Showing 63 of 63on this page. Filters & sort apply to loaded results; URL updates for sharing.63 of 63 on this page
LLM - Int8 - 8-Bit Matrix Multiplication For Transformer at Scale ...
Day 60/75 LLM Quantization to Convert Float32 to Int8 | LLM Evaluation ...
Cutting LLM Costs via Quantization & Fine-Tuning | GenAI ROI
Local Large Language Models | Int8
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析 - NVIDIA 技术博客
LLM 量化技术小结 - 知乎
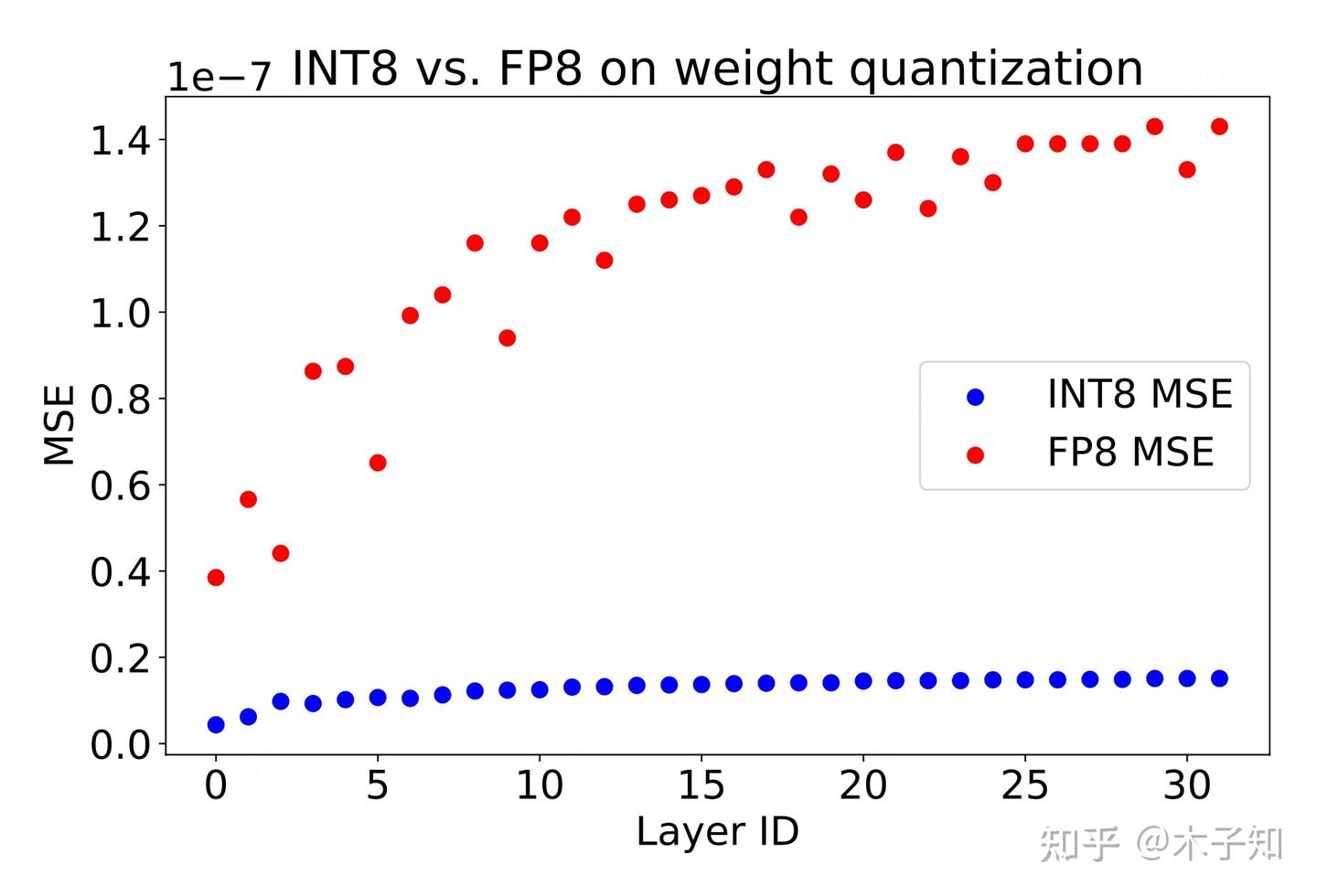
LLM推理量化:FP8 versus INT8 - 知乎
大模型量化技术原理-LLM.int8()、GPTQ-CSDN博客
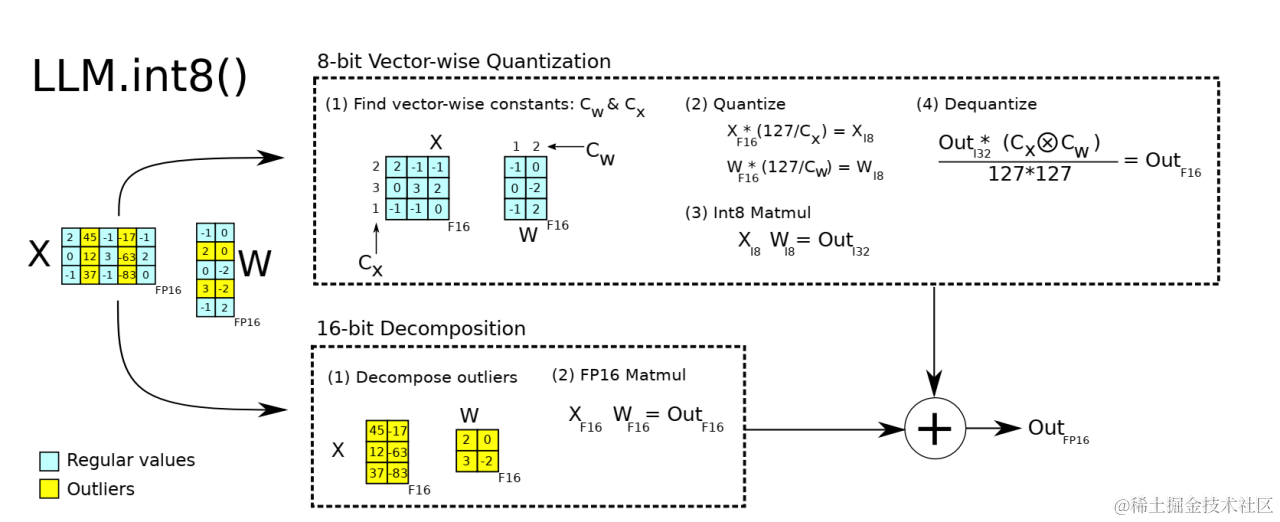
LLM.int8()——自适应混合精度量化方法-CSDN博客
Lê Ngọc Thạch on LinkedIn: LLM.int8() This technique identifies ...
LLM(十一):大语言模型的模型量化(INT8/INT4)技术 - 知乎
模型量化-llm量化 - 知乎
