Showing 118 of 118on this page. Filters & sort apply to loaded results; URL updates for sharing.118 of 118 on this page
LLM Inference - Consumer GPU performance | Puget Systems
LLM Inference - NVIDIA RTX GPU Performance | Puget Systems
LLM Inference Bottleneck: KV Cache vs GPU Memory | Osama Altaf posted ...
Choosing the Right GPU for LLM Inference and Training
SLO-aware GPU Frequency Scaling for Energy Efficient LLM Inference ...
GPU VRAM Calculation for LLM Inference and Training - YouTube
What is GPU Memory and Why it Matters for LLM Inference
LLM Inference Router on GPU Cloud: Smart Model Routing for Cost and ...
Unbelievable! Run 70B LLM Inference on a Single 4GB GPU with This NEW ...
Choosing the right GPU | LLM Inference Handbook
[논문 리뷰] SpecOffload: Unlocking Latent GPU Capacity for LLM Inference on ...
Outshift | LLM inference optimization: An efficient GPU traffic routing ...
Best GPU for LLM Inference and Training – March 2024 [Updated] | BIZON
Demo | LLM Inference on Intel® Data Center GPU Flex Series | Intel ...
Load-Aware GPU Fractioning for LLM Inference on Kubernetes - Olivier ...
Free Video: LLMOps: Accelerate LLM Inference in GPU Using TensorRT-LLM ...
How LLM Inference Works Under the Hood: Prompt Processing and GPU ...
Figure 3 from Efficient LLM inference solution on Intel GPU | Semantic ...
[논문 리뷰] Make LLM Inference Affordable to Everyone: Augmenting GPU ...
LLM Inference GPU Video RAM Calculator - DEV Community
GPU Instance Selection: AI & LLM Inference Benchmarking - YouTube
LLM Inference Acceleration: GPU Optimization for Attention in the ...
Paper page - Efficient LLM inference solution on Intel GPU
Understanding LLM Inference - by Alex Razvant
Understanding GPU for Inference in LLMs | Adaline
The Best GPUs for Local LLM Inference in 2025 | LocalLLM.in
[논문 리뷰] SLO-aware GPU Frequency Scaling for Energy Efficient LLM ...
[论文评述] Characterizing and Optimizing LLM Inference Workloads on CPU-GPU ...
LLM Inference Hardware: Emerging from Nvidia's Shadow
NVIDIA Blackwell Platform Sets New LLM Inference Records in MLPerf ...
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
How to Implement GPU-Based LLM Inference in AO
How to Select the Best GPU for LLM Inference: Benchmarking Insights ...
Maximising GPU Utilisation for LLM Inference: A Comprehensive Guide
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
Parallel CPU-GPU Execution for LLM Inference on Constrained GPUs | AI ...
Exploring Hybrid CPU/GPU LLM Inference | Puget Systems
ISCA`25 LIA A Single-GPU LLM Inference Acceleration with Cooperative ...
How to Calculate GPU Requirements for LLM Inference?
Hardware (CPU, GPU) for Quantized LLM Inference
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
Boosting LLM Inference with Intel GPU: Efficient Solutions and ...
LLM Inference: Inside a Fast LLM Inference Server | by Tushar Vatsa ...
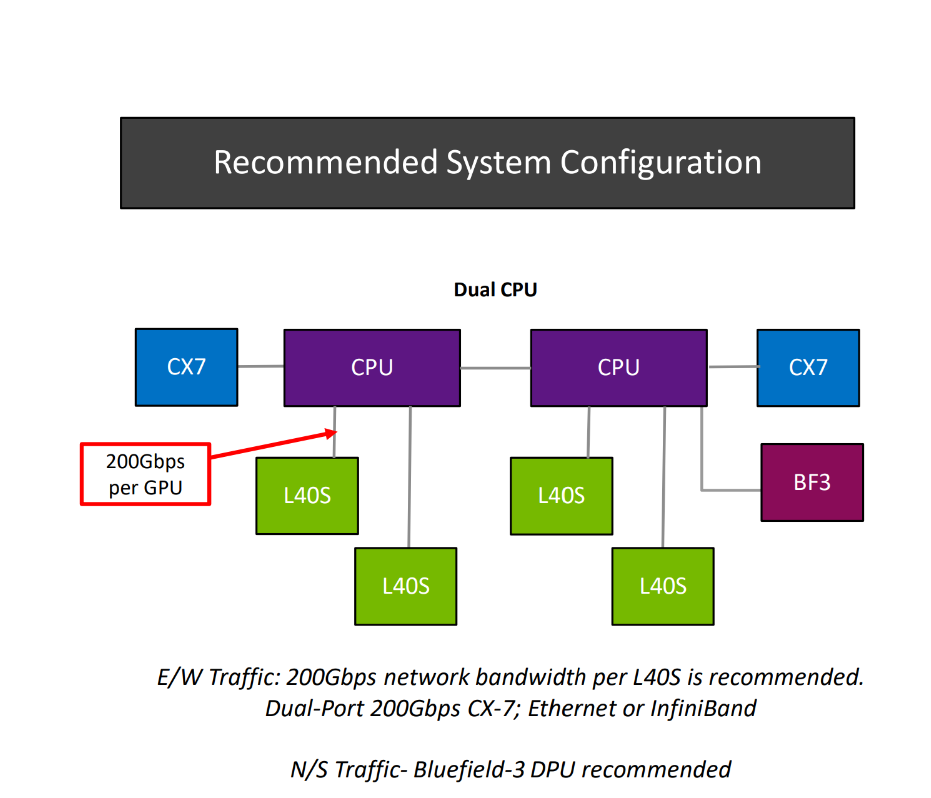
Low-Latency LLM Inference on Multi-GPU Cloud Systems
How Much GPU Memory is Needed for LLM Inference? - YouTube
Advanced NVIDIA GPU Monitoring for LLM Inference: A Deep Dive into H100 ...
Accelerate Large-Scale LLM Inference and KV Cache Offload with CPU-GPU ...
7 Best GPU for LLM in 2026 (Including Local LLM Setups) - Fluence
LIA: A Single-GPU LLM Inference Acceleration with Cooperative AMX ...
Nvidia's H100 NVL Inference Platform is Optimized for LLM Deployments
