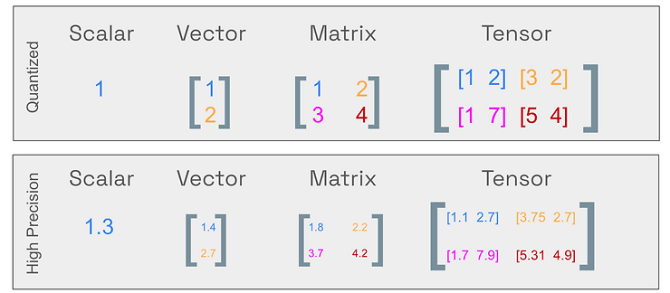
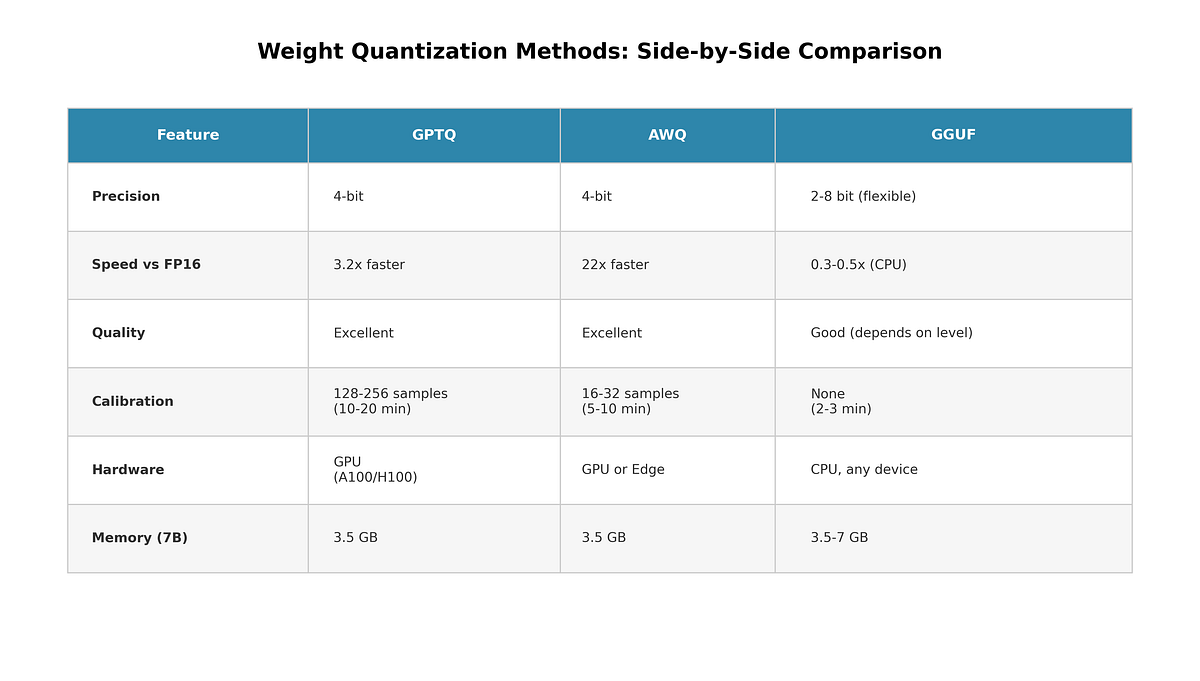
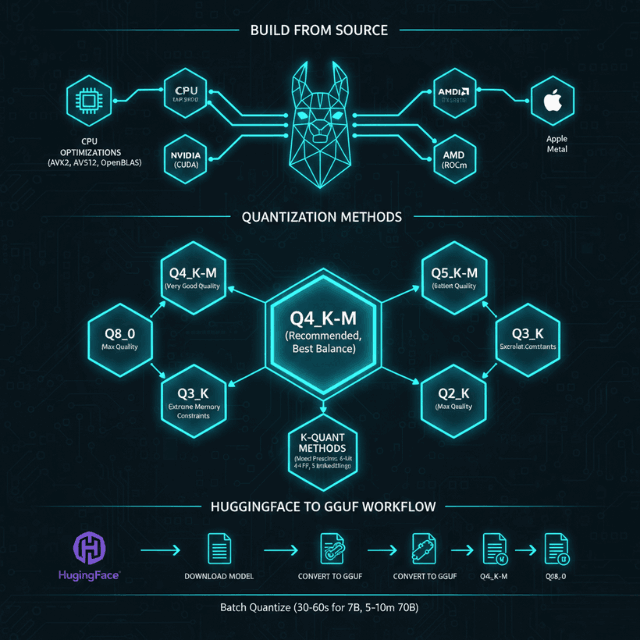
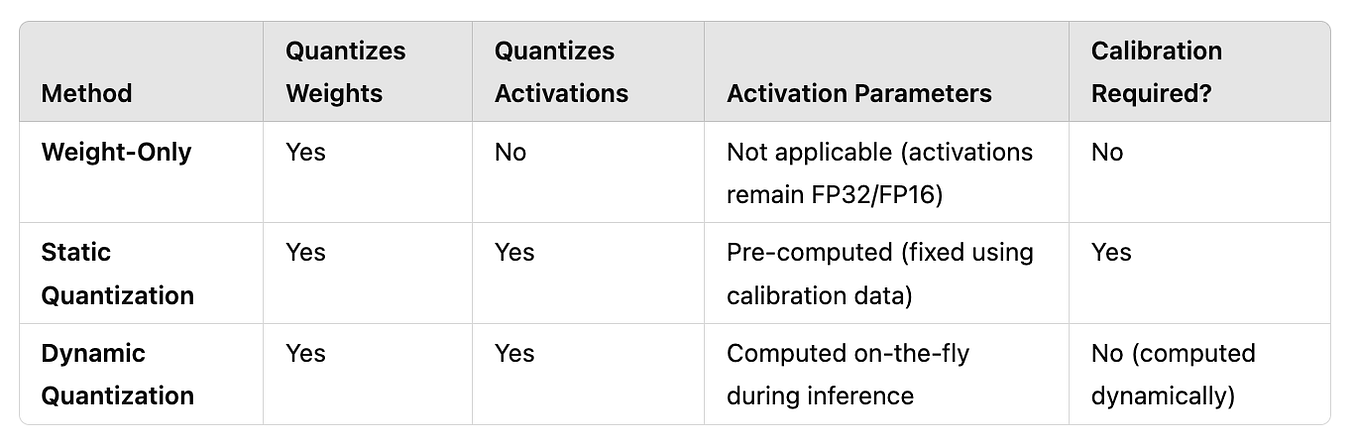
Showing 115 of 115on this page. Filters & sort apply to loaded results; URL updates for sharing.115 of 115 on this page
Top LLM Quantization Methods and Their Impact on Model Quality
Practical Guide to LLM Quantization Methods - Cast AI
GGUF vs GPTQ vs AWQ: LLM Quantization Methods Compared · Technical news ...
LLM Quantization Methods: GPTQ, AWQ, GGUF - Cast AI
LLM Quantization Made Easy: Essential Tips for Success