Mike Lewis, Younes Belkada, Luke Zettlemoyer · LLM.int8(): 8-bit Matrix ...
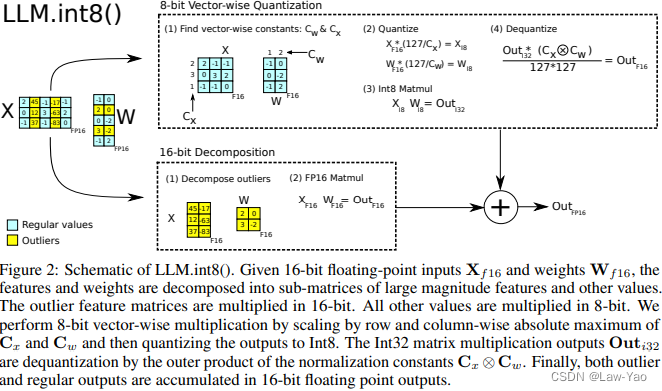
大模型LLM.int8()量化技术原理与代码实现-CSDN博客
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
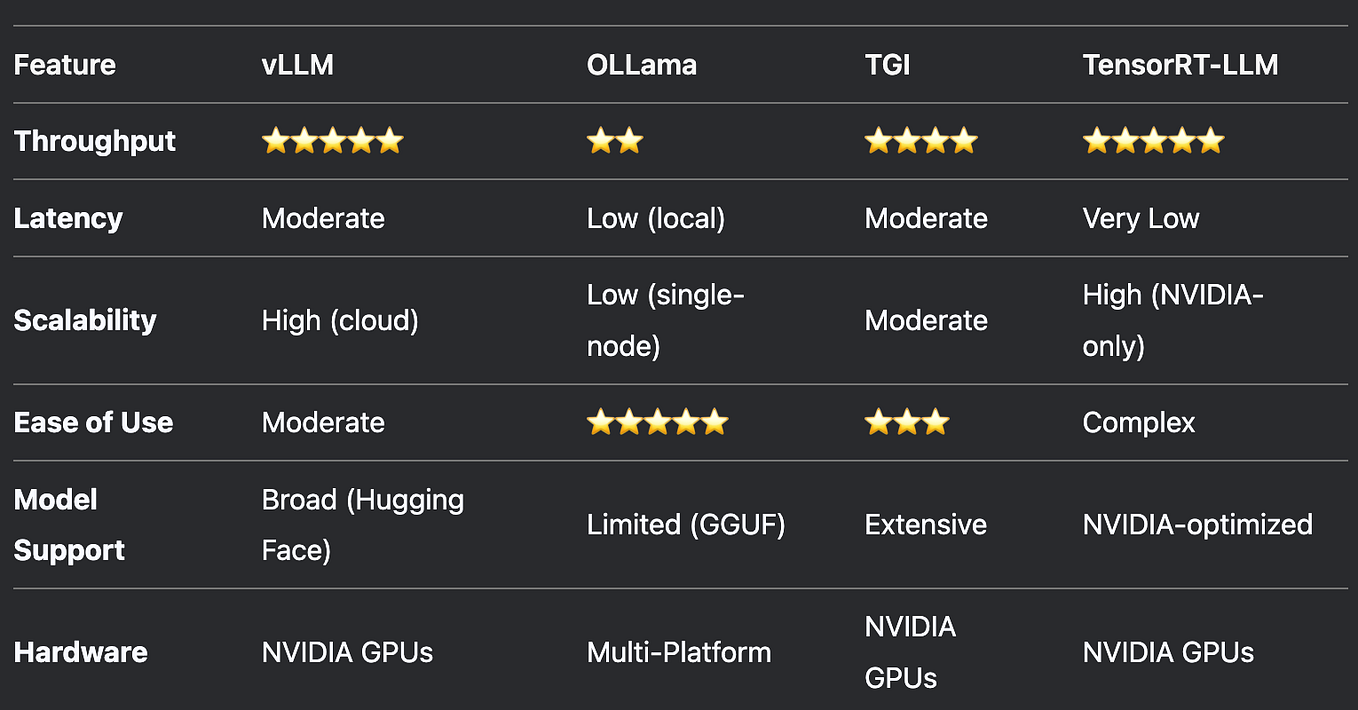
【LLM】vLLM部署与int8量化-CSDN博客
8位混合精度矩阵乘法,小硬件跑大模型 - 知乎
LLM.int8() and Emergent Features — Tim Dettmers
Understanding LLM.int8() Quantization — Picovoice
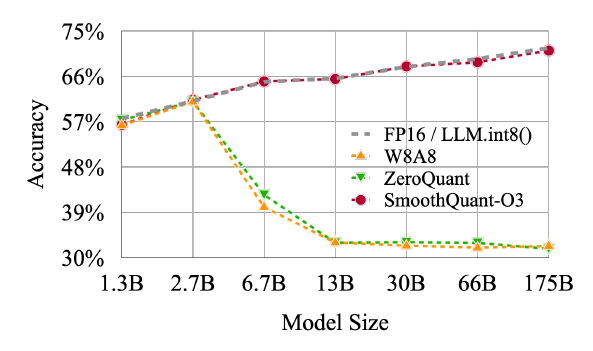
量化算法进阶篇(上):8-bit量化算法 —— 从LLM.int8()到SmoothQuant - 知乎
[핵심][22.08]LLM.int8()
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale | DeepAI
OGAWA, Tadashi on Twitter: "=> "LLM.int8(): 8-bit Matrix Multiplication ...
LLM.int8()
Paper page - LLM.int8(): 8-bit Matrix Multiplication for Transformers ...
[PDF] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale ...
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale ...
llm.int8(): Cuantización 8-bit para Transformers | MaximoFN
LLM.Int8(). LLM.int8(): 8-bit Matrix Multiplication… | by Danny H Lee ...
LLM推理加速05 量化 LLM.int8()和AWQ - 知乎
INT8模型量化:LLM.int8 - 知乎
利用TPU-MLIR实现LLM INT8量化部署 - 知乎
LLM数据类型与精度 (FP16, INT8)
LLM.int8()源码阅读_调用llm.int8-CSDN博客
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale | by ...
Paper review[LLM.int8()]
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...
LLM.int8: 8-bit Matrix Multiplication for Transformers at Scale
AI 十大论文精讲(九):无损失量化革命——LLM.int8 () 破解千亿大模型内存困局-阿里云开发者社区
[LLM量化] LLM.int8(), GPTQ, SmoothQuant, AWQ, SqueezeLLM, ATOM, OmniQuant ...
How SmoothQuant solved LLM.int8() | Aleksa Gordić posted on the topic ...
