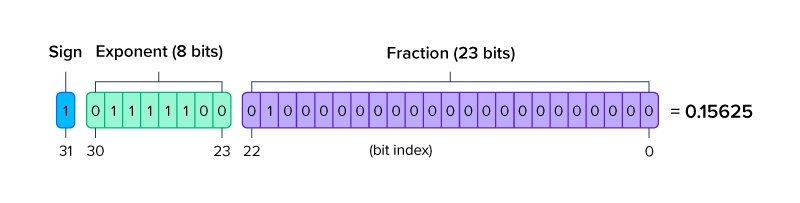
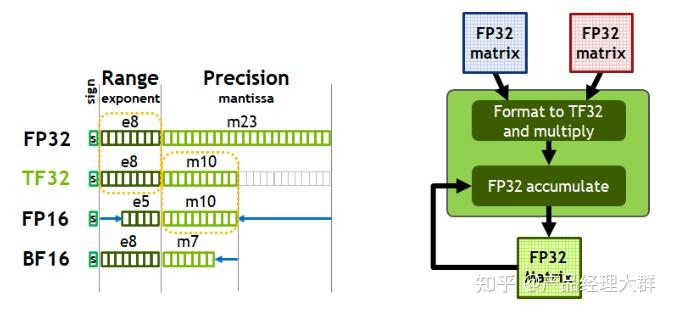
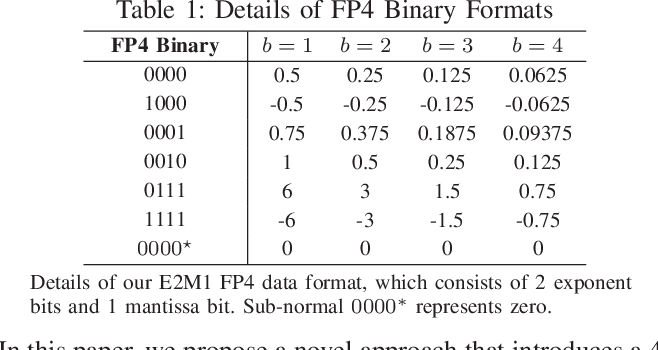
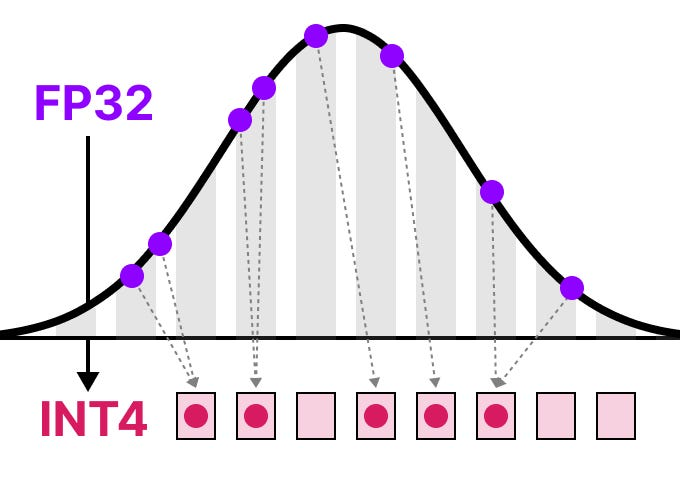
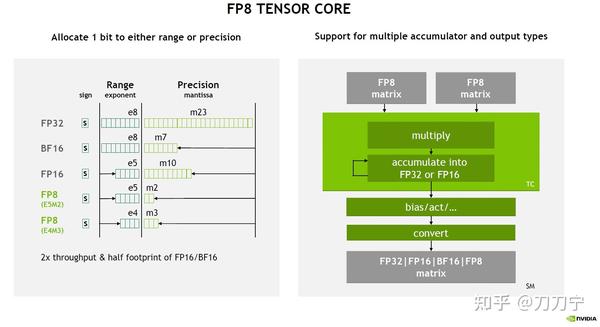
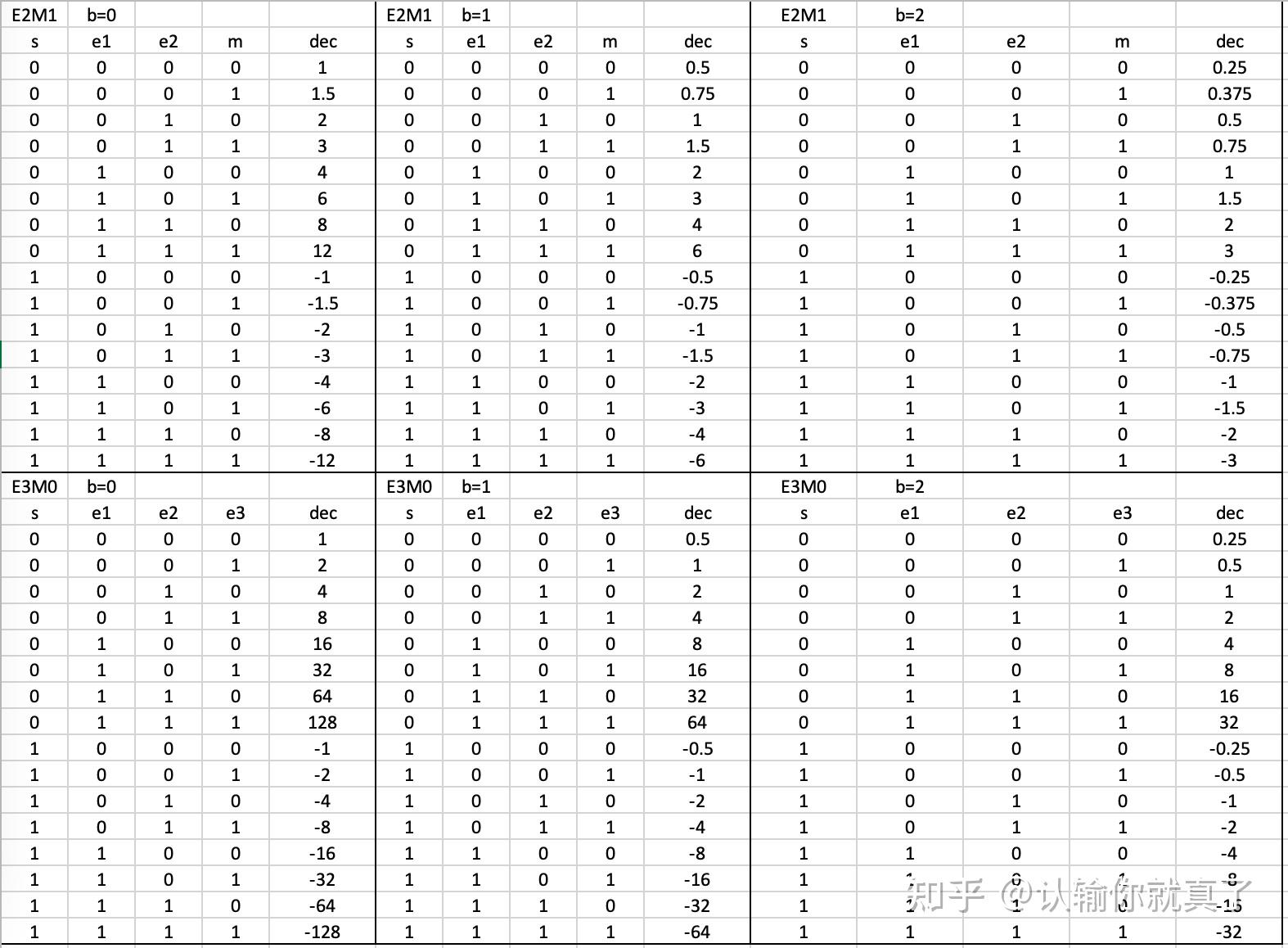
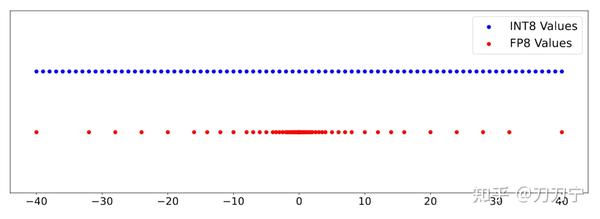
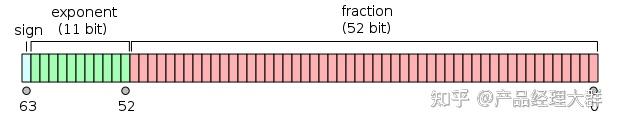
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Float types (fp8, fp4, nf4, ...) · ggml-org llama.cpp · Discussion ...
Using FP8 and FP4 with Transformer Engine — Transformer Engine 2.13.0 ...
