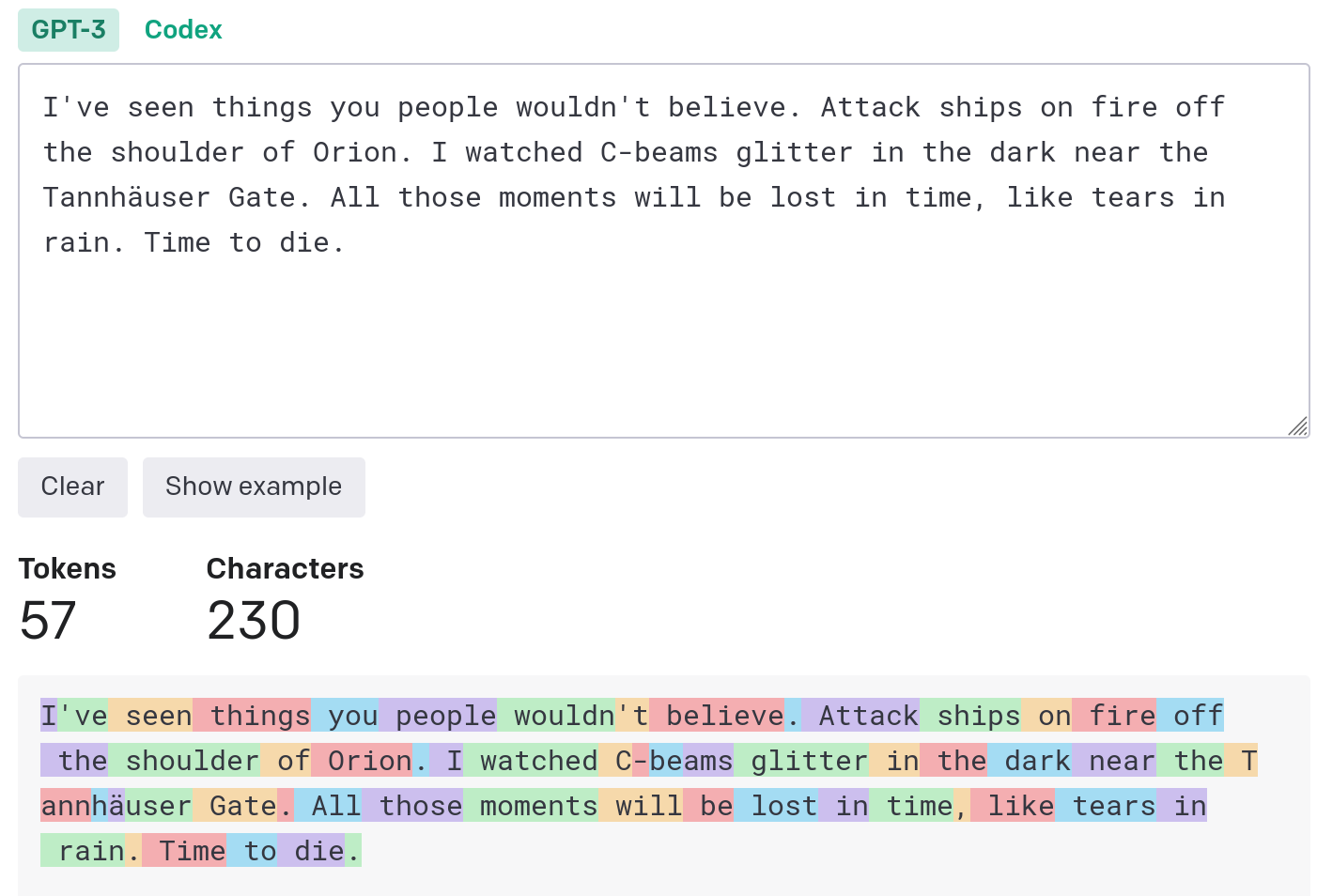
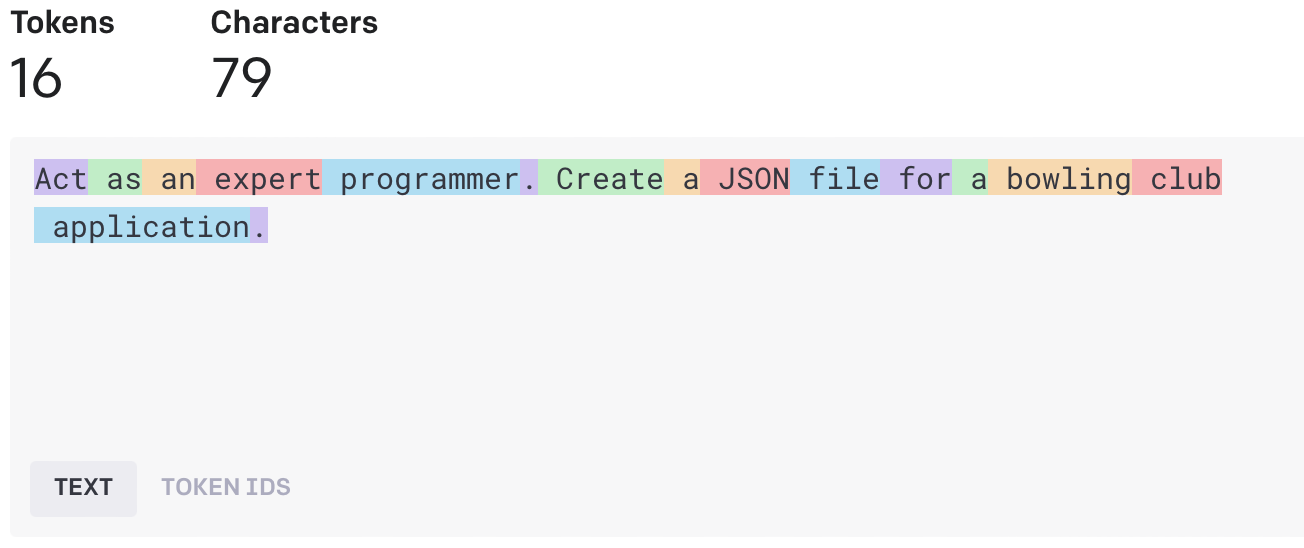
Prompt Token Counter
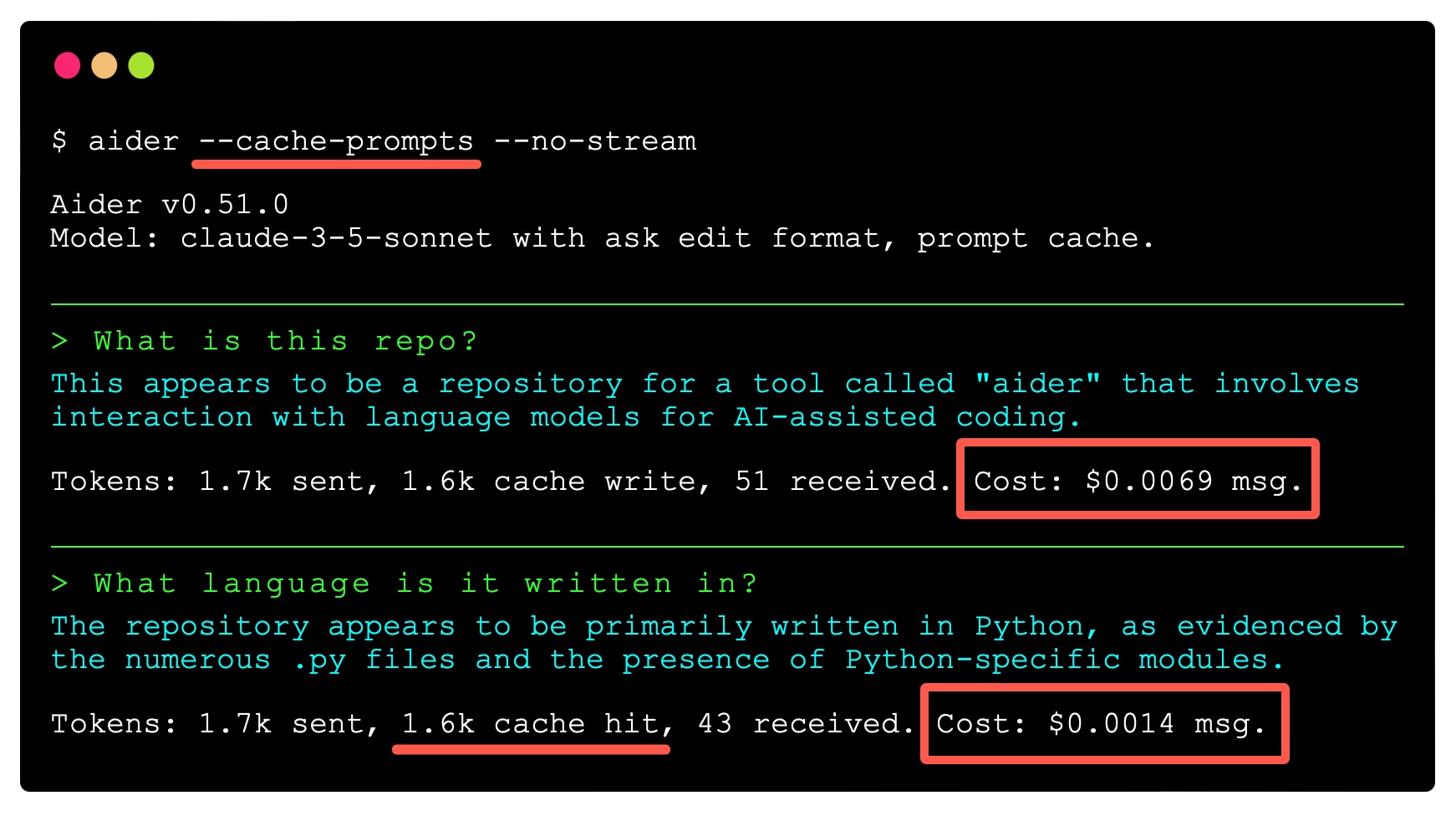
Prompt caching | aider
How to see the number of tokens (prompt_tokens, completion_tokens ...
Prompt Engineering | wesome.org
Prompt Caching Guide (2025): Lower AI Costs with OpenAI, Anthropic, and ...
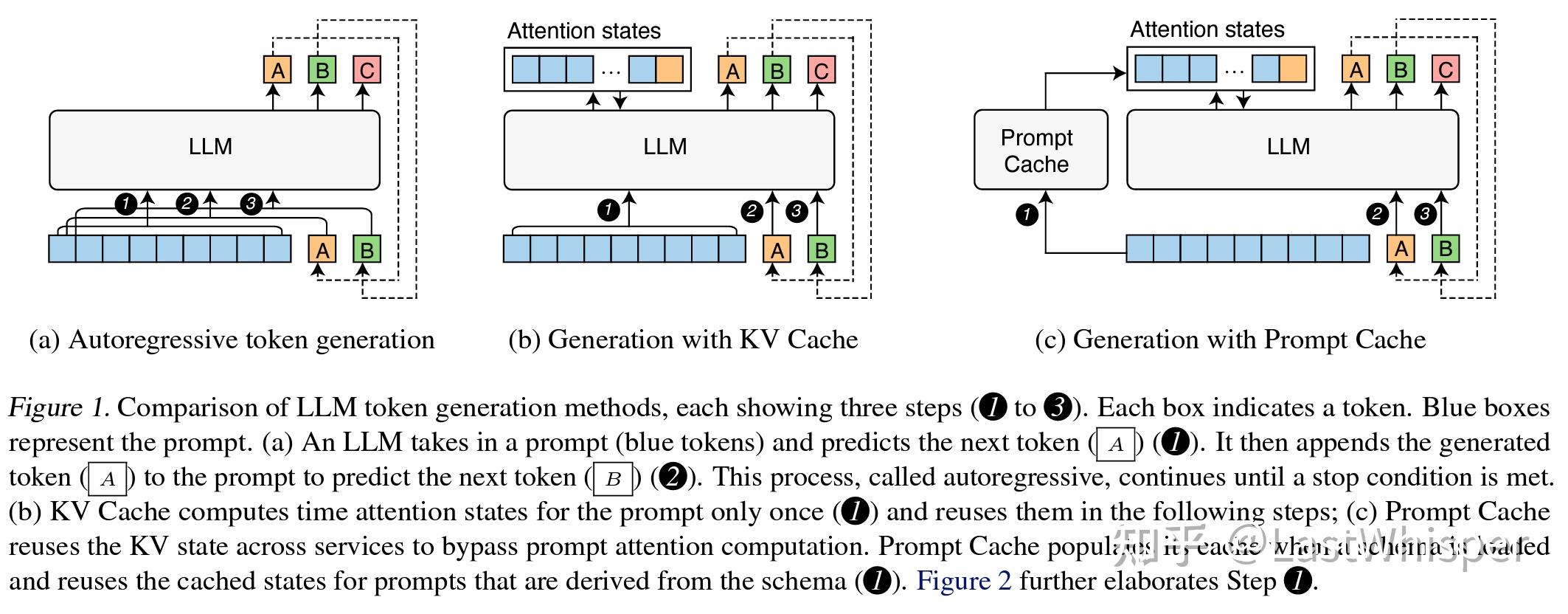
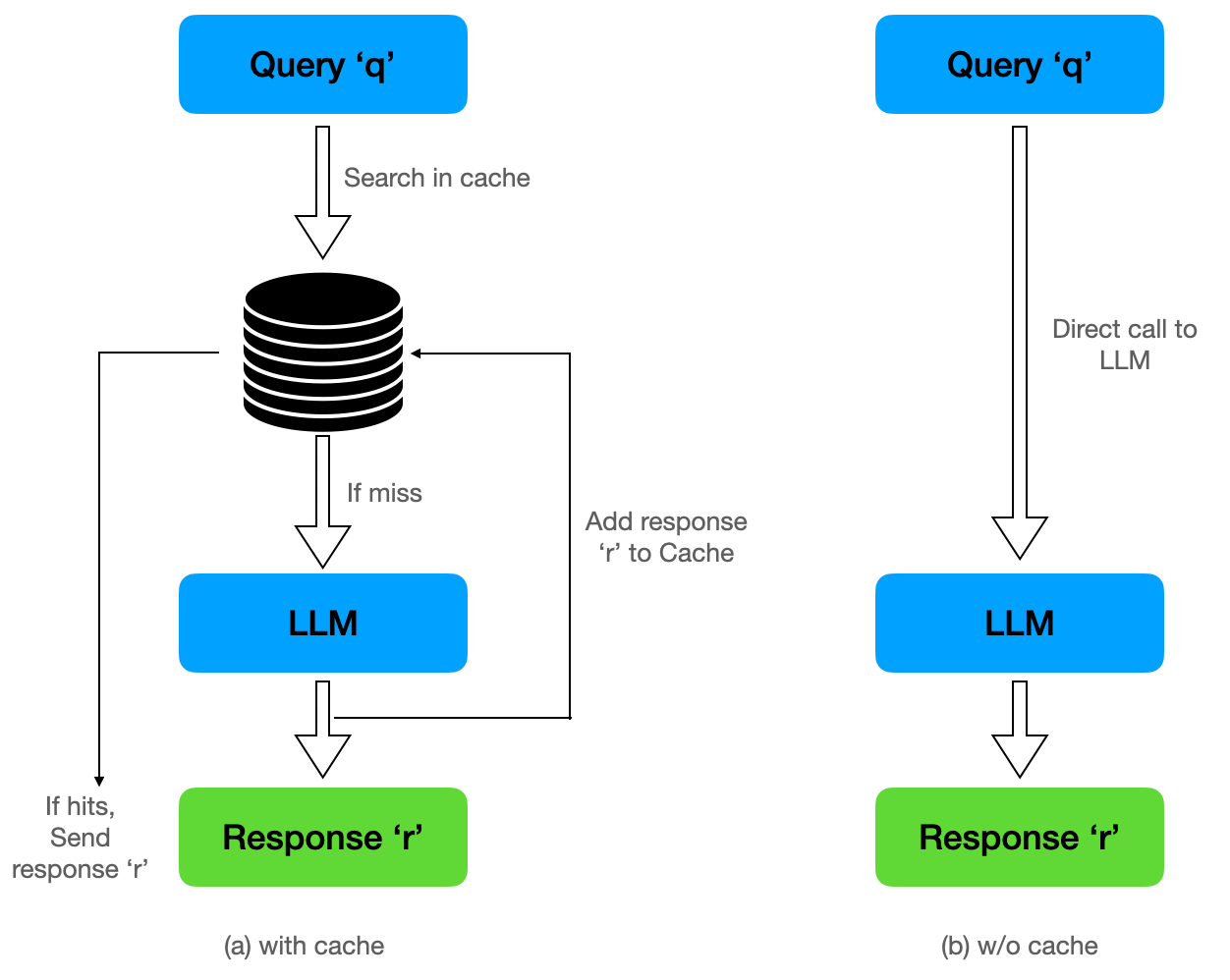
Prompt Caching
How to use Prompt Caching?
