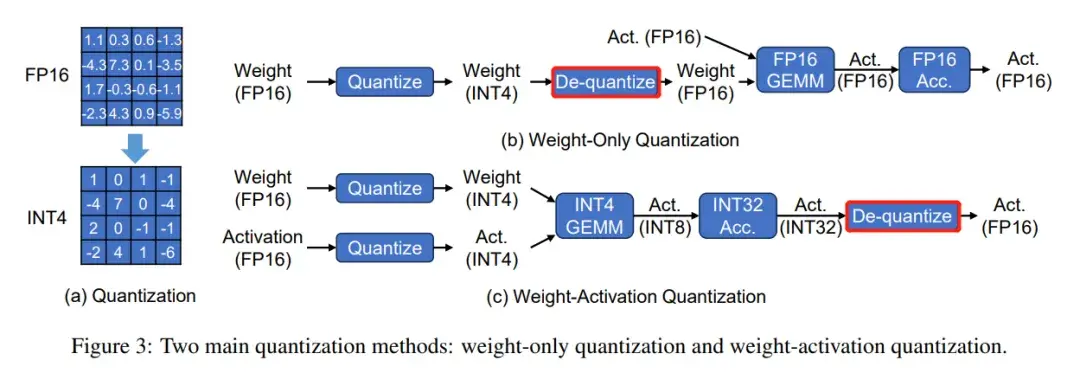
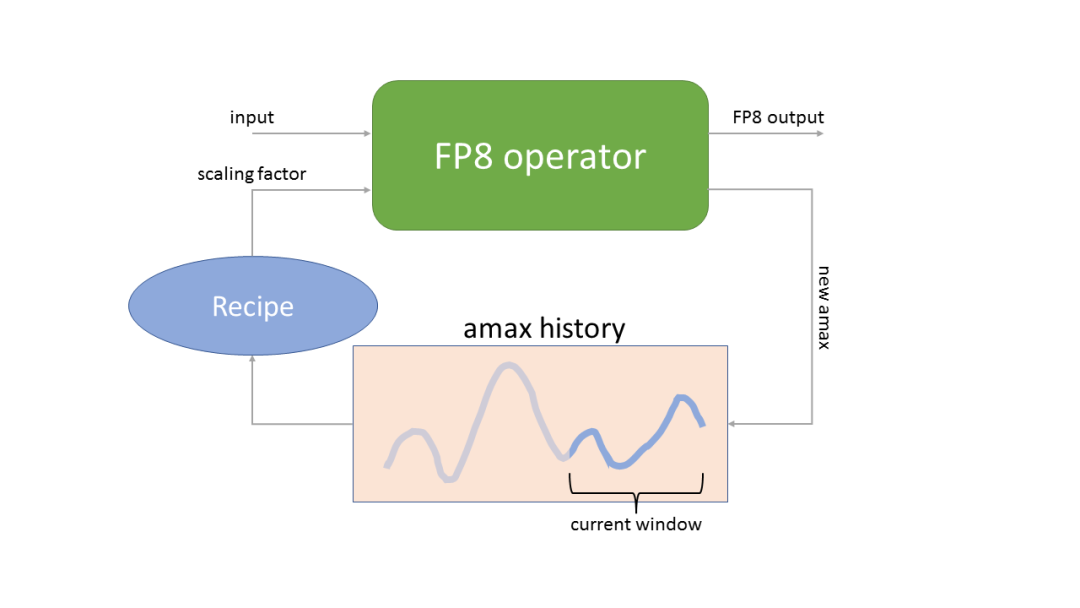
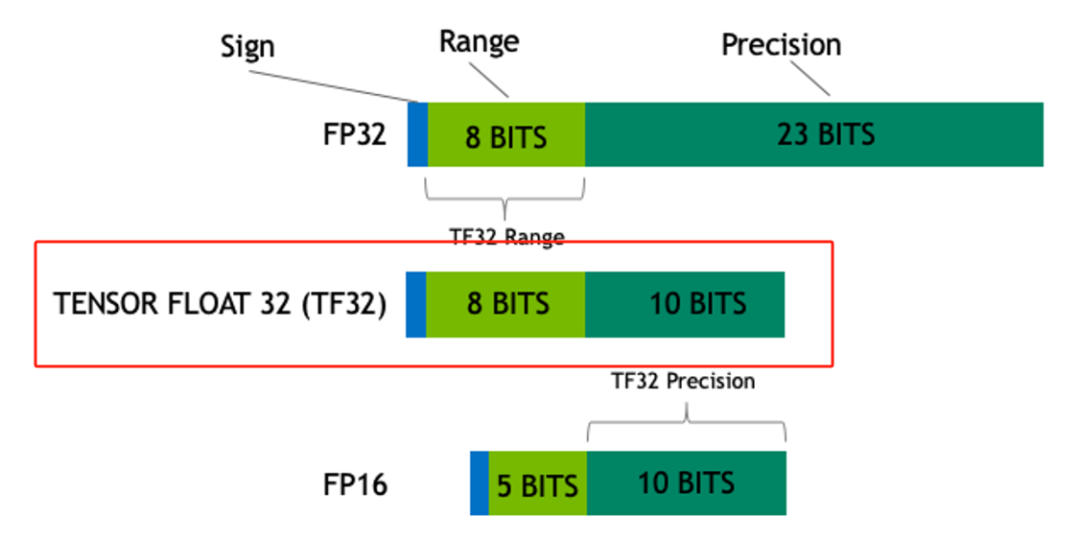
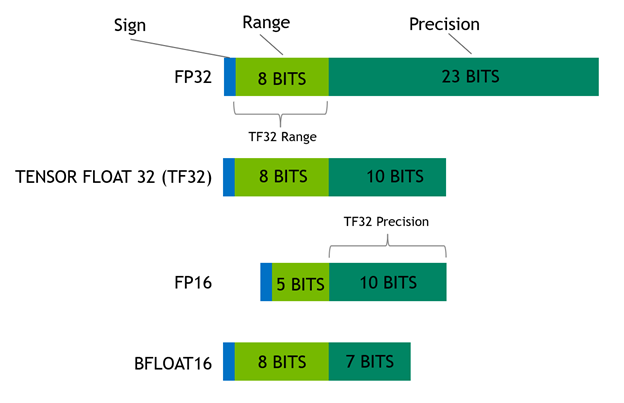
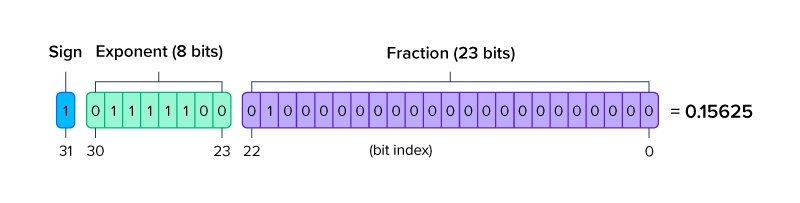
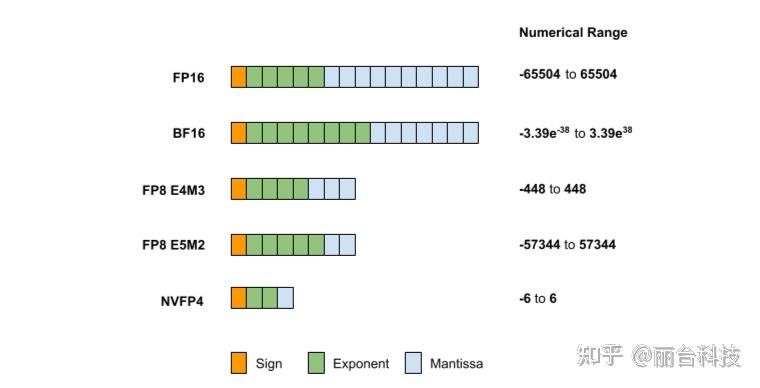
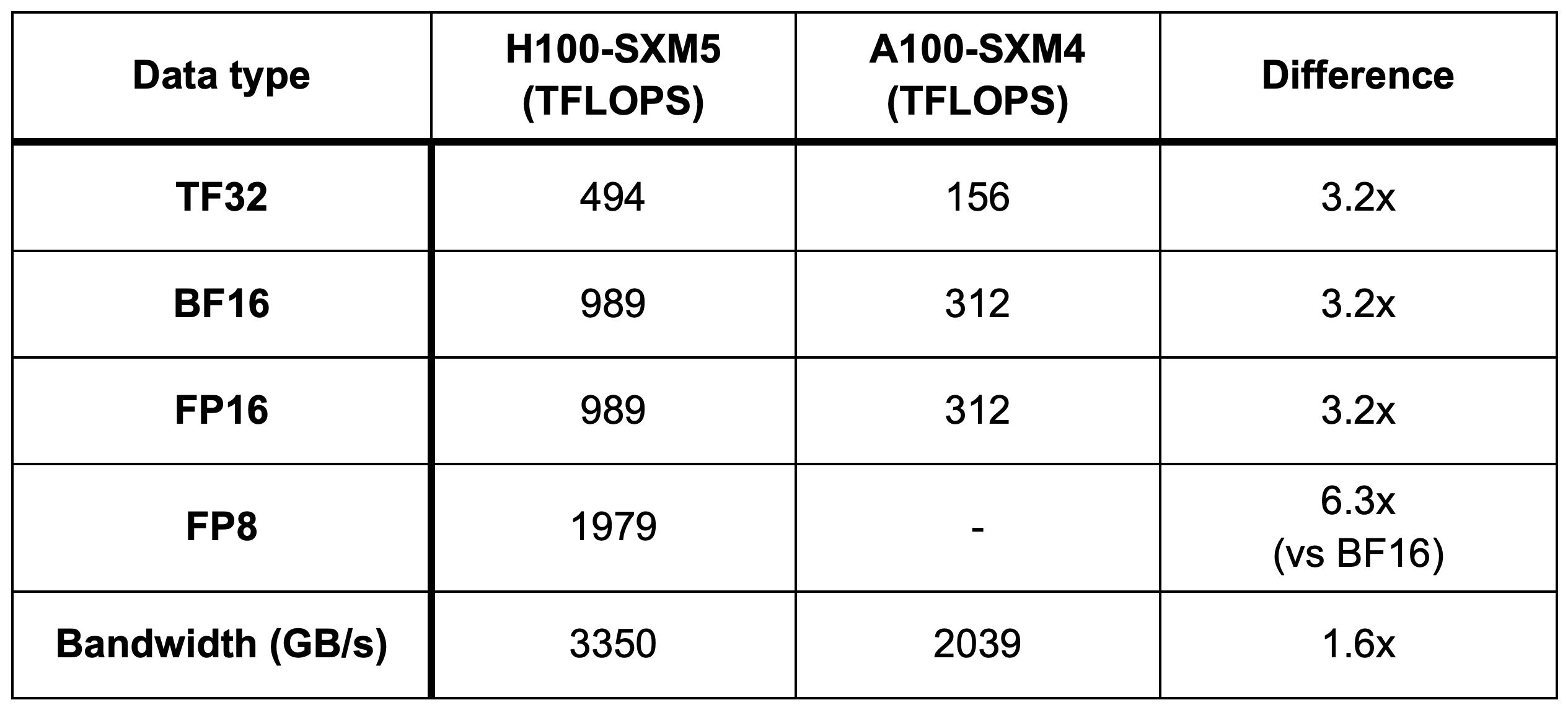
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Optimization Using FP4 Quantization For Ultra-Low Precision Language ...
