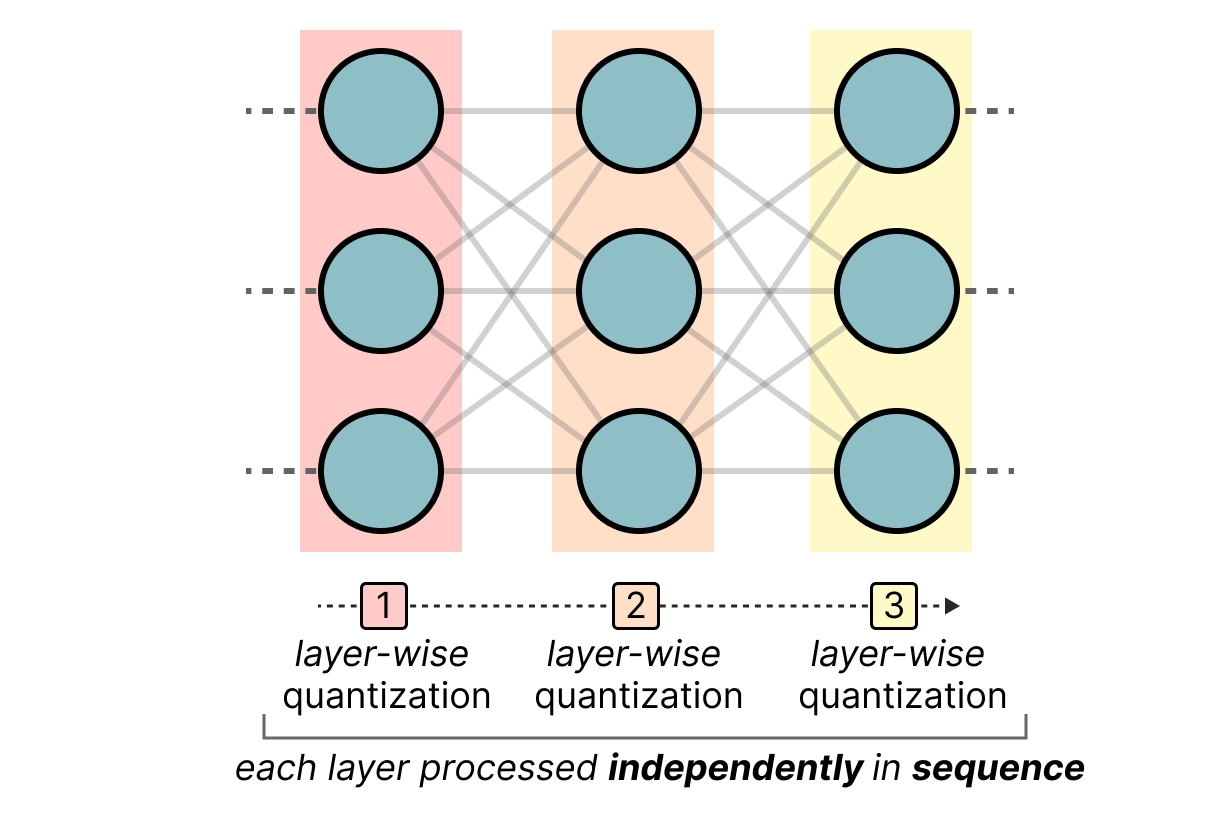
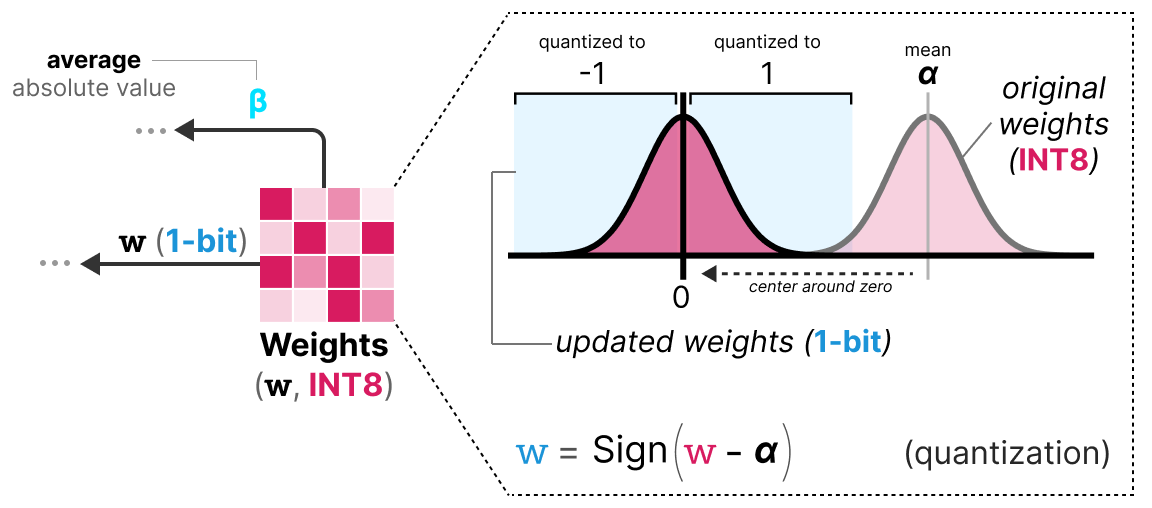
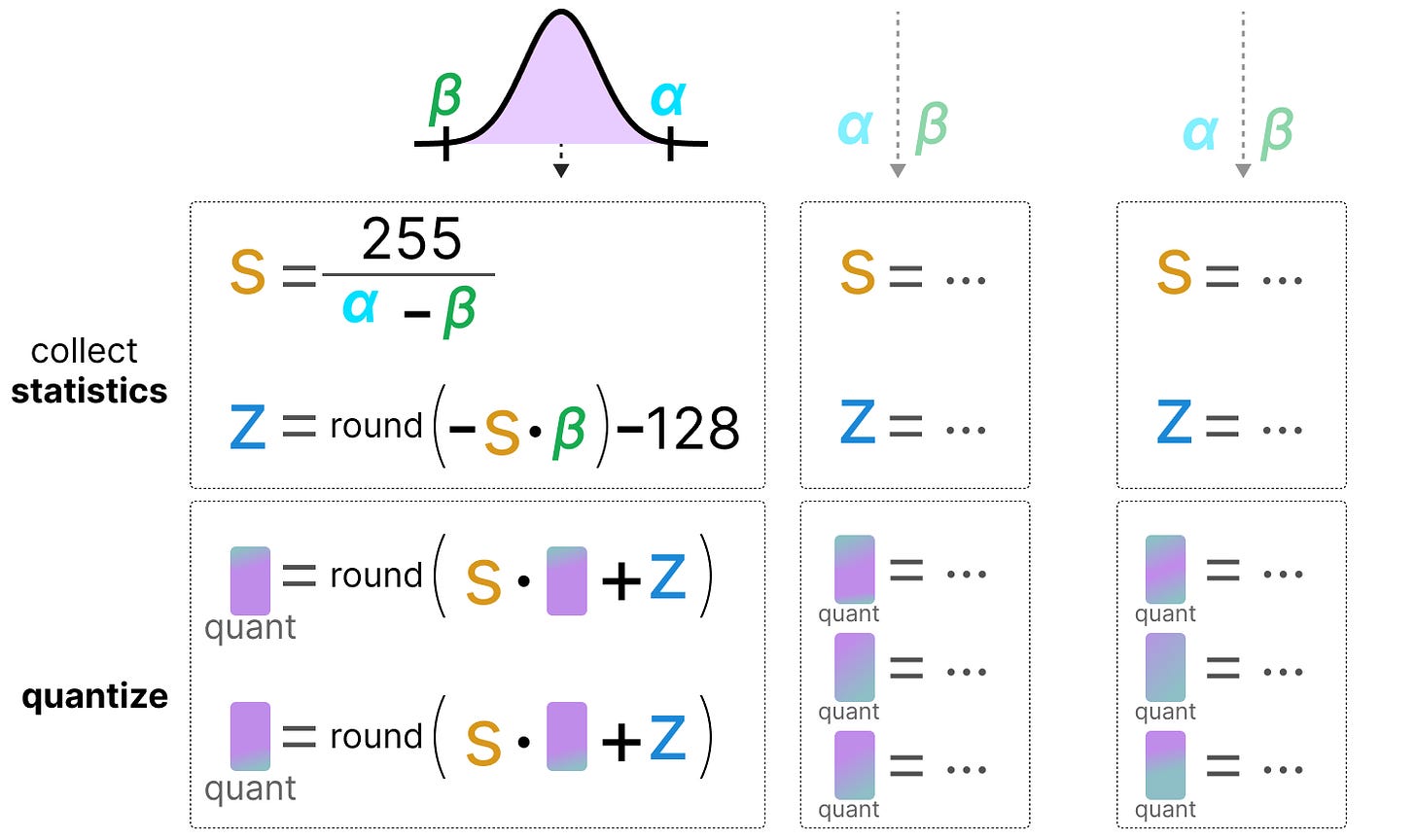
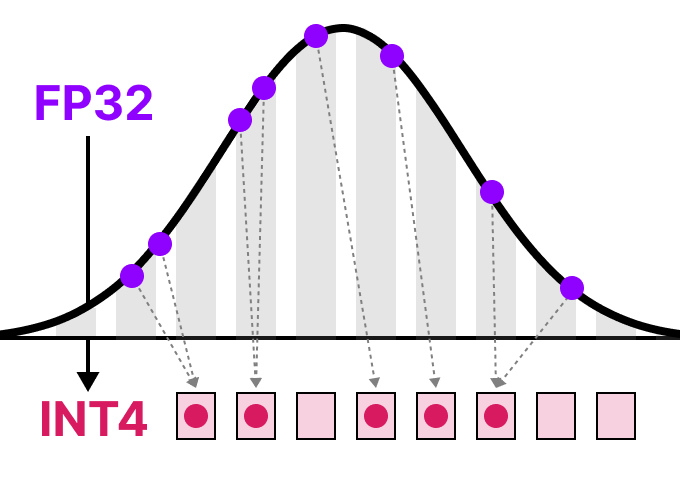
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Dave Swiston: November 2014
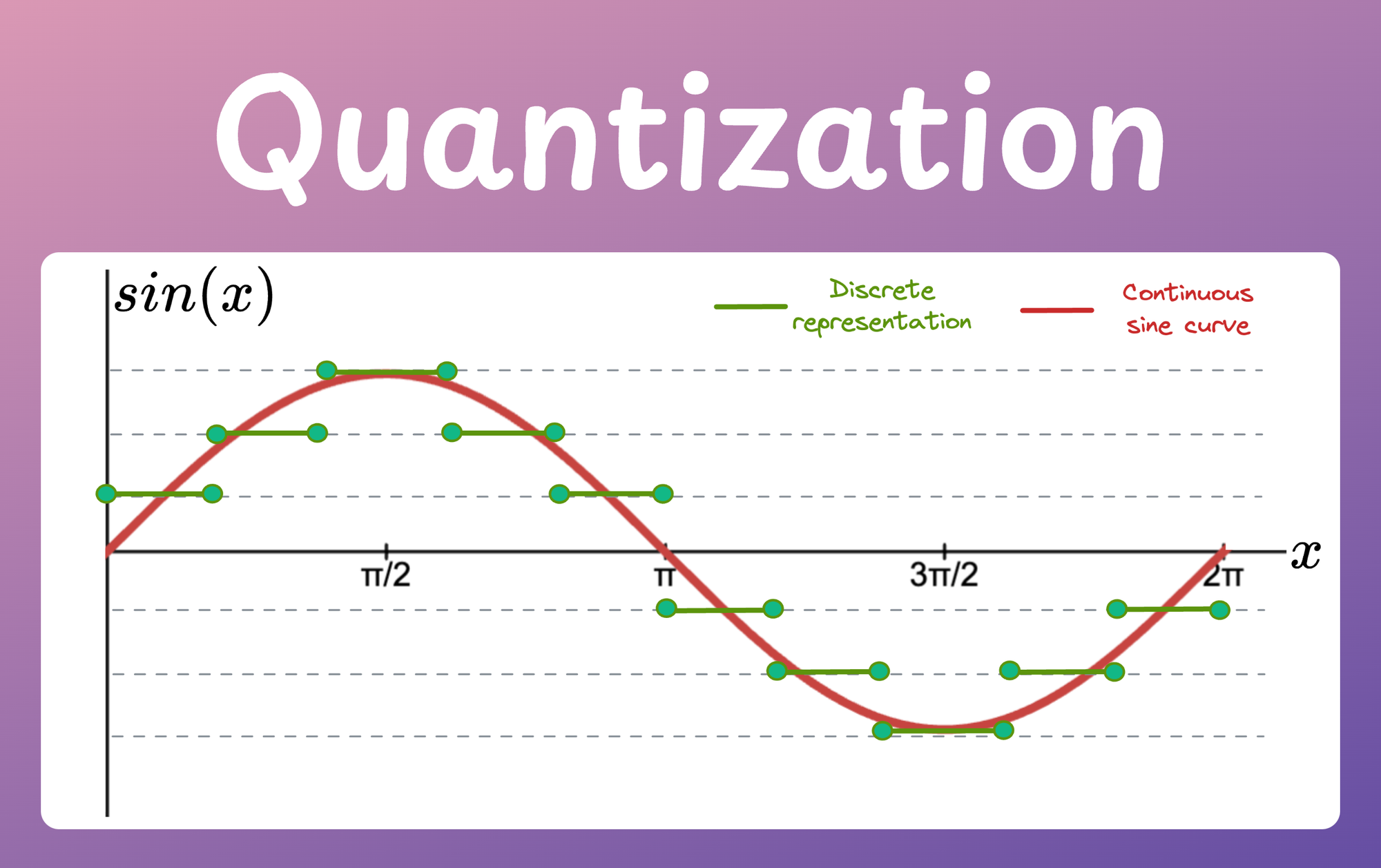