The Complete Guide to Prompt Caching: Cut LLM Costs by 90%
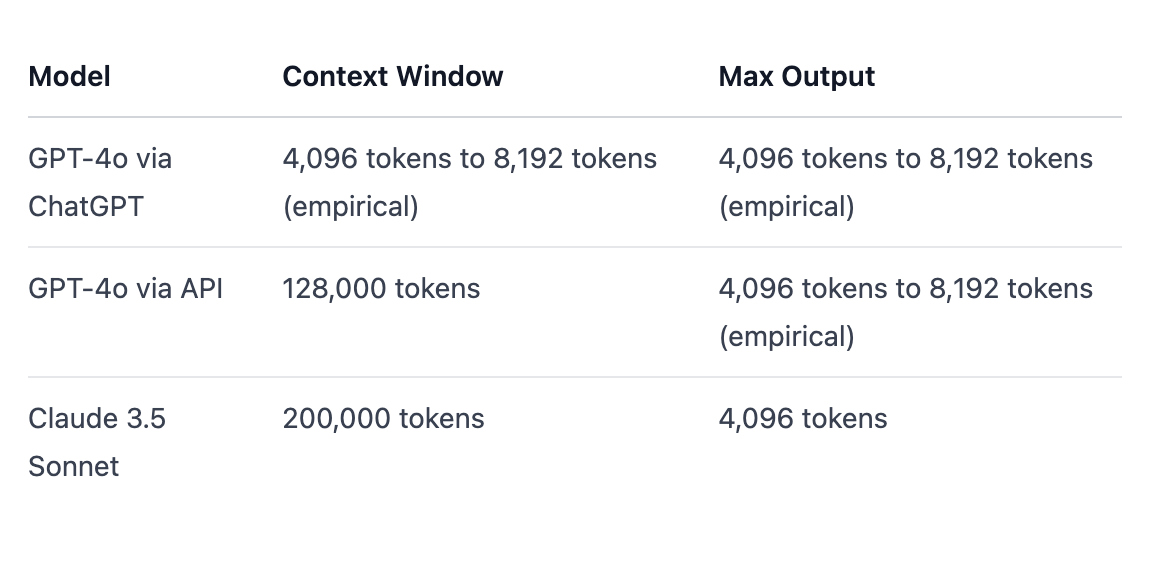
Claude 3.5 Sonnet vs GPT-4o: Context Window and Token Limit | 16x Prompt
What is prompt caching? How it works and when to use it. | Louisa ...
Prompt Caching Calculator — Anthropic Claude Savings, 2026 | HCODX
What is Prompt caching? Prompt caching has now become a common feature ...
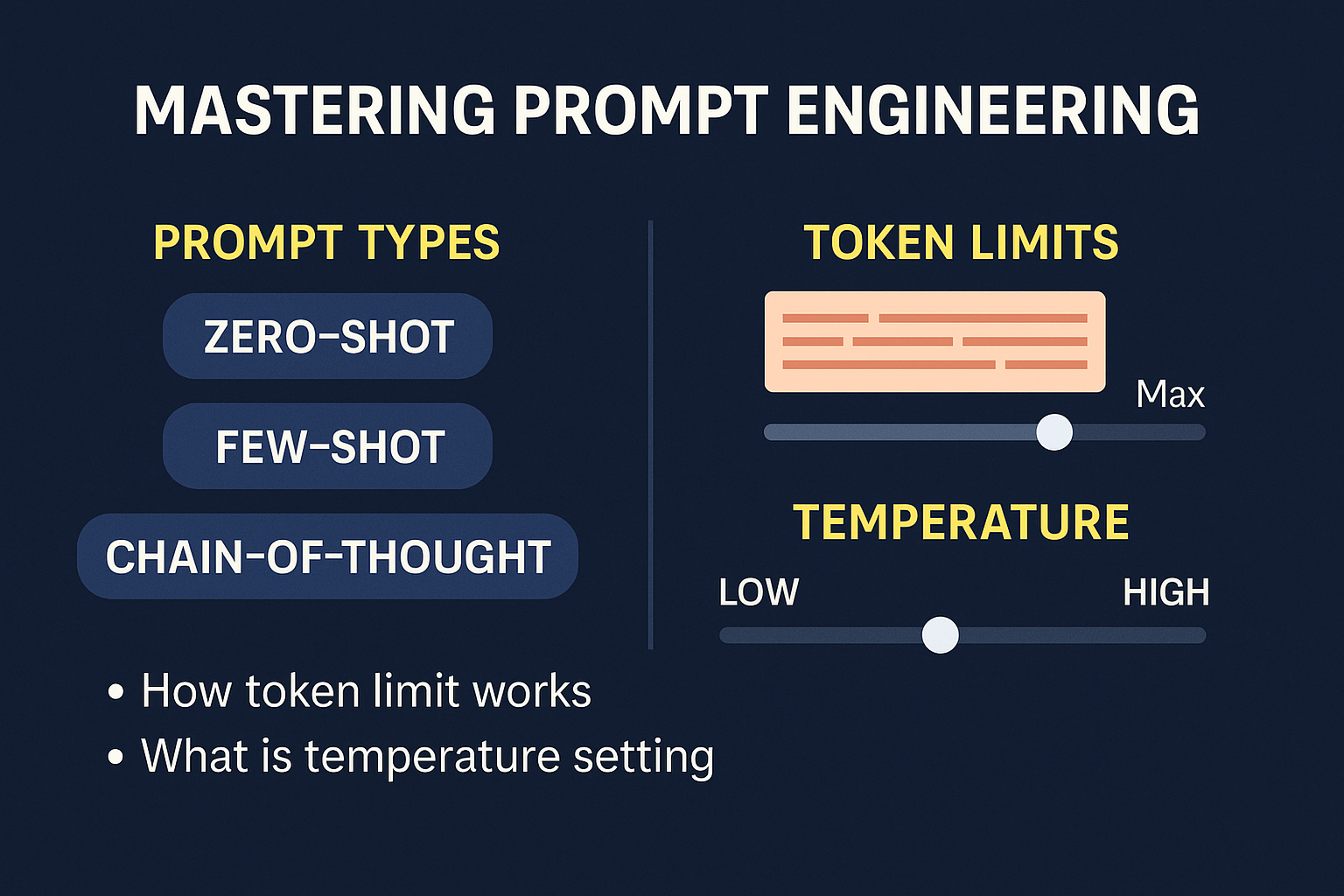
Mastering Prompt Engineering: Prompt Types, Token Limits & Temperature ...
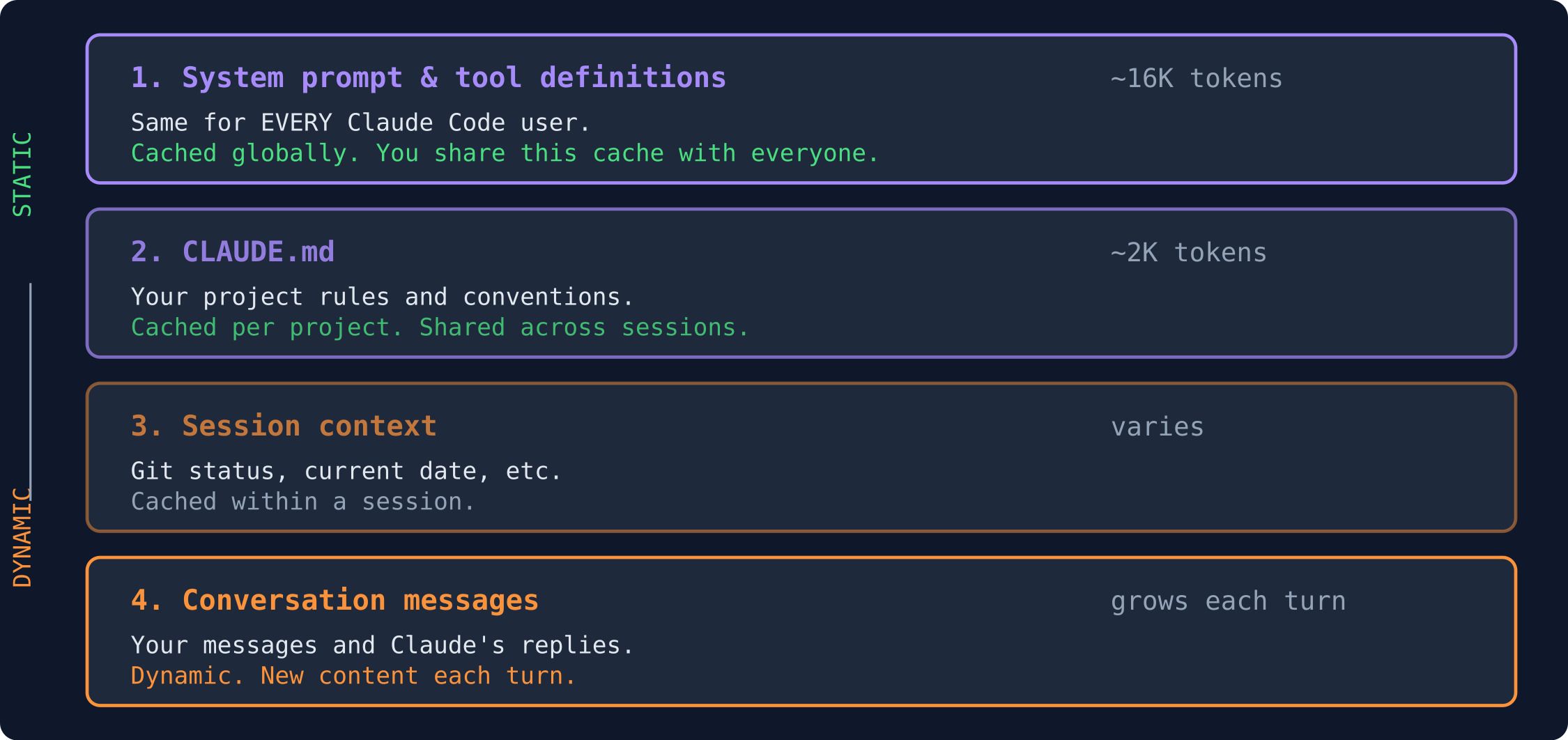
How Prompt Caching Actually Works in Claude Code
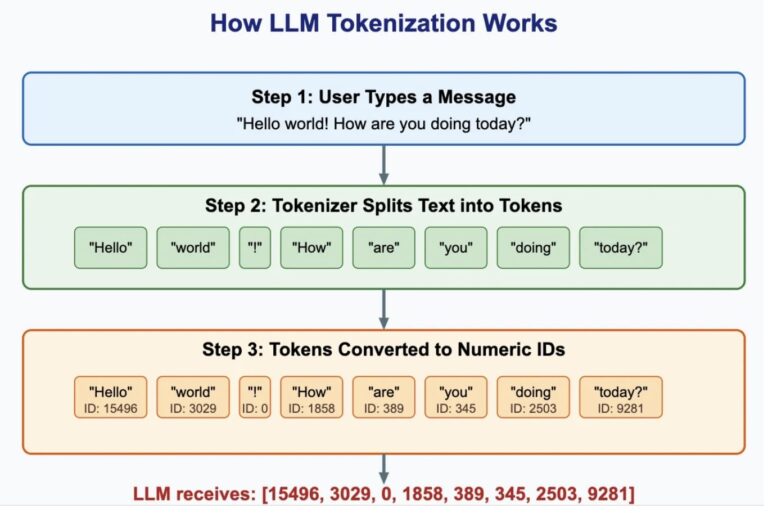
How LLMs use Tokens and Tokenization | by Amit Naik | ExpertMinds | Medium
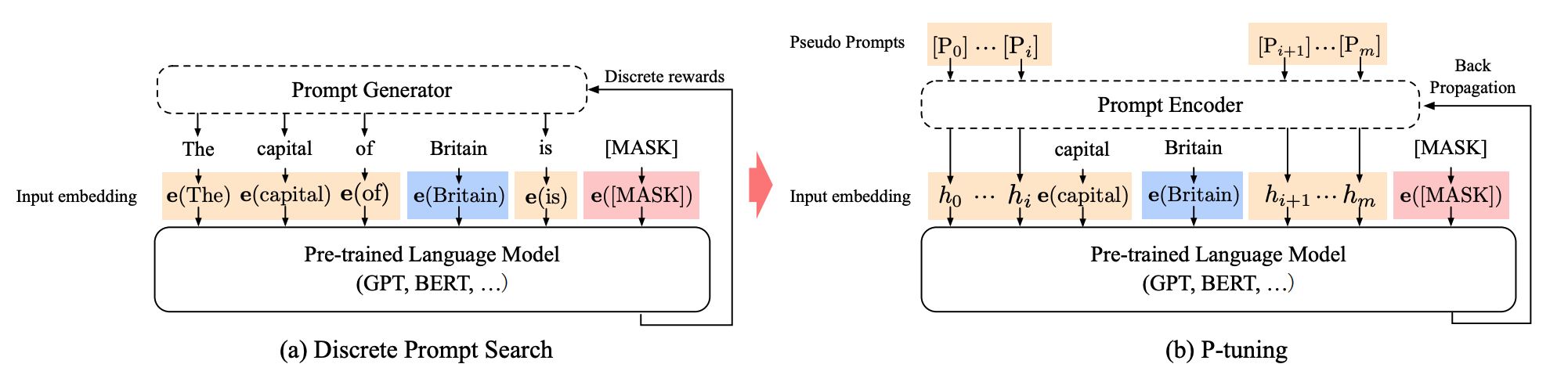
The Power of Scale for Parameter-Efficient Prompt Tuning 论文笔记 - 知乎
Tokens and Tokenization are an Important for Fundamental LLM ...