[논문 리뷰] Towards Efficient Pre-training: Exploring FP4 Precision in ...
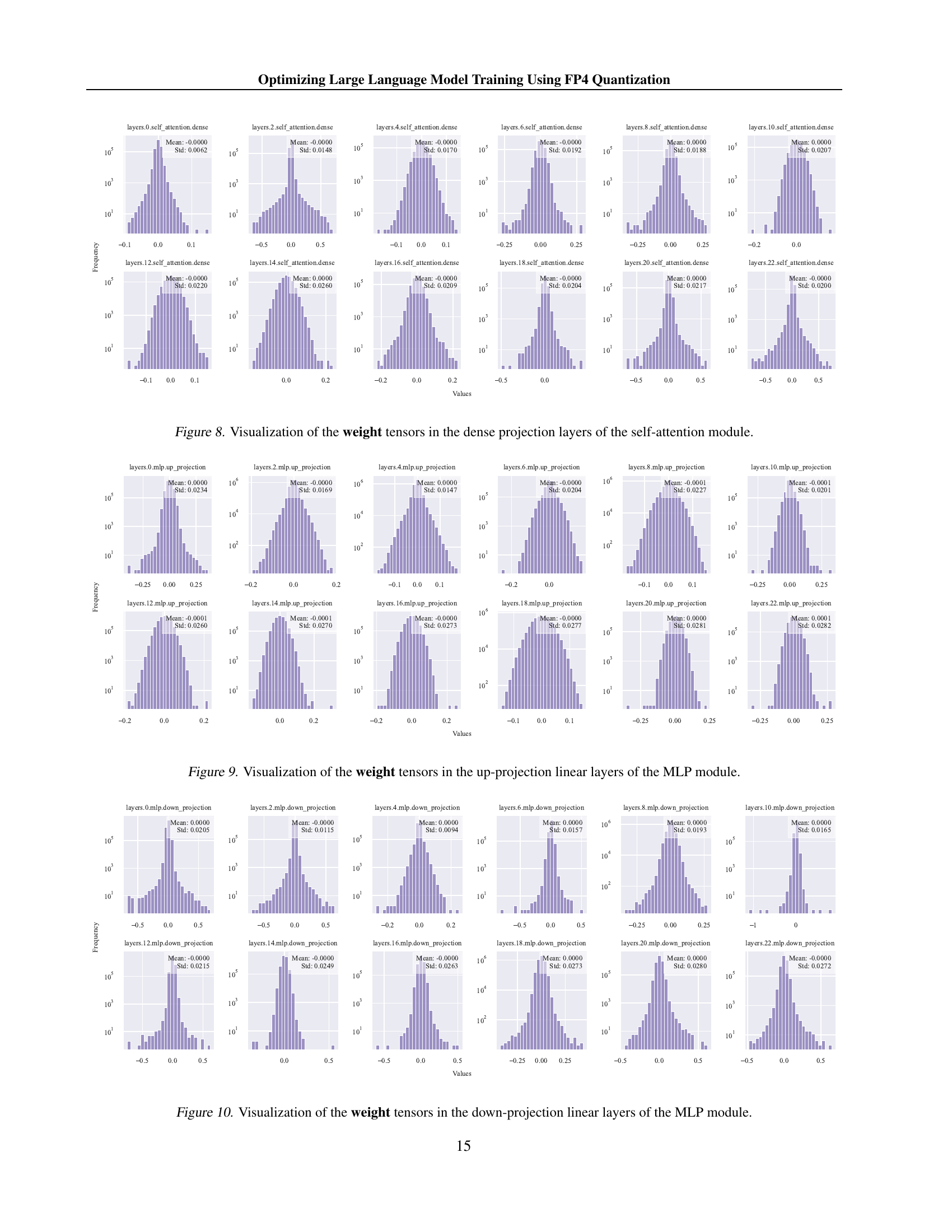
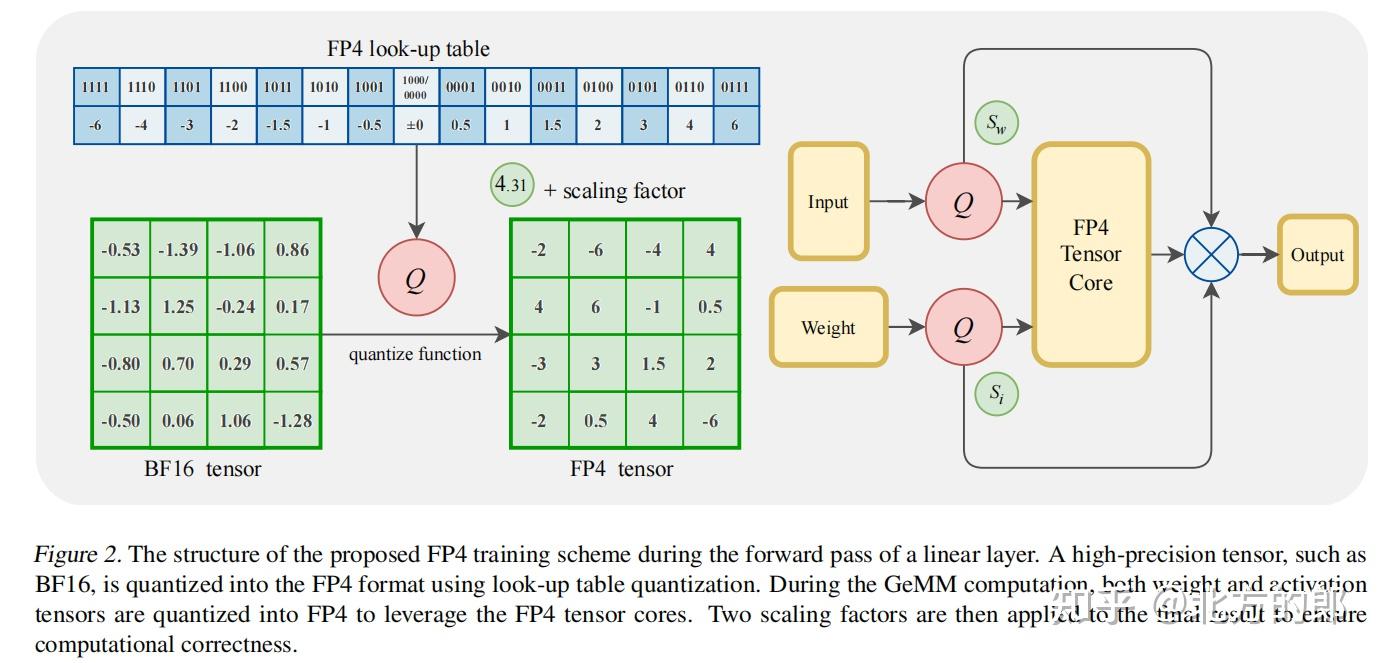
Figure 1 from Optimizing Large Language Model Training Using FP4 ...