(PDF) Characterizing and Optimizing LLM Inference Workloads on CPU-GPU ...
Serverless GPU Inference for LLMs
Paper page - Characterizing and Optimizing LLM Inference Workloads on ...
GPU for LLM Inferencing Guide – OVHcloud Blog
LLM Multi-GPU Batch Inference With Accelerate | by Victor May | Medium
LLM inference optimization: Tutorial & Best Practices | LaunchDarkly
A guide to LLM inference and performance
LLM Inference on multiple GPUs with 🤗 Accelerate | by Geronimo | Medium
Harmonizing Multi-GPUs: Efficient Scaling of LLM Inference | by TitanML ...
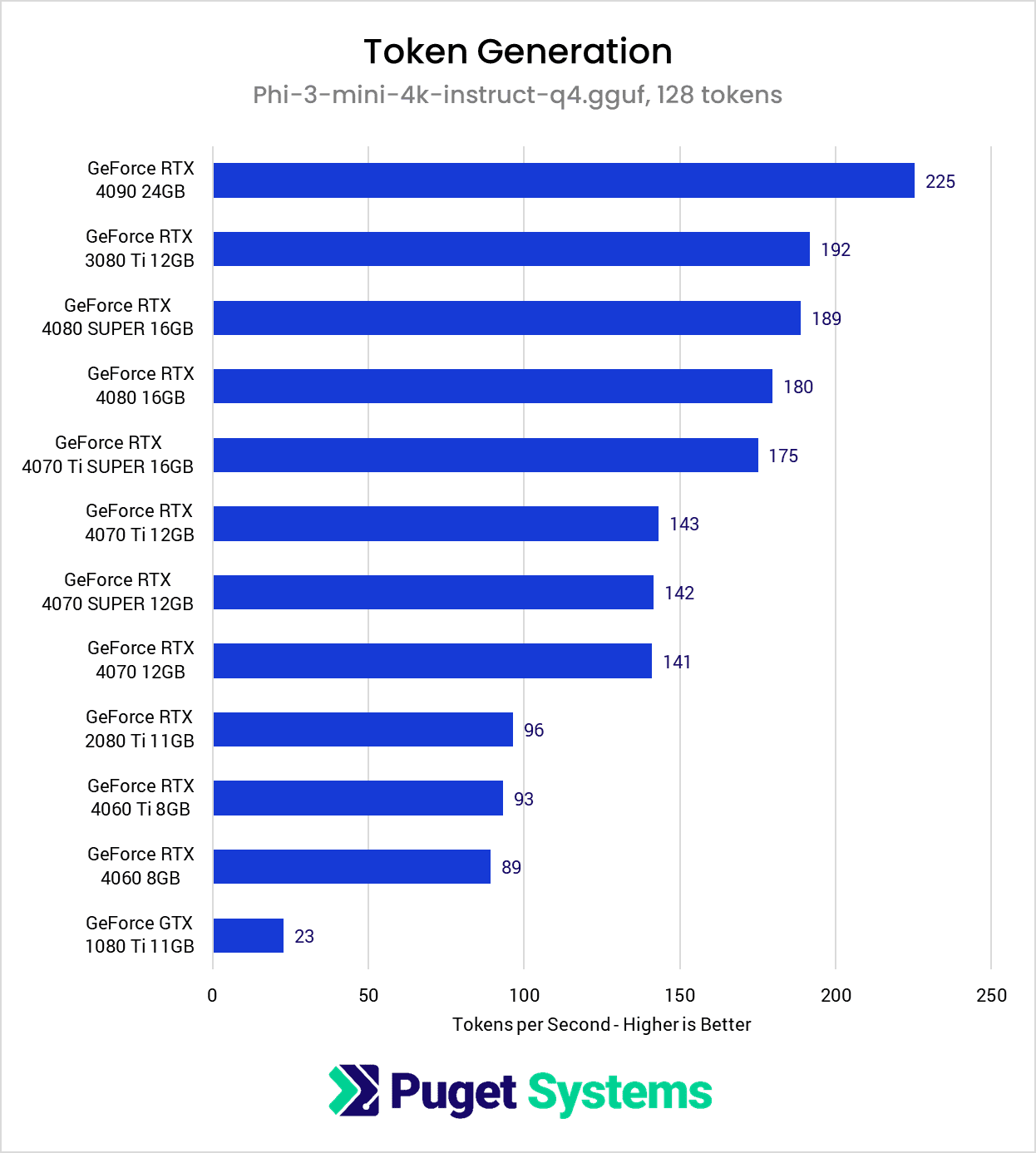
Benchmarking LLM Inference on RTX 4090, RTX 5090, and RTX PRO 6000
CPU-GPU I/O-Aware LLM Inference Reduces Latency in GPUs by Optimizing ...
Making AMD GPUs competitive for LLM inference - Bens Bites
LLM Inference - Hw-Sw Optimizations
CPU-GPU I/O-Aware LLM Inference Reduces Latency In GPUs By Optimizing ...
The Best NVIDIA GPUs for LLM Inference in 2025.pdf
The LLM Inference Wars: A Strategic Analysis of CPU, GPU, and Custom ...
Rychlá LLM inference přes vLLM na NVIDIA RTX PRO 6000
How Much GPU Memory Do You Really Need for Efficient LLM Serving? | by ...
[Project] LLM inference with vLLM and AMD: Achieving LLM inference ...
Squeeze more out of your GPU for LLM inference—a tutorial on Accelerate ...
[논문 리뷰] Accelerating LLM Inference with Precomputed Query Storage
Calculate GPU Requirements for Your LLM Training | by Thiyagarajan ...
GPU Memory Required for Large Language Model Inference with TensorRT ...
[论文评述] A First Look At Efficient And Secure On-Device LLM Inference ...
How to Scale LLM Inference - by Damien Benveniste
🔹GPU Memory for LLMs: Inference vs. Training Selecting the right GPU ...
Figure 2 from Fast and Efficient 2-bit LLM Inference on GPU: 2/4/16-bit ...
Optimizing LLM Inference: GPU Architecture and Performance | Akhil ...
GPU Fundamentals for LLM Inference: Understanding Threads, Warps ...
How to Calculate GPU and vRAM for Infrensing & Fine-tuning LLM
LLM Inference Benchmarking: Performance Tuning with TensorRT-LLM ...
How to Choose the Best GPU for LLM: A Practical Guide
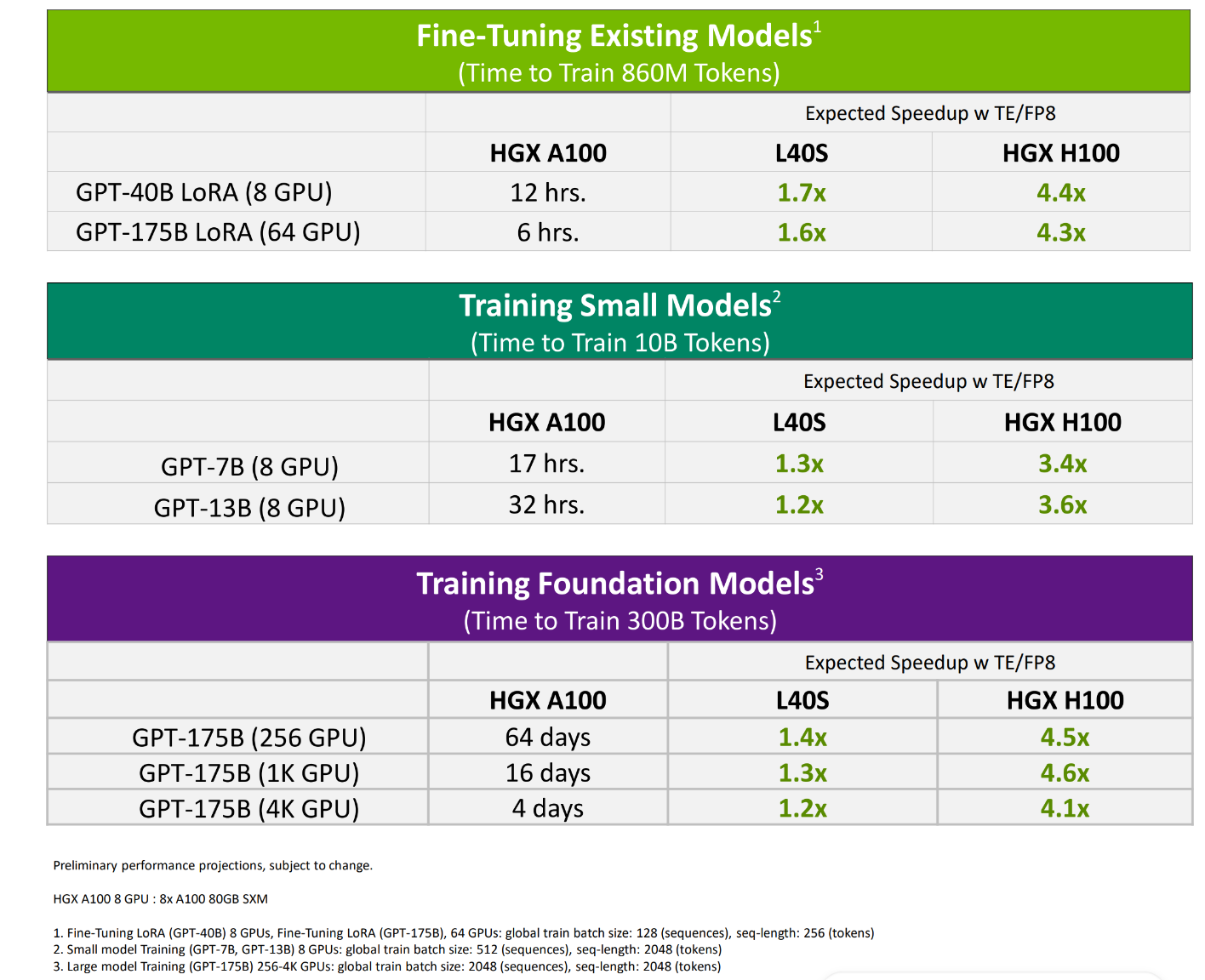
Achieving Top Inference Performance with the NVIDIA H100 Tensor Core ...
Integrating NVIDIA TensorRT-LLM with the Databricks Inference Stack ...
The Future of Serverless Inference for Large Language Models — AI ...
What Is LLM Inference? Process, Latency & Examples Explained (2026)
Nvidia claims first place in MLCommon's first benchmarks for LLM ...
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
Maximizing Efficiency: A Comprehensive Guide to GPU and Memory ...
8 Best LLM VRAM Calculators To Estimate Model Memory Usage - Tech Tactician
6 Best GPUs for Dual & Multi-GPU Local LLM Setups - Tech Tactician
[논문 리뷰] Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch ...
Optimizing LLM Inference: Prefill vs Decode on Multi-GPU NVIDIA Systems ...
How AI and Accelerated Computing Are Driving Energy Efficiency | NVIDIA ...
Why Choose NVIDIA H100 SXM for Peak AI Performance
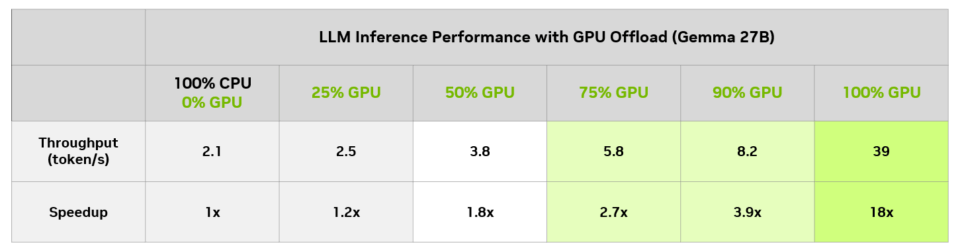
How to Accelerate Larger LLMs Locally on RTX With LM Studio - Edge AI ...
GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA ...
GPU-Benchmarks-on-LLM-Inference: 探索大语言模型推理的GPU性能对比 - 懂AI
Accelerate Larger LLMs Locally on RTX With LM Studio | NVIDIA Blog