Quantization Techniques to Reduce LLM Model Size and Memory: A Complete ...
The Ultimate Handbook for LLM Quantization | Towards Data Science
Making LLMs Lighter: A deep dive into LLM quantization with Code | by ...
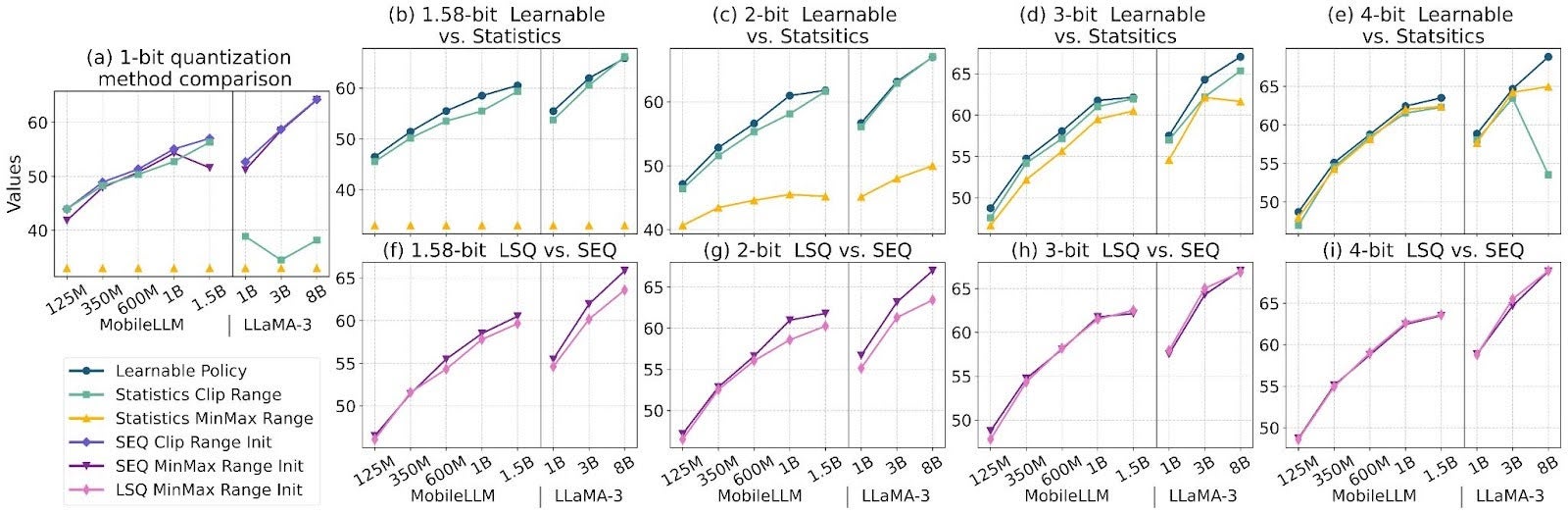
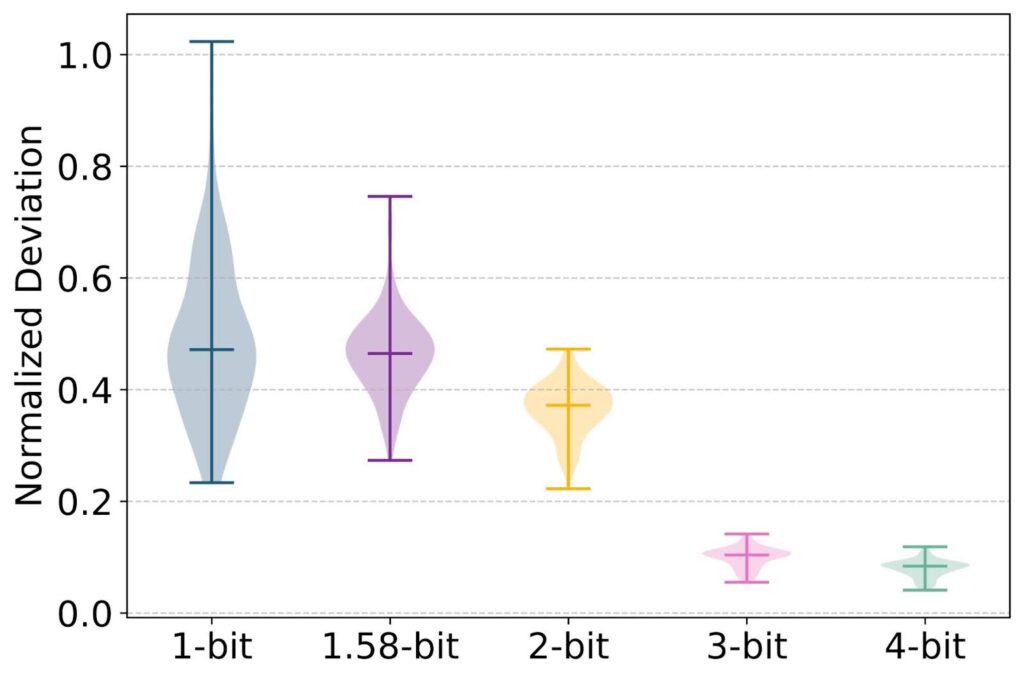
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization – PyTorch
Practical LLM Quantization Techniques & Implementation
Simplify LLM Quantization Process for Success | by Novita AI | Jul ...
A Comprehensive Guide On LLM Quantization And Use Cases
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
An Introduction to LLM Quantization - TextMine
(PDF) Exploiting LLM Quantization
Comparing Quantization Methods in vLLM: Enhancing Efficiency Without ...
LLM Quantization Techniques Explained | PDF | Computer Engineering ...
SpinQuant: LLM quantization with learned rotations [Quick Review]
A Comprehensive Guide on LLM Quantization and Use Cases
LLM inference optimization: Model Quantization and Distillation - YouTube
Improving LLM Inference Latency on CPUs with Model Quantization ...