Understanding Float in Banking: Definitions, Calculations, and Examples
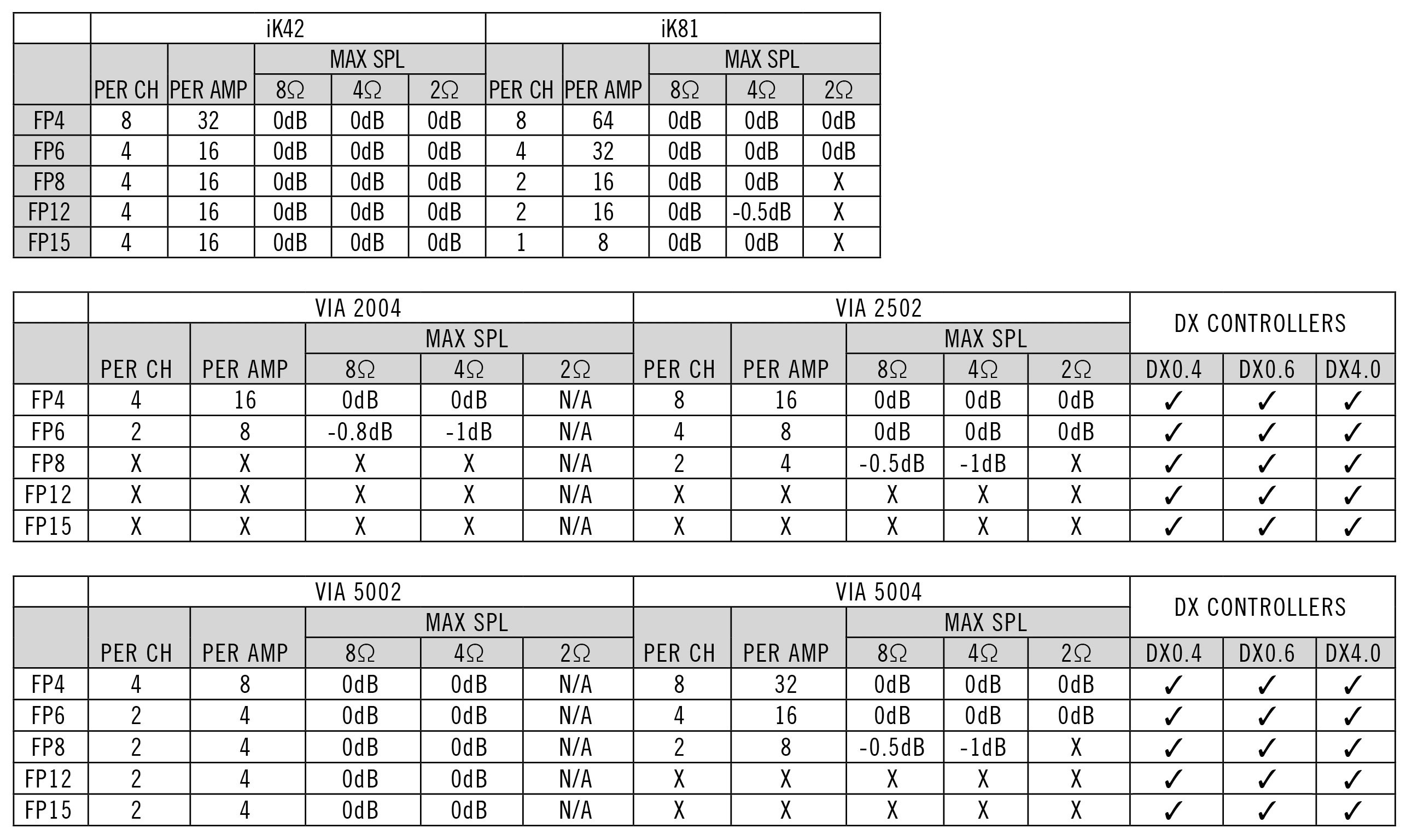
4″ SERIE FP4 - EXA PUMPS
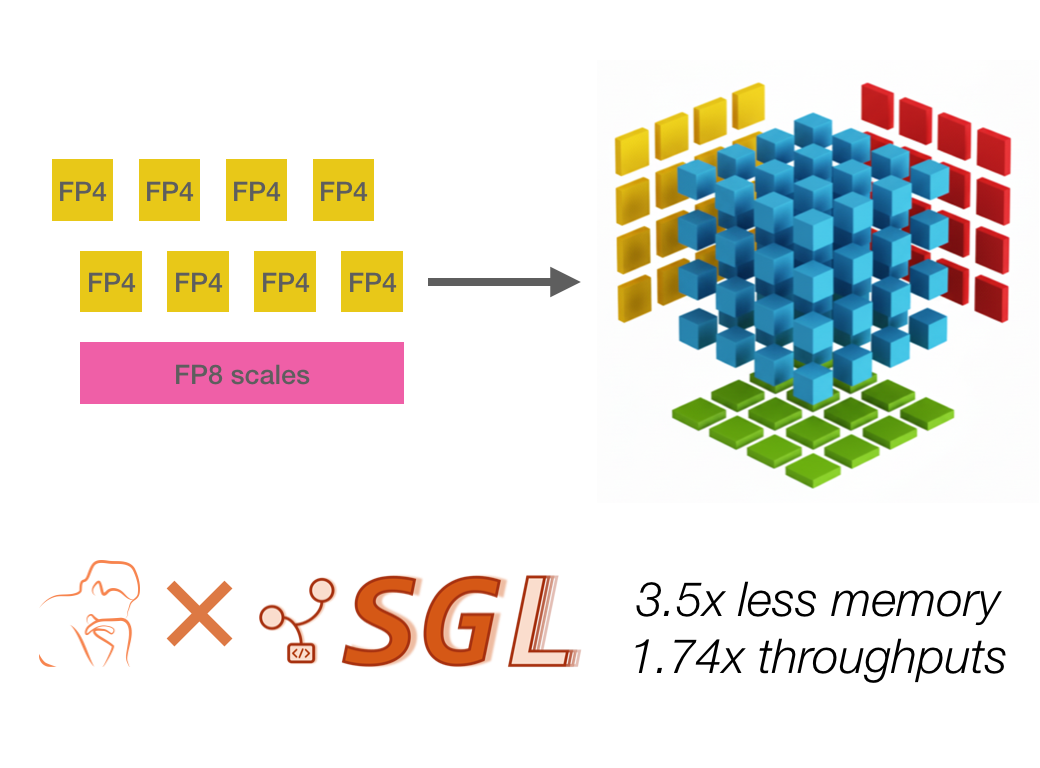
Optimizing FP4 Mixed-Precision Inference on AMD GPUs | LMSYS Org
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
[논문 리뷰] Towards Efficient Pre-training: Exploring FP4 Precision in ...
Pole float conversion chart | Angling Times
Model and Checkpoint Loaders for NF4 and FP4 detailed guide | ComfyUI
The correctly rounded result of í µí± í µí± (1.5) for FP5 and FP4 with ...
How to Convert Integer to Float in Omron PLC?
FP4 Precision: A New AI-Optimized Floating-Point Format | Ramachandra ...
Accelerate Your AI Workflow with FP4 Quantization on Lambda
[Quantization] int4 vs fp4 which to choose?
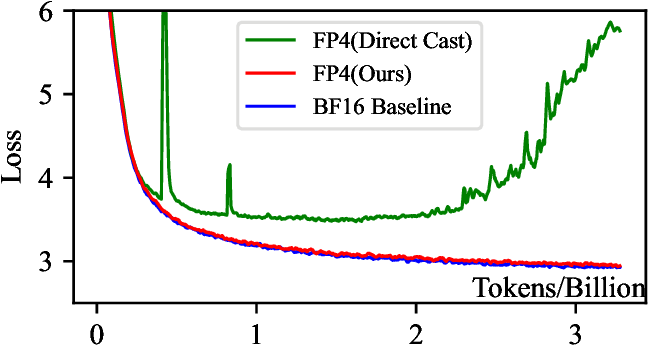
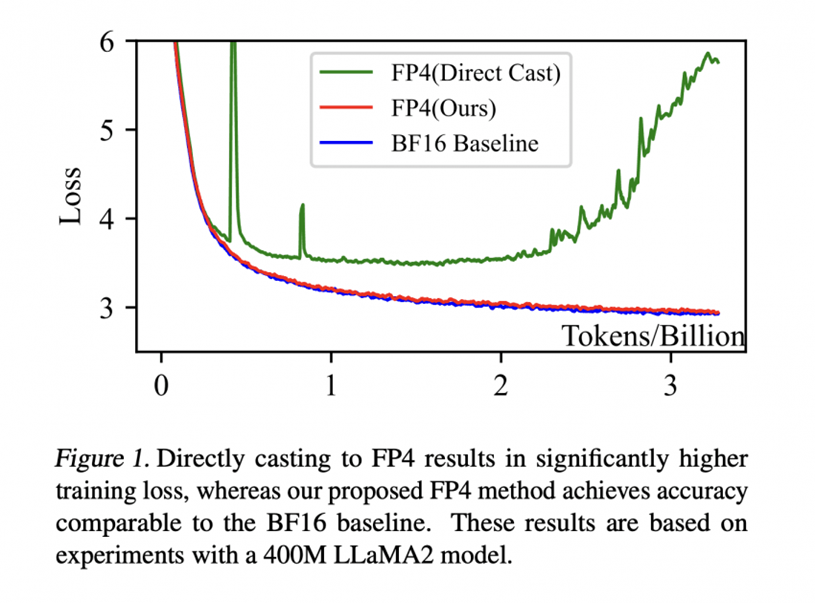
Figure 1 from Optimizing Large Language Model Training Using FP4 ...
A Deepest Study Of Float Switch
NVIDIA TensorRT Unlocks FP4 Image Generation for NVIDIA Blackwell ...
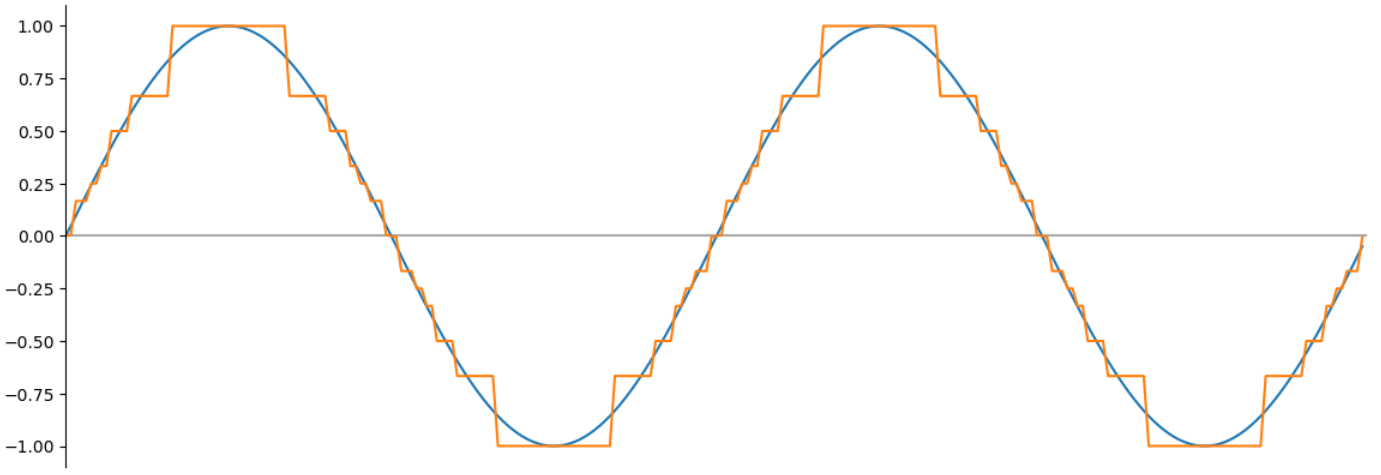
FP4 Ranges and Exclusions of Floating Point Numbers - YouTube
NVIDIA TensorRT 解锁 NVIDIA Blackwell GeForce RTX 50 系列 GPU 的 FP4 图像生成 ...
