Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
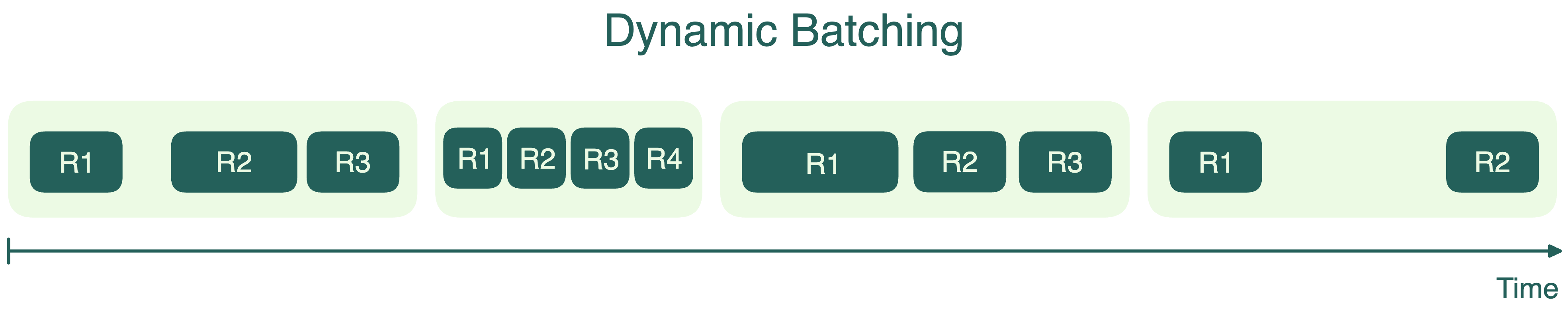
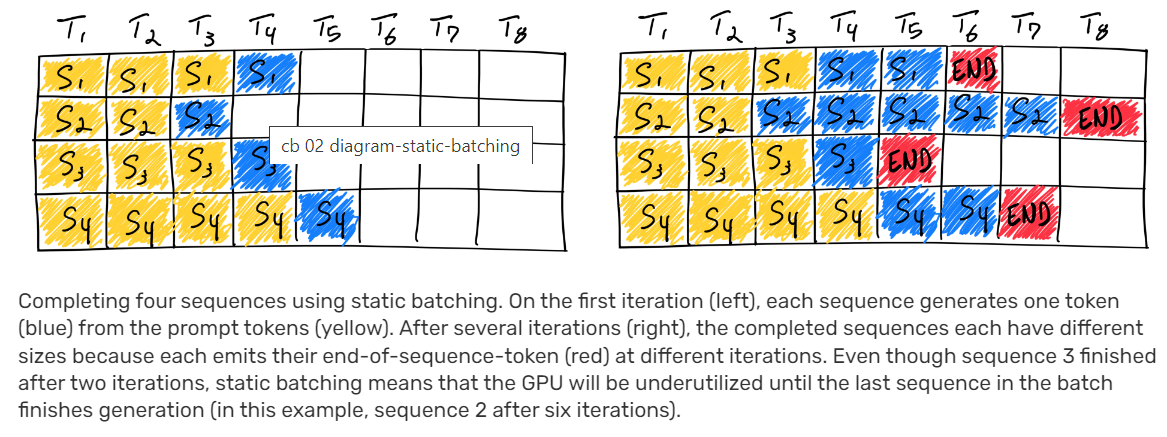
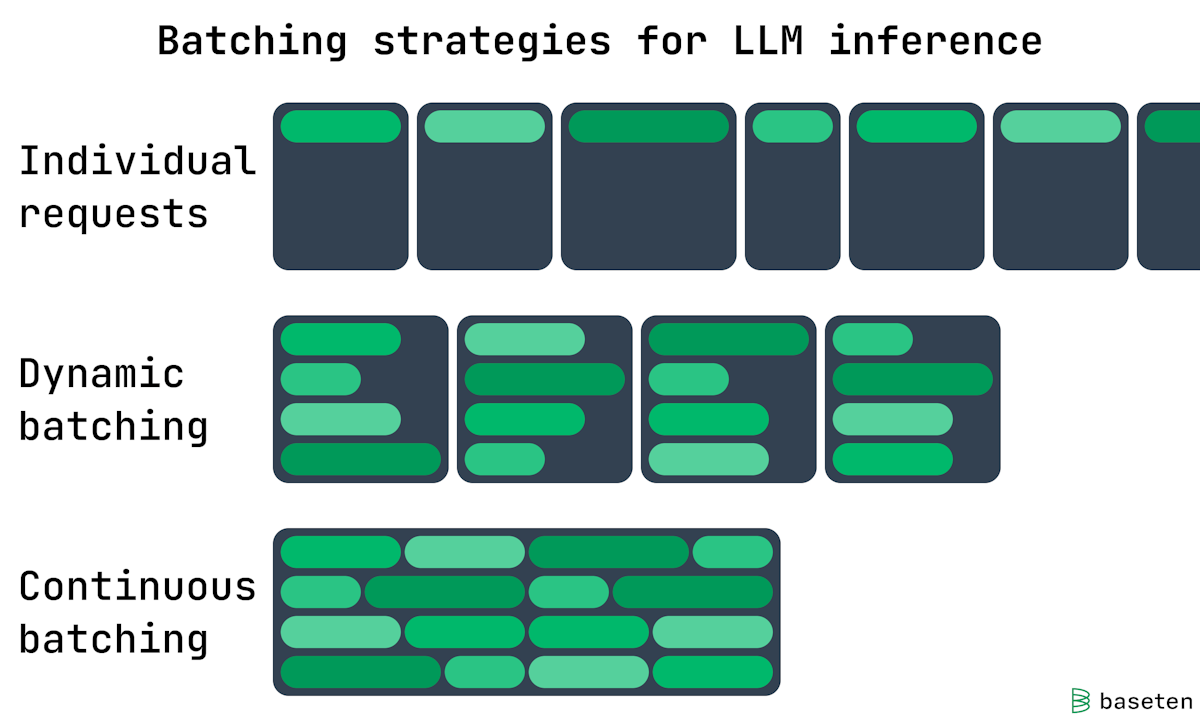
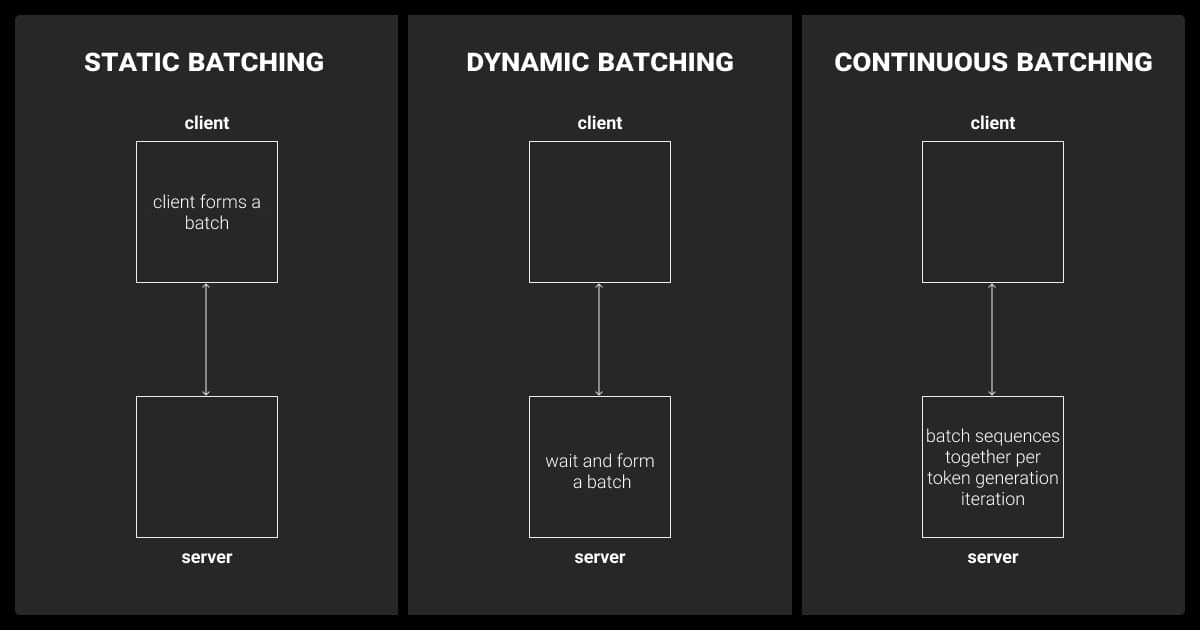
Static, dynamic and continuous batching | LLM Inference Handbook
Dynamic Quality-Latency Aware Routing for LLM Inference in Wireless ...
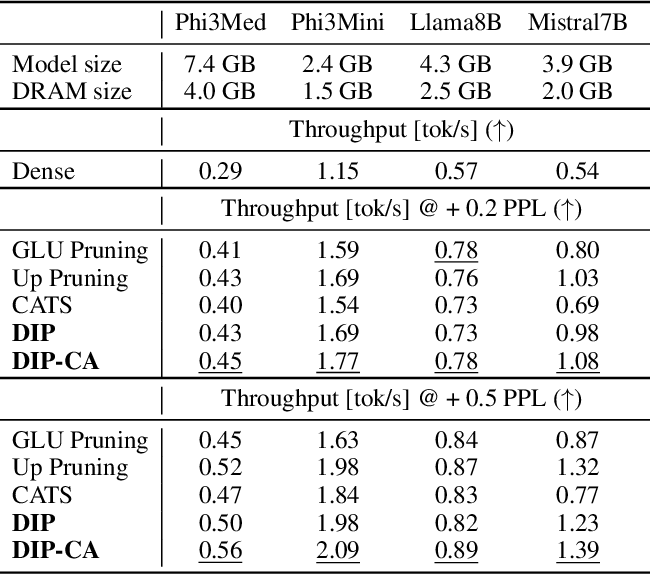
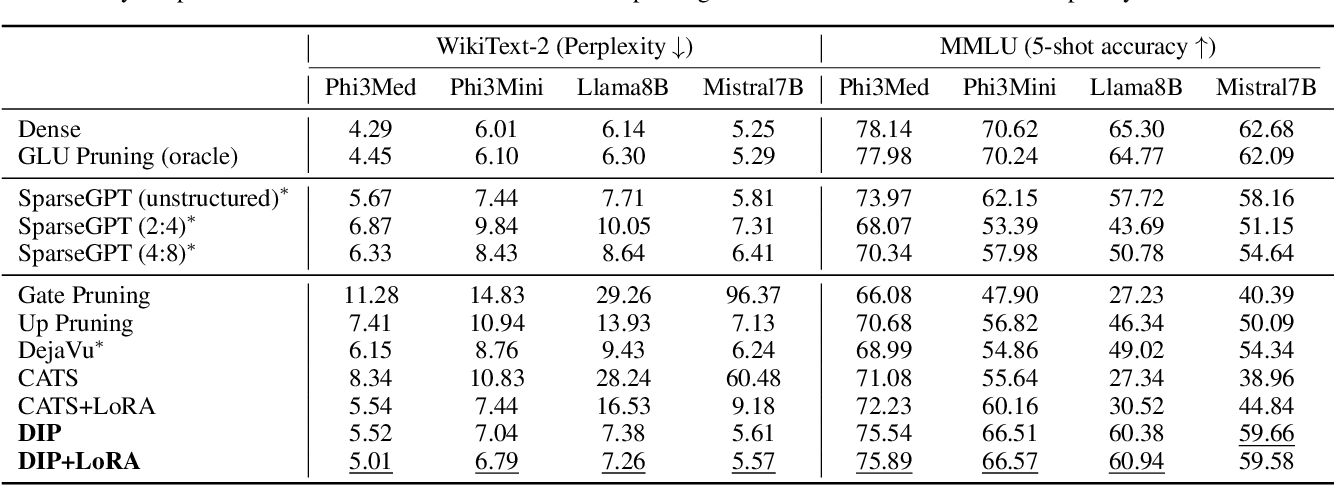
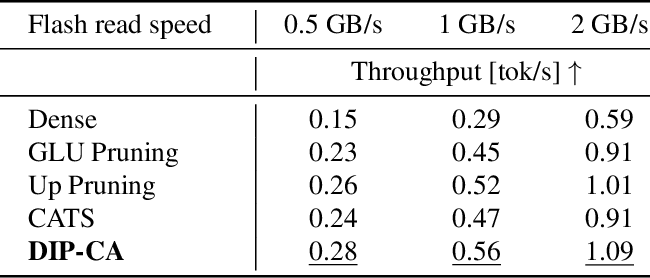
Efficient LLM Inference using Dynamic Input Pruning and Cache-Aware Masking
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference ...
Dynamic LLM Adaptation for Inference | PDF | Cluster Analysis | Applied ...
Table 2 from Efficient LLM Inference using Dynamic Input Pruning and ...
[论文评述] Efficient LLM Inference using Dynamic Input Pruning and Cache ...
Table 1 from Efficient LLM Inference using Dynamic Input Pruning and ...