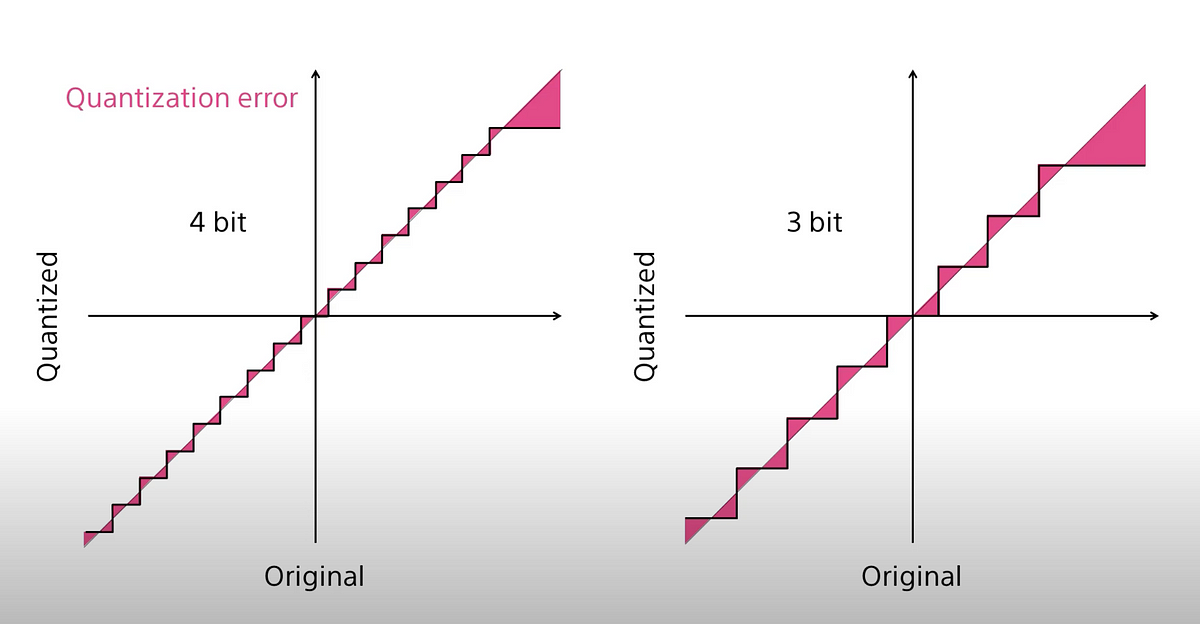
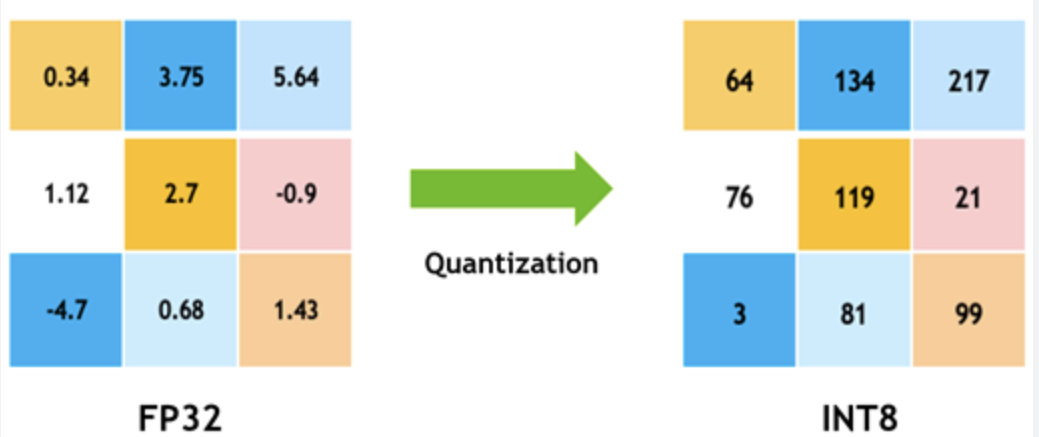
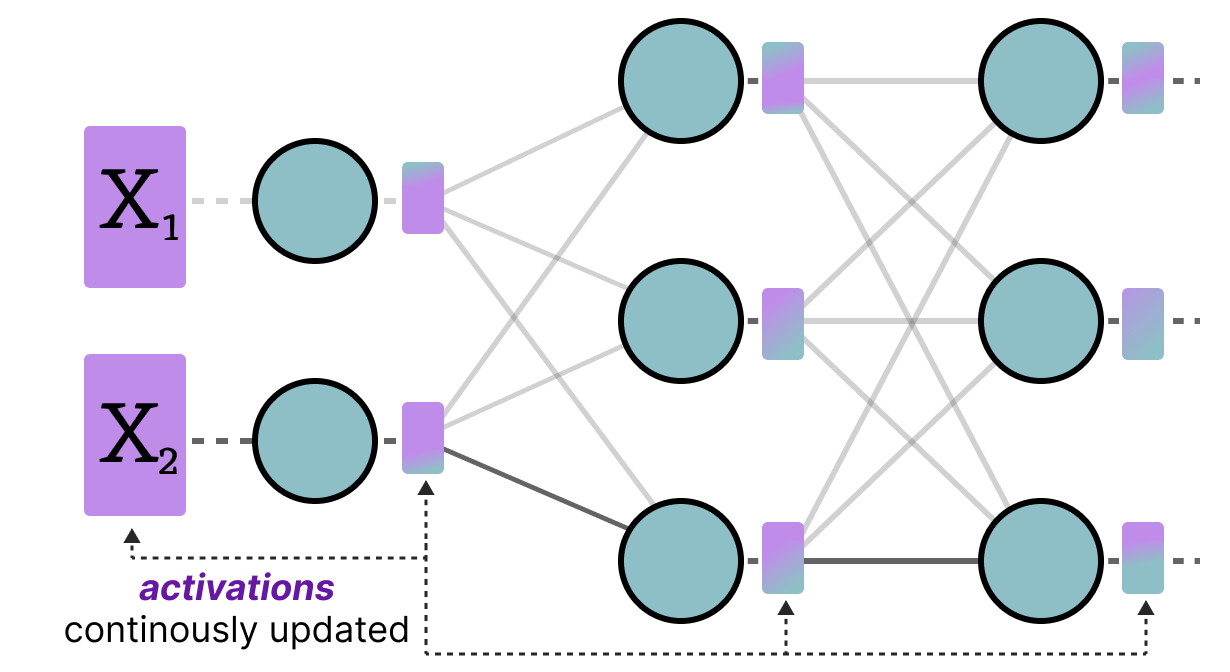
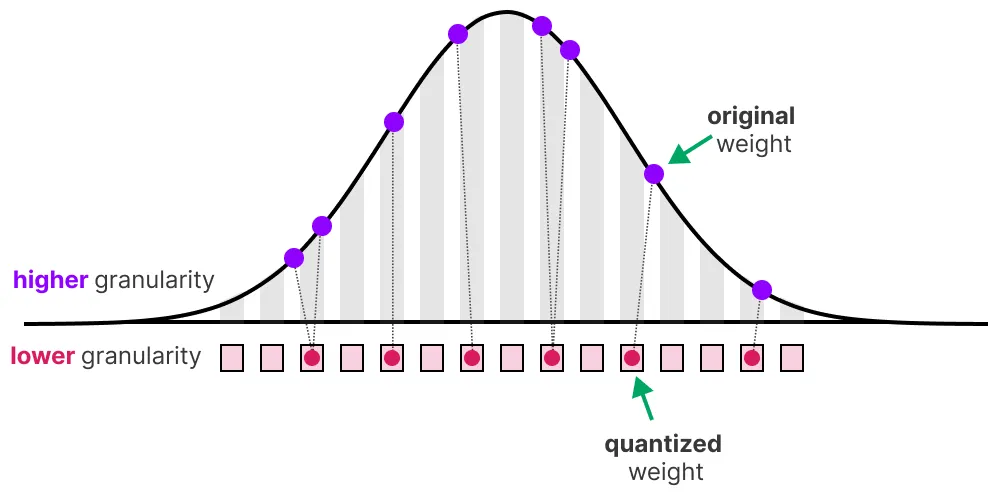
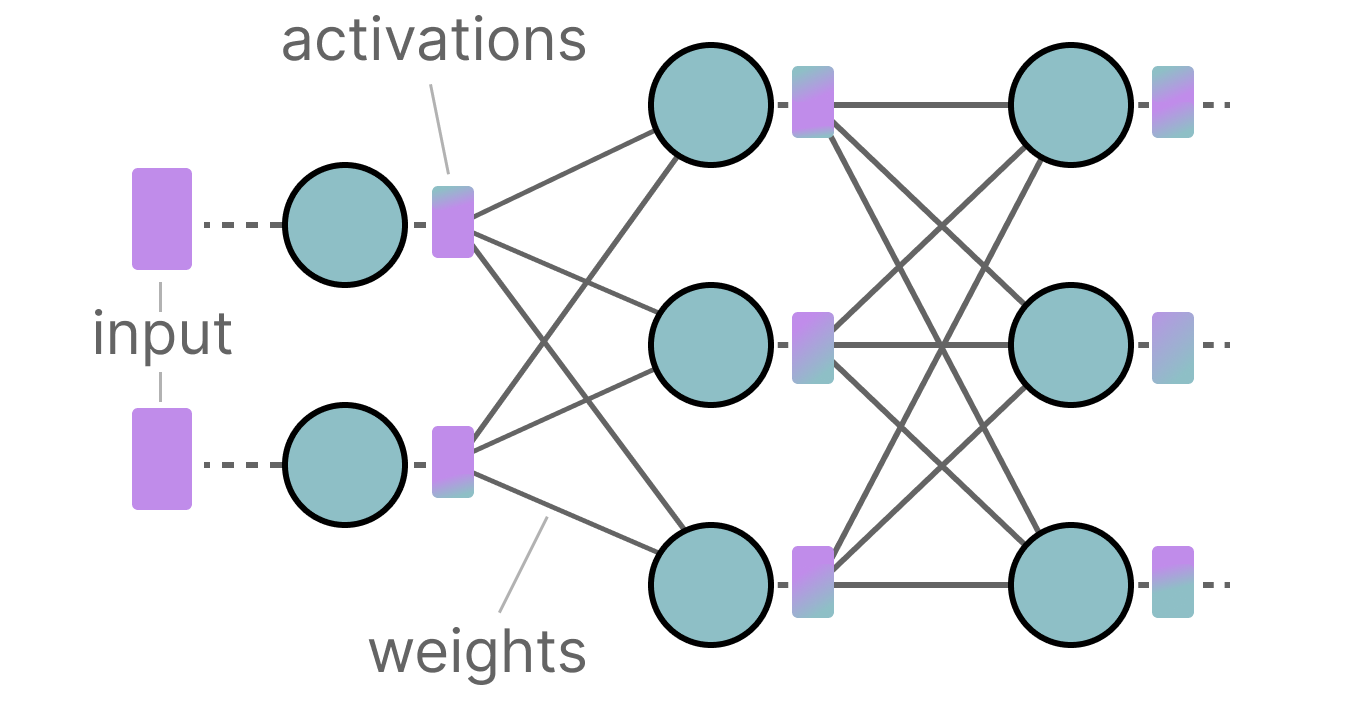
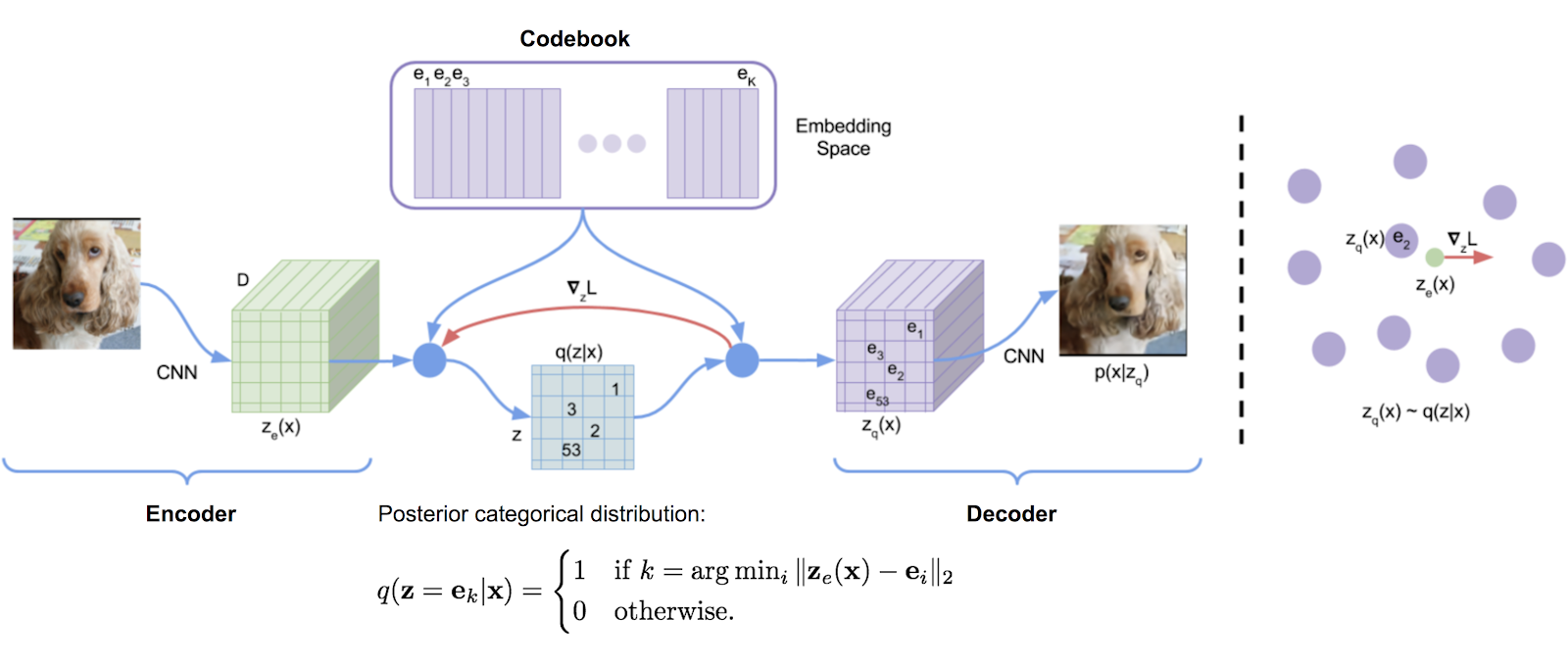
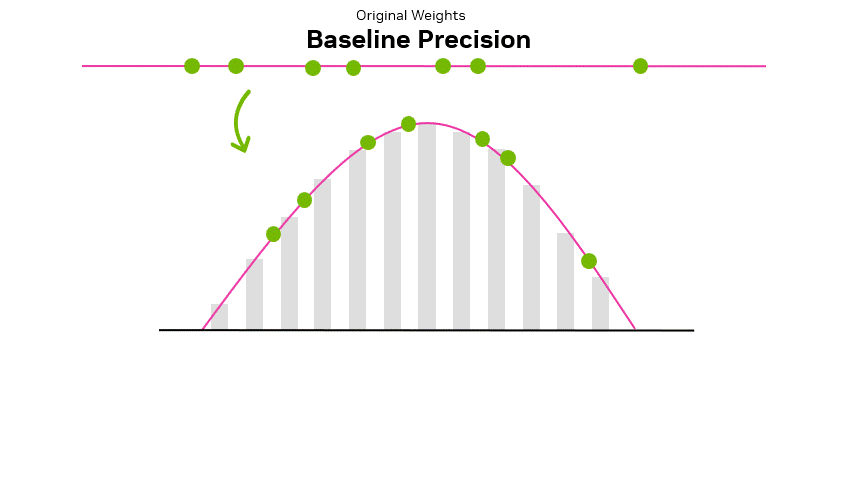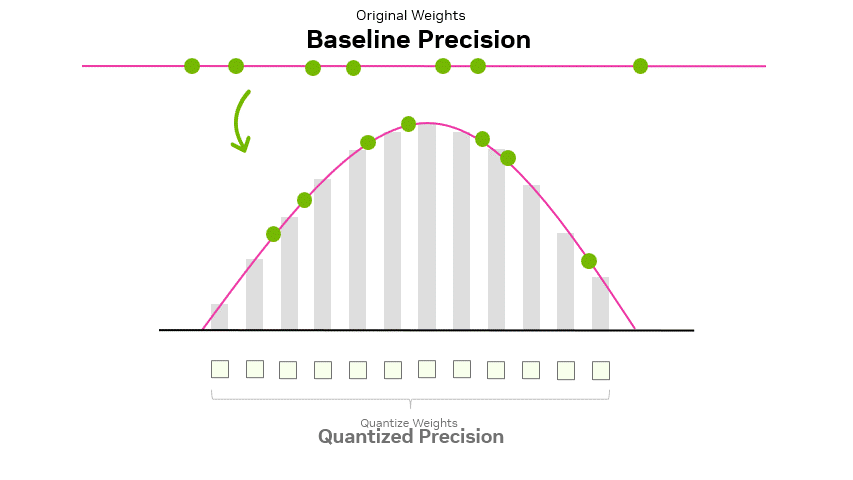