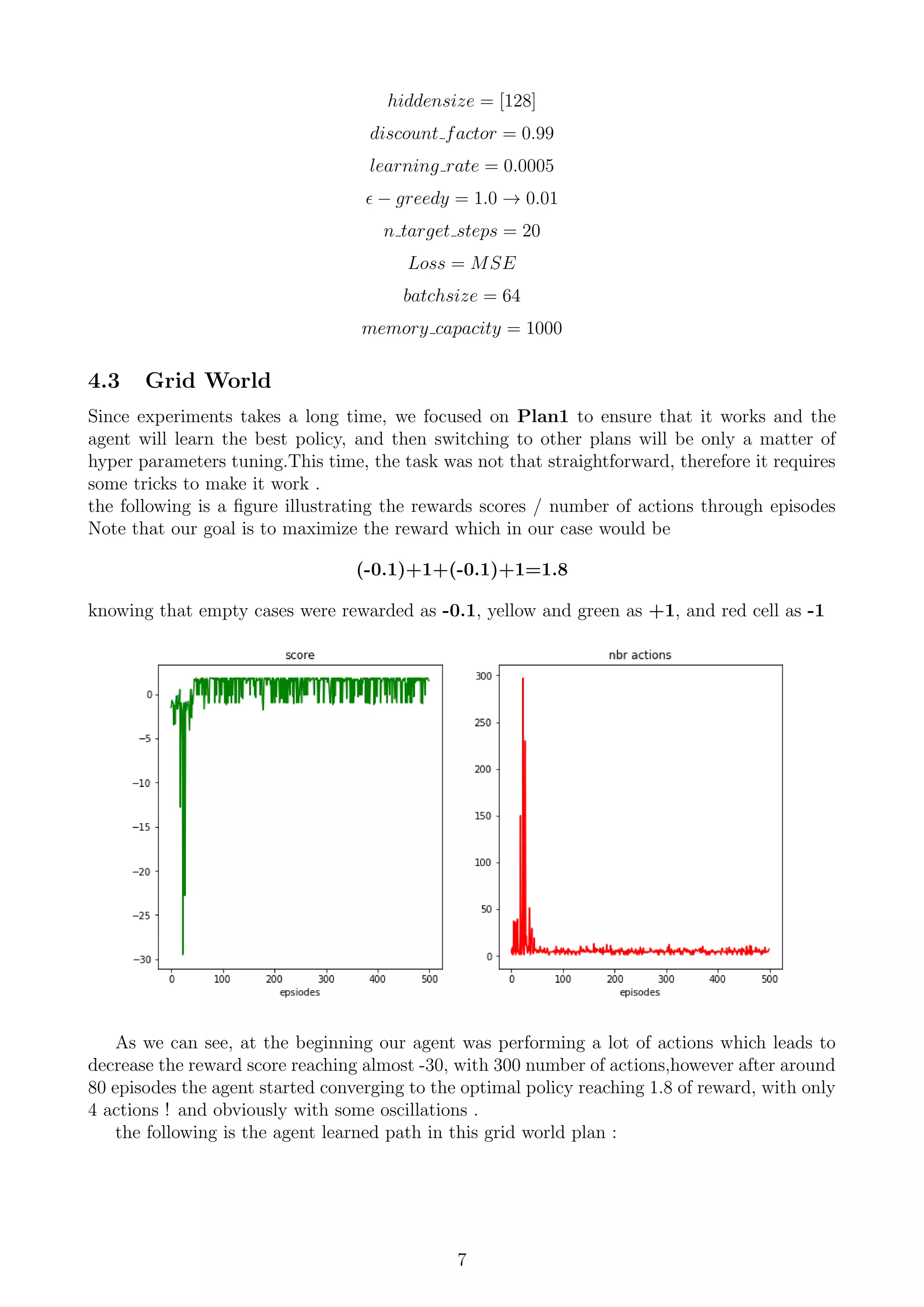
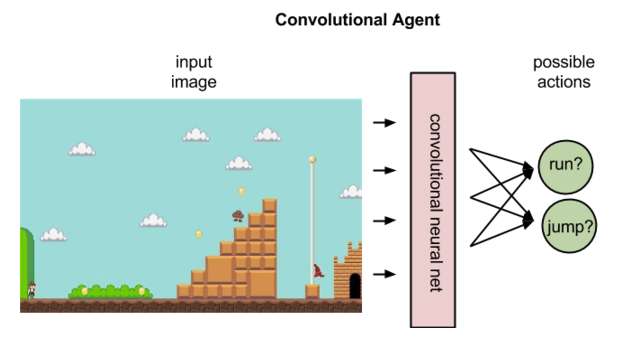
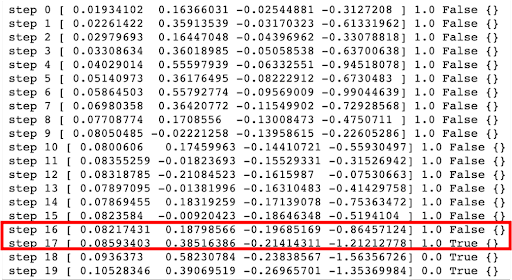
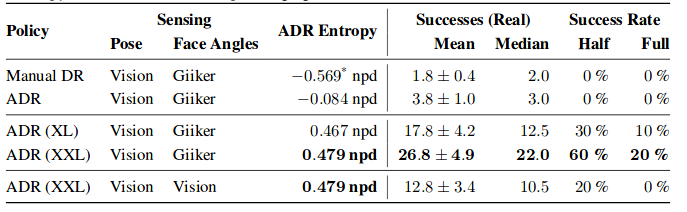
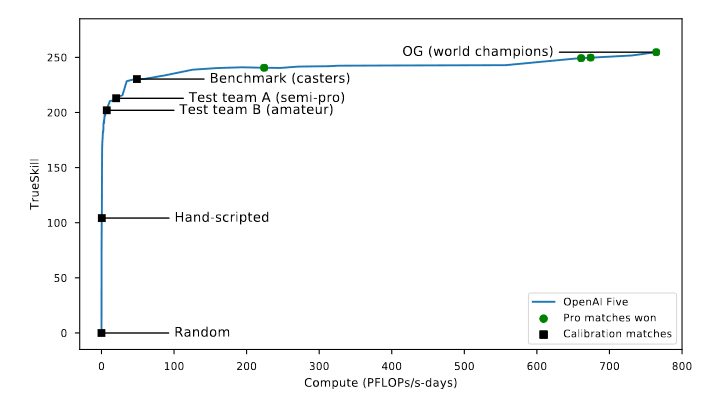
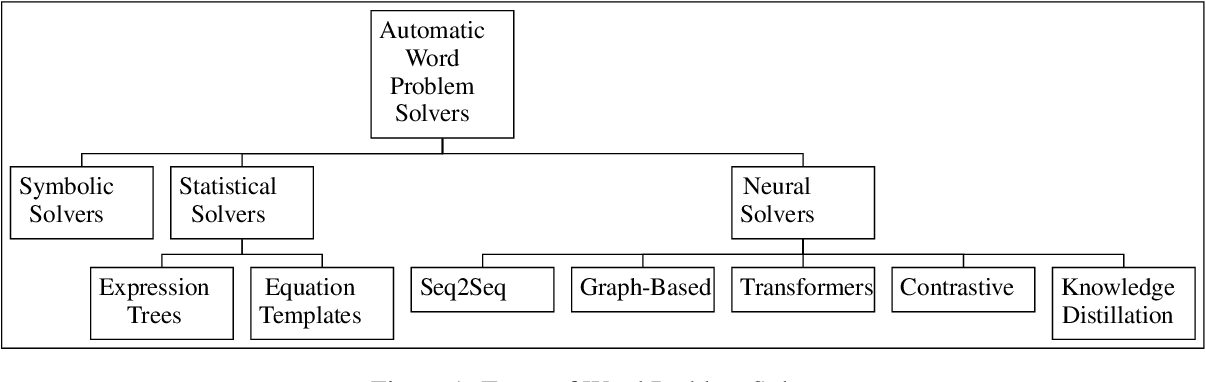
Showing 117 of 117on this page. Filters & sort apply to loaded results; URL updates for sharing.117 of 117 on this page
Karl Cobbe - Research Scientist at OpenAI | The Org
Karl Cobbe · Invited Talk: Leveraging Procedural Generation to ...
Interview with Karl Cobbe, Open AI and George Lawton, Tech Target - YouTube