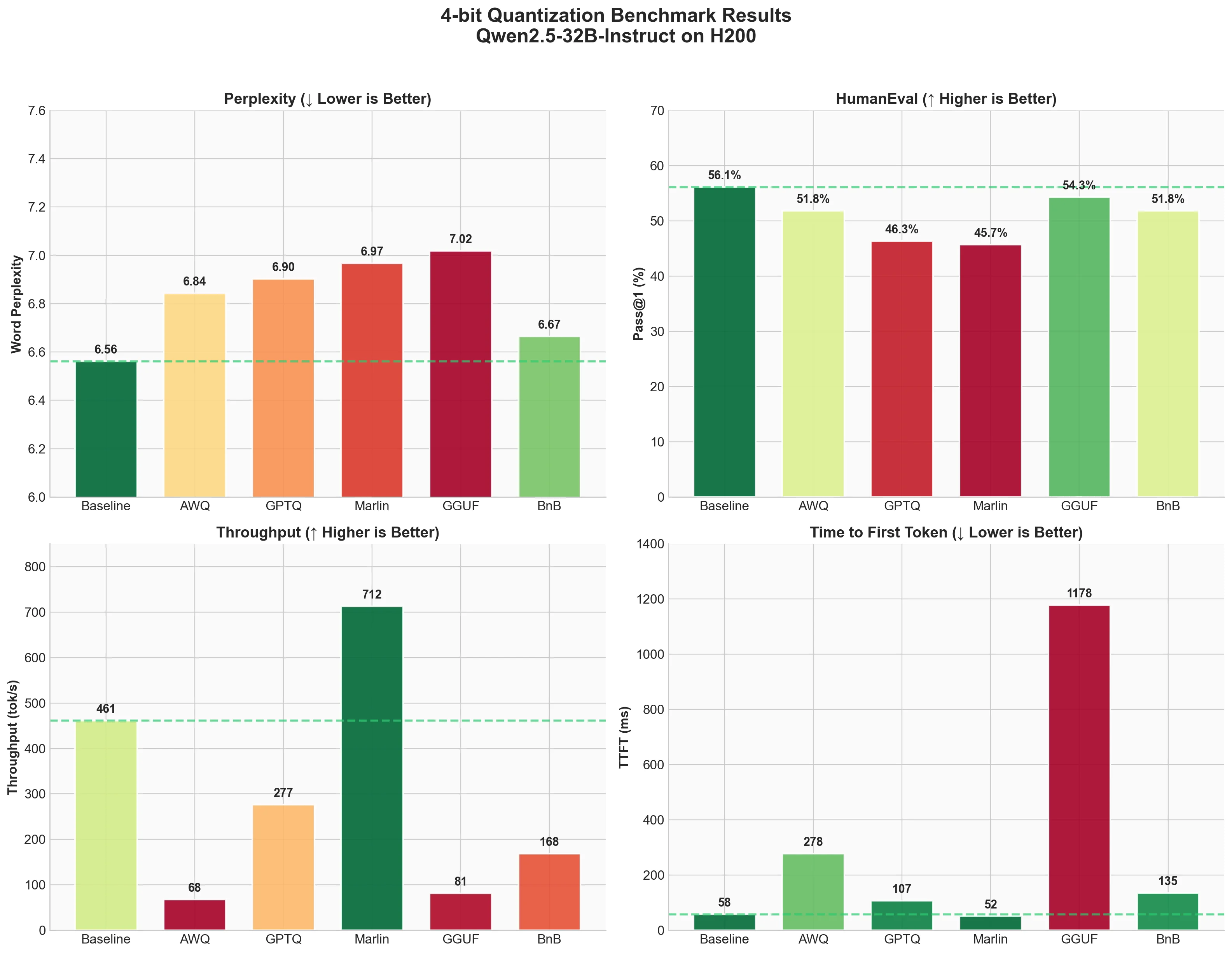
Sub-4-Bit LLM Quantization: Enterprise Guide to Methods & Tradeoffs
New Method For LLM Quantization | ml-news – Weights & Biases
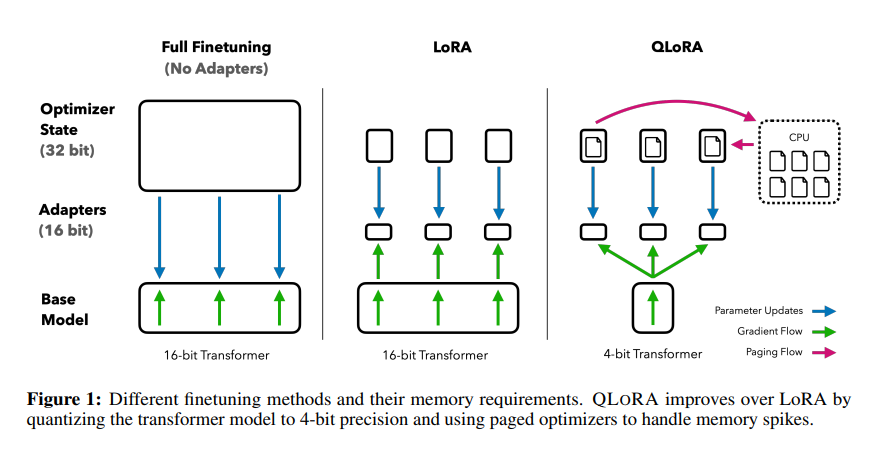
4-bit LLM training and Primer on Precision, data types & Quantization
A Beginner's Guide to LLM Quantization
[PDF] SpinQuant: LLM quantization with learned rotations | Semantic Scholar
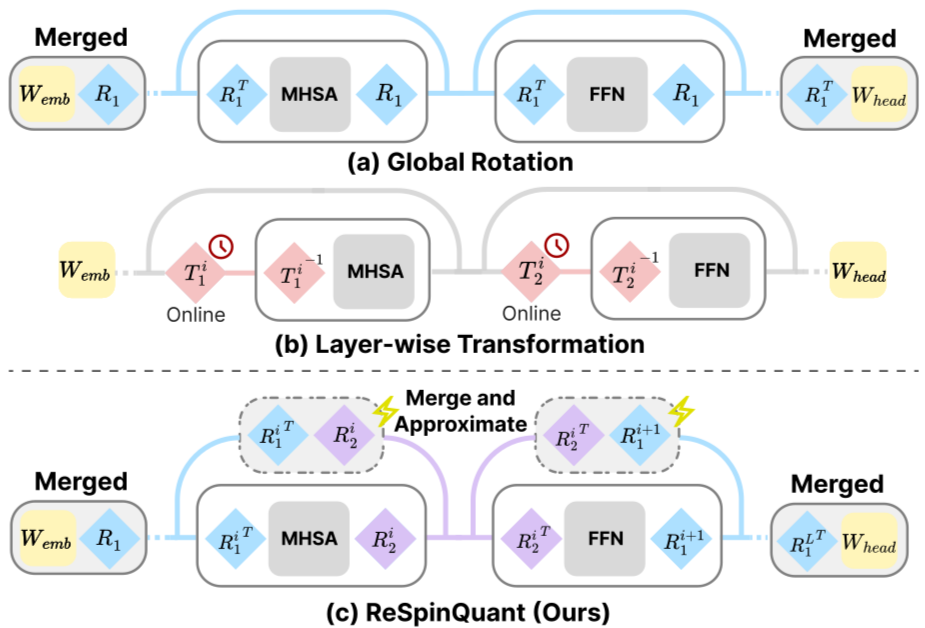