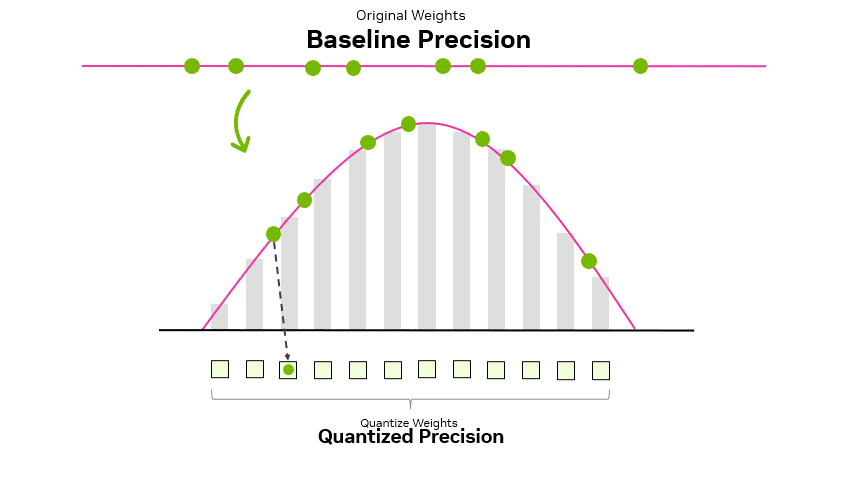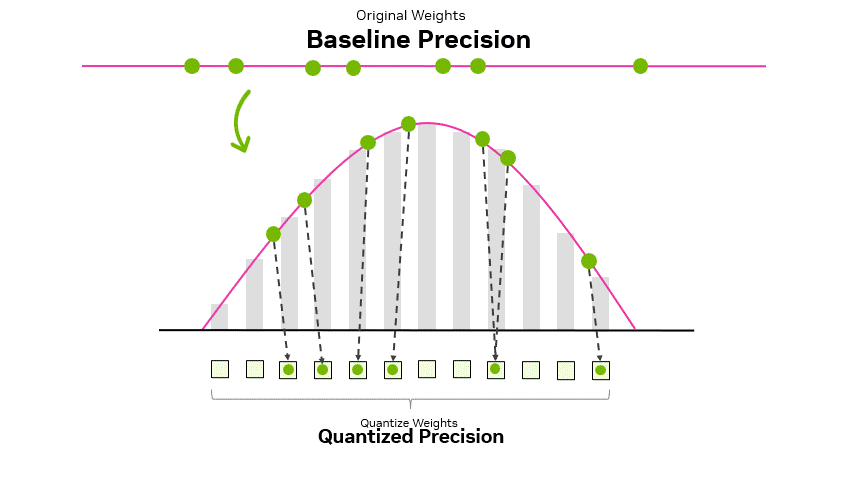
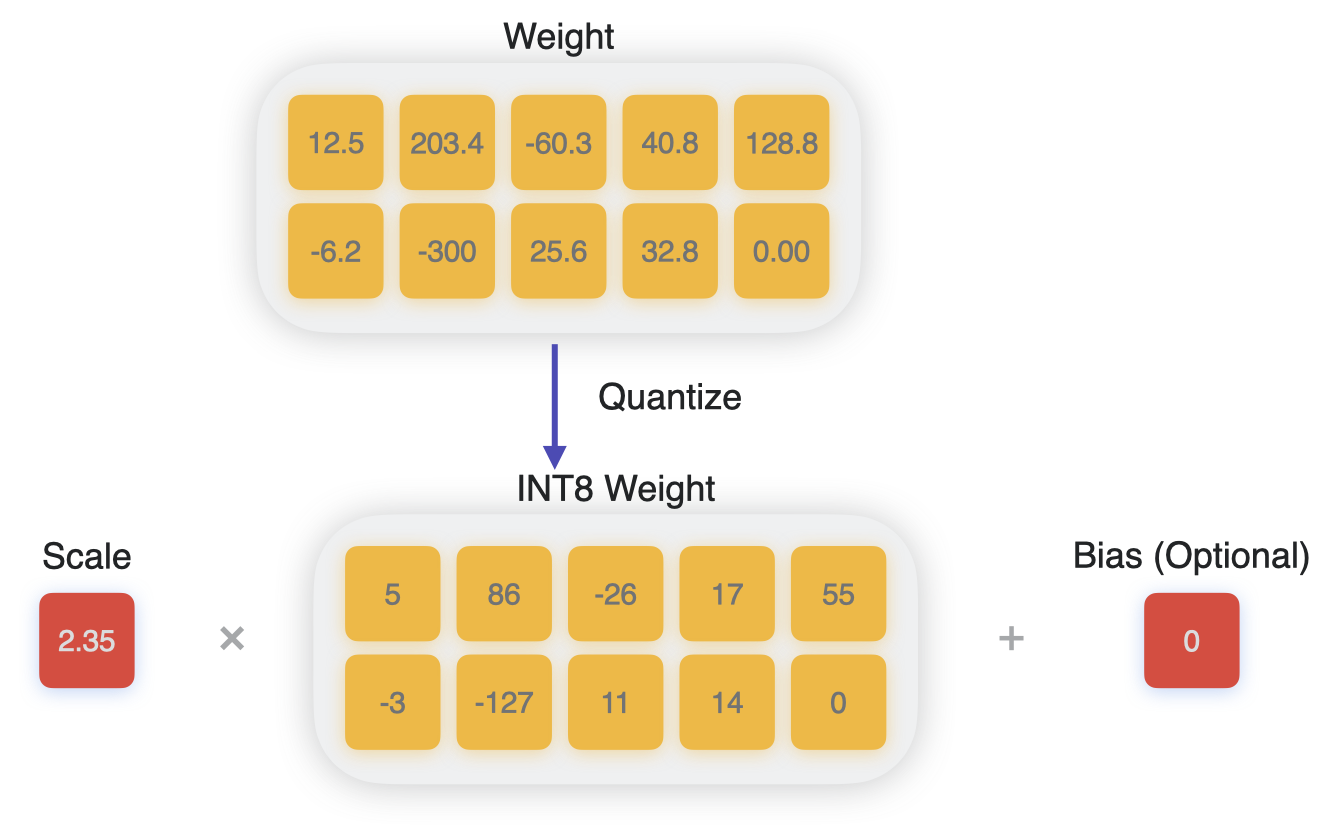
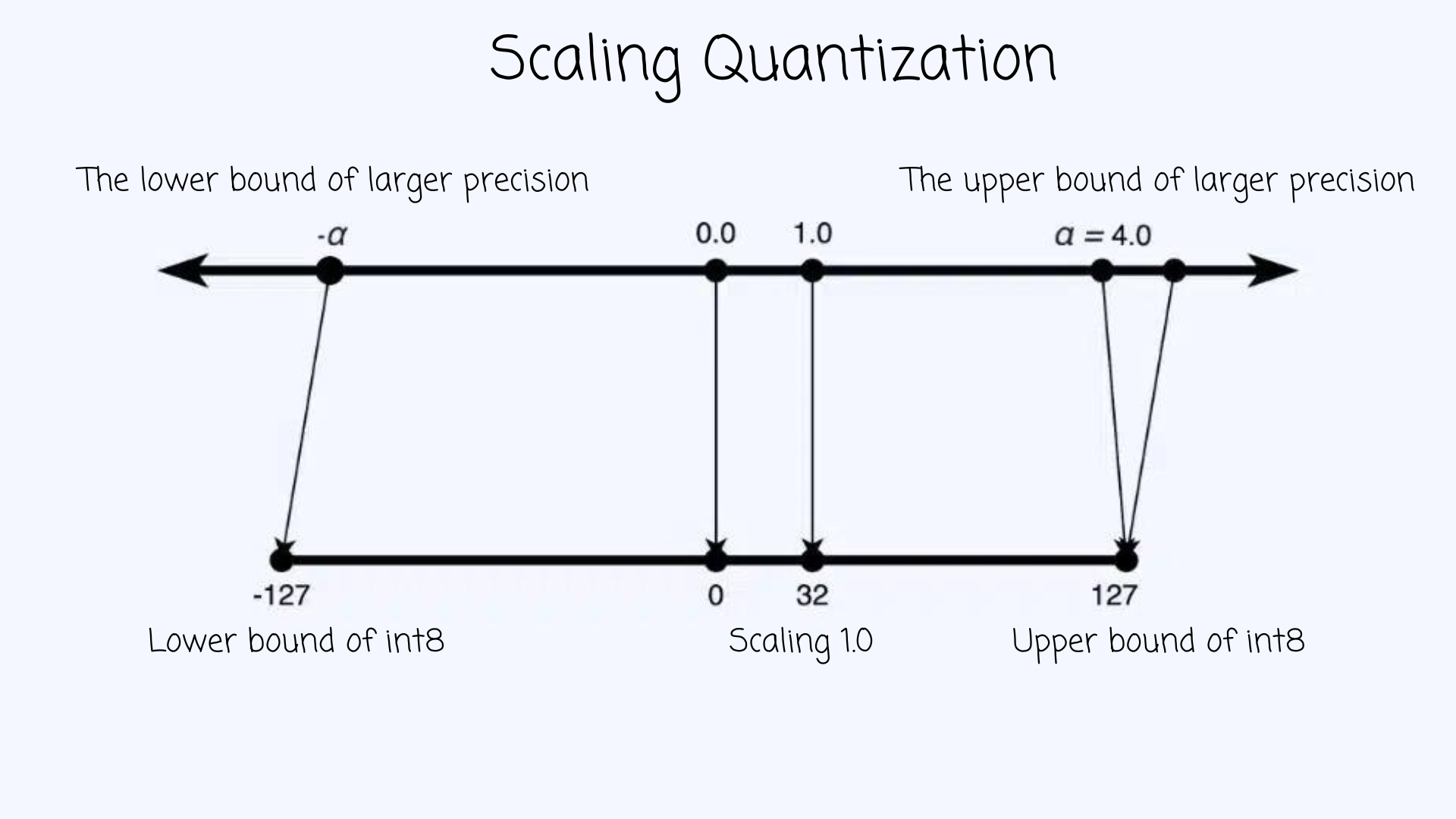
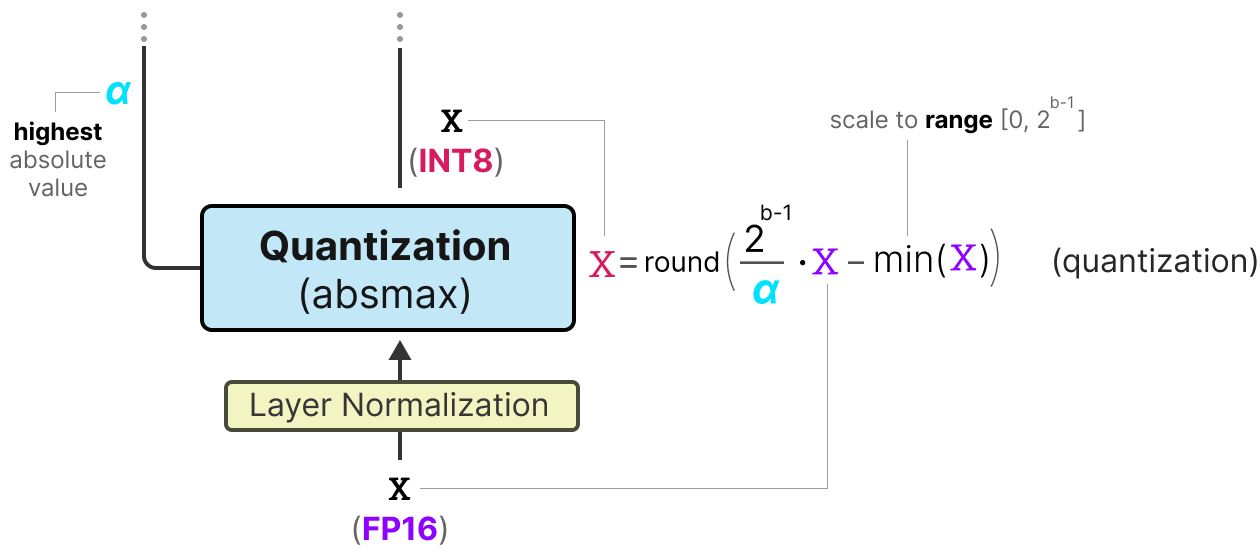
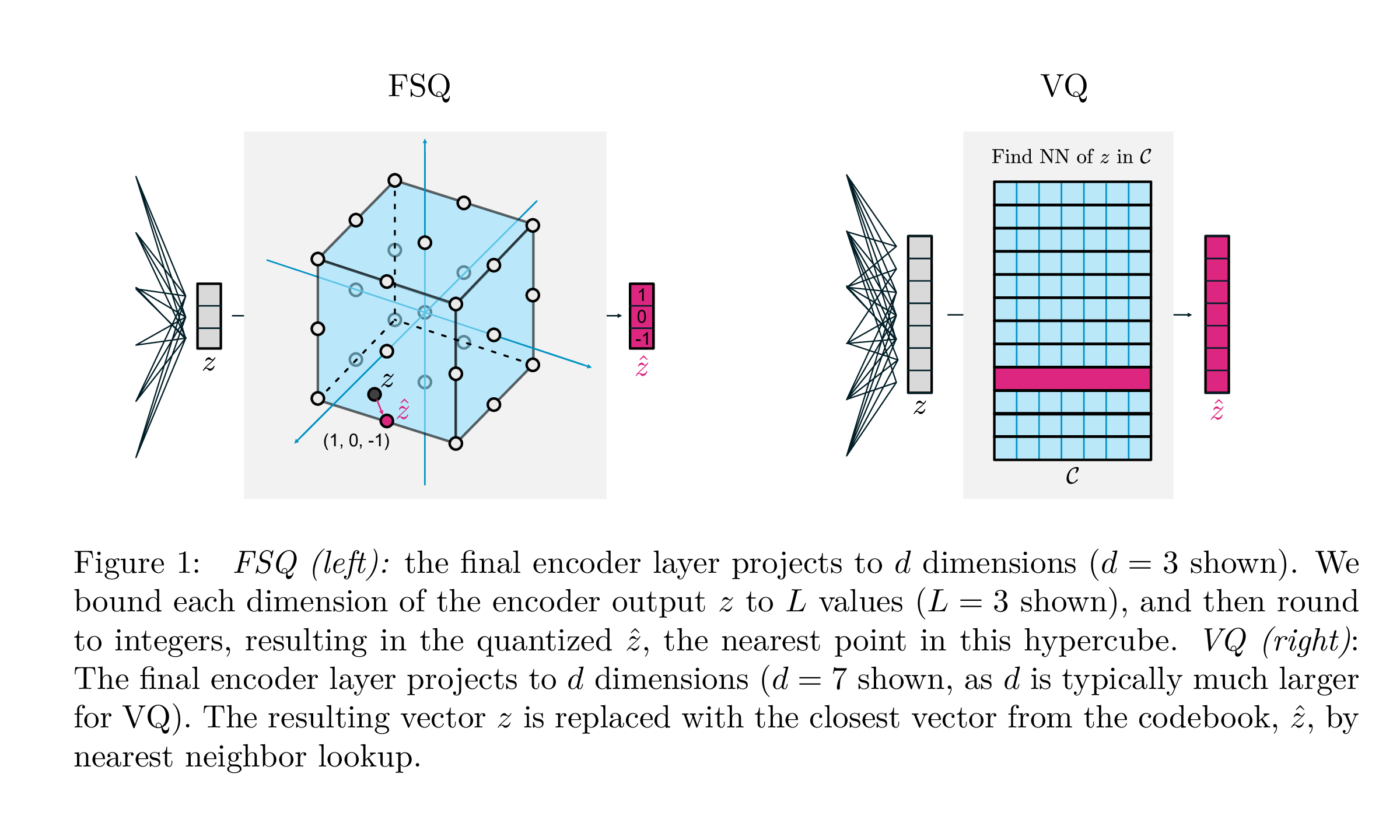
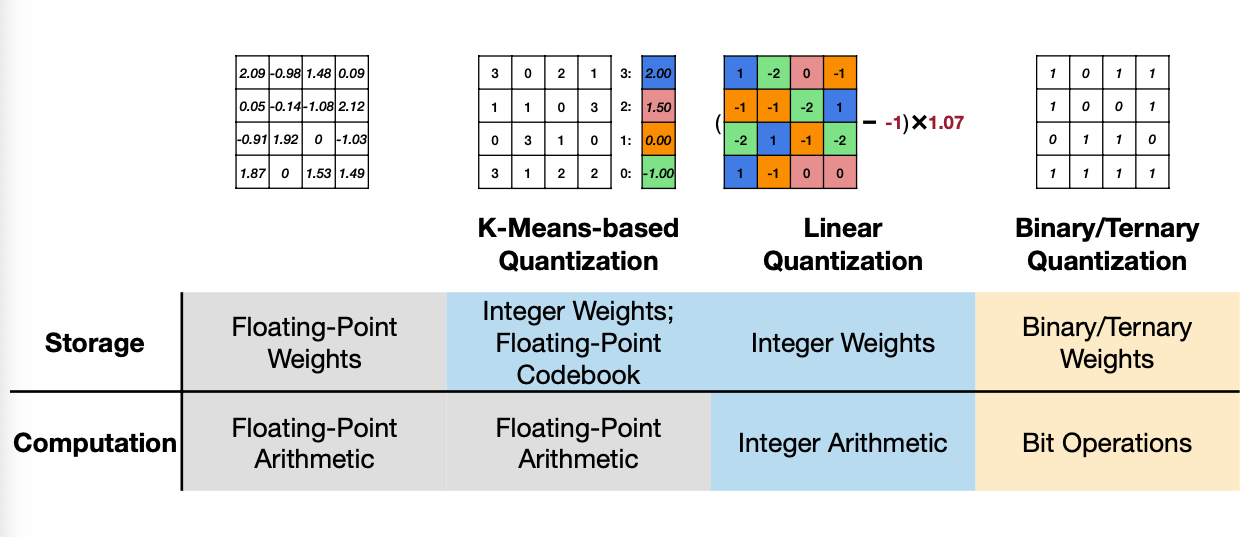
