Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
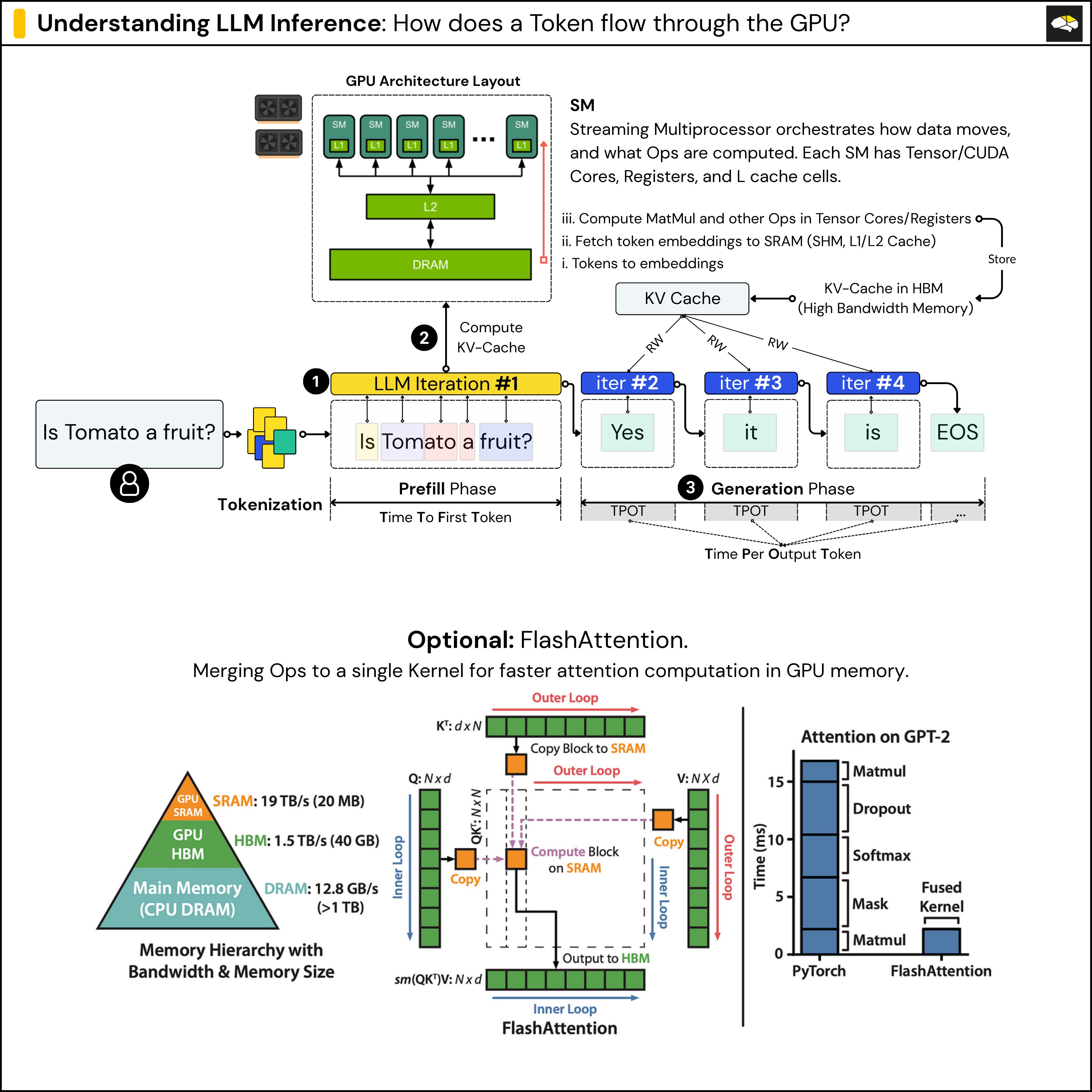
Understanding LLM Inference - by Alex Razvant
LLM Inference Stages Diagram | Stable Diffusion Online
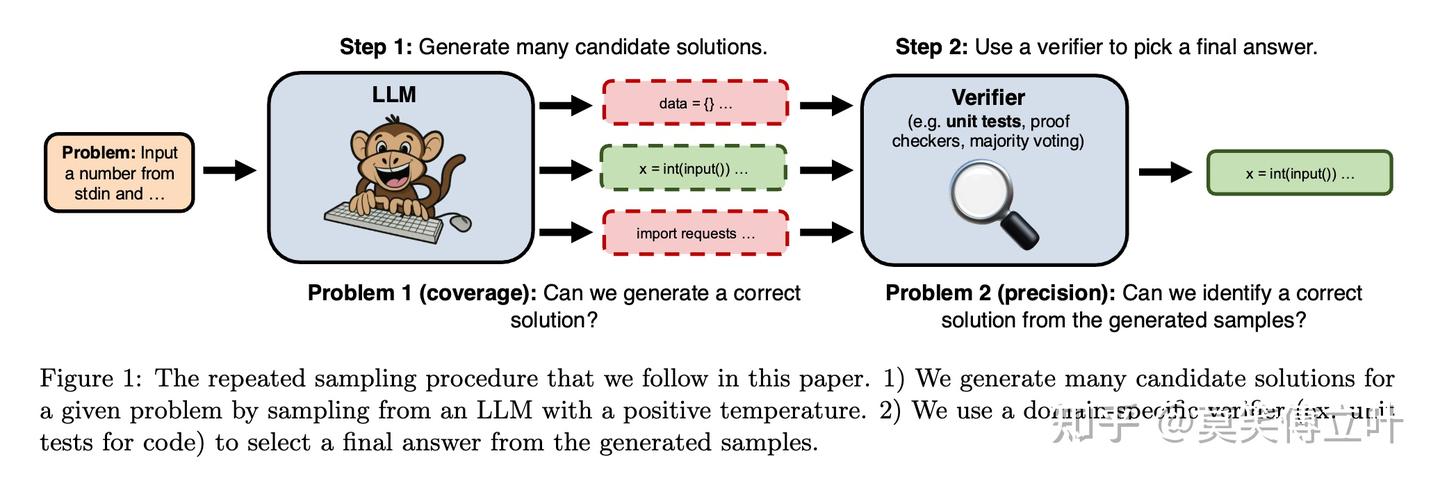
Paper page - Diversified Sampling Improves Scaling LLM inference
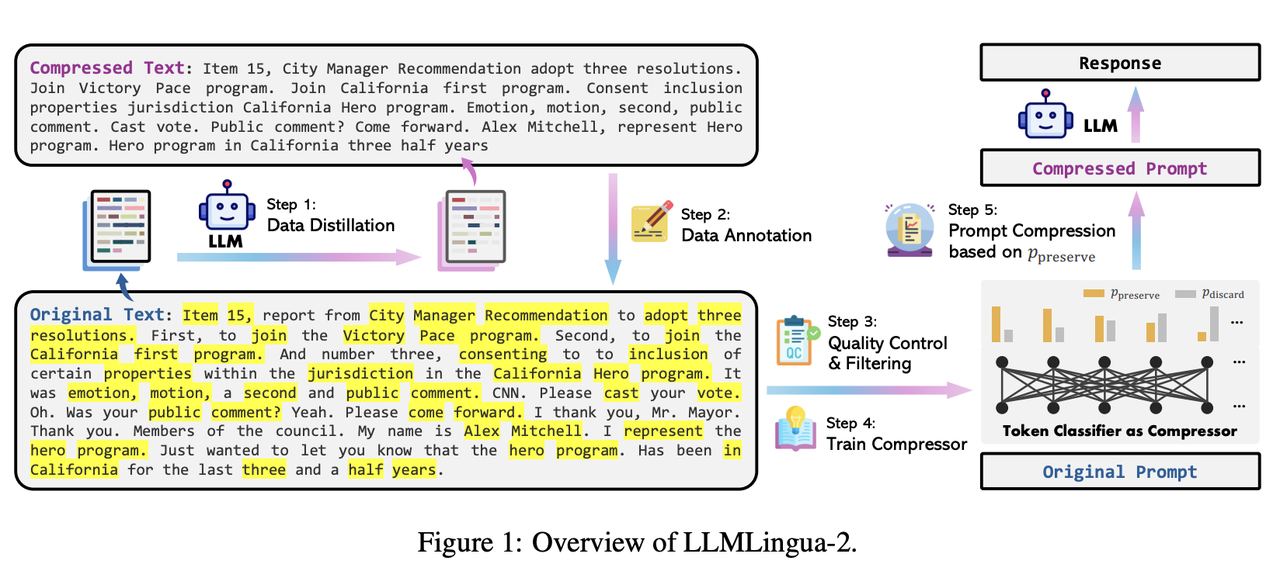
Illustration of the proposed method. (a) LLM inference comprises two ...
The State of LLM Reasoning Model Inference
Understanding LLM Batch Inference | Adaline
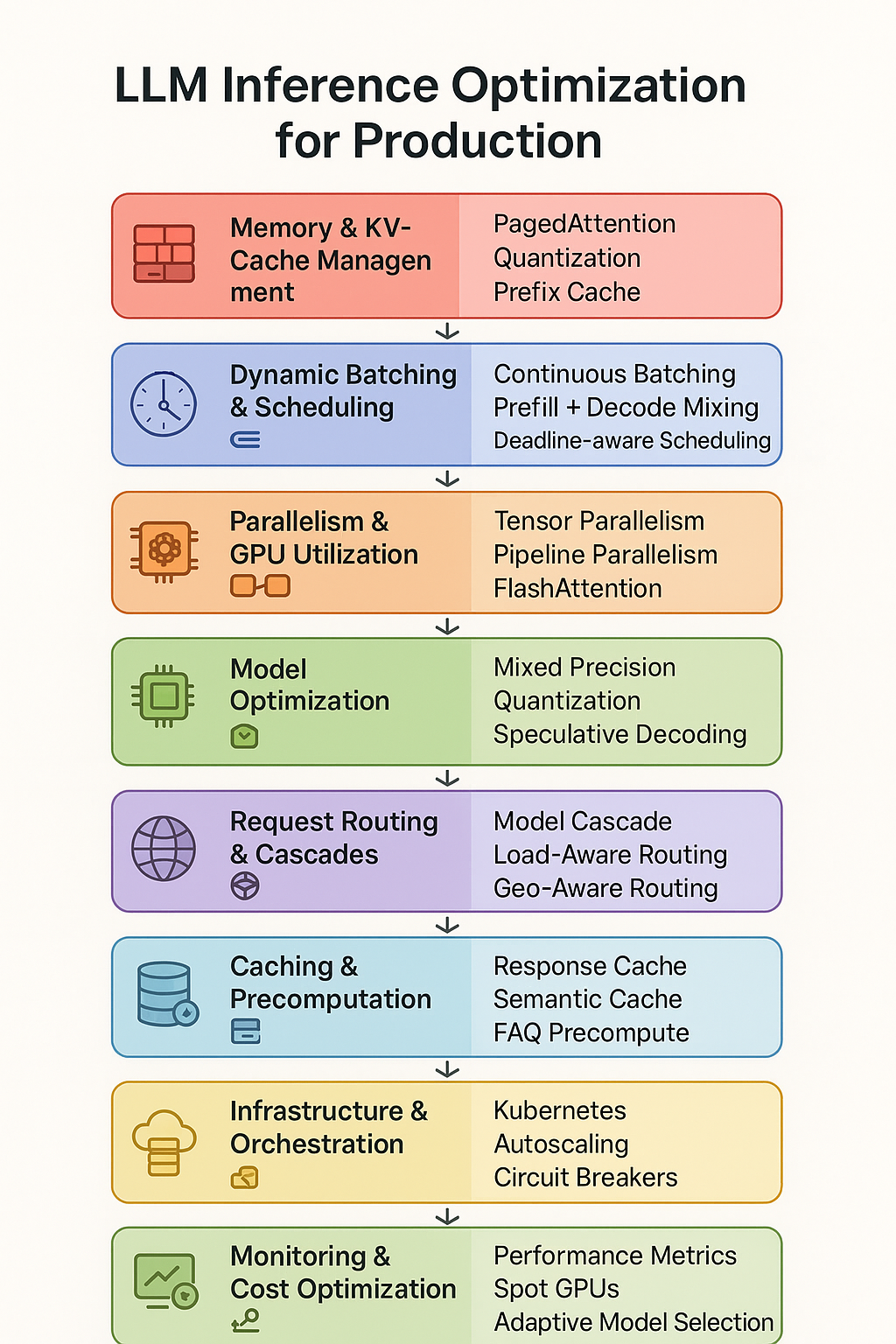
LLM Inference Optimization Techniques | Clarifai Guide
How continuous batching enables 23x throughput in LLM inference ...
Achieve ~2x speed-up in LLM inference with Medusa-1 on Amazon SageMaker ...