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
量化那些事之llm.int8/SpQR/RPTQ - 知乎
(PDF) LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
LLM.int8() od podszewki! - ML-Workout #9 - YouTube





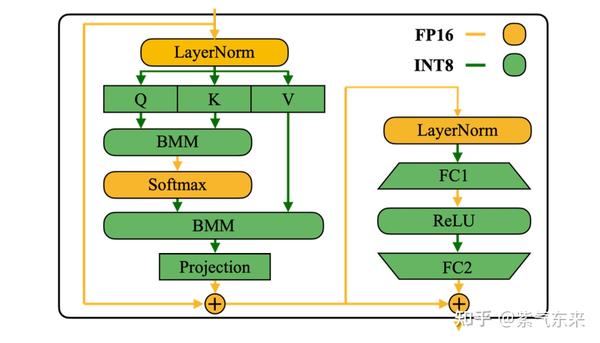

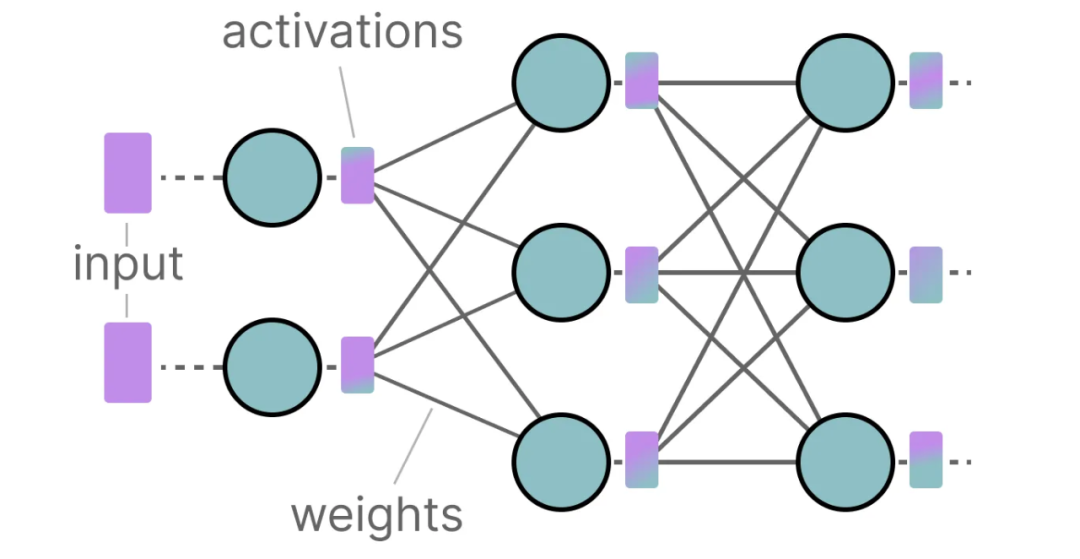