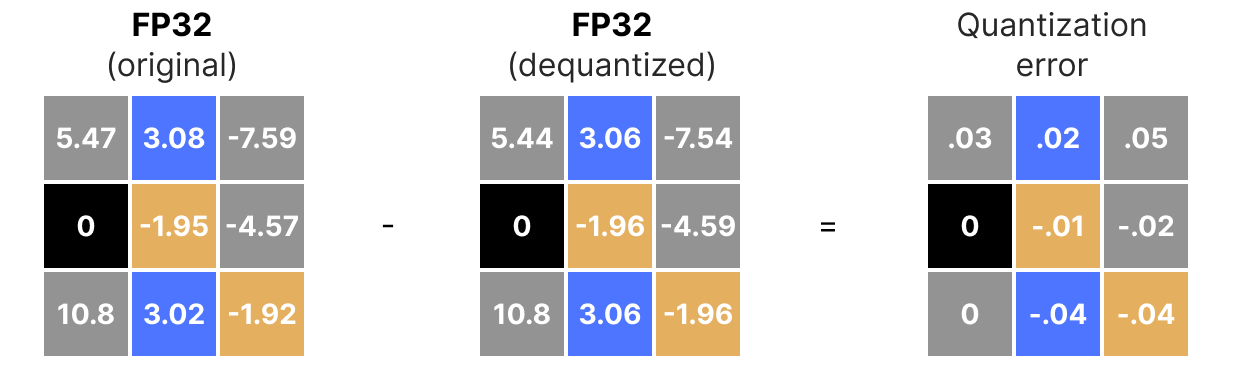
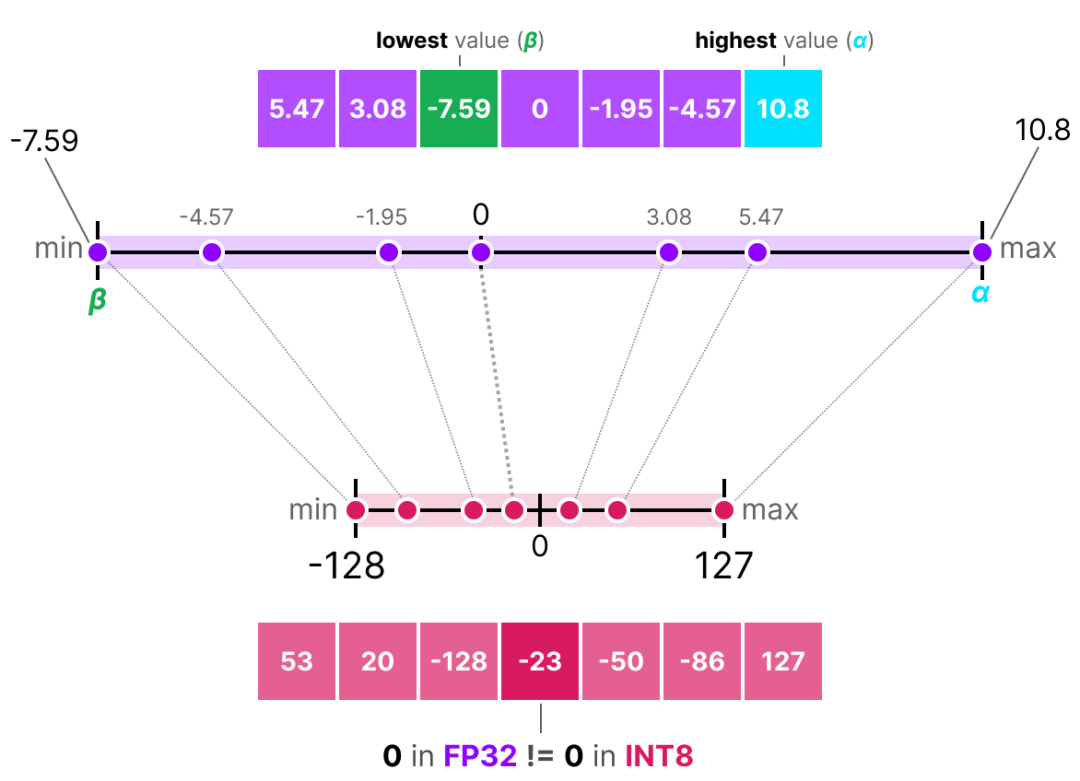
A Visual Guide to Quantization - by Maarten Grootendorst
STaR-Quant: State-Time Consistent Post-Training Quantization for ...
GGUF Quantization Explained: Q4_K_M vs Q8_0 vs F16 — Which to Use in ...
Optimizing LLMs for Performance and Accuracy with Post-Training ...