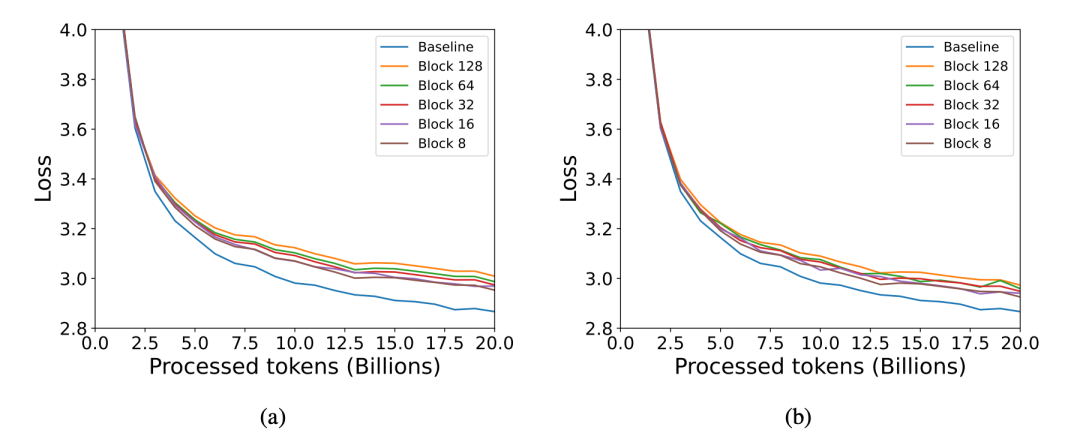
Figure 4 from Optimizing Large Language Model Training Using FP4 ...
NVIDIA TensorRT Unlocks FP4 Image Generation for NVIDIA Blackwell ...
Simulated degree distribution for the O graphs. The empirical FP4 data ...
5,000 words Analysis of FP4 Quantization for Training Large Language ...
[2502.11458] Towards Efficient Pre-training: Exploring FP4 Precision in ...
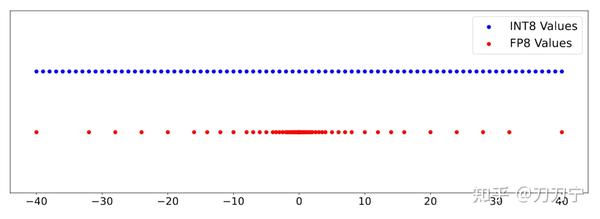
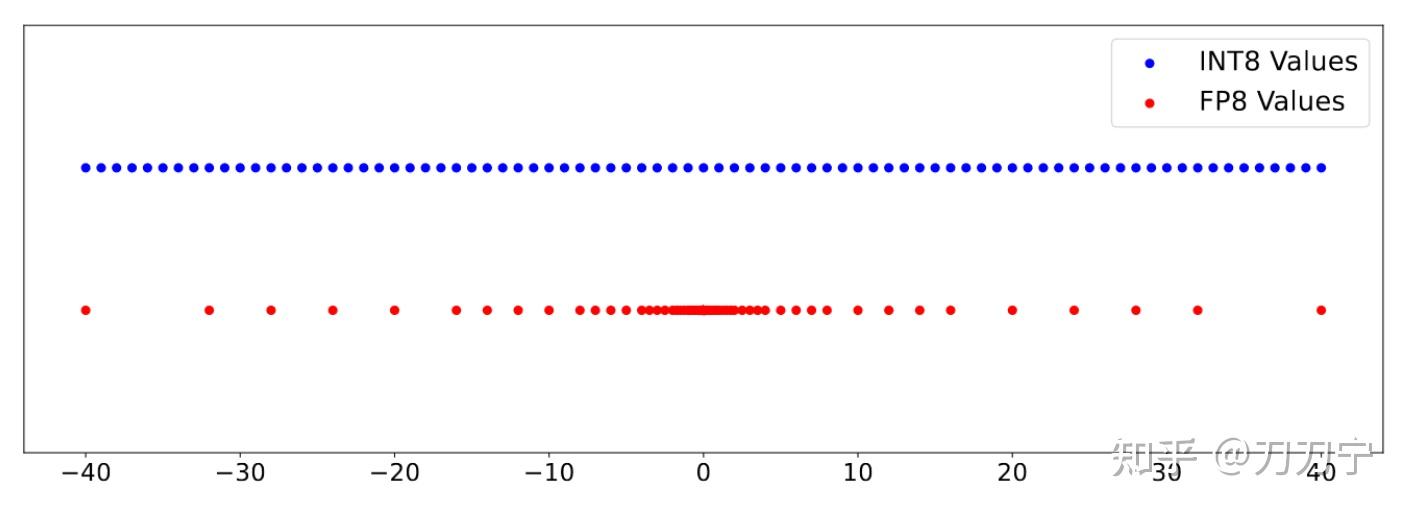
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
Optimizing FP4 Mixed-Precision Inference on AMD GPUs | LMSYS Org
Effects of FP4 on the early activation of B cells induced by the BARS13 ...
Accelerate Your AI Workflow with FP4 Quantization on Lambda
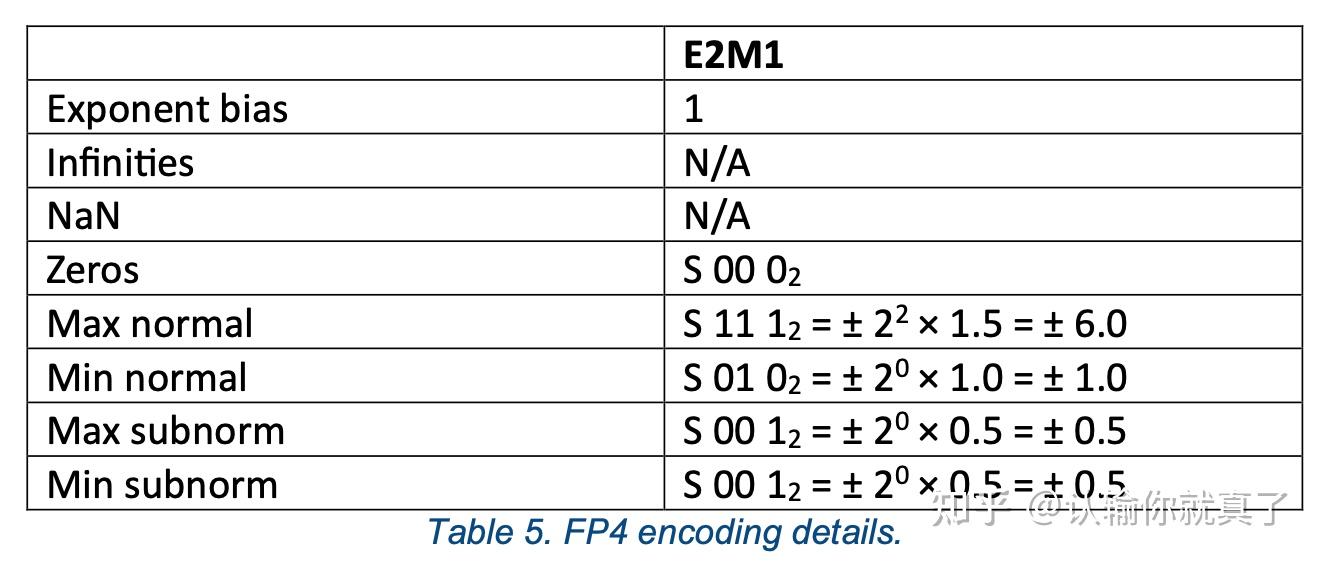
The correctly rounded result of í µí± í µí± (1.5) for FP5 and FP4 with ...