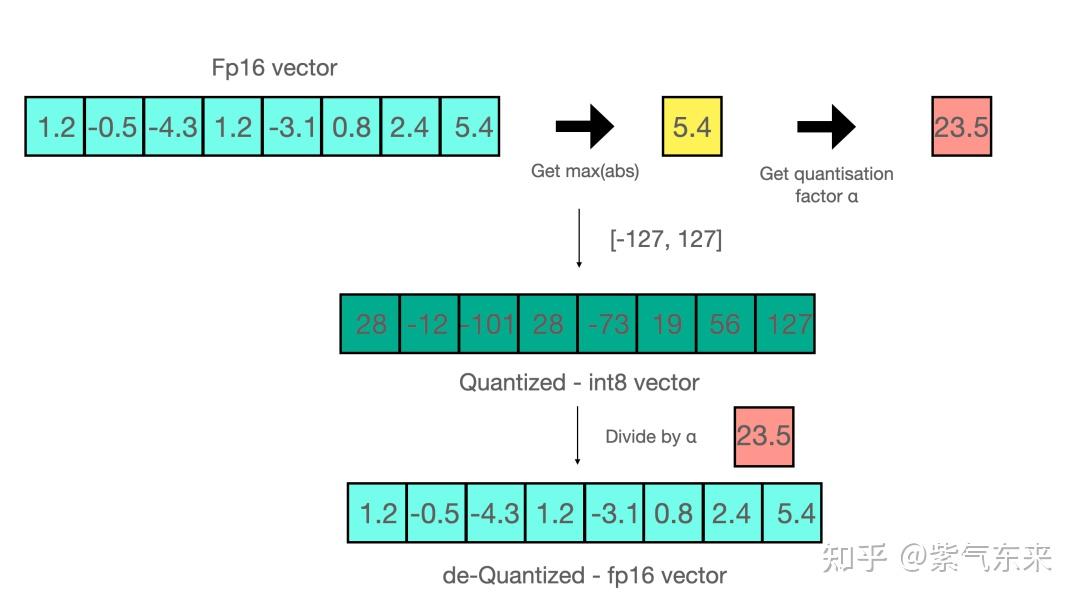
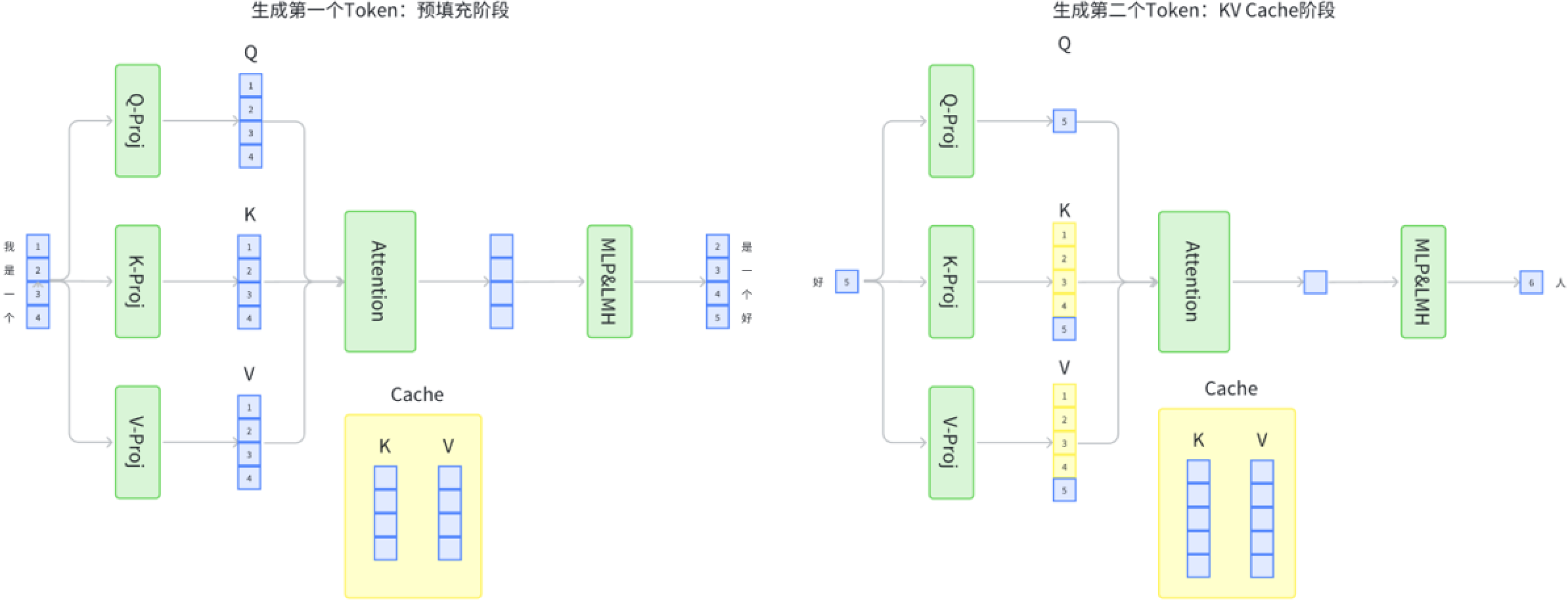
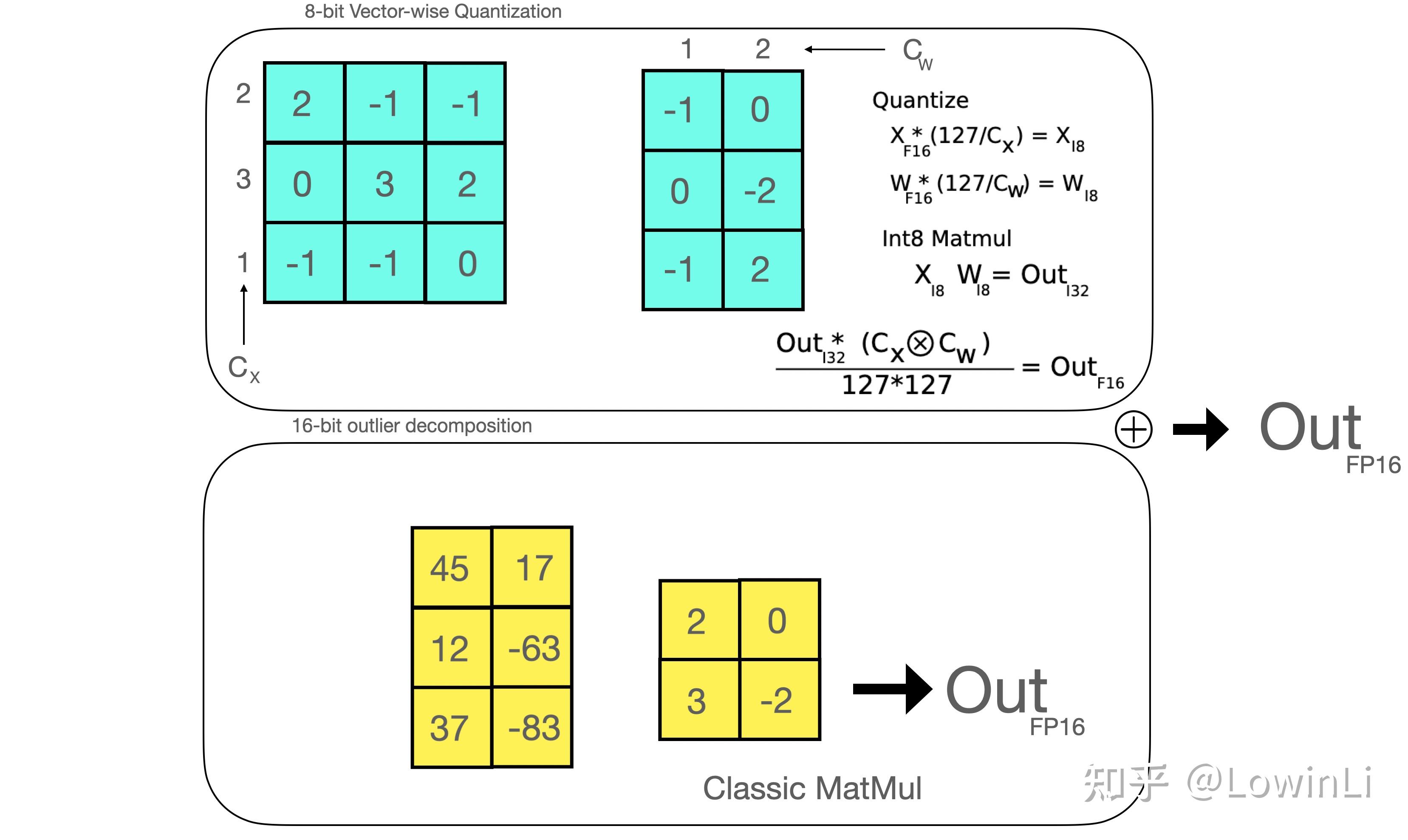
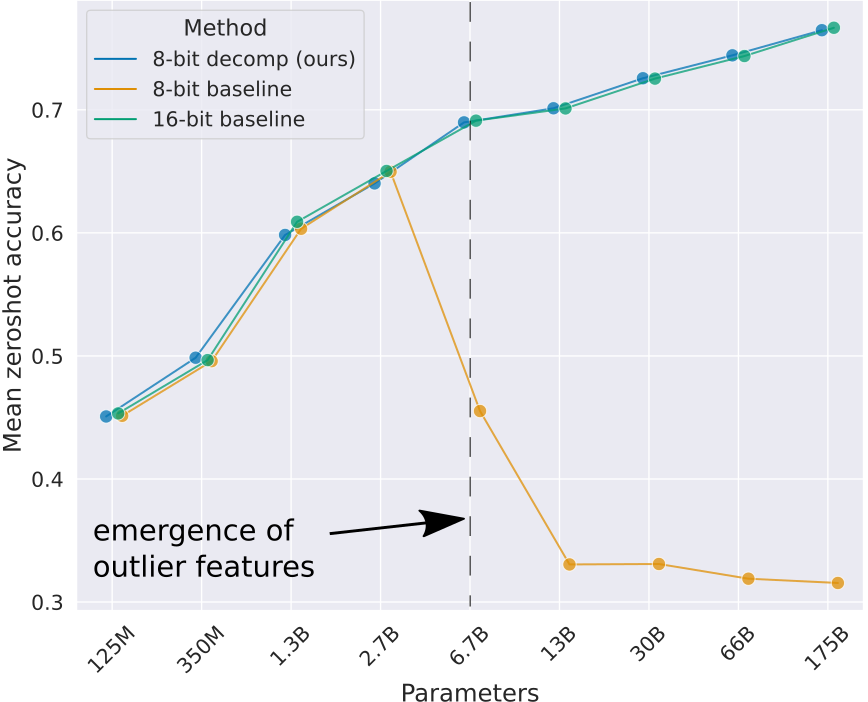