AWQ Quantization Guide: Deploy LLMs at Half the GPU Cost (2026 ...
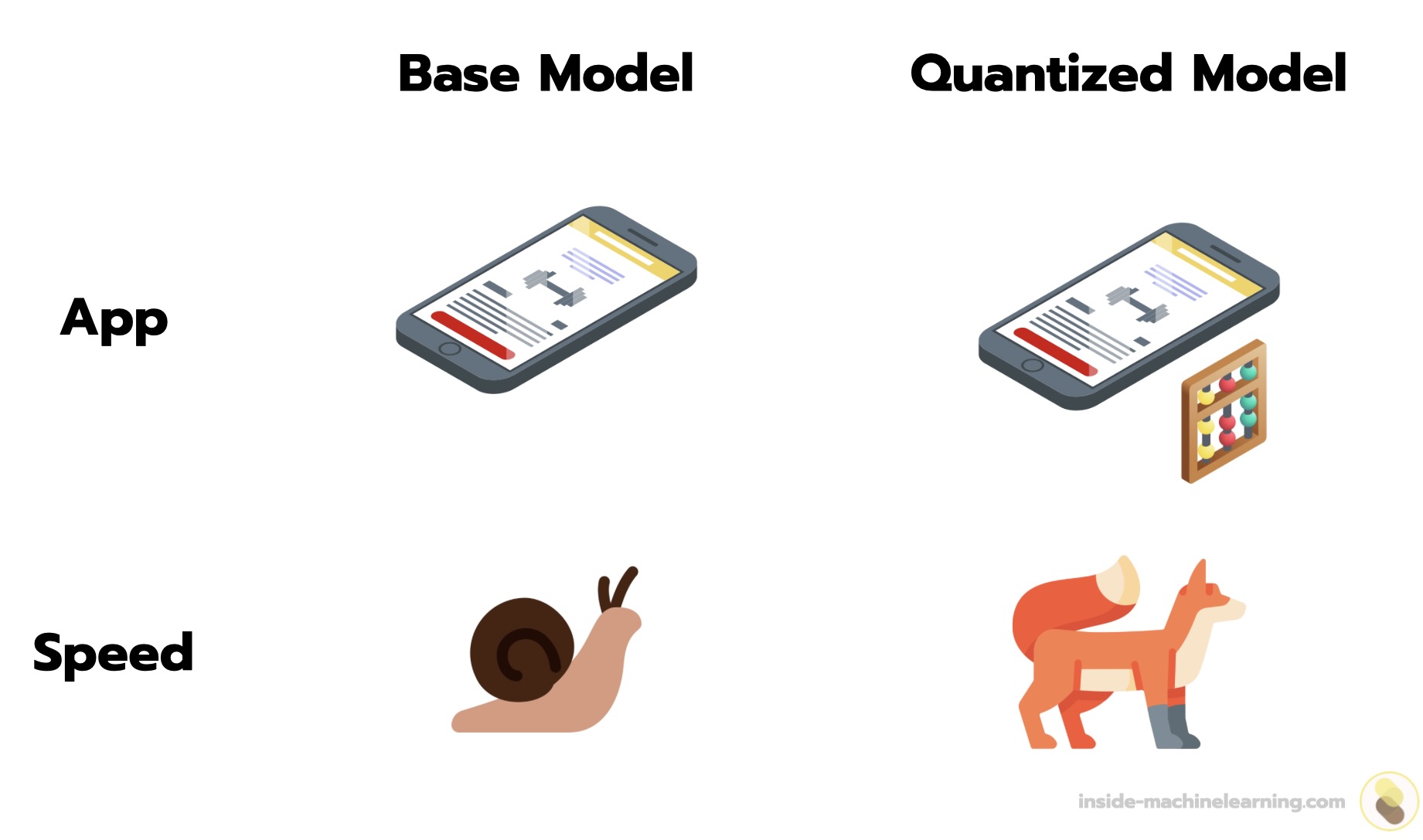
Quantization: Optimize ML Models to Run Them on Tiny Hardware
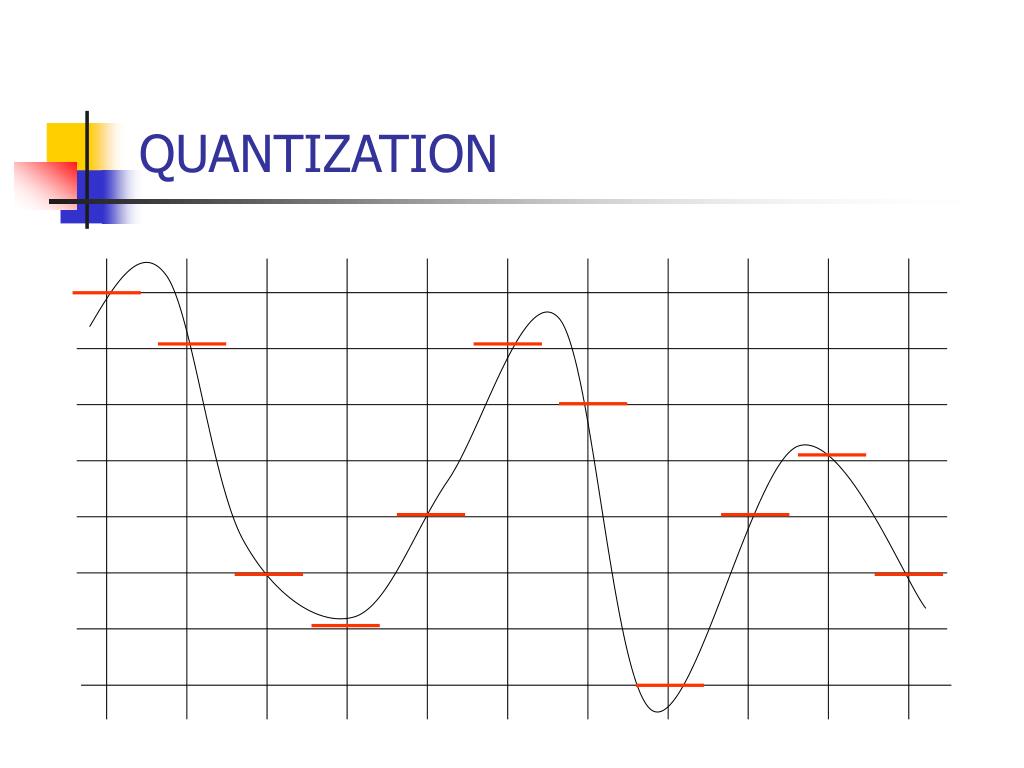
PPT - Quantization and error PowerPoint Presentation, free download ...
