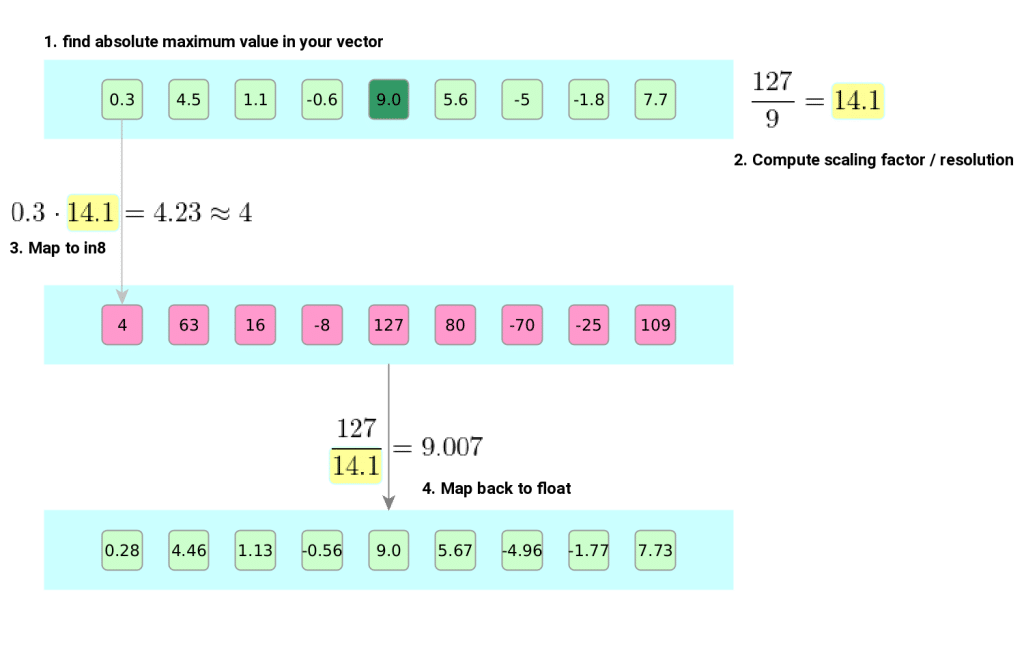
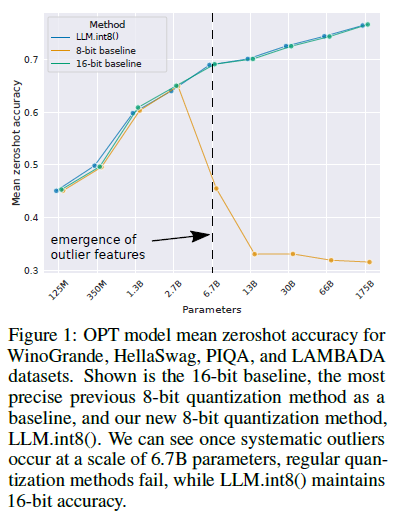
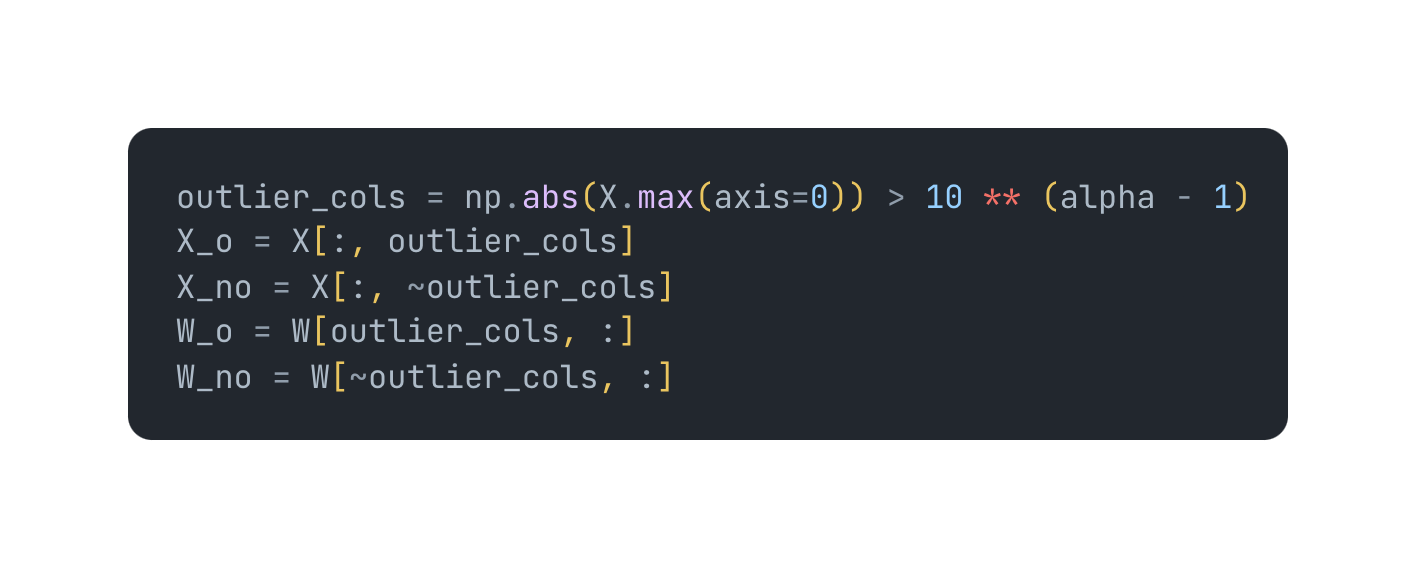
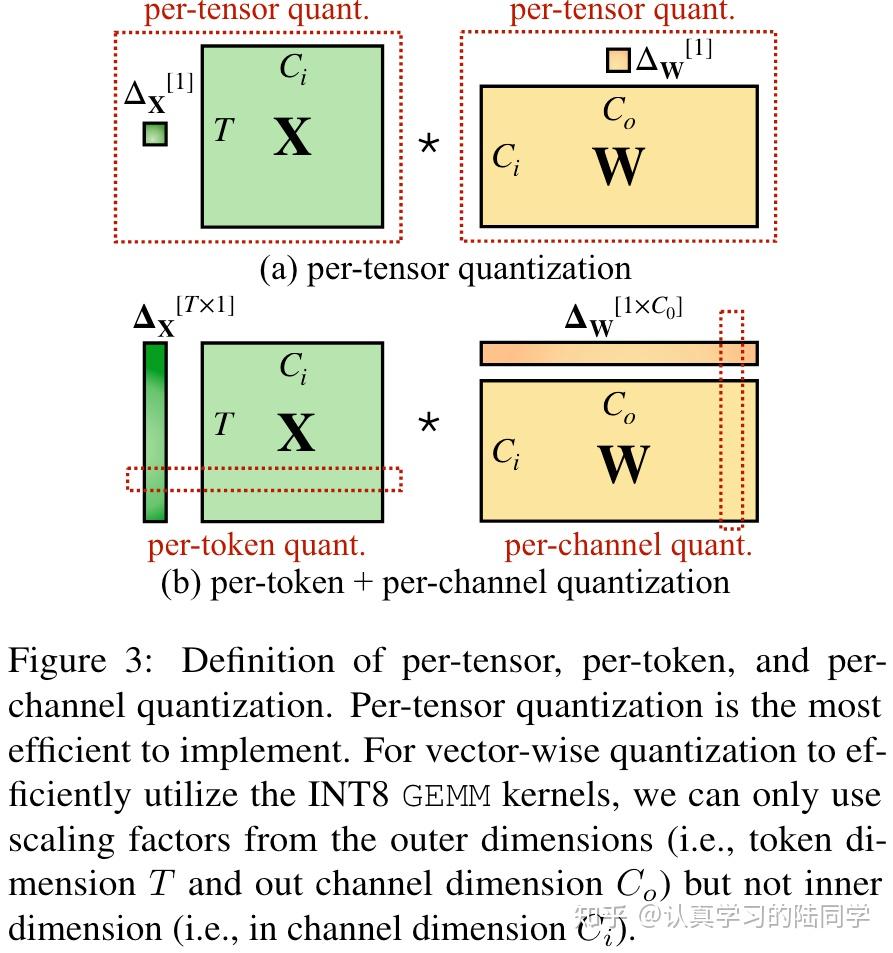
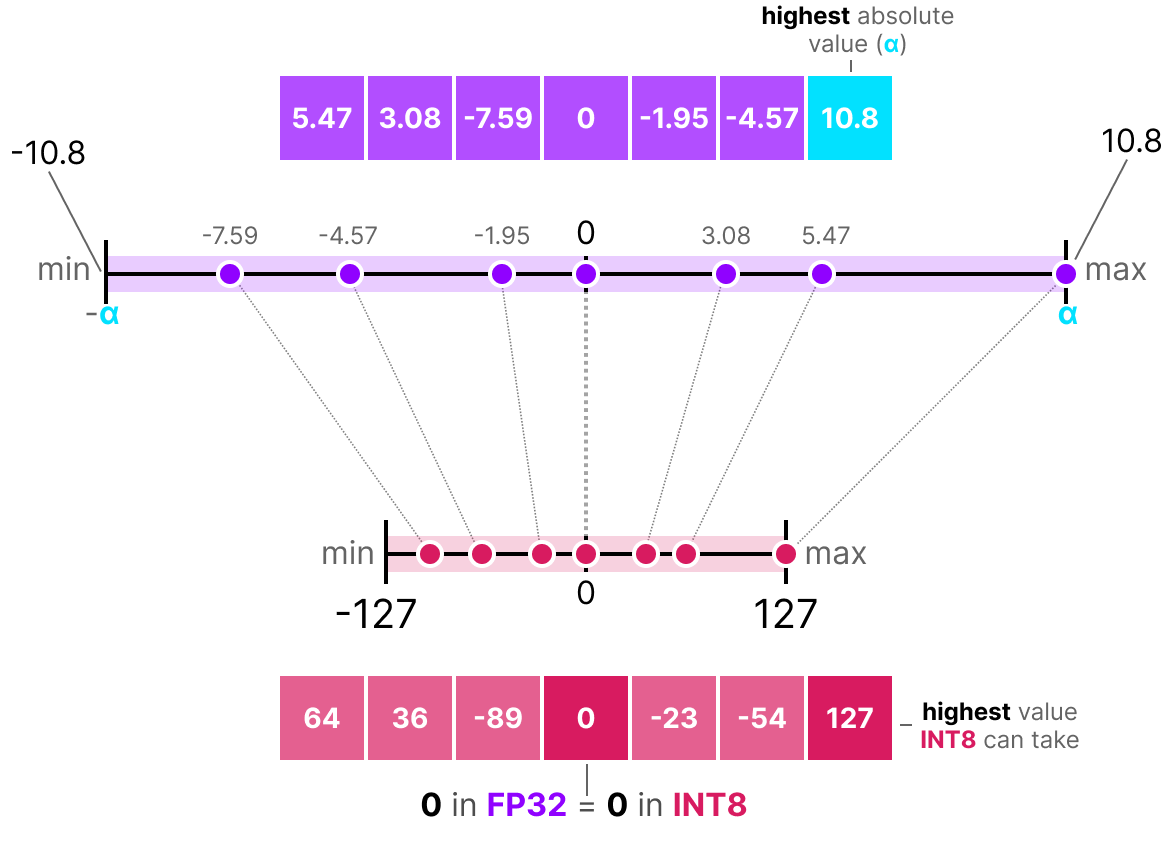
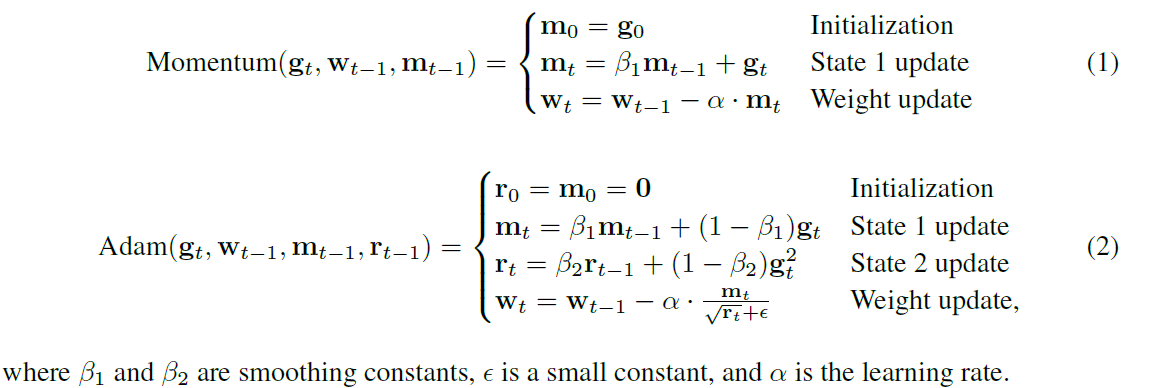Showing 84 of 84on this page. Filters & sort apply to loaded results; URL updates for sharing.84 of 84 on this page
int8 Weight and Activation Quantization - LLM Compressor Docs
Day 60/75 LLM Quantization to Convert Float32 to Int8 | LLM Evaluation ...
Unlocking LLM Performance: Advanced Quantization Techniques on Dell ...
Improving LLM Inference Latency on CPUs with Model Quantization ...
Top LLM Quantization Methods and Their Impact on Model Quality
The Ultimate Handbook for LLM Quantization | Towards Data Science
A Visual Guide to LLM Quantization | Devtalk
8 LLM Quantization Moves for 60% Cheaper Inference | by Hash Block ...
LLM Quantization Explained. Shrinking AI models from feast to fit… | by ...