Ilford FP4 Plus 125 35mm | Bay Photo Film
Optimizing Large Language Model Training Using FP4 Quantization - YouTube
DeepSeek R1의 저 학습 비용과 FP4 방식에 대해 @자료실 - (사)경남ICT협회
FlexPoint FP4 – Generation AV
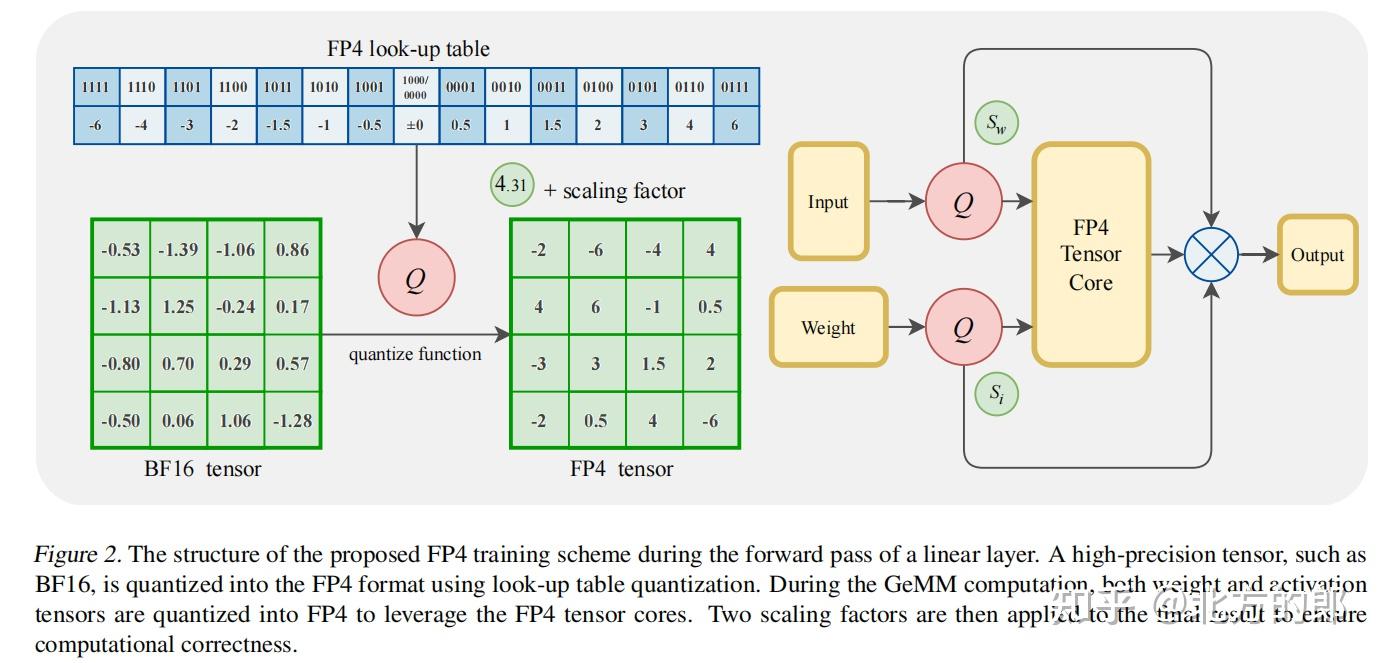
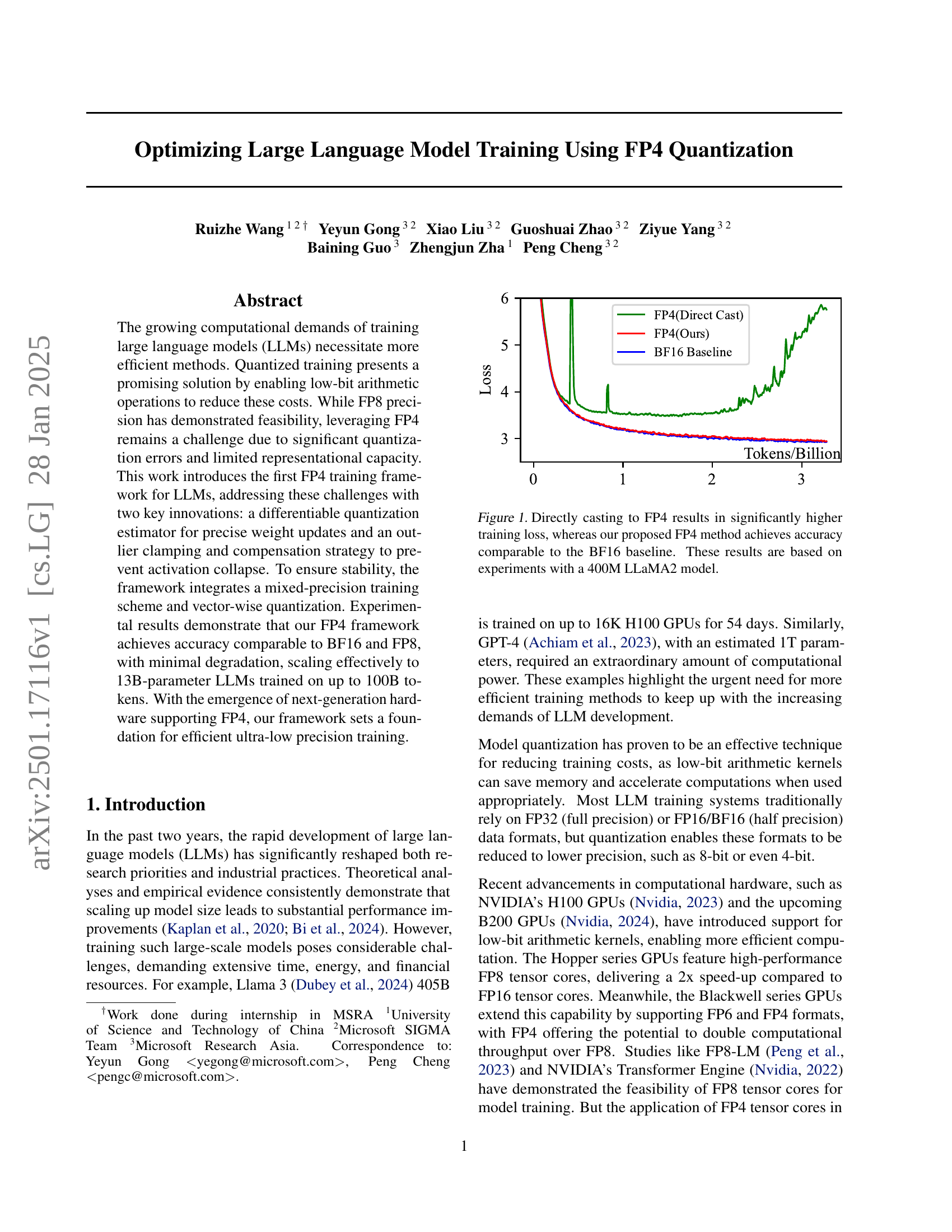
Optimizing Large Language Model Training Using FP4 Quantization
FP4 Tuner - Vance & Hines
FP4 is the new FP16 🔥 Nvidia is moving towards ultra-low precision FP4 ...
An Appreciation Of Ilford Fp4 : What’s the difference between Ilford ...
Paper page - Optimizing Large Language Model Training Using FP4 ...
Optimizing Large Language Model Training Using FP4 Quantization · HF ...
万字解析FP4训练大语言模型:Optimizing Large Language Model Training Using FP4 ...
A Microsoft custom data type for efficient inference – TheWindowsUpdate.com
LLM.fp4 低精度浮点量化大模型 - 知乎
隆重推出 NVFP4,实现高效准确的低精度推理 - NVIDIA 技术博客
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
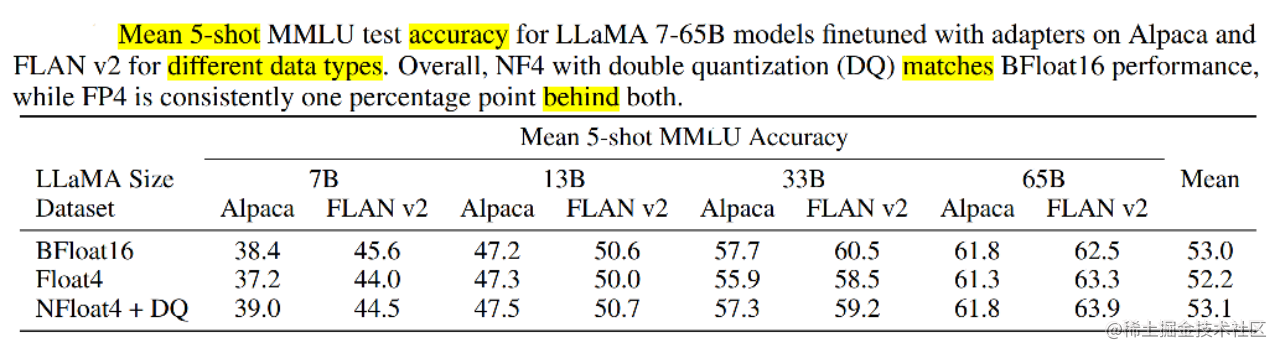
QLORA:LLM的高效量化微调 - 知乎
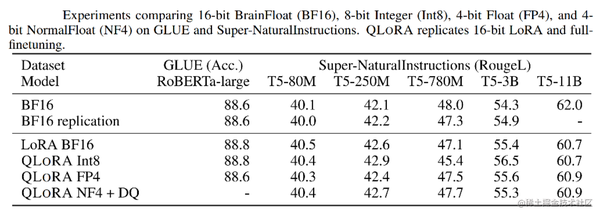
用 bitsandbytes、4 比特量化和 QLoRA 打造亲民的 LLM - 智源社区
量化那些事之FP8与LLM-FP4 - 知乎
Assembly Language & Computer Architecture Lecture (CS 301)
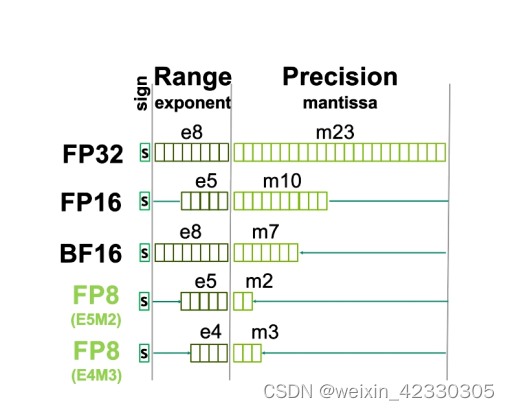
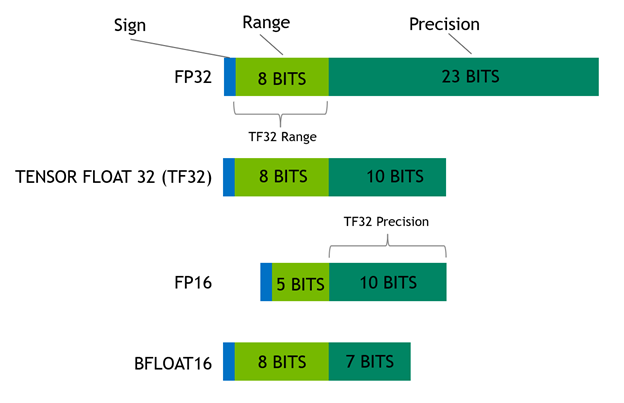
大模型精度:FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8 - 知乎
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference ...