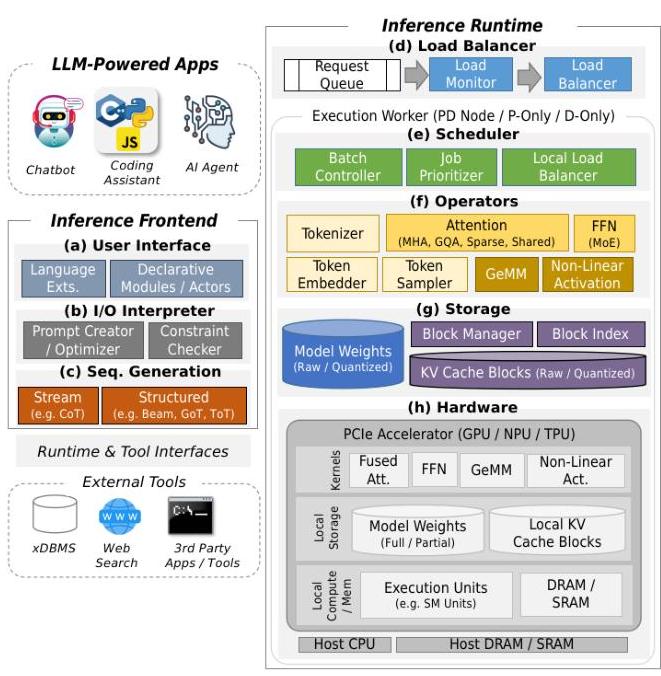
LLM Inference - Hw-Sw Optimizations
(PDF) Diversified Sampling Improves Scaling LLM inference
What is Speculative Sampling? | Boosting LLM inference speed - YouTube
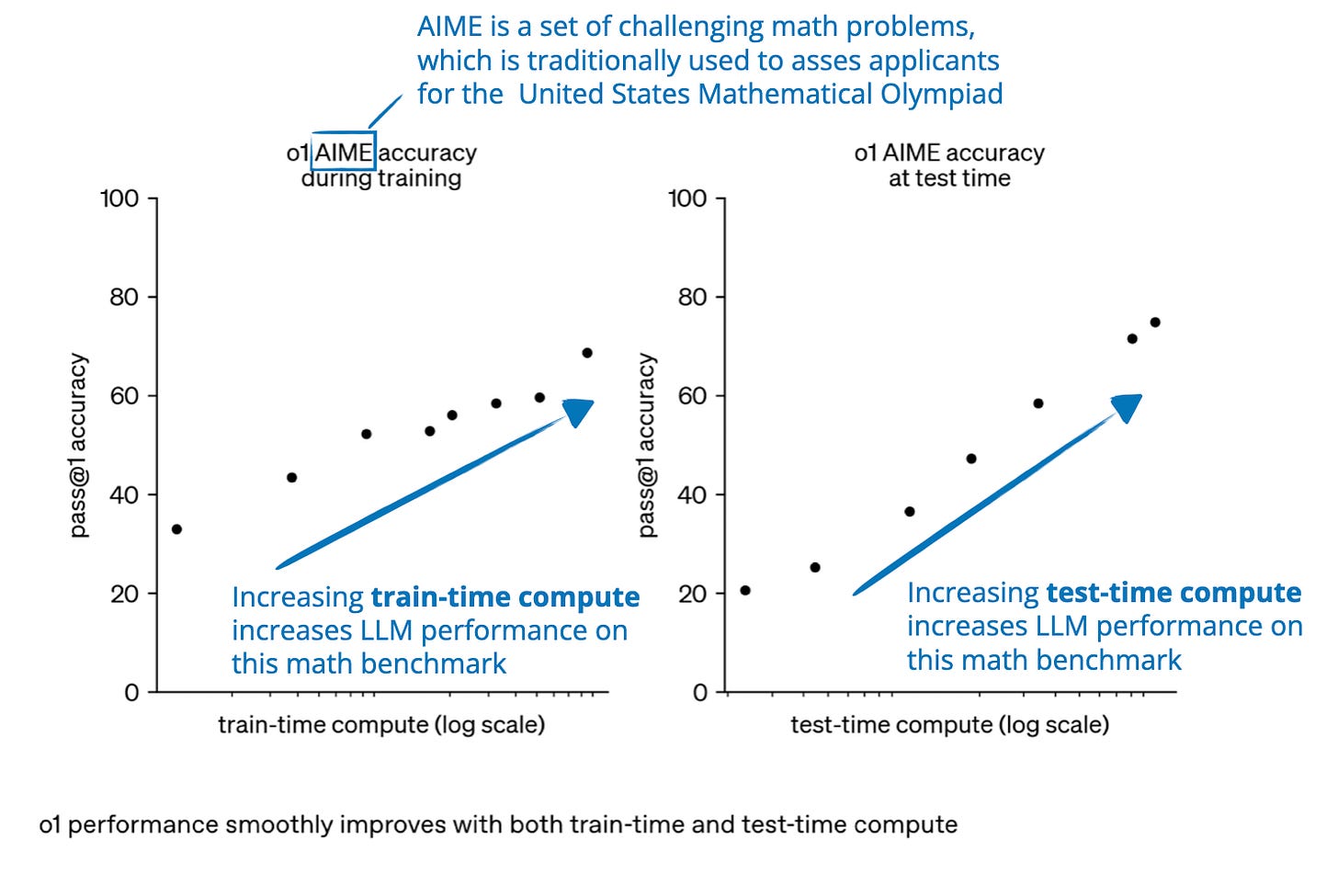
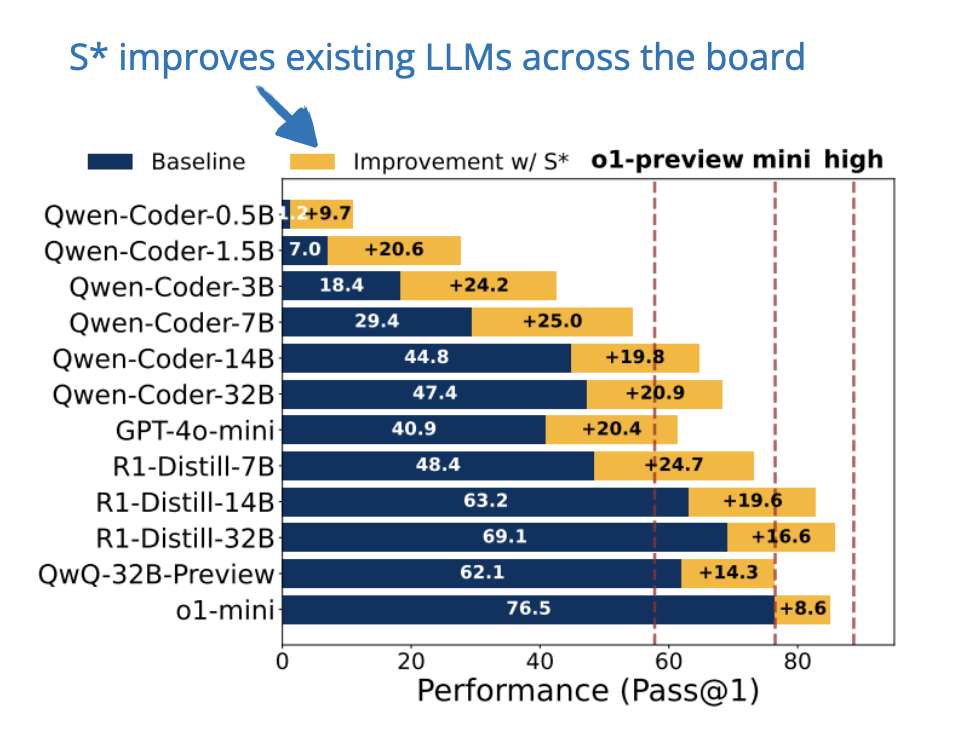
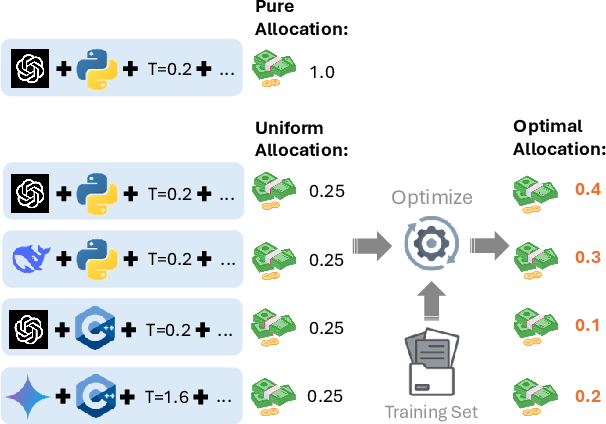
(PDF) Scaling LLM Inference with Optimized Sample Compute Allocation
What Is An LLM | PDF | Sampling (Statistics) | Statistical Inference
LLM Inference Optimization in Production: A Technical Deep Dive | by ...
Scaling LLM Inference Efficiently with Optimized Sample Compute ...
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
(PDF) Improving the inference performance of LLM with code
Efficient LLM Inference Insights | PDF | Computing | Computer Engineering
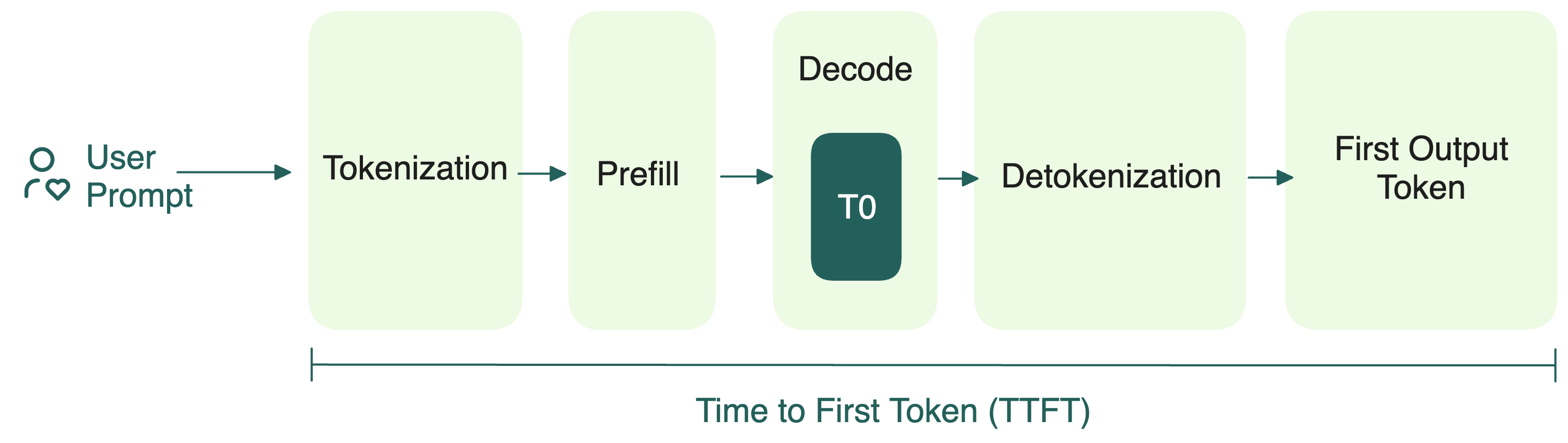
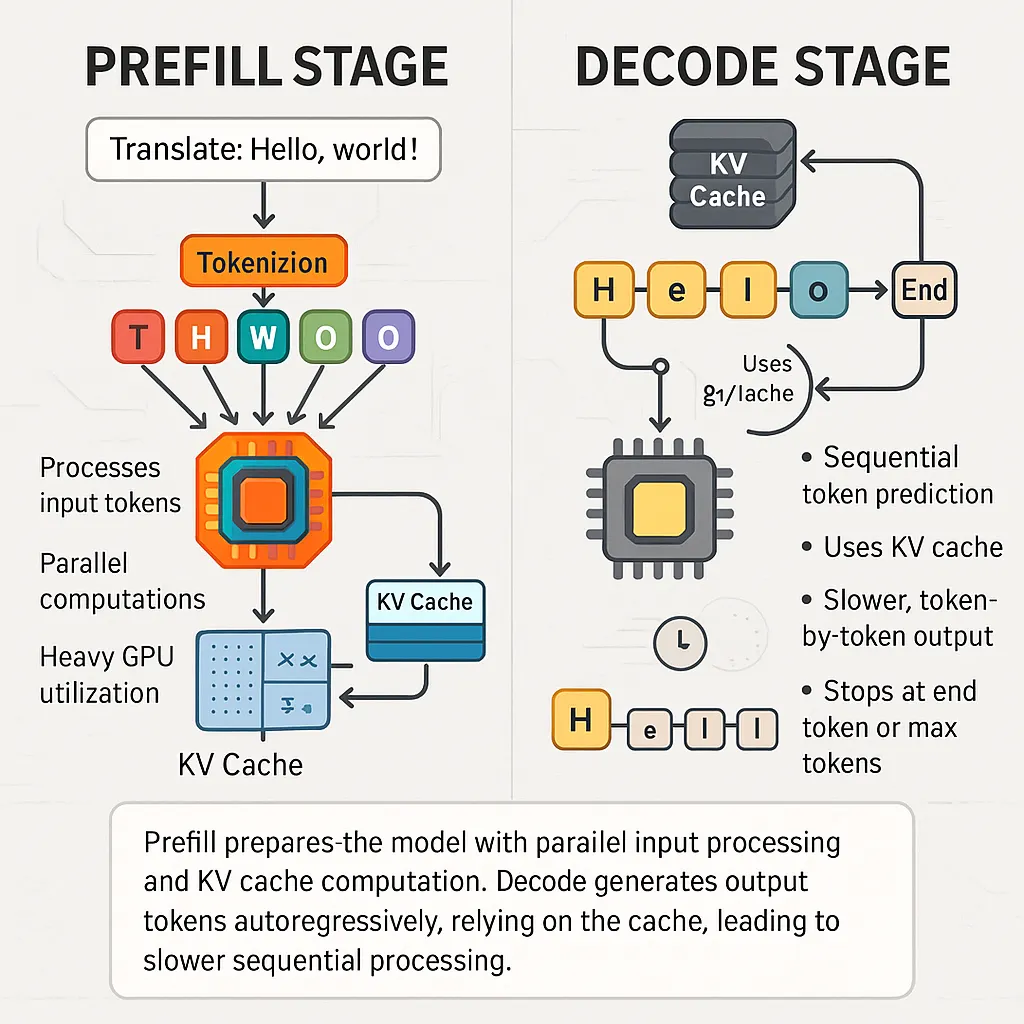
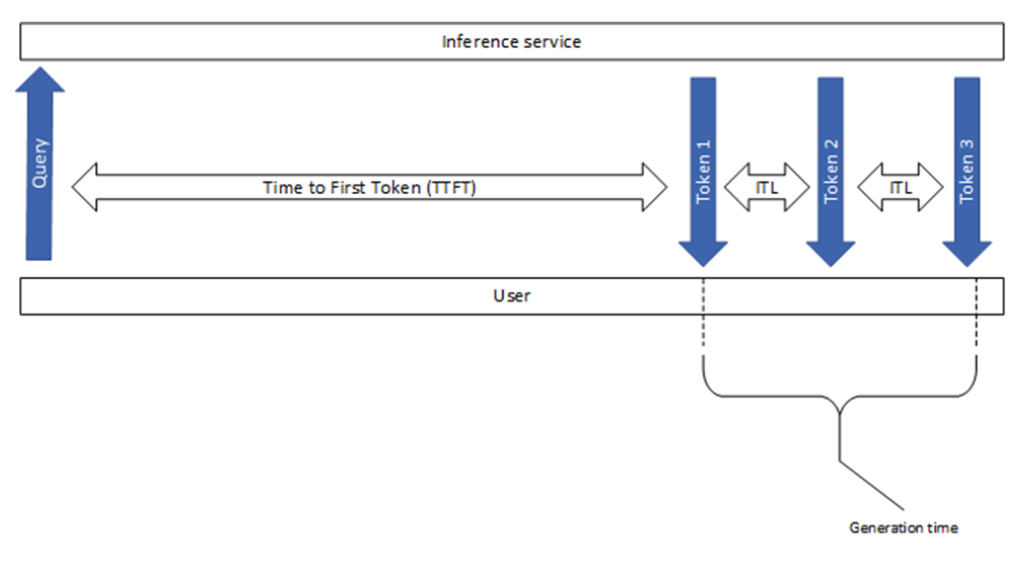
LLM Inference Explained: Prefill vs Decode and Why Latency Matters ...
