Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
BF16 与 FP16 在模型上哪个精度更高呢 - 知乎
FP16 vs FP32 - What Do They Mean and What's the Difference? - ByteXD
Simple FP16 and FP8 training with unit scaling
Data Types Explained: FP32 vs FP16 vs BF16 in Deep Learning - YouTube
Guide to FP8 & FP16: Accelerating AI - Convert FP16 to FP8?
Quantizing LLMs Step-by-Step: Converting FP16 Models to GGUF ...
Tag: FP16 | NVIDIA Technical Blog
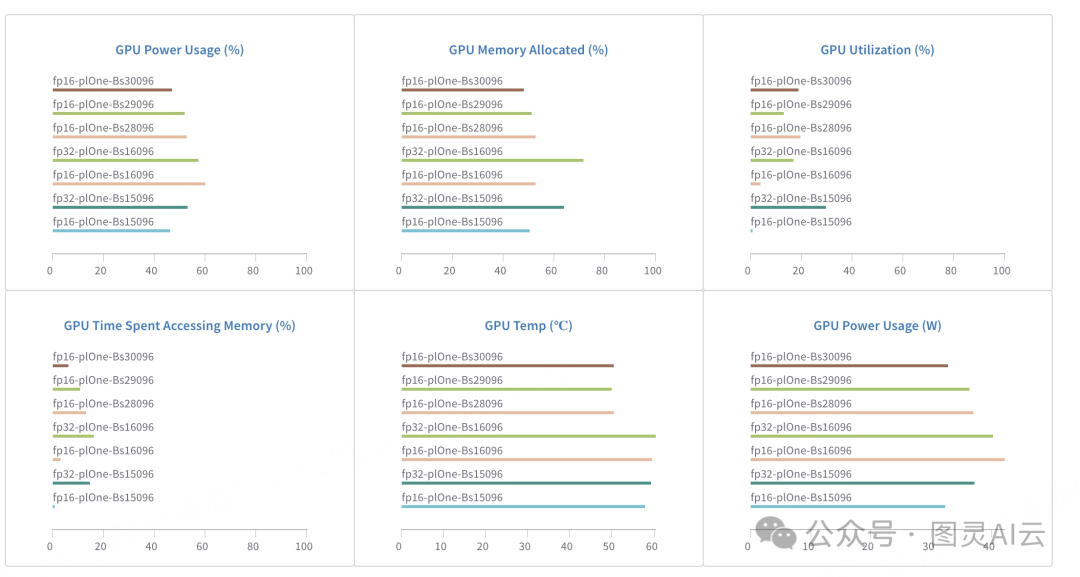
a shows the results of three experiemnts; baseline (FP32), pseudo FP16 ...
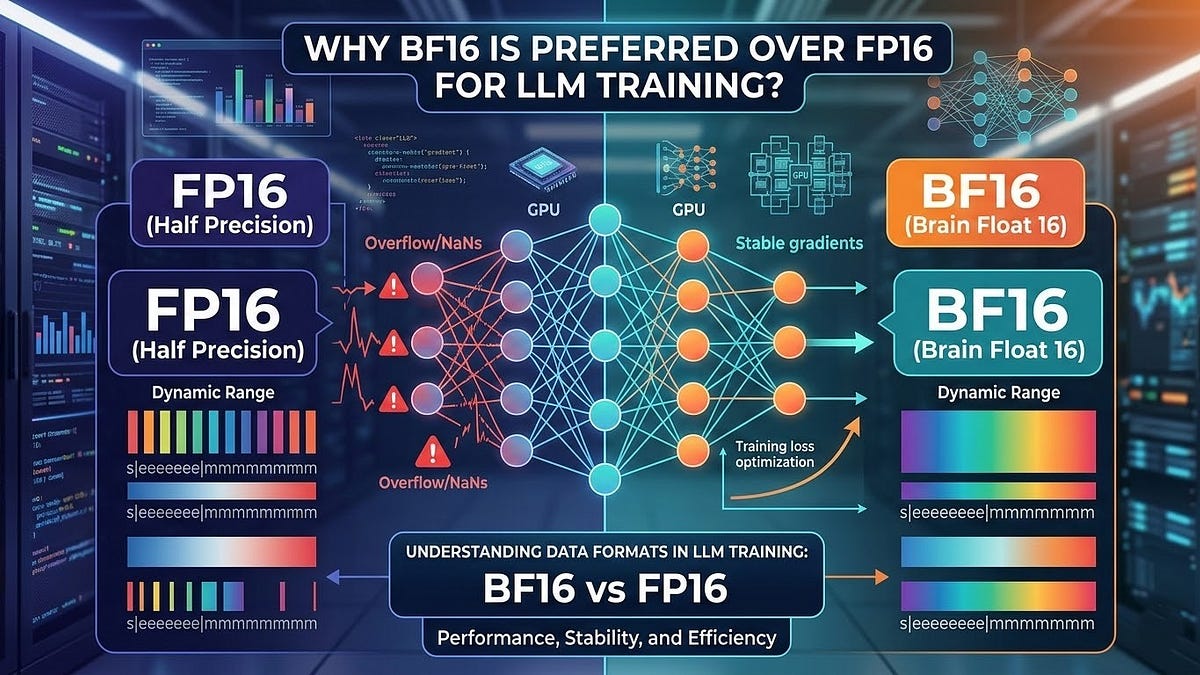
Why BF16 is preferred over FP16 for LLM Training?
How to use FP16 model precision for inference ? · openai whisper ...
Comparison between modeling in FP16 and FP32: the Vp velocity a), the ...
The differences between running simulation at FP32 and FP16 precision ...
#165 - Feat: Add FP16 Precision Control to GUI - Full Feature Parity ...
No speedup between fp16 and int8 precisions · Issue #2197 · NVIDIA ...
lllyasviel/flux_text_encoders · what is the difference FP8 vs FP16 for ...
Understanding int8 vs fp16 Performance Differences with trtexec ...
文生图开源模型 FLUX.1 FP16 与 FP8 模型比较分析 - 知乎
量化-Fp8 和 Fp16 的性能对比 - 知乎
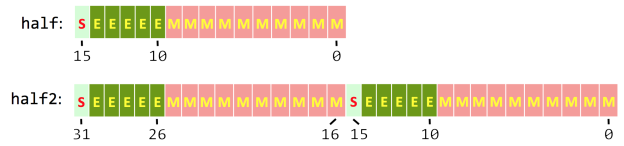
What is the difference between FP16 and BF16? Here a good explanation ...
ValueError: FP16 Mixed precision training with AMP or APEX (`--fp16 ...
How to improve the accuracy of FP16 model ? · Issue #4168 · NVIDIA ...
gpu - Difference of fp16 computing vs fp32 computing in Core ML - Stack ...
FP16 and BF16 Training | huggingface/accelerate | DeepWiki
Vicuna-7b fp16 test - YouTube
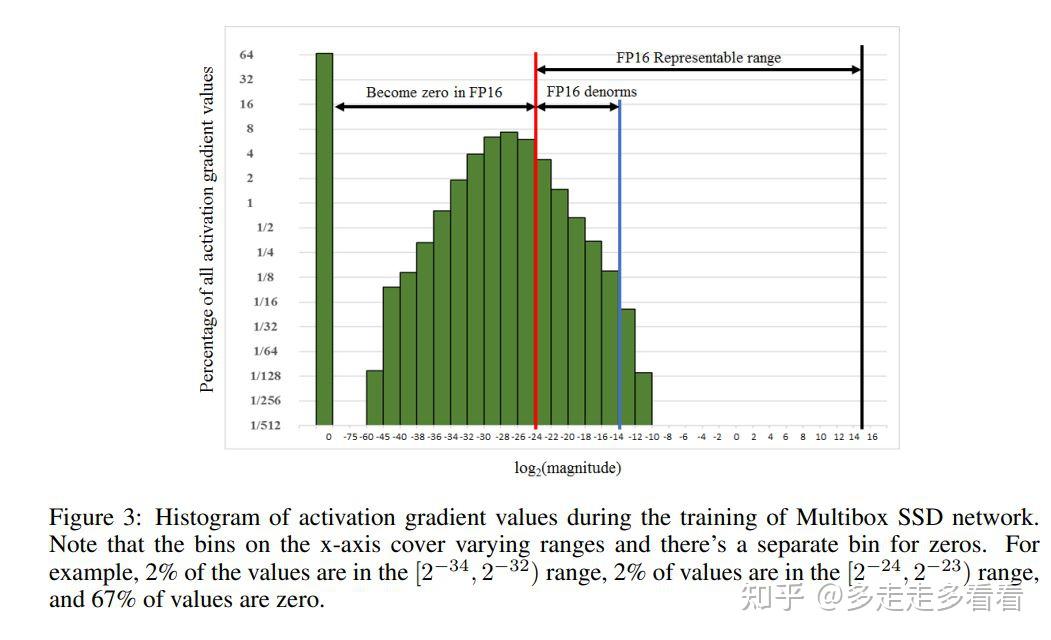
Fp16 Precision Eliminates Training-Inference Mismatch
From FP16 to 1-Bit: Understanding Efficient LLM Inference
ControlNet Colab fp16 models with Automatic 1111 GUI : r/StableDiffusion
GPU 별 FP16 연산 성능 - 그래픽카드
Quantization FP16 model using pytorch_quantization and TensorRT · Issue ...
Export and Inference YOLOv8 with FP16 Precision to TensorRT · Issue ...