PPT - Quantization Error Analysis PowerPoint Presentation, free ...
PPT - Scalar Quantization PowerPoint Presentation - ID:138808
Quantization Of Signal In Digital Communication at Samuel Unwin blog
Quantization (A Guide for complete beginners) | by François Porcher ...
Quantization of Models: Why and How | by Parminder Singh | Artificial ...
Quantization in a nutshell. What is quantization? Why is it so… | by ...
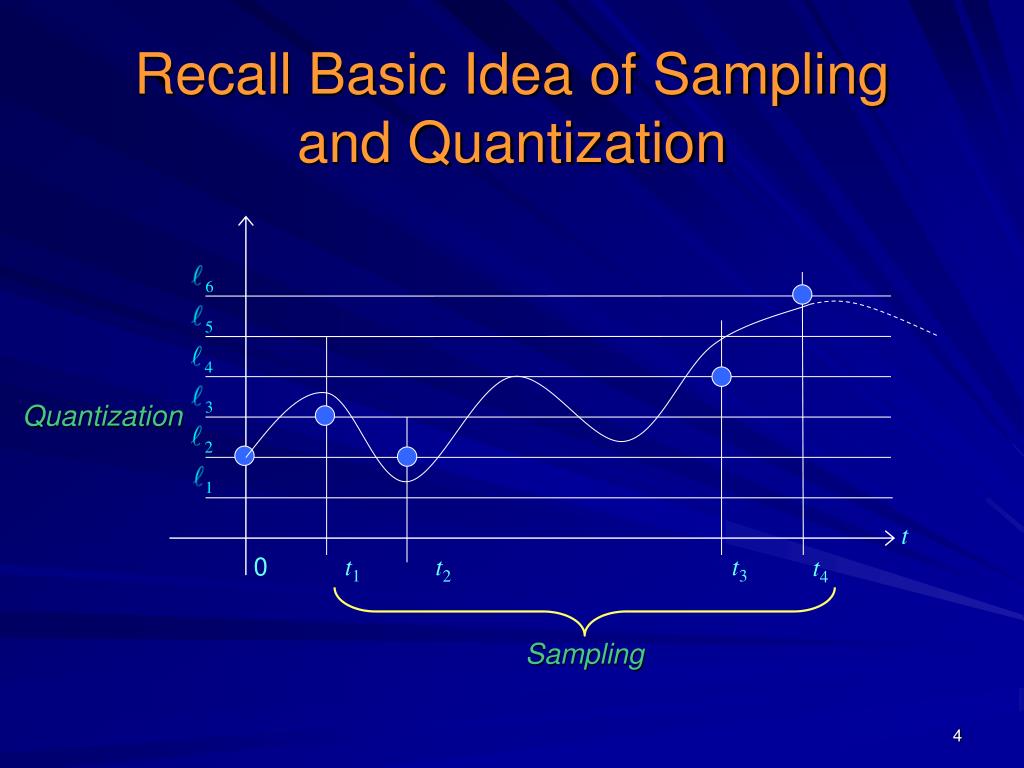
PPT - Lecture 12: Number representation and Quantization effects ...
PPT - HY530 “ ΨΗΦΙΑΚΕΣ ΕΠΙΚΟΙΝΩΝΙΕΣ ” PowerPoint Presentation - ID:3534065
PPT - Number Representation and Quantization Effects in Digital Signal ...
Quantization | PPTX
What Is Quantization Of Signal at Barbara Fowler blog
PPT - Quantization PowerPoint Presentation, free download - ID:3871411
PPT - Lecture #9 PowerPoint Presentation, free download - ID:1731852
Introducing Vector Quantization in Manticore Search
Quantization — Deep Learning Course
Quantization Bits at Amanda Okane blog
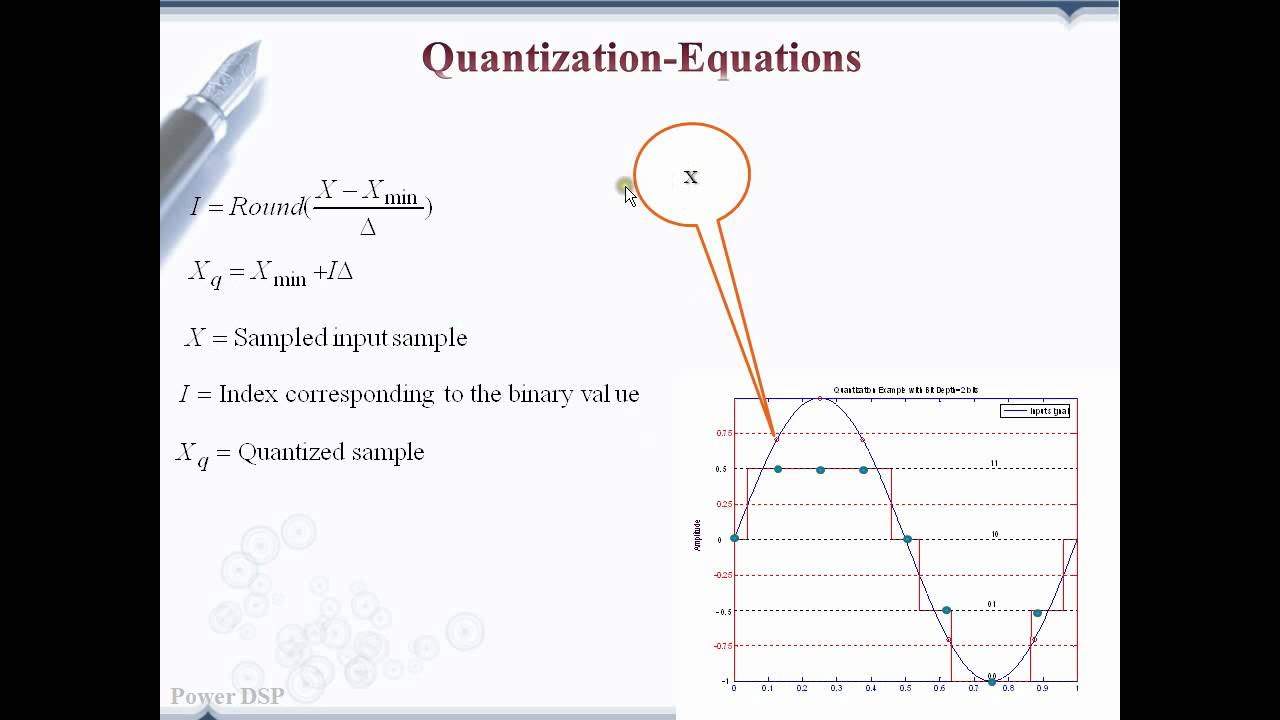
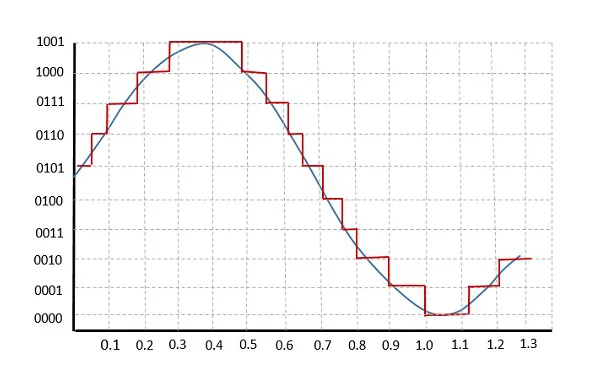
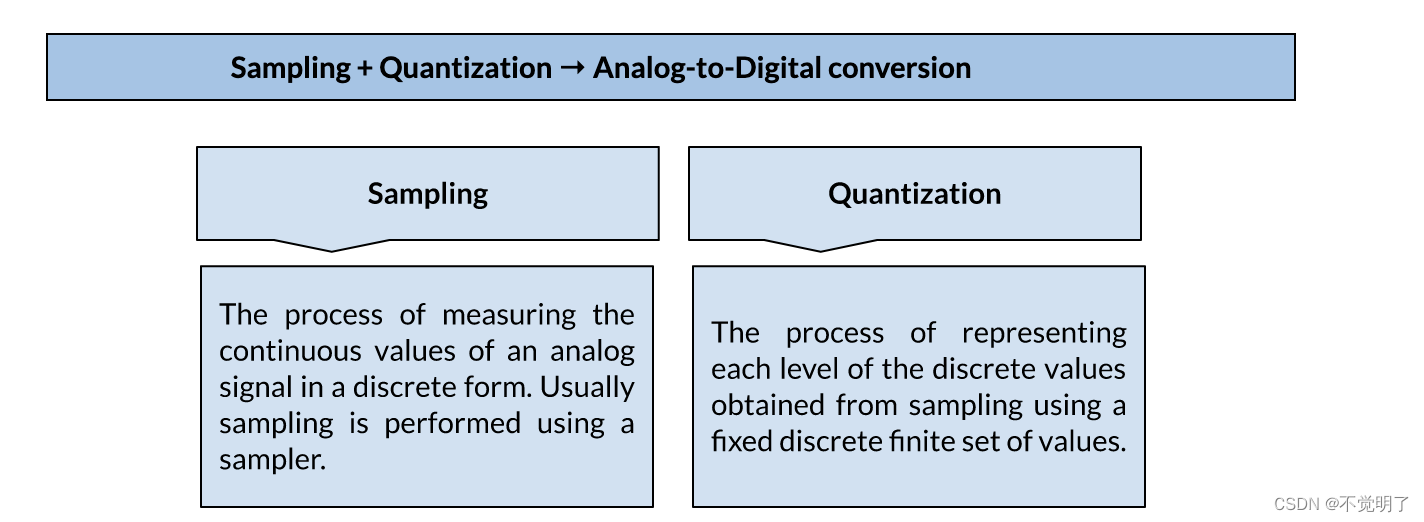
Quantization (Basics, Working Principle, Waveforms, Quantization Error ...