What is LLM Quantization Understanding Its Importance and Techniques
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
Cutting LLM Costs via Quantization & Fine-Tuning | GenAI ROI
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
Comparing LLM Quantization Toolkit Results
An Introduction to LLM Quantization - TextMine
Exploiting LLM Quantization
The Complete Guide to LLM Quantization | LocalLLM.in
Data Types in LLM Quantization
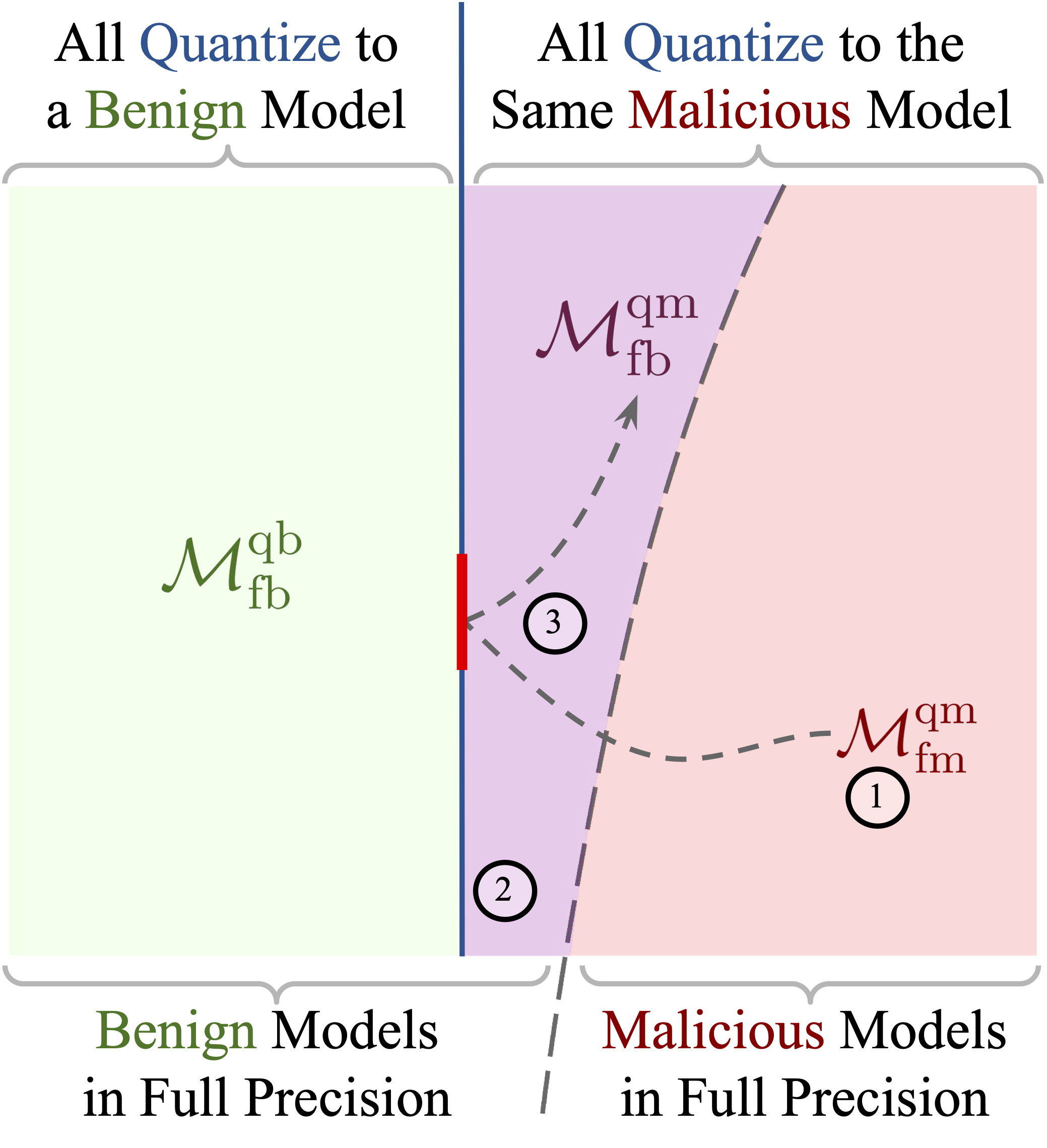
Weights and Activation Quantization (W4A16) :: LLM optimization and ...