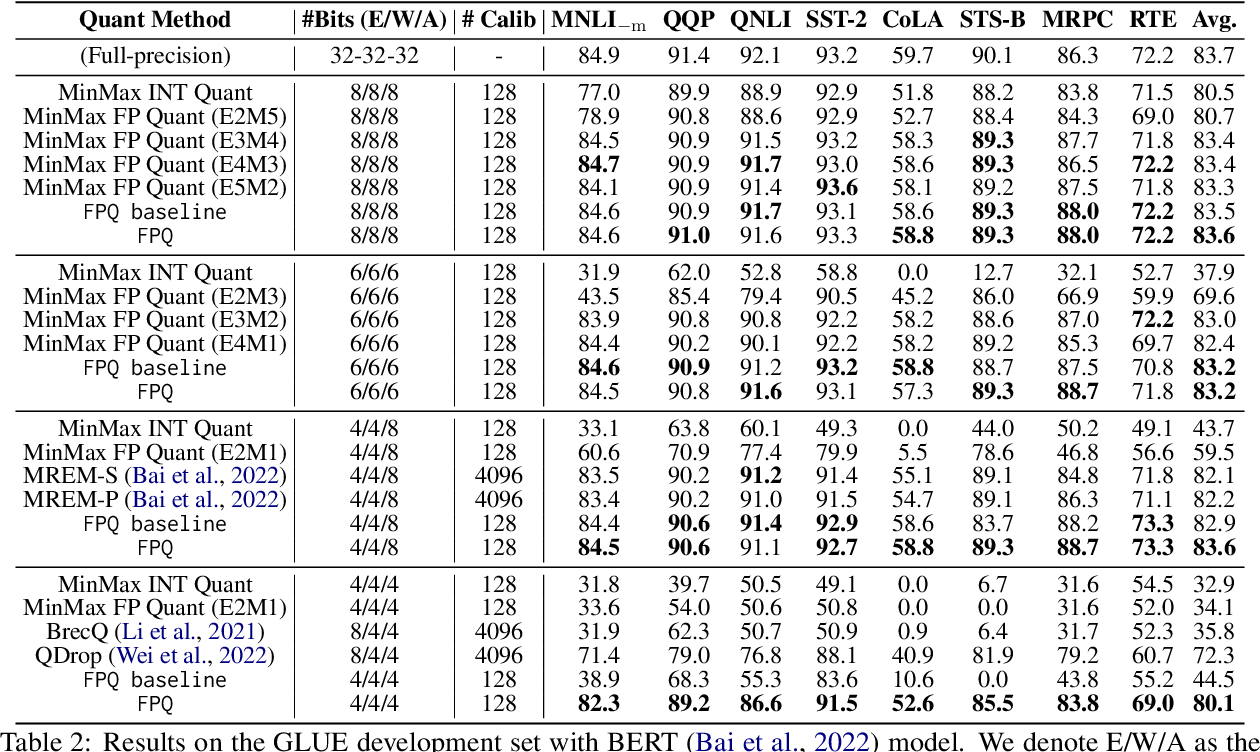
Paper page - LLM-FP4: 4-Bit Floating-Point Quantized Transformers
FP8格式理解解析-CSDN博客
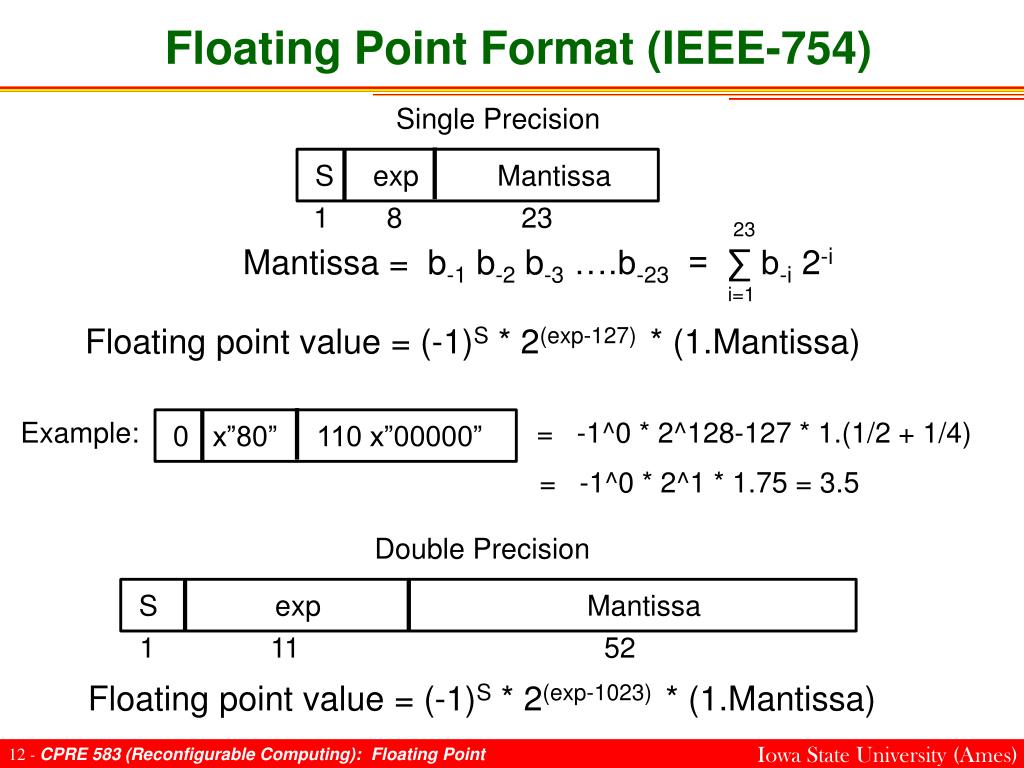
What is FP64, FP32, FP16? Defining Floating Point | Exxact Blog
More In-Depth Details of Floating Point Precision - NVIDIA CUDA ...
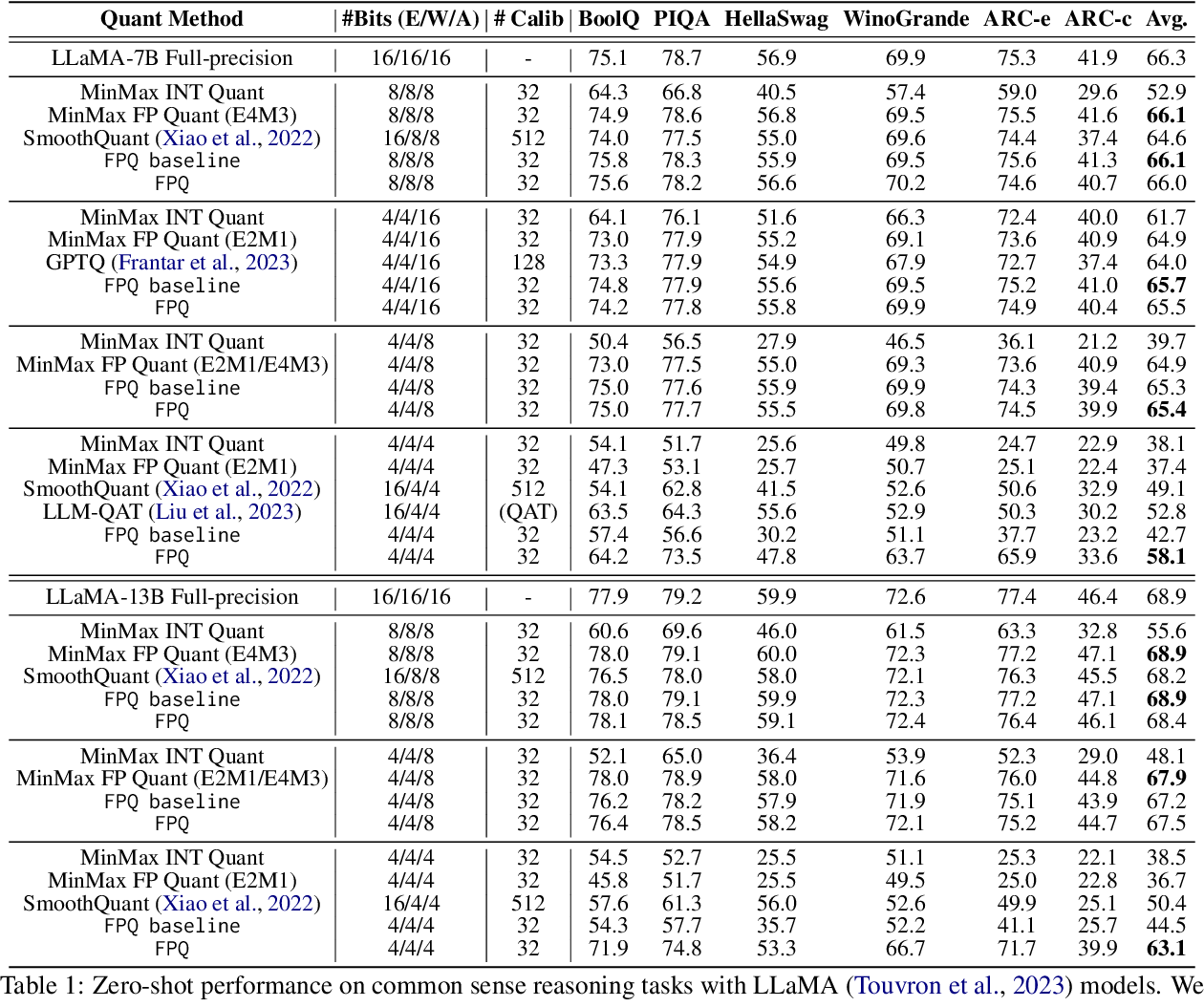
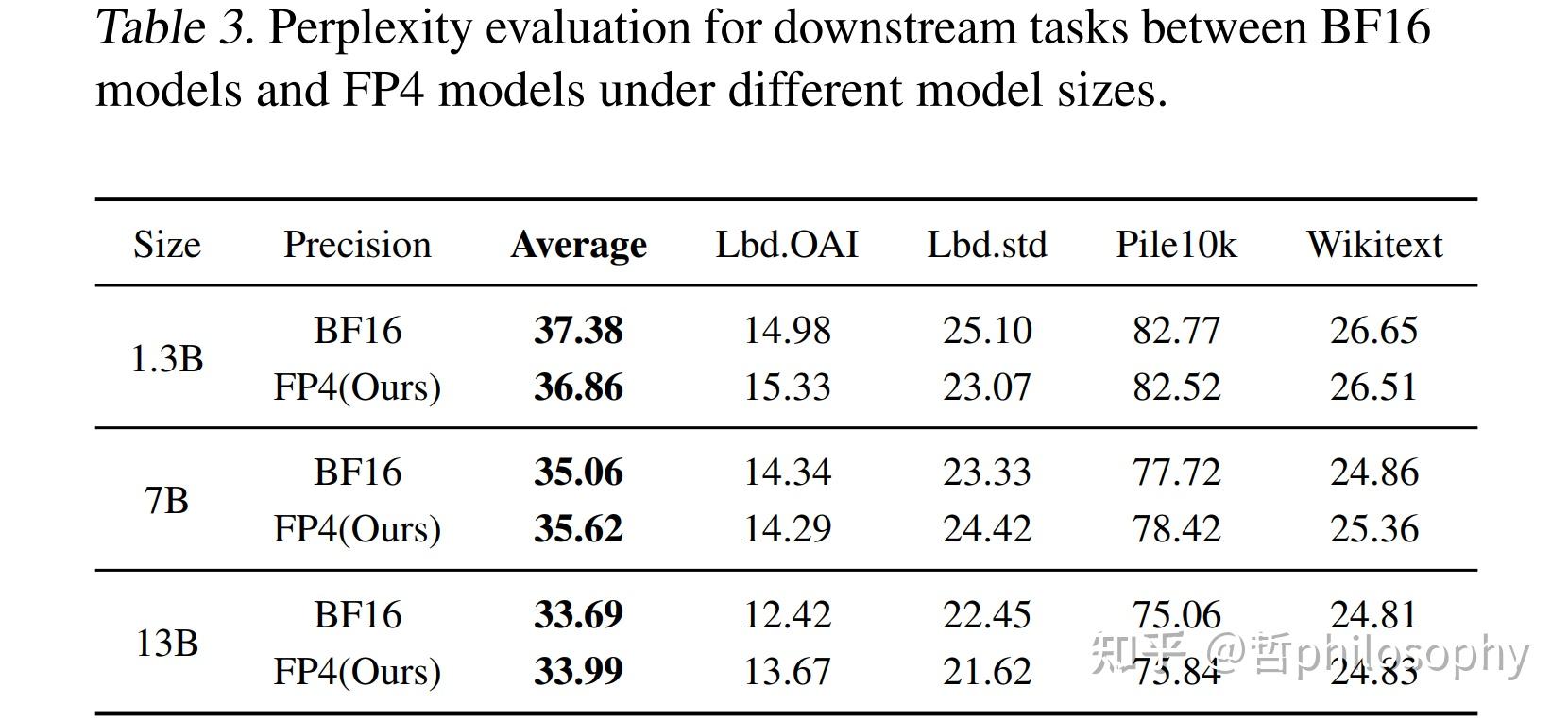
Table 1 from FP4-Quantization: Lossless 4bit Quantization for Large ...