TensorRT:FP16优化加速的原理与实践_tensorrt fp16-CSDN博客
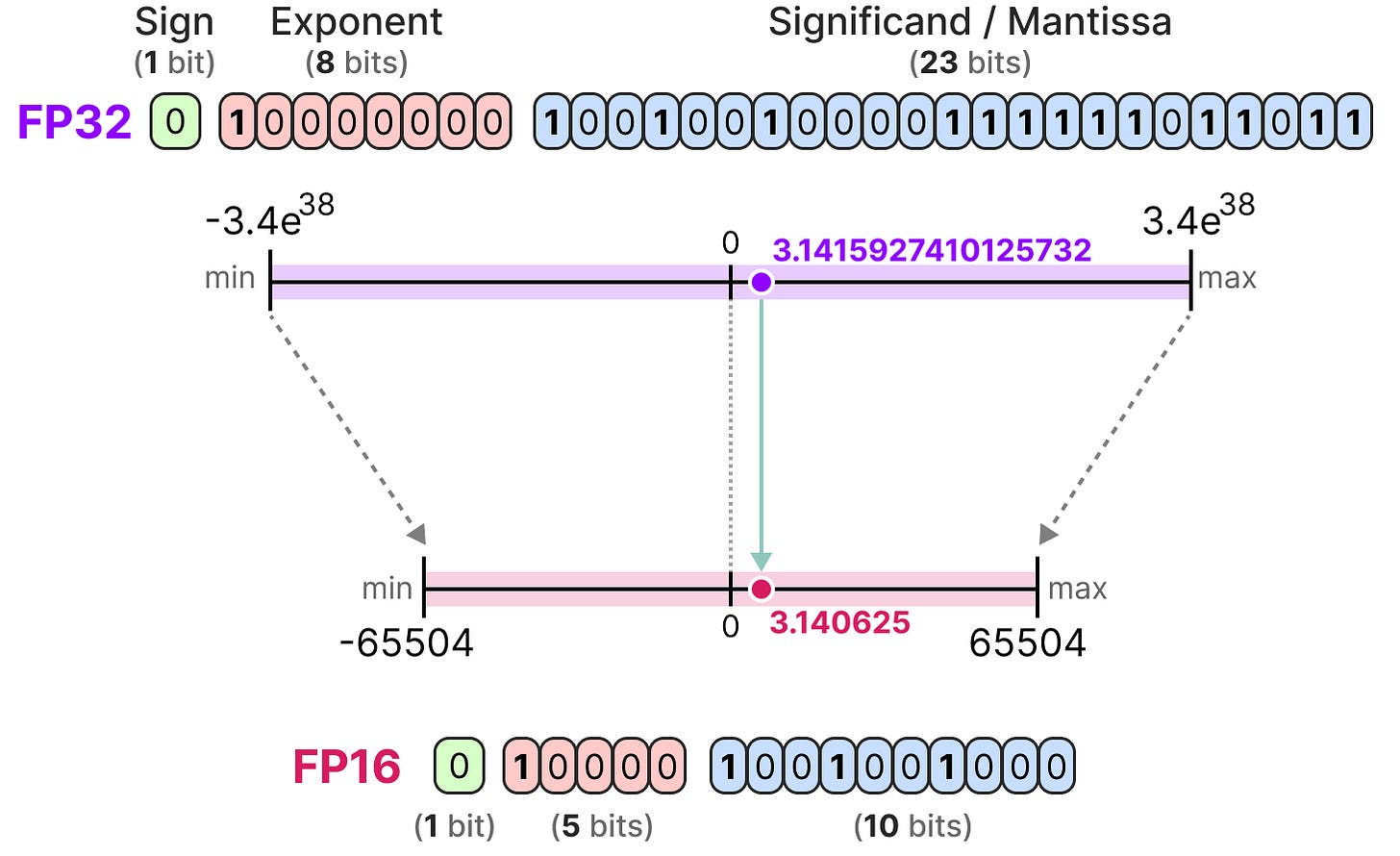
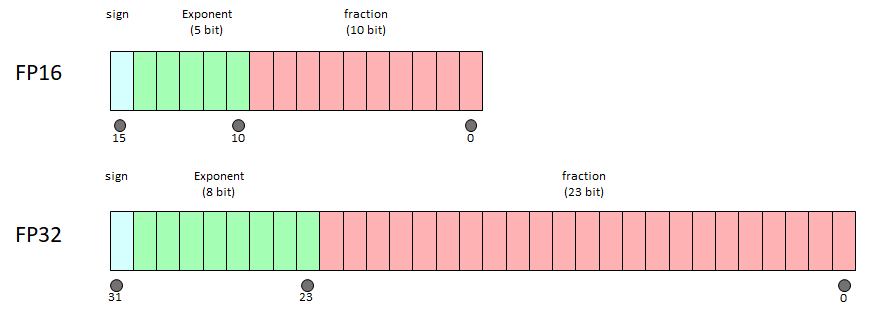
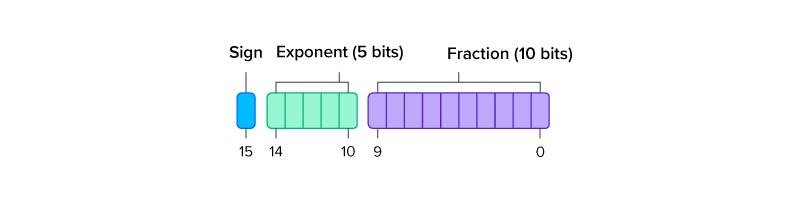
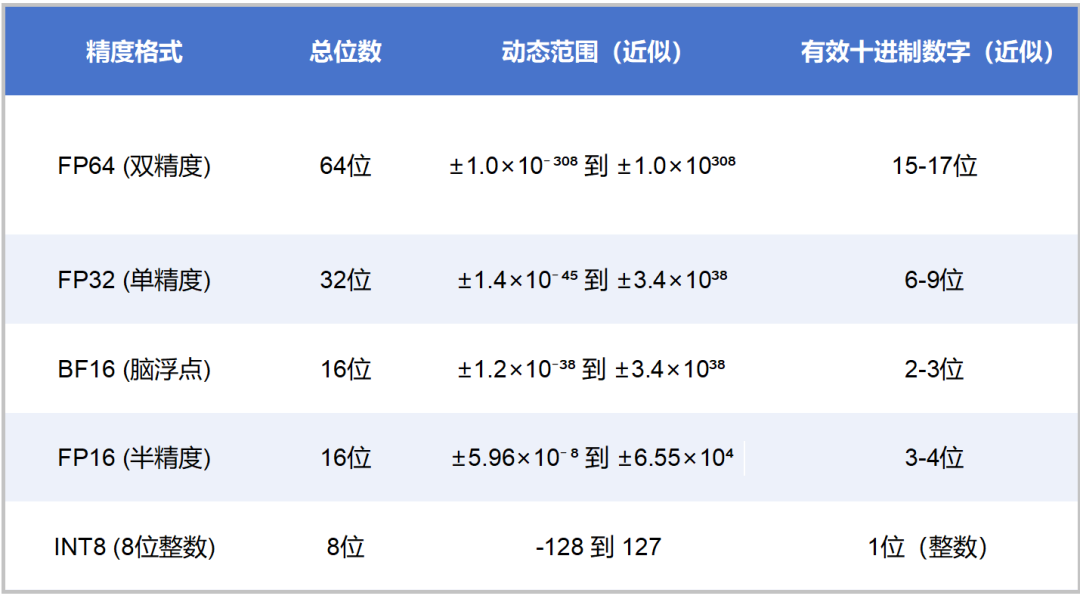
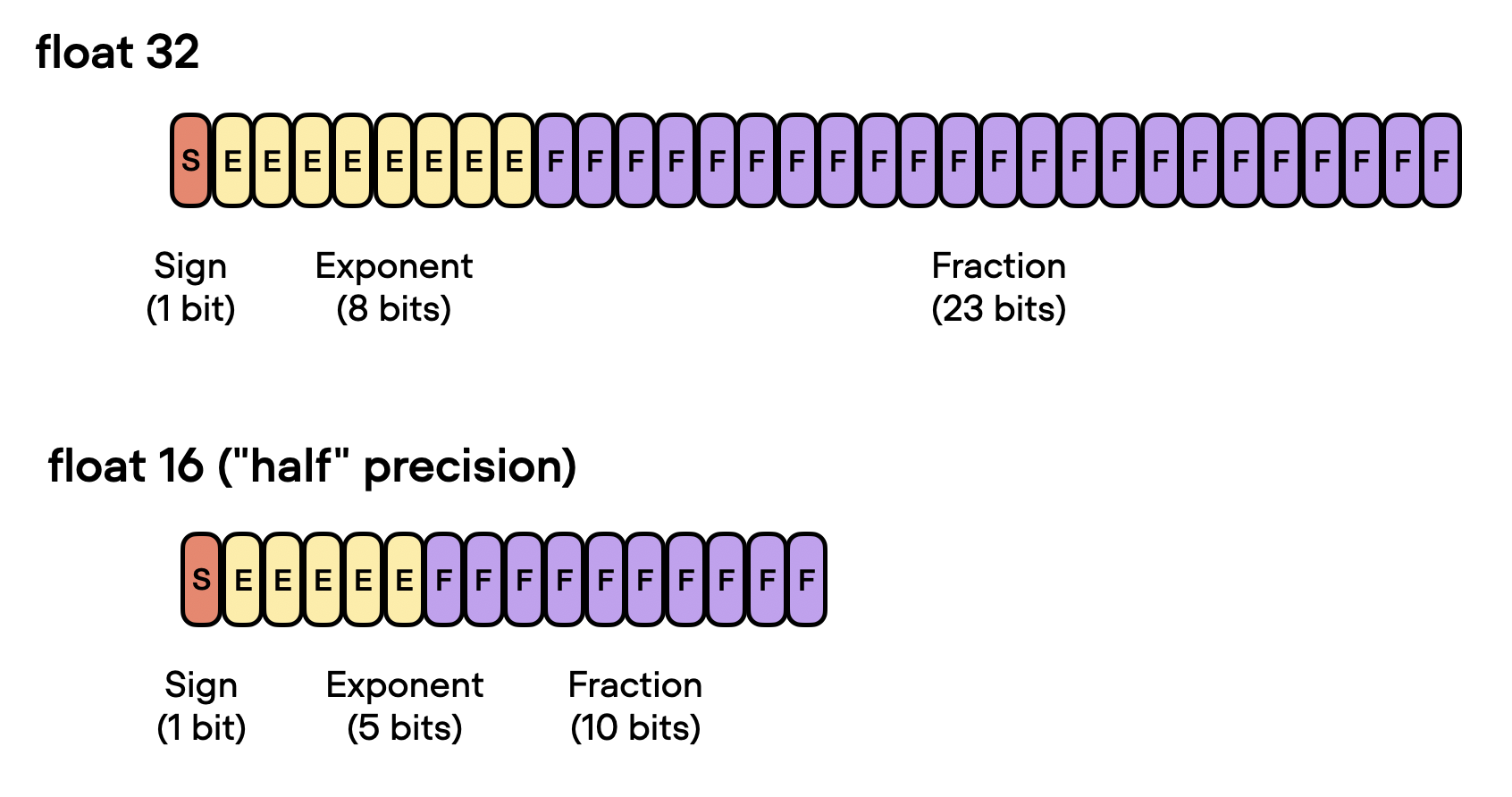
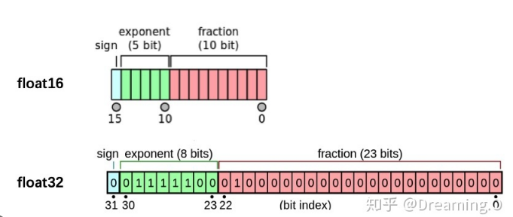
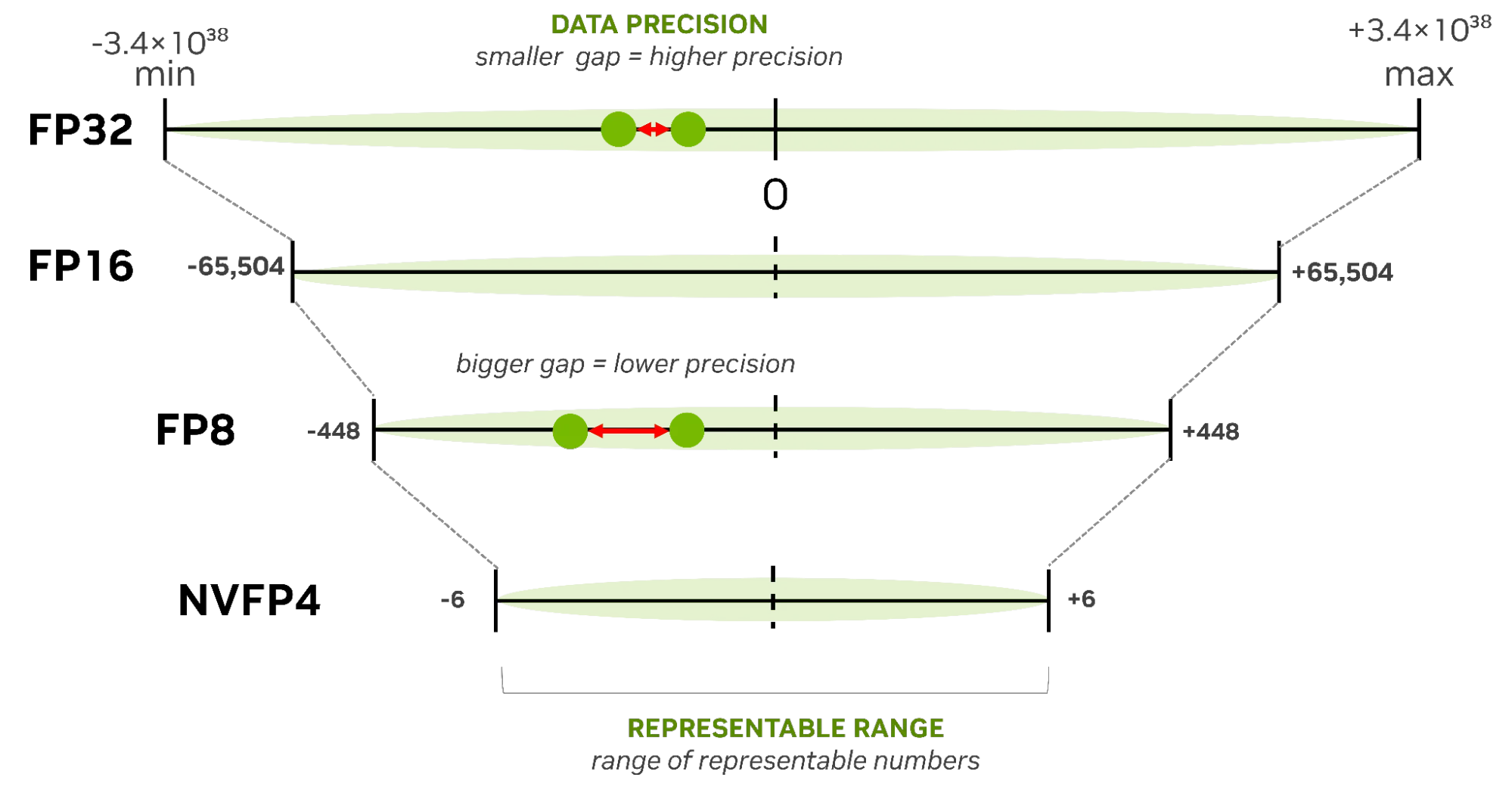