LLM Quantization Methods: GPTQ, AWQ, GGUF - Cast AI
INT8 KV cache + per-channel weight-only quantization leading to wired ...
Simplify LLM Quantization Process for Success | by Novita AI | Jul ...
Day 61/75 LLM Quantization | How Accuracy is maintained? | How FP32 and ...
Practical Guide to LLM Quantization Methods - Cast AI
Quantization | LLM Module
Quantization Techniques for LLM Inference: INT8, INT4, GPTQ, and AWQ ...
Overview of LLM Quantization Techniques & Where to Learn Each of Them ...
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
LLM Quantization-Build and Optimize AI Models Efficiently
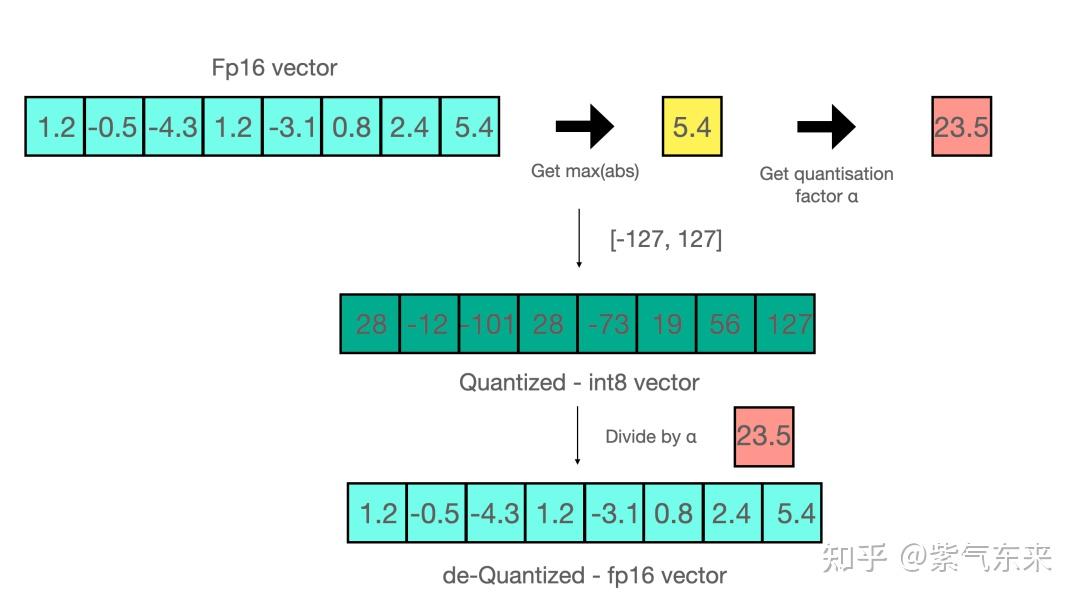
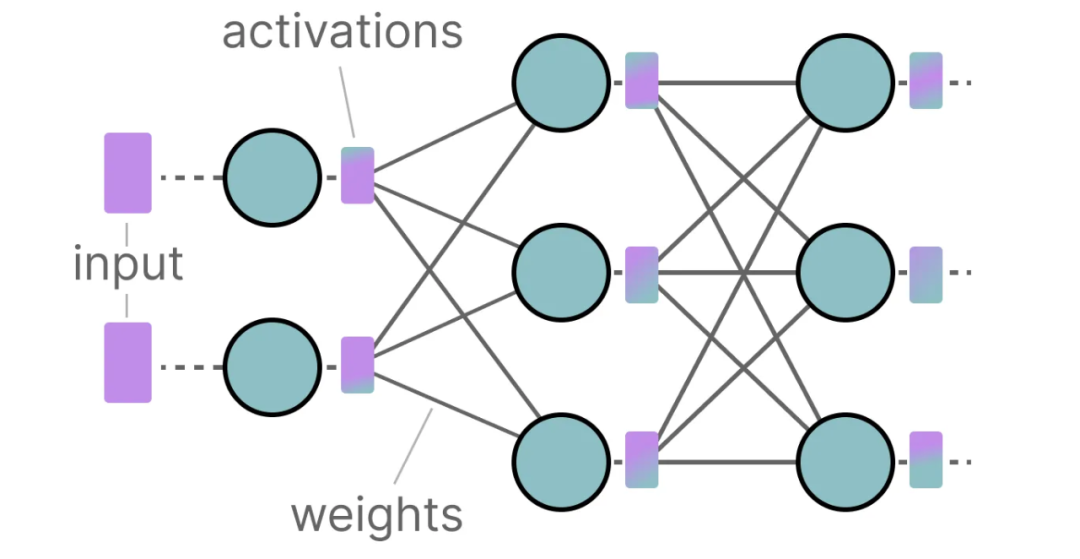
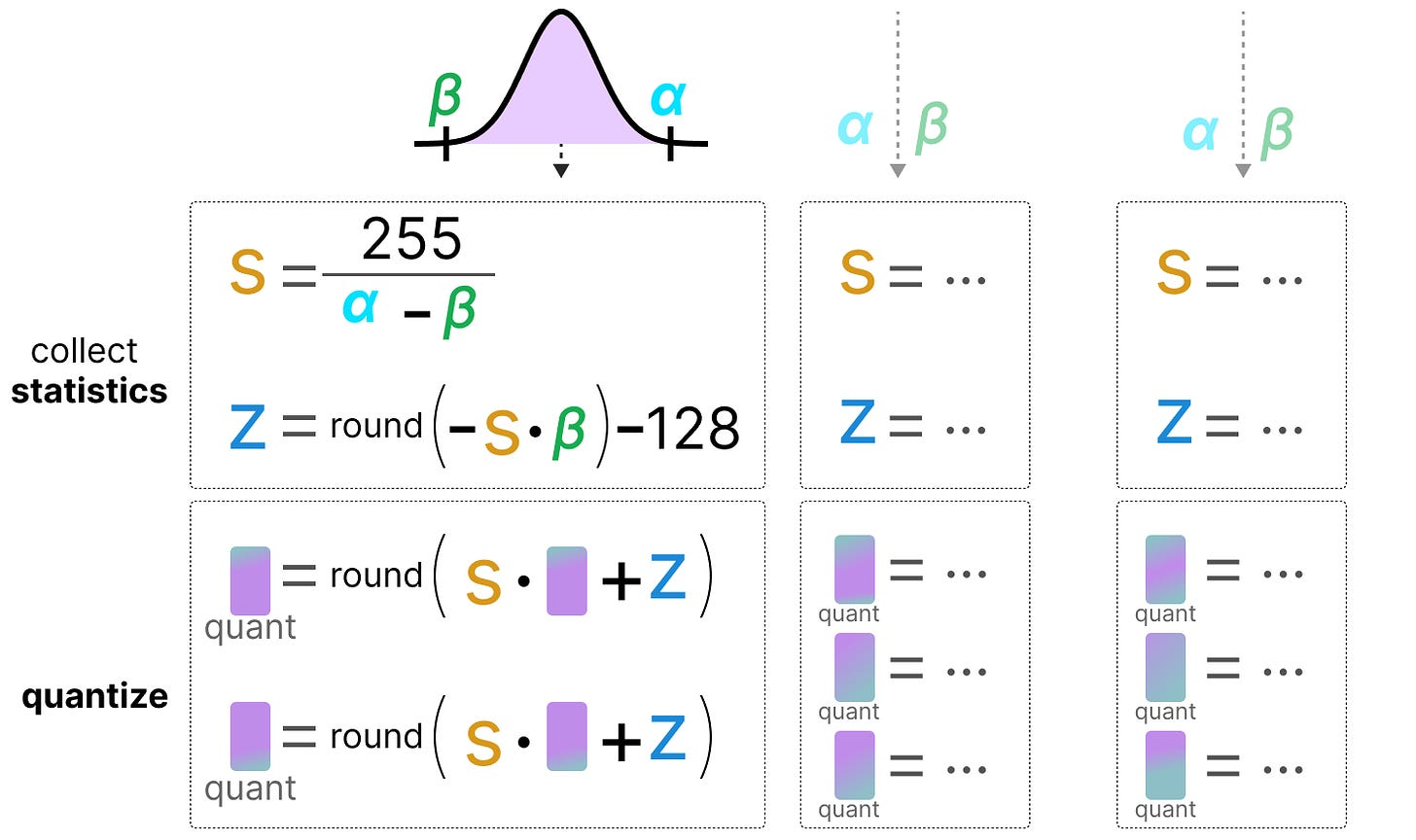
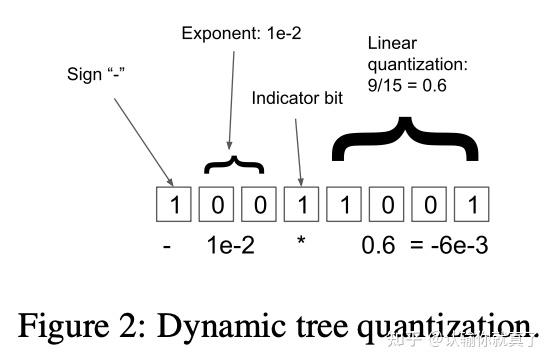
A Visual Guide to Quantization - by Maarten Grootendorst
Local Large Language Models | Int8
Quantization Methods for 100X Speedup in Large Language Model Inference
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
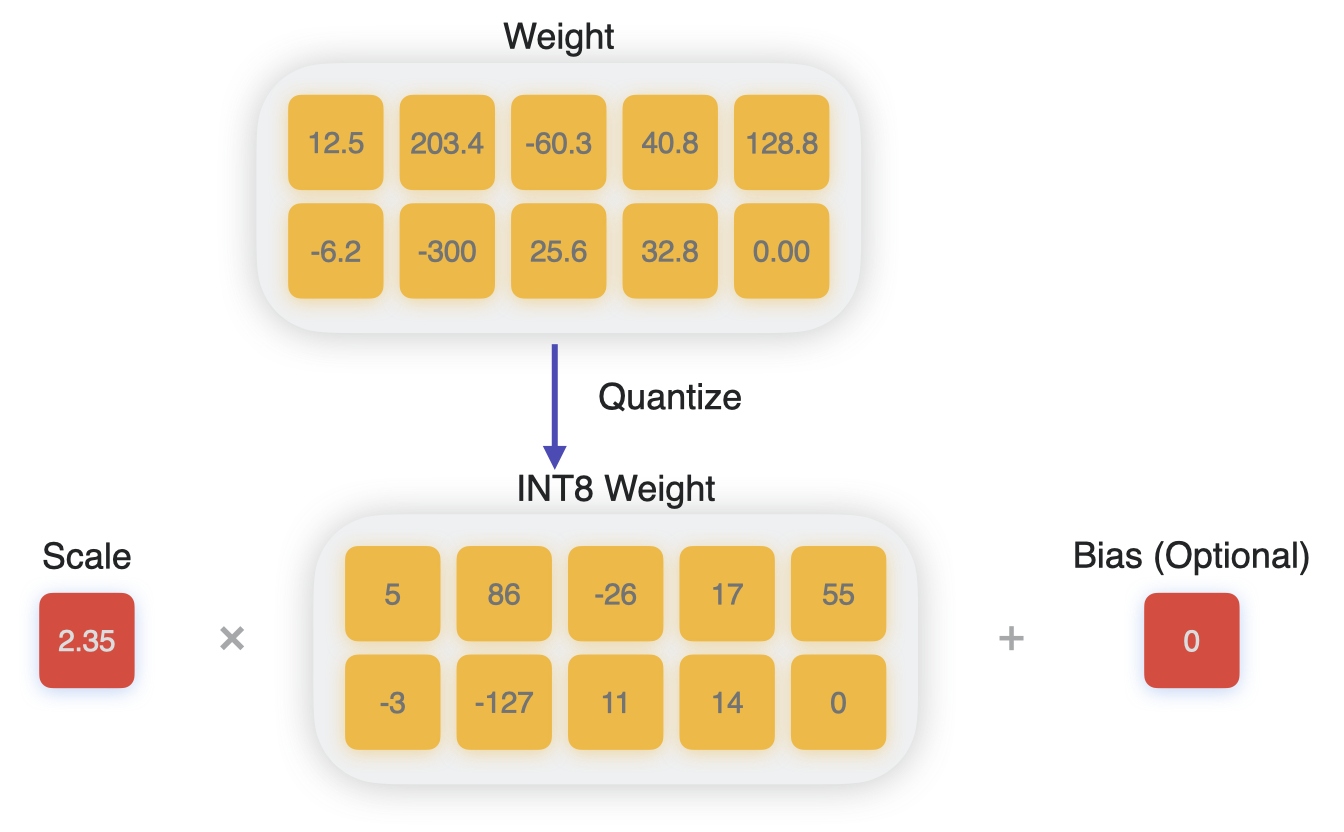
Introduction to Weight Quantization | Towards Data Science