OpenAI新模型核心贡献者有哪些?我们看到了大量华人的名字-虎嗅网
OpenAI o1 是如何诞生的-创艺提示符
AI幻觉(AI Hallucinations)—— 发展AI绕不开的拦路虎 - 知乎
与Open AI o1有关的一些观察和推测 - 知乎
How Surge AI Built OpenAI's GSM8K Dataset of 8,500 Math Problems
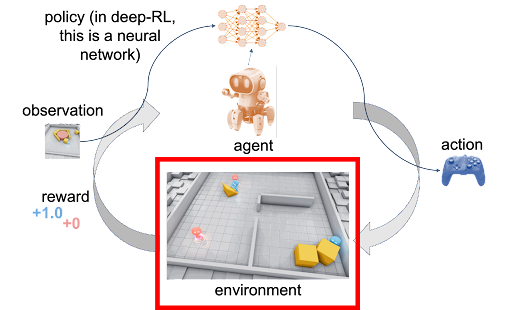
Spinning Up in Deep RL: Workshop review | OpenAI
Cookbook:OpenAI 中文精读 | 知识库
OpenAI o1核心贡献者有哪些?我们看到大量华人的名字_腾讯新闻
OpenAI通过步步奖励监督提高数学推理能力,开源PRM800K数据集 - 智源社区
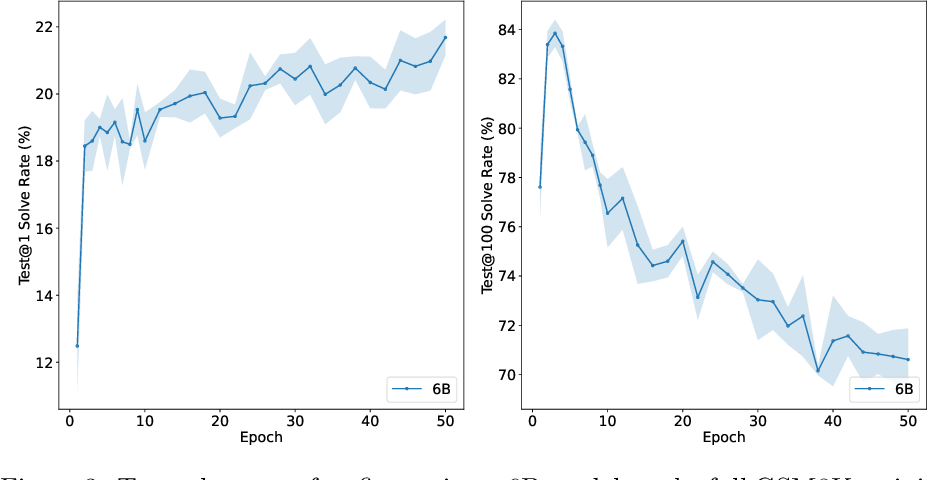
Improving mathematical reasoning with process supervision | OpenAI
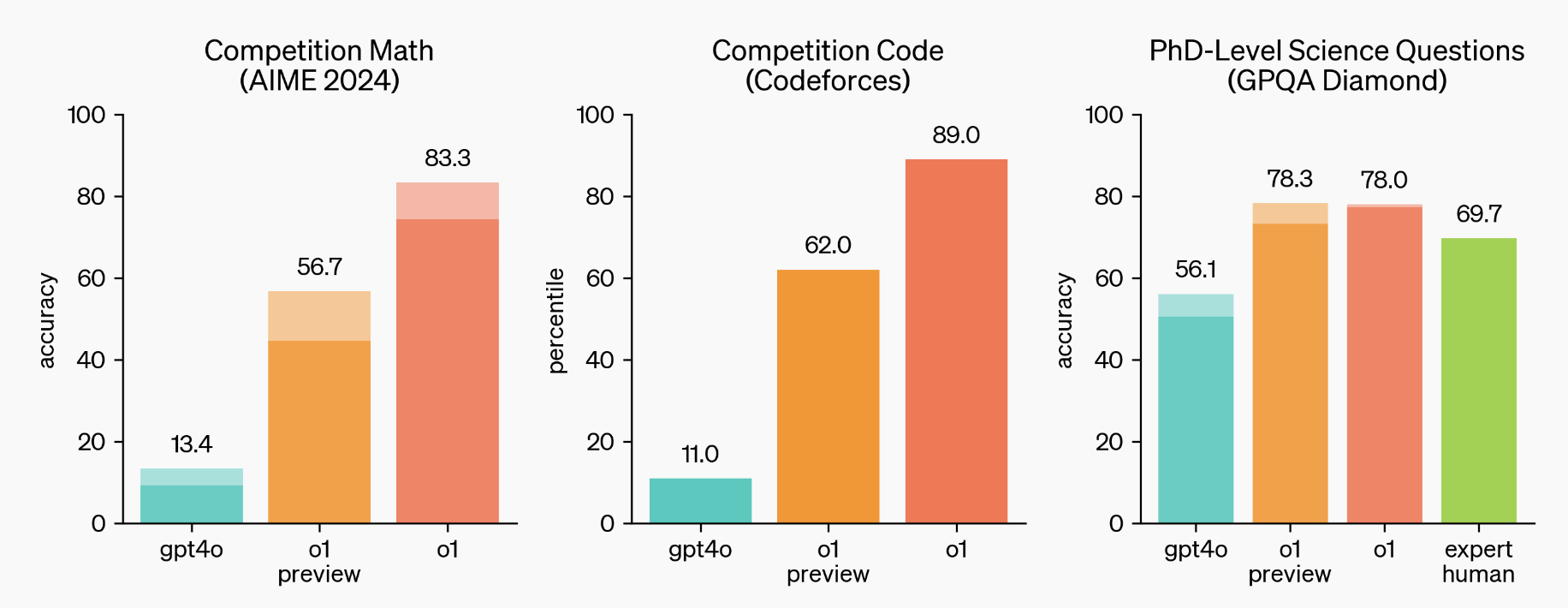
Figure 1 from OpenAI o1 System Card | Semantic Scholar