What is FP64, FP32, FP16? Defining Floating Point | Exxact Blog
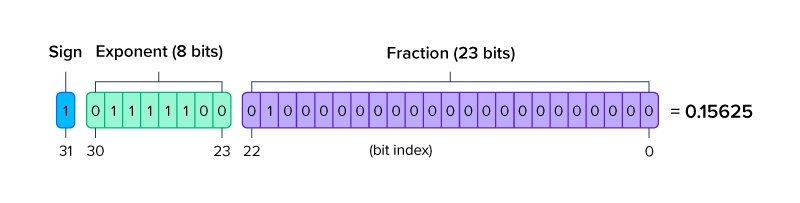
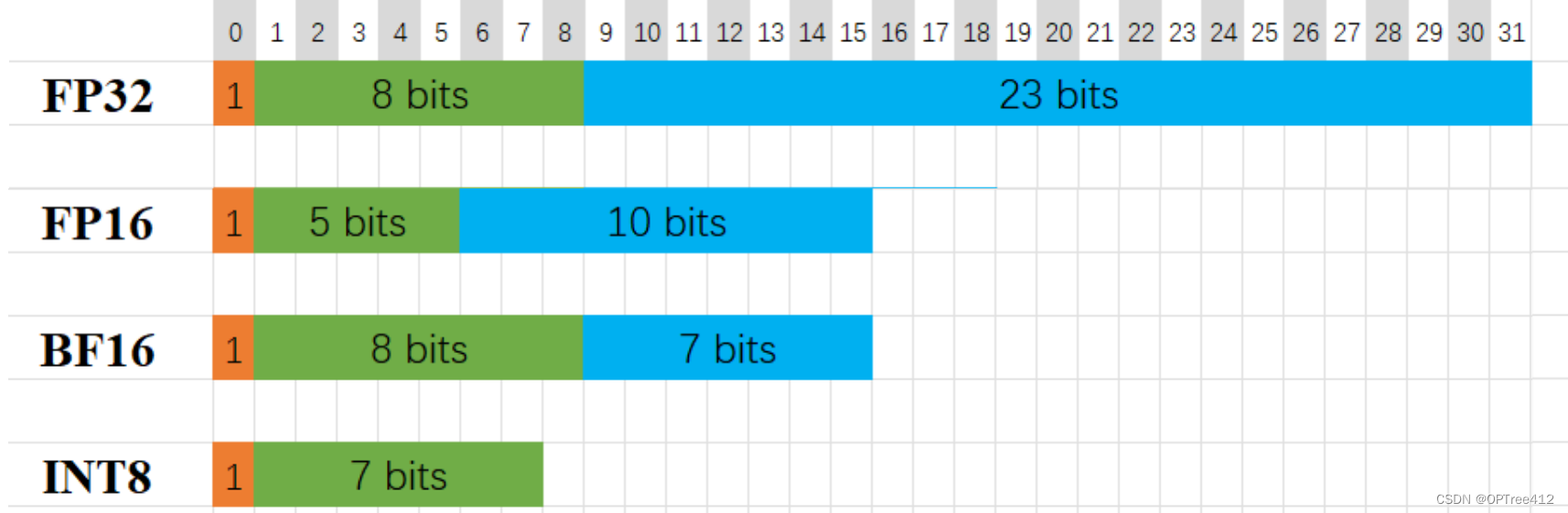
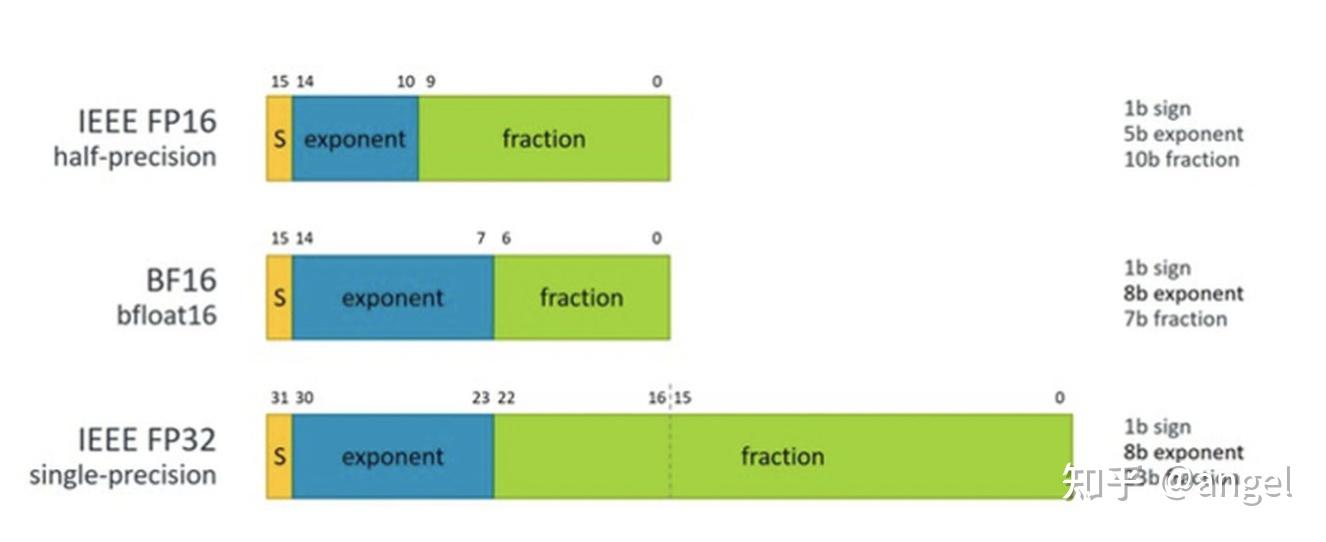
FP16\FP32\INT8\混合精度的含义-CSDN博客
Automatic Mix Precision | MindSpore 2.0 Tutorials | MindSpore
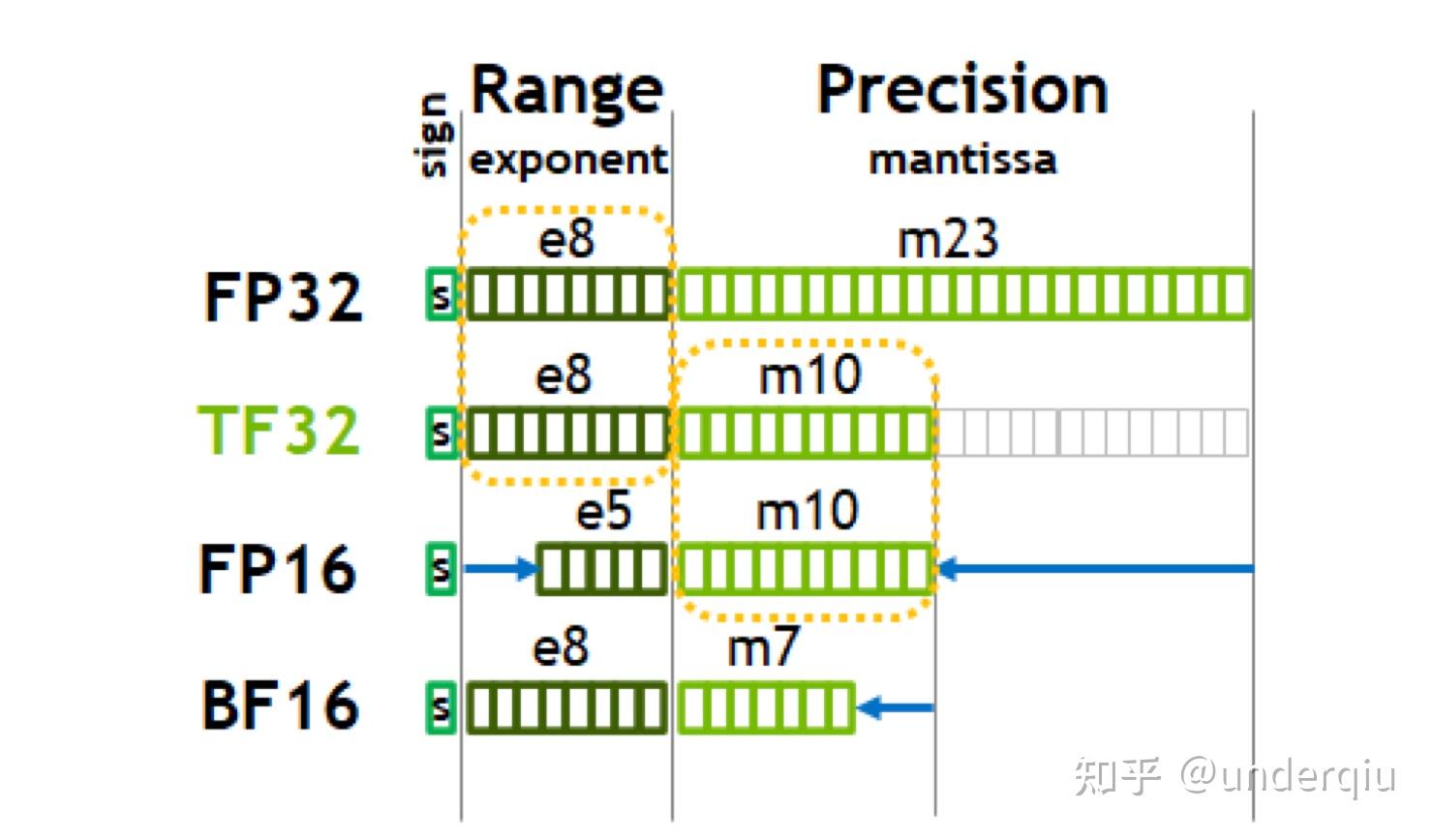