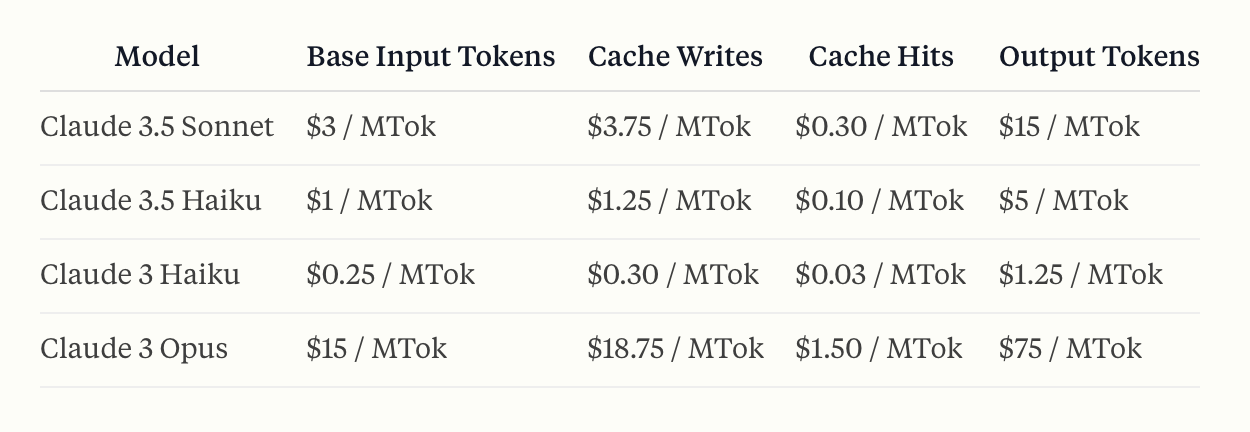
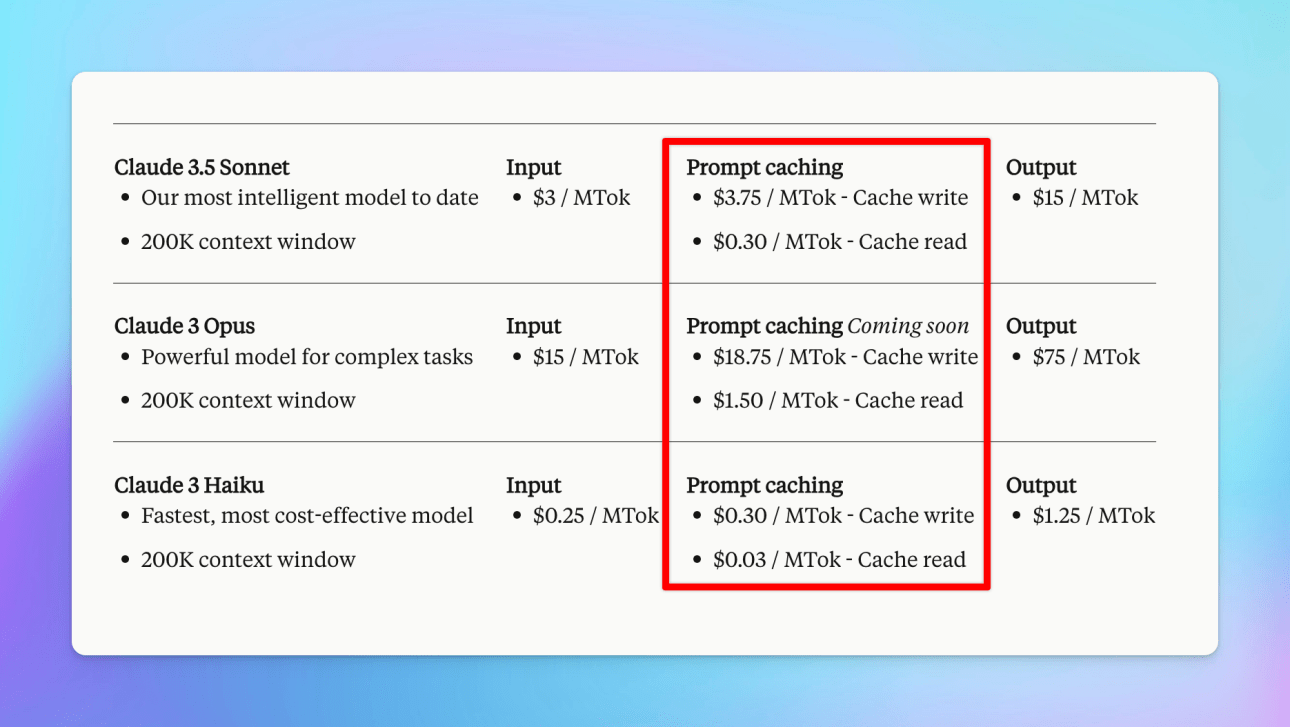
Anthropic Prompt Caching
Understanding the difference between context caching or prompt caching ...
Prompt Caching - Save Money and Time | Unscripted Coding - YouTube
multiple_matching_tokens The cache contains multiple tokens satisfying ...
Prompt caching,一篇就够了。 - 知乎
Generative AI Central on LinkedIn: Want to save money with prompt ...
Prompt Optimization, Reduce LLM Costs and Latency | by Bijit Ghosh | Medium
Why does Cursor consume an absurd amount of cache read tokens ...
LLM Prompt Engineering 实践:原型 · ZMonster's Blog
The Basics of Prompt Engineering - watsonx-prompt-lab
Python ChatGPT API and DeepSeek API: Straight‑to‑the‑Point Guide 🐍🤖
Prompts: Communicating Effectively with Generative AI | Blog | Raja ...
prompt_tokens_cached | langchain_community | LangChain Reference
5 Prompt-Cache Designs That Slash Token Costs | by Praxen | Dec, 2025 ...
Caching techniques in ML systems design | UnfoldAI
Context Cache feature of Qwen models - Alibaba Cloud Model Studio ...
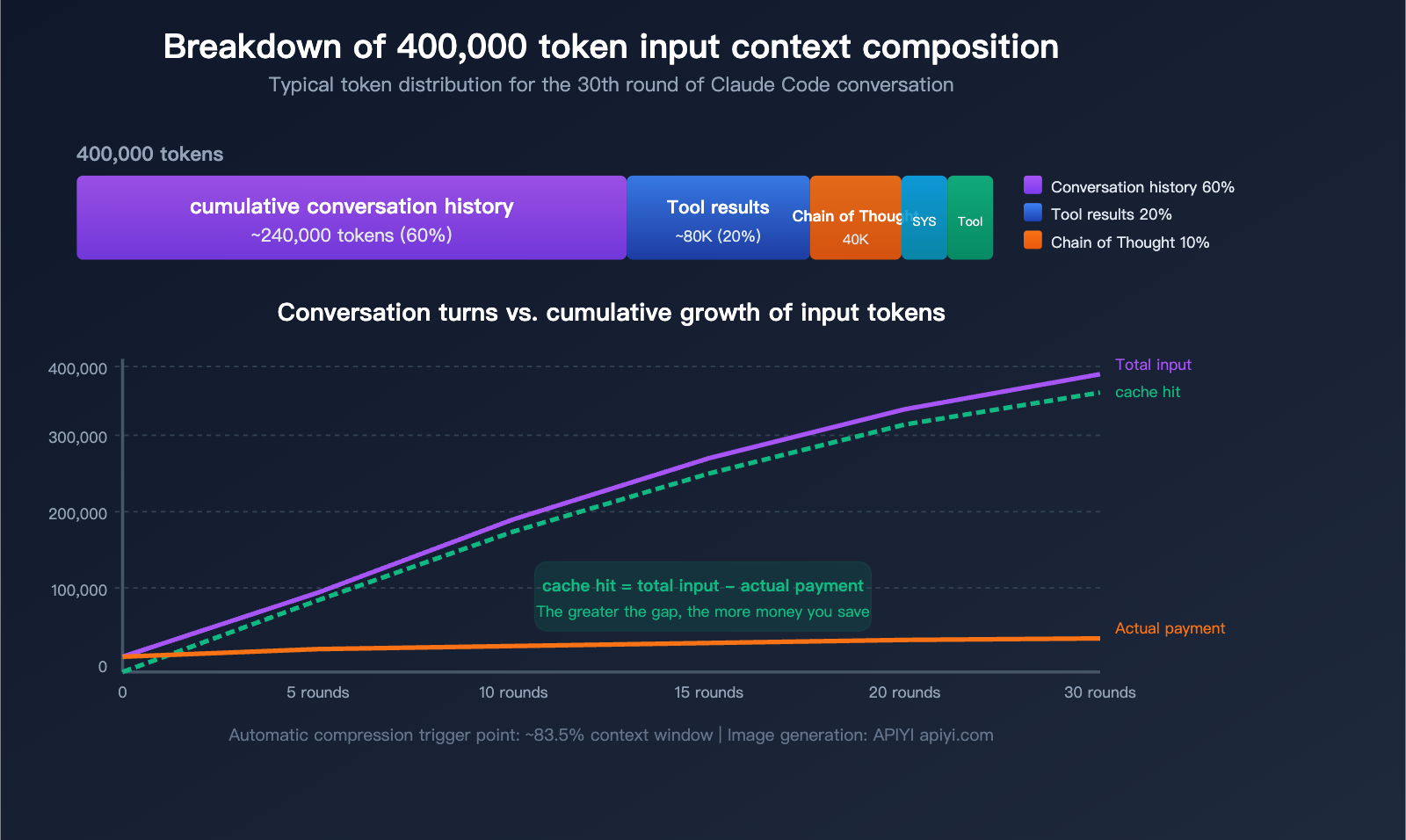
Claude Code cache hit rate increased to 95%: 6 practical tips to reduce ...
Prompting
From 5-7-5 to Thousand Lines: The Case for Longer Prompts – Paul Simmering
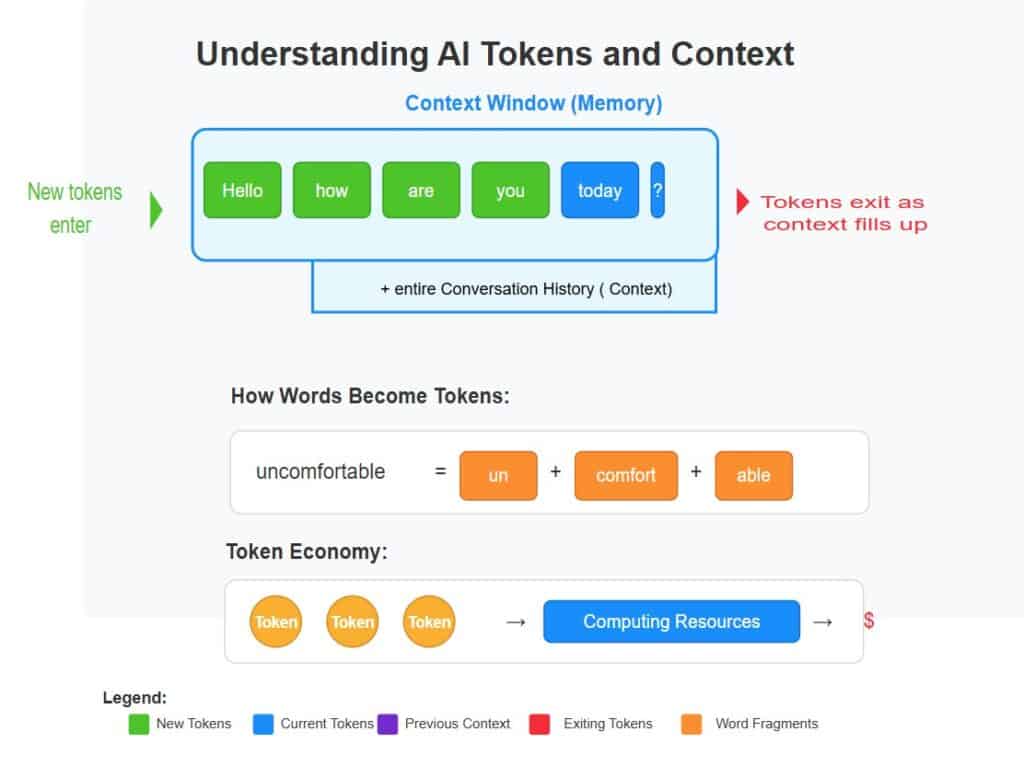
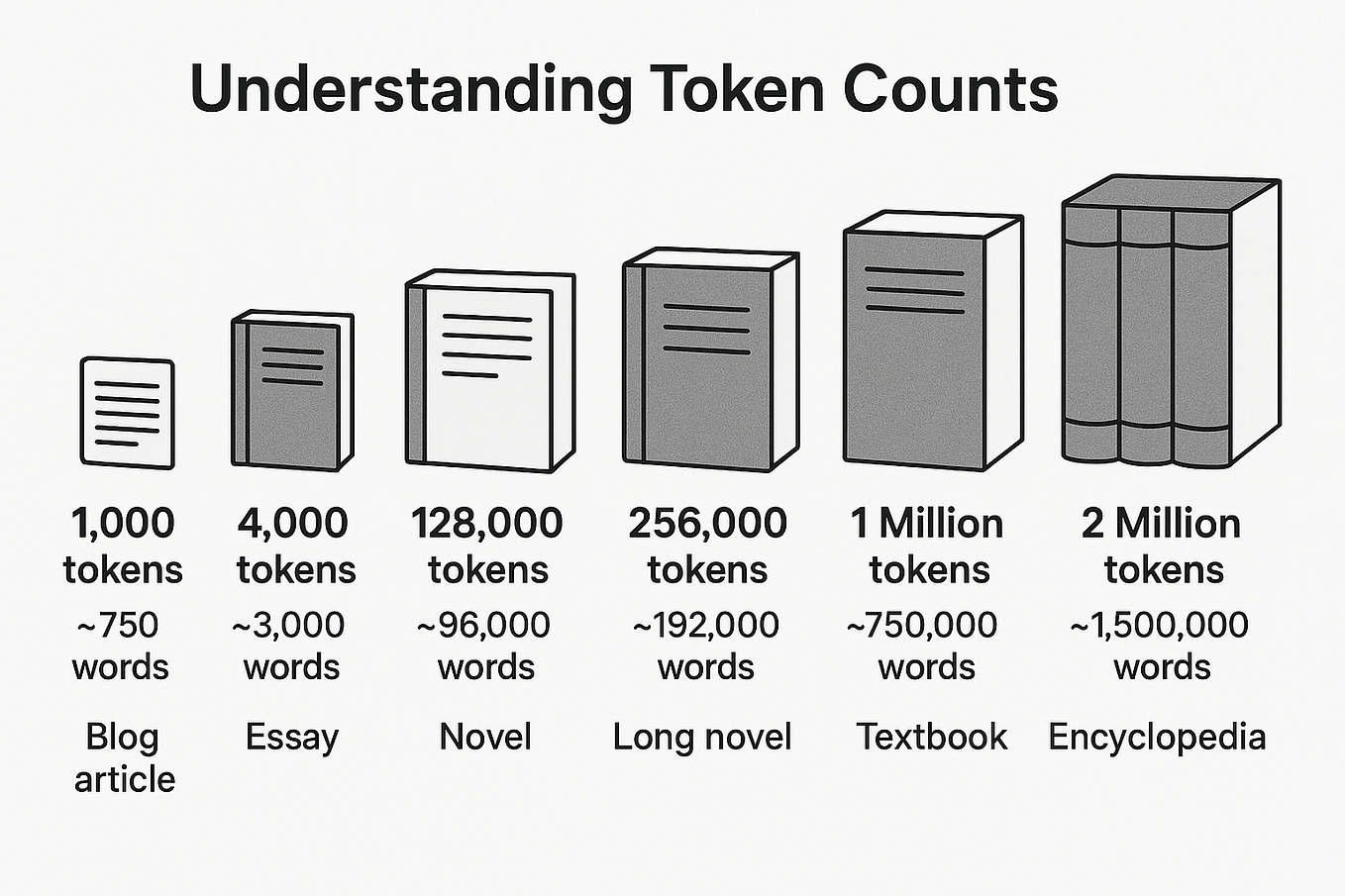
Understanding AI Tokens: The Building Blocks of AI Applications ...