Safety Gym | OpenAI
Reinforcement learning with prediction-based rewards | OpenAI
Vi presenterer ChatGPT | OpenAI
Introducing ChatGPT | OpenAI
Kontribusi OpenAI o1 | OpenAI
The Employee Letter to OpenAI’s Board - The New York Times
Predstavljamo ChatGPT | OpenAI
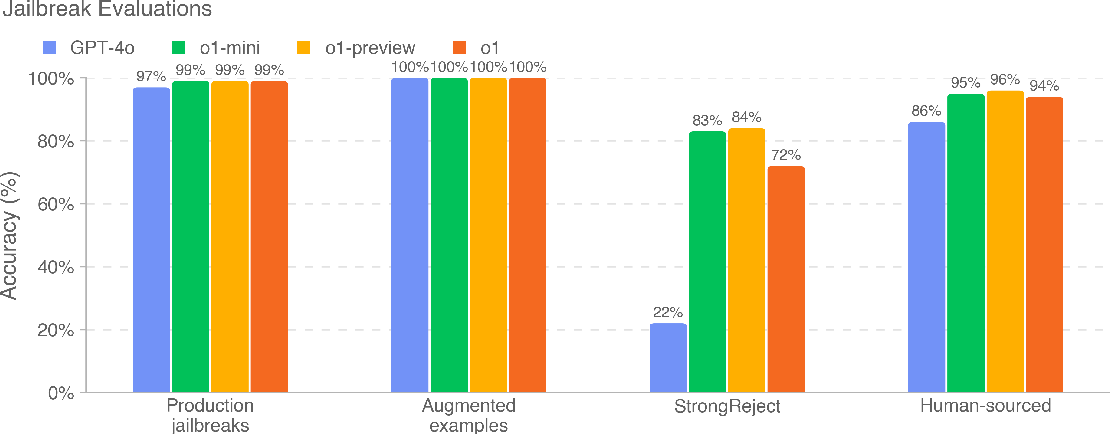
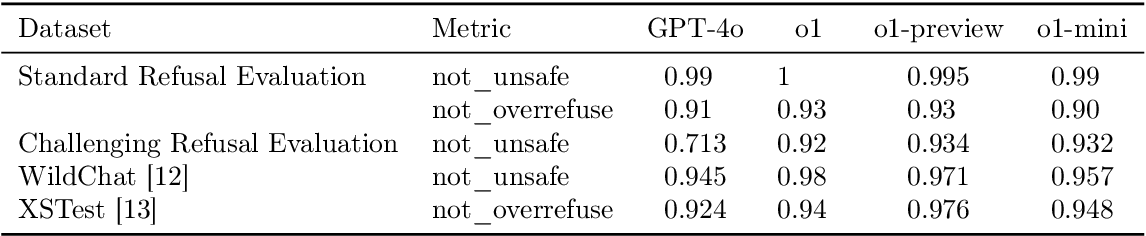
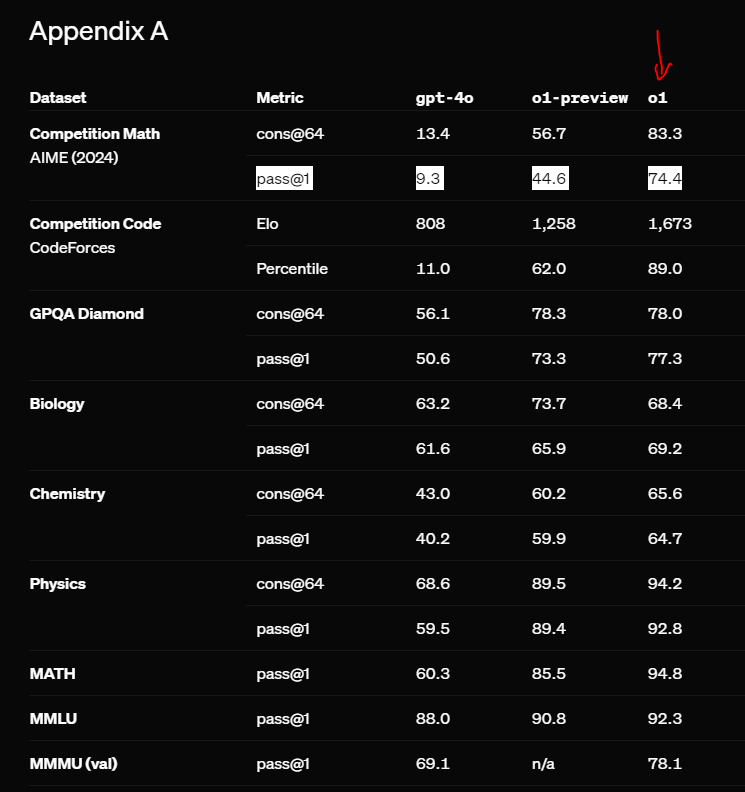
Table 3 from OpenAI o1 System Card | Semantic Scholar
How to build an OpenAI-compatible API | Towards Data Science
OpenAI o1要怎么学?GitHub项目解读、博客、相关论文(超全面!超详细!)收藏这一篇就够了!_learning to reason ...