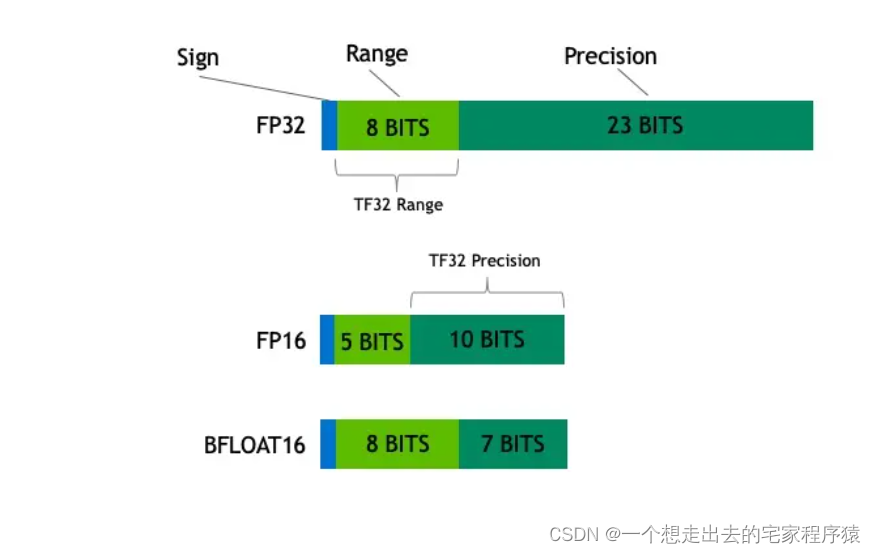
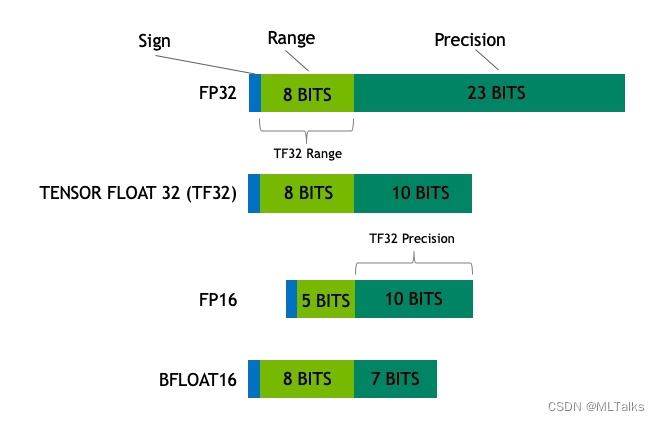
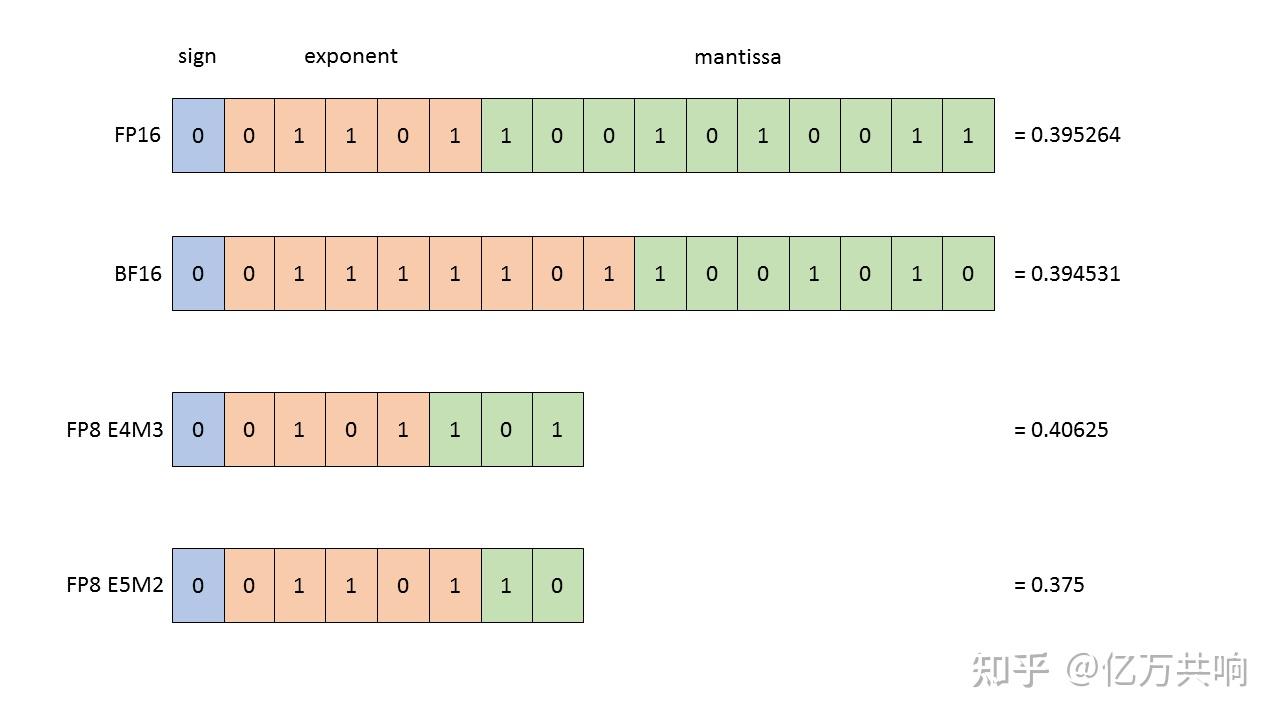
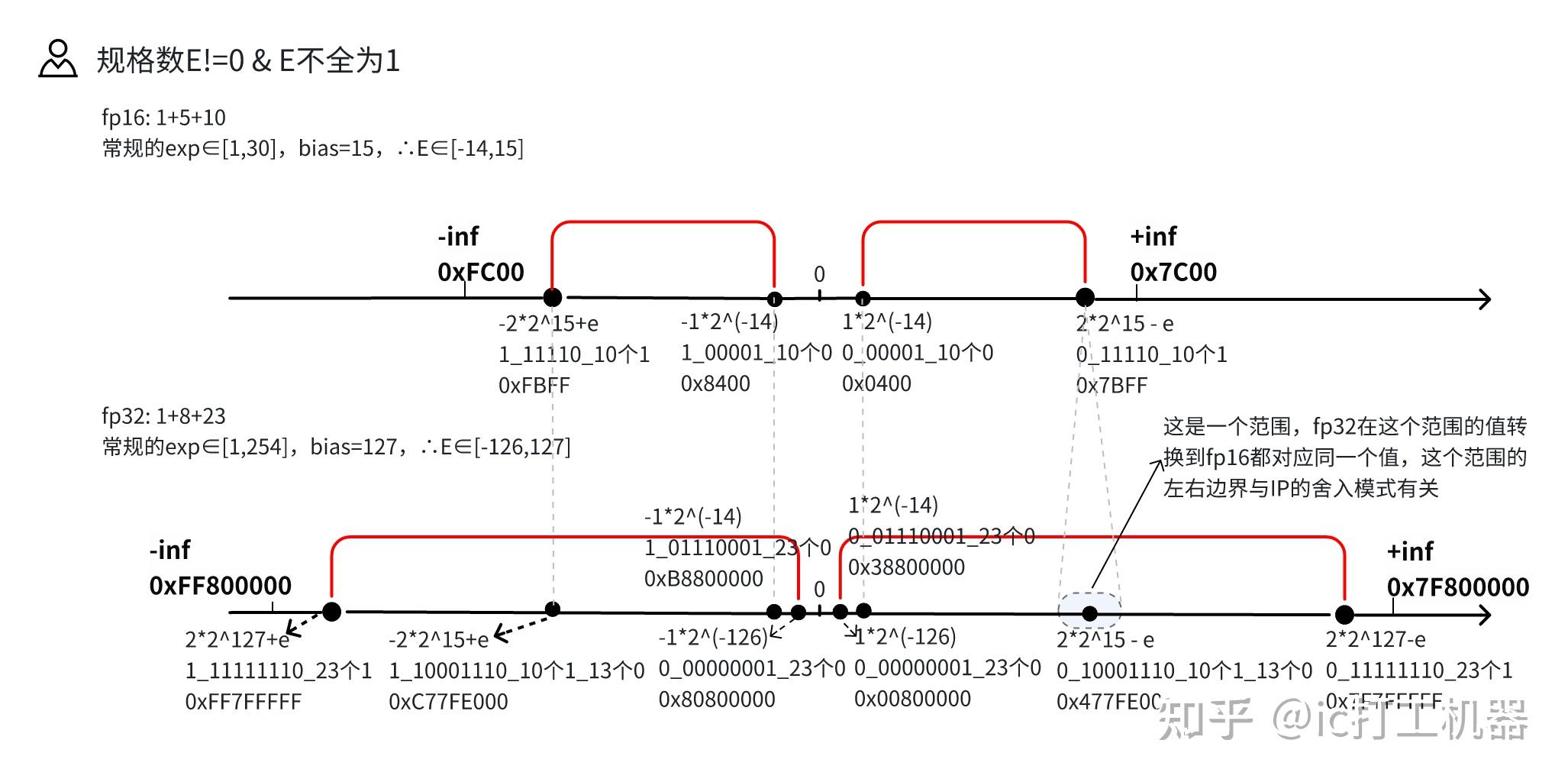
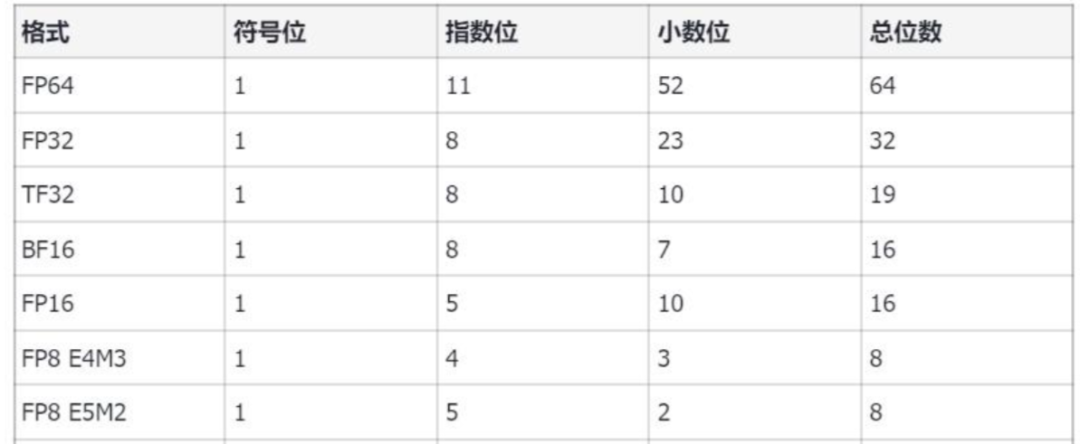
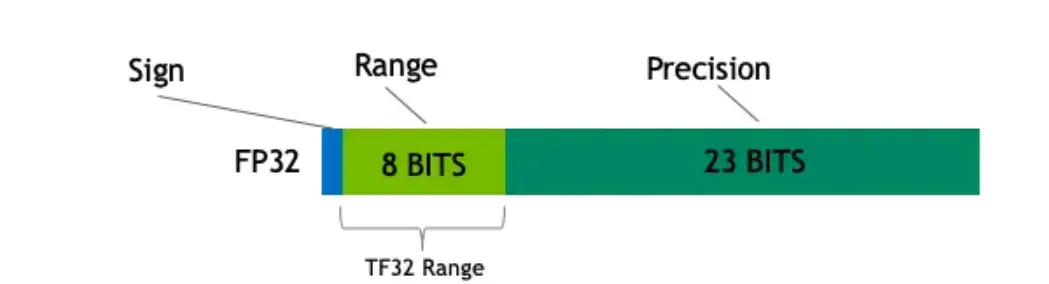
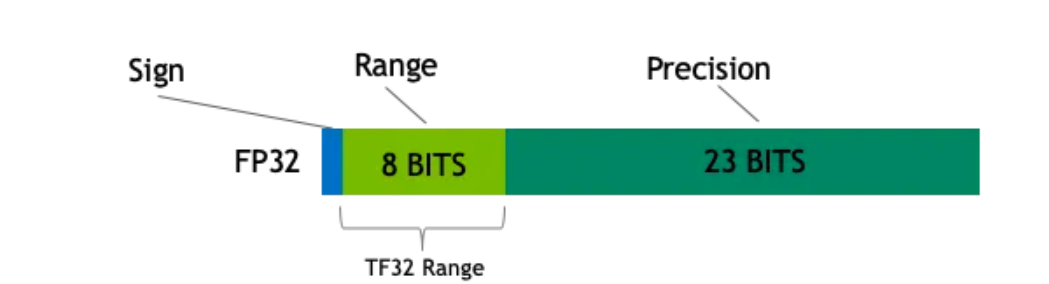
从一次面试搞懂 FP16、BF16、TF32、FP32 - 知乎
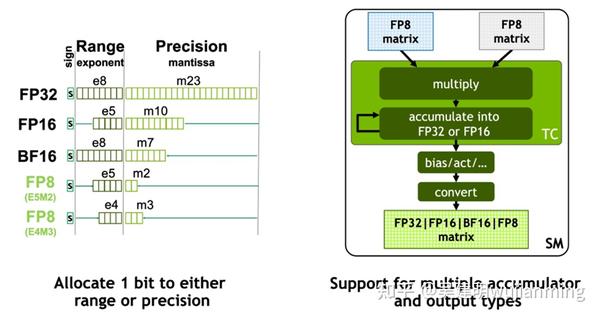
The Road to MX: The Evolution of AI Data Formats (INT8, Bfloat, FP8 ...
fp32、fp16、bf16介绍与使用_fp32和fp16算力区别-CSDN博客
A Visual Guide to Quantization - by Maarten Grootendorst
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
GitHub - sail-sg/Precision-RL: Defeating the Training-Inference ...