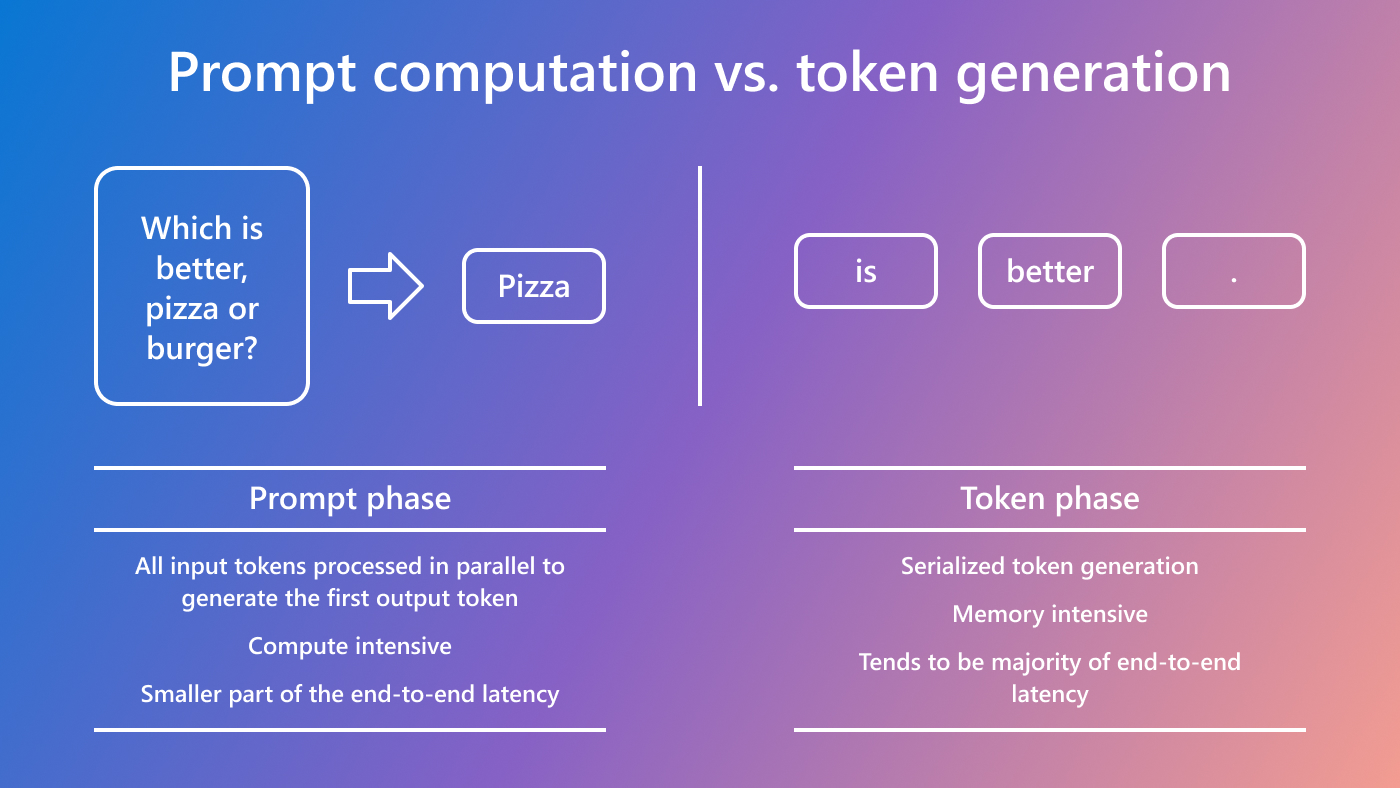
LLM profiling guides KV cache optimization - Microsoft Research
Mastering LLM Techniques: Inference Optimization – GIXtools
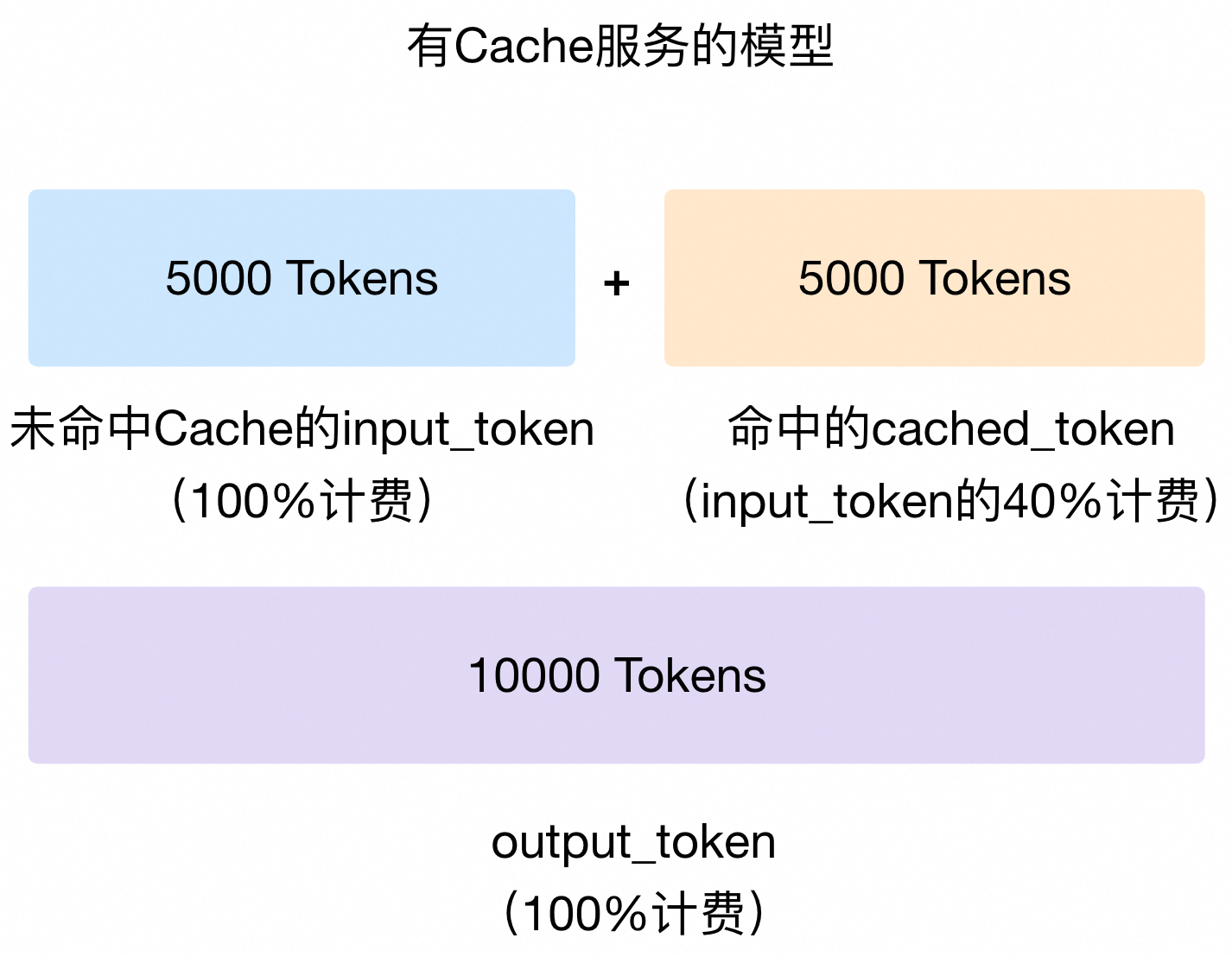
How to use cached_tokens field to calculate cost estimation - API ...
Demystifying Tokens: A Beginners Guide To Understanding AI Building ...
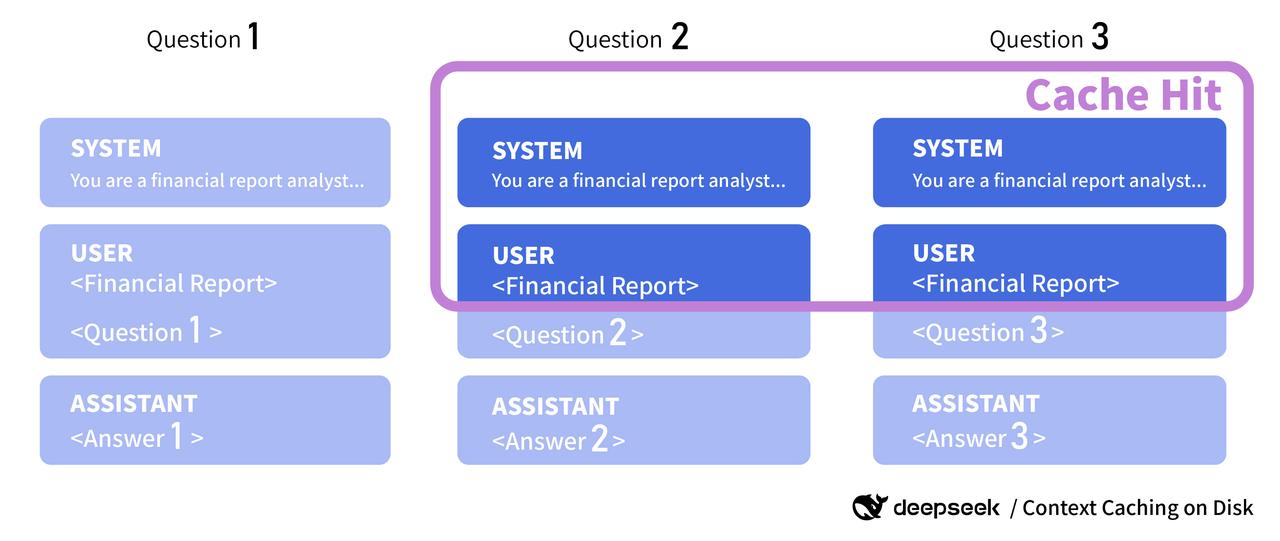
通义千问模型的 Context Cache 功能 - 大模型服务平台百炼 - 阿里云
Large Discrepancy in Output Token Size Between Two Identical GPT-4o ...