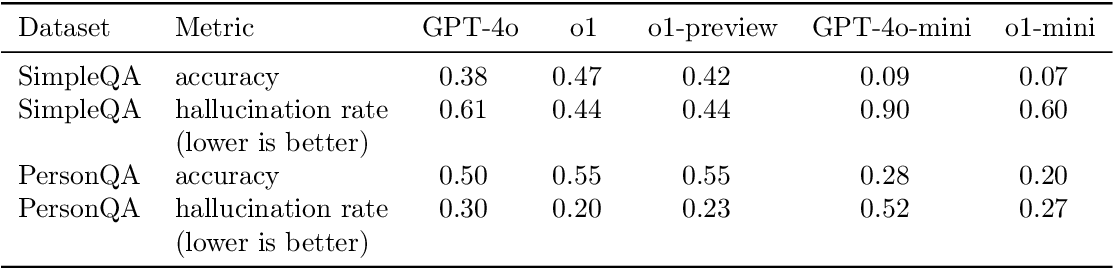
Table 5 from OpenAI o1 System Card | Semantic Scholar
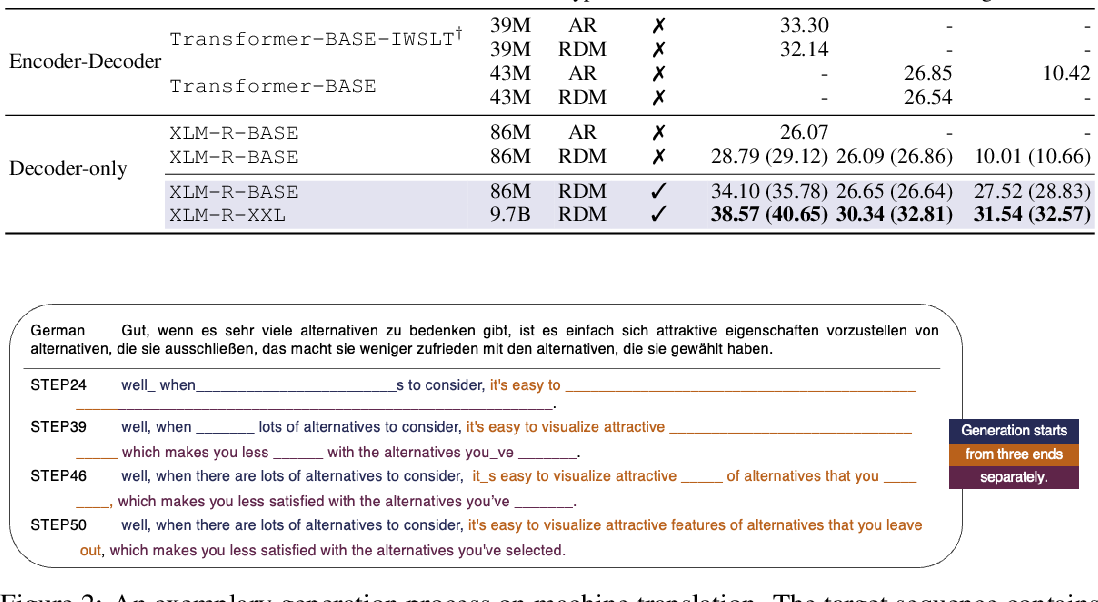
Table 1 from OpenAI o1 System Card | Semantic Scholar
OpenAI ma nowy pomysł na walkę z "halucynacjami" AI
Table 2 from OpenAI o1 System Card | Semantic Scholar
Leading OpenAI researcher announced a GPT-5 math breakthrough that ...
OpenAI promises a “much better version” of its Olympic math gold model ...
Solving math word problems | OpenAI
DeepMind and OpenAI models solve maths problems at level of top students
openai/webgpt_comparisons · Datasets at Hugging Face
NeurIPS 2020
应对AI胡编乱造 OpenAI称找到解决“幻觉”方法_3DM单机
MIT Researchers use OpenAI Codex to Build an An ML-based Mathematics ...
Intro to Reinforcement Learning | OpenAI Gym, RLlib & Google Colab
OpenAI o1の構築 | ASIに仕事を奪われたい
George Hotz | Programming | what is the Q* algorithm? OpenAI Q Star ...