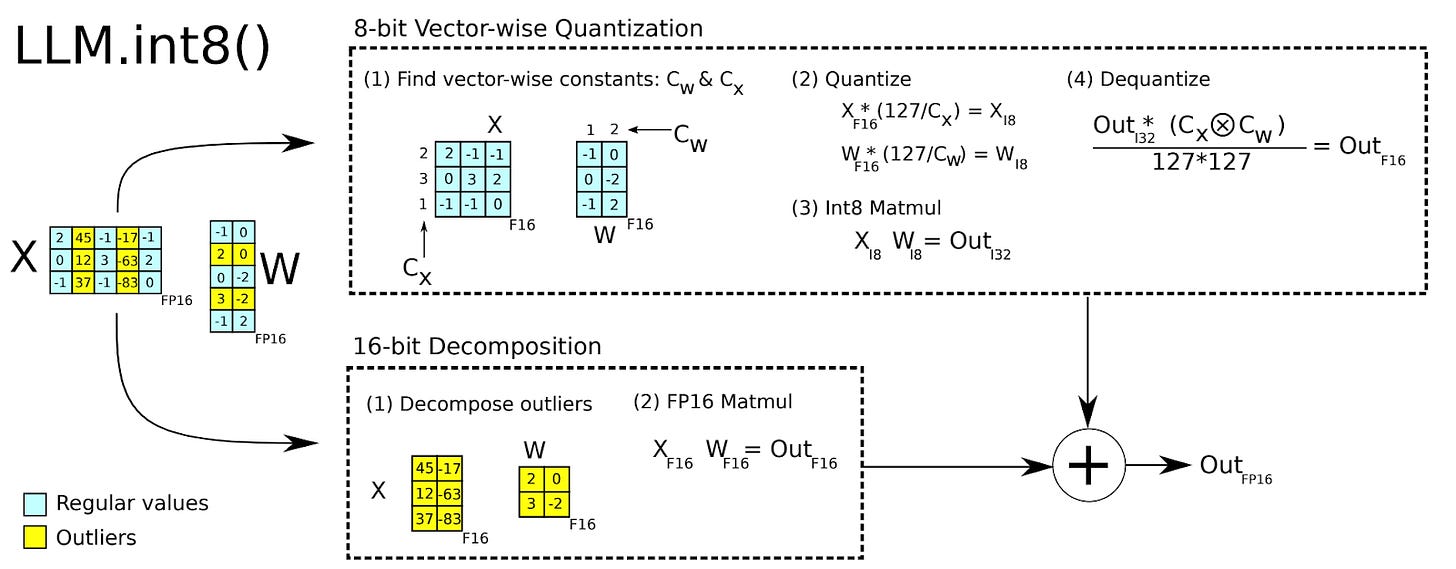
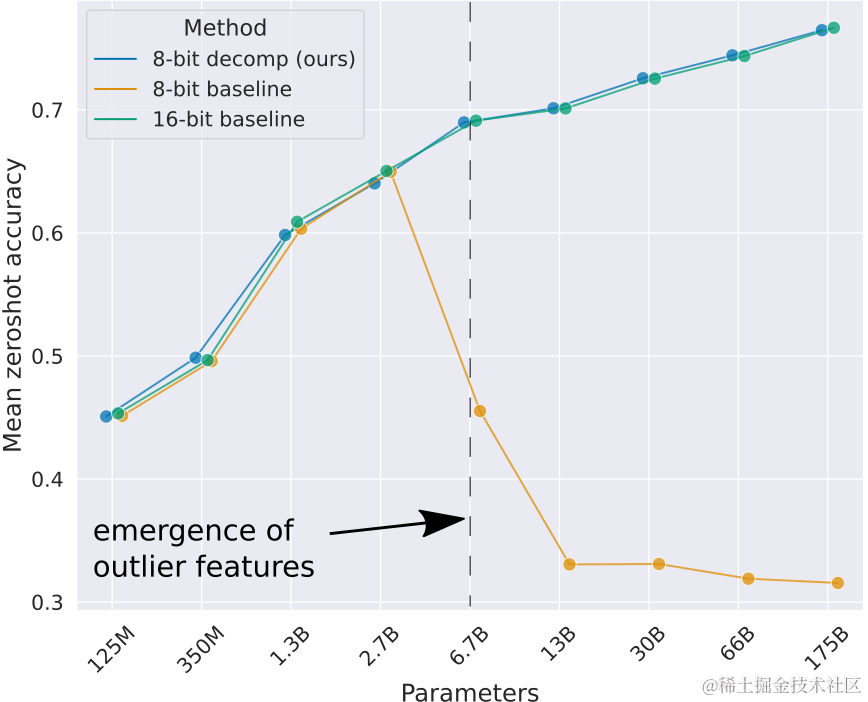
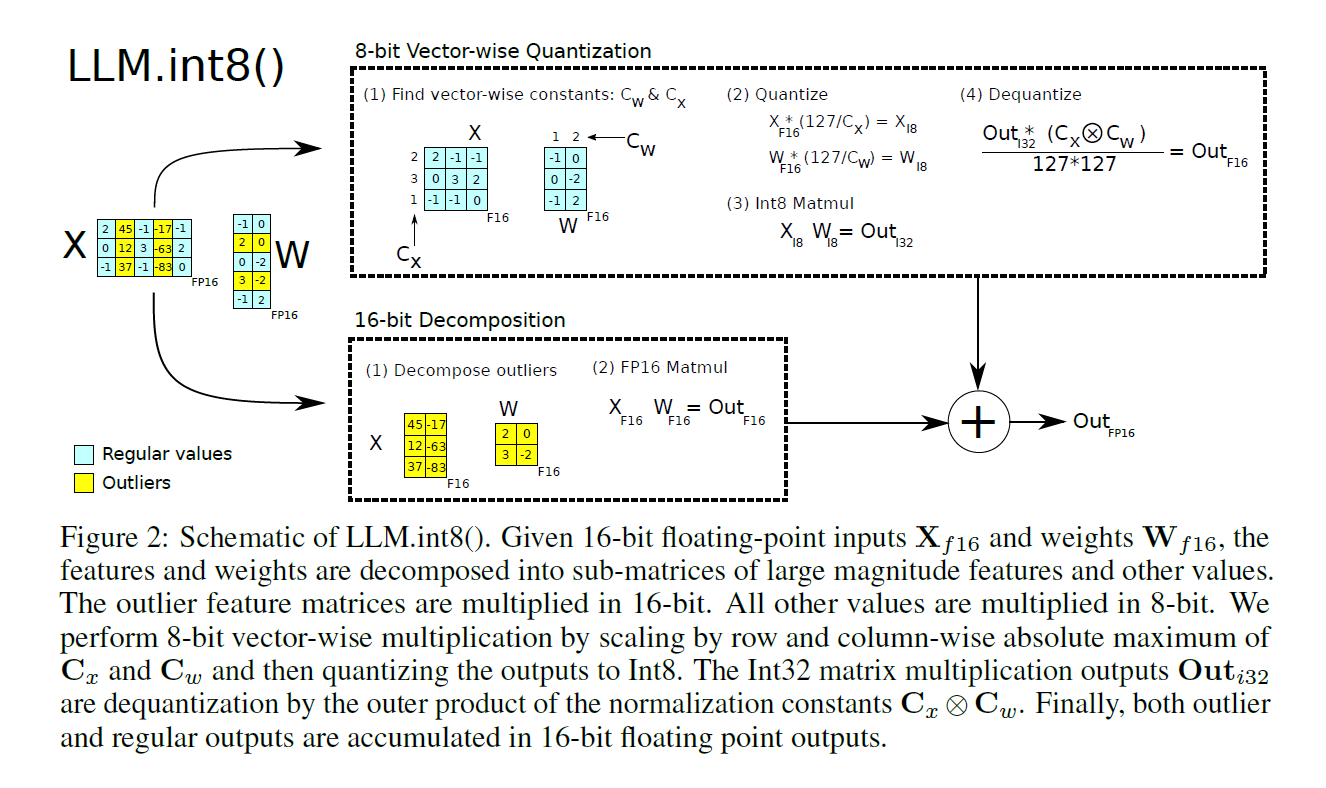
Understanding LLM.int8() Quantization — Picovoice
What is Quantization in LLM? A Complete Guide to Optimizing AI
[Ep3] LLM Quantization: LLM.int8(), QLoRA, GPTQ, ... - YouTube
LLM Quantization: Making models faster and smaller | MatterAI Blog
How Quantization Works & Quantizing SAM
Introduction to Weight Quantization - Origins AI
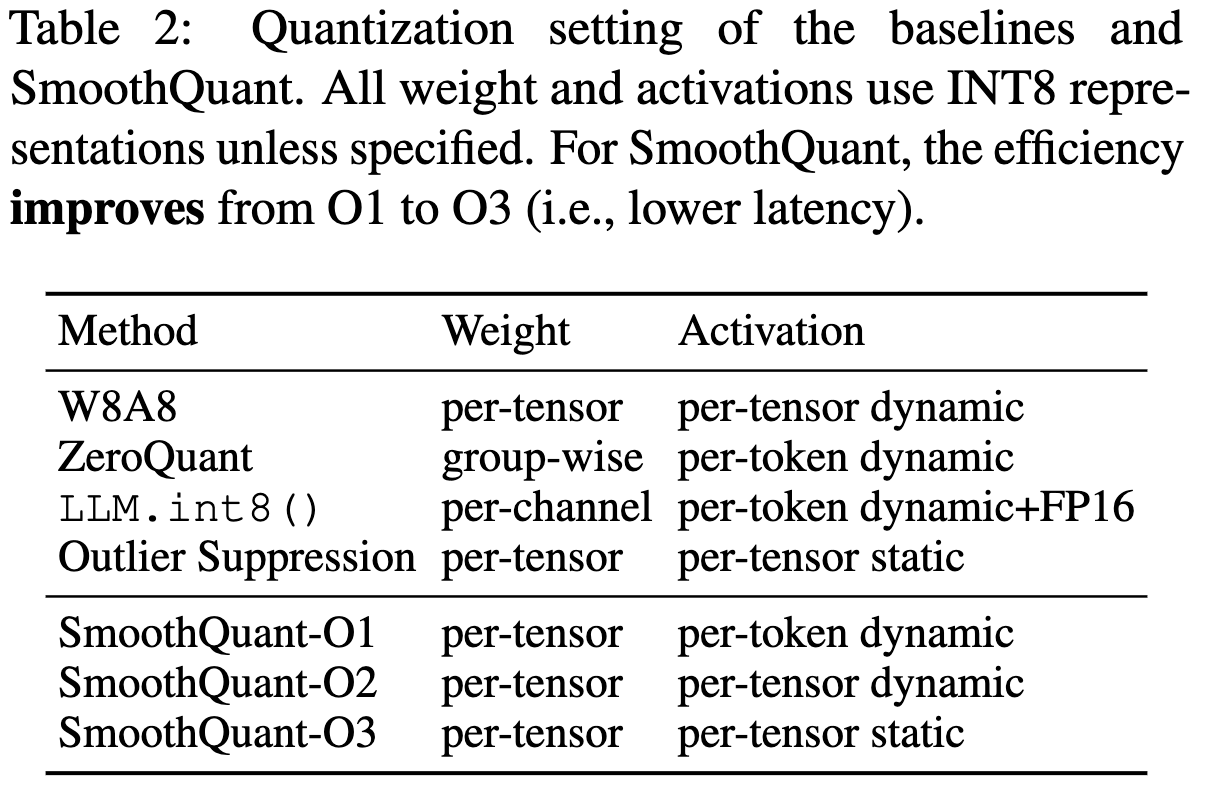
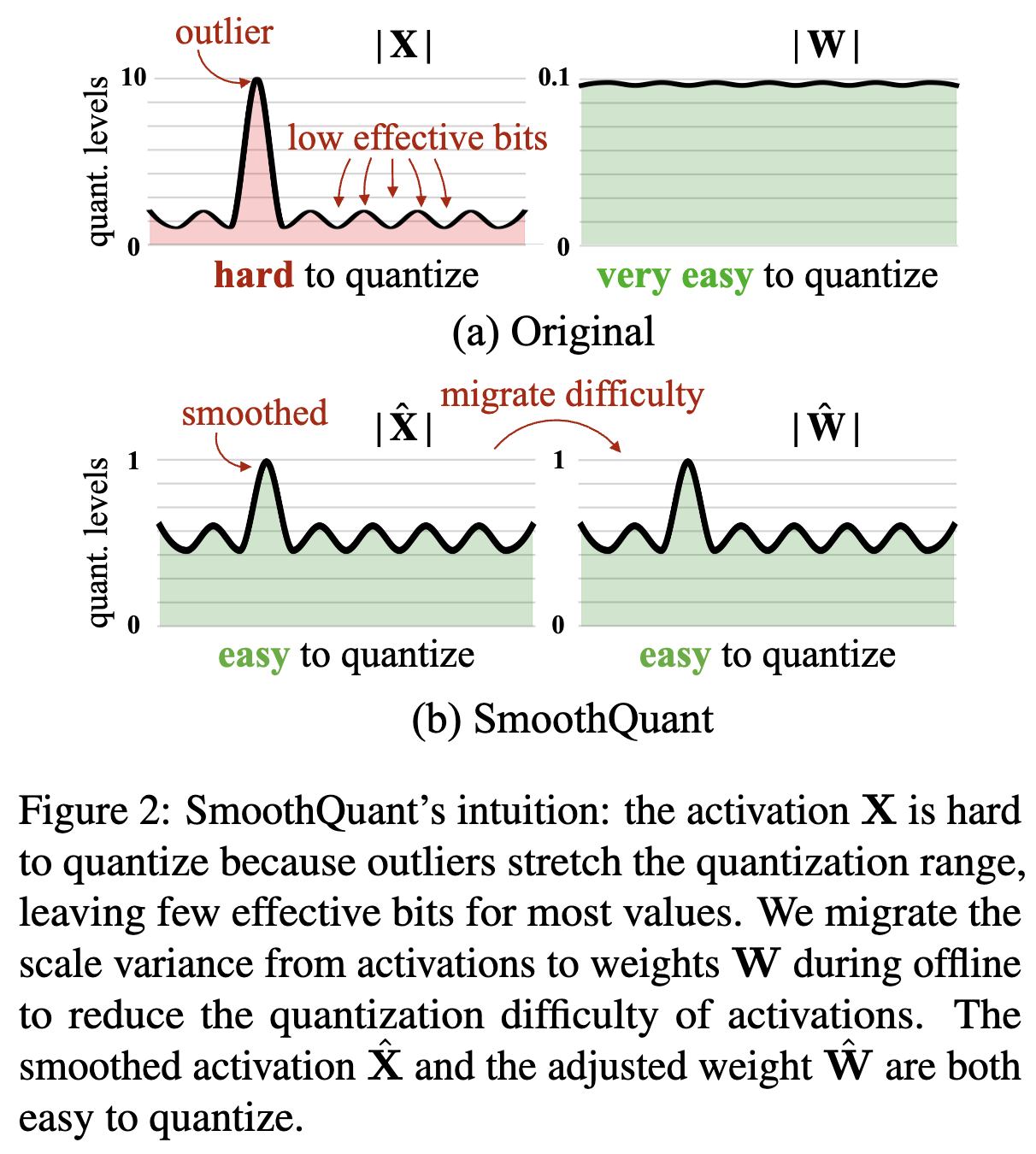
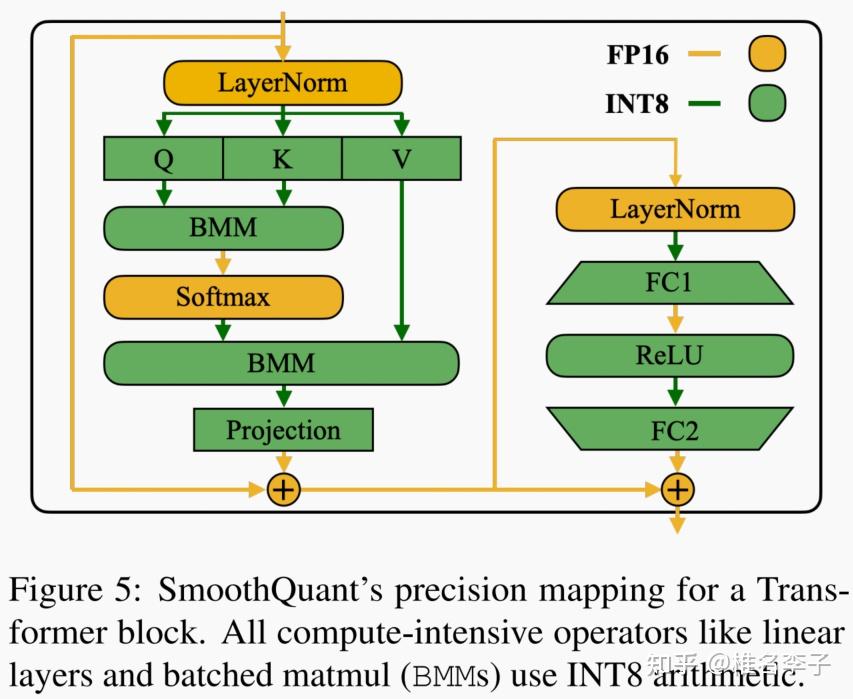