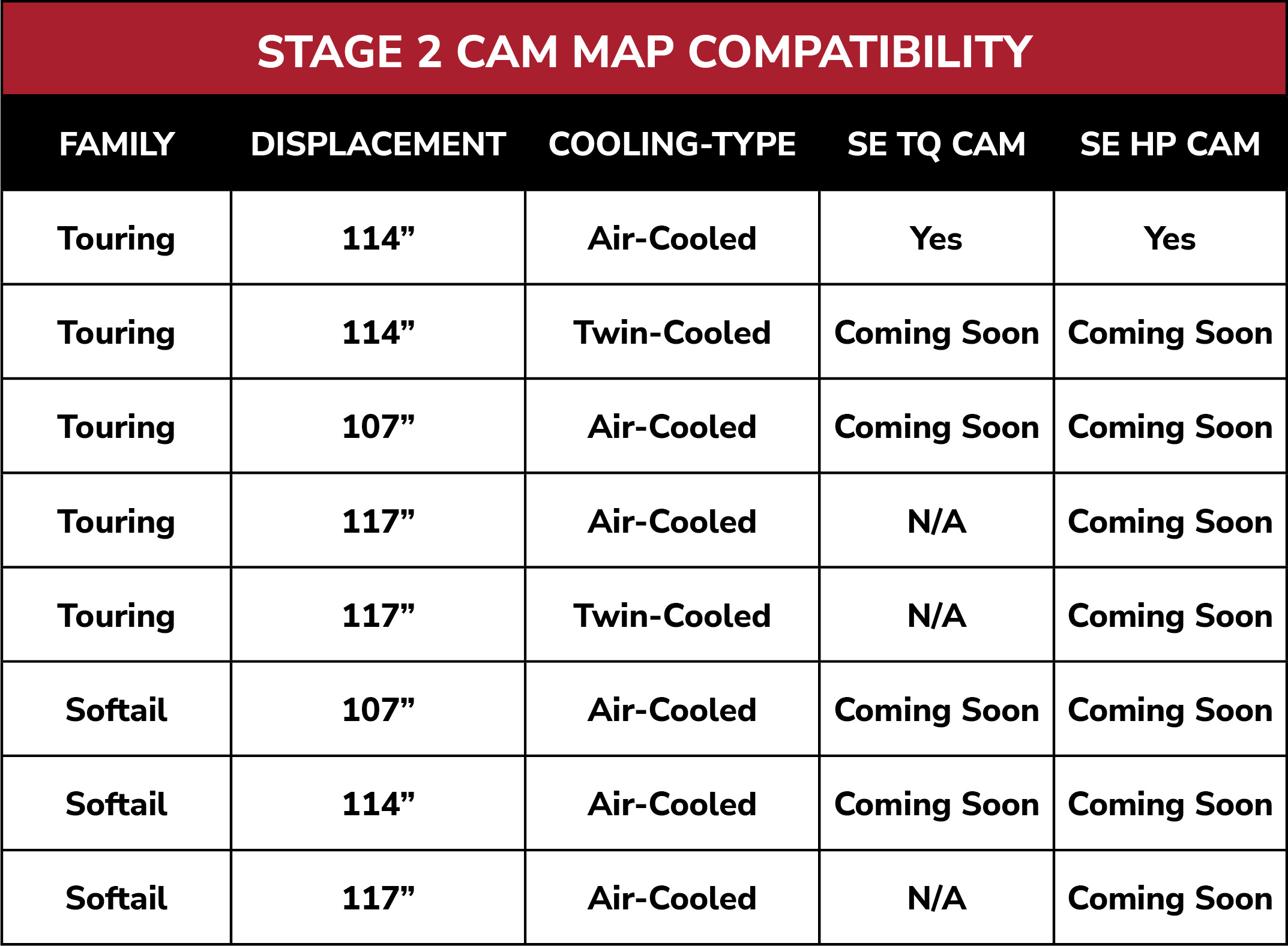
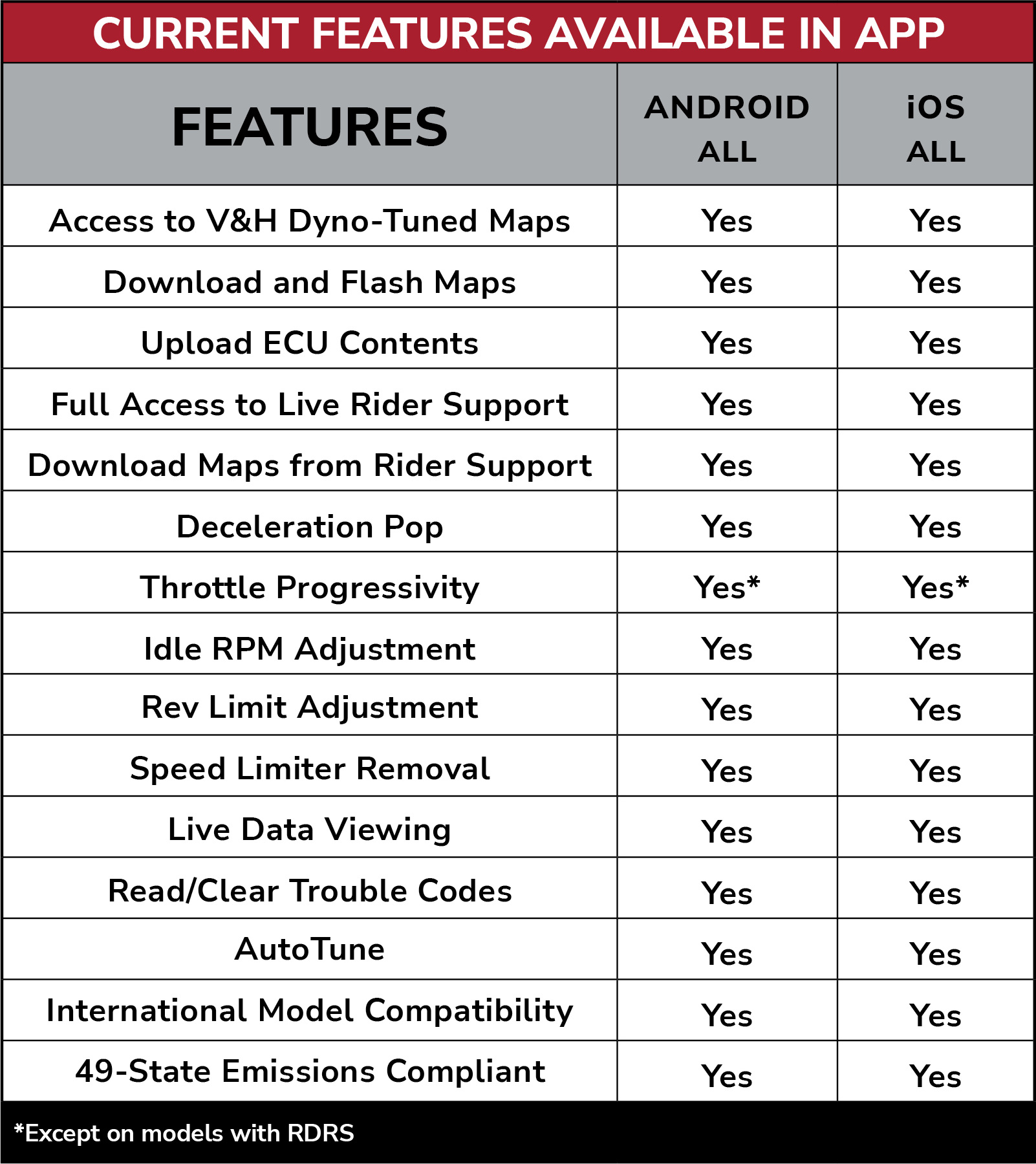
Vance & Hines FP4 2007-2013 Sportster Touring, Softail, Dyna and Stree ...
FP4 Fon Analiz - ONE PORTFÖY DÖRDÜNCÜ HİSSE SENEDİ SERBEST FON (HİSSE ...
FP4 Tuner - Vance & Hines
FP4 All the Way: Fully Quantized Training of LLMs - Explained Simply ...
Optimizing Large Language Model Training Using FP4 Quantization - YouTube
Transcriptome analysis of WWS and LGMDR9 myotubes (A) Graph shows ...