Table 6 from Efficient LLM Inference using Dynamic Input Pruning and ...
Dynamic Rank Allocation for Efficient LLM Inference on GPUs ...
Optimizing LLM Inference with Dynamic Quantization | by Kim, Mingyu ...
Figure 4 from Efficient LLM Inference using Dynamic Input Pruning and ...
[논문 리뷰] DISC: Dynamic Decomposition Improves LLM Inference Scaling
How We Cut LLM Batch Inference Time in Half with Dynamic Prefix ...
Understanding LLM Inference - by Alex Razvant
LLM Inference Optimization Techniques | Clarifai Guide
A Survey of LLM Inference Systems | alphaXiv
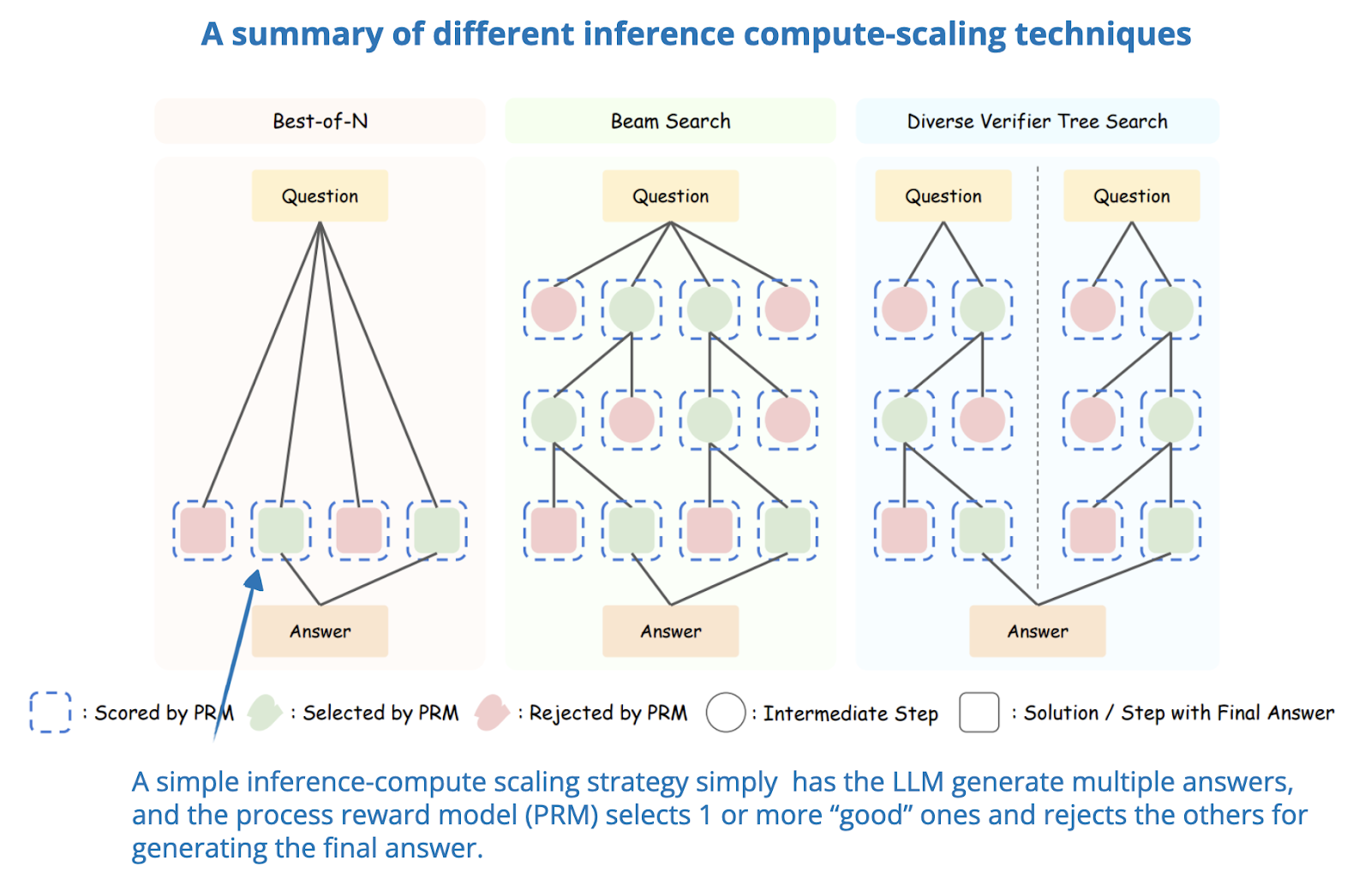
The State of LLM Reasoning Model Inference
LLM Inference Stages Diagram | Stable Diffusion Online
Illustration of the proposed method. (a) LLM inference comprises two ...
LLM Inference - Hw-Sw Optimizations
LLM Inference at Scale: 10 KV-Cache & Batching Wins | by Thinking Loop ...
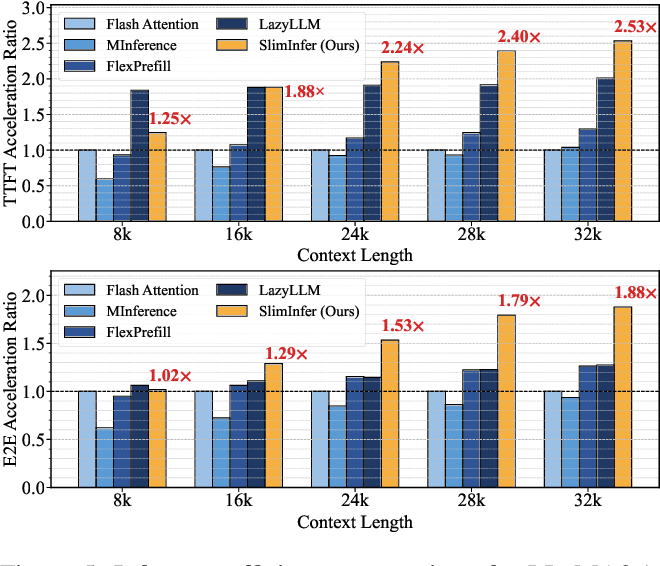
Figure 5 from SlimInfer: Accelerating Long-Context LLM Inference via ...
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
LLM Inference Hardware: Emerging from Nvidia's Shadow
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
(PDF) DASH: Input-Aware Dynamic Layer Skipping for Efficient LLM ...
(PDF) DynamoLLM: Designing LLM Inference Clusters for Performance and ...
[논문 리뷰] LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM ...
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
LLM Inference Performance Engineering: Best Practices | Databricks Blog
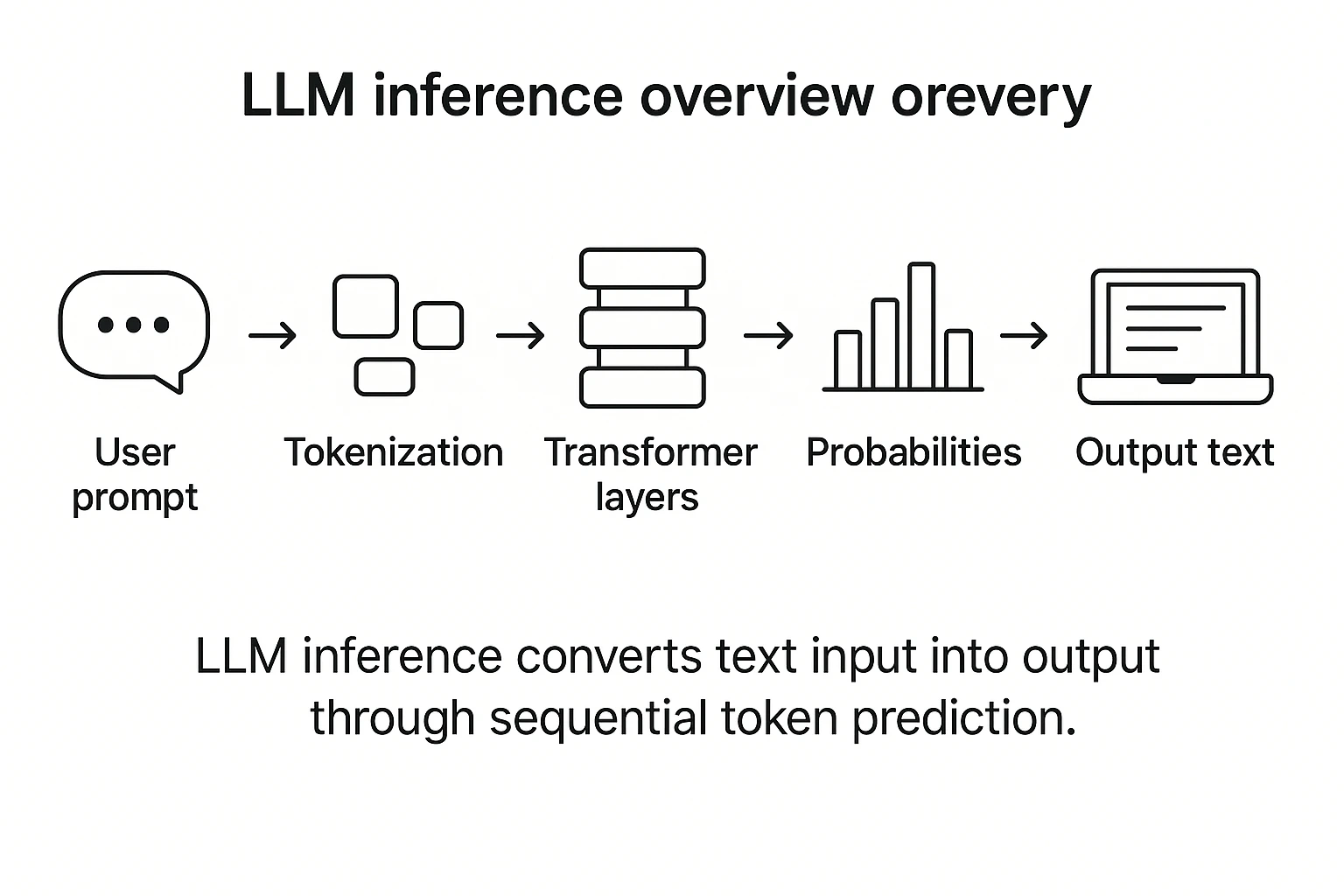
How does LLM inference work? | LLM Inference Handbook
GitHub - bhavinkotak/llm-inference-optimization: LLM inference ...
[2503.05248] Optimizing LLM Inference Throughput via Memory-aware and ...
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
[논문 리뷰] Optimizing LLM Inference Throughput via Memory-aware and SLA ...
High-performance LLM inference | Modal Docs
[LLM] InfiniGen: Efficient Generative Inference of LLMs with Dynamic KV ...
Deep Dive: Optimizing LLM inference - YouTube
Shift Parallelism: Low-Latency, High-Throughput LLM Inference for ...
Illustration of the privacy-preserving LLM inference. The LLM inference ...
How to Build LLM Inference Pipelines for Enterprise Apps
Why is LLM Inference Optimization Important in 2026?
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
How LLM really works: From Training to Talking – The Power of Inference
LLM Inference Optimization Overview - From Data to System Architecture
M: Simple LLM Inference Acceleration Framework With Multiple Decoding ...
Understanding LLM Batch Inference | Adaline
LLM Inference Essentials
LLM Concept Evolution Confirms Active Inference Principles | Network ...