Quantization.pptx
Quantization Digital Signal Processing at Benjamin Whitley blog
A Visual Guide to Quantization - Maarten Grootendorst
notion image
What is Quantization and how to use it with TensorFlow
Tối Ưu Hóa Mô Hình Ngôn Ngữ Lớn với Quantization: Giảm Tải GPU Hiệu Quả ...
LLM Quantization Methods: GPTQ, AWQ, GGUF - Cast AI
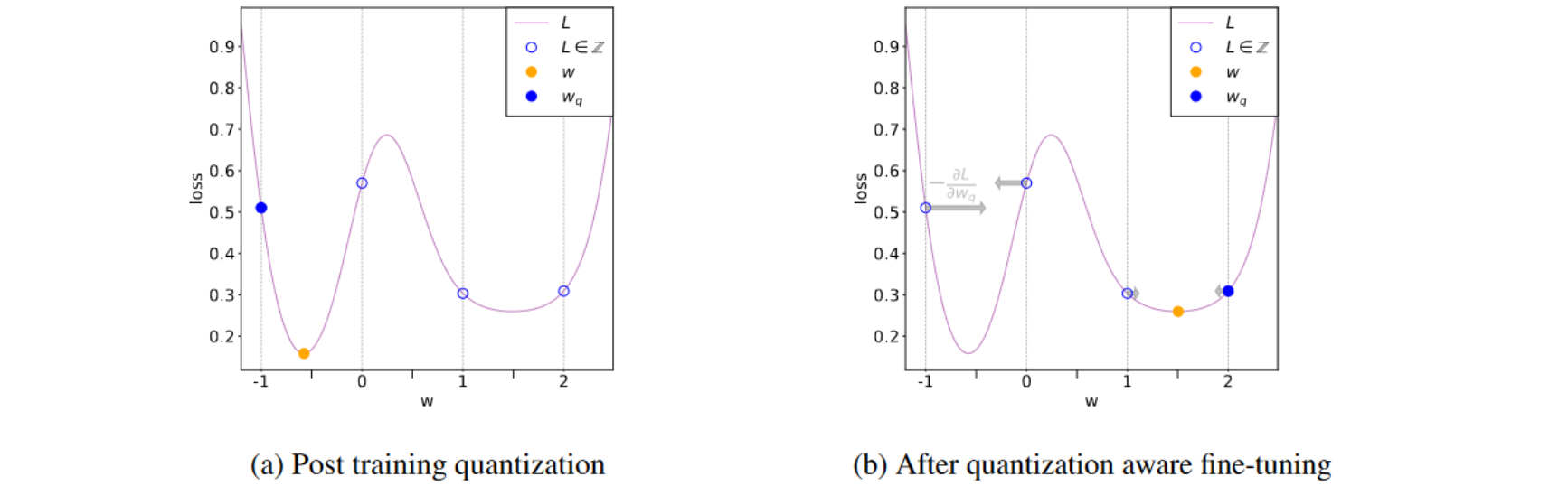
Quantization Aware Training. Train the model taking quantization… | by ...
What is Quantization - Lightning AI
What Is Quantization? Optimizing Data Compression | Coursera
vLLM Quantization Benchmark: AWQ vs FP16 on RTX 4090 | Markaicode
XNNPACK download | SourceForge.net
Making Sense of Quantization
PPT - Lecture 3 Quantization in Signals and Systems PowerPoint ...
LampQ: Towards Accurate Layer-wise Mixed Precision Quantization for ...
Quantization Configuration System | quic/aimet | DeepWiki
LLM Quantization Explained: Q4, Q8, FP16 and VRAM Tradeoffs (2026)
Quantization | PDF
What is quantization of LLMs?
Class 11 &12 NEB solutions science & management | Quantization Of ...
Omnidirectional Continuum Lattice Mechanics: A Deterministic ...
Quantization Errors-CSDN博客
Google DeepMind releases Gemma 4 Quantization-Aware Training ...
LLM Quantization Explained: Q4 vs Q8 — What's the Difference and Which ...
Vector Quantization - Pytorch_vector-quantize-pytorch-CSDN博客
A Beginner's Guide to LLM Quantization
Optimizing LLMs for Performance and Accuracy with Post-training ...
Quantization : comment ça fonctionne ? | Blent.ai
LLM Inference Optimization in 2026: Quantization, Speculative Decoding ...
Uniform Quantization at Eldridge Rucker blog
Paper page - LightMamba: Efficient Mamba Acceleration on FPGA with ...
Huawei Unveils KVarN: A Native vLLM Backend for KV-Cache Quantization ...
Introduction to Quantization cooked in 🤗 with 💗🧑🍳
Gemma 4 on NVIDIA GB10: Quantization Benchmarks for Local Inference ...
Transformed Residual Quantization for Approximate Nearest Neighbor ...
Google releases Gemma 4 quantization-aware training checkpoints ...
Quantization 1/2 - Seunghyun Oh
GPTQ vs AWQ vs NF4: Choosing the Right LLM Quantization Pipeline
Google Introduces TurboQuant: A New Compression Algorithm that Reduces ...
什么是生成模型(Generative Model) - AI百科知识 | AI工具集
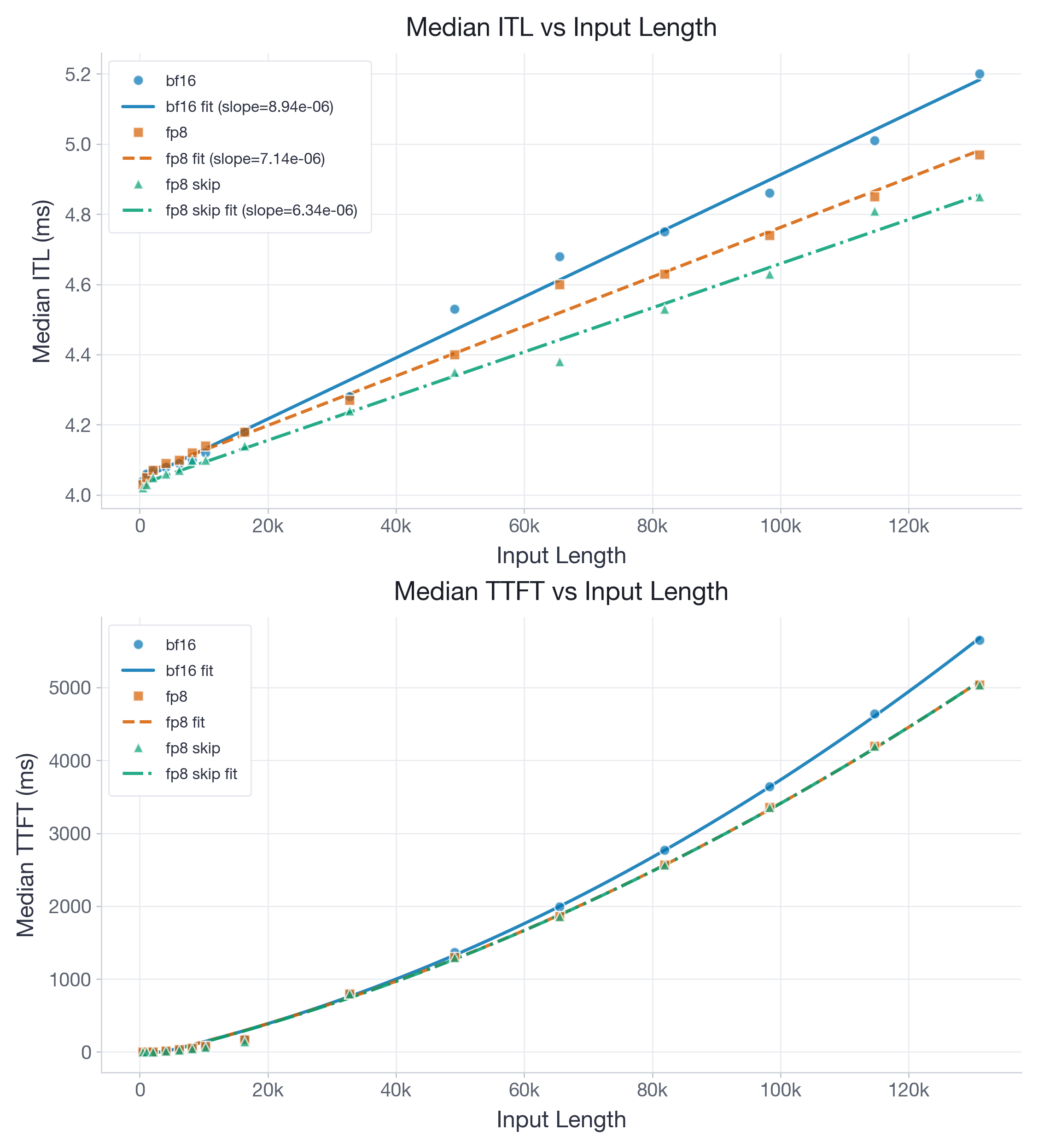
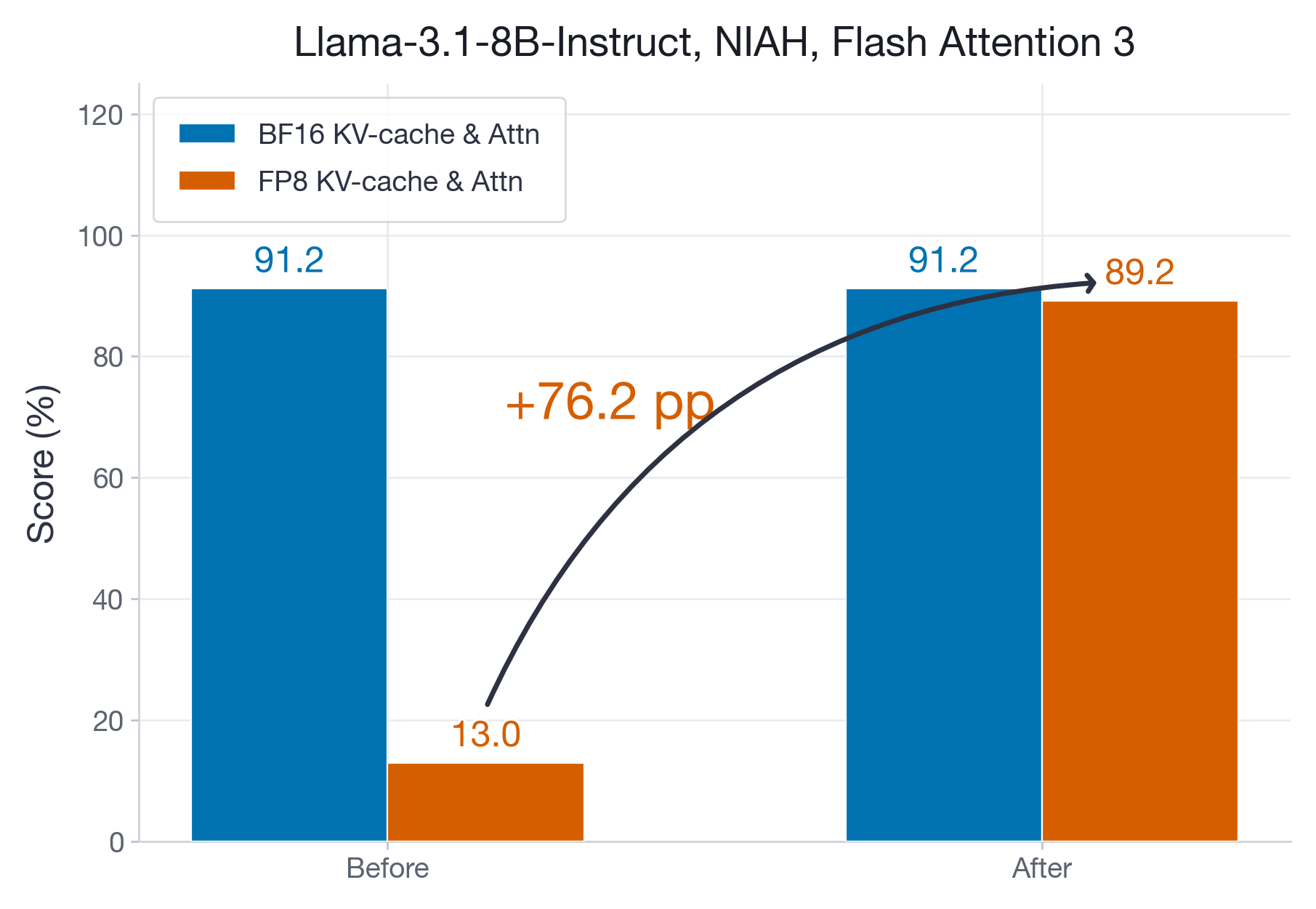
The State of FP8 KV-Cache and Attention Quantization in vLLM | vLLM Blog
MXFP4 Quantization and GPT-OSS. GPT-OSS dropped in early August, and ...