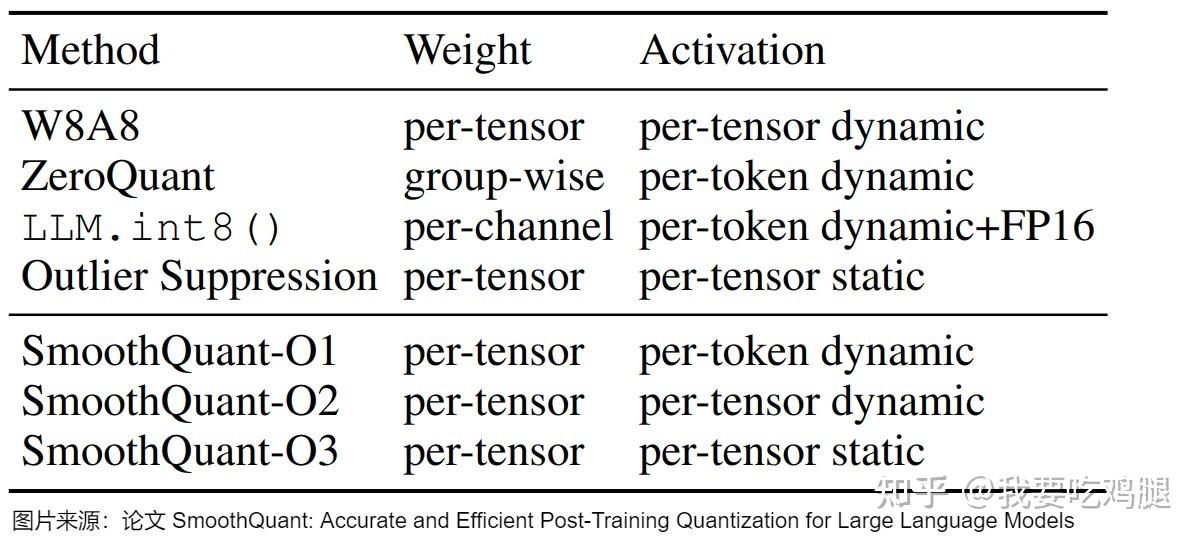


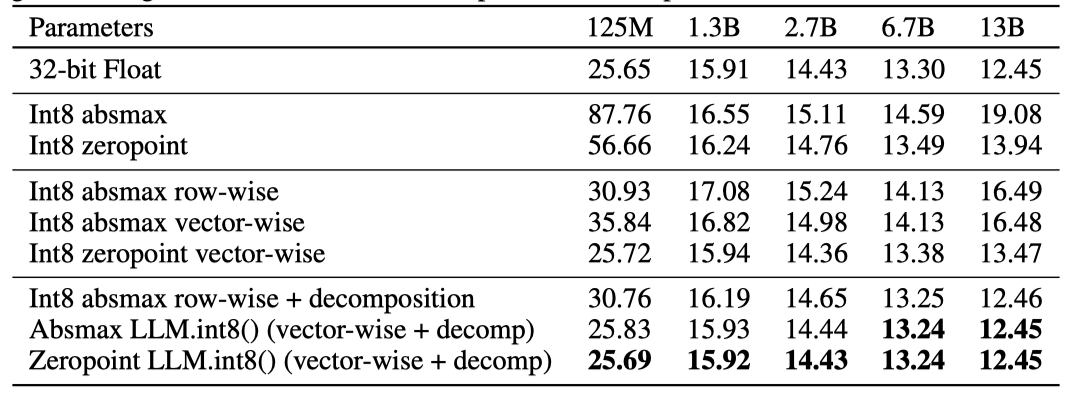



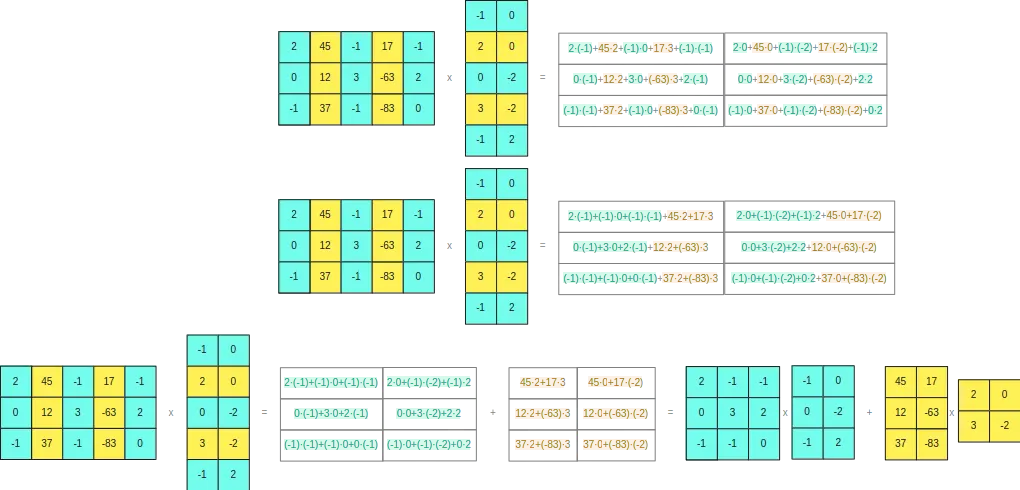