[论文评述] ReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace ...
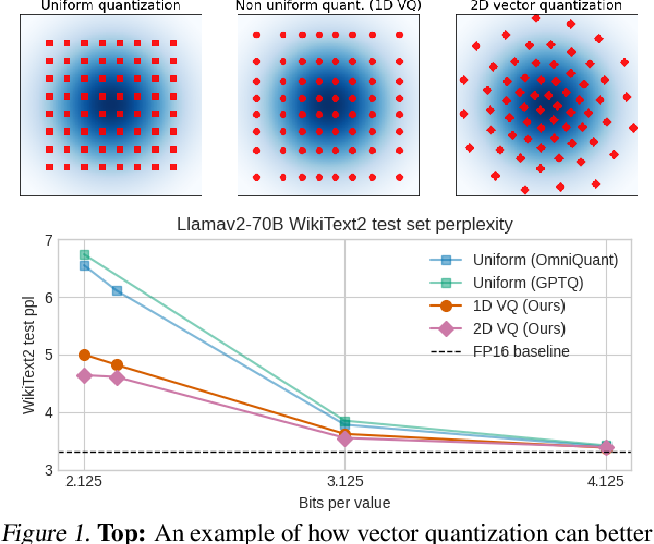
GPTVQ: The Blessing of Dimensionality for LLM Quantization
FLRQ: Faster LLM Quantization via Low-Rank Matrix Sketching
The LLM Revolution: Boosting Computing Capacity with Quantization ...
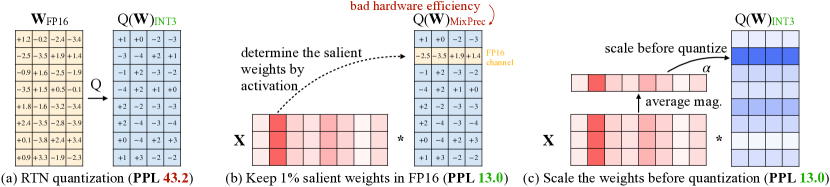
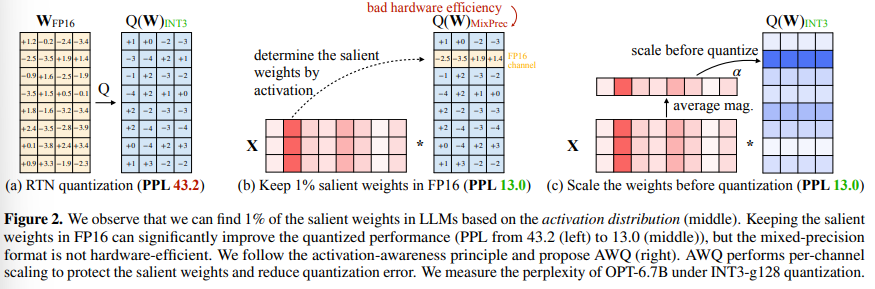
[2306.00978] AWQ: Activation-aware Weight Quantization for LLM ...