GPU技术与动态 - 知乎
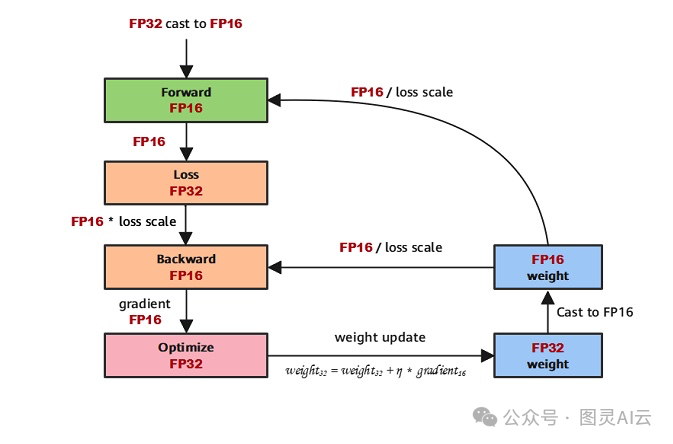
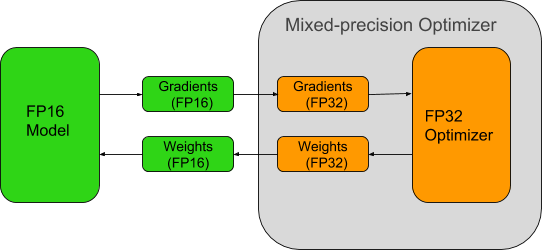
What Every User Should Know About Mixed Precision Training in PyTorch ...
A Hands-On Walkthrough on Model Quantization - Medoid AI
Accelerating Large Language Models with Mixed-Precision Techniques ...
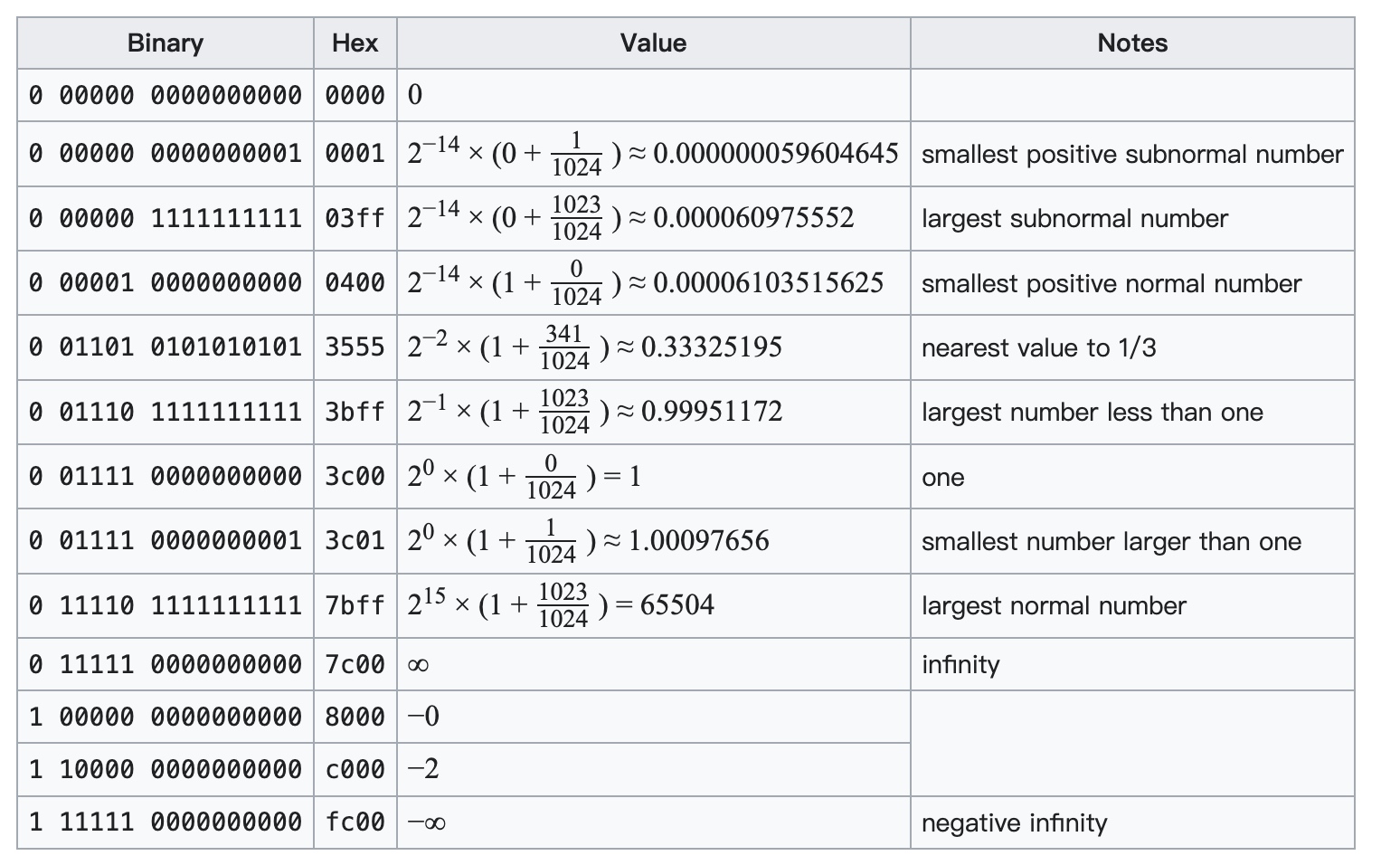
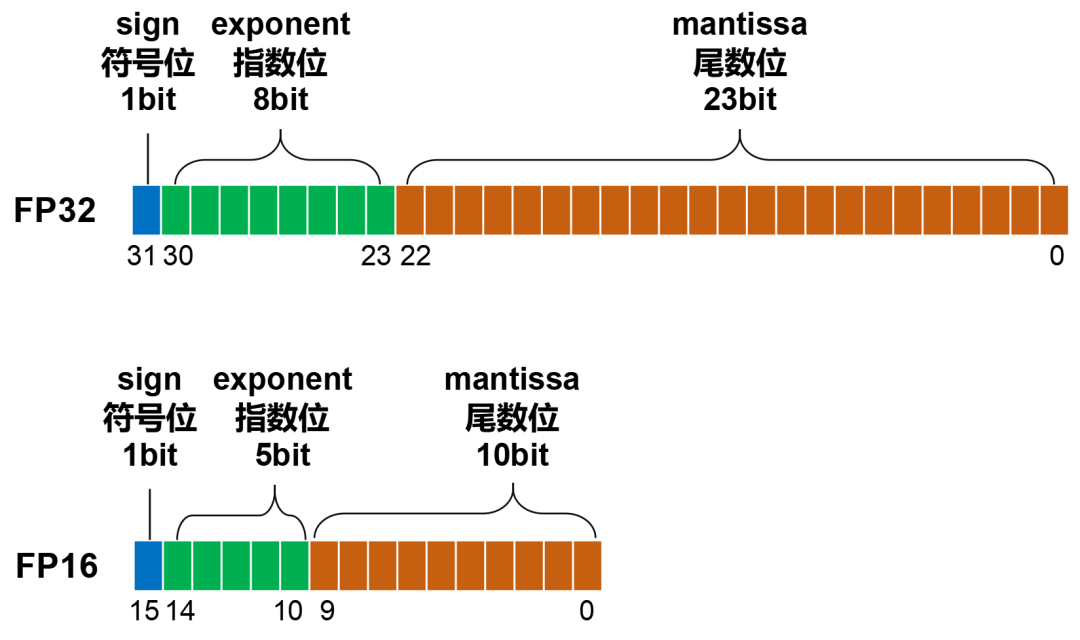
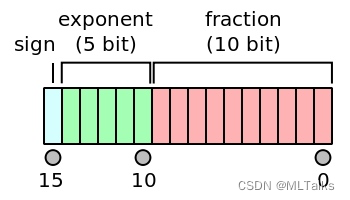
FP16数据格式详解-CSDN博客
深入解析强化学习中的混合精度训练:FP16累加误差与Loss Scaling补偿机制-腾讯云开发者社区-腾讯云
大模型中的计算精度——FP32, FP16, bfp16之类的都是什么???_混合精度训练和fp32的区别-CSDN博客
CUDA使用FP16进行半精度运算_怎么使用半精度计算-CSDN博客
GitHub - SuperLiaoXH/SystolicArray-2D-FP16: 基于FP16的二维脉动阵列电路设计 · GitHub
fp16与fp32简介与试验_fp16和fp32-CSDN博客
FP16数据格式详解 | MLTalks
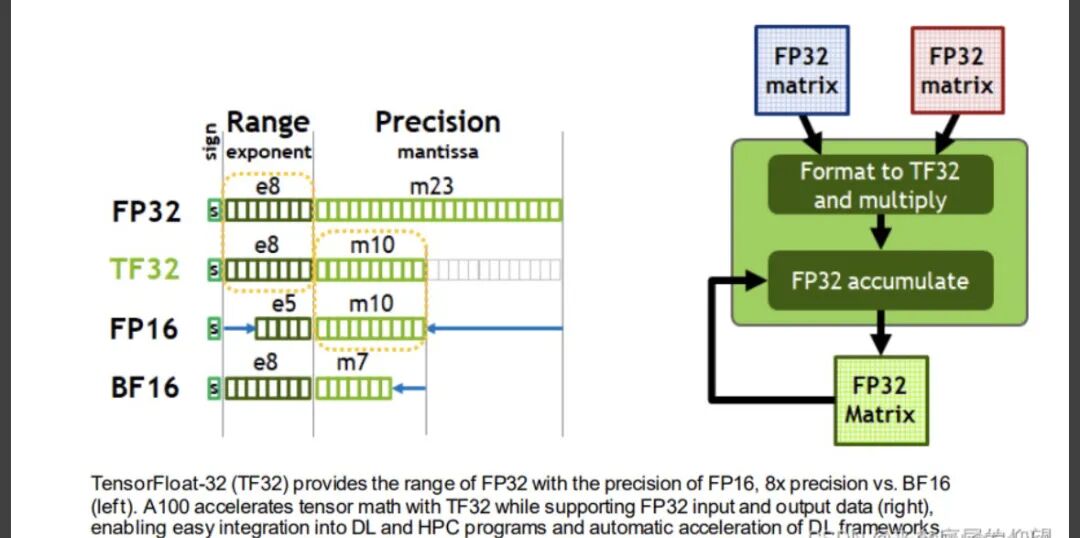
计算精度对比:FP64, FP32, FP16, BFLOAT16, TF32 - 知乎
AMD's FidelityFX Super Resolution Is Just 7% Slower in FP32 Mode vs ...