FP4 Quantization For Inference: Rubin Guide (2026)
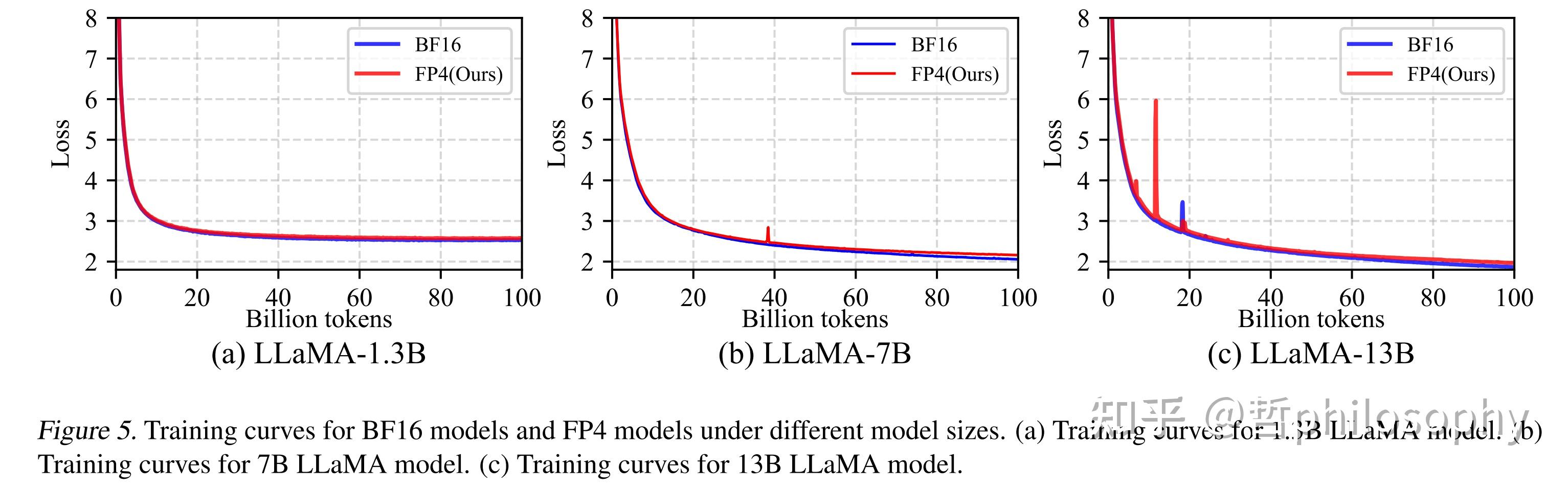
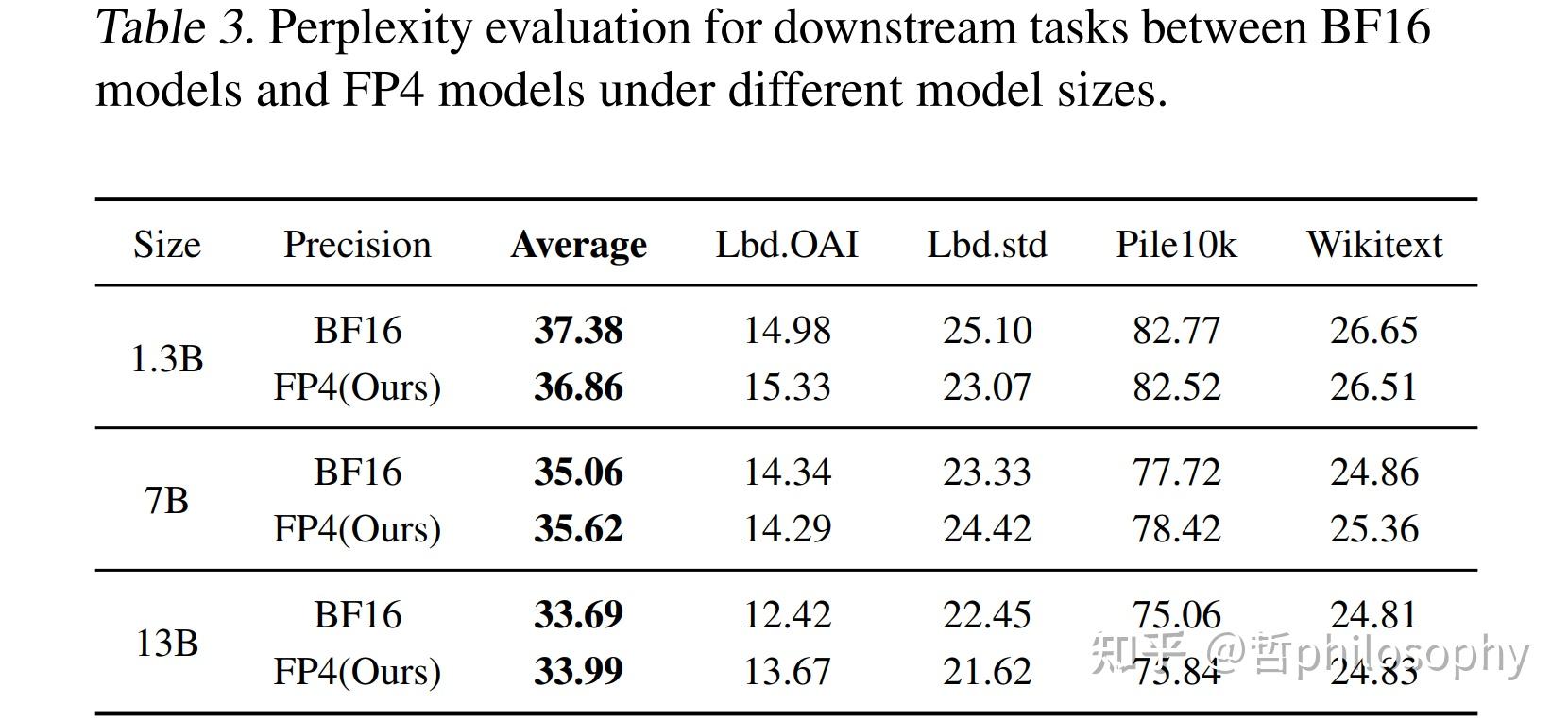
Paper page - Optimizing Large Language Model Training Using FP4 ...
万字解析FP4训练大语言模型:Optimizing Large Language Model Training Using FP4 ...
FP4 is the new FP16 🔥 Nvidia is moving towards ultra-low precision FP4 ...
How to achieve FP8-like performance with FP4 in large models | Eduardo ...
GitHub - aredden/torch-bnb-fp4: Faster Pytorch bitsandbytes 4bit fp4 nn ...
Graph of the function f (p) = 4p(1 − p), relevant to Thm. 3 and Cor. 1 ...
Fp4 Plus: Technical Information | PDF | Exposure (Photography) | Film Speed
FP4 encoding related · Issue #1891 · intel/neural-compressor · GitHub
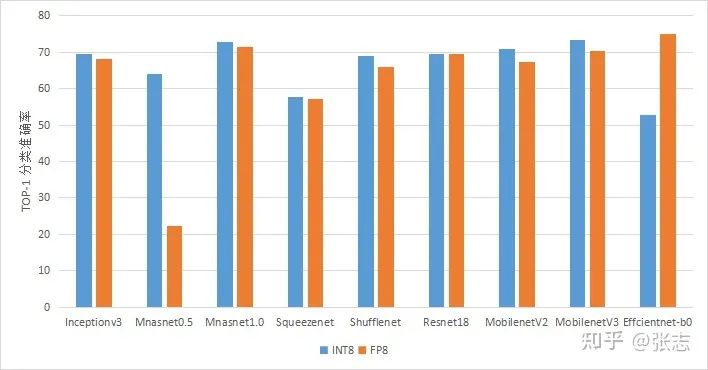
FP8 和 FP4 的精度 - 知乎
Using FP8 and FP4 with Transformer Engine — Transformer Engine 2.15.0 ...
(PDF) Elucidating the Design Space of FP4 training
Optimizing Large Language Model Training Using FP4 Quantization | PDF ...
Example of fit of the FP3 (a) and FP4 (b) spectrum of Titan taken by ...
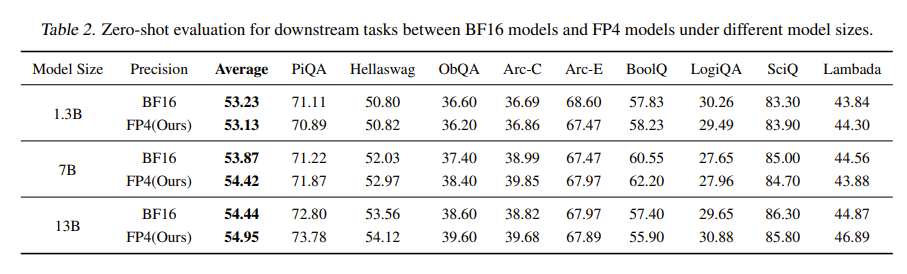
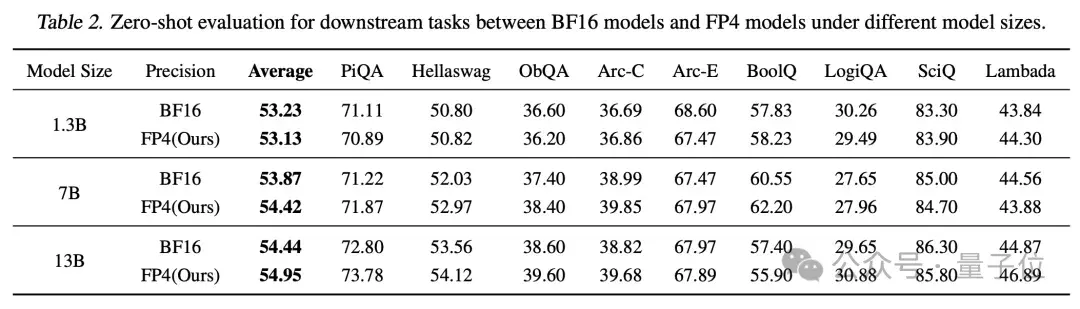
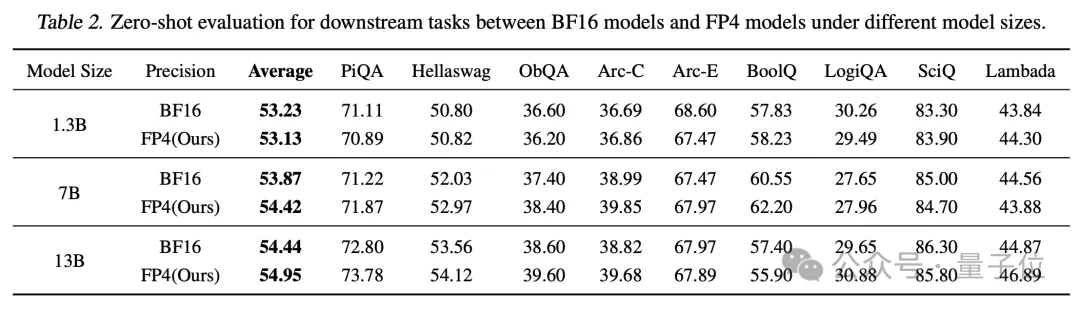
Table 2 from Optimizing Large Language Model Training Using FP4 ...