Introduction to LLM Inference Benchmarking | Yu-Chen Cheng's Blog
Reasoning under Uncertainty: Efficient LLM Inference via Unsupervised ...
(PDF) LLM Inference Serving: Survey of Recent Advances and Opportunities
A Guide to LLM Inference Performance Monitoring | Symbl.ai
LLM inference techniques
Free Video: Common Sampling Methods for Modern NLP - CMU LLM Inference ...
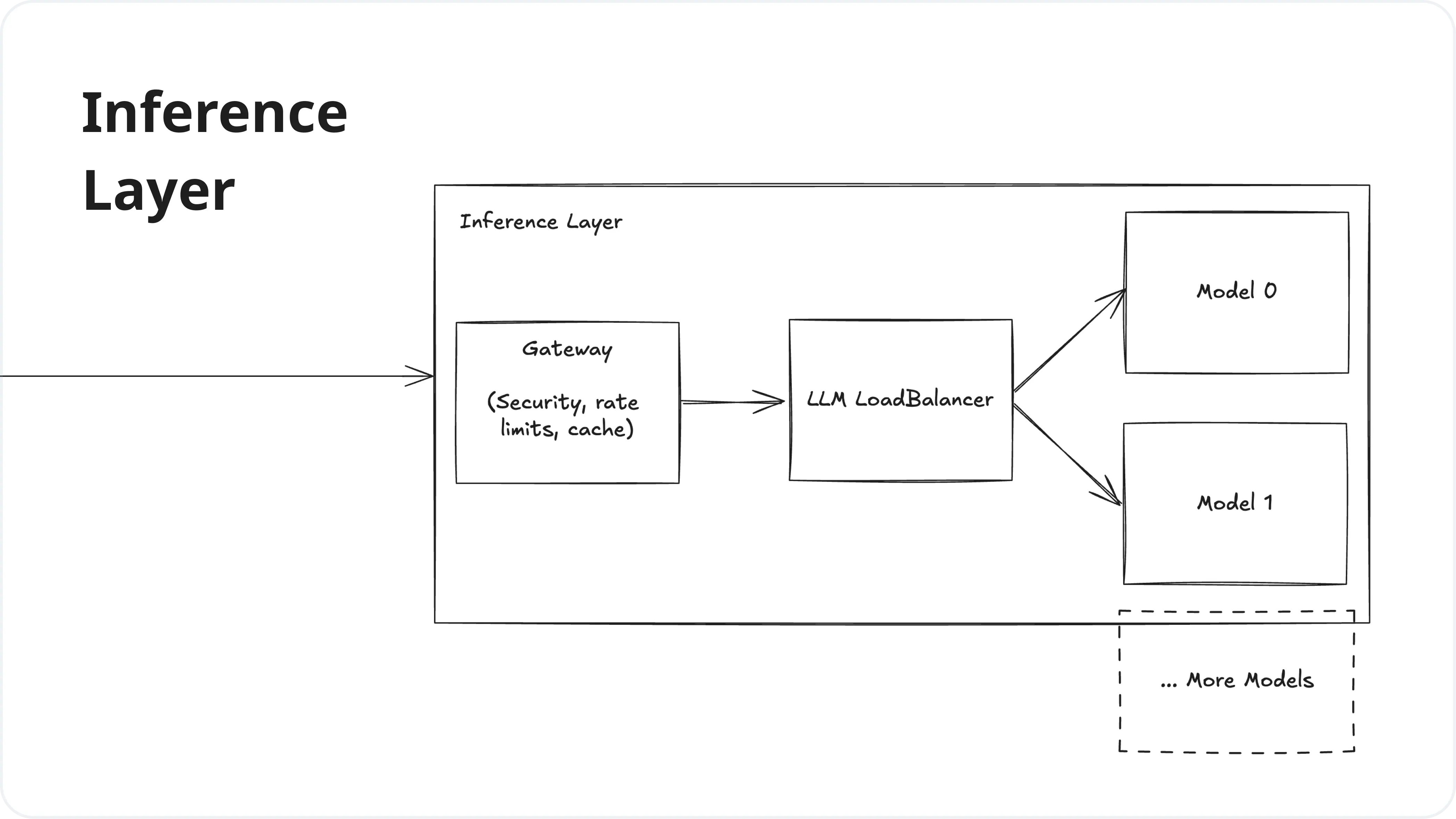
LLM Inference Optimization Overview - From Data to System Architecture
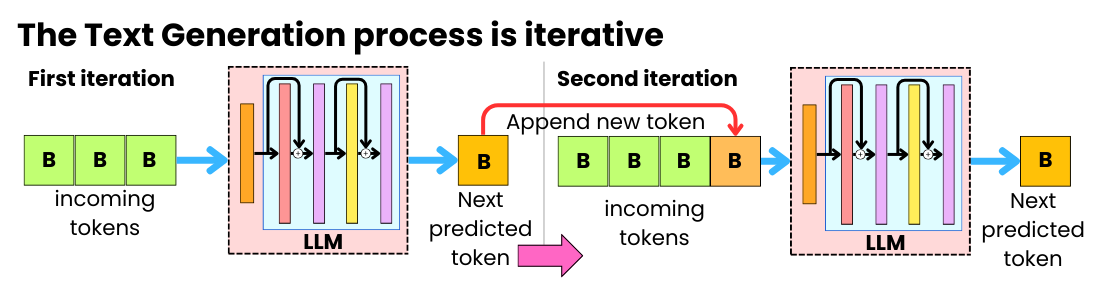
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
Key metrics for LLM inference | LLM Inference Handbook
LLM Inference
How to Build LLM Inference Pipelines for Enterprise Apps
(PDF) Scalable Inference Systems for Real-Time LLM Integration
Star Attention: Efficient LLM Inference over Long Sequences NVIDIA ...
A guide to LLM inference and performance
The LLM Inference Pipeline: From Text to Embeddings and the Power of RAG
LLM Inference v_s Fine-Tuning | PDF | Cognitive Science | Computational ...
LLM inference optimization: Model Quantization and Distillation - YouTube
Illustration of the privacy-preserving LLM inference. The LLM inference ...
Improving LLM Inference Speed: Presenting SampleAttention for Effective ...
(PDF) Accelerating LLM Inference with Staged Speculative Decoding
What is NVIDIA Dynamo LLM Inference Framework
Choosing The Right Inference Framework - LLM Inference Handbook | PDF ...
DynamoLLM: Energy-Efficient LLM Inference | PDF | Graphics Processing ...
How does LLM inference work? | LLM Inference Handbook
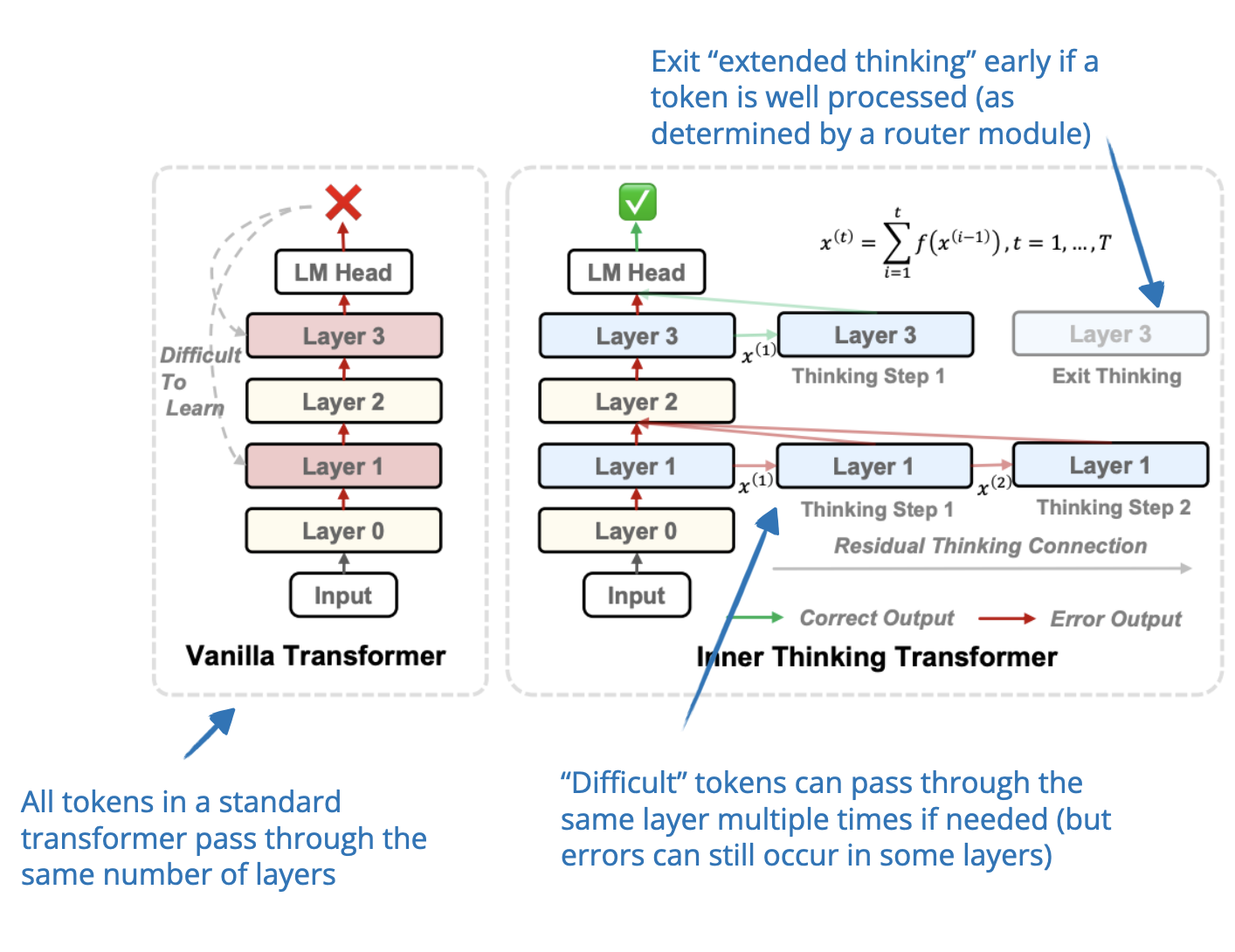
Speculative Decoding via Early-exiting for Faster LLM Inference with ...
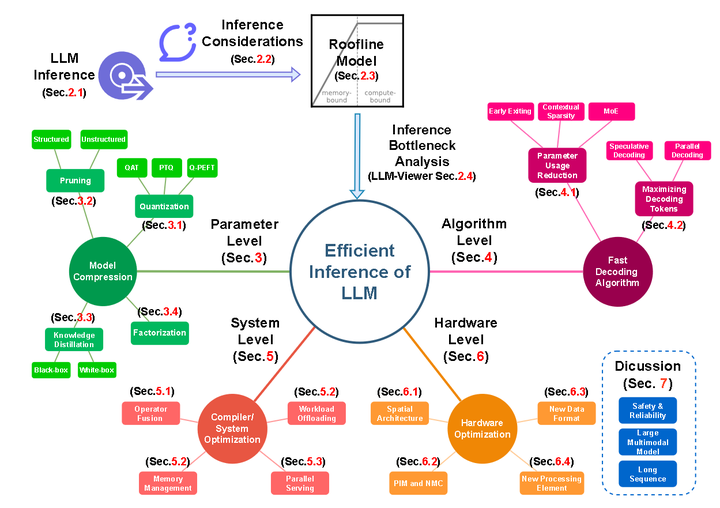
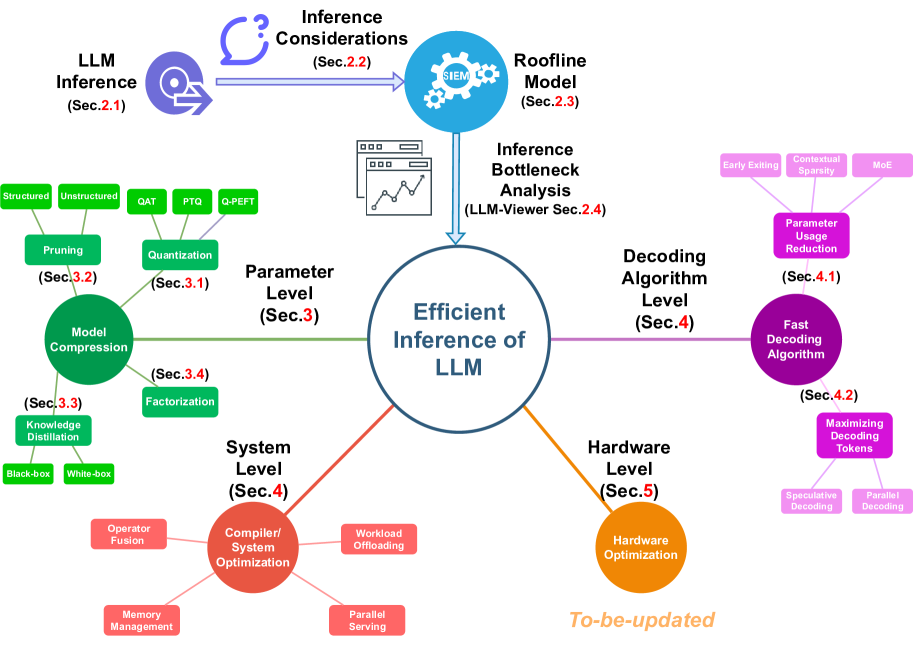
LLM Inference Unveiled: Survey and Roofline Model Insights - 知乎
Figure 2 from Scaling LLM Inference with Optimized Sample Compute ...
How to Scale LLM Inference - by Damien Benveniste
LLM inference does a sampling at the end This is based on parameters ...
🚀 Day 3: Decoding the LLM Inference complexities 🚀 Speculative Sampling ...