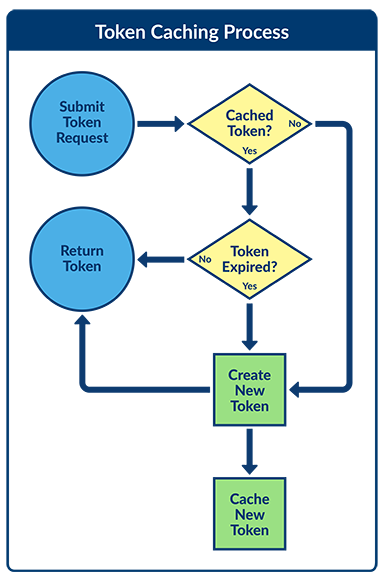
Token Caching
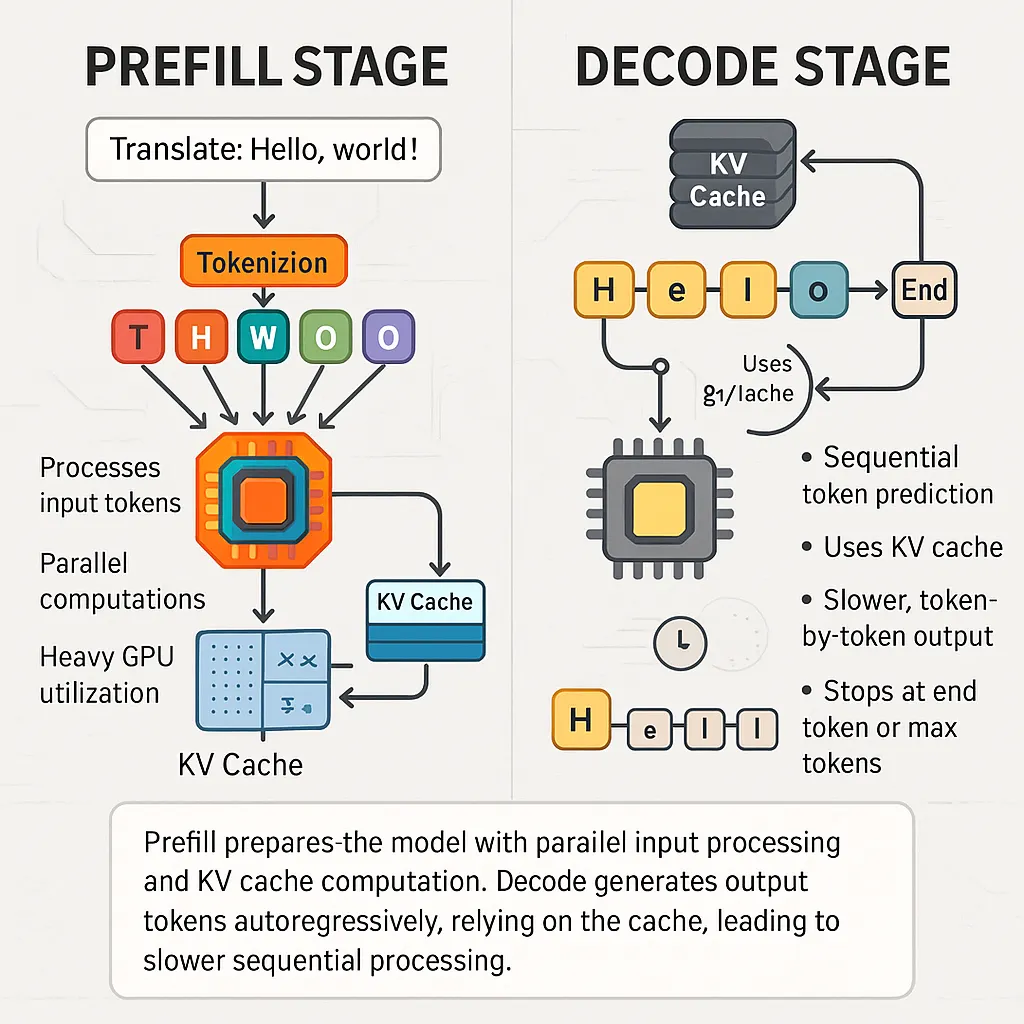
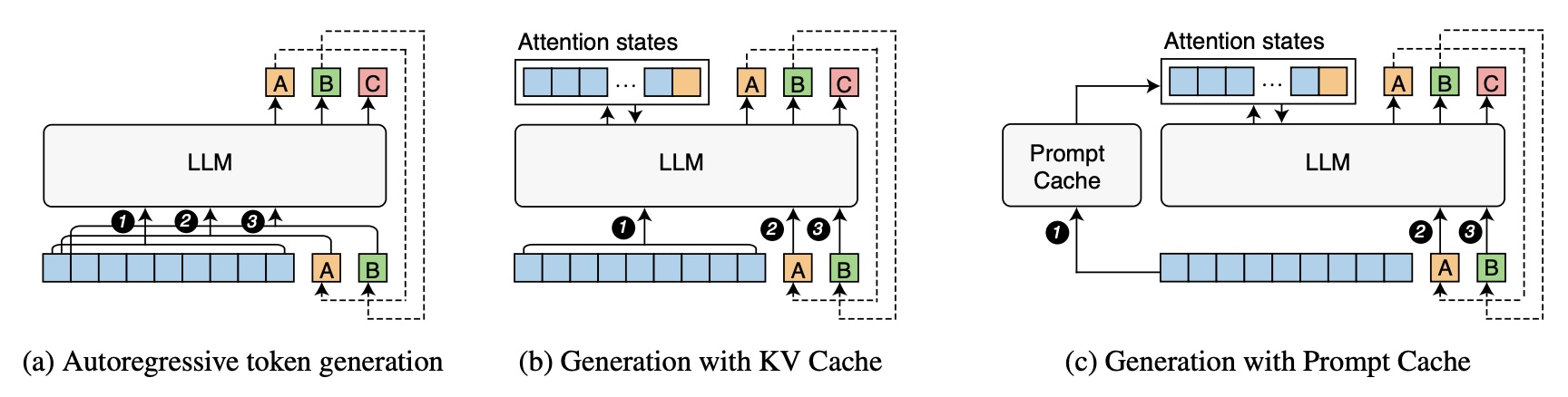
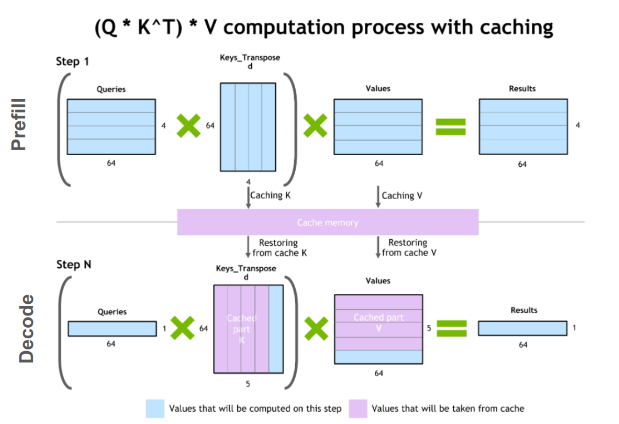
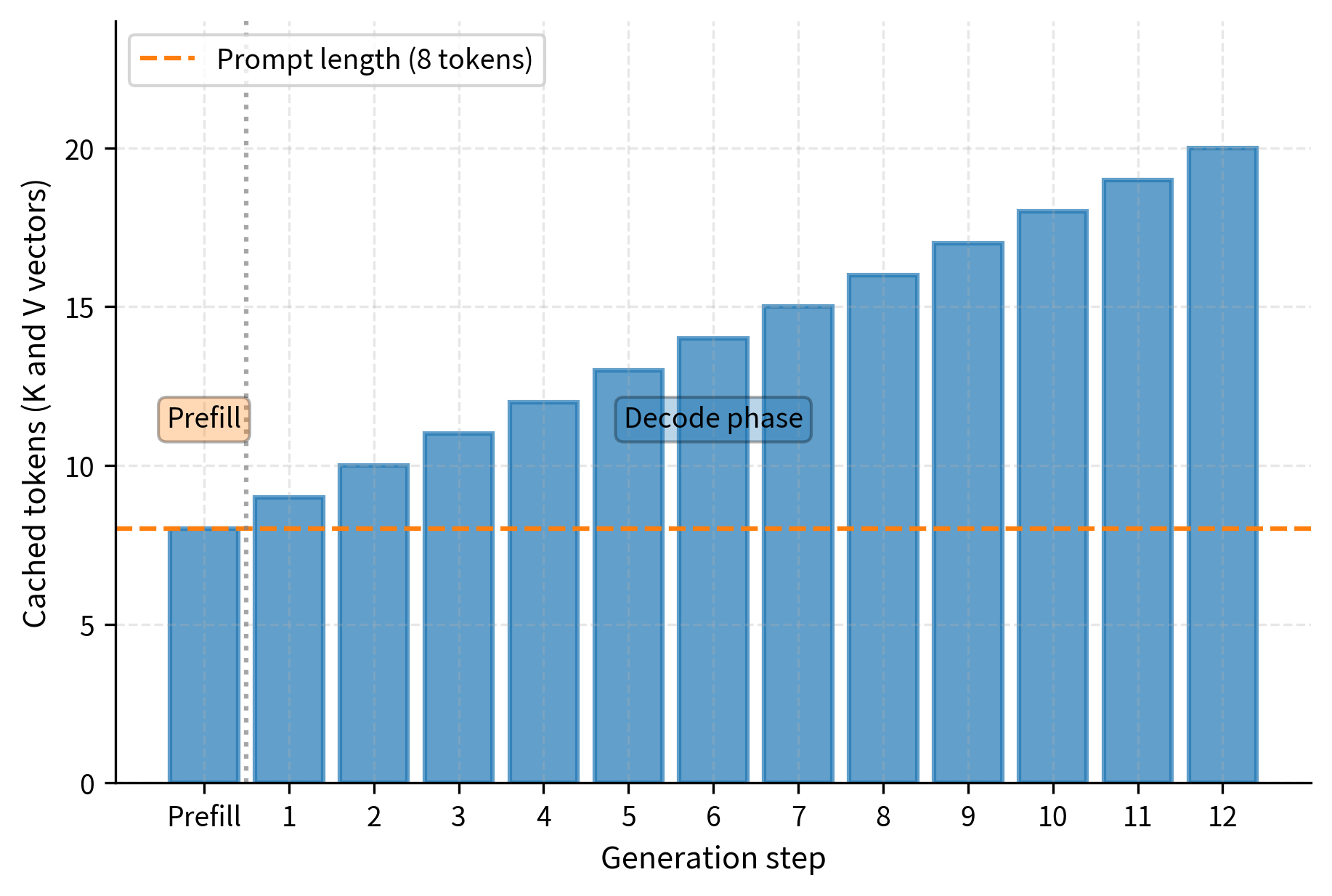
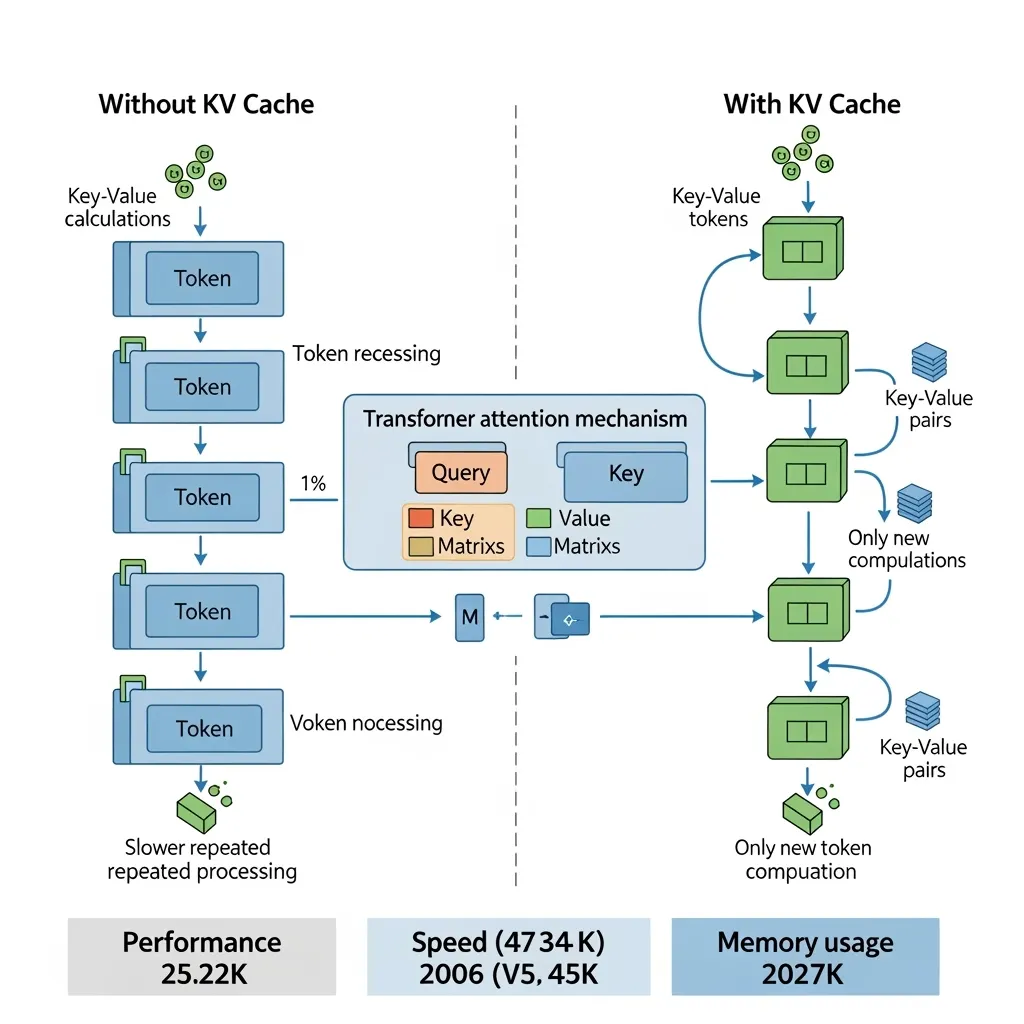
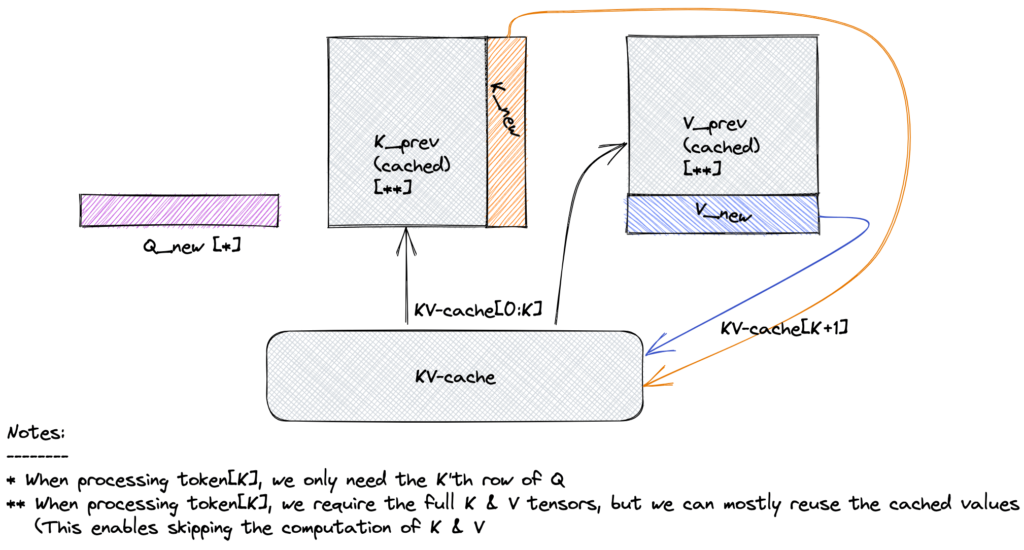
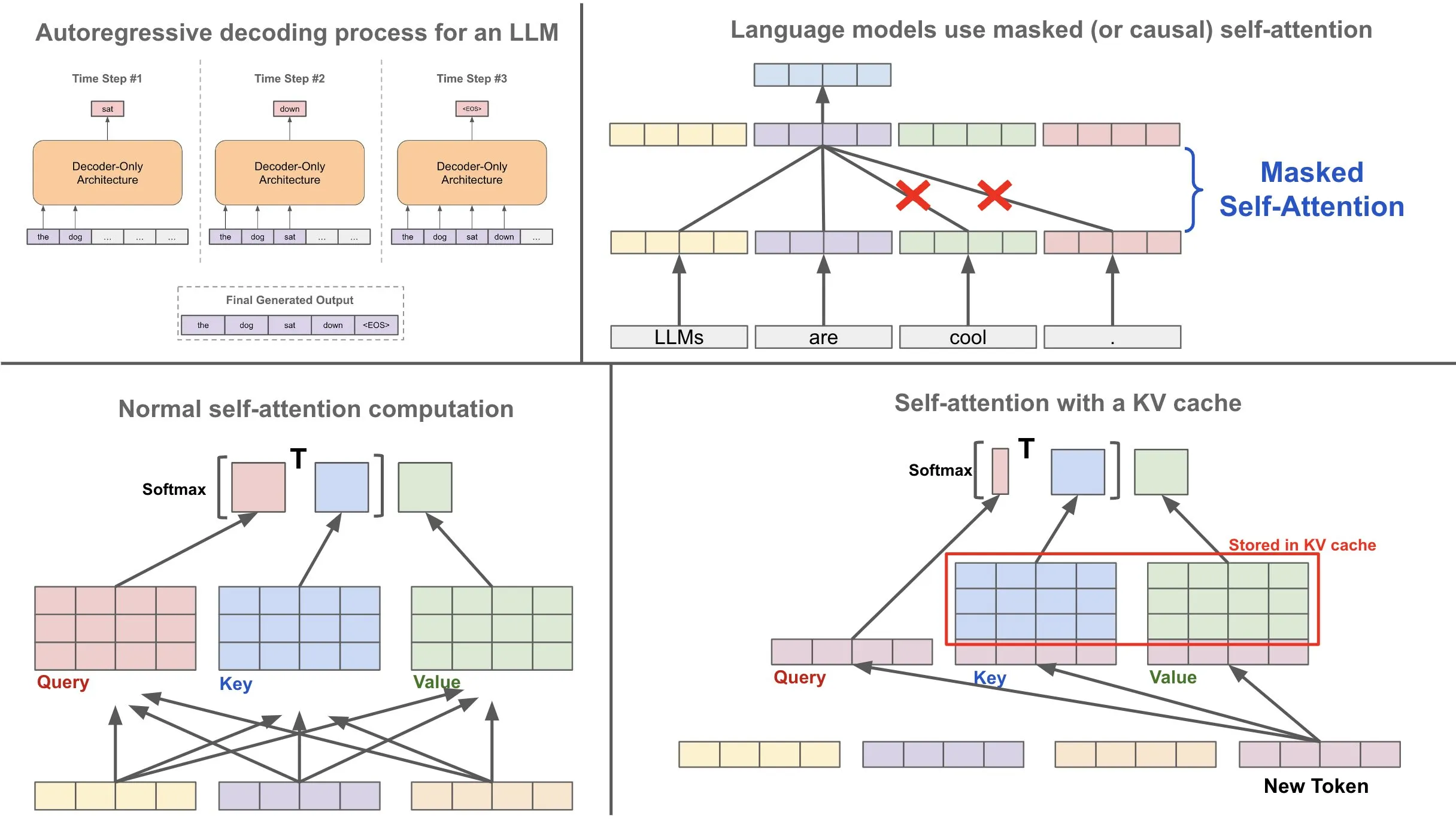
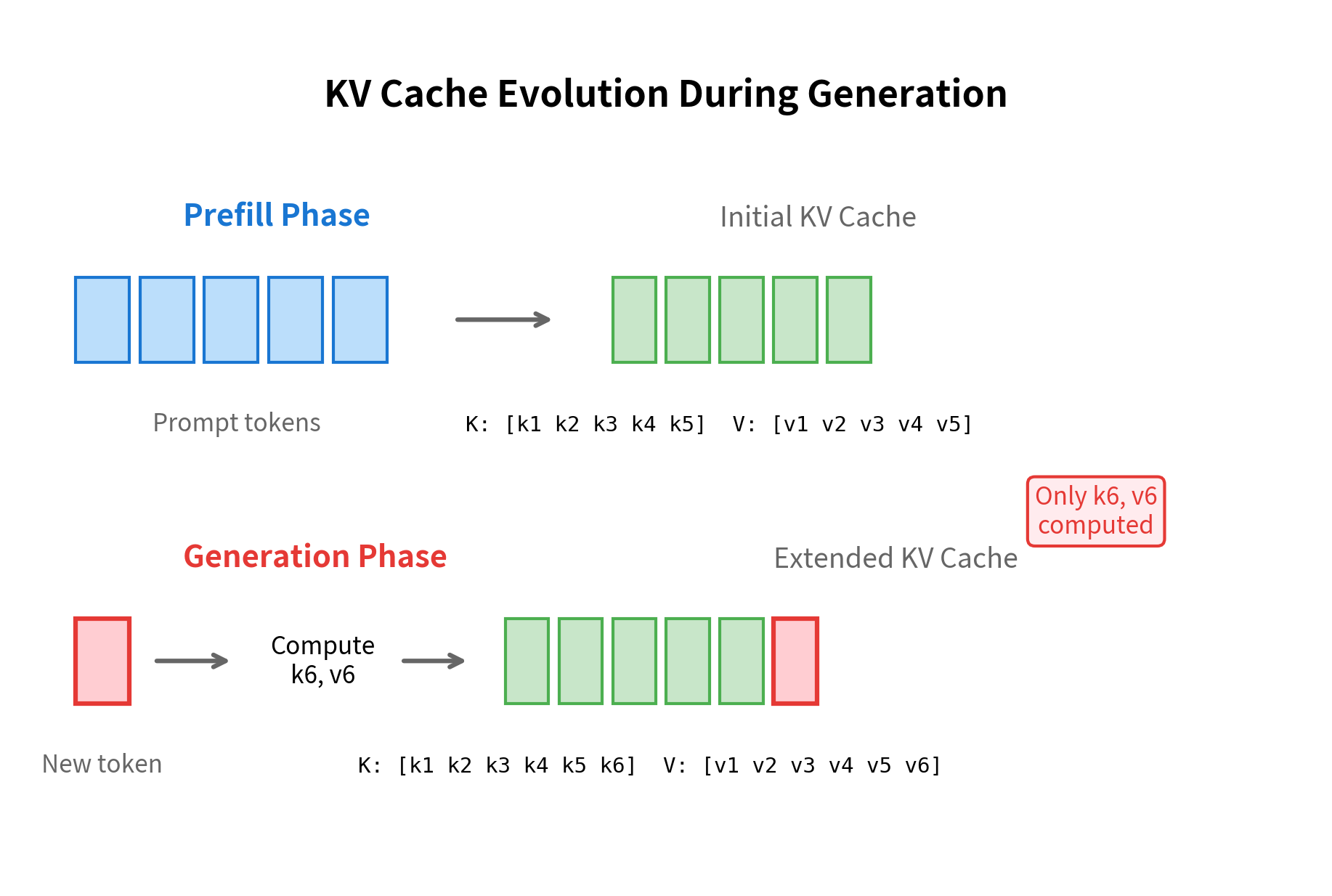
KV Cache Explained: Efficient Attention for LLM Generation ...
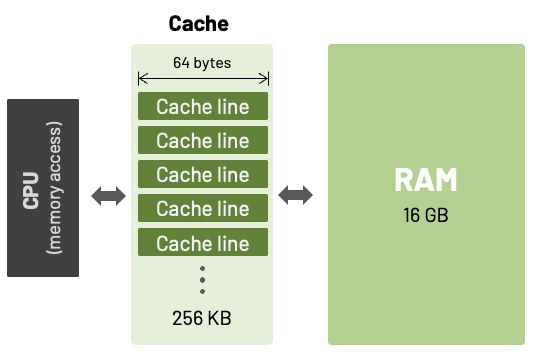
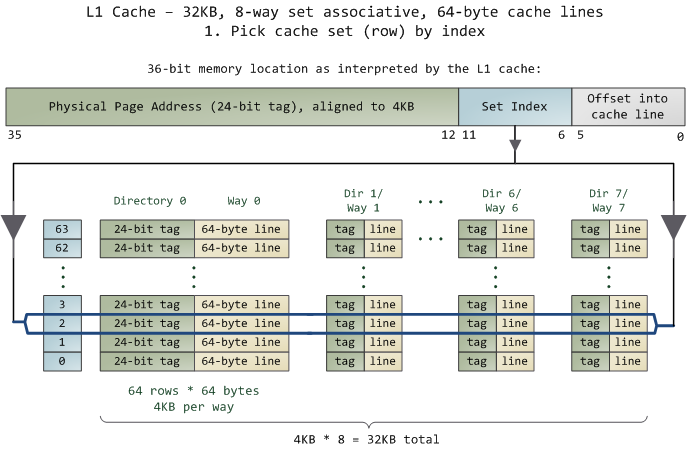