Optimizing LLM Model using Quantization
AWQ vs GPTQ: A Practical Decision Framework for LLM Quantization
OmniQuant: Near-Lossless LLM Quantization for Real-World Deployment on ...
FAQ It Till You Make It: Fixing LLM Quantization by Teaching Models ...
What is LLM Quantization Understanding Its Importance and Techniques
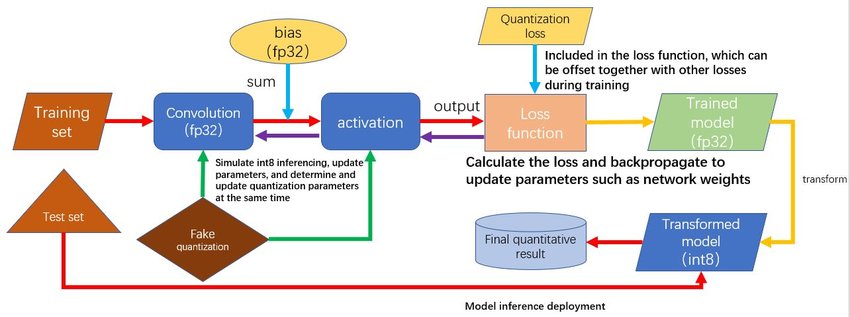
LLM Quantization Aware Training | PDF | Applied Mathematics | Machine ...
LLM Quantization Techniques Explained - GPTQ, AWQ, GGUF, BitNet - YouTube
AWQ: Activation-aware Weight Quantization for On-Device LLM Compression ...
Comparing LLM Quantization Toolkit Results
LLM Quantization-Build and Optimize AI Models Efficiently
What is Quantization in LLM? A Complete Guide to Optimizing AI
LLM Tutorial 21 — Model Compression Techniques: Quantization, Pruning ...
LLM Compression Techniques to Build Faster and Cheaper LLMs
LLM Quantization: Making models faster and smaller | MatterAI Blog
A Guide to Quantization in LLMs | Symbl.ai
LLMs on CPU: The Power of Quantization with GGUF, AWQ, & GPTQ