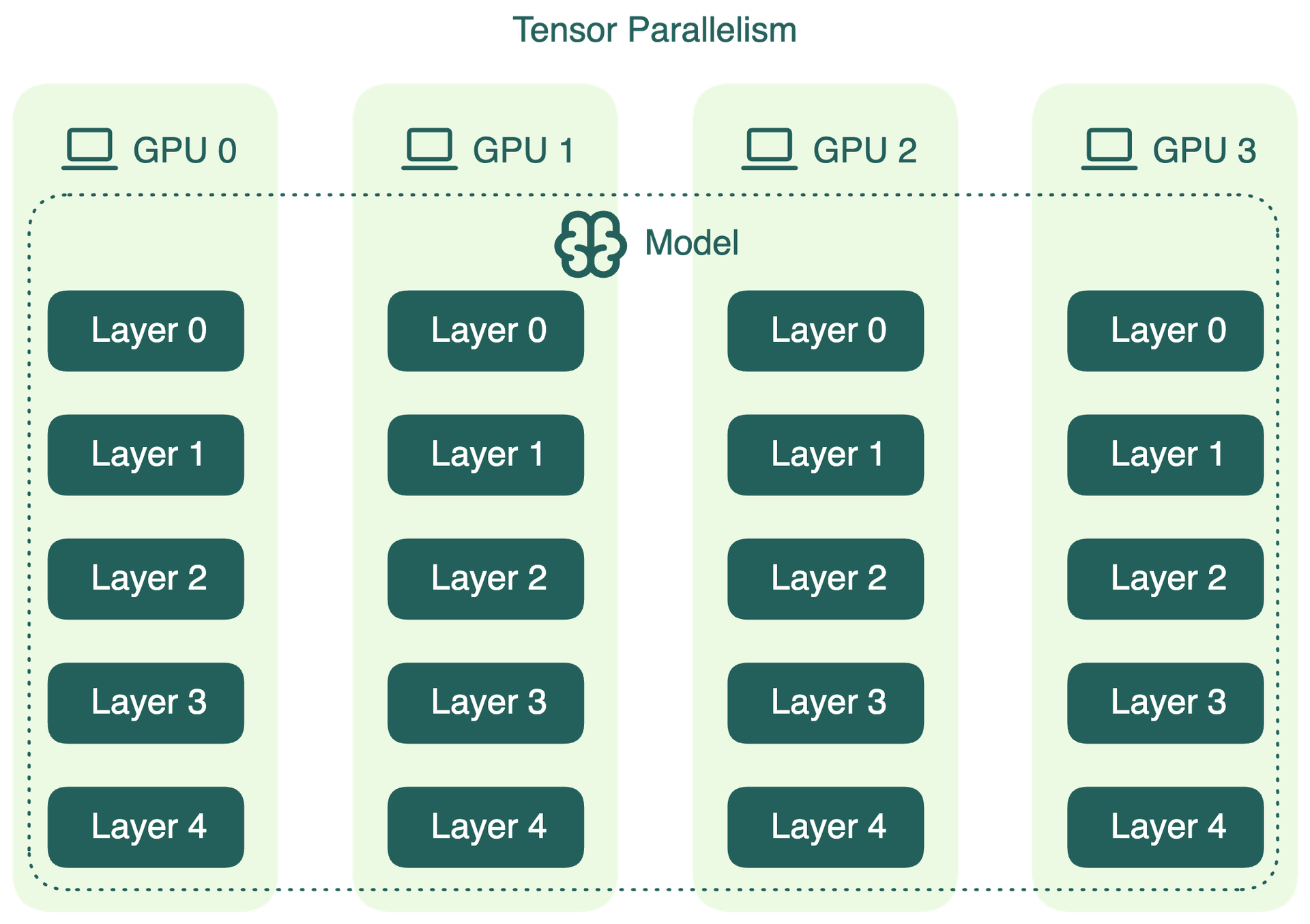


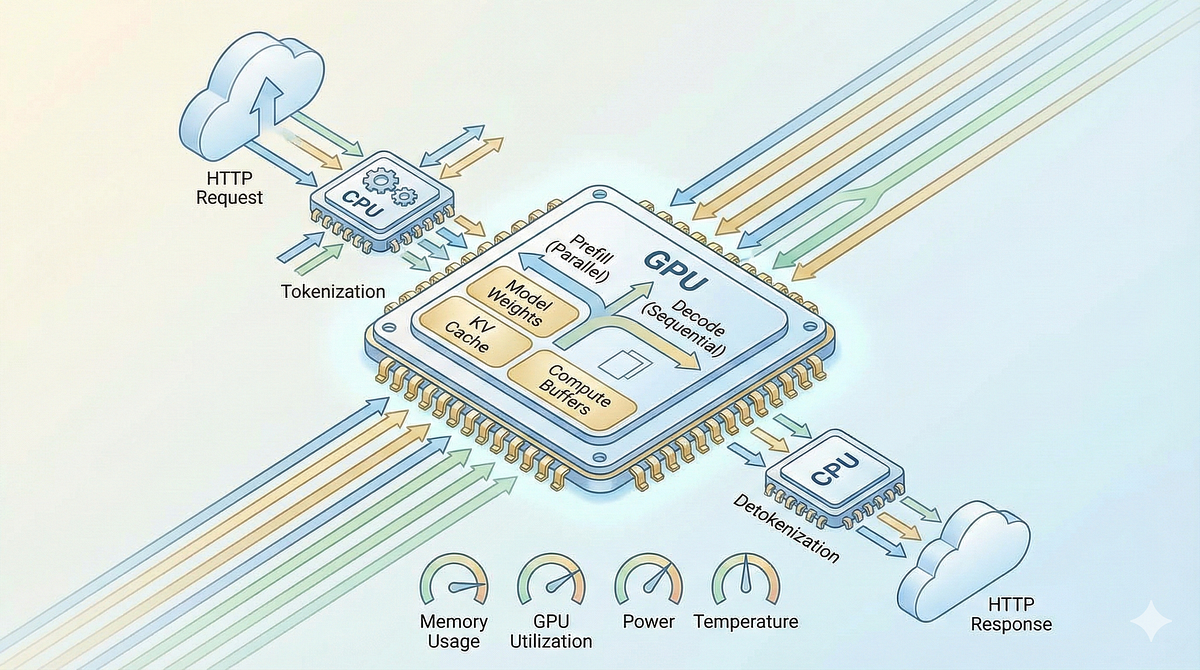




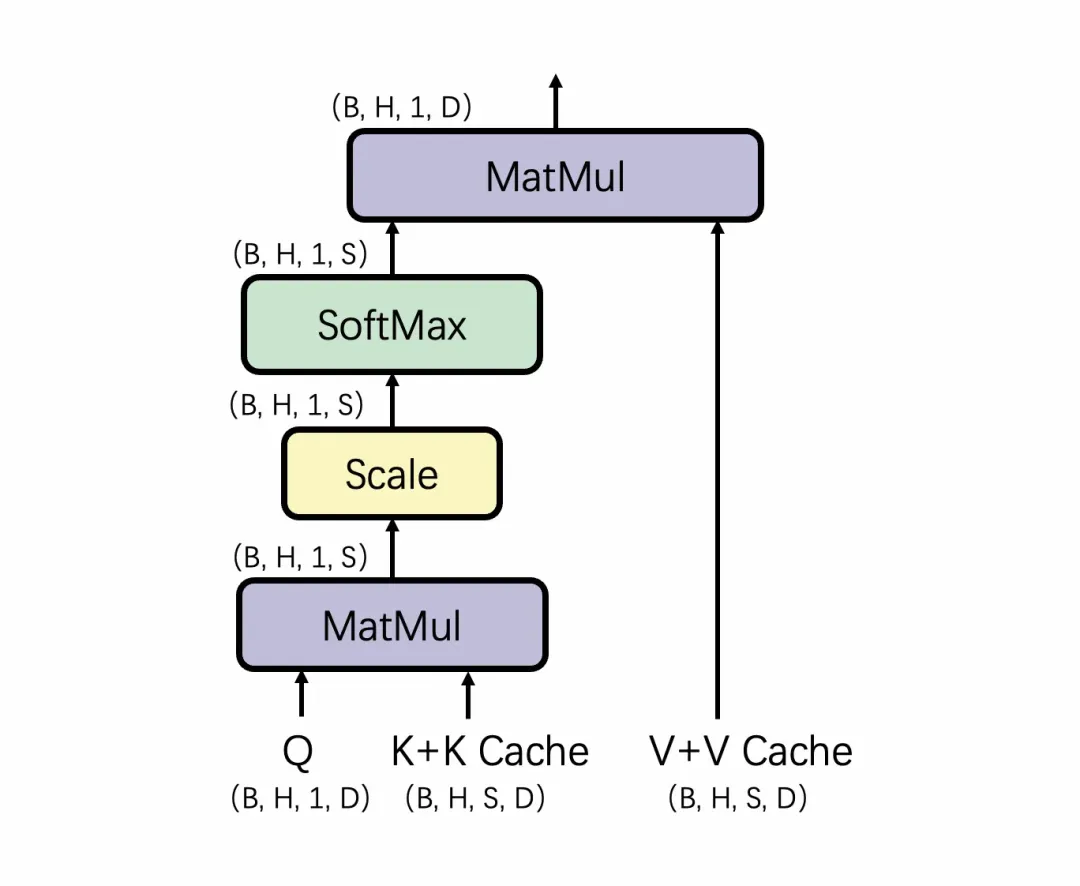