[LLM] SmoothQuant: Accurate and Efficient Post-Training Quantization ...
LLM Quantization: Quantize Model with GPTQ, AWQ, and Bitsandbytes ...
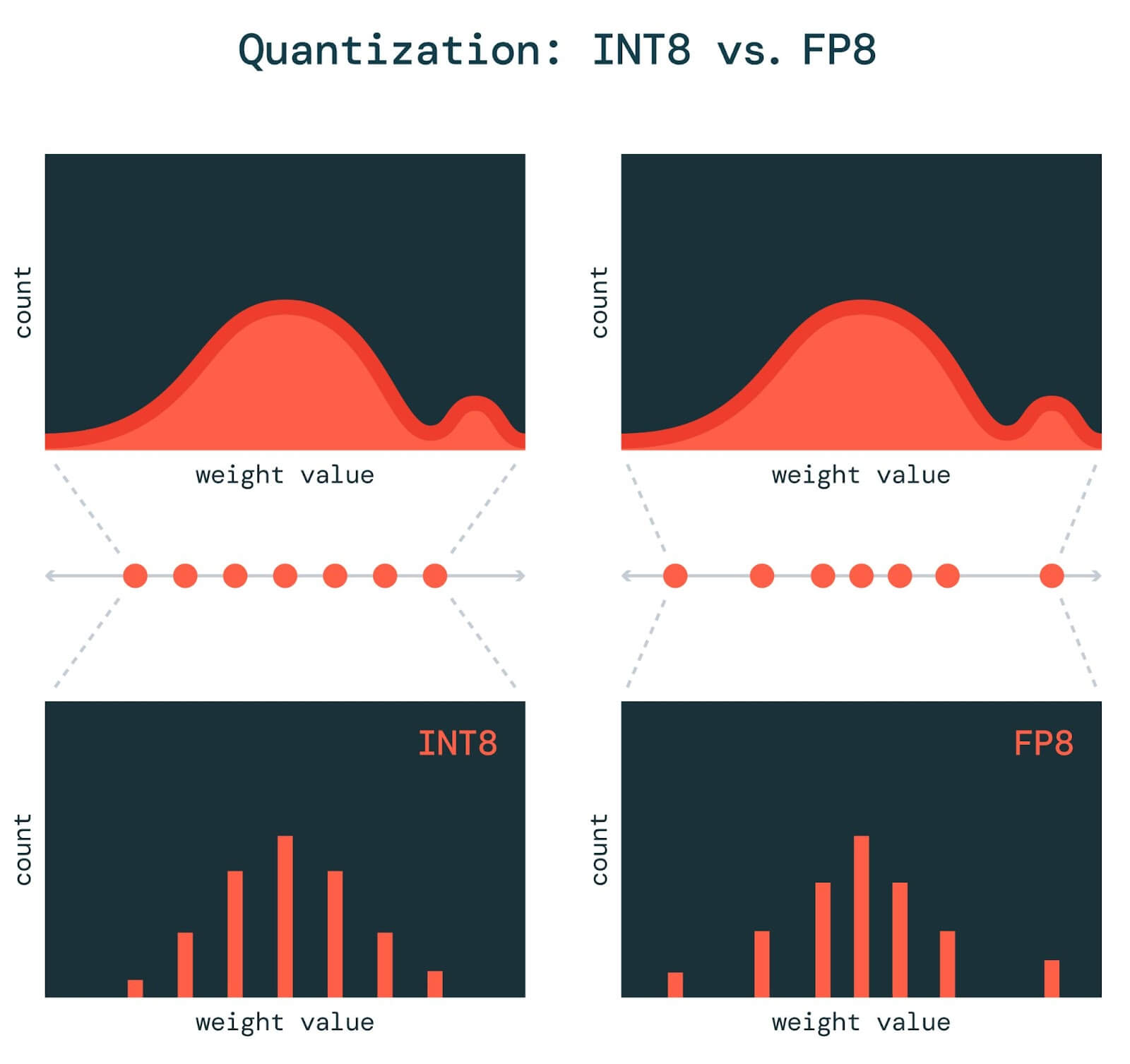
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Quantization Overview — Guide to Core ML Tools
Quark Quantized INT8 Models - a amd Collection
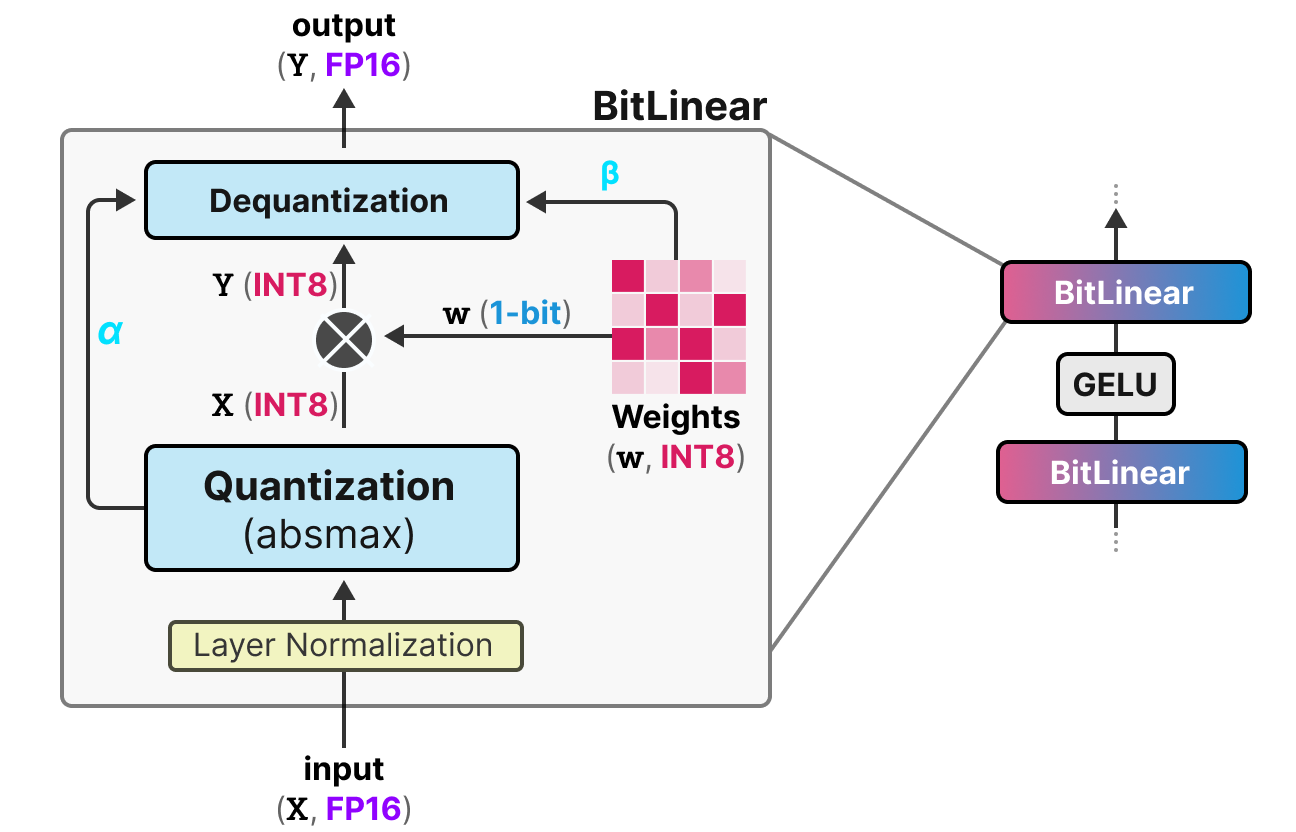
A Deep Dive into LLM Quantization: FP32, BF16, INT8, NF4 & QLoRA | by ...
Support weight only quantization from bfloat16 to int8? · Issue #110 ...