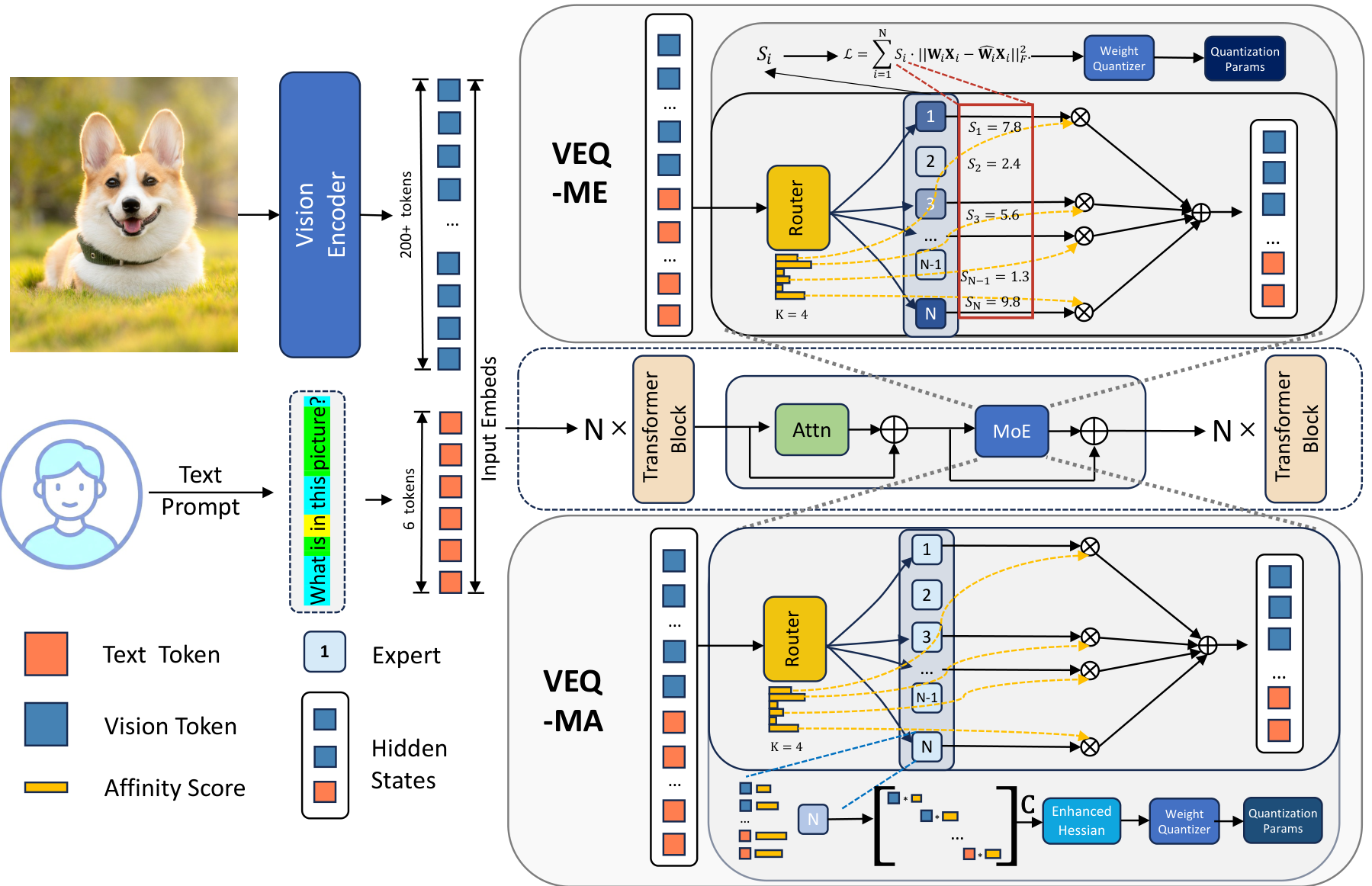
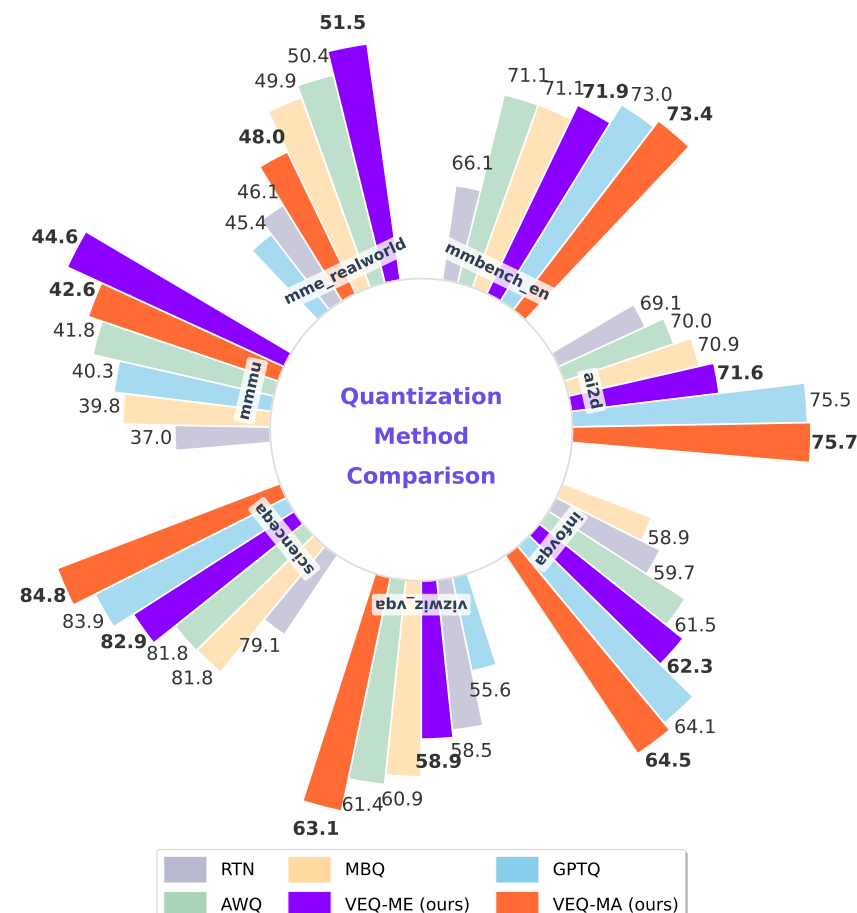
VEQ Modality-Adaptive Quantization for MoE Vision-Language Models_veq ...
Optimizer, Not Model, Dictates Quantization Robustness 🤯 Is ...
量化(Quantization)(深度学习) | UMBRELLA
Top 10 KV Cache Compression Techniques for LLM Inference: Reducing ...
Cohere cracks lossless quantization and native citations with first ...
Quantization - a Hugging Face Space by PEFT
Gemma 4 with quantization-aware training
Survival Guide: How to Run Local AI Without a GPU in 2026 - DSRPT.AI
Model quantization principle and tflite example - Programmer Sought
What Is Quantization In Machine Learning?
Data Science - Department of Mathematics - TUM - Department of Mathematics
Image Quantization | PPTX
FastMamba: A High-Speed and Efficient Mamba Accelerator on FPGA with ...
[LG] BiLLM: Pushing the Limit of Post-Training Quantization for LLMs ...
quantization (Quantization)
How to Run NVIDIA Nemotron 3 Ultra 550B on a Budget GPU Cluster - A ...
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析_大模型量化-CSDN博客
Gemma 4 12B local AI model: RAM, quantization and LM Studio setup ...
I’ll be sharing a 14-part series through Cryptic Design called Signal ...
Huawei's KVarN Puts KV-Cache Quantization Inside vLLM's Backend · Groundy
Gemma 4 Quantization-Aware Training (QAT) weights are now available on ...
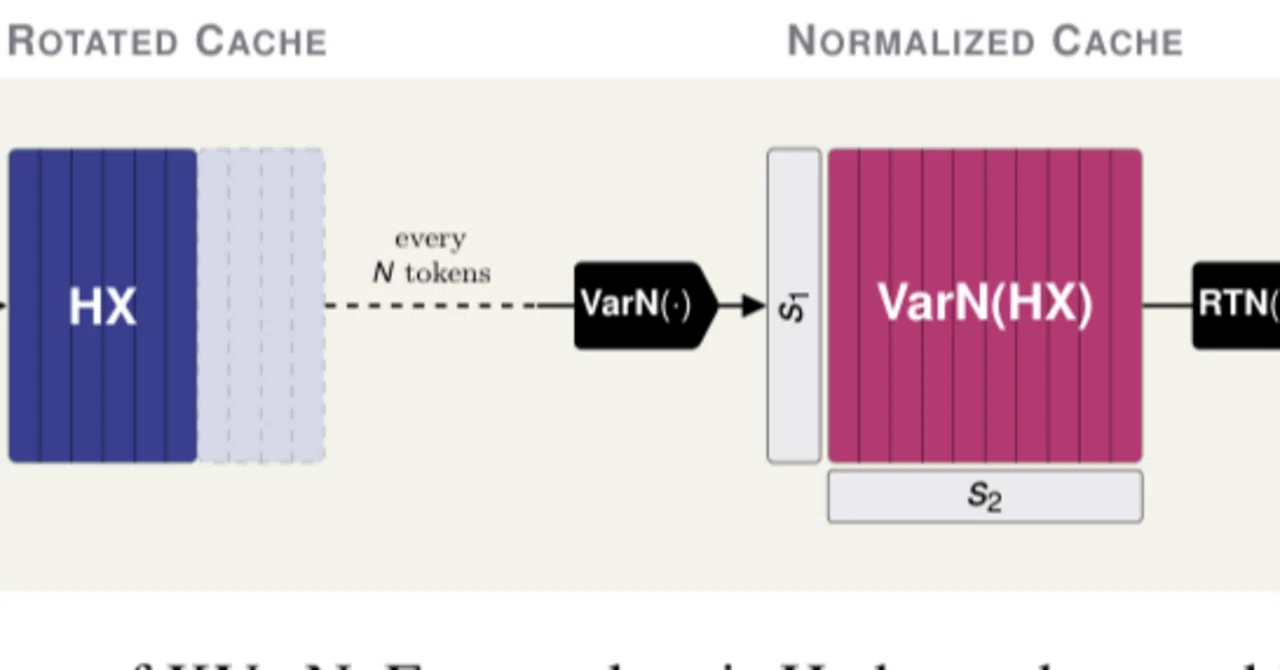
KVarN: Variance-Normalized KV-Cache Quantization Mitigates Error ...
Exploring the Importance and Career Opportunities in Physics Education ...