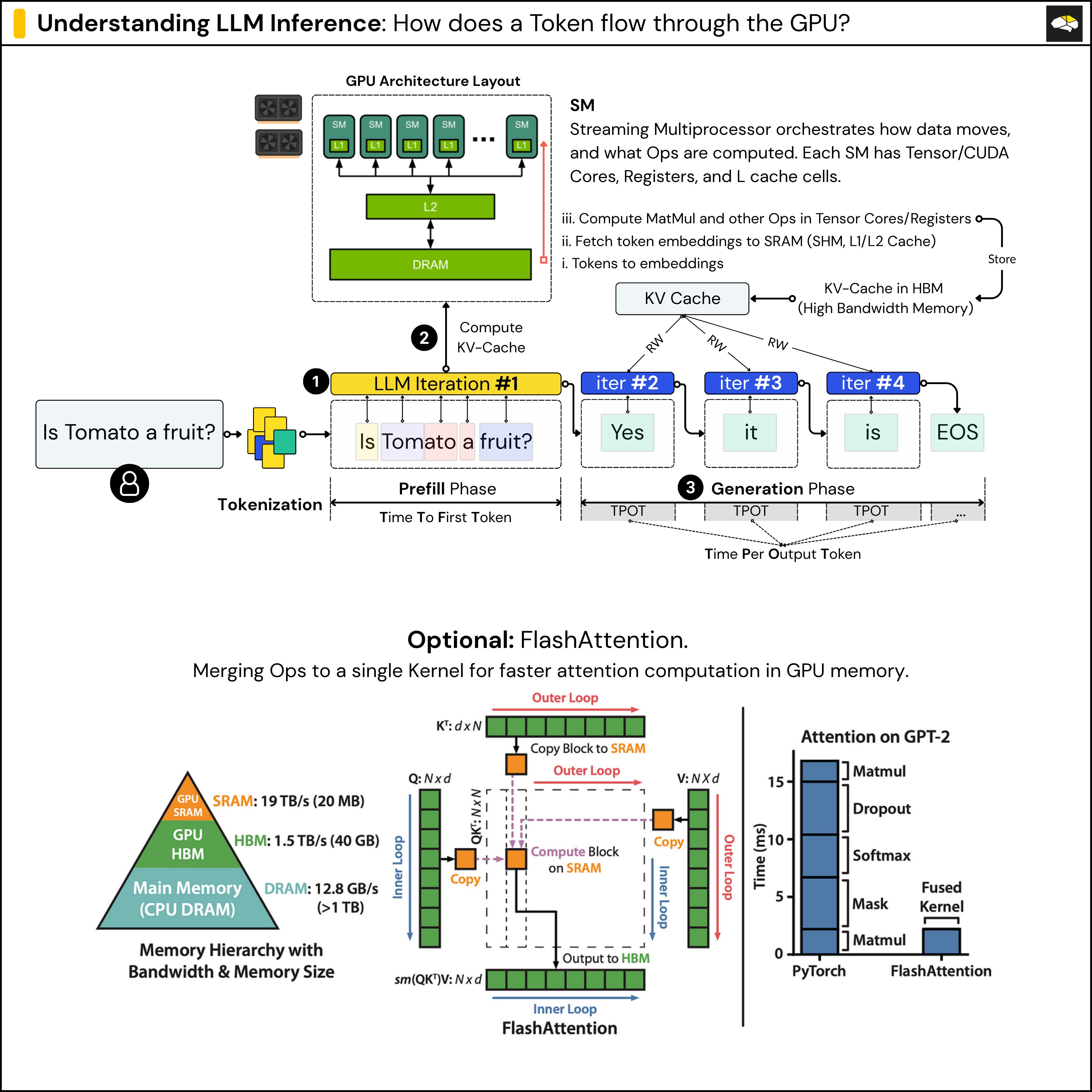

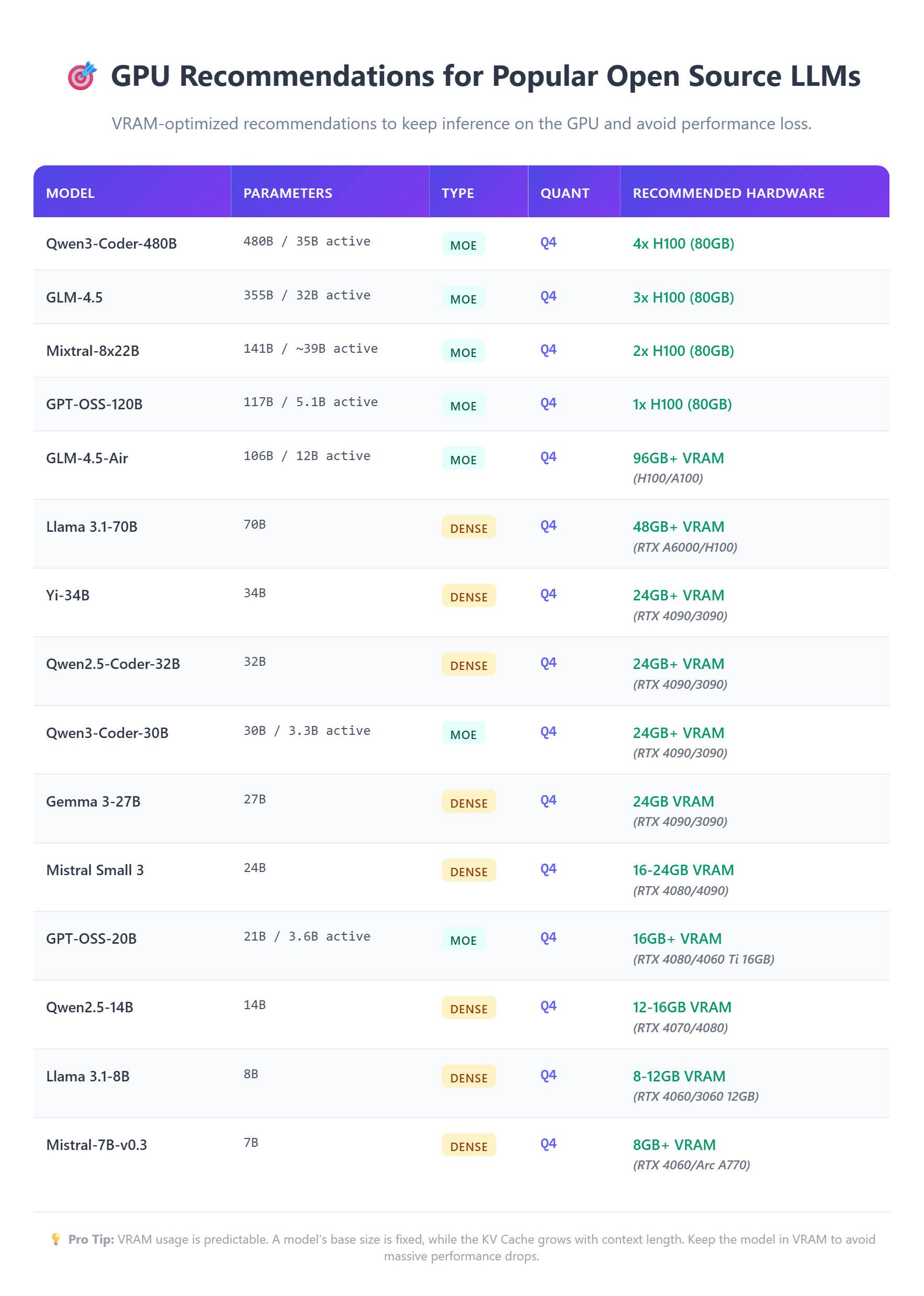























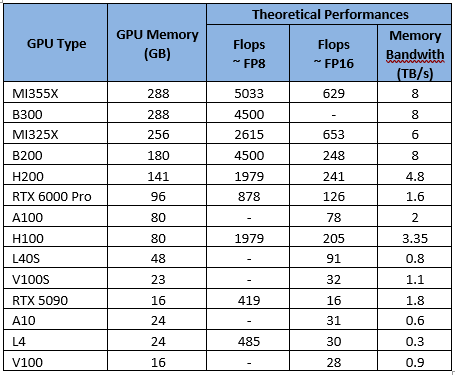