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
LLM Inference Hardware: Emerging from Nvidia's Shadow
A Survey of LLM Inference Systems | alphaXiv
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
Comparing the Top 6 Inference Runtimes for LLM Serving in 2025 - AIBtz.com
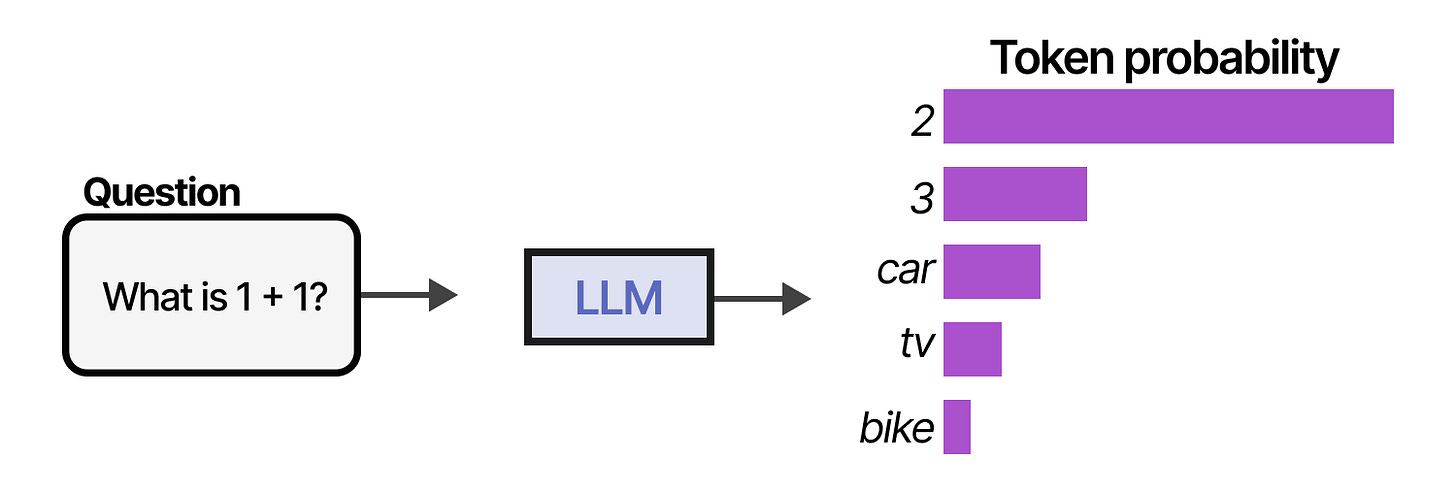
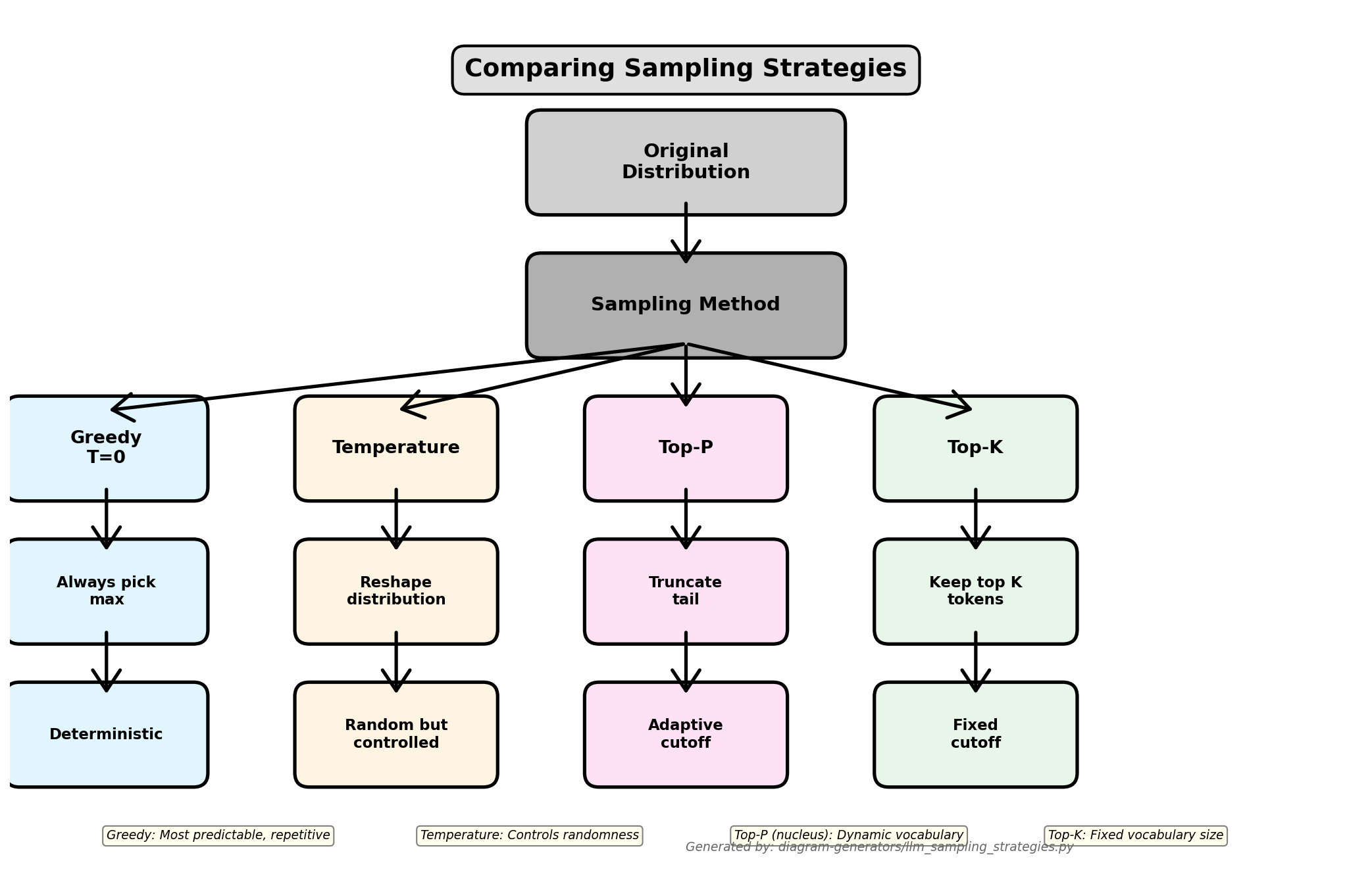
LLM Inference Sampling Methods
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
LLM 生成式配置的推理参数温度 top k tokens等 Generative configuration inference ...
LLM Inference - a zzzac Collection
A Survey of Efficient LLM Inference Serving | PDF | Scheduling ...
LLM Fine-Tuning - LLM Inference Handbook | PDF | Computing | Software ...
Defeating Nondeterminism in LLM Inference - Thinking Machines Lab
How LLM really works: From Training to Talking – The Power of Inference
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
Accelerating LLM Inference - Tradeoffs, Design, and New Ideas
Speculative Decoding — Make LLM Inference Faster | Medium | AI Science
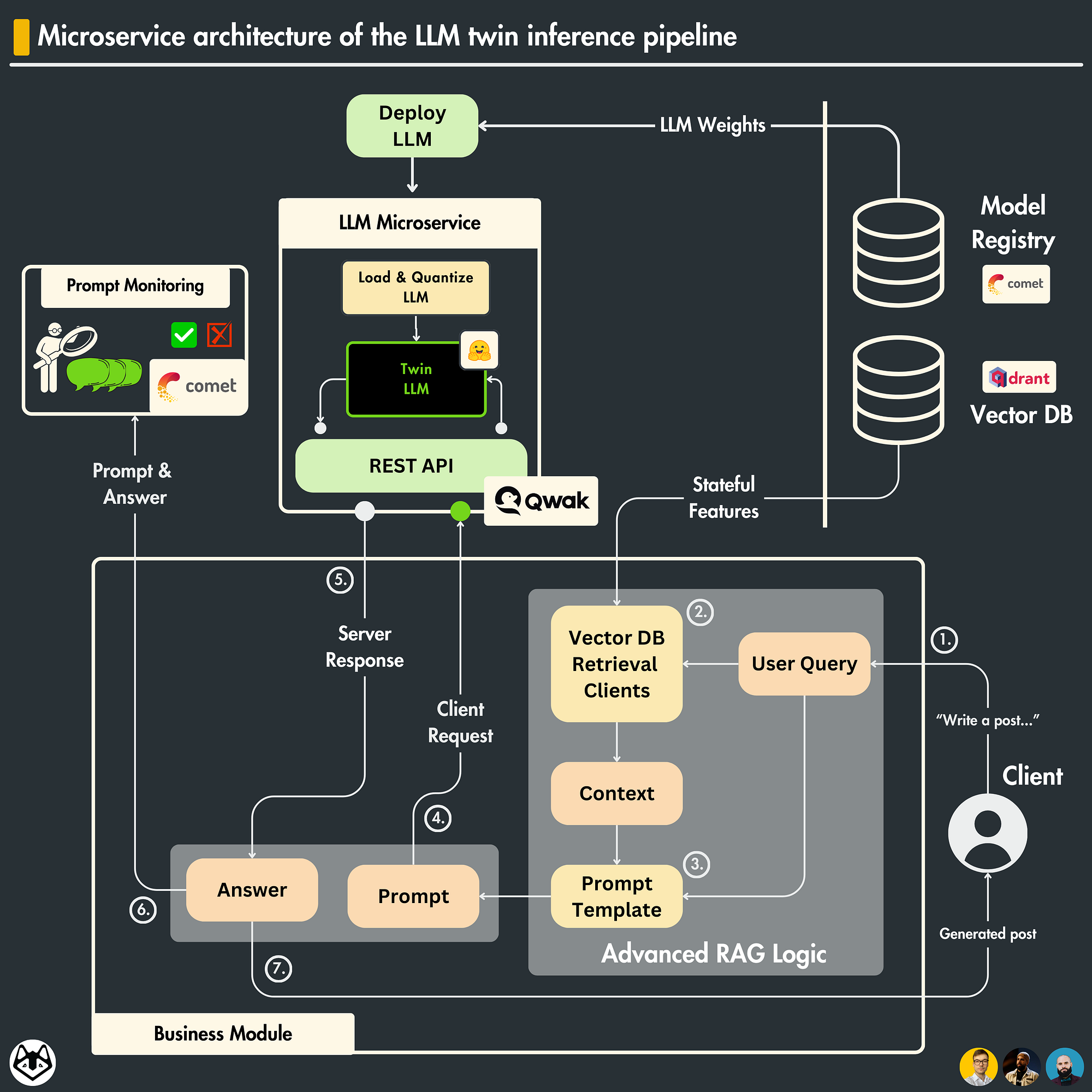
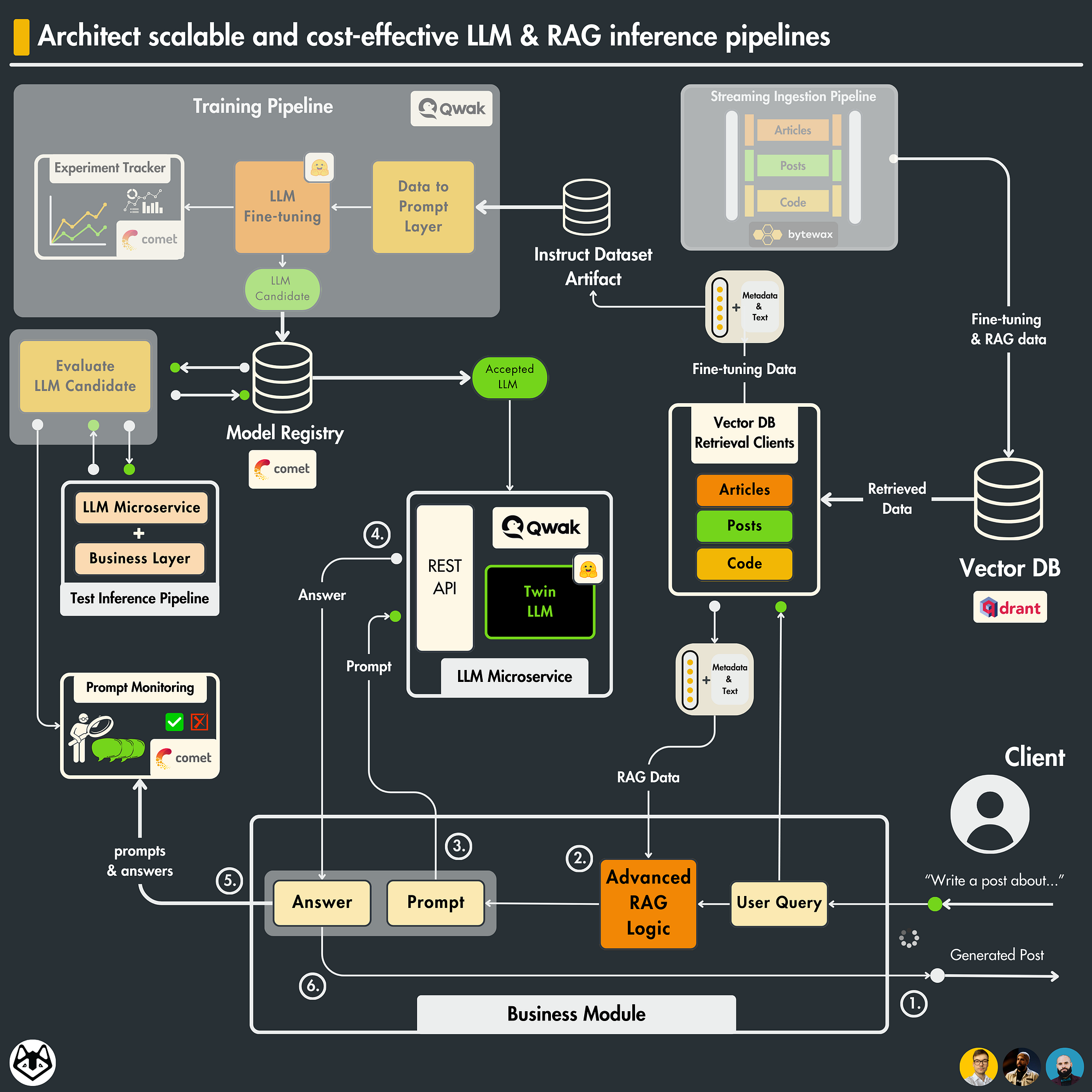
How to Architect Scalable LLM & RAG Inference Pipelines
What Is LLM Inference? Batch Inference In LLM Inference
LLM Inference Workload Insights | PDF | Cache (Computing) | Graphics ...