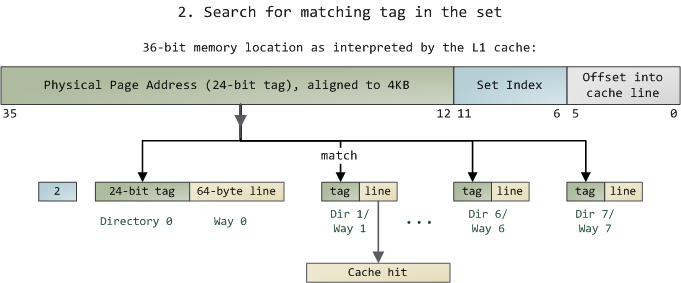
Pikuma: Exploring How Cache Memory Really Works
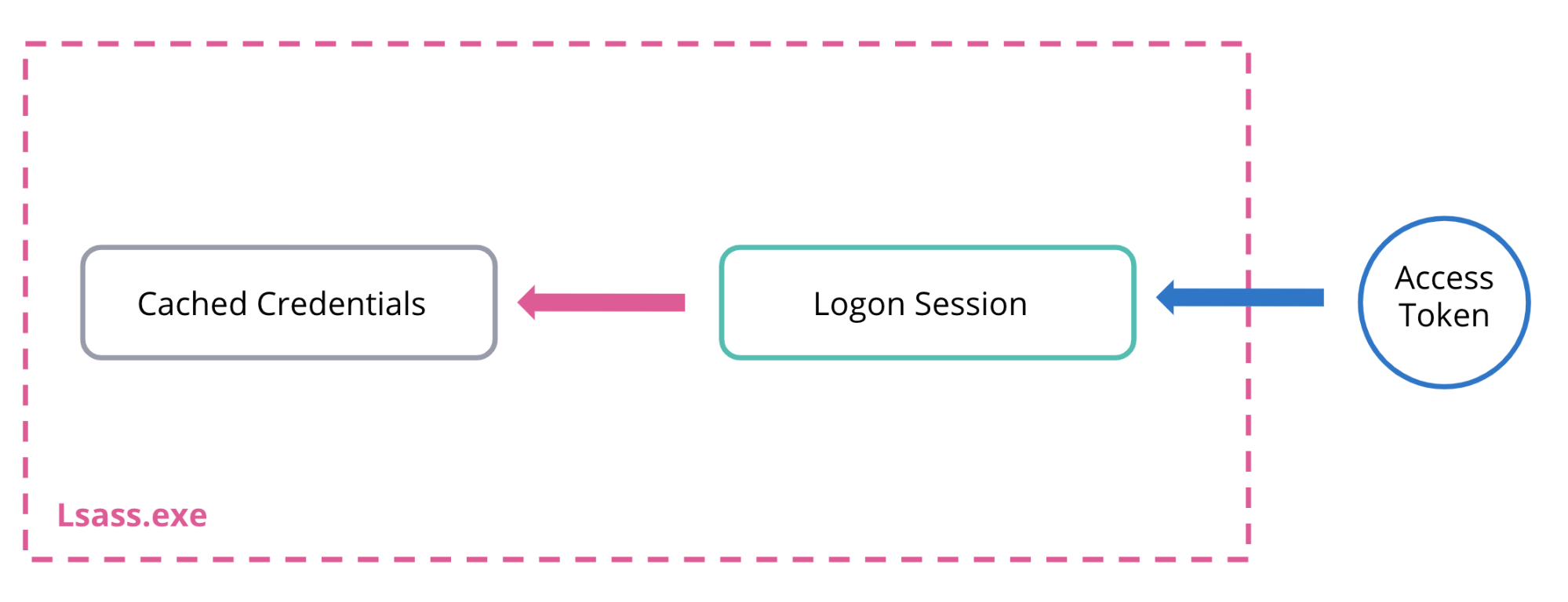
How attackers abuse Access Token Manipulation (ATT&CK T1134) | Elastic Blog
Comparisons of different prompting methods. {V i } M i=1 are the ...
The Power of Examples: Precision Prompting
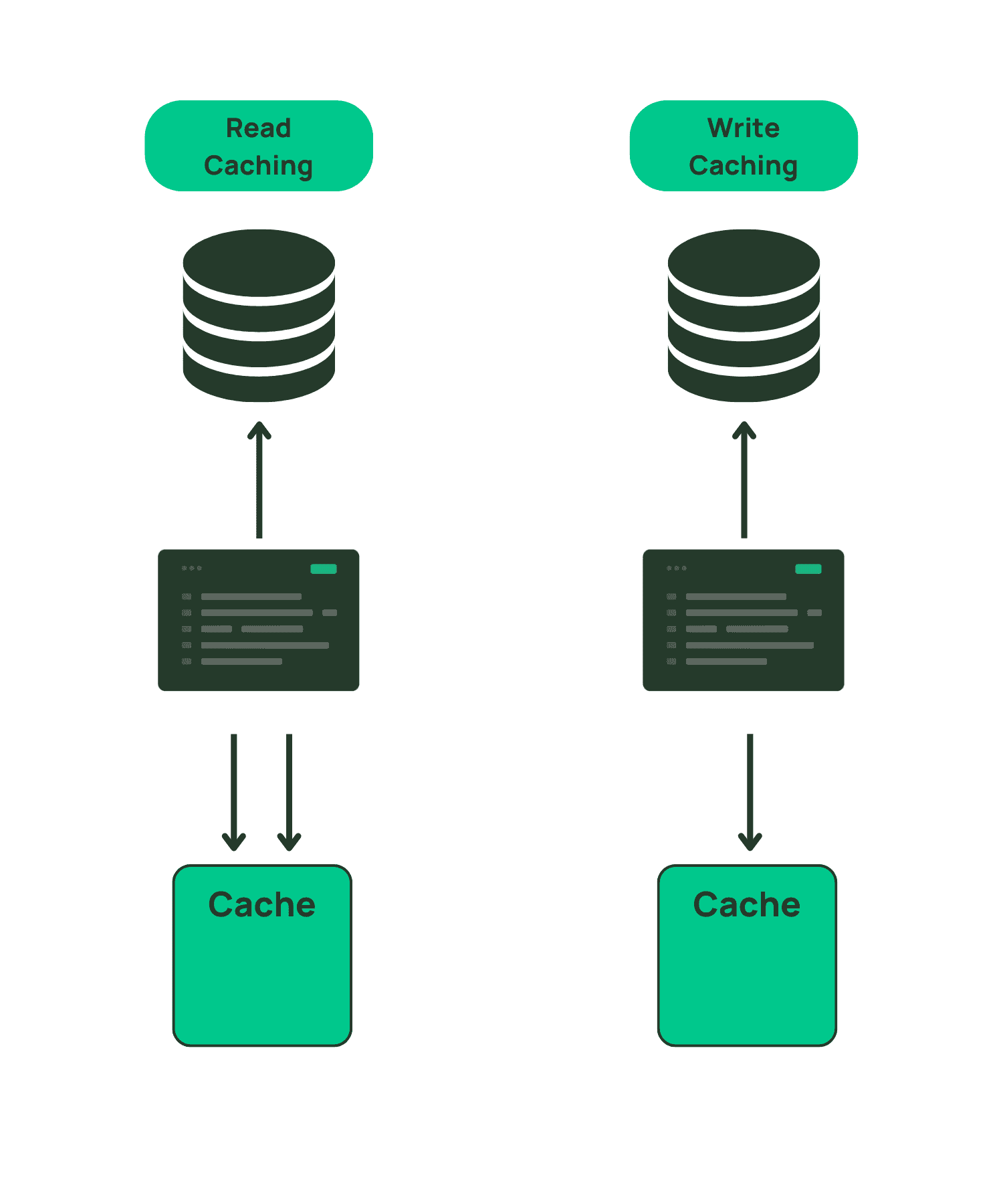
3 crucial caching choices: Where, when, and how - Momento
6 common caching design patterns to execute your caching strategy
🧠Understanding LLM Context Windows: Tokens, Attention, and Challenges ...