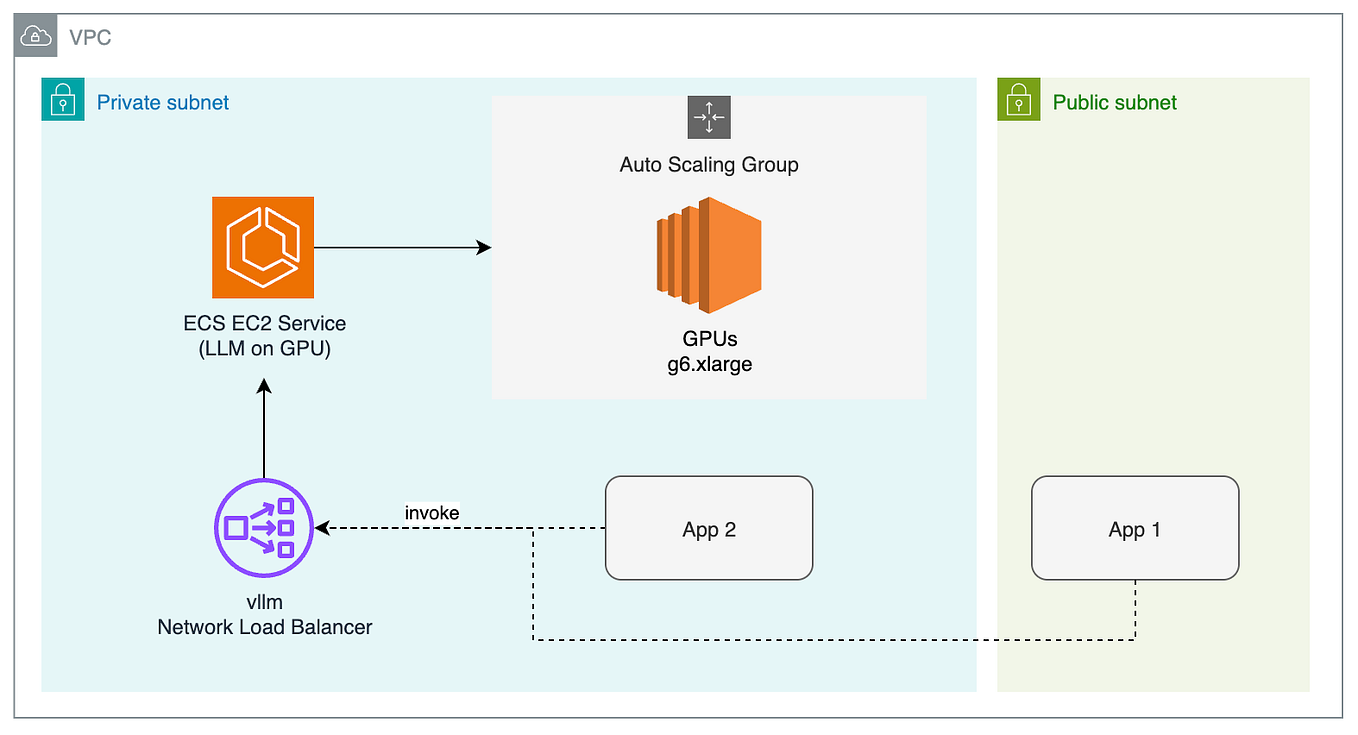
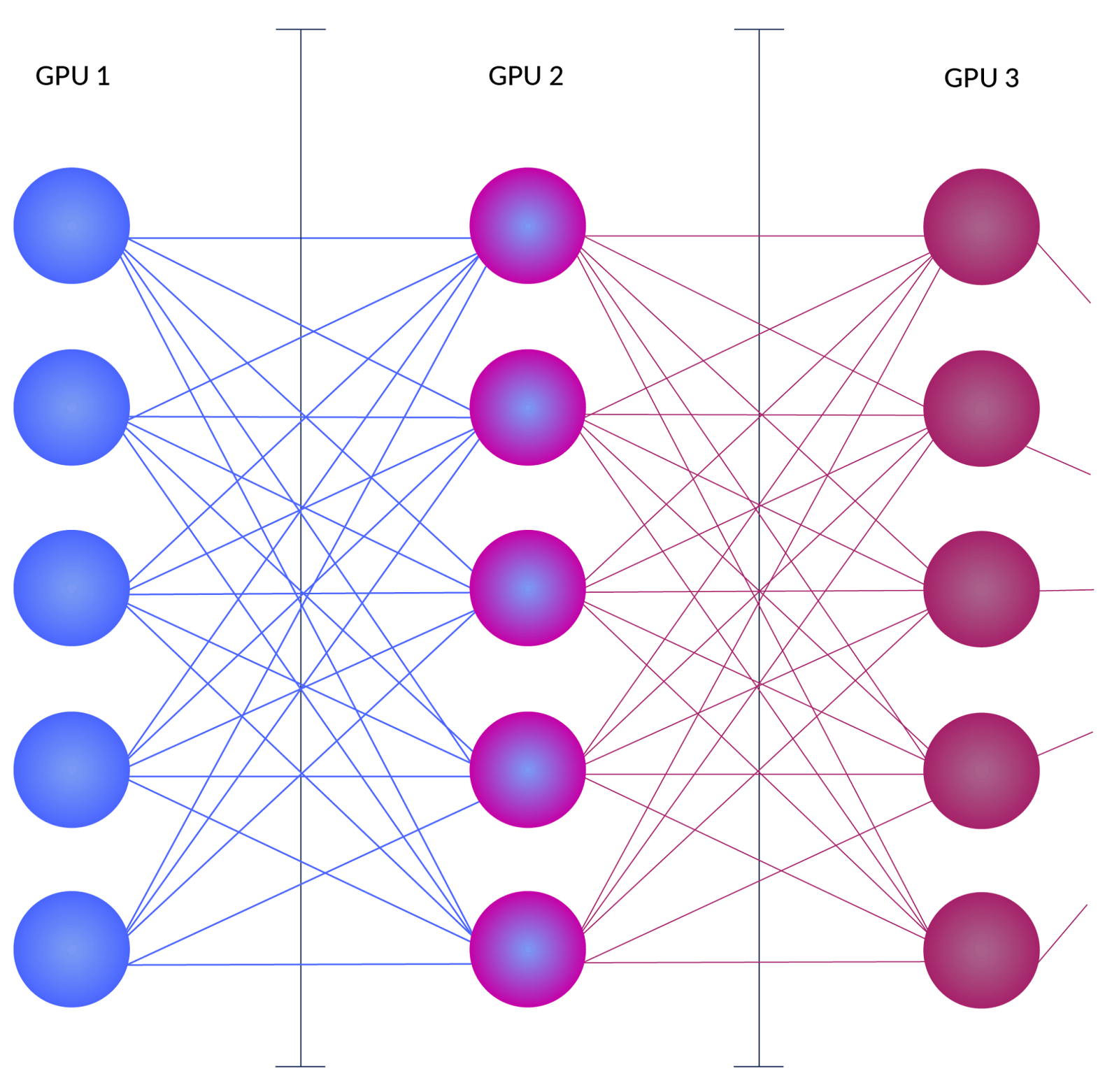
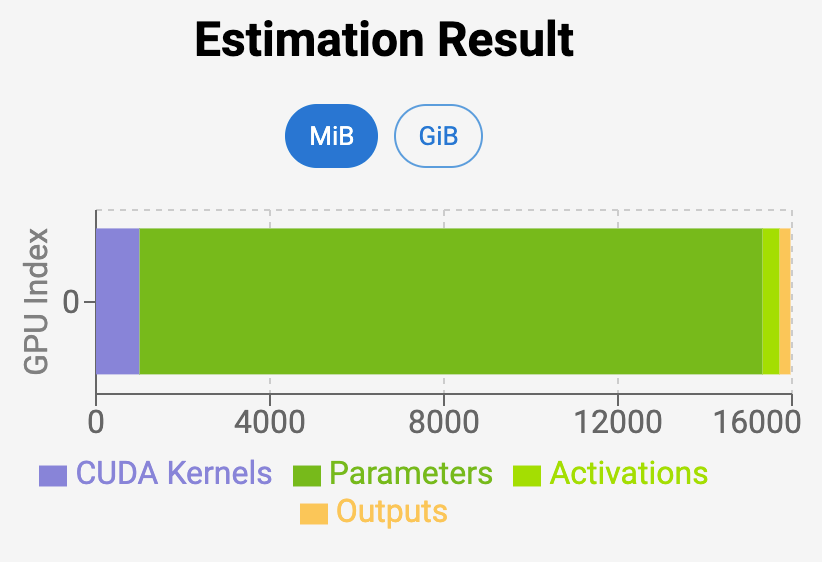
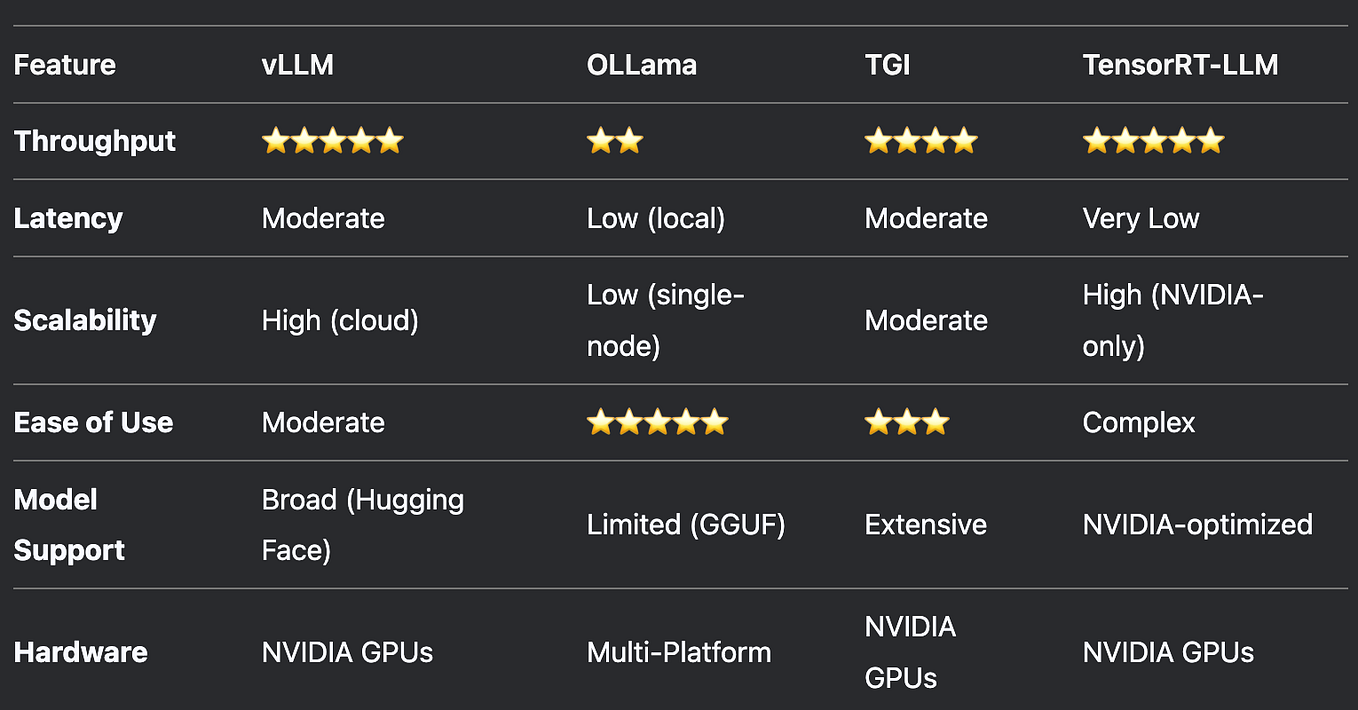