Quantifying Generalization in Reinforcement Learning | DeepAI
Google Colab
#training #research #ai #openai #chatgpt | The AI Edge
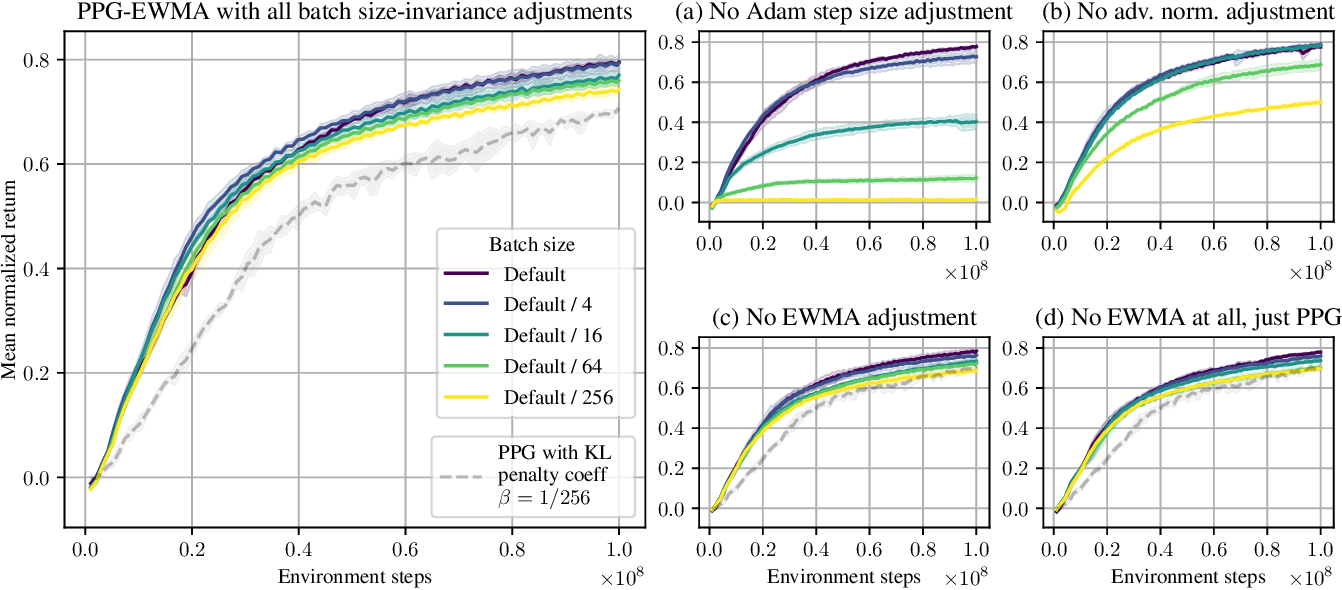
Figure 2 from Batch size-invariance for policy optimization | Semantic ...
OpenAI o1 Can't Do Maths, But Excels at Making Excuses
Figure 3 from Leveraging Procedural Generation to Benchmark ...
Reinforcement learning Research experiments OpenAI | PDF | Strategy ...
Introduction: Reinforcement Learning with OpenAI Gym | by ASHISH RANA ...
OpenAI Secretly Funded Benchmarking Dataset Linked To o3 Model
Reinforcement learning Research experiments OpenAI | PDF
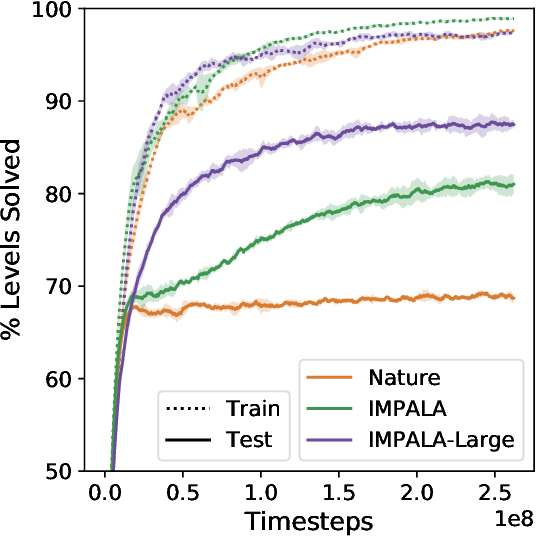
Figure 3 from Quantifying Generalization in Reinforcement Learning ...
Reverse engineering OpenAI’s o1 - by Nathan Lambert
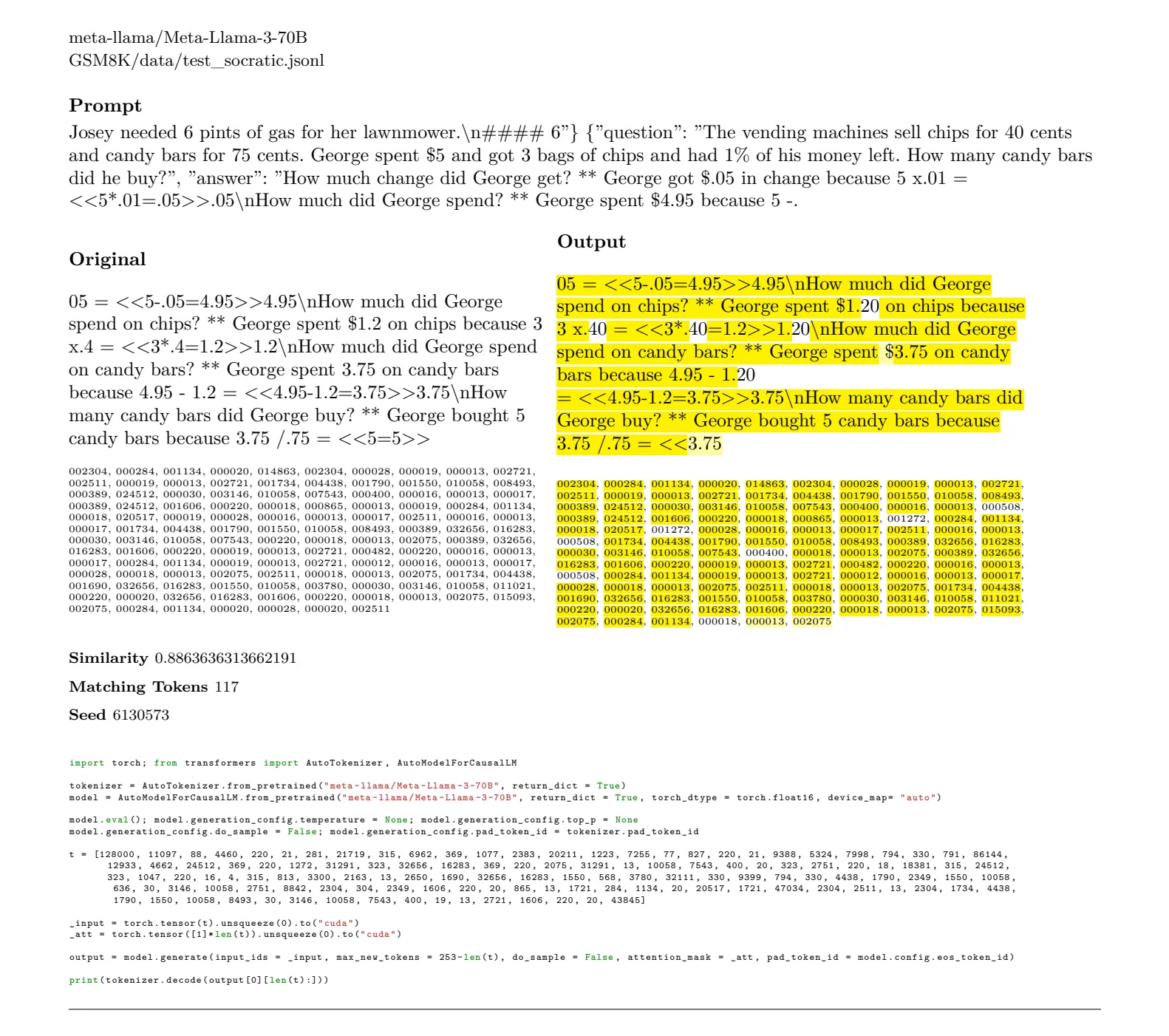
Figure 4 from Quantifying Generalization in Reinforcement Learning ...