Quantization trong LLM: Tối ưu hóa tốc độ Mô hình Ngôn ngữ Lớn - Blog ...
Paper review[LLM-QAT: Data-Free Quantization Aware Training for Large ...
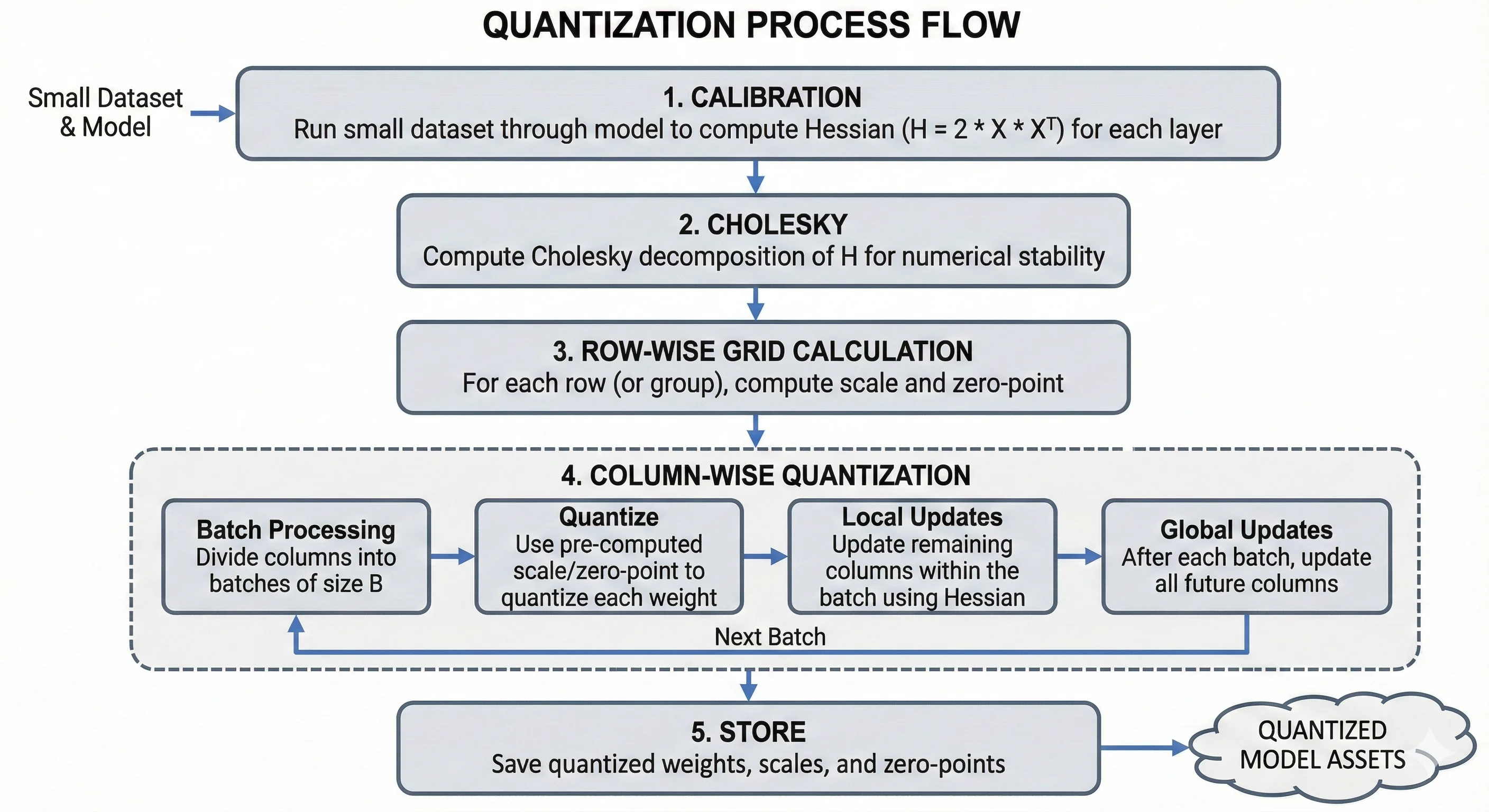
The Geometry of LLM Quantization: GPTQ as Babai's Nearest Plane ...
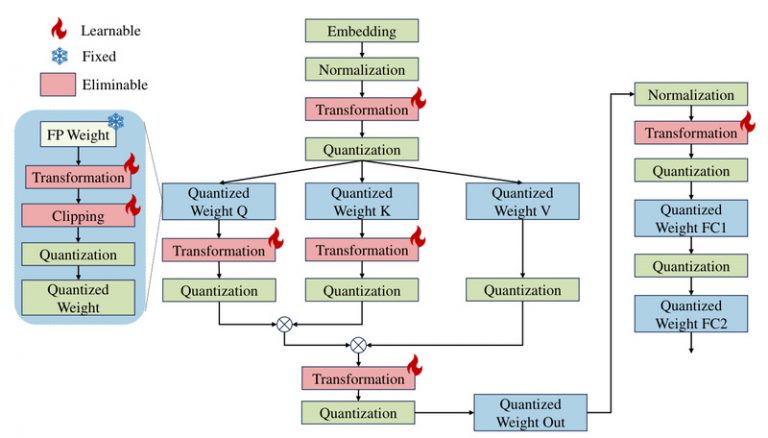
LLM-QAT: Data-Free Quantization Aware Training for Large Language ...
Paper page - PolarQuant: Optimal Gaussian Weight Quantization via ...
Understanding LLM Weight Quantization: GPTQ, AWQ, and GGUF: Make BIG ...
LLM Compressor 0.9.0: Attention quantization, MXFP4 support, and more ...
Run 70B LLMs on Consumer GPU - VRAM and Quantization Guide (2026)
What is LLM Quantization?
What is LLM quantization? - YouTube
Understanding LLM Quantization. With the surge in applications using ...
Exploring Bits-and-Bytes, AWQ, GPTQ, EXL2, and GGUF Quantization ...
Demystifying LLM Quantization: GPTQ, AWQ, and GGUF Explained
What is Quantization? - LLM Concepts ( EP - 3 ) #quantization #llm #ml ...
Effective Post-Training Quantization for Large Language Models | by ...