【干货】大模型算力优化全攻略——FP32、FP16、INT8数据格式精讲与实战应用_fp16和fp32-CSDN博客
您需要知道的:大模型中的算力精度FP16 vs. FP32_fp32和fp16算力区别-CSDN博客
BF16 vs FP16: Key Differences, Precision, and Best Use Cases
大模型开发中的浮点数精度选择:FP32、FP16、BF16详解!-CSDN博客
浮点FP16和浮点FP32精度互转的原理和硬件设计 - 知乎
End-to-End AI for NVIDIA-Based PCs: Optimizing AI by Transitioning from ...
一文了解模型精度(FP16、FP8等)、所需显存计算以及量化概念_fp8 fp16-CSDN博客
circlestone-labs/Anima · FP16_Diagnosis_Report.md
MimicPC - Complete Guide to Flux.1 Models | Mimic PC
AMD Tech Day 2024(三):XDNA 2 AI運算架構解析,Block FP16資料類型運算效率倍增 | T客邦
TNN行业首发Arm 32位 FP16指令加速,理论性能翻倍 - 知乎
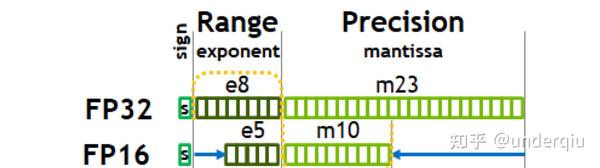
深度学习中的数据类型介绍:FP32, FP16, TF32, BF16, Int16, Int8 ...-CSDN博客
fp16和fp32_fp16 fp32 gpu差异-CSDN博客
FP32、FP16 和 INT8-CSDN博客
Arm Community
What are the FP16, FP32 and FP64? | Aslan, MD
大模型--数据类型FP16 BF16--29 - jack-chen666 - 博客园
FP16与INT8:AI计算中的精度与效率之争-CSDN博客
FP32, FP16, BF16 и FP8 — разбираемся в основных типах чисел с плавающей ...
Developer Guide - NVIDIA Docs
diffusion_pytorch_model-ema-only-fp16.safetensors · tsqn/Z-Image-Turbo ...
模型精度(FP16、FP8等),所需显存计算以及量化概念! - 知乎
Quantization from FP32 to FP16. | Download Scientific Diagram