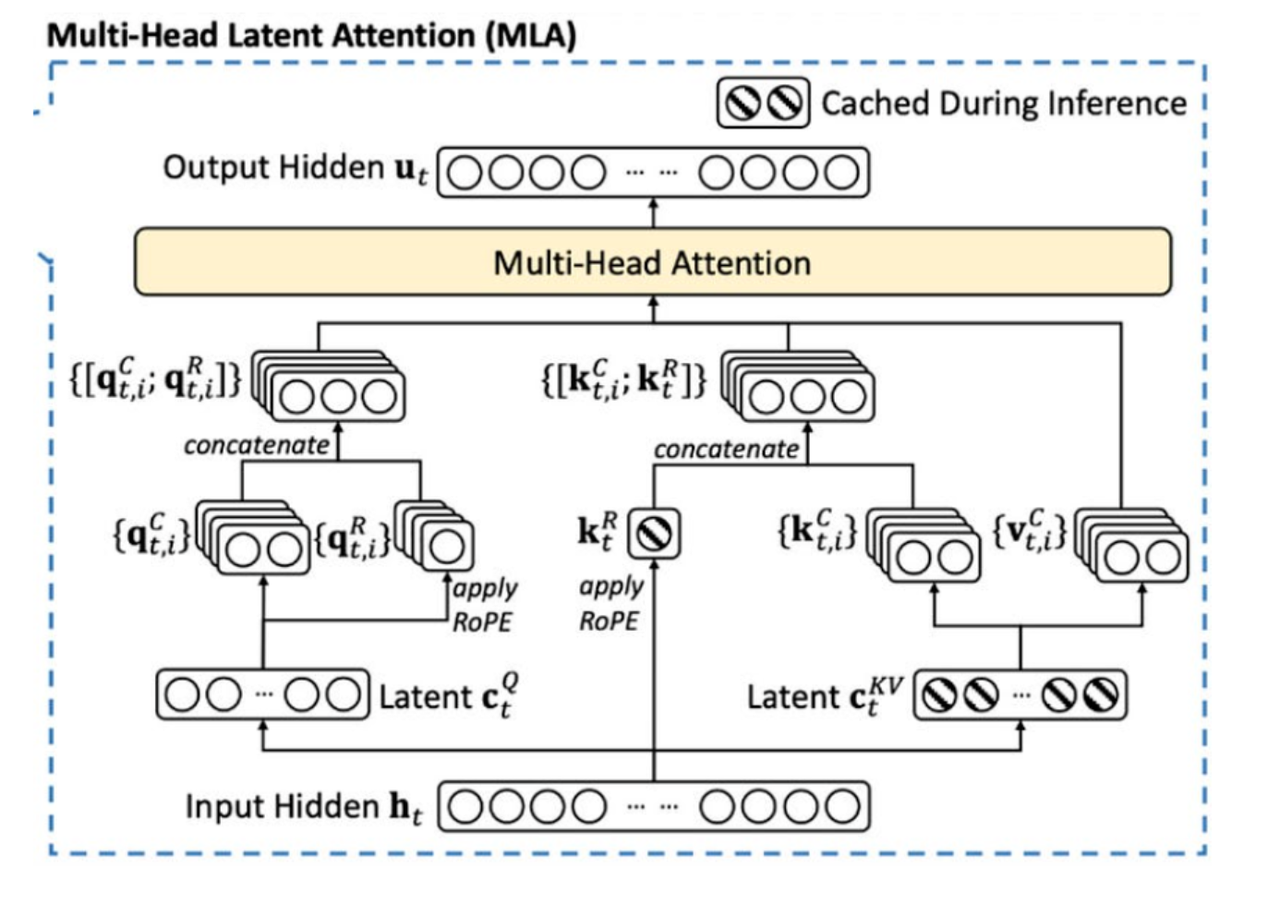
The Physics of LLM Inference
LLM Inference Optimization in Production: A Technical Deep Dive | by ...
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
(PDF) eLLM: Achieving Lossless Million-Token LLM Inference on CPUs ...
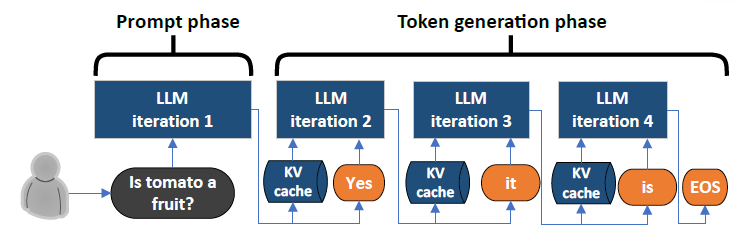
LLM Inference Series: 2. The two-phase process behind LLMs’ responses ...
(PDF) Improving the inference performance of LLM with code
Mastering LLM Techniques: Inference Optimization
Vidur: A Large-Scale Simulation Framework for LLM Inference Performance ...
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
LLM Inference
[논문 리뷰] Dynamic-Width Speculative Beam Decoding for Efficient LLM Inference
LLM inference optimization: Tutorial & Best Practices | LaunchDarkly
[2308.06391] Dynamic Planning with a LLM
DynamoLLM: Designing LLM Inference Clusters for Performance and Energy ...
A guide to LLM inference and performance
How to Scale LLM Inference - by Damien Benveniste
LLM Inference CookBook(持续更新) - 知乎
SGLang Releases Mini Version: Core LLM Inference Engine Implemented in ...
What Is LLM Inference? Process, Latency & Examples Explained (2026)
Understanding LLM Optimization Techniques - by Alex Razvant
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