What Is LLM Inference? Process, Latency & Examples Explained (2026)
LLM Sampling Explained: Selecting the Next Token | Thinking Sand
A Visual Guide to LLM Agents - by Maarten Grootendorst
【LLM推理智能】Scaling Inference Compute with Repeated Sampling - 知乎
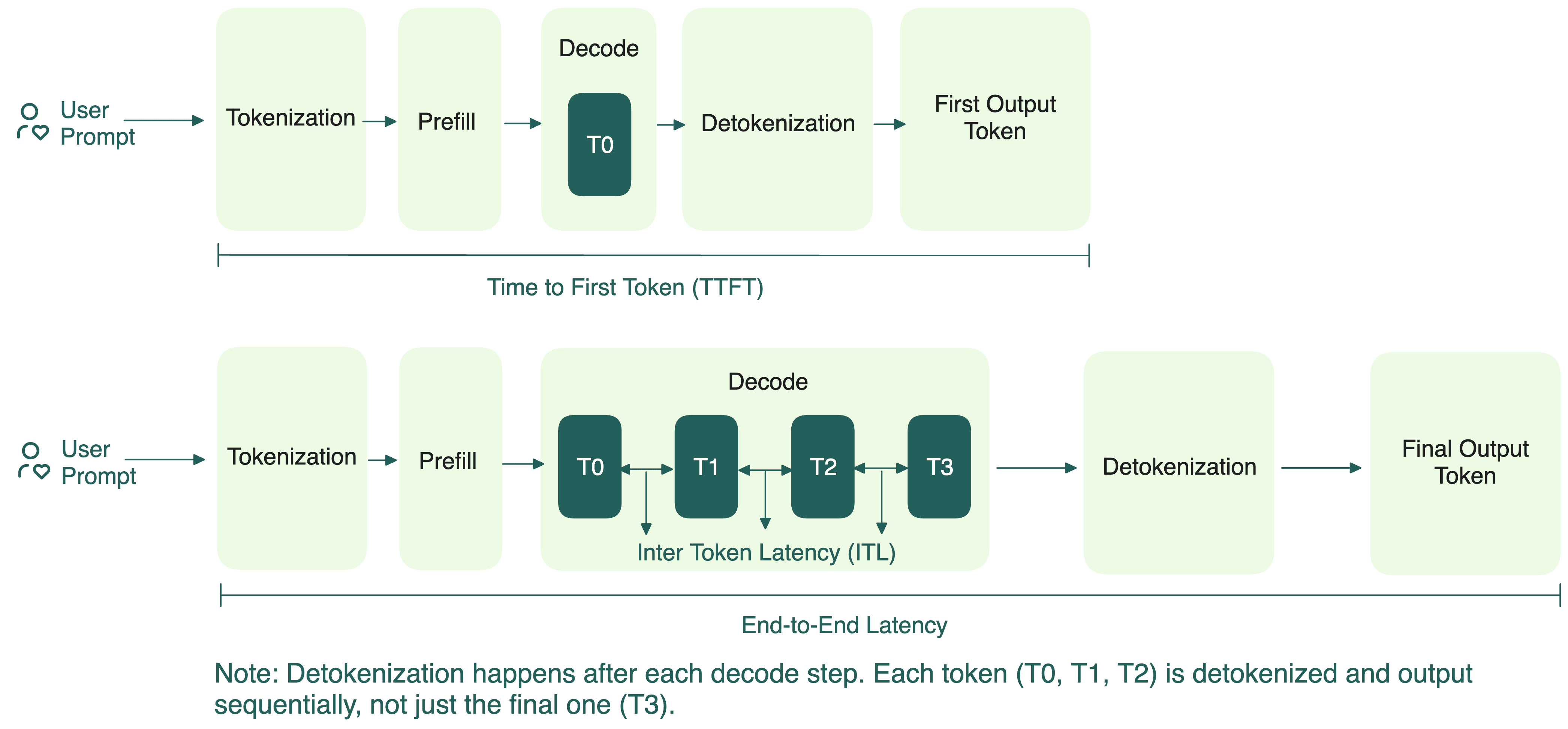
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
Optimizing AI Performance: A Guide to Efficient LLM Deployment
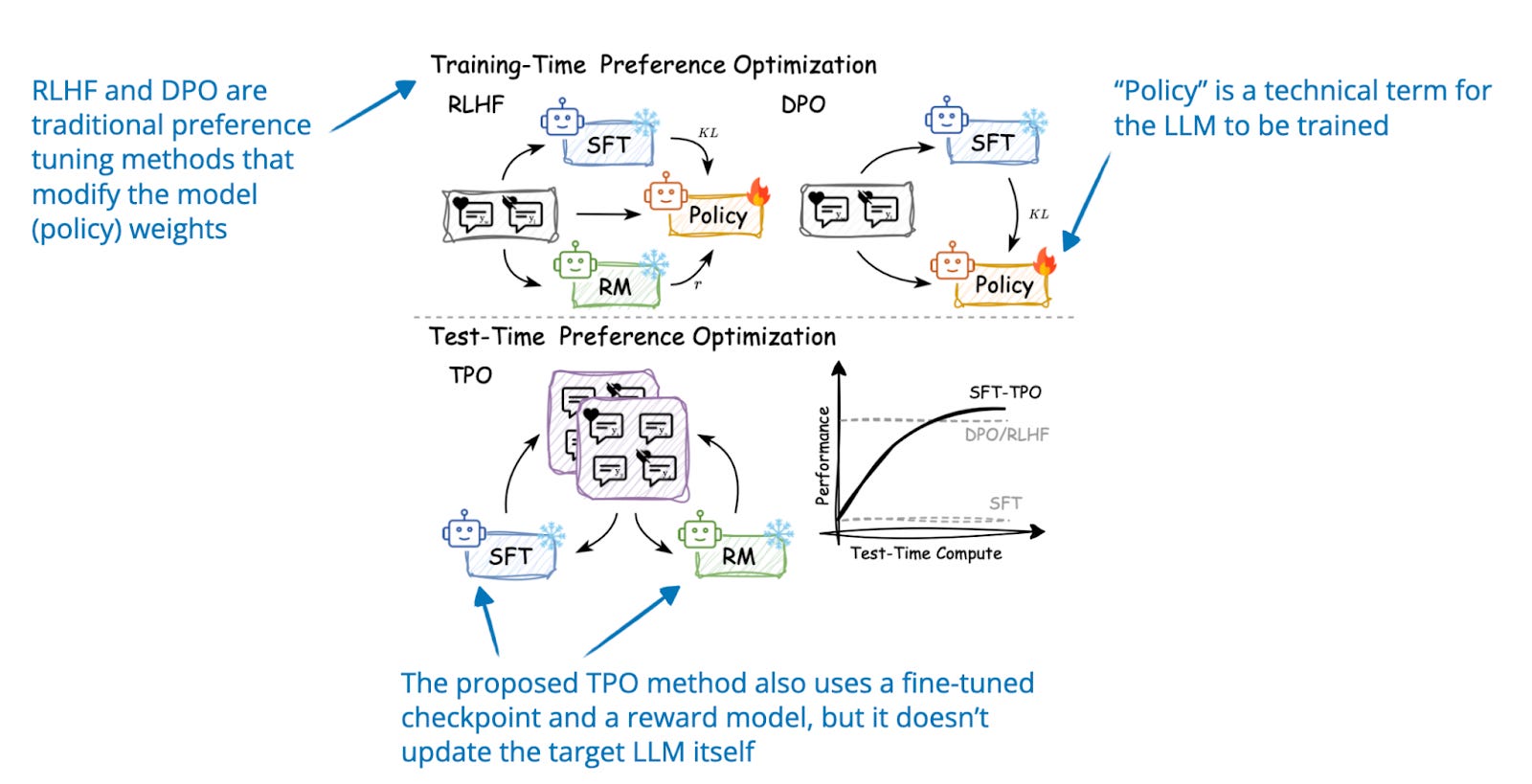
The State of LLM Reasoning Models
Accelerating LLM Inference: Fast Sampling with Gumbel-Max Trick
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
What is LLM Inference? • luminary.blog
LLM Sampling with FastMCP: Using Client LLMs for Scalable AI Workflows ...
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
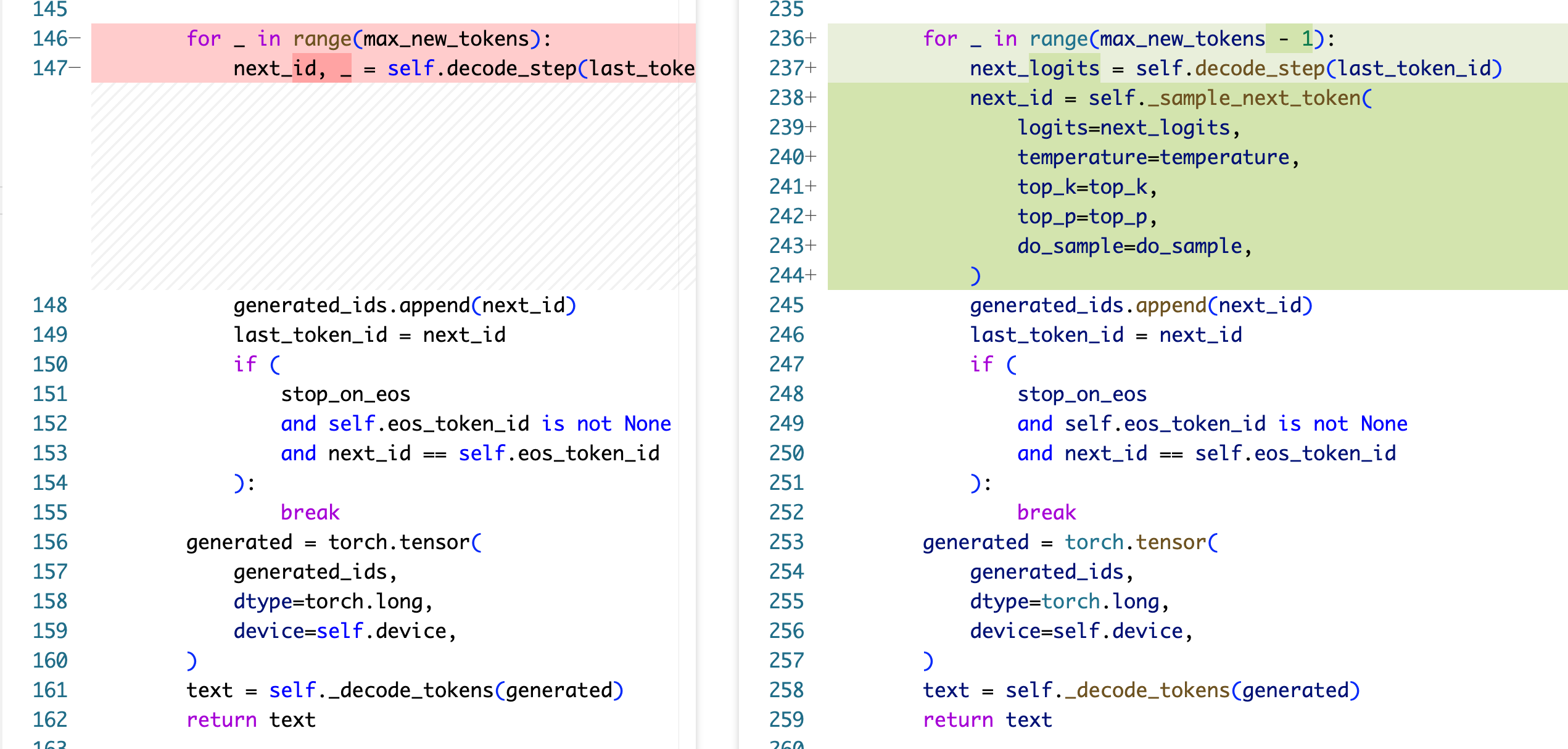
从零实现 LLM Inference:003. Sampling - Wine & Chord
Unveiling LLM Evaluation Focused on Metrics: Challenges and Solutions ...
LLM Benchmarking: Fundamental Concepts - Edge AI and Vision Alliance
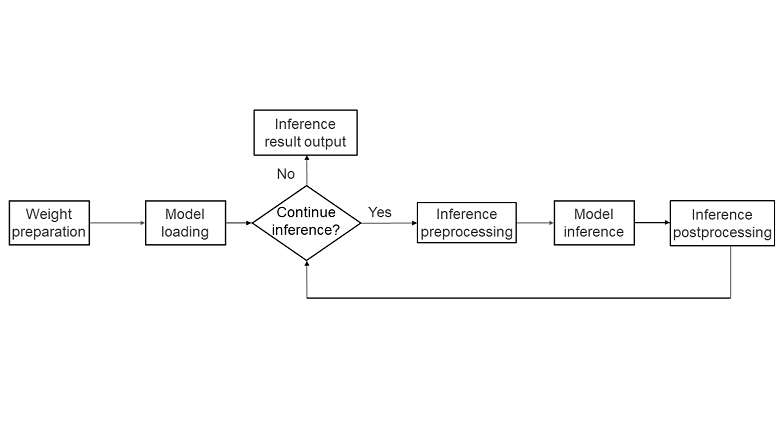
What is LLM Model Inference?
Paper page - Response Length Perception and Sequence Scheduling: An LLM ...
MindSpore Large Language Model Inference — MindSpore master documentation
LLM APIs & Prompt Engineering
Accelerating LLM Inference: Introducing SampleAttention for Efficient ...