【手撕LLM-QLoRA】NF4与双量化-源码解析 - 知乎
4 LLM Compression Techniques That You Can't Miss
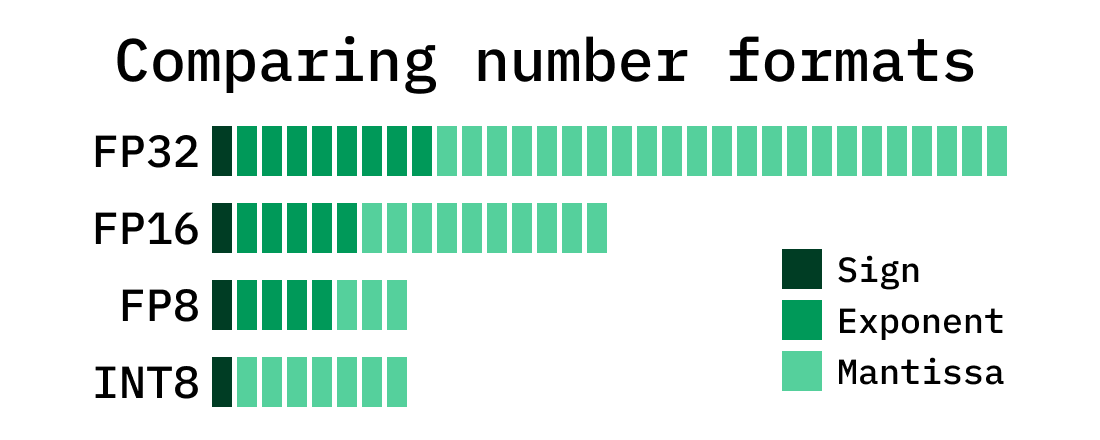
Floating-Point Formats in the World of Machine Learning | Electronic Design
大模型涉及到的精度是啥?FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8区别_fp4和fp8-CSDN博客
CS 400 - Data representation
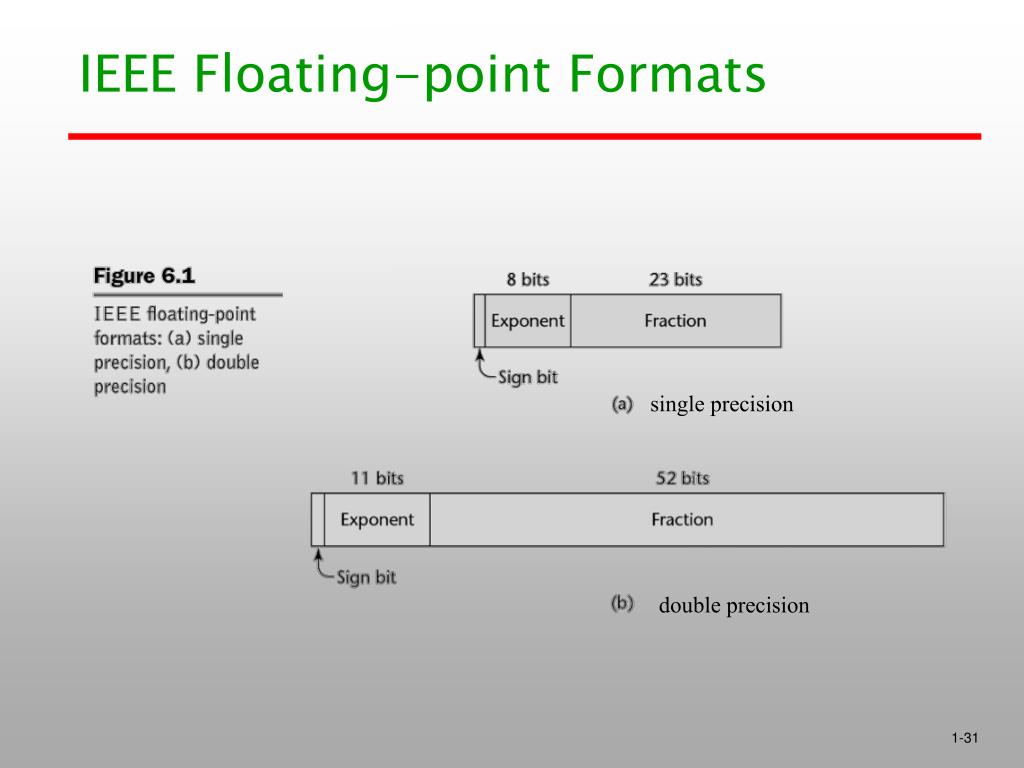
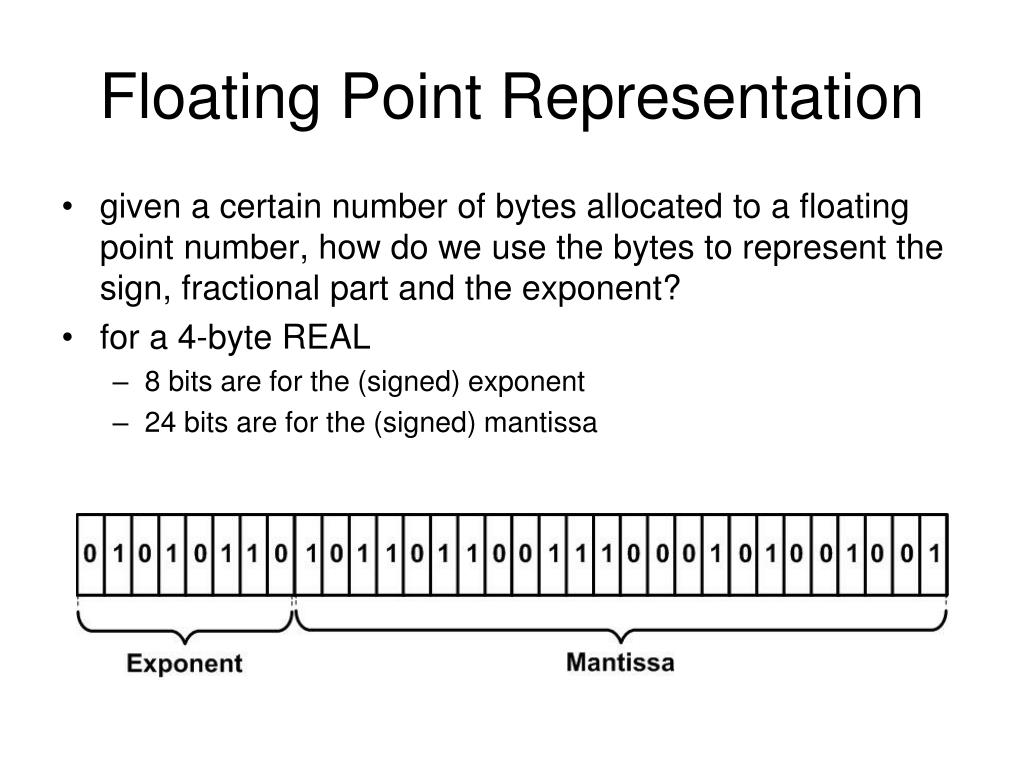
PPT - Chapter 6 PowerPoint Presentation, free download - ID:3923466
FP64、FP32、FP16、FP8简介-CSDN博客
Exxact Corporation | Fremont CA
Optimizing LLMs for Performance and Accuracy with Post-Training ...
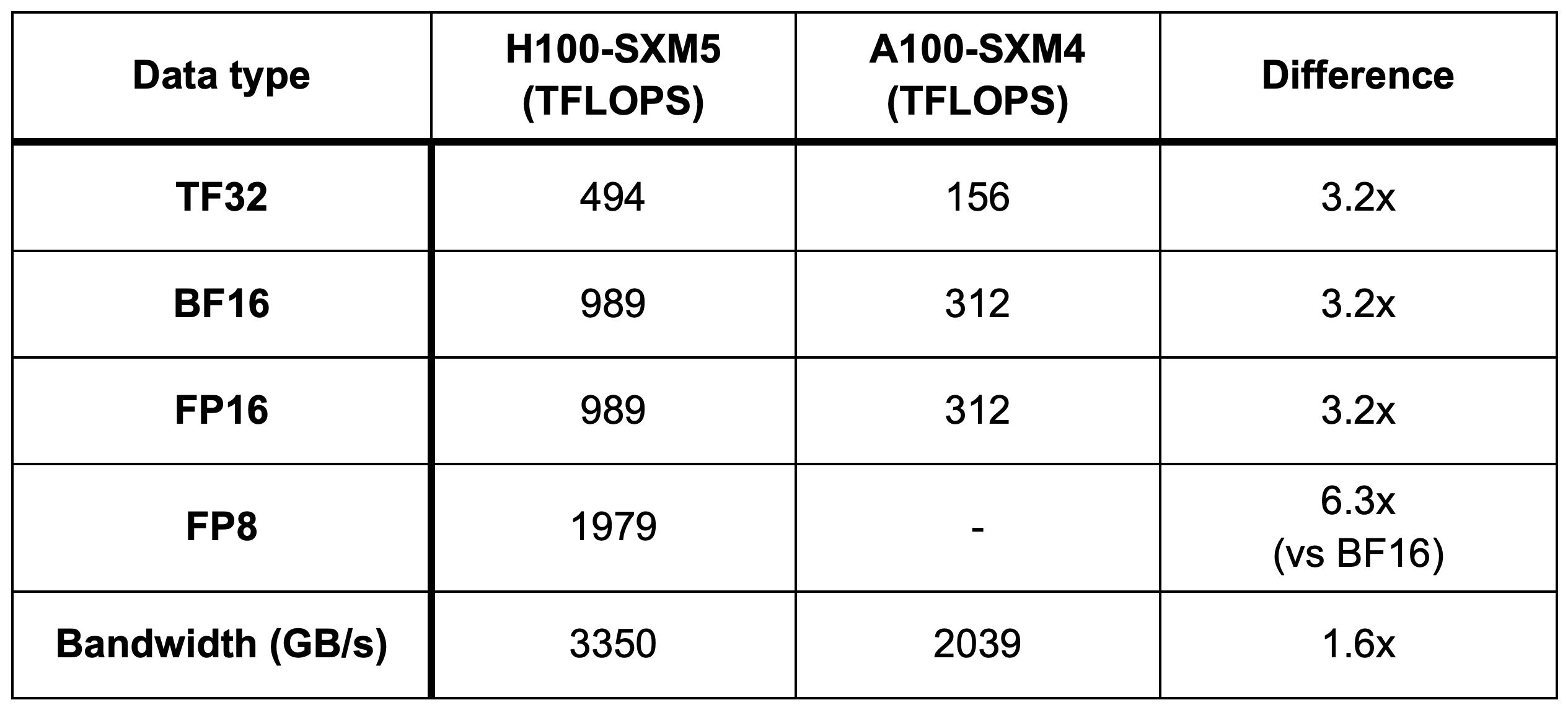
Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave ...