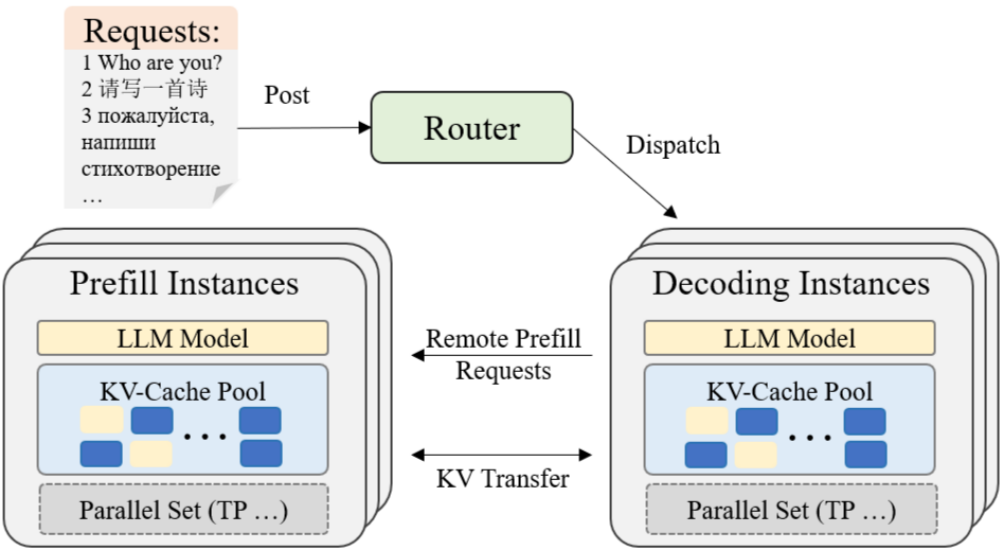
[논문 리뷰] A Dynamic PD-Disaggregation Architecture for Maximizing Goodput ...
LLM Inference: Techniques for Optimized Deployment in 2026 | Label Your ...
Paper page - Ltri-LLM: Streaming Long Context Inference for LLMs with ...
What is LLM Inference? • luminary.blog
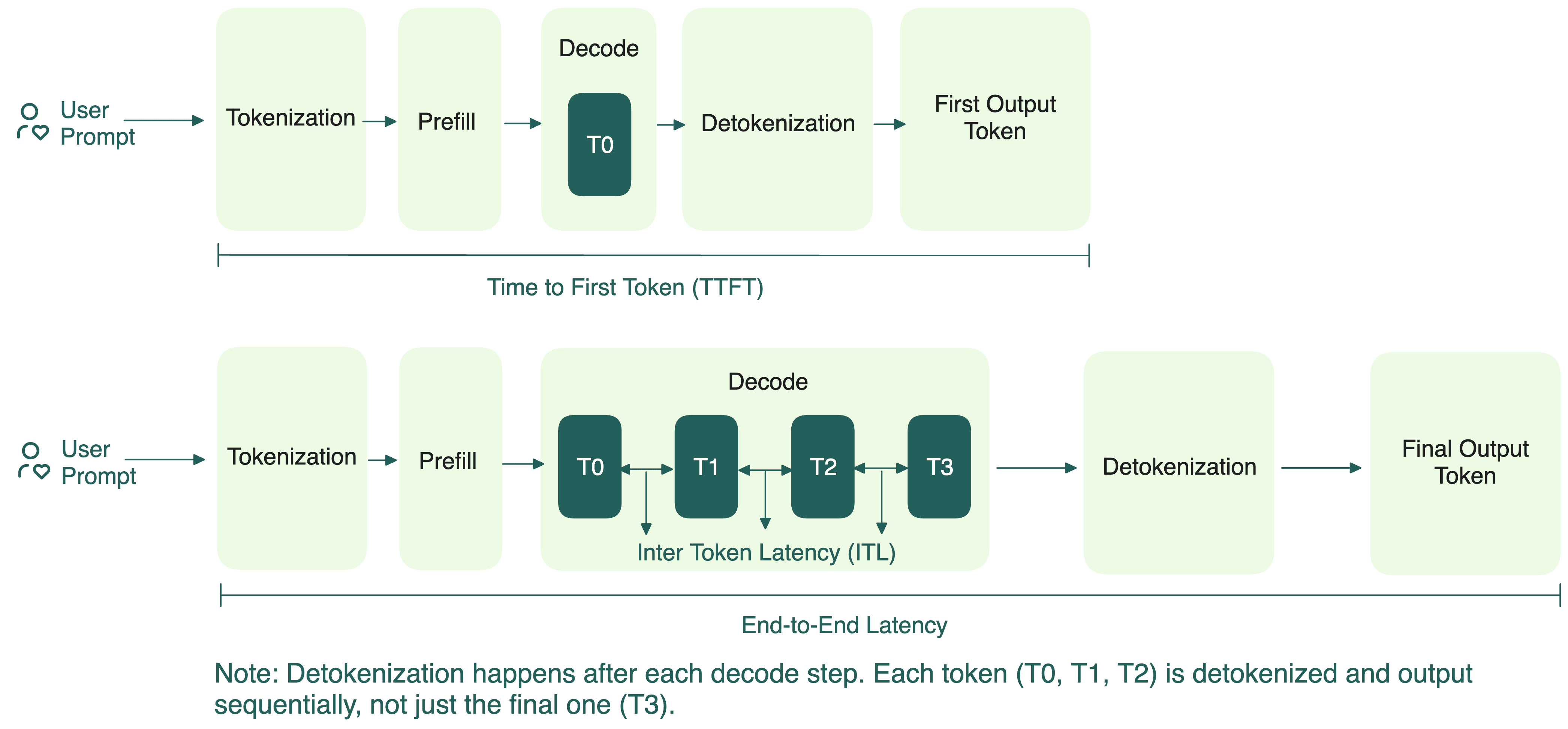
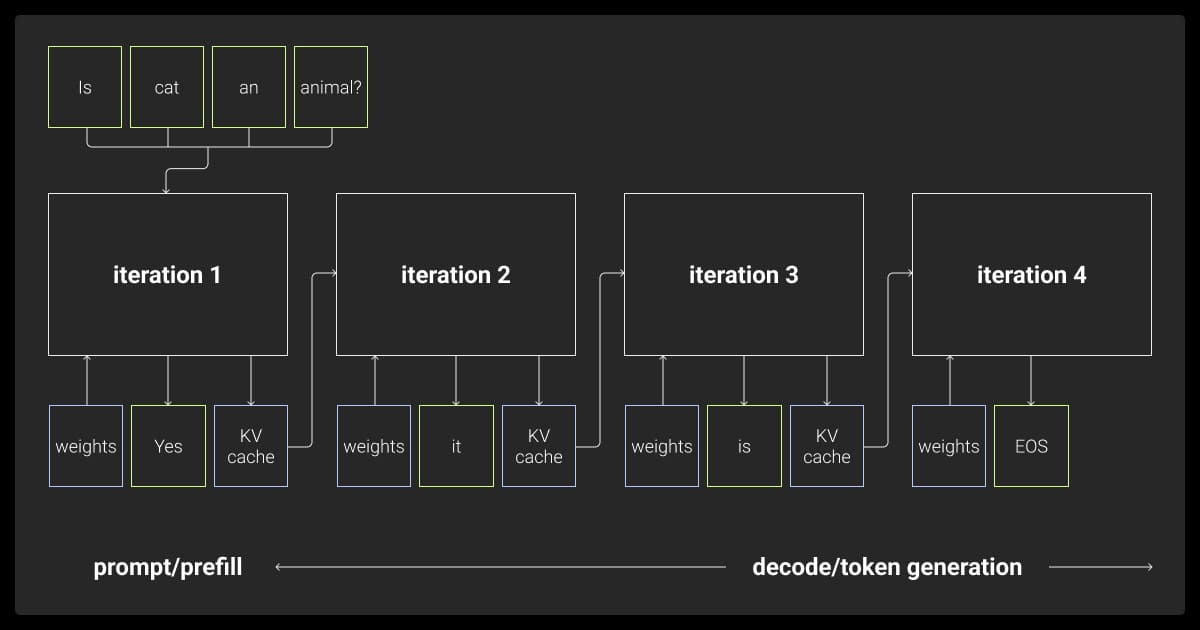
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
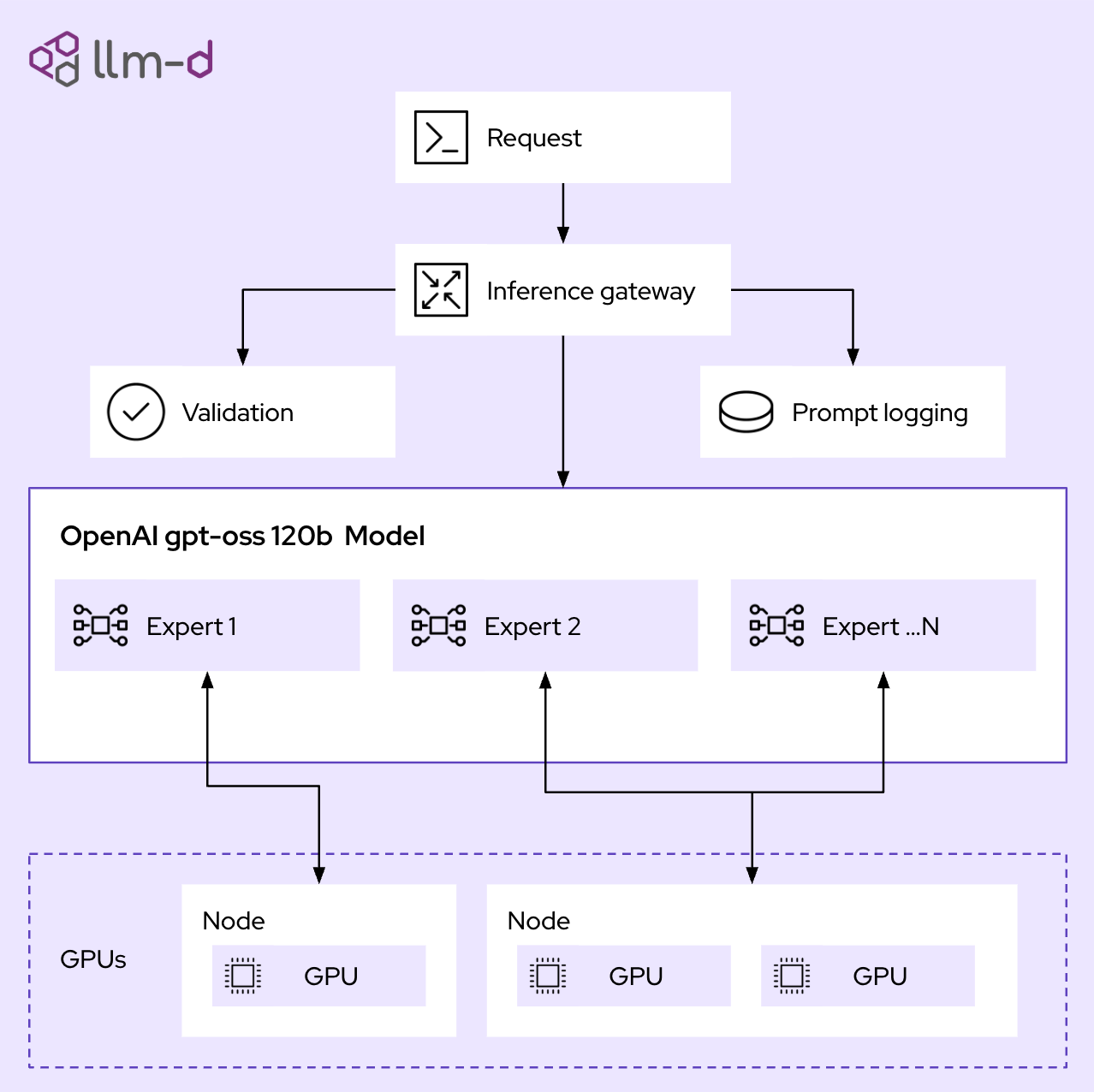
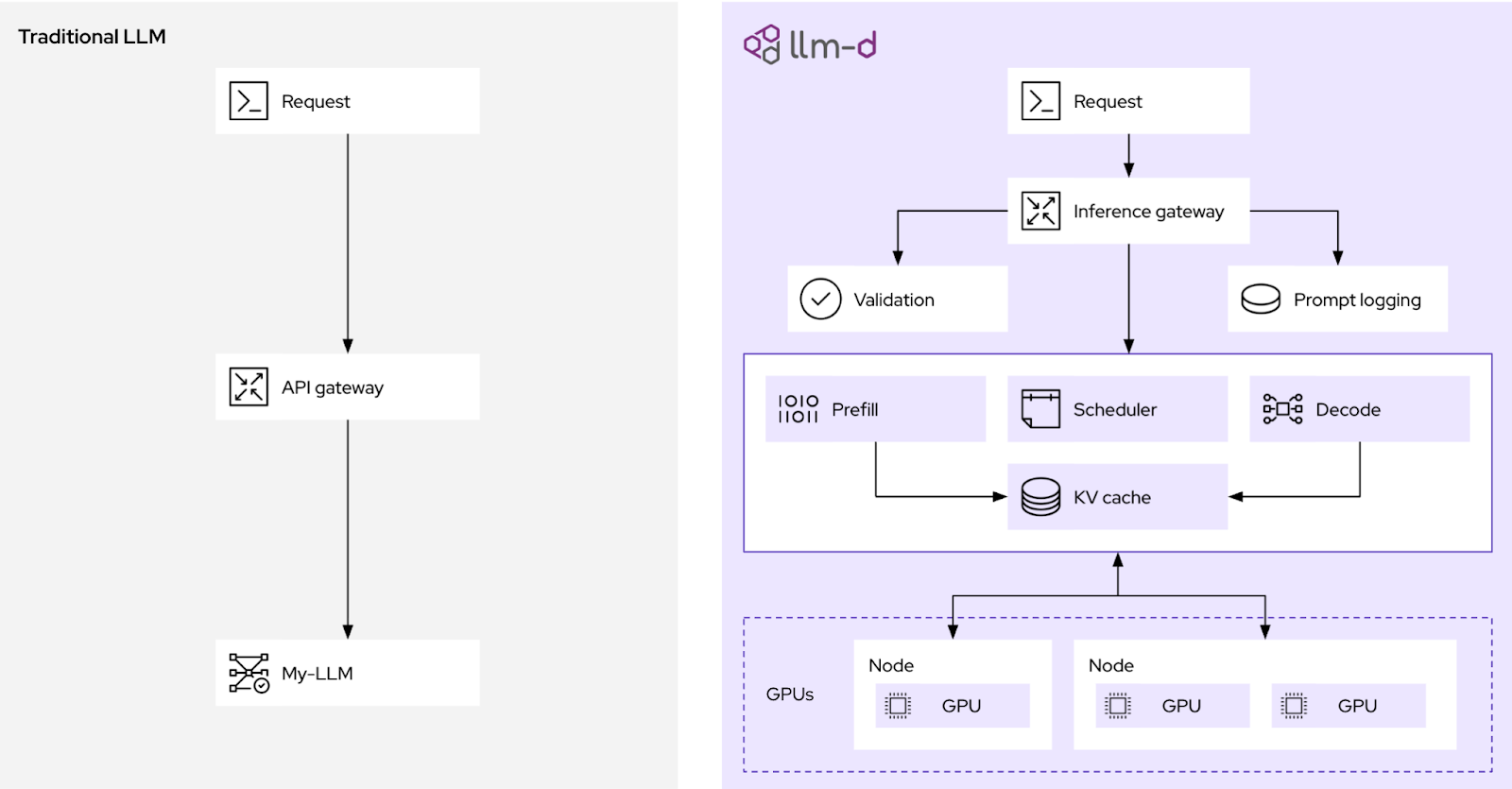
Introduction to distributed inference with llm-d | Red Hat Developer
Understanding The Human-LLM Dynamic A Literature S | PDF | Expert ...
Optimizing AI Performance: A Guide to Efficient LLM Deployment
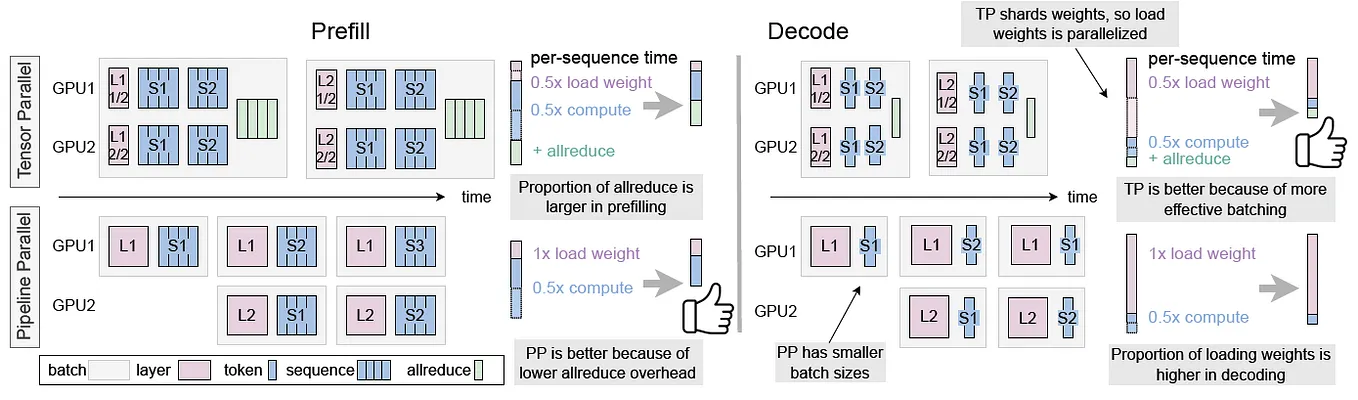
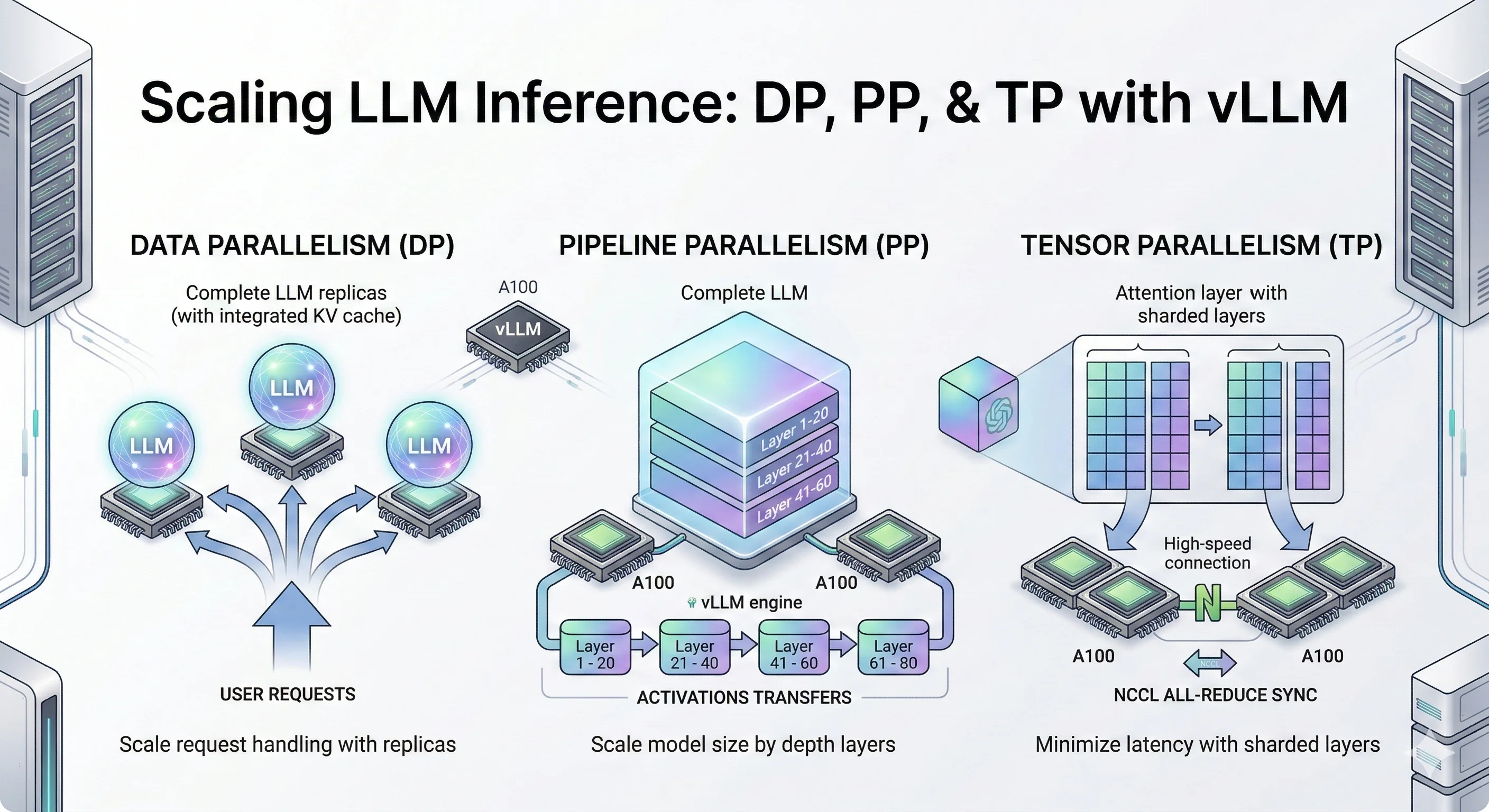
Scaling LLM Inference: Data, Pipeline & Tensor Parallelism in vLLM ...
Topic 23: What is LLM Inference, it's challenges and solutions for it
Optimizing Inference on Large Language Models with NVIDIA TensorRT-LLM ...
Optimizing LLM Inference. Optimization begins where architectures… | by ...
LLM—Learned Parameters vs Structural Limits vs Inference Settings
What is LLM Model Inference?
[논문 리뷰] Ltri-LLM: Streaming Long Context Inference for LLMs with ...