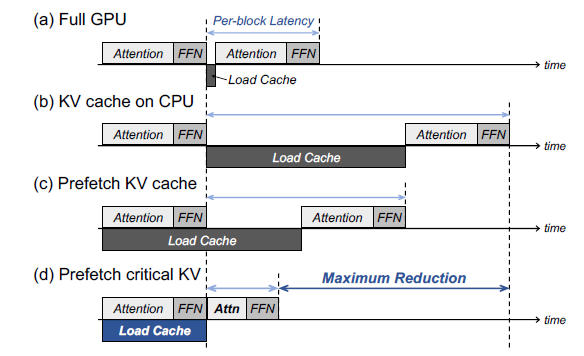








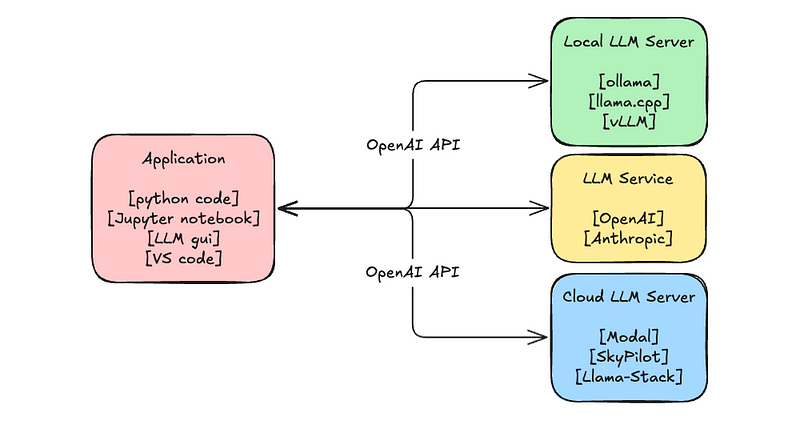
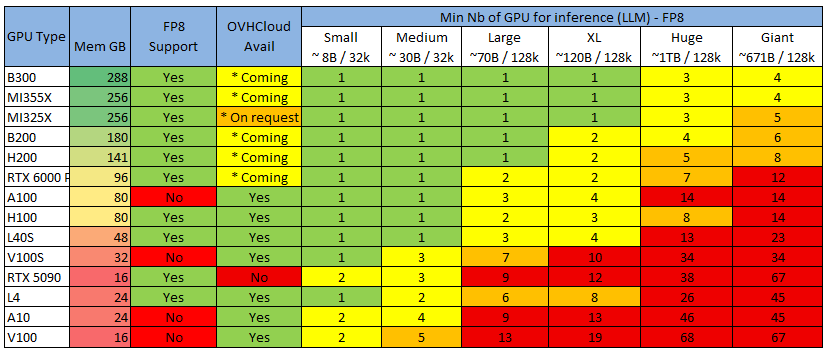