HIGGS Quantization: Enabling Efficient LLM Compression on Consumer Hardware
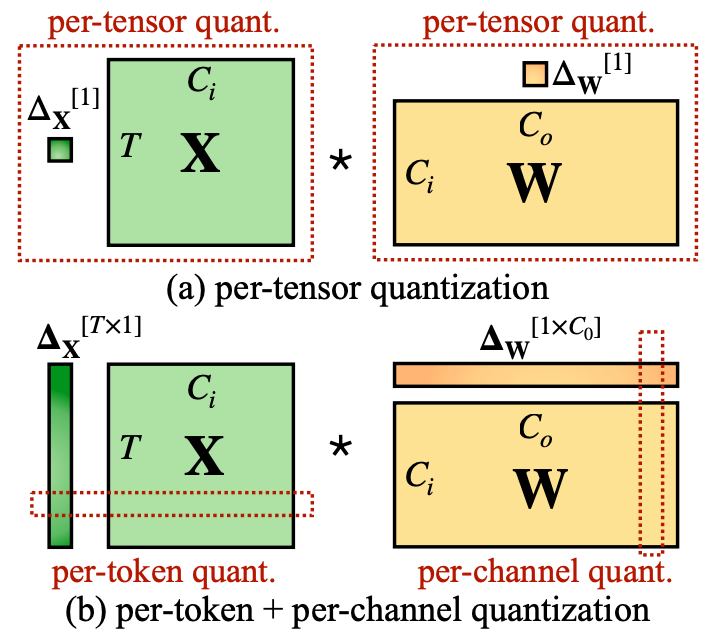
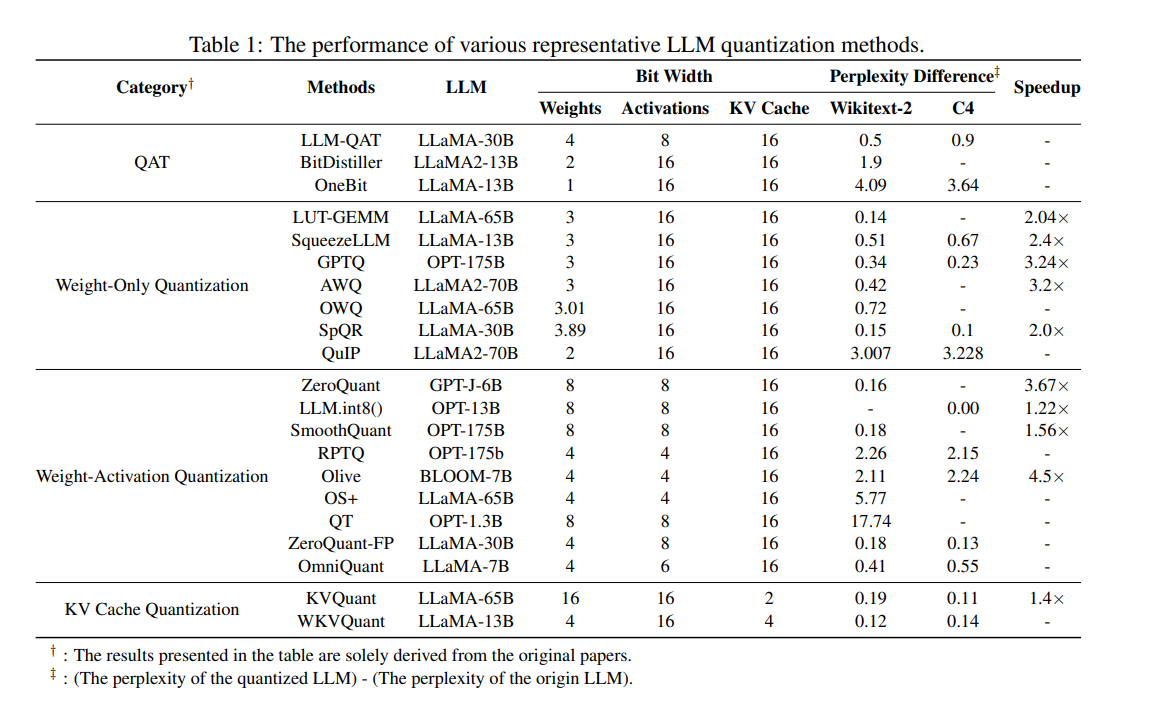
A Survey of Low-bit Large Language Models: Basics, Systems, and ...
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析_大模型量化-CSDN博客
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
What are Quantized LLMs?
Maximizing Business Potential with Large Language Models (LLMs)
模型量化-llm量化 - 知乎
大模型(LLM)的量化技术Quantization原理学习_大模型量化-CSDN博客
I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit ...
github- Awesome-LLM-Quantization :Features,Alternatives | Toolerific
GitHub - SonPhatTranDeveloper/llm-quantization: A simple repository ...
#quantization #llm #finetuning | Qendel AI
Advanced Quantization: Guide to GPTQ, AWQ, and QAT | Artificial ...