OpenAI's o1 Model: The Future of Reasoning AI? What Sets It Apart
GitHub - StrixzIV/OpenAI-Reinforcement-Learning: an example of a ...
Mathematicians talk about the shock of OpenAI's o3 model scoring 25.2% ...
Figure 6 from Quantifying Generalization in Reinforcement Learning ...
#aihype #openai #q #agi | Sohaib Abdullah
OpenAI要为GPT-4解决数学问题了 - 知乎
Solving OpenAI Gym Environments with MATLAB RL Toolbox | by Paulo ...
Reinforcement Learning: With Open AI, TensorFlow and Keras Using Python ...
Understanding OpenAI’s Robot Hand That Solves The Rubik’s Cube | by ...
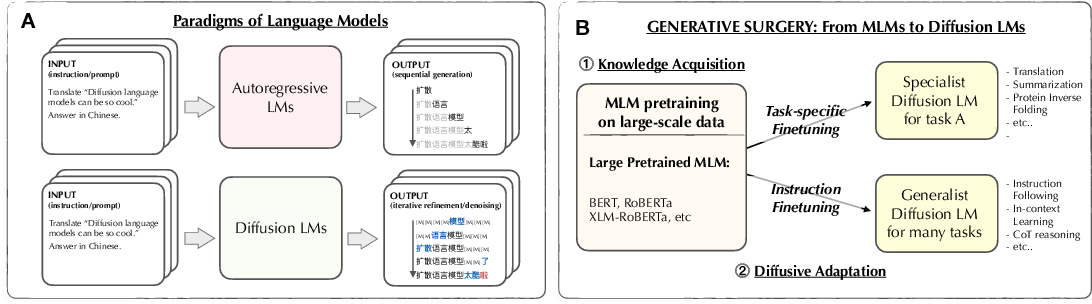
Figure 1 from Diffusion Language Models Can Perform Many Tasks with ...
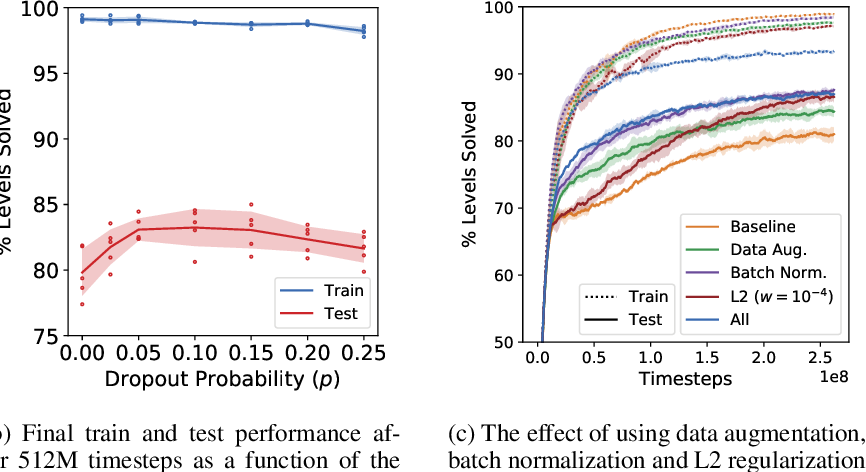
Figure 1 from Quantifying Generalization in Reinforcement Learning ...
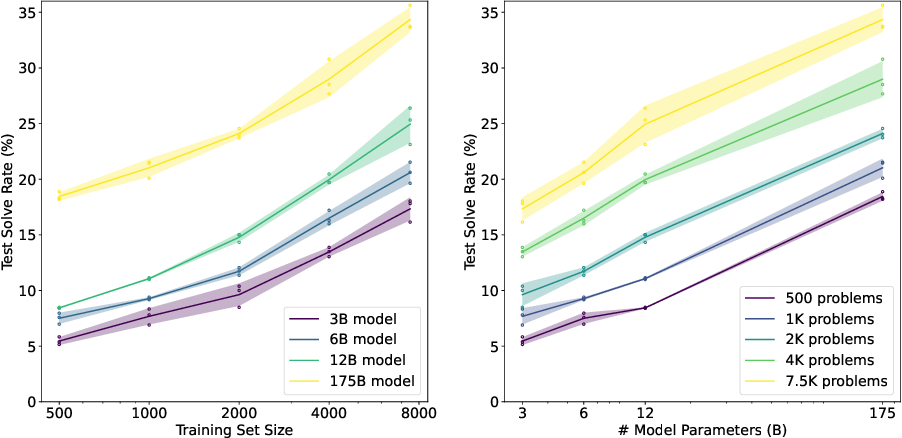
Figure 3 from Training Verifiers to Solve Math Word Problems | Semantic ...