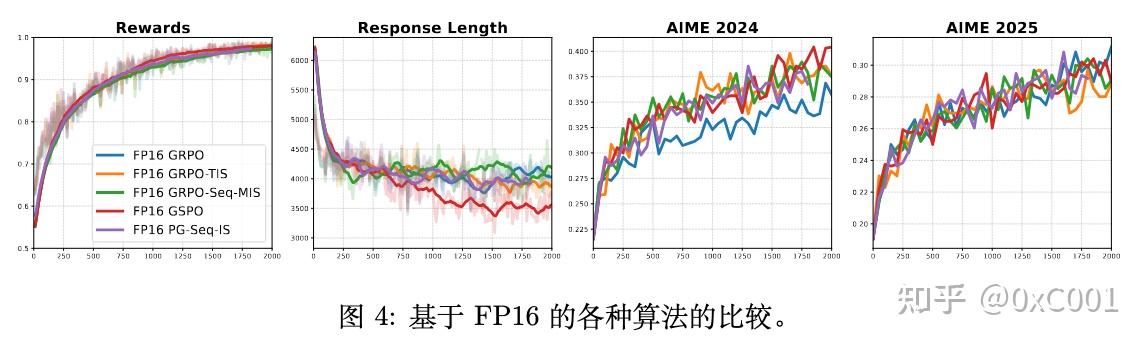
Sea AI Lab 新研究:FP16 可以解决 RL 中的训推不一致 - 知乎
Gdc2024 寒霜跨平台shader的half实践:FP16 Shaders in Frostbite - 知乎
fp16和fp32,神经网络混合精度训练,PYTORCH 采用FP16,Libtorch采用FP16,神经网络混合精度三种避免损失 ...
How to Speed up Deep Learning Models - Speaker Deck
Analysis result under FP16, BF16, and INT16 | Download Scientific Diagram
大模型开发中的浮点数精度选择:FP32、FP16、BF16详解! - 知乎
How to train a Large Language Model using limited hardware? - deepsense.ai
大模型性能优化(一):量化从半精度开始讲,弄懂fp32、fp16、bf16 - 知乎
Top 5 AI Model Optimization Techniques for Faster, Smarter Inference ...
【stable-diffusion企业级教程03】FP16真香!(想说爱你不容易) - 知乎
大模型训练中的 fp32/fp16/bf16、混合精度、训练溢出 - 知乎
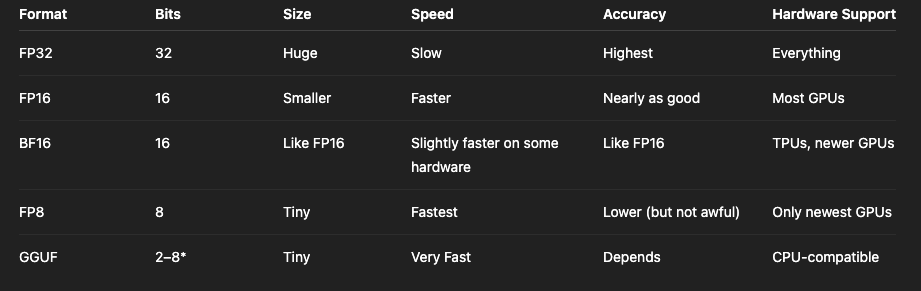
Picking the Right Size Brain: FP16, BF16, FP8, GGUF and What They ...
扩散模型量化 (INT8/FP16)
五大 AI 模型优化技术,实现更快速、更智能的推理 - NVIDIA 技术博客
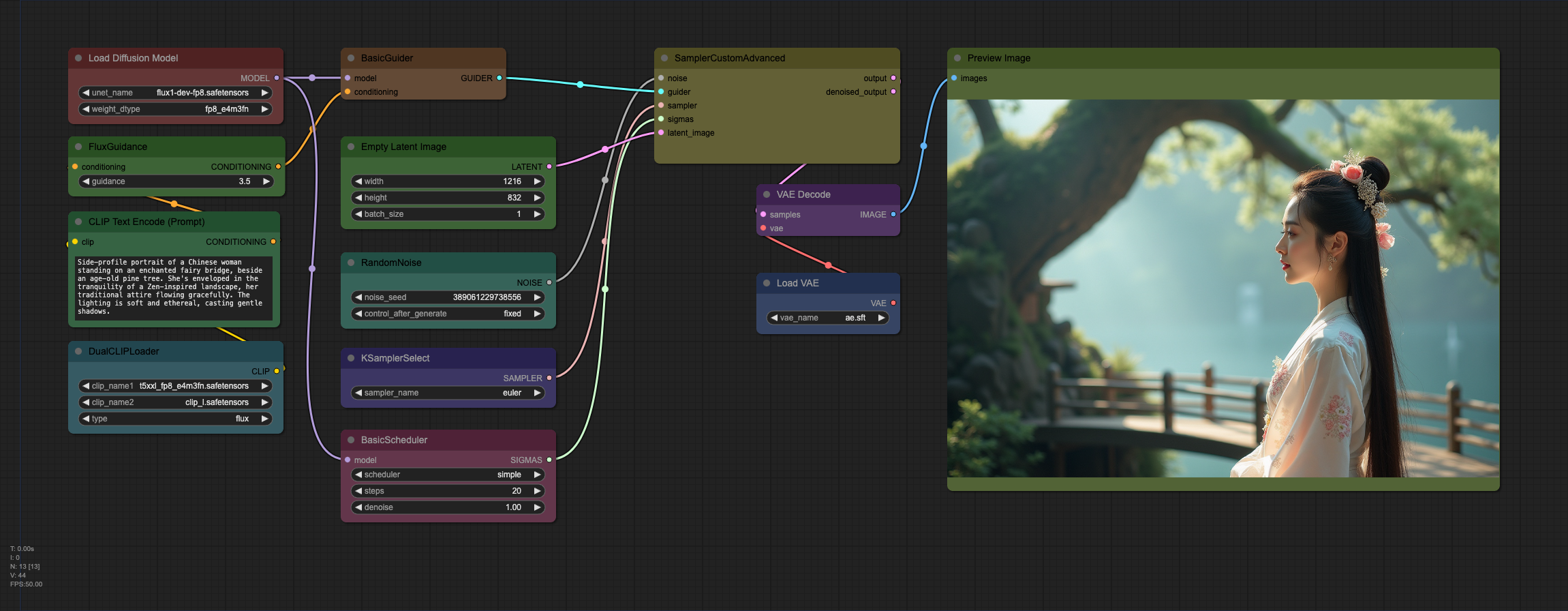
Flux.1 Dev 模型对比FP16格式和Q8_0格式,模型大小差距一半生成图片到到底有多大区别 - YouTube







.png?width=1467&height=1485&name=Scatter%20charts%20(1).png)

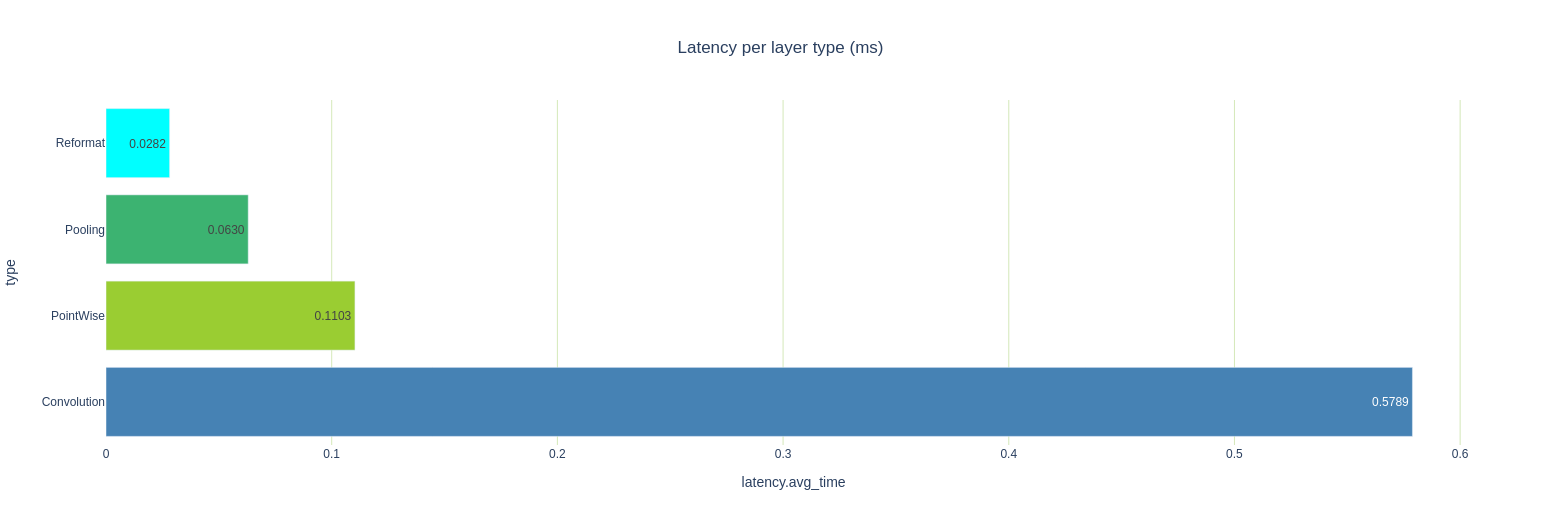






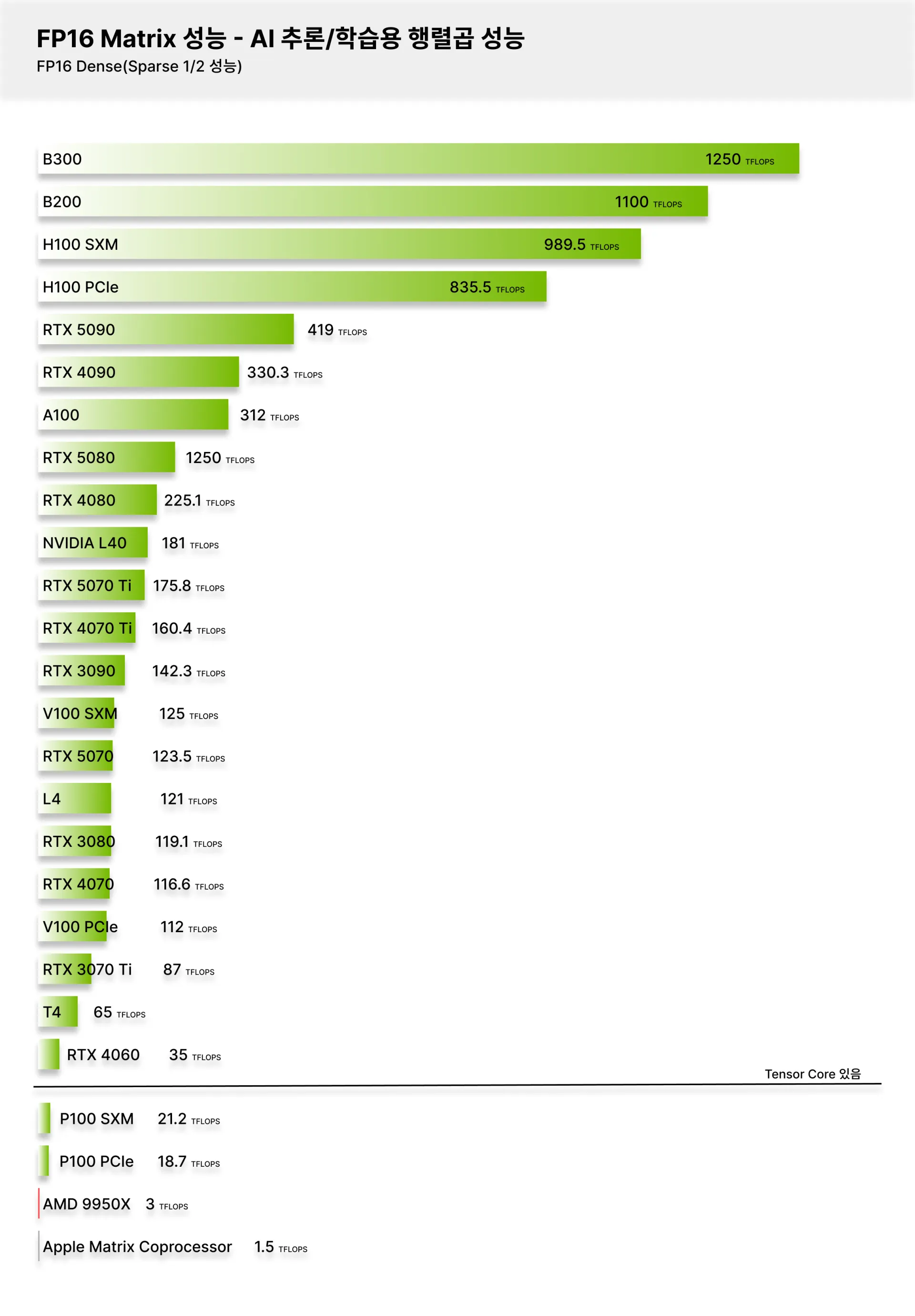


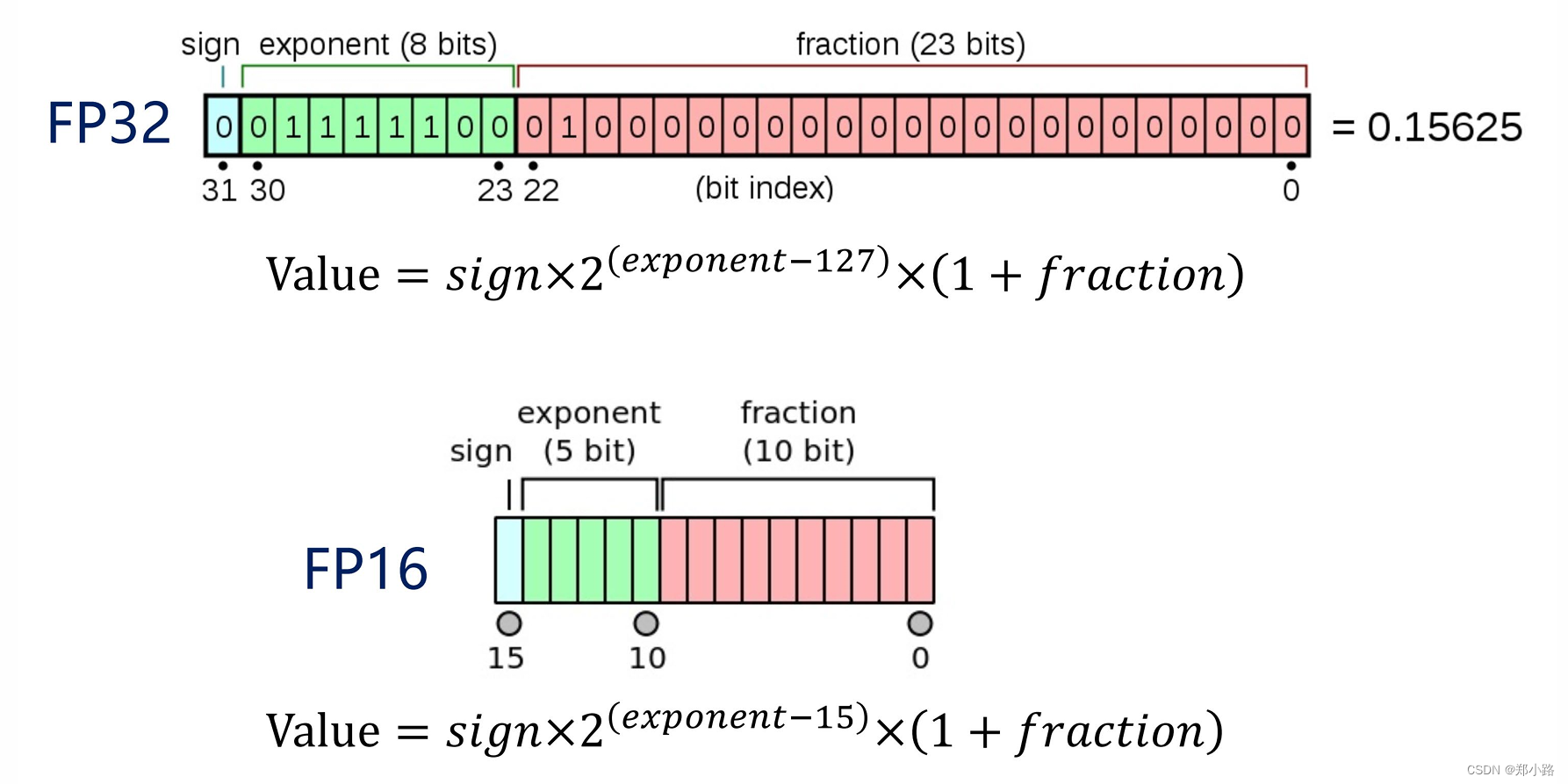
.jpg?format=webp)