Cache: a place for concealment and safekeeping | Many But Finite
KV Cache in Transformer Models - Data Magic AI Blog
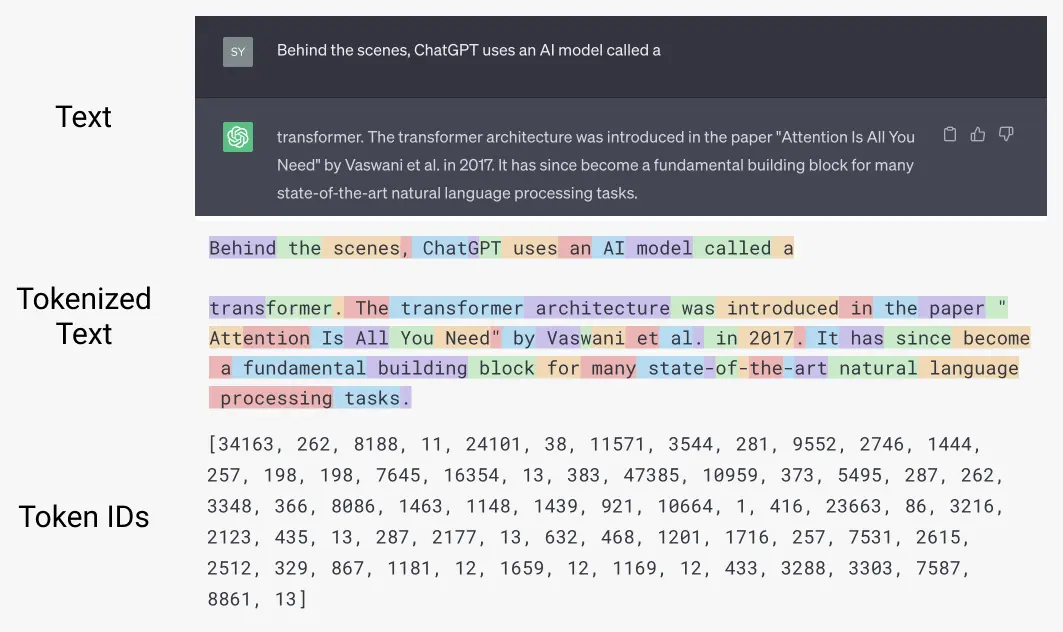
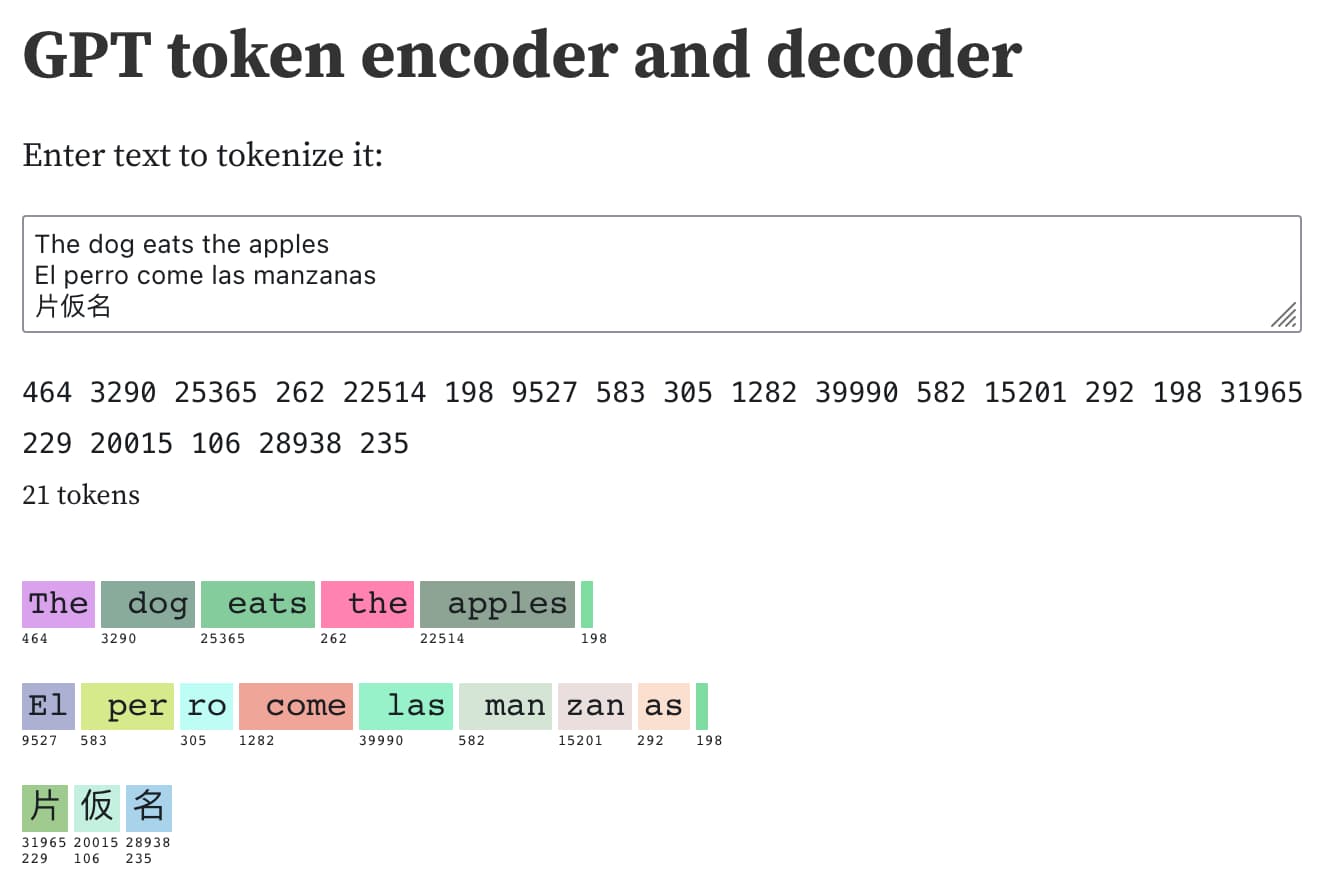
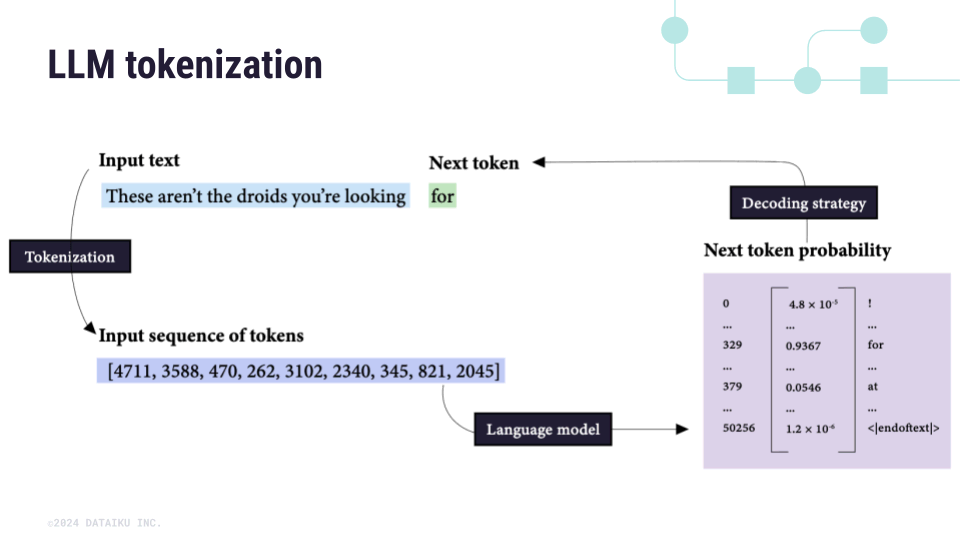
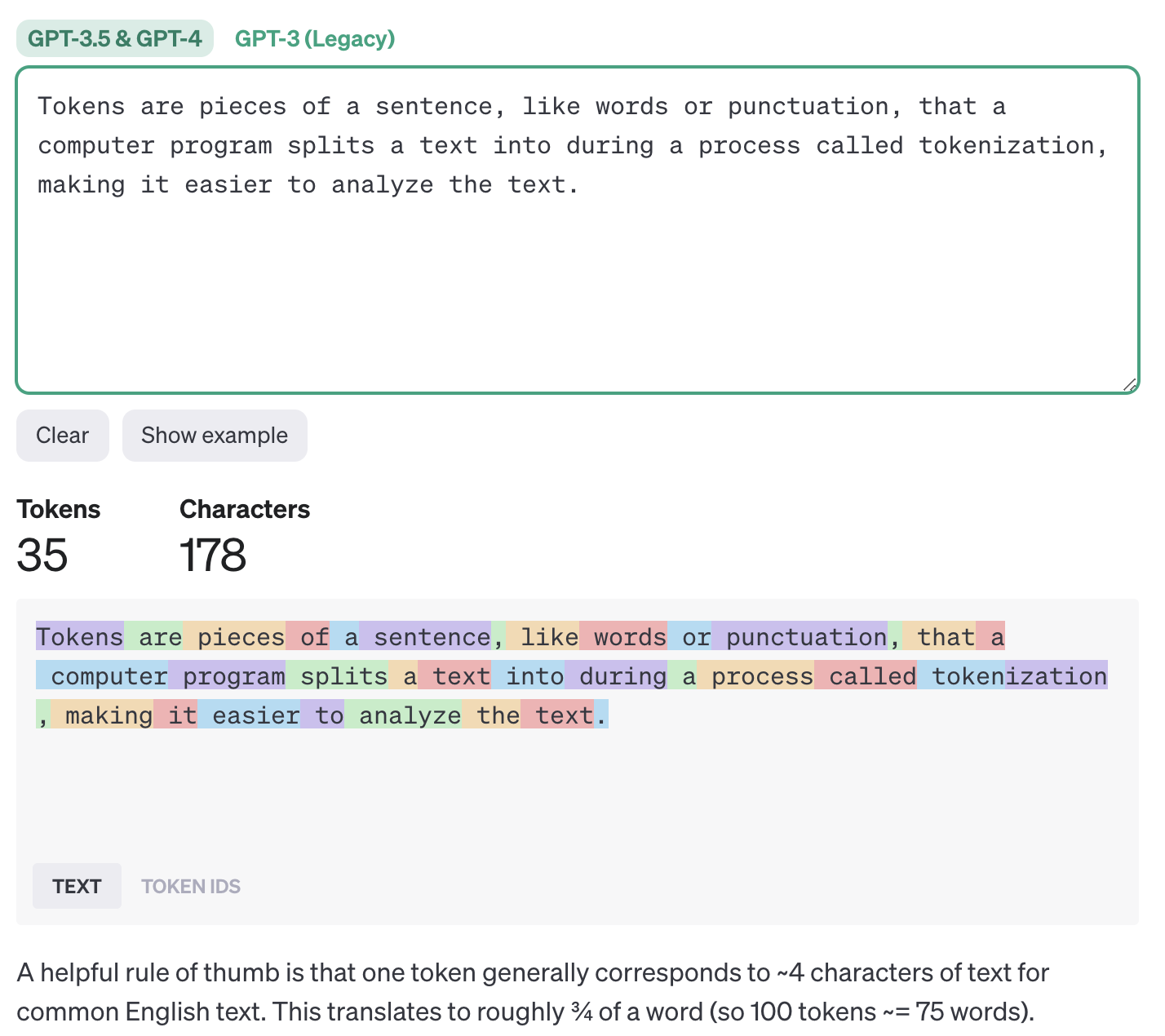
Understanding GPT tokenizers
Dive Into Tokenization, Attention, and Key-Value Caching
Token cache serialization 2x · AzureAD/microsoft-authentication-library ...
Online Solution: Token cache serialization
Token cache serialization - Microsoft Authentication Library for .NET ...
Autoregressive Generation: How GPT Generates Text Token by Token ...