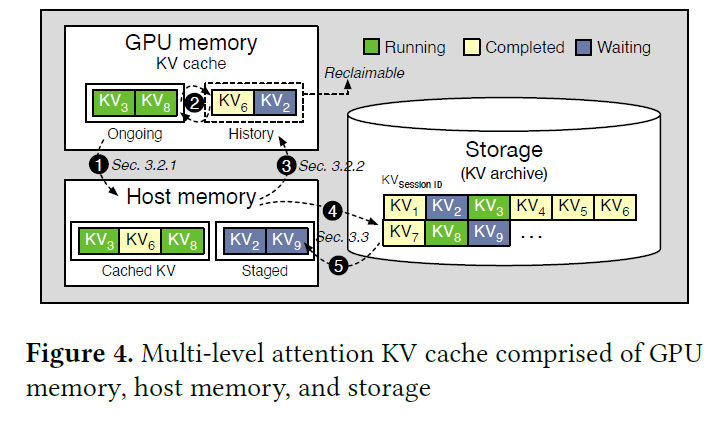


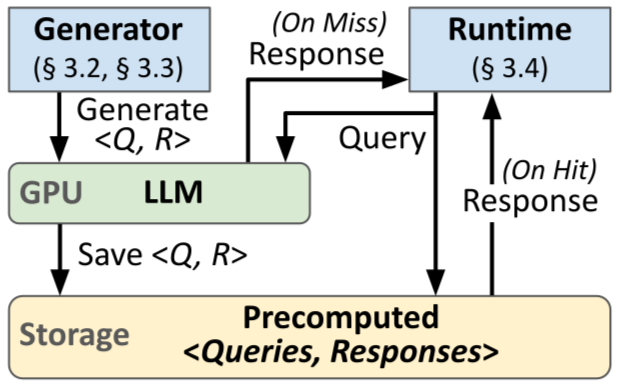











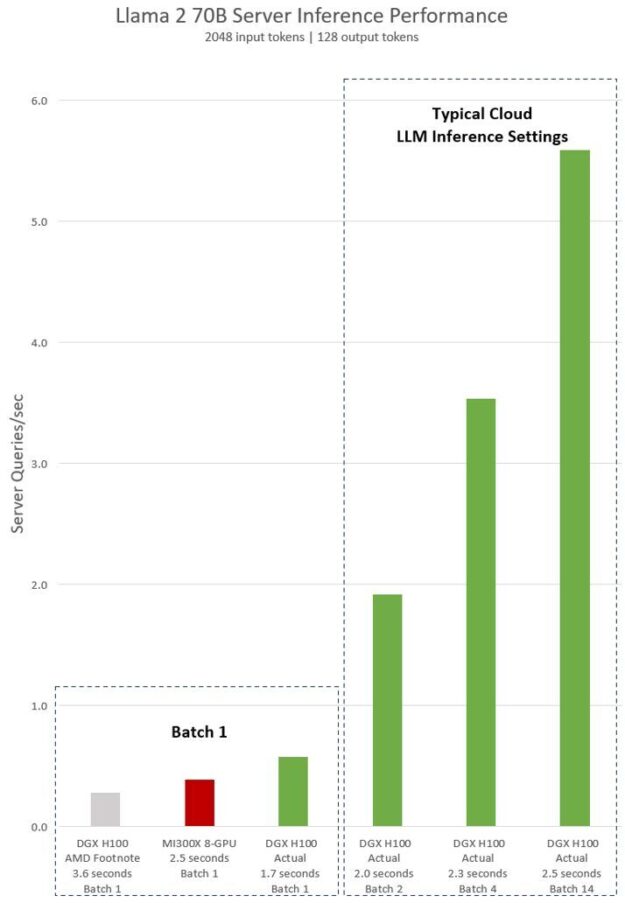
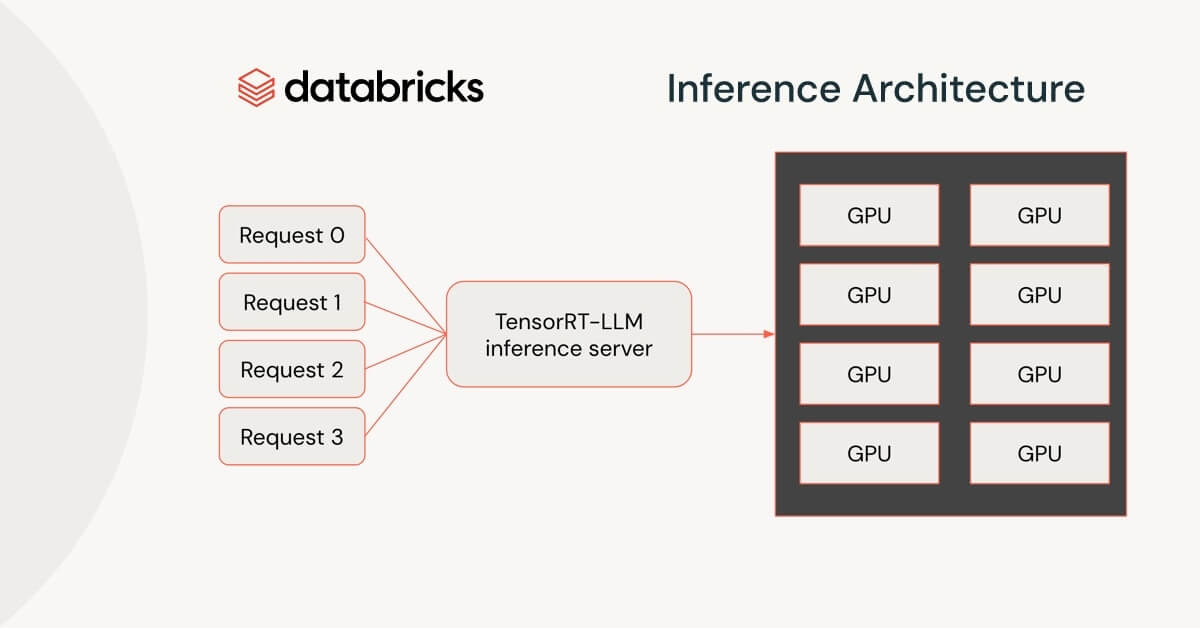

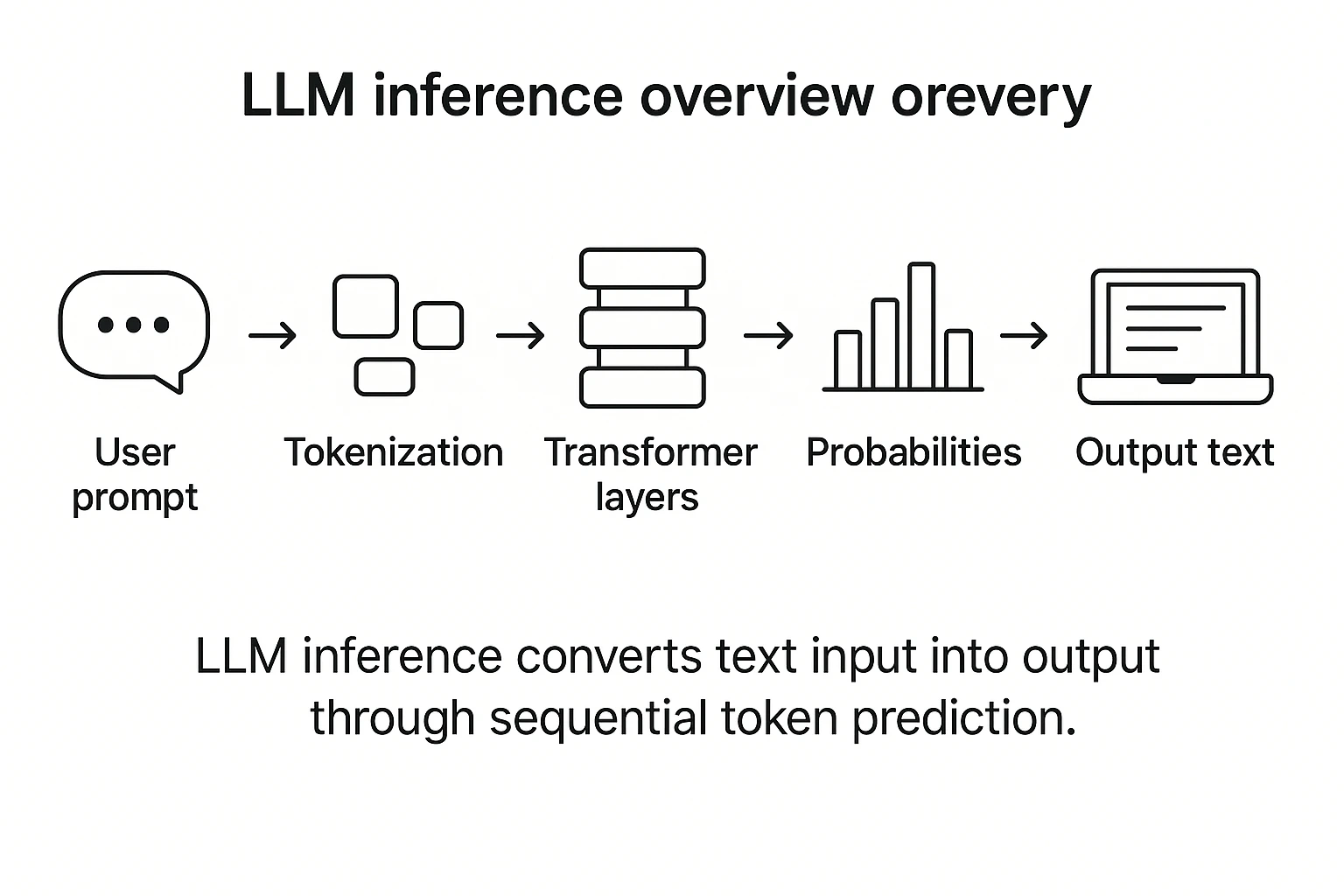
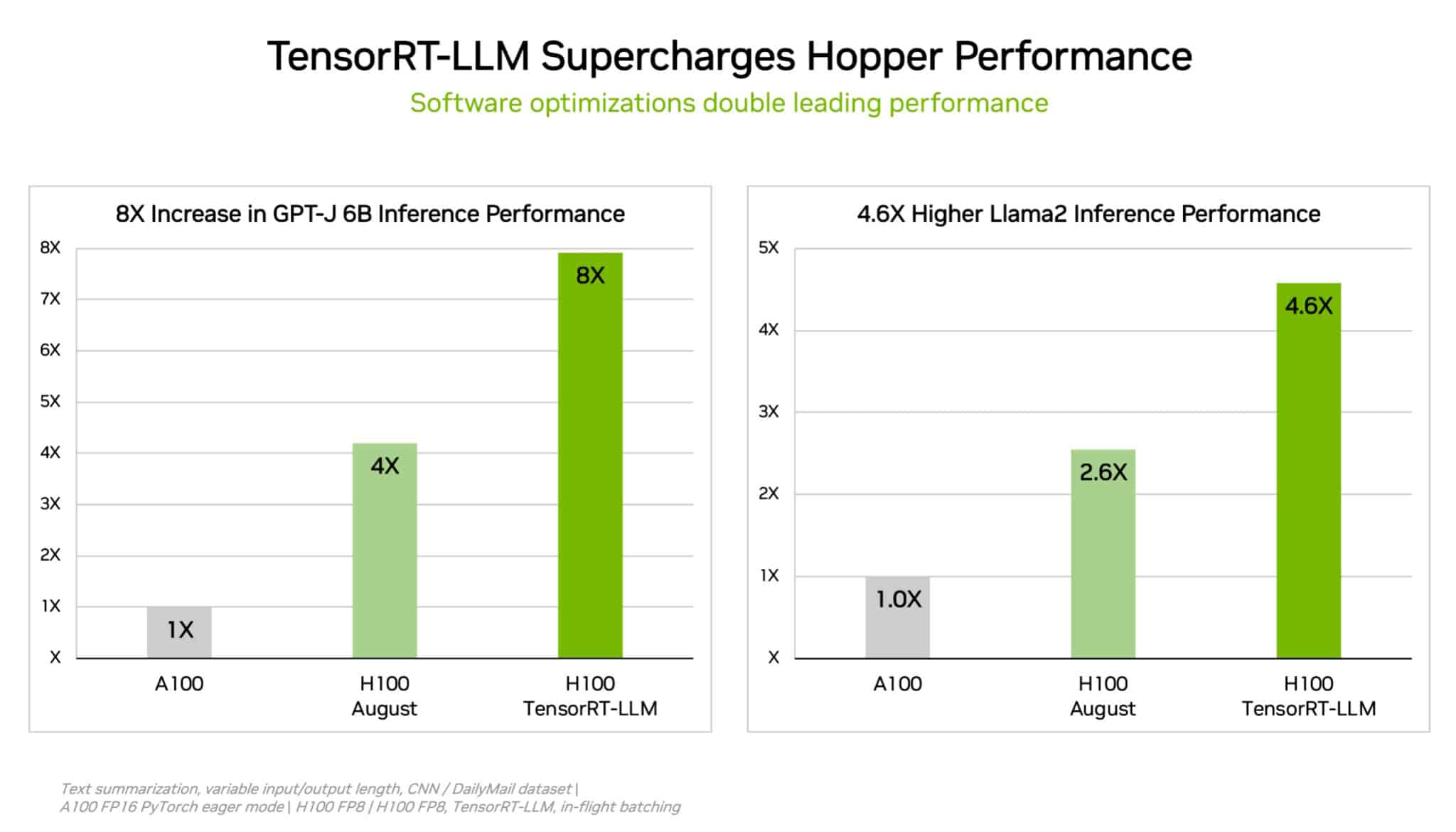