7 ML Quantization Wins (INT8/FP8) Without Quality Freefall | by ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
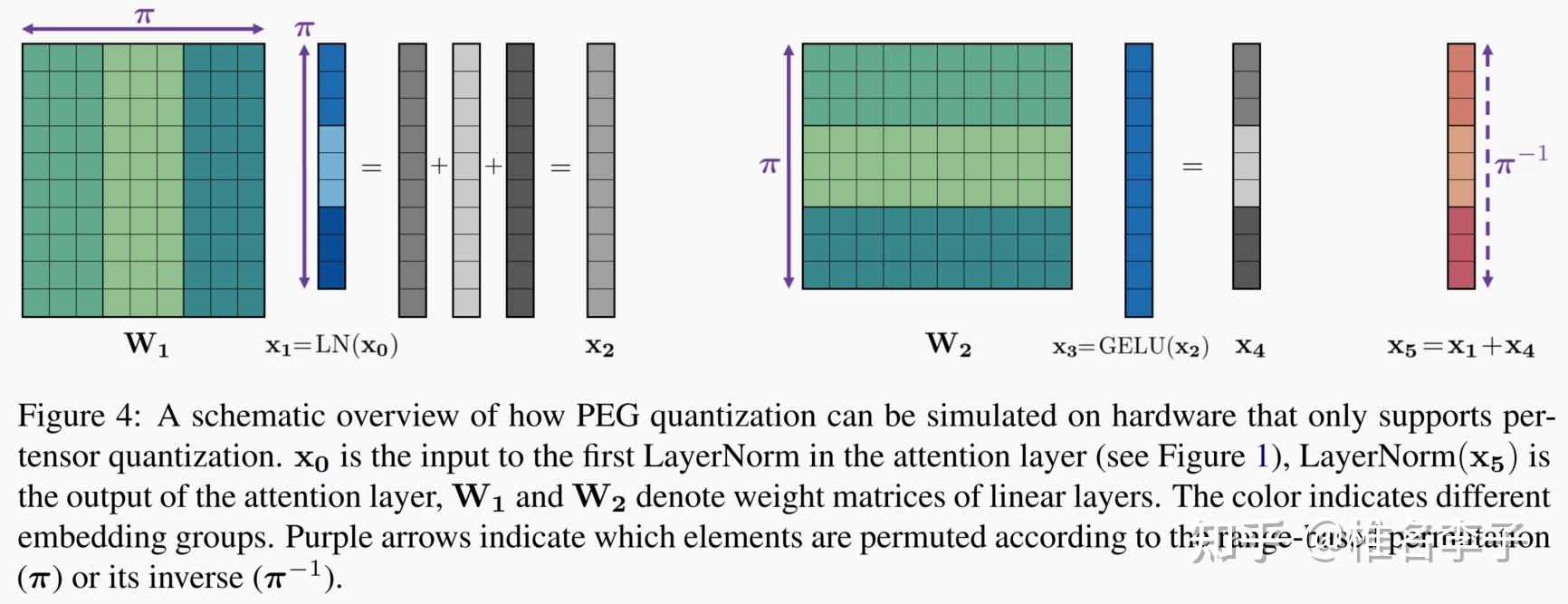
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...
模型量化-llm量化 - 知乎
大模型量化技术原理-LLM.int8()、GPTQ - 知乎
Try Fine-Tuning LLMs at Home | disin7c9
大模型LLM.int8()量化技术原理与代码实现-CSDN博客
[핵심][22.08]LLM.int8()
What are Quantized LLMs?
Lê Ngọc Thạch on LinkedIn: LLM.int8() This technique identifies ...
INT8模型量化:LLM.int8 - 知乎
[LLM量化] LLM.int8(), GPTQ, SmoothQuant, AWQ, SqueezeLLM, ATOM, OmniQuant ...
aashush/quantized-local-llm-int8 at main