Re: Defeating Nondeterminism in LLM Inference, The Future is ...
llm-d: Kubernetes-native distributed inferencing | Red Hat Developer







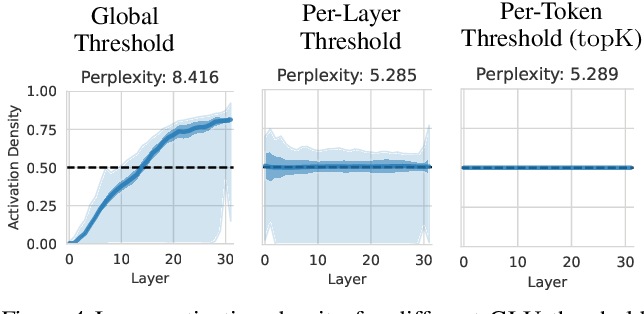


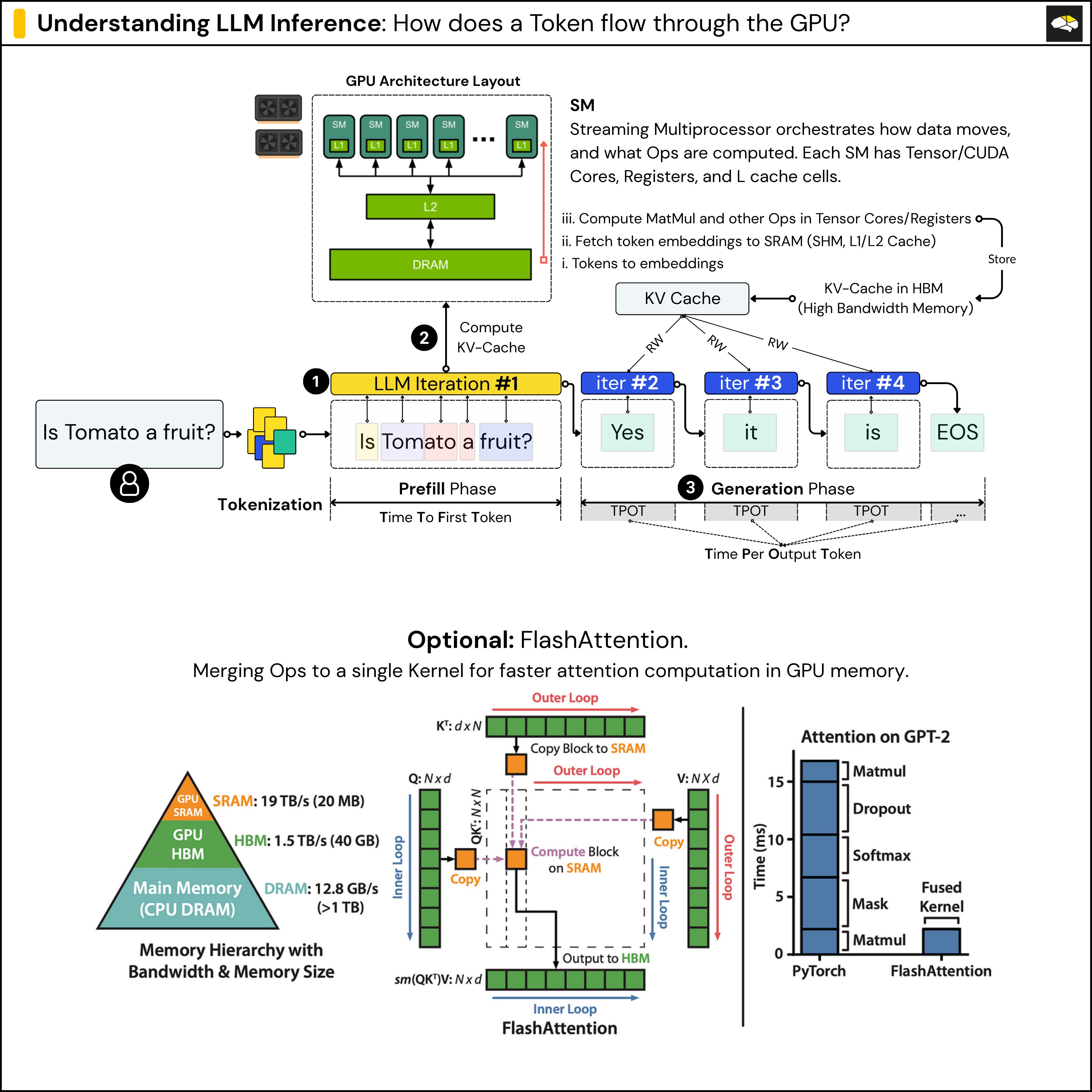

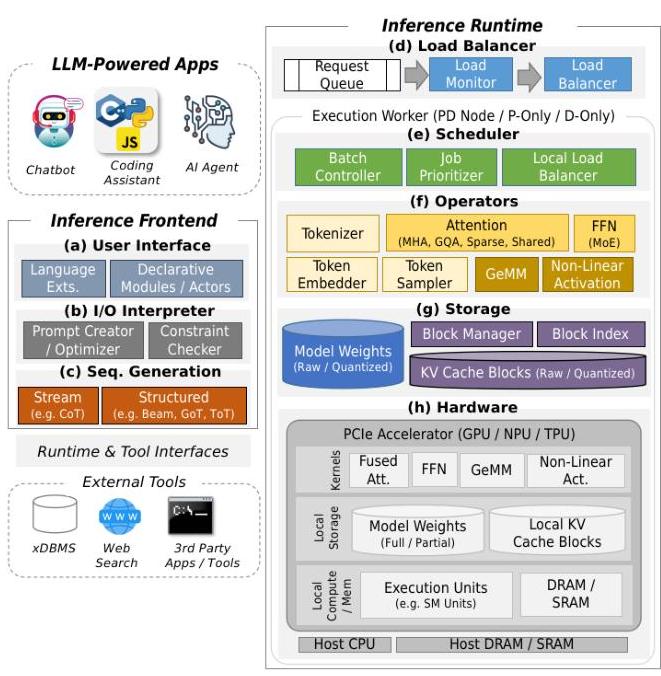