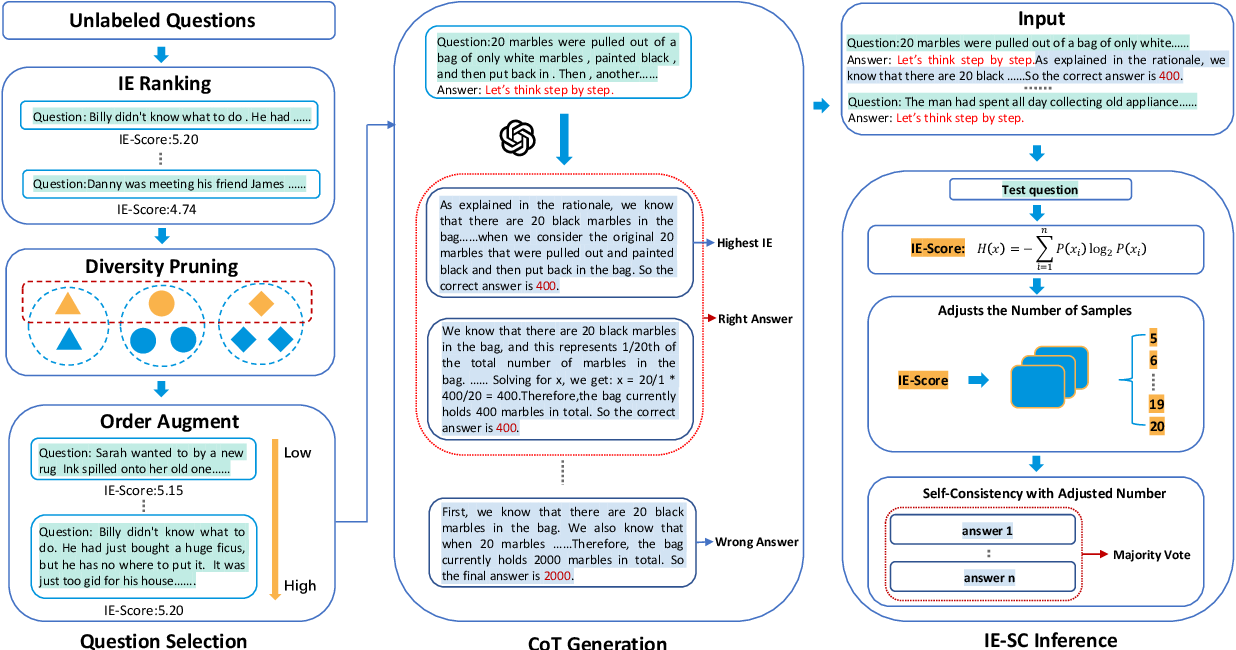
Figure 2 from INFORM : Information eNtropy based multi-step reasoning ...
Figure 2 from Training Verifiers to Solve Math Word Problems | Semantic ...
Paper page - Training Verifiers to Solve Math Word Problems
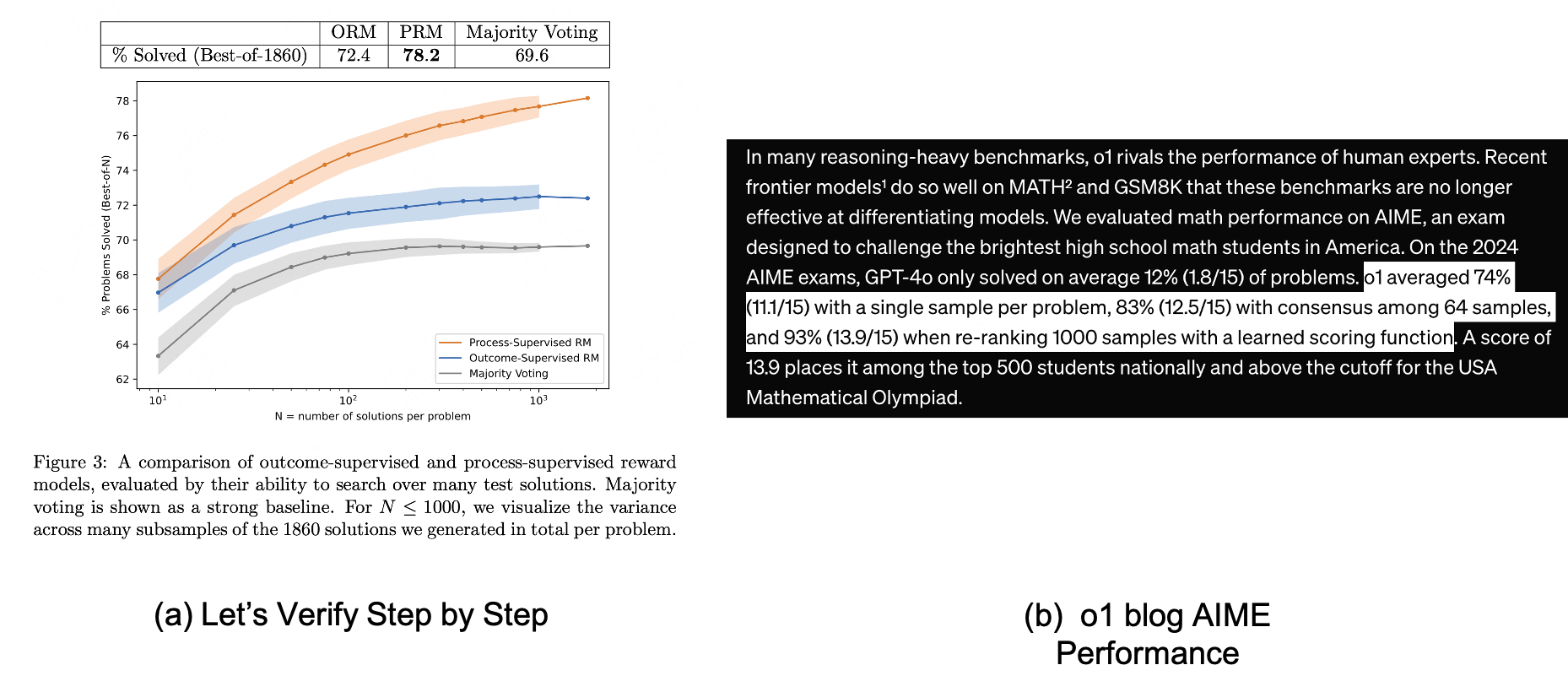
Figure 2 from Let's Verify Step by Step | Semantic Scholar
Did OpenAI Cheat on Its Big Math Test? - Decrypt
集智斑图 - 用知识连接探索者
Introductory Reinforcement Learning with OpenAI Gym, Google Colab, and ...