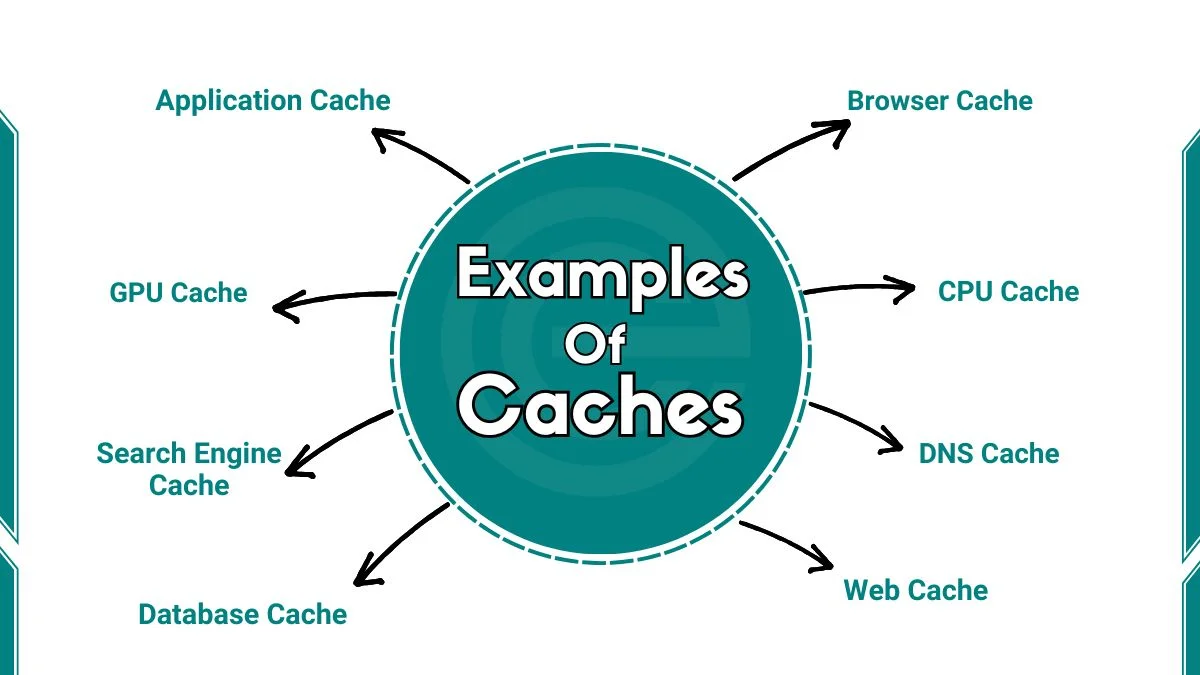
15 Examples of Caches - educatecomputer
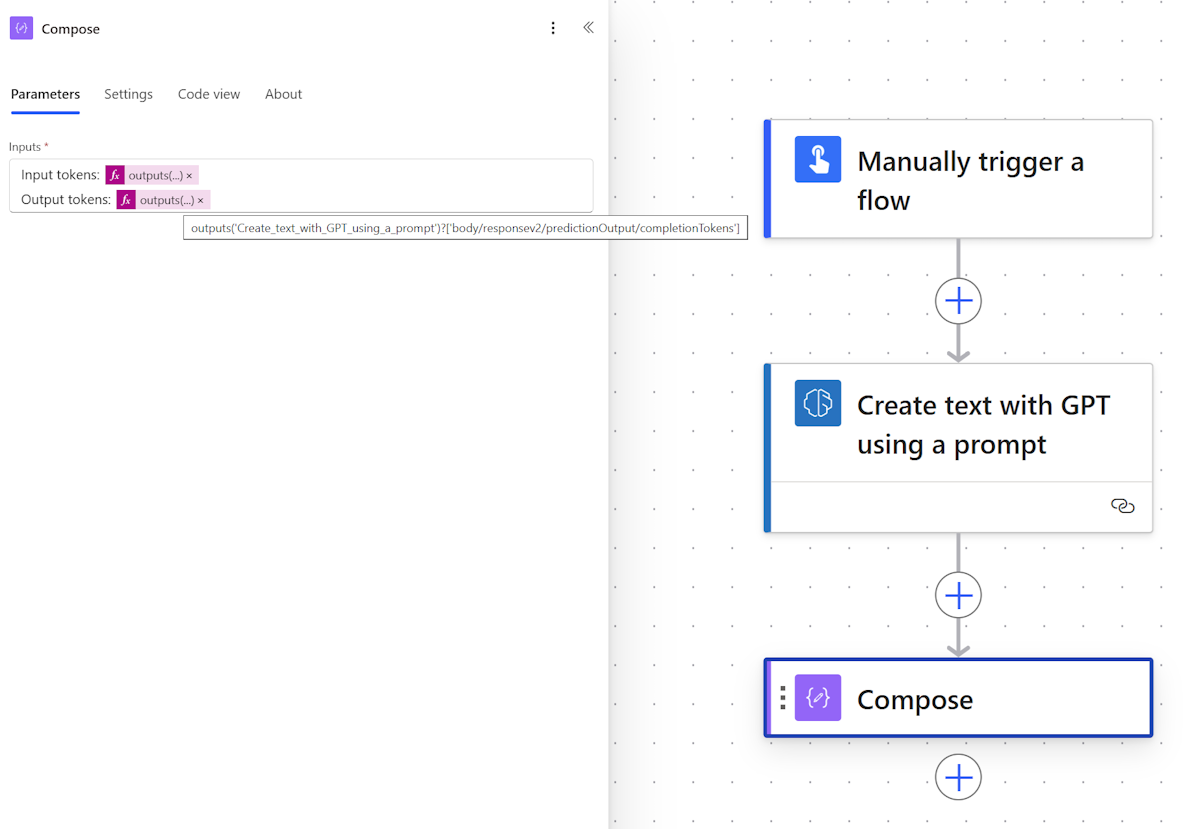
Concept | Large language models and the LLM Mesh - Dataiku Knowledge Base
Jeremy Howard's Threads – Thread Reader App



























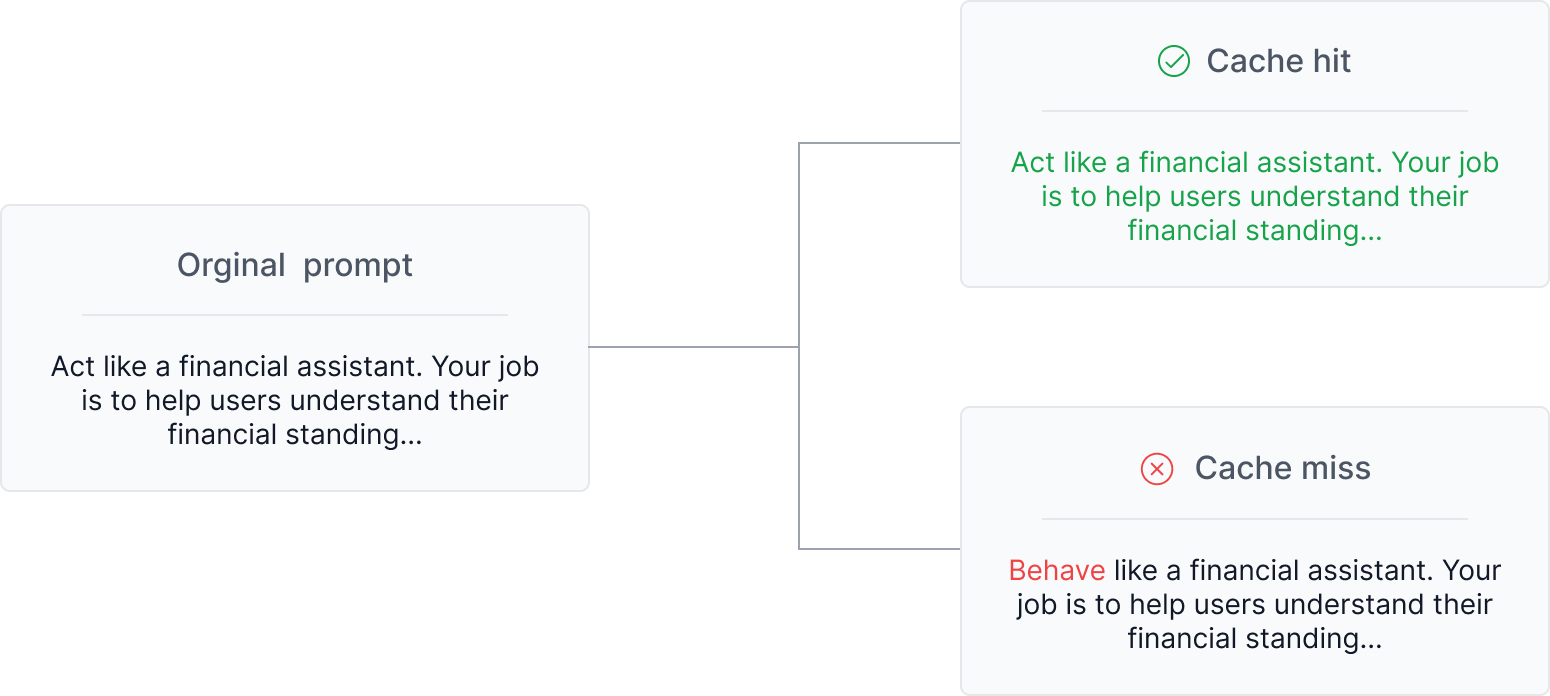
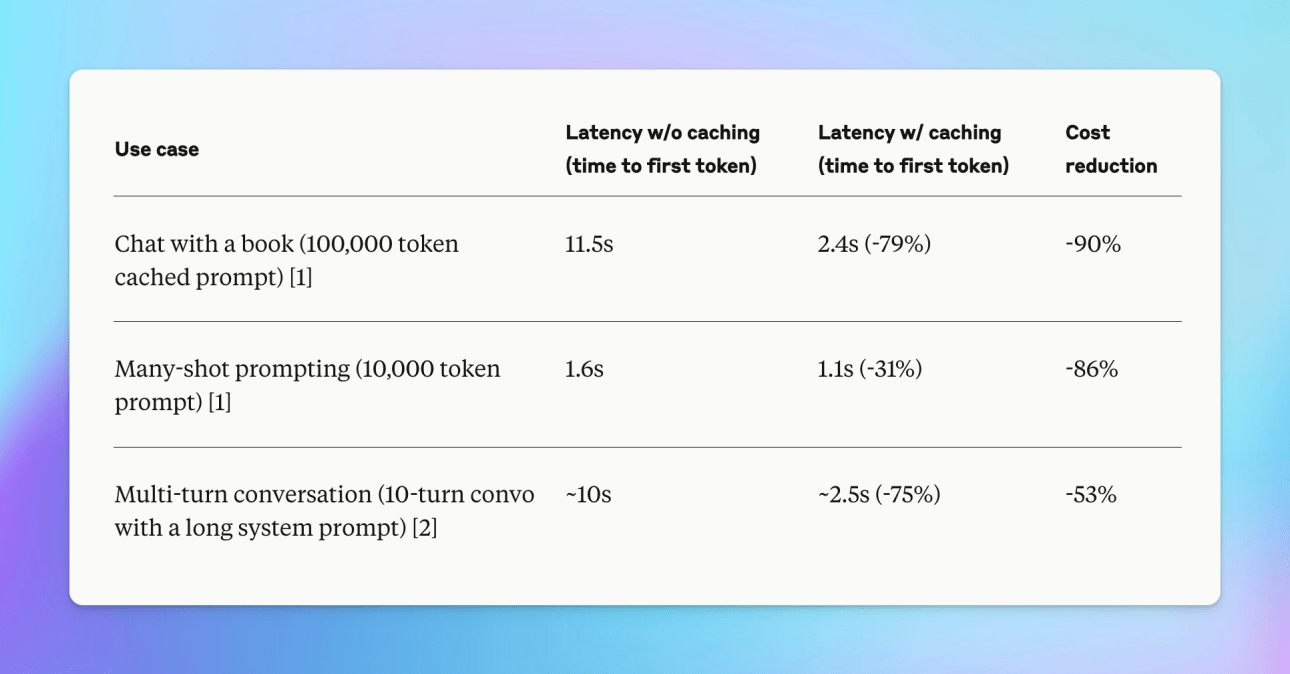
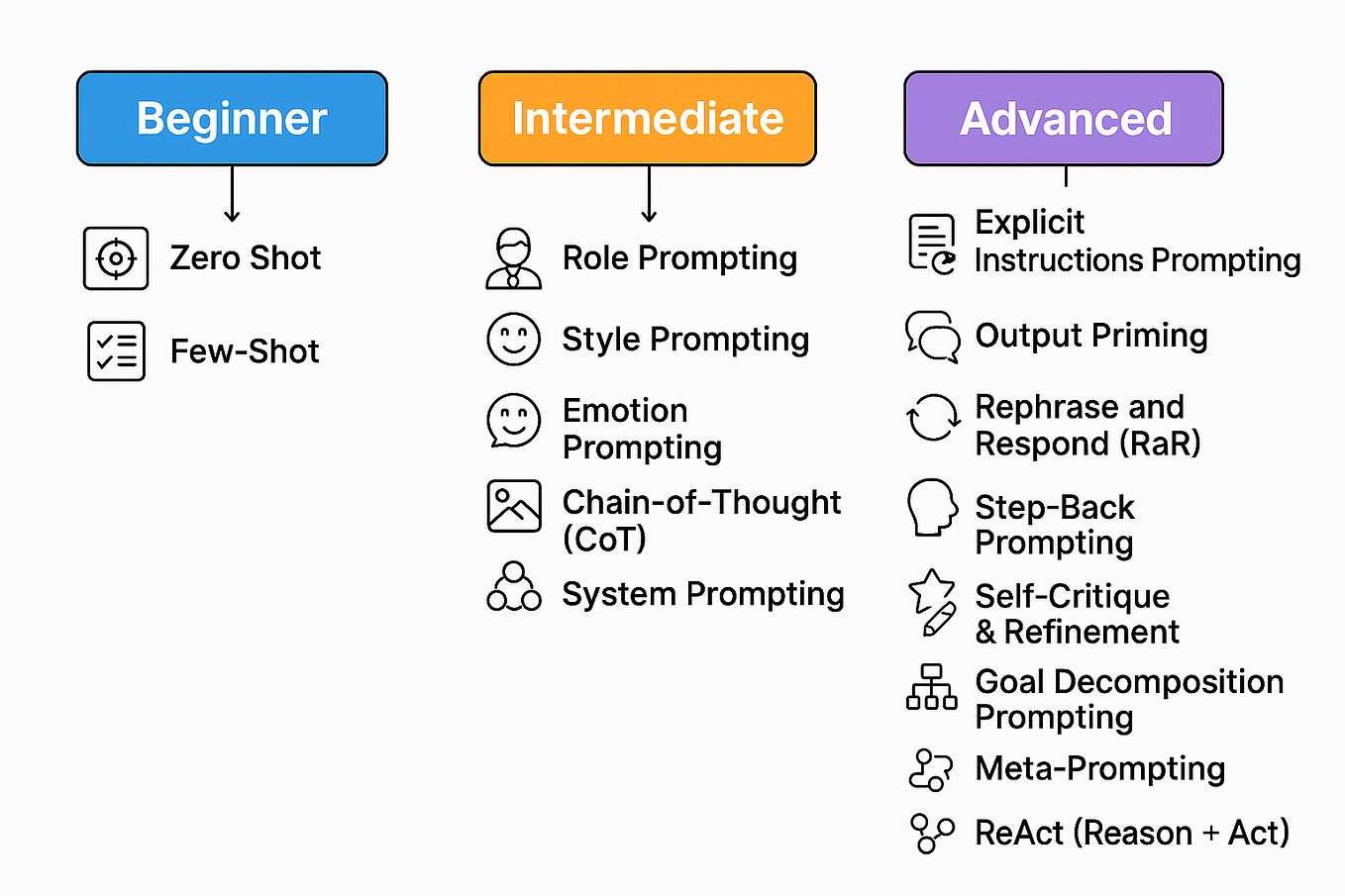
.png)