LLM Sampling: Engineering Deep Dive | MatterAI Blog
A Gentle Introduction to LLM APIs | llmapps – Weights & Biases
The Emerging LLM Stack: A Comprehensive Guide for Developers - Helicone
Rethinking LLM inference: Why developer AI needs a different approach
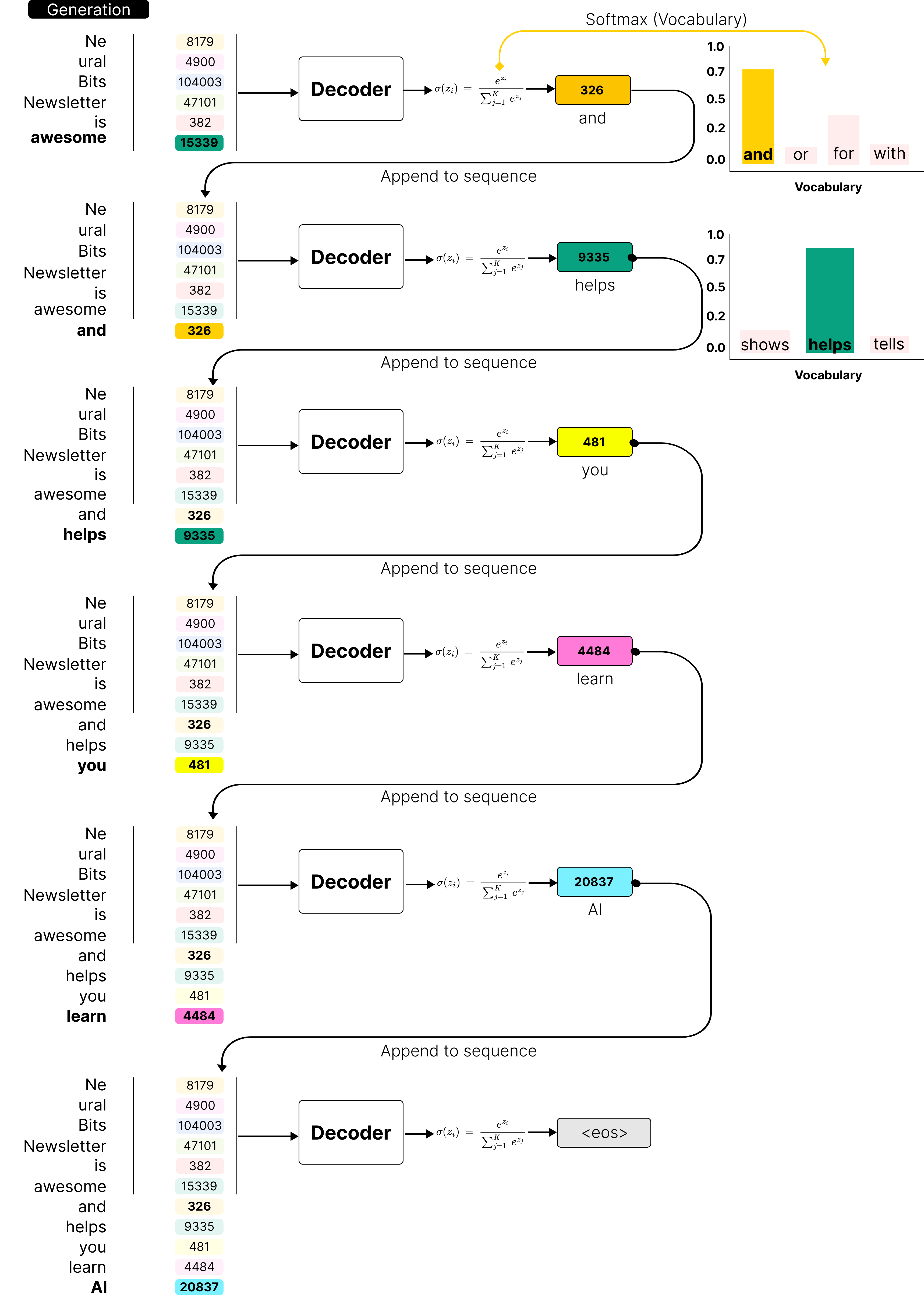
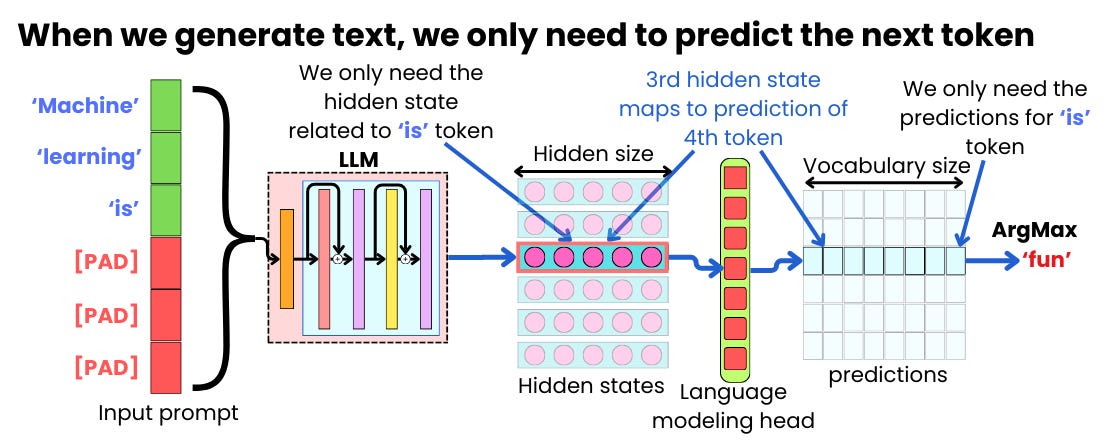
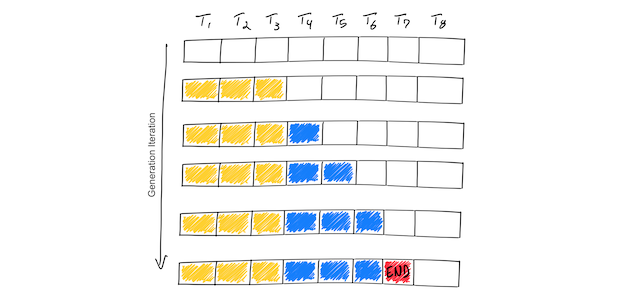
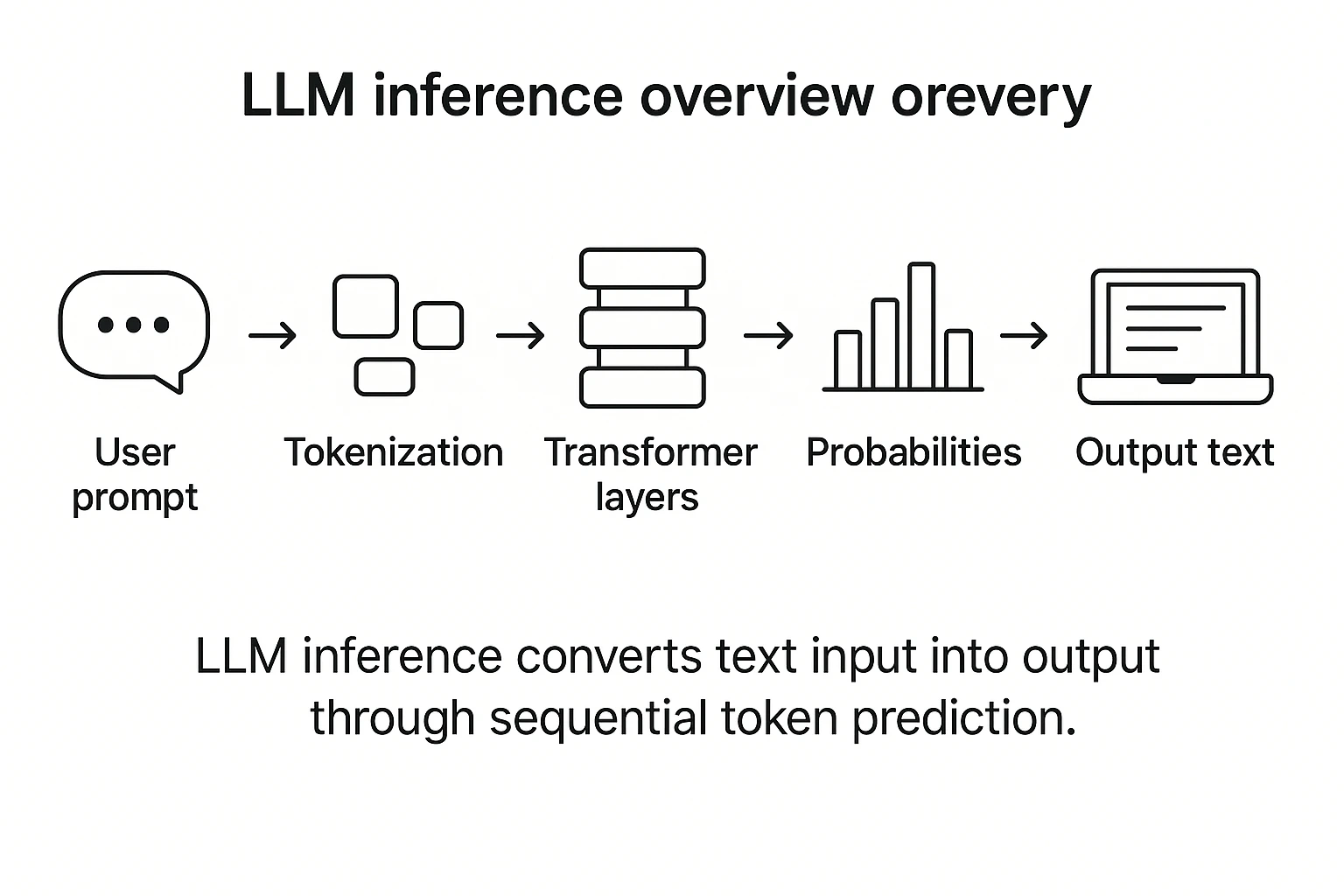
Understanding LLM Inference: How AI Generates Words | DataCamp
Advanced LLM Sampling Methods to Transform AI Outputs