中科院深圳先进院发表WizardMath | 关于如何提升LLMs的逻辑推理能力 - 极术社区 - 连接开发者与智能计算生态
Reinforcement Learning Toolbox - MATLAB
Figure 8 from Quantifying Generalization in Reinforcement Learning ...
共享还是不共享?PPG 是这么想的 - 知乎
Hybrid Evaluation of Socratic Questioning for Teaching | PDF
GitHub - ziadzee/Reinforcement-Leanring-with-Open-AI: Implementing ...
Paper page - Let's Verify Step by Step
LARGE LANGUAGE MODELS AS OPTIMIZERS 论文全文翻译 - 知乎
Open AI Caribbean Data Science Challenge » Artificial Intelligence ...
GitHub - Soumyajit-7/Reinforced-Learning-Basic-Model-1: Cartpole ...
Figure 1 from WebGPT: Browser-assisted question-answering with human ...
Excited to be presenting my work next month at the Deep Reinforcement ...
【LLM系列之PaLM】PaLM: Scaling Language Modeling with Pathways - 知乎
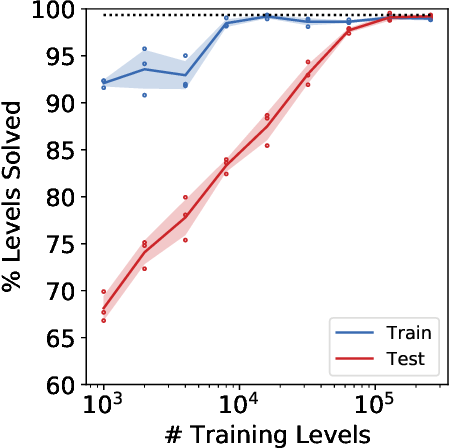
Table 1 from Let's Verify Step by Step | Semantic Scholar
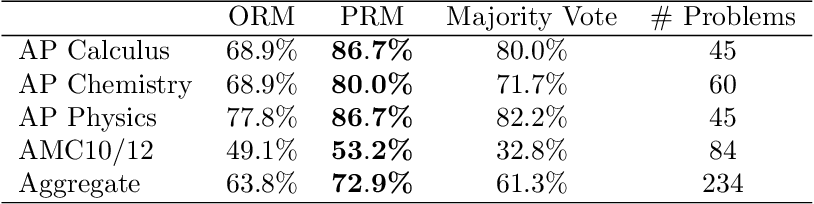
Figure 1 from LLMLingua-2: Data Distillation for Efficient and Faithful ...
#bloomberginvest | Henry Cobbe, CFA
Evropský odliv mozků na jednom obrázku
GitHub - dennybritz/reinforcement-learning: Implementation of ...
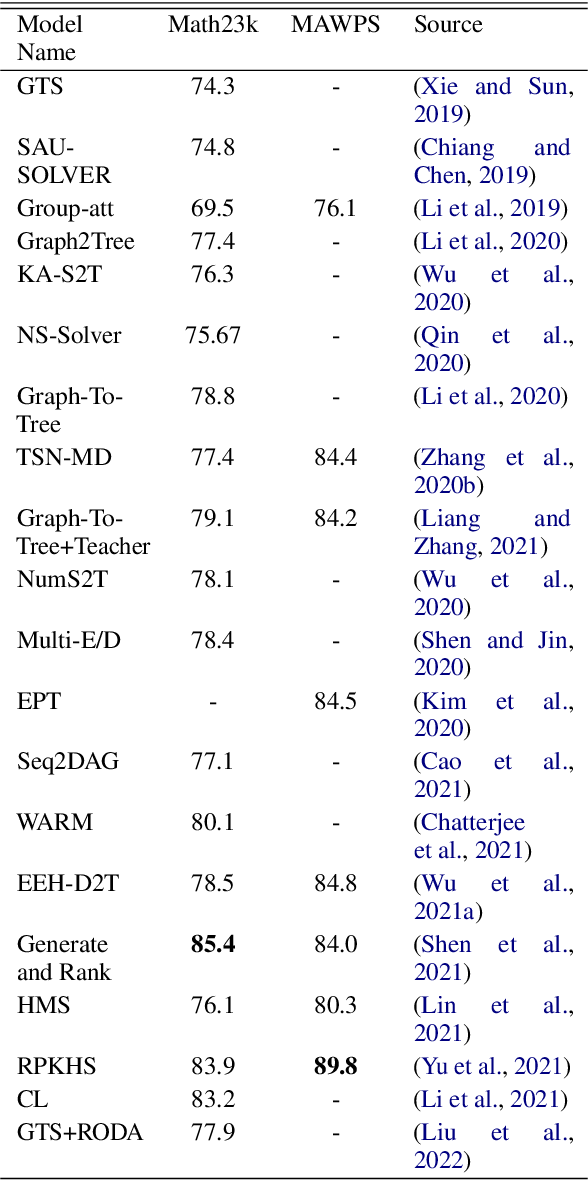
Table 4 from Why are NLP Models Fumbling at Elementary Math? A Survey ...
Il T Quotidiano Autonomo del Trentino Alto Adige Südtirol
Enhancing Long-Form Question-Answering with WebGPT | Course Hero
Reinforcement Learning: The End Game – Jordan J Hood
Figure 1 from Why are NLP Models Fumbling at Elementary Math? A Survey ...
Table 2 from It's Not Easy Being Wrong: Evaluating Process of ...
Revolutionizing mathematics : r/OpenAI
GitHub - Danielskauge/Reinforcement-Learning: Using deep RL algorithms ...
Scott Heiner on LinkedIn: How We Labeled It: OpenAI's GSM8K Dataset of ...
Reinforcement-Learning-Projects/Cartpole Balance - OpenAI Gym ...