Optimizing Large Language Model Training Using FP4 Quantization · HF ...
FlexPoint FP4 – Generation AV
FlexPoint FP4 | 4" Miniature Coaxial Point Source Loudspeaker
Nodes and Edges in Graph Theory
Will a LLM trained with FP4 have frontier-level performance before 2028 ...
隆重推出 NVFP4,实现高效准确的低精度推理 - NVIDIA 技术博客
量化那些事之FP8与LLM-FP4 - 知乎
DeepSeek-V3的FP8训练还不够极致?来看FP4量化训练如何突破算力极限 - 知乎
NVIDIA TensorRT for RTX Introduces an Optimized Inference AI Library on ...
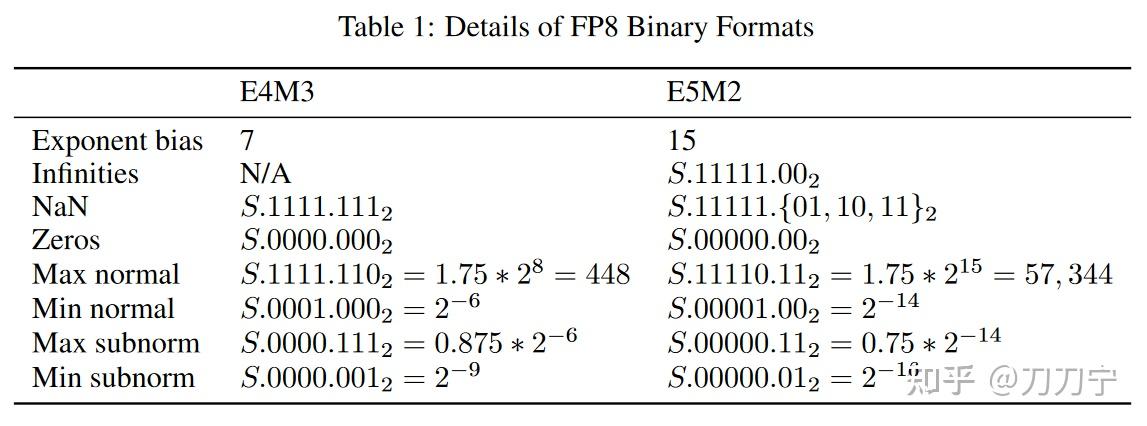
FP8: архитектура формата E4M3 и E5M2 и его роль в Mixed Precision ...
Simulated triangle degree dependence for the O graphs. The empirical ...
NVIDIA Delivers The Promise of Neural Rendering & Gaming With Blackwell ...
A Deeper Analysis of Nvidia RTX 50 Blackwell GPU Architecture
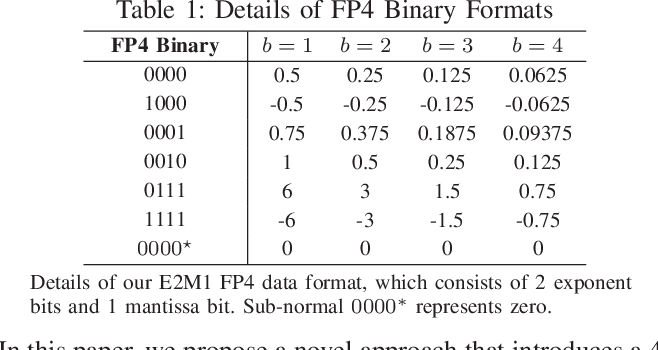
Table 1 from FP4-Quantization: Lossless 4bit Quantization for Large ...
Spectra of DP4 and FP4. Chemical structure, excitation, and emission ...
Optimizing LLMs for Performance and Accuracy with Post-Training ...
大模型笔记(自用)_fp4精度-CSDN博客
wan_FP4_Modifications/fp8_optimization.py at main · eddyhhlure1Eddy/wan ...
Float types (fp8, fp4, nf4, ...) · ggml-org llama.cpp · Discussion ...