大模型参数高效微调技术原理综述(五)-LoRA、AdaLoRA、QLoRA - 知乎
Table 6 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
Figure 1 from All-You-Can-Fit 8-Bit Flexible Floating-Point Format for ...
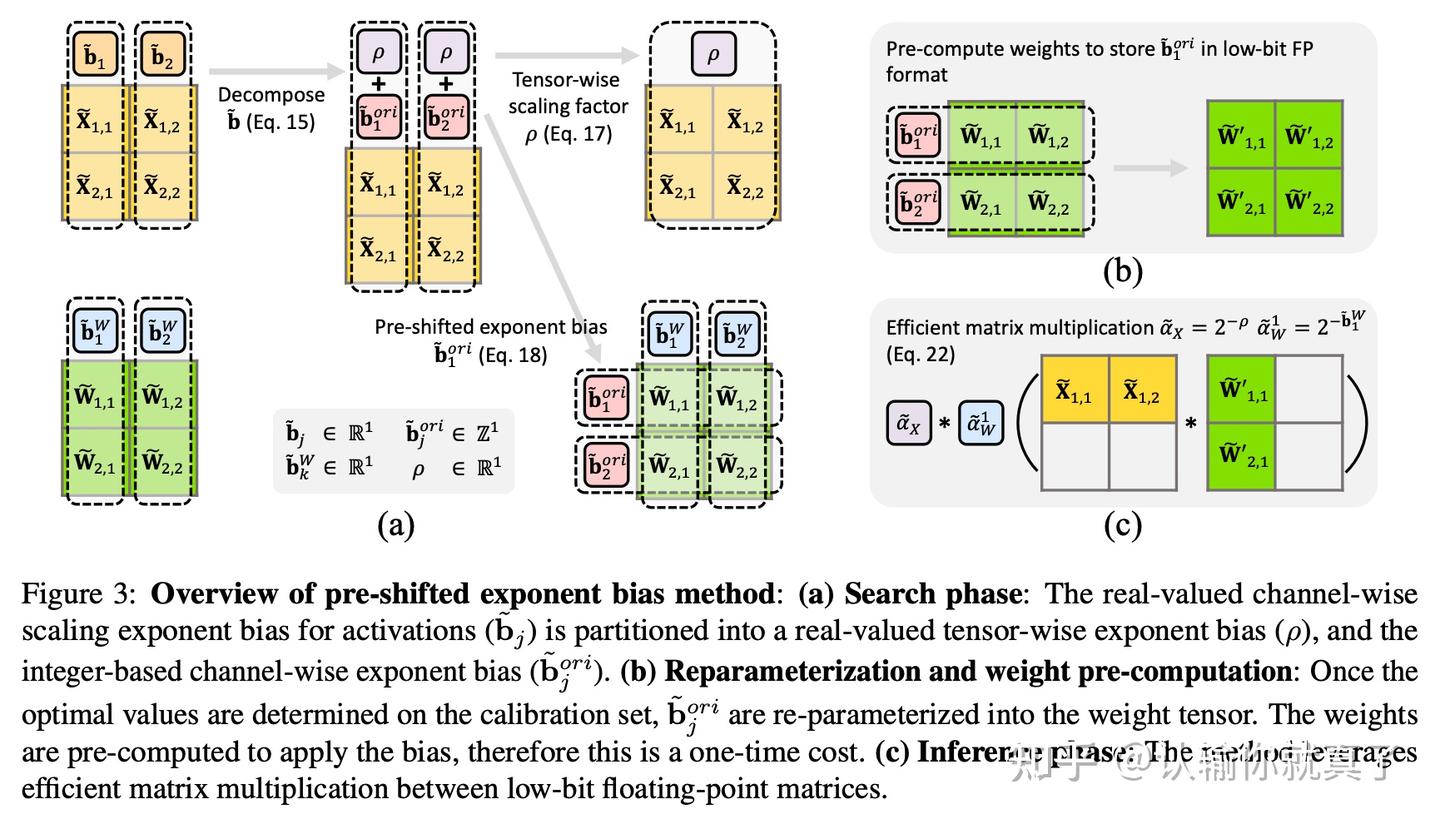
Figure 3 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
模型压缩之量化基础(三):QLORA:高效微调量化LLM - 知乎
LLM-FP4: 4-Bit Floating-Point Quantized Transformers - ACL Anthology
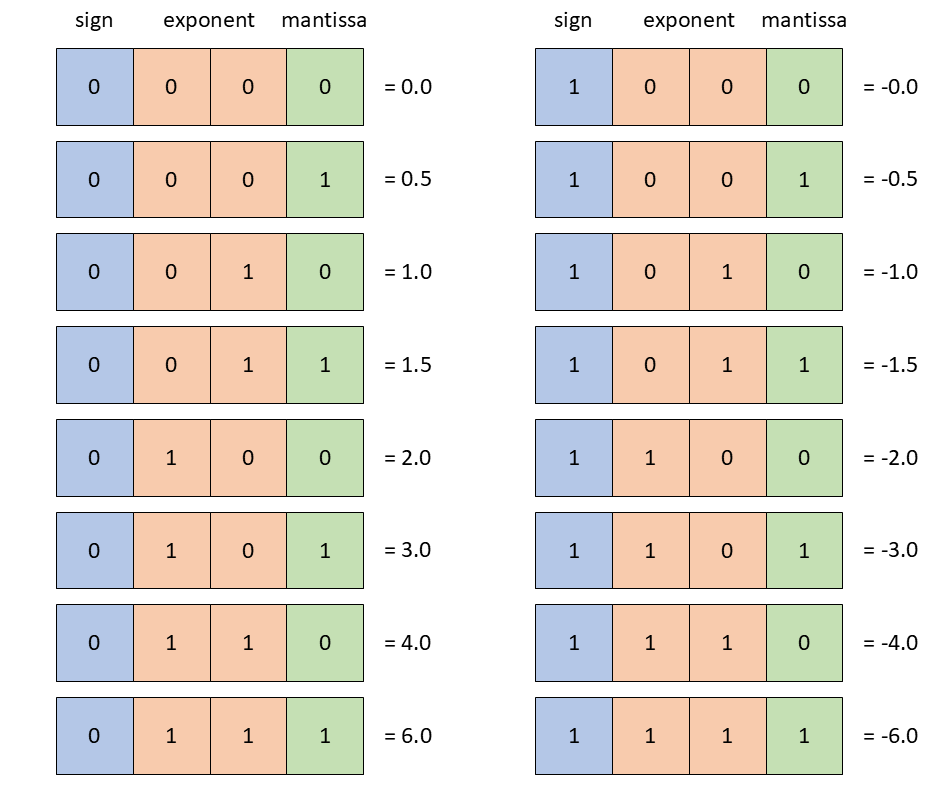
Structure of FP formats. | Download Scientific Diagram
"LLM-FP4: 4-Bit Floating-Point Quantized Transformers"论文阅读 - 知乎
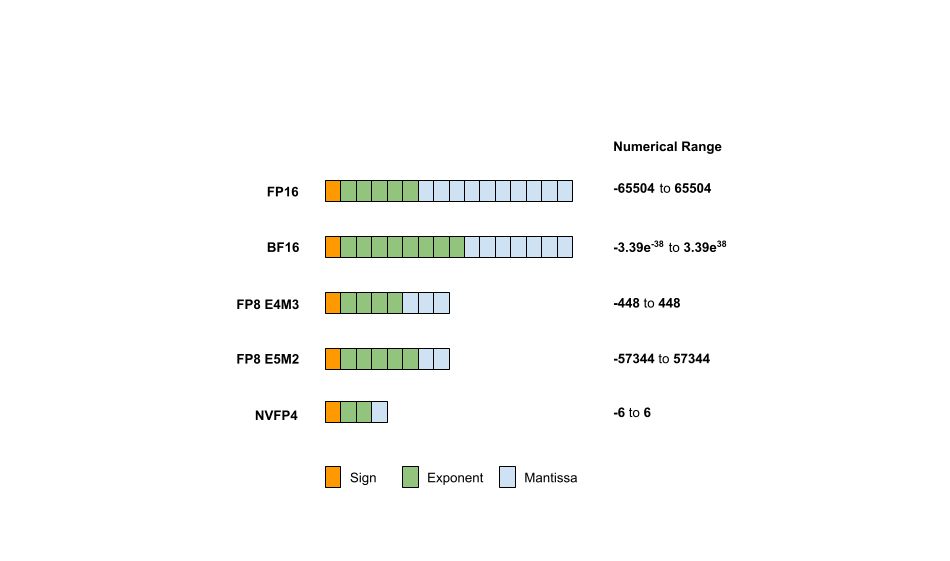
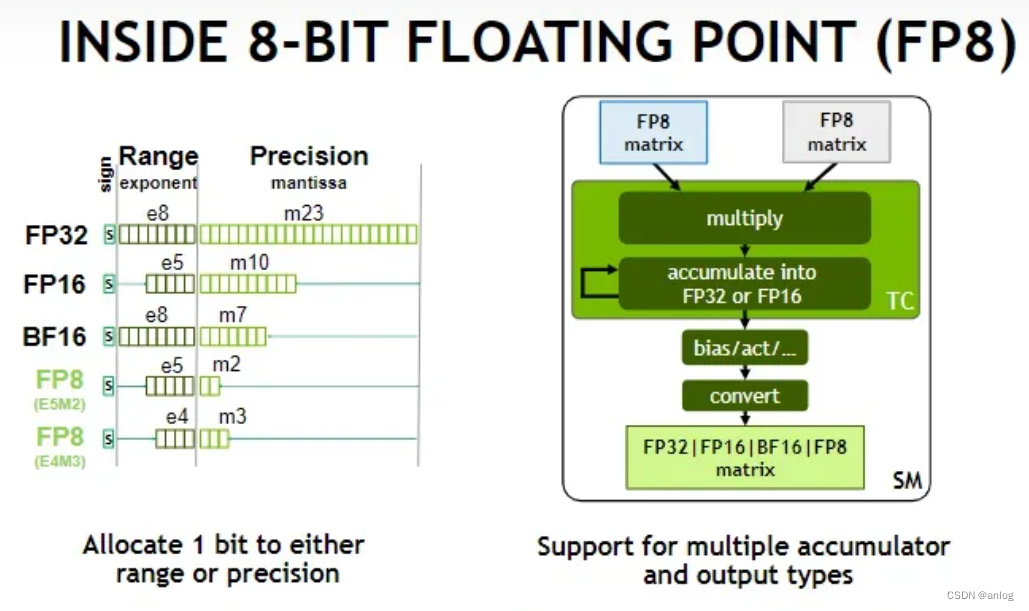
What is FP8, FP6, FP4? | Exxact Blog
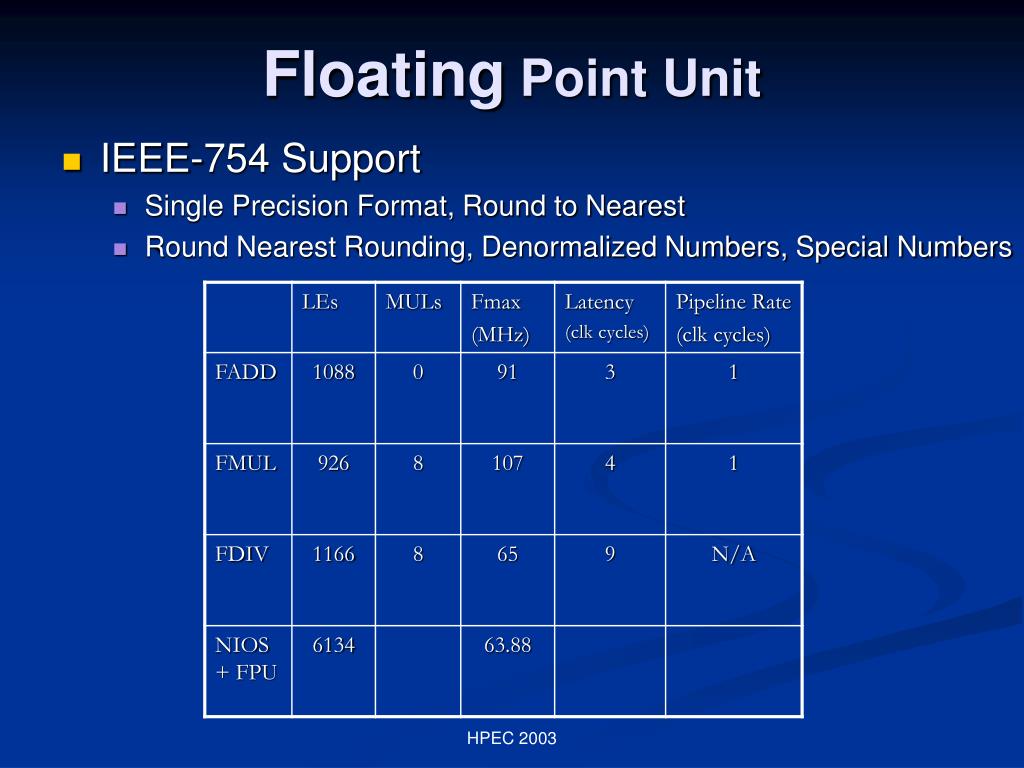
PPT - Ch. 10 Floating Point Unit PowerPoint Presentation, free download ...