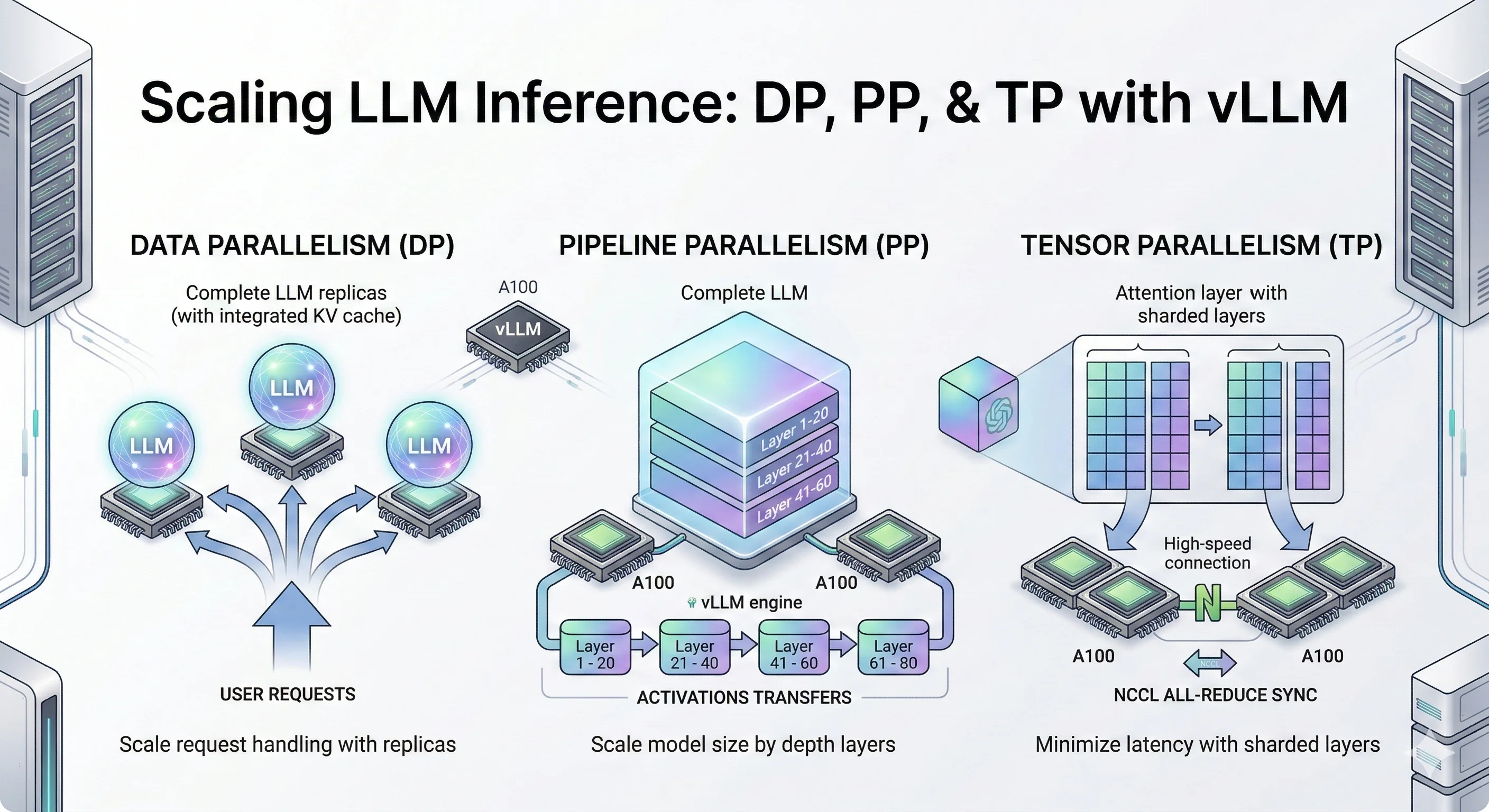


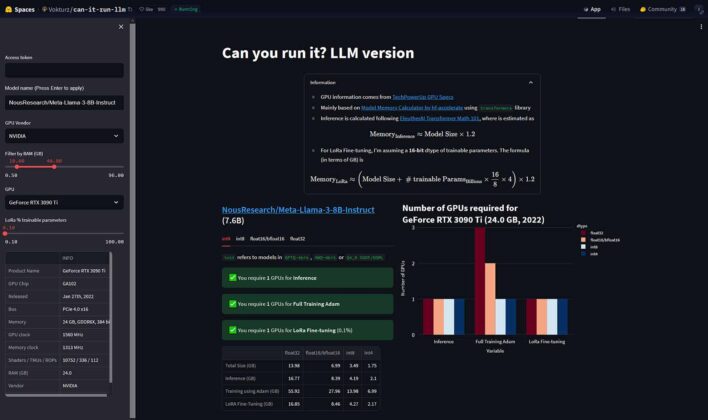

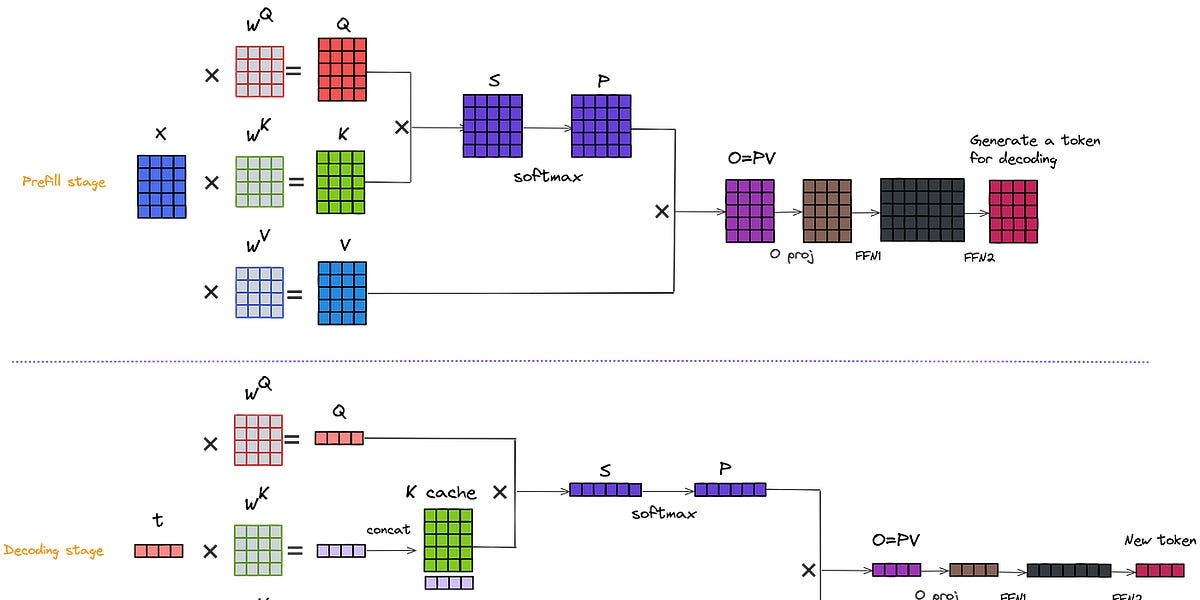
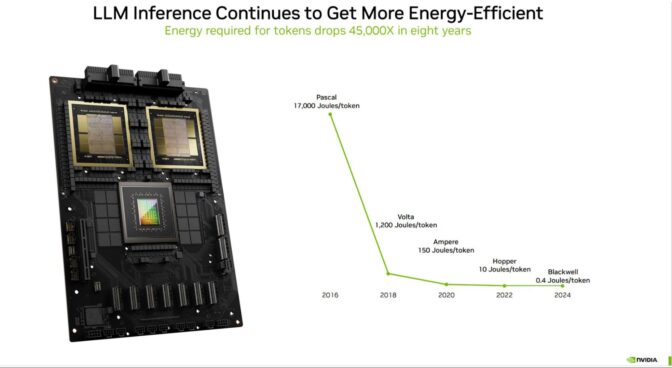
.png?width=1000&height=600&name=Challenges%20in%20LLM%20Training%20and%20AI%20Inference%20Infographics%20(1).png)