万字综述:全面梳理 FP8 训练和推理技术-CSDN博客
DeepSeek技术创新深度解读:从V3与R1与MoE - 知乎
Degree distribution of organizations projection. The tails of the ...
LLM.fp4 低精度浮点量化大模型 - 知乎
Ena regulates filopodial and lamellipodial dynamics. (A–C) Midline ...
Graphs of functions 1 ( ) f p-4 ( ) f p | Download High-Quality ...
Add MXFP4 (FP4 E2M1) and MXFP6 (FP6 E3M2/E2M3) · Issue #116 · jax-ml/ml ...
SageAttention-3: FP4注意力推理+INT8训练尝试 - 知乎
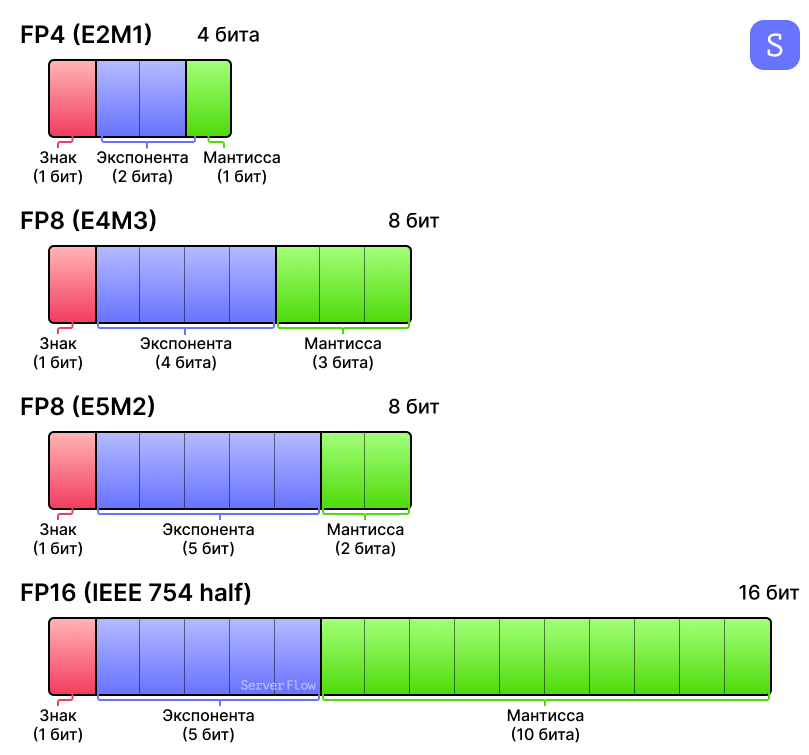
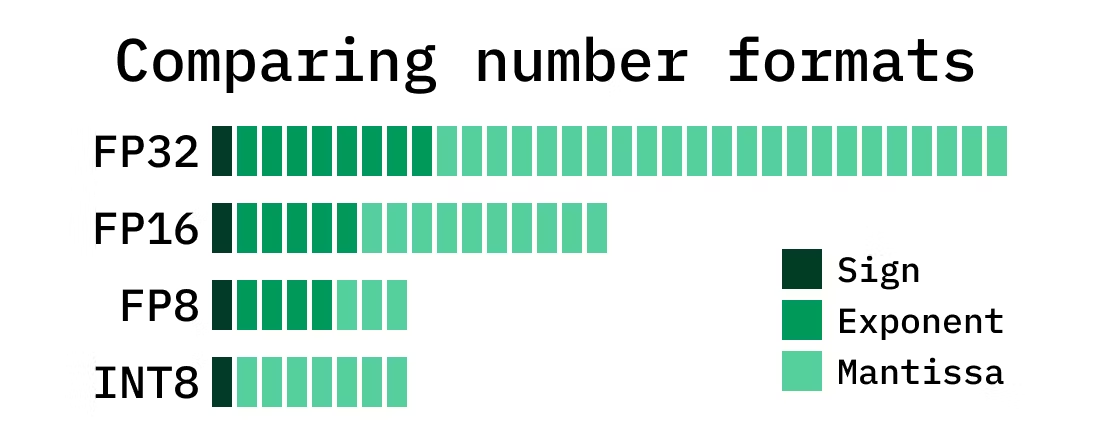
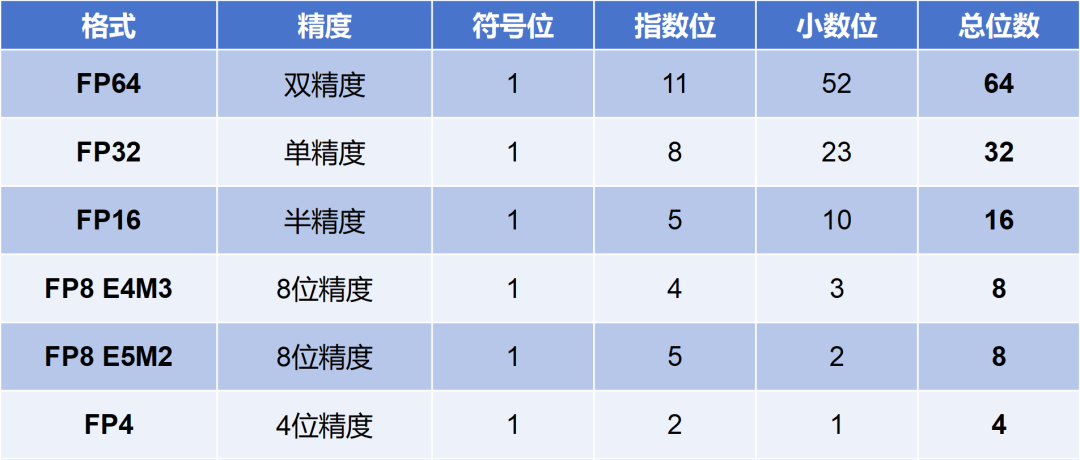
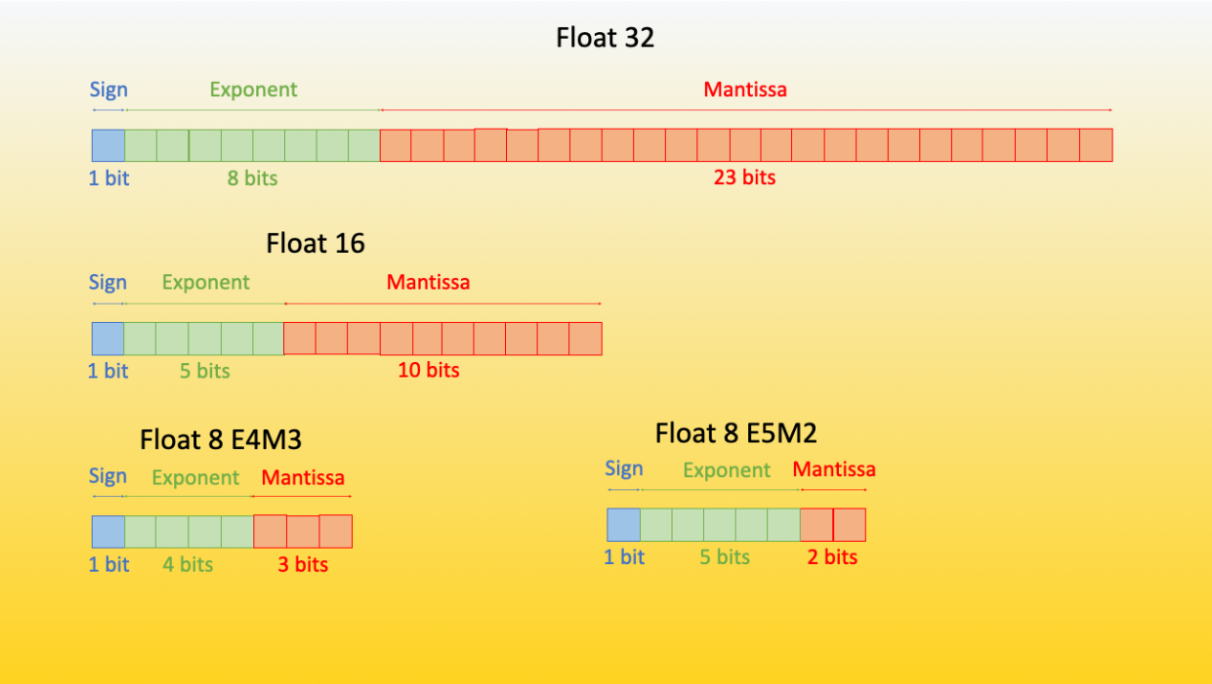
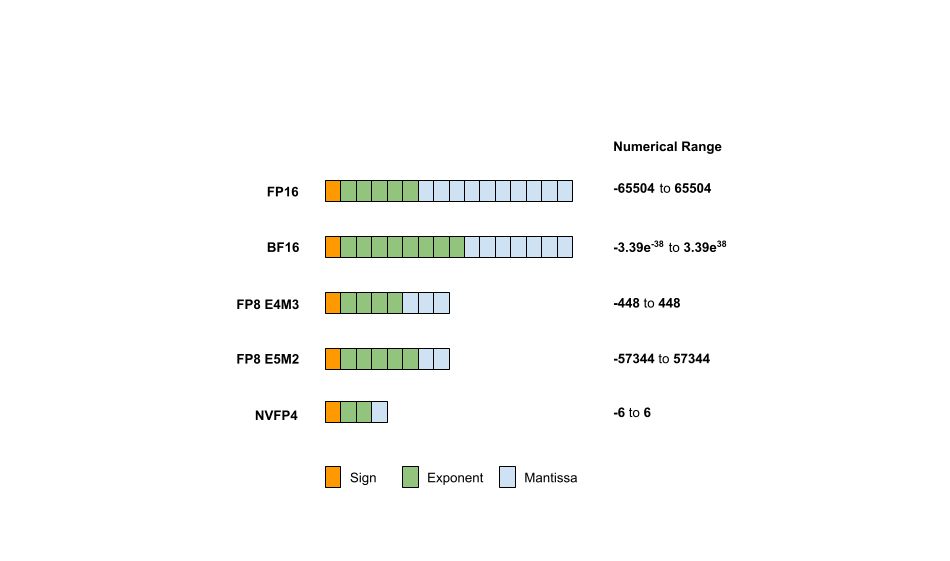
Structure of FP formats. | Download Scientific Diagram
GitHub - silveroxides/ComfyUI_bnb_nf4_fp4_Loaders: Nodes for loading ...
All About Film: Ilford FP4+ - PentaxForums.com
Journal of Applied Polymer Science | Wiley Online Library
Ena positively regulates haemocyte migration speed in vivo. Haemocytes ...
GitHub - eniac/FP4
LLM-FP4 model inference problem · Issue #8 · nbasyl/LLM-FP4 · GitHub
What is FP8, FP6, FP4? | Exxact Blog
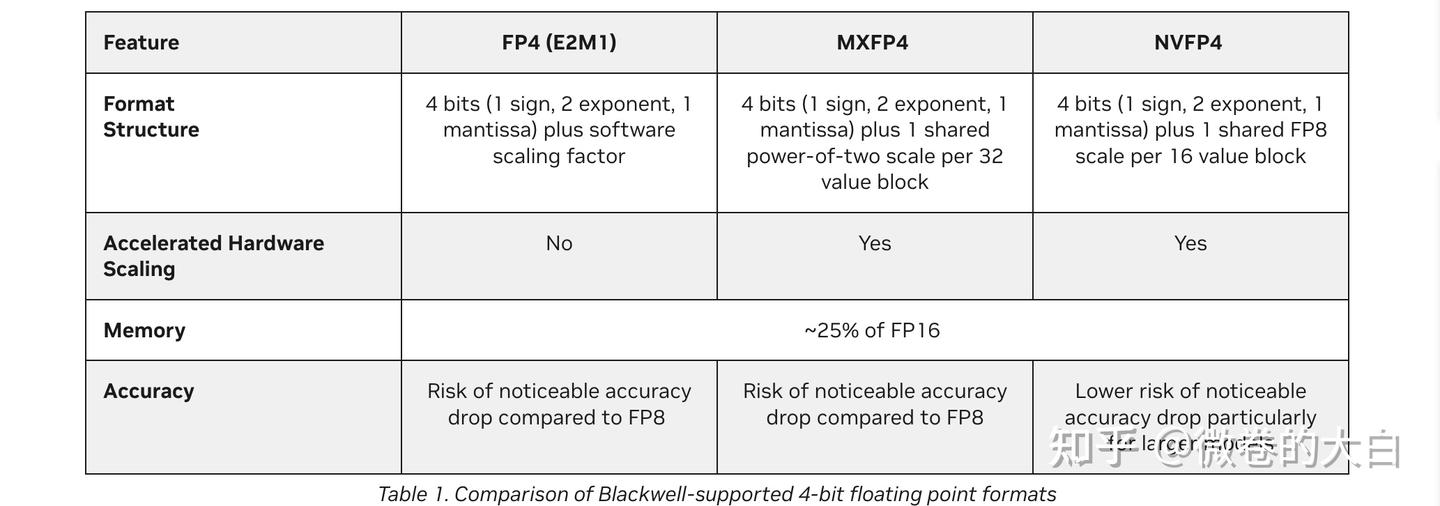
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference ...