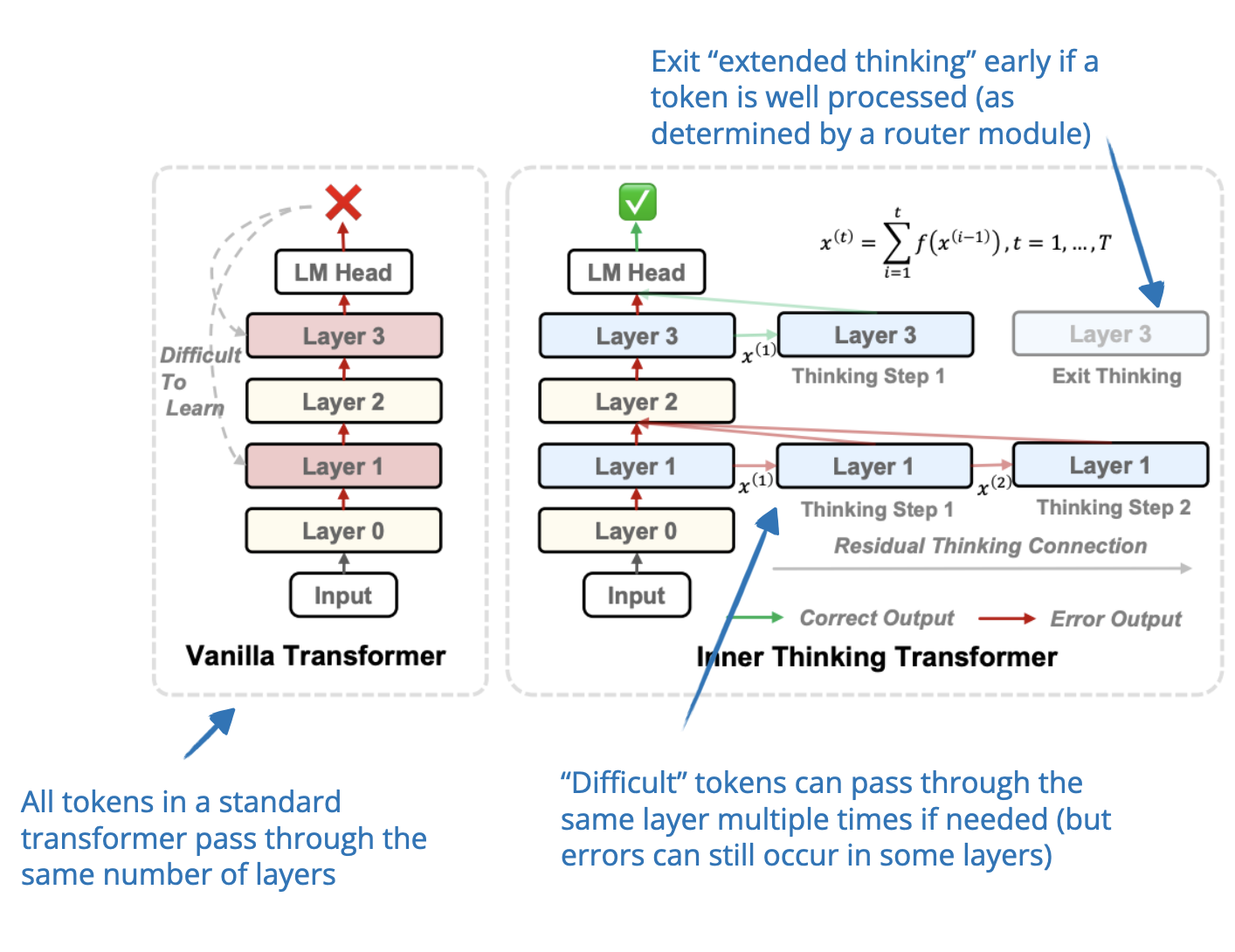
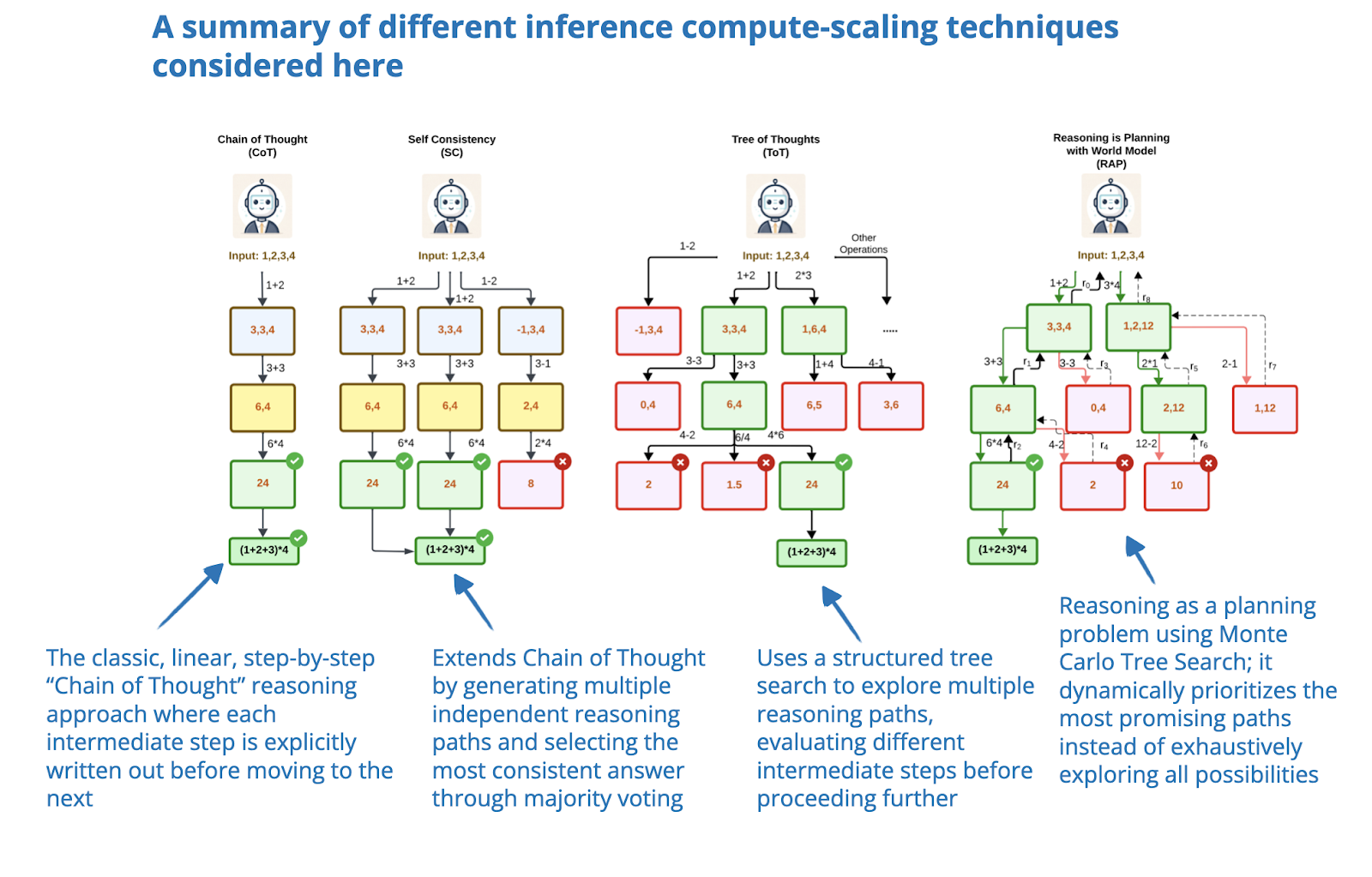
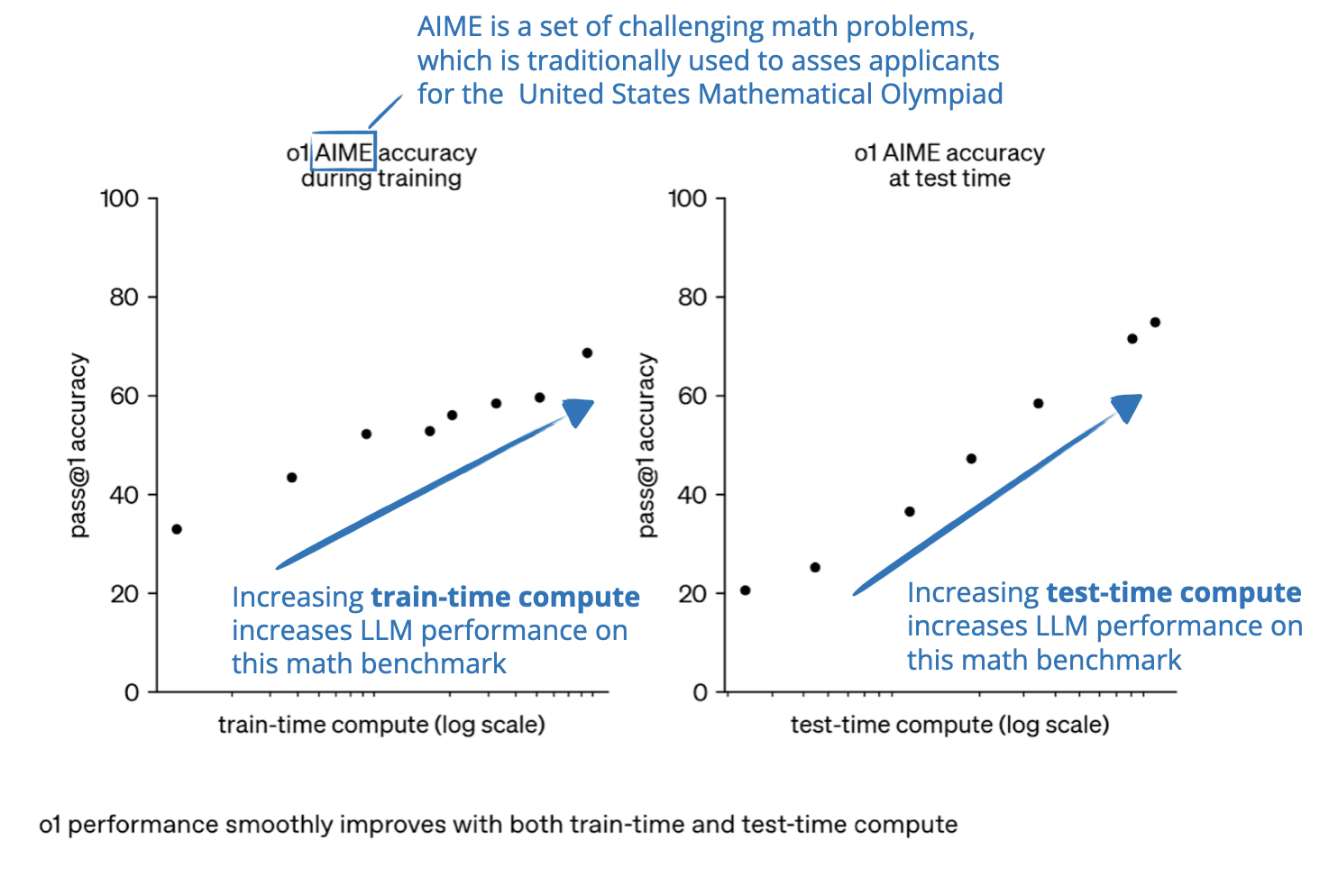

















-png.png?width=8640&height=4320&name=AI%20Model%20Training%20vs%20Inference%20(1)-png.png)






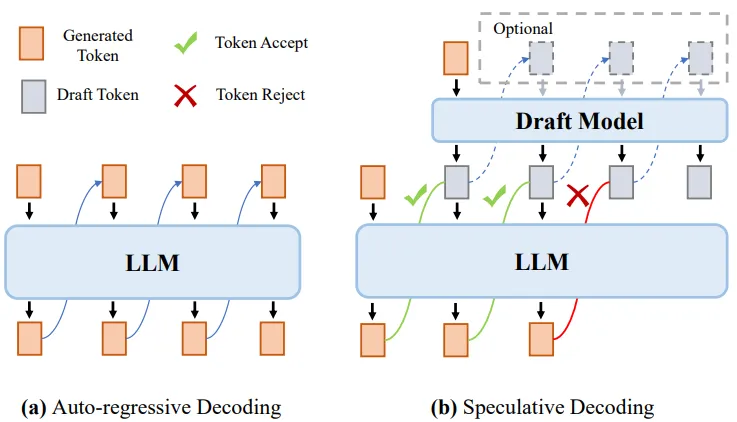
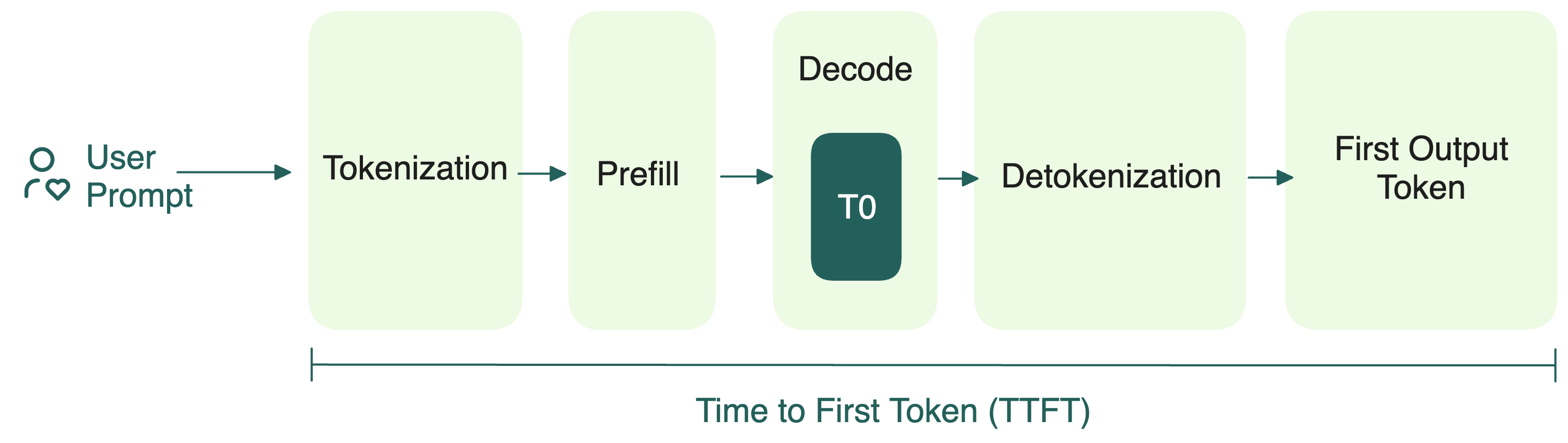