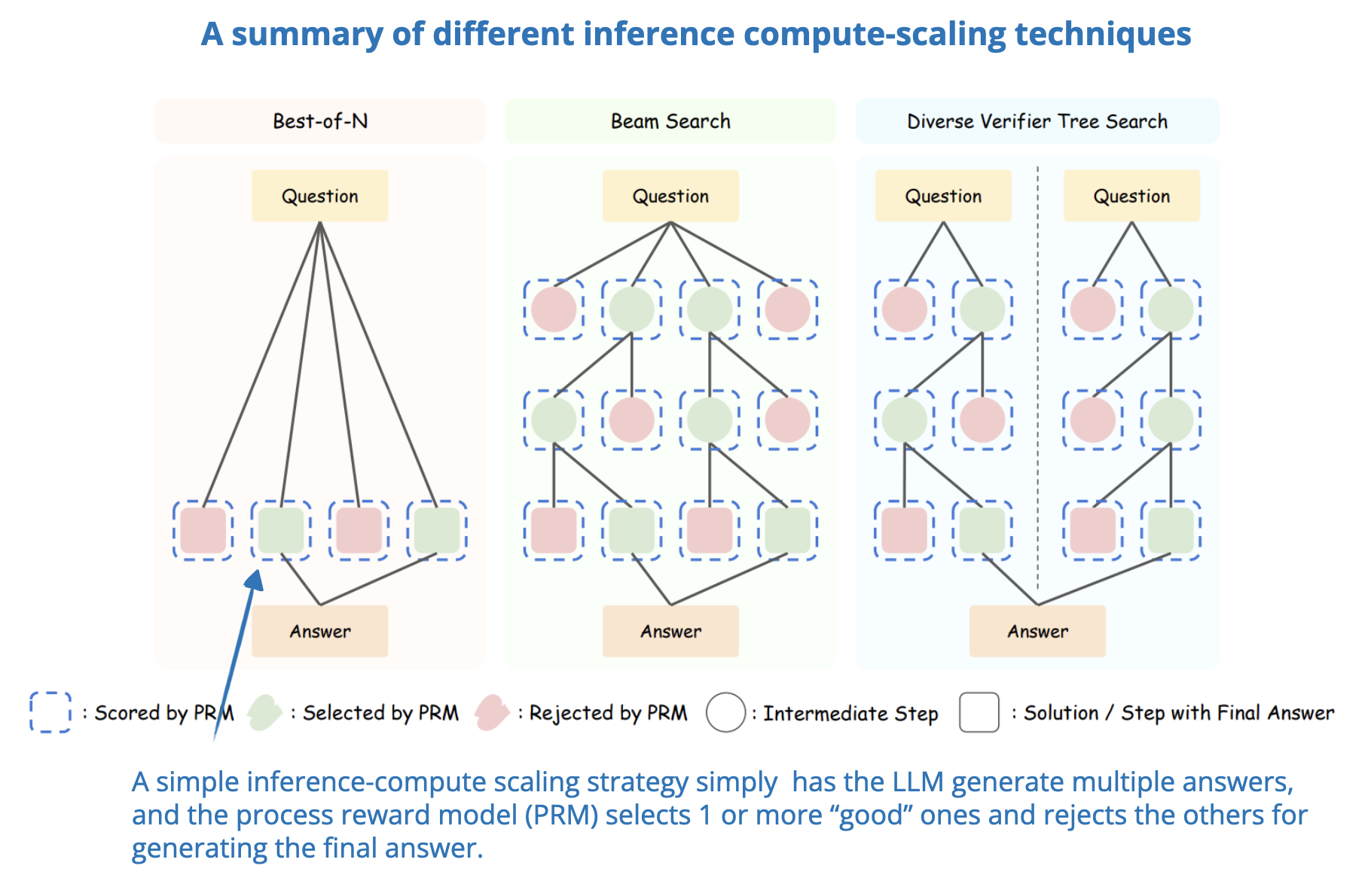
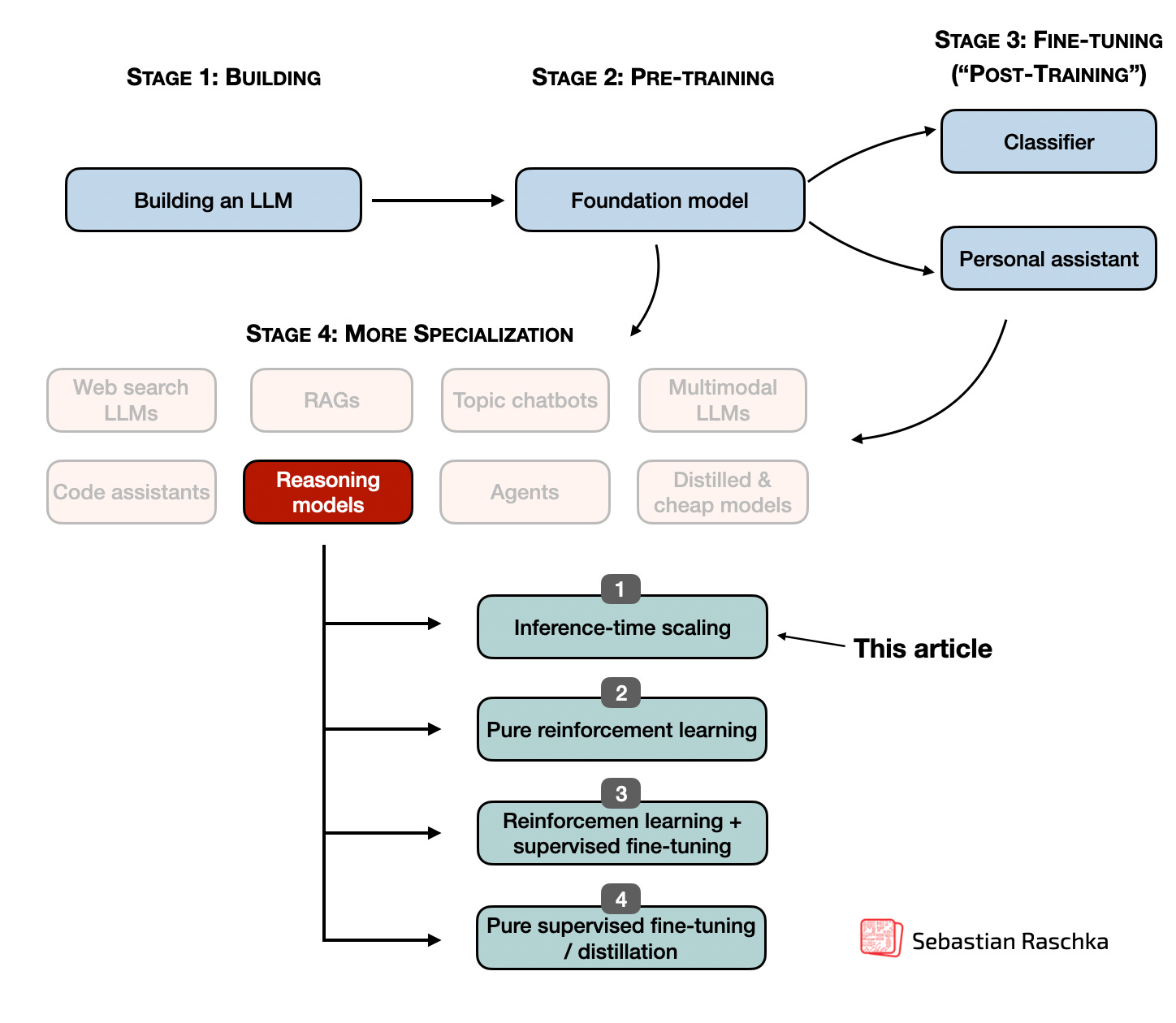
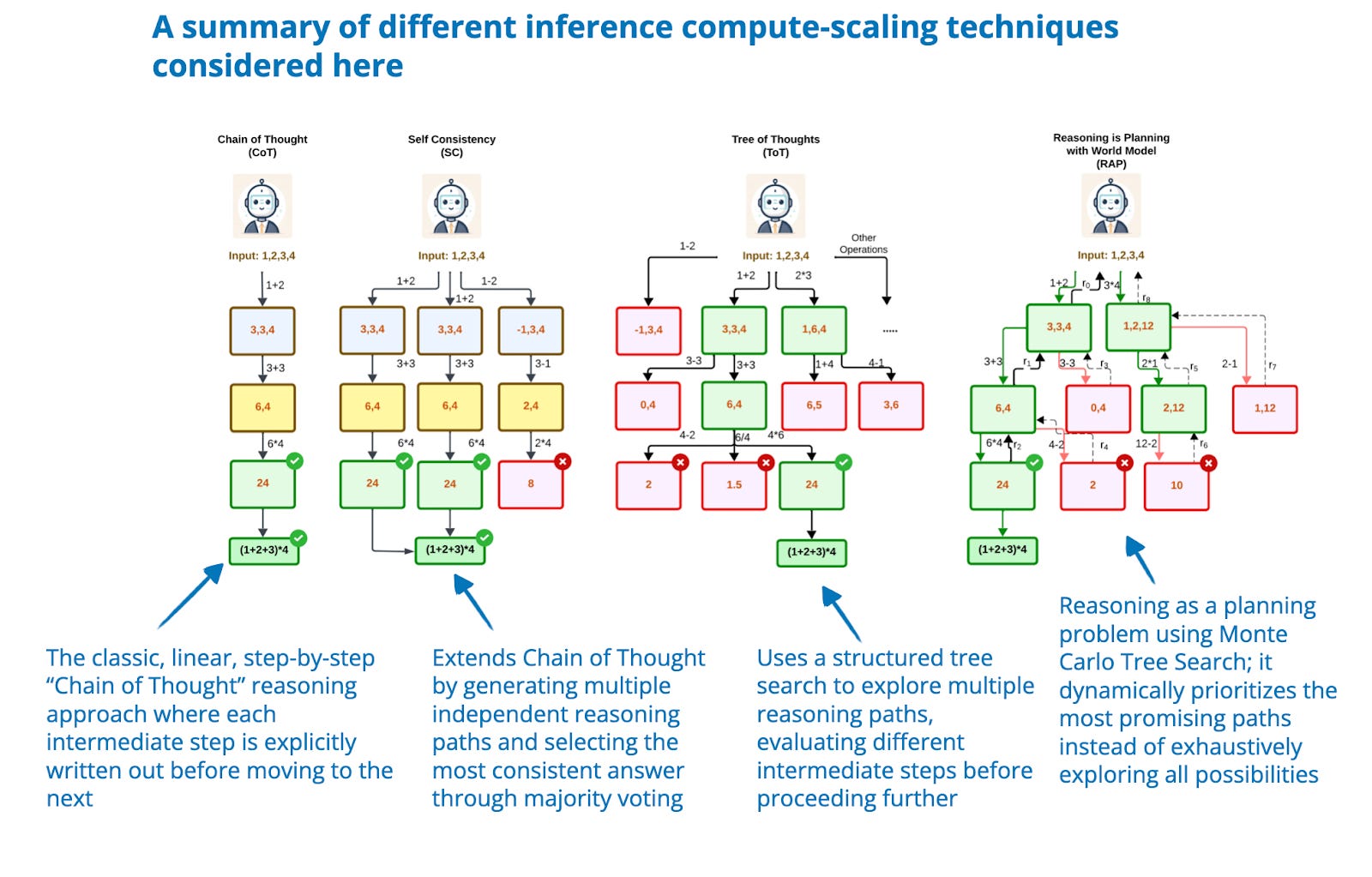
Inference-Time Compute Scaling Methods to Improve Reasoning Models ...
LLM-Inference-Acceleration/attention-mechanism/lisa--layerwise ...
Multi-view Intent Learning and Alignment with Large Language Models for ...
Optimizing Large Language Model Inference: A Deep Dive into Continuous
Comprehensive Analysis and Selection Guide for Large Language Model ...
llm-inference · PyPI
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