A Hands-On Walkthrough on Model Quantization - Medoid AI
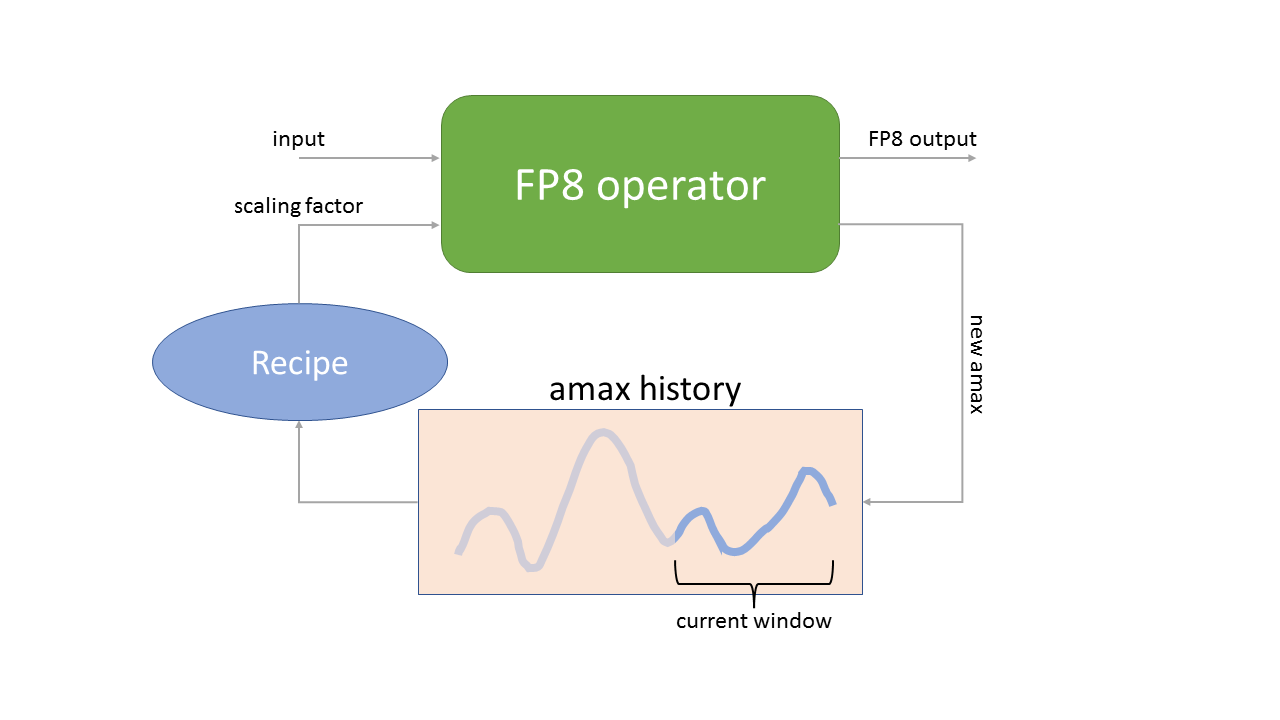
万字综述:全面梳理 FP8 训练和推理技术-CSDN博客
PPT - Chapter Six PowerPoint Presentation, free download - ID:4118821
DeepSeek-V3的FP8训练还不够极致?来看FP4量化训练如何突破算力极限 - 知乎
FP8: Efficient model inference with 8-bit floating point numbers ...
LLM-FP4: 4-Bit Floating-Point Quantized Transformers: Paper and Code
PPT - Reconfigurable Computing Lecture 14: Floating Point PowerPoint ...
PPT - Chapter 6-3 Divider and Floating Point PowerPoint Presentation ...
关于深度学习中的数据结构INT\FLOAT\FP(为使用FP数据类型调用TensorCore的知识储备)_fp int 英文-CSDN博客
Floating Point Precision: Understanding FP64, FP32, and FP16 in Large ...
How Industrial Floats Enhance Emergency Response on Water
PPT - Floating Point: Representation and Instructions PowerPoint ...
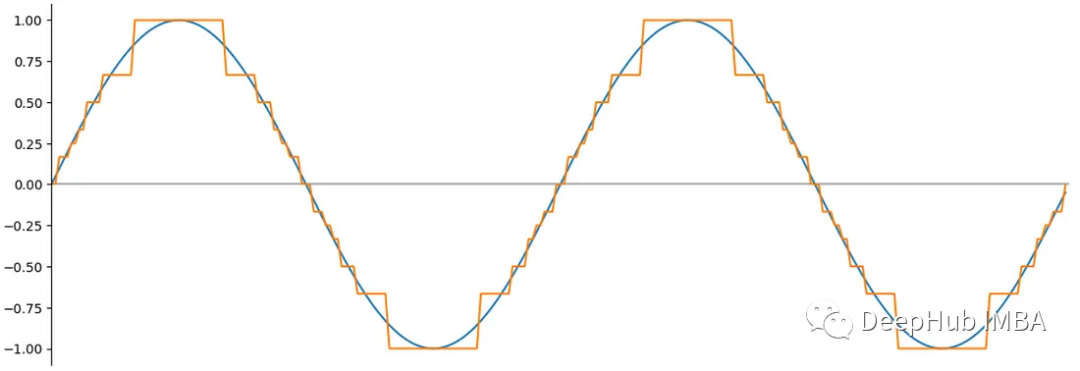
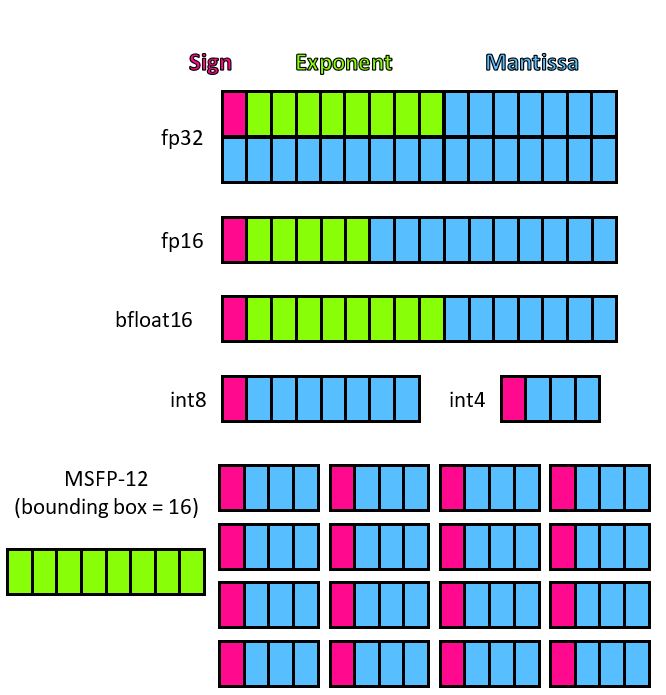
16, 8, and 4-bit Floating Point Formats - How Does it Work? | Towards ...
Line Floats and Their Role in Offshore Operations
GitHub - NVIDIA/TransformerEngine: A library for accelerating ...
initial commit · mit-han-lab/svdq-fp4-flux.1-fill-dev at 5ee9bef
Automatic Performance Improvement for Legacy COBOL | PDF
PPT - Linear Algebra Processor using FPGA PowerPoint Presentation, free ...
Figure 7 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
Figure 2 from Review on 32 bit single precision Floating point unit ...
PPT - Microprocessors PowerPoint Presentation, free download - ID:6610275
The three FP representations used in this paper: (a) Bfloat16, (b ...
大模型涉及到的精度有多少种?FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8都有什么关联,一文讲清楚 - 知乎
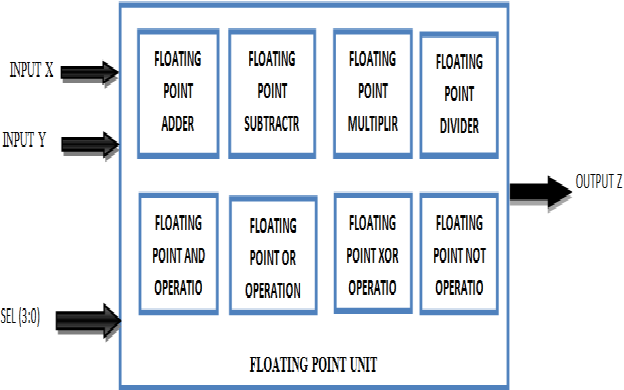
GitHub - choukusepurva/Floating_Point_Unit_Hardware_Implementation ...
Optimal Architecture of Floating-Point Arithmetic for Neural Network ...