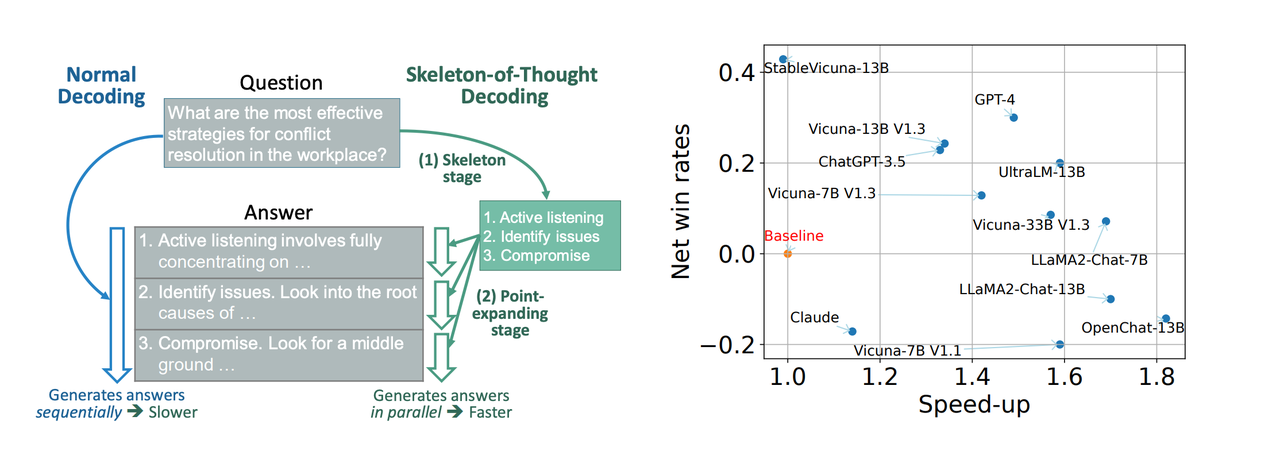
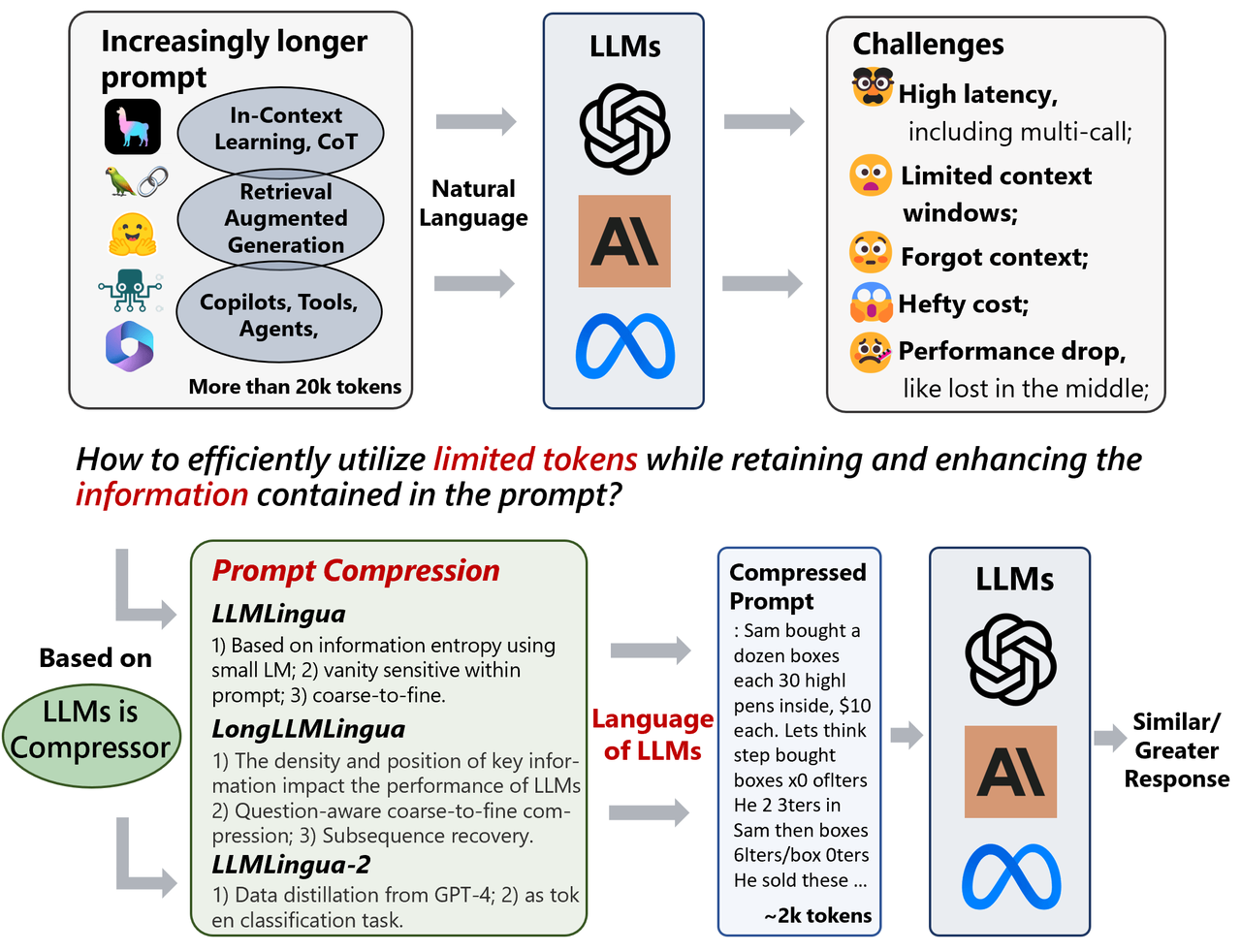









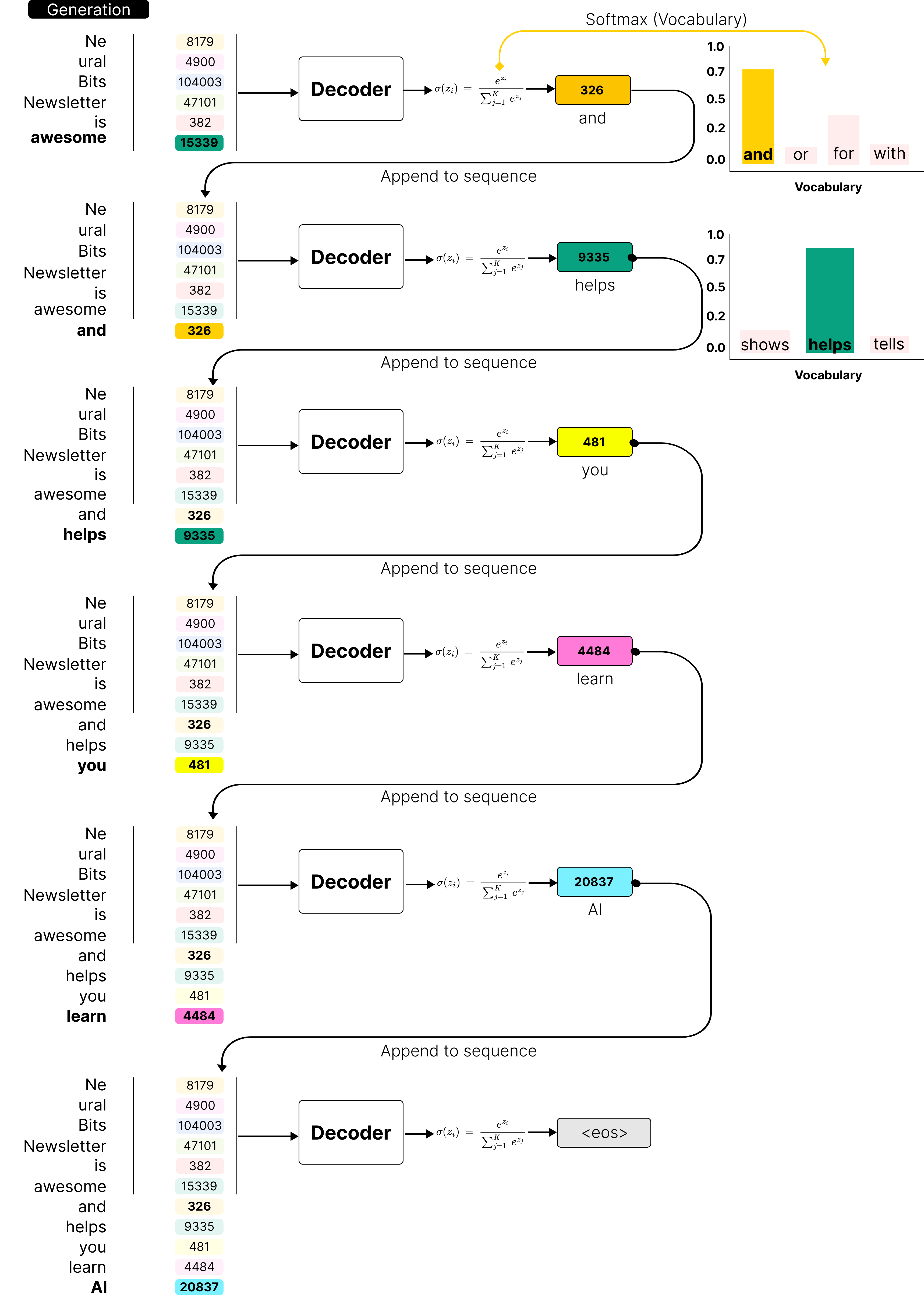
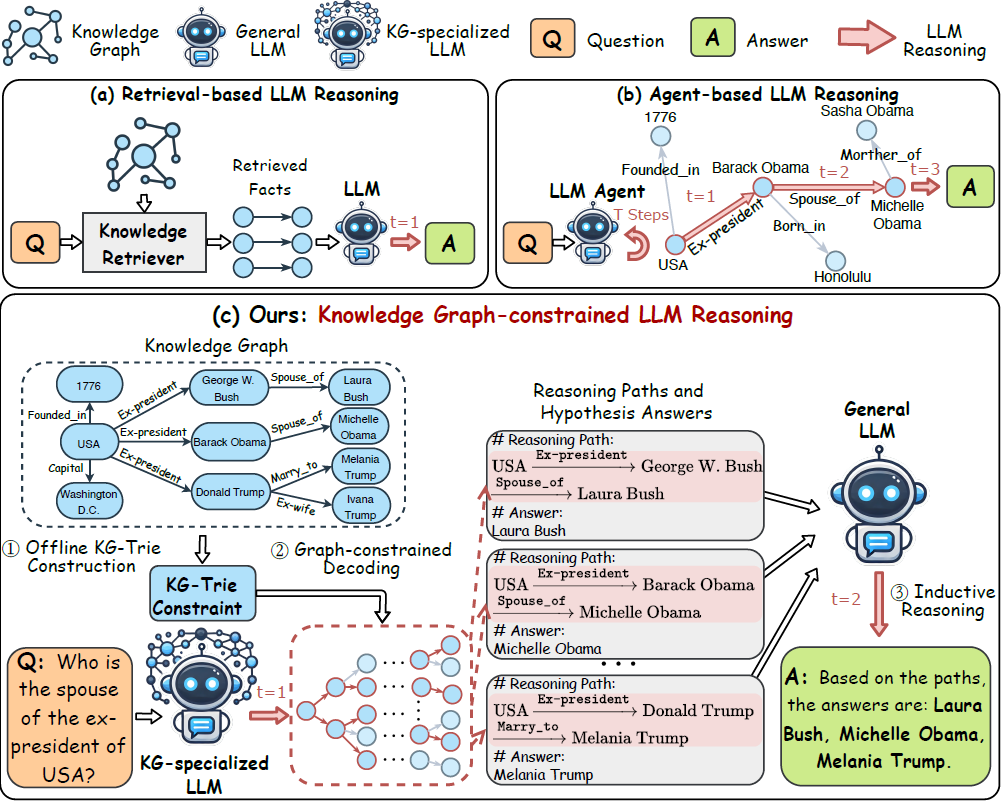
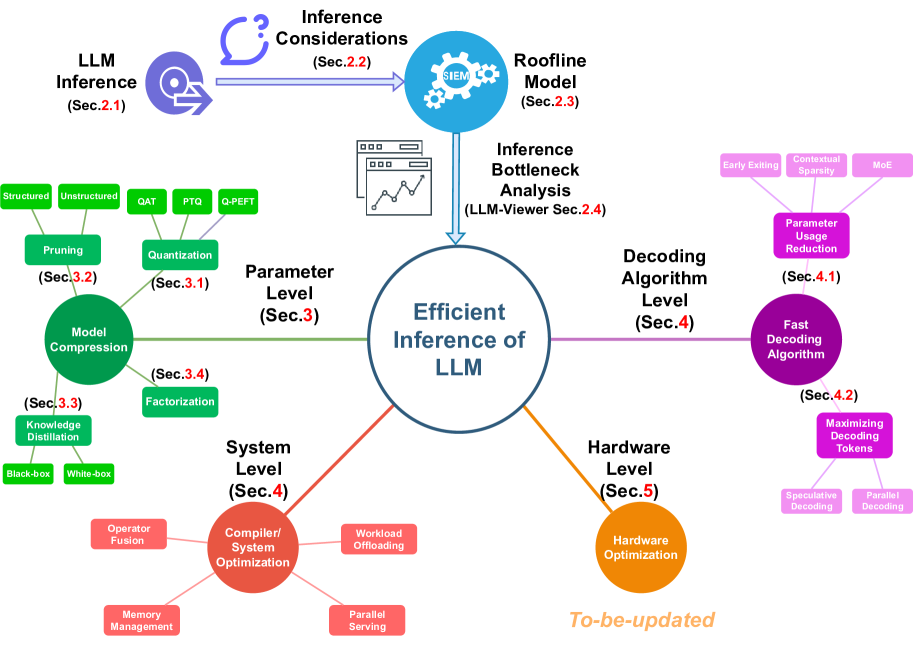
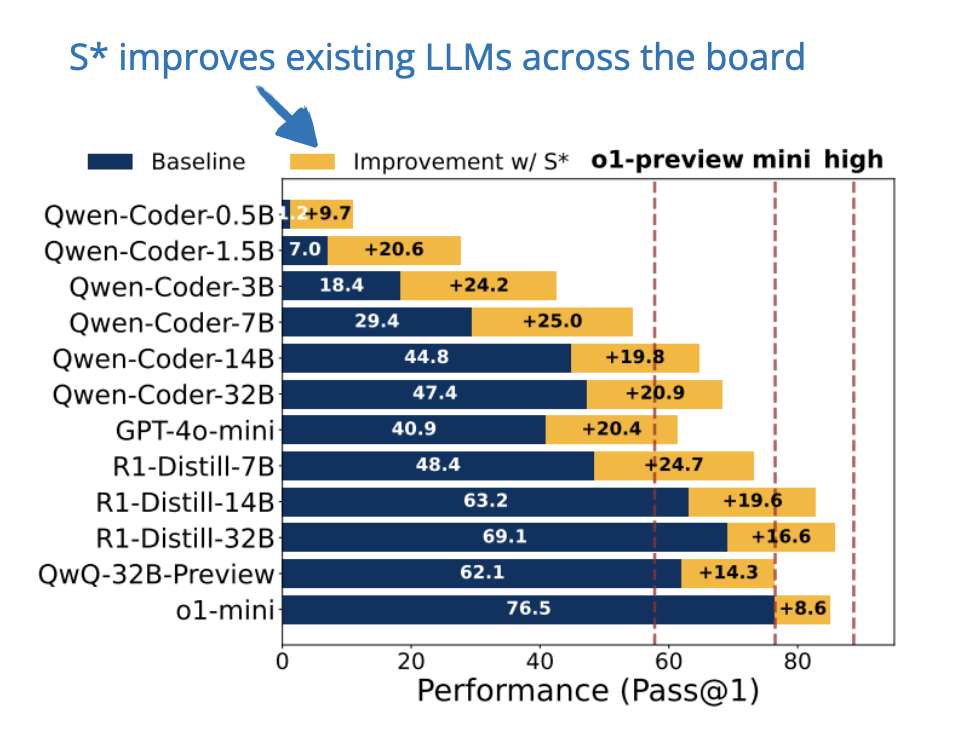