(PDF) Towards Efficient Multi-LLM Inference: Characterization and ...




















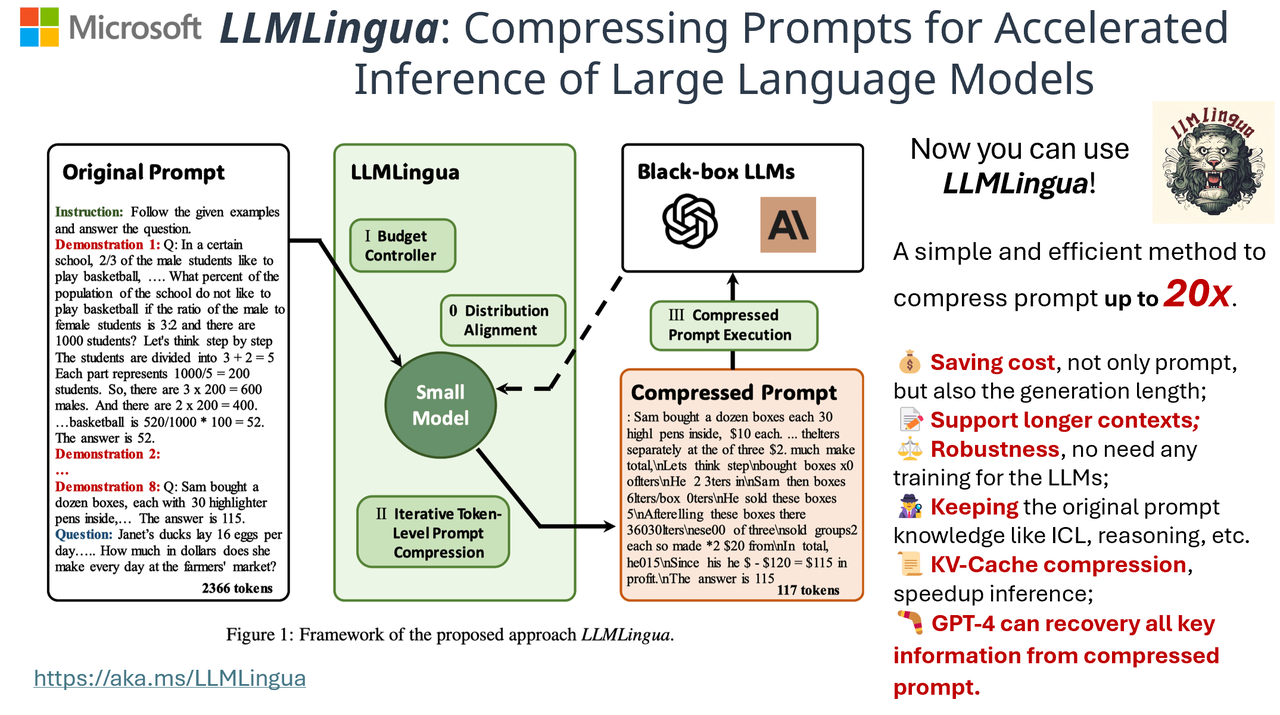
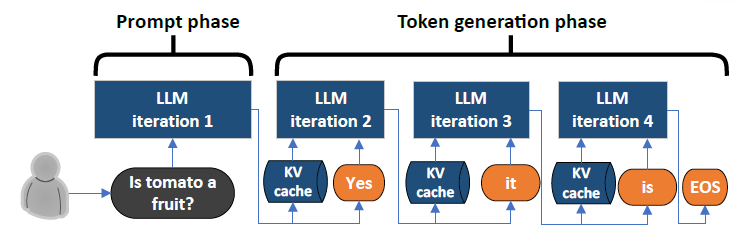

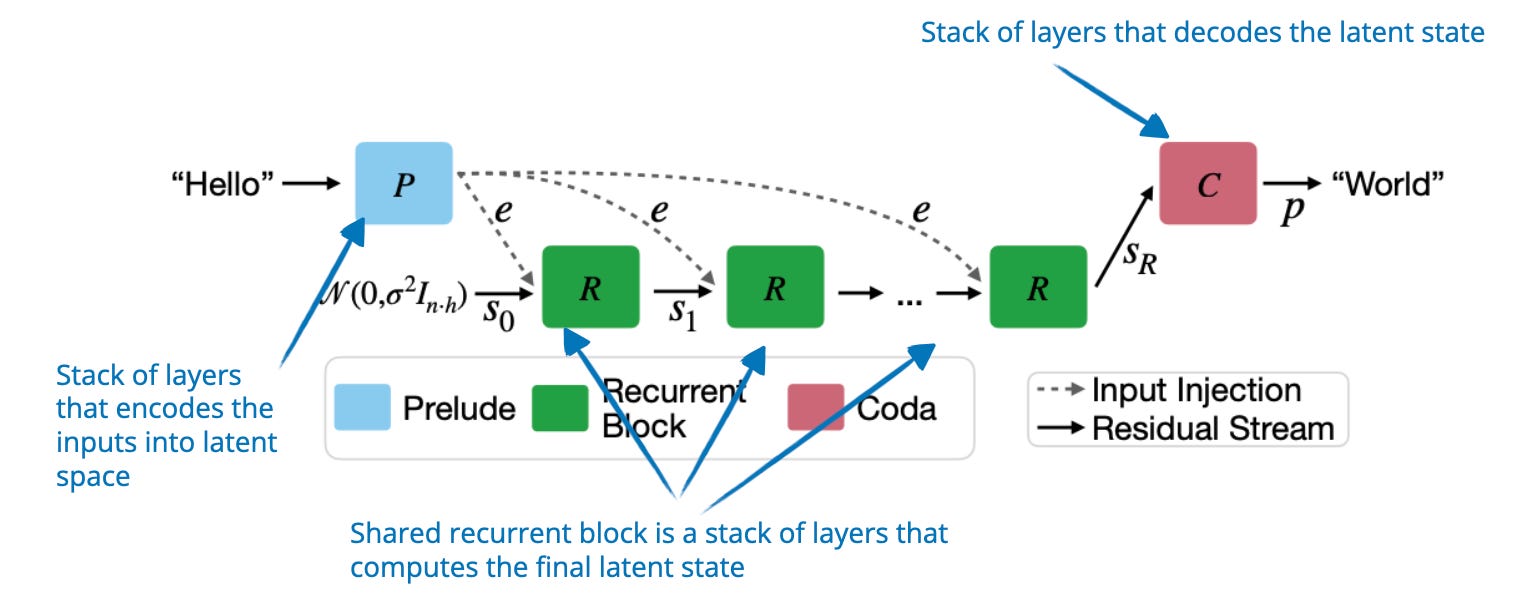
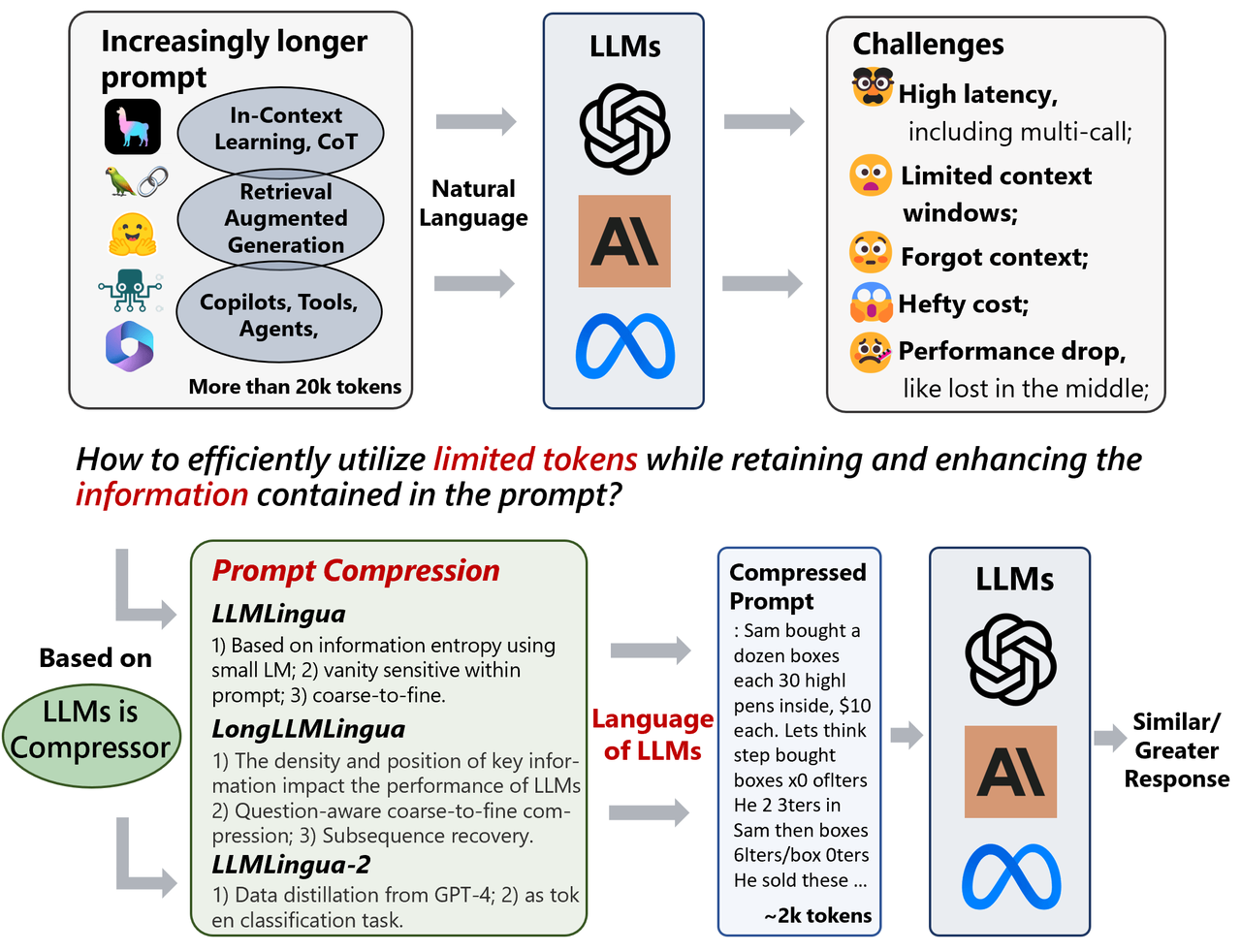









-png.png?width=4320&height=2160&name=AI%20Model%20Training%20vs%20Inference%20(1)-png.png)














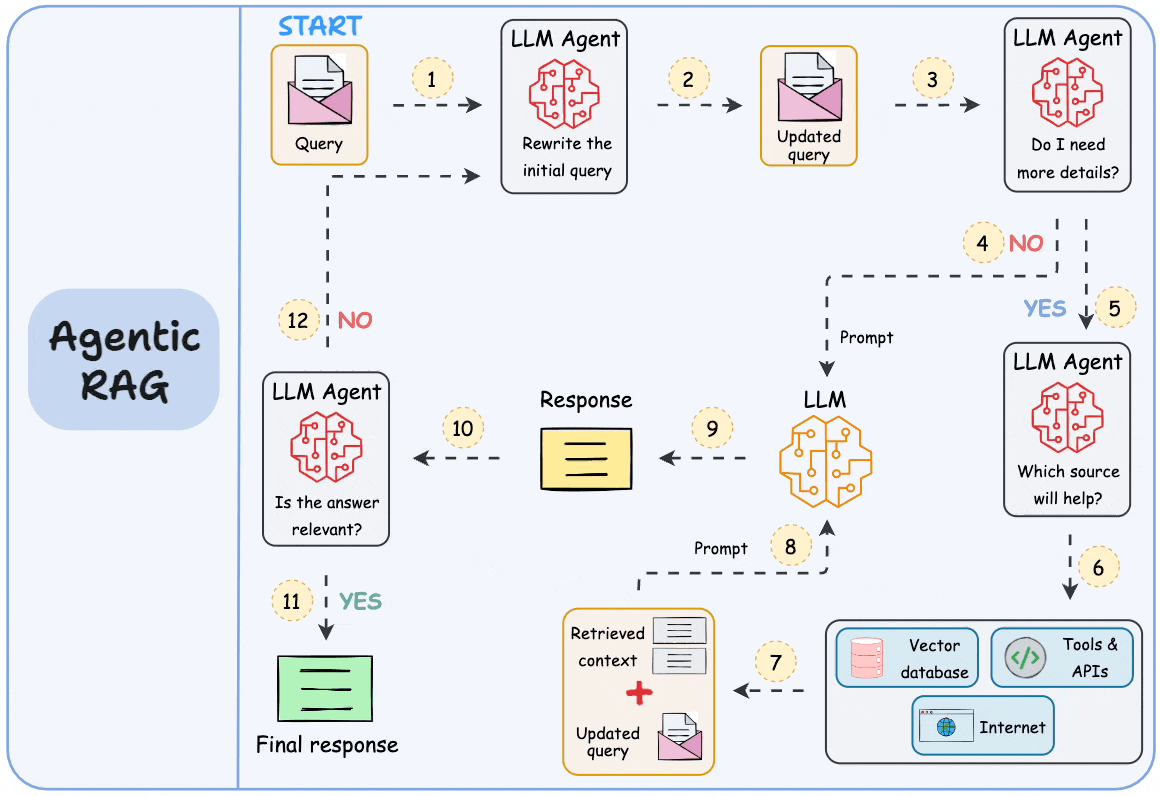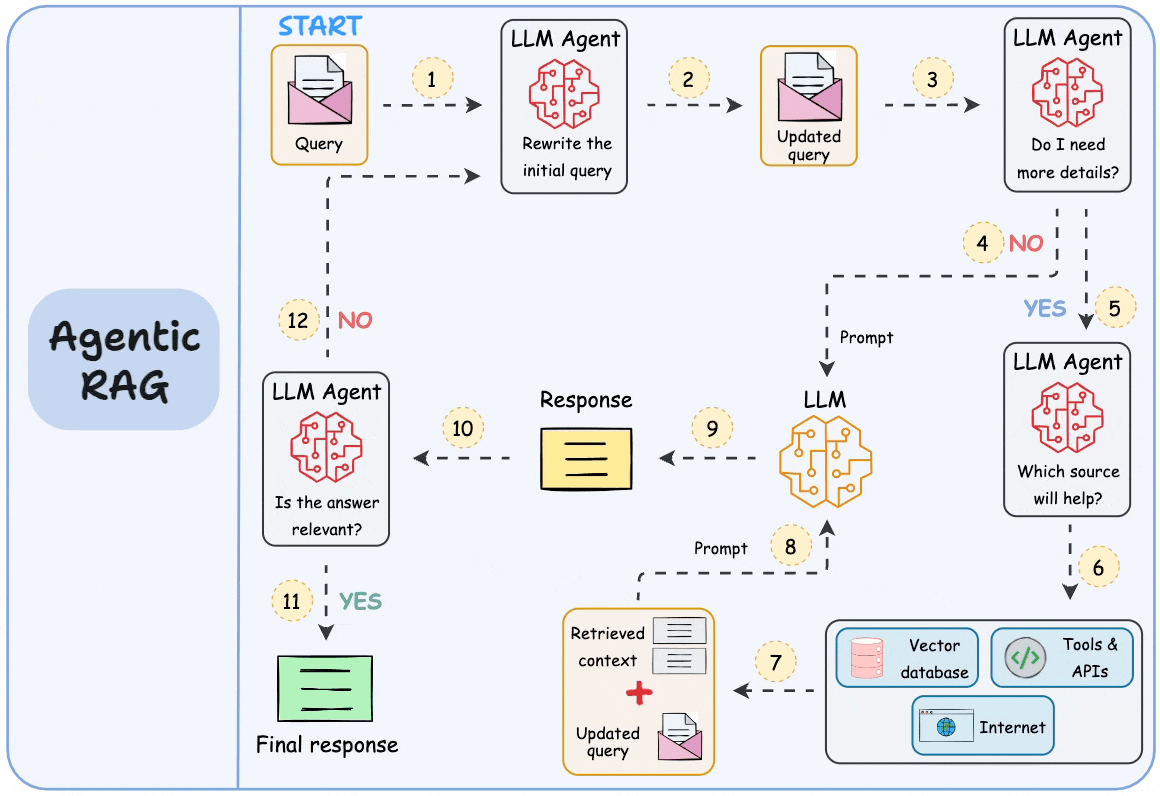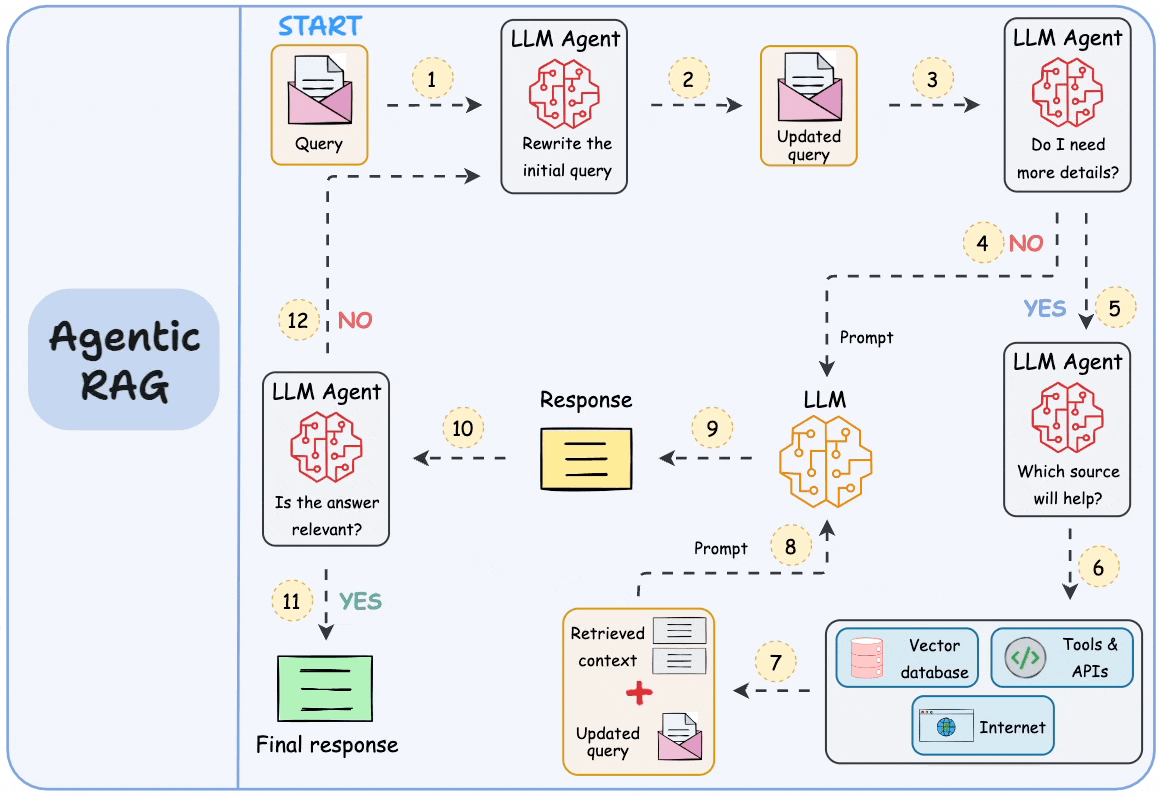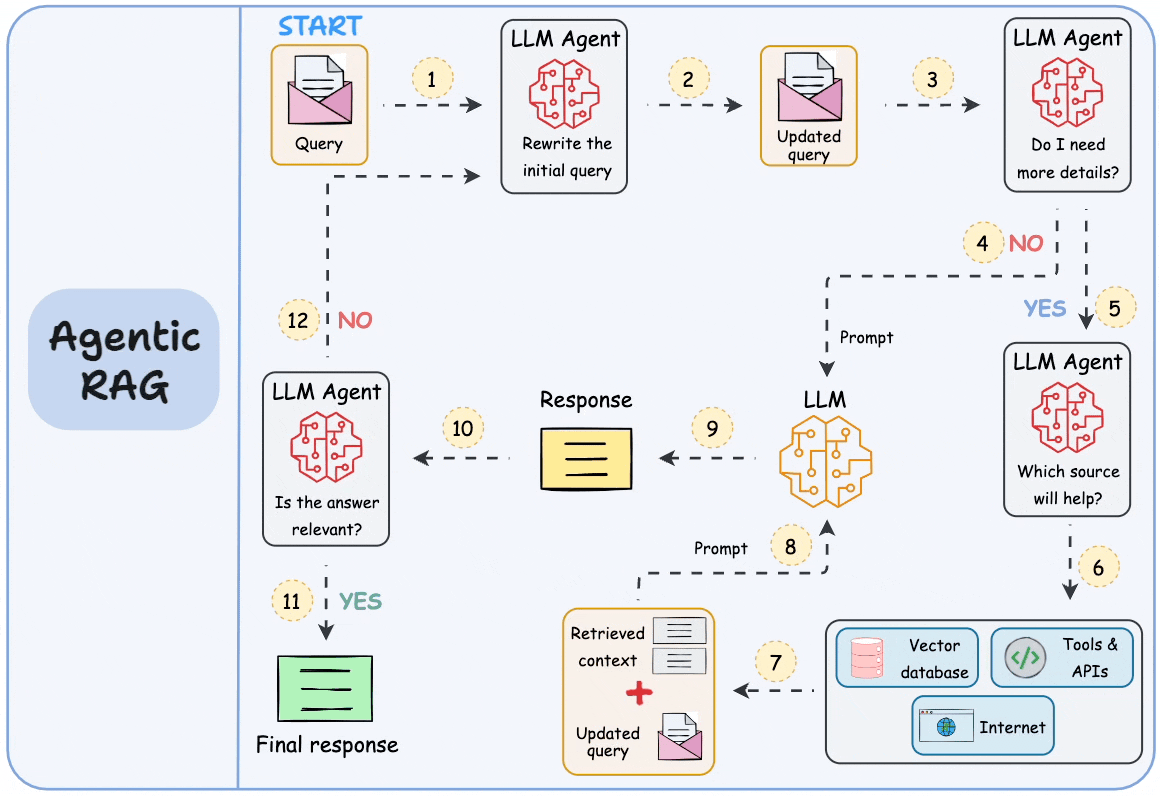




















.png)