FP1-F7, FP1-F3, FP2-F4 EEG signals and estimated phase processes for a ...
GitHub - nbasyl/LLM-FP4: The official implementation of the EMNLP 2023 ...
NVIDIA RTX 5090 と RTX 4090 のネイティブ 4K ベンチマーク - Gamingdeputy Japan
五大 AI 模型优化技术,实现更快速、更智能的推理 - NVIDIA 技术博客
Generative AI 新世界 | 大模型参数高效微调和量化原理概述_fp4-CSDN博客
【干货】大模型算力优化全攻略——FP32、FP16、INT8数据格式精讲与实战应用_fp16和fp32-CSDN博客
FP8 量化:原理、实现与误差分析-轻识
Blackwell与FP4精度:AI量化浪潮中推动端侧发展的“双子星” - 知乎
清华SageAttention3,FP4量化5倍加速!且首次支持8比特训练-51CTO.COM
Blackwell与FP4精度:AI量化浪潮中推动端侧发展的“双子星”_nv fp4-CSDN博客
一文讲清楚大模型涉及到的精度:FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8-CSDN博客
GitHub - Hactiv8-FinalProject4/fp4-MovieApp
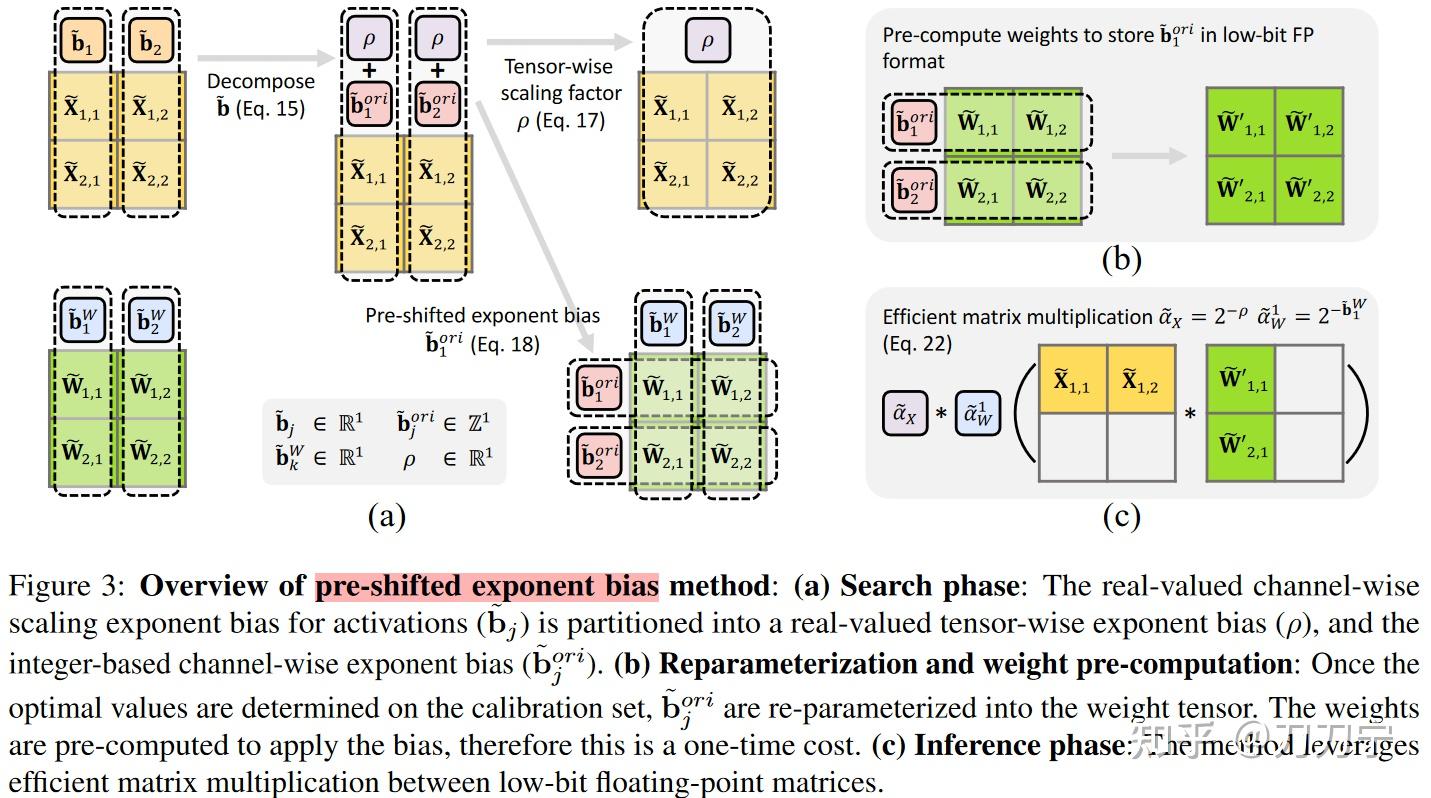
大模型训练开销还能更小!微软推出首个FP4训练框架,训练效果与BF16相当 - 知乎
What is FP64, FP32, FP16? Defining Floating Point | Exxact Blog
Compositions of formulations FP1-FP4 with the synthesized polymers ...
模型量化:核心概念、实现方法与关键作用 - 知乎
CUDA 工具包现已支持 NVIDIA Blackwell 架构 - NVIDIA 技术博客
Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave ...
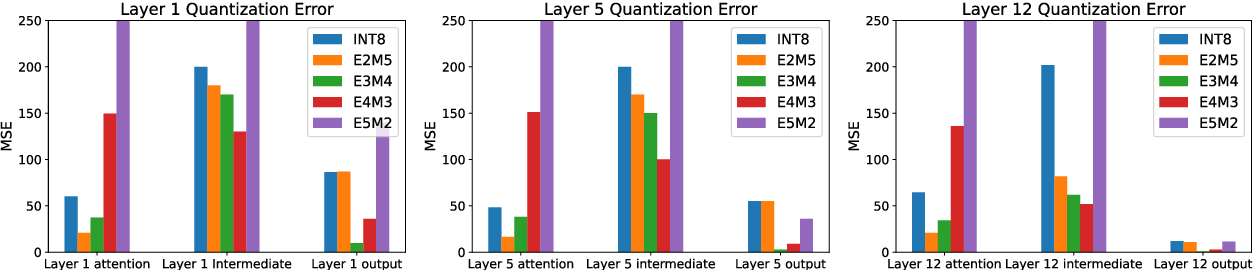
Table 6 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
微软:FP4量化方法训练LLM_optimizing large language model training using fp4-CSDN博客
FP4-RP/RPplus - Metronic
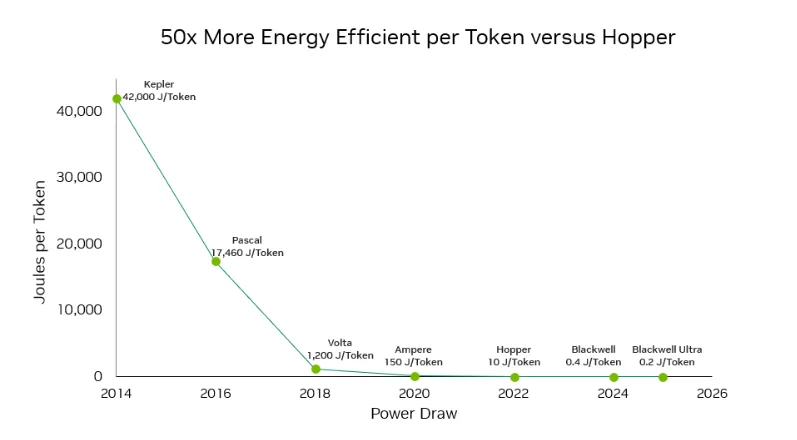
Jensen Huang presents TPS graphs for Blackwell, FP4, NVL72, and Dynamo ...
全面梳理FP8与FP4不同精度训练推理技术与应用 - 知乎
大模型量化3 - 张博的博客 - 博客园
Software update: FP4.FP4G.A.170.20220920 - The Products - Fairphone ...
大模型训练开销还能更小!微软推出首个FP4训练框架,训练效果与BF16相当
模型量化:核心概念、实现方法与关键作用 - NVIDIA 技术博客
GitHub - intel/ipex-llm-tutorial: Accelerate LLM with low-bit (FP4 ...
Final_Project4_Python/PYTN_KampusMerdeka_fp4_NI NYOMAN SEKAR WANDANI ...
全面梳理FP8与FP4不同精度训练推理技术与应用原创ChaoQing超擎数智Ch_财富号_东方财富网
MXFP4, FP4, FP8 - by Prof. Tom Yeh - AI by Hand ️
[PDF] LLM-FP4: 4-Bit Floating-Point Quantized Transformers | Semantic ...
MXFP4, FP4, and FP8: How GPT-OSS Runs 120B Parameters on an 80GB GPU ...