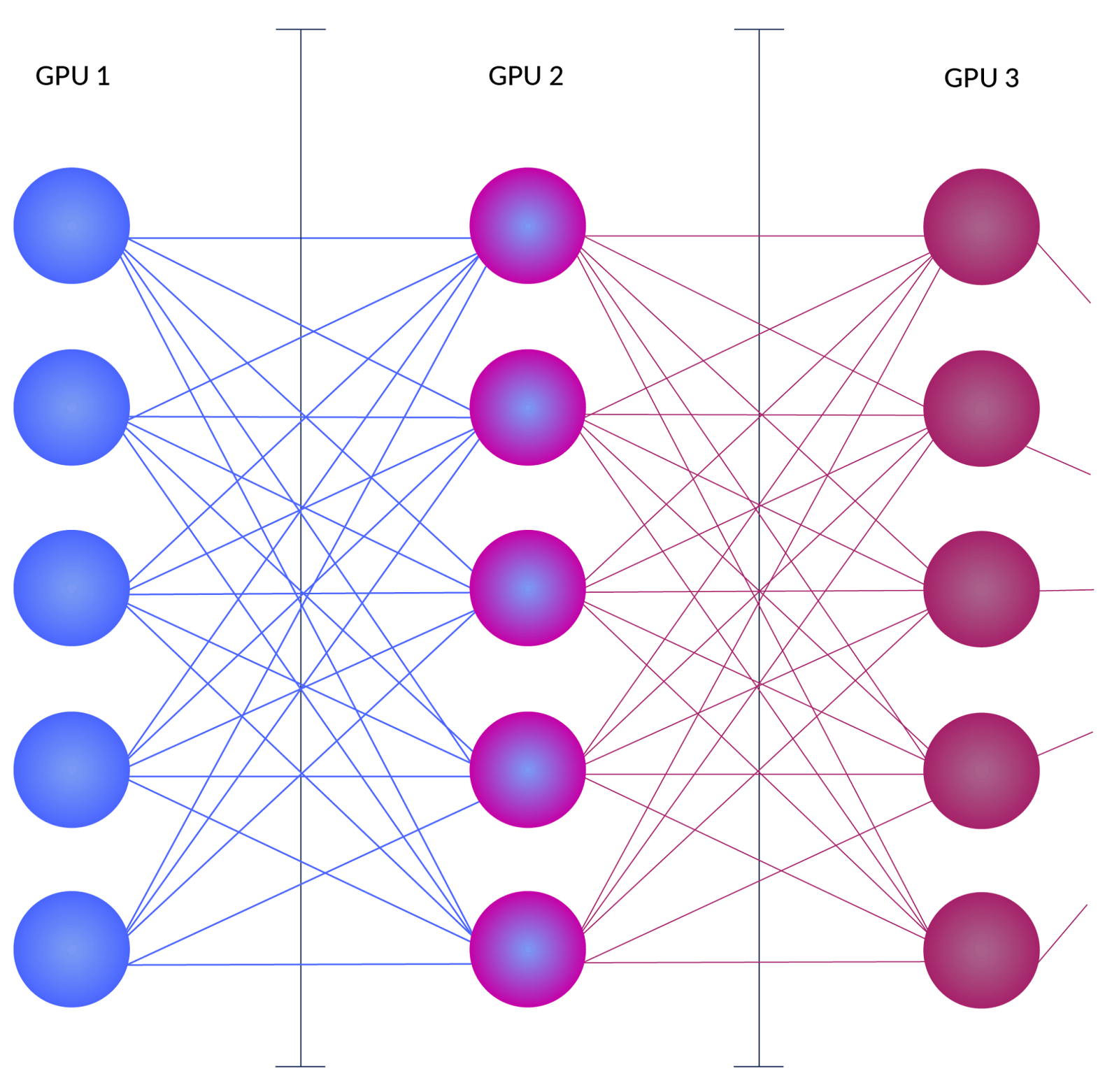


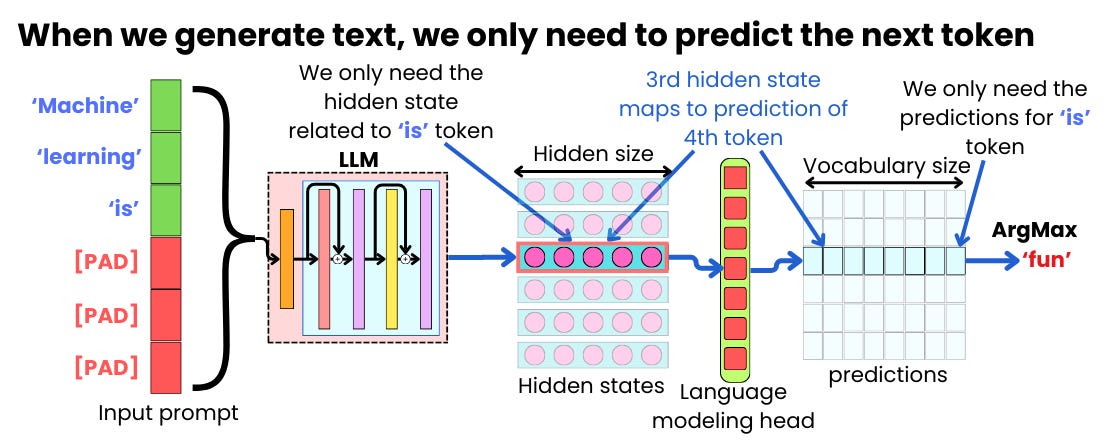
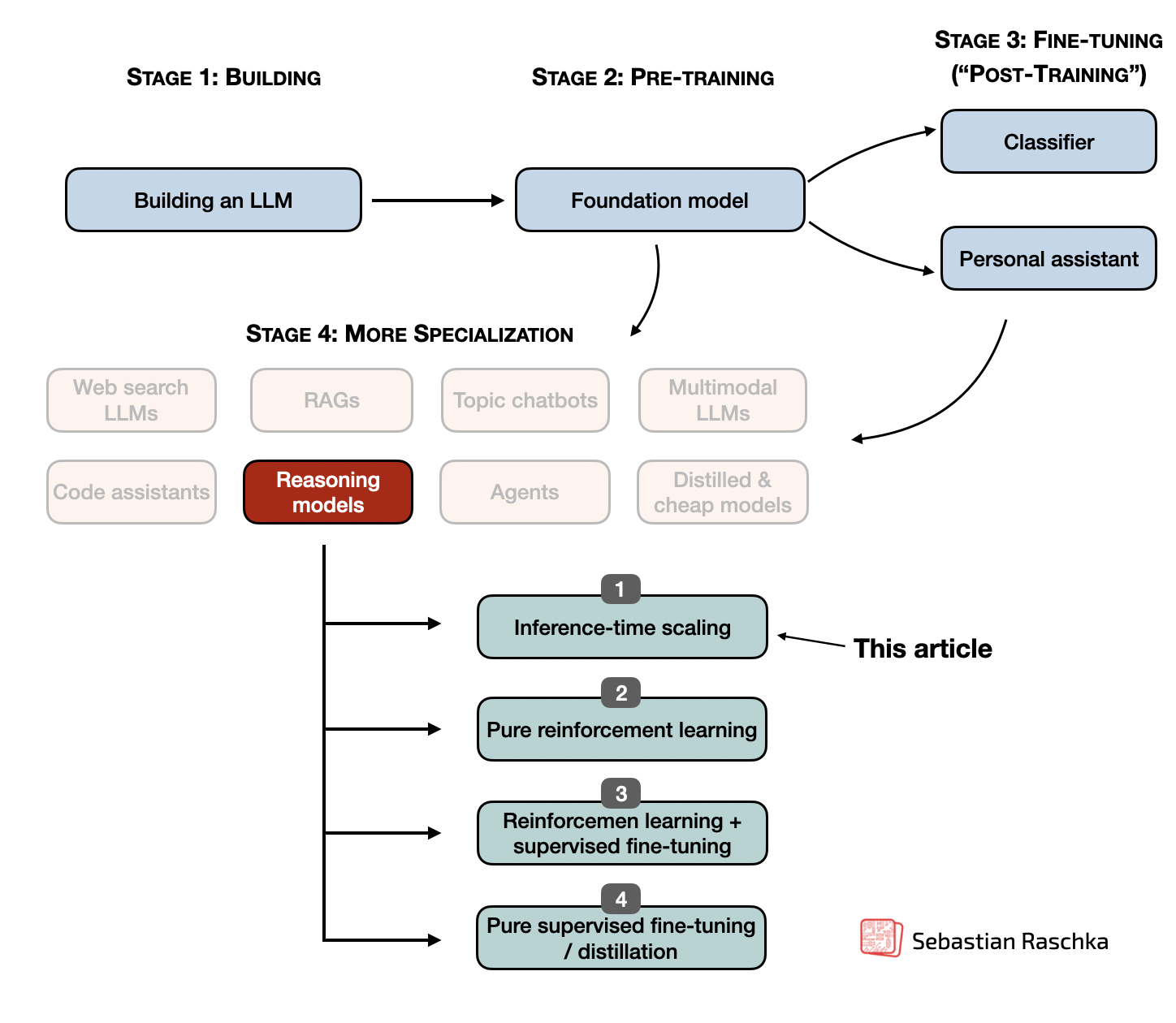
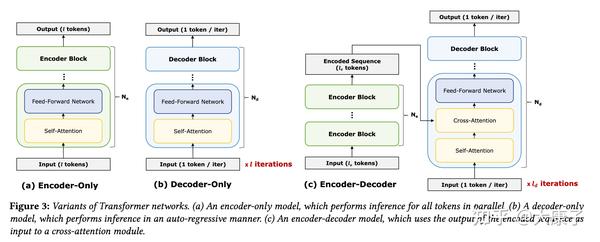
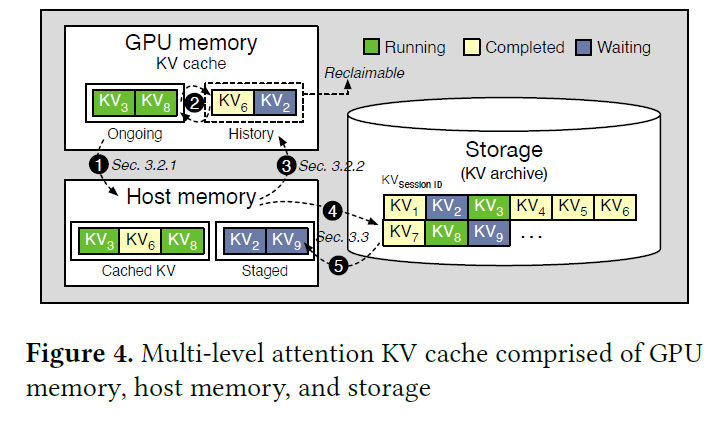
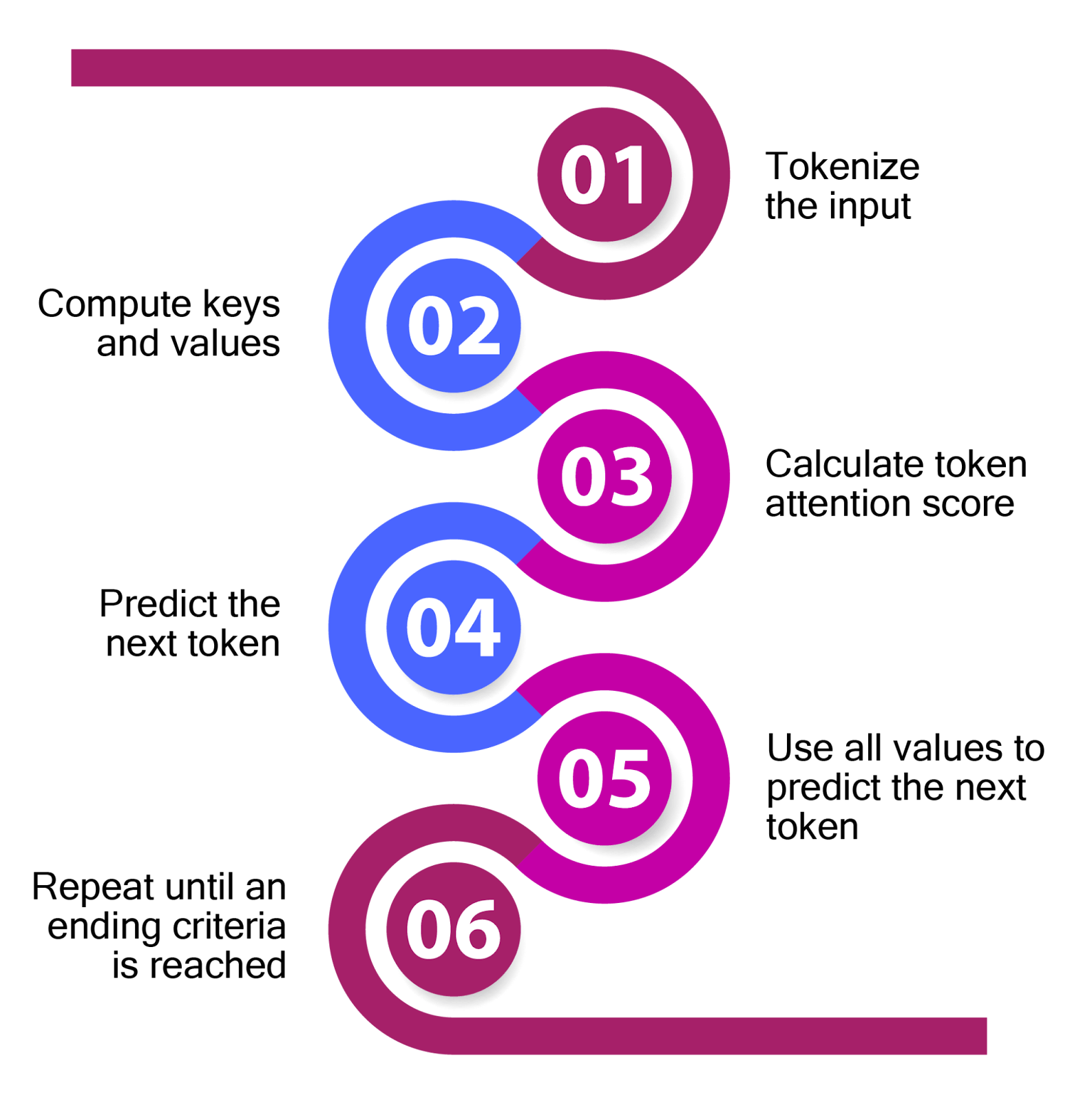
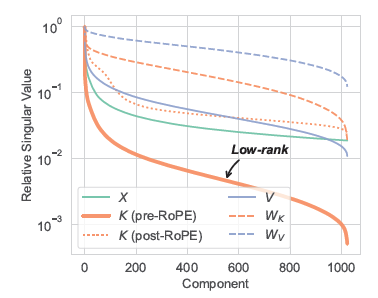














.png)