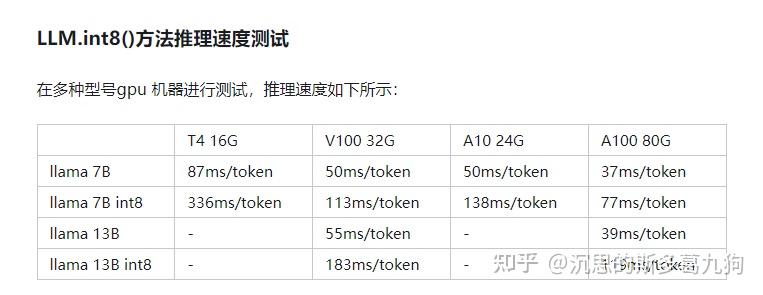
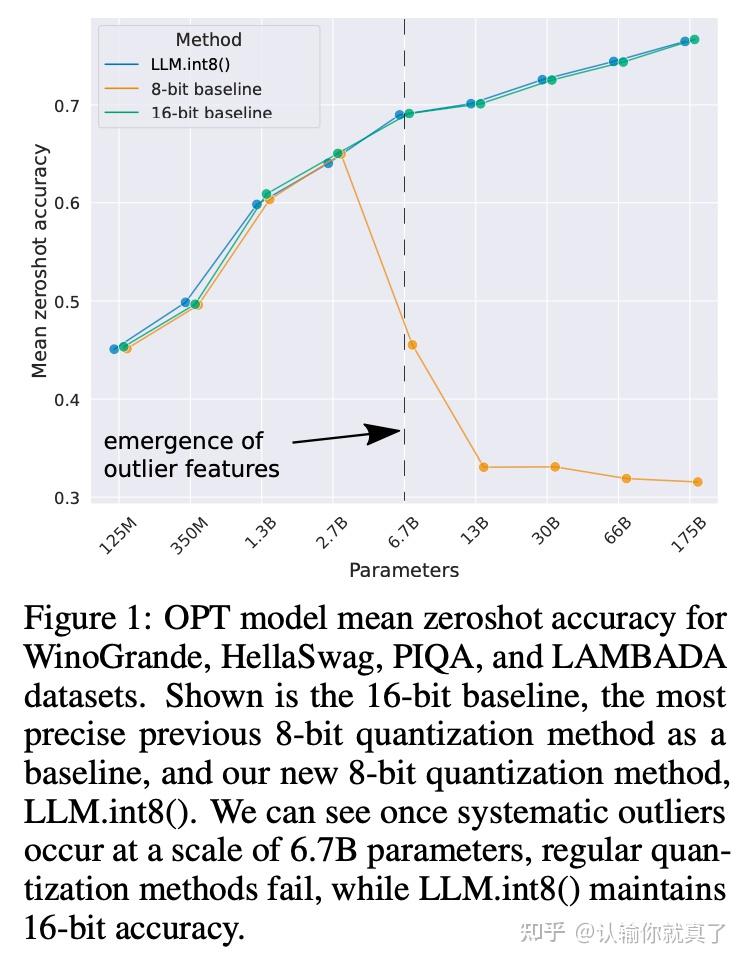
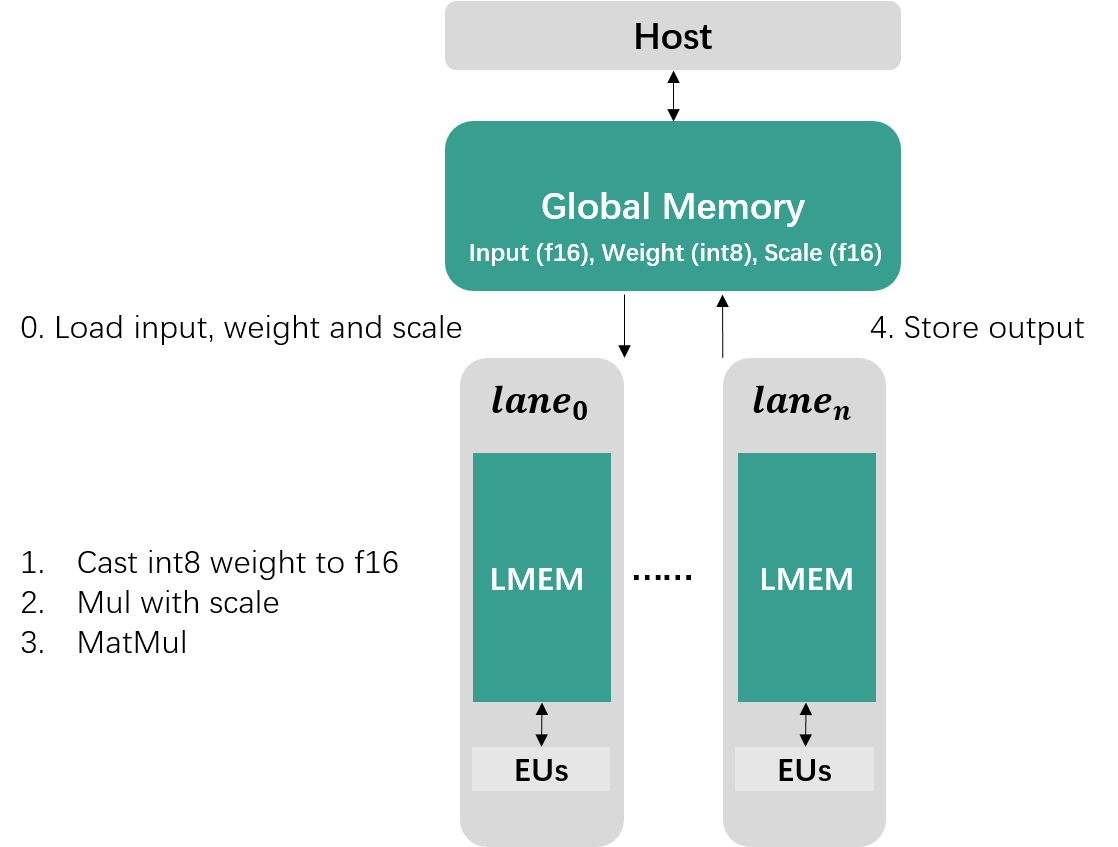
-thumbnail.webp)