FlexPoint Series | Portable Coaxial Point Source Loudspeakers | Martin ...
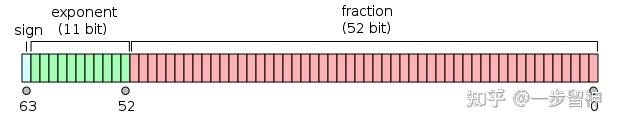
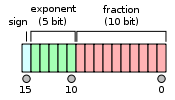
Half-precision floating-point format - Wikipedia
NVIDIA 的 Blackwell 架构:解析 B100、B200 和 GB200_nvidia b100-CSDN博客
PPT - Introduction to Fortran PowerPoint Presentation, free download ...
Table 1 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
Generative AI 新世界 | 大模型参数高效微调和量化原理概述_fp4-CSDN博客
16,8和4位浮点数是如何工作的-腾讯云开发者社区-腾讯云
FPGA-Based Convolutional Neural Network Accelerator with Resource ...
Be aware: Floating Point Operations on ARM Cortex-M4F | MCU on Eclipse
The smart and trusted cycle. | Download Scientific Diagram
Best Floats For Night Fishing at William Fellows blog
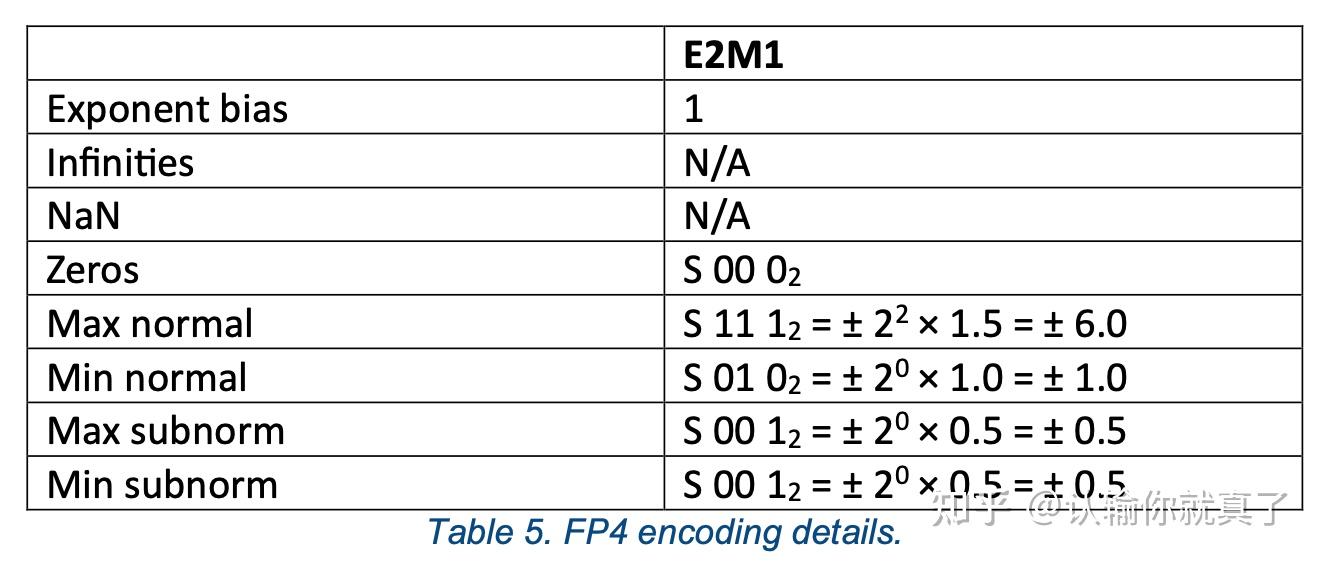
Table 5 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...

:max_bytes(150000):strip_icc()/float.asp-final-d281617436f5445bb62d7ab822dde4e3.png)























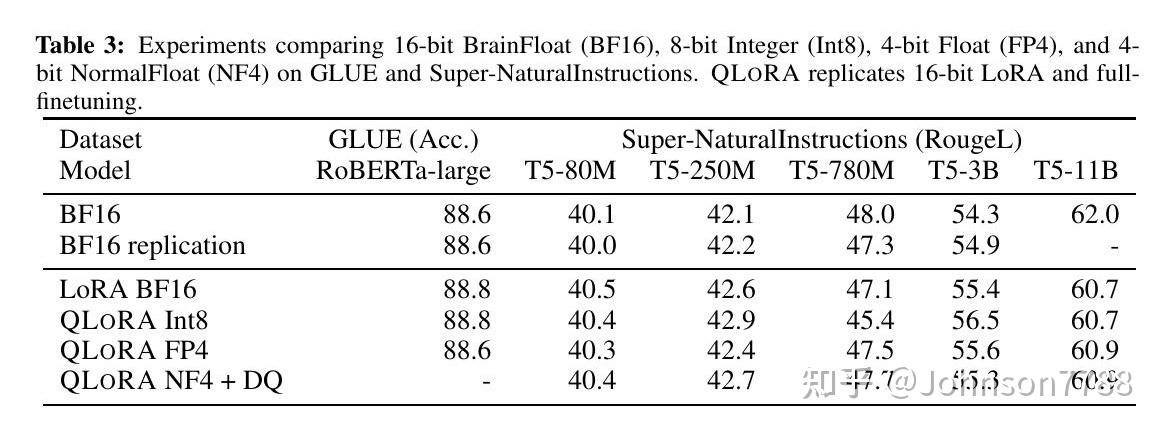
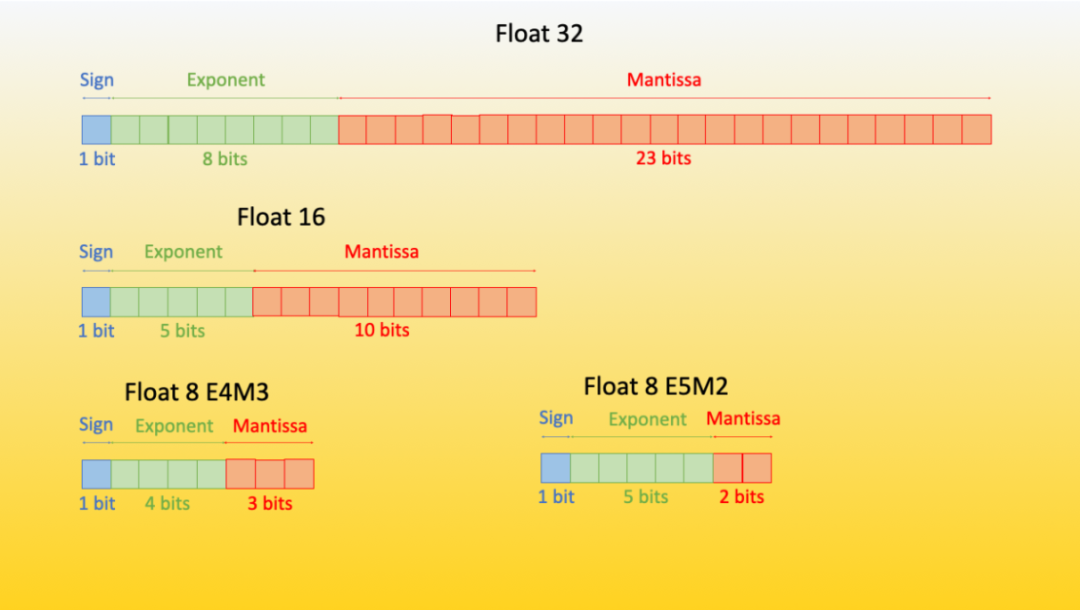
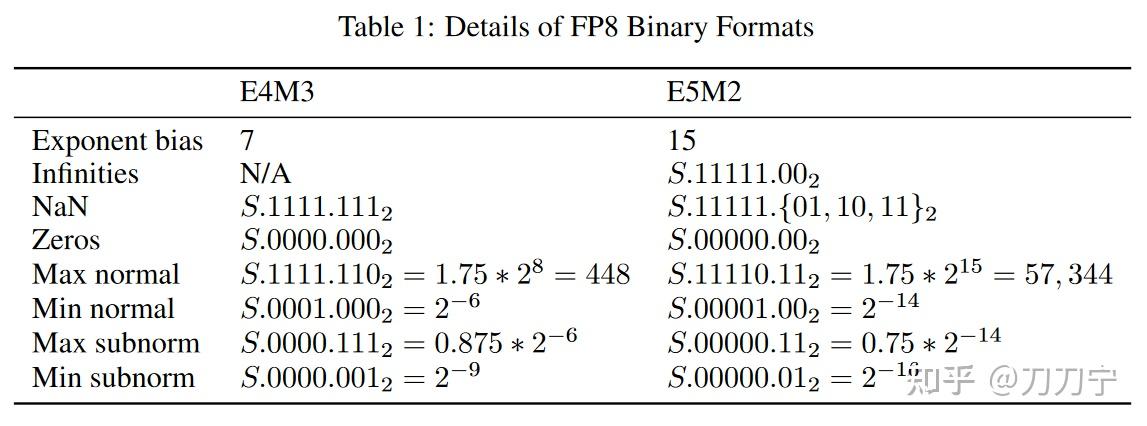

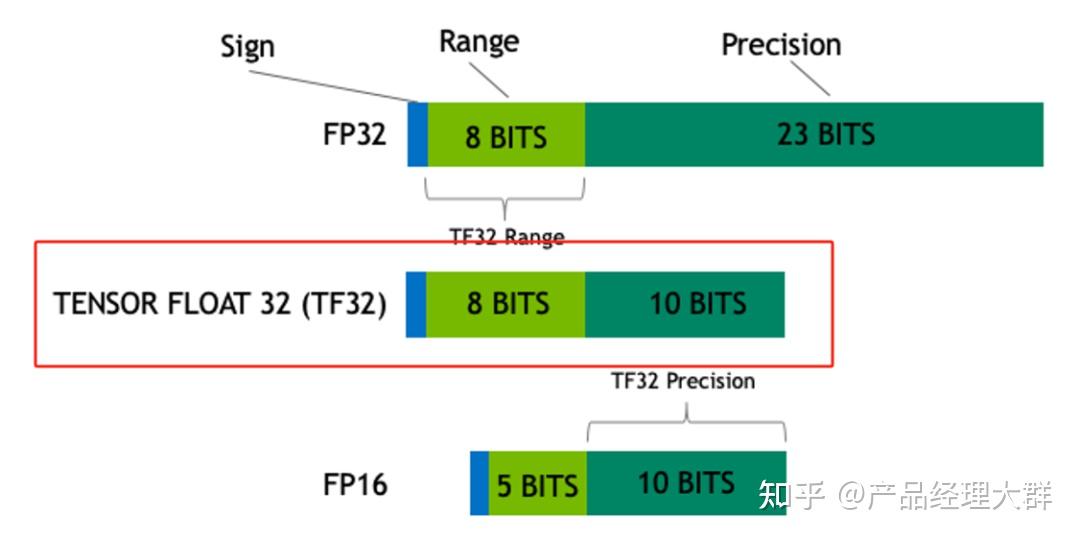


.jpg?format=webp)